⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-06 更新
WateRF: Robust Watermarks in Radiance Fields for Protection of Copyrights
Authors:Youngdong Jang, Dong In Lee, MinHyuk Jang, Jong Wook Kim, Feng Yang, Sangpil Kim
The advances in the Neural Radiance Fields (NeRF) research offer extensive applications in diverse domains, but protecting their copyrights has not yet been researched in depth. Recently, NeRF watermarking has been considered one of the pivotal solutions for safely deploying NeRF-based 3D representations. However, existing methods are designed to apply only to implicit or explicit NeRF representations. In this work, we introduce an innovative watermarking method that can be employed in both representations of NeRF. This is achieved by fine-tuning NeRF to embed binary messages in the rendering process. In detail, we propose utilizing the discrete wavelet transform in the NeRF space for watermarking. Furthermore, we adopt a deferred back-propagation technique and introduce a combination with the patch-wise loss to improve rendering quality and bit accuracy with minimum trade-offs. We evaluate our method in three different aspects: capacity, invisibility, and robustness of the embedded watermarks in the 2D-rendered images. Our method achieves state-of-the-art performance with faster training speed over the compared state-of-the-art methods.
Summary
神经辐射场 (NeRF) 水印可同时适用于隐式和显式 NeRF 表示,以保证 NeRF 的版权保护。
Key Takeaways
- NeRF 水印是保护 NeRF 版权的关键解决方案。
- 该方法适用于隐式和显式 NeRF 表示。
- 该方法使用离散小波变换进行水印。
- 该方法采用延迟反向传播,提高渲染质量和比特精度。
- 该方法在容量、不可见性和鲁棒性方面均取得了最先进的性能。
- 该方法比现有的最先进方法具有更快的训练速度。
- 该方法通过微调 NeRF 在渲染过程中嵌入二进制信息来实现。
-
标题:WateRF:用于版权保护的辐射场中的鲁棒水印
-
作者:Youngdong Jang、Dong In Lee、MinHyuk Jang、Jong Wook Kim、Feng Yang、Sangpil Kim
-
隶属机构:韩国大学
-
关键词:神经辐射场、水印、版权保护、隐式表示、显式表示
-
论文链接:https://kuai-lab.github.io/cvpr2024waterf/,Github 链接:无
-
摘要:
(1):研究背景:神经辐射场(NeRF)在 3D 内容创建和 3D 建模中发挥着重要作用,但保护其版权尚未得到深入研究。NeRF 水印被认为是安全部署基于 NeRF 的 3D 表示的关键解决方案之一。
(2):过去的方法:现有方法仅适用于隐式或显式 NeRF 表示。它们的问题在于无法同时应用于两种表示。
(3):研究方法:本文提出了一种创新的水印方法,可以应用于 NeRF 的两种表示。该方法通过微调 NeRF 在渲染过程中嵌入二进制消息来实现。具体来说,我们提出利用 NeRF 空间中的离散小波变换进行水印。此外,我们采用延迟反向传播技术,并引入与逐块损失相结合的方法,以在最小权衡下提高渲染质量和比特准确性。
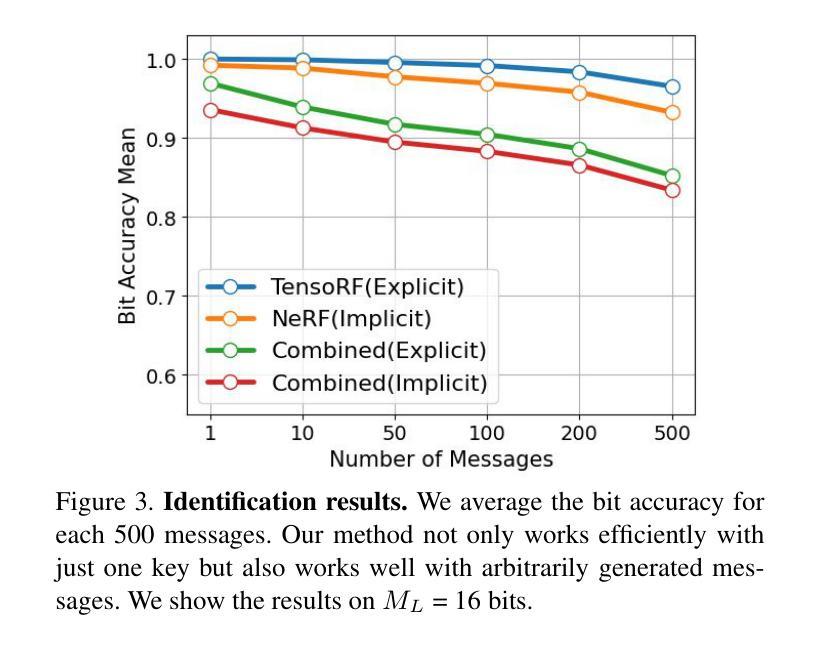
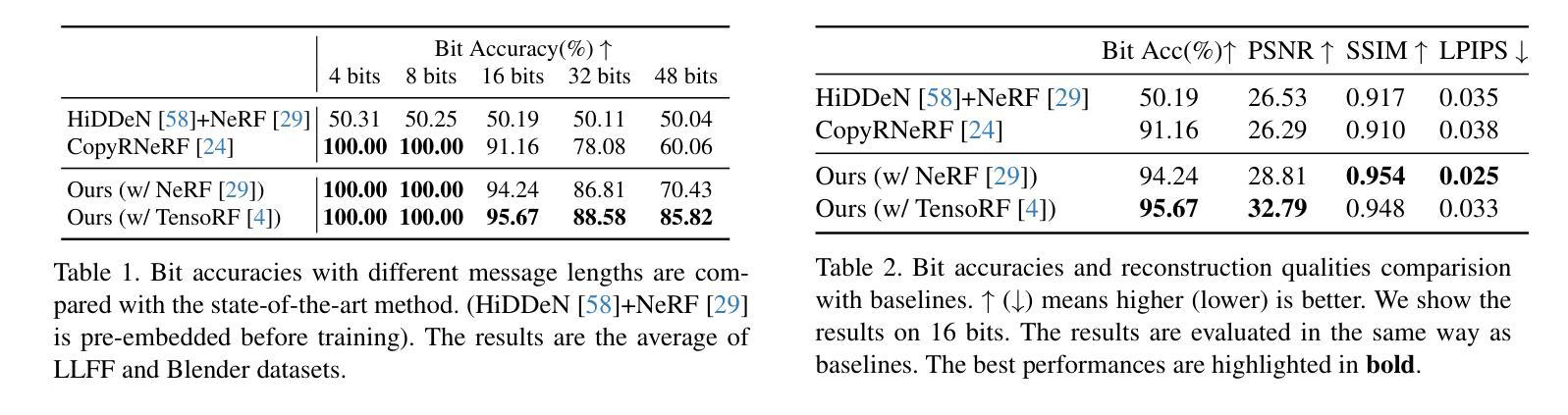
(4):任务和性能:我们在三个不同方面评估了我们的方法:容量、不可见性和嵌入在 2D 渲染图像中的水印的鲁棒性。我们的方法在与最先进的方法相比之下,以更快的训练速度实现了最先进的性能,从而证明了其有效性。
-
Methods:
(1):提出了一种微调 NeRF 的方法,该方法不涉及改变模型的架构来嵌入水印消息。
(2):我们的方法旨在将水印嵌入到 NeRF 模型的权重 θ 中,在渲染图像的频域中。
(3):我们的方法不同于传统的数字水印方法,它专注于训练编码器和解码器。不同之处在于微调过程,它在不使用编码器的情况下嵌入水印。
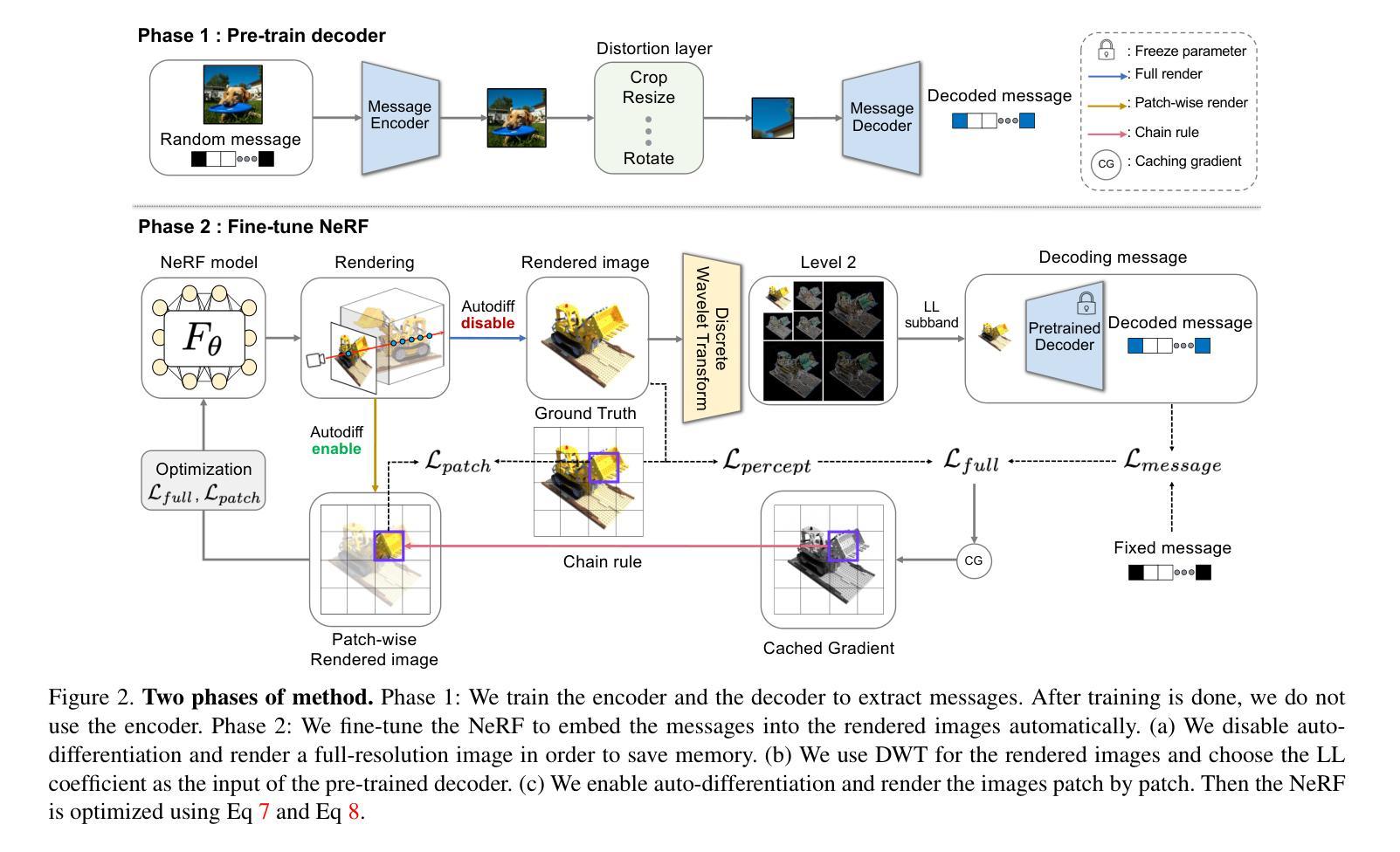
(4):有 2 个阶段:(1)预训练水印解码器 D,(2)微调 NeRF 模型 Fθ 以嵌入消息。
(5):我们的方法如图 2 所示,并在下文详细描述。
(6):预训练水印解码器:我们选择 HiDDeN [58] 架构作为我们的水印解码器。HiDDeN 包含两个用于数据隐藏的卷积网络:水印编码器 E 和水印解码器 D。为了鲁棒性,它包括一个噪声层 N。然而,在这个仅关注解码器性能的训练阶段,我们排除了负责提高视觉质量的对偶损失。在训练完 HiDDeN 模型后,水印编码器 E 在第二阶段没有被使用。
(7):编码器 E 以封面图像 Io ∈ RH×W ×3 和长度为 L 的二进制消息 M ∈ {0, 1}L 为输入。然后 E 将 M 嵌入到 Io 中并生成编码图像 Iw。为了使解码器对旋转和 JPEG 压缩等各种失真具有鲁棒性,Iw 使用噪声层 N 进行转换。由多个卷积层组成的解码器 D 以 Iw 为输入,并提取消息 M′。
(8):M′ = D(N(Iw))
(9):我们利用 sigmoid 函数将提取的消息 M′ 的范围设置为 [0, 1]。消息损失使用 ML 和 sigmoid sg(M′L) 之间的二元交叉熵 (BCE) 计算。
(10):Lmessage = − L∑i=1 Mi · log sg(M′i) + (1 − Mi) · log(1 − sg(M′i)))
(11):解码器经过训练,可以检测经过训练编码器处理的图像中的水印。然而,我们在第二阶段不使用编码器。我们发现,当解码器接收到香草渲染的图像时,提取的消息位之间存在偏差。因此,在训练解码器后,我们对线性解码器层进行 PCA 白化以消除偏差,同时不降低提取能力。
(12):在 DWT 上嵌入和提取水印:在空间域中加水印是一种相对简单的方法,因为它在整个图像中嵌入水印。最近,一种在空间域中对 NeRF 进行微调的水印方法 [16] 浮出水面。尽管在空间域中嵌入消息的微调方法显示出无与伦比的不可见性和消息提取能力,但它容易受到扭曲空间域的攻击,例如裁剪。直接应用来自潜在扩散模型 [7] 的空间域技术不允许有效调整 NeRF 的权重。为了解决这些问题,我们提出了一种在频域而不是空间域中的微调方法。多年来,各种图像水印技术使用频域,包括离散余弦变换 (DCT) 和离散小波变换 (DWT),取得了持续的发展和改进。我们发现 DWT 是将消息编码到 NeRF 模型权重中的合适域。给定相应的相机参数,NeRF 模型渲染 3D 模型的不同视图。我们将渲染图像的像素,表示为 X = (xc, yc) ∈ RH×W ×3,转换为小波形式,其中 c 表示通道。DWT 定义为 [10]:
(13):Wφ(j0, m, n) = 1√MN∑M−1xc=0∑N−1yc=0 f(xc, yc)φj0,m,n(xc, yc),
(14):W i ψ(j, m, n) = 1√MN∑M−1xc=0∑N−1yc=0 f(xc, yc)ψi j,m,n(xc, yc)
(15):其中 φ(x, y) 是尺度函数,ψ(x, y) 是小波函数。Wφ(j0, m, n) 被 LL 子带调用,它是图像在尺度 j0 的近似值,W i ψ 其中 i = {H, V, D} 分别表示 LH、HL、HH 子带。先前的研究选择 LH、HL 和 HH 子带来嵌入水印,因为 LL 子带包含图像的重要信息。然而,我们选择 LL 子带作为解码器 D 的输入,并用 M′ = D(Wφ) 获取提取的消息。使用 HiDDeN 解码器,我们通过实验发现,在 LL 子带中嵌入水印比其他子带更稳健,并且更有效地嵌入水印信息。DWT 的特点是其子带在不同级别上计算;因此,为我们的目的选择一个最佳级别是必要的。1 级将图像分成 4 个子带 (LL1, LH1, HL1, HH1),
- 结论:
(1):本文提出的方法将图像从空间域转换到频域,有效地将水印编码到图像中。我们发现,离散小波变换(DWT)变换和逐块损失可以提高整体图像质量。
(2):创新点:提出了一种神经 3D 水印方法,用于 NeRF 模型。我们的方法分别训练 2D 水印解码器和 NeRF 模型。因此,我们的流水线只需要训练一次解码器,并在不同的 NeRF 水印模型上重复使用它。我们采用图像水印中的传统水印技术,将图像从空间域转换到频域,以有效地将水印编码到图像中。我们发现,离散小波变换(DWT)变换和逐块损失可以提高整体图像质量。
性能:与最先进的方法相比,我们的方法以更快的训练速度实现了最先进的性能,从而证明了其有效性。
工作量:我们的方法在训练和嵌入水印方面具有较低的计算成本,使其适用于实际应用。
点此查看论文截图

Multi-view Action Recognition via Directed Gromov-Wasserstein Discrepancy
Authors:Hoang-Quan Nguyen, Thanh-Dat Truong, Khoa Luu
Action recognition has become one of the popular research topics in computer vision. There are various methods based on Convolutional Networks and self-attention mechanisms as Transformers to solve both spatial and temporal dimensions problems of action recognition tasks that achieve competitive performances. However, these methods lack a guarantee of the correctness of the action subject that the models give attention to, i.e., how to ensure an action recognition model focuses on the proper action subject to make a reasonable action prediction. In this paper, we propose a multi-view attention consistency method that computes the similarity between two attentions from two different views of the action videos using Directed Gromov-Wasserstein Discrepancy. Furthermore, our approach applies the idea of Neural Radiance Field to implicitly render the features from novel views when training on single-view datasets. Therefore, the contributions in this work are three-fold. Firstly, we introduce the multi-view attention consistency to solve the problem of reasonable prediction in action recognition. Secondly, we define a new metric for multi-view consistent attention using Directed Gromov-Wasserstein Discrepancy. Thirdly, we built an action recognition model based on Video Transformers and Neural Radiance Fields. Compared to the recent action recognition methods, the proposed approach achieves state-of-the-art results on three large-scale datasets, i.e., Jester, Something-Something V2, and Kinetics-400.
Summary
基于多视图注意力一致性和神经辐射场,提出时空一致动作识别新方法,实现动作识别领域最优结果。
Key Takeaways
- 提出多视图注意力一致性解决动作识别合理预测问题。
- 定义基于有向格罗莫夫-瓦瑟斯坦距离的多视图一致注意力度量。
- 基于视频变形金刚和神经辐射场构建动作识别模型。
- 在 Jester、Something-Something V2 和 Kinetics-400 三个大规模数据集上达到最优结果。
- 创新性地引入了多视图注意力一致性,解决了动作识别中合理预测的难题。
- 采用新颖的度量方法评估多视图一致注意力。
- 将神经辐射场应用于动作识别,提升了模型在单视图数据集上的泛化能力。
-
标题:多视角动作识别经由定向格罗莫夫-沃瑟斯坦差异
-
作者:Hoang-Quan Nguyen,Thanh-Dat Truong,Khoa Luu
-
单位:阿肯色大学计算机视觉与图像理解实验室
-
关键词:动作识别,多视角注意力一致性,定向格罗莫夫-沃瑟斯坦差异,神经辐射场
-
论文链接:https://arxiv.org/abs/2405.01337
-
摘要:
(1):动作识别是计算机视觉领域的研究热点,现有的基于卷积神经网络和自注意力机制(如 Transformer)的方法在解决动作识别任务的时空维度问题上取得了竞争力的性能。然而,这些方法缺乏对模型关注的动作主体正确性的保证,即如何确保动作识别模型关注适当的动作主体以做出合理的动作预测。
(2):以往方法主要基于卷积神经网络和自注意力机制,但缺乏对模型关注的动作主体正确性的保证。本文提出的方法动机明确,旨在解决动作识别中合理预测的问题。
(3):本文提出了一种多视角注意力一致性方法,利用定向格罗莫夫-沃瑟斯坦差异计算动作视频两个不同视角的两个注意力的相似性。此外,该方法应用神经辐射场的思想,在单视角数据集上训练时隐式渲染新视角的特征。
(4):该方法在 Jester、Something-Something V2 和 Kinetics-400 三个大规模数据集上取得了最先进的结果,证明了其性能可以支持其目标。
- Methods:
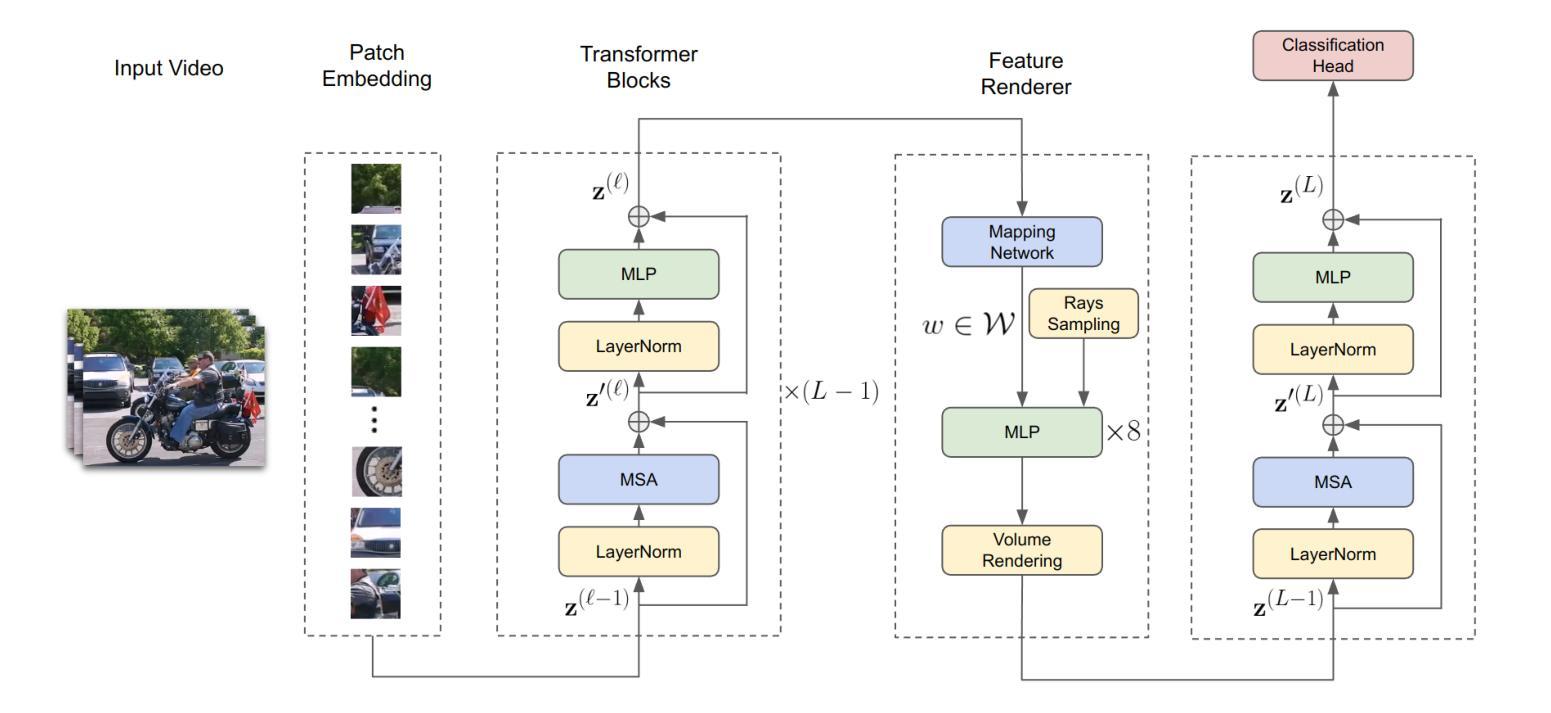
(1):使用 Video Transformer 框架进行动作识别,将视频分解为 patches 并进行位置编码,然后使用 Transformer 编码器提取特征;
(2):采用 Neural Radiance Field 的思想,通过 StyleNeRF 将特征体映射到风格向量,并调节 NeRF 模块中 MLP 层的权重矩阵,以在新的视角下渲染低分辨率特征体;
(3):使用定向格罗莫夫-沃瑟斯坦差异(Directed Gromov-Wasserstein Discrepancy)计算不同视角下动作视频的两个注意力的相似性,该方法通过计算两个空间内定义的度量之间的相似性来比较分布,对相机平移引起的注意力图转换具有鲁棒性。
- 结论:
(1) 本文提出的多视角注意力一致性方法,通过定向格罗莫夫-沃瑟斯坦差异计算不同视角下动作视频的两个注意力的相似性,解决了动作识别中合理预测的问题,取得了最先进的结果。
(2) 创新点:提出多视角注意力一致性方法,利用定向格罗莫夫-沃瑟斯坦差异计算注意力相似性;性能:在 Jester、Something-Something V2 和 Kinetics-400 三个大规模数据集上取得最先进的结果;工作量:需要训练 Neural Radiance Field 模块,计算定向格罗莫夫-沃瑟斯坦差异。
点此查看论文截图