⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-11 更新
Visual Lexicon: Rich Image Features in Language Space
Authors:XuDong Wang, Xingyi Zhou, Alireza Fathi, Trevor Darrell, Cordelia Schmid
We present Visual Lexicon, a novel visual language that encodes rich image information into the text space of vocabulary tokens while retaining intricate visual details that are often challenging to convey in natural language. Unlike traditional methods that prioritize either high-level semantics (e.g., CLIP) or pixel-level reconstruction (e.g., VAE), ViLex simultaneously captures rich semantic content and fine visual details, enabling high-quality image generation and comprehensive visual scene understanding. Through a self-supervised learning pipeline, ViLex generates tokens optimized for reconstructing input images using a frozen text-to-image (T2I) diffusion model, preserving the detailed information necessary for high-fidelity semantic-level reconstruction. As an image embedding in the language space, ViLex tokens leverage the compositionality of natural languages, allowing them to be used independently as “text tokens” or combined with natural language tokens to prompt pretrained T2I models with both visual and textual inputs, mirroring how we interact with vision-language models (VLMs). Experiments demonstrate that ViLex achieves higher fidelity in image reconstruction compared to text embeddings–even with a single ViLex token. Moreover, ViLex successfully performs various DreamBooth tasks in a zero-shot, unsupervised manner without fine-tuning T2I models. Additionally, ViLex serves as a powerful vision encoder, consistently improving vision-language model performance across 15 benchmarks relative to a strong SigLIP baseline.
我们提出一种名为视觉词典(Visual Lexicon)的新型视觉语言。这种语言将丰富的图像信息编码成词汇符号的文本空间,同时保留复杂的视觉细节,这些视觉细节在自然界语言中往往难以传达。与传统的优先关注高级语义(例如CLIP)或像素级重建(例如VAE)的方法不同,ViLex能够同时捕获丰富的语义内容和精细的视觉细节,从而实现高质量图像生成和全面的视觉场景理解。通过自我监督学习管道,ViLex生成了针对使用冻结的文本到图像(T2I)扩散模型重建输入图像的令牌,保留了用于高保真语义级重建的详细信息。作为语言空间中的图像嵌入,ViLex令牌利用自然语言的组合性,可以独立用作“文本令牌”,也可以与自然语言令牌结合,提示预训练的T2I模型同时使用视觉和文本输入,这反映了我们与视觉语言模型(VLM)的交互方式。实验表明,即使在单个ViLex令牌的情况下,ViLex在图像重建方面的保真度也高于文本嵌入。此外,ViLex能够以零样本、无监督的方式成功执行各种DreamBooth任务,无需微调T2I模型。另外,ViLex作为一种强大的视觉编码器,在15个基准测试中相对于强大的SigLIP基线持续提高了视觉语言模型的表现。
论文及项目相关链接
PDF Tech report. 16 pages, 10 figures
Summary
本文介绍了Visual Lexicon这一新颖视觉语言,它能够将丰富的图像信息编码成词汇令的文本空间,同时保留复杂的视觉细节。不同于传统方法,Visual Lexicon能够同时捕捉丰富的语义内容和精细的视觉细节,实现高质量图像生成和全面的视觉场景理解。通过自监督学习流程,它生成了优化的令牌,用于重建输入图像,同时保留高保真语义级重建所需的信息。此外,Visual Lexicon令牌利用自然语言的组合性,可独立作为“文本令牌”使用,也可与自然语言令牌结合,提示预训练的文本到图像模型同时使用视觉和文本输入,模拟我们与视觉语言模型的交互方式。实验表明,Visual Lexicon在图像重建方面实现了高保真度,并能成功执行各种DreamBooth任务,且无需微调文本到图像模型。此外,Visual Lexicon作为强大的视觉编码器,相对于强大的SigLIP基线,在15个基准测试中均表现出改进。
Key Takeaways
- Visual Lexicon是一种新颖的视觉语言,能将图像信息编码成文本空间的词汇令牌。
- 它能同时捕捉丰富的语义内容和精细的视觉细节。
- 通过自监督学习流程,Visual Lexicon生成了用于重建输入图像的令牌。
- Visual Lexicon令牌可独立使用或结合自然语言令牌,为预训练的文本到图像模型提供视觉和文本输入。
- 实验显示Visual Lexicon在图像重建方面具有高保真度。
- Visual Lexicon能成功执行各种DreamBooth任务而无需微调文本到图像模型。
点此查看论文截图



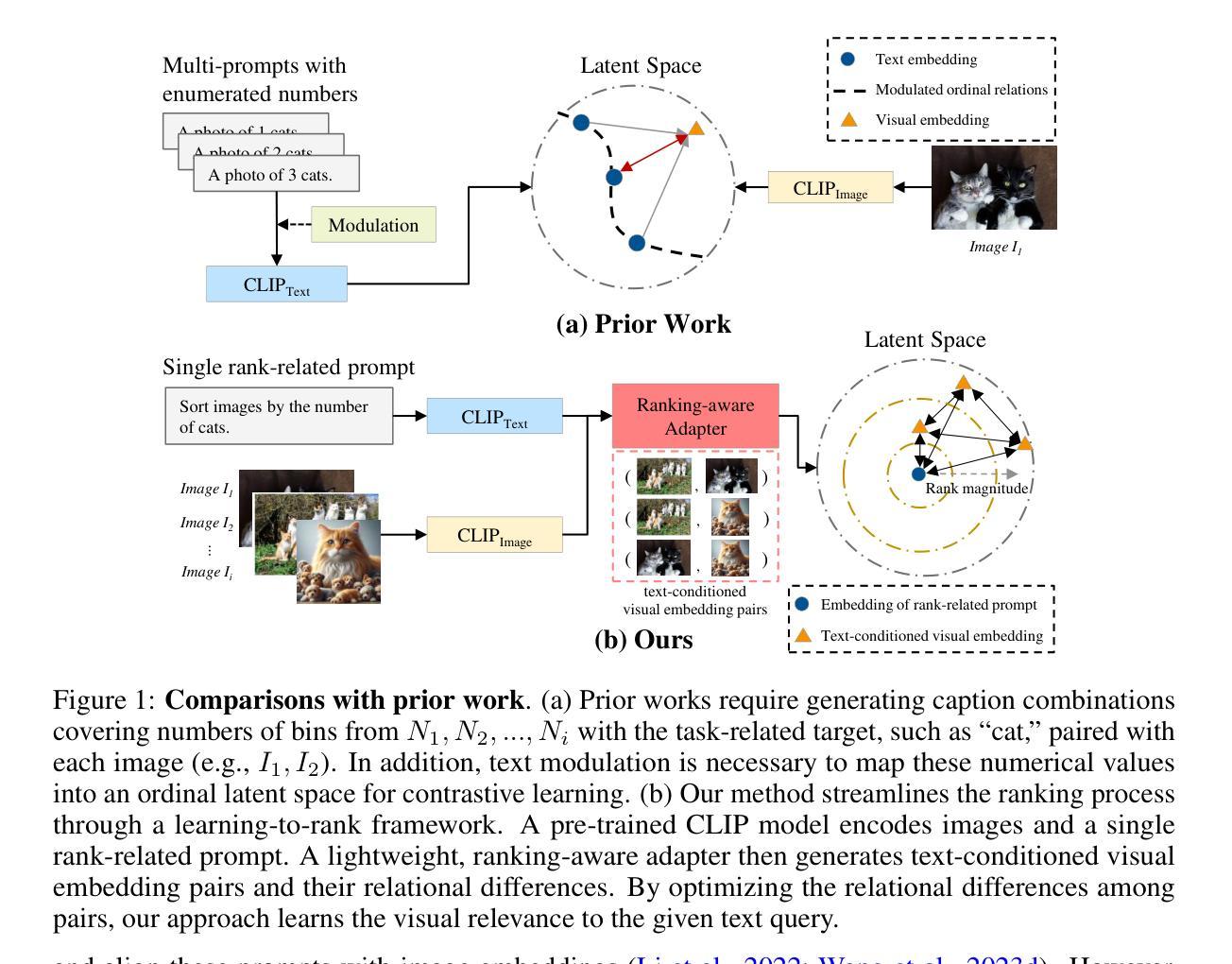
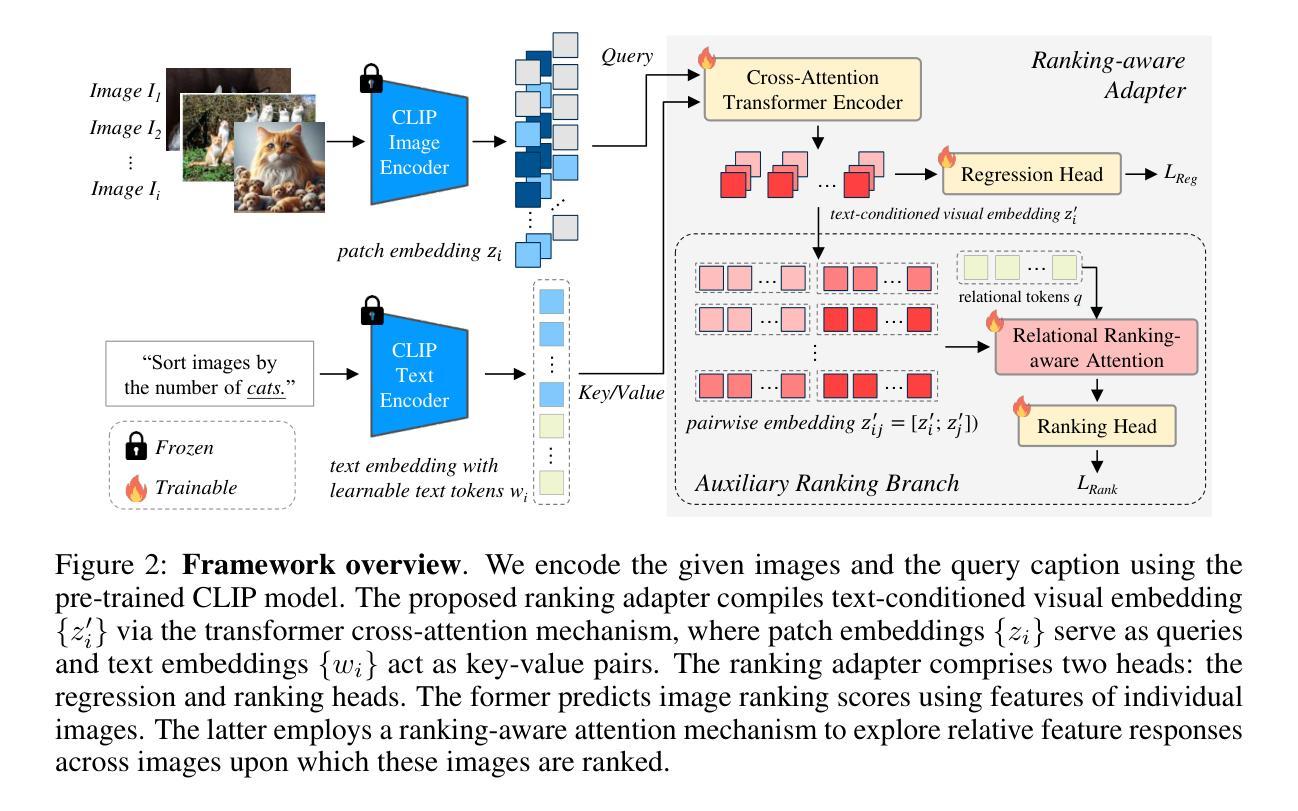
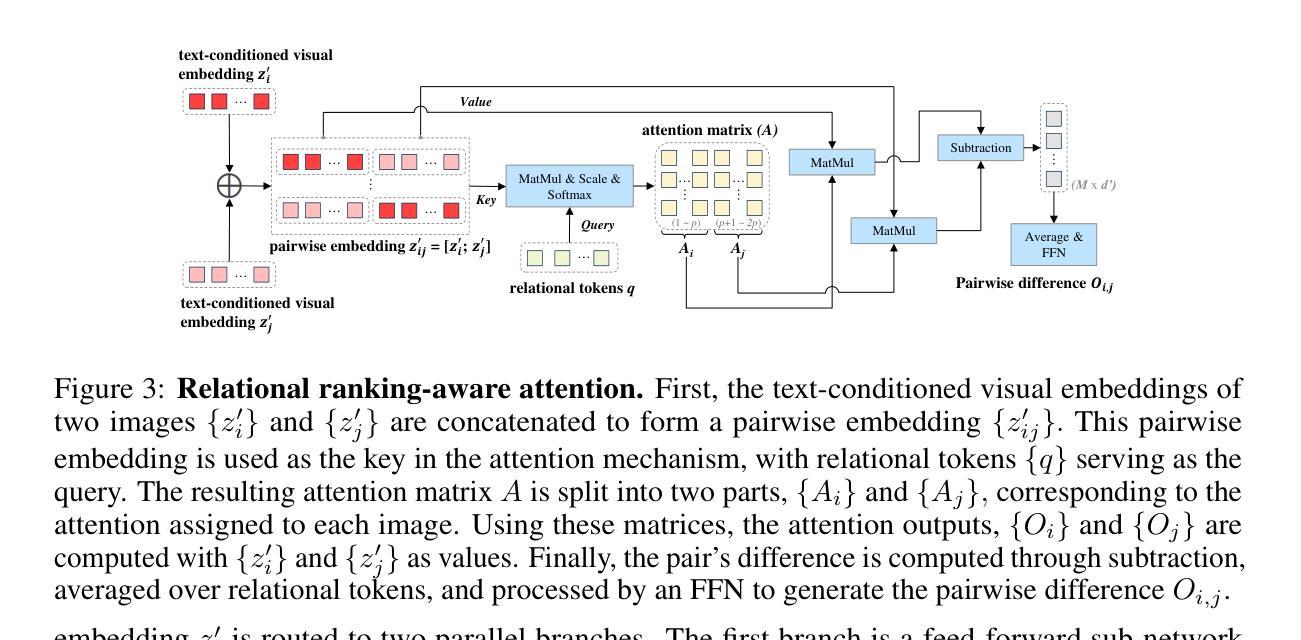
Ranking-aware adapter for text-driven image ordering with CLIP
Authors:Wei-Hsiang Yu, Yen-Yu Lin, Ming-Hsuan Yang, Yi-Hsuan Tsai
Recent advances in vision-language models (VLMs) have made significant progress in downstream tasks that require quantitative concepts such as facial age estimation and image quality assessment, enabling VLMs to explore applications like image ranking and retrieval. However, existing studies typically focus on the reasoning based on a single image and heavily depend on text prompting, limiting their ability to learn comprehensive understanding from multiple images. To address this, we propose an effective yet efficient approach that reframes the CLIP model into a learning-to-rank task and introduces a lightweight adapter to augment CLIP for text-guided image ranking. Specifically, our approach incorporates learnable prompts to adapt to new instructions for ranking purposes and an auxiliary branch with ranking-aware attention, leveraging text-conditioned visual differences for additional supervision in image ranking. Our ranking-aware adapter consistently outperforms fine-tuned CLIPs on various tasks and achieves competitive results compared to state-of-the-art models designed for specific tasks like facial age estimation and image quality assessment. Overall, our approach primarily focuses on ranking images with a single instruction, which provides a natural and generalized way of learning from visual differences across images, bypassing the need for extensive text prompts tailored to individual tasks. Code is available: https://github.com/uynaes/RankingAwareCLIP.
最近,视觉语言模型(VLMs)在下游任务方面取得了重大进展,这些任务需要定量概念,例如面部年龄估计和图像质量评估。这使得VLMs能够探索图像排序和检索等应用。然而,现有研究通常侧重于基于单张图像的推理,并严重依赖于文本提示,从而限制了它们从多张图像中学习全面理解的能力。为了解决这一问题,我们提出了一种有效且高效的方法,该方法将CLIP模型重构为学习排名任务,并引入了一个轻量级适配器以增强CLIP进行文本引导的图像排名。具体来说,我们的方法采用可学习的提示来适应新的排名指令,并使用带有排名感知注意力的辅助分支,利用文本条件下的视觉差异进行图像排名的额外监督。我们的排名感知适配器在各种任务上始终优于微调过的CLIP,并在面部年龄估计和图像质量评估等特定任务设计的最先进模型上取得了具有竞争力的结果。总的来说,我们的方法主要侧重于使用单个指令对图像进行排名,这提供了一种从各图像之间的视觉差异进行学习的自然且通用的方式,而无需针对单个任务量身定制大量文本提示。相关代码可在https://github.com/uynaestRankingAwareCLIP找到。
论文及项目相关链接
PDF github link: https://github.com/uynaes/RankingAwareCLIP
Summary
视觉语言模型(VLMs)的进步促进了下游任务如面部年龄估计和图像质量评估的发展,并探索了图像排序和检索等应用。针对现有研究依赖单图像推理和文本提示的问题,我们提出了一种有效且高效的方法,将CLIP模型重构为学习排名任务,并引入轻量级适配器进行文本指导的图像排名。我们的方法通过可学习的提示来适应排名指令,并引入具有排名感知注意力的辅助分支,利用文本条件下的视觉差异进行额外的排名监督。我们的排名感知适配器在各种任务上的表现一直优于微调过的CLIP,并在面部年龄估计和图像质量评估等特定任务上达到了与最新模型相当的结果。总体而言,我们的方法主要关注于使用单一指令对图像进行排名,提供一种从图像间视觉差异学习的自然且通用方式,无需针对各个任务定制大量文本提示。
Key Takeaways
- 视觉语言模型(VLMs)在面部年龄估计和图像质量评估等下游任务取得显著进展。
- 现有研究主要依赖单图像推理和文本提示,缺乏从多图像学习的综合能力。
- 提出一种将CLIP模型重构为学习排名任务的方法,引入轻量级适配器进行文本指导的图像排名。
- 方法包括适应排名指令的可学习提示,以及具有排名感知注意力的辅助分支。
- 排名感知适配器在各种任务上的表现优于微调过的CLIP。
- 在特定任务上,如面部年龄估计和图像质量评估,该方法达到与最新模型相当的结果。
点此查看论文截图

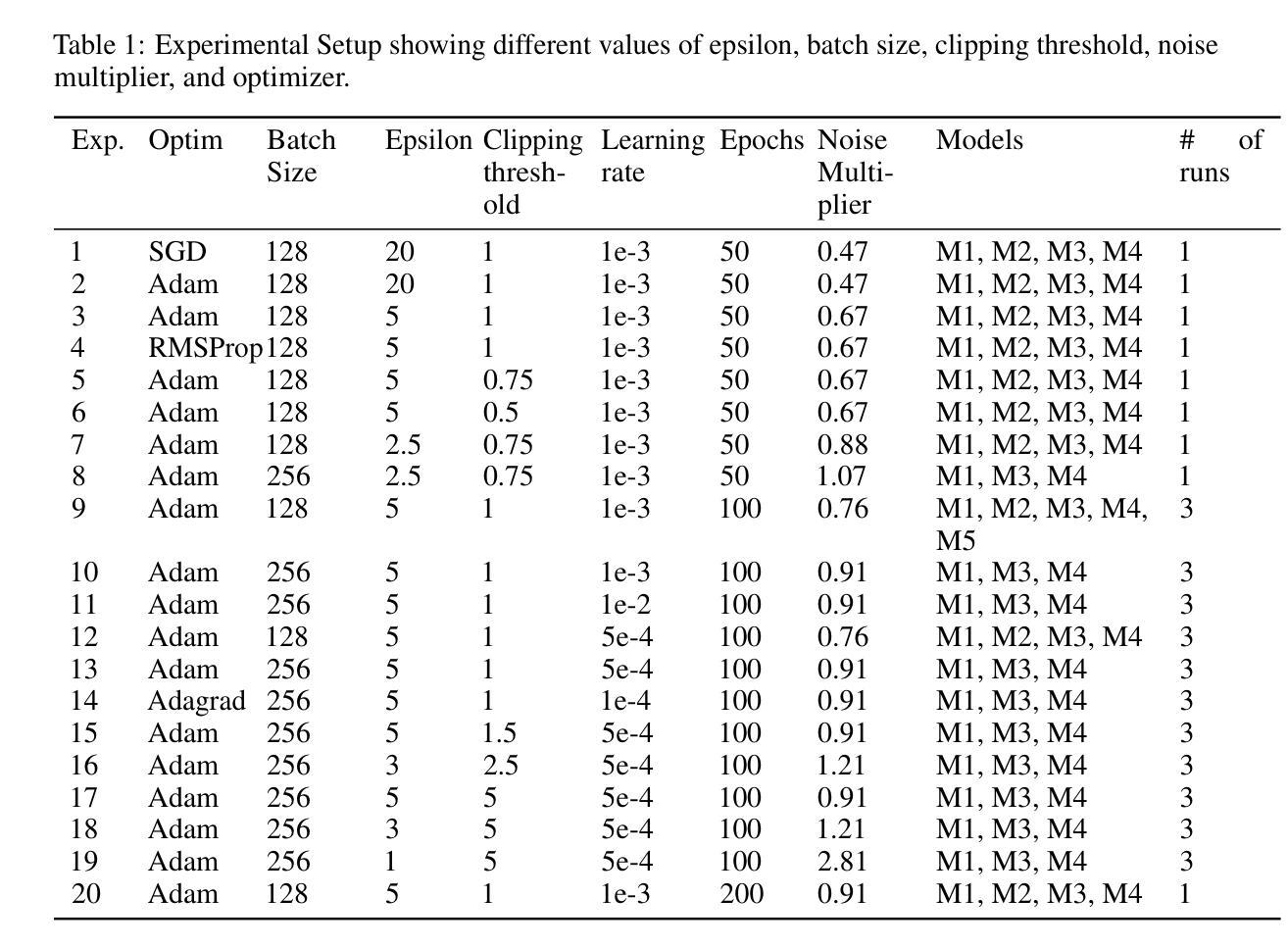
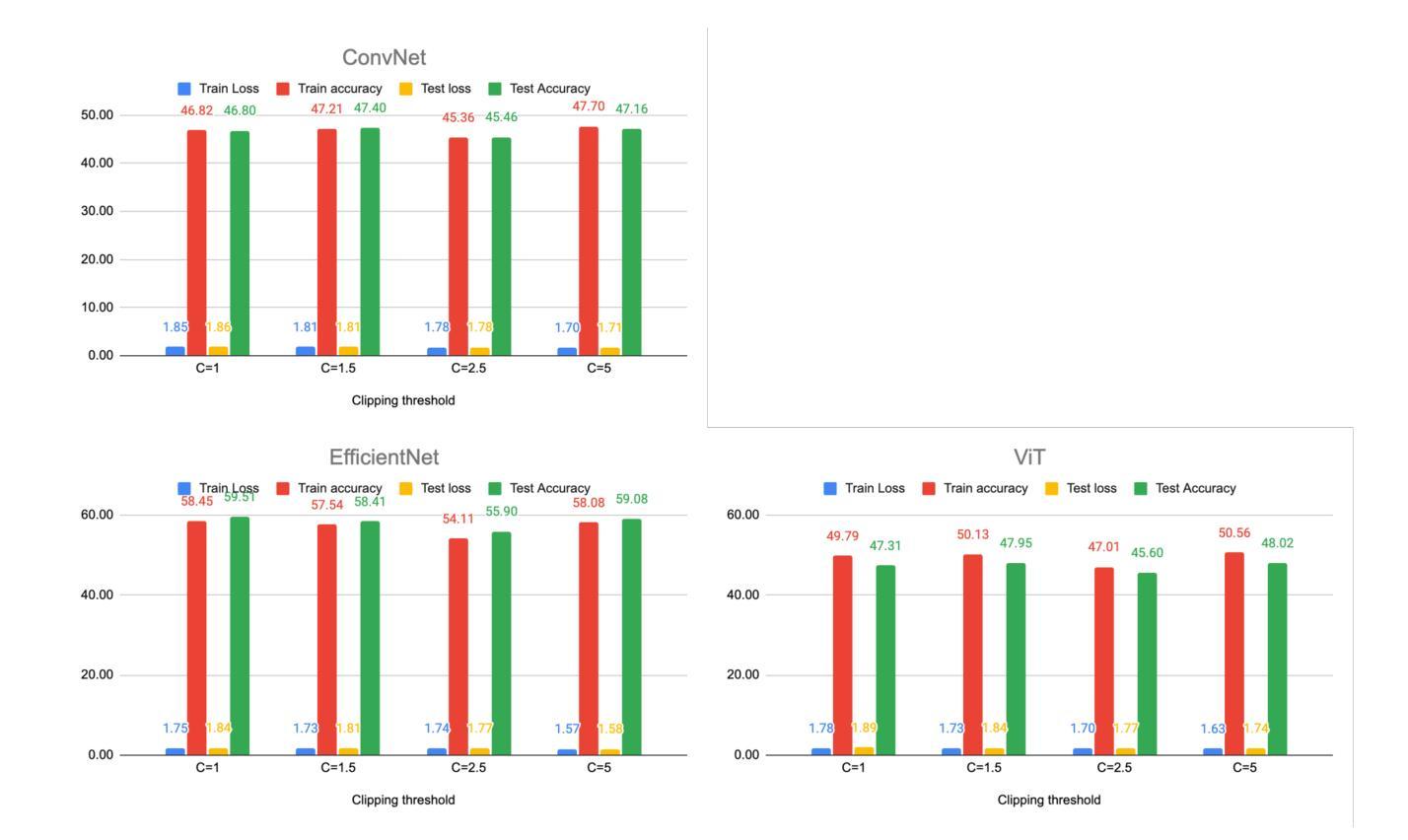
Impact of Privacy Parameters on Deep Learning Models for Image Classification
Authors:Basanta Chaulagain
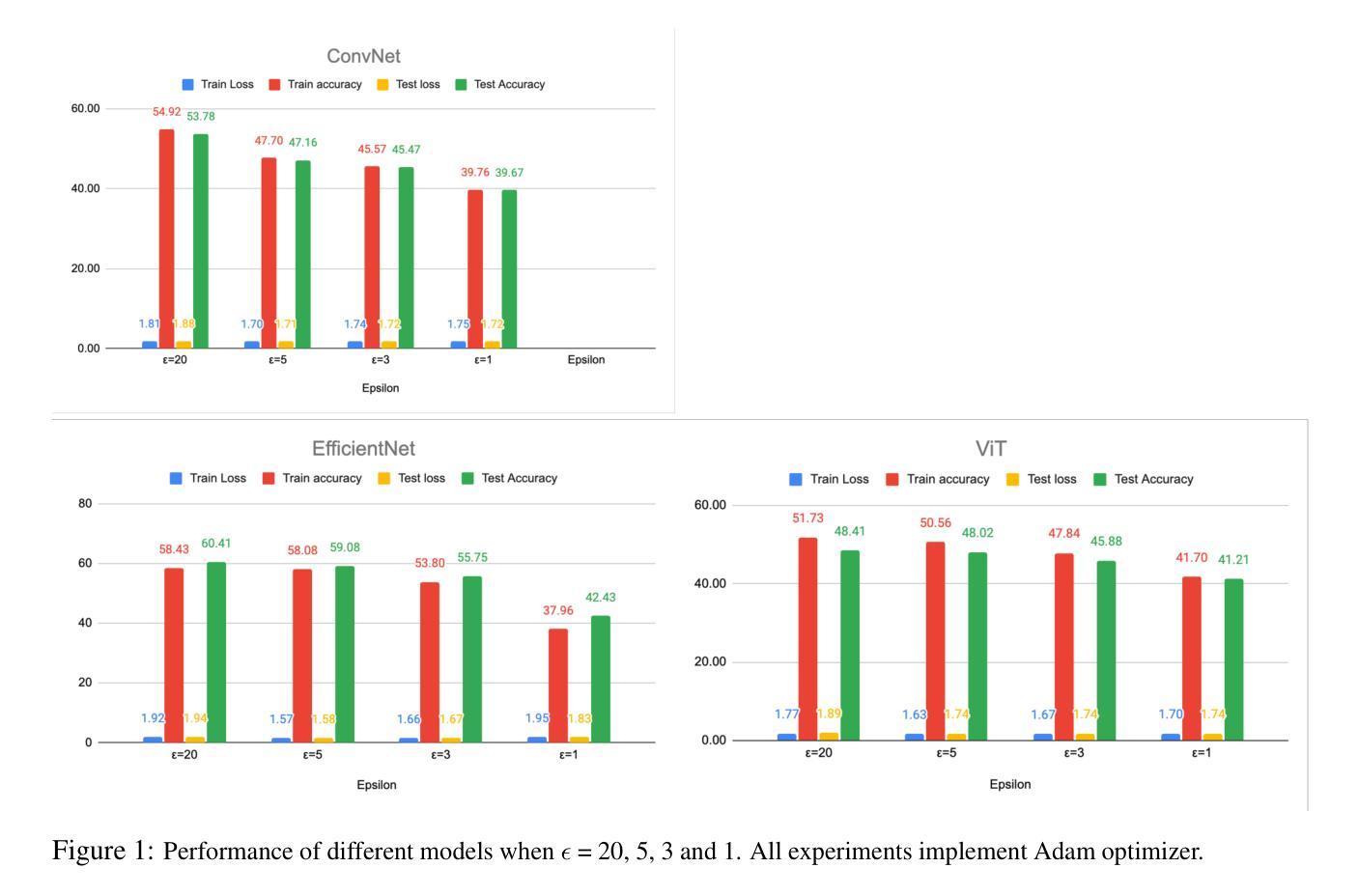
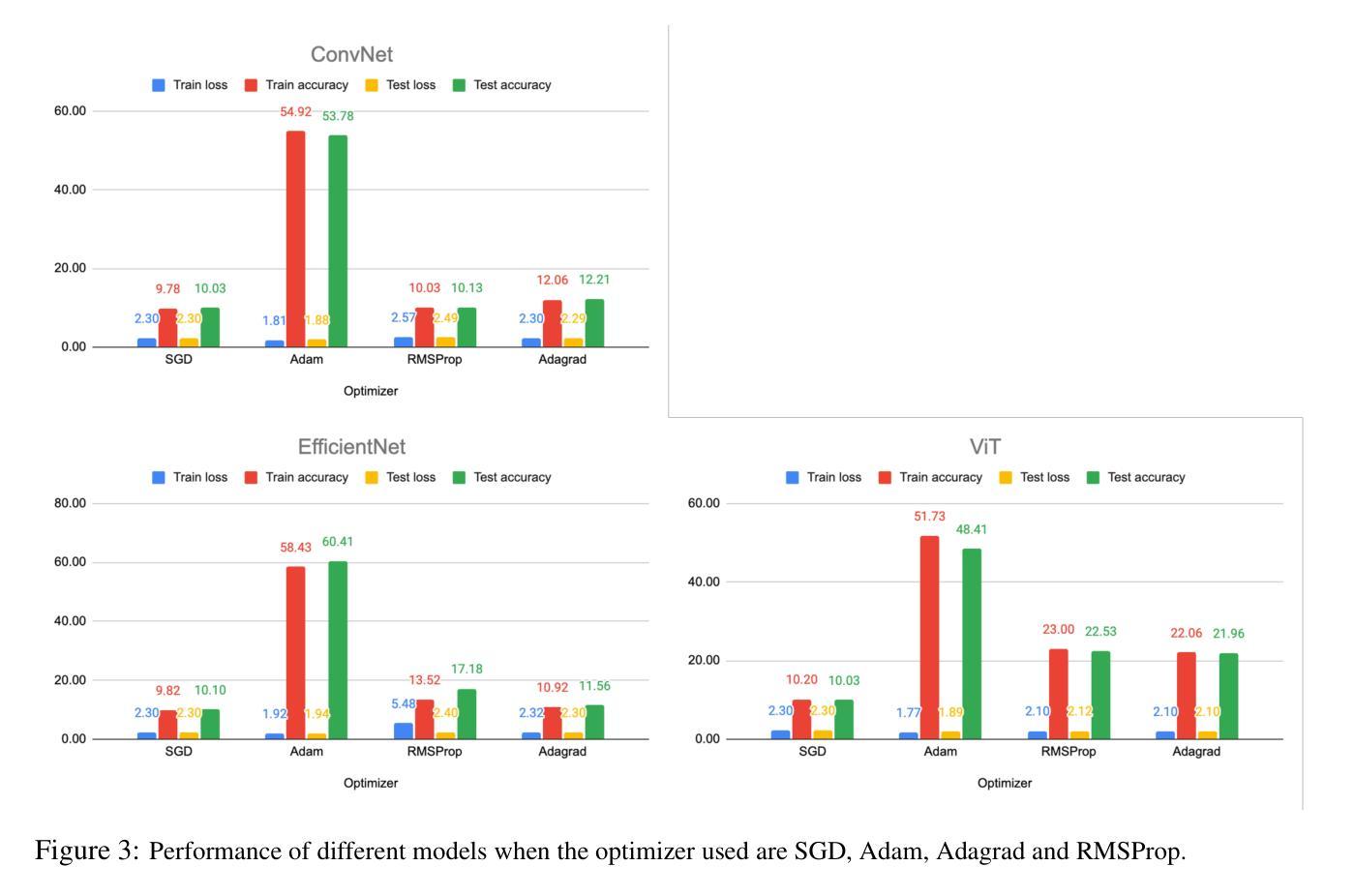
The project aims to develop differentially private deep learning models for image classification on CIFAR-10 datasets \cite{cifar10} and analyze the impact of various privacy parameters on model accuracy. We have implemented five different deep learning models, namely ConvNet, ResNet18, EfficientNet, ViT, and DenseNet121 and three supervised classifiers namely K-Nearest Neighbors, Naive Bayes Classifier and Support Vector Machine. We evaluated the performance of these models under varying settings. Our best performing model to date is EfficientNet with test accuracy of $59.63%$ with the following parameters (Adam optimizer, batch size 256, epoch size 100, epsilon value 5.0, learning rate $1e-3$, clipping threshold 1.0, and noise multiplier 0.912).
该项目旨在针对CIFAR-10数据集开发具有差分隐私保护的深度学习模型,并分析各种隐私参数对模型精度的影响。我们实现了五种不同的深度学习模型,包括ConvNet、ResNet18、EfficientNet、ViT和DenseNet121,以及三种有监督分类器,即K近邻算法、朴素贝叶斯分类器和支持向量机。我们在不同的设置下评估了这些模型的性能。迄今为止表现最好的模型是EfficientNet,测试精度为59.63%,其参数如下:使用Adam优化器,批处理大小为256,周期大小为100,epsilon值为5.0,学习率为$ 1e-3 $,裁剪阈值为1.0,噪声乘数为0.912。
论文及项目相关链接
PDF 10 pages
Summary
本文旨在开发用于CIFAR-10数据集的差分隐私深度学习模型,并分析不同隐私参数对模型精度的影响。实现了EfficientNet等五种深度学习模型和三种有监督分类器,并在不同设置下评估了其性能。表现最好的模型是EfficientNet,测试精度为59.63%。
Key Takeaways
- 项目目标是开发用于图像分类的差分隐私深度学习模型,特别是在CIFAR-10数据集上。
- 实施了五种深度学习模型和三种有监督分类器。
- 深度学习模型的表现受隐私参数影响。
- EfficientNet是表现最好的模型,测试精度达到59.63%。
- 最佳模型使用的参数包括Adam优化器、批次大小为256、周期大小为100等。
- 实现了差分隐私保护,通过调整epsilon值、学习率、裁剪阈值和噪声乘数等参数来保护数据隐私。
点此查看论文截图

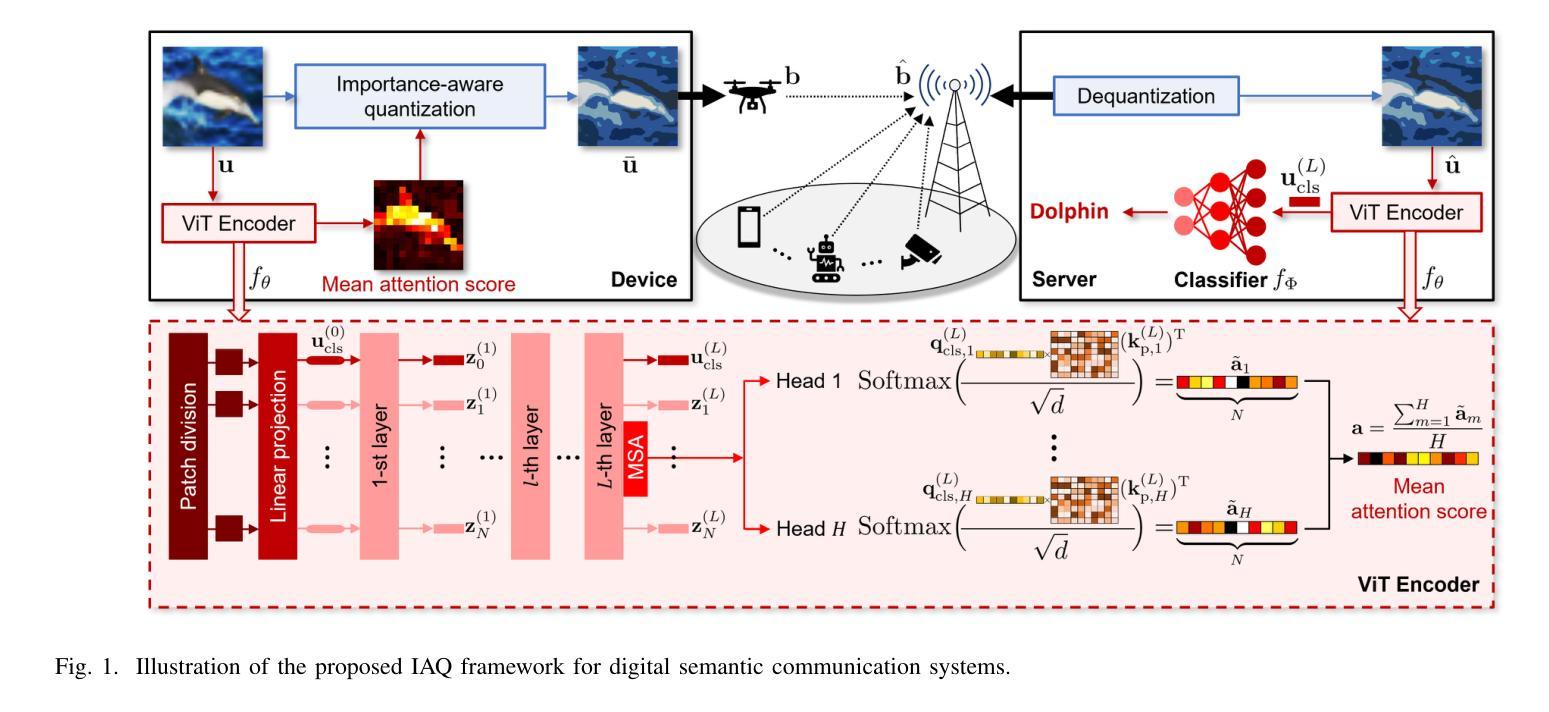
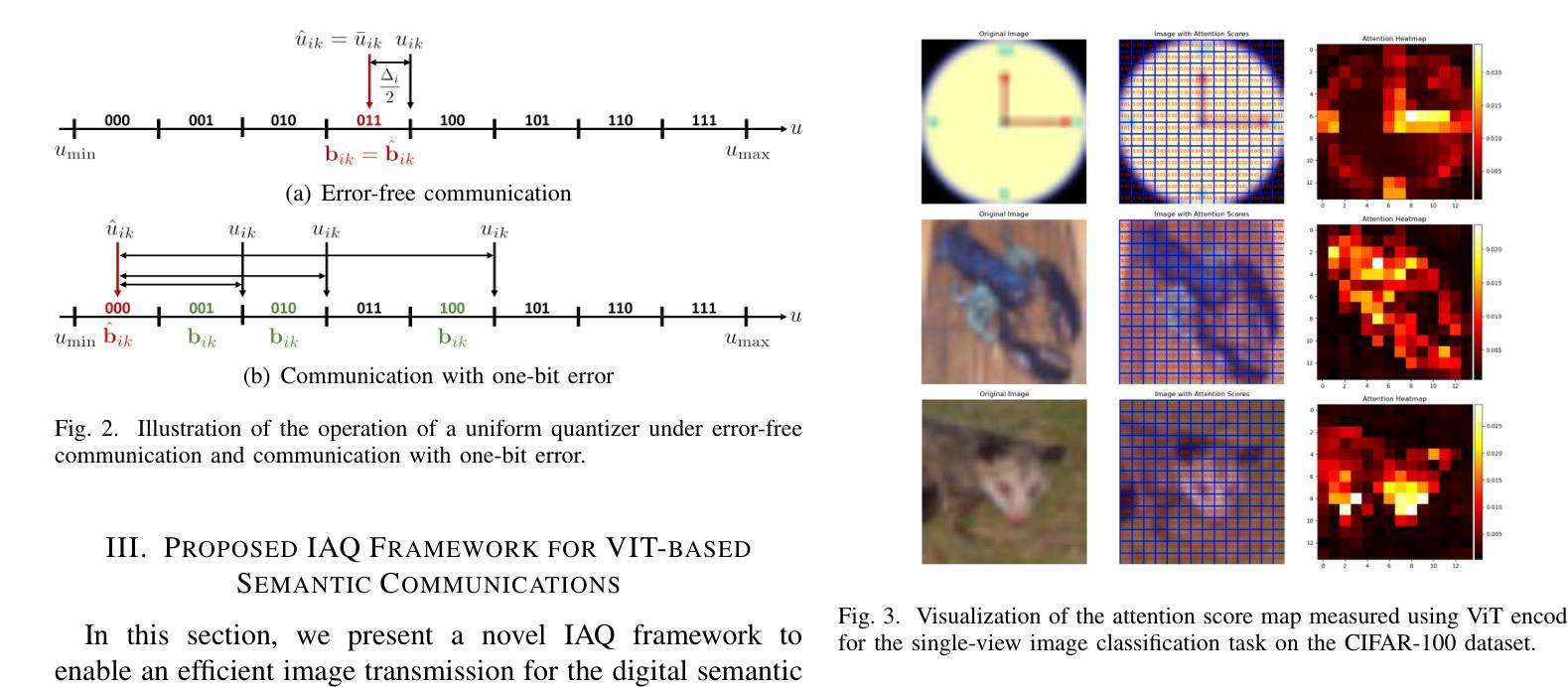
Vision Transformer-based Semantic Communications With Importance-Aware Quantization
Authors:Joohyuk Park, Yongjeong Oh, Yongjune Kim, Yo-Seb Jeon
Semantic communications provide significant performance gains over traditional communications by transmitting task-relevant semantic features through wireless channels. However, most existing studies rely on end-to-end (E2E) training of neural-type encoders and decoders to ensure effective transmission of these semantic features. To enable semantic communications without relying on E2E training, this paper presents a vision transformer (ViT)-based semantic communication system with importance-aware quantization (IAQ) for wireless image transmission. The core idea of the presented system is to leverage the attention scores of a pretrained ViT model to quantify the importance levels of image patches. Based on this idea, our IAQ framework assigns different quantization bits to image patches based on their importance levels. This is achieved by formulating a weighted quantization error minimization problem, where the weight is set to be an increasing function of the attention score. Then, an optimal incremental allocation method and a low-complexity water-filling method are devised to solve the formulated problem. Our framework is further extended for realistic digital communication systems by modifying the bit allocation problem and the corresponding allocation methods based on an equivalent binary symmetric channel (BSC) model. Simulations on single-view and multi-view image classification tasks show that our IAQ framework outperforms conventional image compression methods in both error-free and realistic communication scenarios.
语义通信通过无线信道传输与任务相关的语义特征,相对于传统通信方式,提供了显著的性能提升。然而,大多数现有研究依赖于端到端(E2E)的神经型编码器和解码器的训练,以确保这些语义特征的有效传输。为了在不依赖E2E训练的情况下实现语义通信,本文提出了一种基于视觉转换器(ViT)的重要性感知量化(IAQ)的语义通信系统,用于无线图像传输。本系统的核心思想是利用预训练的ViT模型的注意力得分来量化图像斑块的重要性水平。基于此,我们的IAQ框架根据图像斑块的重要性水平分配不同的量化位数。这是通过制定加权量化误差最小化问题来实现的,其中权重设置为注意力得分的递增函数。然后,设计了一种最优增量分配方法和低复杂度的注水方法来解决所制定的问题。我们通过修改位分配问题和相应的分配方法,基于等效二进制对称信道(BSC)模型,将我们的框架进一步扩展到现实的数字通信系统。在单视图和多视图图像分类任务上的模拟表明,我们的IAQ框架在无误码和真实通信场景中均优于传统图像压缩方法。
论文及项目相关链接
Summary
基于预训练的Vision Transformer模型注意力得分的重要性感知量化(IAQ)框架,实现了无线图像传输的语义通信。通过利用ViT模型的注意力得分来衡量图像块的重要性水平,并为不同的图像块分配不同的量化位数。采用加权量化误差最小化问题来解决该问题,并针对现实数字通信系统进行了框架的进一步扩展。模拟实验表明,该IAQ框架在无误码和真实通信场景中均优于传统图像压缩方法。
Key Takeaways
- 利用预训练的Vision Transformer模型的注意力得分评估图像块重要性水平。
- 语义通信在不依赖端到端训练的情况下可实现高性能无线图像传输。
- 提出重要性感知量化(IAQ)框架,根据图像块的重要性分配不同的量化位数。
- 通过加权量化误差最小化问题来优化IAQ框架的性能。
- 扩展框架以适用于现实数字通信系统,包括基于等效二进制对称信道模型的位分配问题和方法。
- 模拟实验表明IAQ框架在无误码和真实通信场景中表现优异。
点此查看论文截图

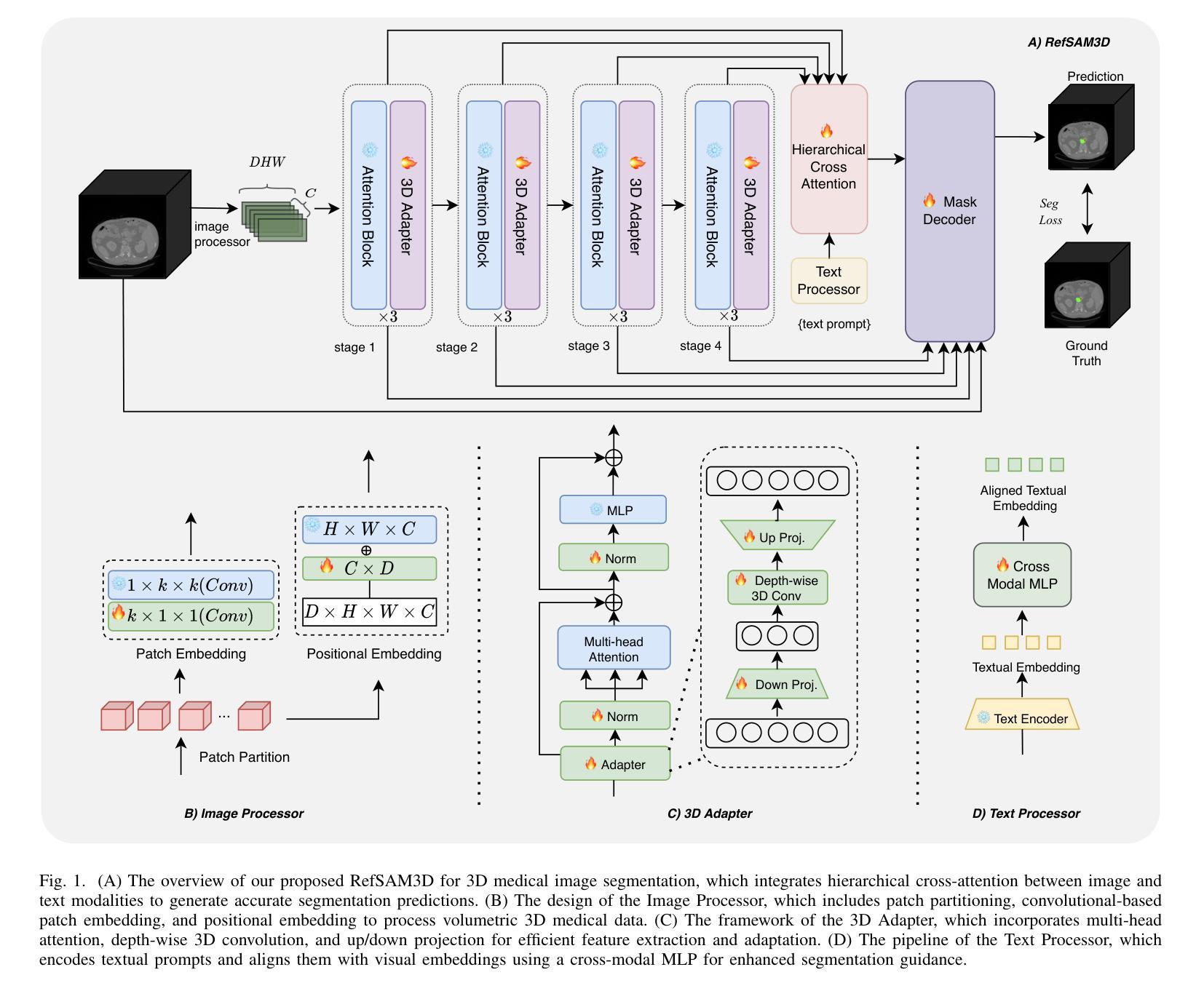
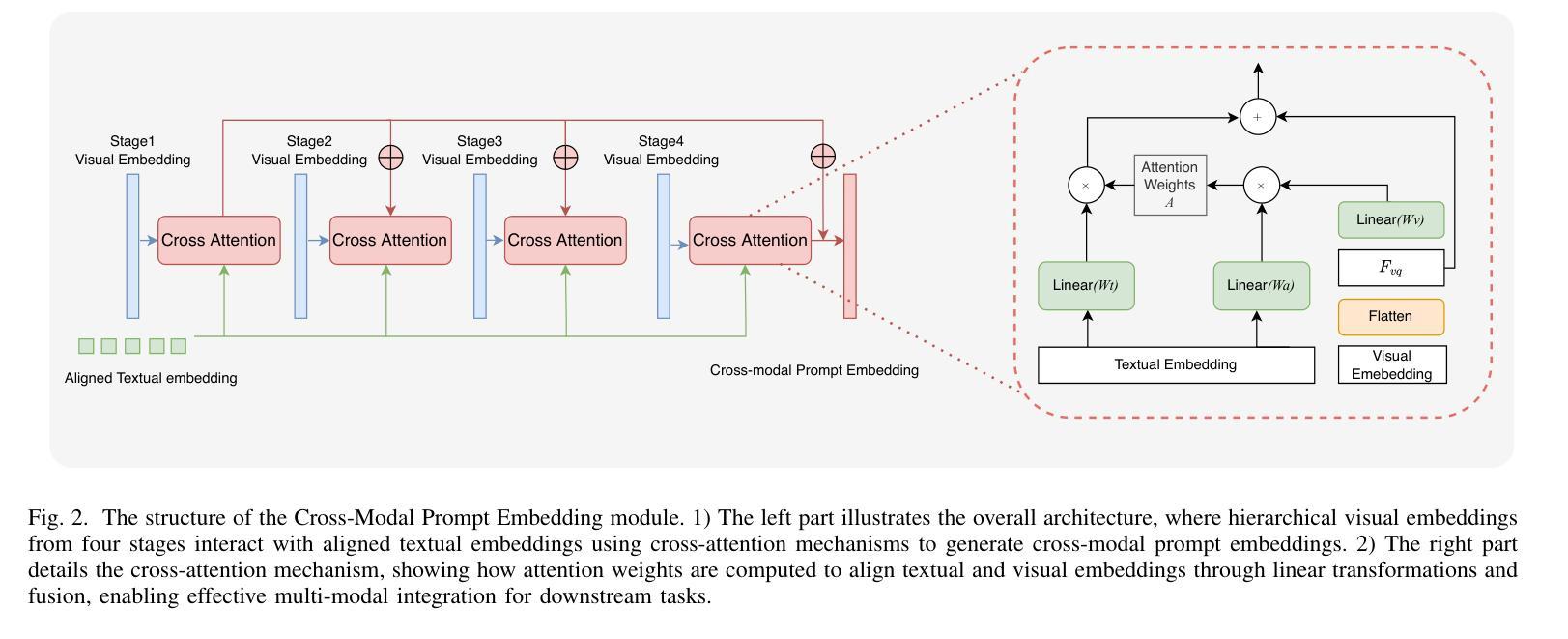
RefSAM3D: Adapting SAM with Cross-modal Reference for 3D Medical Image Segmentation
Authors:Xiang Gao, Kai Lu
The Segment Anything Model (SAM), originally built on a 2D Vision Transformer (ViT), excels at capturing global patterns in 2D natural images but struggles with 3D medical imaging modalities like CT and MRI. These modalities require capturing spatial information in volumetric space for tasks such as organ segmentation and tumor quantification. To address this challenge, we introduce RefSAM3D, which adapts SAM for 3D medical imaging by incorporating a 3D image adapter and cross-modal reference prompt generation. Our approach modifies the visual encoder to handle 3D inputs and enhances the mask decoder for direct 3D mask generation. We also integrate textual prompts to improve segmentation accuracy and consistency in complex anatomical scenarios. By employing a hierarchical attention mechanism, our model effectively captures and integrates information across different scales. Extensive evaluations on multiple medical imaging datasets demonstrate the superior performance of RefSAM3D over state-of-the-art methods. Our contributions advance the application of SAM in accurately segmenting complex anatomical structures in medical imaging.
分段任何事情模型(SAM)最初是建立在二维视觉转换器(ViT)之上,擅长捕捉二维自然图像中的全局模式,但在处理如CT和MRI等三维医学影像时面临挑战。这些模态需要在体积空间中捕获空间信息,以完成如器官分割和肿瘤量化等任务。为了解决这一挑战,我们引入了RefSAM3D,它通过融入三维图像适配器和跨模态参考提示生成,将SAM改编为适用于三维医学影像。我们的方法修改了视觉编码器以处理三维输入,并增强了掩膜解码器以进行直接的三维掩膜生成。我们还整合了文本提示,以提高复杂解剖场景中的分割精度和一致性。通过采用分层注意力机制,我们的模型能够在不同尺度上有效捕获和整合信息。在多个医学影像数据集上的广泛评估表明,RefSAM3D的性能优于最新方法。我们的贡献推动了SAM在医学影像中准确分割复杂解剖结构的应用。
论文及项目相关链接
Summary
基于Segment Anything Model(SAM)构建的RefSAM3D模型,针对三维医学影像如CT和MRI的分割问题进行了优化。它通过引入三维图像适配器和跨模态参考提示生成,改进了视觉编码器和掩膜解码器,实现了直接生成三维掩膜的功能。此外,还通过引入文本提示提高了复杂解剖场景下的分割精度和一致性。采用分层注意力机制,有效捕捉并整合了不同尺度的信息。在多个医学成像数据集上的广泛评估表明,RefSAM3D的性能优于现有方法,为SAM在医学成像中准确分割复杂解剖结构的应用提供了新的突破。
Key Takeaways
- RefSAM3D是基于Segment Anything Model(SAM)构建的,专为处理三维医学影像设计。
- 它通过引入三维图像适配器和跨模态参考提示生成,解决了SAM在处理CT和MRI等医学影像时的局限性。
- RefSAM3D改进了视觉编码器以处理三维输入,并增强了掩膜解码器以直接生成三维掩膜。
- 通过引入文本提示,提高了复杂解剖场景下的分割精度和一致性。
- 采用分层注意力机制,能有效捕捉并整合不同尺度的信息。
- 在多个医学成像数据集上的评估显示,RefSAM3D的性能优于现有方法。
点此查看论文截图

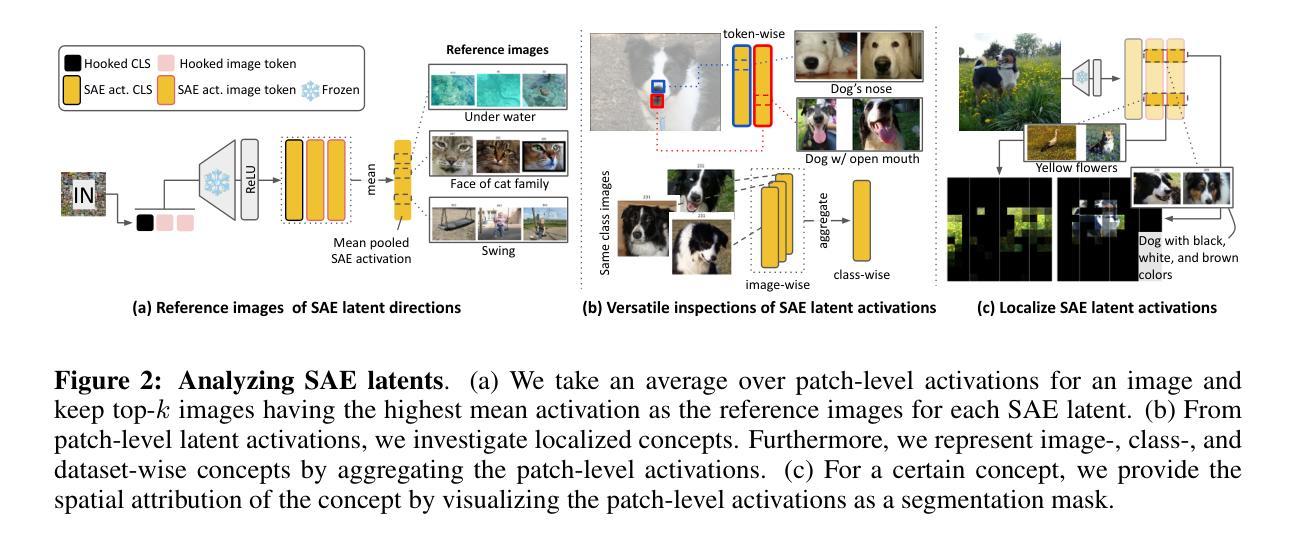
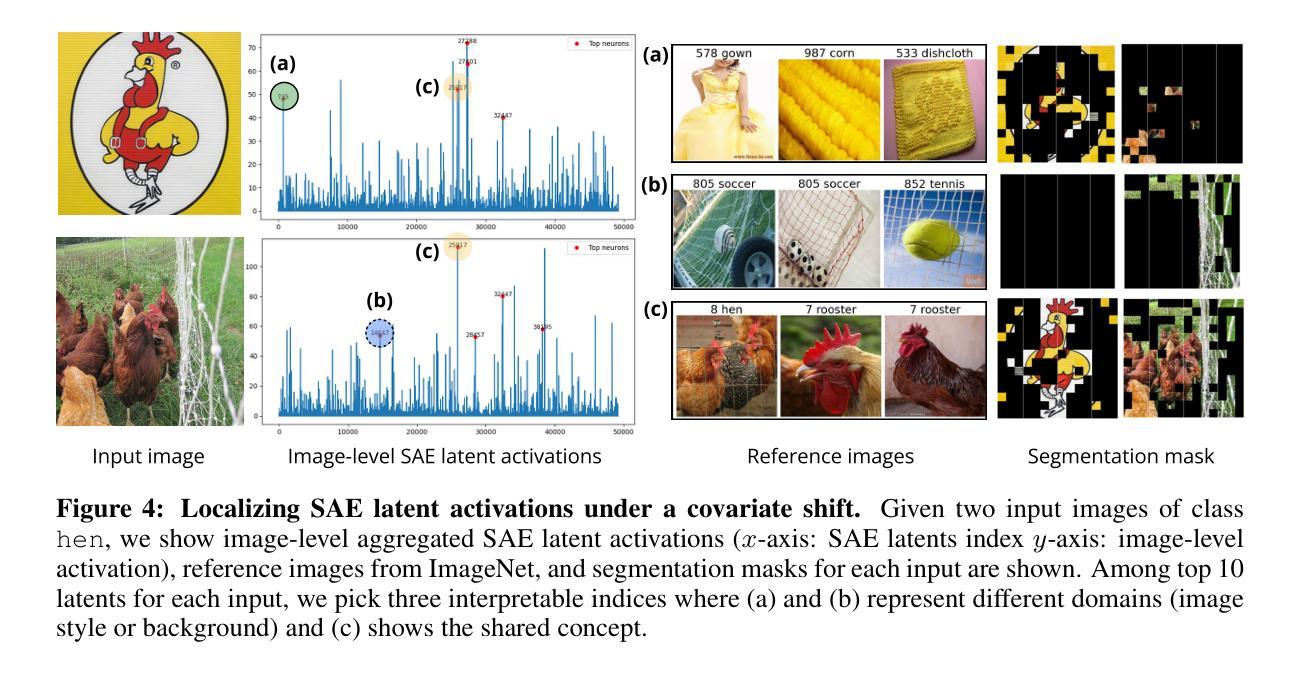
Sparse autoencoders reveal selective remapping of visual concepts during adaptation
Authors:Hyesu Lim, Jinho Choi, Jaegul Choo, Steffen Schneider
Adapting foundation models for specific purposes has become a standard approach to build machine learning systems for downstream applications. Yet, it is an open question which mechanisms take place during adaptation. Here we develop a new Sparse Autoencoder (SAE) for the CLIP vision transformer, named PatchSAE, to extract interpretable concepts at granular levels (e.g. shape, color, or semantics of an object) and their patch-wise spatial attributions. We explore how these concepts influence the model output in downstream image classification tasks and investigate how recent state-of-the-art prompt-based adaptation techniques change the association of model inputs to these concepts. While activations of concepts slightly change between adapted and non-adapted models, we find that the majority of gains on common adaptation tasks can be explained with the existing concepts already present in the non-adapted foundation model. This work provides a concrete framework to train and use SAEs for Vision Transformers and provides insights into explaining adaptation mechanisms.
针对特定目的调整基础模型已经成为为下游应用构建机器学习系统的标准方法。然而,在调整过程中哪些机制起作用还是一个悬而未决的问题。在这里,我们为CLIP视觉转换器开发了一种新的稀疏自动编码器(SAE),命名为PatchSAE,以在颗粒度级别提取可解释的概念(例如形状、颜色或对象的语义)及其补丁式的空间归属。我们探讨了这些概念如何影响下游图像分类任务的模型输出,并研究了最新的基于提示的适应技术如何改变模型输入与这些概念的联系。虽然适应模型和非适应模型的概念激活略有变化,但我们发现,在常见的适应任务中,大部分收益都可以用非适应基础模型中已经存在的概念来解释。这项工作提供了一个用于训练和使用视觉转换器SAE的具体框架,并提供了解释适应机制的见解。
论文及项目相关链接
PDF A demo is available at github.com/dynamical-inference/patchsae
Summary
本文介绍了为特定目的适应基础模型的标准方法,并探讨了适应过程中的机制。为此,开发了一种名为PatchSAE的新稀疏自动编码器(SAE),用于提取CLIP视觉转换器中的可解释概念,如形状、颜色和对象的语义等,并探讨这些概念如何影响下游图像分类任务的模型输出。研究还调查了最近的最新提示驱动适应技术如何改变模型输入与这些概念的联系。尽管适应和非适应模型的概念激活略有变化,但研究发现非适应基础模型已经存在的概念能够解释大多数常见适应任务上的大多数增益。本研究为训练和使用用于视觉转换器的SAE提供了具体框架,并深入解释了适应机制。
Key Takeaways
- 适应了基础模型以适应特定目的已成为建立下游应用机器学习系统的标准方法。
- 开发了一种名为PatchSAE的稀疏自动编码器(SAE)用于CLIP视觉转换器,可以提取可解释的概念,如形状、颜色和对象语义。
- 这些概念在下游图像分类任务中的影响被探索。
- 最新提示驱动适应技术改变了模型输入与概念之间的联系。
- 适应和非适应模型之间的概念激活有轻微变化。
- 非适应基础模型中的现有概念可以解释大多数常见适应任务上的增益。
点此查看论文截图

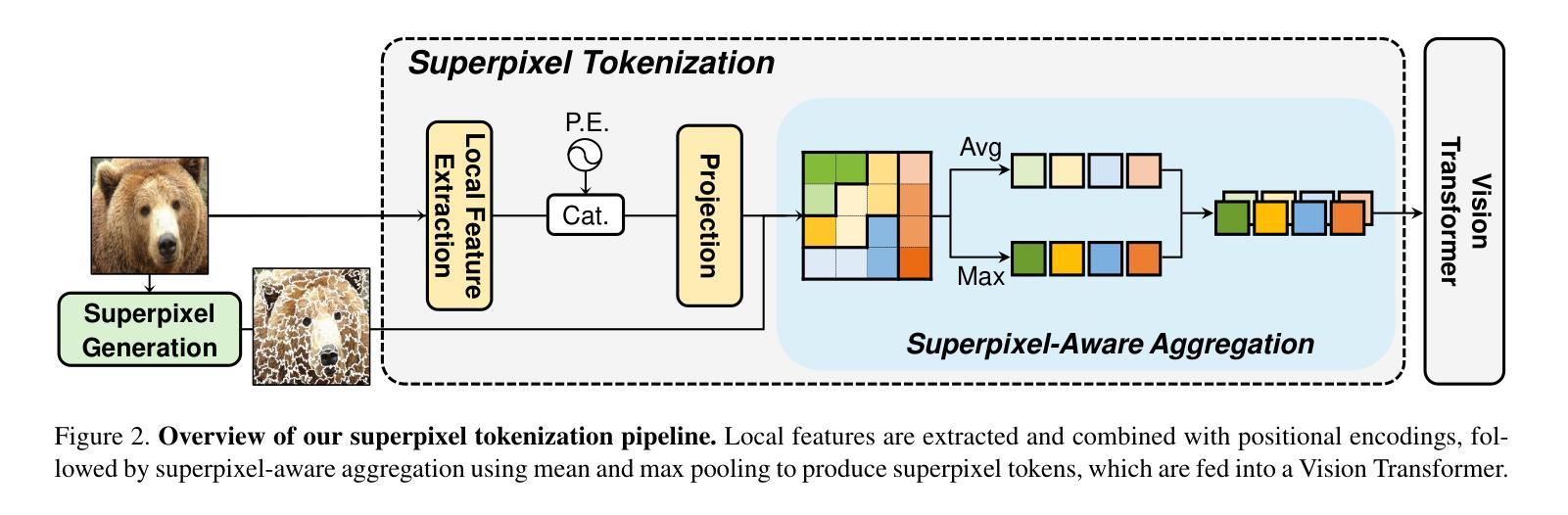
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Authors:Jaihyun Lew, Soohyuk Jang, Jaehoon Lee, Seungryong Yoo, Eunji Kim, Saehyung Lee, Jisoo Mok, Siwon Kim, Sungroh Yoon
Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Transformer是为自然语言处理(NLP)提出的突破性架构,在计算机视觉领域也取得了显著的成功。其成功的关键因素之一是注意力机制,该机制对标记之间的关系进行建模。虽然自然语言处理中的标记化过程确保了单个标记不包含多个语义,但Vision Transformer(ViT)的标记化利用了均匀分割的图像块来生成标记,这可能导致一个标记中包含多个视觉概念。在这项工作中,我们提出了使用超像素标记化替代ViT中的基于网格的标记化方法。超像素标记化使用超像素生成一个包含单一视觉概念的标记。然而,由于超像素具有不同的形状、大小和位置,将超像素集成到ViT标记化中相当具有挑战性。我们的标记化管道由预聚合提取和基于超像素的聚合组成,克服了超像素标记化中出现的挑战。大量实验表明,我们的方法与现有框架兼容性强,提高了ViT在各种下游任务上的准确性和鲁棒性。
论文及项目相关链接
Summary
本文介绍了计算机视觉领域中的Vision Transformer模型,探讨了其基于超像素的token化策略相对于传统基于网格的token化策略的优越性。该策略旨在确保每个token只包含一个视觉概念,并提高了模型的准确性和鲁棒性。
Key Takeaways
- Vision Transformer模型在计算机视觉领域取得了显著成功,其成功的关键在于注意力机制,该机制可以建模token之间的关系。
- 传统基于网格的token化策略可能导致单个token中混合多个视觉概念的问题。
- 为解决上述问题,本文提出了基于超像素的token化策略,确保每个token只包含一个视觉概念。
- 实现超像素token化的过程涉及预聚合提取和超级像素感知聚合等步骤。
- 该策略与现有框架兼容性强,可提高Vision Transformer在各种下游任务上的准确性和鲁棒性。
点此查看论文截图

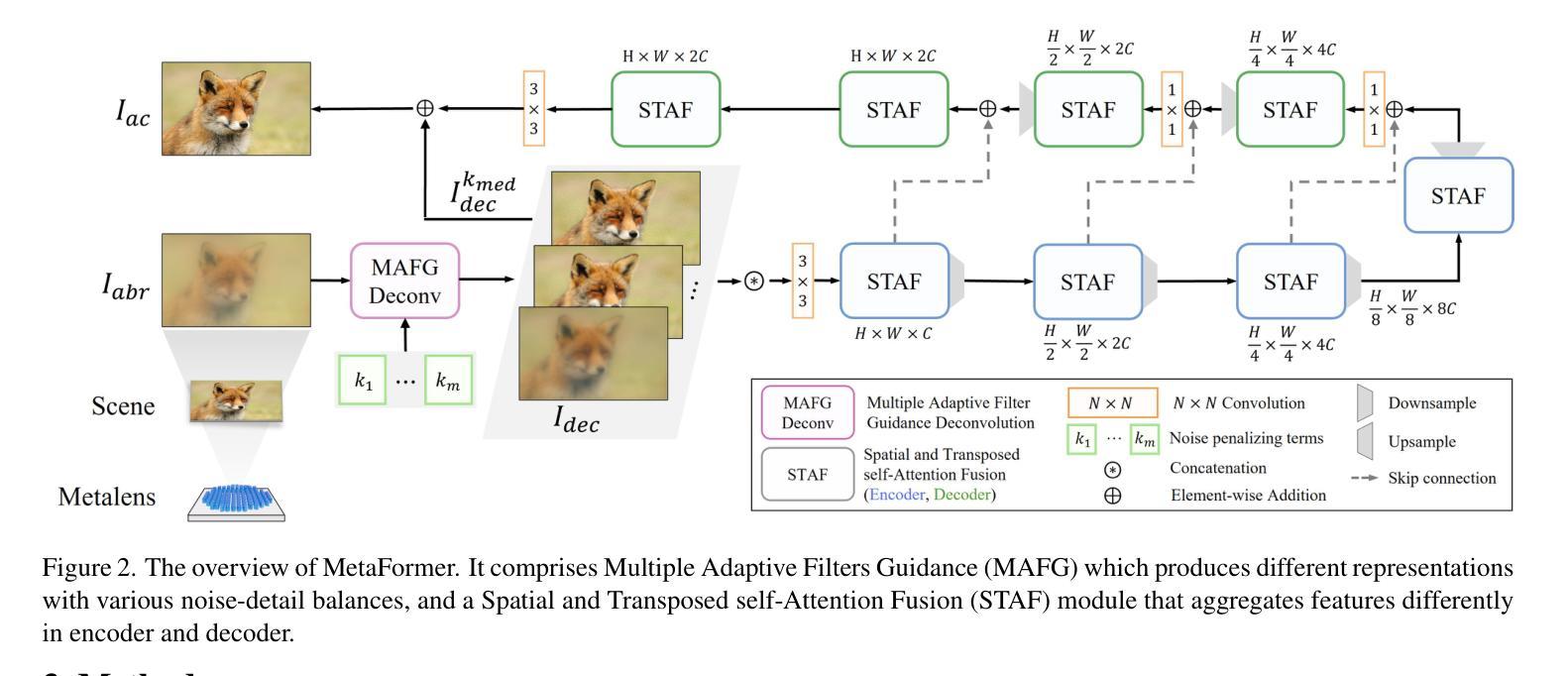
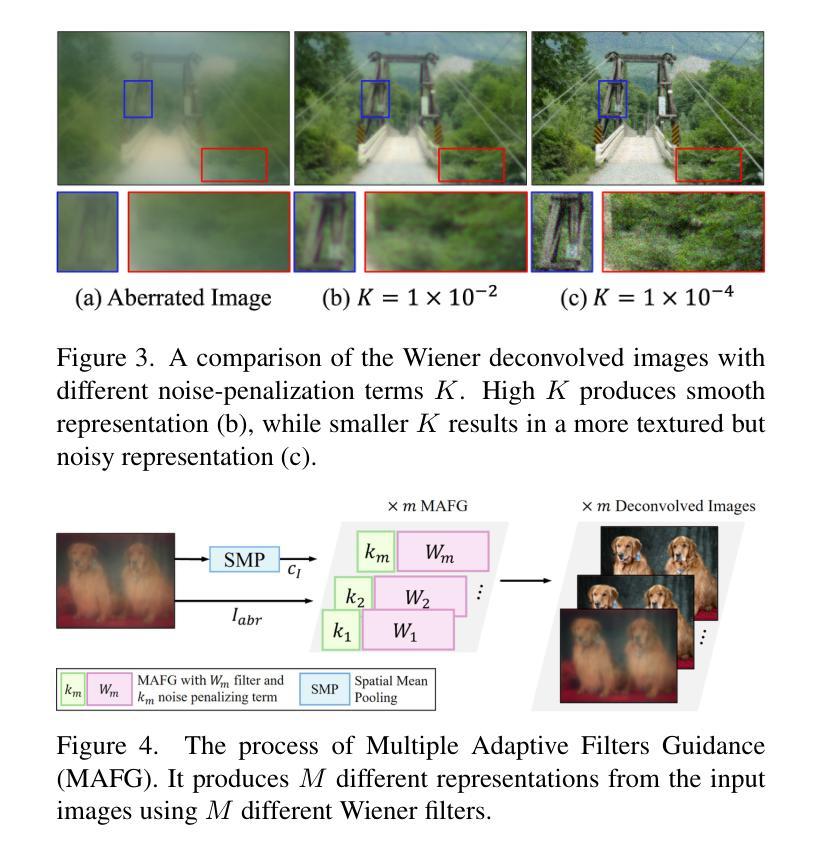
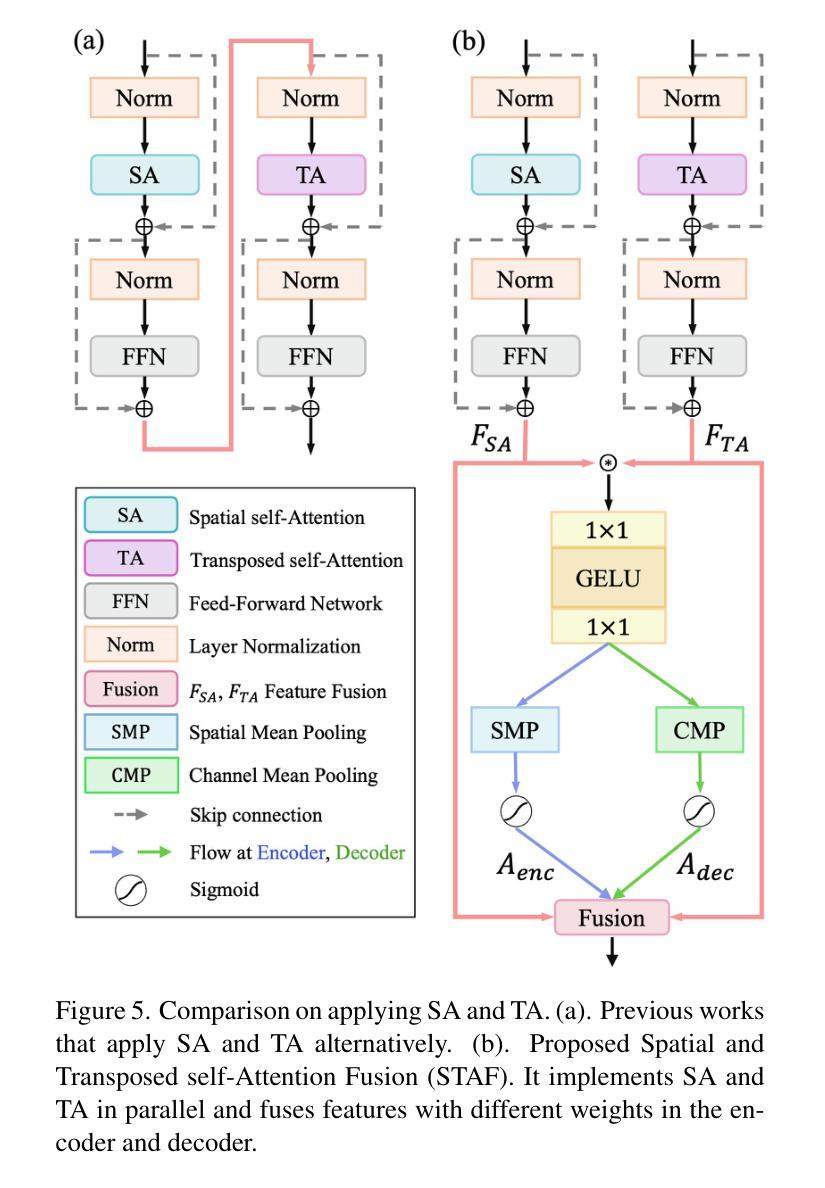
MetaFormer: High-fidelity Metalens Imaging via Aberration Correcting Transformers
Authors:Byeonghyeon Lee, Youbin Kim, Yongjae Jo, Hyunsu Kim, Hyemi Park, Yangkyu Kim, Debabrata Mandal, Praneeth Chakravarthula, Inki Kim, Eunbyung Park
Metalens is an emerging optical system with an irreplaceable merit in that it can be manufactured in ultra-thin and compact sizes, which shows great promise of various applications such as medical imaging and augmented/virtual reality (AR/VR). Despite its advantage in miniaturization, its practicality is constrained by severe aberrations and distortions, which significantly degrade the image quality. Several previous arts have attempted to address different types of aberrations, yet most of them are mainly designed for the traditional bulky lens and not convincing enough to remedy harsh aberrations of the metalens. While there have existed aberration correction methods specifically for metalens, they still fall short of restoration quality. In this work, we propose MetaFormer, an aberration correction framework for metalens-captured images, harnessing Vision Transformers (ViT) that has shown remarkable restoration performance in diverse image restoration tasks. Specifically, we devise a Multiple Adaptive Filters Guidance (MAFG), where multiple Wiener filters enrich the degraded input images with various noise-detail balances, enhancing output restoration quality. In addition, we introduce a Spatial and Transposed self-Attention Fusion (STAF) module, which aggregates features from spatial self-attention and transposed self-attention modules to further ameliorate aberration correction. We conduct extensive experiments, including correcting aberrated images and videos, and clean 3D reconstruction from the degraded images. The proposed method outperforms the previous arts by a significant margin. We further fabricate a metalens and verify the practicality of MetaFormer by restoring the images captured with the manufactured metalens in the wild. Code and pre-trained models are available at https://benhenryl.github.io/MetaFormer
金属透镜是一种新兴的光学系统,具有不可替代的优点,即可以制造为超薄且紧凑的尺寸,在医疗成像和增强/虚拟现实(AR/VR)等各种应用中显示出巨大的潜力。尽管其在小型化方面具有优势,但其实际应用受到严重像差和失真的限制,这会严重降低图像质量。之前的几项技术尝试解决不同类型的像差,但大多数主要是为传统的笨重镜头而设计的,并不足以矫正金属透镜的严苛像差。尽管存在专门针对金属透镜的消像差校正方法,但它们仍达不到所需的恢复质量。在这项工作中,我们提出了MetaFormer,这是一个用于金属透镜捕获图像的像差校正框架,利用视觉变压器(ViT)在多种图像恢复任务中表现出卓越的恢复性能。具体来说,我们设计了一种多重自适应滤波器指导(MAFG),其中多个Wiener滤波器以不同的噪声细节平衡丰富退化输入图像,提高了输出恢复质量。此外,我们引入了空间和转置自注意力融合(STAF)模块,该模块聚合了来自空间自注意力和转置自注意力模块的特征,进一步改善了像差校正。我们进行了大量实验,包括校正失真图像和视频,以及从退化图像中进行清晰的3D重建。所提出的方法大大优于以前的技术。我们进一步制造了一个金属透镜,并通过在实际环境中恢复用制造的金属透镜捕获的图像来验证MetaFormer的实用性。代码和预训练模型可在https://benhenryl.github.io/MetaFormer中找到。
论文及项目相关链接
PDF 19 pages, 18 figures
Summary
金属透镜是一种新兴的光学系统,具有制造超薄、超紧凑的优势,在医疗成像、增强/虚拟现实等领域具有广阔的应用前景。然而,金属透镜存在严重的像差和失真问题,严重影响图像质量。本文提出MetaFormer框架,利用Vision Transformers(ViT)对金属透镜拍摄的图像进行像差校正,通过Multiple Adaptive Filters Guidance(MAFG)和Spatial and Transposed self-Attention Fusion(STAF)模块提高校正质量,实现了像差校正和图像恢复的高质量表现。
Key Takeaways
- 金属透镜具有超薄、超紧凑的优势,在多种应用领域中具有广阔前景。
- 金属透镜存在严重的像差和失真问题,影响图像质量。
- 此前的研究主要关注传统镜头的像差校正,而对金属透镜的像差校正效果不佳。
- MetaFormer框架利用Vision Transformers(ViT)进行金属透镜拍摄的图像像差校正。
- MAFG模块通过多个Wiener滤波器丰富退化输入图像的噪声细节平衡,提高输出恢复质量。
- STAF模块结合空间自注意力和转置自注意力模块的特征,进一步改善像差校正。
点此查看论文截图

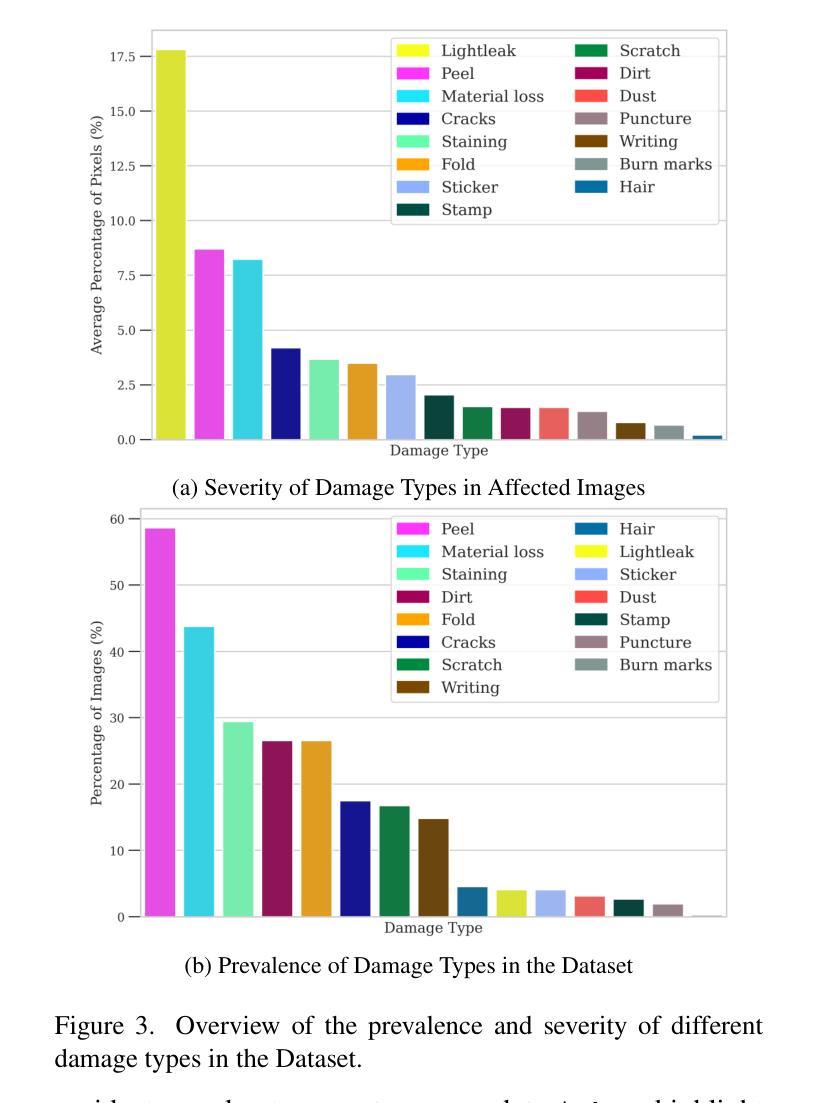
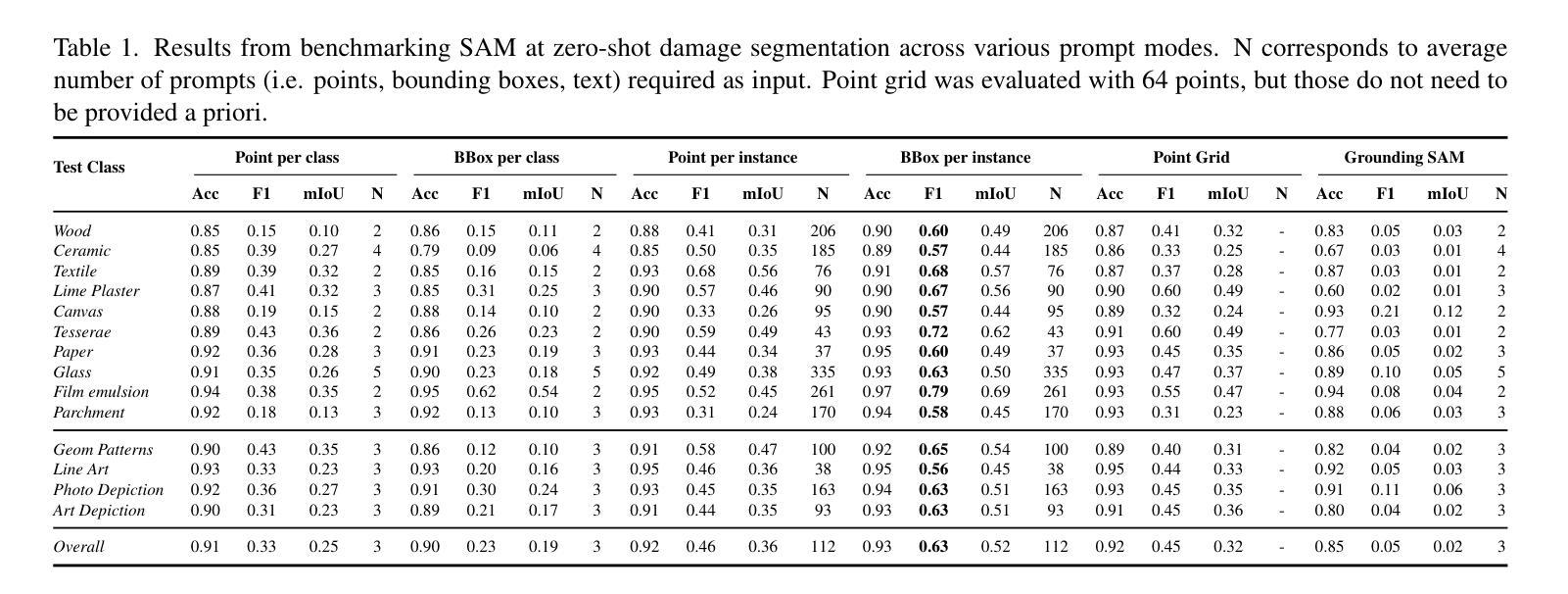
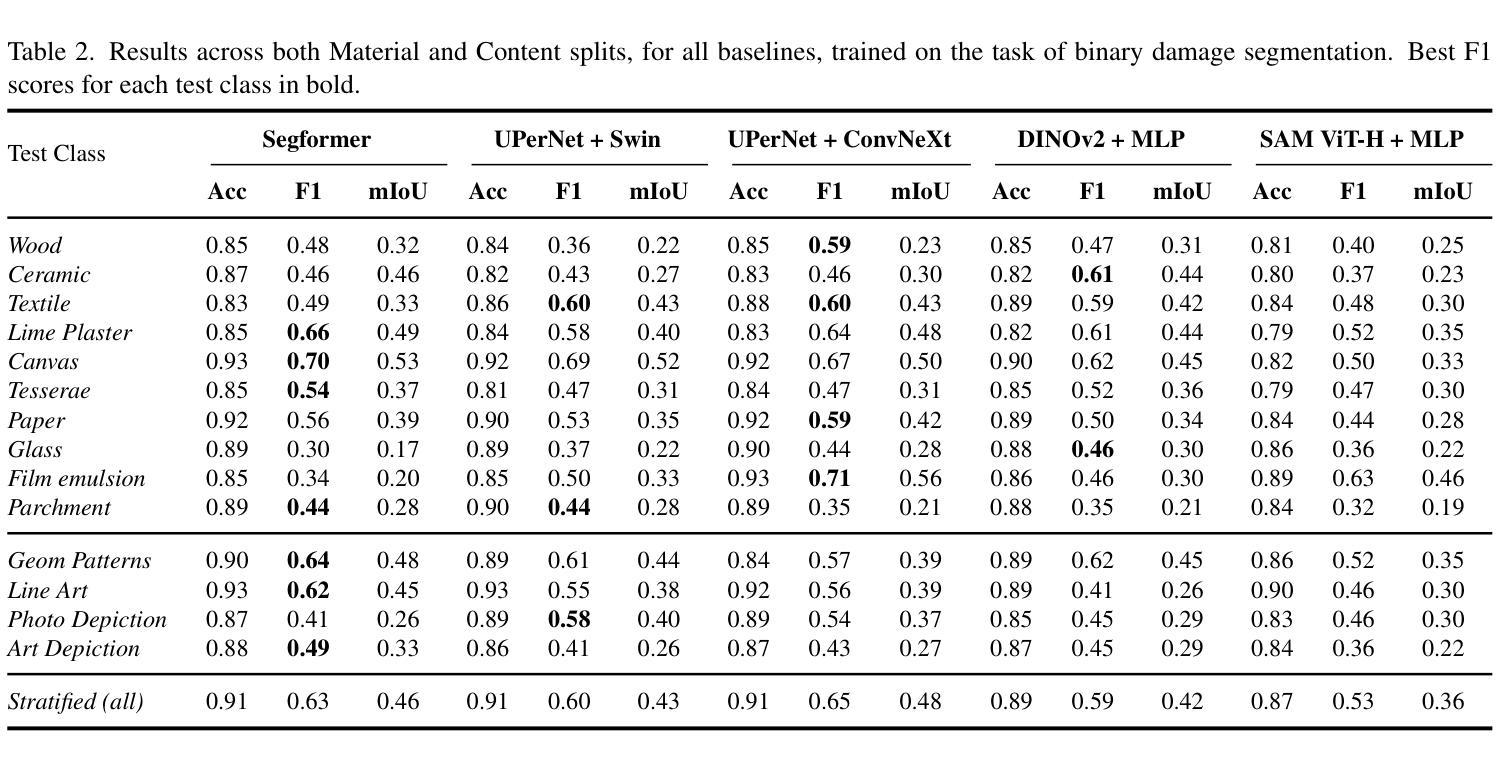
ARTeFACT: Benchmarking Segmentation Models on Diverse Analogue Media Damage
Authors:Daniela Ivanova, Marco Aversa, Paul Henderson, John Williamson
Accurately detecting and classifying damage in analogue media such as paintings, photographs, textiles, mosaics, and frescoes is essential for cultural heritage preservation. While machine learning models excel in correcting degradation if the damage operator is known a priori, we show that they fail to robustly predict where the damage is even after supervised training; thus, reliable damage detection remains a challenge. Motivated by this, we introduce ARTeFACT, a dataset for damage detection in diverse types analogue media, with over 11,000 annotations covering 15 kinds of damage across various subjects, media, and historical provenance. Furthermore, we contribute human-verified text prompts describing the semantic contents of the images, and derive additional textual descriptions of the annotated damage. We evaluate CNN, Transformer, diffusion-based segmentation models, and foundation vision models in zero-shot, supervised, unsupervised and text-guided settings, revealing their limitations in generalising across media types. Our dataset is available at $\href{https://daniela997.github.io/ARTeFACT/}{https://daniela997.github.io/ARTeFACT/}$ as the first-of-its-kind benchmark for analogue media damage detection and restoration.
在模拟媒体(如绘画、照片、纺织品、马赛克和壁画)中准确检测和分类损伤对于文化遗产保护至关重要。虽然机器学习模型在预先知道损伤操作员的情况下擅长纠正退化,但我们发现它们在经过监督训练后仍然无法稳健地预测损伤位置;因此,可靠的损伤检测仍然是一个挑战。受此启发,我们推出了ARTeFACT数据集,该数据集用于检测多种类型的模拟媒体中的损伤,包含超过11,000个注释,涵盖各种主题、媒体和历史来源的15种损伤类型。此外,我们提供了经人工验证的文本提示来描述图像中的语义内容,并推导了注释损伤的额外文本描述。我们评估了CNN、Transformer、基于扩散的分割模型和视觉基础模型在零样本、监督、无监督和文本引导下的设置,揭示了它们在跨媒体类型推广方面的局限性。我们的数据集可在[https://daniela997.github.io/ARTeFACT/]作为模拟媒体损伤检测和恢复的同类首创基准数据集使用。
论文及项目相关链接
PDF Accepted for publication at WACV 2025
Summary
本文介绍了ARTeFACT数据集,该数据集专注于模拟媒体(如绘画、照片、纺织品、马赛克和壁画)的损坏检测。数据集包含超过11,000个注释,涵盖15种不同类型的损坏,涉及各种主题、媒体和历史来源。此外,本文还评估了几种不同的机器学习模型(包括CNN、Transformer、基于扩散的分割模型和基础视觉模型)在不同设置下的性能,并指出了它们在推广方面的局限性。数据集作为模拟媒体损坏检测和恢复的基准测试集,现已公开发布。
Key Takeaways
- ARTeFACT数据集用于检测模拟媒体(如绘画、照片等)的损坏。
- 数据集包含超过11,000个注释,涵盖多种损坏类型。
- 不同类型的机器学习模型在模拟媒体损坏检测方面的局限性被揭示。
- 数据集提供对图像语义内容的文本描述和对损坏的额外文本描述。
- 数据集是第一个针对模拟媒体损坏检测和恢复的基准测试集。
- 在不同设置下(如零样本、监督、无监督和文本引导),模型的表现得到了评估。
点此查看论文截图




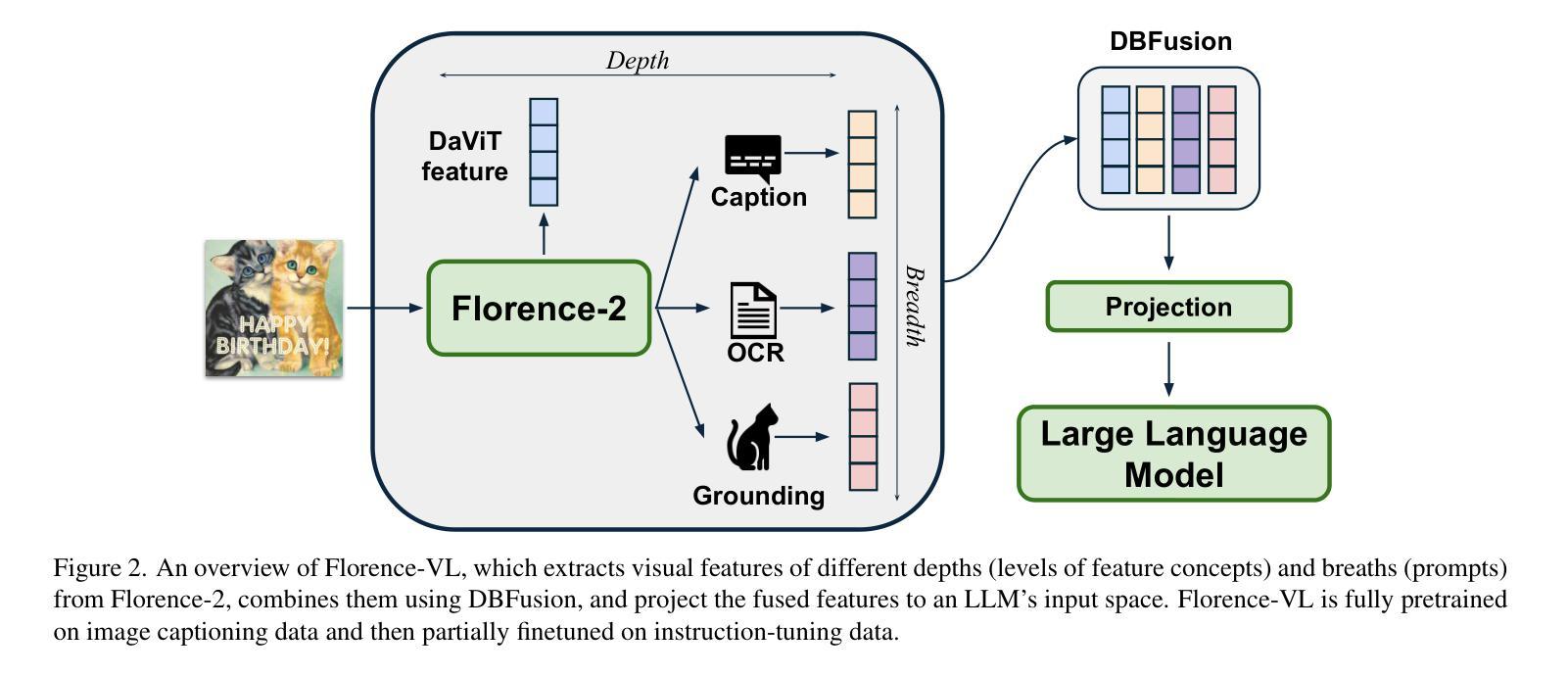
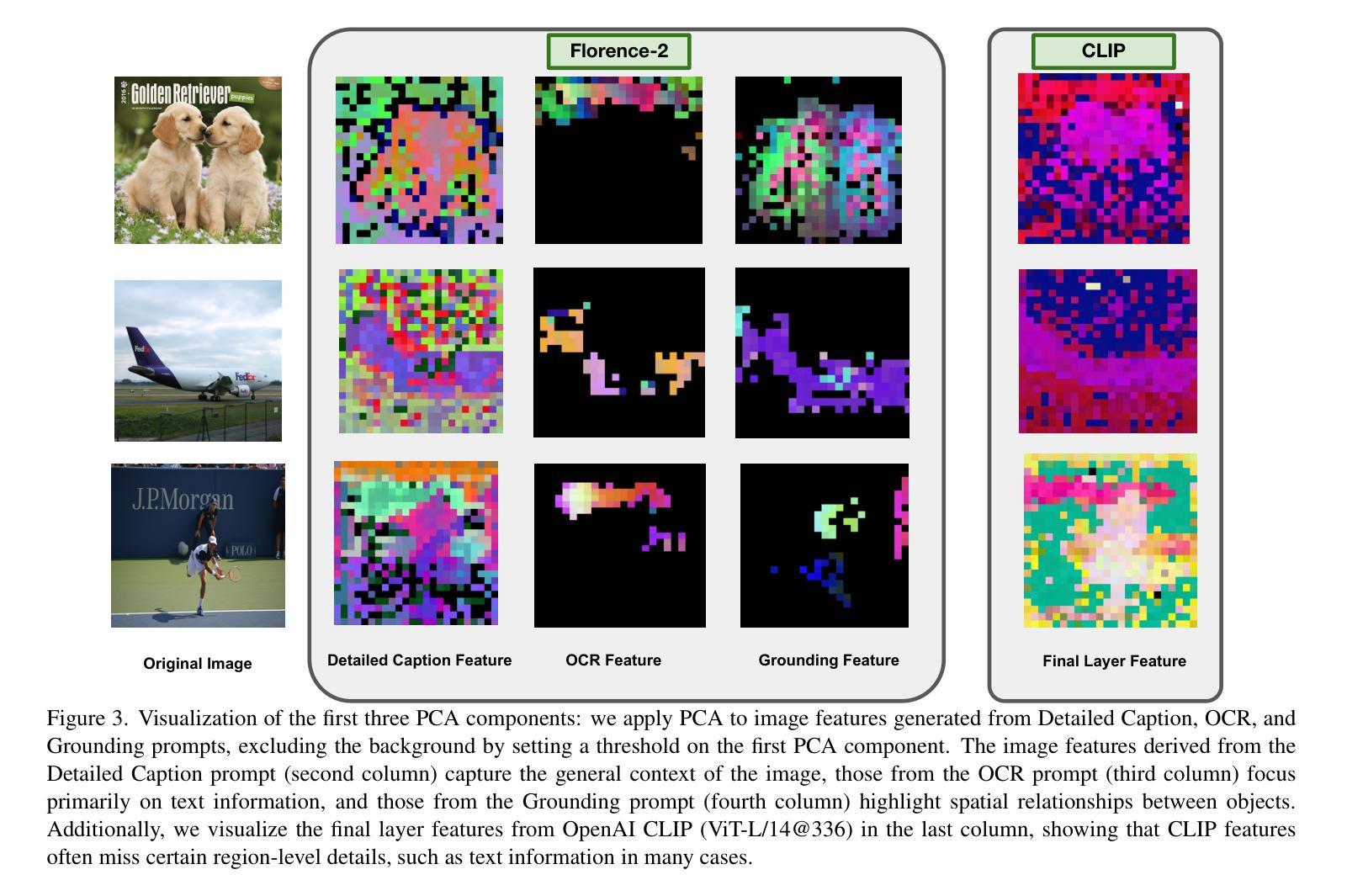
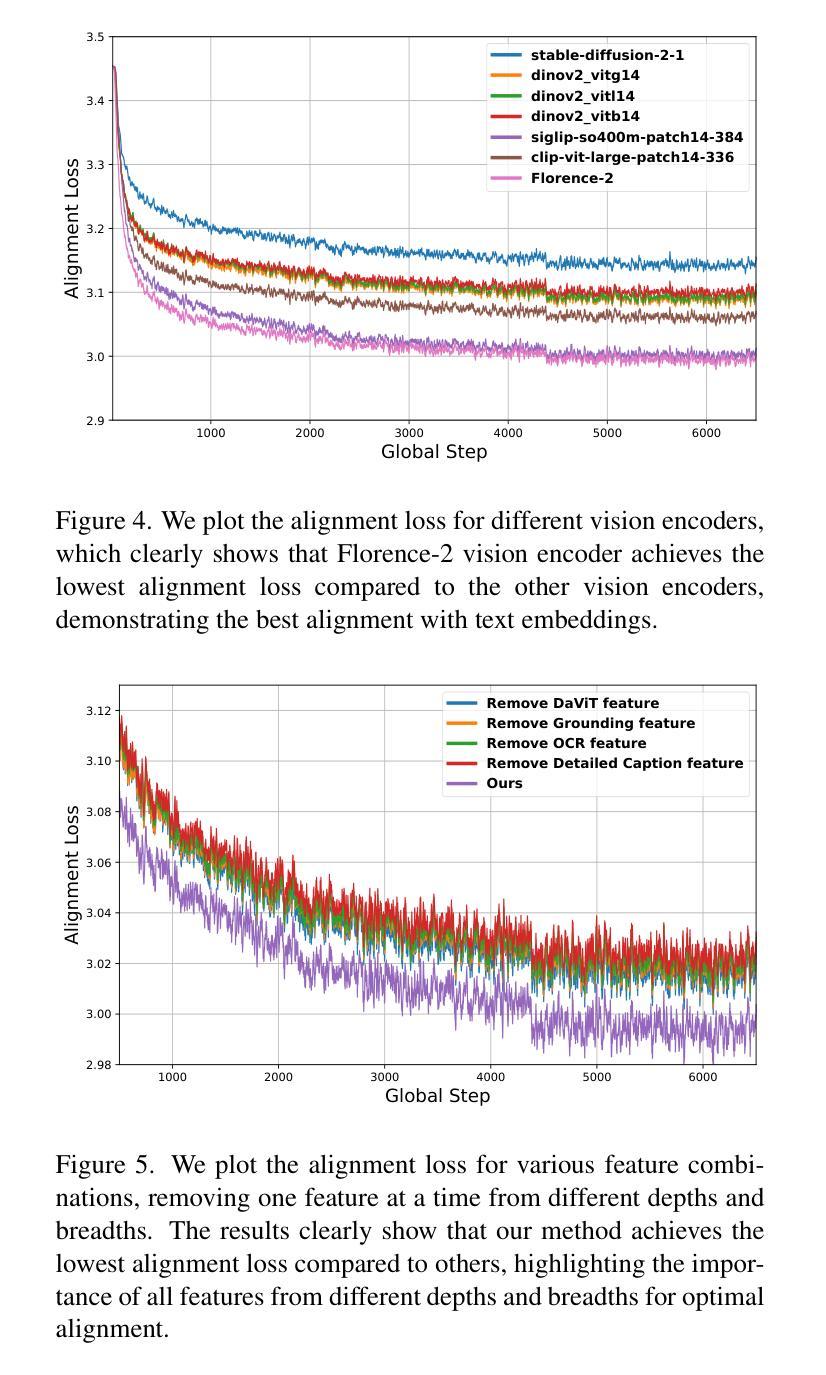
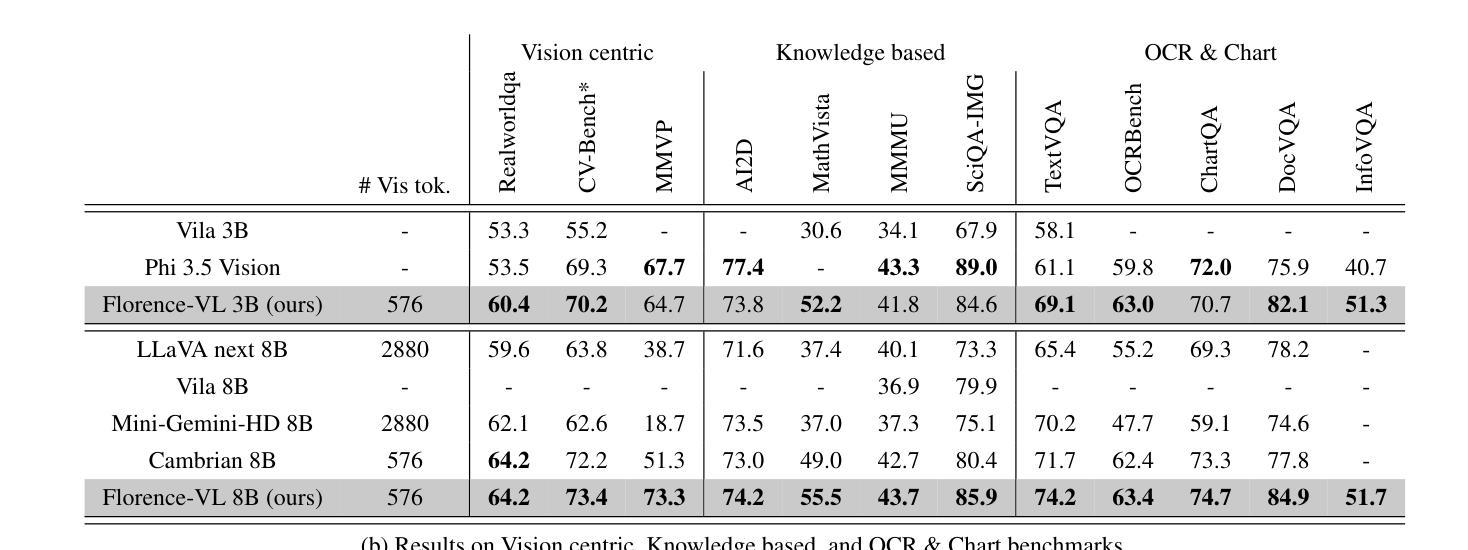
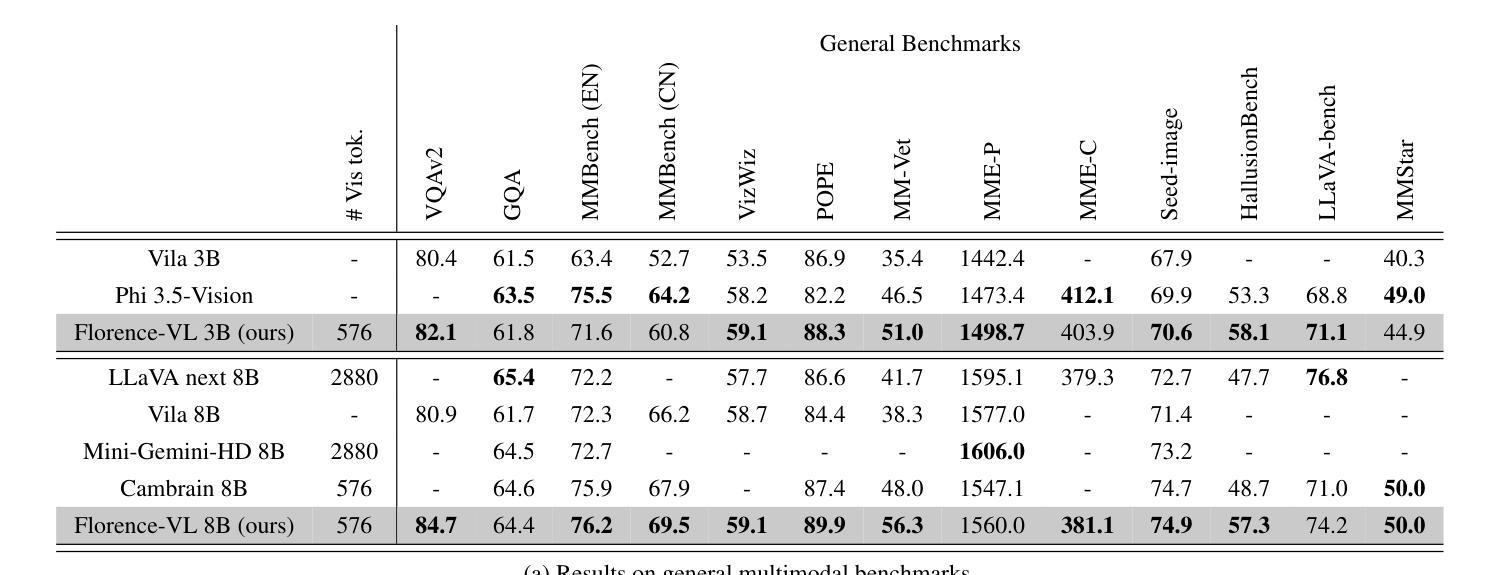
Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion
Authors:Jiuhai Chen, Jianwei Yang, Haiping Wu, Dianqi Li, Jianfeng Gao, Tianyi Zhou, Bin Xiao
We present Florence-VL, a new family of multimodal large language models (MLLMs) with enriched visual representations produced by Florence-2, a generative vision foundation model. Unlike the widely used CLIP-style vision transformer trained by contrastive learning, Florence-2 can capture different levels and aspects of visual features, which are more versatile to be adapted to diverse downstream tasks. We propose a novel feature-fusion architecture and an innovative training recipe that effectively integrates Florence-2’s visual features into pretrained LLMs, such as Phi 3.5 and LLama 3. In particular, we propose “depth-breath fusion (DBFusion)” to fuse the visual features extracted from different depths and under multiple prompts. Our model training is composed of end-to-end pretraining of the whole model followed by finetuning of the projection layer and the LLM, on a carefully designed recipe of diverse open-source datasets that include high-quality image captions and instruction-tuning pairs. Our quantitative analysis and visualization of Florence-VL’s visual features show its advantages over popular vision encoders on vision-language alignment, where the enriched depth and breath play important roles. Florence-VL achieves significant improvements over existing state-of-the-art MLLMs across various multi-modal and vision-centric benchmarks covering general VQA, perception, hallucination, OCR, Chart, knowledge-intensive understanding, etc. To facilitate future research, our models and the complete training recipe are open-sourced. https://github.com/JiuhaiChen/Florence-VL
我们推出了Florence-VL,这是由Florence-2生成式视觉基础模型产生丰富视觉表征的新一代多模态大型语言模型(MLLMs)。不同于广泛使用的通过对比学习训练的CLIP风格视觉转换器,Florence-2能够捕捉不同级别和方面的视觉特征,更易于适应各种下游任务。我们提出了一种新的特征融合架构和创新训练方案,该方案有效地将Florence-2的视觉特征集成到预训练的LLM中,例如Phi 3.5和LLama 3。特别地,我们提出了“深度广度融合(DBFusion)”方法,以融合从不同深度和多个提示提取的视觉特征。我们的模型训练包括整个模型的端到端预训练,然后是投影层和LLM的微调,在精心设计的包括高质量图像字幕和指令调整对的各种开源数据集上。我们对Florence-VL的视觉特征进行了定量分析和可视化,证明了其在视觉语言对齐方面相较于流行视觉编码器的优势,其中丰富的深度和广度扮演着重要角色。Florence-VL在各种多模态和以视觉为中心的基准测试上实现了对现有最先进的MLLM的显著改进,涵盖通用VQA、感知、幻觉、OCR、图表、知识密集型理解等。为了促进未来的研究,我们的模型和完整的训练方案均已开源。有关详细信息,请参见:https://github.com/JiuhaiChen/Florence-VL。
论文及项目相关链接
Summary
佛罗伦萨-VL系列是一个新的多模态大型语言模型家族,它利用佛罗伦萨-2这一生成式视觉基础模型产生丰富的视觉表征。不同于广泛使用的基于对比学习的CLIP风格视觉转换器,佛罗伦萨-2能够捕捉不同层级和方面的视觉特征,更灵活地适应各种下游任务。团队提出了一种新的特征融合架构和创新训练策略,有效地将佛罗伦萨-2的视觉特征融入预训练的LLMs,如Phi 3.5和LLama 3。我们特别提出了“深度广度融合(DBFusion)”技术,融合从不同深度和多重提示提取的视觉特征。模型训练包括整个模型的端到端预训练,以及投影层和LLMs的微调,训练数据是精心设计的多样化开源数据集,包括高质量的图片标题和指令调整对。定量分析以及佛罗伦萨-VL的视觉特征可视化显示,在视觉语言对齐方面,相较于流行的视觉编码器,其深度与广度扮演着重要角色。佛罗伦萨-VL在各种多模态和视觉为中心的基准测试中实现了显著改进,涵盖了一般性问答、感知、幻觉、OCR、图表、知识密集型理解等。我们的模型和完整的训练策略已开源。
Key Takeaways
- Florence-VL介绍了一个新的多模态大型语言模型家族,结合了视觉和语言信息。
- 通过使用Florence-2这一生成式视觉基础模型,实现了丰富的视觉表征。
- 不同于传统的CLIP风格视觉转换器,Florence-2能捕捉不同层级和方面的视觉特征,适用于多种下游任务。
- 提出了一种新的特征融合架构及训练策略,将视觉特征融入预训练的LLMs。
- 深度广度融合(DBFusion)技术用于融合不同深度和多重提示下的视觉特征。
- 模型训练包括端到端预训练及微调阶段,使用了多样化的开源数据集。
点此查看论文截图


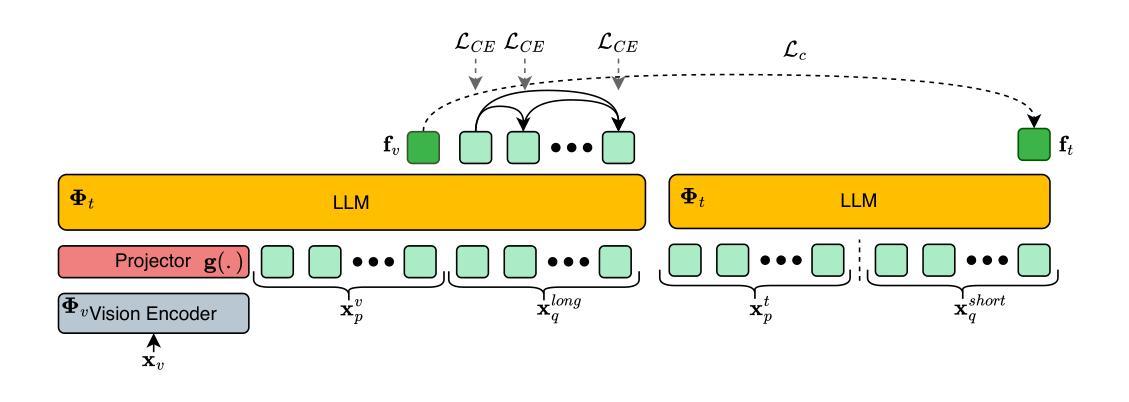
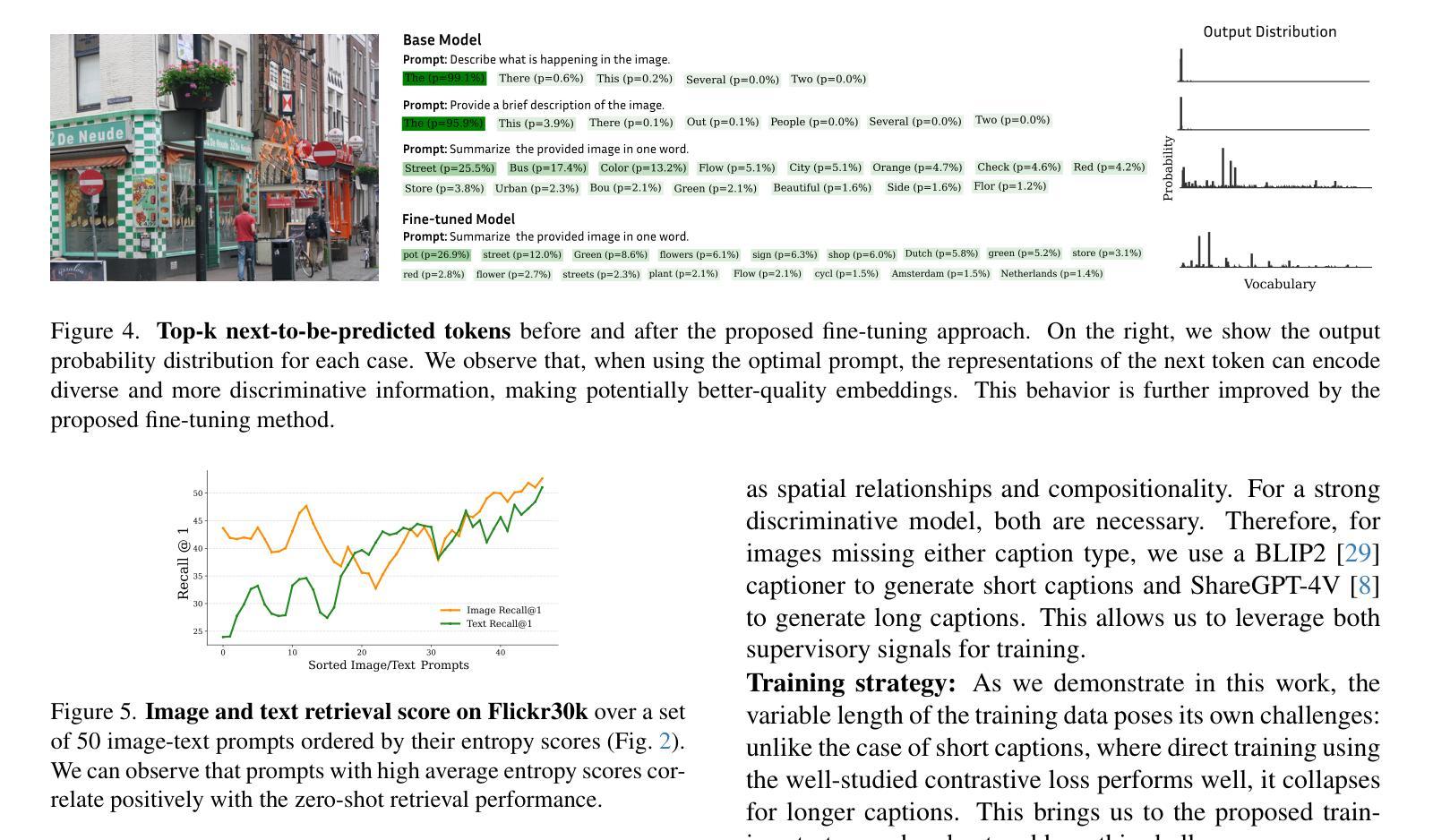
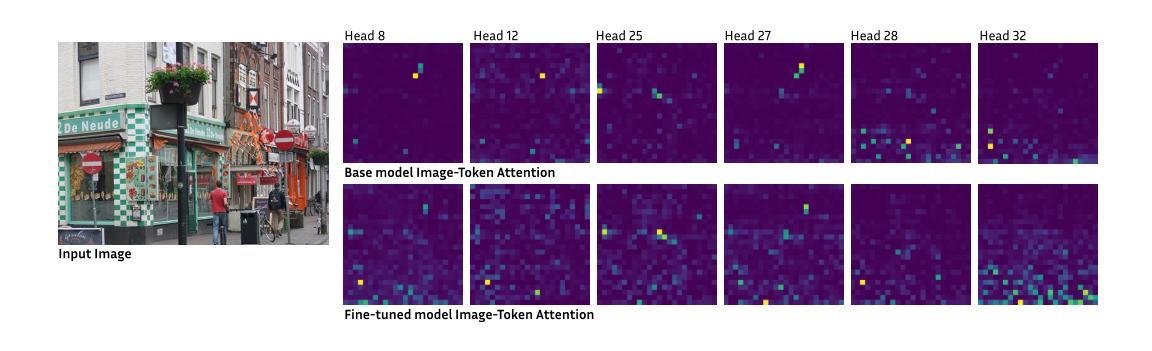
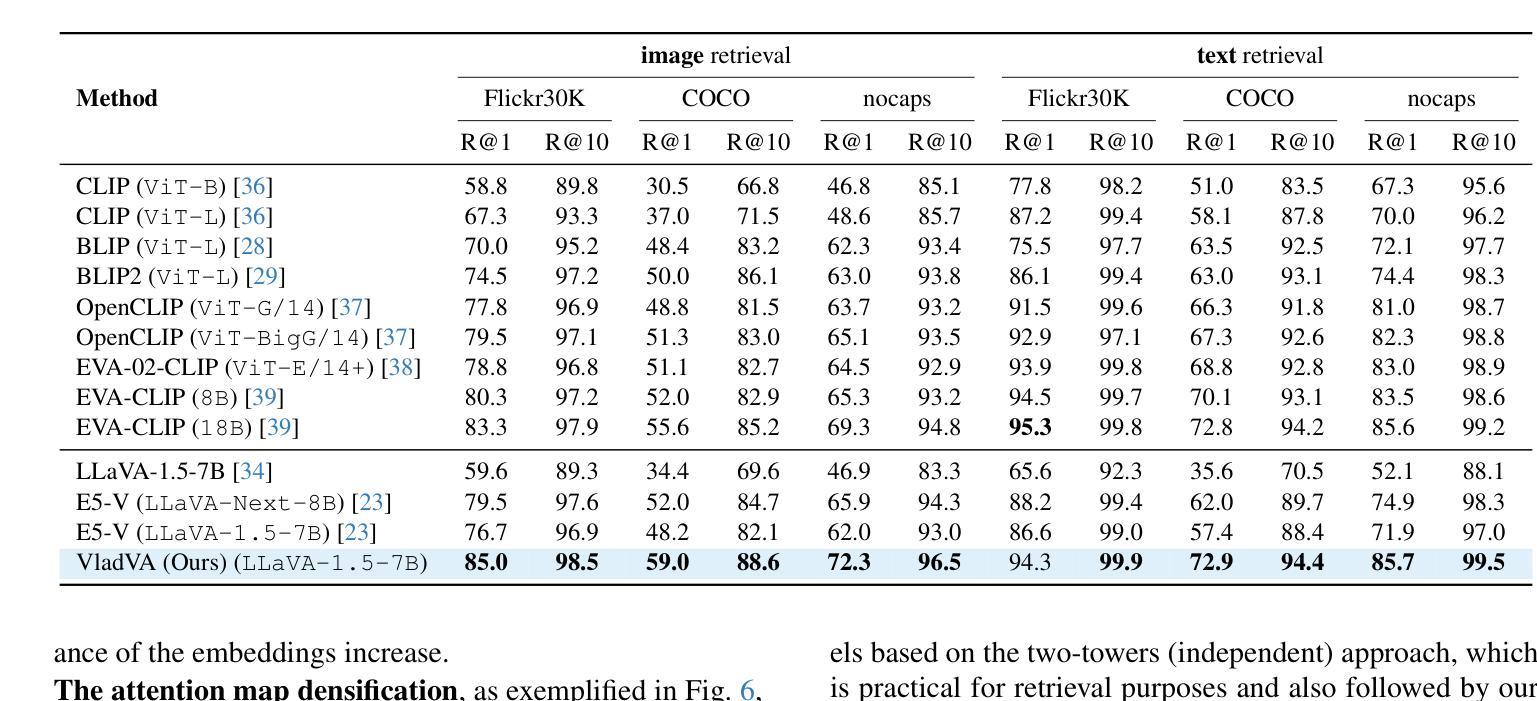
Discriminative Fine-tuning of LVLMs
Authors:Yassine Ouali, Adrian Bulat, Alexandros Xenos, Anestis Zaganidis, Ioannis Maniadis Metaxas, Brais Martinez, Georgios Tzimiropoulos
Contrastively-trained Vision-Language Models (VLMs) like CLIP have become the de facto approach for discriminative vision-language representation learning. However, these models have limited language understanding, often exhibiting a “bag of words” behavior. At the same time, Large Vision-Language Models (LVLMs), which combine vision encoders with LLMs, have been shown capable of detailed vision-language reasoning, yet their autoregressive nature renders them less suitable for discriminative tasks. In this work, we propose to combine “the best of both worlds”: a new training approach for discriminative fine-tuning of LVLMs that results in strong discriminative and compositional capabilities. Essentially, our approach converts a generative LVLM into a discriminative one, unlocking its capability for powerful image-text discrimination combined with enhanced language understanding. Our contributions include: (1) A carefully designed training/optimization framework that utilizes image-text pairs of variable length and granularity for training the model with both contrastive and next-token prediction losses. This is accompanied by ablation studies that justify the necessity of our framework’s components. (2) A parameter-efficient adaptation method using a combination of soft prompting and LoRA adapters. (3) Significant improvements over state-of-the-art CLIP-like models of similar size, including standard image-text retrieval benchmarks and notable gains in compositionality.
对比训练的视觉语言模型(如CLIP)已成为判别式视觉语言表示学习的默认方法。然而,这些模型的语言理解能力有限,通常表现出“词袋”行为。同时,结合了视觉编码器和大型语言模型的大型视觉语言模型(LVLMs)已显示出详细的视觉语言推理能力,但它们的自回归性质使其不太适合判别任务。在这项工作中,我们结合了“两者的优点”:一种用于LVLMs判别精细调整的新训练方法,具有强大的判别和组合能力。本质上,我们的方法将生成式LVLM转换为判别式,解锁其强大的图像文本判别能力,并增强了语言理解。我们的贡献包括:(1)一个精心设计的训练/优化框架,该框架利用可变长度和粒度的图像文本对进行训练,使用对比和下一个令牌预测损失来训练模型。这伴随着消融研究,证明了我们的框架组件的必要性。(2)使用软提示和LoRA适配器组合的参数高效适应方法。(3)在具有类似规模的最先进的CLIP类模型上实现了显著改进,包括标准图像文本检索基准测试和组合性的显著收益。
论文及项目相关链接
PDF Preprint. The first two authors contributed equally
Summary:
本文探讨了对比训练下的视觉语言模型(CLIP等)在视觉语言表示学习方面的应用及其局限性,包括在语言表达和区分任务上的挑战。在此基础上,提出一种新型的用于LVLMs的判别微调训练策略,旨在结合生成和判别模型的优势,提高模型的判别能力和语言理解能力。通过设计图像文本对训练框架,结合对比和下一个令牌预测损失进行训练,并采用软提示和LoRA适配器等方法实现参数高效适应。该策略在标准图像文本检索基准测试中实现了对CLIP等模型的显著改进。
Key Takeaways:
- 对比训练的视觉语言模型(CLIP等)是判别式视觉语言表示学习的主流方法,但存在语言理解局限,表现出“词袋”行为。
- 大型视觉语言模型(LVLMs)结合了视觉编码器和LLMs,能够进行详细的视觉语言推理,但其自回归性质使其不适合进行判别任务。
- 提出了一种新型的LVLMs判别微调训练策略,结合了生成模型和判别模型的优势,使模型具有强大的图像文本鉴别能力和增强的语言理解能力。
- 训练框架利用可变长度和粒度的图像文本对进行训练,结合对比和下一个令牌预测损失。
- 采用软提示和LoRA适配器等方法实现参数高效适应。
- 该策略在标准图像文本检索基准测试中实现了显著改进,包括对CLIP等模型的性能提升。
点此查看论文截图

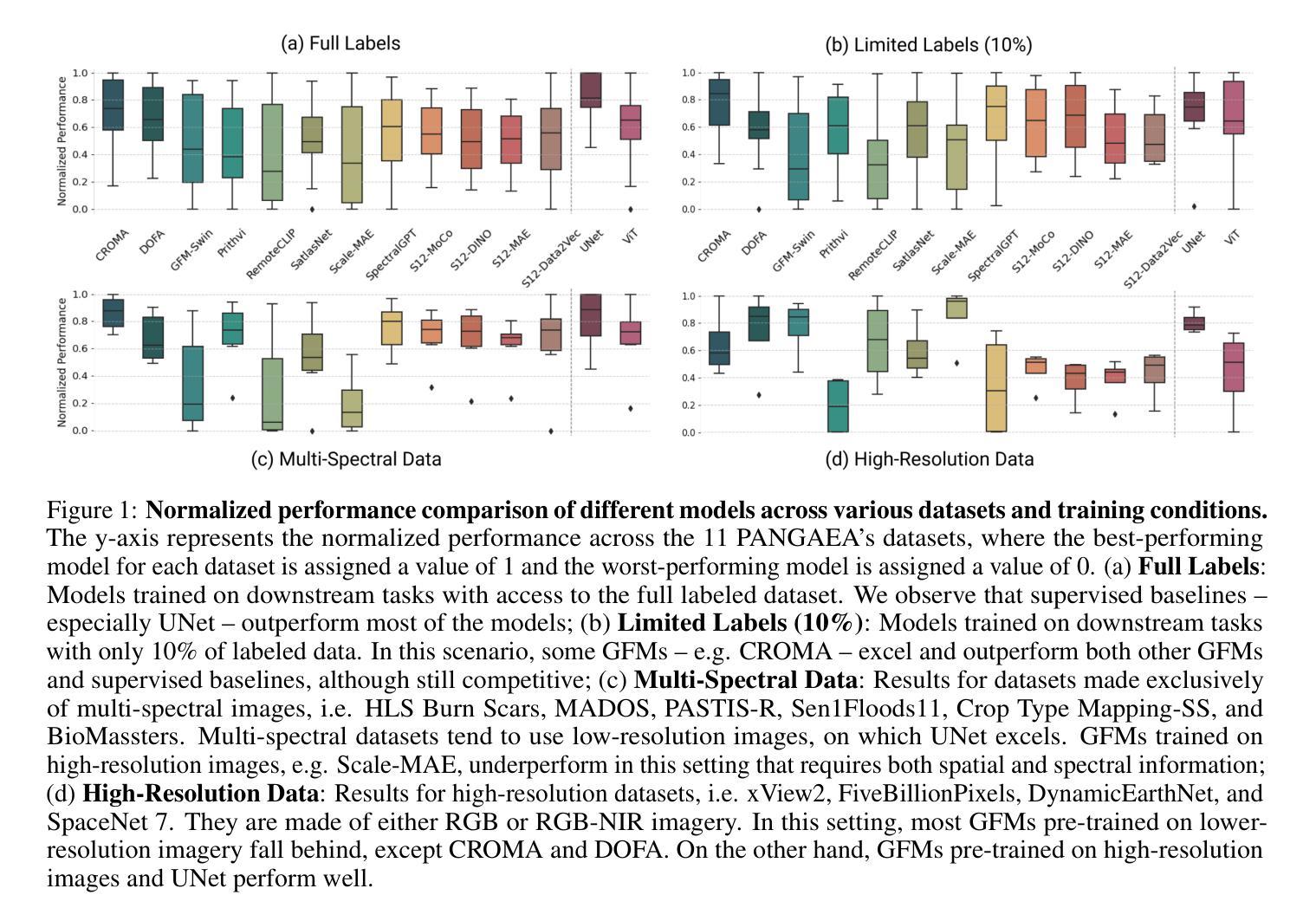
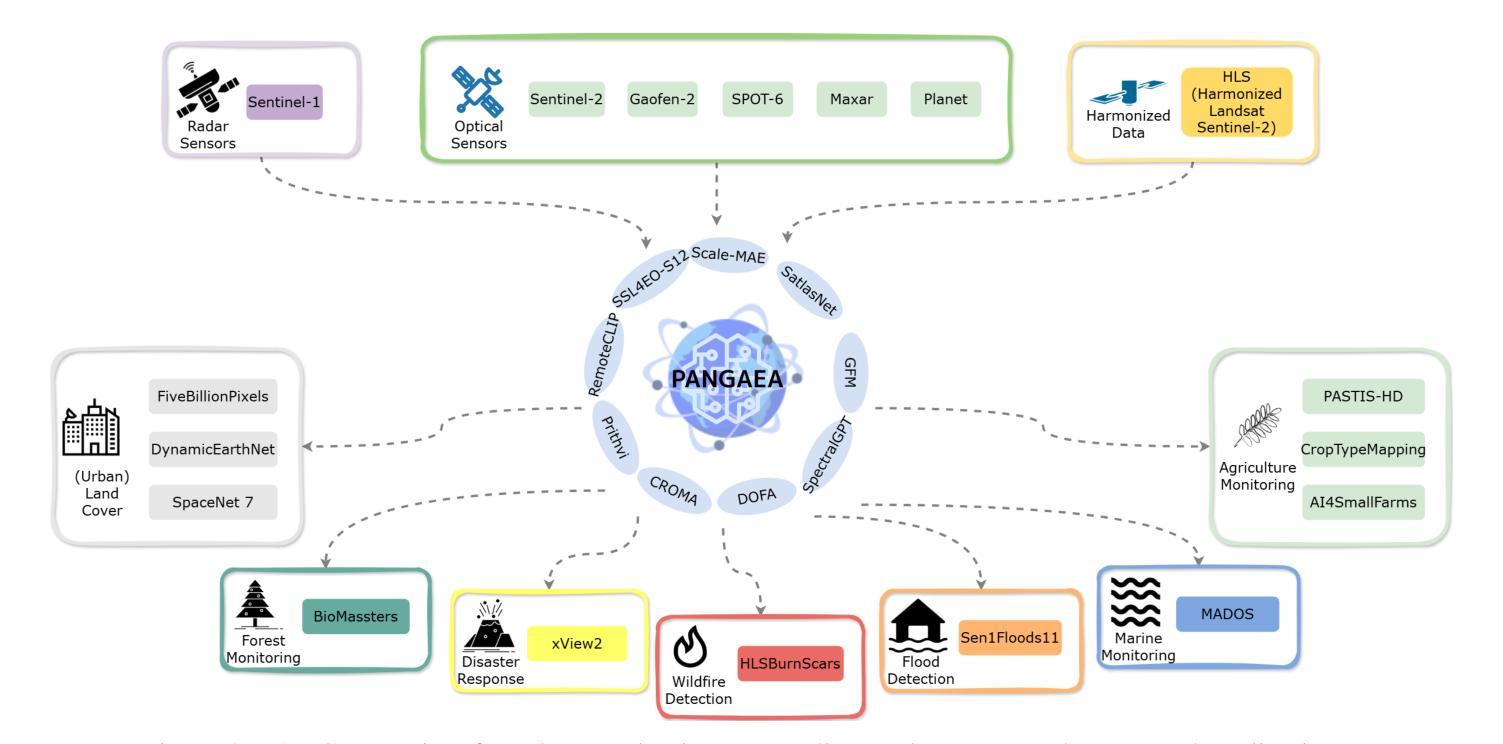
PANGAEA: A Global and Inclusive Benchmark for Geospatial Foundation Models
Authors:Valerio Marsocci, Yuru Jia, Georges Le Bellier, David Kerekes, Liang Zeng, Sebastian Hafner, Sebastian Gerard, Eric Brune, Ritu Yadav, Ali Shibli, Heng Fang, Yifang Ban, Maarten Vergauwen, Nicolas Audebert, Andrea Nascetti
Geospatial Foundation Models (GFMs) have emerged as powerful tools for extracting representations from Earth observation data, but their evaluation remains inconsistent and narrow. Existing works often evaluate on suboptimal downstream datasets and tasks, that are often too easy or too narrow, limiting the usefulness of the evaluations to assess the real-world applicability of GFMs. Additionally, there is a distinct lack of diversity in current evaluation protocols, which fail to account for the multiplicity of image resolutions, sensor types, and temporalities, which further complicates the assessment of GFM performance. In particular, most existing benchmarks are geographically biased towards North America and Europe, questioning the global applicability of GFMs. To overcome these challenges, we introduce PANGAEA, a standardized evaluation protocol that covers a diverse set of datasets, tasks, resolutions, sensor modalities, and temporalities. It establishes a robust and widely applicable benchmark for GFMs. We evaluate the most popular GFMs openly available on this benchmark and analyze their performance across several domains. In particular, we compare these models to supervised baselines (e.g. UNet and vanilla ViT), and assess their effectiveness when faced with limited labeled data. Our findings highlight the limitations of GFMs, under different scenarios, showing that they do not consistently outperform supervised models. PANGAEA is designed to be highly extensible, allowing for the seamless inclusion of new datasets, models, and tasks in future research. By releasing the evaluation code and benchmark, we aim to enable other researchers to replicate our experiments and build upon our work, fostering a more principled evaluation protocol for large pre-trained geospatial models. The code is available at https://github.com/VMarsocci/pangaea-bench.
地理空间基础模型(GFMs)作为从地球观测数据中提取表征的强大工具已经崭露头角,但其评估仍然存在着不一致和狭窄的问题。现有作品经常在次优的下游数据集和任务上进行评估,这些任务通常过于简单或过于狭窄,限制了评估在评估GFMs现实应用中的有用性。此外,当前评估协议中缺乏多样性,未能考虑到图像分辨率、传感器类型和时态的多样性,这进一步加剧了对GFM性能评估的复杂性。特别是,大多数现有基准测试在地理上偏向于北美和欧洲,这引发了人们对GFMs全球适用性的质疑。
为了克服这些挑战,我们引入了泛大陆评价协议(PANGAEA),这是一种标准化的评估协议,涵盖了一系列多样化的数据集、任务、分辨率、传感器模态和时态。它为GFMs建立了稳健且广泛适用的基准测试。我们在该基准测试上对最受欢迎的GFMs进行了公开评估,并分析了它们在多个领域中的性能。特别是,我们将这些模型与有监督的基线(例如UNet和Vanilla ViT)进行比较,并评估它们在面临有限标记数据时的有效性。我们的研究结果突显了GFMs在不同场景下的局限性,表明它们并不始终优于有监督模型。
论文及项目相关链接
Summary
地球观测数据表示提取的强大工具——地理空间基础模型(GFMs)的评价仍存在不一致和狭窄的问题。现有研究在评价时常常使用次优的下游数据集和任务,这些任务过于简单或过于狭窄,限制了评价在评估GFMs现实应用中的实用性。此外,当前的评价协议缺乏多样性,未能考虑到图像分辨率、传感器类型和时态的多元性,进一步增加了评估GFM性能的复杂性。为了解决这些挑战,引入PANGAEA标准化评价协议,涵盖多样化数据集、任务、分辨率、传感器模态和时态,建立稳健且广泛适用的GFMs基准。评估了最受欢迎的GFMs在基准测试上的表现,并分析了它们在多个领域中的性能。特别是,将这些模型与监督基线(如UNet和Vanilla ViT)进行比较,并评估它们在面临有限标记数据时的有效性。研究结果表明GFMs的局限性在不同场景下表现不一,并不始终优于监督模型。PANGAEA设计具有高度可扩展性,允许未来研究中无缝集成新数据集、模型和任务。发布评估代码和基准测试,旨在使其他研究人员能够复制我们的实验并基于我们的工作建立新的研究,促进大型预训练地理空间模型更严谨的评价协议的形成。
Key Takeaways
- GFMs在地球观测数据表示提取中是强大的工具,但评价存在不一致和狭窄的问题。
- 当前评价协议缺乏多样性,未能充分考虑图像分辨率、传感器类型和时态的多元性。
- 引入PANGAEA标准化评价协议,涵盖多样化数据集、任务等,建立稳健且广泛适用的GFMs基准。
- 评估了GFMs在基准测试上的表现,并与监督基线进行比较。
- GFMs在不同场景下面临局限性,并不始终优于监督模型。
- PANGAEA设计具有高度可扩展性,为未来研究提供了无缝集成新数据集、模型和任务的可能性。
点此查看论文截图

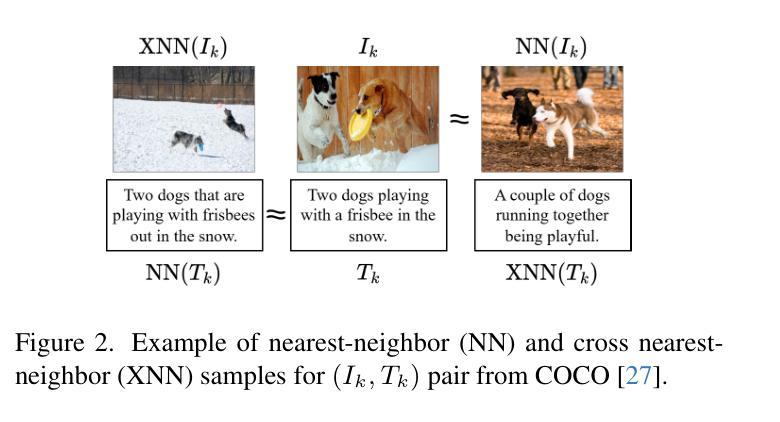
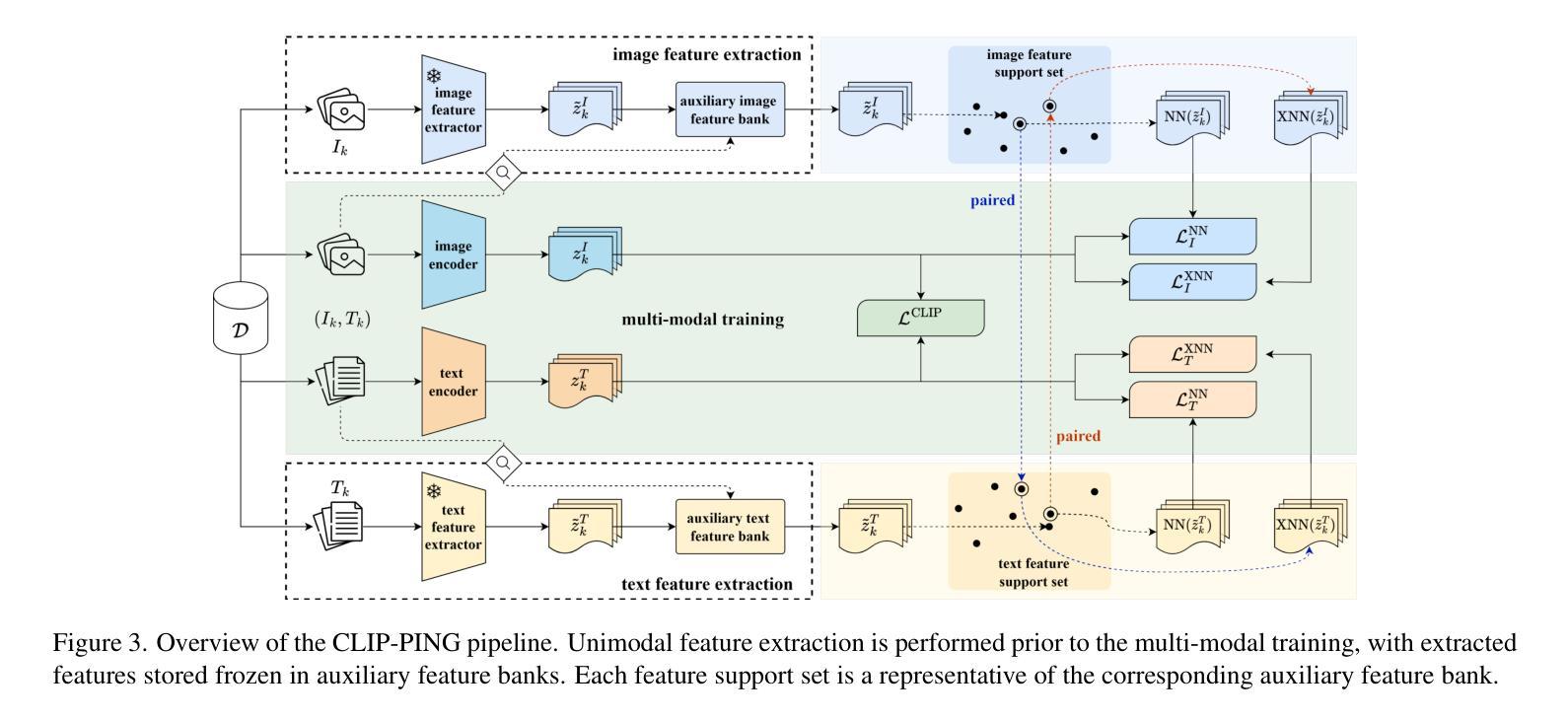
CLIP-PING: Boosting Lightweight Vision-Language Models with Proximus Intrinsic Neighbors Guidance
Authors:Chu Myaet Thwal, Ye Lin Tun, Minh N. H. Nguyen, Eui-Nam Huh, Choong Seon Hong
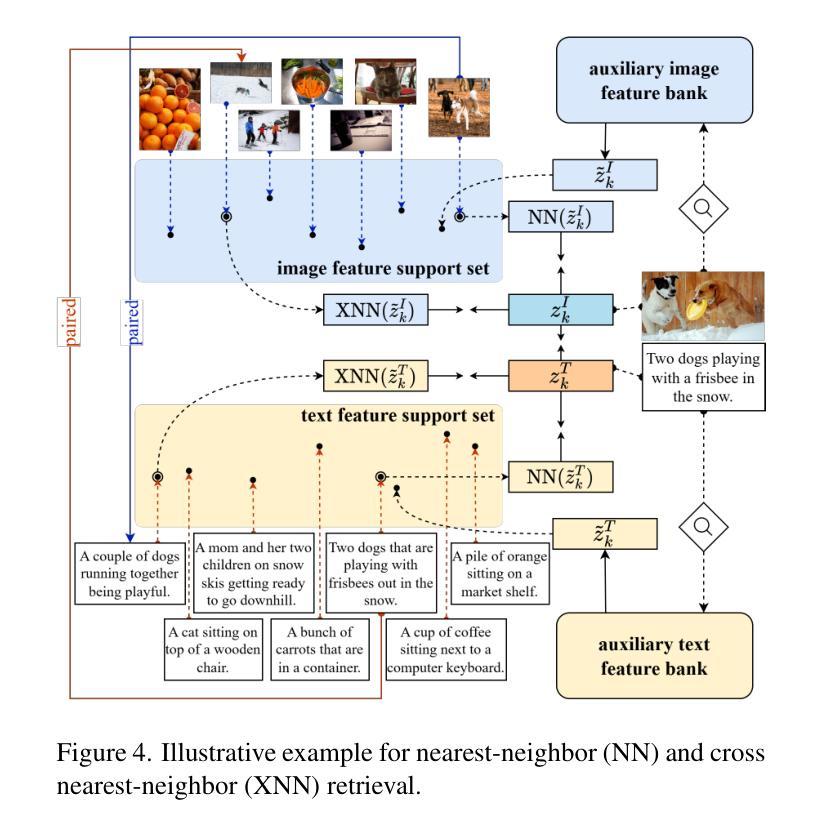
Beyond the success of Contrastive Language-Image Pre-training (CLIP), recent trends mark a shift toward exploring the applicability of lightweight vision-language models for resource-constrained scenarios. These models often deliver suboptimal performance when relying solely on a single image-text contrastive learning objective, spotlighting the need for more effective training mechanisms that guarantee robust cross-modal feature alignment. In this work, we propose CLIP-PING: Contrastive Language-Image Pre-training with Proximus Intrinsic Neighbors Guidance, a simple and efficient training paradigm designed to boost the performance of lightweight vision-language models with minimal computational overhead and lower data demands. CLIP-PING bootstraps unimodal features extracted from arbitrary pre-trained encoders to obtain intrinsic guidance of proximus neighbor samples, i.e., nearest-neighbor (NN) and cross nearest-neighbor (XNN). We find that extra contrastive supervision from these neighbors substantially boosts cross-modal alignment, enabling lightweight models to learn more generic features with rich semantic diversity. Extensive experiments reveal that CLIP-PING notably surpasses its peers in zero-shot generalization and cross-modal retrieval tasks. Specifically, a 5.5% gain on zero-shot ImageNet1K with 10.7% (I2T) and 5.7% (T2I) on Flickr30K, compared to the original CLIP when using ViT-XS image encoder trained on 3 million (image, text) pairs. Moreover, CLIP-PING showcases strong transferability under the linear evaluation protocol across several downstream tasks.
摘要:在Contrastive Language-Image Pre-training(CLIP)大获成功之后,最近的趋势开始转向探索轻量级视觉语言模型在资源受限场景中的适用性。这些模型在仅依赖于单图像文本对比学习目标时,往往表现不佳,这突显了需要更有效的训练机制来保证跨模态特征对齐的稳健性。在这项工作中,我们提出了CLIP-PING:带有Proximus内在邻居引导(Proximus Intralexic Inner Neighbors Guidance)的对比语言图像预训练。这是一种简单高效训练范式,旨在以最小的计算开销和更低的数据需求提升轻量级视觉语言模型的性能。CLIP-PING启动从任意预训练编码器中提取的单模态特征来获得邻近邻居样本的内在引导,即最近邻居(NN)和交叉最近邻居(XNN)。我们发现这些邻居额外的对比监督信息会显著促进跨模态对齐,使轻量级模型能够学习更丰富语义多样性的更通用特征。大量实验表明,CLIP-PING在零样本泛化和跨模态检索任务上显著超过了同类模型。具体来说,使用ViT-XS图像编码器在3百万个(图像,文本)对上训练的CLIP模型相比,在零样本ImageNet1K上提高了5.5%,在Flickr30K上的I2T和T2I分别提高了10.7%和5.7%。此外,CLIP-PING在线性评估协议下具有较强的跨多个下游任务的迁移能力。
论文及项目相关链接
PDF 15 pages, 4 figures, 20 tables
摘要
基于Contrastive Language-Image Pre-training(CLIP)的成功,当前趋势是探索轻量级视觉语言模型在资源受限场景中的应用性。然而,这些模型在仅依赖单一图像文本对比学习目标时通常表现不佳,凸显了需要更有效的训练机制来保证跨模态特征对齐的稳健性。本次研究中,我们提出CLIP-PING:带有Proximus内在邻居指引的对比语言图像预训练,这是一种简单高效的训练范式,旨在以最小的计算开销和更低的数据需求提升轻量级视觉语言模型的性能。CLIP-PING利用从任意预训练编码器提取的单模态特征来引导邻近邻居样本的内在指引,即最近邻(NN)和交叉最近邻(XNN)。我们发现来自这些邻居的额外对比监督显著提升了跨模态对齐,使轻量级模型能够学习更具通用性和丰富语义多样性的特征。大量实验表明,在零样本泛化和跨模态检索任务中,CLIP-PING显著优于同类产品。具体来说,使用ViT-XS图像编码器在3百万(图像、文本)对上训练的CLIP-PING,在零样本ImageNet1K上提高了5.5%,在Flickr30K的图像到文本和文本到图像检索任务上分别提高了10.7%和5.7%。此外,CLIP-PING在线性评估协议下在各种下游任务中展示出强大的迁移性。
要点解析
- 当前趋势是探索轻量级视觉语言模型在资源受限场景的应用。
- 仅依赖单一图像文本对比学习目标的模型表现不佳。
- CLIP-PING训练范式旨在提升轻量级视觉语言模型的性能,具有简单高效、计算开销小、数据需求低的特点。
- CLIP-PING利用预训练编码器提取的单模态特征进行邻近邻居样本的内在指引。
- 来自邻居的额外对比监督显著提升了跨模态对齐。
- CLIP-PING在零样本泛化和跨模态检索任务中表现优异,相较于原CLIP有显著提升。
点此查看论文截图

Beyond [cls]: Exploring the true potential of Masked Image Modeling representations
Authors:Marcin Przewięźlikowski, Randall Balestriero, Wojciech Jasiński, Marek Śmieja, Bartosz Zieliński
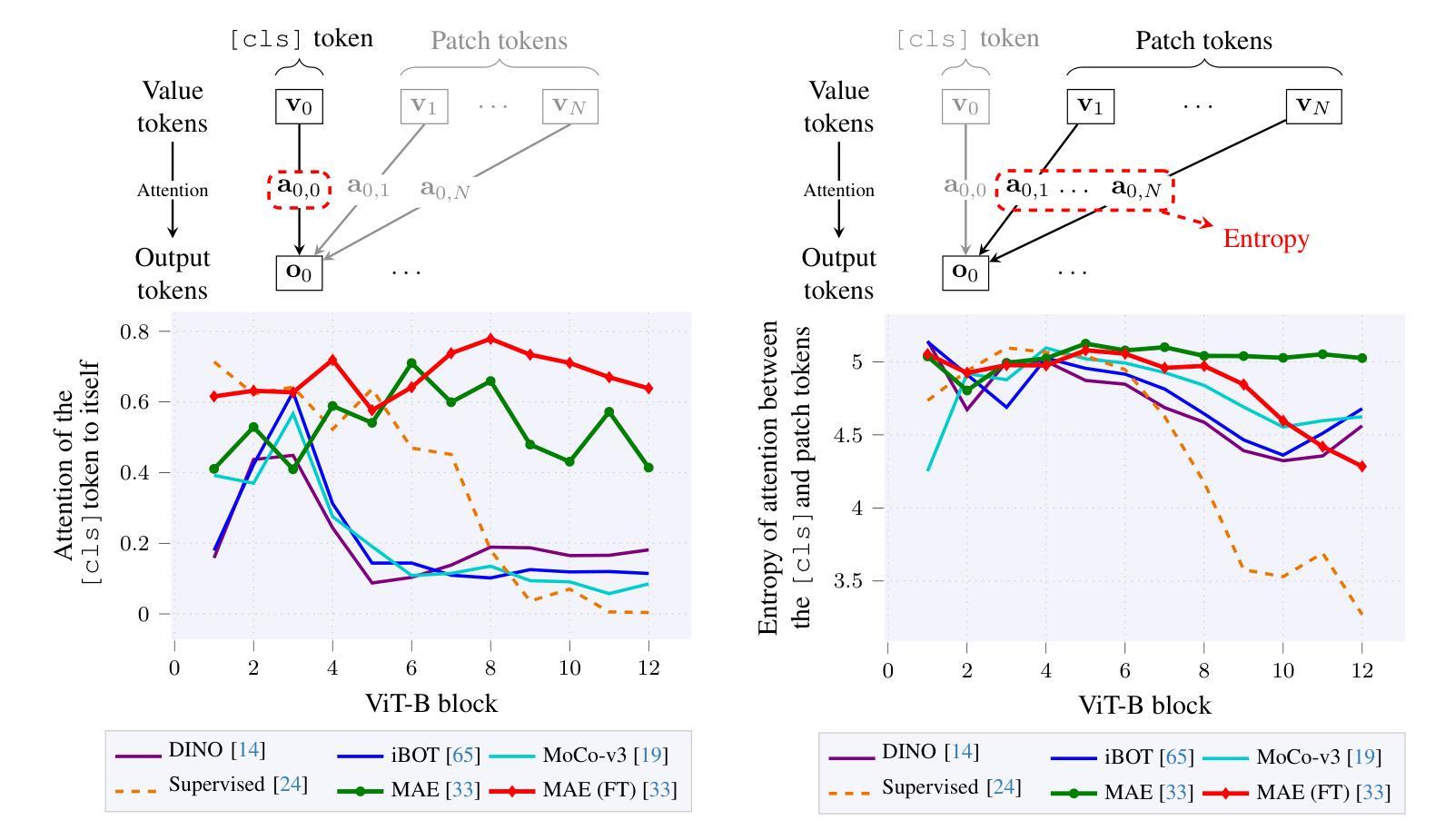
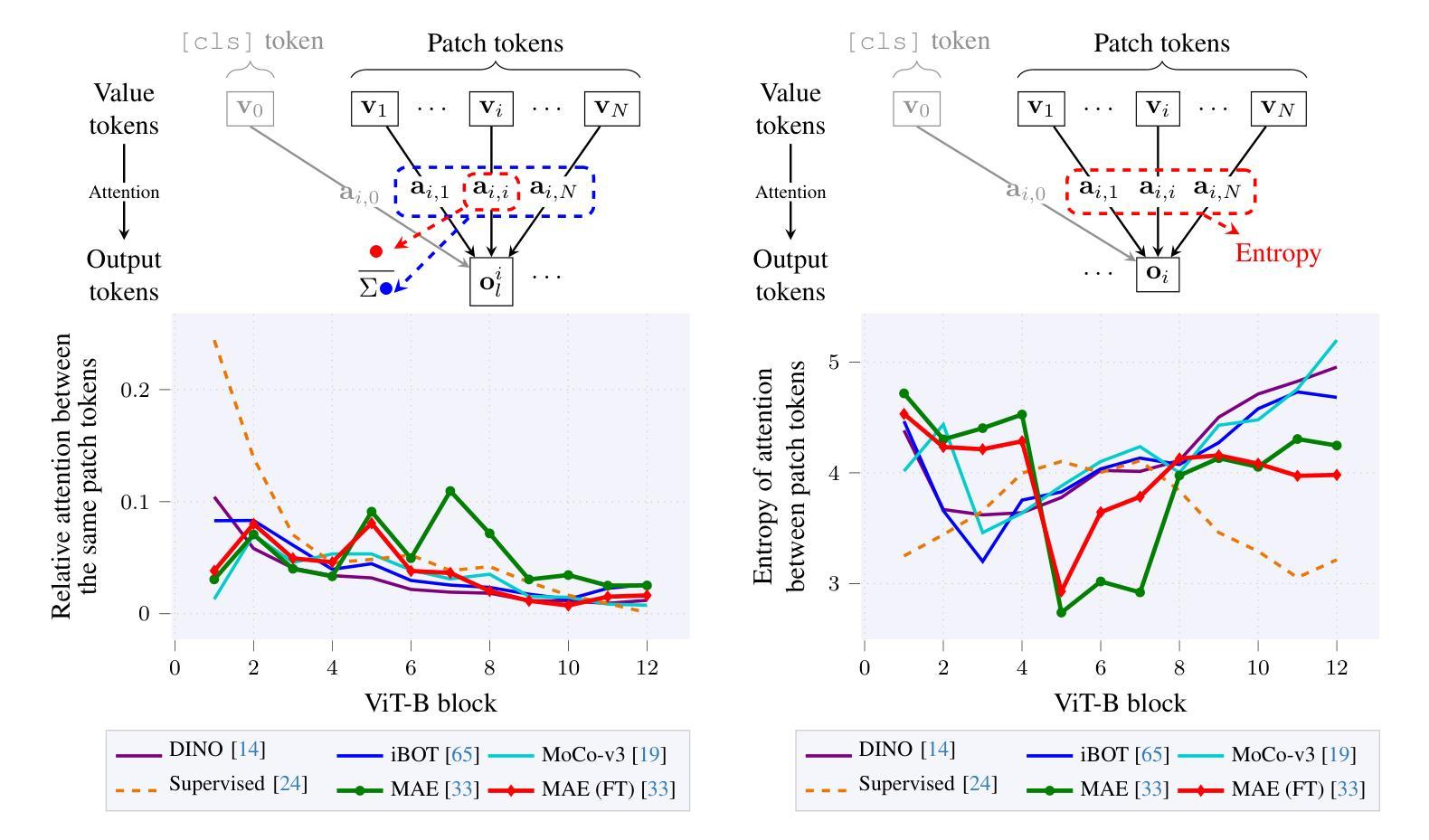
Masked Image Modeling (MIM) has emerged as a popular method for Self-Supervised Learning (SSL) of visual representations. However, for high-level perception tasks, MIM-pretrained models offer lower out-of-the-box representation quality than the Joint-Embedding Architectures (JEA) - another prominent SSL paradigm. To understand this performance gap, we analyze the information flow in Vision Transformers (ViT) learned by both approaches. We reveal that whereas JEAs construct their representation on a selected set of relevant image fragments, MIM models aggregate nearly whole image content. Moreover, we demonstrate that MIM-trained ViTs retain valuable information within their patch tokens, which is not effectively captured by the global [cls] token representations. Therefore, selective aggregation of relevant patch tokens, without any fine-tuning, results in consistently higher-quality of MIM representations. To our knowledge, we are the first to highlight the lack of effective representation aggregation as an emergent issue of MIM and propose directions to address it, contributing to future advances in Self-Supervised Learning.
基于图像掩蔽建模(Masked Image Modeling,MIM)的视觉表示自监督学习方法已经变得非常流行。然而,对于高级感知任务,使用MIM预训练的模型相较于另一种重要的自监督学习范式——联合嵌入架构(Joint-Embedding Architectures,JEA)所提供的即插即用表示质量较低。为了理解这种性能差距,我们分析了两种方法中视觉转换器(Vision Transformers,ViT)的信息流。我们发现,JEA在其选择的与任务相关的图像片段上构建表示,而MIM模型则汇集了近乎整个图像的内容。此外,我们还证明了MIM训练的ViT在其补丁标记中保留了有价值的信息,这些信息没有被全局[cls]标记表示有效地捕获。因此,在不进行任何微调的情况下,有选择地聚合相关的补丁标记,可以得到质量始终较高的MIM表示。据我们所知,我们是首次强调缺乏有效的表示聚合作为MIM的一个新兴问题,并提出了解决这个问题的方向,为自监督学习的未来发展做出了贡献。
论文及项目相关链接
Summary
掩码图像建模(MIM)作为一种自监督学习方法在视觉表示学习中受到广泛关注。然而,对于高级感知任务,MIM预训练模型的表现低于联合嵌入架构(JEA)。通过分析两种方法的视觉变压器(ViT)中的信息流动,我们发现JEA在选定的相关图像片段上构建表示,而MIM模型则几乎整合了整个图像内容。此外,MIM训练的ViT在补丁令牌中保留了有价值的信息,但全球[cls]令牌表示并没有有效地捕获这些信息。因此,通过选择性聚合相关补丁令牌,无需微调即可提高MIM表示的质量。我们是首批强调MIM缺乏有效表示聚合问题并提出解决方向的研究人员之一,为自监督学习的未来发展做出贡献。
Key Takeaways
- MIM作为一种自监督学习方法在视觉表示学习中受到关注。
- 对于高级感知任务,MIM预训练模型的表现低于JEA。
- JEA在选定的相关图像片段上构建表示,而MIM模型整合了几乎整个图像内容。
- MIM训练的ViT在补丁令牌中保留了有价值的信息。
- 全球[cls]令牌表示在MIM中并没有有效地捕获所有有价值的信息。
- 通过选择性聚合相关补丁令牌,可以提高MIM表示的质量。
点此查看论文截图


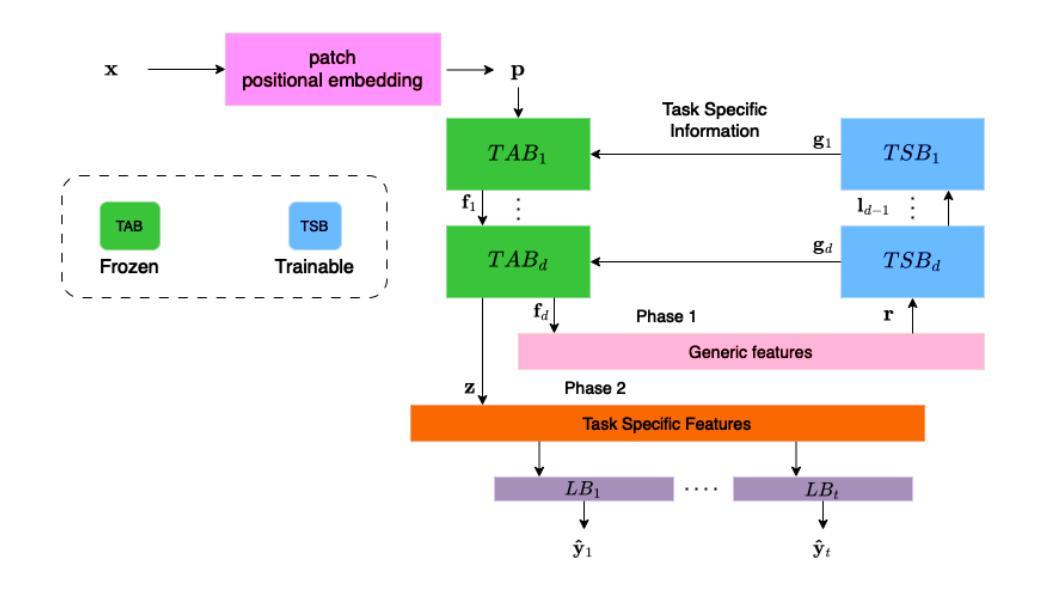
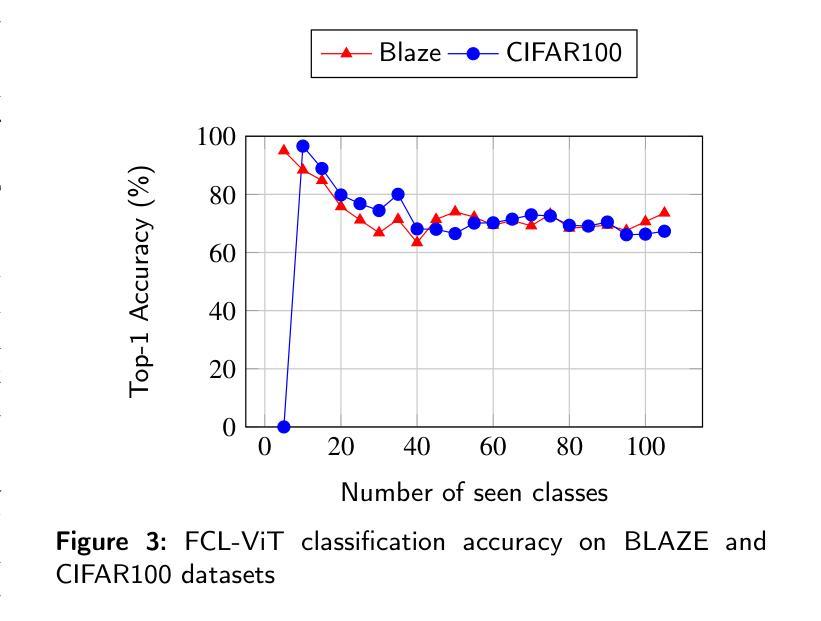
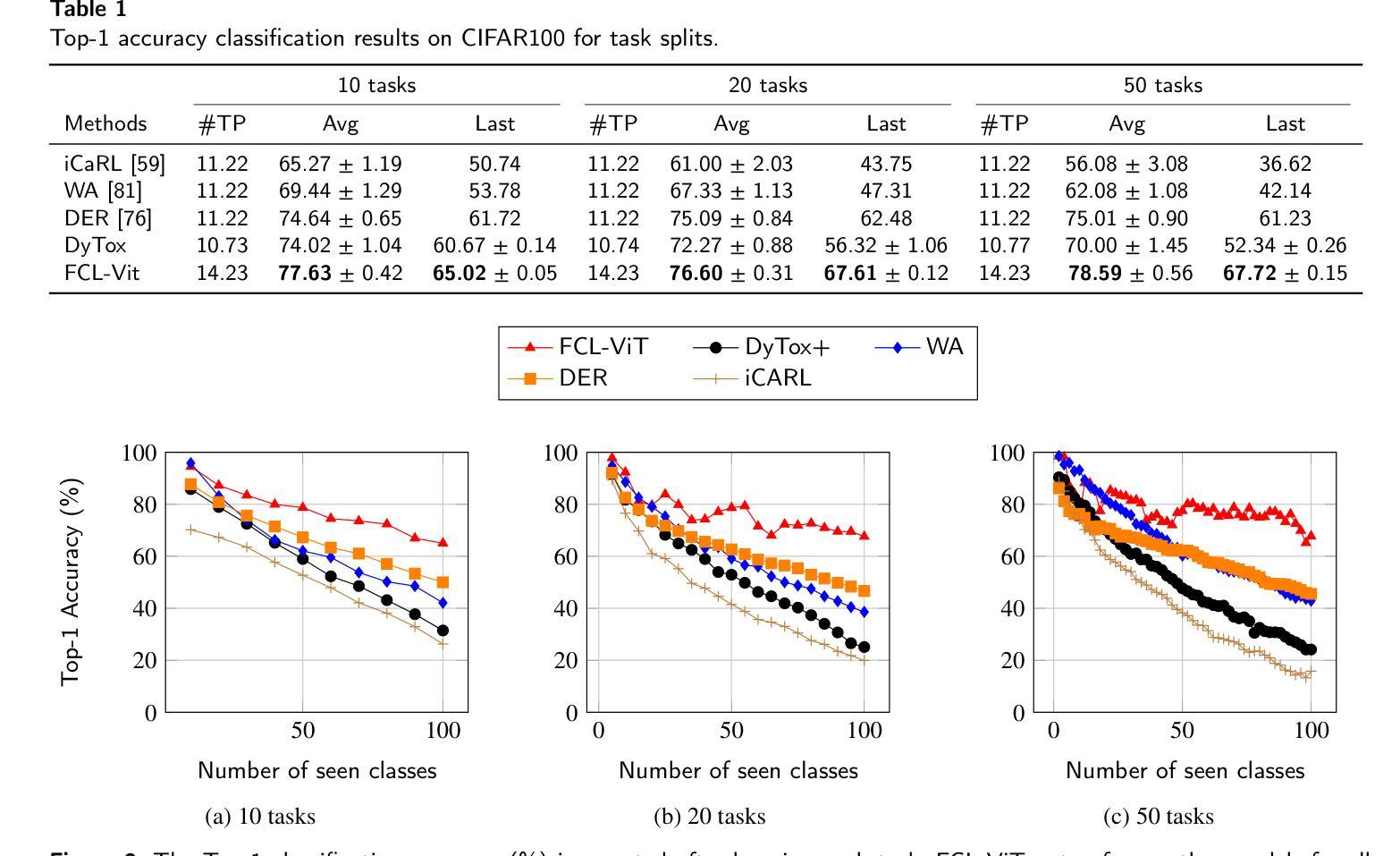
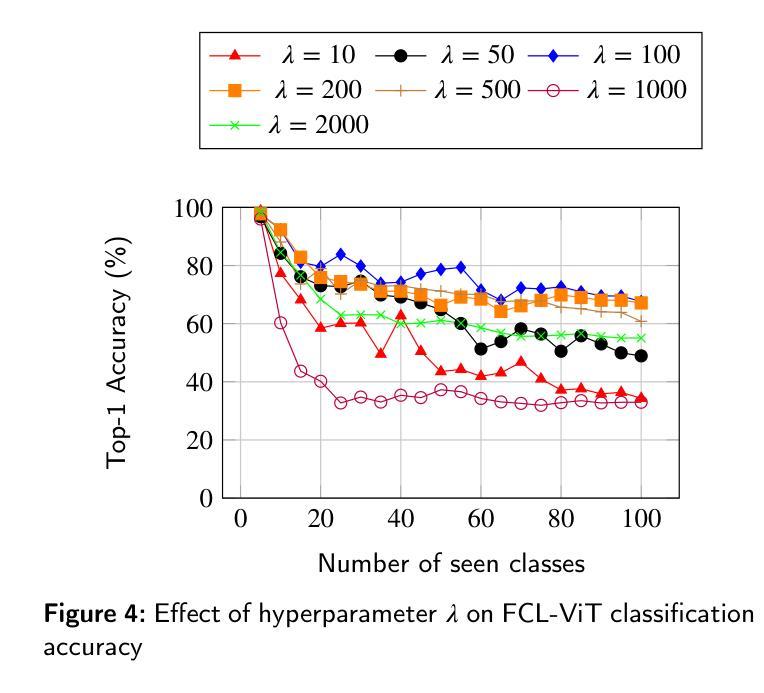
FCL-ViT: Task-Aware Attention Tuning for Continual Learning
Authors:Anestis Kaimakamidis, Ioannis Pitas
Continual Learning (CL) involves adapting the prior Deep Neural Network (DNN) knowledge to new tasks, without forgetting the old ones. However, modern CL techniques focus on provisioning memory capabilities to existing DNN models rather than designing new ones that are able to adapt according to the task at hand. This paper presents the novel Feedback Continual Learning Vision Transformer (FCL-ViT) that uses a feedback mechanism to generate real-time dynamic attention features tailored to the current task. The FCL-ViT operates in two Phases. In phase 1, the generic image features are produced and determine where the Transformer should attend on the current image. In phase 2, task-specific image features are generated that leverage dynamic attention. To this end, Tunable self-Attention Blocks (TABs) and Task Specific Blocks (TSBs) are introduced that operate in both phases and are responsible for tuning the TABs attention, respectively. The FCL-ViT surpasses state-of-the-art performance on Continual Learning compared to benchmark methods, while retaining a small number of trainable DNN parameters.
持续学习(CL)涉及将先前的深度神经网络(DNN)知识适应于新任务,同时不忘旧任务。然而,现代CL技术更注重为现有DNN模型提供记忆能力,而不是设计能够根据当前任务进行适应的新模型。本文提出了一种新型的反馈持续学习视觉转换器(FCL-ViT),它使用反馈机制生成实时动态注意力特征,这些特征可针对当前任务进行定制。FCL-ViT分为两个阶段。在阶段1中,生成通用图像特征,并确定转换器应在当前图像上关注的位置。在阶段2中,生成特定于任务的图像特征,这些特征利用动态注意力。为此,引入了可调自注意力块(TABs)和任务特定块(TSBs),它们在两个阶段中都起作用,并分别负责调整TABs的注意力。与基准方法相比,FCL-ViT在持续学习方面的性能超过了最新技术水平,同时保持了较少的可训练DNN参数。
论文及项目相关链接
Summary
该论文提出了基于反馈机制的反馈连续学习视觉变压器(FCL-ViT),它通过生成针对当前任务的实时动态注意力特征来适应先前的深度神经网络知识并处理新任务。两个阶段分别负责生成通用图像特征和任务特定图像特征,通过引入可调自注意力块和任务特定块,实现注意力调整。与传统的连续学习方法相比,FCL-ViT在保持较小的神经网络参数数量的同时,在连续学习上实现了优于当前技术水平的表现。
Key Takeaways
- FCL-ViT是一种基于反馈机制的连续学习视觉变压器模型。
- 该模型通过生成针对当前任务的实时动态注意力特征来适应新任务。
- FCL-ViT包含两个阶段:第一阶段生成通用图像特征,第二阶段生成任务特定图像特征。
- 可调自注意力块和任务特定块被引入以调整注意力。
- FCL-ViT在保持较小的神经网络参数数量的同时超越了当前的连续学习技术水平的性能表现。
- FCL-ViT具有良好的适用性,可以应用于多种需要连续学习的场景和任务中。
点此查看论文截图

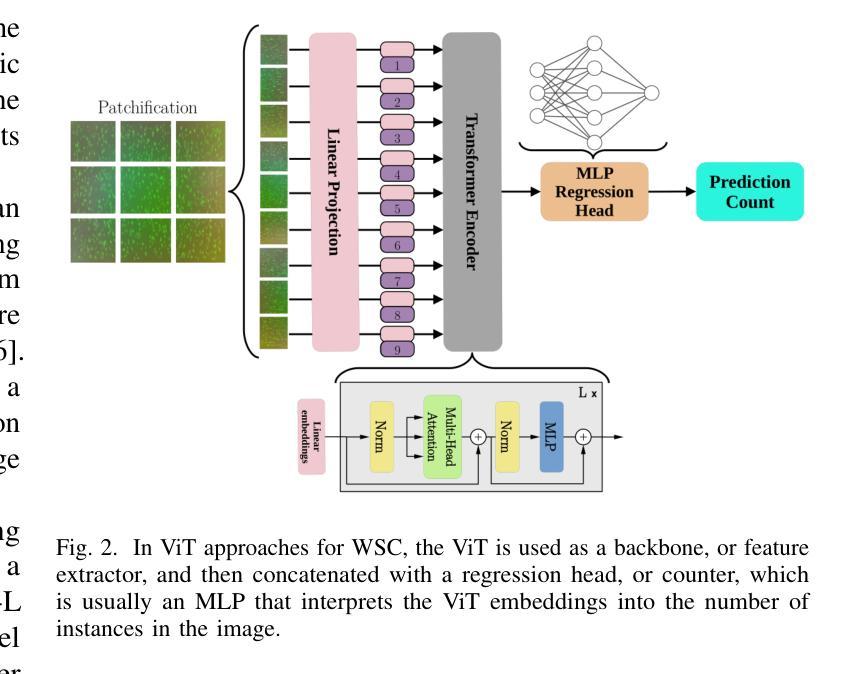
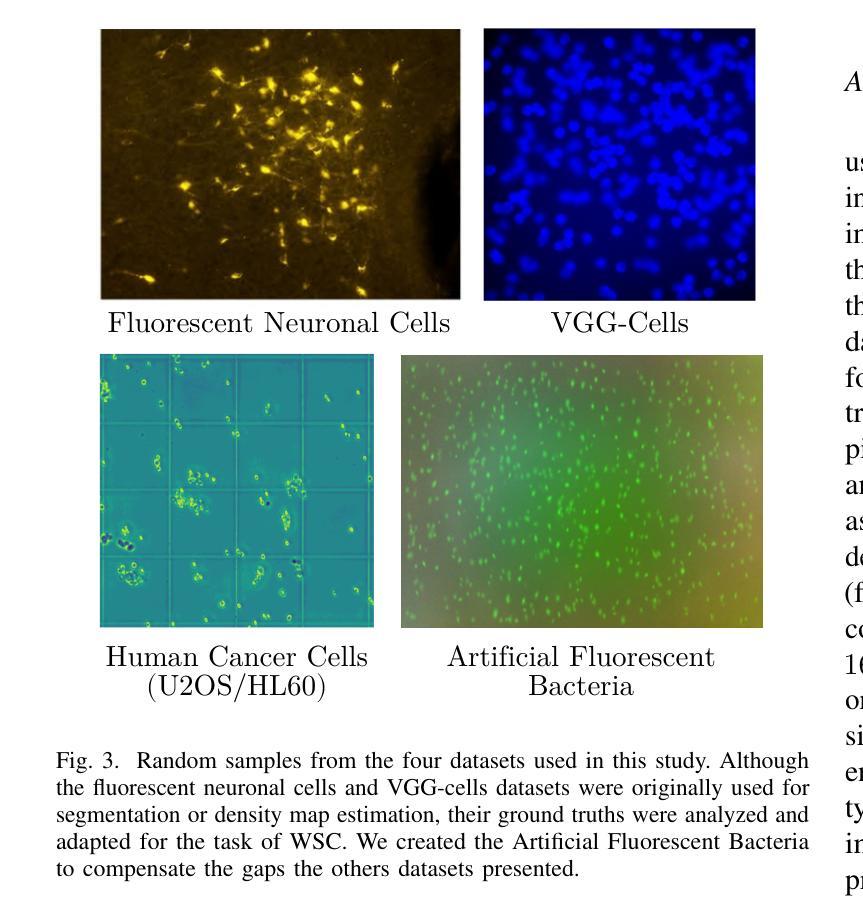
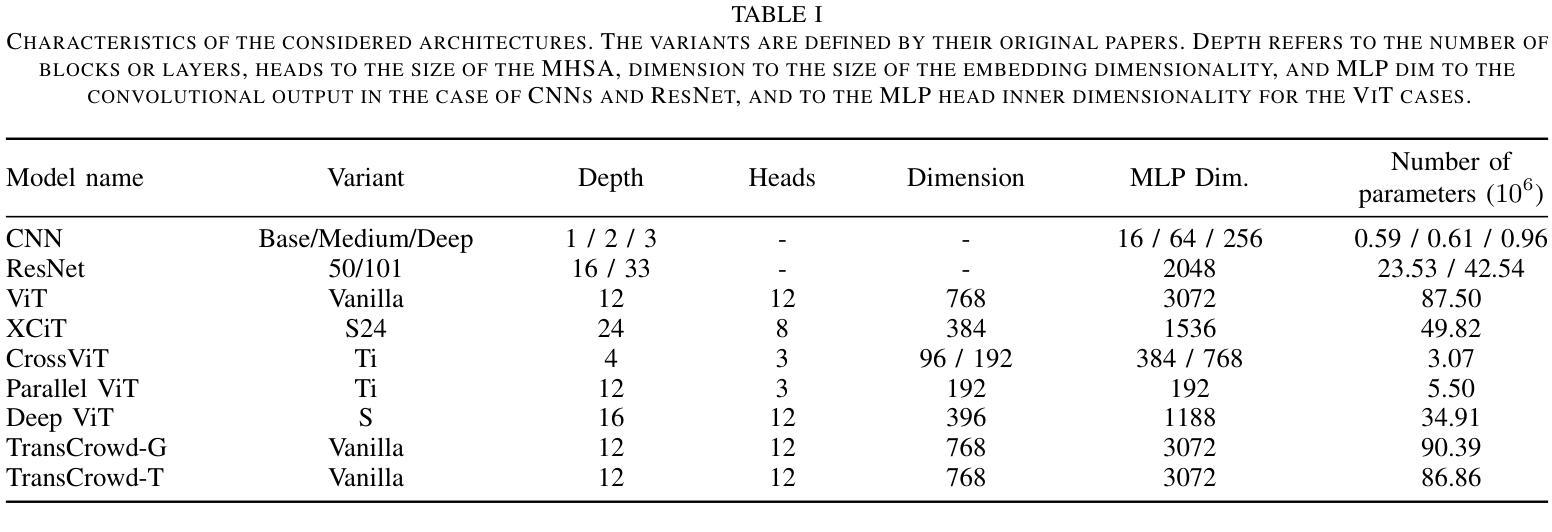
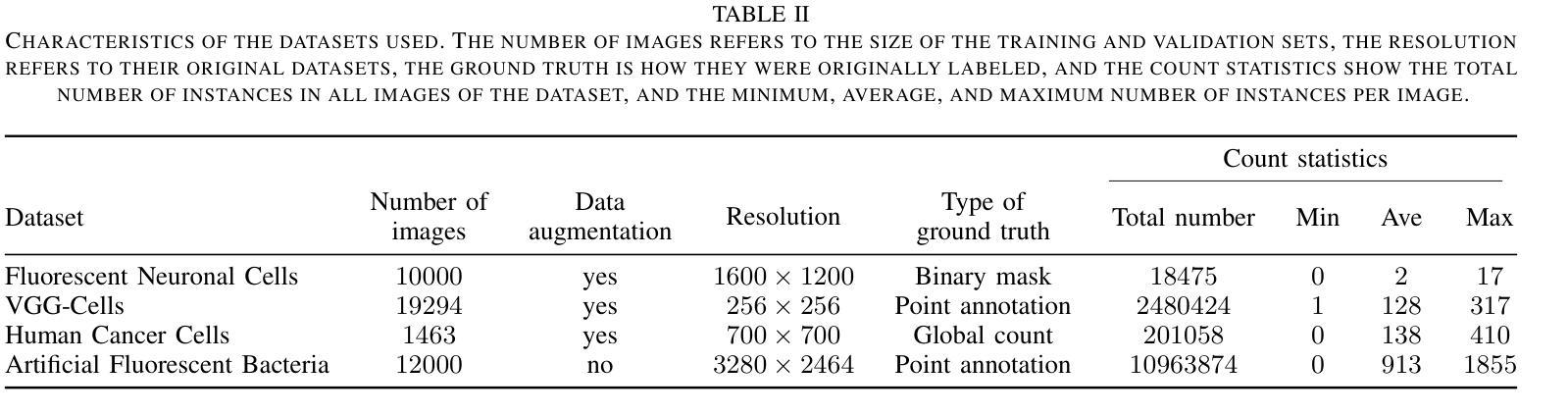
Vision Transformers for Weakly-Supervised Microorganism Enumeration
Authors:Javier Ureña Santiago, Thomas Ströhle, Antonio Rodríguez-Sánchez, Ruth Breu
Microorganism enumeration is an essential task in many applications, such as assessing contamination levels or ensuring health standards when evaluating surface cleanliness. However, it’s traditionally performed by human-supervised methods that often require manual counting, making it tedious and time-consuming. Previous research suggests automating this task using computer vision and machine learning methods, primarily through instance segmentation or density estimation techniques. This study conducts a comparative analysis of vision transformers (ViTs) for weakly-supervised counting in microorganism enumeration, contrasting them with traditional architectures such as ResNet and investigating ViT-based models such as TransCrowd. We trained different versions of ViTs as the architectural backbone for feature extraction using four microbiology datasets to determine potential new approaches for total microorganism enumeration in images. Results indicate that while ResNets perform better overall, ViTs performance demonstrates competent results across all datasets, opening up promising lines of research in microorganism enumeration. This comparative study contributes to the field of microbial image analysis by presenting innovative approaches to the recurring challenge of microorganism enumeration and by highlighting the capabilities of ViTs in the task of regression counting.
微生物计数在许多应用中是一项至关重要的任务,例如在评估污染水平或评估表面清洁度时确保卫生标准。然而,它通常是采用人工监督的方法进行,通常需要手动计数,这使得它变得乏味且耗时。之前的研究表明,可以通过计算机视觉和机器学习方法进行自动化,主要通过实例分割或密度估计技术实现。本研究对用于微生物计数中的弱监督计数的视觉变压器(ViTs)进行了比较分析,将它们与传统的架构(如ResNet)进行了对比,并研究了基于ViT的模型(如TransCrowd)。我们使用四个微生物学数据集训练了不同版本的ViT作为特征提取的架构骨干,以确定图像中微生物总数的潜在新方法。结果表明,虽然ResNet总体上表现更好,但ViT的性能在所有数据集上都表现出了相当的结果,为微生物计数开辟了有前途的研究方向。本研究通过提出创新的解决微生物计数这一持续挑战的方法,并强调ViT在回归计数任务中的能力,为微生物图像分析领域做出了贡献。
论文及项目相关链接
PDF 8 pages, 3 figures, 3 tables, conference
摘要
本文研究了使用视觉转换器(ViTs)对微生物进行弱监督计数的方法,并与传统的ResNet架构进行了对比分析。通过四个微生物学数据集训练不同版本的ViT作为特征提取的架构主干,实验结果表明ResNet总体上表现更好,但ViT的性能在所有数据集上都表现不俗。此项研究对微生物图像分析领域提出了创新的解决方案,强调了ViT在回归计数任务中的能力。
要点
- 微生物计数在许多应用中至关重要,如评估污染水平或评估表面清洁度的健康标准。
- 传统方法需要大量人工计数,繁琐且耗时。
- 研究提出了一种使用视觉转换器(ViTs)自动化进行微生物计数的弱监督方法。
- 对比了ViTs与传统架构(如ResNet)在微生物计数中的性能。
- 在四个微生物学数据集上训练了不同版本的ViT,实验结果表明ViT性能具有竞争力。
- 虽然ResNet总体表现更好,但ViT的潜力不容忽视,为未来研究打开了新的方向。
点此查看论文截图

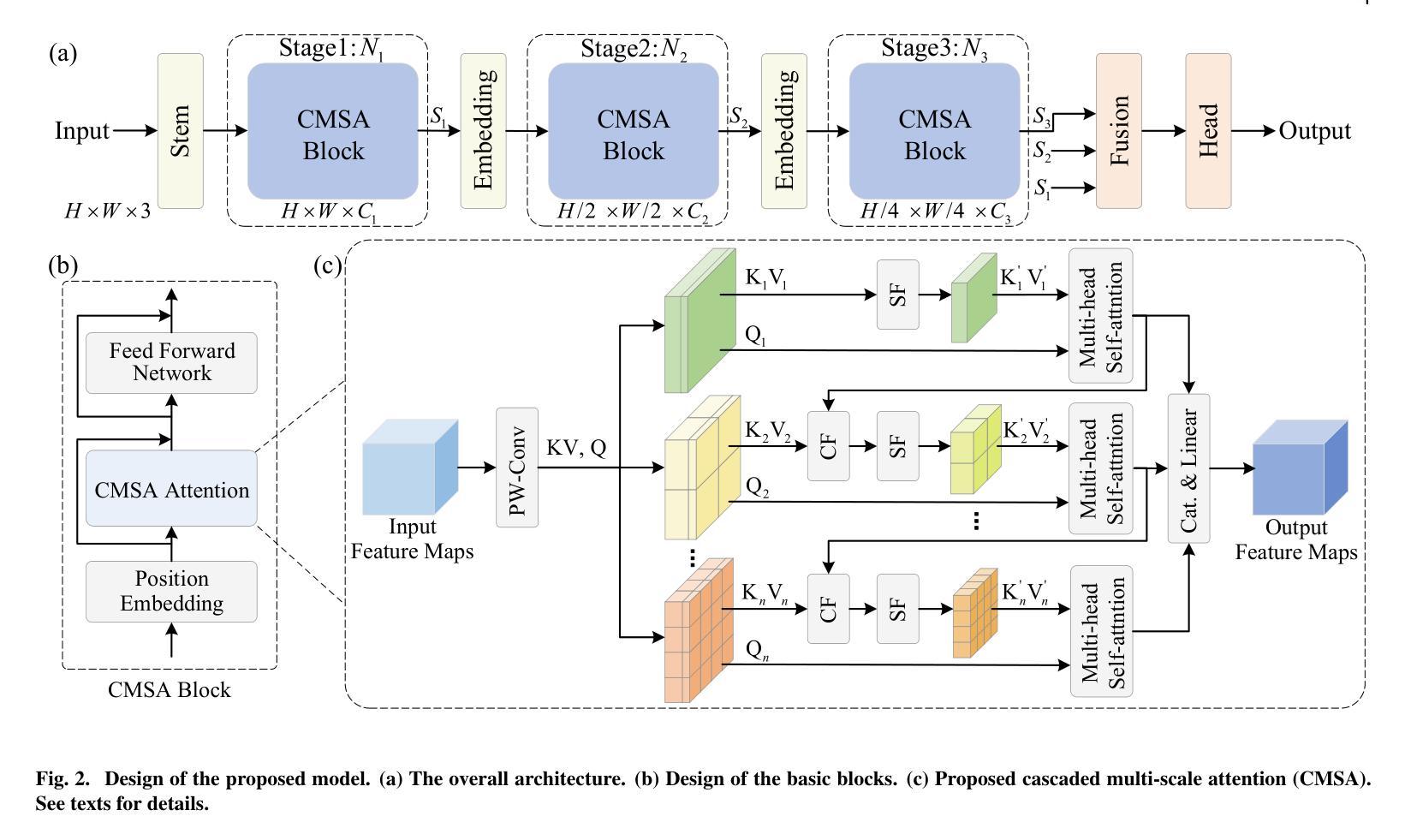
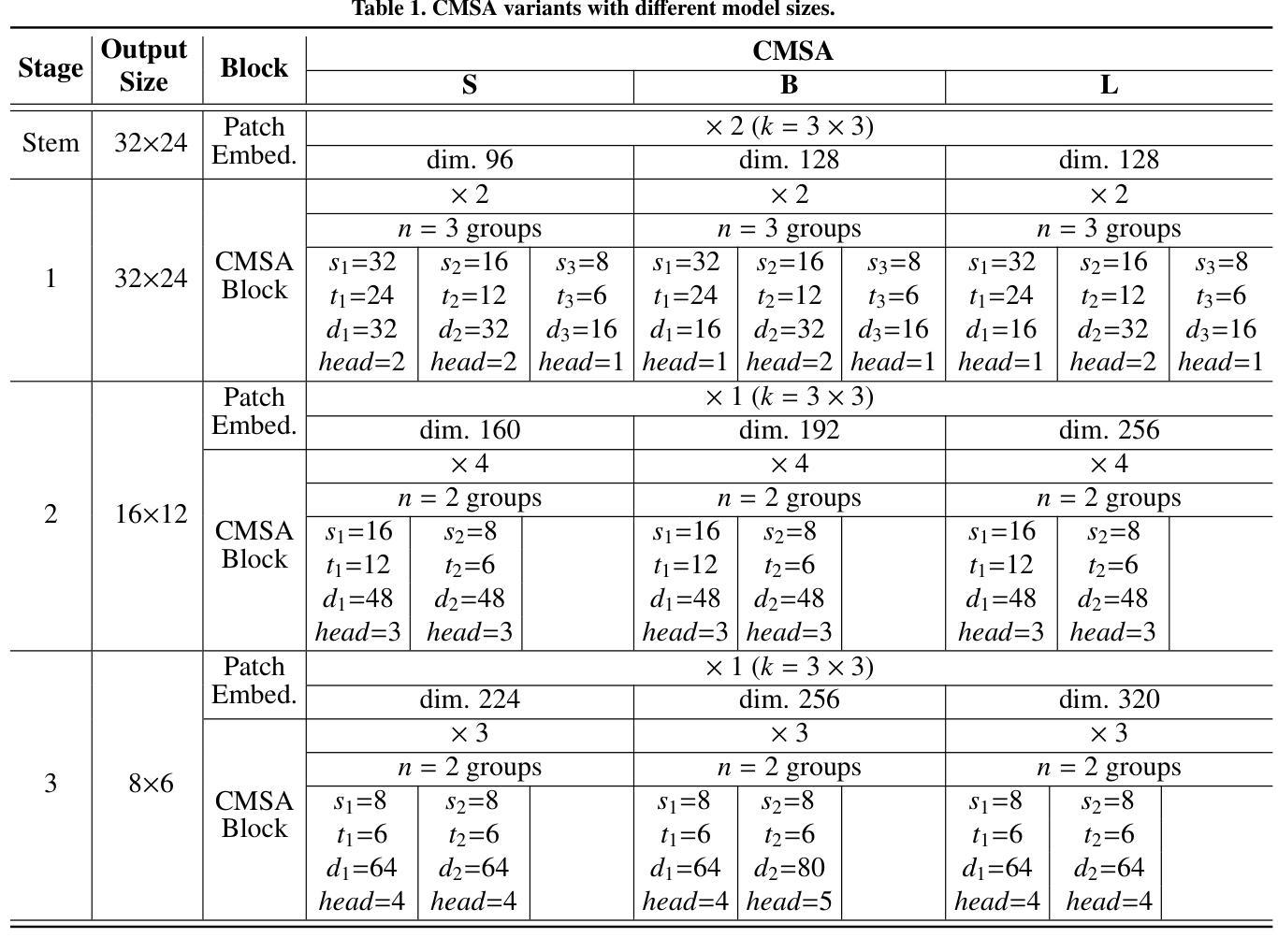
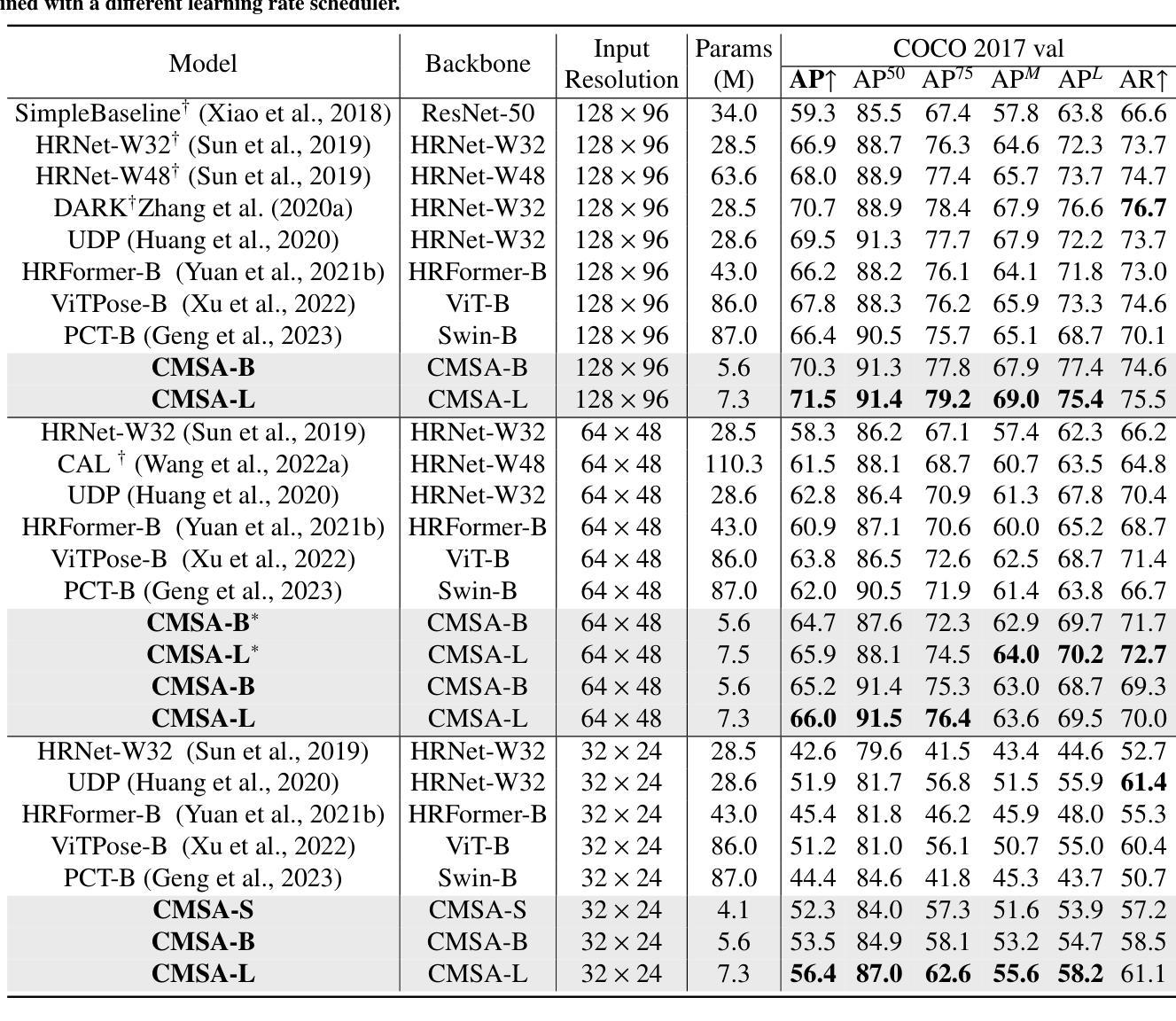
Cascaded Multi-Scale Attention for Enhanced Multi-Scale Feature Extraction and Interaction with Low-Resolution Images
Authors:Xiangyong Lu, Masanori Suganuma, Takayuki Okatani
In real-world applications of image recognition tasks, such as human pose estimation, cameras often capture objects, like human bodies, at low resolutions. This scenario poses a challenge in extracting and leveraging multi-scale features, which is often essential for precise inference. To address this challenge, we propose a new attention mechanism, named cascaded multi-scale attention (CMSA), tailored for use in CNN-ViT hybrid architectures, to handle low-resolution inputs effectively. The design of CMSA enables the extraction and seamless integration of features across various scales without necessitating the downsampling of the input image or feature maps. This is achieved through a novel combination of grouped multi-head self-attention mechanisms with window-based local attention and cascaded fusion of multi-scale features over different scales. This architecture allows for the effective handling of features across different scales, enhancing the model’s ability to perform tasks such as human pose estimation, head pose estimation, and more with low-resolution images. Our experimental results show that the proposed method outperforms existing state-of-the-art methods in these areas with fewer parameters, showcasing its potential for broad application in real-world scenarios where capturing high-resolution images is not feasible. Code is available at https://github.com/xyongLu/CMSA.
在图像识别任务的现实应用(如人体姿态估计)中,相机通常会以低分辨率捕获物体(如人体)。这种情况在提取和利用多尺度特征方面提出了挑战,而对于精确推断而言,多尺度特征往往是至关重要的。为了应对这一挑战,我们提出了一种新的注意力机制,名为级联多尺度注意力(CMSA),它适用于CNN-ViT混合架构,可有效处理低分辨率输入。CMSA的设计实现了跨不同尺度的特征提取和无缝集成,而无需对输入图像或特征图进行降采样。这是通过分组多头自注意力机制与基于窗口的局部注意力相结合,以及在不同尺度上实现多尺度特征的级联融合来实现的。该架构能够有效处理不同尺度的特征,提高模型在低分辨率图像下执行诸如人体姿态估计、头部姿态估计等任务的能力。实验结果表明,该方法在参数较少的情况下,在这些领域超越了现有最先进的方法,展示了其在现实场景中广泛应用的潜力,特别是在无法捕获高分辨率图像的情况下。相关代码可在https://github.com/xyongLu/CMSA上找到。
论文及项目相关链接
PDF 9 pages, 4 figures, 5 tables. The paper is under consideration at Computer Vision and Image Understanding
Summary
本文提出一种针对CNN-ViT混合架构的级联多尺度注意力(CMSA)机制,有效处理低分辨率图像输入。CMSA设计能够提取并无缝融合多尺度特征,无需对输入图像或特征图进行降采样操作。通过分组多头自注意力机制、基于窗口的局部注意力和不同尺度上的多尺度特征级联融合,该架构实现了跨尺度特征处理的有效性,提高了模型在人体姿态估计、头部姿态估计等任务上的性能。实验结果表明,该方法在较少的参数下超越了现有先进技术,在高分辨率图像捕获不可行的实际场景中具有广泛的应用潜力。
Key Takeaways
- 提出了一种名为级联多尺度注意力(CMSA)的新注意力机制,用于处理低分辨率图像。
- CMSA适用于CNN-ViT混合架构,能够提取并融合多尺度特征。
- CMSA设计无需对输入图像或特征图进行降采样。
- 通过结合分组多头自注意力机制、窗口局部注意力和多尺度特征的级联融合,实现了跨尺度特征处理的有效性。
- 该机制提高了模型在人体姿态估计、头部姿态估计等任务上的性能。
- 实验结果表明,CMSA在较少的参数下超越了现有先进技术。
点此查看论文截图

Attacks on multimodal models
Authors:Viacheslav Iablochnikov, Alexander Rogachev
Today, models capable of working with various modalities simultaneously in a chat format are gaining increasing popularity. Despite this, there is an issue of potential attacks on these models, especially considering that many of them include open-source components. It is important to study whether the vulnerabilities of these components are inherited and how dangerous this can be when using such models in the industry. This work is dedicated to researching various types of attacks on such models and evaluating their generalization capabilities. Modern VLM models (LLaVA, BLIP, etc.) often use pre-trained parts from other models, so the main part of this research focuses on them, specifically on the CLIP architecture and its image encoder (CLIP-ViT) and various patch attack variations for it.
当今,能够在聊天格式中同时处理多种模式的模型正日益受到欢迎。然而,尽管这些模型具有广泛的应用前景,但它们也存在潜在的安全风险,特别是考虑到许多模型包含开源组件。因此,研究这些组件的漏洞是否会继承以及其在实际应用中可能带来的风险是非常关键的。这项工作专注于研究针对此类模型的各种攻击,并评估它们的泛化能力。现代视觉语言模型(如LLaVA、BLIP等)经常使用其他模型的预训练部分,因此这项研究的主要部分集中在这类模型上,特别是CLIP架构及其图像编码器(CLIP-ViT)以及针对它的各种补丁攻击变体。
论文及项目相关链接
PDF 19 pages, 13 figures, 3 tables
Summary
当前,能够同时处理多种模态并以聊天形式工作的模型正日益受到欢迎。然而,这些模型存在潜在的安全攻击风险,特别是考虑到许多模型包含开源组件。研究重点是对这些模型的攻击类型以及评估其泛化能力,特别是针对现代VLM模型(如LLaVA、BLIP等)及其主要基于CLIP架构和图像编码器的部分。
Key Takeaways
- 多模态聊天模型日益普及,但存在潜在的安全风险。
- 模型中的开源组件可能带来继承的漏洞。
- 对这类模型的攻击类型研究是关键。
- 现代VLM模型(如LLaVA和BLIP)广泛使用预训练部分。
- 研究重点在于CLIP架构及其图像编码器(CLIP-ViT)。
- 针对CLIP架构的补丁攻击变种是研究的重要组成部分。
点此查看论文截图

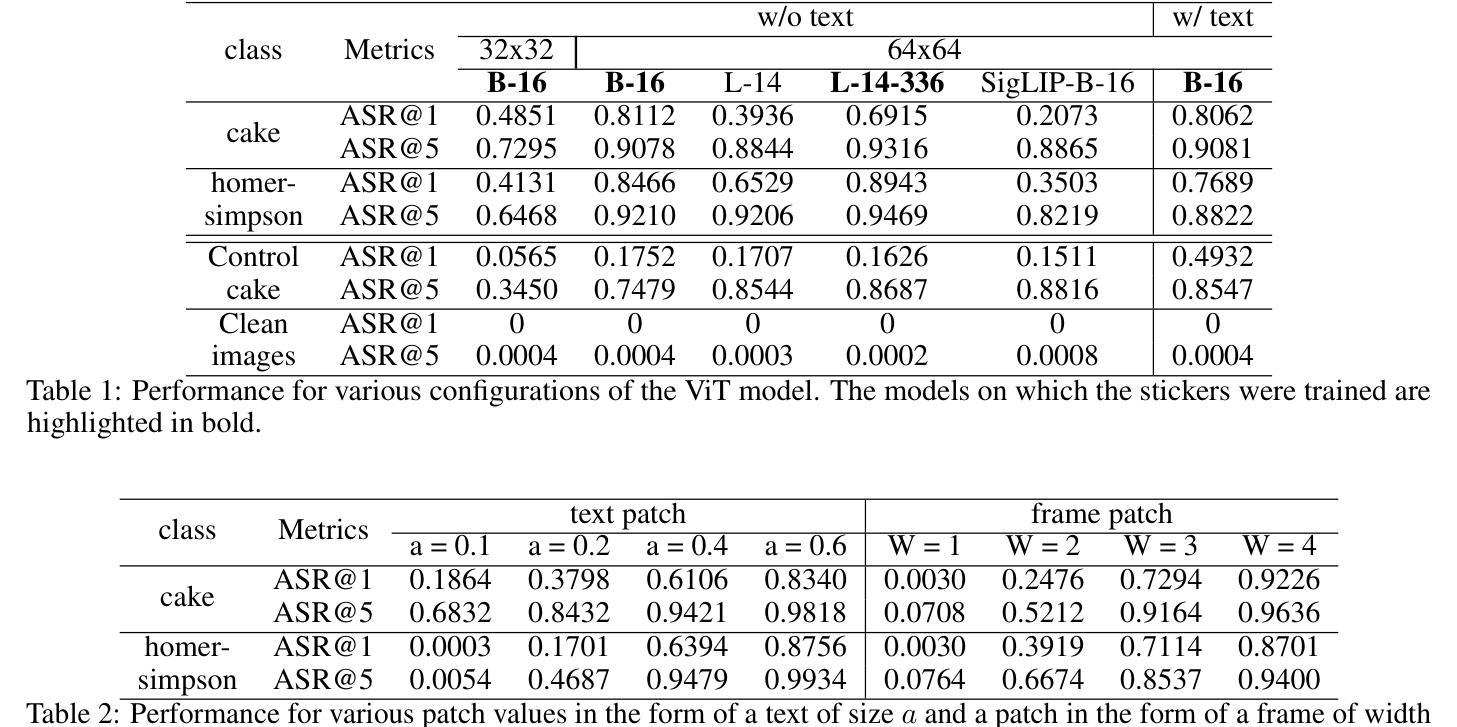
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
Authors:Bikang Pan, Qun Li, Xiaoying Tang, Wei Huang, Zhen Fang, Feng Liu, Jingya Wang, Jingyi Yu, Ye Shi
The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to enhance the robustness further. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix. This matrix effectively partitions datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive representation and precise alignment capabilities of vision-language models for robust prompt learning. We validate NLPrompt through extensive experiments across various noise settings, demonstrating significant performance improvements.
视觉语言基础模型(如CLIP)的出现,已经彻底改变了图像文本表示方法,并通过提示学习(prompt learning)实现了广泛的应用。尽管前景广阔,但现实世界的数据集通常包含带有噪声的标签,这会降低提示学习的性能。在本文中,我们证明了在提示学习中使用平均绝对误差(MAE)损失,即PromptMAE,能够在保持高准确性的同时显著提高对噪声标签的鲁棒性。虽然MAE简单直观且以其稳健性著称,但由于其收敛速度慢以及在提示学习场景外的表现不佳,它在噪声标签学习中很少被使用。为了阐明PromptMAE的稳健性,我们利用特征学习理论表明MAE能够抑制噪声样本的影响,从而提高信噪比并增强整体稳健性。此外,我们引入了基于提示的最优传输数据净化方法PromptOT,以进一步增强稳健性。PromptOT利用视觉语言模型的文本编码器表示作为原型来构建最优传输矩阵。该矩阵有效地将数据集划分为干净和噪声子集,允许对干净子集应用交叉熵损失,对噪声子集应用MAE损失。我们的噪声标签提示学习方法NLPrompt提供了一种简单高效的方法,利用视觉语言模型的表达表示和精确对齐能力来进行稳健的提示学习。我们通过在不同噪声设置下进行的大量实验验证了NLPrompt的有效性,并展示了显著的性能改进。
论文及项目相关链接
Summary
基于CLIP等视觉语言基础模型的出现,图像文本表示技术得以快速发展并应用于各种场景中的提示学习。然而,现实世界的数据集往往含有噪声标签,会影响提示学习的性能。本文提出使用平均绝对误差(MAE)损失进行提示学习,命名为PromptMAE,显著提高对噪声标签的稳健性,同时保持高准确性。我们还介绍了基于提示的最优传输数据净化方法PromptOT,进一步提高稳健性。NLPrompt方法简单高效,利用视觉语言模型的表达表示和精确对齐能力,实现稳健的提示学习,并在各种噪声设置下通过大量实验验证。
Key Takeaways
- CLIP等视觉语言基础模型推动了图像文本表示技术的革命,并广泛应用于提示学习。
- 现实数据集中存在噪声标签问题,影响提示学习性能。
- 使用平均绝对误差(MAE)损失进行提示学习,显著提高对噪声标签的稳健性。
- MAE损失能够抑制噪声样本的影响,提高信噪比。
- 引入基于提示的最优传输数据净化方法PromptOT,进一步增强稳健性。
- NLPrompt方法利用视觉语言模型的特性实现稳健的提示学习。
点此查看论文截图

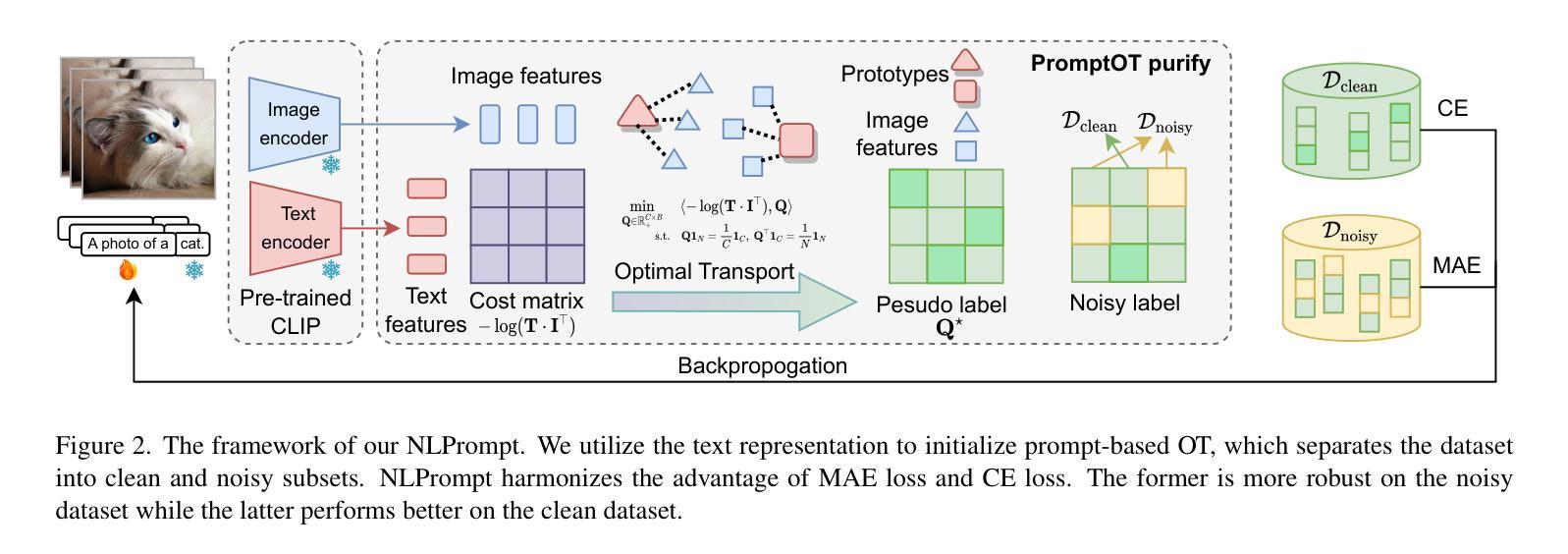
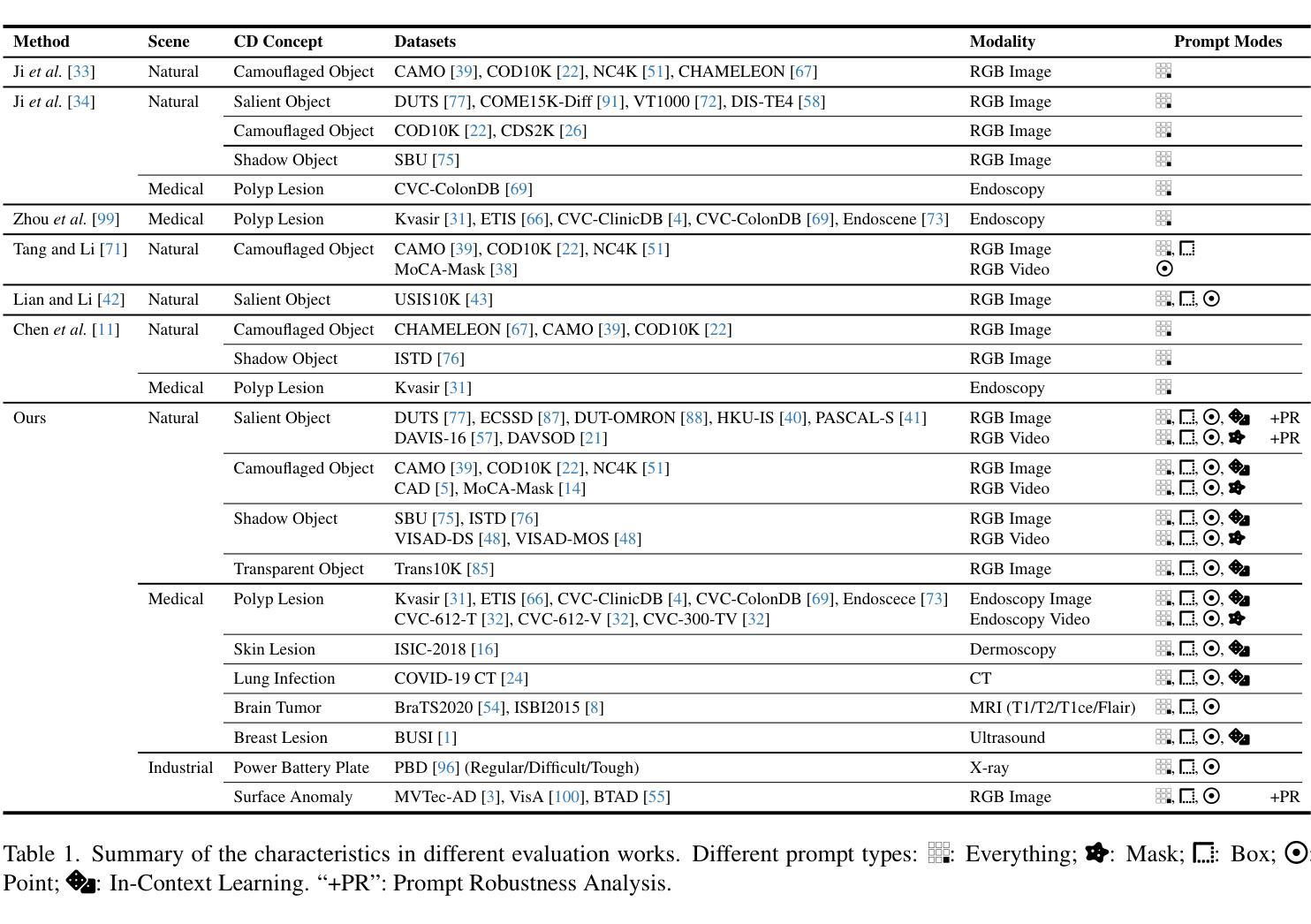
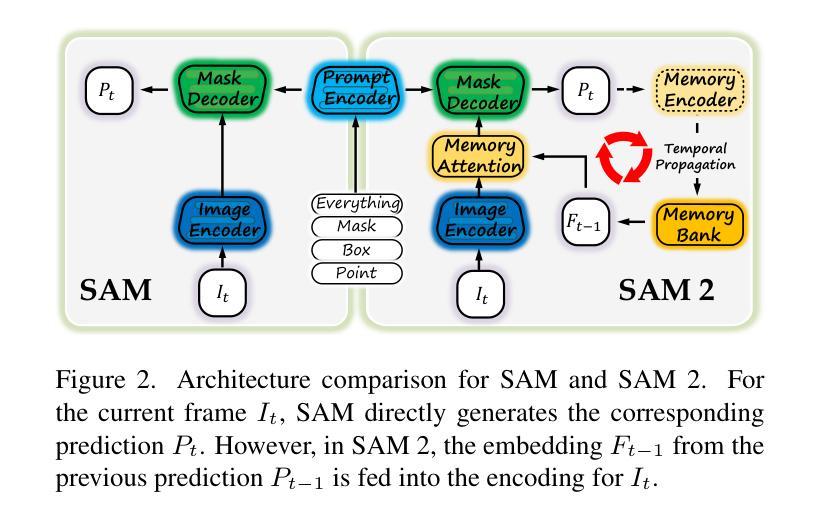
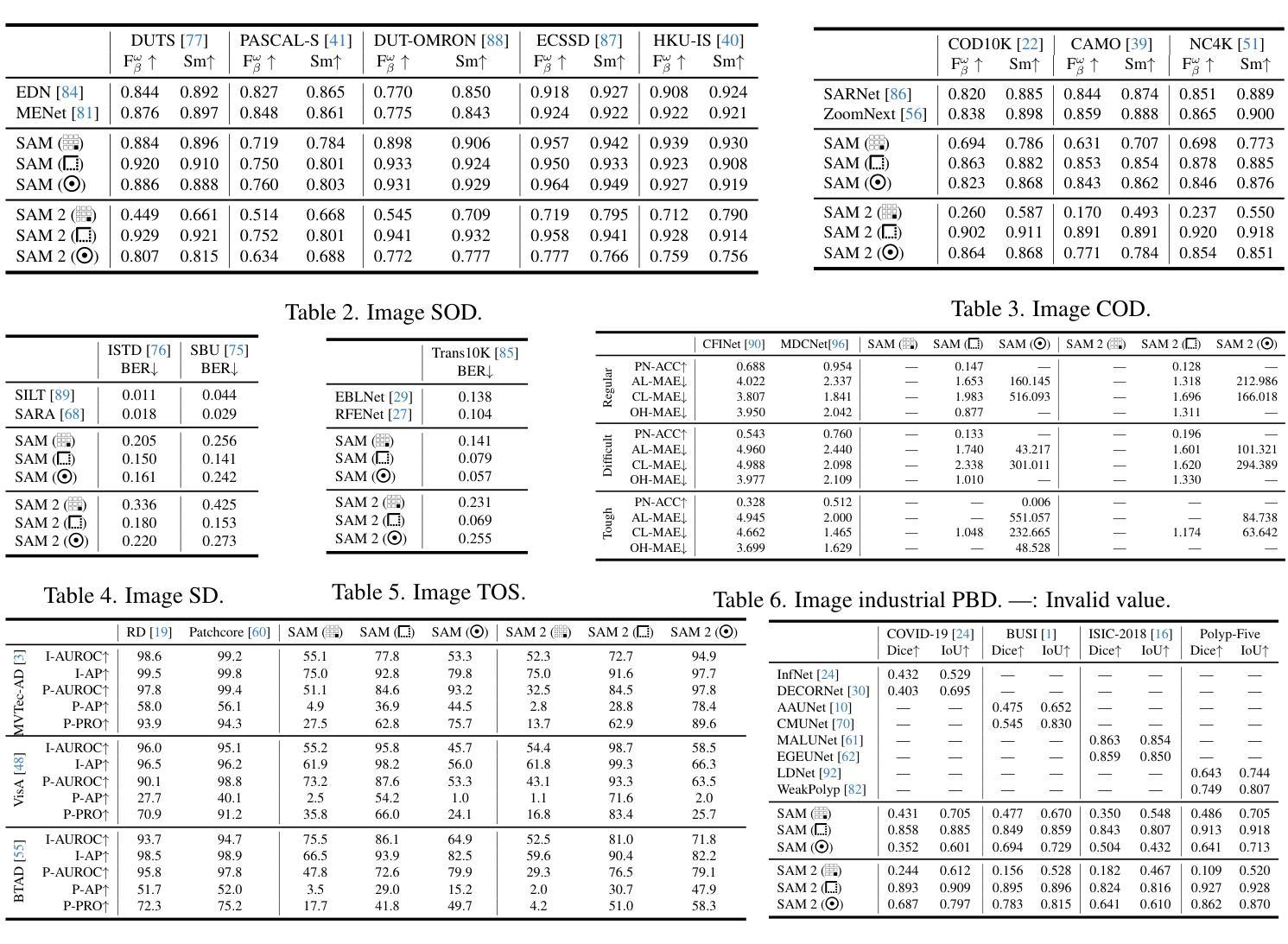
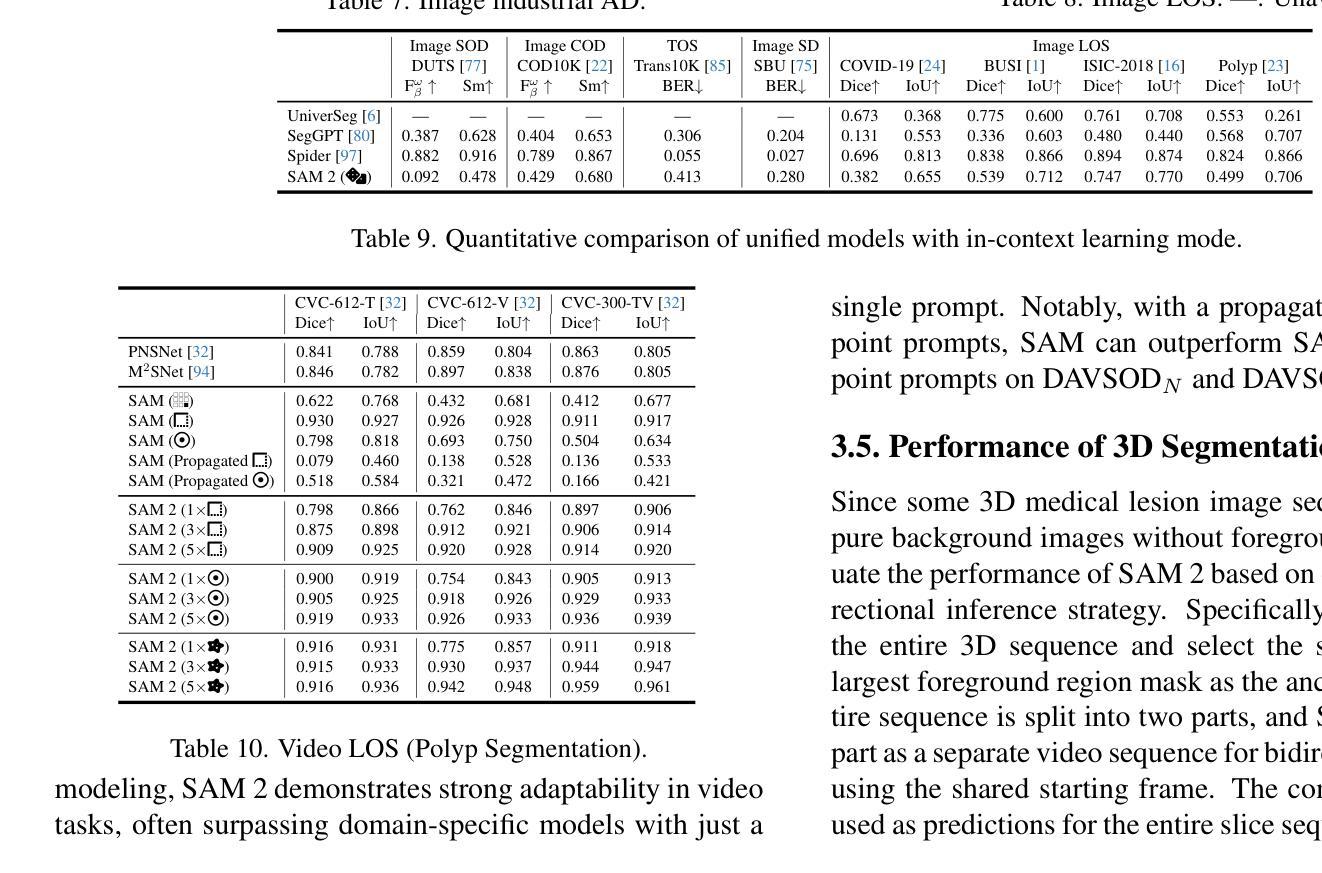
Inspiring the Next Generation of Segment Anything Models: Comprehensively Evaluate SAM and SAM 2 with Diverse Prompts Towards Context-Dependent Concepts under Different Scenes
Authors:Xiaoqi Zhao, Youwei Pang, Shijie Chang, Yuan Zhao, Lihe Zhang, Huchuan Lu, Jinsong Ouyang, Georges El Fakhri, Xiaofeng Liu
As a foundational model, SAM has significantly influenced multiple fields within computer vision, and its upgraded version, SAM 2, enhances capabilities in video segmentation, poised to make a substantial impact once again. While SAMs (SAM and SAM 2) have demonstrated excellent performance in segmenting context-independent concepts like people, cars, and roads, they overlook more challenging context-dependent (CD) concepts, such as visual saliency, camouflage, product defects, and medical lesions. CD concepts rely heavily on global and local contextual information, making them susceptible to shifts in different contexts, which requires strong discriminative capabilities from the model. The lack of comprehensive evaluation of SAMs limits understanding of their performance boundaries, which may hinder the design of future models. In this paper, we conduct a thorough quantitative evaluation of SAMs on 11 CD concepts across 2D and 3D images and videos in various visual modalities within natural, medical, and industrial scenes. We develop a unified evaluation framework for SAM and SAM 2 that supports manual, automatic, and intermediate self-prompting, aided by our specific prompt generation and interaction strategies. We further explore the potential of SAM 2 for in-context learning and introduce prompt robustness testing to simulate real-world imperfect prompts. Finally, we analyze the benefits and limitations of SAMs in understanding CD concepts and discuss their future development in segmentation tasks. This work aims to provide valuable insights to guide future research in both context-independent and context-dependent concepts segmentation, potentially informing the development of the next version - SAM 3.
作为基础模型,SAM(Self-Attention Mask)在计算机视觉的多个领域产生了重大影响,而其升级版SAM 2在视频分割方面增强了能力,有望再次产生巨大影响。虽然SAM(包括SAM和SAM 2)在分割上下文独立概念(如人、汽车和道路)方面表现出卓越的性能,但它们忽视了更具挑战性的上下文依赖(CD)概念,如视觉显著性、伪装、产品缺陷和医学病变。CD概念严重依赖于全局和局部上下文信息,因此在不同的上下文中容易发生变化,这要求模型具备强大的辨别能力。缺乏对SAM的全面评估限制了对其性能边界的理解,这可能会阻碍未来模型的设计。在本文中,我们对SAM在跨越自然、医学和工业场景的二维和三维图像和视频中的11个CD概念进行了全面的定量评估。我们为SAM和SAM 2开发了一个统一的评估框架,该框架支持手动、自动和中间自提示,辅以我们特定的提示生成和交互策略。我们进一步探索了SAM 2在上下文学习中的潜力,并引入提示稳健性测试来模拟现实世界中不完美的提示。最后,我们分析了SAM在理解CD概念方面的优点和局限性,并讨论了其在分割任务的未来发展。这项工作旨在提供有价值的见解,以指导未来在上下文独立和上下文依赖的概念分割方面的研究,为下一版本SAM 3的发展提供信息。
论文及项目相关链接
Summary
SAM模型作为计算机视觉领域的基础模型,已经对多个领域产生了深远影响。其升级版SAM 2在视频分割方面增强了能力,有望再次产生重大影响。虽然SAM系列(SAM和SAM 2)在分割独立上下文概念(如人、汽车和道路)方面表现出卓越性能,但它们忽视了更具挑战性的依赖上下文(CD)概念,如视觉显著性、伪装、产品缺陷和医学病灶等。本文进行了全面的定量评估,探讨了SAM系列在涉及自然、医学和工业场景的二维和三维图像和视频中的11个CD概念上的表现。研究建立了一个统一的评估框架,支持手动、自动和中间自提示方式,同时探讨了SAM 2在上下文学习方面的潜力,并引入了提示稳健性测试以模拟真实世界的不完美提示。分析SAM系列在理解CD概念方面的优势和局限性,为未来的研究工作提供了宝贵见解,可能为下一代模型SAM 3的发展提供指导。
Key Takeaways
- SAM作为基础模型在计算机视觉领域产生了重大影响,其升级版SAM 2在视频分割能力上有所提升。
- SAM系列在分割独立上下文概念上表现优秀,但在依赖上下文的复杂概念上表现欠佳。
- 本文对SAM系列进行了全面的定量评估,涵盖了自然、医学和工业场景中的二维和三维图像以及视频。
- 建立了一个统一的评估框架,支持多种提示方式,并深入探讨了SAM 2的上下文学习能力。
- 引入了提示稳健性测试以模拟真实世界的不完美提示。
- 分析总结了SAM系列在理解依赖上下文概念方面的优势和局限性。
点此查看论文截图

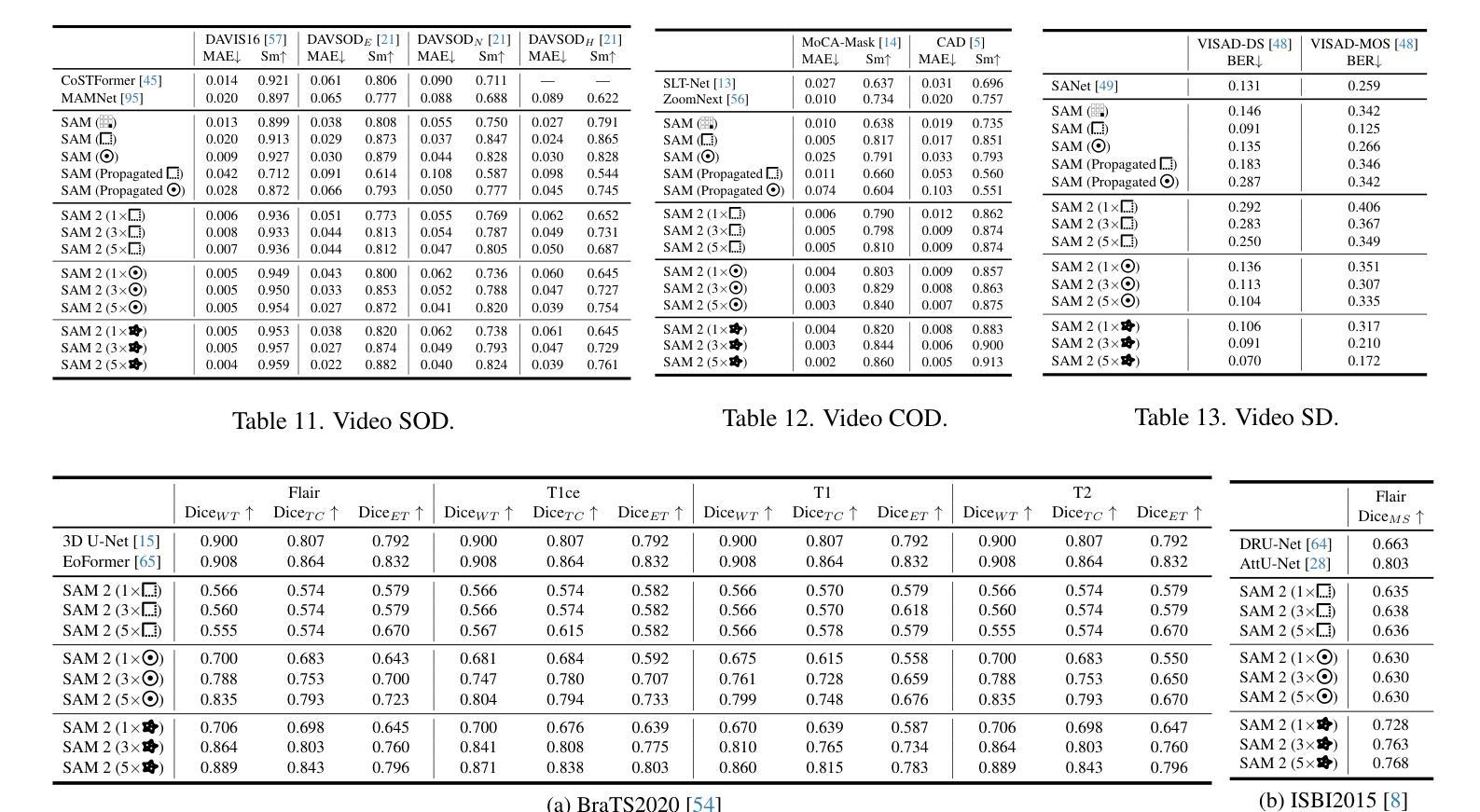
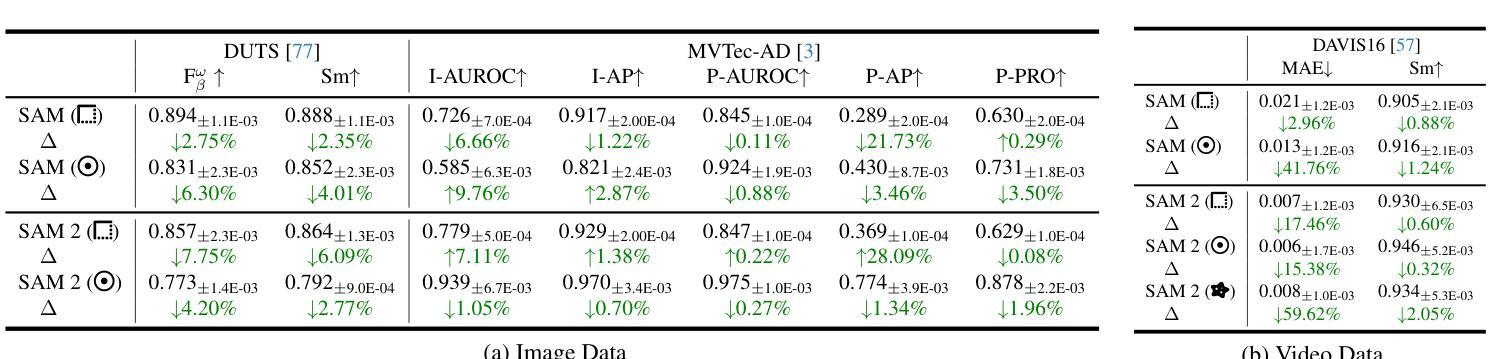
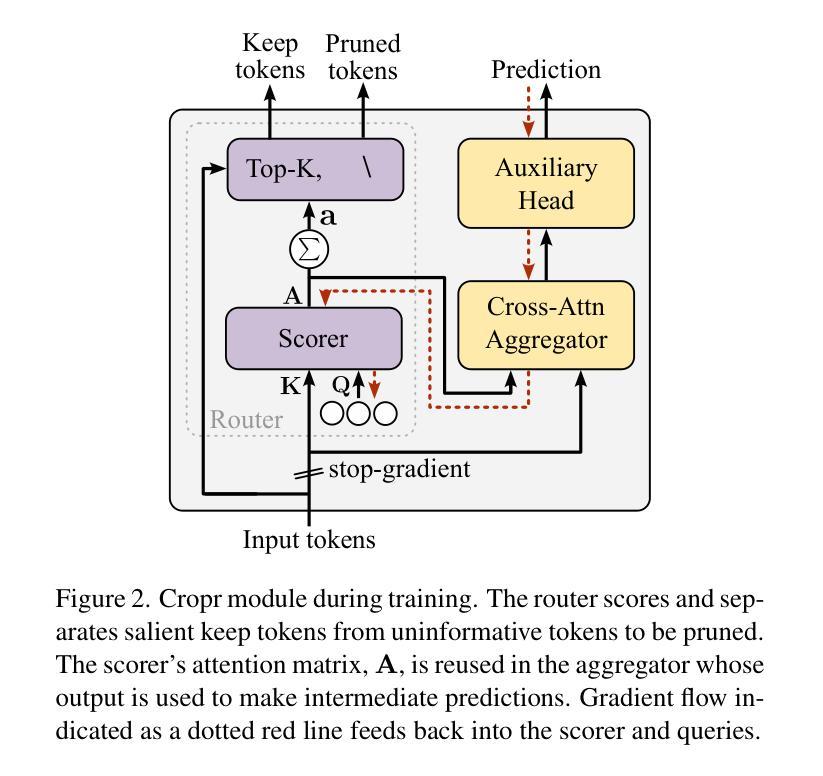
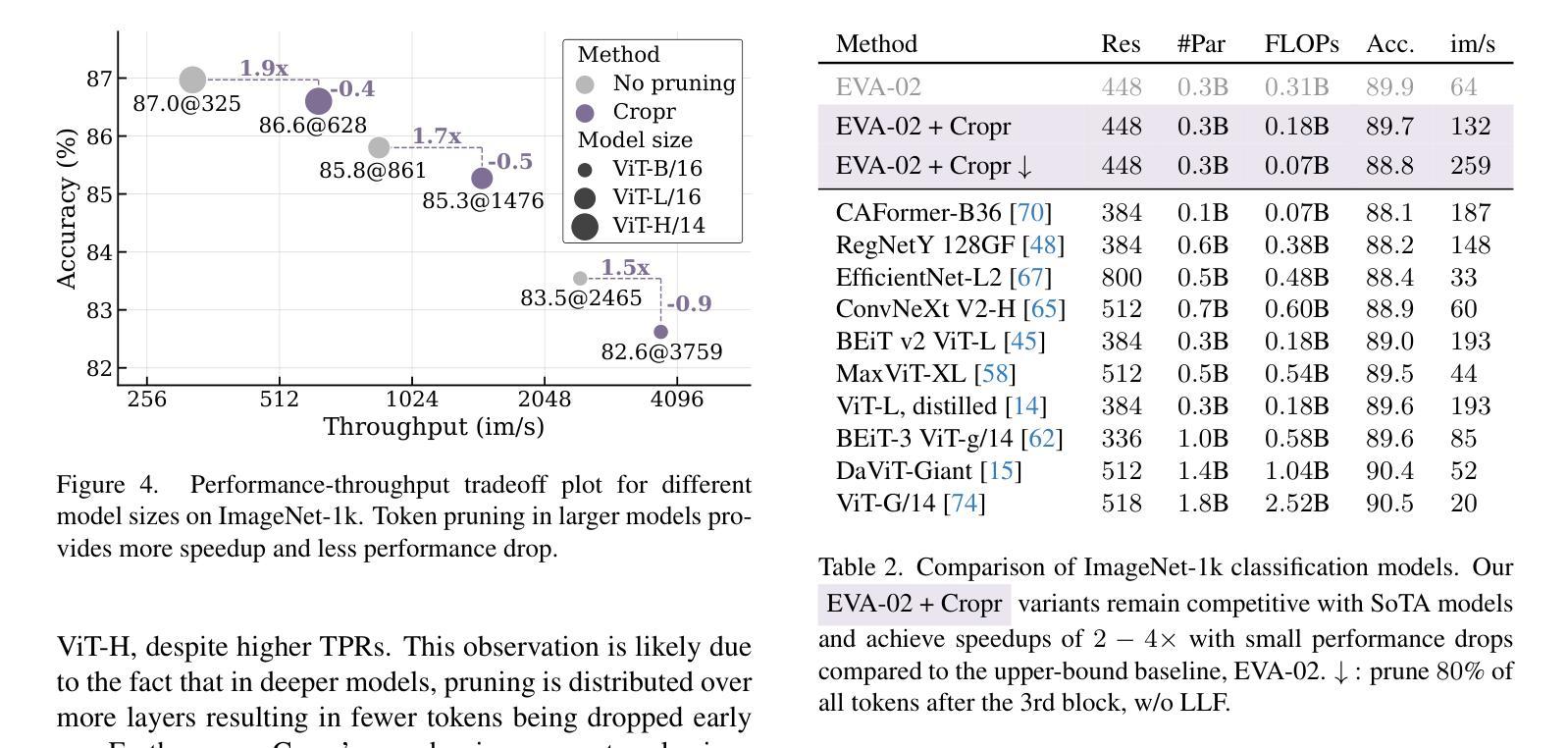
Token Cropr: Faster ViTs for Quite a Few Tasks
Authors:Benjamin Bergner, Christoph Lippert, Aravindh Mahendran
The adoption of Vision Transformers (ViTs) in resource-constrained applications necessitates improvements in inference throughput. To this end several token pruning and merging approaches have been proposed that improve efficiency by successively reducing the number of tokens. However, it remains an open problem to design a token reduction method that is fast, maintains high performance, and is applicable to various vision tasks. In this work, we present a token pruner that uses auxiliary prediction heads that learn to select tokens end-to-end based on task relevance. These auxiliary heads can be removed after training, leading to throughput close to that of a random pruner. We evaluate our method on image classification, semantic segmentation, object detection, and instance segmentation, and show speedups of 1.5 to 4x with small drops in performance. As a best case, on the ADE20k semantic segmentation benchmark, we observe a 2x speedup relative to the no-pruning baseline, with a negligible performance penalty of 0.1 median mIoU across 5 seeds.
将Vision Transformers(ViTs)应用于资源受限的应用场景需要改进推理吞吐量。为此,已经提出了多种令牌修剪和合并方法,通过逐步减少令牌数量来提高效率。然而,设计一个快速、高性能且适用于各种视觉任务的令牌缩减方法仍然是一个悬而未决的问题。在这项工作中,我们提出了一种使用辅助预测头的令牌修剪器,该预测头能够基于任务相关性进行端到端的令牌选择。这些辅助头在训练后可以移除,导致吞吐量接近随机修剪器。我们在图像分类、语义分割、目标检测和实例分割上评估了我们的方法,并显示出1.5到4倍的速度提升以及性能的小幅下降。在最好的情况下,在ADE20k语义分割基准测试中,我们观察到相对于无修剪基准的速度提升了2倍,在5个种子中的中位数mIoU性能损失微乎其微。
论文及项目相关链接
PDF 15 pages, 11 figures
Summary
本文提出了使用辅助预测头进行令牌选择的方法,基于任务相关性端对端地选择令牌,以提高Vision Transformer在资源受限应用中的推理速度。辅助头可以在训练后移除,实现接近于随机剪枝器的推理速度。评估该方法在图像分类、语义分割、目标检测和实例分割任务上的速度提升性能。
Key Takeaways
- Vision Transformer (ViT) 在资源受限的应用中需要提高推理速度。
- 提出了一种使用辅助预测头进行令牌选择和减缩的方法,该方法基于任务相关性端对端地学习。
- 辅助头可以在训练后移除,使得推理速度接近于随机剪枝器。
- 该方法在图像分类、语义分割、目标检测和实例分割任务上进行了评估。
- 与无剪枝基准相比,在ADE20k语义分割基准测试上观察到了2倍的速度提升。
- 在不同的种子运行实验中,性能下降微乎其微,仅为0.1的中值mIoU。
点此查看论文截图



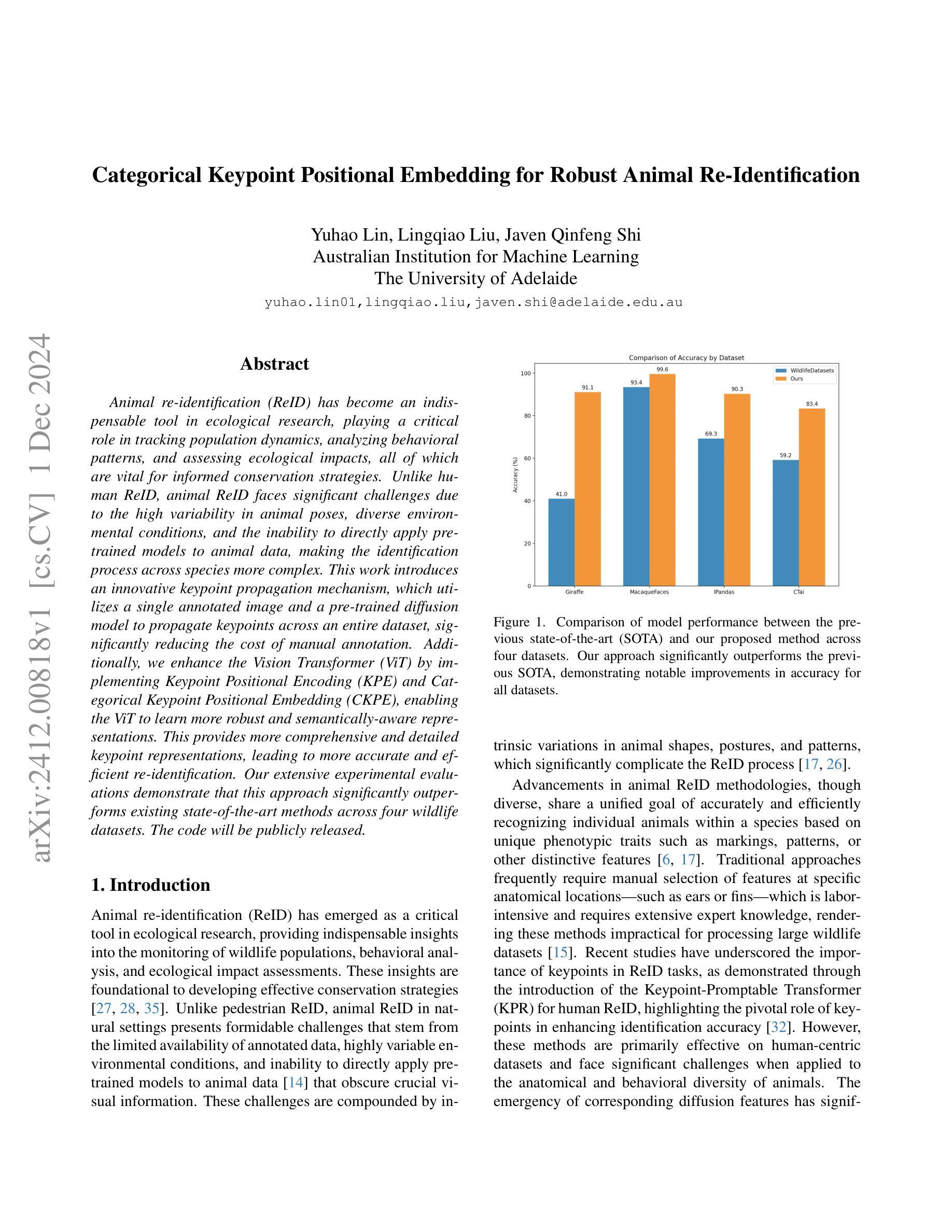
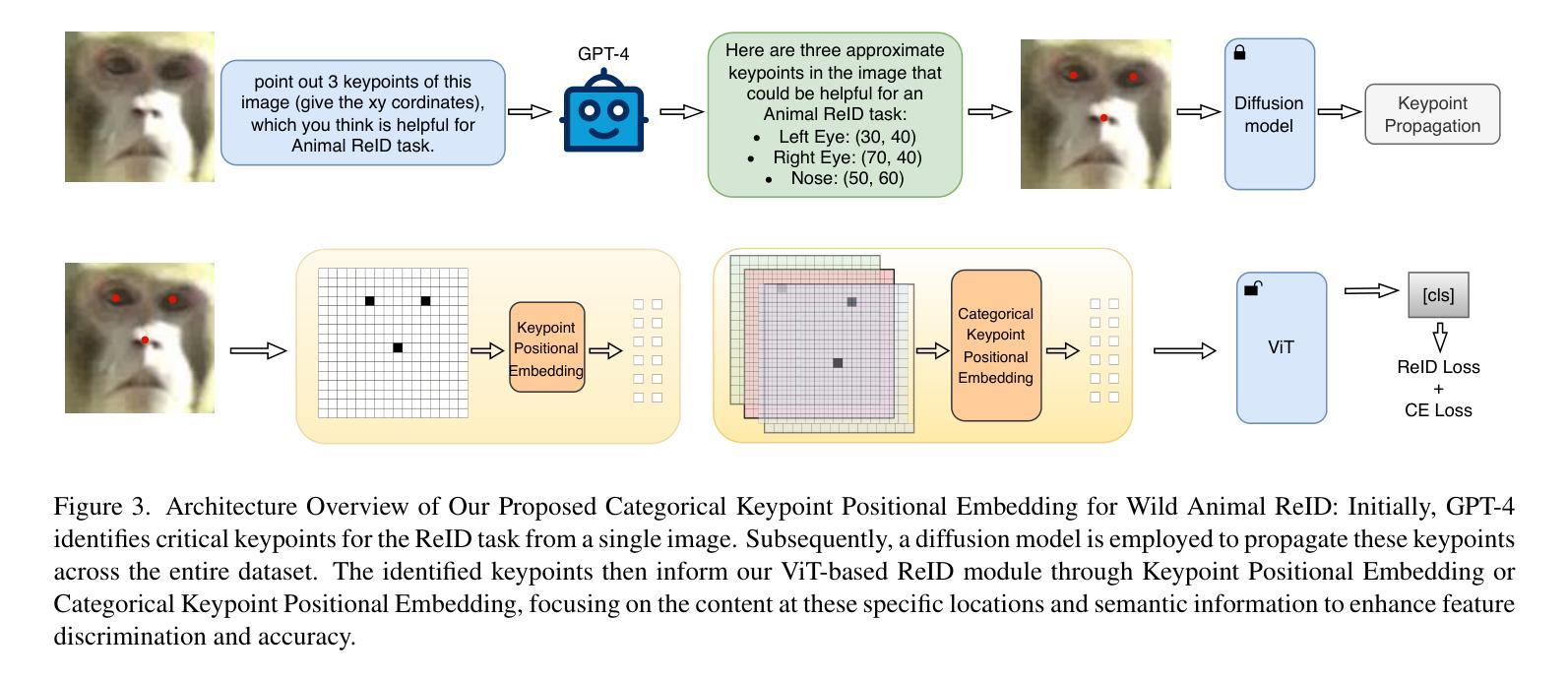
Categorical Keypoint Positional Embedding for Robust Animal Re-Identification
Authors:Yuhao Lin, Lingqiao Liu, Javen Shi
Animal re-identification (ReID) has become an indispensable tool in ecological research, playing a critical role in tracking population dynamics, analyzing behavioral patterns, and assessing ecological impacts, all of which are vital for informed conservation strategies. Unlike human ReID, animal ReID faces significant challenges due to the high variability in animal poses, diverse environmental conditions, and the inability to directly apply pre-trained models to animal data, making the identification process across species more complex. This work introduces an innovative keypoint propagation mechanism, which utilizes a single annotated image and a pre-trained diffusion model to propagate keypoints across an entire dataset, significantly reducing the cost of manual annotation. Additionally, we enhance the Vision Transformer (ViT) by implementing Keypoint Positional Encoding (KPE) and Categorical Keypoint Positional Embedding (CKPE), enabling the ViT to learn more robust and semantically-aware representations. This provides more comprehensive and detailed keypoint representations, leading to more accurate and efficient re-identification. Our extensive experimental evaluations demonstrate that this approach significantly outperforms existing state-of-the-art methods across four wildlife datasets. The code will be publicly released.
动物再识别(ReID)已成为生态研究中不可或缺的工具,在跟踪种群动态、分析行为模式、评估生态影响等方面发挥着关键作用,所有这些都对制定有针对性的保护策略至关重要。与人类ReID不同,动物ReID面临着巨大的挑战,因为动物姿势高度多变、环境条件多样,且无法直接将预训练模型应用于动物数据,使得跨物种的识别过程更加复杂。这项工作引入了一种创新的关键点传播机制,它利用一张带注释的图像和预训练的扩散模型在整个数据集中传播关键点,大大降低了手动注释的成本。此外,我们通过实现关键点位置编码(KPE)和分类关键点位置嵌入(CKPE)增强了视觉转换器(ViT)的功能,使ViT能够学习更稳健、语义感知的表示。这提供了更全面、更详细的关键点表示,导致再识别更准确、更高效。我们在四个野生动物数据集上进行的广泛实验评估表明,该方法显著优于现有最先进的方法。代码将公开发布。
论文及项目相关链接
PDF In review
Summary
本文介绍了动物再识别(ReID)在生态研究中的重要性,并指出了动物ReID面临的挑战,如动物姿态的高可变性、环境条件的多样性以及无法直接将预训练模型应用于动物数据等。为此,本文引入了一种创新的关键点传播机制,利用单个注释图像和预训练的扩散模型在整个数据集中传播关键点,大大降低了手动注释的成本。此外,通过实现关键点位置编码(KPE)和分类关键点位置嵌入(CKPE)增强了视觉变压器(ViT),使ViT能够学习更健壮和语义感知的表示,提供更全面、更详细的关键点表示,从而实现更准确、更高效的再识别。广泛的实验评估表明,该方法在四个野生动物数据集上显著优于现有最先进的方法。
Key Takeaways
- 动物再识别(ReID)在生态研究中具有重要意义,对于跟踪种群动态、分析行为模式和评估生态影响至关重要。
- 动物ReID面临诸多挑战,如动物姿态多变、环境条件多样以及无法直接将预训练模型应用于动物数据。
- 引入了一种创新的关键点传播机制,利用单个注释图像和预训练的扩散模型在整个数据集中传播关键点,降低了手动注释的成本。
- 通过实现关键点位置编码(KPE)和分类关键点位置嵌入(CKPE)增强了视觉变压器(ViT)。
- ViT能够学习更健壮和语义感知的表示,提供更全面、更详细的关键点表示。
- 该方法在四个野生动物数据集上的表现显著优于现有最先进的方法。
- 代码将公开发布。
点此查看论文截图

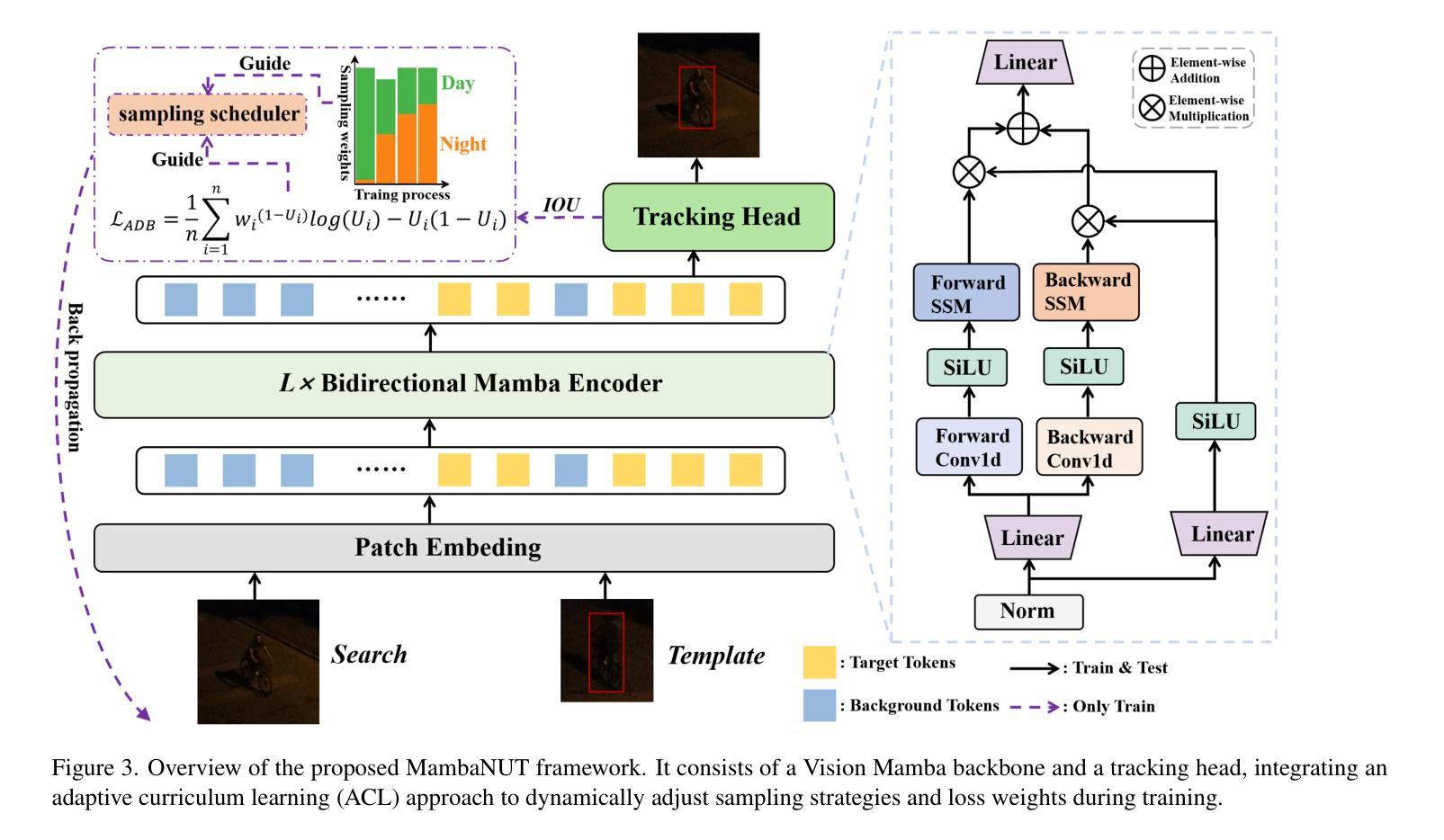
MambaNUT: Nighttime UAV Tracking via Mamba and Adaptive Curriculum Learning
Authors:You Wu, Xiangyang Yang, Xucheng Wang, Hengzhou Ye, Dan Zeng, Shuiwang Li
Harnessing low-light enhancement and domain adaptation, nighttime UAV tracking has made substantial strides. However, over-reliance on image enhancement, scarcity of high-quality nighttime data, and neglecting the relationship between daytime and nighttime trackers, which hinders the development of an end-to-end trainable framework. Moreover, current CNN-based trackers have limited receptive fields, leading to suboptimal performance, while ViT-based trackers demand heavy computational resources due to their reliance on the self-attention mechanism. In this paper, we propose a novel pure Mamba-based tracking framework (\textbf{MambaNUT}) that employs a state space model with linear complexity as its backbone, incorporating a single-stream architecture that integrates feature learning and template-search coupling within Vision Mamba. We introduce an adaptive curriculum learning (ACL) approach that dynamically adjusts sampling strategies and loss weights, thereby improving the model’s ability of generalization. Our ACL is composed of two levels of curriculum schedulers: (1) sampling scheduler that transforms the data distribution from imbalanced to balanced, as well as from easier (daytime) to harder (nighttime) samples; (2) loss scheduler that dynamically assigns weights based on data frequency and the IOU. Exhaustive experiments on multiple nighttime UAV tracking benchmarks demonstrate that the proposed MambaNUT achieves state-of-the-art performance while requiring lower computational costs. The code will be available.
利用低光增强和领域自适应技术,夜间无人机跟踪已经取得了显著进展。然而,对图像增强的过度依赖、高质量夜间数据的稀缺以及忽视白天和夜间跟踪器之间的关系,这些阻碍了端到端可训练框架的发展。此外,当前的CNN(卷积神经网络)跟踪器具有有限的感受野,导致性能不佳,而基于ViT(视觉转换器)的跟踪器由于依赖自注意力机制而需要巨大的计算资源。在本文中,我们提出了一种基于纯Mamba的跟踪框架(MambaNUT),它采用线性复杂度的状态空间模型作为主干,并结合单流架构,在Vision Mamba内集成特征学习和模板搜索耦合。我们引入了一种自适应课程学习(ACL)方法,该方法可以动态调整采样策略和损失权重,从而提高模型的泛化能力。我们的ACL由两个层次的课程调度器组成:(1)采样调度器,它将数据分布从不平衡转变为平衡,同时从更容易(白天)的样本到更困难(夜间)的样本;(2)损失调度器根据数据频率和IOU动态分配权重。在多个夜间无人机跟踪基准测试上的详尽实验表明,所提出的MambaNUT达到了最先进的性能,同时计算成本较低。代码将可用。
论文及项目相关链接
Summary
本文提出一种基于Mamba的纯跟踪框架(MambaNUT),采用具有线性复杂度的状态空间模型作为主干,通过单流架构整合特征学习和模板搜索耦合在Vision Mamba中。引入自适应课程学习(ACL)方法,动态调整采样策略和损失权重,提高模型泛化能力。在多个夜间无人机跟踪基准测试上表现出卓越性能,同时计算成本较低。
Key Takeaways
- 夜间无人机跟踪已取得显著进展,结合低光增强和领域自适应技术。
- 现有方法依赖图像增强、高质量夜间数据不足以及忽视昼夜跟踪关系,阻碍端到端可训练框架的发展。
- CNN基跟踪器具有有限的感受野,性能不佳,而ViT基跟踪器因依赖自注意力机制而计算量大。
- 引入基于Mamba的跟踪框架(MambaNUT),采用具有线性复杂度的状态空间模型。
- MambaNUT采用单流架构,整合特征学习与模板搜索耦合。
- 引入自适应课程学习(ACL)方法,包括数据采样和损失权重动态调整,提高模型泛化能力。
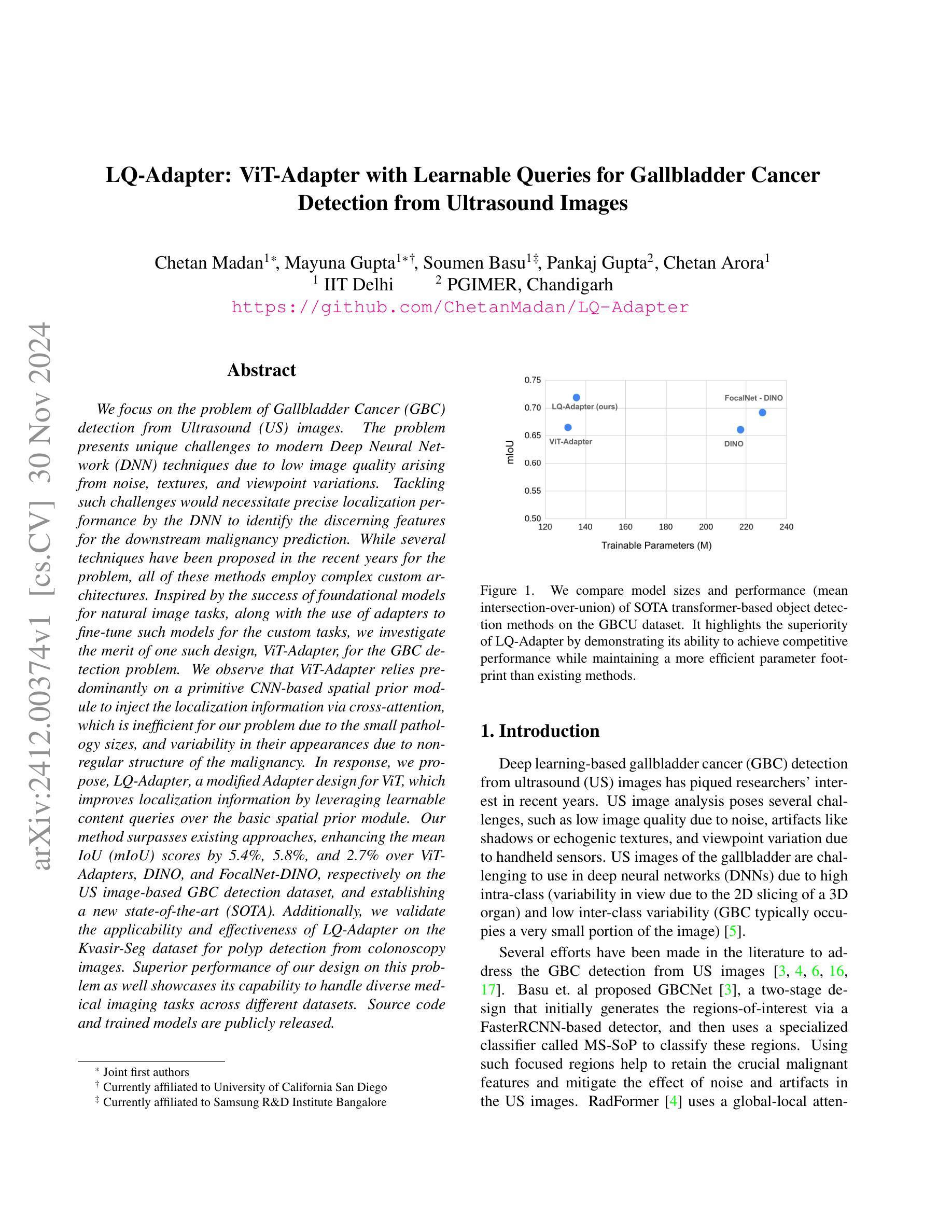
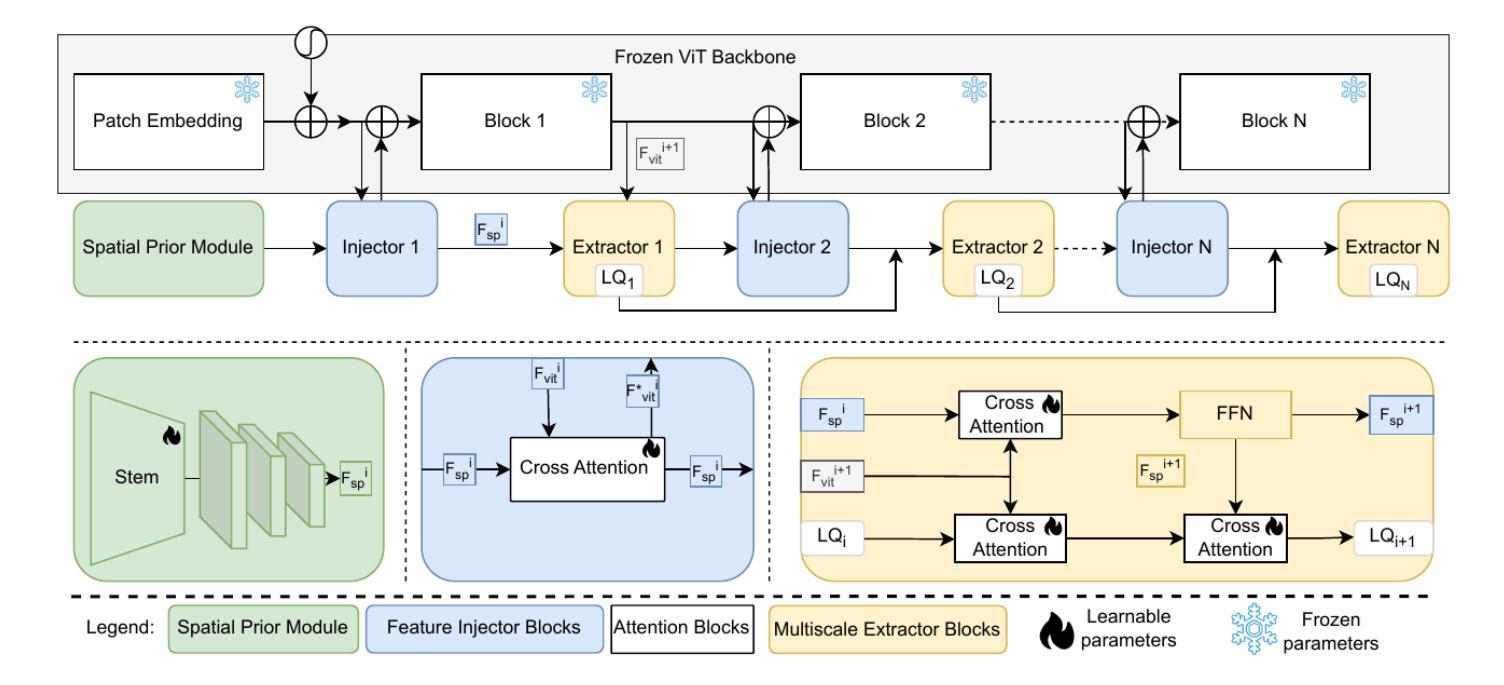
点此查看论文截图

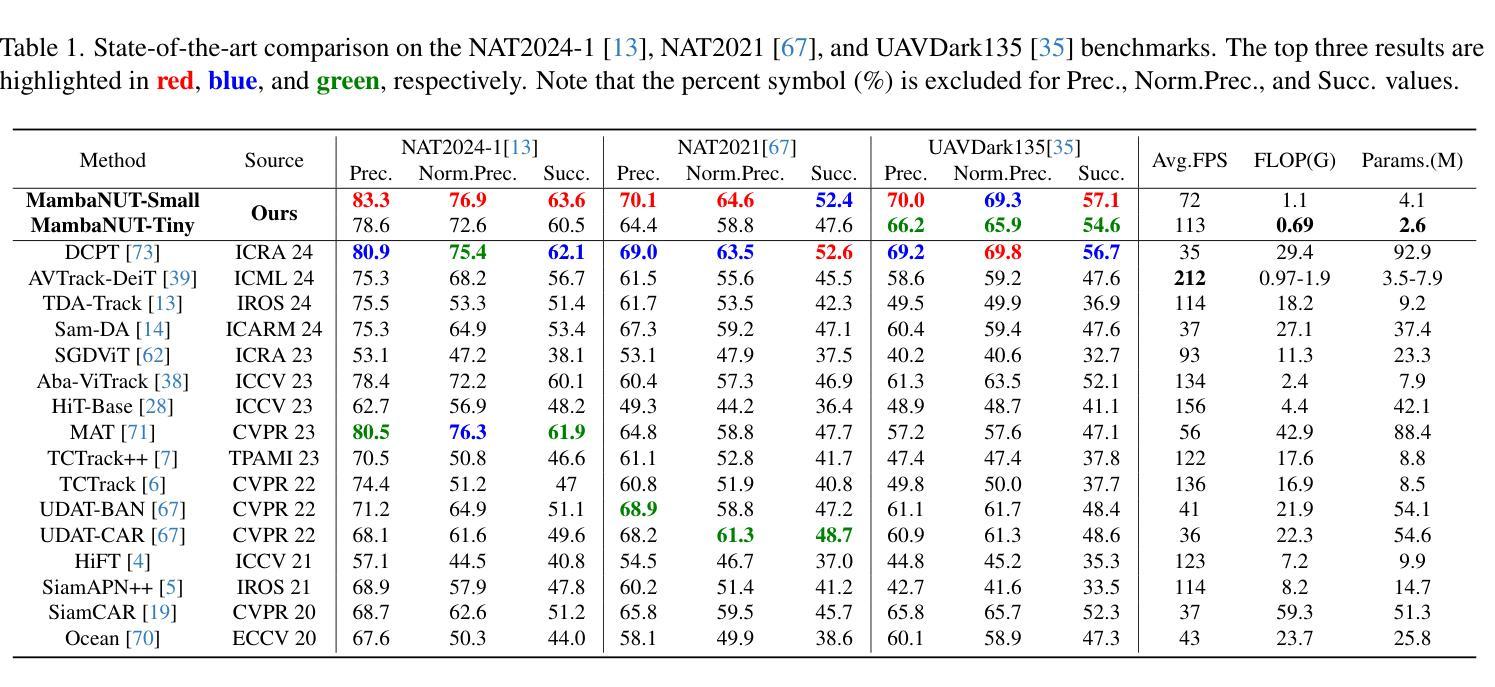
LQ-Adapter: ViT-Adapter with Learnable Queries for Gallbladder Cancer Detection from Ultrasound Image
Authors:Chetan Madan, Mayuna Gupta, Soumen Basu, Pankaj Gupta, Chetan Arora
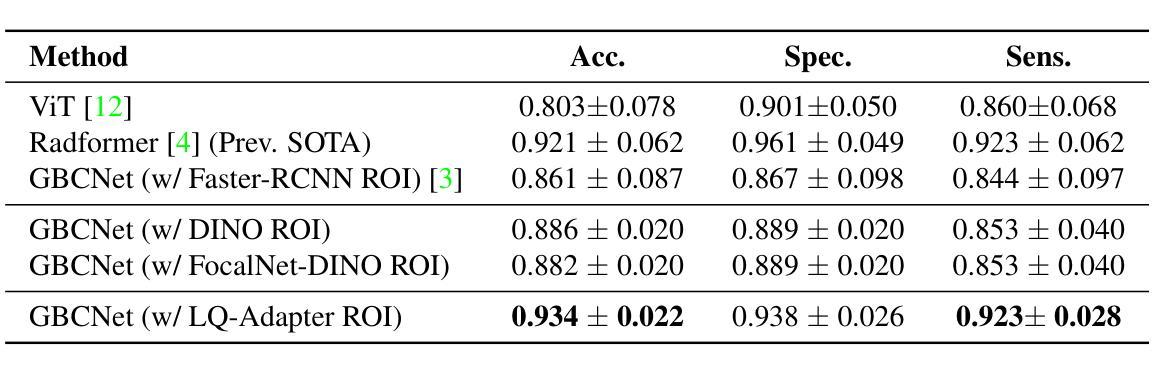
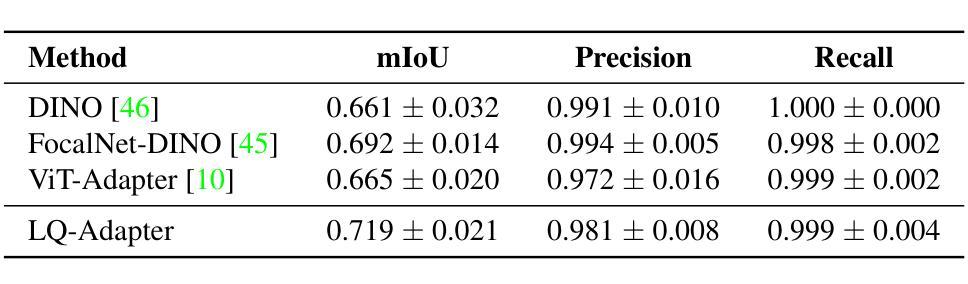
We focus on the problem of Gallbladder Cancer (GBC) detection from Ultrasound (US) images. The problem presents unique challenges to modern Deep Neural Network (DNN) techniques due to low image quality arising from noise, textures, and viewpoint variations. Tackling such challenges would necessitate precise localization performance by the DNN to identify the discerning features for the downstream malignancy prediction. While several techniques have been proposed in the recent years for the problem, all of these methods employ complex custom architectures. Inspired by the success of foundational models for natural image tasks, along with the use of adapters to fine-tune such models for the custom tasks, we investigate the merit of one such design, ViT-Adapter, for the GBC detection problem. We observe that ViT-Adapter relies predominantly on a primitive CNN-based spatial prior module to inject the localization information via cross-attention, which is inefficient for our problem due to the small pathology sizes, and variability in their appearances due to non-regular structure of the malignancy. In response, we propose, LQ-Adapter, a modified Adapter design for ViT, which improves localization information by leveraging learnable content queries over the basic spatial prior module. Our method surpasses existing approaches, enhancing the mean IoU (mIoU) scores by 5.4%, 5.8%, and 2.7% over ViT-Adapters, DINO, and FocalNet-DINO, respectively on the US image-based GBC detection dataset, and establishing a new state-of-the-art (SOTA). Additionally, we validate the applicability and effectiveness of LQ-Adapter on the Kvasir-Seg dataset for polyp detection from colonoscopy images. Superior performance of our design on this problem as well showcases its capability to handle diverse medical imaging tasks across different datasets. Code is released at https://github.com/ChetanMadan/LQ-Adapter
我们主要关注通过超声(US)图像检测胆囊癌(GBC)的问题。由于噪声、纹理和视角变化导致的图像质量低下,这个问题给现代深度神经网络(DNN)技术带来了独特的挑战。要解决这些挑战,DNN需要实现精确的定位性能,以识别用于下游恶性预测的有区别特征。尽管近年来已经提出了几种解决该问题的方法,但所有这些方法都采用复杂的自定义架构。受自然图像任务基础模型成功的启发,以及使用适配器对此类模型进行微调以完成自定义任务,我们研究了一种名为ViT-Adapter的设计优势,用于胆囊癌检测问题。我们发现ViT-Adapter主要依赖于基于原始CNN的空间先验模块,通过交叉注意力注入定位信息,这对于我们的问题是不高效的,因为恶性病变的尺寸较小,而且其外观因非规则结构而具有可变性。作为回应,我们提出了LQ-Adapter,这是一种改进的ViT适配器设计,它通过利用基本空间先验模块上的可学习内容查询来改善定位信息。我们的方法在基于超声图像的胆囊癌检测数据集上超越了现有方法,相较于ViT-Adapters、DINO和FocalNet-DINO分别提高了平均交并比(mIoU)得分5.4%、5.8%和2.7%,并建立了新的最新技术(SOTA)。此外,我们在用于结肠镜图像中的息肉检测的Kvasir-Seg数据集上验证了LQ-Adapter的适用性和有效性。我们的设计在这个问题上的卓越性能也展示了它在处理不同数据集的多样医学成像任务的能力。代码已发布在https://github.com/ChetanMadan/LQ-Adapter。
论文及项目相关链接
PDF Accepted at WACV 2025
摘要
针对胆囊癌超声图像检测问题,研究采用ViT-Adapter改进模型LQ-Adapter。LQ-Adapter通过引入可学习的内容查询模块,改进了原始基于CNN的空间先验模块,提高了定位信息的利用效率,特别是在病灶小且非结构化的恶性病变情况下。在胆囊癌超声图像检测数据集上,LQ-Adapter超越了现有方法,平均交并比(mIoU)得分提高了5.4%、5.8%和2.7%,显示出其在实际应用中的优异性能和跨数据集的泛化能力。此外,LQ-Adapter在结肠镜检查图像的多发性息肉检测上也有很好的表现。此外将发布的代码(网址链接)向公众开放共享以供学习交流使用。对于小型病理检测具有重要的临床价值和广泛的市场前景应用价值有着重要作用。随着对恶性肿瘤疾病的诊疗和科研工作的需求,该研究在医疗影像分析领域的应用前景广阔。该模型能够高效识别肿瘤组织特征并精准定位,有助于提高胆囊癌的诊断精度和治疗成功率。该项技术的成熟与应用无疑为未来的胆囊癌诊断和治疗带来新变革,使小型医疗检测设备高效服务于普通患者基层民众中发挥出重要角色,意义极其重大且充满巨大市场潜力前景无限值得期待其正式投产上线以便面向临床应用以及为广大科研人士提供更多的选择工具和更好的用户体验等方面具有重要意义和期待空间。。。更具体的表现会围绕适应性广泛适用领域涵盖较广通过训练和不断优化技术会满足不同数据集要求中不断提升算法的适应性和精准性带来诊疗方案中的实际应用前景会促进疾病的精准诊断和治疗是当前的科技发展中该领域的有效发展方向具体落实成效需要结合临床应用与实践来证明期望得到广泛关注和进一步的推广实施应用于基层医疗机构面向民众开放以实现远程检测和健康管理给人们的日常生活带来便捷化服务的技术突破成为可能!未来发展潜力值得期待和改进和技术的不断优化发展以期发挥更大的价值和更多的实际案例和应用场景的覆盖帮助改善基层医疗机构对于患者的疾病诊断能力!
关键见解
- 研究集中于胆囊癌的超声图像检测问题,面临低图像质量的挑战。
- 提出LQ-Adapter模型,改进了ViT-Adapter,通过引入可学习的内容查询模块提高定位信息的利用效率。
- 在胆囊癌超声图像检测数据集上的表现超越现有方法,平均交并比得分显著提高。
- LQ-Adapter在结肠镜检查图像的多发性息肉检测任务上也有良好表现。
- 代码已公开共享,有助于学习和交流。
- 该研究在医疗影像分析领域具有广泛的应用前景,能够高效识别肿瘤组织特征并精准定位,提高诊断精度和治疗成功率。
点此查看论文截图
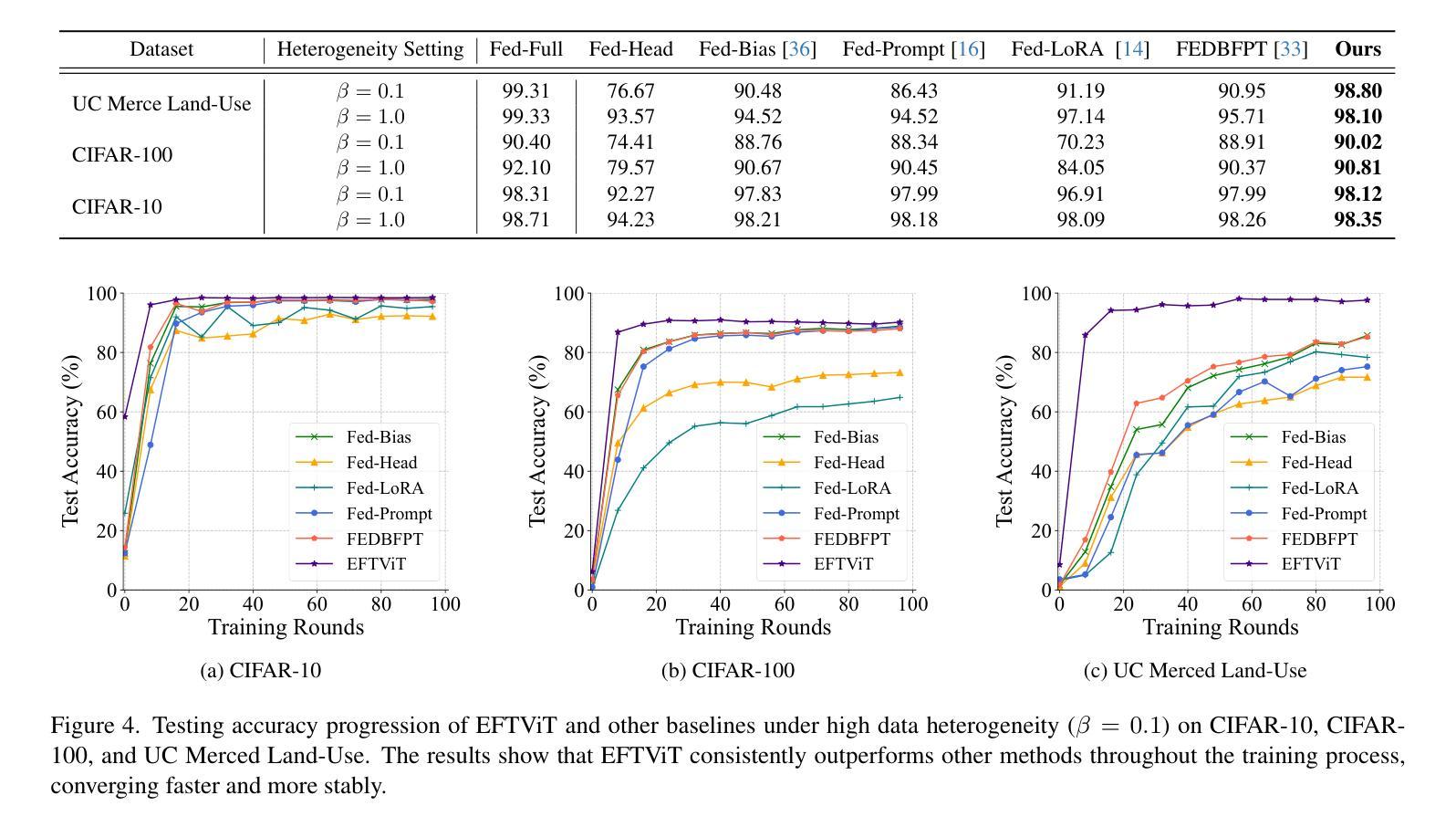
EFTViT: Efficient Federated Training of Vision Transformers with Masked Images on Resource-Constrained Edge Devices
Authors:Meihan Wu, Tao Chang, Cui Miao, Jie Zhou, Chun Li, Xiangyu Xu, Ming Li, Xiaodong Wang
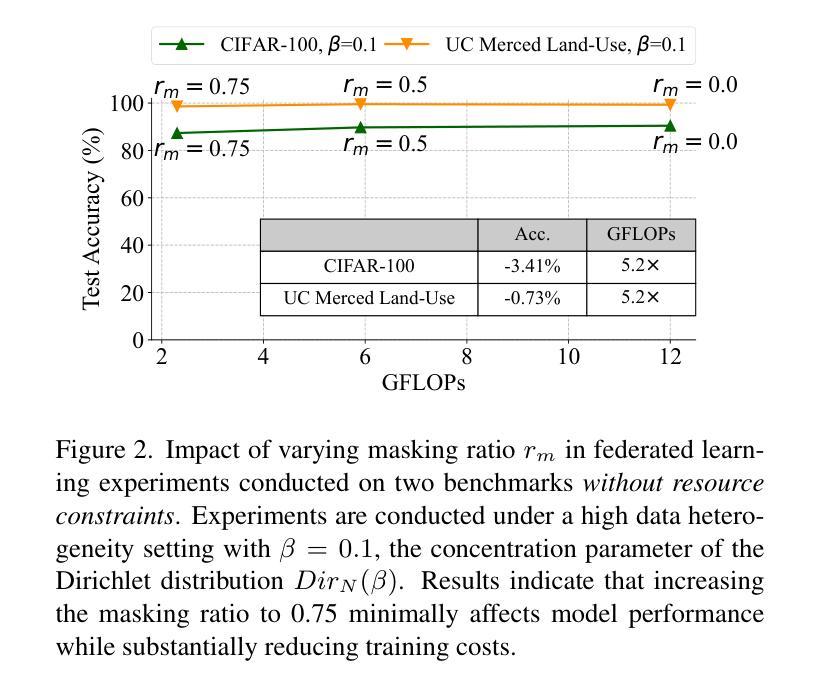
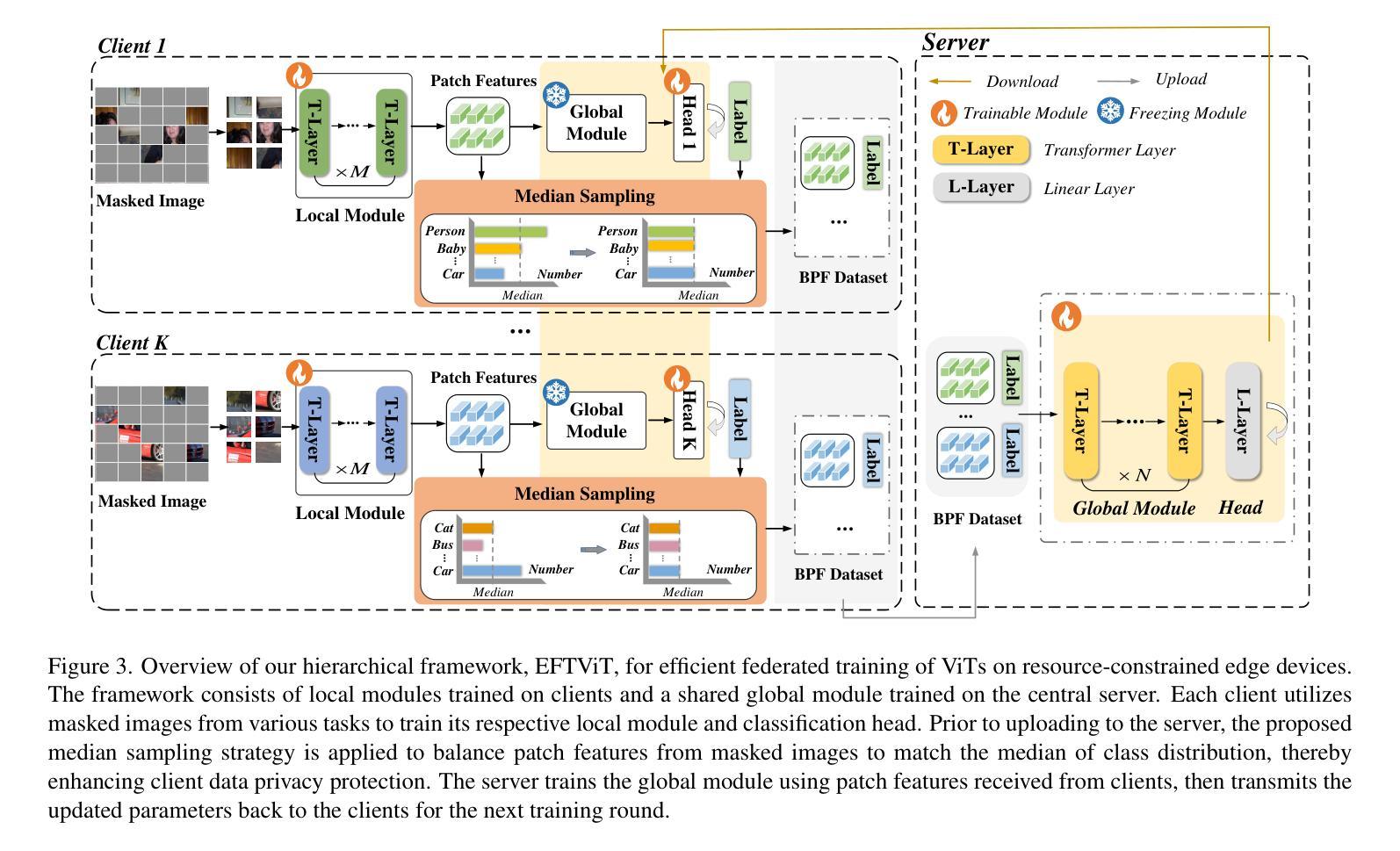
Federated learning research has recently shifted from Convolutional Neural Networks (CNNs) to Vision Transformers (ViTs) due to their superior capacity. ViTs training demands higher computational resources due to the lack of 2D inductive biases inherent in CNNs. However, efficient federated training of ViTs on resource-constrained edge devices remains unexplored in the community. In this paper, we propose EFTViT, a hierarchical federated framework that leverages masked images to enable efficient, full-parameter training on resource-constrained edge devices, offering substantial benefits for learning on heterogeneous data. In general, we patchify images and randomly mask a portion of the patches, observing that excluding them from training has minimal impact on performance while substantially reducing computation costs and enhancing data content privacy protection. Specifically, EFTViT comprises a series of lightweight local modules and a larger global module, updated independently on clients and the central server, respectively. The local modules are trained on masked image patches, while the global module is trained on intermediate patch features uploaded from the local client, balanced through a proposed median sampling strategy to erase client data distribution privacy. We analyze the computational complexity and privacy protection of EFTViT. Extensive experiments on popular benchmarks show that EFTViT achieves up to 28.17% accuracy improvement, reduces local training computational cost by up to 2.8$\times$, and cuts local training time by up to 4.4$\times$ compared to existing methods.
联邦学习研究最近已从卷积神经网络(CNNs)转向视觉转换器(ViTs),这是因为视觉转换器具有卓越的能力。由于ViTs缺乏CNN所固有的2D归纳偏见,因此其训练需要更高的计算资源。然而,在资源受限的边缘设备上有效地训练ViTs的联邦学习在社区中尚未得到探索。在本文中,我们提出了EFTViT,这是一个分层的联邦框架,它利用掩码图像实现在资源受限的边缘设备上的高效全参数训练,为在异构数据上的学习提供了实质性的好处。一般来说,我们将图像分成小块并随机掩盖一部分块,观察到在训练时排除它们对性能的影响微乎其微,同时能大幅减少计算成本并增强数据内容隐私保护。具体来说,EFTViT包括一系列轻量级的本地模块和一个更大的全局模块,分别在客户端和中央服务器上独立更新。本地模块在掩码图像块上进行训练,而全局模块则在从本地客户端上传的中间块特征上进行训练,通过提出的中位数采样策略来平衡,以消除客户端数据分布隐私。我们分析了EFTViT的计算复杂性和隐私保护。在流行基准测试上的广泛实验表明,与现有方法相比,EFTViT实现了高达28.17%的准确率提升,将本地训练的计算成本降低了高达2.8倍,并将本地训练时间缩短了高达4.4倍。
论文及项目相关链接
Summary
该研究提出了EFTViT,一个用于在资源受限的边缘设备上训练ViTs的高效联邦框架。通过使用图像块划分和部分掩蔽的策略,本地模块能够在被掩盖的图像块上进行训练,同时全球模块则通过一种平衡采样策略更新并处理上传的中间特征信息。实验表明,EFTViT能够显著提高训练效率,同时保护数据隐私。相较于现有方法,EFTViT在准确性上提高了高达28.17%,在本地计算成本上降低了高达2.8倍,并减少了高达4.4倍的本地训练时间。
Key Takeaways
- 研究将联邦学习从CNN转向ViT以适应其更高的性能优势。
- EFTViT利用图像块掩蔽技术以降低计算成本并提高数据隐私保护。
- EFTViT框架包括本地模块和全球模块,可独立更新以适应不同训练需求。
- 图像块的掩盖对于训练性能的影响微乎其微。
- 使用提出的中间特征信息采样策略可提高平衡度和数据处理效率。
- 实验结果表明,EFTViT显著提高准确性、计算效率和时间效益。
点此查看论文截图


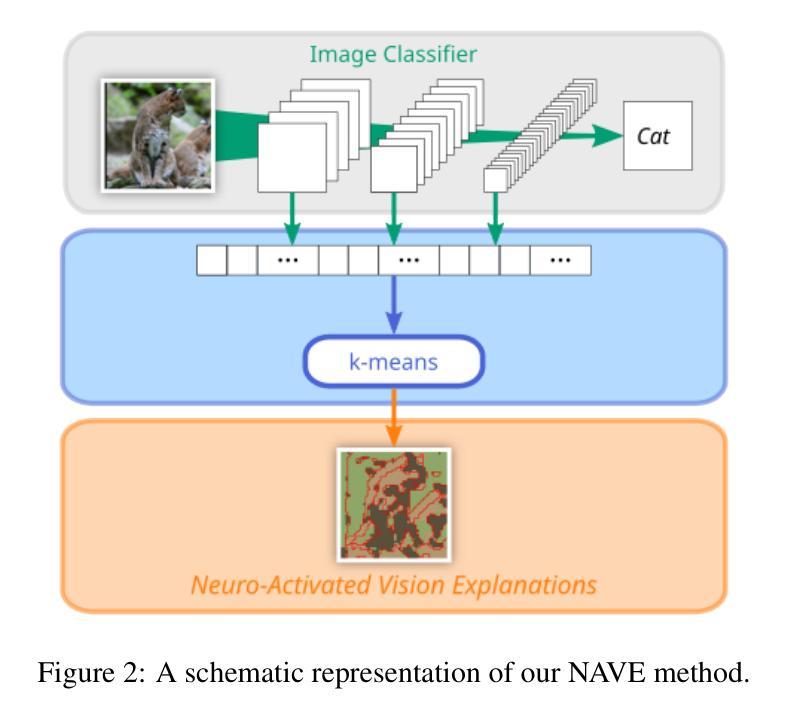
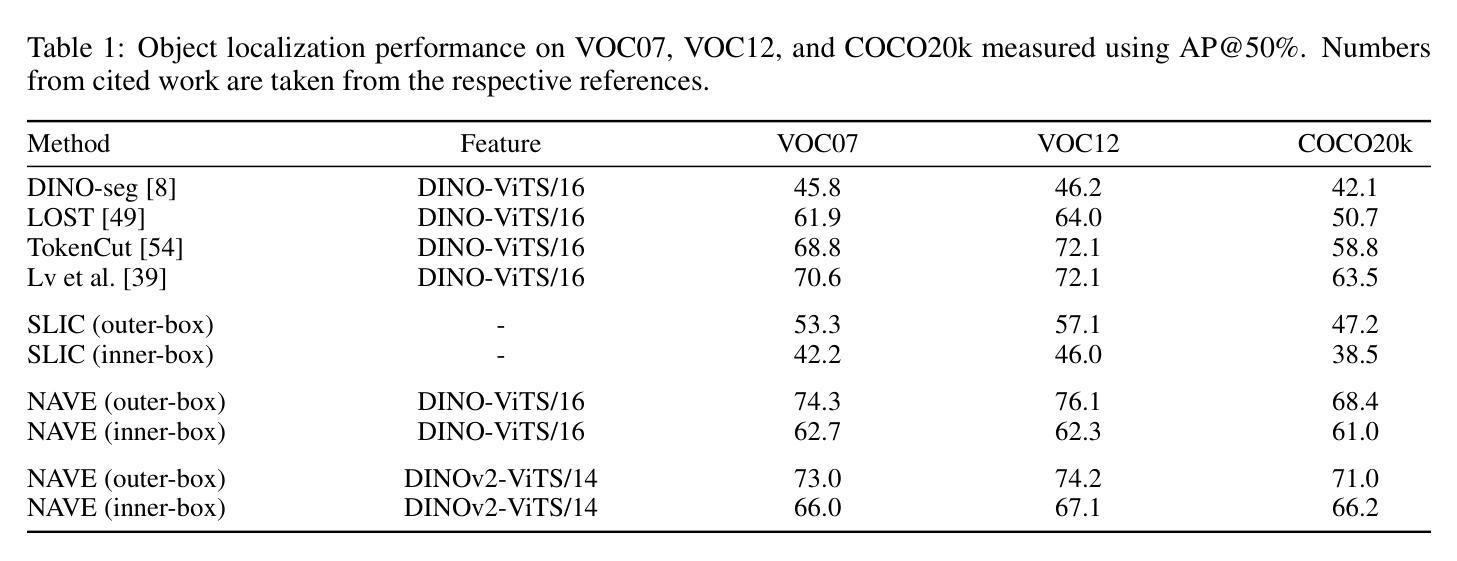
Explaining the Impact of Training on Vision Models via Activation Clustering
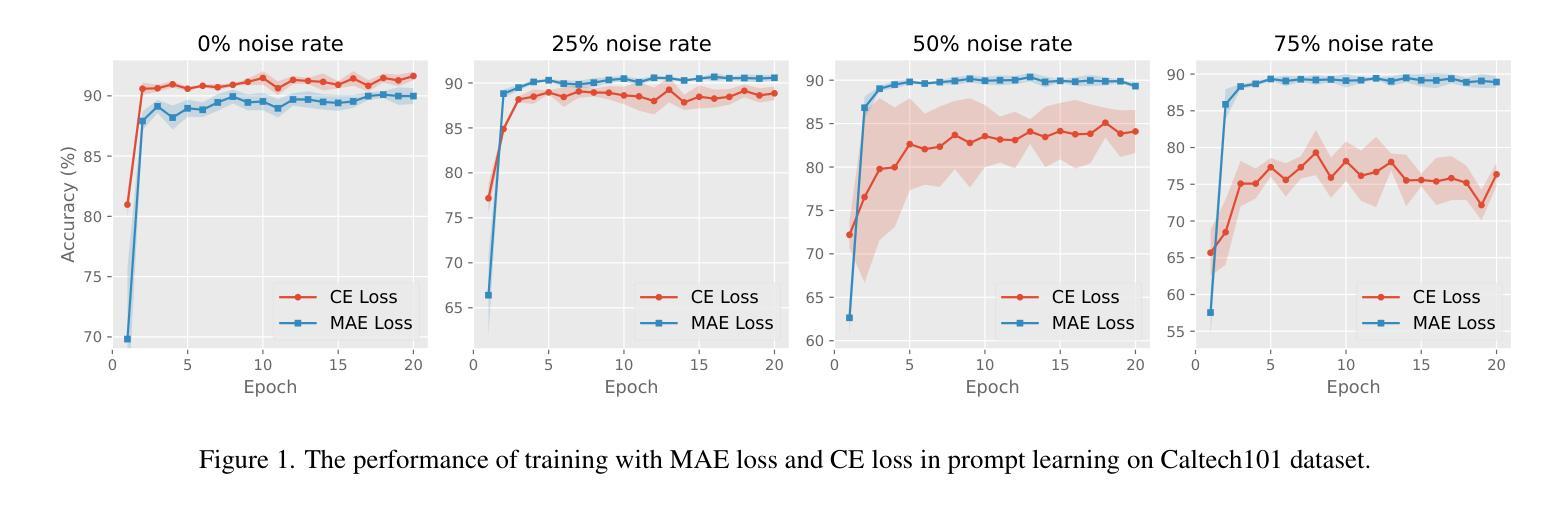
Authors:Ahcène Boubekki, Samuel G. Fadel, Sebastian Mair
Recent developments in the field of explainable artificial intelligence (XAI) for vision models investigate the information extracted by their feature encoder. We contribute to this effort and propose Neuro-Activated Vision Explanations (NAVE), which extracts the information captured by the encoder by clustering the feature activations of the frozen network to be explained. The method does not aim to explain the model’s prediction but to answer questions such as which parts of the image are processed similarly or which information is kept in deeper layers. Experimentally, we leverage NAVE to show that the training dataset and the level of supervision affect which concepts are captured. In addition, our method reveals the impact of registers on vision transformers (ViT) and the information saturation caused by the watermark Clever Hans effect in the training set.
在解释性人工智能(XAI)领域,针对视觉模型的最新发展正在研究特征编码器所提取的信息。我们为此做出贡献并提出了神经激活视觉解释(NAVE),它通过聚类要解释的冻结网络的特征激活来提取编码器捕获的信息。该方法并不旨在解释模型的预测,而是旨在回答诸如图像的哪些部分被类似处理或哪些信息被保留在较深的层次等问题。通过实验,我们利用NAVE显示训练数据集和监督水平会影响捕获哪些概念。此外,我们的方法揭示了寄存器对视觉变压器(ViT)的影响以及训练集中水印Clever Hans效应引起的信息饱和。
论文及项目相关链接
Summary
本摘要探讨了最近关于解释人工智能(XAI)在视觉模型领域的进展,并提出了神经激活视觉解释(NAVE)方法。该方法通过聚类被解释冻结网络的特征激活来提取编码器所捕获的信息。它旨在解答类似的问题,如图像的哪些部分处理相似或深层中保留了哪些信息,而非解释模型的预测。实验表明,训练数据集和监管水平会影响所捕获的概念。此外,该方法揭示了注册表对视觉变压器(ViT)的影响以及训练集中水印导致的Clever Hans效应引发的信息饱和问题。总的来说,摘要提供了有关使用视觉解释模型获取图像信息的见解。
Key Takeaways
以下是该文本的关键见解要点:
- NAVE方法旨在通过聚类特征激活提取视觉模型的编码器所捕获的信息,而不是解释模型的预测。
- NAVE展示了不同概念如何通过视觉模型进行捕捉并强调它们之间的差异如何受训练数据集和监管水平的影响。
- 训练数据集和监管水平对视觉模型捕获的概念有显著影响。
- 该方法揭示了注册表现在对视觉变压器性能中的重要性以及对注册的影响在复杂系统中未充分了解的复杂性的敏感性。尽管此类模型的优势正在被广泛探索(尤其是可以取代某些传统算法),但它们仍然面临一些挑战,例如需要更深入的优化和更全面的测试来确保其在各种情况下的性能一致性。此外,还需要进一步的研究来确保这些模型能够公平地处理所有类型的数据和场景,避免偏见和歧视。由于数据的数量和质量日益成为问题解决的关键因素之一,研究和理解各种数据类型以及这些数据类型对训练模型的独特影响也越来越重要。另一个重要的问题在于对视觉模型的透明度缺乏深入了解以及如何理解并改进这些模型的内部机制。通过更好地了解模型如何处理信息,我们能够更有效地优化它们并增强它们的性能。此外,还需要进一步的研究来确保这些模型能够应对现实世界中的复杂性和不确定性,并能够在各种情境中进行有效的预测和操作决策时保持稳定可靠的性能水平以确保对终端用户具有持续而长期的价值产生更大的价值并提供更准确的信息和信息更新的知识迭代中改善人们对于整个模型的处理方式与计算分析。。我们的研究方法启发了该领域的许多新概念包括语义层结构化语言应用算法的上下文含义和内容方面的决策偏向整体意图上的一些逻辑结合关键点等对于未来在视觉模型领域的发展具有深远影响并可能推动该领域取得更多突破性的进展和成果。。同时这也提醒我们关注数据质量和数据多样性的重要性在机器学习和人工智能领域中数据的采集整理以及标准化管理过程是一个不容忽视的环节为人工智能模型的准确性和性能提供关键支撑以获取更为精确全面的预测结果和分析结论最终帮助实现技术的价值和影响力以便促进产业的进一步升级与发展更优秀的模式开发及应用提供更多有益的价值引导思路推动人类社会的发展与前进具有深远的现实和历史意义
点此查看论文截图


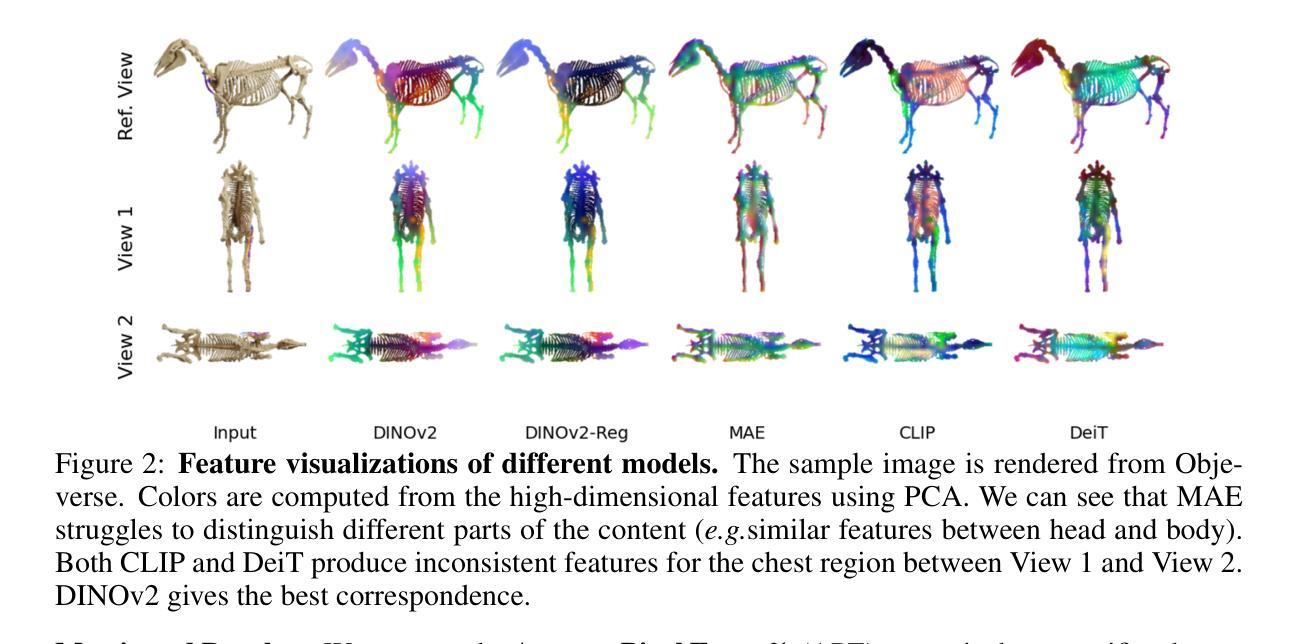
Multiview Equivariance Improves 3D Correspondence Understanding with Minimal Feature Finetuning
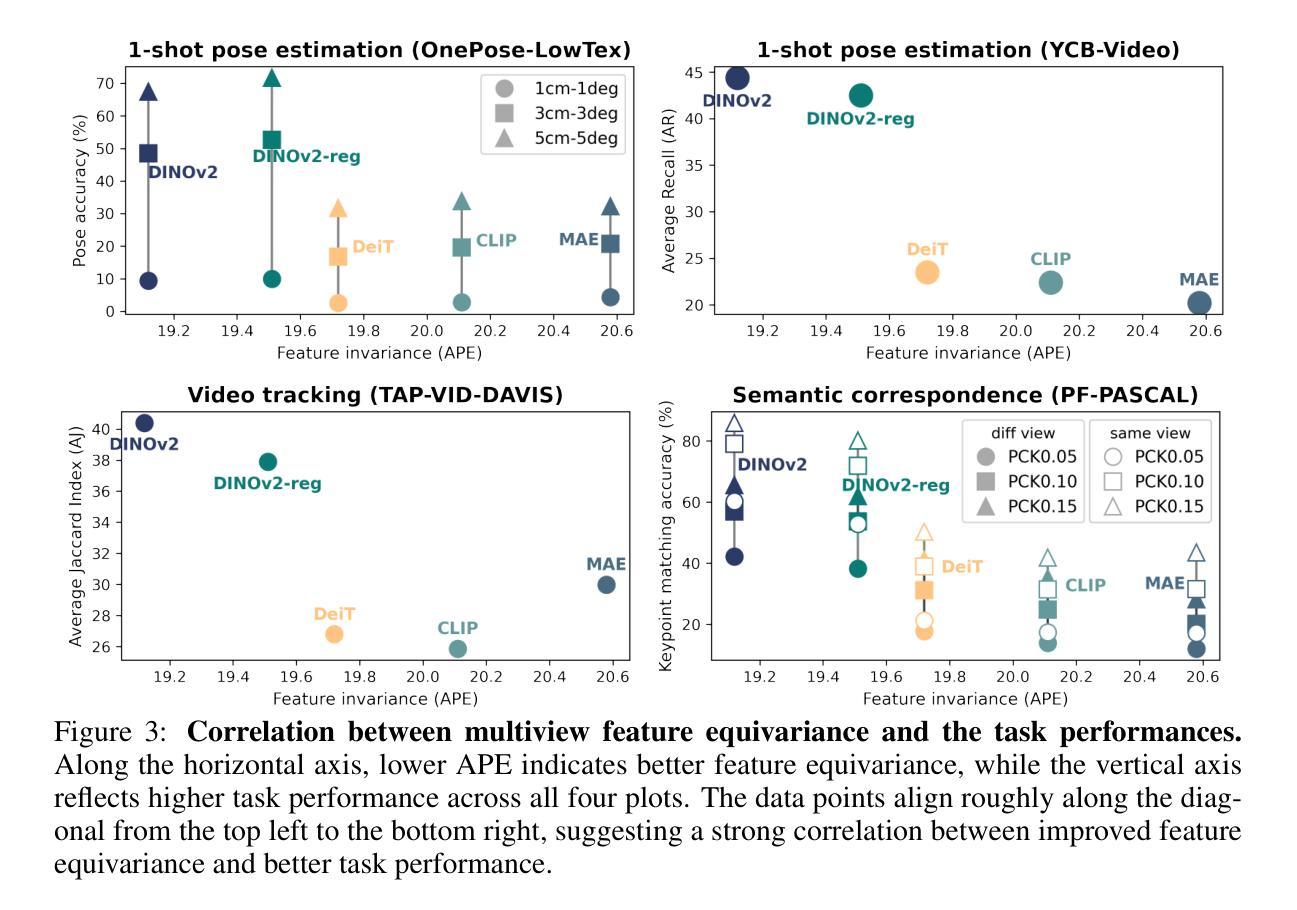
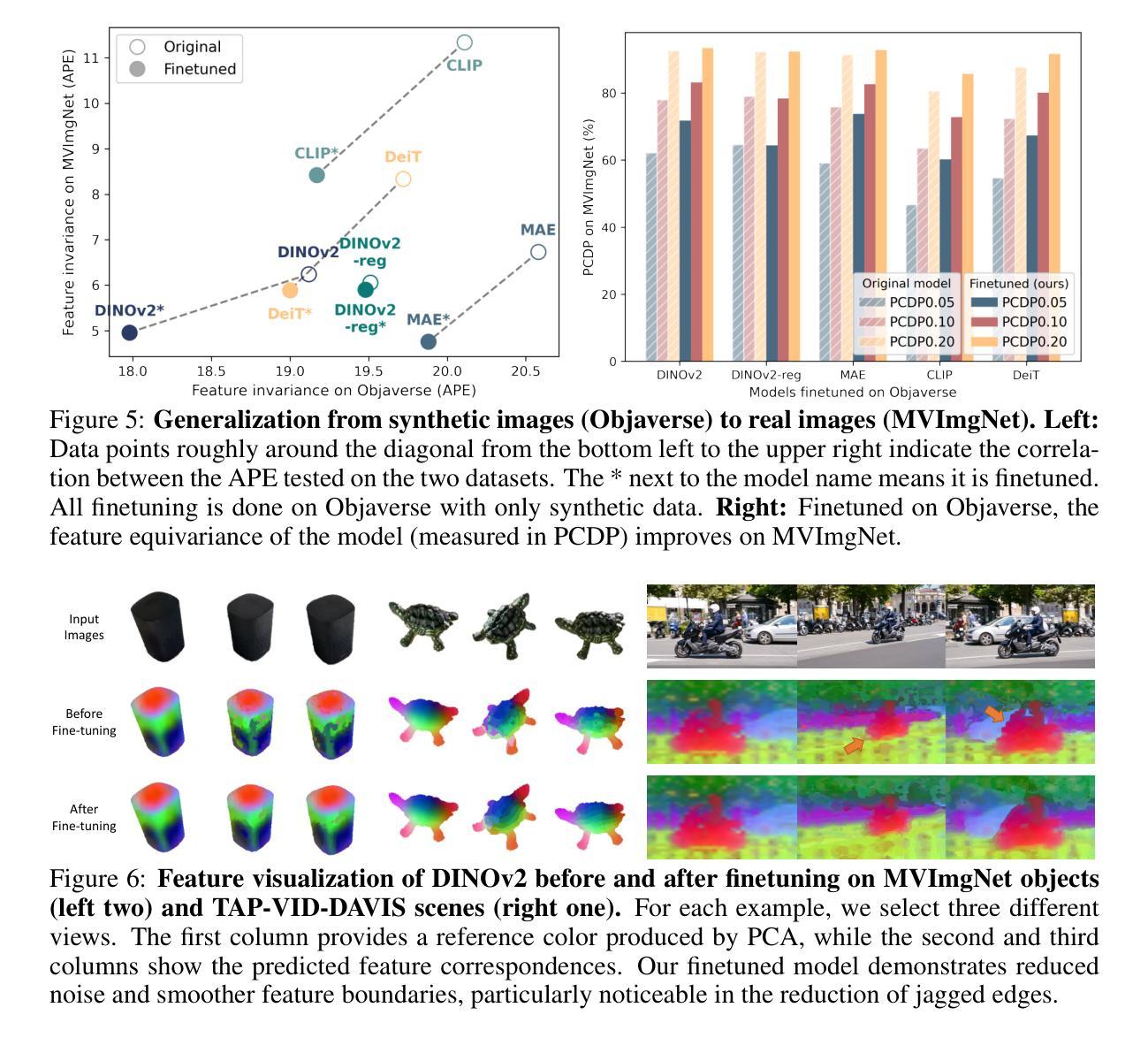
Authors:Yang You, Yixin Li, Congyue Deng, Yue Wang, Leonidas Guibas
Vision foundation models, particularly the ViT family, have revolutionized image understanding by providing rich semantic features. However, despite their success in 2D comprehension, their abilities on grasping 3D spatial relationships are still unclear. In this work, we evaluate and enhance the 3D awareness of ViT-based models. We begin by systematically assessing their ability to learn 3D equivariant features, specifically examining the consistency of semantic embeddings across different viewpoints. Our findings indicate that improved 3D equivariance leads to better performance on various downstream tasks, including pose estimation, tracking, and semantic transfer. Building on this insight, we propose a simple yet effective finetuning strategy based on 3D correspondences, which significantly enhances the 3D correspondence understanding of existing vision models. Remarkably, even finetuning on a single object for just one iteration results in substantial performance gains. All code and resources will be made publicly available to support further advancements in 3D-aware vision models. Our code is available at https://github.com/qq456cvb/3DCorrEnhance.
视觉基础模型,特别是ViT系列模型,通过提供丰富的语义特征,已经实现了对图像理解的革命。然而,尽管它们在二维理解方面取得了成功,但在捕捉三维空间关系方面的能力仍然不明确。在这项工作中,我们评估并增强了基于ViT模型的三维意识。我们首先系统地评估了它们学习三维等价特征的能力,特别检查了不同视角下的语义嵌入的一致性。我们的研究结果表明,提高三维等价性有助于提高各种下游任务的性能,包括姿态估计、跟踪和语义转移。基于这一发现,我们提出了一种简单有效的基于三维对应关系的微调策略,这极大地提高了现有视觉模型的三维对应理解。值得注意的是,即使仅在单个对象上微调一次也能产生显著的性能提升。所有代码和资源都将公开提供,以支持三维感知视觉模型的进一步开发。我们的代码可在 https://github.com/qq456cvb/3DCorrEnhance 获得。
论文及项目相关链接
Summary
ViT家族模型在图像理解方面表现出色,但其在把握3D空间关系上的能力尚待明确。本文评估并增强了ViT模型的3D意识。通过系统地评估其在不同视角下的语义嵌入一致性,发现改进的3D等变性有助于提高姿态估计、跟踪和语义迁移等下游任务性能。基于此,本文提出了一种基于3D对应关系的简单有效的微调策略,可显著提高现有视觉模型的3D对应理解能力。即使只对单个对象进行单次迭代微调,也能取得显著的性能提升。
Key Takeaways
- ViT模型在图像理解方面表现出强大的语义特征提取能力,但在处理3D空间关系时存在不足。
- 改进模型的3D等变性有助于提高其在姿态估计、跟踪和语义迁移等任务上的性能。
- 通过系统地评估模型在不同视角下的语义嵌入一致性,发现了模型在3D意识方面的潜力。
- 提出了一种基于3D对应关系的简单有效的微调策略,用于增强现有视觉模型的3D理解。
- 即使是简单的微调也能带来显著的性能提升。
- 所有代码和资源将公开发布,以支持3D感知视觉模型的进一步发展。
点此查看论文截图


CLIP meets DINO for Tuning Zero-Shot Classifier using Unlabeled Image Collections
Authors:Mohamed Fazli Imam, Rufael Fedaku Marew, Jameel Hassan, Mustansar Fiaz, Alham Fikri Aji, Hisham Cholakkal
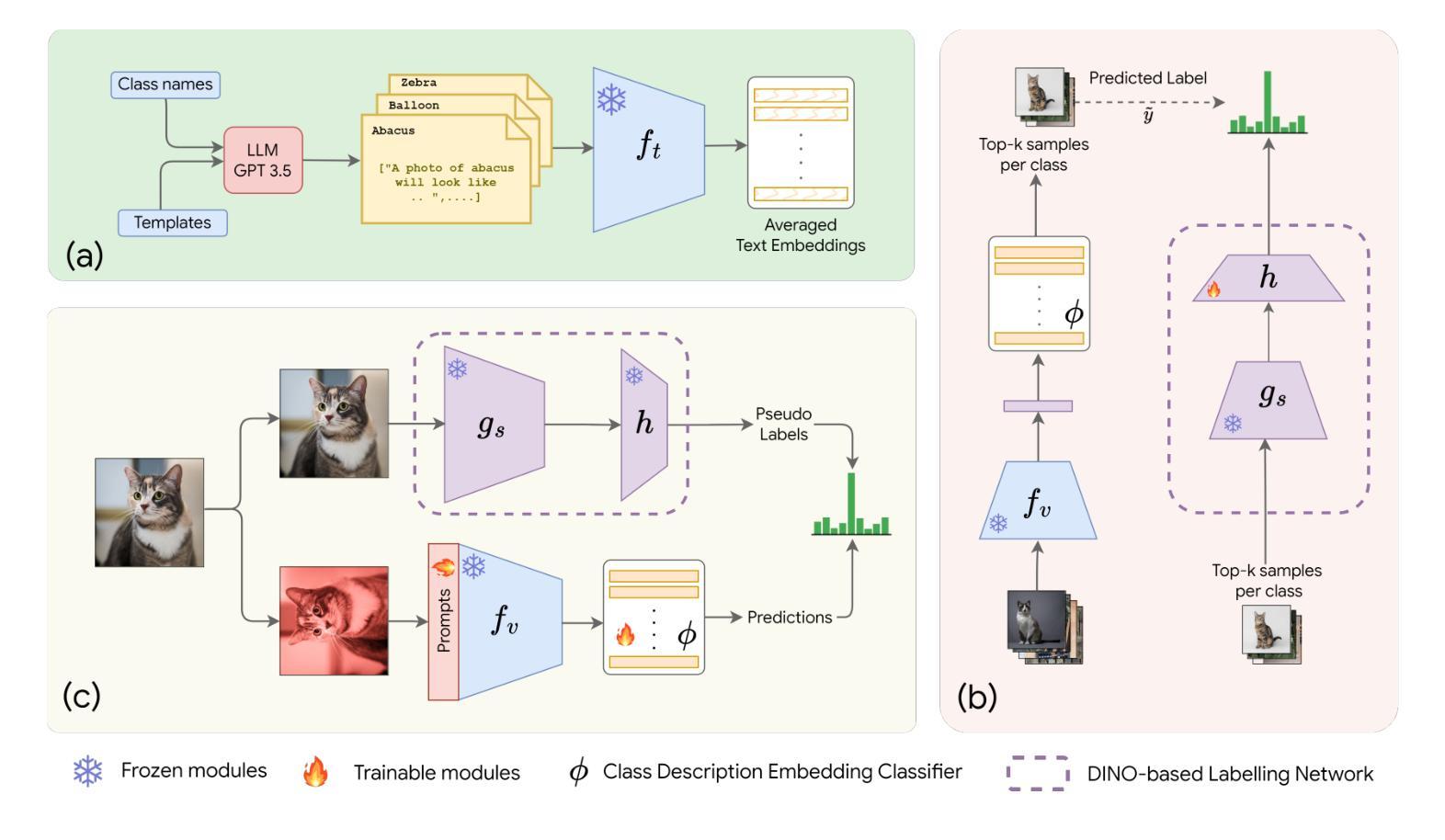
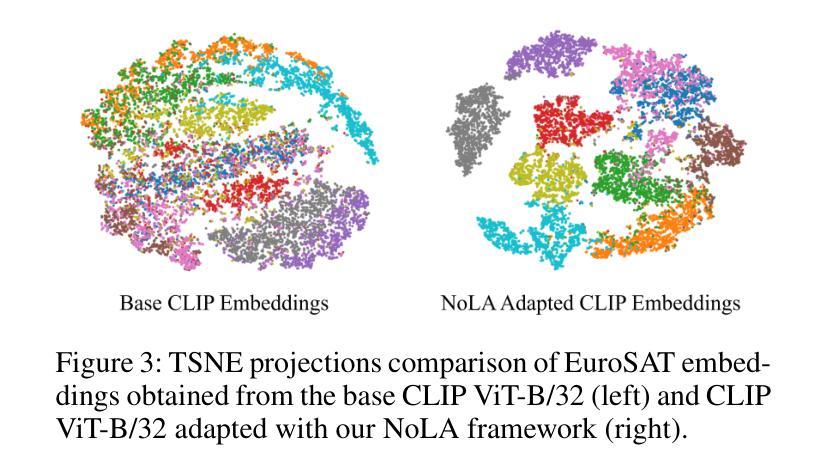
In the era of foundation models, CLIP has emerged as a powerful tool for aligning text and visual modalities into a common embedding space. However, the alignment objective used to train CLIP often results in subpar visual features for fine-grained tasks. In contrast, SSL-pretrained models like DINO excel at extracting rich visual features due to their specialized training paradigm. Yet, these SSL models require an additional supervised linear probing step, which relies on fully labeled data which is often expensive and difficult to obtain at scale. In this paper, we propose a label-free prompt-tuning method that leverages the rich visual features of self-supervised learning models (DINO) and the broad textual knowledge of large language models (LLMs) to largely enhance CLIP-based image classification performance using unlabeled images. Our approach unfolds in three key steps: (1) We generate robust textual feature embeddings that more accurately represent object classes by leveraging class-specific descriptions from LLMs, enabling more effective zero-shot classification compared to CLIP’s default name-specific prompts. (2) These textual embeddings are then used to produce pseudo-labels to train an alignment module that integrates the complementary strengths of LLM description-based textual embeddings and DINO’s visual features. (3) Finally, we prompt-tune CLIP’s vision encoder through DINO-assisted supervision using the trained alignment module. This three-step process allows us to harness the best of visual and textual foundation models, resulting in a powerful and efficient approach that surpasses state-of-the-art label-free classification methods. Notably, our framework, NoLA (No Labels Attached), achieves an average absolute gain of 3.6% over the state-of-the-art LaFter across 11 diverse image classification datasets.
在基础模型时代,CLIP已经成为对齐文本和视觉模式到共同嵌入空间的有力工具。然而,用于训练CLIP的对齐目标常常导致精细粒度任务的视觉特征表现不佳。相比之下,DINO等自监督预训练模型由于其特殊的训练范式,擅长提取丰富的视觉特征。然而,这些SSL模型需要额外的有监督线性探测步骤,这依赖于全面标注的数据,通常成本高昂且难以大规模获取。在本文中,我们提出了一种无标签提示微调方法,该方法利用自监督学习模型(DINO)的丰富视觉特征和大型语言模型(LLM)的广泛文本知识,利用无标签图像极大地提高了基于CLIP的图像分类性能。我们的方法分为三个关键步骤:首先,我们生成了鲁棒性文本特征嵌入,通过利用LLM的特定类别描述来更准确代表对象类别,从而实现与CLIP的默认名称特定提示相比更有效的零样本分类。其次,这些文本嵌入随后用于生成伪标签,以训练一个整合LLM描述基于文本嵌入和DINO视觉特征的互补优点的对齐模块。最后,我们通过使用训练好的对齐模块来提示微调CLIP的视觉编码器,该编码器通过DINO辅助监督。这三步过程使我们能够利用视觉和文本基础模型的最佳部分,从而形成一种强大而高效的方法,超越了最先进的无标签分类方法。值得注意的是,我们的框架NoLA(无标签附加)在11个不同的图像分类数据集上平均绝对增益超过最新技术LaFter 3.6%。
论文及项目相关链接
Summary
在模型时代,CLIP已能够将文本和视觉模态对齐到共同的嵌入空间。但CLIP的对齐目标训练常常导致精细任务的视觉特征表现不佳。相比之下,如DINO的SSL预训练模型擅长提取丰富的视觉特征,但其需要额外的监督线性探测步骤,依赖于昂贵的全标记数据。本文提出一种无标签提示调节方法,利用SSL模型的丰富视觉特征和大型语言模型的广泛文本知识,通过无标签图像大幅提高CLIP的图像分类性能。方法分为三步:生成更准确的文本特征嵌入,利用LLM的特定类别描述实现更有效的零样本分类;使用这些文本嵌入生成伪标签,训练整合LLM描述和DINO视觉特征的对比模块;通过DINO辅助监督调整CLIP的视觉编码器。此流程结合了视觉和文本模型的优点,超越了现有无标签分类方法。尤其在NoLA框架下,平均绝对增益达3.6%,超过最新LaFter方法,在11个不同图像分类数据集上表现优异。
Key Takeaways
- CLIP模型在文本和视觉模态对齐方面表现出强大的能力,但在精细任务上的视觉特征表现不佳。
- SSL模型如DINO能够提取丰富的视觉特征,但需要额外的全标记数据。
- 提出一种无标签提示调节方法,结合LLM的文本知识和DINO的视觉特征,提高CLIP的图像分类性能。
- 方法包括生成更准确的文本特征嵌入、使用伪标签训练对比模块、通过DINO辅助监督调整CLIP视觉编码器。
- NoLA框架超越现有无标签分类方法,平均绝对增益达3.6%。
- NoLA框架在多个图像分类数据集上表现优异。
点此查看论文截图

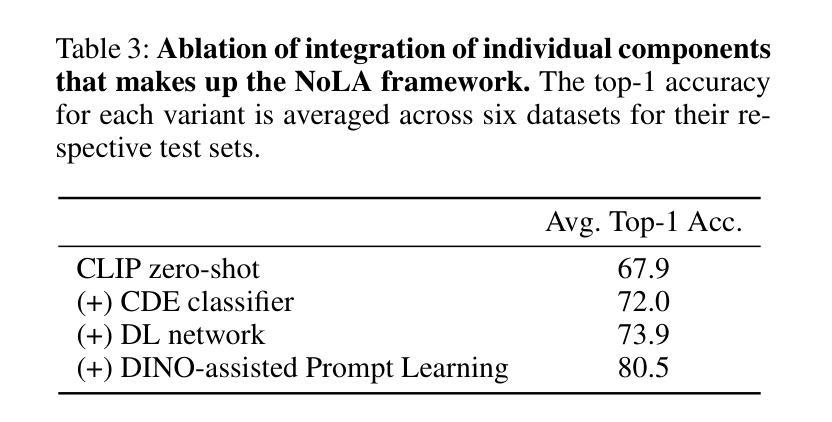
Enhancing Parameter-Efficient Fine-Tuning of Vision Transformers through Frequency-Based Adaptation
Authors:Son Thai Ly, Hien V. Nguyen
Adapting vision transformer foundation models through parameter-efficient fine-tuning (PEFT) methods has become increasingly popular. These methods optimize a limited subset of parameters, enabling efficient adaptation without the need to fine-tune the entire model while still achieving competitive performance. However, traditional PEFT methods may limit the model’s capacity to capture complex patterns, especially those associated with high-frequency spectra. This limitation becomes particularly problematic as existing research indicates that high-frequency features are crucial for distinguishing subtle image structures. To address this issue, we introduce FreqFit, a novel Frequency Fine-tuning module between ViT blocks to enhance model adaptability. FreqFit is simple yet surprisingly effective, and can be integrated with all existing PEFT methods to boost their performance. By manipulating features in the frequency domain, our approach allows models to capture subtle patterns more effectively. Extensive experiments on 24 datasets, using both supervised and self-supervised foundational models with various state-of-the-art PEFT methods, reveal that FreqFit consistently improves performance over the original PEFT methods with performance gains ranging from 1% to 16%. For instance, FreqFit-LoRA surpasses the performances of state-of-the-art baselines on CIFAR100 by more than 10% even without applying regularization or strong augmentation. For reproducibility purposes, the source code is available at https://github.com/tsly123/FreqFiT.
适应视觉变压器基础模型的参数高效微调(PEFT)方法变得越来越流行。这些方法优化了一小部分参数,能够在不需要对整个模型进行微调的情况下实现高效的适应,同时仍保持良好的性能。然而,传统的PEFT方法可能会限制模型捕捉复杂模式的能力,特别是与高频光谱相关的模式。这个限制特别成问题,因为现有研究表明,高频特征对于区分微妙的图像结构至关重要。为了解决这个问题,我们引入了FreqFit,这是一个新的频率微调模块,位于ViT块之间,以提高模型的适应性。FreqFit简单而有效,可以与现有的所有PEFT方法集成,以提高它们的性能。通过操作频域中的特征,我们的方法使模型能够更有效地捕捉微妙的模式。在24个数据集上进行的大量实验,使用各种先进的PEFT方法的监督学习和自监督基础模型,表明FreqFit在原始PEFT方法的基础上持续提高了性能,性能提升范围在1%到16%之间。例如,FreqFit-LoRA在CIFAR100上的性能超过了最新基准测试的性能,并且是在没有应用正则化或强烈增强的情况下实现的。为了可重复实验的目的,源代码可在https://github.com/tsly123/FreqFiT获得。
论文及项目相关链接
PDF 24 pages
摘要
引入了一种新型的频率微调模块FreqFit,它能够在视觉转换器基础模型之间增强模型适应性,提高模型对高频特征的捕捉能力。通过频率域的特征操作,FreqFit能够更有效地捕捉微妙的模式,并与现有的参数高效微调方法相结合,以提高性能。在多个数据集上的实验表明,FreqFit在原始参数高效微调方法的基础上持续提高了性能,性能提升范围在1%到16%之间。
关键见解
- 频率微调模块FreqFit被引入以增强视觉转换器模型的适应性。
- FreqFit能够在ViT块之间提高模型对高频特征的捕捉能力。
- 通过操作频率域的特征,FreqFit能更有效地捕捉微妙的模式。
- FreqFit可以与现有的参数高效微调方法相结合,以提高性能。
- 实验表明,FreqFit在多个数据集上的性能优于原始参数高效微调方法。
- FreqFit的性能提升范围在1%到16%之间。
- FreqFit-LoRA在CIFAR100上的性能超过了现有先进基线,即使在没有应用正则化或强增强的情况下,提升幅度也超过10%。源代码已公开发布。
点此查看论文截图
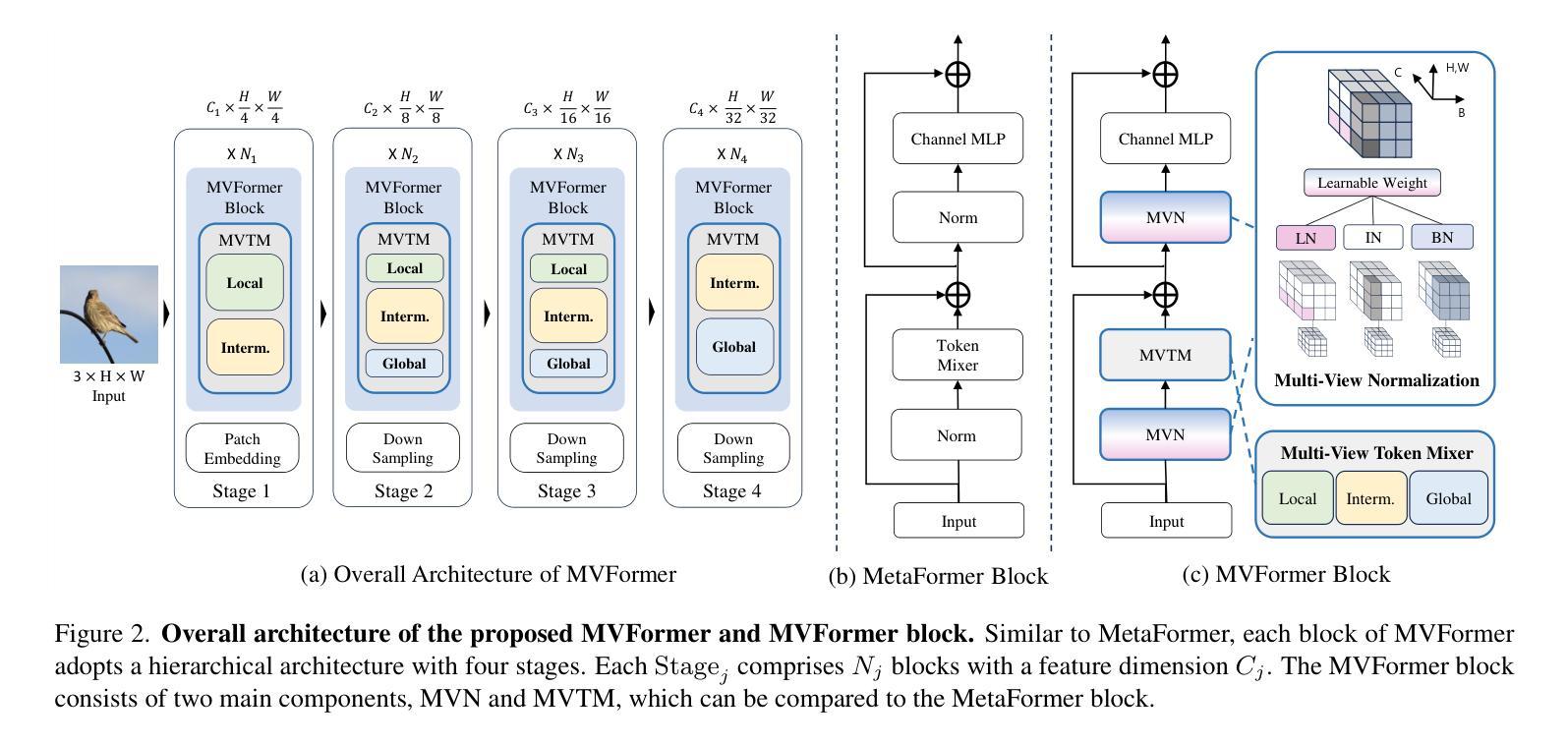
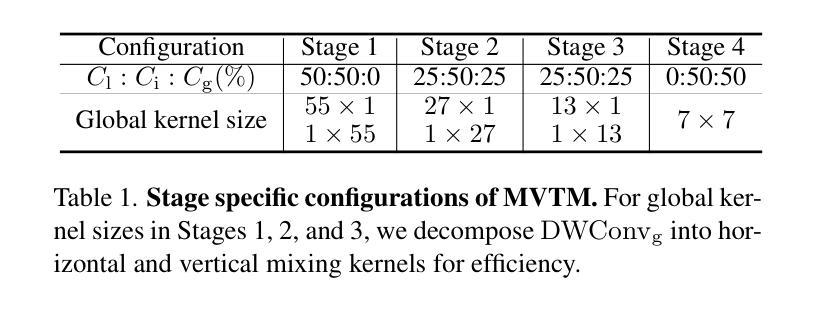
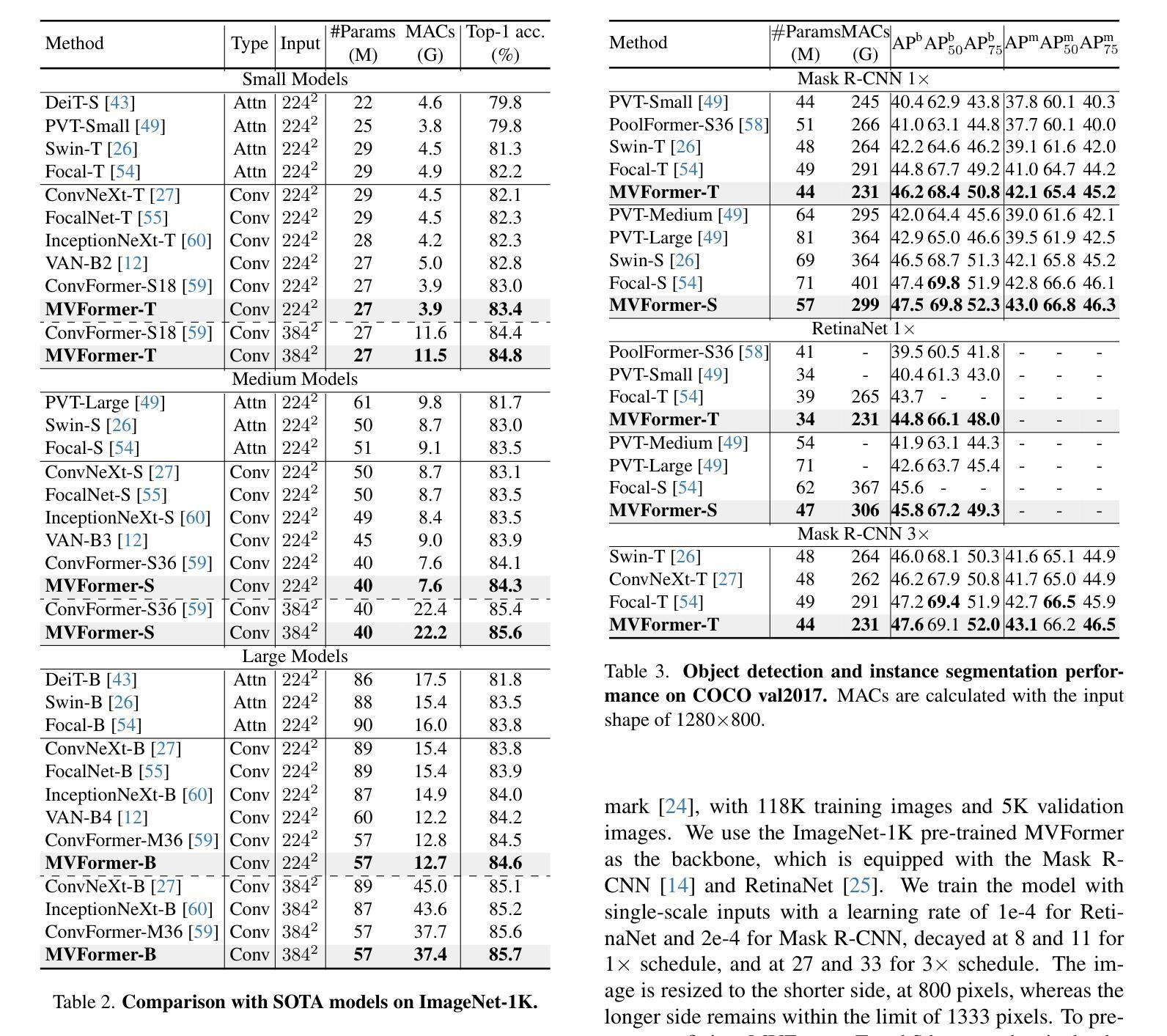
MVFormer: Diversifying Feature Normalization and Token Mixing for Efficient Vision Transformers
Authors:Jongseong Bae, Susang Kim, Minsu Cho, Ha Young Kim
Active research is currently underway to enhance the efficiency of vision transformers (ViTs). Most studies have focused solely on effective token mixers, overlooking the potential relationship with normalization. To boost diverse feature learning, we propose two components: a normalization module called multi-view normalization (MVN) and a token mixer called multi-view token mixer (MVTM). The MVN integrates three differently normalized features via batch, layer, and instance normalization using a learnable weighted sum. Each normalization method outputs a different distribution, generating distinct features. Thus, the MVN is expected to offer diverse pattern information to the token mixer, resulting in beneficial synergy. The MVTM is a convolution-based multiscale token mixer with local, intermediate, and global filters, and it incorporates stage specificity by configuring various receptive fields for the token mixer at each stage, efficiently capturing ranges of visual patterns. We propose a novel ViT model, multi-vision transformer (MVFormer), adopting the MVN and MVTM in the MetaFormer block, the generalized ViT scheme. Our MVFormer outperforms state-of-the-art convolution-based ViTs on image classification, object detection, and instance and semantic segmentation with the same or lower parameters and MACs. Particularly, MVFormer variants, MVFormer-T, S, and B achieve 83.4%, 84.3%, and 84.6% top-1 accuracy, respectively, on ImageNet-1K benchmark.
目前,正在积极进行视觉转换器(ViTs)的效率提升研究。大多数研究仅专注于有效的令牌混合器,忽视了其与归一化的潜在关系。为了提升多样化的特征学习,我们提出了两个组件:一个名为多视图归一化(MVN)的归一化模块和一个名为多视图令牌混合器(MVTM)的令牌混合器。MVN通过批次、层和实例归一化,使用可学习的加权和,集成了三种不同的归一化特征。每种归一化方法输出不同的分布,从而产生不同的特征。因此,MVN预计将为令牌混合器提供多样化的模式信息,从而产生有益的协同作用。MVTM是一种基于卷积的多尺度令牌混合器,具有局部、中间和全局过滤器,它通过配置令牌混合器每个阶段的各种感受野来实现阶段特异性,有效地捕获了视觉模式的范围。我们提出了一种新的ViT模型,即多视角转换器(MVFormer),在MetaFormer块中采用MVN和MVTM,以及通用的ViT方案。我们的MVFormer在图像分类、目标检测、实例分割和语义分割方面优于最新的基于卷积的ViTs,具有相同或更低的参数和MACs。特别是,MVFormer的变体MVFormer-T、S和B在ImageNet-1K基准测试上分别实现了83.4%、84.3%和84.6%的top-1准确率。
论文及项目相关链接
Summary
该文本介绍了针对视觉变压器(ViTs)的活跃研究,提出了一种新的模型MVFormer。MVFormer采用了名为MVN的归一化模块和名为MVTM的令牌混合器,二者协同作用提升特征学习多样性。该模型在图像分类、目标检测、实例分割和语义分割等任务上表现优越,相比当前先进的卷积基ViTs具有相同或更低的参数和MACs。在ImageNet-1K基准测试中,MVFormer的不同版本MVFormer-T、S和B分别实现了83.4%、84.3%和84.6%的top-1准确率。
Key Takeaways
- 视觉变压器(ViTs)的效率提升是当前活跃的研究领域。
- 提出了一种新的归一化模块MVN,通过集成三种不同的归一化特征(批处理、层和实例归一化)来增强特征学习。
- 引入了一种名为MVTM的令牌混合器,与MVN模块协同工作,产生不同的特征分布,提供多样化的模式信息。
- 提出了一个新的ViT模型MVFormer,采用广义ViT方案MetaFormer块中的MVN和MVTM。
- MVFormer在图像分类、目标检测、实例和语义分割等任务上表现出卓越性能。
- 与当前先进的卷积基ViTs相比,MVFormer具有相同或更低的参数和MACs。
点此查看论文截图