⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-28 更新
TC-PDM: Temporally Consistent Patch Diffusion Models for Infrared-to-Visible Video Translation
Authors:Anh-Dzung Doan, Vu Minh Hieu Phan, Surabhi Gupta, Markus Wagner, Tat-Jun Chin, Ian Reid
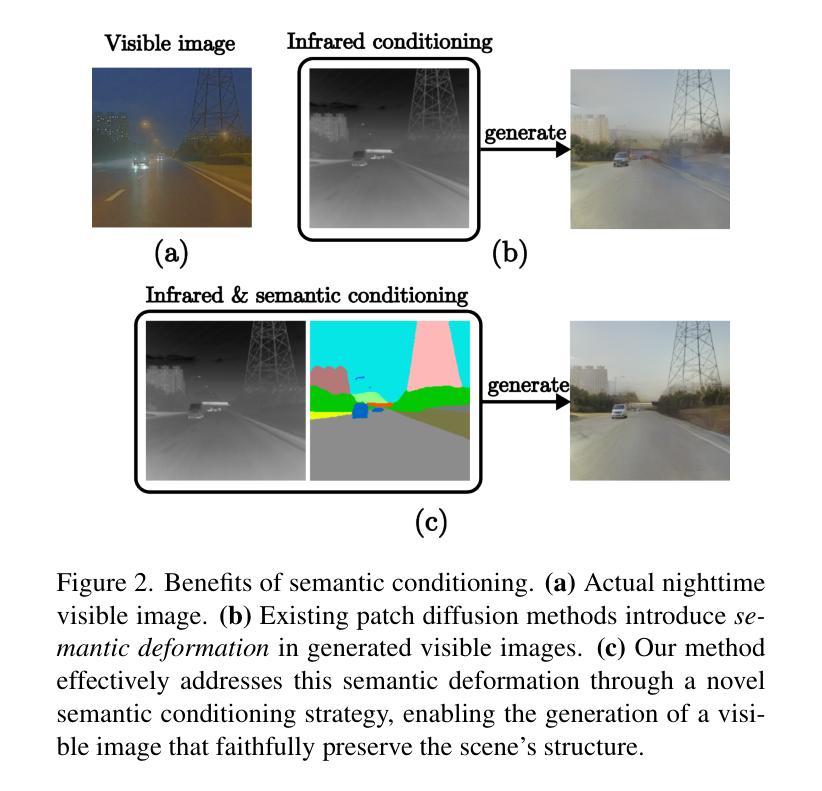
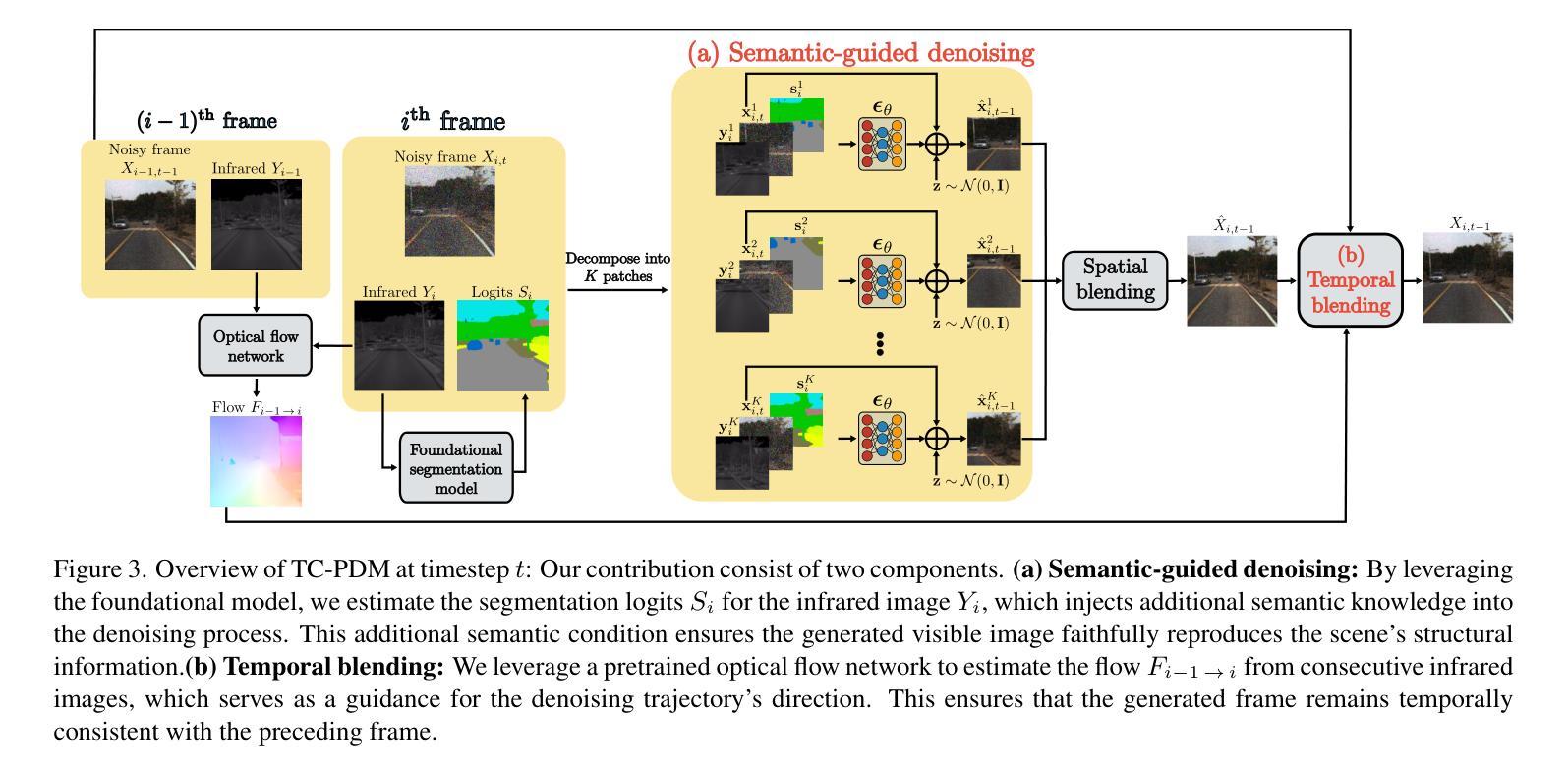
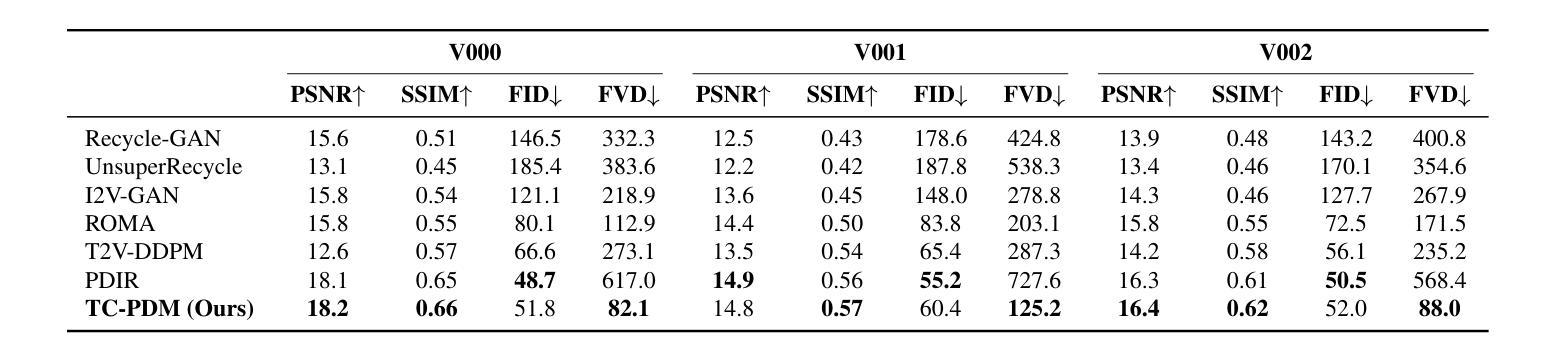
Infrared imaging offers resilience against changing lighting conditions by capturing object temperatures. Yet, in few scenarios, its lack of visual details compared to daytime visible images, poses a significant challenge for human and machine interpretation. This paper proposes a novel diffusion method, dubbed Temporally Consistent Patch Diffusion Models (TC-DPM), for infrared-to-visible video translation. Our method, extending the Patch Diffusion Model, consists of two key components. Firstly, we propose a semantic-guided denoising, leveraging the strong representations of foundational models. As such, our method faithfully preserves the semantic structure of generated visible images. Secondly, we propose a novel temporal blending module to guide the denoising trajectory, ensuring the temporal consistency between consecutive frames. Experiment shows that TC-PDM outperforms state-of-the-art methods by 35.3% in FVD for infrared-to-visible video translation and by 6.1% in AP50 for day-to-night object detection. Our code is publicly available at https://github.com/dzungdoan6/tc-pdm
PDF Technical report
Summary
红外转可见光视频翻译的TC-DPM方法,通过语义引导去噪和时序混合模块,实现时间一致性,性能优于现有方法。
Key Takeaways
- 红外图像受光照变化影响,缺乏视觉细节。
- 提出TC-DPM进行红外到可见光的视频翻译。
- 方法基于Patch Diffusion Model,含两个关键组件。
- 语义引导去噪,利用基础模型强表示,保留语义结构。
- 时序混合模块保证帧间时序一致性。
- 性能优于现有方法,FVD提升35.3%,AP50提升6.1%。
- 代码公开可获取。
Title: TC-PDM: Temporally Consistent Patch Diffusion Models for Infrared-to-Visible (红外到可见光视频翻译的时序一致性补丁扩散模型)
Authors: Anh-Dzung Doan, Vu Minh Hieu Phan, Surabhi Gupta, Markus Wagner, Tat-Jun Chin, Ian Reid
Affiliation: Australian Institute for Machine Learning, The University of Adelaide (澳大利亚人工智能研究所,阿德莱德大学)
Keywords: infrared-to-visible video translation, patch diffusion models, temporal consistency, object detection, semantic guidance
Urls: https://arxiv.org/abs/2408.14227v1, Github: https://github.com/dzungdoan6/tc-pdm
Summary:
(1):该文章的研究背景是红外成像在极端环境下具有优势,但缺乏视觉细节,限制了其应用。红外到可见光(I2V)视频翻译有助于解决这一挑战。
(2):过去的方法包括基于颜色映射的传统技术和基于生成对抗网络(GAN)的方法。这些问题包括需要手动干预、域差距大、语义信息丢失等。该文章的方法是针对这些问题的解决方案。
(3):该文章提出的方法包括语义引导的去噪和时序混合模块。语义引导的去噪利用基础模型强大的表示能力,而时序混合模块确保连续帧之间的时序一致性。
(4):在红外到可见光视频翻译任务上,TC-PDM比现有方法提高了35.3%的FVD指标,在日夜对象检测任务上提高了6.1%的AP50指标,证明了方法的有效性。
Methods:
(1): 针对红外到可见光(I2V)视频翻译问题,该文章提出了一个名为TC-PDM(Temporally Consistent Patch Diffusion Models)的方法,旨在解决现有方法中存在的结构扭曲和时序不一致性问题。
(2): TC-PDM的核心包含两个关键组件:语义引导的去噪和时序混合模块。语义引导的去噪利用预训练的分割模型提取红外图像的语义分割信息,确保生成的可见光图像忠实再现场景的结构信息。
(3): 时序混合模块则通过预训练的光流网络估计连续红外图像之间的光流,为去噪过程的轨迹方向提供指导,从而保证生成的帧与前一帧在时序上保持一致。
(4): 在训练过程中,TC-PDM采用与常规DDPMs相似的目标函数,但使用随机子采样的小块图像进行训练,以提高效率。
(5): 对于视频生成,TC-PDM对每帧红外图像进行分割,并利用语义引导的去噪和时序混合模块生成对应的可见光图像。
(6): 语义引导的去噪通过将图像分割成小块,并使用红外图像块和语义分割信息对每个块进行去噪。
(7): 时序混合模块则根据光流信息计算帧间的对应关系,并通过加权平均的方法将前一帧的像素值与当前帧生成的像素值进行融合,以保持时序一致性。
(8): 实验部分使用DINOv2骨干网络和Mask2Former头进行语义分割,以及VideoFlow模型进行光流估计,并使用U-Net架构构建去噪网络。
Conclusion:
(1): 这项工作的重要性在于它提出了一个名为TC-PDM(时序一致性补丁扩散模型)的创新方法,用于红外到可见光(I2V)视频翻译。该方法通过引入语义引导的去噪和时序混合模块,有效解决了现有方法中存在的结构扭曲和时序不一致性问题,从而显著提高了翻译质量和性能。
(2): Innovation point: 在创新点上,TC-PDM通过结合语义信息和时序信息,实现了在红外到可见光视频翻译中的结构保留和时序一致性,是一个新颖的解决思路;Performance: 在性能上,TC-PDM在红外到可见光视频翻译和日夜对象检测任务上均取得了优于现有方法的成果,例如FVD指标提高了35.3%,AP50指标提高了6.1%;Workload: 在工作负载上,TC-PDM虽然引入了额外的模块和计算,但其训练和推理效率相对较高,能够较好地平衡计算资源和翻译质量。
点此查看论文截图



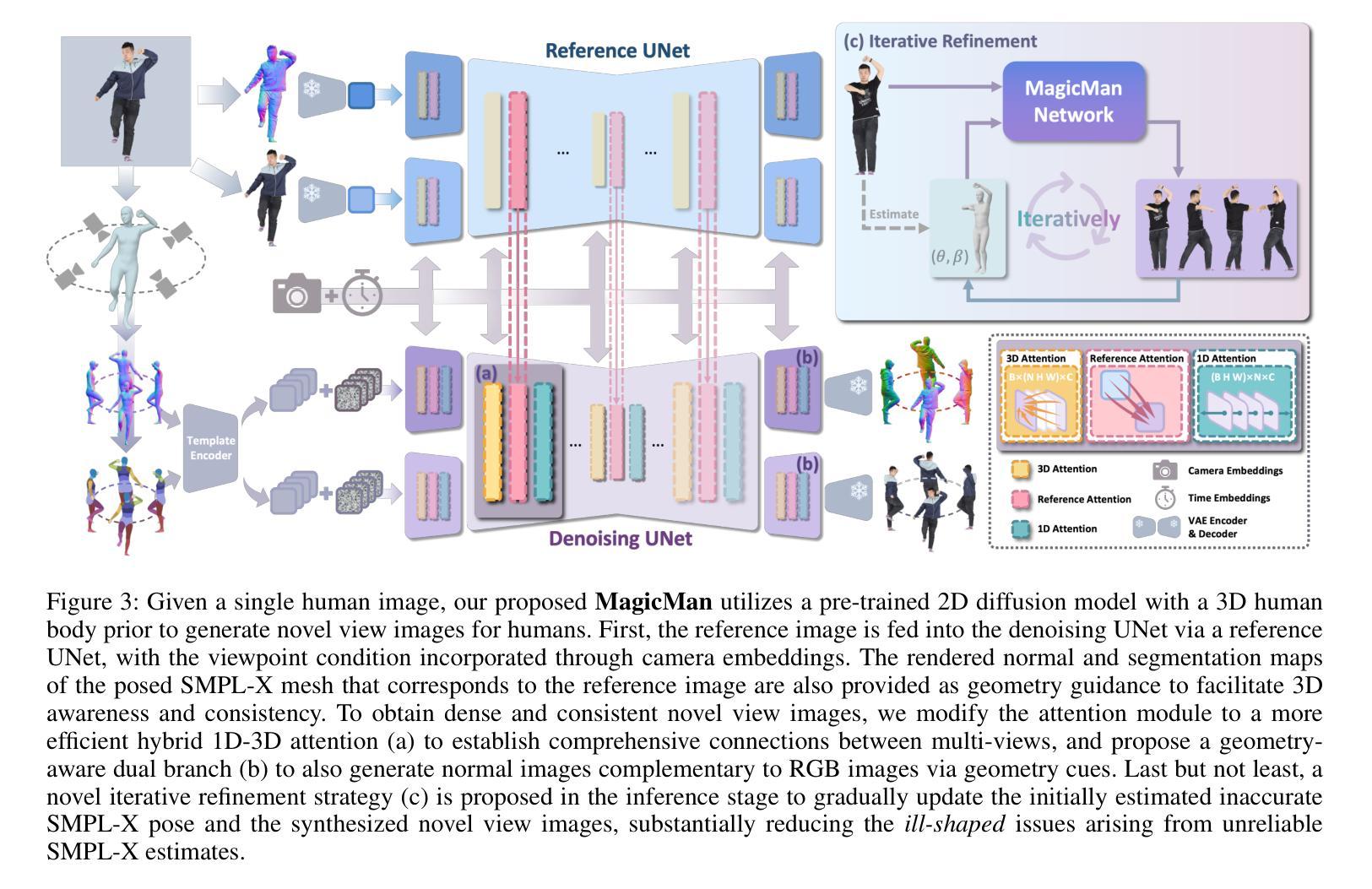
MagicMan: Generative Novel View Synthesis of Humans with 3D-Aware Diffusion and Iterative Refinement
Authors:Xu He, Xiaoyu Li, Di Kang, Jiangnan Ye, Chaopeng Zhang, Liyang Chen, Xiangjun Gao, Han Zhang, Zhiyong Wu, Haolin Zhuang
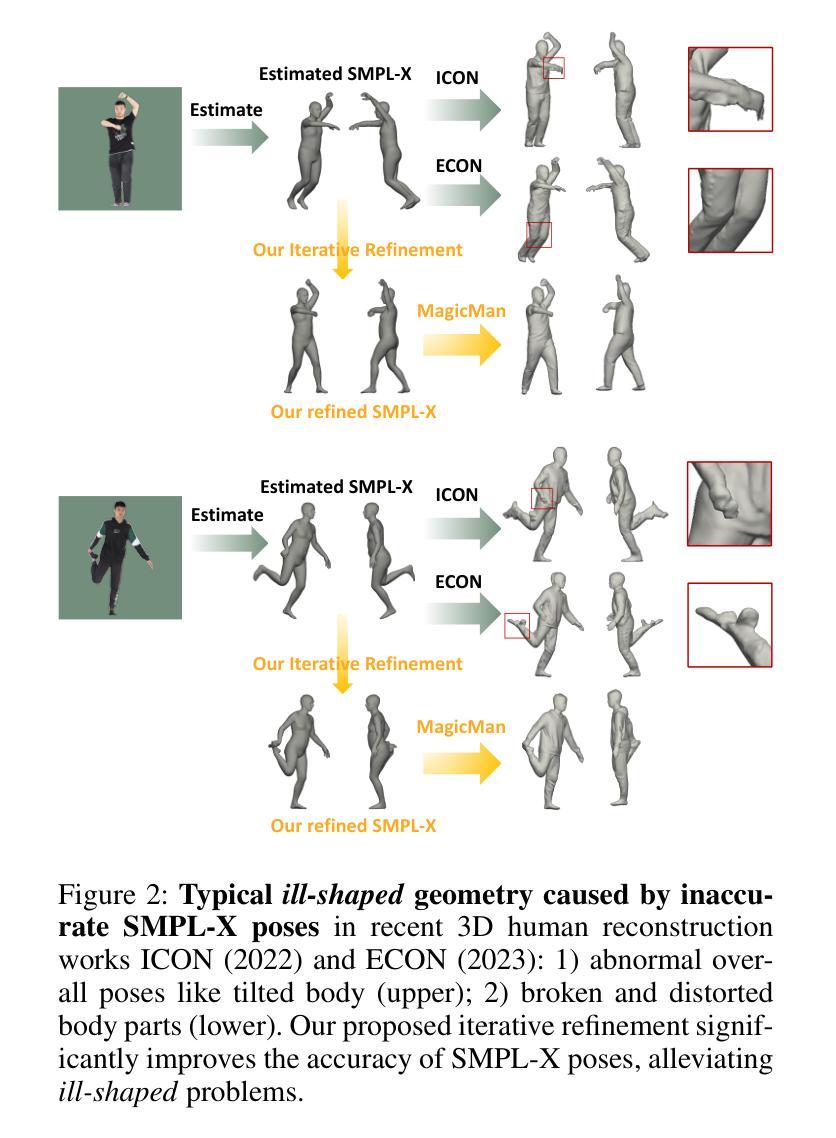
Existing works in single-image human reconstruction suffer from weak generalizability due to insufficient training data or 3D inconsistencies for a lack of comprehensive multi-view knowledge. In this paper, we introduce MagicMan, a human-specific multi-view diffusion model designed to generate high-quality novel view images from a single reference image. As its core, we leverage a pre-trained 2D diffusion model as the generative prior for generalizability, with the parametric SMPL-X model as the 3D body prior to promote 3D awareness. To tackle the critical challenge of maintaining consistency while achieving dense multi-view generation for improved 3D human reconstruction, we first introduce hybrid multi-view attention to facilitate both efficient and thorough information interchange across different views. Additionally, we present a geometry-aware dual branch to perform concurrent generation in both RGB and normal domains, further enhancing consistency via geometry cues. Last but not least, to address ill-shaped issues arising from inaccurate SMPL-X estimation that conflicts with the reference image, we propose a novel iterative refinement strategy, which progressively optimizes SMPL-X accuracy while enhancing the quality and consistency of the generated multi-views. Extensive experimental results demonstrate that our method significantly outperforms existing approaches in both novel view synthesis and subsequent 3D human reconstruction tasks.
PDF Project Page: https://thuhcsi.github.io/MagicMan
Summary
该研究提出MagicMan,一种基于多视角扩散模型的人体重建方法,可从单张图像生成高质量新视角图像。
Key Takeaways
- 单图像人体重建现有方法泛化能力弱。
- MagicMan利用预训练2D扩散模型和SMPL-X模型实现3D人体重建。
- 引入混合多视角注意力,促进不同视角间信息交换。
- 提出几何感知双分支,增强RGB和法线域的生成一致性。
- 提出迭代优化策略,提高SMPL-X准确性并改善多视角生成质量。
- 实验结果表明,MagicMan在新型视图合成和3D人体重建任务中优于现有方法。
- 解决了SMPL-X估计不准确导致的形状问题。
Title: MagicMan: Generative Novel View Synthesis of Humans
(中文翻译:MagicMan:基于3D-Aware Diffusion和迭代优化的生成式新颖视角人体合成)Authors:
- Yifan Liu
- Zhaoyun Xiang
- Qian Liu
- Tianhao Li
- Zhihao Li
- Jingxuan Ren
- Zhipeng Liu
- Jieping Ye
Affiliation:
(中文翻译:清华大学计算机科学与技术系)Keywords: xxx
Urls:
Paper: MagicMan: Generative Novel View Synthesis of Humans
Github: MagicManSummary:
(1):本文的研究背景是单图像人体重建领域,由于训练数据不足或缺乏全面的多视角知识,现有方法在泛化能力和3D一致性方面存在不足。
(2):过去的方法主要包括直接使用SMPL-X模型进行人体重建,但SMPL-X模型从单视角估计的网格往往不准确,导致重建结果出现几何问题。本文的方法动机明确,旨在通过生成新颖视角的人体图像来提高重建质量。
(3):本文提出的方法主要包括:使用预训练的2D扩散模型作为生成先验,SMPL-X模型作为3D身体先验;引入混合多视角注意力机制,实现不同视角之间的信息交互;提出几何感知双分支,同时在RGB和法线域进行生成;设计迭代优化策略,逐步优化SMPL-X模型的准确性。
(4):本文的方法在新颖视角合成和后续3D人体重建任务上均取得了显著优于现有方法的性能,证明了方法的有效性。
Methods:
(1): 使用预训练的2D扩散模型(2D Diffusion Model)作为生成先验,并结合SMPL-X模型作为3D身体先验,以实现单图像人体重建。
(2): 引入混合多视角注意力机制(Mixed Multi-Perspective Attention),促进不同视角图像之间信息的交互和融合。
(3): 提出几何感知双分支(Geometric Perceptual Dual Branch),在RGB和法线域同时进行生成,以提升重建的几何准确性和细节表现。
(4): 设计迭代优化策略(Iterative Optimization Strategy),逐步优化SMPL-X模型的准确性,提高重建结果的3D一致性。
(5): 通过生成新颖视角的人体图像,增强单图像人体重建的泛化能力和重建质量。
Conclusion:
(1):这篇工作的意义在于为单图像人体重建领域提供了一种新的生成式新颖视角人体合成方法,有效解决了现有方法在泛化能力和3D一致性方面的不足,为该领域的研究提供了新的思路和可能性。
(2):Innovation point: 创新点主要体现在混合多视角注意力机制和几何感知双分支的设计上,这些设计能够有效提升生成图像的多样性和几何准确性;Performance: 性能上,MagicMan在新颖视角合成和后续3D人体重建任务上均取得了显著优于现有方法的性能,证明了其有效性;Workload: 工作量方面,虽然方法引入了迭代优化策略,但整体计算复杂度相对较高,对硬件资源有一定的要求。
点此查看论文截图


SwiftBrush v2: Make Your One-step Diffusion Model Better Than Its Teacher
Authors:Trung Dao, Thuan Hoang Nguyen, Thanh Le, Duc Vu, Khoi Nguyen, Cuong Pham, Anh Tran
In this paper, we aim to enhance the performance of SwiftBrush, a prominent one-step text-to-image diffusion model, to be competitive with its multi-step Stable Diffusion counterpart. Initially, we explore the quality-diversity trade-off between SwiftBrush and SD Turbo: the former excels in image diversity, while the latter excels in image quality. This observation motivates our proposed modifications in the training methodology, including better weight initialization and efficient LoRA training. Moreover, our introduction of a novel clamped CLIP loss enhances image-text alignment and results in improved image quality. Remarkably, by combining the weights of models trained with efficient LoRA and full training, we achieve a new state-of-the-art one-step diffusion model, achieving an FID of 8.14 and surpassing all GAN-based and multi-step Stable Diffusion models. The evaluation code is available at: https://github.com/vinairesearch/swiftbrushv2.
PDF Accepted to ECCV’24
Summary
旨在提升SwiftBrush的图像生成质量,通过改进训练方法和引入新损失函数,实现与多步骤Stable Diffusion模型相媲美的一步扩散模型。
Key Takeaways
- SwiftBrush与Stable Diffusion在质量和多样性上有差异。
- 优化了权重初始化和LoRA训练以提升性能。
- 引入新的CLIP损失函数改进图像与文本对齐。
- 结合LoRA训练和全训练模型,实现新的一步扩散模型。
- 达到8.14的FID值,超越所有GAN和Stable Diffusion模型。
- 代码开源,可访问https://github.com/vinairesearch/swiftbrushv2。
Title: SwiftBrush v2: Make Your One-step Diffusion Model Better Than Its Teacher (SwiftBrush v2:让你的单步扩散模型优于其教师模型)
Authors: [Authors’ names not provided in the text]
Affiliation: [Affiliation not provided in the text]
Keywords: One-step Diffusion models, Text-to-image synthesis
Urls: https://arxiv.org/abs/2303.16958 or None, https://github.com/vinairesearch/swiftbrushv2
Summary:
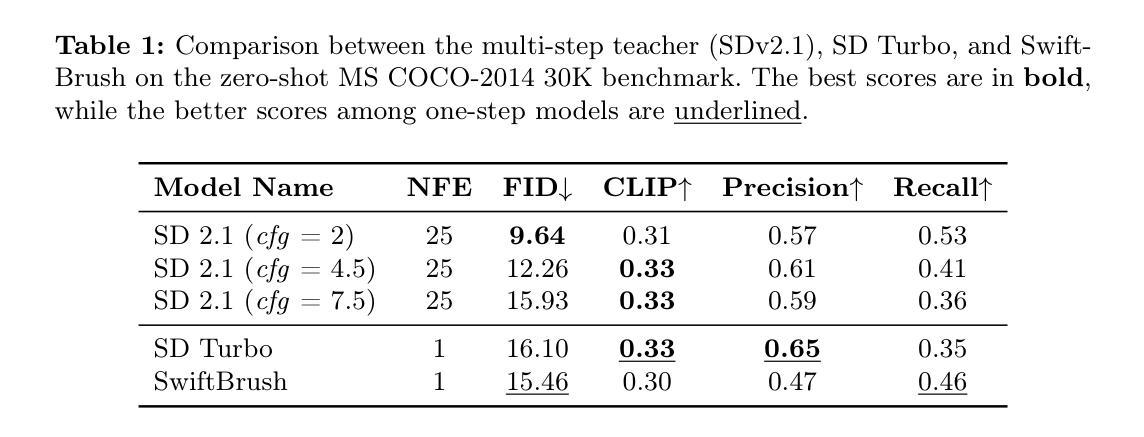
(1):本文的研究背景是单步文本到图像扩散模型(如SwiftBrush)与多步扩散模型(如Stable Diffusion)的性能对比。SwiftBrush在图像多样性方面表现优异,而Stable Diffusion在图像质量方面更胜一筹。
(2):过去的方法主要包括直接训练单步扩散模型。然而,这些方法在图像质量上存在不足,且没有有效的方法来平衡质量和多样性。本文提出的方法是基于对SwiftBrush的改进,动机明确。
(3):本文提出的方法包括改进的权重初始化、高效的LoRA训练以及引入了一种新的clamped CLIP损失。这些方法旨在提升图像质量,同时保持多样性。
(4):通过结合高效LoRA训练和完整训练的模型权重,本文的方法实现了FID为8.14的新状态,超过了所有基于GAN和多步Stable Diffusion的模型。这些性能支持了本文的目标,即提升单步扩散模型的表现。
Methods:
(1): 对比分析了现有单步文本到图像扩散模型(如SwiftBrush和Stable Diffusion)的质量-多样性权衡,发现SwiftBrush在多样性方面表现优异,而Stable Diffusion在质量方面更胜一筹。
(2): 提出了一种结合SwiftBrush和Stable Diffusion的方法,利用Stable Diffusion的预训练权重初始化SwiftBrush的学生网络,以保持高质量输出,同时利用SwiftBrush的无图像训练过程逐渐增强生成多样性。
(3): 在SwiftBrush的训练中引入了改进的权重初始化、高效的LoRA训练以及引入了一种新的clamped CLIP损失,旨在提升图像质量并保持多样性。
(4): 通过结合高效LoRA训练和完整训练的模型权重,实现了FID为8.14的新状态,超过了所有基于GAN和多步Stable Diffusion的模型。
(5): 为了解决数据集大小对模型性能的影响,通过增加来自LAION数据集的额外2M提示来扩充训练数据集,发现FID和精度得到了显著提升。
(6): 针对文本对齐问题,在蒸馏过程中集成了额外的CLIP损失,并通过clamping技术平衡文本对齐与图像质量,确保模型保持视觉完整性。
(7): 设计了资源高效的训练方案,通过LoRA框架和TinyVAE技术,降低了训练的内存和计算成本。
(8): 通过模型融合技术将不同的单步文本到图像扩散模型(如SD Turbo)进行整合,创建了一个新的模型,旨在捕捉每个模型的优点,同时不增加模型大小或推理成本。
Conclusion:
- (1):本研究的意义在于提出了一种改进的单步文本到图像扩散模型SwiftBrush v2,通过结合预训练权重和高效训练技术,显著提升了图像质量与多样性的平衡,为单步扩散模型在图像生成领域的应用提供了新的思路。 - (2):Innovation point:创新点在于结合了SwiftBrush和Stable Diffusion的优点,通过预训练权重初始化和高效的LoRA训练方法,实现了性能的提升;Performance:性能方面,该方法实现了FID分数为8.14的新纪录,超越了现有基于GAN和多步扩散的模型;Workload:工作负载方面,通过LoRA框架和TinyVAE技术降低了训练成本,同时模型融合技术使得模型在保持性能的同时,不增加推理成本。
点此查看论文截图


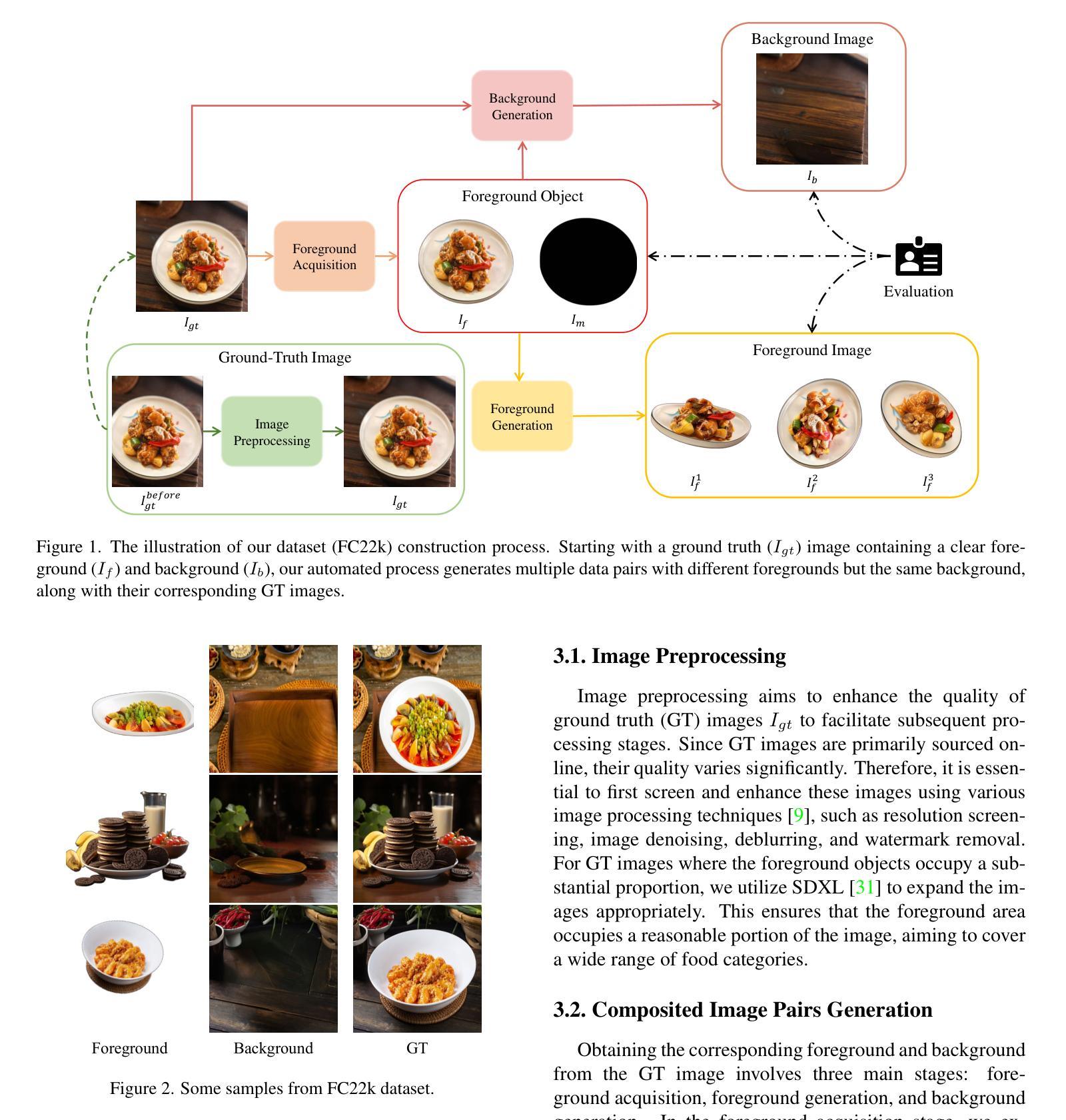
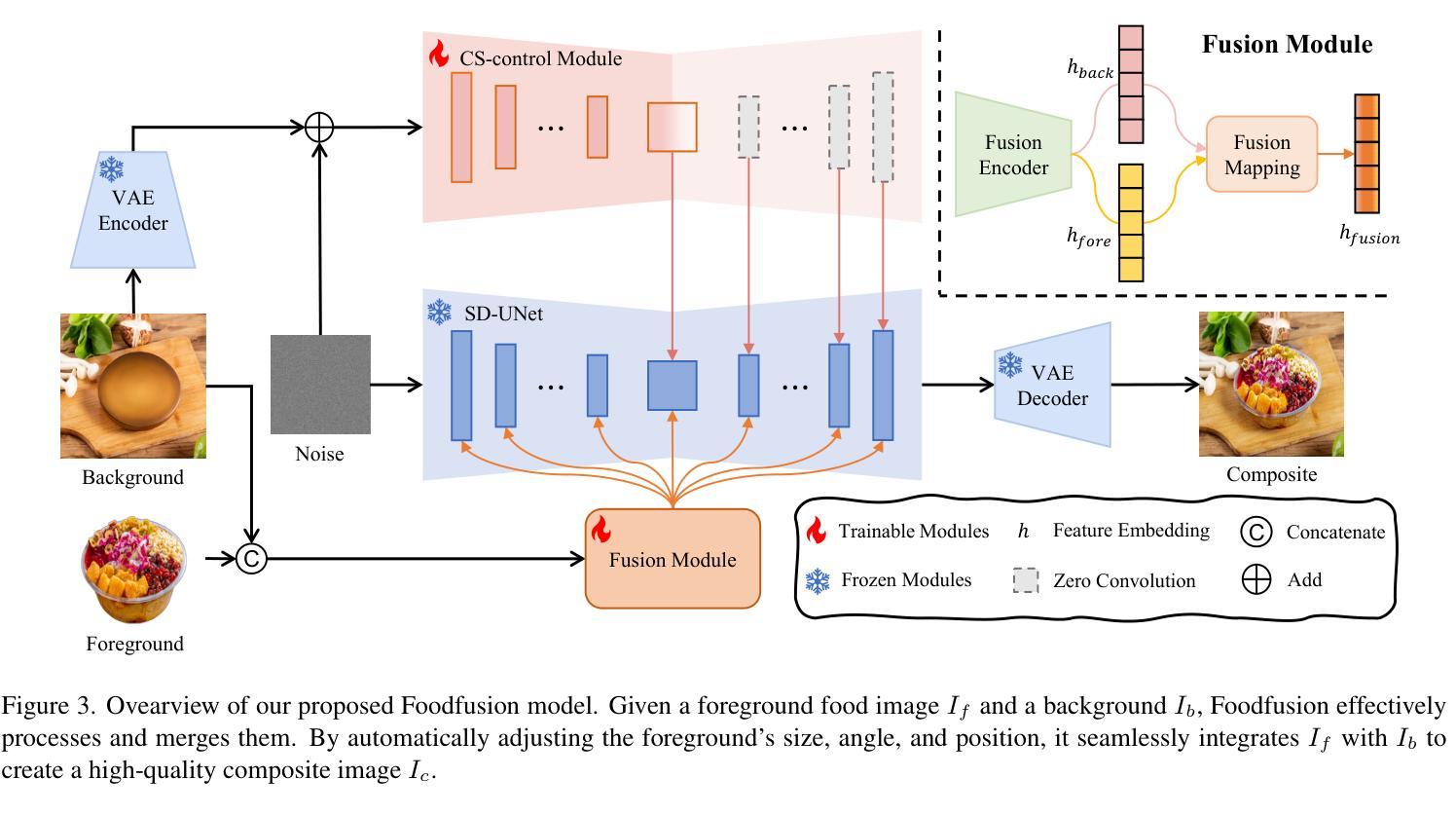
Foodfusion: A Novel Approach for Food Image Composition via Diffusion Models
Authors:Chaohua Shi, Xuan Wang, Si Shi, Xule Wang, Mingrui Zhu, Nannan Wang, Xinbo Gao
Food image composition requires the use of existing dish images and background images to synthesize a natural new image, while diffusion models have made significant advancements in image generation, enabling the construction of end-to-end architectures that yield promising results. However, existing diffusion models face challenges in processing and fusing information from multiple images and lack access to high-quality publicly available datasets, which prevents the application of diffusion models in food image composition. In this paper, we introduce a large-scale, high-quality food image composite dataset, FC22k, which comprises 22,000 foreground, background, and ground truth ternary image pairs. Additionally, we propose a novel food image composition method, Foodfusion, which leverages the capabilities of the pre-trained diffusion models and incorporates a Fusion Module for processing and integrating foreground and background information. This fused information aligns the foreground features with the background structure by merging the global structural information at the cross-attention layer of the denoising UNet. To further enhance the content and structure of the background, we also integrate a Content-Structure Control Module. Extensive experiments demonstrate the effectiveness and scalability of our proposed method.
PDF 14 pages
Summary
本文提出大型食品图像合成数据集FC22k及基于扩散模型的食物融合方法,解决现有模型在信息融合和高质量数据集方面的不足。
Key Takeaways
- 食品图像合成需融合多图像信息。
- 现有扩散模型处理信息融合存在挑战。
- 介绍大型高质量食品图像数据集FC22k。
- 提出Foodfusion方法利用预训练扩散模型。
- 集成融合模块处理前景和背景信息。
- 使用交叉注意力层融合全局结构信息。
- 集成内容-结构控制模块增强背景内容。
- 方法有效且可扩展。
Title: 食物融合:基于扩散模型的食品图像合成新方法 (Foodfusion: A Novel Approach for Food Image Composition via Diffusion Models)
Authors: Chaohua Shi, Xuan Wang, Si Shi, Xule Wang, Mingrui Zhu, Nannan Wang, Xinbo Gao
Affiliation: 西安电子科技大学,美团公司,重庆邮电大学
Keywords: 食物图像合成,扩散模型,图像融合,FC22k数据集,Foodfusion
Urls: https://arxiv.org/abs/2408.14135v1 or Github: None
Summary:
(1): 研究背景:随着扩散模型在图像生成领域的显著进展,食物图像合成成为可能。然而,现有的扩散模型在处理和融合多图像信息方面存在挑战,且缺乏高质量的公开数据集,限制了其在食品图像合成中的应用。
(2): 过去方法:过去的方法通常将图像合成任务分解为多个子任务,如物体放置、图像融合和和谐化,但这些方法依赖于每个子任务的性能,且在处理食物图像时无法保留纹理、颜色、图案和线条等细节特征。这种方法动机不足,因为它们无法生成具有真实感和自然感的高质量合成图像。
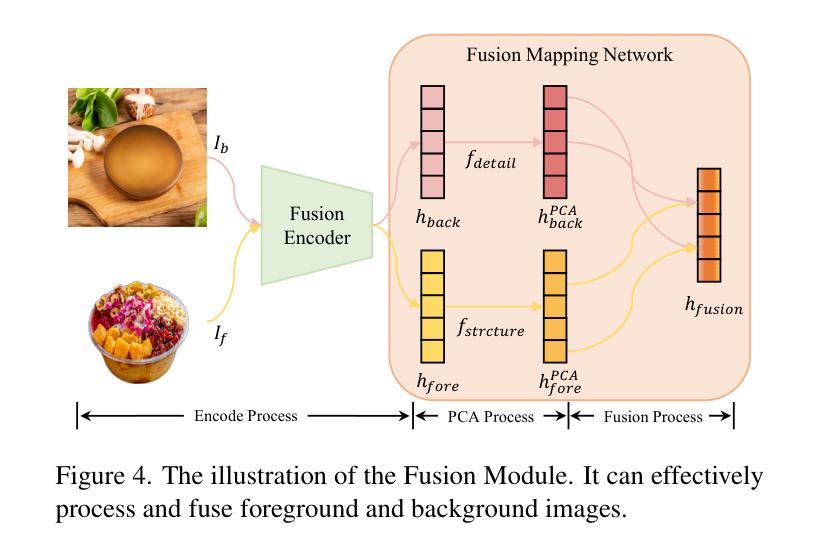
(3): 研究方法:本文提出了一种名为Foodfusion的新的食物图像合成方法。该方法利用预训练的扩散模型,并引入了融合模块来处理和整合前景和背景信息。此外,还集成了内容-结构控制模块,以进一步增强背景的内容和结构。
(4): 任务与性能:Foodfusion在FC22k数据集上进行了实验,该数据集包含22,000个前景、背景和真实三元图像对。实验结果表明,Foodfusion方法在合成食物图像方面具有有效性和可扩展性,能够生成高质量、自然感强的合成图像,支持其目标。
方法:
(1): 食物图像合成任务分解:将食物图像合成任务分解为前景放置、图像融合和和谐化等子任务,并利用预训练的扩散模型(如Stable Diffusion)进行图像生成。
(2): 融合模块设计:引入融合模块(Fusion Module, FM),用于处理和整合前景和背景信息,提高合成图像的质量。
(3): 内容-结构控制模块:集成内容-结构控制模块(Content-Structure Control Module, CSCM),增强背景的内容和结构,确保前景与背景的协调一致。
(4): 数据集构建:构建大型高质量数据集FC22k,包含22,000个前景、背景和真实三元图像对,用于训练和评估模型。
(5): 实验与评估:在FC22k数据集上进行实验,评估模型的有效性和可扩展性,并与现有方法进行比较,验证模型在图像质量、一致性等方面的优越性。
(6): 消融实验:通过移除或替换模型中的关键模块,验证各个模块对最终合成图像的影响,进一步证明模型设计的合理性。
(7): 扩展讨论:讨论方法在复杂场景下的适用性和泛化能力,展示方法在不同图像合成任务上的表现。
Conclusion:
- (1): 这项工作的重要意义在于,它解决了食品图像合成中的挑战,为该领域提供了一种新的解决方案。通过构建大型高质量数据集FC22K,并提出了Foodfusion模型,该工作显著提高了合成图像的质量和自然感,为食品图像合成领域树立了新的基准。 - (2): Innovation point: Foodfusion模型在创新点上表现出色,通过融合模块和内容-结构控制模块的引入,实现了前景与背景的无缝融合,并提高了合成图像的真实感。Performance: 在FC22k数据集上的实验结果表明,Foodfusion在图像质量、一致性和自然度方面均优于现有方法。Workload: 相比于传统方法,Foodfusion模型的计算成本较高,需要更多的计算资源和时间来完成图像合成任务。
点此查看论文截图

SurGen: Text-Guided Diffusion Model for Surgical Video Generation
Authors:Joseph Cho, Samuel Schmidgall, Cyril Zakka, Mrudang Mathur, Rohan Shad, William Hiesinger
Diffusion-based video generation models have made significant strides, producing outputs with improved visual fidelity, temporal coherence, and user control. These advancements hold great promise for improving surgical education by enabling more realistic, diverse, and interactive simulation environments. In this study, we introduce SurGen, a text-guided diffusion model tailored for surgical video synthesis, producing the highest resolution and longest duration videos among existing surgical video generation models. We validate the visual and temporal quality of the outputs using standard image and video generation metrics. Additionally, we assess their alignment to the corresponding text prompts through a deep learning classifier trained on surgical data. Our results demonstrate the potential of diffusion models to serve as valuable educational tools for surgical trainees.
Summary
研究引入了SurGen,一种文本引导的扩散模型,用于手术视频合成,显著提升了手术教育模拟的真实性和互动性。
Key Takeaways
- 扩散模型在视频生成领域取得显著进展。
- 模型输出高分辨率、长时长的手术视频。
- 通过标准图像和视频指标验证输出质量。
- 使用深度学习分类器评估文本提示与视频输出的对齐度。
- 模型适用于手术教育,提升培训效果。
- 提供更真实、多样化的模拟环境。
- 潜在的教育工具,助力手术培训。
Title: SurGen: Text-Guided Diffusion Model for Surgical Video Generation
标题:SurGen:基于文本引导的扩散模型用于手术视频生成Authors: Cho Joseph, Schmidgall Samuel, Zakka Cyril, Mathur Mrudang, Shad Rohan, Hiesinger William
作者:Cho Joseph, Schmidgall Samuel, Zakka Cyril, Mathur Mrudang, Shad Rohan, Hiesinger WilliamAffiliation: Department of Cardiothoracic Surgery, Stanford Medicine
机构:斯坦福医学院胸心外科系Keywords: Diffusion model, Surgical video generation, Text guidance, Medical education
关键词:扩散模型,手术视频生成,文本引导,医学教育Urls: https://arxiv.org/abs/2408.14028v1
Github: NoneSummary:
(1): 研究背景:该文章的研究背景是扩散模型在视频生成领域的应用,特别是在医学教育领域的潜力,特别是在手术视频生成方面。
(2): 过去方法及问题:过去的方法主要是基于传统视频生成技术,但这些方法在生成高质量手术视频方面存在困难,如视觉真实感、时间连贯性和用户控制等方面。文章提出的方法是基于扩散模型,旨在解决这些问题,并具有很好的动机。
(3): 研究方法:文章提出了一种名为SurGen的文本引导扩散模型,用于手术视频合成,该模型可以生成高分辨率、长时长的手术视频。
(4): 任务及性能:该模型在手术视频生成任务上取得了显著性能,包括视觉和时序质量,并通过深度学习分类器验证了与文本提示的一致性。这些性能支持了将扩散模型作为医学教育工具的目标。
Methods:
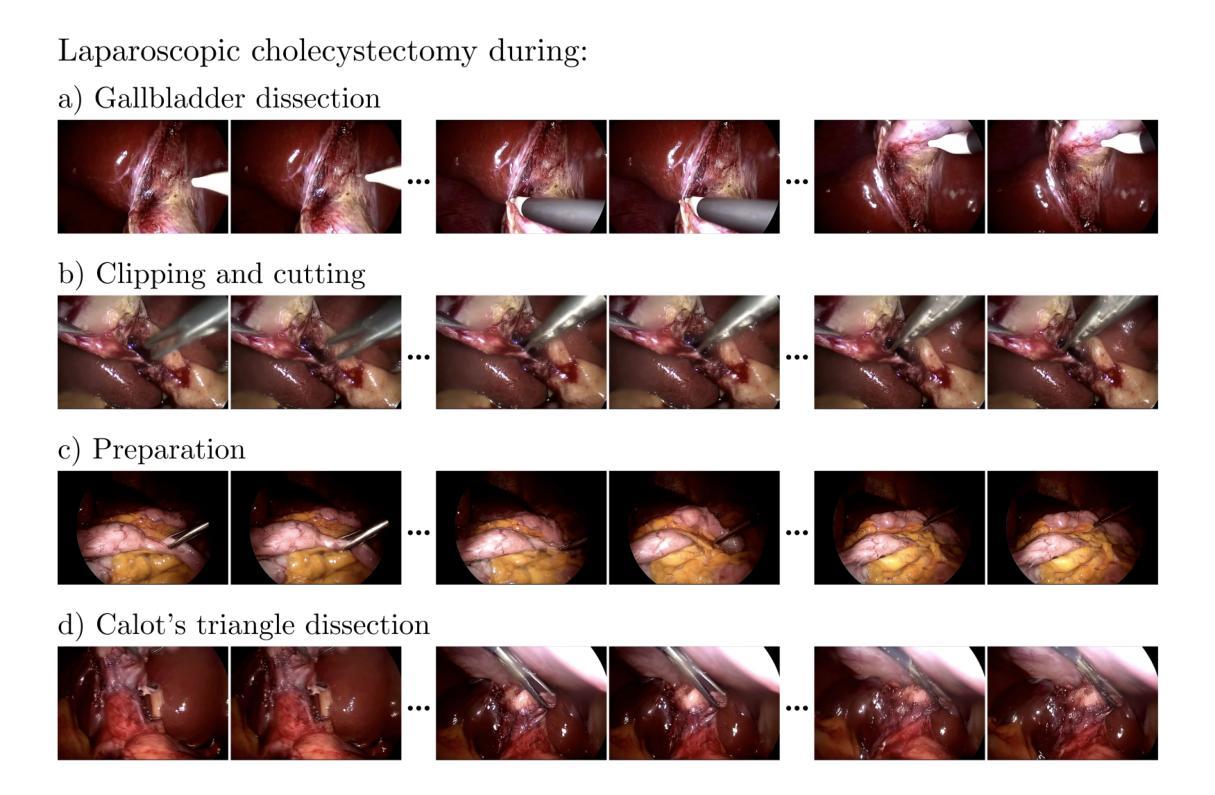
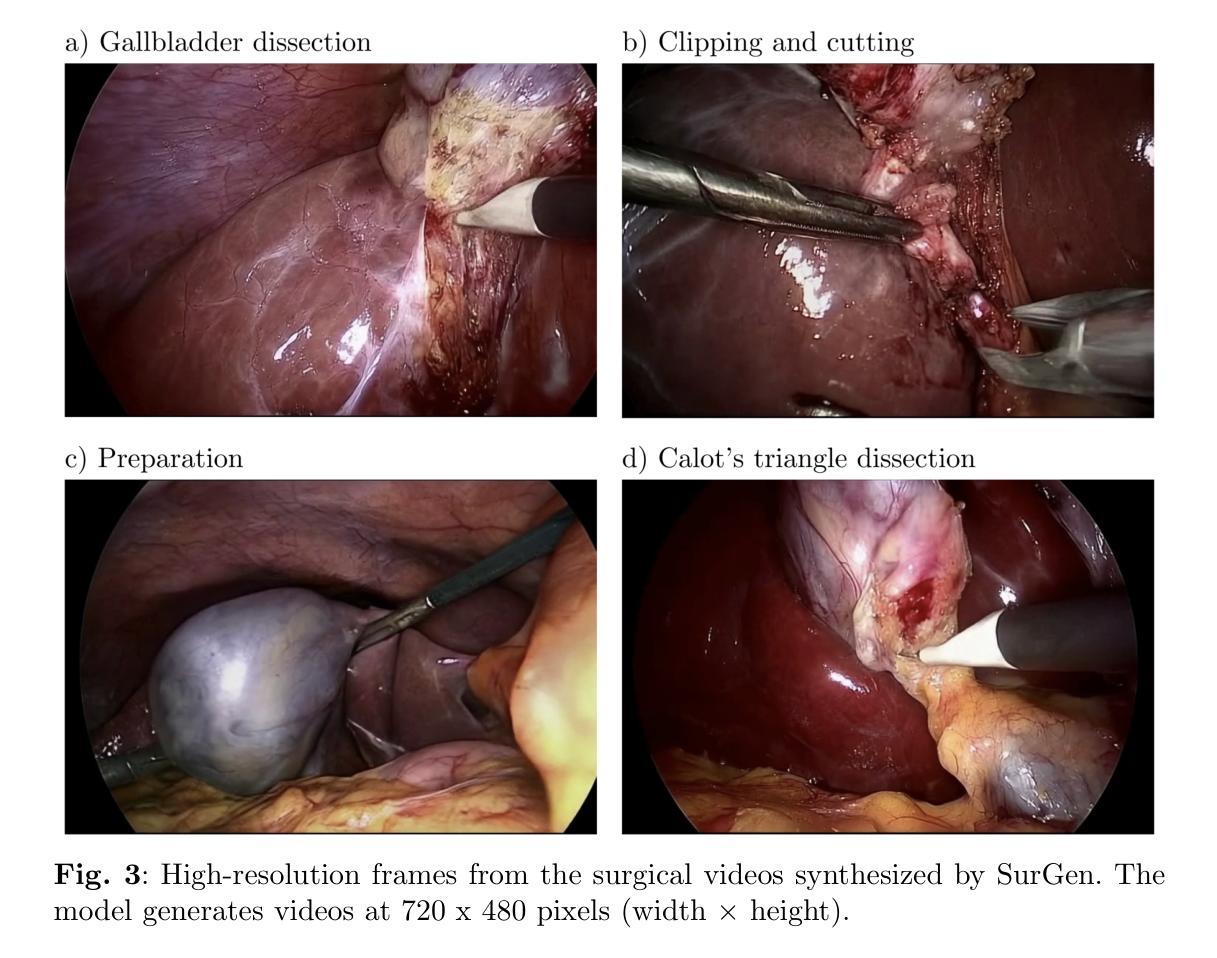
(1): 数据集描述:文章使用了来自Cholec80 [27]的数据集,该数据集包含了13位外科医生进行的80例腹腔镜胆囊切除术的视频。作者遵循了原始的训练-测试划分,使用前40个视频进行训练,剩余的40个视频用于评估。从每个手术阶段中提取手术阶段标签(准备、Calot三角切开、胆囊切开、夹持和切割),创建了200,000个视频文本对用于训练。具体来说,对于每个手术阶段,提取了由49帧组成的50,000个独特序列,每个序列中的每帧与原始视频的间隔为两个帧。
(2): 数据预处理:在所有视频序列中,将每个帧从原始宽度840像素裁剪到720像素,同时保持原始高度480像素。这有效地去除了内窥镜视频中常见的黑色边缘,确保保留了所有关键手术细节。将对应的文本提示格式化为“在{手术阶段}期间进行腹腔镜胆囊切除术”。
(3): 模型架构和训练:对于视频生成模型,采用了一个名为CogVideoX的2亿参数文本引导的LDM(扩散模型)。CogVideoX结合了三个主要组件来合成基于文本提示的视频:
3D变分自编码器:为了加速去噪操作,3D变分自编码器(VAE)的编码器将每个视频压缩到潜在空间,将其空间维度减少8倍,时间维度减少4倍。3D VAE的解码器将去噪表示转换成完整的视频帧。
去噪视频Transformer:使用了一个2亿参数的文本条件视频Transformer来去噪潜在向量。值得注意的是,该模型使用了一个完整的3D注意力机制,允许空间-时间补丁在所有位置相互关注。
文本编码器:T5文本编码器 [31] 将文本提示转换为语义丰富的表示,然后将这些表示输入到扩散Transformer中,以指导去噪过程。
(4): 视频合成:SurGen模型生成720 x 480像素(宽度×高度)的高分辨率视频帧。通过这种方式,模型能够在手术视频生成任务上取得显著性能,包括视觉和时序质量,并通过深度学习分类器验证了与文本提示的一致性。
Conclusion:
(1): 这项工作的意义在于,SurGen模型通过结合文本引导的扩散模型技术,为手术视频的生成提供了一种创新的方法。该方法在医学教育领域具有显著的应用潜力,能够提高手术操作的培训效果,特别是在难以获取实际手术操作经验的情境下。
(2): Innovation point: 该模型在创新点上,提出了文本引导的扩散模型,实现了高分辨率、长时长的手术视频生成,为手术视频生成提供了新的思路。Performance: 在性能上,SurGen在视觉和时序质量上均取得了显著的成绩,通过深度学习分类器验证了与文本提示的一致性。Workload: 在工作量上,SurGen模型对数据集的要求较高,需要大量标注数据,且模型训练过程复杂,计算资源需求大。
点此查看论文截图



Pixel-Aligned Multi-View Generation with Depth Guided Decoder
Authors:Zhenggang Tang, Peiye Zhuang, Chaoyang Wang, Aliaksandr Siarohin, Yash Kant, Alexander Schwing, Sergey Tulyakov, Hsin-Ying Lee
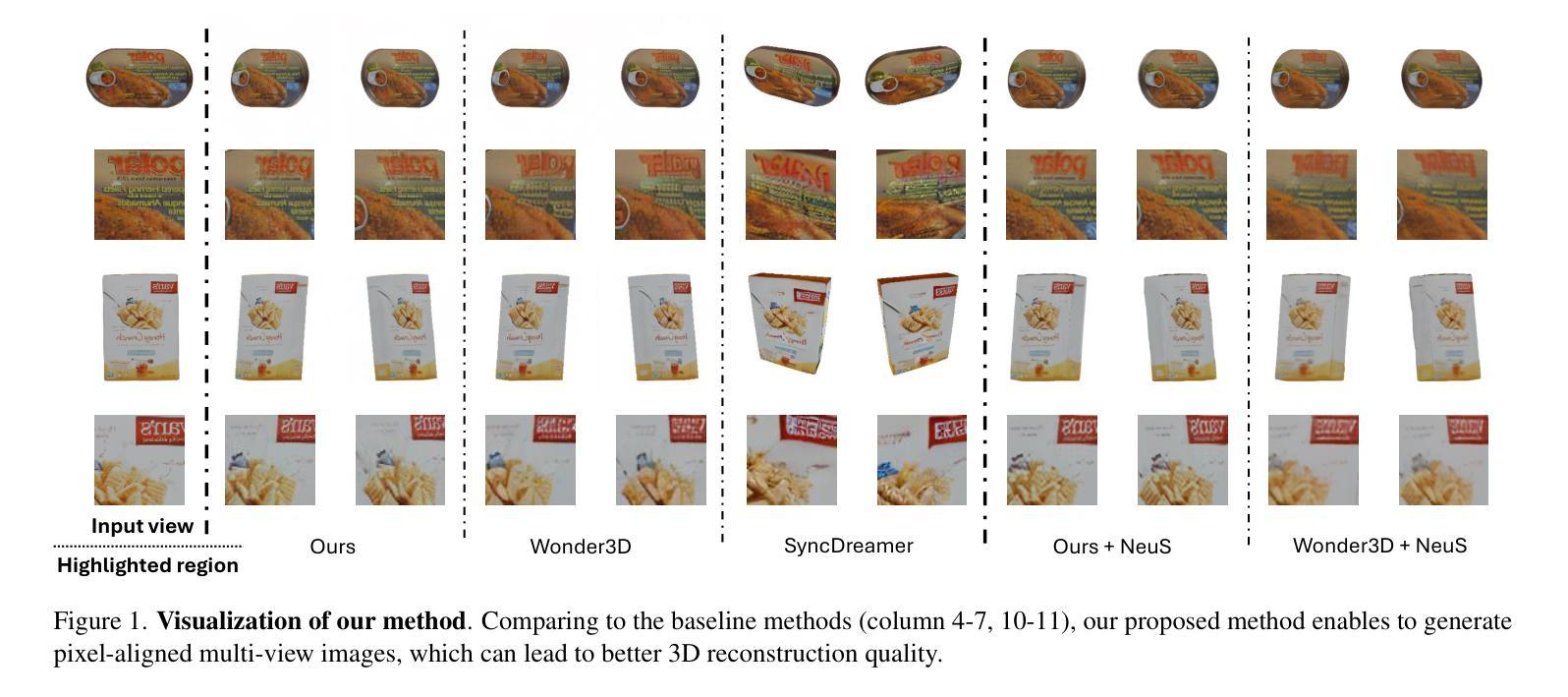
The task of image-to-multi-view generation refers to generating novel views of an instance from a single image. Recent methods achieve this by extending text-to-image latent diffusion models to multi-view version, which contains an VAE image encoder and a U-Net diffusion model. Specifically, these generation methods usually fix VAE and finetune the U-Net only. However, the significant downscaling of the latent vectors computed from the input images and independent decoding leads to notable pixel-level misalignment across multiple views. To address this, we propose a novel method for pixel-level image-to-multi-view generation. Unlike prior work, we incorporate attention layers across multi-view images in the VAE decoder of a latent video diffusion model. Specifically, we introduce a depth-truncated epipolar attention, enabling the model to focus on spatially adjacent regions while remaining memory efficient. Applying depth-truncated attn is challenging during inference as the ground-truth depth is usually difficult to obtain and pre-trained depth estimation models is hard to provide accurate depth. Thus, to enhance the generalization to inaccurate depth when ground truth depth is missing, we perturb depth inputs during training. During inference, we employ a rapid multi-view to 3D reconstruction approach, NeuS, to obtain coarse depth for the depth-truncated epipolar attention. Our model enables better pixel alignment across multi-view images. Moreover, we demonstrate the efficacy of our approach in improving downstream multi-view to 3D reconstruction tasks.
Summary
提出一种新的像素级图像到多视图生成方法,通过在潜在视频扩散模型的VAE解码器中引入深度截断视差注意力层,实现更好的像素对齐。
Key Takeaways
- 使用文本到图像的潜在扩散模型进行多视图生成。
- 以前的方法仅微调U-Net,但导致像素级错位。
- 提出结合多视图图像的VAE解码器中的注意力层。
- 引入深度截断视差注意力,提高空间邻近区域对齐。
- 针对难以获取真实深度的问题,通过扰动输入深度来提高泛化能力。
- 使用NeuS快速多视图到3D重建方法获得粗略深度。
- 模型改善像素对齐,提升下游3D重建任务。
Title: 基于深度引导解码器的像素对齐多视图生成
2. Authors: Zhenggang Tang, Peiye Zhuang, Chaoyang Wang, Aliaksandr Siarohin, Yash Kant, Alexander Schwing, Sergey Tulyakov, Hsin-Ying Lee
3. Affiliation: University of Illinois Urbana-Champaign, Snap Inc., University of Toronto
4. Keywords: Image-to-multi-view generation, VAE decoder, Depth-guided, Epipolar attention, Multi-view to 3D reconstruction
5. Urls: https://arxiv.org/abs/2408.14016v1 or Github: None
6. Summary:
- (1):该文章的研究背景是多视图生成任务,即从单张图像生成新的视图。
- (2):过去的方法通常通过扩展文本到图像的潜在扩散模型到多视图版本来实现,这包括VAE图像编码器和U-Net扩散模型。然而,这些方法在像素级别上存在对齐问题,因为潜在向量的显著下采样和独立解码导致了多个视图之间的像素级对齐错误。该文章提出的方法解决了这一动机。
- (3):该文章提出了一种改进的VAE解码器,其中包含跨多个视图图像的注意力层。具体来说,引入了一种深度截断共线注意力机制,使模型能够关注空间相邻区域,同时保持内存效率。为了解决推理过程中深度信息缺失的问题,文章提出在训练期间对深度输入进行扰动,并在推理期间使用NeuS方法获得粗略深度信息。
- (4):该方法在多视图到3D重建任务中提高了下游性能,表明了其在像素对齐和多视图生成任务中的有效性。Methods:
(1): 提出了一种基于深度引导解码器的多视图生成方法,该方法针对像素对齐问题进行了改进。
(2): 设计了一种改进的变分自动编码器(VAE)解码器,其中包含跨多个视图图像的注意力层,即深度截断共线注意力机制。
(3): 为了解决深度信息缺失问题,在训练期间对深度输入进行扰动,并在推理期间使用NeuS方法获得粗略深度信息。
(4): 在推理过程中,模型能够关注空间相邻区域,同时保持内存效率,从而提高像素对齐的准确性。
(5): 通过在多视图到3D重建任务中的应用,验证了该方法在像素对齐和多视图生成任务中的有效性。
Conclusion:
- (1):该研究工作的重要性在于提出了一种针对像素对齐问题的多视图生成方法,该方法通过改进VAE解码器和引入深度截断共线注意力机制,有效解决了传统方法中存在的像素对齐误差问题,为3D生成任务提供了更精确的多视图图像作为辅助表示。 - (2):Innovation point: 创新点在于提出了基于深度引导解码器的新方法,通过引入深度截断共线注意力机制和扰动深度输入技术,实现了像素级别的多视图图像对齐;Performance: 性能方面,该方法在多视图到3D重建任务中表现优异,验证了其在像素对齐和多视图生成任务中的有效性;Workload: 工作负载方面,虽然该方法在训练和推理过程中引入了一些额外的计算复杂度,但其高效的注意力机制和深度信息处理技术使得整体计算负担相对较低。
点此查看论文截图

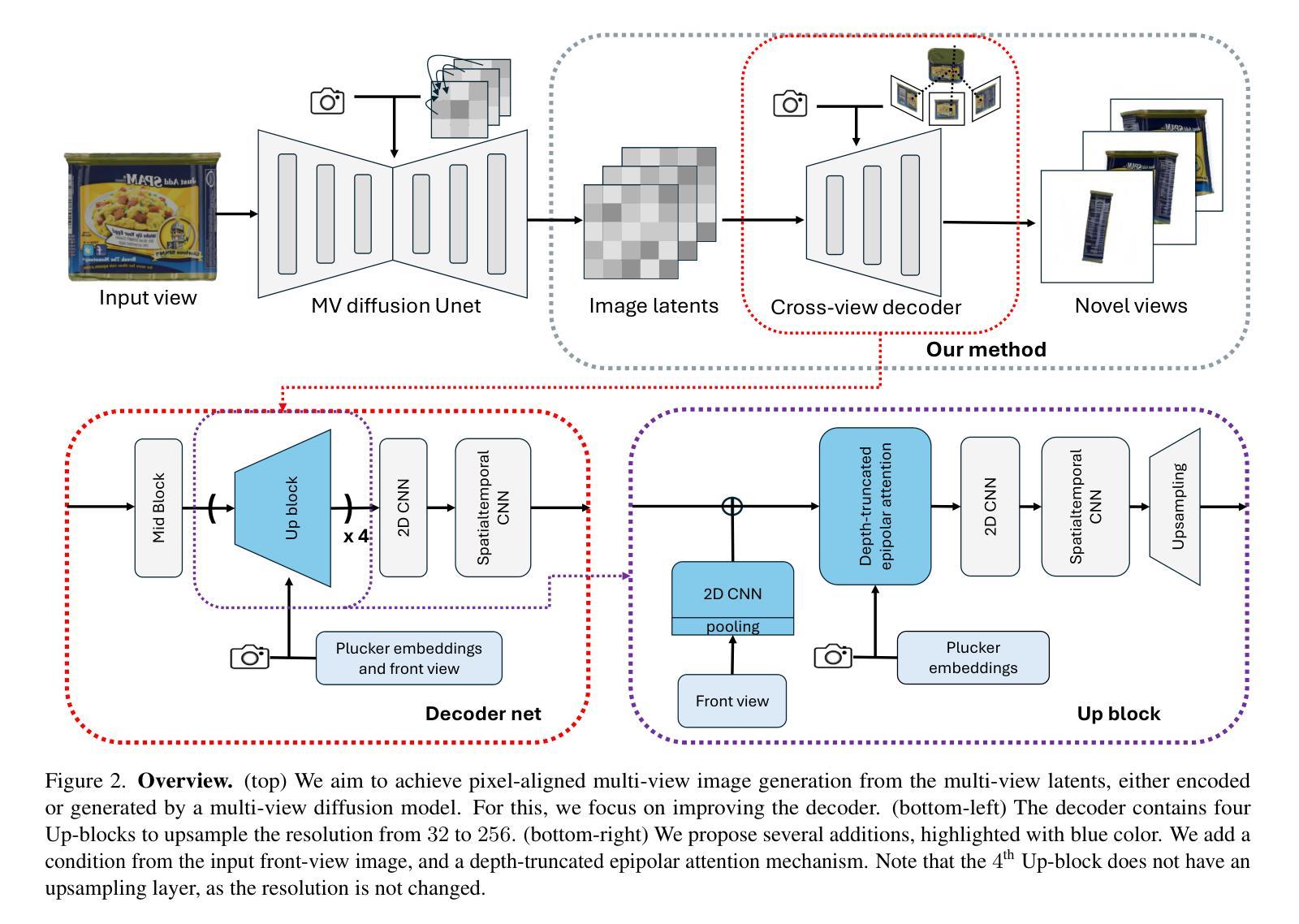


Particle-Filtering-based Latent Diffusion for Inverse Problems
Authors:Amir Nazemi, Mohammad Hadi Sepanj, Nicholas Pellegrino, Chris Czarnecki, Paul Fieguth
Current strategies for solving image-based inverse problems apply latent diffusion models to perform posterior sampling.However, almost all approaches make no explicit attempt to explore the solution space, instead drawing only a single sample from a Gaussian distribution from which to generate their solution. In this paper, we introduce a particle-filtering-based framework for a nonlinear exploration of the solution space in the initial stages of reverse SDE methods. Our proposed particle-filtering-based latent diffusion (PFLD) method and proposed problem formulation and framework can be applied to any diffusion-based solution for linear or nonlinear inverse problems. Our experimental results show that PFLD outperforms the SoTA solver PSLD on the FFHQ-1K and ImageNet-1K datasets on inverse problem tasks of super resolution, Gaussian debluring and inpainting.
PDF Mohammad Hadi Sepanj, Nicholas Pellegrino, and Chris Czarnecki contributed equally
Summary
提出基于粒子滤波的非线性探索解空间框架,在图像逆问题求解中超越现有方法。
Key Takeaways
- 当前图像逆问题求解采用潜在扩散模型进行后验采样。
- 大多数方法未显式探索解空间,仅从高斯分布中抽取单一样本。
- 本文提出粒子滤波框架,探索非线性解空间。
- PFLD方法适用于线性或非线性逆问题求解。
- PFLD在FFHQ-1K和ImageNet-1K数据集上超越现有方法PSLD。
- 实验结果证明PFLD在超分辨率、高斯去模糊和修复任务中表现优异。
- PFLD框架可扩展应用于更多图像逆问题。
Title: 基于粒子滤波的潜在扩散模型在逆问题中的应用 (Particle-Filtering-based Latent Diffusion for Inverse Problems)
Authors: Amir Nazemi, Mohammad Hadi Sepanj, Nicholas Pellegrino, Chris Czarnecki, Paul Fieguth
Affiliation: 加拿大滑铁卢大学系统工程系视觉与图像处理实验室
Keywords: 粒子滤波,潜在扩散模型,逆问题,图像超分辨率,高斯去模糊,图像修复
Urls: Paper , [Github:None]
Summary:
(1):本文的研究背景是图像逆问题求解,当前方法主要利用潜在扩散模型进行后验采样,但普遍缺乏对解空间的探索。
(2):过去的方法包括基于生成模型的方法,如扩散模型(DPS, PSLD, Soft Diffusion等)。这些方法虽然性能出色,但实际应用中鲁棒性不足,对初始化敏感,且未明确探索解空间。
(3):本文提出了一种基于粒子滤波的潜在扩散(PFLD)方法,用于在逆问题的求解过程中对解空间进行非线性探索。该方法结合了粒子滤波和潜在扩散模型,通过多个随机样本在潜在空间中进行迭代,以更好地探索解空间。
(4):PFLD在FFHQ-1K和ImageNet-1K数据集上,在超分辨率、高斯去模糊和图像修复等逆问题任务上,性能优于当前最先进的方法PSLD。这表明PFLD能够有效地提高逆问题求解的鲁棒性和质量,支持其研究目标。
Methods:
- (1): 采用粒子滤波(Particle Filtering,PF)技术,以解决图像逆问题中的不确定性问题。
- (2): 将潜在扩散模型(Latent Diffusion Model,LDM)与粒子滤波结合,形成潜在扩散粒子滤波(Particle-Filtering-based Latent Diffusion,PFLD)方法。
- (3): 使用Cauchy概率分布函数来建模似然概率密度函数(PDF),其中κ参数设置为1,使得PDF与测量值y与模型输出之间的L2距离成比例。
- (4): 通过更新权重来优化粒子滤波过程,权重更新公式基于最优重要采样,其中q(zt-1|zt, y)与p(zt-1|zt)成正比。
- (5): 使用更新后的权重来评估粒子的重要性,并根据重要性对粒子进行采样,从而在潜在空间中进行迭代,探索解空间。
- (6): 在FFHQ-1K和ImageNet-1K数据集上,通过超分辨率、高斯去模糊和图像修复等任务来评估PFLD的性能,并与PSLD等方法进行比较。
Conclusion:
- (1): 这项工作的意义在于提出了基于粒子滤波的潜在扩散模型(PFLD)在图像逆问题中的应用,该方法能够有效提高逆问题求解的鲁棒性和性能,特别是在超分辨率、高斯去模糊和图像修复等任务上表现出色。 - (2): Innovation point: PFLD结合了粒子滤波和潜在扩散模型,实现了对解空间的有效探索;Performance: 在FFHQ-1K和ImageNet-1K数据集上,PFLD在多个逆问题任务上优于PSLD等现有方法;Workload: 与PSLD相比,PFLD在保持高效的同时,显著减少了重复运行所需的时间。
点此查看论文截图
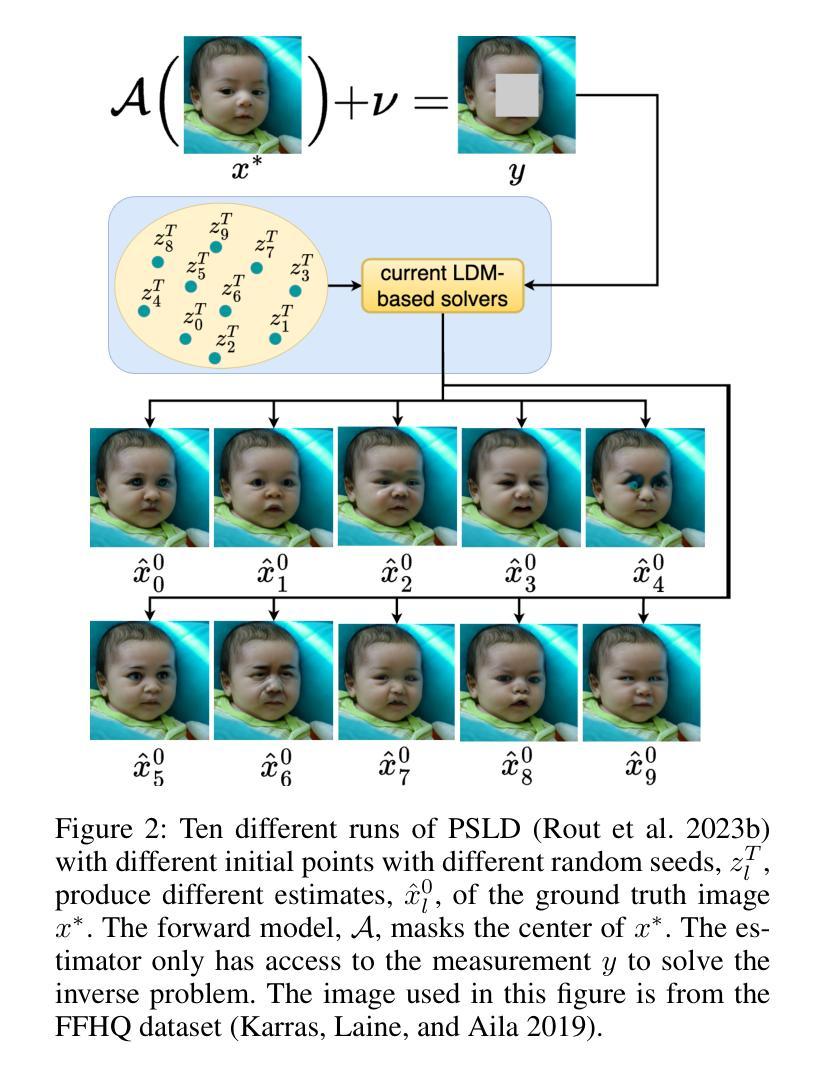



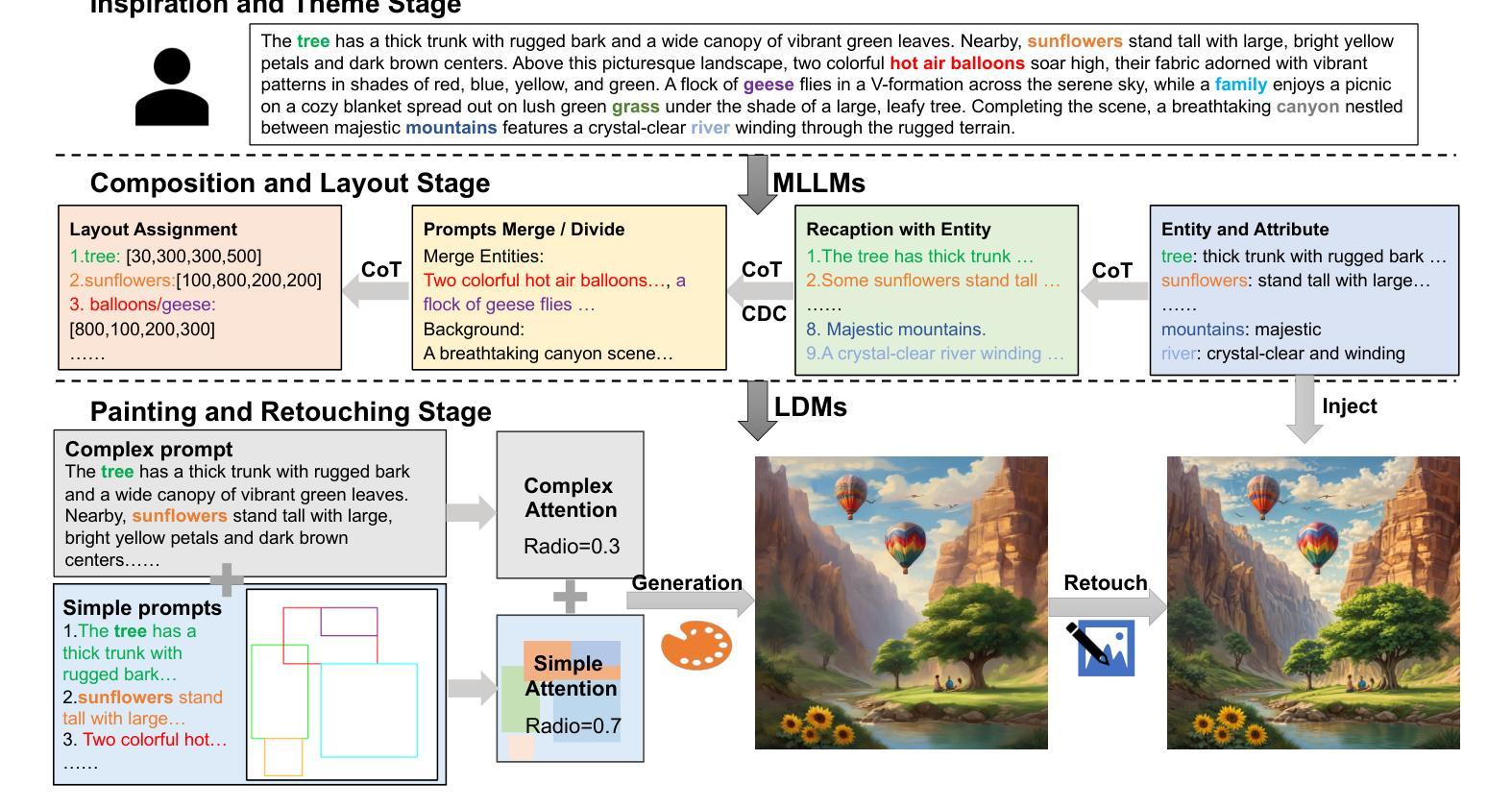
Draw Like an Artist: Complex Scene Generation with Diffusion Model via Composition, Painting, and Retouching
Authors:Minghao Liu, Le Zhang, Yingjie Tian, Xiaochao Qu, Luoqi Liu, Ting Liu
Recent advances in text-to-image diffusion models have demonstrated impressive capabilities in image quality. However, complex scene generation remains relatively unexplored, and even the definition of `complex scene’ itself remains unclear. In this paper, we address this gap by providing a precise definition of complex scenes and introducing a set of Complex Decomposition Criteria (CDC) based on this definition. Inspired by the artists painting process, we propose a training-free diffusion framework called Complex Diffusion (CxD), which divides the process into three stages: composition, painting, and retouching. Our method leverages the powerful chain-of-thought capabilities of large language models (LLMs) to decompose complex prompts based on CDC and to manage composition and layout. We then develop an attention modulation method that guides simple prompts to specific regions to complete the complex scene painting. Finally, we inject the detailed output of the LLM into a retouching model to enhance the image details, thus implementing the retouching stage. Extensive experiments demonstrate that our method outperforms previous SOTA approaches, significantly improving the generation of high-quality, semantically consistent, and visually diverse images for complex scenes, even with intricate prompts.
Summary
该论文提出了一种名为Complex Diffusion的文本到复杂场景图像生成框架,显著提升了图像质量。
Key Takeaways
- 文本到图像扩散模型在复杂场景生成方面仍有待探索。
- 定义了复杂场景并提供了一套复杂分解标准(CDC)。
- 提出了无训练的Complex Diffusion框架,包含构图、绘画和修图三个阶段。
- 利用大语言模型(LLM)的链式思维能力进行复杂提示分解。
- 开发注意力调节方法,引导简单提示到特定区域完成复杂场景绘画。
- 将LLM的详细输出注入修图模型,增强图像细节。
- 实验证明该方法优于现有SOTA方法,显著提升了复杂场景图像生成质量。
Title: Draw Like an Artist: Complex Scene Generation with Diffusion Model via Composition, Painting, and Retouching
(中文翻译:通过构图、绘画和修图,利用扩散模型进行复杂场景生成)Authors: Minghao Liu, Le Zhang, Yingjie Tian, Xiaochao Qu, Luoqi Liu, Ting Liu
Affiliation: University of Chinese Academy of Sciences, Beijing, China; MT Lab, Meitu Inc., Beijing, China
Keywords: Complex scene generation, Diffusion model, Large language model, Composition, Painting, Retouching
Urls: arXiv:2408.13858v1 [cs.CV], Github: None
Summary:
(1):研究背景为近年来文本到图像扩散模型在图像质量上的显著进展,但复杂场景生成仍然相对未探索,对“复杂场景”的定义也尚不明确。
(2):过去的方法包括将布局或框整合到合成过程中,以提高复杂场景中物体关系的连贯性,以及使用注意力引导来改进构图文本到图像合成。然而,这些方法在处理高度复杂的场景提示时存在差距,且“复杂场景”的定义仍然模糊。本文的方法基于艺术家绘画过程的灵感,具有较好的动机。
(3):本文提出了一种名为Complex Diffusion (CxD) 的无监督扩散框架,将复杂场景生成过程分为三个阶段:构图、绘画和修图。该方法利用大型语言模型(LLMs)的强大思维链能力,根据复杂分解标准(CDC)分解复杂提示,并管理构图和布局。
(4):在复杂场景生成任务上,本文的方法显著提高了高质量、语义一致且视觉多样化的图像生成能力,即使在复杂的提示下也是如此,这支持了他们的目标。
Conclusion:
- (1):这项工作的意义在于,它为复杂场景的生成提供了一种创新的解决方案,通过模仿艺术家绘画过程,有效提升了图像生成的质量、语义一致性和视觉多样性。 - (2):Innovation point: 该文创新性地提出了Complex Diffusion (CxD) 框架,将复杂场景生成过程细分为构图、绘画和修图三个阶段,并结合了大型语言模型(LLMs)的能力,为复杂场景提示的处理提供了新的思路;Performance: 在复杂场景生成任务上,CxD框架显著提高了图像生成的质量和多样性;Workload: 相较于现有方法,CxD框架在处理复杂场景提示时可能需要更多的计算资源和时间。
点此查看论文截图

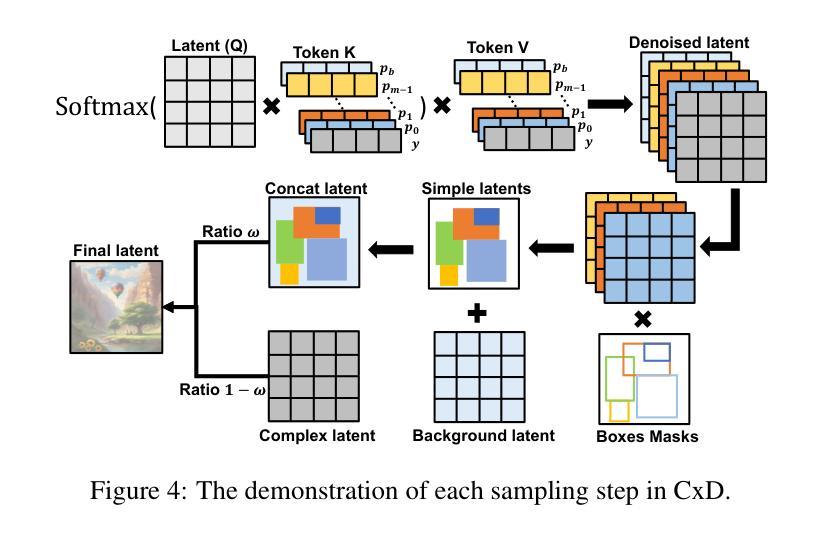


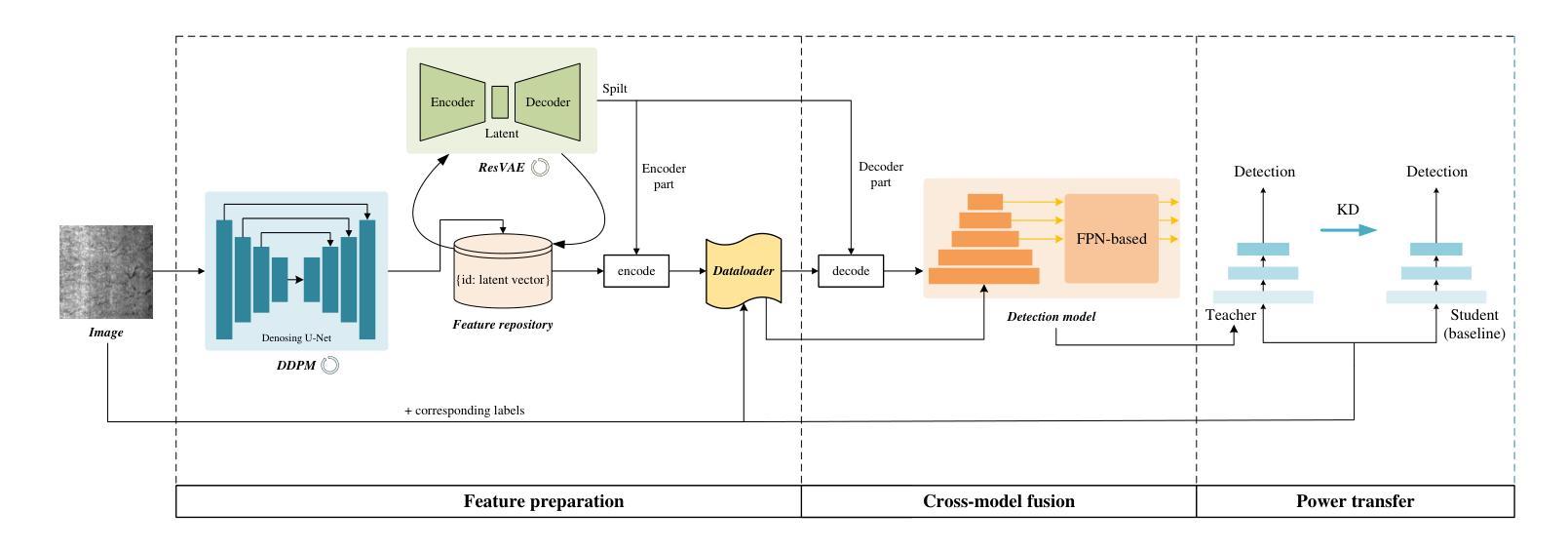
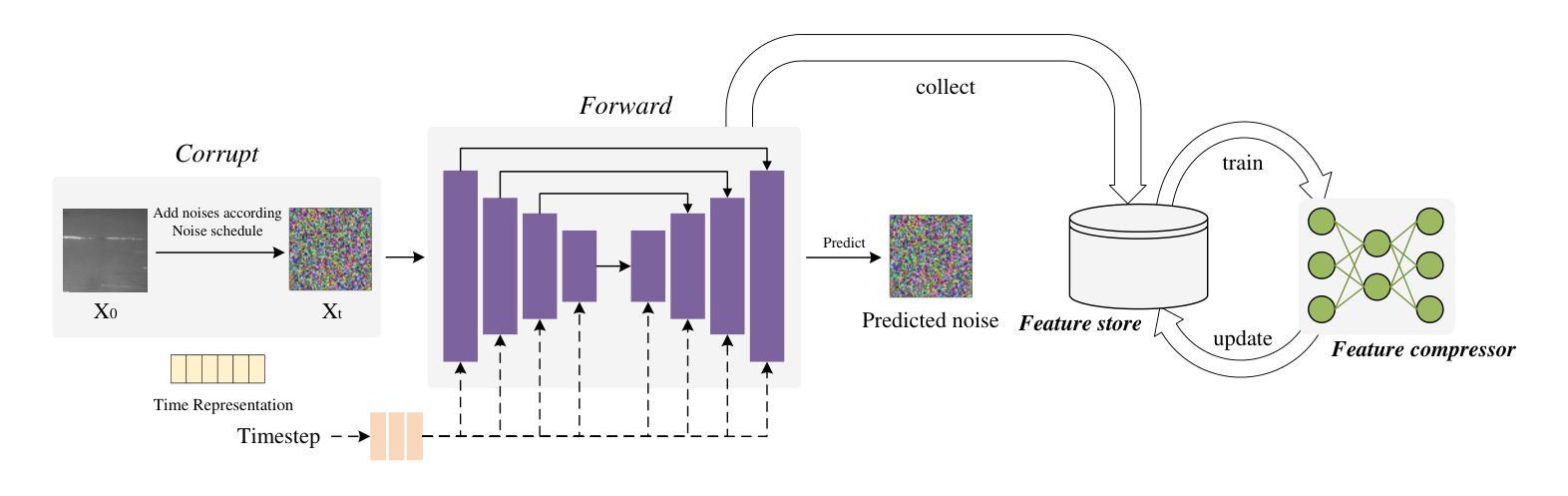
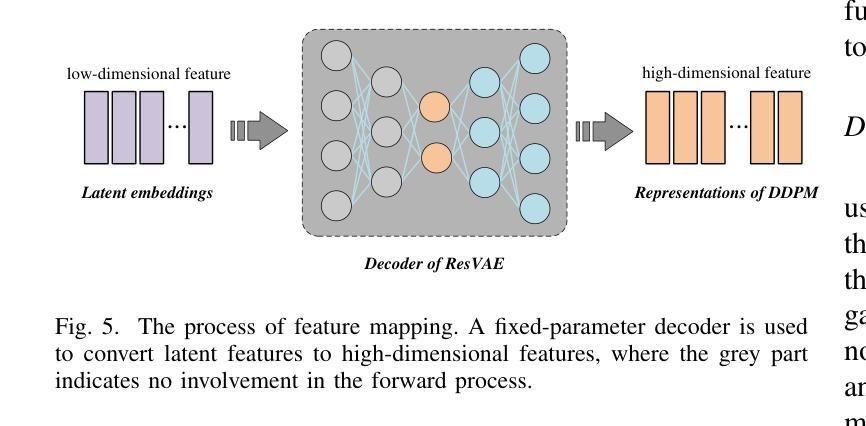
Bring the Power of Diffusion Model to Defect Detection
Authors:Xuyi Yu
Due to the high complexity and technical requirements of industrial production processes, surface defects will inevitably appear, which seriously affects the quality of products. Although existing lightweight detection networks are highly efficient, they are susceptible to false or missed detection of non-salient defects due to the lack of semantic information. In contrast, the diffusion model can generate higher-order semantic representations in the denoising process. Therefore, the aim of this paper is to incorporate the higher-order modelling capability of the diffusion model into the detection model, so as to better assist in the classification and localization of difficult targets. First, the denoising diffusion probabilistic model (DDPM) is pre-trained to extract the features of denoising process to construct as a feature repository. In particular, to avoid the potential bottleneck of memory caused by the dataloader loading high-dimensional features, a residual convolutional variational auto-encoder (ResVAE) is designed to further compress the feature repository. The image is fed into both image backbone and feature repository for feature extraction and querying respectively. The queried latent features are reconstructed and filtered to obtain high-dimensional DDPM features. A dynamic cross-fusion method is proposed to fully refine the contextual features of DDPM to optimize the detection model. Finally, we employ knowledge distillation to migrate the higher-order modelling capabilities back into the lightweight baseline model without additional efficiency cost. Experiment results demonstrate that our method achieves competitive results on several industrial datasets.
Summary
利用扩散模型的高级建模能力提升轻量级检测网络对工业缺陷的检测精度。
Key Takeaways
- 工业生产中表面缺陷影响产品质量。
- 轻量级检测网络效率高,但易误检或漏检。
- 扩散模型能生成高级语义表示。
- 研究旨在将扩散模型融入检测模型。
- 使用DDPM预训练提取去噪过程特征。
- 设计ResVAE压缩特征库以避免内存瓶颈。
- 图像分别通过图像主干和特征库进行特征提取。
- 提出动态交叉融合方法优化检测模型。
- 应用知识蒸馏提升轻量级模型能力。
- 方法在多个工业数据集上表现优异。
Title: D3N: Bring the Power of Diffusion Model to Defect Detection
(中文翻译:D3N:将扩散模型的强大功能应用于缺陷检测)Authors: Xuyi Yu
Affiliation: Institute of Artificial Intelligence and Robotics, Xi’an Jiaotong University, Xi’an, China
Keywords: defect detection, semantic information, DDPM, feature repository, knowledge distillation
Urls: IEEE TRANSACTIONS, Github: None
Summary:
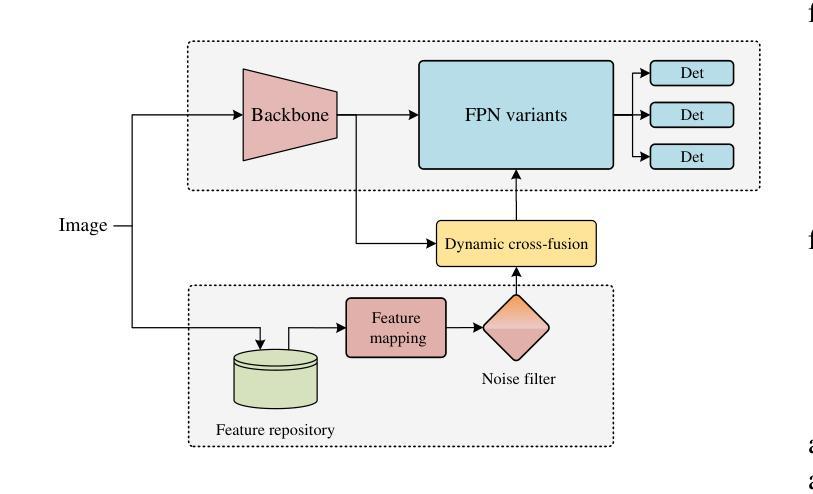
- (1):该文的研究背景是工业生产过程中,由于工艺复杂和技术要求高,表面缺陷不可避免地会出现,这严重影响了产品的质量。尽管现有的轻量级检测网络效率很高,但由于缺乏语义信息,它们容易对非显著缺陷产生误检或漏检。 - (2):过去的方法包括从大规模模型中蒸馏小模型,但这些方法需要大型的教师模型,且由于教师和学生模型维度之间的差异,存在语义差距,难以让学生模型学习到教师模型的所有知识。此外,扩散模型在去噪过程中的中间激活具有高阶语义表示,可以提供有价值的信息,但现有方法需要执行完整的扩散过程,速度不理想。 - (3):本文提出的方法包括预训练去噪扩散概率模型(DDPM)以提取去噪过程中的特征,构建特征库;设计残差卷积变分自编码器(ResVAE)进一步压缩特征库;将图像输入图像骨干和特征库进行特征提取和查询;提出动态交叉融合方法以优化检测模型;最后,使用知识蒸馏将高阶建模能力迁移回轻量级基线模型。 - (4):在多个工业数据集上进行的实验表明,该方法取得了具有竞争力的结果,支持了其目标。Methods:
(1): 预训练去噪扩散概率模型(DDPM)以提取去噪过程中的特征,构建特征库;
(2): 设计残差卷积变分自编码器(ResVAE)进一步压缩特征库;
(3): 将图像输入图像骨干和特征库进行特征提取和查询;
(4): 提出动态交叉融合方法以优化检测模型;
(5): 使用知识蒸馏将高阶建模能力迁移回轻量级基线模型;
(6): 在多个工业数据集上进行实验验证,评估模型性能。
Conclusion:
- (1):该研究具有重要的意义,因为它为缺陷检测领域提供了一种新的思路,即利用扩散模型的高阶建模能力来识别难以检测的目标,从而提高了检测的准确性和鲁棒性。 - (2):Innovation point: 本文创新性地将扩散模型应用于缺陷检测,并提出了基于预训练的DDPM和特征库的构建方法,为轻量级检测网络提供了语义信息,提高了检测精度;Performance: 实验结果表明,该方法在多个工业数据集上取得了具有竞争力的结果,证明了其在性能上的优势;Workload: 虽然该方法在性能上有所提升,但预训练DDPM和特征库的构建过程需要大量的计算资源,增加了模型的工作量。
点此查看论文截图

3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing
Authors:Shichao Dong, Ze Yang, Guosheng Lin
Data augmentation plays a crucial role in deep learning, enhancing the generalization and robustness of learning-based models. Standard approaches involve simple transformations like rotations and flips for generating extra data. However, these augmentations are limited by their initial dataset, lacking high-level diversity. Recently, large models such as language models and diffusion models have shown exceptional capabilities in perception and content generation. In this work, we propose a new paradigm to automatically generate 3D labeled training data by harnessing the power of pretrained large foundation models. For each target semantic class, we first generate 2D images of a single object in various structure and appearance via diffusion models and chatGPT generated text prompts. Beyond texture augmentation, we propose a method to automatically alter the shape of objects within 2D images. Subsequently, we transform these augmented images into 3D objects and construct virtual scenes by random composition. This method can automatically produce a substantial amount of 3D scene data without the need of real data, providing significant benefits in addressing few-shot learning challenges and mitigating long-tailed class imbalances. By providing a flexible augmentation approach, our work contributes to enhancing 3D data diversity and advancing model capabilities in scene understanding tasks.
Summary
利用预训练大模型自动生成3D训练数据,提升3D数据多样性和模型场景理解能力。
Key Takeaways
- 数据增强在深度学习中至关重要,增强模型泛化能力和鲁棒性。
- 标准增强方法有限,缺乏高级多样性。
- 大型模型在感知和内容生成中表现出色。
- 提出一种利用预训练模型自动生成3D训练数据的新方法。
- 使用扩散模型和文本提示生成2D图像。
- 自动改变2D图像中物体的形状。
- 将增强图像转换为3D对象,构建虚拟场景。
- 无需真实数据,自动生成大量3D场景数据。
- 帮助解决小样本学习和长尾类别不平衡问题。
- 提高模型在场景理解任务中的能力。
Title: 3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing (利用生成扩散模型和可控编辑进行合成3D数据增强)
Authors: Shichao Dong, Ze Yang, Guosheng Lin
Affiliation: S-lab, Nanyang Technological University, Singapore; College of Computing and Data Science, Nanyang Technological University, Singapore
Keywords: 3D数据增强,生成扩散模型,可控编辑,数据多样性,场景理解
Urls: arXiv:2408.13788v1 [cs.CV], Github: None
Summary:
(1):该文章的研究背景是3D数据增强在深度学习中的应用,特别是在解决数据不平衡和样本稀疏问题上的挑战。
(2):过去的方法包括简单的数据增强技术,如旋转和翻转,但这些方法受限于初始数据集的多样性。文章提出的方案旨在解决这些问题,并利用预训练的大型基础模型来生成高质量的增强数据。
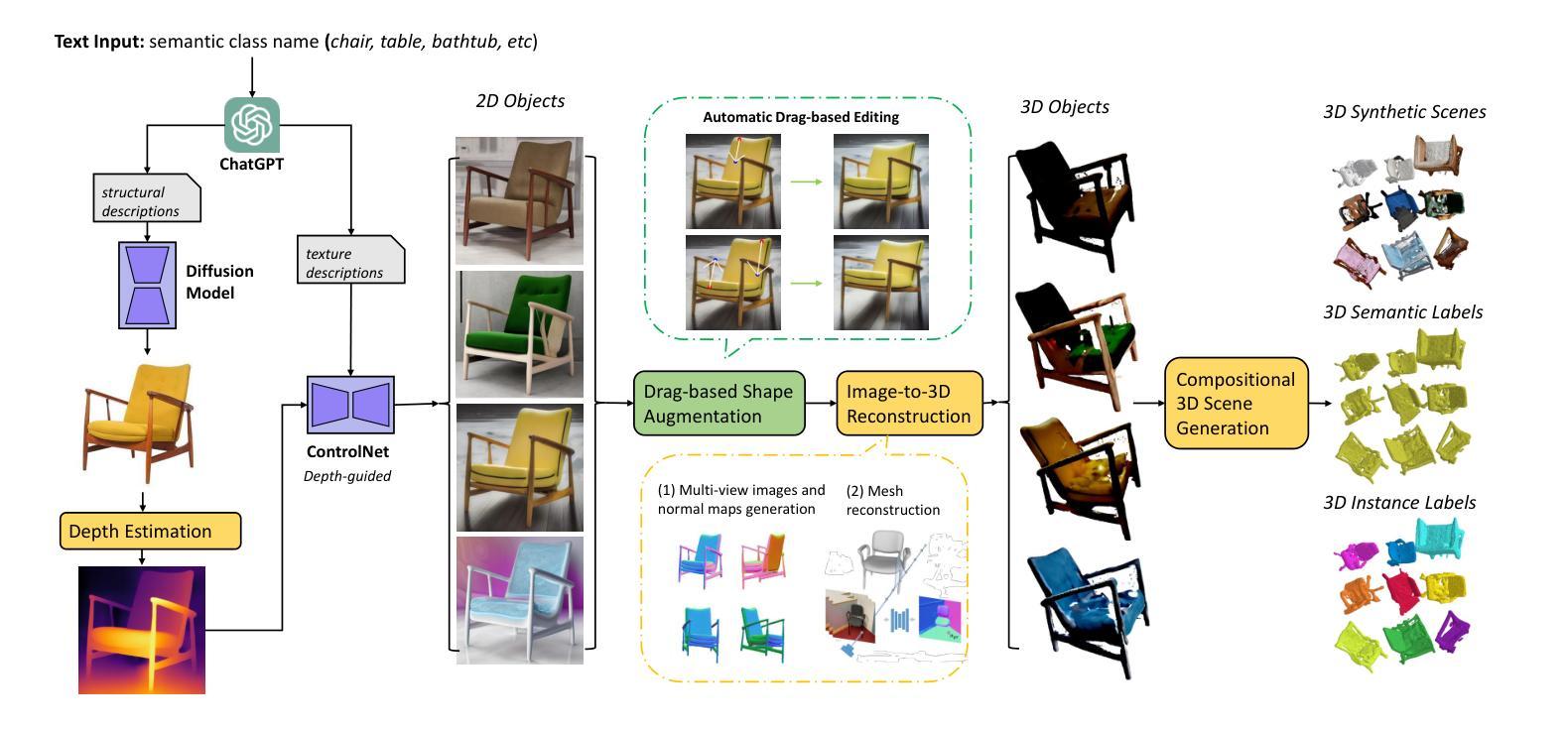
(3):文章提出的方法包括使用扩散模型和聊天机器人生成的文本提示来生成各种结构和外观的单个物体的2D图像,然后通过自动改变物体的形状来增强纹理,并将这些图像转换为3D对象,随机组合成虚拟场景。
(4):该方法在ScanNet-v2数据集上的3D语义分割任务中取得了显著的性能提升,表明其能够有效地提高模型对未见数据的泛化能力和减少过拟合的风险,支持其提高模型性能的目标。
Methods:
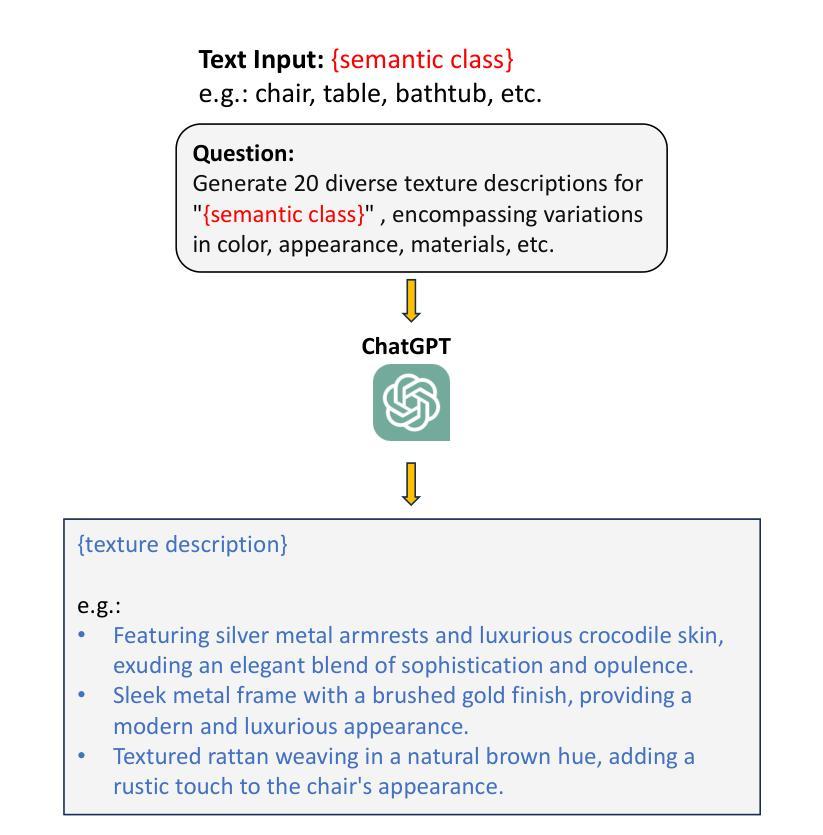
(1): 首先,利用扩散模型和ChatGPT生成的文本提示,生成单个物体的多样化2D图像。
(2):在2D图像中自动调整物体的形状,以增强纹理。
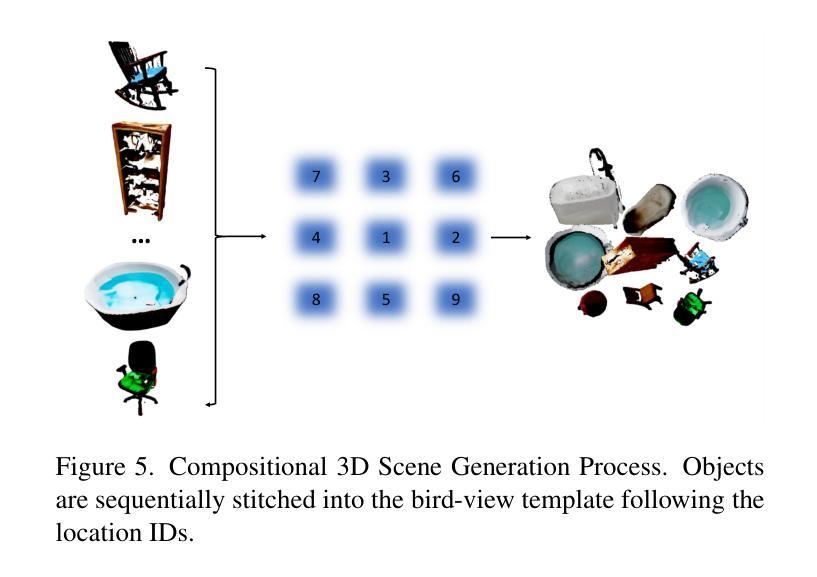
(3):将增强后的2D图像转换为3D对象,并将其随机组合成虚拟场景。
(4):利用ChatGPT生成语义和实例标签,为下游任务训练提供便利。
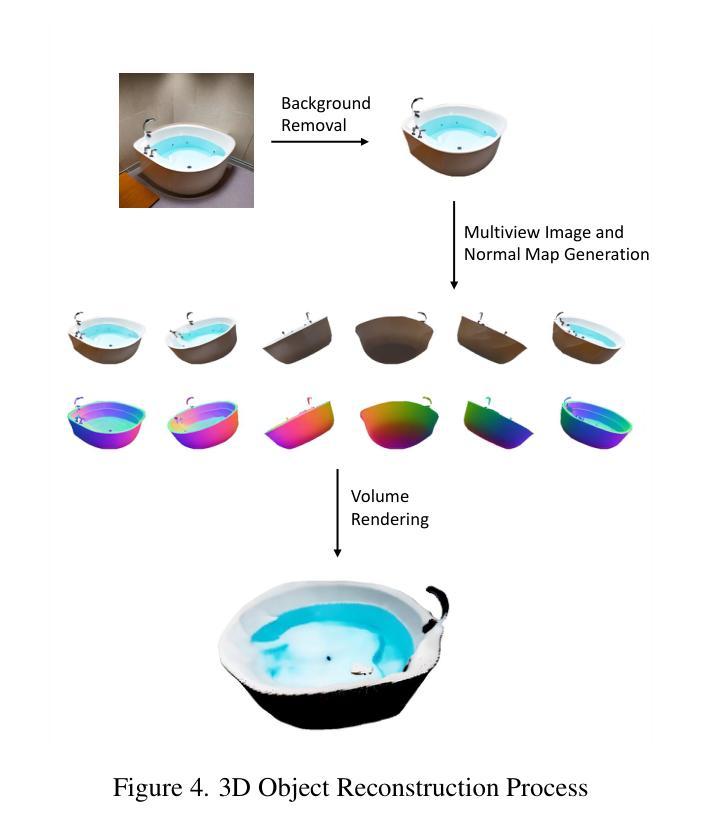
(5):使用预训练的深度学习模型Depth Anything进行多视图图像和法线图生成。
(6):通过体积渲染实现3D对象重建。
(7):采用DragGAN和DragDiffusion等生成模型进行形状交互式控制。
(8):引入低秩自适应(LoRA)模型进行快速微调。
(9):随机选择对象上的点作为种子点,以进行形状调整。
(10):选择随机方向并确定变形方向,然后选择目标点。
(11):根据高斯正态分布和两个关键参数(均值µ和方差σ²)控制形状增强的程度。
(12):将生成的2D图像转换为3D几何信息。
Conclusion:
(1):该研究工作的意义在于提出了一种基于生成扩散模型和可控编辑的合成3D数据增强方法,有效解决了3D场景理解任务中训练数据不足的问题,为3D数据增强和虚拟数据生成提供了新的思路和方法。
(2): Innovation point: 该方法在创新点上,首先利用扩散模型和ChatGPT生成多样化2D图像,结合自动形状调整和3D对象生成技术,实现了对3D场景的合成增强;Performance: 在性能上,该方法在ScanNet-v2数据集上的3D语义分割任务中取得了显著的性能提升,证明了其有效性;Workload: 在工作负载上,该方法虽然需要一定的计算资源,但通过引入LoRA模型和形状交互式控制技术,实现了对模型微调和形状调整的快速实现。
点此查看论文截图


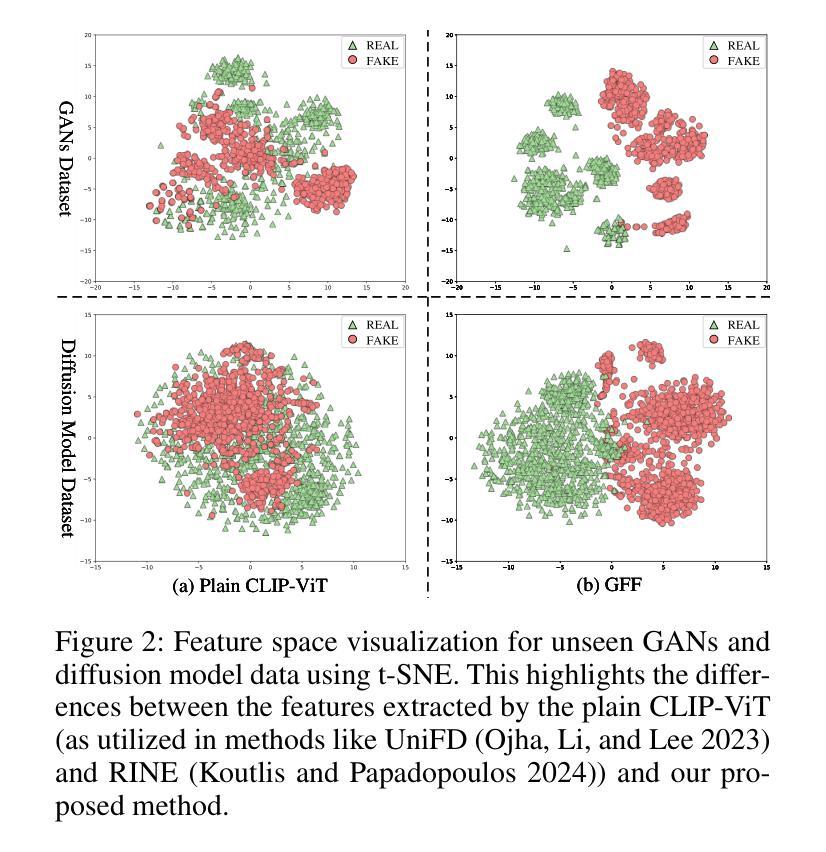
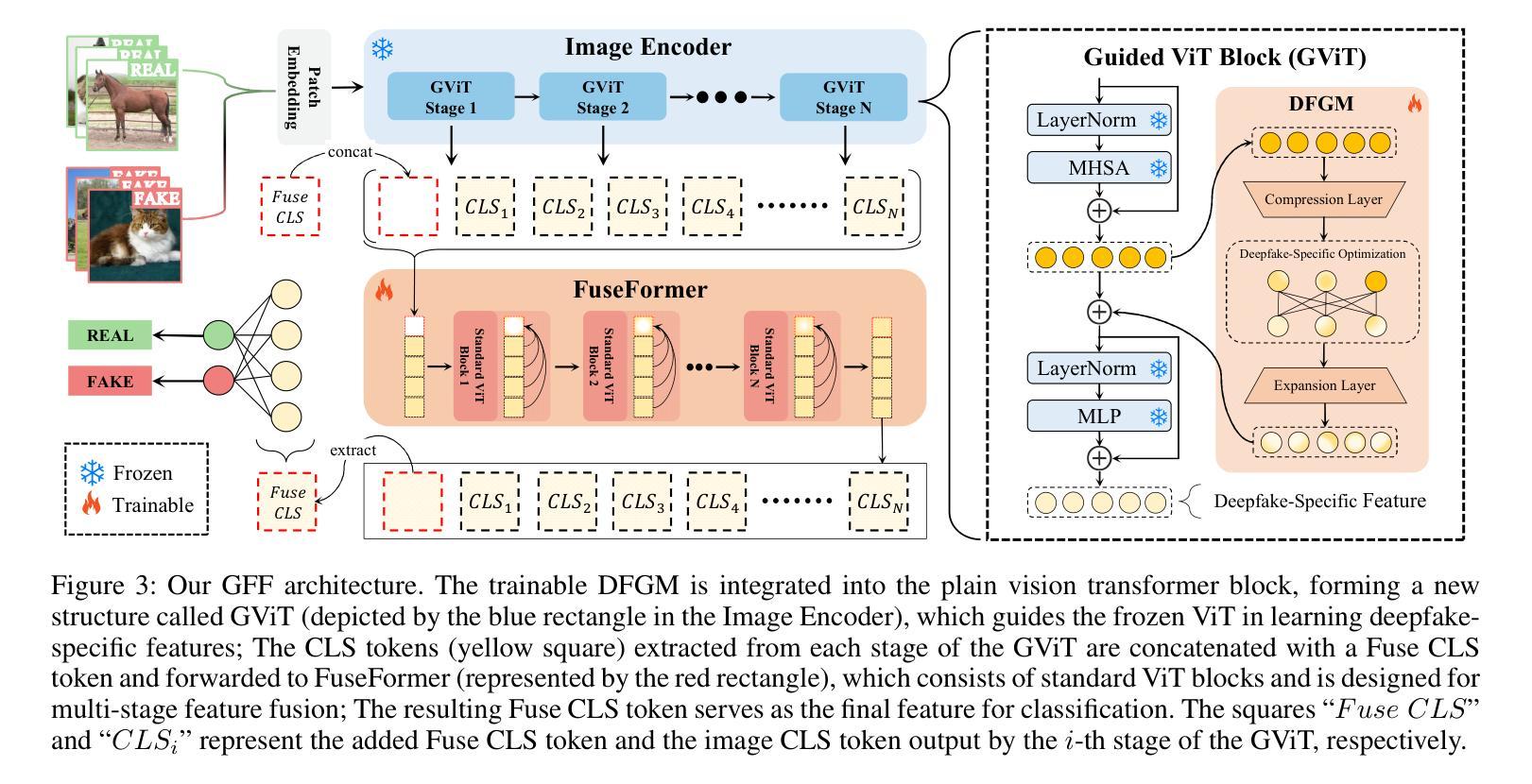
Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection
Authors:Yingjian Chen, Lei Zhang, Yakun Niu, Pei Chen, Lei Tan, Jing Zhou
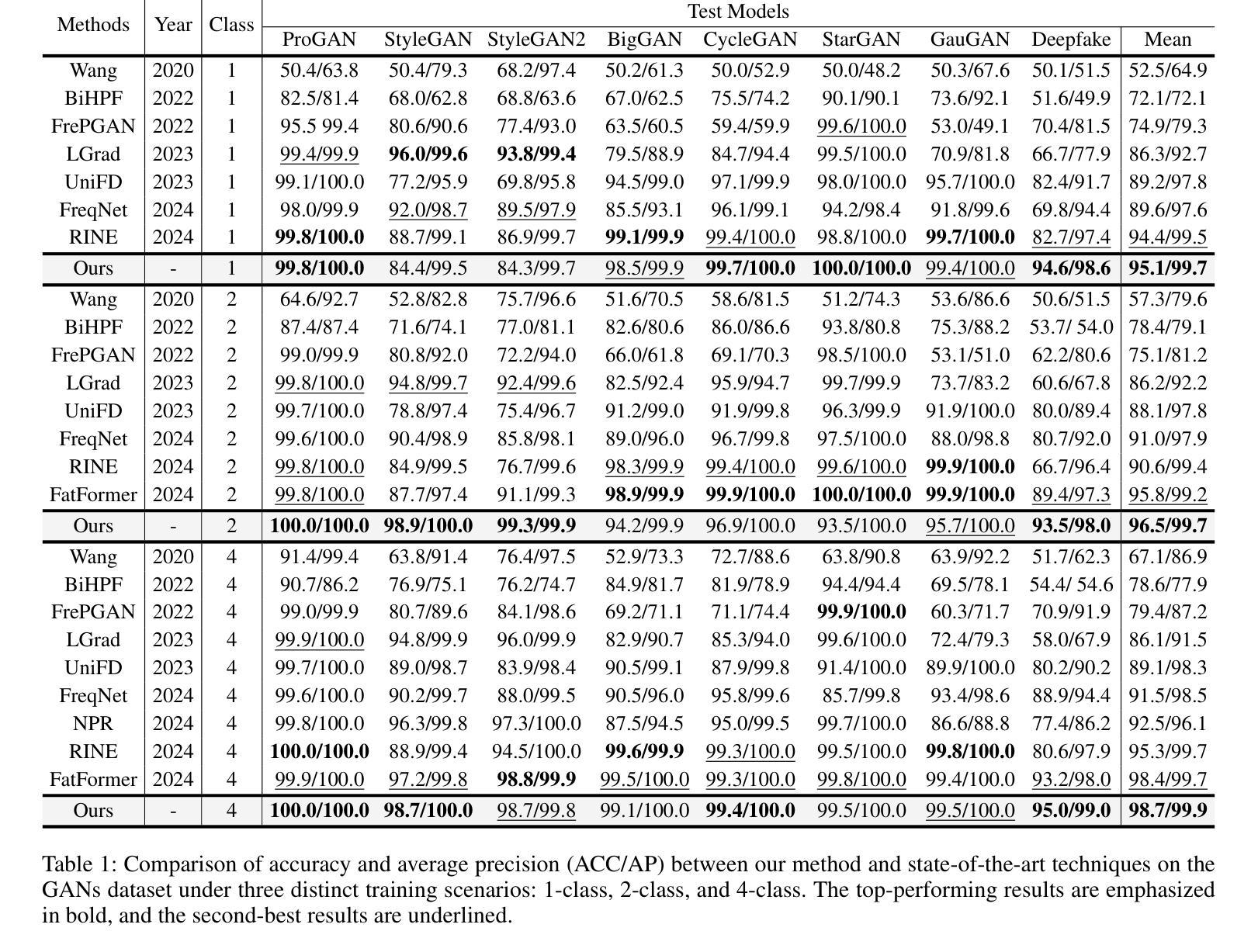
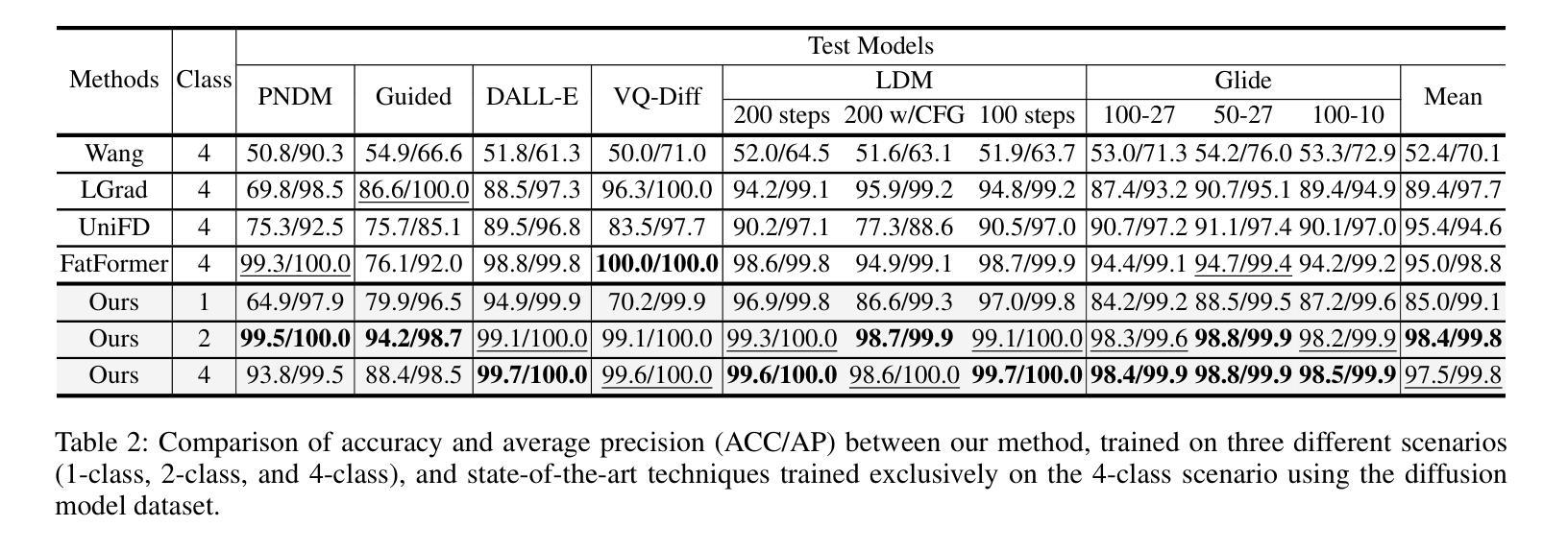
The rise of generative models has sparked concerns about image authenticity online, highlighting the urgent need for an effective and general detector. Recent methods leveraging the frozen pre-trained CLIP-ViT model have made great progress in deepfake detection. However, these models often rely on visual-general features directly extracted by the frozen network, which contain excessive information irrelevant to the task, resulting in limited detection performance. To address this limitation, in this paper, we propose an efficient Guided and Fused Frozen CLIP-ViT (GFF), which integrates two simple yet effective modules. The Deepfake-Specific Feature Guidance Module (DFGM) guides the frozen pre-trained model in extracting features specifically for deepfake detection, reducing irrelevant information while preserving its generalization capabilities. The Multi-Stage Fusion Module (FuseFormer) captures low-level and high-level information by fusing features extracted from each stage of the ViT. This dual-module approach significantly improves deepfake detection by fully leveraging CLIP-ViT’s inherent advantages. Extensive experiments demonstrate the effectiveness and generalization ability of GFF, which achieves state-of-the-art performance with optimal results in only 5 training epochs. Even when trained on only 4 classes of ProGAN, GFF achieves nearly 99% accuracy on unseen GANs and maintains an impressive 97% accuracy on unseen diffusion models.
Summary
提出GFF模型,通过特征引导和融合模块提升深度伪造检测性能。
Key Takeaways
- 生成模型兴起引发图像真实性担忧。
- CLIP-ViT模型在深度伪造检测中取得进展。
- 现有方法依赖与任务无关的视觉特征。
- GFF模型集成特征引导和融合模块。
- DFGM模块指导模型提取特定于深度伪造的特征。
- FuseFormer模块融合ViT各阶段特征。
- GFF在少量训练数据下实现最优性能。
Title: 指导与融合:高效冻结CLIP-ViT及其在深度伪造检测中的应用 (Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection)
Authors: Yingjian Chen, Lei Zhang, Yakun Niu, Pei Chen, Lei Tan, Jing Zhou
Affiliation: 河南大学大数据分析与处理河南省重点实验室 (Henan Key Laboratory of Big Data Analysis and Processing, Henan University)
Keywords: 深度伪造检测, 冻结预训练模型, CLIP-ViT, 特征引导, 特征融合
Urls: https://arxiv.org/abs/2408.13697v1 , Github: None
Summary:
(1):随着生成模型的发展,网络图像的真实性受到质疑,迫切需要有效的通用检测器。该文的研究背景是应对深度伪造检测的挑战。
(2):过去的方法,如基于冻结预训练的CLIP-ViT模型,在深度伪造检测中取得了进展。然而,这些模型通常依赖于冻结网络直接提取的视觉通用特征,其中包含与任务无关的大量信息,导致检测性能有限。本文的方法很好地解决了这一动机问题。
(3):本文提出了一种高效的指导与融合冻结CLIP-ViT(GFF)方法,该方法集成了两个简单而有效的模块。深度伪造特定特征引导模块(DFGM)引导冻结预训练模型提取特定于深度伪造检测的特征,减少无关信息同时保留其泛化能力。多阶段融合模块(FuseFormer)通过融合ViT每个阶段提取的特征来捕捉低级和高级信息。
(4):该方法在深度伪造检测任务上取得了最先进的性能,仅用5个训练周期就达到了最佳结果。即使在只有4个ProGAN类别的数据上训练,GFF在未见过的GANs上达到了近99%的准确率,在未见过的扩散模型上保持了97%的准确率,证明了其性能支持其目标。
Methods:
(1): 针对深度伪造检测的挑战,提出了一种名为GFF(Guided and Fused)的冻结CLIP-ViT模型。
(2): 设计了深度伪造特定特征引导模块(DFGM),该模块引导预训练模型提取与深度伪造检测相关的特征。
(3): 实现了多阶段融合模块(FuseFormer),通过融合不同阶段的特征来捕捉图像的细粒度信息。
(4): 将DFGM和FuseFormer集成到冻结CLIP-ViT中,以提升模型的检测性能。
(5): 在深度伪造检测数据集上进行实验,验证GFF的有效性。
(6): 通过与其他先进方法比较,证明GFF在检测性能上具有优越性。
Conclusion:
(1):该研究工作的重要性在于提出了一个名为GFF(Guided and Fused Frozen CLIP-ViT)的新型深度伪造检测模型,该模型在泛化图像检测任务上表现出色,为深度伪造检测领域提供了新的思路和方法。
(2):Innovation point: GFF模型通过引入深度伪造特定特征引导模块(DFGM)和多阶段融合模块(FuseFormer)实现了对预训练模型的有效利用和性能提升;Performance: 在深度伪造检测任务上取得了最先进的性能,证明了其在GANs和扩散模型数据集上的泛化能力;Workload: 模型结构简单,参数量小,训练周期短,具有良好的可扩展性。
点此查看论文截图

Prompt-Softbox-Prompt: A free-text Embedding Control for Image Editing
Authors:Yitong Yang, Yinglin Wang, Jing Wang, Tian Zhang
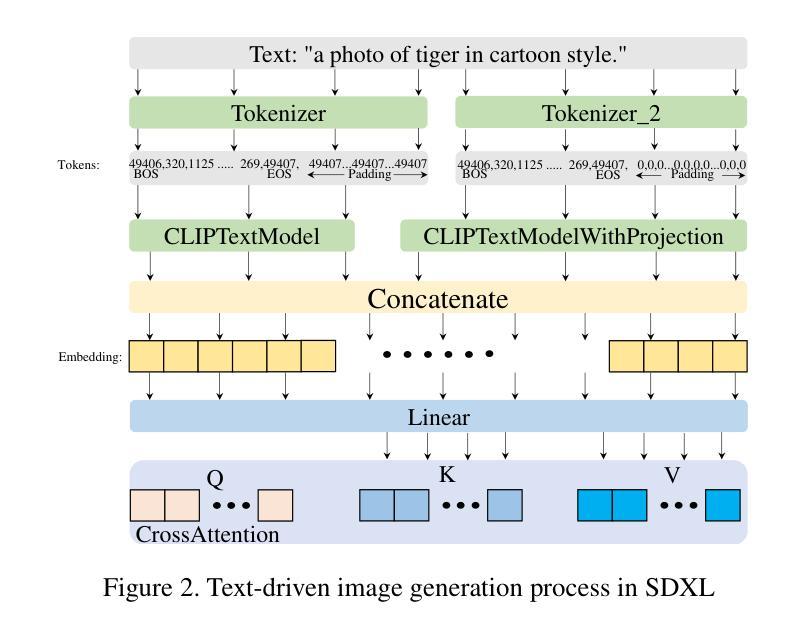
Text-driven diffusion models have achieved remarkable success in image editing, but a crucial component in these models-text embeddings-has not been fully explored. The entanglement and opacity of text embeddings present significant challenges to achieving precise image editing. In this paper, we provide a comprehensive and in-depth analysis of text embeddings in Stable Diffusion XL, offering three key insights. First, while the ‘aug_embedding’ captures the full semantic content of the text, its contribution to the final image generation is relatively minor. Second, ‘BOS’ and ‘Padding_embedding’ do not contain any semantic information. Lastly, the ‘EOS’ holds the semantic information of all words and contains the most style features. Each word embedding plays a unique role without interfering with one another. Based on these insights, we propose a novel approach for controllable image editing using a free-text embedding control method called PSP (Prompt-Softbox-Prompt). PSP enables precise image editing by inserting or adding text embeddings within the cross-attention layers and using Softbox to define and control the specific area for semantic injection. This technique allows for obejct additions and replacements while preserving other areas of the image. Additionally, PSP can achieve style transfer by simply replacing text embeddings. Extensive experimental results show that PSP achieves significant results in tasks such as object replacement, object addition, and style transfer.
Summary
分析Stable Diffusion XL文本嵌入,提出PSP可控图像编辑方法。
Key Takeaways
- 文本嵌入的复杂性影响图像编辑精度。
- ‘aug_embedding’对图像生成影响较小。
- ‘BOS’和’Padding_embedding’无语义信息。
- ‘EOS’包含最多风格特征。
- 单词嵌入各司其职,无干扰。
- PSP通过文本嵌入控制图像编辑。
- PSP在物体替换、添加和风格转换中表现优异。
Title: Prompt-Softbox-Prompt: A free-text Embedding Control for Image Editing
(中文翻译:基于自由文本嵌入控制的图像编辑方法)Authors: Yitong Yang, Yinglin Wang*, Jing Wang, Tian Zhang
Affiliation: School of Information Management Engineering, Shanghai University of Finance and Economics
Keywords: Text-driven diffusion models, image editing, text embeddings, controllable image editing, Stable Diffusion XL
Urls: arXiv:2408.13623v1 [cs.CV], Github: None
Summary:
(1):研究背景:基于文本驱动的扩散模型在图像编辑领域取得了显著的成功,但模型中的关键组件——文本嵌入——尚未得到充分研究。文本嵌入的复杂性和不透明性对实现精确的图像编辑提出了重大挑战。
(2):过去的方法:以往的研究主要集中于基于预训练的扩散模型进行图像编辑,但文本嵌入的耦合性和不透明性限制了图像编辑的可控性。作者提出的方法是基于对文本嵌入的深入分析,旨在提高图像编辑的精确性和可控性。
(3):研究方法:本文对Stable Diffusion XL模型中的文本嵌入进行了全面分析,提出了名为PSP(Prompt-Softbox-Prompt)的新的图像编辑方法。PSP通过在交叉注意力层中插入或添加文本嵌入,并使用Softbox定义和控制语义注入的具体区域,实现了精确的图像编辑。
(4):任务和性能:PSP在物体替换、物体添加和风格迁移等任务上取得了显著成果。实验结果表明,PSP在实现可控图像编辑方面具有很高的性能,支持了其研究目标。
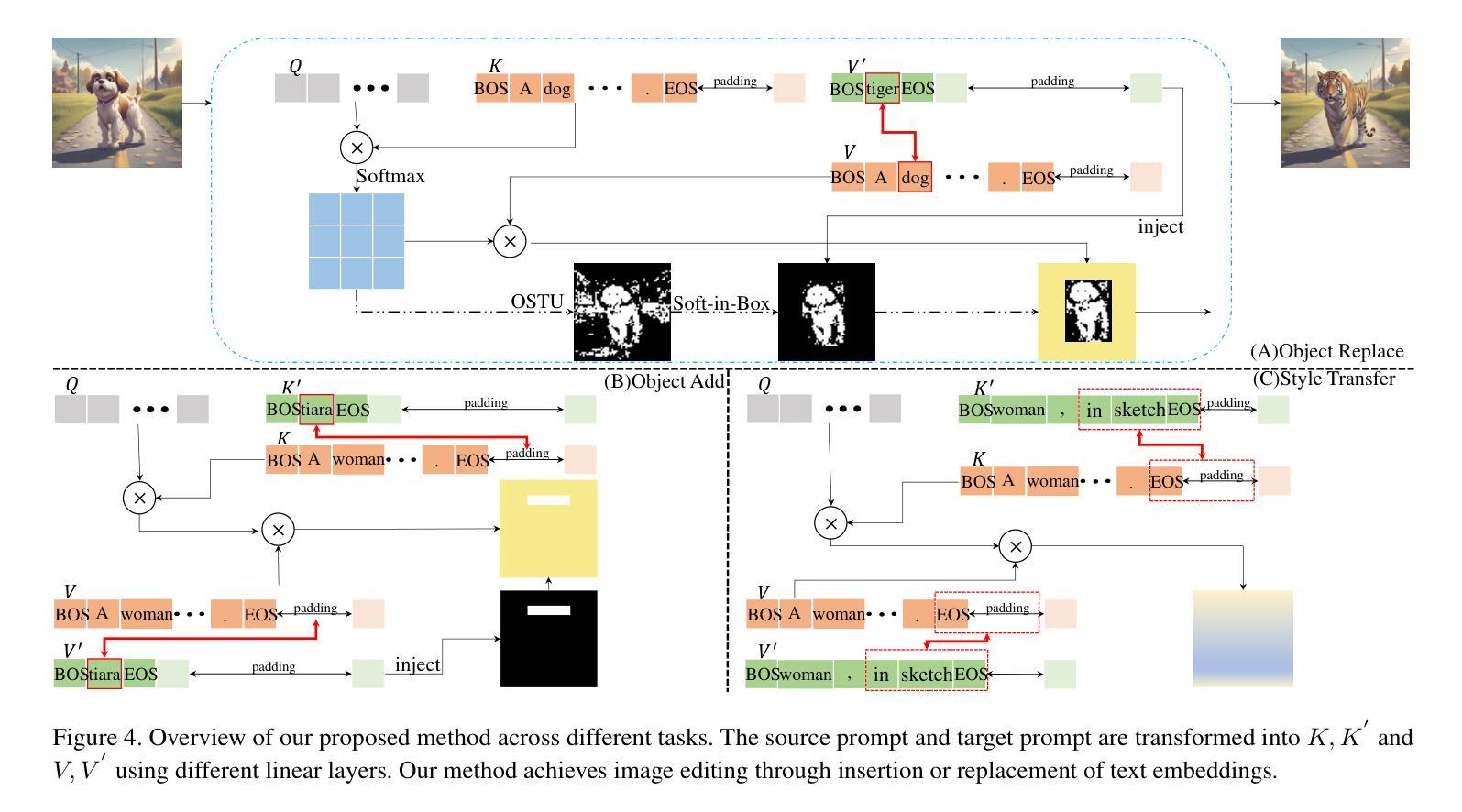
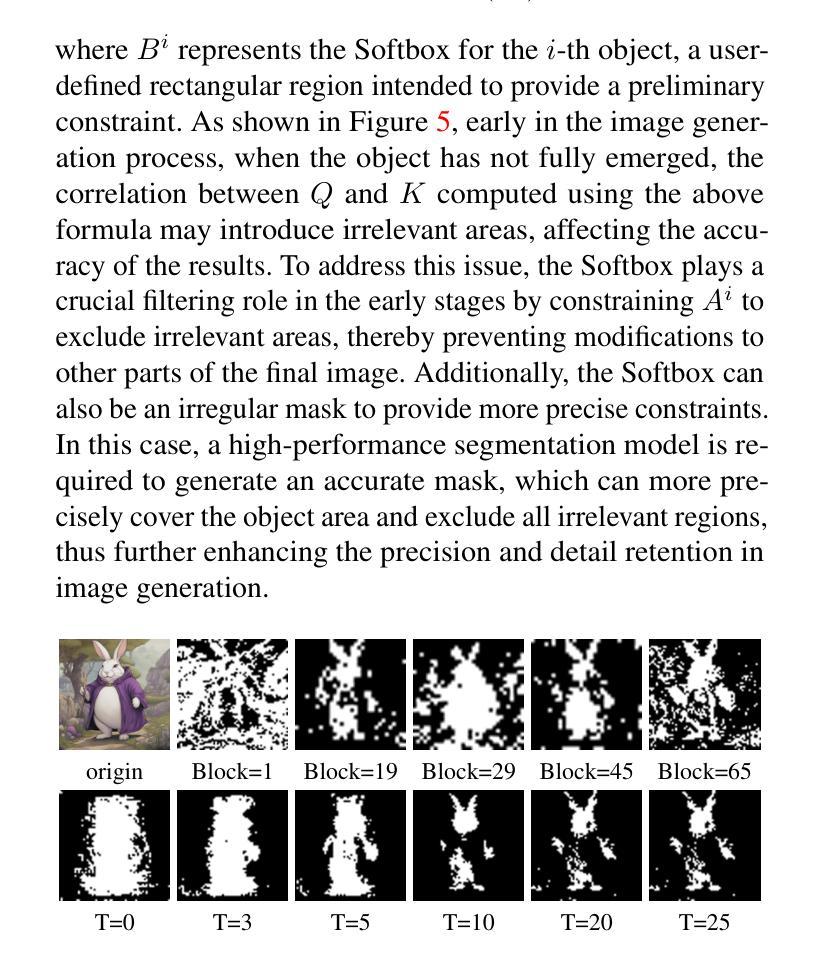
Methods:
(1): 对SDXL模型中的文本嵌入进行了全面分析,揭示了文本嵌入在扩散模型中的作用机制。
(2): 提出了PSP(Prompt-Softbox-Prompt)方法,通过在交叉注意力层中插入或添加文本嵌入,实现精确的图像编辑。
(3): 使用Softbox机制,将目标文本的语义注入到源图像中对应物体的区域,减少源物体的影响。
(4): 通过Otsu方法计算目标物体的掩码,用于指导语义注入。
(5): 在交叉注意力层中使用替换函数,将源图像中的物体替换为目标图像中的物体。
Conclusion:
(1):这项工作的意义在于,它深入研究了文本嵌入在图像编辑中的作用,并提出了PSP(Prompt-Softbox-Prompt)方法,为基于文本驱动的扩散模型在图像编辑领域的应用提供了新的思路和解决方案。
(2): Innovation point: 在创新点上,本文提出的PSP方法通过在交叉注意力层中引入文本嵌入,实现了对图像编辑的精确控制,这一方法在理论上具有创新性,为后续研究提供了新的方向;Performance: 在性能上,PSP在物体替换、物体添加和风格迁移等任务上取得了显著成果,实验结果表明其性能优越;Workload: 在工作负载上,PSP方法对计算资源的要求较高,需要较大的计算资源来支持其在复杂图像上的编辑任务。
点此查看论文截图



DualAnoDiff: Dual-Interrelated Diffusion Model for Few-Shot Anomaly Image Generation
Authors:Ying Jin, Jinlong Peng, Qingdong He, Teng Hu, Hao Chen, Jiafu Wu, Wenbing Zhu, Mingmin Chi, Jun Liu, Yabiao Wang, Chengjie Wang
The performance of anomaly inspection in industrial manufacturing is constrained by the scarcity of anomaly data. To overcome this challenge, researchers have started employing anomaly generation approaches to augment the anomaly dataset. However, existing anomaly generation methods suffer from limited diversity in the generated anomalies and struggle to achieve a seamless blending of this anomaly with the original image. In this paper, we overcome these challenges from a new perspective, simultaneously generating a pair of the overall image and the corresponding anomaly part. We propose DualAnoDiff, a novel diffusion-based few-shot anomaly image generation model, which can generate diverse and realistic anomaly images by using a dual-interrelated diffusion model, where one of them is employed to generate the whole image while the other one generates the anomaly part. Moreover, we extract background and shape information to mitigate the distortion and blurriness phenomenon in few-shot image generation. Extensive experiments demonstrate the superiority of our proposed model over state-of-the-art methods in terms of both realism and diversity. Overall, our approach significantly improves the performance of downstream anomaly detection tasks, including anomaly detection, anomaly localization, and anomaly classification tasks.
Summary
该文提出了一种新的扩散模型DualAnoDiff,通过生成整体图像和异常部分,实现多样化、逼真的异常图像生成。
Key Takeaways
- 异常检测在工业制造中受限于异常数据稀缺。
- 现有异常生成方法存在多样性和融合问题。
- 提出DualAnoDiff,通过双重扩散模型生成图像和异常部分。
- 利用背景和形状信息减少生成图像的失真和模糊。
- 实验证明DualAnoDiff在真实性和多样性方面优于现有方法。
- 显著提升了异常检测、定位和分类任务的性能。
- 模型适用于多种异常检测任务。
Title: 双向关联扩散模型在少样本异常图像生成中的应用
2. Authors: Ying Jin, Jinlong Peng, Qingdong He, Teng Hu, Hao Chen, Jiafu Wu, Wenbing Zhu, Mingmin Chi, Jun Liu, Yabiao Wang, Chengjie Wang
3. Affiliation: 复旦大学
4. Keywords: 异常检测,少样本学习,图像生成,扩散模型,异常数据增强
5. Urls: https://arxiv.org/abs/2408.13509v1 or Github: None
6. Summary:
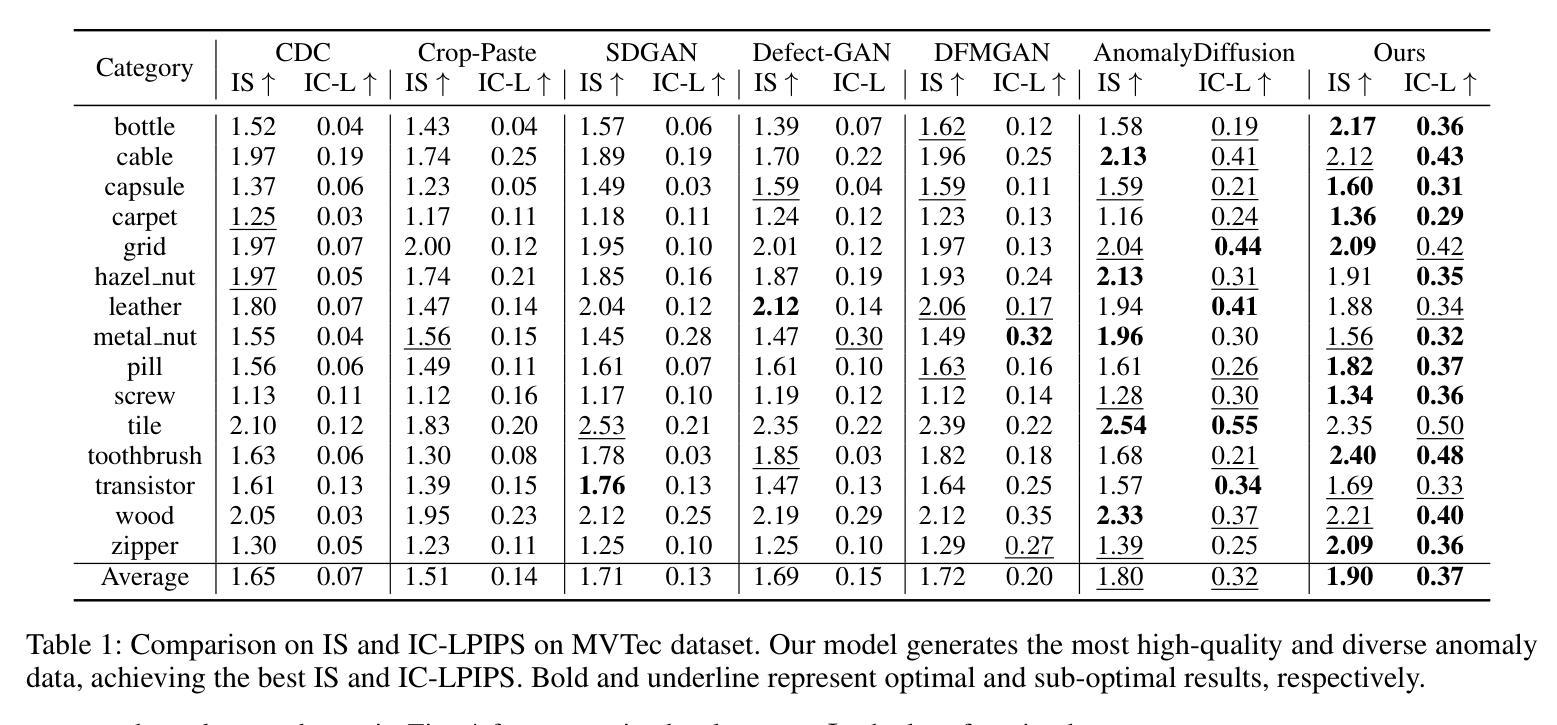
- (1):该文章的研究背景是工业制造中异常检测的性能受限于异常数据的稀缺性。
- (2):过去的方法包括基于模型的方法和生成方法。基于模型的方法通过随机切割和粘贴现有异常或异常纹理数据集的片段到正常样本上,但生成的异常数据不真实。生成方法使用生成模型如GANs和扩散模型来生成异常数据,但GANs需要大量训练数据,且无法生成掩码;DFMGAN虽然迁移到异常数据,但生成的异常不真实,掩码对齐不足;AnomalyDiffusion缺乏显式的对齐约束设计。该方法的动机是为了克服现有方法的局限性。
- (3):该文章提出了一种基于扩散模型的少样本异常图像生成模型DualAnoDiff,通过双向关联扩散模型同时生成整体图像和相应的异常部分,并通过提取背景和形状信息来减轻少样本图像生成中的扭曲和模糊现象。
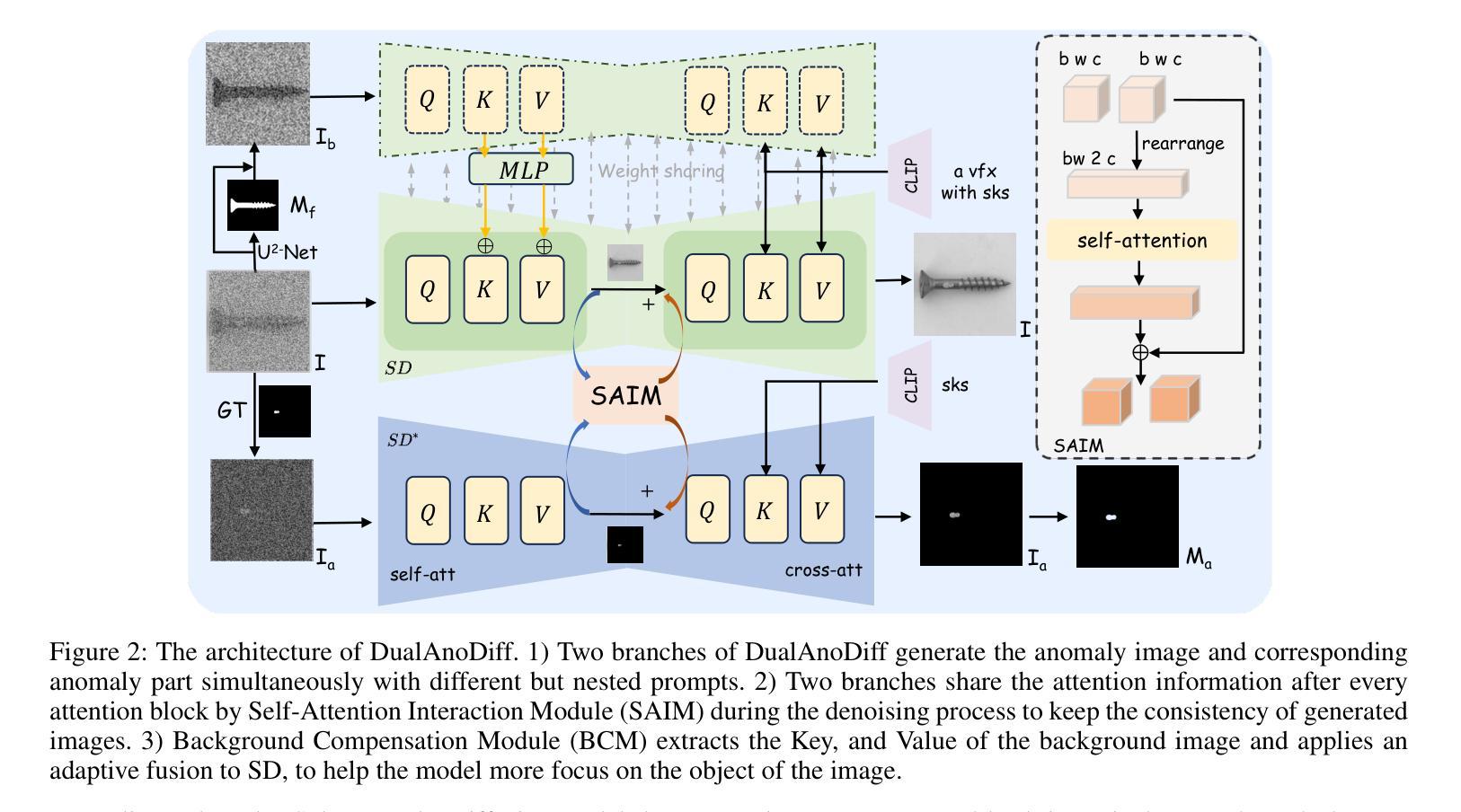
- (4):该模型在异常检测、异常定位和异常分类任务上取得了优于现有方法的性能,证明了其在真实性和多样性方面的优越性,支持了其提高下游异常检测任务性能的目标。Methods:
(1): 该文章针对工业制造中异常检测数据稀缺的问题,提出了一种名为DualAnoDiff的少样本异常图像生成模型。
(2): 该模型将异常图像分解为整体异常图像和相应的异常部分,分别使用两个扩散模型(SD和SD*)生成。
(3): 双向关联扩散模型通过共享信息模块(Self-attention Interaction Module,SAIM)实现两个模型的同步和共享。
(4): 模型使用嵌套提示(Nested Prompts)来指导生成过程,确保生成图像与异常部分之间的包含关系。
(5): 通过添加LoRA(Low-Rank Adaptation)来提高生成图像的多样性和真实性。
(6): 模型通过提取背景和形状信息来减轻少样本图像生成中的扭曲和模糊现象。
(7): 使用现有分割算法或注意力图来生成高质量的异常部分掩码。
(8): 背景补偿模块用于处理训练数据有限导致的问题,提高模型在特定情况下的性能。
Conclusion:
- (1):该研究工作的意义在于针对工业制造领域异常检测数据稀缺的问题,提出了一种基于扩散模型的少样本异常图像生成模型DualAnoDiff,有效提升了异常检测的性能和效率。 - (2):Innovation point: DualAnoDiff模型在创新点上的优势在于提出了双向关联扩散模型,能够同时生成整体图像和相应的异常部分,提高了生成的异常数据的真实性和多样性;Performance: 在异常检测、异常定位和异常分类任务上,DualAnoDiff模型表现优于现有方法,证明了其在性能上的优越性;Workload: 模型设计考虑了少样本场景,通过背景补偿模块和LoRA技术减轻了训练数据有限的问题,但在实际应用中仍需进一步优化以降低计算负载。
点此查看论文截图


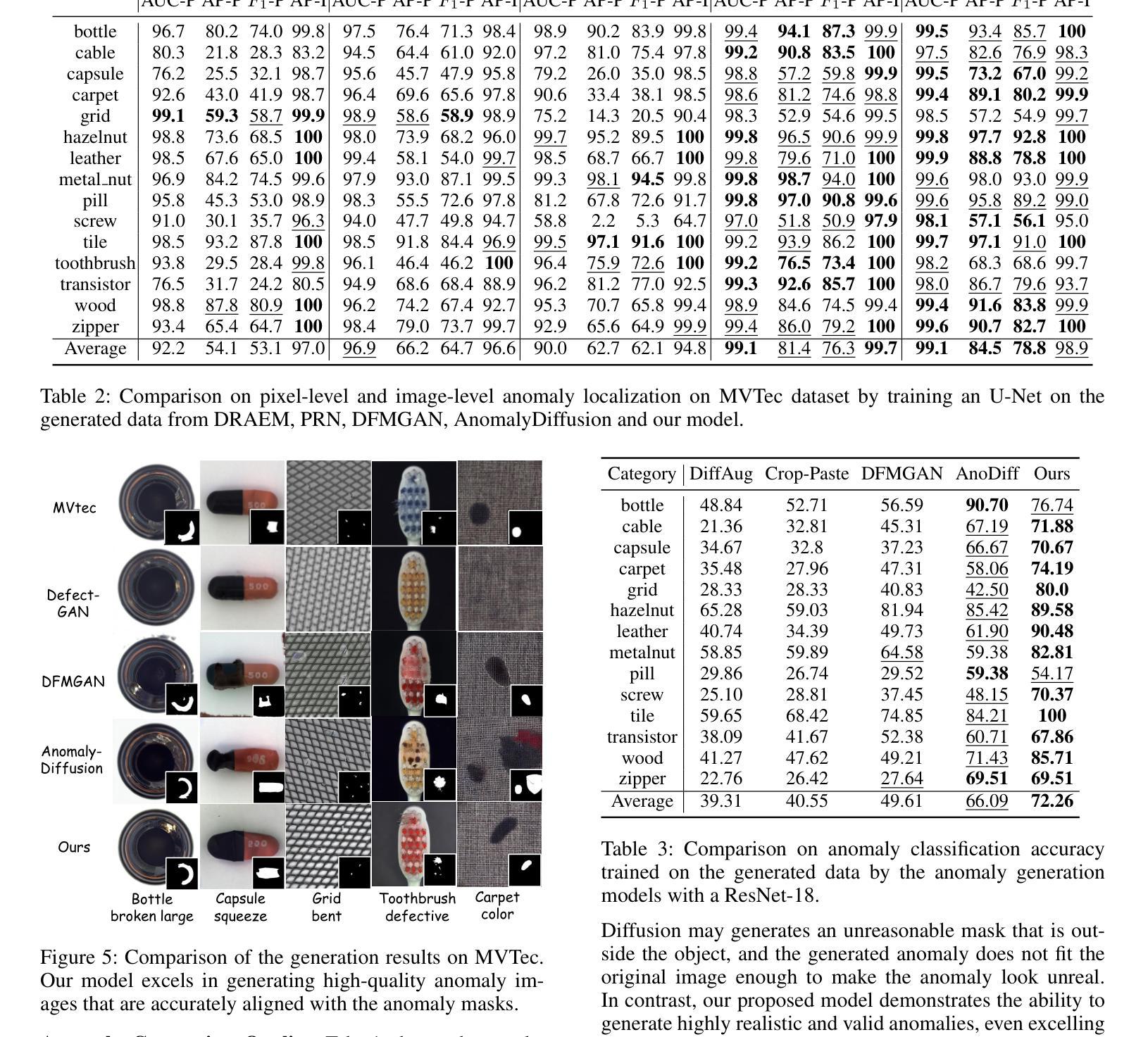
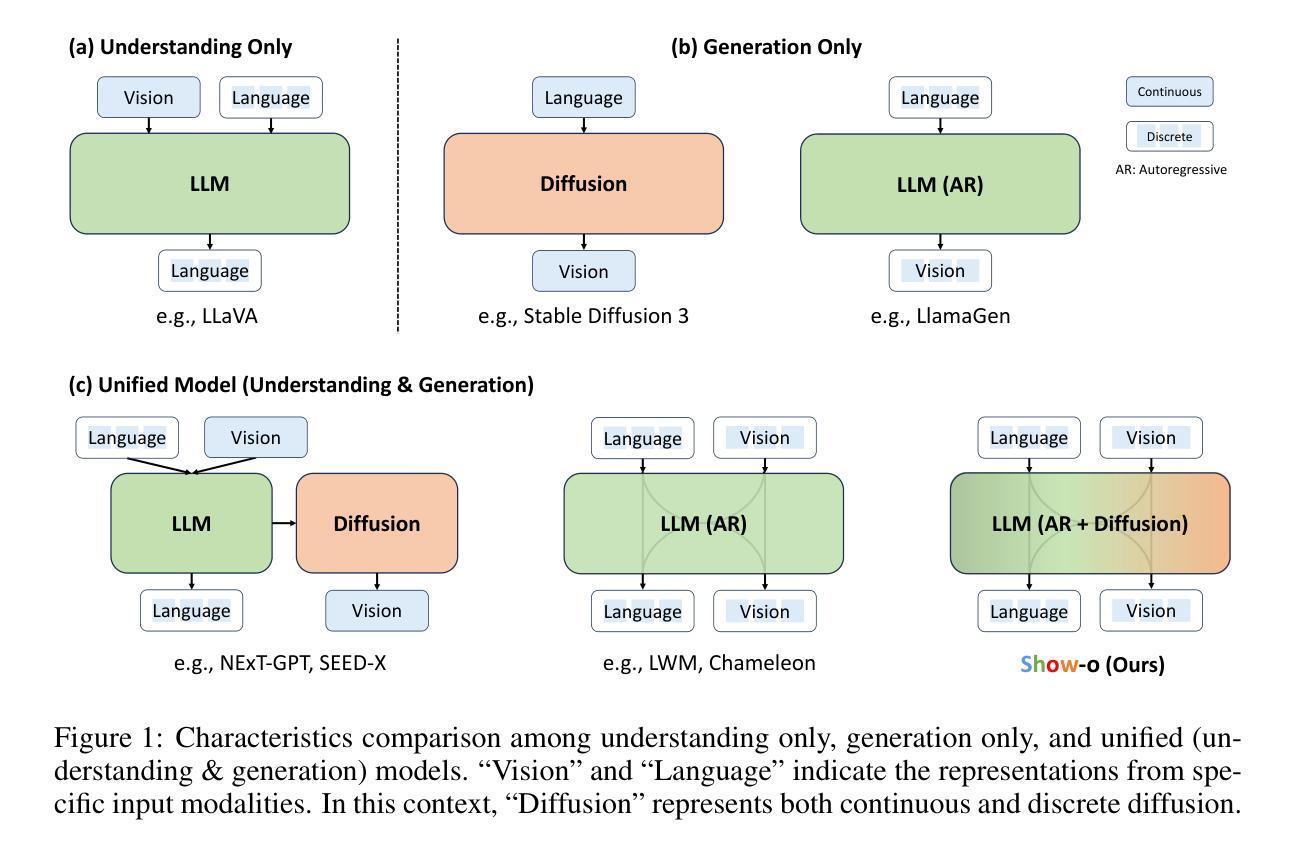
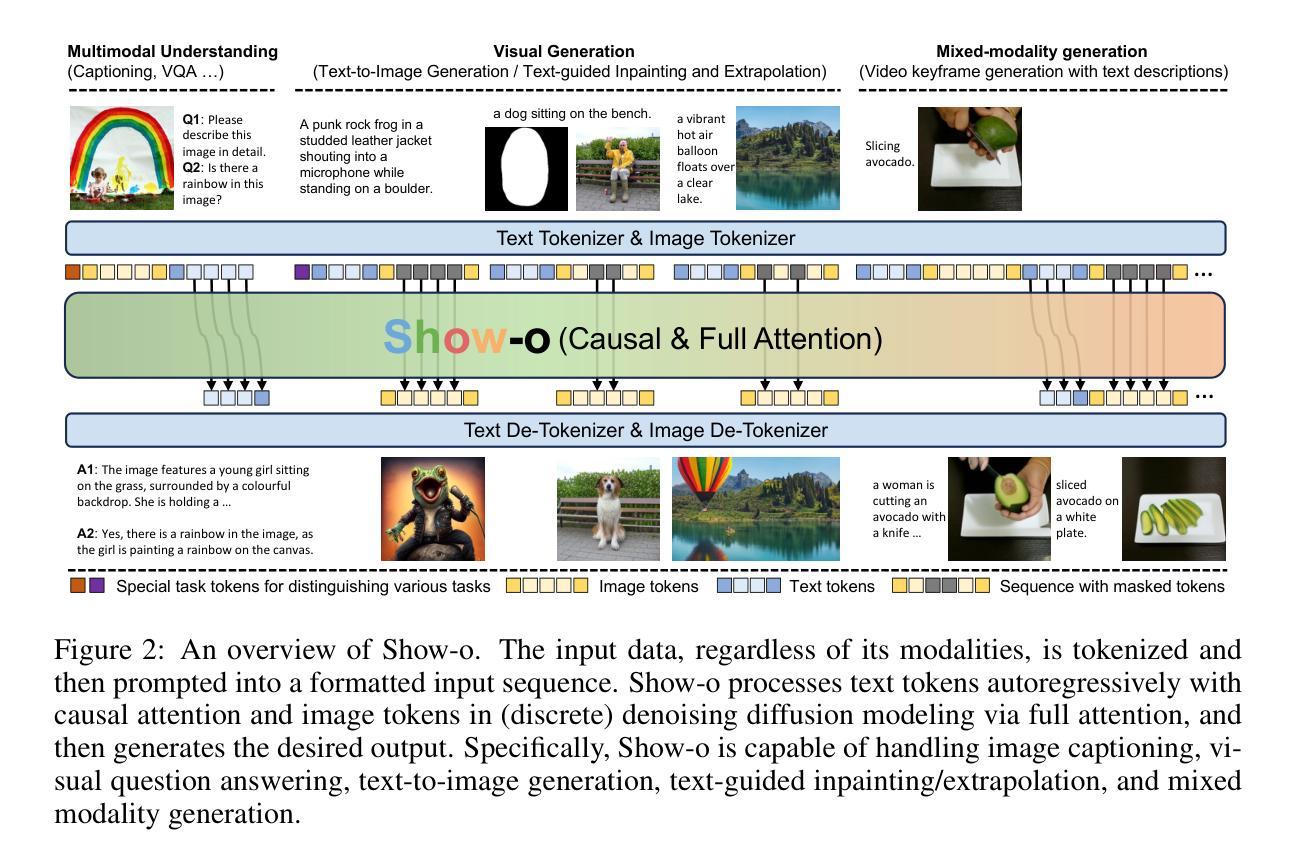
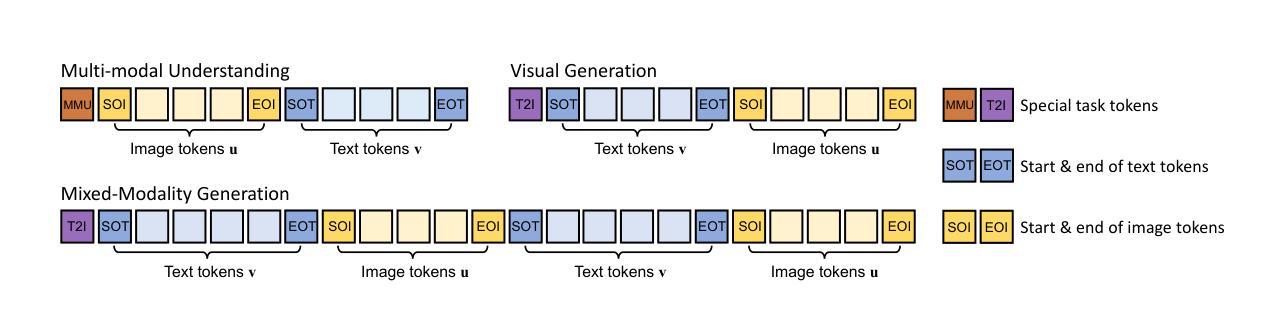
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Authors:Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou
We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
PDF Technical Report
Summary
统一Transformer Show-o模型,融合多模态理解和生成,提升视觉语言任务性能。
Key Takeaways
- Show-o模型融合自回归和扩散建模。
- 支持多种视觉语言任务,如问答、图像生成等。
- 性能优于同类模型,参数更少。
- 有望成为下一代基础模型。
- 开源代码和模型。
- 适用于多种模态的输入输出处理。
- 涵盖多模态理解和生成。
Title: SHOW-O: ONE SINGLE TRANSFORMER TO UNIFY MULTIMODAL UNDERSTANDING AND GENERATION (统一多模态理解和生成的单个Transformer)
Authors: Jinheng Xie†, Weijia Mao†, Zechen Bai†, David Junhao Zhang†, Weihao Wang2, Kevin Qinghong Lin1, Yuchao Gu1, Zhijie Chen2, Zhenheng Yang2, Mike Zheng Shou1∗
Affiliation: Show Lab, National University of Singapore
Keywords: unified transformer, multimodal understanding, generation, vision-language tasks, transformer architecture
Urls: https://arxiv.org/abs/2408.12528, Github: https://github.com/showlab/Show-o
Summary:
(1):本文的研究背景是多模态智能的两个关键支柱——理解和生成。多模态理解方面,多模态大型语言模型(MLLMs)在视觉语言任务上表现出色;而在视觉生成方面,去噪扩散概率模型(DDPMs)在文本到图像/视频生成方面取得了前所未有的性能。
(2):过去的方法主要是将理解和生成视为独立的领域,并使用专门的模型分别处理。例如,NExT-GPT使用基础语言模型进行多模态理解,但需要额外的预训练扩散模型进行图像生成。这种方法的局限性在于模型之间的分离,且不同模型架构的差异使得统一处理成为一个挑战。
(3):本文提出了一种统一的Transformer模型Show-o,它将自回归模型和(离散)扩散模型结合,以适应性地处理各种和混合模态的输入和输出。Show-o可以灵活支持广泛的视觉语言任务。
(4):在多个基准测试中,Show-o的性能与专门针对理解和生成定制的模型相当或更优,且参数数量相当或更大。这显著凸显了其作为下一代基础模型的潜力。
Methods:
(1): 针对多模态理解和生成任务,本文提出了一种名为 Show-o 的统一 Transformer 模型,该模型结合了自回归模型和扩散模型,以适应性地处理不同和混合模态的输入和输出。
(2): 首先,通过将文本和图像数据分别进行分词,将文本和图像转换为离散的 tokens,为统一学习构建输入/输出空间。
(3): 然后,设计了统一的提示策略,将不同类型的输入数据格式化,以便在统一模型中进行学习。
(4): Show-o 继承了现有 LLM 的架构,并在每个注意力层前添加了 QK-Norm 操作,以增强模型的表达能力。
(5): 引入了一种名为“全能注意力机制”的注意力机制,该机制可以根据输入序列的格式自适应地混合和改变注意力模式。
(6): 为了同时进行自回归和扩散建模,采用两个学习目标:下一个 token 预测 (NTP) 和掩码 token 预测 (MTP)。
(7): 提出了一个三阶段的训练流程,以有效地训练统一模型,包括数据准备、模型训练和模型评估。
Conclusion:
- (1):这项工作的重要性在于,它首次提出了一种名为Show-o的统一Transformer模型,该模型能够同时处理多模态理解和生成任务,实现了自回归模型和(离散)扩散模型的统一,为多模态智能的发展提供了新的思路。 - (2):Innovation point: 在创新点上,Show-o模型的设计具有前瞻性,它结合了自回归和扩散模型,为处理不同模态数据提供了一种全新的方法;Performance: 在性能上,Show-o在多个视觉语言任务中表现出色,其性能与专门定制的模型相当甚至更优;Workload: 在工作量上,尽管Show-o模型参数数量与专门模型相当或更大,但其训练流程和评估方法相对高效,降低了整体的工作量。
点此查看论文截图

InstantStyleGaussian: Efficient Art Style Transfer with 3D Gaussian Splatting
Authors:Xin-Yi Yu, Jun-Xin Yu, Li-Bo Zhou, Yan Wei, Lin-Lin Ou
We present InstantStyleGaussian, an innovative 3D style transfer method based on the 3D Gaussian Splatting (3DGS) scene representation. By inputting a target-style image, it quickly generates new 3D GS scenes. Our method operates on pre-reconstructed GS scenes, combining diffusion models with an improved iterative dataset update strategy. It utilizes diffusion models to generate target style images, adds these new images to the training dataset, and uses this dataset to iteratively update and optimize the GS scenes, significantly accelerating the style editing process while ensuring the quality of the generated scenes. Extensive experimental results demonstrate that our method ensures high-quality stylized scenes while offering significant advantages in style transfer speed and consistency.
Summary
基于3D高斯分裂的3D风格迁移,显著提高风格编辑速度和质量。
Key Takeaways
- 引入即时风格高斯,基于3D高斯分裂场景表示的3D风格迁移方法。
- 快速生成目标风格3D场景。
- 结合扩散模型和迭代数据集更新策略。
- 利用扩散模型生成目标风格图像,加入训练数据集,迭代优化场景。
- 显著提升风格编辑速度和质量。
- 实验证明方法生成高质量场景,风格转移速度快、一致性高。
Title: InstantStyleGaussian: Efficient Art Style Transfer
(中文翻译:基于3D高斯散布的快速艺术风格迁移)Authors: Xin-Yi Yu, Jun-Xin Yu, Li-Bo Zhou, Yan Wei, Lin-Lin Ou
Affiliation: (第一作者所属机构,中文翻译:未知,文中未提及)
Keywords: 3D Gaussian Splatting, 3D Style Transfer, Iterative Dataset Update
Urls: arXiv:2408.04249v2 [cs.CV] 26 Aug 2024
Github: NoneSummary:
- (1):该文章的研究背景是随着虚拟现实、机器人模拟和自动驾驶等应用的快速发展,3D场景和模型的编辑变得日益重要。现有的3D场景表示方法如网格和点云在编辑复杂场景和细节时存在挑战。 - (2):过去的方法包括基于扩散编辑和大型语言模型(LLM)的3D模型编辑。这些方法的问题在于需要大量的内存和计算时间,且解码方法会影响最终的风格迁移效果,可能导致多视图不一致性和整体场景质量的下降。该方法的提出是有动机的,因为它旨在提供一种快速且高质量的风格迁移解决方案。 - (3):该论文提出了一种基于3D高斯散布(3DGS)场景表示的3D风格迁移方法。该方法结合了扩散模型和改进的迭代数据集更新策略,通过输入目标风格图像快速生成新的3D场景,并通过迭代更新和优化场景来加速风格编辑过程。 - (4):该方法在3D风格迁移任务上取得了高质量的结果,实现了快速的风格迁移和一致性保持。实验结果表明,该方法在速度和性能上均优于以往的方法,支持了其目标。Methods:
(1): 该方法基于3D高斯散布(3DGS)场景表示,结合了扩散模型(InstantStyle)进行2D图像风格迁移,并改进了InstructNeRF2NeRF中的迭代数据集更新策略。
(2): 利用Nearest Neighbor Feature Matching (NNFM) 损失函数,将2D风格图像中的复杂高频视觉细节传递到3D场景中,以更好地保持局部纹理细节。
(3): 通过迭代更新训练数据集图像,利用图像条件扩散模型来生成新的2D图像,并将其风格迁移效果反馈到3DGS场景中。
(4): 应用边缘检测图以保持场景的基本结构,确保原始物体的形状和结构在传递到GS场景时不会发生显著变化。
(5): 使用L1和LPIPS损失函数训练高斯散布,以处理不同视角的局部不一致纹理。
(6): 实施细节包括使用gsplat库作为底层模型和可视化工具,以及InstantStyle作为扩散模型。通过调整控制网络的条件缩放和文本、图像调整的引导权重来控制扩散模型的更新强度。
(7): 训练过程涉及最多1k次迭代,在A100 GPU上仅需20分钟即可完成场景的风格迁移编辑,其中前15分钟用于扩散模型生成图像,后5分钟将这些图像反向传播到整个场景中。
Conclusion:
- (1):该工作的显著意义在于,它提出了一种基于3D高斯散布的快速艺术风格迁移方法,为3D场景和模型的编辑提供了一种高效且高质量的解决方案。这种方法能够显著提升虚拟现实、机器人模拟和自动驾驶等领域的应用效果。 - (2):Innovation point: InstantStyleGaussian方法在3D风格迁移方面提出了创新性的3D高斯散布场景表示和改进的迭代数据集更新策略,有效提高了风格迁移的速度和质量;Performance: 实验结果显示,该方法在速度和性能上均优于现有方法,实现了快速的风格迁移和一致性保持;Workload: 该方法在A100 GPU上仅需20分钟即可完成场景的风格迁移编辑,显著降低了计算负载。
点此查看论文截图






Diffusion Feedback Helps CLIP See Better
Authors:Wenxuan Wang, Quan Sun, Fan Zhang, Yepeng Tang, Jing Liu, Xinlong Wang
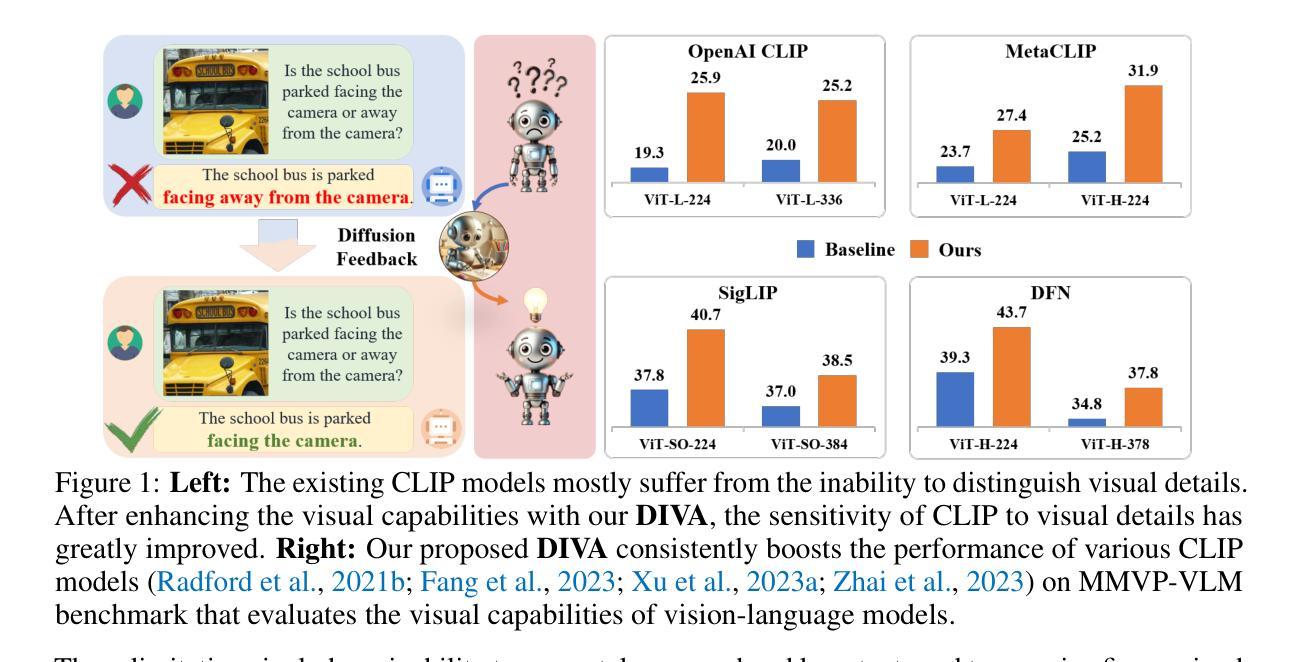
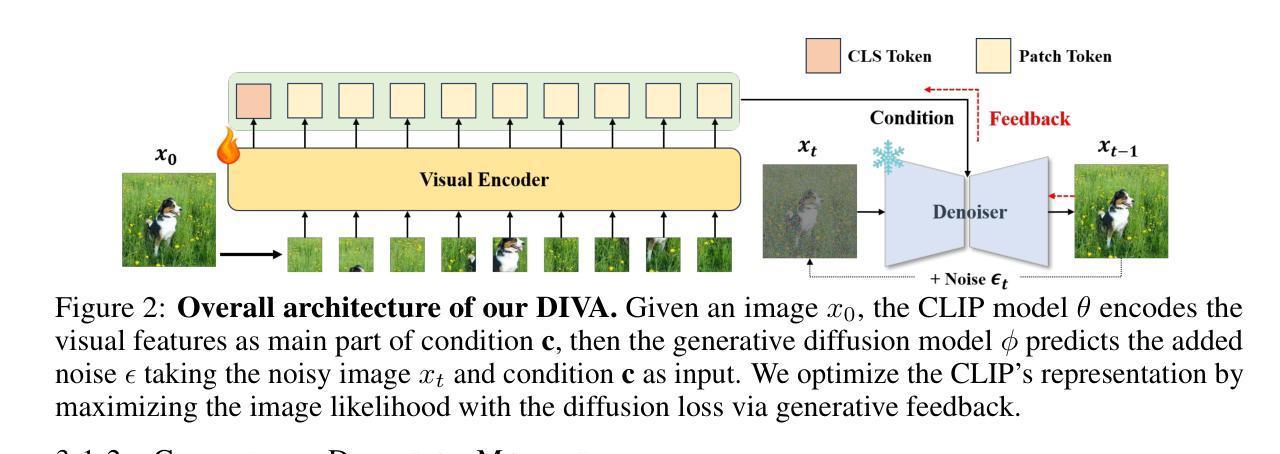
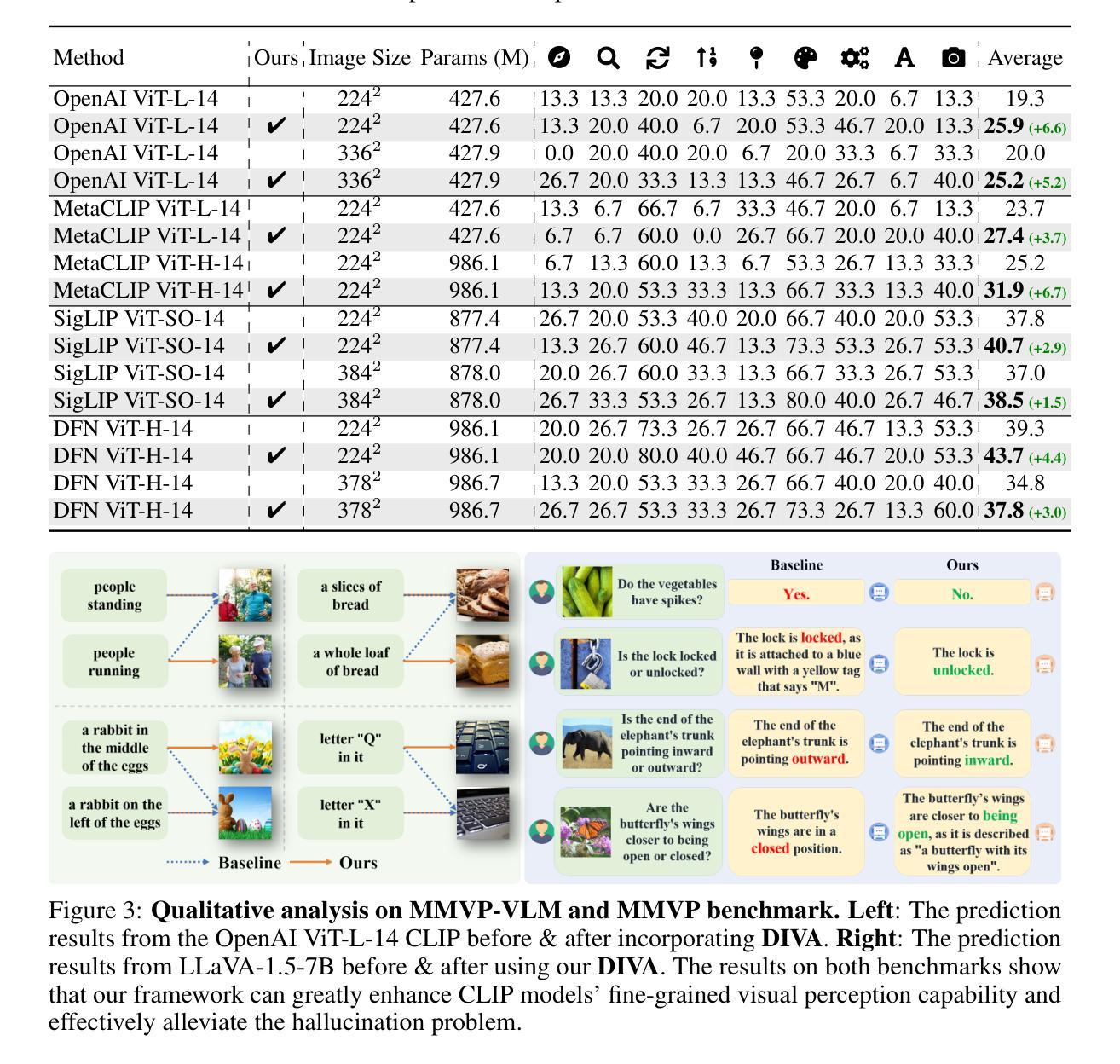
Contrastive Language-Image Pre-training (CLIP), which excels at abstracting open-world representations across domains and modalities, has become a foundation for a variety of vision and multimodal tasks. However, recent studies reveal that CLIP has severe visual shortcomings, such as which can hardly distinguish orientation, quantity, color, structure, etc. These visual shortcomings also limit the perception capabilities of multimodal large language models (MLLMs) built on CLIP. The main reason could be that the image-text pairs used to train CLIP are inherently biased, due to the lack of the distinctiveness of the text and the diversity of images. In this work, we present a simple post-training approach for CLIP models, which largely overcomes its visual shortcomings via a self-supervised diffusion process. We introduce DIVA, which uses the DIffusion model as a Visual Assistant for CLIP. Specifically, DIVA leverages generative feedback from text-to-image diffusion models to optimize CLIP representations, with only images (without corresponding text). We demonstrate that DIVA improves CLIP’s performance on the challenging MMVP-VLM benchmark which assesses fine-grained visual abilities to a large extent (e.g., 3-7%), and enhances the performance of MLLMs and vision models on multimodal understanding and segmentation tasks. Extensive evaluation on 29 image classification and retrieval benchmarks confirms that our framework preserves CLIP’s strong zero-shot capabilities. The code is available at https://github.com/baaivision/DIVA.
Summary
CLIP模型视觉缺陷通过DIVA扩散模型优化,提升视觉能力及多模态理解。
Key Takeaways
- CLIP模型在视觉上存在缺陷,如难以区分方向、数量、颜色和结构。
- CLIP的视觉缺陷限制了基于CLIP的多模态大语言模型(MLLMs)的感知能力。
- 训练CLIP的图像-文本对存在内在偏差,导致视觉能力受限。
- 提出DIVA模型,利用扩散模型优化CLIP表示。
- DIVA通过图像优化CLIP,无需对应文本,提升性能。
- DIVA在MMVP-VLM基准测试中提高了CLIP的细粒度视觉能力。
- DIVA增强MLLMs和视觉模型的多模态理解和分割任务性能。
- 框架保持CLIP的强零样本能力。
- 代码开源于https://github.com/baaivision/DIVA。
Title: CLIP视觉辅助:扩散反馈帮助CLIP更好地工作
Authors: Wenxuan Wang, Quan Sun, Fan Zhang, Yepeng Tang, Jing Liu, Xinlong Wang
Affiliation: 中国科学院自动化研究所
Keywords: CLIP, 多模态预训练, 图像-文本对齐, 扩散模型, 视觉辅助
Urls: https://rubics-xuan.github.io/DIVA/, Github: https://github.com/baaivision/DIVA
Summary:
(1):该文章的研究背景是CLIP(Contrastive Language-Image Pre-training)在跨领域和模态抽象表示方面的优势,以及其视觉感知能力的局限性。
(2):过去的方法主要集中在CLIP的预训练和微调上,但这些方法依赖于图像-文本数据对,且无法处理图像数据。此外,CLIP的视觉感知能力受限,部分原因在于训练数据中的图像-文本对存在固有偏差。该研究方法动机明确,旨在克服CLIP的视觉感知局限。
(3):该文章提出了一种基于扩散模型的后训练方法,称为DIVA,用于提升CLIP的视觉表示能力。DIVA利用文本到图像的扩散模型生成的反馈来优化CLIP的表示,仅使用图像数据(无需对应文本)。
(4):DIVA在MMVP-VLM基准测试中显著提升了CLIP的性能(例如,提高了3-7%),并在多模态理解和分割任务中增强了多模态大型语言模型(MLLMs)和视觉模型的表现。在29个图像分类和检索基准测试中,DIVA框架保持了CLIP的强零样本能力,支持了研究目标。
Methods:
(1): 针对CLIP(Contrastive Language-Image Pre-training)模型在视觉感知能力上的局限性,文章提出了一种基于扩散模型的后训练方法,称为DIVA(Diffusion Feedback for CLIP Visual Assistance)。
(2): DIVA方法利用文本到图像的扩散模型生成的反馈来优化CLIP的视觉表示,这一过程仅使用图像数据,无需对应文本。
(3): 在DIVA中,研究人员探索了不同类型的扩散模型对生成指导的影响,包括DiT (Peebles & Xie, 2023) 和稳定扩散(SD)系列(Rombach et al., 2022a),如1-4, 2-1-base, xl-base-1.0等。
(4): 通过实验,文章发现将SD-2-1-base模型集成到DIVA中可以获得最大的性能提升(即提升6.6%),同时观察到将DiT-XL/2作为生成指导可以增强原始CLIP模型在捕捉视觉细节方面的能力。
(5): 对于包含的SD系列,实验结果也表明DIVA对SD模型版本不敏感,可以在框架内一致地优化CLIP的特征表示。
Conclusion:
- (1):该研究工作的意义在于,首次探索了利用文本到图像的扩散模型生成的反馈来直接优化CLIP模型的表示,有效提升了CLIP模型在视觉感知能力上的表现。 - (2):Innovation point: 创新点:提出了基于扩散模型的CLIP视觉辅助方法(DIVA),通过自监督框架优化CLIP模型,无需额外插件即可显著提升性能;Performance: 性能:在MMVP-VLM基准测试中,DIVA显著提升了CLIP的性能(例如,提高了3-7%),并在多模态理解和分割任务中增强了MLLMs和视觉模型的表现;Workload: 工作量:DIVA框架简单,易于实现,对扩散模型版本不敏感,可适应不同规模的数据和模型。
点此查看论文截图


DiffX: Guide Your Layout to Cross-Modal Generative Modeling
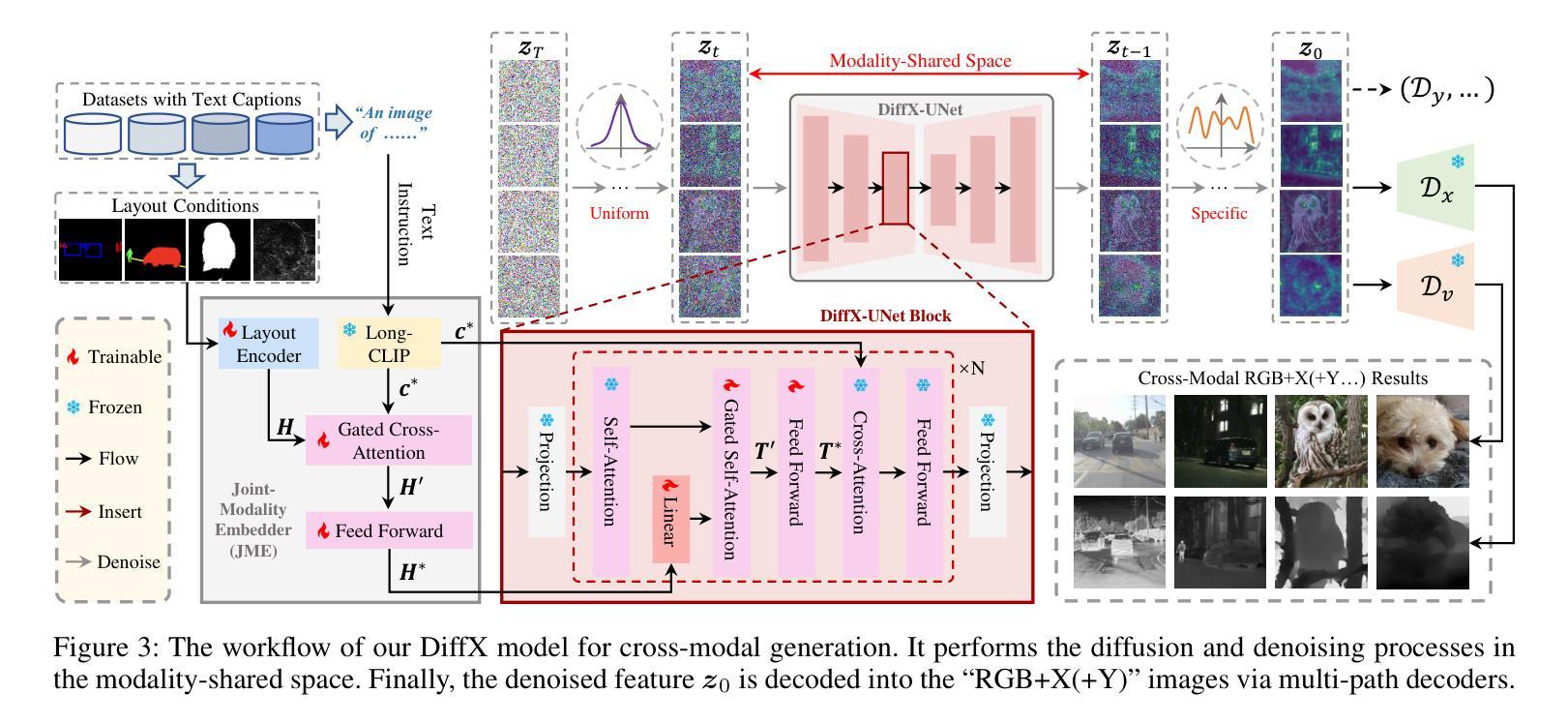
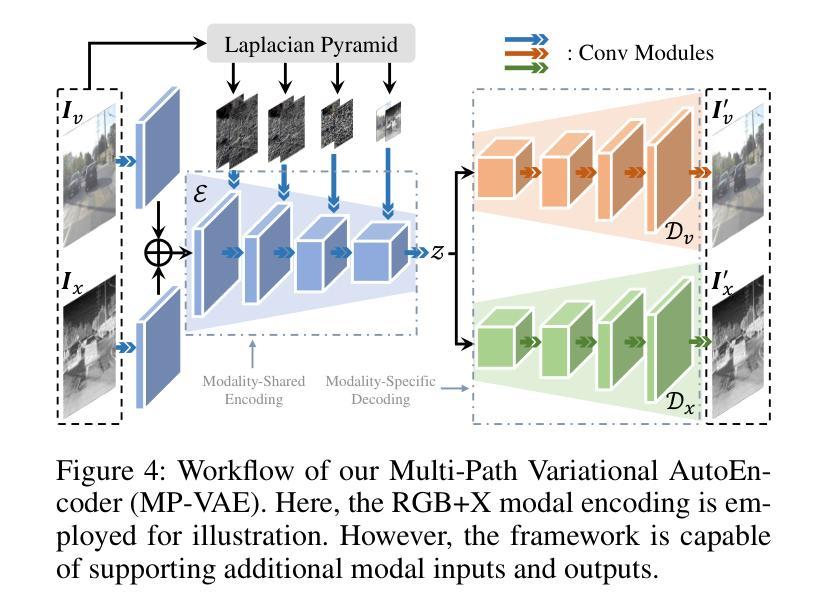
Authors:Zeyu Wang, Jingyu Lin, Yifei Qian, Yi Huang, Shicen Tian, Bosong Chai, Juncan Deng, Qu Yang, Lan Du, Cunjian Chen, Yufei Guo, Kejie Huang
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, such as chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal generation, called DiffX. Notably, our DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space. Moreover, we introduce the Joint-Modality Embedder (JME) to enhance the interaction between layout and text conditions by incorporating a gated attention mechanism. To facilitate the user-instructed training, we construct the cross-modal image datasets with detailed text captions by the Large-Multimodal Model (LMM) and our human-in-the-loop refinement. Through extensive experiments, our DiffX demonstrates robustness in cross-modal ‘’RGB+X’’ image generation on FLIR, MFNet, and COME15K datasets, guided by various layout conditions. It also shows the potential for the adaptive generation of ‘’RGB+X+Y(+Z)’’ images or more diverse modalities on COME15K and MCXFace datasets. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.
Summary
提出DiffX模型,实现跨模态布局引导图像生成,拓展人类感知视角。
Key Takeaways
- Diffusion模型在图像生成方面取得进展,但多限于RGB图像。
- DiffX模型适用于通用布局引导的跨模态图像生成。
- DiffX在模态共享的潜在空间中进行扩散和去噪处理。
- 引入Joint-Modality Embedder (JME)增强布局与文本条件的交互。
- 利用LMM和人工优化构建详细文本描述的跨模态图像数据集。
- DiffX在多个数据集上展示了在RGB+X图像生成的鲁棒性。
- DiffX有潜力在COME15K和MCXFace数据集上生成更多模态的图像。
Title: DiffX: Guide Your Layout to Cross-Modal Generative Modeling
(中文翻译:DiffX:引导布局实现跨模态生成建模)Authors: Zeyu Wang, Jingyu Lin, Yifei Qian, Yi Huang, Shicen Tian, Bosong Chai, Juncan Deng, Qu Yang, Lan Du, Cunjian Chen, Yufei Guo, Kejie Huang
Affiliation: xxx
(浙江大学)Keywords: Diffusion models, Cross-modal generation, Layout guidance, Generative models, Image generation
Urls: https://arxiv.org/abs/2407.15488v4 or https://github.com/zeyuwang-zju/DiffX
Summary:
- (1):该文章的研究背景是人类感知世界的丰富多样性,包括可见光以外的多种模态,如热成像和深度信息。然而,现有的跨模态生成模型主要局限于可见光RGB图像生成,导致跨模态数据增强困难。 - (2):过去的跨模态生成方法主要基于深度生成模型,如变分自编码器(VAEs)和生成对抗网络(GANs),以及布局到图像模型。然而,这些方法存在局限性,例如只能分别生成RGB和X图像,导致图像对错位和不一致。 - (3):本文提出了一种名为DiffX的新型扩散模型,用于跨模态图像生成。DiffX模型在模态共享的潜在空间中执行扩散和去噪过程,并引入了联合模态嵌入器(JME)来增强布局和文本条件之间的交互。 - (4):DiffX在FLIR、MFNet和COME15K数据集上展示了在跨模态“RGB+X”图像生成方面的鲁棒性,并通过各种布局条件进行引导。在COME15K和MCXFace数据集上,DiffX还展示了自适应生成“RGB+X+Y(+Z)”图像或更多模态的潜力。这些性能支持了该模型的目标。Conclusion:
(1):这篇工作的意义在于,DiffX模型通过引入新颖的扩散模型结构,在跨模态图像生成领域取得了显著进展,尤其对于“RGB+X”以及更多模态的图像生成,为跨模态数据增强和图像生成任务提供了新的解决方案。
(2):Innovation point: DiffX模型在跨模态生成建模中提出了新的扩散流程,实现了多模态共享潜在空间中的独立模态扩散和去噪,具有创新性;Performance: 在多个数据集上,DiffX在“RGB+X”图像生成任务中表现出色,且具有生成更多模态图像的潜力;Workload: 模型的训练和运行相对复杂,需要较高的计算资源。
点此查看论文截图