⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-06 更新
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Authors:Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, Michael Zeng
Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
Summary
利用CoVoMix,一种零样本对话语音合成模型,可以生成逼真、连贯且多回合的多人对话语音。
Key Takeaways
- CoVoMix是一款零样本对话语音合成模型。
- CoVoMix能够将对话文本转换为离散标记流,表示各个说话者的语义信息。
- 流匹配声学模型将标记流转换成混合的梅尔频谱图。
- HiFi-GAN模型将梅尔频谱图转换为语音波形。
- CoVoMix采用了一套综合的指标来衡量对话建模和生成的有效性。
- 实验结果表明,CoVoMix生成的对话具有逼真的自然性和连贯性,并且涉及多个说话者参与多轮对话。
- 生成的对话在单个通道内,具有无缝的语音转换(包括重叠语音)和适当的副语言行为(例如笑声)。
-
Title: CoVoMix: 推进零样本语音生成以实现类人多说话者对话
-
Authors: Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, Michael Zeng
-
Affiliation: 上海交通大学
-
Keywords: 零样本语音生成,多说话者对话,语音合成,自然语言处理
-
Urls: Paper: https://arxiv.org/abs/2404.06690 , Github: None
-
Summary:
(1): 研究背景:近年来,零样本文本到语音 (TTS) 建模取得了重大进展,在生成高保真和多样化的语音方面取得了显著进展。然而,对话生成以及在语音中实现类人的自然性仍然是该领域的挑战。
(2): 过去的方法:过去的方法通常使用单流文本到语音模型,无法生成多说话者对话。此外,这些方法通常需要大量标记数据,这在对话场景中可能不可用。
(3): 本文提出的研究方法:本文提出了一种名为 CoVoMix 的模型,用于零样本、类人、多说话者、多轮对话语音生成。CoVoMix 能够首先将对话文本转换为多个离散令牌流,每个令牌流表示单个说话者的语义信息。然后将这些令牌流馈送到基于流匹配的声学模型中以生成混合梅尔谱图。最后,使用 HiFi-GAN 模型生成语音波形。
(4): 实验结果:实验结果表明,CoVoMix 可以生成不仅在自然性和连贯性上类似人类的对话,而且还涉及多个说话者进行多轮对话。这些在单个通道内生成的对话具有无缝的语音转换,包括重叠语音和适当的副语言行为,例如笑声。
- 研究方法:
(1):多流文本到语义模型:基于编码器-解码器架构,将文本标记序列转换为多个离散标记流,每个标记流表示单个说话者的语义信息。
(2):声学模型:基于流匹配的变压器编码器,将语义序列转换为混合梅尔谱图。
(3):声码器:使用 HiFi-GAN 模型从梅尔谱图生成语音波形。
- 结论:
(1):本文提出的 CoVoMix 模型在零样本、类人、多说话者、多轮对话语音生成方面取得了显著进展,为该领域的研究提供了新的思路和方法。
(2):创新点:提出了一种基于流匹配的多流文本到语义模型,能够将对话文本转换为多个离散令牌流,表示单个说话者的语义信息;设计了一种基于流匹配的声学模型,将语义序列转换为混合梅尔谱图;采用 HiFi-GAN 模型生成语音波形,实现了高保真语音合成。
性能:实验结果表明,CoVoMix 生成的对话在自然性和连贯性上类似人类,涉及多个说话者进行多轮对话,具有无缝的语音转换和适当的副语言行为。
工作量:CoVoMix 模型的训练和部署需要大量的数据和计算资源,这可能会限制其在实际应用中的可行性。
点此查看论文截图

Beyond Talking – Generating Holistic 3D Human Dyadic Motion for Communication
Authors:Mingze Sun, Chao Xu, Xinyu Jiang, Yang Liu, Baigui Sun, Ruqi Huang
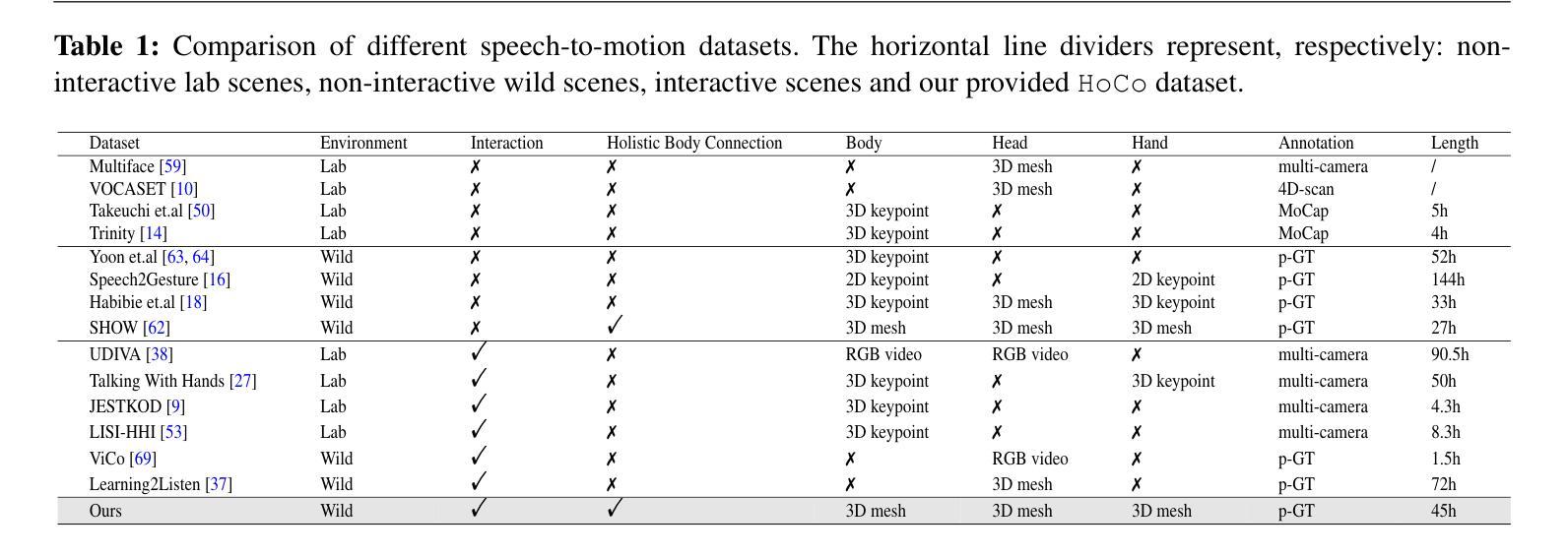
In this paper, we introduce an innovative task focused on human communication, aiming to generate 3D holistic human motions for both speakers and listeners. Central to our approach is the incorporation of factorization to decouple audio features and the combination of textual semantic information, thereby facilitating the creation of more realistic and coordinated movements. We separately train VQ-VAEs with respect to the holistic motions of both speaker and listener. We consider the real-time mutual influence between the speaker and the listener and propose a novel chain-like transformer-based auto-regressive model specifically designed to characterize real-world communication scenarios effectively which can generate the motions of both the speaker and the listener simultaneously. These designs ensure that the results we generate are both coordinated and diverse. Our approach demonstrates state-of-the-art performance on two benchmark datasets. Furthermore, we introduce the HoCo holistic communication dataset, which is a valuable resource for future research. Our HoCo dataset and code will be released for research purposes upon acceptance.
Summary
通过音频特征和文本语义相结合的方式,实现说话人和倾听者3D逼真且协调的动作生成。
Key Takeaways
- 提出音频特征与文本语义信息解耦合的创新任务,生成说话人和倾听者的3D动作。
- 分别训练说话人和倾听者的整体动作VQ-VAE。
- 考虑说话人和倾听者之间的实时相互影响,提出自回归模型,同时生成说话人和倾听者的动作。
- 链式Transformer模型,有效表征现实世界的沟通场景。
- 该方法在两个基准数据集上表现出最先进的性能。
- 引入HoCo整体沟通数据集,为未来研究提供宝贵资源。
- 接受后将HoCo数据集和代码发布用于研究目的。
-
标题:超越说话——生成用于交流的整体 3D 人类双人运动
-
作者:Mingze Sun · Chao Xu · Xinyu Jiang · Yang Liu · Baigui Sun · Ruqi Huang
-
单位:清华大学深圳国际研究生院
-
关键词:Dyadic Motion, Holistic Human Mesh, Communication
-
论文链接:None, Github:None
-
摘要:
(1):研究背景: 近年来,基于大规模人类说话视频的语音生成运动任务取得了显著进展,即从言语线索(如音频片段或转录)中生成谈话中的非语言信号(如面部表情或身体动作),例如人类面部表情、身体姿势和手势。然而,这些方法仅关注说话者,而忽略了听众的反应。
(2):过去方法及其问题: 以往方法主要集中在生成说话者的头部、手势或全身运动,而忽略了听众的反应。此外,这些方法通常需要大量标记数据,这限制了它们的实用性。
(3):本文提出的研究方法: 本文提出了一种新的任务,专注于人类交流,旨在为说话者和听众生成 3D 整体人类动作。该方法的核心是将分解因子化与文本语义信息的结合,从而促进创建更逼真和协调的动作。我们分别针对说话者和听众的整体动作训练 VQ-VAE。我们考虑了说话者和听众之间的实时相互影响,并提出了一种新颖的链式基于 Transformer 的自回归模型,该模型专门设计用于有效表征现实世界中的交流场景,可以同时生成说话者和听众的动作。这些设计确保了我们生成的结果既协调又多样。
(4):方法的性能: 我们的方法在两个基准数据集上展示了最先进的性能。此外,我们引入了 HoCo 整体交流数据集,这是一个对未来研究有价值的资源。我们的 HoCo 数据集和代码将在被接受后发布以供研究使用。
- 方法:
(1):针对说话者和听众的整体动作,分别训练 VQ-VAE;
(2):提出了一种基于 Transformer 的自回归模型,用于有效表征现实世界中的交流场景,可以同时生成说话者和听众的动作;
(3):利用分解因子化与文本语义信息的结合,促进创建更逼真和协调的动作;
(4):在两个基准数据集上展示了最先进的性能;
(5):引入了 HoCo 整体交流数据集,为未来研究提供了宝贵的资源。
- 结论:
(1):本工作将交流纳入人机交互中,提出了一项新颖的任务,为说话者和听众生成 3D 整体人类动作。为此,我们在数据集和模型设计上均做出了贡献。前者方面,我们提供了 HoCo 通信数据集,以供未来沿着此任务进行探索。后者方面,我们提出了一个针对我们任务量身定制的模型,该模型包含新颖的设计,包括 1)用于解耦音频特征的分解,增强了生成更真实和协调的动作;2)用于表征非语言交流的链式自回归模型。此外,我们在两个基准上取得了最先进的性能。
(2):创新点:提出了一种新的任务,专注于生成说话者和听众的 3D 整体人类动作,并设计了一个针对该任务量身定制的模型。 性能:在两个基准数据集上展示了最先进的性能。 工作量:引入了 HoCo 整体交流数据集,为未来研究提供了宝贵的资源。
点此查看论文截图