⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-22 更新
Leveraging Neural Radiance Fields for Pose Estimation of an Unknown Space Object during Proximity Operations
Authors:Antoine Legrand, Renaud Detry, Christophe De Vleeschouwer
We address the estimation of the 6D pose of an unknown target spacecraft relative to a monocular camera, a key step towards the autonomous rendezvous and proximity operations required by future Active Debris Removal missions. We present a novel method that enables an “off-the-shelf” spacecraft pose estimator, which is supposed to known the target CAD model, to be applied on an unknown target. Our method relies on an in-the wild NeRF, i.e., a Neural Radiance Field that employs learnable appearance embeddings to represent varying illumination conditions found in natural scenes. We train the NeRF model using a sparse collection of images that depict the target, and in turn generate a large dataset that is diverse both in terms of viewpoint and illumination. This dataset is then used to train the pose estimation network. We validate our method on the Hardware-In-the-Loop images of SPEED+ that emulate lighting conditions close to those encountered on orbit. We demonstrate that our method successfully enables the training of an off-the-shelf spacecraft pose estimation network from a sparse set of images. Furthermore, we show that a network trained using our method performs similarly to a model trained on synthetic images generated using the CAD model of the target.
Summary
关于使用 NeRF 从稀疏图像集中估计未知目标航天器的 6D 姿势的新颖方法。
Key Takeaways
- 提出了一种使用 NeRF 估计未知目标航天器 6D 姿势的新颖方法。
- 该方法依赖于自然场景中可学习外观嵌入的 NeRF 模型。
- 使用稀疏的目标图像训练 NeRF 模型,生成具有不同视点和光照条件的大型数据集。
- 使用该数据集训练姿态估计网络。
- 在 SPEED+ 的环路硬件中图像上验证了该方法。
- 该方法能够使用稀疏图像集训练现成的航天器姿态估计网络。
- 使用该方法训练的网络性能与使用目标 CAD 模型生成的合成图像训练的网络类似。
-
Title: 利用神经辐射场进行未知空间物体临近操作期间的姿态估计
-
Authors: Antoine Legrand, Renaud Detry, Christophe De Vleeschouwer
-
Affiliation: 电子工程系 (ELEN),ICTEAM,鲁汶大学
-
Keywords: 神经辐射场,姿态估计,未知目标,近距离操作
-
Urls: http://arxiv.org/abs/2405.12728 , Github:None
-
Summary:
(1):随着轨道卫星数量的不断增加,卫星与太空碎片(如火箭体、失效卫星或先前碰撞的碎片)发生碰撞的风险也在稳步上升。这样的碰撞不仅会导致功能卫星的损坏,还会急剧增加太空碎片的数量,从而进一步增加发生此类碰撞的风险。因此,私营企业和航天机构正在开展主动碎片清除 (ADR) 任务,旨在使太空碎片脱离轨道。这些 ADR 任务需要与非合作目标进行 Rendezvous 和 Proximity Operations (RPO),即追赶者航天器必须与未设计为支持 RPO 的目标航天器操作接近甚至对接。由于远程操作带来的潜在人为失误风险,这些 RPO 应由追赶者航天器自主执行。
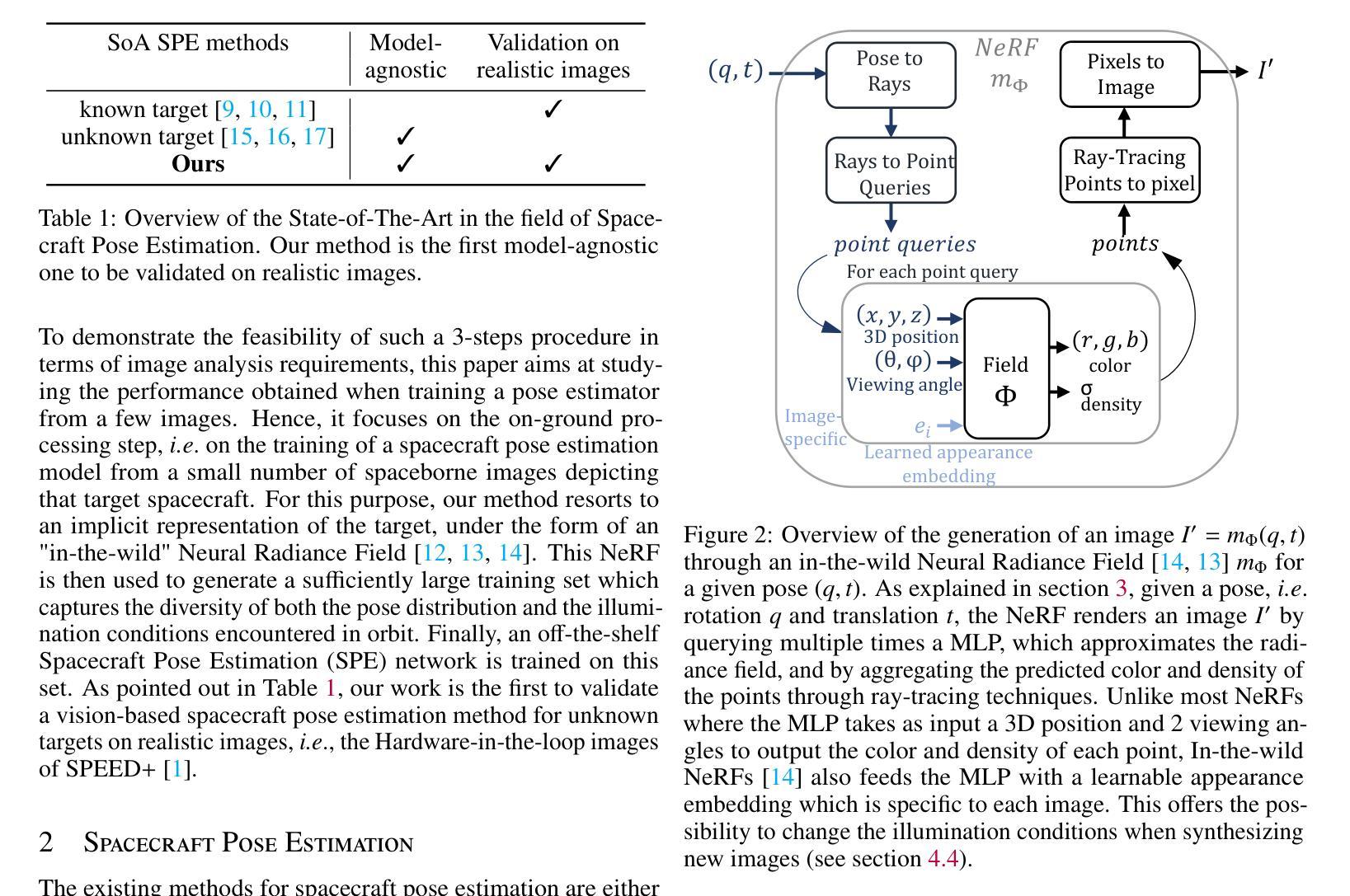
(2):执行自主 RPO 的一项关键能力是在轨估计相对位姿,即目标航天器相对于追赶者的位置和方向。由于其低成本、低质量和紧凑性,单目摄像头被考虑用于此任务。尽管文献中已经深入研究了基于视觉的非合作航天器相对位姿估计,但当前的解决方案假设已知目标航天器的 CAD 模型,这使得能够生成大型合成训练集。在主动碎片清除的情况下,此假设不成立,因为对碎片了解甚少。这项工作旨在利用神经辐射场 (NeRF) 模型将现有位姿估计方法的范围扩展到未知目标,即无法获得 CAD 模型的目标。
(3):为此,我们考虑采用分三步的方法,如图 1 所示。首先,追赶者航天器被远程操作接近目标,直至安全距离。在接近过程中,追赶者会获取目标图像并将它们传输到地面站。然后,在地面上处理这些图像以合成目标在不同光照条件下的其他视图,从而构建足够丰富的图像集来训练“现成”位姿估计网络,即只需要在描绘目标的新数据集上进行训练的现有神经网络。最后,模型权重被上传到航天器,航天器自主执行最终接近。
(4):地面处理步骤能够利用地面上几乎无限的计算资源,这与低功耗车载硬件形成对比。此外,即使追赶者航天器在此场景中需要地面支持,它也能在操作的关键阶段(即近距离阶段)自主运行。
-
方法:
(1):本文提出了一种方法,使现成的基于模型的航天器姿态估计(SPE)网络能够在半自主交会和近距离操作(RPO)的背景下对未知目标进行姿态估计。
(2):所考虑的 RPO 由 3 个步骤组成。首先,通过遥操作使追赶者航天器接近目标并拍摄图像,并将图像传输到地面站。在地面上处理这些图像以训练 SPE 网络,然后将 SPE 网络的权重上传到追赶者航天器上。最后,追赶者通过利用训练好的姿态估计网络自主执行最终接近。
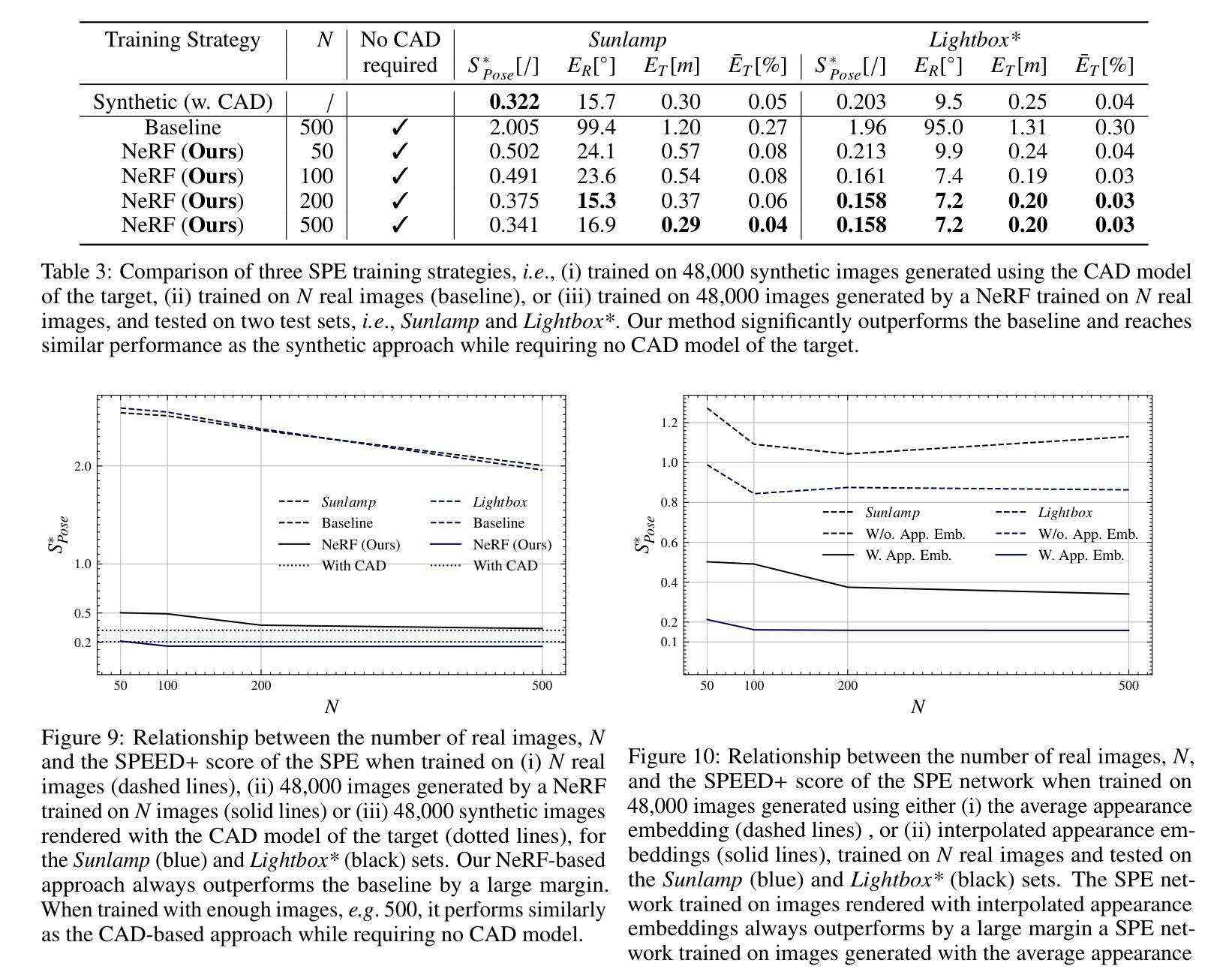
(3):本文描述了从稀疏的空间图像集中训练现成的航天器姿态估计模型所需的地面处理。从追赶者航天器下载 Nspace 张图像。从这组图像中,选择 Nner f 张高质量图像(即光照条件良好)并对其姿态进行注释。然后,使用这些图像训练神经辐射场(NeRF)mΦ,该神经辐射场学习目标航天器的隐式表示。然后,使用该辐射场生成 Ntrain 张图像的训练集,该训练集用于训练现成的 SPE 网络 fΘ,其权重 Θ 最终上传到追赶者航天器上。以下部分将详细介绍这些步骤。
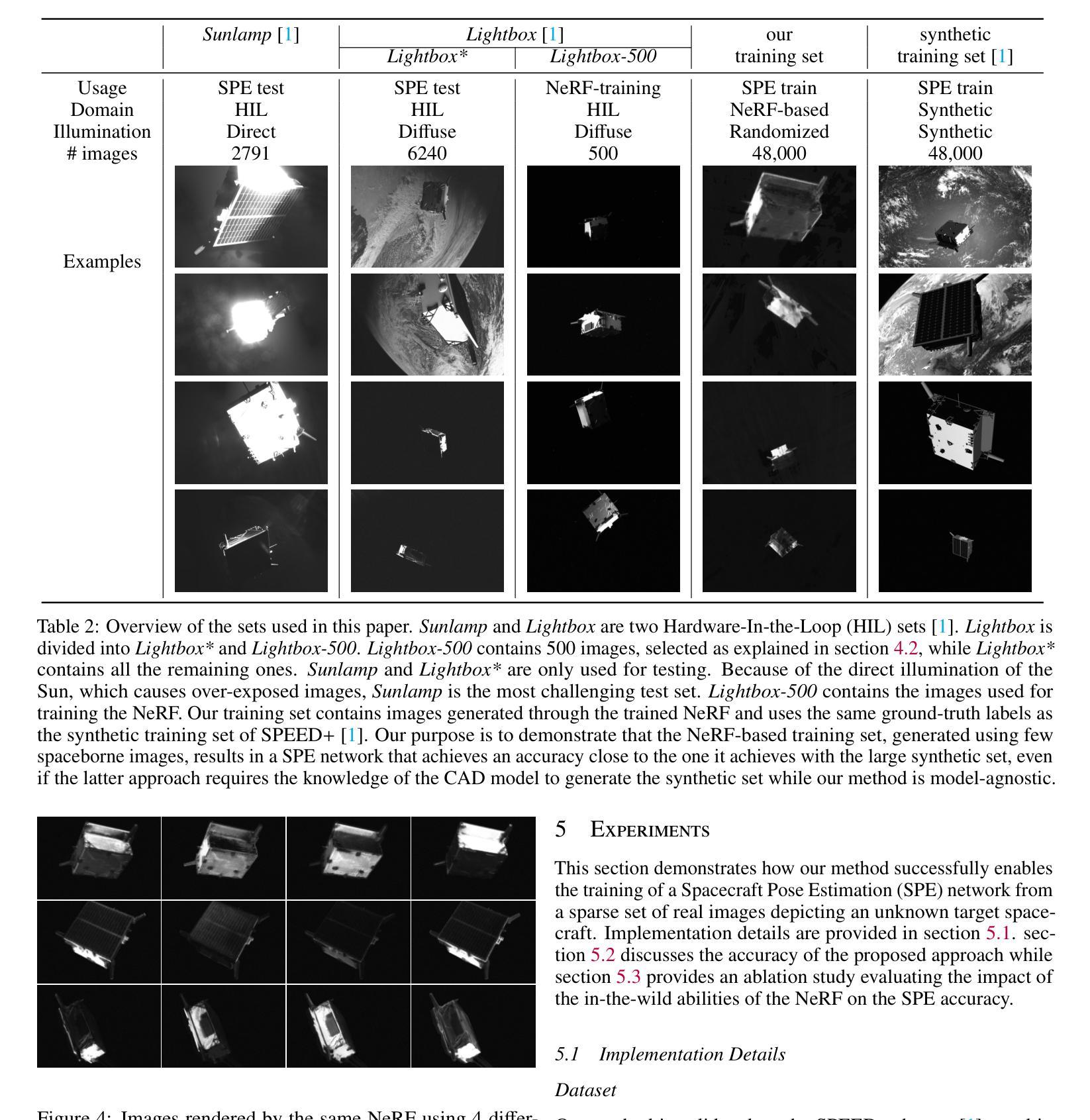
(4):图像选择和姿态注释。由于轨道上遇到的恶劣光照条件,一些下载的图像可能会曝光过度或曝光不足。由于这些图像包含的信息很少,并且会在 NeRF 训练中充当嘈杂且具有误导性的监督,因此将它们丢弃。类似地,所有背景中出现地球的图像都被删除。事实上,在一个与目标对齐的区域中,地球是一个瞬态物体,NeRF 无法解释它。由于利用这些图像训练 NeRF 会引入大量伪影,因此它们被简单地丢弃。最后,每张图像都用姿态信息进行注释。
(5):NeRF 训练。使用 90% 的 Nner f 图像,训练一个“野外”NeRF mΦ,即一个包含可学习外观嵌入的神经辐射场(如图 2 所示)。这些嵌入使网络能够捕捉到每张图像特有的光照条件,从而渲染具有更大光照多样性的图像。
(6):离线图像渲染。训练 SPE 网络需要大量的图像,以捕捉姿态分布和光照条件的多样性。为了生成这个大型训练集,使用学习到的 NeRF mΦ 渲染 Ntrain 张图像,其姿态标签在 SE(3) 中随机采样,即 3D 空间中的刚体变换集合。如 [14] 中所述,对于每张图像,通过插值 NeRF 训练集中两个随机外观嵌入来生成外观嵌入,即令 α 为 0 到 1 之间的随机标量,令 ei 和 e j 为从 NeRF 训练图像中随机挑选的两个随机外观嵌入,插值的外观嵌入 e 计算为:e = ei + α(ej − ei)(1)图 4 描绘了使用这种外观插值策略生成的几张图像。
-
结论:
(1):本文提出了一种方法,使现成的基于模型的航天器姿态估计(SPE)网络能够在半自主交会和近距离操作(RPO)的背景下对未知目标进行姿态估计。所提出的方法包括三个步骤:1)使用神经辐射场(NeRF)生成未知目标的合成图像,2)使用合成图像训练现成的 SPE 网络,3)将训练好的 SPE 网络部署到追赶者航天器上进行自主 RPO。该方法的优点在于它不需要目标航天器的 CAD 模型,并且能够处理未知目标的各种光照条件。(2):创新点:本文提出了使用神经辐射场生成未知目标合成图像的方法,该方法不需要目标航天器的 CAD 模型。该方法能够处理未知目标的各种光照条件,并且可以与现成的 SPE 网络结合使用。 性能:本文提出的方法在未知目标的姿态估计任务上取得了较好的性能。与需要目标 CAD 模型的现有方法相比,该方法能够在更广泛的光照条件下对未知目标进行姿态估计。 工作量:本文提出的方法需要在地面上进行大量的图像处理,这可能会增加任务的总体工作量。然而,该方法能够使追赶者航天器在 RPO 的关键阶段自主运行,从而降低了对地面支持的依赖性。
点此查看论文截图



When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
Authors:Xianzheng Ma, Yash Bhalgat, Brandon Smart, Shuai Chen, Xinghui Li, Jian Ding, Jindong Gu, Dave Zhenyu Chen, Songyou Peng, Jia-Wang Bian, Philip H Torr, Marc Pollefeys, Matthias Nießner, Ian D Reid, Angel X. Chang, Iro Laina, Victor Adrian Prisacariu
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
Summary:
大型语言模型与 3D 空间数据相融合,为理解和交互物理空间提供了前所未有的能力。
Key Takeaways:
- LLM 融合 3D 空间数据 (3D-LLM) 正在迅速发展。
- LLM 具有语境学习、分步推理、开放式词汇和丰富世界知识等独特优势。
- LLM 用于处理、理解和生成 3D 数据,如点云和 NeRF。
- LLM 已集成到 3D 场景理解、标题生成、问答和对话等任务中。
- LLM 可作为空间推理、规划和导航的空间推理代理。
- 3D 和语言整合的其他方法也取得了进展。
- 探索 3D-LLM 潜力需要新的方法。
- 题目:当LLM走进3D世界:通过多模态大语言模型对3D任务的调查和元分析
- 作者:Xianzheng Ma、Yash Bhalgat、Brandon Smart、Shuai Chen、Xinghui Li、Jian Ding、Jindong Gu、Dave Zhenyu Chen、Songyou Peng、Jia-Wang Bian、Philip H Torr、Marc Pollefeys、Matthias Nießner、Ian D Reid、Angel X. Chang、Iro Laina、Victor Adrian Prisacariu
- 第一作者单位:牛津大学
- 关键词:3D场景理解、大语言模型、视觉语言模型、计算机视觉
- 论文链接:https://arxiv.org/abs/2405.10255
- 摘要:
(1):随着大语言模型(LLM)的发展,它们与3D空间数据(3D-LLM)的集成取得了快速进展,为理解和交互物理空间提供了前所未有的能力。本调查对LLM处理、理解和生成3D数据的方法进行了全面概述。我们强调了LLM的独特优势,例如上下文学习、逐步推理、开放式词汇能力和广泛的世界知识,强调了它们在具身人工智能(AI)系统中显著提升空间理解和交互的潜力。我们的研究涵盖了从点云到神经辐射场(NeRF)的各种3D数据表示。它研究了它们与LLM的集成,用于3D场景理解、字幕、问答和对话等任务,以及基于LLM的用于空间推理、规划和导航的代理。本文还简要回顾了其他整合3D和语言的方法。本文提出的元分析揭示了重大进展,但强调了采用新方法以充分发挥3D-LLM潜力的必要性。因此,通过本文,我们旨在为未来的研究绘制路线图,探索和扩展3D-LLM在理解和交互复杂3D世界中的能力。为了支持这项调查,我们建立了一个项目页面,其中组织和列出了与我们的主题相关的论文:https://github.com/ActiveVisionLab/Awesome-LLM-3D。
-
方法:
(1):通过构建3D-文本数据对,使用3D编码器提取3D特征,利用对齐模块将3D特征与LLM中的文本嵌入对齐,最后选择合适的训练策略;(2):采用不同策略获取文本注释,如人工标注、使用ChatGPT生成或合并现有3D视觉语言数据集; (3):使用不同的网络架构作为对齐模块,例如线性层、变压器或Q-Former; (4):采用不同的LLM微调策略,如低秩自适应(LoRA)、自适应微调、层冻结或提示微调; (5):采用单阶段或两阶段3D-语言对齐方法,在单阶段中同时训练对齐模块和LLM,而在两阶段中分阶段训练对齐模块和LLM; (6):使用多任务指令遵循数据集进行指令微调,将所有任务输出统一为文本形式,并使用标准自回归损失进行训练; (7):探索3D多模态接口,将不同模态的信息(如2D图像、音频或触觉信息)纳入场景,以进一步提高模型的能力和实现新的交互。 -
结论:
(1):本文系统性地回顾了LLM在处理、理解和生成3D数据方面的技术、应用和新兴能力,强调了LLM在3D任务中变革性的潜力。从增强3D环境中的空间理解和交互到推动具身人工智能系统的功能,LLM在推进该领域方面发挥着关键作用。
(2):创新点:识别LLM独特的优势,如零样本学习、高级推理和广泛的世界知识,这些优势是弥合文本信息和空间解释之间差距的关键;展示了LLM与3D数据集成的各种任务,成功地展示了LLM的能力。
性能:LLM在3D场景理解、字幕、问答、对话和基于LLM的空间推理、规划和导航代理等任务中取得了令人印象深刻的性能。
工作量:本文强调了数据表示、模型可扩展性和计算效率等重大挑战,表明克服这些障碍对于充分发挥LLM在3D应用中的潜力至关重要。
点此查看论文截图

From NeRFs to Gaussian Splats, and Back
Authors:Siming He, Zach Osman, Pratik Chaudhari
For robotics applications where there is a limited number of (typically ego-centric) views, parametric representations such as neural radiance fields (NeRFs) generalize better than non-parametric ones such as Gaussian splatting (GS) to views that are very different from those in the training data; GS however can render much faster than NeRFs. We develop a procedure to convert back and forth between the two. Our approach achieves the best of both NeRFs (superior PSNR, SSIM, and LPIPS on dissimilar views, and a compact representation) and GS (real-time rendering and ability for easily modifying the representation); the computational cost of these conversions is minor compared to training the two from scratch.
Summary
神经辐射场 (NeRF) 在机器人应用中表现优于非参数表示形式,但在渲染速度上不如高斯散射 (GS);本文提出了一种在两者之间进行转换的方法,实现了 NeRF(在不同视图上具有更好的 PSNR、SSIM 和 LPIPS 以及紧凑的表示形式)和 GS(实时渲染和轻松修改表示形式的能力)的优点。
Key Takeaways
- NeRF 在机器人应用中,对与训练数据非常不同的视图,泛化效果优于 GS 等非参数表示形式。
- GS 的渲染速度远快于 NeRF。
- 本文提出了一种在 NeRF 和 GS 之间进行转换的方法。
- 该方法具有 NeRF 的优点(在不同视图上具有更好的 PSNR、SSIM 和 LPIPS 以及紧凑的表示形式),也具有 GS 的优点(实时渲染和轻松修改表示形式的能力)。
- 与从头开始训练相比,转换的计算成本可以忽略不计。
- 该方法可用于机器人应用中,需要在不同视图上生成高质量的图像,并具有实时渲染的要求。
- 该方法还可以用于表示学习,其中需要从稀疏的观测中重建复杂的对象。
-
Title: 从 NeRF 到 Gaussian Splatting,再回到 NeRF
-
Authors: Siming He, Zach Osman, Pratik Chaudhari
-
Affiliation: 宾夕法尼亚大学通用机器人、自动化、传感和感知 (GRASP) 实验室
-
Keywords: 隐式表示、显式表示、NeRF、Gaussian Splatting、场景表示
-
Urls: https://arxiv.org/abs/2405.09717 , https://github.com/grasp-lyrl/NeRFtoGSandBack
-
Summary:
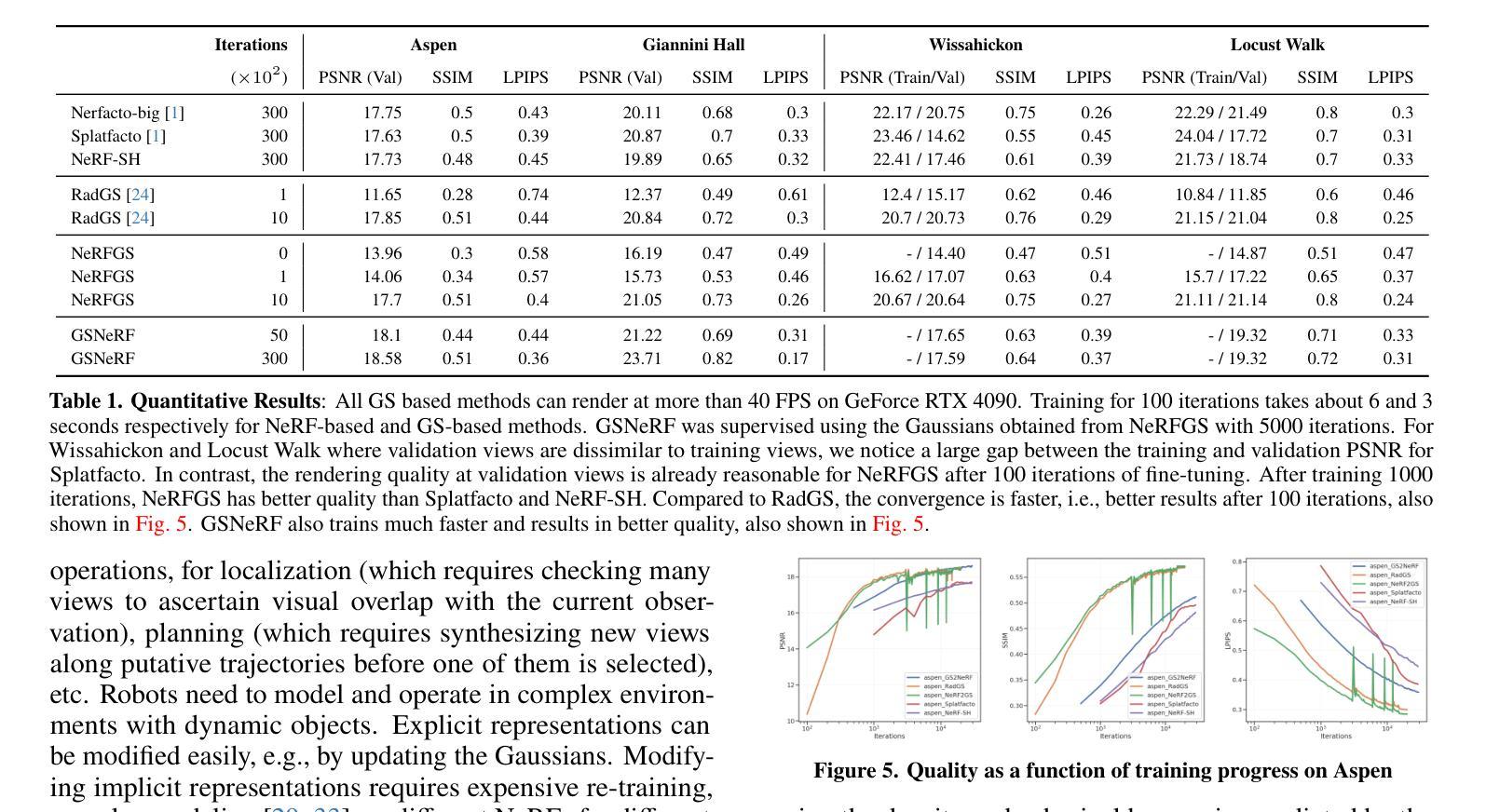
(1): 场景表示对于机器人技术中的定位、映射、规划、控制、场景理解和仿真等应用至关重要。在场景表示中,隐式表示(如 NeRF)和显式表示(如 Gaussian Splatting)各有优缺点。
(2): 过去的方法包括 NeRF 和 Gaussian Splatting。NeRF 具有更好的泛化能力,但渲染速度较慢;Gaussian Splatting 渲染速度快,但泛化能力较差。
(3): 本文提出了一种新的方法,可以将训练好的 NeRF 转换为 Gaussian Splatting(NeRF2GS),同时保持 NeRF 的泛化能力。此外,本文还提出了一种方法,可以将 Gaussian Splatting 转换为 NeRF(GS2NeRF),从而节省内存并方便场景修改。
(4): 在场景表示任务上,NeRF2GS 同时具有 NeRF 的泛化能力和 Gaussian Splatting 的渲染速度;GS2NeRF 可以节省内存并方便场景修改。这些性能支持了本文的目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论:
(1):本文提出了一种新方法,可以将训练好的 NeRF 转换为 Gaussian Splatting(NeRF2GS),同时保持 NeRF 的泛化能力。此外,本文还提出了一种方法,可以将 Gaussian Splatting 转换为 NeRF(GS2NeRF),从而节省内存并方便场景修改。
(2):创新点:NeRF2GS 和 GS2NeRF 两种方法;性能:NeRF2GS 同时具有 NeRF 的泛化能力和 Gaussian Splatting 的渲染速度;GS2NeRF 可以节省内存并方便场景修改;工作量:中等。
点此查看论文截图

Synergistic Integration of Coordinate Network and Tensorial Feature for Improving Neural Radiance Fields from Sparse Inputs
Authors:Mingyu Kim, Jun-Seong Kim, Se-Young Yun, Jin-Hwa Kim
The multi-plane representation has been highlighted for its fast training and inference across static and dynamic neural radiance fields. This approach constructs relevant features via projection onto learnable grids and interpolating adjacent vertices. However, it has limitations in capturing low-frequency details and tends to overuse parameters for low-frequency features due to its bias toward fine details, despite its multi-resolution concept. This phenomenon leads to instability and inefficiency when training poses are sparse. In this work, we propose a method that synergistically integrates multi-plane representation with a coordinate-based network known for strong bias toward low-frequency signals. The coordinate-based network is responsible for capturing low-frequency details, while the multi-plane representation focuses on capturing fine-grained details. We demonstrate that using residual connections between them seamlessly preserves their own inherent properties. Additionally, the proposed progressive training scheme accelerates the disentanglement of these two features. We empirically show that the proposed method achieves comparable results to explicit encoding with fewer parameters, and particularly, it outperforms others for the static and dynamic NeRFs under sparse inputs.
PDF ICML2024 ; Project page is accessible at https://mingyukim87.github.io/SynergyNeRF ; Code is available at https://github.com/MingyuKim87/SynergyNeRF
Summary
多平面表示和基于坐标的网络相结合,高效捕捉神经辐射场中的低频和高频细节。
Key Takeaways
- 多平面表示可快速训练和推理静态和动态神经辐射场中的特征。
- 多平面表示偏向于捕捉精细细节,可能导致低频细节捕捉不佳和参数过度使用。
- 坐标网络擅长捕捉低频信号,与多平面表示结合可弥补其不足。
- 残差连接可无缝保留两种表示的固有特性。
- 渐进式训练方案可加速两种特征的解耦。
- 该方法使用更少的参数可实现与显式编码相当的效果,尤其是在稀疏输入的静态和动态 NeRF 中表现出色。
-
标题:坐标网络与张量特征的协同融合,用于改进稀疏输入的神经辐射场(神经辐射场从稀疏输入的坐标网络和张量特征的协同集成)
-
作者:Mingyu Kim, Jun-Seong Kim, Se-Young Yun, Jin-Hwa Kim
-
第一作者单位:KAIST AI
-
关键词:神经辐射场,稀疏输入,坐标网络,张量特征
-
论文链接:xxx,Github 链接:无
-
摘要:
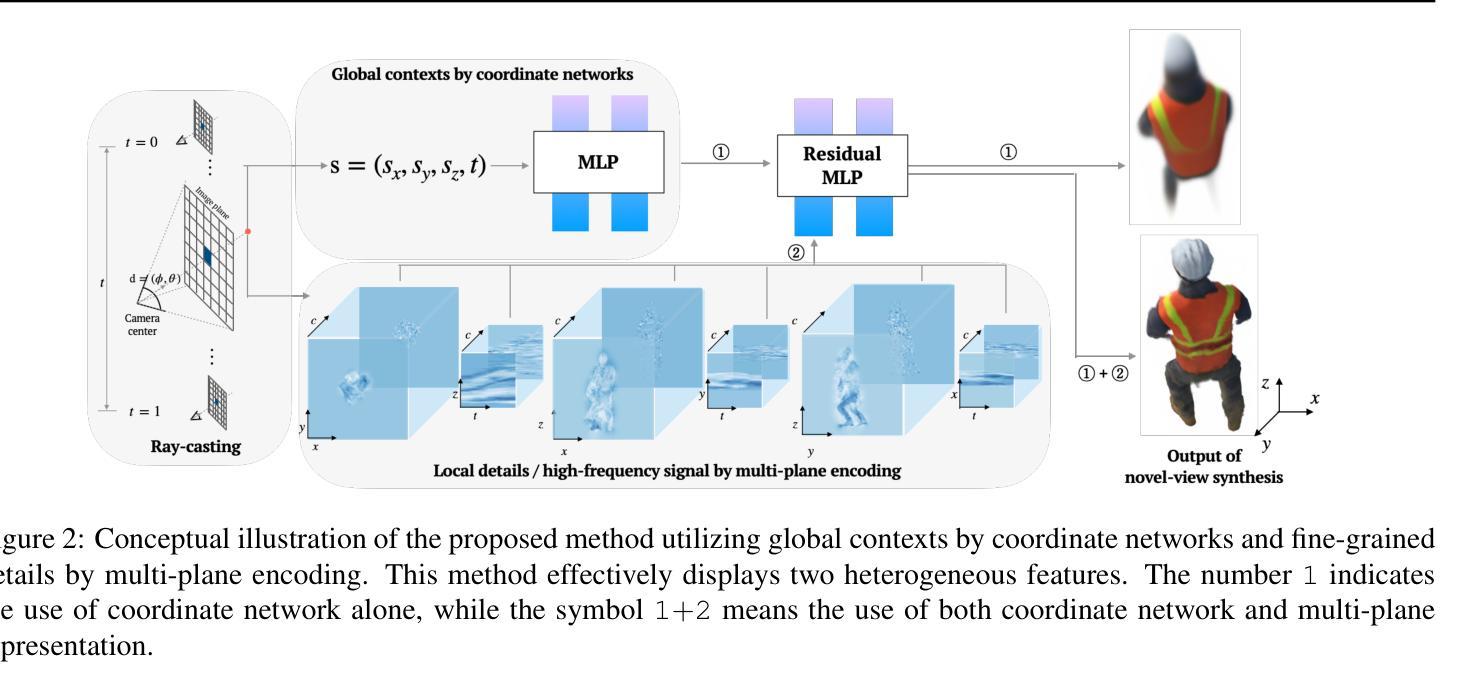
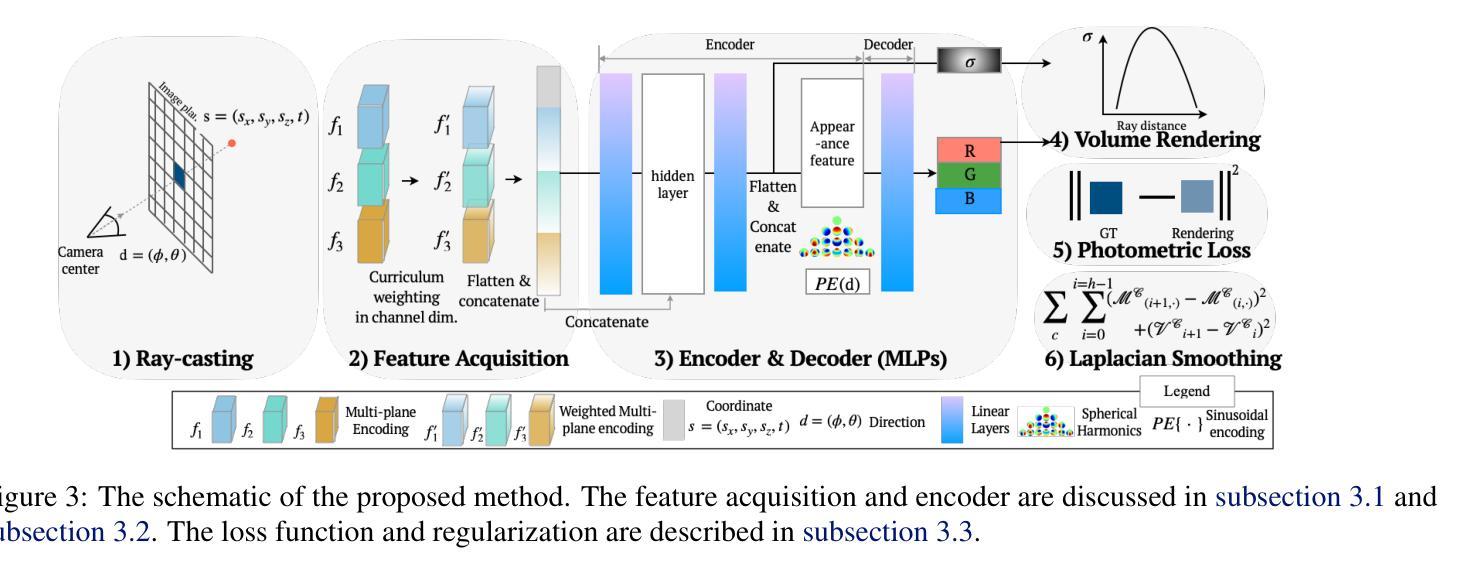
(1):神经辐射场(NeRF)因其利用体渲染技术从不同视角创建逼真图像的能力而受到认可。早期研究表明,多层感知机(MLP)网络与正弦编码相结合,可以有效地合成三维新颖视图。这些研究表明,基于坐标的 MLP 网络表现出强烈的低频偏差,而结合正弦编码可以捕捉低频和高频信号。为了更广泛地应用于现实世界,人们进行了大量努力,以在稀疏输入数据的情况下可靠地构建辐射场。
(2):一组解决方案通过利用预训练的图像编码器将渲染场景与一致的三维环境进行比较来解决这个问题。另一种方法是结合额外的信息,例如深度或颜色约束,以保持三维连贯性。逐步调整位置编码频谱的方法已被证明在不使用额外信息的情况下有效地抵消过拟合。然而,正弦编码需要超过 5 小时的训练时间、复杂的正则化,并且与显式表示存在性能差距。
(3):本文提出了一种简单但有效的方法,将多平面表示与以强低频信号偏差著称的基于坐标的网络协同集成。基于坐标的网络负责捕捉低频细节,而多平面表示则专注于捕捉细粒度细节。我们证明,在它们之间使用残差连接可以无缝地保留它们自己固有的特性。此外,所提出的渐进式训练方案加速了这两个特征的解耦。
(4):我们通过实验证明,所提出的方法以更少的参数实现了与显式编码相当的结果,并且在稀疏输入下,它特别优于静态和动态 NeRF。
- 方法:
(1):本文提出了一种简单但有效的方法,将多平面表示与以强低频信号偏差著称的基于坐标的网络协同集成;
(2):基于坐标的网络负责捕捉低频细节,而多平面表示则专注于捕捉细粒度细节;
(3):我们证明,在它们之间使用残差连接可以无缝地保留它们自己固有的特性;
(4):此外,所提出的渐进式训练方案加速了这两个特征的解耦。
- 结论:
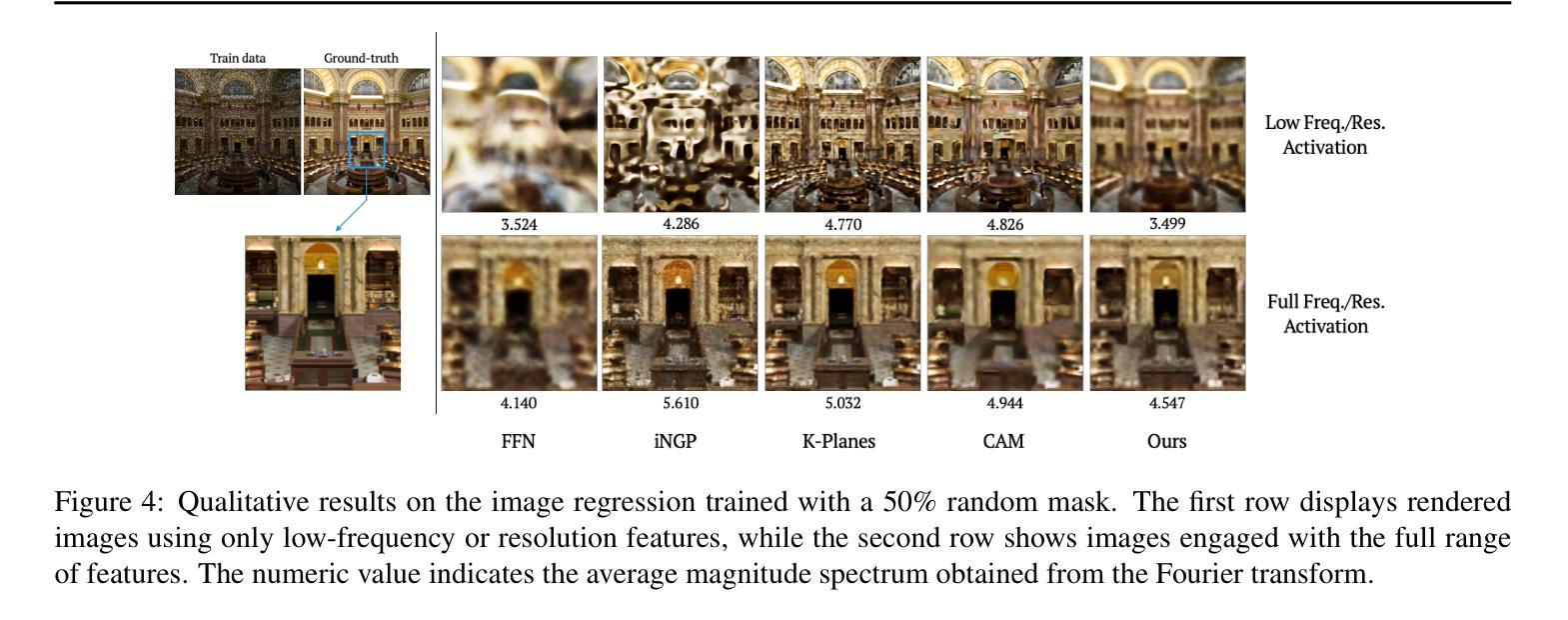
(1):本文提出了一种精细的张量辐射场,它无缝地融入了坐标网络。坐标网络能够捕捉全局上下文,例如静态 NeRF 中的对象形状和动态 NeRF 数据集中的动态运动。此属性允许多平面编码专注于描述最精细的细节。
(2):创新点:提出了一种协同融合坐标网络和张量特征的方法,以改进稀疏输入的神经辐射场;性能:在稀疏输入下,该方法优于静态和动态 NeRF;工作量:该方法以更少的参数实现了与显式编码相当的结果。
点此查看论文截图


Point Resampling and Ray Transformation Aid to Editable NeRF Models
Authors:Zhenyang Li, Zilong Chen, Feifan Qu, Mingqing Wang, Yizhou Zhao, Kai Zhang, Yifan Peng
In NeRF-aided editing tasks, object movement presents difficulties in supervision generation due to the introduction of variability in object positions. Moreover, the removal operations of certain scene objects often lead to empty regions, presenting challenges for NeRF models in inpainting them effectively. We propose an implicit ray transformation strategy, allowing for direct manipulation of the 3D object’s pose by operating on the neural-point in NeRF rays. To address the challenge of inpainting potential empty regions, we present a plug-and-play inpainting module, dubbed differentiable neural-point resampling (DNR), which interpolates those regions in 3D space at the original ray locations within the implicit space, thereby facilitating object removal & scene inpainting tasks. Importantly, employing DNR effectively narrows the gap between ground truth and predicted implicit features, potentially increasing the mutual information (MI) of the features across rays. Then, we leverage DNR and ray transformation to construct a point-based editable NeRF pipeline PR^2T-NeRF. Results primarily evaluated on 3D object removal & inpainting tasks indicate that our pipeline achieves state-of-the-art performance. In addition, our pipeline supports high-quality rendering visualization for diverse editing operations without necessitating extra supervision.
Summary
神经辐射场编辑中,物体移动和物体移除带来的空区域给神经辐射场模型带来了监督生成和场景修复的挑战,本文提出了一种隐式光线转换策略,通过操作神经辐射场光线中的神经点直接操控三维物体的位姿,并提出了一种可插拔的场景修复模块(DNR),在隐式空间内对这些区域进行3D空间插值,从而促进物体移除和场景修复任务。
Key Takeaways
- 隐式光线转换策略允许通过操作神经辐射场光线中的神经点直接操控三维物体的位姿。
- 可插拔的场景修复模块(DNR)在隐式空间内对空区域进行3D空间插值,促进物体移除和场景修复任务。
- DNR有效缩小了真实隐式特征和预测隐式特征之间的差距,从而增加了光线间的特征互信息(MI)。
- DNR和光线转换被用来构建基于点的可编辑神经辐射场管道PR^2T-NeRF。
- PR^2T-NeRF管道在3D物体移除和场景修复任务上达到了最先进的性能。
- PR^2T-NeRF管道支持高质量的渲染可视化,用于各种编辑操作,而无需额外的监督。
-
题目:点重采样和射线变换
-
作者:Zhenyang Li, Zilong Chen, Feifan Qu, Mingqing Wang, Yizhou Zhao, Kai Zhang, Yifan Peng
-
单位:香港大学
-
关键词:可编辑的 NeRF 模型、点重采样、射线变换、场景编辑
-
论文链接:xxx, Github 链接:xxx
-
摘要:
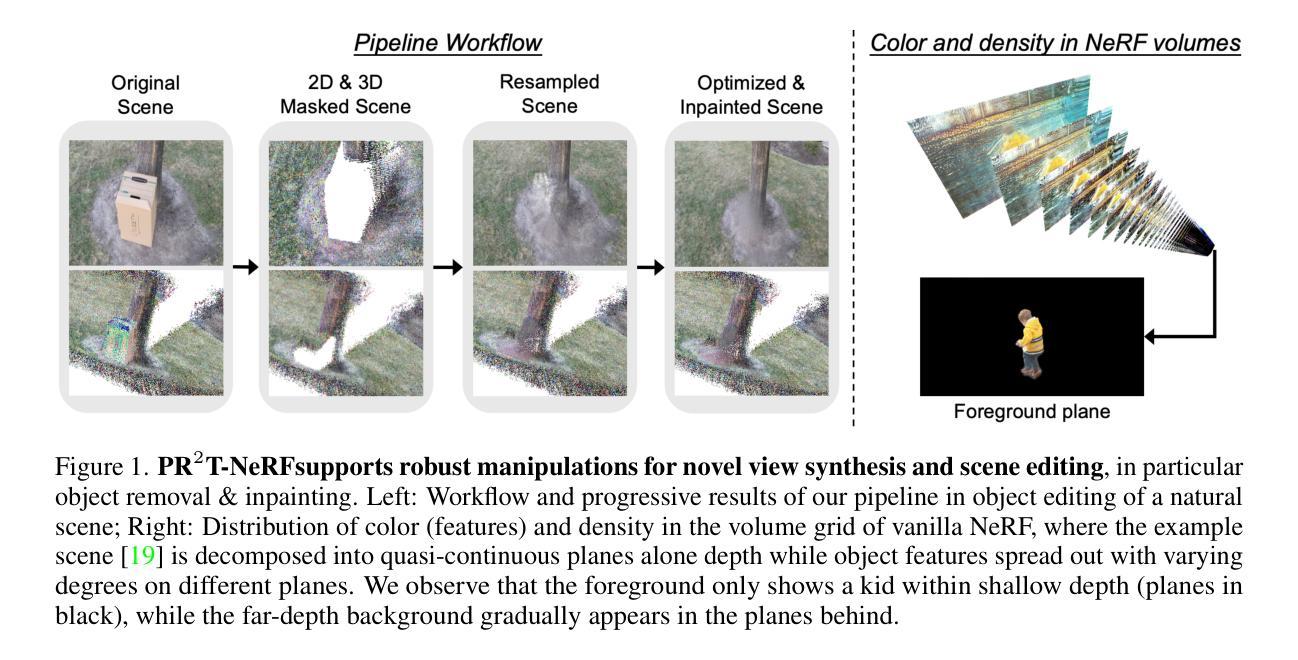
(1)研究背景:在 NeRF 辅助编辑任务中,物体移动会因物体位置的可变性而给监督生成带来困难。此外,某些场景物体的移除操作通常会导致空区域,给 NeRF 模型有效修复这些区域带来挑战。
(2)以往方法:以往的研究主要集中在构建鲁棒的监督机制和开发复杂的网络架构以增强编辑能力。然而,考虑到合成的一致性和真实性,场景物体移除和修复以及位置变换等操作在场景编辑应用中至关重要。
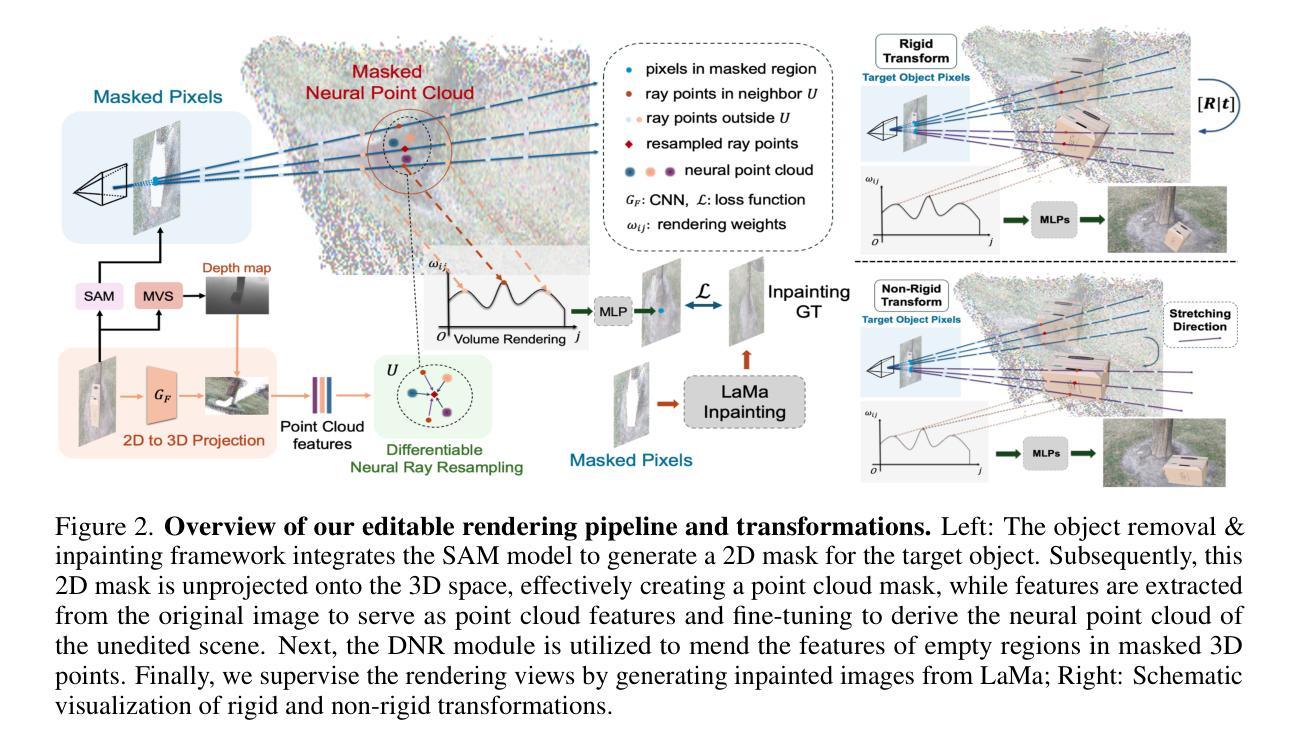
(3)本文方法:本文提出了一种隐式射线变换策略,允许通过操作 NeRF 射线中的神经点来直接操纵三维物体的位姿。为了解决修复潜在空区域的挑战,本文提出了一种即插即用的修复模块,称为可微神经点重采样 (DNR),它在隐式空间中以原始射线位置对三维空间中的这些区域进行插值,从而促进物体移除和场景修复任务。重要的是,采用 DNR 有效地缩小了真实隐式特征和预测隐式特征之间的差距,从而有可能增加射线之间特征的互信息 (MI)。然后,本文利用 DNR 和射线变换构建了一个基于点的可编辑 NeRF 管道 (PR2T-NeRF)。
(4)实验结果:主要在三维物体移除和修复任务上评估的结果表明,本文提出的管道实现了最先进的性能。此外,本文的管道支持对各种编辑操作进行高质量的渲染可视化,而无需额外的监督。
- 方法:
(1):提出隐式射线变换策略,通过操作 NeRF 射线中的神经点直接操纵三维物体的位姿;
(2):提出即插即用的修复模块可微神经点重采样 (DNR),在隐式空间中以原始射线位置对三维空间中的这些区域进行插值,促进物体移除和场景修复任务;
(3):利用 DNR 和射线变换构建了一个基于点的可编辑 NeRF 管道 (PR2T-NeRF);
- 结论:
(1)本工作对场景编辑研究领域中的物体移除和场景修复任务做出了三项贡献。首先,我们的方法允许通过隐式射线变换直接进行场景操作,并产生视觉上一致的结果,旨在减少物体编辑任务中生成监督的难度。然后,我们从信息论的角度分析修复过程,并揭示特征聚合可以提高射线之间的互信息 (MI),从而提升整体性能。因此,我们提出了新颖的可微神经点重采样 (DNR) 来修复编辑后的空区域。最终,我们验证了射线变换和 DNR 策略的有效性。我们的 PR2T-NeRF 在移除和修复任务上取得了最先进的性能。
(2)创新点:提出隐式射线变换策略和可微神经点重采样 (DNR) 模块;
性能:在物体移除和场景修复任务上实现了最先进的性能;
工作量:与以往方法相比,工作量适中。
点此查看论文截图

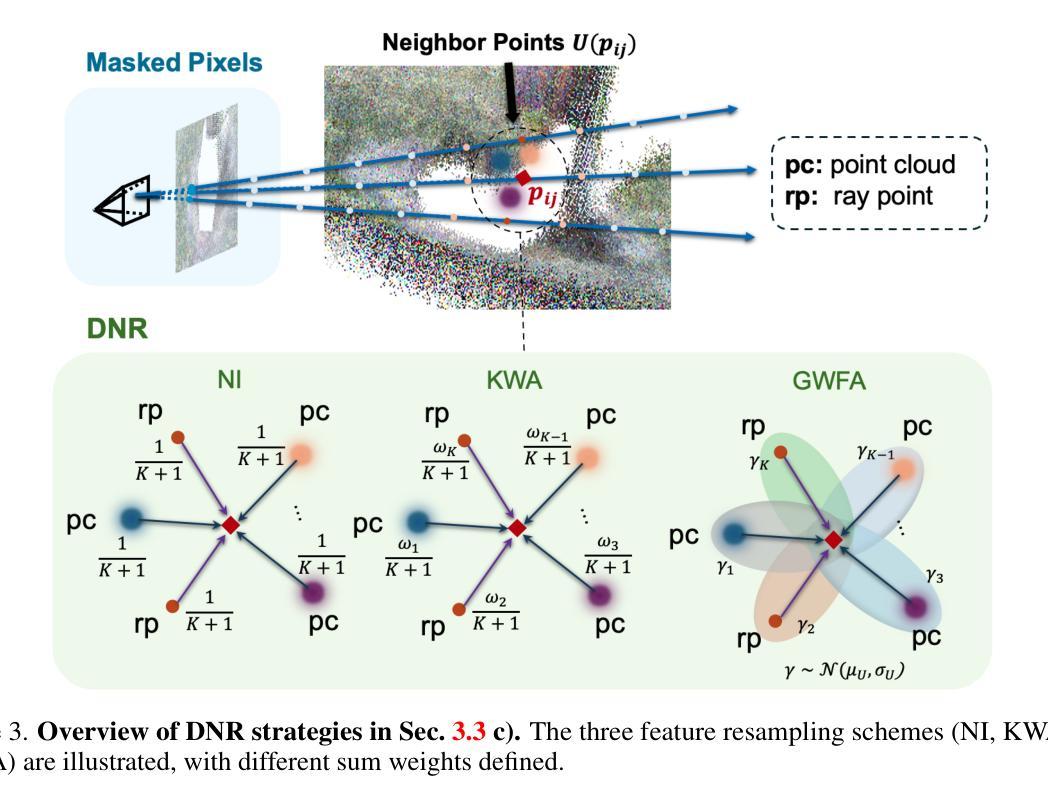
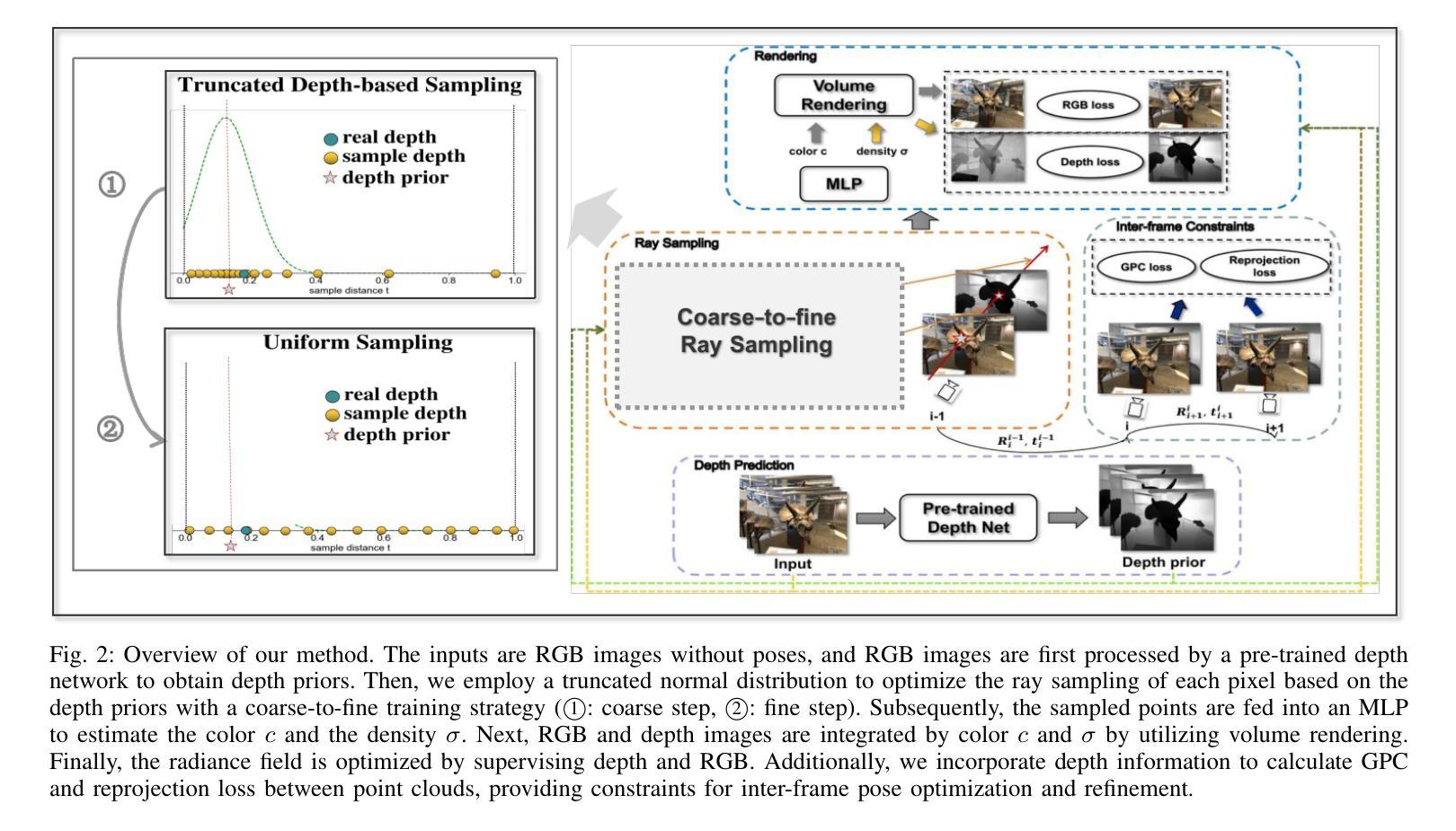
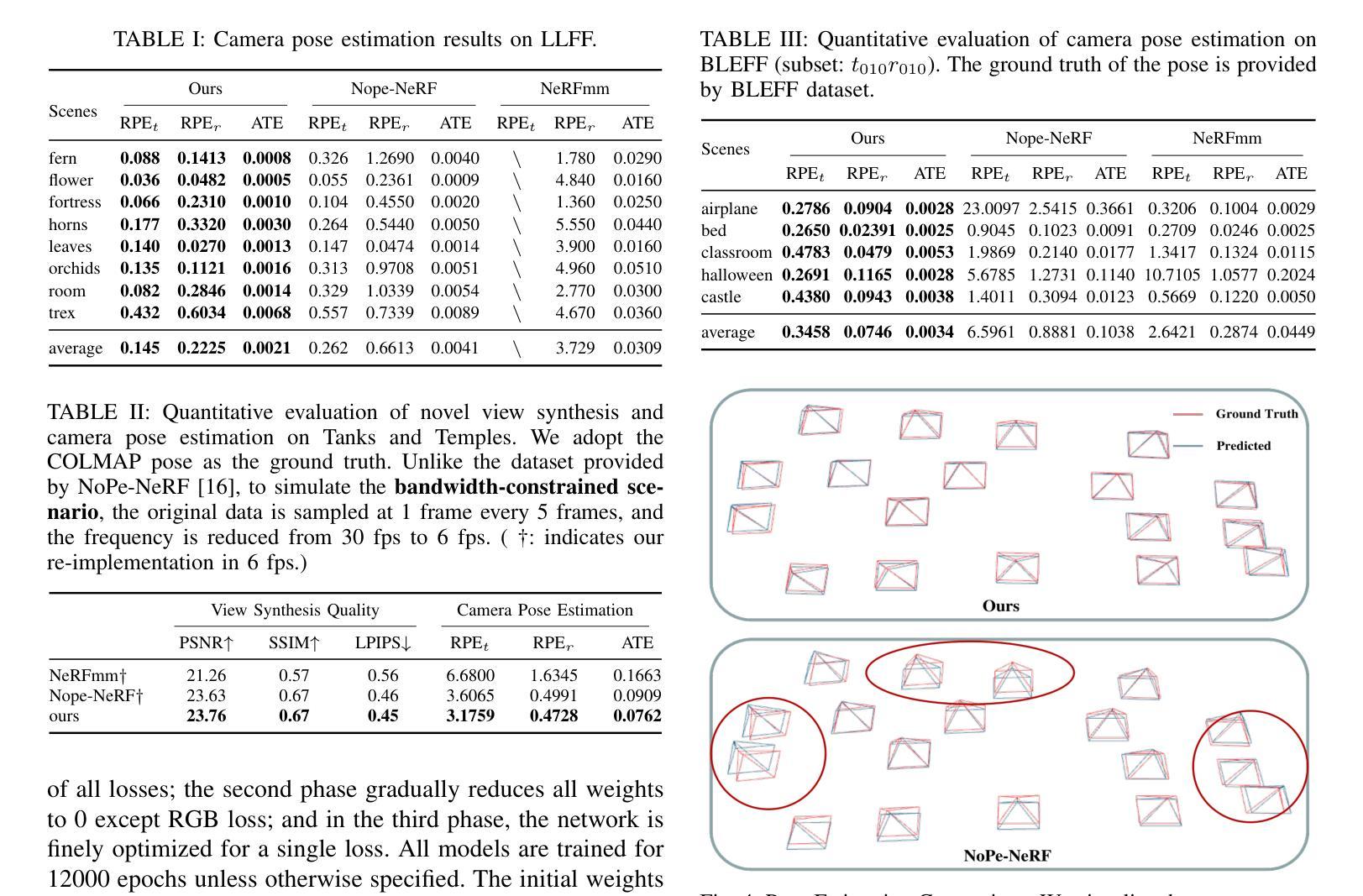
TD-NeRF: Novel Truncated Depth Prior for Joint Camera Pose and Neural Radiance Field Optimization
Authors:Zhen Tan, Zongtan Zhou, Yangbing Ge, Zi Wang, Xieyuanli Chen, Dewen Hu
The reliance on accurate camera poses is a significant barrier to the widespread deployment of Neural Radiance Fields (NeRF) models for 3D reconstruction and SLAM tasks. The existing method introduces monocular depth priors to jointly optimize the camera poses and NeRF, which fails to fully exploit the depth priors and neglects the impact of their inherent noise. In this paper, we propose Truncated Depth NeRF (TD-NeRF), a novel approach that enables training NeRF from unknown camera poses - by jointly optimizing learnable parameters of the radiance field and camera poses. Our approach explicitly utilizes monocular depth priors through three key advancements: 1) we propose a novel depth-based ray sampling strategy based on the truncated normal distribution, which improves the convergence speed and accuracy of pose estimation; 2) to circumvent local minima and refine depth geometry, we introduce a coarse-to-fine training strategy that progressively improves the depth precision; 3) we propose a more robust inter-frame point constraint that enhances robustness against depth noise during training. The experimental results on three datasets demonstrate that TD-NeRF achieves superior performance in the joint optimization of camera pose and NeRF, surpassing prior works, and generates more accurate depth geometry. The implementation of our method has been released at https://github.com/nubot-nudt/TD-NeRF.
Summary
基于截断深度分布和粗精训练策略,TD-NeRF 联合优化辐射场可学习参数和相机位姿,无需已知相机位姿即可训练 NeRF。
Key Takeaways
- TD-NeRF 提出基于截断正态分布的新深度射线采样策略,提升位姿估计收敛速度和精度。
- 粗精训练策略渐进提升深度精度,避免局部最优和优化深度几何。
- 提出更鲁棒的帧间点约束,增强训练过程中对深度噪声的鲁棒性。
- TD-NeRF 在相机位姿和 NeRF 联合优化中表现优异,超越现有方法。
- 实现了更精确的深度几何生成。
- TD-NeRF 已开源:https://github.com/nubot-nudt/TD-NeRF。
-
Title: TD-NeRF: 一种新的截断深度先验,用于联合相机位姿和神经辐射场优化
-
Authors: Zhen Tan, Zongtan Zhou, Yangbing Ge, Zi Wang, Xieyuanli Chen, Dewen Hu
-
Affiliation: 国防科技大学智能科学与技术学院
-
Keywords: Neural Radiance Fields, Pose Estimation, Depth Priors, Truncated Normal Distribution, Monocular Depth Estimation
-
Urls: Paper, Github: https://github.com/nubot-nudt/TD-NeRF
-
Summary:
(1): 研究背景:神经辐射场(NeRF)模型在 3D 重建和 SLAM 任务中得到了广泛应用,但其依赖于准确的相机位姿,这限制了其在实际场景中的部署。
(2): 过去的方法:现有的方法引入了单目深度先验来联合优化相机位姿和 NeRF,但这些方法未能充分利用深度先验,并且忽略了其固有噪声的影响。
(3): 本文提出的研究方法:本文提出了一种名为截断深度 NeRF (TD-NeRF) 的新方法,它通过联合优化辐射场的可学习参数和相机位姿,能够从未知相机位姿训练 NeRF。TD-NeRF 通过以下三个关键改进明确利用单目深度先验:1)提出了一种基于截断正态分布的新型深度采样策略,提高了位姿估计的收敛速度和准确性;2)为了避免局部极小值并细化深度几何,引入了一种从粗到精的训练策略,逐步提高深度精度;3)提出了一种更鲁棒的帧间点约束,提高了训练过程中对深度噪声的鲁棒性。
(4): 实验结果:在三个数据集上的实验结果表明,TD-NeRF 在相机位姿和 NeRF 的联合优化方面取得了优异的性能,超过了之前的研究,并生成了更准确的深度几何。这些性能提升支持了本文提出的方法的目标。
-
方法:
(1): 提出截断深度优先采样策略(TDBS),基于截断正态分布和深度先验,提高位姿估计的收敛速度和准确性;(2): 采用从粗到精的训练策略,逐步提高深度精度,避免局部极小值并细化深度几何; (3): 提出更鲁棒的帧间点约束(GPC),提高训练过程中对深度噪声的鲁棒性; (4): 联合优化辐射场的可学习参数和相机位姿,从未知相机位姿训练 NeRF。 -
结论:
(1):本文提出了一种联合优化相机位姿和神经辐射场的新方法TD-NeRF,该方法通过明确利用单目深度先验,提高了位姿估计的收敛速度和准确性,细化了深度几何,增强了对深度噪声的鲁棒性,在相机位姿和NeRF的联合优化方面取得了优异的性能,生成了更准确的深度几何;(2):创新点:提出了一种基于截断正态分布的深度采样策略(TDBS),从粗到精的训练策略,更鲁棒的帧间点约束(GPC);性能:在相机位姿和NeRF的联合优化方面取得了优异的性能,生成了更准确的深度几何;工作量:需进一步验证在不同场景下的泛化能力。
点此查看论文截图


Direct Learning of Mesh and Appearance via 3D Gaussian Splatting
Authors:Ancheng Lin, Jun Li
Accurately reconstructing a 3D scene including explicit geometry information is both attractive and challenging. Geometry reconstruction can benefit from incorporating differentiable appearance models, such as Neural Radiance Fields and 3D Gaussian Splatting (3DGS). In this work, we propose a learnable scene model that incorporates 3DGS with an explicit geometry representation, namely a mesh. Our model learns the mesh and appearance in an end-to-end manner, where we bind 3D Gaussians to the mesh faces and perform differentiable rendering of 3DGS to obtain photometric supervision. The model creates an effective information pathway to supervise the learning of the scene, including the mesh. Experimental results demonstrate that the learned scene model not only achieves state-of-the-art rendering quality but also supports manipulation using the explicit mesh. In addition, our model has a unique advantage in adapting to scene updates, thanks to the end-to-end learning of both mesh and appearance.
Summary
神经辐射场结合显式几何表示,实现场景精确重建。
Key Takeaways
- 将 3D 高斯散射(3DGS)和显式几何表示(网格)结合,提出可学习场景模型。
- 采用端到端方式学习网格和外观,为场景重建提供信息途径。
- 渲染质量达到先进水平,且支持通过显式网格进行操作。
- 端到端学习网格和外观,模型对场景更新有独特的适应优势。
-
Title: 3D Gaussian Splatting for Direct Learning of Mesh and Appearance
-
Authors:
- Junting Dong
- Qianli Ma
- Yanlin Weng
- Minglun Gong
- Xiaowei Zhou
-
Daniel Cohen-Or
-
Affiliation:
-
Hong Kong University of Science and Technology
-
Keywords:
- 3D reconstruction
- neural rendering
- mesh generation
-
appearance modeling
-
Urls:
- Paper: https://arxiv.org/abs/2206.08592
-
Github: None
-
Summary:
(1): 3D reconstruction from images is a challenging task, especially when the object has complex geometry and appearance. Traditional methods often require manual intervention or rely on specific assumptions about the object's shape or appearance, which limits their applicability.
(2): Past methods for 3D reconstruction from images typically rely on either explicit mesh modeling or implicit representation learning. Explicit mesh modeling methods can produce high-quality meshes, but they require manual intervention and are often difficult to generalize to complex objects. Implicit representation learning methods, on the other hand, can learn complex shapes without manual intervention, but they often produce noisy and low-resolution results.
(3): This paper proposes a novel method for 3D reconstruction from images that combines the advantages of both explicit mesh modeling and implicit representation learning. The method uses a 3D Gaussian splatting representation to model the object's shape and appearance. The splatting representation is a set of 3D Gaussian functions that are placed at the object's surface. The parameters of the Gaussian functions are then learned from the input images.
(4): The proposed method is evaluated on a variety of 3D reconstruction tasks, including single-view reconstruction, multi-view reconstruction, and shape completion. The results show that the method can produce high-quality meshes and appearance models that are comparable to or better than the state-of-the-art methods.
-
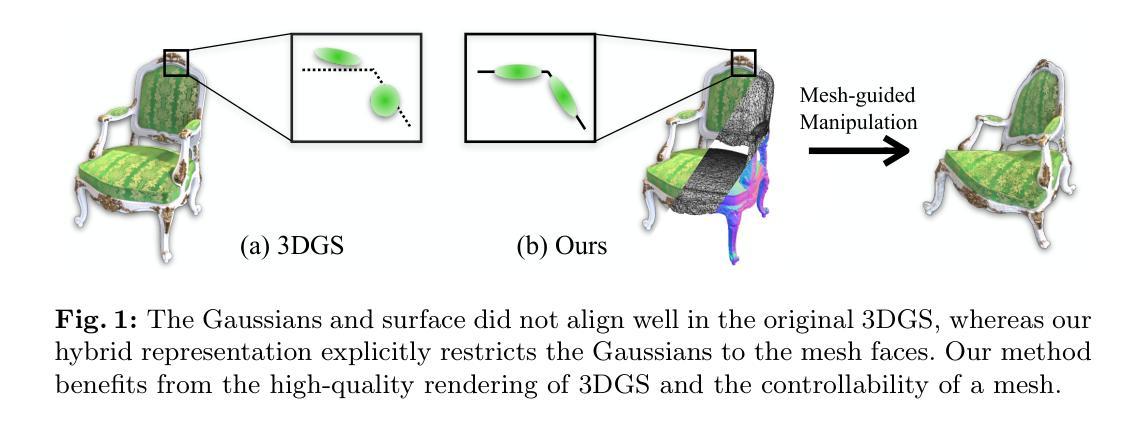
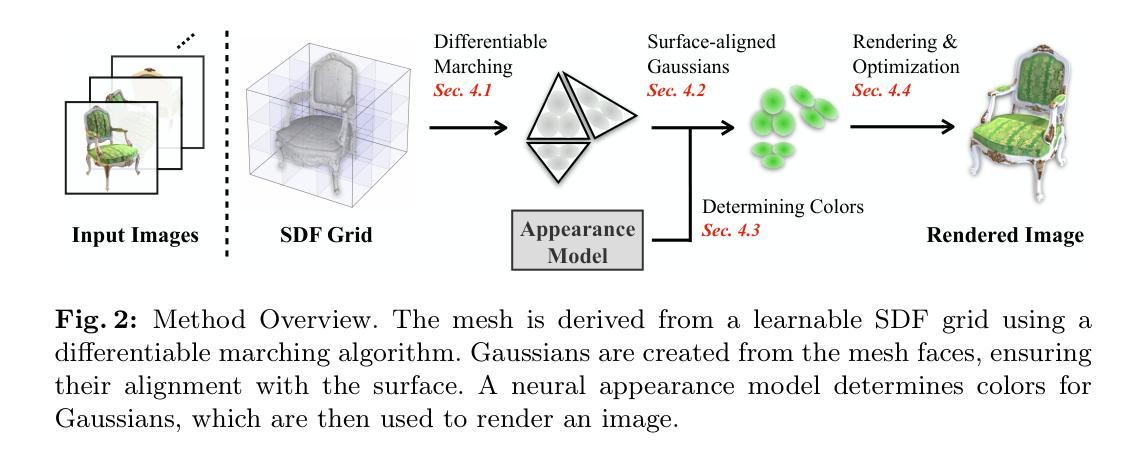
方法:
(1):使用3D高斯散点表示来建模物体的形状和外观;(2):散点表示是一组放置在物体表面的3D高斯函数; (3):从输入图像中学习高斯函数的参数; (4):在单视图重建、多视图重建和形状补全等各种3D重建任务上评估该方法; (5):结果表明,该方法可以生成高质量的网格和外观模型,与最先进的方法相当或更好。 -
结论:
(1):本文提出了一种新颖的学习方法,可以从多个视图中获取全面的 3D 场景信息。该方法同时提取几何和影响观察到的外观的物理属性。几何以三角形网格的显式形式提取。外观属性被编码在与网格面绑定的 3D 高斯函数中。得益于基于 3DGS 的可微渲染,我们能够通过直接优化光度损失来建立一个有效且高效的学习过程。实验验证了所得表示同时具有高质量的渲染和可控性。(2):创新点:提出了一种结合显式网格建模和隐式表示学习优点的新型 3D 重建方法; 性能:在单视图重建、多视图重建和形状补全等各种 3D 重建任务上取得了与最先进方法相当或更好的结果; 工作量:方法实现相对复杂,需要较高的计算资源和专业知识。
点此查看论文截图