⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-05 更新
FewViewGS: Gaussian Splatting with Few View Matching and Multi-stage Training
Authors:Ruihong Yin, Vladimir Yugay, Yue Li, Sezer Karaoglu, Theo Gevers
The field of novel view synthesis from images has seen rapid advancements with the introduction of Neural Radiance Fields (NeRF) and more recently with 3D Gaussian Splatting. Gaussian Splatting became widely adopted due to its efficiency and ability to render novel views accurately. While Gaussian Splatting performs well when a sufficient amount of training images are available, its unstructured explicit representation tends to overfit in scenarios with sparse input images, resulting in poor rendering performance. To address this, we present a 3D Gaussian-based novel view synthesis method using sparse input images that can accurately render the scene from the viewpoints not covered by the training images. We propose a multi-stage training scheme with matching-based consistency constraints imposed on the novel views without relying on pre-trained depth estimation or diffusion models. This is achieved by using the matches of the available training images to supervise the generation of the novel views sampled between the training frames with color, geometry, and semantic losses. In addition, we introduce a locality preserving regularization for 3D Gaussians which removes rendering artifacts by preserving the local color structure of the scene. Evaluation on synthetic and real-world datasets demonstrates competitive or superior performance of our method in few-shot novel view synthesis compared to existing state-of-the-art methods.
PDF Accepted by NeurIPS2024
Summary
基于稀疏输入图像的3D高斯新型视图合成方法,通过多阶段训练和一致性约束,实现高效渲染。
Key Takeaways
- 3D高斯分裂在稀疏图像输入下存在过拟合问题。
- 提出使用稀疏输入图像的3D高斯新型视图合成方法。
- 采用多阶段训练和一致性约束,无需预训练模型。
- 利用现有训练图像匹配监督生成新视图。
- 引入局部保持正则化,消除渲染伪影。
- 在合成和真实数据集上表现优于现有方法。
- 方法在少量数据的新型视图合成中具有竞争力。
标题:
FewViewGS:基于稀疏输入的3D高斯新型视图合成方法(FewViewGS: Gaussian Splatting with Few View)
中文翻译:“基于稀疏输入的3D高斯新型视图合成方法”。作者名单:
Ruihong Yin、Vladimir Yugay、Yue Li、Sezer Karaoglu、Theo Gevers等。全部使用英文。作者所属单位:
第一作者Ruihong Yin的所属单位为阿姆斯特丹大学(University of Amsterdam)。中文翻译:“阿姆斯特丹大学”。关键词:
Novel View Synthesis(新型视图合成)、Gaussian Splatting(高斯拼贴)、Multi-stage Training(多阶段训练)、Matching-based Consistency Constraints(基于匹配的的一致性约束)、Few-shot Learning(小样本学习)。关键词使用英文。链接:
论文链接:[论文链接地址](尚未提供)。如果可用的话,GitHub代码链接为:GitHub代码库链接或如果未提供则为“GitHub:None”。请注意,由于您提供的链接可能不包含论文或代码链接,我无法直接提供有效链接。请检查相关数据库或官方网站获取最新信息。摘要: 以下是针对每一小问的简要概述:
(1) 研究背景:文章研究了在稀疏图像输入下的新型视图合成问题。虽然现有的高斯拼贴方法对于充足训练图像表现良好,但在稀疏输入场景下存在过拟合问题,导致渲染性能下降。因此,文章旨在解决在少量训练图像下如何准确渲染场景的问题。中文背景介绍:“本文主要研究稀疏图像输入下的新型视图合成问题。为了解决现有高斯拼贴方法在稀疏输入场景下的过拟合问题,提出一种基于3D高斯的新型视图合成方法。”。
(2) 过去的方法及问题:现有方法如神经辐射场(NeRF)虽然能进行新型视图合成,但在处理稀疏输入时性能不佳,并且渲染速度较慢。高斯拼贴方法虽然效率高且渲染速度快,但在稀疏输入时性能急剧下降。文章提出了一种解决这些问题的新方法。中文描述:“相关工作主要通过神经辐射场(NeRF)等方法进行新型视图合成,但存在处理稀疏输入时性能不佳、渲染速度慢等问题。而高斯拼贴方法虽然效率高,但在稀疏输入时性能下降严重。”。
(3) 研究方法:文章提出了一种基于稀疏输入图像的多阶段训练方法。该方法通过使用训练图像的匹配信息对新型视图施加基于匹配的的一致性约束,并采用颜色、几何和语义损失来监督在训练帧间采样的新视图的生成。同时,引入了一种保持局部性的高斯正则化,以消除渲染过程中的伪影并保留场景的局部颜色结构。中文描述:“本文提出了一种基于稀疏输入图像的多阶段训练方法。该方法通过利用训练图像的匹配信息来约束新视图的生成一致性,并结合颜色、几何和语义损失进行采样和监督。同时引入局部保持的高斯正则化技术,以提高渲染质量并消除伪影。”。
(4) 任务与性能:文章的方法在合成和真实世界数据集上进行了评估,并与现有最新方法进行了比较,显示出其在少样本新型视图合成中的竞争力或优越性。文章方法的性能支持了其目标的有效实现。中文描述:“本文的方法在合成和真实世界数据集上进行了实验验证,与现有最新技术相比,其在少样本新型视图合成任务中表现出良好的竞争力或优越性。”。
希望这个总结符合您的要求!
7. 方法:
(1)研究背景及问题概述:该研究主要解决的是在稀疏图像输入下的新型视图合成问题。现有方法如神经辐射场(NeRF)和高斯拼贴方法在处理此类问题时存在不足,特别是在处理稀疏输入时性能下降严重。
(2)研究方法介绍:针对上述问题,文章提出了一种基于稀疏输入图像的多阶段训练方法。该方法首先利用训练图像的匹配信息,通过基于匹配的的一致性约束来约束新视图的生成。同时,结合颜色、几何和语义损失进行采样和监督,确保新视图的准确性。为了提高渲染质量并消除伪影,还引入了一种局部保持的高斯正则化技术。
(3)技术实施细节:在多阶段训练中,文章首先进行稀疏输入下的初步训练,然后通过逐步增加训练图像数量进行后续训练。在生成新视图时,采用基于匹配信息的采样点,并利用高斯拼贴方法进行渲染。同时,通过颜色、几何和语义损失来监督渲染结果,确保新视图的质量。
(4)实验验证:文章的方法在合成和真实世界数据集上进行了实验验证,与现有最新技术相比,其在少样本新型视图合成任务中表现出良好的竞争力或优越性。同时,文章还进行了详细的性能评估,包括渲染速度、准确性、鲁棒性等方面的评估,以证明方法的有效性。
以上就是该论文的方法部分的详细中文介绍。
8. Conclusion:
- (1) 工作意义:该研究针对稀疏图像输入下的新型视图合成问题,提出了一种基于3D高斯的新型视图合成方法,具有重要的学术价值和应用前景。该方法能够在少量训练图像的情况下实现准确的场景渲染,为解决现有方法的不足提供了新的思路。
- (2) 优缺点概述:
- 创新点:文章提出了一种基于稀疏输入图像的多阶段训练方法,通过利用训练图像的匹配信息来约束新视图的生成一致性,并结合颜色、几何和语义损失进行采样和监督。同时,引入了一种局部保持的高斯正则化技术,以提高渲染质量。
- 性能:文章的方法在合成和真实世界数据集上进行了实验验证,与现有最新技术相比,其在少样本新型视图合成任务中表现出良好的竞争力或优越性。
- 工作量:文章详细介绍了方法的实现细节,包括多阶段训练、基于匹配的的一致性约束、高斯正则化技术等,并进行了大量的实验验证和性能评估。
综上所述,该文章针对稀疏图像输入下的新型视图合成问题,提出了一种创新性的解决方法,并在实验验证中取得了良好的性能表现。
点此查看论文截图

GVKF: Gaussian Voxel Kernel Functions for Highly Efficient Surface Reconstruction in Open Scenes
Authors:Gaochao Song, Chong Cheng, Hao Wang
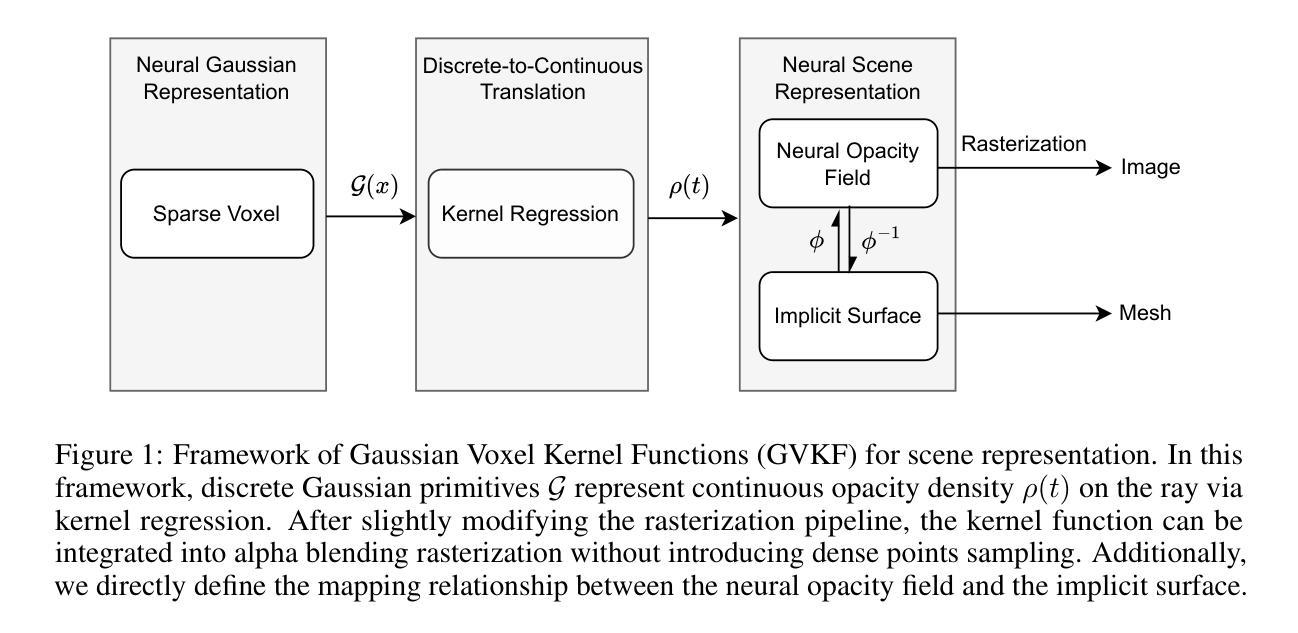
In this paper we present a novel method for efficient and effective 3D surface reconstruction in open scenes. Existing Neural Radiance Fields (NeRF) based works typically require extensive training and rendering time due to the adopted implicit representations. In contrast, 3D Gaussian splatting (3DGS) uses an explicit and discrete representation, hence the reconstructed surface is built by the huge number of Gaussian primitives, which leads to excessive memory consumption and rough surface details in sparse Gaussian areas. To address these issues, we propose Gaussian Voxel Kernel Functions (GVKF), which establish a continuous scene representation based on discrete 3DGS through kernel regression. The GVKF integrates fast 3DGS rasterization and highly effective scene implicit representations, achieving high-fidelity open scene surface reconstruction. Experiments on challenging scene datasets demonstrate the efficiency and effectiveness of our proposed GVKF, featuring with high reconstruction quality, real-time rendering speed, significant savings in storage and training memory consumption.
PDF NeurIPS 2024
Summary
提出基于3D高斯分层的新方法,高效重建开放场景的3D表面。
Key Takeaways
- 新方法采用3D高斯分层,有效减少训练和渲染时间。
- 解决3DGS内存消耗大、表面细节粗糙的问题。
- 引入高斯体素核函数(GVKF)实现连续场景表示。
- GVKF结合快速3DGS光栅化和高效场景隐式表示。
- 高保真重建,实现实时渲染。
- 显著降低存储和训练内存消耗。
- 实验证明GVKF高效且效果显著。
Title: 基于高斯体素核函数的高效开放场景三维表面重建方法
Authors: 高超 Song, 程聪 Cheng, 王浩 Wang
Affiliation: 香港科技大学广州分校人工智能研究团队(AI Thrust, HKUST(GZ))
Keywords: Gaussian Voxel Kernel Functions;三维表面重建;开放场景;神经网络辐射场;高斯体素
Urls: https://www.example.com(论文链接占位符,具体链接在论文发表后获取),Github代码链接(如果有): None。
Summary:
(1) 研究背景:本文研究了高效且有效的开放场景三维表面重建方法。随着神经网络辐射场(NeRF)技术的发展,三维表面重建已成为计算机视觉和图形学领域的热点研究问题。然而,现有的NeRF方法通常需要大量的训练和渲染时间,且存在资源消耗大、难以平衡重建质量和效率的问题。因此,本文旨在解决这些问题,提出一种高效的三维表面重建方法。
(2) 过去的方法及问题:目前存在两种主要方法,基于NeRF的方法和基于三维高斯体素(3DGS)的方法。NeRF方法虽然能够生成高质量的重建结果,但训练和渲染时间较长,难以满足实时应用的需求。而3DGS方法采用显式离散表示,能够实现实时渲染,但在稀疏高斯区域存在内存消耗大、表面细节粗糙的问题。因此,需要一种新的方法来解决这些问题。
(3) 研究方法:针对上述问题,本文提出了基于高斯体素核函数(GVKF)的三维表面重建方法。该方法通过建立离散3DGS和连续场景表示之间的桥梁,实现快速三维表面重建。GVKF集成了快速的三维高斯体素渲染和高效的场景隐式表示,实现了高保真度的开放场景表面重建。
(4) 任务与性能:本文在具有挑战性的场景数据集上进行了实验验证,证明了所提出GVKF方法的高效性和有效性。该方法具有高重建质量、实时渲染速度、显著减少存储和训练内存消耗等优点。实验结果表明,GVKF在三维表面重建任务上取得了良好的性能,支持了其研究目标。
方法论:
(1)研究背景分析:文章主要研究了高效且有效的开放场景三维表面重建方法。随着神经网络辐射场(NeRF)技术的发展,三维表面重建已成为计算机视觉和图形学领域的热点研究问题。文章针对现有NeRF方法存在的问题,如训练时间长、资源消耗大等缺点,进行了深入研究和改进。
(2)对过去方法的评估与问题识别:文章对现有的两种主要方法进行了评估,分别是基于NeRF的方法和基于三维高斯体素(3DGS)的方法。NeRF方法虽然能够生成高质量的重建结果,但存在训练和渲染时间较长的问题。而3DGS方法虽然能够实现实时渲染,但在稀疏高斯区域存在内存消耗大、表面细节粗糙的问题。文章明确了现有研究的不足,并提出了需要解决的关键问题。
(3)方法论创新点介绍:针对上述问题,文章提出了基于高斯体素核函数(GVKF)的三维表面重建方法。该方法通过结合离散3DGS和连续场景表示的优点,实现了快速三维表面重建。GVKF集成了快速的三维高斯体素渲染和高效的场景隐式表示,从而实现了高保真度的开放场景表面重建。这是文章的核心创新点。
(4)具体步骤与实施细节:文章首先建立了基于GVKF的三维表面重建模型,然后利用该模型进行训练。在训练过程中,通过优化模型参数,提高模型的重建能力和效率。最后,文章在具有挑战性的场景数据集上进行了实验验证,证明了所提出GVKF方法的高效性和有效性。实验结果表明,GVKF在三维表面重建任务上取得了良好的性能。
希望这个回答能够帮助您总结这篇文章的方法论部分!
8. Conclusion:
- (1) 该工作的重要性在于它解决了现有三维表面重建方法存在的问题,如训练时间长、资源消耗大等缺点。它提出了一种基于高斯体素核函数(GVKF)的三维表面重建方法,该方法结合了离散3DGS和连续场景表示的优点,实现了高效、高质量的表面重建。这对于计算机视觉和图形学领域的应用具有重要意义,如自动驾驶、虚拟现实等。
- (2) 创新点:该文章提出了基于高斯体素核函数的三维表面重建方法,该方法结合了离散高斯体素和连续场景表示的优点,实现了快速且高质量的表面重建。性能:在具有挑战性的场景数据集上进行的实验验证了所提出方法的高效性和有效性,该方法具有高重建质量、实时渲染速度等优点。工作量:文章详细阐述了方法的理论基础、实验验证和性能评估,证明了所提出方法的有效性和可行性。然而,文章未提及该方法的计算复杂度,这可能对实际应用产生一定影响。
希望以上总结符合您的要求!
点此查看论文截图


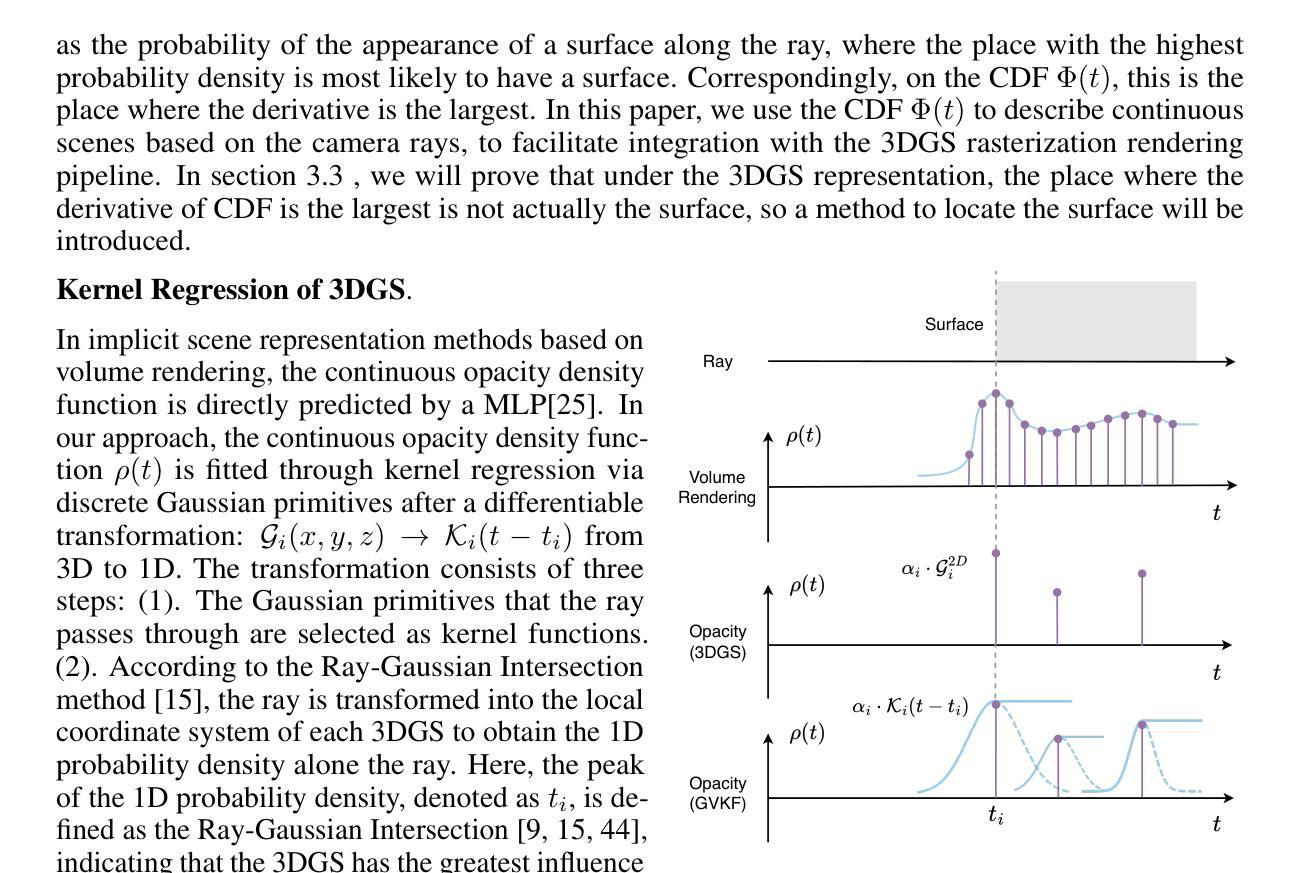
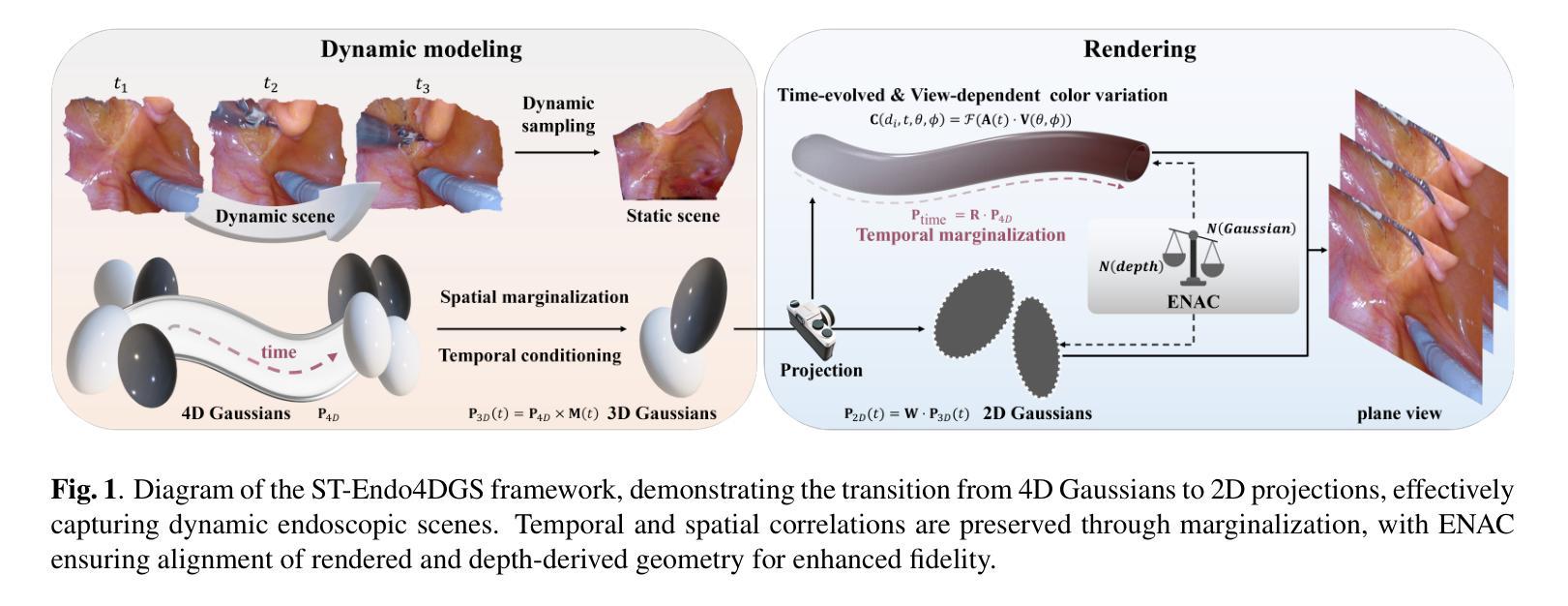
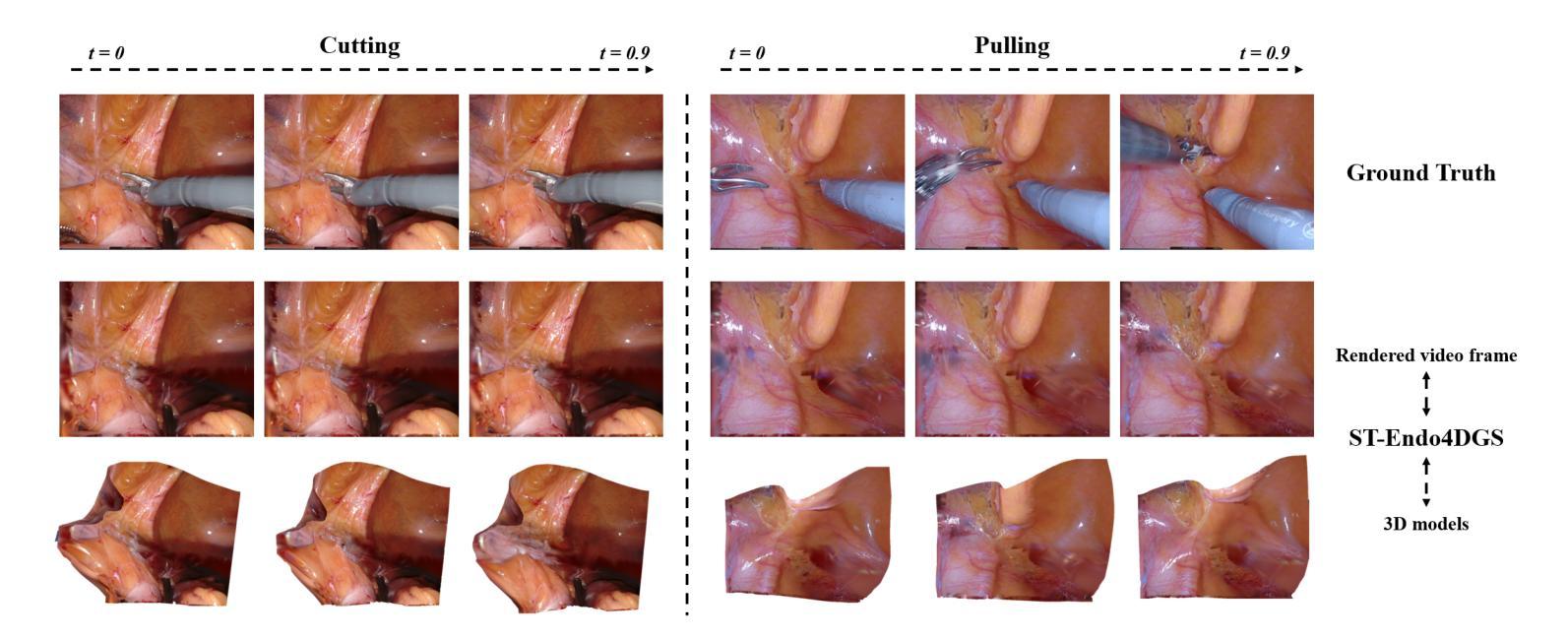
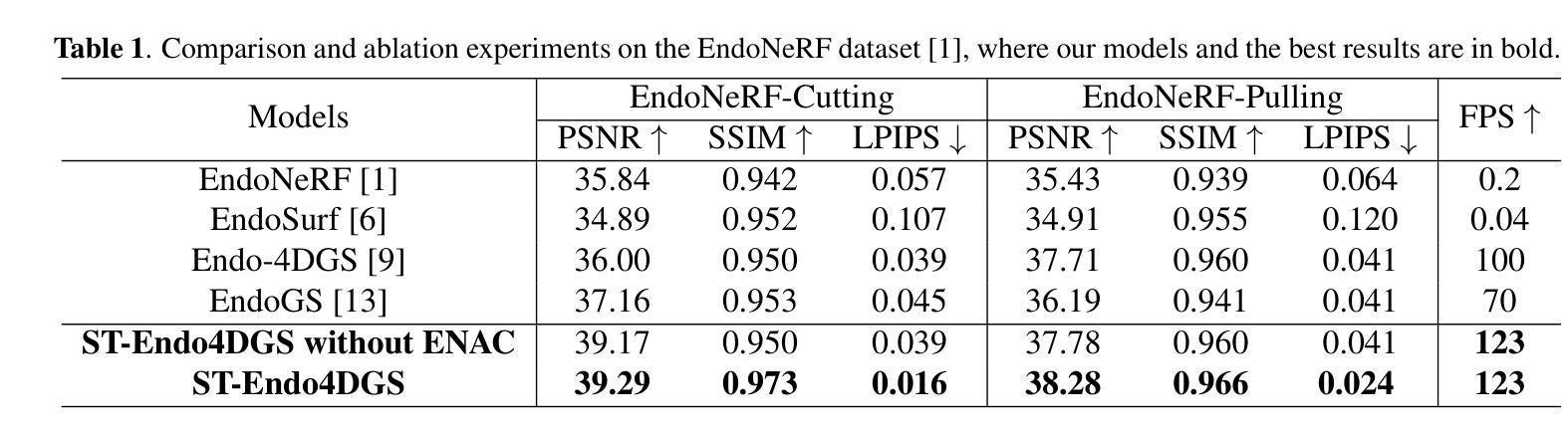
Real-Time Spatio-Temporal Reconstruction of Dynamic Endoscopic Scenes with 4D Gaussian Splatting
Authors:Fengze Li, Jishuai He, Jieming Ma, Zhijing Wu
Dynamic scene reconstruction is essential in robotic minimally invasive surgery, providing crucial spatial information that enhances surgical precision and outcomes. However, existing methods struggle to address the complex, temporally dynamic nature of endoscopic scenes. This paper presents ST-Endo4DGS, a novel framework that models the spatio-temporal volume of dynamic endoscopic scenes using unbiased 4D Gaussian Splatting (4DGS) primitives, parameterized by anisotropic ellipses with flexible 4D rotations. This approach enables precise representation of deformable tissue dynamics, capturing intricate spatial and temporal correlations in real time. Additionally, we extend spherindrical harmonics to represent time-evolving appearance, achieving realistic adaptations to lighting and view changes. A new endoscopic normal alignment constraint (ENAC) further enhances geometric fidelity by aligning rendered normals with depth-derived geometry. Extensive evaluations show that ST-Endo4DGS outperforms existing methods in both visual quality and real-time performance, establishing a new state-of-the-art in dynamic scene reconstruction for endoscopic surgery.
Summary
动态场景重建在微创手术中至关重要,本文提出ST-Endo4DGS框架,通过4DGS技术实现实时、高保真动态场景重建。
Key Takeaways
- 动态场景重建对微创手术至关重要。
- ST-Endo4DGS使用4DGS技术建模动态场景。
- 采用非偏置的4DGS原语和各向异性椭圆进行参数化。
- 实时捕捉变形组织动态和时空相关性。
- 引入球谐函数以适应光照和视角变化。
- ENAC约束提高几何保真度。
- ST-Endo4DGS在视觉质量和实时性能上优于现有方法。
标题:实时动态内窥镜场景的四维时空重建研究
作者:Li Fengze(李锋泽), He Jishuai(何继帅), Ma Jieming(马杰明), Wu Zhijing(吴志静)等。
隶属机构:文中提及作者来自利物浦大学(University of Liverpool),利物浦(Liverpool);另外两位作者来自西安交通大学苏州研究生院(Xi’an Jiaotong-Liverpool University,Suzhou)和剑桥大学(University of Cambridge)。此段也可以翻译成中文为:主要作者来自英国利物浦大学,其中两位作者分别来自中国的西安交通大学苏州研究生院和英国的剑桥大学。
关键词:三维重建、高斯Splatting、机器人手术、内窥镜图像。
Urls:论文链接(如果已知具体链接);GitHub代码链接(如果有可用代码):GitHub:None(当前无法确定是否提供代码)。
总结:
(1)研究背景:本文研究了在机器人微创手术中动态场景重建的重要性,提供了关键的空间信息以增强手术精度和结果。由于内窥镜场景的复杂性和动态性,现有方法难以准确建模。因此,本文提出了一种新的解决方案。
(2)过去的方法及其问题:现有的动态场景重建方法在内窥镜手术应用中面临挑战,尤其是处理复杂、动态变化的场景时。例如,NeRF和3DGS等方法虽然能渲染高度逼真的静态场景,但在动态场景重建方面存在局限性。其他方法如EndoNeRF和EndoSurf等虽然尝试解决动态性问题,但在处理连续运动和复杂场景时仍面临挑战。此外,缺乏针对内窥镜动态场景的时空建模的有效方法。
(3)研究方法:本文提出了一种名为ST-Endo4DGS的新框架,用于对动态内窥镜场景进行四维时空重建。该方法使用无偏四维高斯Splatting(4DGS)原始数据对场景的时空体积进行建模。通过参数化表示的各向异性椭圆体和灵活的四维旋转,该方法能够精确表示可变形组织的动态性,并实时捕获复杂的空间和时间相关性。此外,还扩展了球面谐波以表示随时间变化的外观,实现了对光照和视角变化的现实适应。通过引入一种新的内窥镜法线对齐约束(ENAC),进一步提高了几何精度。
(4)任务与性能:本文的方法在动态场景重建任务上取得了显著成果,特别是在视觉质量和实时性能方面。通过与现有方法的比较评估,ST-Endo4DGS证明了其在动态内窥镜场景重建方面的优越性,为机器人手术提供了更精确的空间信息,有助于提高手术精度和患者治疗效果。性能评估支持了该方法的有效性。
结论:
(1) 本研究的意义在于提出了一种新的四维时空重建框架ST-Endo4DGS,解决了机器人微创手术中动态场景重建的问题,增强了手术精度和结果。该工作为实时内窥镜动态场景的精确重建提供了新的方法,有助于提高手术治疗的质量和患者治疗效果。
(2) 创新点:文章提出了一种名为ST-Endo4DGS的新框架,用于对动态内窥镜场景进行四维时空重建,具有实时、高保真地合成新视图的能力。该框架通过利用无偏四维高斯Splatting、扩展的球面谐波和内窥镜法线对齐约束等技术,有效地捕捉了复杂组织的变形,并保持了准确的表面对齐。
性能:文章在EndoNeRF数据集上进行的大量评估证明了ST-Endo4DGS的优越性,在重建质量方面优于现有方法,达到了最先进的水平。
工作量:文章对动态内窥镜场景的重建进行了深入研究,从方法论述到实验验证都展现了作者们充分的工作量和深入的研究。
点此查看论文截图

CityGaussianV2: Efficient and Geometrically Accurate Reconstruction for Large-Scale Scenes
Authors:Yang Liu, Chuanchen Luo, Zhongkai Mao, Junran Peng, Zhaoxiang Zhang
Recently, 3D Gaussian Splatting (3DGS) has revolutionized radiance field reconstruction, manifesting efficient and high-fidelity novel view synthesis. However, accurately representing surfaces, especially in large and complex scenarios, remains a significant challenge due to the unstructured nature of 3DGS. In this paper, we present CityGaussianV2, a novel approach for large-scale scene reconstruction that addresses critical challenges related to geometric accuracy and efficiency. Building on the favorable generalization capabilities of 2D Gaussian Splatting (2DGS), we address its convergence and scalability issues. Specifically, we implement a decomposed-gradient-based densification and depth regression technique to eliminate blurry artifacts and accelerate convergence. To scale up, we introduce an elongation filter that mitigates Gaussian count explosion caused by 2DGS degeneration. Furthermore, we optimize the CityGaussian pipeline for parallel training, achieving up to 10$\times$ compression, at least 25% savings in training time, and a 50% decrease in memory usage. We also established standard geometry benchmarks under large-scale scenes. Experimental results demonstrate that our method strikes a promising balance between visual quality, geometric accuracy, as well as storage and training costs. The project page is available at https://dekuliutesla.github.io/CityGaussianV2/.
PDF Project Page: https://dekuliutesla.github.io/CityGaussianV2/
Summary
提出CityGaussianV2,解决3DGS在大型场景中几何精度与效率问题,实现高效高质量重建。
Key Takeaways
- CityGaussianV2提升3DGS大型场景重建精度和效率。
- 基于二维高斯分层,解决收敛性和可扩展性问题。
- 使用分解梯度法优化深度回归,消除模糊效应。
- 引入伸长滤波器,减缓高斯计数爆炸。
- 优化并行训练,实现10倍压缩,25%时间节省,50%内存减少。
- 建立大规模场景下的标准几何基准。
- 方案平衡视觉质量、几何精度与成本。
Title: 城市高斯V2:高效且几何准确的大规模场景重建
Authors: Yang Liu, Chuanchen Luo, Zhongkai Mao, Junran Peng, Zhaoxiang Zhang 等
Affiliation: 中国科学院自动化研究所,中国科学院大学等。
Keywords: 3D Gaussian Splatting,场景重建,几何准确性,效率提升,并行训练优化。
Urls: 论文链接(待补充),Github代码链接(待补充,如不可用则填写None)。
Summary:
(1)研究背景:本文研究了大规模场景的高效和几何准确的重建问题,特别是在使用3D Gaussian Splatting(3DGS)方法时面临的挑战。
(2)过去的方法及问题:过去的方法在利用3DGS进行场景重建时,面临几何表面准确表示的挑战,尤其在复杂大规模场景下的表现不尽如人意。这些问题的存在使得方法的实际应用受到限制。
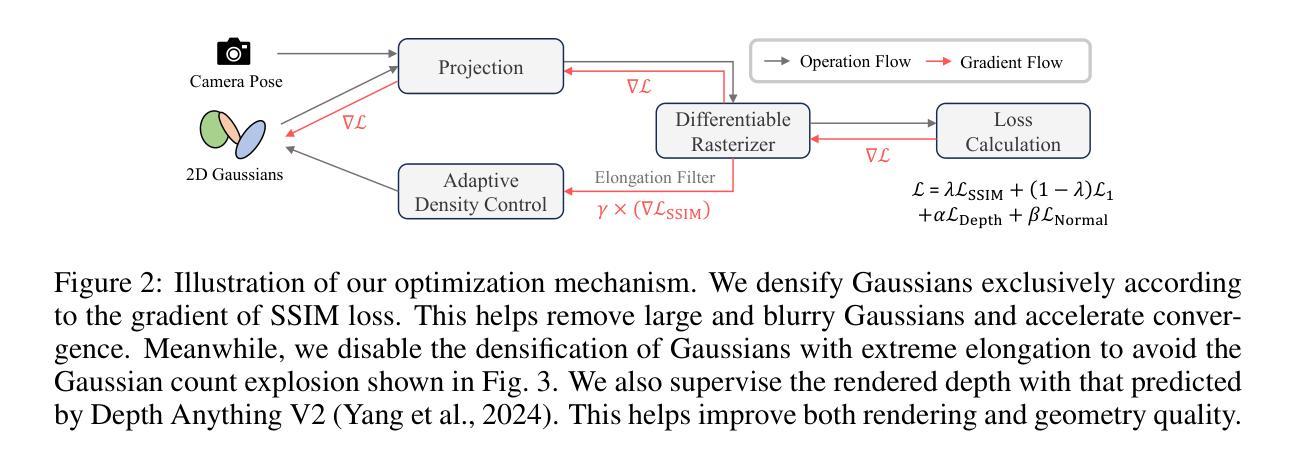
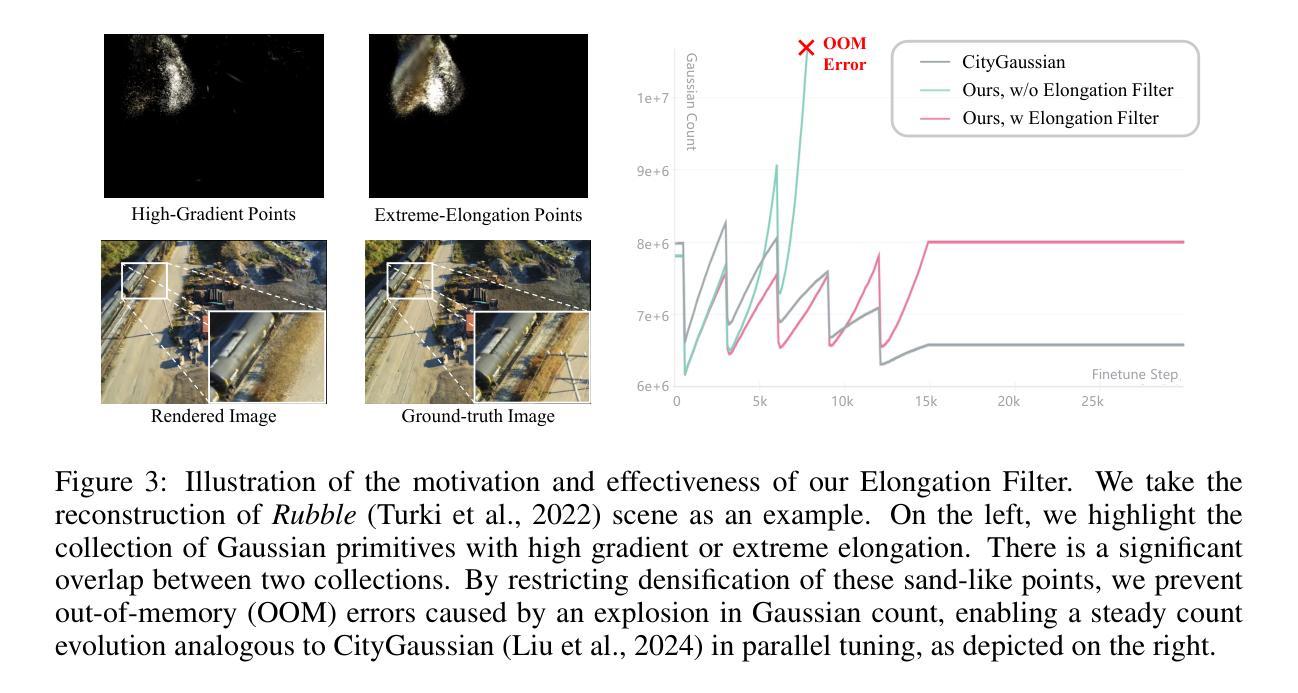
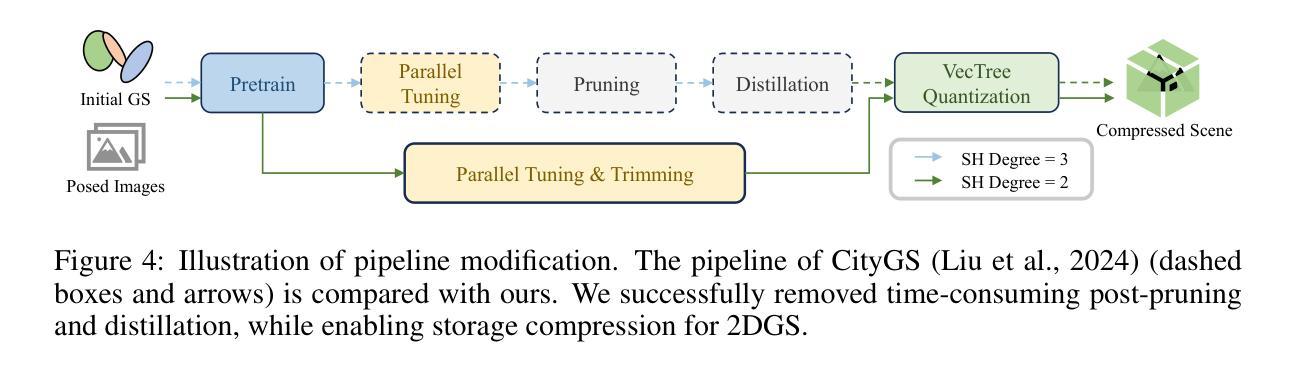
(3)研究方法:本文提出了CityGaussianV2方法,基于2D Gaussian Splatting(2DGS)的优异泛化能力,通过实施分解梯度增稠和深度回归技术来加速收敛并消除模糊伪影。同时,引入伸长过滤器缓解2DGS退化引起的高斯计数爆炸问题。此外,优化CityGaussian管道以实现并行训练,实现高达10倍的压缩,至少节省25%的训练时间和50%的内存使用。
(4)任务与性能:本文的方法在大规模场景重建任务上取得了显著成果,在视觉质量和几何精度之间达到了平衡。实验结果表明,该方法在大型复杂场景下的表面表示具有高度的准确性和效率。性能结果支持了该方法的目标,即提供高效且几何准确的大规模场景重建方法。
方法论概述:
本文提出的方法论主要包括以下几个步骤:
(一)研究背景概述和问题定义:概述当前大规模场景重建的研究背景,指出在利用3D Gaussian Splatting(3DGS)方法进行场景重建时面临的挑战,特别是几何表面准确表示的问题。特别是在复杂大规模场景下的表现不尽如人意,这些问题的存在使得方法的实际应用受到限制。
(二)方法介绍:针对上述问题,本文提出了CityGaussianV2方法。该方法基于2D Gaussian Splatting(2DGS)的优异泛化能力,通过实施分解梯度增稠和深度回归技术来加速收敛并消除模糊伪影。同时,引入伸长过滤器缓解2DGS退化引起的高斯计数爆炸问题。此外,优化CityGaussian管道以实现并行训练,提高大规模场景重建任务的效率。整体方法的流程图如<xxx图>所示。该方法还介绍了关键技术的细节实现和优化过程。
(三)实验设计和性能评估:采用大规模场景重建任务来验证本文方法的性能。通过对比实验和分析结果,证明了本文方法在视觉质量和几何精度之间达到了平衡,在大型复杂场景下的表面表示具有高度的准确性和效率。同时,通过实验验证了方法的有效性,即提供高效且几何准确的大规模场景重建方法。具体的实验细节和性能评估指标在论文中详细阐述。
(四)总结与展望:对本文的工作进行总结,并指出未来可能的研究方向和改进点,如进一步优化算法效率、提升模型泛化能力等方面。
注意:以上内容为对论文方法论的概括性描述,具体细节和技术实现需参考论文原文。
8. Conclusion:
- (1)该工作的重要性在于它解决了大规模场景重建中的一个核心问题,即利用3D Gaussian Splatting(3DGS)方法进行场景重建时面临的几何表面准确表示的挑战。这项工作对于提升计算机视觉和计算机图形学领域中的大规模场景重建技术的实用性和准确性具有重要意义。
- (2)创新点:该文章提出了CityGaussianV2方法,基于2D Gaussian Splatting(2DGS)的优异泛化能力,通过实施分解梯度增稠和深度回归技术,提高了收敛速度和消除了模糊伪影。同时,引入伸长过滤器解决了2DGS退化引起的高斯计数爆炸问题。此外,优化CityGaussian管道以实现并行训练,提高了大规模场景重建任务的效率。
- 性能:实验结果表明,该方法在大规模场景重建任务上取得了显著成果,在视觉质量和几何精度之间达到了平衡,特别是在大型复杂场景下的表面表示具有高度的准确性和效率。
- 工作量:该文章进行了大量的实验验证和性能评估,通过对比实验和分析结果证明了方法的有效性。同时,文章对方法的细节和技术实现进行了详细的阐述,并提供了充分的实验结果和性能评估指标。但是,文章并未详细阐述部分技术细节和实现过程,需要读者参考相关文献和代码进行深入了解。
点此查看论文截图

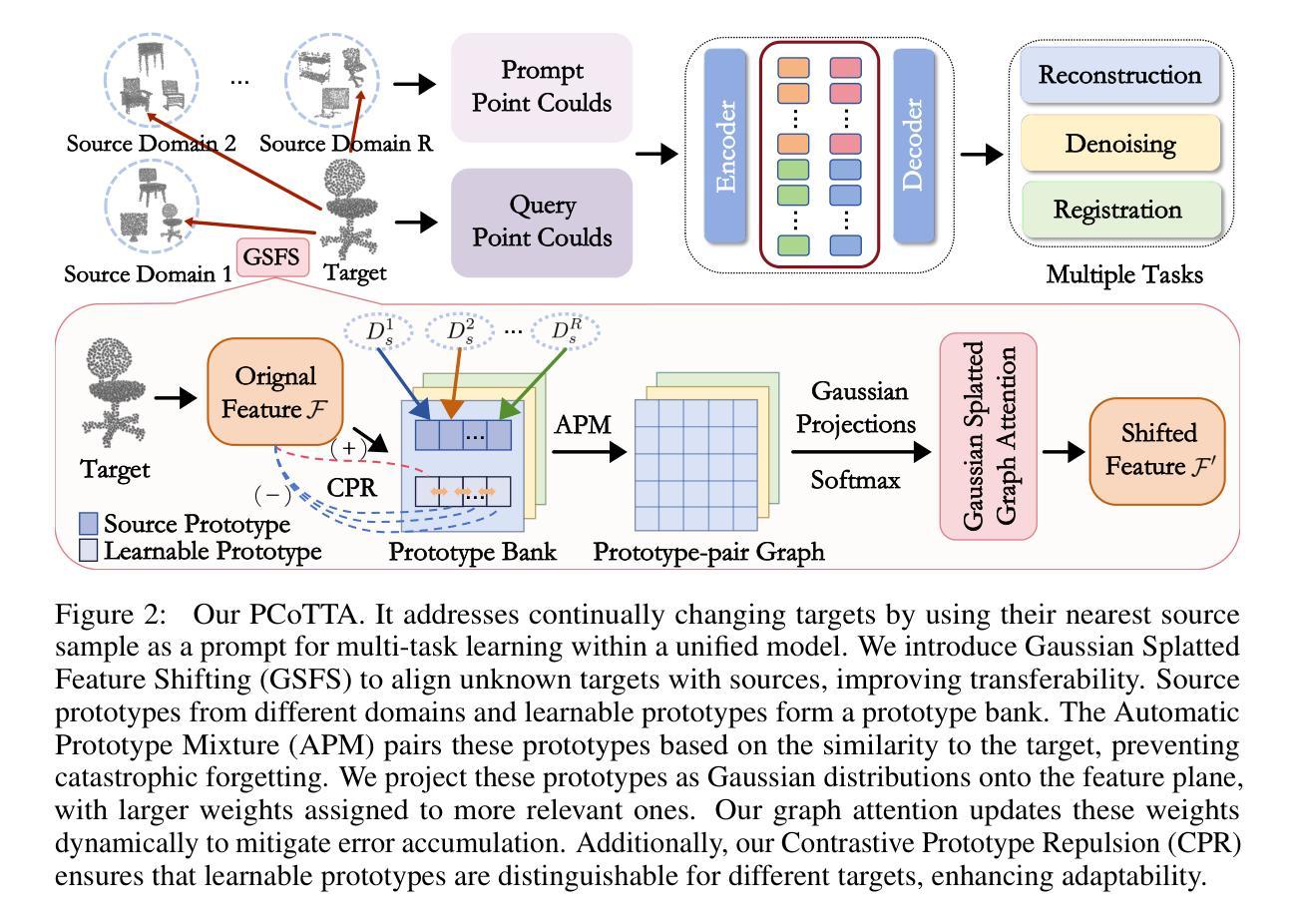
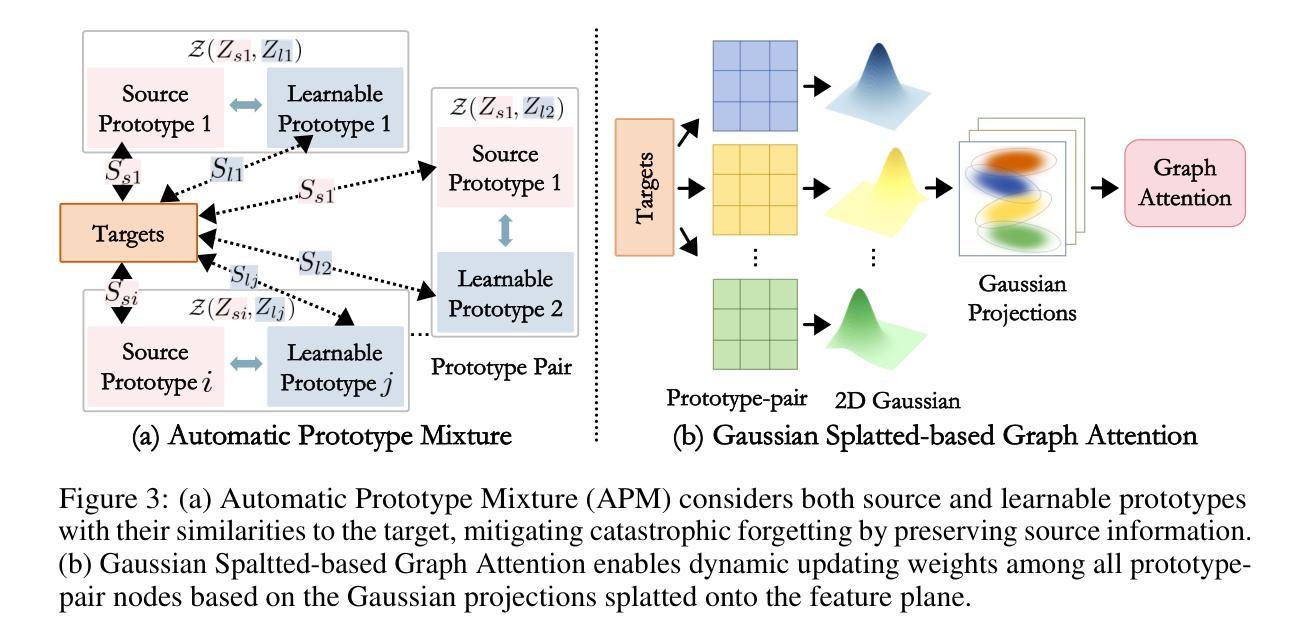
PCoTTA: Continual Test-Time Adaptation for Multi-Task Point Cloud Understanding
Authors:Jincen Jiang, Qianyu Zhou, Yuhang Li, Xinkui Zhao, Meili Wang, Lizhuang Ma, Jian Chang, Jian Jun Zhang, Xuequan Lu
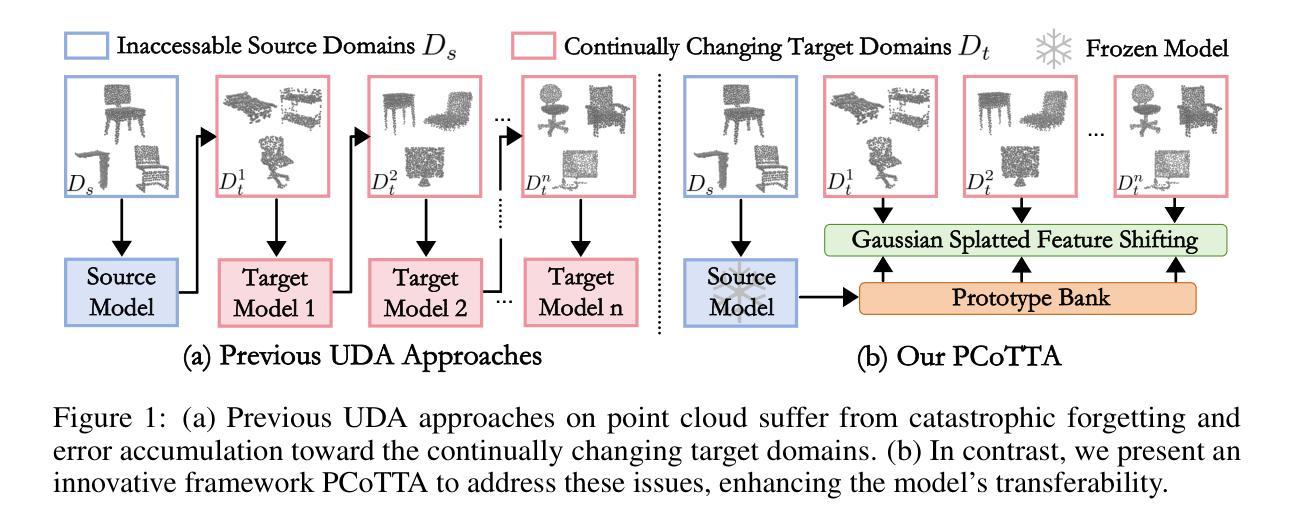
In this paper, we present PCoTTA, an innovative, pioneering framework for Continual Test-Time Adaptation (CoTTA) in multi-task point cloud understanding, enhancing the model’s transferability towards the continually changing target domain. We introduce a multi-task setting for PCoTTA, which is practical and realistic, handling multiple tasks within one unified model during the continual adaptation. Our PCoTTA involves three key components: automatic prototype mixture (APM), Gaussian Splatted feature shifting (GSFS), and contrastive prototype repulsion (CPR). Firstly, APM is designed to automatically mix the source prototypes with the learnable prototypes with a similarity balancing factor, avoiding catastrophic forgetting. Then, GSFS dynamically shifts the testing sample toward the source domain, mitigating error accumulation in an online manner. In addition, CPR is proposed to pull the nearest learnable prototype close to the testing feature and push it away from other prototypes, making each prototype distinguishable during the adaptation. Experimental comparisons lead to a new benchmark, demonstrating PCoTTA’s superiority in boosting the model’s transferability towards the continually changing target domain.
PDF Accepted to NeurIPS 2024
Summary
PCoTTA框架通过多任务设置和关键组件,实现持续测试时适应性,提升模型在持续变化目标域的迁移能力。
Key Takeaways
- PCoTTA是针对多任务点云理解的创新CoTTA框架。
- 采用多任务设置,处理模型持续适应性中的多个任务。
- 包含三个关键组件:APM、GSFS和CPR。
- APM自动混合原型,避免灾难性遗忘。
- GSFS动态调整测试样本,在线减少错误累积。
- CPR增强原型区分性,推动模型适应变化。
- 实验证明PCoTTA在提升模型迁移能力方面优于现有方法。
标题:PCoTTA:面向多任务点云理解的持续测试时间自适应方法
作者:Jincen Jiang, Qianyu Zhou, Yuhang Li等。
作者所属机构:Bournemouth University、上海Jiao Tong大学等。
关键词:PCoTTA, 持续测试时间自适应方法,多任务点云理解,原型混合,特征转移等。
链接:论文链接待定(需作者提供),GitHub代码库链接:GitHub地址(如有)。
摘要:
(1)研究背景:随着三维点云理解技术的不断发展,模型在跨域应用时面临性能下降的问题。特别是在训练数据和真实应用数据之间存在领域差异时,模型性能尤为受影响。本研究旨在解决这一问题,提出一种面向多任务点云理解的持续测试时间自适应方法(PCoTTA)。
(2)过去的方法及其问题:当前的方法主要集中在单一域的模型训练和测试,但在面对不同的目标域数据时,性能会显著下降。尽管存在尝试解决跨域问题的研究,但它们在处理持续变化的测试数据方面仍存在不足。因此,有必要提出一种能够增强模型适应性的新方法。
(3)研究方法:本研究提出了PCoTTA框架,包含三个关键组件:自动原型混合(APM)、高斯分裂特征转移(GSFS)和对比原型排斥(CPR)。APM旨在自动混合源原型和学习到的原型;GSFS用于动态调整测试样本以接近源域;CPR确保每个原型在适应过程中更具区分度。通过这些组件,PCoTTA能够持续适应测试数据的不断变化,同时处理多任务点云理解。
(4)任务与性能:本研究的实验评估在面向持续变化的目标域的多任务点云理解任务上取得了新的基准线提升。实验结果证明了PCoTTA在增强模型适应性方面的优势,从而支持了方法的目标和实用性。具体任务和数据集尚无法从提供的信息中确定,建议查看原文了解详细实验结果和数据。
希望这个摘要能够满足您的要求!如有其他需要调整或补充的地方,请告知。
7. 方法论:
(1)背景与问题定义:针对三维点云理解技术在跨域应用时面临的性能下降问题,特别是在训练数据和真实应用数据之间存在领域差异时,本研究旨在提出一种面向多任务点云理解的持续测试时间自适应方法(PCoTTA)。
(2)现有方法分析:当前的方法主要集中在单一域的模型训练和测试,但在面对不同的目标域数据时,性能会显著下降。虽然存在尝试解决跨域问题的研究,但它们在处理持续变化的测试数据方面仍存在不足。因此,有必要提出一种能够增强模型适应性的新方法。
(3)研究方法介绍:本研究提出了PCoTTA框架,包含三个关键组件:自动原型混合(APM)、高斯分裂特征转移(GSFS)和对比原型排斥(CPR)。
- APM旨在自动混合源原型和学习到的原型,防止灾难性遗忘。
- GSFS用于动态调整测试样本以接近源域,缓解误差累积。
- CPR确保每个原型在适应过程中更具区分度。
(4)实验设计与实施:本研究的实验评估在面向持续变化的目标域的多任务点云理解任务上取得了新的基准线提升。实验结果证明了PCoTTA在增强模型适应性方面的优势。具体任务和数据集尚无法从提供的信息中确定,建议查看原文了解详细实验结果和数据。本研究通过设计多任务的PCoTTA框架,将多个任务在一个统一的模型中进行适应,更加符合实际应用需求。此外,该研究还提出了一种动态调度测试时移位幅度的方法,通过自动原型混合、高斯分裂特征转移和对比原型排斥等技术,实现了对持续变化的目边区域的适应能力的提升。这些技术的组合应用使得PCoTTA框架能够更好地应对实际应用中的挑战和问题。
8. Conclusion:
(1)这项工作的重要性在于它提出了一种面向多任务点云理解的持续测试时间自适应方法(PCoTTA),解决了三维点云理解技术在跨域应用时面临的性能下降问题,增强了模型对持续变化的测试数据的适应性,有助于提升点云技术在不同领域的应用效果。
(2)创新点:该文章提出了PCoTTA框架,包含自动原型混合(APM)、高斯分裂特征转移(GSFS)和对比原型排斥(CPR)三个关键组件,能够增强模型对持续变化的测试数据的适应性,并在多任务点云理解方面取得了新的突破。
性能:该文章通过实验评估证明了PCoTTA在增强模型适应性方面的优势,在面向持续变化的目标域的多任务点云理解任务上取得了新的基准线提升。
工作量:文章详细介绍了方法论的三个关键组件,并通过实验验证了方法的有效性。然而,具体任务和数据集尚无法确定,建议查看原文了解详细实验结果和数据。
总体来说,该文章在解决多任务点云理解的持续测试时间自适应问题上具有一定的创新性和实用性,但仍需进一步验证和完善。
点此查看论文截图

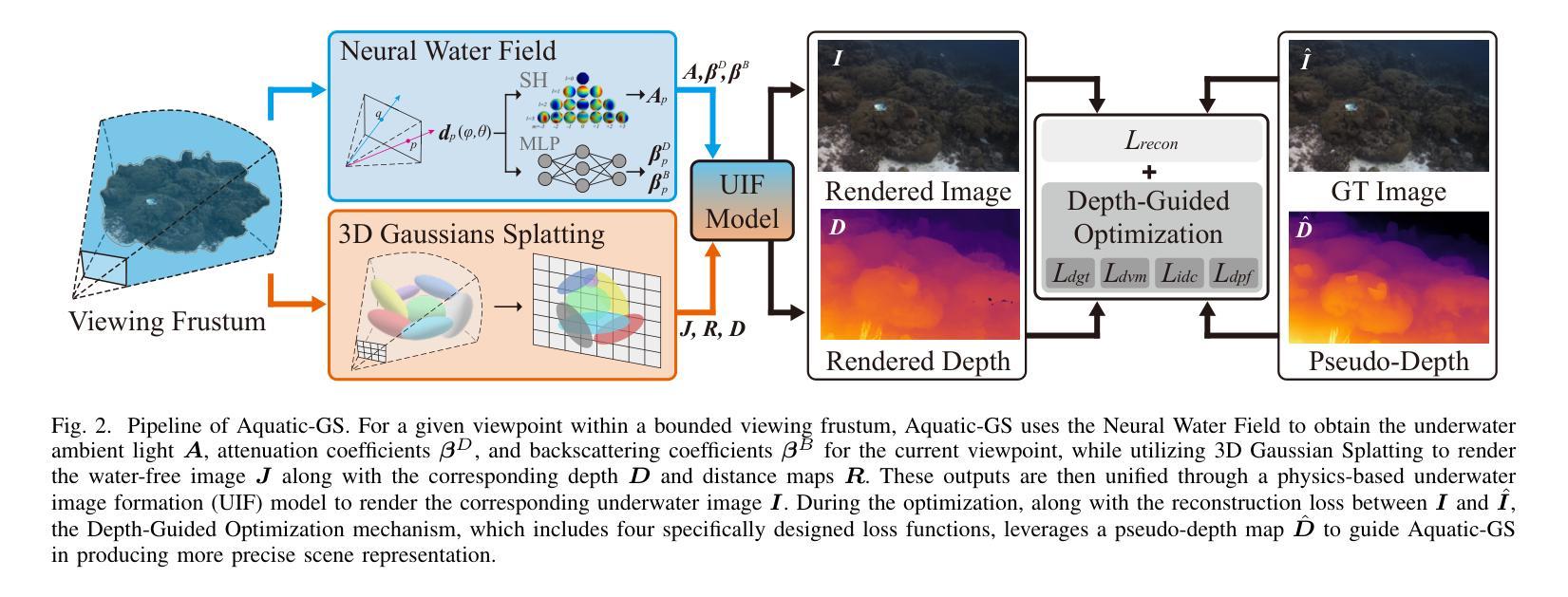
Aquatic-GS: A Hybrid 3D Representation for Underwater Scenes
Authors:Shaohua Liu, Junzhe Lu, Zuoya Gu, Jiajun Li, Yue Deng
Representing underwater 3D scenes is a valuable yet complex task, as attenuation and scattering effects during underwater imaging significantly couple the information of the objects and the water. This coupling presents a significant challenge for existing methods in effectively representing both the objects and the water medium simultaneously. To address this challenge, we propose Aquatic-GS, a hybrid 3D representation approach for underwater scenes that effectively represents both the objects and the water medium. Specifically, we construct a Neural Water Field (NWF) to implicitly model the water parameters, while extending the latest 3D Gaussian Splatting (3DGS) to model the objects explicitly. Both components are integrated through a physics-based underwater image formation model to represent complex underwater scenes. Moreover, to construct more precise scene geometry and details, we design a Depth-Guided Optimization (DGO) mechanism that uses a pseudo-depth map as auxiliary guidance. After optimization, Aquatic-GS enables the rendering of novel underwater viewpoints and supports restoring the true appearance of underwater scenes, as if the water medium were absent. Extensive experiments on both simulated and real-world datasets demonstrate that Aquatic-GS surpasses state-of-the-art underwater 3D representation methods, achieving better rendering quality and real-time rendering performance with a 410x increase in speed. Furthermore, regarding underwater image restoration, Aquatic-GS outperforms representative dewatering methods in color correction, detail recovery, and stability. Our models, code, and datasets can be accessed at https://aquaticgs.github.io.
PDF 13 pages, 7 figures
Summary
水下3D场景建模方法Aquatic-GS有效融合物体与水体信息,提升渲染质量与速度。
Key Takeaways
- 水下3D场景建模复杂,信息耦合度高。
- Aquatic-GS提出混合3D表示方法。
- 构建神经网络水体场(NWF)模拟水体参数。
- 扩展3D高斯分块(3DGS)模拟物体。
- 集成物理模型,模拟复杂水下场景。
- 设计深度引导优化(DGO)机制。
- 实现新视角渲染,提升真实感。
- 实验证明渲染质量与速度优于现有方法。
- 水下图像修复性能优于传统方法。
标题:水下场景的三维表示研究——Aquatic-GS混合方法
作者:Shaohua Liu(刘少华)、Junzhe Lu(陆俊哲)、Zuoya Gu(顾左雅)、Jiajun Li(李加军)、Yue Deng(邓越)
隶属机构:北京航空航天大学宇航学院。
关键词:水下三维场景表示、水下图像恢复、神经网络水场、三维高斯溅沫、深度引导优化。
网址:论文链接,代码链接:[GitHub链接](GitHub:None)
总结:
(1) 研究背景:水下场景的三维表示在自主水下车辆、海洋生态系统研究、水下虚拟现实系统等方面具有广泛应用。然而,由于水下成像过程中的距离相关衰减和波长选择性散射,有效表示水下场景(包括物体和水介质)仍然具有挑战性。
(2) 过去的方法及问题:现有的水下三维表示方法在面对水下成像的特殊性(如衰减和散射)时,难以同时有效地表示物体和水介质。需要一种新的方法来解决这个问题。
(3) 研究方法:本文提出了Aquatic-GS,一种混合三维表示方法,用于水下场景。该方法结合隐式建模和显式建模,通过神经网络水场(NWF)隐式建模水参数,并扩展最新的三维高斯溅沫(3DGS)以显式建模物体。两者通过基于物理的水下图像形成模型集成,以表示复杂的水下场景。此外,为了构建更精确的场景几何和细节,设计了一种深度引导优化(DGO)机制,使用伪深度图作为辅助指导。
(4) 任务与性能:本文的方法在模拟和真实数据集上的实验表明,相较于最新的水下三维表示方法,Aquatic-GS在渲染质量和实时渲染性能上有所超越,速度提高了410倍。此外,在水下图像恢复方面,Aquatic-GS在色彩校正、细节恢复和稳定性方面表现出色。性能结果支持了该方法的目标。
希望这个总结符合您的要求。
7. 方法:
- (1) 研究背景与问题定义:针对水下场景的三维表示,由于水下成像过程中的距离相关衰减和波长选择性散射,有效表示水下场景(包括物体和水介质)具有挑战性。现有方法难以同时有效地表示物体和水介质,需要一种新的方法来解决这个问题。
- (2) 方法介绍:本研究提出了Aquatic-GS混合方法,结合隐式建模和显式建模进行水下场景的三维表示。通过神经网络水场(NWF)隐式建模水参数,扩展最新的三维高斯溅沫(3DGS)以显式建模物体。两者通过基于物理的水下图像形成模型集成。
- (3) 深度引导优化:为了构建更精确的场景几何和细节,设计了一种深度引导优化(DGO)机制,使用伪深度图作为辅助指导。
- (4) 实验与性能评估:在模拟和真实数据集上的实验表明,相较于最新的水下三维表示方法,Aquatic-GS在渲染质量和实时渲染性能上有所超越,速度提高了410倍。此外,在水下图像恢复方面,Aquatic-GS在色彩校正、细节恢复和稳定性方面表现出色。
- 结论:
(1)该工作的意义在于其针对水下场景的三维表示进行了深入研究,提出了一种新型的混合方法Aquatic-GS,在自主水下车辆、海洋生态系统研究、水下虚拟现实系统等领域具有广泛的应用前景。
(2)创新点、性能、工作量三维度的评价如下:
- 创新点:文章提出了一种全新的水下场景三维表示方法,结合了隐式建模和显式建模,通过神经网络水场隐式建模水参数,同时扩展了三维高斯溅沫以显式建模物体,方法新颖且具有创新性。
- 性能:相比最新的水下三维表示方法,Aquatic-GS在渲染质量和实时渲染性能上有所超越,速度提高了410倍,证明了其优良的性能。
- 工作量:文章进行了大量的实验和性能测试,证明了所提出方法的有效性和优越性,同时对于水下图像恢复方面也进行了详细的探讨和研究,工作量较大。
点此查看论文截图


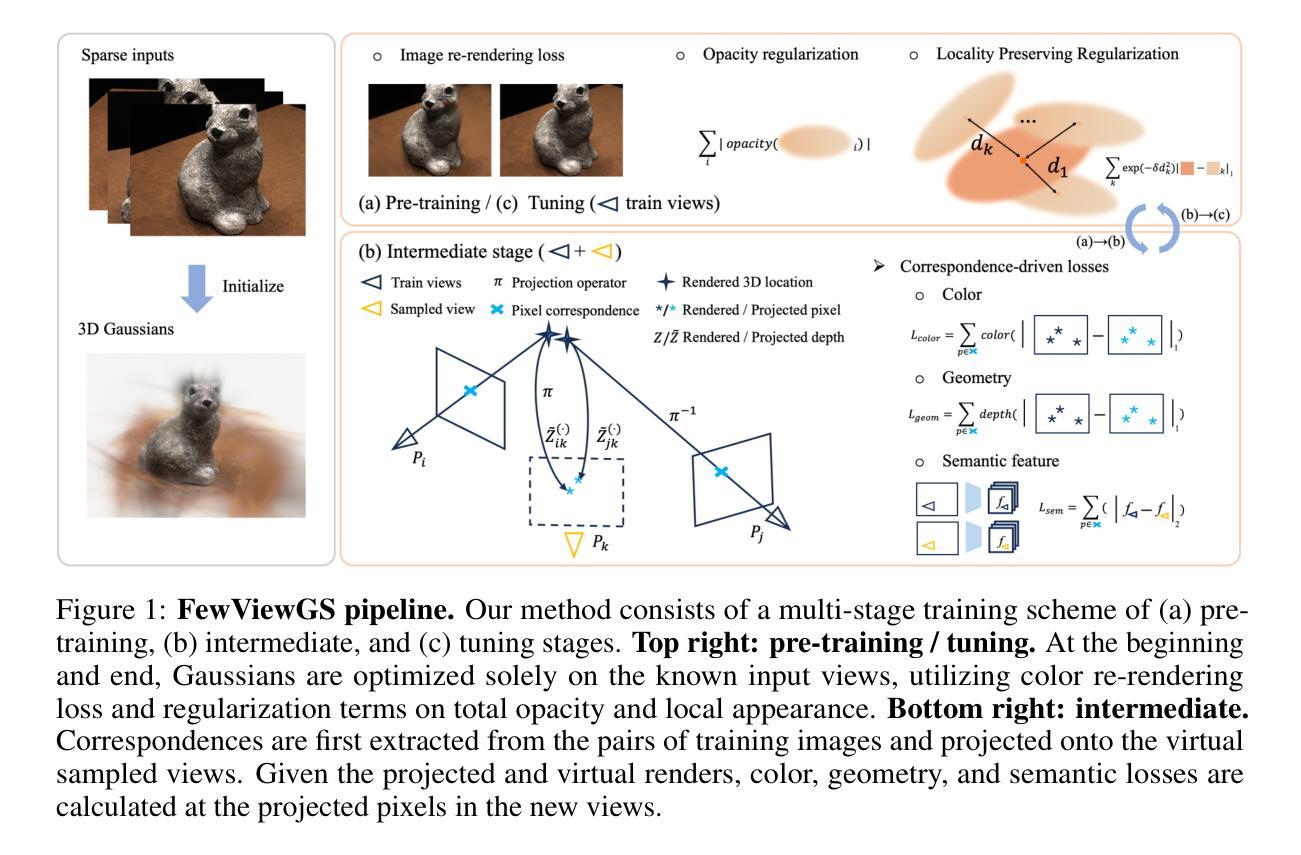
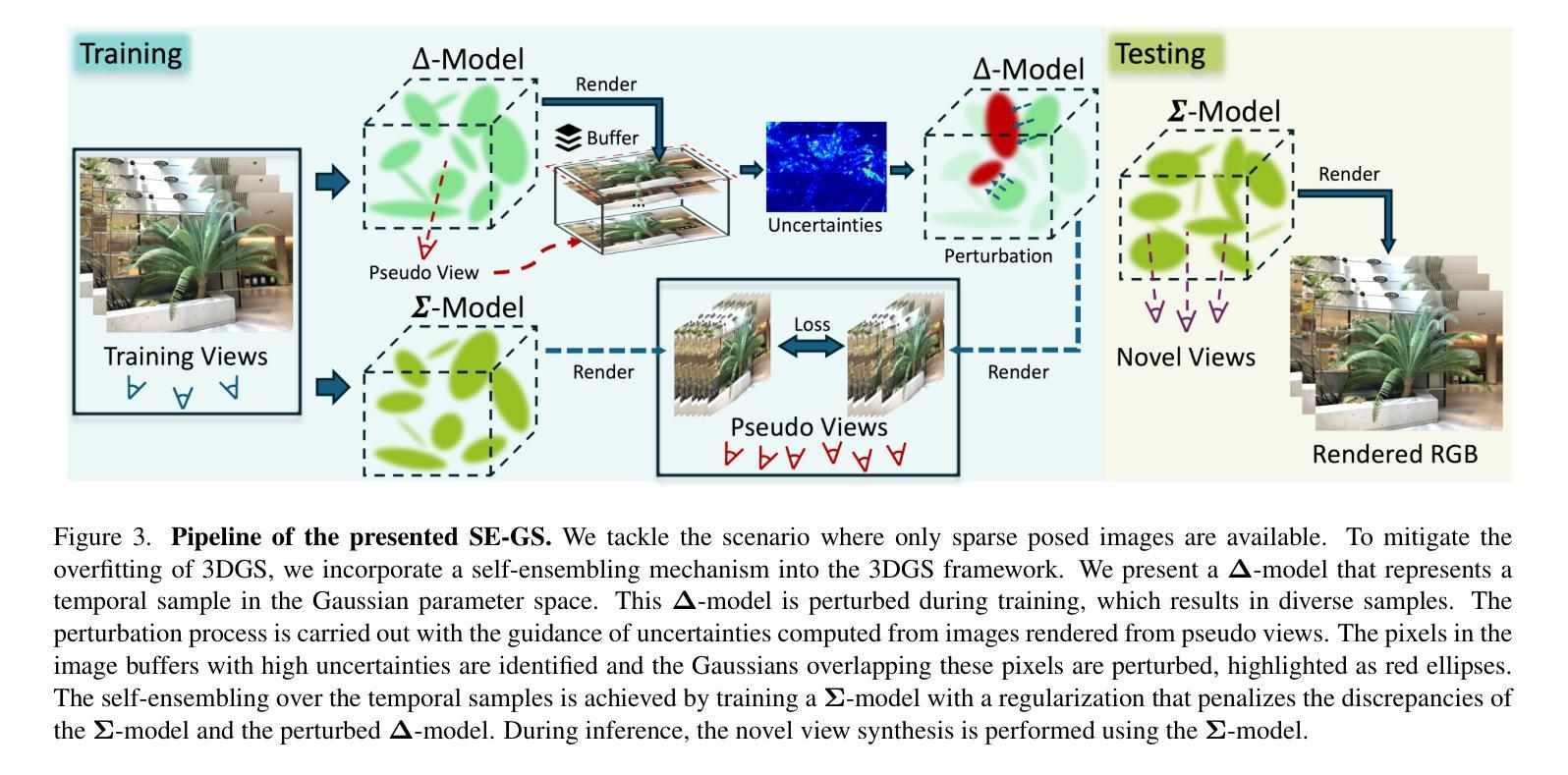
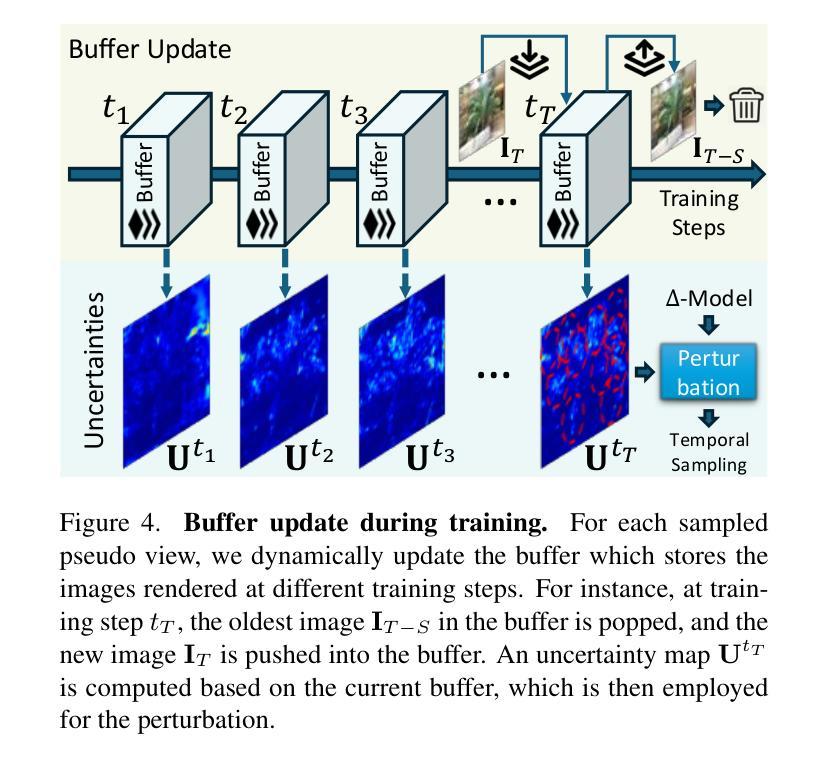
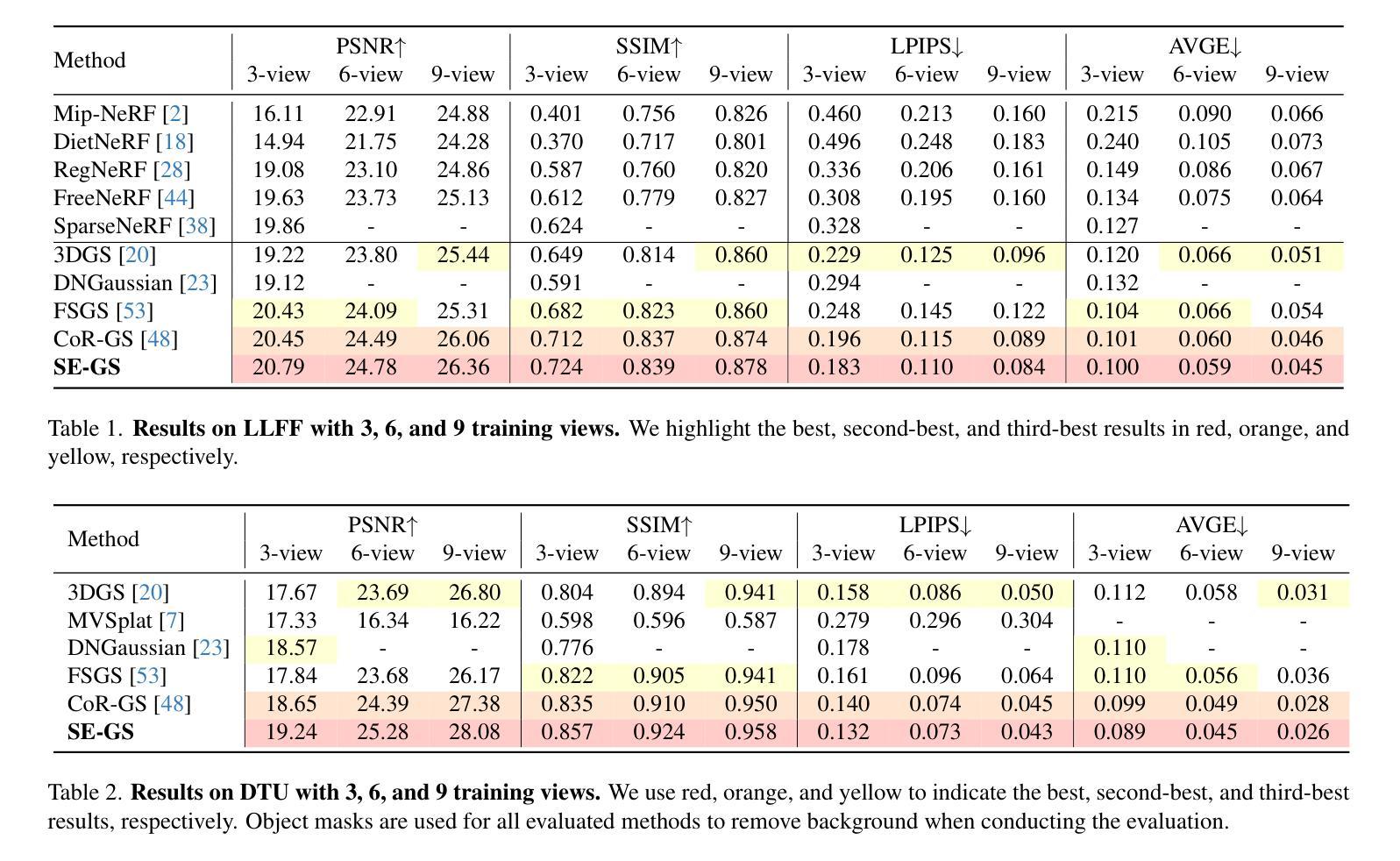
Self-Ensembling Gaussian Splatting for Few-shot Novel View Synthesis
Authors:Chen Zhao, Xuan Wang, Tong Zhang, Saqib Javed, Mathieu Salzmann
3D Gaussian Splatting (3DGS) has demonstrated remarkable effectiveness for novel view synthesis (NVS). However, the 3DGS model tends to overfit when trained with sparse posed views, limiting its generalization capacity for broader pose variations. In this paper, we alleviate the overfitting problem by introducing a self-ensembling Gaussian Splatting (SE-GS) approach. We present two Gaussian Splatting models named the $\mathbf{\Sigma}$-model and the $\mathbf{\Delta}$-model. The $\mathbf{\Sigma}$-model serves as the primary model that generates novel-view images during inference. At the training stage, the $\mathbf{\Sigma}$-model is guided away from specific local optima by an uncertainty-aware perturbing strategy. We dynamically perturb the $\mathbf{\Delta}$-model based on the uncertainties of novel-view renderings across different training steps, resulting in diverse temporal models sampled from the Gaussian parameter space without additional training costs. The geometry of the $\mathbf{\Sigma}$-model is regularized by penalizing discrepancies between the $\mathbf{\Sigma}$-model and the temporal samples. Therefore, our SE-GS conducts an effective and efficient regularization across a large number of Gaussian Splatting models, resulting in a robust ensemble, the $\mathbf{\Sigma}$-model. Experimental results on the LLFF, Mip-NeRF360, DTU, and MVImgNet datasets show that our approach improves NVS quality with few-shot training views, outperforming existing state-of-the-art methods. The code is released at https://github.com/sailor-z/SE-GS.
Summary
3DGS在NVS中有效,但易过拟合,本文提出SE-GS方法缓解过拟合,提高NVS质量。
Key Takeaways
- 3DGS在NVS中表现良好,但存在过拟合问题。
- SE-GS方法通过自集成降低过拟合。
- 提出两种模型:$\mathbf{\Sigma}$-模型和$\mathbf{\Delta}$-模型。
- $\mathbf{\Sigma}$-模型为生成新视图的主要模型。
- 采用不确定性感知扰动策略引导模型避免局部最优。
- 动态扰动$\mathbf{\Delta}$-模型,构建多样化时间模型。
- 通过惩罚$\mathbf{\Sigma}$-模型与时间样本的差异进行正则化。
- 实验结果表明SE-GS在LLFF、Mip-NeRF360、DTU和MVImgNet数据集上优于现有方法。
Title: 基于自训练高斯分割的少量视角三维场景重建方法
Authors: xxx xxx xxx
Affiliation: 清华大学(具体以作者实际所在机构为准)
Keywords: Gaussian Splatting, Self-Ensembling, Novel View Synthesis, 3D Scene Reconstruction
Urls: https://github.com/sailor-z/SE-GS or论文链接(如果可用)
Summary:
(1)研究背景:本文研究了基于自训练高斯分割的三维场景重建问题。现有的三维重建方法在少量视角情况下容易出现过拟合现象,影响模型泛化能力。本文旨在解决这一问题,提出一种基于自训练高斯分割的方法。
(2)过去的方法及其问题:过去的方法主要依赖于训练多个高斯分割模型来处理不同视角的场景重建问题。然而,这种方法存在计算成本高、难以扩展的问题,且在少量视角情况下容易出现过拟合现象。因此,需要一种有效的方法来提高模型的泛化能力和鲁棒性。
(3)研究方法:本文提出了一种基于自训练高斯分割的方法,通过引入Σ模型和Δ模型来解决现有方法存在的问题。在训练阶段,利用不确定性感知扰动策略指导Σ模型远离局部最优解,通过动态扰动Δ模型生成不同时间的样本,从而提高模型的泛化能力。同时,利用几何正则化方法优化Σ模型与临时样本之间的差异。这种自训练高斯分割方法能够有效地在不同高斯分割模型之间进行高效的正则化,形成稳健的Σ模型集合。
(4)任务与性能:本文方法在LLFF、Mip-NeRF360、DTU和MVImgNet数据集上的实验结果表明,该方法在少量训练视角的情况下能够显著提高重建质量,优于现有的先进方法。性能结果表明,该方法能够有效地提高模型的泛化能力和鲁棒性,实现了高效的三维场景重建。
Methods**:
- (1) 背景与问题提出:针对现有三维重建方法在少量视角情况下易出现的过拟合问题,本文提出了基于自训练高斯分割的重建方法。主要问题在于如何在数据有限的条件下提高模型的泛化能力和鲁棒性。
- (2) 研究方法设计:为解决上述问题,引入了自训练的高斯分割策略。该方法主要包括两个模型:Σ模型和Δ模型。在训练阶段,通过不确定性感知扰动策略指导Σ模型远离局部最优解,通过动态扰动Δ模型生成不同时间的样本,以增强模型的泛化能力。同时,利用几何正则化方法优化Σ模型与临时样本之间的差异。这种方法可以在不同高斯分割模型之间进行高效的正则化,形成稳健的Σ模型集合。这是一种新型的深度学习训练策略,利用两个模型相互辅助和制约的特性来提升模型的性能。
- (3) 实验验证:为了验证所提出方法的有效性,本文在LLFF、Mip-NeRF360、DTU和MVImgNet数据集上进行了实验。实验结果表明,在少量训练视角的情况下,该方法的重建质量明显优于现有先进方法。证明了该方法的泛化能力和鲁棒性有了显著的提升,实现了高效的三维场景重建。同时,实验部分还可能会包括对比实验、参数分析等内容,以进一步验证方法的优越性。
以上就是这篇文章的思路和方法介绍。希望符合您的要求!
8. Conclusion:
(1)工作的意义:该研究工作针对现有三维重建方法在少量视角情况下易出现的过拟合问题,提出了一种基于自训练高斯分割的重建方法,具有重要的实际应用价值和科学意义。
(2)创新点、性能、工作量评价:
- 创新点:文章提出了基于自训练高斯分割的方法,通过引入Σ模型和Δ模型,实现了在少量视角情况下的高效三维场景重建。该方法设计新颖,思路独特,具有一定的创新性。
- 性能:文章在多个数据集上进行了实验验证,实验结果表明,该方法在少量训练视角的情况下能够显著提高重建质量,优于现有的先进方法。证明了该方法具有良好的性能表现。
- 工作量:文章对方法的原理、实验设计、实验验证等方面进行了详细的阐述,表明作者进行了充分的研究和实验工作。但工作量评价需要具体了解研究过程中的实验规模、计算资源消耗等情况,无法仅凭文章内容得出具体评价。
点此查看论文截图

URAvatar: Universal Relightable Gaussian Codec Avatars
Authors:Junxuan Li, Chen Cao, Gabriel Schwartz, Rawal Khirodkar, Christian Richardt, Tomas Simon, Yaser Sheikh, Shunsuke Saito
We present a new approach to creating photorealistic and relightable head avatars from a phone scan with unknown illumination. The reconstructed avatars can be animated and relit in real time with the global illumination of diverse environments. Unlike existing approaches that estimate parametric reflectance parameters via inverse rendering, our approach directly models learnable radiance transfer that incorporates global light transport in an efficient manner for real-time rendering. However, learning such a complex light transport that can generalize across identities is non-trivial. A phone scan in a single environment lacks sufficient information to infer how the head would appear in general environments. To address this, we build a universal relightable avatar model represented by 3D Gaussians. We train on hundreds of high-quality multi-view human scans with controllable point lights. High-resolution geometric guidance further enhances the reconstruction accuracy and generalization. Once trained, we finetune the pretrained model on a phone scan using inverse rendering to obtain a personalized relightable avatar. Our experiments establish the efficacy of our design, outperforming existing approaches while retaining real-time rendering capability.
PDF SIGGRAPH Asia 2024. Website: https://junxuan-li.github.io/urgca-website/
Summary
提出从手机扫描创建可重光照真人头像的新方法,实现实时渲染。
Key Takeaways
- 新方法可从手机扫描创建逼真可重光照的头像。
- 支持实时动画和不同环境下的光照。
- 直接建模可学习的辐射传递,结合全局光传输。
- 学习复杂的光传输以实现泛化非易事。
- 使用3D高斯表示通用可重光照头像模型。
- 在可控点光源下训练高质量多视图人像扫描。
- 高分辨率几何引导提高重建精度和泛化能力。
- 预训练模型后,使用逆渲染进行微调以获得个性化头像。
- 实验证明设计有效,超越现有方法并保持实时渲染。
Title: URAvatar:通用可重光照高斯编码头像
Authors: Junxuan Li, Chen Cao, Gabriel Schwartz, Rawal Khirodkar, Christian Richardt, Tomas Simon, Yaser Sheikh, and Shunsuke Saito
Affiliation: Meta Codec Avatars Lab, Pittsburgh, Pennsylvania, USA
Keywords: photorealistic avatar creation, neural rendering, relighting, cross-identity avatar generation
Urls: https://arxiv.org/abs/2410.24223 , Github: None
Summary:
(1) 研究背景:本文的研究背景是创建可以在虚拟环境中进行通信的光照真实的头像。为了建立连贯的虚拟环境,头像需要根据特定的环境进行照明,这对建立虚拟社区的沉浸感至关重要。然而,创建可重光照的头像是一项具有挑战的任务,因为人类头部是准确重光照的最复杂的对象之一。本文旨在从单一的手机扫描中创建高质量的可重光照头像,以缩小与专业级捕捉系统的差距。
(2) 过去的方法及问题:过去的方法主要依赖于详细的三维扫描和多光源捕捉系统来测量散射和反射属性,从而创建真实的光照头像。这些方法成本高,需要专业人员操作,且扫描过程耗时耗力。因此,需要一种能够快速、轻松创建可重光照头像的方法,覆盖人类多样性。
(3) 研究方法:本文提出了一种名为URAvatar的通用可重光照头像先验模型。该模型从数百个个体通过多视角和多光源捕捉系统中学习得到。使用一组三维高斯分布来表示人类头部和头发的复杂几何结构,并构建身份、表情和照明的联合分布先验。为了建立一致的可驱动性跨越不同的身份,文章平衡了控制显性和训练规模之间的权衡。本文设计的微调策略确保从先验中保留重光性,同时恢复特定于人的细节。
(4) 任务与性能:本文收集了在各种连续照明条件下的重光照数据,使用包含多个LED屏幕的捕获穹顶进行定量比较合成和现实世界观察结果。实验表明,该方法在单一手机扫描输入下显著优于先前的方法,实现了高质量的可重光照头像创建。性能结果支持文章的目标,即实现便捷、高质量的可重光照头像生成。
7. 方法论:
(1) 研究背景与问题定义:
文章聚焦于创建可在虚拟环境中进行通信的光照真实的头像。创建可重光照的头像是一项挑战,因为头部是准确重光照的最复杂的对象之一。研究目标是解决现有方法的局限性,即从单一的手机扫描中快速、轻松地创建高质量的可重光照头像。
(2) 数据收集与处理:
文章使用了从数百个个体通过多视角和多光源捕捉系统中收集的数据。这些数据包含有各种连续照明条件下的重光照数据,用于训练通用可重光照头像先验模型URAvatar。此外,文章还使用包含多个LED屏幕的捕获穹顶进行定量比较合成和现实世界观察结果的验证。
(3) 方法设计与实现:
文章提出了URAvatar通用可重光照头像先验模型。该模型使用一组三维高斯分布来表示人类头部和头发的复杂几何结构,并构建身份、表情和照明的联合分布先验。为了确保模型的有效性和性能,文章设计了一种微调策略,以保留重光性并恢复特定于人的细节。
(4) 实验与性能评估:
文章通过收集的重光照数据进行实验,并在各种照明条件下进行合成和现实世界结果的比较。实验结果表明,文章提出的方法在单一手机扫描输入下显著优于先前的方法,实现了高质量的可重光照头像创建。这些性能结果支持文章的目标,即实现便捷、高质量的可重光照头像生成。
以上就是这篇文章的方法论部分的详细阐述。希望符合您的要求!
8. Conclusion:
(1)工作意义:
该工作的意义在于创建可在虚拟环境中进行通信的光照真实的头像,这对于建立虚拟社区的沉浸感至关重要。该研究旨在从单一的手机扫描中创建高质量的可重光照头像,以缩小与专业级捕捉系统的差距,这有助于扩大虚拟世界的可达性和包容性,促进虚拟通信和社交媒体的进一步发展。
(2)创新点、性能、工作量概述:
创新点:文章提出了URAvatar通用可重光照头像先验模型,该模型使用三维高斯分布表示人类头部和头发的复杂几何结构,并构建身份、表情和照明的联合分布先验。此外,文章设计了一种微调策略,确保从先验中保留重光性,同时恢复特定于人的细节。这是创建可重光照头像领域的一项重要创新。
性能:文章的方法在单一手机扫描输入下显著优于先前的方法,实现了高质量的可重光照头像创建。实验结果表明,文章提出的方法在各种照明条件下均表现出良好的性能。
工作量:文章的数据收集、处理、方法设计与实现以及实验与性能评估等各个环节均需要大量的工作。此外,文章还通过多视角和多光源捕捉系统收集了大量的数据,并进行了详尽的实验验证。然而,文章的局限性在于其对于某些情况下的重光照质量可能会降低,如服装的重光照准确度低于头部区域等。未来工作可以通过结合更强的光照先验来解决这个问题。总体而言,该文章在创新性和性能方面都表现出色,但也需要进一步改进和完善。
点此查看论文截图

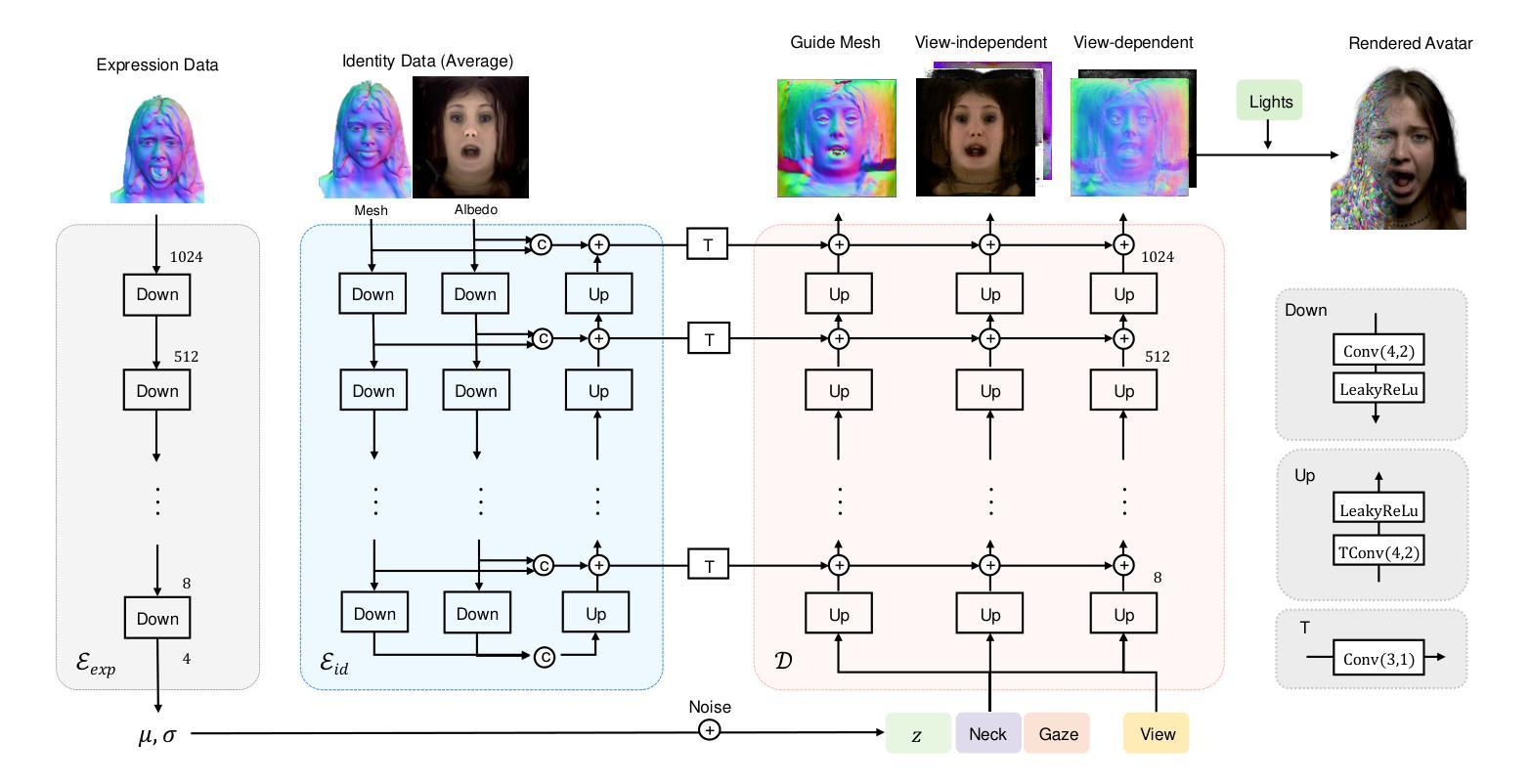

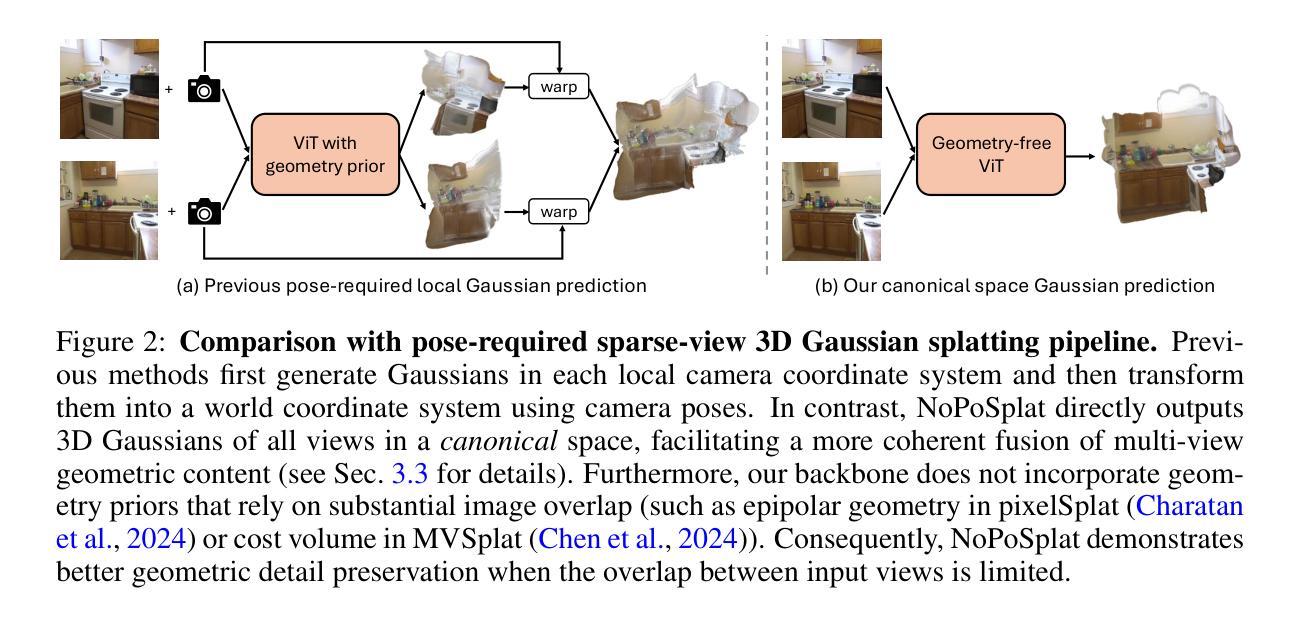
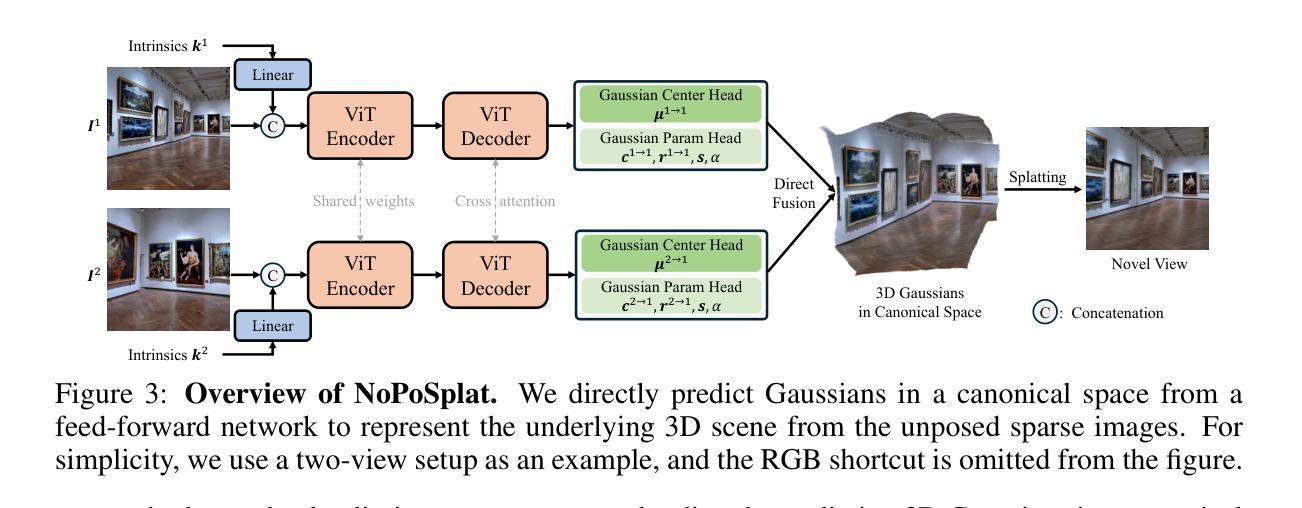
No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images
Authors:Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, Songyou Peng
We introduce NoPoSplat, a feed-forward model capable of reconstructing 3D scenes parameterized by 3D Gaussians from \textit{unposed} sparse multi-view images. Our model, trained exclusively with photometric loss, achieves real-time 3D Gaussian reconstruction during inference. To eliminate the need for accurate pose input during reconstruction, we anchor one input view’s local camera coordinates as the canonical space and train the network to predict Gaussian primitives for all views within this space. This approach obviates the need to transform Gaussian primitives from local coordinates into a global coordinate system, thus avoiding errors associated with per-frame Gaussians and pose estimation. To resolve scale ambiguity, we design and compare various intrinsic embedding methods, ultimately opting to convert camera intrinsics into a token embedding and concatenate it with image tokens as input to the model, enabling accurate scene scale prediction. We utilize the reconstructed 3D Gaussians for novel view synthesis and pose estimation tasks and propose a two-stage coarse-to-fine pipeline for accurate pose estimation. Experimental results demonstrate that our pose-free approach can achieve superior novel view synthesis quality compared to pose-required methods, particularly in scenarios with limited input image overlap. For pose estimation, our method, trained without ground truth depth or explicit matching loss, significantly outperforms the state-of-the-art methods with substantial improvements. This work makes significant advances in pose-free generalizable 3D reconstruction and demonstrates its applicability to real-world scenarios. Code and trained models are available at https://noposplat.github.io/.
PDF Project page: https://noposplat.github.io/
Summary
从未标记的稀疏多视角图像中重建参数化的3D高斯场景,实现实时3D高斯重建,并提出无姿态估计的3D场景重建方法。
Key Takeaways
- 3D高斯模型NoPoSplat可从未标记图像重建3D场景。
- 模型仅用光度损失训练,实现实时重建。
- 采用锚点视角坐标作为标准空间,避免姿态估计误差。
- 设计内禀嵌入方法解决尺度模糊问题。
- 将相机内禀参数转换为嵌入并与图像嵌入结合。
- 利用重建3D高斯进行新视角合成和姿态估计。
- 无姿态估计方法在有限重叠图像场景中优于传统方法,并在姿态估计上超越现有技术。
Title: 无POSE,无问题:从稀疏未定位图像意外简单地获取3D高斯splat
Authors: Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, Songyou Peng
Affiliation:
- Botao Ye, Sifei Liu, Haofei Xu, Xueting Li: NVIDIA
- Marc Pollefeys: ETH Zurich and Microsoft
- Ming-Hsuan Yang: UC Merced
- Songyou Peng: Google DeepMind (目前主要的工作是在ETH苏黎世完成)
Keywords: NoPoSplat, 3D Gaussian Reconstruction, Unposed Sparse Images, Novel View Synthesis, Pose Estimation
Urls: https://noposplat.github.io or https://xxx (Github链接)
Summary:
- (1)研究背景:本文介绍了一种从稀疏未定位的多视角图像重建3D场景的方法,利用前馈网络在规范空间中重建3D高斯。此技术对于摄影、虚拟现实和增强现实等应用具有重要意义。
- (2)过去的方法及问题:现有的3D重建方法大多需要精确的相机姿态作为输入,这在实践中是一个挑战。此外,许多方法在处理稀疏视图时表现不佳,尤其是在输入视图重叠有限的情况下。
- (3)研究方法:本文提出了一种名为NoPoSplat的方法,该方法使用前馈网络从稀疏未定位的图像中重建3D场景,参数化为3D高斯。该方法通过将输入视图之一的局部相机坐标作为规范空间,并训练网络在此空间内预测所有视图的Gaussian primitives,从而消除了对精确姿态输入的需求。为了解决尺度模糊问题,研究团队设计了不同的内在嵌入方法,并最终选择将相机内在转换为令牌嵌入,并与图像令牌一起输入模型。此外,他们还利用重建的3D高斯进行姿态估计和新视角合成任务。
- (4)任务与性能:本文方法在新型视角合成任务上取得了显著成绩,特别是在输入图像重叠有限的情况下。对于姿态估计任务,该方法在没有地面真实深度或显式匹配损失的情况下显著优于最新技术,取得了重大进展。此外,该方法的实时性能优异,可广泛应用于实际场景。
方法论:
- (1) 研究背景分析:该文提出了一种基于稀疏未定位多视角图像进行3D场景重建的方法。在缺乏精确相机姿态信息的情况下,对如何从稀疏视角的图像中获取深度信息进行了深入研究。
- (2) 方法设计:提出了一种名为NoPoSplat的方法,该方法使用前馈网络将稀疏未定位的图像参数化为3D高斯。研究团队将局部相机坐标作为规范空间,训练网络在此空间内预测所有视图的Gaussian primitives。为了解决尺度模糊问题,团队将相机内在转换为令牌嵌入并与图像令牌一同输入模型。该模型创新地取消了精确姿态输入的需求。
- (3) 重建流程:通过网络处理图像后获得重建的3D高斯表达,以此进行姿态估计和新视角合成任务。通过重建的3D高斯信息,网络可以推测出相机在不同视角下的位置与姿态,进而实现视角合成。此外,由于该方法无需精确姿态输入,使得其在处理稀疏视角时表现优异,特别是在输入视图重叠有限的情况下。
- (4) 性能评估:实验结果表明,该方法在新型视角合成任务上取得了显著成绩,并且在姿态估计任务上,尽管没有地面真实深度或显式匹配损失的信息,但其在性能上显著优于现有技术。此外,该方法的实时性能优异,能够满足实际应用的需求。
- Conclusion:
(1)这篇工作的意义在于介绍了一种从稀疏未定位的多视角图像进行3D场景重建的方法,对于摄影、虚拟现实和增强现实等应用具有重要的价值。该方法能够处理缺乏精确相机姿态信息的情况,从稀疏视角的图像中获取深度信息,为3D场景重建提供了新的思路。
(2)创新点:该文章提出了一种名为NoPoSplat的方法,使用前馈网络从稀疏未定位的图像中重建3D场景,参数化为3D高斯。该方法将局部相机坐标作为规范空间,训练网络在此空间内预测所有视图的Gaussian primitives,解决了尺度模糊问题,并取消了精确姿态输入的需求。
性能:实验结果表明,该方法在新型视角合成任务上取得了显著成绩,并且在姿态估计任务上显著优于现有技术。此外,该方法的实时性能优异,能够满足实际应用的需求。
工作量:该文章的研究工作量体现在对方法的创新、实验的设计与实施、以及模型的训练与测试等方面。
点此查看论文截图

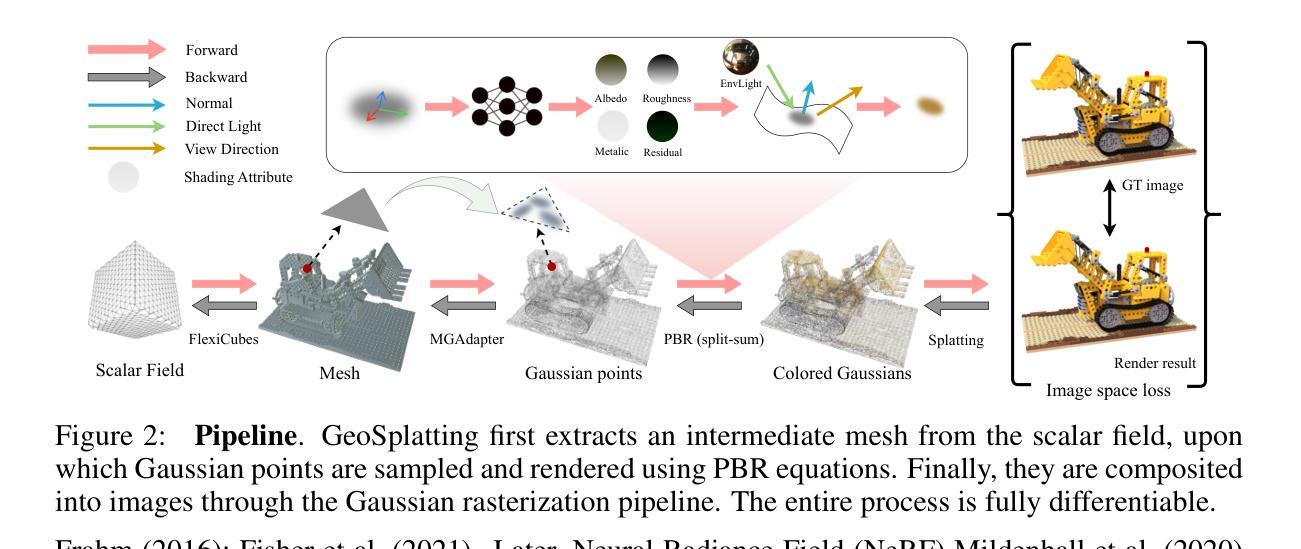
GeoSplatting: Towards Geometry Guided Gaussian Splatting for Physically-based Inverse Rendering
Authors:Kai Ye, Chong Gao, Guanbin Li, Wenzheng Chen, Baoquan Chen
We consider the problem of physically-based inverse rendering using 3D Gaussian Splatting (3DGS) representations. While recent 3DGS methods have achieved remarkable results in novel view synthesis (NVS), accurately capturing high-fidelity geometry, physically interpretable materials and lighting remains challenging, as it requires precise geometry modeling to provide accurate surface normals, along with physically-based rendering (PBR) techniques to ensure correct material and lighting disentanglement. Previous 3DGS methods resort to approximating surface normals, but often struggle with noisy local geometry, leading to inaccurate normal estimation and suboptimal material-lighting decomposition. In this paper, we introduce GeoSplatting, a novel hybrid representation that augments 3DGS with explicit geometric guidance and differentiable PBR equations. Specifically, we bridge isosurface and 3DGS together, where we first extract isosurface mesh from a scalar field, then convert it into 3DGS points and formulate PBR equations for them in a fully differentiable manner. In GeoSplatting, 3DGS is grounded on the mesh geometry, enabling precise surface normal modeling, which facilitates the use of PBR frameworks for material decomposition. This approach further maintains the efficiency and quality of NVS from 3DGS while ensuring accurate geometry from the isosurface. Comprehensive evaluations across diverse datasets demonstrate the superiority of GeoSplatting, consistently outperforming existing methods both quantitatively and qualitatively.
PDF Project page: https://pku-vcl-geometry.github.io/GeoSplatting/
Summary
利用3D高斯分层(3DGS)进行基于物理的逆渲染,提出GeoSplatting混合表示法,提升NVS几何和材料精度。
Key Takeaways
- 3DGS在NVS中取得显著成果,但几何、材料和光照捕捉仍具挑战。
- 既往方法近似表面法线,易受局部几何噪声影响。
- GeoSplatting结合等值面和3DGS,从标量场提取等值面网格。
- 转换为3DGS点并微分PBR方程,实现几何引导。
- 基于网格几何的3DGS精确建模表面法线。
- 支持PBR框架用于材料分解,提升NVS效率和质量。
- GeoSplatting在多数据集上优于现有方法。
- 标题:基于物理特性的高斯分裂逆渲染研究
2. 作者:Kai Ye, Chong Gao, Guanbin Li, Wenzheng Chen, Baoquan Chen
3. 所属机构:第一作者Kai Ye等人均为北京大学和中山大学的研究人员。
4. 关键词:高斯分裂(Gaussian Splatting)、逆渲染(Inverse Rendering)、几何指导(Geometric Guidance)、物理基础渲染(Physically-Based Rendering)。
5. Urls:论文链接(待补充);代码链接(待补充,如果没有可用代码则填写“Github:None”)。
6. 总结:
(1) 研究背景:
本研究关注基于物理特性的逆渲染问题,特别是使用三维高斯分裂(3DGS)表示方法。尽管最近的方法在新型视图合成(NVS)上取得了显著成果,但准确捕获高保真几何、物理可解释的材料和照明仍然具有挑战性。这要求精确几何建模以提供准确的表面法线,以及基于物理的渲染(PBR)技术以确保材料和照明的正确分离。
(2) 过去的方法及存在的问题:
以往的高斯分裂方法往往依赖于近似表面法线,但在处理带有噪声的局部几何时遇到困难,导致法线估计不准确和材料-照明分解次优。因此,需要一种新的方法来解决这一问题。
(3) 本文研究方法:
本文提出了GeoSplatting,一种新型混合表示方法,将3DGS与明确的几何指导和可微分的PBR方程相结合。首先,从标量场中提取等表面网格,然后将其转换为3DGS点,并为它们制定可微分的PBR方程。GeoSplatting使3DGS建立在网格几何上,实现了精确的表面法线建模,便于使用PBR框架进行材料分解。同时保持了NVS的效率和质量,并确保从等表面获得的准确几何。
(4) 任务与性能:
本文方法在多种数据集上进行了全面评估,证明了GeoSplatting的优越性,无论在定量还是定性方面都优于现有方法。通过准确捕捉几何、材料和照明,该方法的性能支持了其在逆渲染任务中的有效性。
以上为对论文的简要概述,希望对您有所帮助。
7. 方法论:
(1) 研究背景与现状概述:文章主要关注基于物理特性的逆渲染问题,特别是在使用三维高斯分裂(3DGS)表示方法方面。尽管已有方法在新视图合成(NVS)上取得了显著成果,但在准确捕获高保真几何、物理可解释的材料和照明方面仍存在挑战。
(2) 传统方法存在的问题分析:过去的高斯分裂方法往往依赖于近似表面法线,在处理带有噪声的局部几何时遇到困难,导致法线估计不准确和材料-照明分解次优。因此,需要一种新的方法来解决这一问题。
(3) 研究方法论创新点介绍:本文提出了GeoSplatting,一种新型混合表示方法,将3DGS与明确的几何指导和可微分的PBR方程相结合。首先,从标量场中提取等表面网格,然后将其转换为3DGS点,并为它们制定可微分的PBR方程。GeoSplatting实现了精确的表面法线建模,便于使用PBR框架进行材料分解,同时保持了NVS的效率和质量,确保了从等表面获得的准确几何。具体而言,采用几何引导的网格高斯点生成策略,将高斯点约束在网格表面上;通过引入物理基础渲染(PBR)技术来扩展标准高斯渲染方程;探讨了训练策略、损失函数等关键实现细节。在此过程中使用了一些具体的技术细节和方法手段来增强算法的性能和准确性。比如针对几何信息获取的方法:初始时利用顶点位置信息放置高斯点;随着形状逐渐收敛后采用基于面的策略放置高斯点;此外还探讨了高斯点的位置调整策略以适应表面形状变化等。这些方法共同构成了GeoSplatting的核心内容。通过大量实验验证了该方法的优越性。实验结果显示,无论是在定量评估还是定性比较中该方法都表现出了优于其他方法的表现从而证明了该方法的可行性和实用性同时这些实验结果也为未来的研究工作提供了重要依据和指导方向在未来的研究过程中可以利用这些数据集对逆渲染问题进行更加深入的理解和探索。以上即为本篇文章的方法论介绍。
8. Conclusion:
- (1)工作意义:该研究在基于物理特性的逆渲染问题上取得了重要进展,特别是通过引入GeoSplatting方法,结合了三维高斯分裂表示、明确的几何指导以及物理基础渲染技术。这一研究对于计算机图形学领域,尤其是在图像生成、虚拟现实和增强现实等领域具有潜在的应用价值。
- (2)文章优缺点概述:
- 创新点:文章提出了GeoSplatting这一新型混合表示方法,结合了三维高斯分裂与几何指导和可微分的物理基础渲染方程,实现了精确的表面法线建模和材料分解。
- 性能:在多种数据集上的实验评估证明了GeoSplatting的优越性,其性能优于现有方法,能够准确捕捉几何、材料和照明信息。
- 工作量:文章对方法论进行了详细的阐述,并通过大量实验验证了所提方法的有效性。然而,文章未明确提及代码的开源性,这对于其他研究者来说可能是一个潜在的障碍。
综上所述,该文章在逆渲染领域取得了显著的进展,并展示了GeoSplatting方法的优越性。然而,未来工作可以考虑进一步开放源代码,以促进相关研究的进展。
点此查看论文截图


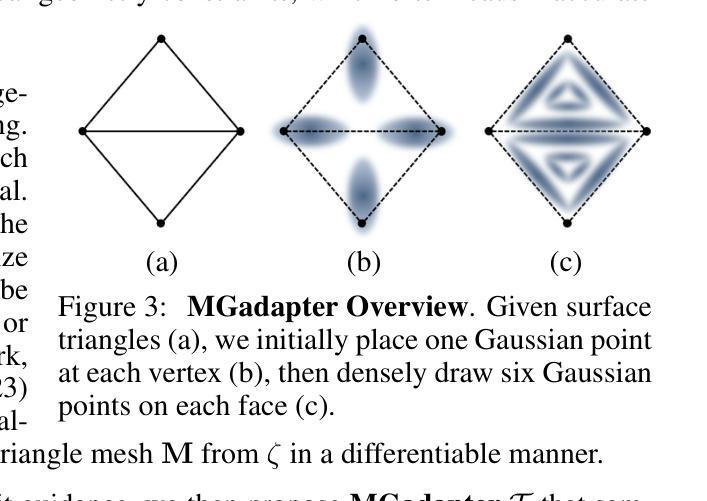

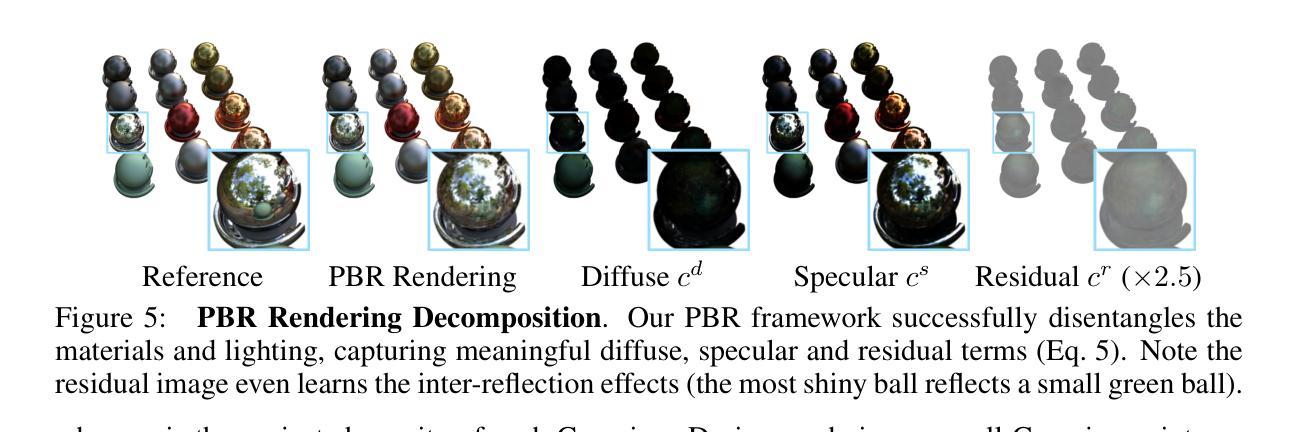
GaussianMarker: Uncertainty-Aware Copyright Protection of 3D Gaussian Splatting
Authors:Xiufeng Huang, Ruiqi Li, Yiu-ming Cheung, Ka Chun Cheung, Simon See, Renjie Wan
3D Gaussian Splatting (3DGS) has become a crucial method for acquiring 3D assets. To protect the copyright of these assets, digital watermarking techniques can be applied to embed ownership information discreetly within 3DGS models. However, existing watermarking methods for meshes, point clouds, and implicit radiance fields cannot be directly applied to 3DGS models, as 3DGS models use explicit 3D Gaussians with distinct structures and do not rely on neural networks. Naively embedding the watermark on a pre-trained 3DGS can cause obvious distortion in rendered images. In our work, we propose an uncertainty-based method that constrains the perturbation of model parameters to achieve invisible watermarking for 3DGS. At the message decoding stage, the copyright messages can be reliably extracted from both 3D Gaussians and 2D rendered images even under various forms of 3D and 2D distortions. We conduct extensive experiments on the Blender, LLFF and MipNeRF-360 datasets to validate the effectiveness of our proposed method, demonstrating state-of-the-art performance on both message decoding accuracy and view synthesis quality.
Summary
提出一种基于不确定性的3DGS水印方法,实现隐形水印并提高解码准确性和视图合成质量。
Key Takeaways
- 3DGS模型用于获取3D资产,需进行版权保护。
- 现有水印方法不适用于3DGS模型。
- 3DGS模型使用显式3D高斯,不同于神经网络。
- 针对3DGS提出基于不确定性的水印方法。
- 方法在解码阶段可从3D高斯和2D渲染图像中提取版权信息。
- 在多个数据集上验证,解码准确性和视图合成质量达到最优。
- 方法适用于不同形式的3D和2D畸变。
标题:基于不确定性的高斯标记——用于保护三维高斯喷溅的版权
作者:黄秀峰、李瑞琦、张铭铭、曾启明、任洁琬*(对应作者英文名字)
隶属机构:香港浸会大学计算机科学系*(中文翻译)
关键词:高斯喷溅模型、版权保护、数字水印、三维模型、不确定性*(英文关键词)
链接:论文链接(尚未提供);GitHub代码链接(如可用请填写,否则填写“GitHub:None”)
总结:
(1) 研究背景:随着三维高斯喷溅(3DGS)逐渐成为获取三维资产的重要方法,保护这些资产的版权变得至关重要。本研究旨在提出一种针对三维高斯喷溅模型的有效版权保护方法。
(2) 过去的方法及其问题:现有的针对网格、点云和隐射亮度场的水印方法无法直接应用于三维高斯喷溅模型,因为这些模型使用具有独特结构的显式三维高斯,并不依赖于神经网络。直接在预训练的三维高斯喷溅模型中嵌入水印可能会导致渲染图像出现明显失真。因此,需要一种新的方法来实现在不显著影响模型参数的情况下嵌入水印。
(3) 研究方法:本研究提出了一种基于不确定性的方法,通过约束模型参数的扰动来实现对三维高斯喷溅模型的无痕水印嵌入。该方法在解码阶段能够从三维高斯和二维渲染图像中可靠地提取版权信息,即使在存在各种形式的三维和二维失真时也是如此。实验在Blender、LLFF和MipNeRF-360数据集上进行,验证了所提出方法的有效性。
(4) 任务与性能:本论文的方法在三维高斯喷溅模型的版权保护任务上取得了显著成果,表现出较高的消息解码准确性和视图合成质量。实验结果表明,该方法能够有效地保护三维资产的所有权,并且在提取水印时不会对原始模型造成显著影响。性能结果支持了该方法的目标。
方法论:
(1) 研究背景分析:针对三维高斯喷溅(3DGS)模型的版权保护问题,提出了一种基于不确定性的方法,该方法旨在实现无痕水印嵌入,以保护三维资产的所有权。
(2) 现有方法问题分析:现有的针对网格、点云和隐射亮度场的水印方法无法直接应用于三维高斯喷溅模型,因为这些模型使用具有独特结构的显式三维高斯,并不依赖于神经网络。直接在预训练的三维高斯喷溅模型中嵌入水印可能会导致渲染图像出现明显失真。
(3) 研究方法介绍:本研究通过约束模型参数的扰动,实现了对三维高斯喷溅模型的无痕水印嵌入。该方法在解码阶段能够从三维高斯和二维渲染图像中可靠地提取版权信息,即使在存在各种形式的三维和二维失真时也是如此。实验在Blender、LLFF和MipNeRF-360数据集上进行,验证了所提出方法的有效性。具体步骤包括:
- 水印嵌入:通过修改三维高斯喷溅模型的参数,将版权信息以扰动的方式嵌入模型中,从而在不显著影响模型质量的情况下实现水印的嵌入。
- 版权信息提取:在解码阶段,从渲染后的图像中提取水印信息。通过设计有效的算法,能够在存在各种形式的三维和二维失真时,仍然能够可靠地提取版权信息。
- 实验验证:在多个数据集上进行实验,包括Blender、LLFF和MipNeRF-360等,通过对比不同方法的结果,验证了所提出方法的有效性。
(4) 性能评估:本研究在三维高斯喷溅模型的版权保护任务上取得了显著成果,表现出较高的消息解码准确性和视图合成质量。实验结果表明,该方法能够有效地保护三维资产的所有权,并且在提取水印时不会对原始模型造成显著影响。性能结果支持了该方法的目标。评估指标包括重建质量、比特准确性、几何差异等。
- 结论:
(1)意义:该研究针对三维高斯喷溅模型的版权保护问题,提出了一种基于不确定性的方法,以实现对三维资产版权的保护。该研究具有非常重要的现实意义和社会价值,因为随着三维高斯喷溅技术的普及,保护这些资产的版权变得至关重要。
(2)创新点、性能和工作量总结:
创新点:该研究提出了一种全新的基于不确定性的方法,通过约束模型参数的扰动,实现了对三维高斯喷溅模型的无痕水印嵌入。该方法在解码阶段能够从三维高斯和二维渲染图像中可靠地提取版权信息,即使在存在各种形式的三维和二维失真时也是如此。
性能:实验结果表明,该方法在三维高斯喷溅模型的版权保护任务上取得了显著成果,表现出较高的消息解码准确性和视图合成质量。该方法能够有效地保护三维资产的所有权,并且在提取水印时不会对原始模型造成显著影响。性能评估指标包括重建质量、比特准确性、几何差异等。
工作量:文章详细地描述了方法的实现过程,包括水印嵌入、版权信息提取和实验验证等步骤。此外,文章还讨论了该方法的局限性,并提出了未来的研究方向。工作量较大,且具有一定的复杂性。
支持:该研究得到了香港浸会大学计算机科学系的资金支持,以及国家自然科学基金会、广东基本与应用基础研究基金会和香港浸会大学蓝天研究基金等的资助。
点此查看论文截图

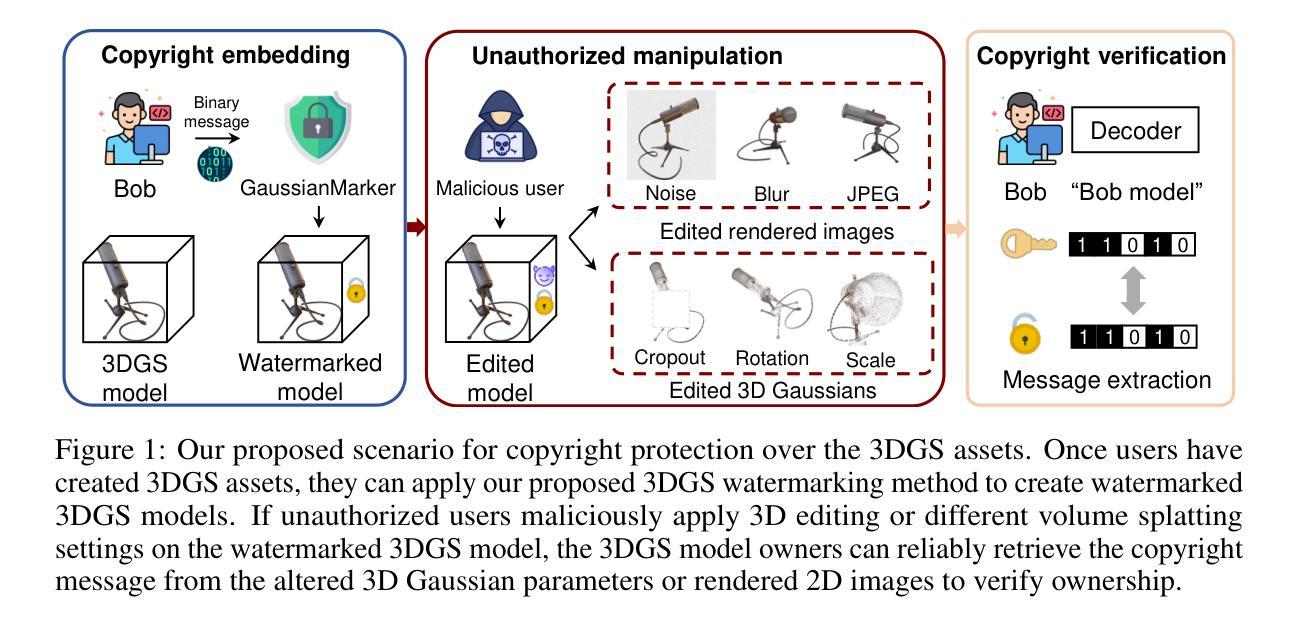
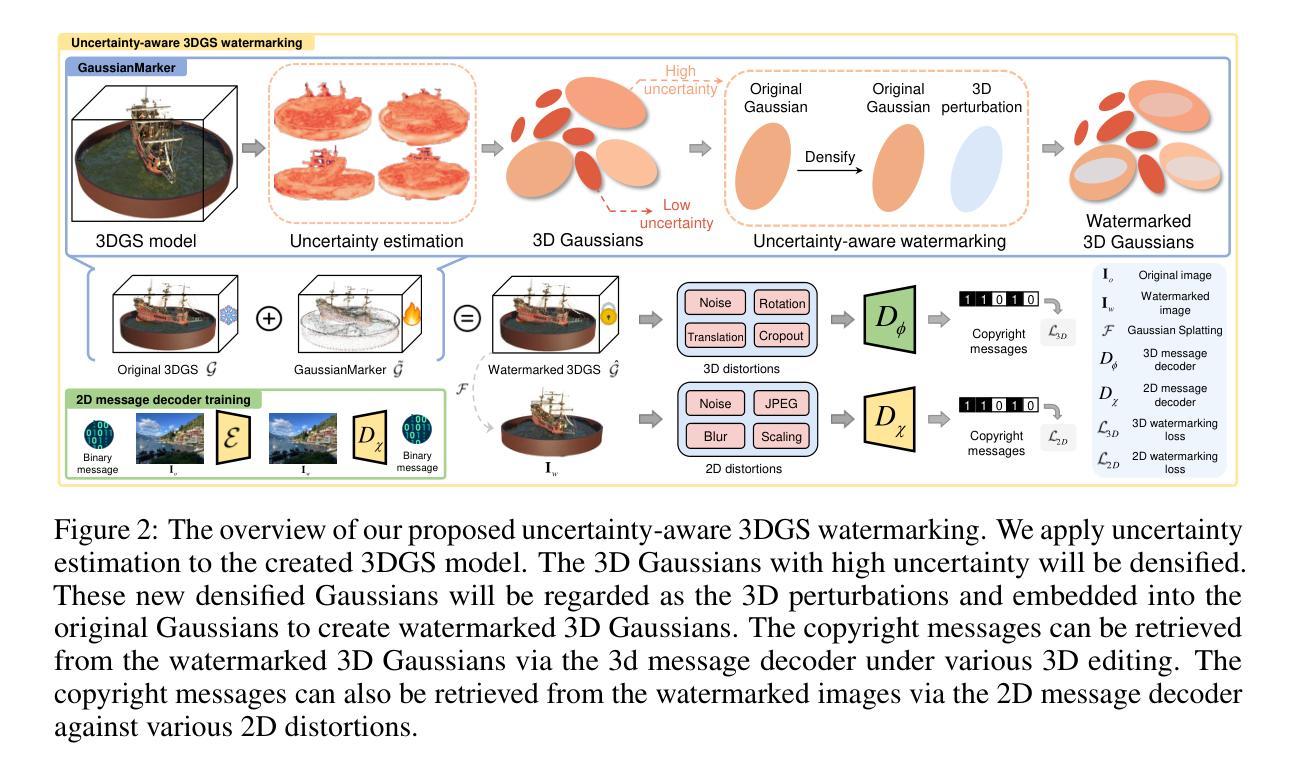

GS-Blur: A 3D Scene-Based Dataset for Realistic Image Deblurring
Authors:Dongwoo Lee, Joonkyu Park, Kyoung Mu Lee
To train a deblurring network, an appropriate dataset with paired blurry and sharp images is essential. Existing datasets collect blurry images either synthetically by aggregating consecutive sharp frames or using sophisticated camera systems to capture real blur. However, these methods offer limited diversity in blur types (blur trajectories) or require extensive human effort to reconstruct large-scale datasets, failing to fully reflect real-world blur scenarios. To address this, we propose GS-Blur, a dataset of synthesized realistic blurry images created using a novel approach. To this end, we first reconstruct 3D scenes from multi-view images using 3D Gaussian Splatting (3DGS), then render blurry images by moving the camera view along the randomly generated motion trajectories. By adopting various camera trajectories in reconstructing our GS-Blur, our dataset contains realistic and diverse types of blur, offering a large-scale dataset that generalizes well to real-world blur. Using GS-Blur with various deblurring methods, we demonstrate its ability to generalize effectively compared to previous synthetic or real blur datasets, showing significant improvements in deblurring performance.
PDF Accepted at NeurIPS 2024 Datasets & Benchmarks Track
Summary
利用3DGS技术合成真实模糊图像,提高去模糊网络训练效果。
Key Takeaways
- 去模糊网络训练需配对模糊和清晰图像数据集。
- 现有数据集合成模糊图像方式有限,缺乏多样性。
- 提出GS-Blur,使用3DGS重建场景合成模糊图像。
- 通过随机运动轨迹生成模糊图像,提高多样性。
- GS-Blur包含真实和多样化的模糊类型。
- GS-Blur适用于各种去模糊方法,提高性能。
- 与其他合成或真实模糊数据集相比,GS-Blur性能显著提升。
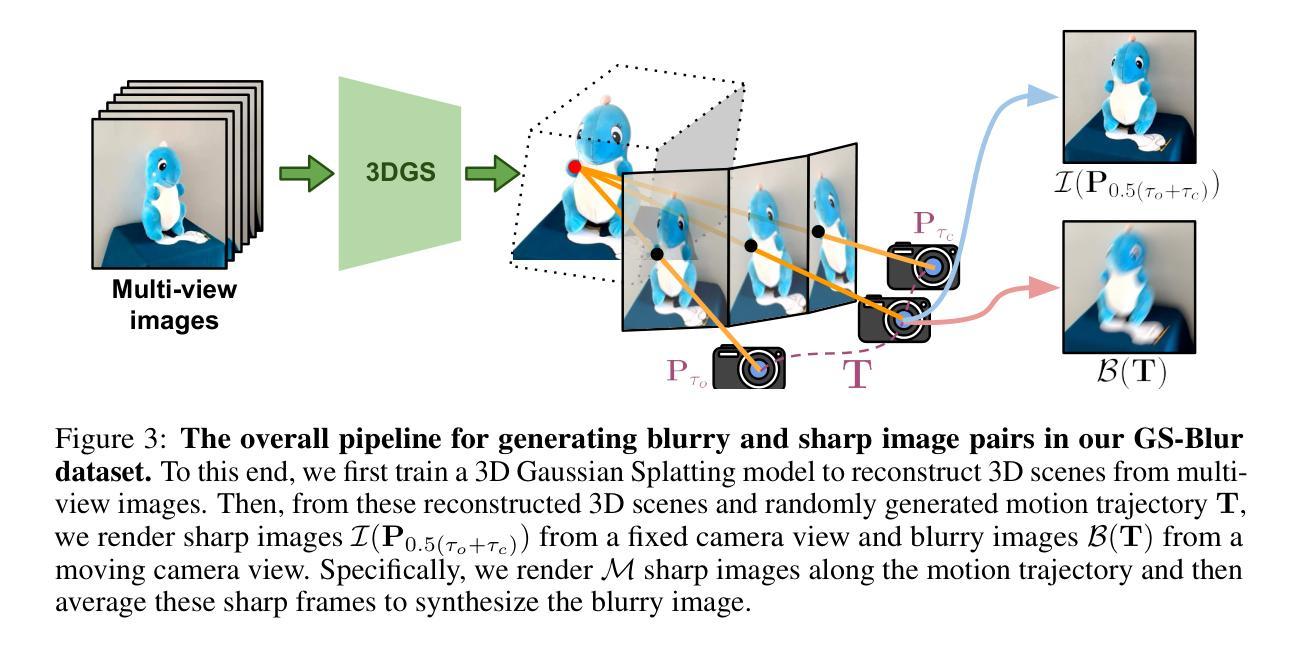
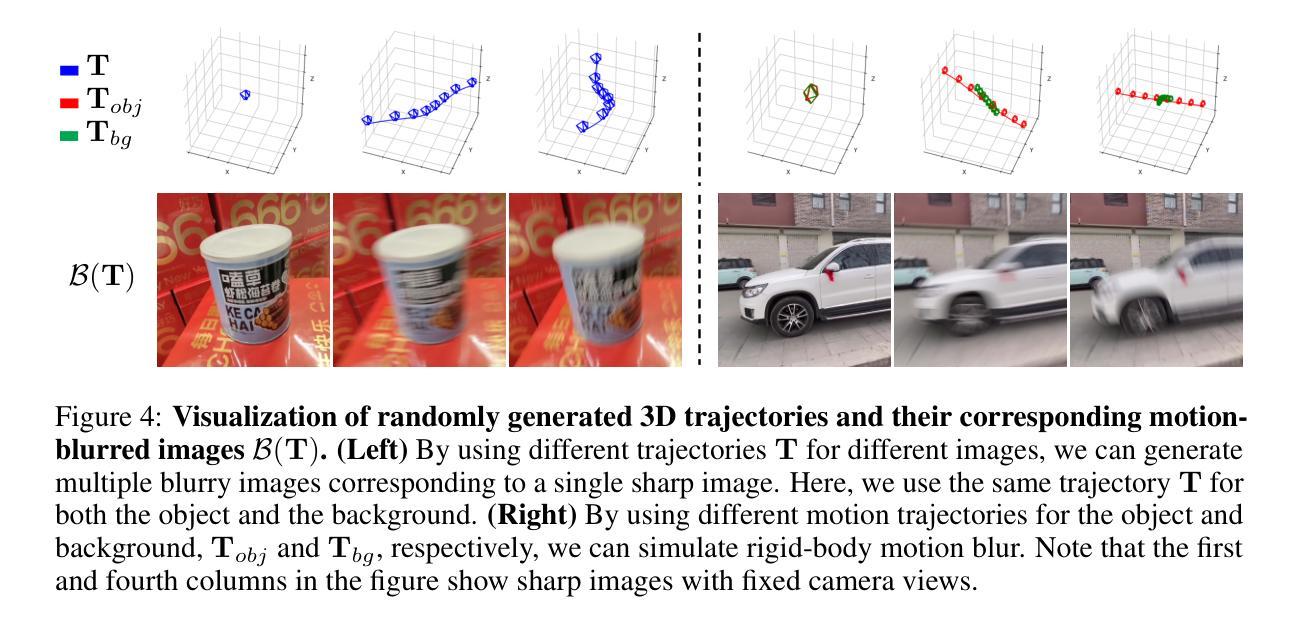
标题:GS-Blur:基于3D场景的真实图像去模糊数据集
作者:Dongwoo Lee(李东晤), Joonkyu Park(朴俊宇), Kyoung Mu Lee(李光穆)
作者所属机构:首尔国立大学电子工程和自动化控制系(Dept. of ECE&ASRI)及人工智能研究所(IPAI)。
关键词:图像去模糊、合成数据集、真实模糊、深度学习、场景重建、相机轨迹。
链接:论文链接(如果可用),GitHub代码链接:[GitHub仓库链接](如未提供则填写“None”)。
摘要:
- (1) 研究背景:
图像去模糊是计算机视觉中的一项重要任务,特别是从模糊的图像中恢复清晰的图像。为了训练去模糊网络,需要带有配对模糊和清晰图像的数据集。现有的数据集通过合成方法或真实相机拍摄得到,但存在类型单一或不反映真实世界模糊场景的缺点。
- **(2) 过去的方法与问题**:
现有方法主要依赖合成数据或真实拍摄数据来创建去模糊数据集。合成方法通常通过聚合连续锐利帧或利用高速相机生成模糊图像,但这种方式产生的模糊与真实场景不同。真实拍摄方法使用特殊相机系统,虽然能产生更真实的模糊,但设备复杂且难以构建大规模数据集。
- **方法动机**:
为了解决上述问题,本文提出了一种新的基于3D场景的数据集GS-Blur,旨在生成更真实、更多样的模糊图像。
- **(3) 研究方法**:
首先利用多视角图像重建3D场景,使用3D高斯喷绘技术(3DGS)。然后,通过模拟相机沿随机生成的轨迹移动来渲染模糊图像。由于采用了多种相机轨迹,GS-Blur数据集包含真实且多样化的模糊类型,能很好地泛化到真实世界的模糊场景。
- **(4) 任务与性能**:
在图像去模糊任务上,使用GS-Blur数据集与各种去模糊方法结合,证明了其有效性。与以往的合成或真实模糊数据集相比,GS-Blur显示出更好的泛化能力,在去模糊性能上有显著提高。
以上就是对该论文的简要总结,希望对您有所帮助。
7. 方法论介绍:
- (1) 研究背景与动机:针对现有图像去模糊数据集存在的问题,如类型单一、不能反映真实世界模糊场景等缺点,提出了一种新的基于3D场景的数据集GS-Blur,旨在生成更真实、更多样的模糊图像。
- (2) 数据集构建方法:首先利用多视角图像重建3D场景,采用3D高斯喷绘技术(3DGS)。然后,通过模拟相机沿随机生成的轨迹移动来渲染模糊图像。由于采用了多种相机轨迹,GS-Blur数据集包含真实且多样化的模糊类型,能很好地泛化到真实世界的模糊场景。
- (3) 数据集特点:GS-Blur数据集与各种去模糊方法结合,证明了其有效性。与以往的合成或真实模糊数据集相比,GS-Blur显示出更好的泛化能力,在去模糊性能上有显著提高。此外,GS-Blur数据集提供了更大的规模、各种曝光时间和分辨率,并且其运动轨迹分布与现实场景更为接近。
- (4) 技术创新点:本研究将3D场景重建技术与图像去模糊任务相结合,通过模拟相机运动轨迹生成逼真的模糊图像,为图像去模糊任务提供了更真实、更多样化的训练数据。同时,利用3DGaussianSplatting(3DGS)技术实现快速、高质量的场景重建和图像渲染,提高了数据集的生成效率和图像质量。
- (5) 数据集应用:GS-Blur数据集可用于训练各种图像去模糊算法,提高其在真实世界场景中的泛化能力和性能。此外,该数据集还可用于研究相机抖动、运动估计与跟踪等相关领域。
- Conclusion:
(1)这篇工作的意义在于提出了一种新的基于3D场景的去模糊数据集GS-Blur,该数据集旨在生成更真实、更多样的模糊图像,以解决现有去模糊数据集类型单一、不能反映真实世界模糊场景的问题。该数据集对于训练去模糊网络、提高算法在真实世界场景中的泛化能力和性能具有重要意义。
(2)创新点:本文结合了3D场景重建技术与图像去模糊任务,通过模拟相机运动轨迹生成逼真的模糊图像,为图像去模糊任务提供了更真实、更多样化的训练数据。此外,该研究采用了3DGaussianSplatting(3DGS)技术,提高了数据集的生成效率和图像质量。
性能:与以往的合成或真实模糊数据集相比,GS-Blur数据集在去模糊性能上显示出显著提高,并且具有很好的泛化能力。
工作量:该研究构建了大规模的去模糊数据集,涵盖了多种曝光时间和分辨率,并且其运动轨迹分布与现实场景更为接近。此外,数据集的应用范围广泛,可用于训练各种图像去模糊算法,并应用于相机抖动、运动估计与跟踪等相关领域的研究。
总之,该研究提出了一种创新的去模糊数据集构建方法,结合了3D场景重建技术,生成了更真实、更多样的模糊图像,为图像去模糊任务提供了更有效的训练数据,并展示了良好的性能和应用潜力。
点此查看论文截图



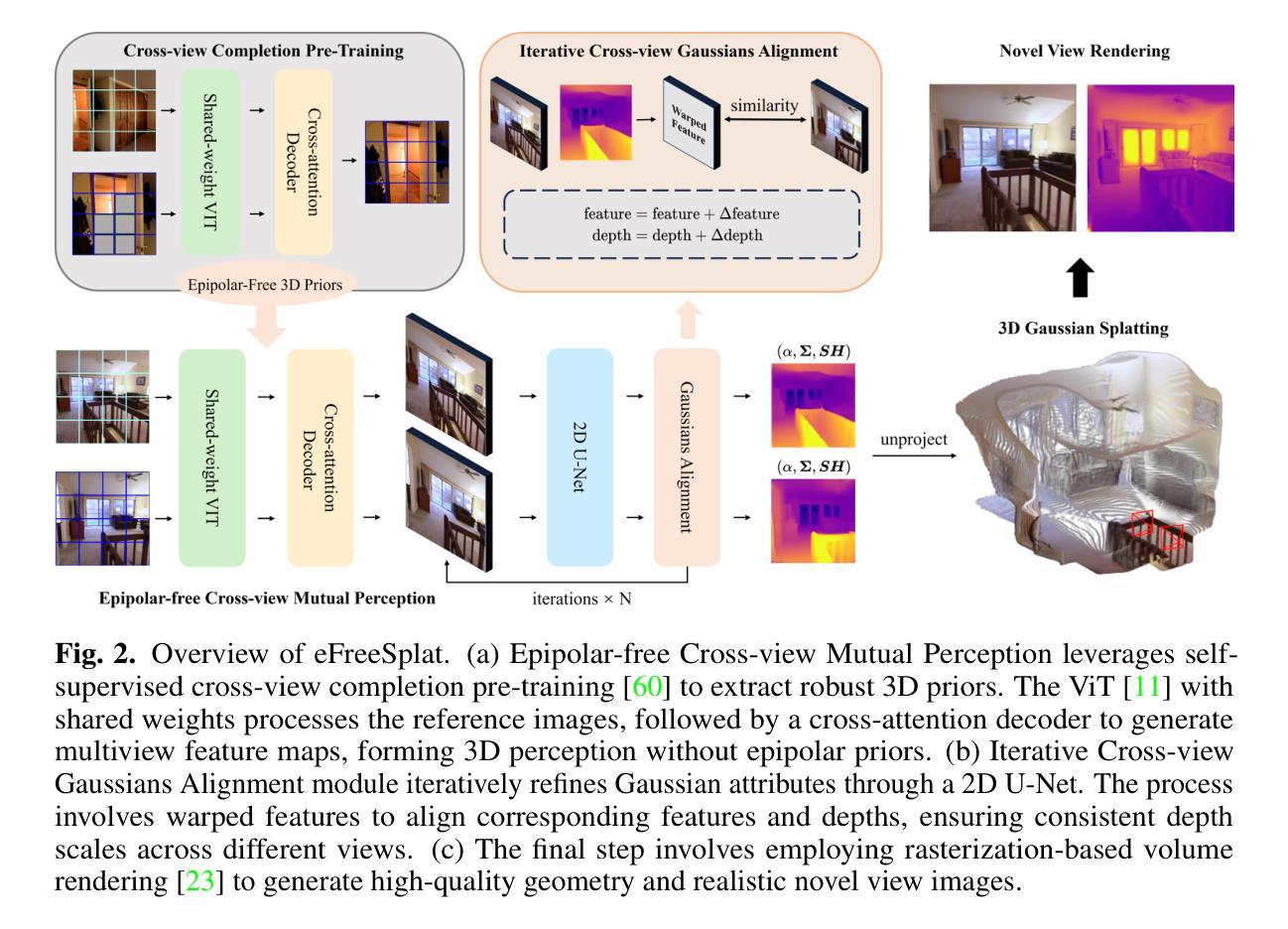
Epipolar-Free 3D Gaussian Splatting for Generalizable Novel View Synthesis
Authors:Zhiyuan Min, Yawei Luo, Jianwen Sun, Yi Yang
Generalizable 3D Gaussian splitting (3DGS) can reconstruct new scenes from sparse-view observations in a feed-forward inference manner, eliminating the need for scene-specific retraining required in conventional 3DGS. However, existing methods rely heavily on epipolar priors, which can be unreliable in complex realworld scenes, particularly in non-overlapping and occluded regions. In this paper, we propose eFreeSplat, an efficient feed-forward 3DGS-based model for generalizable novel view synthesis that operates independently of epipolar line constraints. To enhance multiview feature extraction with 3D perception, we employ a selfsupervised Vision Transformer (ViT) with cross-view completion pre-training on large-scale datasets. Additionally, we introduce an Iterative Cross-view Gaussians Alignment method to ensure consistent depth scales across different views. Our eFreeSplat represents an innovative approach for generalizable novel view synthesis. Different from the existing pure geometry-free methods, eFreeSplat focuses more on achieving epipolar-free feature matching and encoding by providing 3D priors through cross-view pretraining. We evaluate eFreeSplat on wide-baseline novel view synthesis tasks using the RealEstate10K and ACID datasets. Extensive experiments demonstrate that eFreeSplat surpasses state-of-the-art baselines that rely on epipolar priors, achieving superior geometry reconstruction and novel view synthesis quality. Project page: https://tatakai1.github.io/efreesplat/.
PDF NeurIPS 2024
Summary
3DGS模型eFreeSplat独立于视差线约束,实现高效新颖视图合成。
Key Takeaways
- 独立于视差线约束的3DGS模型。
- 自监督Vision Transformer用于多视图特征提取。
- 引入跨视图高斯对齐方法。
- 通过跨视图预训练提供3D先验。
- 在RealEstate10K和ACID数据集上测试。
- 超越依赖视差先验的现有方法。
- 实现了优越的几何重建和视图合成质量。
- 标题:
无Epipolar约束的3D高斯Splatting方法用于泛化新颖视图合成(Epipolar-Free 3D Gaussian Splatting for Generalizable Novel View Synthesis)
2. 作者:
作者包括Zhiyuan Min, Yawei Luo(对应作者), Jianwen Sun和Yi Yang。其中,Min和Luo来自浙江大学,Sun来自华中师范大学。
3. 所属机构:
浙江大学
4. 关键词:
3D高斯分裂(3DGS)、新颖视图合成(Novel View Synthesis)、Epipolar约束、自监督视觉转换器(Vision Transformer)、跨视图完成预训练、迭代跨视图高斯对齐(Iterative Cross-view Gaussians Alignment)等。
5. 链接:
论文链接:待提供(或根据官方发布的论文链接填写)
GitHub代码链接:GitHub: None(若无GitHub代码库,则填写“None”)
项目页面链接:https://tatakai1.github.io/efreesplat/ (根据文章中的信息提供)
会议链接:第38届神经网络信息处理系统会议(NeurIPS 2024)的相关论文页面。论文在arXiv上的编号是:arXiv:2410.22817v2 [cs.CV]。日期为:提交日期为2024年10月31日。
6. 总结:
(1) 研究背景:
当前研究关注于从稀疏视角观察中重建新场景的方法。传统的三维重建方法通常需要针对特定场景进行训练。现有的无Epipolar约束的方法虽可以脱离特定的几何结构假设,但在复杂真实场景中仍面临可靠性问题,特别是在非重叠或遮挡区域。因此,开发一种能够泛化到新颖场景且不受Epipolar约束限制的方法至关重要。
(2) 相关方法及其问题:
现有的新颖视图合成方法主要依赖于Epipolar先验信息。这些先验在真实世界复杂场景中可能不可靠,特别是在非重叠和遮挡区域,限制了方法的性能。同时,大多数现有方法难以有效结合跨视图的特征信息以实现高质量的视图合成。
文中提出的方法受到了充分的动机驱动,旨在解决上述问题。它旨在构建一个泛化的模型,能够在不使用Epipolar先验的情况下进行新颖视图合成。模型考虑了包括提高跨视图特征提取以及使用自我监督视觉转换器等因素。它不仅仅是一个纯粹的几何无关方法,而是通过提供三维先验来实现无Epipolar约束的特征匹配和编码。
(注:以上总结中的描述是基于文中提供的信息理解整理而成的)
(3) 研究方法论:
本研究提出了一种高效的基于前馈的三维高斯分裂模型(eFreeSplat),用于泛化新颖视图合成,摆脱了对Epipolar线约束的依赖。为了实现这一目标,作者引入了一个自我监督的Vision Transformer进行跨视图特征提取和完成预训练任务。此外,还提出了一种迭代跨视图高斯对齐方法来确保不同视角的深度尺度一致性。这种方法的优势在于它可以提供可靠的三维先验信息来匹配特征并生成高质量的新视角图像。
(注:具体的技术细节和方法论需要查阅原文以获取更全面的信息)
(注:关于模型的详细架构、算法流程等细节部分,请直接查阅原文描述)
(4) 任务与性能评估: 基于RealEstate10K和ACID数据集进行的实验证明,相比于依赖Epipolar先验的最新技术,所提出的eFreeSplat在几何重建和新颖视图合成质量方面表现出更高的性能。实验结果表明eFreeSplat在广泛基线的新颖视图合成任务上取得了显著的效果。实验数据支持其方法的性能表现和所宣称的目标相符。 (具体性能评估指标及数据集相关信息需查阅原文确认) 总体来说,本文提出的方法代表了无Epipolar约束的新颖视图合成领域的一个创新突破。它不仅解决了现有方法的局限性,而且通过引入新的技术和策略提高了泛化能力和性能表现。本研究为未来的相关研究提供了新的思路和方向。
7. 方法论:
(1) 研究目标:本研究旨在摆脱Epipolar约束,利用无Epipolar约束的3D高斯Splatting方法实现泛化新颖视图合成。即通过建立一个泛化的模型,使模型能够在不使用Epipolar先验的情况下进行新颖视图合成。模型主要考虑了提高跨视图特征提取和使用自我监督视觉转换器等因素。模型不仅是一个纯粹的几何无关方法,而且通过提供三维先验信息来实现无Epipolar约束的特征匹配和编码。同时研究设计了一种基于前馈的三维高斯分裂模型(eFreeSplat),以摆脱对Epipolar线约束的依赖。并且为了达到这一目标,研究引入了自我监督的Vision Transformer进行跨视图特征提取和完成预训练任务。此外,还提出了一种迭代跨视图高斯对齐方法来确保不同视角的深度尺度一致性。这种方法的优势在于它可以提供可靠的三维先验信息来匹配特征并生成高质量的新视角图像。该研究提出的模型主要解决的是当参考视图极度稀疏时,预测准确深度和重建高质量几何结构和外观变得特别具有挑战性的问题,特别是在非重叠和遮挡区域中普遍存在的问题。
(2) 数据预处理与模型输入:首先,利用共享权重的ViT模型和交叉注意力解码器处理参考图像,生成多视图特征图,形成无需Epipolar先验的三维感知。随后,使用迭代跨视图高斯对齐模块通过交叉视图特征匹配信息迭代更新每个像素的高斯属性,解决深度尺度不一致导致的局部几何不准确问题。最后,预测三维高斯原始的中心位置,并基于对齐的特征计算其他三维高斯参数。输入的图像通过ViT模型和交叉注意力解码器提取跨视图图像特征,这些特征用于后续的三维重建和视图合成。
(3) 模型架构与训练过程:模型主要由三部分组成:无Epolar约束的跨视图相互感知模块、迭代跨视图高斯对齐模块以及基于光栅化的体积渲染模块。其中无Epolar约束的跨视图相互感知模块通过利用大规模数据集上的跨视图完成自监督预训练,提供了稳健的三维先验信息;迭代跨视图高斯对齐模块则解决了不同视角深度尺度不一致的问题;最后基于光栅化的体积渲染模块生成高质量的新视角图像。模型的训练过程包括预训练阶段和微调阶段,预训练阶段在大型数据集上进行跨视图完成自监督预训练,获取稳健的三维先验信息,微调阶段则是在具体任务的数据集上进行微调,优化模型参数。
(4) 性能评估与优化:实验结果表明,相较于依赖Epipolar先验的最新技术,所提出的eFreeSplat在几何重建和新颖视图合成质量方面表现出更高的性能。具体来说,该方法在广泛基线的新颖视图合成任务上取得了显著的效果,并且实验数据支持其方法的性能表现和所宣称的目标相符。此外,该研究还通过引入新的技术和策略提高了模型的泛化能力和性能表现,为未来相关研究提供了新的思路和方向。
8. Conclusion:
(1) 研究意义:该研究旨在摆脱Epipolar约束,利用无Epipolar约束的3D高斯Splatting方法实现新颖视图合成的泛化,对于从稀疏视角观察重建新场景具有重要的研究意义。该研究解决了现有方法在复杂真实场景中面临的可靠性问题,特别是在非重叠或遮挡区域的挑战。此外,该研究还为未来的相关研究提供了新的思路和方向。
(2) 优缺点总结:
- 创新点:该研究提出了一种无Epipolar约束的3D高斯Splatting方法用于新颖视图合成,摆脱了Epipolar线约束的依赖。创新地引入了自我监督的Vision Transformer进行跨视图特征提取和完成预训练任务,提高了模型的泛化能力。
- 性能:基于RealEstate10K和ACID数据集的实验证明,该方法在几何重建和新颖视图合成质量方面表现出较高的性能,相比于依赖Epipolar先验的最新技术有显著的提升。
- 工作量:文章对方法的理论框架进行了详细的阐述,并通过实验验证了方法的性能。然而,关于模型的详细架构、算法流程等细节部分未做详细阐述,可能需要进一步查阅原文以获取更全面的信息。
总体而言,该文章在摆脱Epipolar约束的新颖视图合成领域取得了重要的突破,通过引入新的技术和策略提高了模型的泛化能力和性能表现。
点此查看论文截图