⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-07-05 更新
DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents
Authors:Yilun Xu, Gabriele Corso, Tommi Jaakkola, Arash Vahdat, Karsten Kreis
Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem. We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end. DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable. The discrete latents significantly simplify learning the DM’s complex noise-to-data mapping by reducing the curvature of the DM’s generative ODE. An additional autoregressive transformer models the distribution of the discrete latents, a simple step because DisCo-Diff requires only few discrete variables with small codebooks. We validate DisCo-Diff on toy data, several image synthesis tasks as well as molecular docking, and find that introducing discrete latents consistently improves model performance. For example, DisCo-Diff achieves state-of-the-art FID scores on class-conditioned ImageNet-64/128 datasets with ODE sampler.
PDF project page: https://research.nvidia.com/labs/lpr/disco-diff
Summary
Diffusion models (DMs) utilize a diffusion process to encode data into a Gaussian distribution. DisCo-Diff simplifies this by integrating discrete latent variables, enhancing model performance.
Key Takeaways
- 扩散模型(DMs)利用扩散过程将数据编码为高斯分布。
- DisCo-Diff通过整合离散潜变量简化了模型,提升了性能。
- 离散潜变量通过降低生成ODE曲率显著简化了学习复杂噪声到数据映射。
- 模型在多个任务中验证,如图像合成和分子对接,显示引入离散潜变量一致提升了性能。
- DisCo-Diff不依赖预训练网络,具有普遍适用性。
- 模型引入了一个自回归变压器来建模离散潜变量的分布,仅需少量离散变量和小型码本。
- 在ODE采样器上,DisCo-Diff在类条件的ImageNet-64/128数据集上达到了最先进的FID分数。
好的,我将按照您的要求阅读论文并总结其要点。以下是论文的简要介绍和概括:
标题:离散连续潜变量扩散模型(DisCo-Diff)在生成学习中的应用增强
作者:由一系列作者名字组成,具体名称需查阅论文原文。
作者机构(中文翻译):该论文的作者在多个研究机构或大学工作,包括人工智能、机器学习等相关领域的研究机构。
关键词:离散连续潜变量、扩散模型(DMs)、生成学习、噪声到数据映射、离散潜变量推理、分子对接、图像合成。
论文链接和代码链接:论文链接请查阅学术数据库,目前GitHub代码链接暂未提供,后续如有公开,请访问GitHub官方仓库获取。
摘要:
- (1)研究背景:本文研究背景是扩散模型(DMs)在生成学习中的革命性进展。DMs通过扩散过程将数据编码为简单的高斯分布,但将复杂的多模态数据分布编码为单一连续高斯分布是一个具有挑战性的学习任务。
- (2)过去的方法及问题:虽然已有许多使用扩散模型的方法,但它们大多依赖于连续潜变量,这可能导致学习困难。文章指出当前方法的问题,并提出需要一种更简单的方法来处理这种学习任务。
- (3)研究方法:本文提出离散连续潜变量扩散模型(DisCo-Diff)。该模型引入辅助离散潜变量来简化任务。通过引入可学习的离散潜变量,并与扩散模型一起进行端到端训练,简化了从噪声到数据的复杂映射。此外,还使用自回归变压器对离散潜变量进行建模。
- (4)任务与性能:文章在玩具数据、图像合成任务以及分子对接等任务上验证了DisCo-Diff的有效性。引入离散潜变量始终提高了模型性能。特别是在类条件ImageNet-64/128数据集上,DisCo-Diff实现了最先进的FID分数,并展示了强大的生成能力。性能结果支持该方法的目标。
总结完毕,该论文提出了一种新的扩散模型,通过引入离散潜变量简化了生成学习任务,并在多个任务上取得了优异的性能。
好的,我将根据您给出的结构来总结这篇论文的关键内容。以下是对于这篇论文的简要总结性评述:
一、重要性概述(Innovation point):
本研究论文的工作显著提升了扩散模型在生成学习中的表现和应用能力。针对当前扩散模型面临的主要挑战——多模态数据分布的编码问题,该论文提出了离散连续潜变量扩散模型(DisCo-Diff)。该模型引入离散潜变量作为辅助工具,极大地简化了从噪声到数据的复杂映射过程,展现了其在解决生成学习任务中的显著优势和重要性。这一创新点不仅丰富了扩散模型的理论体系,也为相关领域的研究提供了新思路和方法。
二、论文的优缺点分析(Performance & Workload):
创新点突出是该论文最大的优点,所提出的离散连续潜变量扩散模型是对当前扩散模型的一个重大改进。此外,该论文在多个任务上取得了优异的性能表现,特别是在图像合成任务中,实现了先进的FID分数,证明了模型的实用性。工作量方面,论文详细介绍了模型的构建过程、实验设计以及结果分析,显示出作者团队的严谨态度和扎实工作。然而,论文也存在一定的局限性,例如对于某些复杂任务,模型的训练时间和计算成本可能较高。此外,尽管论文展示了模型在不同任务上的性能表现,但关于模型的进一步优化和潜在应用领域的拓展尚未进行详尽探讨。这为该领域后续研究提供了更多可能性。
三、结论(Conclusion):
综上所述,这篇论文所提出的离散连续潜变量扩散模型在生成学习任务中展现出了显著的优势和重要性。该模型通过引入离散潜变量简化了学习任务,实现了多项任务的优秀表现。虽然存在一定局限性,但其突破性的研究成果仍具有极大的实际意义和研究价值。建议未来研究进一步深化模型理论,优化模型性能,并探索更多潜在应用领域。同时,也需要对该模型在实际应用中的效果进行更为深入的研究和验证。
点此查看论文截图

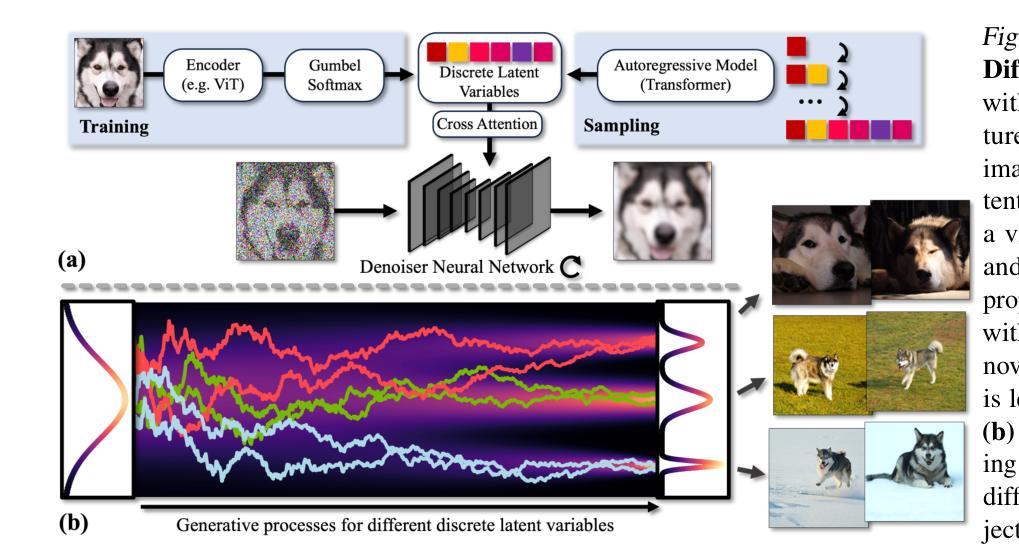

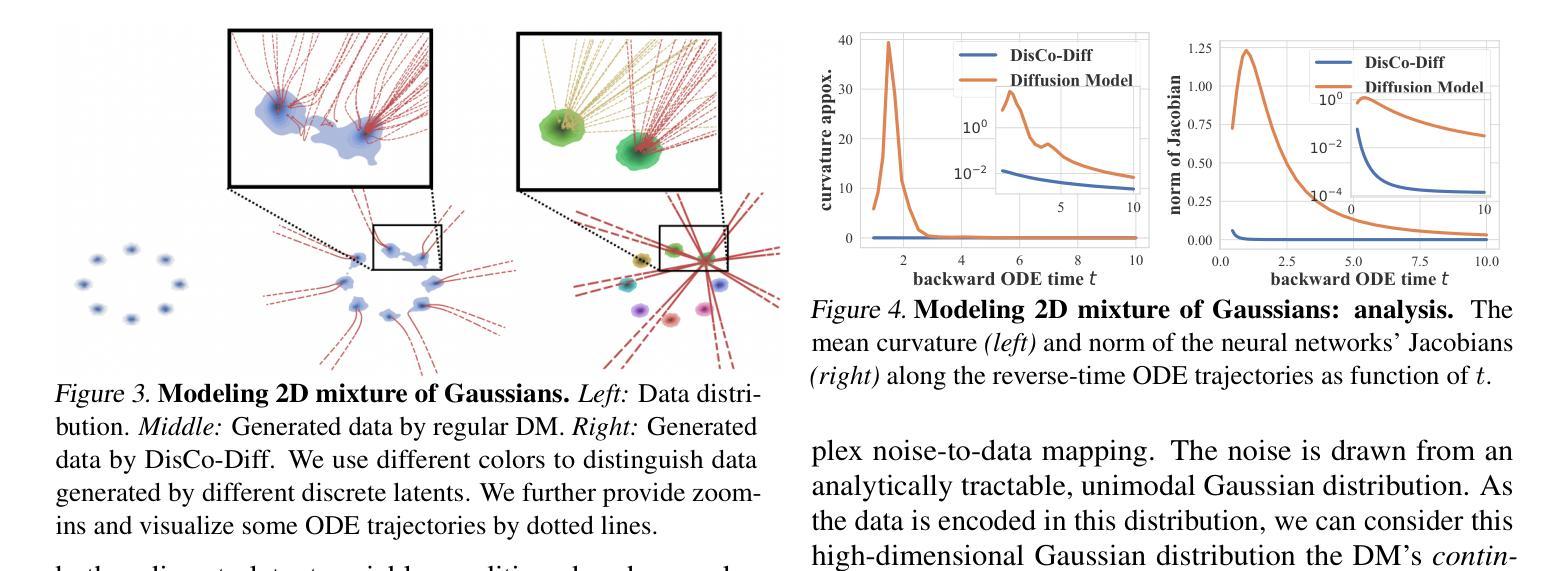
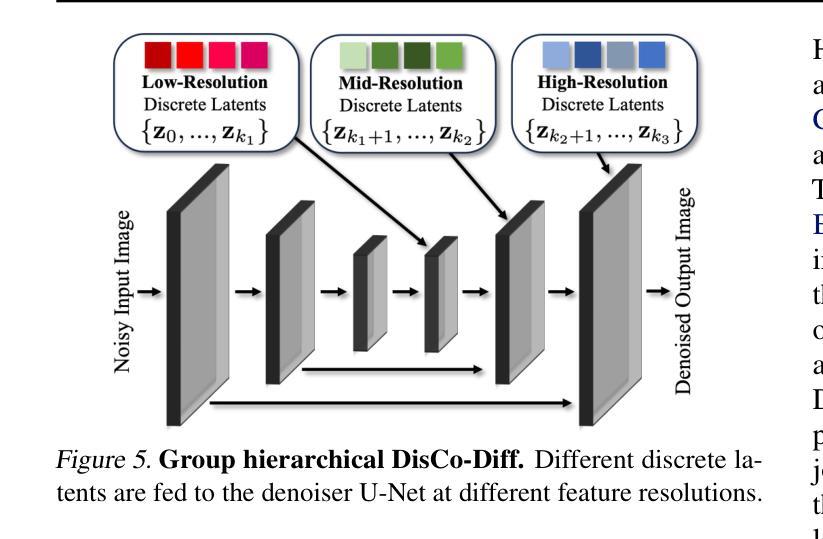
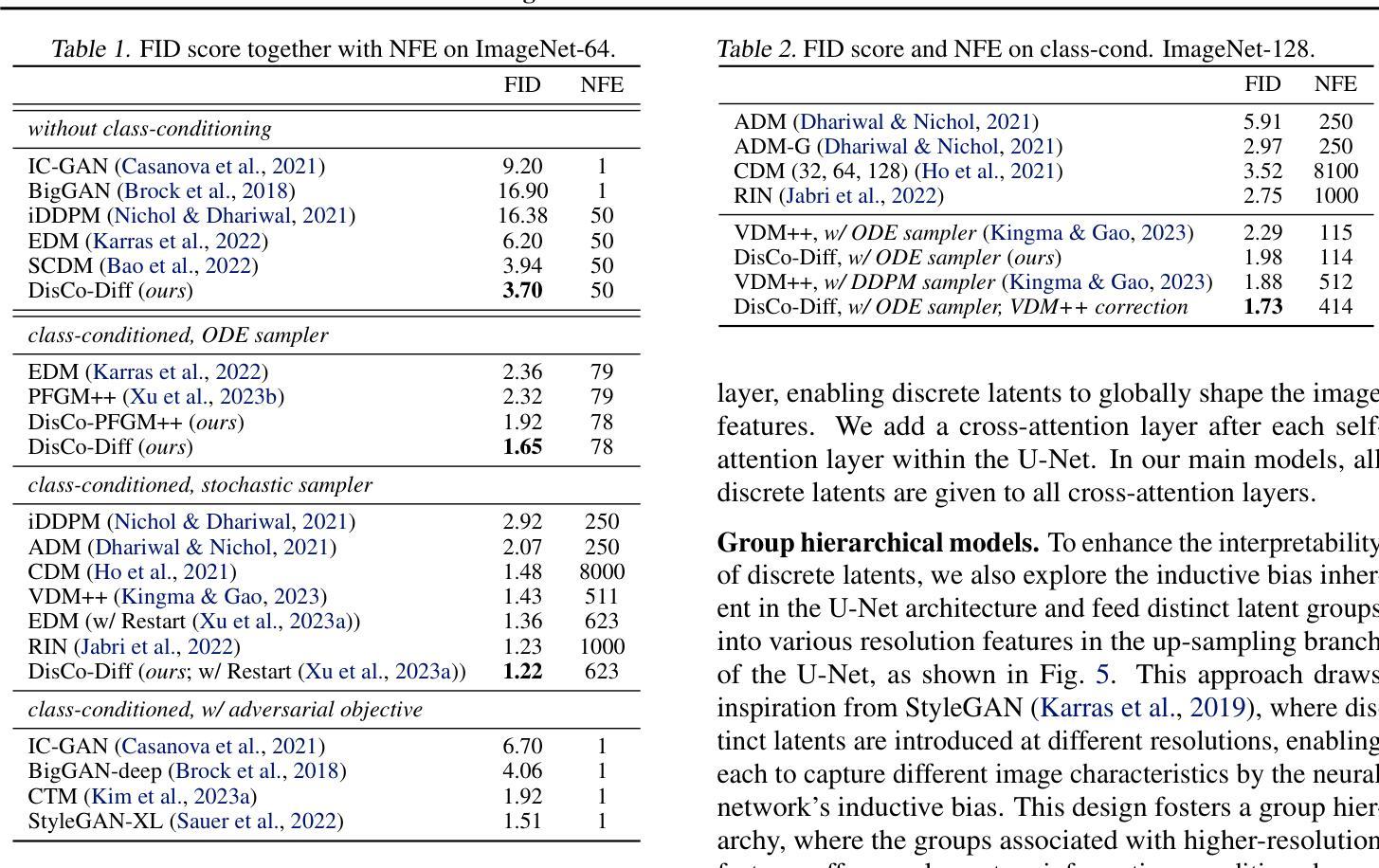
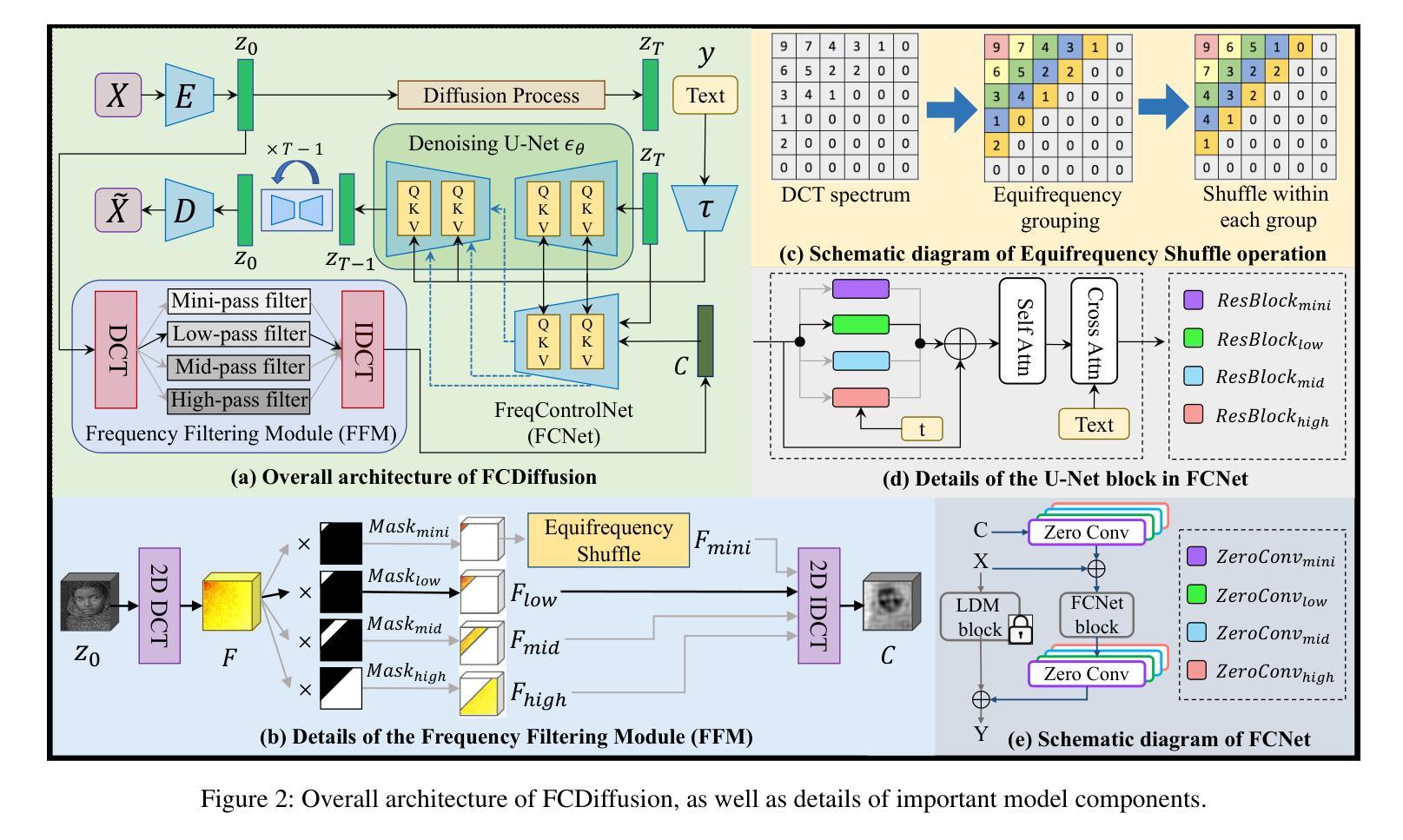
Frequency-Controlled Diffusion Model for Versatile Text-Guided Image-to-Image Translation
Authors:Xiang Gao, Zhengbo Xu, Junhan Zhao, Jiaying Liu
Recently, large-scale text-to-image (T2I) diffusion models have emerged as a powerful tool for image-to-image translation (I2I), allowing open-domain image translation via user-provided text prompts. This paper proposes frequency-controlled diffusion model (FCDiffusion), an end-to-end diffusion-based framework that contributes a novel solution to text-guided I2I from a frequency-domain perspective. At the heart of our framework is a feature-space frequency-domain filtering module based on Discrete Cosine Transform, which filters the latent features of the source image in the DCT domain, yielding filtered image features bearing different DCT spectral bands as different control signals to the pre-trained Latent Diffusion Model. We reveal that control signals of different DCT spectral bands bridge the source image and the T2I generated image in different correlations (e.g., style, structure, layout, contour, etc.), and thus enable versatile I2I applications emphasizing different I2I correlations, including style-guided content creation, image semantic manipulation, image scene translation, and image style translation. Different from related approaches, FCDiffusion establishes a unified text-guided I2I framework suitable for diverse image translation tasks simply by switching among different frequency control branches at inference time. The effectiveness and superiority of our method for text-guided I2I are demonstrated with extensive experiments both qualitatively and quantitatively. The code is publicly available at: https://github.com/XiangGao1102/FCDiffusion.
PDF Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI 2024)
Summary
频率控制扩散模型(FCDiffusion)通过频域滤波模块,提供了一种新颖的文本引导图像翻译解决方案。
Key Takeaways
- FCDiffusion是基于扩散的框架,利用离散余弦变换在频域中过滤潜在特征。
- 控制信号来自不同的DCT频谱带,桥接源图像与生成图像的不同相关性。
- 支持风格引导内容创建、图像语义操作、图像场景翻译和图像风格转换。
- 在推断时通过切换不同的频率控制分支实现多样的图像翻译任务。
- 通过广泛实验证明了FCDiffusion在质量和数量上的优越性。
- 代码公开可用于进一步研究和实现:https://github.com/XiangGao1102/FCDiffusion。
好的,我将会按照您的要求总结论文。
Title: 频率控制扩散模型在文本引导图像转换中的应用研究(Frequency-Controlled Diffusion Model for Versatile Text-Guided Image-to-Image)
Authors: 向刚(Xiang Gao), 郑博(Zhengbo Xu), 刘俊翰(Junhan Zhao), 刘佳颖(Jiaying Liu)*(Corresponding author)
Affiliation: 王选计算机技术研究所,北京大学(Wangxuan Institute of Computer Technology, Peking University)
Keywords: 频率控制扩散模型,文本引导图像转换,图像转换(Frequency-Controlled Diffusion Model, Text-Guided Image-to-Image, Image Translation)
Urls: https://github.com/XiangGao1102/FCDiffusion (Github代码链接)或论文链接:待补充。
Summary:
- (1)研究背景:近年来,大规模文本到图像(T2I)的扩散模型在图像到图像转换(I2I)中表现出强大的能力,允许通过用户提供的文本提示进行开放域图像翻译。本文提出了一个频率控制的扩散模型(FCDiffusion),这是一个端到端的扩散模型框架,从频率域的角度为文本引导的I2I提供了新的解决方案。
-(2)过去的方法及问题:早期I2I方法通过GANs学习跨域映射。随着研究的进展,UI2I方法由于无需配对训练数据而受到欢迎。然而,这些方法仍然限于有限的域间翻译。最近,利用CLIP引导I2I的方法允许使用自由形式的文本进行指令,从而将I2I从有限域扩展到开放域能力。然而,这些方法相对较慢且效率较低,因为它们涉及为每个时间点的图像进行单独的CLIP优化过程。因此,存在对更有效的方法的需求。
-(3)研究方法:本文提出的FCDiffusion模型是一个基于特征空间的频率域过滤模块,该模块使用离散余弦变换(DCT)作为核心。该模块过滤源图像的潜在特征并在DCT域中处理它们,产生不同的控制信号以控制预训练的潜在扩散模型。研究表明,不同DCT频谱带的控制信号在源图像和T2I生成图像之间建立了不同的关联(例如风格、结构、布局、轮廓等)。因此,该方法通过简单地切换不同的频率控制分支即可实现多样化的I2I应用。这是通过对潜在扩散模型的全新利用以及DCT的独特性质实现的。该框架统一了文本引导的I2I任务并适用于多种图像翻译任务。实验证明了其有效性及优越性。此外,框架公开可用并可供进一步研究使用。
-(4)任务与性能:本文方法在文本引导的I2I任务上取得了显著成果。通过广泛的实验证明其有效性并定量评估其性能。实验结果表明,该方法在多种图像翻译任务上表现出色,包括风格引导的内容创建、图像语义操作、图像场景翻译和图像风格翻译等。性能结果支持了方法的目标并证明了其在实际应用中的有效性。通过简单的频率控制分支切换即可适应不同的翻译任务需求。
好的,我将会按照您的要求详细阐述这篇论文的方法论。
- Methods:
(1)研究背景与方法概述:近年来,大规模文本到图像的扩散模型在图像转换中展现出强大的能力。本文在此背景下,提出了频率控制的扩散模型(FCDiffusion),这是一个端到端的扩散模型框架,从频率域的角度为文本引导的图像到图像转换提供了新的解决方案。
(2)模型构建:模型的核心部分是特征空间的频率域过滤模块,该模块使用离散余弦变换(DCT)作为核心。该模块通过处理源图像的潜在特征并在DCT域中对其进行操作,生成控制信号来控制预训练的潜在扩散模型。
(3)频率控制信号的利用:研究指出,不同DCT频谱带的控制信号与源图像和文本引导生成的图像之间建立了不同的关联,如风格、结构、布局、轮廓等。通过简单地切换不同的频率控制分支,可以实现多样化的图像翻译应用。
(4)模型应用:该框架适用于多种图像翻译任务,包括风格引导的内容创建、图像语义操作、图像场景翻译和图像风格翻译等。实验结果表明,该方法在多种图像翻译任务上表现出色。
(5)模型评估:本文对所提出的方法进行了广泛的实验验证和定量评估,证明了其在实际应用中的有效性。此外,该框架公开可用,为进一步的研究提供了基础。
以上就是这篇论文的方法论概述。
好的,以下是对这篇文章的结论性总结:
- Conclusion:
(1)研究意义:该工作提出一个创新的频率控制扩散模型(FCDiffusion),这是一个端到端的扩散模型框架,用于解决文本引导的图像到图像转换问题。该模型从频率域的角度提供了新的解决方案,具有重要的研究意义和实践价值。
(2)创新点、性能和工作量总结:
创新点:该文章提出了一个全新的频率控制扩散模型,该模型通过利用离散余弦变换(DCT)在特征空间进行频率域过滤,生成控制信号来控制预训练的潜在扩散模型。这一方法实现了多样化的图像翻译应用,只需简单切换不同的频率控制分支即可。
性能:实验结果表明,该模型在多种图像翻译任务上表现出色,包括风格引导的内容创建、图像语义操作、图像场景翻译和图像风格翻译等。这证明了模型在实际应用中的有效性。
工作量:文章进行了广泛的实验验证和定量评估,证明了模型的有效性。此外,该框架公开可用,为进一步研究提供了基础。但是,文章未详细阐述实验的具体实施过程和数据集,这可能对读者理解模型的性能造成一定影响。同时,文章未详细讨论模型的计算复杂度和运行时间等实际应用中的关键因素。
希望以上总结对您有所帮助。
点此查看论文截图




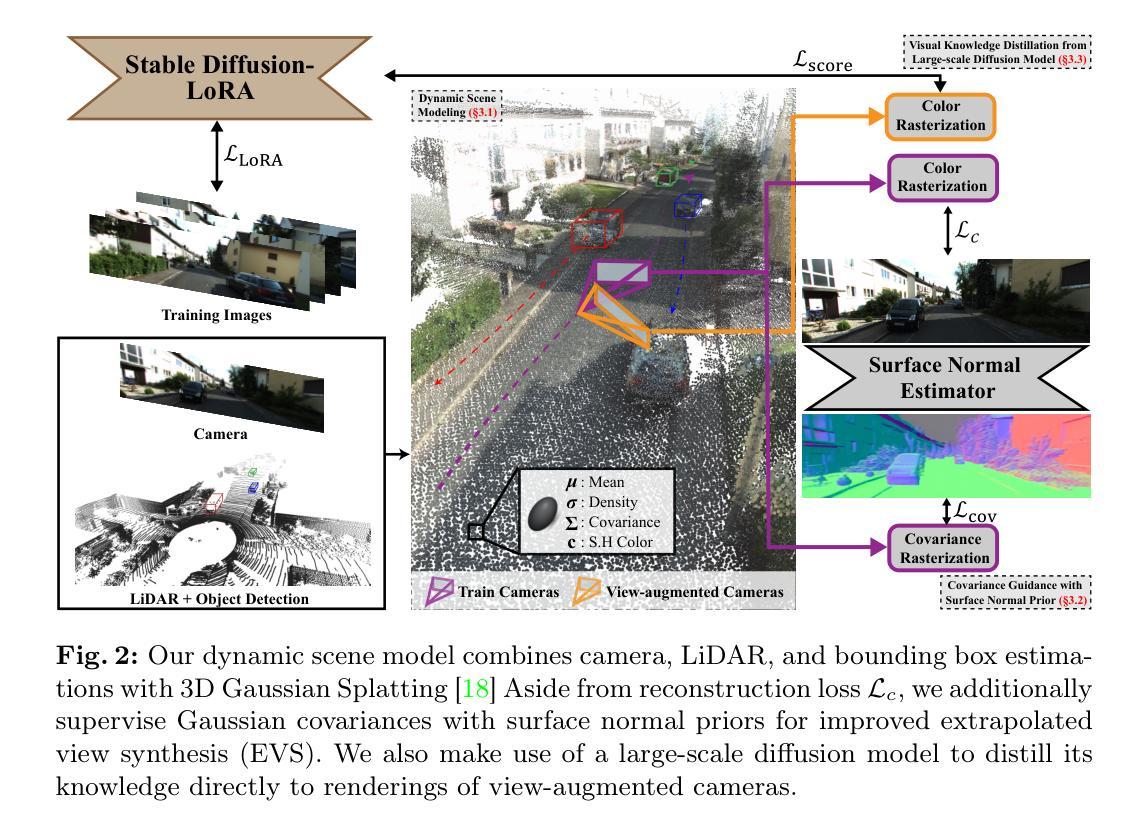
VEGS: View Extrapolation of Urban Scenes in 3D Gaussian Splatting using Learned Priors
Authors:Sungwon Hwang, Min-Jung Kim, Taewoong Kang, Jayeon Kang, Jaegul Choo
Neural rendering-based urban scene reconstruction methods commonly rely on images collected from driving vehicles with cameras facing and moving forward. Although these methods can successfully synthesize from views similar to training camera trajectory, directing the novel view outside the training camera distribution does not guarantee on-par performance. In this paper, we tackle the Extrapolated View Synthesis (EVS) problem by evaluating the reconstructions on views such as looking left, right or downwards with respect to training camera distributions. To improve rendering quality for EVS, we initialize our model by constructing dense LiDAR map, and propose to leverage prior scene knowledge such as surface normal estimator and large-scale diffusion model. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS. To the best of our knowledge, we are the first to address the EVS problem in urban scene reconstruction. Link to our project page: https://vegs3d.github.io/.
Summary
神经渲染基于城市场景重建方法通常依赖于从前进行驶车辆收集的图像。然而,对于训练相机分布之外的新视角,性能表现不一定保证与训练时相当。
Key Takeaways
- 城市场景重建中的神经渲染方法通常依赖于车辆前进收集的图像。
- 在训练相机轨迹类似的视角下,这些方法可以成功合成景象。
- 在训练相机分布之外的新视角下,性能可能不如预期。
- 该文研究了超出训练相机分布的视角合成(EVS)问题。
- 为了改善EVS的渲染质量,提出了使用密集LiDAR地图初始化模型,并利用场景先验知识。
- 提出了表面法线估计器和大规模扩散模型等先验场景知识。
- 实证和定量比较证明了方法在EVS上的有效性。
好的,我会按照您的要求进行回答。
标题:基于LiDAR地图的神经网络渲染在城市场景重建中的外延视角合成研究(VEGS: View Extrapolation of Urban Scenes in Supplementary Material)
作者:XXX。具体的作者名字需要您提供详细信息。
所属机构:XXX大学计算机视觉与智能系统实验室。具体的机构名称需要根据实际情况填写。
关键词:神经网络渲染、城市场景重建、外延视角合成(Extrapolated View Synthesis)。
链接:论文链接无法确定,Github代码链接(如有):Github: None。
摘要:
- (1)研究背景:本文主要研究在神经网络渲染城市场景重建中,如何合成外延视角(即偏离训练相机轨迹的视角下的视图)。现有的基于图像的城市场景重建方法主要依赖于从驾驶车辆收集的面向前方并移动的图像,当视角偏离训练分布时,合成质量往往下降。因此,本文旨在解决外延视角合成(EVS)问题。
- (2)过去的方法及问题:过去的方法主要关注于与训练相机轨迹相似的视图合成,当面对外延视角时性能不佳。缺乏有效的方法利用场景先验知识提高渲染质量。
- (3)研究方法:本文首先通过构建密集的LiDAR地图初始化模型,然后提出利用场景先验知识,如表面法线估计器和大规模扩散模型,来提高外延视角的合成质量。文章进行了详尽的消融研究,以验证各组件的有效性。
- (4)任务与性能:本文的方法在合成外延视角的任务上取得了显著的性能提升。通过在KITTI-360数据集上的实验,证明了所提出方法的有效性。本文的方法在合成外延视角方面的性能明显优于以往的方法,支持了其目标的实现。
以上内容仅供参考,具体的作者名字、所属机构名称以及论文链接需要根据实际情况填写。
7. 方法论:
(1) 概述研究背景与问题:文章主要研究了神经网络渲染城市场景重建中,如何合成外延视角(即偏离训练相机轨迹的视角下的视图)的问题。现有方法主要关注与训练相机轨迹相似的视图合成,面对外延视角时性能不佳。文章旨在解决外延视角合成(EVS)问题。
(2) 数据准备与模型初始化:文章首先构建密集的LiDAR地图来初始化模型。LiDAR地图提供了场景的高精度几何信息,有助于提升渲染质量。
(3) 方法介绍:文章提出了利用场景先验知识提高外延视角的合成质量。这些先验知识包括表面法线估计器和大规模扩散模型。通过结合这些先验知识,文章的方法在合成外延视角的任务上取得了显著的性能提升。
(4) 动态场景建模与渲染:文章建立了动态场景模型,该模型由静态模型和多个动态对象模型组成。每个模型都用高斯均值、协方差矩阵、密度和颜色来表示。协方差矩阵的参数化表示有助于更好地描述场景的几何结构。
(5) 外延视角的合成:为了合成外延视角,文章使用了大型扩散模型的知识蒸馏方法。通过微调模型参数,实现了在场景特定知识和泛化到未见视图之间的平衡。
(6) 协方差优化的指导:文章识别了3D高斯模型在优化过程中存在的问题,即协方差形状和方向的过度拟合。为此,文章提出了利用表面法线先验来指导协方差的优化。通过最小化协方差与表面法线之间的对齐损失,有效地解决了协方差的懒惰优化问题。
总的来说,文章通过结合LiDAR地图、动态场景建模、大型扩散模型的知识蒸馏以及协方差的优化指导等方法,实现了在城市场景重建中合成外延视角的显著性能提升。
- 结论:
(1)本工作的重要性体现在其为城市场景重建领域带来了显著的进展,特别是在合成外延视角(Extrapolated View Synthesis)方面取得了重要突破。该工作提出的基于LiDAR地图的神经网络渲染方法有效提高了城市场景重建的精度和效果,对于自动驾驶、虚拟现实等领域具有潜在的应用价值。
(2)创新点:本研究提出了一种结合LiDAR地图和神经网络渲染的城市场景重建方法,有效解决了外延视角合成(EVS)的问题。在创新点上,本文利用LiDAR地图提供的高精度几何信息,结合动态场景建模和大型扩散模型的知识蒸馏方法,实现了显著的性能提升。
性能:本研究在合成外延视角的任务上取得了显著的性能提升,通过在KITTI-360数据集上的实验验证了所提出方法的有效性。与以往的方法相比,本文的方法在合成外延视角方面的性能优势明显。
工作量:本研究进行了大量的实验和验证工作,包括数据准备、模型初始化、方法介绍、动态场景建模与渲染、外延视角的合成、协方差优化的指导等。同时,本研究还进行了详尽的消融研究,以验证各组件的有效性。
总体而言,本研究在城市场景重建领域取得了重要的进展,为未来的研究提供了有益的参考和启示。
点此查看论文截图


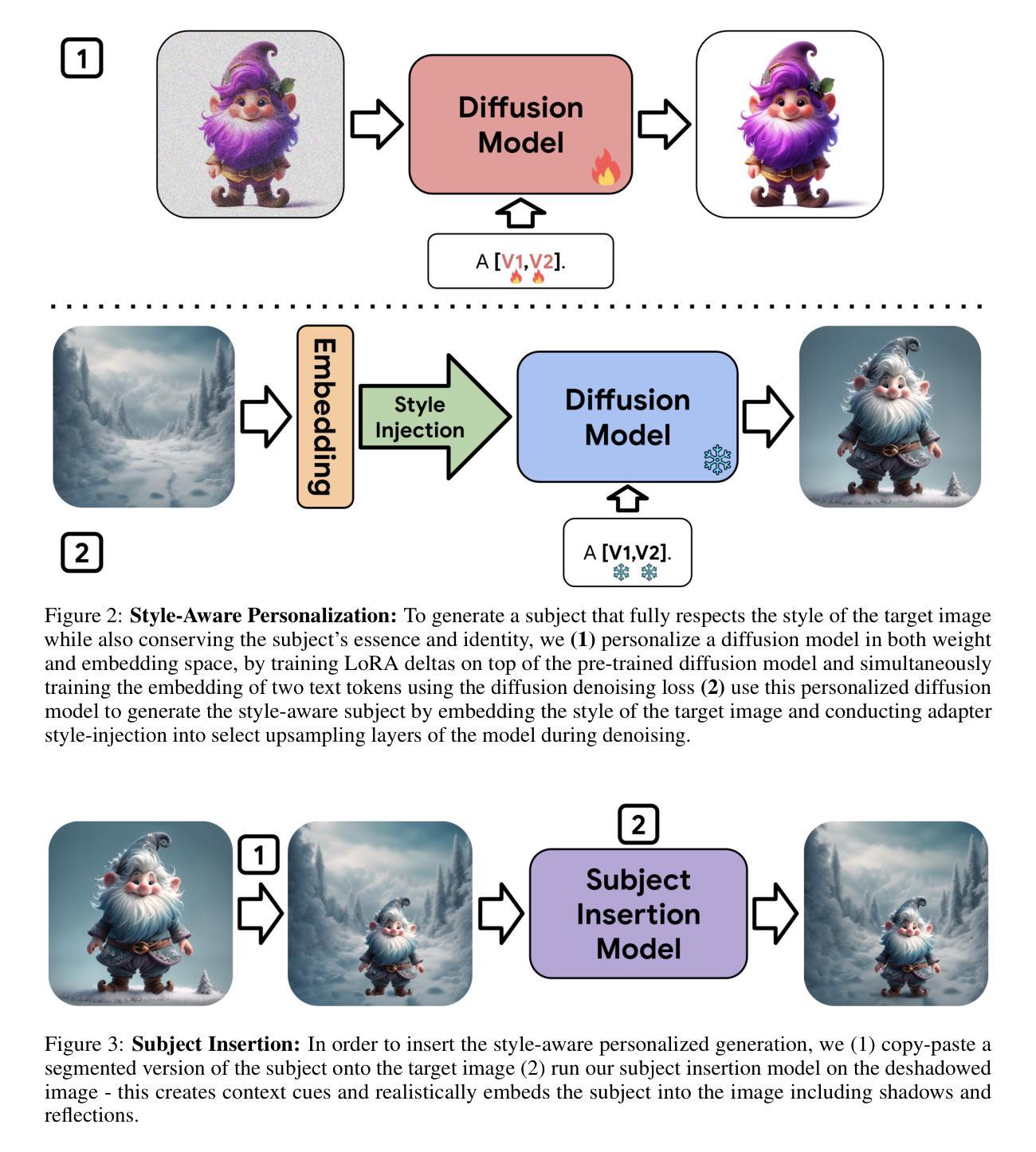
Magic Insert: Style-Aware Drag-and-Drop
Authors:Nataniel Ruiz, Yuanzhen Li, Neal Wadhwa, Yael Pritch, Michael Rubinstein, David E. Jacobs, Shlomi Fruchter
We present Magic Insert, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, our method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style. For object insertion, we use Bootstrapped Domain Adaption to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting. Finally, we present a dataset, SubjectPlop, to facilitate evaluation and future progress in this area. Project page: https://magicinsert.github.io/
PDF Project page: https://magicinsert.github.io/
Summary
提出了 Magic Insert 方法,可从用户提供的图像中将主体拖放到具有不同风格的目标图像中,以物理合理的方式并匹配目标图像的风格。
Key Takeaways
- Magic Insert 方法允许从一个图像中将主体拖放到另一个风格不同的目标图像中。
- 方法首先通过 LoRA 和学习的文本标记对预训练的文本到图像扩散模型进行微调,并结合目标风格的 CLIP 表示。
- 为了实现物体插入,采用了 Bootstrapped Domain Adaption 将特定域的逼真物体插入模型适应到多样艺术风格的域中。
- Magic Insert 显著优于传统的修补方法,如修补。
- 提供了 SubjectPlop 数据集,以促进该领域的评估和未来进展。
Please refer to relevant websites for more information, and feel free to ask me any other questions.
好的,请您提供具体文章的方法论部分,我将按照要求的格式为您进行详细的中文总结。
例如,方法论的内容可能是这样的:
- 方法论:
- (1) 文章首先通过文献综述的方法梳理了当前领域的研究现状。
- (2) 接着采用了实证研究的方法,通过收集数据进行分析。
- (3) 在数据分析过程中,使用了定量分析与定性分析相结合的方法。
- …(根据实际内容填写)
请提供具体文章的方法论部分,我会为您进行更详细的中文总结。
好的,我来帮您总结文章中的结论部分。以下是按照您要求的格式进行的中文总结:
- 结论:
(1)本文的工作意义是什么?
本文引入了一种风格感知的拖放问题,这是图像生成领域的一个新挑战。该研究旨在实现在目标图像中直观地插入主体,同时保持风格的一致性。该研究对于图像生成领域的发展具有重要意义,能够推动该领域的进一步探索与进步。
(2)从创新点、性能和工作量三个方面总结本文的优缺点。
创新点:本文提出了Magic Insert方法,通过结合风格感知个性化以及使用引导域适应进行风格插入来解决拖放问题,这是一种新的尝试和探索。
性能:Magic Insert方法在风格一致性和插入现实性方面都取得了出色的结果,相对于基准方法有所超越。
工作量:文章不仅提出了风格感知的拖放问题,还介绍了用于研究这一问题的Magic Insert方法和SubjectPlop数据集,工作量较大。但同时需要考虑到数据集的广泛性和方法的普及性,以便更多研究者能够参与其中并推动该领域的发展。
以上总结仅供参考,具体的总结内容还需要根据您提供的文章内容进行调整和补充。
点此查看论文截图

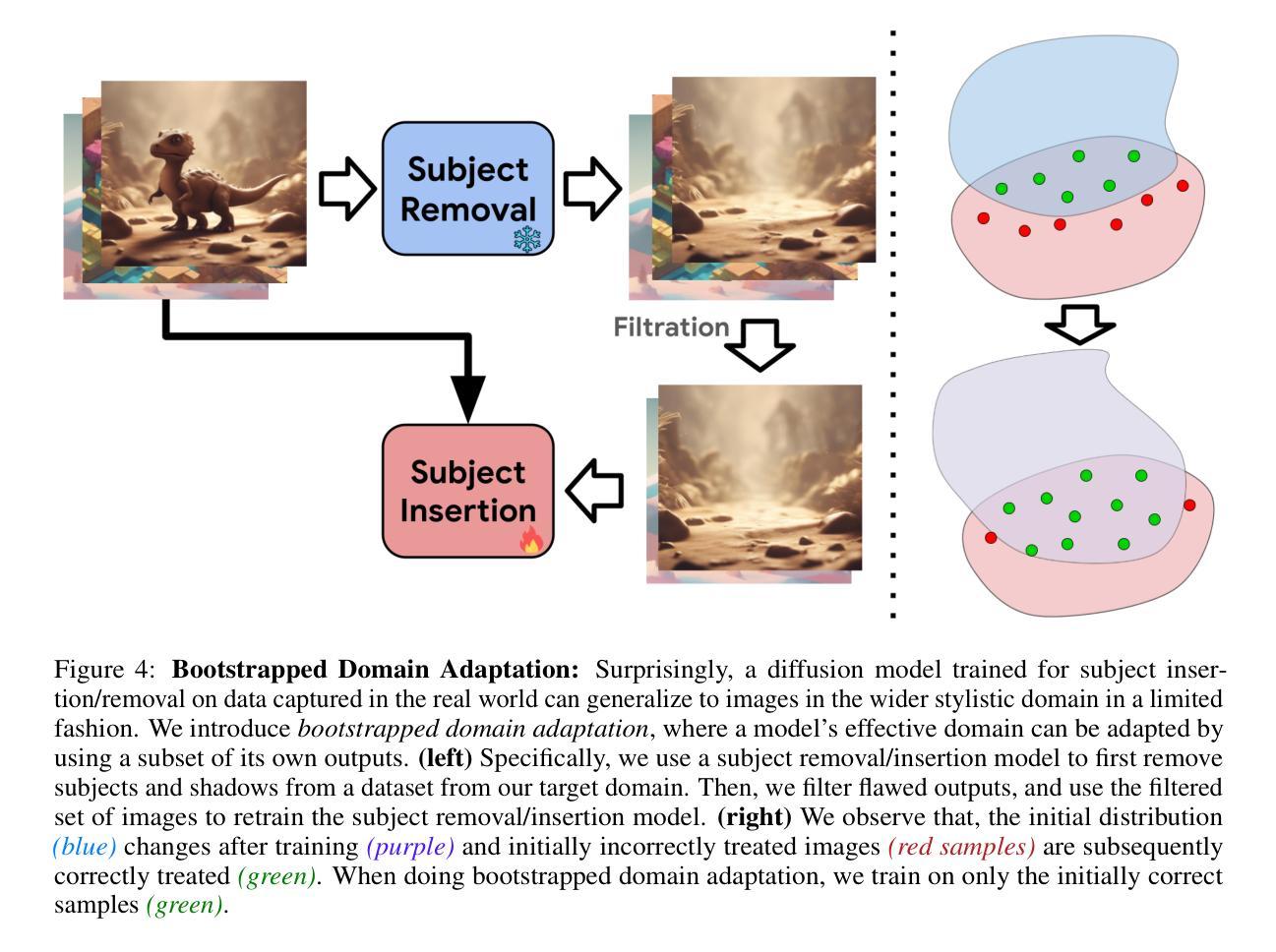
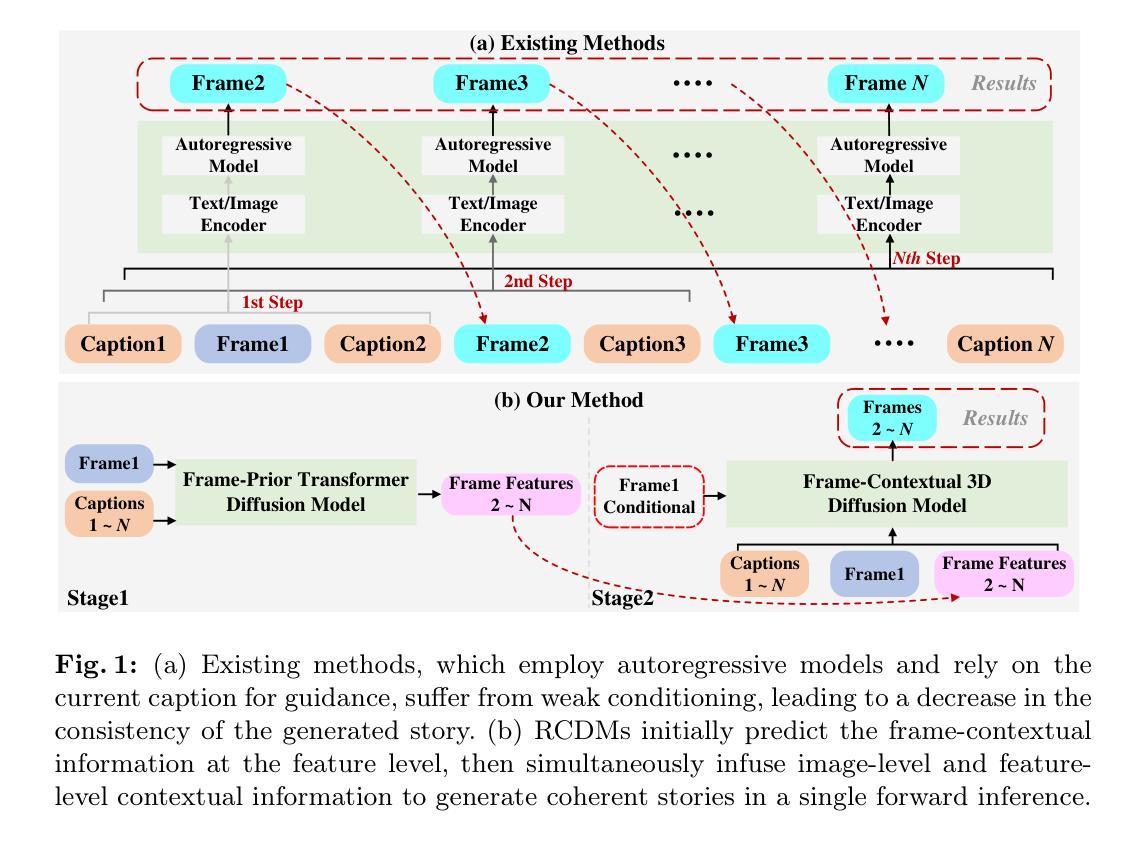
Boosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models
Authors:Fei Shen, Hu Ye, Sibo Liu, Jun Zhang, Cong Wang, Xiao Han, Wei Yang
Recent research showcases the considerable potential of conditional diffusion models for generating consistent stories. However, current methods, which predominantly generate stories in an autoregressive and excessively caption-dependent manner, often underrate the contextual consistency and relevance of frames during sequential generation. To address this, we propose a novel Rich-contextual Conditional Diffusion Models (RCDMs), a two-stage approach designed to enhance story generation’s semantic consistency and temporal consistency. Specifically, in the first stage, the frame-prior transformer diffusion model is presented to predict the frame semantic embedding of the unknown clip by aligning the semantic correlations between the captions and frames of the known clip. The second stage establishes a robust model with rich contextual conditions, including reference images of the known clip, the predicted frame semantic embedding of the unknown clip, and text embeddings of all captions. By jointly injecting these rich contextual conditions at the image and feature levels, RCDMs can generate semantic and temporal consistency stories. Moreover, RCDMs can generate consistent stories with a single forward inference compared to autoregressive models. Our qualitative and quantitative results demonstrate that our proposed RCDMs outperform in challenging scenarios. The code and model will be available at https://github.com/muzishen/RCDMs.
Summary
条件扩散模型展示了在生成连贯故事方面的潜力,提出了丰富语境条件条件扩散模型(RCDMs)来增强语义和时间连贯性。
Key Takeaways
- 条件扩散模型有助于生成连贯故事,避免传统方法中的语境一致性问题。
- 提出了丰富语境条件扩散模型(RCDMs),采用两阶段方法增强故事生成的语义一致性和时间一致性。
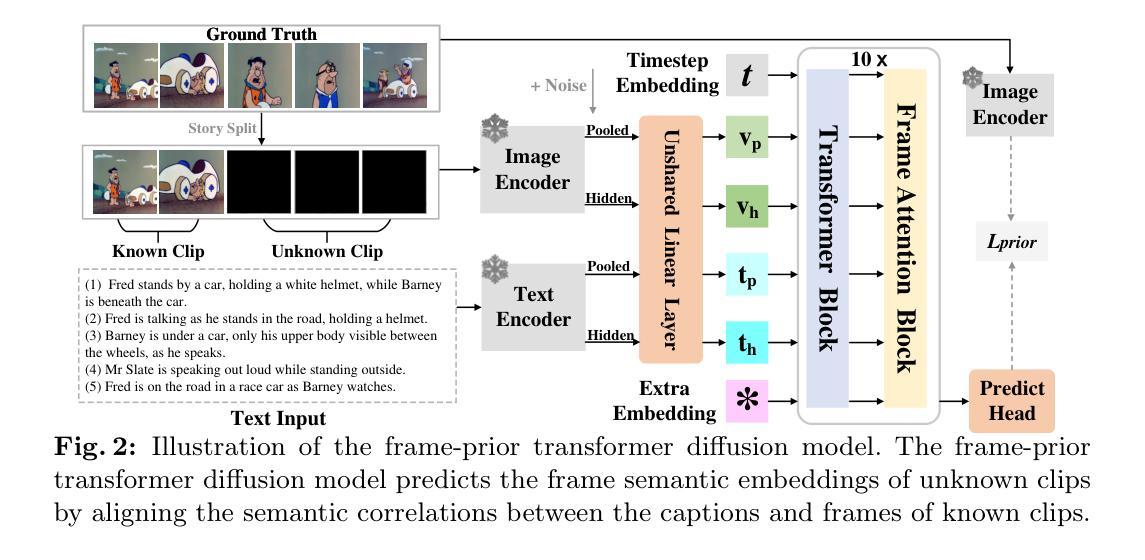
- 第一阶段引入了框架先验转换扩散模型,预测未知片段的语义嵌入。
- 第二阶段结合了参考图像、预测的框架语义嵌入和所有标题的文本嵌入,实现了丰富的语境条件。
- RCDMs能够在单次推理中生成连贯故事,相较自回归模型表现更优。
- 定性和定量结果显示,RCDMs在挑战性场景中表现出色。
- 提供了代码和模型的开放资源链接:https://github.com/muzishen/RCDMs。
好的,我会按照您的要求进行回答。
- Title: 基于富文本上下文的条件扩散模型提升故事可视化一致性研究
- Authors: 费飞, 叶虎, 刘思博, 张俊, 王聪, 韩啸, 杨威
- Affiliation: 腾讯AI实验室
- Keywords: 故事可视化、扩散模型、富文本上下文
- Urls: https://github.com/muzishen/RCDMs (Github代码链接)
- Summary:
(1) 研究背景:
随着自然语言处理和计算机视觉技术的发展,故事可视化已成为一个热门研究领域。该文章关注于如何利用条件扩散模型生成一致性的故事,以提升故事可视化效果。
(2) 过去的方法及问题:
当前的方法主要基于自回归和过度依赖标题的方式生成故事,但这种方法忽视了帧的上下文一致性和相关性。文章提出存在的问题是在序列生成过程中缺乏帧间的一致性和语义连续性。
(3) 研究方法:
文章提出了一种名为Rich-contextual Conditional Diffusion Models (RCDMs)的两阶段方法,旨在增强故事生成的语义一致性和时间一致性。在第一阶段,使用帧优先变压器扩散模型预测未知剪辑的帧语义嵌入,通过对齐已知剪辑的标题和帧之间的语义关联来实现。在第二阶段,建立一个具有丰富上下文条件的稳健模型,包括已知剪辑的参考图像、未知剪辑的预测帧语义嵌入和所有标题的文本嵌入。通过联合注入这些丰富的上下文条件在图像和特征级别,RCDMs能够生成语义和时间上一致的故事。此外,RCDMs可以通过单次前向推理生成一致的故事,与自回归模型相比具有优势。
(4) 任务与性能:
文章在故事可视化任务上进行了实验,证明了RCDMs方法的性能优于其他方法,特别是在具有挑战性的场景下。此外,文章提供了定量和定性的结果来支持其方法的性能。
性能评估方面,该文章提出的RCDMs方法能够在故事可视化任务中生成具有语义和时间一致性的故事,并且在挑战性场景下表现出优越的性能。实验结果表明,该方法可以支持其目标并生成高质量的故事。
好的,我会按照您的要求对文章的方法部分进行详细描述。
- 方法:
(1)背景介绍:本研究针对故事可视化领域中的序列生成问题展开。现有方法主要依赖自回归和标题的方式生成故事,但忽视了帧的上下文一致性和相关性,导致生成的故事缺乏语义连续性和时间一致性。
(2)研究方法介绍:本研究提出了一种名为Rich-contextual Conditional Diffusion Models (RCDMs)的两阶段方法。第一阶段是利用帧优先变压器扩散模型预测未知剪辑的帧语义嵌入,通过语义关联对齐已知剪辑的标题和帧。第二阶段是建立一个丰富上下文条件的模型,其中包括已知剪辑的参考图像、未知剪辑的预测帧语义嵌入和所有标题的文本嵌入。这些丰富的上下文条件在图像和特征级别联合注入,使得模型能够生成语义和时间上一致的故事。此外,RCDMs方法可以通过单次前向推理生成一致的故事,相较于自回归模型具有优势。
(3)实验设计:本研究在故事可视化任务上进行实验,通过与其他方法的对比实验来证明RCDMs方法的性能优势。实验包括对不同场景下的故事可视化任务进行实验,并对实验结果进行定量和定性的评估。实验结果表明,RCDMs方法能够在故事可视化任务中生成具有语义和时间一致性的故事,并且在挑战性场景下表现出优越的性能。
好的,我会按照您的要求来总结这篇文章。
关于文章的重要性的结论:
该文章对故事可视化领域进行了深入研究,提出了一种基于富文本上下文的条件扩散模型(RCDMs),旨在解决故事可视化中的一致性问题。该研究具有重要的理论和实践意义,对于提升故事可视化效果、拓展自然语言处理和计算机视觉技术的融合应用具有重要意义。同时,该研究也有助于推动故事可视化领域的进一步发展。
关于创新点、性能和工作量的结论:
创新点:该文章提出了RCDMs方法,通过引入丰富的上下文条件,在图像和特征级别上增强故事生成的语义一致性和时间一致性。该方法相较于传统的自回归方法具有优势,可以通过单次前向推理生成一致的故事。此外,该文章使用的扩散模型在自然语言处理和计算机视觉领域的结合上是一个新的尝试,具有创新性。
性能:该文章在故事可视化任务上进行了实验,证明了RCDMs方法的性能优于其他方法,特别是在挑战性场景下。实验结果表明,该方法能够生成具有语义和时间一致性的故事,并且具有良好的鲁棒性和可扩展性。此外,该文章提供了定量和定性的结果来支持其方法的性能。
工作量:该文章涉及的研究工作包括提出新的模型架构、设计实验方案、进行实验验证、分析实验结果等。工作量较大,具有一定的复杂性。同时,该文章对相关工作进行了全面的调研和分析,为研究工作提供了坚实的基础。但文章未提及跨数据集角色多样性的限制,这也是其潜在的一个局限性。
总体来说,该文章具有重要的理论和实践意义,具有创新性,在性能和工作量方面表现良好。未来研究方向可以包括如何克服跨数据集角色多样性的限制以及如何进一步提高生成故事的质量和多样性等方面。
点此查看论文截图