⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-10 更新
Multimodal Whole Slide Foundation Model for Pathology
Authors:Tong Ding, Sophia J. Wagner, Andrew H. Song, Richard J. Chen, Ming Y. Lu, Andrew Zhang, Anurag J. Vaidya, Guillaume Jaume, Muhammad Shaban, Ahrong Kim, Drew F. K. Williamson, Bowen Chen, Cristina Almagro-Perez, Paul Doucet, Sharifa Sahai, Chengkuan Chen, Daisuke Komura, Akihiro Kawabe, Shumpei Ishikawa, Georg Gerber, Tingying Peng, Long Phi Le, Faisal Mahmood
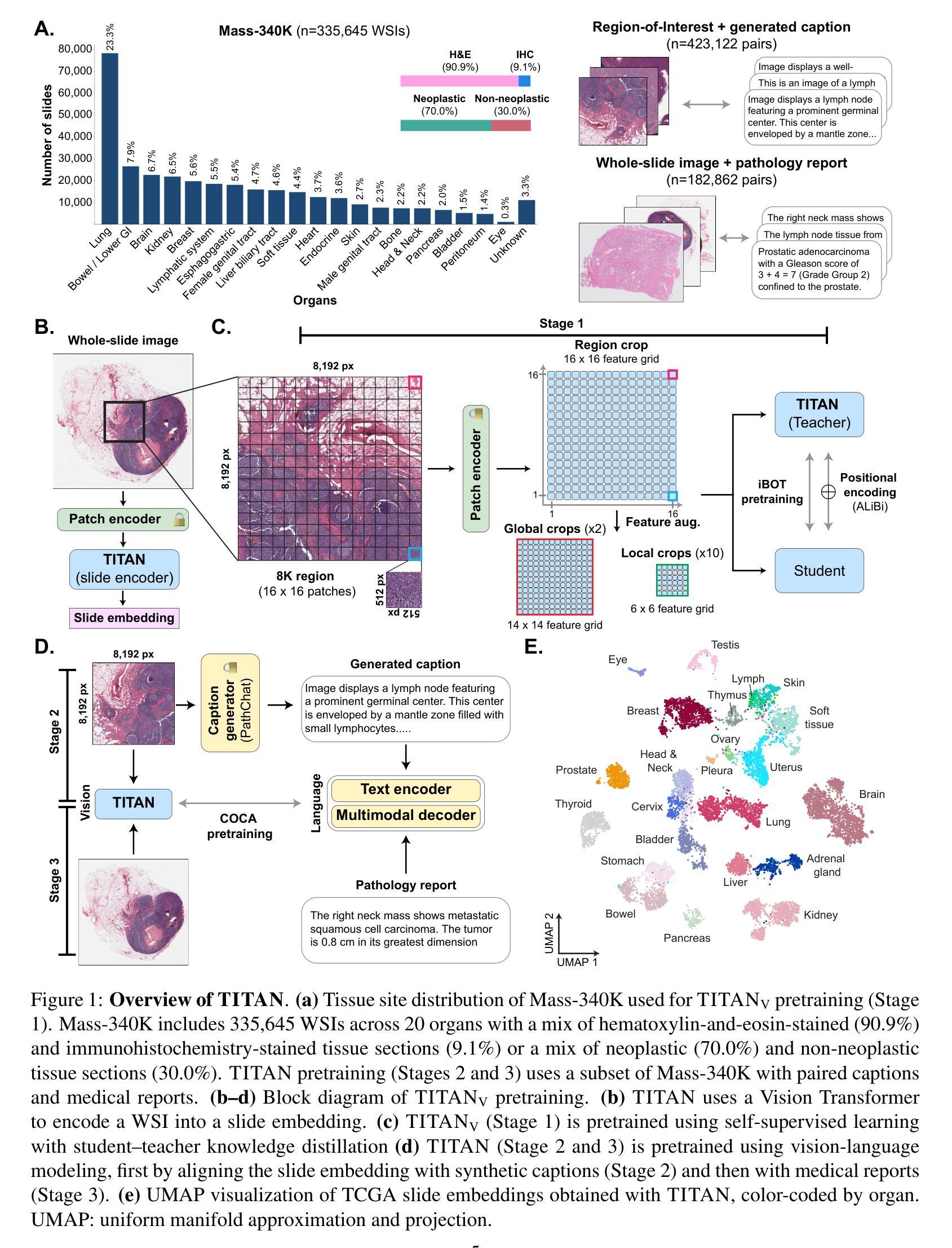
The field of computational pathology has been transformed with recent advances in foundation models that encode histopathology region-of-interests (ROIs) into versatile and transferable feature representations via self-supervised learning (SSL). However, translating these advancements to address complex clinical challenges at the patient and slide level remains constrained by limited clinical data in disease-specific cohorts, especially for rare clinical conditions. We propose TITAN, a multimodal whole slide foundation model pretrained using 335,645 WSIs via visual self-supervised learning and vision-language alignment with corresponding pathology reports and 423,122 synthetic captions generated from a multimodal generative AI copilot for pathology. Without any finetuning or requiring clinical labels, TITAN can extract general-purpose slide representations and generate pathology reports that generalize to resource-limited clinical scenarios such as rare disease retrieval and cancer prognosis. We evaluate TITAN on diverse clinical tasks and find that TITAN outperforms both ROI and slide foundation models across machine learning settings such as linear probing, few-shot and zero-shot classification, rare cancer retrieval and cross-modal retrieval, and pathology report generation.
计算病理学领域已经发生了变革,得益于基础模型的最新进展,这些模型通过自我监督学习(SSL)将组织病理学感兴趣区域(ROI)编码成通用和可转移的特征表示。然而,将这些进展转化为针对患者和切片级别的复杂临床挑战仍然受到特定疾病队列中临床数据有限的制约,尤其是对于罕见的临床状况。我们提出了TITAN,这是一个多模式全切片基础模型,使用335,645张全切片图像(WSI)通过视觉自我监督学习和视觉语言对齐进行预训练,并辅以相应的病理报告和由多模式生成式AI病理助手生成的423,122个合成标题。TITAN无需微调或要求临床标签,即可提取通用切片表示并生成适用于资源有限的临床场景的病理报告,如罕见疾病检索和癌症预后。我们在多种临床任务上评估了TITAN的表现,发现无论是在线性探测、少样本和零样本分类、罕见癌症检索和跨模态检索,还是病理报告生成等机器学习环境中,TITAN的表现都优于ROI和切片基础模型。
论文及项目相关链接
PDF The code is accessible at https://github.com/mahmoodlab/TITAN
摘要
基于自监督学习(SSL)的最新进展,计算病理学领域已经能够将组织病理学感兴趣区域(ROI)编码为通用和可转移的特征表示,从而推动了该领域的发展。然而,在患者和切片层面应对复杂的临床挑战时,尤其是在罕见临床条件下,由于特定疾病队列的临床数据有限,将这些进步转化为实际应用仍面临挑战。本文提出TITAN模型,这是一种多模态全切片基础模型,通过使用335,645张全切片图像(WSIs)进行视觉自监督学习和视觉语言对齐进行预训练,并融合了相应的病理报告和由多模态生成AI辅助生成的423,122张合成幻灯片字幕。TITAN无需微调且不需要临床标签,就能够提取通用的幻灯片表示并生成病理报告,可推广到资源有限的临床场景中,如罕见疾病检索和癌症预后。我们对TITAN进行了多样化的临床任务评估,发现其在机器学习设置(如线性探测、小样本和零样本分类、罕见癌症检索和跨模态检索以及病理报告生成)中表现优于ROI和幻灯片基础模型。
要点
- 计算病理学领域因基础模型的最新进展而变革,这些模型通过自监督学习将组织病理学感兴趣区域编码为通用和可转移的特征表示。
- 将这些进步应用于患者和切片级别的临床挑战时仍面临限制,特别是缺乏特定疾病的临床数据和罕见临床条件下的数据。
- 提出了TITAN多模态全切片基础模型,利用大量的全切片图像、病理报告和合成字幕进行预训练。
- TITAN模型无需微调或临床标签,能在多种临床任务中表现优异,包括罕见疾病检索、癌症预后预测等。
点此查看论文截图

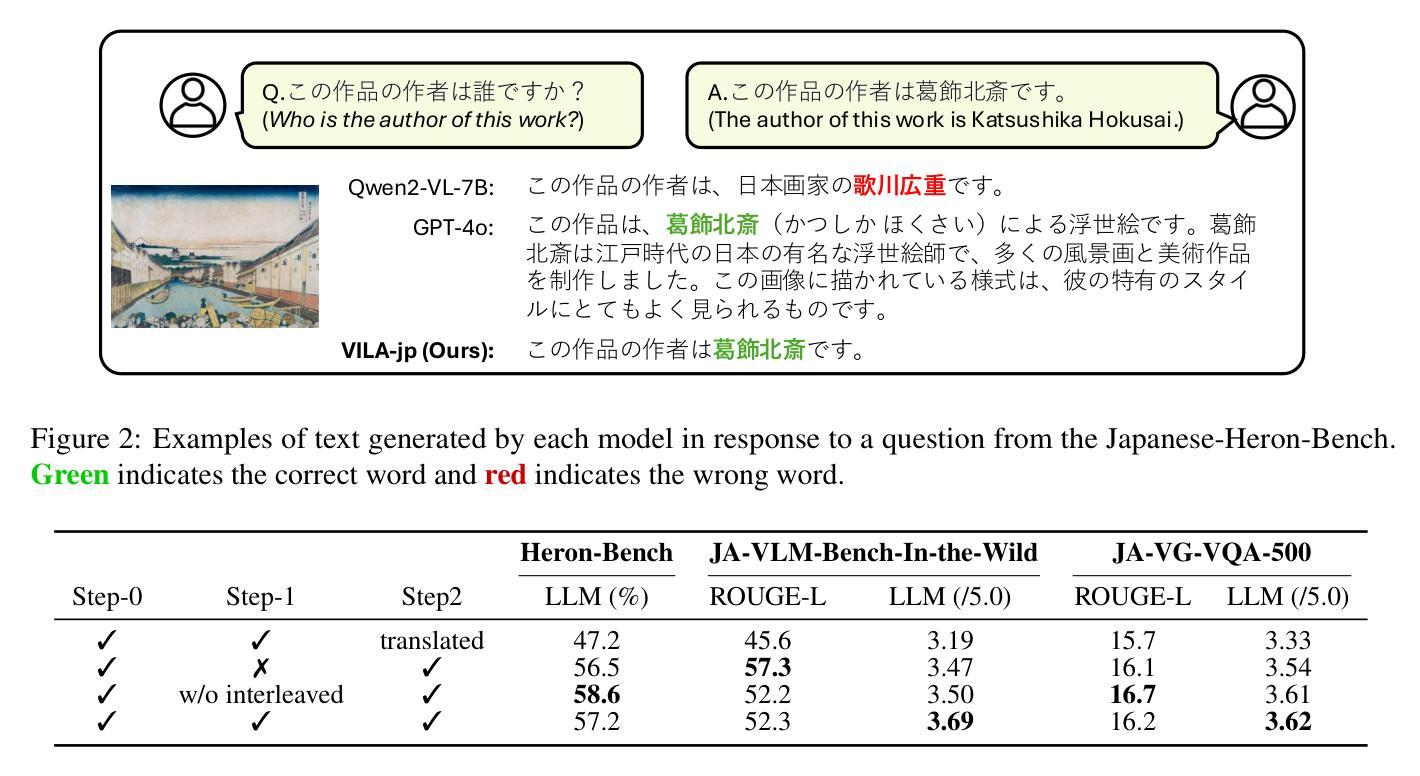
Constructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model
Authors:Keito Sasagawa, Koki Maeda, Issa Sugiura, Shuhei Kurita, Naoaki Okazaki, Daisuke Kawahara
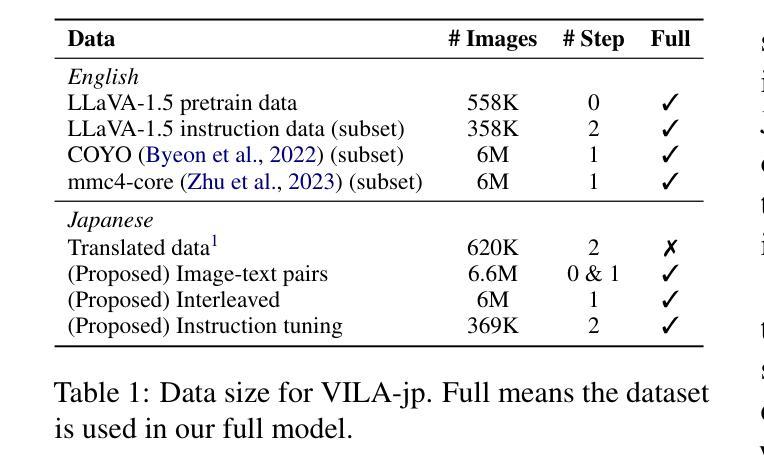
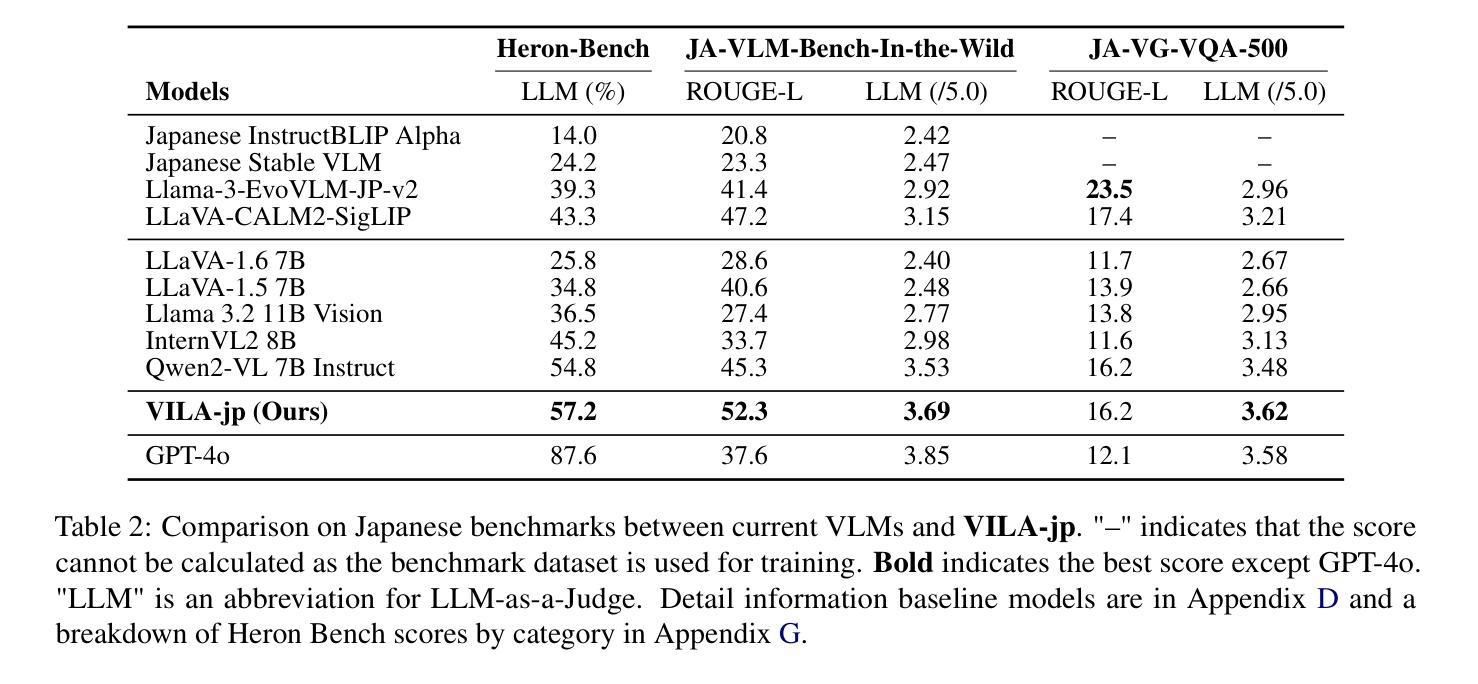
To develop high-performing Visual Language Models (VLMs), it is essential to prepare multimodal resources, such as image-text pairs, interleaved data, and instruction data. While multimodal resources for English are abundant, there is a significant lack of corresponding resources for non-English languages, such as Japanese. To address this problem, we take Japanese as a non-English language and propose a method for rapidly creating Japanese multimodal datasets from scratch. We collect Japanese image-text pairs and interleaved data from web archives and generate Japanese instruction data directly from images using an existing VLM. Our experimental results show that a VLM trained on these native datasets outperforms those relying on machine-translated content.
为了开发高性能的视觉语言模型(VLMs),准备多模态资源至关重要,例如图像文本对、交错数据和指令数据。虽然英语的多模态资源非常丰富,但非英语语言(如日语)的相应资源却严重匮乏。为了解决这一问题,我们以日语为非英语语言为例,提出了一种从零开始快速创建日语多模态数据集的方法。我们从网络档案中收集日语图像文本对和交错数据,并使用现有的VLM直接从图像生成日语指令数据。我们的实验结果表明,在这些本地数据集上训练的VLM的性能优于那些依赖于机器翻译内容的模型。
论文及项目相关链接
PDF 15 pages, 7 figures
Summary
本文介绍了为开发高性能视觉语言模型(VLMs),准备多模态资源如图像文本对、交错数据等的重要性。由于非英语语言的相应资源严重匮乏,例如日语,该研究提出一种从零开始快速创建日语多模态数据集的方法。通过从网络档案收集日语图像文本对和交错数据,并利用现有VLM直接从图像生成日语指令数据,实验结果显示在本地数据集上训练的VLM表现优于依赖机器翻译内容的模型。
Key Takeaways
- 多模态资源对开发高性能视觉语言模型至关重要,包括图像文本对、交错数据等。
- 非英语语言的相应资源如日语等存在严重匮乏的问题。
- 研究提出了一种快速创建日语多模态数据集的方法。
- 通过从网络档案收集日语图像文本对和交错数据。
- 利用现有视觉语言模型直接从图像生成日语指令数据。
- 在本地数据集上训练的视觉语言模型表现优于依赖机器翻译内容的模型。
点此查看论文截图

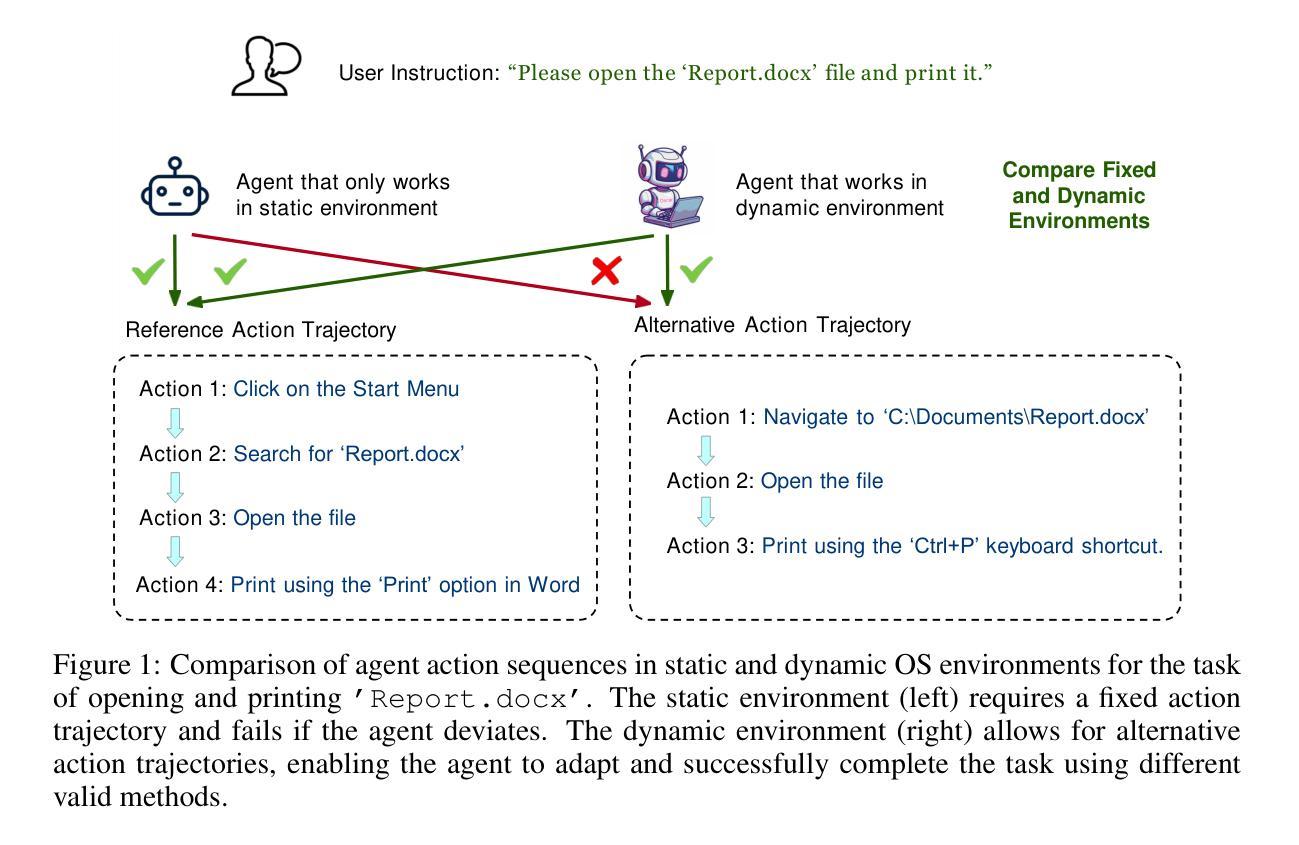
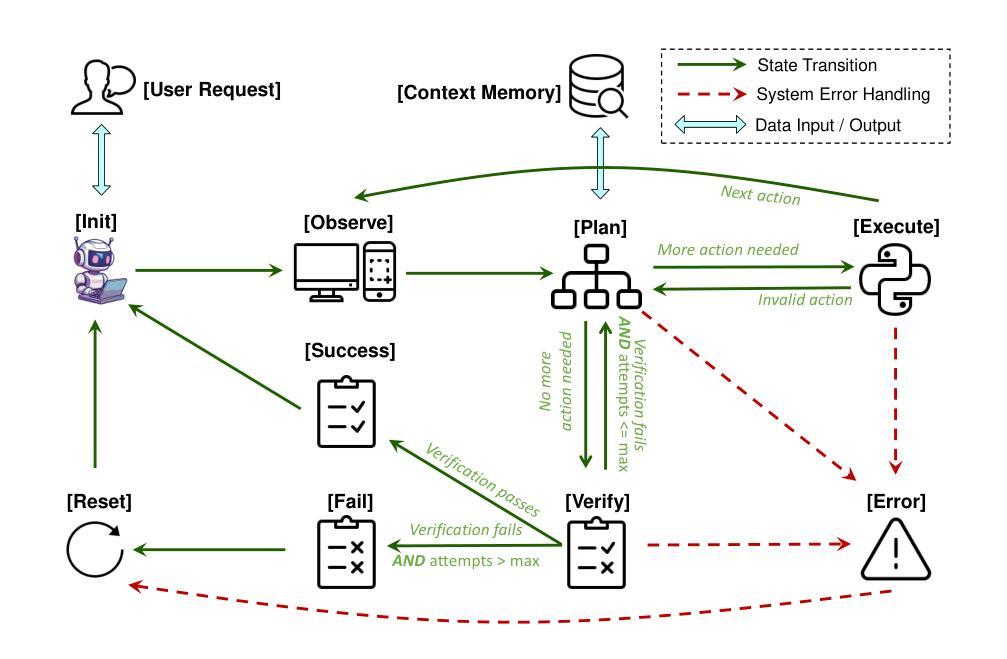
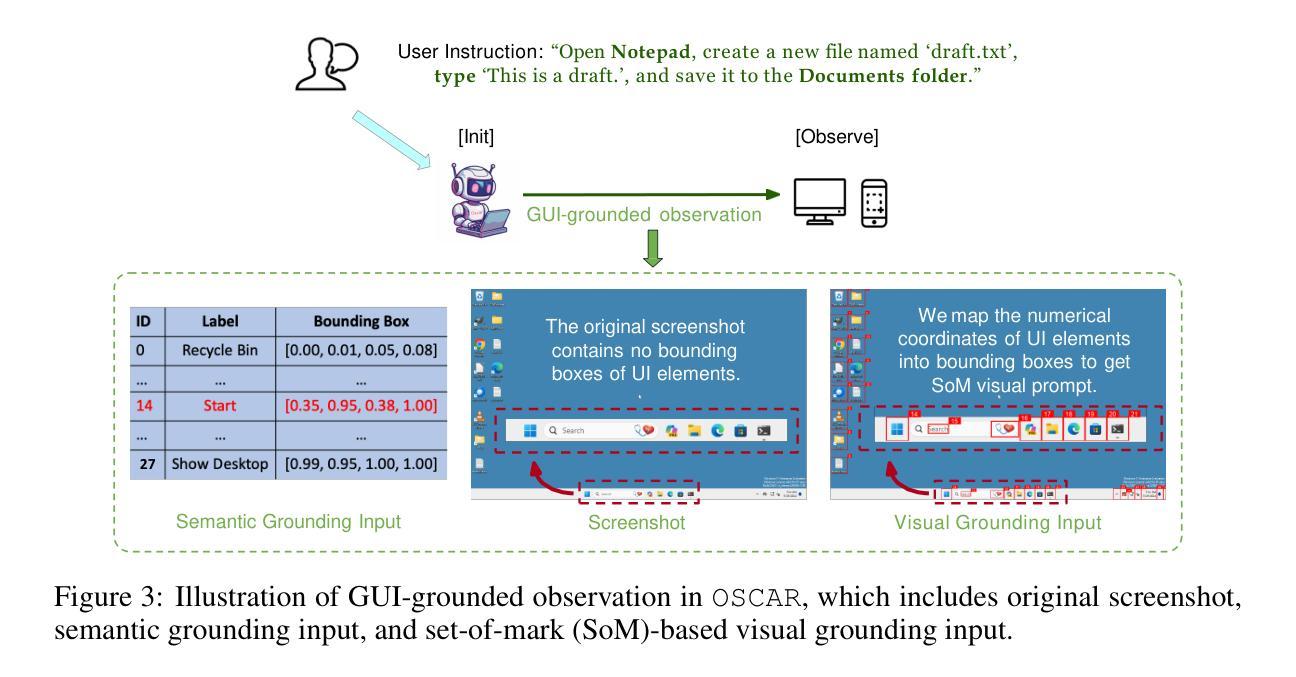
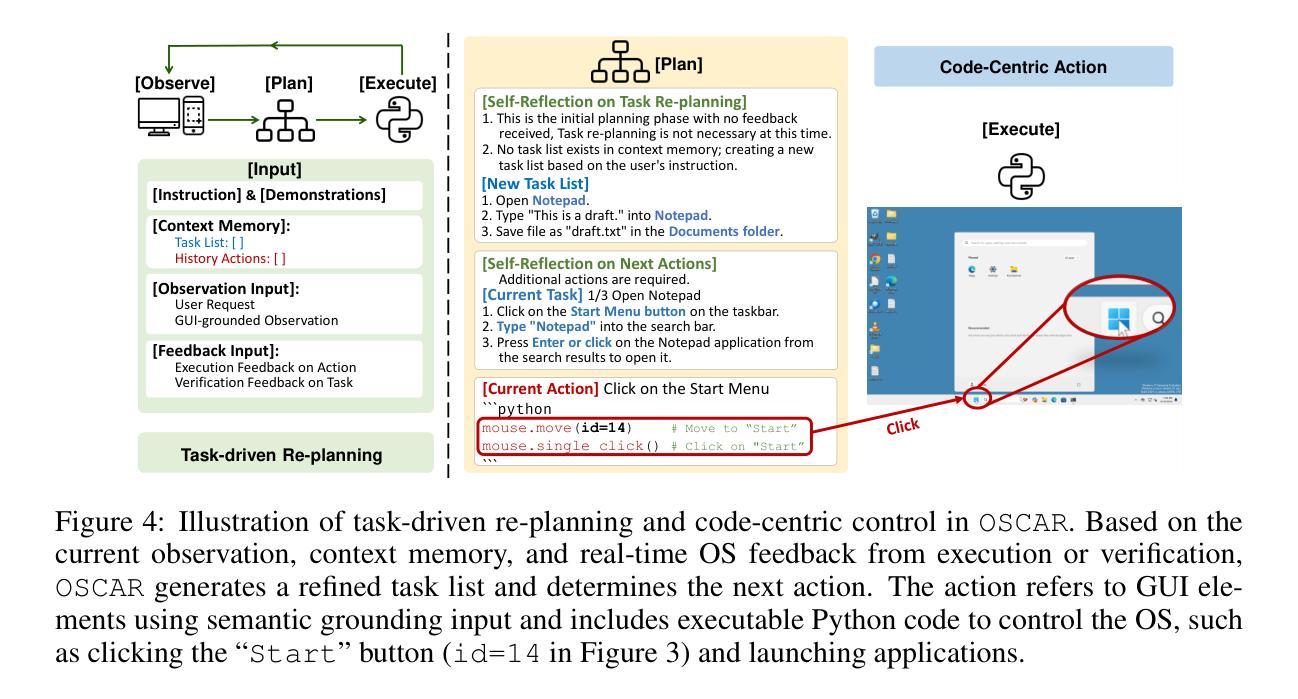
OSCAR: Operating System Control via State-Aware Reasoning and Re-Planning
Authors:Xiaoqiang Wang, Bang Liu
Large language models (LLMs) and large multimodal models (LMMs) have shown great potential in automating complex tasks like web browsing and gaming. However, their ability to generalize across diverse applications remains limited, hindering broader utility. To address this challenge, we present OSCAR: Operating System Control via state-Aware reasoning and Re-planning. OSCAR is a generalist agent designed to autonomously navigate and interact with various desktop and mobile applications through standardized controls, such as mouse and keyboard inputs, while processing screen images to fulfill user commands. OSCAR translates human instructions into executable Python code, enabling precise control over graphical user interfaces (GUIs). To enhance stability and adaptability, OSCAR operates as a state machine, equipped with error-handling mechanisms and dynamic task re-planning, allowing it to efficiently adjust to real-time feedback and exceptions. We demonstrate OSCAR’s effectiveness through extensive experiments on diverse benchmarks across desktop and mobile platforms, where it transforms complex workflows into simple natural language commands, significantly boosting user productivity. Our code will be open-source upon publication.
大型语言模型(LLM)和多模态大模型(LMM)在自动化浏览网页和玩游戏等复杂任务方面显示出巨大潜力。然而,它们在跨不同应用程序方面的泛化能力仍然有限,阻碍了其更广泛的应用。为了应对这一挑战,我们推出了OSCAR:基于状态感知推理和重新规划的操作系统控制。OSCAR是一个通用智能体,旨在通过标准化的控制(如鼠标和键盘输入)自主浏览和与各种桌面和移动应用程序进行交互,同时处理屏幕图像以执行用户命令。OSCAR将人类指令翻译成可执行的Python代码,从而实现对图形用户界面(GUI)的精确控制。为了提高稳定性和适应性,OSCAR作为一个状态机运行,配备了错误处理机制和动态任务重新规划,使其能够高效地适应实时反馈和异常情况。我们通过桌面和移动平台上各种基准测试的广泛实验证明了OSCAR的有效性,它可以将复杂的工作流程转化为简单的自然语言命令,从而极大地提高了用户的工作效率。我们的代码将在发表时开源。
论文及项目相关链接
PDF Work in progress
Summary
OSCAR是一个通用代理,可通过标准化控制自主导航和与各种桌面和移动应用程序进行交互,如鼠标和键盘输入,同时处理屏幕图像以执行用户命令。它能够将人类指令翻译成可执行的Python代码,实现对图形用户界面(GUI)的精确控制。OSCAR采用状态机工作方式,具有错误处理机制和动态任务规划,可高效适应实时反馈和异常。在桌面和移动平台的多样化基准测试中,OSCAR通过自然语言命令执行复杂的工作流程,显著提高用户生产率。
Key Takeaways
- OSCAR是LLM和LMM领域的进步,可以自动化执行复杂的任务如网页浏览和游戏。
- OSCAR设计用于自主导航和与各种应用程序交互。
- OSCAR通过标准化控制(如鼠标和键盘)以及处理屏幕图像来执行用户命令。
- OSCAR能将人类指令翻译成Python代码,实现GUI的精确控制。
- OSCAR采用状态机工作方式,具有稳定性和适应性。
- OSCAR具有错误处理机制和动态任务规划功能。
点此查看论文截图

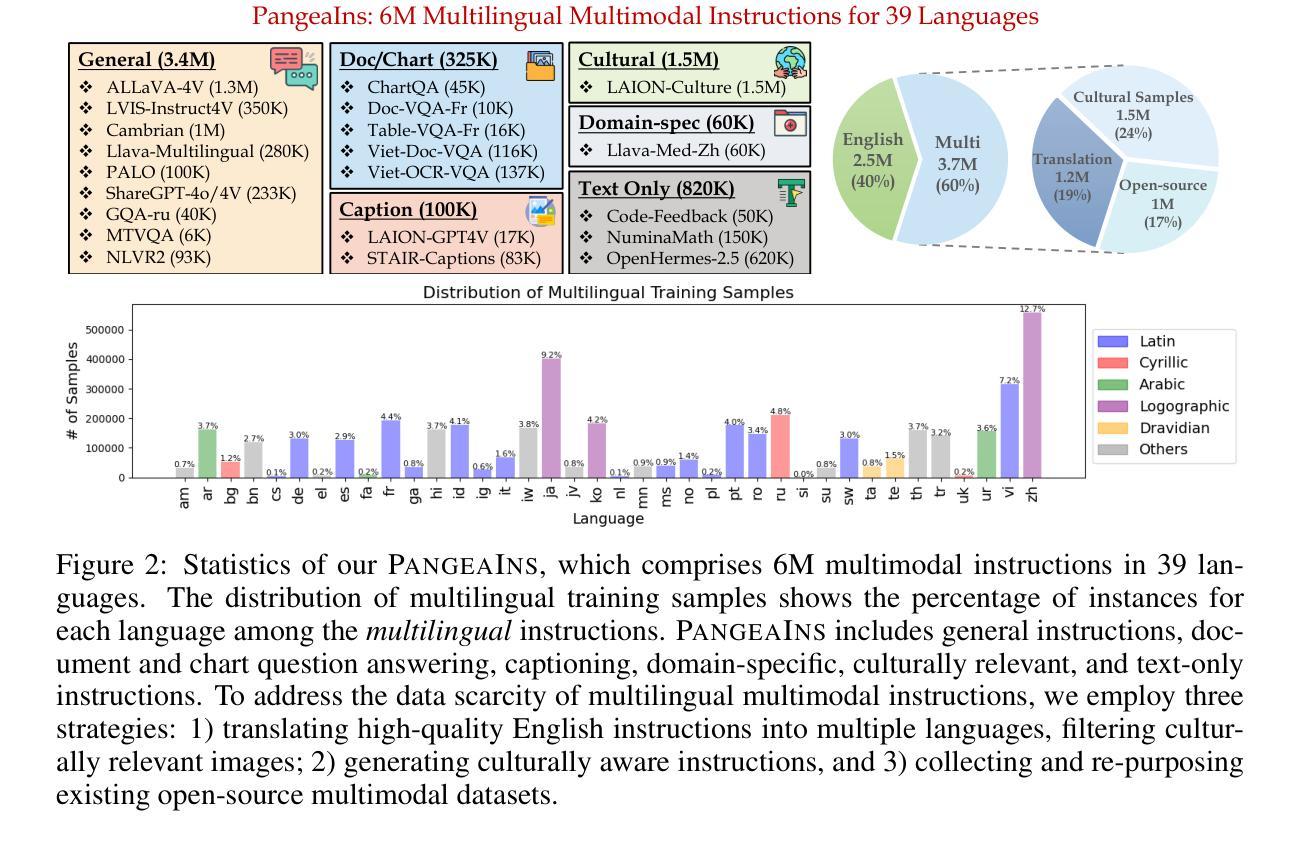
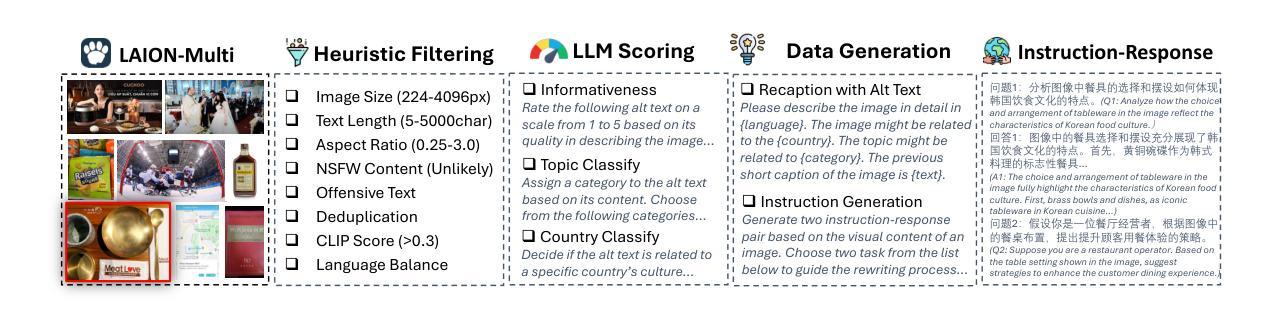
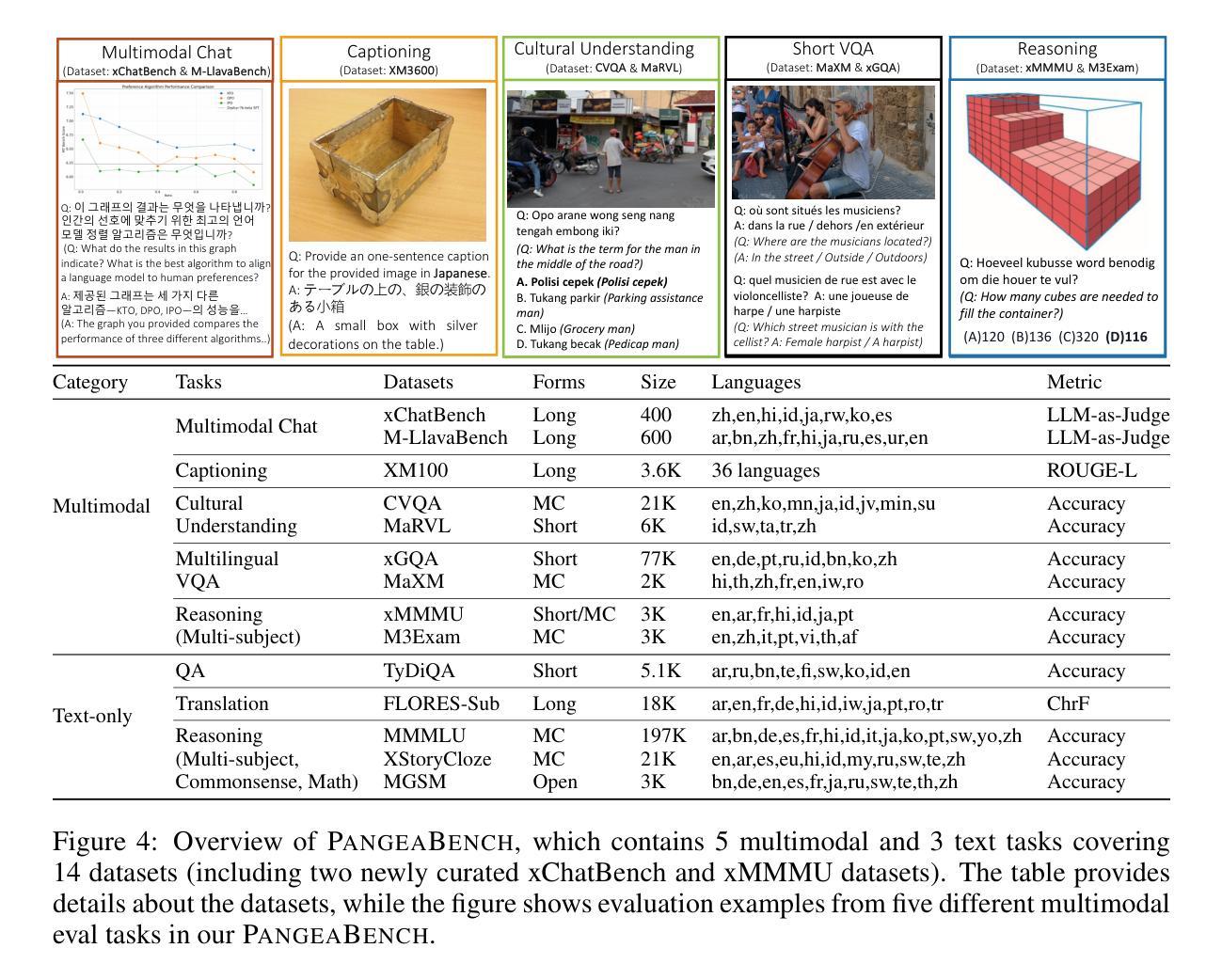
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Authors:Xiang Yue, Yueqi Song, Akari Asai, Seungone Kim, Jean de Dieu Nyandwi, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy, Graham Neubig
Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world’s languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models’ capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
尽管最近多模态大型语言模型(MLLMs)取得了进展,但它们的开发主要集中在英语和西方为中心的数据集和任务上,导致世界上大多数语言和多样化的文化背景代表性不足。本文介绍了Pangea,这是一个在PangeaIns上训练的多语言多模态大型语言模型。PangeaIns是一个包含39种语言的多样化600万指令数据集。PangeaIns的特点包括:1)高质量的英语指令,2)精心机器翻译的指令,以及3)文化相关的多模态任务,以确保跨文化覆盖。为了严格评估模型的能力,我们推出了PangeaBench,这是一个包含14个数据集、覆盖47种语言的全面评估套件。结果表明,在多种语言和多样化的文化背景环境中,Pangea显著优于现有开源模型。消融研究进一步揭示了英语数据比例、语言流行度和多模态训练样本数量对整体性能的重要性。我们完全开源我们的数据、代码和训练检查点,以促进包容性和稳健的多语言MLLMs的发展,推动更广泛的语言和文化领域的公平和可访问性。
论文及项目相关链接
PDF 54 pages, 27 figures
Summary
一篇论文介绍了Pangea,这是一个基于PangeaIns数据集的多语言多模态大型语言模型。该数据集包含高质量的英文指令、经过机器翻译后的指令以及跨文化相关的多模态任务,覆盖39种语言。论文还介绍了用于评估模型能力的PangeaBench评估套件。研究表明,Pangea在多语言环境和不同文化背景下显著优于现有开源模型。论文公开了数据集、代码和训练检查点,以促进开发包容性强、稳健的多语言大型语言模型,推动更广泛的语言和文化领域的公平性和可访问性。
Key Takeaways
- Pangea是一个多语言多模态的大型语言模型,旨在解决现有模型主要集中在英语和西方中心数据集和任务上的问题,涵盖39种语言。
- PangeaIns数据集包含高质量的英文指令、机器翻译后的指令以及跨文化相关的多模态任务,确保跨文化的覆盖。
- 论文介绍了PangeaBench评估套件,用于全面评估模型能力,涵盖47种语言。
- Pangea在多语言环境和不同文化背景下的性能显著优于现有开源模型。
- 论文进行的消减研究揭示了英语数据比例、语言流行度和多模态训练样本数量对模型性能的整体影响。
- 论文公开了数据集、代码和训练检查点,以促进开发更包容、更稳健的多语言大型语言模型。
点此查看论文截图

SwaQuAD-24: QA Benchmark Dataset in Swahili
Authors:Alfred Malengo Kondoro
This paper proposes the creation of a Swahili Question Answering (QA) benchmark dataset, aimed at addressing the underrepresentation of Swahili in natural language processing (NLP). Drawing from established benchmarks like SQuAD, GLUE, KenSwQuAD, and KLUE, the dataset will focus on providing high-quality, annotated question-answer pairs that capture the linguistic diversity and complexity of Swahili. The dataset is designed to support a variety of applications, including machine translation, information retrieval, and social services like healthcare chatbots. Ethical considerations, such as data privacy, bias mitigation, and inclusivity, are central to the dataset development. Additionally, the paper outlines future expansion plans to include domain-specific content, multimodal integration, and broader crowdsourcing efforts. The Swahili QA dataset aims to foster technological innovation in East Africa and provide an essential resource for NLP research and applications in low-resource languages.
本文提议创建一个斯瓦希里语问答(QA)基准数据集,旨在解决自然语言处理(NLP)中斯瓦希里语的代表性不足问题。该数据集借鉴了SQuAD、GLUE、KenSwQuAD和KLUE等现有的基准测试,将重点放在提供高质量、注释过的问题答案对上,这些对捕捉斯瓦希里语的语言多样性和复杂性至关重要。该数据集旨在支持多种应用,包括机器翻译、信息检索以及医疗保健聊天机器人等社会服务。在数据集开发过程中,道德考量(如数据隐私、偏见缓解和包容性)占据核心地位。此外,本文还概述了未来扩展计划,包括包含特定领域的内容、多模式集成和更广泛的众包工作。斯瓦希里语QA数据集旨在促进东非的技术创新,并为低资源语言中的NLP研究与应用提供重要资源。
论文及项目相关链接
Summary
针对斯瓦希里语在自然语言处理(NLP)中的代表性不足问题,本文提出了创建斯瓦希里语问答(QA)基准数据集的建议。该数据集致力于提供高质量的注释问答对,体现斯瓦希里语的语言多样性和复杂性。该数据集的设计旨在支持多种应用,包括机器翻译、信息检索和社会服务(如医疗聊天机器人)。伦理考量,如数据隐私、偏见缓解和包容性,是数据集开发的核心。此外,本文还介绍了未来扩展计划,包括纳入领域特定内容、多模式集成和更广泛的众包努力。斯瓦希里语QA数据集旨在促进东非的技术创新,并为低资源语言中的NLP研究与应用提供重要资源。
Key Takeaways
- 提出创建斯瓦希里语问答(QA)基准数据集,以解决NLP中斯瓦希里语的代表性不足问题。
- 数据集将借鉴现有基准测试,如SQuAD、GLUE、KenSwQuAD和KLUE,并提供高质量的注释问答对。
- 数据集设计支持多种应用,包括机器翻译、信息检索和社会服务。
- 伦理考量(如数据隐私、偏见缓解和包容性)是数据集开发的核心。
- 计划未来纳入领域特定内容、多模式集成和众包努力以扩展数据集。
- 斯瓦希里语QA数据集旨在促进东非的技术创新。
点此查看论文截图

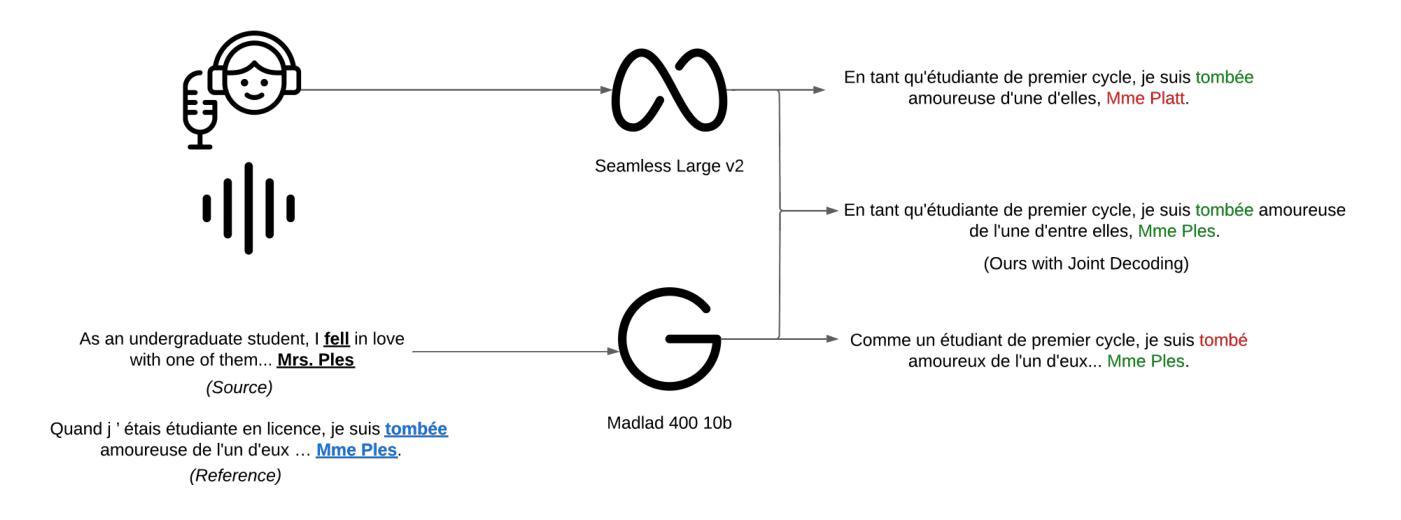
Plug, Play, and Fuse: Zero-Shot Joint Decoding via Word-Level Re-ranking Across Diverse Vocabularies
Authors:Sai Koneru, Matthias Huck, Miriam Exel, Jan Niehues
Recent advancements in NLP have resulted in models with specialized strengths, such as processing multimodal inputs or excelling in specific domains. However, real-world tasks, like multimodal translation, often require a combination of these strengths, such as handling both translation and image processing. While individual translation and vision models are powerful, they typically lack the ability to perform both tasks in a single system. Combining these models poses challenges, particularly due to differences in their vocabularies, which limit the effectiveness of traditional ensemble methods to post-generation techniques like N-best list re-ranking. In this work, we propose a novel zero-shot ensembling strategy that allows for the integration of different models during the decoding phase without the need for additional training. Our approach re-ranks beams during decoding by combining scores at the word level, using heuristics to predict when a word is completed. We demonstrate the effectiveness of this method in machine translation scenarios, showing that it enables the generation of translations that are both speech- and image-aware while also improving overall translation quality (We will release the code upon paper acceptance.).
近年来,自然语言处理领域的进步导致了具有专门优势的模型的出现,如处理多模式输入或在特定领域表现卓越。然而,现实世界中的任务,如多模式翻译,通常需要这些优势的组合,如同时处理翻译和图像处理。虽然单独的翻译和视觉模型功能强大,但它们通常缺乏在一个系统中执行这两个任务的能力。将这些模型组合起来带来了挑战,尤其是由于它们词汇表的差异,这限制了传统集成方法采用后生成技术的有效性,如N-best列表重排。在这项工作中,我们提出了一种新型的零样本集成策略,允许在解码阶段集成不同的模型,无需额外的训练。我们的方法通过在单词层面结合分数对光束进行重新排名,并使用启发式方法来预测单词何时完成。我们证明了该方法在机器翻译场景中的有效性,展示它能够在生成翻译时兼顾语音和图像感知能力,同时提高整体翻译质量。(论文被接受后我们将发布代码。)
论文及项目相关链接
PDF WMT 2024
Summary
近期自然语言处理(NLP)的进展带来了具有专业优势的模型,如在处理多模式输入或在特定领域表现卓越。然而,如多模态翻译等现实任务需要同时处理翻译和图像处理等多种任务,单一模型难以满足。结合这些模型面临挑战,特别是词汇差异问题,传统集成方法如N-best列表重排等方法在后期生成技术中效果不佳。本研究提出了一种新型零样本集成策略,可在解码阶段集成不同模型,无需额外训练。该方法通过结合词汇级分数进行解码阶段的重新排名,并利用启发式方法来预测词汇完成度。研究表明,此方法在机器翻译场景中能有效生成既兼顾语音又考虑图像的翻译,并提高了整体翻译质量。
Key Takeaways
- NLP领域的最新进展带来了具有专业优势的模型,这些模型在特定任务上表现卓越。
- 现实任务如多模态翻译需要同时处理多种任务,单一模型难以满足这些复杂需求。
- 结合多个模型面临挑战,特别是词汇差异问题。
- 传统集成方法在后期生成技术中效果不佳。
- 本研究提出了一种新型的零样本集成策略,可以在解码阶段集成不同的模型。
- 该策略通过结合词汇级分数进行解码阶段的重新排名,以提高翻译质量。
- 研究表明,此方法能生成既考虑语音又考虑图像的翻译,提高了整体翻译质量。
点此查看论文截图


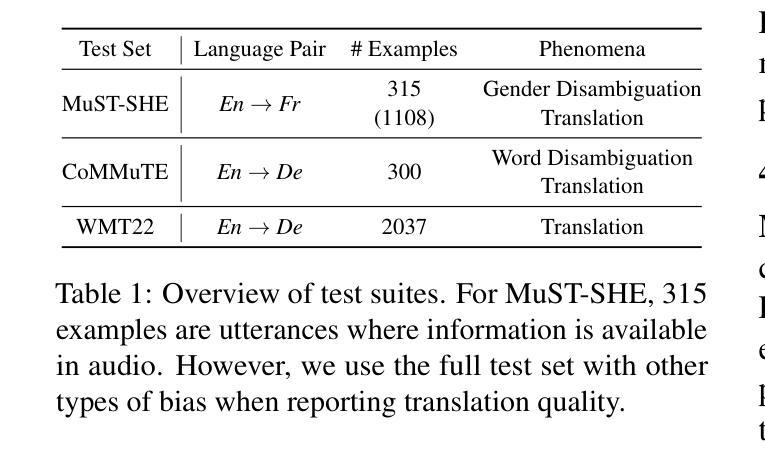
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
Authors:Jingqun Tang, Qi Liu, Yongjie Ye, Jinghui Lu, Shu Wei, Chunhui Lin, Wanqing Li, Mohamad Fitri Faiz Bin Mahmood, Hao Feng, Zhen Zhao, Yanjie Wang, Yuliang Liu, Hao Liu, Xiang Bai, Can Huang
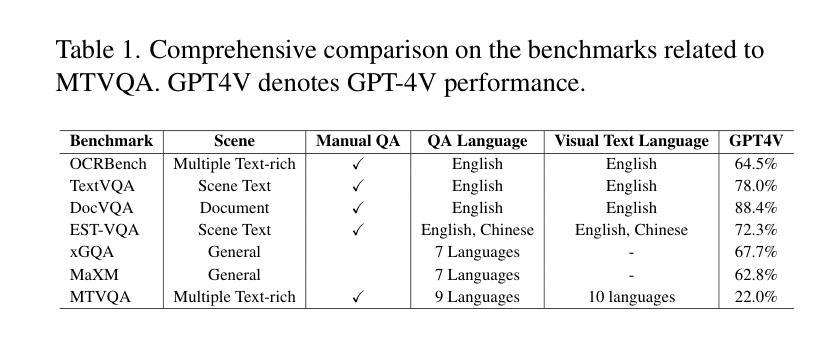
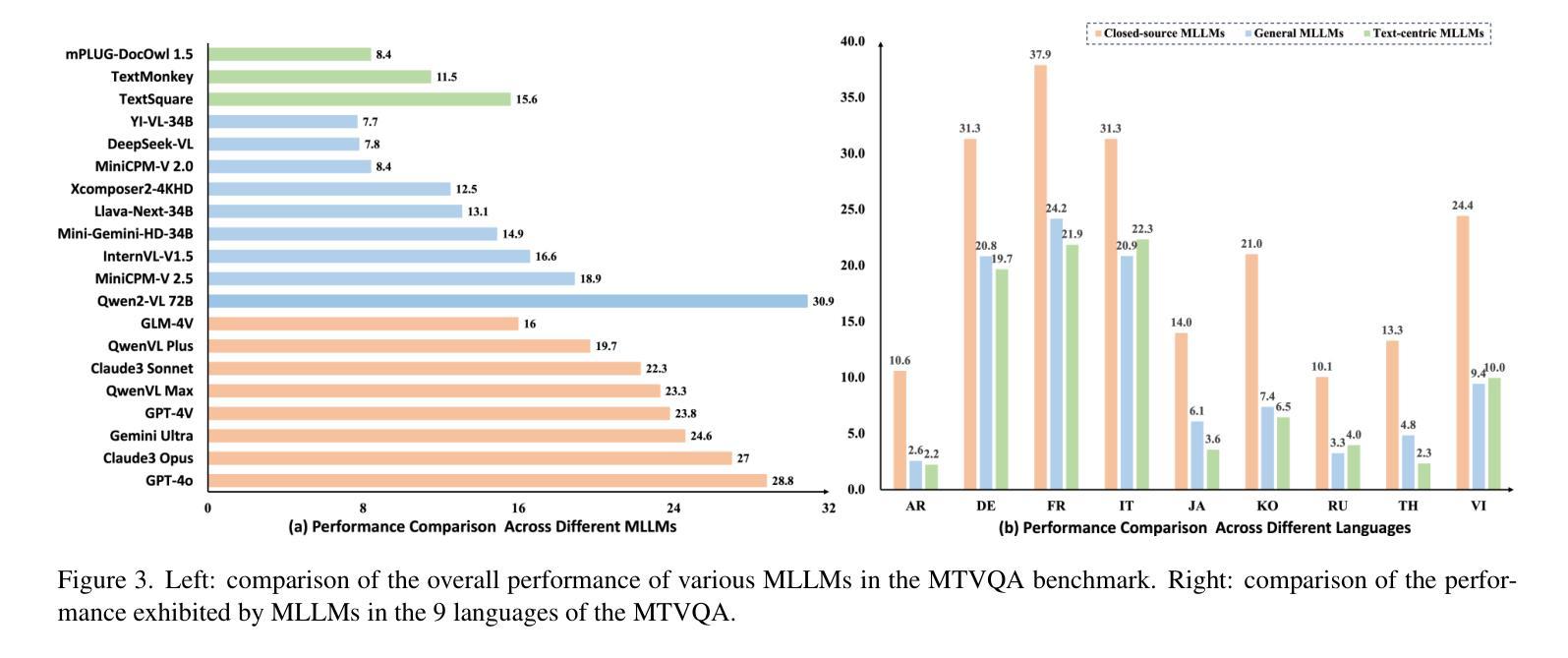
Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. Nonetheless, most existing TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets through translation engines, the translation-based protocol encounters a substantial “visual-textual misalignment” problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Moreover, it fails to address complexities related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we tackle multilingual TEC-VQA by introducing MTVQA, the first benchmark featuring high-quality human expert annotations across 9 diverse languages, consisting of 6,778 question-answer pairs across 2,116 images. Further, by comprehensively evaluating numerous state-of-the-art Multimodal Large Language Models~(MLLMs), including Qwen2-VL, GPT-4o, GPT-4V, Claude3, and Gemini, on the MTVQA benchmark, it is evident that there is still a large room for performance improvement (Qwen2-VL scoring 30.9 versus 79.7 for human performance), underscoring the value of MTVQA. Additionally, we supply multilingual training data within the MTVQA dataset, demonstrating that straightforward fine-tuning with this data can substantially enhance multilingual TEC-VQA performance. We aspire that MTVQA will offer the research community fresh insights and stimulate further exploration in multilingual visual text comprehension. The project homepage is available at https://bytedance.github.io/MTVQA/.
文本中心化的视觉问答(TEC-VQA)在适当的形式下,不仅促进了文本中心化视觉环境中的人机交互,还作为评估文本中心化场景理解领域中AI模型的实际黄金标准。然而,现有的TEC-VQA基准测试主要集中在英语和中文等资源丰富的语言上。尽管有开创性的工作通过翻译引擎在非文本中心化的VQA数据集中扩展了多种语言的问答对,但基于翻译的方法在应用于TEC-VQA时遇到了重大的“视觉文本不对齐”问题。具体来说,它优先考虑问答对中的文本,而忽视图像中的视觉文本。此外,它无法处理与细微意义、上下文失真、语言偏见和问题类型多样性相关的复杂性。在这项工作中,我们通过引入MTVQA来解决多语言TEC-VQA问题,MTVQA是第一个在9种不同语言上具有高质量人类专家注释的基准测试,包含2,116张图片中的6,778个问答对。此外,通过全面评估众多最先进的多媒体大型语言模型(MLLMs),包括Qwen2-VL、GPT-4o、GPT-4V、Claude3和Gemini在MTVQA基准上的表现,显然还有很大的性能提升空间(Qwen2-VL得分为30.9,而人类表现得分为79.7),这凸显了MTVQA的价值。另外,我们在MTVQA数据集中提供了多语言训练数据,证明使用此数据进行简单微调可以显著增强多语言TEC-VQA的性能。我们期望MTVQA能为研究界提供新的见解,并激发多语言视觉文本理解方面的进一步探索。项目主页可在[https://bytedance.github.io/MTVQA/]访问。
论文及项目相关链接
摘要
文本中心的视觉问答(TEC-VQA)不仅有利于文本为中心的视觉环境中的人机交互,而且是评估文本中心场景理解领域AI模型的黄金标准。然而,现有的TEC-VQA基准测试主要集中在英语和中文等资源丰富的语言上。尽管有先驱工作通过翻译引擎扩展了非文本中心VQA数据集的多语言问答对,但翻译协议应用于TEC-VQA时遇到了“视觉文本不对齐”的问题。它优先考虑问答对中的文本,而忽视图像中的视觉文本。此外,它未能解决与微妙意义、上下文扭曲、语言偏见和问题类型多样性相关的复杂性。在这项工作中,我们通过引入MTVQA来解决多语言TEC-VQA问题,MTVQA是第一个在9种不同语言中具有高质量人类专家注释的基准测试,包含6778个问答对和2116张图像。此外,通过对多种最先进的多媒体大型语言模型(MLLMs)进行全面评估,包括Qwen2-VL、GPT-4o、GPT-4V、Claude3和Gemini在MTVQA基准上的评估表现仍然有很大的提升空间(Qwen2-VL得分为30.9分,人类表现得分为79.7分),这凸显了MTVQA的价值。此外,我们还在MTVQA数据集中提供了多语言训练数据,证明使用此数据进行微调可以大大提高多语言TEC-VQA的性能。我们希望MTVQA能为研究社区提供新的见解,并激发多语言视觉文本理解领域的进一步探索。项目主页位于https://bytedance.github.io/MTVQA/。
关键见解
- 文本中心的视觉问答(TEC-VQA)对于评估AI模型在文本中心场景理解领域的性能具有重要意义。
- 现有的TEC-VQA基准测试主要集中在高资源语言上,如英语和中文。
- 翻译协议应用于TEC-VQA时存在“视觉文本不对齐”的问题。
- MTVQA是第一个包含9种不同语言高质量人类专家注释的基准测试,具有多种语言问答对和图像数据。
- 当前最先进的多媒体大型语言模型在MTVQA基准测试上的表现仍有待提升。
- MTVQA提供了多语言训练数据,证明通过微调可以提高多语言TEC-VQA的性能。
- MTVQA为研究领域提供了宝贵资源,有望激发多语言视觉文本理解领域的进一步探索。
点此查看论文截图