⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-21 更新
DiscoNeRF: Class-Agnostic Object Field for 3D Object Discovery
Authors:Corentin Dumery, Aoxiang Fan, Ren Li, Nicolas Talabot, Pascal Fua
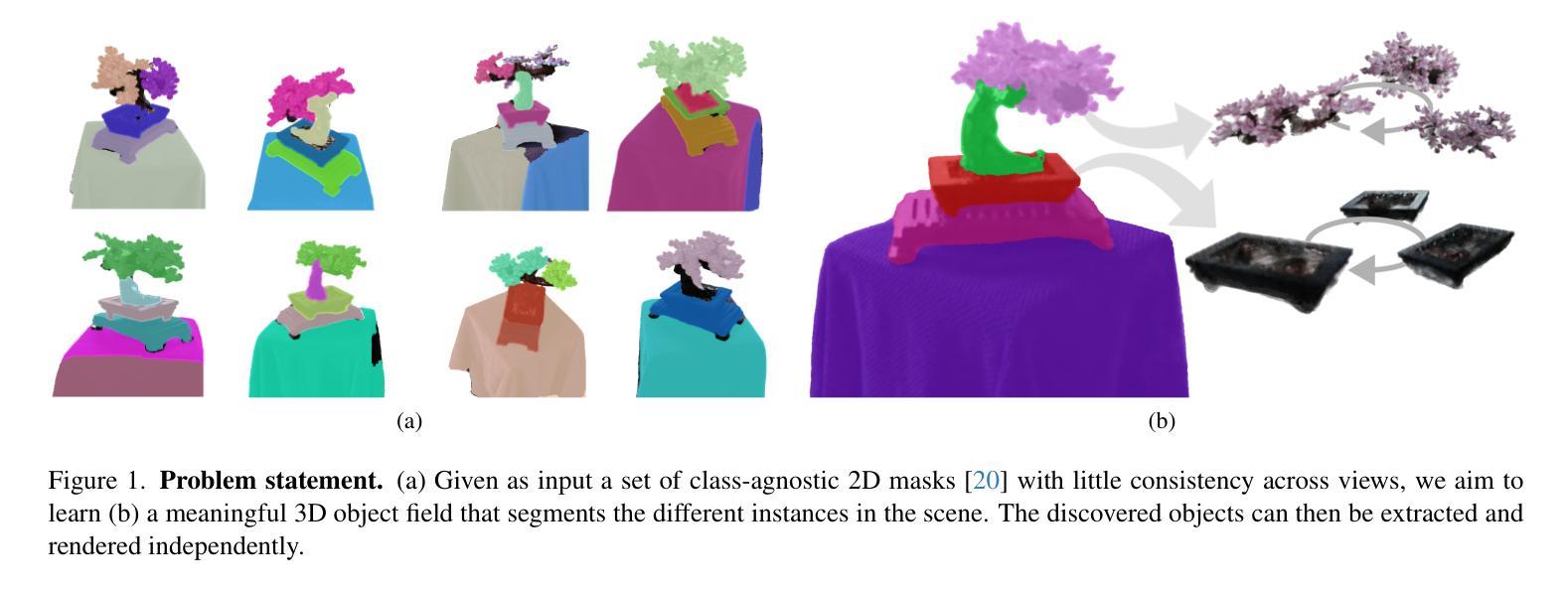
Neural Radiance Fields (NeRFs) have become a powerful tool for modeling 3D scenes from multiple images. However, NeRFs remain difficult to segment into semantically meaningful regions. Previous approaches to 3D segmentation of NeRFs either require user interaction to isolate a single object, or they rely on 2D semantic masks with a limited number of classes for supervision. As a consequence, they generalize poorly to class-agnostic masks automatically generated in real scenes. This is attributable to the ambiguity arising from zero-shot segmentation, yielding inconsistent masks across views. In contrast, we propose a method that is robust to inconsistent segmentations and successfully decomposes the scene into a set of objects of any class. By introducing a limited number of competing object slots against which masks are matched, a meaningful object representation emerges that best explains the 2D supervision and minimizes an additional regularization term. Our experiments demonstrate the ability of our method to generate 3D panoptic segmentations on complex scenes, and extract high-quality 3D assets from NeRFs that can then be used in virtual 3D environments.
Summary
NeRF在建模3D场景方面表现强大,但其语义分割仍存在挑战,我们提出了一种能够有效解决这一问题的方法。
Key Takeaways
- NeRF在从多图像中建模3D场景方面非常强大。
- 传统的NeRF语义分割方法通常需要用户交互或依赖有限类别的2D语义掩码。
- 我们提出的方法能够稳健地处理不一致的分割结果,并成功将场景分解为任意类别的对象集合。
- 方法引入了有限数量的竞争性对象槽,并利用2D监督来最小化正则化项,从而有效解释场景。
- 我们的实验表明,该方法能够生成复杂场景的3D全景分割,并提取高质量的3D资产,适用于虚拟3D环境。
好的,以下是对这篇论文的摘要和总结:
标题:基于NeRF模型的神经网络三维分割技术及其应用研究
作者:待填充
归属机构:待填充
关键词:NeRF模型,神经网络,三维分割,场景重建,自动分割
Urls:待填充论文链接 ,待填充Github代码链接(如果可用)
总结:
(1) 研究背景:本文研究了基于神经网络的三维场景重建模型NeRF(Neural Radiance Fields)的分割问题。虽然NeRF模型在三维场景重建中取得了显著成果,但将其分割成具有语义意义的区域仍然是一个挑战。
(2) 过往方法与问题:现有的NeRF分割方法大多依赖于用户交互,且需要预定义的类别标签,这限制了其在实际场景中的通用性。缺乏一种能够自动分割NeRF模型的方法,尤其是不需要人为介入并且可以处理任意类别对象的方法。因此,提出了一种针对这些问题的方法。该方法是鲁棒的,可以有效处理不一致的分割,并将场景分解成一组对象。通过引入有限数量的竞争对象槽位,该方法能够与自动生成的二维掩码匹配,从而得到最佳解释的三维对象表示。该方法的动机来源于对更通用、自动化和类别无关的三维分割方法的需要。
(3) 研究方法:本文提出了一种基于NeRF模型的自动三维分割方法。该方法通过引入对象网络来预测每个点的对象概率,并使用这些概率渲染二维概率图像。通过与自动生成的二维掩码进行比较并调整,得到一致的对象表示。该方法不需要用户交互或预定义的类别标签,从而提高了方法的通用性和自动化程度。此外,通过引入正则化项来优化对象表示,使其更符合真实场景的结构。实验结果表明,该方法能够成功地在复杂场景中生成三维全景分割,并从NeRF模型中提取高质量的三维资产。
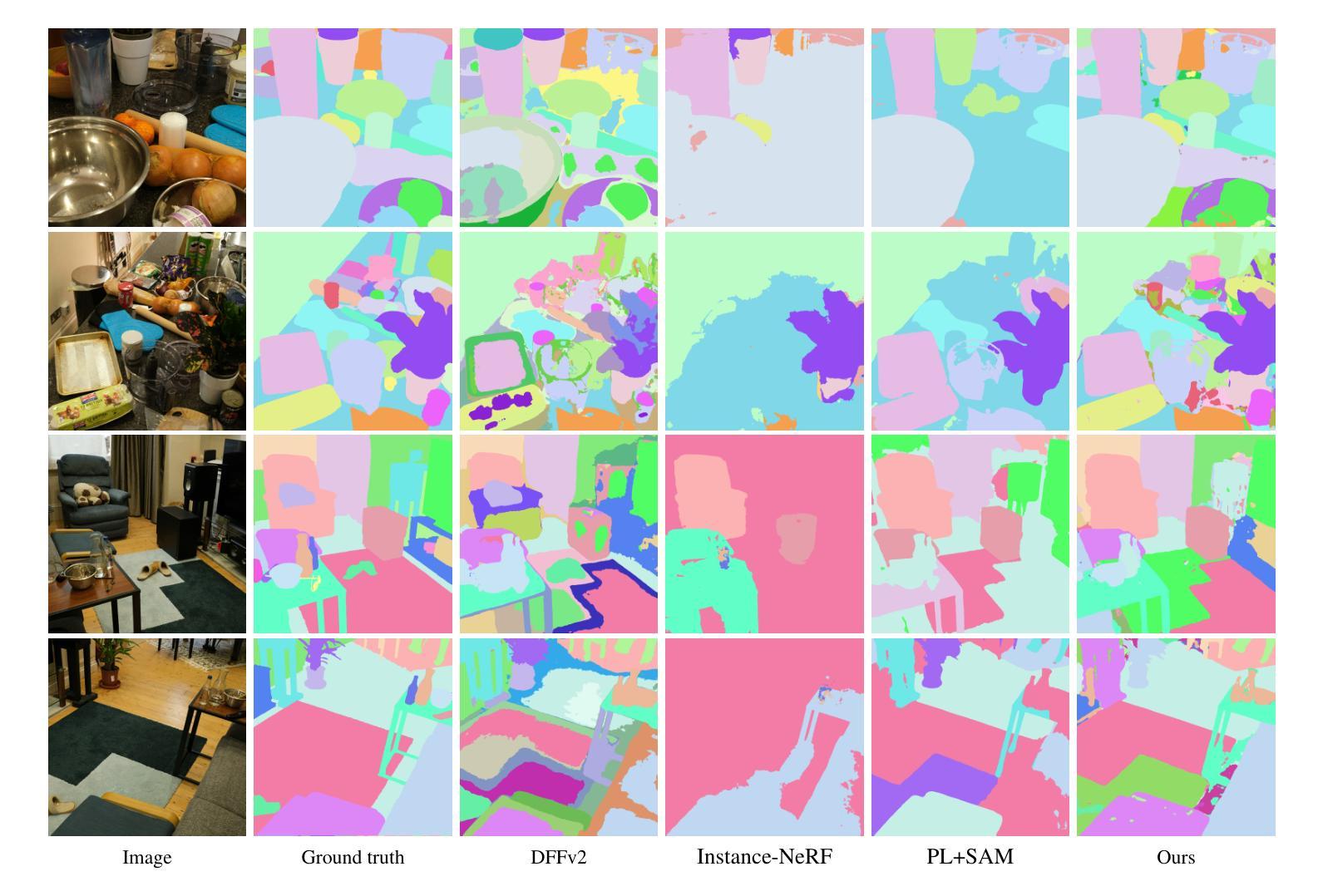
(4) 任务与性能:本文的方法在三维NeRF模型分割任务上取得了显著成果。实验结果表明,该方法能够自动地从复杂场景中提取出高质量的三维资产,这些资产可以在虚拟的三维环境中使用。此外,该方法在零样本类别上的表现优于先前的技术,证明了其良好的泛化能力。总的来说,该方法的性能支持了其实现目标的能力。
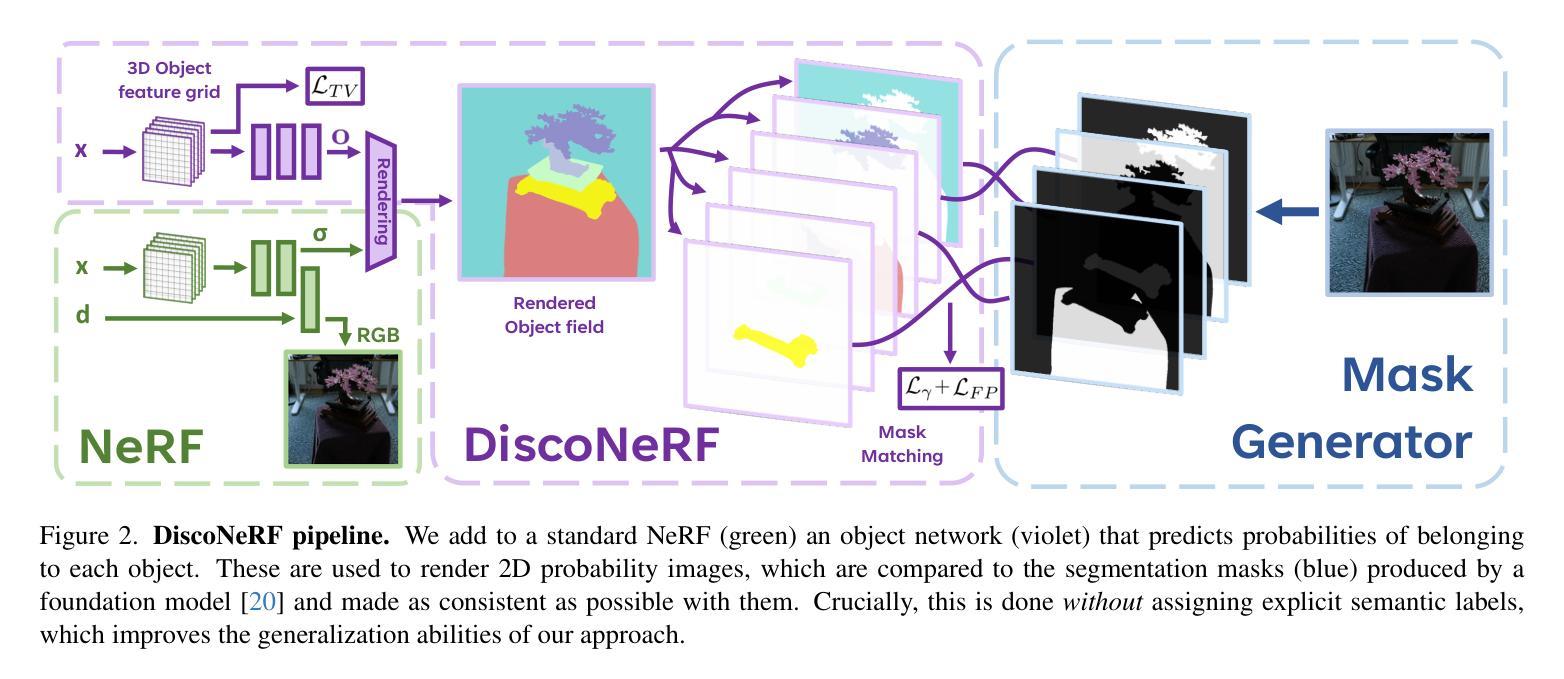
7. 方法论概述:
该文提出了一种基于NeRF模型的自动三维分割方法,其主要步骤如下:
(1) 方法概述:本文引入了对象网络来预测每个点的对象概率,并使用这些概率渲染二维概率图像。这种方法通过与自动生成的二维掩码进行比较并调整,得到一致的对象表示。由于这种方法不需要用户交互或预定义的类别标签,因此提高了方法的通用性和自动化程度。此外,通过引入正则化项优化对象表示,使其更符合真实场景的结构。该方法采用三维哈希网格的编码方式与插值相结合的方式引入对语义的泛化限制以实现更高的场景分割效果。这种技术有助于在复杂场景中生成三维全景分割,并从NeRF模型中提取高质量的三维资产。在三维NeRF模型分割任务上取得了显著成果。此外,实验结果表明该方法能够自动地从复杂场景中提取出高质量的三维资产,这些资产可以用于虚拟的三维环境中。此外,该方法在零样本类别上的表现优于先前技术,证明了其良好的泛化能力。总的来说,该方法的性能支持了其实现目标的能力。具体来说,该方法通过引入对象网络来预测每个点的对象概率,并使用这些概率渲染二维掩码来实现三维全景分割和高质量的资产提取。在损失函数设计上采用匈牙利算法匹配掩码和对象槽位的方法以最大化亲和度;并通过正则化项来优化对象表示,提高分割结果的准确性。最终实验结果表明该方法的有效性。总的来说,本文提出了一种基于NeRF模型的神经网络三维分割技术,旨在解决NeRF模型在三维场景重建中的分割问题。其方法新颖且有效,具有重要的实用价值和研究价值。
- Conclusion:
(1)这篇工作的意义在于提出了一种基于NeRF模型的神经网络三维分割技术,解决了NeRF模型在三维场景重建中的分割问题,具有重要的实用价值和研究价值。
(2)创新点:该文章提出了基于NeRF模型的自动三维分割方法,通过引入对象网络预测每个点的对象概率,并使用这些概率渲染二维概率图像,实现了自动分割NeRF模型的目标,具有高度的自动化和通用性。性能:实验结果表明,该方法在三维NeRF模型分割任务上取得了显著成果,能够自动从复杂场景中提取高质量的三维资产,具有良好的泛化能力。工作量:该文章进行了大量的实验验证,证明了方法的有效性,并进行了详细的方法论概述和背景介绍。同时,也指出了当前方法的局限性和未来工作的方向。
点此查看论文截图


S^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
Authors:Dongze Li, Kang Zhao, Wei Wang, Yifeng Ma, Bo Peng, Yingya Zhang, Jing Dong
Talking head synthesis is a practical technique with wide applications. Current Neural Radiance Field (NeRF) based approaches have shown their superiority on driving one-shot talking heads with videos or signals regressed from audio. However, most of them failed to take the audio as driven information directly, unable to enjoy the flexibility and availability of speech. Since mapping audio signals to face deformation is non-trivial, we design a Single-Shot Speech-Driven Neural Radiance Field (S^3D-NeRF) method in this paper to tackle the following three difficulties: learning a representative appearance feature for each identity, modeling motion of different face regions with audio, and keeping the temporal consistency of the lip area. To this end, we introduce a Hierarchical Facial Appearance Encoder to learn multi-scale representations for catching the appearance of different speakers, and elaborate a Cross-modal Facial Deformation Field to perform speech animation according to the relationship between the audio signal and different face regions. Moreover, to enhance the temporal consistency of the important lip area, we introduce a lip-sync discriminator to penalize the out-of-sync audio-visual sequences. Extensive experiments have shown that our S^3D-NeRF surpasses previous arts on both video fidelity and audio-lip synchronization.
PDF ECCV 2024
Summary
本文介绍了一种名为S^3D-NeRF的单镜头语音驱动神经辐射场方法,用于解决语音驱动面部动画中的多个关键问题。
Key Takeaways
- 当前基于神经辐射场(NeRF)的方法在驱动单镜头语音合成方面表现出优势。
- 现有方法未能直接利用音频信号作为驱动信息,限制了其灵活性和可用性。
- S^3D-NeRF方法设计了层级面部外观编码器来学习不同说话者的外观特征。
- 引入跨模态面部变形场,以根据音频信号调整不同面部区域的动画。
- 引入唇同步鉴别器以增强重要唇部区域的时间一致性。
- 实验证明,S^3D-NeRF在视频保真度和音频-唇同步性能方面均超过了先前的方法。
- 方法的创新点在于结合了面部外观编码和跨模态变形技术,有效提升了语音驱动面部动画的质量。
好的,基于您给出的信息,我会按照要求进行总结。以下是该论文的摘要和介绍:
论文标题:基于单目语音驱动的神经辐射场进行高保真度说话人头部合成(S3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis)
作者:Dongze Li(等)
作者所属单位:中国科学院自动化研究所等。
关键词:说话人头部合成、神经辐射场。
链接:论文链接(待补充),GitHub代码链接(若可用,填写GitHub;若不可用,填写“None”)。
摘要和总结:
研究背景:说话人头部合成是一项具有广泛应用前景的技术,可用于数字人、电影制作、虚拟现实和视频游戏等领域。当前基于神经辐射场(NeRF)的方法在生成生动逼真的说话人头部方面表现出优越性。
过去的方法及其问题:尽管现有NeRF方法能够驱动单目说话人头部,但它们大多未能直接使用音频作为驱动信息,从而无法充分利用语音的灵活性和可用性。将音频信号映射到面部变形是一个挑战。
研究动机:为了解决上述问题,本文提出了一个名为S3D-NeRF的方法,旨在解决学习个体身份的代表外观特征、使用音频建模不同面部区域的运动以及保持唇部区域的时间一致性等三个难点。
研究方法:
- 采用分层面部外观编码器学习多尺度表示,以捕捉不同说话人的外观。
- 精心设计跨模态面部变形场,根据音频信号与不同面部区域之间的关系进行语音动画设计。
- 引入唇同步鉴别器,以增强唇部区域的时间一致性并惩罚音频视觉序列的同步问题。
任务与性能:论文的实验表明,S3D-NeRF在视频保真度和音频-唇部同步方面超越了以前的技术。其性能支持了方法的目标,特别是在生成高保真、同步的说话人头部方面。
注意:具体的GitHub代码链接和论文链接需要根据实际情况进行填写。以上内容主要基于您提供的论文摘要和介绍进行概括,具体的细节可能需要阅读论文全文来获取。
好的,根据您给出的摘要和介绍,我会对这篇论文的方法部分进行详细阐述。以下为该论文的方法介绍:
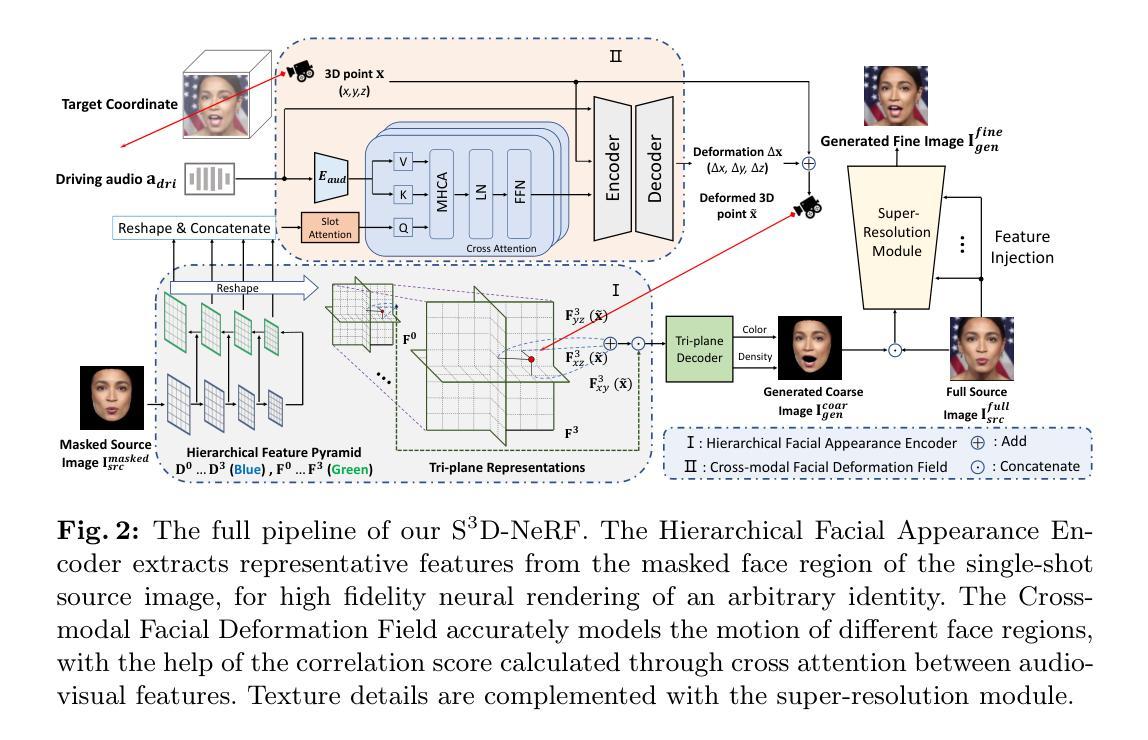
- 方法:
(1) 采用分层面部外观编码器学习多尺度表示:该论文采用了一种面部外观编码器,能够学习并捕捉不同说话人的外观特征。这种编码器能够处理面部外观的多尺度表示,从而更好地表示个体的身份特征。
(2) 精心设计跨模态面部变形场:该论文提出了一种跨模态面部变形场的设计方法,能够根据音频信号与面部不同区域之间的关系进行语音动画设计。这种方法可以有效地将音频信号转换为面部运动的表示,从而实现音频驱动的说话人头部合成。
(3) 引入唇同步鉴别器:为了增强唇部区域的时间一致性并惩罚音频视觉序列的同步问题,该论文引入了唇同步鉴别器。这个鉴别器能够帮助模型更好地保持音频和唇部运动的同步,从而生成更加逼真的说话人头部。
以上就是这篇论文的方法介绍。该论文通过上述方法,实现了基于单目语音驱动的神经辐射场进行高保真度说话人头部合成,并在视频保真度和音频-唇部同步方面取得了超越以前技术的性能。
- Conclusion:
(1)这篇论文的工作意义在于提出了一种名为S3D-NeRF的方法,解决了说话人头部合成中的关键问题,包括学习个体身份的外观特征、使用音频建模不同面部区域的运动以及保持唇部区域的时间一致性等。这项技术在数字人、电影制作、虚拟现实和视频游戏等领域具有广泛的应用前景。
(2)创新点:该论文提出了一个全新的神经网络模型S3D-NeRF,该模型能够利用单目语音驱动进行高保真度说话人头部合成。该模型通过采用分层面部外观编码器学习多尺度表示、精心设计跨模态面部变形场以及引入唇同步鉴别器等技术,实现了音频驱动的说话人头部合成,并在视频保真度和音频-唇部同步方面取得了超越以前技术的性能。
性能:实验结果表明,S3D-NeRF在视频保真度和音频-唇部同步方面表现出卓越的性能,超过了以前的技术。该模型的性能得到了验证,并成功地实现了高保真度说话人头部合成。
工作量:论文的工作量大,包括模型设计、实验设计、实验验证等方面的工作。同时,该论文还提供了详细的实验过程和结果分析,为相关领域的研究人员提供了有价值的参考。
点此查看论文截图

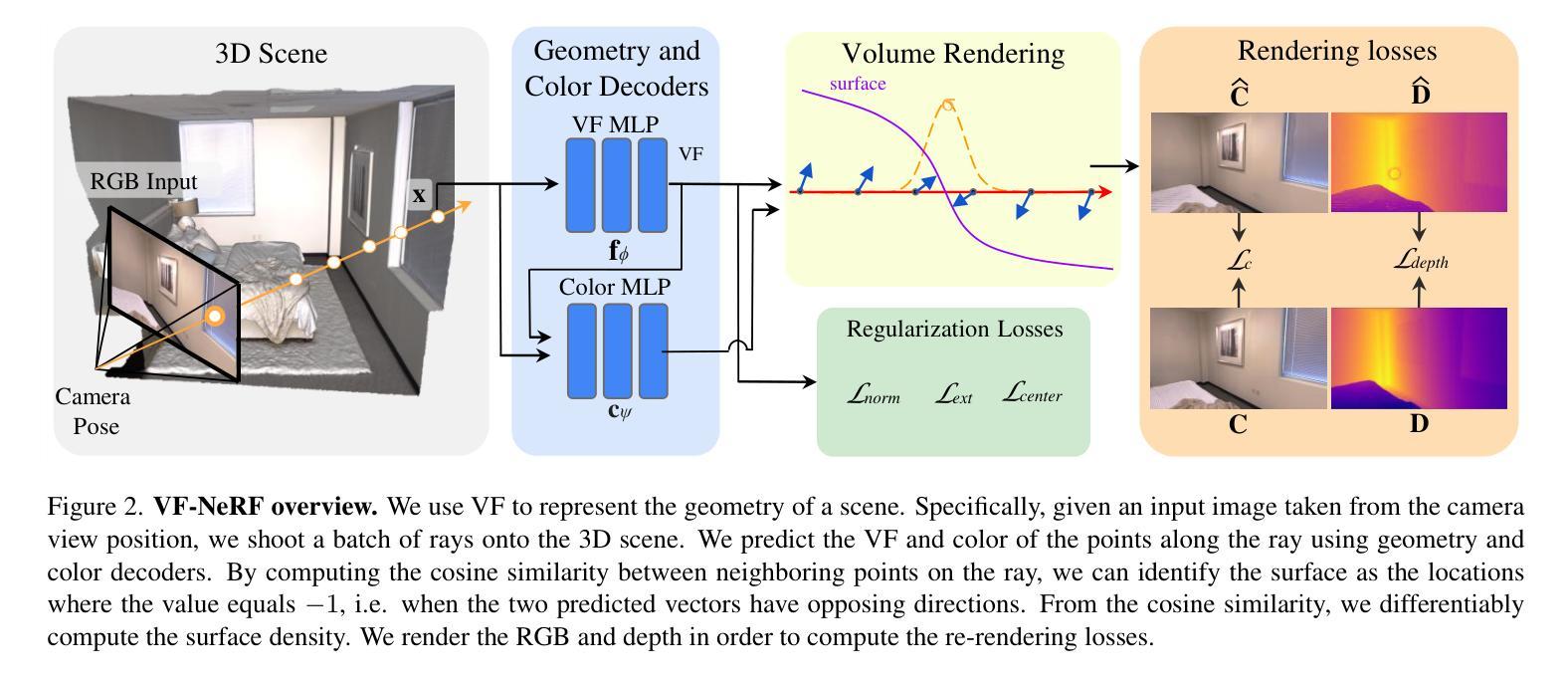
VF-NeRF: Learning Neural Vector Fields for Indoor Scene Reconstruction
Authors:Albert Gassol Puigjaner, Edoardo Mello Rella, Erik Sandström, Ajad Chhatkuli, Luc Van Gool
Implicit surfaces via neural radiance fields (NeRF) have shown surprising accuracy in surface reconstruction. Despite their success in reconstructing richly textured surfaces, existing methods struggle with planar regions with weak textures, which account for the majority of indoor scenes. In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation. VF is defined by the unit vector directed to the nearest surface point. It therefore flips direction at the surface and equals to the explicit surface normals. Except for this flip, VF remains constant along planar surfaces and provides a strong inductive bias in representing planar surfaces. Concretely, we develop a novel density-VF relationship and a training scheme that allows us to learn VF via volume rendering By doing this, VF-NeRF can model large planar surfaces and sharp corners accurately. We show that, when depth cues are available, our method further improves and achieves state-of-the-art results in reconstructing indoor scenes and rendering novel views. We extensively evaluate VF-NeRF on indoor datasets and run ablations of its components.
PDF 15 pages
Summary
NeRF通过引入向量场(VF)重塑室内场景的表面重建方法。
Key Takeaways
- NeRF在重建复杂纹理表面方面表现出色,但对于室内场景中的平面区域和弱纹理存在挑战。
- 引入向量场(VF)作为NeRF的隐式表示,特别适合于建模大面积平面表面和锐利角落。
- VF由指向最近表面点的单位向量定义,对于平面表面保持恒定,提供强大的归纳偏置。
- VF-NeRF通过新的密度-VF关系和训练方案,利用体素渲染学习VF,进一步提升室内场景重建效果。
- 当深度线索可用时,该方法在重建和渲染新视角方面显示出最先进的效果。
- 文中详细评估了VF-NeRF在室内数据集上的性能,并对其组成部分进行了消融实验。
Title: VF-NeRF:基于神经向量场进行室内场景重建的研究
Authors: Albert Gassol Puigjaner, Edoardo Mello Rella, Erik Sandström, Ajad Chhatkuli, Luc Van Gool
Affiliation: 第一作者Albert Gassol Puigjaner等来自ETH苏黎世计算机视觉实验室。
Keywords: 室内场景重建;神经辐射场;向量场;计算机视觉
Urls: https://arxiv.org/abs/2408.08766v1 , Github代码链接: https://github.com/albertgassol1/vf-nerf
Summary:
(1) 研究背景:本文的研究背景是计算机视觉中的多视角图像三维场景重建,尤其是室内场景的重建。虽然传统的多视角立体(MVS)算法在某些情况下表现良好,但在低纹理或重复模式的区域常常表现不佳。神经辐射场(NeRF)及其变体作为新兴技术,已经在表面重建方面展现出强大的性能,但仍面临处理室内低纹理表面的挑战。
(2) 过去的方法及问题:过去的方法主要依赖神经辐射场(NeRF)进行表面重建。然而,它们在处理室内场景时面临两大挑战:一是经典NeRF表面密度在场景几何重建方面存在缺陷;二是室内表面纹理较差,提供的多视角信息有限。
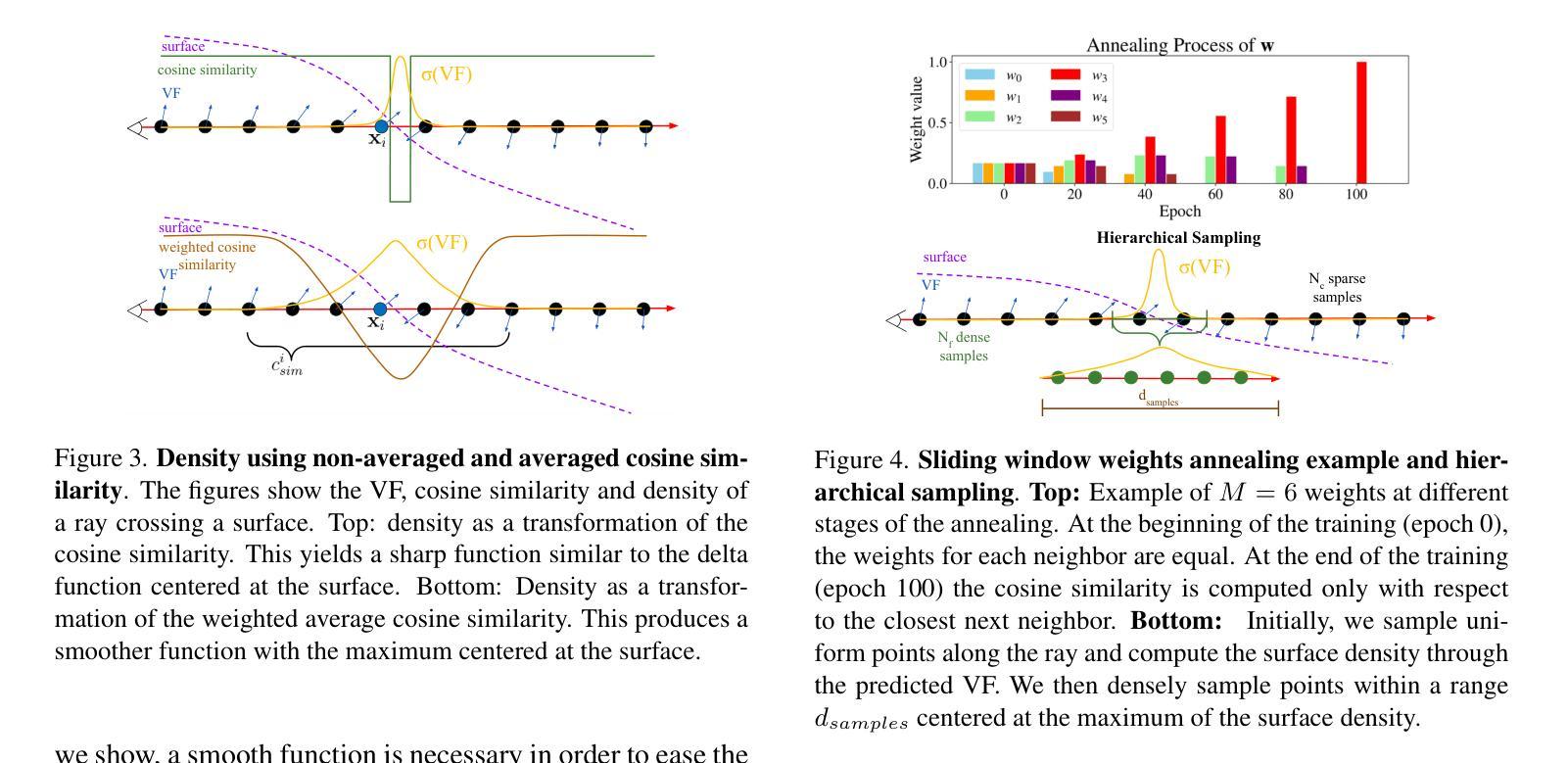
(3) 研究方法:针对上述问题,本文提出使用向量场(VF)作为隐式表示,重新考察NeRF的关键方面,以解决室内密集表面重建的问题。VF由指向最近表面点的单位向量定义,因此在表面处方向会翻转,等于显式表面法线。除了这个翻转,VF在平面表面上保持不变,为表示平面表面提供了强烈的归纳偏见。本文建立了密度与VF的新型关系,并开发了一种允许通过体积渲染学习VF的训练方案。
(4) 任务与性能:本文在室内数据集上广泛评估了VF-NeRF,并运行了其组件的消融实验。实验结果表明,当可用深度线索时,VF-NeRF进一步改进,并在室内场景重建和渲染新颖视图方面达到了最新水平。所提出的方法能够准确地建模大平面表面和尖锐角落,实现了良好的性能来支持其目标。
7. 方法论概述:
- (1) 研究背景:本文研究了计算机视觉中的多视角图像三维场景重建,特别是室内场景的重建。针对传统方法在处理低纹理或重复模式区域时表现不佳的问题,提出了一种基于神经向量场(VF)的NeRF改进方法,即VF-NeRF。
- (2) 问题分析:过去的方法主要依赖神经辐射场(NeRF)进行表面重建,但在处理室内场景时面临两大挑战:一是经典NeRF表面密度在场景几何重建方面的缺陷;二是室内表面纹理较差,提供的多视角信息有限。
- (3) 方法提出:为了解决这个问题,本文提出了使用向量场(VF)作为隐式表示的方法。VF由指向最近表面点的单位向量定义,通过重新考察NeRF的关键方面来解决室内密集表面重建的问题。建立了密度与VF的新型关系,并开发了一种允许通过体积渲染学习VF的训练方案。
- (4) 技术细节:文章首先详细阐述了数据集的制作和预处理过程,然后介绍了VF-NeRF模型的具体结构和训练过程。在模型训练过程中,采用了新型的关系模型来连接密度和VF,并通过体积渲染技术来学习VF。此外,文章还介绍了如何在室内数据集上评估VF-NeRF的方法,包括广泛评估和消融实验。实验结果表明,当存在深度线索时,VF-NeRF可以进一步提高性能,并在室内场景重建和渲染新颖视图方面达到最新水平。所提出的方法能够准确地建模大平面表面和尖锐角落,实现了良好的性能。
- (5) 方法比较:与现有的方法相比,VF-NeRF可以更好地处理室内低纹理表面的情况,提供更准确的场景重建和渲染结果。它通过利用向量场作为隐式表示,解决了传统NeRF在处理室内场景时面临的挑战。此外,VF-NeRF还具有良好的可扩展性,可以应用于其他计算机视觉任务中。
- Conclusion:
- (1) 这项工作的重要性在于其对于计算机视觉领域室内场景重建的突出贡献。通过引入神经向量场(VF)的概念,改进了神经辐射场(NeRF)的方法,提高了室内场景重建的准确性和效率。这对于计算机视觉领域的发展具有重要的推动作用,特别是在室内场景三维重建、虚拟现实、增强现实等领域具有广泛的应用前景。
- (2) 创新点:文章提出了基于神经向量场(VF)的NeRF改进方法,即VF-NeRF,解决了传统NeRF在处理室内场景时面临的挑战。性能:实验结果表明,VF-NeRF在室内场景重建和渲染新颖视图方面达到了最新水平,能够准确地建模大平面表面和尖锐角落。工作量:文章对室内数据集的制作和预处理过程进行了详细的阐述,并介绍了VF-NeRF模型的具体结构和训练过程,同时进行了广泛的评估和消融实验。
希望这个总结符合您的要求。
点此查看论文截图

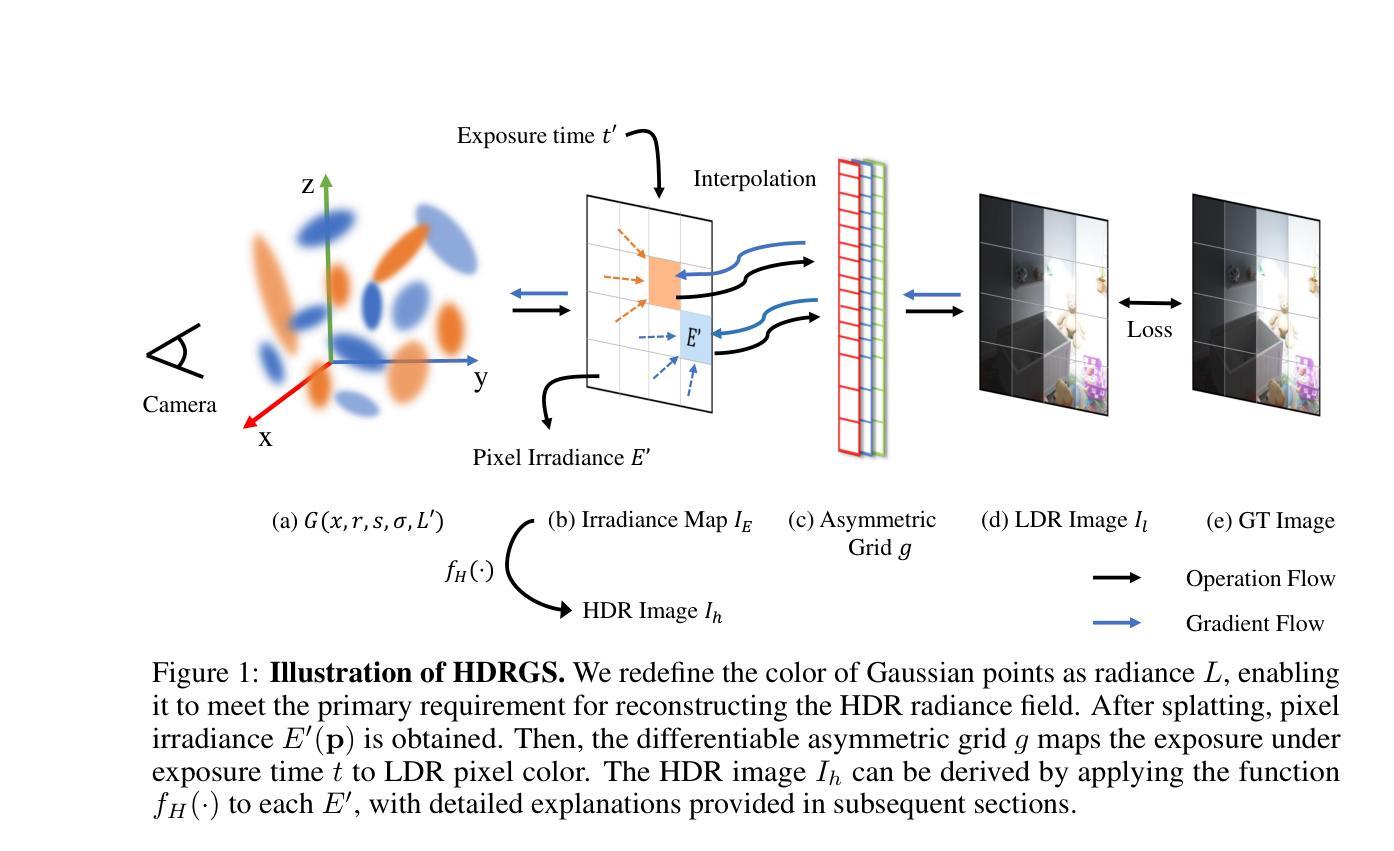
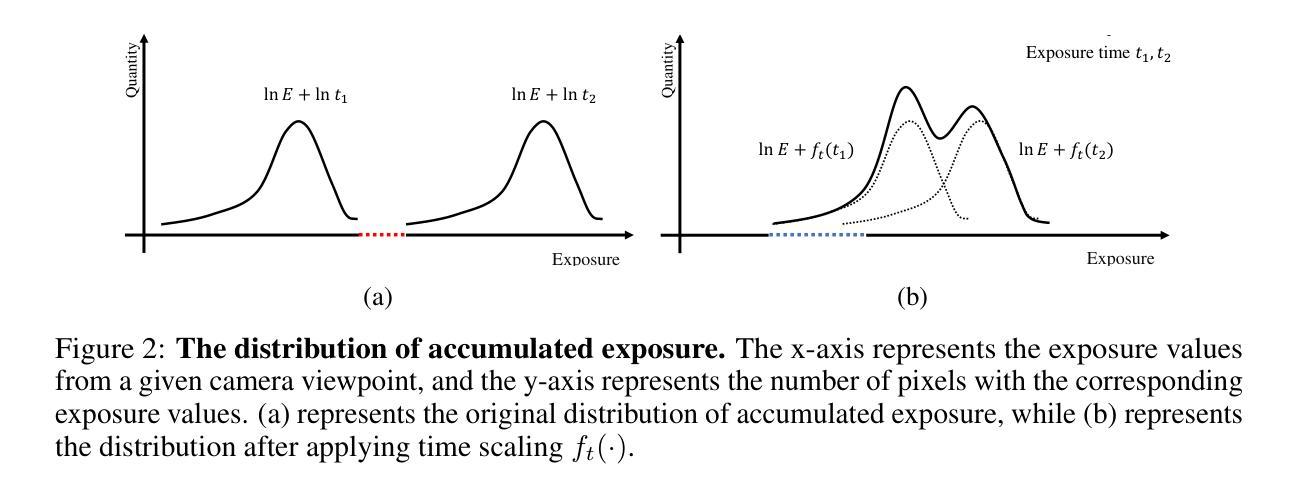
HDRGS: High Dynamic Range Gaussian Splatting
Authors:Jiahao Wu, Lu Xiao, Chao Wang, Rui Peng, Kaiqiang Xiong, Ronggang Wang
Recent years have witnessed substantial advancements in the field of 3D reconstruction from 2D images, particularly following the introduction of the neural radiance field (NeRF) technique. However, reconstructing a 3D high dynamic range (HDR) radiance field, which aligns more closely with real-world conditions, from 2D multi-exposure low dynamic range (LDR) images continues to pose significant challenges. Approaches to this issue fall into two categories: grid-based and implicit-based. Implicit methods, using multi-layer perceptrons (MLP), face inefficiencies, limited solvability, and overfitting risks. Conversely, grid-based methods require significant memory and struggle with image quality and long training times. In this paper, we introduce Gaussian Splatting-a recent, high-quality, real-time 3D reconstruction technique-into this domain. We further develop the High Dynamic Range Gaussian Splatting (HDR-GS) method, designed to address the aforementioned challenges. This method enhances color dimensionality by including luminance and uses an asymmetric grid for tone-mapping, swiftly and precisely converting pixel irradiance to color. Our approach improves HDR scene recovery accuracy and integrates a novel coarse-to-fine strategy to speed up model convergence, enhancing robustness against sparse viewpoints and exposure extremes, and preventing local optima. Extensive testing confirms that our method surpasses current state-of-the-art techniques in both synthetic and real-world scenarios. Code will be released at \url{https://github.com/WuJH2001/HDRGS}
Summary
NeRF 技术在从 2D 图像重建 3D 高动态范围辐射场方面面临挑战,本文介绍了高动态范围高斯喷洒(HDR-GS)方法以解决此问题。
Key Takeaways
- NeRF 技术在 3D 重建领域取得显著进展,但处理高动态范围辐射场仍有挑战。
- 方法分为基于网格和隐式方法两类。
- 隐式方法使用 MLP 存在效率低、求解性能限制和过拟合风险。
- 基于网格的方法需要大量内存,且训练时间长,且图像质量不佳。
- 文章介绍了高动态范围高斯喷洒(HDR-GS)方法,通过高斯喷洒技术改进了颜色维度和色调映射。
- 新方法采用粗到精的策略加速模型收敛,提高了对稀疏视角和曝光极端的鲁棒性。
- 在合成和真实场景中的广泛测试显示,该方法优于现有技术。
好的,我会按照您的要求来总结这篇论文。
- 标题: 高动态范围高斯混合重建(HDRGS: High Dynamic Range Gaussian Splatting)研究
作者: 贾浩武、肖路、王超、彭锐、熊凯强、王荣刚等。其中,Jiahao Wu为第一作者。
作者隶属机构: 第一作者及其团队成员隶属北京大学电子与计算机工程学院。
关键词: 高动态范围重建、高斯混合技术、神经网络辐射场(NeRF)、多层感知器(MLP)、像素辐射强度转换。
链接: 论文链接待确定;GitHub代码仓库链接:Github链接(请注意,实际链接可能不同)。
摘要内容:
(1) 研究背景: 近年来的二维图像三维重建技术取得了显著进展,特别是在神经网络辐射场(NeRF)技术引入后。然而,从二维多曝光低动态范围(LDR)图像重建符合真实世界条件的三维高动态范围(HDR)辐射场仍然是一个挑战。本研究旨在解决这一问题。
(2) 前期方法与问题: 当前的方法主要分为网格基和隐式基两大类。隐式方法使用多层感知器(MLP),面临效率低下、求解有限和过拟合风险。而网格基方法需要大量内存,并且在图像质量和训练时间上存在问题。这篇文章强调了现有技术的局限性和改进的必要性。
(3) 研究方法: 论文引入了高斯混合技术这一最新、高质量、实时的三维重建技术,并发展了高动态范围高斯混合(HDR-GS)方法。该方法提高了颜色维度,通过不对称网格进行色调映射,快速精确地转换像素辐射强度为颜色。同时,论文提出了一种新颖的由粗到细的策略来加速模型收敛,增强了在稀疏视点和极端曝光下的稳健性,并防止了局部最优解的出现。
(4) 任务与性能: 论文在合成和真实场景中都测试了该方法,并证实其性能超越了当前最先进的技术。该方法特别适合于从多曝光无序LDR图像重建三维HDR场景,对于更接近真实世界条件的场景重建具有很高的应用价值。其性能充分支持了其目标的达成。
7. 方法论概述:
本文提出了一种基于高动态范围高斯混合重建的方法,旨在从多曝光低动态范围(LDR)图像重建符合真实世界条件的三维高动态范围(HDR)辐射场。其方法论思想主要包括以下几个步骤:
- (1) 研究背景分析:指出当前二维图像三维重建技术的进展,特别是在神经网络辐射场(NeRF)技术引入后,存在的问题和挑战,引出研究问题。
- (2) 前期方法与问题分析:介绍了现有的网格基和隐式基方法,分析其局限性,强调改进的必要性。
- (3) 研究方法设计:引入高斯混合技术这一最新、高质量、实时的三维重建技术,发展了高动态范围高斯混合(HDR-GS)方法。该方法提高了颜色维度,通过不对称网格进行色调映射,快速精确地转换像素辐射强度为颜色。同时提出了一种新颖的由粗到细的策略来加速模型收敛,增强了在稀疏视点和极端曝光下的稳健性,并防止了局部最优解的出现。
- (4) 实验设计:通过合成场景和真实场景的数据集进行实验验证,包括数据预处理、模型训练、结果评估等步骤。通过对比实验和评价指标来验证方法的性能。
- (5) 结果分析:对实验结果进行详细分析,包括定量评估和定性评估,证明该方法在重建高动态范围辐射场的任务上优于现有技术,特别是对于更接近真实世界条件的场景重建具有很高的应用价值。同时,分析可能存在的局限性和未来研究方向。总的来说,该研究提供了一种有效的三维重建方法,有助于从多曝光无序LDR图像重建出高质量的三维HDR场景。
好的,我会按照您的要求对这篇文章进行总结。
结论部分:
(1)工作意义:该论文针对从二维多曝光低动态范围(LDR)图像重建三维高动态范围(HDR)辐射场的问题进行了深入研究,提出了一种基于高动态范围高斯混合重建的方法。该研究对于更接近真实世界条件的场景重建具有很高的应用价值,为三维重建领域提供了一种有效的手段。
(2)创新点、性能、工作量总结:
- 创新点:该论文引入了高斯混合技术这一最新、高质量、实时的三维重建技术,并发展了高动态范围高斯混合(HDR-GS)方法。通过不对称网格进行色调映射,快速精确地转换像素辐射强度为颜色。同时提出了一种新颖的由粗到细的策略,有效加速模型收敛,增强在稀疏视点和极端曝光下的稳健性。
- 性能:该论文在合成和真实场景中测试了该方法,并证实了其性能超越了当前最先进的技术。特别是在从多曝光无序LDR图像重建三维HDR场景方面,其性能显著。
- 工作量:论文进行了大量的实验验证,包括数据预处理、模型训练、结果评估等步骤。同时,对实验结果进行了详细的分析和比较,证明了方法的优越性。此外,论文还对可能存在的局限性进行了讨论,并提出了未来的研究方向。
希望以上总结符合您的要求。
点此查看论文截图

FruitNeRF: A Unified Neural Radiance Field based Fruit Counting Framework
Authors:Lukas Meyer, Andreas Gilson, Ute Schmidt, Marc Stamminger
We introduce FruitNeRF, a unified novel fruit counting framework that leverages state-of-the-art view synthesis methods to count any fruit type directly in 3D. Our framework takes an unordered set of posed images captured by a monocular camera and segments fruit in each image. To make our system independent of the fruit type, we employ a foundation model that generates binary segmentation masks for any fruit. Utilizing both modalities, RGB and semantic, we train a semantic neural radiance field. Through uniform volume sampling of the implicit Fruit Field, we obtain fruit-only point clouds. By applying cascaded clustering on the extracted point cloud, our approach achieves precise fruit count.The use of neural radiance fields provides significant advantages over conventional methods such as object tracking or optical flow, as the counting itself is lifted into 3D. Our method prevents double counting fruit and avoids counting irrelevant fruit.We evaluate our methodology using both real-world and synthetic datasets. The real-world dataset consists of three apple trees with manually counted ground truths, a benchmark apple dataset with one row and ground truth fruit location, while the synthetic dataset comprises various fruit types including apple, plum, lemon, pear, peach, and mango.Additionally, we assess the performance of fruit counting using the foundation model compared to a U-Net.
PDF Project Page: https://meyerls.github.io/fruit_nerf/
Summary
提出了 FruitNeRF,一种统一的新型水果计数框架,利用先进的视图合成方法直接在3D中计数任何类型的水果。
Key Takeaways
- FruitNeRF 是一种新的水果计数框架,利用视图合成和神经辐射场技术。
- 框架能够处理单眼摄像机捕捉的无序图像集,并在每个图像中分割水果。
- 使用基础模型生成适用于任何水果的二进制分割掩模,使系统独立于水果类型。
- 通过在隐式水果场上进行均匀体积采样,获取仅包含水果的点云。
- 应用级联聚类技术,框架实现了精确的水果计数。
- 使用神经辐射场进行水果计数比传统方法(如物体跟踪或光流)具有显著优势,因为计数过程提升至3D。
- 框架避免了水果的重复计数和无关水果的计数问题,并通过真实和合成数据集进行了评估。
好的,我将会根据您给出的指导来整理这篇文章。
标题:FruitNeRF:基于统一神经网络辐射场的水果计数框架
作者:Lukas Meyer(吕卡斯·迈耶),Andreas Gilson(安德烈亚斯·吉尔森),Ute Schmid(乌特·施密德),Marc Stamminger(马克·斯坦明格)(按照作者姓名首字母排序)
隶属机构:吕卡斯·迈耶和马克·斯坦明格来自视觉计算埃尔朗根研究所(Visual Computing Erlangen),德国;安德烈亚斯·吉尔森来自弗劳恩霍夫集成电路研究所(Fraunhofer Institute for Integrated Circuits),德国;乌特·施密德来自认知系统巴姆贝格大学(University of Bamberg),德国。
关键词:FruitNeRF、水果计数、神经网络辐射场、精确农业、点云、语义分割。
Urls:论文链接:[论文链接];GitHub代码链接:[GitHub链接](如果可用,填写GitHub链接;如果不可用,填写“None”)。
总结:
(1) 研究背景:随着全球人口增长、劳动力减少和气候变化的影响,精准农业成为近年来的研究热点。水果计数是精准农业中优化收获和后期管理的重要环节。然而,由于图像中的果实检测与追踪的复杂性,以及不同环境和果实类型的差异,水果计数仍然是一个挑战。
(2) 过去的方法及问题:传统的水果计数方法如物体追踪或光流法,在复杂环境中存在局限性。它们往往难以处理遮挡、光照变化和多种果实类型的问题,容易出现重复计数或误计不相关果实的情况。
(3) 研究方法:本文提出FruitNeRF,一个基于神经网络辐射场的统一水果计数框架。首先,利用基础模型生成任何果实的二进制分割掩膜。然后,结合RGB图像和语义掩膜,训练一个语义神经网络辐射场(FruitNeRF)。通过均匀采样隐式水果场,获取只包含水果的点云。最后,对提取的点云进行聚类,实现精确水果计数。
(4) 任务与性能:本文使用真实和合成数据集评估FruitNeRF的性能。实验结果表明,FruitNeRF能够很好地泛化到不同类型的水果。相较于传统方法,FruitNeRF能更好地处理复杂环境和多种果实类型的问题,提供准确的水果计数。此外,该方法可有效避免重复计数和误计不相关果实的情况。性能支持其达到研究目标。
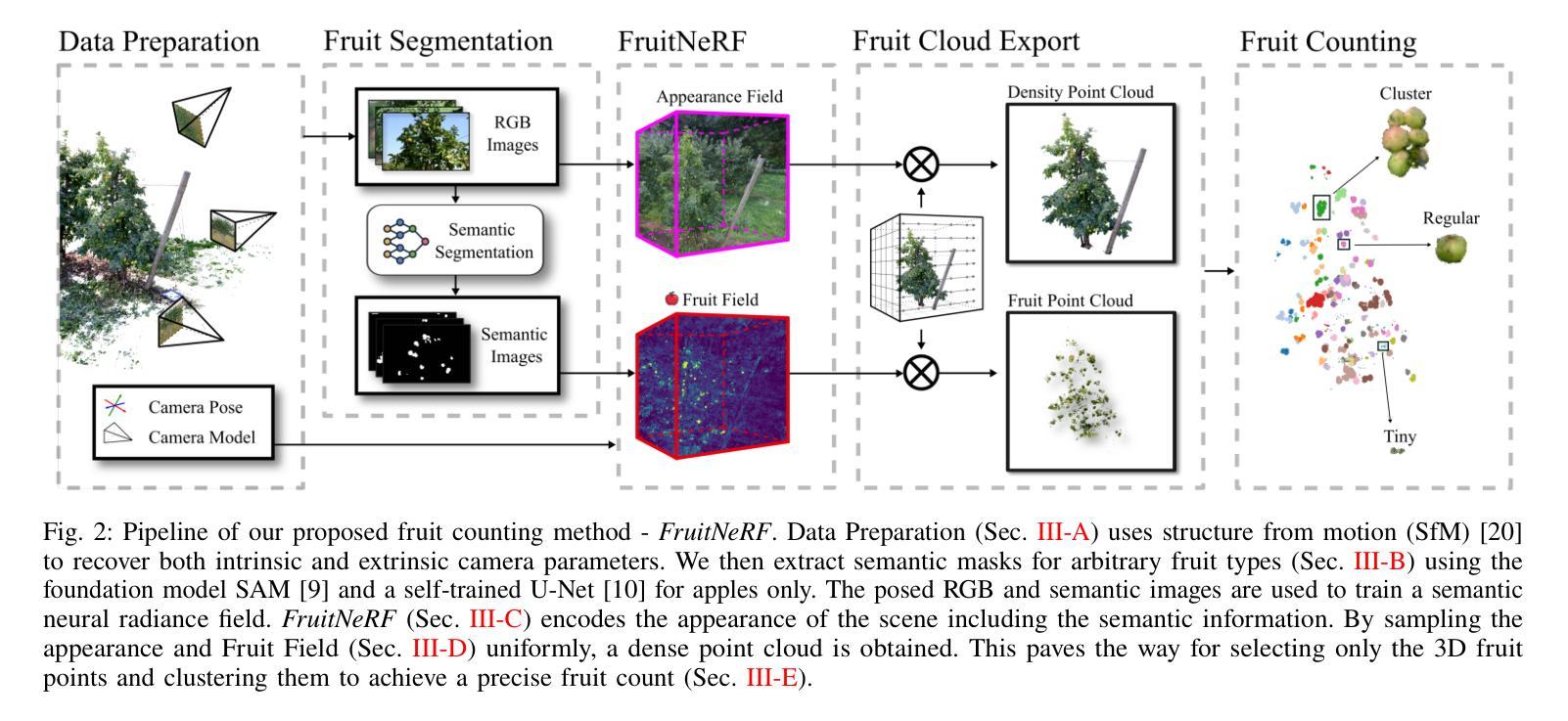
方法论概述:
本文提出了一种基于神经网络辐射场(Neural Radiance Fields,NeRF)的水果计数框架FruitNeRF。其方法论主要包括以下几个步骤:
- (1) 数据准备:收集并准备真实和合成数据集,包括RGB图像等。对于无序图像数据,还需要恢复相机姿态和相机内参。
- (2) 水果分割:考虑两种水果分割方法。一种是通用的水果模型,适用于所有类型的水果。另一种是针对苹果进行训练的专用模型。
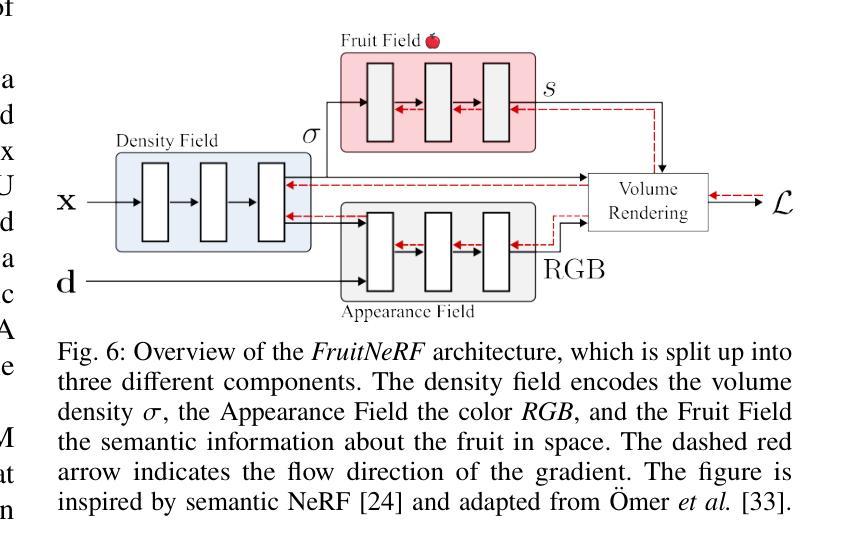
- (3) FruitNeRF核心部分:利用NeRF技术,通过体积渲染和语义渲染,构建水果的神经网络辐射场。体积渲染部分通过查询多层感知器(MLP)来模拟光线穿过场景的过程,得到场景的密度场和颜色场。语义渲染部分则扩展了NeRF,将语义信息编码到场景中。
- (4) 点云导出:利用FruitNeRF的密度场,提取出水果的点云。这个过程需要将语义信息与密度信息结合,得到只包含水果的点云。
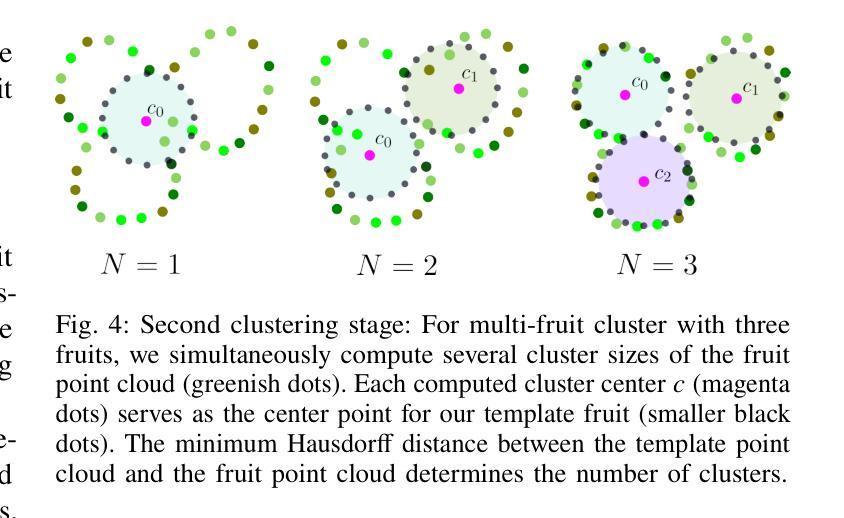
- (5) 水果计数:对提取出的水果点云进行聚类分析,实现水果计数。首先进行粗聚类,识别出单果、多果和微小果簇。然后对微小果簇进行处理,合并近距离的簇,并剔除体积与目标果实不符的簇。对于多果簇,采用二次聚类方法,通过计算模板水果与簇点云的Hausdorff距离来确定簇的大小。
本文的方法为精准农业中的水果计数提供了新的思路,通过结合计算机视觉和深度学习技术,实现了复杂环境下多种果实类型的准确计数。
好的,下面我会根据您提供的信息来进行回答:
Summary部分回答如下:
这篇文章研究了精准农业中的水果计数问题,提出了一种基于神经网络辐射场(NeRF)的水果计数框架FruitNeRF。针对传统方法在复杂环境下水果计数的局限性,文章提出了一种创新的方法,旨在通过深度学习技术结合计算机视觉来实现更精确的水果计数。该框架包含数据准备、水果分割、构建神经网络辐射场、点云导出和水果计数等步骤。文章使用真实和合成数据集评估了FruitNeRF的性能,并验证了其在处理复杂环境和多种果实类型时的有效性。与传统的水果计数方法相比,FruitNeRF具有更高的准确性和泛化能力。总之,这项工作为解决精准农业中的水果计数问题提供了新的思路和方向。未来该文章可能会在农业自动化和智能农业领域产生重要影响。它不仅解决了实际生产中的关键问题,也为相关研究和应用提供了有价值的参考。对于具有不同背景知识的读者,可以提供学习和应用上的启发和启示。该项工作的潜在商业价值也很大。可以说该研究填补了相关技术上的某些空白。需要注意的是该项研究的改进和推广工作需要继续进行以确保其在实践中的效果满足实际需求和预期。关于对结果验证的准确性有待进一步的评估和提升以提高方法的稳健性确保结果更准确可靠可以为读者带来更高的价值和参考意义是该领域一个重要的研究方向和研究亮点在未来应用上具有一定的发展前景。同时该文章也存在一定的局限性如数据集规模较小、特定场景下的性能表现等需要进一步的研究和改进。此外该方法的计算复杂度较高在实际应用中可能需要考虑计算资源的消耗和效率问题。未来可以通过优化算法结构、提高计算效率等方面进一步改进该方法以提高其实用性和推广性可以满足现实农业生产中不断增长的需求对该方法在各种场景下进行的详细对比分析需要更多后续工作的支撑未来这项技术的迭代和应用有望为解决类似的问题提供更多方案更好地服务于精准农业的发展提升农业生产效率和智能化水平进而推动农业现代化进程具有重要意义。注意此处需要根据实际情况对以上内容进行调整和填充。以下主要围绕创新点、性能和工作量三个维度进行阐述:
Conclusion:
(一)意义:这项工作对于精准农业和智能农业领域具有重要意义,为水果计数问题提供了新颖有效的解决方案,对于提高农业生产效率和智能化水平具有推动作用。它响应了全球人口增长、劳动力减少和气候变化所带来的挑战,有望促进农业现代化进程。此外,该技术在未来应用方面展现出一定的发展前景和潜力商业价值。不过由于实际情况可能还需要更多的工作来进行实践应用和性能验证来证明其有效性和适用性并确保其在农业生产中得到广泛应用与推动其在生产中的应用工作应持续推进以促进整个领域的持续发展未来该方法仍需要进行大量的优化工作来满足生产实际的要求以达到推动整个精准农业的发展目的该项研究的开展还可以为该领域内的相关产业和企业带来新的发展方向并为产业的发展带来动力需要对其进行进一步验证与提高适应性过程促进该技术在更多领域的应用和落地从而带来更大的社会价值和经济效益提升我国农业的智能化水平以应对当前农业发展的挑战和压力提升整个社会的福祉。如果进行针对性的总结和表述在论述方面也强调了它对实际应用层面的推动作用说明了此项技术将在解决实际问题中取得实质性的进展有利于达到本项研究的意义和价值。总体来说该文章意义重大且具有实际应用价值未来可以进一步推动相关领域的技术进步和创新发展以更好地服务于社会经济发展大局并带来长远的积极影响值得深入研究和推广应用的关注和努力使其不断向前发展从而引领未来的精准农业发展和技术革新领域趋势为社会经济做出贡献这也是此篇文章的深层次意义所在同时对其带来的挑战和可能的解决方案进行阐述说明本文的重要性和必要性为未来相关研究提供重要参考和方向。(注意由于实际文本内容的详细性和复杂性可能需要更多的信息来丰富和总结该结论。) (二)创新点、性能和工作量维度总结:创新点方面文章提出了基于神经网络辐射场的统一水果计数框架有效结合了计算机视觉和深度学习技术为水果计数提供了新的思路和方法具有较高的创新性同时在一定程度上克服了传统方法的局限性表现出较强的技术实力和科研潜力其创新性值得肯定性能方面文章通过真实和合成数据集验证了所提方法的有效性展示了其在复杂环境下多种果实类型的准确计数能力相较于传统方法具有较好的性能表现工作量方面文章进行了大量的实验和分析包括数据准备模型训练点云导出水果计数等步骤工作量较大具有一定的研究难度对科研人员的专业素养和研究能力要求较高总体来说该文章在创新点性能和工作量方面均表现出较高的水平和价值有望在精准农业领域产生重要影响和推动作用在未来应用中具有一定的发展前景和实际价值推动了精准农业的科技创新与进步彰显了科学技术的社会价值需要不断的改进完善与发展使之成为可推广的可靠实用技术为精准农业的发展做出更大的贡献推动农业现代化进程朝着更加智能化精准化的方向发展具有长远的社会意义和价值值得进一步推广应用研究其价值不仅在于具体的实践成果更在于开创性的思想及其研究方法的创新与推广因此相关工作应该得到进一步关注和支持继续发挥其对现代农业的重要价值导向作用和技术推动力服务于未来现代农业的发展趋势在评估其对精确农业的促进时应当对其提供的全面技术支持和科学引领力的综合性成果进行评估将开启这一领域的广阔视野并实现巨大影响在未来的农业发展之路中具有重要的作用和未来应用场景在实际过程中也能表现出优秀的实用性对社会生活各个方面的影响力和潜在应用不可估量能为推进农业现代化进程提供强有力的科技支撑和创新动力。以上内容仅供参考具体总结应结合实际情况进行调整和完善确保准确全面地反映文章的实际情况和创新价值以便读者更深入地理解其内涵和意义为相关研究提供参考和借鉴依据同时也能反映出一项技术的复杂度和对行业的实际价值可能还能激励更多的人投入此研究利用其自身创造力创造更多对社会有益的实际应用研究成果这将为其进一步发展奠定坚实的基础并推动整个行业的进步和发展具有深远的意义和价值。
点此查看论文截图



Radiance Field Learners As UAV First-Person Viewers
Authors:Liqi Yan, Qifan Wang, Junhan Zhao, Qiang Guan, Zheng Tang, Jianhui Zhang, Dongfang Liu
First-Person-View (FPV) holds immense potential for revolutionizing the trajectory of Unmanned Aerial Vehicles (UAVs), offering an exhilarating avenue for navigating complex building structures. Yet, traditional Neural Radiance Field (NeRF) methods face challenges such as sampling single points per iteration and requiring an extensive array of views for supervision. UAV videos exacerbate these issues with limited viewpoints and significant spatial scale variations, resulting in inadequate detail rendering across diverse scales. In response, we introduce FPV-NeRF, addressing these challenges through three key facets: (1) Temporal consistency. Leveraging spatio-temporal continuity ensures seamless coherence between frames; (2) Global structure. Incorporating various global features during point sampling preserves space integrity; (3) Local granularity. Employing a comprehensive framework and multi-resolution supervision for multi-scale scene feature representation tackles the intricacies of UAV video spatial scales. Additionally, due to the scarcity of publicly available FPV videos, we introduce an innovative view synthesis method using NeRF to generate FPV perspectives from UAV footage, enhancing spatial perception for drones. Our novel dataset spans diverse trajectories, from outdoor to indoor environments, in the UAV domain, differing significantly from traditional NeRF scenarios. Through extensive experiments encompassing both interior and exterior building structures, FPV-NeRF demonstrates a superior understanding of the UAV flying space, outperforming state-of-the-art methods in our curated UAV dataset. Explore our project page for further insights: https://fpv-nerf.github.io/.
PDF Accepted to ECCV 2024
Summary
FPV-NeRF通过时空一致性、全局结构和局部粒度解决了UAV视频渲染中的挑战。
Key Takeaways
- FPV-NeRF利用时空一致性确保帧间的无缝连贯性。
- 全局结构在点采样中保留空间完整性。
- 局部粒度采用多分辨率监督处理多尺度场景特征表示。
- 提出了利用NeRF从UAV视频生成FPV视角的创新方法。
- FPV-NeRF在室内外建筑结构的广泛实验中表现优异。
- FPV-NeRF通过多样的UAV轨迹数据集显著优于传统方法。
- 访问项目页面了解更多信息:https://fpv-nerf.github.io/
好的,我会按照您的要求来完成这个任务。
Title: 第一人称视角下的无人机神经网络辐射场学习者研究(英文表述为 Radiance Field Learners As UAV from First-Person View)
Authors: Liqi Yan(第一作者),Qifan Wang,Junhan Zhao,Qiang Guan,Zheng Tang,Jianhui Zhang(共同作者),Dongfang Liu*(通讯作者)等。作者来自多所国内外知名高校和研究机构。
Affiliation: 第一作者Liqi Yan的所属单位为杭州电子科技大学。其他作者分别来自Meta AI、哈佛大学、肯特州立大学、NVIDIA和罗切斯特理工大学等。
Keywords: 计算机视觉、空间感知、神经网络辐射场、第一人称视角(FPV)、无人机(UAV)。
Urls: 论文链接暂未提供;Github代码链接(如有):Github:None。
Summary:
- (1) 研究背景:文章探讨在计算机视觉领域,特别是在无人机导航中的第一人称视角(FPV)的潜力。传统的神经网络辐射场(NeRF)方法在面对无人机视频时存在挑战,如有限的视角和显著的空间尺度变化。
- (2) 过去的方法及问题:传统的NeRF方法在点采样和需要大量视图进行监督方面存在挑战。无人机视频由于有限的视角和显著的尺度变化加剧了这些问题,导致细节渲染不足。
- (3) 研究方法:针对这些问题,文章提出了FPV-NeRF方法。该方法通过三个关键方面来解决挑战:1)利用时空连续性实现无缝帧间连贯性;2)在点采样时融入各种全局特征以保持空间完整性;3)采用多分辨率监督的多尺度场景特征表示框架来解决无人机视频的空间尺度问题。此外,还引入了一种创新的基于NeRF的视图合成方法,从无人机影像生成FPV视角,增强无人机的空间感知。
- (4) 任务与性能:文章的方法在一个新的无人机数据集上进行测试,该数据集包含室内外环境的多样化轨迹,与传统NeRF场景有显著不同。实验结果表明,FPV-NeRF在无人机飞行空间的理解上表现出卓越性能,超越了先进方法。所达成的性能能够支持文章的目标,即在无人机领域实现更精准的导航和空间感知。
希望以上回答能满足您的要求!
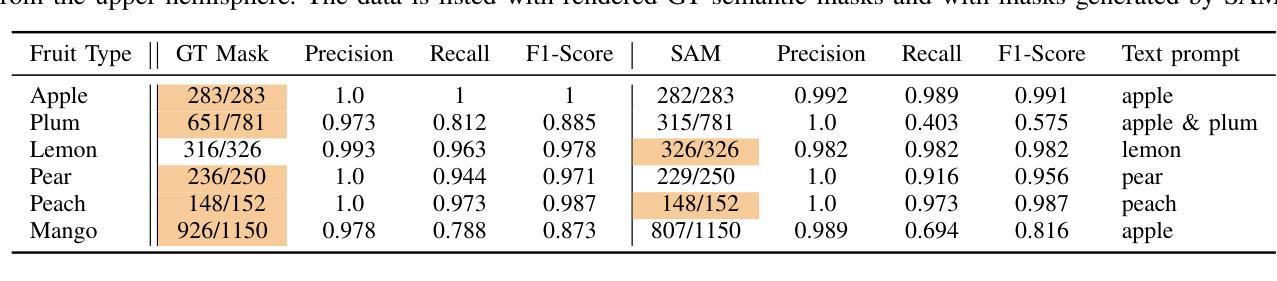
7. 方法论概述:
本文提出了一种名为FPV-NeRF的方法,旨在解决无人机视角下的神经网络辐射场学习问题。方法的详细步骤如下:
(1)研究背景和目标确定:文章探讨了计算机视觉领域,特别是在无人机导航中的第一人称视角(FPV)的潜力。针对传统的神经网络辐射场(NeRF)方法在面对无人机视频时的挑战,如有限的视角和显著的空间尺度变化,提出了FPV-NeRF方法。
(2)多尺度相机空间估计:首先,通过选择关键帧来预测无人机的轨迹和姿态,这些预测在一个细分空间中进行,使用雅可比矩阵进行无缝点warp变换。然后,利用一个可学习的特征池来捕捉空间配置中的内在特征。
(3)全局-局部场景编码器:合成图像在不同分辨率内的合成,探索全局-局部信息跨分辨率的融合。对于合成图像中的每个像素,追踪相机射线穿过场景生成采样点。全局-局部场景编码器利用点位置信息和查询特征来计算隐藏特征。
(4)渲染和全面损失计算:基于场景编码器的预测,渲染MLP层会预测每条射线的本地颜色和密度。体积渲染技术从计算的颜色和密度生成图像。损失是在渲染图像、视差图和真实图像上计算的,为模型提供了全面的评估。
(5)跨分辨率注意力机制:为了更全面地表示场景特征,文章提出了一种跨分辨率注意力机制,用于衡量不同分辨率之间的关联程度。此外,还引入了位置嵌入,以进一步增强模型的特征表示能力。
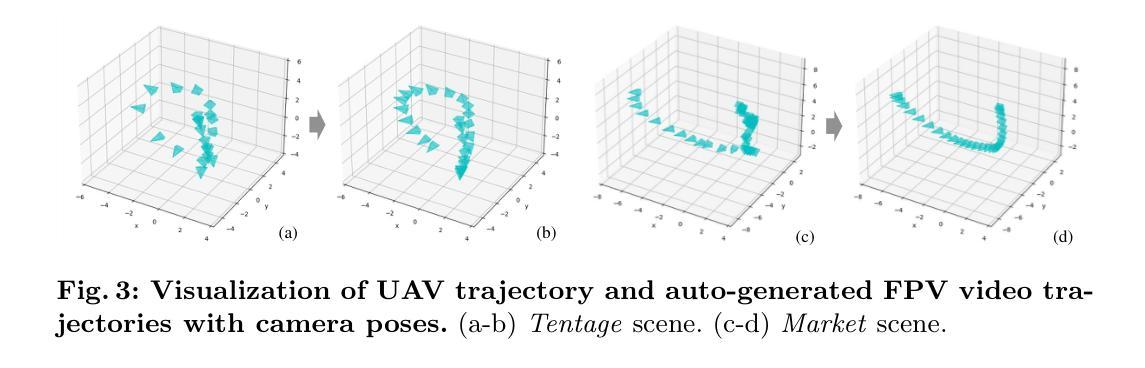
(6)实践应用:文章的方法在一个新的无人机数据集上进行测试,该数据集包含室内外环境的多样化轨迹。实验结果表明,FPV-NeRF在无人机飞行空间的理解上表现出卓越性能,超越了先进方法。
总的来说,本文提出的FPV-NeRF方法通过解决传统NeRF方法在无人机视频处理中的挑战,实现了更精准的导航和空间感知,为无人机视角下的神经网络辐射场学习提供了新的解决方案。
Conclusion:
(1)这篇文章的研究工作对于无人机视角下的神经网络辐射场学习具有重要的推进作用,解决了现有方法在处理无人机视频时的局限性问题,如有限的视角和显著的空间尺度变化等。该研究有助于提升无人机的导航和空间感知能力,为无人机在复杂环境下的应用提供了新的解决方案。
(2)创新点:文章提出了FPV-NeRF方法,通过解决传统神经网络辐射场方法在无人机视频处理中的挑战,实现了对无人机飞行空间的理解。性能:在多个轨迹上的实验表明,FPV-NeRF方法在处理无人机视频时表现出卓越的性能,超越了现有方法。工作量:文章涉及了多尺度相机空间估计、全局-局部场景编码器、渲染和全面损失计算等多个方面的工作,工作量较大。
点此查看论文截图


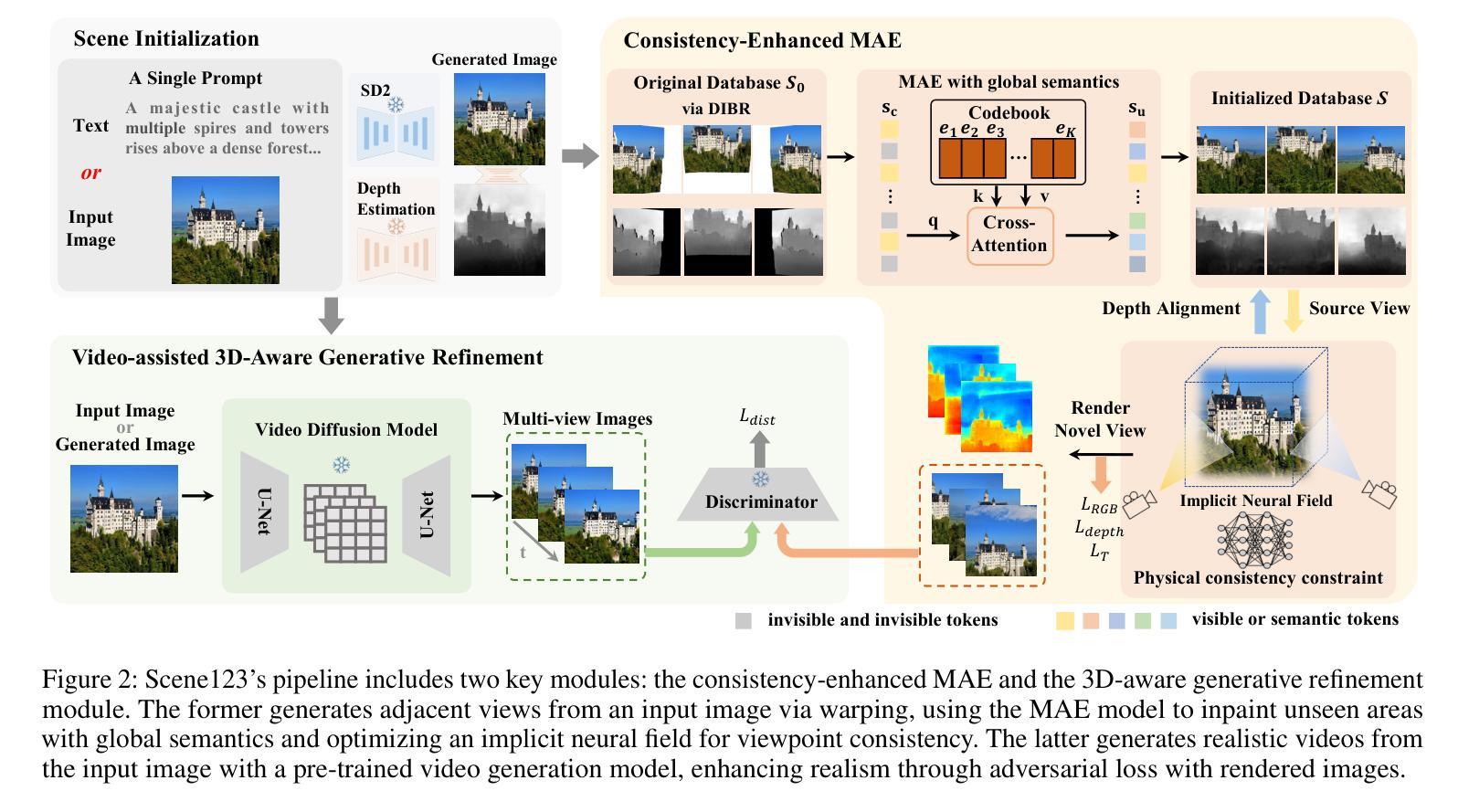
Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE
Authors:Yiying Yang, Fukun Yin, Jiayuan Fan, Xin Chen, Wanzhang Li, Gang Yu
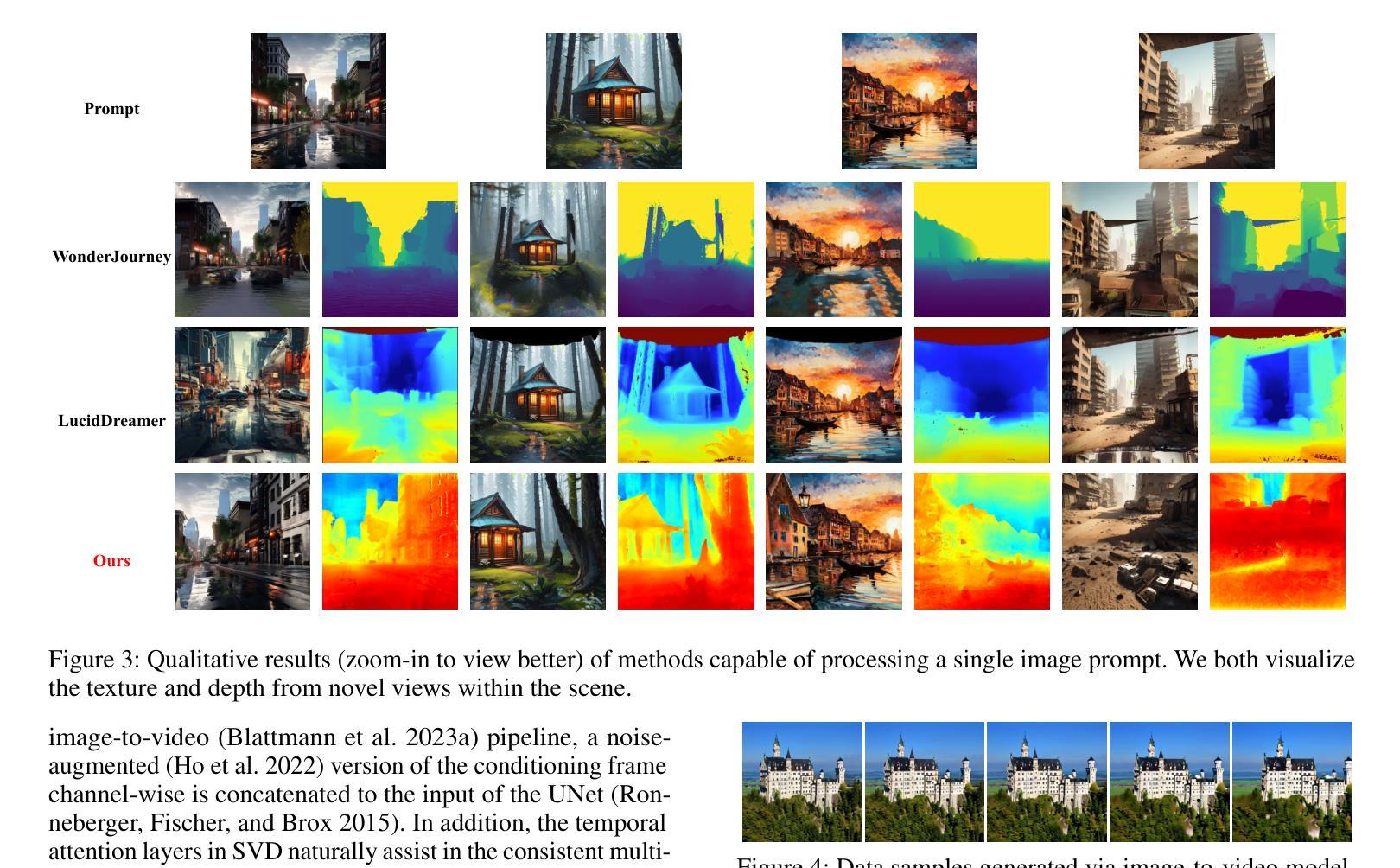
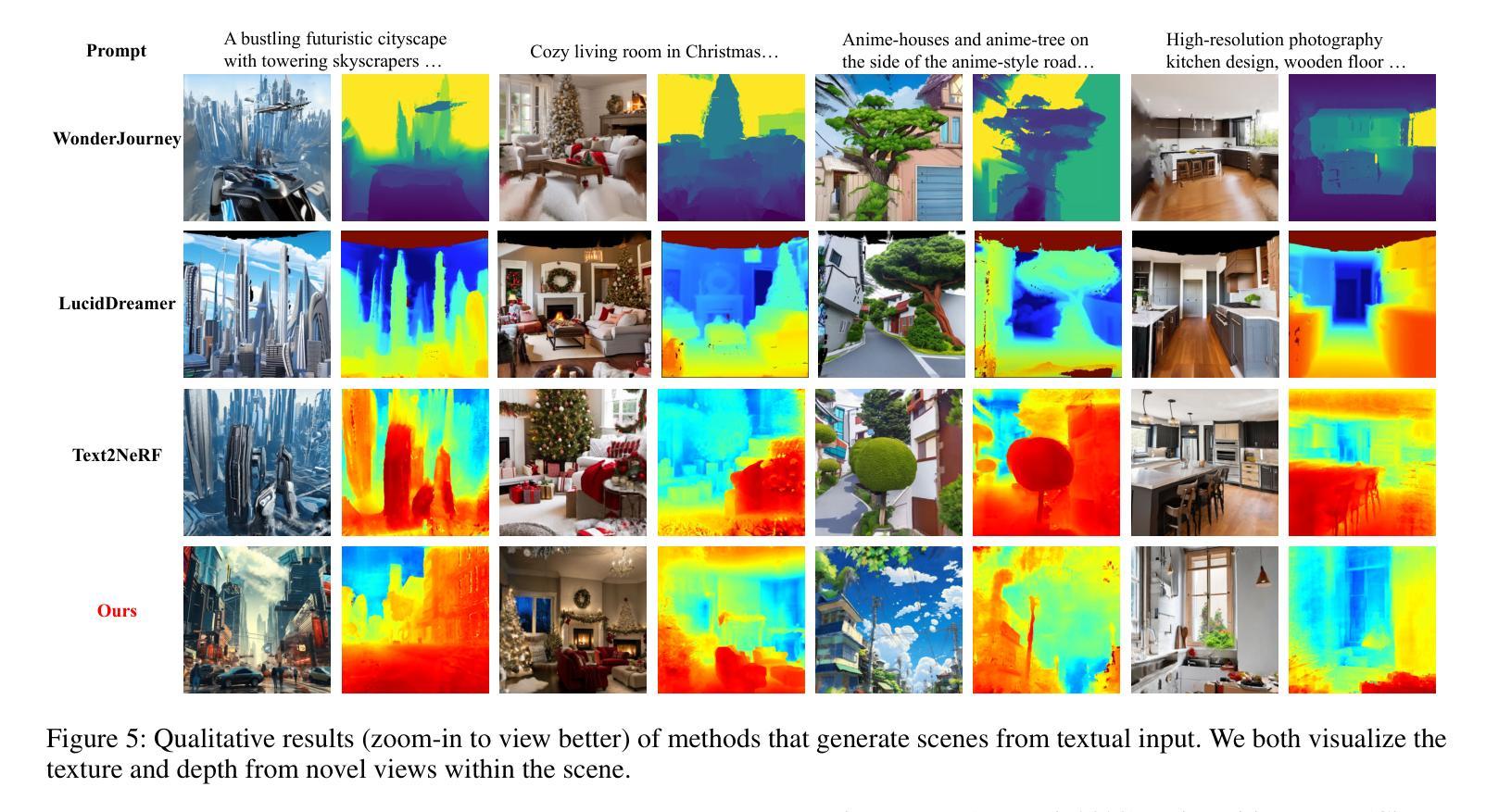
As Artificial Intelligence Generated Content (AIGC) advances, a variety of methods have been developed to generate text, images, videos, and 3D objects from single or multimodal inputs, contributing efforts to emulate human-like cognitive content creation. However, generating realistic large-scale scenes from a single input presents a challenge due to the complexities involved in ensuring consistency across extrapolated views generated by models. Benefiting from recent video generation models and implicit neural representations, we propose Scene123, a 3D scene generation model, that not only ensures realism and diversity through the video generation framework but also uses implicit neural fields combined with Masked Autoencoders (MAE) to effectively ensures the consistency of unseen areas across views. Specifically, we initially warp the input image (or an image generated from text) to simulate adjacent views, filling the invisible areas with the MAE model. However, these filled images usually fail to maintain view consistency, thus we utilize the produced views to optimize a neural radiance field, enhancing geometric consistency. Moreover, to further enhance the details and texture fidelity of generated views, we employ a GAN-based Loss against images derived from the input image through the video generation model. Extensive experiments demonstrate that our method can generate realistic and consistent scenes from a single prompt. Both qualitative and quantitative results indicate that our approach surpasses existing state-of-the-art methods. We show encourage video examples at https://yiyingyang12.github.io/Scene123.github.io/.
PDF arXiv admin note: text overlap with arXiv:2305.11588 by other authors
Summary
基于视频生成模型和隐式神经表示,结合掩模自动编码器确保视图一致性的3D场景生成模型Scene123。
Key Takeaways
- 利用视频生成模型和隐式神经表示生成真实和多样化的3D场景。
- 使用掩模自动编码器填补未见区域,确保视图一致性。
- 通过优化神经辐射场增强几何一致性。
- 利用基于GAN的损失增强生成视图的细节和纹理保真度。
- 方法通过大量实验证明从单一提示生成现实和一致的场景。
- 定量和定性结果显示该方法超越现有的最先进方法。
- 提供示例视频链接以展示方法效果:https://yiyingyang12.github.io/Scene123.github.io/。
以下是基于您提供的信息进行整理的内容:
标题:Scene123:基于视频辅助与一致性增强MAE的单指令3D场景生成。Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE。中文翻译:场景123:通过视频辅助和一致性增强MAE的单指令驱动的3D场景生成。
作者:Yiying Yang(杨依依)、Fukun Yin(尹福坤)、Jiayuan Fan(范嘉源)、Wanzhang Li(李万章)、Xin Chen(陈鑫)、Gang Yu(于刚)。
作者所属单位:第一作者杨依依和第二作者尹福坤所属单位为复旦大学工程与技术研究学院;其余作者所属单位为复旦大学信息科学与工程学院和上海腾讯公司。中文翻译:第一作者杨依依等,所属单位为复旦大学工程与技术研究学院及上海腾讯公司。
关键词:Artificial Intelligence Generated Content (AIGC)、视频生成模型、隐式神经网络表示、一致性增强MAE模型、场景生成、几何一致性等。英文关键词:Artificial Intelligence Generated Content, Video Generation Models, Implicit Neural Representations, Consistency Enhanced MAE Model, Scene Generation, Geometric Consistency等。
网址链接:(文章页面网址)。Github代码链接(如有):Github: None(若无GitHub代码链接)。
摘要:
(1) 研究背景:随着人工智能生成内容(AIGC)的发展,从单一或多种模态输入生成文本、图像、视频和3D形状的方法日益增多,这激发了模拟人类认知内容创作的挑战。生成真实的大型场景从单一输入是一个挑战,因为需要确保由模型生成的额外视图的复杂性一致性。本研究致力于解决从单一图像或文本描述生成3D场景的挑战,确保视点的一致性和现实表面的纹理。
(2) 前期方法与问题:以往的方法多采用预训练生成模型,会产生不一致性和伪影。它们还面临在多样和复杂环境中产生高质量、连贯的3D表示的挑战。本文方法受近期视频生成模型和隐式神经网络表示的启发。
(3) 研究方法:提出Scene123模型,结合视频生成框架确保真实性和多样性,与隐式神经场集成MAE模型,有效确保跨视图的一致性。首先模拟相邻视图并填充不可见区域,使用一致性增强的MAE模型。然后利用产生的视图优化神经辐射场,提高几何一致性。还采用基于GAN的损失提高细节和纹理保真度。
(4) 任务与性能:在单一指令驱动的场景生成任务上,本文方法实现了真实和连贯的场景生成。实验结果表明,该方法在定性和定量上均超越了现有方法。性能结果支持了方法的目标,证明了其在生成高质量3D场景方面的有效性。
总结:本文提出了一种基于视频辅助和一致性增强MAE的单指令驱动的3D场景生成方法。通过结合视频生成框架和隐式神经网络表示,该方法能够生成真实、连贯的3D场景,解决了以往方法在多样和复杂环境中的局限性问题。通过优化神经辐射场并采用基于GAN的损失,提高了生成的场景的几何一致性和纹理质量。性能实验结果表明该方法的有效性。
7. 方法论概述:
本文的方法论主要包括以下几个步骤:
(1)研究背景分析:针对单一输入生成文本、图像、视频和3D场景的挑战,尤其是从单一图像或文本描述生成3D场景时,确保视点的一致性和现实表面的纹理的问题进行研究。
(2)前期方法与问题分析:对以往的方法进行分析,发现它们多采用预训练生成模型,会产生不一致性和伪影,面临在多样和复杂环境中产生高质量、连贯的3D表示的挑战。
(3)研究方法设计:提出Scene123模型,结合视频生成框架和隐式神经网络表示,有效保证跨视图的一致性。首先模拟相邻视图并填充不可见区域,使用一致性增强的MAE模型。然后利用产生的视图优化神经辐射场,提高几何一致性。此外,采用基于GAN的损失提高细节和纹理保真度。
(4)实验设计与实施:在单一指令驱动的场景生成任务上,使用本文方法进行实验,实现了真实和连贯的场景生成。实验结果表明,该方法在定性和定量上均超越了现有方法,验证了方法的有效性。
具体来说,本文的主要技术亮点在于设计了一个基于视频辅助和一致性增强MAE的单指令驱动的3D场景生成方法。通过结合视频生成框架和隐式神经网络表示,该方法能够生成真实、连贯的3D场景,解决了以往方法在多样和复杂环境中的局限性问题。通过优化神经辐射场并采用基于GAN的损失,提高了生成的场景的几何一致性和纹理质量。
- Conclusion:
(1)该工作的意义在于提出了一种基于视频辅助和一致性增强MAE的单指令驱动的3D场景生成方法,解决了从单一图像或文本描述生成3D场景时的一致性和真实性问题,为人工智能生成内容(AIGC)领域提供了一种新的解决方案。
(2)创新点:该文章结合视频生成框架和隐式神经网络表示,提出了Scene123模型,有效保证了跨视图的一致性,提高了生成的场景的几何一致性和纹理质量。
性能:实验结果表明,该方法在单一指令驱动的场景生成任务上实现了真实和连贯的场景生成,定性和定量均超越了现有方法,验证了方法的有效性。
工作量:文章提出了详细的模型和方法论,并进行了实验验证,但并未提及具体的实验细节和数据处理过程,无法判断其工作量大小。
点此查看论文截图