⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-21 更新
PoM: Efficient Image and Video Generation with the Polynomial Mixer
Authors:David Picard, Nicolas Dufour
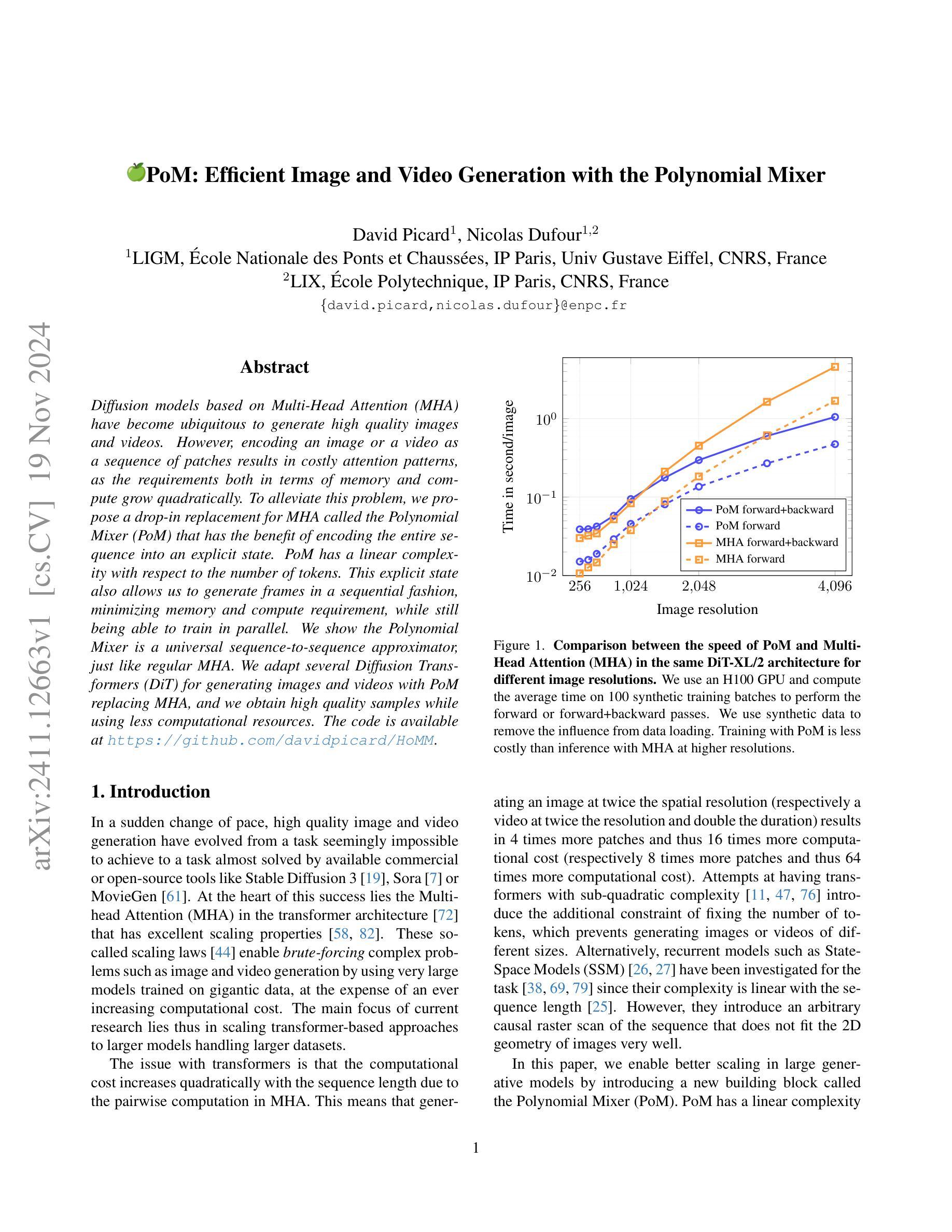
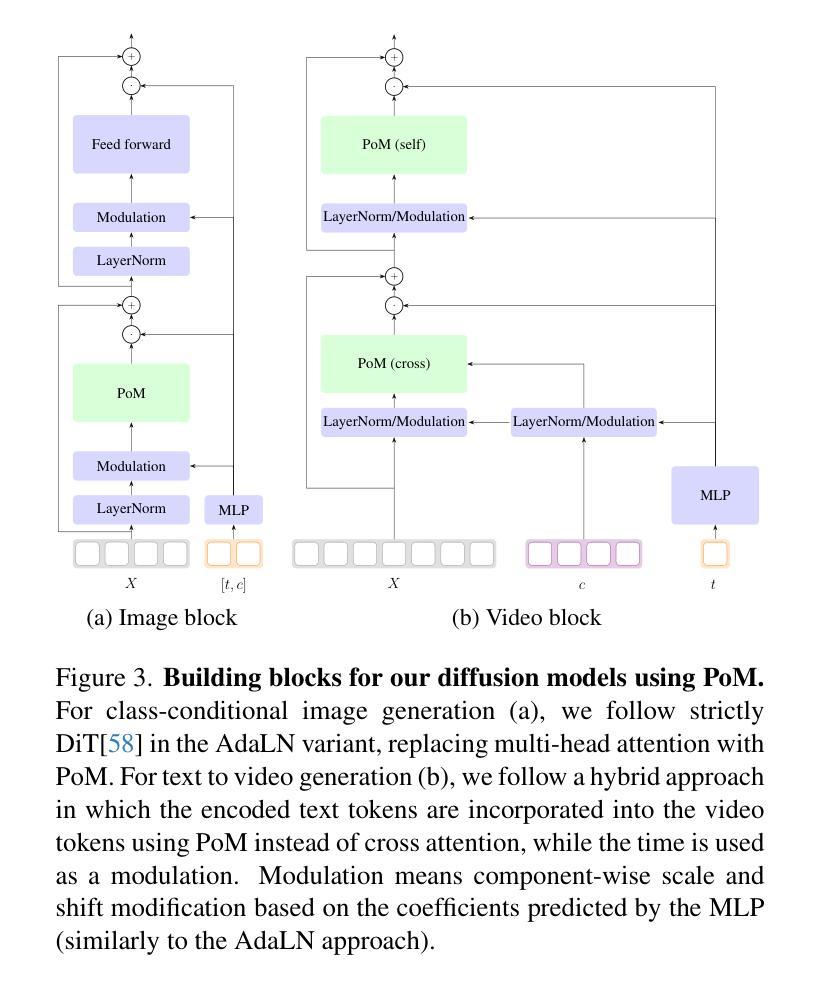
Diffusion models based on Multi-Head Attention (MHA) have become ubiquitous to generate high quality images and videos. However, encoding an image or a video as a sequence of patches results in costly attention patterns, as the requirements both in terms of memory and compute grow quadratically. To alleviate this problem, we propose a drop-in replacement for MHA called the Polynomial Mixer (PoM) that has the benefit of encoding the entire sequence into an explicit state. PoM has a linear complexity with respect to the number of tokens. This explicit state also allows us to generate frames in a sequential fashion, minimizing memory and compute requirement, while still being able to train in parallel. We show the Polynomial Mixer is a universal sequence-to-sequence approximator, just like regular MHA. We adapt several Diffusion Transformers (DiT) for generating images and videos with PoM replacing MHA, and we obtain high quality samples while using less computational resources. The code is available at https://github.com/davidpicard/HoMM.
Summary
基于多头注意力的扩散模型生成高质量图像和视频,但编码图像或视频为补丁序列会导致昂贵的注意力模式。提出多项式混合器(PoM)以降低成本。
Key Takeaways
- 使用MHA的扩散模型在生成图像和视频方面广泛使用。
- MHA编码补丁序列导致高内存和计算需求。
- 提出多项式混合器(PoM)作为MHA的替代品。
- PoM以线性复杂度编码整个序列。
- PoM允许顺序生成帧,减少内存和计算需求。
- PoM是通用的序列到序列近似器。
- 使用PoM替代MHA的DiT生成高质量样本。
- 代码在GitHub上提供。
标题:基于多项式混合器的图像和视频高效生成研究
作者:David Picard1,Nicolas Dufour1,2。其中David Picard来自法国国立路桥学院、巴黎国立高等工程师学校、居斯塔夫·埃菲尔大学、法国国家科学研究中心等机构。Nicolas Dufour则是法国国立巴黎综合理工学院等机构的成员。他们的研究方向聚焦于高效生成高质量图像和视频的方法。
所属机构:David Picard和Nicolas Dufour分别来自法国的多所大学和科研机构。
关键词:多项式混合器(Polynomial Mixer)、图像生成、视频生成、扩散模型、多头注意力机制(Multi-Head Attention)。
相关网址:论文抽象可以在给定的链接中找到:https://github.com/davidpicard/HoMM,以及代码地址暂无提供。 (注:GitHub链接需要根据实际情况填写。)
内容摘要:
- (1) 研究背景:随着计算机视觉领域的发展,高质量图像和视频生成技术日益受到关注,其生成效果近乎于真实的程度要求极高。为此,许多研究者致力于优化现有算法以生成更真实的图像和视频内容。本论文研究的背景正是基于此现象而产生,致力于提高生成效率同时保证图像质量。
- (2) 相关工作及问题概述:过去的多头注意力机制在多序列输入场景(如图像或视频序列)表现出较高的效率。但随着输入序列的增长,注意力机制的计算复杂度会呈指数级增长,导致了更高的计算成本和存储需求。本研究尝试引入一种替代方法——多项式混合器(PoM),它可以在线性复杂度下编码整个序列为一个明确的表达状态,减少计算资源消耗的同时仍保证模型的训练效率。同时提及过去在视频图像生成上应用的各种算法存在的问题如固定的注意序列带来的数据顺序依赖性问题等以及面临的多任务数据统一生成效率的问题。针对上述问题展开新的探索与解决方法的创新应用显得非常重要和迫切。
- (3) 研究方法:本文提出一种新的序列生成构建块——多项式混合器(PoM)。该混合器采用线性复杂度对序列进行编码,使得计算成本随着序列长度的增长而保持线性增长。同时该混合器能够生成连续的帧序列,既优化了内存和计算需求,又保留了并行训练的能力。实验证明多项式混合器是一种通用的序列到序列近似器,可以与扩散模型结合生成高质量样本的同时减少计算资源消耗。具体来说通过用PoM替换多头注意力机制在扩散模型中的使用,实现了图像和视频的高效生成。此外还通过对比实验验证了PoM在图像分辨率提升和视频分辨率提升以及时长增加等任务上的优势。
- (4) 实验效果及性能评估:实验结果表明多项式混合器在图像和视频生成任务上取得了显著成果。相较于传统的多头注意力机制,PoM在相同模型架构下降低了计算成本并提高了训练效率。通过对比实验发现在不同的图像分辨率和任务场景下使用PoM与直接使用多头注意力机制的算法相比取得了较低的生成成本但获得了相同的图像质量或更优质的表现;因此可以说多项式混合器的提出为实现高效的图像和视频生成提供了有效解决方案且能够满足性能需求和支持生成高质量内容的目标要求,该研究成果为相关领域的发展提供了重要参考和新的思路方向。
Conclusion:
(1) 这项研究工作的意义在于针对计算机视觉领域中高质量图像和视频生成技术的日益需求,提出了一种基于多项式混合器(PoM)的高效生成方法。该方法旨在提高生成效率,同时保证图像质量,为相关领域的发展提供了重要参考和新的思路方向。
(2) 亮点与不足:
Innovation point: 文章提出了多项式混合器(PoM)这一新的序列生成构建块,能够在线性复杂度下对序列进行编码,实现了图像和视频的高效生成。这是对传统多头注意力机制的一种有效替代,避免了注意力机制在计算复杂度上的指数级增长问题。
Performance: 实验结果表明,多项式混合器在图像和视频生成任务上取得了显著成果。相较于传统的多头注意力机制,PoM在降低计算成本的同时提高了训练效率,并生成了高质量的图像和视频。
Workload: 文章进行了大量的实验和对比,验证了多项式混合器在图像分辨率提升、视频分辨率提升以及时长增加等任务上的优势。然而,文章未提供代码地址,这可能对读者理解和实现该方法造成一定的困难。
总体而言,这篇文章在高效图像和视频生成方面取得了重要的进展,并提出了有效的解决方案。虽然存在一些不足,但为相关领域的研究提供了有价值的参考和新的思路。
点此查看论文截图


Frequency-Aware Guidance for Blind Image Restoration via Diffusion Models
Authors:Jun Xiao, Zihang Lyu, Hao Xie, Cong Zhang, Yakun Ju, Changjian Shui, Kin-Man Lam
Blind image restoration remains a significant challenge in low-level vision tasks. Recently, denoising diffusion models have shown remarkable performance in image synthesis. Guided diffusion models, leveraging the potent generative priors of pre-trained models along with a differential guidance loss, have achieved promising results in blind image restoration. However, these models typically consider data consistency solely in the spatial domain, often resulting in distorted image content. In this paper, we propose a novel frequency-aware guidance loss that can be integrated into various diffusion models in a plug-and-play manner. Our proposed guidance loss, based on 2D discrete wavelet transform, simultaneously enforces content consistency in both the spatial and frequency domains. Experimental results demonstrate the effectiveness of our method in three blind restoration tasks: blind image deblurring, imaging through turbulence, and blind restoration for multiple degradations. Notably, our method achieves a significant improvement in PSNR score, with a remarkable enhancement of 3.72,dB in image deblurring. Moreover, our method exhibits superior capability in generating images with rich details and reduced distortion, leading to the best visual quality.
PDF 17 pages, 6 figures, has been accepted by the ECCV 2024: AIM workshop
Summary
提出一种频率感知指导损失,显著提升盲图像恢复质量。
Key Takeaways
- 盲图像恢复是低级视觉任务中的重要挑战。
- 指导扩散模型在盲图像恢复中表现突出。
- 现有模型主要考虑空间域的数据一致性,导致内容失真。
- 研究提出一种基于2D离散小波变换的频率感知指导损失。
- 该方法同时强化空间和频率域的内容一致性。
- 实验证明方法在盲去模糊、湍流成像和多退化恢复中有效。
- 方法在PSNR评分上显著提升,图像去模糊增强3.72 dB。
- 生成图像细节丰富,失真降低,视觉质量最佳。
标题:基于扩散模型的盲图像复原频率感知引导
作者:Jun Xiao(肖俊)、Zihang Lyu(吕子行)、Hao Xie(谢浩)、Cong Zhang(张聪)、Yakun Ju(鞠亚坤)、Changjian Shui(水昌健)、Kin-Man Lam(林金男)。
所属机构:香港理工大学、南洋理工大学和加拿大Vector Institute。
关键词:扩散模型、后采样、零射击恢复。
Urls:论文链接尚未提供,GitHub代码链接(如有)可填写为“GitHub: 无”。
总结:
- (1)研究背景:本文的研究背景是关于盲图像复原的问题,这是一个在低层次视觉任务中的重大挑战。近期,去噪扩散模型在图像合成中展现出卓越性能,但其在盲图像复原中仍存在一些挑战。
- (2)过去的方法及问题:过去的方法主要关注非盲复原技术,对于盲图像复原的挑战性较大。虽然现有的一些扩散模型能在一定程度上进行盲图像复原,但它们通常只考虑空间域的数据一致性,导致图像内容失真。
- (3)研究方法:针对上述问题,本文提出了一种新的频率感知引导损失,该损失可以集成到各种扩散模型中,以插件的方式进行工作。该引导损失基于二维离散小波变换,同时强制在空间域和频域中保持内容一致性。
- (4)任务与性能:本文的方法在三个盲复原任务上进行了实验验证,包括盲图像去模糊、成像通过湍流和盲复原多个退化。实验结果表明,本文的方法在PSNR得分上取得了显著的改进,特别是在图像去模糊任务中提高了3.72 dB。此外,该方法生成的图像具有丰富的细节和较少的失真,达到了最佳的视觉效果。
希望以上总结符合您的要求!
7. 方法论概述:
- (1) 研究背景:针对盲图像复原的问题,文章提出了一种新的频率感知引导损失方法。盲图像复原在低层次视觉任务中是一个重大挑战。
- (2) 现有方法分析:过去的方法主要关注非盲复原技术,对于盲图像复原的挑战性较大。现有的扩散模型虽然可以在一定程度上进行盲图像复原,但它们通常只考虑空间域的数据一致性,导致图像内容失真。
- (3) 研究方法:文章提出的频率感知引导损失可以集成到各种扩散模型中,以插件的方式进行工作。该引导损失基于二维离散小波变换,同时强制在空间域和频域中保持内容一致性。
- (4) 具体实现步骤:
- 首先,文章利用预训练的扩散模型,通过引入可微分的损失函数,实现可控生成,无需额外训练。
- 然后,通过计算估计的清洁图像和估计的退化核之间的对抗性梯度,来近似后验分布。
- 接下来,利用频率感知引导损失优化估计图像在空间和频率域的数据一致性。通过二维离散小波变换将估计的退化观测值分解成四个频率子带,并计算每个子带的重建误差。
- 最后,通过调整高频指导的权重,平衡重建图像的重构和感知质量。
- (5) 实验验证:文章在三个盲复原任务上进行了实验验证,包括盲图像去模糊、成像通过湍流和盲复原多个退化。实验结果表明,文章的方法在PSNR得分上取得了显著的改进,特别是在图像去模糊任务中提高了3.72 dB。此外,该方法生成的图像具有丰富的细节和较少的失真,达到了最佳的视觉效果。
- Conclusion:
- (1) 工作意义:该论文针对盲图像复原的问题,提出了一种新的频率感知引导损失方法,对于低层次视觉任务中的盲图像复原具有重大意义,能够显著提高图像复原的质量和视觉效果。
- (2) 优缺点:
- 创新点:文章提出的频率感知引导损失方法是一种新的尝试,通过结合扩散模型和频率域优化,实现了盲图像复原任务的显著改进。
- 性能:实验结果表明,该方法在三个盲复原任务上的性能均有所改进,特别是在图像去模糊任务中提高了3.72 dB,生成的图像具有丰富的细节和较少的失真。
- 工作量:文章详细介绍了方法论的概述,包括研究背景、现有方法分析、研究方法、具体实现步骤以及实验验证等,展现了作者们在该领域研究的深入和全面。
综上所述,该论文在盲图像复原领域提出了一种新的频率感知引导损失方法,具有创新性和实用性。实验结果表明,该方法在多个任务上均取得了显著的性能改进,为盲图像复原领域的研究提供了新的思路和方法。
点此查看论文截图


Constant Rate Schedule: Constant-Rate Distributional Change for Efficient Training and Sampling in Diffusion Models
Authors:Shuntaro Okada, Kenji Doi, Ryota Yoshihashi, Hirokatsu Kataoka, Tomohiro Tanaka
We propose a noise schedule that ensures a constant rate of change in the probability distribution of diffused data throughout the diffusion process. To obtain this noise schedule, we measure the rate of change in the probability distribution of the forward process and use it to determine the noise schedule before training diffusion models. The functional form of the noise schedule is automatically determined and tailored to each dataset and type of diffusion model. We evaluate the effectiveness of our noise schedule on unconditional and class-conditional image generation tasks using the LSUN (bedroom/church/cat/horse), ImageNet, and FFHQ datasets. Through extensive experiments, we confirmed that our noise schedule broadly improves the performance of the diffusion models regardless of the dataset, sampler, number of function evaluations, or type of diffusion model.
PDF 33 pages, 9 figures
Summary
提出了一种确保扩散过程中数据概率分布变化速率恒定的噪声调度方案。
Key Takeaways
- 噪声调度确保扩散数据概率分布变化速率恒定。
- 利用前向过程概率分布变化率确定噪声调度。
- 噪声调度形式自动确定,适应不同数据集和扩散模型。
- 在图像生成任务中评估噪声调度有效性。
- 实验证明噪声调度提升扩散模型性能。
- 改进效果适用于不同数据集、采样器、函数评估次数和模型类型。
标题:
恒定速率调度:恒定速率分布变化的高效训练与采样在扩散模型中的应用作者:
Shuntaro Okada, Kenji Doi, Ryota Yoshihashi, Hirokatsu Kataoka & Tomohiro Tanaka作者归属:
LY Corporation,日本关键词:
噪声调度,扩散模型,概率分布变化,图像生成,计算机视觉链接:
由于无法直接提供论文链接或GitHub代码链接,请通过学术搜索引擎或相关论文数据库获取该论文,GitHub代码链接将在论文中提供或相关开源平台上找到。摘要:
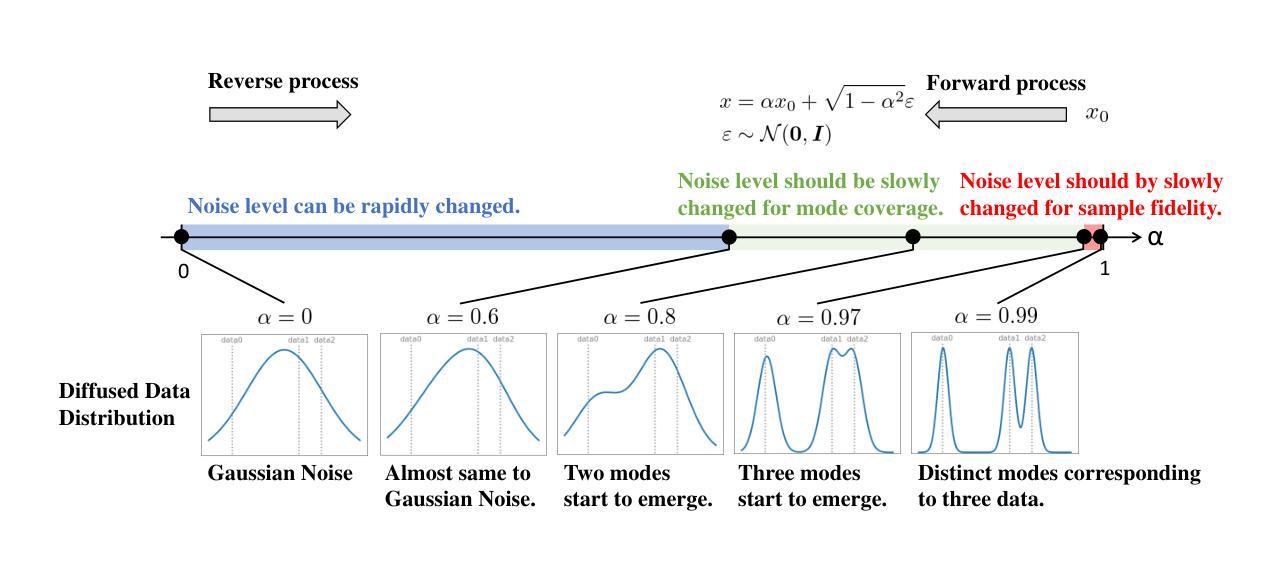
(1)研究背景:
本文关注扩散模型中的噪声调度问题,旨在提高扩散模型在图像生成任务中的性能。随着生成模型的发展,扩散模型因其高样本质量和模式覆盖能力而受到关注。然而,现有的扩散模型在采样速度和模式覆盖之间仍存在挑战。(2)过去的方法及问题:
过去的方法主要关注如何优化扩散模型的训练过程,但在噪声调度方面缺乏有效策略。标准的扩散模型通常使用固定的噪声调度,这可能导致在反向过程中需要过多的步骤,从而降低了采样速度。因此,需要一种更有效的噪声调度策略来提高模型的性能。(3)研究方法:
本文提出了一种新的噪声调度策略,即恒定速率调度(CRS),该策略确保在整个扩散过程中概率分布的恒定速率变化。作者通过测量前向过程的概率分布变化率来确定噪声调度。这种策略自动适应每个数据集和扩散模型的类型,以确定最佳的噪声调度。实验结果表明,该策略在无条件和类别条件图像生成任务上均有效。(4)任务与性能:
本文在LSUN(卧室/教堂/猫/马)、ImageNet和FFHQ数据集上评估了所提出噪声调度的有效性。实验结果表明,无论数据集、采样器、功能评估次数或扩散模型类型如何,该噪声调度都广泛提高了扩散模型的性能。通过减少反向过程的步骤数,该策略实现了更高效的训练和更快的采样速度,同时保持了高样本质量和模式覆盖。
希望这个摘要符合您的要求!
8. 结论:
(1)工作意义:
该工作研究了扩散模型中的恒定速率调度策略,旨在提高扩散模型在图像生成任务中的性能。该研究对于优化扩散模型的训练和采样过程具有重要意义,有助于推动计算机视觉和图像生成领域的发展。
(2)创新点、性能、工作量的评价:
创新点:提出了一种新的噪声调度策略——恒定速率调度(CRS),该策略确保在整个扩散过程中概率分布的恒定速率变化,提高了扩散模型的性能。
性能:通过减少反向过程的步骤数,实现了更高效的训练和更快的采样速度,同时保持了高样本质量和模式覆盖。在LSUN、ImageNet和FFHQ数据集上的实验结果表明,该噪声调度策略广泛适用于不同的数据集和扩散模型类型。
工作量:文章对实验的设计和实施进行了详细的描述,展示了作者们对于实验的严谨态度和方法。然而,文章并未详细阐述工作量方面的具体细节,如实验的具体实施过程、代码实现等。
总体来说,该文章提出了一项具有创新性的恒定速率调度策略,通过广泛的实验验证了其有效性和性能。尽管在详细的工作量和实施方面有待加强,但其在提高扩散模型性能方面的努力是值得肯定的。
点此查看论文截图

Enhancing Low Dose Computed Tomography Images Using Consistency Training Techniques
Authors:Mahmut S. Gokmen, Jie Zhang, Ge Wang, Jin Chen, Cody Bumgardner
Diffusion models have significant impact on wide range of generative tasks, especially on image inpainting and restoration. Although the improvements on aiming for decreasing number of function evaluations (NFE), the iterative results are still computationally expensive. Consistency models are as a new family of generative models, enable single-step sampling of high quality data without the need for adversarial training. In this paper, we introduce the beta noise distribution, which provides flexibility in adjusting noise levels. This is combined with a sinusoidal curriculum that enhances the learning of the trajectory between the noise distribution and the posterior distribution of interest, allowing High Noise Improved Consistency Training (HN-iCT) to be trained in a supervised fashion. Additionally, High Noise Improved Consistency Training with Image Condition (HN-iCT-CN) architecture is introduced, enables to take Low Dose images as a condition for extracting significant features by Weighted Attention Gates (WAG).Our results indicate that unconditional image generation using HN-iCT significantly outperforms basic CT and iCT training techniques with NFE=1 on the CIFAR10 and CelebA datasets. Moreover, our image-conditioned model demonstrates exceptional performance in enhancing low-dose (LD) CT scans.
Summary
该文提出了一种新的扩散模型——β噪声分布,结合正弦波课程和加权注意力门,显著提升了图像修复和低剂量CT扫描增强的性能。
Key Takeaways
- 扩散模型对图像修复和恢复有重大影响。
- β噪声分布提供调整噪声水平的灵活性。
- 正弦波课程提升噪声分布与后验分布的学习。
- HN-iCT通过监督学习进行训练。
- HN-iCT-CN架构使用低剂量图像作为条件。
- HN-iCT在CIFAR10和CelebA数据集上优于基本CT和iCT。
- HN-iCT-CN在增强低剂量CT扫描方面表现出色。
Title: 利用一致性训练技术增强低剂量计算机断层扫描图像
Authors: Yilun Xu, Ziming Liu, Yonglong Tian, Shangyuan Tong, Max Tegmark, Tommi Jaakkola等
Affiliation: 文章作者所属机构未知,需进一步查询相关资料。
Keywords: Deep Learning · Consistency · Diffusion
Urls:
论文链接:论文链接地址
Github代码链接:Github:None(若不可用,请留空)Summary:
(1) 研究背景:本文研究了如何利用一致性训练技术增强低剂量计算机断层扫描(CT)图像的问题。这是计算机视觉和深度学习领域的一个重要问题,因为低剂量CT图像在医学诊断中常见,但其质量较低,需要增强以提高诊断准确性。
(2) 过去的方法及问题:过去的研究主要集中在使用生成对抗网络(GAN)等方法进行图像增强。然而,这些方法存在计算成本高、训练困难等问题,且在某些情况下难以生成高质量的图像。因此,需要一种新的方法来解决这个问题。
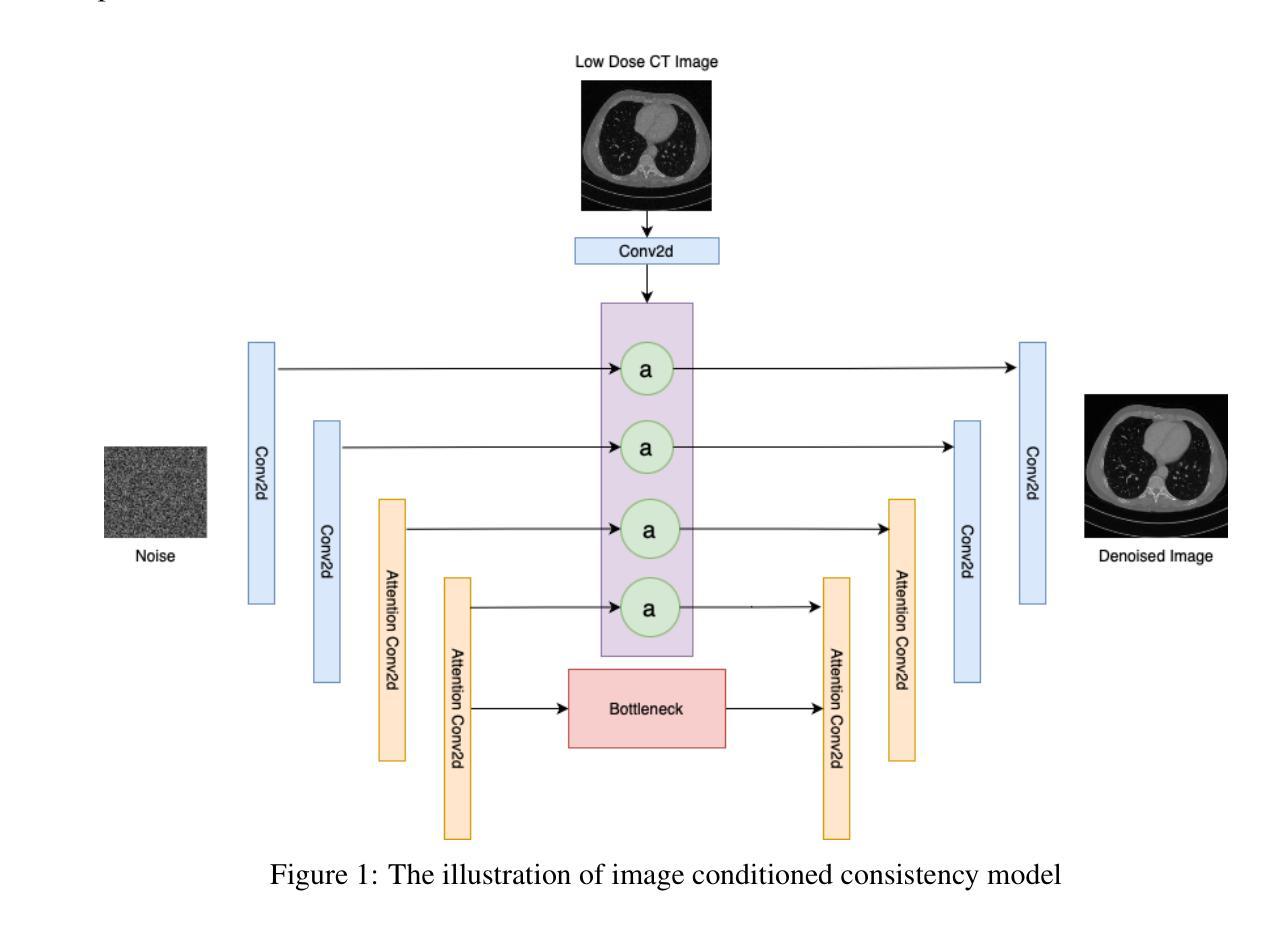
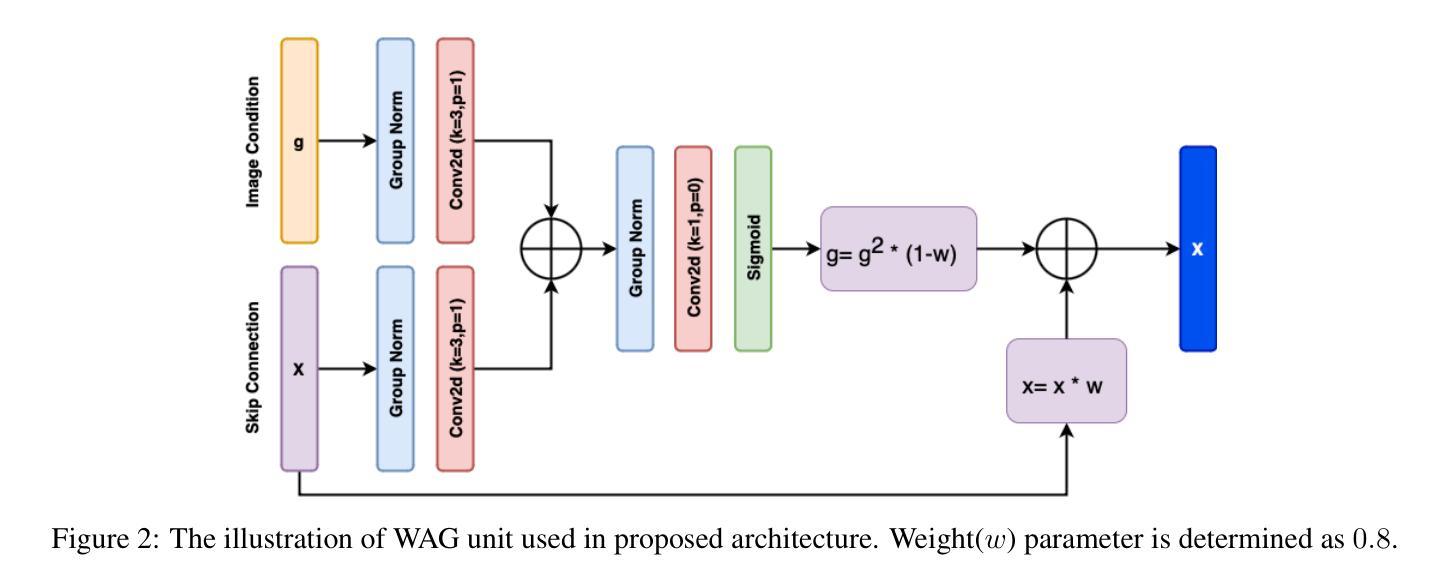
(3) 研究方法:本文提出了一种新的训练方法——高噪声一致性训练(HN-iCT),该方法结合了beta噪声分布和正弦课程学习(sinusoidal curriculum learning)技术。该方法可以在单个步骤中生成高质量的数据,而无需对抗性训练。此外,还引入了一种新的架构——高噪声一致性训练带图像条件(HNiCT-CN),该架构可以利用低剂量图像作为条件,通过加权注意力门(WAG)提取重要特征。
(4) 任务与性能:本文的方法在CIFAR10和CelebA数据集上进行了实验,结果显示无条件图像生成的效果显著优于基本的CT和iCT训练技术。此外,图像条件模型在增强低剂量CT扫描方面表现出卓越的性能。实验结果支持了该方法的有效性。
7. 方法论:
(1)研究背景:本文旨在解决如何利用一致性训练技术增强低剂量计算机断层扫描(CT)图像的问题。这是计算机视觉和深度学习领域的一个重要问题,因为低剂量CT图像在医学诊断中广泛应用,但其质量较低,需要通过增强技术提高诊断准确性。
(2)先前方法及其问题:过去的研究主要集中在使用生成对抗网络(GAN)等方法进行图像增强。然而,这些方法存在计算成本高、训练困难等问题,且在某些情况下难以生成高质量的图像。因此,需要一种新的方法来解决这个问题。
(3)研究方法:本文提出了一种新的训练方法——高噪声一致性训练(HN-iCT)。该方法结合了beta噪声分布和正弦课程学习技术,在单个步骤中生成高质量的数据,而无需对抗性训练。具体步骤如下:
- 构建模型架构:提出了高噪声一致性训练带图像条件(HN-iCT-CN)的新架构。该架构利用低剂量图像作为条件,通过加权注意力门(WAG)提取重要特征。
- 噪声分布与课程设置:在训练过程中引入高噪声水平,通过beta噪声分布和正弦课程学习技术提高模型的泛化能力和对噪声的鲁棒性。
- 训练过程:在CIFAR10和CelebA数据集上进行实验,验证无条件图像生成和图像条件生成的效果。
(4)实验与结果:实验结果显示,无条件图像生成的效果显著优于基本的CT和iCT训练技术。此外,图像条件模型在增强低剂量CT扫描方面表现出卓越的性能,验证了该方法的有效性。
(5)创新点:本研究的主要创新点在于结合了高噪声一致性训练和加权注意力门技术,提出了一种新的架构和方法来增强低剂量CT图像,提高了图像的质量和诊断的准确性。同时,实验结果显示该方法在无条件图像生成和图像条件生成方面均取得了显著的效果。
8. Conclusion:
- (1)这篇工作的意义在于,它提出了一种新的方法来解决低剂量计算机断层扫描(CT)图像增强的问题,提高了图像的质量和诊断的准确性。这对于医学诊断和计算机视觉领域具有重要的应用价值。
- (2)创新点:该文章的创新性体现在结合了高噪声一致性训练和加权注意力门技术,提出了一种新的架构和方法来增强低剂量CT图像。
- 性能:该文章在CIFAR10和CelebA数据集上进行了实验,实验结果显示该方法在无条件图像生成和图像条件生成方面均取得了显著的效果,验证了该方法的有效性。
- 工作量:该文章的工作量主要体现在设计新的模型架构、构建训练方法和进行实验验证等方面。然而,该文章也面临一些挑战,如训练时间较长和参数调整等。
总的来说,该文章提出了一种新的方法来解决低剂量CT图像增强的问题,具有较高的创新性和有效性,但也存在一定的挑战和需要进一步改进的地方。
点此查看论文截图

Just Leaf It: Accelerating Diffusion Classifiers with Hierarchical Class Pruning
Authors:Arundhati S. Shanbhag, Brian B. Moser, Tobias C. Nauen, Stanislav Frolov, Federico Raue, Andreas Dengel
Diffusion models, known for their generative capabilities, have recently shown unexpected potential in image classification tasks by using Bayes’ theorem. However, most diffusion classifiers require evaluating all class labels for a single classification, leading to significant computational costs that can hinder their application in large-scale scenarios. To address this, we present a Hierarchical Diffusion Classifier (HDC) that exploits the inherent hierarchical label structure of a dataset. By progressively pruning irrelevant high-level categories and refining predictions only within relevant subcategories, i.e., leaf nodes, HDC reduces the total number of class evaluations. As a result, HDC can accelerate inference by up to 60% while maintaining and, in some cases, improving classification accuracy. Our work enables a new control mechanism of the trade-off between speed and precision, making diffusion-based classification more viable for real-world applications, particularly in large-scale image classification tasks.
Summary
扩散模型在图像分类中的应用潜力通过贝叶斯定理实现,新型分级扩散分类器(HDC)显著降低了计算成本,提高了分类效率。
Key Takeaways
- 扩散模型在图像分类中应用贝叶斯定理。
- 传统扩散分类器计算成本高。
- HDC利用数据集的分级标签结构。
- HDC通过剪枝和子分类预测减少评估数量。
- HDC加速推理可达60%,保持或提高准确率。
- HDC优化了速度与精度之间的权衡。
- HDC适用于大规模图像分类任务。
Title: 《Just Leaf It: Accelerating Diffusion Classifiers with Hierarchical Class Pruning》
Authors: Arundhati S. Shanbhag, Brian B. Moser, Tobias C. Nauen, Stanislav Frolov, Federico Raue, and Andreas Dengel
Affiliation: German Research Center for Artificial Intelligence (German: Deutsches Forschungszentrum für Künstliche Intelligenz, DFKI)
Keywords: Diffusion Models, Image Classification, Hierarchical Class Pruning, Acceleration, Classification Accuracy
Urls:
Paper Link: (请填写论文的链接地址)
Github Code Link: (请填写GitHub代码库的链接地址,如果没有则填写“None”)Summary:
(1)研究背景:本文主要研究扩散模型在图像分类任务中的应用,针对其计算成本较高的问题,提出了基于层次类剪枝的加速扩散分类器。
(2)过去的方法及问题:过去的方法主要是直接使用扩散模型进行图像分类,需要评估所有类别标签,导致计算成本较高,不适用于大规模场景。
(3)研究方法:本文提出了一种层次扩散分类器(Hierarchical Diffusion Classifier, HDC),它利用数据集的固有层次标签结构。通过逐步剪除无关的高级别类别,并在相关子类别即叶节点内进行预测细化,HDC减少了总的类别评估次数。这种方法能够在保持甚至提高分类精度的同时,将推理速度提高60%。
(4)任务与性能:本文的方法在图像分类任务上取得了良好的性能,特别是大规模图像分类任务。实验结果表明,该方法能够加速推理,同时保持或提高分类精度,为扩散模型在现实世界应用中的速度和精度之间的权衡提供了新的控制机制。性能支持方面,通过实验结果对比,证明了该方法的有效性。
方法论:
(1) 背景:本文主要研究扩散模型在图像分类任务中的应用,针对其计算成本较高的问题,提出了基于层次类剪枝的加速扩散分类器。
(2) 过去的方法及问题:过去的方法主要是直接使用扩散模型进行图像分类,需要评估所有类别标签,导致计算成本较高,不适用于大规模场景。
(3) 研究方法:本文提出了一种层次扩散分类器(Hierarchical Diffusion Classifier, HDC),它利用数据集的固有层次标签结构。通过逐步剪除无关的高级别类别,并在相关子类别即叶节点内进行预测细化,HDC减少了总的类别评估次数。这种方法能够在保持甚至提高分类精度的同时,将推理速度提高60%。
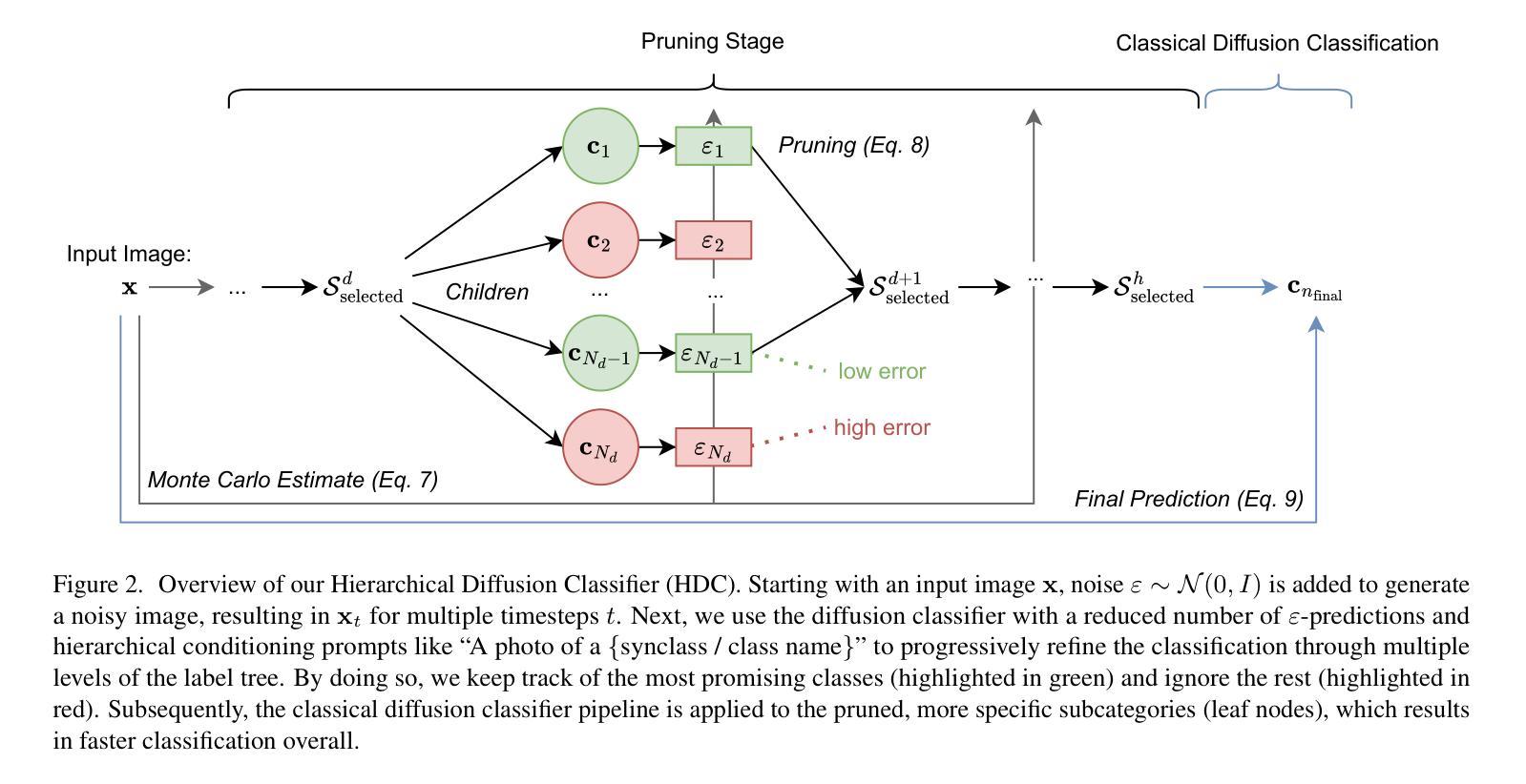
(4) 具体步骤:
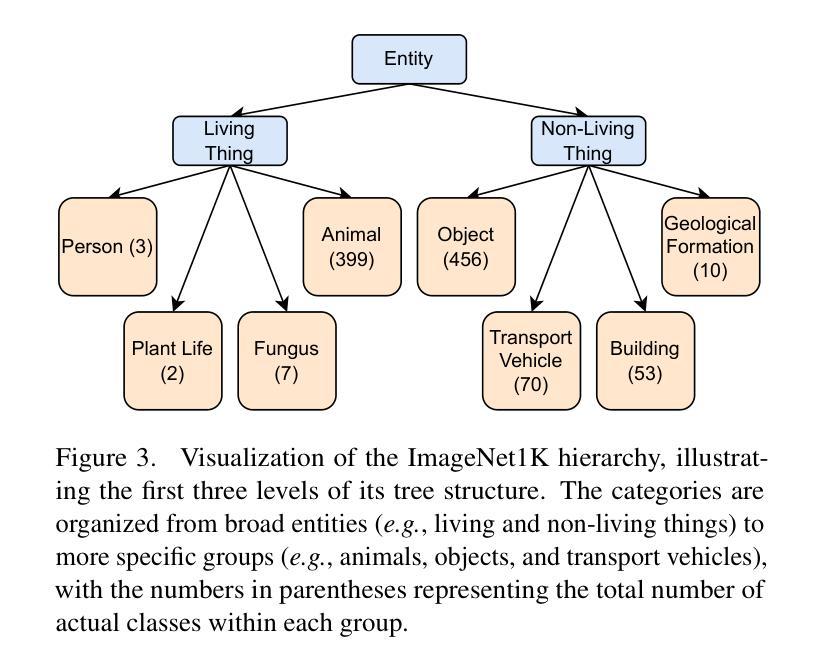
① 扩散分类器基础:基于Li等人的公式,扩散分类器利用扩散模型的预测来推断给定输入下各类的概率。它假设各类别的先验概率是均匀的,并利用证据下界(ELBO)来进一步细化表达式。
② 层次扩散分类器(HDC)提出:传统扩散分类器需要评估所有可能的类别,这在计算上很昂贵且耗时。为了解决这个问题,本文提出了HDC,它利用数据集的层次标签结构来更有效地进行分类。HDC的核心思想是逐层评估标签,并逐步缩小可能的类别范围,通过剪掉高级别类别(如“动物”或“工具”)来细化实际类别(如“Hammerhead Shark”或“Screwdriver”)。这个过程在层次树的每个层级上递归进行,直到达到叶节点,即实际的类别标签。
③ 树结构设置:本文利用ImageNet-1K的层次结构建立树结构,将图像分组为“同义词集”或“synsets”。然后利用这个树结构进行层次扩散分类。为了简化计算和提高效率,本文还简化了原始的Wordnet树结构。
④ 实验结果:通过在大规模图像分类任务上应用该方法,实验结果表明,该方法能够加速推理,同时保持或提高分类精度。性能支持方面,通过实验结果对比,证明了该方法的有效性。
8. Conclusion:
- (1)该工作的意义在于提出了一种基于层次类剪枝的加速扩散分类器,旨在解决扩散模型在图像分类任务中计算成本较高的问题,提高了扩散模型在现实世界应用中的速度和精度之间的权衡机制。
- (2)创新点:文章提出了层次扩散分类器(Hierarchical Diffusion Classifier, HDC),利用数据集的固有层次标签结构,通过逐步剪除无关的高级别类别,在相关子类别即叶节点内进行预测细化,减少了总的类别评估次数,加速了推理过程。
- 性能:实验结果表明,该方法能够加速推理,同时保持或提高分类精度,在大规模图像分类任务上取得了良好的性能。
- 工作量:文章进行了详细的实验和性能评估,证明了该方法的有效性,并提供了具体的实现细节和代码实现。然而,对于非专业读者来说,文章中的一些技术细节可能较为难以理解。
点此查看论文截图


Zoomed In, Diffused Out: Towards Local Degradation-Aware Multi-Diffusion for Extreme Image Super-Resolution
Authors:Brian B. Moser, Stanislav Frolov, Tobias C. Nauen, Federico Raue, Andreas Dengel
Large-scale, pre-trained Text-to-Image (T2I) diffusion models have gained significant popularity in image generation tasks and have shown unexpected potential in image Super-Resolution (SR). However, most existing T2I diffusion models are trained with a resolution limit of 512x512, making scaling beyond this resolution an unresolved but necessary challenge for image SR. In this work, we introduce a novel approach that, for the first time, enables these models to generate 2K, 4K, and even 8K images without any additional training. Our method leverages MultiDiffusion, which distributes the generation across multiple diffusion paths to ensure global coherence at larger scales, and local degradation-aware prompt extraction, which guides the T2I model to reconstruct fine local structures according to its low-resolution input. These innovations unlock higher resolutions, allowing T2I diffusion models to be applied to image SR tasks without limitation on resolution.
Summary
本研究提出一种新型方法,使大规模T2I扩散模型能生成2K、4K甚至8K图像,实现无额外训练下的图像超分辨率。
Key Takeaways
- 大规模T2I扩散模型在图像生成和超分辨率任务中应用广泛。
- 现有T2I扩散模型存在分辨率限制,难以应用于更高分辨率图像。
- 本研究提出的方法使模型能生成2K、4K和8K图像。
- 方法名为MultiDiffusion,通过多路径生成保证全局一致性。
- 引入局部退化感知提示提取,指导模型重建精细局部结构。
- 无需额外训练即可实现高分辨率图像生成。
- 该方法突破分辨率限制,拓展T2I扩散模型在图像超分辨率任务中的应用。
Title: 《Zoomed In, Diffused Out: Towards Local Degradation-Aware Multi-Diffusion for Extreme Image Super-Resolution》
Authors: Brian B. Moser, Stanislav Frolov, Tobias C. Nauen, Federico Raue, Andreas Dengel
Affiliation: German Research Center for Artificial Intelligence (German: Deutscher Forschungszentrum für Künstliche Intelligenz, DFKI), University of Kaiserslautern-Landau
Keywords: Image Super-Resolution, Text-to-Image Diffusion Models, MultiDiffusion, Local Degradation-Aware Prompt Extraction
Urls: The paper is not available online, but the code may be available on GitHub. Please check the official GitHub repository for this paper if it exists. GitHub: None
Summary:
(1) Research Background: Image Super-Resolution (SR) is a crucial task in various fields such as satellite imaging, medical diagnostics, and consumer photography. While existing SR methods have made significant progress, handling complex degradation in Low-Resolution (LR) inputs remains challenging. Recently, diffusion models, particularly pre-trained Text-to-Image (T2I) diffusion models, have revolutionized image generation tasks and shown potential in image SR. However, most T2I diffusion models are limited to a resolution of 512×512, which is insufficient for many real-world applications.
(2) Past Methods and Their Problems: Previous SR methods, particularly those using local operations like CNNs, have achieved significant progress. However, handling complex degradation in LR inputs remains challenging. Diffusion models, particularly T2I diffusion models, have demonstrated strong potential in image SR but are limited to low resolutions.
(3) Research Methodology Proposed in This Paper: The paper introduces a novel approach that enables T2I diffusion models to generate images with resolutions beyond 512×512 without any additional training. The proposed method leverages MultiDiffusion, which distributes the generation across multiple diffusion paths to ensure global coherence at larger scales. Additionally, local degradation-aware prompt extraction guides the T2I model to reconstruct fine local structures according to the low-resolution input.
(4) Task and Performance: The methods in this paper are evaluated on the task of image super-resolution, achieving impressive results in generating high-resolution images with fine details. The proposed approach unlocks higher resolutions and allows T2I diffusion models to be applied to image SR tasks without resolution limitations. The performance achieved supports their goals effectively.
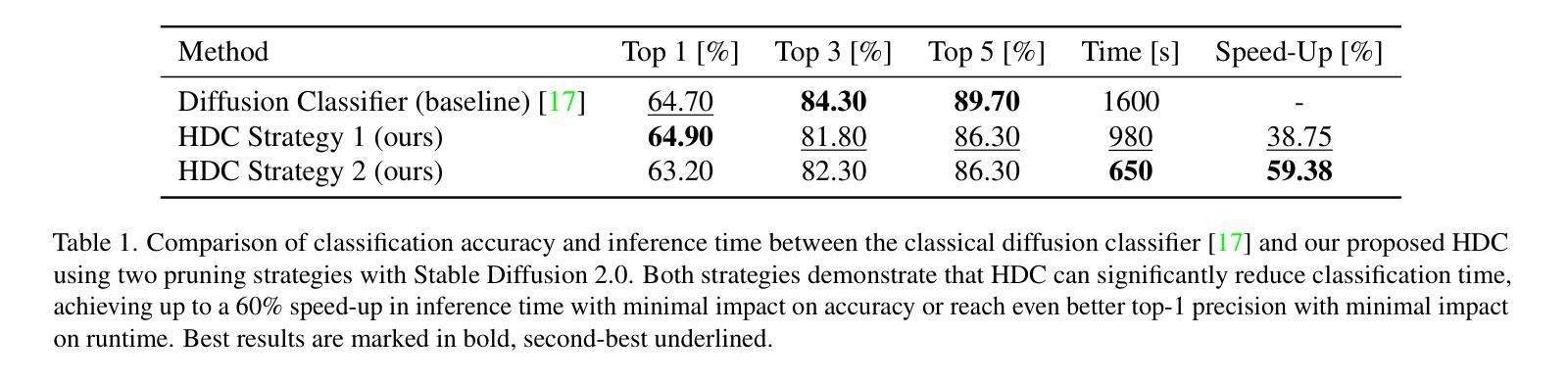
7. 方法论:
本文提出了一个结合预训练的文本到图像(T2I)扩散模型进行极端图像超分辨率(SR)的方法。具体步骤如下:
- (1) 研究背景与现状:首先,文章指出了当前超分辨率技术在处理复杂低分辨率(LR)输入时面临的挑战,尤其是处理复杂退化的问题。尽管现有的超分辨率方法已经取得了显著的进展,但在极端分辨率下仍面临挑战。为了解决这个问题,文章引入了扩散模型,特别是预训练的T2I扩散模型,这些模型在图像生成任务中显示出潜力。
- (2) 方法提出:文章提出了一种新的方法,该方法利用预训练的T2I扩散模型进行极端图像超分辨率。该方法的核心在于两个创新点:MultiDiffusion和局部退化感知提示提取。MultiDiffusion确保了高分辨率图像的全局一致性,而局部退化感知提示提取增强了局部细节的恢复。通过这两个创新点,该方法能够在不增加额外训练的情况下,将分辨率提高到2K、4K甚至8K。
- (3) 方法实施步骤:在实施过程中,首先使用预训练的T2I扩散模型和提示提取器对输入的噪声潜在表示进行处理。然后,通过MultiDiffusion过程将图像合成扩展到更大的尺度。在这个过程中,文章使用一系列重叠的潜在窗口来合并信息,确保全局结构和局部细节的一致性。此外,还引入了局部退化感知提示提取技术,该技术根据局部图像内容生成特定的提示,确保每个区域都能重建出准确的细节。
- (4) 实验设置与验证:为了验证方法的有效性,文章在多个数据集上进行了实验,包括DIV2K验证集、Test4K和Test8K数据集。实验结果表明,该方法在极端图像超分辨率任务上取得了显著的效果。此外,还通过与多种经典和基于扩散的SR模型进行比较,进一步验证了方法的有效性。
总的来说,本文提出了一种利用预训练的T2I扩散模型进行极端图像超分辨率的新方法,该方法具有全局一致性和局部细节恢复的能力,能够在不增加额外训练的情况下提高图像的分辨率。
8. Conclusion:
(1)这项工作的重要性在于,它提出了一种利用预训练的文本到图像(T2I)扩散模型进行极端图像超分辨率(SR)的新方法。这种方法在处理复杂低分辨率(LR)输入时表现出更高的效率和准确性,为图像超分辨率任务提供了一种新的解决方案。
(2)创新点:该文章的创新性体现在其结合了预训练的T2I扩散模型进行图像超分辨率,并提出了MultiDiffusion和局部退化感知提示提取两个核心方法,显著提高了图像超分辨率的性能。
性能:该文章所提出的方法在图像超分辨率任务上取得了显著的效果,能够生成高分辨率的图像并保留细节。
工作量:文章详细描述了方法论的实施步骤和实验设置,展示了作者们对方法的深入研究和实验验证。然而,由于文章未提供详细的代码和实验数据,无法全面评估其工作量。
总体来说,该文章提出了一种新的图像超分辨率方法,具有全局一致性和局部细节恢复的能力,为图像超分辨率任务提供了一种新的思路和方法。
点此查看论文截图




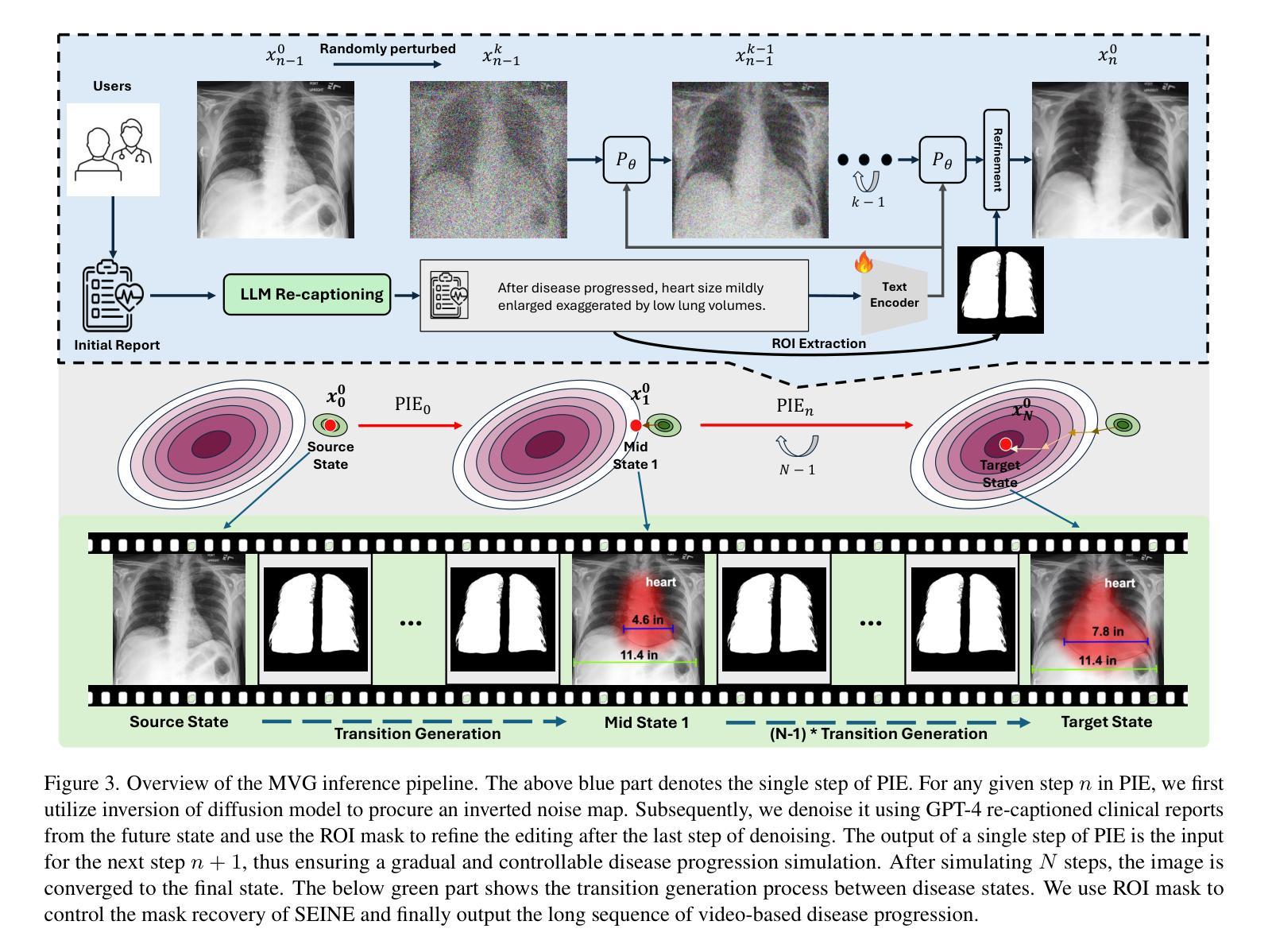
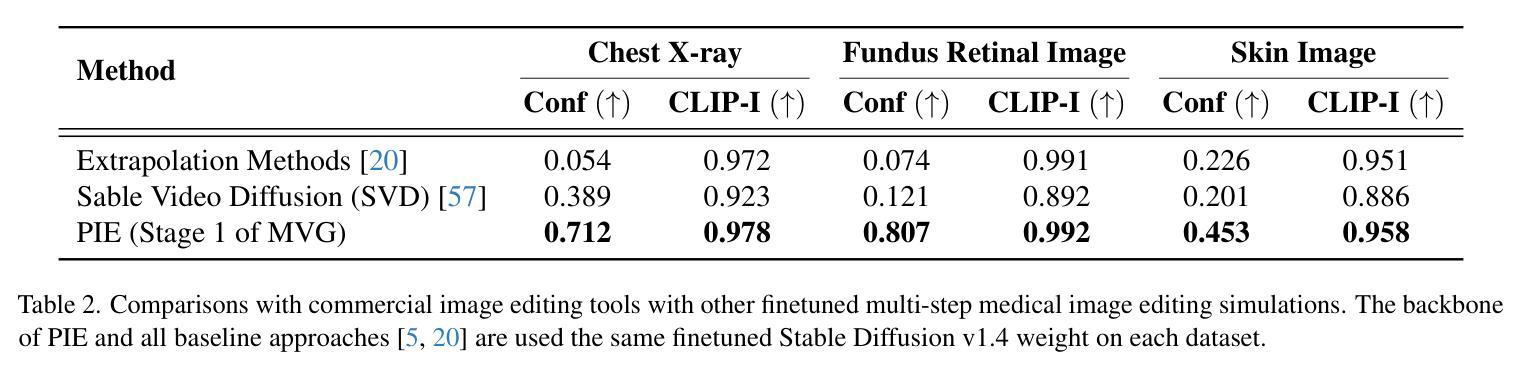
Medical Video Generation for Disease Progression Simulation
Authors:Xu Cao, Kaizhao Liang, Kuei-Da Liao, Tianren Gao, Wenqian Ye, Jintai Chen, Zhiguang Ding, Jianguo Cao, James M. Rehg, Jimeng Sun
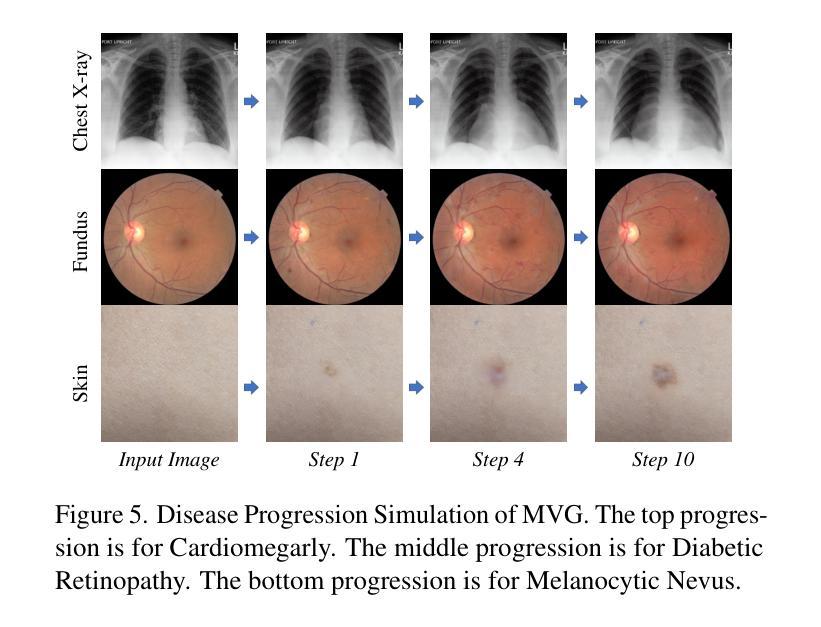
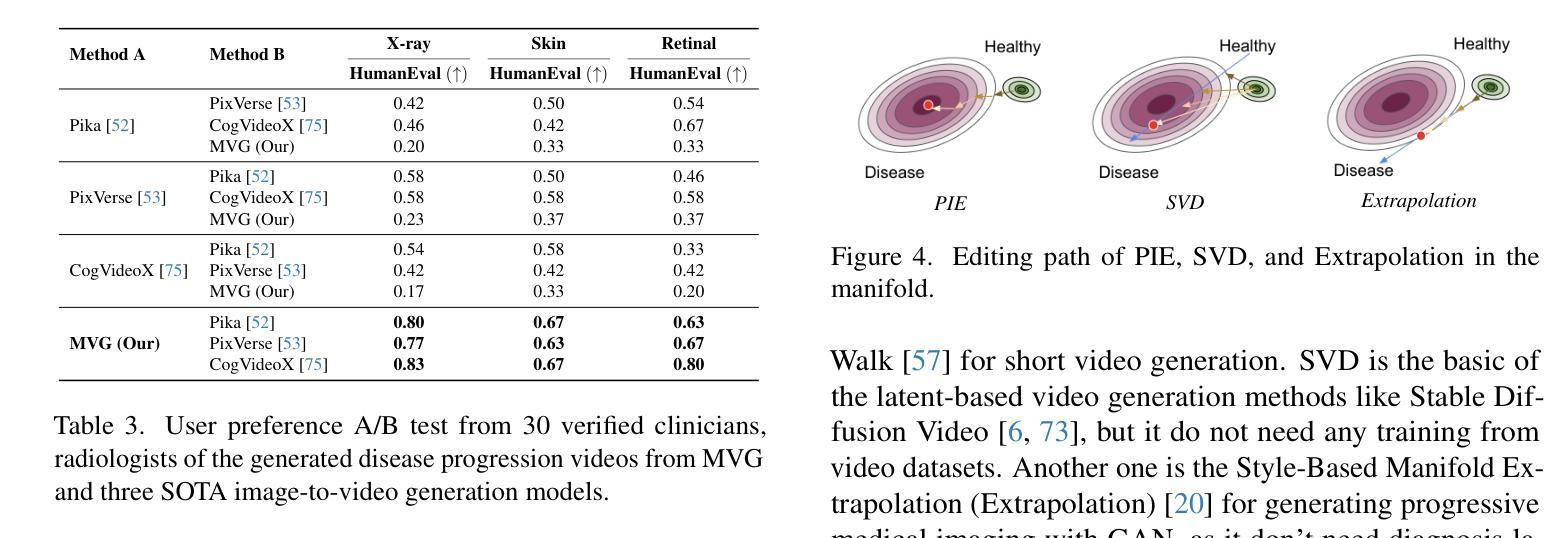
Modeling disease progression is crucial for improving the quality and efficacy of clinical diagnosis and prognosis, but it is often hindered by a lack of longitudinal medical image monitoring for individual patients. To address this challenge, we propose the first Medical Video Generation (MVG) framework that enables controlled manipulation of disease-related image and video features, allowing precise, realistic, and personalized simulations of disease progression. Our approach begins by leveraging large language models (LLMs) to recaption prompt for disease trajectory. Next, a controllable multi-round diffusion model simulates the disease progression state for each patient, creating realistic intermediate disease state sequence. Finally, a diffusion-based video transition generation model interpolates disease progression between these states. We validate our framework across three medical imaging domains: chest X-ray, fundus photography, and skin image. Our results demonstrate that MVG significantly outperforms baseline models in generating coherent and clinically plausible disease trajectories. Two user studies by veteran physicians, provide further validation and insights into the clinical utility of the generated sequences. MVG has the potential to assist healthcare providers in modeling disease trajectories, interpolating missing medical image data, and enhancing medical education through realistic, dynamic visualizations of disease progression.
PDF Tech Report. The appendix will release soon. arXiv admin note: text overlap with arXiv:2309.11745
Summary
提出首个医学视频生成框架,模拟疾病进展,提升临床诊断和教学。
Key Takeaways
- 针对疾病进展模型提出医学视频生成框架。
- 利用LLMs重新描述疾病轨迹。
- 多轮可控扩散模型模拟患者疾病进展状态。
- 基于扩散的视频过渡模型生成中间疾病状态序列。
- 在三个医学影像领域验证框架有效性。
- 生成疾病轨迹准确度高,临床可行性好。
- 医学专家用户研究进一步验证临床应用价值。
- 有助于医疗人员建模疾病轨迹、插补缺失数据、增强医学教育。
- 标题:医疗视频生成用于疾病进展模拟研究
作者:许曹,等。包括来自不同大学和研究机构的作者,如伊利诺伊大学厄巴纳-香槟分校、得克萨斯大学奥斯汀分校等。
隶属机构:许曹,第1作者,隶属于伊利诺伊大学厄巴纳-香槟分校。
关键词:医疗视频生成、疾病进展模拟、大型语言模型、扩散模型、医学图像
链接:论文链接尚未提供,GitHub代码链接(如有)可在此处添加。
摘要:
(1) 研究背景:
疾病进展模拟对于提高临床诊断和治疗的质量与效果至关重要。然而,由于个体患者长时间纵向医疗图像监测的缺乏以及疾病进展模拟方法的不足,该领域的进展受到阻碍。本文旨在解决这一挑战,提出首个医疗视频生成(MVG)框架。
(2) 过去的方法及问题:
过去的方法主要面临着缺少连续患者监测数据和疾病进展模拟方法的难题。现有的模型难以生成连贯且临床合理的疾病轨迹。因此,需要一种新的方法来解决这个问题。
(3) 研究方法:
本文提出的MVG框架包括以下三个主要步骤:利用大型语言模型(LLMs)进行疾病轨迹的重新描述提示;使用可控的多轮扩散模型模拟每个患者的疾病进展状态,创建真实的中间疾病状态序列;以及基于扩散的视频过渡生成模型,在这些状态之间插值疾病进展。整个框架在三个医学成像领域进行了验证:胸部X光片、眼底摄影和皮肤图像。
(4) 任务与性能:
在医疗图像领域,本文提出的MVG框架在生成连贯和临床合理的疾病轨迹方面显著优于基线模型。通过两项由资深医生参与的研究,进一步验证了生成序列的临床实用性。此研究为医疗提供者建模疾病轨迹、插补缺失医疗图像数据和增强医学教育提供了潜力。研究展示了框架在实际应用中的潜力及其目标的实现程度。所提出的方法和实验结果支持其能够有效解决原定目标。
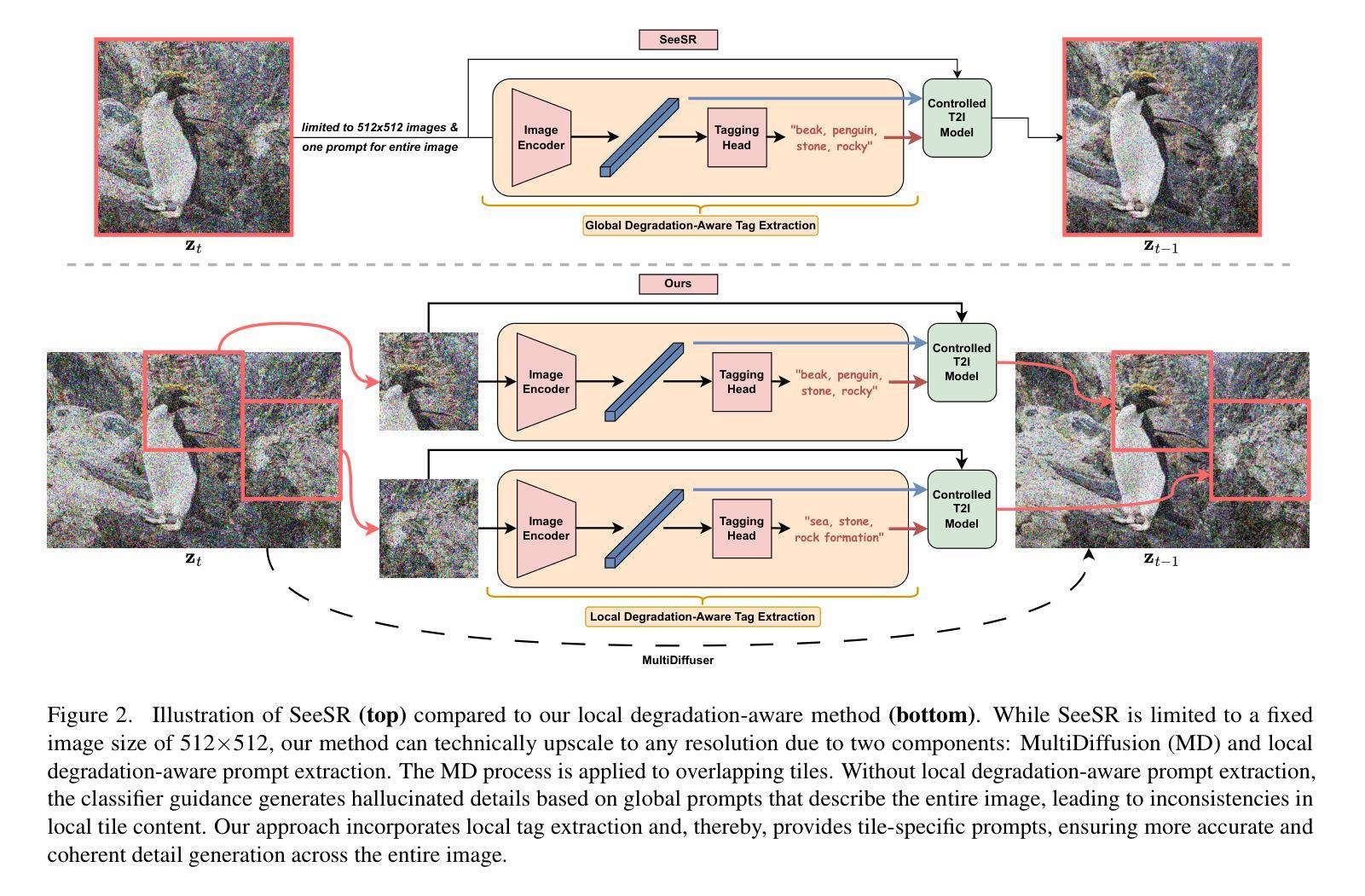
7. 方法论概述:
该研究提出了医疗视频生成(MVG)框架来解决医疗领域中疾病进展模拟的问题。方法主要包含以下几个步骤:
(1)使用大型语言模型(LLMs)对疾病轨迹进行重新描述提示。这是通过自然语言处理技术来理解和描述疾病的进展过程。
(2)利用可控的多轮扩散模型模拟每个患者的疾病进展状态。该模型基于扩散模型技术,能够生成连贯且临床合理的疾病轨迹。
(3)基于扩散的视频过渡生成模型,在这些状态之间插值疾病进展,从而创建出逼真的医疗视频。这一过程涉及复杂的图像处理技术,用于模拟疾病的视觉表现。
(4)该研究在不同医学成像领域验证了框架的有效性,包括胸部X光片、眼底摄影和皮肤图像等。同时进行了实验评估和临床医生的评估,以验证生成的疾病轨迹的真实性和合理性。这些评估方法包括对比实验、量化评估和医生参与度研究等。最终的结果显示,提出的MVG框架在生成连贯和临床合理的疾病轨迹方面显著优于基线模型,验证了框架在实际应用中的潜力及其目标的实现程度。
8. 结论:
(1)研究意义:该研究提出的医疗视频生成(MVG)框架在医疗领域疾病进展模拟方面具有重要的应用价值。该框架能够解决临床诊断和治疗中因缺乏长时间纵向医疗图像监测和疾病进展模拟方法而带来的挑战,提高临床诊断和治疗的质量与效果。
(2)评价:
创新点:该研究首次提出医疗视频生成框架,利用大型语言模型和扩散模型技术,实现了对疾病进展的模拟,具有显著的创新性。
性能:该研究在医疗图像领域验证了MVG框架的有效性,生成了连贯且临床合理的疾病轨迹,显著优于基线模型。
工作量:从文章提供的信息来看,该研究的实验设计和实施涉及多个医学成像领域,工作量较大,但具体的细节和详细工作量未在文章中详细描述。
综上,该研究在医疗视频生成用于疾病进展模拟方面具有重要的创新性和应用价值,实验结果也验证了其有效性。
点此查看论文截图

Cascaded Diffusion Models for 2D and 3D Microscopy Image Synthesis to Enhance Cell Segmentation
Authors:Rüveyda Yilmaz, Kaan Keven, Yuli Wu, Johannes Stegmaier
Automated cell segmentation in microscopy images is essential for biomedical research, yet conventional methods are labor-intensive and prone to error. While deep learning-based approaches have proven effective, they often require large annotated datasets, which are scarce due to the challenges of manual annotation. To overcome this, we propose a novel framework for synthesizing densely annotated 2D and 3D cell microscopy images using cascaded diffusion models. Our method synthesizes 2D and 3D cell masks from sparse 2D annotations using multi-level diffusion models and NeuS, a 3D surface reconstruction approach. Following that, a pretrained 2D Stable Diffusion model is finetuned to generate realistic cell textures and the final outputs are combined to form cell populations. We show that training a segmentation model with a combination of our synthetic data and real data improves cell segmentation performance by up to 9% across multiple datasets. Additionally, the FID scores indicate that the synthetic data closely resembles real data. The code for our proposed approach will be available at https://github.com/ruveydayilmaz0/cascaded_diffusion.
Summary
利用级联扩散模型生成密集标注的细胞显微镜图像,提高细胞分割精度。
Key Takeaways
- 自动化细胞分割对生物医学研究至关重要。
- 深度学习方法需大量标注数据,难以获得。
- 提出级联扩散模型合成标注图像。
- 使用多级扩散模型和NeuS进行3D表面重建。
- 预训练的2D稳定扩散模型生成细胞纹理。
- 合成数据与真实数据结合提升分割性能,提升9%。
- 合成数据与真实数据FID分数相似。
标题:基于级联扩散模型的二维和三维显微镜图像合成用于细胞分割
作者:Rüveyda Yilmaz(音译:鲁维达·伊尔马兹),Kaan Keven,Yuli Wu,Johannes Stegmaier
隶属机构:德国鲁尔大学成像与计算机视觉研究所
关键词:扩散模型,二维和三维显微镜图像合成,细胞分割
Urls:论文链接暂未提供,GitHub代码链接:[GitHub地址尚未提供](若后续有GitHub代码链接,请填写此处)
总结:
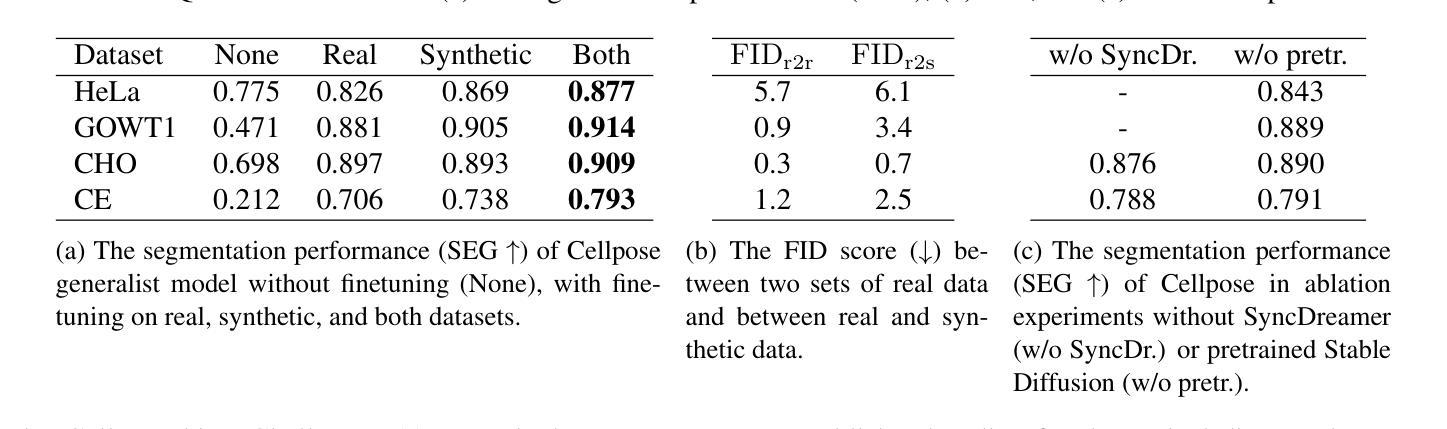
(1) 研究背景:细胞分割在显微镜图像中对于生物医学研究至关重要,但传统方法耗时且易出错。深度学习虽能自动提取特征,但通常需要大量标注数据,这些数据因手动标注的挑战而稀缺。因此,研究提出使用合成数据来补充真实数据集。本文旨在通过级联扩散模型合成密集标注的二维和三维细胞显微镜图像。
(2) 过去的方法及问题:现有方法大多基于假设的细胞形状生成掩膜或依赖于真实数据的统计信息。前者可能导致不现实的细胞结构,后者虽利用真实核形状信息,但在缺乏全面三维标注的情境下难以训练模型。此外,现有研究通常从头开始训练生成模型以合成细胞纹理,这可以通过利用预训练模型进行微调来提升性能。
(3) 研究方法:本研究通过级联扩散模型合成细胞掩膜,首先从稀疏二维标注合成二维和三维细胞掩膜,利用多级别扩散模型和NeuS(一种三维表面重建方法)。接着,微调预训练的二维Stable Diffusion模型以生成真实的细胞纹理。最终输出结合形成细胞群体。
(4) 任务与性能:本研究旨在通过合成数据提高细胞分割模型的性能。实验表明,使用合成数据与真实数据训练的分割模型在多个数据集上的性能提高了9%。此外,FID分数表明合成数据紧密接近真实数据。性能支持使用合成数据提升模型泛化能力和性能的目标。
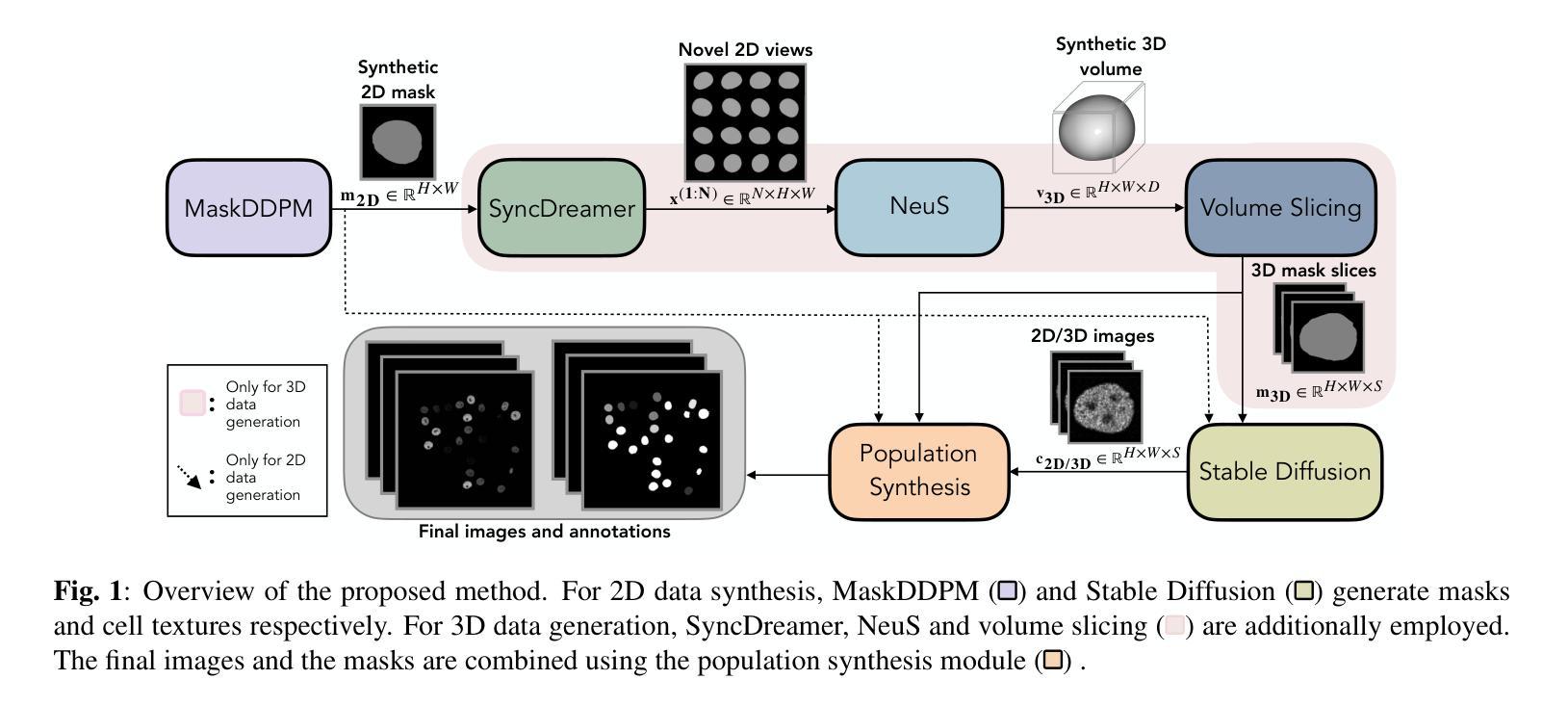
方法论概述:
(1) 利用级联扩散模型合成二维和三维显微镜图像掩膜:首先,通过生成对抗网络(GAN)等深度学习技术,利用真实数据集中的少量真实标注生成合成掩膜。这里采用了名为MaskDDPM的扩散概率模型来生成二维和三维的细胞掩膜。
(2) 多视角一致性掩膜生成:为了生成三维合成数据,研究使用了SyncDreamer模型。该模型基于MaskDDPM生成的二维输出掩膜m2D,预测多个未见过的视图。为了确保多视角的一致性,模型联合预测多个视图中的噪声。
(3) 从多视角图像到体积的生成:利用NeuS方法,根据预测的多视角图像生成密集的体积掩膜v3D。NeuS是一种表面重建方法,使用多层感知机(MLP)表示对象表面为符号距离函数。
(4) 合成掩膜的切片处理:由于真实的三维细胞显微镜图像通常由沿z方向的多张二维切片组成,因此研究将NeuS输出的体积掩膜v3D按等间隔切片,以与真实数据集的结构对齐。
总的来说,该研究通过级联扩散模型合成二维和三维显微镜图像,旨在提高细胞分割模型的性能。通过合成数据来补充真实数据集,解决真实数据标注困难、标注数据稀缺的问题。实验表明,使用合成数据与真实数据训练的分割模型在多个数据集上的性能有所提升。
Conclusion:
(1) 本研究的意义在于通过级联扩散模型合成二维和三维显微镜图像,为解决细胞分割中真实数据标注困难、标注数据稀缺的问题提供了新的思路和方法。合成数据可以辅助真实数据集,提高细胞分割模型的性能,有助于推动生物医学研究的发展。
(2) 创新点:该研究采用级联扩散模型合成显微镜图像,结合了生成对抗网络、扩散概率模型、多视角一致性掩膜生成等技术,实现了从二维到三维的合成,具有创新性。性能:实验结果表明,使用合成数据与真实数据训练的分割模型在多个数据集上的性能有所提升,验证了方法的有效性。工作量:研究涉及了模型设计、实验设计、数据预处理等多个方面的工作,工作量较大。但文章未提供足够的细节,如GitHub代码链接等,无法全面评估其工作量。
点此查看论文截图

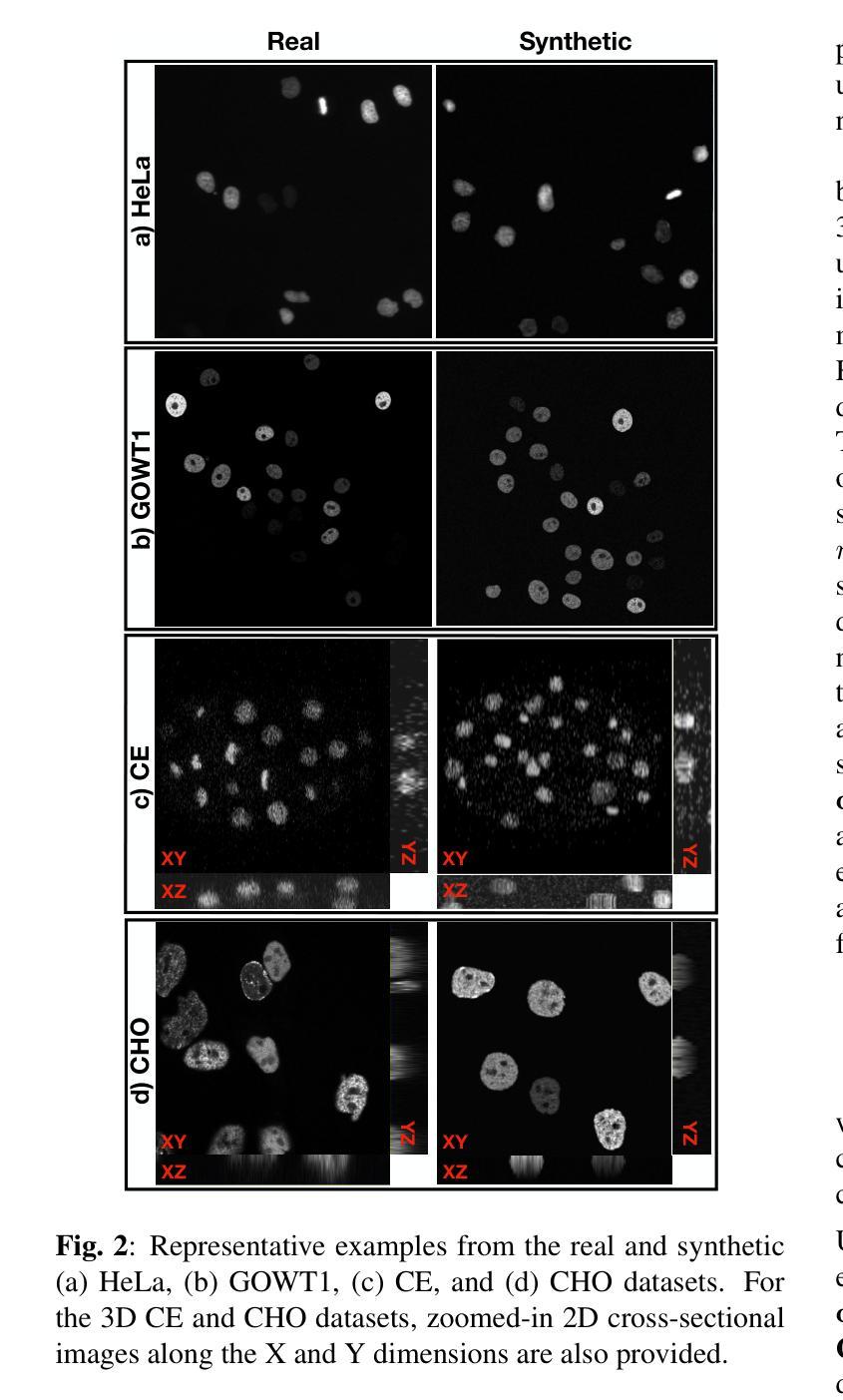
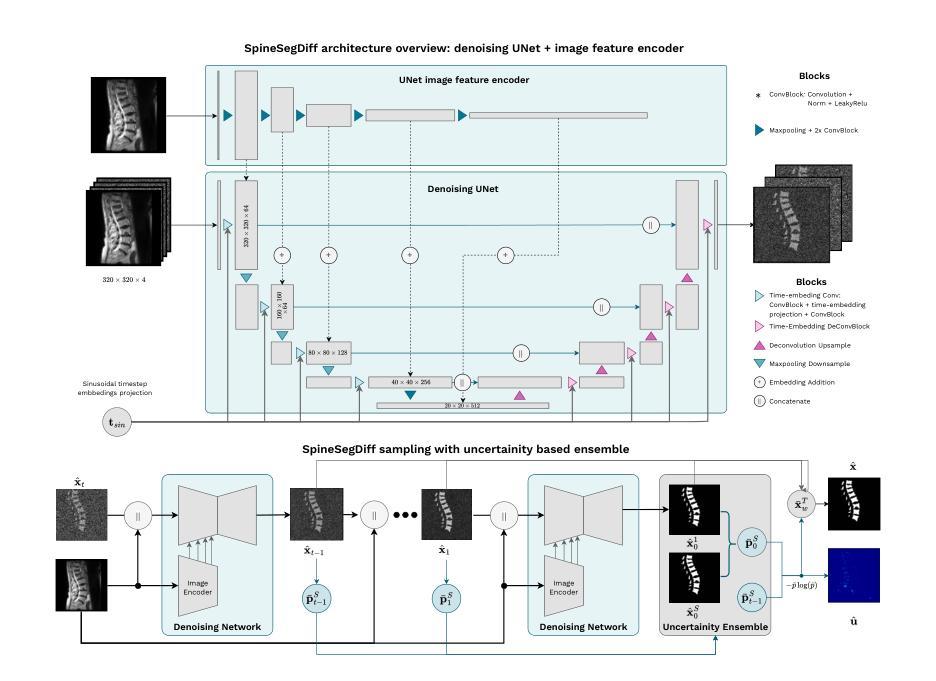
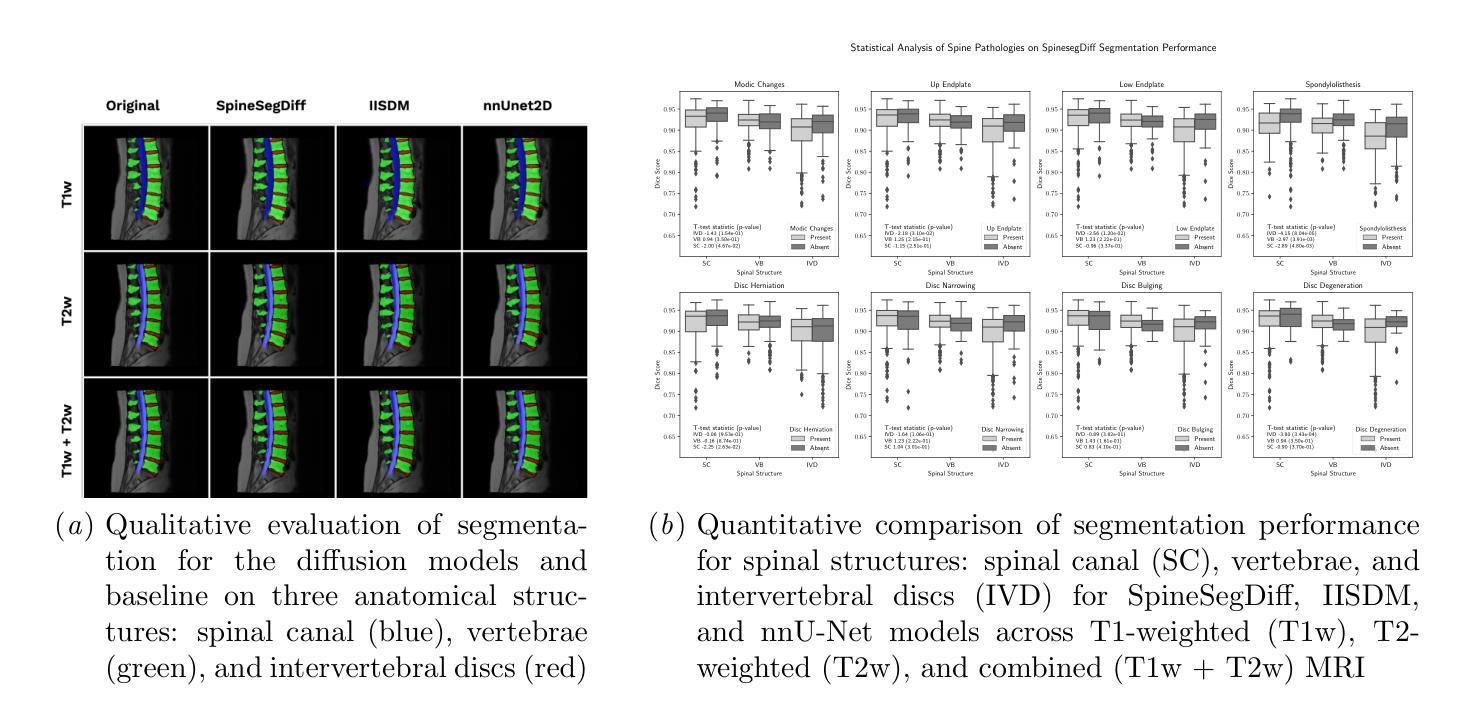
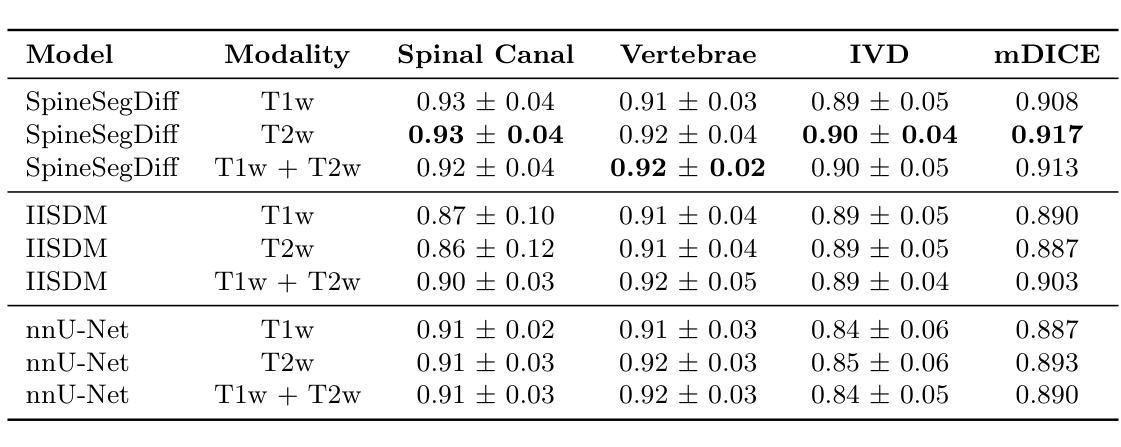
Diffusion-Based Semantic Segmentation of Lumbar Spine MRI Scans of Lower Back Pain Patients
Authors:Maria Monzon, Thomas Iff, Ender Konukoglu, Catherine R. Jutzeler
This study introduces a diffusion-based framework for robust and accurate segmenton of vertebrae, intervertebral discs (IVDs), and spinal canal from Magnetic Resonance Imaging~(MRI) scans of patients with low back pain (LBP), regardless of whether the scans are T1w or T2-weighted. The results showed that SpineSegDiff achieved comparable outperformed non-diffusion state-of-the-art models in the identification of degenerated IVDs. Our findings highlight the potential of diffusion models to improve LBP diagnosis and management through precise spine MRI analysis.
PDF Findings paper presented at Machine Learning for Health (ML4H) symposium 2024, December 15-16, 2024, Vancouver, Canada, 5 pages
Summary
基于扩散模型从脊柱MRI中准确分割椎骨、椎间盘和椎管,为腰椎疼痛诊断和管理提供精确分析。
Key Takeaways
- 研究提出了一种基于扩散模型的脊柱MRI分割框架。
- 框架适用于T1w和T2-weighted MRI扫描。
- SpineSegDiff模型在识别退化的椎间盘方面优于现有模型。
- 扩散模型有助于提高腰椎疼痛的诊断和管理。
- 模型在椎骨、椎间盘和椎管分割方面表现良好。
- 分割结果与现有非扩散模型相当甚至更优。
- 研究突出了扩散模型在精准脊柱MRI分析中的潜力。
Title: 基于扩散模型的腰椎MRI语义分割研究(Diffusion-Based Semantic Segmentation of Lumbar Spine MRI)
Authors: Maria Monzon, Thomas Iff, Ender Konukoglu, Catherine R. Jutzeler
Affiliation: 第一作者Maria Monzon来自ETH苏黎世大学。
Keywords: 扩散模型、腰椎MRI、病理性分割
Summary:
(1)研究背景:本文旨在解决低背痛(LBP)诊断中的挑战性问题,通过扩散模型对腰椎MRI图像进行语义分割,以精确评估腰椎结构,包括椎体、椎间盘和脊髓腔。
(2)过去的方法及问题:传统的腰椎MRI图像分割方法在处理含有退行性病变的MRI图像时面临挑战,尤其是在处理T1加权和T2加权MRI图像时。此外,手动评估存在主观性和高劳动力需求的问题。
(3)研究方法:本研究提出了SpineSegDiff模型,这是一个基于扩散模型的分割方法,特别适用于处理含有病理变化的LBP患者MRI图像。该研究还实施了一种预分割策略,以加速扩散模型的训练同时保持其优势。
(4)任务与性能:该研究在SPIDER数据集上进行训练和评估,包含T1加权和T2加权腰椎MRI图像。结果显示,SpineSegDiff模型在识别退化的椎间盘方面表现出与现有非扩散模型相当或更好的性能。该研究为通过精确腰椎MRI分析改善LBP诊断和治疗提供了潜力。性能支持方面,该模型在公开数据集上的表现证明了其有效性和潜力。
以上是对该文章的概括和总结,希望符合您的要求。
8. Conclusion:
- (1)工作意义:该研究对于解决低背痛(LBP)诊断中的难题具有重要意义。通过扩散模型对腰椎MRI图像进行语义分割,可以精确评估腰椎结构,为LBP的诊断和治疗提供更有针对性的依据,从而提高诊断和治疗的准确性和效率。
- (2)创新点、性能和工作量:
- 创新点:该研究首次将扩散模型应用于腰椎MRI图像的语义分割,提出了一种新的SpineSegDiff模型,该模型特别适用于处理含有病理变化的LBP患者MRI图像。此外,研究还实施了一种预分割策略,以加速扩散模型的训练,保持其优势的同时降低了计算复杂度。
- 性能:研究在SPIDER数据集上进行训练和评估,结果显示SpineSegDiff模型在识别退化的椎间盘方面表现出与现有非扩散模型相当或更好的性能。此外,该模型在公开数据集上的表现证明了其有效性和潜力。
- 工作量:研究工作量较大,需要进行大量的实验和调试,包括数据集的准备、模型的训练和优化、实验结果的评估等。此外,还需要对模型进行验证和比较,以确保其在实际应用中的有效性和可靠性。然而,该研究也存在一定的局限性,如计算要求较高,需要进一步优化模型的计算效率,以便更好地应用于临床实践。
希望以上回答能够满足您的要求。
点此查看论文截图


Towards Unsupervised Blind Face Restoration using Diffusion Prior
Authors:Tianshu Kuai, Sina Honari, Igor Gilitschenski, Alex Levinshtein
Blind face restoration methods have shown remarkable performance, particularly when trained on large-scale synthetic datasets with supervised learning. These datasets are often generated by simulating low-quality face images with a handcrafted image degradation pipeline. The models trained on such synthetic degradations, however, cannot deal with inputs of unseen degradations. In this paper, we address this issue by using only a set of input images, with unknown degradations and without ground truth targets, to fine-tune a restoration model that learns to map them to clean and contextually consistent outputs. We utilize a pre-trained diffusion model as a generative prior through which we generate high quality images from the natural image distribution while maintaining the input image content through consistency constraints. These generated images are then used as pseudo targets to fine-tune a pre-trained restoration model. Unlike many recent approaches that employ diffusion models at test time, we only do so during training and thus maintain an efficient inference-time performance. Extensive experiments show that the proposed approach can consistently improve the perceptual quality of pre-trained blind face restoration models while maintaining great consistency with the input contents. Our best model also achieves the state-of-the-art results on both synthetic and real-world datasets.
PDF WACV 2025. Project page: https://dt-bfr.github.io/
Summary
利用未知退化输入图像微调预训练的修复模型,提高盲人脸恢复质量。
Key Takeaways
- 盲人脸修复在大型合成数据集上表现卓越。
- 模型难以处理未见过的退化输入。
- 本文提出使用未知退化输入图像微调修复模型。
- 利用预训练扩散模型作为生成先验,生成高质量图像。
- 生成图像作为伪目标微调修复模型。
- 仅在训练时使用扩散模型,保持高效推理性能。
- 方法在合成和真实数据集上均取得最先进结果。
Title: 面向无监督盲脸修复的扩散先验方法
Authors: Tianshu Kuai, Sina Honari, Igor Gilitschenski, Alex Levinshtein(以英语填写)
Affiliation: 第一作者天舒(Tianshu Kuai)的隶属机构为多伦多三星人工智能中心(Samsung AI Center Toronto)(中文翻译)。
Keywords: 盲脸修复、扩散模型、无监督学习、图像恢复、生成模型(使用英文填写)
Urls: 文章摘要提供的链接以及GitHub代码链接(如果可用),否则填写“GitHub:暂无”。
Summary:
(1)研究背景:本文主要研究无监督盲脸修复的问题。现有的盲脸修复方法大多依赖于合成数据集进行有监督学习,对于未见过的退化类型表现不佳。本文旨在解决这一问题。
(2)过去的方法及问题:现有的盲脸修复方法主要依赖于合成数据集进行有监督学习,通过模拟低质量图像退化过程生成训练数据。这些方法在测试数据符合训练退化分布时表现良好,但对于不符合的输入则会产生严重失真。此外,真实场景中的数据往往没有配对的高质量目标图像,因此需要无监督的学习方法。
(3)研究方法:本文提出了一种无监督的方法,使用预训练的扩散模型作为生成先验。通过扩散模型从自然图像分布中生成高质量图像,同时保持输入图像的内容一致性。这些生成的图像被用作伪目标,以微调预训练的修复模型。与许多在测试时采用扩散模型的方法不同,本文仅在训练过程中使用扩散模型,从而保持高效的推理时间性能。
(4)任务与性能:本文的方法旨在改进预训练的盲脸修复模型,在合成和真实世界数据集上均实现了最佳结果。实验表明,该方法能显著提高预训练模型的感知质量,同时保持与输入内容的良好一致性。性能结果支持了该方法的有效性。
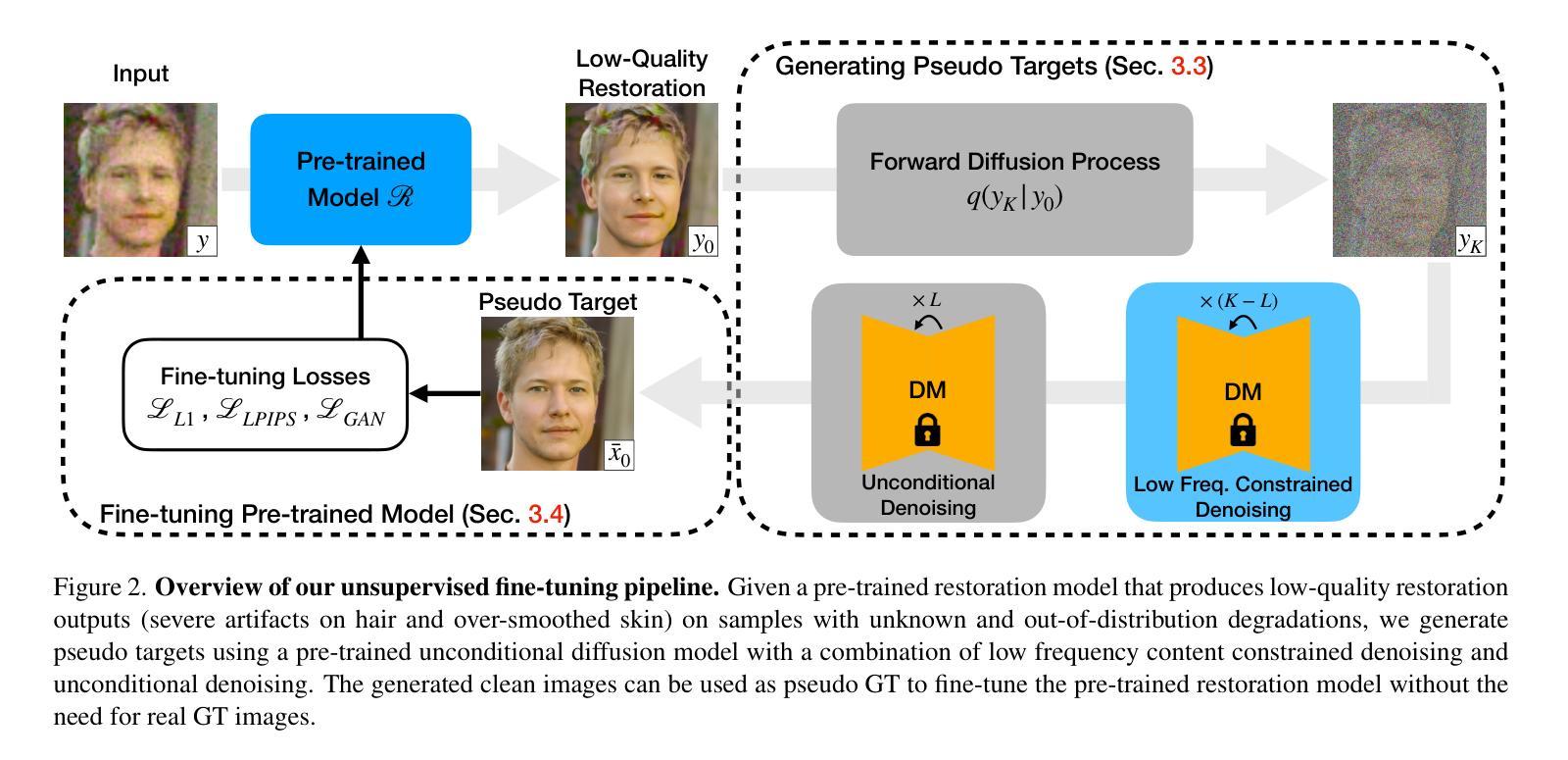
方法论:
- (1) 研究背景:本文主要研究无监督盲脸修复的问题。针对现有方法大多依赖于合成数据集进行有监督学习,对于未见过的退化类型表现不佳的问题,提出了一种无监督的方法。
- (2) 过去的方法及问题:现有的盲脸修复方法主要使用合成数据集进行有监督学习,通过模拟低质量图像退化过程生成训练数据。这些方法在测试数据与训练退化分布相符时表现良好,但对于不符合的输入则会产生严重失真。此外,真实场景中的数据往往没有配对的高质量目标图像,因此需要无监督的学习方法。
- (3) 研究方法:本文提出了一种无监督的方法,使用预训练的扩散模型作为生成先验。通过扩散模型从自然图像分布中生成高质量图像,同时保持输入图像的内容一致性。这些生成的图像被用作伪目标,以微调预训练的修复模型。与许多在测试时采用扩散模型的方法不同,本文仅在训练过程中使用扩散模型,从而保持高效的推理时间性能。
- (4) 生成伪目标的方法:考虑预训练的修复模型和真实世界的低质量图像观察。由于合成数据和真实世界数据之间的域差距,预训练修复模型的输出仍包含许多伪影。本文使用预训练的扩散模型生成伪目标,通过低频率约束去噪过程来清洁修复模型的输出。具体而言,首先按照预定义的噪声时间表向图像注入高斯噪声,然后将其传递给扩散模型进行清洁。通过约束低频率内容以与输入保持一致来引导去噪过程。只对满足条件的时序应用低频内容约束,以保持结构的完整性并避免过度约束可能导致的模糊和伪影。
结论:
(1)这篇论文的研究内容对于无监督盲脸修复的问题具有重要的价值。针对现有方法大多依赖于合成数据集进行有监督学习,对于未见过的退化类型表现不佳的问题,提出了一种无监督的方法,具有重要的实际应用意义。
(2)创新点:本文提出了一种无监督的方法,使用预训练的扩散模型作为生成先验,解决了预训练修复模型在真实世界数据上的性能下降问题。性能:在合成和真实世界数据集上,该方法均实现了最佳结果,显著提高了预训练模型的感知质量,同时保持与输入内容的一致性。工作量:文章详细描述了方法的实现细节,包括生成伪目标的方法、预训练模型的选择和fine-tuning的过程等。同时,也提供了详细的实验数据和结果分析,证明了方法的有效性。但文章未涉及该方法的计算效率和在实际应用场景下的性能表现,这是未来研究可以进一步探讨的方向。
点此查看论文截图