⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-06 更新
X-Oscar: A Progressive Framework for High-quality Text-guided 3D Animatable Avatar Generation
Authors:Yiwei Ma, Zhekai Lin, Jiayi Ji, Yijun Fan, Xiaoshuai Sun, Rongrong Ji
Recent advancements in automatic 3D avatar generation guided by text have made significant progress. However, existing methods have limitations such as oversaturation and low-quality output. To address these challenges, we propose X-Oscar, a progressive framework for generating high-quality animatable avatars from text prompts. It follows a sequential Geometry->Texture->Animation paradigm, simplifying optimization through step-by-step generation. To tackle oversaturation, we introduce Adaptive Variational Parameter (AVP), representing avatars as an adaptive distribution during training. Additionally, we present Avatar-aware Score Distillation Sampling (ASDS), a novel technique that incorporates avatar-aware noise into rendered images for improved generation quality during optimization. Extensive evaluations confirm the superiority of X-Oscar over existing text-to-3D and text-to-avatar approaches. Our anonymous project page: https://xmu-xiaoma666.github.io/Projects/X-Oscar/.
PDF ICML2024
Summary
文本提出的 X-Oscar 框架可以从文本提示生成高质量的可动画头像,它采用几何->纹理->动画的顺序范式,并引入自适应变异参数和基于头像的评分蒸馏采样技术来解决过饱和和低质量输出的问题。
Key Takeaways
- X-Oscar 是一个渐进式框架,从文本提示生成高质量的可动画头像。
- 它采用顺序的几何->纹理->动画范式,简化了优化过程。
- 自适应变异参数将头像表示为训练期间的自适应分布,以解决过饱和问题。
- 基于头像的评分蒸馏采样技术将基于头像的噪声融入渲染图像,以提高优化过程中的生成质量。
- 广泛的评估证实 X-Oscar 优于现有的文本到 3D 和文本到头像方法。
- 项目主页:https://xmu-xiaoma666.github.io/Projects/X-Oscar/。
- 论文标题:X-Oscar:一个用于生成高质量文本引导式3D可动画角色的渐进式框架
- 作者:Yiwei Ma, Zhekai Lin, Jiayi Ji, Yijun Fan, Xiaoshuai Sun, Rongrong Ji
- 第一作者单位:厦门大学多媒体可信感知与高效计算教育部重点实验室
- 关键词:文本引导式3D角色生成、渐进式生成、自适应变分参数、角色感知得分蒸馏采样
- 论文链接:https://arxiv.org/pdf/2405.00954.pdf ,Github代码链接:无
-
摘要: (1):随着深度学习的兴起,3D人体重建领域取得了显著进展,但现有方法主要专注于从视觉线索重建人体,难以满足融入创造力、编辑和控制的需求。 (2):现有文本引导式3D角色生成方法存在过饱和和输出质量低的问题。 (3):本文提出了一种渐进式框架X-Oscar,通过“几何→纹理→动画”的顺序生成模式,并引入自适应变分参数和角色感知得分蒸馏采样技术,来解决过饱和问题并提高生成质量。 (4):在文本到3D和文本到角色生成任务上,X-Oscar在生成质量和动画保真度方面均优于现有方法,证明了其有效性。
-
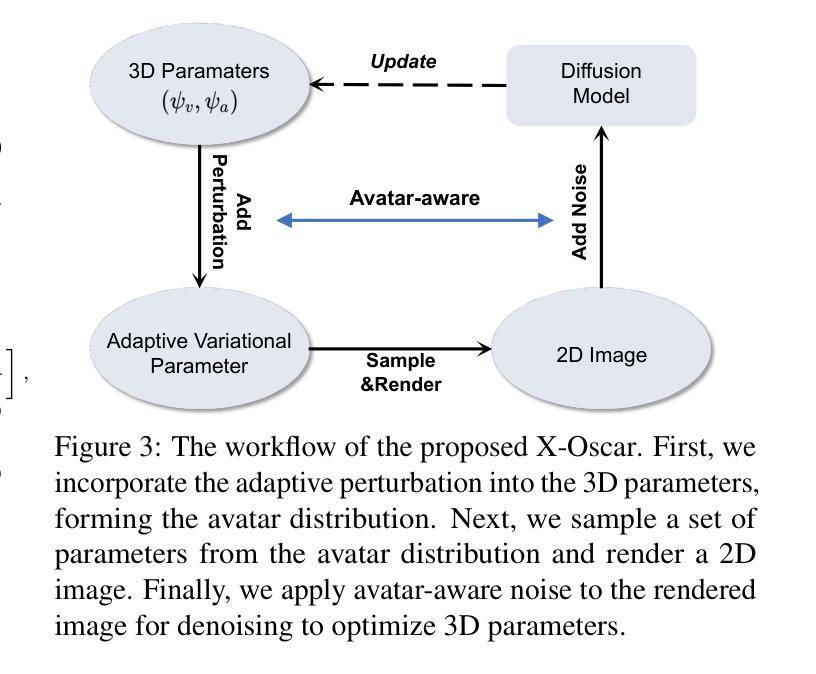
方法: (1):提出渐进式框架X-Oscar,通过“几何→纹理→动画”的顺序生成模式,解决过饱和问题并提高生成质量; (2):引入自适应变分参数(AVP),采用可训练的自适应分布表示虚拟形象,解决虚拟形象生成中常见的过饱和问题; (3):提出虚拟形象感知得分蒸馏采样(ASDS),将几何感知和外观感知噪声融入去噪过程中,使预训练的扩散模型能够感知生成虚拟形象的当前状态,从而产生高质量的输出。
-
结论:
(1):本文提出的X-Oscar框架在文本引导式3D可动画角色生成领域具有重要意义,为该领域的研究和应用提供了新的思路和方法。
(2):创新点:X-Oscar框架创新性地提出了渐进式生成模式、自适应变分参数和角色感知得分蒸馏采样技术,有效解决了文本引导式3D角色生成中存在的过饱和问题和输出质量低的问题。
性能:在文本到3D和文本到角色生成任务上,X-Oscar框架在生成质量和动画保真度方面均优于现有方法,证明了其有效性和优越性。
工作量:X-Oscar框架的实现需要较高的计算资源和专业知识,对于普通用户来说,使用和部署可能存在一定的难度。
点此查看论文截图