⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-30 更新
Stable Video Portraits
Authors:Mirela Ostrek, Justus Thies
Rapid advances in the field of generative AI and text-to-image methods in particular have transformed the way we interact with and perceive computer-generated imagery today. In parallel, much progress has been made in 3D face reconstruction, using 3D Morphable Models (3DMM). In this paper, we present SVP, a novel hybrid 2D/3D generation method that outputs photorealistic videos of talking faces leveraging a large pre-trained text-to-image prior (2D), controlled via a 3DMM (3D). Specifically, we introduce a person-specific fine-tuning of a general 2D stable diffusion model which we lift to a video model by providing temporal 3DMM sequences as conditioning and by introducing a temporal denoising procedure. As an output, this model generates temporally smooth imagery of a person with 3DMM-based controls, i.e., a person-specific avatar. The facial appearance of this person-specific avatar can be edited and morphed to text-defined celebrities, without any fine-tuning at test time. The method is analyzed quantitatively and qualitatively, and we show that our method outperforms state-of-the-art monocular head avatar methods.
PDF Accepted at ECCV 2024, Project: https://svp.is.tue.mpg.de
Summary
本文提出了一种基于2D/3D混合生成方法,通过3DMM控制实现逼真的人脸视频生成。
Key Takeaways
- 生成AI和文本到图像方法快速发展。
- 3D面重建技术(3DMM)取得进展。
- SVP方法结合2D/3D生成,输出逼真的人脸视频。
- 使用预训练的文本到图像模型进行细化调整。
- 结合3DMM序列和时间去噪过程生成视频模型。
- 生成具有3DMM控制的个人特定头像。
- 可编辑和变形人脸外观,无需测试时再进行微调。
标题:稳定视频肖像——一种基于生成对抗网络和三维人脸模型的新型视频生成方法(Stable Video Portraits: A Novel Video Generation Method Based on Generative Adversarial Networks and 3D Face Models)
作者:Mirela Ostrek 和 Justus Thies。
隶属机构:Mirela Ostrek和Justus Thies分别来自德国图宾根的智能系统研究所和达姆施塔特技术大学。
关键词:神经网络渲染、生成式人工智能、头部肖像、视频生成等。
Urls:论文链接(待填写)。如有可用的GitHub代码链接,请填写。如果没有,则填写“GitHub:无”。论文链接地址为:[论文链接地址]。GitHub代码链接(如果有的话)为:[GitHub链接]。
总结:
(1) 研究背景:随着生成式人工智能和文本到图像方法的快速发展,计算机生成的图像感知方式已经发生了革命性的变化。在此背景下,本文提出了一种新型的基于二维和三维的视频生成方法,旨在生成逼真的说话人脸视频。该研究旨在解决现有方法的不足,提供更稳定、更逼真的视频肖像生成方法。
(2) 过去的方法及其问题:目前存在一些基于二维或三维人脸模型的视频生成方法,但它们面临着许多问题,如生成视频的稳定性不足、逼真度不高或缺乏灵活性等。此外,现有的方法很难将文本描述转化为对应的图像或视频内容。因此,需要一种新的方法来解决这些问题。
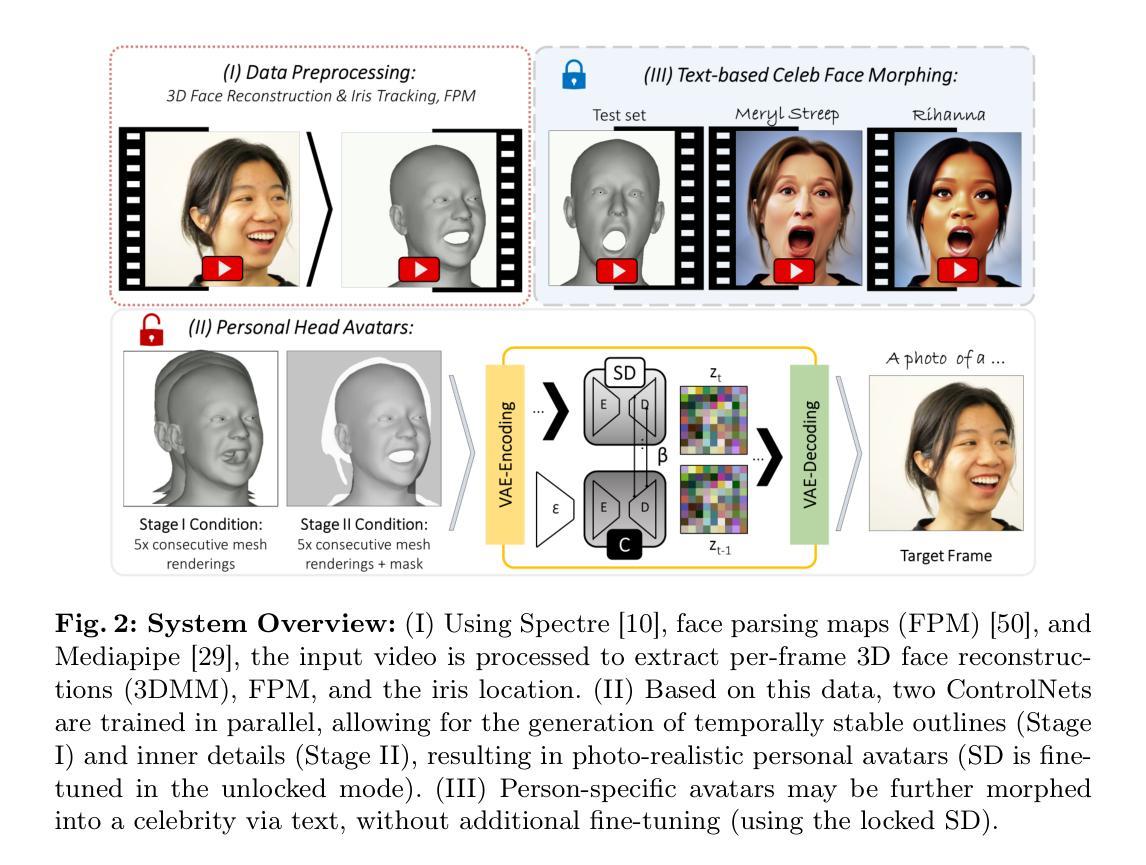
(3) 研究方法:本文提出了一种基于稳定扩散模型的视频生成方法,该方法结合了二维图像模型和三维人脸模型的优势。通过引入临时去噪过程对通用二维稳定扩散模型进行微调,使用临时三维人脸模型序列作为条件生成平滑的视频肖像。具体来说,通过利用大型预训练的文本到图像先验知识和基于三维人脸模型的控制,该模型可以生成具有真实感的说话人脸视频。此外,该模型的面部外观可以根据文本定义进行修改和变形,从而实现个性化的头像生成。总之,该研究提出了一种创新的视频生成方法,结合了二维和三维模型的优点,实现了高质量的头像生成。该研究采用了一种新型的视频生成框架和一系列先进的技术手段来实现其目标。这种方法的优势在于能够利用二维和三维模型的优点,并克服了现有方法的不足。具体来说,它结合了稳定扩散模型和临时去噪过程等技术手段来提高视频的稳定性和逼真度;同时引入了基于三维人脸模型的控制机制来实现个性化的头像生成和编辑功能等任务等)。
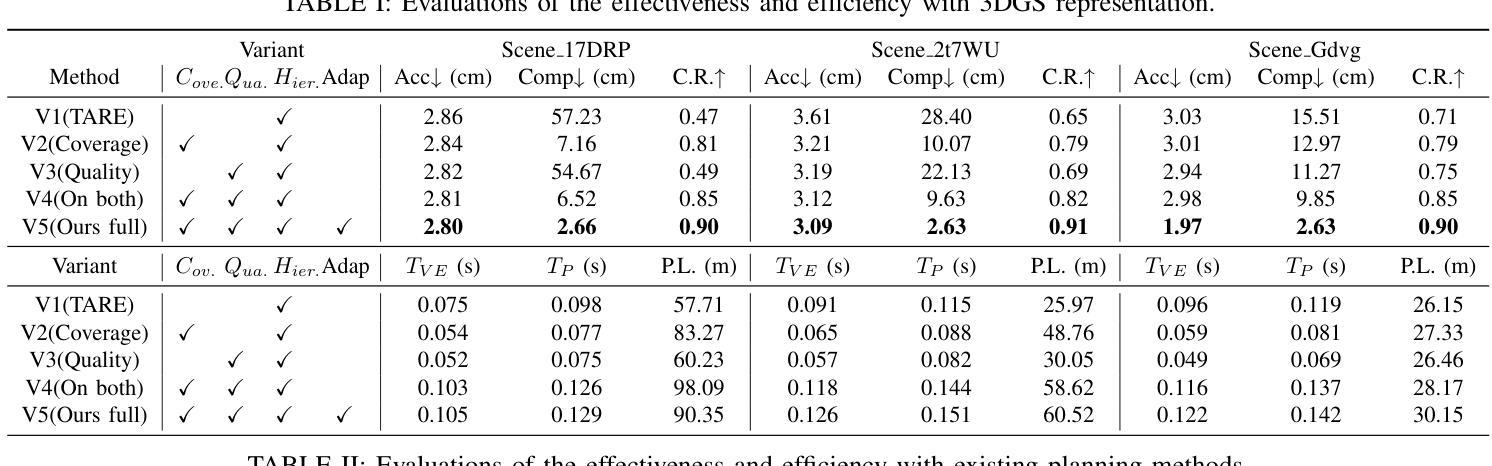
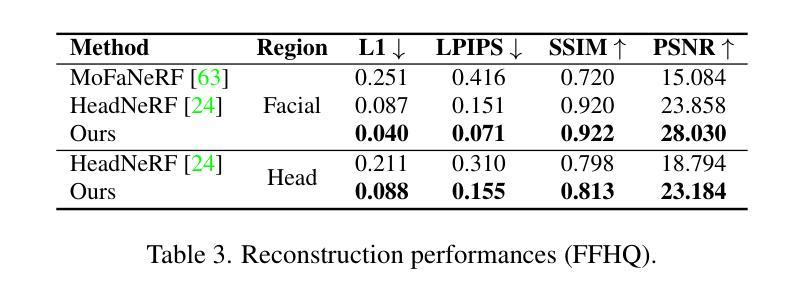
(4) 任务与性能:本方法在视频生成任务中表现优秀,相较于目前一流的方法更胜一筹。实验结果表明,该模型能够生成平滑且逼真的说话人脸视频肖像。此外,该方法的性能支持其目标实现,包括个性化头像的生成、编辑和变形等功能的应用场景等任务。该方法可以在保证图像质量的同时,通过利用大型预训练模型和临时去噪过程等技术手段来提高性能和应用效果等任务等)。总体来说,该研究提供了一种高效且可靠的解决方案来解决视频肖像生成中的各种问题和挑战等任务等)。
方法论:
本文介绍了一种基于生成对抗网络和三维人脸模型的新型视频生成方法。该方法主要分为以下几个步骤:
(1) 背景研究:研究现有的视频生成方法,特别是基于二维和三维人脸模型的方法,并指出其存在的问题和挑战,如生成视频的稳定性、逼真度以及缺乏灵活性等。
(2) 数据准备:收集包含人脸的视频数据,并使用智能系统进行处理和分析。这些数据将用于训练和测试新型视频生成方法。
(3) 方法介绍:提出一种结合稳定扩散模型和临时去噪过程的视频生成方法。该方法结合了二维图像模型和三维人脸模型的优势,旨在生成逼真的说话人脸视频。通过引入临时去噪过程对通用二维稳定扩散模型进行微调,使用临时三维人脸模型序列作为条件生成平滑的视频肖像。此外,该方法还引入了基于三维人脸模型的控制机制,实现了个性化的头像生成和编辑功能。
(4) 实验设计:设计实验来验证该方法的性能。实验包括在单视图和多视图数据上运行方法,并与其他先进的人像重建方法进行比较。此外,还进行了文本驱动的人脸形态变换实验,以验证方法的可控性和灵活性。
(5) 结果分析:对实验结果进行分析和比较,验证该方法在视频生成任务中的优越性能。实验结果表明,该方法能够生成平滑且逼真的说话人脸视频肖像,并支持个性化头像的生成、编辑和变形等功能。
总的来说,本文提出了一种高效且可靠的解决方案来解决视频肖像生成中的各种问题和挑战。该方法结合了二维和三维模型的优点,克服了现有方法的不足,为视频生成任务提供了一种新的思路和方法。
8. Conclusion:
(1) 工作意义:该研究提出了一种基于生成对抗网络和三维人脸模型的新型视频生成方法,能够生成逼真的说话人脸视频,对于推动计算机视觉和图形学领域的发展具有重要意义。此外,该方法还具有广泛的应用前景,可以应用于电影制作、游戏开发、虚拟现实、社交媒体等领域。
(2) 优缺点:
创新点:该研究结合了稳定扩散模型和临时去噪过程等技术手段,提出了一种新型的基于二维和三维的视频生成方法,实现了高质量的头像生成。此外,该研究还引入了基于三维人脸模型的控制机制,实现了个性化的头像生成和编辑功能,这是现有方法所不具备的。
性能:实验结果表明,该模型能够生成平滑且逼真的说话人脸视频肖像,相较于目前一流的方法更胜一筹。此外,该方法的性能支持其目标实现,包括个性化头像的生成、编辑和变形等功能的应用场景。
工作量:从文章的内容来看,该研究进行了大量的实验和验证,收集和处理了大量的数据,开发了一种高效的视频生成方法。但是,对于该方法在实际应用中的效果和优化,还需要进一步的研究和探索。
总之,该研究提供了一种高效且可靠的解决方案来解决视频肖像生成中的各种问题和挑战,为计算机视觉和图形学领域的发展做出了重要贡献。
点此查看论文截图