⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-30 更新
LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Authors:Huan Wang, Feitong Tan, Ziqian Bai, Yinda Zhang, Shichen Liu, Qiangeng Xu, Menglei Chai, Anish Prabhu, Rohit Pandey, Sean Fanello, Zeng Huang, Yun Fu
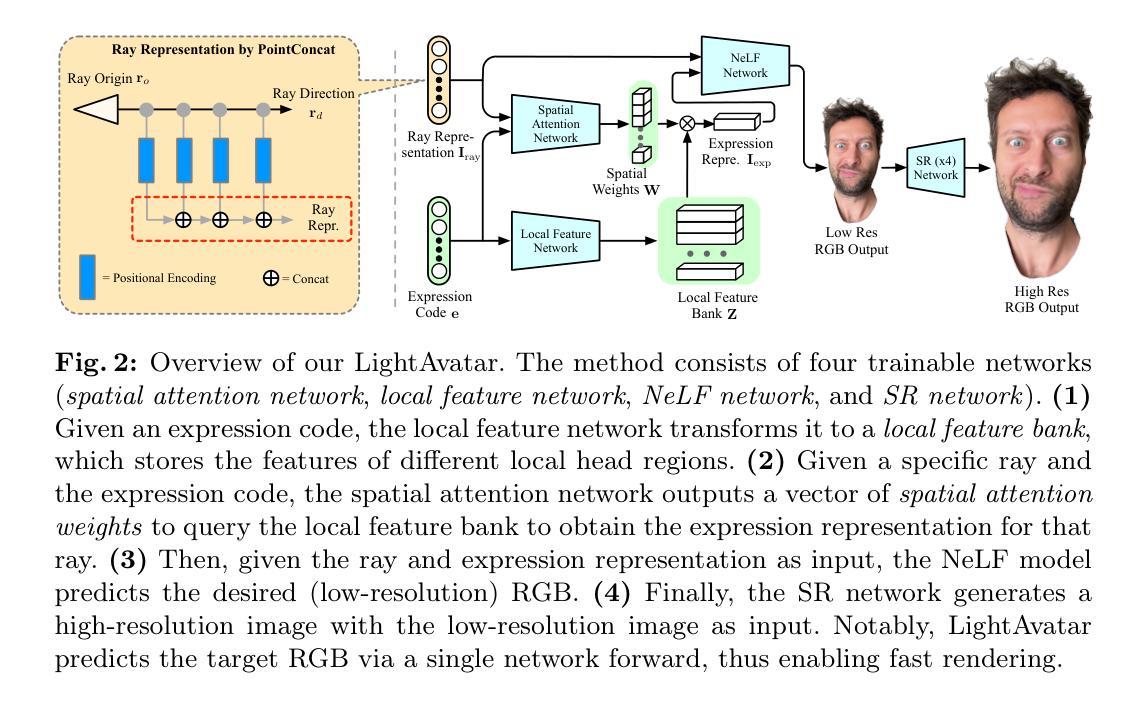
Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
PDF Appear in ECCV’24 CADL Workshop. Code: https://github.com/MingSun-Tse/LightAvatar-TensorFlow
Summary
利用NeRFs构建真实头像,通过NeLFs实现快速渲染。
Key Takeaways
- NeRFs在构建真实头像方面达到SOTA质量。
- NeRFs渲染速度慢,限制其在资源受限设备上的应用。
- LightAvatar基于NeLFs,实现从3DMM参数和相机姿态快速渲染头像。
- LightAvatar不使用网格或体积渲染,提高效率。
- 优化网络设计以实现NeLF模型的实时效率和训练稳定性。
- 使用预训练模型作为教师,通过蒸馏策略生成伪数据训练。
- 引入扭曲场网络校正真实数据拟合误差,提升模型学习效果。
标题:LightAvatar:基于神经光照场的高效头部化身技术
作者:Huan Wang及其他合著者(具体名单见原文)
隶属机构:第一作者Huan Wang曾在美国东北大学和Google实习。
关键词:神经光照场(NeLF)、头部化身、实时渲染、神经网络、参数模型
链接:论文链接(待补充,具体链接以实际发布为准),GitHub代码链接(待补充,具体链接以实际发布为准)
摘要:
- (1) 研究背景:本文的研究背景是关于基于神经光照场的高效头部化身技术。近年来,神经辐射场(NeRF)在构建逼真的头部化身方面取得了显著进展,但它们的主要局限性是渲染速度慢,无法广泛应用于资源受限的设备。因此,本文提出了基于神经光照场(NeLF)的LightAvatar模型,旨在解决这一问题。
- (2) 过去的方法及其问题:过去的方法主要基于NeRF技术构建头部化身,虽然质量高,但渲染速度慢。这个问题限制了它们在资源受限设备上的广泛应用。因此,需要一种更高效的头部化身技术来满足实时应用的需求。
- (3) 研究方法:本文提出了基于神经光照场(NeLF)的LightAvatar模型。该模型通过单个网络前向传递,从3DMM参数和相机姿态渲染图像,无需使用网格或体积渲染。为解决实时效率和训练稳定性方面的挑战,本文引入了专门的网络设计,以获得适当的NeLF模型表示,并维持低浮点运算(FLOPs)预算。同时,采用基于蒸馏的训练策略,使用预训练的化身模型作为教师进行合成数据的训练。
- (4) 任务与性能:本文的方法在头部化身任务上取得了显著成果,实现了较快的渲染速度和较高的图像质量。与现有方法相比,LightAvatar在渲染速度和图像质量方面均有所超越。实验结果表明,该方法达到了预期的目标,为实时应用提供了高效的头部化身技术。
希望这个总结符合您的要求!
7. 方法论概述:
本研究采用了一种基于神经光照场(NeLF)的高效头部化身技术,即LightAvatar模型。方法论主要包含以下几个步骤:
- (1) 研究背景分析:文章首先分析了当前头部化身技术的局限性,如渲染速度慢,无法广泛应用于资源受限的设备等。
- (2) 问题提出:针对上述问题,提出了基于神经光照场(NeLF)的LightAvatar模型,旨在实现高效头部化身技术,满足实时应用的需求。
- (3) 模型构建:LightAvatar模型通过单个网络前向传递,从3DMM参数和相机姿态渲染图像,无需使用网格或体积渲染。为了应对实时效率和训练稳定性方面的挑战,引入了专门的网络设计,并维持低浮点运算(FLOPs)预算。同时,采用基于蒸馏的训练策略,使用预训练的化身模型作为教师进行合成数据的训练。
- (4) 实验验证:文章通过实验验证了LightAvatar模型的有效性,在头部化身任务上取得了显著成果,实现了较快的渲染速度和较高的图像质量。实验结果表明,该方法达到了预期的目标,为实时应用提供了高效的头部化身技术。此外,还对模型的性能进行了对比分析,验证了其在渲染速度和图像质量方面的优势。这一结果验证了基于神经光照场的LightAvatar模型在实际应用中的可行性和优越性。
以上内容仅供参考,具体细节和方法论的实施方式可能需要根据原文进行详细解读和梳理。
8. Conclusion:
- (1) 本研究的工作意义重大。在头部化身技术领域,该文章提出了一种基于神经光照场(NeLF)的LightAvatar模型,解决了现有技术渲染速度慢、无法广泛应用于资源受限设备的问题。该研究为实时应用提供了高效的头部化身技术,具有重要的实际应用价值。
- (2) 创新点:本文的创新之处在于提出了基于神经光照场(NeLF)的LightAvatar模型,通过单个网络前向传递,从3DMM参数和相机姿态渲染图像,实现了高效的头部化身技术。
性能:实验结果表明,LightAvatar模型在头部化身任务上取得了显著成果,实现了较快的渲染速度和较高的图像质量,优于现有方法。
工作量:文章对模型的构建和实验验证进行了详细的阐述,但关于具体实现的细节和技术难度未做深入探讨,如网络设计的具体结构、蒸馏训练策略的具体实施方式等。
以上结论仅供参考,具体评价可能需要根据原文的详细内容进行深入分析。
点此查看论文截图

Gaussian Deja-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities
Authors:Peizhi Yan, Rabab Ward, Qiang Tang, Shan Du
Recent advancements in 3D Gaussian Splatting (3DGS) have unlocked significant potential for modeling 3D head avatars, providing greater flexibility than mesh-based methods and more efficient rendering compared to NeRF-based approaches. Despite these advancements, the creation of controllable 3DGS-based head avatars remains time-intensive, often requiring tens of minutes to hours. To expedite this process, we here introduce the ``Gaussian D'ej`a-vu” framework, which first obtains a generalized model of the head avatar and then personalizes the result. The generalized model is trained on large 2D (synthetic and real) image datasets. This model provides a well-initialized 3D Gaussian head that is further refined using a monocular video to achieve the personalized head avatar. For personalizing, we propose learnable expression-aware rectification blendmaps to correct the initial 3D Gaussians, ensuring rapid convergence without the reliance on neural networks. Experiments demonstrate that the proposed method meets its objectives. It outperforms state-of-the-art 3D Gaussian head avatars in terms of photorealistic quality as well as reduces training time consumption to at least a quarter of the existing methods, producing the avatar in minutes.
PDF 11 pages, Accepted by WACV 2025 in Round 1
Summary
3DGS技术优化,构建高效可控的3D头像生成模型。
Key Takeaways
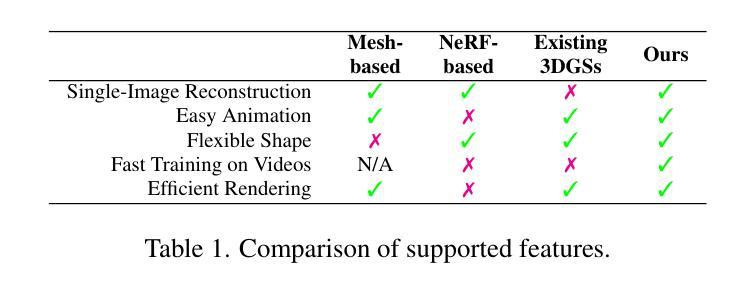
- 3DGS在3D头像建模中提供比网格方法更大的灵活性和比NeRF更高效的渲染。
- 现有3DGS头像创建耗时,需数分钟至数小时。
- 提出“Gaussian D'ej`a-vu”框架,先获取头像通用模型,再个性化定制。
- 通用模型基于大规模2D图像数据集训练。
- 利用单目视频进一步精炼3D头像。
- 提出可学习的表达式感知校正混合图,实现快速收敛。
- 新方法在真实感和训练时间上优于现有方法,缩短至四分之一。
标题:基于高斯混合模型的快速可控三维头像创建研究
作者:严培植、沃德·拉巴巴、唐强、杜山
隶属机构:严培植、沃德·拉巴巴隶属加拿大不列颠哥伦比亚大学,唐强隶属华为加拿大分公司,杜山隶属加拿大不列颠哥伦比亚大学奥肯根校区。
关键词:高斯混合模型、三维头像创建、可控性、渲染效率、个性化模型
链接:论文链接(待补充),GitHub代码链接(待补充,若无则填写“None”)
总结:
- (1)研究背景:
随着虚拟现实、增强现实、游戏制作等领域的发展,对快速创建高质量三维头像的需求日益增加。文章探讨如何高效地创建具有可控性的三维高斯头像模型,以解决现有方法的效率和质量控制问题。
-(2)过去的方法及存在的问题:
现有方法主要包括基于网格的方法和基于NeRF的方法。基于网格的方法虽然渲染效率高,但缺乏灵活性;而基于NeRF的方法虽然灵活,但渲染效率较低。文章旨在克服这些方法的不足,提出一种更高效、高质量且可控的三维高斯头像创建方法。-(3)研究方法:
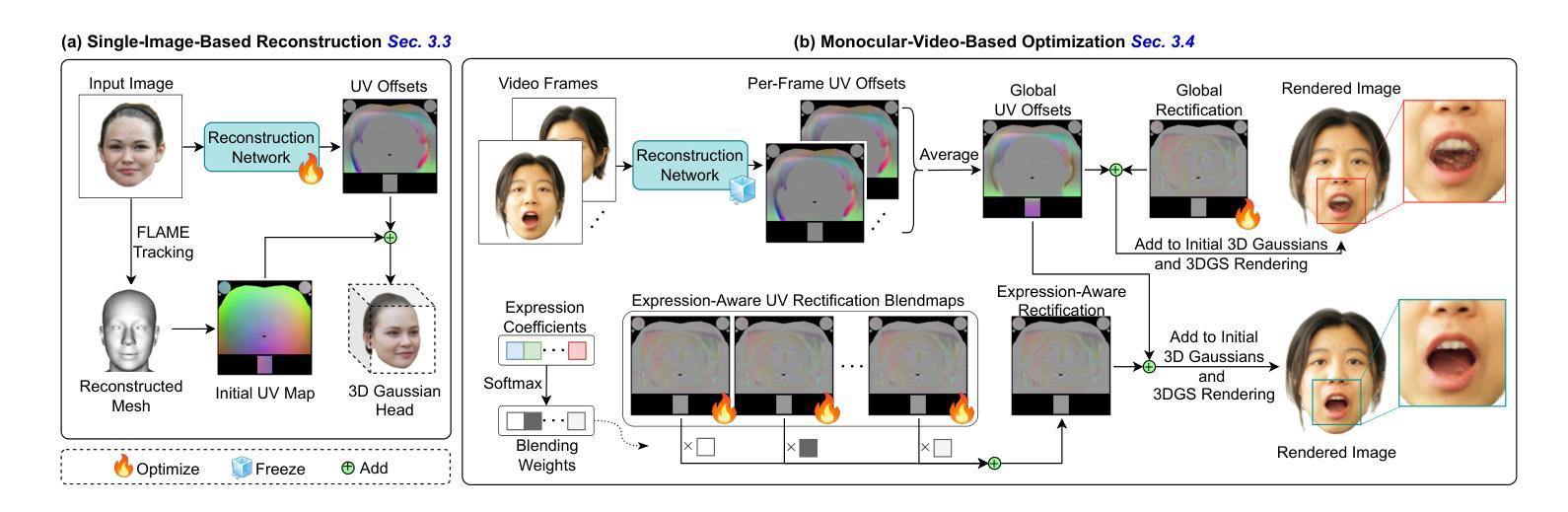
文章提出了“Gaussian D´ej`a-vu”框架,首先通过大型二维图像数据集训练通用模型,然后个性化结果。通用模型采用三维高斯混合模型,通过单目视频进一步精细化,实现个性化头像。为个性化处理,文章提出了可学习的表情感知校正混合图(blendmaps),以纠正初始三维高斯模型,确保快速收敛,无需依赖神经网络。-(4)任务与性能:
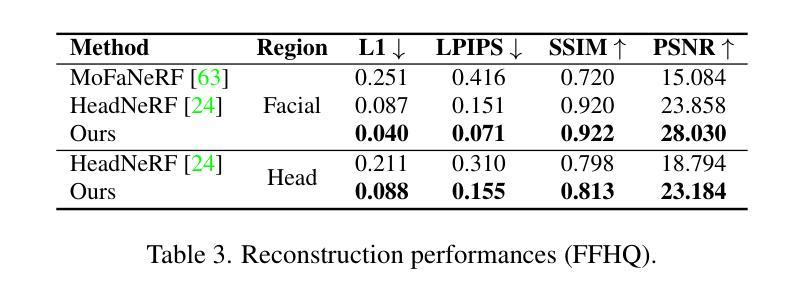
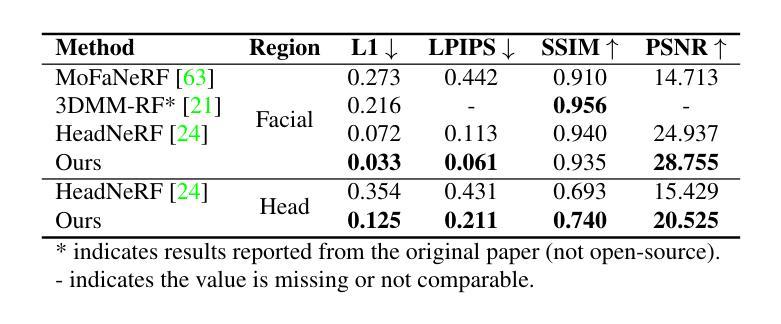
文章的方法旨在创建高质量的三维高斯头像模型,具有可控的面部表情和视角。实验表明,该方法在照片逼真质量方面优于现有方法,并将训练时间消耗减少至少四分之一,能够在几分钟内生成头像。这些性能表明该方法在支持其目标方面取得了显著进展。- (1)研究背景:
请注意,由于缺少详细的论文内容,某些信息可能无法完全准确概括。以上内容仅供参考,请在实际阅读论文后做出更为准确的总结和评价。
7. 方法论:
这篇文章提出了一个基于高斯混合模型的快速可控三维头像创建方法,具体步骤如下:
(1) 研究背景与动机:针对现有三维头像创建方法(如基于网格的方法和基于NeRF的方法)存在的效率和质量控制问题,文章旨在开发一种更高效、高质量且可控的三维头像创建方法。
(2) 数据准备:首先,通过大型二维图像数据集训练通用模型。这些数据集可能包含各种面部表情和角度的头像图像。
(3) 通用模型构建:利用三维高斯混合模型创建通用模型。这个模型具有良好的通用性和灵活性,能够适应多种不同的头像形状和表情。
(4) 个性化处理:为了创建个性化的三维头像,文章提出了可学习的表情感知校正混合图(blendmaps)。这种技术用于纠正初始的三维高斯模型,以确保快速收敛并达到个性化效果。
(5) 实验流程:在实际实验中,通过单目视频进一步精细化通用模型,实现个性化头像的创建。实验过程包括数据采集、模型训练、模型评估等步骤。
(6) 性能评估:通过实验对比,证明该方法在照片逼真质量方面优于现有方法,并将训练时间消耗减少至少四分之一。此外,该方法能够在几分钟内生成高质量的三维头像。
总的来说,该文章通过结合高斯混合模型和个性化处理技术,提出了一种高效、高质量且可控的三维头像创建方法。这种方法克服了现有方法的不足,为虚拟现实、增强现实、游戏制作等领域提供了一种新的解决方案。
8. 结论:
- (1) 该研究工作在虚拟现实、增强现实、游戏制作等领域具有重要意义,它提供了一种快速创建高质量三维头像的新方法,满足了这些领域对高质量三维头像的日益增长的需求。
- (2) 创新点:该文章提出了一种基于高斯混合模型的快速可控三维头像创建方法,该方法结合了大型二维图像数据集和个性化处理技术,实现了高质量、高效率的三维头像创建。同时,文章还提出了可学习的表情感知校正混合图(blendmaps)技术,用于纠正初始三维高斯模型,确保快速收敛并达到个性化效果。
性能:实验结果表明,该方法在照片逼真质量方面优于现有方法,训练时间消耗减少至少四分之一,能够在几分钟内生成高质量的三维头像。这表明该文章提出的方法在性能和效率方面都取得了显著的进展。
工作量:文章对方法的实现进行了详细的描述和解释,提供了清晰的实验过程和结果,工作量较为充足。但是,由于缺少详细的论文内容,无法全面评估其工作量的大小。
点此查看论文截图