⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-11 更新
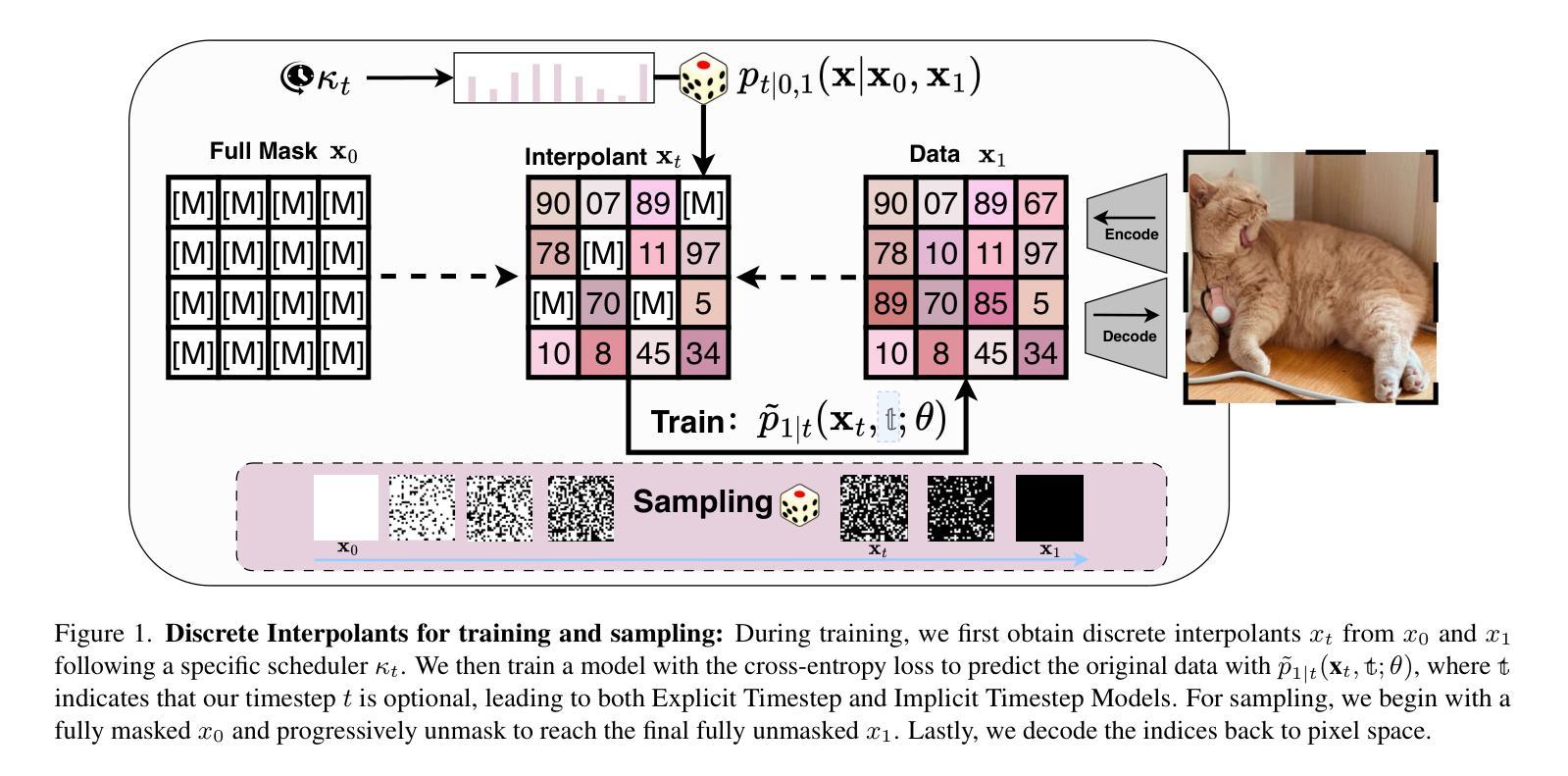
[MASK] is All You Need
Authors:Vincent Tao Hu, Björn Ommer
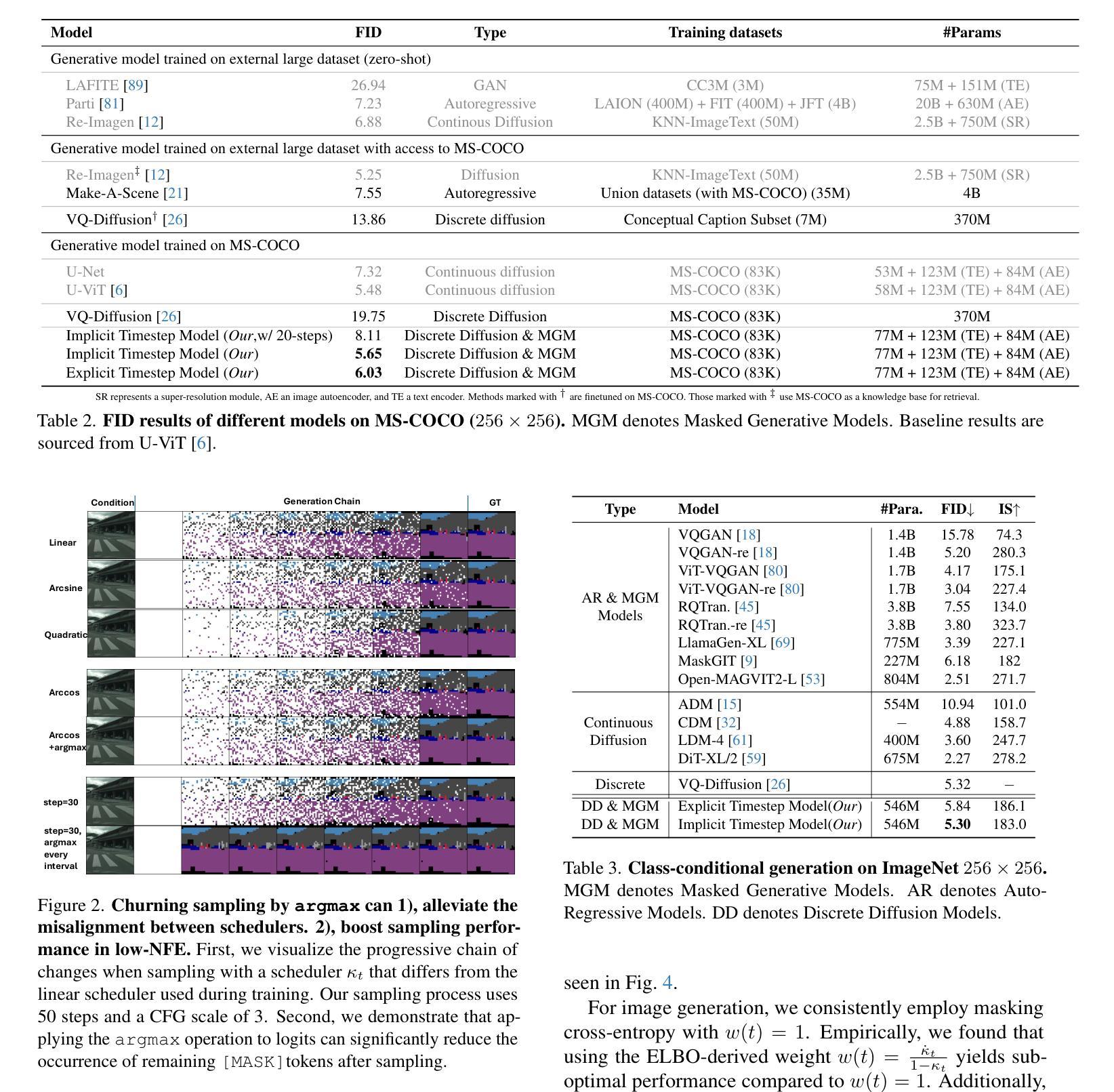
In generative models, two paradigms have gained attraction in various applications: next-set prediction-based Masked Generative Models and next-noise prediction-based Non-Autoregressive Models, e.g., Diffusion Models. In this work, we propose using discrete-state models to connect them and explore their scalability in the vision domain. First, we conduct a step-by-step analysis in a unified design space across two types of models including timestep-independence, noise schedule, temperature, guidance strength, etc in a scalable manner. Second, we re-cast typical discriminative tasks, e.g., image segmentation, as an unmasking process from [MASK]tokens on a discrete-state model. This enables us to perform various sampling processes, including flexible conditional sampling by only training once to model the joint distribution. All aforementioned explorations lead to our framework named Discrete Interpolants, which enables us to achieve state-of-the-art or competitive performance compared to previous discrete-state based methods in various benchmarks, like ImageNet256, MS COCO, and video dataset FaceForensics. In summary, by leveraging [MASK] in discrete-state models, we can bridge Masked Generative and Non-autoregressive Diffusion models, as well as generative and discriminative tasks.
在生成模型中,有两种范式在各种应用中受到了关注:基于下一步预测的掩码生成模型和基于下一步噪声预测的非自回归模型,例如扩散模型。在这项工作中,我们提出使用离散状态模型将它们连接起来,并探索其在视觉领域的可扩展性。首先,我们在统一的设计空间中对两种类型的模型进行分步分析,包括时间步独立性、噪声调度、温度、指导强度等,以可扩展的方式进行研究。其次,我们将典型的判别任务(例如图像分割)重新定义为离散状态模型上的去掩码过程。这使我们能够执行各种采样过程,包括通过仅训练一次来对联合分布进行建模的灵活条件采样。所有上述探索都引领我们构建了名为“离散插值”的框架,该框架使我们能够在ImageNet256、MS COCO和FaceForensics视频数据集等各种基准测试中达到或保持与以前基于离散状态的方法相比的先进水平。总之,通过利用离散状态模型中的[MASK],我们可以架起掩码生成模型和非自回归扩散模型之间的桥梁,以及生成任务和判别任务之间的桥梁。
论文及项目相关链接
PDF Technical Report (WIP), Project Page(code, model, dataset): https://compvis.github.io/mask/
Summary:
本文探讨了生成模型中的两种范式:基于下一步预测的掩码生成模型和基于下一步噪声预测的非自回归模型,例如扩散模型。通过离散状态模型连接这两种范式,并在视觉领域探索其可扩展性。通过统一设计空间对两种模型进行逐步分析,包括时间步独立性、噪声调度、温度、指导强度等。此外,将典型的判别任务重新构建为离散状态模型上的去掩码过程,使采样过程更加灵活,只需一次训练即可对联合分布进行建模。所有这些探索都得益于名为“离散插值”的框架,该框架在ImageNet256、MS COCO和FaceForensics视频数据集上实现了与基于离散状态的前人方法相比具有竞争力或最先进的性能。总的来说,利用离散状态模型中的掩码,可以架起连接掩码生成和非自回归扩散模型的桥梁,以及生成和判别任务。
Key Takeaways:
- 介绍了生成模型中的两种范式:掩码生成模型和非自回归模型(如扩散模型)。
- 通过离散状态模型连接这两种范式,并在视觉领域探索其可扩展性。
- 在统一设计空间中对两种模型进行逐步分析,包括时间步独立性、噪声调度等关键因素。
- 将判别任务重新构建为离散状态模型上的去掩码过程,实现灵活的采样过程。
- 提出了名为“离散插值”的框架,实现了在多个基准测试上的先进性能。
- 利用离散状态模型中的掩码,连接了不同类型的生成模型和任务。
点此查看论文截图



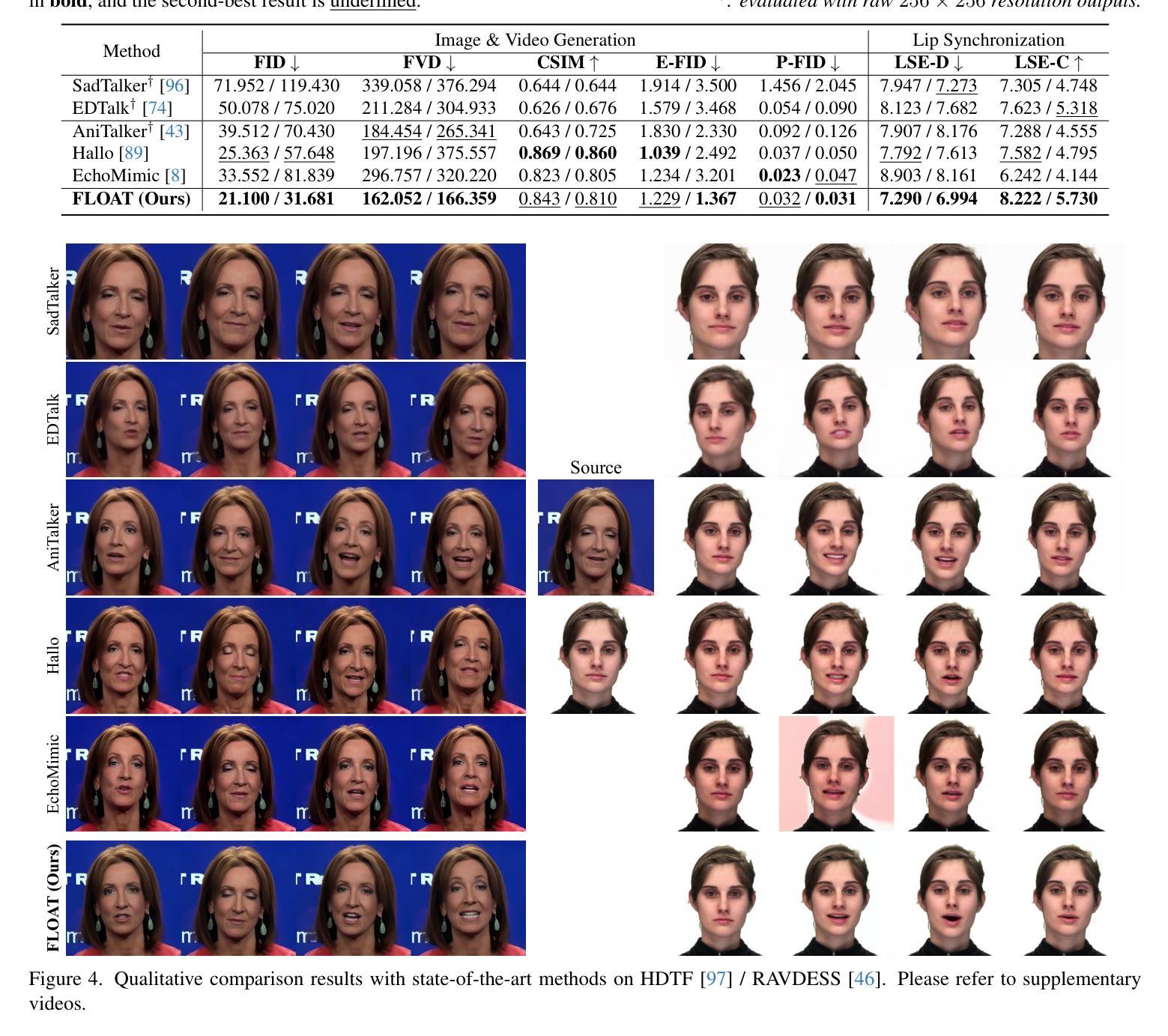
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
Authors:Feihong He, Gang Li, Fuhui Sun, Mengyuan Zhang, Lingyu Si, Xiaoyan Wang, Li Shen
The rapid development of generative diffusion models has significantly advanced the field of style transfer. However, most current style transfer methods based on diffusion models typically involve a slow iterative optimization process, e.g., model fine-tuning and textual inversion of style concept. In this paper, we introduce FreeStyle, an innovative style transfer method built upon a pre-trained large diffusion model, requiring no further optimization. Besides, our method enables style transfer only through a text description of the desired style, eliminating the necessity of style images. Specifically, we propose a dual-stream encoder and single-stream decoder architecture, replacing the conventional U-Net in diffusion models. In the dual-stream encoder, two distinct branches take the content image and style text prompt as inputs, achieving content and style decoupling. In the decoder, we further modulate features from the dual streams based on a given content image and the corresponding style text prompt for precise style transfer. Our experimental results demonstrate high-quality synthesis and fidelity of our method across various content images and style text prompts. Compared with state-of-the-art methods that require training, our FreeStyle approach notably reduces the computational burden by thousands of iterations, while achieving comparable or superior performance across multiple evaluation metrics including CLIP Aesthetic Score, CLIP Score, and Preference. We have released the code at: https://github.com/FreeStyleFreeLunch/FreeStyle.
生成式扩散模型的快速发展极大地推动了风格转移领域的进步。然而,当前大多数基于扩散模型的风格转移方法通常涉及缓慢的迭代优化过程,例如模型微调的风格概念文本反转。在本文中,我们介绍了FreeStyle,这是一种创新的风格转移方法,它建立在预先训练的大型扩散模型之上,无需进一步优化。此外,我们的方法仅通过目标风格的文本描述来实现风格转移,从而消除了对风格图像的需求。具体来说,我们提出了双流编码器(encoder)和单流解码器(decoder)架构,替代扩散模型中的传统U-Net。在双流编码器中,两个独立的分支接收内容图像和风格文本提示作为输入,从而实现内容和风格的解耦。在解码器中,我们进一步根据给定的内容图像和相应的风格文本提示调制来自双流的特性,以实现精确的风格转移。我们的实验结果证明,我们的方法在多种内容图像和风格文本提示下能合成高质量且忠实的作品。与需要训练的最先进方法相比,我们的FreeStyle方法通过数千次迭代显著减少了计算负担,同时在多个评价指标上取得了相当或更好的性能,包括CLIP美学分数、CLIP分数和偏好分数。我们已在https://github.com/FreeStyleFreeLunch/FreeStyle发布代码。
论文及项目相关链接
Summary
本文介绍了基于预训练的大型扩散模型的风格转换新方法FreeStyle。该方法无需进一步优化,只需通过文本描述所需风格即可实现风格转换,无需风格图像。采用双流编码器与单流解码器架构,实现内容与风格的解耦,并在解码器中根据给定内容图像和相应风格文本提示进行特征调制,实现精确的风格转换。实验结果证明,该方法在各种内容图像和风格文本提示下能合成高质量且保真度高的结果。
Key Takeaways
- FreeStyle是一种基于预训练大型扩散模型的风格转换方法,无需进一步优化。
- 仅通过文本描述所需风格即可实现风格转换。
- 采用双流编码器与单流解码器架构,实现内容与风格的解耦。
- 在解码器中根据给定内容图像和相应风格文本提示进行特征调制。
- 实现了高合成质量和在各种评价度量下的优异性能。
- 与需要训练的其他方法相比,FreeStyle显著减少了计算负担。
点此查看论文截图