⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-11 更新
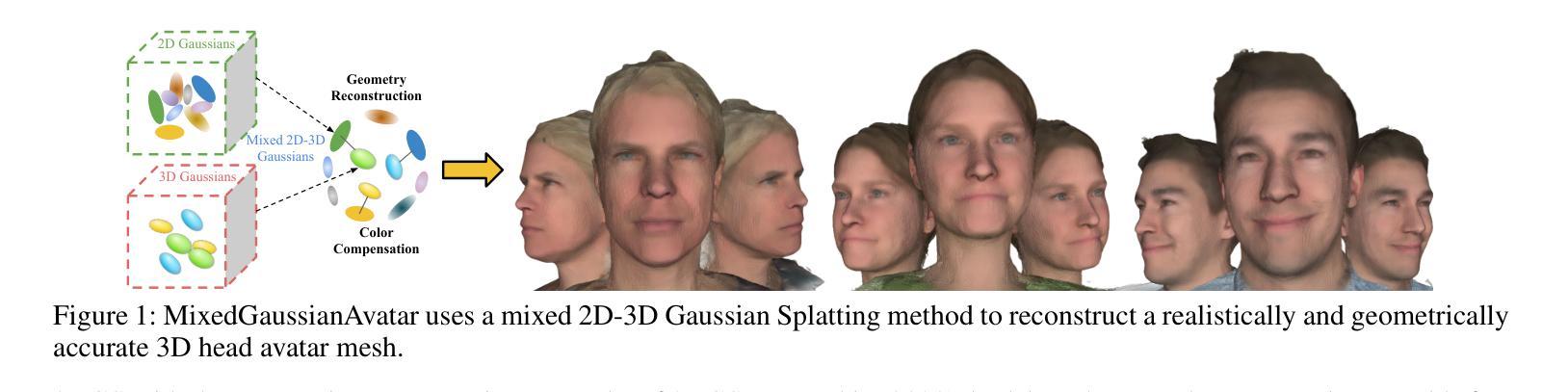
MixedGaussianAvatar: Realistically and Geometrically Accurate Head Avatar via Mixed 2D-3D Gaussian Splatting
Authors:Peng Chen, Xiaobao Wei, Qingpo Wuwu, Xinyi Wang, Xingyu Xiao, Ming Lu
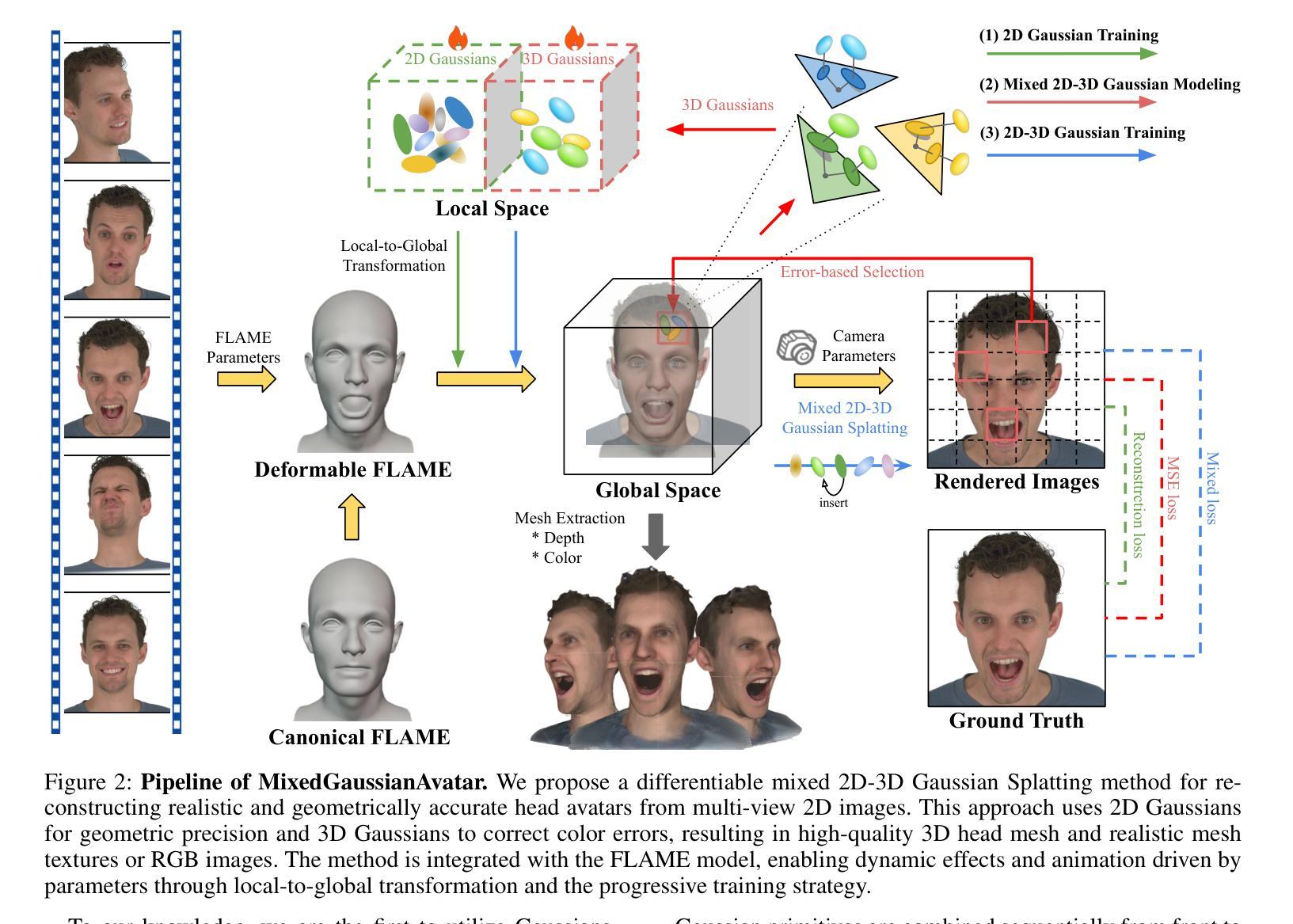
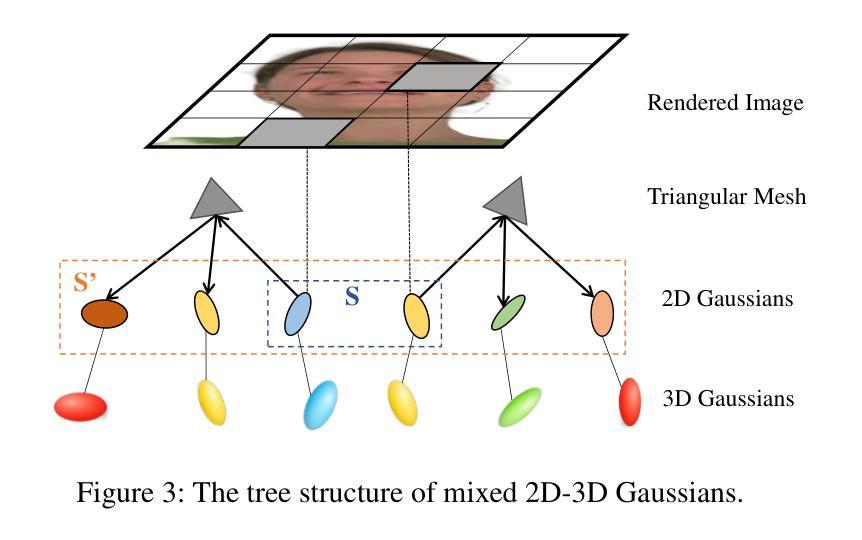
Reconstructing high-fidelity 3D head avatars is crucial in various applications such as virtual reality. The pioneering methods reconstruct realistic head avatars with Neural Radiance Fields (NeRF), which have been limited by training and rendering speed. Recent methods based on 3D Gaussian Splatting (3DGS) significantly improve the efficiency of training and rendering. However, the surface inconsistency of 3DGS results in subpar geometric accuracy; later, 2DGS uses 2D surfels to enhance geometric accuracy at the expense of rendering fidelity. To leverage the benefits of both 2DGS and 3DGS, we propose a novel method named MixedGaussianAvatar for realistically and geometrically accurate head avatar reconstruction. Our main idea is to utilize 2D Gaussians to reconstruct the surface of the 3D head, ensuring geometric accuracy. We attach the 2D Gaussians to the triangular mesh of the FLAME model and connect additional 3D Gaussians to those 2D Gaussians where the rendering quality of 2DGS is inadequate, creating a mixed 2D-3D Gaussian representation. These 2D-3D Gaussians can then be animated using FLAME parameters. We further introduce a progressive training strategy that first trains the 2D Gaussians and then fine-tunes the mixed 2D-3D Gaussians. We demonstrate the superiority of MixedGaussianAvatar through comprehensive experiments. The code will be released at: https://github.com/ChenVoid/MGA/.
重建高保真3D头像在虚拟现实等各种应用中至关重要。前沿方法使用神经辐射场(NeRF)重建逼真的头像,但受限于训练和渲染速度。基于3D高斯拼贴(3DGS)的近期方法显著提高了训练和渲染的效率。然而,3DGS的表面不一致导致几何精度不佳;后来的2DGS使用2D表面元素以提高几何精度,但牺牲了渲染保真度。为了结合2DGS和3DGS的优点,我们提出了一种名为MixedGaussianAvatar的新方法,用于进行真实且几何准确的头像重建。我们的主要思想是使用2D高斯重建3D头像的表面,以确保几何精度。我们将2D高斯附加到FLAME模型的三角网格上,并在2DGS的渲染质量不足的地方连接到额外的3D高斯,创建混合的2D-3D高斯表示。这些2D-3D高斯可以使用FLAME参数进行动画设置。我们还引入了一种逐步训练策略,首先训练2D高斯,然后对混合的2D-3D高斯进行微调。我们通过全面的实验证明了MixedGaussianAvatar的优势。代码将在https://github.com/ChenVoid/MGA/发布。
简化解释
论文及项目相关链接
PDF Project: https://chenvoid.github.io/MGA/
Summary
该文本介绍了在虚拟现实中重建高保真3D头像的重要性,以及采用神经网络辐射场(NeRF)和基于三维高斯展开(3DGS)的方法在重建真实头像方面的进展。然而,这些方法存在训练与渲染速度的限制以及几何精度问题。为此,提出了一种名为MixedGaussianAvatar的新方法,利用二维高斯重建三维头部的表面,保证了几何精度,同时引入了混合的二维-三维高斯表示,并可以通过FLAME参数进行动画渲染。通过渐进式训练策略进行模型训练和优化。最终通过实验证明了MixedGaussianAvatar的优势。
Key Takeaways
- 重建高保真3D头像在虚拟现实等应用中至关重要。
- 当前方法如NeRF和3DGS在重建真实头像方面存在局限性,如训练与渲染速度、几何精度问题。
- MixedGaussianAvatar方法结合了2DGS和3DGS的优点,旨在实现真实且几何准确的头像重建。
- 该方法利用二维高斯重建三维头部表面,同时引入混合的二维-三维高斯表示。
- 通过连接FLAME模型的三角网格和附加的三维高斯,提高了渲染质量。
- 采用渐进式训练策略进行模型训练和优化。
点此查看论文截图


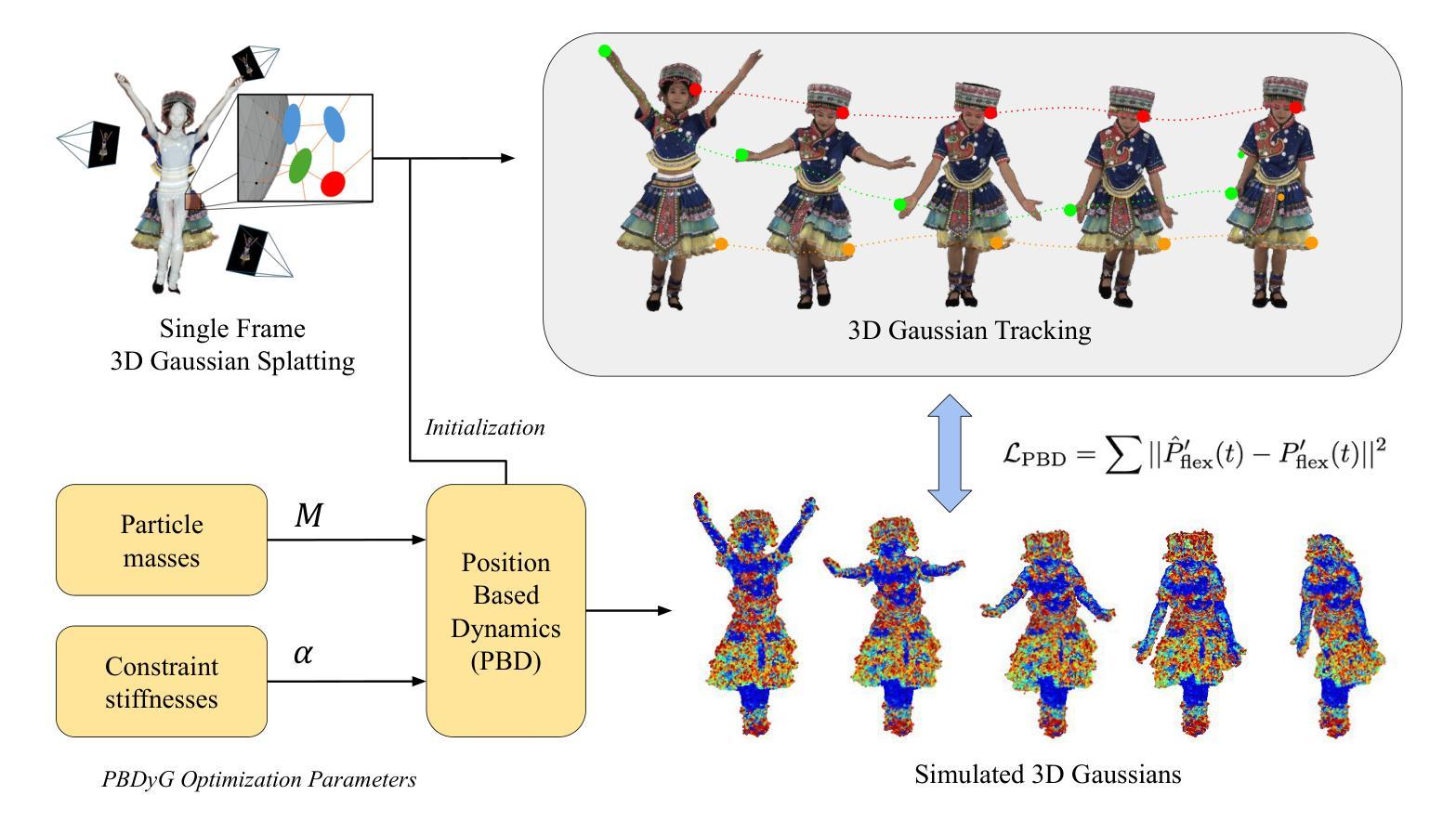
PBDyG: Position Based Dynamic Gaussians for Motion-Aware Clothed Human Avatars
Authors:Shota Sasaki, Jane Wu, Ko Nishino
This paper introduces a novel clothed human model that can be learned from multiview RGB videos, with a particular emphasis on recovering physically accurate body and cloth movements. Our method, Position Based Dynamic Gaussians (PBDyG), realizes movement-dependent'' cloth deformation via physical simulation, rather than merely relying on pose-dependent’’ rigid transformations. We model the clothed human holistically but with two distinct physical entities in contact: clothing modeled as 3D Gaussians, which are attached to a skinned SMPL body that follows the movement of the person in the input videos. The articulation of the SMPL body also drives physically-based simulation of the clothes’ Gaussians to transform the avatar to novel poses. In order to run position based dynamics simulation, physical properties including mass and material stiffness are estimated from the RGB videos through Dynamic 3D Gaussian Splatting. Experiments demonstrate that our method not only accurately reproduces appearance but also enables the reconstruction of avatars wearing highly deformable garments, such as skirts or coats, which have been challenging to reconstruct using existing methods.
本文介绍了一种可以从多视角RGB视频中学习的新型穿衣人体模型,特别侧重于恢复物理上准确的身体和衣物运动。我们的方法,基于位置动态高斯(PBDyG),通过物理模拟实现“运动相关”的衣物变形,而不是仅仅依赖“姿态相关”的刚性变换。我们对穿衣人体进行整体建模,但接触的两个物理实体是独特的:将衣物建模为三维高斯,附着在跟随输入视频人物动作的带皮肤SMPL身体上。SMPL身体的关节活动还驱动衣物高斯基于物理的模拟,将角色变形为新的姿势。为了运行基于位置的动态模拟,物理特性包括质量和材料刚度是通过动态三维高斯喷绘从RGB视频中估计出来的。实验表明,我们的方法不仅准确地再现了外观,还实现了对穿着高度可变形服装的角色重建,如裙子或外套,这在以前的方法中一直是一个挑战。
论文及项目相关链接
Summary
本文介绍了一种新型穿衣人体模型,该模型可从多角度RGB视频中学习,并特别重视恢复物理准确的身体和衣物动作。通过基于位置的动态高斯方法,实现了通过物理模拟的“动作相关”衣物变形,而不是仅依赖于“姿势相关”的刚性变换。该模型将穿衣的人体视为一个整体,但分为两个接触的物理实体:衣物被视为三维高斯分布,附着在随输入视频人物动作而变化的皮肤化SMPL身体上。SMPL身体的关节活动也驱动衣物的基于物理的高斯模拟,将角色转换为新的姿势。为了运行基于位置的动态模拟,通过动态三维高斯模板从RGB视频中估计质量、材料刚度等物理属性。实验表明,该方法不仅准确还原外观,还能重建穿着高度可变形服装的角色,如裙子或外套,这在现有方法中是一个挑战。
Key Takeaways
- 本文提出了一种新的穿衣人体模型学习方法,可从多角度RGB视频中学习并建立物理准确的动作模型。
- 利用基于位置的动态高斯(PBDyG)方法实现物理模拟的衣物变形。
- 将穿衣的人体视为整体,分为两个接触的物理实体:衣物和皮肤化SMPL身体。
- SMPL身体的关节活动驱动衣物的物理模拟。
- 通过动态三维高斯模板从RGB视频中估计物理属性,如质量和材料刚度。
- 方法能准确还原外观并重建高度可变形服装的角色。
点此查看论文截图


A multidimensional measurement of photorealistic avatar quality of experience
Authors:Ross Cutler, Babak Naderi, Vishak Gopal, Dharmendar Palle
Photorealistic avatars are human avatars that look, move, and talk like real people. The performance of photorealistic avatars has significantly improved recently based on objective metrics such as PSNR, SSIM, LPIPS, FID, and FVD. However, recent photorealistic avatar publications do not provide subjective tests of the avatars to measure human usability factors. We provide an open source test framework to subjectively measure photorealistic avatar performance in ten dimensions: realism, trust, comfortableness using, comfortableness interacting with, appropriateness for work, creepiness, formality, affinity, resemblance to the person, and emotion accuracy. We show that the correlation of nine of these subjective metrics with PSNR, SSIM, LPIPS, FID, and FVD is weak, and moderate for emotion accuracy. The crowdsourced subjective test framework is highly reproducible and accurate when compared to a panel of experts. We analyze a wide range of avatars from photorealistic to cartoon-like and show that some photorealistic avatars are approaching real video performance based on these dimensions. We also find that for avatars above a certain level of realism, eight of these measured dimensions are strongly correlated. This means that avatars that are not as realistic as real video will have lower trust, comfortableness using, comfortableness interacting with, appropriateness for work, formality, and affinity, and higher creepiness compared to real video. In addition, because there is a strong linear relationship between avatar affinity and realism, there is no uncanny valley effect for photorealistic avatars in the telecommunication scenario. We provide several extensions of this test framework for future work and discuss design implications for telecommunication systems. The test framework is available at https://github.com/microsoft/P.910.
超写实虚拟人是看起来像、移动和说话都像真实人类的虚拟人。基于PSNR、SSIM、LPIPS、FID和FVD等客观指标,超写实虚拟人的性能最近得到了显著提高。然而,最近的超写实虚拟人出版物并没有提供主观测试,以测量虚拟人的可用性因子。我们提供了一个开源测试框架,主观地测量超写实虚拟人在十个维度上的性能:真实性、信任度、使用舒适度、交互舒适度、工作适宜性、怪异感、正式程度、亲和力、与人的相似性以及情绪准确性。我们展示这些主观指标中的九个与PSNR、SSIM、LPIPS、FID和FVD的关联很微弱,情绪准确度的关联则适中。与专家小组相比,众包主观测试框架高度可复制且准确。我们分析了从超写实到卡通般的各种虚拟人,并显示一些超写实虚拟人在这些维度上已接近真实视频的性能。我们还发现,对于达到一定现实水平的虚拟人,这八个测量维度之间存在强烈关联。这意味着与现实视频相比,不那么真实的虚拟人将在信任度、使用舒适度、交互舒适度、工作适宜性、正式程度和亲和力方面较低,并且会有更高的怪异感。此外,由于虚拟人亲和力和现实感之间存在强烈的线性关系,因此在电信场景中,超写实虚拟人不会出现诡异谷效应。我们为这个测试框架提供了几个未来工作的扩展,并讨论了电信系统设计的影响。测试框架可在https://github.com/microsoft/P.910获取。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2204.06784
Summary
该文本介绍了逼真虚拟人的概念及其性能评估。虽然客观指标如PSNR、SSIM等有所提升,但主观测试对于衡量虚拟人在人机交互中的可用性至关重要。因此,文章提供了一个开源测试框架来主观测量虚拟人在十个维度上的性能,并发现某些高度逼真的虚拟人在这些维度上的表现已接近真实视频。此外,对于达到一定真实水平的虚拟人,八个测量维度之间存在强烈的相关性。最后,文章讨论了该测试框架的扩展和未来工作设计的影响。
Key Takeaways
- 逼真虚拟人的定义和最新进展。
- 文章强调了主观测试在评估虚拟人性能中的重要性,因为客观指标无法全面反映人类在使用和交互过程中的感受。
- 文章提供了一个开源测试框架,用于主观测量虚拟人在多个维度(如真实感、信任度、舒适性等)的性能。
- 高度逼真的虚拟人在这些维度上的表现已接近真实视频。
- 对于达到一定真实水平的虚拟人,多个测量维度之间存在强烈的相关性。
- 文章讨论了测试框架的扩展性以及对未来电信系统设计的潜在影响。
点此查看论文截图


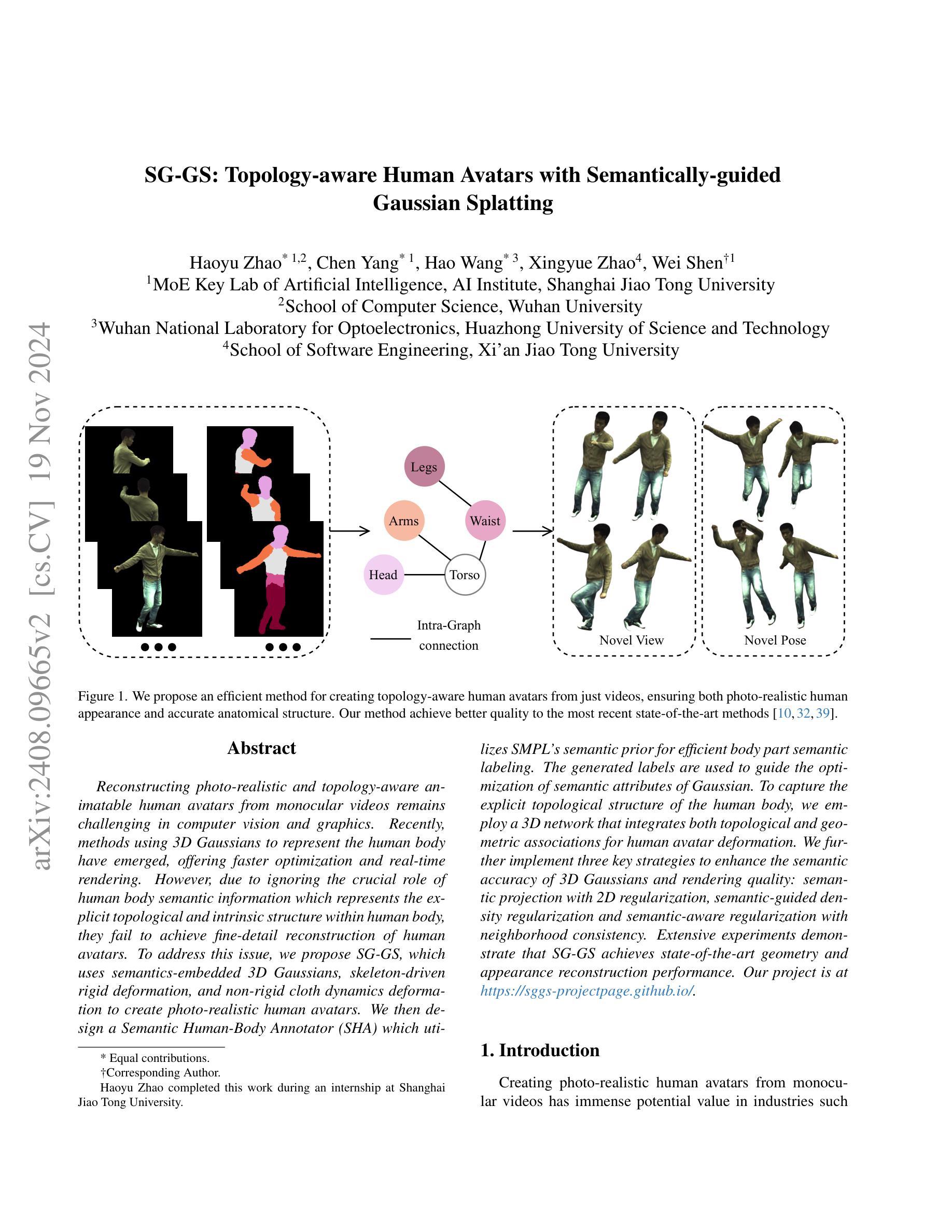
Topology-aware Human Avatars with Semantically-guided Gaussian Splatting
Authors:Haoyu Zhao, Chen Yang, Hao Wang, Xingyue Zhao, Wei Shen
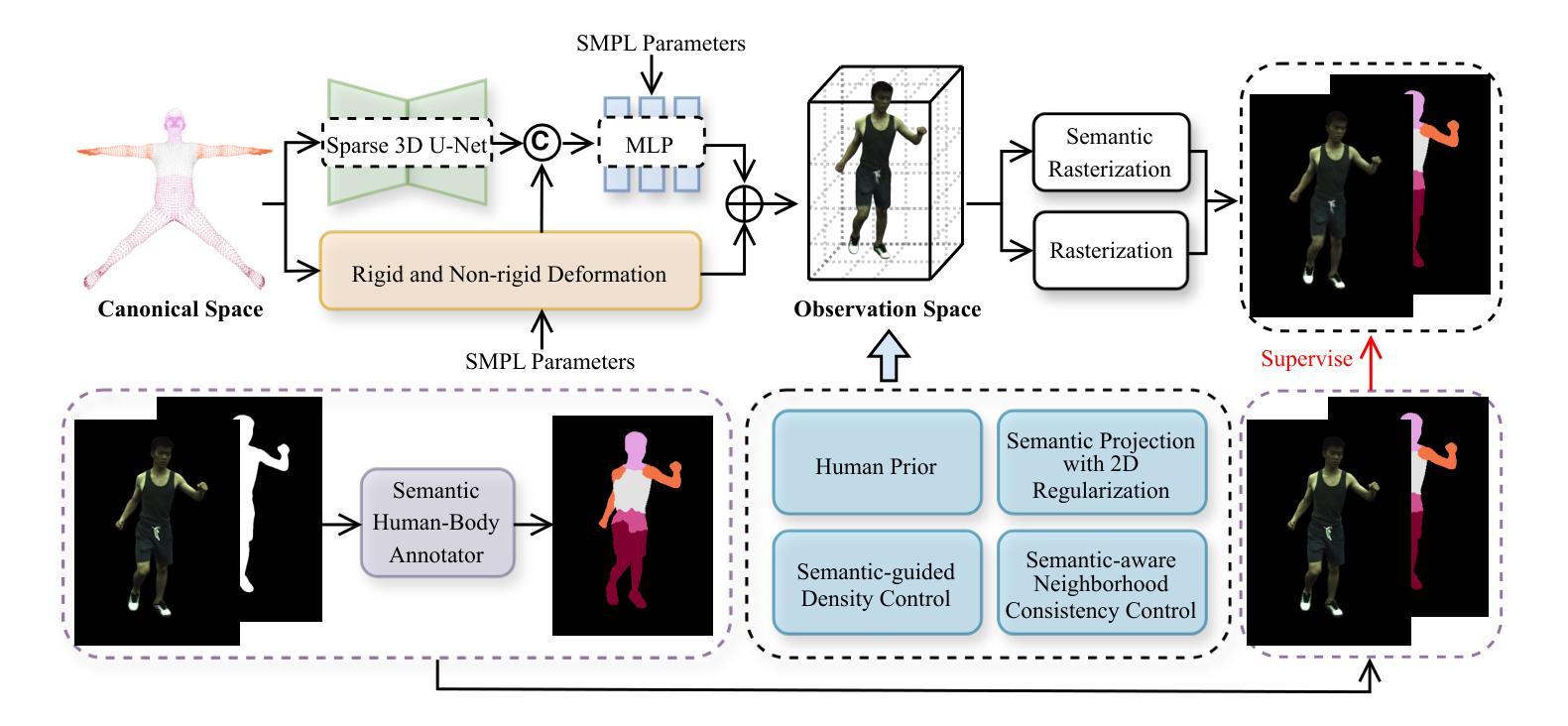
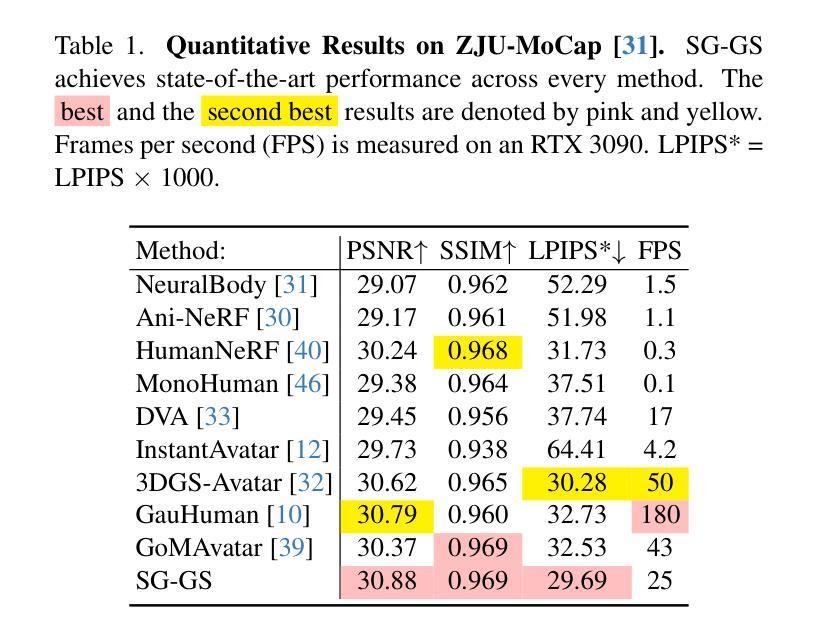
Reconstructing photo-realistic and topology-aware animatable human avatars from monocular videos remains challenging in computer vision and graphics. Recently, methods using 3D Gaussians to represent the human body have emerged, offering faster optimization and real-time rendering. However, due to ignoring the crucial role of human body semantic information which represents the explicit topological and intrinsic structure within human body, they fail to achieve fine-detail reconstruction of human avatars. To address this issue, we propose SG-GS, which uses semantics-embedded 3D Gaussians, skeleton-driven rigid deformation, and non-rigid cloth dynamics deformation to create photo-realistic human avatars. We then design a Semantic Human-Body Annotator (SHA) which utilizes SMPL’s semantic prior for efficient body part semantic labeling. The generated labels are used to guide the optimization of semantic attributes of Gaussian. To capture the explicit topological structure of the human body, we employ a 3D network that integrates both topological and geometric associations for human avatar deformation. We further implement three key strategies to enhance the semantic accuracy of 3D Gaussians and rendering quality: semantic projection with 2D regularization, semantic-guided density regularization and semantic-aware regularization with neighborhood consistency. Extensive experiments demonstrate that SG-GS achieves state-of-the-art geometry and appearance reconstruction performance.
从单目视频中重建真实感且具备拓扑感知能力的可动画人类化身,在计算机视觉和图形学中仍然是一个挑战。近期,使用3D高斯表示人体的方法已经出现,它们提供了更快的优化和实时渲染。然而,由于忽略了人体语义信息在表示人体内部明确的拓扑结构和内在结构中的关键作用,这些方法无法实现人类化身的精细细节重建。为了解决这一问题,我们提出了SG-GS方法,它使用嵌入语义的3D高斯、骨架驱动的刚性变形和非刚性布料动态变形来创建真实感的人类化身。然后,我们设计了一个语义人体标注器(SHA),它利用SMPL的语义先验进行高效的身体部位语义标注。生成的标签用于引导高斯语义属性的优化。为了捕捉人体的明确拓扑结构,我们采用了一个3D网络,该网络结合了拓扑和几何关联,用于人类化身的变形。我们还实施了三种关键策略,以提高3D高斯和渲染质量的语义准确性:带有二维正则化的语义投影、语义引导密度正则化和具有邻域一致性的语义感知正则化。大量实验表明,SG-GS在几何和外观重建方面达到了最先进的性能。
论文及项目相关链接
Summary
该文本介绍了一种利用语义嵌入的三维高斯模型、骨架驱动的刚性变形和非刚性布料动力学变形技术,创建逼真人类虚拟形象的方法。为解决忽略人体语义信息导致的精细重建问题,提出了SG-GS方法,并结合语义人体标注器(SHA)和一系列优化策略,实现了先进的人形几何和外观重建效果。
Key Takeaways
- 重建基于单目视频的光学逼真且具有拓扑感知的可动画人类虚拟形象在计算机视觉和图形学中仍然具有挑战性。
- 现有使用三维高斯模型的方法虽然能加快优化和实时渲染,但忽略了人体语义信息的重要性,无法实现精细重建。
- SG-GS方法利用语义嵌入的三维高斯模型、骨架驱动的刚性变形和非刚性布料动力学变形技术,以创建逼真的虚拟人类形象。
- SHA(语义人体标注器)利用SMPL的语义先验进行高效的身体部位语义标注,用于指导高斯语义属性的优化。
- 通过结合拓扑和几何关联的三维网络,捕捉人体的显式拓扑结构,实现人类虚拟形象的变形。
- 实施三个关键策略以提高三维高斯模型的语义准确性和渲染质量,包括语义投影与二维正则化、语义引导密度正则化和语义感知的邻域一致性正则化。
点此查看论文截图

3D-Consistent Human Avatars with Sparse Inputs via Gaussian Splatting and Contrastive Learning
Authors:Haoyu Zhao, Hao Wang, Chen Yang, Wei Shen
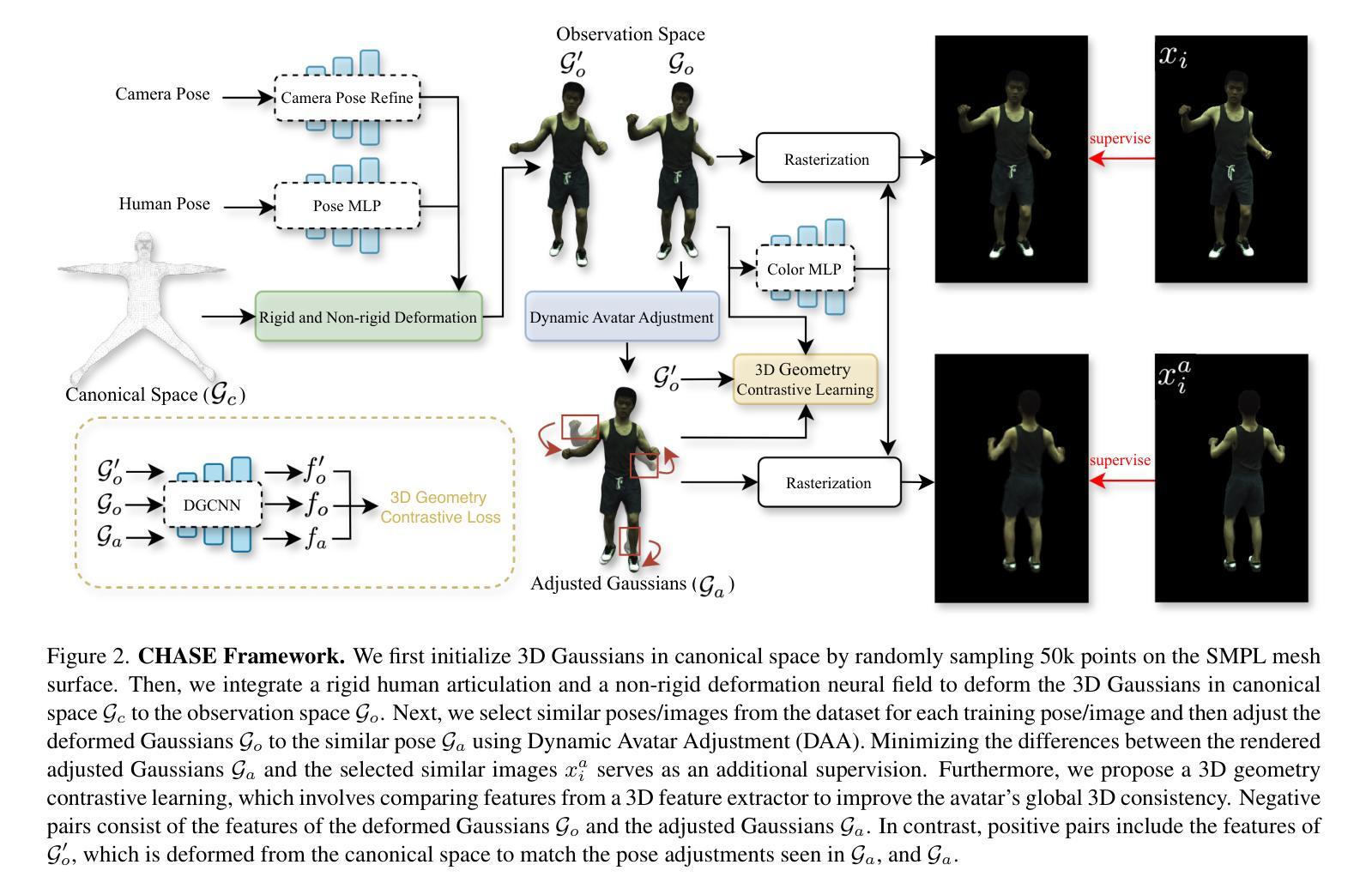
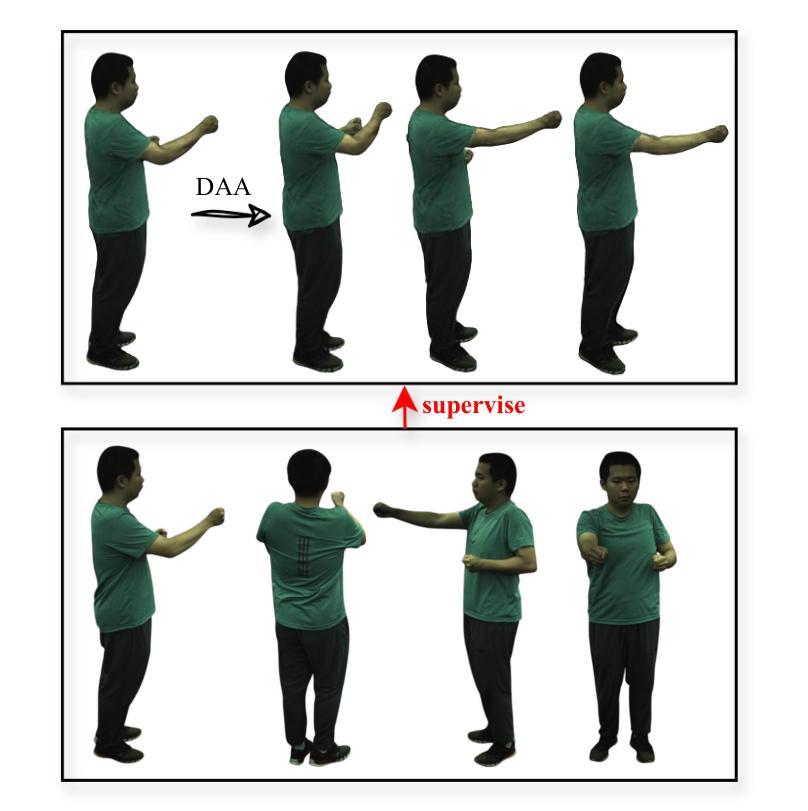
Existing approaches for human avatar generation–both NeRF-based and 3D Gaussian Splatting (3DGS) based–struggle with maintaining 3D consistency and exhibit degraded detail reconstruction, particularly when training with sparse inputs. To address this challenge, we propose CHASE, a novel framework that achieves dense-input-level performance using only sparse inputs through two key innovations: cross-pose intrinsic 3D consistency supervision and 3D geometry contrastive learning. Building upon prior skeleton-driven approaches that combine rigid deformation with non-rigid cloth dynamics, we first establish baseline avatars with fundamental 3D consistency. To enhance 3D consistency under sparse inputs, we introduce a Dynamic Avatar Adjustment (DAA) module, which refines deformed Gaussians by leveraging similar poses from the training set. By minimizing the rendering discrepancy between adjusted Gaussians and reference poses, DAA provides additional supervision for avatar reconstruction. We further maintain global 3D consistency through a novel geometry-aware contrastive learning strategy. While designed for sparse inputs, CHASE surpasses state-of-the-art methods across both full and sparse settings on ZJU-MoCap and H36M datasets, demonstrating that our enhanced 3D consistency leads to superior rendering quality.
当前的人形化身生成方法,无论是基于NeRF的方法还是基于3D高斯平板印刷(3DGS)的方法,在保持3D一致性方面都面临困难,并且在细节重建方面表现出退化,特别是在使用稀疏输入进行训练时更为明显。为了应对这一挑战,我们提出了CHASE,这是一个新型框架,仅通过稀疏输入就能实现密集输入级别的性能,主要通过两个关键创新点:跨姿势内在3D一致性监督和3D几何对比学习。我们建立在先前的骨架驱动方法的基础上,结合刚体变形和非刚性布料动力学,首先建立具有基本3D一致性的基准化身。为了提高稀疏输入下的3D一致性,我们引入了动态化身调整(DAA)模块,该模块通过利用训练集中的相似姿势来优化变形后的高斯函数。通过最小化调整后的高斯函数与参考姿势之间的渲染差异,DAA为化身重建提供了额外的监督。我们还通过一种新型几何感知对比学习策略来保持全局3D一致性。虽然是为稀疏输入而设计的,但CHASE在ZJU-MoCap和H36M数据集上的全面和稀疏设置方面都超越了最先进的方法,表明我们增强的3D一致性导致了更高的渲染质量。
论文及项目相关链接
Summary
本文提出了一种新型框架CHASE,用于解决人类角色生成的问题。该框架能够在稀疏输入下实现密集输入级别的性能,主要通过两个关键创新点:跨姿态的3D一致性监督和3D几何对比学习。通过引入动态角色调整模块,增强稀疏输入下的3D一致性,并通过几何感知对比学习策略维持全局3D一致性。在ZJU-MoCap和H36M数据集上,CHASE在稀疏和完整输入场景下均超越现有方法,展现出卓越的三维渲染质量。
Key Takeaways
- CHASE框架解决了现有方法在生成人类角色时的挑战,实现了密集输入级别的性能。
- CHASE通过跨姿态的3D一致性监督和3D几何对比学习两个关键创新点实现高性能。
- 动态角色调整模块增强了稀疏输入下的渲染性能,减少重建差异并提升了性能表现。
- 动态角色调整模块采用对类似姿态的数据集进行训练,为重建提供了额外的监督。
- CHASE框架维持全局的3D一致性,采用新颖的几何感知对比学习策略。
- 在多个数据集上,CHASE在稀疏和完整输入场景下均超越现有方法。
点此查看论文截图


AniFaceDiff: Animating Stylized Avatars via Parametric Conditioned Diffusion Models
Authors:Ken Chen, Sachith Seneviratne, Wei Wang, Dongting Hu, Sanjay Saha, Md. Tarek Hasan, Sanka Rasnayaka, Tamasha Malepathirana, Mingming Gong, Saman Halgamuge
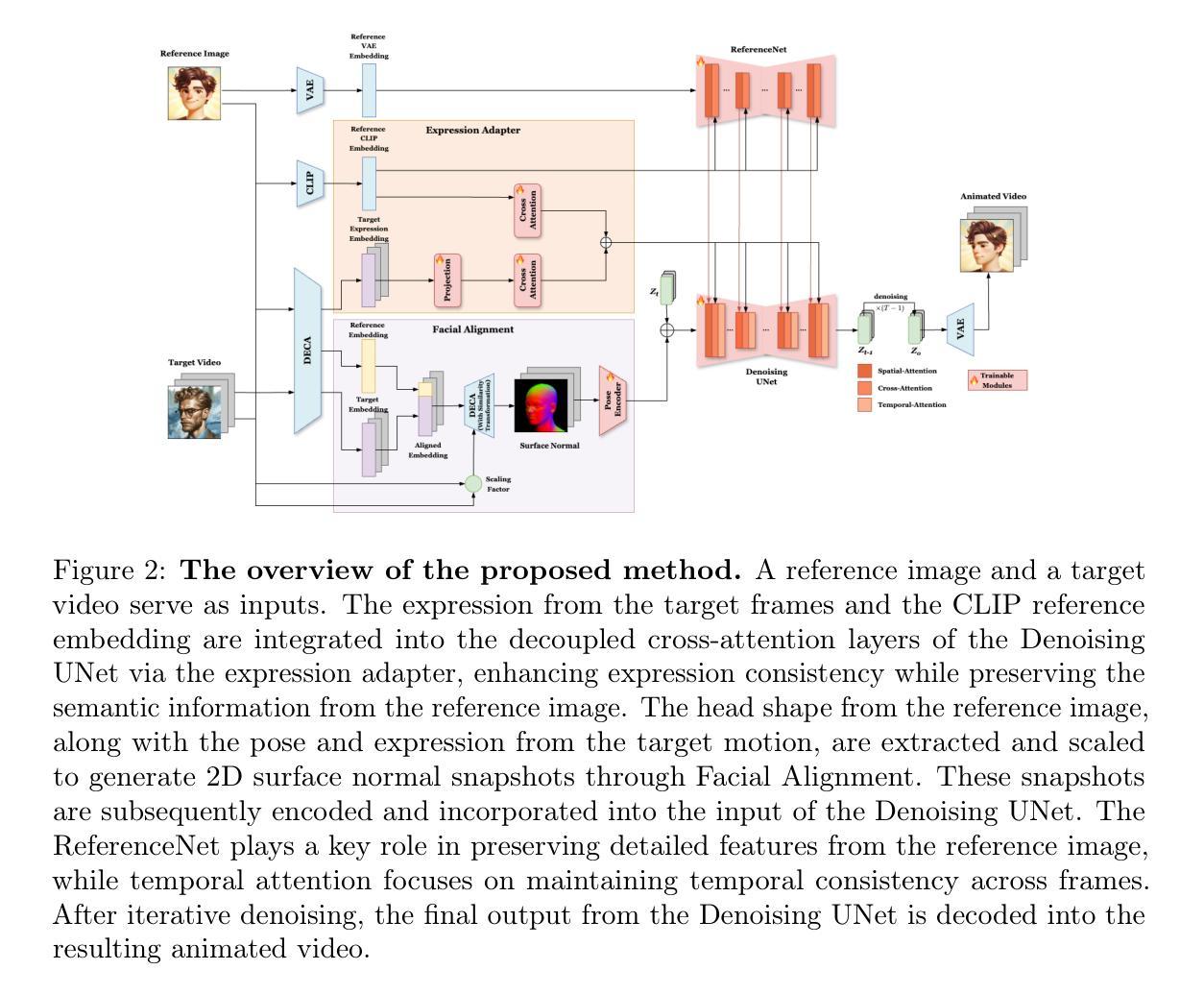
Animating stylized avatars with dynamic poses and expressions has attracted increasing attention for its broad range of applications. Previous research has made significant progress by training controllable generative models to synthesize animations based on reference characteristics, pose, and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce unintended features from the target motion, while also causing a loss of expression-related details, particularly when applied to stylized animation. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for animating stylized avatars. First, we propose a refined spatial conditioning approach by Facial Alignment to prevent the inclusion of identity characteristics from the target motion. Then, we introduce an Expression Adapter that incorporates additional cross-attention layers to address the potential loss of expression-related information. Our approach effectively preserves pose and expression from the target video while maintaining input image consistency. Extensive experiments demonstrate that our method achieves state-of-the-art results, showcasing superior image quality, preservation of reference features, and expression accuracy, particularly for out-of-domain animation across diverse styles, highlighting its versatility and strong generalization capabilities. This work aims to enhance the quality of virtual stylized animation for positive applications. To promote responsible use in virtual environments, we contribute to the advancement of detection for generative content by evaluating state-of-the-art detectors, highlighting potential areas for improvement, and suggesting solutions.
使用动态姿势和表情制作动画风格的化身已经因其广泛的应用领域而越来越受到关注。之前的研究通过训练可控生成模型来合成基于参考特征、姿势和表情条件的动画,已经取得了重大进展。然而,这些方法在控制姿势和表情的机制时,常常会无意中引入目标动作的额外特征,同时也会失去与表情相关的细节,特别是在应用于动画风格化时。本文提出了一种基于Stable Diffusion的新方法,称为AniFaceDiff,并融入了一个用于动画风格化化身的新型条件模块。首先,我们通过面部对齐提出了一种精细的空间条件方法,以防止目标运动中的身份特征被包含进来。然后,我们引入了一个表情适配器,它结合了额外的交叉注意力层,以解决可能丢失与表情相关的信息的问题。我们的方法有效地保留了目标视频中的姿势和表情,同时保持了输入图像的一致性。大量实验表明,我们的方法达到了最先进的水平,展现了卓越的图片质量、对参考特征的保留和表情的准确性,尤其是在不同风格的域外动画中,凸显了其通用性和强大的泛化能力。本工作的目标是提高虚拟风格化动画的质量,用于积极的应用。为了促进虚拟环境中负责任的使用,我们通过评估最先进的检测器,来推动生成内容的检测发展,突出潜在的可改进领域,并提出解决方案。
论文及项目相关链接
Summary
基于Stable Diffusion的新方法AniFaceDiff,应用于动态调整个性化动画人物形象的姿态和表情。通过面部对齐技术改进空间调节方式,防止目标运动的身份特征被引入,同时引入表情适配器,通过额外的交叉注意力层解决表情相关信息可能丢失的问题。该方法能很好地保留目标视频的姿态和表情,同时保持输入图像的一致性。实验结果达到领先水平,表现出优越的图像质量、对参考特征的保留以及准确的表情表达,特别是适用于跨不同风格的动画创作,展现了其通用性和强大的泛化能力。该工作旨在提升虚拟个性化动画的质量,并对虚拟环境中的负责任使用做出贡献。同时评估了现有的检测生成内容的技术,指出潜在的改进领域并给出解决方案。
Key Takeaways
- 利用Stable Diffusion的AniFaceDiff方法提升个性化动画人物形象的姿态和表情控制效果。
- 通过面部对齐技术避免目标运动身份特征的干扰。
- 采用新设计的表情适配器以改善表情相关信息的保留情况。
- 方法保留了目标视频的姿态和表情,同时维持输入图像的一致性。
- 实验结果领先,图像质量高、保留参考特征、准确表达表情,尤其适用于跨风格动画创作。
- 方法展现出强大的通用性和泛化能力。
- 对虚拟个性化动画质量的提升做出贡献,并关注虚拟环境中的负责任使用。
点此查看论文截图


A philosophical and ontological perspective on Artificial General Intelligence and the Metaverse
Authors:Martin Schmalzried
This paper leverages various philosophical and ontological frameworks to explore the concept of embodied artificial general intelligence (AGI), its relationship to human consciousness, and the key role of the metaverse in facilitating this relationship. Several theoretical frameworks underpin this exploration, such as embodied cognition, Michael Levin’s computational boundary of a “Self,” Donald D. Hoffman’s Interface Theory of Perception, and Bernardo Kastrup’s analytical idealism, which lead to considering our perceived outer reality as a symbolic representation of alternate inner states of being, and where AGI could embody a different form of consciousness with a larger computational boundary. The paper further discusses the developmental stages of AGI, the requirements for the emergence of an embodied AGI, the importance of a calibrated symbolic interface for AGI, and the key role played by the metaverse, decentralized systems, open-source blockchain technology, as well as open-source AI research. It also explores the idea of a feedback loop between AGI and human users in metaverse spaces as a tool for AGI calibration, as well as the role of local homeostasis and decentralized governance as preconditions for achieving a stable embodied AGI. The paper concludes by emphasizing the importance of achieving a certain degree of harmony in human relations and recognizing the interconnectedness of humanity at a global level, as key prerequisites for the emergence of a stable embodied AGI.
本文利用多种哲学和本体论框架,探讨具身通用人工智能(AGI)的概念、其与人类意识的关系,以及元宇宙在促进这种关系中的关键作用。本文的探讨基于多个理论框架,如具身认知、迈克尔·莱文的“自我”计算边界、唐纳德·霍夫曼的界面感知理论以及贝尔纳多·卡斯特鲁的分析理想主义,这些理论引导我们考虑我们所感知的外部现实是存在不同内在状态的象征性表现,而AGI可能体现了一种具有更大计算边界的不同形式的意识。论文还进一步讨论了AGI的发展阶段、具身AGI出现的要求、为AGI提供校准符号界面的重要性,以及元宇宙、去中心化系统、开源区块链技术以及开源人工智能研究的关键作用。此外,它还探索了元空间内AGI和人类用户之间的反馈循环作为AGI校准工具的理念,以及实现稳定具身AGI的本地稳态和去中心化治理的先决条件。本文最后强调,实现一定程度的和谐人际关系和认识到人类在全球层面的相互关联性,是实现稳定具身AGI的关键先决条件。
论文及项目相关链接
PDF Presented at the conference second international conference on human-centred AI ethics: seeing the human in the artificial (HCAIE 2023): https://ethics-ai.eu/hcaie2023/
Summary:
此论文探讨实体化人工智能一般智能(AGI)的概念及其在元宇宙中的角色。它利用多种哲学和本体论框架探讨AGI与人类意识的关联,提出计算边界与自我意识、感知接口理论及虚拟现实的重要性等观点。强调开发阶段的需求和象征性界面的校准。文章探讨AGI和用户的元宇宙空间的反馈循环及其在AI校准中的价值。
Key Takeaways:
以下是该文本的关键见解:
- 论文探讨了实体化人工智能一般智能(AGI)的概念及其在元宇宙中的角色。
- 通过哲学和本体论框架探索AGI与人类意识的关联。
- 计算边界、自我意识与感知接口理论在探讨AGI时非常重要。
- AGI发展需要达到特定的成熟度阶段,并需要校准象征性界面。
- 元宇宙和开放源代码区块链技术对于实现实体化AGI至关重要。
点此查看论文截图

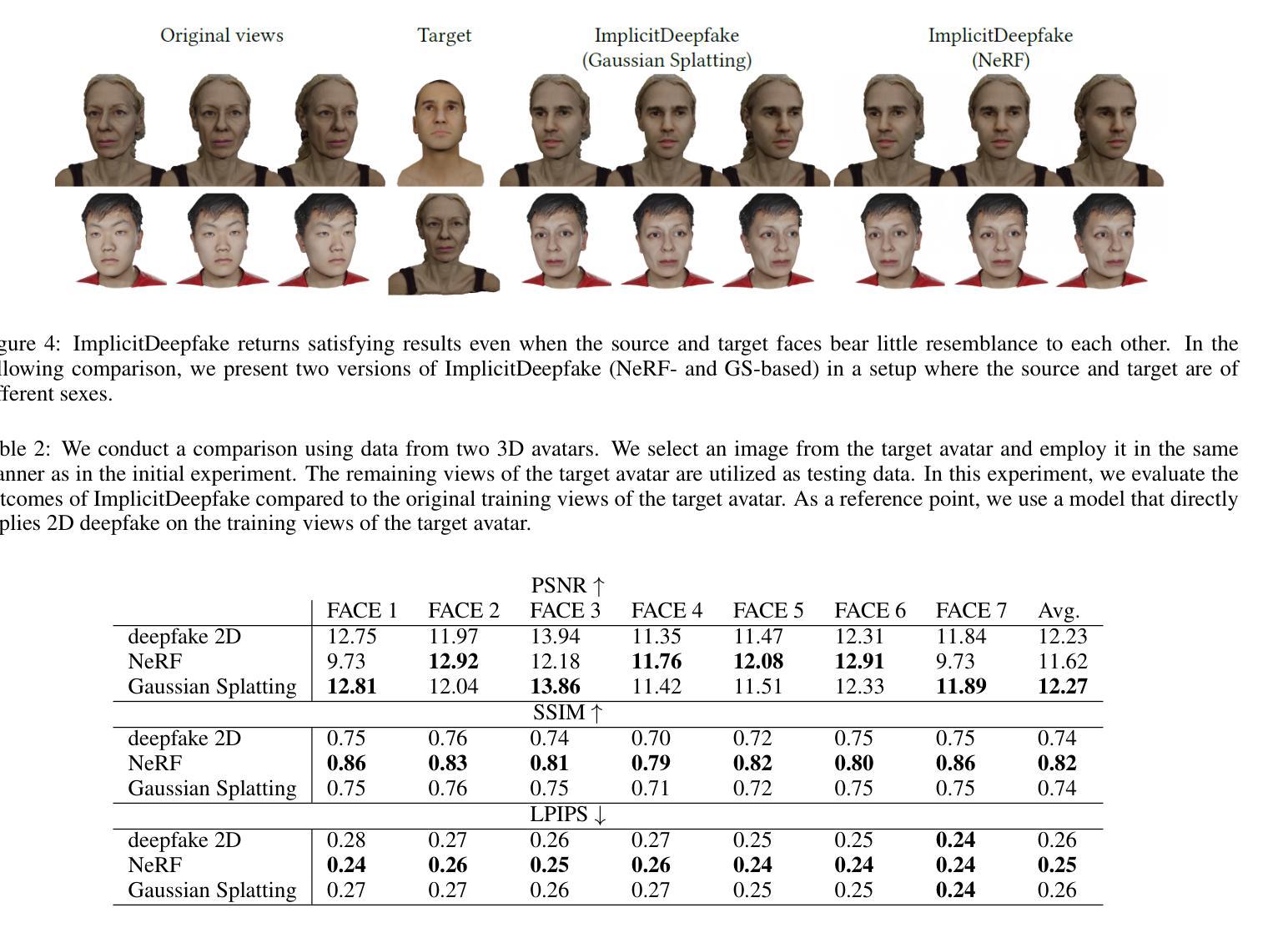
Deepfake for the Good: Generating Avatars through Face-Swapping with Implicit Deepfake Generation
Authors:Georgii Stanishevskii, Jakub Steczkiewicz, Tomasz Szczepanik, Sławomir Tadeja, Jacek Tabor, Przemysław Spurek
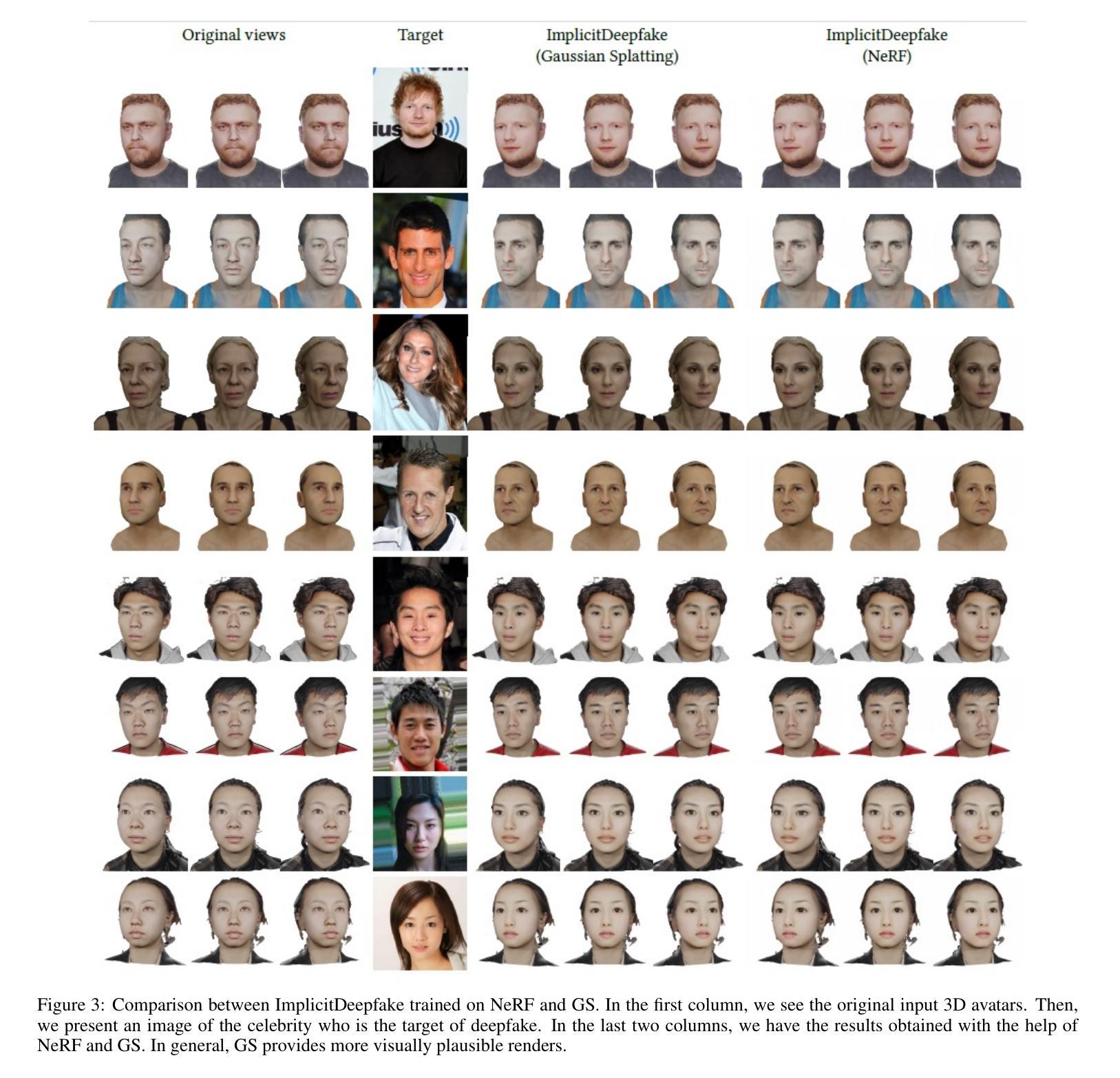
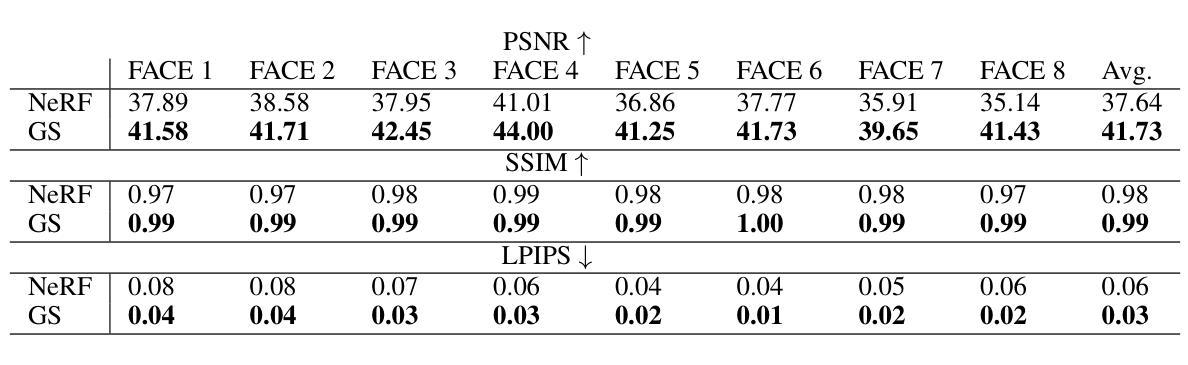
Numerous emerging deep-learning techniques have had a substantial impact on computer graphics. Among the most promising breakthroughs are the rise of Neural Radiance Fields (NeRFs) and Gaussian Splatting (GS). NeRFs encode the object’s shape and color in neural network weights using a handful of images with known camera positions to generate novel views. In contrast, GS provides accelerated training and inference without a decrease in rendering quality by encoding the object’s characteristics in a collection of Gaussian distributions. These two techniques have found many use cases in spatial computing and other domains. On the other hand, the emergence of deepfake methods has sparked considerable controversy. Deepfakes refers to artificial intelligence-generated videos that closely mimic authentic footage. Using generative models, they can modify facial features, enabling the creation of altered identities or expressions that exhibit a remarkably realistic appearance to a real person. Despite these controversies, deepfake can offer a next-generation solution for avatar creation and gaming when of desirable quality. To that end, we show how to combine all these emerging technologies to obtain a more plausible outcome. Our ImplicitDeepfake uses the classical deepfake algorithm to modify all training images separately and then train NeRF and GS on modified faces. Such simple strategies can produce plausible 3D deepfake-based avatars.
大量新兴的深度学习技术已经对计算机图形产生了重大影响。其中最有前途的突破之一是神经辐射场(NeRF)和高斯拼贴(GS)的兴起。NeRF使用神经网络权重编码物体的形状和颜色,利用少量已知相机位置的图片来生成新视角。相比之下,GS通过在一组高斯分布中编码物体特性,从而实现了加速训练和推理,同时不降低渲染质量。这两种技术在空间计算和其他领域找到了许多用例。另一方面,深度伪造方法的出现引起了相当大的争议。深度伪造是指使用人工智能生成的视频,这些视频紧密模仿真实镜头。使用生成模型,它们可以修改面部特征,能够创建具有惊人逼真度的身份或表情改变,看起来就像一个真实的人。尽管存在这些争议,但深度伪造在质量足够高的情况下,可以为化身创建和游戏提供下一代解决方案。为此,我们展示了如何结合所有这些新兴技术来获得更可信的结果。我们的ImplicitDeepfake使用经典的深度伪造算法分别修改所有训练图像,然后在修改后的面部上训练NeRF和GS。这种简单的策略可以产生基于深度伪造的逼真3D化身。
论文及项目相关链接
Summary
新一代深度学习技术如Neural Radiance Fields(NeRF)和Gaussian Splatting(GS)对计算机图形产生了重大影响。它们被广泛用于空间计算等领域。同时,深度伪造技术的出现引发了争议。深度伪造技术可以生成逼真视频,但也可以被用于创建虚假身份或表情。研究人员尝试结合这些新兴技术,如使用经典深度伪造算法修改训练图像,然后利用NeRF和GS在修改后的面部上训练,以产生更逼真的三维深度伪造虚拟人。
Key Takeaways
- 深度学习技术对计算机图形产生了重大影响,特别是Neural Radiance Fields(NeRF)和Gaussian Splatting(GS)的突破。
- NeRF使用神经网络权重编码物体形状和颜色,能够从已知相机位置的少量图像生成新视角。
- GS通过高斯分布集合编码物体特性,加速训练和推理,同时不降低渲染质量。
- 深度伪造技术引发了争议,但可以用于创建高质量的虚拟人和游戏角色。
- 结合深度学习技术和深度伪造算法可以产生更逼真的三维深度伪造虚拟人。
点此查看论文截图


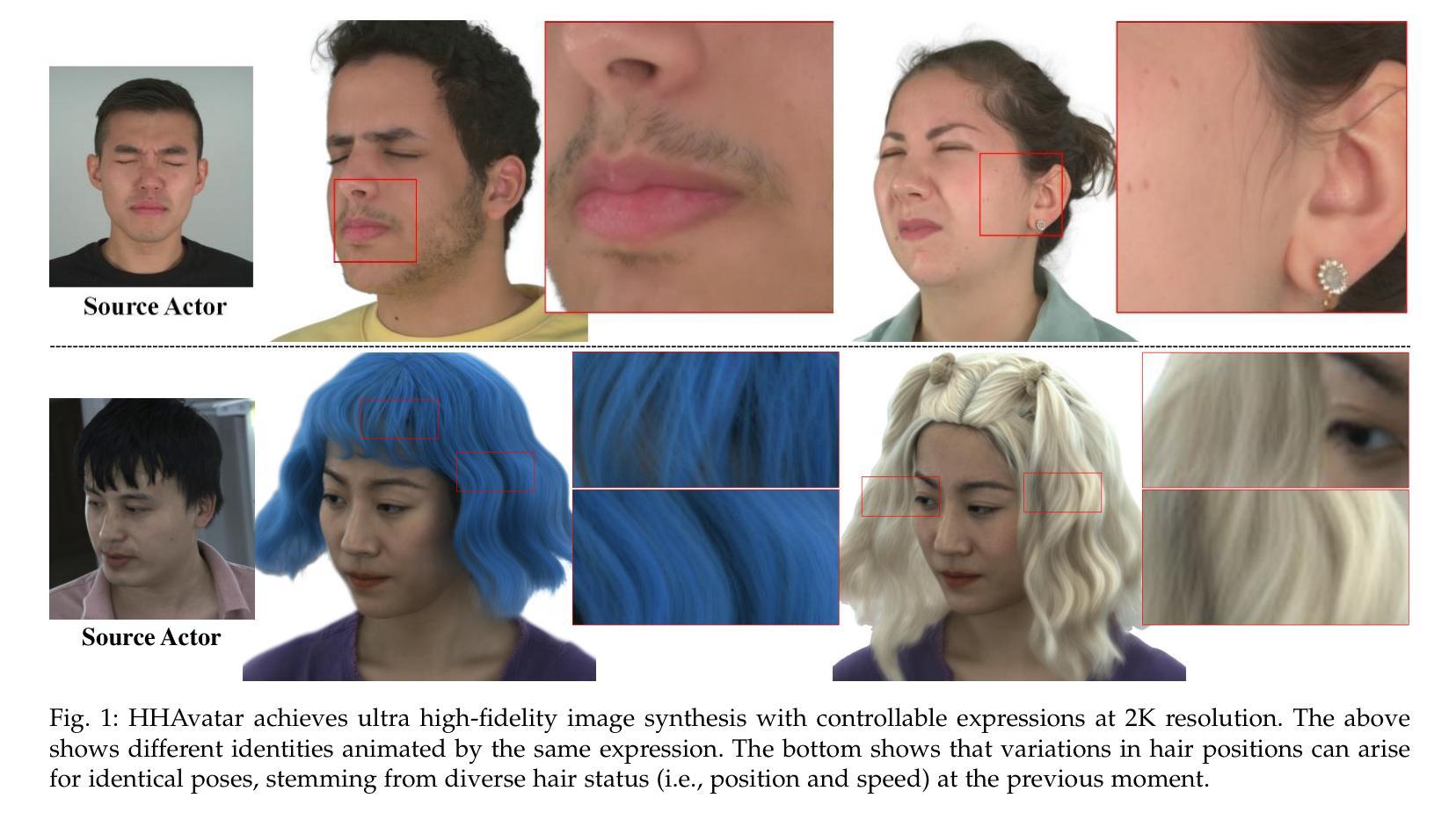
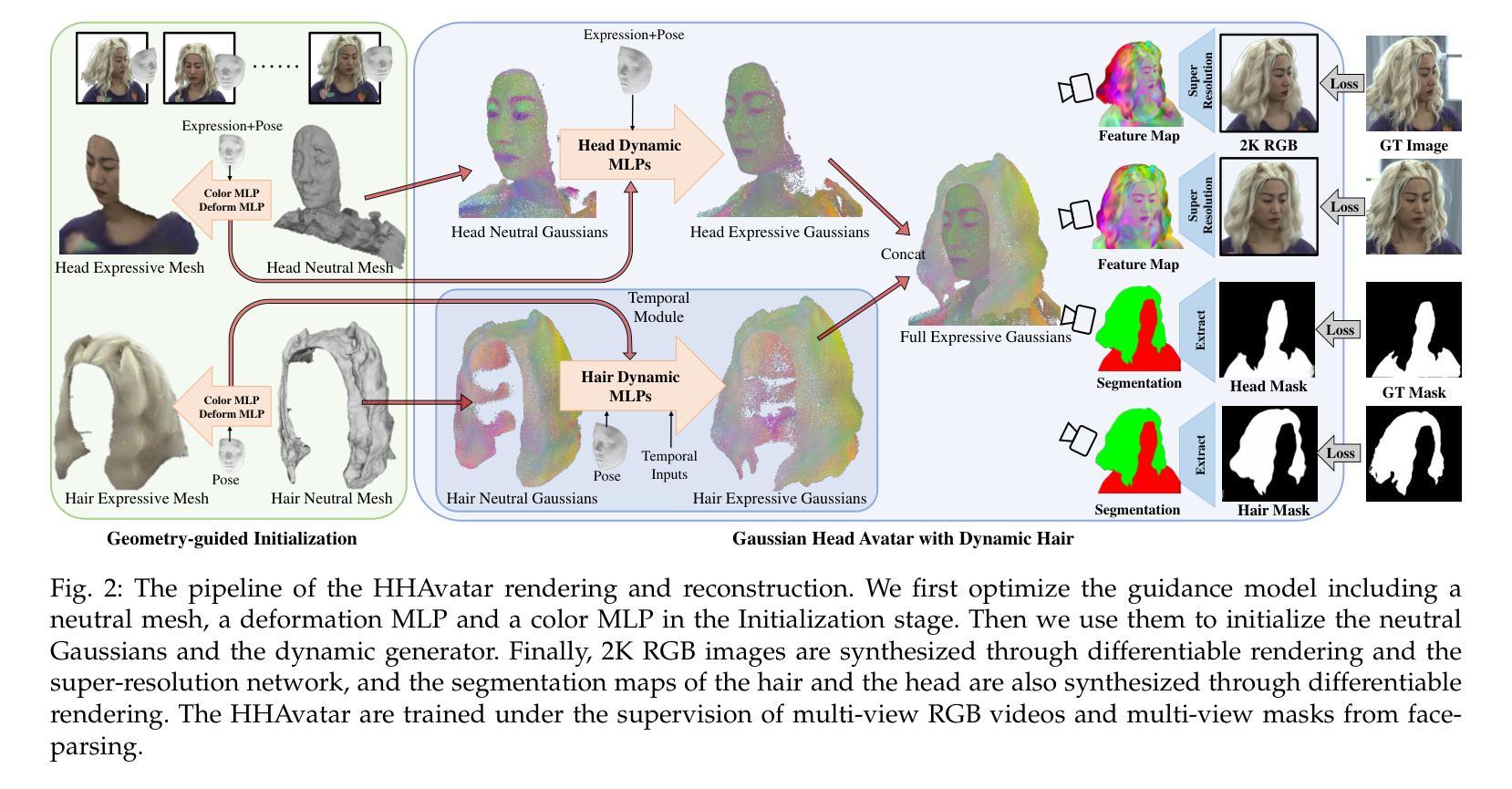
HHAvatar: Gaussian Head Avatar with Dynamic Hairs
Authors:Zhanfeng Liao, Yuelang Xu, Zhe Li, Qijing Li, Boyao Zhou, Ruifeng Bai, Di Xu, Hongwen Zhang, Yebin Liu
Creating high-fidelity 3D head avatars has always been a research hotspot, but it remains a great challenge under lightweight sparse view setups. In this paper, we propose HHAvatar represented by controllable 3D Gaussians for high-fidelity head avatar with dynamic hair modeling. We first use 3D Gaussians to represent the appearance of the head, and then jointly optimize neutral 3D Gaussians and a fully learned MLP-based deformation field to capture complex expressions. The two parts benefit each other, thereby our method can model fine-grained dynamic details while ensuring expression accuracy. Furthermore, we devise a well-designed geometry-guided initialization strategy based on implicit SDF and Deep Marching Tetrahedra for the stability and convergence of the training procedure. To address the problem of dynamic hair modeling, we introduce a hybrid head model into our avatar representation based Gaussian Head Avatar and a training method that considers timing information and an occlusion perception module to model the non-rigid motion of hair. Experiments show that our approach outperforms other state-of-the-art sparse-view methods, achieving ultra high-fidelity rendering quality at 2K resolution even under exaggerated expressions and driving hairs reasonably with the motion of the head
创建高保真3D头部化身一直是研究的热点,但在轻量级稀疏视图设置下,这仍然是一个巨大的挑战。在本文中,我们提出了HHAvatar,采用可控的3D高斯表示高保真头部化身,具有动态头发建模。我们首先使用3D高斯来表示头部的外观,然后通过联合优化中性3D高斯和完全学习的MLP基变形场来捕捉复杂的表情。这两部分相互受益,因此我们的方法可以在保证表情准确性的同时,对细微的动态细节进行建模。此外,我们基于隐式SDF和深度四面体网格设计了一种良好的几何引导初始化策略,以提高训练过程的稳定性和收敛性。为了解决动态头发建模的问题,我们将混合头部模型引入我们的化身表示基于高斯头部化身,并开发了一种考虑时间信息和遮挡感知模块的训练方法,以模拟头发的非刚性运动。实验表明,我们的方法在稀疏视图设置下优于其他最新技术,即使在夸张表情下也能达到超高的渲染质量(2K分辨率),并且能够合理驱动头发随着头部的运动而运动。
论文及项目相关链接
PDF Project Page: https://liaozhanfeng.github.io/HHAvatar
Summary
基于可控的3D高斯分布的HHAvatar方法被提出,用于创建高保真度的头部虚拟人,具有动态头发建模。该方法使用中性高斯分布和基于MLP的变形场联合优化,以捕捉复杂的表情。此外,还设计了一种基于隐式SDF和Deep Marching Tetrahedra的几何引导初始化策略,以提高训练过程的稳定性和收敛性。针对动态头发建模问题,引入了混合头部模型和考虑时序信息的训练方法,以及遮挡感知模块来模拟头发的非刚性运动。该方法在稀疏视图下实现了超高保真度的渲染质量。
Key Takeaways
- 提出了HHAvatar方法,使用可控的3D高斯分布创建高保真度的头部虚拟人。
- 通过中性高斯分布和基于MLP的变形场联合优化,捕捉复杂表情。
- 几何引导初始化策略提高了训练过程的稳定性和收敛性。
- 引入了混合头部模型和考虑时序信息的训练方法,以处理动态头发建模问题。
- 引入了遮挡感知模块来模拟头发的非刚性运动。
- 该方法在稀疏视图下实现了超高保真度的渲染质量,甚至在夸张表情下也能保持效果。
点此查看论文截图

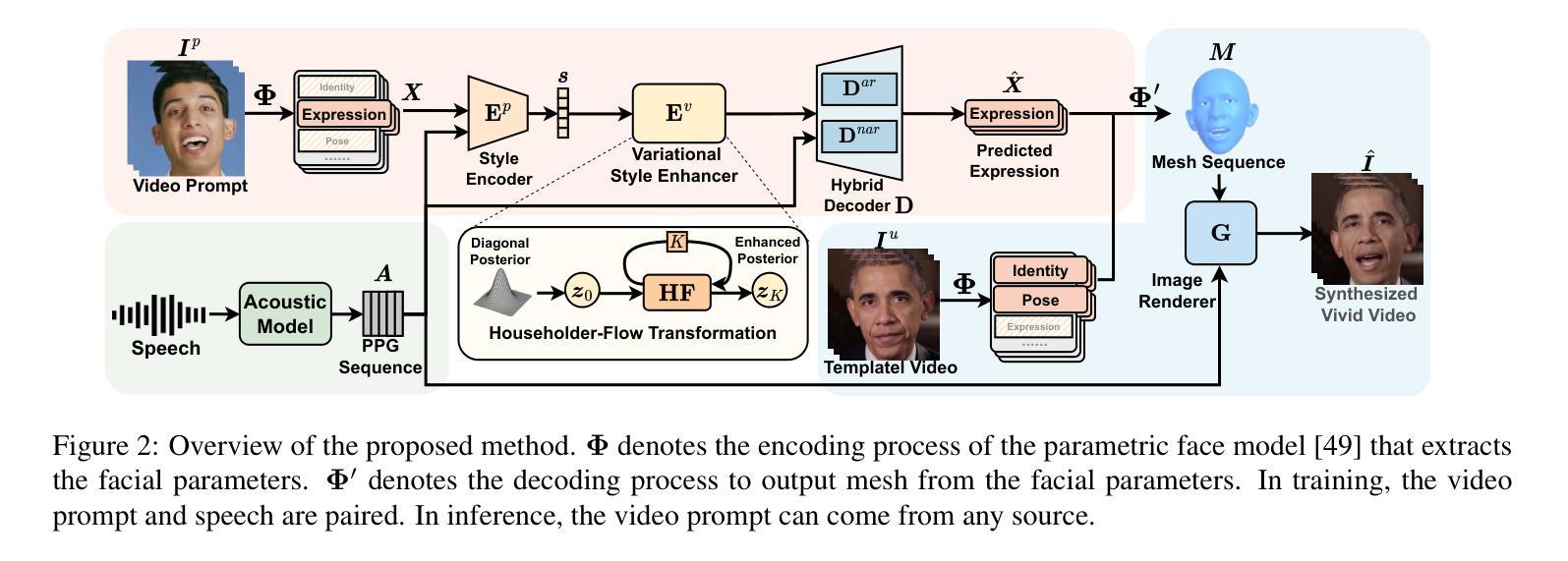
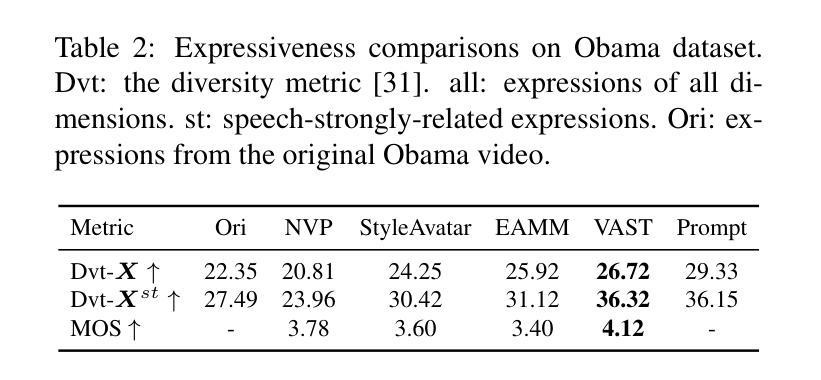
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Authors:Liyang Chen, Zhiyong Wu, Runnan Li, Weihong Bao, Jun Ling, Xu Tan, Sheng Zhao
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
当前的人脸生成方法主要聚焦于语音与嘴唇的同步。然而,对于面部说话风格的调查不足导致了生成的虚拟形象缺乏生命力和单调性。之前的大部分工作都无法模仿来自任意视频提示的表达风格,也无法确保生成视频的真实性。本文提出了一种无监督的变风格转移模型(VAST),以赋予中性写实风格的虚拟形象生命力。我们的模型由三个关键部分组成:一个风格编码器,用于从给定的视频提示中提取面部风格表示;一个混合面部表情解码器,用于模拟准确的语音相关动作;一个变风格增强器,用于增强风格空间,使其具有高度表达力和意义。我们对面部风格学习进行了关键设计,使得模型能够灵活地捕捉来自任意视频提示的表达性面部风格,并将其以零样本的方式转移到个性化图像渲染器中。实验结果表明,所提出的方法有助于生成更加生动、更真实的说话虚拟形象,并具备更丰富的表现力。
论文及项目相关链接
PDF Accepted by ICCV2023
Summary
文章提出了一个无监督的变分风格迁移模型(VAST),用于生动化中性逼真的头像。该模型包含三个关键组件:从给定视频提示中提取面部风格表示的风格编码器;对精确语音相关动作进行建模的混合面部表情解码器;增强风格空间以使其高度表达和意义丰富的变分风格增强器。该模型能够灵活地捕捉任意视频提示中的表达性面部风格,并将其零样本转移到个性化图像渲染器上。实验结果证明,该方法有助于提高说话头像的生动性、真实性和表达性。
Key Takeaways
- 当前面部生成方法主要关注语音-唇部同步,但对面部讲话风格的研究不足,导致生成的头像缺乏生命力和单调。
- 论文提出了一种无监督的变分风格迁移模型(VAST),旨在生动化中性逼真的头像。
- VAST模型包含三个关键组件:风格编码器、混合面部表情解码器和变分风格增强器。
- 风格编码器能够从给定的视频提示中提取面部风格表示。
- 混合面部表情解码器能够准确建模语音相关的动作。
- 变分风格增强器能够增强风格空间,使生成的面部表情更丰富、有意义。
点此查看论文截图