⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-24 更新
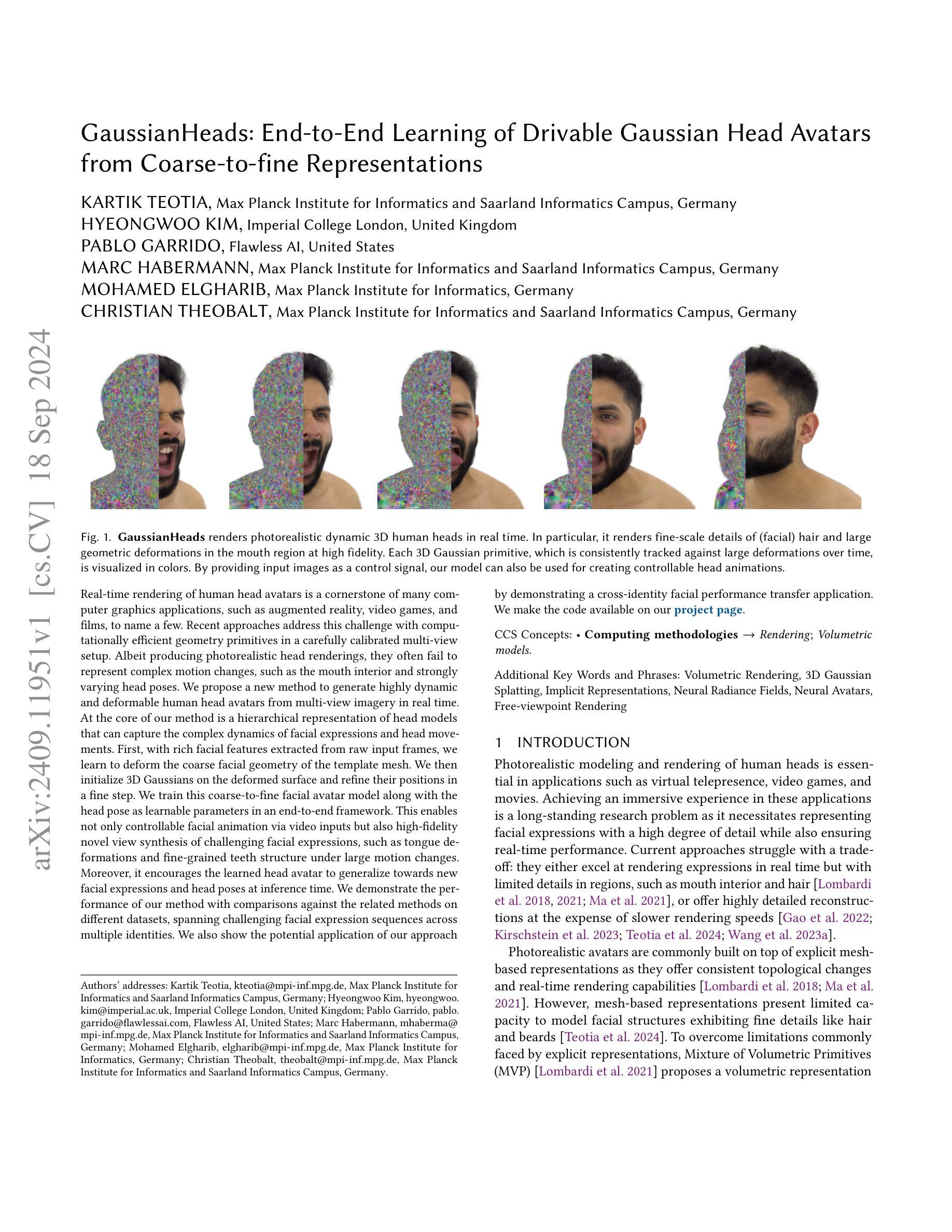
GaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations
Authors:Kartik Teotia, Hyeongwoo Kim, Pablo Garrido, Marc Habermann, Mohamed Elgharib, Christian Theobalt
Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.
PDF ACM Transaction on Graphics (SIGGRAPH Asia 2024); Project page: https://vcai.mpi-inf.mpg.de/projects/GaussianHeads/
Summary
基于多视角图像实时生成动态可变形虚拟人头部模型。
Key Takeaways
- 实时渲染人像头部在AR、游戏、电影等领域应用广泛。
- 现有方法在处理复杂运动变化如口腔内部和头部姿态变化时存在不足。
- 提出一种基于多视角图像的实时动态头部模型生成方法。
- 采用分层表示捕捉面部表情和头部运动的复杂动态。
- 通过学习原始帧的丰富面部特征,变形模板网格的粗略面部几何形状。
- 初始化3D高斯并在细粒度上调整其位置,训练粗到细的头部模型。
- 实现可控的面部动画和高保真新型视图合成,支持跨身份面部表现迁移。
Title: 高斯头模型:实时学习的驱动式高斯头像端对端学习
Authors: Kartik Teotia,Hyeongwoo Kim,Pablo Garrido,Marc Habermann,Mohamed Elgharib,Christian Theobalt
Affiliation: 第一作者为Max Planck Institute for Informatics和Saarland Informatics Campus。其余作者分布在不同机构。
Keywords: Gaussian Head Model; Real-time Rendering; End-to-End Learning; Volumetric Rendering; 3D Gaussian Splatting; Neural Avatars等。
Summary:
- (1) 研究背景:本文研究如何创建高度逼真且可实时渲染的3D人像模型,特别关注人脸表情的细节和实时性能的需求。这在虚拟现场出席、电子游戏和电影等领域具有广泛的应用价值。现有的方法常常面临在细节和实时性能之间的权衡问题。
- (2) 过去的方法及其问题:当前的方法主要通过使用高效几何原语在精心校准的多视角设置下解决这一挑战。虽然这些方法可以产生逼真的头部渲染,但它们往往无法表示复杂的运动变化,如嘴巴内部和头部姿势的大幅变化。因此,对一种能够捕捉复杂面部动态的新方法的需求是迫切的。
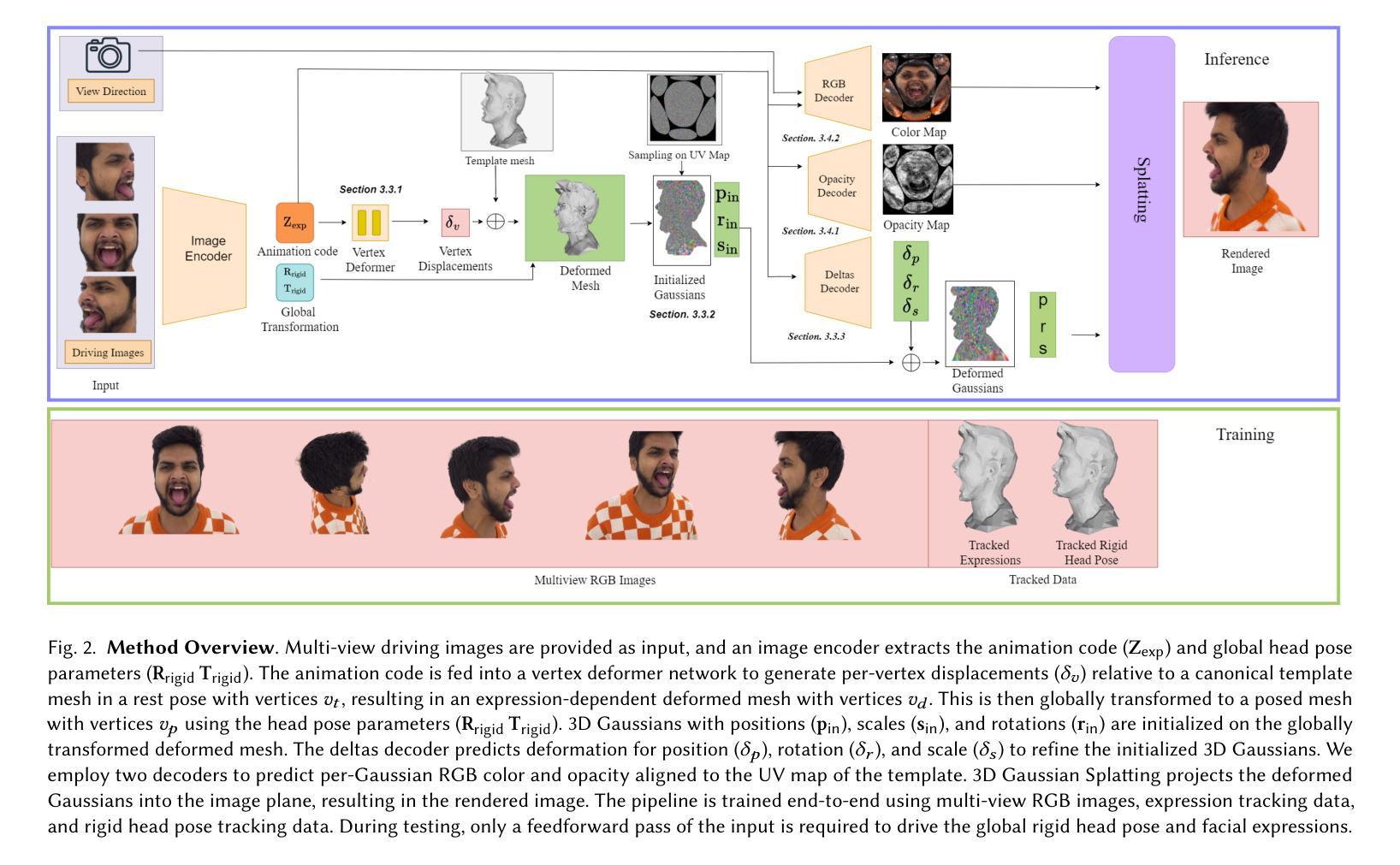
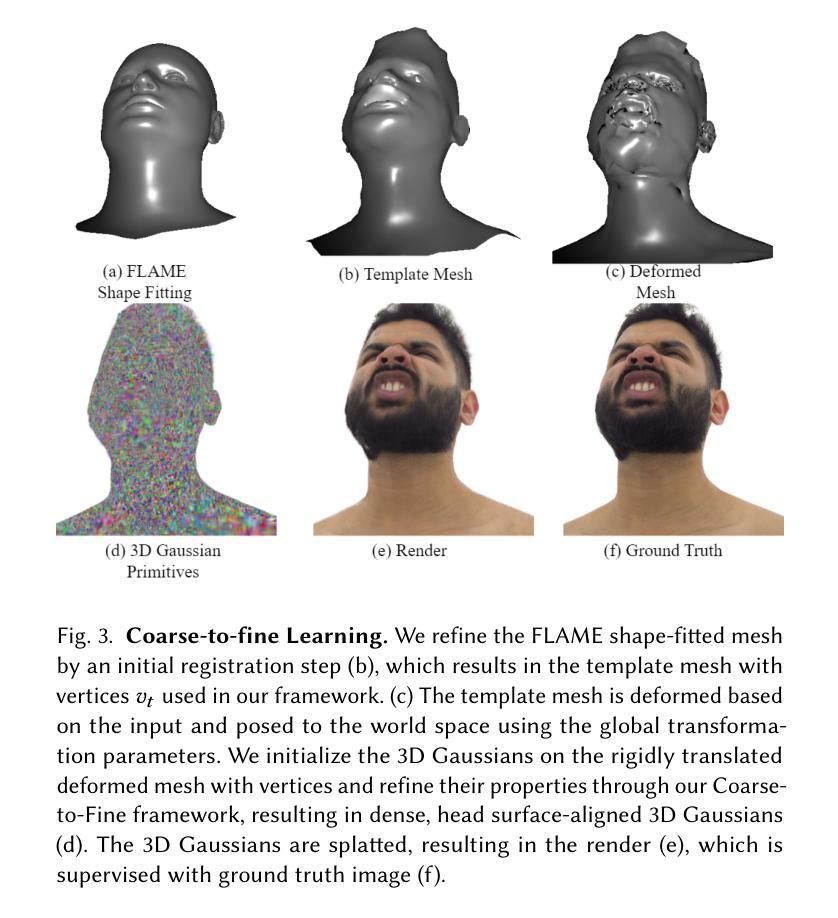
- (3) 研究方法:本文提出了一种基于多视角图像实时生成高度动态和可变形头部模型的新方法。核心在于一种层次化的头部模型表示,可以捕捉面部表情和头部运动的复杂动态。首先通过提取原始帧的丰富面部特征来变形模板网格的粗糙面部几何。然后在变形的表面上初始化三维高斯分布,并在精细步骤中微调其位置。通过端到端的框架学习这种粗细面部动画模型以及与头部姿态相关的参数。这使得不仅可以通过视频输入控制面部动画,还可以实现具有挑战性的面部表情的高保真新视角合成,如舌头变形和精细的牙齿结构的大幅运动变化。此外,它鼓励学习到的头部模型在推理时间对新的面部表情和头部姿势进行泛化。
- (4) 任务与性能:本文的方法在具有挑战性的面部表情序列和不同身份的数据集上进行了比较测试,展示了其优越性。此外,还展示了该方法在跨身份面部性能转移应用中的潜力。实验结果表明,该方法在生成高度逼真且可驱动的头部模型方面取得了显著进展,尤其是在细节渲染和实时性能方面。
方法论:
(1) 研究背景:本文研究如何创建高度逼真且可实时渲染的3D人像模型,特别关注人脸表情的细节和实时性能的需求。在虚拟现场出席、电子游戏和电影等领域具有广泛的应用价值。现有的方法常常面临在细节和实时性能之间的权衡问题。
(2) 过去的方法及其问题:之前的方法主要通过使用高效几何原语在精心校准的多视角设置下解决这一挑战。虽然这些方法可以产生逼真的头部渲染,但它们往往无法表示复杂的运动变化,如嘴巴内部和头部姿势的大幅变化。因此,对一种能够捕捉复杂面部动态的新方法的需求是迫切的。
(3) 研究方法:本文提出了一种基于多视角图像实时生成高度动态和可变形头部模型的新方法。核心在于一种层次化的头部模型表示,可以捕捉面部表情和头部运动的复杂动态。首先,通过提取原始帧的丰富面部特征来变形模板网格的粗糙面部几何。然后在变形的表面上初始化三维高斯分布,并在精细步骤中微调其位置。通过端到端的框架学习这种粗细面部动画模型以及与头部姿态相关的参数。这使得不仅可以通过视频输入控制面部动画,还可以实现具有挑战性的面部表情的高保真新视角合成,如舌头变形和精细的牙齿结构的大幅运动变化。
(4) 任务与性能:该方法在具有挑战性的面部表情序列和不同身份的数据集上进行了比较测试,展示了其优越性。此外,还展示了该方法在跨身份面部性能转移应用中的潜力。实验结果表明,该方法在生成高度逼真且可驱动的头部模型方面取得了显著进展,尤其是在细节渲染和实时性能方面。
(5) 具体实现步骤:
- 使用3D高斯【Kerbl等人,2023】作为基本表示,引入几种新颖的损失函数和设计选择,以确保高速渲染和高质重建。
- 利用多视角面部性能数据,通过端到端的框架学习粗到细的面部表达和头部运动捕捉策略。
- 训练过程中,采用基于多视角面部标志的跟踪实现来跟踪FLAME参数。
- 在测试时,只需通过训练好的编码器和解码器进行一次前向传递,即可渲染出主体。
- 通过高效的CNN基于解码器预测高斯属性的RGB值和透明度,结合快速光栅化技术实现实时渲染。
Conclusion:
- (1)工作意义:该论文的研究对于创建高度逼真且可实时渲染的3D人像模型具有重要意义,特别是在虚拟现场出席、电子游戏和电影等领域。它解决了在细节和实时性能之间权衡的难题,为创建高度逼真的头部模型提供了新的方法。
- (2)创新点、性能、工作量总结:
- 创新点:论文提出了一种基于多视角图像实时生成高度动态和可变形头部模型的新方法,该方法通过层次化的头部模型表示捕捉面部表情和头部运动的复杂动态。
- 性能:该方法在具有挑战性的面部表情序列和不同身份的数据集上进行了比较测试,展示了其优越性。实验结果表明,该方法在生成高度逼真且可驱动的头部模型方面取得了显著进展,尤其是在细节渲染和实时性能方面。
- 工作量:论文实现了高效的3D高斯表示、多视角面部性能数据利用、基于多视角面部标志的跟踪实现等关键技术,并通过端到端的框架进行了学习和优化。同时,论文还展示了该方法在跨身份面部性能转移应用中的潜力。
注:以上结论是对文章的一个大致总结,如果需要更详细或具体的评价,可能需要对论文进行更深入的研究和理解。
点此查看论文截图

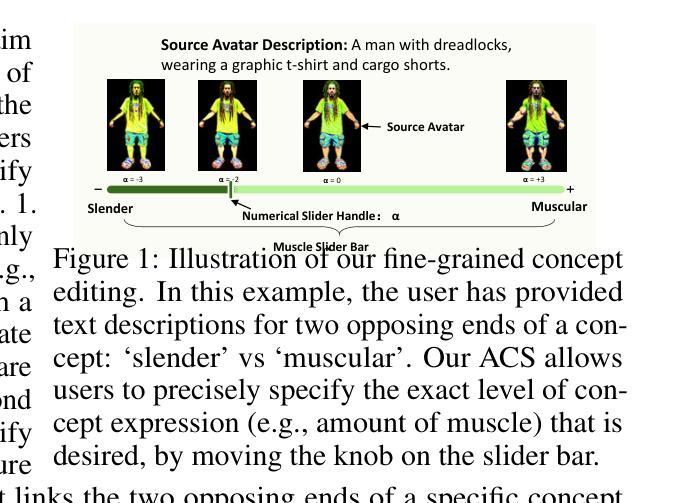
Avatar Concept Slider: Manipulate Concepts In Your Human Avatar With Fine-grained Control
Authors:Yixuan He, Lin Geng Foo, Ajmal Saeed Mian, Hossein Rahmani, Jun Liu
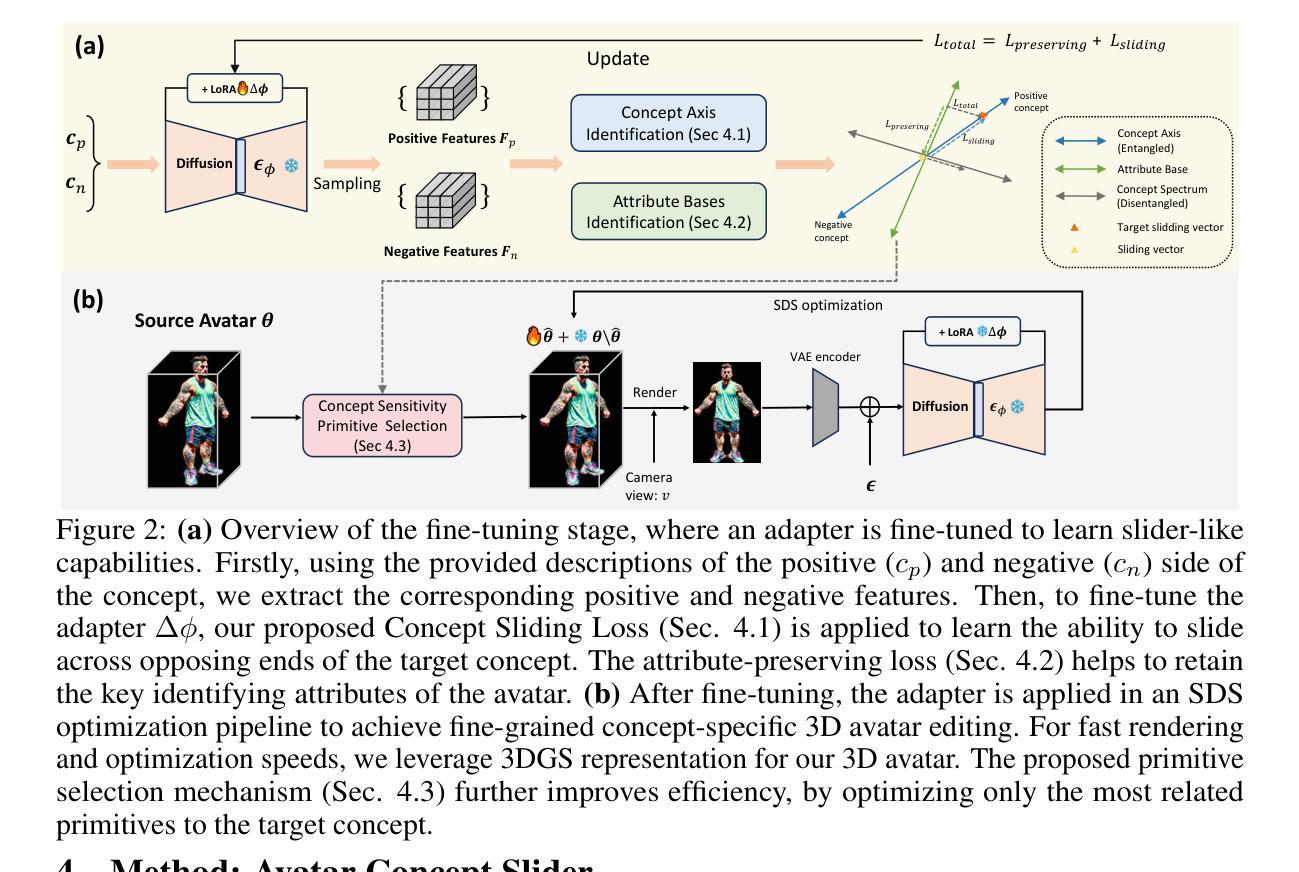
Language based editing of 3D human avatars to precisely match user requirements is challenging due to the inherent ambiguity and limited expressiveness of natural language. To overcome this, we propose the Avatar Concept Slider (ACS), a 3D avatar editing method that allows precise manipulation of semantic concepts in human avatars towards a specified intermediate point between two extremes of concepts, akin to moving a knob along a slider track. To achieve this, our ACS has three designs. 1) A Concept Sliding Loss based on Linear Discriminant Analysis to pinpoint the concept-specific axis for precise editing. 2) An Attribute Preserving Loss based on Principal Component Analysis for improved preservation of avatar identity during editing. 3) A 3D Gaussian Splatting primitive selection mechanism based on concept-sensitivity, which updates only the primitives that are the most sensitive to our target concept, to improve efficiency. Results demonstrate that our ACS enables fine-grained 3D avatar editing with efficient feedback, without harming the avatar quality or compromising the avatar’s identifying attributes.
Summary
基于语言编辑3D虚拟人像匹配用户需求挑战大,提出Avatar Concept Slider (ACS)方法,实现精确编辑。
Key Takeaways
- 语言编辑3D虚拟人像匹配难度高,因自然语言模糊性及表达有限。
- 提出3D虚拟人像编辑方法——Avatar Concept Slider (ACS)。
- ACS包括三个设计:基于线性判别分析的概念滑动损失、基于主成分分析的特征保留损失、基于概念敏感性的3D高斯分层原语选择机制。
- 精确编辑,优化反馈,不损害虚拟人像质量或身份特征。
- 实现细粒度3D虚拟人像编辑。
- 提高编辑效率。
- 保持虚拟人像原始特征。
标题:基于概念滑块的3D人物角色编辑方法研究
作者:何翊轩、林耿福、Ajmal Saeed Mian、侯赛因·拉赫曼尼、刘军
所属机构:何翊轩和林耿福来自新加坡技术设计大学,Ajmal Saeed Mian来自澳大利亚西澳大学,侯赛因·拉赫曼尼来自兰卡斯特大学,刘军也来自新加坡技术设计大学。
关键词:Avatar编辑、概念滑块、语言编辑、3D模型、精细控制
链接:论文链接。代码链接:Github:None(如果可用,请提供代码仓库链接)
摘要:
(1)研究背景:随着游戏开发、电影制作、虚拟角色创建等领域的快速发展,对3D人物角色的编辑需求日益增长。现有的基于文本的编辑方法存在模糊性和表达局限性,难以满足精细化的编辑需求。
(2)过去的方法及问题:现有的3D人物角色编辑方法主要依赖文本提示作为指导信号,存在表达模糊和局限性大的问题。这些方法难以实现对人物角色语义概念的精确操控。
(3)研究方法:本文提出了一种基于概念滑块的3D人物角色编辑方法。该方法通过概念滑块实现语义概念的精确操控,通过设计概念滑动损失、属性保留损失和基于概念敏感性的3D高斯样条选择机制,实现了精细化的编辑反馈和高效的编辑过程。
(4)任务与性能:本文的方法在创建和编辑个性化数字人物角色方面取得了良好效果。实验结果表明,该方法能够在不损害角色质量和不损害角色识别属性的情况下,实现精细化的3D人物角色编辑。这一性能支持了该方法的实用性和有效性。
请注意,以上内容仅根据您提供的论文摘要和引言进行概括,具体的实验细节、方法实施和性能分析需要在阅读全文后进行深入理解。
8. 结论:
(1) 这项工作的意义在于提出了一种基于概念滑块的3D人物角色编辑方法,解决了现有编辑方法的模糊性和表达局限性问题,满足了游戏开发、电影制作等领域对3D人物角色精细编辑的需求。
(2) 创新点:本文提出了基于概念滑块的3D人物角色编辑方法,通过概念滑块实现语义概念的精确操控,设计概念滑动损失、属性保留损失和基于概念敏感性的3D高斯样条选择机制,实现了精细化的编辑反馈和高效的编辑过程。
性能:实验结果表明,该方法能够在不损害角色质量和不损害角色识别属性的情况下,实现精细化的3D人物角色编辑。这一性能证明了该方法的实用性和有效性。
工作量:文章对理论进行了详细的阐述,但关于实际应用的实验和验证部分相对较少,工作量略显不足。此外,尽管作者提出了概念滑块的方法,但并未提供代码仓库链接以供读者进一步研究和实现。
点此查看论文截图