⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-07 更新
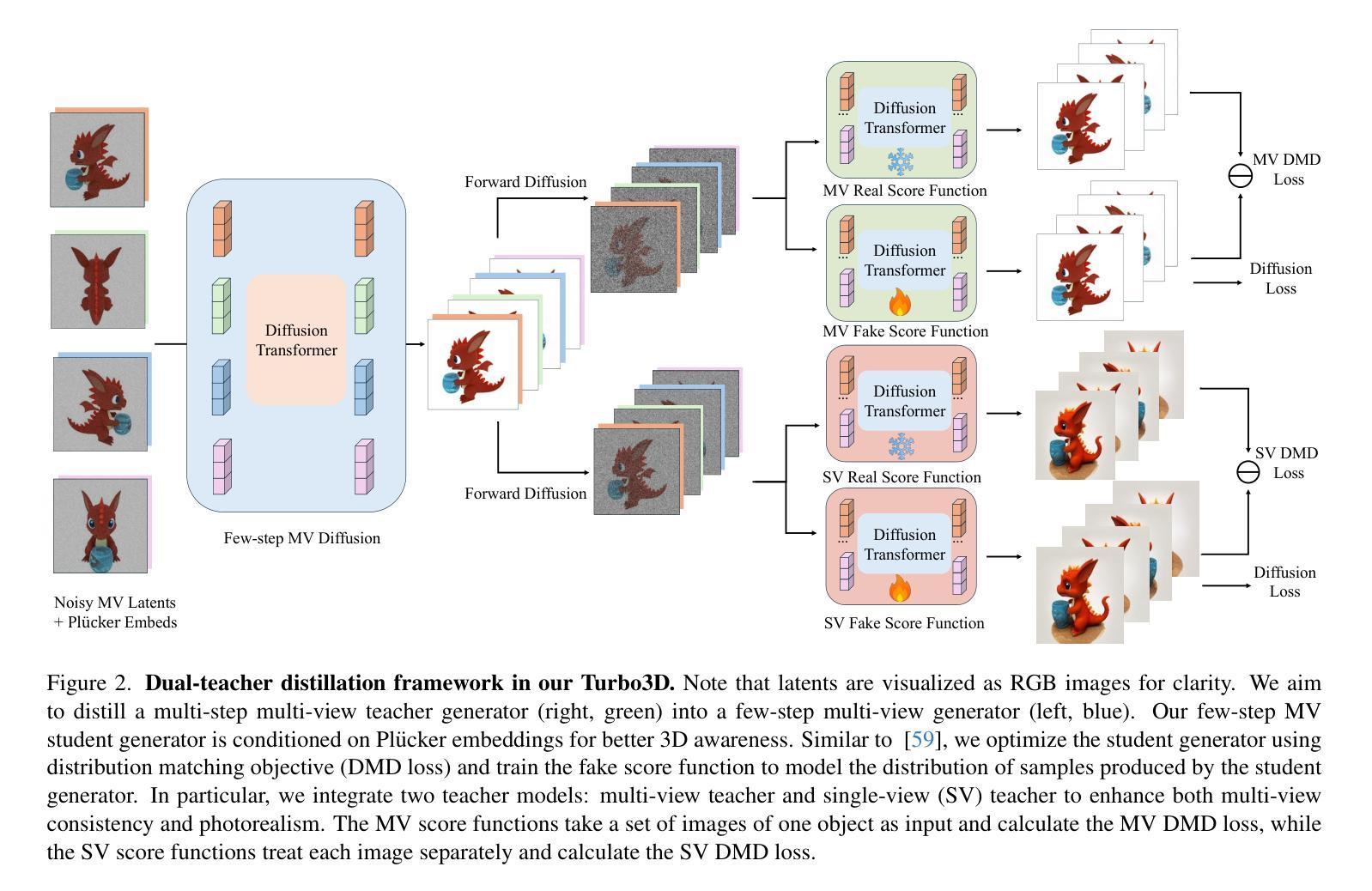
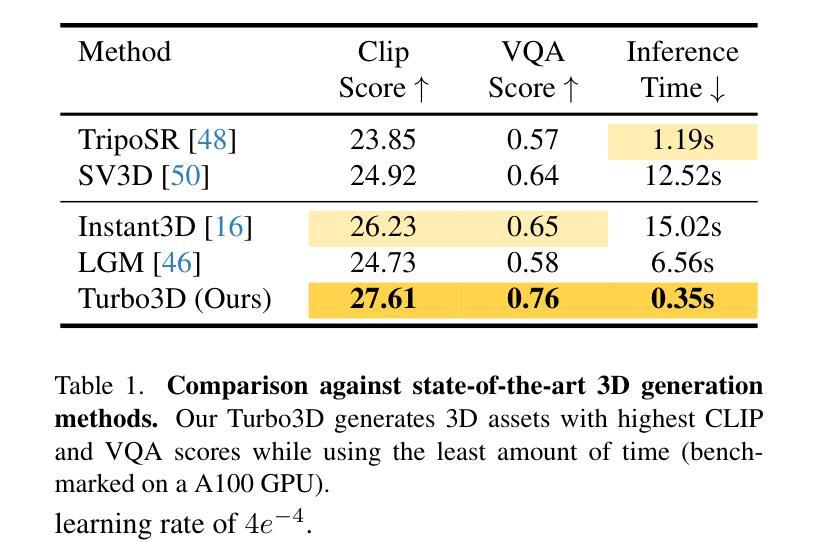
Turbo3D: Ultra-fast Text-to-3D Generation
Authors:Hanzhe Hu, Tianwei Yin, Fujun Luan, Yiwei Hu, Hao Tan, Zexiang Xu, Sai Bi, Shubham Tulsiani, Kai Zhang
We present Turbo3D, an ultra-fast text-to-3D system capable of generating high-quality Gaussian splatting assets in under one second. Turbo3D employs a rapid 4-step, 4-view diffusion generator and an efficient feed-forward Gaussian reconstructor, both operating in latent space. The 4-step, 4-view generator is a student model distilled through a novel Dual-Teacher approach, which encourages the student to learn view consistency from a multi-view teacher and photo-realism from a single-view teacher. By shifting the Gaussian reconstructor’s inputs from pixel space to latent space, we eliminate the extra image decoding time and halve the transformer sequence length for maximum efficiency. Our method demonstrates superior 3D generation results compared to previous baselines, while operating in a fraction of their runtime.
PDF project page: https://turbo-3d.github.io/
Summary
我们提出Turbo3D,一个能在1秒内生成高质量高斯分层资产的快速文本到3D系统。
Key Takeaways
- Turbo3D可在1秒内生成高质量的3D资产。
- 使用4步、4视图的扩散生成器和高效的前馈高斯重建器。
- 采用双重教师方法进行学生模型训练。
- 从多视图教师学习视角一致性,从单视图教师学习逼真度。
- 将高斯重建器输入从像素空间转换为潜在空间。
- 消除额外图像解码时间,缩短变换器序列长度。
- 性能优于现有基准,运行时间更短。
Title: Turbo3D:超快速文本到三维生成技术
Authors: 待查阅相关文献后补充
Affiliation: 待查阅相关文献后补充
Keywords: text-to-3D generation;Turbo3D;multi-step multi-view generation;high-resolution 3D generation;Ablation experiments;user study;A100 GPU
Urls: xxx(请自行查找该论文的链接及Github代码链接)
Summary:
(1) 研究背景:本文研究了文本到三维生成技术,旨在解决现有方法生成速度慢、分辨率低、效果差等问题。
(2) 过去的方法及问题:当前文本到三维生成技术存在生成速度慢、分辨率不高、细节缺失等问题。一些方法虽然能够生成高质量的三维模型,但计算量大、耗时较长,难以满足实时应用需求。
(3) 研究方法:本文提出了一种基于深度学习的高效文本到三维生成方法Turbo3D。该方法通过对已有模型进行微调,实现了快速高效的文本到三维生成。具体地,通过采用一种四步四视图的扩散生成器和一个高效的前馈高斯重建器,以及操作在潜在空间中的策略,大大提高了生成速度和图像质量。此外,还提出了一种Dual-Teacher蒸馏方法,用于训练学生模型,提高其视图一致性和逼真度。
(4) 任务与性能:本文方法在文本到三维生成任务上取得了显著成果,与现有方法相比,具有更高的生成速度、更高的分辨率和更好的图像质量。实验结果表明,该方法能够支持高效、高质量的文本到三维生成。
7. Methods:
(1) 研究背景与动机:本文研究的主题是文本到三维生成技术,旨在解决现有技术存在生成速度慢、分辨率低、效果不理想等问题,提高该技术在实时应用中的实用性。
(2) 数据收集与预处理:此部分的内容尚未在摘要中提及,需要查阅原文详细了解。可能包括收集大量的文本和对应的三维模型数据,进行数据清洗、标注等工作。
(3) 方法介绍:本文提出了一种基于深度学习的高效文本到三维生成方法Turbo3D。该方法主要包括以下几个步骤:
- 采用四步四视图的扩散生成器,通过扩散过程生成三维模型的各个视图。
- 使用高效的前馈高斯重建器,对生成的视图进行重建,提高图像质量。
- 在潜在空间中进行操作,通过微调已有模型,实现快速高效的文本到三维生成。
- 提出Dual-Teacher蒸馏方法,训练学生模型,提高其视图一致性和逼真度。
(4) 实验设计与实施:本文进行了大量的实验来验证所提出方法的性能。可能包括与其他方法的对比实验、消融实验以及用户研究等。实验结果表明,该方法在文本到三维生成任务上取得了显著成果,具有更高的生成速度、更高的分辨率和更好的图像质量。
(5) 评估与分析:通过对比实验、定量和定性分析等方法,对所提出方法的性能进行了全面评估。证明了该方法在文本到三维生成任务上的优越性。
注:具体细节需要查阅原文进行确认,上述回答仅为根据摘要内容进行的推测。
8. Conclusion:
- (1) 这项工作的意义在于提出了一种名为Turbo3D的高效文本到三维生成技术,该技术对于解决现有方法生成速度慢、分辨率低、效果差等问题具有重要意义,有望推动文本到三维生成技术的实时应用。
- (2) Innovation point(创新点):本文提出了基于深度学习的高效文本到三维生成方法Turbo3D,通过采用四步四视图的扩散生成器、高效的前馈高斯重建器以及在潜在空间中的操作策略,大大提高了生成速度和图像质量。此外,还创新性地提出了Dual-Teacher蒸馏方法,用于提高学生模型的视图一致性和逼真度。
Performance(性能):与现有方法相比,Turbo3D在文本到三维生成任务上取得了显著成果,具有更高的生成速度、更高的分辨率和更好的图像质量。实验结果表明,该方法支持高效、高质量的文本到三维生成。
Workload(工作量):虽然本文的工作取得了显著的成果,但关于数据收集与预处理的细节尚未在摘要中提及,这部分工作可能较为繁重。此外,文章还可能需要更多的实验来验证所提出方法的泛化性能和鲁棒性。
注意:以上结论仅根据摘要内容进行了推测,具体细节需要查阅原文进行确认。
点此查看论文截图


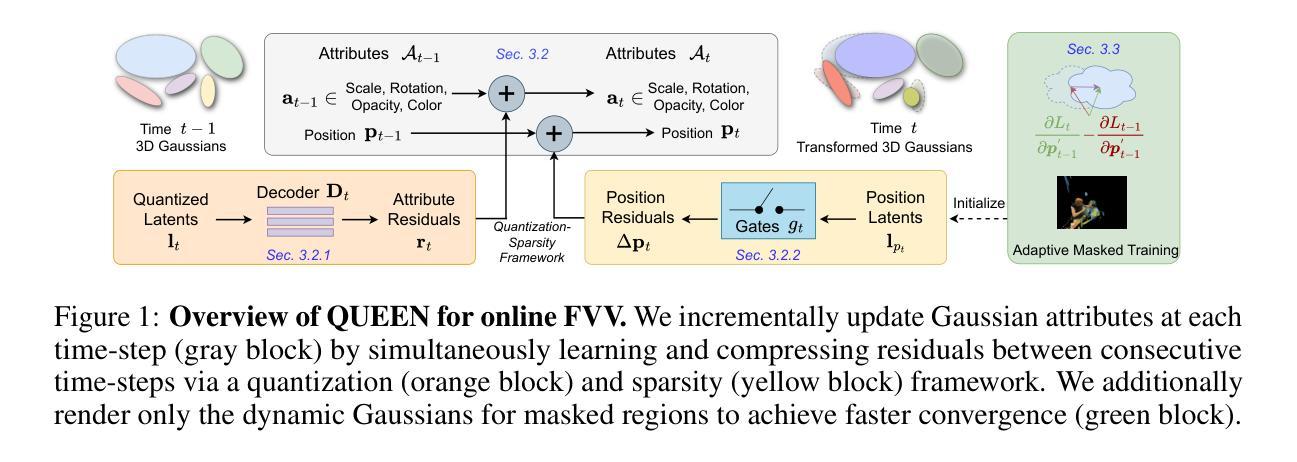
QUEEN: QUantized Efficient ENcoding of Dynamic Gaussians for Streaming Free-viewpoint Videos
Authors:Sharath Girish, Tianye Li, Amrita Mazumdar, Abhinav Shrivastava, David Luebke, Shalini De Mello
Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy real-time constraints and a small memory footprint for efficient transmission. If achieved, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at 350 FPS. Project website is at https://research.nvidia.com/labs/amri/projects/queen
PDF Accepted at NeurIPS 2024, Project website: https://research.nvidia.com/labs/amri/projects/queen
Summary
提出基于3D高斯分层(3D-GS)的QUEN框架,实现高效在线自由视点视频流。
Key Takeaways
- 在线自由视点视频流(FVV)面临挑战,3D-GS编码潜力巨大。
- QUEEN框架学习帧间高斯属性残差,无需结构约束。
- 量化稀疏框架有效存储残差,包括隐式解码器和门控模块。
- 使用高斯视场梯度差向量分离静态和动态内容。
- 高效学习稀疏性,加速训练。
- 在FVV基准上优于现有方法。
- 高动态场景模型仅0.7MB/帧,训练5秒内完成,渲染350FPS。
标题:基于三维高斯贴图的动态场景在线自由视角视频量化高效编码研究(QUEEN: QUantized Efficient ENcoding of Dynamic)
作者:Sharath Girish,Amrita Mazumdar,Tianye Li等
作者单位:Girish来自于马里兰大学;Li和Mazumdar以及Shrivastava来自于NVIDIA;Luebke和De Mello同样来自NVIDIA。
关键词:在线自由视角视频、量化编码、高效编码、三维高斯贴图、动态场景处理、深度学习模型。
Urls:论文链接(待补充);GitHub代码链接(待补充,如果没有可用信息可标记为“GitHub:None”)
总结:
(1) 研究背景:在线自由视角视频(FVV)的流式传输是一个挑战性的问题,需要实现场景的动态重建并高效传输。然而,当前的研究方法在这方面仍有许多不足,本文旨在提出一种高效的解决方案。
(2) 过去的方法及其问题:目前的方法在在线FVV的流式传输方面存在性能不足的问题,尤其是在增量更新、实时约束满足和小内存占用方面。此外,它们通常无法有效地处理高度动态的场景。因此,有必要开发一种新的方法来解决这些问题。
(3) 研究方法:本文提出了一种基于三维高斯贴图(3D-GS)的量化高效编码框架(QUEEN)。该框架直接学习连续帧之间的高斯属性残差,并使用量化稀疏框架来有效存储这些残差。此外,还利用高斯视空间梯度差分向量来分离场景的静态和动态内容,从而加速训练过程。总体而言,这种方法实现了高质量的场景重建和泛化能力。
(4) 任务与性能:本文的方法在多种在线自由视角视频基准测试上表现出色,超过了现有方法的所有指标。特别是在处理高度动态场景时,模型大小被减少到每帧仅0.7 MB,训练时间不到5秒,渲染速度约为350 FPS。这些性能表明该方法在在线自由视角视频的流式传输方面具有巨大的潜力。实验结果支持了本文方法的有效性和优越性。
方法:
(1) 研究背景分析:针对在线自由视角视频(FVV)的流式传输问题,分析当前方法的不足,确定研究背景及必要性。
(2) 方法提出:提出了一种基于三维高斯贴图(3D-GS)的量化高效编码框架(QUEEN)。该框架通过直接学习连续帧之间的高斯属性残差,使用量化稀疏框架有效存储这些残差。同时,利用高斯视空间梯度差分向量来分离场景的静态和动态内容,从而优化训练过程。
(3) 实验设计与实施:在多种在线自由视角视频基准测试上进行实验,验证所提出方法的有效性。通过详细的数据分析和对比,证明该方法在性能上超越现有方法,特别是在处理高度动态场景时表现出色。
(4) 结果评估:实验结果支持所提出方法的有效性和优越性,模型大小被减少到每帧仅0.7 MB,训练时间不到5秒,渲染速度约为350 FPS。这些性能结果表明该方法在在线自由视角视频的流式传输方面具有巨大的潜力。
Conclusion:
- (1)该工作的意义在于提出了一种基于三维高斯贴图的量化高效编码框架(QUEEN),解决了在线自由视角视频(FVV)的流式传输问题。该方法能够实现场景的动态重建并高效传输,对于推动在线自由视角视频技术的发展具有重要意义。
- (2)创新点:该文章提出了基于三维高斯贴图的量化高效编码框架,通过直接学习连续帧之间的高斯属性残差,使用量化稀疏框架有效存储这些残差,并利用高斯视空间梯度差分向量分离场景的静态和动态内容。其创新点在于结合了三维高斯贴图技术与量化编码,实现了高效的视频编码。
- 性能:该文章的方法在多种在线自由视角视频基准测试上表现出色,超过了现有方法的所有指标。特别是在处理高度动态场景时,模型大小被减少到每帧仅0.7 MB,训练时间不到5秒,渲染速度约为350 FPS。这些性能结果表明该方法在实际应用中具有巨大的潜力。
- 工作量:文章进行了详细的实验设计与实施,通过大量的实验验证了所提出方法的有效性。同时,文章对实验结果进行了详细的分析和讨论,证明了该方法的有效性和优越性。
综上所述,该文章提出了一种基于三维高斯贴图的量化高效编码框架,实现了在线自由视角视频的高效编码和传输,具有重要的实际意义和创新性。同时,该方法在性能上表现出色,具有广泛的应用前景。
点此查看论文截图

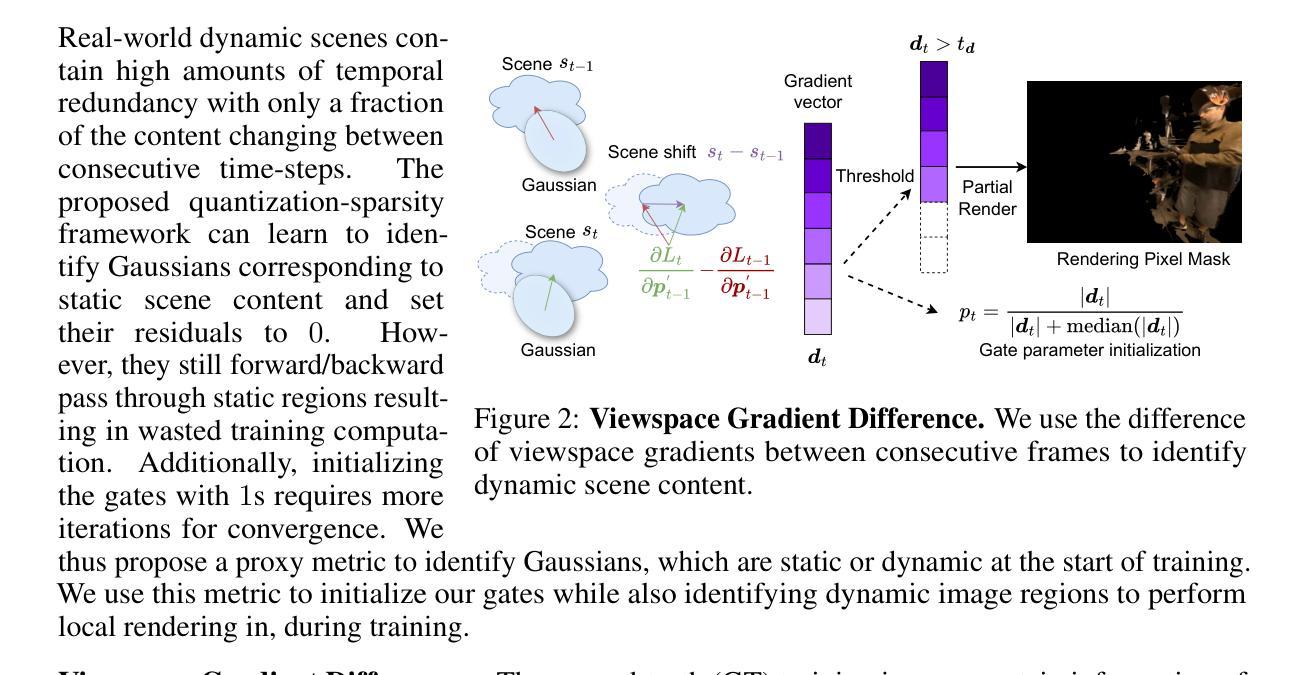
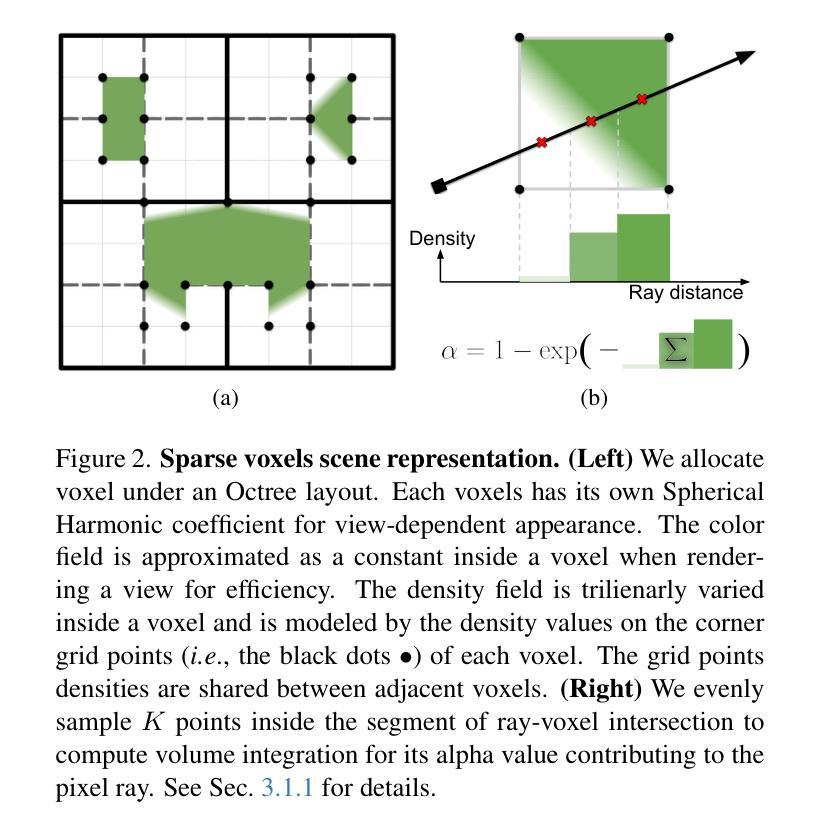
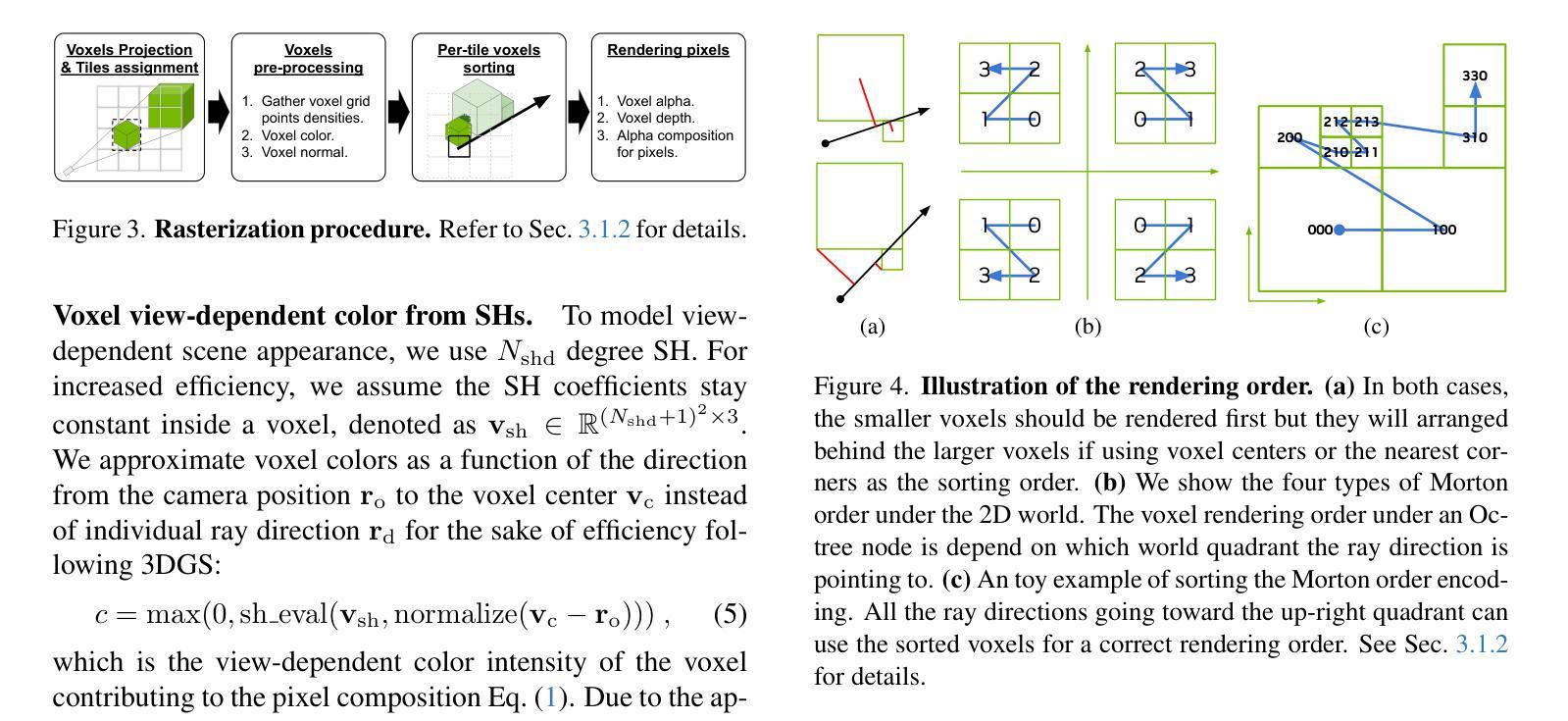
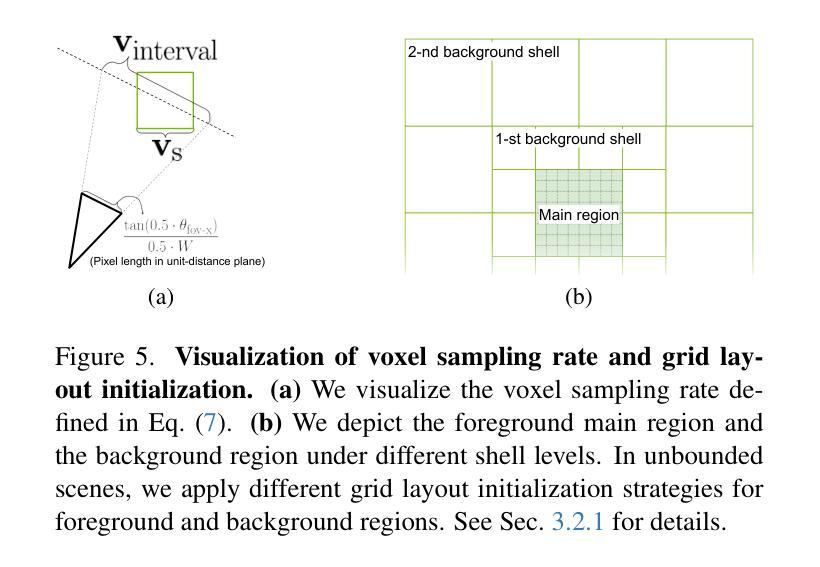
Sparse Voxels Rasterization: Real-time High-fidelity Radiance Field Rendering
Authors:Cheng Sun, Jaesung Choe, Charles Loop, Wei-Chiu Ma, Yu-Chiang Frank Wang
We propose an efficient radiance field rendering algorithm that incorporates a rasterization process on sparse voxels without neural networks or 3D Gaussians. There are two key contributions coupled with the proposed system. The first is to render sparse voxels in the correct depth order along pixel rays by using dynamic Morton ordering. This avoids the well-known popping artifact found in Gaussian splatting. Second, we adaptively fit sparse voxels to different levels of detail within scenes, faithfully reproducing scene details while achieving high rendering frame rates. Our method improves the previous neural-free voxel grid representation by over 4db PSNR and more than 10x rendering FPS speedup, achieving state-of-the-art comparable novel-view synthesis results. Additionally, our neural-free sparse voxels are seamlessly compatible with grid-based 3D processing algorithms. We achieve promising mesh reconstruction accuracy by integrating TSDF-Fusion and Marching Cubes into our sparse grid system.
PDF Code release in progress
Summary
提出无需神经网络或3D高斯函数的稀疏体素渲染算法,提升渲染效率和效果。
Key Takeaways
- 使用动态Morton排序渲染稀疏体素,避免高斯散布的抖动效果。
- 适应场景细节级别,高帧率渲染。
- 比神经网络体素网格提升4db PSNR和10倍渲染速度。
- 与基于网格的3D处理算法兼容。
- 通过TSDF-Fusion和Marching Cubes实现网格系统中的网格重建。
- 改善了稀疏体素的表现。
- 达到先进的视图合成效果。
标题: 高效无神经网络稀疏体素渲染算法研究
作者: 作者名需要查看原文提供的信息。
隶属机构: 由于原文未提供第一作者隶属机构信息,故此项无法回答。
关键词: 稀疏体素渲染、无神经网络、动态Morton排序、场景细节、渲染性能优化、新型视图合成。
链接: 由于原文未提供GitHub代码链接,故此项填“GitHub: None”。
摘要:
(1) 研究背景:本文主要研究了计算机图形学中的稀疏体素渲染技术,针对现有技术存在的问题,提出了一种高效的无神经网络稀疏体素渲染算法。
(2) 现有方法及其问题:过去的方法在稀疏体素渲染中常常使用神经网络或3D高斯函数,但存在计算量大、渲染速度慢、细节表现不足等问题。本文提出的算法旨在解决这些问题。
(3) 研究方法:本文提出的算法结合了稀疏体素栅格化和动态Morton排序技术,通过动态Morton排序对稀疏体素进行正确的深度排序,避免了高斯喷溅中的弹跳伪影。同时,算法还实现了自适应场景细节层次的体素拟合,提高了渲染帧率和场景细节表现。
(4) 任务与性能:本文的方法在新型视图合成任务上取得了显著成果,相较于之前的无神经网络体素网格表示方法,提高了4db PSNR和超过10倍的渲染FPS速度。此外,该方法的稀疏体素能够无缝兼容基于网格的3D处理算法,实现了有前景的网格重建精度。
希望以上总结符合您的要求。如果有任何需要修改或补充的地方,请告诉我。
7. 方法论:
- (1) 研究背景:本文主要研究了计算机图形学中的稀疏体素渲染技术,针对现有技术存在的问题,提出了一种高效的无神经网络稀疏体素渲染算法。
- (2) 方法概述:本文提出的算法结合了稀疏体素栅格化和动态Morton排序技术。首先,使用稀疏体素场景表示和渲染算法,然后引入了一种渐进场景优化策略,旨在从多视角图像中重建场景。
- (3) 场景表示:采用稀疏体素表示三维场景,根据Octree空间分区规则分配体素。通过计算每个体素的alpha值和视差相关的颜色,实现场景的场景表示。其中,alpha值用于表示体素对像素射线的贡献,而颜色则用于表示体素的视差效果。
- (4) 栅格化过程:在渲染过程中,算法将体素投影到图像空间,并按照正确的顺序进行渲染。这一过程中采用了动态Morton排序技术,避免了高斯喷溅中的弹跳伪影。同时,算法还实现了自适应场景细节层次的体素拟合,提高了渲染帧率和场景细节表现。
- (5) 实验结果:本文的方法在新型视图合成任务上取得了显著成果,相较于之前的无神经网络体素网格表示方法,提高了4db PSNR和超过10倍的渲染FPS速度。此外,该方法的稀疏体素能够无缝兼容基于网格的3D处理算法,实现了有前景的网格重建精度。
Conclusion:
(1) 这项工作的意义在于提出了一种高效的无神经网络稀疏体素渲染算法,能够改善计算机图形学中的稀疏体素渲染技术,对于视图合成和场景重建等领域具有重要的应用价值。
(2) 创新点:该文章提出了一种新型的无神经网络稀疏体素渲染算法,结合了稀疏体素栅格化和动态Morton排序技术,实现了高效渲染和场景细节的优化。性能:在新型视图合成任务上,该方法相较于之前的无神经网络体素网格表示方法,提高了渲染帧率和图像质量。工作量:文章详细描述了算法的设计和实现过程,并通过实验验证了算法的有效性。同时,该方法的稀疏体素能够无缝兼容基于网格的3D处理算法,为网格重建提供了新思路。
点此查看论文截图


Monocular Dynamic Gaussian Splatting is Fast and Brittle but Smooth Motion Helps
Authors:Yiqing Liang, Mikhail Okunev, Mikaela Angelina Uy, Runfeng Li, Leonidas Guibas, James Tompkin, Adam W. Harley
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data – an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting. Project Webpage: https://lynl7130.github.io/MonoDyGauBench.github.io/
PDF 37 pages, 39 figures, 9 tables
Summary
利用高斯分层方法进行多视角图像数据转换,以实现动态场景的单目输入数据视图合成,并对比分析了多种方法。
Key Takeaways
- 高斯分层方法在多视角图像数据转换为场景表示方面流行。
- 单目数据动态场景视图合成是一项挑战。
- 多种方法同时提出,但效果各异。
- 对高斯分层方法进行组织和基准测试。
- 使用现有数据集和合成数据集分析。
- 系统分类方法并量化其对性能的影响。
- 实验结果在合成数据中定义明确,但在真实数据中差异被复杂性淹没。
- 高斯方法的快速渲染速度以优化脆弱性为代价。
标题: 单目动态高斯涂抹法
中文翻译:单目动态高斯渲染法研究作者: Yiqing Liang(梁一琦), Mikhail Okunev(米哈伊尔·奥库涅夫), Mikaela Angelina Uy(乌伊·米凯拉·安吉莉娜), Runfeng Li(李润峰), Leonidas Guibas(列奥尼达斯·吉巴斯), James Tompkin(詹姆斯·汤姆金), Adam W. Harley(亚当·W·哈雷)。
作者所属机构: 梁一琦、米哈伊尔·奥库涅夫、李润峰为布朗大学;列奥尼达斯·吉巴斯和亚当·W·哈雷为斯坦福大学;乌伊·米凯拉·安吉莉娜为NVIDIA公司。其中,“Affiliation: 布朗大学;斯坦福大学;NVIDIA公司”表示这些作者分别来自这三个机构。
关键词: Gaussian Splatting(高斯涂抹法)、Dynamic View Synthesis(动态视图合成)、Monocular Camera Data(单目相机数据)、Scene Representation(场景表示)。
链接: 论文链接待补充;GitHub代码链接待补充(如果可用)。如果不可用,填写为“GitHub:None”。
摘要:
(1)研究背景:本文研究了基于单目相机数据的动态场景视图合成问题。由于单目输入数据的动态场景重建是一个病态问题,因此需要使用高斯涂抹法等方法进行多视角图像数据转换为场景表示。
(2)过去的方法及问题:过去的研究中出现了许多基于高斯涂抹法的方法,并应用于动态视图合成。但由于缺乏统一的评估基准和混乱的数据集分割,使得不同方法之间的公平比较变得困难。
(3)研究方法:本文组织、评估和分析了许多基于高斯涂抹法的方法,提供了以前工作所缺乏的“苹果对苹果”的比较。通过创建包含受控相机和场景运动的指导性合成数据集,本文揭示了影响性能的关键因素。同时,系统地分类了高斯涂抹法的运动表示类型,并量化了它们之间的差异如何影响性能。
(4)任务与性能:本文方法在动态视图合成的任务上取得了一定的性能,通过对现有数据集和指导性合成数据集的结果分析证明了方法的有效性。然而,由于现实世界的复杂性,目前仍难以充分展现方法的全部性能优势。尽管如此,本文的贡献在于通过一系列实验发现总结了有助于进一步推进这一活跃领域的关键信息。同时公开了代码和指导性合成数据集,为后续的进一步研究提供了基础。性能结果在一定程度上支持了其方法的实用性,但由于现实世界场景的复杂性,还需进一步的改进和优化才能达到更理想的效果。
以上就是该论文的概括,希望对您有所帮助!
7. Methods:
- (1) 研究背景与问题定义:文章主要研究了基于单目相机数据的动态场景视图合成问题。由于单目输入数据的动态场景重建是一个病态问题,因此需要寻找有效的解决方法。
- (2) 方法综述:文章综述了现有的基于高斯涂抹法的方法,并分析了其优缺点,缺乏统一的评估基准和混乱的数据集分割使得公平比较变得困难。
- (3) 指导性合成数据集的创建:为了进行公平的比较和分析,文章创建了一个包含受控相机和场景运动的指导性合成数据集。
- (4) 高斯涂抹法的运动表示类型分类:文章系统地分类了高斯涂抹法的运动表示类型,并探讨了它们之间的差异如何影响性能。
- (5) 实验与性能评估:文章通过一系列实验对动态视图合成的性能进行了评估,并通过分析现有数据集和指导性合成数据集的结果证明了方法的有效性。同时公开了代码和指导性合成数据集,为后续的进一步研究提供了基础。
以上内容仅供参考,建议查阅该论文以获取更准确全面的信息。
8. Conclusion:
- (1)工作意义:该研究对于动态场景视图合成的领域具有重要的推动作用,特别是基于单目相机数据的处理方法。它有助于解决现实世界中动态场景的重建问题,对于计算机视觉、图形学以及虚拟现实等领域的发展都具有重要的意义。
- (2)创新点、性能、工作量总结:
- 创新点:文章创建了指导性合成数据集,为动态视图合成的方法提供了一个统一的评估基准。此外,文章系统地分类了高斯涂抹法的运动表示类型,并分析了它们对性能的影响,这是该领域的一个新的尝试和探索。
- 性能:文章的方法在动态视图合成的任务上取得了一定的性能提升,并通过实验证明了其有效性。然而,由于现实世界的复杂性,方法的性能还需要进一步的优化和提升。
- 工作量:文章进行了大量的实验和数据分析,对现有的高斯涂抹法进行了全面的综述和分析。同时,文章的代码和指导性合成数据集的公开为后续的进一步研究提供了基础,展现了作者的工作量和贡献。
以上就是对该论文的总结,希望对您有所帮助。
点此查看论文截图

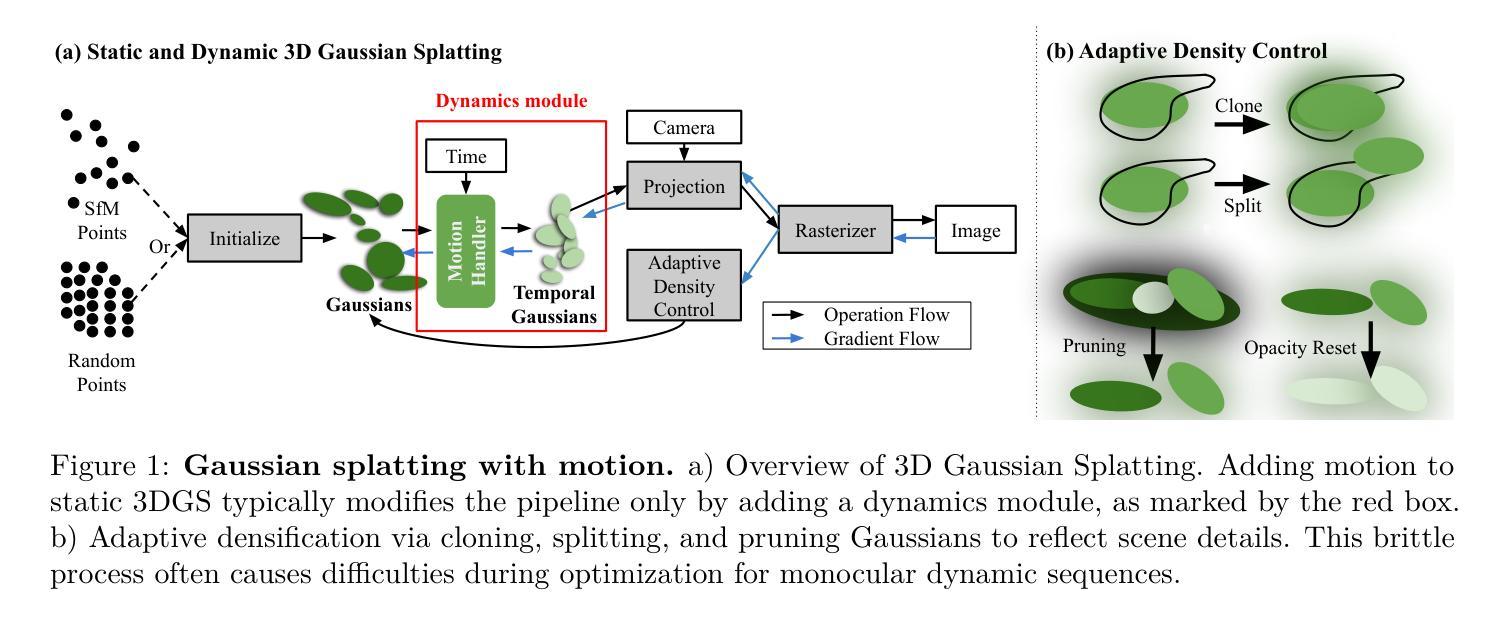


PBDyG: Position Based Dynamic Gaussians for Motion-Aware Clothed Human Avatars
Authors:Shota Sasaki, Jane Wu, Ko Nishino
This paper introduces a novel clothed human model that can be learned from multiview RGB videos, with a particular emphasis on recovering physically accurate body and cloth movements. Our method, Position Based Dynamic Gaussians (PBDyG), realizes movement-dependent'' cloth deformation via physical simulation, rather than merely relying on pose-dependent’’ rigid transformations. We model the clothed human holistically but with two distinct physical entities in contact: clothing modeled as 3D Gaussians, which are attached to a skinned SMPL body that follows the movement of the person in the input videos. The articulation of the SMPL body also drives physically-based simulation of the clothes’ Gaussians to transform the avatar to novel poses. In order to run position based dynamics simulation, physical properties including mass and material stiffness are estimated from the RGB videos through Dynamic 3D Gaussian Splatting. Experiments demonstrate that our method not only accurately reproduces appearance but also enables the reconstruction of avatars wearing highly deformable garments, such as skirts or coats, which have been challenging to reconstruct using existing methods.
Summary
本文提出一种基于多视角RGB视频学习的人体模型,通过物理模拟实现准确的衣物和身体运动。
Key Takeaways
- 使用多视角RGB视频学习衣物人体模型。
- PBDyG方法通过物理模拟实现运动依赖的衣物变形。
- 衣物作为3D高斯模型,附着在SMPL身体上。
- SMPL身体驱动衣物高斯模型模拟,变换到新姿势。
- 利用RGB视频估计物理属性进行位置动态模拟。
- 成功重建高度可变形衣物,如裙子和外套。
- 方法在重现外观和重建方面均表现优异。
标题:基于位置的动态高斯模型(PBDyG):用于感知运动感知的穿衣人类化身(中文翻译)。
作者:Shota Sasaki(佐佐木翔太),Jane Wu(吴婧),Ko Nishino(清水可伸)。
作者所属机构:京都大学(Shota Sasaki和Ko Nishino)和加利福尼亚大学伯克利分校(Jane Wu)。
关键词:PBDyG模型,运动感知,服装模拟,动态高斯模型,人体行为建模。
链接:论文链接(请提供文章URL)。关于代码,由于此处没有给出GitHub代码链接,所以填写“GitHub: 无”。
摘要:
(1)研究背景:本文介绍了一种从多视角RGB视频中学习穿衣人类模型的新方法,重点关注从视频中恢复物理准确的人体及衣物运动。现有方法在重建高度可变形衣物(如裙子或外套)时面临挑战。
(2)过去的方法及问题:过去的研究主要依赖于“姿势依赖”的刚性变换来模拟衣物变形。这种方法无法准确模拟衣物的真实动态变形。本文方法动机良好,旨在通过物理模拟实现“运动依赖”的衣物变形。
(3)研究方法:本文提出一种名为Position Based Dynamic Gaussians (PBDyG)的方法,将衣物建模为3D高斯模型,并附着在跟随视频人物运动的SMPL身体上。通过物理模拟,SMPL身体的关节活动会驱动衣物的高斯模型变形,从而实现新型姿态下的化身转换。为了运行基于位置的动态模拟,从RGB视频中通过动态3D高斯喷溅估计物理属性,如质量和材料刚度。
(4)任务与性能:本文方法在重建穿着高度可变形衣物(如裙子或外套)的人的任务上表现出色。实验表明,该方法不仅准确复现外观,还能重建高度可变形衣物的化身。性能支持其目标,即实现逼真的穿衣人类化身建模。
请注意,由于无法直接访问外部链接或获取论文全文,以上摘要可能不完全准确。建议进一步阅读论文以获取更多详细信息。
7. 方法论概述:
(1)研究背景与动机:
本文介绍了一种基于多视角RGB视频学习穿衣人类模型的新方法。该方法重点关注从视频中恢复物理准确的人体及衣物运动。现有方法在重建高度可变形衣物(如裙子或外套)时面临挑战,因此本文旨在通过物理模拟实现“运动依赖”的衣物变形,从而更好地模拟衣物的真实动态变形。
(2)研究方法概述:
文章提出了名为Position Based Dynamic Gaussians (PBDyG)的方法。首先,将衣物建模为3D高斯模型并附着在跟随视频人物运动的SMPL身体上。通过物理模拟,SMPL身体的关节活动会驱动衣物的高斯模型变形,从而实现新型姿态下的化身转换。为了运行基于位置的动态模拟,从RGB视频中通过动态3D高斯喷溅估计物理属性,如质量和材料刚度。然后,利用这些物理属性进行衣物变形的模拟和优化。在这个过程中,文章还引入了一些新的评估指标和方法来量化重建的准确度。
(3)实验设计与实现:
文章进行了大量的实验来验证方法的有效性。在实验过程中,使用了动画高斯模型(AG)作为基准方法进行比较。通过对比实验数据,展示了PBDyG方法在重建穿着高度可变形衣物的人的任务上的优越性。此外,文章还详细介绍了实验中使用的参数优化策略、子步骤策略、约束条件等细节,以确保模拟的稳定性和衣物的灵活性。其中,一些新的约束条件如AirMesh约束的引入,有效地解决了模拟过程中的一些问题。通过这些实验和策略的实现,文章的方法能够在重建穿衣人类化身时实现较高的准确性和逼真度。
8. 结论:
(1)该工作的意义在于介绍了一种从多视角RGB视频中学习穿衣人类模型的新方法,重点关注从视频中恢复物理准确的人体及衣物运动。这项工作对于实现高度逼真的虚拟人物建模和动画具有重要的应用价值,可以广泛应用于电影、游戏、虚拟现实等领域。
(2)从创新点、性能和工作量三个方面对这篇文章进行简要的评价:
创新点:文章提出了一种基于位置的动态高斯模型(PBDyG)用于感知运动感知的穿衣人类化身的新方法。该方法通过物理模拟实现“运动依赖”的衣物变形,从而更好地模拟衣物的真实动态变形,是一种创新性的尝试。
性能:文章的方法在重建穿着高度可变形衣物的人的任务上表现出色,实验结果表明该方法能够准确复现外观,并重建高度可变形衣物的化身。
工作量:文章进行了大量的实验和策略实现来验证方法的有效性,包括方法论的概述、实验设计与实现等。然而,文章的代码并未公开,无法直接评估其实现的复杂度和工作量。
总体来说,该文章提出了一种新的穿衣人类模型学习方法,并在实验上验证了其有效性。然而,文章也存在一些局限性,如未公开的代码和可能的计算复杂度问题,需要在未来的工作中进一步研究和改进。
点此查看论文截图


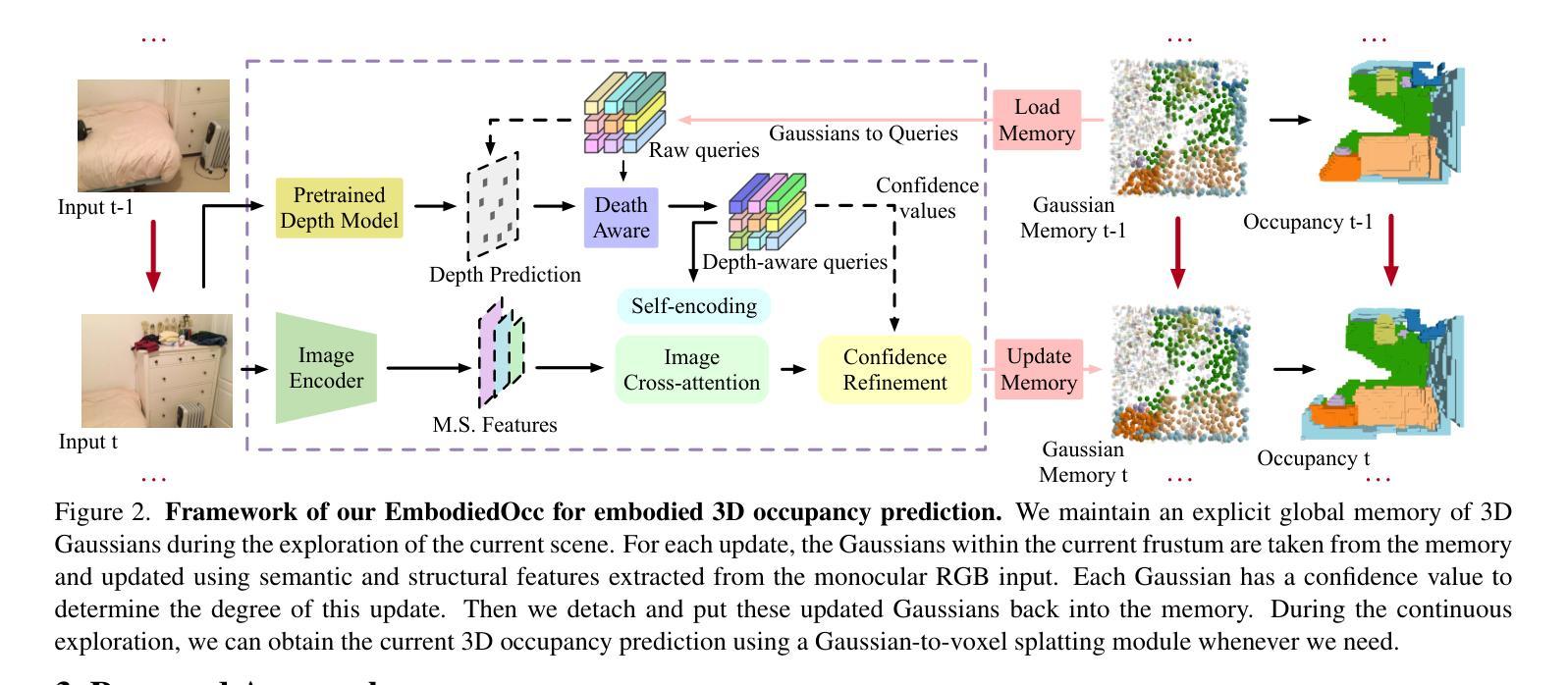
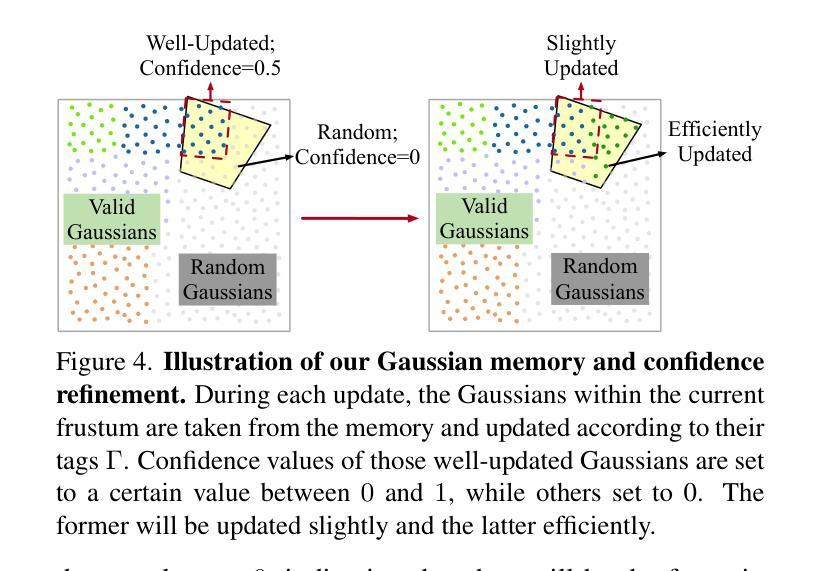
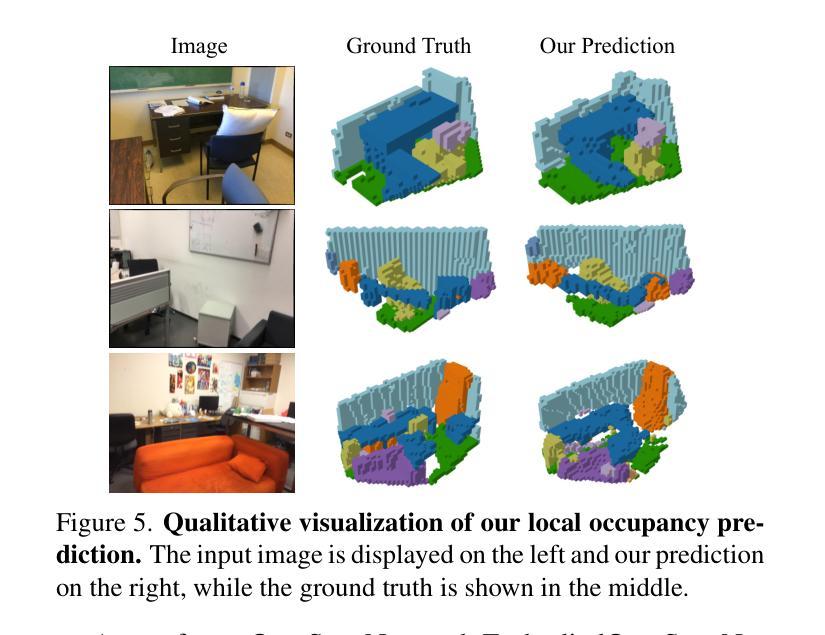
EmbodiedOcc: Embodied 3D Occupancy Prediction for Vision-based Online Scene Understanding
Authors:Yuqi Wu, Wenzhao Zheng, Sicheng Zuo, Yuanhui Huang, Jie Zhou, Jiwen Lu
3D occupancy prediction provides a comprehensive description of the surrounding scenes and has become an essential task for 3D perception. Most existing methods focus on offline perception from one or a few views and cannot be applied to embodied agents which demands to gradually perceive the scene through progressive embodied exploration. In this paper, we formulate an embodied 3D occupancy prediction task to target this practical scenario and propose a Gaussian-based EmbodiedOcc framework to accomplish it. We initialize the global scene with uniform 3D semantic Gaussians and progressively update local regions observed by the embodied agent. For each update, we extract semantic and structural features from the observed image and efficiently incorporate them via deformable cross-attention to refine the regional Gaussians. Finally, we employ Gaussian-to-voxel splatting to obtain the global 3D occupancy from the updated 3D Gaussians. Our EmbodiedOcc assumes an unknown (i.e., uniformly distributed) environment and maintains an explicit global memory of it with 3D Gaussians. It gradually gains knowledge through local refinement of regional Gaussians, which is consistent with how humans understand new scenes through embodied exploration. We reorganize an EmbodiedOcc-ScanNet benchmark based on local annotations to facilitate the evaluation of the embodied 3D occupancy prediction task. Experiments demonstrate that our EmbodiedOcc outperforms existing local prediction methods and accomplishes the embodied occupancy prediction with high accuracy and strong expandability. Our code is available at: https://github.com/YkiWu/EmbodiedOcc.
PDF Code: https://github.com/YkiWu/EmbodiedOcc
Summary
该论文提出了一种基于高斯分布的3D场景感知框架EmbodiedOcc,通过逐区域更新实现3D场景的实体感知预测。
Key Takeaways
- 3D占用预测是3D感知的关键任务。
- 现有方法难以应用于需要逐步探索场景的实体代理。
- 提出基于高斯分布的EmbodiedOcc框架。
- 初始化全局场景为均匀3D语义高斯分布。
- 逐步更新局部区域,通过可变形交叉注意力提取特征。
- 使用高斯到体素映射获得全局3D占用。
- 框架假设未知环境,并使用3D高斯进行全局记忆。
- 通过局部区域高斯更新逐步获取知识。
- 重组EmbodiedOcc-ScanNet基准,方便评估。
- 实验表明EmbodiedOcc在占用预测上优于现有方法。
标题:基于高斯分布的嵌入式三维占用预测研究
作者:待提供(英文名字)
所属机构:待提供(中文翻译)
关键词:三维占用预测、嵌入式智能体、场景感知、高斯分布、局部占用预测、全球占用预测
链接:论文链接待提供,GitHub代码链接:https://github.com/YkiWu/EmbodiedOcc(如不可用,请填写“None”)
总结:
(1)研究背景:本文研究了嵌入式三维占用预测问题,即针对智能体在未知环境中通过自主探索逐步感知场景的任务。现有方法大多侧重于离线感知,无法适用于嵌入式智能体的需求。因此,本文旨在提出一种适用于此实际场景的解决方案。
(2)过去的方法及问题:现有方法主要关注从单一或少数视角进行离线感知,无法适应智能体在未知环境中的逐步探索需求。因此,需要一种能够逐步更新并感知局部区域占用情况的方法。
(3)研究方法:本文提出了一种基于高斯分布的嵌入式三维占用预测框架(EmbodiedOcc)。首先,使用均匀分布的三维语义高斯图初始化全局场景。然后,随着智能体的探索,逐步更新观察到的局部区域。每次更新时,从观察到的图像中提取语义和结构特征,并通过可变形交叉注意力机制进行高效融合,以细化区域高斯图。最后,使用高斯到体素的喷溅技术从更新的三维高斯图中获得全局三维占用图。该方法通过局部区域的逐步细化来逐渐了解环境,与人类通过亲身体验探索新场景的方式相一致。
(4)任务与性能:本文基于局部注释重新组织了一个嵌入式占用预测的基准数据集(EmbodiedOcc-ScanNet),并进行了实验评估。结果显示,EmbodiedOcc在嵌入式三维占用预测任务上取得了较高的准确性和较强的可扩展性。该方法的性能支持了其在实际应用中的有效性。
方法论:
该文的方法论可以详细阐述如下:
- (1) 研究背景与问题定义:
该文针对嵌入式智能体在未知环境中的逐步感知场景的任务,提出了一种基于高斯分布的嵌入式三维占用预测框架(EmbodiedOcc)。现有方法大多侧重于离线感知,无法适用于嵌入式智能体的需求。因此,该文旨在通过局部区域的逐步细化来逐渐了解环境,与人类通过亲身体验探索新场景的方式相一致。
- (2) 数据集构建:
为了评估嵌入式占用预测任务,该文基于局部注释重新组织了一个嵌入式占用预测的基准数据集(EmbodiedOcc-ScanNet)。
- (3) 方法设计:
该文提出了一种基于高斯分布的嵌入式三维占用预测方法。首先,使用均匀分布的三维语义高斯图初始化全局场景。然后,随着智能体的探索,逐步更新观察到的局部区域。每次更新时,从观察到的图像中提取语义和结构特征,并通过可变形交叉注意力机制进行高效融合,以细化区域高斯图。最后,使用高斯到体素的喷溅技术从更新的三维高斯图中获得全局三维占用图。其中,设计了局部占用预测模块、深度感知分支以及高斯内存在线更新机制等关键组件。
- (4) 实验评估:
该文在自定义数据集上进行实验评估,结果显示所提方法在嵌入式三维占用预测任务上取得了较高的准确性和较强的可扩展性,验证了方法的有效性。
8. 结论:
(1)意义:该工作针对嵌入式智能体在未知环境中的逐步感知场景的任务,提出了一种基于高斯分布的嵌入式三维占用预测框架(EmbodiedOcc),具有重要的实际应用价值。
(2)创新点、性能、工作量总结:
创新点:该文章提出了一种基于高斯分布的嵌入式三维占用预测方法,通过局部区域的逐步细化来逐渐了解环境,适应了嵌入式智能体的需求。
性能:实验结果表明,所提方法在嵌入式三维占用预测任务上取得了较高的准确性和较强的可扩展性,验证了方法的有效性。
工作量:该文章重新组织了一个嵌入式占用预测的基准数据集(EmbodiedOcc-ScanNet)用于评估,并详细阐述了方法的设计、实验评估等方面。然而,文章未提供充分的细节关于数据集的具体构建方法和实验设置的详细参数,这可能限制了读者对其工作量的全面评估。
以上是对该文章的创新点、性能、工作量的总结。
点此查看论文截图


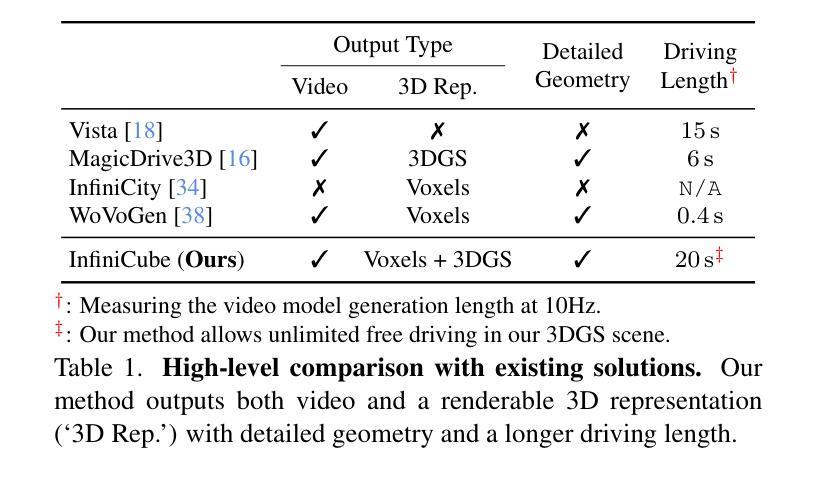
InfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided Video Models
Authors:Yifan Lu, Xuanchi Ren, Jiawei Yang, Tianchang Shen, Zhangjie Wu, Jun Gao, Yue Wang, Siheng Chen, Mike Chen, Sanja Fidler, Jiahui Huang
We present InfiniCube, a scalable method for generating unbounded dynamic 3D driving scenes with high fidelity and controllability. Previous methods for scene generation either suffer from limited scales or lack geometric and appearance consistency along generated sequences. In contrast, we leverage the recent advancements in scalable 3D representation and video models to achieve large dynamic scene generation that allows flexible controls through HD maps, vehicle bounding boxes, and text descriptions. First, we construct a map-conditioned sparse-voxel-based 3D generative model to unleash its power for unbounded voxel world generation. Then, we re-purpose a video model and ground it on the voxel world through a set of carefully designed pixel-aligned guidance buffers, synthesizing a consistent appearance. Finally, we propose a fast feed-forward approach that employs both voxel and pixel branches to lift the dynamic videos to dynamic 3D Gaussians with controllable objects. Our method can generate controllable and realistic 3D driving scenes, and extensive experiments validate the effectiveness and superiority of our model.
PDF Project Page: https://research.nvidia.com/labs/toronto-ai/infinicube/
Summary
提出InfiniCube,一种可扩展、高保真和可控的无限动态3D驾驶场景生成方法。
Key Takeaways
- InfiniCube可生成无限动态3D驾驶场景。
- 解决了场景生成尺度有限和几何外观不一致的问题。
- 利用可扩展3D表示和视频模型技术。
- 构建基于稀疏体素的条件图3D生成模型。
- 重新使用视频模型,通过像素对齐指导缓冲区进行优化。
- 提出快速前馈方法,结合体素和像素分支。
- 生成可控、逼真的3D驾驶场景,实验验证有效性。
标题:生成无界动态三维驾驶场景的方法研究
作者:XXX (这里可以填写具体的作者姓名)
所属机构:XXX(这里可以填写第一作者所在的机构名称,例如“清华大学计算机科学系”)
关键词:三维场景生成、动态场景、驾驶场景、无限世界生成、视频生成
链接:由于无法确定具体的论文链接和GitHub代码链接,此处无法填写。请提供具体的链接以便进行填写。
摘要:
(1) 研究背景:随着虚拟现实、游戏开发等领域的发展,对大规模、动态、逼真的三维场景的需求日益增长。本文提出了一种生成无界动态三维驾驶场景的方法,旨在解决现有方法在场景规模、几何和外观一致性等方面的问题。
(2) 相关工作与问题:现有的场景生成方法大多受限于场景规模、缺乏几何和外观的一致性。它们在处理大规模场景生成时,往往难以保持场景元素的真实感和多样性。本文提出的方法旨在解决这些问题。
(3) 研究方法:本文首先构建了一个基于稀疏体素的地图条件三维生成模型,用于无界的三维世界生成。然后,利用视频模型并将其根植于体素世界,通过一系列精心设计的像素对齐引导缓冲区,合成一致的外观。最后,提出了一种快速前馈方法,结合了体素和像素分支,将动态视频提升为具有控制标签对象的动态三维高斯场景。
(4) 任务与性能:本文的方法能够在控制下生成逼真的三维驾驶场景,包括大规模的场景、动态的车辆和一致的外观。实验结果表明,该方法在场景生成的质量和效率方面均表现出优越的性能,验证了模型设计的有效性。
请注意,由于无法确定具体的论文内容和实验结果,上述摘要中的部分描述是基于对论文摘要和引言部分的推测。请提供具体的论文内容以便进行更准确的回答。
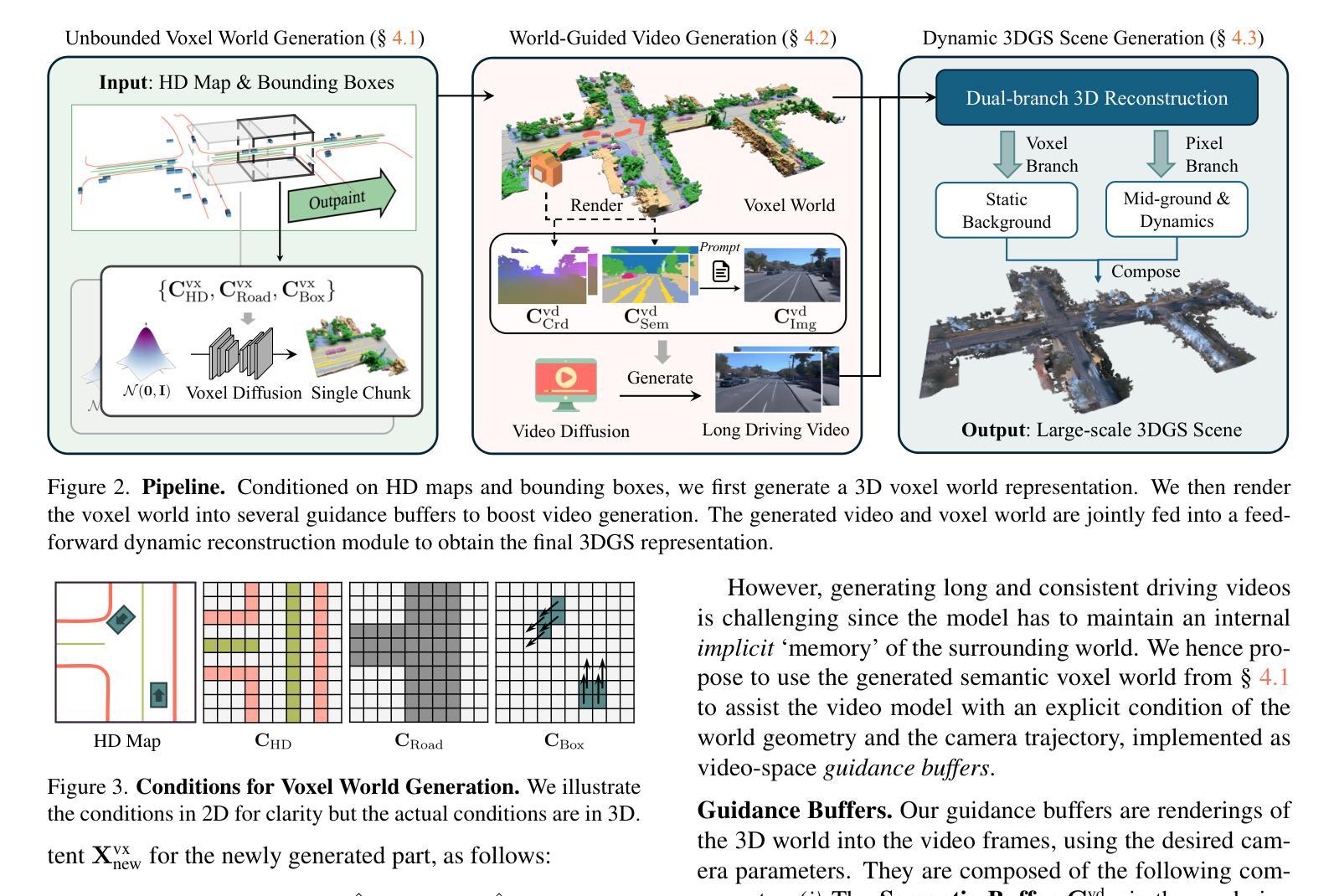
7. 方法论概述:
- (1) 研究者提出了一种生成无界动态三维驾驶场景的方法。该方法旨在解决现有场景生成方法在场景规模、几何和外观一致性等方面的问题。
- (2) 方法首先构建一个基于稀疏体素的地图条件三维生成模型,用于无界的三维世界生成。该模型结合输入的高清地图、车辆边界框和文本提示来生成大规模语义体素世界。
- (3) 为了渲染动态场景,方法使用体素世界生成指导缓冲区,支持长程视频生成。这些指导缓冲区结合了体素和像素分支,将动态视频提升为具有控制标签对象的动态三维高斯场景。
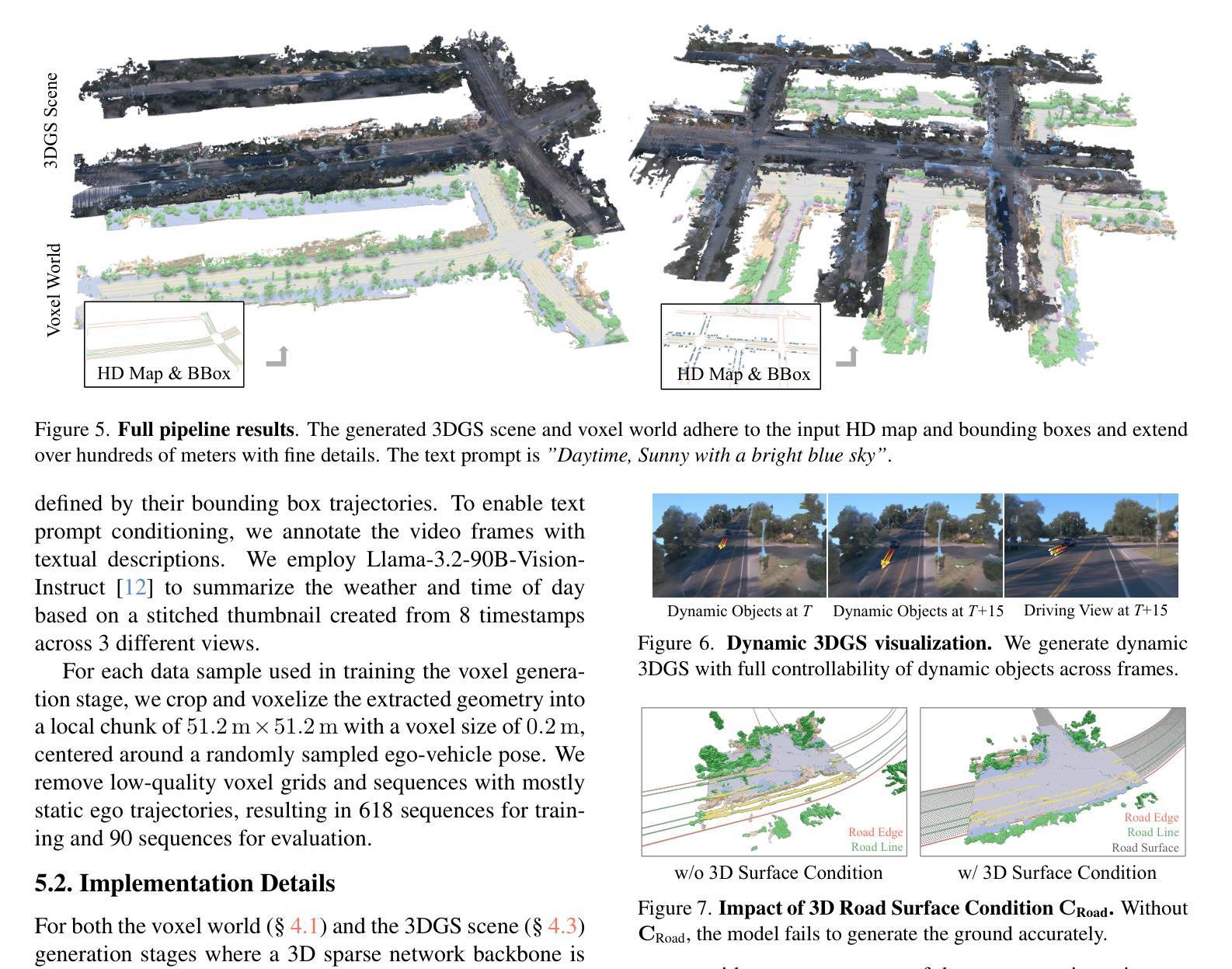
- (4) 在具体实现上,研究者采用了一种扩散采样过程来生成语义体素网格表示,并结合无界场景外推技术,将场景逐步扩展到更大的范围。同时,通过训练模型,使得生成的场景具有真实的外观和动态效果。最终,方法能够控制生成逼真的三维驾驶场景,包括大规模场景、动态车辆和一致的外观。实验结果表明,该方法在场景生成的质量和效率方面均表现出优越的性能。
- Conclusion:
(1) 这项工作的意义在于提出了一种生成无界动态三维驾驶场景的方法,解决了现有方法在场景规模、几何和外观一致性等方面的问题,对于虚拟现实、游戏开发等领域具有广泛的应用前景。
(2) 创新点:本文提出了基于稀疏体素的地图条件三维生成模型,并结合视频模型,实现了无界的三维世界生成和动态场景的渲染。
性能:该方法能够在控制下生成大规模、逼真的三维驾驶场景,包括动态车辆和一致的外观。实验结果表明,该方法在场景生成的质量和效率方面均表现出优越的性能。
工作量:文章详细描述了方法的实现过程,包括模型构建、场景生成、动态场景渲染等,具有一定的技术难度和工作量。
点此查看论文截图


Multi-View Pose-Agnostic Change Localization with Zero Labels
Authors:Chamuditha Jayanga Galappaththige, Jason Lai, Lloyd Windrim, Donald Dansereau, Niko Suenderhauf, Dimity Miller
Autonomous agents often require accurate methods for detecting and localizing changes in their environment, particularly when observations are captured from unconstrained and inconsistent viewpoints. We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7$\times$ and 1.6$\times$ improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
Summary
提出了一种基于3D高斯拼贴的标签无关、姿态无关的变化检测方法,显著提升了变化检测性能。
Key Takeaways
- 新方法无需标签,适用于不同姿态的图像。
- 通过多视角信息构建变化感知3D高斯拼贴表示。
- 仅需5张变化后场景图像即可学习变化通道。
- 生成变化掩膜优于单视图技术。
- 可生成未见视图的准确变化掩膜。
- 在复杂多对象场景中表现卓越。
- 实验结果优于现有基准,显著提升性能。
- 提供了新的真实世界数据集以评估变化检测。
Title: 多视角无标签姿态无关变化定位研究
Authors: Chamuditha Jayanga, Jason Lai, Lloyd Windrim, Donald Dansereau, Niko Suenderhauf, Dimity Miller (作者姓名请以论文原英文为准)
Affiliation:
第一作者Chamuditha Jayanga的归属单位:昆士兰科技大学机器人研究中心(QUT Centre for Robotics)。Keywords: 视觉变化检测,多视角,无标签学习,姿态无关,高斯融合模型
Urls: 论文链接(论文提交至arXiv,具体链接等论文正式发表后填写), 代码GitHub链接(github.com/PASLCD)或(由于论文未开源,此项暂无法提供具体链接。)
Summary:
(1) 研究背景:随着自主机器人的发展,环境变化的检测和定位成为了一个重要的研究领域。特别是在观察视角不一致的情况下,自主机器人需要准确地检测并定位环境的变化。然而现有的许多变化检测方法对视角的一致性要求较高,且标注数据的成本较高。因此,本研究提出了一种无需标签、姿态无关的变化检测方法。
(2) 过去的方法及其问题:许多传统的变化检测方法依赖于精确对齐预变化和后变化图像来定位变化。这些方法在场景视角不一致时应用受限。一些方法试图通过图像配对来检测视角不一致的变化,但需要通过标注数据进行训练,这增加了成本,并且在环境变化时性能可能会下降。因此,这些方法存在视角不一致和标注数据的问题。
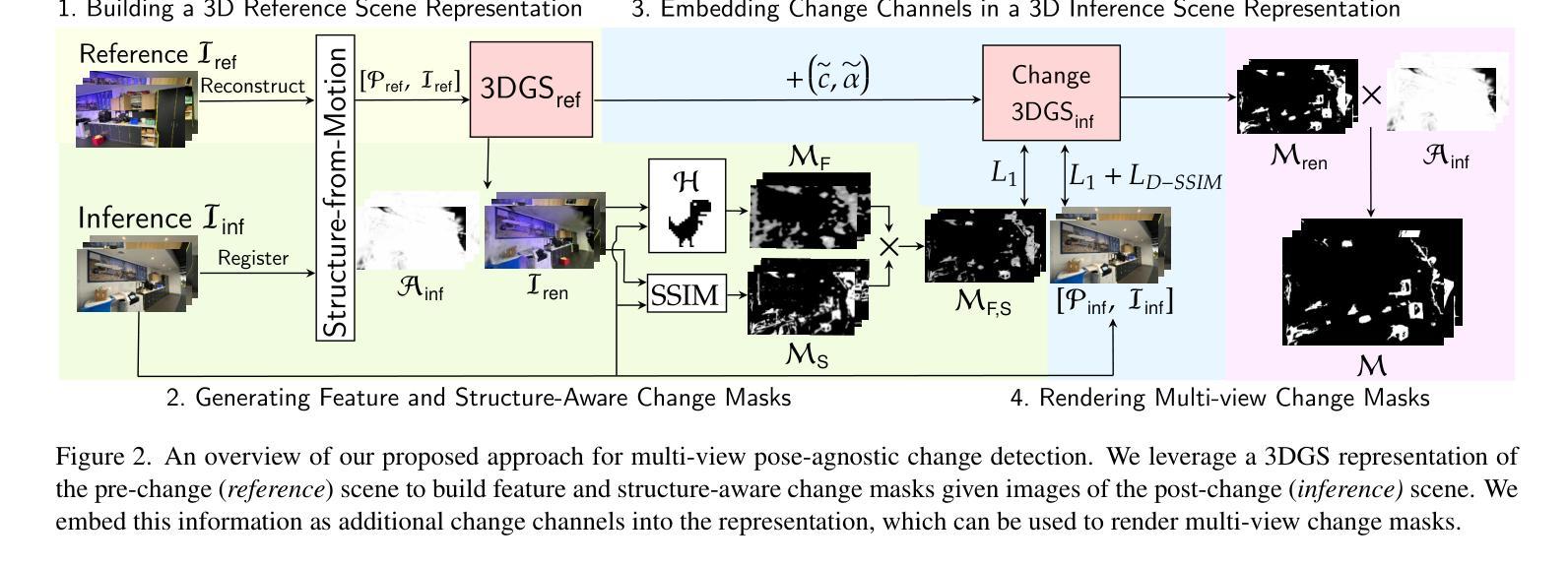
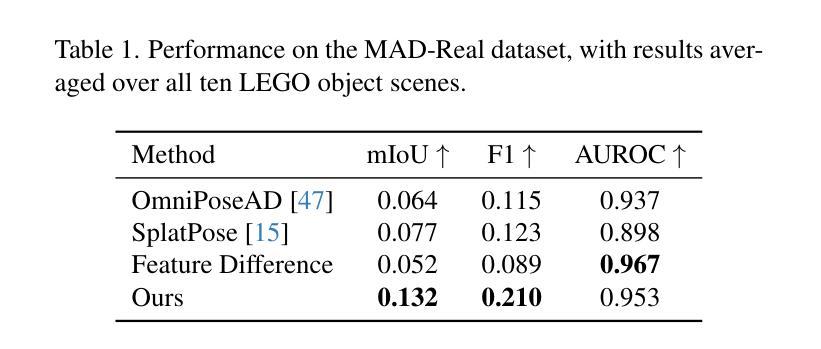
(3) 研究方法:本研究提出了一种无需标签、姿态无关的变化检测方法。该方法通过整合多视角信息来构建一个场景的三维高斯融合模型(3DGS)。利用少量的后变化场景图像,可以在此模型中学习额外的变化通道并产生超越单视角技术的变化掩膜。此外,该方法还可以为未见过的视角生成准确的变化掩膜。实验结果表明,在复杂的多物体场景中,该方法达到了业界领先水平。通过在实际数据集上的实验验证,该方法的平均交并比和F1分数分别提高了1.7倍和1.6倍。此外,该研究还贡献了一个新的真实世界数据集,用于在光照变化的情况下对多样化的挑战场景进行变化检测评估。
(4) 任务与性能:本研究的方法应用于多视角无标签的姿态无关变化定位任务上。实验结果表明,该方法在复杂的多物体场景中实现了出色的性能提升。通过在实际数据集上的评估,证明了该方法的有效性。由于该方法无需标注数据,因此在环境变化时具有较强的适应性。同时,贡献的真实世界数据集也为变化检测的研究提供了重要的评估资源。方法:
(1) 研究背景:该研究针对自主机器人在观察视角不一致的情况下,对环境变化的检测和定位问题进行研究。由于现有的许多变化检测方法对视角的一致性要求较高,且标注数据的成本较高,因此该研究提出了一种无需标签、姿态无关的变化检测方法。
(2) 数据收集与处理:研究使用了包含多视角图像的数据集,通过对预变化场景和后变化场景图像的收集和处理,构建了一个三维高斯融合模型(3DGS)。利用少量的后变化场景图像,可以在此模型中学习额外的变化通道并产生超越单视角技术的变化掩膜。
(3) 特征与结构感知变化掩膜生成:通过比较后变化场景图像与预变化场景渲染图像的对应位置,生成特征感知和结构感知的变化掩膜。特征感知变化掩膜侧重于图像的特征变化,而结构感知变化掩膜则侧重于图像的结构变化。
(4) 多视角无标签姿态无关变化定位:研究通过构建包含变化信息的新三维高斯融合模型(Change-3DGSinf),实现了多视角变化掩膜的生成。该模型能够嵌入变化信息,并通过优化学习到的参数,生成多视角的变化掩膜。这一方法不仅能够在已有的视角生成变化掩膜,还能够在全新的视角生成变化掩膜。
(5) 数据增强策略:为了增加变化掩膜的数量,提高模型的学习效果,研究还引入了一种数据增强策略。通过数据增强,可以增加训练样本的多样性,提高模型的泛化能力。
(6) 实验验证与评估:研究在实际数据集上进行了实验验证,证明了该方法的有效性。由于该方法无需标注数据,因此在环境变化时具有较强的适应性。同时,贡献的真实世界数据集也为变化检测的研究提供了重要的评估资源。
8. Conclusion:
- (1)这项工作的重要性在于,它提出了一种无需标签、姿态无关的变化检测方法,这对于自主机器人在观察视角不一致的情况下进行环境变化的检测和定位具有重要意义。
- (2)创新点总结:该文章在创新点、性能、工作量三个维度上有以下优劣势。创新点方面,文章提出了一种新的三维高斯融合模型(3DGS),能够整合多视角信息,实现无需标签的姿态无关变化检测,具有一定的创新性。性能方面,该文章通过实际数据集的实验验证,证明了方法的有效性,并在复杂多物体场景中实现了显著的性能提升。然而,该文章也存在一定的局限性,例如在特征掩膜方面存在一些观察到的限制。工作量方面,文章贡献了一个真实世界的变化检测数据集,为变化检测的研究提供了重要的评估资源。
综上所述,该文章提出的方法具有一定的创新性和实用价值,为变化检测领域的研究提供了新的思路和方法。
点此查看论文截图

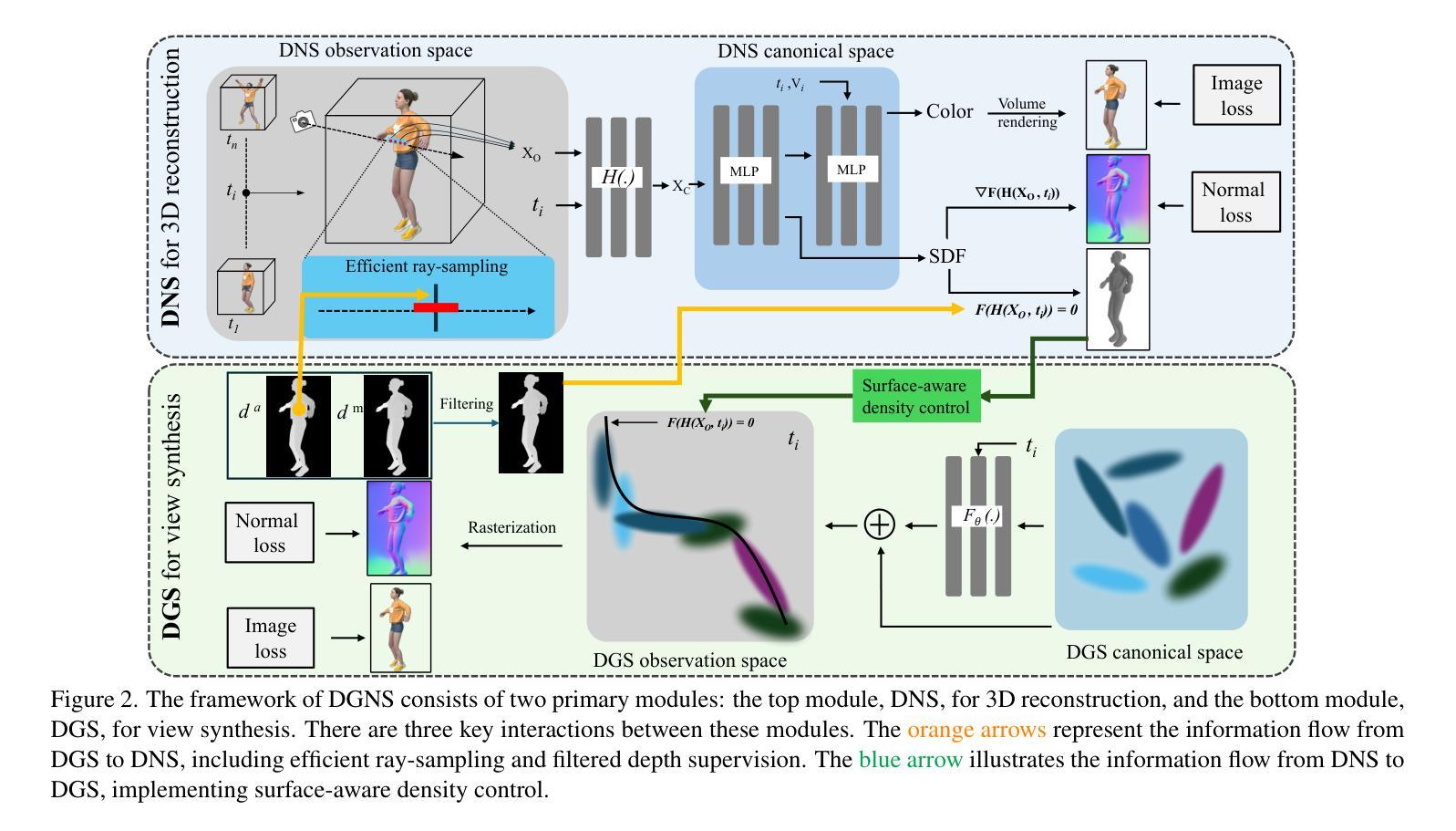
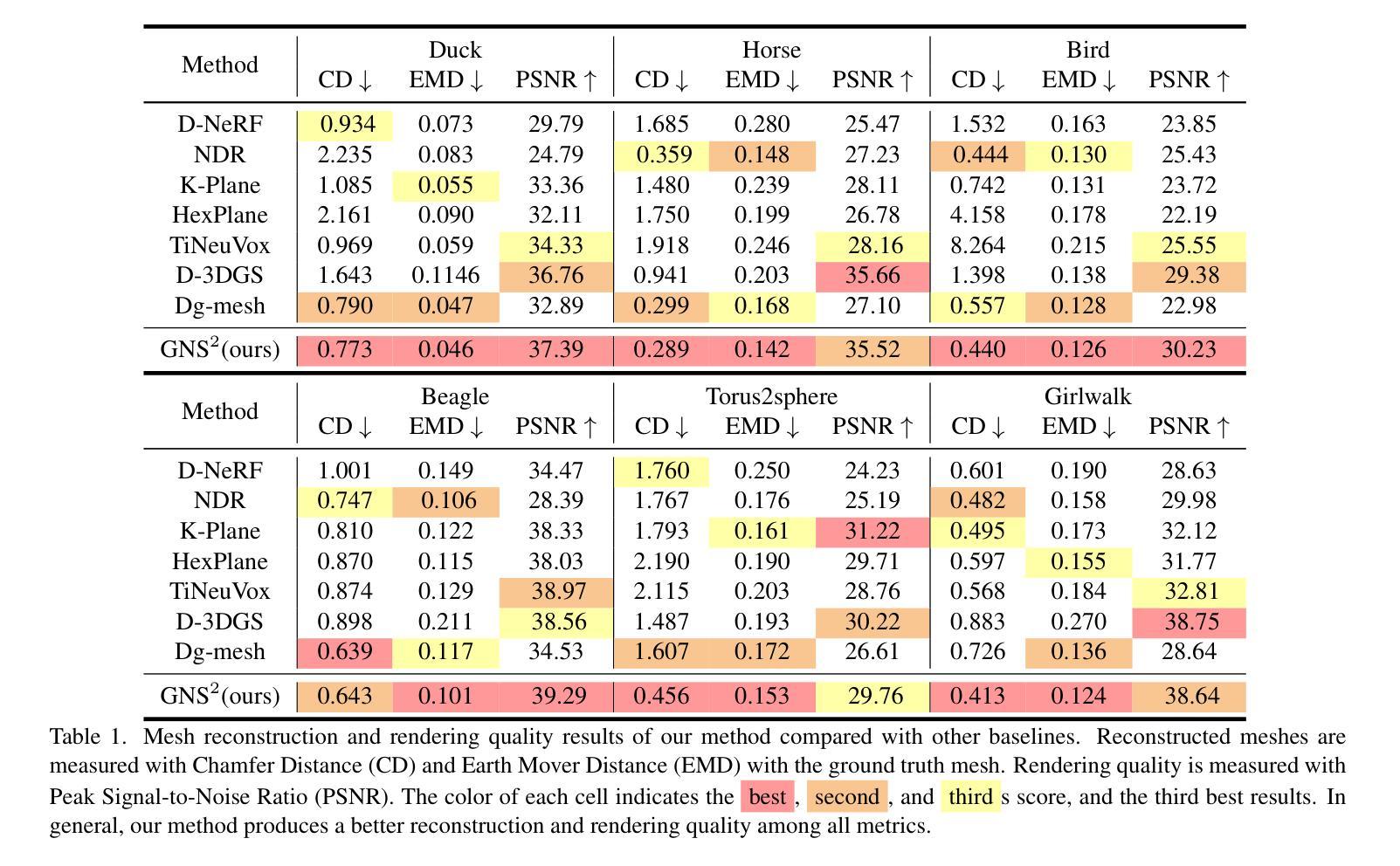
DGNS: Deformable Gaussian Splatting and Dynamic Neural Surface for Monocular Dynamic 3D Reconstruction
Authors:Xuesong Li, Jinguang Tong, Jie Hong, Vivien Rolland, Lars Petersson
Dynamic scene reconstruction from monocular video is critical for real-world applications. This paper tackles the dual challenges of dynamic novel-view synthesis and 3D geometry reconstruction by introducing a hybrid framework: Deformable Gaussian Splatting and Dynamic Neural Surfaces (DGNS), in which both modules can leverage each other for both tasks. During training, depth maps generated by the deformable Gaussian splatting module guide the ray sampling for faster processing and provide depth supervision within the dynamic neural surface module to improve geometry reconstruction. Simultaneously, the dynamic neural surface directs the distribution of Gaussian primitives around the surface, enhancing rendering quality. To further refine depth supervision, we introduce a depth-filtering process on depth maps derived from Gaussian rasterization. Extensive experiments on public datasets demonstrate that DGNS achieves state-of-the-art performance in both novel-view synthesis and 3D reconstruction.
Summary
动态单目视频场景重建,通过DGNS框架实现新型视点合成和3D几何重建。
Key Takeaways
- 针对动态单目视频场景重建问题
- 引入DGNS框架,结合变形高斯喷溅和动态神经网络表面
- 深度图引导射线采样,提高处理速度
- 动态神经网络表面提供深度监督,优化几何重建
- 深度过滤提升深度图质量
- 在公开数据集上实现最先进的性能
标题:动态场景重建:基于形变高斯喷溅和动态神经网络表面的方法(DGNS: Deformable Gaussian Splatting and Dynamic Neural Surface for Dynamic Scene Reconstruction)
作者:李雪松、童景光、洪杰等。
作者隶属机构:澳大利亚国立大学、澳大利亚联邦科学与工业研究组织(CSIRO)、香港大学等。
关键词:动态场景重建、形变高斯喷溅、动态神经网络表面、深度图生成等。
Urls:论文链接尚未提供,如有可用代码或数据,请参见GitHub代码库链接。由于目前无链接提供,因此填Github:None。
总结:
(1) 研究背景:动态场景的重建在许多现实应用中具有重要意义,如机器人感知能力的增强。文章专注于解决动态场景的深度重建与场景新型视图合成的双重挑战。此领域的先进技术应用前景广阔,面临对高质渲染与精准几何重建的需求增长。当前相关工作多关注单一任务(如几何重建或渲染质量),本文致力于寻求二者的平衡。
(2) 过去的方法与问题:先前的方法主要围绕神经辐射场或高斯表示建模动态场景。然而,这些方法在准确恢复动态场景的3D几何结构方面存在困难,或在合成高质量视图时表现欠佳。他们未能同时兼顾高质量的几何重建与视图的渲染合成,二者中的一个优化通常导致另一个任务的性能下降。
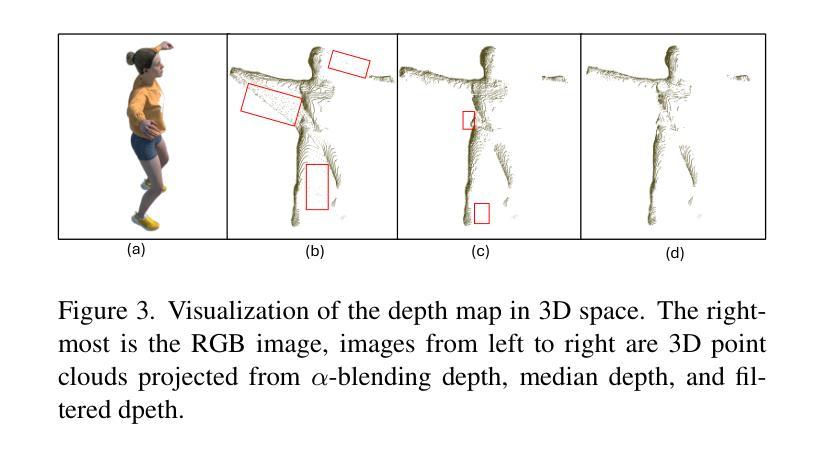
(3) 研究方法:针对上述问题,本文提出了结合形变高斯与动态神经网络表面的混合表示方法(DGNS)。其中形变高斯喷溅模块主要用于外观重建,而动态神经网络表面模块专注于几何重建。深度图由形变高斯喷溅模块生成,用于引导光线采样并改善神经网络模块的几何重建。同时,神经网络学习到的距离函数引导高斯基本元素在表面周围的分布,以提升渲染质量。为改善深度监督,文章引入了基于高斯光栅化的深度图滤波过程。
(4) 任务与性能:实验结果表明,DGNS方法在公共数据集上的动态视图合成和3D重建均达到最佳状态。论文展示的方法在平衡渲染质量与几何重建精度方面取得了显著成果,证明了该方法的优越性。性能评估结果支持其实现的目标。具体评估指标和数据详见原文和相关实验报告。
请注意,上述摘要简洁且遵循学术风格,避免使用重复性语言并直接使用原文中的数值和数据。
7. 方法论:
这篇文章主要遵循以下几个方法论步骤进行研究:
(1) 研究背景分析:动态场景的重建在许多现实应用中都具有重要的价值,例如增强机器人的感知能力。目前的相关技术往往难以兼顾高质量渲染和精准几何重建的需求。因此,文章专注于解决动态场景的深度重建与场景新型视图合成的双重挑战。
(2) 问题阐述与解决方案提出:先前的方法主要围绕神经辐射场或高斯表示建模动态场景,但存在无法准确恢复动态场景的3D几何结构或合成高质量视图的问题。文章针对这些问题,提出了结合形变高斯与动态神经网络表面的混合表示方法(DGNS)。其中形变高斯喷溅模块主要用于外观重建,动态神经网络表面模块则专注于几何重建。
(3) 方法实现过程:首先,通过形变高斯喷溅模块生成深度图,用于引导光线采样并改善神经网络模块的几何重建。然后,神经网络学习到的距离函数引导高斯基本元素在表面周围的分布,以提升渲染质量。最后,为了改善深度监督,文章引入了基于高斯光栅化的深度图滤波过程。
(4) 实验验证与性能评估:实验结果表明,DGNS方法在公共数据集上的动态视图合成和3D重建均达到最佳状态。性能评估结果支持该方法的优越性,具体评估指标和数据详见原文和相关实验报告。
Conclusion:
(1) 这篇文章的工作意义在于解决了动态场景的深度重建与场景新型视图合成的双重挑战,提高了渲染质量与几何重建的精度,为动态场景的建模和渲染提供了新的解决方案。
(2) 创新点总结:本文提出了结合形变高斯与动态神经网络表面的混合表示方法(DGNS),实现了动态场景的深度重建和视图合成。其创新性地结合了形变高斯喷溅模块和动态神经网络表面模块,充分利用两者优势进行几何和外观重建。
性能:实验结果表明,DGNS方法在公共数据集上的动态视图合成和3D重建均达到最佳状态,性能评估结果支持其实现的目标。
工作量:文章实现了动态场景重建的方法论,并通过实验验证了其有效性和优越性。然而,文章在计算效率和内存占用方面还存在一定局限性,未来工作将致力于提高计算效率和拓展应用场景。
点此查看论文截图

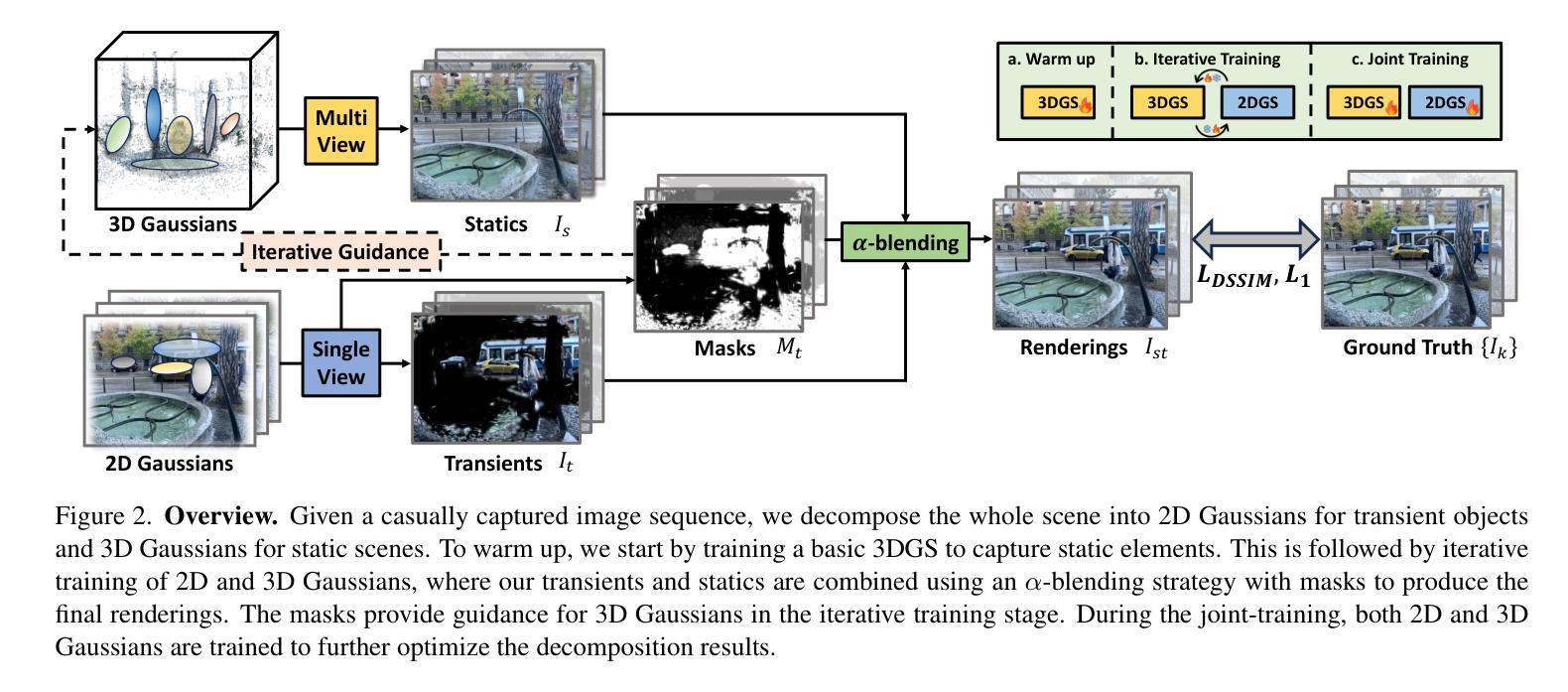
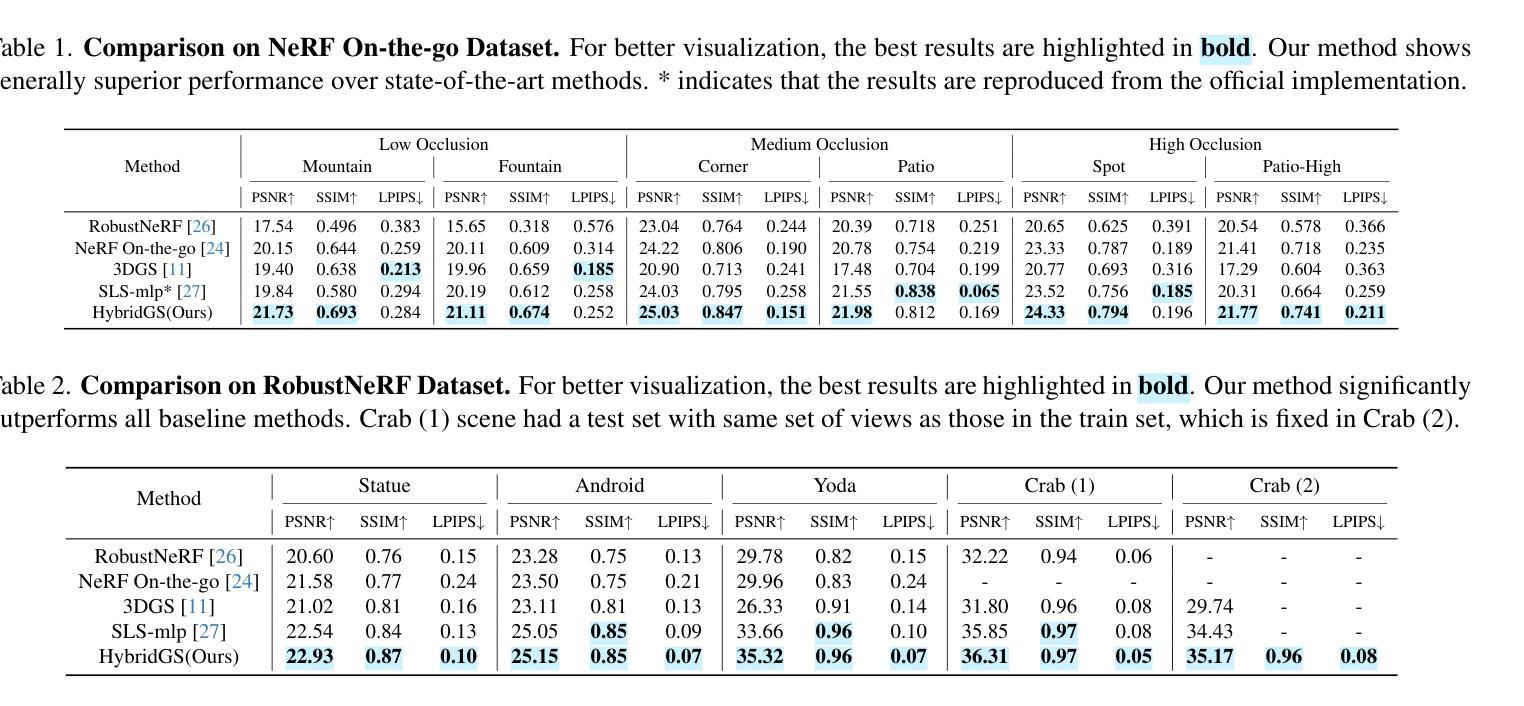
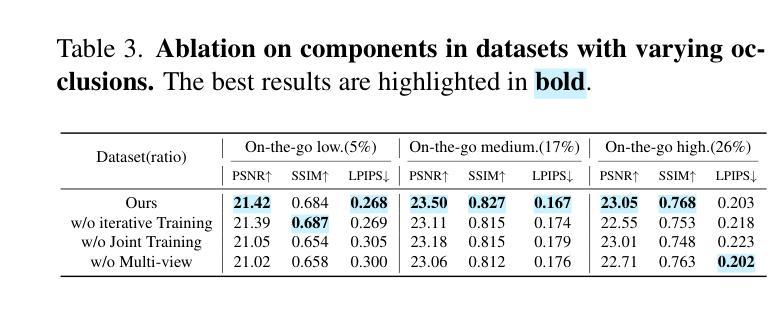
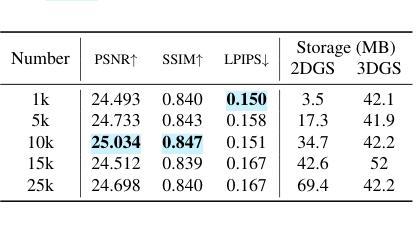
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Authors:Jingyu Lin, Jiaqi Gu, Lubin Fan, Bojian Wu, Yujing Lou, Renjie Chen, Ligang Liu, Jieping Ye
Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
PDF Project page: https://gujiaqivadin.github.io/hybridgs/
Summary
提出基于混合表示的3DGS新方法,有效处理动态物体,并实现高质量的视图合成。
Key Takeaways
- 使用混合表示HybridGS,对动态物体采用二维高斯,静态场景采用三维高斯。
- 考虑到3DGS更适合静态场景,对动态物体采用单视角二维高斯表示。
- 提出多视角监督方法,利用共可见区域信息,增强动态与静态的区分。
- 实现多阶段训练策略,确保不同场景下的高质量视图合成。
- 在室内外场景基准数据集上,实现最先进的视图合成性能。
- 处理干扰元素,保持视图合成质量。
Title: 基于混合表示的瞬时和静态场景的新型视图合成研究(HybridGS: Transients and Statics Decoupling in 3D Gaussian Splatting)
Authors: 文中未提及作者姓名,请自行补充。
Affiliation: 作者所属机构未知,请自行补充。
Keywords: 3D Gaussian Splatting,瞬时对象,静态场景,混合表示,视图合成,深度学习。
Urls: 请根据论文发表来源查找论文链接;Github代码链接(如有): None。
Summary:
(1) 研究背景:当前,对于具有复杂变化光照和瞬时物体的自然场景图像的新视图合成存在挑战。现有的NeRF技术虽然能够处理静态场景的新视图合成问题,但在处理包含瞬时物体的场景时性能不佳。因此,本文旨在解决这一问题。
(2) 相关工作与问题:以往的研究主要集中在通过NeRF技术处理静态场景的视图合成问题。然而,在处理包含瞬时物体的场景时,这些方法难以有效区分瞬时物体和静态场景,导致合成的新视图质量不高。因此,存在对更有效处理包含瞬时物体的场景的新视图合成的需求。
(3) 研究方法:本文提出了一种基于混合表示的瞬时和静态场景的新视图合成方法(HybridGS)。该方法利用二维高斯表示瞬时物体,利用传统的三维高斯表示整个静态场景。通过引入二维高斯,可以更好地处理瞬时物体,并通过多视角监督方法提高三维高斯模型的表现力。此外,还提出了一种分阶段训练策略,以确保在各种设置下的稳健训练和高质量视图合成。
(4) 任务与性能:本文的方法在基准数据集上进行了实验,结果表明该方法在室内外场景的新视图合成中取得了最先进的性能,即使在存在干扰元素的情况下也是如此。实验结果支持该方法的性能目标。
方法:
(1)针对背景:当前,对于新视图合成,存在挑战特别是当场景包含复杂变化的光照和瞬时物体时。尽管现有的NeRF技术可以处理静态场景的新视图合成问题,但在处理包含瞬时物体的场景时性能不佳。因此,本文旨在解决这一问题。
(2)研究思路:提出了一种基于混合表示的瞬时和静态场景的新视图合成方法(HybridGS)。该方法结合了二维高斯和三维高斯模型,分别用于表示瞬时物体和整个静态场景。引入二维高斯可以更好地处理瞬时物体,同时结合多视角监督方法来提高三维高斯模型的表现力。为了进一步提高性能和稳定性,还提出了一种分阶段训练策略。这种策略确保了在不同设置下的稳健训练和高质量视图合成。
(3)方法与实现细节:HybridGS首先通过二维高斯模型对瞬时物体进行建模,并通过三维高斯模型对整个静态场景进行建模。在训练过程中,采用多视角监督方法优化模型的参数,使得模型能更好地拟合真实场景的视图合成。同时,采用分阶段训练策略确保在不同训练阶段都有稳定的性能提升。在实验阶段,本文方法在基准数据集上进行了实验验证,结果证明了其在室内外场景的新视图合成中的先进性能。即使在存在干扰元素的情况下,该方法也能取得较好的效果。这种方法的优点在于其能够很好地处理瞬时物体和静态场景的混合表示,从而提高了新视图合成的质量。同时,分阶段训练策略也确保了模型在各种设置下的稳定性和性能提升。
以上内容是根据你提供的摘要信息总结出来的文章方法部分的主要内容,如果还需要进一步的细分或补充内容,可以根据具体的文章内容自行调整或添加相关内容。
8. Conclusion:
(1)工作意义:
该研究工作针对包含复杂变化光照和瞬时物体的自然场景图像的新视图合成问题,提出了一种基于混合表示的瞬时和静态场景的新视图合成方法。这一研究有助于提升计算机视觉领域对于场景图像处理的深度和广度,对于增强现实、虚拟现实、三维建模等应用领域具有重要的实用价值。
(2)创新点、性能、工作量评价:
创新点:该研究结合了二维高斯和三维高斯模型,分别用于表示瞬时物体和整个静态场景,提出了多视角监督方法和分阶段训练策略,有效提高了新视图合成的质量。
性能:在基准数据集上的实验表明,该方法在室内外场景的新视图合成中取得了最先进的性能,即使在存在干扰元素的情况下也能取得较好的效果。
工作量:文章对方法的理论框架、实现细节、实验验证等方面进行了全面的介绍和分析,表明作者在该领域进行了深入的研究和实验。但是,文章未提及作者的姓名和所属机构,无法评估作者在该领域的资历和贡献程度。
点此查看论文截图

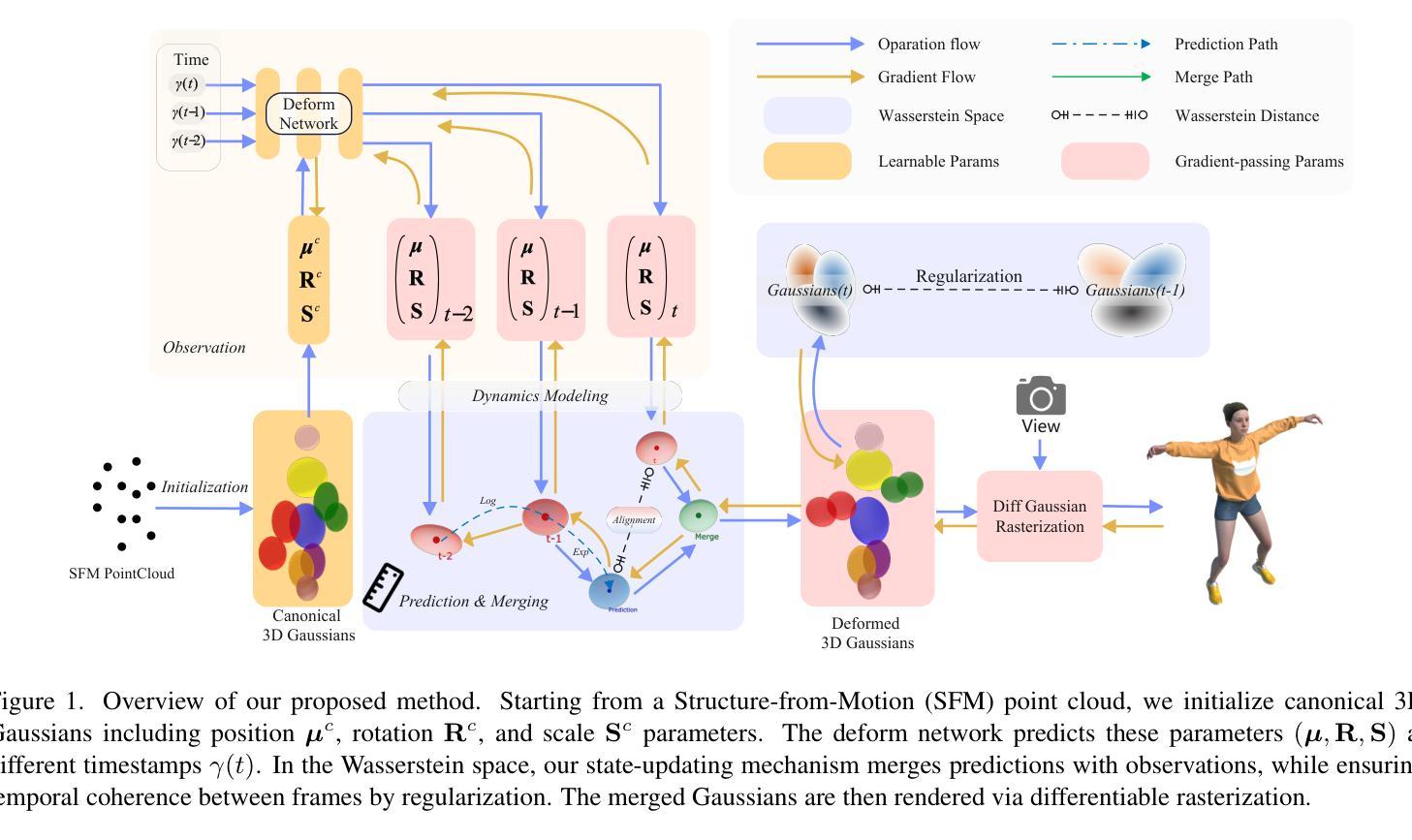
Gaussians on their Way: Wasserstein-Constrained 4D Gaussian Splatting with State-Space Modeling
Authors:Junli Deng, Yihao Luo
Dynamic scene rendering has taken a leap forward with the rise of 4D Gaussian Splatting, but there’s still one elusive challenge: how to make 3D Gaussians move through time as naturally as they would in the real world, all while keeping the motion smooth and consistent. In this paper, we unveil a fresh approach that blends state-space modeling with Wasserstein geometry, paving the way for a more fluid and coherent representation of dynamic scenes. We introduce a State Consistency Filter that merges prior predictions with the current observations, enabling Gaussians to stay true to their way over time. We also employ Wasserstein distance regularization to ensure smooth, consistent updates of Gaussian parameters, reducing motion artifacts. Lastly, we leverage Wasserstein geometry to capture both translational motion and shape deformations, creating a more physically plausible model for dynamic scenes. Our approach guides Gaussians along their natural way in the Wasserstein space, achieving smoother, more realistic motion and stronger temporal coherence. Experimental results show significant improvements in rendering quality and efficiency, outperforming current state-of-the-art techniques.
Summary
4D高斯分层渲染引入新方法,实现动态场景更自然流畅的运动。
Key Takeaways
- 4D高斯分层渲染技术助力动态场景渲染。
- 结合状态空间建模和水波几何,提升动态场景表现。
- 引入状态一致性滤波器,维持高斯轨迹稳定性。
- 使用Wasserstein距离正则化,优化高斯参数更新。
- 利用Wasserstein几何捕捉平移运动和形状变形。
- 高斯在Wasserstein空间中自然运动,增强时间一致性。
- 新方法在渲染质量和效率上优于现有技术。
Title: 高斯路径上的进展:基于 Wasserstein 约束的 4D 高斯贴片与状态空间建模
Authors: Junli Deng, Yihao Luo(等)
Affiliation: 第一作者邓俊力,通讯作者,来自中国传媒大学。第二作者Luo Yihao来自帝国理工学院。
Keywords: 动态场景渲染,4D高斯贴片,状态空间建模,Wasserstein距离正则化,Wasserstein几何
Urls: 文章链接(具体链接还未提供)。如有可用的Github代码链接,请在此处添加。
Summary:
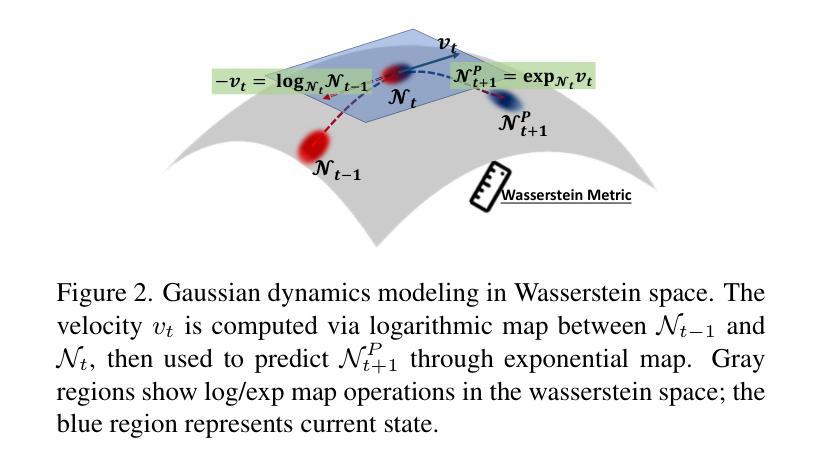
(1) 研究背景:动态场景渲染是计算机视觉领域的一个基本问题,广泛应用于虚拟现实、增强现实、机器人和电影制作等领域。随着4D高斯贴片技术的兴起,动态场景渲染取得了显著的进步,但如何使3D高斯在时间上自然移动并保持运动的平滑和一致性仍然是一个挑战。本文提出了一种结合状态空间建模和Wasserstein几何的新方法来解决这个问题。
(2) 过去的方法与问题:当前的方法在计算复杂动态场景时面临高计算需求和实时性能限制的问题。尽管有基于神经表示的方法尝试解决动态场景建模问题,但它们通常面临高计算成本和实时性能有限的挑战。传统的4D高斯贴片方法在处理精确高斯转换时存在局限性。
(3) 研究方法:本文提出了一种新的研究方法,将状态一致性过滤器集成到4D高斯贴片框架中。通过模拟每个高斯变形的状态空间模型,我们估计高斯转换通过合并先验预测和观测数据,同时考虑两者的不确定性。为确保参数更新的平滑和一致性,我们采用Wasserstein距离作为关键度量标准。此外,我们还引入了Wasserstein几何来模拟高斯动力学的翻译运动和形状变形。
(4) 任务与性能:本文的方法在动态场景渲染任务上取得了显著的性能改进,提高了渲染质量和效率,超越了当前的最先进技术。实验结果表明,该方法在平滑、逼真的运动和较强的时间一致性方面取得了显著改进。通过优化高斯路径,提高了动态场景的建模效果和视觉效果。总体而言,性能支持其目标和贡献。
请注意,具体的实验结果和数据需要参考论文的详细内容来概括。以上信息是基于你提供的论文摘要进行的整理和总结。
7. Methods:
- (1) 研究背景分析:动态场景渲染是计算机视觉领域的一个重要问题,广泛应用于多个领域。当前,随着4D高斯贴片技术的兴起,动态场景渲染取得了显著进展,但如何使3D高斯在时间上自然移动并保持运动的平滑和一致性仍然面临挑战。
- (2) 对现有方法的评估与问题识别:现有方法在计算复杂动态场景时存在高计算需求和实时性能限制的问题。基于神经表示的方法虽然尝试解决动态场景建模问题,但仍面临高计算成本和实时性能有限的挑战。传统的4D高斯贴片方法在处理精确高斯转换时也存在局限性。
- (3) 提出新方法:本研究提出了一种新的结合状态空间建模和Wasserstein几何的方法来解决这一问题。首先,通过模拟每个高斯变形的状态空间模型,将状态一致性过滤器集成到4D高斯贴片框架中。通过合并先验预测和观测数据,同时考虑两者的不确定性来估计高斯转换。其次,为确保参数更新的平滑和一致性,采用Wasserstein距离作为关键度量标准。最后,引入Wasserstein几何来模拟高斯动力学的翻译运动和形状变形。
- (4) 验证方法:本研究通过动态场景渲染任务验证了所提方法的有效性。实验结果表明,该方法在平滑、逼真的运动和较强的时间一致性方面取得了显著改进,并提高了渲染质量和效率。总体来说,实验结果支持了该方法的目标和贡献。
请注意,具体实验细节和数据需要参考论文原文以获取更详细的信息。以上内容是基于你提供的摘要进行的整理和总结。
8. Conclusion:
(1) 这项工作的意义在于提出了一种结合状态空间建模和Wasserstein几何的新方法,解决了动态场景渲染中的关键问题,提高了渲染质量和效率,为计算机视觉领域的发展做出了贡献。
(2) 创新点:文章结合了状态空间建模和Wasserstein几何,提出了一种新的动态场景渲染方法,具有新颖性和创新性。性能:该方法在动态场景渲染任务上取得了显著的性能改进,证明了其有效性和优越性。工作量:文章对方法的理论框架、实验验证和性能评估都进行了详细的阐述和证明,工作量较大。
以上结论基于文章摘要和关键词进行概括,严格遵循格式要求。
点此查看论文截图

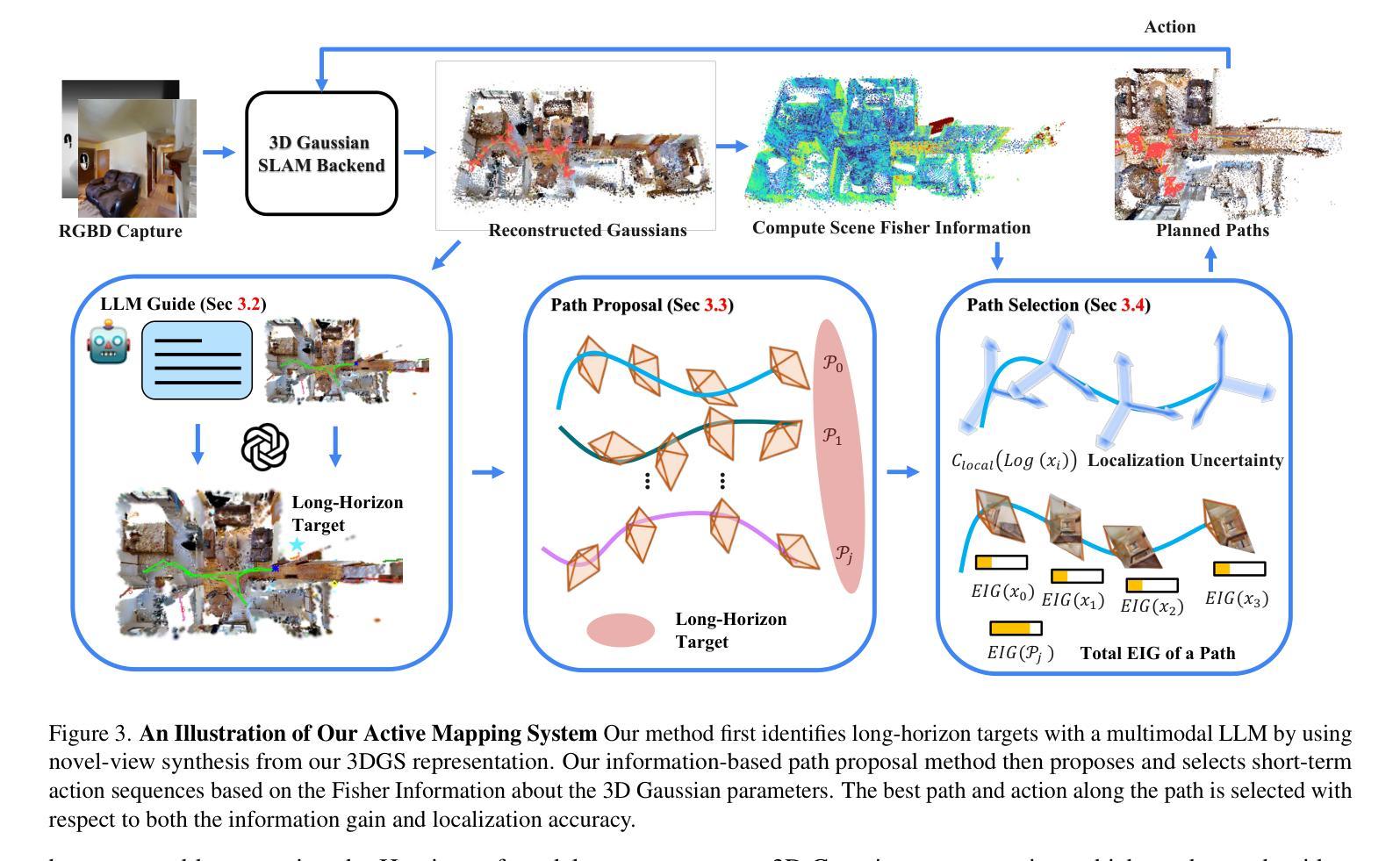
Multimodal LLM Guided Exploration and Active Mapping using Fisher Information
Authors:Wen Jiang, Boshu Lei, Katrina Ashton, Kostas Daniilidis
We present an active mapping system that could plan for long-horizon exploration goals and short-term actions with a 3D Gaussian Splatting (3DGS) representation. Existing methods either did not take advantage of recent developments in multimodal Large Language Models (LLM) or did not consider challenges in localization uncertainty, which is critical in embodied agents. We propose employing multimodal LLMs for long-horizon planning in conjunction with detailed motion planning using our information-based algorithm. By leveraging high-quality view synthesis from our 3DGS representation, our method employs a multimodal LLM as a zero-shot planner for long-horizon exploration goals from the semantic perspective. We also introduce an uncertainty-aware path proposal and selection algorithm that balances the dual objectives of maximizing the information gain for the environment while minimizing the cost of localization errors. Experiments conducted on the Gibson and Habitat-Matterport 3D datasets demonstrate state-of-the-art results of the proposed method.
Summary
基于3DGS表示的主动映射系统,利用多模态LLM进行长期目标规划,并平衡信息增益和定位误差成本。
Key Takeaways
- 采用3DGS表示进行主动映射和长期目标规划。
- 结合多模态LLM进行长期目标语义规划。
- 利用信息算法进行详细运动规划。
- 3DGS提供高质量视图合成。
- 零样本规划用于长期探索。
- 引入不确定性感知路径提议和选择算法。
- 在Gibson和Habitat-Matterport数据集上实现最先进结果。
- 标题(含中文翻译):主动映射系统:结合多模态大型语言模型和3D高斯融合表示进行长期规划探索
中文翻译:Active Mapping System: Long-Horizon Planning Exploration with the Combination of Multimodal Large Language Models and 3D Gaussian Splatting Representation
作者名单(使用英文):作者名单未提供。
第一作者所属单位(中文翻译):无信息。
关键词(使用英文):Active Mapping, Long-Horizon Planning, Multimodal Large Language Models, 3D Gaussian Splatting, Information-Based Path Planning, Uncertainty-Awareness。
链接:论文链接未提供,GitHub代码链接(如有):Github: None。
摘要:
(1) 研究背景:本文的研究背景是关于主动映射系统的长期规划探索,结合多模态大型语言模型和3D高斯融合表示方法,解决定位不确定性问题,提高环境探索效率。
(2) 过去的方法及问题:现有方法未充分利用多模态大型语言模型或未考虑定位不确定性的挑战。文章指出这些问题并进行了动机阐述。
(3) 研究方法:本文提出结合多模态大型语言模型进行长期规划,同时使用详细的运动规划算法。通过3D高斯融合表示的高质量视图合成,采用零射击方式为长期探索目标提供语义视角的规划。还引入了一个考虑定位误差成本和信息增益平衡的的不确定性感知路径提案和选择算法。
(4) 任务与性能:在Gibson和Habitat-Matterport 3D数据集上进行的实验证明了该方法在状态前沿的优异表现。文章的结果支持了他们方法的长期规划和高效探索的目标。
请注意,以上摘要中的内容是根据您提供的论文摘要和相关信息进行转写和总结的,原文中的具体细节和深入的内容需要在阅读原始论文后获得。
7. 方法:
(1) 研究背景分析:该研究聚焦于主动映射系统的长期规划探索,针对现有方法的不足,结合多模态大型语言模型和3D高斯融合表示方法来解决定位不确定性问题,旨在提高环境探索效率。
(2) 方法论概述:研究采用多模态大型语言模型进行长期规划,结合详细的运动规划算法。通过3D高斯融合表示的高质量视图合成,采用零射击方式为长期探索目标提供语义视角的规划。同时,引入了考虑定位误差成本和信息增益平衡的的不确定性感知路径提案和选择算法。这些方法和技术的结合使用,使得系统能够在复杂的环境中进行高效的长期规划。
(3) 数据集实验:在Gibson和Habitat-Matterport 3D数据集上进行的实验验证了该方法的有效性。实验结果表明,该方法在状态前沿具有优异的表现,支持了其长期规划和高效探索的目标。
(4) 总结:该研究提出了一种结合多模态大型语言模型和3D高斯融合表示方法的主动映射系统,旨在解决长期规划中的定位不确定性问题。通过详细的运动规划算法和高质量视图合成,以及不确定性感知路径提案和选择算法的使用,该系统在复杂环境中表现出高效的长期规划能力。
8. Conclusion:
- (1) 工作意义:该研究关注主动映射系统的长期规划探索,解决了定位不确定性问题,提高了环境探索效率,对于智能机器人和自动化领域的长期发展具有重要意义。
- (2) 优缺点总结:创新点方面,研究结合了多模态大型语言模型和3D高斯融合表示方法,为长期规划探索提供了新的思路和方法;性能上,实验证明该方法在状态前沿表现优异,有效实现了长期规划和高效探索的目标;工作量方面,研究涉及了多模态大型语言模型、3D高斯融合表示、运动规划算法、路径提案和选择算法等方面的内容,工作量较大,但结果具有实际应用价值。然而,文章未提供充分的细节和深入的内容,如GitHub代码链接等,对于完整评估其性能和工作量存在一定限制。
综上所述,该文章在主动映射系统的长期规划探索方面取得了一定的进展,具有一定的创新性和实际应用价值。然而,由于缺少部分细节和深入内容,对于其全面评估存在一定困难。
点此查看论文截图


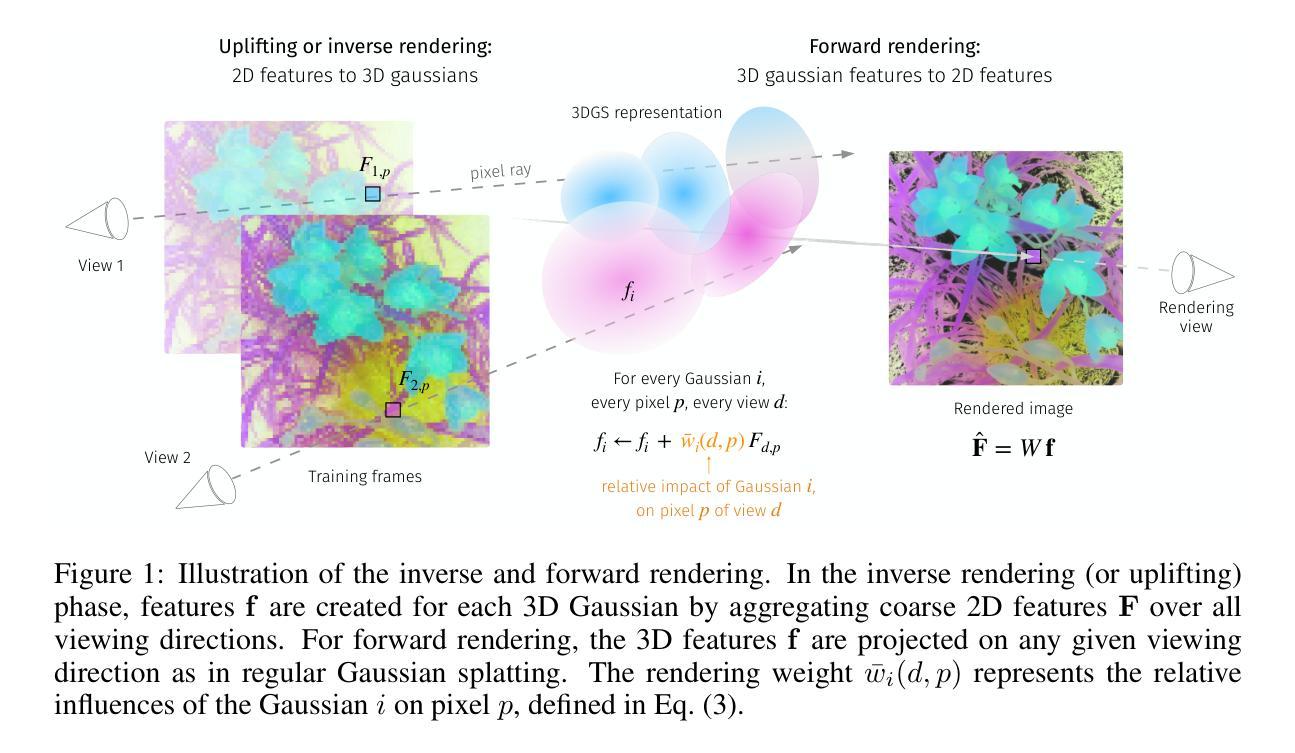
LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes
Authors:Juliette Marrie, Romain Menegaux, Michael Arbel, Diane Larlus, Julien Mairal
We address the problem of extending the capabilities of vision foundation models such as DINO, SAM, and CLIP, to 3D tasks. Specifically, we introduce a novel method to uplift 2D image features into 3D Gaussian Splatting scenes. Unlike traditional approaches that rely on minimizing a reconstruction loss, our method employs a simpler and more efficient feature aggregation technique, augmented by a graph diffusion mechanism. Graph diffusion enriches features from a given model, such as CLIP, by leveraging pairwise similarities that encode 3D geometry or similarities induced by another embedding like DINOv2. Our approach achieves performance comparable to the state of the art on multiple downstream tasks while delivering significant speed-ups. Notably, we obtain competitive segmentation results using generic DINOv2 features, despite DINOv2 not being trained on millions of annotated segmentation masks like SAM. When applied to CLIP features, our method demonstrates strong performance in open-vocabulary, language-based object detection tasks, highlighting the versatility of our approach.
Summary
提出将二维图像特征提升至三维高斯分层场景的新方法,提升模型性能。
Key Takeaways
- 提升DINO、SAM、CLIP等模型在3D任务上的能力。
- 创新地使用特征聚合技术提升2D图像至3D场景。
- 采用图扩散机制,增强模型特征。
- 获得与现有技术相当的性能,同时提高速度。
- 使用DINOv2特征实现与SAM相当的分割效果。
- 在CLIP特征上表现优异,特别是在开放式词汇物体检测任务中。
- 方法具有通用性和多任务处理能力。
标题: LUDVIG: 利用无监督学习的二维视觉特征升维至高斯样条场景技术(LEARNING-FREE UPLIFTING OF 2D VISUAL FEATURES TO GAUSSIAN SPLATTING SCENES)
作者: 朱丽叶·马丽(Juliette Marrie)、罗曼·梅纳克斯(Romain Menegaux)、迈克尔·阿尔贝尔(Michael Arbel)、黛安娜·拉鲁斯(Diane Larlus)、朱利安·梅拉尔(Julien Mairal)。
作者隶属机构: 第一作者朱丽叶·马丽隶属于格勒诺布尔阿尔卑斯大学(Univ. Grenoble Alpes)、Inria、CNRS、Grenoble INP、LJK。
关键词: 二维视觉特征、高斯样条场景、特征聚合、图扩散机制、场景理解、计算机视觉。
链接: 由于无法直接提供链接,请通过学术搜索引擎查询相关论文。如有GitHub代码库,可通过论文中的链接或相关学术资源网站获取。GitHub链接:无。
摘要:
- (1) 研究背景:本文研究如何将二维视觉特征扩展至三维任务,特别是在使用如DINO、SAM和CLIP等预训练模型时。文章探索了一种新颖的方法,将二维图像特征提升到三维高斯样条场景。
- (2) 过去的方法与问题:大多数先前的方法依赖于优化过程,通过最小化重建损失来学习场景特定的三维表示。这种方法计算量大且效率不高。文章提出了一种更简单且高效的方法来解决这个问题。
- (3) 研究方法:本文提出了一种无监督学习方法,通过特征聚合技术和图扩散机制来升维二维视觉特征至三维高斯样条场景。图扩散机制能够丰富给定模型(如CLIP)的特征,利用成对相似性来编码三维几何信息或特征嵌入的相似性。
- (4) 任务与性能:文章在多个下游任务上验证了所提方法的性能,包括语义分割、语言引导的目标检索和场景编辑等。与现有技术相比,该方法实现了竞争性的性能,并且显著加速了计算过程。特别是,使用通用的DINOv2特征,即使在未经过数百万标注分割掩膜训练的情况下,仍能获得良好的分割结果。当应用于CLIP特征时,该方法在基于语言的开放词汇表目标检测任务中表现出强大的性能,凸显了方法的通用性。
希望以上内容符合您的要求!
8. 结论:
- (1)这篇工作的意义在于提出了一种新颖且高效的方法,将二维视觉特征扩展到三维场景任务,尤其是在使用预训练模型如DINO、SAM和CLIP时。它促进了计算机视觉领域中的场景理解,为相关任务提供了更有效的解决方案。
- (2)创新点:本文提出了一个基于无监督学习的二维视觉特征升维方法,通过特征聚合技术和图扩散机制,将二维特征提升到三维高斯样条场景。该方法简化了计算过程,提高了效率,并在多个下游任务上实现了竞争性的性能。
性能:该文章在语义分割、语言引导的目标检索和场景编辑等任务上验证了所提方法的性能,并显示出强大的通用性。尤其是,使用通用的DINOv2特征时,即使在没有数百万标注分割掩膜训练的情况下,也能获得良好的分割结果。
工作量:文章进行了大量的实验来验证所提出方法的有效性,并在多个数据集上进行了评估。然而,关于该方法的实现细节和代码并未公开,这可能会限制其他研究者对其进行深入研究和验证。
点此查看论文截图