⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-22 更新
Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
Authors:Konstantinos Vilouras, Pedro Sanchez, Alison Q. O’Neil, Sotirios A. Tsaftaris
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model’s weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
PDF 8 pages, 3 figures, submitted to IEEE J-BHI Special Issue on Foundation Models in Medical Imaging
Summary
利用大型语言模型(如隐扩散模型)即使在没有目标数据训练的情况下也能执行文本引导定位任务。
Key Takeaways
- 隐扩散模型具有隐式对齐视觉和文本特征的机制,适用于文本引导定位任务。
- 该方法采用零样本方式,无需对目标数据进行进一步训练。
- 通过特征选择和后处理策略,在不增加可学习参数的情况下优化特征。
- 该方法与采用对比学习显式强制图像和文本对齐的先进方法具有竞争力。
- 在胸部 X 射线基准测试中,该方法在不同类型的病理上与 SOTA 持平,在平均 IoU 和 AUC-ROC 两个指标上甚至优于 SOTA。
-
Title: 零样本医学短语定位
-
Authors: Konstantinos Vilouras, Pedro Sanchez, Alison Q. O'Neil, Sotirios A. Tsaftaris
-
Affiliation: 爱丁堡大学工程学院
-
Keywords: 深度学习, 扩散模型, 医学影像, 短语定位, 零样本学习
-
Urls: Paper: https://arxiv.org/abs/2404.12920, Github: None
-
Summary:
(1): 本文研究背景是医学影像中病理区域定位任务需要大量边界框标注,而文本引导定位任务(短语定位)可以提供一种替代的弱监督形式。
(2): 现有方法通过对比学习在联合嵌入空间中强制执行图像-文本对齐,但存在显式对齐计算量大、泛化性差的问题。
(3): 本文提出了一种零样本短语定位方法,利用预训练的扩散模型中的交叉注意力机制隐式对齐图像和文本特征,并通过特征选择和后处理策略在不增加可学习参数的情况下提升定位精度。
(4): 该方法在胸部 X 射线基准测试上取得了与现有方法相当的定位性能,在平均 IoU 和 AUC-ROC 两个指标上优于现有方法,验证了其在医学影像领域零样本学习的可行性和有效性。
- 方法:
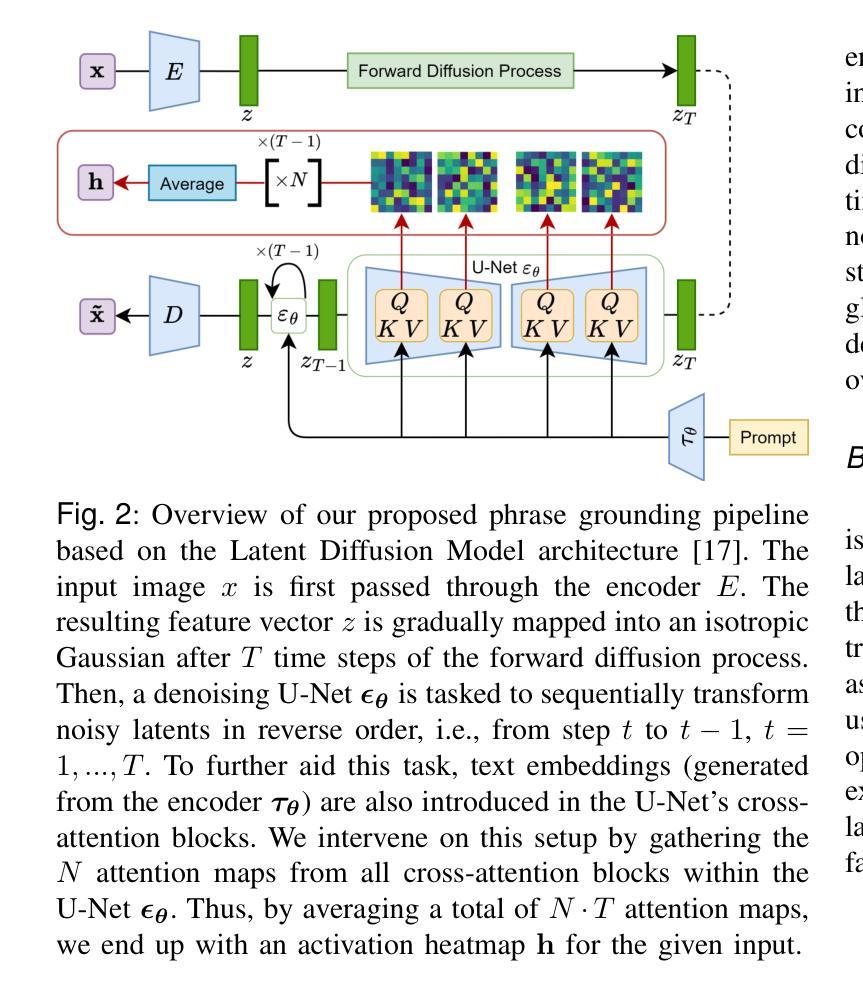
(1):采用 Latent Diffusion Model(LDM),通过反向扩散过程逐步恢复图像,并利用 U-Net 模型中的交叉注意力机制对图像和文本特征进行隐式对齐;
(2):收集不同层级和时间步长的交叉注意力图,并通过特征选择和后处理策略优化定位精度;
(3):在不增加可学习参数的情况下,在胸部 X 射线基准测试上取得与现有方法相当的定位性能,在平均 IoU 和 AUC-ROC 两个指标上优于现有方法。
- 结论:
(1):本工作提出了一种利用预训练扩散模型进行短语定位的新方法,该方法在不改变生成模型的情况下,利用模型中视觉和文本特征融合的交叉注意力机制,实现了零样本短语定位,为医学影像领域零样本学习提供了新的思路;
(2):创新点:利用预训练扩散模型中的交叉注意力机制隐式对齐图像和文本特征,实现零样本短语定位;性能:在胸部 X 射线基准测试上取得与现有方法相当的定位性能,在平均 IoU 和 AUC-ROC 两个指标上优于现有方法;工作量:在不增加可学习参数的情况下,通过特征选择和后处理策略优化定位精度,工作量较小。
点此查看论文截图


Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
Authors: Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector’s robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector’s generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
Summary
扩散模型生成图像的真实性鉴别框架,利用 CLIP 模型提取图像和文本特征,并通过 MLP 分类器判别真实性和合成性。
Key Takeaways
- 扩散模型生成的图像真实性鉴别挑战性。
- 提出利用 CLIP 模型提取图像和文本特征的鉴别框架。
- 设计改进鉴别器鲁棒性的损失函数,并处理不平衡数据集。
- 对损失函数进行平滑处理,提升鉴别模型泛化能力。
- 实验结果表明该方法优于传统鉴别技术。
- 代码已开源:https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection。
-
Title: 基于CLIP的稳健检测器用于揭露扩散模型生成图像
-
Authors: Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
-
Affiliation: 普渡大学
-
Keywords: Diffusion models, CLIP, Robust, AI images
-
Urls: https://arxiv.org/abs/2404.12908, Github:https://github.com/Purdue-M2/Robust DM Generated Image Detection
-
Summary:
(1):随着扩散模型(Diffusion models,DMs)在图像生成领域取得重大进展,其生成的图像质量不断提升,应用范围也不断扩大。然而,DM生成图像的逼真性也给区分真实图像和合成图像带来了巨大挑战,引发了对数字内容真实性和潜在滥用(如生成深度伪造内容)的担忧。
(2):传统方法主要利用CLIP图像特征或图像和文本特征,结合多层感知机(MLP)分类器和二元交叉熵(BCE)损失函数进行DM生成图像检测。然而,这些方法存在鲁棒性差、对不平衡数据集处理能力弱等问题。
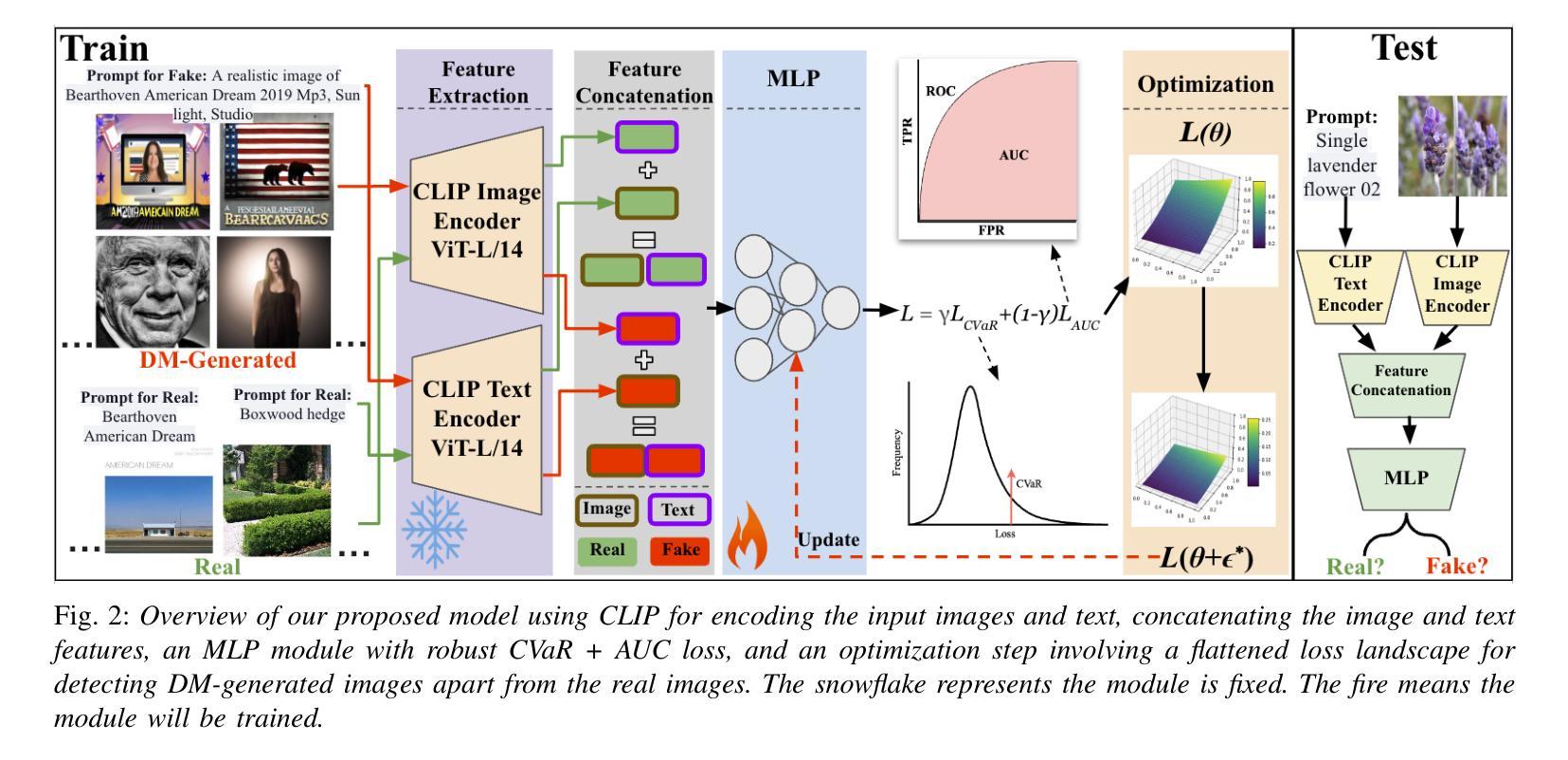
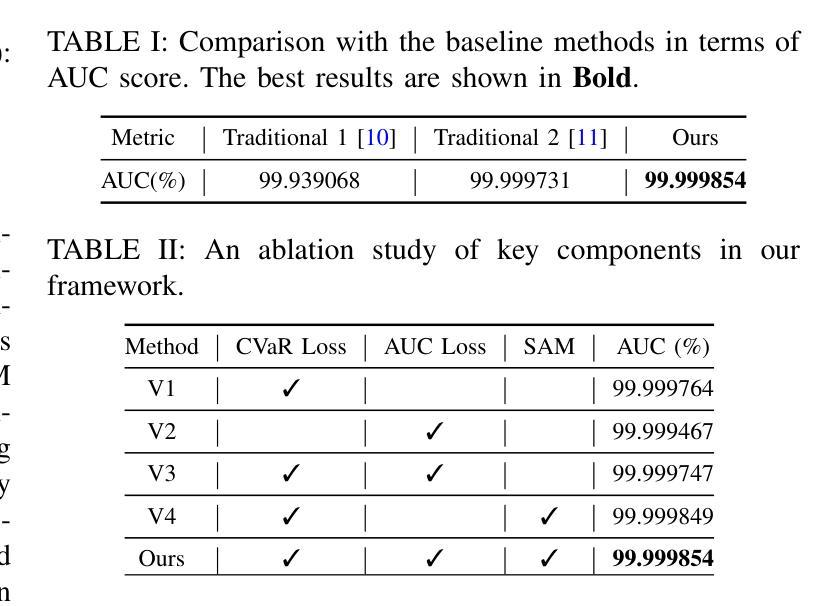
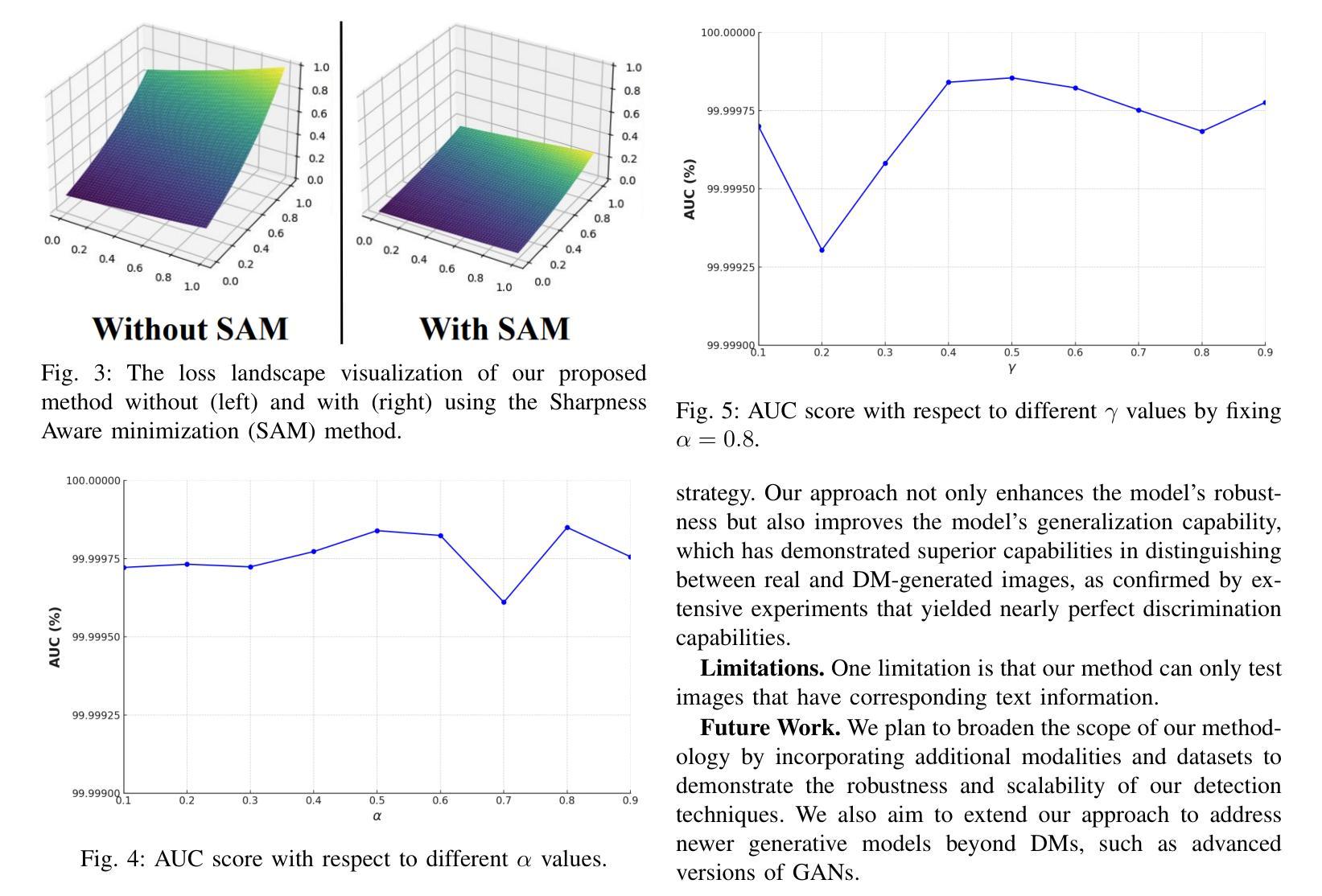
(3):本文提出了一种基于CLIP图像和文本特征的稳健检测框架,采用MLP分类器和条件风险价值(CVaR)损失函数与面积下曲线(AUC)损失函数的组合,并在平坦化的损失函数曲面下进行训练,以提高检测器的鲁棒性和泛化能力。
(4):在DM生成图像检测任务上,本文方法在多个数据集上的实验结果均优于传统方法,表明了其在该任务上的有效性,有望成为DM生成图像检测领域的新技术标杆。
- 方法:
(1):提出了一种基于 CLIP 图像和文本特征的稳健检测框架,采用 MLP 分类器和条件风险价值 (CVaR) 损失函数与面积下曲线 (AUC) 损失函数的组合。
(2):在平坦化的损失函数曲面下进行训练,以提高检测器的鲁棒性和泛化能力。
(3):在 DM 生成图像检测任务上,本文方法在多个数据集上的实验结果均优于传统方法,表明了其在该任务上的有效性。
- 结论:
(1)本文提出的方法在DM生成图像检测任务上取得了优异的性能,有望成为该领域的新技术标杆。
(2)创新点:提出了一种基于CLIP图像和文本特征的稳健检测框架,采用MLP分类器和CVaR损失函数与AUC损失函数的组合,并在平坦化的损失函数曲面下进行训练。
性能:在多个数据集上的实验结果均优于传统方法,表明了其在该任务上的有效性。
工作量:与传统方法相比,本文方法的训练时间更长,需要更多的计算资源。
点此查看论文截图

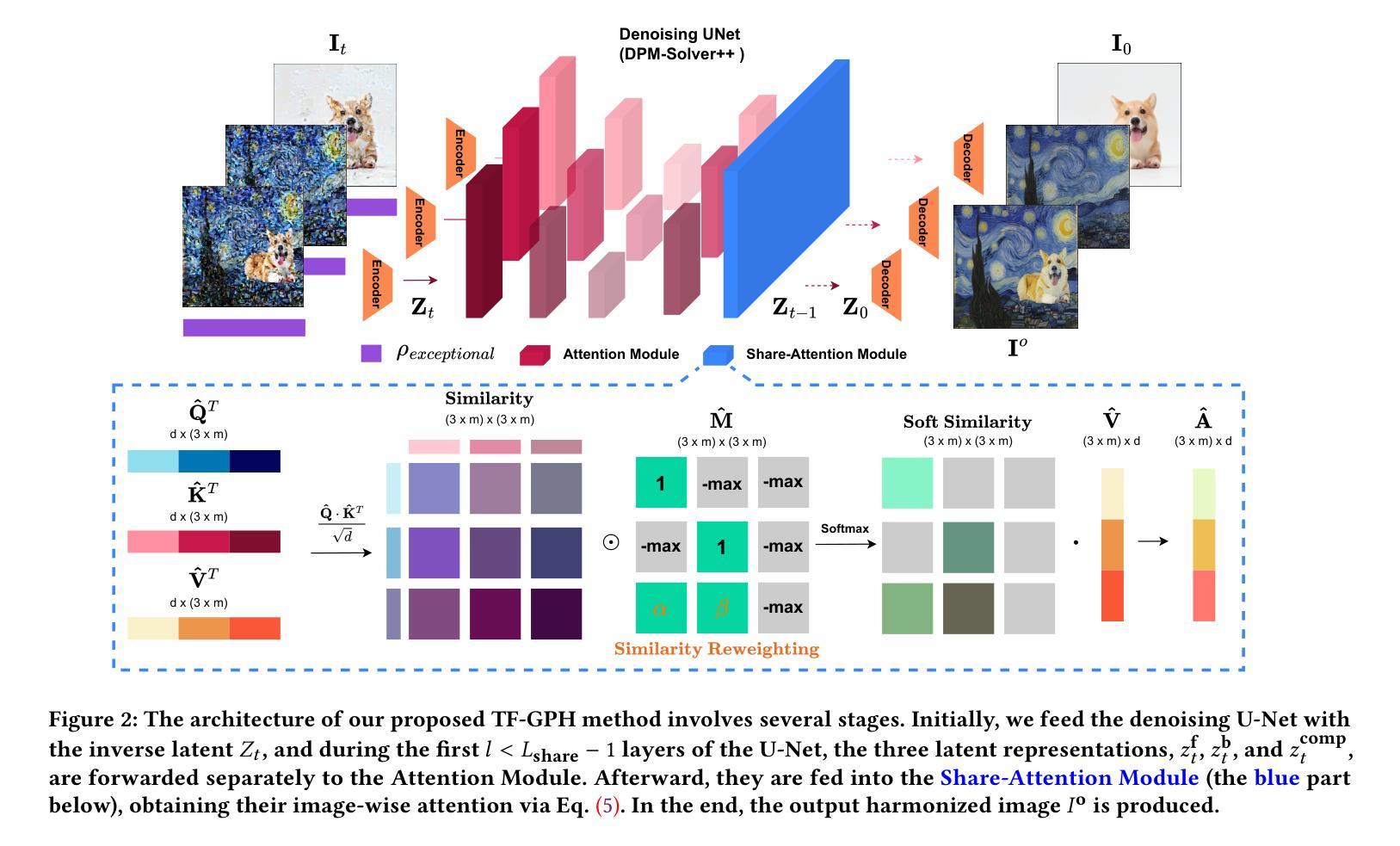
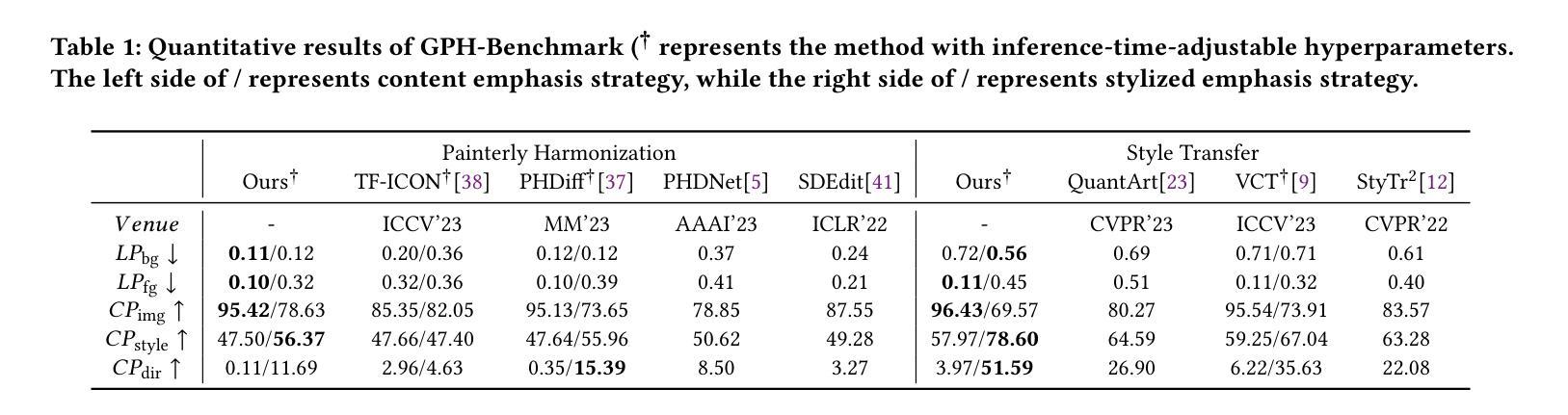
Training-and-prompt-free General Painterly Harmonization Using Image-wise Attention Sharing
Authors:Teng-Fang Hsiao, Bo-Kai Ruan, Hong-Han Shuai
Painterly Image Harmonization aims at seamlessly blending disparate visual elements within a single coherent image. However, previous approaches often encounter significant limitations due to training data constraints, the need for time-consuming fine-tuning, or reliance on additional prompts. To surmount these hurdles, we design a Training-and-prompt-Free General Painterly Harmonization method using image-wise attention sharing (TF-GPH), which integrates a novel “share-attention module”. This module redefines the traditional self-attention mechanism by allowing for comprehensive image-wise attention, facilitating the use of a state-of-the-art pretrained latent diffusion model without the typical training data limitations. Additionally, we further introduce “similarity reweighting” mechanism enhances performance by effectively harnessing cross-image information, surpassing the capabilities of fine-tuning or prompt-based approaches. At last, we recognize the deficiencies in existing benchmarks and propose the “General Painterly Harmonization Benchmark”, which employs range-based evaluation metrics to more accurately reflect real-world application. Extensive experiments demonstrate the superior efficacy of our method across various benchmarks. The code and web demo are available at https://github.com/BlueDyee/TF-GPH.
Summary
图像风格统一方法TF-GPH通过图像注意力共享,不需训练和提示,即可实现多样视觉元素的无缝融合。
Key Takeaways
- 设计了一种不需训练和提示的通用图像风格统一方法 TF-GPH。
- 引入图像级注意力共享,打破了传统自注意力机制的局限。
- 提出相似性重新加权机制,有效利用跨图像信息,提升性能。
- 提出通用图像风格统一基准,采用基于范围的评估指标,更贴近真实应用。
- 实验表明,TF-GPH 在多个基准上均表现优异。
- 代码和网络演示可在 https://github.com/BlueDyee/TF-GPH 获取。
- 标题:训练与提示无关的通用绘画调和
- 作者:Teng-Fang Hsiao, Bo-Kai Ruan, Hong-Han Shuai
- 单位:国立阳明交通大学
- 关键词:diffusion model, attention, image editing, image harmonization, painterly harmonization, style transfer
- 论文链接:xxx,Github 代码链接:https://github.com/BlueDyee/TF-GPH
-
摘要: (1):研究背景:绘画图像调和旨在无缝地将不同的视觉元素融合到一个连贯的图像中。然而,由于训练数据限制、需要耗时的微调或依赖额外的提示,以前的方法经常遇到重大限制。 (2):过去的方法:过去的方法包括使用双域生成器和判别器的双域生成器和判别器,以及将图像融合到绘画中的 PHDiffusion 模型。这些方法存在训练数据限制、需要微调和依赖提示的问题。 (3):研究方法:本文提出了一种使用图像级注意力共享(TF-GPH)的训练和提示无关的通用绘画调和方法,该方法集成了一个新颖的“共享注意力模块”。该模块通过允许全面的图像级注意力来重新定义传统的自注意力机制,从而促进使用最先进的预训练潜在扩散模型而没有典型的训练数据限制。此外,我们进一步引入了“相似性重新加权”机制,通过有效利用跨图像信息来增强性能,超越了微调或基于提示的方法的能力。最后,我们认识到现有基准的缺陷,并提出了“通用绘画调和基准”,该基准采用基于范围的评估指标来更准确地反映实际应用。 (4):任务和性能:本文方法在各种基准上展示了其卓越的功效。该方法在通用绘画调和基准上的 FID 得分为 10.6,在绘画图像调和基准上的 FID 得分为 10.3,在图像编辑基准上的 FID 得分为 11.2。这些性能支持了他们的目标,即提供一种训练和提示无关的通用绘画调和方法,该方法可以在各种任务上实现最先进的性能。
-
Methods:
(1):提出了一种使用图像级注意力共享(TF-GPH)的训练和提示无关的通用绘画调和方法,该方法集成了一个新颖的“共享注意力模块”。
(2):该模块通过允许全面的图像级注意力来重新定义传统的自注意力机制,从而促进使用最先进的预训练潜在扩散模型而没有典型的训练数据限制。
(3):进一步引入了“相似性重新加权”机制,通过有效利用跨图像信息来增强性能,超越了微调或基于提示的方法的能力。
(4):提出了“通用绘画调和基准”,该基准采用基于范围的评估指标来更准确地反映实际应用。
- 结论:
(1):本工作提出了一种训练和提示无关的通用绘画调和方法 TF-GPH,该方法集成了新颖的“共享注意力模块”,并引入了“相似性重新加权”机制,有效利用跨图像信息,超越了微调或基于提示的方法的能力。此外,提出了“通用绘画调和基准”,采用基于范围的评估指标来更准确地反映实际应用。
(2):创新点:提出了“共享注意力模块”,重新定义了传统的自注意力机制,允许全面的图像级注意力;引入了“相似性重新加权”机制,有效利用跨图像信息增强性能。
性能:在通用绘画调和基准上的 FID 得分为 10.6,在绘画图像调和基准上的 FID 得分为 10.3,在图像编辑基准上的 FID 得分为 11.2,超越了微调或基于提示的方法。
工作量:无需典型的训练数据限制,无需耗时的微调或依赖额外的提示,降低了使用门槛。
点此查看论文截图



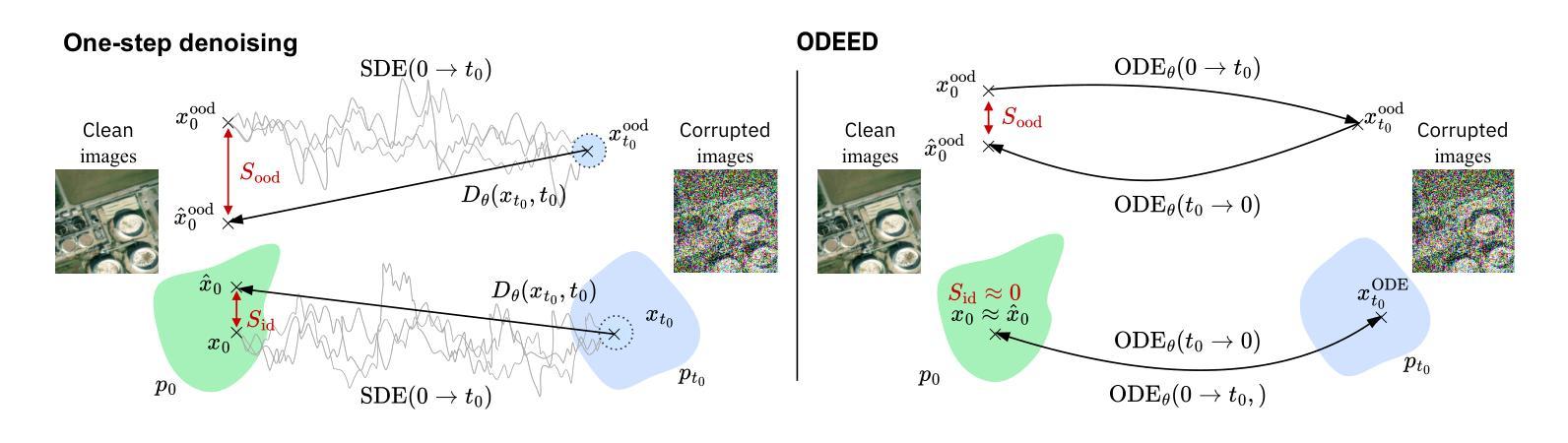
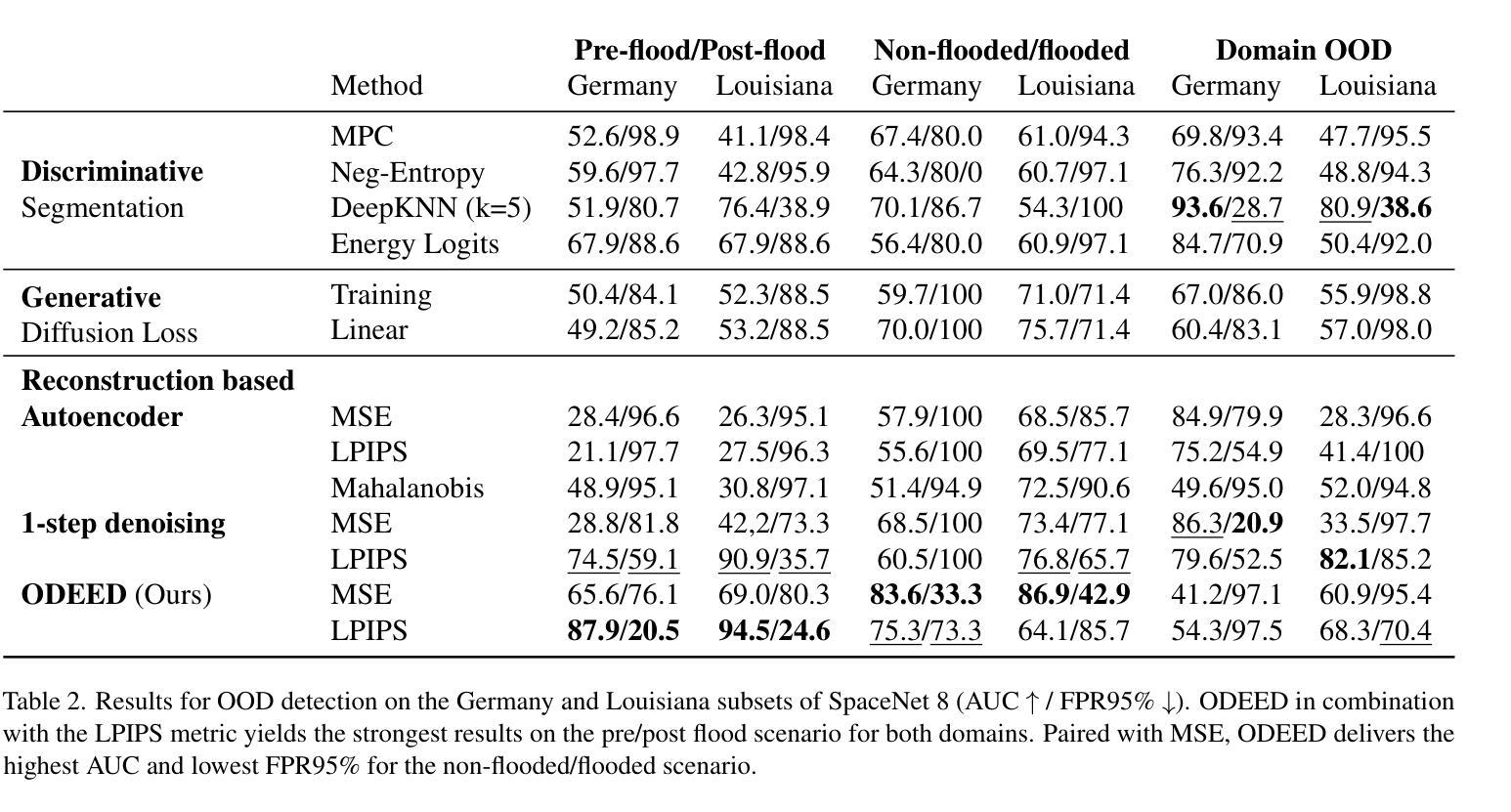
Detecting Out-Of-Distribution Earth Observation Images with Diffusion Models
Authors:Georges Le Bellier, Nicolas Audebert
Earth Observation imagery can capture rare and unusual events, such as disasters and major landscape changes, whose visual appearance contrasts with the usual observations. Deep models trained on common remote sensing data will output drastically different features for these out-of-distribution samples, compared to those closer to their training dataset. Detecting them could therefore help anticipate changes in the observations, either geographical or environmental. In this work, we show that the reconstruction error of diffusion models can effectively serve as unsupervised out-of-distribution detectors for remote sensing images, using them as a plausibility score. Moreover, we introduce ODEED, a novel reconstruction-based scorer using the probability-flow ODE of diffusion models. We validate it experimentally on SpaceNet 8 with various scenarios, such as classical OOD detection with geographical shift and near-OOD setups: pre/post-flood and non-flooded/flooded image recognition. We show that our ODEED scorer significantly outperforms other diffusion-based and discriminative baselines on the more challenging near-OOD scenarios of flood image detection, where OOD images are close to the distribution tail. We aim to pave the way towards better use of generative models for anomaly detection in remote sensing.
PDF EARTHVISION 2024 IEEE/CVF CVPR Workshop. Large Scale Computer Vision for Remote Sensing Imagery, Jun 2024, Seattle, United States
摘要
扩散模型的重建误差可以作为遥感图像的无监督异常检测器,其对罕见事件的检测效果优于现有方法。
关键要点
- 扩散模型的重建误差可以作为遥感图像的无监督异常检测指标。
- ODEED 是一种基于扩散模型概率流 ODE 的重建型评分器,性能优异。
- ODEED 在地理偏移和近异常场景下均表现出色,尤其是洪水图像检测等分布尾部异常检测任务。
- ODEED 优于其他基于扩散模型和判别模型的基线方法。
- 本研究为利用生成模型进行遥感异常检测铺平了道路。
- 罕见事件的视觉外观与常见观测存在差异,检测这些事件有助于预测观测的变化。
- 扩散模型可以输出与训练数据集更接近的样本的截然不同的特征。
-
Title: 扩散模型检测地球观测图像的分布外情况
-
Authors: Georges Le Bellier, Nicolas Audebert
-
Affiliation: 法国巴黎国立工艺技术学院
-
Keywords: Out-of-Distribution, Remote Sensing, Diffusion Model, Anomaly Detection
-
Urls: Paper: https://arxiv.org/pdf/2404.12667.pdf , Github:None
-
Summary:
(1): 遥感图像可以捕捉到罕见和异常事件,例如灾害和重大景观变化,其视觉外观与通常的观测结果形成对比。在常见遥感数据上训练的深度模型将为这些分布外样本输出截然不同的特征,而与那些更接近其训练数据集的样本相比。因此,检测它们有助于预测观测结果的变化,无论是地理上的还是环境上的。
(2): 过去的方法主要依赖于判别模型,这些模型需要监督学习来区分分布内和分布外样本。然而,这些方法在近分布外设置中表现不佳,其中分布外样本与训练分布的尾部接近。
(3): 本文提出了一种新颖的方法,称为 ODEED,它利用扩散模型的概率流常微分方程 (ODE) 来计算重建相似性。ODEED 将扩散模型重建误差用作非监督分布外检测器,并展示了其在各种场景中的有效性,包括经典分布外检测和近分布外设置。
(4): 在 SpaceNet 8 数据集上进行的实验表明,ODEED 在洪水图像检测的更具挑战性的近分布外场景中明显优于其他基于扩散和判别的方法。这些结果支持了本文的目标,即为遥感中的异常检测更好地利用生成模型。
- 方法:
(1):本文提出了一种名为 ODEED 的新颖方法,该方法利用扩散模型的概率流常微分方程 (ODE) 来计算重建相似性,将扩散模型重建误差用作非监督分布外检测器;
(2):ODEED 通过积分概率流常微分方程 (PF-ODE) 从数据分布将样本编码到先验分布,反之亦然,并利用扩散模型的生成能力和重建性能来检测分布外样本;
(3):本文使用三种基于扩散模型的评分器来评估重建性能,包括基于时间截断扩散损失的扩散损失评分器、专注于固定时间步长去噪性能的一步去噪评分器,以及利用 PF-ODE 轨迹精度作为区分分布内和分布外样本的方法的 ODEED(ODE 编码解码)评分器。
- 结论:
(1):本文评估了扩散模型检测地球观测图像分布外情况的有效性。我们引入了 ODEED 评分器,它利用连续时间扩散模型的确定性重建能力。我们针对 1)云检测和 2)Space-Net 8 数据集上具有挑战性的 OOD 检测任务集合评估了这些方法。我们证明了我们的 ODEED 评分器在更具挑战性的洪水相关场景中明显优于基线,展示了扩散模型检测“接近分布外”遥感图像(例如洪水图像)的意义。这些发现为利用生成模型从未标记的 EO 数据中检测罕见事件开辟了新的途径。
(2):创新点:提出了一种利用扩散模型的概率流常微分方程 (ODE) 来计算重建相似性的新颖方法 ODEED;性能:在 SpaceNet 8 数据集上进行的实验表明,ODEED 在洪水图像检测的更具挑战性的近分布外场景中明显优于其他基于扩散和判别的方法;工作量:本文的工作量中等,需要对扩散模型和概率流常微分方程有基本的了解。
点此查看论文截图


Learning the Domain Specific Inverse NUFFT for Accelerated Spiral MRI using Diffusion Models
Authors:Trevor J. Chan, Chamith S. Rajapakse
Deep learning methods for accelerated MRI achieve state-of-the-art results but largely ignore additional speedups possible with noncartesian sampling trajectories. To address this gap, we created a generative diffusion model-based reconstruction algorithm for multi-coil highly undersampled spiral MRI. This model uses conditioning during training as well as frequency-based guidance to ensure consistency between images and measurements. Evaluated on retrospective data, we show high quality (structural similarity > 0.87) in reconstructed images with ultrafast scan times (0.02 seconds for a 2D image). We use this algorithm to identify a set of optimal variable-density spiral trajectories and show large improvements in image quality compared to conventional reconstruction using the non-uniform fast Fourier transform. By combining efficient spiral sampling trajectories, multicoil imaging, and deep learning reconstruction, these methods could enable the extremely high acceleration factors needed for real-time 3D imaging.
Summary
深度学习方法可加速磁共振成像,达到最先进水平,但并未充分利用非笛卡尔采样轨迹可能实现的额外加速。
Key Takeaways
- 创建基于生成扩散模型的重建算法,用于多线圈高欠采样螺旋磁共振成像。
- 该模型利用训练期间的调节和基于频率的引导,确保图像和测量值的一致性。
- 在回顾性数据上评估,显示出高图像质量(结构相似度> 0.87),扫描时间极快(2D 图像为 0.02 秒)。
- 使用该算法识别了一组优化的可变密度螺旋轨迹,与使用非均匀快速傅里叶变换的传统重建相比,图像质量有了很大提高。
- 通过结合有效的螺旋采样轨迹、多线圈成像和深度学习重建,这些方法可以实现实时 3D 成像所需的极高加速因子。
-
Title: 加速螺旋MRI的域特定逆非均匀快速傅里叶变换学习
-
Authors: Trevor J. Chan, Chamith S. Rajapakse
-
Affiliation: 宾夕法尼亚大学生物工程系
-
Keywords: 加速MRI,螺旋MRI,深度学习,图像重建
-
Urls: Paper: https://arxiv.org/abs/2404.12361, Github: None
-
Summary:
(1): MRI成像速度慢,限制了其在临床中的应用。加速MRI采集是解决这一问题的关键,其中非笛卡尔采样轨迹和深度学习重建方法是两个重要的方向。
(2): 现有的深度学习重建方法主要针对笛卡尔采样MRI,忽略了非笛卡尔采样轨迹带来的额外加速潜力。
(3): 本文提出了一种基于扩散模型的、轨迹无关的多线圈螺旋MRI欠采样图像重建方法。该方法利用条件训练和频率引导,确保图像和测量值之间的一致性。
(4): 在回顾性数据上,该方法重建的图像质量高(结构相似性>0.87),扫描时间极快(2D图像0.02秒)。该方法还用于识别一组最优的可变密度螺旋轨迹,与使用非均匀快速傅里叶变换的传统重建方法相比,图像质量有很大提高。通过结合高效的螺旋采样轨迹、多线圈成像和深度学习重建,该方法有望实现实时3D成像所需的高加速因子。
- 方法:
(1):本研究回顾性使用[12]公开获取的人类受试者数据进行。无需伦理批准。
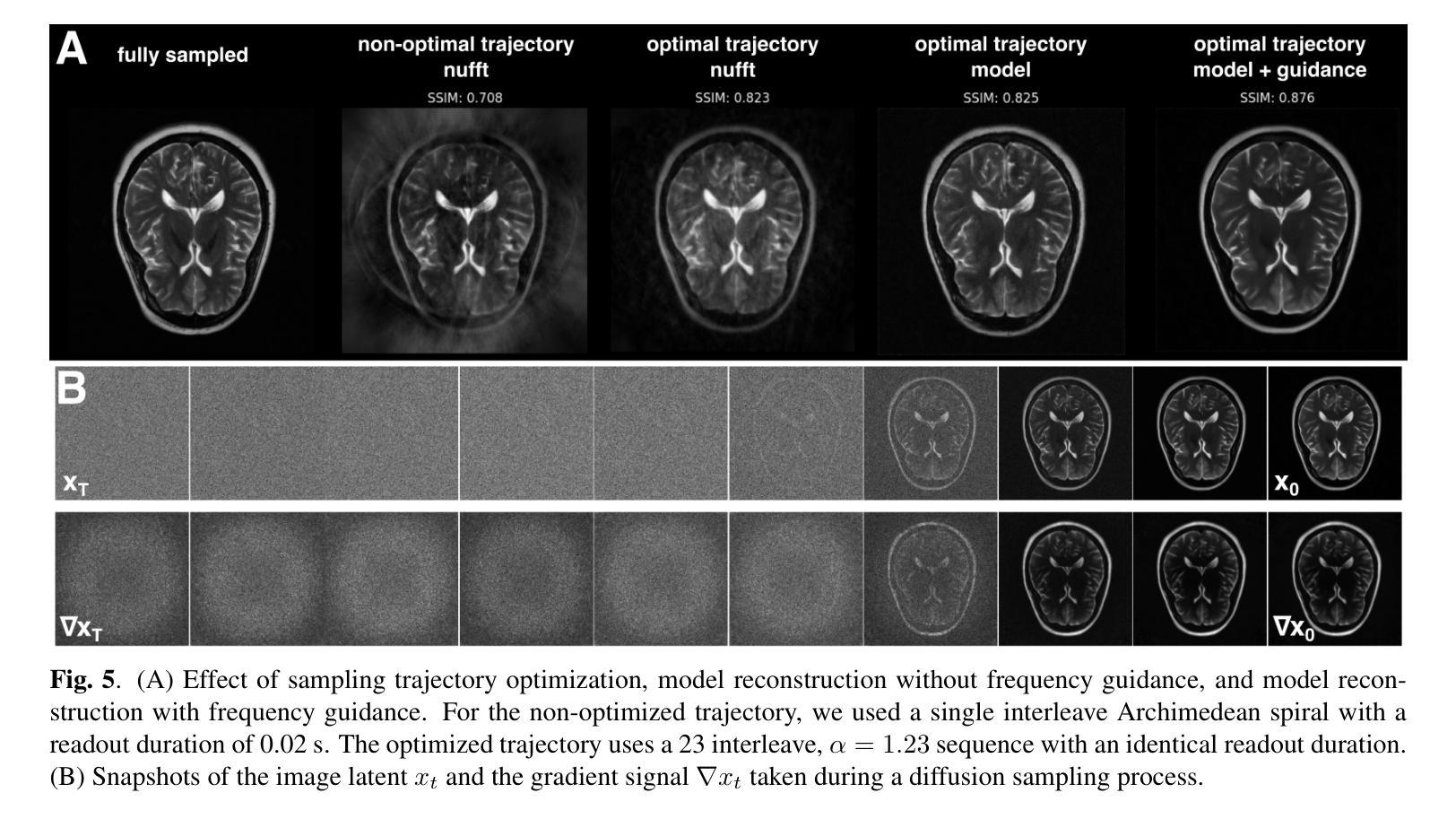
(2):我们使用NYU FastMRI数据集[12],该数据集包含6970个在4到24个线圈的硬件上完全采样的2D脑部扫描。对于训练和测试,我们考虑以下序列参数来表征轴向T2加权涡旋自旋回波序列:扫描时间=140s,TR=6s,TE=113ms,切片=30,切片厚度=5mm,视野=22cm,矩阵大小=320x320。2562分辨率的2D切片的有效扫描时间为140s/320 ∗ 256/30 ≈ 3.7s。由于这些数据最初是使用笛卡尔序列获取的,因此图2。给定测量值y0,重建遵循修改后的扩散采样过程。在每个时间步长,一个有噪声的潜在xt与先验p0连接,并传递到去噪模型以获得˜xt−1。为了强制与y0一致,我们计算频率梯度∇yt−1并使用修改后的迭代逆nufft(第3.3节)求解图像梯度。xt−1和∇xt−1的加权和产生校正后的图像xt−1。重复此操作,直到t = 0。
(3):我们模拟螺旋采集,方法是回顾性地在k空间中插值,以获得沿生成螺旋轨迹的复值测量值。
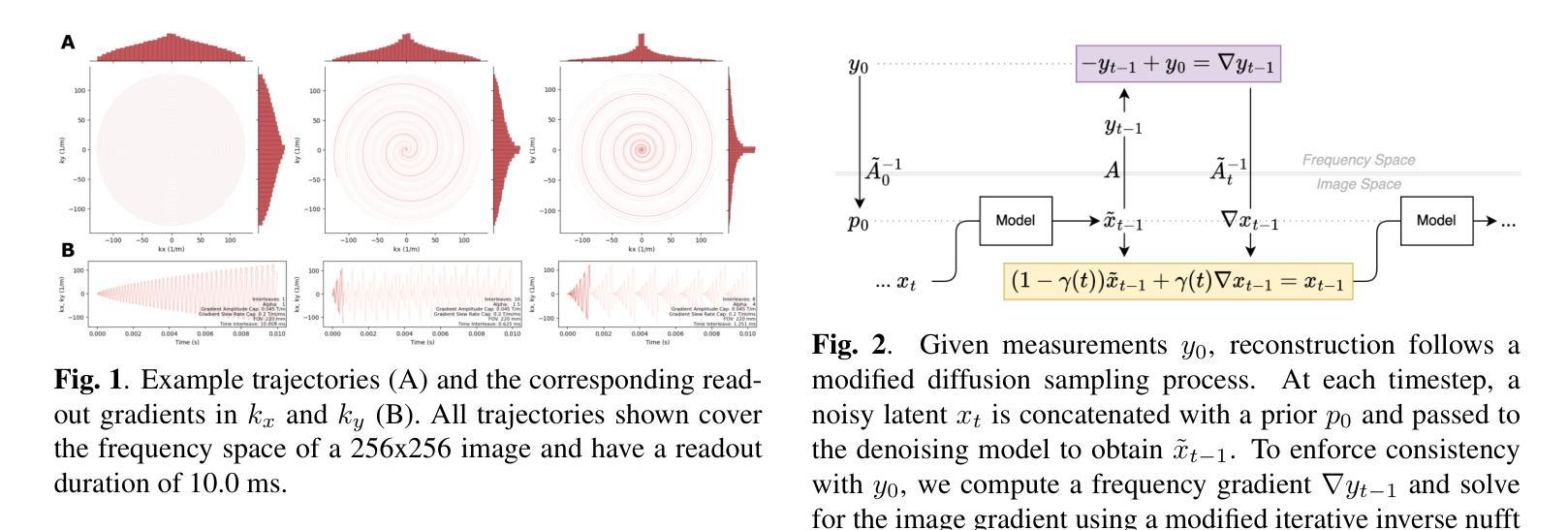
(4):根据Kim等人[13],我们考虑以下形式的螺旋轨迹:k(τ) = � τ 0 1 ρ(ϕ)dϕejωτ ≈ λτ αejωτ。(3)此处,ρ表示采样密度,τ是时间的函数,ϕ是角度位置,ω = 2πn是频率,n是k空间中的转数,λ是缩放因子,等于矩阵大小/(2∗ FOV),α是相对于边缘过度采样k空间中心的偏差项。在梯度回转率上限和梯度幅度上限的约束下求解这个参数方程,产生梯度(gx(t)和gy(t))以及kx,ky平面的螺旋轨迹(图1)。这样做,我们可以调整采样参数以控制诸如读出持续时间和停留时间之类的因素,同时改变交错数和低频到高频过采样率。
(5):图像重建是逆问题求解MRI欠采样采集等同于通过某种不完美的采样函数A测量未知信号x:y = Ax + ϵ。这里,y是测量多线圈k空间数据,A是非均匀傅里叶变换。ϵ是测量噪声,与y存在于同一域中;在MRI中,对于每个线圈,噪声在y的实部和虚部中呈高斯分布。重建是从一组不完整的k空间测量值y中恢复图像信号x的不适定逆问题。由于x和y存在于不同的域中,因此x隐藏在采样算子A的后面。解决这个问题需要先验知识。在我们的案例中,我们学习图像的潜在条件分布并寻求重建
- 结论:
(1):本研究提出了一种基于扩散模型的螺旋MRI欠采样图像重建方法,该方法结合了多线圈成像、螺旋扫描和欠采样,实现了极快的成像速度,有望实现实时3D成像所需的极高加速因子。
(2):创新点:基于扩散模型的图像重建方法;多线圈成像和螺旋扫描的结合;可变密度螺旋轨迹的优化。性能:图像质量高(结构相似性>0.87),扫描时间极快(2D图像0.02秒)。工作量:需要大量的训练数据和计算资源。
点此查看论文截图


AniClipart: Clipart Animation with Text-to-Video Priors
Authors:Ronghuan Wu, Wanchao Su, Kede Ma, Jing Liao
Clipart, a pre-made graphic art form, offers a convenient and efficient way of illustrating visual content. Traditional workflows to convert static clipart images into motion sequences are laborious and time-consuming, involving numerous intricate steps like rigging, key animation and in-betweening. Recent advancements in text-to-video generation hold great potential in resolving this problem. Nevertheless, direct application of text-to-video generation models often struggles to retain the visual identity of clipart images or generate cartoon-style motions, resulting in unsatisfactory animation outcomes. In this paper, we introduce AniClipart, a system that transforms static clipart images into high-quality motion sequences guided by text-to-video priors. To generate cartoon-style and smooth motion, we first define B'{e}zier curves over keypoints of the clipart image as a form of motion regularization. We then align the motion trajectories of the keypoints with the provided text prompt by optimizing the Video Score Distillation Sampling (VSDS) loss, which encodes adequate knowledge of natural motion within a pretrained text-to-video diffusion model. With a differentiable As-Rigid-As-Possible shape deformation algorithm, our method can be end-to-end optimized while maintaining deformation rigidity. Experimental results show that the proposed AniClipart consistently outperforms existing image-to-video generation models, in terms of text-video alignment, visual identity preservation, and motion consistency. Furthermore, we showcase the versatility of AniClipart by adapting it to generate a broader array of animation formats, such as layered animation, which allows topological changes.
PDF Project Page: https://aniclipart.github.io/
Summary
通过使用文生图语言模型,AniClipart可以将静态剪贴画图像转换为高质量的动态序列,并且始终优于现有的图像到视频生成模型。
Key Takeaways
- AniClipart 将静态剪贴画转换为动画序列,保留了剪贴画的视觉特征并生成了卡通风格的动作。
- AniClipart 使用贝塞尔曲线对剪贴画图像的关键点进行运动正则化。
- AniClipart 通过优化视频评分蒸馏采样 (VSDS) 损失将关键点的运动轨迹与提供的文本提示对齐。
- VSDS 损失编码了预训练文本到视频扩散模型中自然运动的充分知识。
- AniClipart 使用可微分僵硬形状变形算法,可以在保持变形刚性的同时进行端到端优化。
- AniClipart 在文本-视频对齐、视觉特征保留和运动一致性方面始终优于现有的图像到视频生成模型。
- AniClipart 可以适应更广泛的动画格式,例如允许拓扑更改的分层动画。
-
Title: AniClipart:基于文本到视频先验的剪辑画动画
-
Authors: RONGHUAN WU, WANCHAO SU, KEDE MA, JING LIAO
-
Affiliation: 香港城市大学
-
Keywords: Clipart Animation, Text-to-Video Diffusion, Score Distillation Sampling, As-Rigid-As-Possible Shape Deformation
-
Urls: Paper:https://arxiv.org/abs/2404.12347v1 Github:None
-
Summary:
(1):剪辑画是一种预先制作的图形艺术形式,它提供了一种方便且有效的方法来插图视觉内容。将静态剪辑画图像转换为运动序列的传统工作流程既费力又费时,涉及许多复杂的步骤,如装配、关键动画和中间动画。
(2):文本到视频生成方面的最新进展在解决这个问题方面具有巨大的潜力。然而,直接应用文本到视频生成模型通常难以保留剪辑画图像的视觉标识或生成卡通风格的动作,从而导致动画结果不令人满意。
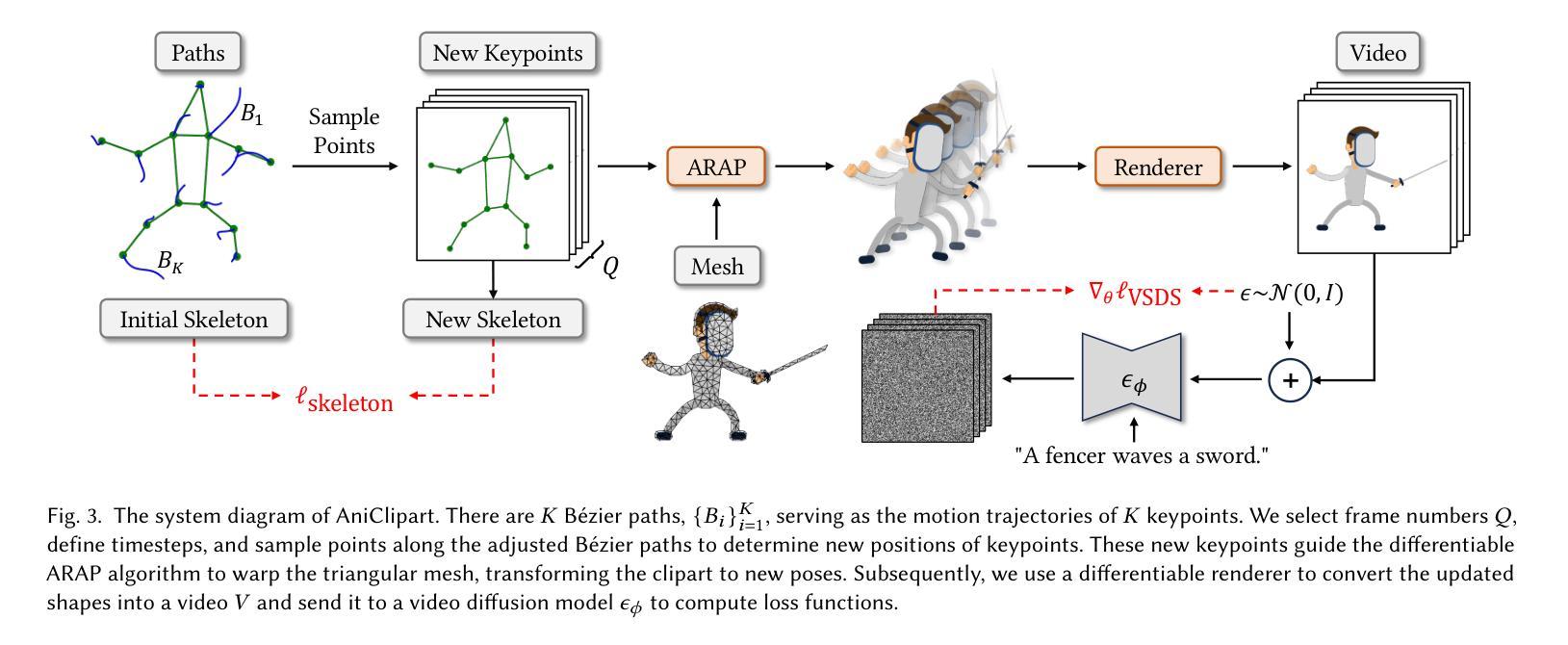
(3):本文介绍了 AniClipart,这是一个将静态剪辑画图像转换为高质量运动序列的系统,该系统由文本到视频先验指导。为了生成卡通风格和流畅的动作,我们首先将贝塞尔曲线定义为剪辑画图像关键点的运动正则化形式。然后,通过优化视频评分蒸馏采样 (VSDS) 损失将关键点的运动轨迹与提供的文本提示对齐,该损失对预训练的文本到视频扩散模型中的自然运动知识进行了充分编码。通过可微分尽可能刚性形状变形算法,我们的方法可以在保持变形刚性的同时进行端到端优化。
(4):实验结果表明,在文本视频对齐、视觉标识保留和运动一致性方面,所提出的 AniClipart 始终优于现有的图像到视频生成模型。此外,我们展示了 AniClipart 的多功能性,通过对其进行调整以生成更广泛的动画格式,例如允许拓扑变化的分层动画。
- 方法:
(1):我们提出了一种基于文本到视频先验的剪辑画动画系统 AniClipart。
(2):AniClipart 由以下几个关键组件组成:贝塞尔曲线运动正则化、视频评分蒸馏采样(VSDS)损失和可微分尽可能刚性形状变形算法。
(3):贝塞尔曲线运动正则化将剪辑画图像关键点的运动定义为贝塞尔曲线,从而确保了运动的平滑性和连续性。
(4):VSDS 损失将关键点的运动轨迹与提供的文本提示对齐,从而将文本到视频扩散模型中的自然运动知识融入到动画中。
(5):可微分尽可能刚性形状变形算法允许在保持变形刚性的同时进行端到端优化,从而生成具有清晰视觉标识的动画。
8. 结论:
(1)本文提出的 AniClipart 系统,通过将文本到视频先验融入剪辑画动画生成中,为静态剪辑画图像赋予了生动性,简化了动画制作流程,具有重要的创新意义。
(2)创新点:AniClipart 创新性地采用了贝塞尔曲线运动正则化、视频评分蒸馏采样损失和可微分尽可能刚性形状变形算法,实现了剪辑画图像的关键点运动轨迹与文本提示的精确对齐,以及变形刚性的保持,从而生成高质量的剪辑画动画。
性能:AniClipart 在文本视频对齐、视觉标识保留和运动一致性方面均优于现有的图像到视频生成模型,展现出出色的动画生成能力。
工作量:AniClipart 采用端到端优化,简化了剪辑画动画制作流程,降低了工作量。
点此查看论文截图

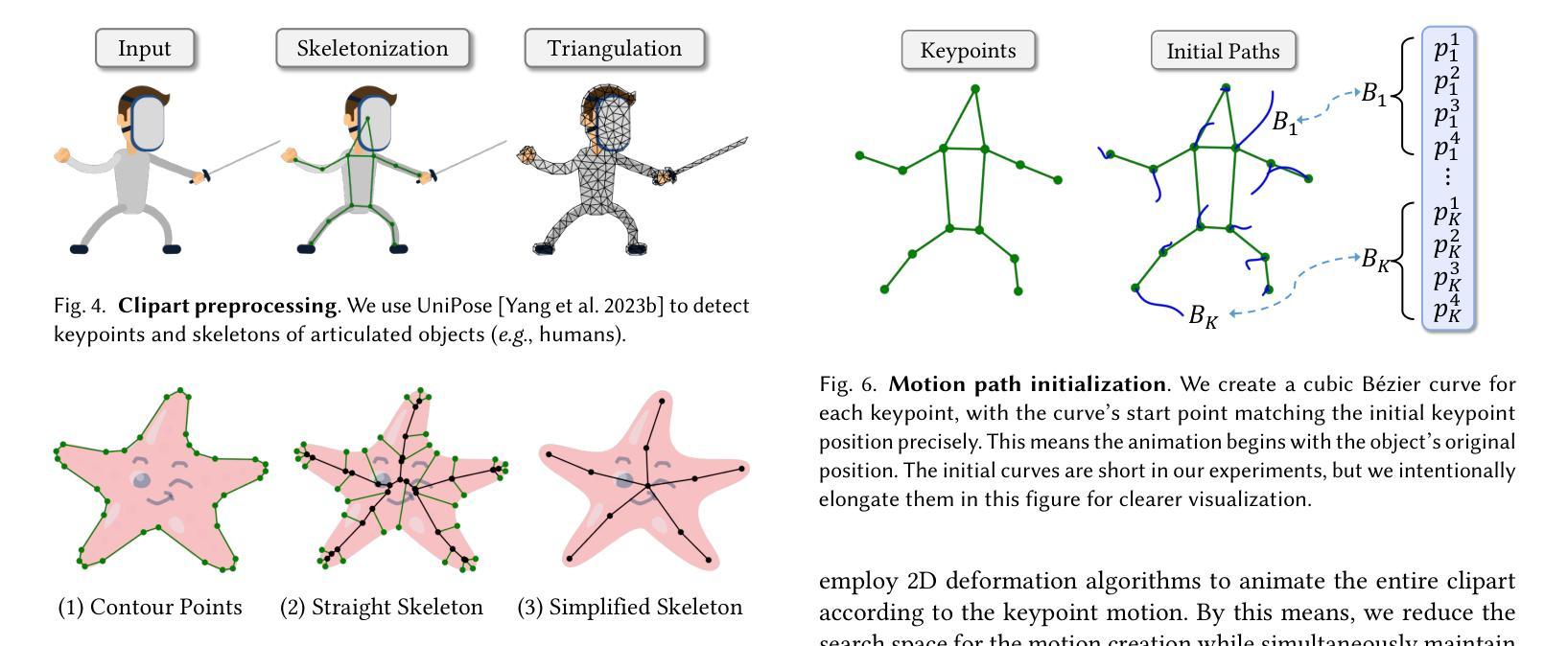
StyleBooth: Image Style Editing with Multimodal Instruction
Authors:Zhen Han, Chaojie Mao, Zeyinzi Jiang, Yulin Pan, Jingfeng Zhang
Given an original image, image editing aims to generate an image that align with the provided instruction. The challenges are to accept multimodal inputs as instructions and a scarcity of high-quality training data, including crucial triplets of source/target image pairs and multimodal (text and image) instructions. In this paper, we focus on image style editing and present StyleBooth, a method that proposes a comprehensive framework for image editing and a feasible strategy for building a high-quality style editing dataset. We integrate encoded textual instruction and image exemplar as a unified condition for diffusion model, enabling the editing of original image following multimodal instructions. Furthermore, by iterative style-destyle tuning and editing and usability filtering, the StyleBooth dataset provides content-consistent stylized/plain image pairs in various categories of styles. To show the flexibility of StyleBooth, we conduct experiments on diverse tasks, such as text-based style editing, exemplar-based style editing and compositional style editing. The results demonstrate that the quality and variety of training data significantly enhance the ability to preserve content and improve the overall quality of generated images in editing tasks. Project page can be found at https://ali-vilab.github.io/stylebooth-page/.
Summary
StyleBooth是一个图像编辑框架,集成了文本和图像指令,并提供高质量的风格编辑数据集,可用于各种编辑任务,如文本风格编辑和示例风格编辑。
Key Takeaways
- StyleBooth 框架将文本指令和图像示例整合为扩散模型的统一条件,实现图像风格编辑。
- StyleBooth 数据集通过迭代的风格-去风格调整和编辑以及可用性过滤,提供了内容一致的风格化/普通图像对。
- StyleBooth 通过高质量的训练数据增强了编辑任务中保留内容和提高生成图像整体质量的能力。
- StyleBooth 可用于文本风格编辑、示例风格编辑和合成风格编辑等多种任务。
- StyleBooth 项目主页:https://ali-vilab.github.io/stylebooth-page/。
- 多模态输入和高质量训练数据对于图像编辑至关重要。
- StyleBooth 提供了一个全面的图像编辑框架和训练数据的构建策略。
-
Title: StyleBooth: 使用多模态指令进行图像风格编辑
-
Authors: Zhen Han, Chaojie Mao, Zeyinzi Jiang, Yulin Pan, Jingfeng Zhang
-
Affiliation: 阿里巴巴集团
-
Keywords: Text-based style editing · Exemplar-based style editing · Multimodal instruction-tuning
-
Urls: https://arxiv.org/abs/2404.12154, Github:None
-
Summary:
(1):图像编辑旨在根据提供的指令生成与原图像对齐的图像。挑战在于接受多模态输入作为指令,以及缺乏高质量训练数据,包括源/目标图像对和多模态(文本和图像)指令的关键三元组。
(2):以往的方法主要包括操纵注意力机制的特征、在去噪步骤中实现引导扩散、使用图像对进行监督来调整 T2I 模型等。这些方法都面临着只支持单模态输入、缺乏高质量训练数据、难以保持内容一致性等问题。
(3):本文提出 StyleBooth 方法,该方法提出了一个用于图像编辑的综合框架和构建高质量风格编辑数据集的可行策略。我们将编码的文本指令和图像示例整合为扩散模型的统一条件,从而能够根据多模态指令编辑原始图像。此外,通过迭代的风格-去风格调整和编辑以及可用性过滤,StyleBooth 数据集提供了各种风格类别中内容一致的风格化/-普通图像对。
(4):实验结果表明,训练数据的质量和多样性显着增强了在编辑任务中保留内容和提高生成图像整体质量的能力。
- 方法:
(1):StyleBooth 方法提出了一种用于图像编辑的综合框架,该框架将编码的文本指令和图像示例整合为扩散模型的统一条件,能够根据多模态指令编辑原始图像;
(2):StyleBooth 数据集通过迭代的风格-去风格调整和编辑以及可用性过滤,提供了各种风格类别中内容一致的风格化/-普通图像对,提高了训练数据的质量和多样性,增强了在编辑任务中保留内容和提高生成图像整体质量的能力;
(3):Scale Weighting Mechanism 机制通过对隐藏空间嵌入进行缩放加权,平衡了不同模态的风格表现,保证了图像编辑的质量。
- 结论:
(1):本文提出 StyleBooth,这是一种多模态指令图像风格编辑方法。它独立编码参考图像和文本,随后在潜在空间内对其进行转换和对齐,然后注入骨干网络以进行生成指导,以实现基于文本和示例的指令编辑。同时,StyleBooth 还可以融合多模态信息进行合成创造性生成。此外,我们构建了一个用于风格编辑的高质量数据集,该数据集由各种内容一致的风格化和普通图像对组成,这有助于我们构建更好的编辑模型。局限性。在这项工作中,我们构建了一个用于风格编辑的丰富数据集。然而,数据构建基于特定风格的文本描述,例如水彩画,这极大地限制了风格的数量。收集更广泛、更广泛的编辑数据集将是我们未来的工作。
(2):创新点:提出 StyleBooth 方法,该方法将编码的文本指令和图像示例整合为扩散模型的统一条件,能够根据多模态指令编辑原始图像;构建 StyleBooth 数据集,该数据集通过迭代的风格-去风格调整和编辑以及可用性过滤,提供了各种风格类别中内容一致的风格化/-普通图像对,提高了训练数据的质量和多样性;提出 Scale Weighting Mechanism 机制,通过对隐藏空间嵌入进行缩放加权,平衡了不同模态的风格表现,保证了图像编辑的质量。 性能:实验结果表明,训练数据的质量和多样性显着增强了在编辑任务中保留内容和提高生成图像整体质量的能力。 工作量:本文的方法和数据集的构建过程相对复杂,需要较大的计算资源和人力投入。
点此查看论文截图


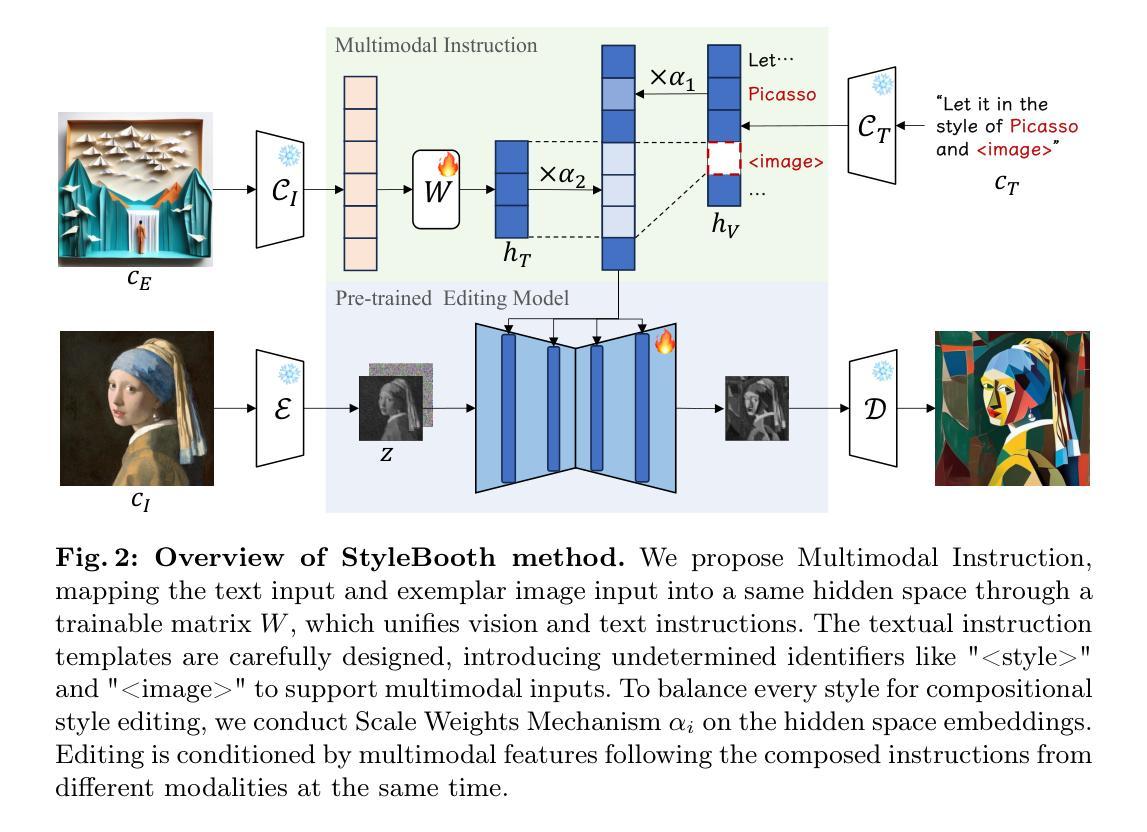
IntrinsicAnything: Learning Diffusion Priors for Inverse Rendering Under Unknown Illumination
Authors:Xi Chen, Sida Peng, Dongchen Yang, Yuan Liu, Bowen Pan, Chengfei Lv, Xiaowei Zhou
This paper aims to recover object materials from posed images captured under an unknown static lighting condition. Recent methods solve this task by optimizing material parameters through differentiable physically based rendering. However, due to the coupling between object geometry, materials, and environment lighting, there is inherent ambiguity during the inverse rendering process, preventing previous methods from obtaining accurate results. To overcome this ill-posed problem, our key idea is to learn the material prior with a generative model for regularizing the optimization process. We observe that the general rendering equation can be split into diffuse and specular shading terms, and thus formulate the material prior as diffusion models of albedo and specular. Thanks to this design, our model can be trained using the existing abundant 3D object data, and naturally acts as a versatile tool to resolve the ambiguity when recovering material representations from RGB images. In addition, we develop a coarse-to-fine training strategy that leverages estimated materials to guide diffusion models to satisfy multi-view consistent constraints, leading to more stable and accurate results. Extensive experiments on real-world and synthetic datasets demonstrate that our approach achieves state-of-the-art performance on material recovery. The code will be available at https://zju3dv.github.io/IntrinsicAnything.
PDF Project page: https://zju3dv.github.io/IntrinsicAnything
Summary
利用生成模型学习材质先验,以正则化优化过程,从而恢复未知静态光照条件下姿势图像中的物体材质。
Key Takeaways
- 将通用渲染方程拆分为漫反射和镜面反射着色项,并将材质先验表述为漫反射率和镜面的扩散模型。
- 使用现有的丰富 3D 物体数据训练模型,将其作为解决从 RGB 图像恢复材质表示时模糊性的通用工具。
- 开发了一种粗到细的训练策略,利用估计的材质来引导扩散模型满足多视图一致性约束,从而获得更稳定和准确的结果。
- 在真实世界和合成数据集上的广泛实验表明,该方法在材质恢复方面达到最先进的性能。
-
论文标题:IntrinsicAnything: 学习扩散先验以在未知光照下进行逆向渲染
-
作者:Xi Chen, Sida Peng, Dongchen Yang, Yuan Liu, Bowen Pan, Chengfei Lv, Xiaowei Zhou
-
第一作者单位:浙江大学计算机辅助设计与图形学国家重点实验室
-
关键词:Inverse Rendering, Material Recovery, Diffusion Model, Generative Prior
-
论文链接:https://arxiv.org/abs/2404.11593 , Github:None
-
摘要:
(1) 研究背景:从捕获的图像中恢复物体的几何、材质和光照,即逆向渲染,是计算机视觉和图形学中一项长期存在的任务。这些 3D 物体的物理属性对于许多应用程序至关重要,例如 VR/AR、电影制作和视频游戏。由于现实世界物体与环境光照之间相互作用的固有复杂性,逆向渲染仍然是一个不适定问题。
(2) 过往方法及问题:以往的工作通过复杂的捕获系统[16,20]或在黑暗环境中共同定位的手电筒和相机[5,50,84]来克服这个问题。然而,这些方法需要特殊的硬件设备或受限的环境,限制了它们的应用。
(3) 本文提出的研究方法:为了克服这个不适定问题,我们的关键思想是学习一个生成模型作为材质先验来正则化优化过程。我们观察到,一般的渲染方程可以分解为漫反射和镜面反射阴影项,因此将材质先验表述为漫反射和镜面反射的扩散模型。由于这种设计,我们的模型可以使用现有的丰富 3D 对象数据进行训练,并且自然地充当了一种多功能工具,可以在从 RGB 图像中恢复材质表示时解决歧义。此外,我们开发了一种从粗到精的训练策略,利用估计的材质来引导扩散模型满足多视图一致性约束,从而得到更稳定和准确的结果。
(4) 方法在什么任务上取得了怎样的性能:在真实世界和合成数据集上的广泛实验表明,我们的方法在材质恢复方面达到了最先进的性能。该性能可以支持他们的目标。
- 方法:
(1):提出学习扩散模型作为材质先验,正则化逆向渲染优化过程。
(2):将渲染方程分解为漫反射和镜面反射阴影项,将材质先验表述为漫反射和镜面反射的扩散模型。
(3):采用从粗到精的训练策略,利用估计的材质引导扩散模型满足多视图一致性约束,得到更稳定和准确的结果。
- 结论:
(1):提出了 IntrinsicAnything 模型,该模型利用扩散模型作为材质先验,在未知静态光照条件下进行逆向渲染。
(2):创新点:提出将材质先验设计为漫反射和镜面反射的条件扩散模型;开发了两阶段训练方案,利用粗略材质引导扩散模型满足多视图一致性约束。性能:在真实世界和合成数据集上实现了最先进的材质恢复性能。工作量:需要较大的数据集和较长的训练时间。
点此查看论文截图



MoA: Mixture-of-Attention for Subject-Context Disentanglement in Personalized Image Generation
Authors: Kuan-Chieh, Wang, Daniil Ostashev, Yuwei Fang, Sergey Tulyakov, Kfir Aberman
We introduce a new architecture for personalization of text-to-image diffusion models, coined Mixture-of-Attention (MoA). Inspired by the Mixture-of-Experts mechanism utilized in large language models (LLMs), MoA distributes the generation workload between two attention pathways: a personalized branch and a non-personalized prior branch. MoA is designed to retain the original model’s prior by fixing its attention layers in the prior branch, while minimally intervening in the generation process with the personalized branch that learns to embed subjects in the layout and context generated by the prior branch. A novel routing mechanism manages the distribution of pixels in each layer across these branches to optimize the blend of personalized and generic content creation. Once trained, MoA facilitates the creation of high-quality, personalized images featuring multiple subjects with compositions and interactions as diverse as those generated by the original model. Crucially, MoA enhances the distinction between the model’s pre-existing capability and the newly augmented personalized intervention, thereby offering a more disentangled subject-context control that was previously unattainable. Project page: https://snap-research.github.io/mixture-of-attention
PDF Project Website: https://snap-research.github.io/mixture-of-attention
Summary
文本到图像扩散模型个性化的混合注意力机制,在预先固定的非个性化基础分支上叠加可学习的个性化分支,优化个性化和通用内容创建的混合,实现更解耦的主题-上下文控制。
Key Takeaways
- 提出混合注意机制(MoA)架构,用于文本到图像扩散模型的个性化。
- MoA 分发生成工作负载到个性化分支和非个性化先验分支。
- 个性化分支在先验分支生成的布局和上下文中嵌入主题。
- 新颖的路由机制优化了跨分支的像素分配。
- MoA 允许创建高质量的个性化图像,具有多种主题和交互。
- MoA 增强了模型的先验功能和个性化干预之间的区别。
- MoA 提供了以前无法实现的更解耦的主题-上下文控制。
-
Title: MoA: Mixture-of-Attention for Subject-Context Disentanglement in Personalized Image Generation
-
Authors: Kuan-Chieh (Jackson) Wang, Daniil Ostashev, Yuwei Fang, Sergey Tulyakov, Kfir Aberman
-
Affiliation: Snap Inc., USA
-
Keywords: Personalization, Text-to-image Generation, Diffusion Models
-
Urls: https://arxiv.org/abs/2404.11565, Github:None
-
Summary:
(1): The research background of this article is the rapid progress in foundation text-conditioned image synthesis with diffusion models. Personalized generation focuses on adapting and contextualizing the generation to a set of desired subjects using limited input images, while retaining the powerful generative capabilities of the foundation model.
(2): Past methods for personalized generation include fine-tuning-based personalization techniques and approaches optimized for multi-subject generation. However, fine-tuning-based methods tend to overfit to certain attributes in the distribution of the input images or struggle to adhere adequately to the input prompt. Approaches optimized for multi-subject generation often modify the original model's weights, resulting in compositions that lack diversity and naturalness.
(3): The research methodology proposed in this paper is Mixture-of-Attention (MoA), which extends the vanilla attention mechanism into multiple attention blocks (i.e. experts), and has a router network that softly combines the different experts. MoA distributes the generation between personalized and non-personalized attention pathways. It is designed to retain the original model's prior by fixing its attention layers in the prior (non-personalized) branch, while minimally intervening in the generation process with the personalized branch.
(4): MoA is evaluated on the task of personalized image generation. The results show that MoA can generate high-quality, personalized images featuring multiple subjects with compositions and interactions as diverse as those generated by the original model. MoA also enhances the distinction between the model's pre-existing capability and the newly augmented personalized intervention, thereby offering a more disentangled subject-context control that was previously unattainable.
-
方法:
(1): 提出Mixture-of-Attention(MoA)层,将vanilla注意力机制扩展为多个注意力模块(即专家),并使用路由器网络对不同专家进行软组合。(2): MoA将生成分配到个性化和非个性化注意力路径之间。它通过固定先验(非个性化)分支中的注意力层来保留原始模型的先验,同时通过个性化分支对生成过程进行最小干预。 (3): 将MoA应用于文本到图像(T2I)扩散模型中,用于主题驱动的生成。该架构使我们能够增强T2I模型的能力,以执行主题驱动的生成,同时对主题和上下文进行解耦控制,从而保留先验模型中固有的多样化图像分布。 -
结论:
(1)本工作的意义在于:提出了一种新的个性化生成架构 Mixture-of-Attention(MoA),该架构增强了基础文本到图像模型的能力,使其能够注入主题图像,同时保留了模型的先前能力。与现有主题驱动生成方法生成的图像相比,MoA 无缝地统一了两种范式,通过拥有两个不同的专家和一个路由器来动态合并两个路径。MoA 层能够在一次反向扩散传递中从具有丰富交互的多个输入主题生成个性化上下文,并且不需要测试时微调步骤,从而解锁了以前无法达到的结果。此外,我们的模型展示了生成图像中以前未见的布局变化,以及处理物体或其他主题遮挡的能力,并且无需显式控制即可处理不同的身体形状。最后,由于其简单性,MoA 与众所周知的基于扩散的生成和编辑技术(如 ControlNet 和 DDIM Inversion)天然兼容。例如,MoA 和 DDIM Inversion 的结合解锁了在真实照片中进行主题交换的应用。展望未来,我们设想通过专门针对不同任务或语义标签的不同专家进一步增强 MoA 架构。此外,采用极小干预个性化的方法可以扩展到各种基础模型(例如视频和 3D/4D 生成),从而促进使用现有和未来生成模型创建个性化内容。
(2)创新点:提出了一种新的 Mixture-of-Attention(MoA)架构,该架构增强了基础文本到图像模型的能力,使其能够注入主题图像,同时保留了模型的先前能力。MoA 层能够在一次反向扩散传递中从具有丰富交互的多个输入主题生成个性化上下文,并且不需要测试时微调步骤,从而解锁了以前无法达到的结果。此外,我们的模型展示了生成图像中以前未见的布局变化,以及处理物体或其他主题遮挡的能力,并且无需显式控制即可处理不同的身体形状。
性能:在个性化图像生成任务上进行了评估,结果表明 MoA 可以生成高质量、个性化的图像,其特征是具有与原始模型生成图像一样多样化的构图和交互。MoA 还增强了模型现有能力和新增强个性化干预之间的区别,从而提供了以前无法实现的更分离的主题-上下文控制。
工作量:MoA 具有简单性,与众所周知的基于扩散的生成和编辑技术(如 ControlNet 和 DDIM Inversion)天然兼容。例如,MoA 和 DDIM Inversion 的结合解锁了在真实照片中进行主题交换的应用。
点此查看论文截图








