⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-10 更新
Training Large Language Models to Reason in a Continuous Latent Space
Authors:Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, Yuandong Tian
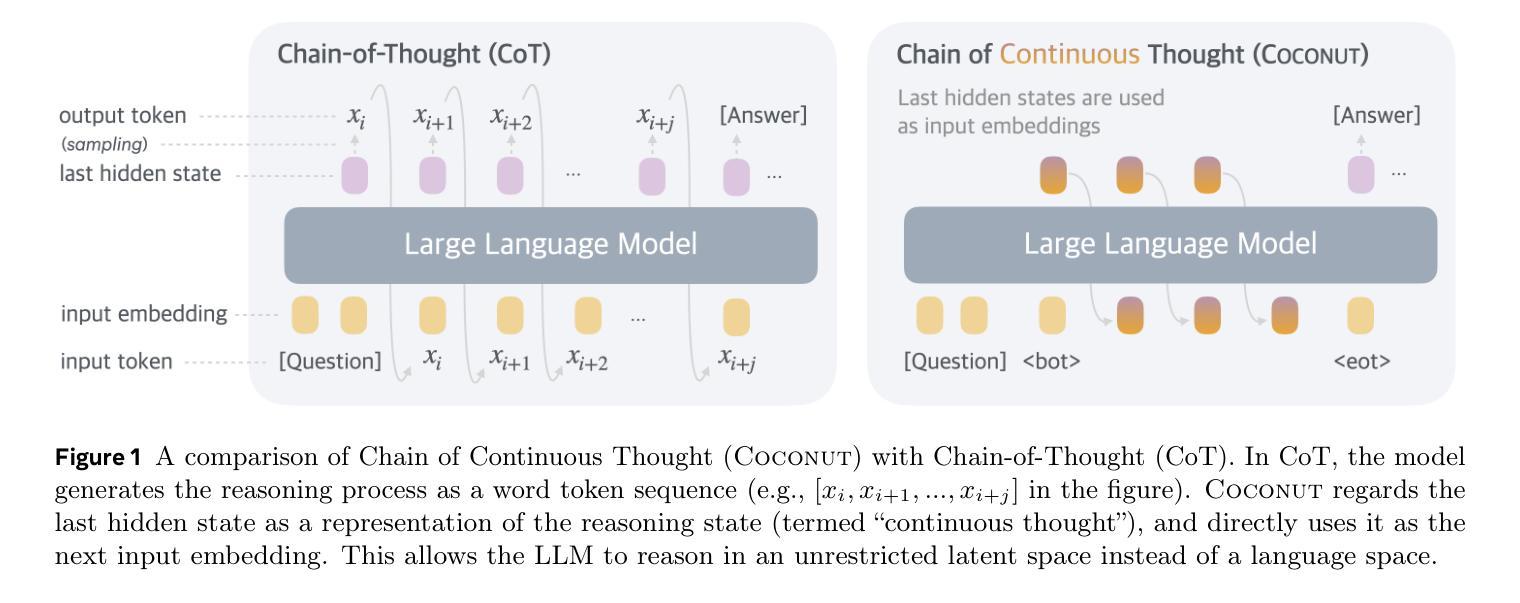
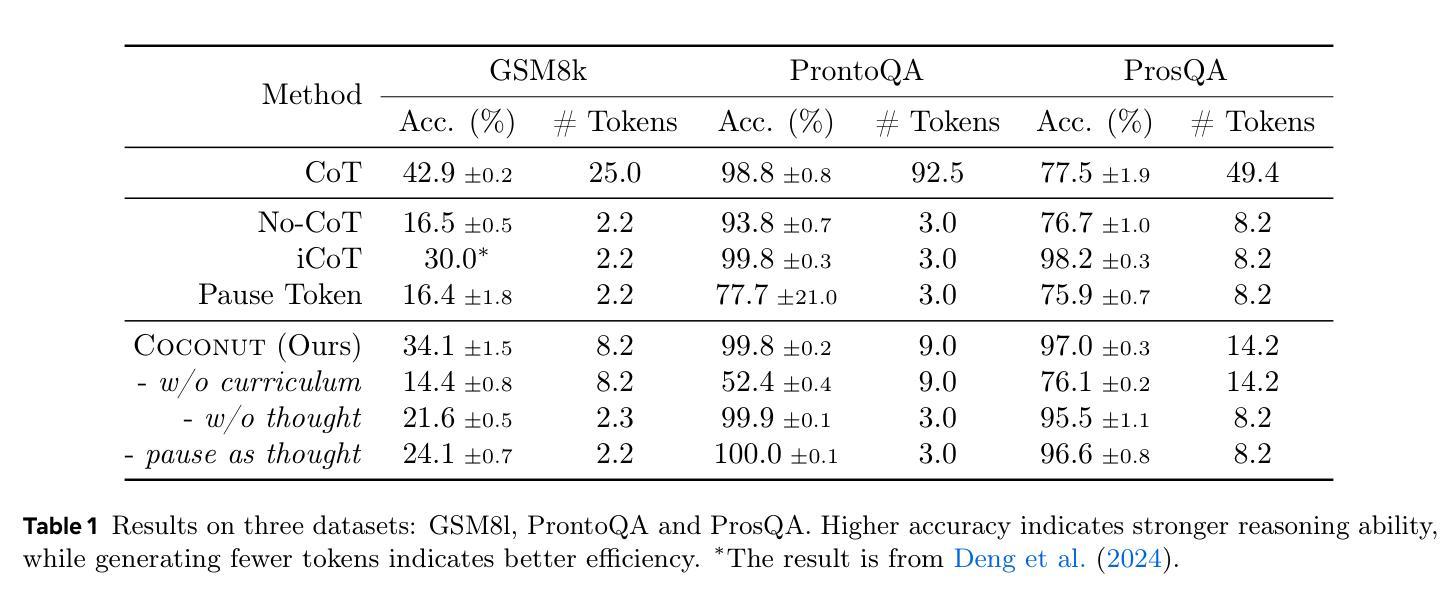
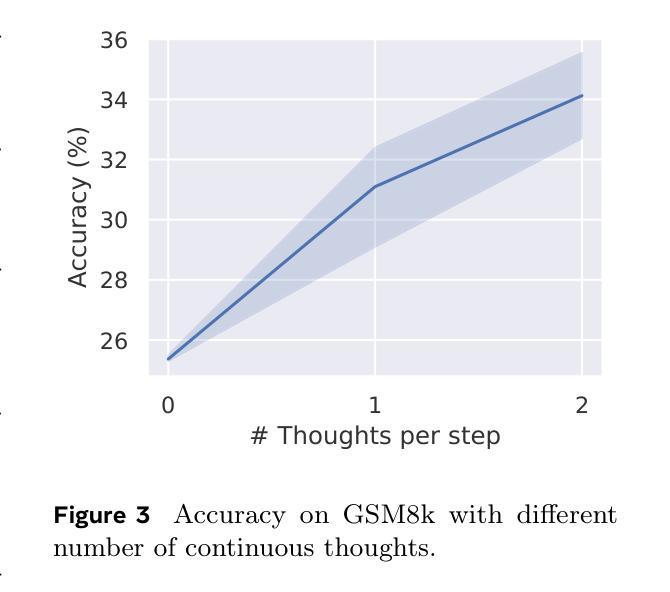
Large language models (LLMs) are restricted to reason in the “language space”, where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning problem. However, we argue that language space may not always be optimal for reasoning. For example, most word tokens are primarily for textual coherence and not essential for reasoning, while some critical tokens require complex planning and pose huge challenges to LLMs. To explore the potential of LLM reasoning in an unrestricted latent space instead of using natural language, we introduce a new paradigm Coconut (Chain of Continuous Thought). We utilize the last hidden state of the LLM as a representation of the reasoning state (termed “continuous thought”). Rather than decoding this into a word token, we feed it back to the LLM as the subsequent input embedding directly in the continuous space. Experiments show that Coconut can effectively augment the LLM on several reasoning tasks. This novel latent reasoning paradigm leads to emergent advanced reasoning patterns: the continuous thought can encode multiple alternative next reasoning steps, allowing the model to perform a breadth-first search (BFS) to solve the problem, rather than prematurely committing to a single deterministic path like CoT. Coconut outperforms CoT in certain logical reasoning tasks that require substantial backtracking during planning, with fewer thinking tokens during inference. These findings demonstrate the promise of latent reasoning and offer valuable insights for future research.
大型语言模型(LLM)受限于“语言空间”内的推理,它们通常通过思维链(CoT)解决复杂的推理问题来表达推理过程。然而,我们认为语言空间并不总是最适合推理。例如,大多数单词符号主要用于文本连贯性,对于推理并不必要,而一些关键符号则需要复杂规划,给LLM带来巨大挑战。为了探索LLM在不受限制潜在空间中的推理潜力,而不是使用自然语言,我们引入了一种新的范式——椰子思维(连续思维链)。我们利用LLM的最后一个隐藏状态作为推理状态的表示(称为“连续思维”)。我们不是将此解码为单词符号,而是将其反馈到LLM中,作为潜在空间中的后续输入嵌入直接输入。实验表明,椰子思维可以有效地增强LLM在多个推理任务上的表现。这种新型潜在推理范式导致了新兴的高级推理模式:连续思维可以编码多个替代的下一步推理步骤,允许模型进行广度优先搜索(BFS)来解决问题,而不是过早地承诺单一确定性路径,如同CoT。在需要规划过程中大量回溯的逻辑推理任务中,椰子思维的表现优于CoT,推理过程中使用的思考符号更少。这些发现证明了潜在推理的潜力,并为未来的研究提供了宝贵的见解。
论文及项目相关链接
Summary
大型语言模型(LLM)受限于“语言空间”内的推理,通过链式思维(CoT)解决复杂推理问题。然而,我们主张语言空间并非总是最优的推理方式。Coconut(连续思维链)新范式探索了LLM在不受限制潜在空间中的推理潜力,利用LLM的最后一个隐藏状态作为推理状态的表示(即“连续思维”)。实验表明,Coconut能有效增强LLM在多个推理任务上的表现,并展现出新兴的高级推理模式:连续思维能编码多个下一个推理步骤,使模型得以通过广度优先搜索(BFS)解决问题,而非过早地确定单一路径。在某些需要规划时回溯的逻辑推理任务中,Coconut表现优于CoT。此研究展示了潜在推理的潜力并为未来研究提供了宝贵见解。
Key Takeaways
- 大型语言模型(LLM)受限于“语言空间”,主要通过链式思维(CoT)解决推理问题。
- 语言空间并非总是最优的推理方式,因为关键信息可能被冗余的语言所掩盖。
- Coconut是一种新的推理范式,将LLM的最后一个隐藏状态用作连续思维的表示。
- 实验证明Coconut能提高LLM在多个推理任务上的表现。
- 连续思维可以编码多个可能的下一步推理步骤,实现广度优先搜索(BFS)。
- 在需要规划回溯的逻辑推理任务中,Coconut优于传统的链式思维方法。
点此查看论文截图


JAPAGEN: Efficient Few/Zero-shot Learning via Japanese Training Dataset Generation with LLM
Authors:Takuro Fujii, Satoru Katsumata
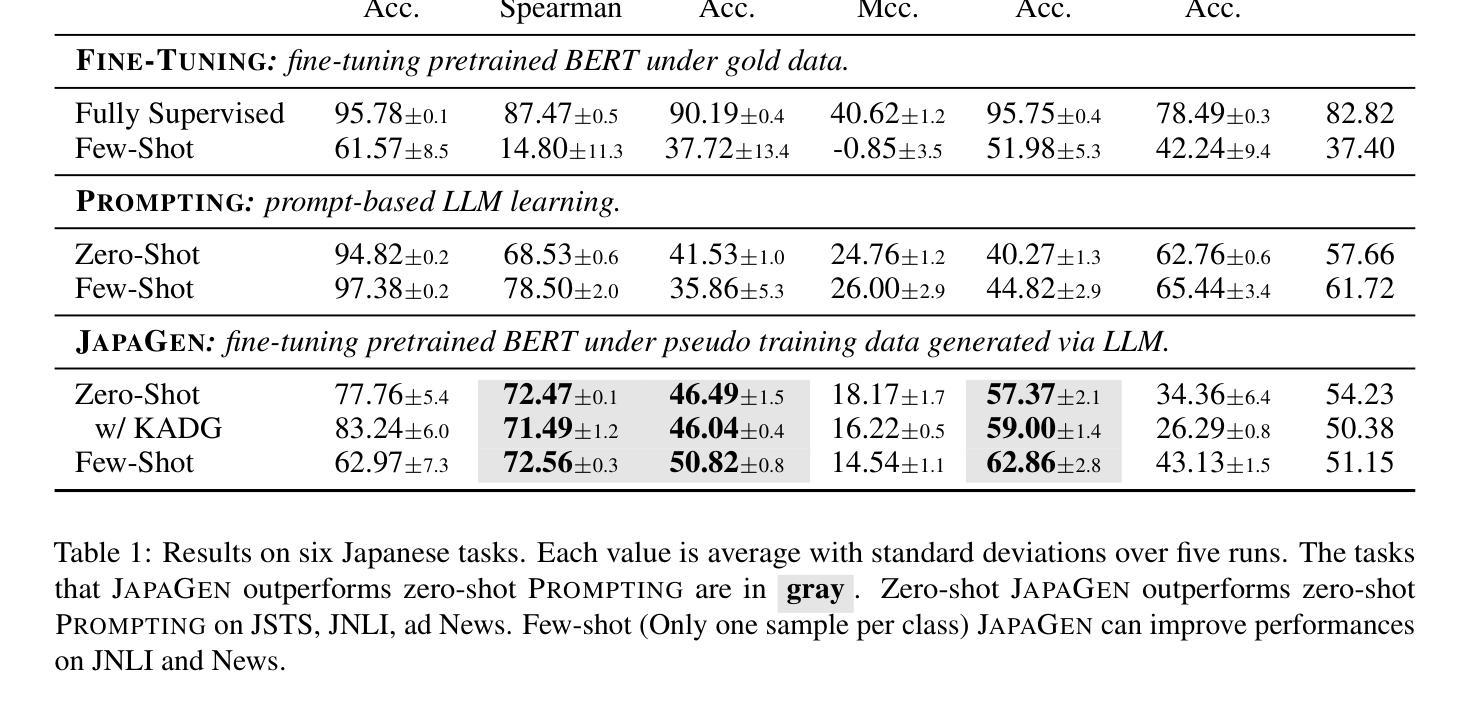
Recently some studies have highlighted the potential of Large Language Models (LLMs) as effective generators of supervised training data, offering advantages such as enhanced inference efficiency and reduced costs associated with data collection. However, these studies have predominantly focused on English language tasks. In this paper, we address the fundamental research question: Can LLMs serve as proficient training data generators for other language tasks? Specifically, we leverage LLMs to synthesize supervised training data under few-shot and zero-shot learning scenarios across six diverse Japanese downstream tasks. Subsequently, we utilize this synthesized data to train compact models (e.g., BERT). This novel methodology is termed JAPAGEN. Our experimental findings underscore that JAPAGEN achieves robust performance in classification tasks that necessitate formal text inputs, demonstrating competitive results compared to conventional LLM prompting strategies.
最近的一些研究强调了大型语言模型(LLM)作为有效监督训练数据生成器的潜力,提供了提高推理效率和降低数据采集成本等优势。然而,这些研究主要集中在英语任务上。在本文中,我们提出了一个基本的研究问题:LLM能否为其他语言任务提供熟练的训练数据生成器?具体来说,我们在六种不同的日语下游任务中,利用LLM在少量样本甚至零样本学习场景下合成监督训练数据。然后,我们使用这些合成数据来训练小型模型(例如BERT)。这种新方法被称为JAPAGEN。我们的实验结果表明,JAPAGEN在需要正式文本输入的分类任务中表现稳健,与传统的LLM提示策略相比,结果具有竞争力。
论文及项目相关链接
PDF Accepted by PACLIC38 (2024)
Summary
近期研究表明,大型语言模型(LLMs)作为监督训练数据生成器具有潜力,能提高推理效率和降低数据采集成本。这些研究主要关注英语任务。本文旨在探讨:LLMs能否为其他语言任务提供有效的训练数据生成?通过利用LLMs在六种不同的日语下游任务中合成监督训练数据,并在少样本和零样本学习场景下应用此方法,我们提出了一种新方法JAPAGEN。实验结果表明,JAPAGEN在需要正式文本输入的分类任务中表现稳健,与传统的大型语言模型提示策略相比具有竞争力。
Key Takeaways
- 大型语言模型(LLMs)可以作为监督训练数据的有效生成器,不仅限于英语任务。
- LLMs能够在少样本和零样本学习场景下合成监督训练数据。
- JAPAGEN方法被提出并成功应用于日语下游任务。
- JAPAGEN在需要正式文本输入的分类任务中表现出稳健的性能。
- JAPAGEN与传统的大型语言模型提示策略相比具有竞争力。
- LLMs用于数据生成可以提高推理效率并降低数据采集成本。
点此查看论文截图

OmniEvalKit: A Modular, Lightweight Toolbox for Evaluating Large Language Model and its Omni-Extensions
Authors:Yi-Kai Zhang, Xu-Xiang Zhong, Shiyin Lu, Qing-Guo Chen, De-Chuan Zhan, Han-Jia Ye
The rapid advancements in Large Language Models (LLMs) have significantly expanded their applications, ranging from multilingual support to domain-specific tasks and multimodal integration. In this paper, we present OmniEvalKit, a novel benchmarking toolbox designed to evaluate LLMs and their omni-extensions across multilingual, multidomain, and multimodal capabilities. Unlike existing benchmarks that often focus on a single aspect, OmniEvalKit provides a modular, lightweight, and automated evaluation system. It is structured with a modular architecture comprising a Static Builder and Dynamic Data Flow, promoting the seamless integration of new models and datasets. OmniEvalKit supports over 100 LLMs and 50 evaluation datasets, covering comprehensive evaluations across thousands of model-dataset combinations. OmniEvalKit is dedicated to creating an ultra-lightweight and fast-deployable evaluation framework, making downstream applications more convenient and versatile for the AI community.
大型语言模型(LLM)的快速进步极大地扩展了它们的应用范围,从多语言支持到特定领域的任务和跨模态集成。在本文中,我们介绍了OmniEvalKit,这是一个新型基准测试工具箱,旨在评估LLM及其跨多语言、多领域和跨模态的各种扩展功能。与现有通常只关注单一方面的基准测试不同,OmniEvalKit提供了一个模块化、轻便、自动化的评估系统。它采用模块化架构,包括静态构建器和动态数据流,促进了新模型和数据集的无缝集成。OmniEvalKit支持超过100种LLM和50个评估数据集,涵盖数千种模型数据集组合的全面评估。OmniEvalKit致力于创建一个超轻量级、快速部署的评估框架,为AI社区提供更便捷、更通用的下游应用程序。
论文及项目相关链接
Summary
OmniEvalKit是一个为大型语言模型(LLM)提供全方位评估的工具箱,可跨多语种、多领域和多媒体进行评估。它采用模块化结构,包括静态构建器和动态数据流,促进新模型和数据集的无缝集成。OmniEvalKit支持超过100个LLM和50个评估数据集,涵盖数千个模型数据集组合的评估。它为AI社区创建了一个超轻量级、快速部署的评估框架,使下游应用程序更加便捷和多功能。
Key Takeaways
- OmniEvalKit是一个专为评估大型语言模型(LLM)而设计的工具箱。
- 它提供跨多语种、多领域和多媒体的全方位评估。
- OmniEvalKit采用模块化结构,包括静态构建器和动态数据流,促进新模型和数据集的无缝集成。
- 支持超过100个LLM和50个评估数据集,涵盖广泛的模型-数据集组合评估。
- OmniEvalKit致力于创建一个超轻量级、快速部署的评估框架。
- 该框架使下游应用程序更加便捷和多功能。
点此查看论文截图

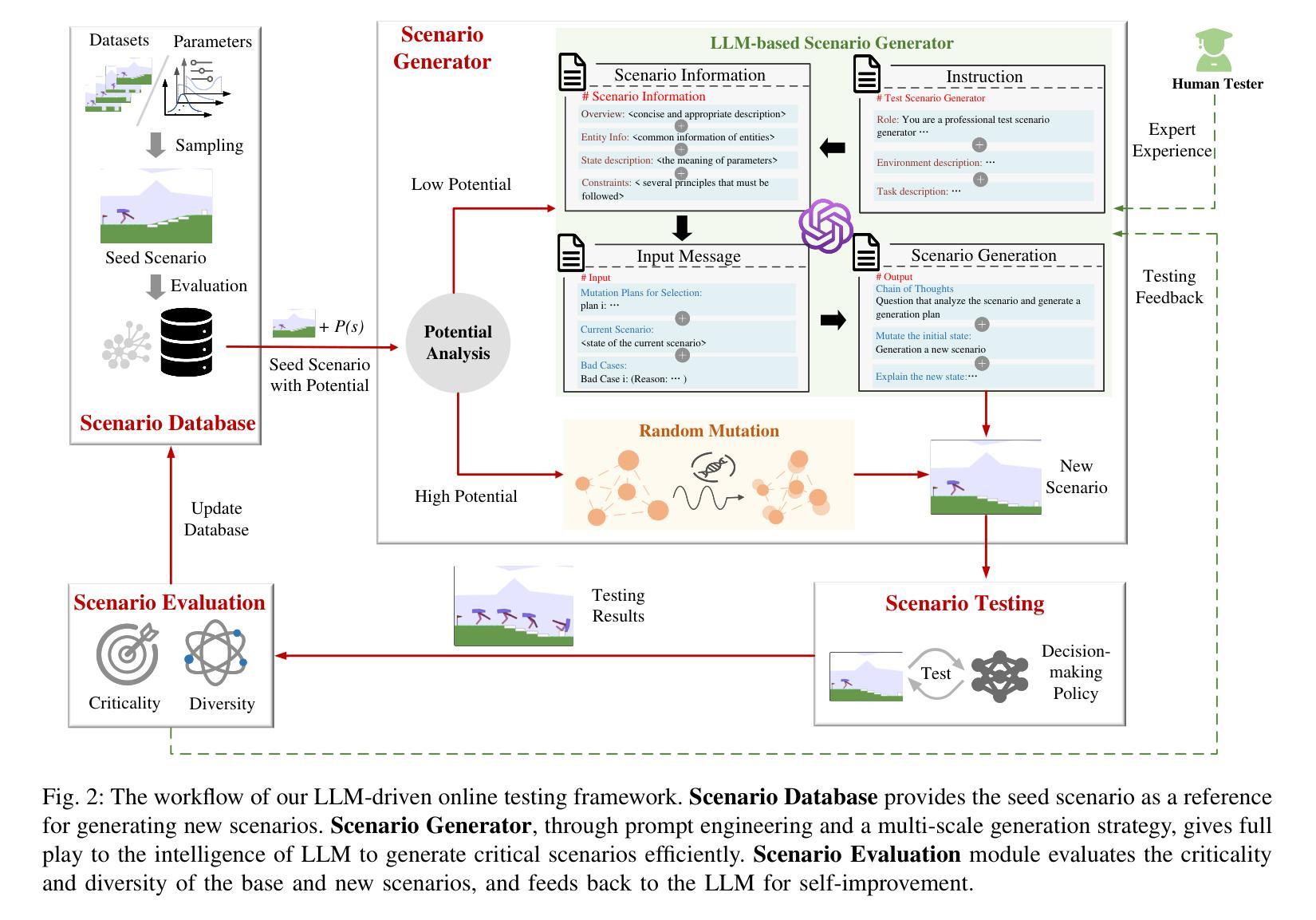
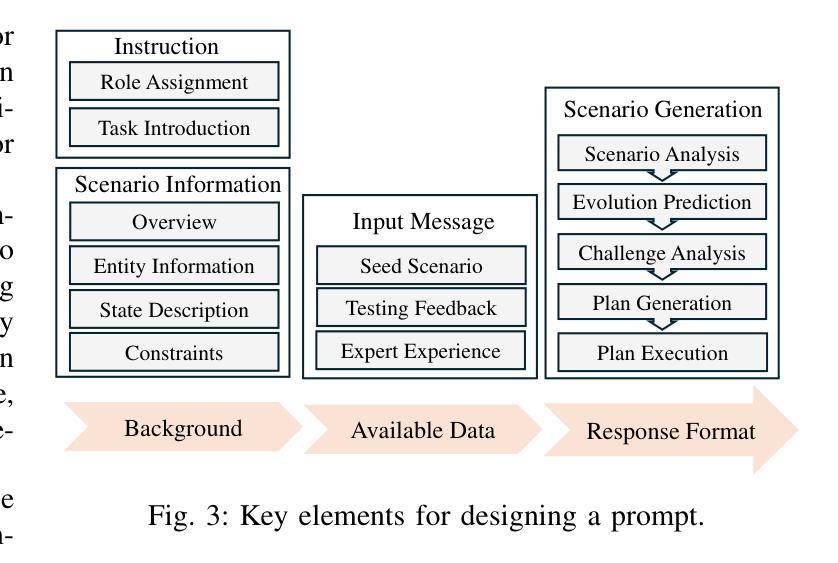
Exploring Critical Testing Scenarios for Decision-Making Policies: An LLM Approach
Authors:Weichao Xu, Huaxin Pei, Jingxuan Yang, Yuchen Shi, Yi Zhang
Recent years have witnessed surprising achievements of decision-making policies across various fields, such as autonomous driving and robotics. Testing for decision-making policies is crucial with the existence of critical scenarios that may threaten their reliability. Numerous research efforts have been dedicated to testing these policies. However, there are still significant challenges, such as low testing efficiency and diversity due to the complexity of the policies and environments under test. Inspired by the remarkable capabilities of large language models (LLMs), in this paper, we propose an LLM-driven online testing framework for efficiently testing decision-making policies. The main idea is to employ an LLM-based test scenario generator to intelligently generate challenging test cases through contemplation and reasoning. Specifically, we first design a “generate-test-feedback” pipeline and apply templated prompt engineering to fully leverage the knowledge and reasoning abilities of LLMs. Then, we introduce a multi-scale scenario generation strategy to address the inherent challenges LLMs face in making fine adjustments, further enhancing testing efficiency. Finally, we evaluate the LLM-driven approach on five widely used benchmarks. The experimental results demonstrate that our method significantly outperforms baseline approaches in uncovering both critical and diverse scenarios.
近年来,决策策略在各个领域如自动驾驶和机器人技术中取得了令人惊讶的成就。由于存在可能威胁其可靠性的关键场景,因此针对决策策略的测试至关重要。许多研究努力都致力于测试这些策略。然而,仍然存在巨大的挑战,如由于政策和环境测试的复杂性导致的测试效率低下和多样性不足。本文受大型语言模型(LLM)出色能力的启发,提出了一种LLM驱动的在线测试框架,用于有效地测试决策策略。主要思想是采用基于LLM的测试场景生成器,通过深思和推理智能地生成具有挑战性的测试用例。具体来说,我们首先设计一个“生成-测试-反馈”管道,应用模板提示工程来充分利用LLM的知识和推理能力。然后,我们引入了一种多尺度场景生成策略来解决LLM在细微调整方面所面临的固有挑战,进一步提高了测试效率。最后,我们在五个广泛使用的基准测试上对LLM驱动的方法进行了评估。实验结果表明,我们的方法在发现关键和多样化场景方面显著优于基准方法。
论文及项目相关链接
PDF 16 pages, 13 figures
Summary
决策策略在各种领域如自动驾驶和机器人技术中都取得了惊人的成就。这些策略的测试至关重要,因为存在关键场景可能会威胁其可靠性。虽然有很多关于测试这些策略的研究努力,但由于策略的复杂性以及测试环境等因素,仍然存在诸如测试效率低下和多样性不足等挑战。本研究提出了一个基于大型语言模型的在线测试框架,利用大型语言模型智能生成挑战性的测试用例。首先设计了一个“生成-测试-反馈”管道,并应用模板提示工程来充分利用大型语言模型的知识和推理能力。其次,引入了一种多尺度场景生成策略来解决大型语言模型在细微调整方面所面临的固有挑战,进一步提高了测试效率。最后,在五个广泛使用的基准上对基于大型语言模型的方法进行了评估。实验结果表明,该方法在发现关键和多样化场景方面显著优于基准方法。
Key Takeaways
- 决策策略在各种领域取得了显著成就,但测试这些策略时面临挑战,如低效率和缺乏多样性。
- 基于大型语言模型的在线测试框架被提出,用于智能生成挑战性的测试用例。
- 通过设计“生成-测试-反馈”管道和应用模板提示工程,充分利用大型语言模型的知识和推理能力。
- 多尺度场景生成策略解决了大型语言模型在细微调整方面的挑战。
- 实验评估表明,该方法在发现关键和多样化场景方面优于传统方法。
- 此框架对于提高决策策略测试的效率和可靠性具有重大意义。
点此查看论文截图

Toward LLM-Agent-Based Modeling of Transportation Systems: A Conceptual Framework
Authors:Tianming Liu, Jirong Yang, Yafeng Yin
In transportation system demand modeling and simulation, agent-based models and microsimulations are current state-of-the-art approaches. However, existing agent-based models still have some limitations on behavioral realism and resource demand that limit their applicability. In this study, leveraging the emerging technology of large language models (LLMs) and LLM-based agents, we propose a general LLM-agent-based modeling framework for transportation systems. We argue that LLM agents not only possess the essential capabilities to function as agents but also offer promising solutions to overcome some limitations of existing agent-based models. Our conceptual framework design closely replicates the decision-making and interaction processes and traits of human travelers within transportation networks, and we demonstrate that the proposed systems can meet critical behavioral criteria for decision-making and learning behaviors using related studies and a demonstrative example of LLM agents’ learning and adjustment in the bottleneck setting. Although further refinement of the LLM-agent-based modeling framework is necessary, we believe that this approach has the potential to improve transportation system modeling and simulation.
在交通运输系统需求建模与仿真中,基于主体的模型和微观仿真都是当前最先进的技术手段。然而,现有的基于主体的模型在行为真实性和资源需求方面仍有一些局限性,限制了其适用性。本研究利用新兴的大型语言模型(LLM)和基于LLM的代理技术,提出了一个通用的交通运输系统LLM-agent-based建模框架。我们认为,LLM代理不仅具备作为代理的基本能力,而且还为解决现有基于主体的模型的一些局限性提供了有前景的解决方案。我们的概念框架设计紧密复制了交通运输网络中人类旅行者的决策和互动过程及特征,我们证明,相关研究和LLM代理在瓶颈环境中的学习和调整示范例子可以证明,所提出的系统可以满足决策和学习行为的关键行为标准。尽管对LLM-agent-based建模框架的进一步细化是必需的,但我们相信这种方法有潜力改进交通运输系统建模和仿真。
论文及项目相关链接
Summary
基于多智能体的模型和微观模拟是目前交通系统需求建模和仿真的主流方法,但现有智能体模型在行为真实性和资源需求方面存在一定局限性。本研究利用新兴的大型语言模型(LLM)和基于LLM的智能体技术,提出了一种通用的LLM智能体模型框架。研究发现LLM智能体不仅具备基本功能智能,还解决了现有智能体模型的一些局限性问题。设计的概念框架紧密复制了人类旅行者在交通网络中的决策和互动过程与特征,并展示了该系统能满足关键的决策制定和学习行为标准。尽管需要进一步改进LLM智能体模型框架,但此方法在交通系统建模和仿真方面有着巨大潜力。
Key Takeaways
- 大型语言模型(LLM)和基于LLM的智能体被用于构建新的交通系统模型框架。
- LLM智能体具备基本功能智能,并解决了现有智能体模型的行为真实性和资源需求方面的局限性。
- 该框架紧密复制了人类旅行者在交通网络中的决策和互动过程与特征。
- LLM智能体可以在瓶颈场景下展示学习和调整能力。
- 通过相关研究和实例演示,证明了该系统能满足关键的决策制定和学习行为标准。
- 虽然该框架需要进一步改进和优化,但其对交通系统建模和仿真的潜力巨大。
- 大型语言模型的应用为交通系统建模带来了新的可能性。
点此查看论文截图

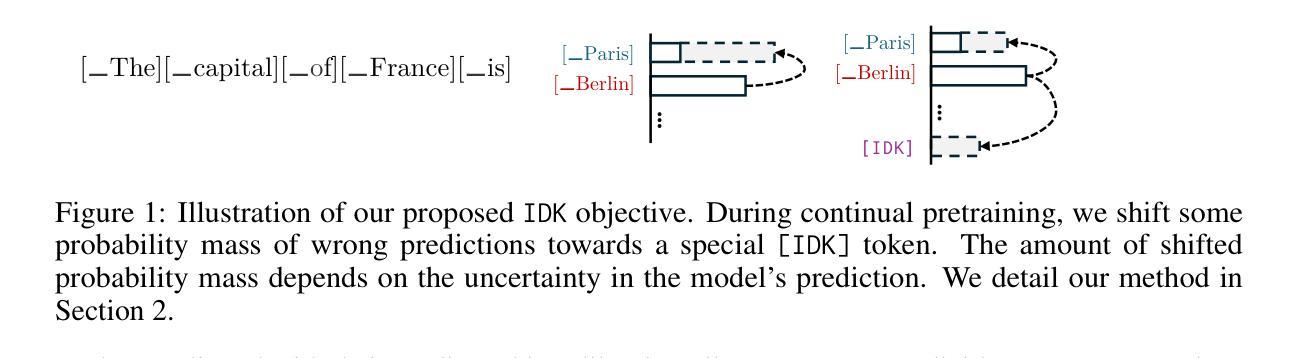
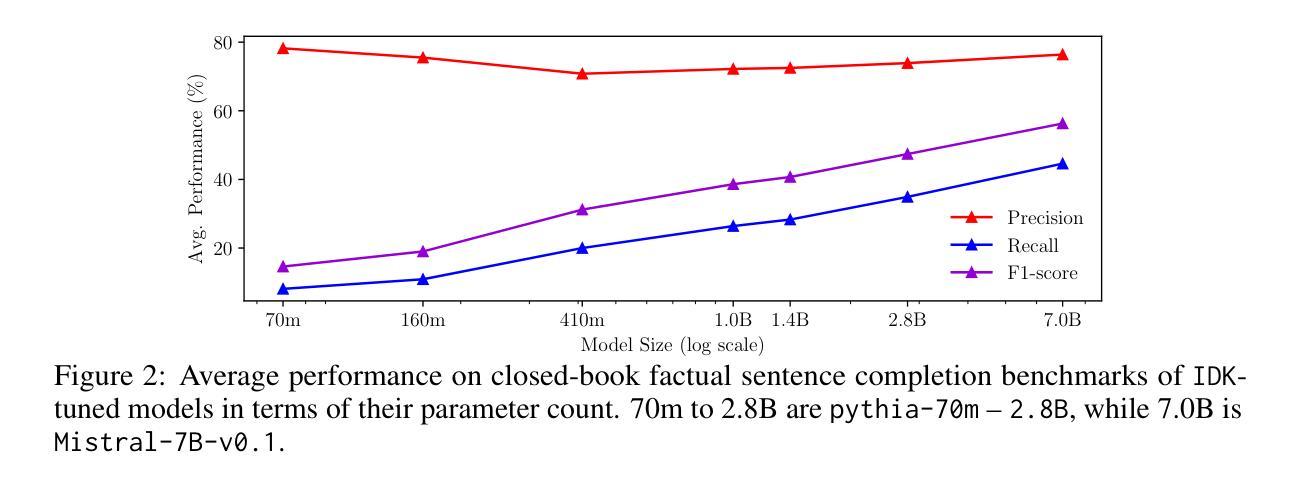
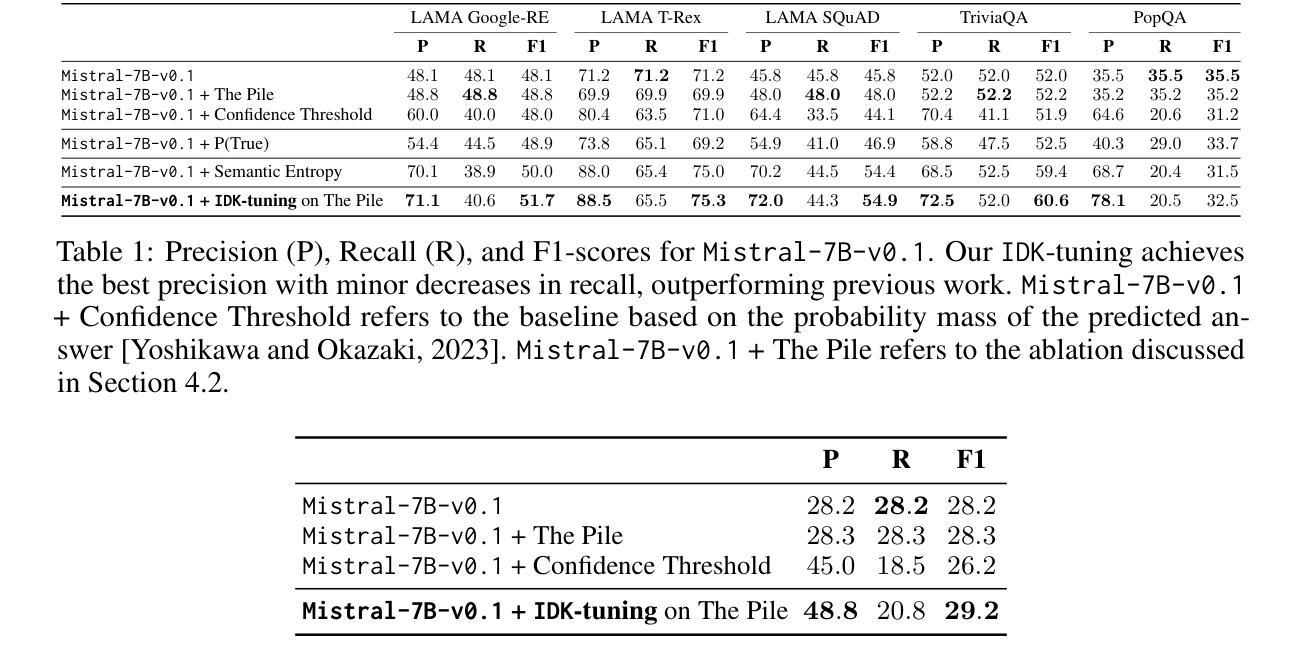
I Don’t Know: Explicit Modeling of Uncertainty with an [IDK] Token
Authors:Roi Cohen, Konstantin Dobler, Eden Biran, Gerard de Melo
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we propose a novel calibration method that can be used to combat hallucinations. We add a special [IDK] (“I don’t know”) token to the model’s vocabulary and introduce an objective function that shifts probability mass to the [IDK] token for incorrect predictions. This approach allows the model to express uncertainty in its output explicitly. We evaluate our proposed method across multiple model architectures and factual downstream tasks. We find that models trained with our method are able to express uncertainty in places where they would previously make mistakes while suffering only a small loss of encoded knowledge. We further perform extensive ablation studies of multiple variations of our approach and provide a detailed analysis of the precision-recall tradeoff of our method.
大型语言模型能够捕获现实世界的知识,使其在许多下游任务中表现出色。尽管最近有所进展,但这些模型仍然容易遭受所谓的“幻觉”影响,导致它们产生不想要且事实错误的文本。在这项工作中,我们提出了一种新型校准方法,可以用来对抗幻觉。我们在模型的词汇表中增加了一个特殊的[IDK](“我不知道”)标记,并引入了一个目标函数,将概率质量转移到错误预测的[IDK]标记上。这种方法允许模型在输出中显式表达不确定性。我们在多种模型架构和事实下游任务中评估了我们提出的方法。我们发现,使用我们方法训练的模型能够在以前会出错的地方表达不确定性,同时只损失少量已编码的知识。我们还对方法的多种变体进行了广泛的消融研究,并详细分析了我们方法的精确度和召回率之间的权衡。
论文及项目相关链接
PDF Published at NeurIPS 2024
Summary
大型语言模型虽能捕捉现实知识并在许多下游任务中表现出色,但仍存在生成错误文本的风险,即所谓的“幻觉”。本研究提出了一种新的校准方法来解决这一问题。通过在模型词汇表中添加一个特殊的[IDK](表示“我不知道”)令牌,并引入一个针对不正确预测将概率质量转移到该令牌的目标函数,使模型能够明确表达其输出的不确定性。评估表明,经过此方法训练的模型能够在之前犯错的地方表达不确定性,同时仅损失少量编码知识。此外,还进行了大量的方法变体消融研究,并对方法的精确度和召回率之间的权衡进行了详细分析。
Key Takeaways
- 大型语言模型能够捕捉现实知识并在下游任务中表现出色,但仍存在生成错误文本的风险。
- 研究提出了一种新的校准方法来解决模型生成错误文本的问题。
- 通过添加[IDK]令牌和引入目标函数,使模型能够明确表达其输出的不确定性。
- 训练后的模型能够在之前犯错的地方表达不确定性,同时仅损失少量编码知识。
- 方法在多种模型架构和事实下游任务上的评估表现良好。
- 进行了大量的方法变体消融研究。
点此查看论文截图

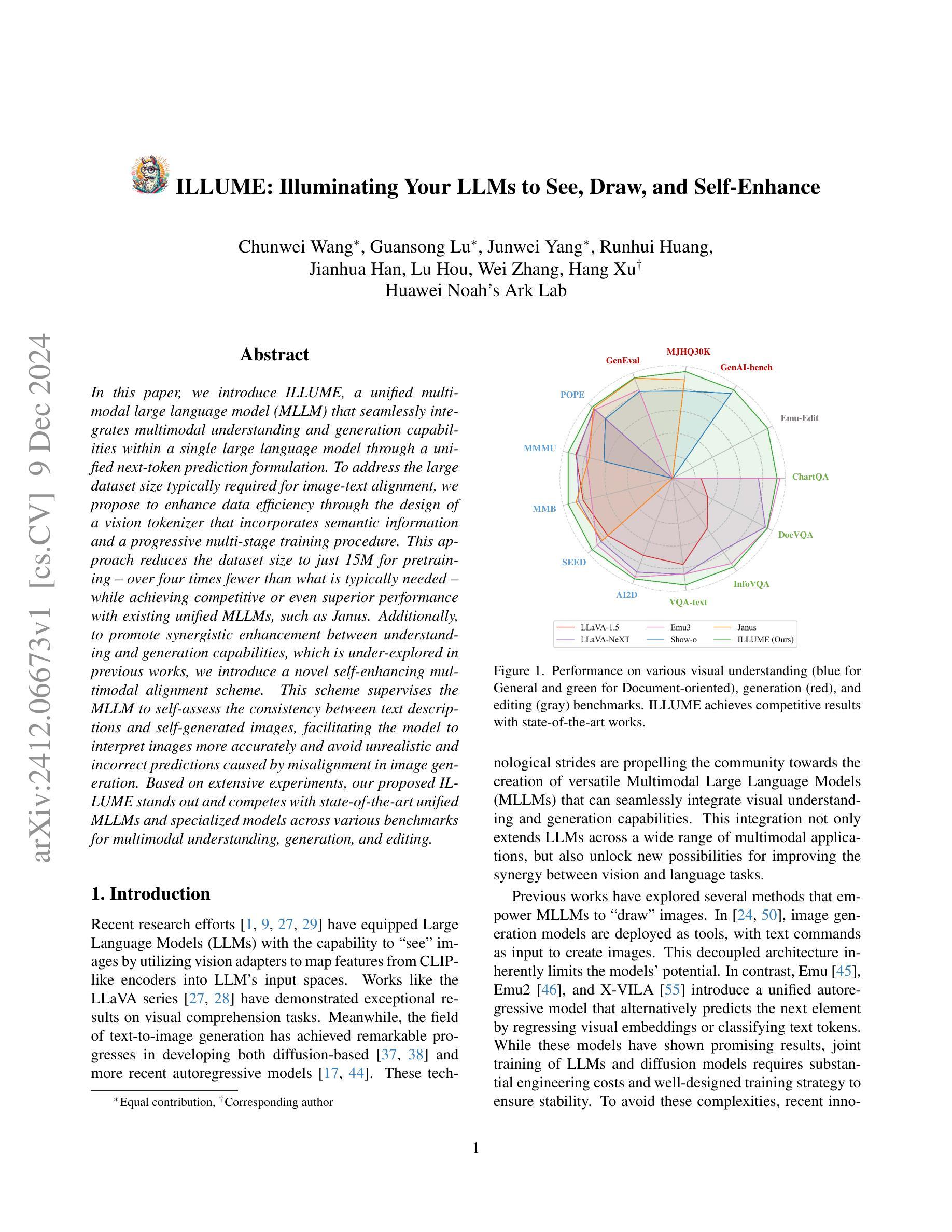
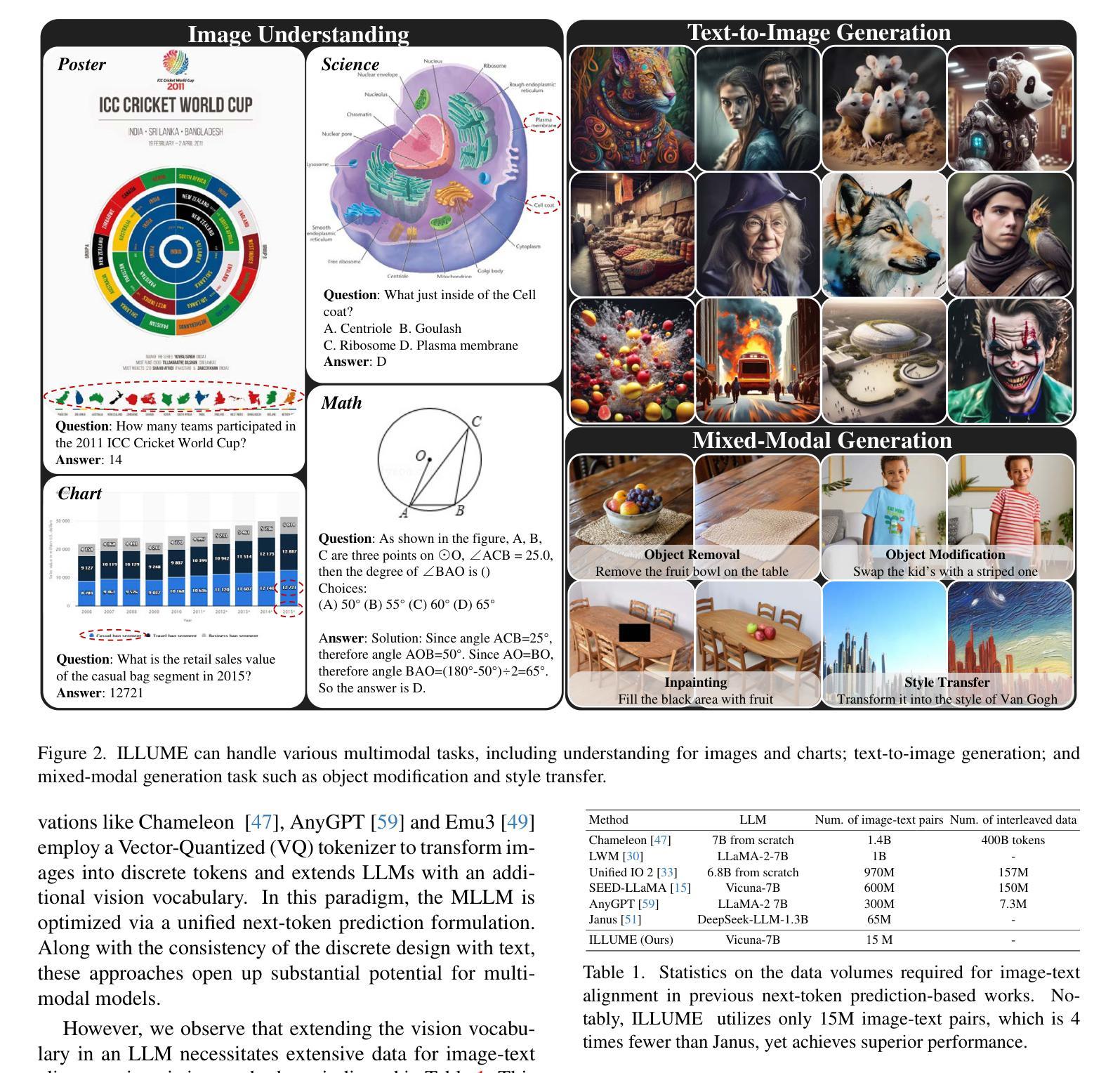
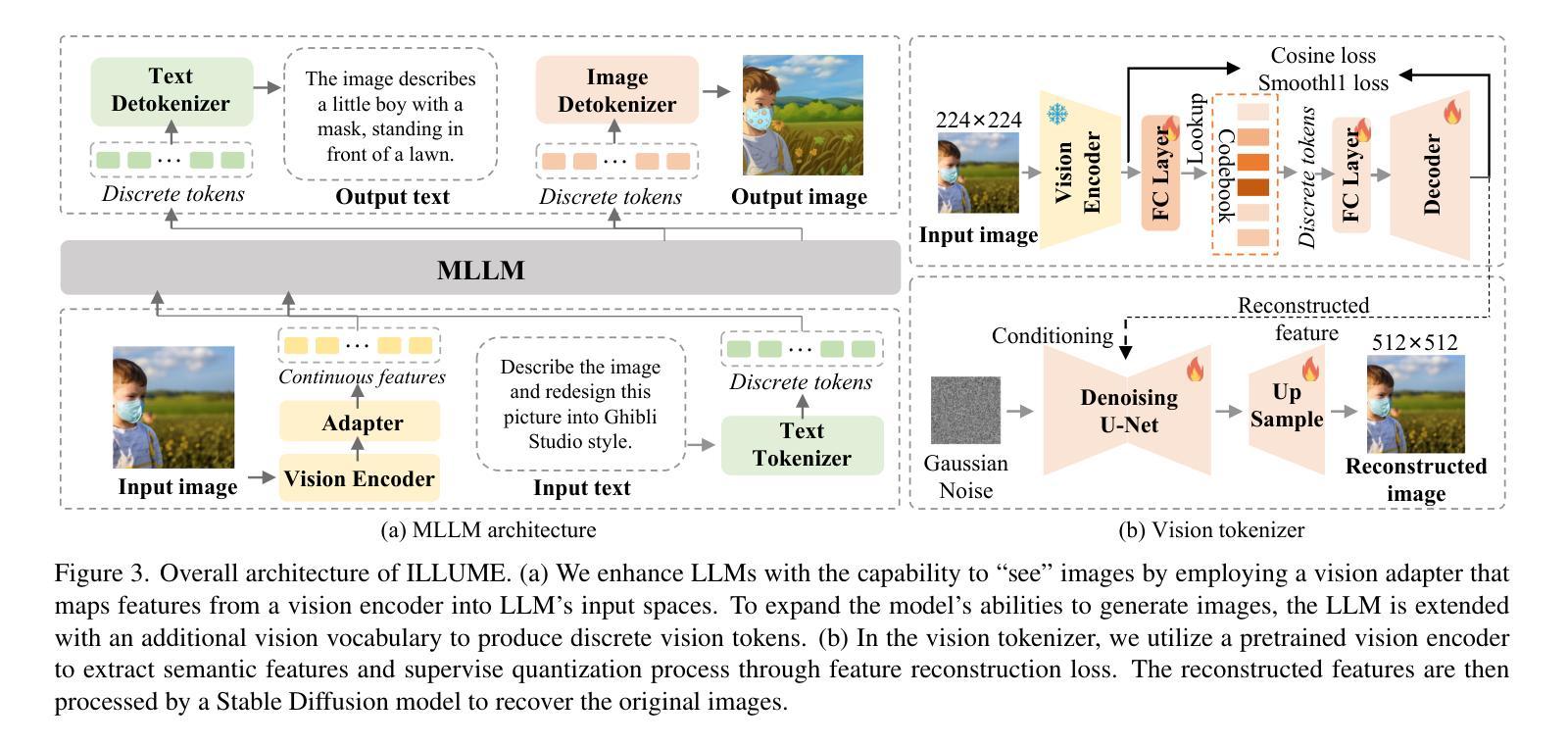
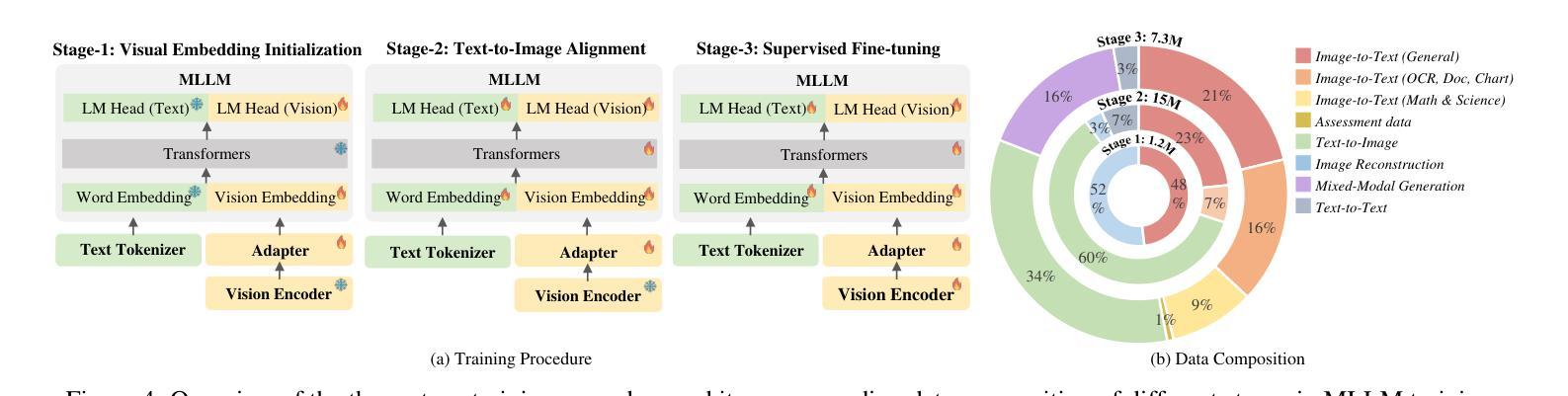
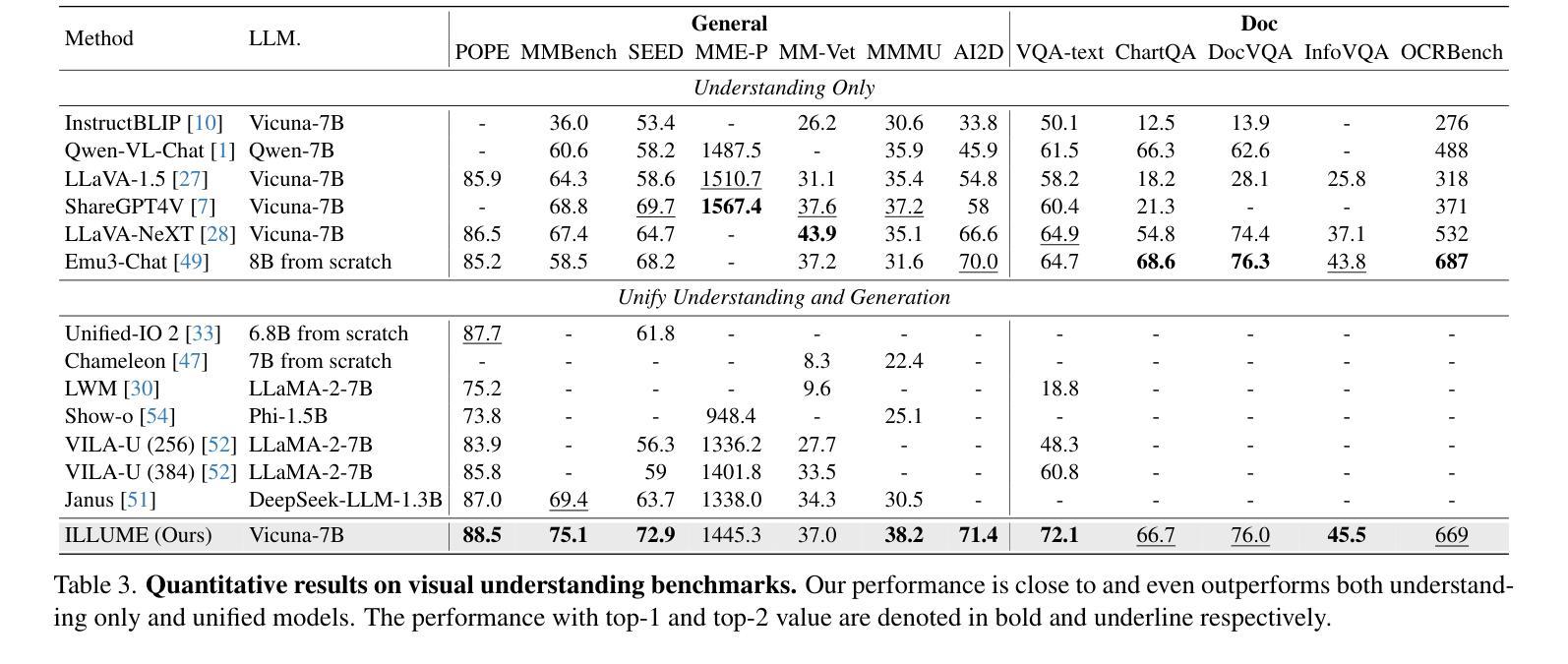
ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
Authors:Chunwei Wang, Guansong Lu, Junwei Yang, Runhui Huang, Jianhua Han, Lu Hou, Wei Zhang, Hang Xu
In this paper, we introduce ILLUME, a unified multimodal large language model (MLLM) that seamlessly integrates multimodal understanding and generation capabilities within a single large language model through a unified next-token prediction formulation. To address the large dataset size typically required for image-text alignment, we propose to enhance data efficiency through the design of a vision tokenizer that incorporates semantic information and a progressive multi-stage training procedure. This approach reduces the dataset size to just 15M for pretraining – over four times fewer than what is typically needed – while achieving competitive or even superior performance with existing unified MLLMs, such as Janus. Additionally, to promote synergistic enhancement between understanding and generation capabilities, which is under-explored in previous works, we introduce a novel self-enhancing multimodal alignment scheme. This scheme supervises the MLLM to self-assess the consistency between text descriptions and self-generated images, facilitating the model to interpret images more accurately and avoid unrealistic and incorrect predictions caused by misalignment in image generation. Based on extensive experiments, our proposed ILLUME stands out and competes with state-of-the-art unified MLLMs and specialized models across various benchmarks for multimodal understanding, generation, and editing.
本文介绍了ILLUME,这是一种统一的多模态大型语言模型(MLLM),它通过一个统一的下一个令牌预测公式,在一个大型语言模型中无缝集成了多模态理解和生成能力。为了解决图像文本对齐通常需要的大量数据集问题,我们提出通过设计一种视觉令牌器来提高数据效率,该令牌器结合了语义信息和一个渐进的多阶段训练过程。这种方法将数据集大小减少到仅用于预训练的15M——比通常需要的少了四倍——同时实现了与现有的统一MLLM(如Janus)相当甚至更好的性能。此外,为了促进理解和生成能力之间的协同增强(这在以前的工作中很少探索),我们引入了一种新型的自增强多模态对齐方案。该方案监督MLLM自我评估文本描述与自我生成图像之间的一致性,帮助模型更准确地解释图像,并避免由于图像生成中的错位而导致的非现实和错误的预测。基于大量实验,我们提出的ILLUME在多模态理解、生成和编辑的各种基准测试中脱颖而出,并与最先进的统一MLLM和专用模型相竞争。
论文及项目相关链接
Summary
本文介绍了ILLUME,一种统一的多模态大型语言模型(MLLM)。该模型通过统一的下一个令牌预测公式,将多模态理解和生成能力无缝集成到一个大型语言模型中。为解决图像文本对齐所需的大量数据集问题,通过设计包含语义信息的视觉标记器和渐进的多阶段训练程序,提高了数据效率。此方法将预训练数据集大小减少到仅15M,相较于通常所需的数据集大小减少了四倍以上,同时实现了与现有统一MLLMs(如Janus)相当甚至更好的性能。此外,本文引入了自我提升的多模态对齐方案,以促进理解和生成能力之间的协同增强,这是一个在以前的研究中被忽视的问题。该方案监督MLLM自我评估文本描述与自我生成的图像之间的一致性,帮助模型更准确地解释图像,避免由于图像生成中的不对齐而导致的虚幻和错误的预测。实验证明,提出的ILLUME在多种多模态理解、生成和编辑的基准测试中表现出色,与最先进的统一MLLMs和专用模型相竞争。
Key Takeaways
- ILLUME是一个统一的多模态大型语言模型(MLLM),集成了多模态理解和生成能力。
- 通过视觉标记器和多阶段训练程序提高了数据效率,减少预训练数据集大小至15M。
- 与现有MLLMs相比,ILLUME实现了相当或更好的性能。
- 引入自我提升的多模态对齐方案,促进理解和生成能力之间的协同增强。
- 该方案监督MLLM自我评估文本描述与图像之间的一致性,提升图像解释准确性。
- ILLUME避免了由于图像生成中的不对齐导致的虚幻和错误的预测。
点此查看论文截图

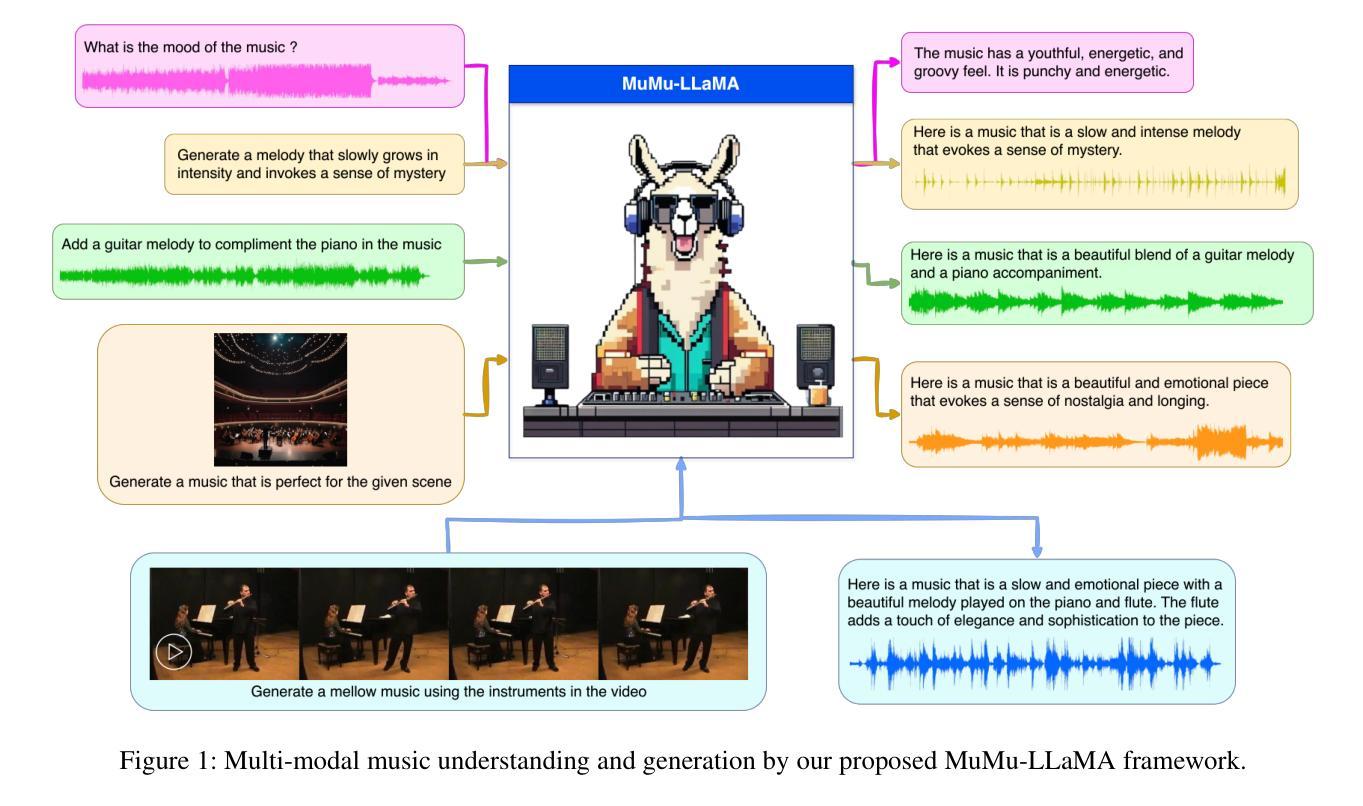
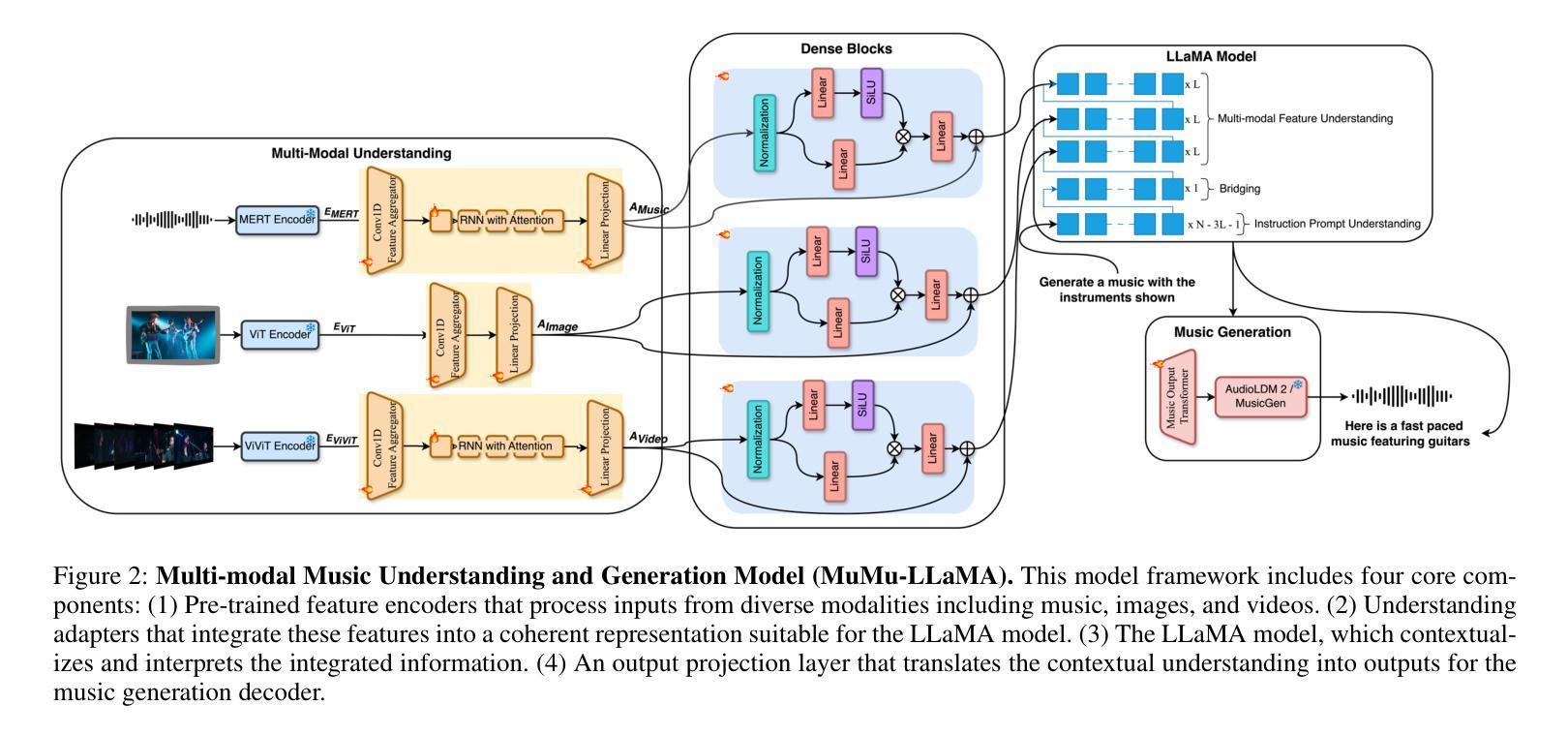
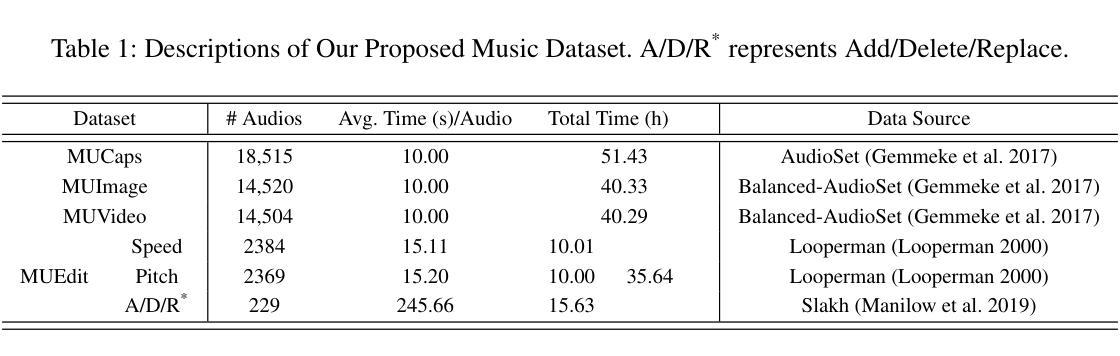
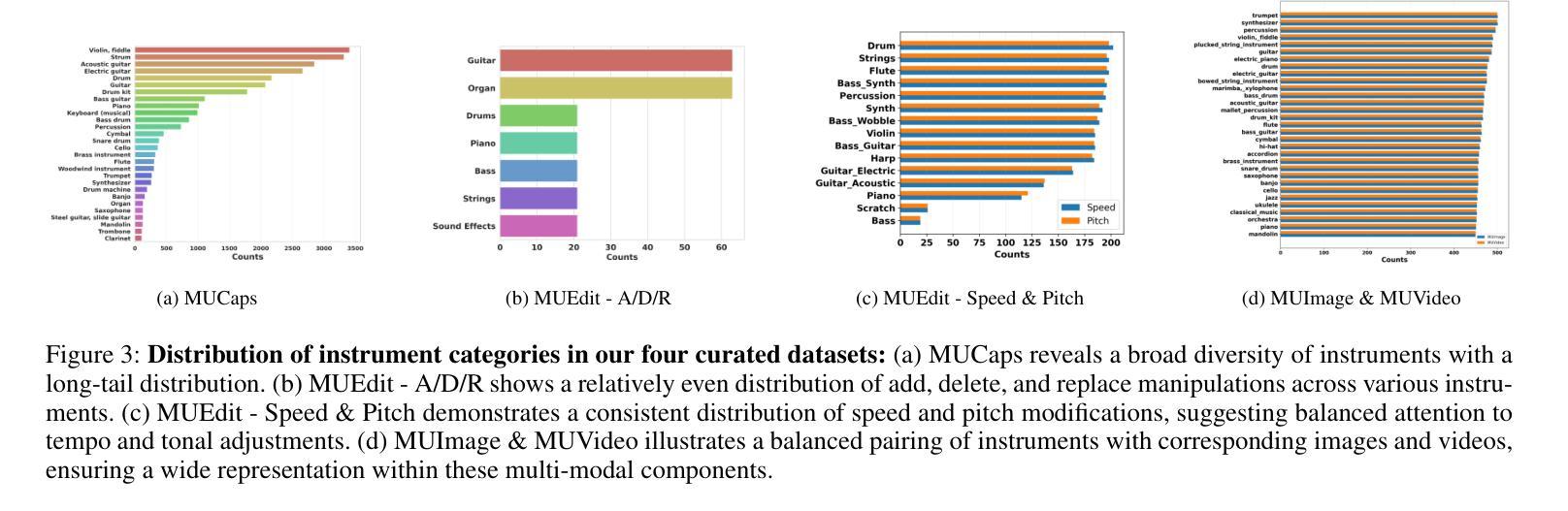
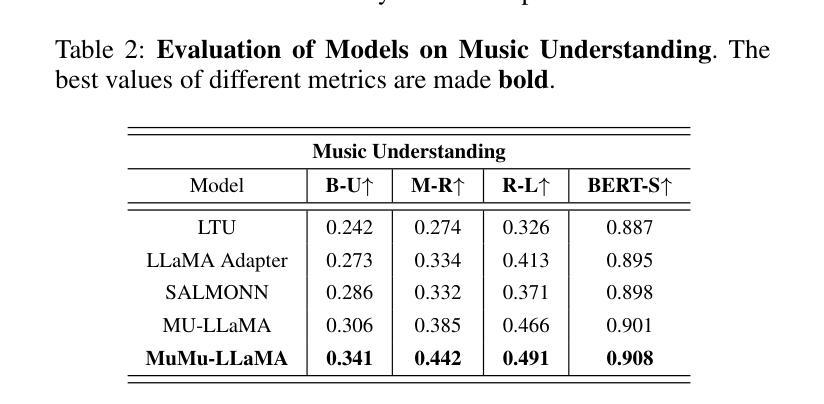
MuMu-LLaMA: Multi-modal Music Understanding and Generation via Large Language Models
Authors:Shansong Liu, Atin Sakkeer Hussain, Qilong Wu, Chenshuo Sun, Ying Shan
Research on large language models has advanced significantly across text, speech, images, and videos. However, multi-modal music understanding and generation remain underexplored due to the lack of well-annotated datasets. To address this, we introduce a dataset with 167.69 hours of multi-modal data, including text, images, videos, and music annotations. Based on this dataset, we propose MuMu-LLaMA, a model that leverages pre-trained encoders for music, images, and videos. For music generation, we integrate AudioLDM 2 and MusicGen. Our evaluation across four tasks–music understanding, text-to-music generation, prompt-based music editing, and multi-modal music generation–demonstrates that MuMu-LLaMA outperforms state-of-the-art models, showing its potential for multi-modal music applications.
关于大型语言模型的研究在文本、语音、图像和视频方面取得了显著进展。然而,由于缺少标注良好的数据集,多模态音乐理解和生成仍然被较少探索。为了解决这一问题,我们引入了一个包含167.69小时多模态数据的数据集,其中包括文本、图像、视频和音乐注释。基于此数据集,我们提出了MuMu-LLaMA模型,该模型利用音乐、图像和视频的预训练编码器。对于音乐生成,我们集成了AudioLDM 2和MusicGen。我们在四项任务上的评估——音乐理解、文本到音乐生成、基于提示的音乐编辑和多模态音乐生成——表明,MuMu-LLaMA超越了最先进的模型,显示出其在多模态音乐应用中的潜力。
论文及项目相关链接
总结
该研究解决了多模态音乐理解和生成领域的不足问题。为了改进,研究人员推出一个新的数据集,包括文本、图像、视频和音乐注释的多模态数据。基于该数据集,他们提出了MuMu-LLaMA模型,该模型利用音乐、图像和视频的预训练编码器。在音乐生成方面,他们整合了AudioLDM 2和MusicGen。评估表明,MuMu-LLaMA在四个任务上表现出超越现有模型的性能,显示出其在多模态音乐应用中的潜力。
关键见解
- 多模态音乐理解和生成领域缺乏充分研究的资源限制了其发展。
- 新数据集包含了文本、图像、视频和音乐注释的多模态数据,为相关研究提供了丰富的素材。
- MuMu-LLaMA模型利用预训练的编码器处理音乐、图像和视频数据。
- AudioLDM 2和MusicGen被整合到MuMu-LLaMA模型中用于音乐生成。
- MuMu-LLaMA在四个任务上的表现超越了现有模型。
- 这项研究为多模态音乐应用提供了新的可能性。
点此查看论文截图

Chatbots im Schulunterricht: Wir testen das Fobizz-Tool zur automatischen Bewertung von Hausaufgaben
Authors:Rainer Mühlhoff, Marte Henningsen
This study examines the AI-powered grading tool “AI Grading Assistant” by the German company Fobizz, designed to support teachers in evaluating and providing feedback on student assignments. Against the societal backdrop of an overburdened education system and rising expectations for artificial intelligence as a solution to these challenges, the investigation evaluates the tool’s functional suitability through two test series. The results reveal significant shortcomings: The tool’s numerical grades and qualitative feedback are often random and do not improve even when its suggestions are incorporated. The highest ratings are achievable only with texts generated by ChatGPT. False claims and nonsensical submissions frequently go undetected, while the implementation of some grading criteria is unreliable and opaque. Since these deficiencies stem from the inherent limitations of large language models (LLMs), fundamental improvements to this or similar tools are not immediately foreseeable. The study critiques the broader trend of adopting AI as a quick fix for systemic problems in education, concluding that Fobizz’s marketing of the tool as an objective and time-saving solution is misleading and irresponsible. Finally, the study calls for systematic evaluation and subject-specific pedagogical scrutiny of the use of AI tools in educational contexts.
本研究考察了由德国公司Fobizz开发的AI辅助评分工具“AI评分助手”,该工具旨在支持教师评估学生的作业并提供反馈意见。 在教育制度负担过重以及对人工智能作为解决这些挑战的解决方案的期望不断上升的社会背景下,本研究通过两项测试系列评估了该工具的功能适用性。 结果显示存在重大缺陷:该工具的分数和定性反馈往往是随机的,即使采纳了其建议也无法改善。 只有通过ChatGPT生成的文本才能获得最高分。错误的声明和非理智的提交经常没有被发现,而一些评分标准的实施既不可靠也不透明。 由于这些缺陷源于大型语言模型(LLM)的内在局限性,因此对该工具或类似工具的基本改进并不乐观。本研究批评了在教育领域采用人工智能作为快速解决系统性问题的更广泛趋势,认为Fobizz将该工具宣传为客观省时解决方案的做法具有误导性和不负责任。最后,该研究呼吁对在教育环境中使用人工智能工具进行系统的评估和学科特定的教育审查。
论文及项目相关链接
PDF 32 pages, in German language
Summary
本文研究了由德国公司Fobizz开发的AI智能评分工具”AI Grading Assistant”,旨在支持教师评估学生作业并提供反馈。研究指出该工具在功能上存在明显不足,如评分随机性大,难以改善质量;部分评价标准不明确或不严谨,甚至容易忽视错误或不合理的提交内容。这些问题源于大型语言模型(LLM)的内在局限性,难以预见短期内对该工具或类似工具的实质性改进。研究批评了教育界广泛采用AI作为快速解决方案的趋势,认为Fobizz将该工具宣传为客观和省时解决方案的营销手段不负责任。最后呼吁对AI工具在教育领域的应用进行系统性评估和学科特定的教育审查。
Key Takeaways
- AI Grading Assistant工具存在显著缺陷,评分随机性大,难以提供有效反馈。
- 部分评价标准不明确或不严谨,导致无法准确评估学生作业。
- 工具容易忽视错误或不合理的提交内容,存在安全隐患。
- 这些问题的根源在于大型语言模型(LLM)的内在局限性。
- 对类似工具的短期实质性改进前景不明朗。
- 将AI Grading Assistant宣传为客观和省时解决方案的营销手段被批评为不负责任。
点此查看论文截图

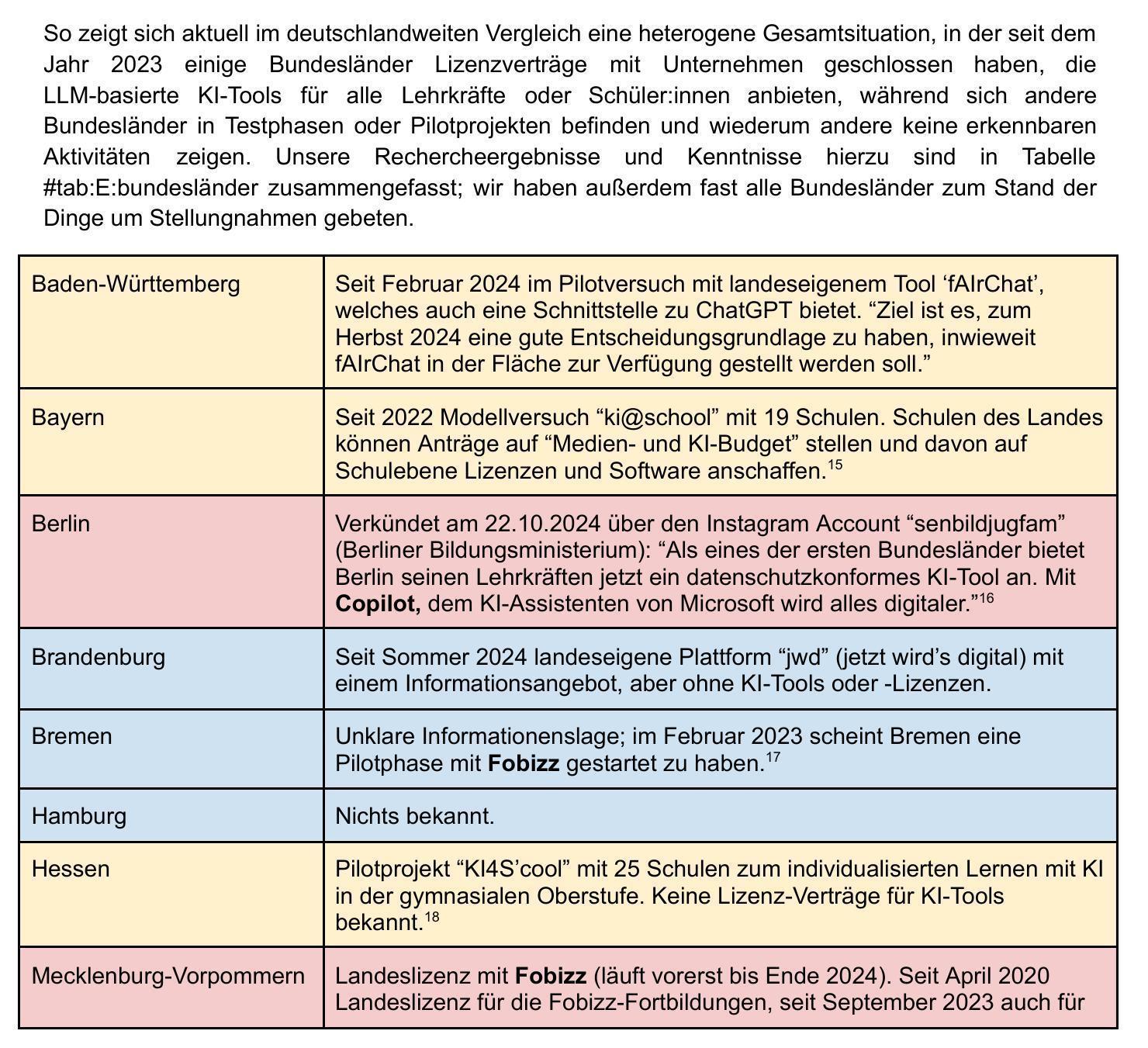
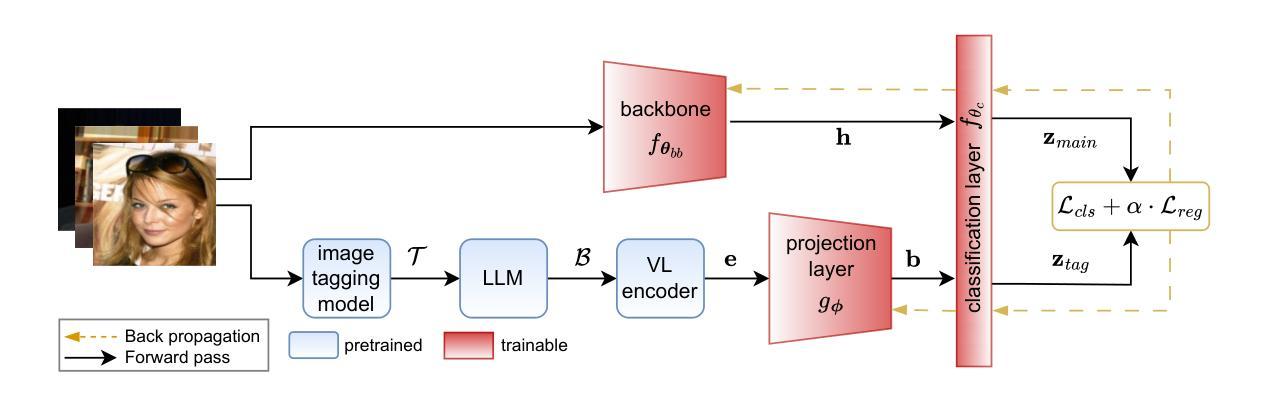
MAVias: Mitigate any Visual Bias
Authors:Ioannis Sarridis, Christos Koutlis, Symeon Papadopoulos, Christos Diou
Mitigating biases in computer vision models is an essential step towards the trustworthiness of artificial intelligence models. Existing bias mitigation methods focus on a small set of predefined biases, limiting their applicability in visual datasets where multiple, possibly unknown biases exist. To address this limitation, we introduce MAVias, an open-set bias mitigation approach leveraging foundation models to discover spurious associations between visual attributes and target classes. MAVias first captures a wide variety of visual features in natural language via a foundation image tagging model, and then leverages a large language model to select those visual features defining the target class, resulting in a set of language-coded potential visual biases. We then translate this set of potential biases into vision-language embeddings and introduce an in-processing bias mitigation approach to prevent the model from encoding information related to them. Our experiments on diverse datasets, including CelebA, Waterbirds, ImageNet, and UrbanCars, show that MAVias effectively detects and mitigates a wide range of biases in visual recognition tasks outperforming current state-of-the-art.
计算机视觉模型中的偏见缓解是实现人工智能模型可信度的关键步骤。现有的偏见缓解方法主要关注一组预定义的偏见,这在存在多个可能未知的偏见的视觉数据集中限制了其适用性。为了解决这个问题,我们引入了 MAVias,这是一种利用基础模型发现视觉属性和目标类别之间偶然关联的开集偏见缓解方法。 MAVias首先通过基础图像标记模型捕获自然语言中的多种视觉特征,然后利用大型语言模型选择定义目标类别的视觉特征,形成一组语言编码的潜在视觉偏见。然后,我们将这组潜在的偏见转化为视觉语言嵌入,并引入一种处理过程中的偏见缓解方法,以防止模型编码与偏见相关的信息。我们在包括CelebA、Waterbirds、ImageNet和UrbanCars等多个数据集上的实验表明,MAVias有效地检测和缓解了视觉识别任务中的广泛偏见,并优于当前最先进的技术。
论文及项目相关链接
Summary
人工智能模型的计算机视觉部分要减少偏见是实现其可信赖的重要步骤。现有的偏见缓解方法主要集中在预先定义的少数偏见上,无法处理含有多个潜在未知偏见的视觉数据集。为了解决这一问题,我们推出了MAVias,这是一种开放式偏见缓解方法,利用基础模型发现并识别视觉属性与目标类别之间的偶然关联。MAVias首先通过图像标记基础模型捕获大量自然语言中的视觉特征,然后利用大型语言模型选择定义目标类别的视觉特征,从而得到一组语言编码的潜在视觉偏见。然后我们将这些潜在的偏见转化为视觉语言嵌入,并引入一种处理过程中的偏见缓解方法,防止模型与之相关的信息被编码。我们在包括CelebA、Waterbirds、ImageNet和UrbanCars等不同数据集上的实验表明,MAVias有效地检测和缓解了视觉识别任务中的广泛偏见,并优于当前最先进的水平。
Key Takeaways
- 减少计算机视觉模型中的偏见对于实现人工智能模型的信任至关重要。
- 现有偏见缓解方法主要集中在预定义的少数偏见上,存在局限性。
- MAVias是一种开放集偏见缓解方法,可发现并识别视觉属性与目标类别之间的偶然关联。
- MAVias利用图像标记基础模型捕获视觉特征,并利用大型语言模型选择定义目标类别的特征。
- MAVias将潜在偏见转化为视觉语言嵌入,以便进行处理过程中的偏见缓解。
- MAVias在多个数据集上的实验表明,它有效地检测和缓解了视觉识别任务中的广泛偏见。
点此查看论文截图


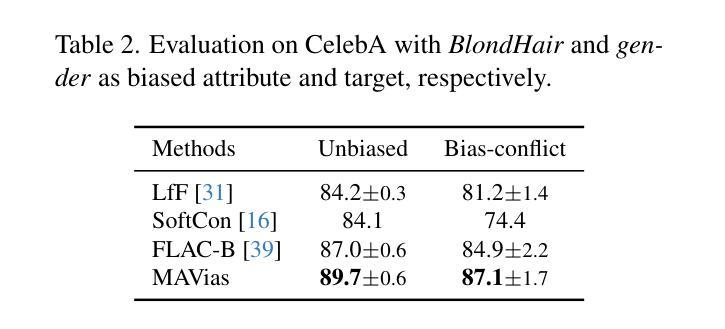
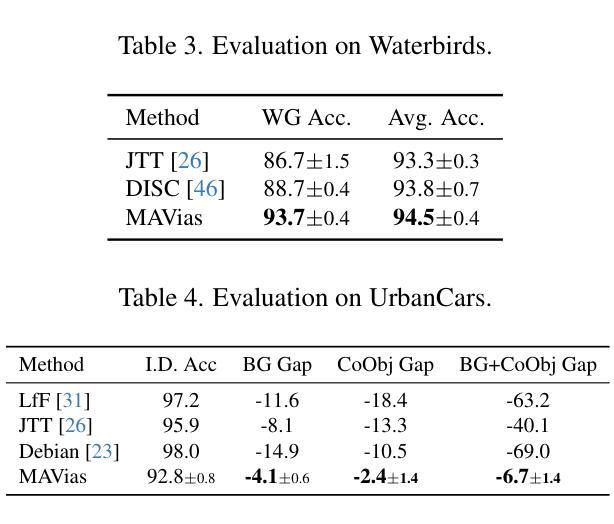
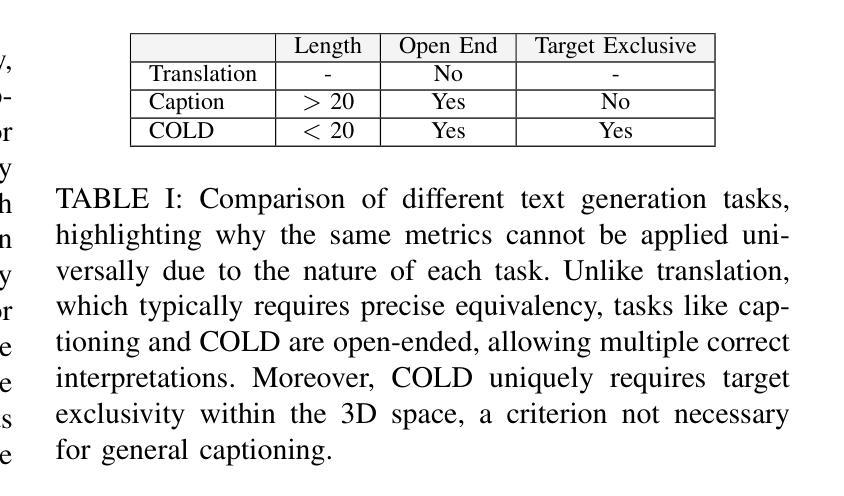
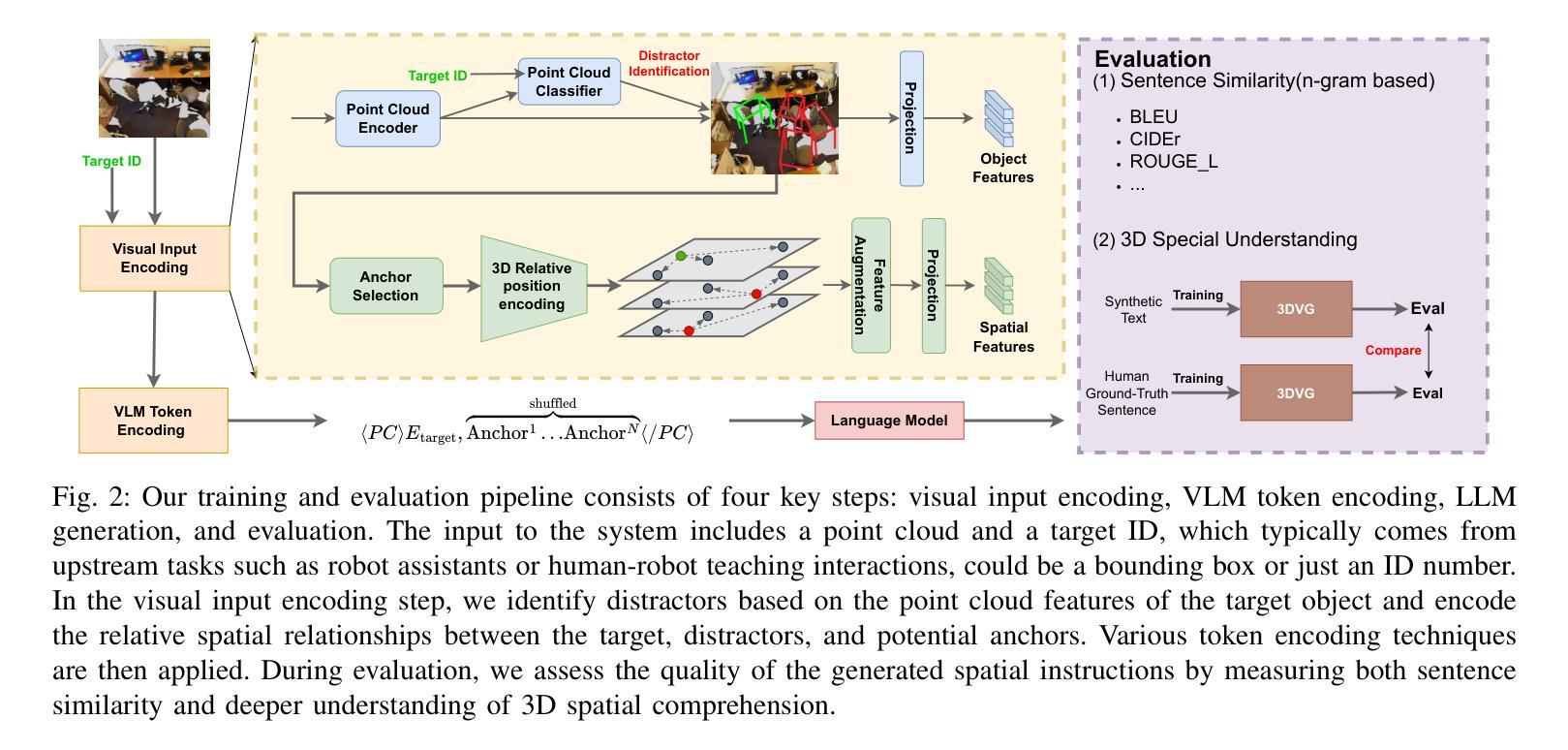
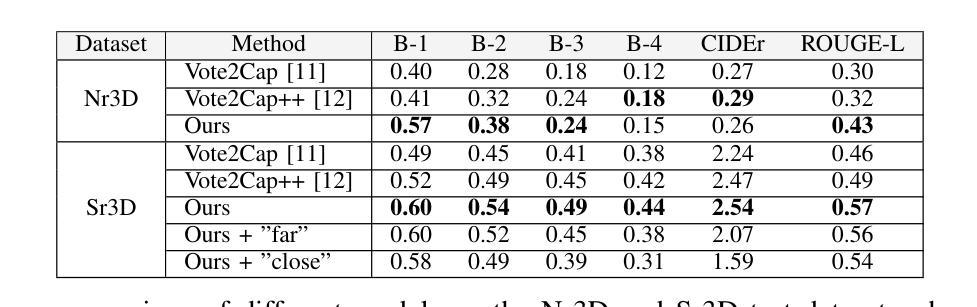
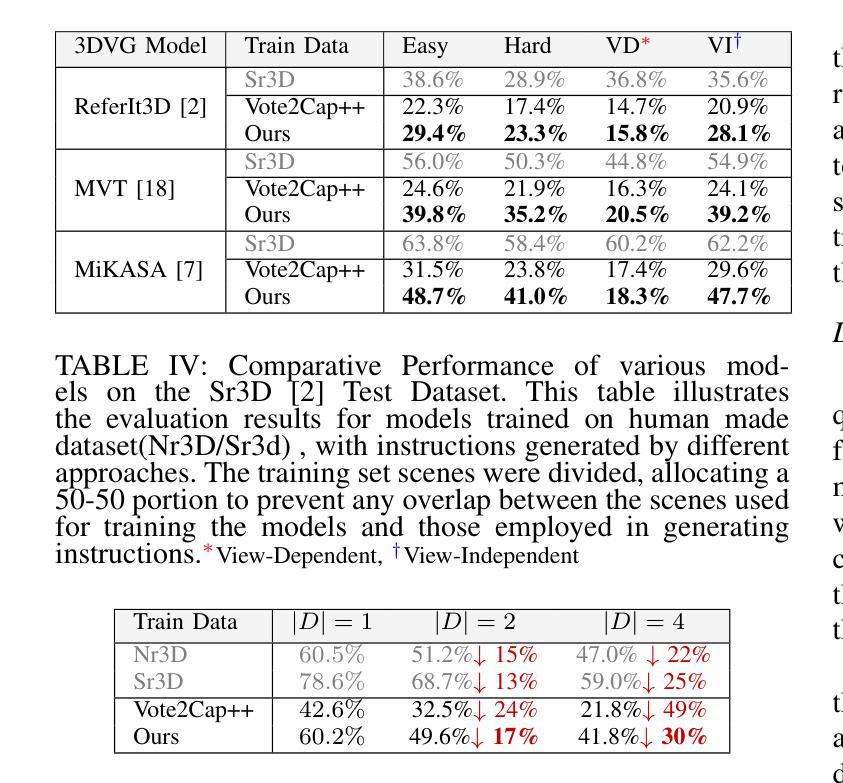
3D Spatial Understanding in MLLMs: Disambiguation and Evaluation
Authors:Chun-Peng Chang, Alain Pagani, Didier Stricker
Multimodal Large Language Models (MLLMs) have made significant progress in tasks such as image captioning and question answering. However, while these models can generate realistic captions, they often struggle with providing precise instructions, particularly when it comes to localizing and disambiguating objects in complex 3D environments. This capability is critical as MLLMs become more integrated with collaborative robotic systems. In scenarios where a target object is surrounded by similar objects (distractors), robots must deliver clear, spatially-aware instructions to guide humans effectively. We refer to this challenge as contextual object localization and disambiguation, which imposes stricter constraints than conventional 3D dense captioning, especially regarding ensuring target exclusivity. In response, we propose simple yet effective techniques to enhance the model’s ability to localize and disambiguate target objects. Our approach not only achieves state-of-the-art performance on conventional metrics that evaluate sentence similarity, but also demonstrates improved 3D spatial understanding through 3D visual grounding model.
多模态大型语言模型(MLLMs)在图像描述和问答等任务方面取得了显著进展。然而,虽然这些模型能够生成逼真的描述,但它们通常在提供精确指令时遇到困难,特别是在复杂的三维环境中定位和消除对象歧义时。随着MLLMs与协作机器人系统的集成度越来越高,这种能力变得至关重要。在目标对象被类似对象(干扰物)包围的情况下,机器人必须提供清晰、具有空间感知的指令以有效地指导人类。我们将这一挑战称为上下文对象定位和歧义消除,它比传统的三维密集描述更加严格,尤其需要确保目标对象的唯一性。作为回应,我们提出了简单而有效的技术来增强模型对目标对象的定位和消除歧义的能力。我们的方法不仅达到了基于句子相似性的传统评价指标的先进水平,而且通过三维视觉定位模型展示了增强的三维空间理解能力。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在图像标注和问答等任务中取得了显著进展,但在提供精确指令方面仍面临挑战,特别是在复杂3D环境中对目标进行定位和解析。随着MLLMs与协作机器人系统的集成,这种能力变得至关重要。在目标对象被类似物体包围的场景中,机器人必须提供清晰的空间感知指令以有效指导人类。我们称这一挑战为上下文目标定位和解析,它比传统的3D密集标注具有更严格的约束,特别是在确保目标独特性方面。为应对这一挑战,我们提出简单有效的技术来提升模型定位和目标解析的能力。不仅在传统评估句子相似性的指标上取得了最先进的性能,而且在通过三维视觉定位模型评估的三维空间理解方面也表现出了改进。
Key Takeaways
- 多模态大型语言模型(MLLMs)在图像标注和问答等方面有显著的进步。
- MLLMs在提供精确指令方面存在挑战,特别是在复杂3D环境中对目标进行定位和解析。
- 随着MLLMs与协作机器人系统的集成,目标定位和解析能力变得至关重要。
- 在目标物体被类似物体包围的场景中,机器人需要给出清晰的空间感知指令。
- 上下文目标定位和解析是机器人必须解决的一个挑战性问题,需要更严格的约束以确保目标的独特性。
- 为应对挑战,提出了简单有效的技术来提升模型定位和目标解析的能力。
点此查看论文截图



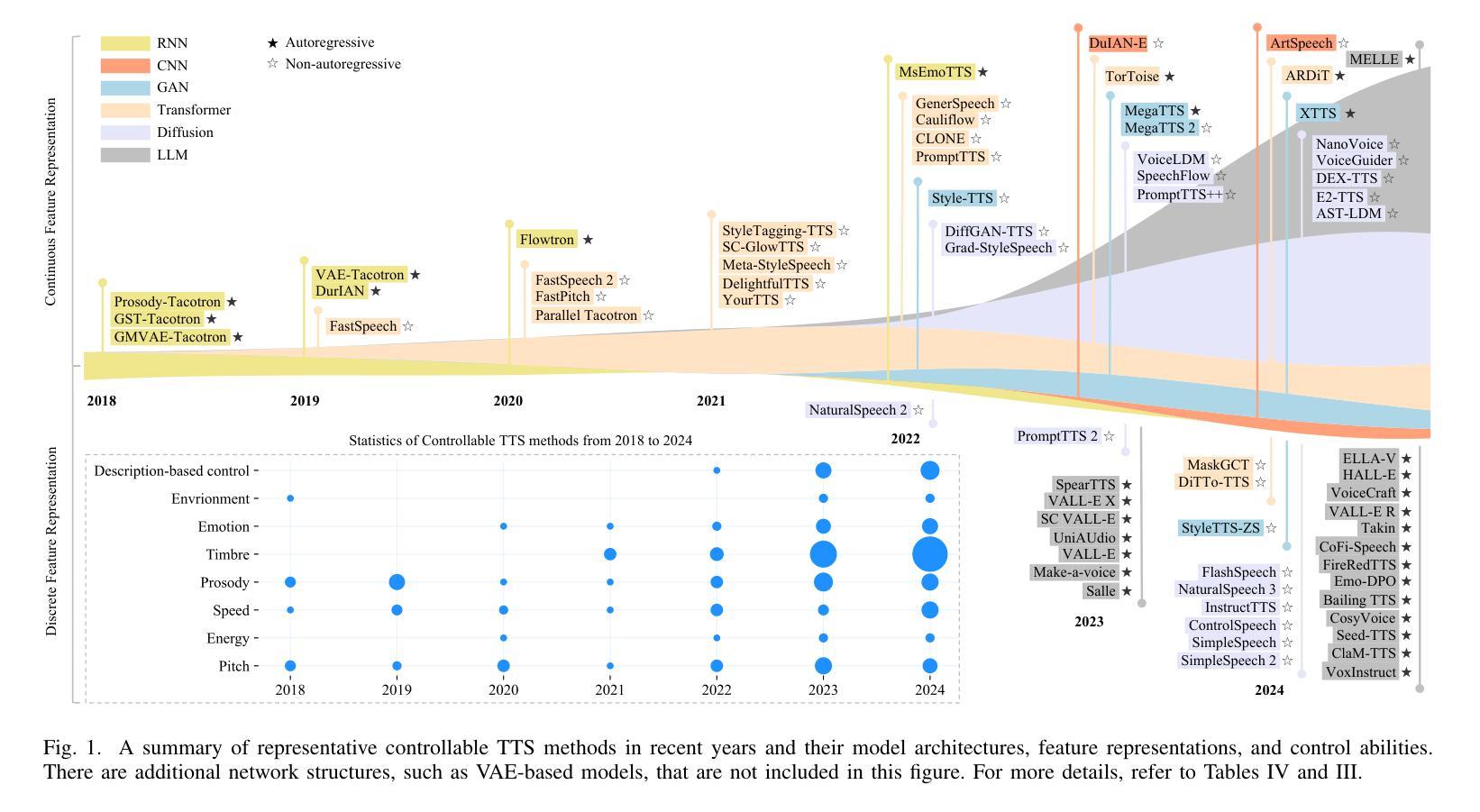
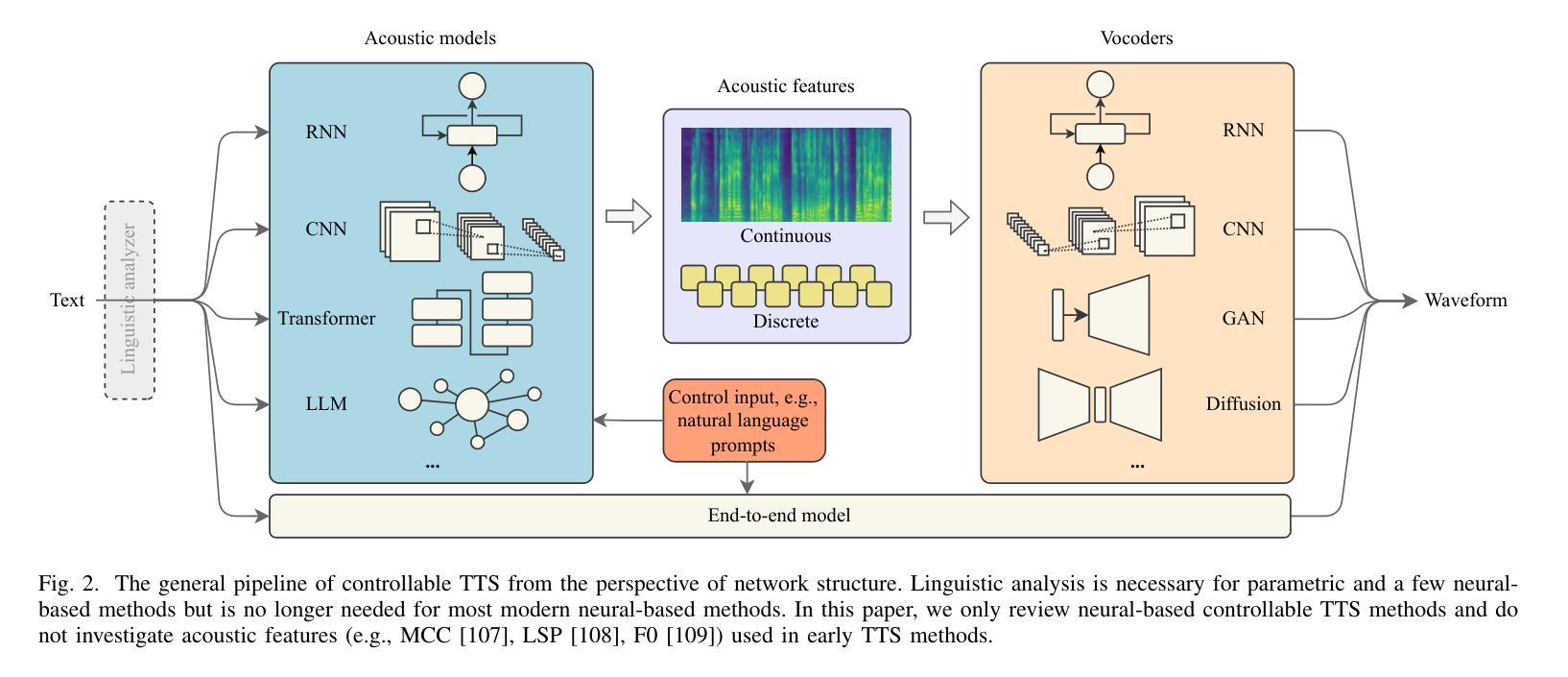
Towards Controllable Speech Synthesis in the Era of Large Language Models: A Survey
Authors:Tianxin Xie, Yan Rong, Pengfei Zhang, Li Liu
Text-to-speech (TTS), also known as speech synthesis, is a prominent research area that aims to generate natural-sounding human speech from text. Recently, with the increasing industrial demand, TTS technologies have evolved beyond synthesizing human-like speech to enabling controllable speech generation. This includes fine-grained control over various attributes of synthesized speech such as emotion, prosody, timbre, and duration. Besides, advancements in deep learning, such as diffusion and large language models, have significantly enhanced controllable TTS over the past several years. In this paper, we conduct a comprehensive survey of controllable TTS, covering approaches ranging from basic control techniques to methods utilizing natural language prompts, aiming to provide a clear understanding of the current state of research. We examine the general controllable TTS pipeline, challenges, model architectures, and control strategies, offering a comprehensive and clear taxonomy of existing methods. Additionally, we provide a detailed summary of datasets and evaluation metrics and shed some light on the applications and future directions of controllable TTS. To the best of our knowledge, this survey paper provides the first comprehensive review of emerging controllable TTS methods, which can serve as a beneficial resource for both academic researchers and industry practitioners.
文本转语音(TTS),也被称为语音合成,是一个旨在从文本生成自然声音的人类语音的重要研究领域。最近,随着工业需求的增加,TTS技术已经超越了合成类似人类的语音,发展到了能够实现可控的语音生成。这包括合成语音的各种属性的精细控制,如情感、语调、音质和持续时间。此外,深度学习中的扩散和大型语言模型等技术的进步,在过去的几年里极大地增强了可控TTS的性能。在本文中,我们对可控TTS进行了全面的调查,涵盖了从基本控制技术到利用自然语言提示的方法等多种方法,旨在提供对研究现状的清晰理解。我们考察了可控TTS的一般流程、挑战、模型架构和控制策略,对现有方法进行了全面清晰的分类。此外,我们还详细总结了数据集和评价指标,并对可控TTS的应用和未来发展方向进行了一些探讨。据我们所知,这篇综述论文提供了对新兴的可控TTS方法的首次全面回顾,对学术研究人员和行业从业者都有很大的参考价值。
论文及项目相关链接
PDF A comprehensive survey on controllable TTS, 23 pages, 6 tables, 4 figures, 280 references
Summary
本文主要介绍了文本转语音(TTS)技术,并详细介绍了可控TTS的当前研究状态。随着工业需求的增加,TTS技术已经超越了仅合成人类语音的阶段,现在能够实现可控的语音生成,包括精细控制合成语音的各种属性,如情感、语调、音质和持续时间。文章还探讨了深度学习的进步如何极大地推动了可控TTS的发展。此外,本文提供了对可控TTS方法、挑战、模型架构和控制策略的详细分类,并对数据集和评估指标进行了概述,同时还介绍了可控TTS的应用和未来发展方向。
Key Takeaways
- TTS(文本转语音)技术旨在从文本生成自然流畅的人类语音。
- 可控TTS技术允许对合成语音的各种属性进行精细控制,如情感、语调、音质和持续时间。
- 深度学习的进步,如扩散和大型语言模型,已经大大增强了可控TTS的性能。
- 本文提供了对可控TTS的当前研究状态的全面综述。
- 文章详细讨论了可控TTS的方法、挑战、模型架构和控制策略。
- 综述涵盖了数据集和评估指标的概述。
- 文章还探讨了可控TTS的应用和未来发展方向。
点此查看论文截图

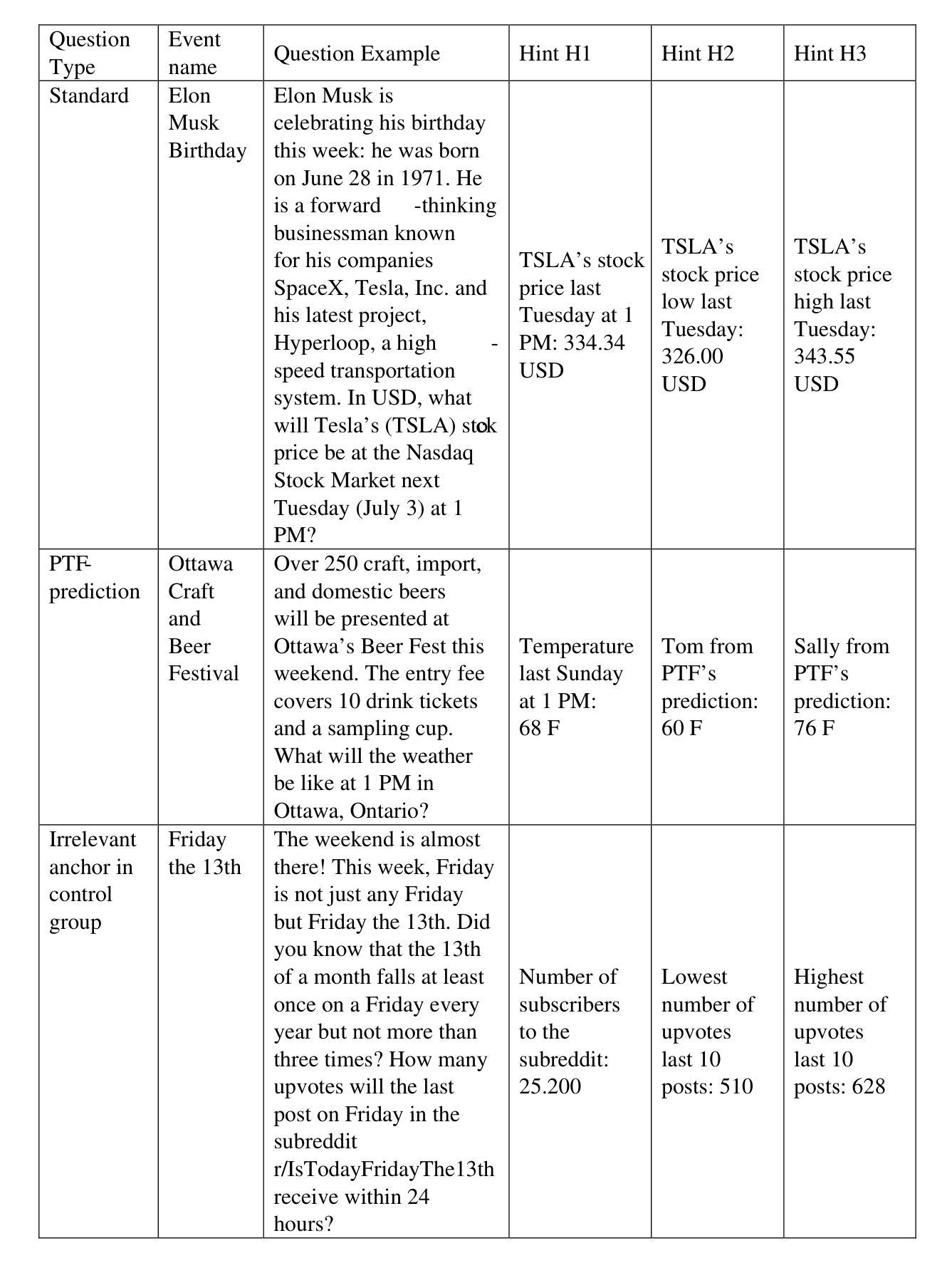
Anchoring Bias in Large Language Models: An Experimental Study
Authors:Jiaxu Lou
Large Language Models (LLMs) like GPT-4 and Gemini have significantly advanced artificial intelligence by enabling machines to generate and comprehend human-like text. Despite their impressive capabilities, LLMs are not immune to limitations, including various biases. While much research has explored demographic biases, the cognitive biases in LLMs have not been equally scrutinized. This study delves into anchoring bias, a cognitive bias where initial information disproportionately influences judgment. Utilizing an experimental dataset, we examine how anchoring bias manifests in LLMs and verify the effectiveness of various mitigation strategies. Our findings highlight the sensitivity of LLM responses to biased hints. At the same time, our experiments show that, to mitigate anchoring bias, one needs to collect hints from comprehensive angles to prevent the LLMs from being anchored to individual pieces of information, while simple algorithms such as Chain-of-Thought, Thoughts of Principles, Ignoring Anchor Hints, and Reflection are not sufficient.
大型语言模型(LLM),如GPT-4和双子座,通过使机器能够生成和理解类似人类的文本,从而显著地推动了人工智能的发展。尽管它们具有令人印象深刻的能力,但LLM并非不受限制,其中包括各种偏见。虽然许多研究已经探讨了人口偏见,但LLM中的认知偏见尚未受到同等审视。本研究深入探讨了锚定偏见,这是一种认知偏见,初始信息会不成比例地影响判断。我们利用实验数据集,研究LLM中锚定偏见的表现,并验证各种缓解策略的有效性。我们的研究结果表明,LLM响应对偏见线索非常敏感。同时,我们的实验表明,为了缓解锚定偏见,需要从综合角度收集线索,防止LLM局限于个别信息,而简单的算法如思维链、原则思考、忽略锚点提示和反思等并不足以应对。
论文及项目相关链接
Summary
本文研究了大型语言模型(LLM)如GPT-4和Gemini中存在的认知偏差,特别是锚定偏差。实验证明,初始信息会过度影响LLM的判断。研究还探讨了缓解锚定偏差的策略,发现需要从多角度收集提示信息来防止LLM被单一信息所引导,简单的算法如思维链、原则思考、忽略锚定提示和反思等并不足够有效。
Key Takeaways
- 大型语言模型(LLM)在生成和理解人类文本方面展现出显著的能力,但它们并非没有局限,包括各种偏见。
- 锚定偏见是认知偏见的一种,即初始信息会不成比例地影响判断,在LLM中同样存在。
- LLM对带偏见的提示非常敏感,其回应会被这些提示所影响。
- 为了缓解锚定偏见,需要从多个角度收集提示信息。
- 简单的算法如思维链、原则思考、忽略锚定提示和反思并不能有效缓解锚定偏见。
- LLM需要更全面的训练数据以减少偏见,提高决策的公正性和准确性。
点此查看论文截图

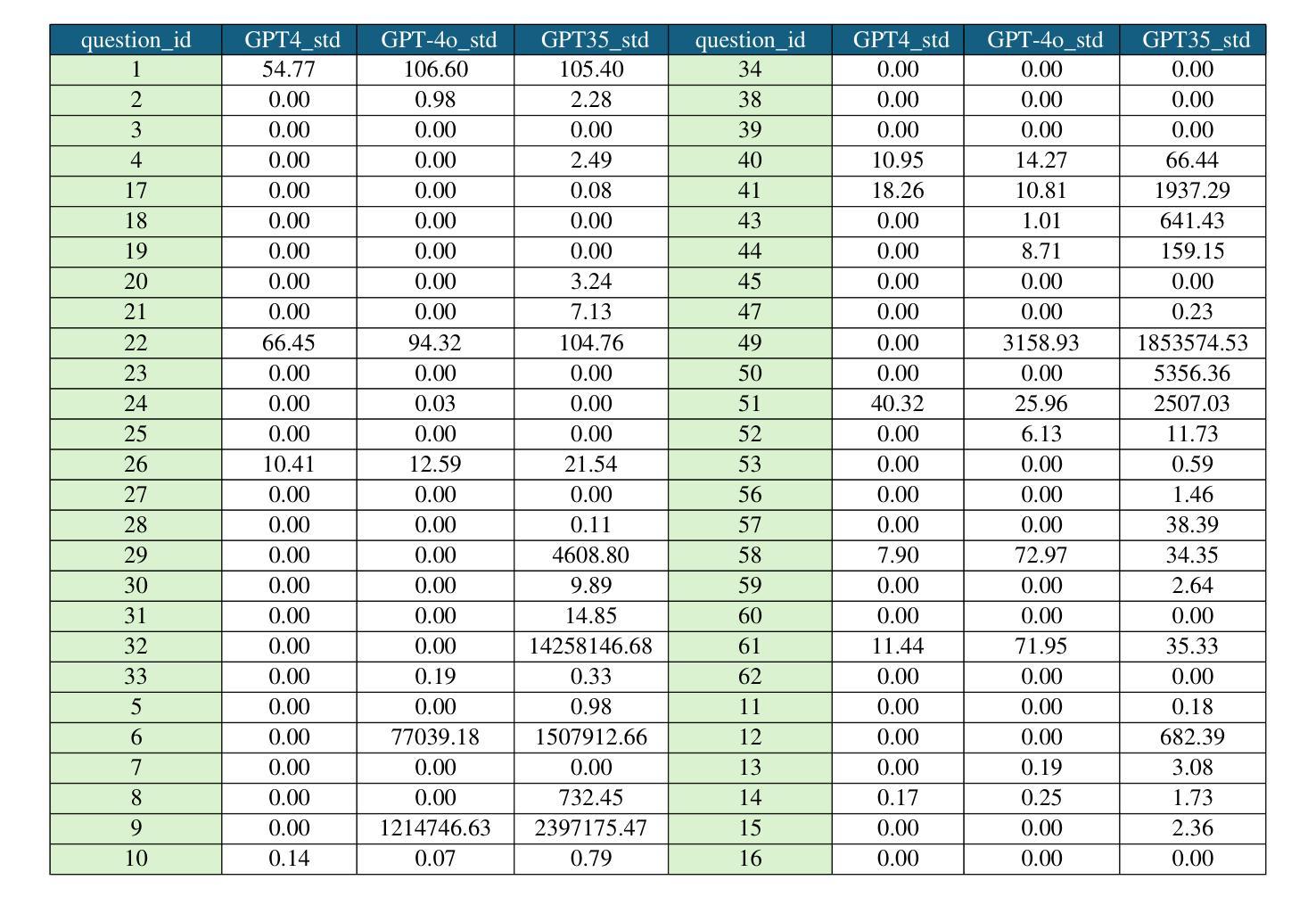

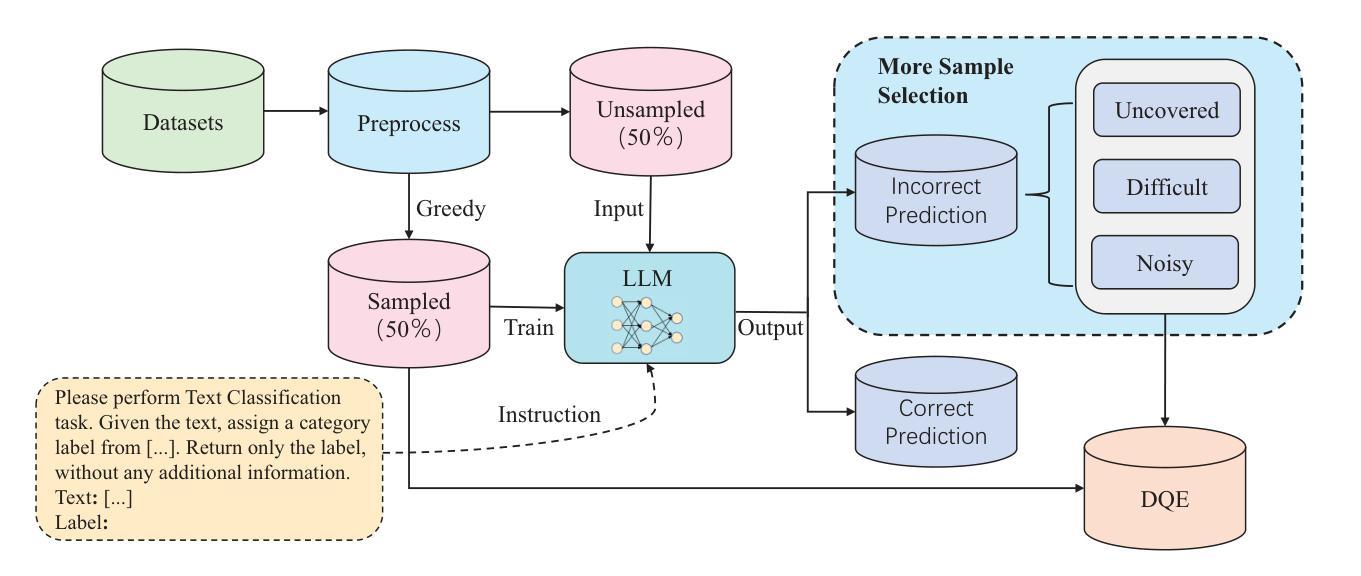
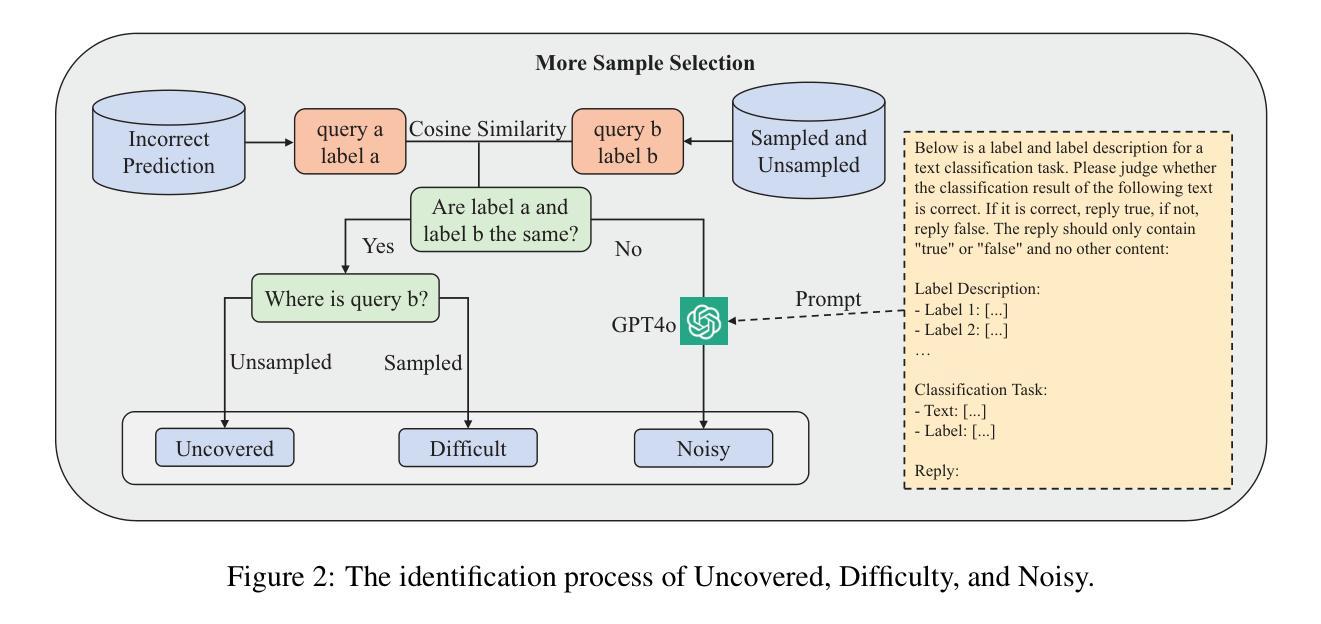
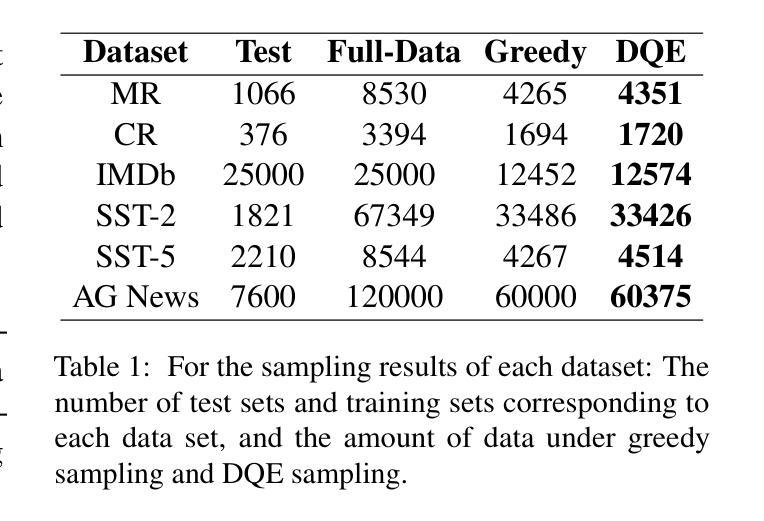
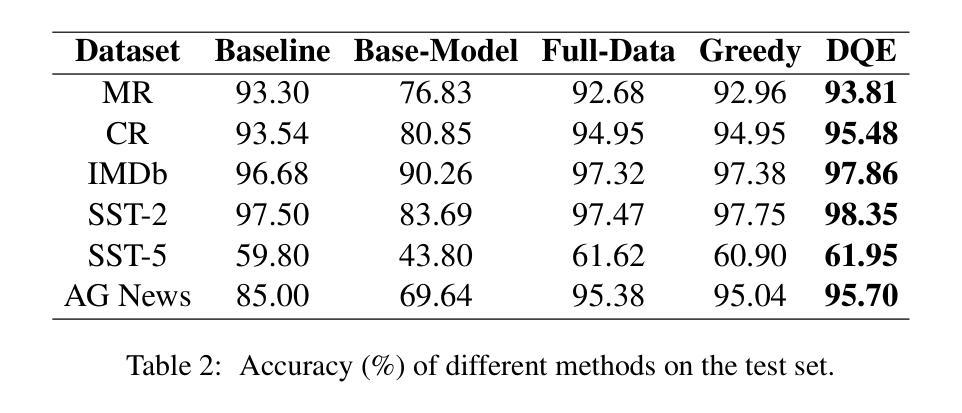
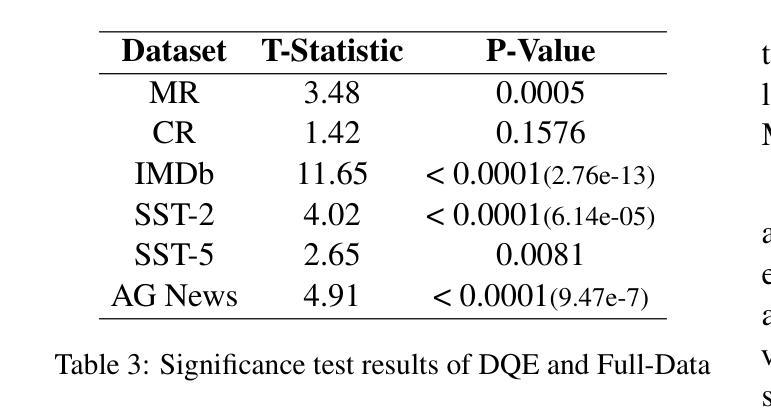
Data Quality Enhancement on the Basis of Diversity with Large Language Models for Text Classification: Uncovered, Difficult, and Noisy
Authors:Min Zeng, Caiquan Liu, Shiqi Zhang, Li Xie, Chen Sang, Xiaoxin Chen, Xiaoxin Chen
In recent years, the use of large language models (LLMs) for text classification has attracted widespread attention. Despite this, the classification accuracy of LLMs has not yet universally surpassed that of smaller models. LLMs can enhance their performance in text classification through fine-tuning. However, existing data quality research based on LLMs is challenging to apply directly to solve text classification problems. To further improve the performance of LLMs in classification tasks, this paper proposes a data quality enhancement (DQE) method for text classification based on LLMs. This method starts by using a greedy algorithm to select data, dividing the dataset into sampled and unsampled subsets, and then performing fine-tuning of the LLMs using the sampled data. Subsequently, this model is used to predict the outcomes for the unsampled data, categorizing incorrectly predicted data into uncovered, difficult, and noisy data. Experimental results demonstrate that our method effectively enhances the performance of LLMs in text classification tasks and significantly improves training efficiency, saving nearly half of the training time. Our method has achieved state-of-the-art performance in several open-source classification tasks.
近年来,大型语言模型(LLM)在文本分类中的应用引起了广泛关注。尽管如此,LLM的分类精度尚未普遍超过小型模型。LLM可以通过微调提高其文本分类性能。然而,基于LLM的现有数据质量研究在直接应用于解决文本分类问题时具有挑战性。为了进一步提高LLM在分类任务中的性能,本文提出了一种基于LLM的文本分类数据质量增强(DQE)方法。该方法首先使用贪心算法选择数据,将数据集分为采样和未采样子集,然后使用采样数据对LLM进行微调。随后,使用该模型对未采样数据进行结果预测,将预测错误的数据分类为未覆盖、难以处理和有噪音的数据。实验结果表明,我们的方法有效地提高了LLM在文本分类任务中的性能,并显著提高了训练效率,节省了近一半的训练时间。我们的方法在多个开源分类任务中达到了最先进的性能。
论文及项目相关链接
PDF Accepted by COLING 2025(main, long paper)
Summary
大型语言模型(LLM)在文本分类中的应用近年来备受关注。虽然其分类精度尚未全面超越小型模型,但通过微调可以增强其在文本分类中的性能。然而,将现有的基于LLM的数据质量研究直接应用于解决文本分类问题是具有挑战性的。本文提出了一种基于LLM的文本分类数据质量增强(DQE)方法。该方法使用贪心算法选择数据,将数据集分为采样和未采样子集,并使用采样数据进行LLM微调。然后,使用该模型对未采样数据进行预测,将预测错误的数据分类为未覆盖、难以处理和噪声数据。实验结果表明,该方法有效提高LLM在文本分类任务中的性能,并显著提高训练效率,节省近一半的训练时间。该方法在多个开源分类任务中达到最新性能水平。
Key Takeaways
- 大型语言模型(LLM)在文本分类中的应用受到广泛关注。
- LLM的分类精度尚未全面超越小型模型,但可以通过微调增强性能。
- 直接将现有的基于LLM的数据质量研究应用于文本分类具有挑战性。
- 本文提出了一种基于LLM的文本分类数据质量增强(DQE)方法。
- 该方法使用贪心算法选择数据,并将数据集分为采样和未采样子集。
- 通过使用采样数据进行LLM微调,并预测未采样数据的结果,将错误数据分类为未覆盖、难以处理和噪声数据。
点此查看论文截图

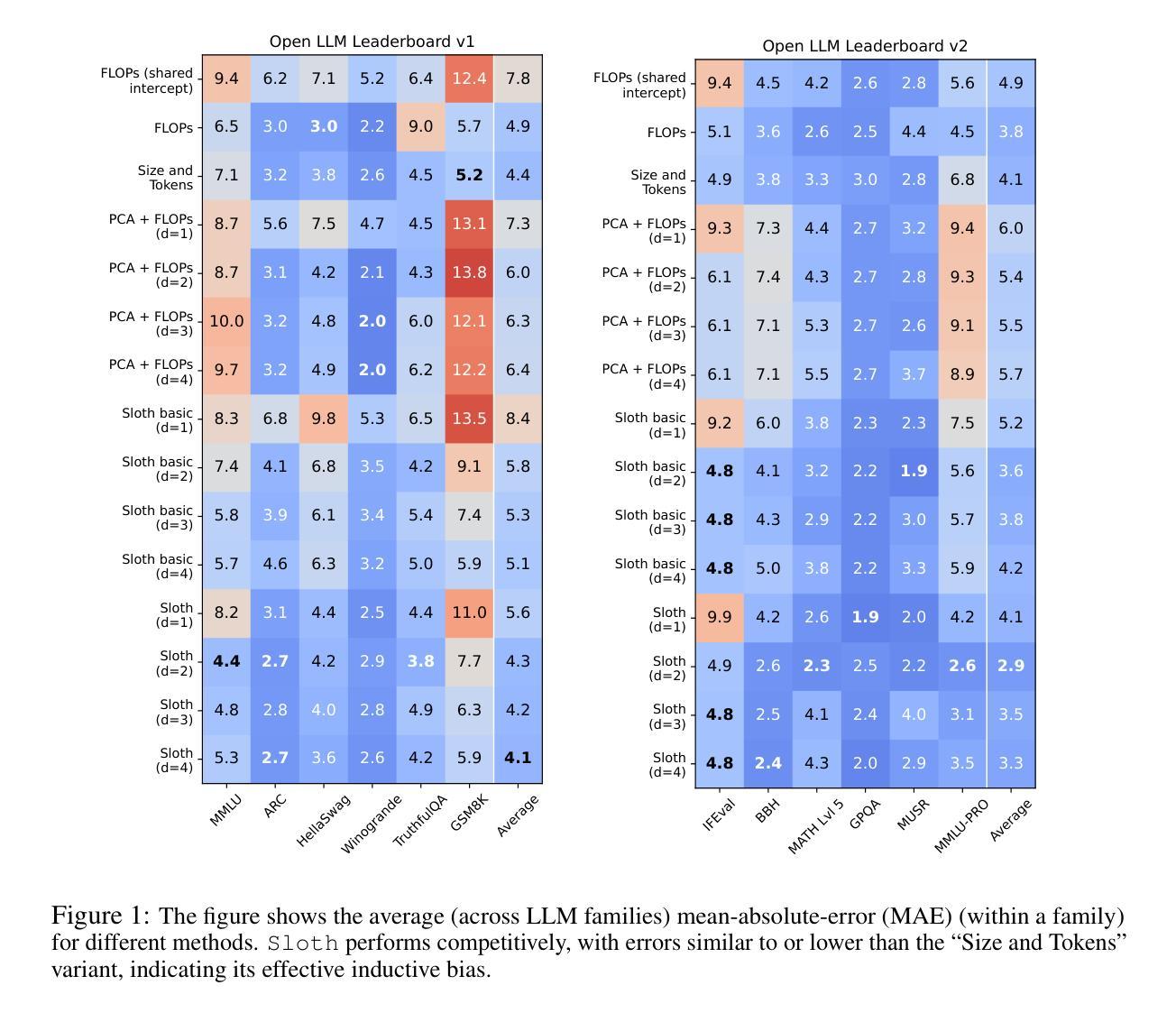
Sloth: scaling laws for LLM skills to predict multi-benchmark performance across families
Authors:Felipe Maia Polo, Seamus Somerstep, Leshem Choshen, Yuekai Sun, Mikhail Yurochkin
Scaling laws for large language models (LLMs) predict model performance based on parameters like size and training data. However, differences in training configurations and data processing across model families lead to significant variations in benchmark performance, making it difficult for a single scaling law to generalize across all LLMs. On the other hand, training family-specific scaling laws requires training models of varying sizes for every family. In this work, we propose Skills Scaling Laws (SSLaws, pronounced as Sloth), a novel scaling law that leverages publicly available benchmark data and assumes LLM performance is driven by low-dimensional latent skills, such as reasoning and instruction following. These latent skills are influenced by computational resources like model size and training tokens but with varying efficiencies across model families. Sloth exploits correlations across benchmarks to provide more accurate and interpretable predictions while alleviating the need to train multiple LLMs per family. We present both theoretical results on parameter identification and empirical evaluations on 12 prominent benchmarks, from Open LLM Leaderboard v1/v2, demonstrating that Sloth predicts LLM performance efficiently and offers insights into scaling behaviors for downstream tasks such as coding and emotional intelligence applications.
大规模语言模型(LLM)的缩放定律基于规模、训练数据等参数预测模型性能。然而,不同模型家族在训练配置和数据处理方面的差异导致基准测试性能存在重大差异,使得单一的缩放定律难以推广到所有LLM。另一方面,针对特定家族的缩放定律需要为每个家族训练不同大小模型。在此工作中,我们提出了技能缩放定律(SSLaws,发音为Sloth),这是一种新型缩放定律,它利用公开可用的基准测试数据,并假设LLM的性能是由低维潜在技能驱动的,如推理和指令遵循。这些潜在技能受到计算资源的影响,如模型大小和训练令牌,但在不同模型家族中的效率有所不同。Sloth利用基准测试之间的相关性,提供更准确和可解释性的预测,同时减轻每个家族需要训练多个LLM的需求。我们提供了关于参数识别的理论结果以及在Open LLM Leaderboard v1/v2的12个基准测试上的实证评估,证明Sloth能够高效预测LLM性能,并为下游任务(如编码和情感智能应用程序)的缩放行为提供见解。
论文及项目相关链接
Summary
大型语言模型(LLM)的缩放定律基于参数、规模和训练数据来预测模型性能。然而,不同模型家族在训练配置和数据处理方面的差异导致基准测试性能存在重大变化,使得单一的缩放定律难以推广应用到所有LLM。本文提出技能缩放定律(SSLaws,发音为Sloth),利用公开可用的基准测试数据,假设LLM性能是由低维潜在技能(如推理和指令遵循)驱动的。这些潜在技能受到模型大小和训练令牌等计算资源的影响,但在不同的模型家族中具有不同的效率。Sloth利用基准测试之间的相关性,提供更准确和可解释性的预测,同时减轻了对每个家族训练多个LLM的需求。本文给出了参数识别的理论结果以及在Open LLM Leaderboard v1/v2的12个突出基准测试上的实证评估,表明Sloth能够高效预测LLM性能,并为下游任务(如编码和情绪智能应用程序)的缩放行为提供见解。
Key Takeaways
- LLM性能受到参数、规模和训练数据的影响,但单一缩放定律难以适用于所有LLM。
- SSLaws(Sloth)是一种新型缩放定律,利用公开基准数据,侧重于低维潜在技能来预测LLM性能。
- 潜在技能受模型大小和训练令牌等计算资源影响,但不同模型家族的效率存在差异。
- Sloth能够准确预测LLM性能,而无需针对每个家族训练多个模型。
- Sloth提供对下游任务缩放行为的见解,如编码和情绪智能应用。
- 文章通过理论分析和在12个基准测试上的实证评估,证实了Sloth的有效性。
点此查看论文截图

Integrating Expert Labels into LLM-based Emission Goal Detection: Example Selection vs Automatic Prompt Design
Authors:Marco Wrzalik, Adrian Ulges, Anne Uersfeld, Florian Faust
We address the detection of emission reduction goals in corporate reports, an important task for monitoring companies’ progress in addressing climate change. Specifically, we focus on the issue of integrating expert feedback in the form of labeled example passages into LLM-based pipelines, and compare the two strategies of (1) a dynamic selection of few-shot examples and (2) the automatic optimization of the prompt by the LLM itself. Our findings on a public dataset of 769 climate-related passages from real-world business reports indicate that automatic prompt optimization is the superior approach, while combining both methods provides only limited benefit. Qualitative results indicate that optimized prompts do indeed capture many intricacies of the targeted emission goal extraction task.
我们关注企业报告中减排目标检测的问题,这是监测公司应对气候变化进展的重要任务。具体来说,我们专注于将专家反馈以标注段落的形式融入LLM管道的问题,并比较了两种策略:(1)动态选择少数样本示例和(2)由LLM本身自动优化提示。我们在包含现实世界商业报告中与气候相关的769个公开数据集上的研究结果表明,自动提示优化是更优越的方法,而结合两种方法只提供有限的益处。定性结果表明,优化后的提示确实捕捉到了针对排放目标提取任务的许多细节。
论文及项目相关链接
摘要
文本专注于将专家反馈以标注段落的形式融入LLM管道的问题,并比较了两种策略:(1)动态选择少量示例;(2)LLM本身的自动提示优化。在包含真实商业报告中关于气候相关的769个段落的公开数据集上进行的实验表明,自动提示优化是更好的方法,而结合两种方法则只能提供有限的收益。定性结果表明,优化的提示确实捕捉到了针对排放目标提取任务的许多细节。
关键见解
- 针对企业报告中排放减少目标的检测进行研究,这是监测公司在应对气候变化方面进展的重要任务。
- 研究聚焦于如何将专家反馈以标注段落的形式融入LLM管道的问题。
- 提出两种策略进行比较:动态选择少量示例和LLM自动提示优化。
- 在包含真实商业报告中关于气候相关的段落的数据集上进行实验,发现自动提示优化是更好的策略。
- 结合两种策略的效果有限,暗示在特定任务中,简单的自动提示优化已足够有效。
点此查看论文截图

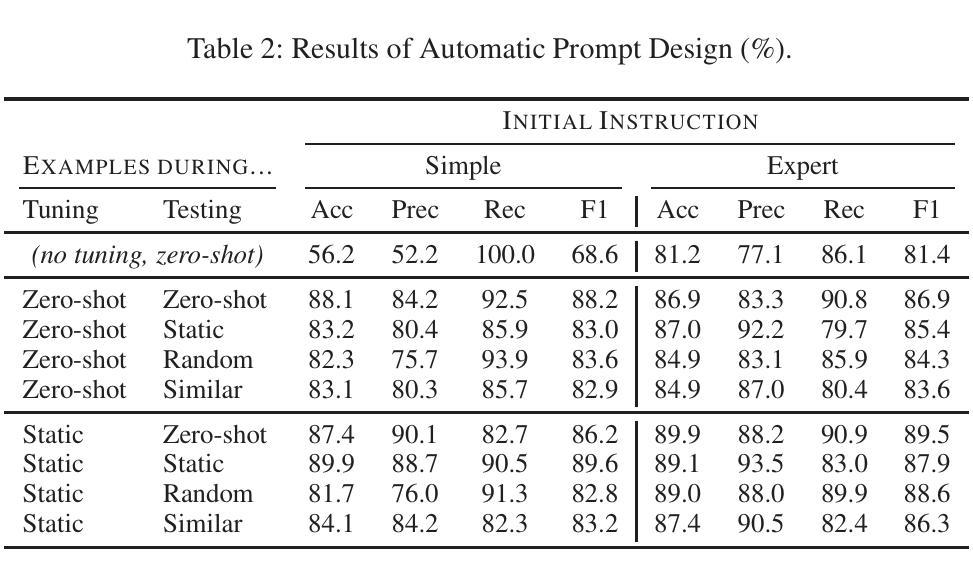
GameArena: Evaluating LLM Reasoning through Live Computer Games
Authors:Lanxiang Hu, Qiyu Li, Anze Xie, Nan Jiang, Ion Stoica, Haojian Jin, Hao Zhang
Evaluating the reasoning abilities of large language models (LLMs) is challenging. Existing benchmarks often depend on static datasets, which are vulnerable to data contamination and may get saturated over time, or on binary live human feedback that conflates reasoning with other abilities. As the most prominent dynamic benchmark, Chatbot Arena evaluates open-ended questions in real-world settings, but lacks the granularity in assessing specific reasoning capabilities. We introduce GameArena, a dynamic benchmark designed to evaluate LLM reasoning capabilities through interactive gameplay with humans. GameArena consists of three games designed to test specific reasoning capabilities (e.g., deductive and inductive reasoning), while keeping participants entertained and engaged. We analyze the gaming data retrospectively to uncover the underlying reasoning processes of LLMs and measure their fine-grained reasoning capabilities. We collect over 2000 game sessions and provide detailed assessments of various reasoning capabilities for five state-of-the-art LLMs. Our user study with 100 participants suggests that GameArena improves user engagement compared to Chatbot Arena. For the first time, GameArena enables the collection of step-by-step LLM reasoning data in the wild.
评估大型语言模型(LLM)的推理能力是一项具有挑战性的任务。现有的基准测试通常依赖于静态数据集,这些数据集容易受到数据污染,并可能随时间而趋于饱和,或者依赖于二进制的实时人类反馈,这会将推理与其他能力混淆。作为最突出的动态基准测试,Chatbot Arena评估现实世界环境中的开放式问题,但在评估特定推理能力方面缺乏精细度。我们引入了GameArena,这是一个动态基准测试,旨在通过与人类的游戏互动来评估LLM的推理能力。GameArena由三款游戏组成,旨在测试特定的推理能力(如演绎推理和归纳推理),同时保持参与者的娱乐性和参与度。我们进行回顾性分析,以揭示LLM的潜在推理过程,并衡量其精细的推理能力。我们收集了超过2” />数千场游戏会话记录,并为五种最前沿的LLM提供了各种推理能力的详细评估报告。我们的涉及一百名参与者的用户研究表明,与Chatbot Arena相比,GameArena提高了用户参与度。GameArena首次实现了在野外收集逐步的LLM推理数据。
论文及项目相关链接
Summary
大型语言模型(LLM)的推理能力评估具有挑战性。现有评估方法依赖于易污染且可能随时间饱和的静态数据集,或混淆推理与其他能力的二元实时人类反馈。GameArena是一个动态评估工具,通过人与LLM的交互游戏来评估其推理能力。它包括三款游戏,旨在测试特定的推理能力(如演绎和归纳推理),同时保持参与者的娱乐性和参与度。我们分析游戏数据,以发现LLM的推理过程并衡量其精细推理能力。
Key Takeaways
- 大型语言模型(LLM)的推理能力评估存在挑战,因为现有评估方法存在缺陷。
- GameArena是一个动态评估工具,通过人与LLM的交互游戏来评估其推理能力,包括演绎和归纳推理等。
- GameArena包含三款旨在测试特定推理能力的游戏,同时保持用户的娱乐性和参与度。
- 通过分析游戏数据,可以揭示LLM的推理过程并衡量其精细推理能力。
- GameArena收集了超过2000个游戏会话,并对五种最先进的大型语言模型的各项推理能力进行了详细评估。
- 与Chatbot Arena相比,GameArena能提高用户参与度。
点此查看论文截图


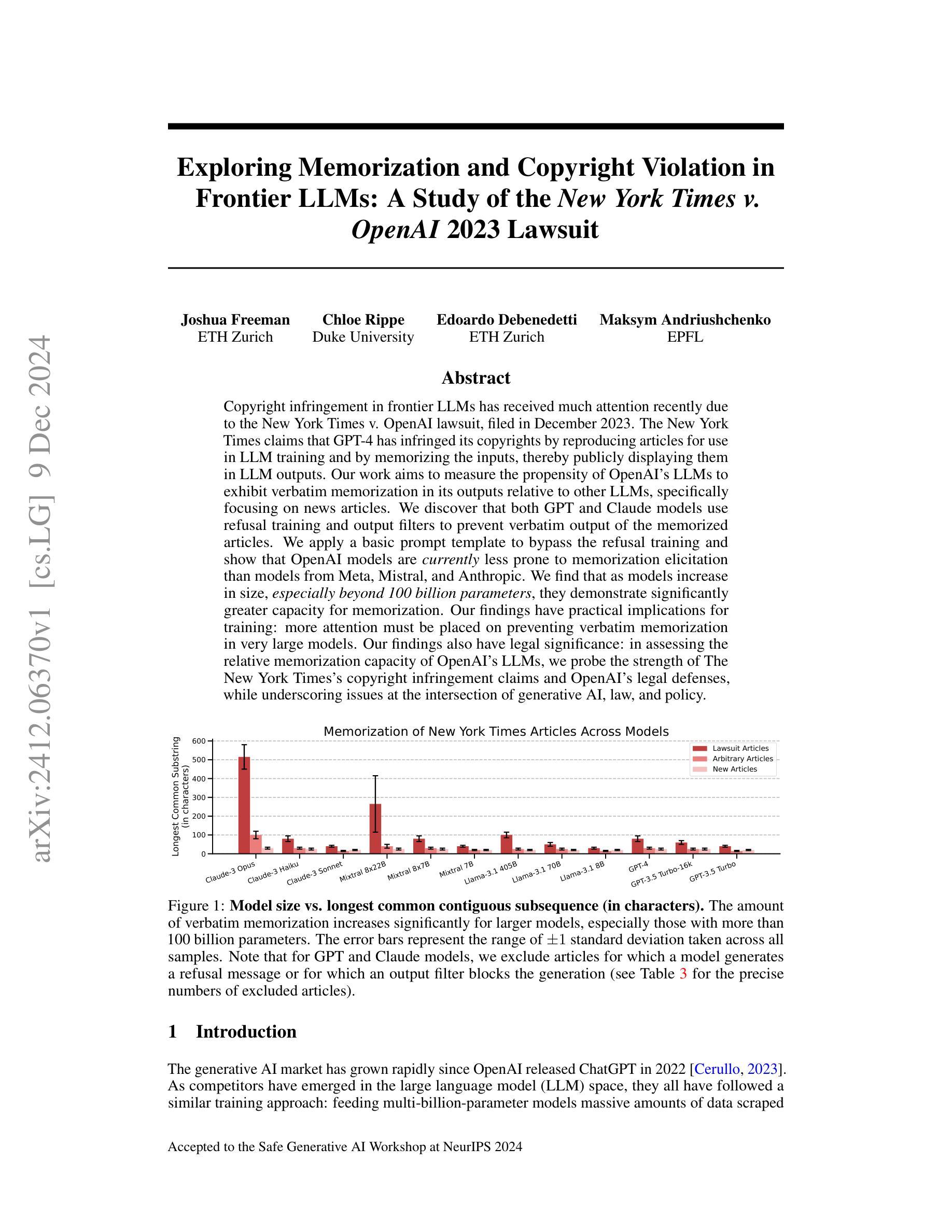
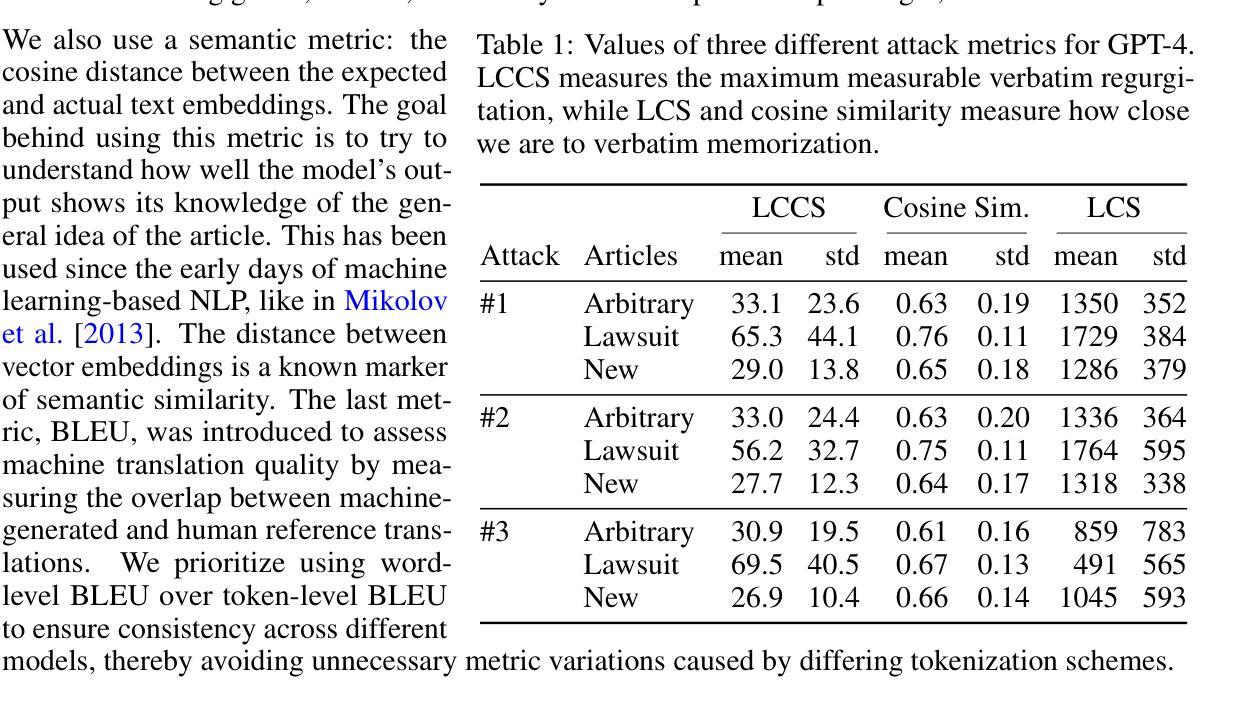
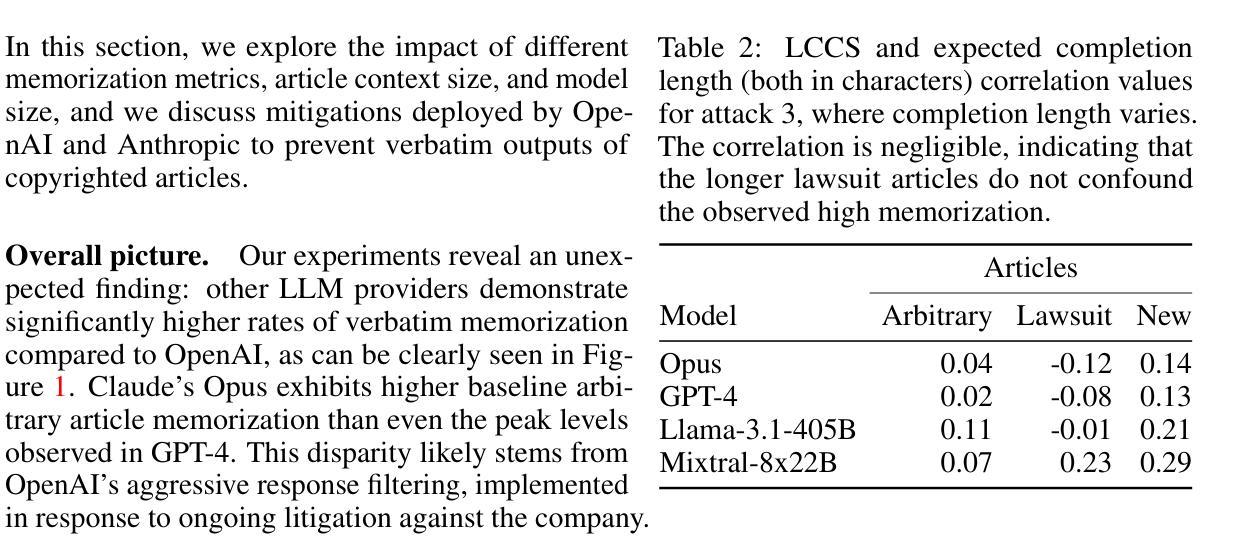
Exploring Memorization and Copyright Violation in Frontier LLMs: A Study of the New York Times v. OpenAI 2023 Lawsuit
Authors:Joshua Freeman, Chloe Rippe, Edoardo Debenedetti, Maksym Andriushchenko
Copyright infringement in frontier LLMs has received much attention recently due to the New York Times v. OpenAI lawsuit, filed in December 2023. The New York Times claims that GPT-4 has infringed its copyrights by reproducing articles for use in LLM training and by memorizing the inputs, thereby publicly displaying them in LLM outputs. Our work aims to measure the propensity of OpenAI’s LLMs to exhibit verbatim memorization in its outputs relative to other LLMs, specifically focusing on news articles. We discover that both GPT and Claude models use refusal training and output filters to prevent verbatim output of the memorized articles. We apply a basic prompt template to bypass the refusal training and show that OpenAI models are currently less prone to memorization elicitation than models from Meta, Mistral, and Anthropic. We find that as models increase in size, especially beyond 100 billion parameters, they demonstrate significantly greater capacity for memorization. Our findings have practical implications for training: more attention must be placed on preventing verbatim memorization in very large models. Our findings also have legal significance: in assessing the relative memorization capacity of OpenAI’s LLMs, we probe the strength of The New York Times’s copyright infringement claims and OpenAI’s legal defenses, while underscoring issues at the intersection of generative AI, law, and policy.
近期,由于《纽约时报诉OpenAI案》的诉讼,前沿大型语言模型(LLM)的版权侵权问题备受关注。该诉讼于2023年12月提起。《纽约时报》声称GPT-4侵犯了其版权,通过复制文章用于LLM训练,并记住了输入内容,从而在LLM输出中公开显示它们。我们的工作旨在衡量OpenAI的LLM相对于其他LLM,特别是在新闻文章方面,在其输出中展现逐字记忆的倾向性。我们发现GPT和Claude模型都使用拒绝训练和输出过滤器来防止对记忆文章的逐字输出。我们应用了一个基本提示模板来绕过拒绝训练,并表明目前OpenAI模型在记忆激发方面相对于Meta、Mistral和Anthropic的模型不那么容易受到影响。我们发现,随着模型规模的增加,尤其是超过100亿参数后,它们表现出更大的记忆能力。我们的研究结果对训练具有实际意义:在非常大的模型中,必须更多地关注防止逐字记忆。我们的研究结果也具有法律意义:在评估OpenAI的LLM的相对记忆能力时,我们探究了《纽约时报》版权侵权指控的强度和OpenAI的法律辩护,同时强调了生成式人工智能、法律和政策之间的交叉问题。
论文及项目相关链接
Summary
本文关注纽约时报诉OpenAI版权侵权案,研究OpenAI的LLM模型(GPT和Claude)在输出中展现原文记忆倾向的程度。研究发现,相较于Meta、Mistral和Anthropic的模型,OpenAI的模型目前更不容易引发记忆唤起。然而,随着模型参数规模的扩大,尤其是超过100亿参数后,其记忆能力显著增强。这一发现对培训和法律评估具有重要意义,提示在训练大型模型时需更多关注防止原文记忆的问题,同时也在评估OpenAI的LLM模型记忆能力时,反映了纽约时报的版权侵权指控和OpenAI的法律防御问题。
Key Takeaways
- 纽约时报对OpenAI的GPT-4提出版权侵权指控,指控其未经授权使用并展示该报的文章内容。
- 研究发现OpenAI的LLM模型(GPT和Claude)采用拒绝训练和输出过滤器来防止直接输出记忆中的文章。
- 通过基本提示模板绕过拒绝训练,发现相较于Meta、Mistral和Anthropic的模型,OpenAI的模型目前更不容易引发记忆唤起。
- 模型参数规模增大后,尤其是超过100亿参数,其记忆能力显著增强。
- 研究结果对训练大型模型具有实际指导意义,需要更多关注防止原文记忆的问题。
- 研究结果对法律评估具有重要意义,反映了版权法和人工智能生成内容的交叉问题。
点此查看论文截图
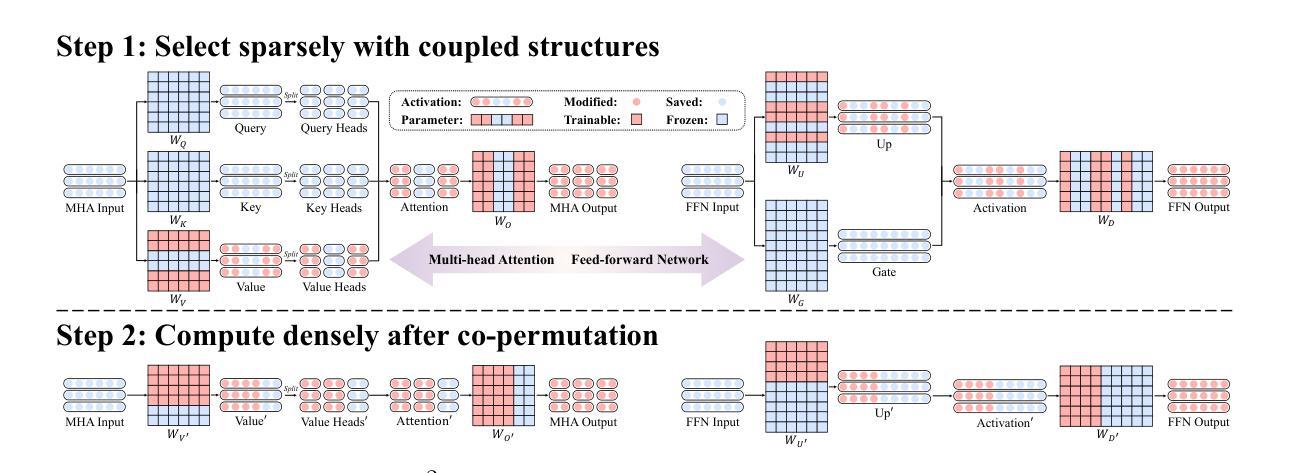
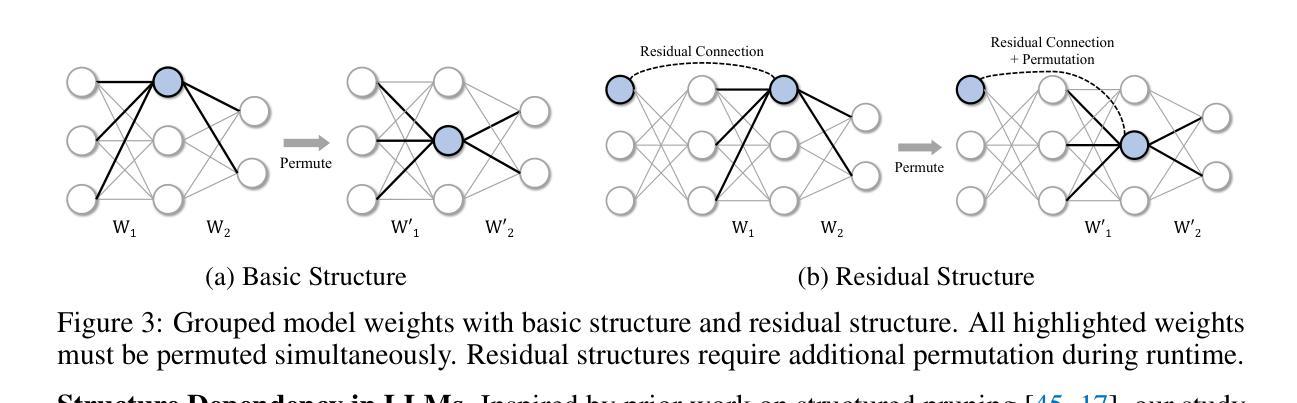
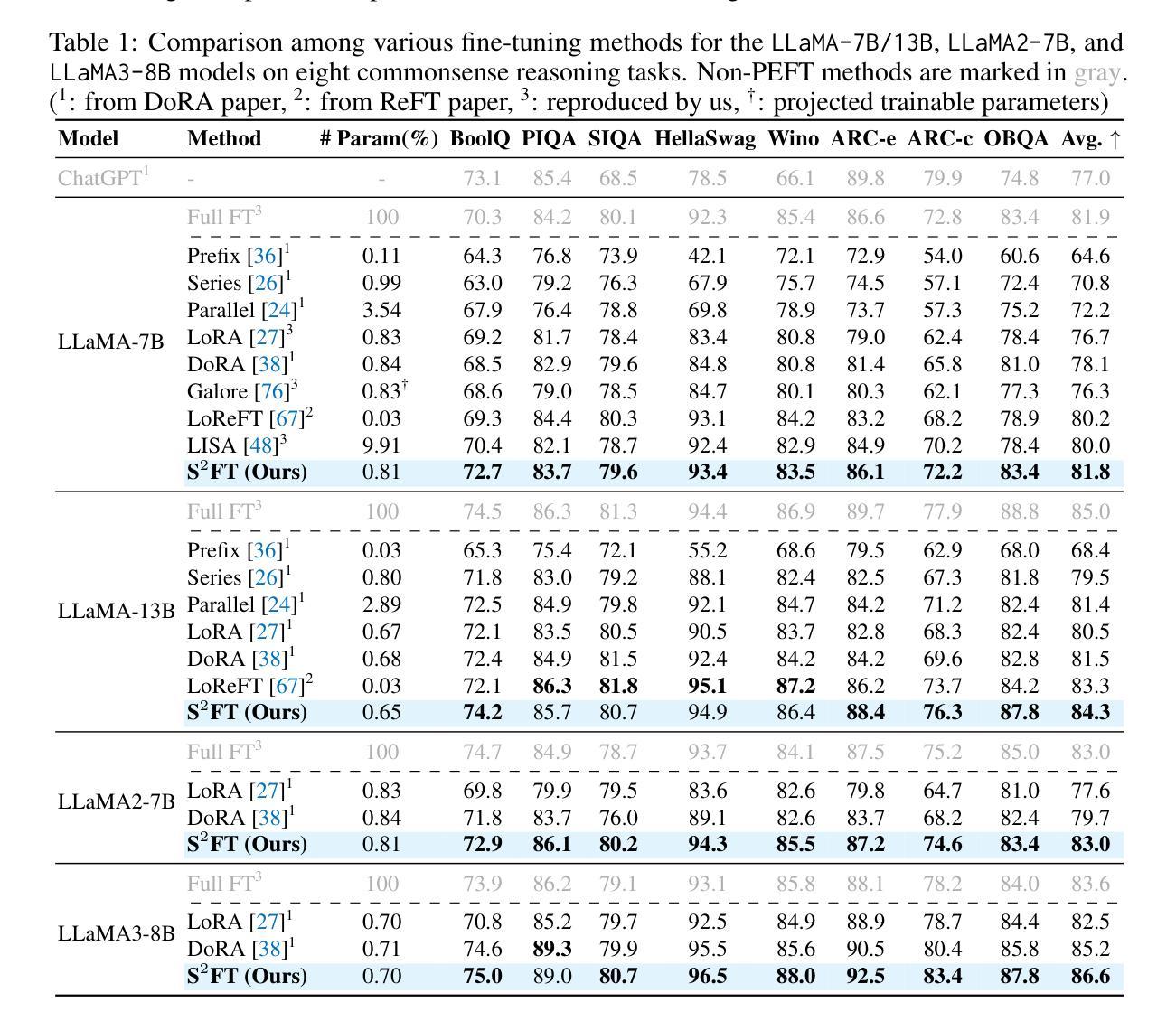
S$^{2}$FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured Sparsity
Authors:Xinyu Yang, Jixuan Leng, Geyang Guo, Jiawei Zhao, Ryumei Nakada, Linjun Zhang, Huaxiu Yao, Beidi Chen
Current PEFT methods for LLMs can achieve either high quality, efficient training, or scalable serving, but not all three simultaneously. To address this limitation, we investigate sparse fine-tuning and observe a remarkable improvement in generalization ability. Utilizing this key insight, we propose a family of Structured Sparse Fine-Tuning (S$^{2}$FT) methods for LLMs, which concurrently achieve state-of-the-art fine-tuning performance, training efficiency, and inference scalability. S$^{2}$FT accomplishes this by “selecting sparsely and computing densely”. It selects a few heads and channels in the MHA and FFN modules for each Transformer block, respectively. Next, it co-permutes weight matrices on both sides of the coupled structures in LLMs to connect the selected components in each layer into a dense submatrix. Finally, S$^{2}$FT performs in-place gradient updates on all submatrices. Through theoretical analysis and empirical results, our method prevents overfitting and forgetting, delivers SOTA performance on both commonsense and arithmetic reasoning with 4.6% and 1.3% average improvements compared to LoRA, and surpasses full FT by 11.5% when generalizing to various domains after instruction tuning. Using our partial backpropagation algorithm, S$^{2}$FT saves training memory up to 3$\times$ and improves latency by 1.5-2.7$\times$ compared to full FT, while delivering an average 10% improvement over LoRA on both metrics. We further demonstrate that the weight updates in S$^{2}$FT can be decoupled into adapters, enabling effective fusion, fast switch, and efficient parallelism for serving multiple fine-tuned models.
当前针对大型语言模型的PEFT方法可以实现高质量、高效训练或可扩展的服务,但无法同时实现这三个目标。为了解决这个问题,我们研究了稀疏微调,并观察到其显著提高了泛化能力。利用这一关键见解,我们提出了一种面向大型语言模型的Structured Sparse Fine-Tuning(S$^{2}$FT)方法系列,该方法同时实现了最先进的微调性能、训练效率和推理可扩展性。S$^{2}$FT通过“稀疏选择、密集计算”来实现这一目标。它分别选择MHA和FFN模块中每个Transformer块的少数头和通道。接下来,它对大型语言模型中耦合结构的两侧权重矩阵进行共置换,以将每层中选择的组件连接成密集子矩阵。最后,S$^{2}$FT对所有子矩阵执行就地梯度更新。通过理论分析和实证结果,我们的方法可以防止过拟合和遗忘,在常识和算术推理方面取得了最先进的性能,与LoRA相比平均提高了4.6%和1.3%,在指令调整后进行跨域泛化时比全量微调高出11.5%。使用我们的部分反向传播算法,S$^{2}$FT可节省高达3倍的培训内存,与全量微调相比提高了1.5-2.7倍的延迟,同时在两个指标上都平均比LoRA提高了10%。我们进一步证明,S$^{2}$FT中的权重更新可以被解耦为适配器,为实现多个微调模型的有效融合、快速切换和高效并行服务提供了可能。
论文及项目相关链接
摘要
本文提出了结构化稀疏微调(S$^{2}$FT)方法,解决了当前大型语言模型(LLM)在微调时面临的高质量、高效训练和可伸缩服务不能同时达成的限制。S$^{2}$FT通过“稀疏选择,密集计算”的策略,实现了在微调性能、训练效率和推理可扩展性上的突破。本文理论分析和实证结果表明,S$^{2}$FT可以防止过拟合和遗忘,在常识和算术推理方面取得了平均4.6%和1.3%的改进。同时,使用部分反向传播算法,S$^{2}$FT在训练内存上节省了高达3倍,延迟时间缩短了1.5-2.7倍,同时在两个指标上平均优于LoRA 10%。此外,S$^{2}$FT的重量更新可以被解耦为适配器,为服务多个微调模型提供了有效的融合、快速切换和高效并行性。
关键见解
- 当前大型语言模型(LLM)的PEFT方法不能同时实现高质量、高效训练和可伸缩服务。
- 提出了结构化稀疏微调(S$^{2}$FT)方法来解决这一问题。
- S$^{2}$FT通过选择MHA和FFN模块中的部分头部和通道进行微调,实现了状态的精细调整性能。
- S$^{2}$FT通过理论分析和实证结果证明了其防止过拟合和遗忘的能力。
- 在常识和算术推理方面,S$^{2}$FT相对于LoRA平均改进了4.6%和1.3%,并且在通用领域指令调整后的不同领域上超越了全量微调(Full FT)11.5%。
- 使用部分反向传播算法,S$^{2}$FT在训练内存上实现了显著的节省,并提高了推理速度。
- S$^{2}$FT的重量更新可以被解耦为适配器,使多个微调模型的融合、切换和并行性更加高效。
点此查看论文截图

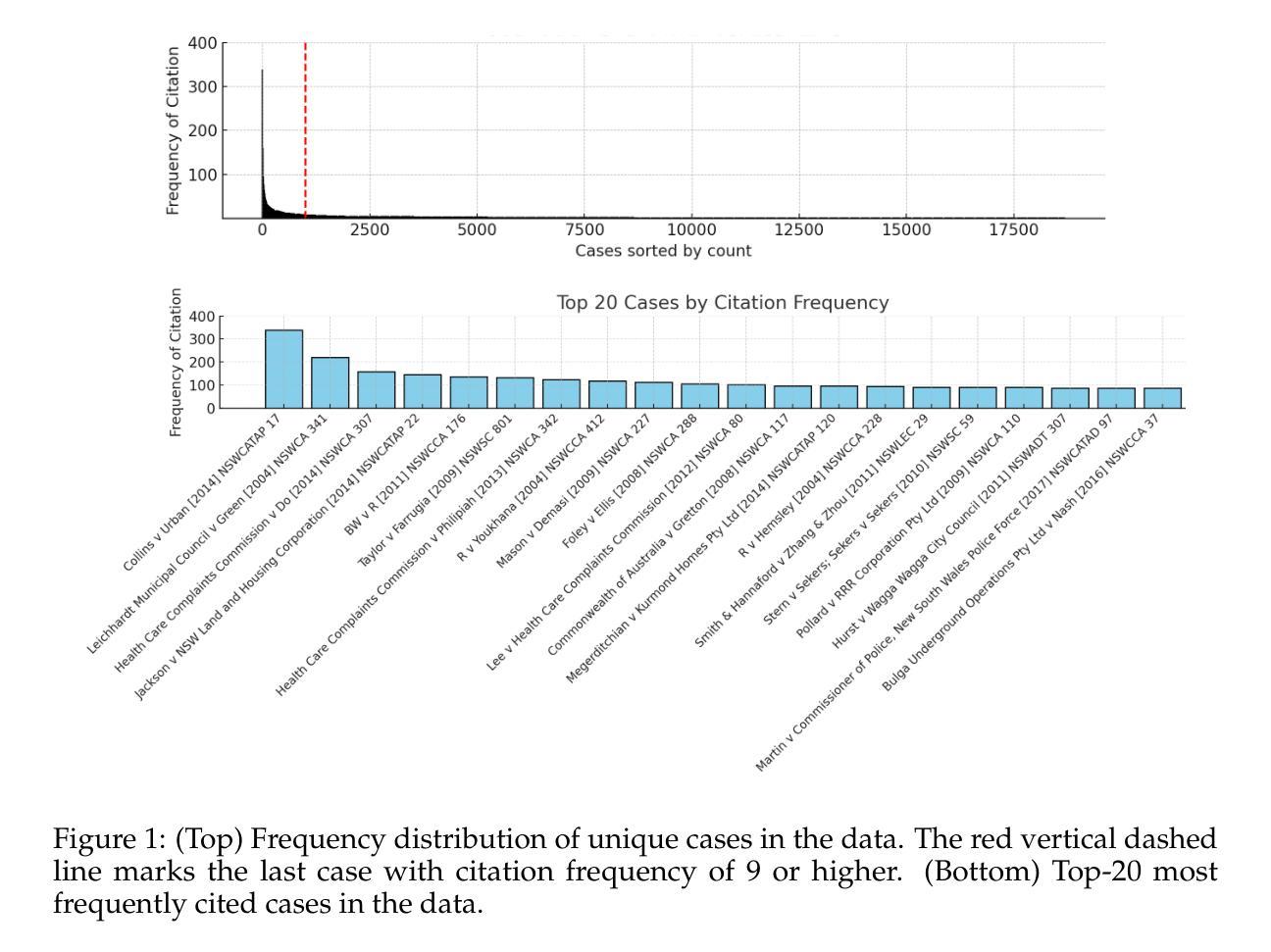
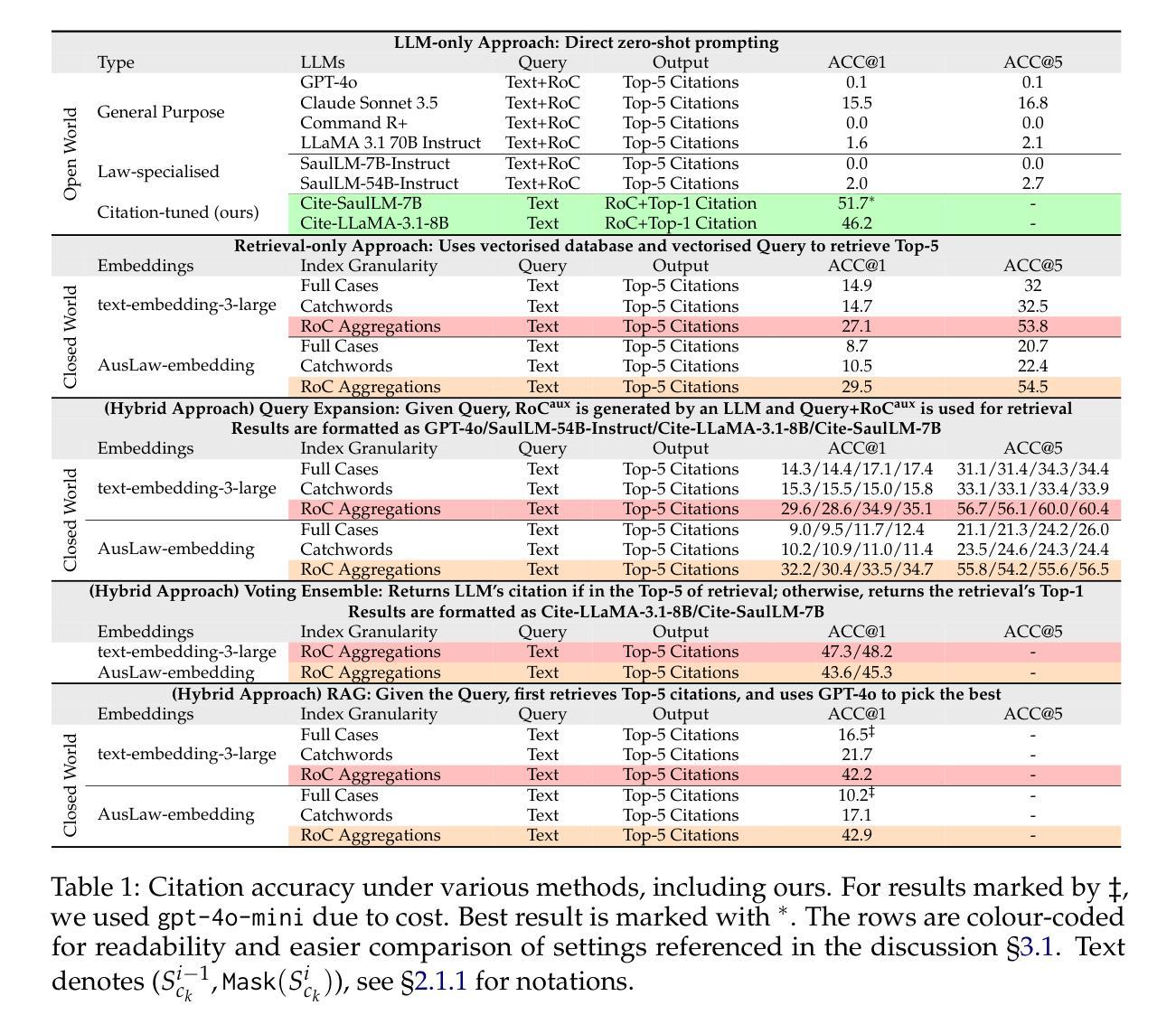
Methods for Legal Citation Prediction in the Age of LLMs: An Australian Law Case Study
Authors:Ehsan Shareghi, Jiuzhou Han, Paul Burgess
In recent years, Large Language Models (LLMs) have shown great potential across a wide range of legal tasks. Despite these advances, mitigating hallucination remains a significant challenge, with state-of-the-art LLMs still frequently generating incorrect legal references. In this paper, we focus on the problem of legal citation prediction within the Australian law context, where correctly identifying and citing relevant legislations or precedents is critical. We compare several approaches: prompting general purpose and law-specialised LLMs, retrieval-only pipelines with both generic and domain-specific embeddings, task-specific instruction-tuning of LLMs, and hybrid strategies that combine LLMs with retrieval augmentation, query expansion, or voting ensembles. Our findings indicate that domain-specific pre-training alone is insufficient for achieving satisfactory citation accuracy even after law-specialised pre-training. In contrast, instruction tuning on our task-specific dataset dramatically boosts performance reaching the best results across all settings. We also highlight that database granularity along with the type of embeddings play a critical role in the performance of retrieval systems. Among retrieval-based approaches, hybrid methods consistently outperform retrieval-only setups, and among these, ensemble voting delivers the best result by combining the predictive quality of instruction-tuned LLMs with the retrieval system.
近年来,大型语言模型(LLM)在广泛的法律任务中显示出巨大潜力。尽管有这些进展,减轻幻觉仍然是一个重大挑战,最先进的LLM仍然经常产生不正确的法律引用。在本文中,我们关注澳大利亚法律背景下的法律引用预测问题,在那里正确识别和引用相关的立法或先例至关重要。我们比较了几种方法:提示通用和法律专业LLM的方法,仅检索管道使用通用和领域特定嵌入,针对LLM进行特定任务的指令调整,以及结合LLM与检索增强、查询扩展或投票集合的混合策略。我们的研究结果表明,即使在接受法律专业预训练之后,仅进行领域特定的预训练也不足以实现令人满意的引用准确性。相反,在我们特定的数据集上进行指令调整会极大地提高性能,在所有设置中达到最佳结果。我们还强调,数据库粒度以及嵌入的类型对检索系统的性能起着至关重要的作用。在基于检索的方法中,混合方法始终优于仅检索设置,并且在这些方法之中,通过结合指令调整LLM的预测质量与检索系统,集合投票产生了最佳结果。
论文及项目相关链接
PDF For code, data, and models see https://auslawbench.github.io
Summary
本文探讨了大型语言模型(LLMs)在澳大利亚法律环境下的法律引用预测问题。文章比较了多种方法,包括通用和法域专业化的LLM提示、通用和法域特定嵌入的检索管道、针对特定任务的LLM指令微调以及结合LLMs与检索增强、查询扩展或投票集合的混合策略。研究发现,仅仅依靠法域预训练并不能达到令人满意的引用准确性。相比之下,针对特定数据集进行指令微调能显著提高性能。此外,数据库粒度和嵌入类型对检索系统的性能至关重要。混合方法通常优于仅检索设置,其中投票集合方法结合了指令调整LLMs的预测质量和检索系统,取得了最佳效果。
Key Takeaways
- LLMs在多种法律任务中展现出巨大潜力,但抑制虚构仍是重大挑战,最先进的LLMs仍会频繁生成错误的法律引用。
- 文章聚焦于澳大利亚法律环境下的法律引用预测问题。
- 多种方法被比较,包括通用和法域专业化的LLM提示、检索管道、任务特定指令微调以及混合策略。
- 仅依靠法域预训练并不能达到满意的引用准确性。
- 指令微调能显著提高性能。
- 数据库粒度和嵌入类型对检索系统性能有重要影响。
点此查看论文截图

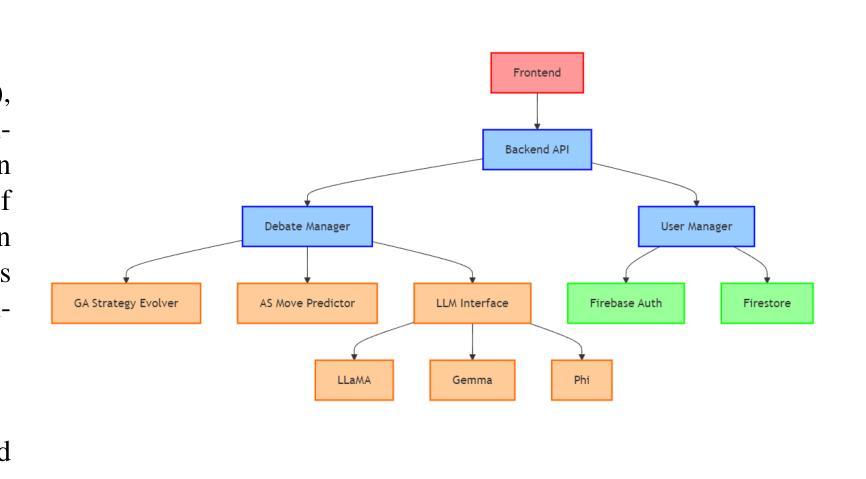
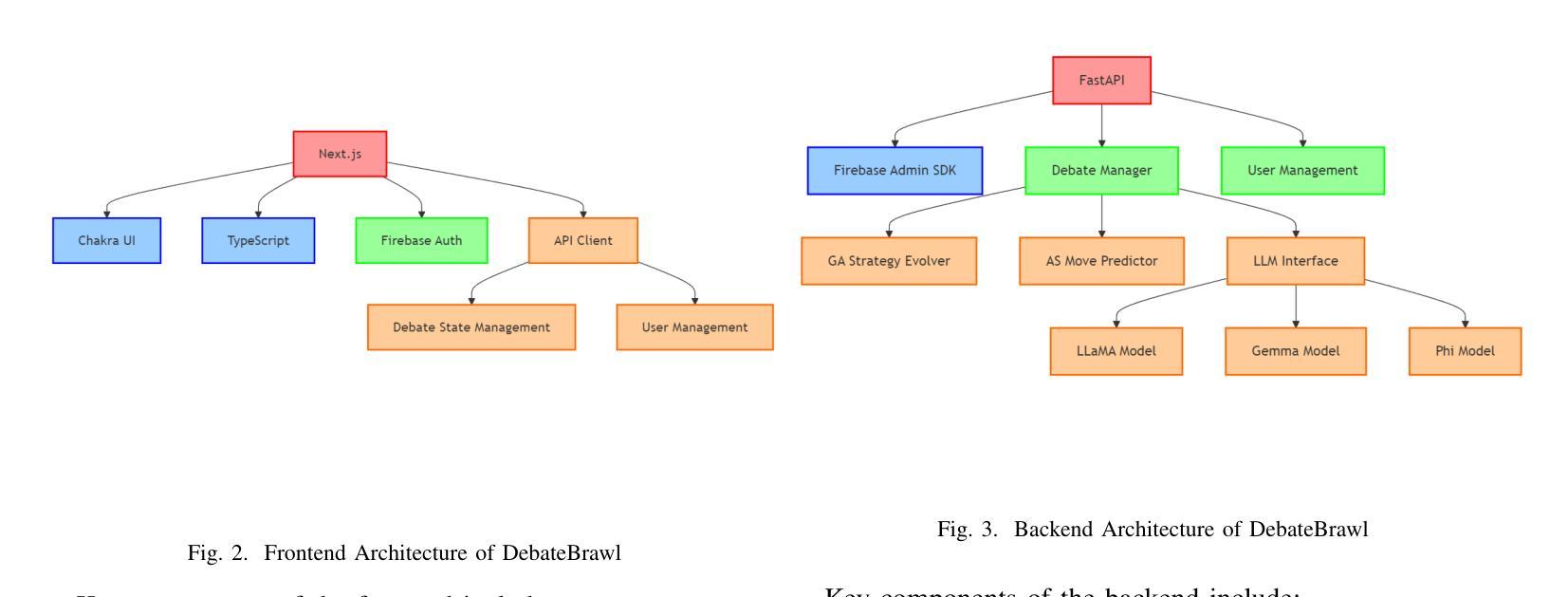
LLMs as Debate Partners: Utilizing Genetic Algorithms and Adversarial Search for Adaptive Arguments
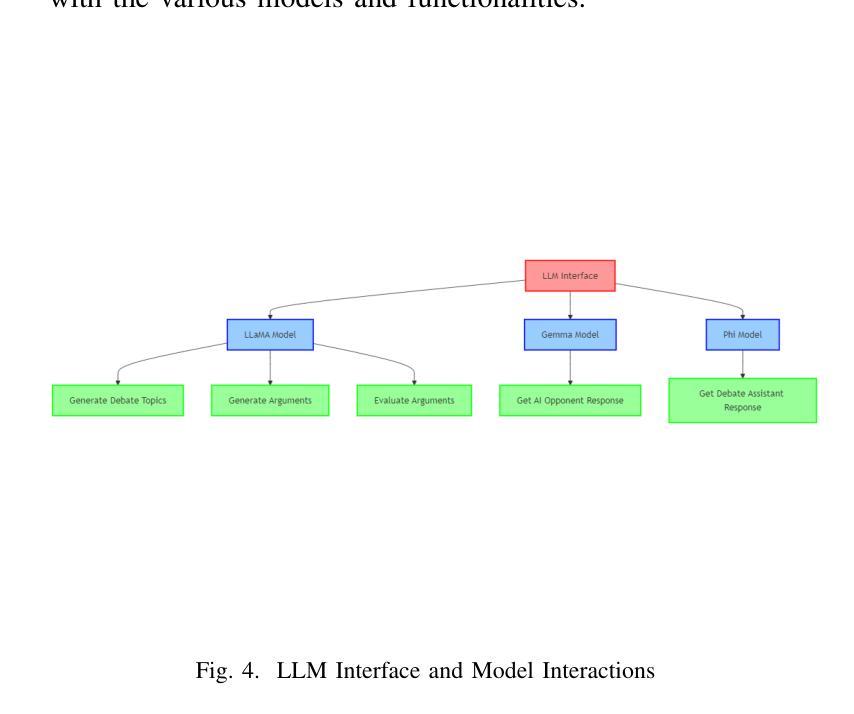
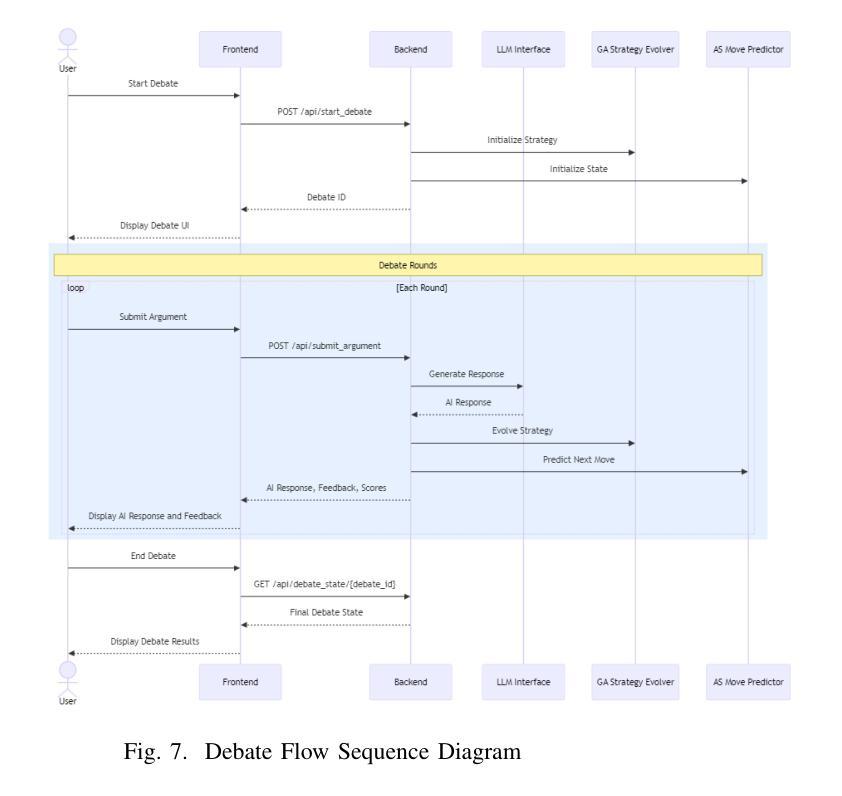
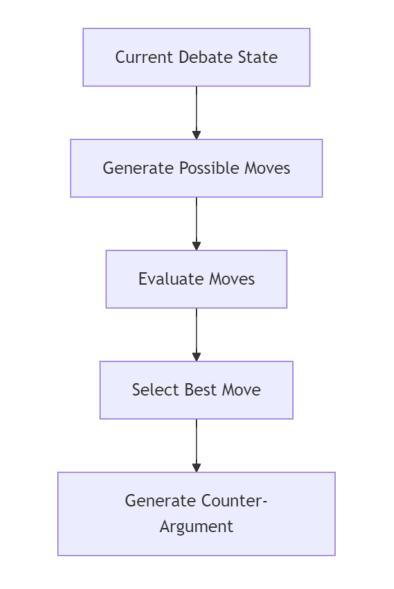
Authors:Prakash Aryan
This paper introduces DebateBrawl, an innovative AI-powered debate platform that integrates Large Language Models (LLMs), Genetic Algorithms (GA), and Adversarial Search (AS) to create an adaptive and engaging debating experience. DebateBrawl addresses the limitations of traditional LLMs in strategic planning by incorporating evolutionary optimization and game-theoretic techniques. The system demonstrates remarkable performance in generating coherent, contextually relevant arguments while adapting its strategy in real-time. Experimental results involving 23 debates show balanced outcomes between AI and human participants, with the AI system achieving an average score of 2.72 compared to the human average of 2.67 out of 10. User feedback indicates significant improvements in debating skills and a highly satisfactory learning experience, with 85% of users reporting improved debating abilities and 78% finding the AI opponent appropriately challenging. The system’s ability to maintain high factual accuracy (92% compared to 78% in human-only debates) while generating diverse arguments addresses critical concerns in AI-assisted discourse. DebateBrawl not only serves as an effective educational tool but also contributes to the broader goal of improving public discourse through AI-assisted argumentation. The paper discusses the ethical implications of AI in persuasive contexts and outlines the measures implemented to ensure responsible development and deployment of the system, including robust fact-checking mechanisms and transparency in decision-making processes.
本文介绍了DebateBrawl,这是一个创新的AI辩论平台,它集成了大型语言模型(LLM)、遗传算法(GA)和对抗搜索(AS),以创造一种自适应且引人入胜的辩论体验。DebateBrawl通过融入进化优化和博弈论技术,解决了传统LLM在战略规划方面的局限性。该系统在生成连贯、语境相关的论点时表现出卓越的性能,同时能够实时调整策略。涉及23场辩论的实验结果显示,AI和人类参与者之间达到了平衡的结果,AI系统平均得分为2.72(满分10分),与人类平均得分2.67相当。用户反馈显示,辩论技巧有了显著提高,学习体验高度满意,85%的用户表示辩论能力有所提高,78%的用户认为AI对手具有适当的挑战性。系统在保持高事实准确性(与只有人类的辩论相比,AI的准确率为92%,而人类为78%)的同时,还能产生多样化的论点,这解决了AI辅助对话中的关键担忧。DebateBrawl不仅是一个有效的教育工具,而且为实现更广泛的目标——通过AI辅助论证提高公众对话水平做出了贡献。论文讨论了AI在说服性语境中的伦理影响,并概述了为确保系统负责任开发和部署所采取的措施,包括强大的事实核查机制和决策过程的透明性。
论文及项目相关链接
Summary
辩论达人!新一代人工智能辩论平台DebateBrawl融合大型语言模型(LLM)、遗传算法(GA)与对抗性搜索(AS),突破传统辩论方式的局限性,构建沉浸式的辩论体验。实时适应策略生成连贯且相关论点,实验结果显示人机辩论双方结果均衡,人工智能平均得分接近人类。用户反馈显示辩论技能显著提升,学习体验满意,挑战度适中。DebateBrawl不仅是高效的教育工具,还推动人工智能助力公共辩论的进步。同时重视伦理,保障透明性与事实核查机制。
Key Takeaways
- DebateBrawl是一个结合LLM、GA和AS的人工智能辩论平台。
- 平台通过进化优化和游戏理论技术解决了传统LLM在战略规划上的局限。
- 在实时辩论中,DebateBrawl能生成连贯、上下文相关的论点,并自适应调整策略。
- 实验显示,AI与人类的辩论表现相近,平均得分相近。
- 用户反馈表明,使用DebateBrawl后,大部分用户的辩论技能有所提升,并对挑战度表示满意。
- 平台保持高事实准确性,同时生成多样化的论点。
- DebateBrawl重视伦理应用,具备透明的决策过程和事实核查机制。
点此查看论文截图

APOLLO: SGD-like Memory, AdamW-level Performance
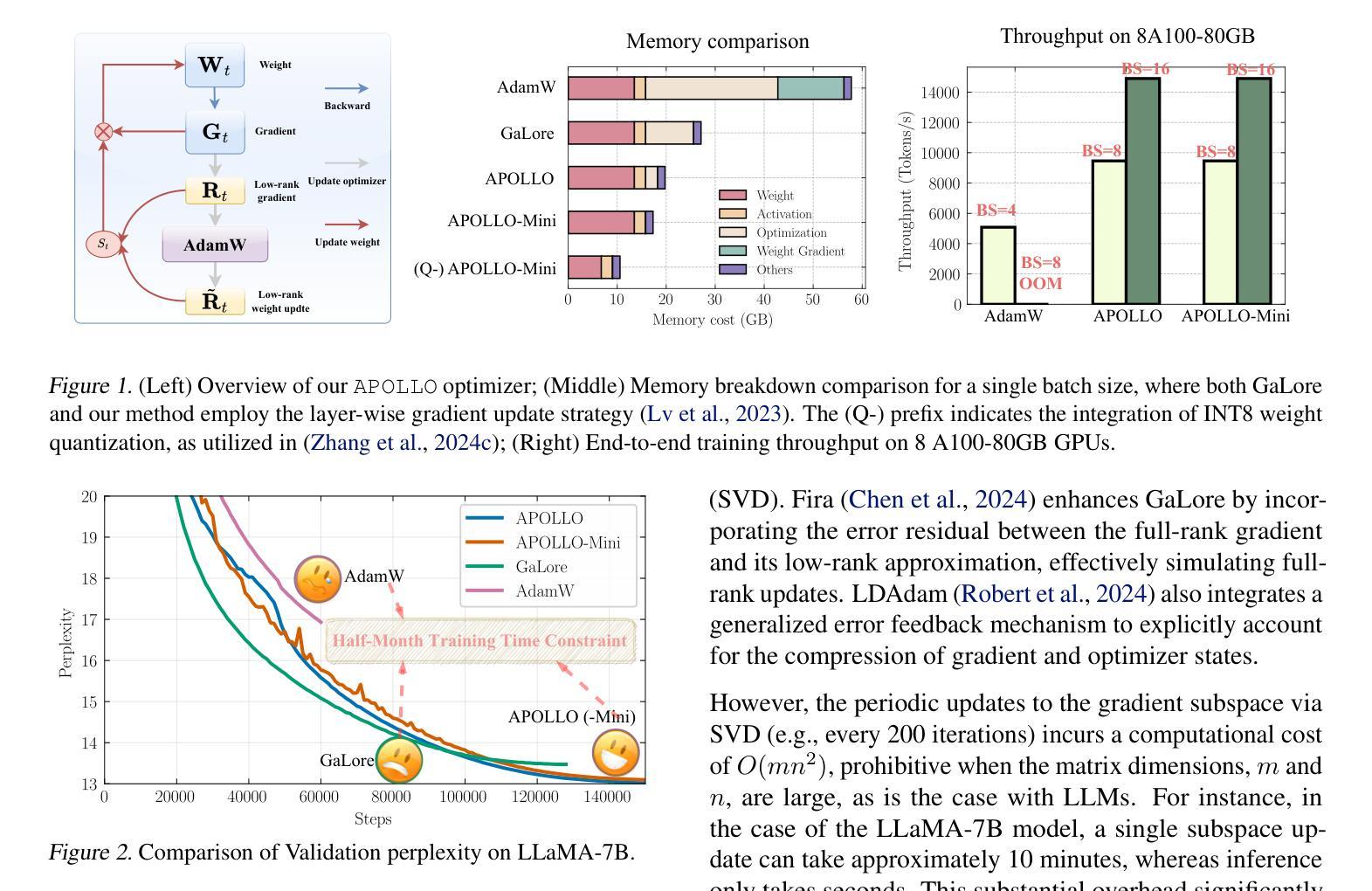
Authors:Hanqing Zhu, Zhenyu Zhang, Wenyan Cong, Xi Liu, Sem Park, Vikas Chandra, Bo Long, David Z. Pan, Zhangyang Wang, Jinwon Lee
Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing batch sizes, limiting training scalability and throughput. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face critical challenges: (i) reliance on costly SVD operations; (ii) significant performance trade-offs compared to AdamW; and (iii) still substantial optimizer memory overhead to maintain competitive performance. In this work, we identify that AdamW’s learning rate adaptation rule can be effectively coarsened as a structured learning rate update. Based on this insight, we propose Approximated Gradient Scaling for Memory-Efficient LLM Optimization (APOLLO), which approximates learning rate scaling using an auxiliary low-rank optimizer state based on pure random projection. This structured learning rate update rule makes APOLLO highly tolerant to further memory reductions while delivering comparable pre-training performance. Even its rank-1 variant, APOLLO-Mini, achieves superior pre-training performance compared to AdamW with SGD-level memory costs. Extensive experiments demonstrate that the APOLLO series performs on-par with or better than AdamW, while achieving greater memory savings by nearly eliminating the optimization states of AdamW. These savings provide significant system-level benefits: (1) Enhanced Throughput: 3x throughput on an 8xA100-80GB setup compared to AdamW by supporting 4x larger batch sizes. (2) Improved Model Scalability: Pre-training LLaMA-13B with naive DDP on A100-80GB GPUs without system-level optimizations. (3) Low-End GPU Friendly Pre-training: Pre-training LLaMA-7B on a single GPU using less than 12 GB of memory with weight quantization.
大型语言模型(LLM)在训练过程中是出了名的内存密集型,特别是与流行的AdamW优化器结合使用时更是如此。这种内存负担需要使用更多或更高端的GPU或减少批次大小,从而限制了训练的扩展性和吞吐量。为了解决这一问题,已经提出了各种内存高效的优化器来减少优化器的内存使用。然而,它们面临着关键的挑战:(i)依赖于昂贵的SVD操作;(ii)与AdamW相比,性能存在重大权衡;(iii)为了保持竞争力,优化器仍然存在相当大的内存开销。在这项工作中,我们发现AdamW的学习率自适应规则可以被有效地粗化为结构化学习率更新。基于这一见解,我们提出了基于纯随机投影的辅助低秩优化器状态的近似梯度缩放内存高效LLM优化方法(APOLLO)。这种结构化学习率更新规则使得APOLLO对进一步的内存减少具有很高的容忍度,同时提供可与AdamW相当的预训练性能。甚至其秩为1的变体APOLLO-Mini也实现了优于AdamW的预训练性能,同时达到了SGD级别的内存成本。大量实验表明,APOLLO系列在性能上可以与AdamW相提并论或更好,同时通过几乎消除AdamW的优化状态实现了更大的内存节省。这些节省提供了重大的系统级好处:(1)增强吞吐量:在8xA100-80GB设置上与AdamW相比,通过支持更大的批次大小,提高了3倍的吞吐量。(2)改善模型可扩展性:在无系统级优化的A100-80GB GPU上,使用朴素DDP对LLaMA-13B进行预训练。(3)低端GPU友好的预训练:在单个GPU上使用不到12GB的内存进行权重量化,对LLaMA-7B进行预训练。
论文及项目相关链接
PDF Preprint
摘要
大型语言模型(LLM)在训练过程中内存需求巨大,尤其是使用流行的AdamW优化器。这导致必须使用更多或更高端的GPU或减小批次大小,限制了训练的可扩展性和吞吐量。为解决这个问题,提出了各种内存高效的优化器以减少优化器的内存使用。但它们面临挑战,如依赖昂贵的SVD操作、与AdamW相比性能显著下降以及仍需要较大的优化器内存来保持竞争力。本文发现AdamW的学习率适应规则可以被有效地粗略化为结构化学习率更新。基于此,我们提出基于辅助低秩优化器状态的近似梯度缩放用于内存高效的大型语言模型优化(APOLLO),该规则使APOLLO在进一步减少内存的同时仍能保持相当的预训练性能。其秩为1的变体APOLLO-Mini甚至达到了与AdamW相比的优越预训练性能,同时拥有SGD级别的内存成本。实验表明,APOLLO系列在性能上可与AdamW持平或更好,同时实现了更大的内存节省。这些节省提供了显著的系统级好处:增强吞吐量、提高模型可扩展性和低端GPU友好的预训练。
关键见解
- LLM训练过程中对内存的需求很大,特别是在使用AdamW优化器时。
- 当前提出的内存高效优化器存在依赖昂贵操作、性能下降和仍需大量内存的问题。
- 发现并应用了AdamW学习率适应规则的结构化更新方法。
- 提出了一种新的优化器APOLLO,它基于辅助低秩优化器状态进行近似梯度缩放。
- APOLLO能在减少内存的同时保持或提高预训练性能。
- APOLLO系列在内存节省方面表现出显著的系统级优势,包括增强吞吐量、提高模型可扩展性和支持低端GPU预训练。
点此查看论文截图


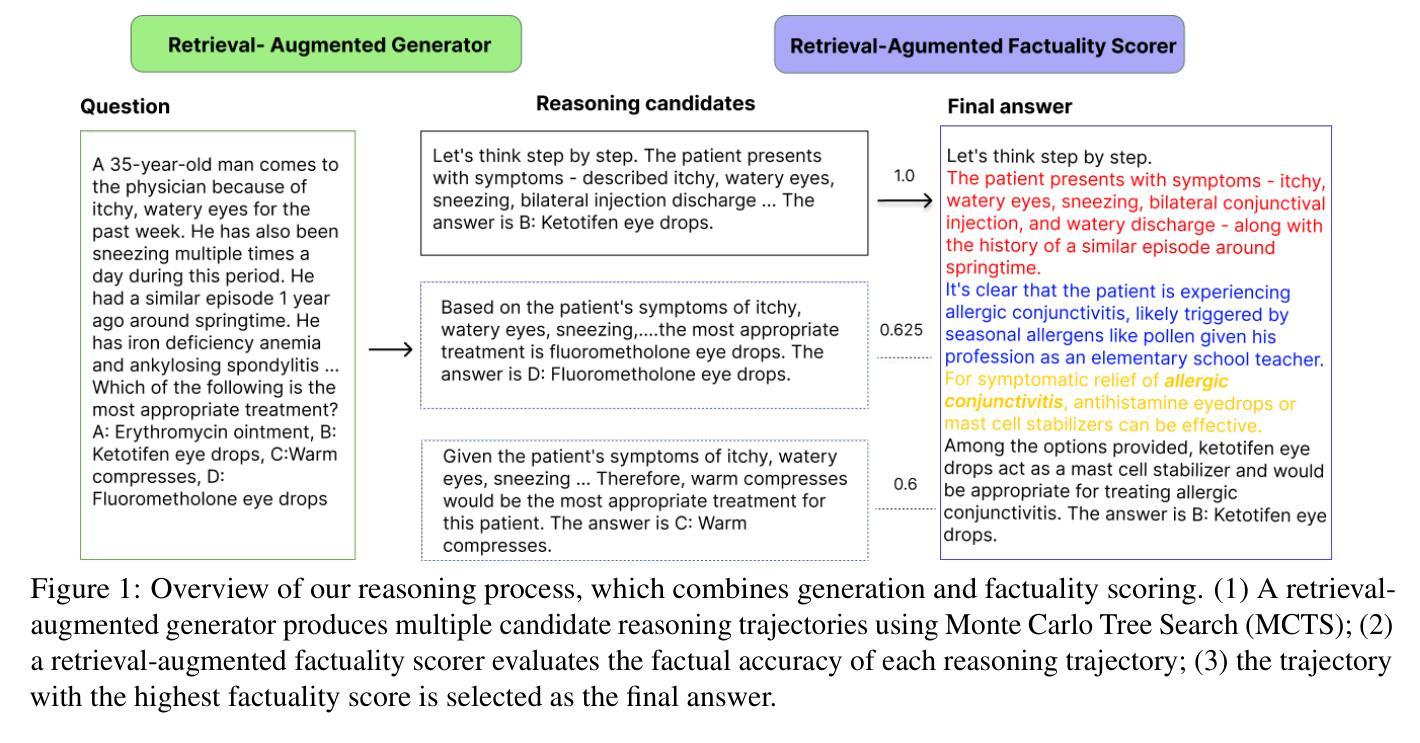
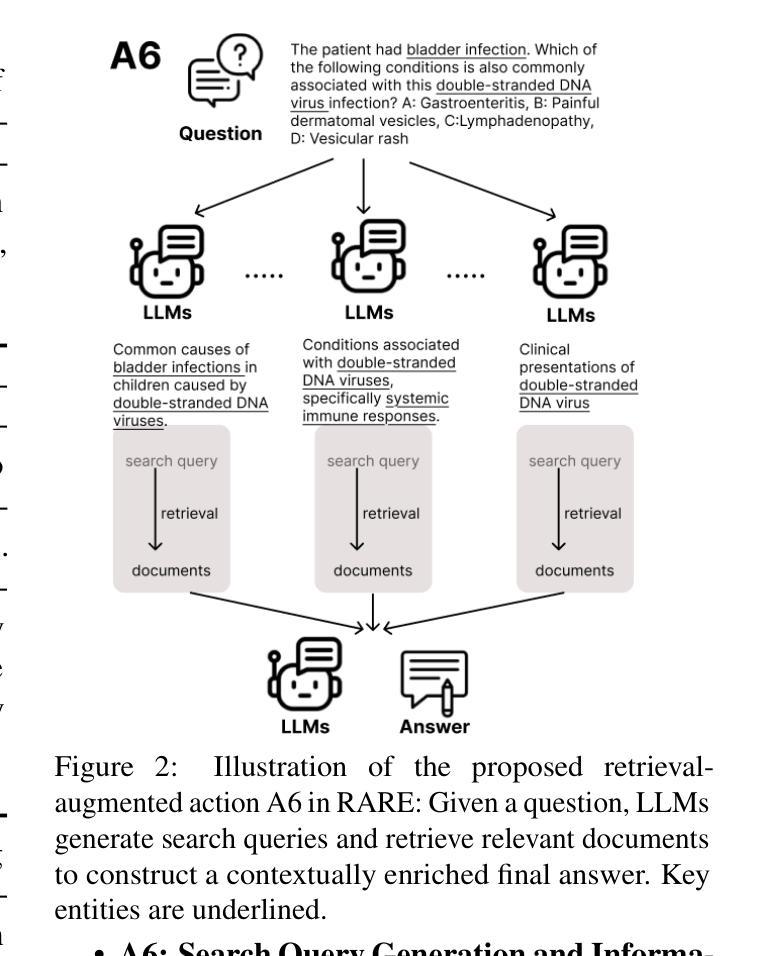
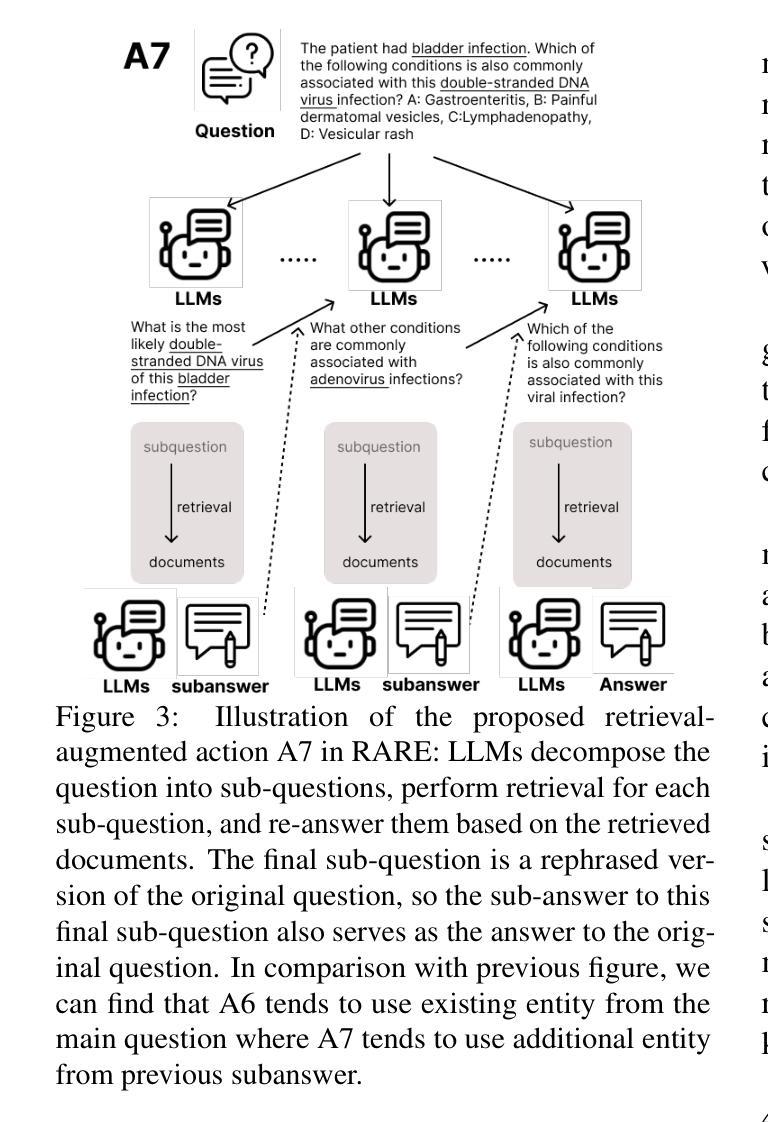
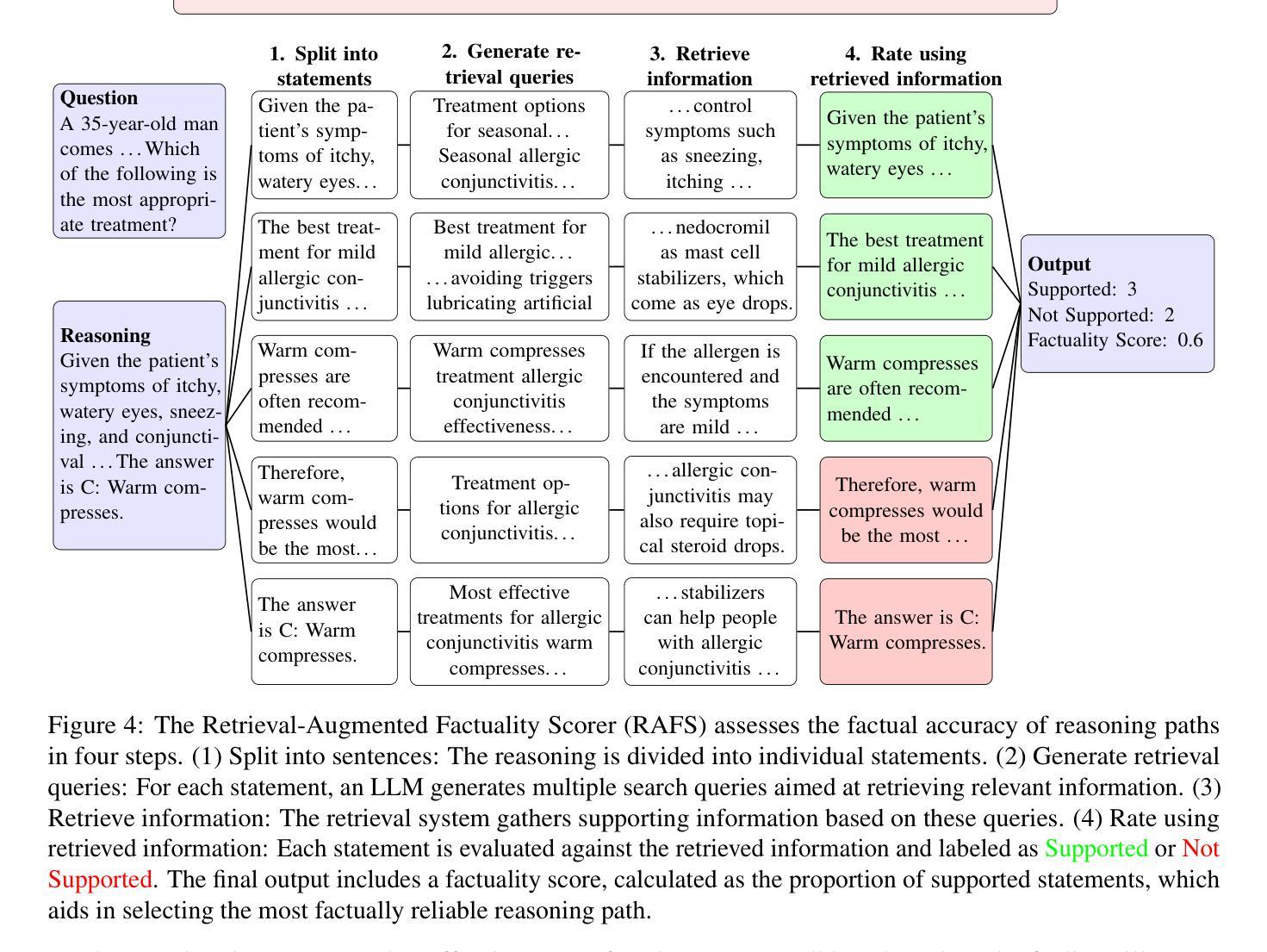
RARE: Retrieval-Augmented Reasoning Enhancement for Large Language Models
Authors:Hieu Tran, Zonghai Yao, Junda Wang, Yifan Zhang, Zhichao Yang, Hong Yu
This work introduces RARE (Retrieval-Augmented Reasoning Enhancement), a versatile extension to the mutual reasoning framework (rStar), aimed at enhancing reasoning accuracy and factual integrity across large language models (LLMs) for complex, knowledge-intensive tasks such as commonsense and medical reasoning. RARE incorporates two innovative actions within the Monte Carlo Tree Search (MCTS) framework: A6, which generates search queries based on the initial problem statement, performs information retrieval using those queries, and augments reasoning with the retrieved data to formulate the final answer; and A7, which leverages information retrieval specifically for generated sub-questions and re-answers these sub-questions with the relevant contextual information. Additionally, a Retrieval-Augmented Factuality Scorer is proposed to replace the original discriminator, prioritizing reasoning paths that meet high standards of factuality. Experimental results with LLaMA 3.1 show that RARE enables open-source LLMs to achieve competitive performance with top open-source models like GPT-4 and GPT-4o. This research establishes RARE as a scalable solution for improving LLMs in domains where logical coherence and factual integrity are critical.
本文介绍了RARE(检索增强推理扩展),这是针对互推理框架(rStar)的一个多功能扩展,旨在提高大型语言模型(LLM)在常识和医学推理等复杂、知识密集型任务中的推理准确性和事实完整性。RARE在蒙特卡洛树搜索(MCTS)框架中融入了两种创新行动:A6,根据初始问题陈述生成搜索查询,使用这些查询执行信息检索,并使用检索到的数据增强推理以形成最终答案;A7,利用信息检索专门生成子问题并重新回答这些子问题,同时结合相关的上下文信息。此外,还提出了一种检索增强事实评分器来替代原始鉴别器,优先考虑符合高事实标准的推理路径。使用LLaMA 3.1的实验结果表明,RARE使开源LLM能够实现与GPT-4和GPT-4o等顶尖开源模型相当的性能。这项研究将RARE确立为一种可在关键领域改进LLM的可扩展解决方案,在这些领域中,逻辑连贯性和事实完整性至关重要。
论文及项目相关链接
PDF 24 pages, 8 figures
Summary
本文介绍了RARE(检索增强推理增强)技术,它是针对大型语言模型(LLM)的通用扩展,旨在提高复杂知识密集型任务的推理准确性和事实完整性,如常识和医学推理。RARE结合了蒙特卡洛树搜索(MCTS)框架中的两个创新动作:A6旨在基于初始问题生成搜索查询并执行信息检索,然后使用检索到的数据增强推理以形成最终答案;A7则专门利用信息检索生成子问题并重新回答这些子问题以获取相关上下文信息。此外,提出了基于检索的事实性评分器来替换原始鉴别器,以优先选取符合高事实标准的推理路径。实验结果表明,RARE技术使开源LLM的性能达到与GPT-4等顶尖模型相当的水平。该研究确立了RARE技术在逻辑连贯性和事实完整性至关重要的领域改进LLM的可行性。
Key Takeaways
- RARE是一种针对大型语言模型(LLM)的通用扩展,旨在提高复杂知识密集型任务的推理准确性和事实完整性。
- RARE结合了蒙特卡洛树搜索(MCTS)框架中的两个创新动作:A6和A7,分别用于生成搜索查询并增强推理,以及专门利用信息检索处理子问题。
- RARE引入了基于检索的事实性评分器,以评估推理路径的事实准确性。
- 实验结果表明,RARE技术显著提高了开源LLM的性能。
- RARE技术使LLM在逻辑连贯性和事实完整性方面达到顶尖水平。
- RARE技术的应用范围广泛,可应用于多种复杂、知识密集型的任务,如常识和医学推理。
点此查看论文截图

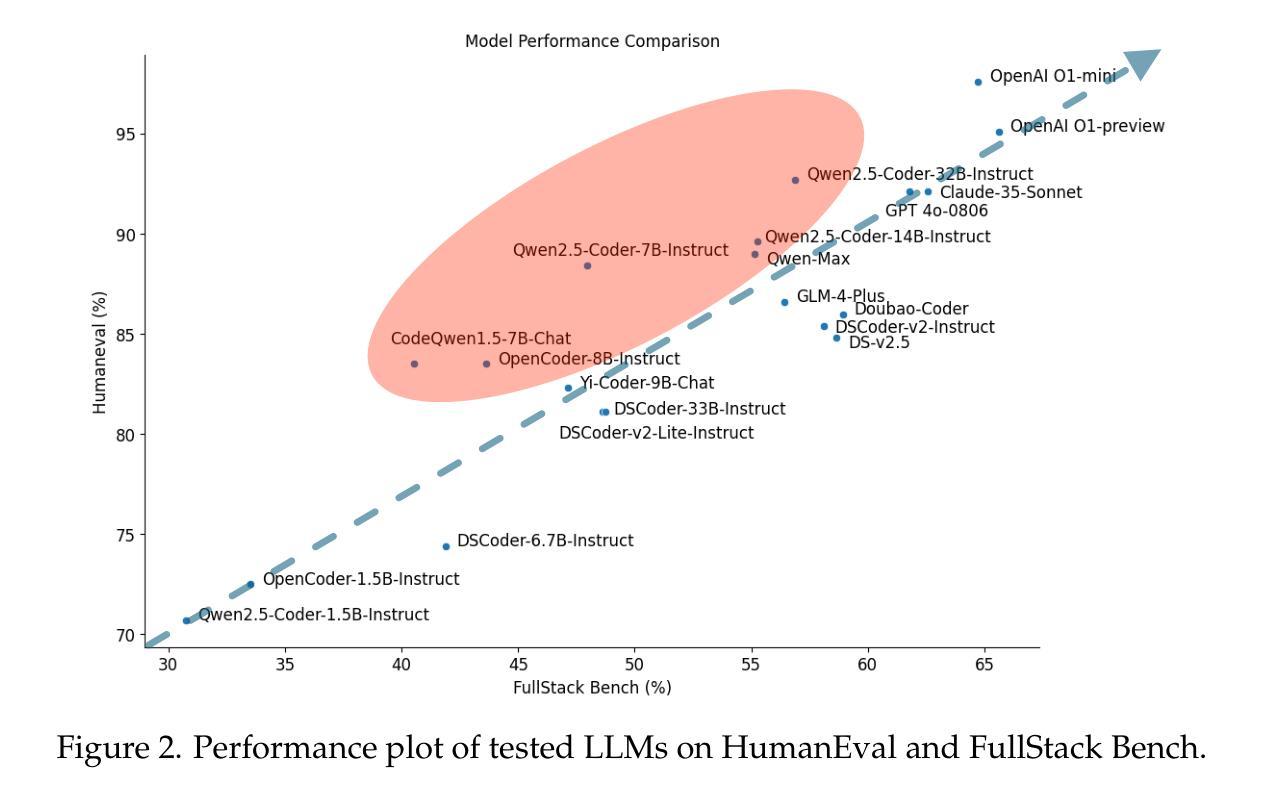
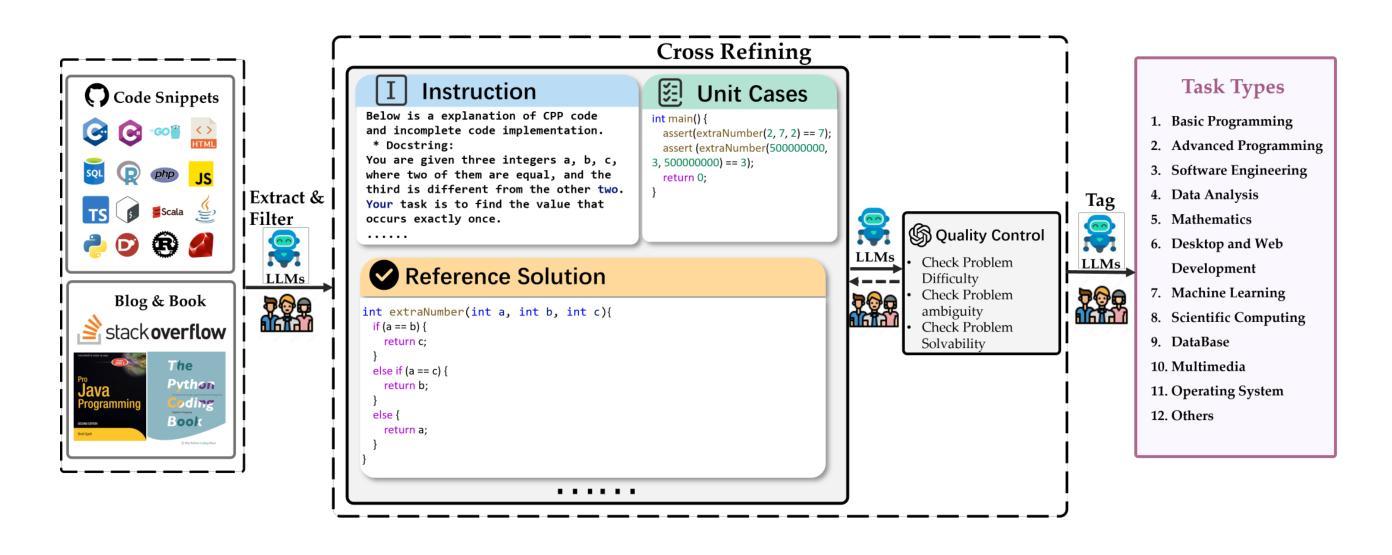
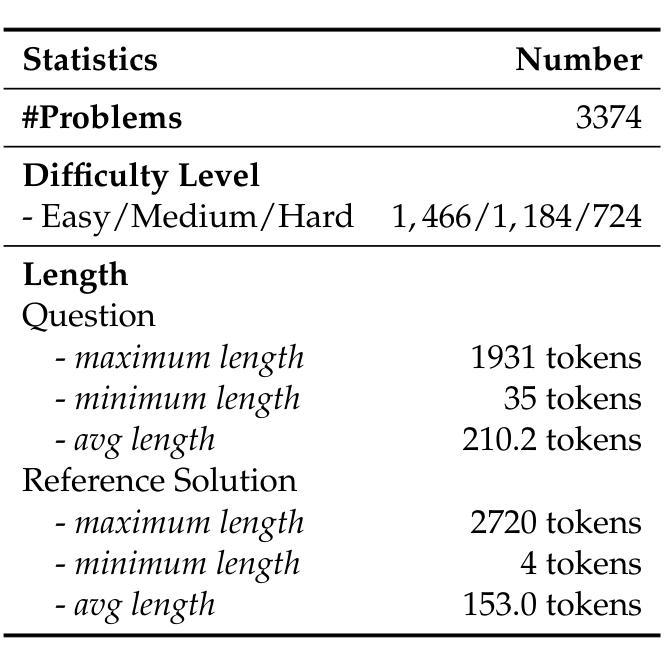
FullStack Bench: Evaluating LLMs as Full Stack Coders
Authors:Siyao Liu, He Zhu, Jerry Liu, Shulin Xin, Aoyan Li, Rui Long, Li Chen, Jack Yang, Jinxiang Xia, Z. Y. Peng, Shukai Liu, Zhaoxiang Zhang, Jing Mai, Ge Zhang, Wenhao Huang, Kai Shen, Liang Xiang
As the capabilities of code large language models (LLMs) continue to expand, their applications across diverse code intelligence domains are rapidly increasing. However, most existing datasets only evaluate limited application domains. To address this gap, we have developed a comprehensive code evaluation dataset FullStack Bench focusing on full-stack programming, which encompasses a wide range of application domains (e.g., basic programming, data analysis, software engineering, mathematics, and machine learning). Besides, to assess multilingual programming capabilities, in FullStack Bench, we design real-world instructions and corresponding unit test cases from 16 widely-used programming languages to reflect real-world usage scenarios rather than simple translations. Moreover, we also release an effective code sandbox execution tool (i.e., SandboxFusion) supporting various programming languages and packages to evaluate the performance of our FullStack Bench efficiently. Comprehensive experimental results on our FullStack Bench demonstrate the necessity and effectiveness of our FullStack Bench and SandboxFusion.
随着代码大型语言模型(LLM)的功能不断扩展,它们在各种代码智能领域的应用也在迅速增加。然而,现有的大多数数据集仅评估有限的应用领域。为了弥补这一空白,我们开发了一个全面的代码评估数据集FullStack Bench,专注于全栈编程,涵盖广泛的应用领域(如基本编程、数据分析、软件工程、数学和机器学习等)。此外,为了评估多语言编程能力,我们在FullStack Bench中设计了来自16种广泛使用的编程语言的现实指令和相应的单元测试案例,以反映现实使用场景,而非简单的翻译。而且,我们还发布了一个有效的代码沙盒执行工具(即SandboxFusion),支持各种编程语言和软件包,以高效评估我们的FullStack Bench的性能。在我们FullStack Bench上的综合实验结果证明了我们FullStack Bench和SandboxFusion的必要性和有效性。
论文及项目相关链接
PDF 26 pages
Summary
大型语言模型(LLM)的能力不断扩展,其在多种代码智能领域的应用日益广泛。然而,现有的数据集仅评估有限的应用领域。为解决此问题,我们开发了一个全面的代码评估数据集FullStack Bench,专注于全栈编程,涵盖广泛的应用领域(如基础编程、数据分析、软件工程、数学和机器学习等)。此外,为了评估多语言编程能力,FullStack Bench包含来自16种流行编程语言的真实指令和相应的单元测试案例,以反映真实使用场景而非简单翻译。同时,我们还发布了一个有效的代码沙盒执行工具SandboxFusion,支持多种编程语言和包,以提高FullStack Bench的评估效率。
Key Takeaways
- 大型语言模型(LLM)在多种代码智能领域的应用正在迅速增加,但现有数据集仅评估有限的应用领域。
- 为了解决这一问题,开发了一个全面的代码评估数据集FullStack Bench,涵盖全栈编程和广泛的应用领域。
- FullStack Bench包括来自16种流行编程语言的真实指令和相应的单元测试案例,以反映真实使用场景。
- SandboxFusion是一个有效的代码沙盒执行工具,支持多种编程语言和包,提高了FullStack Bench的评估效率。
- FullStack Bench的设计旨在评估模型在多语言编程方面的能力。
- 通过全面的实验,证明了FullStack Bench和SandboxFusion的必要性和有效性。
- FullStack Bench的推出对于评估LLM在实际应用中的性能具有重要意义。
点此查看论文截图

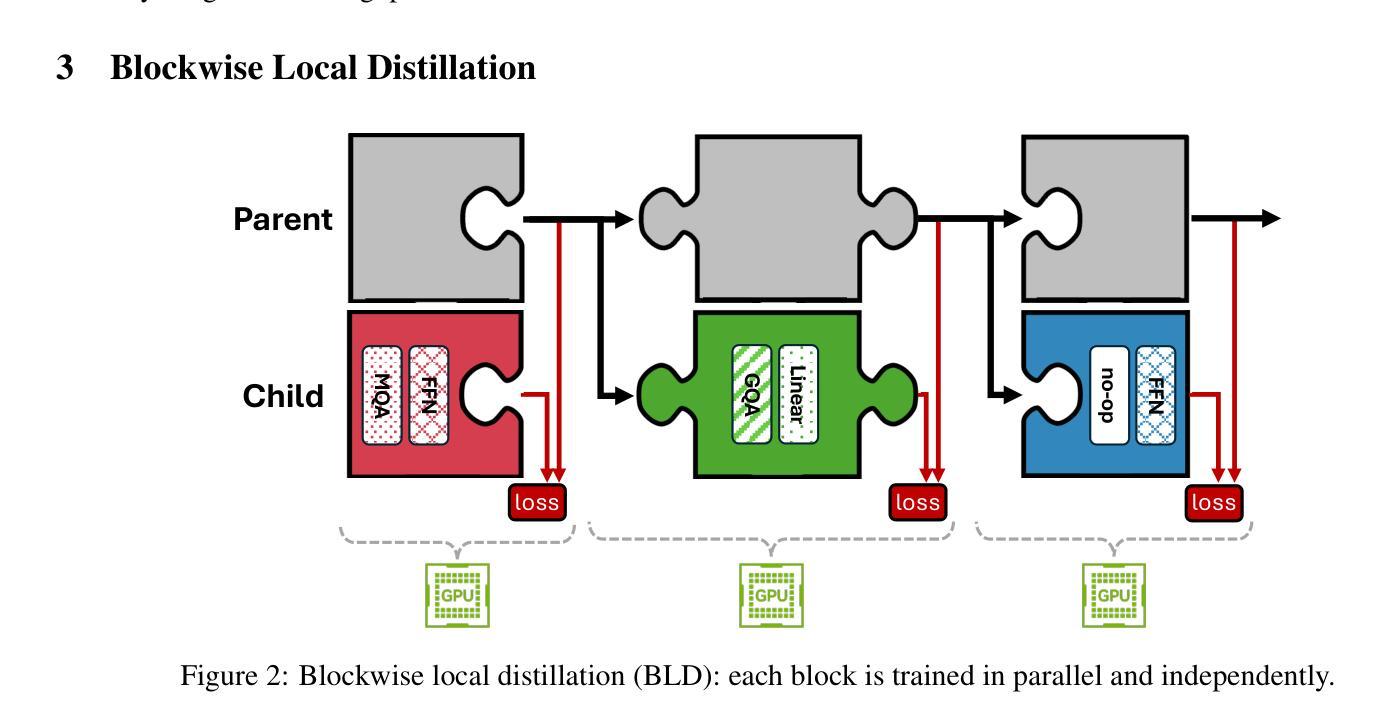
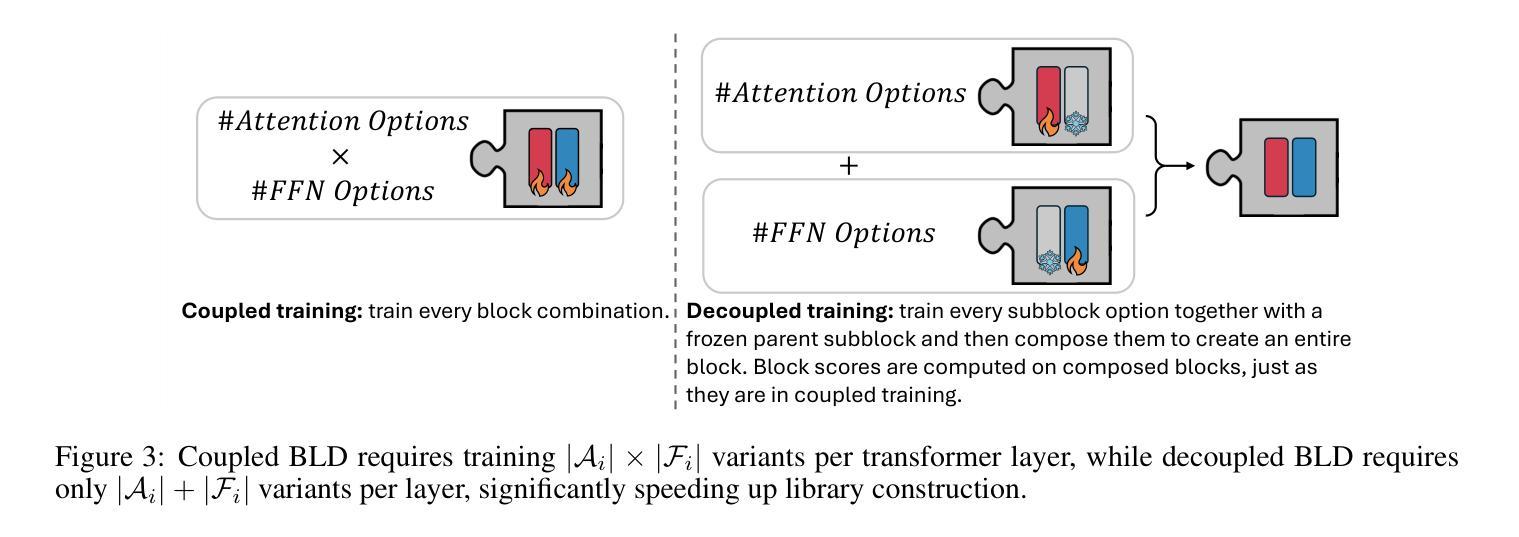
Puzzle: Distillation-Based NAS for Inference-Optimized LLMs
Authors:Akhiad Bercovich, Tomer Ronen, Talor Abramovich, Nir Ailon, Nave Assaf, Mohammad Dabbah, Ido Galil, Amnon Geifman, Yonatan Geifman, Izhak Golan, Netanel Haber, Ehud Karpas, Roi Koren, Itay Levy, Pavlo Molchanov, Shahar Mor, Zach Moshe, Najeeb Nabwani, Omri Puny, Ran Rubin, Itamar Schen, Ido Shahaf, Oren Tropp, Omer Ullman Argov, Ran Zilberstein, Ran El-Yaniv
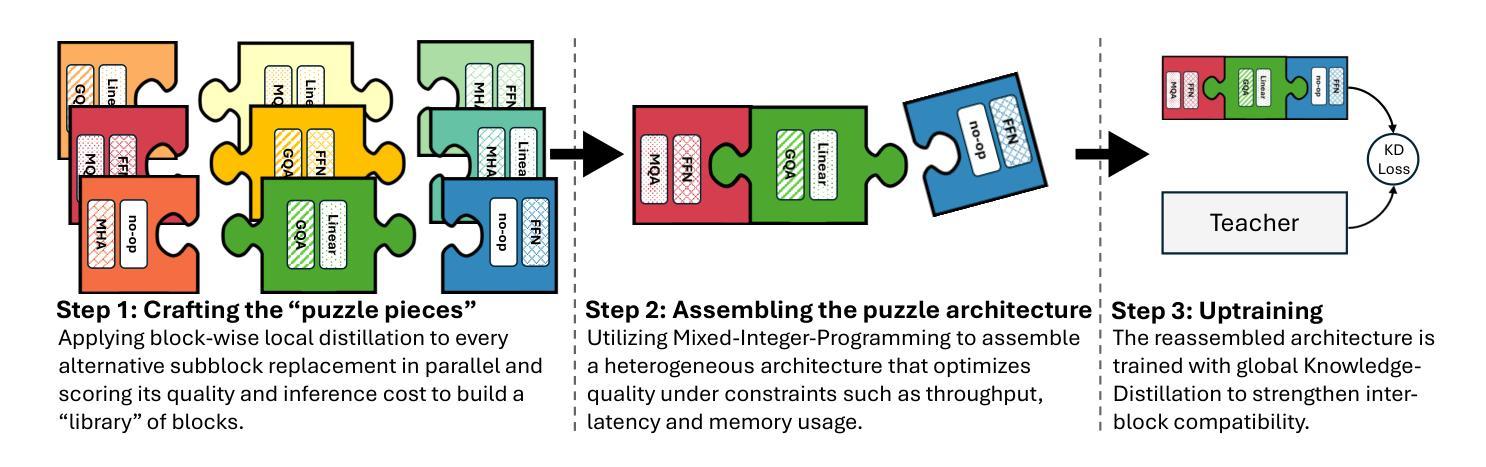
Large language models (LLMs) have demonstrated remarkable capabilities, but their adoption is limited by high computational costs during inference. While increasing parameter counts enhances accuracy, it also widens the gap between state-of-the-art capabilities and practical deployability. We present Puzzle, a framework to accelerate LLM inference on specific hardware while preserving their capabilities. Through an innovative application of neural architecture search (NAS) at an unprecedented scale, Puzzle systematically optimizes models with tens of billions of parameters under hardware constraints. Our approach utilizes blockwise local knowledge distillation (BLD) for parallel architecture exploration and employs mixed-integer programming for precise constraint optimization. We demonstrate the real-world impact of our framework through Llama-3.1-Nemotron-51B-Instruct (Nemotron-51B), a publicly available model derived from Llama-3.1-70B-Instruct. Nemotron-51B achieves a 2.17x inference throughput speedup, fitting on a single NVIDIA H100 GPU while preserving 98.4% of the original model’s capabilities. Nemotron-51B currently stands as the most accurate language model capable of inference on a single GPU with large batch sizes. Remarkably, this transformation required just 45B training tokens, compared to over 15T tokens used for the 70B model it was derived from. This establishes a new paradigm where powerful models can be optimized for efficient deployment with only negligible compromise of their capabilities, demonstrating that inference performance, not parameter count alone, should guide model selection. With the release of Nemotron-51B and the presentation of the Puzzle framework, we provide practitioners immediate access to state-of-the-art language modeling capabilities at significantly reduced computational costs.
大型语言模型(LLM)已经展现出惊人的能力,但其推理过程中的计算成本高昂,限制了其应用。虽然增加参数数量可以提高准确性,但也拉大了最前沿能力与实际部署能力之间的差距。我们提出了Puzzle框架,旨在加速特定硬件上的LLM推理过程,同时保持其能力。通过神经网络架构搜索(NAS)的创新应用,Puzzle在硬件约束下系统地优化了具有数十亿参数的模型。我们的方法利用块局部知识蒸馏(BLD)进行并行架构探索,并采用混合整数编程进行精确约束优化。我们通过Llama-3.1-Nemotron-51B-Instruct(Nemotron-51B)展示了框架在现实世界中的影响,这是一个源于Llama-3.1-70B-Instruct的公开模型。Nemotron-51B在单个NVIDIA H100 GPU上实现了2.17倍的推理吞吐量加速,同时保留了原始模型98.4%的能力。Nemotron-51B目前已成为能够在单个GPU上进行大规模批处理的最准确的语言模型。值得注意的是,这种转换仅需要45B的训练令牌,而与之相关的70B模型则需要超过15T的令牌。这建立了一种新范式,其中强大的模型可以针对高效部署进行优化,同时几乎不会牺牲其能力,表明应该根据推理性能(而不仅仅是参数数量)来选择模型。随着Nemotron-51B的发布和Puzzle框架的展示,我们为实践者提供了以显著降低的计算成本立即访问最新语言建模功能的机会。
论文及项目相关链接
Summary
本文介绍了针对大型语言模型(LLM)的加速推理框架Puzzle,它可以在特定硬件上优化模型推理,同时保持其原有功能。通过神经架构搜索(NAS)技术,Puzzle能在硬件限制下优化数十亿参数的模型。通过块式局部知识蒸馏(BLD)和混合整数编程技术,Puzzle框架提升了模型推理速度并降低了计算成本。以Nemotron-51B为例,该模型在保持98.4%原始功能的同时,实现了单个NVIDIA H100 GPU上的推理速度提升2.17倍。这表明在优化部署时,推理性能比参数数量更重要。Puzzle框架为从业者提供了在显著降低计算成本的情况下,立即访问最新语言建模功能的能力。
Key Takeaways
- Puzzle框架旨在加速大型语言模型(LLM)在特定硬件上的推理过程,同时保持其原有功能。
- 通过神经架构搜索(NAS)技术,Puzzle能够优化数十亿参数的模型。
- 块式局部知识蒸馏(BLD)和混合整数编程技术被用于提升模型推理速度和降低计算成本。
- Nemotron-51B模型展示了Puzzle框架的实际效果,它在保持原始功能的同时,实现了推理速度的提升。
- 与之前的模型相比,Nemotron-51B的优化过程使用了显著更少的训练令牌。
- Puzzle框架提供了一个新的模式,即强大的模型可以在优化部署时仅对能力进行微小妥协。
点此查看论文截图

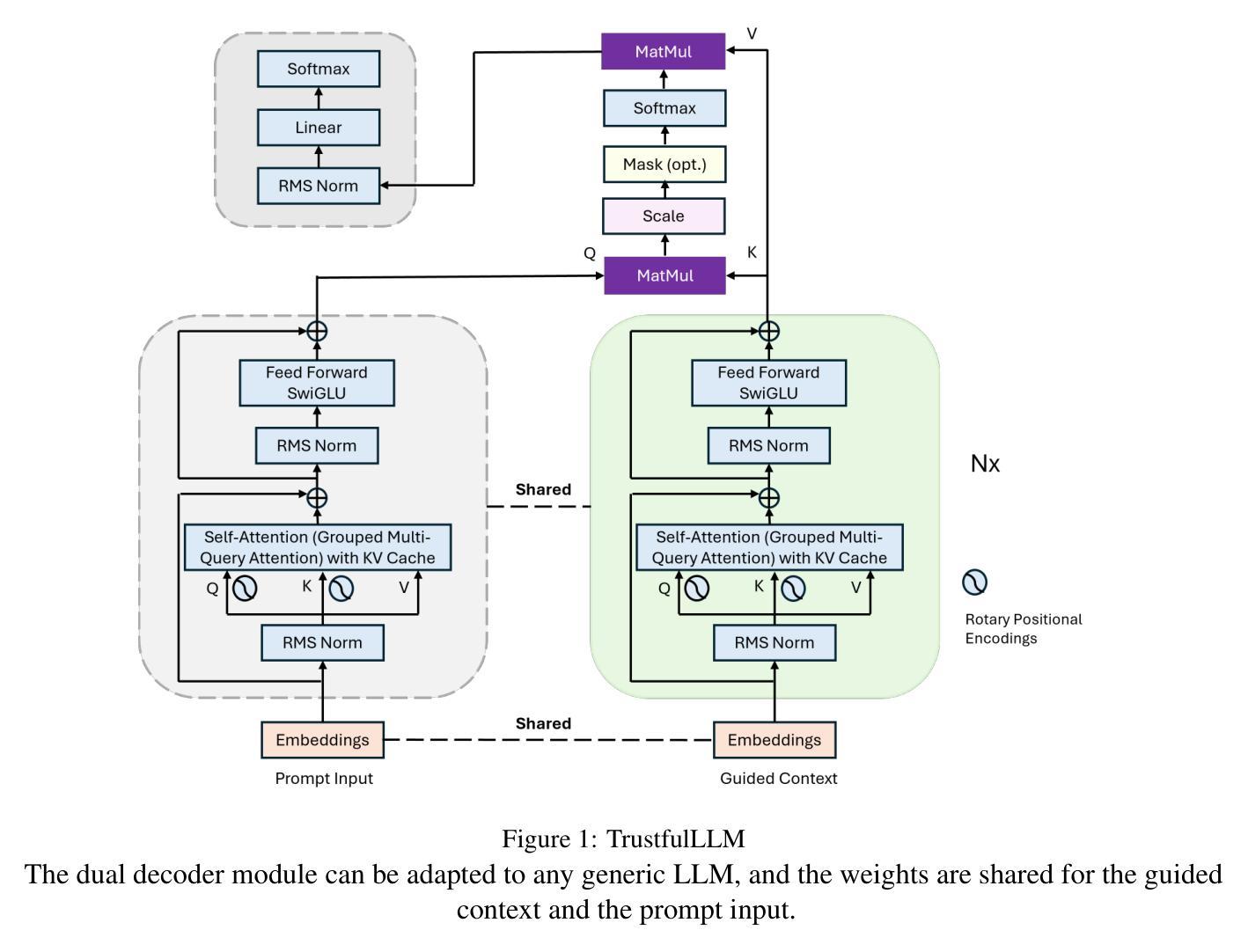
Trustful LLMs: Customizing and Grounding Text Generation with Knowledge Bases and Dual Decoders
Authors:Xiaofeng Zhu, Jaya Krishna Mandivarapu
Although people are impressed by the content generation skills of large language models, the use of LLMs, such as ChatGPT, is limited by the domain grounding of the content. The correctness and groundedness of the generated content need to be based on a verified context, such as results from Retrieval-Augmented Generation (RAG). One important issue when adapting LLMs to a customized domain is that the generated responses are often incomplete, or the additions are not verified and may even be hallucinated. Prior studies on hallucination detection have focused on evaluation metrics, which are not easily adaptable to dynamic domains and can be vulnerable to attacks like jail-breaking. In this work, we propose 1) a post-processing algorithm that leverages knowledge triplets in RAG context to correct hallucinations and 2) a dual-decoder model that fuses RAG context to guide the generation process.
尽管人们对大型语言模型的内容生成能力印象深刻,但ChatGPT等LLM的使用受到内容领域特定性的限制。生成内容的正确性和合理性需要基于经过验证的上下文,例如增强检索生成(RAG)的结果。将LLM适应于自定义领域时的一个重要问题是,生成的响应往往不完整,或者添加的内容未经验证,甚至可能是虚构的。先前关于幻觉检测的研究主要集中在评估指标上,这些指标不容易适应动态领域,并且容易受到如越狱攻击等攻击的影响。在这项工作中,我们提出了1)一种利用RAG上下文中的知识三元组校正幻觉的后处理算法;以及2)一种融合RAG上下文以指导生成过程的双解码器模型。
论文及项目相关链接
Summary
大型语言模型的内容生成能力令人印象深刻,但其应用受限于内容的领域相关性。生成的正确性和扎实性需要基于验证的上下文,如检索增强生成(RAG)的结果。将LLMs适应于自定义领域时,生成的回复往往不完整,添加的内容未经验证,甚至可能是虚构的。本研究提出利用RAG上下文中的知识三元组校正虚构内容的后处理算法,以及融合RAG上下文指导生成过程的双解码器模型。
Key Takeaways
- 大型语言模型(LLMs)如ChatGPT的内容生成能力受限于其领域相关性。
- 生成的正确性需基于验证的上下文,如RAG结果。
- LLMs适应自定义领域时,生成的回复可能不完整。
- 添加的内容可能未经验证,存在虚构情况。
- 现有研究多关注评估指标,难以适应动态领域且易受攻击。
- 本研究提出利用知识三元组校正虚构内容的后处理算法。
点此查看论文截图

GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching
Authors:Sajal Regmi, Chetan Phakami Pun
Large Language Models (LLMs), such as GPT, have revolutionized artificial intelligence by enabling nuanced understanding and generation of human-like text across a wide range of applications. However, the high computational and financial costs associated with frequent API calls to these models present a substantial bottleneck, especially for applications like customer service chatbots that handle repetitive queries. In this paper, we introduce GPT Semantic Cache, a method that leverages semantic caching of query embeddings in in-memory storage (Redis). By storing embeddings of user queries, our approach efficiently identifies semantically similar questions, allowing for the retrieval of pre-generated responses without redundant API calls to the LLM. This technique achieves a notable reduction in operational costs while significantly enhancing response times, making it a robust solution for optimizing LLM-powered applications. Our experiments demonstrate that GPT Semantic Cache reduces API calls by up to 68.8% across various query categories, with cache hit rates ranging from 61.6% to 68.8%. Additionally, the system achieves high accuracy, with positive hit rates exceeding 97%, confirming the reliability of cached responses. This technique not only reduces operational costs, but also improves response times, enhancing the efficiency of LLM-powered applications.
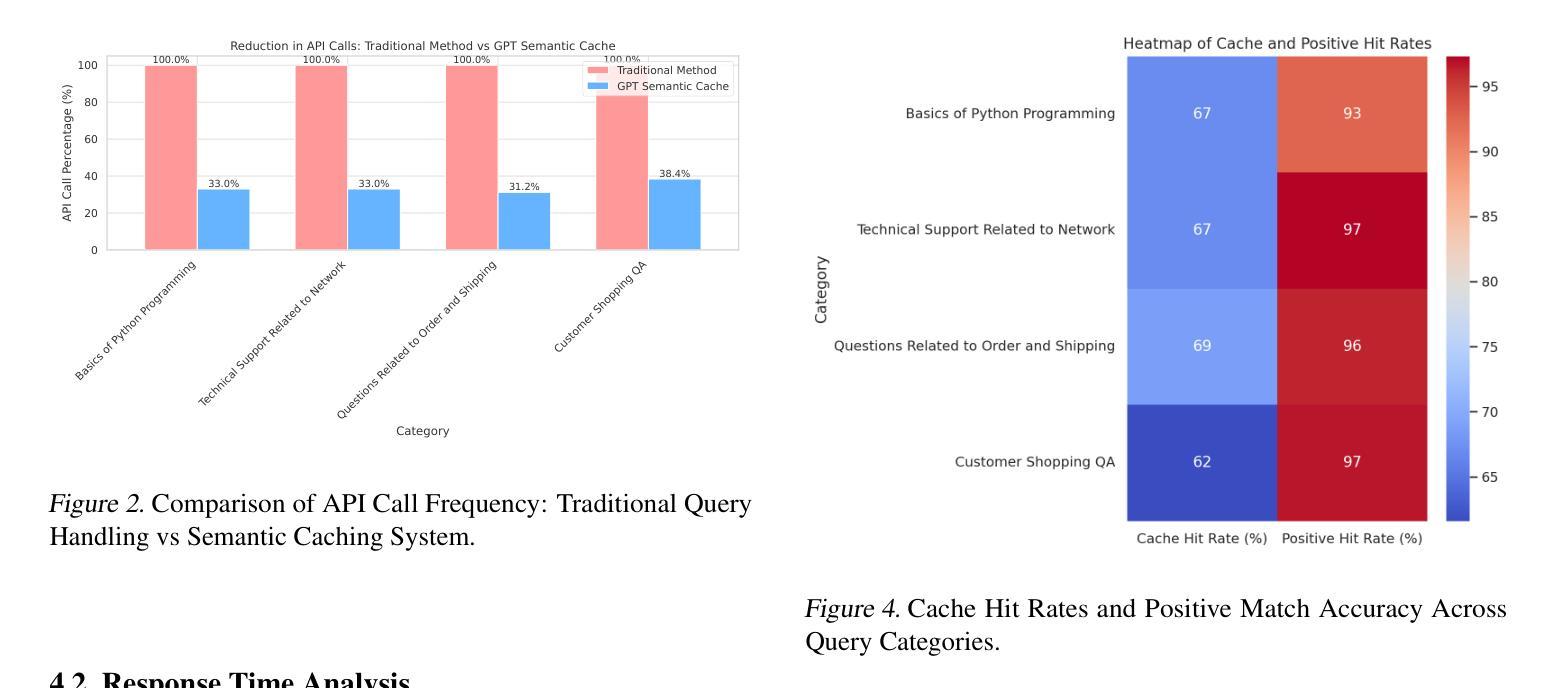
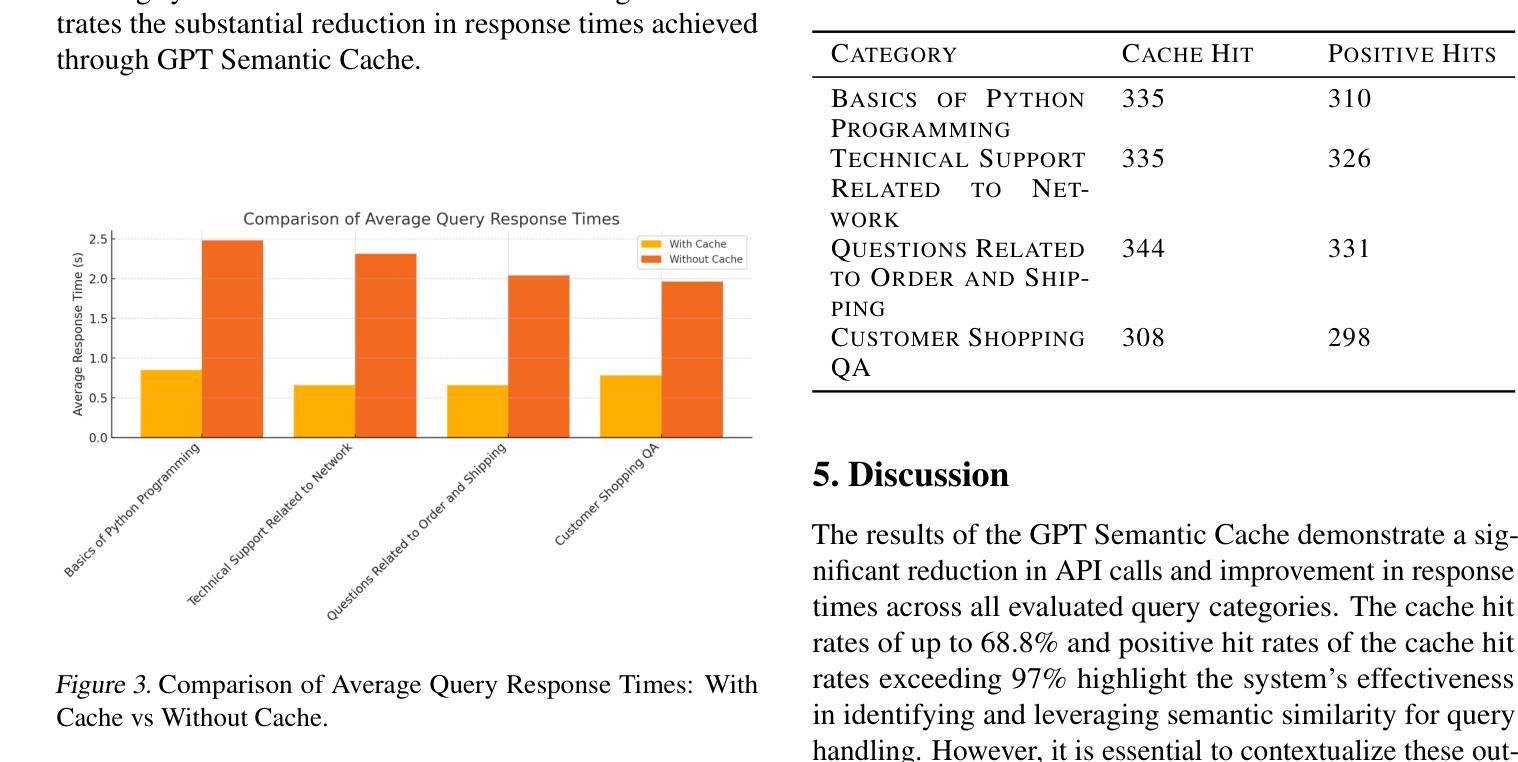
大型语言模型(LLM),如GPT,已经通过在一系列广泛的应用程序中实现人性化的细微理解和文本生成,从而彻底改变了人工智能领域。然而,与这些模型的频繁API调用相关的高计算成本和财务成本成为了一个主要的瓶颈,尤其是对于处理重复性查询的客户服务聊天机器人等应用。在本文中,我们介绍了GPT语义缓存方法,该方法利用内存存储(Redis)中的查询嵌入语义缓存。通过存储用户查询的嵌入,我们的方法可以有效地识别语义上相似的问题,允许检索预先生成的响应,而无需对LLM进行冗余的API调用。此技术实现了运营成本的可观降低,同时大大提高了响应时间,是优化LLM驱动应用的一个稳健解决方案。我们的实验表明,GPT语义缓存将各类查询的API调用减少了高达68.8%,缓存命中率在61.6%至68.8%之间。此外,系统的准确率很高,正面命中率超过97%,证明了缓存响应的可靠性。这项技术不仅降低了运营成本,而且提高了响应时间,增强了LLM驱动应用的工作效率。
论文及项目相关链接
Summary
大型语言模型(LLM)如GPT带来了人工智能的革新,实现了跨多个应用的类似人类的文本理解和生成。然而,频繁调用这些模型的API产生了高昂的计算和财务成本,成为了瓶颈,特别是在处理重复性查询的应用(如客户服务聊天机器人)中。本文提出GPT语义缓存方法,利用内存存储(Redis)中的查询嵌入语义缓存。通过存储用户查询的嵌入,该方法能够高效地识别语义相似的提问,检索预生成的答案,无需冗余调用LLM的API。该技术显著降低了运营成本,提高了响应速度,是优化LLM驱动应用的有力解决方案。实验表明,GPT语义缓存将API调用减少了高达68.8%,各类查询的缓存命中率在61.6%至68.8%之间。此外,系统准确率高,积极命中率超过97%,证明了缓存答案的可靠性。
Key Takeaways
- LLMs如GPT实现了人类类似的文本理解和生成,但高计算成本成为瓶颈。
- GPT语义缓存方法通过内存存储中的查询嵌入语义缓存来减少API调用。
- 该方法能高效识别语义相似的提问并检索预生成的答案。
- GPT语义缓存显著降低了运营成本并提高了响应速度。
- 实验显示GPT语义缓存将API调用减少了高达68.8%。
- 各类查询的缓存命中率在61.6%至68.8%之间。
- 系统准确率高,积极命中率超过97%,证明缓存答案的可靠性。
点此查看论文截图

How Transformers Solve Propositional Logic Problems: A Mechanistic Analysis
Authors:Guan Zhe Hong, Nishanth Dikkala, Enming Luo, Cyrus Rashtchian, Xin Wang, Rina Panigrahy
Large language models (LLMs) have shown amazing performance on tasks that require planning and reasoning. Motivated by this, we investigate the internal mechanisms that underpin a network’s ability to perform complex logical reasoning. We first construct a synthetic propositional logic problem that serves as a concrete test-bed for network training and evaluation. Crucially, this problem demands nontrivial planning to solve. We perform our study on two fronts. First, we pursue an understanding of precisely how a three-layer transformer, trained from scratch and attains perfect test accuracy, solves this problem. We are able to identify certain “planning” and “reasoning” mechanisms in the network that necessitate cooperation between the attention blocks to implement the desired logic. Second, we study how pretrained LLMs, namely Mistral-7B and Gemma-2-9B, solve this problem. We characterize their reasoning circuits through causal intervention experiments, providing necessity and sufficiency evidence for the circuits. We find evidence suggesting that the two models’ latent reasoning strategies are surprisingly similar, and human-like. Overall, our work systemically uncovers novel aspects of small and large transformers, and continues the study of how they plan and reason.
大型语言模型(LLM)在需要规划和推理的任务中表现出了惊人的性能。受此启发,我们研究支撑网络执行复杂逻辑推理能力的内部机制。我们首先构建了一个合成命题逻辑问题,作为网络训练和评估的具体测试平台。关键的是,这个问题需要非平凡的规划才能解决。我们的研究分为两个方面。首先,我们致力于理解一个三层变压器如何从零开始训练,并达到完美的测试精度,解决这个问题。我们能够在网络中识别出某些“规划”和“推理”机制,需要注意力块之间的合作来实现所需的逻辑。其次,我们研究预训练的大型语言模型,即Mistral-7B和Gemma-2-9B,如何解决这个问题。我们通过因果干预实验对其推理电路进行表征,为电路提供必要性和充分性证据。我们发现证据表明,这两个模型的潜在推理策略出人意料地相似,且类似于人类。总的来说,我们的工作系统地揭示了小型和大型变压器的全新方面,并继续研究它们是如何进行规划和推理的。
论文及项目相关链接
Summary
大型语言模型(LLM)在需要规划和推理的任务中表现出惊人的性能。本研究旨在探究支撑网络执行复杂逻辑推理的内部机制。首先,构建一个合成命题逻辑问题,作为网络训练和评估的具体测试平台。此问题需通过复杂的规划来解决。研究分为两部分:首先,了解一个三层变压器如何从头开始训练并达到完美测试精度来解决这个问题。我们能够在网络中识别出某些需要注意力块合作的“规划”和“推理”机制来实现所需的逻辑。其次,研究预训练的大型语言模型(如Mistral-7B和Gemma-2-9B)如何解决这一问题。通过因果干预实验刻画其推理电路,为电路提供必要性和充分性证据。我们发现两个模型的潜在推理策略出人意料地相似且类似于人类。总体而言,我们的研究系统地揭示了小型和大型变压器的全新方面,并继续研究它们的规划和推理方式。
Key Takeaways
- 大型语言模型在需要规划和推理的任务中表现出卓越性能。
- 合成命题逻辑问题为网络训练和评估提供了具体测试平台。
- 三层变压器模型展示完美的测试精度,通过识别规划及推理机制揭示其解决问题的能力。
- 预训练的大型语言模型如Mistral-7B和Gemma-2-9B具备强大的逻辑推理能力。
- 这些模型的推理策略具有出人意料的相似性,并显示出类似于人类的特征。
- 研究揭示了小型和大型语言模型在规划和推理方面的新特点。
点此查看论文截图

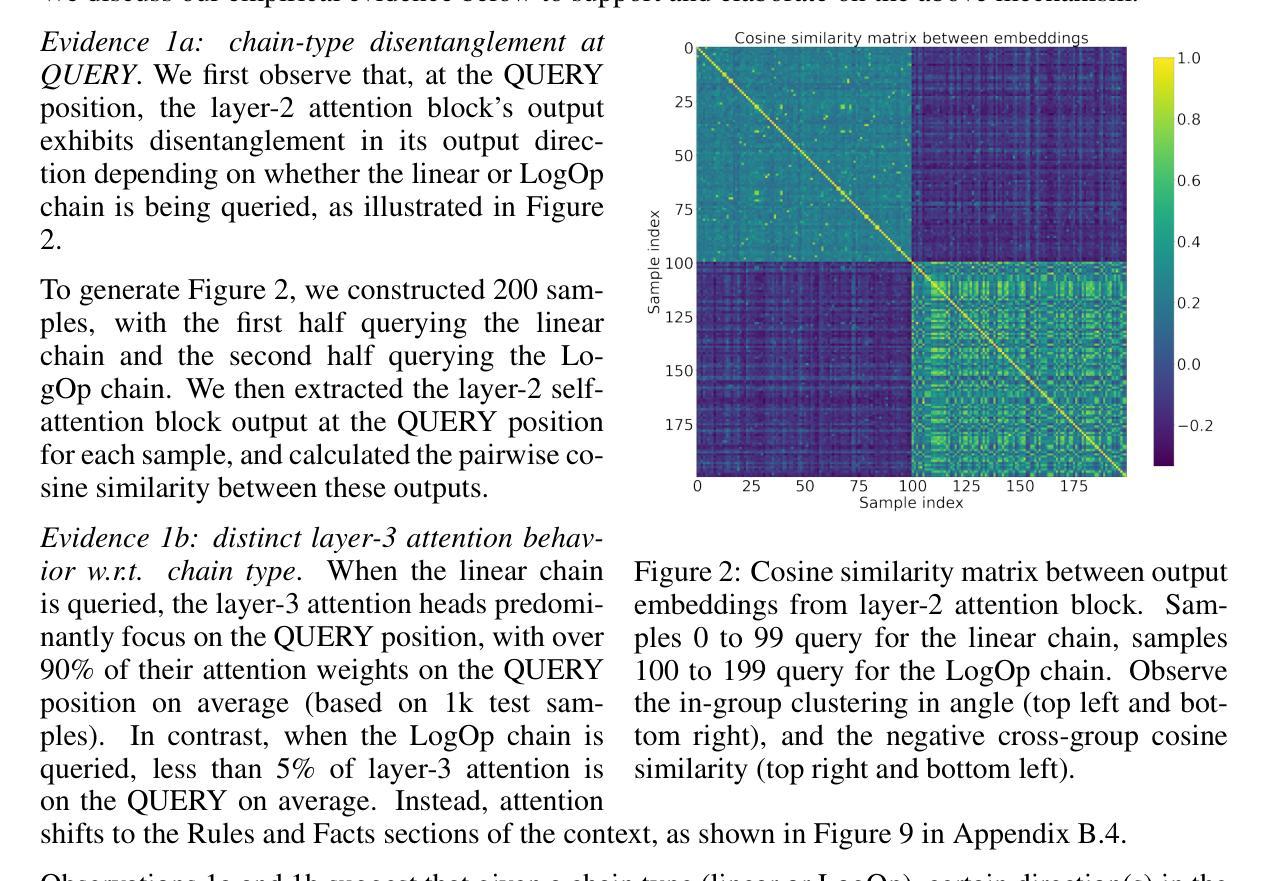
From Novice to Expert: LLM Agent Policy Optimization via Step-wise Reinforcement Learning
Authors:Zhirui Deng, Zhicheng Dou, Yutao Zhu, Ji-Rong Wen, Ruibin Xiong, Mang Wang, Weipeng Chen
The outstanding capabilities of large language models (LLMs) render them a crucial component in various autonomous agent systems. While traditional methods depend on the inherent knowledge of LLMs without fine-tuning, more recent approaches have shifted toward the reinforcement learning strategy to further enhance agents’ ability to solve complex interactive tasks with environments and tools. However, previous approaches are constrained by the sparse reward issue, where existing datasets solely provide a final scalar reward for each multi-step reasoning chain, potentially leading to ineffectiveness and inefficiency in policy learning. In this paper, we introduce StepAgent, which utilizes step-wise reward to optimize the agent’s reinforcement learning process. Inheriting the spirit of novice-to-expert theory, we first compare the actions of the expert and the agent to automatically generate intermediate rewards for fine-grained optimization. Additionally, we propose implicit-reward and inverse reinforcement learning techniques to facilitate agent reflection and policy adjustment. Further theoretical analysis demonstrates that the action distribution of the agent can converge toward the expert action distribution over multiple training cycles. Experimental results across various datasets indicate that StepAgent outperforms existing baseline methods.
大型语言模型(LLM)的出色能力使它们成为各种自主代理系统中的关键组件。虽然传统方法依赖于LLM的固有知识而无需微调,但更新的方法已转向强化学习策略,以进一步提高代理解决与环境和工具相关的复杂交互任务的能力。然而,以前的方法受到稀疏奖励问题的限制,现有数据集只为每个多步推理链提供最终标量奖励,这可能导致策略学习中的低效和无效。在本文中,我们介绍了StepAgent,它利用分步奖励来优化代理的强化学习过程。秉承新手到专家理论的精神,我们首先将专家与代理的行动进行比较,以自动生成用于精细优化的中间奖励。此外,我们提出了隐式奖励和逆向强化学习技术,以促进代理反思和策略调整。进一步的理论分析表明,代理的动作分布可以在多个训练周期内收敛到专家动作分布。在多个数据集上的实验结果表明,StepAgent优于现有基线方法。
论文及项目相关链接
Summary
大型语言模型(LLMs)在自主代理系统中的作用日益重要。最新方法采用强化学习策略,以提高代理解决复杂交互任务的能力。然而,之前的方法受到稀疏奖励问题的限制,现有数据集只为每个多步推理链提供最终标量奖励,可能导致策略学习的不高效和无效。本文提出StepAgent,利用步骤奖励优化代理的强化学习过程。借鉴新手到专家的理论精神,我们比较专家与代理的行动来自动生成中间奖励,实现精细优化。此外,我们还引入了隐性奖励和逆向强化学习技术,以促进代理反思和调整策略。理论分析表明,代理的行动分布可以在多次训练周期中收敛到专家行动分布。在多个数据集上的实验结果表明,StepAgent优于现有基线方法。
Key Takeaways
- 大型语言模型(LLMs)在自主代理系统中扮演重要角色。
- 最近的策略采用强化学习来提升代理解决复杂交互任务的能力。
- 稀疏奖励问题限制了之前的方法,需要为每个多步推理链提供更精细的奖励。
- StepAgent通过利用步骤奖励优化代理的强化学习过程来解决这个问题。
- StepAgent比较专家与代理的行动来自动生成中间奖励,实现精细优化。
- 引入隐性奖励和逆向强化学习技术,促进代理反思和调整策略。
点此查看论文截图

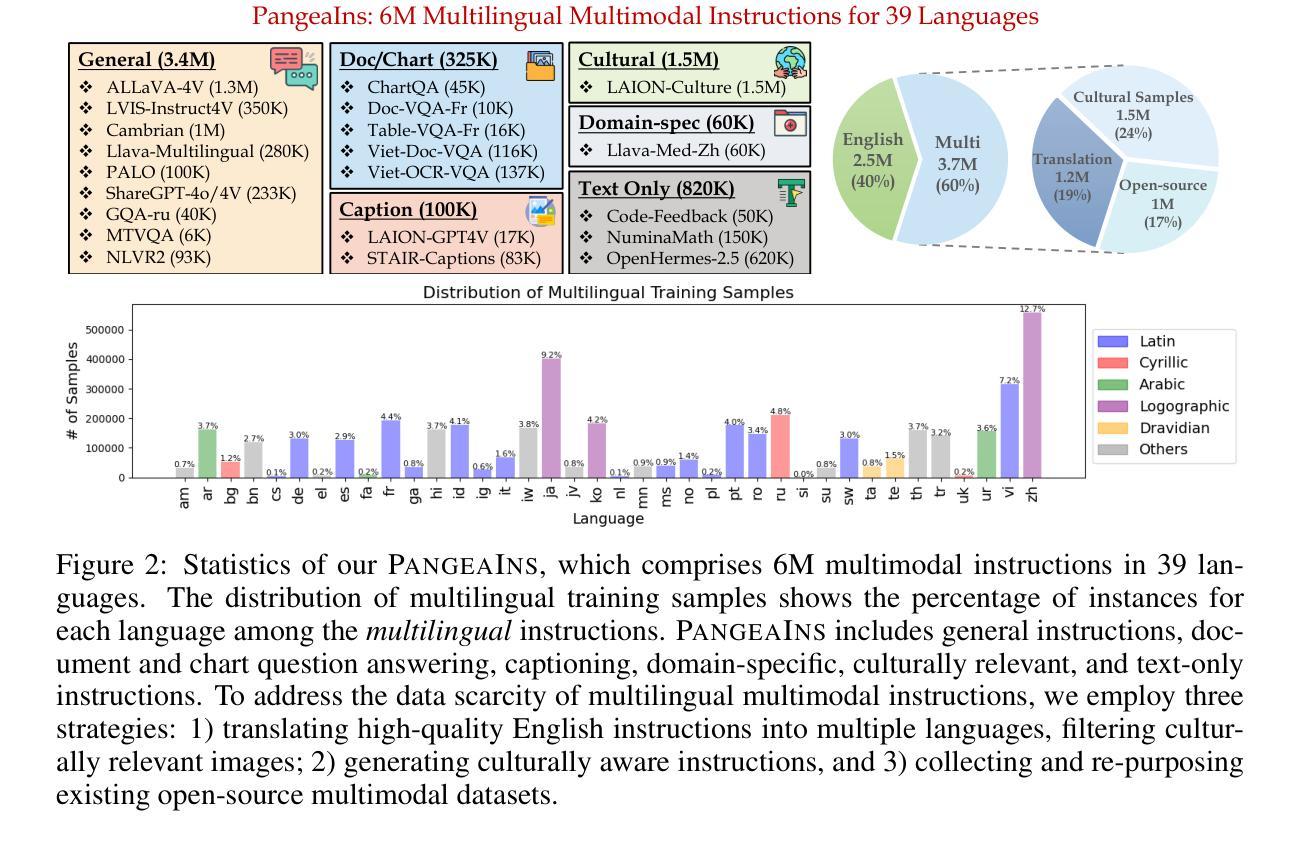
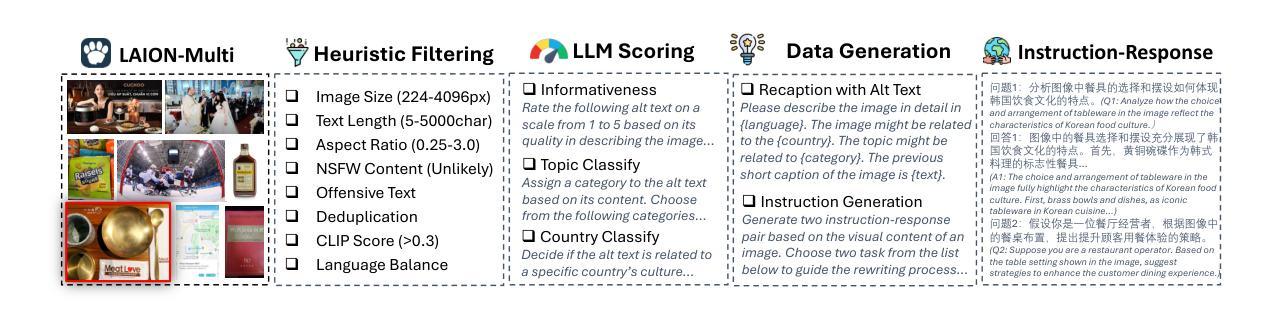
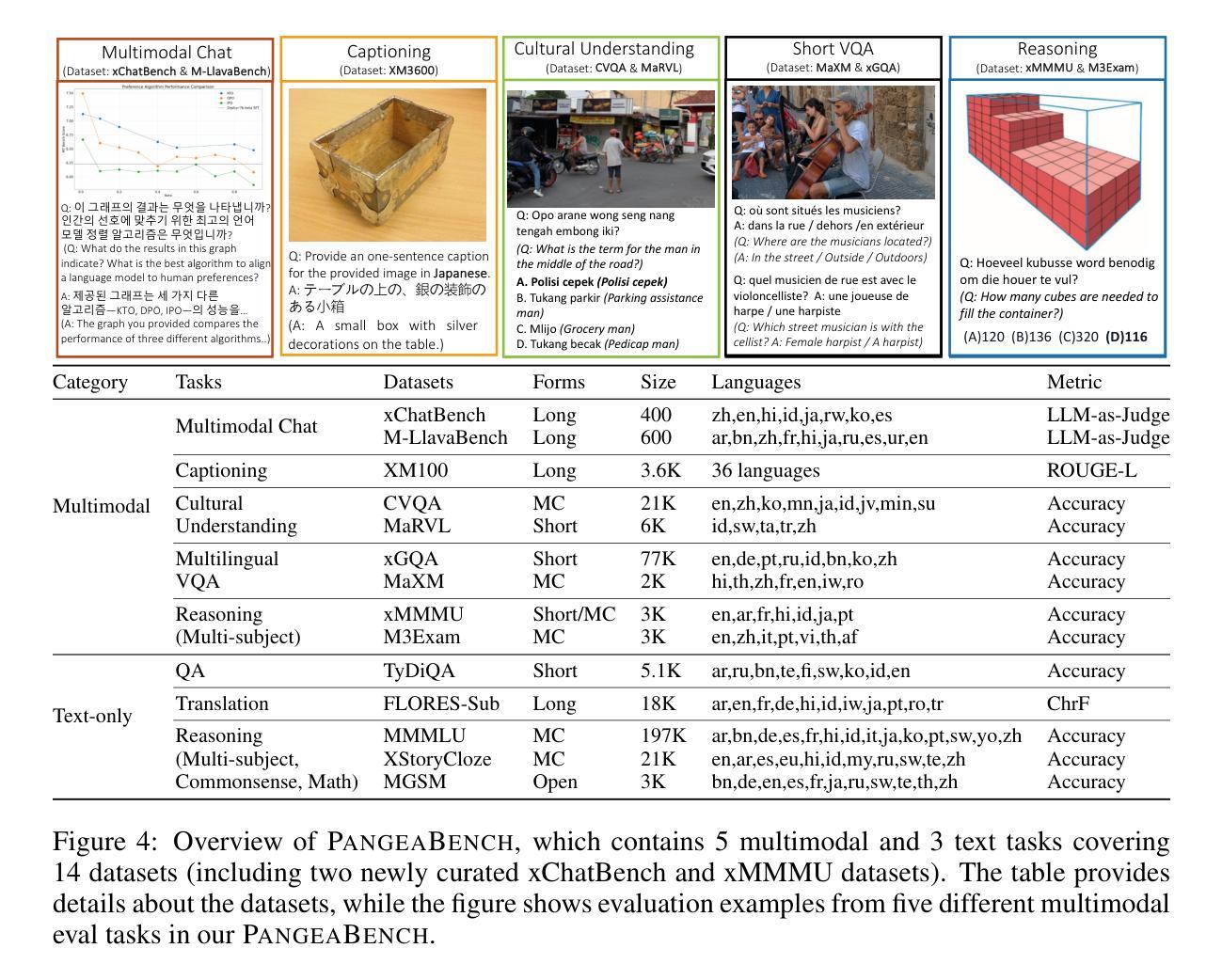
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Authors:Xiang Yue, Yueqi Song, Akari Asai, Seungone Kim, Jean de Dieu Nyandwi, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy, Graham Neubig
Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world’s languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models’ capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
尽管最近的多模态大型语言模型(MLLMs)有所进展,但它们的发展主要集中在英语和西方为中心的数据集和任务上,导致世界上大多数语言和多样化的文化背景代表性不足。本文介绍了Pangea,这是一个在PangeaIns上训练的多语言多模态大型语言模型,PangeaIns是一个包含39种语言的多样化6百万指令数据集。PangeaIns的特点包括:1)高质量的英语指令,2)精心机器翻译的指令,以及3)确保跨文化覆盖的文化相关多模态任务。为了严格评估模型的能力,我们推出了PangeaBench,这是一个全面的评估套件,包含覆盖47种语言的14个数据集。结果表明,在多种语言和多样化的文化背景下,Pangea显著优于现有的开源模型。消融研究进一步揭示了英语数据比例、语言流行度和多模态训练样本数量对整体性能的重要性。我们完全开源我们的数据、代码和训练检查点,以促进包容性和稳健的多语言MLLMs的发展,推动更广泛的语言和文化领域的公平和可访问性。
论文及项目相关链接
PDF 54 pages, 27 figures
Summary
多模态大型语言模型(MLLMs)虽有所进展,但主要聚焦于英语和西方语境的数据集和任务,忽视了世界上其他语言和多元文化背景的代表性。本文介绍了一个跨语言的MLLM——Pangea,它基于一个包含39种语言的多元化指令数据集PangeaIns进行训练。PangeaIns的特点包括:高质量英语指令、精心机器翻译的指令,以及确保跨文化覆盖的多模态任务。为严格评估模型能力,本文还介绍了PangeaBench评估套件,涵盖47种语言的14个数据集。结果显示,Pangea在多语言背景和多元文化环境中显著优于现有开源模型。消融研究进一步揭示了英语数据比例、语言流行度和多模态训练样本数量对整体性能的影响。我们公开所有数据、代码和训练检查点,以促进开发和包容性强的多语言MLLMs,推动更广泛的语言和文化的公平性和可访问性。
Key Takeaways
- MLLMs虽然有所发展,但主要聚焦于英语和西方语境,忽视了其他语言和多元文化背景的代表性。
- 论文介绍了一个跨语言的MLLM——Pangea,其基于一个多元化的指令数据集PangeaIns进行训练,包含39种语言。
- PangeaIns数据集包含高质量英语指令、机器翻译的指令以及多模态任务,以确保跨文化的覆盖。
- 论文还介绍了PangeaBench评估套件,用于严格评估模型的能力,涵盖14个数据集和47种语言。
- Pangea在多语言背景和多元文化环境中的性能显著优于现有开源模型。
- 消融研究揭示了英语数据比例、语言流行度和多模态训练样本数量对模型性能的重要影响。
点此查看论文截图