⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-07 更新
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation
Authors:Longtao Zheng, Yifan Zhang, Hanzhong Guo, Jiachun Pan, Zhenxiong Tan, Jiahao Lu, Chuanxin Tang, Bo An, Shuicheng Yan
Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, achieving seamless audio-lip synchronization, maintaining long-term identity consistency, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing memory states to store information from a longer past context to guide temporal modeling via linear attention; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, audio-lip synchronization, identity consistency, and expression-emotion alignment.
PDF Project Page: https://memoavatar.github.io
Summary
提出基于记忆引导的EMO情感感知扩散模型(MEMO),实现身份一致性、表情自然且与音频同步的说话视频生成。
Key Takeaways
- 研究针对视频扩散模型在说话视频生成中的新潜力。
- 面临音频唇同步、身份一致性和表情自然性的挑战。
- 提出MEMO模型,包含记忆引导时序模块和情感感知音频模块。
- 记忆引导模块通过线性注意力指导时序建模,增强长期身份一致性和运动平滑性。
- 情感感知模块使用多模态注意力增强音频-视频交互,并通过情感自适应层规范调整面部表情。
- MEMO模型在多种图像和音频类型上生成更逼真的说话视频,全面超越现有方法。
Title: 基于记忆引导扩散模型的表达性对话视频生成研究(MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation)
Authors: Longtao Zheng, Yifan Zhang, Hanzhong Guo, Jiachun Pan, Zhenxiong Tan, Jiahao Lu, Chuanxin Tang, Bo An, Shuicheng Yan
Affiliation:
部分作者来自于天空AI公司(Skywork AI),南洋理工大学(Nanyang Technological University),新加坡国立大学(National University of Singapore)。Keywords: 音频驱动的视频生成,记忆引导扩散模型,身份一致性,表情与情感对齐,视频扩散模型。
Urls: Paper Url: 暂时无法提供直接链接。Github代码链接:Github: None(若存在,请提供链接)
Summary:
(1) 研究背景:随着虚拟形象、数字内容创作和实时通信等领域的快速发展,音频驱动对话视频生成技术受到广泛关注。然而,实现无缝的音频与口型同步、长期身份一致性以及自然、与音频对齐的表情生成仍是该技术的挑战。
(2) 过去的方法及问题:现有的视频扩散模型虽然在音频驱动的对话视频生成方面取得进展,但在保持长期身份一致性、口型与音频同步以及自然表情生成方面仍存在不足。大部分方法使用交叉注意力来结合音频指导视频生成,并通常基于过去2-4帧进行生成以提高运动平滑度,但这种方法存在长期身份不一致的问题。此外,一些方法使用单一的情感标签来指导整个视频的情感表达,忽略了音频中情感的细微变化。
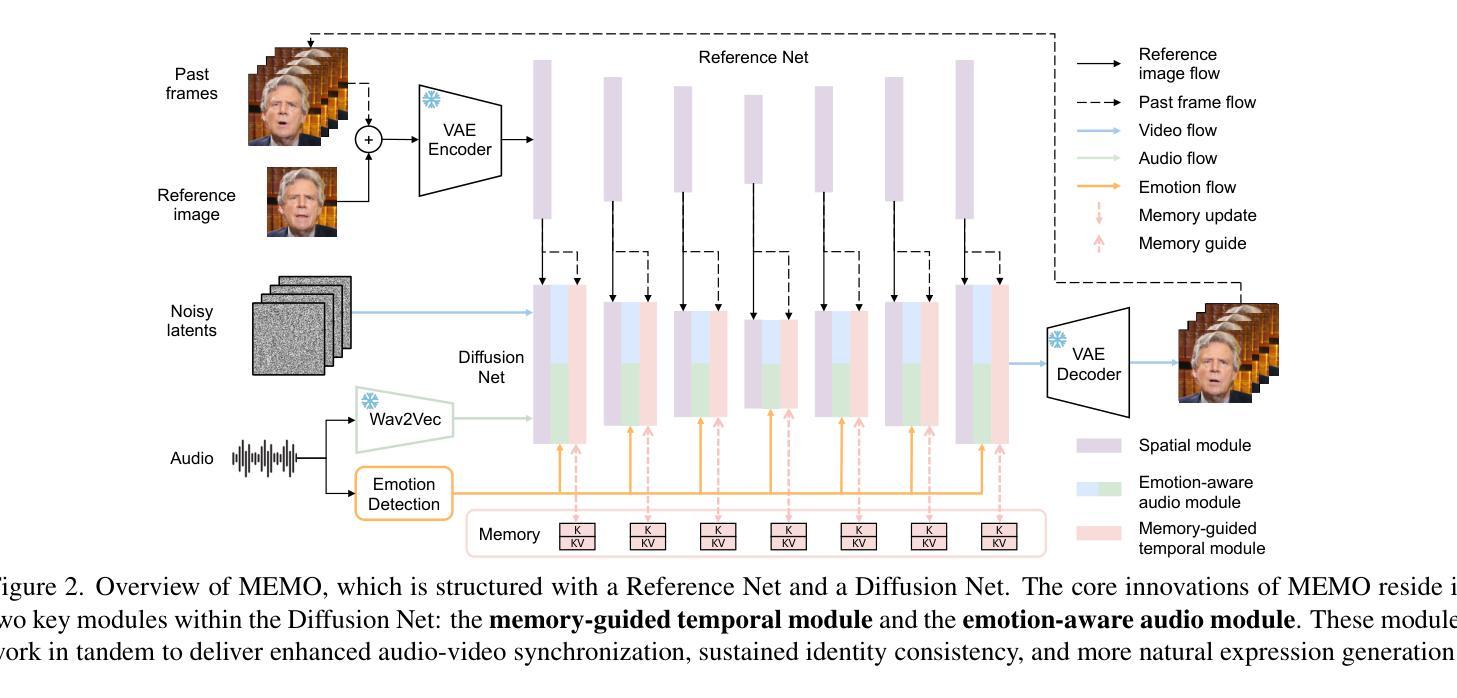
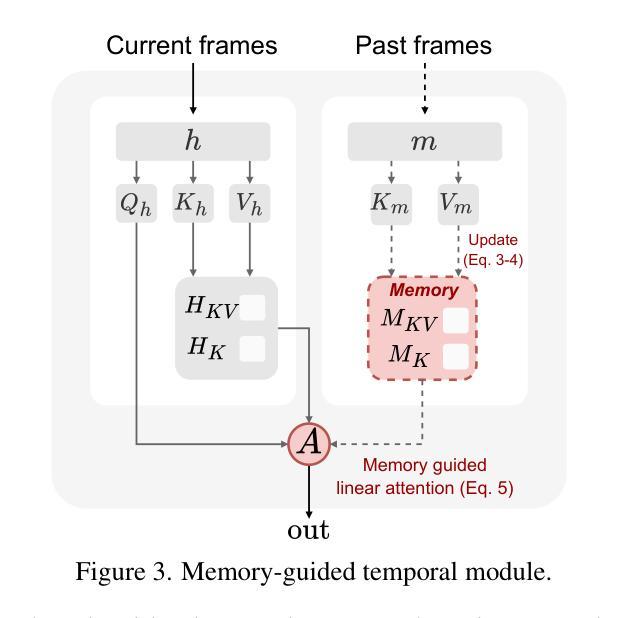
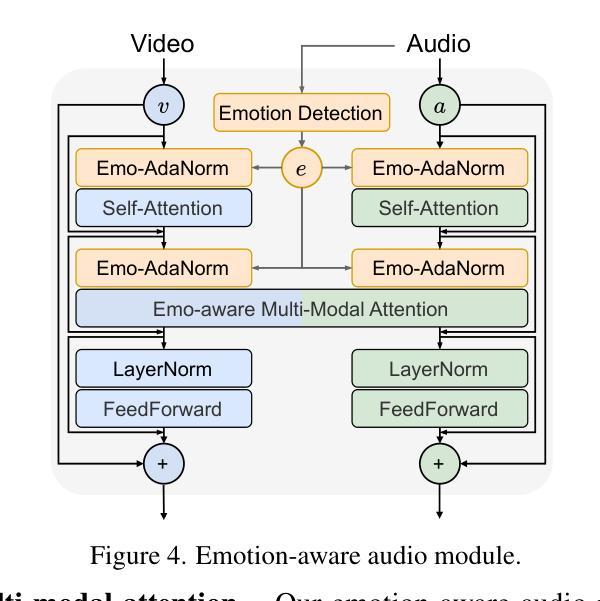
(3) 研究方法:针对上述问题,本文提出了基于记忆引导扩散模型的表达性对话视频生成方法(MEMO)。该方法包含两个关键模块:a. 记忆引导时序模块,通过开发记忆状态来存储更长时间的上下文信息,并通过线性注意力来指导时序建模,从而提高长期身份一致性和运动平滑度;b. 情感感知音频模块,通过多模态注意力增强音频与视频的交互,同时通过从音频中检测到的情感来微调面部表情。使用情感自适应层归一化来细化表情表达。本文提出了MEMO模型生成更具真实感的对话视频。通过广泛的定量和定性评估证明MEMO在整体质量、音频口型同步、身份一致性和表情情感对齐方面优于现有方法。
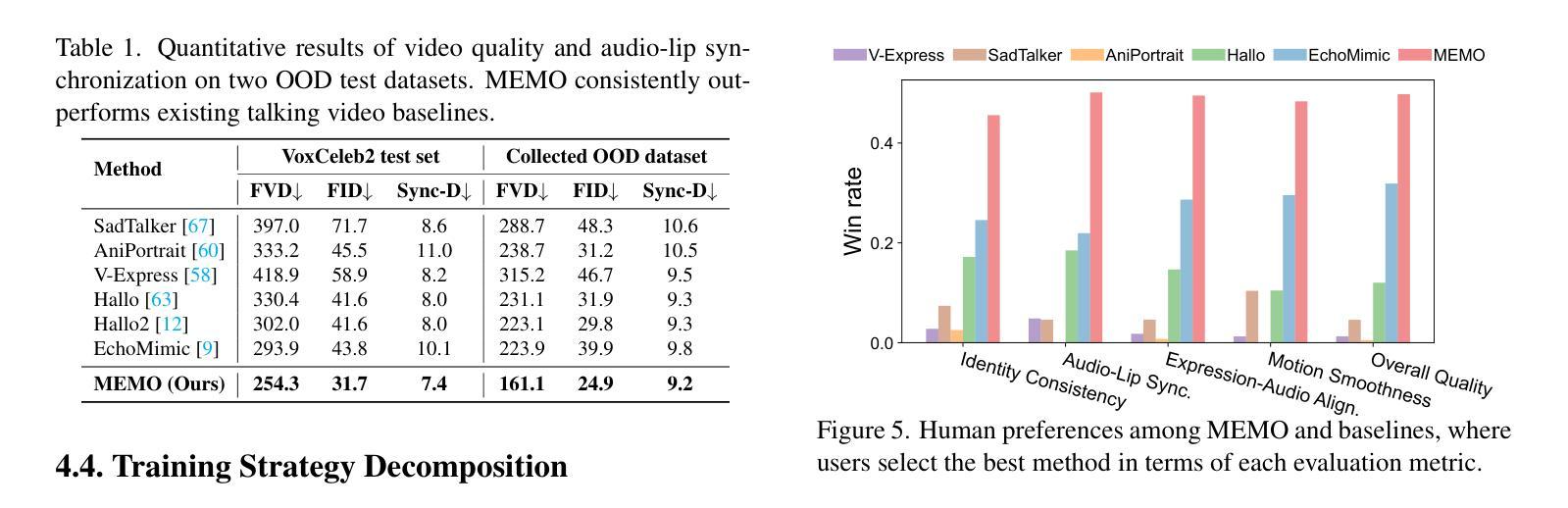
(4) 任务与性能:本文的方法在音频驱动的对话视频生成任务上取得了显著的性能提升。生成的视频展示出了更高的身份一致性、音频口型同步精度以及更自然的表情表达。实验结果表明该方法能够有效支持其设定的目标。
7. 方法论:
(1) 研究背景:该研究针对音频驱动对话视频生成技术展开,针对无缝音频与口型同步、长期身份一致性以及自然情感表达生成技术的挑战展开研究。
(2) 现有方法的问题:现有视频扩散模型在音频驱动对话视频生成方面虽有所进展,但在长期身份一致性、口型与音频同步以及自然表情生成方面仍存在不足。大部分方法使用交叉注意力来结合音频指导视频生成,但这种方法存在长期身份不一致的问题。此外,一些方法忽略了音频中情感的细微变化。
(3) 研究方法:针对上述问题,提出了基于记忆引导扩散模型的表达性对话视频生成方法(MEMO)。首先,设计了一个记忆引导时序模块,通过开发记忆状态来存储更长时间的上下文信息,并通过线性注意力来指导时序建模,以提高长期身份一致性和运动平滑度。其次,设计了一个情感感知音频模块,通过多模态注意力增强音频与视频的交互,同时根据音频中检测到的情感微调面部表情。使用情感自适应层归一化来细化表情表达。通过广泛的定量和定性评估,证明MEMO在整体质量、音频口型同步、身份一致性和表情情感对齐方面优于现有方法。
(4) 训练策略:MEMO的训练分为两个阶段,每个阶段都有特定的目标。第一阶段是面部域适应,初始化Reference Net和Diffusion Net的空间模块使用SD 1.5的权重。在此阶段,适应Reference Net、Diffusion Net的空间注意力模块和原始文本交叉注意力模块到面部域。第二阶段是情感解耦稳健训练,将情感感知音频模块和记忆引导时序模块集成到Diffusion Net中。首先对新添加的模块进行热身训练,保持第一阶段模块固定。热身完成后,所有模块联合训练。在此阶段使用情感条件流损失并扩大数据集进行更全面的训练。当训练视频片段来源于MEAD时采用情感解耦训练策略。此外,研究还发现即使应用了数据处理管道后仍然存在一些噪声数据导致扩散训练不稳定和模型优化偏差。为了缓解这一问题,进一步开发了一种稳健的训练策略,通过过滤掉损失值突然超过特定大值(本例中为0.1)的数据点来提高模型的鲁棒性。该方法的情感条件流损失通常会收敛并波动在约0.03左右。
8. Conclusion:
- (1) 该研究工作的意义在于针对音频驱动对话视频生成技术的挑战展开研究,特别是在无缝音频与口型同步、长期身份一致性以及自然情感表达生成技术方面。这项工作为相关领域提供了一种有效的方法,有望推动虚拟形象、数字内容创作和实时通信等领域的发展。
- (2) 创新点:该文章提出了基于记忆引导扩散模型的表达性对话视频生成方法(MEMO),通过记忆引导时序模块和情感感知音频模块的设计,有效提高了长期身份一致性、音频口型同步精度以及表情表达的自然度。
- 性能:通过实验验证,MEMO在音频驱动的对话视频生成任务上取得了显著的性能提升,生成的视频展示出了更高的身份一致性、音频口型同步精度以及更自然的表情表达。
- 工作量:文章进行了广泛的实验验证,包括方法论和训练策略的研究,证明了MEMO的有效性。然而,文章未提供Github代码链接,无法评估其代码复现的难度和工作量。
希望以上内容能够满足您的要求。
点此查看论文截图

INFP: Audio-Driven Interactive Head Generation in Dyadic Conversations
Authors:Yongming Zhu, Longhao Zhang, Zhengkun Rong, Tianshu Hu, Shuang Liang, Zhipeng Ge
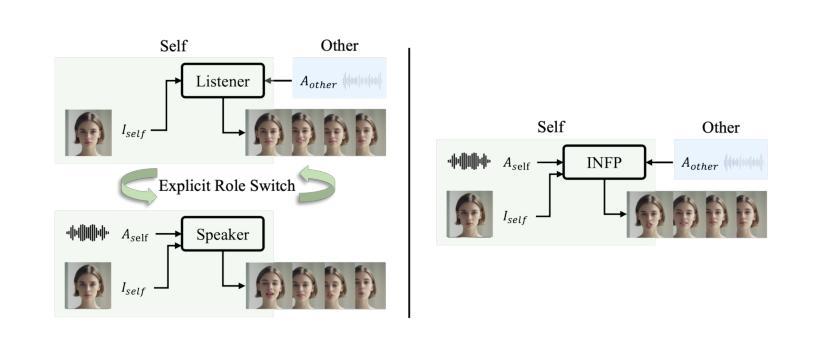
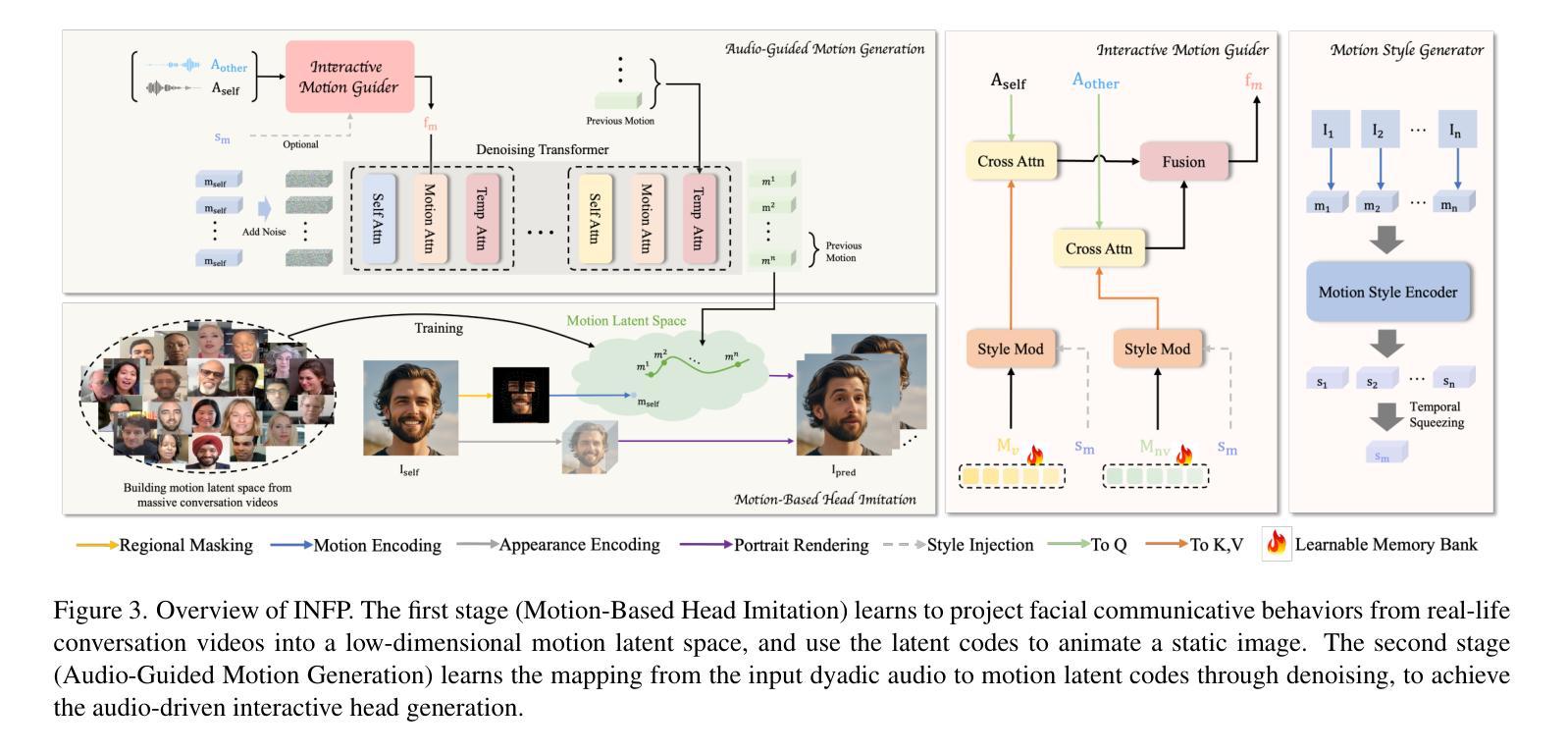
Imagine having a conversation with a socially intelligent agent. It can attentively listen to your words and offer visual and linguistic feedback promptly. This seamless interaction allows for multiple rounds of conversation to flow smoothly and naturally. In pursuit of actualizing it, we propose INFP, a novel audio-driven head generation framework for dyadic interaction. Unlike previous head generation works that only focus on single-sided communication, or require manual role assignment and explicit role switching, our model drives the agent portrait dynamically alternates between speaking and listening state, guided by the input dyadic audio. Specifically, INFP comprises a Motion-Based Head Imitation stage and an Audio-Guided Motion Generation stage. The first stage learns to project facial communicative behaviors from real-life conversation videos into a low-dimensional motion latent space, and use the motion latent codes to animate a static image. The second stage learns the mapping from the input dyadic audio to motion latent codes through denoising, leading to the audio-driven head generation in interactive scenarios. To facilitate this line of research, we introduce DyConv, a large scale dataset of rich dyadic conversations collected from the Internet. Extensive experiments and visualizations demonstrate superior performance and effectiveness of our method. Project Page: https://grisoon.github.io/INFP/.
Summary
提出INFP,一种基于音频的双向头部生成框架,实现社交智能对话。
Key Takeaways
- INFP旨在实现社交智能对话,注重双向互动。
- 模型自动切换发言与聆听状态,无需手动分配角色。
- 包含运动头部模仿和音频引导运动生成两个阶段。
- 运动头部模仿从视频学习面部交流行为。
- 音频引导运动生成通过去噪将音频映射到运动代码。
- 使用DyConv数据集,包含丰富的双向对话。
- 实验证明方法具有优越性能和有效性。
Title: INFP:双人对话中的音频驱动交互式头部生成
Authors: Yongming Zhu,Longhao Zhang,Zhengkun Rong,Tianshu Hu,Shuang Liang,Zhipeng Ge(由字节跳动公司支持)
Affiliation: 作者们均来自字节跳动公司。
Keywords: 音频驱动头部生成,双人对话,交互性,面部表达,动作生成,深度学习。
Urls: https://arisecvpr24.github.io/INFP_ProjectPage/ 论文链接,Github代码链接(如有可用)。当前暂无代码链接提供。
Summary:
(1) 研究背景:随着人工智能技术的发展,构建具有交互性的对话代理成为了一个热门的研究领域。本文旨在解决在双人对话场景中音频驱动的交互式头部生成问题,使代理能够根据不同的音频信号进行动态的面部表情和头部动作。
(2) 过去的方法及其问题:现有研究主要集中在单方面的音频驱动头部生成,如说话或聆听,忽视了双人对话中的交互性。此外,大多数方法需要手动分配角色和明确的角色切换,无法适应动态的对话场景。
(3) 研究方法:本文提出了一种新颖的音频驱动头部生成框架INFP,适用于双人对话场景。该框架包含两个阶段:基于运动的头部模仿阶段和音频引导的运动生成阶段。第一阶段学习从真实对话视频中将面部沟通行为投影到一个低维运动潜在空间,并使用这些运动潜在代码来驱动静态图像。第二阶段学习从输入的双人对话音频到运动潜在代码的映射,从而实现音频驱动的头部生成。
(4) 任务与性能:本文在DyConv数据集上进行了实验和可视化展示,该数据集包含丰富的双人对话场景。实验结果表明,INFP方法在交互式场景中实现了优越的头部生成性能,能够根据不同的音频信号进行动态的面部表情和头部动作切换。性能支持达到了研究目标。
希望以上回答能满足您的要求!
7. Methods:
- (1) 研究首先明确了问题的定义和背景,包括音频驱动的交互式头部生成在双人对话场景中的重要性。此外,对当前的研究现状进行了回顾,指出了现有方法的不足和局限性。
- (2) 针对现有方法的不足,研究提出了一种新颖的音频驱动头部生成框架INFP。该框架包含两个阶段:基于运动的头部模仿阶段和音频引导的运动生成阶段。在第一个阶段中,研究使用深度学习模型从真实对话视频中提取面部沟通行为,并将这些行为投影到一个低维运动潜在空间。此外,该研究还利用这些运动潜在代码来驱动静态图像。在第二个阶段中,研究通过训练深度学习模型来学习从双人对话音频到运动潜在代码的映射,从而实现音频驱动的头部生成。
- (3) 为了验证所提出方法的有效性,研究在DyConv数据集上进行了实验和可视化展示。实验结果表明,INFP方法在交互式场景中实现了优越的头部生成性能,能够根据不同的音频信号进行动态的面部表情和头部动作切换。此外,该研究还对所提出方法的关键参数进行了详细的分析和讨论,以验证其有效性和可靠性。
希望以上内容符合您的要求!
8. Conclusion:
- (1) 这项研究工作的意义在于提出了一种新颖的音频驱动交互式头部生成框架INFP,旨在解决双人对话场景中的音频驱动交互式头部生成问题。该研究对于提升人工智能技术在对话代理领域的应用具有重要意义,能够更好地模拟人类对话时的面部表情和头部动作,提高对话代理的真实感和交互性。
- (2) 创新点:本文提出了一个适用于双人对话场景的音频驱动头部生成框架INFP,该框架能够根据不同的音频信号进行动态的面部表情和头部动作生成,且能够适应不同的对话角色,无需手动分配角色和明确的角色切换。
性能:在DyConv数据集上的实验结果表明,INFP方法实现了优越的头部生成性能。
工作量:文章对方法的原理、实验设计、实验过程以及结果分析等方面进行了详细的阐述,但文章未提及该研究的代码开源情况,且数据量和工作复杂度方面未进行具体阐述。
希望以上答复能够满足您的要求!
点此查看论文截图


IF-MDM: Implicit Face Motion Diffusion Model for High-Fidelity Realtime Talking Head Generation
Authors:Sejong Yang, Seoung Wug Oh, Yang Zhou, Seon Joo Kim
We introduce a novel approach for high-resolution talking head generation from a single image and audio input. Prior methods using explicit face models, like 3D morphable models (3DMM) and facial landmarks, often fall short in generating high-fidelity videos due to their lack of appearance-aware motion representation. While generative approaches such as video diffusion models achieve high video quality, their slow processing speeds limit practical application. Our proposed model, Implicit Face Motion Diffusion Model (IF-MDM), employs implicit motion to encode human faces into appearance-aware compressed facial latents, enhancing video generation. Although implicit motion lacks the spatial disentanglement of explicit models, which complicates alignment with subtle lip movements, we introduce motion statistics to help capture fine-grained motion information. Additionally, our model provides motion controllability to optimize the trade-off between motion intensity and visual quality during inference. IF-MDM supports real-time generation of 512x512 resolution videos at up to 45 frames per second (fps). Extensive evaluations demonstrate its superior performance over existing diffusion and explicit face models. The code will be released publicly, available alongside supplementary materials. The video results can be found on https://bit.ly/ifmdm_supplementary.
PDF underreview in CVPR 2025
Summary
提出了一种基于单图和音频输入的高分辨率说话头生成新方法。
Key Takeaways
- 新方法可从单图和音频生成高分辨率说话头视频。
- 避免了显式人脸模型(如3DMM和面部特征点)的局限性。
- 使用隐式运动编码面部,提高视频生成质量。
- 解决了隐式运动与细微唇部动作对齐的问题。
- 提供运动可控性,优化运动强度与视觉质量之间的权衡。
- 支持实时生成512x512分辨率的视频,最高45fps。
- 性能优于现有扩散模型和显式人脸模型。
- 公开代码和补充材料。
- 视频结果可在指定链接查看。
Title: 隐式面部运动扩散模型用于高质量实时对话头部生成研究
Authors: Sejong Yang, Seoung Wug Oh, Yang Zhou, Seon Joo Kim (Adobe Research & Yonsei University)
Affiliation: 第一作者来自Yonsei University。其他几位作者来自Adobe Research。
Keywords: Talking Head Generation, Video Diffusion Model, Implicit Face Motion, High-Fidelity Realtime Generation
Urls: 论文链接:论文链接(暂时无法提供GitHub代码链接)
Summary:
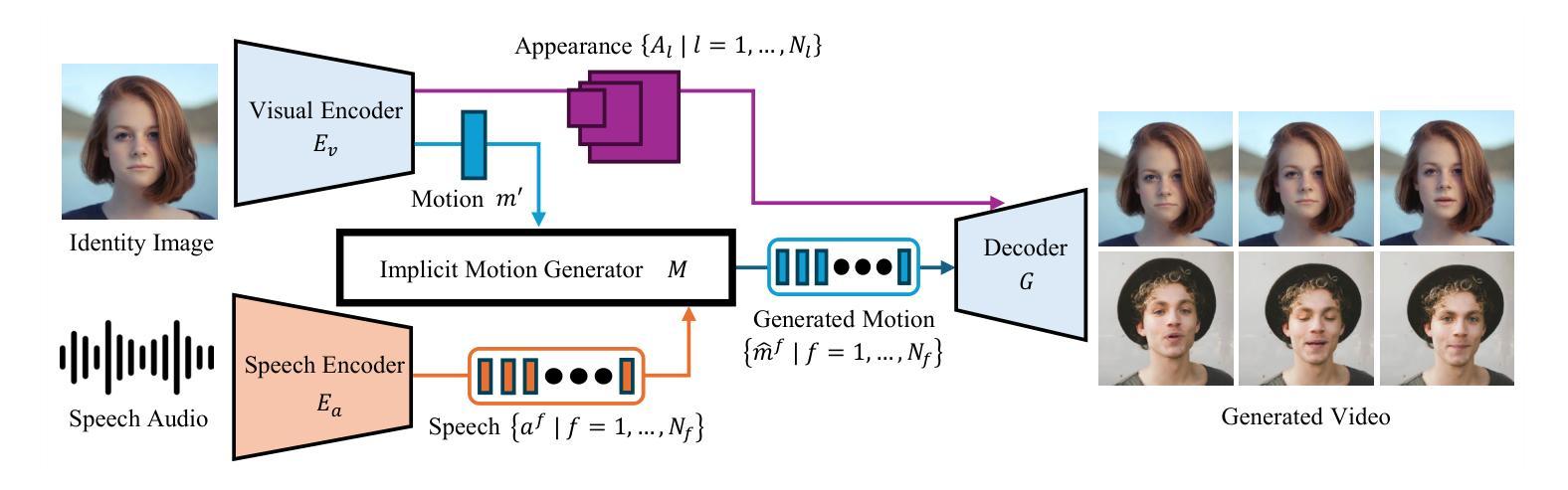
(1) 研究背景:本文主要关注从单张图像和音频输入生成高质量对话视频的任务。尽管已有使用显式面部模型(如3D形态模型,面部特征点)的方法在该任务上取得一定成果,但它们生成的高保真视频质量仍有待提高。同时,基于生成模型的视频扩散模型虽然可以实现高视频质量,但其处理速度慢,难以应用于实际场景。因此,本文提出了一种新的隐式面部运动扩散模型(IF-MDM)。
(2) 过去的方法及其问题:过去的方法主要分为两类,一类是使用显式面部模型的方法,这类方法虽然计算效率较高,但难以生成高质量的视频,因为它们缺乏对面部运动的精确捕捉以及细节帧的生成能力。另一类是视频扩散模型,虽然它们可以生成高质量的视频,但计算量大,处理速度慢。因此,现有的方法难以在保持高视频质量的同时实现实时生成。
(3) 研究方法:针对上述问题,本文提出了隐式面部运动扩散模型(IF-MDM)。该模型采用隐式运动编码人类面部到面向感知的压缩面部潜在空间,从而增强视频生成能力。尽管隐式运动缺乏显式模型的空间分离特性,我们引入了运动统计信息来帮助捕获精细的运动信息。此外,我们的模型还提供了运动可控性,以在推理过程中优化运动强度与视觉质量的权衡。IF-MDM支持以高达每秒45帧的速度实时生成512x512分辨率的视频。
(4) 任务与性能:本文的方法在谈话头部生成任务上取得了显著成果。与现有的扩散和显式面部模型相比,IF-MDM表现出卓越的性能。实验结果表明,IF-MDM能够生成高质量的视频,同时保持实时性能,证明了其有效性。论文中提供的视频结果可以在相关链接中找到。
7. 方法:
(1) 研究背景:文章主要关注如何从单张图像和音频输入生成高质量对话视频的任务。针对现有方法存在的问题,如显式面部模型生成视频质量不高和基于生成模型的视频扩散模型处理速度慢等,提出了一种新的隐式面部运动扩散模型(IF-MDM)。
(2) 方法概述:首先,文章介绍了隐式运动编码人类面部的理论基础知识,将其编码到面向感知的压缩面部潜在空间,以增强视频生成能力。为了捕获精细的运动信息,引入了运动统计信息。此外,该模型还提供了运动可控性,以在推理过程中优化运动强度与视觉质量的权衡。
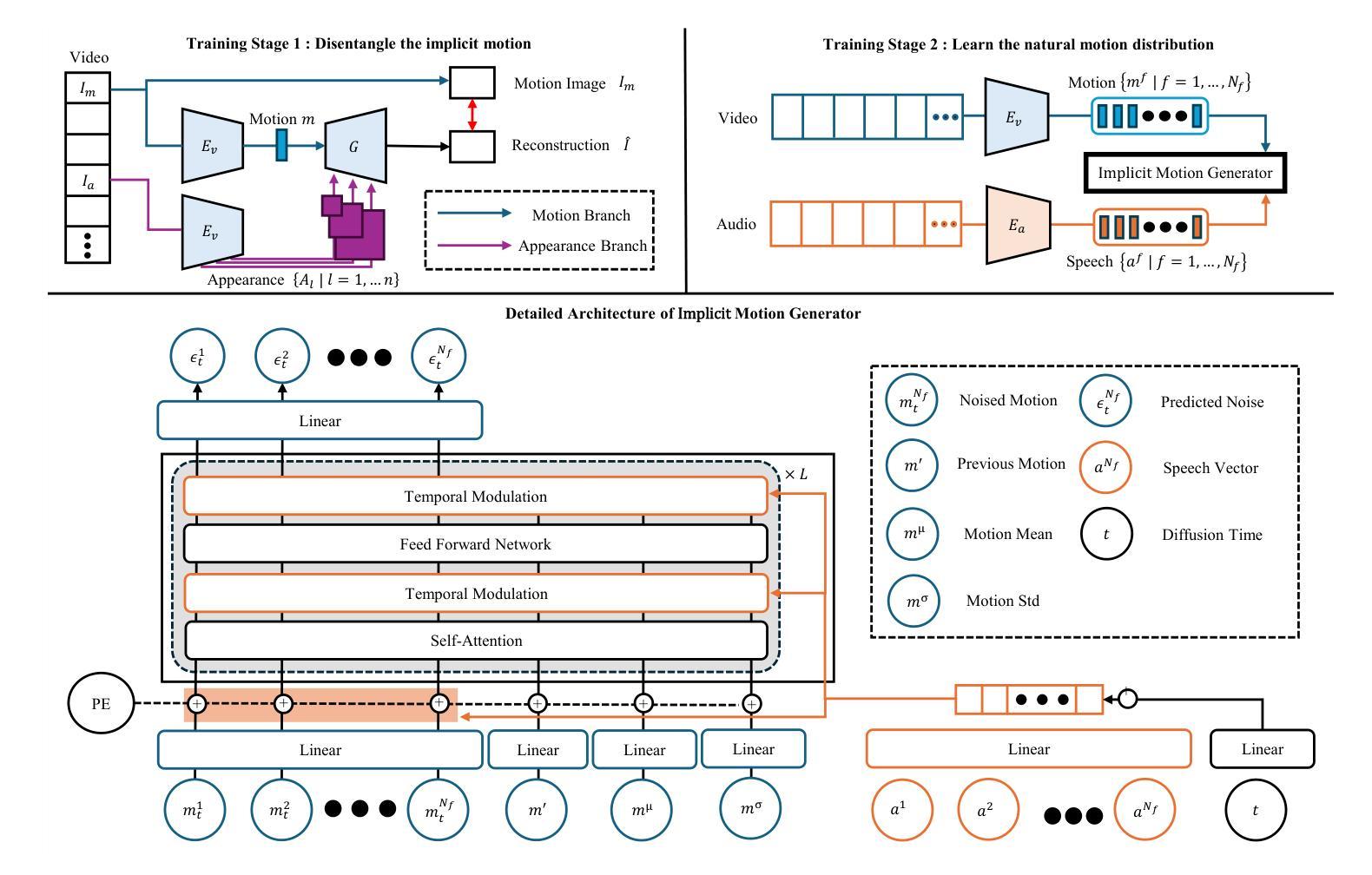
(3) 扩散模型初步介绍:介绍了扩散模型的理论基础,这是一种通过正向过程将数据分布转化为已知噪声分布,并通过反向过程生成新数据样本的生成模型。在本文中,隐式运动生成器被集成到扩散管道中用于推理。
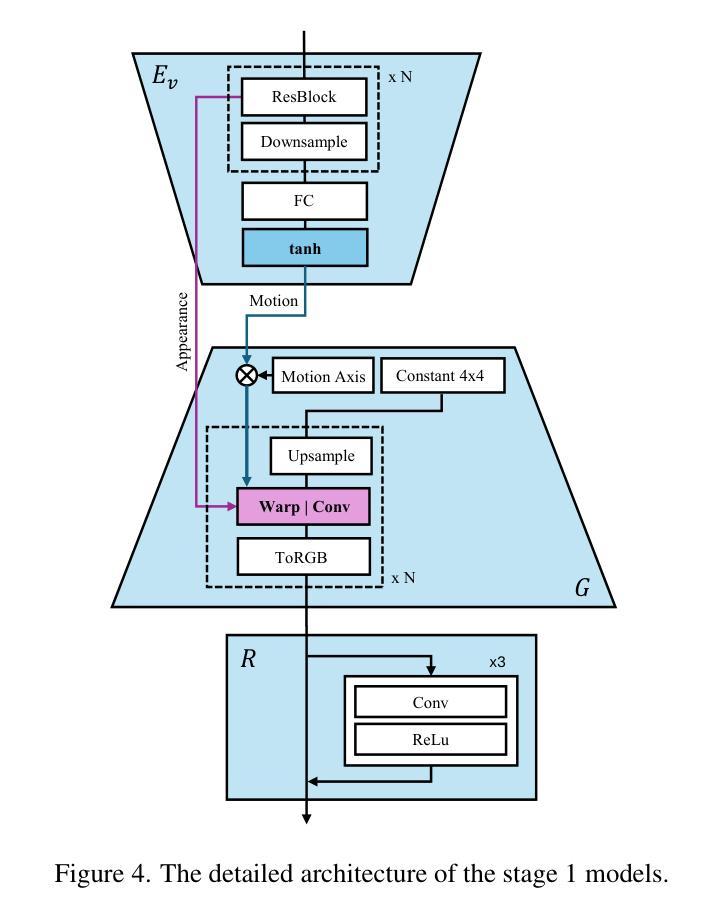
(4) 训练过程:训练分为两个阶段。第一阶段的目标是学习外观和运动的表示分离,通过利用身份图像和对应的运动图像进行训练,学习压缩运动向量。第二阶段则训练隐式运动生成器学习自然运动序列的分布,使用冻结的视觉编码器和语音编码器,提取运动向量序列和语音向量序列进行训练。
(5) 隐式运动生成器设计:介绍了隐式运动生成器的详细架构,包括其如何接受语音指导以合成表达和同步的头部视频。为了提高生成的运动质量,引入了运动均值和标准差作为附加条件指导,帮助模型学习整体运动动力学。同时,利用时序调制技术将语音向量和扩散时间融入生成过程,确保生成的视频与音频节奏和动力学对齐。
总的来说,本文提出的隐式面部运动扩散模型(IF-MDM)在谈话头部生成任务上取得了显著成果,实现了高质量实时视频生成。
8. Conclusion:
(1) 这项工作的意义在于提出了一种新的隐式面部运动扩散模型(IF-MDM),用于从单张图像和音频输入生成高质量对话视频。该模型在谈话头部生成任务上具有显著成果,具有重要的实际应用价值,可应用于虚拟助手、数字化身、视频会议和内容创作等领域,能够提升用户体验、可访问性和个性化,为数字媒体、通信和娱乐等领域带来革新。
(2) 创新点:该文章提出了隐式面部运动扩散模型(IF-MDM),结合隐式运动编码和扩散模型理论,实现了高质量实时视频生成。其引入运动统计信息和可控性优化,提高了运动信息的捕获和生成质量。此外,该模型在谈话头部生成任务上取得了显著成果,证明了其有效性和创新性。
性能:该模型实现了高质量的视频生成,同时保持了实时性能,支持高达每秒45帧的速度生成512x512分辨率的视频。与现有的扩散和显式面部模型相比,IF-MDM表现出卓越的性能。
工作量:文章详细阐述了模型的设计和实现过程,包括训练过程、隐式运动生成器的设计和实现等。工作量较大,但文章结构清晰,逻辑严谨,易于理解。
然而,该文章也存在一定的局限性,未来工作将聚焦于扩展IF-MDM的能力,处理更复杂的场景、多样化的环境条件和进一步提高生成视频的可控性和表现力。同时,也需要关注潜在伦理问题,如虚假信息等问题。
点此查看论文截图