⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-13 更新
Digital Avatars: Framework Development and Their Evaluation
Authors:Timothy Rupprecht, Sung-En Chang, Yushu Wu, Lei Lu, Enfu Nan, Chih-hsiang Li, Caiyue Lai, Zhimin Li, Zhijun Hu, Yumei He, David Kaeli, Yanzhi Wang
We present a novel prompting strategy for artificial intelligence driven digital avatars. To better quantify how our prompting strategy affects anthropomorphic features like humor, authenticity, and favorability we present Crowd Vote - an adaptation of Crowd Score that allows for judges to elect a large language model (LLM) candidate over competitors answering the same or similar prompts. To visualize the responses of our LLM, and the effectiveness of our prompting strategy we propose an end-to-end framework for creating high-fidelity artificial intelligence (AI) driven digital avatars. This pipeline effectively captures an individual’s essence for interaction and our streaming algorithm delivers a high-quality digital avatar with real-time audio-video streaming from server to mobile device. Both our visualization tool, and our Crowd Vote metrics demonstrate our AI driven digital avatars have state-of-the-art humor, authenticity, and favorability outperforming all competitors and baselines. In the case of our Donald Trump and Joe Biden avatars, their authenticity and favorability are rated higher than even their real-world equivalents.
PDF This work was presented during the IJCAI 2024 conference proceedings for demonstrations
Summary
提出了一种新的提示策略,用于驱动人工智能数字化身,通过创新的视觉工具和“众筹评分”机制展示其优越的幽默、真实感和好感度。
Key Takeaways
- 提出了新的提示策略,用于驱动人工智能数字化身。
- 引入了“众筹评分”机制,评估大型语言模型在不同提示下的表现。
- 提出了端到端框架,用于创建高保真度的人工智能数字化身。
- 开发了实时音视频流算法,支持从服务器到移动设备的流畅传输。
- 数字化身在幽默、真实感和好感度等方面优于竞争对手和基准模型。
- Donald Trump 和 Joe Biden 的数字化身比其现实世界等价物更具真实感和好感度。
- 研究成果显示,新方法显著提高了数字化身的人性化交互效果。
好的,我会按照您的要求来整理这篇论文的信息。
标题: 数字化身:框架开发及其评估
中文翻译: Digital Avatars: Framework Development and Their Evaluation作者: Timothy Rupprecht、Sung-En Chang、Yushu Wu等。
英文作者名单: Timothy Rupprecht1, Sung-En Chang1, Yushu Wu1, Lei Lu1, Enfu Nan1, Chih-hsiang Li1, Caiyue Lai1, Zhimin Li1, Zhijun Hu1, Yumei He2, David Kaeli1 和 Yanzhi Wang1。作者隶属: 东北大学电子与计算机工程系和杜兰大学。
中文隶属: 作者隶属东北大学电子与计算机工程系和杜兰大学。关键词: 大型语言模型(LLM)、数字化身、人工智能驱动、提示策略、度量指标。
英文关键词: Large Language Model (LLM), Digital Avatar, Artificial Intelligence-driven, Prompting Strategy, Evaluation Metrics。链接: 请提供论文的链接和GitHub代码链接(如有)。论文链接:[论文链接]。GitHub代码链接:[GitHub链接](如果可用,填写具体的GitHub链接,如不可用则填写”None”)。
摘要:
- (1) 研究背景:本文研究了在人工智能驱动的数字化身领域,如何有效地使用提示策略来增强化身的幽默感、真实感和好感度。研究背景是随着虚拟角色角色扮演平台的兴起,对于真实、生动地呈现虚拟角色的需求日益增长。
- (2) 相关方法及其问题:现有的平台主要通过文本交互进行虚拟角色角色扮演,但响应效果仍无法真实地呈现现实世界角色的个性。因此,需要一种新的提示策略来提升LLM的响应质量。过去的方法缺乏有效度量指标来评估数字化身的幽默感、真实感和好感度。
- (3) 研究方法:本文提出了一种新的提示策略,称为“展示而非告诉”策略,用于提升LLM在角色扮演中的幽默感、真实感和好感度。同时,开发了一个端到端的数字化身框架,通过可视化工具展示LLM的响应效果。为了量化评估数字化身的质量,提出了一种新的度量指标——Crowd Vote。
- (4) 任务与性能:本文在创建数字化身的任务上进行了实验,并比较了不同提示策略下LLM的性能。实验结果显示,使用“展示而非告诉”策略的数字化身在幽默感、真实感和好感度方面均优于其他方法,甚至超过了现实世界角色的等效物。性能结果支持了该方法的有效性。
以上是关于该论文的概括和解读,希望对您有帮助。
好的,我会按照您的要求对论文的
- 方法论:
(1) 提出新的提示策略——“展示而非告诉”策略,用于提升大型语言模型(LLM)在角色扮演中的幽默感、真实感和好感度。该策略通过提供示例让LLM直接学习,而非仅通过指令进行学习。初始提示中会提供大量现实角色的特性回应示例,并定义角色的基本特征,以期模拟真实世界的反应。为了增加回应的生动性和趣味性,还融入了幽默元素。
(2) 开发了一个端到端的数字化身框架,展示了在这项工作中开发的提示策略。该框架包括语音识别、文本转语音、说话面部合成和视频选择算法等模块。使用局部实现的最先进技术,无论基线架构如何,都能得到相同的定性趋势。该框架首次使用端到端的AI驱动数字化身管道,包括用于化身说话的的大型语言模型。
(3) 提出了名为“Crowd Vote”的新型评估指标。这是基于Crowd Score(一种利用大型语言模型作为评判来衡量幽默效果的方法)的改进方法。不同于原有的Crowd Score仅从大量笑话中排序出最有趣的笑话,Crowd Vote要求具有不同性格的评委从多个LLM候选回应中选择最能体现真实性、友好性或幽默感的回答。这种方法可以帮助研究人员更准确地评估数字化身的性能和质量。例如,在比较不同提示策略下LLM的性能时,可以通过观察评委对不同回应的投票结果来评估不同策略的优劣。这种评价方式更贴近现实世界的实际应用场景,有助于研究人员更好地了解数字化身的性能表现。例如,在某个对话场景中,不同LLM生成的回应可能略有差异,通过评委的投票结果可以直观地看出哪种回应更具说服力和自然性。因此,“Crowd Vote”评价指标的引入对于评估数字化身的性能和质量具有重要意义。
以上就是对该论文方法的解读和总结,希望对您有所帮助。
好的,我会按照您的要求来总结这篇论文的结论。以下是回答:
- Conclusion:
(1)这篇论文的研究对于人工智能驱动的数字化身领域具有重要意义。它提出了一种新的提示策略来提升大型语言模型在角色扮演中的表现,并开发了一个端到端的数字化身框架来展示这种策略的效果。此外,论文还提出了一种新的度量指标来评估数字化身的性能。这些成果有助于提升虚拟角色角色扮演平台的真实感和生动性,满足日益增长的对真实、生动地呈现虚拟角色的需求。
(2)创新点:论文提出了一种新的提示策略——“展示而非告诉”,该策略通过提供示例让大型语言模型学习角色的特性回应,提高了角色扮演的幽默感、真实感和好感度。此外,论文还开发了一个端到端的数字化身框架,并首次使用了端到端的AI驱动数字化身管道。这些创新点都是对数字化身领域的贡献。
性能:论文通过实验验证了所提出的提示策略和数字化身框架的有效性。实验结果显示,使用“展示而非告诉”策略的数字化身在幽默感、真实感和好感度方面均优于其他方法,甚至超过了现实世界角色的等效物。此外,论文提出的度量指标也表现出了良好的评估效果。
工作量:论文的工作量较大,涉及到多个方面的研究和实验。包括提出新的提示策略、开发数字化身框架、设计实验验证等。不过,具体的工作量评估需要更深入的了解和研究,无法仅凭摘要给出准确的评价。
点此查看论文截图


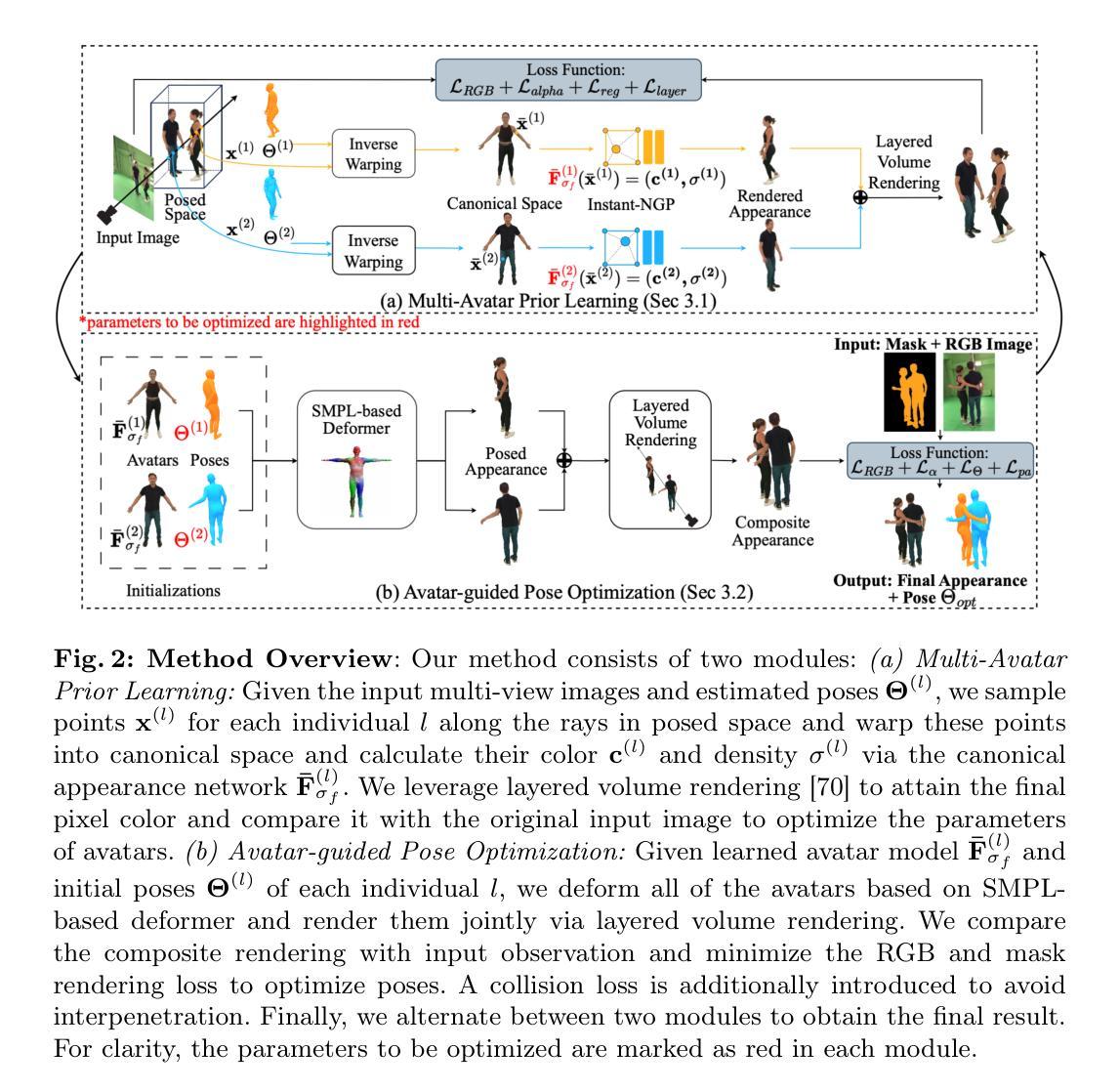
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Authors:Feichi Lu, Zijian Dong, Jie Song, Otmar Hilliges
Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
PDF Project Page: https://feichilu.github.io/AvatarPose/
Summary
利用个性化的隐式神经化身作为先验,显著改进多人近距离交互情境下的3D姿势估计。
Key Takeaways
- 提出利用个性化隐式神经化身作为先验来改进3D姿势估计的方法。
- 方法通过稀疏多视角视频的分层体积渲染有效重建化身。
- 新方法绕过了准确2D关节检测困难,直接优化基于颜色和轮廓渲染损失的3D姿势。
- 引入碰撞损失来处理化身的重叠区域,增加穿透约束。
- 通过交替优化3D姿势和化身,提高了方法的鲁棒性和精确度。
- 在多个公共数据集上展示出最先进的性能。
- 解决了多人近距离交互中的2D关节估计和姿势优化的挑战。
Title: 基于个性化隐式神经网络先验的多人紧密交互三维姿态估计方法(AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction)
Authors: Feichi Lu, Zijian Dong, Jie Song, Otmar Hilliges.
Affiliation: 作者来自苏黎世联邦理工学院计算机科学系和德国马普智能系统研究所。
Keywords: human pose estimation, human close interaction, multi-view pose estimation, avatar prior.
Urls: 论文链接:论文链接,GitHub代码链接:Github:None。
Summary:
(1)研究背景:本文研究了从稀疏多视角视频估计多个紧密交互人的3D姿态和形状的问题。尽管已有一些多视角方法,但它们常常面临在估计紧密交互人的3D姿态和形状时的挑战。
(2)过去的方法及问题:现有方法主要依赖于准确的2D关节估计,但在人们紧密交互时,由于遮挡和身体接触,准确获取2D关节估计非常困难。
(3)研究方法:针对这些问题,本文提出了一种利用个性化隐式神经网络先验的新方法。首先,通过分层体积渲染从稀疏多视角视频中重建avatar。然后,利用重建的avatar先验,基于颜色和轮廓渲染损失直接优化3D姿态。此外,为了处理交互穿透问题,本文提出了在avatar重叠形状区域上的碰撞损失来添加穿透约束。最后,以交替的方式同时优化3D姿态和avatar。
(4)任务与性能:本文方法在多个公共数据集上实现了最先进的性能,证明了该方法的有效性。实验结果表明,该方法在估计多人紧密交互的3D姿态和形状任务上取得了显著的性能提升。
7. Methods:
- (1) 研究背景分析:文章针对从稀疏多视角视频估计多个紧密交互人的3D姿态和形状的问题展开研究。由于现有方法在处理紧密交互时面临诸多挑战,如遮挡和身体接触导致的准确获取2D关节估计困难等。
- (2) 方法概述:文章提出了一种利用个性化隐式神经网络先验的新方法来解决这一问题。首先,通过分层体积渲染技术从稀疏多视角视频中重建avatar。然后,利用重建的avatar先验信息,基于颜色和轮廓渲染损失直接优化3D姿态。
- (3) 交互处理策略:为了处理交互穿透问题,文章提出了在avatar重叠形状区域上的碰撞损失来添加穿透约束。这一策略能有效处理因紧密交互而产生的穿透问题。
- (4) 优化过程:最后,以交替的方式同时优化3D姿态和avatar,以达到更准确的估计结果。实验结果表明,该方法在多个公共数据集上实现了最先进的性能,证明了其有效性。
- (5) 实验验证:文章通过在实际数据集上进行实验验证,证明了该方法在估计多人紧密交互的3D姿态和形状任务上取得了显著的性能提升。
- Conclusion:
(1) 这项工作的意义在于提出了一种基于个性化隐式神经网络先验的多人紧密交互三维姿态估计方法,解决了从稀疏多视角视频估计多个紧密交互人的3D姿态和形状的问题,填补了相关领域的空白。
(2) 创优点:文章的创新点在于利用重建的avatar作为个性化先验信息,指导姿态优化,使得在多人紧密交互的场景下,能够更有效地估计3D姿态。同时,文章提出的碰撞损失有效地处理了交互穿透问题。
性能:文章的方法在多个公共数据集上实现了最先进的性能,证明了该方法的有效性。
工作量:文章进行了大量的实验验证,证明了方法的有效性,并在实际数据集上进行了广泛应用。此外,文章还对过去的方法进行了全面的回顾和分析,为后续研究提供了有力的支持。
总的来说,这篇文章在创新点、性能和工作量方面都表现出了一定的优势,为多人紧密交互三维姿态估计领域的研究提供了新的思路和方法。
点此查看论文截图