⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-27 更新
DreamWaltz-G: Expressive 3D Gaussian Avatars from Skeleton-Guided 2D Diffusion
Authors:Yukun Huang, Jianan Wang, Ailing Zeng, Zheng-Jun Zha, Lei Zhang, Xihui Liu
Leveraging pretrained 2D diffusion models and score distillation sampling (SDS), recent methods have shown promising results for text-to-3D avatar generation. However, generating high-quality 3D avatars capable of expressive animation remains challenging. In this work, we present DreamWaltz-G, a novel learning framework for animatable 3D avatar generation from text. The core of this framework lies in Skeleton-guided Score Distillation and Hybrid 3D Gaussian Avatar representation. Specifically, the proposed skeleton-guided score distillation integrates skeleton controls from 3D human templates into 2D diffusion models, enhancing the consistency of SDS supervision in terms of view and human pose. This facilitates the generation of high-quality avatars, mitigating issues such as multiple faces, extra limbs, and blurring. The proposed hybrid 3D Gaussian avatar representation builds on the efficient 3D Gaussians, combining neural implicit fields and parameterized 3D meshes to enable real-time rendering, stable SDS optimization, and expressive animation. Extensive experiments demonstrate that DreamWaltz-G is highly effective in generating and animating 3D avatars, outperforming existing methods in both visual quality and animation expressiveness. Our framework further supports diverse applications, including human video reenactment and multi-subject scene composition.
PDF Project page: https://yukun-huang.github.io/DreamWaltz-G/
Summary
利用预训练的2D扩散模型和分数蒸馏采样,提出DreamWaltz-G框架,实现从文本到可动3D虚拟人生成。
Key Takeaways
- 结合2D扩散模型和SDS,实现文本到3D虚拟人生成。
- DreamWaltz-G框架基于骨骼引导的分数蒸馏和混合3D高斯虚拟人表示。
- 骨骼引导的分数蒸馏增强SDS监督的视角和姿态一致性。
- 混合3D高斯虚拟人表示结合神经隐式场和参数化3D网格,实现实时渲染。
- 实验证明DreamWaltz-G在生成和动画3D虚拟人方面优于现有方法。
- 框架支持人视频重演和多主题场景合成等应用。
- 提升了动画表达性和视觉质量。
标题:DreamWaltz-G:基于文本驱动的动画3D角色生成学习框架
作者:黄玉坤、王建安、曾爱玲、IEEE会员、郑俊杰、IEEE会员、张磊、IEEE资深会员、刘希辉、IEEE会员
所属机构:(按顺序)香港大学(HKU)、Astribot公司、腾讯公司、中国科学技术大学(USTC)、国际数字经济学院(IDEA)。
关键词:3D角色生成、3D人类模型、动态动画、扩散模型、分数蒸馏、3D高斯。
链接:论文链接(待补充),GitHub代码链接(如有)。
摘要:
(1) 研究背景:随着电影制作、游戏设计、虚拟现实等技术的快速发展,对高质量的3D角色生成的需求日益增长。传统的3D角色创建方法耗时耗力,而基于文本的3D角色生成成为了一种新的趋势。本文提出了一种基于文本驱动的零样本学习框架DreamWaltz-G,用于高质量的动画3D角色生成。
(2) 过往方法与问题:虽然现有方法利用预训练的二维扩散模型和分数蒸馏采样(SDS)在文本到三维角色的生成上取得了显著成果,但在生成高质量且能进行动态动画的三维角色方面仍面临挑战。问题包括几何结构的不准确,纹理细节的缺失,以及动态姿态下的变形问题等。
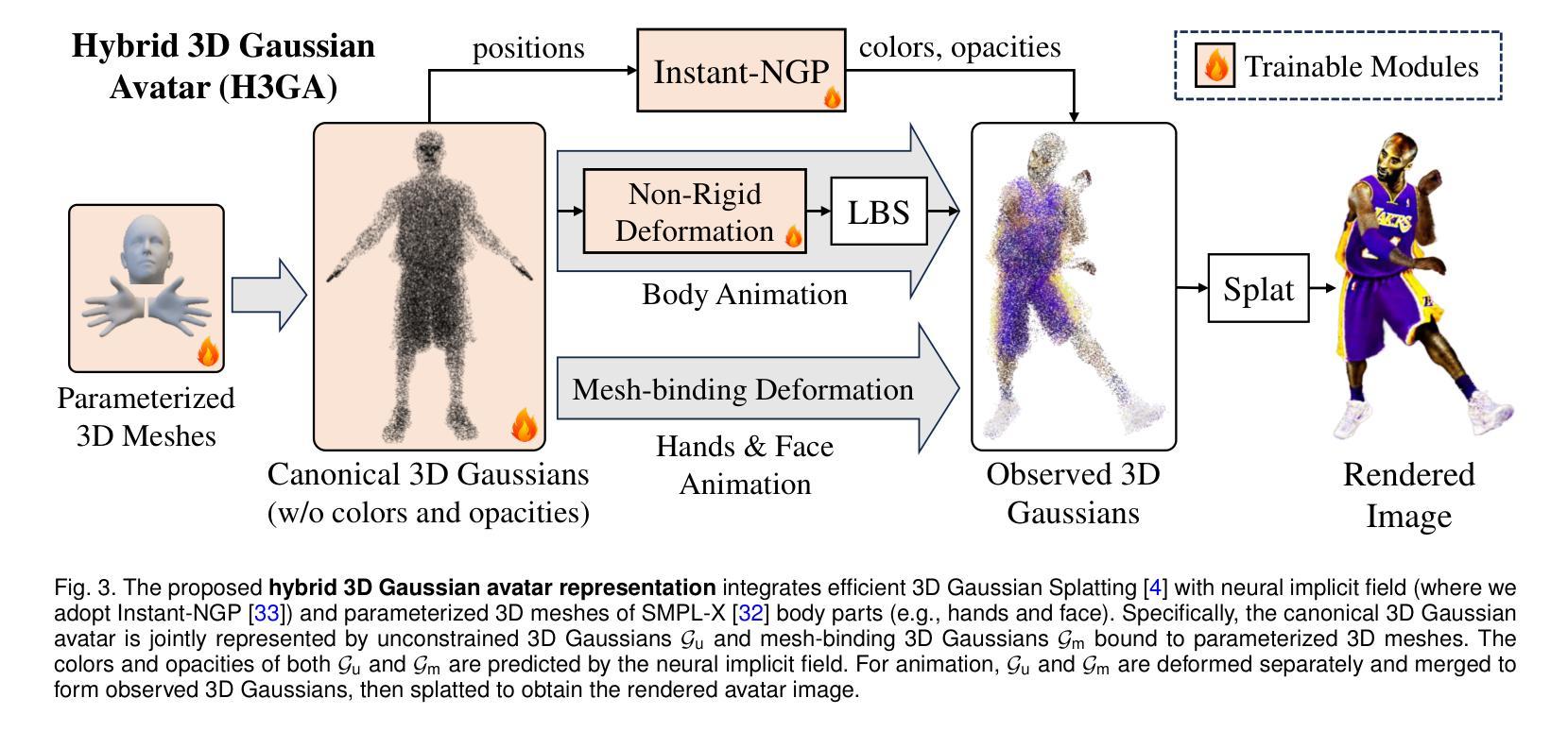
(3) 研究方法:本文提出的DreamWaltz-G框架通过Skeleton-guided Score Distillation(SkelSD)和Hybrid 3D Gaussian Avatars(H3GA)解决了上述问题。SkelSD通过将三维人体模板的骨架控制引入二维扩散模型,增强了SDS的稳定性并保持了三维一致性。H3GA则是一种混合的三维表示方法,旨在适应SDS优化并实现动态动画。具体来说,H3GA结合了神经隐式场和参数化三维网格,以实现实时渲染、稳定的SDS优化和动态动画。
(4) 任务与性能:本文在文本驱动的3D角色生成任务上进行了实验验证,DreamWaltz-G框架在视觉质量和动画表现力方面均表现出卓越的性能,超过了现有方法。此外,该框架还支持多种应用,如人类视频重演和多主体场景组合等。实验结果证明了其有效性和实用性。
希望这个概括符合您的要求!如有任何修改或进一步的需求,请告知。
7. 方法论:
(1)研究背景:随着电影制作、游戏设计、虚拟现实等技术的快速发展,对高质量的3D角色生成的需求日益增长。传统的3D角色创建方法耗时耗力,因此,研究出一种基于文本驱动的零样本学习框架DreamWaltz-G用于高质量的动画3D角色生成显得尤为重要。
(2)现有问题与挑战:现有方法虽然已经在文本到三维角色的生成上取得显著成果,但仍存在几何结构不准确、纹理细节缺失以及在动态姿态下的变形问题等挑战。
(3)研究方法介绍:针对上述问题与挑战,本文提出了基于文本驱动的零样本学习框架DreamWaltz-G。该框架主要包括两个部分:Skeleton-guided Score Distillation(SkelSD)和Hybrid 3D Gaussian Avatars(H3GA)。SkelSD通过将三维人体模板的骨架控制引入二维扩散模型,增强了SDS的稳定性并保持了三维一致性。H3GA则是一种混合的三维表示方法,旨在适应SDS优化并实现动态动画。具体来说,H3GA结合了神经隐式场和参数化三维网格,以实现实时渲染、稳定的SDS优化和动态动画。
(4)实验验证与性能表现:本文在文本驱动的3D角色生成任务上进行了实验验证,结果显示DreamWaltz-G框架在视觉质量和动画表现力方面均表现出卓越的性能,超过了现有方法。此外,该框架还支持多种应用,如人类视频重演和多主体场景组合等。实验结果证明了其有效性和实用性。
以上就是这篇论文的方法论部分的详细介绍。希望符合您的要求。
8. Conclusion:
(1) 这项工作的意义在于提出了一种基于文本驱动的零样本学习框架DreamWaltz-G,用于高质量的动画3D角色生成。该框架的应用能够简化3D角色创建流程,满足电影制作、游戏设计、虚拟现实等领域对高质量3D角色的需求。
(2) 创新点:文章提出了Skeleton-guided Score Distillation(SkelSD)和Hybrid 3D Gaussian Avatars(H3GA)方法,解决了现有方法在3D角色生成中的几何结构不准确、纹理细节缺失以及在动态姿态下的变形问题。
性能:实验验证显示,DreamWaltz-G框架在视觉质量和动画表现力方面表现出卓越的性能,超过了现有方法。
工作量:文章涉及的实验和验证工作量大,证明了该框架的有效性和实用性。
总体而言,这篇文章在3D角色生成领域具有一定的创新性和实用性,对于相关领域的研究者和从业人员具有一定的参考和借鉴意义。
点此查看论文截图



Gaussian Déjà-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities
Authors:Peizhi Yan, Rabab Ward, Qiang Tang, Shan Du
Recent advancements in 3D Gaussian Splatting (3DGS) have unlocked significant potential for modeling 3D head avatars, providing greater flexibility than mesh-based methods and more efficient rendering compared to NeRF-based approaches. Despite these advancements, the creation of controllable 3DGS-based head avatars remains time-intensive, often requiring tens of minutes to hours. To expedite this process, we here introduce the ``Gaussian D'ej`a-vu” framework, which first obtains a generalized model of the head avatar and then personalizes the result. The generalized model is trained on large 2D (synthetic and real) image datasets. This model provides a well-initialized 3D Gaussian head that is further refined using a monocular video to achieve the personalized head avatar. For personalizing, we propose learnable expression-aware rectification blendmaps to correct the initial 3D Gaussians, ensuring rapid convergence without the reliance on neural networks. Experiments demonstrate that the proposed method meets its objectives. It outperforms state-of-the-art 3D Gaussian head avatars in terms of photorealistic quality as well as reduces training time consumption to at least a quarter of the existing methods, producing the avatar in minutes.
PDF 11 pages, Accepted by WACV 2025 in Round 1
Summary
3DGS头像建模技术升级,提出“Gaussian D'ej`a-vu”框架,缩短个性化建模时间。
Key Takeaways
- 3DGS技术提升3D头像建模灵活性,渲染效率高。
- 创建3DGS头像需耗时,新框架旨在加速此过程。
- 框架包括通用模型训练和个性化定制。
- 通用模型基于大型2D图像数据集训练。
- 个性化定制通过单目视频实现,优化3D Gaussians。
- 使用可学习的表达感知混合图校正,提高收敛速度。
- 新方法在真实感质量和训练时间上优于现有技术。
Title: 高斯戴贾维:创建可控的3D高斯头部化身的方法
Abstract: 该论文提出了一种创建可控的3D高斯头部化身的方法,通过训练一个重建模型在大型人脸图像数据集上获得通用模型,并将其用于初始化个性化的头部化身。该方法使用合成和真实图像数据集进行训练,并通过单目视频进一步细化得到个性化的头部化身。实验表明,该方法在达到目标的同时,在逼真度和训练时间消耗方面优于现有的最先进的3D高斯头化身技术。Authors: PeiZhi Yan(皮志燕), Rabab Ward(拉巴卜·沃德), Qiang Tang(唐强), Shan Du(单杜)等。
Affiliation: 隶属于英国哥伦比亚大学(Yan和Ward)以及华为加拿大研究中心(Tang)。Du来自英国哥伦比亚大学奥肯根校区。
Keywords: 3D Gaussian Head Avatar, Gaussian D´ej`a-vu, Controllable Avatars, 3D Face Reconstruction, Personalized Avatars。
Urls: 请查看原文提供的链接。关于GitHub代码链接,由于我无法直接访问GitHub或其他在线数据库来查找信息,所以无法提供具体的链接。如果论文中有提及具体的GitHub链接,请直接在论文中查找。
Summary:
- (1)研究背景:随着视频游戏、虚拟现实和增强现实、电影制作、远程出席等行业的快速发展,创建逼真的三维头部化身变得越来越重要。现有的方法虽然取得了一定的成果,但在效率、质量和可控性方面仍存在挑战。因此,本文提出了一种创建可控的3D高斯头部化身的新方法。
- (2)过去的方法及其问题:现有的方法主要基于网格或NeRF技术创建三维头部化身。这些方法虽然可以实现一定程度的逼真度,但在效率、渲染速度和控制方面存在问题。此外,个性化头部化身创建通常需要大量的时间和计算资源。因此,需要一种新的方法来克服这些问题。
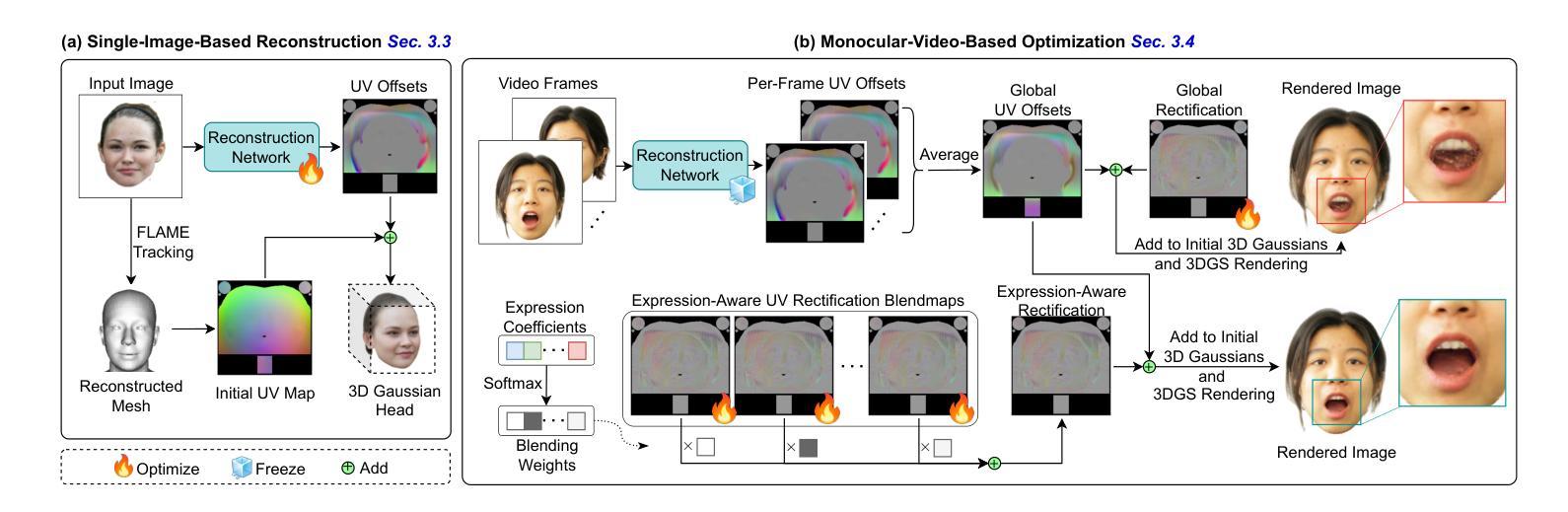
- (3)研究方法:本文提出了高斯戴贾维(Gaussian Deja-vu)框架来创建可控的3D高斯头部化身。首先,通过训练一个重建模型在大型人脸图像数据集上获得通用模型。然后,使用合成和真实图像数据集进行训练,并通过单目视频进一步细化得到个性化的头部化身。为了个性化,本文提出了可学习的表情感知校正映射图(learnable expression-aware rectification blendmaps),用于纠正初始的3D高斯模型,确保快速收敛且不依赖神经网络。
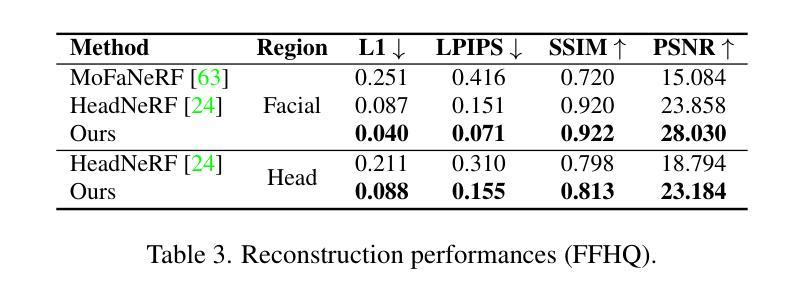
- (4)任务与性能:实验表明,该方法在创建逼真的三维头部化身方面表现出优异的性能,不仅提高了质量,而且大大减少了训练时间消耗。与传统方法相比,该方法的训练时间至少减少了四分之一,能够在几分钟内生成头部化身。这些成果支持了该方法的有效性。
希望以上内容符合您的要求。
7. Methods:
- (1) 研究背景分析:随着视频游戏、虚拟现实和增强现实等行业的快速发展,创建逼真的三维头部化身变得越来越重要。现有的方法在效率、质量和可控性方面存在挑战。
- (2) 数据准备:首先,研究团队使用大型人脸图像数据集训练了一个重建模型,获得了通用模型。接着,使用合成和真实图像数据集进行训练。
- (3) 个性化头部化身创建:通过单目视频进一步细化,得到个性化的头部化身。为了实现个性化,研究团队提出了可学习的表情感知校正映射图(learnable expression-aware rectification blendmaps),用于纠正初始的3D高斯模型。
- (4) 方法优化:该研究采用的高斯戴贾维(Gaussian Deja-vu)框架确保了快速收敛,并且不依赖神经网络,从而大大提高了创建个性化头部化身的效率。
- (5) 实验验证:实验结果表明,该方法在创建逼真的三维头部化身方面表现出优异的性能,不仅提高了质量,而且大大减少了训练时间消耗。与传统方法相比,该方法的训练时间至少减少了四分之一,能够在几分钟内生成头部化身。
Conclusion:
(1) 这项工作的意义在于提出了一种创建可控的3D高斯头部化身的新方法,具有重要的应用价值。随着视频游戏、虚拟现实和增强现实等行业的快速发展,创建逼真的三维头部化身的需求越来越迫切。该研究提出的D´ej`a-vu框架能够基于单张图像进行三维重建,并通过学习和调整实现个性化表达,具有广泛的应用前景。
(2) 创新点:该研究提出了一种新的创建可控的3D高斯头部化身的方法,具有显著的创新性。与传统的三维头部化身创建方法相比,该研究采用了先进的深度学习技术,并结合图像合成和真实图像数据集进行训练,实现了较高的逼真度和训练效率。同时,该研究还提出了可学习的表情感知校正映射图(learnable expression-aware rectification blendmaps),用于纠正初始的3D高斯模型,确保了快速收敛且不依赖神经网络。性能:实验结果表明,该方法在创建逼真的三维头部化身方面表现出优异的性能,不仅提高了质量,而且大大减少了训练时间消耗。与传统方法相比,该方法的训练时间至少减少了四分之一。工作量:该研究的工作量较大,涉及到大量的数据准备、模型训练和实验验证等工作。但研究结果具有显著的成效,为后续的相关研究提供了有益的参考和启示。
点此查看论文截图

Barbie: Text to Barbie-Style 3D Avatars
Authors:Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
Recent advances in text-guided 3D avatar generation have made substantial progress by distilling knowledge from diffusion models. Despite the plausible generated appearance, existing methods cannot achieve fine-grained disentanglement or high-fidelity modeling between inner body and outfit. In this paper, we propose Barbie, a novel framework for generating 3D avatars that can be dressed in diverse and high-quality Barbie-like garments and accessories. Instead of relying on a holistic model, Barbie achieves fine-grained disentanglement on avatars by semantic-aligned separated models for human body and outfits. These disentangled 3D representations are then optimized by different expert models to guarantee the domain-specific fidelity. To balance geometry diversity and reasonableness, we propose a series of losses for template-preserving and human-prior evolving. The final avatar is enhanced by unified texture refinement for superior texture consistency. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation, supporting flexible apparel combination and animation. The code will be released for research purposes. Our project page is: https://xiaokunsun.github.io/Barbie.github.io/.
PDF 9 pages, 7 figures, Project page: https://xiaokunsun.github.io/Barbie.github.io/
Summary
提出Barbie框架,实现精细解耦的3D虚拟人生成。
Key Takeaways
- 文章提出Barbie框架,用于生成可穿戴多样化服装的3D虚拟人。
- 通过语义对齐的分离模型实现人体和服装的精细解耦。
- 采用不同专家模型优化解耦的3D表示,确保特定领域的高保真度。
- 设计一系列损失函数,平衡几何多样性和合理性。
- 统一纹理细化提升纹理一致性。
- 实验证明Barbie在服装组合和动画方面优于现有方法。
- 代码将公开发布,方便研究。
Title: 基于文本指导的Barbie风格3D虚拟人生成研究
Authors: Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
Affiliation: 南京大学教授Sun Xiaokun等
Keywords: Text-to-Avatar Generation; 3D Avatar; Text-Guided; Fine-grained Disentanglement; Domain-Specific Fidelity
Urls: https://xiaokunsun.github.io/Barbie.github.io/;Github: None
Summary:
(1) 研究背景:近年来,随着AR/VR技术的普及,创建3D数字人类引起了广泛关注。自动生成3D虚拟人的方法需要大规模的三维人类数据用于训练,这极大地限制了其应用范围。得益于文本到图像和文本到3D领域的快速发展,利用自然语言输入进行虚拟人生成已成为越来越受欢迎的研究方向。
(2) 过去的方法及问题:现有的文本到虚拟人的工作大致分为两类:生成整体虚拟人和生成身体与服装的解耦模型。整体虚拟人的生成方法虽然可以实现较高的逼真度,但缺乏灵活性,无法自由更换服装或进行服装转移等应用。解耦方法的目的是将身体和衣物分别建模,但存在精细度不足、服装和配饰生成不真实等问题。
(3) 研究方法:本研究提出了一种新型的基于文本指导的Barbie风格3D虚拟人生成框架。该框架通过语义对齐的分离模型实现身体和服装的精细解耦。使用不同的专家模型对解耦后的3D表示进行优化,以保证领域特定的保真度。通过一系列损失函数平衡几何多样性和合理性,同时采用统一的纹理优化算法提高纹理一致性。
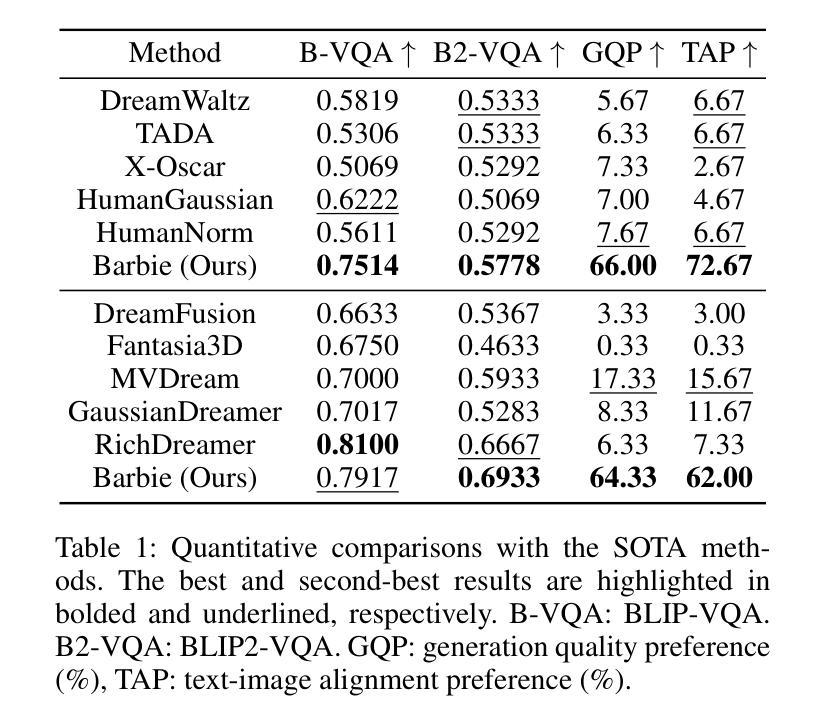
(4) 任务与性能:本研究的方法在着装人类生成和服装生成方面表现出优异的性能,支持灵活的服装组合和动画。实验结果表明,Barbie在几何多样性、纹理逼真度和细节精细度等方面均优于现有方法。性能结果支持该研究的目标,即生成具有高度逼真度、多样性和解耦度的Barbie风格3D虚拟人。
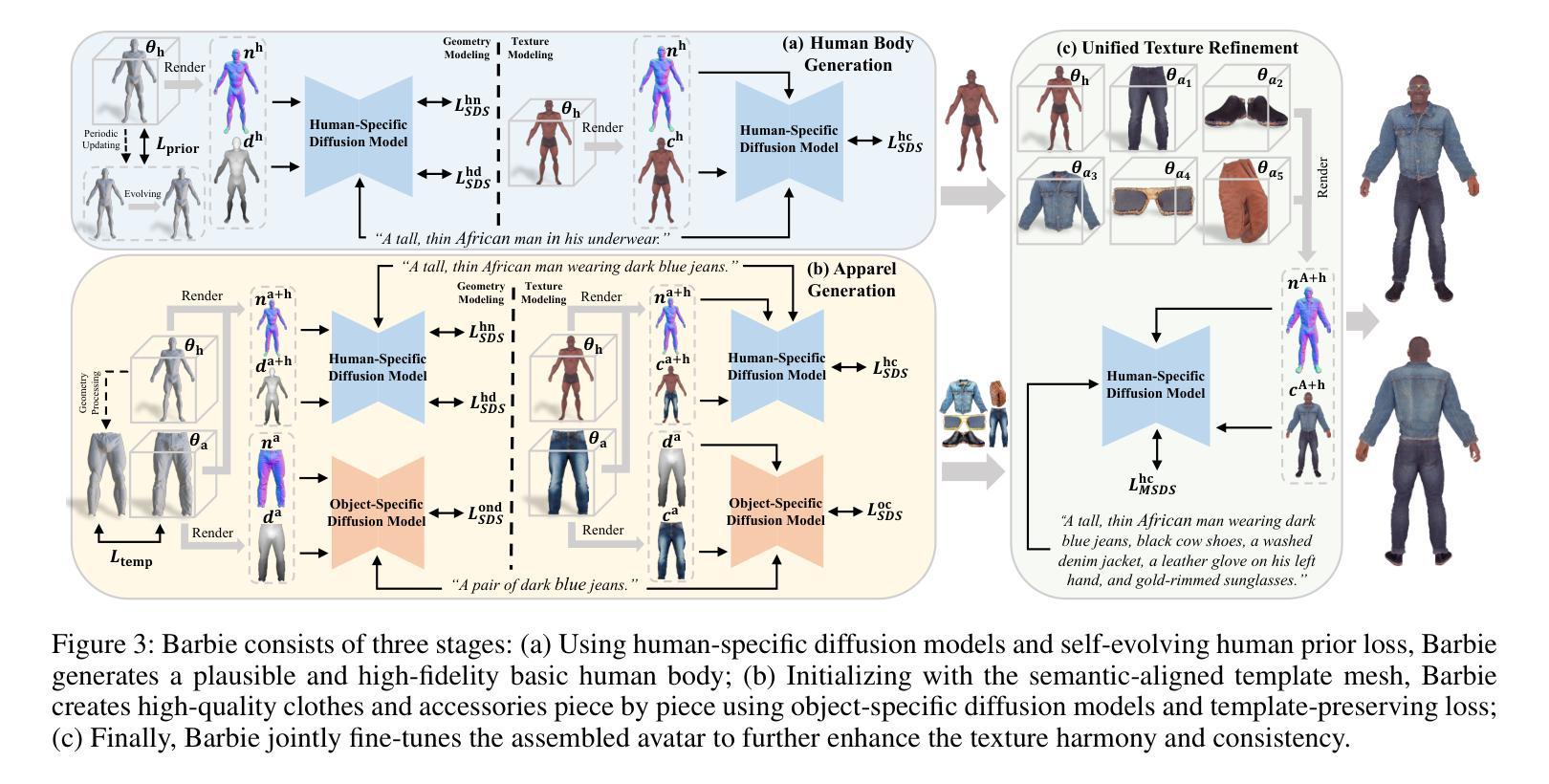
7. 方法论:
- (1) 研究背景:近年来,随着AR/VR技术的普及,创建3D数字人类引起了广泛关注。自动生成3D虚拟人的方法需要大规模的三维人类数据用于训练,这极大地限制了其应用范围。该研究提出了一种基于文本指导的Barbie风格3D虚拟人生成框架,旨在解决现有方法的问题。
- (2) 研究方法:该研究采用了一种新型的基于文本指导的Barbie风格3D虚拟人生成框架。首先,利用SMPL-X参数化人体模型表示全身的形状、姿态和表情。然后,采用Score Distillation Sampling方法,借助预训练的T2I模型指导3D表示与输入文本对齐。此外,研究采用了DMTet混合表示法,能够高效表示隐式签名距离函数(SDF)和可微分的四面体层。
- (3) 流程设计:研究流程分为三个关键阶段。第一阶段是生成高质量的人体,采用有针对性的专家扩散模型进行特定正则化,产生高质量和合理的人体(Sec. 3.3)。第二阶段是生成服装,采用对象特定的扩散模型进行纹理建模(Sec. 3.4)。最后是组成虚拟人的微调阶段,采用统一的纹理优化算法提高纹理的一致性(Sec. 3.5)。
- (4) 技术细节:在人体生成方面,研究采用SMPL-X网格进行准确的初始输入,并采用可微分渲染器和SDS损失来优化形状参数β,根据输入的基本人体描述确定基本人体形状。在几何建模方面,研究利用人类特定的扩散模型进行几何优化,包括正常适应扩散模型、深度适应扩散模型和纹理创建模型。此外,研究还引入了一种自我进化的人类先验损失,通过周期性地适应网格Minit来平衡生成的多样性和合理性。在纹理建模方面,利用正常对齐的扩散模型创建真实和高质量的纹理。
- (5) 创新点:该研究的主要创新在于实现了身体和服装的精细解耦,通过领域特定的保真度优化和统一的纹理优化算法,生成具有高度逼真度、多样性和解耦度的Barbie风格3D虚拟人。同时,该研究的方法在着装人类生成和服装生成方面表现出优异的性能,支持灵活的服装组合和动画。
总的来说,该研究的方法为创建高度逼真、多样且解耦的3D虚拟人提供了一种有效的解决方案。
- Conclusion:
(1) 这项工作的意义在于提出了一种基于文本指导的Barbie风格3D虚拟人生成方法,具有广泛的应用前景。它能够根据自然语言输入生成具有高度逼真度、多样性和解耦度的虚拟人,为创建个性化的虚拟角色提供了新的可能性。同时,该方法还展示了在服装生成和组合方面的优异性能,为虚拟时尚、虚拟世界等领域的开发提供了有力支持。
(2) 创新点:该文章的创新之处在于实现了身体和服装的精细解耦,通过领域特定的保真度优化和统一的纹理优化算法,生成了具有高度逼真度、多样性和解耦度的Barbie风格3D虚拟人。其技术细节中的SMPL-X参数化人体模型表示、Score Distillation Sampling方法、DMTet混合表示法等均体现了作者的技术水平与创新思维。但现有的工作可能仍然存在对于复杂纹理和细节的处理不够完善的问题,未来的研究可以进一步探索如何进一步提高生成虚拟人的逼真度和细节质量。性能上,该文章的方法在几何多样性、纹理逼真度和细节精细度等方面均优于现有方法,体现了其优越的性能表现。工作量上,该文章对方法论进行了详细的阐述和实验验证,展示了作者们丰富的工作量和技术积累。
点此查看论文截图