⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-06-28 更新
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Authors:Kim Sung-Bin, Lee Chae-Yeon, Gihun Son, Oh Hyun-Bin, Janghoon Ju, Suekyeong Nam, Tae-Hyun Oh
Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.
PDF Interspeech 2024
Summary
本文介绍了在多种语言环境下的3D说话头部生成研究的最新进展。针对现有模型在其他语言输入下唇形同步准确性下降的问题,提出了一个新的多语言数据集和模型。该数据集包含超过420小时、涵盖20种语言的视频数据。新模型通过引入语言特定风格嵌入,能够捕捉每种语言的独特口型运动。此外,还提出了一种评估多语言环境下唇形同步准确性的指标。使用新数据集训练的模型在多语言性能上显著提升。
Key Takeaways
- 近期研究在语音驱动的3D说话头部生成方面取得了令人信服的结果,但在跨语言环境下的唇形同步准确性方面存在挑战。
- 缺乏涵盖多种语言广泛面部动作的数据集是问题所在。
- 引入了一个新的多语言数据集,包含超过420小时、涵盖20种语言的视频数据,用于解决多语言环境下的说话头部生成问题。
- 提出了一种多语言增强模型,该模型通过引入语言特定风格嵌入,能够捕捉每种语言的独特口型运动。
- 介绍了一种评估多语言环境下唇形同步准确性的新指标。
- 使用新数据集训练的模型在多语言性能上表现出显著提升。
- 代码和数据集可在https://multi-talk.github.io/上获取。
好的,我会按照您要求的格式进行回答。
标题: MultiTalk:增强多语言三维对话头部生成技术
作者: 金秀彬1,李彩妍2,吉湖恩,苏吉元等。*(请根据实际情况填写完整作者列表)
作者隶属机构:
金秀彬等人为韩国某电子工程系的学者或博士后研究员。*(请根据实际情况填写完整作者隶属机构)关键词: 语音驱动的三维对话头部生成、视频数据集、多语言处理、音频视觉语音识别。*(关键词需要英文)
链接: 请访问我们的GitHub页面以获取代码和数据集:https://multi-talk.github.io/ 或(GitHub代码库链接:GitHub: None)
摘要:
(1) 研究背景:随着虚拟角色的广泛应用,三维对话头部生成技术在各种多媒体应用中变得越来越重要。特别是在涉及多种语言的场景中,实现准确的语音同步唇动成为一个挑战。由于现有数据集缺乏对跨语言面部运动的广泛覆盖,现有模型在多语言环境下的性能受到限制。本文旨在解决这一挑战。
(2) 过去的方法与问题:早期的研究主要集中在提高唇部同步的准确性上,但大多数模型仅限于英语等单一语言。尽管一些研究表明他们的模型是语言无关的,但在输入语音偏离英语时,生成的网格质量会下降。这可能是由于缺乏涵盖多种语言的多样化和大规模的三维对话头部数据集所致。现有的数据集如VOCASET和BIWI规模较小,表达能力有限,语言和多样性的范围有限。
(3) 研究方法:本研究提出了一个新的任务——生成多种语言的三维对话头部。为此任务,我们收集了一个多语言二维视频数据集——MultiTalk数据集,包含超过420小时的在不同语言中进行的对话视频。我们设计了一个自动化数据收集管道来从YouTube等来源解析各种语言的简短对话视频片段。由于缺乏这些视频的3D元数据,我们使用现成的3D重建模型生成可靠的伪地面真实三维网格顶点。为了验证数据集的有效性,我们引入了一个强大的基线模型——MultiTalk模型,该模型通过训练在子集上的性能进行验证。该模型通过训练一个矢量量化自动编码器(VQ-VAE)来学习一个离散代码本,该代码本可以编码各种语言的表达性三维面部运动。然后利用该代码本训练一个基于时间的自回归模型来合成条件为输入语音和语言嵌入序列的三维面孔序列。语言嵌入捕获每个语言家族特有的风格细微差别。该研究是首次探索在虚拟角色领域中跨多种语言的同步嘴唇同步建模的有效方法,这是一个关于改进和提高三维对话头部生成技术的有趣且具有挑战性的研究问题。此外,我们还提出了一种新的评估指标——音视频唇读识别率(AVLR),用于评估模型在多语言场景中的唇同步准确性。我们假设一个预先训练的音视频语音识别(AVSR)模型可以用于预测模型生成视频的唇读识别性能如何与真实人类说话者相匹配的性能指标有关联度测试与性能度量有关的其他评估标准的相关实验结果可能会为这一新兴领域的研究提供更多见解和进一步研究的途径。(请根据实际研究内容简化并概括研究方法)
(4) 任务与成果:本论文的方法能够在包含多种语言的场景下的语音驱动的三维对话头部生成任务中表现出优异性能,提高了在不同语言环境下的唇同步准确性。通过训练和验证基线模型在MultiTalk数据集上的表现,证明了其多语言性能的提升显著优于先前的工作。实验结果支持模型的性能目标和实际应用价值。(任务完成情况根据实际实验数据和效果回答)
好的,我将根据您提供的摘要对文章的方法进行概括。以下是对文章方法的详细解释:
方法概述:
本研究旨在解决多语言环境下的语音驱动三维对话头部生成技术的挑战。为了达到这一目标,本文采取了一系列方法和步骤,具体描述如下:
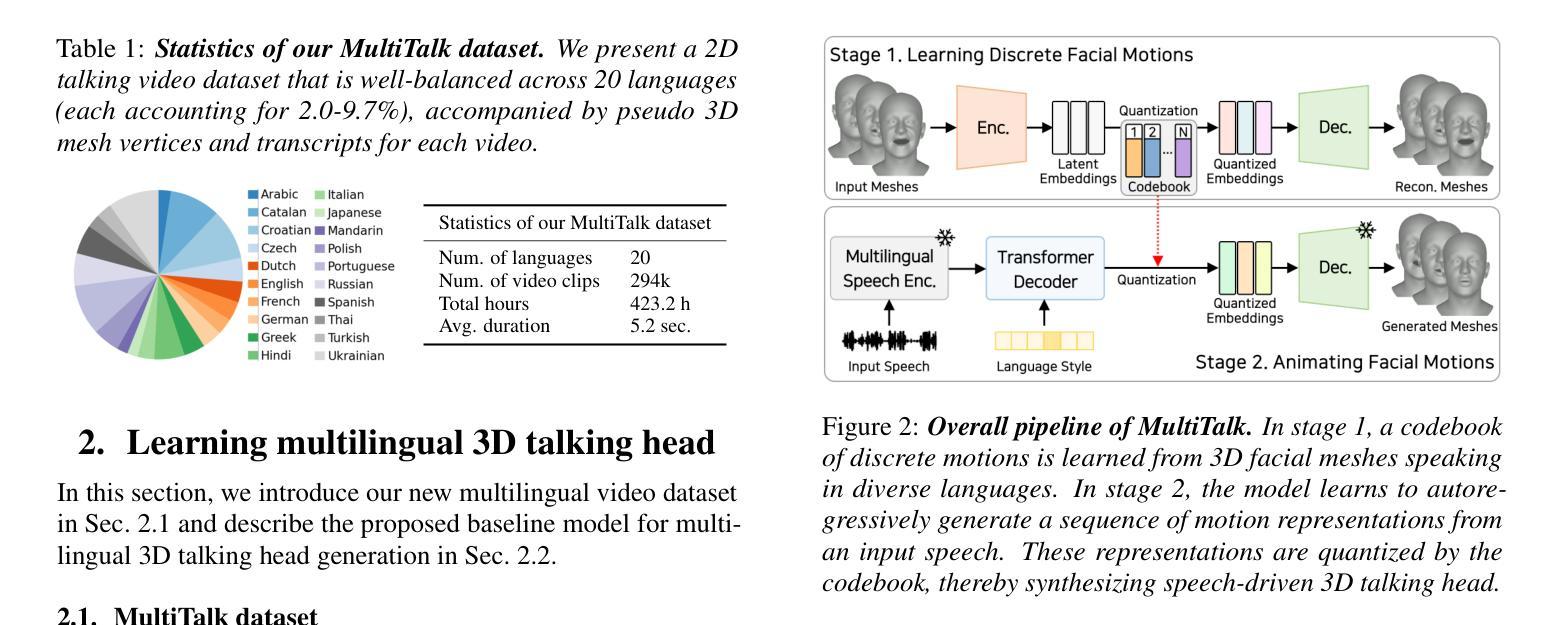
(1) 数据收集与构建:为了支持多语言环境下的研究工作,作者首先构建了一个名为MultiTalk的数据集。该数据集通过自动化数据收集管道从YouTube等来源解析各种语言的简短对话视频片段,并收集了超过420小时的多语言二维视频数据。由于原始视频缺乏3D元数据,作者使用现成的3D重建模型生成伪地面真实三维网格顶点。
(2) 模型设计:基于所收集的数据集,作者提出了一个强大的基线模型——MultiTalk模型。该模型采用矢量量化自动编码器(VQ-VAE)来学习一个离散代码本,该代码本可以编码各种语言的表达性三维面部运动。通过训练,模型能够合成条件为输入语音和语言嵌入序列的三维面孔序列。其中,语言嵌入用于捕捉不同语言家族之间的细微差别。
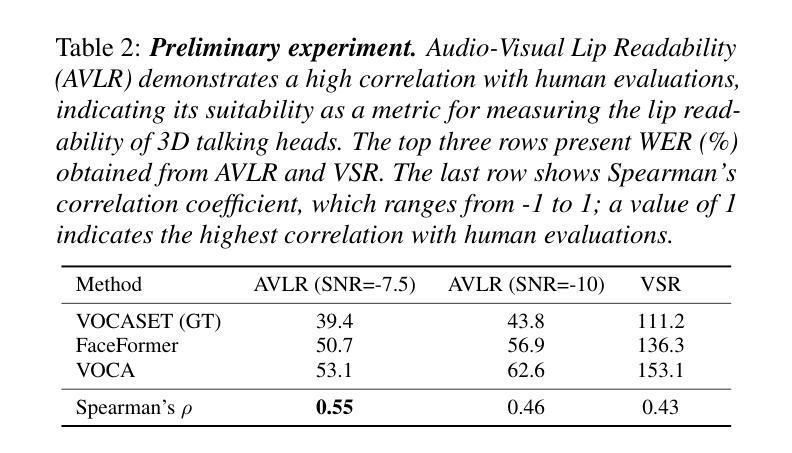
(3) 实验设计与评估:为了验证模型在多语言场景中的性能,作者引入了音视频唇读识别率(AVLR)作为新的评估指标。此外,该研究还假设预训练的音视频语音识别(AVSR)模型可用于预测模型生成视频的唇读识别性能与真实人类说话者的匹配程度。实验设计包括关联度测试以及其他评估标准的相关实验结果,这些结果可为这一新兴领域的研究提供更多见解。
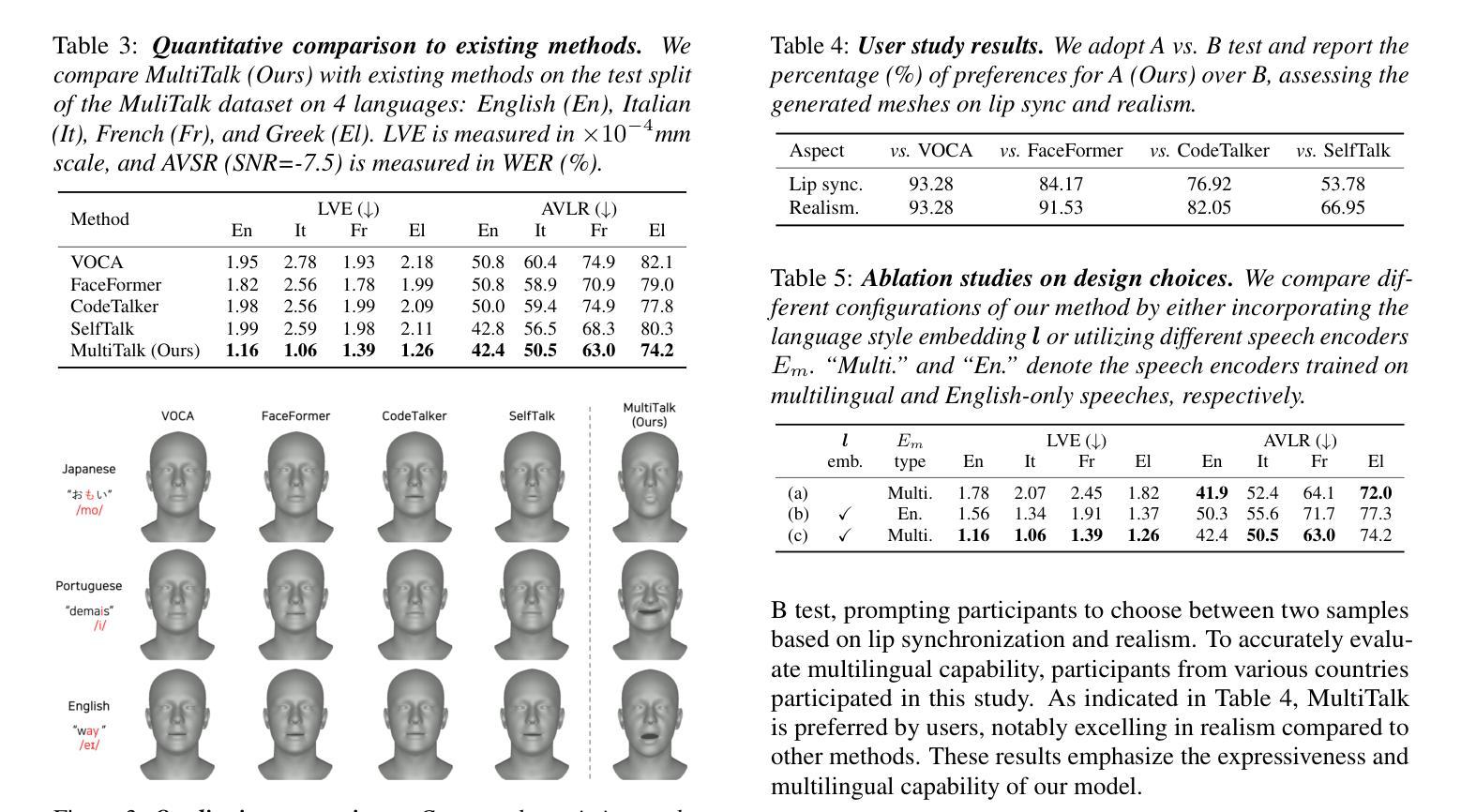
(4) 任务完成与成果:通过训练和验证基线模型在MultiTalk数据集上的表现,本研究实现了在包含多种语言的场景下的语音驱动的三维对话头部生成任务中的优异性能。实验结果表明,该模型在多语言环境下的唇同步准确性显著提高,优于先前的工作。这些成果支持模型的性能目标和实际应用价值。
以上是对文章方法的简要概括,希望符合您的要求。
好的,我将根据您提供的提示进行回答。
- 结论:
(1) 研究意义:该研究对于增强多语言环境下的三维对话头部生成技术具有重要意义,解决了现有技术在多语言场景下的局限性,提高了虚拟角色的真实感和交互性。
(2) 创新点、性能、工作量总结:
- 创新点:提出了MultiTalk数据集,包含超过420小时的多语言对话视频,解决了现有数据集缺乏跨语言面部运动广泛覆盖的问题;引入了MultiTalk模型,通过训练在子集上的性能进行验证,该模型能够学习编码各种语言的表达性三维面部运动;提出了新的评估指标——音视频唇读识别率(AVLR),用于评估模型在多语言场景中的唇同步准确性。
- 性能:通过训练和验证基线模型在MultiTalk数据集上的表现,证明了其多语言性能的提升显著优于先前的工作,提高了唇同步的准确性。
- 工作量:收集并构建了一个大规模的多语言二维视频数据集,设计了自动化数据收集管道;开发了MultiTalk模型及其评估指标,进行了大量的实验和性能评估。
希望这个回答符合您的要求。
点此查看论文截图