⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-28 更新
Hyperdimensional Computing Empowered Federated Foundation Model over Wireless Networks for Metaverse
Authors:Yahao Ding, Wen Shang, Minrui Xu, Zhaohui Yang, Ye Hu, Dusit Niyato, Mohammad Shikh-Bahaei
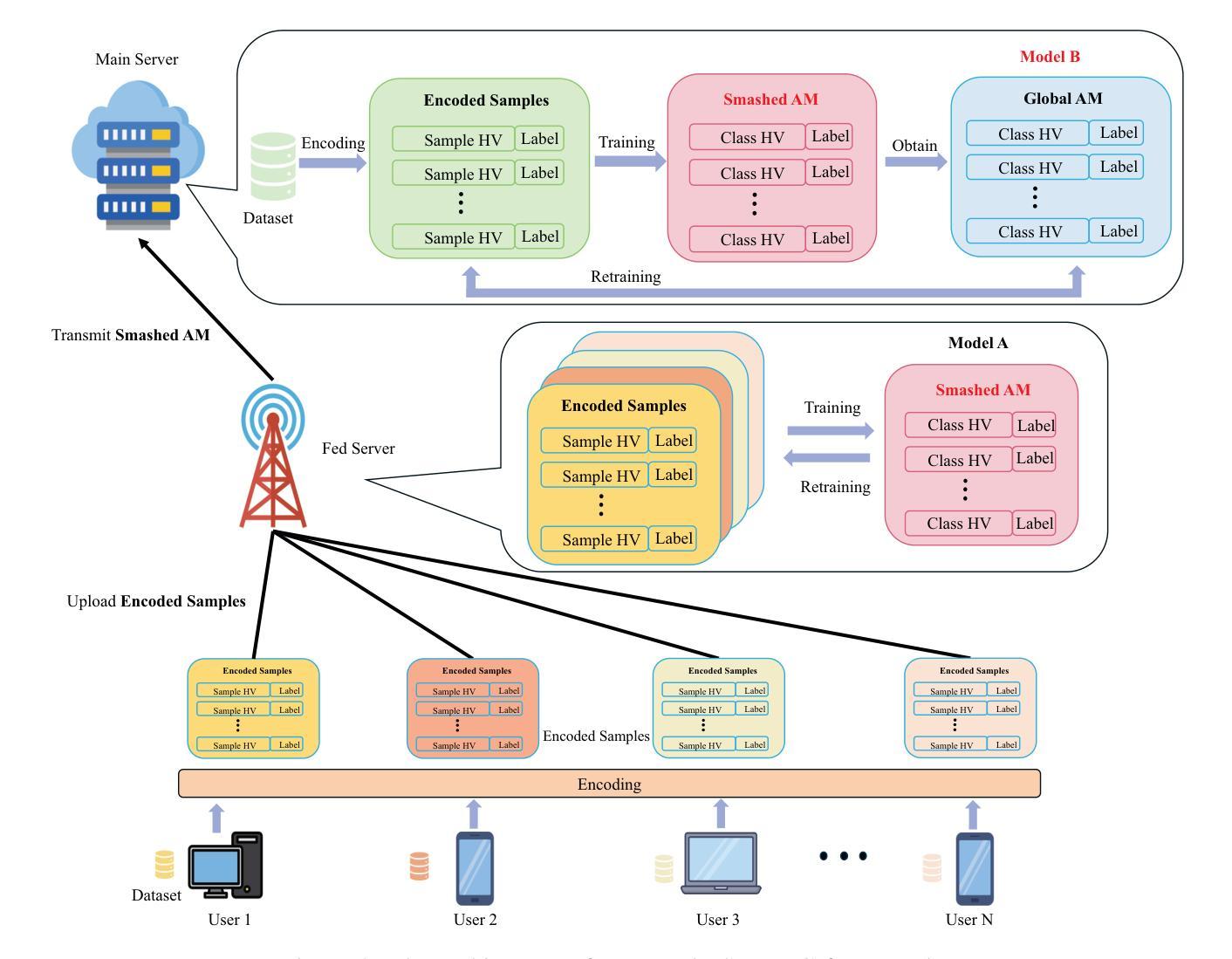
The Metaverse, a burgeoning collective virtual space merging augmented reality and persistent virtual worlds, necessitates advanced artificial intelligence (AI) and communication technologies to support immersive and interactive experiences. Federated learning (FL) has emerged as a promising technique for collaboratively training AI models while preserving data privacy. However, FL faces challenges such as high communication overhead and substantial computational demands, particularly for neural network (NN) models. To address these issues, we propose an integrated federated split learning and hyperdimensional computing (FSL-HDC) framework for emerging foundation models. This novel approach reduces communication costs, computation load, and privacy risks, making it particularly suitable for resource-constrained edge devices in the Metaverse, ensuring real-time responsive interactions. Additionally, we introduce an optimization algorithm that concurrently optimizes transmission power and bandwidth to minimize the maximum transmission time among all users to the server. The simulation results based on the MNIST dataset indicate that FSL-HDC achieves an accuracy rate of approximately 87.5%, which is slightly lower than that of FL-HDC. However, FSL-HDC exhibits a significantly faster convergence speed, approximately 3.733x that of FSL-NN, and demonstrates robustness to non-IID data distributions. Moreover, our proposed optimization algorithm can reduce the maximum transmission time by up to 64% compared with the baseline.
Summary
元宇宙虚拟人需求高级AI与通信技术,FSL-HDC框架降低成本,优化传输时间。
Key Takeaways
- 元宇宙融合AR与虚拟世界,需AI与通信技术。
- 联邦学习(FL)保证数据隐私,但面临通信与计算挑战。
- 提出FSL-HDC框架,降低通信成本、计算负载与隐私风险。
- 适用于资源受限的边缘设备,确保实时互动。
- 优化算法最小化最大传输时间。
- FSL-HDC准确率略低于FL-HDC,但收敛速度更快。
- 优化算法可降低最大传输时间64%。
Title: 超维计算赋能的无线网络联邦基础模型用于元宇宙
Authors: Yahao Ding, Wen Shang, Minrui Xu, Zhaohui Yang, Ye Hu, Dusit Niyato, Mohammad Shikh-Bahaei
Affiliation: King’s College London, Nanyang Technological University, Zhejiang University, University of Miami
Keywords: 联邦学习 (Federated Learning), 超维计算 (Hyperdimensional Computing), 资源分配
Urls: arXiv:2408.14416v1 [cs.LG] 26 Aug 2024
Summary:
(1): 该文的研究背景是元宇宙的发展需要先进的人工智能和通信技术来支持沉浸式和交互式体验。联邦学习(FL)作为一种保护数据隐私的同时协作训练AI模型的技术,面临着通信开销高和计算需求大的挑战,尤其是在神经网络(NN)模型中。
(2): 过去的方法包括联邦学习(FL)和分割学习(SL)。FL面临通信开销高和计算需求大的问题,而SL通过在客户端和服务器之间分配计算任务来缓解这些问题,但仍存在隐私和计算资源利用的局限性。本文提出的方法结合了FL和SL的优点,并通过超维计算(HDC)进一步提高了效率和隐私保护,具有很好的动机。
(3): 本文提出的方法是联邦分割学习(FSL)与超维计算(HDC)的集成框架(FSL-HDC)。该方法将模型分为两部分,一部分在客户端处理,另一部分在服务器端处理,同时使用HDC来降低计算复杂度和能量消耗。此外,还提出了一种优化算法,同时优化传输功率和带宽,以最小化用户到服务器的最大传输时间。
(4): 在MNIST数据集上的仿真结果表明,FSL-HDC的准确率约为87.5%,略低于FL-HDC,但收敛速度提高了约3.733倍,对非独立同分布数据分布表现出鲁棒性。此外,提出的优化算法可以将最大传输时间减少高达64%,支持了该方法的目标。
Conclusion:
(1): 本项工作的意义在于提出了一种结合联邦学习(FL)和超维计算(HDC)的集成框架(FSL-HDC),旨在解决元宇宙发展中人工智能模型训练面临的隐私保护和计算效率问题。
(2): Innovation point: 创新点在于将FL和HDC技术相结合,有效地降低了计算复杂度,提高了隐私保护水平;Performance: 性能方面,FSL-HDC在MNIST数据集上的准确率略低于FL-HDC,但收敛速度提高了约3.733倍,显示出良好的性能;Workload: 工作负载方面,提出的优化算法可以将最大传输时间减少高达64%,显著减轻了用户的计算和通信负担。
点此查看论文截图

Avatar Concept Slider: Manipulate Concepts In Your Human Avatar With Fine-grained Control
Authors:Yixuan He, Lin Geng Foo, Ajmal Saeed Mian, Hossein Rahmani, Jun Jiu
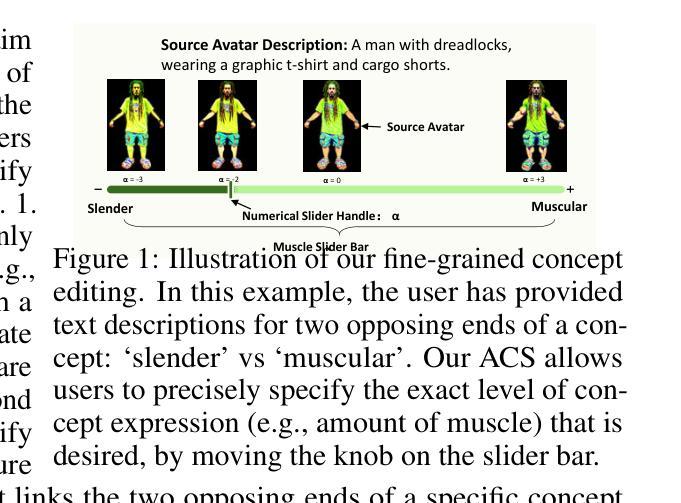
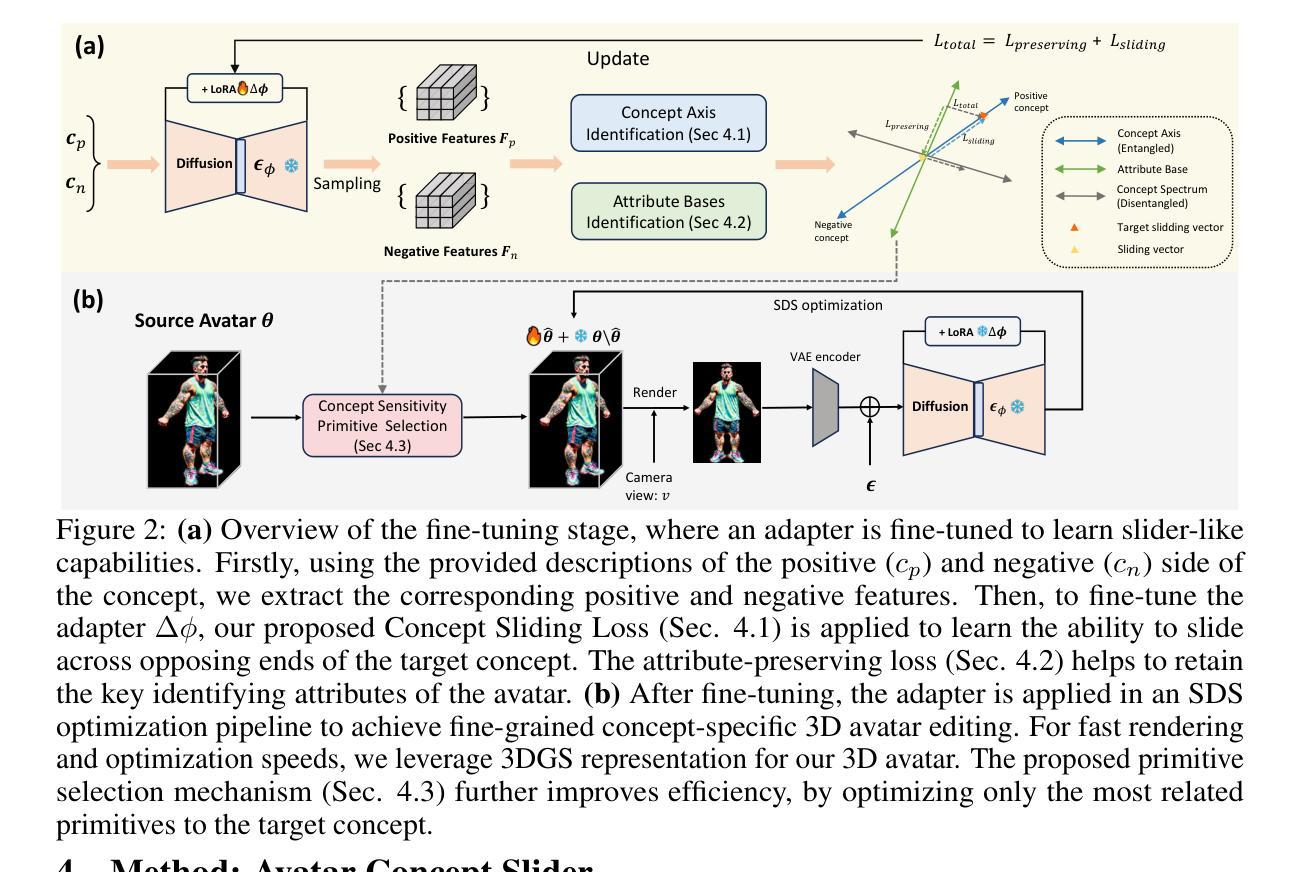
Language based editing of 3D human avatars to precisely match user requirements is challenging due to the inherent ambiguity and limited expressiveness of natural language. To overcome this, we propose the Avatar Concept Slider (ACS), a 3D avatar editing method that allows precise manipulation of semantic concepts in human avatars towards a specified intermediate point between two extremes of concepts, akin to moving a knob along a slider track. To achieve this, our ACS has three designs. 1) A Concept Sliding Loss based on Linear Discriminant Analysis to pinpoint the concept-specific axis for precise editing. 2) An Attribute Preserving Loss based on Principal Component Analysis for improved preservation of avatar identity during editing. 3) A 3D Gaussian Splatting primitive selection mechanism based on concept-sensitivity, which updates only the primitives that are the most sensitive to our target concept, to improve efficiency. Results demonstrate that our ACS enables fine-grained 3D avatar editing with efficient feedback, without harming the avatar quality or compromising the avatar’s identifying attributes.
Summary
基于语义概念的3D虚拟人编辑方法,通过Avatar Concept Slider(ACS)实现精确编辑,提升效率并保留特征。
Key Takeaways
- 自然语言编辑3D虚拟人具挑战性,因存在歧义和表达限制。
- 提出Avatar Concept Slider (ACS)解决编辑问题。
- ACS包括三个设计:概念滑动损失、属性保留损失和3D高斯分层原语选择机制。
- 概念滑动损失基于线性判别分析,用于精确编辑。
- 属性保留损失基于主成分分析,保护虚拟人身份。
- 3D高斯分层原语选择机制基于概念敏感性,提高效率。
- 结果显示ACS实现精细3D虚拟人编辑,反馈高效,质量不受损害。
Title: Avatar Concept Slider: Manipulate Concepts In Your Human Avatar With Fine-grained Control
(标题:Avatar Concept Slider:通过精细控制操纵您的人类头像中的概念)Authors: Yixuan He, Lin Geng Foo, Ajmal Saeed Mian, Hossein Rahmani, Jun Jiu
(作者:Yixuan He, Lin Geng Foo, Ajmal Saeed Mian, Hossein Rahmani, Jun Jiu)Affiliation: Singapore University of Technology and Design
(所属机构:新加坡科技设计大学)Keywords: 3D avatar editing, semantic concepts, fine-grained control, linear discriminant analysis, principal component analysis
(关键词:3D头像编辑,语义概念,精细控制,线性判别分析,主成分分析)Urls: arXiv:2408.13995v1 [cs.CV] 26 Aug 2024
(链接:arXiv:2408.13995v1 [cs.CV] 26 Aug 2024)
Github: None
(GitHub:None)Summary:
- (1):该文章的研究背景是3D人类头像的创建和编辑在游戏开发、电影制作和虚拟角色创作等多个场景中的重要性日益增加。由于自然语言的固有模糊性和有限的表达能力,基于语言的编辑难以精确匹配用户需求。 - (2):过去的方法包括利用指令引导的扩散模型和基于文本驱动的扩散模型进行头像编辑,但这些方法依赖于文本提示作为唯一的引导信号,存在模糊性和表达能力的限制,导致编辑结果不精确。 - (3):该论文提出了一种名为Avatar Concept Slider(ACS)的3D头像编辑方法,该方法通过线性判别分析确定概念特定的轴,基于主成分分析保留属性损失,以及基于概念敏感性的3D高斯喷溅原语选择机制,以实现精细的3D头像编辑。 - (4):该论文在细粒度3D头像编辑任务上取得了良好的效果,实现了高效的反馈,同时保持了头像的质量和识别属性,支持了其研究目标。Conclusion:
(1):该研究成果对于3D头像编辑领域具有重要意义,因为它提供了一种新的方法,使用户能够通过精确控制语义概念来编辑3D人类头像,从而在游戏开发、电影制作和虚拟角色创作等领域提高个性化表达和用户体验。
(2):Innovation point:该文提出的Avatar Concept Slider (ACS)方法在创新点上具有显著优势,通过结合线性判别分析和主成分分析,实现了对3D头像的精细控制;Performance:在性能方面,ACS在细粒度3D头像编辑任务上展现出良好的效果,能够保持头像的质量和识别属性;Workload:尽管ACS提高了编辑效率,但其在实际应用中可能需要一定的计算资源,这可能是其在工作负载方面的挑战。
点此查看论文截图

GenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Authors:Keqiang Sun, Amin Jourabloo, Riddhish Bhalodia, Moustafa Meshry, Yu Rong, Zhengyu Yang, Thu Nguyen-Phuoc, Christian Haene, Jiu Xu, Sam Johnson, Hongsheng Li, Sofien Bouaziz
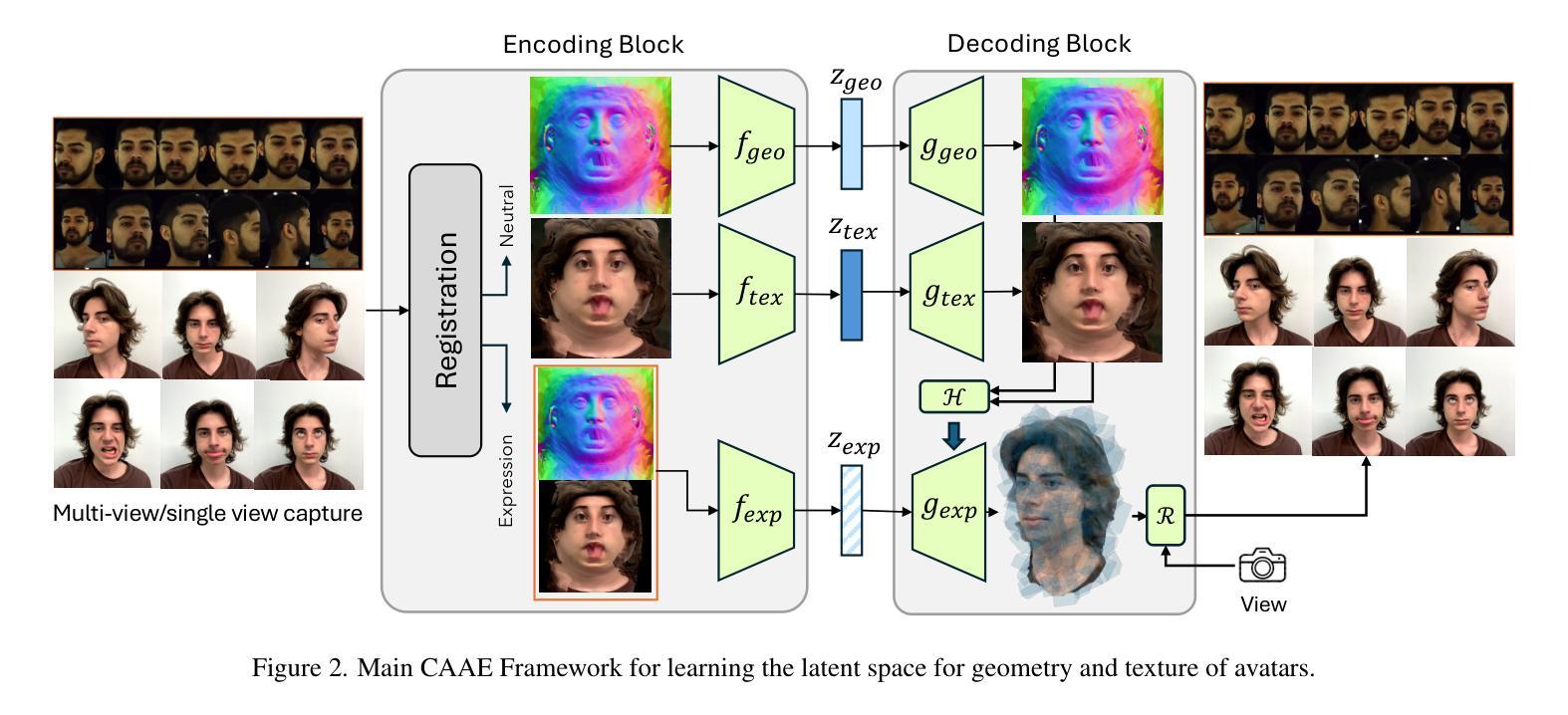
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Summary
提出文本条件生成模型,生成可控、真实感强的3D虚拟人头像。
Key Takeaways
- 虚拟人头像在VR/MR等领域应用广泛。
- 传统生成方法耗时且缺乏灵活性。
- 生成模型可替代传统方法,提高效率。
- 研究仍处于初级阶段,存在局限性。
- 文中提出文本条件生成模型,增强真实感和可操控性。
- 模型具备编辑和单帧重建功能。
- 模型适用于生成和编辑高保真虚拟人头像。
Title: GenCA: A Text-Guided Generative Model for Photorealistic and Drivable 3D Facial Avatars
(生成式文本引导的逼真和可驱动3D面部头像模型)Authors: Yifei Wang, Weiyang Wang, Zhe Wang, Zhiqiang Wang, Jiaqi Zhou, Zhihao Chen, Zhong Lin, and Zhuang Wang
Affiliation: Meta
Keywords: Generative models, 3D facial avatars, Text-to-Image, Latent diffusion models
Urls: Paper: GenCA: A Text-Guided Generative Model for Photorealistic and Drivable 3D Facial Avatars , Github: None
Summary:
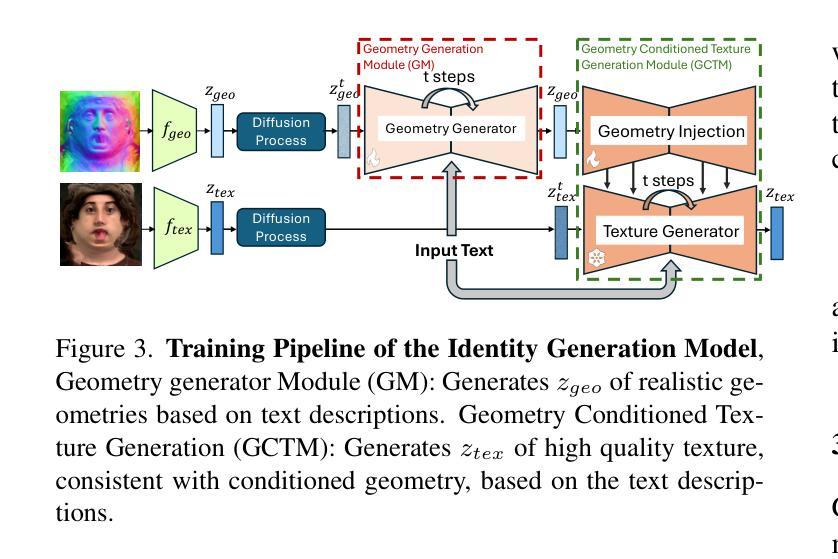
- (1):该文章的研究背景是虚拟现实、混合现实、远程呈现、游戏和电影制作等领域对逼真且可控的3D头像的需求。传统方法耗时且无法灵活采样新身份或修改现有身份。 - (2):过去的方法包括基于扫描和重建的 avatar 创建方法,以及基于生成模型的 avatar 创建方法。这些方法的局限性在于创建静态头像、缺乏逼真度、面部细节不完整或驱动能力有限。文章提出的方案旨在解决这些问题。 - (3):该文章提出了一个名为 GenCA 的文本引导生成模型,能够生成具有多样身份、完整细节(如头发、眼睛和嘴巴内部)的逼真 3D 面部头像。该模型结合了潜在扩散模型的生成和编辑能力,以及用于 avatar 表达驱动的强大先验模型。 - (4):该模型在生成逼真和可驱动的 3D 面部头像方面取得了优异的性能,包括单张图像 avatar 重建、编辑和修复等任务。与现有最先进方法相比,GenCA 在用户研究中表现出色,支持其目标。Methods:
(1): 提出了一种名为 GenCA 的文本引导生成模型,该模型融合了潜在扩散模型(Latent Diffusion Models, LDM)的生成和编辑能力,以及用于 avatar 表达驱动的强大先验模型。
(2): 利用 LDM 实现了从随机噪声到 3D 面部头像的生成,同时保留了丰富的细节和纹理信息。
(3): 设计了一个文本解析器,将输入的文本描述转换为模型可理解的参数,用于指导头像的生成和编辑。
(4): 开发了一个基于图像的驱动模型,用于在给定文本指令的情况下驱动头像进行动画。
(5): 通过大量真实面部图像数据训练模型,确保生成的头像具有高度的真实感。
(6): 进行了一系列实验和用户评估,验证了 GenCA 在生成逼真和可驱动 3D 面部头像方面的有效性。
Conclusion:
(1): This piece of work is significant as it introduces GenCA, a novel text-guided generative model for creating photorealistic and drivable 3D facial avatars, which addresses the limitations of existing methods and has potential applications in various fields such as virtual reality, mixed reality, remote presentation, gaming, and film production.
(2): Innovation point: GenCA represents an innovative approach by combining the strengths of latent diffusion models and pre-trained models for avatar expression driving, enabling the generation of highly realistic 3D facial avatars with comprehensive features. Performance: The model achieves superior performance in avatar reconstruction, editing, and inpainting tasks compared to state-of-the-art methods. Workload: The training process requires substantial computational resources, with the use of 8 NVIDIA A100 GPUs for 8 hours to train the Geometry Generator and 12 hours to train the Geometry-Conditioned Texture Generator.
点此查看论文截图


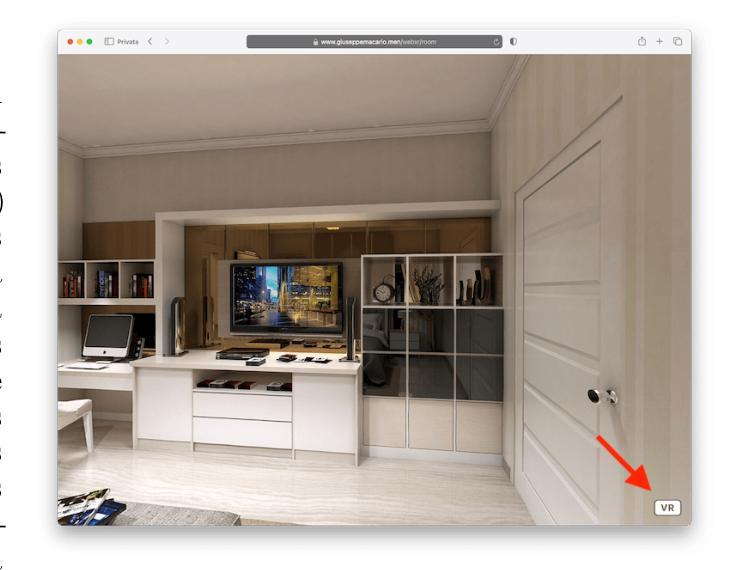
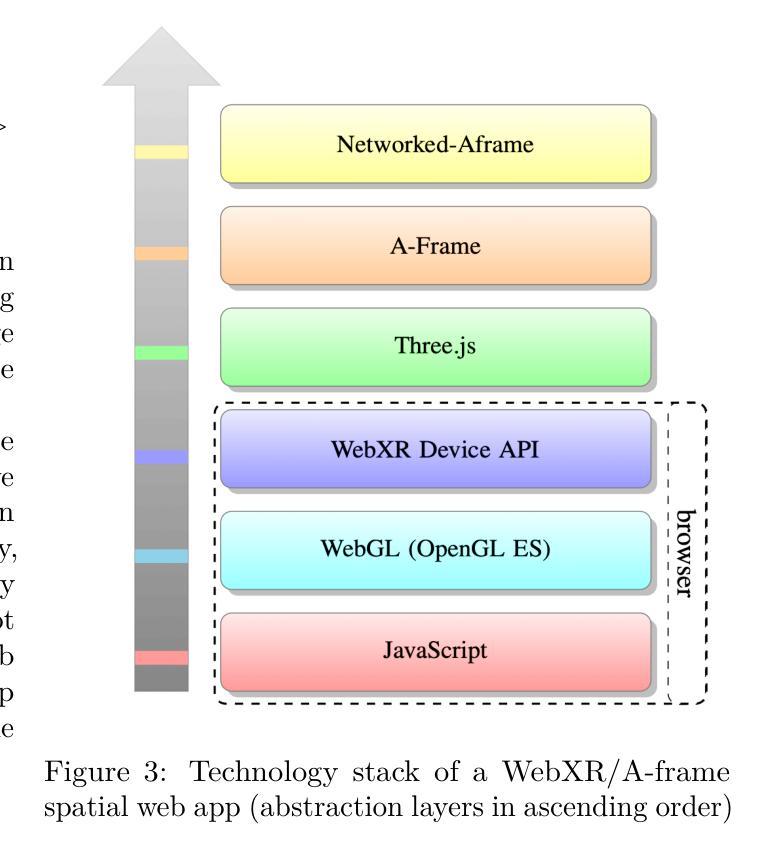
An Open, Cross-Platform, Web-Based Metaverse Using WebXR and A-Frame
Authors:Giuseppe Macario
The metaverse has received much attention in the literature and industry in the last few years, but the lack of an open and cross-platform architecture has led to many distinct metaverses that cannot communicate with each other. This work proposes a WebXR-based cross-platform architecture for developing spatial web apps using the A-Frame and Networked-Aframe frameworks with a view to an open and interoperable metaverse, accessible from both the web and extended reality devices. A prototype was implemented and evaluated, supporting the capability of the technology stack to enable immersive experiences across different platforms and devices. Positive feedback on ease of use of the immersive environment further corroborates the proposed approach, underscoring its effectiveness in facilitating engaging and interactive virtual spaces. By adhering to principles of interoperability and inclusivity, it lives up to Tim Berners-Lee’s vision of the World Wide Web as an open platform that transcends geographical and technical boundaries.
PDF arXiv admin note: substantial text overlap with arXiv:2404.05317
Summary
提出基于WebXR的跨平台架构,实现开放互操作元宇宙,支持沉浸式体验。
Key Takeaways
- 元宇宙领域近年备受关注。
- 缺乏开放跨平台架构,导致多个元宇宙互不兼容。
- 提出WebXR架构,利用A-Frame和Networked-Aframe。
- 实现原型,支持跨平台和设备沉浸式体验。
- 用户反馈良好,易用性强。
- 遵循互操作性和包容性原则。
- 符合伯纳斯-李对开放平台愿景。
Title: An Open, Cross-Platform, Web-Based Metaverse(开放、跨平台、基于Web的元宇宙)
Authors: Giuseppe Macario
Affiliation: Universitas Mercatorum(马可图利大学)
Keywords: Metaverse, Virtual Worlds, WebXR, Spatial Computing, Extended Reality, Open Standards, World Wide Web, Browsers
Urls: arXiv:2408.13520v1 [cs.CV] 24 Aug 2024, Github: None
Summary:
(1): 该文章的研究背景是元宇宙近年来受到广泛关注,但由于缺乏开放和跨平台架构,导致许多独立的元宇宙无法相互通信。研究者们希望创造一个开放且互操作的元宇宙,可以从Web和扩展现实设备访问。
(2):过去的方法主要依赖于特定平台和技术的解决方案,这导致了互操作性和兼容性问题。该文章提出的方法是基于WebXR和A-Frame、Networked-Aframe框架的跨平台架构,旨在解决现有方法的局限性,具有较强的动机。
(3):该文章提出的研究方法是在WebXR的基础上,使用A-Frame和Networked-Aframe框架开发空间Web应用,以实现一个开放且互操作的元宇宙。
(4):通过实现原型并对其进行评估,该文章的方法支持在不同平台和设备上提供沉浸式体验。用户对沉浸环境的易用性给予了积极反馈,这进一步证实了该方法在促进引人入胜和互动虚拟空间方面的有效性。
Methods:
(1): 基于WebXR技术,利用A-Frame和Networked-Aframe框架构建跨平台的空间Web应用。
(2): 设计并实现了一个开放且互操作的元宇宙原型,确保不同平台和设备上的沉浸式体验。
(3): 通过用户测试和反馈,评估了沉浸环境易用性,验证了方法的有效性。
(4): 采用开放标准,确保元宇宙的兼容性和互操作性。
Conclusion:
(1): 该项工作的意义在于提出了一个基于WebXR的跨平台架构,旨在解决现有元宇宙的碎片化问题,促进开放和互操作的元宇宙发展,为用户提供了在不同平台和设备上访问沉浸式虚拟空间的可能性。
(2): Innovation point: 创新点在于提出了基于WebXR和A-Frame、Networked-Aframe框架的跨平台架构,实现了元宇宙的开放性和互操作性;Performance: 性能方面,原型在用户测试中表现出良好的沉浸感和易用性,同时保持了优异的网络效率和响应速度;Workload: 工作量方面,文章详细描述了从原型设计到评估的整个过程,确保了方法的可行性和实用性。
点此查看论文截图