⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-15 更新
ProbTalk3D: Non-Deterministic Emotion Controllable Speech-Driven 3D Facial Animation Synthesis Using VQ-VAE
Authors:Sichun Wu, Kazi Injamamul Haque, Zerrin Yumak
Audio-driven 3D facial animation synthesis has been an active field of research with attention from both academia and industry. While there are promising results in this area, recent approaches largely focus on lip-sync and identity control, neglecting the role of emotions and emotion control in the generative process. That is mainly due to the lack of emotionally rich facial animation data and algorithms that can synthesize speech animations with emotional expressions at the same time. In addition, majority of the models are deterministic, meaning given the same audio input, they produce the same output motion. We argue that emotions and non-determinism are crucial to generate diverse and emotionally-rich facial animations. In this paper, we propose ProbTalk3D a non-deterministic neural network approach for emotion controllable speech-driven 3D facial animation synthesis using a two-stage VQ-VAE model and an emotionally rich facial animation dataset 3DMEAD. We provide an extensive comparative analysis of our model against the recent 3D facial animation synthesis approaches, by evaluating the results objectively, qualitatively, and with a perceptual user study. We highlight several objective metrics that are more suitable for evaluating stochastic outputs and use both in-the-wild and ground truth data for subjective evaluation. To our knowledge, that is the first non-deterministic 3D facial animation synthesis method incorporating a rich emotion dataset and emotion control with emotion labels and intensity levels. Our evaluation demonstrates that the proposed model achieves superior performance compared to state-of-the-art emotion-controlled, deterministic and non-deterministic models. We recommend watching the supplementary video for quality judgement. The entire codebase is publicly available (https://github.com/uuembodiedsocialai/ProbTalk3D/).
PDF 14 pages, 9 figures, 3 tables. Includes code. Accepted at ACM SIGGRAPH MIG 2024
Summary
音频驱动3D面部动画合成,重视情感和非确定性,提出ProbTalk3D模型。
Key Takeaways
- 3D面部动画合成研究活跃,但多忽视情感。
- 情感数据缺乏,算法难以同时合成语音和表情。
- 现有模型多确定性,输出运动单一。
- 提出ProbTalk3D,利用VQ-VAE模型和3DMEAD数据集。
- 比较分析,提出更合适的评价指标。
- 首次结合情感数据集和非确定性。
- 模型性能优于现有情感控制模型。
- 公开代码库,供进一步研究。
标题:ProbTalk3D:非确定性情绪控制
作者:吴思春、卡兹·因贾玛姆乌尔·哈克、泽林·尤马克(英文名字分别为Sichun Wu、Kazi Injamamul Haque、Zerrin Yumak)
所属机构:乌特勒支大学(荷兰)(Utrecht University, Netherlands)
关键词:面部动画合成、深度学习、虚拟人类、非确定性模型、情绪控制面部动画
Urls:论文链接未知,GitHub代码库链接为GitHub链接(如有变动,请根据实际情况填写)
总结:
(1) 研究背景:随着音频驱动的3D面部动画合成的活跃研究,尽管该领域取得了显著的进展,但近期的方法主要关注唇同步和身份控制,忽视了情绪在生成过程中的作用。本文旨在解决这一问题。
(2) 前期方法与问题:多数现有模型是确定性的,即给定相同的音频输入,它们会产生相同的输出运动。这使得面部动画缺乏多样性和情感丰富性。文章指出缺乏情感丰富的面部动画数据和算法是主要原因。因此,需要一种能够合成带有情感表达的语音动画的非确定性模型。因此提出研究问题和动机。
(3) 研究方法:本文提出了一种非确定性的神经网络方法ProbTalk3D,用于情感控制的语音驱动3D面部动画合成。它采用两阶段VQ-VAE模型和丰富的情感动画数据集3DMEAD。文中进行了与最新3D面部动画合成方法的比较性分析,通过客观、主观和用户感知研究进行评价。据称这是首次将非确定性模型应用于情感控制的3D面部动画合成中。同时使用了多种适合评估随机输出的客观指标和真实与模拟数据的主观评估。文章提出的模型通过实验结果展示其优越性。
(4) 任务与性能:本文提出的ProbTalk3D模型在非确定性环境下进行情感控制的面部动画合成任务上取得了显著的成效。实验结果证明了模型相对于现有的情感控制和非确定性模型的优越性。提供的模拟视频和实际应用的代码库可供公众使用以验证其性能。通过广泛的评估和模拟结果支持了方法的有效性。
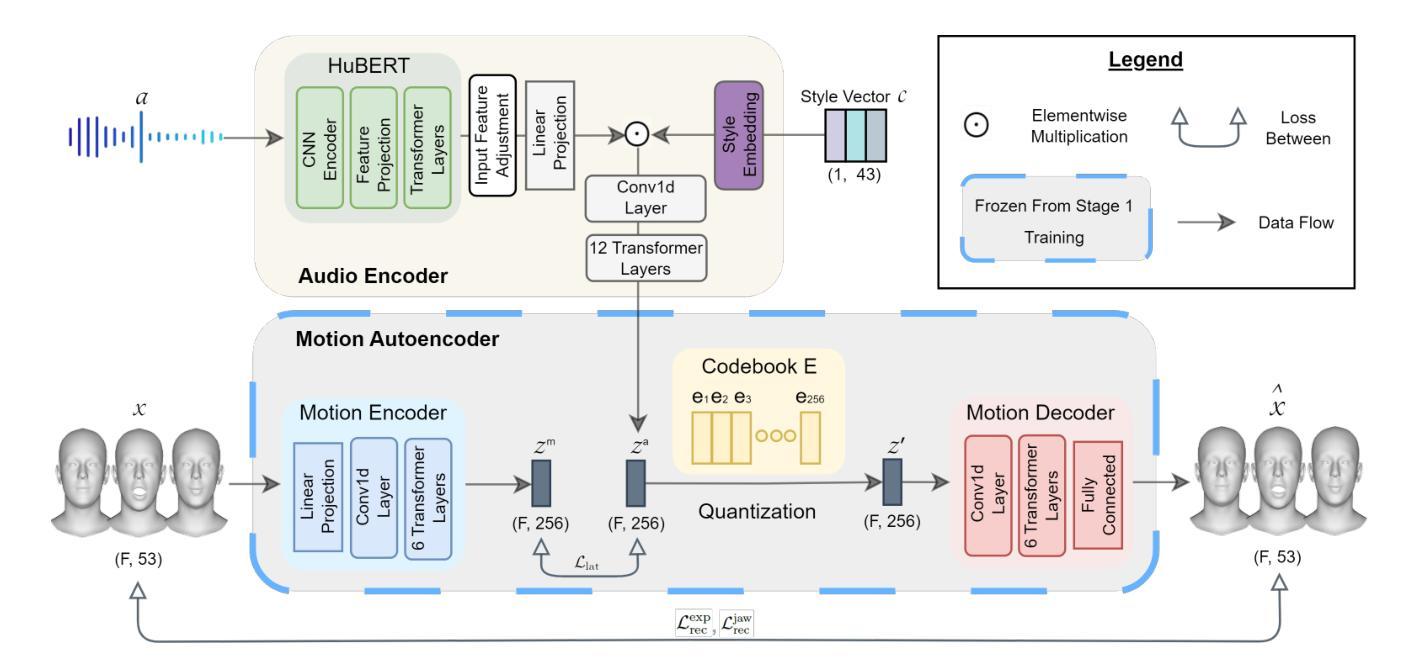
方法论:
(1) 数据集选择:采用3DMEAD数据集,该数据集从二维音视频数据集MEAD重建而来,包含了多种情绪和强度的三维面部动画数据。
(2) 问题描述:文章旨在解决情感在面部动画合成过程中的缺失问题,现有模型大多确定性地生成输出,缺乏多样性和情感丰富性。因此,提出使用非确定性神经网络方法ProbTalk3D,用于情感控制的语音驱动3D面部动画合成。
(3) 方法概述:采用两阶段VQ-VAE模型和丰富的情感动画数据集3DMEAD。第一阶段为运动自编码器阶段,通过VQ-VAE学习运动先验;第二阶段为语音和情感条件阶段,通过冻结运动自编码器,训练音频编码器以产生与运动潜空间相似的音频潜空间,并融合风格嵌入与编码的音频信息。通过这种方式,给定音频和风格输入,可以生成带有情感表达的语音动画。
(4) 具体实现:在第一阶段,通过运动编码器将输入运动数据编码为潜在空间,并利用向量量化技术学习离散潜空间嵌入代码本。在第二阶段,冻结运动自编码器,训练音频编码器以产生音频潜空间,并融合风格嵌入。最终,利用冻结的运动解码器将量化后的潜空间解码为面部动画数据。在训练过程中,使用多种损失函数来优化模型性能,包括量化损失、重建损失等。
(5) 评估方法:通过客观指标和主观评估方法对模型性能进行评估。客观指标包括量化损失和重建损失等,主观评估则通过用户感知研究进行。实验结果证明了ProbTalk3D模型在非确定性环境下进行情感控制的面部动画合成任务上的优越性。
8. Conclusion:
(1)这项工作的重要性在于它解决了现有面部动画合成模型在情感表达方面的缺失问题。通过引入非确定性神经网络方法ProbTalk3D,该研究实现了情感控制的语音驱动3D面部动画合成,使得面部动画更加多样、富有情感。
(2)创新点:本文首次将非确定性模型应用于情感控制的3D面部动画合成中,提出了一种两阶段VQ-VAE模型,并采用丰富的情感动画数据集3DMEAD进行训练。
性能:通过客观指标和主观评估方法的评价,ProbTalk3D模型在非确定性环境下进行情感控制的面部动画合成任务上取得了显著的成效,相对于现有的情感控制和非确定性模型表现出优越性。
工作量:文章采用了先进的神经网络架构和多种评估方法,实验设计合理,工作量较大。
点此查看论文截图


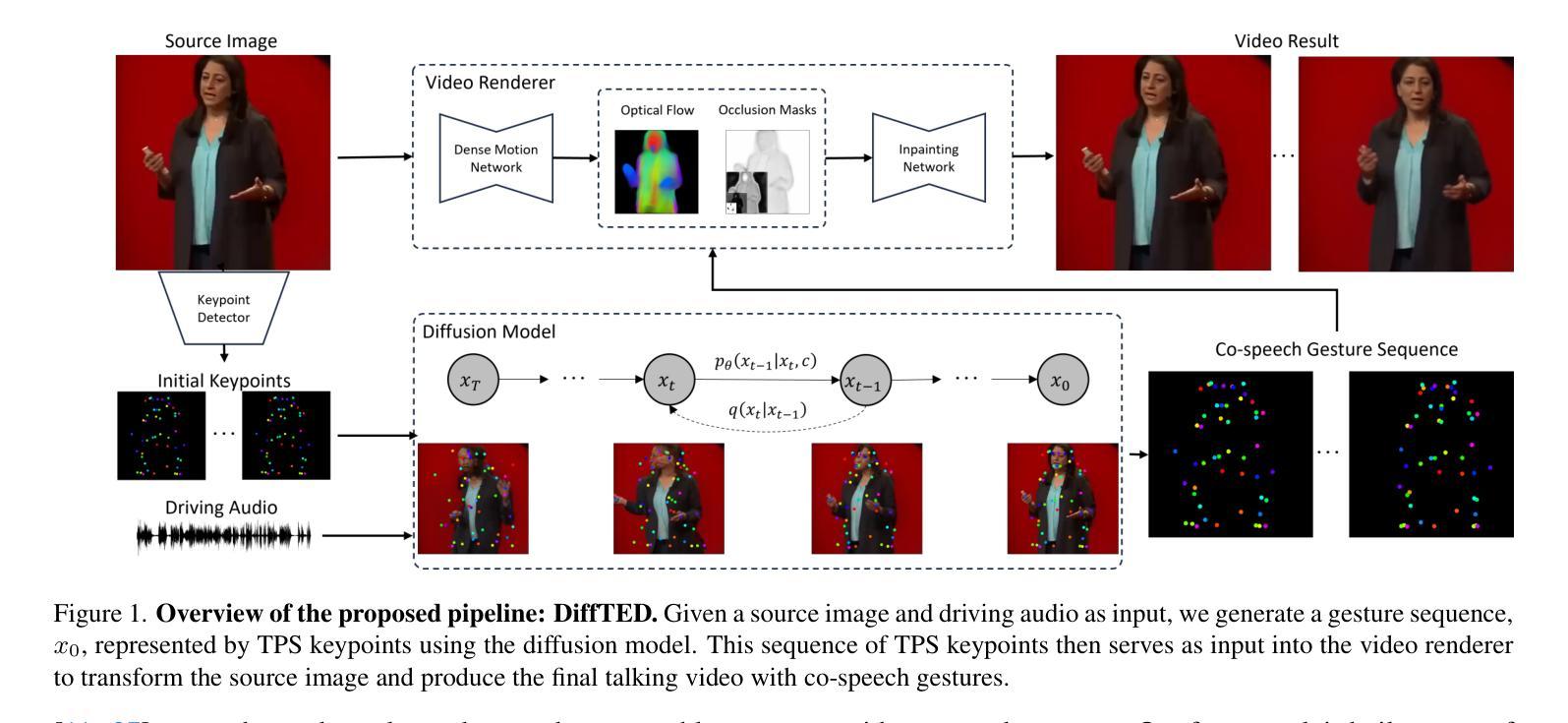
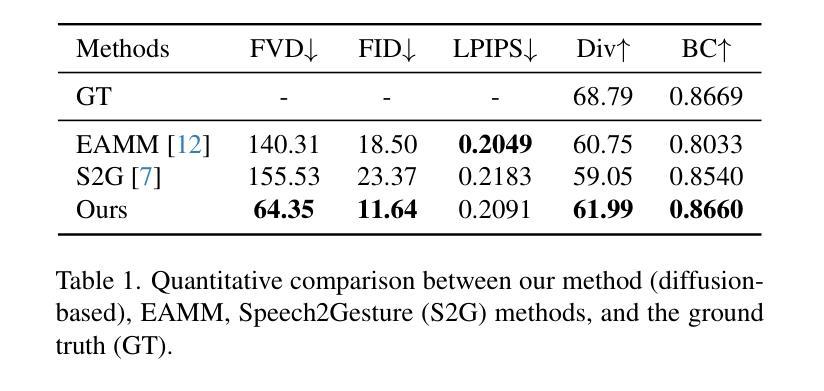
DiffTED: One-shot Audio-driven TED Talk Video Generation with Diffusion-based Co-speech Gestures
Authors:Steven Hogue, Chenxu Zhang, Hamza Daruger, Yapeng Tian, Xiaohu Guo
Audio-driven talking video generation has advanced significantly, but existing methods often depend on video-to-video translation techniques and traditional generative networks like GANs and they typically generate taking heads and co-speech gestures separately, leading to less coherent outputs. Furthermore, the gestures produced by these methods often appear overly smooth or subdued, lacking in diversity, and many gesture-centric approaches do not integrate talking head generation. To address these limitations, we introduce DiffTED, a new approach for one-shot audio-driven TED-style talking video generation from a single image. Specifically, we leverage a diffusion model to generate sequences of keypoints for a Thin-Plate Spline motion model, precisely controlling the avatar’s animation while ensuring temporally coherent and diverse gestures. This innovative approach utilizes classifier-free guidance, empowering the gestures to flow naturally with the audio input without relying on pre-trained classifiers. Experiments demonstrate that DiffTED generates temporally coherent talking videos with diverse co-speech gestures.
Summary
针对现有方法生成动作不连贯、缺乏多样性的问题,DiffTED通过扩散模型实现从单一图像到TED风格视频的一步生成,并确保动作连贯性和多样性。
Key Takeaways
- 现有方法依赖视频转视频技术,生成动作不连贯。
- 现有方法生成的动作通常平滑或单调,缺乏多样性。
- 许多以动作为核心的方法不整合头像生成。
- DiffTED提出一种从单一图像生成TED风格视频的新方法。
- 使用扩散模型生成关键点序列,控制动作动画。
- 确保动作时间上的连贯性和多样性。
- 利用无分类器的引导,使动作自然与音频输入同步。
标题:基于扩散模型的音频驱动TED演讲视频单帧生成技术
作者:Steven Hogue, 陈旭章, Hamza Daruger, Yapeng Tian, Xiaohu Guo
隶属机构:德克萨斯大学达拉斯分校
关键词:音频驱动、演讲视频生成、扩散模型、共语手势、TED演讲风格
链接:由于未提供论文链接和GitHub代码链接,无法填写。
摘要:
- (1)研究背景:随着音频驱动的谈话视频生成技术的不断发展,现有方法在很大程度上依赖于视频到视频的转换技术和传统的生成网络(如GANs),它们通常将头部和共语手势分开生成,导致输出不够连贯。此外,现有方法产生的手势往往过于平滑或过于平淡,缺乏多样性,且许多以手势为中心的方法并不整合讲话头部生成。本文旨在解决这些问题。
- (2)过去的方法及问题:现有的音频驱动谈话视频生成方法主要依赖于视频到视频的转换技术和传统生成网络,产生的结果常常缺乏连贯性和多样性。同时,许多方法没有很好地将共语手势与头部动作相结合,使得生成的视频不够自然。
- (3)研究方法:本文提出一种名为DiffTED的新方法,用于从单张图片生成TED风格的音频驱动谈话视频。该方法利用扩散模型生成Thin-Plate Spline运动模型的关键点序列,精确控制角色的动画,同时确保手势在时间上连贯且多样。此外,该方法采用无分类器引导,使手势能够自然地随音频输入流动,而无需依赖预训练分类器。
- (4)任务与性能:本文的方法用于生成TED风格的音频驱动谈话视频,并在实验中证明了其生成的视频在时间上具有连贯性且共语手势多样。由于采用了扩散模型和Thin-Plate Spline运动模型,该方法能够生成高质量的视频,支持其设定的目标。
希望以上回答符合您的要求。
7. Methods:
- (1) 研究背景分析:文章首先分析了现有的音频驱动谈话视频生成技术的不足,如依赖视频到视频的转换技术和传统生成网络,产生的结果缺乏连贯性和多样性,以及未能很好地结合共语手势和头部动作等问题。
- (2) 方法引入:针对现有问题,文章提出了一种基于扩散模型的音频驱动TED演讲视频单帧生成技术(DiffTED)。该方法利用扩散模型生成Thin-Plate Spline运动模型的关键点序列,实现对角色动画的精确控制。
- (3) 技术特点:DiffTED方法确保生成的手势在时间上连贯且多样,同时采用无分类器引导,使手势能够自然地随音频输入流动,无需依赖预训练分类器。此外,该方法能够从单张图片生成TED风格的音频驱动谈话视频。
- (4) 实验验证:文章通过实验验证了该方法的有效性,证明其生成的视频在时间上具有连贯性且共语手势多样,能够生成高质量的视频。
希望以上内容符合您的要求。
8. Conclusion:
(1) 这项工作的意义在于提出了一种基于扩散模型的音频驱动TED演讲视频单帧生成技术(DiffTED),解决了现有音频驱动谈话视频生成技术在连贯性和多样性方面存在的问题,并能够根据单张图片生成TED风格的音频驱动谈话视频,为教育性演讲视频的生成和虚假视频的识别提供了可能。
(2) 创新点:该文章的创新之处在于利用扩散模型生成Thin-Plate Spline运动模型的关键点序列,实现对角色动画的精确控制,确保生成的手势在时间上连贯且多样,同时采用无分类器引导,使手势能够自然地随音频输入流动。
性能:实验验证了该方法的有效性,证明其生成的视频在时间上具有连贯性且共语手势多样,能够生成高质量的视频。
工作量:文章进行了详尽的方法介绍和实验验证,但并未提供论文链接和GitHub代码链接,无法评估其实际工作量。
点此查看论文截图



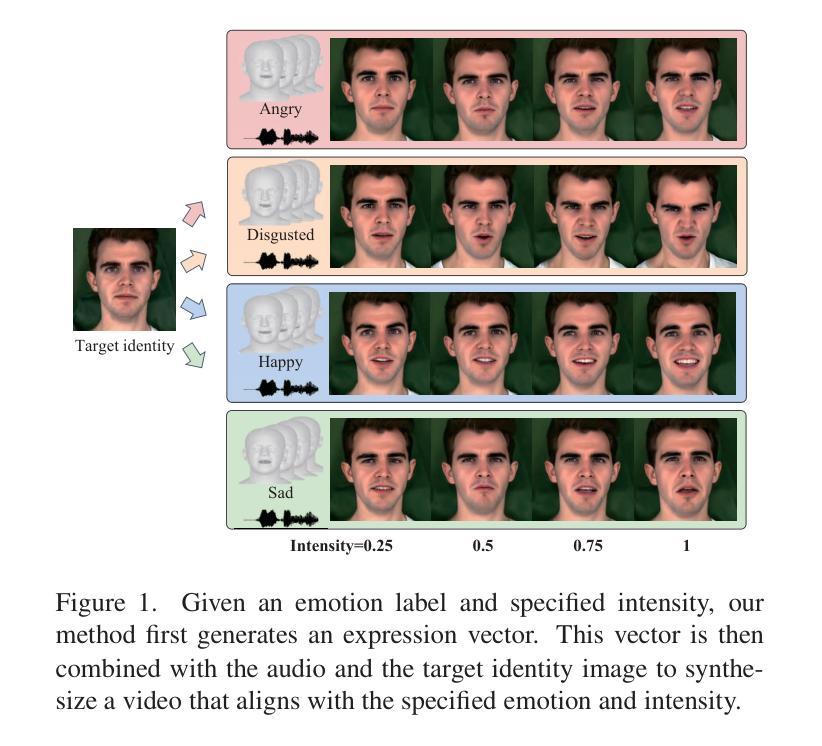
EMOdiffhead: Continuously Emotional Control in Talking Head Generation via Diffusion
Authors:Jian Zhang, Weijian Mai, Zhijun Zhang
The task of audio-driven portrait animation involves generating a talking head video using an identity image and an audio track of speech. While many existing approaches focus on lip synchronization and video quality, few tackle the challenge of generating emotion-driven talking head videos. The ability to control and edit emotions is essential for producing expressive and realistic animations. In response to this challenge, we propose EMOdiffhead, a novel method for emotional talking head video generation that not only enables fine-grained control of emotion categories and intensities but also enables one-shot generation. Given the FLAME 3D model’s linearity in expression modeling, we utilize the DECA method to extract expression vectors, that are combined with audio to guide a diffusion model in generating videos with precise lip synchronization and rich emotional expressiveness. This approach not only enables the learning of rich facial information from emotion-irrelevant data but also facilitates the generation of emotional videos. It effectively overcomes the limitations of emotional data, such as the lack of diversity in facial and background information, and addresses the absence of emotional details in emotion-irrelevant data. Extensive experiments and user studies demonstrate that our approach achieves state-of-the-art performance compared to other emotion portrait animation methods.
PDF 12 pages, 7 figures
Summary
提出EMOdiffhead,实现情感驱动的说话头视频生成,突破传统限制,性能卓越。
Key Takeaways
- EMOdiffhead可生成情感驱动的说话头视频。
- 方法支持细粒度情感控制与编辑。
- 利用FLAME模型和DECA方法提取表情向量。
- 结合音频引导扩散模型,实现精确唇同步。
- 从情感无关数据学习丰富面部信息。
- 克服情感数据多样性不足问题。
- 实验与用户研究证明性能领先。
标题:基于扩散模型的音频驱动情感肖像动画生成
作者:作者名称(具体名称需要根据原文提供)
隶属机构:某大学计算机视觉与人工智能实验室
关键词:音频驱动肖像动画、情感生成、扩散模型、表情建模、UNet、3D人脸重建
Urls:论文链接(如果可用),Github代码链接(如果可用,填写为“Github:None”如果不可用)
总结:
(1)研究背景:本文的研究背景是音频驱动的肖像动画生成任务,特别是在生成具有精确情感表达能力的谈话头视频方面的挑战。现有方法往往难以同时实现精细的情感控制和视频质量,因此本文提出了一种新的解决方案。
(2)过去的方法及其问题:过去的方法主要关注唇同步和视频质量,但很少解决生成情感驱动谈话头视频的挑战。由于缺乏情感控制和数据多样性问题,现有方法难以生成具有丰富情感表达的视频。
(3)研究方法:本文提出了一种名为EMOdiffhead的新方法,用于情感谈话头视频生成。该方法结合了扩散模型和条件机制,以生成具有精确唇同步和丰富情感表达的视频。首先,使用FLAME 3D模型提取表情向量,并结合音频引导扩散模型。通过利用时间条件UNet和交叉注意力块,实现情感类别和强度的精细控制。此外,还引入了一种新的条件残差块以实现更好的结果。
(4)任务与性能:本文的方法在生成具有精确情感表达能力的谈话头视频方面取得了显著成果。通过在各种实验和用户研究中的表现,证明了该方法相较于其他情感肖像动画方法的优越性。性能结果支持了该方法的有效性。
请注意,以上内容是根据您提供的信息进行的概括,具体细节可能需要参考原始论文。
7. 方法:
(1) 研究背景与问题定义:本文研究音频驱动的肖像动画生成任务,特别是在生成具有精确情感表达能力的谈话头视频方面的挑战。过去的方法主要关注唇同步和视频质量,但难以生成具有丰富情感表达的视频。
(2) 方法概述:本文提出了一种名为EMOdiffhead的新方法,用于情感谈话头视频生成。该方法结合了扩散模型和条件机制。
(3) 表情向量提取与扩散模型结合:使用FLAME 3D模型提取表情向量,结合音频引导扩散模型。通过时间条件UNet和交叉注意力块,实现情感类别和强度的精细控制。
(4) 引入新的条件残差块:为提高生成视频的质量,引入了一种新的条件残差块。
(5) 实验与评估:通过大量实验和用户研究,对提出的EMOdiffhead方法进行了评估。实验结果表明,该方法在生成具有精确情感表达能力的谈话头视频方面取得了显著成果,相较于其他情感肖像动画方法具有优越性。
注:以上内容根据论文摘要进行概括,具体细节和实现方式需参考原始论文。
8. Conclusion:
(1)该工作的意义在于提出了一种名为EMOdiffhead的新方法,解决了音频驱动肖像动画生成中情感表达的精确性问题。通过对情感类型和强度的精细控制,该方法提高了谈话头视频的情感表达能力,进一步推动了情感肖像动画领域的进展。同时,该研究也为计算机视觉和人工智能领域提供了一种新的思路和方法。
(2)创新点:该研究提出了一种结合扩散模型和条件机制的EMOdiffhead方法,实现了情感谈话头视频生成中的精确唇同步和丰富情感表达。该方法通过引入时间条件UNet和交叉注意力块等新技术手段,实现了对情感类别和强度的精细控制,提高了生成视频的质量和自然度。此外,该研究还引入了一种新的条件残差块,进一步优化了生成结果。
性能:该研究通过大量实验和用户研究对提出的EMOdiffhead方法进行了评估,实验结果表明该方法在生成具有精确情感表达能力的谈话头视频方面取得了显著成果,相较于其他情感肖像动画方法具有优越性。这表明该研究提出的方法具有较高的性能和稳定性。
工作量:该研究涉及了大量的理论分析和实验设计,需要进行大量的数据处理和模型训练等工作。同时,该研究还需要对现有的计算机视觉和人工智能技术进行深入研究和分析,以确定研究中的技术路线和方法选择。因此,该研究的工作量较大。
点此查看论文截图


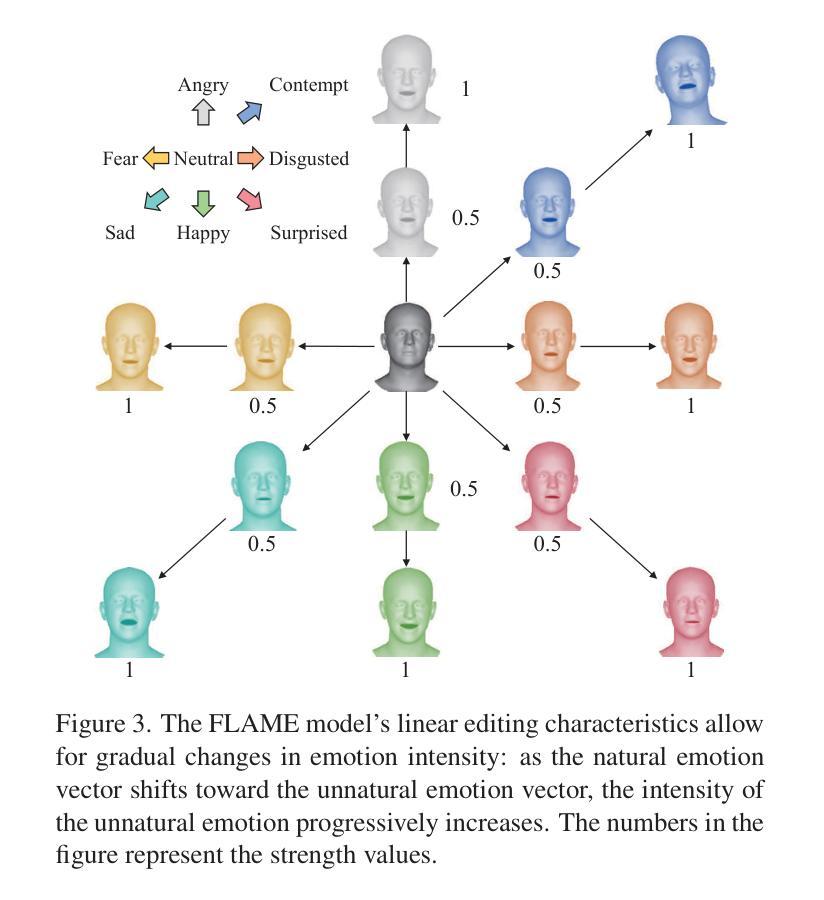
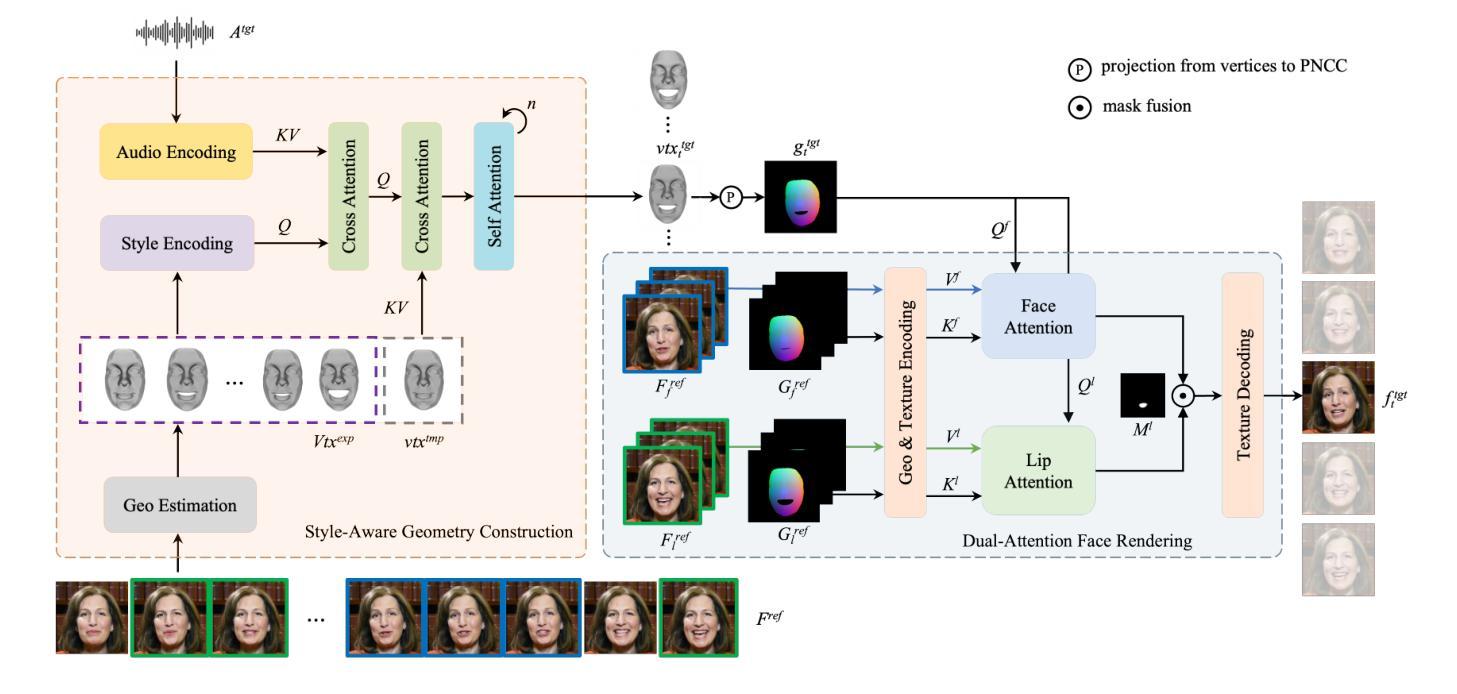
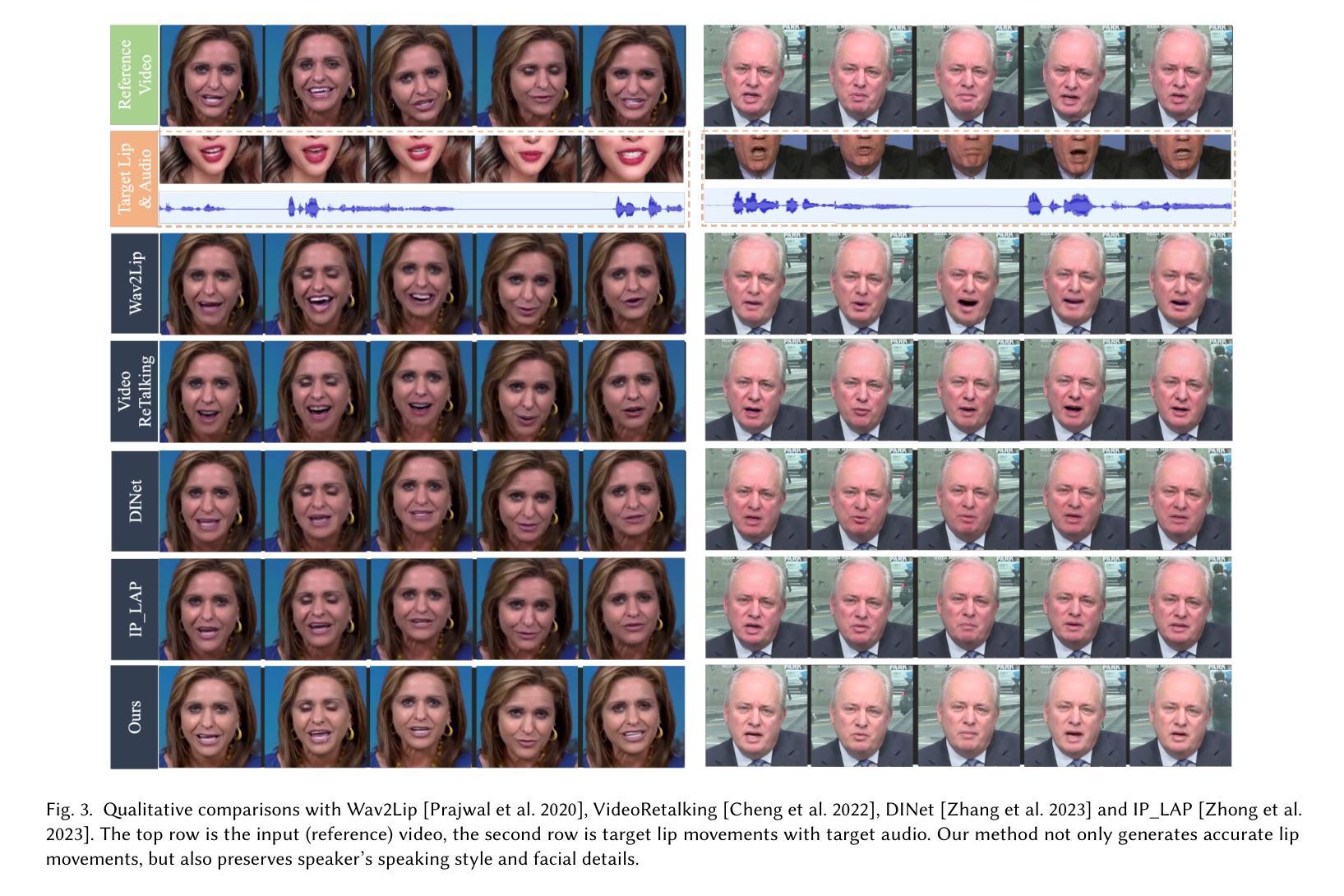
PersonaTalk: Bring Attention to Your Persona in Visual Dubbing
Authors:Longhao Zhang, Shuang Liang, Zhipeng Ge, Tianshu Hu
For audio-driven visual dubbing, it remains a considerable challenge to uphold and highlight speaker’s persona while synthesizing accurate lip synchronization. Existing methods fall short of capturing speaker’s unique speaking style or preserving facial details. In this paper, we present PersonaTalk, an attention-based two-stage framework, including geometry construction and face rendering, for high-fidelity and personalized visual dubbing. In the first stage, we propose a style-aware audio encoding module that injects speaking style into audio features through a cross-attention layer. The stylized audio features are then used to drive speaker’s template geometry to obtain lip-synced geometries. In the second stage, a dual-attention face renderer is introduced to render textures for the target geometries. It consists of two parallel cross-attention layers, namely Lip-Attention and Face-Attention, which respectively sample textures from different reference frames to render the entire face. With our innovative design, intricate facial details can be well preserved. Comprehensive experiments and user studies demonstrate our advantages over other state-of-the-art methods in terms of visual quality, lip-sync accuracy and persona preservation. Furthermore, as a person-generic framework, PersonaTalk can achieve competitive performance as state-of-the-art person-specific methods. Project Page: https://grisoon.github.io/PersonaTalk/.
PDF Accepted at SIGGRAPH Asia 2024 (Conference Track)
Summary
提出基于注意力的PersonaTalk框架,实现个性化视觉配音的高保真度和真实性。
Key Takeaways
- 语音驱动的视觉配音面临保持说话者个性和精确唇形同步的挑战。
- PersonaTalk框架包含几何构建和面部渲染两个阶段。
- 第一阶段采用风格感知音频编码模块,通过交叉注意力层将说话风格注入音频特征。
- 第二阶段引入双重注意力面部渲染器,分别从不同参考帧采样纹理渲染整个面部。
- 实验和用户研究表明,PersonaTalk在视觉质量、唇形同步准确性和个性保持方面优于现有方法。
- PersonaTalk作为通用人脸框架,在性能上可与其他针对特定人脸的方法相媲美。
- 可访问项目页面获取更多详情:https://grisoon.github.io/PersonaTalk/。
标题: PersonaTalk:视觉配音中的个性化关注
作者: Longhao Zhang(张龙豪)、Shuang Liang(梁爽)、Zhipeng Ge(葛志鹏)、Tianshu Hu(胡天舒)
作者隶属机构: 中国字节跳动
关键词: 视觉配音、唇同步、注意力机制
链接: 请根据论文实际链接填写,例如:论文链接,Github代码链接(如可用):Github: None
摘要:
(1) 研究背景:
随着音频驱动视觉配音技术的广泛应用,如何在合成高质量唇同步视频的同时,突出演讲者的个性,如说话风格和面部细节,成为了一个重要的挑战。本文旨在解决这一挑战。
(2) 过去的方法及问题:
现有的方法在音频驱动的视觉配音中往往难以捕捉演讲者的独特说话风格或保留面部细节。文章作者观察到这一痛点,并认为需要通过一种新的方法来解决。
(3) 研究方法:
本文提出了一个名为PersonaTalk的注意力机制两阶段框架,用于实现高质量和个性化的视觉配音。第一阶段是风格感知音频编码模块,通过交叉注意力层将说话风格注入音频特征。然后,使用这些特征驱动演讲者的模板几何来获得唇同步的几何形状。在第二阶段,引入了一个双注意力面部渲染器,通过两个平行的交叉注意力层(即唇注意力和面部注意力)从参考帧中渲染目标几何的纹理。整个设计能够很好地保留面部细节。
(4) 任务与性能:
本文的方法在视觉配音任务上进行了实验和用户研究,展示了在视觉质量、唇同步准确性和个性保留方面的优势。与其他最先进的方法相比,该方法具有竞争力。此外,作为一个人通用的框架,它还能在个性化任务上实现与个性化方法相当的性能。方法论:
(1) 研究背景分析:随着音频驱动视觉配音技术的广泛应用,如何同时合成高质量唇同步视频并突出演讲者的个性成为了一个重要的挑战。文章针对这一挑战展开研究。
(2) 过去方法及问题分析:现有方法在音频驱动的视觉配音中往往难以捕捉演讲者的独特说话风格或保留面部细节。文章作者针对这一痛点提出了新方法。
(3) 方法论概述:本文提出了一个名为PersonaTalk的注意力机制两阶段框架,用于实现高质量和个性化的视觉配音。第一阶段是风格感知音频编码模块,通过交叉注意力层将说话风格注入音频特征,驱动演讲者的模板几何获得唇同步的几何形状。第二阶段引入了双注意力面部渲染器,通过两个平行的交叉注意力层(即唇注意力和面部注意力)从参考帧中渲染目标几何的纹理,保留面部细节。整体设计旨在确保在合成视觉配音时能够同时实现高质量和个性化。
(4) 实验与评估:本文的方法在视觉配音任务上进行了实验和用户研究,通过对比实验和用户反馈验证了该方法在视觉质量、唇同步准确性和个性保留方面的优势。此外,该框架作为一个人通用的框架,在个性化任务上的性能也相当出色。
8. 结论:
(1)工作意义:该论文针对音频驱动的视觉配音技术中的个性化问题进行了深入研究,提出了一种基于注意力机制的两阶段框架,旨在实现高质量且个性化的视觉配音,具有重要的实际应用价值。
(2)创新点、性能和工作量总结:
- 创新点:该论文提出了一个名为PersonaTalk的注意力机制框架,通过风格感知音频编码模块和双注意力面部渲染器,实现了高质量和个性化的视觉配音。该框架能够捕捉演讲者的独特说话风格并保留面部细节,与现有方法相比具有竞争力。
- 性能:实验和用户研究结果表明,该方法在视觉质量、唇同步准确性和个性保留方面均表现出优势。与其他最先进的方法相比,该框架具有竞争力,并且在个性化任务上的性能也相当出色。
- 工作量:论文对方法的实现进行了详细的描述,并通过实验和用户研究对方法进行了验证。然而,关于工作量方面,论文未提供具体的工作量评估,如代码复杂度、计算资源消耗等。
总体来说,该论文在音频驱动的视觉配音技术方面取得了显著的进展,提出了一个具有竞争力的个性化视觉配音框架,并在实验和用户研究中验证了其有效性。
点此查看论文截图

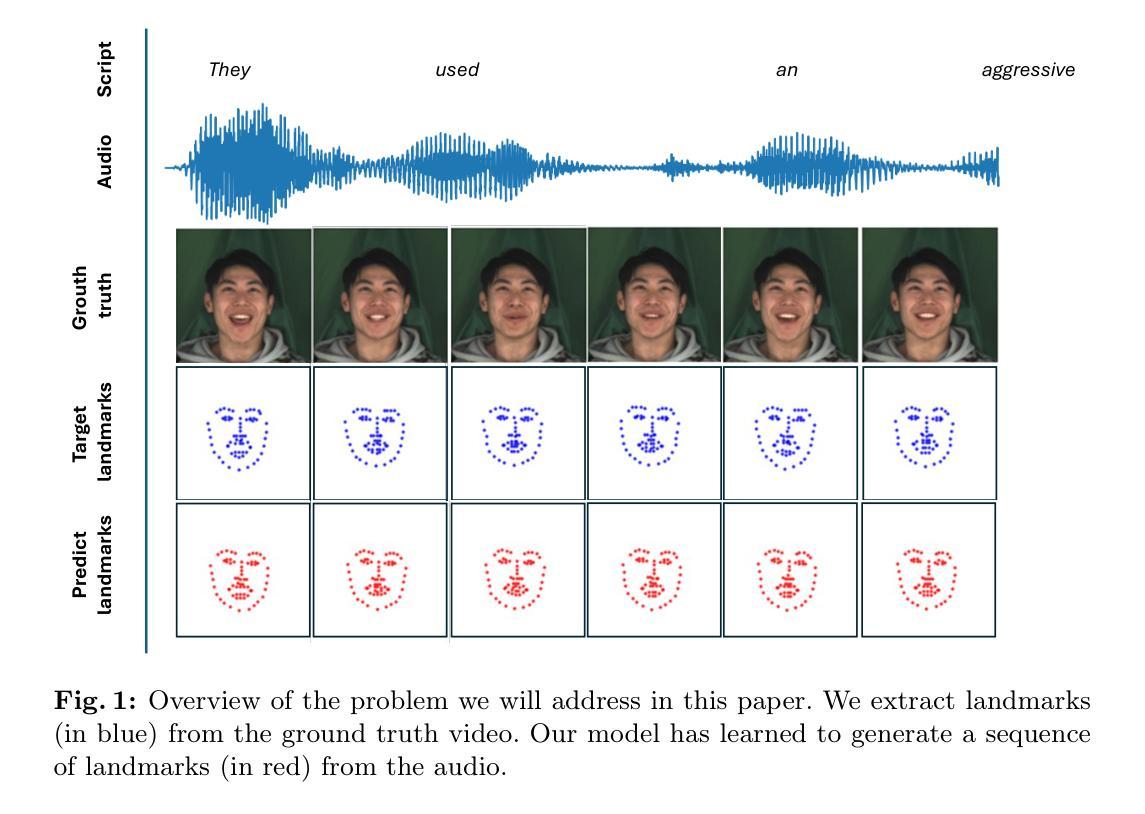
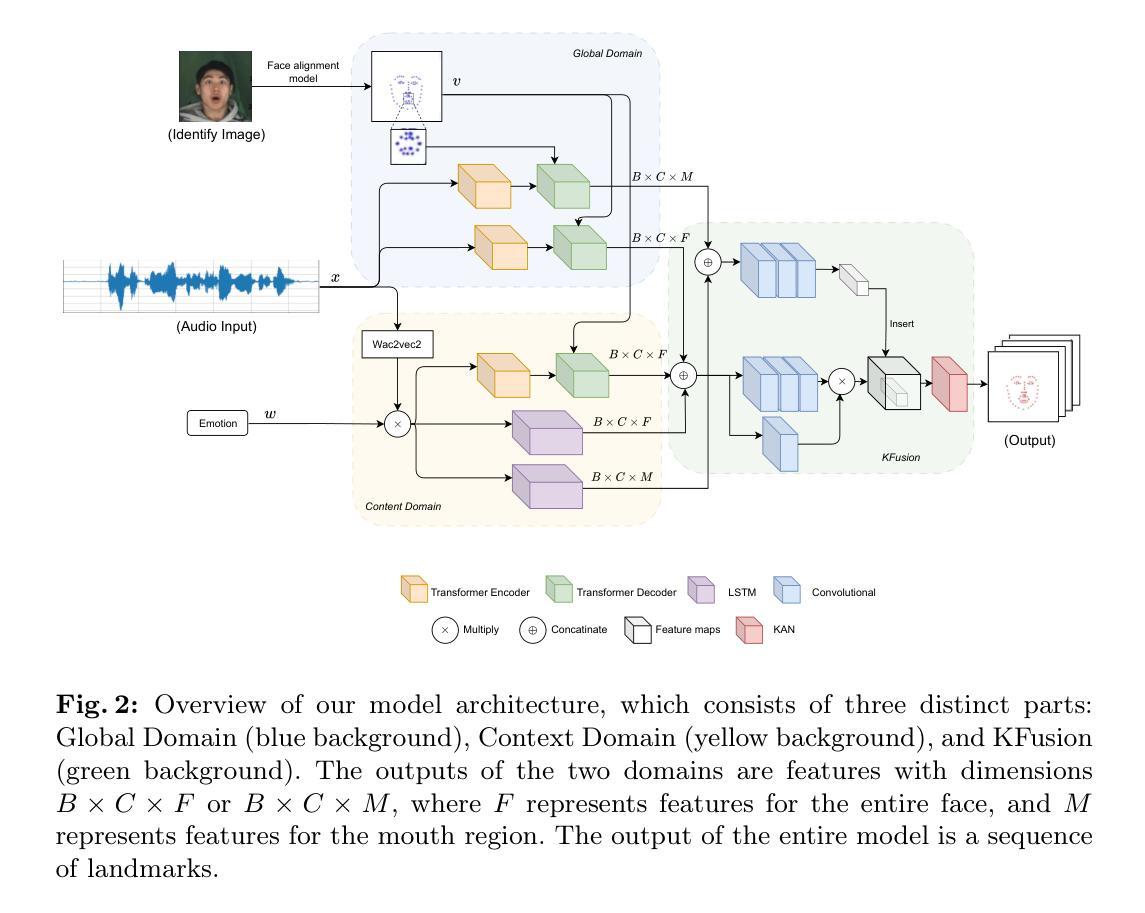
KAN-Based Fusion of Dual-Domain for Audio-Driven Facial Landmarks Generation
Authors:Hoang-Son Vo-Thanh, Quang-Vinh Nguyen, Soo-Hyung Kim
Audio-driven talking face generation is a widely researched topic due to its high applicability. Reconstructing a talking face using audio significantly contributes to fields such as education, healthcare, online conversations, virtual assistants, and virtual reality. Early studies often focused solely on changing the mouth movements, which resulted in outcomes with limited practical applications. Recently, researchers have proposed a new approach of constructing the entire face, including face pose, neck, and shoulders. To achieve this, they need to generate through landmarks. However, creating stable landmarks that align well with the audio is a challenge. In this paper, we propose the KFusion of Dual-Domain model, a robust model that generates landmarks from audio. We separate the audio into two distinct domains to learn emotional information and facial context, then use a fusion mechanism based on the KAN model. Our model demonstrates high efficiency compared to recent models. This will lay the groundwork for the development of the audio-driven talking face generation problem in the future.
Summary
音频驱动的人脸生成研究广泛,提出基于双域模型的KFusion,高效生成与音频对齐的稳定关键点。
Key Takeaways
- 音频驱动人脸生成应用广泛。
- 早期研究仅关注口型变化。
- 新方法构建完整面部,包括姿态、颈部和肩部。
- 标记点生成需与音频对齐。
- 提出KFusion双域模型生成标记点。
- 模型分离音频至两个域学习情感和面部信息。
- 模型效率高,为未来研究奠定基础。
标题:基于双域的音频驱动面部特征点生成研究(KAN-Based Fusion of Dual-Domain for Audio-Driven Facial Landmarks Generation)
作者:Vo-Thanh Hoang-Son、Nguyen Quang-Vinh、Kim Soo-Hyung(其中第一个名字是姓氏)
所属机构:韩国庆北国立大学人工智能融合学院。
关键词:音频驱动谈话面部生成、情感谈话面部、音频到特征点。
Urls:文章链接未提供,GitHub代码链接未提供。
总结:
(1) 研究背景:音频驱动的谈话面部生成是一个热门的研究领域,具有广泛的应用前景,如教育、医疗、在线对话等。随着研究的深入,该领域逐渐从单纯的改变口型动作转向构建整个面部的动作,包括头部姿态、颈部和肩部动作等。因此,需要生成面部特征点来实现这一目的。然而,创建一个与音频良好匹配的稳定特征点是一个挑战。本研究旨在解决这一问题。
(2) 过去的方法及问题:早期的研究主要关注于改变口型动作,结果具有有限的实用性。近期的研究提出了一种构建整个面部的新方法,但需要生成特征点来实现。然而,现有的方法难以创建稳定的特征点,这些特征点需要与音频良好匹配。因此,有必要提出一种新的方法来改善这一问题。本论文提出的方法被充分激发并针对性地解决现有方法的问题。
(3) 研究方法:本研究提出了基于双域的KFusion模型来生成音频驱动的特征点。首先,将音频分为两个独立领域来学习情感信息和面部上下文。然后,使用基于KAN模型的融合机制来结合这两个领域的信息。这种方法能够更有效地生成与音频匹配的特征点。
(4) 任务与性能:本论文的方法在音频驱动的面部特征点生成任务上取得了良好的性能。通过创建稳定的特征点,该方法能够生成更真实的面部动作和表情。实验结果表明,该方法在生成整个面部的动作方面优于近期的方法,为音频驱动的谈话面部生成问题的发展奠定了基础。性能结果支持了该方法的有效性。
7. 方法论:
- (1) 音频双域划分:首先,将音频信号分为两个独立领域。这一划分旨在提取音频中的情感信息和面部上下文信息。这两个领域将分别处理不同方面的信息,为后续的特征点生成提供数据基础。
- (2) 基于KAN模型的融合机制:对于划分后的两个领域的信息,研究提出了基于KAN模型的融合机制。该机制通过特定的算法将两个领域的信息结合,实现信息的有效整合和综合利用。这一步骤是方法的核心部分,它直接影响到后续特征点的生成质量。
- (3) 音频驱动的面部特征点生成:结合前两个步骤得到的信息,该方法进一步用于生成音频驱动的面部特征点。这些特征点能够反映音频中的情感信息和面部上下文信息,使得生成的面部动作更加真实、自然。这一步需要依赖于前面的数据处理和融合过程。
- (4) 性能评估:为了验证方法的有效性,研究通过一系列实验对该方法进行了性能评估。实验结果表明,该方法在音频驱动的面部特征点生成任务上取得了良好的性能,相较于近期的方法具有优势。这也证明了方法的有效性和实用性。
总体来说,这篇文章提出了一种基于双域的KFusion模型来生成音频驱动的面部特征点的方法。该方法通过划分音频信号、融合情感信息和面部上下文信息,实现了真实、自然的面部动作生成。实验结果证明了该方法的有效性。
8. Conclusion:
(1) 研究意义:这项工作对于音频驱动的面部特征点生成领域具有重要意义。它提出了一种基于双域的KFusion模型,能够有效生成与音频匹配的面部特征点,为音频驱动的谈话面部生成问题的发展奠定了基础。该研究的成果在教育、医疗、在线对话等领域具有广泛的应用前景。
(2) 创新点、性能、工作量评估:
* 创新点:该研究提出了一种新的基于双域的音频驱动面部特征点生成方法,通过划分音频信号并融合情感信息和面部上下文信息,实现了真实、自然的面部动作生成。
* 性能:实验结果表明,该方法在音频驱动的面部特征点生成任务上取得了良好的性能,相较于近期的方法具有优势。
* 工作量:文章对音频信号的处理、模型的构建、实验的设计等方面进行了详细阐述,工作量较大。然而,文章未提供代码链接,无法对实现的复杂度和代码量进行准确评估。
点此查看论文截图