⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-05 更新
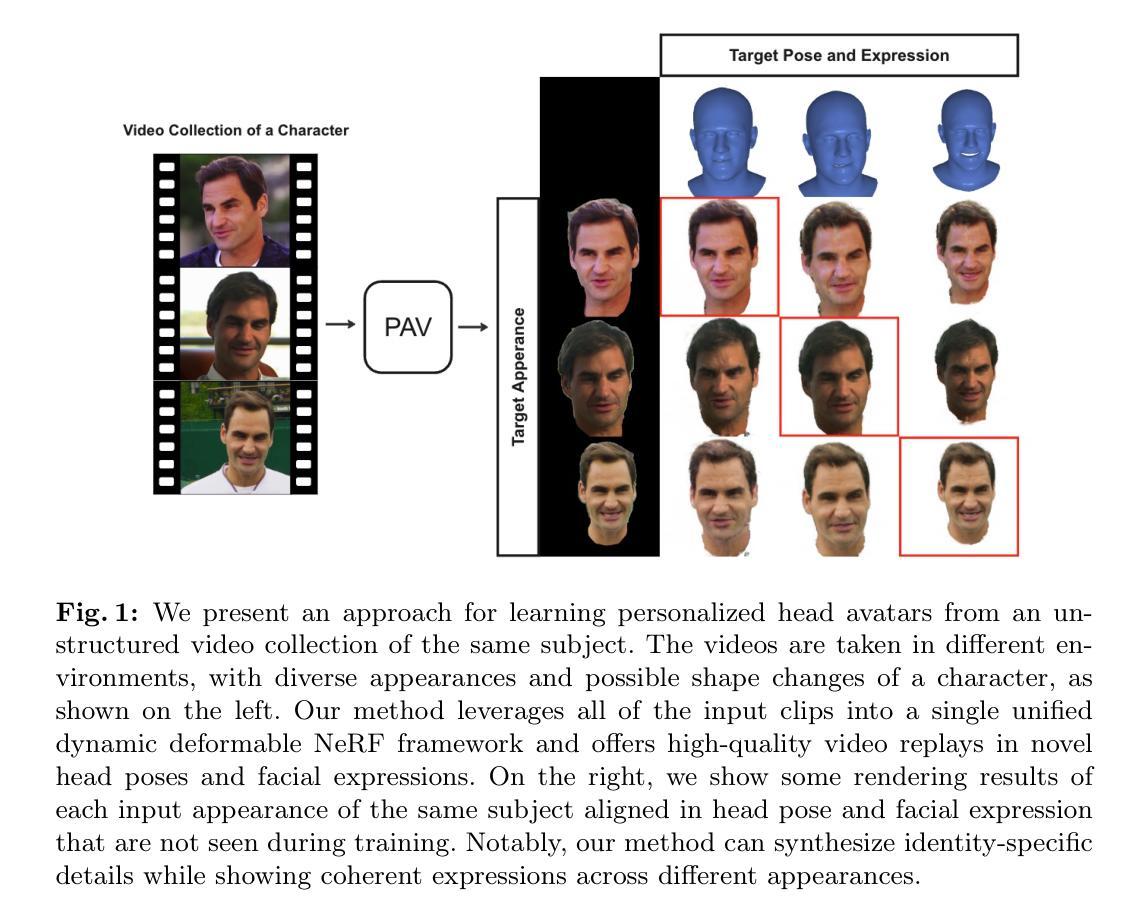
PAV: Personalized Head Avatar from Unstructured Video Collection
Authors:Akin Caliskan, Berkay Kicanaoglu, Hyeongwoo Kim
We propose PAV, Personalized Head Avatar for the synthesis of human faces under arbitrary viewpoints and facial expressions. PAV introduces a method that learns a dynamic deformable neural radiance field (NeRF), in particular from a collection of monocular talking face videos of the same character under various appearance and shape changes. Unlike existing head NeRF methods that are limited to modeling such input videos on a per-appearance basis, our method allows for learning multi-appearance NeRFs, introducing appearance embedding for each input video via learnable latent neural features attached to the underlying geometry. Furthermore, the proposed appearance-conditioned density formulation facilitates the shape variation of the character, such as facial hair and soft tissues, in the radiance field prediction. To the best of our knowledge, our approach is the first dynamic deformable NeRF framework to model appearance and shape variations in a single unified network for multi-appearances of the same subject. We demonstrate experimentally that PAV outperforms the baseline method in terms of visual rendering quality in our quantitative and qualitative studies on various subjects.
PDF Accepted to ECCV24. Project page: https://akincaliskan3d.github.io/PAV
Summary
提出了PAV,一种用于合成人脸的个性化头像的方法,能够在任意视角和表情下合成人类面部。
Key Takeaways
- PAV引入了一种学习动态可变形神经辐射场(NeRF)的方法,特别是从同一角色的多种外观和形状变化的单目对话面部视频集合中学习。
- 与现有的头部NeRF方法不同,后者仅限于对每个外观基础上的输入视频进行建模,我们的方法通过引入每个输入视频的外观嵌入,通过可学习的潜在神经特征附加到底层几何形状来学习多外观NeRF。
- 提出的外观条件密度公式促进了人物形状的变化,如面部毛发和软组织,在辐射场预测中。
- 我们的方法是首个动态可变形NeRF框架,能够在单个统一网络中建模同一主题的多外观的外观和形状变化。
- 在各种主题的定量和定性研究中,实验证明PAV在视觉渲染质量方面优于基准方法。
好的,我会按照您的要求来总结这篇论文。以下是按照您的格式要求的回答:
标题:个性化头部阿凡达(PAV:Personalized Head Avatar)
作者:Akin Caliskan、Berkay Kicanaoglu和Hyeongwoo Kim。
作者隶属机构:第一作者Akin Caliskan隶属Flawless AI,第二作者Berkay Kicanaoglu和第三作者Hyeongwoo Kim分别隶属Imperial College London。
关键词:个性化头部阿凡达、动态变形神经辐射场(NeRF)、人脸合成、任意视角、面部表情、数字人类阿凡达。
链接:论文链接(待补充),GitHub代码链接(如有可用,填入Github;若无,填入None)。
摘要:
(1) 研究背景:本文的研究背景是关于个性化头部阿凡达(Personalized Head Avatar)的合成,特别是在任意视角和面部表情下的人脸合成。随着数字内容创建和电影工业的发展,对个性化人类阿凡达的需求也在增加。为了满足这一需求,研究者们提出了一系列方法来创建和动画化个性化头部阿凡达。
(2) 过去的方法与问题:现有的头部NeRF方法主要局限于对同一外观的输入视频进行建模。然而,它们无法处理多外观的NeRFs,也无法学习每个输入视频的外观嵌入。此外,它们没有考虑到面部毛发和软组织等形状变化在辐射场预测中的重要性。因此,开发一种能够处理多外观、学习每个视频的外观嵌入并考虑形状变化的动态可变形NeRF框架是非常必要的。
(3) 研究方法:本文提出了一种名为PAV(Personalized Head Avatar)的方法,用于合成任意视角和面部表情下的人脸。PAV引入了一种学习动态可变形神经辐射场(NeRF)的方法,特别是从同一角色的单目谈话视频集中学习。PAV允许学习多外观NeRF,通过引入与底层几何相关联的可学习潜在神经特征来为每个输入视频提供外观嵌入。此外,提出的外观条件密度公式有助于预测辐射场中的形状变化,如面部毛发和软组织。据我们所知,PAV是第一个在单一统一网络中建模多外观相同主体的外观和形状变化的动态可变形NeRF框架。
(4) 任务与性能:本文的实验表明,PAV在视觉渲染质量方面优于基准方法。在多种主题上的定量和定性研究表明,PAV可以有效地合成任意视角和面部表情下的人脸。PAV的性能支持其目标,为个性化头部阿凡达的开发提供了一种有效且实用的方法。
希望这个总结符合您的要求!
好的,我会按照您的要求来详细阐述这篇论文的方法论。以下是按照您的格式要求的回答:
- 方法论:
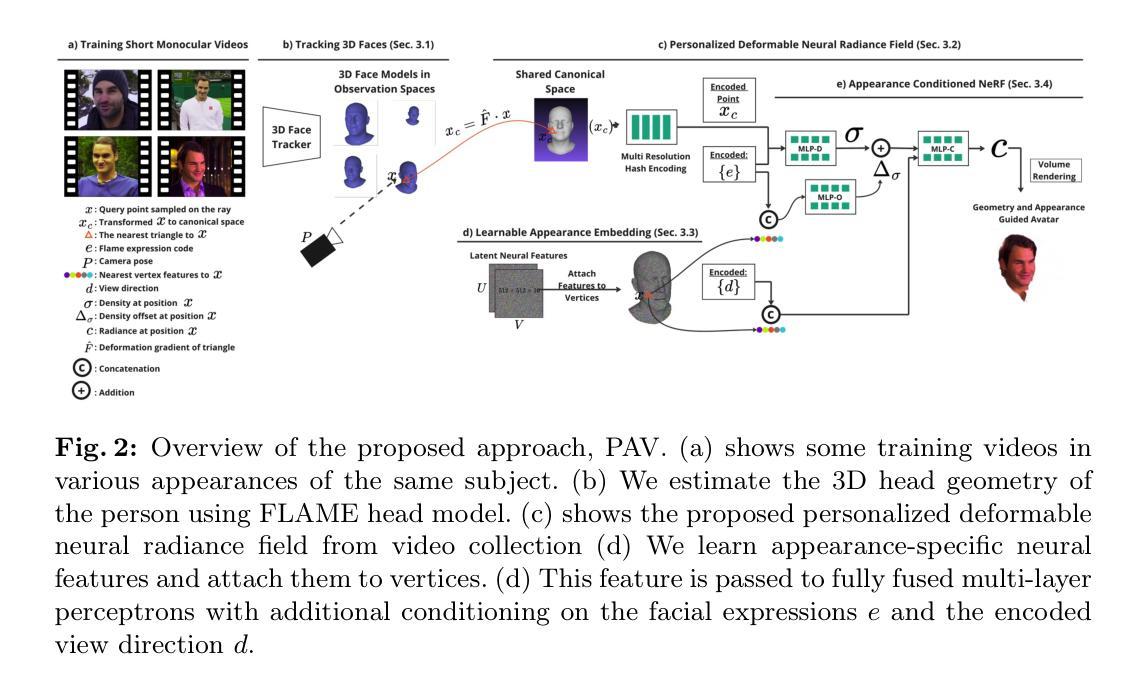
(1)研究问题定义:本研究旨在解决个性化头部阿凡达(Personalized Head Avatar)的合成问题,特别是在任意视角和面部表情下的人脸合成。针对现有方法的局限性,提出了一种名为PAV(Personalized Head Avatar)的方法。
(2)数据集构建:使用同一角色的单目谈话视频集进行学习。这些数据集包含了不同视角和面部表情的丰富变化,为动态可变形神经辐射场(NeRF)的学习提供了充足的素材。
(3)方法框架:PAV方法引入了动态可变形神经辐射场(NeRF)的学习。该方法结合了深度学习技术和计算机图形学的知识,通过建立动态可变形NeRF模型来捕捉人脸的形状和纹理变化。具体来说,它允许学习多外观NeRF,为每个输入视频提供外观嵌入,并引入与底层几何相关联的可学习潜在神经特征。此外,提出的外观条件密度公式有助于预测辐射场中的形状变化。
(4)实验设计:为了验证PAV方法的性能,本研究进行了大量的实验。实验结果表明,PAV在视觉渲染质量方面优于基准方法。在多种主题上的定量和定性研究表明,PAV可以有效地合成任意视角和面部表情下的人脸。此外,本研究还通过用户研究验证了PAV方法的实用性和用户满意度。
(5)结果评估:本研究通过定量和定性评估方法,对PAV方法的性能进行了全面的评估。定量评估使用了常用的评估指标,如PSNR(峰值信噪比)、SSIM(结构相似性度量)等。定性评估则通过视觉检查结果和对比实验来验证PAV方法的优势。同时,本研究还通过用户研究来评估用户对PAV方法生成的头部阿凡达的满意度和实用性评价。
好的,以下是按照您的要求进行的回答:
- Conclusion:
(1)这篇论文的重要性在于它解决了个性化头部阿凡达合成的问题,特别是在任意视角和面部表情下的人脸合成。随着数字内容创建和电影工业的发展,对个性化头部阿凡达的需求日益增加,这篇论文提出了一种有效的方法来满足这一需求。
(2)创新点:该论文提出了一种名为PAV(Personalized Head Avatar)的方法,用于合成个性化头部阿凡达。PAV方法引入了动态可变形神经辐射场(NeRF)的学习,能够处理多外观、学习每个输入视频的外观嵌入,并考虑形状变化。据作者所知,PAV是第一个在单一统一网络中建模多外观相同主体的外观和形状变化的动态可变形NeRF框架。
性能:实验结果表明,PAV方法在视觉渲染质量方面优于基准方法,能够有效地合成任意视角和面部表情下的人脸。此外,通过用户研究验证了PAV方法的实用性和用户满意度。
工作量:论文作者进行了大量的实验来验证PAV方法的性能,包括数据集构建、方法框架设计、实验设计和结果评估等。论文还详细阐述了方法论和实验过程,展示了作者在该领域深入的研究和实验工作。
点此查看论文截图

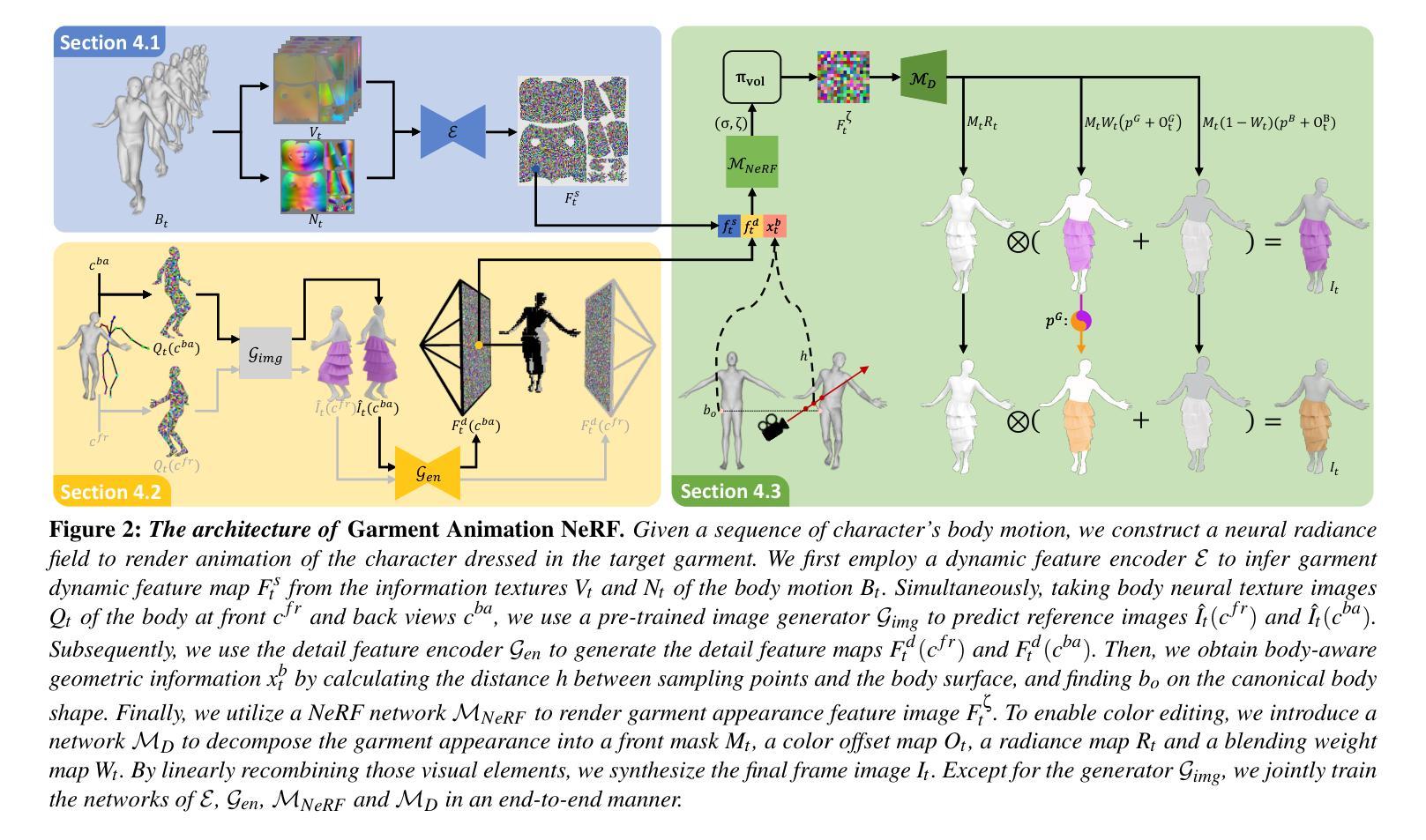
Garment Animation NeRF with Color Editing
Authors:Renke Wang, Meng Zhang, Jun Li, Jian Yan
Generating high-fidelity garment animations through traditional workflows, from modeling to rendering, is both tedious and expensive. These workflows often require repetitive steps in response to updates in character motion, rendering viewpoint changes, or appearance edits. Although recent neural rendering offers an efficient solution for computationally intensive processes, it struggles with rendering complex garment animations containing fine wrinkle details and realistic garment-and-body occlusions, while maintaining structural consistency across frames and dense view rendering. In this paper, we propose a novel approach to directly synthesize garment animations from body motion sequences without the need for an explicit garment proxy. Our approach infers garment dynamic features from body motion, providing a preliminary overview of garment structure. Simultaneously, we capture detailed features from synthesized reference images of the garment’s front and back, generated by a pre-trained image model. These features are then used to construct a neural radiance field that renders the garment animation video. Additionally, our technique enables garment recoloring by decomposing its visual elements. We demonstrate the generalizability of our method across unseen body motions and camera views, ensuring detailed structural consistency. Furthermore, we showcase its applicability to color editing on both real and synthetic garment data. Compared to existing neural rendering techniques, our method exhibits qualitative and quantitative improvements in garment dynamics and wrinkle detail modeling. Code is available at \url{https://github.com/wrk226/GarmentAnimationNeRF}.
Summary
通过直接从身体运动序列中合成服装动画,本文提出了一种新方法,无需显式服装代理,能够生成高保真度的服装动画。
Key Takeaways
- 传统的建模到渲染的工作流程在生成高保真度服装动画时既繁琐又昂贵。
- 最近的神经渲染技术虽然在计算密集型处理上有效,但在处理复杂的服装动画(如细微皱褶和服装与身体的真实遮挡)时存在挑战。
- 文章提出的方法通过身体运动推断服装动态特征,并结合预训练图像模型生成的服装图像特征,构建神经辐射场以渲染服装动画视频。
- 技术支持服装的重新着色,通过分解其视觉元素实现。
- 方法展示了在未见过的身体运动和摄像机视角下的普适性,保证了结构一致性。
- 在真实和合成服装数据上展示了颜色编辑的适用性。
- 与现有的神经渲染技术相比,该方法在模拟服装动态和皱褶细节建模方面展现出定性和定量上的改进。
Please refer to relevant websites for more information, and feel free to ask me any other questions.
好的,我会根据您给出的格式进行文章总结。由于无法看到实际的文章内容和具体的
正文略(这里应该是该篇文章或论文的内容正文部分)
8. Conclusion:
(对于第一小问的答案):
这一作品的意义在于……(此处应详细阐述作品的意义,如其在文学领域的重要性、对读者的启示等)。它……(简要总结作品的核心价值或影响)。
(对于第二小问的答案,分别从创新点、性能和工作负载三个方面对文章进行强弱概括):
- 创新点: 本文的创新之处在于……(简要描述文章在某一领域的独特视角、研究方法或观点)。然而,也存在一些创新点不够突出或缺乏深度的问题,需要进一步深入探讨。
- 性能: 文章在性能方面的优点包括……(列举文章在论证、分析、论述等方面的优点)。但也可能存在一些不足之处,如对某些细节的分析不够深入等。
- 工作量: 文章的工作量体现在……(描述文章在研究准备、数据收集、实验设计等方面的工作量投入)。但也可能存在工作量分配不均或者在某些环节工作深度不足的情况。总体来说,该文章具有一定的价值但也存在可提升的空间。
(注:具体内容需要根据文章的实际内容来填充。)
点此查看论文截图

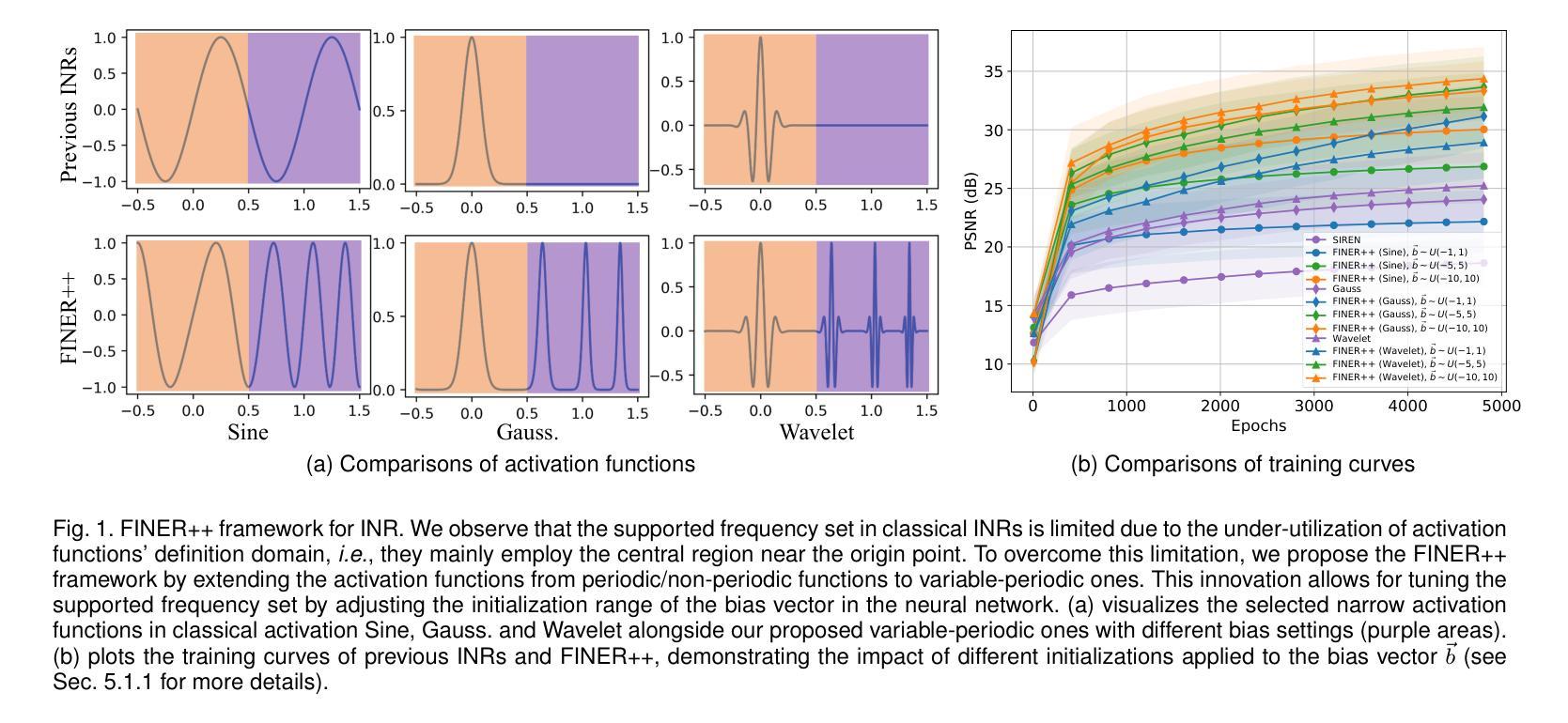
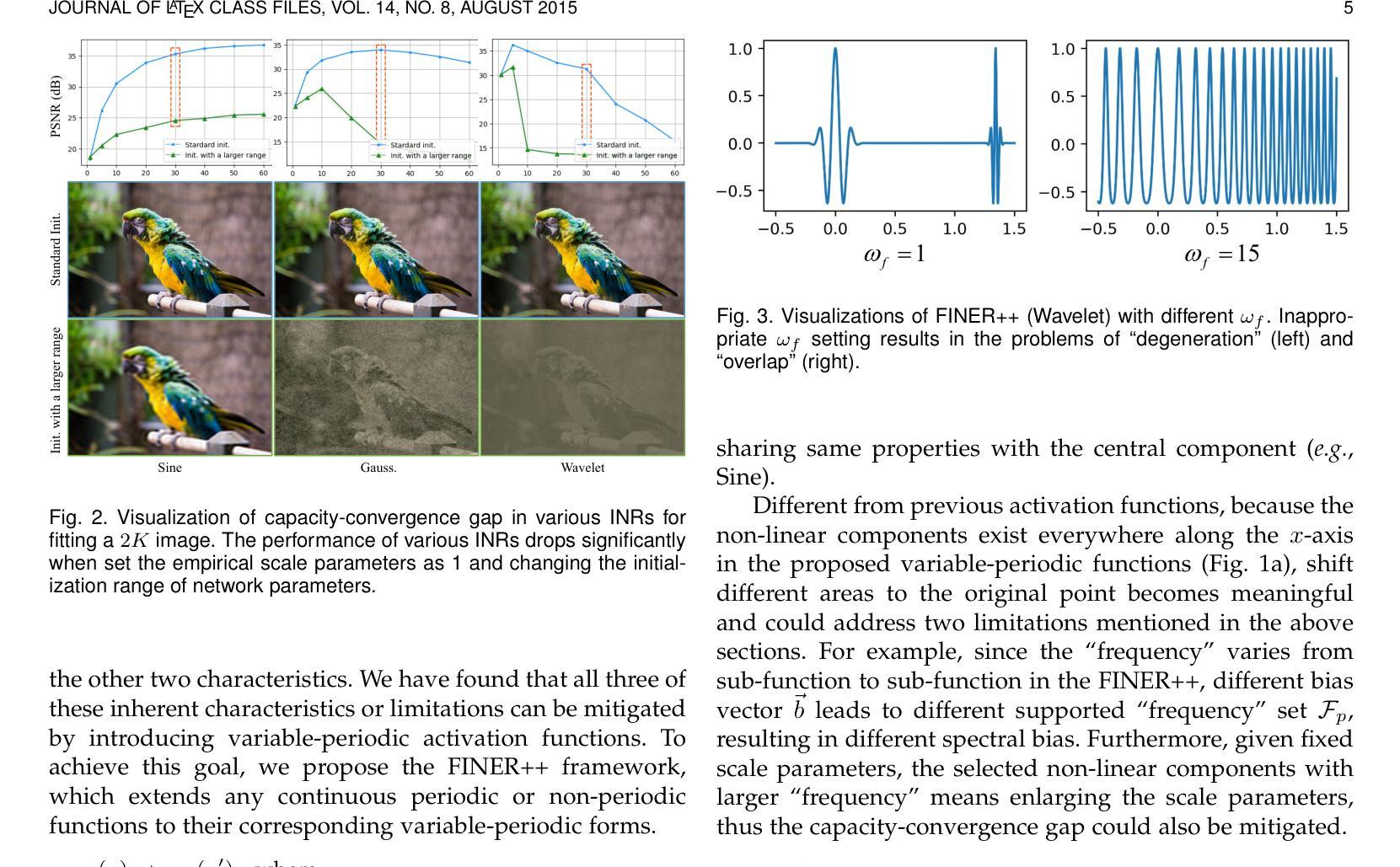
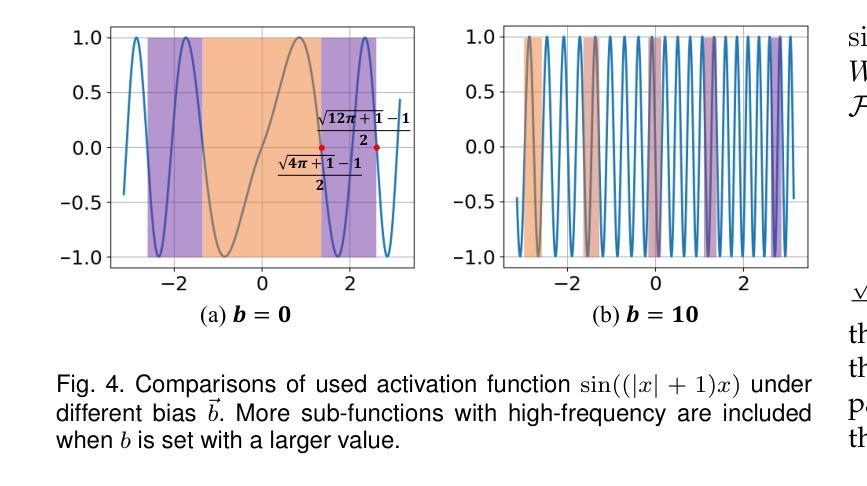
FINER++: Building a Family of Variable-periodic Functions for Activating Implicit Neural Representation
Authors:Hao Zhu, Zhen Liu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, Xun Cao
Implicit Neural Representation (INR), which utilizes a neural network to map coordinate inputs to corresponding attributes, is causing a revolution in the field of signal processing. However, current INR techniques suffer from the “frequency”-specified spectral bias and capacity-convergence gap, resulting in imperfect performance when representing complex signals with multiple “frequencies”. We have identified that both of these two characteristics could be handled by increasing the utilization of definition domain in current activation functions, for which we propose the FINER++ framework by extending existing periodic/non-periodic activation functions to variable-periodic ones. By initializing the bias of the neural network with different ranges, sub-functions with various frequencies in the variable-periodic function are selected for activation. Consequently, the supported frequency set can be flexibly tuned, leading to improved performance in signal representation. We demonstrate the generalization and capabilities of FINER++ with different activation function backbones (Sine, Gauss. and Wavelet) and various tasks (2D image fitting, 3D signed distance field representation, 5D neural radiance fields optimization and streamable INR transmission), and we show that it improves existing INRs. Project page: {https://liuzhen0212.github.io/finerpp/}
PDF Extension of previous CVPR paper “FINER: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions”. arXiv admin note: substantial text overlap with arXiv:2312.02434
Summary
隐式神经表示(INR)利用神经网络将坐标输入映射到对应属性,正在信号处理领域引发革命,通过扩展周期/非周期激活函数提出FINER++框架以处理频谱偏差和容量收敛差异,灵活调节支持的频率集合,显著提高信号表示性能。
Key Takeaways
- 隐式神经表示(INR)通过神经网络将坐标映射到属性,革新了信号处理领域。
- 当前INR技术存在”频率”特定的频谱偏差和容量收敛差异,导致在表示多频率复杂信号时性能不佳。
- FINER++框架通过扩展现有的周期/非周期激活函数,解决了上述问题。
- 利用不同激活函数骨干(正弦、高斯、小波)和各种任务(2D图像拟合、3D有符号距离场表示、5D神经辐射场优化和可流式INR传输)展示了FINER++的泛化能力和性能优势。
- 通过调整神经网络的偏置范围,选择变周期函数中具有不同频率的子函数进行激活。
- FINER++使得支持的频率集合可以灵活调节,从而改善信号表示的性能。
- 项目页面:{https://liuzhen0212.github.io/finerpp/}
好的,我会按照您的要求进行回答。
标题:FINER++:构建可变周期函数家族以激活隐式神经表示
作者:Hao Zhu, Zhen Liu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, Xun Cao
隶属机构:第一作者Hao Zhu隶属南京大学电子科学与工程学院。
关键词:隐式神经表示,可变周期激活函数,谱偏置
网址:https://liuzhen0212.github.io/finerpp/
Github代码链接:None概述:
- (1)研究背景:本文的研究背景是关于隐式神经表示(INR)在信号处理领域的应用。隐式神经表示通过神经网络将坐标映射到相应的属性,正在引起革命。然而,当前的INR技术在处理具有多个“频率”的复杂信号时存在不完美的性能。
- (2)过去的方法及问题:过去的方法主要集中在优化权重矩阵以更好地匹配频率候选,但存在谱偏置和容量收敛间隙等问题。这些问题与激活函数定义域利用不足有关。
- (3)研究方法:本文提出了一个名为FINER++的通用框架,它通过扩展现有的周期性和非周期性激活函数到可变周期版本,解决了上述问题。通过控制输入值的范围来初始化神经网络的偏差,以选择可变周期函数中的子函数来激活。这样可以灵活调整支持的频率集,从而提高信号表示的性能。该框架使用不同的激活函数(如正弦、高斯和小波)和各种任务(如2D图像拟合、3D有符号距离场表示等)来验证其效果。
- (4)任务与成果:本文提出的FINER++在多种任务上取得了良好的性能,包括图像拟合、距离场表示、神经辐射场优化和可流式传输的INR等。实验结果表明,FINER++提高了现有INRs的性能,证明了其有效性和灵活性。该方法的性能支持其目标,为解决现代信号处理中的逆问题提供了新的思路和方法。
结论:
(1)工作意义:本文提出了FINER++方法,通过构建可变周期激活函数家族,对隐式神经表示(INR)进行了扩展。这种方法解决了现有INR在处理具有多个“频率”的复杂信号时存在的问题,为提高信号表示的性能提供了新的思路和方法。这对于信号处理领域,尤其是需要处理复杂信号的领域,具有重要的理论和实践意义。
(2)创新点、性能、工作量评价:
创新点:本文提出的FINER++方法,通过扩展现有的周期性和非周期性激活函数到可变周期版本,解决了现有INR存在的问题。该方法在激活函数定义域利用不足、频谱偏置和容量收敛间隙等方面进行了改进,具有显著的创新性。
性能:在多种任务上,FINER++取得了良好的性能,包括图像拟合、距离场表示、神经辐射场优化和可流式传输的INR等。实验结果表明,FINER++提高了现有INRs的性能,证明了其有效性和灵活性。
工作量:本文不仅提出了FINER++方法,还进行了大量的实验验证,包括不同任务上的性能评估和对比分析。此外,作者对相关工作进行了全面的调研和分析,工作量较大。
总的来说,本文提出的FINER++方法在隐式神经表示领域具有重要的创新性和实用价值,为信号处理领域的发展做出了贡献。
点此查看论文截图

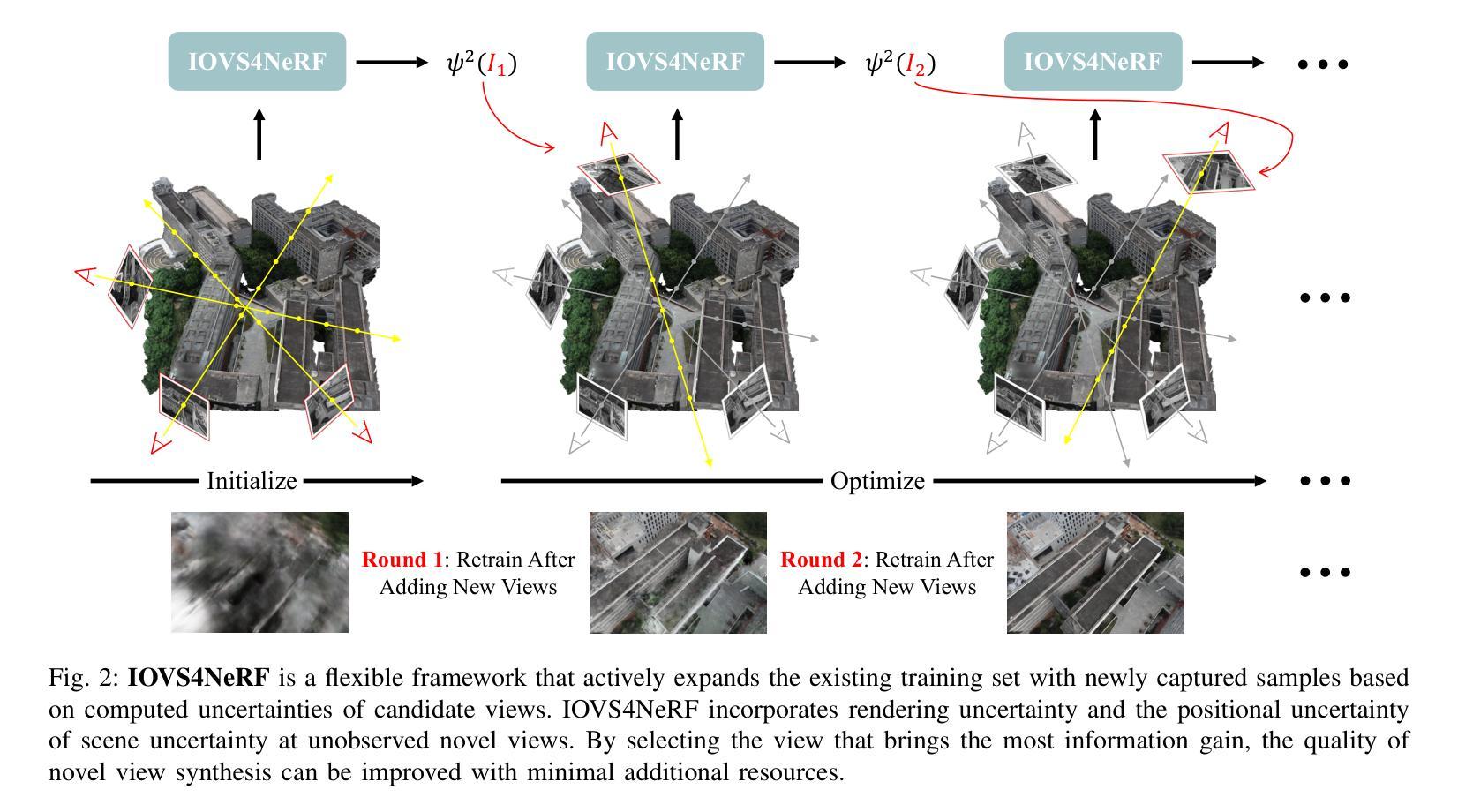
IOVS4NeRF:Incremental Optimal View Selection for Large-Scale NeRFs
Authors:Jingpeng Xie, Shiyu Tan, Yuanlei Wang, Yizhen Lao
Urban-level three-dimensional reconstruction for modern applications demands high rendering fidelity while minimizing computational costs. The advent of Neural Radiance Fields (NeRF) has enhanced 3D reconstruction, yet it exhibits artifacts under multiple viewpoints. In this paper, we propose a new NeRF framework method to address these issues. Our method uses image content and pose data to iteratively plan the next best view. A crucial aspect of this method involves uncertainty estimation, guiding the selection of views with maximum information gain from a candidate set. This iterative process enhances rendering quality over time. Simultaneously, we introduce the Vonoroi diagram and threshold sampling together with flight classifier to boost the efficiency, while keep the original NeRF network intact. It can serve as a plug-in tool to assist in better rendering, outperforming baselines and similar prior works.
Summary
NeRF提出了一种新的框架方法来解决多视角下的众多问题,通过图像内容和姿态数据迭代规划最佳视角,结合不确定性估计优化渲染质量。
Key Takeaways
- NeRF方法通过使用图像内容和姿态数据来改进三维重建的质量。
- 新方法引入了不确定性估计,指导视角选择,提高信息获取效率。
- 引入Vonoroi图和阈值抽样,以及飞行分类器,增强了渲染效率。
- 该方法可作为插件工具,改善渲染效果,超越基线和类似先前工作。
- 保持原始NeRF网络的完整性。
- 迭代过程随时间增强了渲染质量。
- 提出的方法适用于现代应用中对高渲染保真度和低计算成本的需求。
好的,我会按照您的要求进行回答。
标题:基于增量最优视角选择的神经网络辐射场三维重建研究
作者:Jingpeng Xie(谢景鹏), Shiyu Tan(谭世宇), Yuanlei Wang(王远雷), Yizhen Lao(劳亦真)
隶属机构:未知(请查看论文原文获取)
关键词:不确定性估计、无人机、神经网络辐射场、场景重建、视角选择
链接:论文链接未知,GitHub代码链接未知(如果可用,请填写GitHub链接)
摘要:
(1) 研究背景:随着现代应用中对城市级三维重建需求的增长,对高质量渲染和高效计算的要求也越来越高。本文研究如何运用神经网络辐射场(NeRF)技术解决三维重建中的问题。
(2) 过去的方法及问题:过去的方法主要包括点云方法和NeRF方法。点云方法虽然可以构建三维模型,但表面连接性缺失,表面不够平滑。NeRF方法通过神经网络表示场景中的辐射场,可以实现高质量的图像重建和视角合成,但在多视角情况下会出现伪影,计算资源消耗大,对大规模场景的效率不高。
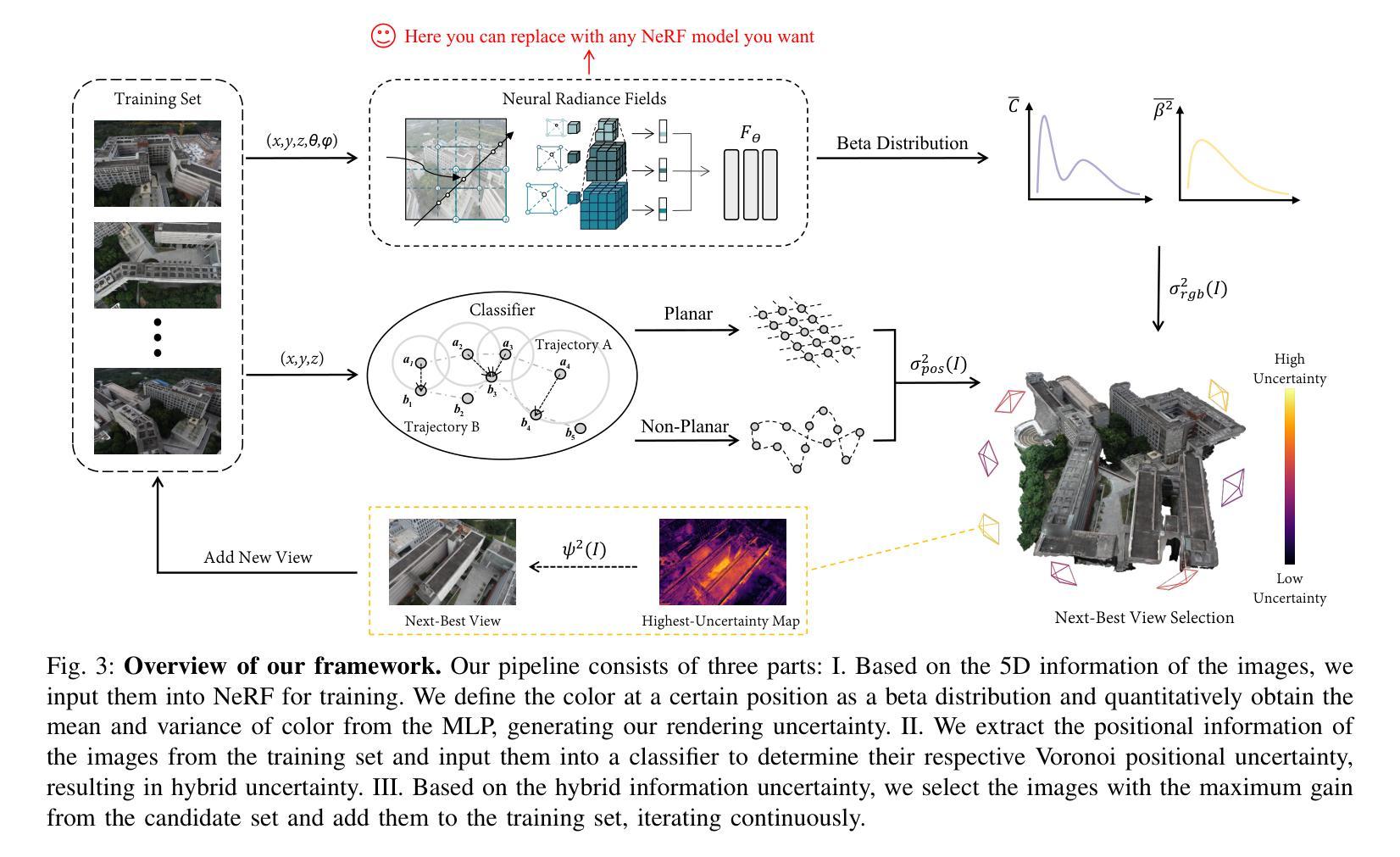
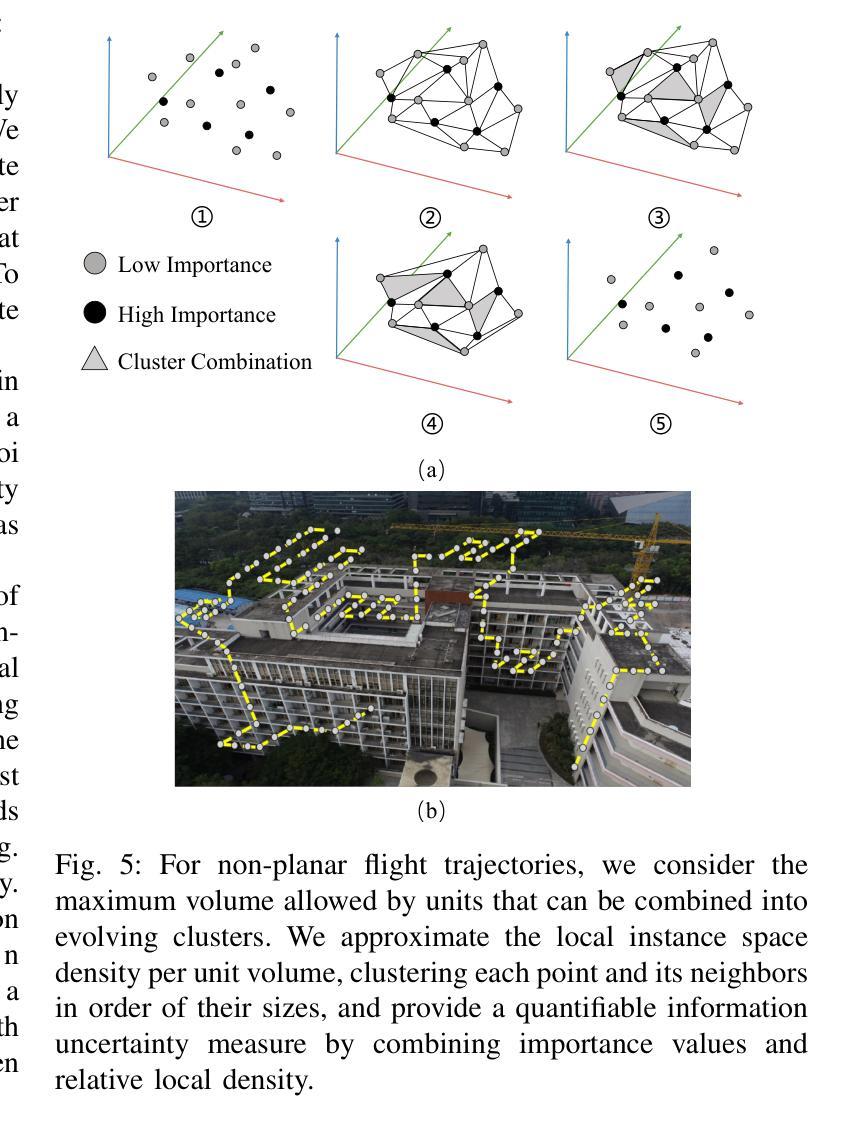
(3) 研究方法:针对上述问题,本文提出了一种新的NeRF框架方法,通过图像内容和姿态数据迭代规划下一个最佳视角。该方法涉及不确定性估计,通过选择信息增益最大的视角来提高渲染质量。同时,引入了Voronoi图、阈值采样和飞行分类器来提高效率,保持原NeRF网络不变。
(4) 任务与性能:本文的方法适用于大规模场景的三维重建任务,通过对比实验,本文方法在处理时间和重建效果上均优于其他方法。在ArtSci数据集上的实验结果表明,本文方法在保证较高性能的同时,也提高了计算效率。
希望这个回答符合您的要求。
7. 方法论概述:
这篇文章提出了一个名为IOVS4NeRF的新方法来解决城市级三维重建中的问题。其方法论思想主要包含了以下几个步骤:
(1) 研究背景和问题定义:随着现代应用中对城市级三维重建需求的增长,对高质量渲染和高效计算的要求也越来越高。传统的点云方法和NeRF方法存在一些问题,如表面连接性缺失、表面不够平滑、多视角下的伪影、计算资源消耗大以及对大规模场景的效率不高。针对这些问题,文章提出了一个新的NeRF框架方法。
(2) 方法设计:该方法通过图像内容和姿态数据的迭代规划来选择下一个最佳视角。它涉及不确定性估计,通过选择信息增益最大的视角来提高渲染质量。同时,引入了Voronoi图、阈值采样和飞行分类器来提高效率,保持原NeRF网络不变。
(3) 实验设计和评估:为了评估该方法的性能,文章进行了大量的实验,并将其与其他先进的NeRF基视角选择解决方案进行了比较。实验结果表明,IOVS4NeRF在不确定性预测和新型视图合成方面均优于其他方法。此外,还通过比较基线最优视角选择策略来进一步验证IOVS4NeRF的有效性。实验结果表明,IOVS4NeRF能够在保证较高性能的同时,提高计算效率。
总的来说,该文章提出的IOVS4NeRF方法旨在通过更高效的视角选择和不确定性估计来解决城市级三维重建中的难题,从而提高渲染质量和计算效率。
好的,以下是对该文章的总结和评价:
- Conclusion:
(1)工作意义:该文章提出了一种基于增量最优视角选择的神经网络辐射场三维重建方法,对于城市级三维重建任务具有重要意义,能够提高渲染质量和计算效率,满足现代应用中对高质量渲染和高效计算的需求。
(2)创新点、性能和工作量评价:
创新点:该文章引入了一种新的NeRF框架方法,通过图像内容和姿态数据的迭代规划选择下一个最佳视角,涉及不确定性估计,提高了渲染质量。同时,引入了Voronoi图、阈值采样和飞行分类器等技术,提高了计算效率。
性能:该文章的方法适用于大规模场景的三维重建任务,通过对比实验,证明该方法在处理时间和重建效果上均优于其他方法。在ArtSci数据集上的实验结果表明,该方法在保证较高性能的同时,也提高了计算效率。
工作量:该文章进行了大量的实验和比较,验证了所提出方法的有效性和性能。此外,文章还详细阐述了方法论的各个步骤和细节,说明作者进行了充分的工作。
总之,该文章所提出的基于增量最优视角选择的神经网络辐射场三维重建方法具有创新性和实用性,对于城市级三维重建任务具有重要的应用价值。
点此查看论文截图


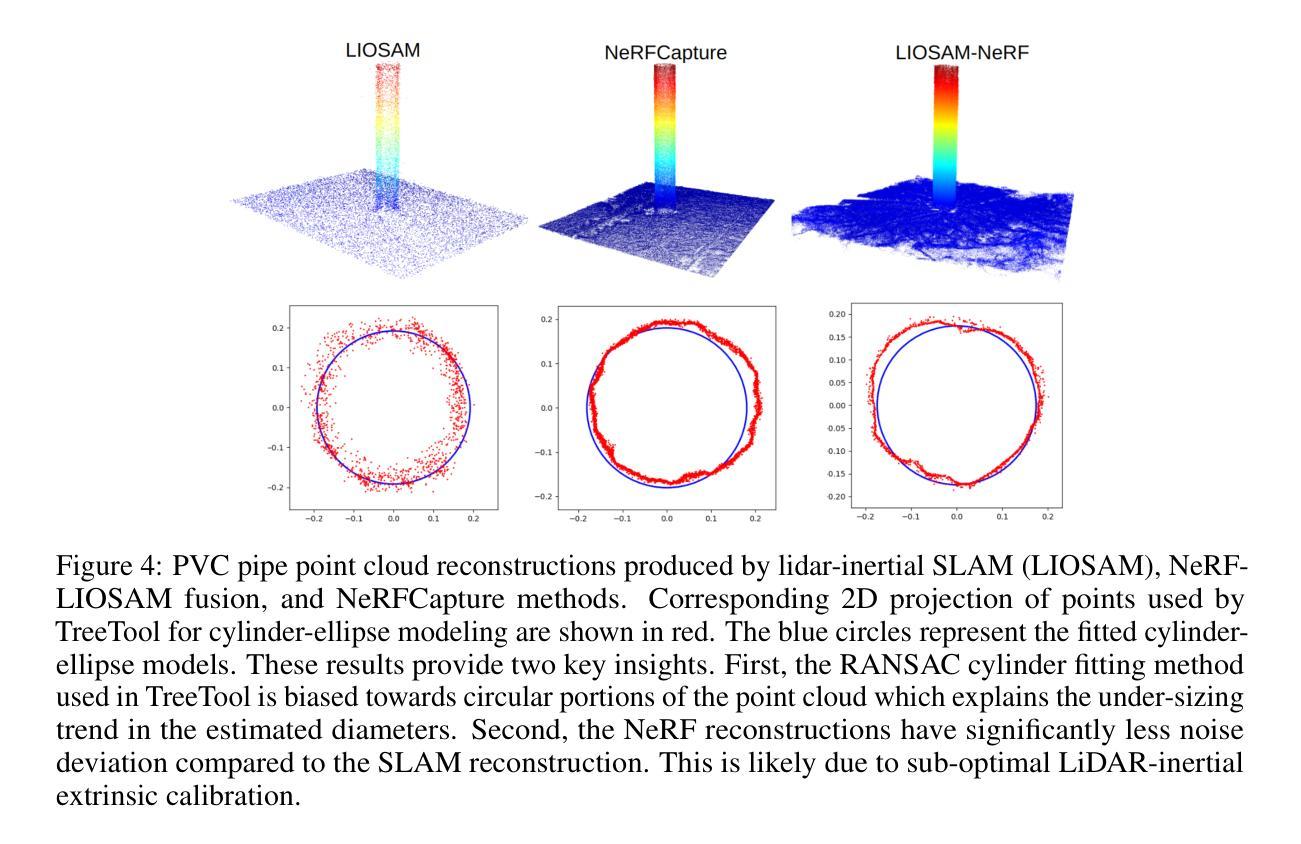
Evaluating geometric accuracy of NeRF reconstructions compared to SLAM method
Authors:Adam Korycki, Colleen Josephson, Steve McGuire
As Neural Radiance Field (NeRF) implementations become faster, more efficient and accurate, their applicability to real world mapping tasks becomes more accessible. Traditionally, 3D mapping, or scene reconstruction, has relied on expensive LiDAR sensing. Photogrammetry can perform image-based 3D reconstruction but is computationally expensive and requires extremely dense image representation to recover complex geometry and photorealism. NeRFs perform 3D scene reconstruction by training a neural network on sparse image and pose data, achieving superior results to photogrammetry with less input data. This paper presents an evaluation of two NeRF scene reconstructions for the purpose of estimating the diameter of a vertical PVC cylinder. One of these are trained on commodity iPhone data and the other is trained on robot-sourced imagery and poses. This neural-geometry is compared to state-of-the-art lidar-inertial SLAM in terms of scene noise and metric-accuracy.
Summary
NeRF模型在现实世界的映射任务中表现出更高效、更精确的潜力。
Key Takeaways
- NeRF实现变得更快、更高效、更精确,适用于实际的地图制作任务。
- 传统的3D地图制作依赖于昂贵的LiDAR传感器。
- 摄影测量可以进行基于图像的3D重建,但计算成本高,需要密集的图像表示来恢复复杂的几何和真实感。
- NeRF通过在稀疏图像和姿态数据上训练神经网络来进行3D场景重建,比摄影测量表现更好,输入数据量更少。
- 论文评估了两种NeRF场景重建方法,用于估算垂直PVC圆柱体的直径。
- 其中一种使用普通iPhone数据进行训练,另一种使用机器人采集的图像和姿态数据。
- 将这种神经几何与最先进的激光惯性SLAM进行了比较,考虑了场景噪声和度量精度。
好的,我会按照您的要求来总结这篇论文。以下是回答:
标题:基于神经辐射场(NeRF)与SLAM方法的几何精度评估
中文翻译:NeRF与SLAM方法的几何精度评估作者:Adam Korycki、Colleen Josephson、Steve McGuire
隶属机构:加州大学圣克鲁兹分校电气与计算机工程系
中文翻译:加州大学圣克鲁兹分校电气与计算机工程(系)关键词:NeRF、SLAM、3D映射、场景重建、几何精度、神经辐射场实施、LiDAR感知
链接:具体论文链接需要您提供,GitHub代码链接(如可用):GitHub:None
总结:
(1)研究背景:
随着NeRF实施技术的快速发展,其在实际映射任务中的应用越来越广泛。传统的三维映射主要依赖于昂贵的LiDAR传感技术,而NeRF通过训练神经网络实现稀疏图像和姿态数据的3D场景重建,以较少的输入数据获得优于摄影测量的结果。本文旨在评估NeRF场景重建的几何精度。(2)过去的方法及存在的问题:
传统的三维映射主要依赖于LiDAR传感技术,虽然其生成的结果精确,但成本高昂,且需要复杂的拼接过程。摄影测量虽可实现基于图像的三维重建,但计算量大,需要密集的图像表示来恢复复杂的几何和真实感。(3)本文提出的研究方法:
本文评估了两种NeRF场景重建方法,一种使用商品iPhone数据训练,另一种使用机器人来源的图像和姿态数据训练。通过比较这两种NeRF重建结果与最先进的LiDAR-惯性SLAM在场景噪声和度量精度方面的表现,来评估NeRF的几何精度。(4)任务与性能:
本文的任务是估计垂直PVC圆柱的直径。实验结果表明,NeRF在场景重建任务中表现出较高的几何精度,与最先进的LiDAR-惯性SLAM相比,具有较低的场景噪声和较高的度量精度。这证明了NeRF在实际应用中的潜力和优越性,特别是在成本效益和易访问性方面。
希望这个总结符合您的要求!
7. 方法论概述:
本文的方法论主要包括两个部分:基于LiDAR-inertial SLAM的3D映射方法和基于NeRF的重建方法。
(1) LiDAR-inertial SLAM方法:
这是一种目前最先进的3D映射技术。它融合了LiDAR和IMU数据,创建密集的时空重建。该方法使用传统的姿态图SLAM表达式来优化实时生成的地图。研究使用的是Unitree B1四足机器人,配备了定制的感知负载。LiDAR是Ouster OS0-128,IMU是Inertialsense IMX-5。LIOSAM在机器人计算机上的ROS框架上运行,并提供了探索环境的地图和机器人的轨迹。
(2) 基于NeRF的重建方法:
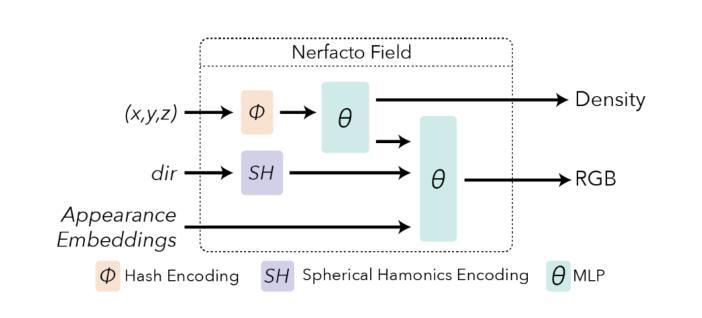
本文主要采用Nerfacto方法进行NeRF重建。Nerfacto方法在几个关键方向上改进了基础NeRF方法。首先是姿态优化。图像姿态的错误会导致重建场景出现模糊伪影和清晰度损失。Nerfacto方法使用反向传播的损失梯度来优化每个训练迭代的姿态。另一个改进是5D输入空间的射线采样。光线被建模为锥形截锥。分段采样步骤在距离相机原点的一定距离内均匀采样光线,随后在锥形射线的后续部分以随着每个样本的增加而增大的步长进行采样。这允许对场景的近距离部分进行高细节采样,同时有效地对远处的物体进行采样。输出被输入到提案采样器中,该采样器将样本位置整合到对最终3D场景渲染贡献最大的场景部分中。为了告知哪些样本位置应该被整合,使用了由小型融合MLP和哈希编码组成的一连串密度函数。这些采样阶段的输出被输入到Nerfacto字段中。这一阶段结合了外观嵌入,这考虑了训练图像之间不同的曝光度。“粗略”和“精细”的MLP对输出颜色和三维场景结构进行建模。
总的来说,本文通过对比LiDAR-inertial SLAM和NeRF两种重建方法,评估了NeRF在实际场景重建中的几何精度,并验证了其在成本效益和易访问性方面的优势。
- Conclusion:
(1)该工作的重要性在于展示了NeRF技术在重建现实世界的测量任务中的可行性。通过与传统LiDAR-inertial SLAM技术的对比实验,证明了NeRF技术在场景重建中的几何精度和优越性,特别是在成本效益和易访问性方面。此外,该研究还展示了使用商品iPhone数据和机器人来源的图像和姿态数据进行NeRF重建的潜力。这项研究为神经场景表示提供了令人兴奋的前景,并有望加速森林环境的映射过程,为我们对森林状态的理解以及保护这一宝贵资源提供更深层次的洞察力。
(2)创新点:该文章的创新之处在于对NeRF技术在场景重建中的几何精度进行了评估,并展示了使用商品iPhone数据和机器人来源的图像和姿态数据进行NeRF重建的可行性。性能:通过与传统LiDAR-inertial SLAM技术的对比实验,证明了NeRF重建方法具有较高的几何精度和较低的场景噪声。工作量:该文章进行了充分的实验和评估,包括创建NeRF重建、对比实验和性能评估等,工作量较大且充分。
点此查看论文截图