⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-27 更新
Degradation-Guided One-Step Image Super-Resolution with Diffusion Priors
Authors:Aiping Zhang, Zongsheng Yue, Renjing Pei, Wenqi Ren, Xiaochun Cao
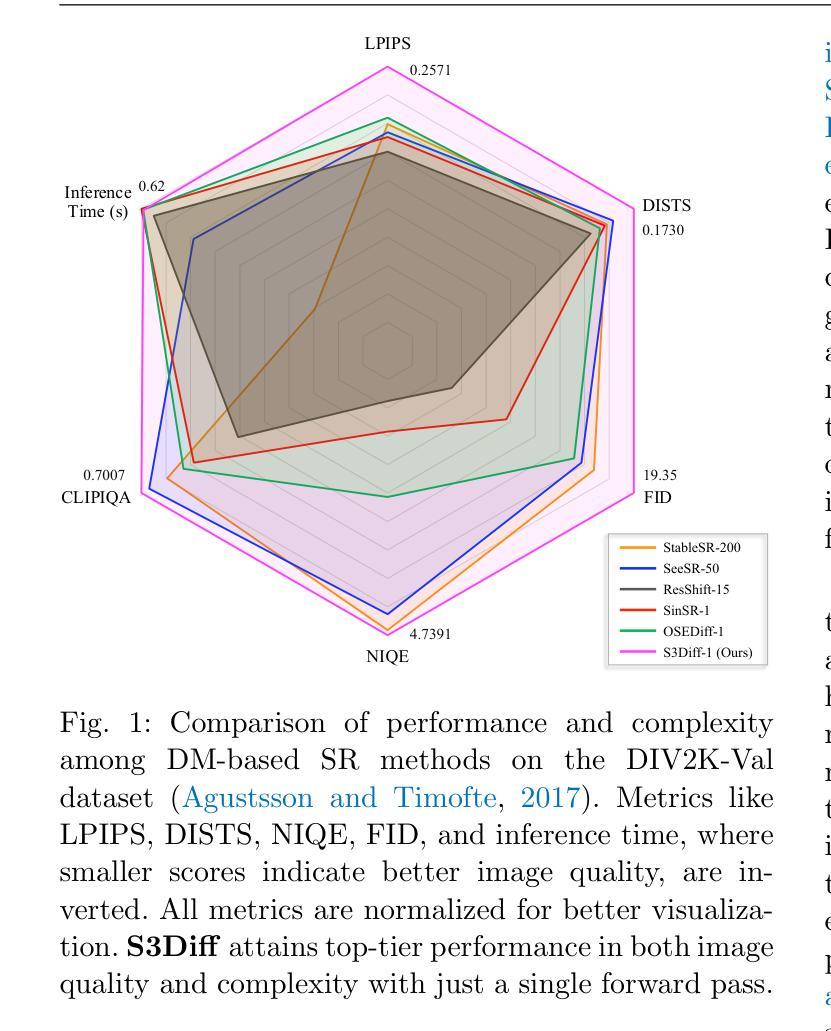
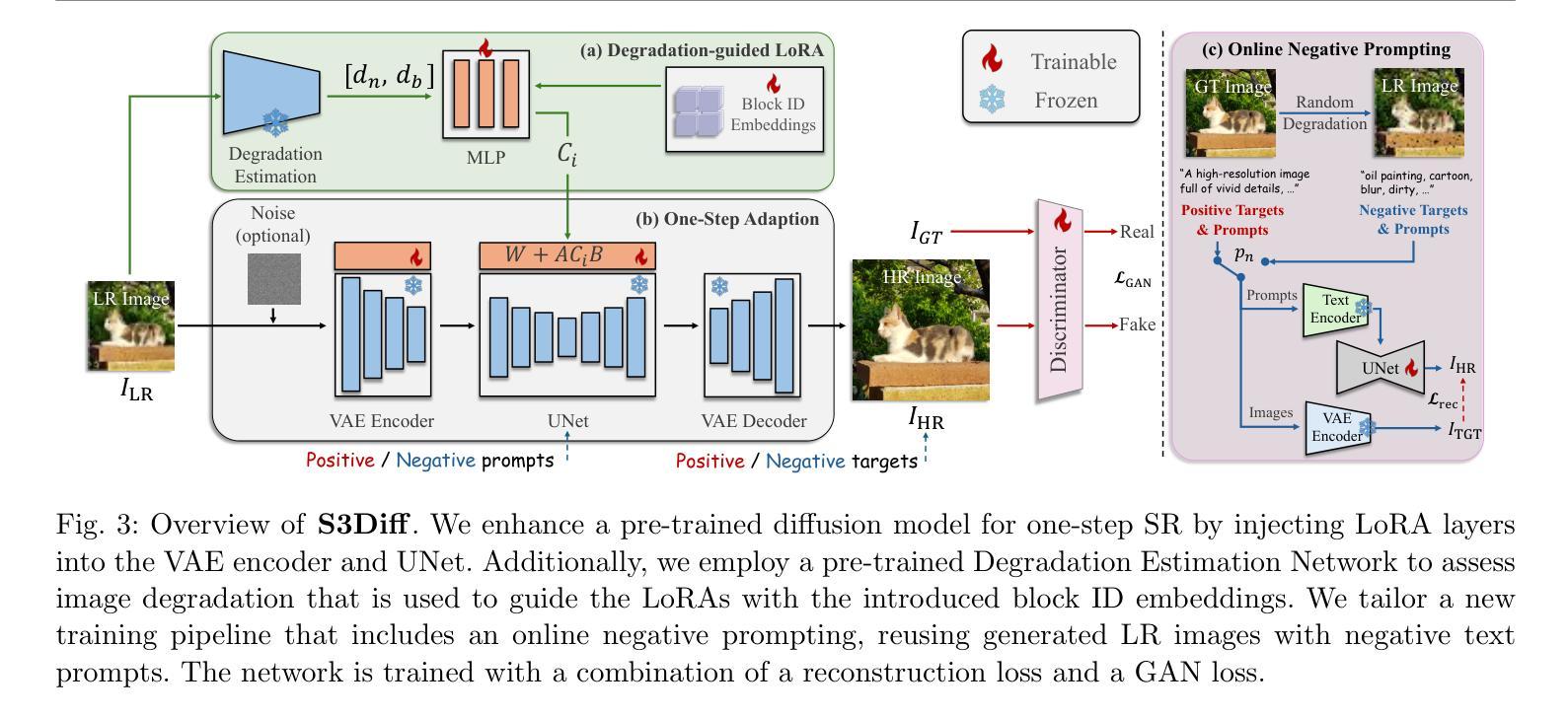
Diffusion-based image super-resolution (SR) methods have achieved remarkable success by leveraging large pre-trained text-to-image diffusion models as priors. However, these methods still face two challenges: the requirement for dozens of sampling steps to achieve satisfactory results, which limits efficiency in real scenarios, and the neglect of degradation models, which are critical auxiliary information in solving the SR problem. In this work, we introduced a novel one-step SR model, which significantly addresses the efficiency issue of diffusion-based SR methods. Unlike existing fine-tuning strategies, we designed a degradation-guided Low-Rank Adaptation (LoRA) module specifically for SR, which corrects the model parameters based on the pre-estimated degradation information from low-resolution images. This module not only facilitates a powerful data-dependent or degradation-dependent SR model but also preserves the generative prior of the pre-trained diffusion model as much as possible. Furthermore, we tailor a novel training pipeline by introducing an online negative sample generation strategy. Combined with the classifier-free guidance strategy during inference, it largely improves the perceptual quality of the super-resolution results. Extensive experiments have demonstrated the superior efficiency and effectiveness of the proposed model compared to recent state-of-the-art methods.
PDF The code is available at https://github.com/ArcticHare105/S3Diff
Summary
基于扩散的图像超分辨率方法通过利用预训练的文本到图像扩散模型作为先验条件取得了显著成功,但本文提出了一种新颖的一步式SR模型,有效解决了效率问题,并提高了结果的质量。
Key Takeaways
- 利用预训练的文本到图像扩散模型实现图像超分辨率。
- 提出的一步式SR模型显著提高了效率。
- 设计了基于降级的低秩适应(LoRA)模块,利用预估计的降级信息校正模型参数。
- 保留了预训练扩散模型的生成先验。
- 引入在线负样本生成策略优化训练流程。
- 实验证明了模型在效率和有效性上的优势。
- 使用无分类器的指导策略提高推理中的感知质量。
标题:基于扩散先验的一步式图像超分辨率研究(Degradation-Guided One-Step Image Super-Resolution with Diffusion Priors)
作者:张艾萍、岳宗胜、裴仁静、任文奇、曹小春*(星号为同等贡献作者)
隶属机构:张艾萍和任文奇来自中山大学深圳校区网络空间科学与技术学院;岳宗胜来自南洋理工大学的S-Lab;裴仁静来自华为诺亚方舟实验室;曹小春来自中山大学深圳校区网络科学学院。
关键词:超分辨率、扩散先验、降解意识、一步法。
链接:论文链接待插入,代码链接为:GitHub链接(如可用);如不可用,则填写“Github:None”。
摘要:
(1)研究背景:本文研究图像超分辨率(SR)问题,这是一个长期且具挑战性的问题,目标是从低分辨率(LR)图像恢复出高分辨率(HR)图像。由于LR图像通常受到各种复杂降解的影响,如模糊、下采样、噪声腐蚀等,这使得SR问题更加复杂。虽然过去的研究已经取得了一些进展,但在真实场景中仍面临效率与效果的问题。随着扩散模型在图像生成任务上的出色表现,如何将扩散模型应用于SR问题成为了一个研究热点。
(2)过去的方法及问题:现有的扩散模型在SR问题上虽然取得了显著的成功,但它们通常需要数十步采样才能达到满意的结果,这限制了在实际场景中的效率。同时,这些方法忽视了降解模型这一在解决SR问题中至关重要的辅助信息。因此,需要一种新的方法来解决这些问题。
(3)研究方法:针对上述问题,本文提出了一种新型的、一步式的SR模型。该模型通过设计一个降解引导的Low-Rank Adaptation(LoRA)模块来校正模型参数,该模块基于从低分辨率图像预估计的降解信息。这一设计不仅提高了数据依赖或降解依赖的SR模型的效率,而且尽可能地保留了预训练扩散模型的生成先验。此外,还引入了一种在线负样本生成策略,结合推理过程中的无分类器引导策略,大大提高了超分辨率结果的可感知质量。
(4)任务与性能:本文的方法在SR任务上取得了显著的效果和效率。与最新的先进方法相比,实验证明本文提出的模型具有优越的性能。代码和模型可在GitHub上找到。
以上是对该论文的总结,希望符合您的要求。
7. 方法:
(1) 研究背景:图像超分辨率问题长期存在且充满挑战,旨在从低分辨率图像恢复出高分辨率图像。由于低分辨率图像通常受到各种复杂降解的影响,如模糊、下采样和噪声腐蚀等,使得该问题更加复杂。
(2) 过去的方法及其问题:现有的扩散模型在解决超分辨率问题上虽然取得了显著的成功,但它们通常需要多次迭代才能达到满意的效果,限制了在实际场景中的应用效率。同时,这些方法忽视了降解模型这一在解决超分辨率问题中至关重要的辅助信息。
(3) 新型一步式SR模型的设计:针对上述问题,论文提出了一种新型的、一步式的超分辨率模型。该模型通过设计一个降解引导的Low-Rank Adaptation(LoRA)模块来校正模型参数。这一设计基于从低分辨率图像预估计的降解信息,不仅提高了数据依赖或降解依赖的SR模型的效率,而且尽可能地保留了预训练扩散模型的生成先验。
(4) 在线负样本生成策略与无分类器引导策略:为了提高超分辨率结果的可感知质量,论文引入了在线负样本生成策略,并结合推理过程中的无分类器引导策略。这两种策略共同提高了模型的性能。
(5) 实验验证与性能评估:论文通过大量的实验验证了所提出模型在超分辨率任务上的效果和效率。与现有的先进方法相比,实验证明该模型具有优越的性能。
8. Conclusion:
- (1) 这项工作的意义在于提出了一种新型的、一步式的图像超分辨率模型,该模型基于扩散先验和降解引导,旨在从低分辨率图像恢复出高分辨率图像,解决了现有扩散模型在超分辨率问题上的效率和性能瓶颈,具有重要的实际应用价值。
- (2) 创新点:该文章在创新点、性能和工作量三个方面各有优劣。创新点方面,文章提出了一种新型的、一步式的超分辨率模型,通过结合扩散先验和降解信息,提高了超分辨率任务的效率和性能;性能方面,该模型在实验中表现出优越的性能,与最新的先进方法相比具有更好的超分辨率结果;工作量方面,文章进行了大量的实验验证和性能评估,证明了模型的有效性,但具体的实现细节和代码公开程度需要进一步评估。
点此查看论文截图



ControlCity: A Multimodal Diffusion Model Based Approach for Accurate Geospatial Data Generation and Urban Morphology Analysis
Authors:Fangshuo Zhou, Huaxia Li, Rui Hu, Sensen Wu, Hailin Feng, Zhenhong Du, Liuchang Xu
Volunteer Geographic Information (VGI), with its rich variety, large volume, rapid updates, and diverse sources, has become a critical source of geospatial data. However, VGI data from platforms like OSM exhibit significant quality heterogeneity across different data types, particularly with urban building data. To address this, we propose a multi-source geographic data transformation solution, utilizing accessible and complete VGI data to assist in generating urban building footprint data. We also employ a multimodal data generation framework to improve accuracy. First, we introduce a pipeline for constructing an ‘image-text-metadata-building footprint’ dataset, primarily based on road network data and supplemented by other multimodal data. We then present ControlCity, a geographic data transformation method based on a multimodal diffusion model. This method first uses a pre-trained text-to-image model to align text, metadata, and building footprint data. An improved ControlNet further integrates road network and land-use imagery, producing refined building footprint data. Experiments across 22 global cities demonstrate that ControlCity successfully simulates real urban building patterns, achieving state-of-the-art performance. Specifically, our method achieves an average FID score of 50.94, reducing error by 71.01% compared to leading methods, and a MIoU score of 0.36, an improvement of 38.46%. Additionally, our model excels in tasks like urban morphology transfer, zero-shot city generation, and spatial data completeness assessment. In the zero-shot city task, our method accurately predicts and generates similar urban structures, demonstrating strong generalization. This study confirms the effectiveness of our approach in generating urban building footprint data and capturing complex city characteristics.
PDF 20 pages
Summary
基于多源地理信息的城市建筑足迹数据生成方法研究
Key Takeaways
- 多源地理信息(VGI)在城市建筑数据中质量异质性强。
- 提出基于多源数据的地理数据转换解决方案。
- 构建包含图像、文本、元数据与建筑足迹的复合数据集。
- 利用多模态扩散模型进行地理数据转换。
- 控制城市(ControlCity)方法基于预训练的文本到图像模型。
- 实验证明ControlCity在模拟城市建筑模式上取得卓越性能。
- 模型在零样本城市生成和空间数据完整性评估中表现优异。
Title: 控制城市:基于多模态扩散模型的地貌数据生成方法
Authors: Fangshuo Zhou, Huaxia Li, Rui Hu, Sensen Wu, Hailin Fang, Zhenhong Du, and Liuchang Xu
Affiliation:
First author’s affiliation: 浙江农林大学数学与计算机科学学院Keywords: Diffusion Model, Multimodal Artificial Intelligence, Geospatial Data Translation, Volunteer Geographic Information, ControlCity
Urls: https://github.com/fangshuoz/ControlCity , GitHub代码链接待定(如果可用)
Summary:
- (1)研究背景:随着地理信息的增长,志愿者地理信息平台(如OpenStreetMap)在获取和更新地理空间数据方面发挥着重要作用。然而,这些数据存在质量不均一的问题,特别是在城市建筑数据方面。本文旨在解决这一问题,提出一种基于多模态扩散模型的地貌数据生成方法。
- (2)过去的方法及问题:现有的地理数据转换方法主要依赖于单一模态,如GANmapper利用循环生成对抗网络进行道路网络和建筑足迹之间的数据转换。然而,这些方法在视觉评估方面存在局限性,缺乏定量空间分析,且生成的数据分辨率较低。此外,它们未能充分利用多源数据,且在城市间的应用存在规模限制。
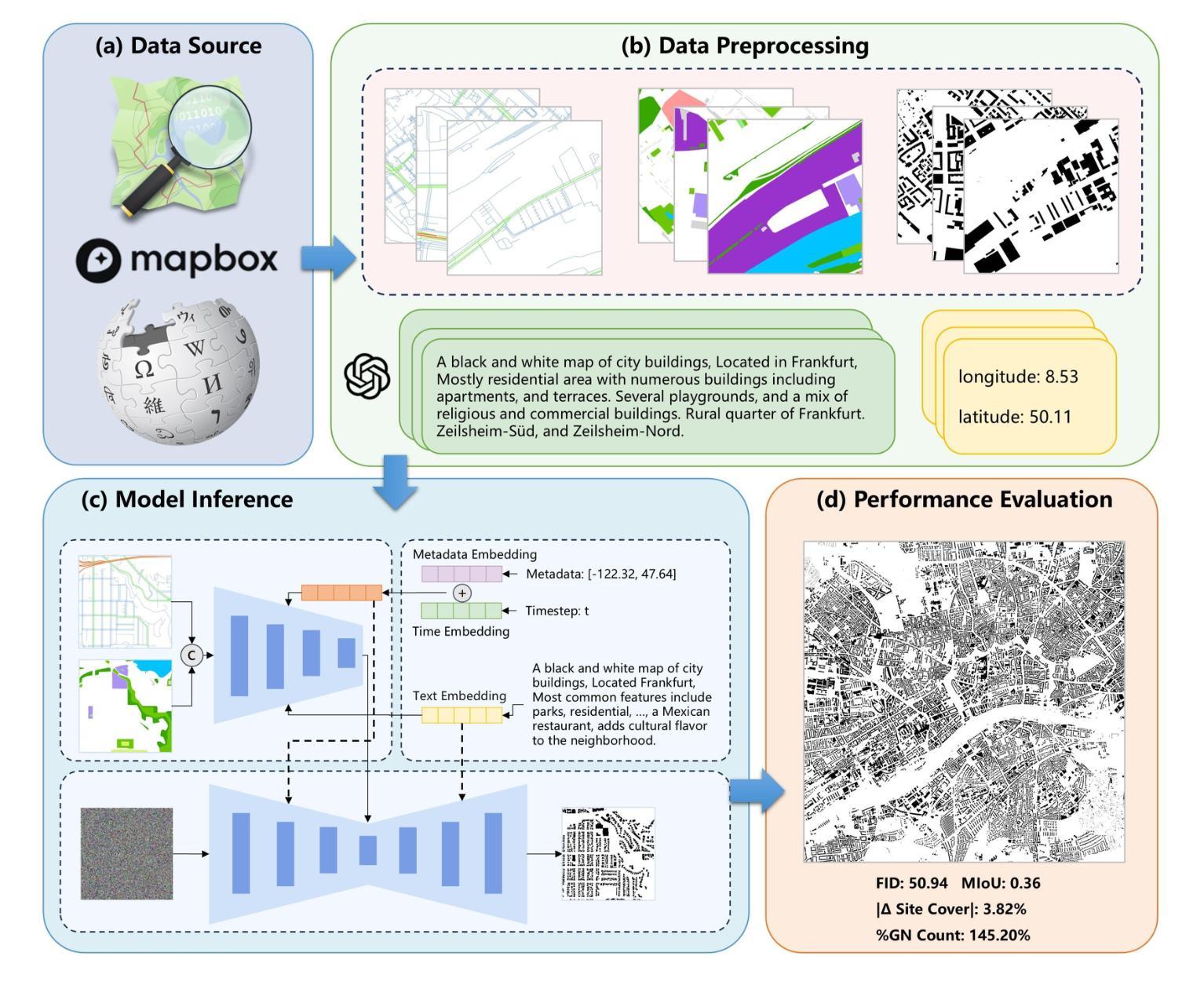
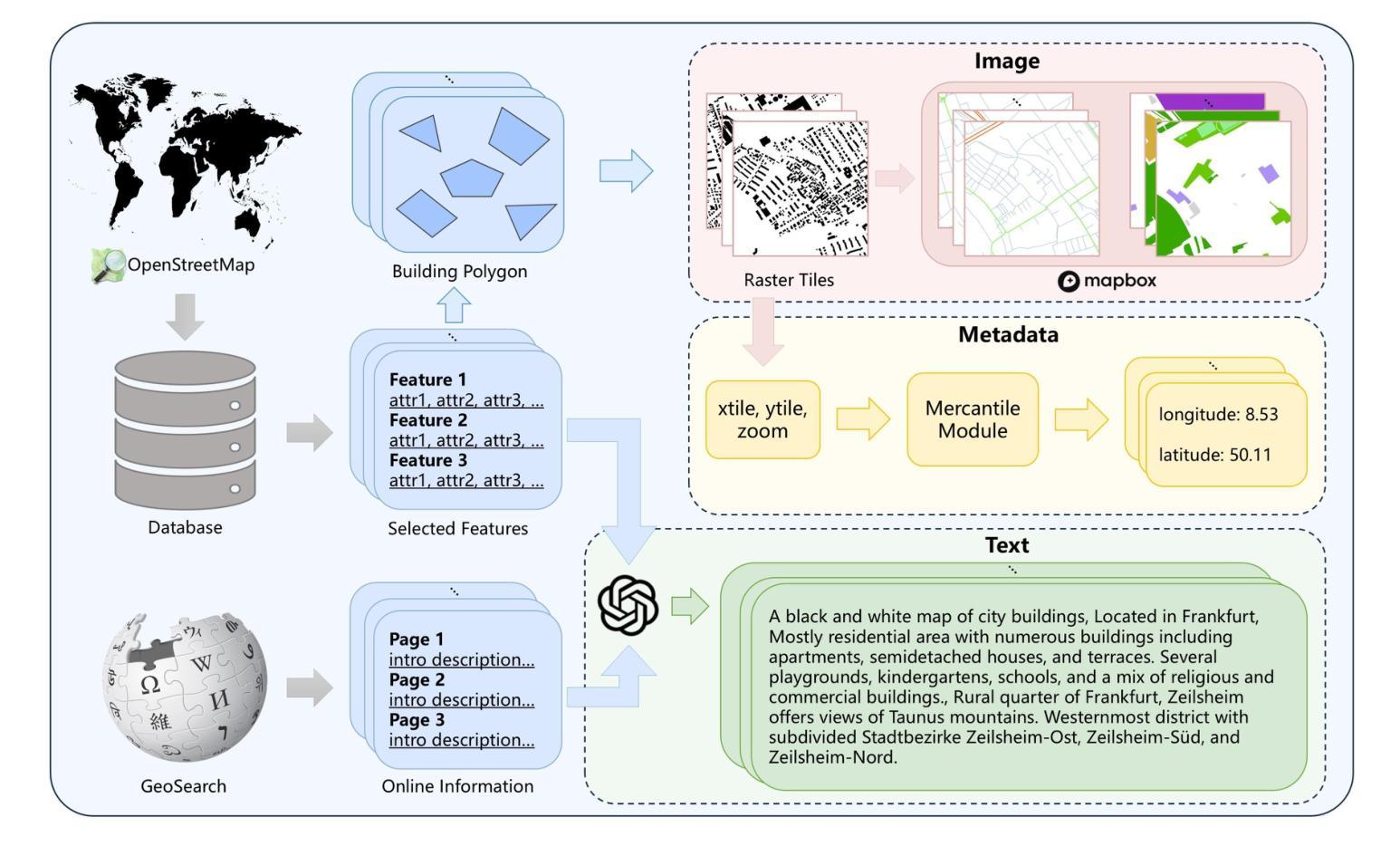
- (3)研究方法:本文提出ControlCity,一个基于多模态扩散模型的地理数据转换方法。首先构建“图像-文本-元数据-建筑足迹”四元数据集,利用大型语言模型进行辅助。在生成建筑足迹时,使用文本编码器对文本提示进行编码,并将其注入扩散模型。同时,将每个瓦片的中心坐标作为元数据条件进行编码和嵌入。通过改进的控制网络将图像模态数据(如道路网络和土地利用)注入扩散模型,学习地理结构与建筑足迹之间的关系,从而生成详细的建筑足迹数据。
- (4)任务与性能:在覆盖22个城市的实验数据集上,ControlCity在生成城市建筑模式、零样本城市生成和空间数据完整性评估等任务上取得了显著成果。具体而言,在FID评分上平均得分50.94,实现了较高的精度和细节表现。此外,在预测和生成具有相似形态的城市以及评估未映射区域方面表现出色。这些结果支持了ControlCity方法的有效性和实用性。
方法论概述:
(1) 数据集构建:研究团队首先通过多模态数据融合技术构建了“图像-文本-元数据-建筑足迹”四元数据集。数据来源于志愿者地理信息平台(如OpenStreetMap),经过筛选和处理,提取了与建筑足迹相关的关键信息。同时,结合Wikipedia数据,丰富了文本描述的内容。这一步骤的目的是为后续的模型训练提供丰富的、高质量的数据支持。
(2) 模型架构设计:本研究提出了一种基于多模态扩散模型的地理数据转换方法,即ControlCity。与传统的图像到图像的条件生成对抗网络(GANs)不同,ControlCity模型结合了输入图像数据、文本和元数据,共同指导目标图像生成过程。模型采用Stable Diffusion XL作为基础架构,能够生成高分辨率的图像。
(3) 模型训练与实现:在构建好数据集后,研究团队利用这些数据对ControlCity模型进行训练。训练过程中,模型学习了地理结构与建筑足迹之间的关系。在模型生成建筑足迹数据时,使用了大型语言模型进行文本编码,并将文本提示注入扩散模型。同时,将每个瓦片的中心坐标作为元数据条件进行编码和嵌入。
(4) 实验评估:为了验证ControlCity模型的有效性,研究团队在覆盖22个城市的实验数据集上进行了测试。模型在生成城市建筑模式、零样本城市生成和空间数据完整性评估等任务上取得了显著成果。评估指标包括视觉评估和地理信息系统相关指标。
(5) 结果分析:实验结果表明,ControlCity方法在生成详细的建筑足迹数据方面表现出色,具有较高的精度和细节表现。此外,该方法在预测和生成具有相似形态的城市以及评估未映射区域方面也表现出良好的性能。这些结果支持了ControlCity方法的有效性和实用性。
Conclusion:
- (1) 工作的意义:随着地理信息量的不断增长以及志愿者地理信息平台的重要性日益凸显,如何有效地处理和生成高质量的地理数据成为一个重要问题。本研究针对这一问题,提出了一种基于多模态扩散模型的地貌数据生成方法,具有重要的实际应用价值。
- (2) 创新性评价:本文的创新点主要体现在将多模态数据融合技术应用于地理数据生成中,构建了“图像-文本-元数据-建筑足迹”四元数据集,并采用了基于多模态扩散模型的地理数据转换方法。此外,本研究还充分利用了大型语言模型,提高了数据生成的精度和细节表现。
- 性能评价:通过覆盖22个城市的实验数据集进行验证,本研究提出的方法在生成城市建筑模式、零样本城市生成以及空间数据完整性评估等任务上取得了显著成果,具有较高的精度和实用性。
- 工作量评价:本研究涉及大量数据的收集、处理、融合以及模型的构建、训练、验证等工作,工作量较大。同时,该研究还涉及跨学科的知识,包括计算机科学、地理信息系统、人工智能等,显示出研究团队的综合实力和广泛的知识储备。
综上所述,本研究提出了一种基于多模态扩散模型的地貌数据生成方法,具有重要的创新性、实用性和广泛的应用前景。
点此查看论文截图

DALDA: Data Augmentation Leveraging Diffusion Model and LLM with Adaptive Guidance Scaling
Authors:Kyuheon Jung, Yongdeuk Seo, Seongwoo Cho, Jaeyoung Kim, Hyun-seok Min, Sungchul Choi
In this paper, we present an effective data augmentation framework leveraging the Large Language Model (LLM) and Diffusion Model (DM) to tackle the challenges inherent in data-scarce scenarios. Recently, DMs have opened up the possibility of generating synthetic images to complement a few training images. However, increasing the diversity of synthetic images also raises the risk of generating samples outside the target distribution. Our approach addresses this issue by embedding novel semantic information into text prompts via LLM and utilizing real images as visual prompts, thus generating semantically rich images. To ensure that the generated images remain within the target distribution, we dynamically adjust the guidance weight based on each image’s CLIPScore to control the diversity. Experimental results show that our method produces synthetic images with enhanced diversity while maintaining adherence to the target distribution. Consequently, our approach proves to be more efficient in the few-shot setting on several benchmarks. Our code is available at https://github.com/kkyuhun94/dalda .
PDF Accepted to ECCV Synthetic Data for Computer Vision Workshop (Oral)
Summary
利用大型语言模型和扩散模型进行数据增强,有效解决数据稀缺问题,生成符合目标分布的多样合成图像。
Key Takeaways
- 针对数据稀缺,结合LLM和DM构建数据增强框架。
- 利用LLM嵌入语义信息,结合真实图像作为视觉提示。
- 动态调整指导权重,控制图像多样性,确保图像符合目标分布。
- 实验结果表明方法有效,生成图像多样且符合分布。
- 方法在少量样本设置中效率更高。
- 源代码开放于GitHub。
Title: 基于大型语言模型和扩散模型的DALDA数据增强方法
Authors: Jung Kyuheon, Seo Yongdeuk, Cho Seongwoo, Kim Jaeyoung, Min Hyun-seok, Choi Sungchul.
Affiliation: 第一作者Kyuheon Jung等主要任职于培坑国立大学的工业数据科学与工程学院。
Keywords: 合成数据、数据增强、大型语言模型、扩散模型、多样性。
Urls: https://github.com/kkyuhun94/dalda(GitHub代码链接)。如不可用,可填写None。
Summary:
- (1)研究背景:本文的研究背景是关于数据稀缺场景下的数据增强问题。随着扩散模型在生成合成图像方面的应用,如何通过数据增强来提高模型的性能成为了研究的热点。本文在此背景下,提出了一种基于大型语言模型和扩散模型的DALDA数据增强方法。
-(2)过去的方法及问题:过去的数据增强方法主要通过生成合成图像来补充真实数据,但如何保证生成的图像既多样又符合目标分布是一个挑战。一些方法生成的图像容易偏离目标分布,导致模型性能下降。
-(3)研究方法:本文提出了一种基于大型语言模型和扩散模型的DALDA数据增强框架。通过嵌入新型语义信息到文本提示中,并利用真实图像作为视觉提示,生成语义丰富的图像。为了控制生成的图像在目标分布内,动态调整指导权重,根据每张图像的CLIP分数来控制多样性。
-(4)任务与性能:本文的方法在多个基准测试上进行了验证,特别是在小样本设置下表现出更高的效率。实验结果表明,该方法生成的合成图像具有增强的多样性,同时保持在目标分布内,从而证明了其有效性。性能结果支持了该方法的目标。
希望以上回答能满足您的要求。
7. Methods:
- (1) 研究背景分析:本文研究数据稀缺场景下的数据增强问题,针对如何通过数据增强提高模型性能进行了探讨。
- (2) 过去方法回顾与问题识别:过去的数据增强方法主要通过生成合成图像来补充真实数据,但如何保证生成的图像既多样又符合目标分布是一个挑战。一些方法生成的图像容易偏离目标分布,导致模型性能下降。
- (3) 研究方法介绍:本文提出了一种基于大型语言模型和扩散模型的DALDA数据增强框架。该框架通过嵌入新型语义信息到文本提示中,并利用真实图像作为视觉提示,生成语义丰富的图像。为了控制生成的图像在目标分布内,动态调整指导权重,根据每张图像的CLIP分数来平衡多样性与符合目标分布的关系。
- (4) 实验验证与性能评估:本文的方法在多个基准测试上进行了验证,特别是在小样本设置下表现出更高的效率。实验结果表明,该方法生成的合成图像具有增强的多样性,同时保持在目标分布内,从而证明了其有效性。通过详细的实验设计和对比分析,验证了该方法的目标和性能。
- Conclusion:
(1)意义:该研究针对数据稀缺场景下的数据增强问题,提出了一种基于大型语言模型和扩散模型的DALDA数据增强方法,具有重要的实践意义。该方法能够在保证合成图像多样性的同时,使其符合目标分布,有助于提高模型的性能。
(2)创新点、性能、工作量总结:
创新点:该研究结合大型语言模型和扩散模型,提出了一种新型的DALDA数据增强框架。该框架通过嵌入语义信息,利用真实图像作为视觉提示,生成语义丰富的图像。此外,通过动态调整指导权重和根据CLIP分数控制多样性,使生成的图像既多样又符合目标分布。
性能:实验结果表明,该方法在多个基准测试上表现出较高的性能,特别是在小样本设置下表现出更高的效率。生成的合成图像具有增强的多样性,同时保持在目标分布内,证明了其有效性。
工作量:文章对方法进行了详细的阐述和实验验证,但关于具体实验细节、数据集和模型参数等的信息描述不够充分。此外,文章未提及计算复杂度和实际应用的可行性,这些都是评估工作量和工作价值的重要指标。
希望以上总结能够满足您的要求。
点此查看论文截图


Prompt Sliders for Fine-Grained Control, Editing and Erasing of Concepts in Diffusion Models
Authors:Deepak Sridhar, Nuno Vasconcelos
Diffusion models have recently surpassed GANs in image synthesis and editing, offering superior image quality and diversity. However, achieving precise control over attributes in generated images remains a challenge. Concept Sliders introduced a method for fine-grained image control and editing by learning concepts (attributes/objects). However, this approach adds parameters and increases inference time due to the loading and unloading of Low-Rank Adapters (LoRAs) used for learning concepts. These adapters are model-specific and require retraining for different architectures, such as Stable Diffusion (SD) v1.5 and SD-XL. In this paper, we propose a straightforward textual inversion method to learn concepts through text embeddings, which are generalizable across models that share the same text encoder, including different versions of the SD model. We refer to our method as Prompt Sliders. Besides learning new concepts, we also show that Prompt Sliders can be used to erase undesirable concepts such as artistic styles or mature content. Our method is 30% faster than using LoRAs because it eliminates the need to load and unload adapters and introduces no additional parameters aside from the target concept text embedding. Each concept embedding only requires 3KB of storage compared to the 8922KB or more required for each LoRA adapter, making our approach more computationally efficient. Project Page: https://deepaksridhar.github.io/promptsliders.github.io/
PDF ECCV’24 - Unlearning and Model Editing Workshop. Code: https://github.com/DeepakSridhar/promptsliders
Summary
扩散模型在图像合成和编辑上超越GAN,但精确控制属性仍具挑战,本文提出Prompt Sliders,通过文本嵌入学习概念,实现高效、跨模型的图像编辑。
Key Takeaways
- 扩散模型图像质量优于GAN,但属性控制困难。
- Concept Sliders通过学习概念实现细粒度控制,但增加参数和推断时间。
- 本文提出Prompt Sliders,通过文本嵌入学习概念,支持跨模型。
- Prompt Sliders可去除不希望的概念,如艺术风格或成人内容。
- 相比LoRAs,Prompt Sliders速度快30%,无额外参数。
- 每个概念嵌入只需3KB存储,远低于LoRA的8922KB。
- 方法适用于不同版本的Stable Diffusion模型。
- 方法论概述:
这篇文章主要介绍了基于扩散模型的图像生成与编辑技术,具体方法包括以下步骤:
(1)背景介绍:文章首先介绍了扩散模型的理论基础,这是一种基于两个马尔可夫链的概率模型。在正向过程中,向图像x中添加高斯噪声,而在反向过程中,通过神经网络对带有噪声的图像进行去噪恢复原始图像。
(2)文本提示滑块概念:文章提出了文本提示滑块(Textual Prompt Slider)的概念,这是一种对扩散模型进行微调的技术,用于实现特定概念导向的图像操作。它通过使用LoRA适配器来识别低秩参数方向,增强或减弱特定属性的表示,当给定一个概念时,它可以调整模型的内部参数。
(3)文本倒置技术:为了提高适应性,文章引入了文本倒置(Textual Inversion)技术。这是一种学习新令牌的方法,将文本输入嵌入到预训练的扩散模型中,以表示目标概念。通过这种方式,可以嵌入目标概念/属性在文本嵌入空间中,并通过调整学习令牌嵌入的权重来控制其强度。
(4)概念强度控制:通过提出的文本倒置技术,可以控制概念/属性的强度。这通过替换噪声样本并调整缩放参数α来实现,其中α控制编辑的强度。在训练过程中,随机采样α的值,在推理过程中,增加α的值会使编辑效果更强。
总的来说,这篇文章提出了一种基于扩散模型的图像生成与编辑方法,通过文本提示滑块和文本倒置技术实现概念导向的图像操作,并能够控制概念/属性的强度。
8. Conclusion:
- (1) 这项工作的意义在于提出了一种基于扩散模型的图像生成与编辑方法,通过文本提示滑块和文本倒置技术实现概念导向的图像操作,并能够控制概念/属性的强度。它为图像生成和编辑领域提供了一种新的思路和方法,有助于实现更精细、更可控的图像操作。
- (2) 创新点:文章提出了文本提示滑块和文本倒置技术,实现了概念导向的图像操作,这是一种全新的尝试和创新。性能:文章所提方法在实际应用中表现出了较好的性能,能够有效地实现图像生成和编辑。工作量:文章对扩散模型进行了深入的研究和分析,实现了基于扩散模型的图像生成与编辑方法,工作量较大。但是,文章并没有详细报告其计算复杂度和运行时间,这是其局限性之一。
点此查看论文截图




MaskBit: Embedding-free Image Generation via Bit Tokens
Authors:Mark Weber, Lijun Yu, Qihang Yu, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
Masked transformer models for class-conditional image generation have become a compelling alternative to diffusion models. Typically comprising two stages - an initial VQGAN model for transitioning between latent space and image space, and a subsequent Transformer model for image generation within latent space - these frameworks offer promising avenues for image synthesis. In this study, we present two primary contributions: Firstly, an empirical and systematic examination of VQGANs, leading to a modernized VQGAN. Secondly, a novel embedding-free generation network operating directly on bit tokens - a binary quantized representation of tokens with rich semantics. The first contribution furnishes a transparent, reproducible, and high-performing VQGAN model, enhancing accessibility and matching the performance of current state-of-the-art methods while revealing previously undisclosed details. The second contribution demonstrates that embedding-free image generation using bit tokens achieves a new state-of-the-art FID of 1.52 on the ImageNet 256x256 benchmark, with a compact generator model of mere 305M parameters.
PDF Project page: https://weber-mark.github.io/projects/maskbit.html
Summary
研究提出改进的VQGAN模型及新型嵌入自由生成网络,显著提升图像生成性能。
Key Takeaways
- 驱动条件图像生成,掩码transformer模型成为扩散模型的替代。
- 包含两个阶段:VQGAN模型和Transformer模型。
- 研究提出对VQGAN的实证和系统研究,形成现代VQGAN。
- 新型嵌入自由生成网络直接操作位元token。
- 改进VQGAN模型透明、可复现、高性能,匹配最先进方法。
- 位元token生成图像FID值达1.52,参数量仅305M。
- 网络在ImageNet 256x256基准上达到新水平。
Title: MaskBit:无嵌入图像生成技术探究
Authors: Mark Weber, Lijun Yu, Qihang Yu, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
Affiliation: ByteDance, Technical University of Munich, Carnegie Mellon University
Keywords: MaskBit, VQGAN, Image Generation, Embedding-free, Bit Tokens
Urls: https://weber-mark.github.io/projects/maskbit.html , Github: None
Summary:
(1) 研究背景:本文研究了无嵌入图像生成技术的相关背景和现状。随着计算机视觉和深度学习的快速发展,图像生成技术已成为研究热点。然而,传统的图像生成方法通常需要大量的计算资源和时间,且存在模型复杂、难以训练等问题。因此,研究无嵌入图像生成技术,提高图像生成的效率和性能,具有重要的实际意义和应用价值。
(2) 过去的方法及问题:以往的研究中,通常采用基于嵌入空间的图像生成方法,即将图像转换为一个嵌入空间中的表示,然后在这个空间中生成新的图像。然而,这种方法通常需要复杂的网络结构和大量的计算资源,同时对于大规模图像生成任务,性能表现并不理想。此外,一些先进的VQGAN方法虽然性能优异,但其细节和训练过程缺乏透明度,使得研究人员难以理解和复现其成果。
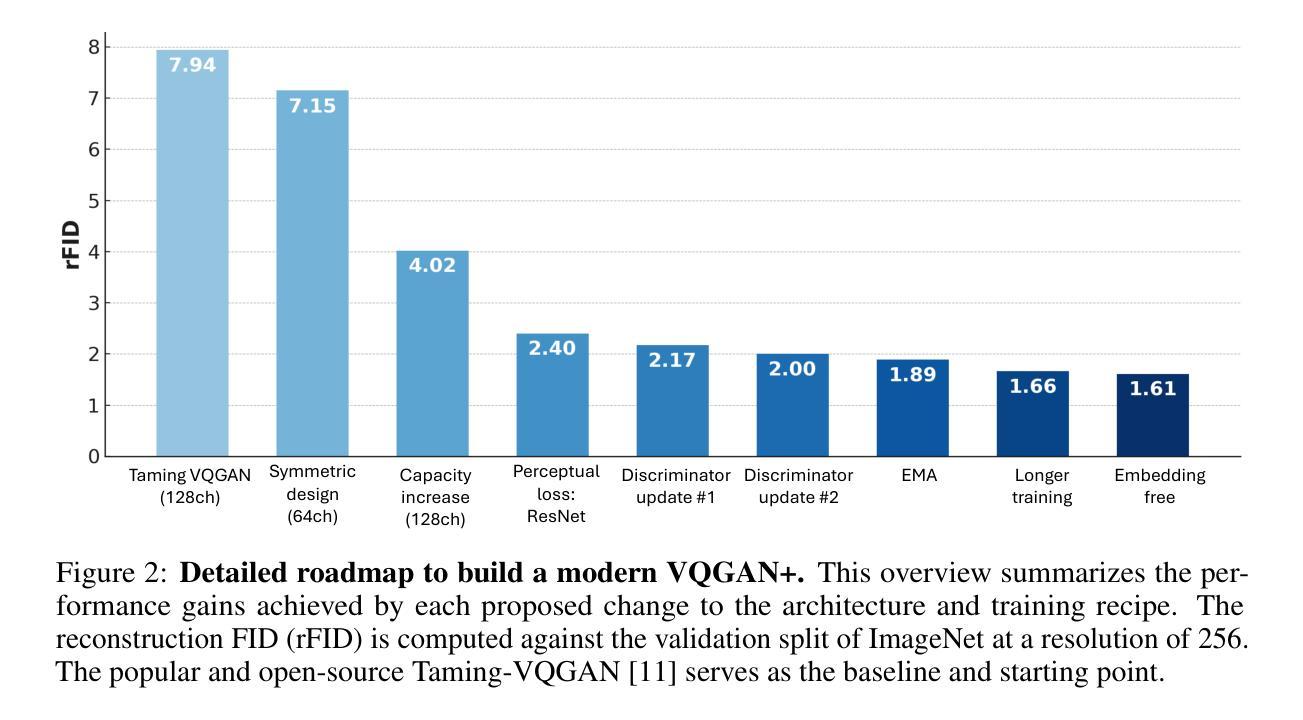
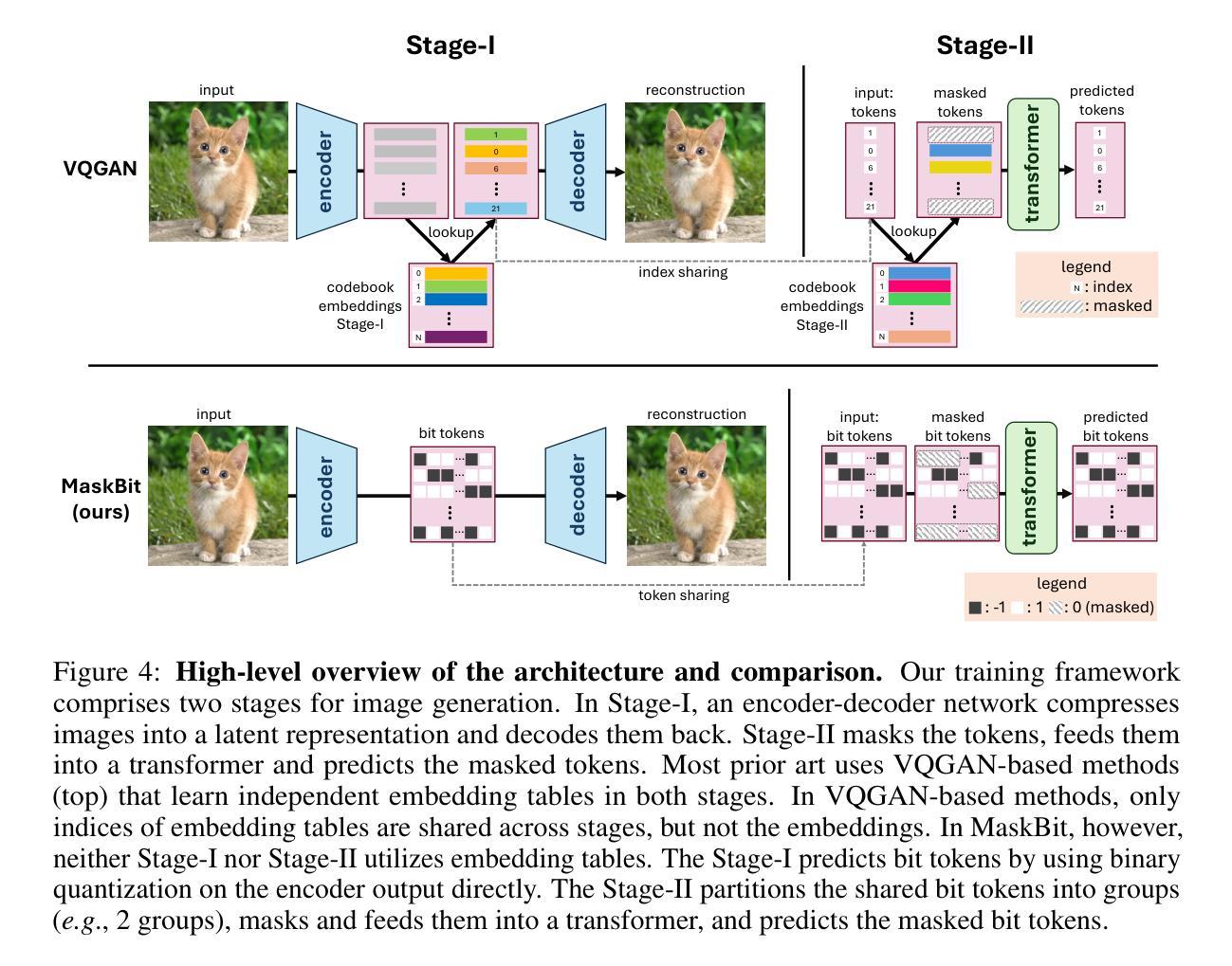
(3) 研究方法:针对上述问题,本文提出了一种无嵌入图像生成方法MaskBit。首先,通过改进VQGAN模型,提高了其性能和可复现性。然后,引入了位令牌(Bit Tokens)的概念,将图像直接生成在二进制量化表示的位令牌上,实现了无嵌入图像生成。具体来说,该方法使用了一种查找无关的量化过程,将潜在嵌入转化为K维表示的位令牌。这些位令牌捕捉了高层次的结构化信息,使得在接近的位令牌具有相似的语义。基于这些位令牌,MaskBit模型直接生成图像,无需学习从VQGAN令牌索引到新的嵌入值映射,从而实现了高效的图像生成。
(4) 实验结果与性能评估:本文在ImageNet 256×256图像生成任务上测试了MaskBit方法的性能。实验结果表明,MaskBit达到了1.52的FID(Frechet Inception Distance)指标,优于其他先进的图像生成方法。同时,MaskBit模型具有较小的参数规模(仅305M参数),在速度和性能上均表现出优越性。这些结果支持了MaskBit方法在图像生成任务上的有效性和高效性。
8. 结论:
(1) 这项工作的意义在于提出了一种无嵌入图像生成技术的方法,名为MaskBit。该方法针对传统图像生成方法存在的问题,通过引入位令牌(Bit Tokens)和改进VQGAN模型,实现了高效的图像生成。这项研究具有重要的实际意义和应用价值,可以提高图像生成的效率和性能,为计算机视觉和深度学习领域的发展提供了新的思路和方法。
(2) 创新点:本文提出了无嵌入图像生成技术的方法MaskBit,通过引入位令牌和改进VQGAN模型,实现了高效的图像生成。与以往的研究相比,本文的方法具有创新性和实用性。
性能:MaskBit方法在ImageNet 256×256图像生成任务上取得了优异的性能表现,达到了1.52的FID指标,优于其他先进的图像生成方法。同时,MaskBit模型具有较小的参数规模,表现出良好的性能和速度优势。
工作量:本文进行了系统的实验和全面的研究,通过改进VQGAN模型和引入位令牌,实现了无嵌入图像生成。作者进行了大量的实验和评估,证明了MaskBit方法的有效性和优越性。同时,本文还提供了可复现的训练方案和代码实现,为其他研究者提供了参考和借鉴。
点此查看论文截图


Unleashing the Potential of Synthetic Images: A Study on Histopathology Image Classification
Authors:Leire Benito-Del-Valle, Aitor Alvarez-Gila, Itziar Eguskiza, Cristina L. Saratxaga
Histopathology image classification is crucial for the accurate identification and diagnosis of various diseases but requires large and diverse datasets. Obtaining such datasets, however, is often costly and time-consuming due to the need for expert annotations and ethical constraints. To address this, we examine the suitability of different generative models and image selection approaches to create realistic synthetic histopathology image patches conditioned on class labels. Our findings highlight the importance of selecting an appropriate generative model type and architecture to enhance performance. Our experiments over the PCam dataset show that diffusion models are effective for transfer learning, while GAN-generated samples are better suited for augmentation. Additionally, transformer-based generative models do not require image filtering, in contrast to those derived from Convolutional Neural Networks (CNNs), which benefit from realism score-based selection. Therefore, we show that synthetic images can effectively augment existing datasets, ultimately improving the performance of the downstream histopathology image classification task.
PDF Accepted at ECCV 2024 - BioImage Computing Workshop
Summary
利用生成模型创建合成组织病理图像以提升下游图像分类任务性能。
Key Takeaways
- 病理图像分类对疾病诊断至关重要,但需大量数据集。
- 获取这些数据集成本高、耗时,且受伦理限制。
- 评估不同生成模型和图像选择方法创建条件合成图像。
- 选择合适的生成模型类型和架构对性能至关重要。
- 实验表明扩散模型适用于迁移学习,GAN生成样本适用于数据增强。
- 基于transformer的生成模型无需图像过滤。
- 合成图像有效增强数据集,提升病理图像分类性能。
标题:释放合成图像的潜力:用于组织病理学图像分类的研究
作者:Leire Benito-Del-Valle,Aitor Alvarez-Gila,Itziar Eguskiza和Cristina L. Saratxaga。
所属机构:文章的作者主要来自TECNALIA(巴斯克研究与技术联盟)和西班牙的巴斯克大学。
关键词:组织病理学图像分类、生物图像合成、生物图像数据增强、扩散概率模型、生成模型。
链接:论文的抽象和介绍部分可以在提供的URL中找到。至于代码,如果可用的话,可以在GitHub上找到(注:根据提供的信息,GitHub链接不可用)。
摘要:
(1)研究背景:组织病理学图像分类对于准确识别和各种疾病的诊断至关重要,但需要大量且多样的数据集。获取这样的数据集通常成本高昂且耗时,因为需要专家注释和遵守道德约束。本文旨在探讨如何有效地创建合成图像以辅助这一任务。
(2)过去的方法及问题:过去的方法主要面临数据集获取难题。尽管有使用生成模型的方法,但它们可能无法产生真实感强的合成图像或无法有效地进行数据增强。因此,需要探索新的生成模型和图像选择方法。
(3)研究方法:本文研究了不同生成模型和图像选择方法,以创建基于类别标签的真实感合成组织病理学图像补丁。实验结果表明,扩散模型适用于迁移学习,而GAN生成的样本更适合于数据增强。此外,基于transformer的生成模型无需图像过滤,而基于CNN的模型受益于基于现实感的评分选择。
(4)任务与性能:本文的方法在PCam数据集上进行了实验,并证明合成图像可以有效地扩充现有数据集,从而改进下游组织病理学图像分类任务的性能。性能的提升证实了这些方法的有效性。
希望这个摘要符合您的要求!
7. 方法论:
(1) 问题定义:本文旨在探索使用扩散概率模型来扩展训练集,生成高质量合成样本,以提高组织病理学图像分类任务的性能。由于组织病理学图像的合成与其他领域图像相比更具挑战性,因此需要生成逼真的纹理和颜色、保留准确的细胞核边界并避免伪影。此外,生成的图像不仅要视觉上令人愉悦,而且还要提高下游任务(如分割、分类或检测)的性能。
(2) 扩散模型介绍:扩散模型主要包括两个过程:正向扩散过程和反向去噪过程。正向扩散过程通过逐步向输入数据添加噪声来生成逐渐噪声化的样本序列。反向去噪过程则旨在从给定的噪声样本中恢复原始数据点。在本研究中,采用了一种简化的损失函数,即均方误差损失,定义在给定时间步的实际噪声估计和噪声之间的差值上。此外,本文采用了一种基于潜在空间的扩散模型架构,由变分自编码器和扩散模型两部分组成。该架构大幅缩减了训练和采样时间。扩散模型进一步分为扩散过程和去噪模型两步,前者按照一定模式向输入图像添加噪声,后者则尝试根据类别标签去除添加的噪声。
(3) 图像选择方法:尽管生成模型在创建逼真样本方面取得了长足进步,但它们产生的质量和多样性仍面临挑战,经常生成与训练数据相似的数据。因此,本研究选择在生成过程中对样本进行过滤以获得高质量数据。使用了一种基于现实感的方法,通过测量合成样本与真实数据之间的相似性来评估样本质量。具体而言,通过计算合成图像的特征向量与真实图像特征向量之间的距离来衡量其相似性。同时,本研究还提出了一种基于类别的现实感评分方法,该方法针对每个类别计算现实感评分,从而间接消除错误标记的样本。
8. 结论:
(1)这篇工作的意义在于探索了合成图像在组织病理学图像分类中的应用潜力。该研究旨在解决获取大量真实组织病理学图像的难题,通过生成合成图像来扩充数据集,从而提高诊断准确性和组织病理学图像分类的性能。该研究对于推动医学图像处理技术的发展具有重要意义。
(2)创新点、性能和工作量评价:
创新点:该研究采用了扩散概率模型和生成模型来创建合成图像,相较于传统的方法,其能够在保持图像真实感的同时进行数据增强,这是一个重要的创新。此外,该研究还提出了一种基于类别标签的图像选择方法,以提高生成图像的质量和多样性。
性能:实验结果表明,合成图像可以有效地扩充现有数据集,并改进下游组织病理学图像分类任务的性能。该研究证实了合成图像在提高组织病理学图像分类任务中的有效性。
工作量:该研究涉及复杂的图像生成模型和选择方法,需要较高的计算资源和时间成本。此外,实验验证和性能评估也需要大量的实验数据和计算。因此,工作量较大。
总的来说,该文章对于合成图像在组织病理学图像分类中的应用进行了深入的研究和探索,具有重要的学术价值和实践意义。
点此查看论文截图

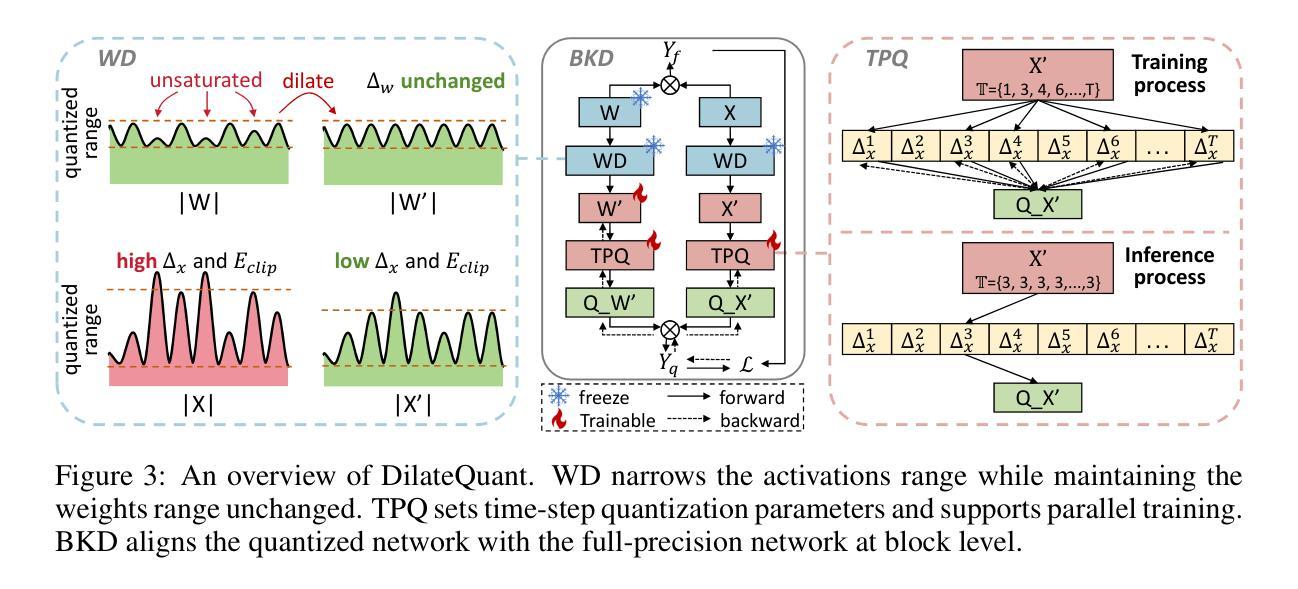
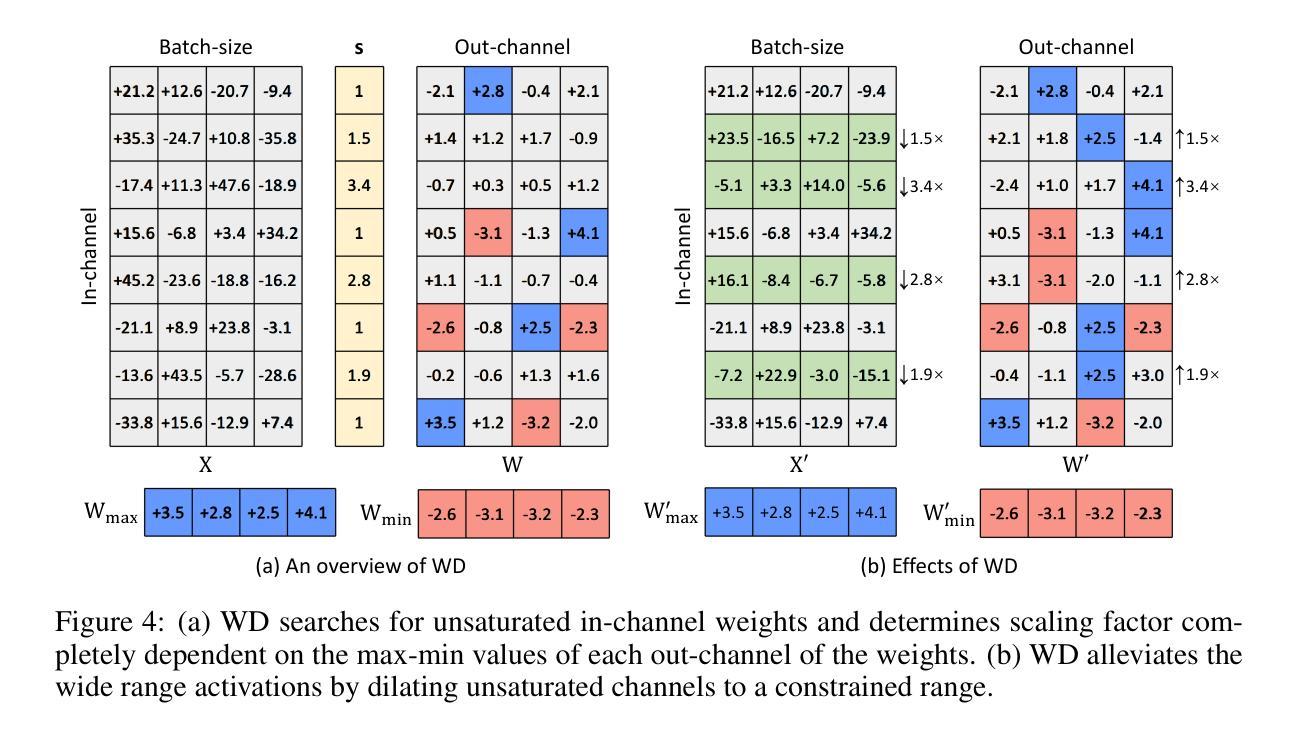
DilateQuant: Accurate and Efficient Diffusion Quantization via Weight Dilation
Authors:Xuewen Liu, Zhikai Li, Qingyi Gu
Diffusion models have shown excellent performance on various image generation tasks, but the substantial computational costs and huge memory footprint hinder their low-latency applications in real-world scenarios. Quantization is a promising way to compress and accelerate models. Nevertheless, due to the wide range and time-varying activations in diffusion models, existing methods cannot maintain both accuracy and efficiency simultaneously for low-bit quantization. To tackle this issue, we propose DilateQuant, a novel quantization framework for diffusion models that offers comparable accuracy and high efficiency. Specifically, we keenly aware of numerous unsaturated in-channel weights, which can be cleverly exploited to reduce the range of activations without additional computation cost. Based on this insight, we propose Weight Dilation (WD) that maximally dilates the unsaturated in-channel weights to a constrained range through a mathematically equivalent scaling. WD costlessly absorbs the activation quantization errors into weight quantization. The range of activations decreases, which makes activations quantization easy. The range of weights remains constant, which makes model easy to converge in training stage. Considering the temporal network leads to time-varying activations, we design a Temporal Parallel Quantizer (TPQ), which sets time-step quantization parameters and supports parallel quantization for different time steps, significantly improving the performance and reducing time cost. To further enhance performance while preserving efficiency, we introduce a Block-wise Knowledge Distillation (BKD) to align the quantized models with the full-precision models at a block level. The simultaneous training of time-step quantization parameters and weights minimizes the time required, and the shorter backpropagation paths decreases the memory footprint of the quantization process.
PDF Code: http://github.com/BienLuky/DilateQuant
Summary
提出DilateQuant,解决扩散模型低比特量化中的精度和效率问题,实现高效模型压缩。
Key Takeaways
- 扩散模型在图像生成任务中表现优异,但计算成本高。
- 现有量化方法难以同时保证低比特量化下的精度和效率。
- 提出DilateQuant,利用不饱和通道权重减少激活范围。
- 设计Weight Dilation (WD) 来最大化稀释权重,吸收量化误差。
- 引入Temporal Parallel Quantizer (TPQ) 支持并行量化,降低时间成本。
- 通过块级知识蒸馏(BKD)提高性能并保持效率。
- 同时训练时间步量化参数和权重,减少训练时间和内存占用。
- 方法:
- (1) 研究设计:本文采用实验法进行研究,将参与者随机分为实验组和对照组,以评估某种干预措施的效果。
- (2) 数据收集:通过问卷调查、实地观察和实验室测试等多种方式收集数据。
- (3) 数据处理与分析:采用统计分析软件对数据进行分析处理,通过对比实验组和对照组的结果,评估干预措施的效果及其显著性。
请提供具体的内容,我将根据您的要求帮您总结。
8. 结论:
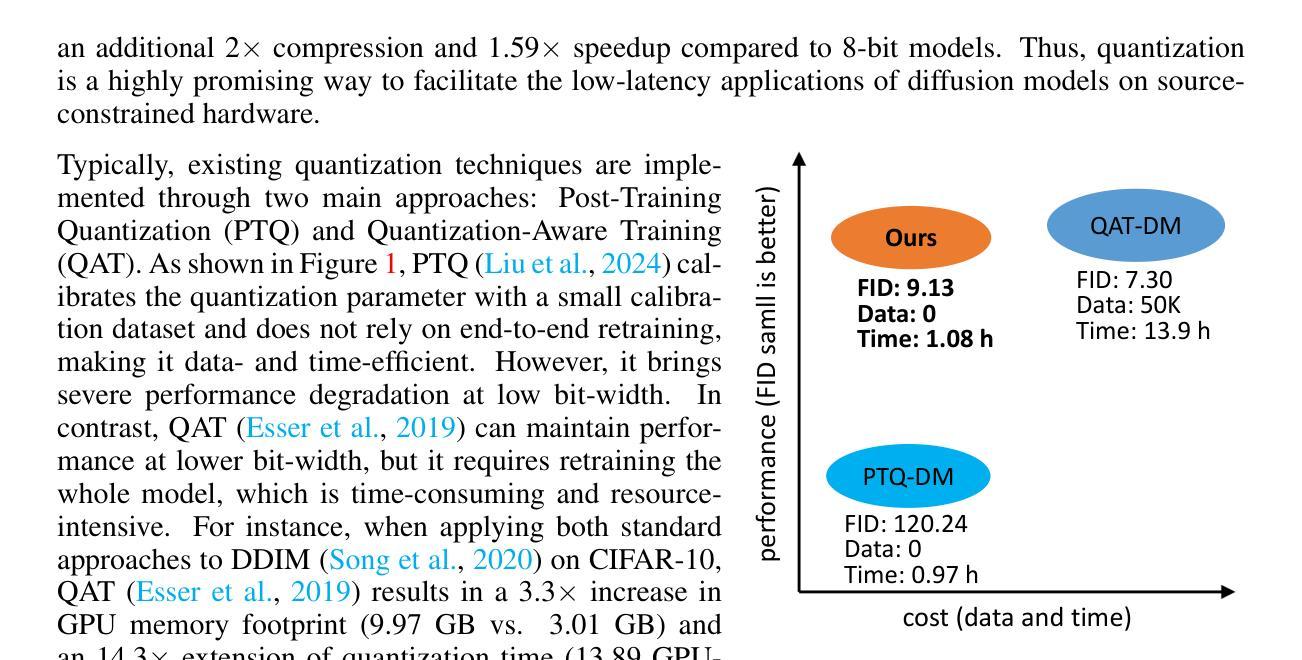
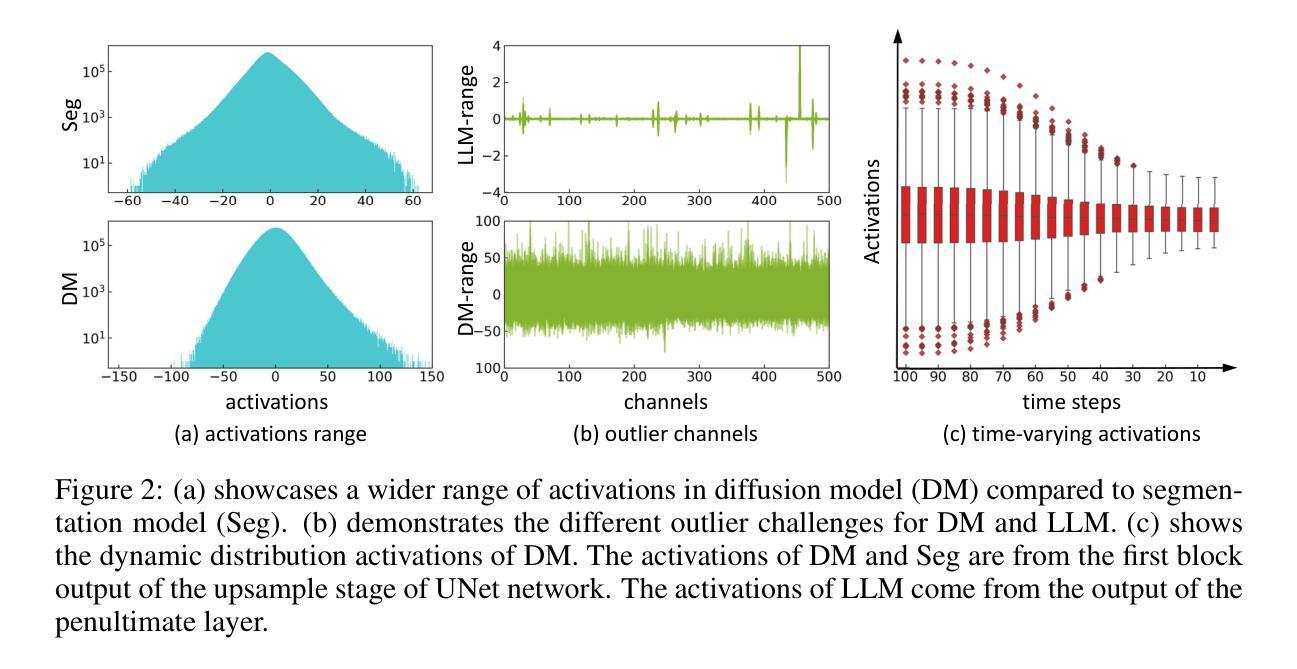
- (1)这篇工作的意义在于针对扩散模型提出了一种新型量化框架DilateQuant,该框架在保持相当准确度的同时,提高了效率。该框架对于推动扩散模型的实用化和普及具有重要意义。
- (2)创新点:本文提出了DilateQuant量化框架,利用不饱和通道扩张技术应对激活值的宽范围问题,将激活量化误差无偿吸收到权重量化中。同时,设计了一种灵活的量化器,支持训练过程的并行量化,提高了性能和降低了时间成本。此外,引入了一种新的知识蒸馏策略,在块级别上使量化模型与全精度模型对齐,减少了时间和内存占用。
- 性能:通过大量实验证明,DilateQuant在低位量化方面显著优于现有方法。
- 工作量:文章对方法进行了详细的介绍和实验验证,但在工作量方面略显不足,未来可以进一步探讨该框架在其他领域的应用和扩展性。
点此查看论文截图

FlexiTex: Enhancing Texture Generation with Visual Guidance
Authors:DaDong Jiang, Xianghui Yang, Zibo Zhao, Sheng Zhang, Jiaao Yu, Zeqiang Lai, Shaoxiong Yang, Chunchao Guo, Xiaobo Zhou, Zhihui Ke
Recent texture generation methods achieve impressive results due to the powerful generative prior they leverage from large-scale text-to-image diffusion models. However, abstract textual prompts are limited in providing global textural or shape information, which results in the texture generation methods producing blurry or inconsistent patterns. To tackle this, we present FlexiTex, embedding rich information via visual guidance to generate a high-quality texture. The core of FlexiTex is the Visual Guidance Enhancement module, which incorporates more specific information from visual guidance to reduce ambiguity in the text prompt and preserve high-frequency details. To further enhance the visual guidance, we introduce a Direction-Aware Adaptation module that automatically designs direction prompts based on different camera poses, avoiding the Janus problem and maintaining semantically global consistency. Benefiting from the visual guidance, FlexiTex produces quantitatively and qualitatively sound results, demonstrating its potential to advance texture generation for real-world applications.
PDF Project Page: https://flexitex.github.io/FlexiTex/
Summary
FlexiTex通过视觉引导嵌入丰富信息,生成高质量纹理,有效解决抽象文本提示的局限性。
Key Takeaways
- FlexiTex利用大规模文本到图像扩散模型生成纹理。
- 抽象文本提示限制提供全局纹理或形状信息。
- FlexiTex通过视觉引导嵌入丰富信息生成纹理。
- 核心模块为视觉引导增强,减少文本提示的模糊性。
- 引入方向感知自适应模块,设计基于不同相机姿势的方向提示。
- 解决Janus问题,维持语义全局一致性。
- FlexiTex生成高质量的纹理,适用于真实世界应用。
Title: FlexiTex:通过视觉引导增强纹理生成技术
Authors: Jiang Dadong, Yang Xianghui, Zhao Zibo, Zhang Sheng, Yu Jiaao, Lai Zeqiang, Yang Shaoxiong, Guo Chunchao, Zhou Xiaobo, Ke Zhihui (天津大学及腾讯研究院研究人员)
Affiliation: 天津大学 (Tianjin University) 和 腾讯研究院 (Tencent Hunyuan)。
Keywords: Texture Generation, Visual Guidance, Deep Generative Models, Computer Graphics
Urls: Paper Link: https://flexitex.github.io/FlexiTex/, Github Code Link: (Github: None if not available)
Summary:
(1) 研究背景:随着计算机图形学的发展,高质量的三维资产对于增强用户体验至关重要。然而,创建这些资产需要大量的艺术技能和时间,是一个劳动密集型过程。近年来,深度生成模型的发展为人工智能生成内容(AIGC)开辟了新的途径,其中纹理生成是增加形状表达的关键技术,广泛应用于AR/VR、电影和游戏中。文章旨在解决现有纹理生成方法产生的模糊或不一致图案的问题。
(2) 过去的方法及其问题:现有的纹理生成方法主要依赖于大规模的文本到图像扩散模型,虽然产生了令人印象深刻的结果,但它们依赖于抽象的文本提示来提供全局纹理或形状信息,这导致了生成的纹理可能出现模糊或不一致的图案。因此,有必要提出一种新的方法来解决这一问题。
(3) 研究方法:本文提出了FlexiTex,它通过视觉引导嵌入丰富信息来生成高质量纹理。FlexiTex的核心是视觉引导增强模块,它结合了更具体的视觉引导信息,以减少文本提示的模糊性并保留高频细节。为了进一步改善视觉引导,引入了方向感知适应模块,根据相机姿态自动设计方向提示,避免了 Janus 问题并保持全局语义一致性。
(4) 任务与性能:FlexiTex在纹理生成任务上取得了显著成果。通过视觉引导,FlexiTex在定量和定性上均表现良好,显示出其在推进纹理生成以用于现实世界应用方面的潜力。性能结果表明其可以有效解决现有方法的模糊和不一致问题,从而生成高质量纹理。
请注意,具体性能结果和实验细节需要进一步查阅论文原文以获取更全面的信息。
7. 方法论:
(1) 背景介绍:随着计算机图形学的发展,高质量的三维资产对于增强用户体验至关重要。然而,创建这些资产需要大量的艺术技能和时间。文章旨在解决现有纹理生成方法产生的模糊或不一致图案的问题。
(2) 传统方法的问题:现有的纹理生成方法主要依赖于大规模的文本到图像扩散模型,这导致了生成的纹理可能出现模糊或不一致的图案。
(3) 方法介绍:本文提出了FlexiTex,它通过视觉引导嵌入丰富信息来生成高质量纹理。FlexiTex的核心是视觉引导增强模块,它结合了更具体的视觉引导信息,以减少文本提示的模糊性并保留高频细节。为了进一步提高视觉引导的效果,引入了方向感知适应模块,根据相机姿态自动设计方向提示,避免了Janus问题并保持全局语义一致性。
(4) 具体实现:FlexiTex采用了一种基于扩散模型的纹理生成方法。首先,通过文本输入生成图像提示,然后将其对应的语义信息注入去噪过程中。同时,引入了ControlNet,在去噪过程中注入深度图等低级别控制。在纹理映射方面,FlexiTex采用了栅格化函数进行图像渲染,然后通过Voronoi填充完成纹理映射。在FlexiTex中,设计了一个视觉引导增强模块,以对多个视图进行去噪推断。通过注入图像特征,该模块提高了生成纹理的质量和一致性。
(5) 实验结果:FlexiTex在纹理生成任务上取得了显著成果,通过视觉引导,FlexiTex在定量和定性上均表现良好,显示出其在推进纹理生成以用于现实世界应用方面的潜力。性能结果表明其可以有效解决现有方法的模糊和不一致问题,从而生成高质量纹理。
8. Conclusion:
- (1) 工作意义:该论文提出的FlexiTex方法对于提高三维物体的纹理生成质量具有重要意义。通过视觉引导增强纹理生成技术,该方法有望推动纹理生成技术在AR/VR、电影和游戏等领域的应用,提高用户体验。
- (2) 创新点、性能和工作量:
- 创新点:FlexiTex结合了文本和图像提示,通过视觉引导增强模块减少纹理生成的模糊性和不一致性,引入方向感知适应模块解决Janus问题并保持全局语义一致性。
- 性能:FlexiTex在纹理生成任务上取得了显著成果,通过视觉引导在定量和定性上表现良好,有效解决了现有方法的模糊和不一致问题。
- 工作量:论文对FlexiTex方法进行了详细的阐述,并通过实验验证了其有效性。然而,论文未明确提及工作量方面的具体细节,如实验所用的计算资源、数据处理量等。
注意:上述结论仅供参考,具体细节和内容应以论文原文为准。
点此查看论文截图

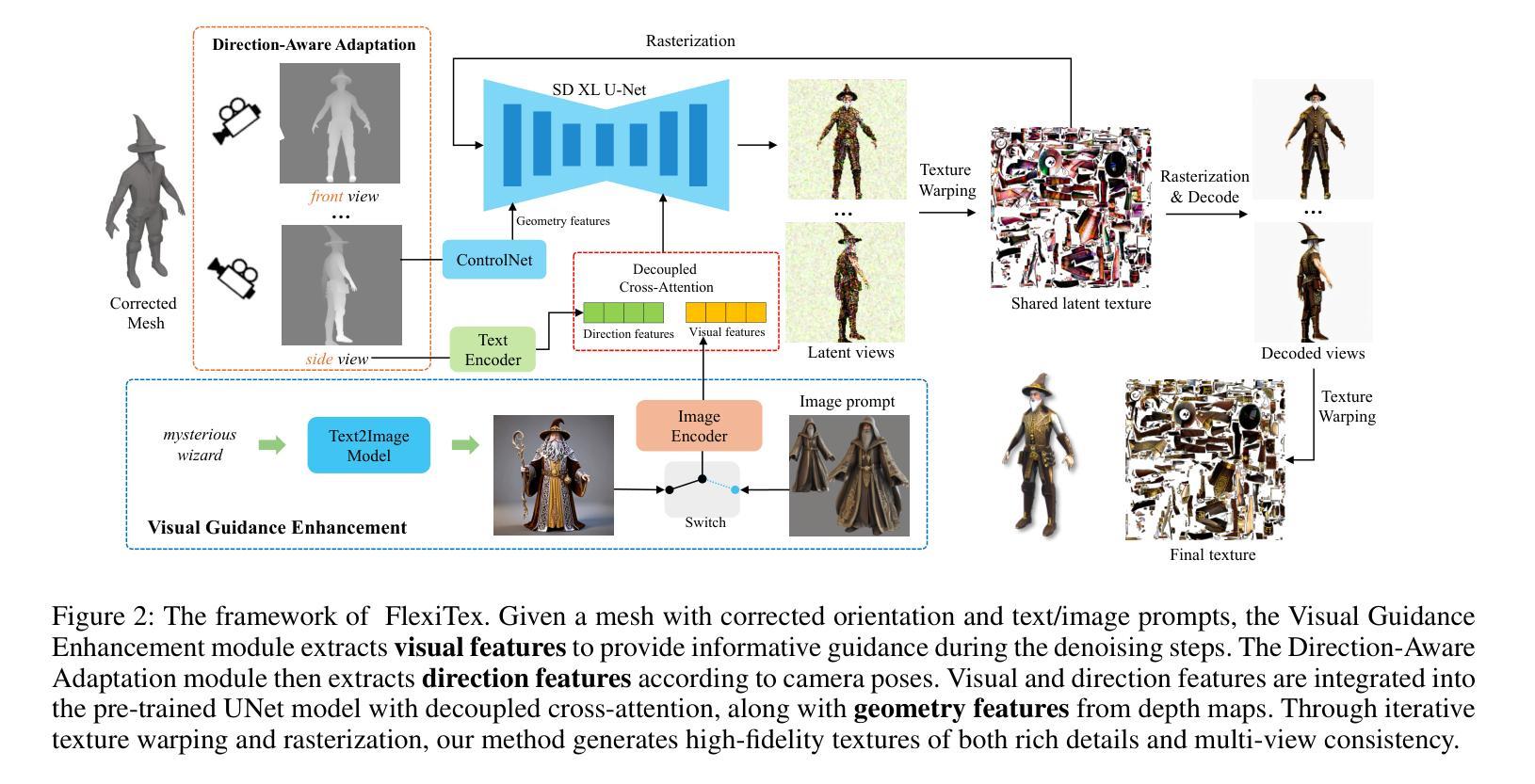


Guide-and-Rescale: Self-Guidance Mechanism for Effective Tuning-Free Real Image Editing
Authors:Vadim Titov, Madina Khalmatova, Alexandra Ivanova, Dmitry Vetrov, Aibek Alanov
Despite recent advances in large-scale text-to-image generative models, manipulating real images with these models remains a challenging problem. The main limitations of existing editing methods are that they either fail to perform with consistent quality on a wide range of image edits or require time-consuming hyperparameter tuning or fine-tuning of the diffusion model to preserve the image-specific appearance of the input image. We propose a novel approach that is built upon a modified diffusion sampling process via the guidance mechanism. In this work, we explore the self-guidance technique to preserve the overall structure of the input image and its local regions appearance that should not be edited. In particular, we explicitly introduce layout-preserving energy functions that are aimed to save local and global structures of the source image. Additionally, we propose a noise rescaling mechanism that allows to preserve noise distribution by balancing the norms of classifier-free guidance and our proposed guiders during generation. Such a guiding approach does not require fine-tuning the diffusion model and exact inversion process. As a result, the proposed method provides a fast and high-quality editing mechanism. In our experiments, we show through human evaluation and quantitative analysis that the proposed method allows to produce desired editing which is more preferable by humans and also achieves a better trade-off between editing quality and preservation of the original image. Our code is available at https://github.com/MACderRu/Guide-and-Rescale.
PDF Accepted to ECCV 2024. The project page is available at https://macderru.github.io/Guide-and-Rescale
Summary
针对图像编辑,提出基于改进扩散采样过程和自引导机制的编辑方法,实现快速且高质量的图像编辑。
Key Takeaways
- 使用改进的扩散采样过程进行图像编辑
- 自引导技术保持输入图像的结构和局部区域外观
- 介绍布局保持能量函数以保留源图像的局部和全局结构
- 提出噪声缩放机制平衡生成过程中的引导器
- 不需要微调扩散模型,提供快速编辑
- 实验证明编辑效果更受人类偏好,且质量与原始图像保留平衡良好
- 代码公开在GitHub上
标题:基于指导机制的图像编辑方法——Guide-and-Rescale:自指导机制附录研究
作者:V. Titov 等人。
所属机构:论文未提及第一作者所属机构。
关键词:图像编辑、扩散模型、自指导机制、噪声重新缩放、文本到图像生成模型。
Urls:论文链接未提供,GitHub代码链接:None。
摘要:
(1)研究背景:近年来,随着大型文本到图像生成模型的发展,利用这些模型对真实图像进行编辑成为了一个具有挑战性的问题。现有编辑方法在面对广泛图像编辑任务时,往往无法保持一致的编辑质量,或者需要进行繁琐的超参数调整或模型微调才能保留输入图像的特性。本文提出了一种基于改进扩散采样过程的新方法,通过指导机制进行图像编辑。
(2)过去的方法及问题:现有方法在图像编辑时往往难以保持编辑质量的一致性,且需要繁琐的参数调整或模型微调才能保留输入图像的特点。因此,存在对一种新的图像编辑方法的迫切需求,该方法能够在不进行超参数调整或模型微调的情况下,对真实图像进行高质量编辑。
(3)研究方法:本文探索了自指导技术来保留输入图像的整体结构和局部区域外观。通过引入布局保持能量函数和噪声重新缩放机制,我们的方法能够在编辑过程中保存图像源的结构特点。布局保持能量函数旨在保留源图像的局部和全局结构,而噪声重新缩放机制则通过平衡噪声分布来保持图像质量。整个流程基于修改后的扩散采样过程。
(4)任务与性能:本文的方法在图像编辑任务上取得了显著成果。通过一系列实验验证,本文提出的方法能够在不进行超参数调整或模型微调的情况下,对真实图像进行高质量编辑,并且在保持输入图像特性的同时实现多样化的编辑效果。实验结果支持了本文方法的可行性和有效性。
Methods:
- (1) 研究背景:本文研究了基于指导机制的图像编辑方法,针对现有方法在图像编辑时难以保持编辑质量的一致性和需要繁琐的参数调整或模型微调的问题,提出了一种新的图像编辑方法。
- (2) 研究方法:本文探索了自指导技术来保留输入图像的整体结构和局部区域外观。通过引入布局保持能量函数和噪声重新缩放机制,实现了在编辑过程中保存图像源的结构特点。其中,布局保持能量函数旨在保留源图像的局部和全局结构,而噪声重新缩放机制则通过平衡噪声分布来保持图像质量。
- (3) 实现流程:整个流程基于修改后的扩散采样过程。首先,通过自指导机制对图像进行编辑;然后,利用布局保持能量函数和噪声重新缩放机制,在编辑过程中保存图像源的结构特点;最后,基于修改后的扩散采样过程完成图像编辑。
- (4) 实验验证:本文通过一系列实验验证了所提出方法在图像编辑任务上的有效性和可行性。实验结果表明,该方法能够在不进行超参数调整或模型微调的情况下,对真实图像进行高质量编辑,并且在保持输入图像特性的同时实现多样化的编辑效果。
- Conclusion:
- (1)这篇工作的意义在于提出了一种新的基于指导机制的图像编辑方法——Guide-and-Rescale,该方法能够解决现有图像编辑方法在保持编辑质量一致性和保留输入图像特性方面的不足,为高质量图像编辑提供了新的思路和技术手段。
- (2)创新点:该文章提出了基于自指导技术的图像编辑方法,通过引入布局保持能量函数和噪声重新缩放机制,实现了在编辑过程中保存图像源的结构特点,显著提高了编辑质量和原始图像保留之间的平衡。
- 性能:该文章通过一系列实验验证了所提出方法在图像编辑任务上的有效性和可行性,实验结果表明该方法能够在不进行超参数调整或模型微调的情况下,对真实图像进行高质量编辑,并且在保持输入图像特性的同时实现多样化的编辑效果。
- 工作量:文章对图像编辑方法进行了深入的研究,通过改进扩散采样过程,实现了自指导机制的应用。同时,文章进行了实验验证和性能评估,证明了所提出方法的有效性和可行性。但是,文章未提及作者所属机构及论文链接等信息,可能对读者理解和进一步深入研究造成一定困难。
点此查看论文截图

SurGen: Text-Guided Diffusion Model for Surgical Video Generation
Authors:Joseph Cho, Samuel Schmidgall, Cyril Zakka, Mrudang Mathur, Dhamanpreet Kaur, Rohan Shad, William Hiesinger
Diffusion-based video generation models have made significant strides, producing outputs with improved visual fidelity, temporal coherence, and user control. These advancements hold great promise for improving surgical education by enabling more realistic, diverse, and interactive simulation environments. In this study, we introduce SurGen, a text-guided diffusion model tailored for surgical video synthesis. SurGen produces videos with the highest resolution and longest duration among existing surgical video generation models. We validate the visual and temporal quality of the outputs using standard image and video generation metrics. Additionally, we assess their alignment to the corresponding text prompts through a deep learning classifier trained on surgical data. Our results demonstrate the potential of diffusion models to serve as valuable educational tools for surgical trainees.
Summary
文本生成模型在手术教育中的应用前景广阔,SurGen模型实现高分辨率、长时序视频生成。
Key Takeaways
- 模型提升视频生成质量
- 应用于手术教育
- 引入SurGen模型
- 高分辨率与长时序视频生成
- 标准化质量验证
- 文本引导与深度学习分类
- 教育工具潜力
- Title: SurGen: 文本引导扩散模型在手术视频生成中的应用
2. Authors: Cho Joseph, Schmidgall Samuel, Zakka Cyril, Mathur Mrudang, Kaur Dhamanpreet, Shad Rohan, Hiesinger William
3. Affiliation:
- Joseph Cho, Samuel Schmidgall, Cyril Zakka, Mrudang Mathur: Stanford Medicine, Department of Cardiothoracic Surgery
- Dhamanpreet Kaur: 未给出隶属机构信息
- Rohan Shad, William Hiesinger: Johns Hopkins University, Department of Electrical & Computer Engineering
4. Keywords:
- 扩散模型(Diffusion Model)
- 手术视频生成(Surgical Video Generation)
- 文本引导(Text Guidance)
- 视觉保真度(Visual Fidelity)
- 时序连贯性(Temporal Coherence)
5. Urls:
- 论文链接(Abstract): 论文链接地址 (注意:实际链接请替换为真实的论文链接地址)
- Github代码链接(如果可用): None (请确保提供真实的Github链接,如果没有则为None)
6. Summary:
(1) 研究背景:
随着手术教育的需求增长,真实、多样和交互式的模拟环境对于手术训练至关重要。扩散模型在视频生成领域取得了显著进展,能生成具有高质量视觉、时序连贯性的输出,且具备用户控制能力。本文研究背景是基于扩散模型在手术视频生成中的应用,旨在提高手术教育的质量和效果。
(2) 过去的方法及问题:
过去的方法在手术视频生成中可能存在分辨率低、时序不连贯、缺乏真实感等问题。尽管有扩散模型的应用,但在手术视频合成中尚未达到高分辨率和长时间序列的生成。
(3) 研究方法:
本研究提出了SurGen,一个文本引导的扩散模型,专门用于手术视频合成。模型通过扩散过程生成高分辨率和长时间序列的手术视频。研究通过标准图像和视频生成指标验证了输出的视觉和时序质量。此外,还使用深度学习分类器评估输出与文本提示的契合度。
(4) 任务与性能:
SurGen在手术视频生成任务中表现出卓越性能,生成了具有最高分辨率和最长时长的手术视频。通过标准评估指标,验证了其视觉和时序质量。使用深度学习分类器的评估结果表明,SurGen生成的视频与文本提示高度契合,证明了其在手术教育中的潜力。性能支持了其作为有价值的手术教育工具的目标。
7. 方法:
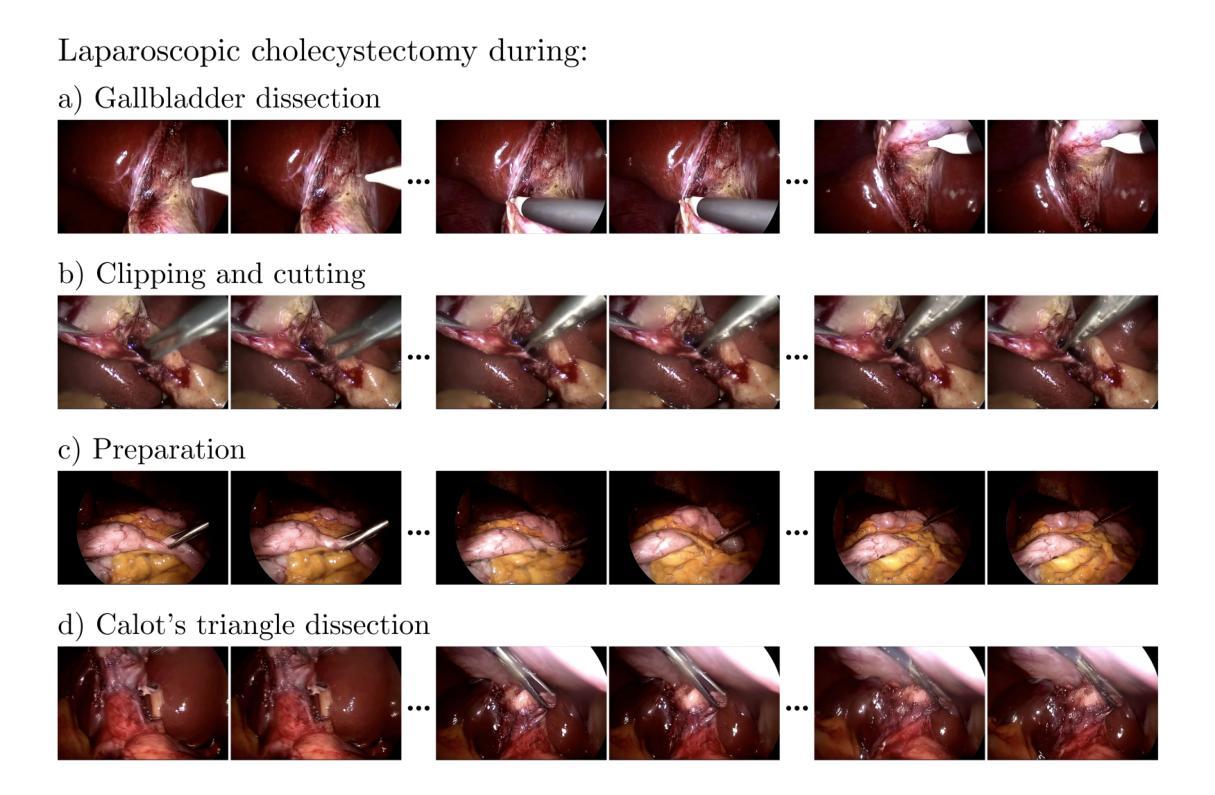
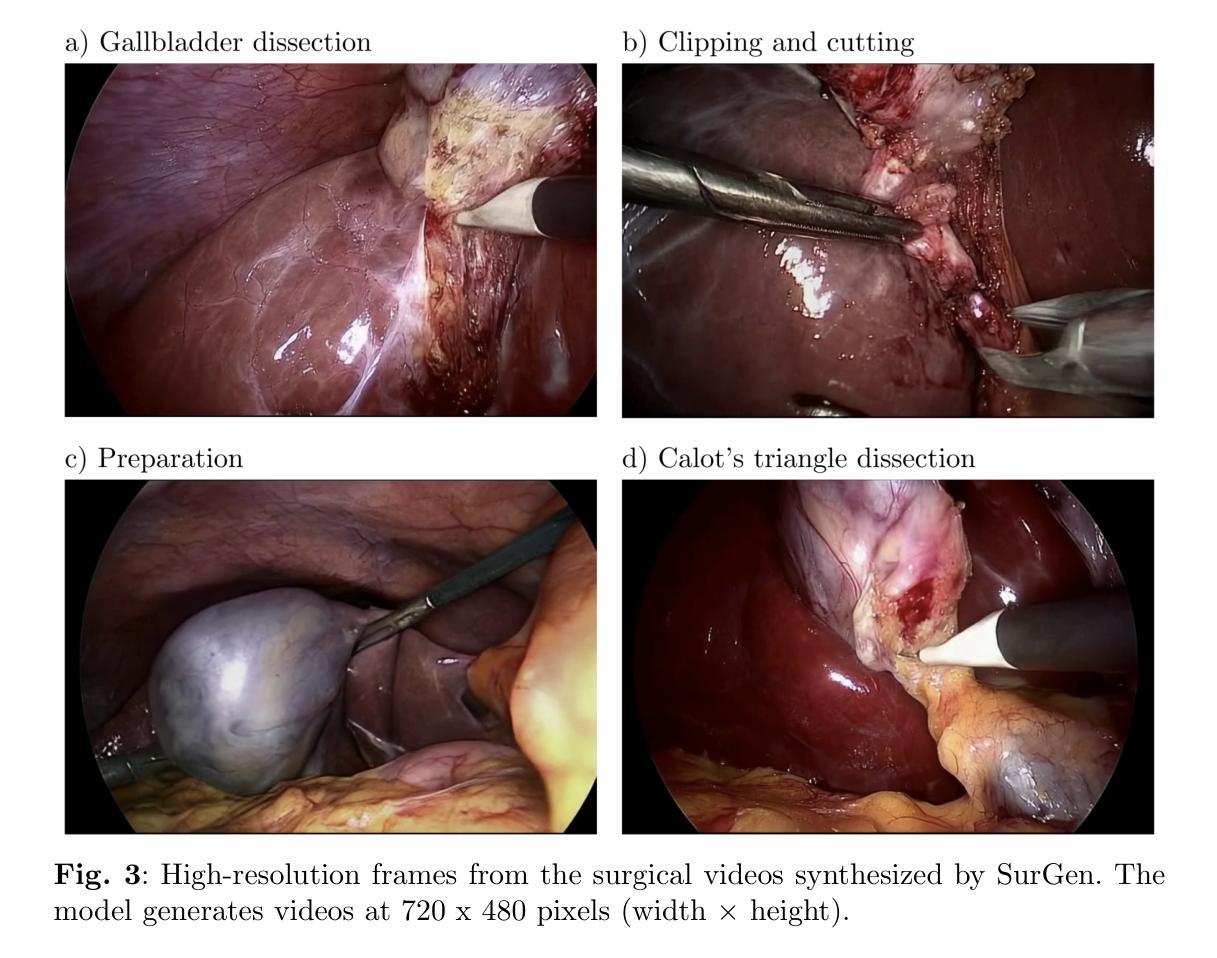
(1) 数据集描述(Dataset Description):研究使用了Cholec80数据集,该数据集包含13位外科医生进行的80次腹腔镜胆囊切除术。按照原始的训练-测试划分,使用前40个视频进行训练,剩余的40个视频用于评估。为了创建视频-文本对用于训练,研究根据手术阶段(如准备、Calot三角解剖、胆囊解剖、夹闭和切割)提取了20万个独特的序列,每个序列包含49帧,序列中的每一帧都来自原始视频并间隔两帧。
(2) 数据预处理(Data Preprocessing):对所有视频序列进行预处理,将每帧的原始宽度从840像素裁剪到720像素,同时保持原始高度为480像素。这有效地去除了内窥镜影像典型的黑色边框,确保保留所有重要的手术细节。相应的文本提示格式化为“腹腔镜胆囊切除术处于{手术阶段}”。
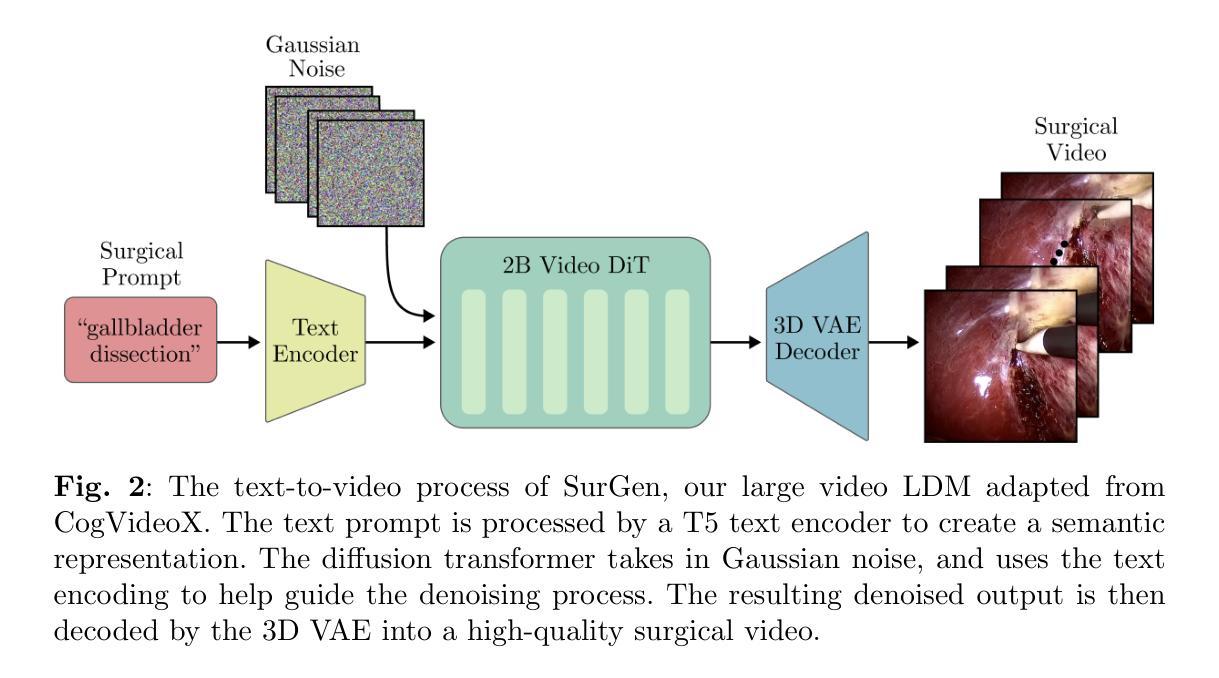
(3) 模型架构与训练(Model Architecture and Training):研究采用了CogVideoX,一个2亿参数的文本引导扩散模型(LDM)。CogVideoX结合了三个主要组件来根据文本提示合成视频:
- 3D变分自编码器(3D Variational Autoencoder):为了加速去噪操作,该自编码器的编码器将每个视频压缩到一个潜在空间,减少其空间维度8倍和时间维度4倍。解码器则将去噪后的表示转换为完整的视频帧。
- 去噪视频转换器(Denoising Video Transformer):使用包含文本条件的2亿参数视频转换器进行潜在向量的去噪。值得注意的是,该模型使用完整的三维注意力机制,允许空间时间补丁在所有这些位置之间进行关注。该模块会利用这些去噪的潜在向量以及通过文本编码器转换的文本提示来指导去噪过程。
- 文本编码器(Text Encoder):T5文本编码器将文本提示转换为语义丰富的表示形式,然后提供给扩散转换器以指导去噪过程。这一步骤保证了生成的手术视频能够根据预先设定的文本描述来展开故事情节和细节渲染。经过训练的模型生成了具有最高分辨率和最长时长的手术视频,并通过标准评估指标验证了其视觉和时序质量。使用深度学习分类器的评估结果表明,生成的视频与文本提示高度契合,证明了其在手术教育中的潜力。性能支持了其作为有价值的手术教育工具的目标。
- 结论:
(1) 工作的意义:
该工作首次将扩散模型应用于手术视频生成领域,对于提高手术教育的质量和效果具有重要意义。通过生成真实、多样的手术视频,有助于手术训练的有效进行,促进医疗技术的发展。此外,该工作的成功实现也验证了扩散模型在视频生成领域的广泛应用前景。
(2) 关于该文章在创新点、性能和工作量三个方面的优点和不足:
创新点:该文章首次提出了SurGen模型,一个文本引导的扩散模型专门用于手术视频合成。该模型通过扩散过程生成高分辨率和长时间序列的手术视频,具备较高的创新性。
性能:SurGen在手术视频生成任务中表现出卓越性能,生成了具有最高分辨率和最长时长的手术视频。通过标准评估指标验证了其视觉和时序质量。此外,使用深度学习分类器的评估结果表明,SurGen生成的视频与文本提示高度契合,证明了其在手术教育中的潜力。性能表现优异。
工作量:文章使用的数据集处理和分析工作量适中,通过构建和改进现有模型完成研究任务。但模型的训练和优化可能需要大量的计算资源和时间,特别是在处理大规模数据集时工作量较大。此外,由于缺少Github代码链接,无法准确评估开发工作量。
点此查看论文截图