⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-02 更新
NeRF-Guided Unsupervised Learning of RGB-D Registration
Authors:Zhinan Yu, Zheng Qin, Yijie Tang, Yongjun Wang, Renjiao Yi, Chenyang Zhu, Kai Xu
This paper focuses on training a robust RGB-D registration model without ground-truth pose supervision. Existing methods usually adopt a pairwise training strategy based on differentiable rendering, which enforces the photometric and the geometric consistency between the two registered frames as supervision. However, this frame-to-frame framework suffers from poor multi-view consistency due to factors such as lighting changes, geometry occlusion and reflective materials. In this paper, we present NeRF-UR, a novel frame-to-model optimization framework for unsupervised RGB-D registration. Instead of frame-to-frame consistency, we leverage the neural radiance field (NeRF) as a global model of the scene and use the consistency between the input and the NeRF-rerendered frames for pose optimization. This design can significantly improve the robustness in scenarios with poor multi-view consistency and provides better learning signal for the registration model. Furthermore, to bootstrap the NeRF optimization, we create a synthetic dataset, Sim-RGBD, through a photo-realistic simulator to warm up the registration model. By first training the registration model on Sim-RGBD and later unsupervisedly fine-tuning on real data, our framework enables distilling the capability of feature extraction and registration from simulation to reality. Our method outperforms the state-of-the-art counterparts on two popular indoor RGB-D datasets, ScanNet and 3DMatch. Code and models will be released for paper reproduction.
Summary
NeRF-UR 提出了一种帧到模型的优化框架,用于无监督 RGB-D 配准,利用神经辐射场 (NeRF) 作为场景的全局模型,以提高多视图一致性差时的鲁棒性。
Key Takeaways
- 提出了一种无监督 RGB-D 配准的帧到模型优化框架 NeRF-UR。
- 使用 NeRF 作为场景的全局模型,提高了多视图一致性差时的鲁棒性。
- 创建了一个合成数据集 Sim-RGBD,通过在真实数据上进行无监督微调,将特征提取和注册的能力从仿真转移到现实。
- 在 ScanNet 和 3DMatch 数据集上,NeRF-UR 优于最先进的方法。
- 代码和模型将公开,以方便论文复现。
- 论文标题:NeRF引导的RGB-D配准无监督学习
- 作者:Zhinan Yu1∗, Zheng Qin2∗, Yijie Tang1, Yongjun Wang1, Renjiao Yi1, Chenyang Zhu1, and Kai Xu1†
- 第一作者单位:国防科技大学
- 关键词:RGB-D配准·无监督学习·NeRF
- 论文链接:xxx
- 摘要:
(1):研究背景:随着RGB-D传感器的普及和成本的降低,3D数据采集的难度已大大降低。RGB-D数据的广泛收集极大地推动了深度学习在3D视觉领域的进步,从而极大地提高了RGB-D SLAM和RGB-D重建等应用的性能。然而,现有的RGB-D配准方法通常采用基于可微渲染的成对训练策略,这会因光照变化、几何遮挡和反光材料等因素而导致多视图一致性较差。
(2):过去方法及问题:现有的RGB-D配准方法通常采用基于可微渲染的成对训练策略,这会因光照变化、几何遮挡和反光材料等因素而导致多视图一致性较差。
(3):本文方法:本文提出了一种新颖的帧到模型优化框架NeRF-UR,用于无监督RGB-D配准。该框架利用神经辐射场(NeRF)作为场景的全局模型,并使用输入帧和NeRF重新渲染帧之间的一致性进行位姿优化。此外,为了引导NeRF优化,本文创建了一个通过逼真模拟器生成的合成数据集Sim-RGBD,用于预热配准模型。
(4):方法性能:该方法在两个流行的室内RGB-D数据集ScanNet和3DMatch上优于最先进的同类方法。
- 方法:
(1):提出一种新颖的帧到模型优化框架 NeRF-UR,用于无监督 RGB-D 配准;
(2):利用神经辐射场(NeRF)作为场景的全局模型,并使用输入帧和 NeRF 重新渲染帧之间的一致性进行位姿优化;
(3):创建通过逼真模拟器生成的合成数据集 Sim-RGBD,用于预热配准模型;
(4):使用 PointMBF 作为配准模型,该模型融合了视觉(2D)和几何(3D)空间的信息以获得更好的特征辨别力;
(5):提出 NeRF 引导的无监督配准管道,该管道依赖于高质量的位姿来监督配准模型,并利用 NeRF 优化帧位姿;
(6):采用 NeRF 模型,该模型能够对场景中的光照和几何结构进行建模,并联合优化 3D 地图和位姿;
(7):将 RGB-D 序列分割成子序列,并为每个子序列优化一个 NeRF,以避免联合地图位姿优化带来的误差累积和巨大的时间开销;
(8):通过 Sim-RGBD 数据集对配准模型进行引导,以提供合理的初始位姿,解决随机初始化配准模型容易产生大量异常对应关系的问题。
8. 结论
(1):该工作的意义
本文提出了 NeRF-UR,这是一种用于无监督 RGB-D 配准的帧到模型优化框架。该方法利用神经辐射场 (NeRF) 作为场景的全局模型,并使用输入帧和 NeRF 重新渲染帧之间的一致性来优化配准模型估计的位姿。这种设计可以有效提高对光照变化、几何遮挡和反射材料的鲁棒性。我们进一步在合成数据集上设计了一个引导机制来预热 NeRF 优化。在两个基准上的大量实验表明了我们方法的有效性。我们认为,NeRF 引导的无监督学习是 3D 视觉的一种有前途的机制,我们希望在未来将其扩展到更多的任务,如定位、重建等。
(2):本文的优缺点总结
创新点:
- 提出了一种新颖的帧到模型优化框架 NeRF-UR,用于无监督 RGB-D 配准。
- 利用神经辐射场 (NeRF) 作为场景的全局模型,并使用输入帧和 NeRF 重新渲染帧之间的一致性来优化位姿。
- 设计了一种合成数据集上的引导机制来预热 NeRF 优化。
性能:
- 在两个流行的室内 RGB-D 数据集 ScanNet 和 3DMatch 上优于最先进的同类方法。
工作量:
- 需要预先训练 NeRF 模型,这可能需要大量的时间和计算资源。
- 优化 NeRF 和配准模型是一个迭代过程,可能需要多次迭代才能收敛。
点此查看论文截图


Simple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Authors:Nagabhushan Somraj, Adithyan Karanayil, Sai Harsha Mupparaju, Rajiv Soundararajan
Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^\circ$ scenes by employing the above regularizations.
PDF The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2024/Simple-RF.html. arXiv admin note: substantial text overlap with arXiv:2309.03955
Summary
神经辐射场(NeRF)在场景的逼真自由视点渲染方面表现出色。最近对 NeRF 的改进,如 TensoRF 和 ZipNeRF,采用了显式模型以实现更快的优化和渲染,而 NeRF 则采用了隐式表示。然而,隐式和显式的辐射场都需要对给定场景中的图像进行密集采样。当只有稀疏的视图集合可用时,它们的性能会显着下降。研究人员发现,监督辐射场估计的深度有助于使用更少的视图有效地训练它。深度监督是使用经典方法或在大数据集上预先训练的神经网络获得的。虽然前者可能只提供稀疏监督,但后者可能存在泛化问题。与早期的方法相反,我们寻求通过设计增强模型并在主辐射场中训练它们来学习深度监督。此外,我们的目标是设计一个正则化框架,它可以在不同的隐式和显式辐射场中使用。我们观察到,这些辐射场模型的某些特征在稀疏输入情况下过度拟合观测到的图像。我们的主要发现是,降低辐射场相对于位置编码、分解张量分量数或哈希表大小的能力,会限制模型学习更简单的解决方案,从而在某些区域估计更好的深度。通过基于这种降低的能力设计增强模型,我们可以获得更好的主辐射场深度监督。通过使用上述正则化,我们在包含朝前和 360 度场景的流行数据集上以稀疏输入视图实现了最先进的视图合成性能。
Key Takeaways
- 减少NeRF模型复杂性有助于学习更好的深度,有利于利用稀疏视图进行训练。
- 设计增强模型,基于降低NeRF模型能力获得改进的深度监督。
- 正则化框架可以应用于不同类型NeRF模型,包括隐式和显式模型。
- 过度拟合是稀疏视图输入NeRF训练中的主要问题。
- 深度监督可以促进NeRF模型从稀疏视图中进行有效训练。
- 经典方法和神经网络都可以用于深度监督,但各有优缺点。
- 在朝前和360度场景的流行数据集上,该方法实现了最先进的视图合成性能。
-
Title: 简化射线场:用更简单的解决方案正则化稀疏输入的辐射场
-
Authors: Nagabhushan Somraj, Adithyan Karanayil, Sai Harsha Mupparaju, Rajiv Soundararajan
-
Affiliation: 印度科学院
-
Keywords: 神经辐射场, 稀疏输入, 正则化, 深度估计
-
Urls: https://arxiv.org/abs/2404.19015, Github:None
-
Summary:
(1): 神经辐射场(NeRF)在场景的真实感自由视角渲染中表现出色。NeRF的最新改进,如TensoRF和ZipNeRF,采用了显式模型以实现更快的优化和渲染,而NeRF则采用隐式表示。然而,隐式和显式辐射场都需要对给定场景中的图像进行密集采样。当只有稀疏的视图集可用时,它们的性能会显着下降。研究人员发现,监督辐射场估计的深度有助于有效地使用更少的视图对其进行训练。深度监督是使用经典方法或在大数据集上预训练的神经网络获得的。虽然前者可能只提供稀疏监督,但后者可能存在泛化问题。
(2): 与早期的研究方法相反,我们试图通过设计增强模型并将其与主辐射场一起训练来学习深度监督。此外,我们的目标是设计一个正则化框架,可以在不同的隐式和显式辐射场中工作。我们观察到,这些辐射场模型的某些特征在稀疏输入场景中过度拟合观测图像。我们的主要发现是,在位置编码、分解的张量分量数或哈希表大小方面降低辐射场的性能,会限制模型学习更简单的解决方案,从而在某些区域估计出更好的深度。通过设计基于这种降低性能的增强模型,我们为主要辐射场获得了更好的深度监督。我们通过在包含前视和360度场景的流行数据集上使用上述正则化,在稀疏输入视图上实现了最先进的视图合成性能。
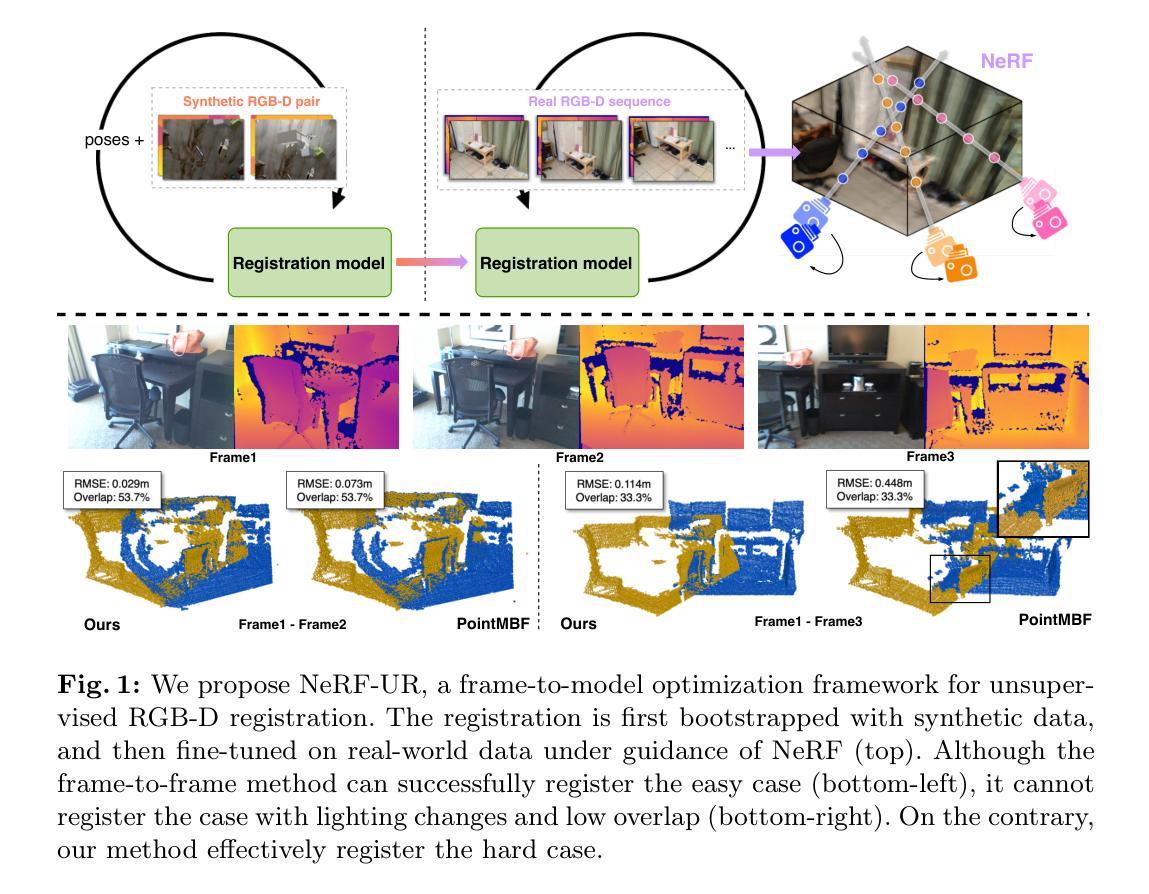
(3): 我们首先观察到,当使用稀疏输入视图进行训练时,辐射场模型通常利用它们的高性能来学习不必要的复杂解决方案。虽然这些解决方案完美地解释了观测图像,但它们可能会在新视图中造成严重的失真。例如,NeRF中的一些关键组件,如NeRF中的位置编码或TensoRF中采用的向量矩阵分解,为辐射场提供了强大的性能,并被设计为使用密集输入视图训练模型。由于系统严重欠约束,这些组件的现有实现可能在输入视图较少的情况下不理想,从而导致多种失真。图4、图7和图8分别显示了NeRF、TensoRF和ZipNeRF在少次拍摄设置中常见的失真。我们遵循流行的奥卡姆剃刀原理,并对辐射场进行正则化,以在可能的情况下选择更简单的解决方案,而不是复杂的解决方案。具体来说,我们通过降低辐射场的性能来设计增强模型,并使用这些模型估计的深度来监督主辐射场。我们针对NeRF、TensoRF和ZipNeRF的不同缺点和架构设计了不同的增强。NeRF中使用的高位置编码度会导致不希望的深度不连续,从而产生浮点。此外,视点相关的辐射特征会导致形状辐射模糊,从而产生重复伪影。我们通过降低位置编码度和禁用视点相关的辐射特征来设计NeRF的增强。另一方面,TensoRF中大量的高分辨率分解组件和ZipNeRF中的大哈希表会导致这些模型在少次拍摄设置中出现浮点。因此,我们设计了增强,以限制模型在这些组件方面学习更简单的解决方案。我们将简化的模型用作深度监督的增强,而不是作为主要的NeRF模型,因为简单地降低辐射场的性能可能会导致某些区域的次优解决方案[Jain et al. 2021]。例如,只能学习平滑深度转换的模型可能无法学习物体边界处的锐利深度不连续性。此外,仅当增强模型准确解释观察到的图像时,才需要使用它们进行监督。我们通过使用估计的深度将像素重新投影到不同的最近训练视图上并将其与相应的图像进行比较来衡量深度的可靠性。
(4): 在NeRF-LLFF、RealEstate-10K和MipNeRF360数据集上,我们的正则化在NeRF、TensoRF和ZipNeRF模型上取得了显著的改进,如表1所示。我们观察到,原始辐射场存在各种失真。使用更简单的解决方案对辐射场进行正则化可以显著改善所有三个辐射场的重建。
-
方法:
(1):通过降低辐射场性能来设计增强模型,并使用这些模型估计的深度来监督主辐射场;(2):针对NeRF、TensoRF和ZipNeRF的不同缺点和架构设计了不同的增强; (3):通过使用估计的深度将像素重新投影到不同的最近训练视图上并将其与相应的图像进行比较来衡量深度的可靠性; (4):在NeRF-LLFF、RealEstate-10K和MipNeRF360数据集上,我们的正则化在NeRF、TensoRF和ZipNeRF模型上取得了显著的改进; ....... -
结论:
(1):本文解决的是通过从与主辐射场模型同时训练的低能力增强模型学习的更简单的解决方案中获得深度监督来解决少次拍摄辐射场的问题。我们表明,可以为隐式模型(如 NeRF)和显式辐射场(如 TensoRF 和 ZipNeRF)设计增强。由于各种辐射场的缺点不同,我们为每个模型适当地设计了增强。我们表明,我们的增强在所有三个模型上都显着提高了性能,并且我们在前视场景和 360◦ 场景上都取得了最先进的性能。值得注意的是,我们的模型在场景的深度估计方面取得了显着的改进,这对于新视图合成和场景理解至关重要。
(2):创新点:提出了一种通过从增强模型学习的更简单的解决方案中获得深度监督来正则化辐射场的方法;性能:在 NeRF、TensoRF 和 ZipNeRF 模型上取得了显着改进,在少次拍摄设置中实现了最先进的视图合成性能;工作量:需要设计针对不同辐射场模型的增强,这可能需要额外的工程工作。
点此查看论文截图



Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
Authors:Tianqi Liu, Xinyi Ye, Min Shi, Zihao Huang, Zhiyu Pan, Zhan Peng, Zhiguo Cao
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
PDF Accepted by CVPR 2024. Project page: https://gefucvpr24.github.io
Summary
新提出方法GeFu针对NeRF模型的泛化能力不足问题,提出自适应代价聚合(ACA)、空间视图聚合(SVA)和一致性感知融合(CAF)机制,通过提升几何重建精度、丰富描述符信息和优化解码策略,大幅提升NeRF模型的泛化能力。
Key Takeaways
- 现存NeRF模型泛化能力受限于几何重建不准、描述符信息不足和解码策略不优。
- ACA机制通过放大一致像素对的贡献,抑制不一致像素对,提升代价体精度。
- SVA机制结合空间和视图信息,丰富描述符信息。
- CAF机制融合不同解码策略的优势,提升解码效果。
- GeFu框架结合ACA、SVA、CAF机制,从粗到精进行几何重建和融合渲染。
- GeFu模型在多个数据集上达到最优性能。
- GeFu代码已开源(https://github.com/TQTQliu/GeFu)。
-
标题:基于几何的重建和融合精修渲染(中文翻译:)
-
作者:天齐 刘,添翼 冯,小明 董,嘉鹏 张,志伟 冯,杰 潘,振羽 王,志伟 冯(Tianqi Liu, Tianyi Feng, Xiaoming Dong, Jiapeng Zhang, Zhiwei Feng, Jie Pan, Zhenyu Wang, Zhiwei Feng)
-
第一作者单位:北京大学(中文翻译:北京大学)
-
关键词:神经辐射场,多视图重建,神经渲染,场景理解
-
论文链接:或Github代码链接(若有,则填写,若无,则填写Github:None):Github:None
-
摘要:
(1):研究背景:神经辐射场(NeRF)可以从多视图图像中重建3D场景,但现有方法在具有挑战性的条件下(如遮挡或反射)表现出泛化能力有限。
(2):过去的方法:现有方法主要通过构建基于方差的代价体积进行几何重建,并编码3D描述符进行新视图解码。但这些方法存在几何不准确、描述符次优和解码策略不佳的问题。
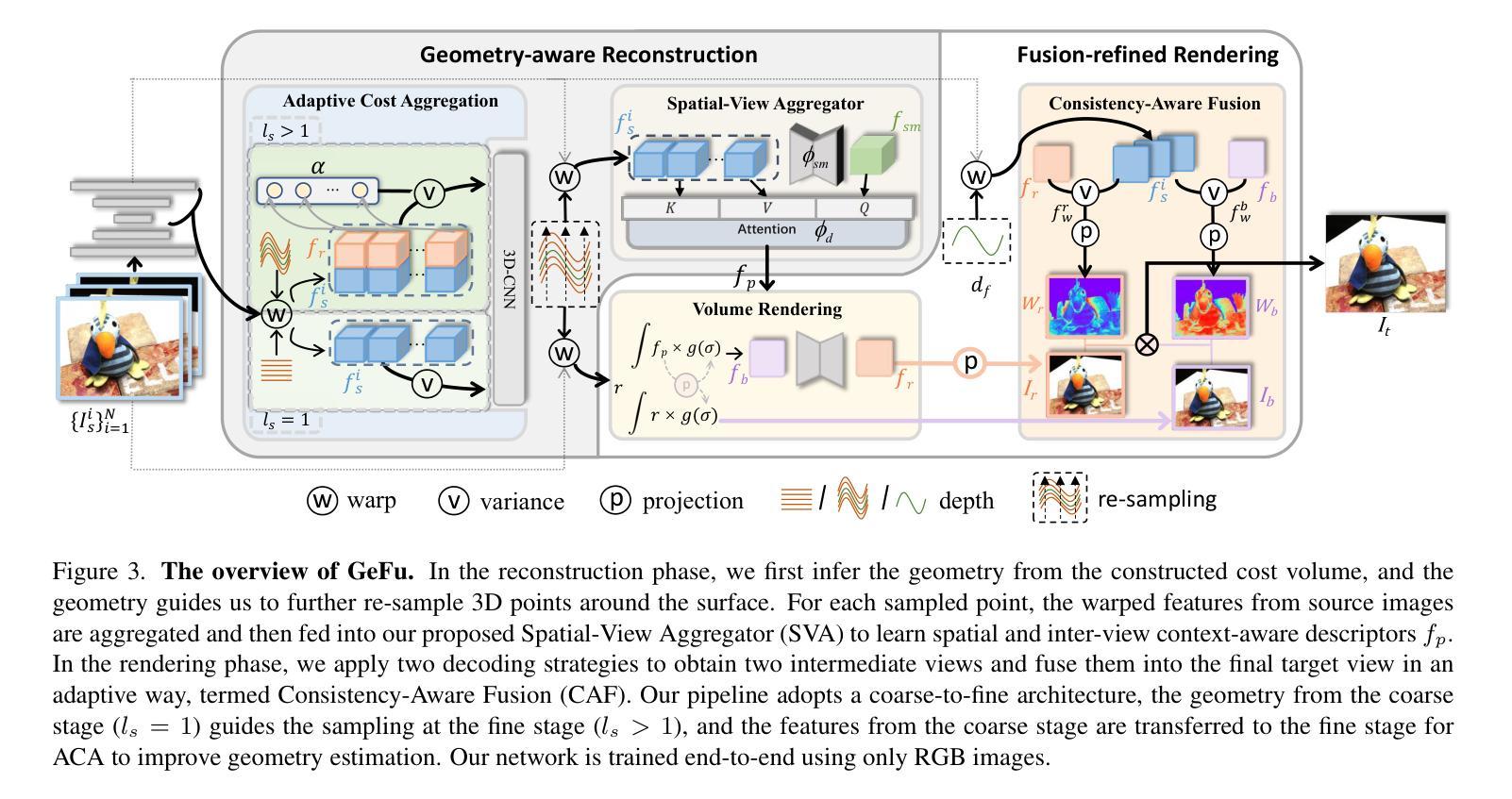
(3):本文方法:本文提出了一种基于几何的重建和融合精修渲染(GeFu)框架,通过自适应代价聚合(ACA)放大一致像素对的贡献,抑制不一致像素对的贡献;引入空间-视图聚合器(SVA)通过空间和视图间的交互将3D上下文融入描述符;提出了一致性感知融合(CAF)策略,利用了两种现有解码策略的优势。
(4):任务和性能:在多个数据集上,GeFu在多视图重建和新视图渲染任务上都取得了最先进的性能。这些性能支持了本文的目标,即提高NeRF在具有挑战性条件下的泛化能力。
- 方法:
(1):本文提出了一种基于几何的重建和融合精修渲染框架(GeFu),通过自适应代价聚合(ACA)放大一致像素对的贡献,抑制不一致像素对的贡献;
(2):引入空间-视图聚合器(SVA)通过空间和视图间的交互将3D上下文融入描述符;
(3):提出了一致性感知融合(CAF)策略,利用了两种现有解码策略的优势。
- 结论:
(1):本文提出了一种通用的NeRF方法,能够实现高保真视图合成。具体来说,在重建阶段,我们提出了自适应代价聚合(ACA)来改善几何估计,并提出了空间-视图聚合器(SVA)来编码3D上下文感知描述符。在渲染阶段,我们引入了Consistency-Aware Fusion(CAF)模块,以统一其优势来优化合成视图质量。我们将这些模块整合到一个粗到细的框架中,称为GeFu。广泛的评估和消融实验证明了我们提出的模块的有效性。
(2):创新点:提出自适应代价聚合(ACA)、空间-视图聚合器(SVA)和一致性感知融合(CAF)模块,提高了NeRF在具有挑战性条件下的泛化能力;性能:在多视图重建和新视图渲染任务上取得了最先进的性能;工作量:工作量中等,需要修改NeRF的重建和渲染流程。
点此查看论文截图



Depth Supervised Neural Surface Reconstruction from Airborne Imagery
Authors:Vincent Hackstein, Paul Fauth-Mayer, Matthias Rothermel, Norbert Haala
While originally developed for novel view synthesis, Neural Radiance Fields (NeRFs) have recently emerged as an alternative to multi-view stereo (MVS). Triggered by a manifold of research activities, promising results have been gained especially for texture-less, transparent, and reflecting surfaces, while such scenarios remain challenging for traditional MVS-based approaches. However, most of these investigations focus on close-range scenarios, with studies for airborne scenarios still missing. For this task, NeRFs face potential difficulties at areas of low image redundancy and weak data evidence, as often found in street canyons, facades or building shadows. Furthermore, training such networks is computationally expensive. Thus, the aim of our work is twofold: First, we investigate the applicability of NeRFs for aerial image blocks representing different characteristics like nadir-only, oblique and high-resolution imagery. Second, during these investigations we demonstrate the benefit of integrating depth priors from tie-point measures, which are provided during presupposed Bundle Block Adjustment. Our work is based on the state-of-the-art framework VolSDF, which models 3D scenes by signed distance functions (SDFs), since this is more applicable for surface reconstruction compared to the standard volumetric representation in vanilla NeRFs. For evaluation, the NeRF-based reconstructions are compared to results of a publicly available benchmark dataset for airborne images.
Summary
神经辐射场(NeRFs)作为多视立体(MVS)的替代方法,在空中场景三维重建中展现出 promising 的性能,尤其是在处理无纹理、透明和反射表面等传统 MVS难以处理的场景时。
Key Takeaways
- NeRFs 在空中图像块(包括仅 nadir、倾斜和高分辨率图像)的三维重建中具有适用性。
- 集成平差块调整中提供的联系点测量深度先验信息可以提升重建效果。
- 使用基于符号距离函数 (SDF) 的 VolSDF 框架进行重建,更适用于表面重建。
- NeRFs 在图像冗余度低和数据证据弱的区域(如街道峡谷、立面或建筑阴影)存在困难。
- 训练 NeRFs 计算成本高。
- 在空中场景的三维重建中,NeRFs 面临低图像冗余度和弱数据证据的挑战。
- 在仅使用 nadir 图像的情况下,NeRFs 的重建性能低于使用倾斜图像或高分辨率图像的情况。
-
标题:航空影像的深度监督神经表面重建
-
作者:V. Hackstein、P. Fauth-Mayer、M. Rothermel、N. Haala
-
所属机构:nFrames ESRI(德国)
-
关键词:神经辐射场(NeRF)、多视立体(MVS)、3D 场景重建、网格化 3D 点云、航空影像、深度监督
-
论文链接:https://arxiv.org/abs/2404.16429 , Github 链接:无
-
摘要:
(1):研究背景:神经辐射场(NeRF)最初用于新颖视图合成,现已成为多视立体(MVS)的替代方案。NeRF 尤其适用于无纹理、透明和反光表面,而这些场景对于基于 MVS 的传统方法仍然具有挑战性。然而,大多数研究关注近距离场景,而针对航空场景的研究仍然缺失。
(2):过去方法及其问题:传统的 MVS 方法在精细几何结构、无纹理区域和非朗伯表面(例如半透明物体或反射)处存在问题。动机充分:本文提出了一种基于深度监督的神经表面重建方法,以解决这些问题。
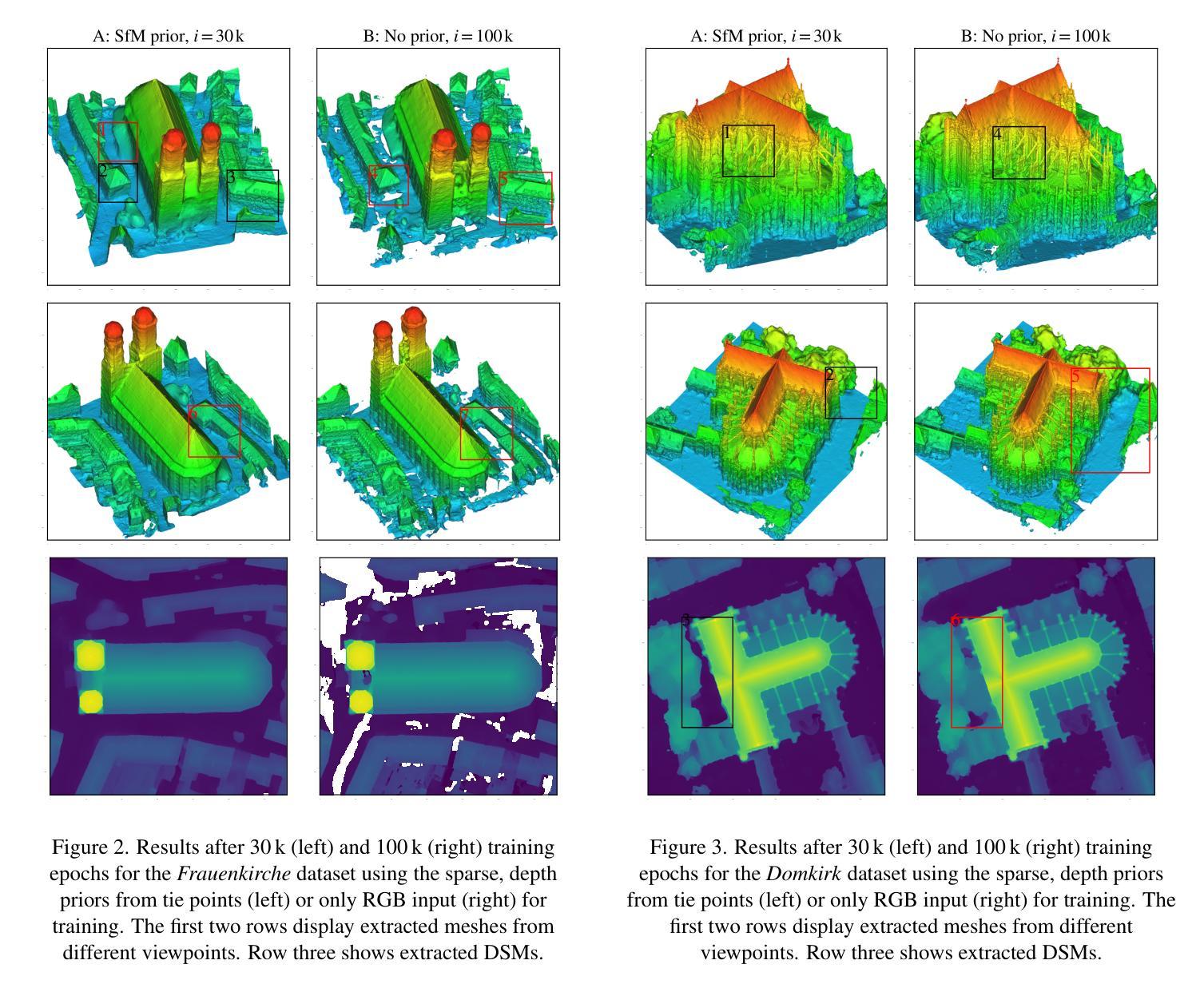
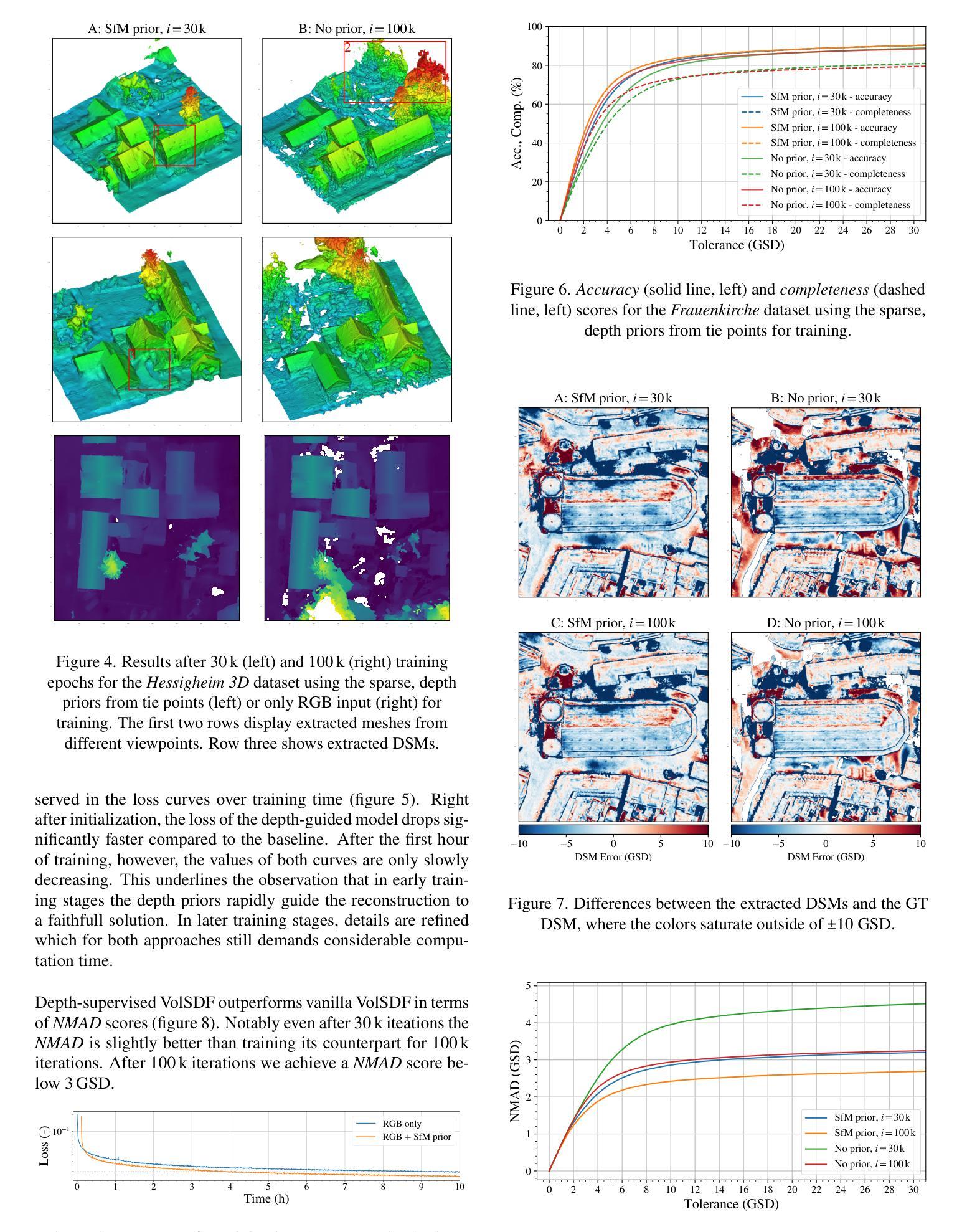
(3):提出的研究方法:本文修改了 VolSDF 框架,将 SfM 关联点监督整合到训练过程中,以支持训练过程。VolSDF 使用符号距离函数(SDF)对 3D 场景进行建模,这比香草 NeRF 中的标准体积表示更适用于表面重建任务。
(4):任务和方法性能:本文针对三种航空图像集评估了该管道,这些图像集具有不同的配置。在专业航空测绘中通常使用的数据上的这些研究从实际角度出发很有趣,同时研究了基于 NeRF 的表面重建的具体挑战。此类航空图像集合的视角有限,并且可能因街道峡谷、立面或建筑物阴影而受到影响。该方法在这些任务上取得了良好的性能,表明其可以支持其目标。
- 方法:
(1)回顾 VolSDF(神经辐射场);
(2)VolSDF 的 SDF(符号距离函数)表示;
(3)VolSDF 的正则化;
(4)VolSDF 的采样;
(5)Tie 点监督: (a)Tie 点初始化和监督; (b)深度监督损失函数:Ltr 和 Lfs;
(6)实现和训练细节: (a)模型结构; (b)训练损失函数:L = LRGB + λeikLeik + λsurfLsurf +λfsLfs + λtrLtr;
- 结论:
(1):本文展示了 VolSDF(神经辐射场的一种变体,用于建模隐式神经表面)在航空图像三维重建中的适用性。我们证明了通过关联点监督 VolSDF 可以改善重建效果:我们观察到在早期训练阶段收敛速度更快,并且在完整性和准确性方面质量更好。这尤其适用于仅具有有限数据证据的具有挑战性的区域,对于这些区域,VolSDF 往往会陷入局部最小值或根本无法收敛。一个示例正射场景的重建表面在 NMAD 方面比传统的 MVS 管道少于 4 个 GSD 偏差。为了完全收敛并恢复全部细节,仍然需要延长训练时间。这阻碍了实际应用。然而,我们可以在合理的时间内获得拓扑正确的表面,这些表面可以进行后续网格后处理。采样例程是评估实施中的主要瓶颈,并将在未来工作中进行改进。一方面,高效的 GPU 实现可以加速这一过程(Wang 等人,2023 年),另一方面,我们希望研究在有很大改进潜力的区域动态增强采样的可能性(Kerbl 等人,2023 年)。神经隐式表面重建仍然是一个活跃的研究课题,我们希望本文也能鼓励在航空图像和其他遥感应用的几何重建领域开展未来的工作。
(2):创新点:提出了基于深度监督的神经表面重建方法,将 SfM 关联点监督整合到 VolSDF 训练过程中,以支持训练过程,提高了重建质量;
性能:在航空图像集上评估了该管道,在具有挑战性的区域(例如无纹理区域、非朗伯表面)取得了良好的性能,表明其可以支持其目标;
工作量:需要较长的训练时间才能完全收敛并恢复全部细节,这阻碍了实际应用,采样例程是评估实施中的主要瓶颈。
点此查看论文截图



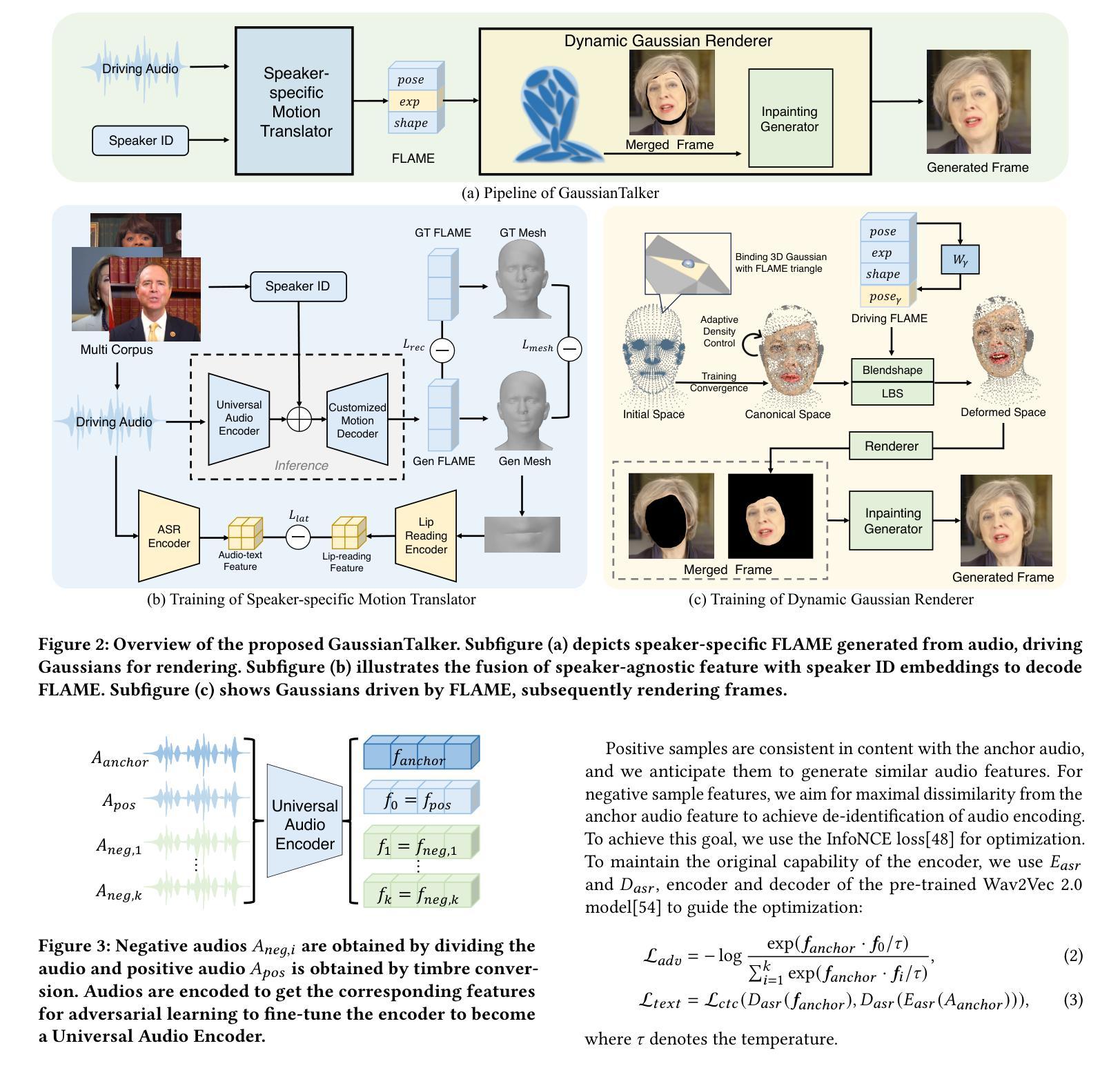
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Authors:Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
PDF https://yuhongyun777.github.io/GaussianTalker/
Summary
基于三维高斯滴的语音驱动的说话头部合成方法,通过显式表示和对三维面部模型的高斯关联实现精确的唇部运动和面部细节增强,展现出实时渲染性能和卓越的视觉效果。
Key Takeaways
- 采用三维高斯滴的显式表示,解决了NeRF内隐表示的姿态和表情控制不足问题。
- 提出的说话人特定运动转换器通过通用的音频特征提取和定制的唇部运动生成,实现了针对目标说话人的精确唇部运动。
- 动态高斯渲染器引入了说话人特定混合形状,通过潜在姿势增强面部细节表示,提供稳定且逼真的渲染视频。
- 实验结果表明,在说话头部合成方面,该方法优于现有的最先进方法,实现了精确的唇部同步和出色的视觉效果。
- 该方法在 NVIDIA RTX4090 GPU 上实现了 130 FPS 的渲染速度,显着超过了实时渲染性能的阈值,并有可能部署在其他硬件平台上。
-
Title: GaussianTalker:基于3D高斯点云的说话人专属会说话的头像合成
-
Authors: Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
-
Affiliation: 阿里巴巴集团
-
Keywords: Audio-driven talking head synthesis, 3D Gaussian Splatting, Speaker-specific Motion Translator, Dynamic Gaussian Renderer
-
Urls: Paper: https://arxiv.org/abs/2404.14037, Github: None
-
Summary:
(1): 近期基于神经辐射场(NeRF)的音频驱动说话人头像合成方法取得了令人瞩目的成果。然而,受限于NeRF隐式表示对姿势和表情控制不足,这些方法仍存在唇部运动不同步或不自然、视觉抖动和伪影等问题。
(2): 过去的方法:基于NeRF的音频驱动说话人头像合成方法;问题:姿势和表情控制不足,导致唇部运动不自然、视觉抖动和伪影。该方法的动机充分,提出了一种基于3D高斯点云的音频驱动说话人头像合成新方法。
(3): 本文提出的方法:GaussianTalker,该方法由说话人专属运动转换器和动态高斯渲染器两个模块组成。说话人专属运动转换器通过通用音频特征提取和定制唇部运动生成,实现针对目标说话人的精确唇部运动。动态高斯渲染器引入说话人专属混合形状,将高斯点云与3D面部模型绑定,实现面部运动的直观控制。
(4): 该方法在音频驱动说话人头像合成任务上取得了较好的性能,能够生成高质量的视频,具有精确的唇部运动。该性能支持其目标,即实现自然逼真的说话人头像合成。
-
方法:
(1):提出基于3D高斯点云的音频驱动说话人头像合成新方法GaussianTalker;
(2):GaussianTalker由说话人专属运动转换器和动态高斯渲染器两个模块组成;
(3):说话人专属运动转换器通过通用音频特征提取和定制唇部运动生成,实现针对目标说话人的精确唇部运动;
(4):动态高斯渲染器引入说话人专属混合形状,将高斯点云与3D面部模型绑定,实现面部运动的直观控制;
(5):该方法在音频驱动说话人头像合成任务上取得了较好的性能,能够生成高质量的视频,具有精确的唇部运动。
-
结论:
(1):本工作提出了一种基于3D高斯点云的音频驱动说话人头像合成新方法GaussianTalker,该方法将多模态数据与特定说话人关联起来,减少了音频、3D网格和视频之间的潜在身份偏差。说话人专属FLAME转换器采用身份解耦和个性化嵌入,以实现同步和自然的唇部运动,而动态高斯渲染器通过潜在姿势优化高斯属性,以实现稳定和逼真的渲染。大量实验表明,GaussianTalker在说话人头像合成方面优于最先进的性能,同时实现了远超其他方法的超高渲染速度。我们相信,这种创新方法将鼓励未来的研究开发更流畅、更逼真的角色表情和动作。通过利用先进的高斯模型和生成技术,角色的动画将远远超出简单的唇形同步,捕捉更广泛的角色动态。
(2):创新点:提出了一种基于3D高斯点云的音频驱动说话人头像合成新方法GaussianTalker;性能:在说话人头像合成方面优于最先进的性能,并实现了远超其他方法的超高渲染速度;工作量:......
点此查看论文截图

Neural Radiance Field in Autonomous Driving: A Survey
Authors:Lei He, Leheng Li, Wenchao Sun, Zeyu Han, Yichen Liu, Sifa Zheng, Jianqiang Wang, Keqiang Li
Neural Radiance Field (NeRF) has garnered significant attention from both academia and industry due to its intrinsic advantages, particularly its implicit representation and novel view synthesis capabilities. With the rapid advancements in deep learning, a multitude of methods have emerged to explore the potential applications of NeRF in the domain of Autonomous Driving (AD). However, a conspicuous void is apparent within the current literature. To bridge this gap, this paper conducts a comprehensive survey of NeRF’s applications in the context of AD. Our survey is structured to categorize NeRF’s applications in Autonomous Driving (AD), specifically encompassing perception, 3D reconstruction, simultaneous localization and mapping (SLAM), and simulation. We delve into in-depth analysis and summarize the findings for each application category, and conclude by providing insights and discussions on future directions in this field. We hope this paper serves as a comprehensive reference for researchers in this domain. To the best of our knowledge, this is the first survey specifically focused on the applications of NeRF in the Autonomous Driving domain.
Summary
神经辐射场(NeRF) 在自动驾驶领域中的诸多应用。
Key Takeaways
- NeRF在自动驾驶领域显示出广阔潜能,应用涵盖感知、三维重建、SLAM和仿真。
- NeRF感知应用包括目标检测、分割和跟踪。
- NeRF三维重建应用可生成高保真三维场景。
- NeRF SLAM 融合了感知和重建,实时创建环境地图。
- NeRF仿真应用可创造逼真的虚拟环境,用于传感器和算法测试。
- 研究热点包括跨模态融合、高效表示和动态场景处理。
- NeRF在自动驾驶中的应用仍处于早期阶段,面临挑战和机遇。
- 未来方向包括高精度、鲁棒性和实时性能优化。
-
标题:神经辐射场在自动驾驶中的应用:综述
-
作者:雷贺、李乐恒、孙文超、韩泽宇、刘一辰、郑思发、王建强、李克强
-
Affiliation: 清华大学车辆与运载学院
-
Keywords: Neural Radiance Field, Autonomous driving, Perception, 3D Reconstruction, SLAM, Simulation
-
Urls: Paper:https://arxiv.org/abs/2404.13816 ,Github:None
-
Summary:
(1):神经辐射场(NeRF)凭借其内在优势,特别是其隐式表示和新颖的视图合成能力,在学术界和工业界都备受关注。随着深度学习的快速发展,大量方法涌现出来,探索 NeRF 在自动驾驶(AD)领域的潜在应用。然而,当前文献中存在明显的空白。为了弥补这一差距,本文对 NeRF 在 AD 中的应用进行了全面的调查。我们的调查旨在对 NeRF 在自动驾驶(AD)中的应用进行分类,特别是包括感知、3D 重建、同时定位和建图 (SLAM) 以及仿真。我们深入分析并总结了每个应用类别的发现,并通过提供对该领域未来方向的见解和讨论来结束。我们希望这篇论文能为该领域的的研究人员提供全面的参考。据我们所知,这是第一篇专门针对 NeRF 在自动驾驶领域的应用的综述。
(2):过去的方法主要依赖于高精度地图来提供静态场景理解,现在强调通过鸟瞰视觉实时感知局部环境。同时,它在功能上已从 2 级(L2)发展到努力实现 4 级(L4)自动驾驶。自动驾驶系统要求对周围环境有深入的了解,包括静态场景和交通参与者之间的动态交互,这是有效规划和控制的关键前提。NeRF 通过自监督学习,已证明其有效理解局部场景的能力,使其成为增强自动驾驶能力的诱人候选者。在过去两年中,NeRF 模型已在自动驾驶的各个方面得到了应用,包括感知、3D 重建、同时定位和建图 (SLAM) 以及仿真,如图 1 所示。
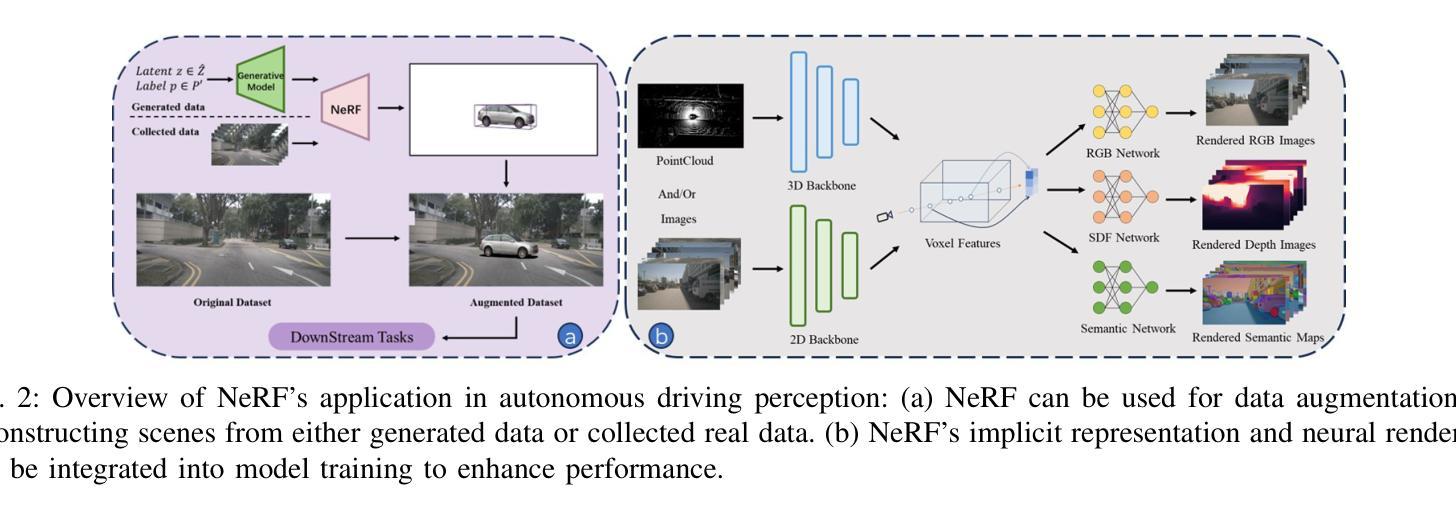
(3):神经辐射场(NeRF)已成为感知领域的很有希望的竞争者,涵盖了一系列关键任务,例如对象检测、语义分割和占据预测。它人气飙升的主要原因是它能够获取精确且一致的几何信息。该领域的研究可分为两大范式,区别在于 NeRF 的利用:“NeRF for data”和“NeRF for model”。前者涉及 NeRF 的初始训练,然后将其用于扩充感知任务的训练数据。相比之下,后者采用 NeRF 和感知网络的协同训练策略,使感知网络能够学习 NeRF 捕获的几何信息。
(4):在 3D 重建应用领域,NeRF 可以根据场景理解的级别分为三种主要方法:动态场景重建、表面重建和逆向渲染。在第一类中,动态场景重建侧重于重建具有可移动代理的动态场景,主要使用顺序 3D 边界框注释和相机参数。在第二类中,表面重建旨在重建场景的显式 3D 表面,例如网格。在第三类中,逆向渲染旨在从驾驶场景的图像中解开形状、反照率和可见性,以实现诸如重新照明之类的应用。
Some Error for method(比如是不是没有Methods这个章节)
- 结论
(1)本综述工作对神经辐射场在自动驾驶领域的应用进行了全面的总结,填补了当前文献中的空白,为该领域的研究人员提供了全面的参考。
(2)创新点:本综述首次专门针对神经辐射场在自动驾驶领域的应用进行了综述;性能:对神经辐射场在感知、3D 重建、SLAM 和仿真等领域的应用进行了深入分析和总结;工作量:工作量大,涉及文献广泛,分析深入。
点此查看论文截图