⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-21 更新
SG-GS: Photo-realistic Animatable Human Avatars with Semantically-Guided Gaussian Splatting
Authors:Haoyu Zhao, Chen Yang, Hao Wang, Xingyue Zhao, Wei Shen
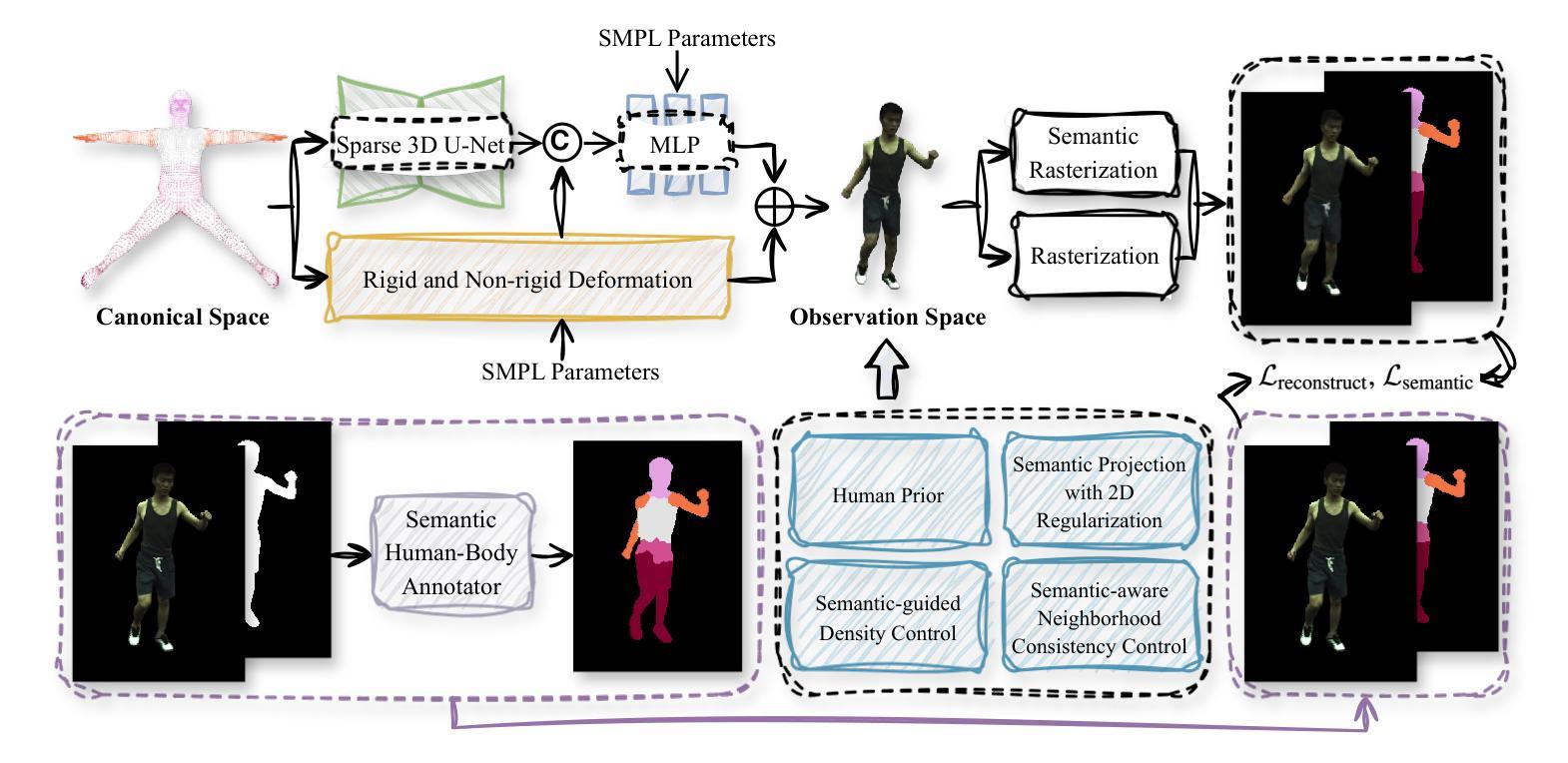
Reconstructing photo-realistic animatable human avatars from monocular videos remains challenging in computer vision and graphics. Recently, methods using 3D Gaussians to represent the human body have emerged, offering faster optimization and real-time rendering. However, due to ignoring the crucial role of human body semantic information which represents the intrinsic structure and connections within the human body, they fail to achieve fine-detail reconstruction of dynamic human avatars. To address this issue, we propose SG-GS, which uses semantics-embedded 3D Gaussians, skeleton-driven rigid deformation, and non-rigid cloth dynamics deformation to create photo-realistic animatable human avatars from monocular videos. We then design a Semantic Human-Body Annotator (SHA) which utilizes SMPL’s semantic prior for efficient body part semantic labeling. The generated labels are used to guide the optimization of Gaussian semantic attributes. To address the limited receptive field of point-level MLPs for local features, we also propose a 3D network that integrates geometric and semantic associations for human avatar deformation. We further implement three key strategies to enhance the semantic accuracy of 3D Gaussians and rendering quality: semantic projection with 2D regularization, semantic-guided density regularization and semantic-aware regularization with neighborhood consistency. Extensive experiments demonstrate that SG-GS achieves state-of-the-art geometry and appearance reconstruction performance.
PDF 12 pages, 5 figures
Summary
通过使用语义嵌入的3D高斯模型和骨架驱动的刚性变形,SG-GS方法能够从单眼视频中创建逼真的可动人体化身。
Key Takeaways
- 使用语义嵌入的3D高斯模型和骨架驱动的刚性变形,能够提高动态人体化身的细节重建能力。
- 设计了语义人体部分注释器(SHA),利用SMPL的语义先验进行高效的语义标签生成。
- 提出了三维网络,整合几何和语义关联,用于人体化身的变形,以解决点级MLP局部特征接受域有限的问题。
- 引入了三种策略以提升3D高斯模型的语义精度和渲染质量:语义投影与2D正则化、语义引导的密度正则化以及语义感知的邻域一致性正则化。
- SG-GS方法在几何和外观重建性能上实现了最先进水平,通过广泛实验验证了其有效性。
标题:基于语义引导的逼真动画人类半身像重建研究
作者:Zhao Haoyu(赵浩宇)、Yang Chen(杨晨)、Wang Hao(王浩)、Zhao Xingyue(赵星越)、Shen Wei(沈炜)等。
所属机构:上海交通大学人工智能研究院等。
关键词:语义引导、高斯模型、人体动画重建等。
Urls:论文链接待补充,GitHub代码链接待补充(如果可用)。
摘要:
(1)研究背景:本文研究基于单目视频生成逼真动画人类半身像的技术。此技术在计算机视觉和图形学领域具有挑战性,广泛应用于游戏、扩展现实故事叙述、远程呈现等领域。
(2)过去的方法及问题:虽然使用三维高斯模型表示人体进行重建的方法能更快优化和实时渲染,但它们忽略了人体语义信息(如内在结构和连接),导致动态人类半身像精细细节重建失败。
(3)研究方法:本文提出SG-GS方法,使用嵌入语义的三维高斯模型、骨架驱动刚性变形和非刚性布料动态变形来创建动画。设计语义人体标注器(SHA)利用SMPL的语义先验进行高效身体部分语义标注。为解决点级MLP的局部特征受限问题,提出一个三维网络,集成几何和语义关联进行半身像变形。同时实施三种关键策略提高三维高斯语义准确性和渲染质量。
(4)任务与性能:本文方法在静态场景的新视图合成任务上实现最先进的性能,通过大量实验验证SG-GS在几何和外观重建方面的优越性。性能支持其目标,即创建高质量、逼真的动画人类半身像。
方法论概述:
本文提出一种基于语义引导的逼真动画人类半身像重建方法(SG-GS方法)。其方法论主要包括以下几个步骤:
(1)提出使用嵌入语义的三维高斯模型、骨架驱动刚性变形和非刚性布料动态变形来创建动画。
(2)设计语义人体标注器(SHA),利用SMPL的语义先验进行高效身体部分语义标注。
(3)为解决点级MLP的局部特征受限问题,提出一个三维网络,集成几何和语义关联进行半身像变形。
(4)实施三种关键策略提高三维高斯语义准确性和渲染质量,包括语义投影与二维正则化、语义引导密度正则化和语义感知邻域一致性控制。
其中,具体实现方式如下:
- 语义人体标注器(SHA):通过使用SMPL模型的姿态感知形状先验,结合可微骨骼变换,对标准人体模型进行变形。然后,通过自定义的点渲染函数,将变形的SMPL模型渲染成图像,并通过k近邻算法对前景掩膜进行语义级别的标注,实现身体部分的精确语义标注。
- 三维几何和语义感知网络:为了有效地利用三维几何和语义信息,提出了一个三维几何和语义感知网络。该网络通过稀疏卷积操作,提取点云的局部几何和语义特征,然后结合语义属性进行优化,以实现更精细的变形和更真实的渲染效果。
- 变形和优化:通过刚性变形和非刚性变形相结合的方式,将高斯模型从规范空间变形到观察空间。在变形过程中,利用语义信息进行指导,提高变形的准确性和自然度。同时,通过实施一系列优化策略,如语义投影与二维正则化、语义引导密度正则化和语义感知邻域一致性控制等,进一步提高语义准确性和渲染质量。
本文的方法在静态场景的新视图合成任务上实现了最先进的性能,通过大量实验验证了其在几何和外观重建方面的优越性。
Conclusion:
(1)意义:该研究对于计算机视觉和图形学领域具有重要的价值,特别是在游戏、扩展现实故事叙述、远程呈现等方面,逼真动画人类半身像重建技术具有重要的应用前景。该研究能够推动相关领域的技术进步,增强虚拟世界的真实感和交互性。
(2)创新点、性能和工作量综述:
- 创新点:文章提出了基于语义引导的逼真动画人类半身像重建方法(SG-GS方法),集成了三维高斯模型、骨架驱动刚性变形和非刚性布料动态变形等技术,并利用语义人体标注器和三维网络进行高效的语义标注和半身像变形。此外,文章还实施了多种关键策略提高三维高斯语义准确性和渲染质量。
- 性能:文章在静态场景的新视图合成任务上实现了最先进的性能,并通过大量实验验证了其在几何和外观重建方面的优越性。与现有技术相比,该方法能够创建高质量、逼真的动画人类半身像。
- 工作量:文章进行了详尽的实验和验证,包括多种数据集上的实验、对比实验和消融实验等,证明了方法的有效性和优越性。同时,文章还进行了系统的理论分析和阐述,包括方法的设计原理、实现细节和优缺点等。
点此查看论文截图

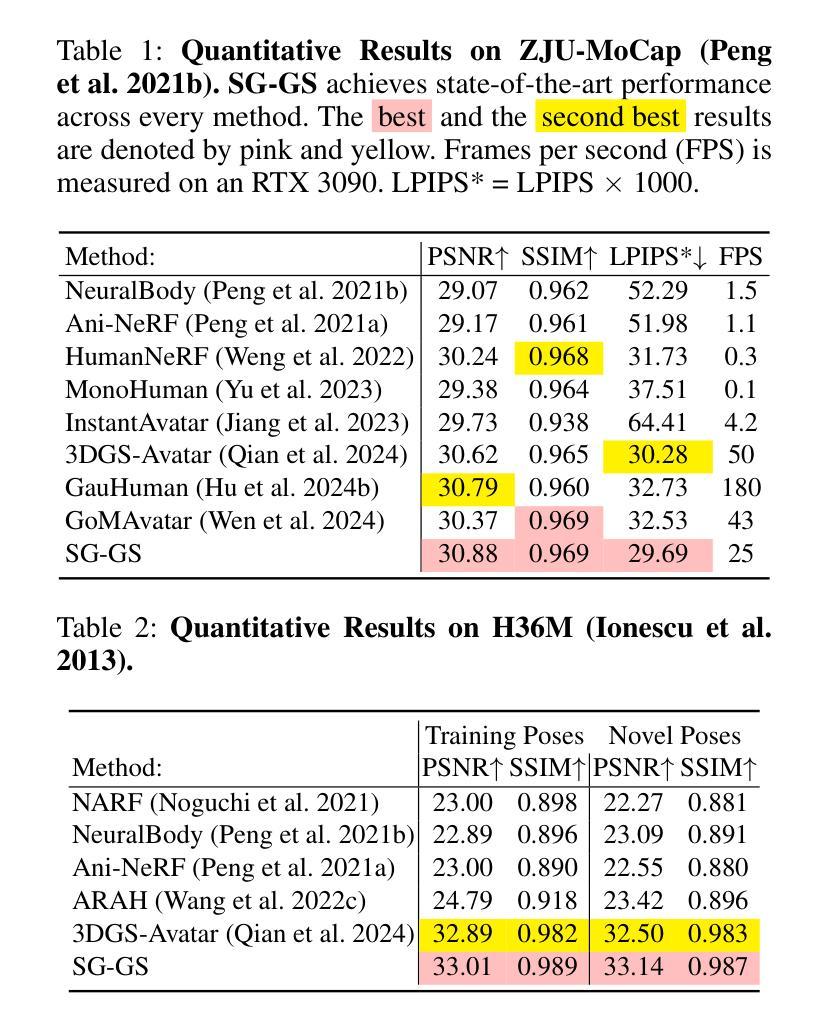


CHASE: 3D-Consistent Human Avatars with Sparse Inputs via Gaussian Splatting and Contrastive Learning
Authors:Haoyu Zhao, Hao Wang, Chen Yang, Wei Shen
Recent advancements in human avatar synthesis have utilized radiance fields to reconstruct photo-realistic animatable human avatars. However, both NeRFs-based and 3DGS-based methods struggle with maintaining 3D consistency and exhibit suboptimal detail reconstruction, especially with sparse inputs. To address this challenge, we propose CHASE, which introduces supervision from intrinsic 3D consistency across poses and 3D geometry contrastive learning, achieving performance comparable with sparse inputs to that with full inputs. Following previous work, we first integrate a skeleton-driven rigid deformation and a non-rigid cloth dynamics deformation to coordinate the movements of individual Gaussians during animation, reconstructing basic avatar with coarse 3D consistency. To improve 3D consistency under sparse inputs, we design Dynamic Avatar Adjustment(DAA) to adjust deformed Gaussians based on a selected similar pose/image from the dataset. Minimizing the difference between the image rendered by adjusted Gaussians and the image with the similar pose serves as an additional form of supervision for avatar. Furthermore, we propose a 3D geometry contrastive learning strategy to maintain the 3D global consistency of generated avatars. Though CHASE is designed for sparse inputs, it surprisingly outperforms current SOTA methods \textbf{in both full and sparse settings} on the ZJU-MoCap and H36M datasets, demonstrating that our CHASE successfully maintains avatar’s 3D consistency, hence improving rendering quality.
PDF 13 pages, 6 figures
Summary
提出了一种新方法CHASE,结合了3D一致性监督和几何对比学习,显著提高了稀疏输入下人物头像合成的效果。
Key Takeaways
- 使用CHASE方法,结合了骨架驱动的刚性变形和非刚性布料动力学变形,实现了基本的头像合成,并保持了粗略的3D一致性。
- 引入Dynamic Avatar Adjustment(DAA)机制,根据数据集中类似姿态/图像调整变形高斯分布,进一步提高了稀疏输入情况下的3D一致性。
- 设计了3D几何对比学习策略,有助于维持生成头像的全局3D一致性。
- CHASE方法在ZJU-MoCap和H36M数据集上展示出色,无论是在全输入还是稀疏输入条件下,均优于当前技术水平。
- 成功提升了头像合成的渲染质量,并展示了在头像的3D一致性方面的显著改进。
- NeRFs和3DGS方法在3D一致性和细节重建方面存在挑战,尤其是在稀疏输入情况下表现不佳。
- CHASE方法结合了多种技术,有效克服了现有方法的局限性,为虚拟人头像合成领域带来了新的发展方向。
好的,我会按照您的要求来总结这篇论文。
标题:基于高斯分裂和对比学习的稀疏输入下三维一致人形化身研究(CHASE: 3D-Consistent Human Avatars with Sparse Inputs via Gaussian Splatting and Contrastive Learning)
作者:Haoyu Zhao, Hao Wang, Chen Yang, Wei Shen等。
隶属机构:上海交通大学人工智能实验室等。
关键词:Human Avatar合成、稀疏输入、高斯分裂、对比学习、三维一致性。
Urls:论文链接待定,代码GitHub链接待定(如果可用)。
摘要:
(1)研究背景:本文研究了在稀疏输入条件下,如何合成具有三维一致性的人形化身。近年来,虽然人形化身合成技术已经取得显著进展,但在稀疏输入条件下保持三维一致性和细节重建仍存在挑战。
(2)过去的方法及问题:现有的方法大多依赖于丰富的输入数据,如多视角图像或深度传感器数据。然而,在稀疏输入条件下,这些方法往往难以保持三维一致性并重建出高质量的细节。因此,需要一种新的方法来解决这个问题。
(3)研究方法:本文提出了一种基于高斯分裂和对比学习的方法来解决稀疏输入下的三维一致人形化身合成问题。首先,通过结合骨架驱动的刚性变形和非刚性布料动力学变形,创建具有粗略三维一致性的基本化身。然后,通过动态化身调整(DAA)策略,基于数据集中的相似姿势/图像对变形的高斯进行微调。此外,还提出了一种3D几何对比学习策略,以维持生成化身的全球三维一致性。
(4)任务与性能:本文的方法在ZJU-MoCap和H36M数据集上进行了测试,并在全数据和稀疏输入两种设置下均取得了出色的性能。结果表明,该方法在稀疏输入条件下成功地保持了化身的三维一致性,提高了渲染质量。性能结果支持了该方法的目标实现。
以上就是对该论文的概括,希望对你有所帮助。
好的,我将根据您提供的论文内容详细阐述这篇论文的方法论思想。
- 方法论:
(1)研究背景与问题概述:文章首先概述了在稀疏输入条件下合成具有三维一致性的人形化身的技术挑战,并指出现有方法的不足。
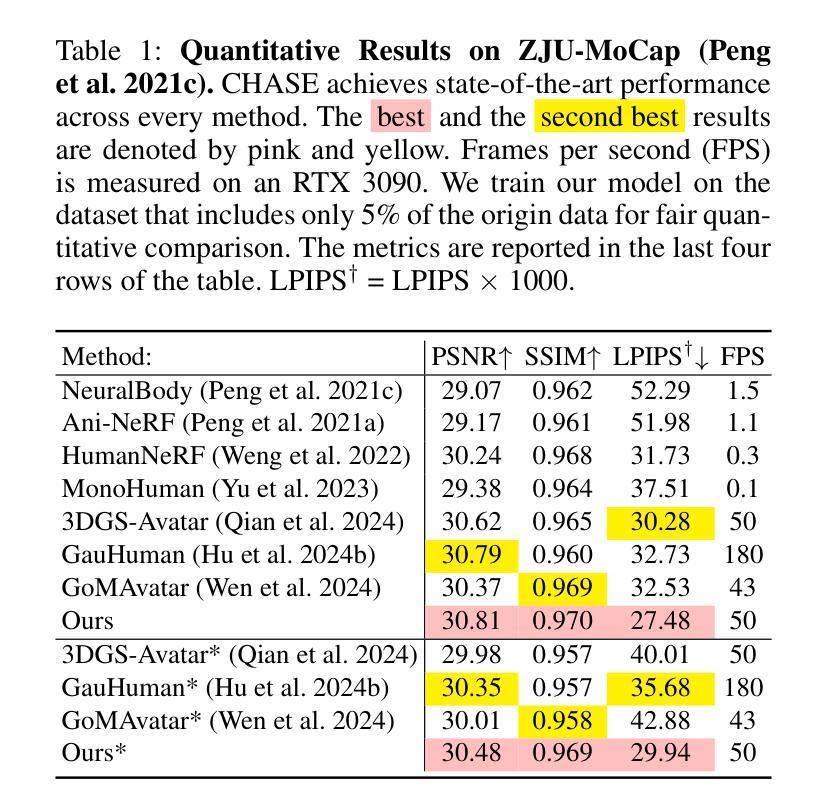
(2)研究方法概述:为了解决上述问题,文章提出了一种基于高斯分裂和对比学习的方法来解决稀疏输入下的三维一致人形化身合成问题。该方法的流程如图1所示。
(3)输入数据处理与模型构建:文章的输入包括从单目视频中获得的图像、拟合的SMPL参数以及图像的前景色掩码。模型通过对3D高斯模型在规范空间进行优化,然后通过变形匹配观测空间并进行渲染。这一过程中结合了骨架驱动的刚性变形和非刚性布料动力学变形技术。
(4)动态化身调整策略:为了解决极端稀疏输入的问题,文章提出了一种动态化身调整(DAA)策略。该策略基于数据集中的相似姿势/图像对变形的高斯进行微调,通过引入额外的二维图像监督,提高了人形化身的三维一致性。
(5)非刚性变形网络设计:为了实现对规范空间中的高斯模型的非刚性变形,文章设计了一个非刚性变形网络。该网络以高斯模型的规范位置和SMPL姿势编码作为输入,输出各种参数的偏移量,从而实现高斯模型的变形。
(6)刚性变换与皮肤网格技术:变形后的高斯模型进一步通过基于LBS的刚性变换映射到观测空间,通过与目标姿势对齐的变换矩阵实现。为了精确控制三维高斯模型,文章从SMPL模型中采样了稀疏控制点,并利用LBS权重获得密集运动场。
(7)动态调整过程与结果优化:利用稀疏控制点的LBS权重对变形后的高斯模型进行微调,以实现对选定相似姿势的精确匹配。调整过程通过最小化调整后的化身渲染图像与选定相似姿势图像之间的差异来实现额外的监督,从而增强动画化身的创建。
(8)三维几何对比学习策略:为了保持生成的化身在全球范围内的三维一致性,文章提出了一个三维几何对比学习策略。该策略将三维高斯模型视为一个三维点云,并采用DGCNN作为特征提取器来处理不同姿势下的点云特征,确保在动画过程中的三维一致性。
以上就是这篇论文的方法论思想概述。希望对你有所帮助。
好的,以下是这篇论文的总结:
- Conclusion:
(1)研究意义:本文研究了在稀疏输入条件下如何合成具有三维一致性的人形化身,解决了现有方法在稀疏输入条件下难以保持三维一致性和细节重建的问题。该研究对于人工智能领域的人形化身合成技术具有重要的推动作用,有助于实现更加真实、生动的人形动画。此外,该研究在虚拟现实、增强现实、游戏制作等领域也有广泛的应用前景。
(2)论文的优缺点:
创新点:本文提出了基于高斯分裂和对比学习的方法来解决稀疏输入下的三维一致人形化身合成问题,该方法结合了骨架驱动的刚性变形和非刚性布料动力学变形技术,通过动态化身调整策略和三维几何对比学习策略来保持化身的三维一致性。该方法在稀疏输入条件下取得了显著的性能提升,具有较高的创新性。
性能:本文的方法在ZJU-MoCap和H36M数据集上进行了测试,并在全数据和稀疏输入两种设置下均取得了出色的性能。实验结果表明,该方法在稀疏输入条件下成功地保持了化身的三维一致性,提高了渲染质量。
工作量:文章涉及了较多的技术细节和实验验证,包括输入数据处理、模型构建、动态化身调整策略、非刚性变形网络设计、刚性变换与皮肤网格技术、动态调整过程与结果优化以及三维几何对比学习策略等。工作量较大,但实验结果证明了方法的有效性。
综上所述,本文提出了一种创新的基于高斯分裂和对比学习的人形化身合成方法,在稀疏输入条件下取得了显著的性能提升,具有较高的学术价值和应用前景。
点此查看论文截图

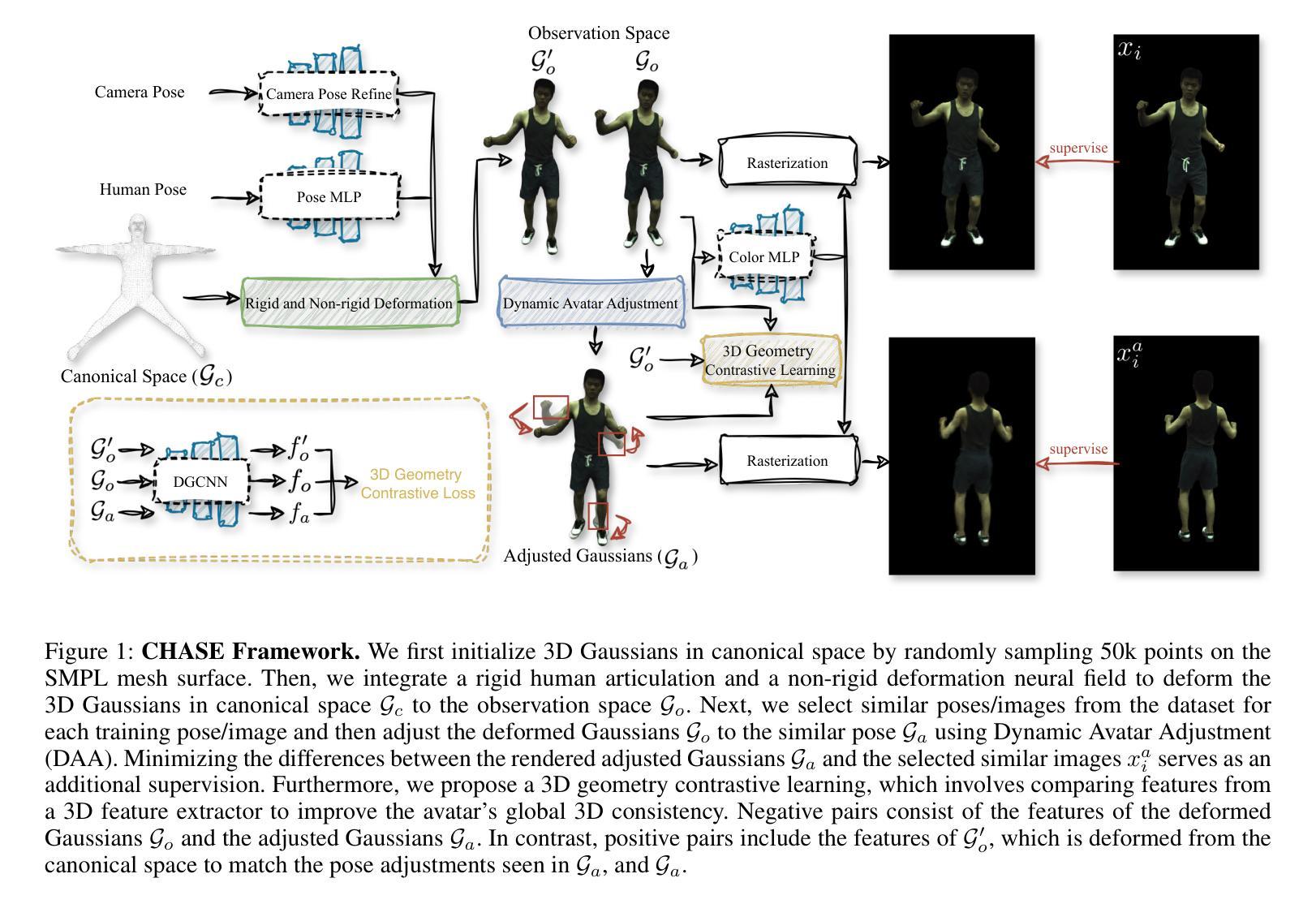
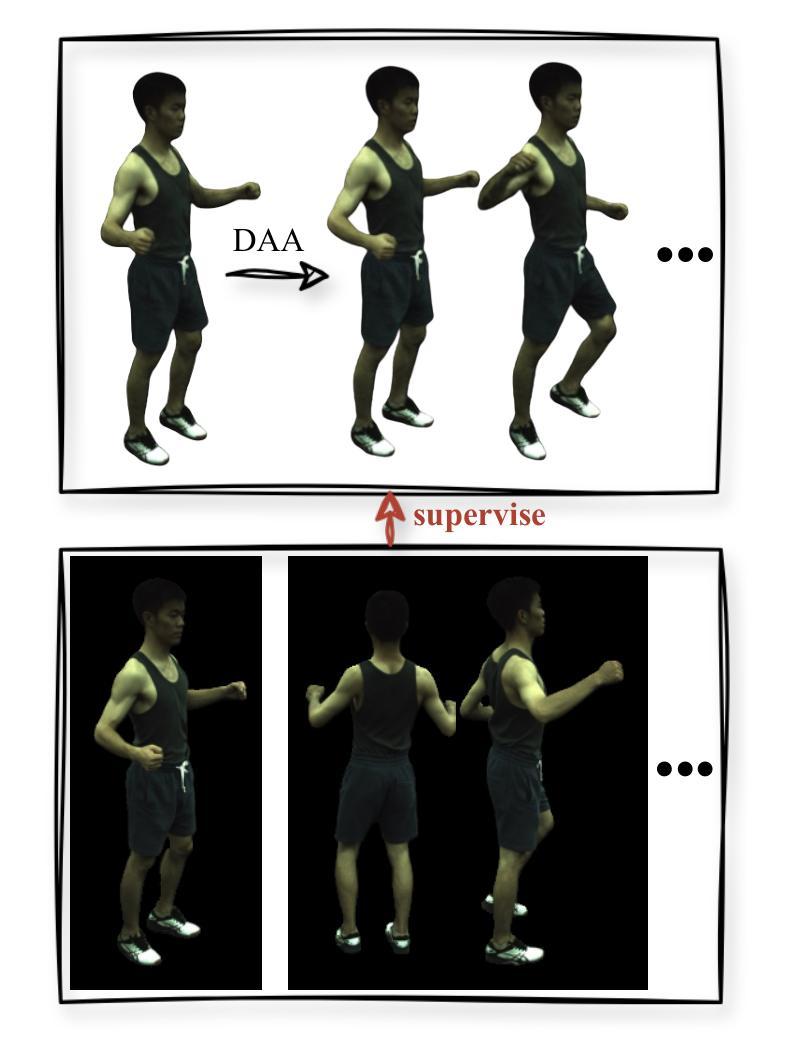
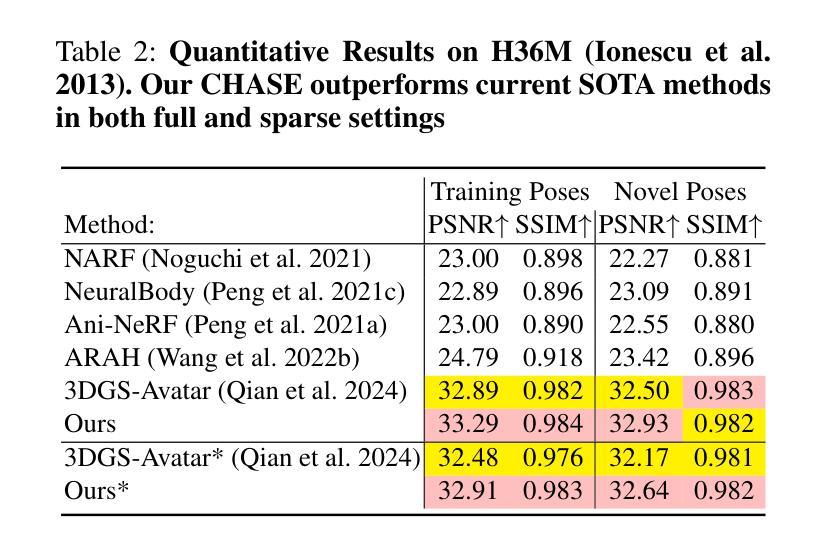

Barbie: Text to Barbie-Style 3D Avatars
Authors:Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
Recent advances in text-guided 3D avatar generation have made substantial progress by distilling knowledge from diffusion models. Despite the plausible generated appearance, existing methods cannot achieve fine-grained disentanglement or high-fidelity modeling between inner body and outfit. In this paper, we propose Barbie, a novel framework for generating 3D avatars that can be dressed in diverse and high-quality Barbie-like garments and accessories. Instead of relying on a holistic model, Barbie achieves fine-grained disentanglement on avatars by semantic-aligned separated models for human body and outfits. These disentangled 3D representations are then optimized by different expert models to guarantee the domain-specific fidelity. To balance geometry diversity and reasonableness, we propose a series of losses for template-preserving and human-prior evolving. The final avatar is enhanced by unified texture refinement for superior texture consistency. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation, supporting flexible apparel combination and animation. The code will be released for research purposes. Our project page is: https://2017211801.github.io/barbie.github.io/.
PDF 9 pages, 7 figures
Summary
Barbie提出了一种新的框架,通过语义对齐分离人体和服装模型,实现了3D化身的精细解缠和高保真建模。
Key Takeaways
- Barbie框架采用语义对齐分离模型,实现了人体和服装的精细解缠。
- 通过专家模型优化,保证了领域特定的保真度。
- 提出了一系列损失函数,用于保持模板和进化人体先验,平衡几何多样性和合理性。
- 引入统一的纹理细化技术,提升了纹理一致性。
- 在服装生成和人体动画方面,Barbie优于现有方法。
- 研究支持灵活的服装组合和动画展示。
- 该研究将发布代码以供研究使用,项目页面链接为:https://2017211801.github.io/barbie.github.io/。
好的,我会按照您的要求总结这篇论文。
标题:Barbie:基于文本到Barbie风格3D角色的生成
作者:Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
隶属机构:南京大学、中国移动研究学院、北京大学、南京理工大学
关键词:文本指导3D角色生成,Barbie风格角色,语义对齐模型,精细分解,领域特定保真度优化
链接:论文链接:待确定;GitHub代码链接:GitHub可用时填写(当前为None)
摘要:
(1)研究背景:随着虚拟世界和增强现实技术的发展,创建逼真的三维数字人物成为研究的热点。近年来,文本指导的三维角色生成取得了进展,但仍面临精细分解和高保真度建模等挑战。本文提出一种生成Barbie风格三维角色的新方法。
(2)过去的方法及问题:现有的文本指导三维角色生成方法主要分为两类:整体角色生成和身体和服装的精细分解生成。整体角色生成方法无法灵活控制服装和配件,而精细分解方法则面临领域特定保真度损失的问题。本文提出的方法旨在解决这些问题。
(3)研究方法:本研究提出了一种名为Barbie的新框架,用于生成逼真的Barbie风格三维角色。该方法通过语义对齐的分离模型实现身体和服装的精细分解。然后,通过不同的专家模型对这些解耦的三维表示进行优化,以保证领域特定的保真度。同时,通过一系列损失函数平衡几何多样性和合理性,并对最终的角色进行纹理优化,以提高纹理一致性。
(4)任务与性能:本研究在服装人生成和服装生成任务上进行了实验,结果表明Barbie在生成具有Barbie风格的三维角色方面表现出色,支持灵活的服装组合和动画。性能结果表明,Barbie在几何多样性、纹理质量和与文本描述的一致性方面达到了先进水平。
希望这个摘要符合您的要求!
7. 方法论:
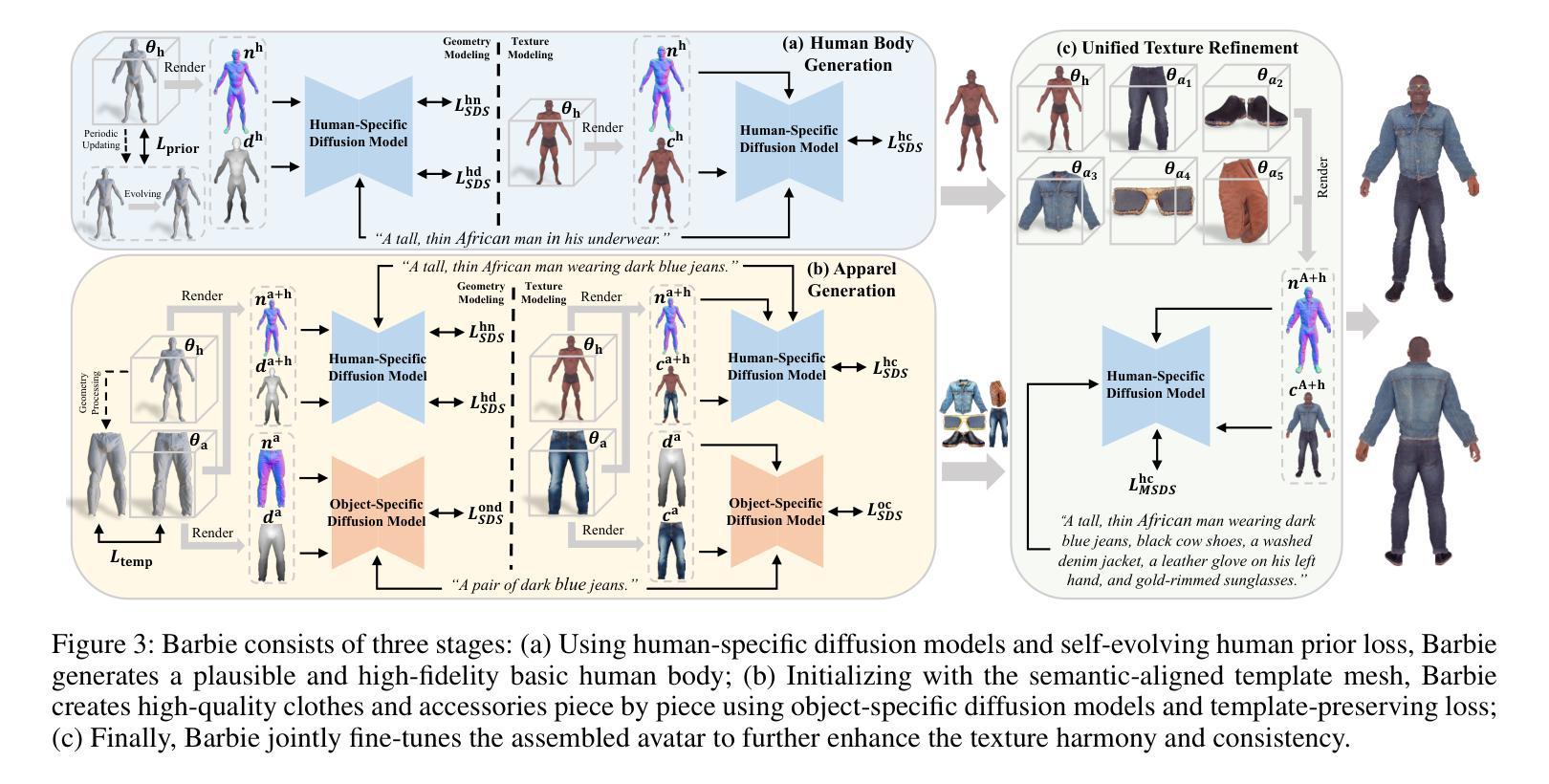
- (1) 首先,研究团队提出了名为Barbie的新框架,用于生成逼真的Barbie风格三维角色。该框架基于语义对齐的分离模型,实现了身体和服装的精细分解。
- (2) 在生成角色时,研究团队采用了分阶段的方法。首先进行人体生成初始化,使用SMPL-X网格建立精确初始输入。然后对人体几何建模进行优化,使用人类特定的扩散模型(如HumanNorm中的模型)进行详细的身体建模。为了平衡生成的几何形状的多样性和合理性,研究团队引入了一种自我进化的先验损失函数。这种损失函数会周期性地适应人体几何形状的变化,同时保留拓扑结构,为后续服装的初始化和组合提供了可靠但多样化的先验知识。
- (3) 在服装和配饰的生成阶段,研究团队利用对象特定的扩散模型对每件衣物和配饰进行高质量创建。最后进行统一纹理优化,以增强整个角色的纹理和谐性和一致性。整个过程中涉及多种损失函数,包括SDS损失和先验损失等,用于优化生成的角色的几何形状和纹理质量。总体来说,该文章通过精细分解、领域特定保真度优化和自进化先验损失等方法,实现了基于文本指导生成Barbie风格三维角色的目标。
- Conclusion:
(1) 这项工作的意义在于提出了一种基于文本指导生成Barbie风格三维角色的新方法,为虚拟世界和增强现实技术中的三维角色生成提供了新的思路和技术手段。
(2) 创新点:该文章通过精细分解、领域特定保真度优化和自进化先验损失等方法,实现了基于文本指导生成Barbie风格三维角色的目标,具有一定的创新性。性能:在服装人生成和服装生成任务上的实验结果表明,Barbie在生成具有Barbie风格的三维角色方面表现出色,支持灵活的服装组合和动画,具有较高的性能。工作量:该文章实现了一种完整的框架和方法,包括人体和服装的精细分解、领域特定保真度优化、自进化先验损失等,工作量较大。
总体来说,该文章为基于文本指导的三维角色生成提供了新的思路和方法,具有一定的创新性和应用价值。
点此查看论文截图



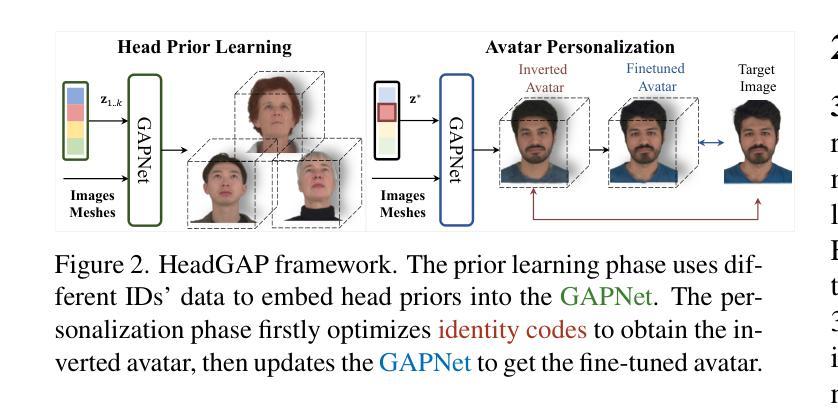
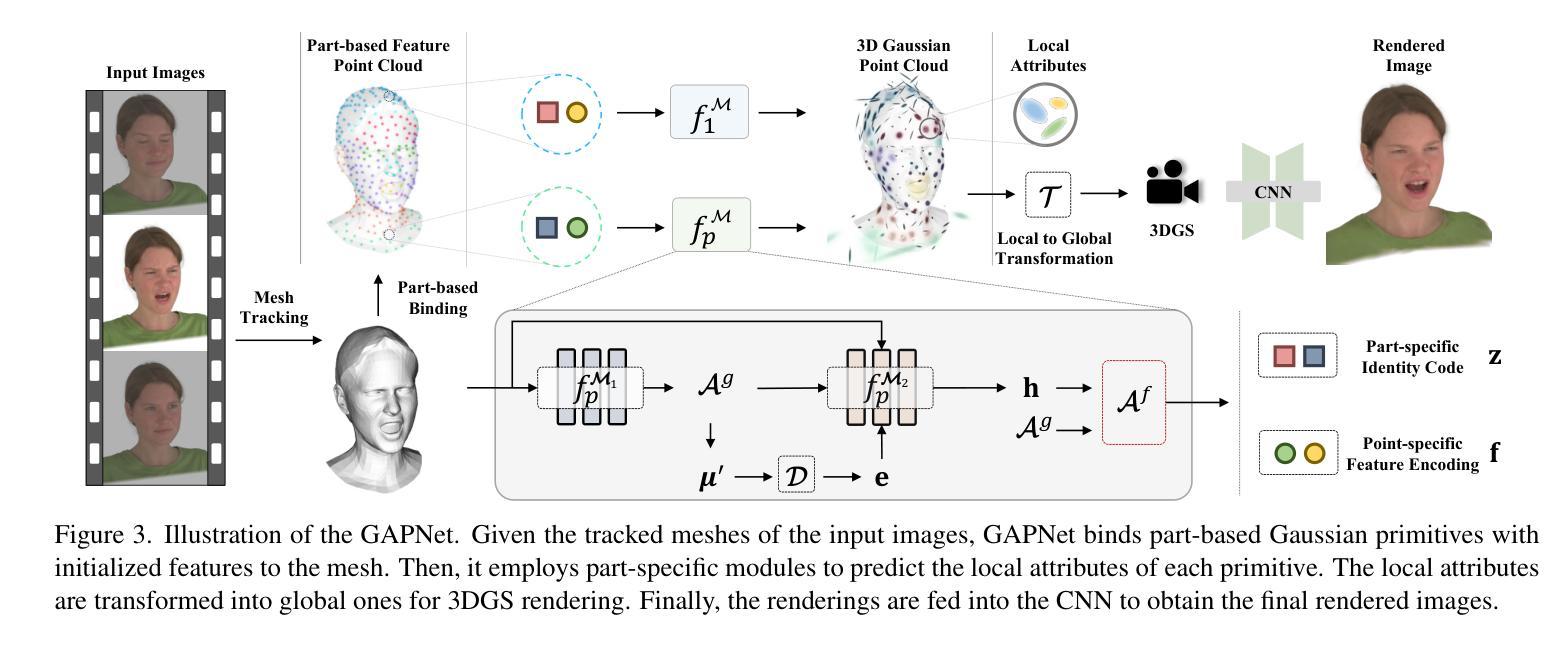
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Authors:Xiaozheng Zheng, Chao Wen, Zhaohu Li, Weiyi Zhang, Zhuo Su, Xu Chang, Yang Zhao, Zheng Lv, Xiaoyuan Zhang, Yongjie Zhang, Guidong Wang, Lan Xu
In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential. Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization. Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives. During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
PDF Project page: https://headgap.github.io/
Summary
提出了一种新颖的三维头像创建方法,能够从少样本野外数据中进行高保真和可动性强的泛化。
Key Takeaways
- 创新的3D头像创建方法,能够从少样本数据中进行个性化建模。
- 引入先验知识至关重要,特别是在这种不受约束的问题情境中。
- 方法包括先验学习和头像创建两个阶段。
- 使用基于高斯飞溅的自动解码器网络和基于部件的动态建模来捕捉先验信息。
- 采用身份共享编码和个性化潜变量码以学习高斯原语的属性。
- 利用反演和微调策略实现快速头像个性化。
- 实验证明,模型能够有效地利用头部先验知识,并成功泛化到少样本个性化,达到了照片级渲染质量、多视角一致性和稳定动画效果。
Please refer to relevant websites for more information, and feel free to ask me any other questions.
好的,请您提供需要总结的论文方法部分的内容,我会按照您的要求进行详细且简洁的中文总结。请确保您提供的内容清晰、连贯,我会尽力理解并按照要求的格式进行整理。如果没有具体的文章内容,我无法进行准确的总结。请提供具体的方法描述或相关段落,以便我能够帮助您完成这个任务。
- 结论:
(1)xxx。这项工作提出了一种创建高度真实感的3D头像的新方法,通过利用少量图像生成个性化头像,具有重要的应用价值和实践意义。它对于虚拟现实、增强现实、游戏设计等领域具有重要的推动作用。
(2)创新点:该文章的创新性主要体现在提出了一种基于高斯先验模型的个性化头像生成方法,通过引入GAPNet网络,能够利用大规模3D头像数据学习得到的3D高斯先验模型,辅助生成新型身份的头像。同时,文章展示了该方法在创建高度真实感的头像和稳健的动画方面的优越性。
性能:该文章所述方法在创建个性化头像方面具有优异的性能表现,能够在少量图像的情况下生成高质量的头像。此外,该方法还具有较好的泛化性能,能够在不同主体之间实现较为稳健的动画效果。
工作量:该文章涉及大量的实验和细节实现,工作量较大。文章详细介绍了数据集的处理、模型的构建、训练过程的细节等,体现了作者在研究中的严谨性和深入性。
点此查看论文截图