⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-21 更新
JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation
Authors:Xuyang Cao, Guoxin Wang, Sheng Shi, Jun Zhao, Yang Yao, Jintao Fei, Minyu Gao
Audio-driven portrait animation has made significant advances with diffusion-based models, improving video quality and lipsync accuracy. However, the increasing complexity of these models has led to inefficiencies in training and inference, as well as constraints on video length and inter-frame continuity. In this paper, we propose JoyVASA, a diffusion-based method for generating facial dynamics and head motion in audio-driven facial animation. Specifically, in the first stage, we introduce a decoupled facial representation framework that separates dynamic facial expressions from static 3D facial representations. This decoupling allows the system to generate longer videos by combining any static 3D facial representation with dynamic motion sequences. Then, in the second stage, a diffusion transformer is trained to generate motion sequences directly from audio cues, independent of character identity. Finally, a generator trained in the first stage uses the 3D facial representation and the generated motion sequences as inputs to render high-quality animations. With the decoupled facial representation and the identity-independent motion generation process, JoyVASA extends beyond human portraits to animate animal faces seamlessly. The model is trained on a hybrid dataset of private Chinese and public English data, enabling multilingual support. Experimental results validate the effectiveness of our approach. Future work will focus on improving real-time performance and refining expression control, further expanding the applications in portrait animation. The code is available at: https://github.com/jdh-algo/JoyVASA.
Summary
基于扩散模型的音频驱动肖像动画,通过解耦面部表示框架和扩散转换器,有效提升了视频质量和唇形同步,支持多语言和动物面部动画。
Key Takeaways
- 扩散模型提升音频驱动肖像动画质量。
- 解耦面部表示框架延长视频时长。
- 扩散转换器直接从音频生成运动序列。
- 生成器结合3D面部表示和运动序列渲染动画。
- 支持多语言和动物面部动画。
- 模型训练于中英文混合数据集。
- 未来工作将关注实时性能和表情控制。
标题:基于扩散模型的音频驱动面部动画与动物图像动画研究(JOYVASA:基于扩散的音频驱动面部动态与头部运动生成)
作者:Xuyang Cao(曹旭阳)、Guoxin Wang(王国新)、Sheng Shi(史升)、Jun Zhao(赵军)、Yang Yao(姚杨)、Jintao Fei(费金涛)、Minyu Gao(高敏瑜)。所有作者均来自JD Health International Inc。
所属机构:论文作者所属机构为JD Health International Inc。
关键词:Decoupled Facial Representation(解耦面部表示)、Diffusion Model(扩散模型)、Portrait Animation(肖像动画)、Animal Image Animation(动物图像动画)。
论文链接和GitHub代码链接:论文链接为arXiv上的预印本,GitHub代码链接为:https://jdh-algo.github.io/JoyVASA。如GitHub链接不可使用,则填写”None”。
摘要:
- (1) 研究背景:近年来,音频驱动的肖像动画领域取得了显著的进步,这主要得益于基于扩散的生成模型的出现。这些创新方法显著提高了生成的视频质量和唇同步的准确性,并广泛应用于数字头像、虚拟助手、娱乐等领域。
- (2) 相关工作及其问题:当前的方法虽然取得了一定的成功,但随着模型复杂性的增加,训练和推理的效率下降,视频长度和帧间连续性的约束也显现出来。因此,有必要提出一种新的方法来解决这些问题。
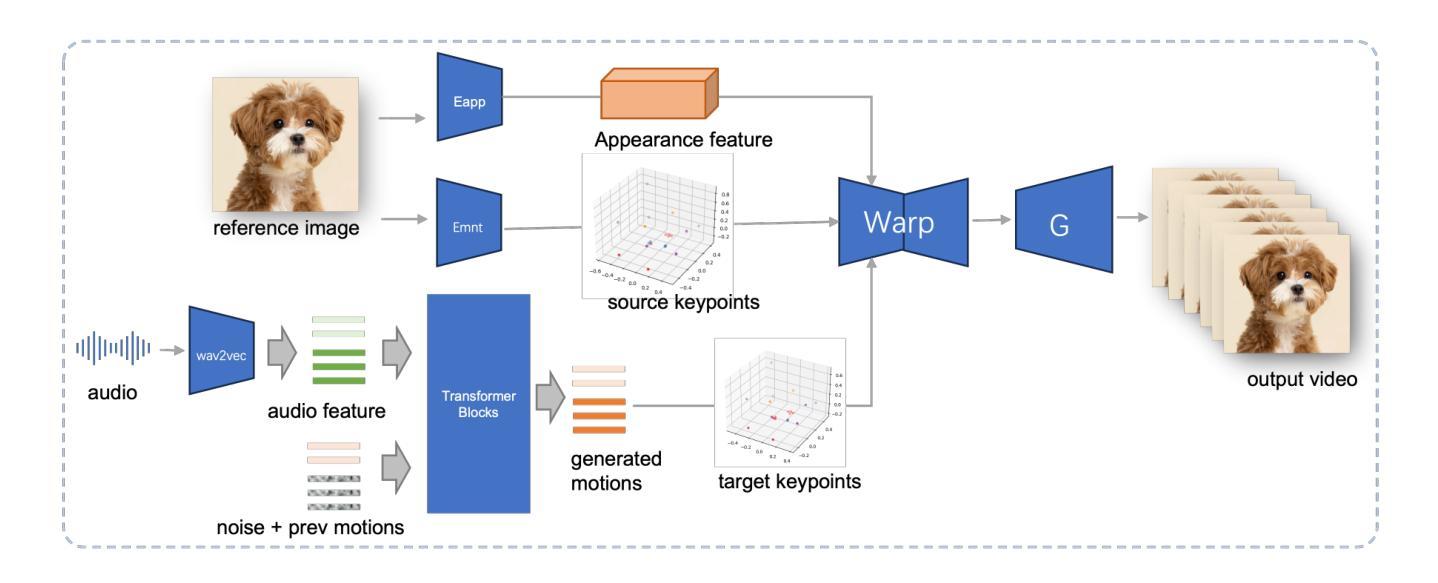
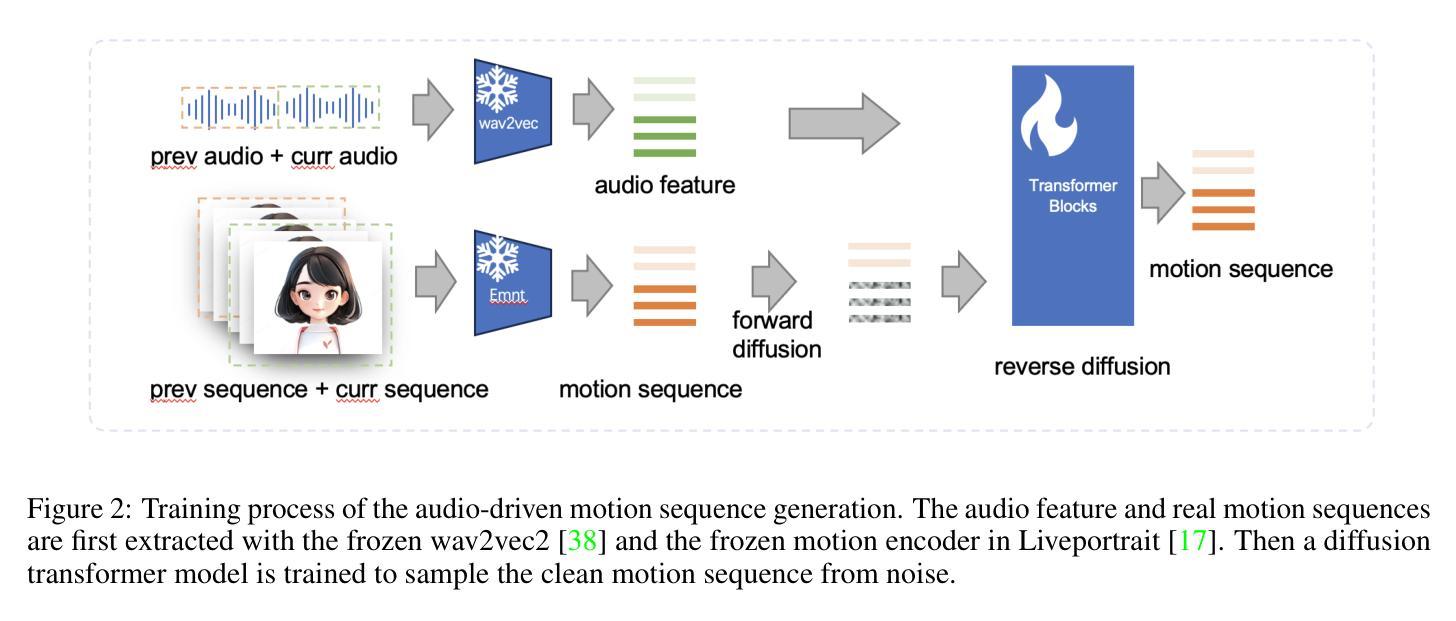
- (3) 研究方法:论文提出了JoyVASA方法,这是一种基于扩散的面部动态和头部运动生成方法。首先,引入了一个解耦的面部表示框架,将动态面部表情与静态3D面部表示分离。然后,训练一个扩散变压器来直接从音频线索生成运动序列,独立于角色身份。最后,使用3D面部表示和生成的运动序列作为输入,通过第一阶段训练的生成器渲染高质量动画。这种方法能够生成更长的视频,并且能无缝地动画化动物的面孔。
- (4) 任务与性能:论文的方法在肖像动画和动物图像动画任务上取得了良好的性能,验证了方法的有效性。实验结果表明,该方法能够生成高质量的视频,并且具有良好的实时性能和表情控制能力。未来的工作将集中在提高实时性能和细化表情控制,进一步扩展框架在肖像动画领域的应用。
以上是对这篇论文的简要总结,希望符合您的要求。
7. 方法:
(1) 研究背景:近年来,音频驱动的肖像动画领域得益于基于扩散的生成模型的发展而取得了显著进步。
(2) 问题阐述:尽管当前方法已经取得了一定的成功,但模型复杂性增加导致训练和推理效率下降,同时视频长度和帧间连续性的约束也显现出来。为了解决这些问题,论文提出了JoyVASA方法。
(3) 方法论核心:JoyVASA是一种基于扩散的面部动态和头部运动生成方法。首先,引入解耦的面部表示框架,将动态面部表情与静态3D面部表示分离。接着,训练一个扩散变压器,直接从音频线索生成运动序列,独立于角色身份。最后,利用3D面部表示和生成的运动序列作为输入,通过训练的生成器渲染高质量动画。该方法能生成更长的视频,并能无缝地动画化动物的面孔。
(4) 技术细节:该方法采用扩散模型技术,结合解耦的面部表示和3D面部渲染技术,实现了高质量的面部动画和动物图像动画。实验结果表明,该方法能生成高质量的视频,具有良好的实时性能和表情控制能力。
(5) 实验与评估:论文在肖像动画和动物图像动画任务上进行了实验,验证了方法的有效性。未来的工作将集中在提高实时性能和细化表情控制,进一步扩展框架在肖像动画领域的应用。
8. 结论:
(1)该作品的意义在于其对于音频驱动的肖像动画和动物图像动画领域的贡献。它提出了一种基于扩散模型的面部动态和头部运动生成方法,有效解决了当前方法的不足,提高了训练和推理效率,能够生成更长的视频并无缝地动画化动物的面孔。
(2)创新点:该文章的创新之处在于提出了JoyVASA方法,这是一种基于扩散模型的音频驱动面部动态与头部运动生成方法。该方法通过引入解耦的面部表示框架和训练扩散变压器,实现了高质量的面部动画和动物图像动画。
性能:该文章在肖像动画和动物图像动画任务上取得了良好的性能,验证了方法的有效性。实验结果表明,该方法能够生成高质量的视频,具有良好的实时性能和表情控制能力。
工作量:该文章进行了大量的实验和评估,验证了方法的有效性,并展示了其在实际应用中的潜力。此外,文章的结构清晰,内容详实,表明作者进行了充分的研究和实验工作。
点此查看论文截图