⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-22 更新
Learn2Talk: 3D Talking Face Learns from 2D Talking Face
Authors:Yixiang Zhuang, Baoping Cheng, Yao Cheng, Yuntao Jin, Renshuai Liu, Chengyang Li, Xuan Cheng, Jing Liao, Juncong Lin
Speech-driven facial animation methods usually contain two main classes, 3D and 2D talking face, both of which attract considerable research attention in recent years. However, to the best of our knowledge, the research on 3D talking face does not go deeper as 2D talking face, in the aspect of lip-synchronization (lip-sync) and speech perception. To mind the gap between the two sub-fields, we propose a learning framework named Learn2Talk, which can construct a better 3D talking face network by exploiting two expertise points from the field of 2D talking face. Firstly, inspired by the audio-video sync network, a 3D sync-lip expert model is devised for the pursuit of lip-sync between audio and 3D facial motion. Secondly, a teacher model selected from 2D talking face methods is used to guide the training of the audio-to-3D motions regression network to yield more 3D vertex accuracy. Extensive experiments show the advantages of the proposed framework in terms of lip-sync, vertex accuracy and speech perception, compared with state-of-the-arts. Finally, we show two applications of the proposed framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting based avatar animation.
Summary
通过借鉴2D说话人脸的唇形同步(lip-sync)和语音感知的专业知识,Learn2Talk框架构建了一个更好的3D说话人脸网络。
Key Takeaways
- 提出了Learn2Talk框架,将2D说话人脸的专业知识应用于3D说话人脸网络。
- 设计了3D唇形同步专家模型,追求音频和3D面部动作之间的唇形同步。
- 使用2D说话人脸方法选择的教师模型来指导音频到3D动作回归网络的训练,以提高3D顶点精度。
- 实验表明,该框架在唇形同步、顶点精度和语音感知方面优于现有技术。
- 展示了该框架的两个应用:视听语音识别和语音驱动的3D高斯喷射动画。
-
标题:Learn2Talk:3D Talking Face Learns from 2D(3D 说话人脸从 2D 说话人脸中学习)
-
作者:Yixiang Zhuang, Baoping Cheng, Yao Cheng, Yuntao Jin, Renshuai Liu, Chengyang Li, Xuan Cheng, Jing Liao, Juncong Lin
-
第一作者单位:暂无
-
关键词:Speech-driven, 3D Facial Animation, 2D Talking face, Transformer, 3D Gaussian Splatting
-
论文链接:暂无,Github 链接:https://lkjkjoiuiu.github.io/Learn2Talk/
-
摘要:
(1):研究背景:语音驱动的面部动画方法主要包含 3D 和 2D 说话人脸两大类,近年来两者都备受研究关注。然而,据我们所知,3D 说话人脸的研究并未像 2D 说话人脸那样深入,在唇形同步(lip-sync)和言语感知方面存在差距。
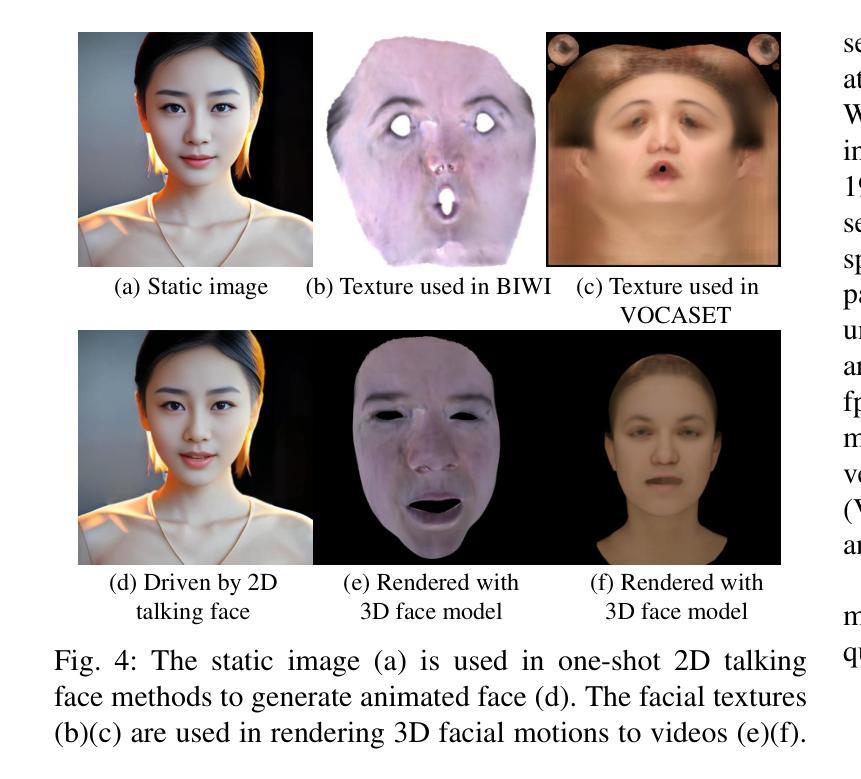
(2):以往方法:以往方法主要分为 2D 和 3D 说话人脸方法。2D 说话人脸方法通常在像素空间(例如图像、视频)中生成唇部运动或头部运动以匹配给定的输入音频流,而 3D 说话人脸方法使用时间 3D 顶点数据(例如 3D 人脸模板、混合形状参数)来表示面部运动。与 2D 说话人脸方法相比,3D 说话人脸方法可以合成更细微的唇部动作,因为细粒度的唇形校正可以在 3D 空间中更好地执行。此外,3D 面部动画具有重要的优势,因为它可以与 3D 模型或虚拟角色无缝集成,从而实现更逼真的交互。
(3):本文提出的研究方法:为了弥合两者之间的差距,我们提出了一个名为 Learn2Talk 的学习框架,该框架可以通过利用 2D 说话人脸领域的两个专业知识点来构建更好的 3D 说话人脸网络。首先,受音频视频同步网络的启发,设计了一个 3D 同步唇部专家模型,以追求音频和 3D 面部动作之间的唇形同步。其次,使用从 2D 说话人脸方法中选择的教师模型来指导音频到 3D 动作回归网络的训练,以产生更高的 3D 顶点精度。
(4):方法在什么任务上取得了什么性能:广泛的实验表明,与最先进的方法相比,所提出的框架在唇形同步、顶点精度和言语感知方面具有优势。最终,我们展示了所提出框架的两个应用:视听语音识别和语音驱动的基于 3D 高斯泼溅的头像动画。这些结果表明,Learn2Talk 可以有效地利用 2D 说话人脸的专业知识来提高 3D 说话人脸的性能,从而为语音驱动的面部动画领域做出贡献。
-
方法:
(1): 受音频视频同步网络的启发,设计了 3D 同步唇部专家模型 SyncNet3D,以追求音频和 3D 面部动作之间的唇形同步;(2): 使用从 2D 说话人脸方法中选择的教师模型 LipReadNet 来指导音频到 3D 动作回归网络 Audio2Mesh 的训练,以产生更高的 3D 顶点精度; (3): 提出了一种联合训练框架,将 SyncNet3D 和 Audio2Mesh 结合起来,通过联合损失函数优化,使 3D 说话人脸模型同时满足唇形同步和顶点精度要求。 -
结论:
(1):本工作通过借鉴 2D 说话人脸领域的专业知识,提出了一种名为 Learn2Talk 的学习框架,有效提升了 3D 说话人脸的性能,为语音驱动的面部动画领域做出了贡献。
(2):创新点:Learn2Talk 创新性地将 3D 同步唇部专家模型 SyncNet3D 与教师模型 LipReadNet 相结合,通过联合训练,实现了 3D 说话人脸模型在唇形同步和顶点精度方面的双重提升。
性能:在唇形同步、顶点精度和言语感知方面,Learn2Talk 均优于最先进的方法。
工作量:Learn2Talk 的训练过程较为复杂,需要同时训练 SyncNet3D 和 Audio2Mesh 两个模型,并且需要从 2D 说话人脸方法中选择教师模型。
点此查看论文截图