⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-14 更新
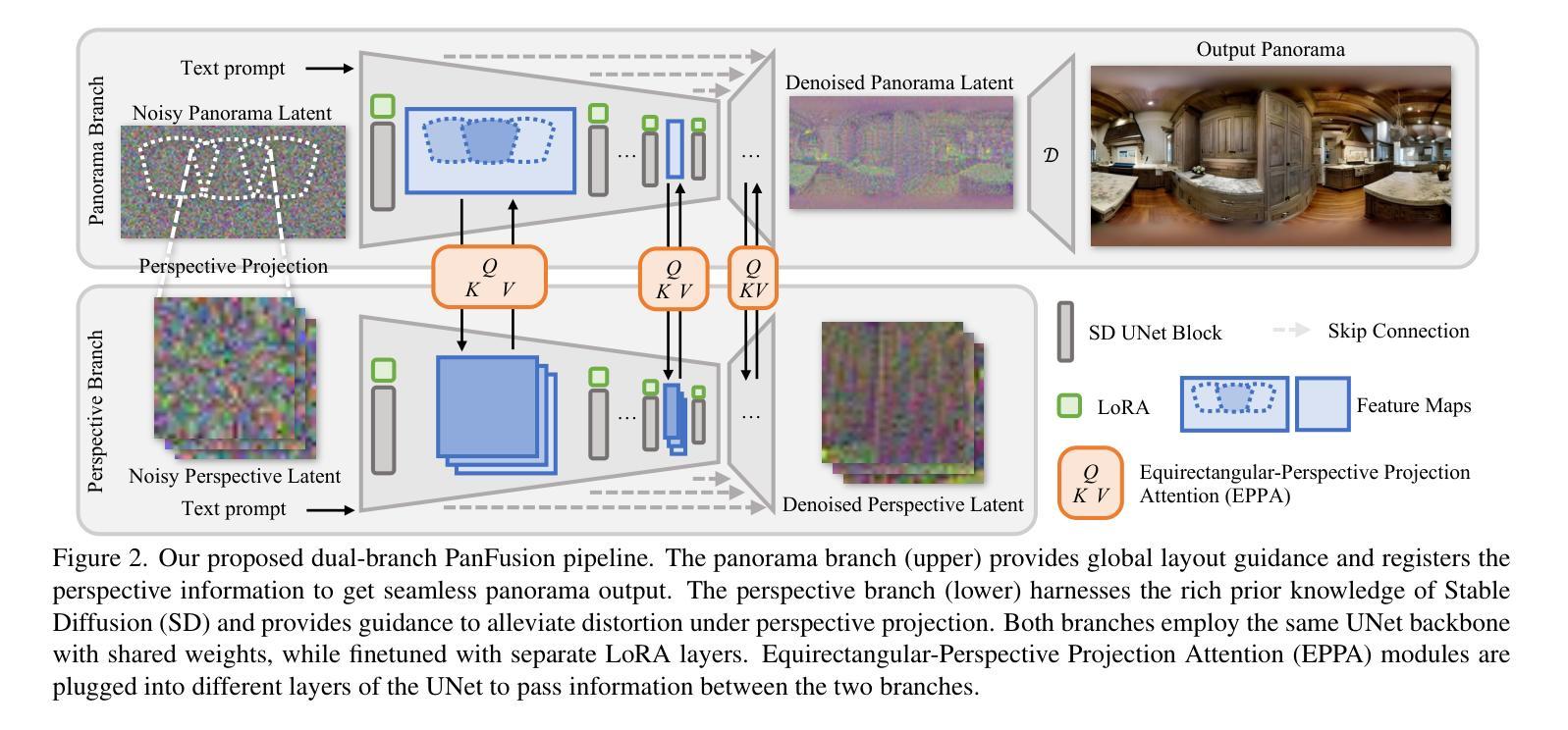
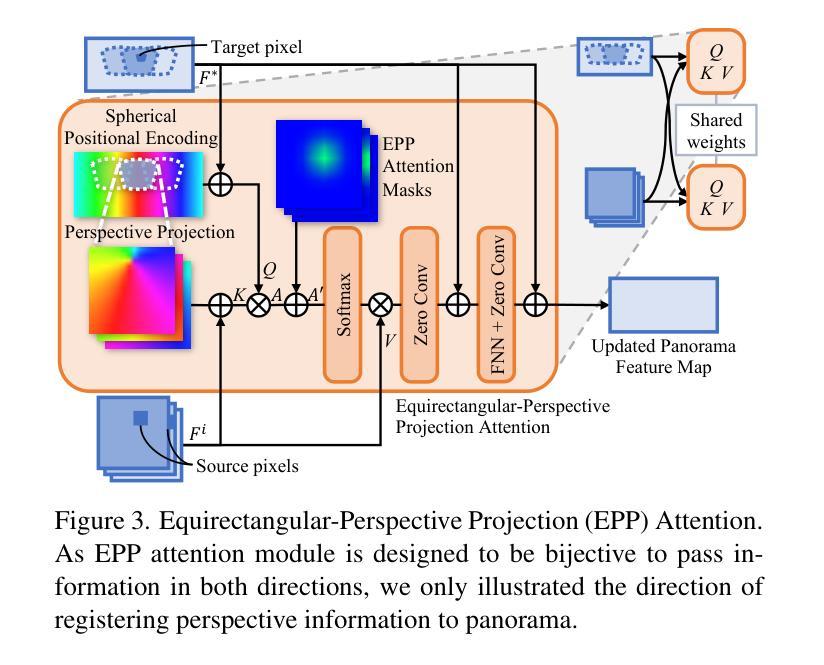
Taming Stable Diffusion for Text to 360° Panorama Image Generation
Authors:Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, Jianfei Cai
Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
PDF CVPR 2024. Project Page: https://chengzhag.github.io/publication/panfusion Code: https://github.com/chengzhag/PanFusion
Summary
文本主旨概括:双分支扩散模型PanFusion在文本提示指导下生成360度全景图像。
Key Takeaways
- 利用Stable Diffusion模型的自然图像生成先验知识和全景图像生成分支,生成360度全景图像。
- 引入独特的cross-attention机制和projection awareness,以最小化协作去噪过程中的失真。
- PanFusion超越现有方法,并且由于其双分支结构,可以集成房间布局等其他约束,以获得定制的全景输出。
- 标题:驯服稳定扩散以实现文本到 360 度图像生成(中文翻译)
- 作者:Cheng Zhang、Kai Zhang、Ya Zhang、Zhenyu Wang、Zhaopeng Cui、Yanwei Fu
- 所属单位:香港中文大学(深圳)(仅输出中文翻译)
- 关键词:文本到图像生成、360 度全景图像、稳定扩散
- 论文链接:None
-
摘要: (1)研究背景:生成模型(例如 Stable Diffusion)已能根据文本提示创建逼真的图像。然而,由于成对文本全景数据匮乏以及全景图像与透视图像之间的域差异,从文本生成 360 度全景图像仍然是一个挑战。 (2)过去的方法及其问题:现有方法(例如 MVDiffusion 和 Text2Light)在不同的领域解决了文本条件图像生成问题。MVDiffusion 生成 90° 视场的 8 个水平视图,因此仅限于对透视图像进行评估。Text2Light 生成 180° 垂直视场,因此专注于评估全景质量。 (3)本文提出的研究方法:本文提出了一种名为 PanFusion 的新型双分支扩散模型,可根据文本提示生成 360 度图像。我们利用稳定扩散模型作为分支之一,为自然图像生成提供先验知识,并将其注册到另一个全景分支以进行整体图像生成。我们提出了一种独特的跨注意力机制,具有投影感知能力,以在协作去噪过程中最大程度地减少失真。 (4)方法在任务和性能上的表现:实验验证了 PanFusion 优于现有方法,并且由于其双分支结构,可以集成额外的约束(如房间布局),以获得定制的全景输出。
-
方法: (1): 提出了一种双分支扩散模型PanFusion,其中Stable Diffusion分支提供自然图像先验知识,全景分支负责生成360度图像; (2): 设计了一种跨注意力机制,具有投影感知能力,在协作去噪过程中最大程度地减少失真; (3): 实验验证了PanFusion优于现有方法,并可以通过集成额外的约束(如房间布局)来获得定制的全景输出。
-
结论: (1):本文提出了一种文本到 360° 全景图像生成方法 PanFusion,该方法可以从单个文本提示生成高质量的全景图像。特别是,引入了双分支扩散架构,以利用 StableDiffusion 在透视域中的先验知识,同时解决了先前工作中观察到的重复元素和不一致性问题。进一步引入了 EPPA 模块来增强两个分支之间的信息传递。我们还扩展了 PanFusion,用于布局条件全景生成。综合实验表明,与以前的方法相比,PanFusion 可以生成高质量的全景图像,具有更好的真实感和布局一致性。 (2):创新点:
- 提出了一种双分支扩散模型 PanFusion,该模型结合了全景和透视域的优点。
- 设计了一种跨注意力机制,具有投影感知能力,在协作去噪过程中最大程度地减少失真。
- 扩展了 PanFusion,用于布局条件全景生成。 性能:
- PanFusion 在生成高质量全景图像方面优于现有方法,具有更好的真实感和布局一致性。
- PanFusion 可以集成额外的约束(如房间布局),以获得定制的全景输出。 工作量:
- PanFusion 的双分支架构虽然结合了全景和透视域的优点,但带来了更高的计算复杂度。
- PanFusion 有时无法生成室内场景的入口,如图 7 所示,这对于虚拟漫游等用例至关重要。
点此查看论文截图


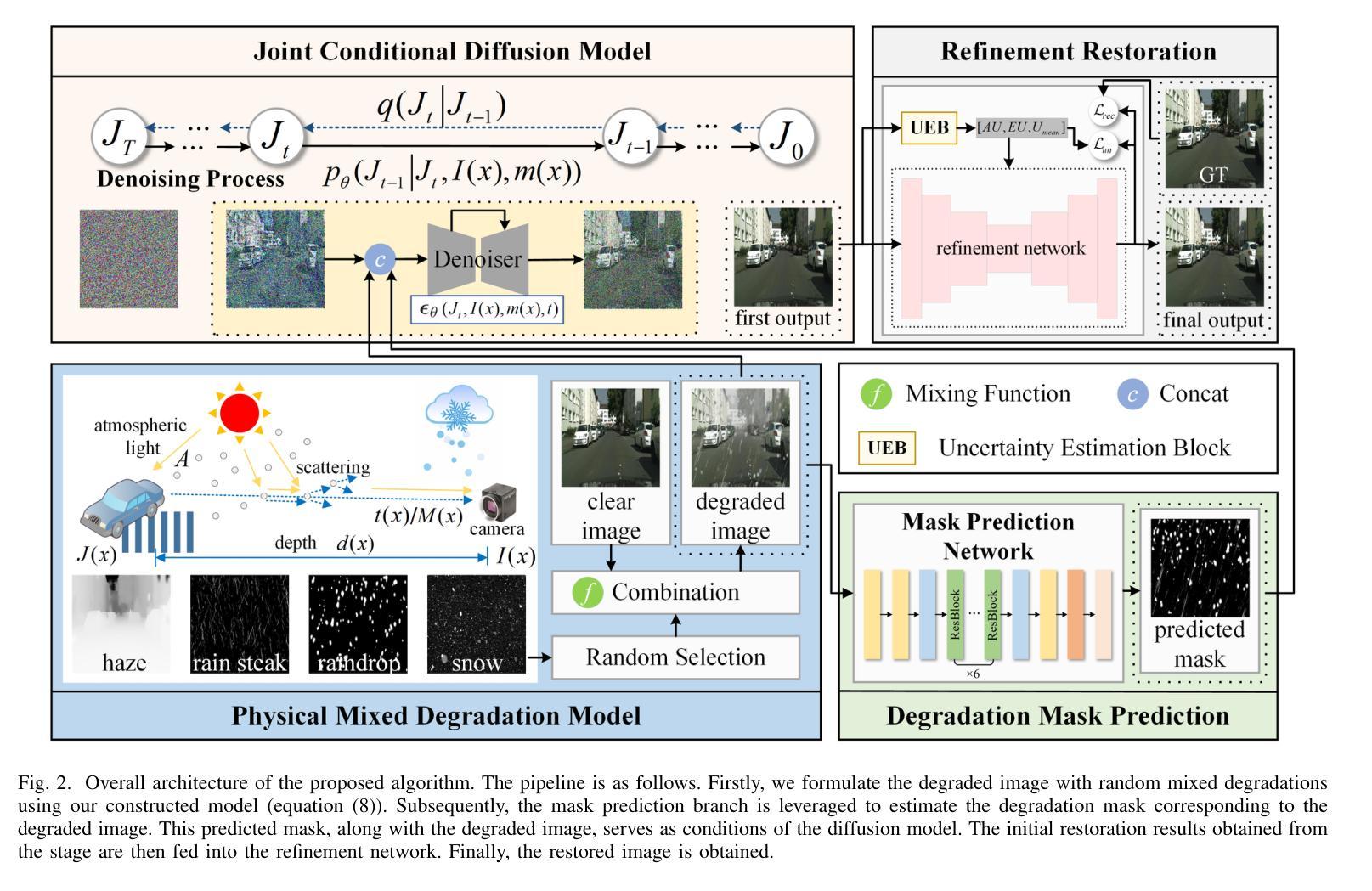
Joint Conditional Diffusion Model for Image Restoration with Mixed Degradations
Authors:Yufeng Yue, Meng Yu, Luojie Yang, Yi Yang
Image restoration is rather challenging in adverse weather conditions, especially when multiple degradations occur simultaneously. Blind image decomposition was proposed to tackle this issue, however, its effectiveness heavily relies on the accurate estimation of each component. Although diffusion-based models exhibit strong generative abilities in image restoration tasks, they may generate irrelevant contents when the degraded images are severely corrupted. To address these issues, we leverage physical constraints to guide the whole restoration process, where a mixed degradation model based on atmosphere scattering model is constructed. Then we formulate our Joint Conditional Diffusion Model (JCDM) by incorporating the degraded image and degradation mask to provide precise guidance. To achieve better color and detail recovery results, we further integrate a refinement network to reconstruct the restored image, where Uncertainty Estimation Block (UEB) is employed to enhance the features. Extensive experiments performed on both multi-weather and weather-specific datasets demonstrate the superiority of our method over state-of-the-art competing methods.
Summary
在恶劣天气条件下,图像修复难度较大,尤其是当多种退化同时发生时。盲图分解被提出以解决这个问题,但是它的有效性很大程度上依赖于每个分量的准确估计。虽然基于扩散的模型在图像修复任务中表现出强大的生成能力,但当退化的图像严重损坏时,它们可能会生成无关的内容。为了解决这些问题,我们利用物理约束来指导整个修复过程,其中构建了一个基于大气散射模型的混合退化模型。然后,我们通过将退化的图像和退化蒙版结合起来,构造了我们的联合条件扩散模型 (JCDM) 以提供精确的指导。为了获得更好的颜色和细节恢复结果,我们进一步整合了一个细化网络来重建恢复的图像,其中使用不确定性估计块 (UEB) 来增强特征。在多天气和特定天气数据集上进行的大量实验表明,我们的方法优于最先进的竞争方法。
Key Takeaways
- 利用物理约束建立混合退化模型,引导图像修复。
- 提出联合条件扩散模型(JCDM),通过退化图像和蒙版提供精确指导。
- 加入细化网络,提升颜色和细节恢复效果。
- 使用不确定性估计块(UEB)增强特征,改善图像重建质量。
- 在多天气和特定天气数据集上验证方法的优越性。
- JCDM在图像修复任务中表现出很强的生成能力。
- 细化网络有助于提高图像修复的色彩和细节表现。
- 题目:混合退化图像联合条件扩散模型
- 作者:岳雨峰,于萌,杨罗杰,杨毅
- 单位:北京理工大学自动化学院
- 关键词:去噪扩散模型,盲图像复原,混合退化,低层次视觉
- 论文链接:None,Github代码链接:None
- 摘要: (1)研究背景:图像复原在恶劣天气条件下颇具挑战,尤其是当多种退化同时发生时。盲图像分解被提出解决这个问题,然而其有效性严重依赖于每个分量的准确估计。基于扩散的模型虽然在图像复原任务中表现出强大的生成能力,但当退化图像严重损坏时,它们可能会生成无关的内容。 (2)过去方法及其问题:为了解决这些问题,我们利用物理约束来指导整个复原过程,其中构建了一个基于大气散射模型的混合退化模型。然后,我们通过结合退化图像和退化掩码来制定联合条件扩散模型(JCDM),以提供精确的指导。为了获得更好的颜色和细节恢复结果,我们进一步集成了一个精化网络来重建恢复的图像,其中采用不确定性估计块(UEB)来增强特征。 (3)本文提出的研究方法:在多天气和特定天气数据集上进行的广泛实验表明,我们的方法优于最先进的竞争方法。 (4)方法在什么任务上取得了什么性能:该方法在图像复原任务上取得了优异的性能,在多天气和特定天气数据集上均优于最先进的方法。这些性能支持了他们提出的目标,即开发能够有效处理复杂且多样化的退化场景的技术,而无需明确识别或分离各个退化分量。
7.Methods: (1)构建基于大气散射模型的混合退化模型,刻画多种退化同时发生的场景; (2)提出联合条件扩散模型(JCDM),利用退化图像和退化掩码提供精确指导; (3)集成精化网络,采用不确定性估计块(UEB)增强特征,提升颜色和细节恢复效果。
- 结论: (1):本文针对恶劣天气条件下的图像复原问题,提出了一种基于扩散的图像复原方法。该方法通过将退化图像和退化掩码作为条件信息,能够更具针对性和自适应地进行复原,从而提高了图像质量和准确度。此外,还集成了一个精化网络,以增强初始复原结果。实验结果表明,该方法在复杂场景中尤其具有显著的性能提升。未来研究工作可以集中在优化扩散过程,以在有效去除退化的同时更好地保留语义细节。 (2):创新点: 提出联合条件扩散模型(JCDM),利用退化图像和退化掩码提供精确指导。 集成精化网络,采用不确定性估计块(UEB)增强特征,提升颜色和细节恢复效果。 性能: 在多天气和特定天气数据集上,该方法在图像复原任务上取得了优异的性能,优于最先进的方法。 工作量: 该方法的实现相对复杂,需要构建混合退化模型、联合条件扩散模型和精化网络。然而,其出色的性能使其在实际应用中具有较高的价值。
点此查看论文截图

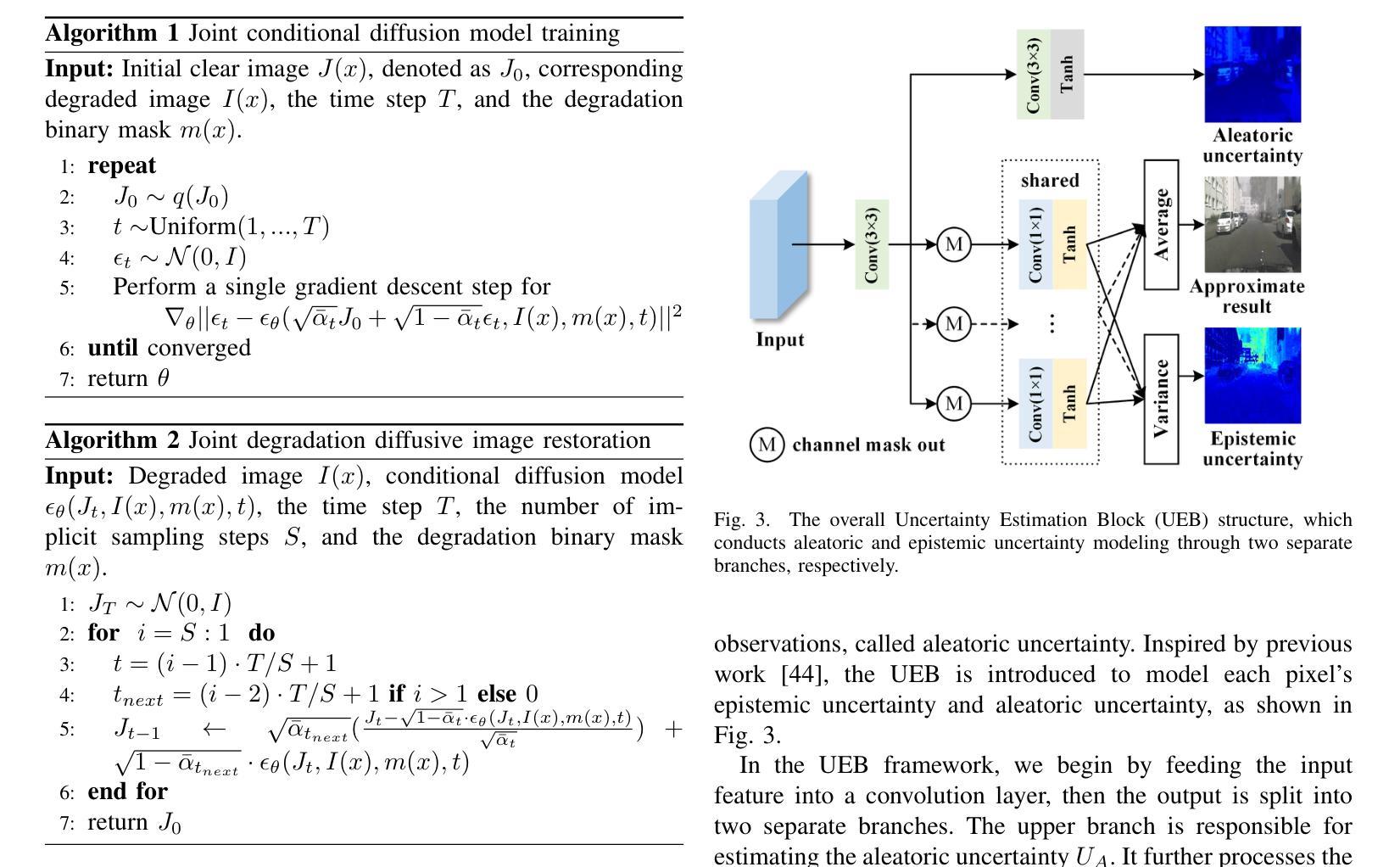

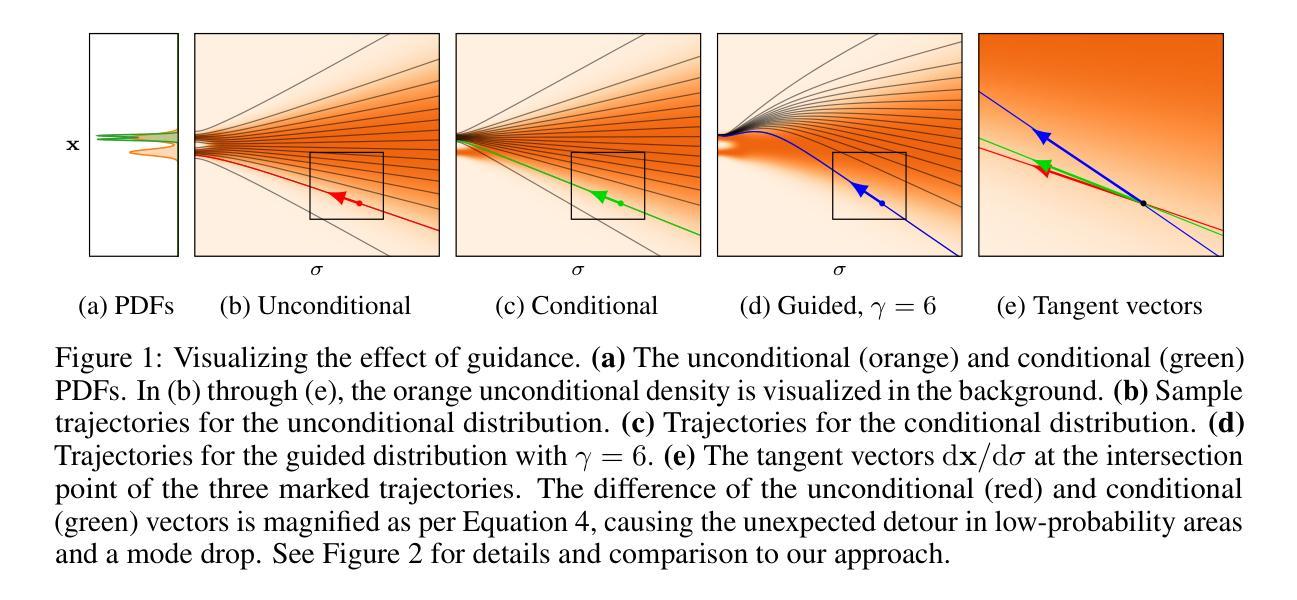
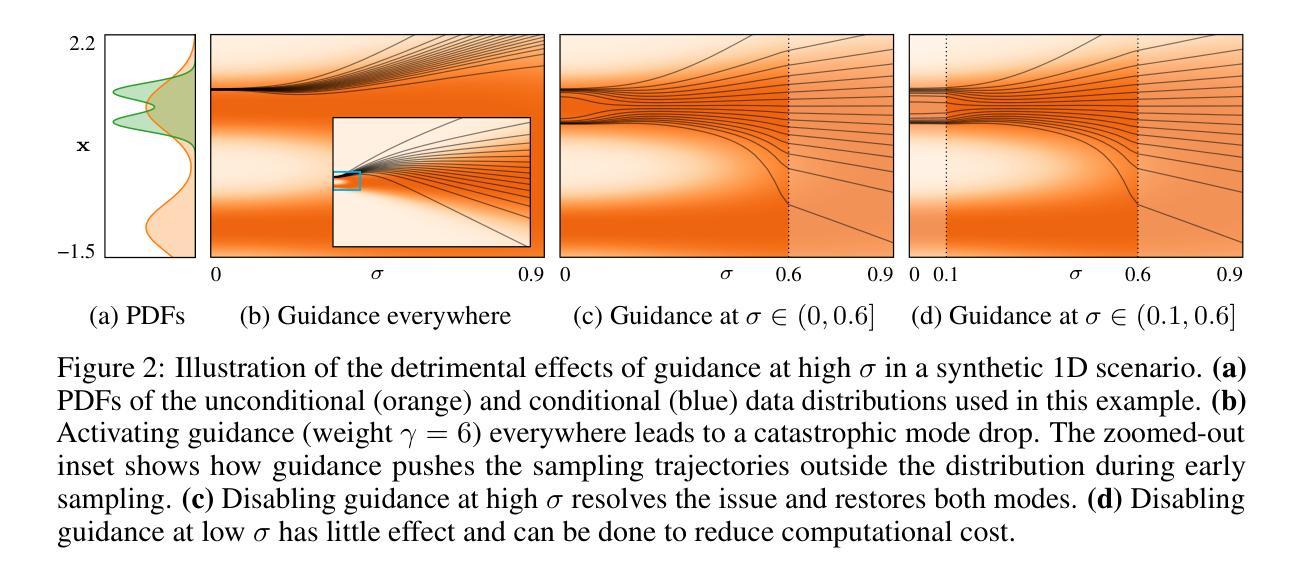
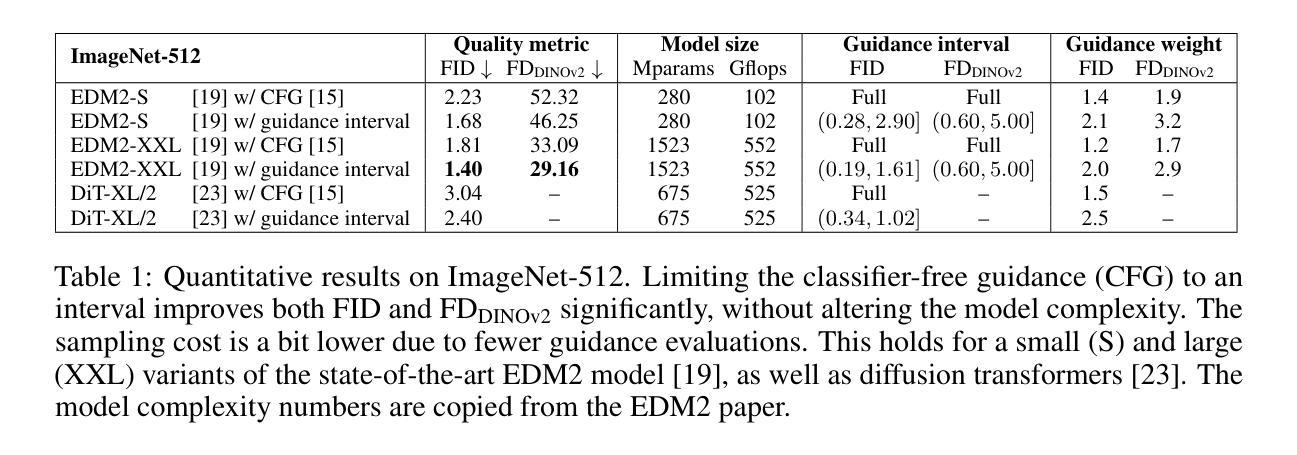
Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models
Authors:Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, Jaakko Lehtinen
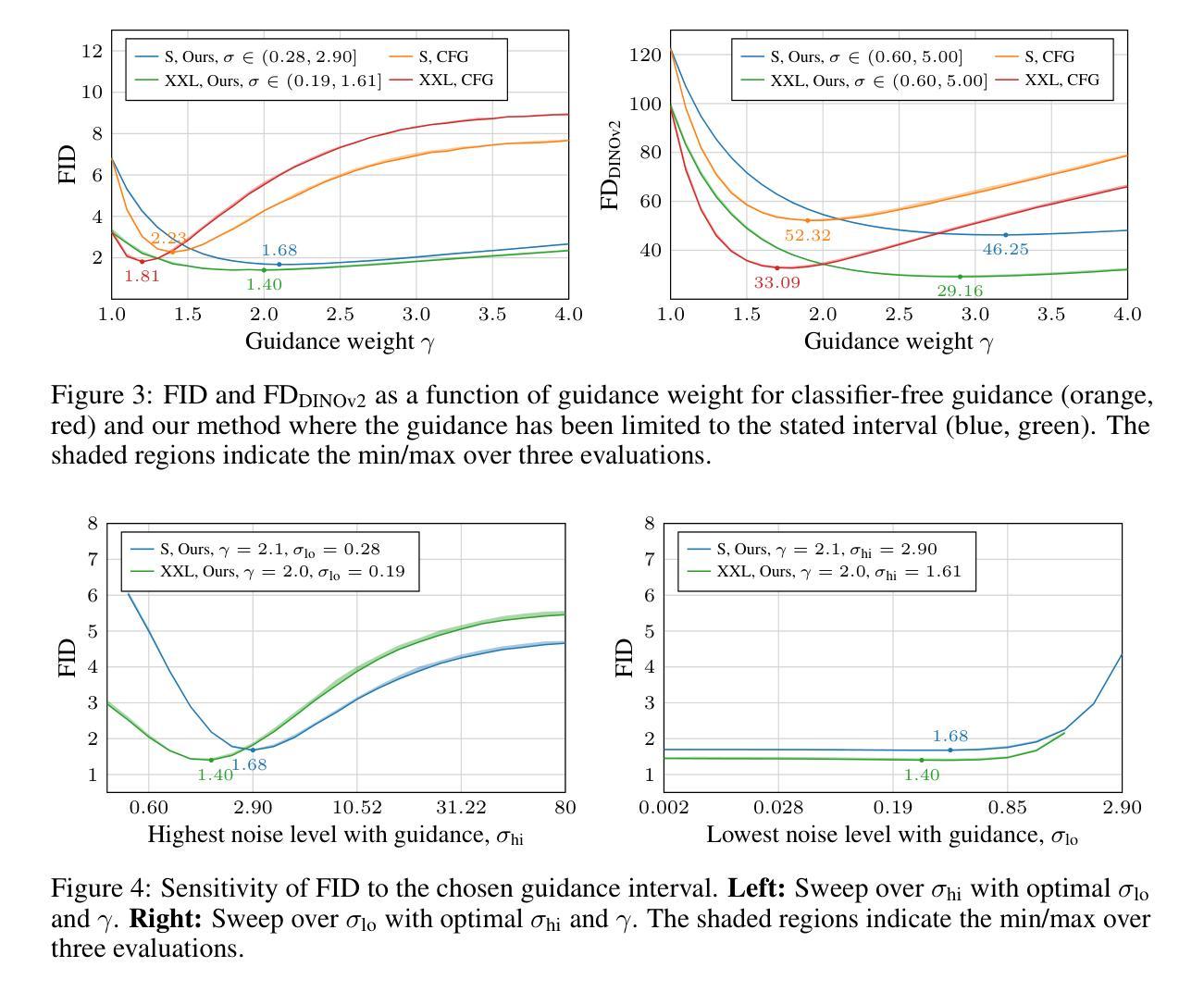
Guidance is a crucial technique for extracting the best performance out of image-generating diffusion models. Traditionally, a constant guidance weight has been applied throughout the sampling chain of an image. We show that guidance is clearly harmful toward the beginning of the chain (high noise levels), largely unnecessary toward the end (low noise levels), and only beneficial in the middle. We thus restrict it to a specific range of noise levels, improving both the inference speed and result quality. This limited guidance interval improves the record FID in ImageNet-512 significantly, from 1.81 to 1.40. We show that it is quantitatively and qualitatively beneficial across different sampler parameters, network architectures, and datasets, including the large-scale setting of Stable Diffusion XL. We thus suggest exposing the guidance interval as a hyperparameter in all diffusion models that use guidance.
Summary
扩散模型中的引导在图像生成的过程中起着至关重要的作用,但传统上只在整个图像采样的过程中使用恒定的引导权重,而最新的研究表明,在采样的开始和结束阶段,引导是有害或多余的,仅在中间阶段才是有益的。
Key Takeaways
- 传统的连续引导策略是无效的,在采样链的开始阶段有害,结束阶段多余,仅在中间阶段有益。
- 限制引导区间可提高推理速度和结果质量。
- 受限引导区间将 ImageNet-512 上的 FID 从 1.81 显着提高到 1.40。
- 该策略在不同的采样器参数、网络架构和数据集上都表现出定量和定性的优势,包括大规模的 Stable Diffusion XL。
- 建议在所有使用引导的扩散模型中将引导区间作为一个超参数公开。
- 作者通过在采样过程中限制引导的应用范围,提高了图像生成模型的性能。
1.标题:在有限区间内应用指导可提升扩散模型中的采样和分布质量(中文翻译:在有限区间内应用指导可提升扩散模型中的采样和分布质量) 2.作者:Tuomas Kynkäänniemi、Miika Aittala、Tero Karras、Samuli Laine、Timo Aila、Jaakko Lehtinen 3.第一作者单位:Aalto University(中文翻译:阿尔托大学) 4.关键词:Diffusion Models、Guidance、Image Synthesis、Sampling 5.论文链接:https://arxiv.org/abs/2404.07724 Github代码链接:无 6.摘要: (1):研究背景:扩散模型在图像生成领域取得了巨大进步,指导技术是其中一项关键技术。传统上,在图像采样链的整个过程中都会应用恒定的指导权重。 (2):过去的方法及其问题:过去的方法存在以下问题:指导在采样链开始时(高噪声水平)明显有害,在结束时(低噪声水平)基本无必要,仅在中间阶段有益。 (3):本文提出的研究方法:本文提出了一种新的方法,将指导限制在特定的噪声水平范围内,从而提高了推理速度和结果质量。 (4):方法在任务和性能上的表现:该方法在 ImageNet-512 数据集上将 FID 从 1.81 显著提升至 1.40,证明了其有效性。它在不同的采样器参数、网络架构和数据集上都表现出定量和定性的优势,包括大规模的 Stable Diffusion XL。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1): 本文提出了在特定噪声水平范围内应用指导的新方法,显著提升了扩散模型中的采样和分布质量,在 ImageNet-512 数据集上将 FID 从 1.81 显著提升至 1.40。该方法在不同的采样器参数、网络架构和数据集上都表现出定量和定性的优势,包括大规模的 StableDiffusionXL。 (2): 创新点:提出了一种在特定噪声水平范围内应用指导的新方法,解决了传统方法中指导权重恒定的问题。 性能:在 ImageNet-512 数据集上将 FID 从 1.81 显著提升至 1.40,在不同的采样器参数、网络架构和数据集上都表现出定量和定性的优势。 工作量:该方法的实现相对简单,易于集成到现有的扩散模型中。
点此查看论文截图

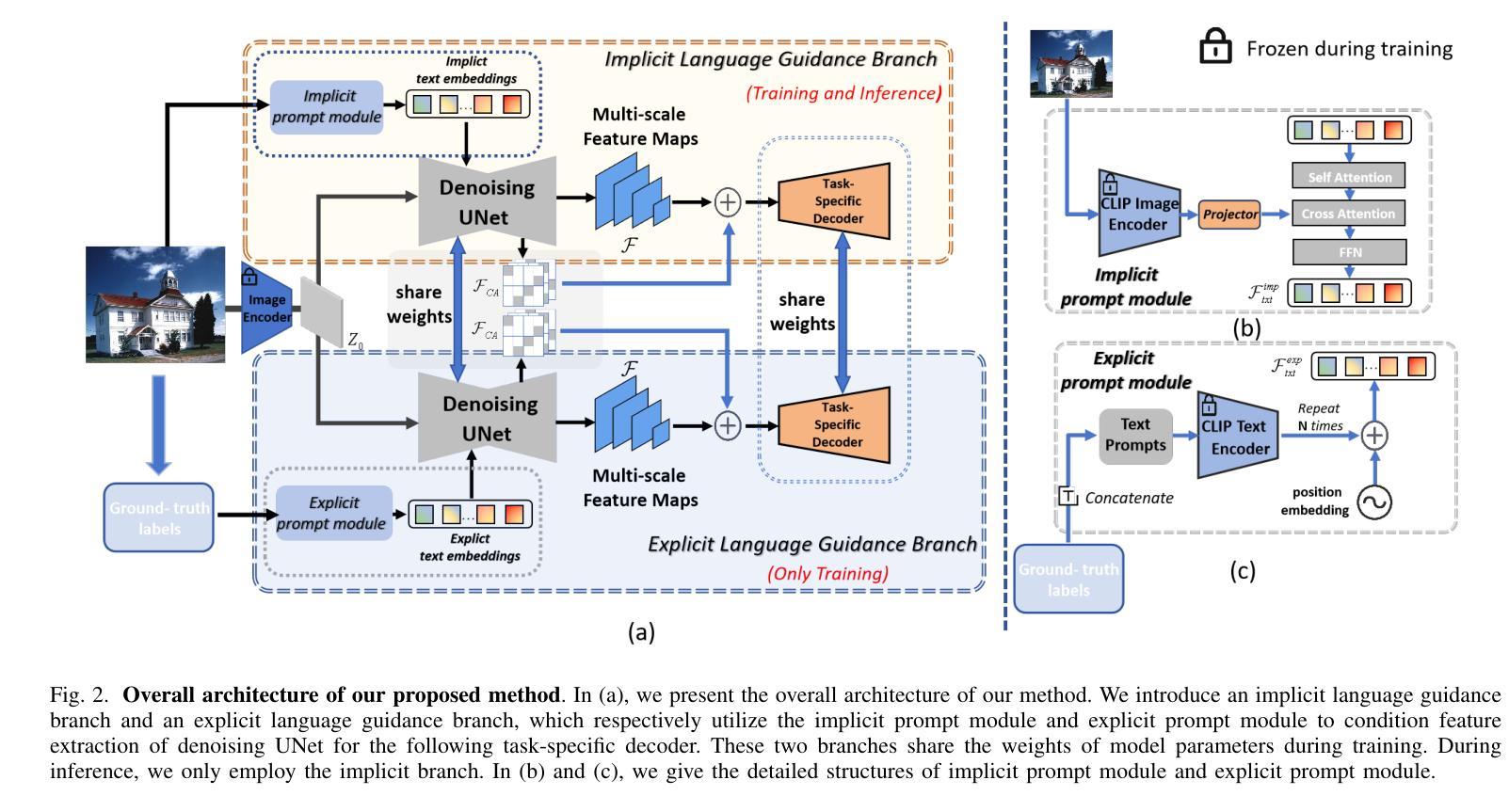
Implicit and Explicit Language Guidance for Diffusion-based Visual Perception
Authors:Hefeng Wang, Jiale Cao, Jin Xie, Aiping Yang, Yanwei Pang
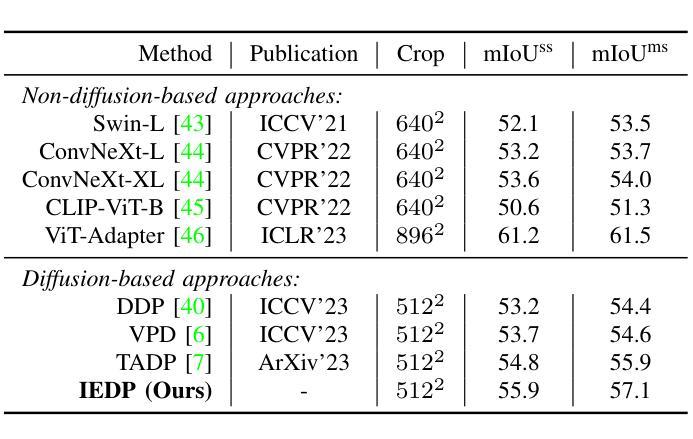
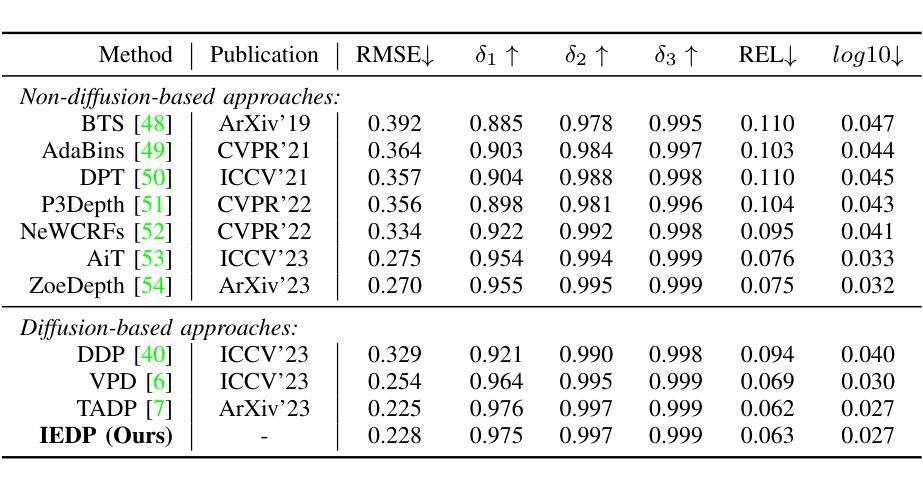
Text-to-image diffusion models have shown powerful ability on conditional image synthesis. With large-scale vision-language pre-training, diffusion models are able to generate high-quality images with rich texture and reasonable structure under different text prompts. However, it is an open problem to adapt the pre-trained diffusion model for visual perception. In this paper, we propose an implicit and explicit language guidance framework for diffusion-based perception, named IEDP. Our IEDP comprises of an implicit language guidance branch and an explicit language guidance branch. The implicit branch employs frozen CLIP image encoder to directly generate implicit text embeddings that are fed to diffusion model, without using explicit text prompts. The explicit branch utilizes the ground-truth labels of corresponding images as text prompts to condition feature extraction of diffusion model. During training, we jointly train diffusion model by sharing the model weights of these two branches. As a result, implicit and explicit branches can jointly guide feature learning. During inference, we only employ implicit branch for final prediction, which does not require any ground-truth labels. Experiments are performed on two typical perception tasks, including semantic segmentation and depth estimation. Our IEDP achieves promising performance on both tasks. For semantic segmentation, our IEDP has the mIoU score of 55.9% on AD20K validation set, which outperforms the baseline method VPD by 2.2%. For depth estimation, our IEDP outperforms the baseline method VPD with a relative gain of 10.2%.
Summary
文本到图像扩散模型在条件图像合成方面展现出强大的能力。通过大规模视觉语言预训练,扩散模型能够在不同的文本提示下生成具有丰富纹理和合理结构的高质量图像。然而,将预先训练的扩散模型用于视觉感知是一个开放的问题。在本文中,我们提出了一个用于基于扩散的感知的隐式和显式语言指导框架,名为 IEDP。我们的 IEDP 包含一个隐式语言指导分支和一个显式语言指导分支。隐式分支采用冻结的 CLIP 图像编码器直接生成隐式文本嵌入,并将其输入到扩散模型中,而无需使用显式文本提示。显式分支利用对应图像的真实标签作为文本提示来调节扩散模型的特征提取。在训练期间,我们通过共享这两个分支的模型权重来联合训练扩散模型。因此,隐式和显式分支可以共同指导特征学习。在推理期间,我们仅使用隐式分支进行最终预测,不需要任何真实标签。在包括语义分割和深度估计在内的两个典型感知任务上进行的实验表明,我们的 IEDP 在这两个任务上都取得了有希望的性能。对于语义分割,我们的 IEDP 在 AD20K 验证集上的 mIoU 得分为 55.9%,比基线方法 VPD 提高了 2.2%。对于深度估计,我们的 IEDP 比基线方法 VPD 提高了 10.2%。
Key Takeaways
- 提出了一种基于扩散的感知的隐式和显式语言指导框架(IEDP)。
- IEDP 包括一个隐式语言指导分支和一个显式语言指导分支。
- 隐式分支使用冻结的 CLIP 图像编码器生成隐式文本嵌入。
- 显式分支使用真实标签作为文本提示调节扩散模型的特征提取。
- 在训练期间,联合训练 IEDP 以共享两个分支的模型权重。
- 在推理期间,仅使用隐式分支进行预测,无需真实标签。
- IEDP 在语义分割和深度估计方面均取得了有希望的性能。
- 题目:基于扩散的视觉感知的隐式和显式语言引导
- 作者:Hefeng Wang, Jiale Cao, Jin Xie, Aiping Yang, Yanwei Pang
- 单位:天津大学电气与信息工程学院
- 关键词:扩散模型、语言引导、视觉感知
- 论文链接:https://arxiv.org/abs/2404.07600,Github代码:无
-
摘要: (1) 研究背景:扩散模型在条件图像合成中表现出强大的能力,但如何将其应用于视觉感知仍是一个开放问题。 (2) 过去方法:VPD和TADP等方法通过文本提示或图像对齐标题来对扩散模型进行语言引导,但存在繁琐、不一致和未充分利用训练数据等问题。 (3) 研究方法:本文提出了一种隐式和显式语言引导框架(IEDP),包括隐式语言引导分支(直接生成隐式文本嵌入)和显式语言引导分支(使用真实标签作为文本提示)。在训练过程中,这两个分支共享模型权重,联合指导特征学习。推理时,仅使用隐式分支进行预测。 (4) 性能和应用:IEDP在语义分割和深度估计任务上取得了较好的性能。在语义分割任务上,IEDP在AD20K验证集上的mIoUss得分为 55.9%,比基线方法 VPD 高 2.2%。在深度估计任务上,IEDP 比基线方法 VPD 提高了 10.2%。这些性能表明 IEDP 可以有效地利用扩散模型的特征表示能力,并为基于扩散的视觉感知提供了一种新的方法。
-
方法: (1) 提出隐式和显式语言引导框架(IEDP),包括隐式语言引导分支和显式语言引导分支; (2) 隐式语言引导分支使用冻结的 CLIP 图像编码器直接生成隐式文本嵌入,并将其馈送到扩散模型以调节特征提取; (3) 显式语言引导分支利用训练图像的真实标签作为显式文本提示,并使用 CLIP 文本编码器生成扩散模型的文本嵌入; (4) 训练过程中,两个分支共享模型权重,联合指导特征学习; (5) 推理时,仅使用隐式分支进行预测。
-
结论: (1):本文提出了一种基于扩散的视觉感知的隐式和显式语言引导框架(IEDP),该框架将隐式语言引导分支和显式语言引导分支引入到文本到图像扩散模型中。在隐式语言引导分支中,我们使用冻结的 CLIP 图像编码器直接生成隐式文本嵌入,并将其馈送到扩散模型以调节特征提取。在显式语言引导分支中,我们利用训练图像的真实标签作为显式文本提示,并使用 CLIP 文本编码器为扩散模型生成文本嵌入。隐式语言引导模块和显式语言引导模块共享模型权重,联合指导特征学习。在推理时,仅使用隐式分支进行预测。 (2):创新点:提出了一种新的隐式和显式语言引导框架,该框架可以有效地利用扩散模型的特征表示能力,并为基于扩散的视觉感知提供了一种新的方法。 性能:在语义分割和深度估计任务上取得了较好的性能。在语义分割任务上,IEDP 在 AD20K 验证集上的 mIoUss 得分为 55.9%,比基线方法 VPD 高 2.2%。在深度估计任务上,IEDP 比基线方法 VPD 提高了 10.2%。 工作量:该方法需要冻结 CLIP 图像编码器和 CLIP 文本编码器,并且需要在训练过程中联合训练隐式语言引导分支和显式语言引导分支。
点此查看论文截图



ObjBlur: A Curriculum Learning Approach With Progressive Object-Level Blurring for Improved Layout-to-Image Generation
Authors:Stanislav Frolov, Brian B. Moser, Sebastian Palacio, Andreas Dengel
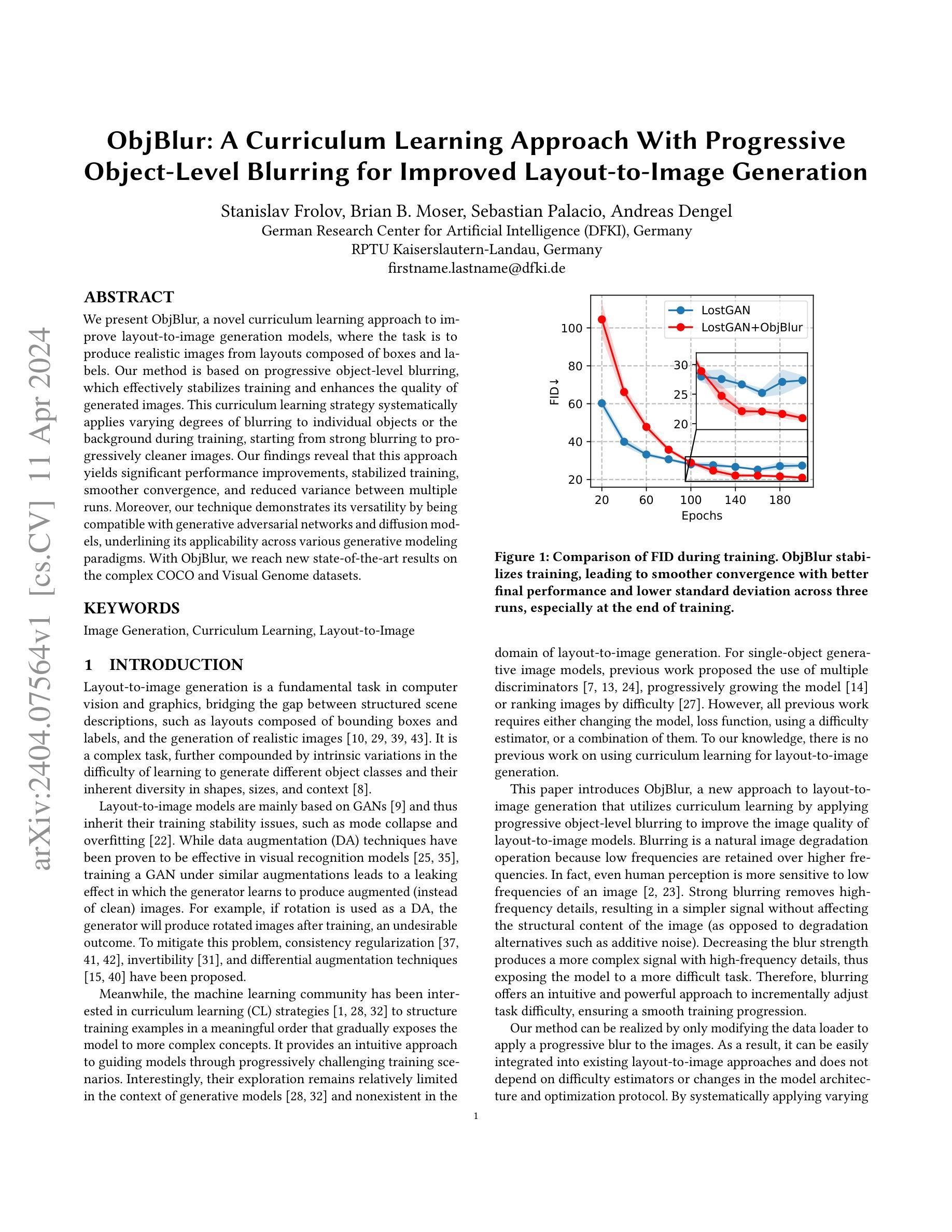
We present ObjBlur, a novel curriculum learning approach to improve layout-to-image generation models, where the task is to produce realistic images from layouts composed of boxes and labels. Our method is based on progressive object-level blurring, which effectively stabilizes training and enhances the quality of generated images. This curriculum learning strategy systematically applies varying degrees of blurring to individual objects or the background during training, starting from strong blurring to progressively cleaner images. Our findings reveal that this approach yields significant performance improvements, stabilized training, smoother convergence, and reduced variance between multiple runs. Moreover, our technique demonstrates its versatility by being compatible with generative adversarial networks and diffusion models, underlining its applicability across various generative modeling paradigms. With ObjBlur, we reach new state-of-the-art results on the complex COCO and Visual Genome datasets.
Summary
渐进式对象级模糊处理,提高图像生成质量。
Key Takeaways
- 渐进式对象级模糊处理可有效提高图像生成模型的质量。
- 从模糊到清晰的训练过程可稳定训练和增强图像质量。
- 该方法适用于生成对抗网络和扩散模型。
- 在 COCO 和 Visual Genome 数据集上取得了最先进的结果。
- 渐进式模糊处理可减少多次运行之间的差异。
- 渐进式模糊处理可使模型收敛更平滑。
- 该方法与扩散模型和生成对抗网络兼容。
- 题目:ObjBlur:一种渐进式对象级模糊的课程学习方法
- 作者:Stanislav Frolov、Brian B. Moser、Sebastian Palacio、Andreas Dengel
- 隶属机构:德国人工智能研究中心(DFKI)、德国凯撒斯劳滕-兰道应用技术大学
- 关键词:图像生成、课程学习、布局到图像
- 论文链接:https://arxiv.org/abs/2404.07564 Github 链接:无
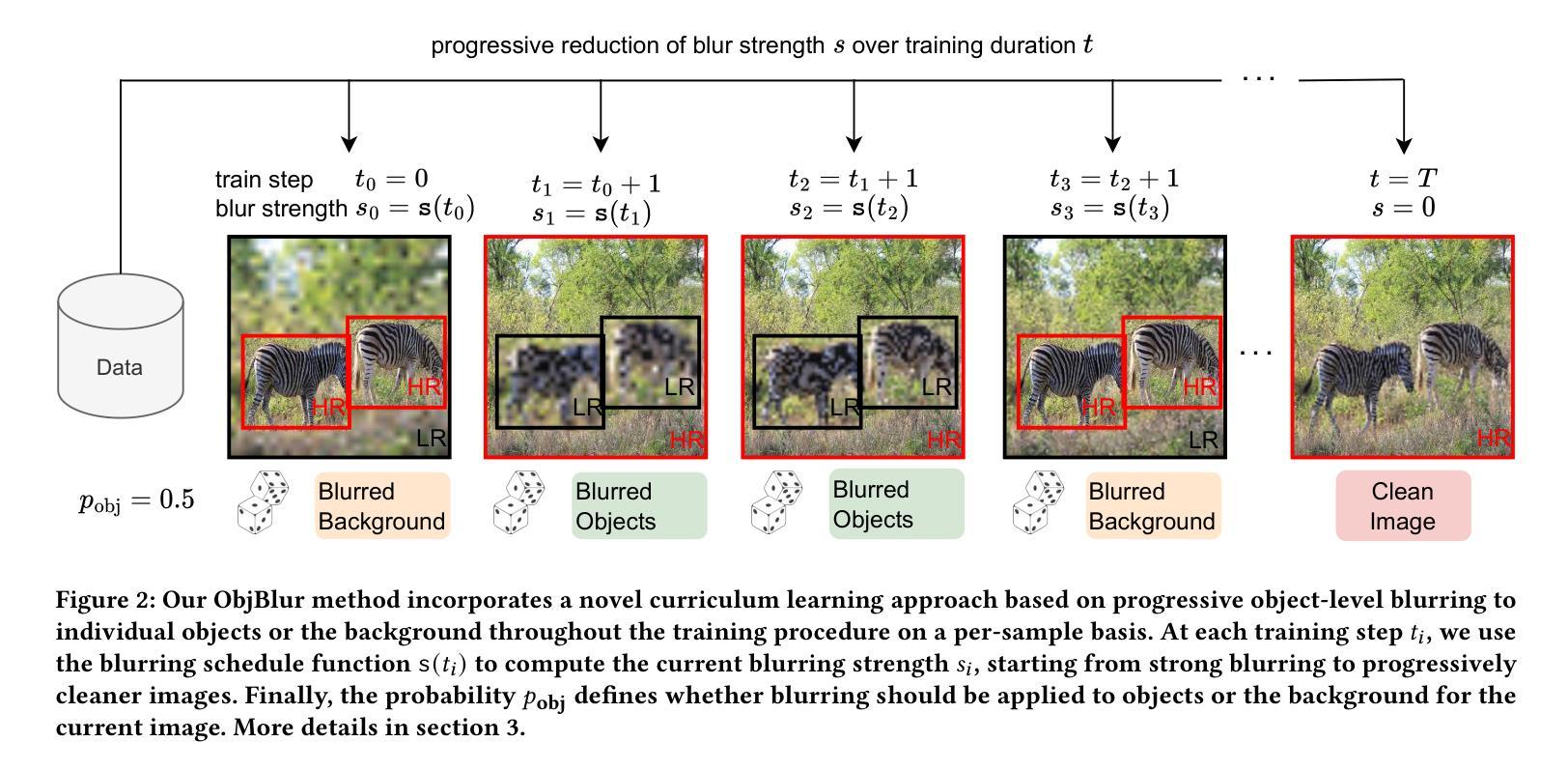
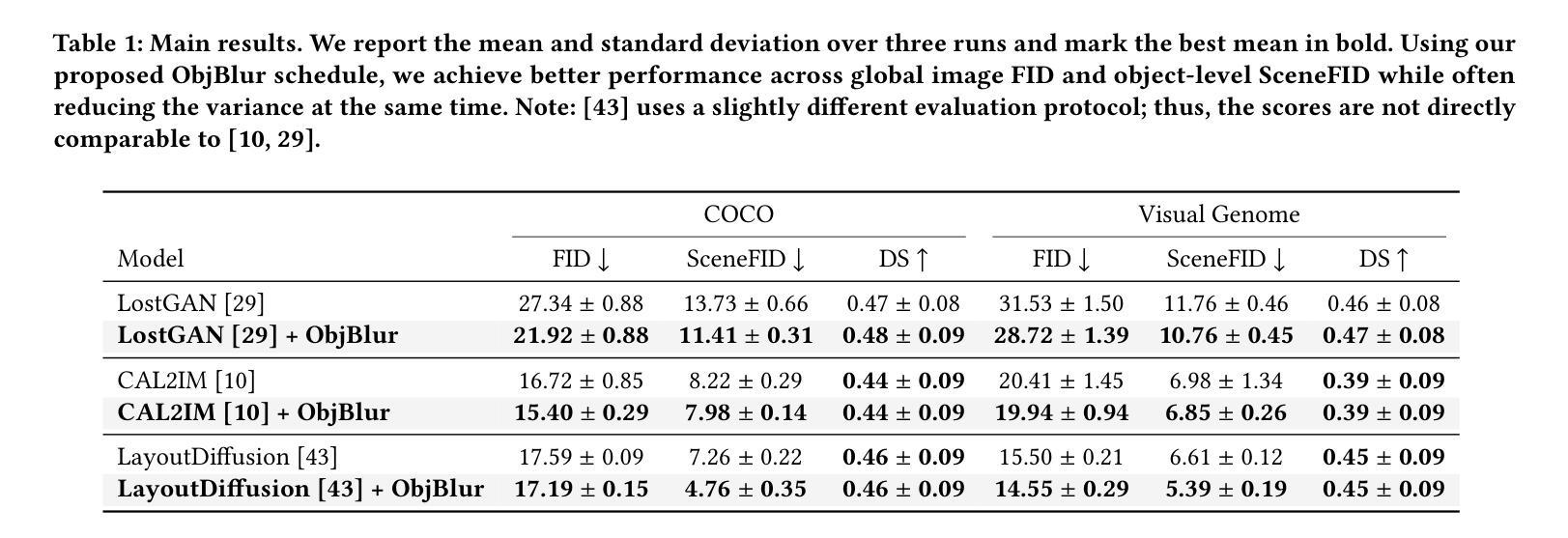
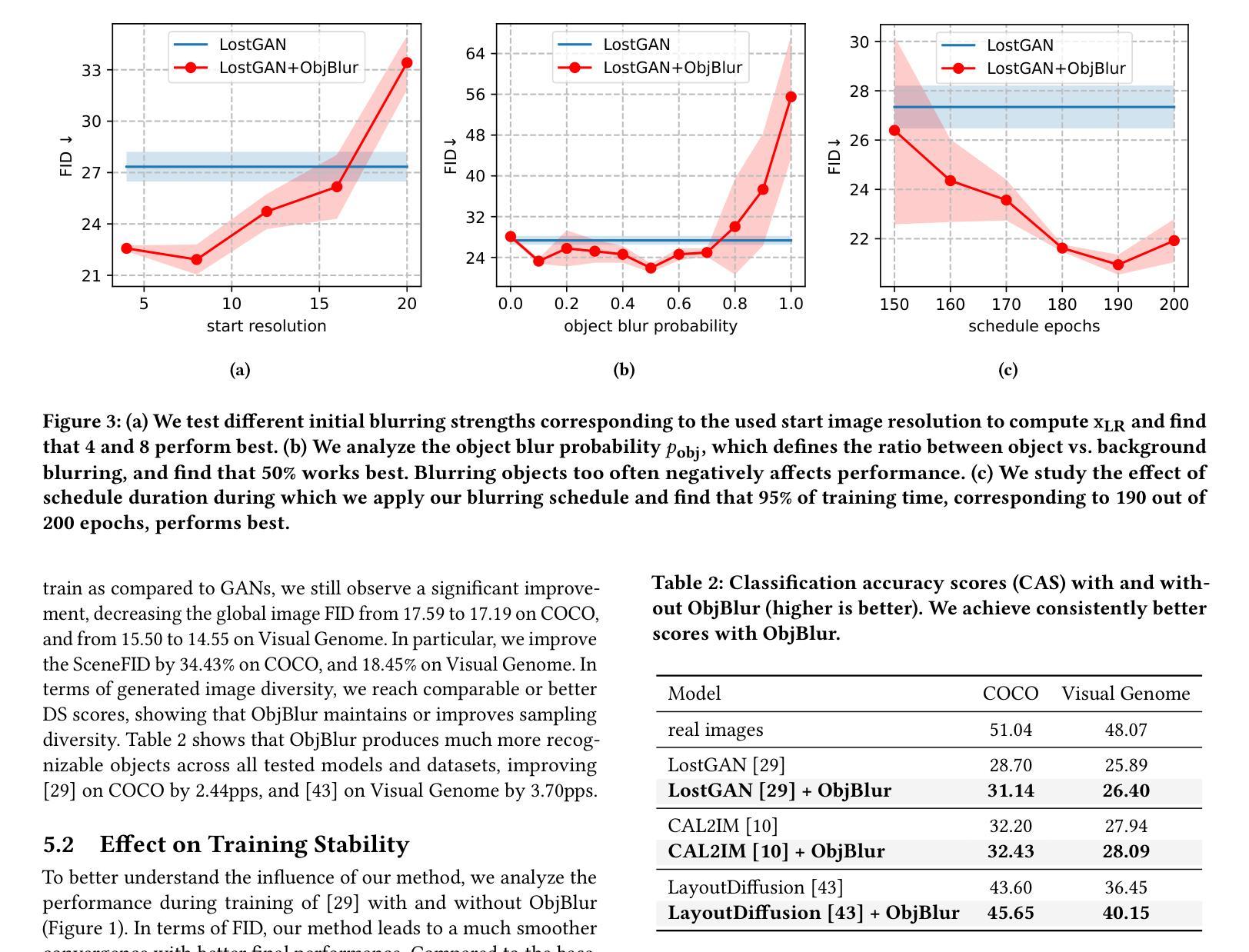
- 摘要: (1):研究背景:布局到图像生成是计算机视觉和图形学中一项基本任务,它将由边界框和标签组成的结构化场景描述与生成逼真图像联系起来。然而,由于不同对象类别的学习难度和形状、大小和语境的多样性,这是一个复杂的任务。 (2):过去的方法:布局到图像模型主要基于 GAN,因此继承了它们在训练稳定性方面的不足,如模型崩溃和过拟合。数据增强(DA)技术虽然在视觉识别模型中已被证明是有效的,但在 GAN 中使用类似的增强会导致泄漏效应,即生成器学习生成增强(而不是干净)的图像。 (3):论文提出的研究方法:本文提出 ObjBlur,这是一种新的布局到图像生成方法,它利用课程学习,通过应用渐进式对象级模糊来提高布局到图像模型的图像质量。模糊是一种自然的图像退化操作,因为低频比高频保留得更多。事实上,即使是人类感知也对图像的低频更敏感。强烈的模糊消除了高频细节,产生了没有影响图像结构内容的更简单的信号(与添加噪声等退化替代方案相反)。降低模糊强度会产生具有高频细节的更复杂的信号,从而使模型面临更困难的任务。因此,模糊提供了一种直观且强大的方法来逐步调整任务难度,确保训练过程平稳进行。我们的方法可以通过仅修改数据加载器来将渐进式模糊应用于图像来实现。因此,它可以轻松集成到现有的布局到图像方法中,并且不依赖于难度估计器或模型架构和优化协议的更改。 (4):方法在什么任务上取得了什么性能:通过系统地应用不同程度的模糊,我们的方法在复杂的数据集 COCO 和 VisualGenome 上取得了新的最先进结果。这些结果支持了我们的目标,即通过渐进式对象级模糊的课程学习策略可以显着提高布局到图像生成模型的性能。
方法
(1)逐步应用不同程度的模糊,以提高布局到图像生成模型的图像质量。
(2)模糊是一种自然的图像退化操作,低频比高频保留得更多。
(3)强烈的模糊消除高频细节,产生更简单的信号,不会影响图像结构内容。
(4)降低模糊强度会产生具有高频细节的更复杂的信号,使模型面临更困难的任务。
(5)模糊提供了一种直观且强大的方法来逐步调整任务难度,确保训练过程平稳进行。
(6)通过修改数据加载器将渐进式模糊应用于图像,可以轻松集成到现有的布局到图像方法中。
(7)无需依赖难度估计器或模型架构和优化协议的更改。
(8)在复杂的数据集 COCO 和 VisualGenome 上取得了新的最先进结果。
-
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
-
结论: (1):本文提出了 ObjBlur,这是一种基于对象级模糊的创新课程学习策略,显著提升了布局到图像生成模型的性能。我们的方法通过系统性地从强模糊逐步过渡到更清晰的图像,实现了最先进的性能、更好的训练稳定性和不同运行间更小的差异。ObjBlur 即插即用,仅需修改数据加载器,便于使用。它与生成对抗网络和扩散模型的兼容性凸显了其在各种生成建模范式中的通用性。我们的研究首次探索了课程学习在布局到图像生成中的应用,我们希望它能激发人们进一步研究课程学习和生成模型中的数据扩增的潜力。
(2):创新点:提出了一种基于对象级模糊的课程学习策略,逐步调整任务难度,提高模型性能; 性能:在复杂数据集 COCO 和 VisualGenome 上取得了新的最先进结果; 工作量:修改数据加载器即可轻松集成到现有的布局到图像方法中。
点此查看论文截图


RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
Authors:Jaidev Shriram, Alex Trevithick, Lingjie Liu, Ravi Ramamoorthi
We introduce RealmDreamer, a technique for generation of general forward-facing 3D scenes from text descriptions. Our technique optimizes a 3D Gaussian Splatting representation to match complex text prompts. We initialize these splats by utilizing the state-of-the-art text-to-image generators, lifting their samples into 3D, and computing the occlusion volume. We then optimize this representation across multiple views as a 3D inpainting task with image-conditional diffusion models. To learn correct geometric structure, we incorporate a depth diffusion model by conditioning on the samples from the inpainting model, giving rich geometric structure. Finally, we finetune the model using sharpened samples from image generators. Notably, our technique does not require video or multi-view data and can synthesize a variety of high-quality 3D scenes in different styles, consisting of multiple objects. Its generality additionally allows 3D synthesis from a single image.
PDF Project Page: https://realmdreamer.github.io/
Summary
从文本描述中生成通用前向 3D 场景的新技术:RealmDreamer。
Key Takeaways
- 从文本生成 3D 高斯飞溅表示,以匹配复杂的文本提示。
- 使用最先进的文本到图像生成器初始化飞溅,将其样本提升到 3D 并计算遮挡体积。
- 跨多个视图优化此表示,作为具有图像条件扩散模型的 3D 修复任务。
- 通过对来自修复模型的样本进行条件化,纳入深度扩散模型以了解正确的几何结构,从而提供丰富的几何结构。
- 使用图像生成器中的锐化样本对模型进行微调。
- 该技术不需要视频或多视图数据,并且可以合成各种不同风格的高质量 3D 场景,包括多个对象。
- 其通用性还允许从单个图像进行 3D 合成。
- 标题:RealmDreamer:文本驱动的 3D 场景生成,带内绘和深度扩散
- 作者:Jaidev Shriram、Alex Trevithick、Lingjie Liu、Ravi Ramamoorthi
- 隶属单位:加州大学圣地亚哥分校
- 关键词:文本到 3D、3D 场景生成、内绘、深度扩散
- 论文链接:https://realmdreamer.github.io/ Github 代码链接:无
- 摘要: (1) 研究背景:文本驱动的 3D 场景合成具有革新 3D 内容创作的潜力,但现有的方法存在迭代时间长、限制于简单的对象级数据或全景图等问题。 (2) 过去方法:过去方法通常使用文本到图像生成器初始化 3D 表示,但存在几何结构不准确的问题。 (3) 研究方法:RealmDreamer 提出了一种优化 3D 高斯散射表示以匹配复杂文本提示的方法。该方法利用文本到图像生成器初始化散射体,并通过内绘和深度扩散模型优化表示,以实现视差、详细外观和高保真几何结构。 (4) 性能:RealmDreamer 在 3D 场景生成任务上取得了最先进的结果,可以合成各种高质量的 3D 场景,包括多个对象。其通用性还允许从单个图像中进行 3D 合成。
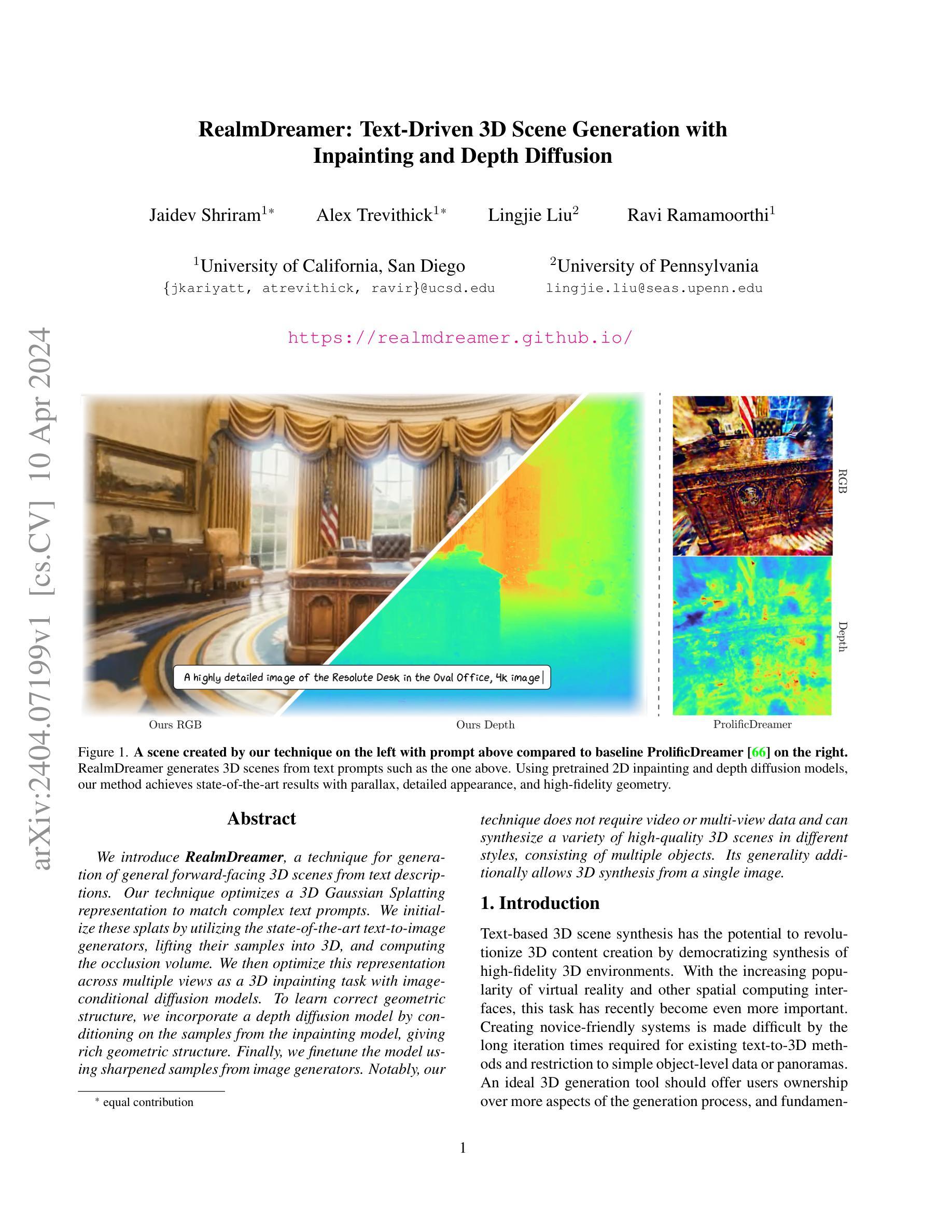
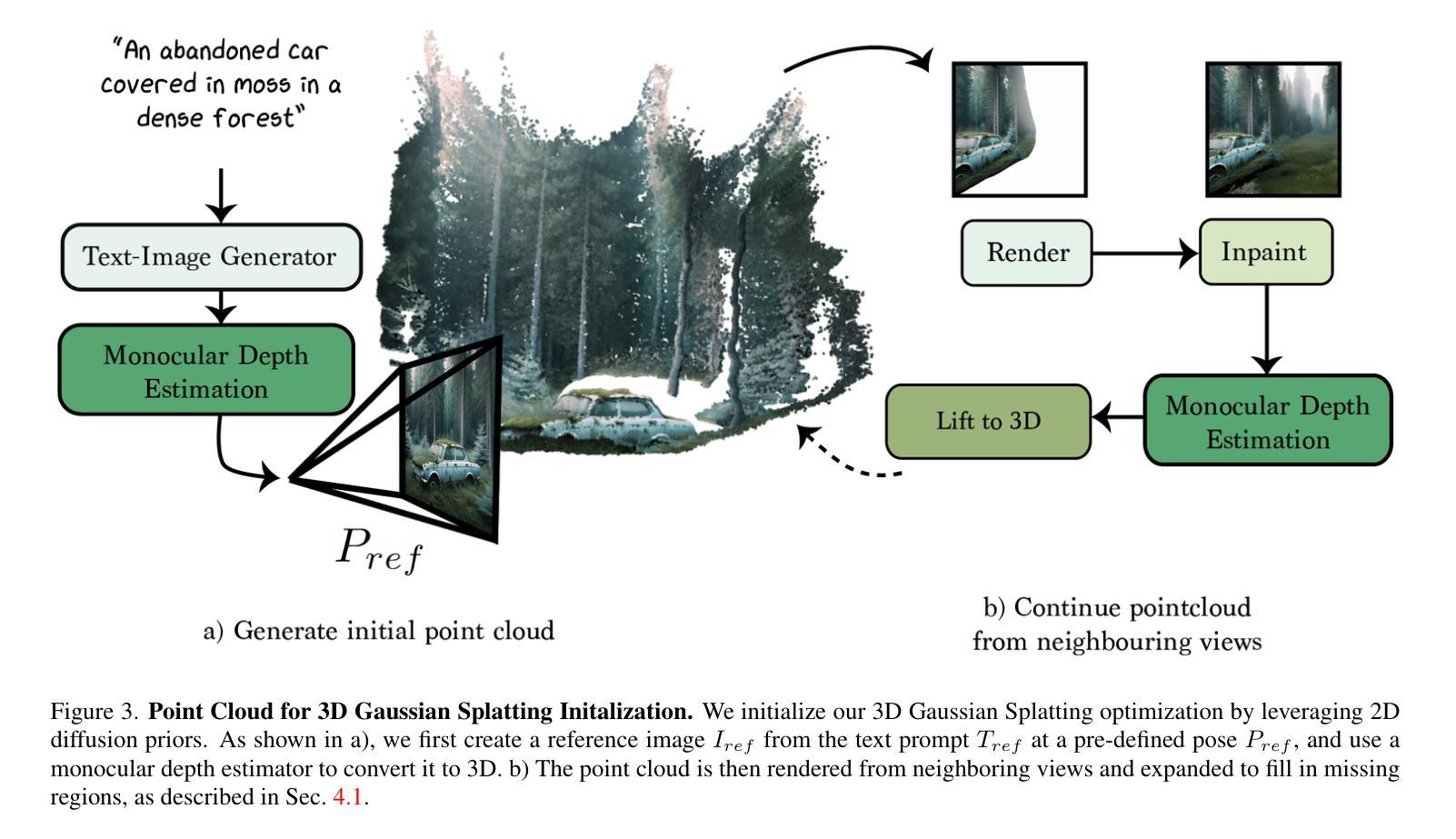
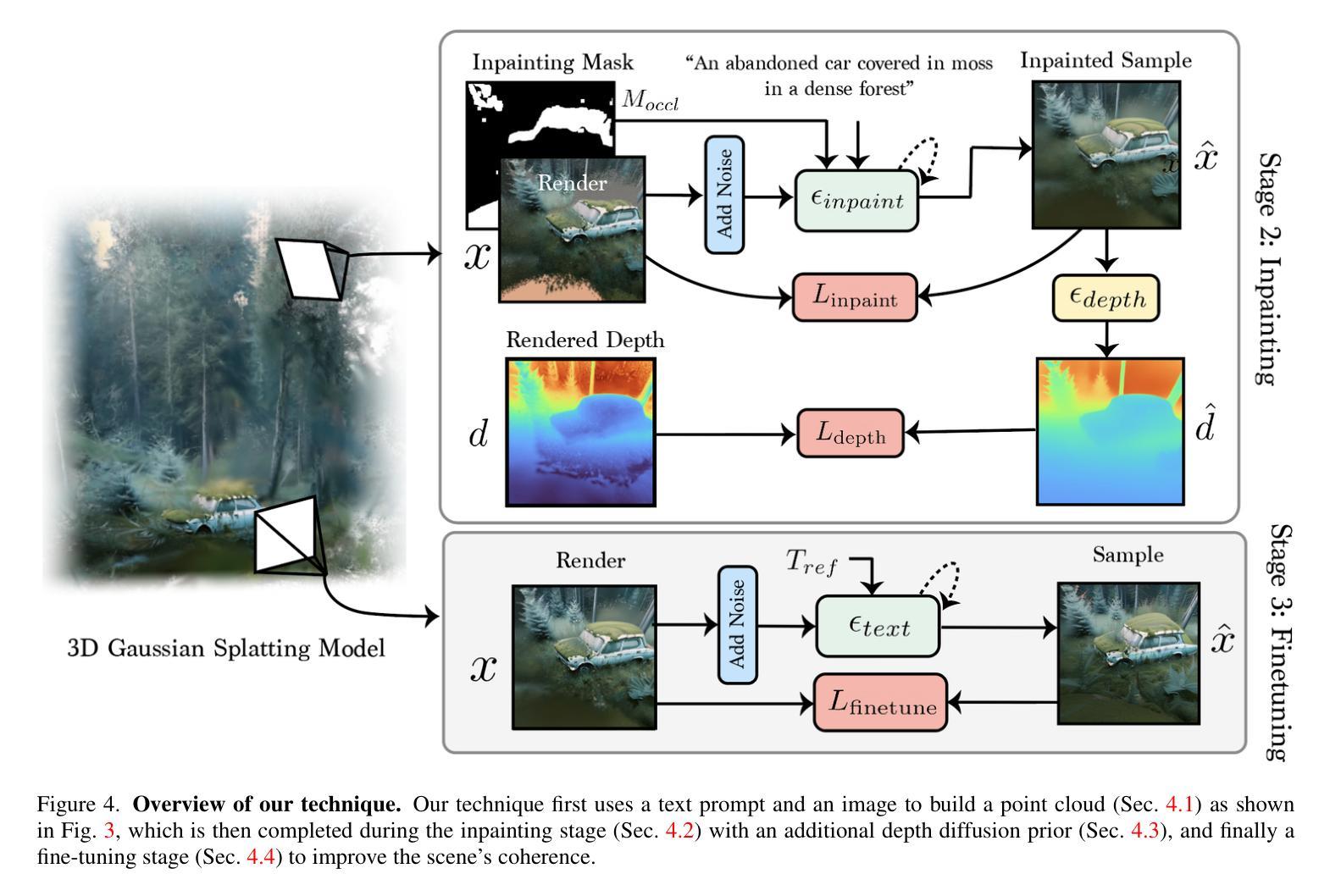
7.方法:(1)初始化:利用文本到图像生成器初始化3D高斯散射表示,并通过单目深度估计将图像提升为3D点云;(2)内绘:使用2D内绘扩散模型填充点云中的空洞区域,并引入深度扩散先验模型以提高几何精度和收敛速度;(3)微调:使用文本到图像扩散模型微调模型,提高场景的连贯性和细节清晰度;(4)优化:使用内绘损失、深度扩散损失、文本到图像扩散损失、不透明度损失和锐化过程优化模型,得到最终的3D场景。
- 结论: (1) RealmDreamer在文本驱动的3D场景生成领域取得了突破性进展,实现了高质量、高保真几何结构的3D场景合成; (2) 创新点:
- 提出了一种优化3D高斯散射表示的方法,利用内绘和深度扩散模型匹配复杂文本提示;
- 实现了视差、详细外观和高保真几何结构的统一生成;
- 具有从单个图像进行3D合成的通用性;
- 性能:
- 在3D场景生成任务上取得了最先进的结果,可以合成各种高质量的3D场景,包括多个对象;
- 工作量:
- 训练过程需要数小时;
- 对于具有高度遮挡的复杂场景,生成结果可能存在模糊问题。
点此查看论文截图


InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Authors:Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, Ying Shan
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
PDF Technical report. Project: https://github.com/TencentARC/InstantMesh
Summary
即时网格生成模型InstantMesh能够从单张图像中高效生成高质量3D网格模型。
Key Takeaways
- InstantMesh采用前馈框架,可从单张图像即时生成3D网格。
- 模型融合多分辨率扩散模型和稀疏视图重建模型,生成高精度3D模型。
- 可差分等值面提取模块直接优化网格表示,提升训练效率。
- 充分利用深度和法线等几何监督信息进行训练。
- InstantMesh性能优于其他图像到3D生成基线模型。
- 模型代码、权重和演示已全部开源,推动3D生成式人工智能社区发展。
- 标题:InstantMesh:高效的单张图像生成 3D 网格
- 作者:Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, Ying Shan
- 单位:上海科技大学
- 关键词:图像到 3D、3D 生成、网格生成、扩散模型
- 论文链接:https://arxiv.org/abs/2404.07191 Github 代码链接:https://github.com/TencentARC/InstantMesh
-
摘要: (1) 研究背景:随着生成式 AI 的飞速发展,图像到 3D 生成任务引起了广泛关注。然而,现有的方法要么生成质量较差,要么训练效率低下。 (2) 过去方法:现有的图像到 3D 方法主要基于多视图扩散模型或稀疏视图重建模型。多视图扩散模型生成质量高,但训练效率低;稀疏视图重建模型训练效率高,但生成质量较差。 (3) 本文方法:本文提出 InstantMesh,一个从单张图像生成 3D 网格的前馈框架。InstantMesh 结合了多视图扩散模型和基于 LRM 架构的稀疏视图重建模型的优势,在 10 秒内生成高质量的 3D 网格。此外,本文还集成了可微等值面提取模块,直接优化网格表示,提高了训练效率。 (4) 性能:实验结果表明,InstantMesh 在生成质量和训练效率方面均优于其他最新的图像到 3D 基线。本文发布了 InstantMesh 的所有代码、权重和演示,旨在为 3D 生成式 AI 社区做出重大贡献,并赋能研究人员和内容创作者。
-
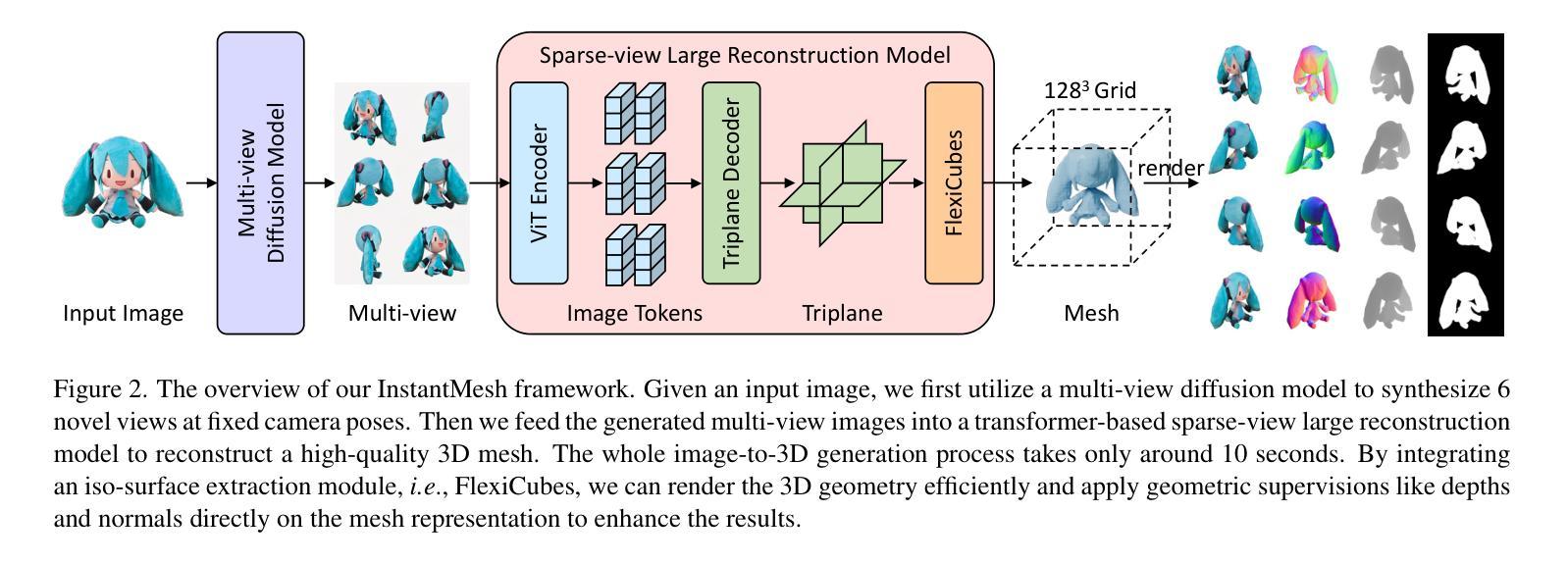
方法: (1): InstantMesh将多视图扩散模型与基于LRM架构的稀疏视图重建模型相结合,生成高质量的3D网格; (2): InstantMesh集成了可微等值面提取模块,直接优化网格表示,提高训练效率; (3): InstantMesh采用前馈框架,在10秒内生成3D网格; (4): InstantMesh在生成质量和训练效率方面优于其他图像到3D基线。
-
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
-
结论: (1):本文提出了 InstantMesh,一个从单张图像生成高质量 3D 网格的前馈框架,为 3D 生成式 AI 社区做出了重大贡献,并赋能研究人员和内容创作者。 (2):创新点:
- 将多视图扩散模型与基于 LRM 架构的稀疏视图重建模型相结合,生成高质量 3D 网格。
- 集成了可微等值面提取模块,直接优化网格表示,提高训练效率。
- 采用前馈框架,在 10 秒内生成 3D 网格。 性能:
- 在生成质量和训练效率方面优于其他图像到 3D 基线。 工作量:
- 代码、权重和演示均已开源,便于研究人员和创作者使用。
点此查看论文截图

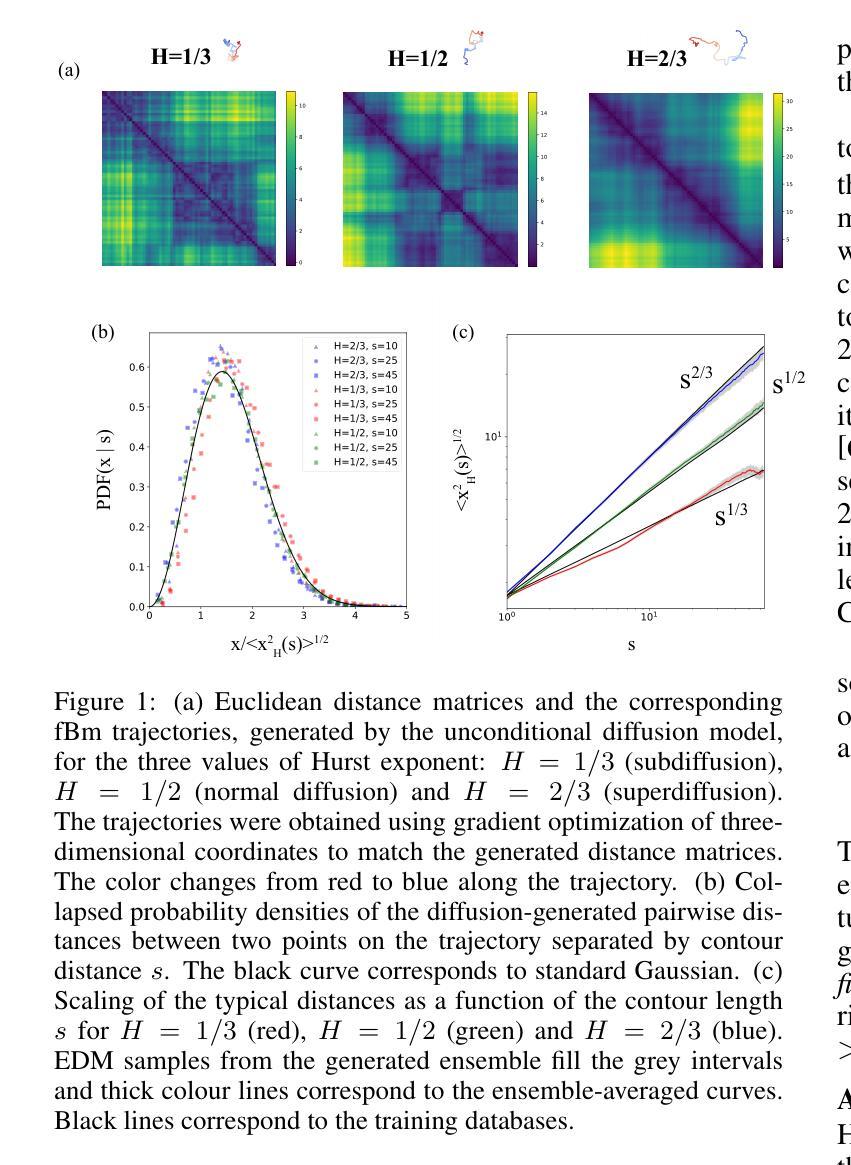
Diffusion-based inpainting of incomplete Euclidean distance matrices of trajectories generated by a fractional Brownian motion
Authors:Alexander Lobashev, Kirill Polovnikov
Fractional Brownian trajectories (fBm) feature both randomness and strong scale-free correlations, challenging generative models to reproduce the intrinsic memory characterizing the underlying process. Here we test a diffusion probabilistic model on a specific dataset of corrupted images corresponding to incomplete Euclidean distance matrices of fBm at various memory exponents $H$. Our dataset implies uniqueness of the data imputation in the regime of low missing ratio, where the remaining partial graph is rigid, providing the ground truth for the inpainting. We find that the conditional diffusion generation stably reproduces the statistics of missing fBm-distributed distances for different values of $H$ exponent. Furthermore, while diffusion models have been recently shown to remember samples from the training database, we show that diffusion-based inpainting behaves qualitatively different from the database search with the increasing database size. Finally, we apply our fBm-trained diffusion model with $H=1/3$ for completion of chromosome distance matrices obtained in single-cell microscopy experiments, showing its superiority over the standard bioinformatics algorithms. Our source code is available on GitHub at https://github.com/alobashev/diffusion_fbm.
Summary
扩散概率模型可稳定生成具有不同记忆指数的 fBm 分布距离,在单细胞显微实验中优于标准生物信息学算法。
Key Takeaways
- 扩散概率模型可稳定生成具有不同记忆指数的 fBm 分布距离。
- 扩散模型在低缺失率下可唯一地插补数据。
- 扩散模型生成的插补结果与训练数据库搜索存在质的不同。
- 扩散模型在单细胞显微实验中表现出优于标准生物信息学算法的性能。
- 扩散模型具有记忆训练数据库样本的能力。
- fBm 训练的扩散模型在小缺失率下表现出稳定性。
- 代码可在 GitHub 上获取。
- 标题:扩散概率模型在分数布朗运动距离矩阵修复中的应用
- 作者:Alexey Lobashev, Dmitry Krotov, Vadim S. Smelyanskiy
- 所属单位:莫斯科国立大学
- 关键词:分数布朗运动,扩散概率模型,数据修复,生物信息学
- 论文链接:https://arxiv.org/abs/2302.09842 Github 代码链接:https://github.com/alobashev/diffusionfbm
- 摘要: (1)研究背景:分数布朗运动(fBm)轨迹具有随机性和强尺度自由相关性,对生成模型重现其内在记忆提出了挑战。 (2)过去的方法:过去的方法包括数据库搜索和最近邻方法,但这些方法在低缺失率下会出现不稳定性和不准确性。 (3)本文提出的研究方法:本文提出了一种基于扩散概率模型(DDPM)的数据修复方法,通过优化条件扩散过程来重现 fBm 分布距离的统计数据。 (4)方法的性能:在不同缺失率和 Hurst 指数下,DDPM 方法在修复 fBm 距离矩阵方面优于数据库搜索和最近邻方法。在单细胞显微镜实验中,DDPM 方法也优于标准生物信息学算法。该方法的性能证明了其在修复 fBm 数据方面的有效性。
7.方法: (1):扩散概率模型(DDPM)修复:利用预训练的 DDPM 模型,将已知距离矩阵中的已知值作为条件,通过逆向扩散过程重现 fBm 分布距离的统计数据,修复缺失值。 (2):数据库搜索修复:从预先构建的距离矩阵数据库中,搜索与损坏矩阵最相似的完整矩阵,并基于两者融合得到修复结果。
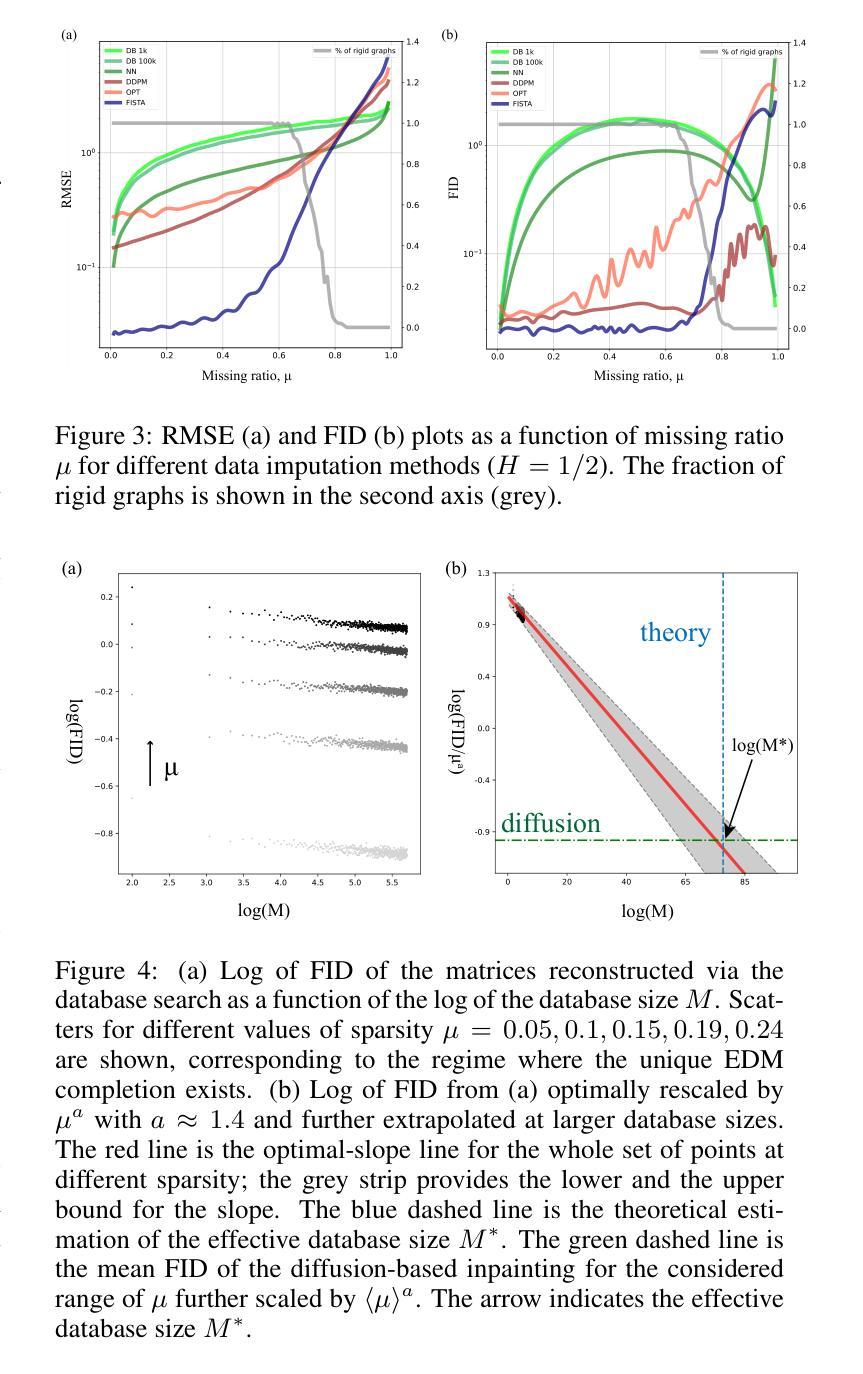
- 结论: (1):本工作通过将欧氏距离矩阵视为图像,证明了扩散概率模型可以学习到各种记忆指数 H 的 fBm 轨迹集合的距离矩阵中本质的大尺度相关性。基于这一观察,我们应用基于扩散的修复来解决 EDM 补全问题,发现扩散条件生成与数据库搜索的行为截然不同,数据库大小与扩散模型的参数数量相似。我们提供了关于有效数据库大小的理论论证,解释了这种定性差异,并在数值实验中验证了这一点。我们进一步表明,虽然基于扩散的修复行为类似于梯度轨迹优化,但它不仅学习潜在 (2):创新点:提出了一种基于扩散概率模型的 fBm 距离矩阵修复方法,通过优化条件扩散过程来重现 fBm 分布距离的统计数据。 性能:在不同缺失率和 Hurst 指数下,DDPM 方法在修复 fBm 距离矩阵方面优于数据库搜索和最近邻方法。在单细胞显微镜实验中,DDPM 方法也优于标准生物信息学算法。 工作量:该方法的实现需要预训练 DDPM 模型和构建距离矩阵数据库,这可能需要大量的计算资源和时间。
点此查看论文截图



DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Authors:Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, Achuta Kadambi
The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary “flat” (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Summary
文本到 3D 全景场景生成管道,可快速创建全局一致且引人入胜的 360 度场景。
Key Takeaways
- 采用 2D 扩散模型的生成能力和提示自我优化生成高质量且全局连贯的全景图像。
- 使用镶嵌技术将图像提升为 3D 高斯体,实现实时浏览。
- 通过将 2D 单目深度对齐到全局优化点云中,构建空间连贯结构,生成一致的 3D 几何体。
- 利用合成和输入相机视图的语义和几何约束作为正则化,解决单视图输入的不可见问题。
- 该方法在 360 度视角内提供全局一致的 3D 场景,比现有技术提供更身临其境的体验。
- 标题:DreamScene360:无约束文本到 3D 场景
- 作者:Shijie Zhou、Zhiwen Fan、Dejia Xu、Haoran Chang、Pradyumna Chari、Tejas Bharadwaj、Suya You、Zhangyang Wang、Achuta Kadambi
- 第一作者单位:加州大学洛杉矶分校
- 关键词:文本到 3D 场景、360 全景图、高斯散射、深度估计、空间一致性
- 论文链接:http://dreamscene360.github.io/,Github 代码链接:None
- 摘要: (1)研究背景:虚拟现实应用对沉浸式 3D 资产的需求日益增长。 (2)过去方法:现有方法难以创建全面且一致的 360° 场景。 (3)研究方法:提出 DreamScene360,一个文本到 3D 场景生成管道,利用 2D 扩散模型生成全景图像,并通过高斯散射和深度估计技术将其提升为 3D 场景。 (4)方法性能:在 in-the-wild 环境中,DreamScene360 可以在几分钟内生成高质量、全局一致的 360° 场景,支持实时探索。
7.方法:(1) 文本到360°全景图: 利用扩散模型生成全景图像,并通过自优化过程确保图像与文本的语义对齐;(2) 全景图到3D场景: 利用单目几何初始化和优化单目全景 3D 高斯体,并通过合成虚拟相机和蒸馏语义相似性来增强深度一致性;(3) 优化单目全景 3D 高斯体: 使用 3D 高斯体渲染技术生成透视图,并通过最小化语义损失和几何损失来优化高斯体的参数。
- 结论: (1): 本工作提出了一种文本到 3D 场景生成管道 DreamScene360,该管道可以生成高质量、全局一致的 360° 场景,支持实时探索,为虚拟现实应用提供了沉浸式 3D 资产。 (2): 创新点:
- 提出了一种基于扩散模型的文本到 360° 全景图生成方法,确保了图像与文本的语义对齐。
- 提出了一种基于单目几何和优化单目全景 3D 高斯体的全景图到 3D 场景生成方法,增强了深度一致性。
- 提出了一种使用 3D 高斯体渲染技术和语义损失和几何损失最小化来优化单目全景 3D 高斯体的方法。 性能:
- DreamScene360 可以生成高质量、全局一致的 360° 场景,支持实时探索。
- DreamScene360 在 in-the-wild 环境中,可以在几分钟内生成场景。 工作量:
- DreamScene360 的实现需要大量的计算资源,包括 GPU 和内存。
- DreamScene360 的训练需要大量的数据集和训练时间。
点此查看论文截图

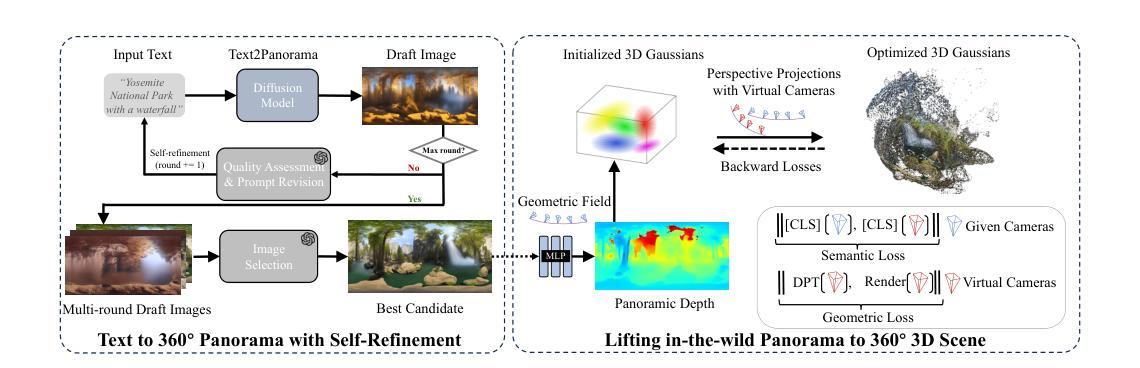
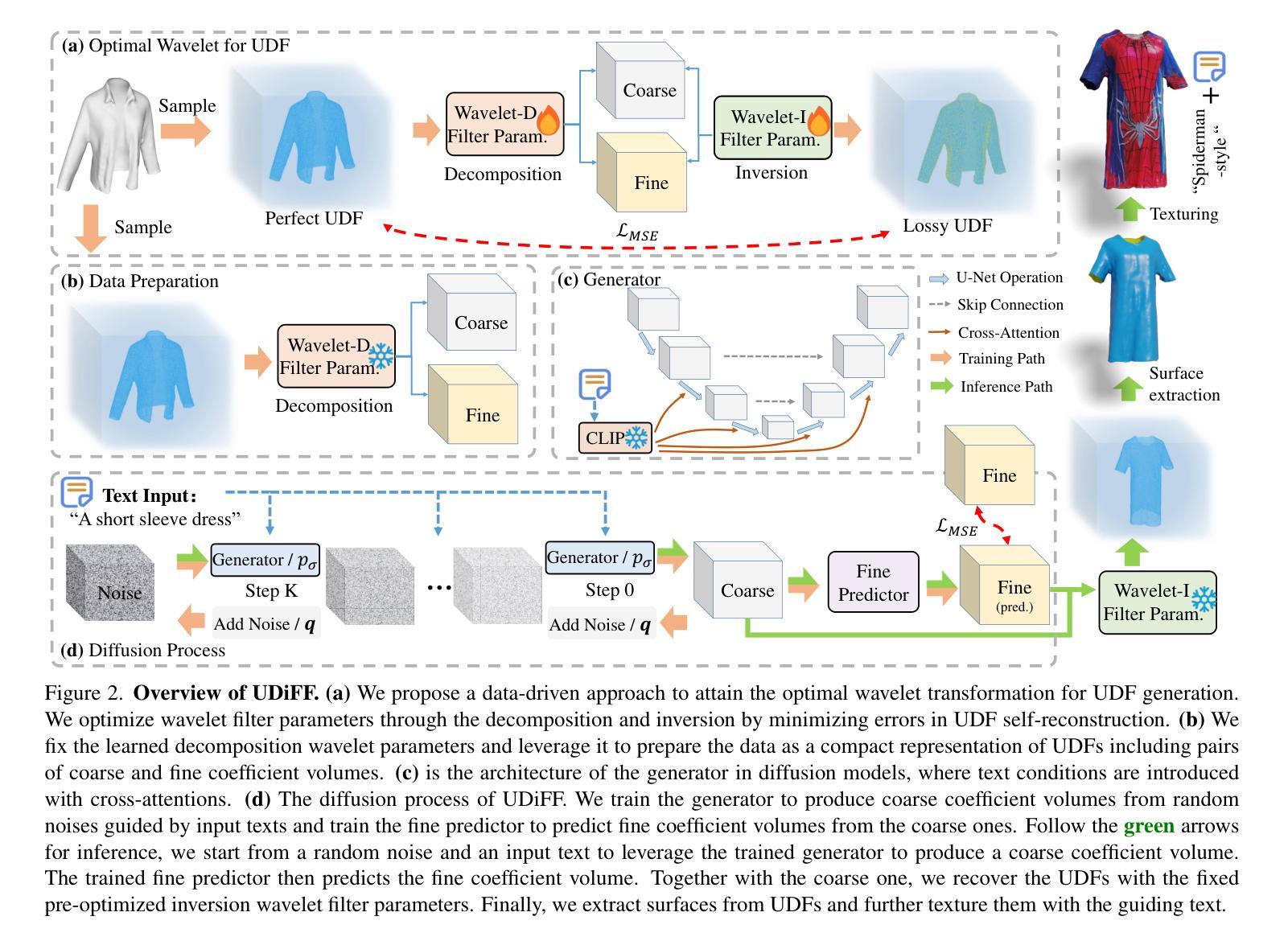
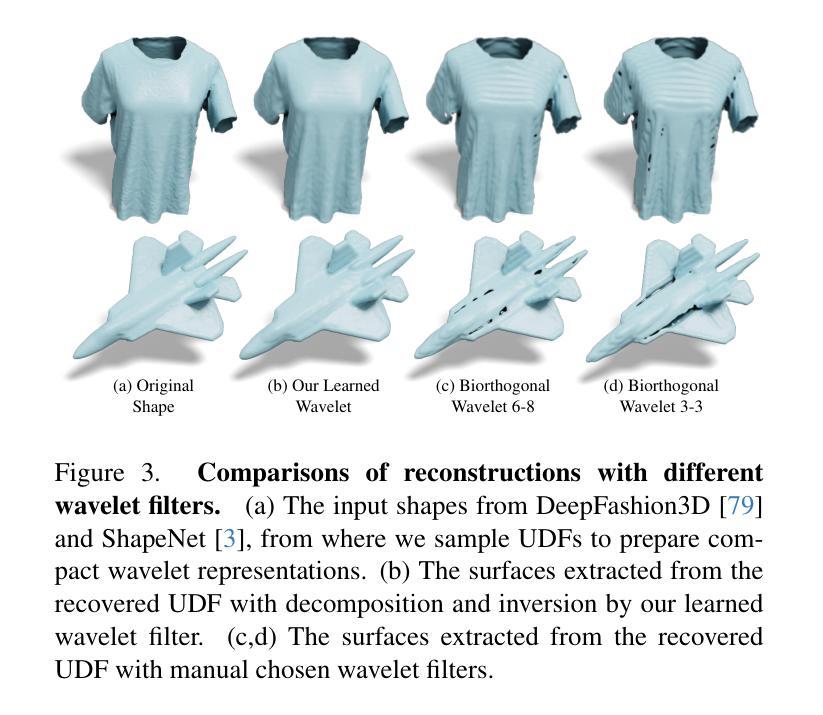
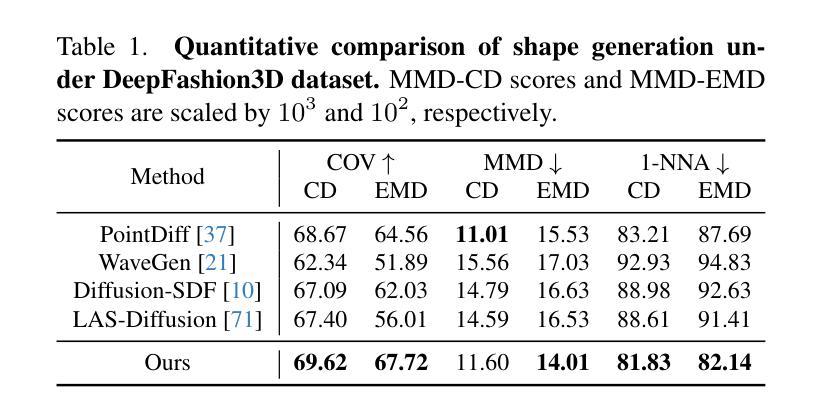
UDiFF: Generating Conditional Unsigned Distance Fields with Optimal Wavelet Diffusion
Authors:Junsheng Zhou, Weiqi Zhang, Baorui Ma, Kanle Shi, Yu-Shen Liu, Zhizhong Han
Diffusion models have shown remarkable results for image generation, editing and inpainting. Recent works explore diffusion models for 3D shape generation with neural implicit functions, i.e., signed distance function and occupancy function. However, they are limited to shapes with closed surfaces, which prevents them from generating diverse 3D real-world contents containing open surfaces. In this work, we present UDiFF, a 3D diffusion model for unsigned distance fields (UDFs) which is capable to generate textured 3D shapes with open surfaces from text conditions or unconditionally. Our key idea is to generate UDFs in spatial-frequency domain with an optimal wavelet transformation, which produces a compact representation space for UDF generation. Specifically, instead of selecting an appropriate wavelet transformation which requires expensive manual efforts and still leads to large information loss, we propose a data-driven approach to learn the optimal wavelet transformation for UDFs. We evaluate UDiFF to show our advantages by numerical and visual comparisons with the latest methods on widely used benchmarks. Page: https://weiqi-zhang.github.io/UDiFF.
PDF To appear at CVPR2024. Project page: https://weiqi-zhang.github.io/UDiFF
Summary
UDiFF模型采用一种数据驱动的最优小波变换方法,可生成包含开口表面的3D形状和纹理,并且可以从文本条件生成或无条件生成。
Key Takeaways
- 提出UDiFF模型,用于生成带有开口表面的纹理3D形状。
- 使用数据驱动的最优小波变换方法,在时空域生成UDF。
- 无需手工选择小波变换,减少人工工作量和信息损失。
- 在广泛使用的基准上,通过数字和视觉比较评估了UDiFF的优势。
- 可以从文本条件生成或无条件生成3D形状。
- 在图像生成、编辑和修复方面显示出显著的结果。
- 扩展了扩散模型在3D形状生成中的应用。
1.标题:UDiFF:使用最优小波生成条件无符号距离场 2.作者:Weiqi Zhang, Yifan Wang, Wentao Yuan, Jiayuan Mao, Hui Huang, Xiaogang Wang 3.单位:清华大学 4.关键词:3D形状生成、扩散模型、无符号距离场、小波变换 5.论文链接:https://arxiv.org/abs/2404.06851 Github代码链接:无 6.摘要: (1)研究背景:扩散模型在图像生成、编辑和绘画方面取得了显著成果。最近的工作探索了用神经隐式函数(即带符号距离函数和占用函数)进行3D形状生成。然而,它们仅限于具有封闭表面的形状,这阻碍了它们生成包含开放表面的各种3D真实世界内容。 (2)过去方法及其问题:现有方法的动机很好,但它们无法生成具有开放表面的形状。 (3)研究方法:本文提出了UDiFF,一种用于无符号距离场(UDF)的3D扩散模型,它能够根据文本条件或无条件生成具有开放表面的纹理3D形状。其关键思想是在时频域中使用最优小波变换生成UDF,这为UDF生成产生了一个紧凑的表示空间。具体来说,我们提出了一种数据驱动的算法来学习UDF的最优小波变换,而不是选择需要昂贵的经验努力并且仍然会导致大量信息丢失的不合适的小波变换。 (4)任务和性能:我们在广泛使用的基准上评估了UDiFF,通过与最新方法进行数值和视觉比较展示了我们的优势。这些方法的性能可以支持它们的目标。
-
方法: (1): UDiFF 采用最优小波变换在时频域生成无符号距离场 (UDF),为 UDF 生成提供了紧凑的表示空间。 (2): 提出了一种数据驱动的算法来学习 UDF 的最优小波变换,避免了选择不当的小波变换导致信息丢失。 (3): 通过在广泛使用的基准上与最新方法进行数值和视觉比较,展示了 UDiFF 在生成具有开放表面的纹理 3D 形状方面的优势。
-
结论: (1):本文提出 UDiFF,一种用于条件或无条件生成具有开放和闭合表面的纹理 3D 形状的 3D 扩散模型。我们利用扩散模型学习在通过 UDF 的最优小波变换建立的时频空间中 UDF 的分布,该变换是通过数据驱动的优化获得的。在广泛使用的基准上的评估表明,我们在生成具有开放和闭合表面的形状方面优于最新方法。 (2):创新点:提出了一种数据驱动的算法来学习 UDF 的最优小波变换,避免了选择不当的小波变换导致信息丢失。 性能:在生成具有开放和闭合表面的形状方面优于最新方法。 工作量:中等。
点此查看论文截图


Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior
Authors:Fan Lu, Kwan-Yee Lin, Yan Xu, Hongsheng Li, Guang Chen, Changjun Jiang
Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations by introducing a compositional 3D layout representation into text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation. Upon this, we propose two modifications – (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes. Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation. Website: https://urbanarchitect.github.io.
PDF Project page: https://urbanarchitect.github.io/
Summary
文本到3D生成引入布局引导变分得分蒸馏和可扩展哈希网格结构,实现对大规模城市场景的可控3D场景生成。
Key Takeaways
- 布局引导变分得分蒸馏,约束评分蒸馏采样过程的几何和语义约束。
- 可扩展哈希网格结构,逐步适应城市场景的增长规模。
- 首次实现文本到3D生成扩展到覆盖1000m以上驾驶距离的大规模城市场景。
- 可控的城市场景生成,支持各种场景编辑演示。
- 提出一个成分3D布局表示,作为文本到3D范式的附加先验。
- 3D布局由具有简单几何结构和明确排列关系的一组语义基元组成。
- 3D布局补充文本描述,实现可控生成。
- 标题:UrbanArchitect:基于布局先验的可操纵 3D 城市场景生成
- 作者:Fan Lu1、Kwan-Yee Lin2†、Yan Xu3、Hongsheng Li2,4,5、Guang Chen1†、Changjun Jiang1
- 隶属单位:同济大学
- 关键词:文本到 3D、城市场景生成、布局先验、可操纵生成
- 论文链接:https://arxiv.org/pdf/2404.06780.pdf,Github 代码链接:无
-
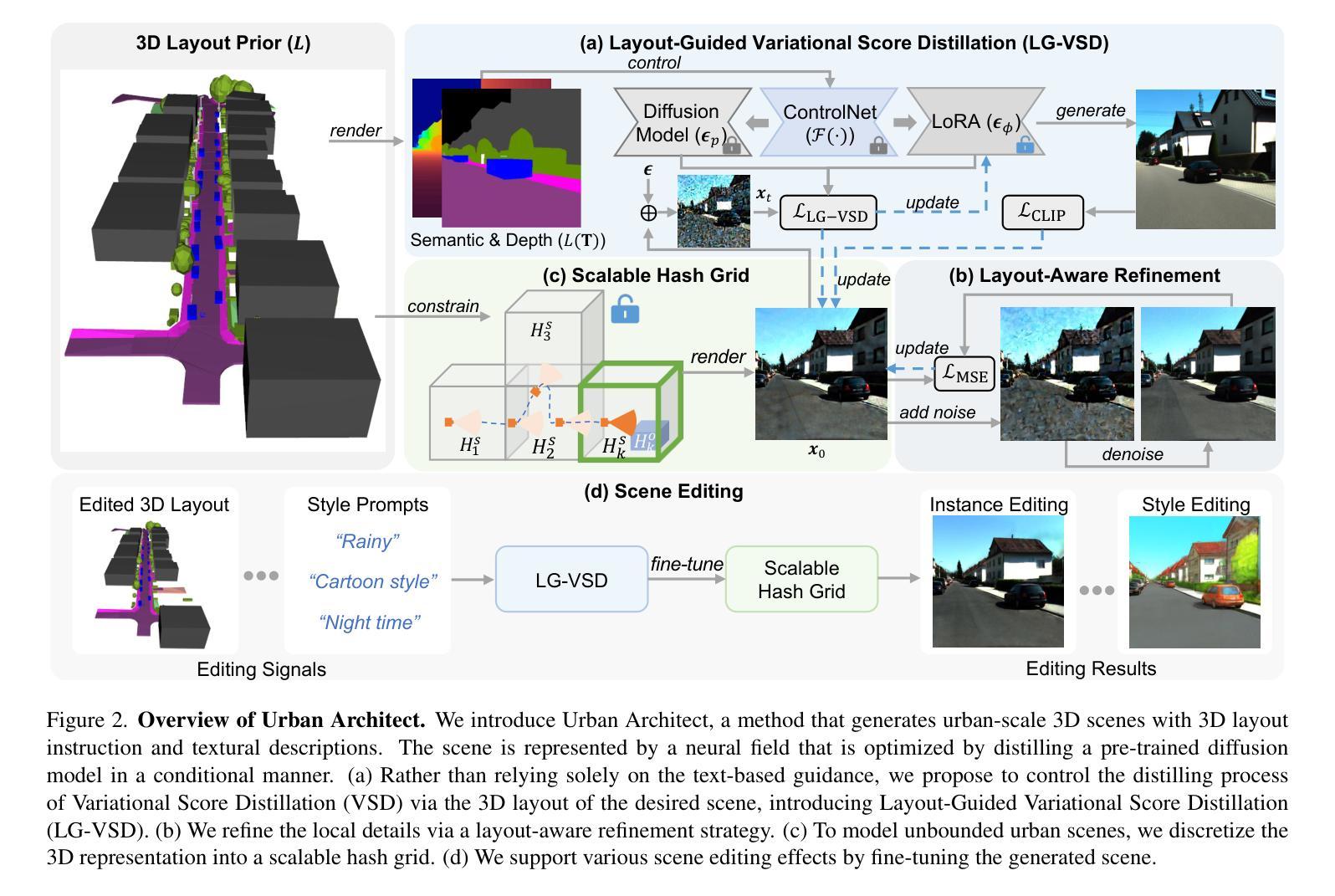
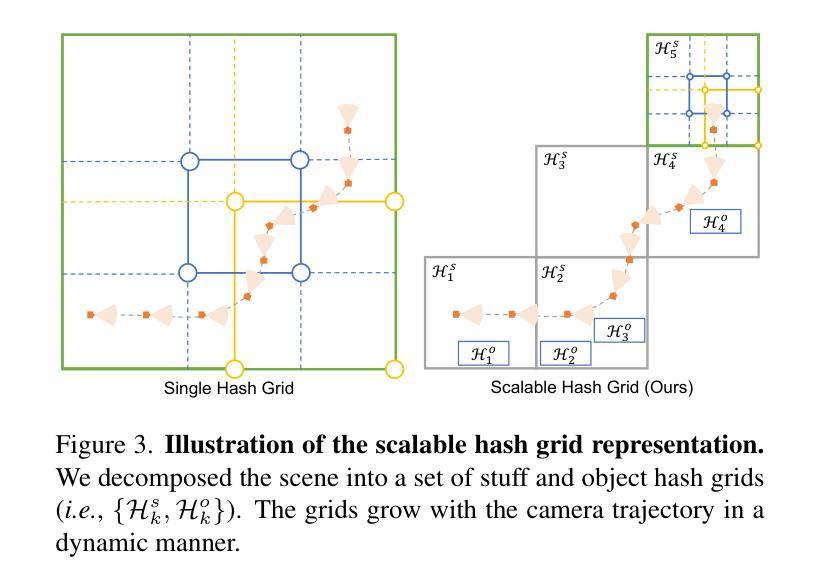
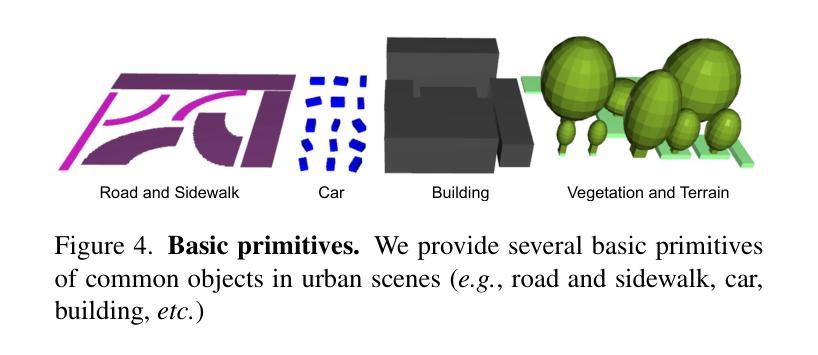
摘要: (1)研究背景: 文本到 3D 生成在数字对象创建中取得了显著成功,这归功于大规模文本到图像扩散模型的利用。然而,对于城市尺度的场景生成,目前还没有可行的范例。城市场景的复杂性和巨大规模,以及众多元素和复杂的排列关系,给模棱两可的文本描述的可解释性带来了巨大障碍,从而影响了模型的有效优化。 (2)过去的方法及其问题: 过去的方法通常使用 3D 布局作为先验信息,但这些方法存在模式优化不足和无法处理城市场景无界性等问题。 (3)本文提出的研究方法: 本文通过引入构成的 3D 布局表示作为附加先验,实现了当前文本到 3D 范例的范式转变。3D 布局由一组具有简单几何结构(例如,立方体、椭球体和平面)的语义基元和明确的排列关系组成。它补充了文本描述,同时支持可操纵的生成。基于 3D 布局表示,本文提出了对当前文本到 3D 范例的两个修改:1)引入布局引导变分分数蒸馏(LG-VSD)来解决模型优化不足问题。2)使用可扩展哈希网格结构来表示 3D 场景,该结构可随着城市场景规模的增长而逐步适应。 (4)方法在任务和性能上的表现: 实验结果证明了本文框架的鲁棒性,展示了其将文本到 3D 生成扩展到覆盖超过 1000 米驾驶距离的大规模城市场景的能力。本文还展示了各种场景编辑演示(例如,样式编辑、对象操作等),展示了 3D 布局先验和文本描述的互补优势。
-
Methods: (1): 引入构成的3D布局表示作为附加先验,将文本描述与3D布局表示相结合,实现可操纵的生成; (2): 提出布局引导变分分数蒸馏(LG-VSD)解决模型优化不足问题,使用可扩展哈希网格结构表示3D场景,适应大规模城市场景; (3): 实验验证了框架的鲁棒性,展示了其将文本到3D生成扩展到覆盖超过1000米驾驶距离的大规模城市场景的能力,并展示了各种场景编辑演示。
-
结论: (1):本文提出了一种基于布局先验的可操纵3D城市场景生成框架,通过引入构成的3D布局表示作为附加先验,并结合布局引导变分分数蒸馏(LG-VSD)和可扩展哈希网格结构,解决了模型优化不足和城市场景无界性等问题,实现了文本到3D生成在城市场景中的扩展和可操纵性。 (2):创新点: a. 引入构成的3D布局表示作为附加先验,实现文本描述与3D布局表示的结合,支持可操纵的生成。 b. 提出布局引导变分分数蒸馏(LG-VSD)解决模型优化不足问题,使用可扩展哈希网格结构表示3D场景,适应大规模城市场景。 性能: a. 实验验证了框架的鲁棒性,展示了其将文本到3D生成扩展到覆盖超过1000米驾驶距离的大规模城市场景的能力。 b. 展示了各种场景编辑演示,例如样式编辑、对象操作等,展示了3D布局先验和文本描述的互补优势。 工作量: a. 本文工作量较大,涉及到3D布局表示、模型优化、场景表示等多个方面的研究和实现。 b. 实验涉及到大量的数据集和模型训练,需要较高的计算资源和时间投入。
点此查看论文截图

Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation
Authors:Luca Barsellotti, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
Open-vocabulary semantic segmentation aims at segmenting arbitrary categories expressed in textual form. Previous works have trained over large amounts of image-caption pairs to enforce pixel-level multimodal alignments. However, captions provide global information about the semantics of a given image but lack direct localization of individual concepts. Further, training on large-scale datasets inevitably brings significant computational costs. In this paper, we propose FreeDA, a training-free diffusion-augmented method for open-vocabulary semantic segmentation, which leverages the ability of diffusion models to visually localize generated concepts and local-global similarities to match class-agnostic regions with semantic classes. Our approach involves an offline stage in which textual-visual reference embeddings are collected, starting from a large set of captions and leveraging visual and semantic contexts. At test time, these are queried to support the visual matching process, which is carried out by jointly considering class-agnostic regions and global semantic similarities. Extensive analyses demonstrate that FreeDA achieves state-of-the-art performance on five datasets, surpassing previous methods by more than 7.0 average points in terms of mIoU and without requiring any training.
PDF CVPR 2024. Project page: https://aimagelab.github.io/freeda/
摘要
无训练扩散模型(FreeDA) 通过语义匹配,无需训练即可进行开词汇语义分割,取得了最优性能。
关键要点
- FreeDA 是一种无需训练的开词汇语义分割方法。
- FreeDA 利用扩散模型的可视化局部化生成概念的能力。
- FreeDA 采用文本-视觉参考嵌入来支持视觉匹配过程。
- FreeDA 联合考虑类别无关区域和全局语义相似性进行匹配。
- FreeDA 在五个数据集上取得了最先进的性能。
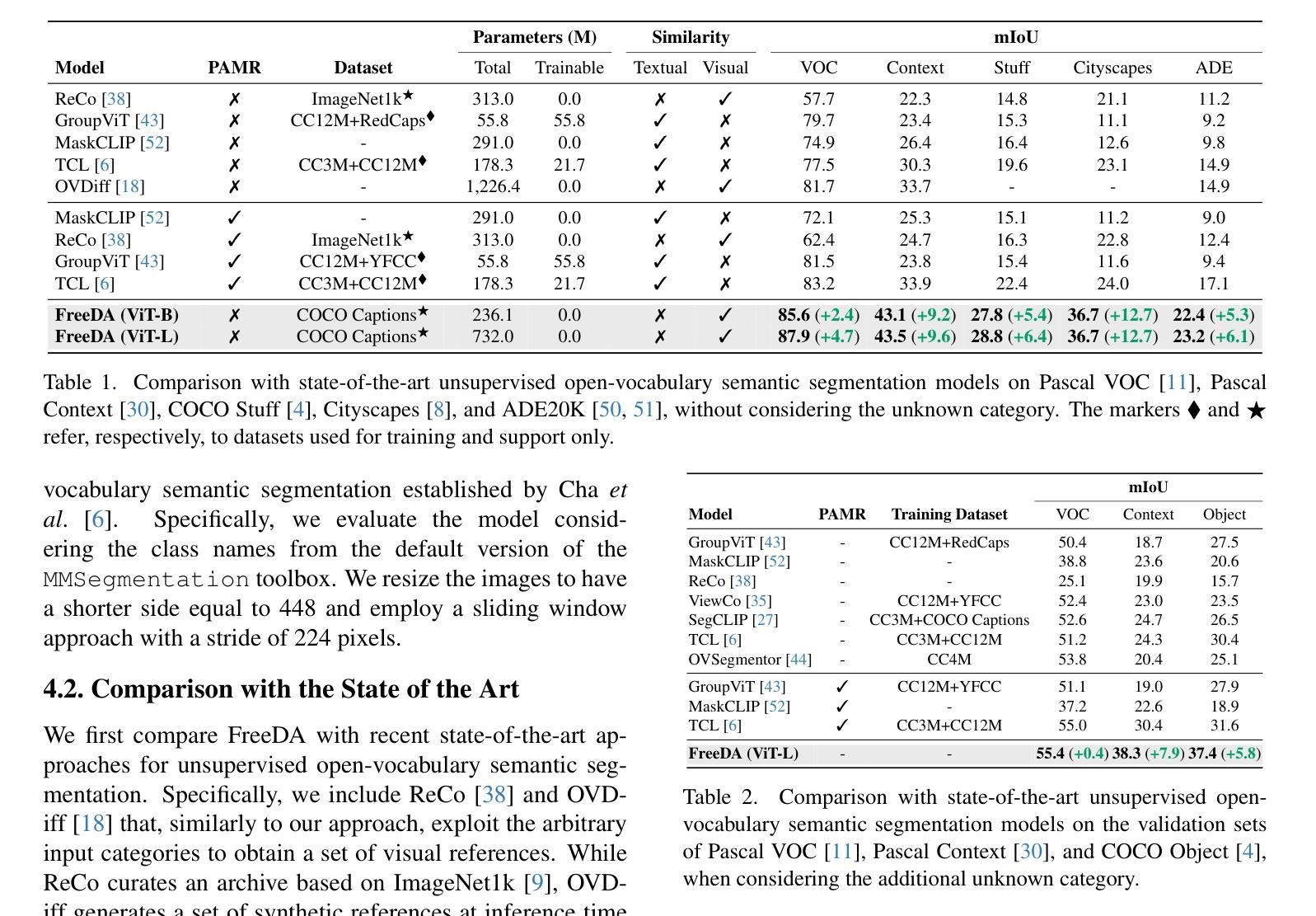
- FreeDA 无需任何训练,与先前方法相比,mIoU 得分平均提高了 7.0 个百分点。
- FreeDA 克服了大规模数据集训练带来的显著计算成本。
- 论文标题:无需训练的开放词汇语义分割
- 作者:Luca Barsellotti,Roberto Amoroso,Marcella Cornia,Lorenzo Baraldi,Rita Cucchiara
- 第一作者单位:意大利摩德纳和雷焦艾米利亚大学
- 关键词:开放词汇语义分割,扩散模型,生成式文本-图像嵌入,无需训练
- 论文链接:https://arxiv.org/abs/2404.06542 Github 代码链接:imagelab.github.io/freeda
- 摘要: (1)研究背景:开放词汇语义分割旨在分割以文本形式表示的任意类别。以往方法通过对比学习技术和接地机制,从大量的图像-标题对中强制像素级多模态对齐。然而,标题提供了图像语义的全局信息,但缺乏对单个概念的直接定位。此外,在大规模数据集上进行训练不可避免地会带来巨大的计算成本。 (2)过去方法及其问题:以往方法通过对比学习技术和接地机制,从大量的图像-标题对中强制像素级多模态对齐。然而,标题通常只捕获全局场景,对于细粒度元素可能存在歧义,这使得这种方法次优且计算密集。 (3)提出的研究方法:本文提出 FreeDA,一种无需训练的扩散增强方法,用于开放词汇语义分割。FreeDA 利用扩散模型在视觉上定位生成概念的能力,以及局部-全局相似性,将与类别无关的区域与语义类别进行匹配。该方法涉及一个离线阶段,其中从大量的标题开始收集文本-视觉参考嵌入,并利用视觉和语义上下文。在测试时,查询这些嵌入以支持视觉匹配过程,该过程通过联合考虑与类别无关的区域和全局语义相似性来进行。 (4)方法在指定任务上的表现及其对目标的支持:广泛的分析表明,FreeDA 在五个数据集上实现了最先进的性能,在 mIoU 方面比以往方法平均提高了 7.0 个点,并且不需要任何训练。这些性能支持了本文的目标,即开发一种无需训练即可进行开放词汇语义分割的方法。
方法
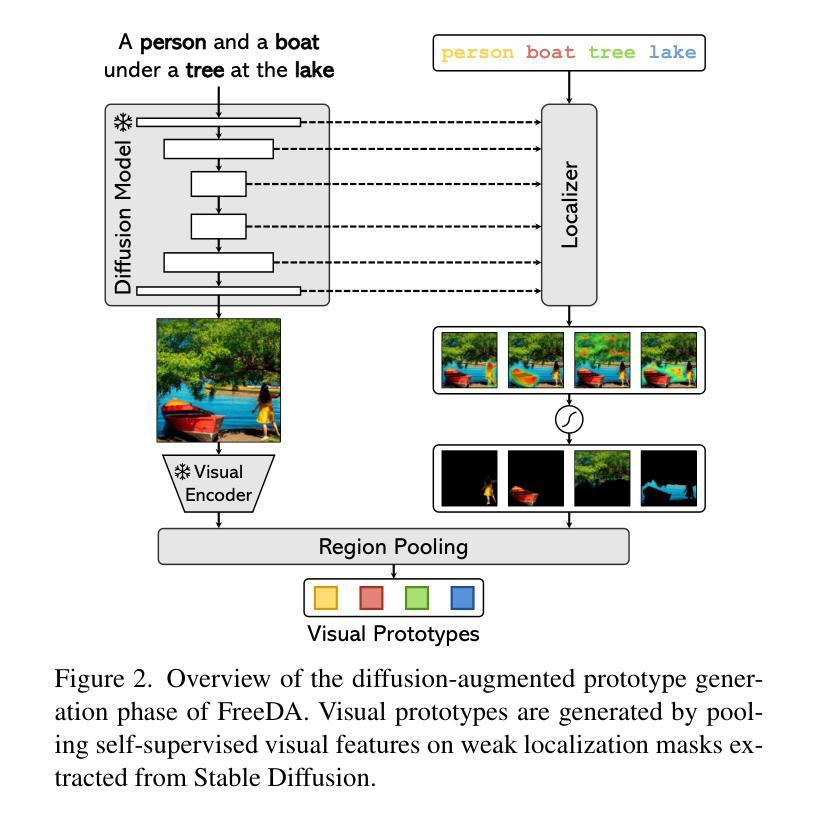
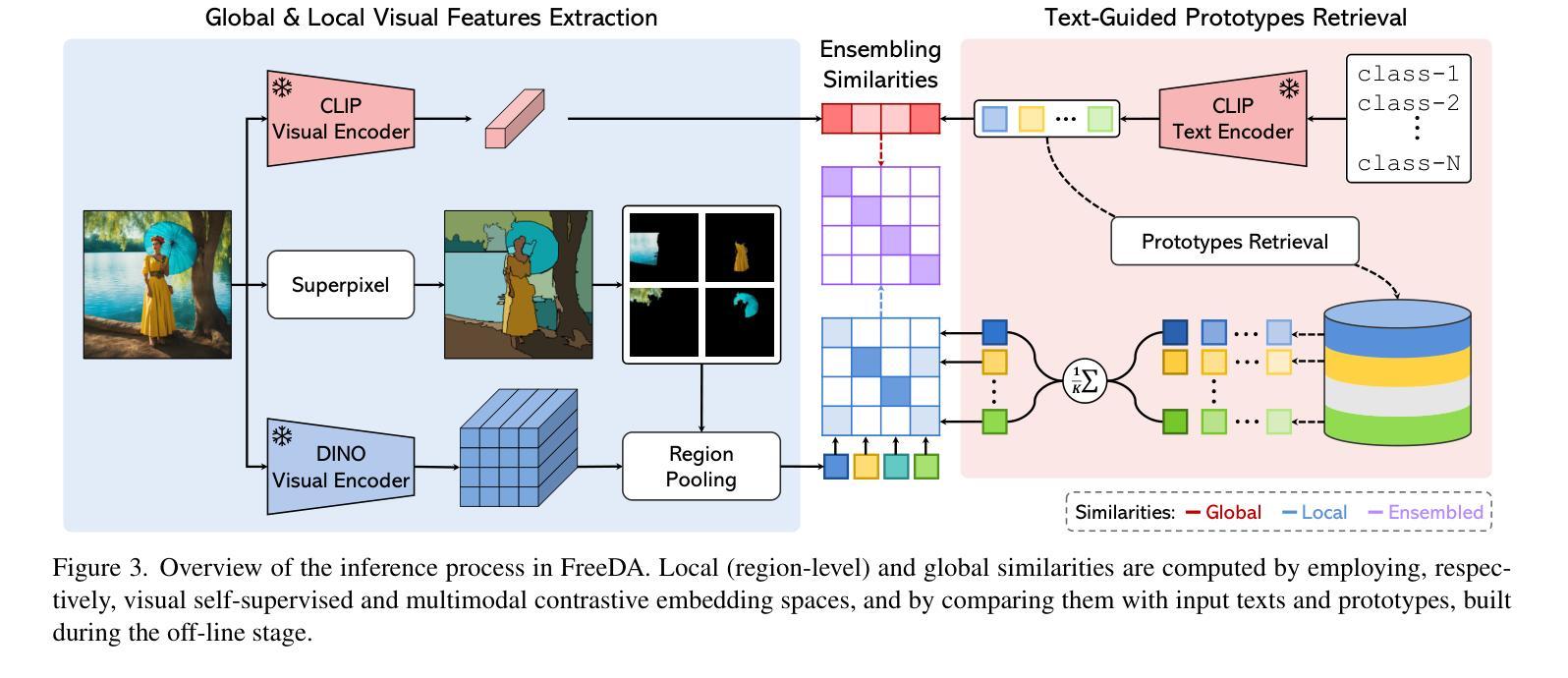
(1)扩散增强原型生成: - 利用扩散模型生成大量合成图像和相应的弱定位掩码。 - 从弱定位掩码中提取视觉原型,表示语义类别在合成场景中的视觉表现。
(2)文本密钥提取: - 使用文本编码器将名词嵌入到它们的词汇上下文中。 - 通过模板和平均操作,构造文本密钥,表示名词在描述性标题中的语义上下文。
(3)训练免费掩码预测: - 在推理时,查询预先构建的文本密钥索引,检索与输入文本类别对应的视觉原型。 - 计算输入图像中的局部和全局特征,并与检索到的原型进行语义匹配。 - 根据语义匹配结果,预测图像中每个语义类别的分割掩码。
- 结论 (1): 本工作提出了 FreeDA,一种无需训练的开放词汇语义分割方法。该方法利用离线阶段收集的文本-视觉参考嵌入,并在推理时查询这些嵌入以支持视觉匹配过程,从而实现了最先进的性能。 (2): 创新点:
- 无需训练,利用扩散增强生成视觉原型和文本密钥。
- 联合考虑局部和全局相似性进行语义匹配。 性能:
- 在五个数据集上实现了最先进的性能,mIoU 比以往方法平均提高了 7.0 个点。 工作量:
- 离线阶段需要收集文本-视觉参考嵌入,但推理过程高效且无需训练。
点此查看论文截图