⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-12 更新
ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
Authors:Mengqi Lei, Haochen Wu, Xinhua Lv, Xin Wang
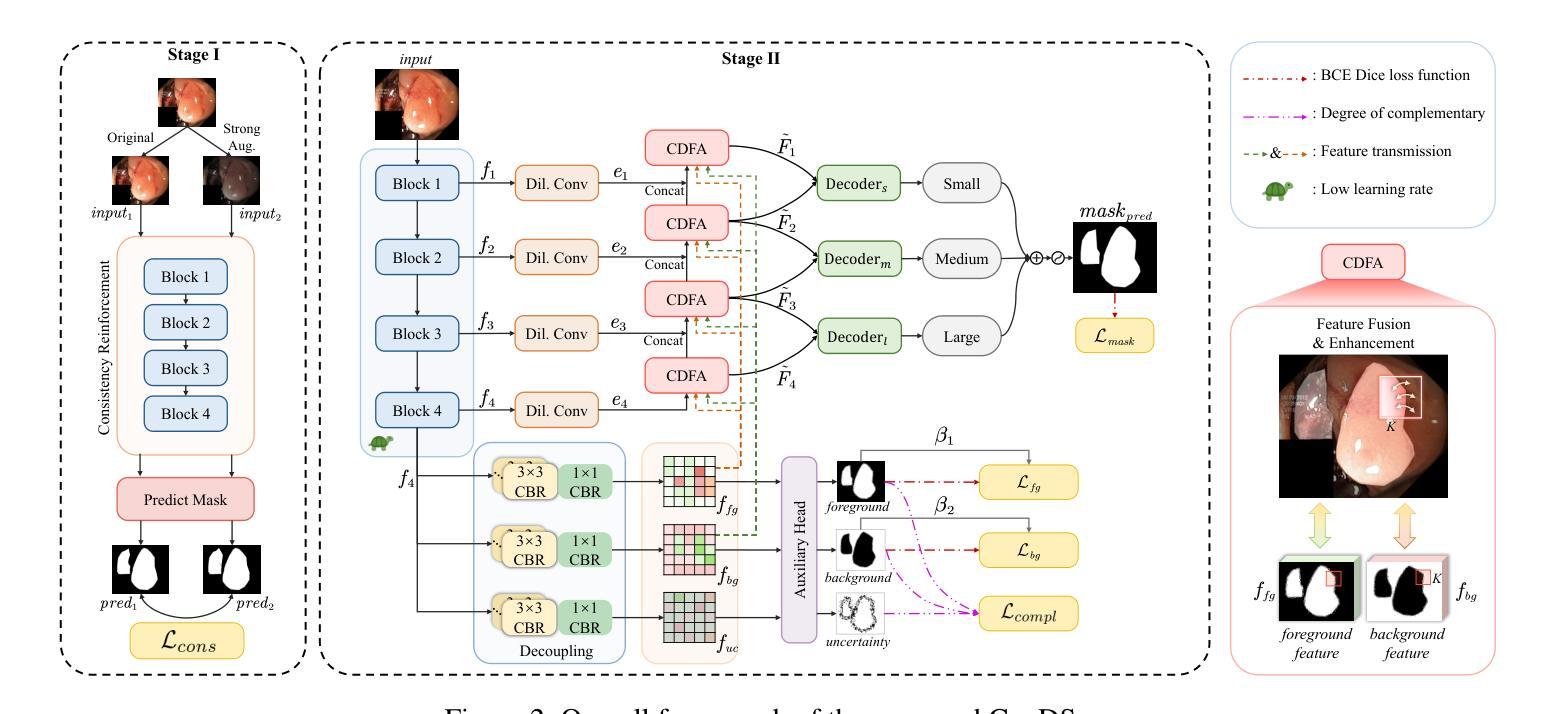
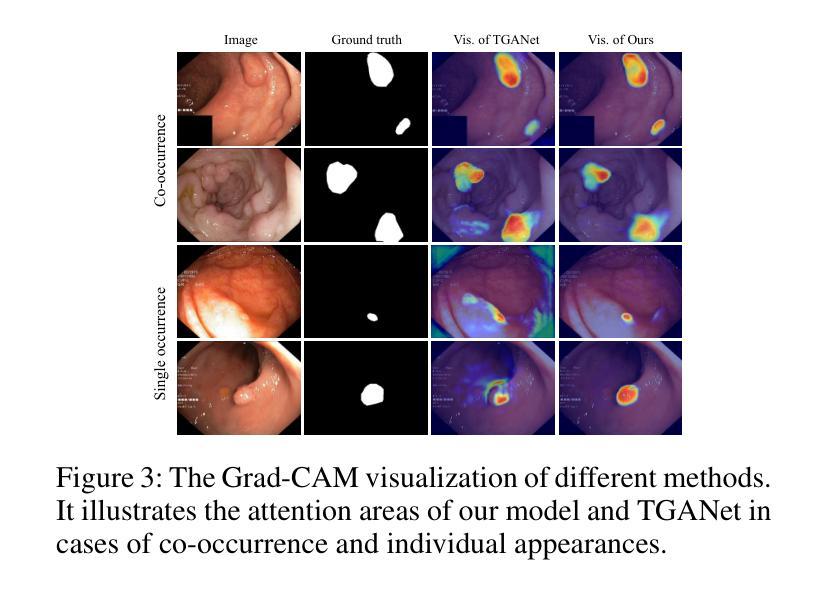
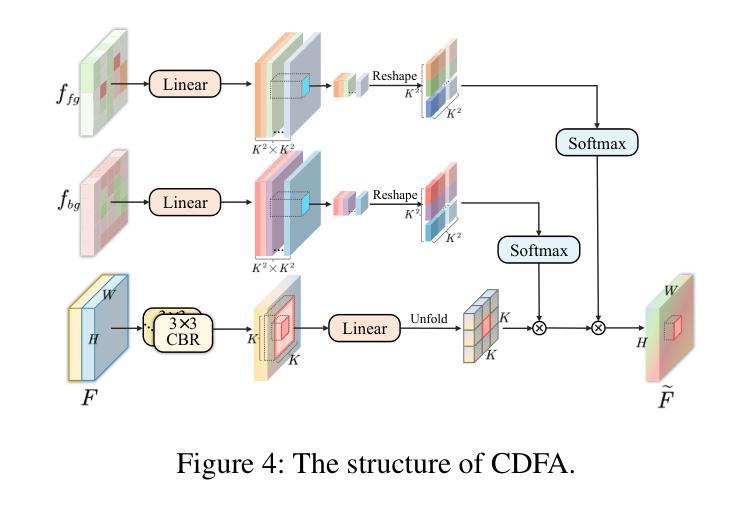
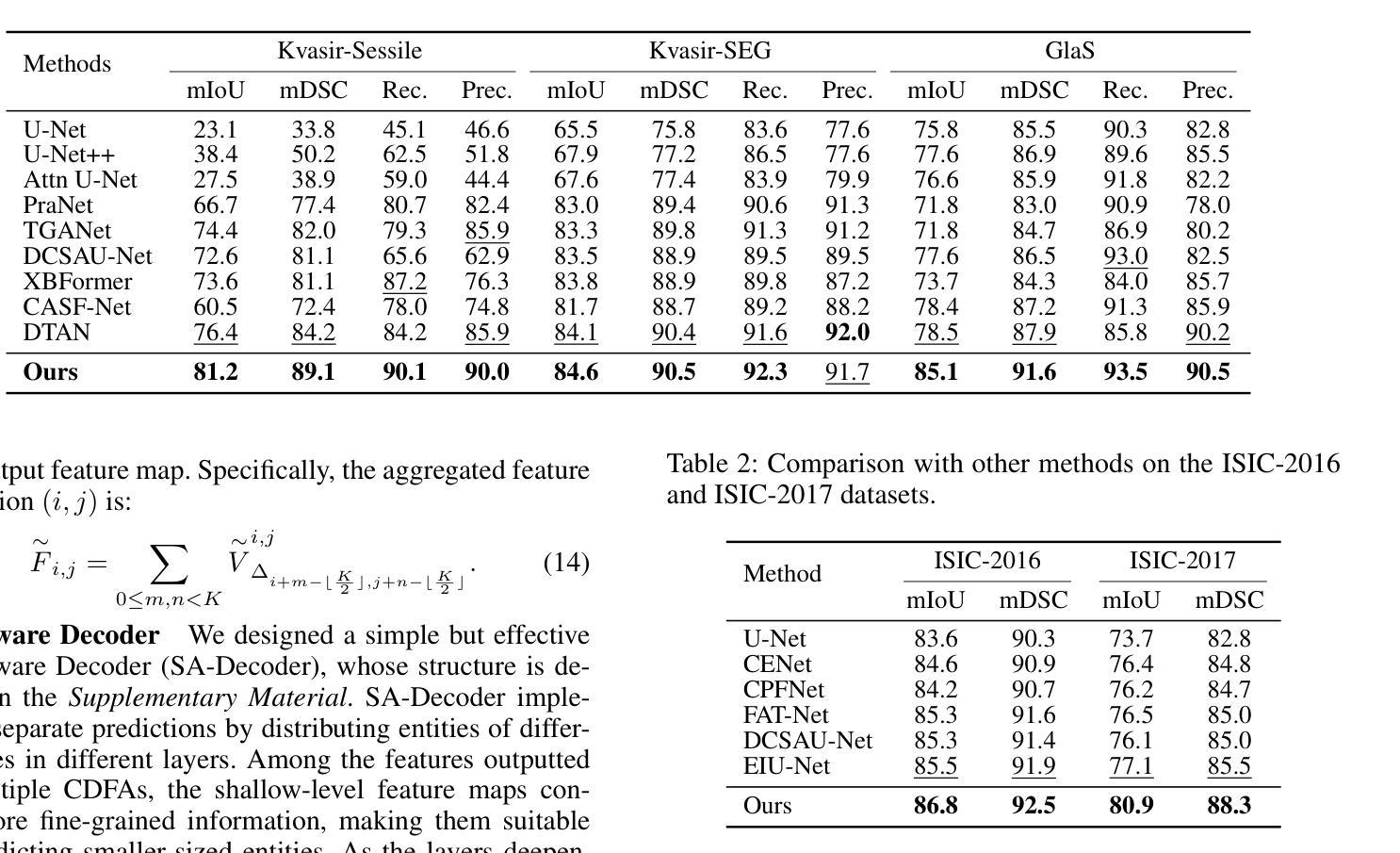
Medical image segmentation plays an important role in clinical decision making, treatment planning, and disease tracking. However, it still faces two major challenges. On the one hand, there is often a ``soft boundary’’ between foreground and background in medical images, with poor illumination and low contrast further reducing the distinguishability of foreground and background within the image. On the other hand, co-occurrence phenomena are widespread in medical images, and learning these features is misleading to the model’s judgment. To address these challenges, we propose a general framework called Contrast-Driven Medical Image Segmentation (ConDSeg). First, we develop a contrastive training strategy called Consistency Reinforcement. It is designed to improve the encoder’s robustness in various illumination and contrast scenarios, enabling the model to extract high-quality features even in adverse environments. Second, we introduce a Semantic Information Decoupling module, which is able to decouple features from the encoder into foreground, background, and uncertainty regions, gradually acquiring the ability to reduce uncertainty during training. The Contrast-Driven Feature Aggregation module then contrasts the foreground and background features to guide multi-level feature fusion and key feature enhancement, further distinguishing the entities to be segmented. We also propose a Size-Aware Decoder to solve the scale singularity of the decoder. It accurately locate entities of different sizes in the image, thus avoiding erroneous learning of co-occurrence features. Extensive experiments on five medical image datasets across three scenarios demonstrate the state-of-the-art performance of our method, proving its advanced nature and general applicability to various medical image segmentation scenarios. Our released code is available at \url{https://github.com/Mengqi-Lei/ConDSeg}.
医学图像分割在临床决策、治疗规划和疾病追踪中发挥着重要作用。然而,它仍然面临两大挑战。一方面,医学图像中前景和背景之间往往存在“软边界”,照明不良和对比度低进一步降低了图像中前景和背景的辨别力。另一方面,医学图像中的共现现象普遍存在,学习这些特征会对模型的判断产生误导。为了解决这些挑战,我们提出了一种通用的框架,称为对比驱动医学图像分割(ConDSeg)。首先,我们开发了一种名为一致性增强的对比训练策略。它旨在提高编码器在各种照明和对比度场景中的稳健性,使模型即使在恶劣环境中也能提取高质量的特征。其次,我们引入了一个语义信息解耦模块,该模块能够将编码器的特征解耦为前景、背景和不确定区域,逐渐在训练中获取减少不确定性的能力。然后,对比驱动特征聚合模块对比前景和背景特征,引导多级别特征融合和关键特征增强,进一步区分要分割的实体。我们还提出了一种大小感知解码器,以解决解码器的尺度单一性问题。它准确地定位图像中不同大小的实体,从而避免对共现特征的错误学习。在三种场景下的五个医学图像数据集上的大量实验表明,我们的方法达到了最新性能水平,证明了其在各种医学图像分割场景中的先进性和通用适用性。我们发布的代码可在[https://github.com/Mengqi-Lei/ConDSeg]获取。
论文及项目相关链接
PDF This paper has been accepted by AAAI-2025
摘要
针对医学图像分割面临的挑战,如前景与背景之间的模糊边界、照明不佳、对比度低以及共现现象,提出了一种通用框架Contrast-Driven Medical Image Segmentation (ConDSeg)。该框架包括对比训练策略、语义信息解耦模块、对比驱动特征聚合模块和尺寸感知解码器,以提高模型在多种环境下的鲁棒性,区分前景和背景,解决尺度单一性问题。在五个医学图像数据集上的实验证明了该方法的前沿性能和在各种医学图像分割场景中的通用适用性。
关键见解
- 医学图像分割在临床决策、治疗规划和疾病追踪中起到重要作用,但仍面临前景与背景边界模糊、照明和对比度问题以及共现现象的挑战。
- 提出了一种名为Contrast-Driven Medical Image Segmentation (ConDSeg)的通用框架来应对这些挑战。
- ConDSeg采用对比训练策略,提高模型在各种环境下的鲁棒性,并提取高质量特征。
- 语义信息解耦模块能够将从编码器获取的特征分离为前景、背景和不确定性区域,逐渐降低不确定性。
- 对比驱动特征聚合模块通过对比前景和背景特征来引导多级别特征融合和关键特征增强,进一步区分要分割的实体。
- 尺寸感知解码器解决了解码器尺度单一性问题,准确定位图像中不同大小的实体,避免共现特征的错误学习。
- 在五个医学图像数据集上的实验证明了ConDSeg的前沿性能和通用适用性。
点此查看论文截图

Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning
Authors:Can Yaras, Siyi Chen, Peng Wang, Qing Qu
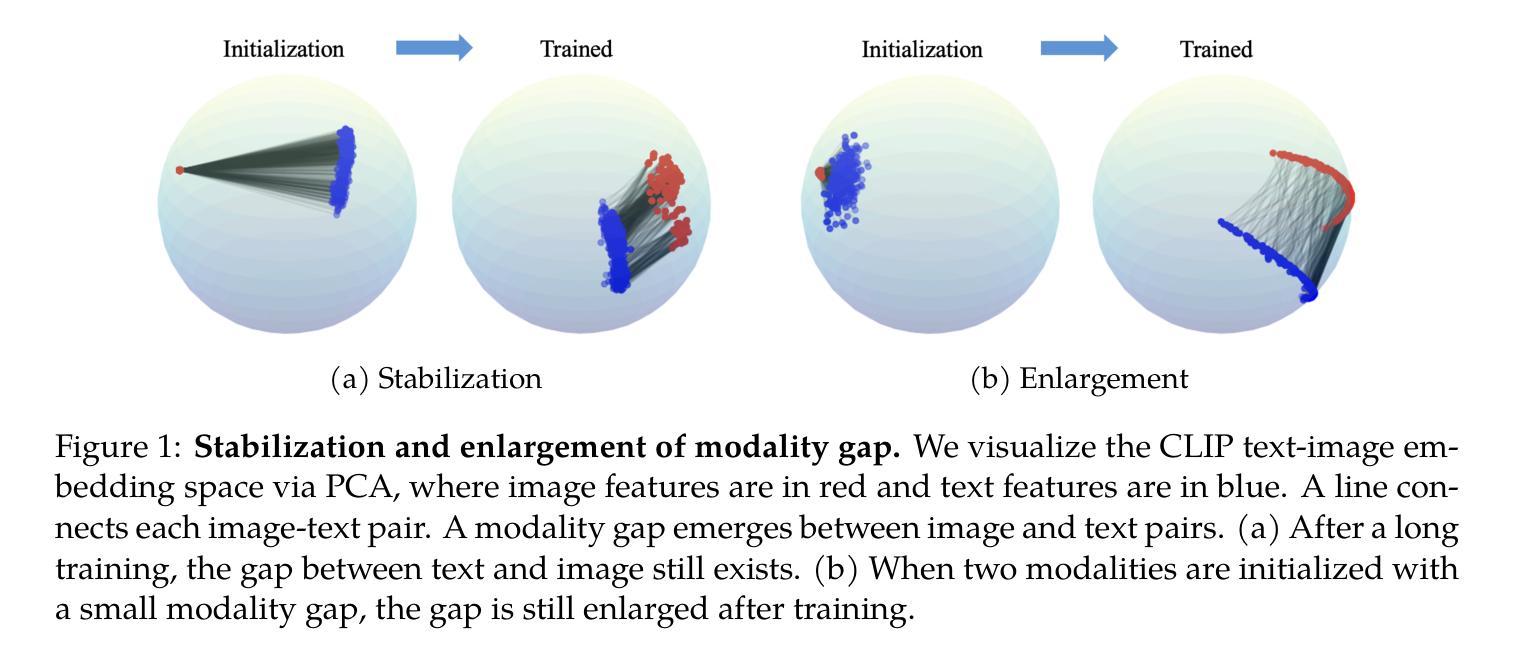
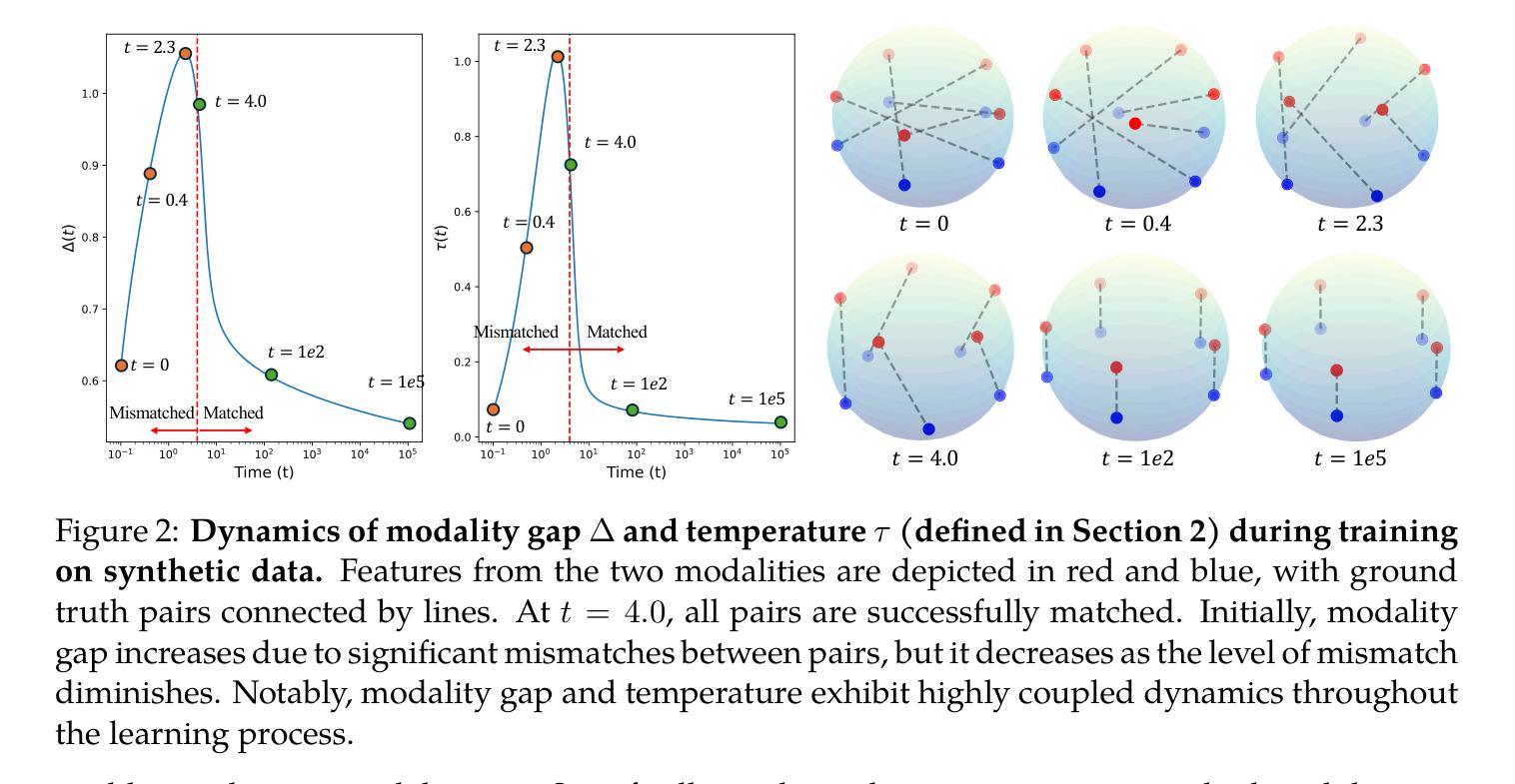
Multimodal learning has recently gained significant popularity, demonstrating impressive performance across various zero-shot classification tasks and a range of perceptive and generative applications. Models such as Contrastive Language-Image Pretraining (CLIP) are designed to bridge different modalities, such as images and text, by learning a shared representation space through contrastive learning. Despite their success, the working mechanisms underlying multimodal learning are not yet well understood. Notably, these models often exhibit a modality gap, where different modalities occupy distinct regions within the shared representation space. In this work, we conduct an in-depth analysis of the emergence of modality gap by characterizing the gradient flow learning dynamics. Specifically, we identify the critical roles of mismatched data pairs and a learnable temperature parameter in causing and perpetuating the modality gap during training. Furthermore, our theoretical insights are validated through experiments on practical CLIP models. These findings provide principled guidance for mitigating the modality gap, including strategies such as appropriate temperature scheduling and modality swapping. Additionally, we demonstrate that closing the modality gap leads to improved performance on tasks such as image-text retrieval.
多模态学习近期受到广泛关注,其在多种零样本分类任务以及一系列感知和生成应用中表现出令人印象深刻的效果。例如,对比语言图像预训练(CLIP)模型旨在通过对比学习学习不同模态(如图像和文本)的共享表示空间,从而桥接不同模态。尽管取得了成功,但多模态学习的工作机制尚不完全清楚。值得注意的是,这些模型经常出现模态间隙问题,其中不同的模态在共享表示空间中占据不同的区域。在这项工作中,我们通过表征梯度流学习动态深入分析模态间隙的产生。具体来说,我们确定了不匹配数据对和可学习温度参数在造成和维持模态间隙中的关键作用。此外,我们通过在实际CLIP模型上的实验验证了我们的理论见解。这些发现提供了缓解模态间隙的原则指导,包括适当的温度调度和模态交换等策略。此外,我们还证明了缩小模态间隙可以提高图像文本检索等任务的性能。
论文及项目相关链接
PDF The first two authors contributed equally to this work
Summary
本文探讨了多模态学习在多任务中的表现,特别是对比学习在跨模态任务中的应用。文章深入分析了模态间隙的产生原因,包括不匹配的数据对和可学习的温度参数的影响,并提出了减少模态间隙的策略,如适当的温度调度和模态交换。实验结果表明,缩小模态间隙有助于提高图像文本检索等任务的性能。
Key Takeaways
- 多模态学习通过对比学习在不同模态(如图像和文本)之间建立联系,广泛应用于零样本分类任务和感知生成应用。
- 多模态学习模型(如CLIP)存在模态间隙问题,即不同模态在共享表示空间中占据不同区域。
- 模态间隙的产生与不匹配的数据对和可学习的温度参数有关。
- 温度调度和模态交换等策略有助于缓解模态间隙问题。
- 缩小模态间隙有助于提高图像文本检索等任务的性能。
- 本文通过理论分析和实验验证了上述观点。
点此查看论文截图

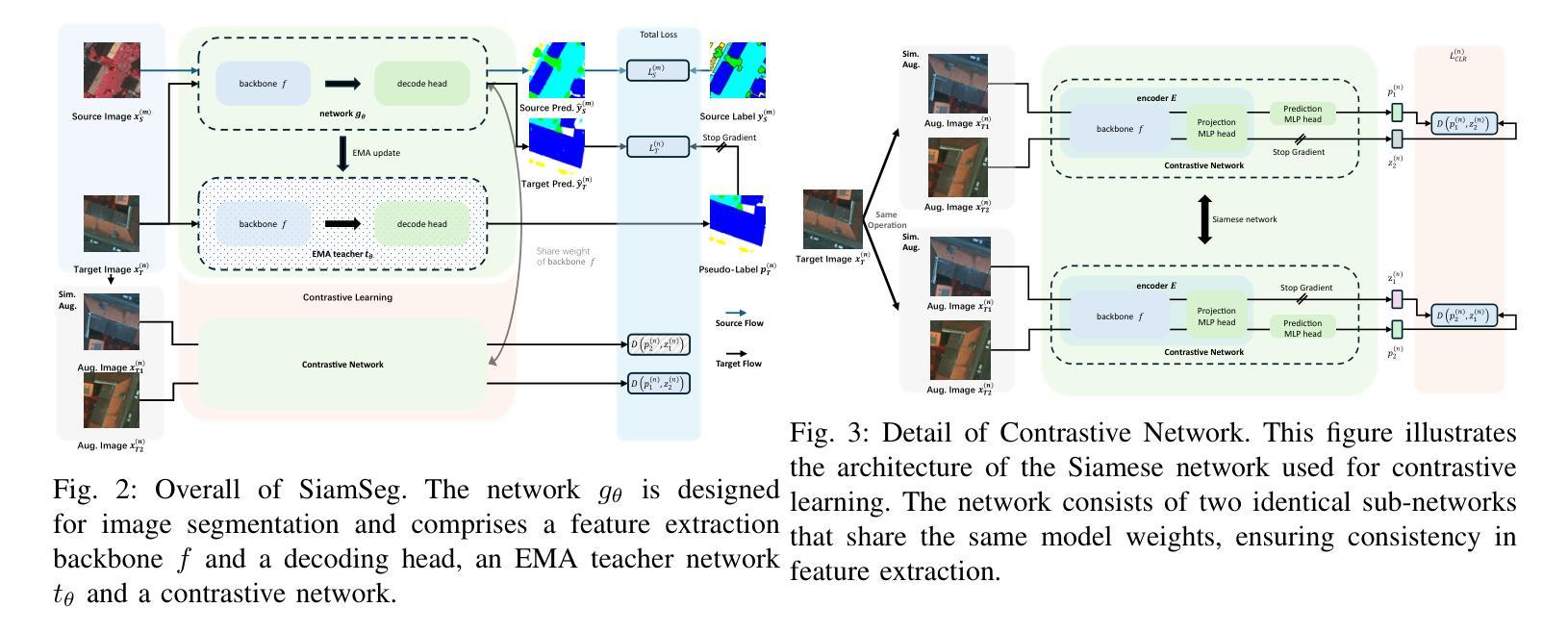
SiamSeg: Self-Training with Contrastive Learning for Unsupervised Domain Adaptation Semantic Segmentation in Remote Sensing
Authors:Bin Wang, Fei Deng, Shuang Wang, Wen Luo, Zhixuan Zhang, Peifan Jiang
Semantic segmentation of remote sensing (RS) images is a challenging yet essential task with broad applications. While deep learning, particularly supervised learning with large-scale labeled datasets, has significantly advanced this field, the acquisition of high-quality labeled data remains costly and time-intensive. Unsupervised domain adaptation (UDA) provides a promising alternative by enabling models to learn from unlabeled target domain data while leveraging labeled source domain data. Recent self-training (ST) approaches employing pseudo-label generation have shown potential in mitigating domain discrepancies. However, the application of ST to RS image segmentation remains underexplored. Factors such as variations in ground sampling distance, imaging equipment, and geographic diversity exacerbate domain shifts, limiting model performance across domains. In that case, existing ST methods, due to significant domain shifts in cross-domain RS images, often underperform. To address these challenges, we propose integrating contrastive learning into UDA, enhancing the model’s ability to capture semantic information in the target domain by maximizing the similarity between augmented views of the same image. This additional supervision improves the model’s representational capacity and segmentation performance in the target domain. Extensive experiments conducted on RS datasets, including Potsdam, Vaihingen, and LoveDA, demonstrate that our method, SimSeg, outperforms existing approaches, achieving state-of-the-art results. Visualization and quantitative analyses further validate SimSeg’s superior ability to learn from the target domain. The code is publicly available at https://github.com/woldier/SiamSeg.
遥感(RS)图像的语义分割是一项具有挑战性但至关重要的任务,广泛应用于各个领域。深度学习,特别是利用大规模标记数据集进行监督学习,已经大大推动了这一领域的发展,但是获取高质量标记数据仍然成本高昂且耗时。无监督域自适应(UDA)提供了一种有前途的替代方案,使模型能够从目标域的无标签数据中学习,同时利用源域的有标签数据。最近采用伪标签生成进行自我训练(ST)的方法在减少域差异方面显示出潜力。然而,将ST应用于RS图像分割仍然未被充分探索。地面采样距离、成像设备和地理多样性的变化等因素加剧了域偏移,限制了模型在不同域之间的性能。在这种情况下,由于跨域RS图像中的域偏移较大,现有的ST方法往往表现不佳。为了解决这些挑战,我们提出将对比学习整合到UDA中,通过最大化同一图像增强视图之间的相似性,增强模型在目标域中捕获语义信息的能力。这种额外的监督提高了模型的表示能力和目标域的分割性能。在包括Potsdam、Vaihingen和LoveDA的RS数据集上进行的广泛实验表明,我们的SimSeg方法优于现有方法,取得了最新结果。可视化和定量分析进一步验证了SimSeg从目标域学习的卓越能力。代码公开在https://github.com/woldier/SiamSeg。
论文及项目相关链接
摘要
遥感图像语义分割是一项具有挑战但至关重要的任务,广泛应用于多个领域。深度学习,特别是使用大规模标记数据集的有监督学习,已在此领域取得显著进展,但获取高质量标记数据成本高昂且耗时。无监督域自适应(UDA)提供了一种有前途的替代方案,使模型能够从未标记的目标域数据中学习,同时利用标记的源域数据。最近采用伪标签生成的自训练(ST)方法显示出减少域差异潜力。然而,将ST应用于遥感图像分割仍被较少探索。遥感图像的跨域自训练方法由于受地面采样距离、成像设备和地理多样性等因素的影响,常常表现不佳。为了应对这些挑战,我们提出将对比学习整合到UDA中,通过最大化同一图像增强视图之间的相似性,增强模型在目标域捕获语义信息的能力。这种额外的监督提高了模型的表示能力和目标域的分割性能。在遥感数据集Potsdam、Vaihingen和LoveDA上进行的广泛实验表明,我们的SimSeg方法优于现有方法,取得了最新结果。可视化及定量分析进一步验证了SimSeg在目标域中的学习能力。相关代码已公开于https://github.com/woldier/SiamSeg。
关键见解
- 语义分割在遥感图像中是一项重要且具有挑战性的任务,具有广泛的应用价值。
- 尽管深度学习在该领域有所进展,但获取高质量标记数据仍然成本高昂且耗时。
- 无监督域自适应(UDA)提供了一种利用标记的源域数据和未标记的目标域数据的方案。
- 自训练(ST)方法通过伪标签生成在减少域差异方面具有潜力,但在遥感图像分割方面的应用仍然有限。
- 现有的自训练方法在遥感图像跨域中因多种因素(如地面采样距离、成像设备和地理多样性)而表现不佳。
- 整合对比学习可以增强模型在目标域中的语义信息捕获能力,通过最大化同一图像的增强视图之间的相似性来提高模型的性能。
点此查看论文截图

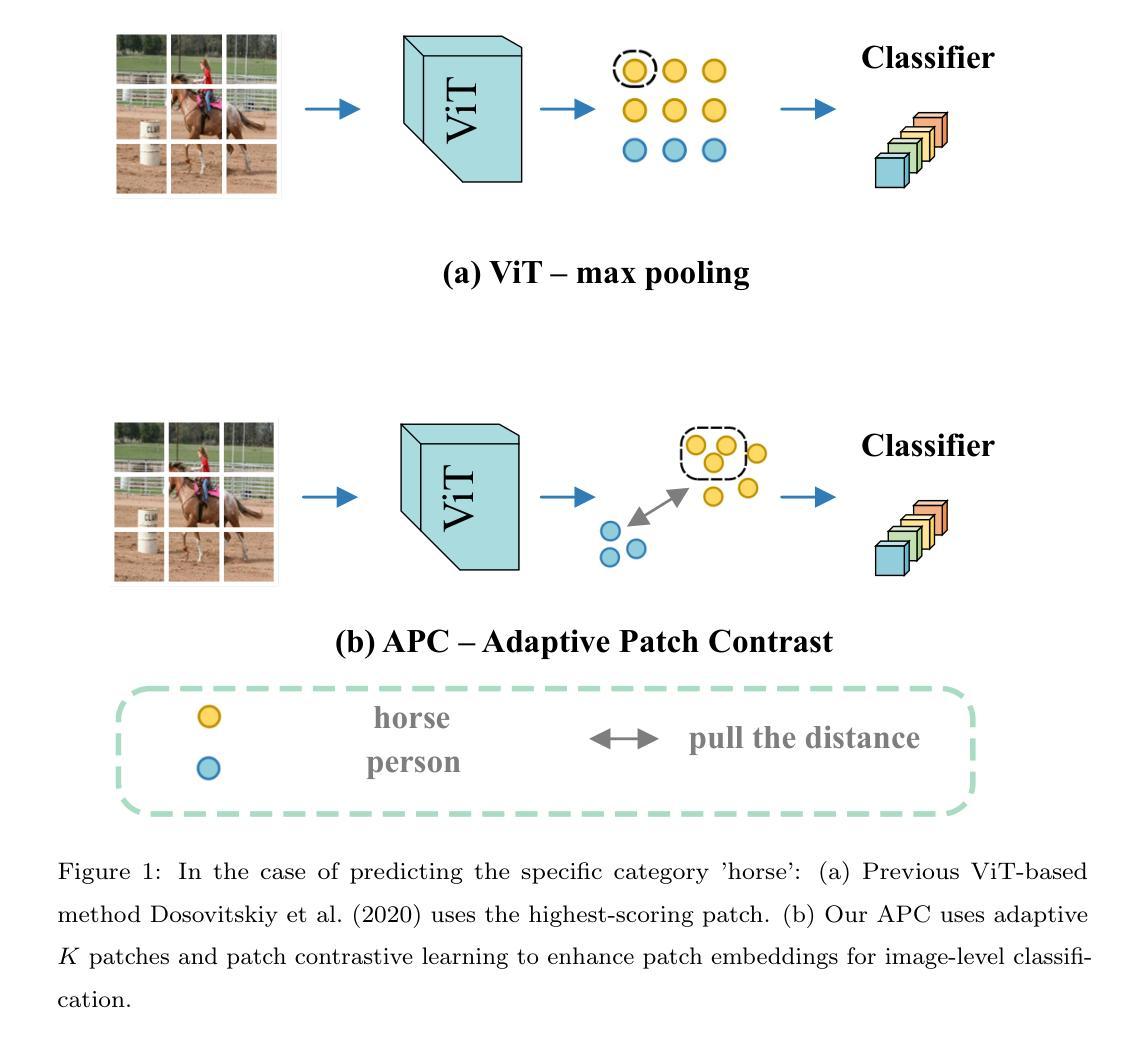
Adaptive Patch Contrast for Weakly Supervised Semantic Segmentation
Authors:Wangyu Wu, Tianhong Dai, Zhenhong Chen, Xiaowei Huang, Jimin Xiao, Fei Ma, Renrong Ouyang
Weakly Supervised Semantic Segmentation (WSSS) using only image-level labels has gained significant attention due to its cost-effectiveness. The typical framework involves using image-level labels as training data to generate pixel-level pseudo-labels with refinements. Recently, methods based on Vision Transformers (ViT) have demonstrated superior capabilities in generating reliable pseudo-labels, particularly in recognizing complete object regions, compared to CNN methods. However, current ViT-based approaches have some limitations in the use of patch embeddings, being prone to being dominated by certain abnormal patches, as well as many multi-stage methods being time-consuming and lengthy in training, thus lacking efficiency. Therefore, in this paper, we introduce a novel ViT-based WSSS method named \textit{Adaptive Patch Contrast} (APC) that significantly enhances patch embedding learning for improved segmentation effectiveness. APC utilizes an Adaptive-K Pooling (AKP) layer to address the limitations of previous max pooling selection methods. Additionally, we propose a Patch Contrastive Learning (PCL) to enhance patch embeddings, thereby further improving the final results. Furthermore, we improve upon the existing multi-stage training framework without CAM by transforming it into an end-to-end single-stage training approach, thereby enhancing training efficiency. The experimental results show that our approach is effective and efficient, outperforming other state-of-the-art WSSS methods on the PASCAL VOC 2012 and MS COCO 2014 dataset within a shorter training duration.
使用仅图像级标签的弱监督语义分割(WSSS)因其成本效益而备受关注。典型的框架是使用图像级标签作为训练数据,通过改进生成像素级伪标签。最近,基于视觉转换器(ViT)的方法在生成可靠的伪标签方面表现出卓越的能力,特别是在识别完整的对象区域方面优于CNN方法。然而,当前的ViT方法在使用补丁嵌入时存在一些局限性,容易受到某些异常补丁的主导,并且许多多阶段方法在训练和推理过程中耗时长,因此缺乏效率。因此,本文介绍了一种新型的基于ViT的WSSS方法,名为自适应补丁对比(APC),该方法显著增强了补丁嵌入学习,提高了分割效果。APC利用自适应K池化(AKP)层解决了之前最大池化选择方法的局限性。此外,我们提出了补丁对比学习(PCL)以增强补丁嵌入,从而进一步提高最终结果。此外,我们改进了现有的多阶段训练框架,将其转变为端到端的单阶段训练方法,从而提高了训练效率。实验结果表明,我们的方法有效且高效,在PASCAL VOC 2012和MS COCO 2014数据集上超越了其他最先进的WSSS方法,并在较短的训练时间内取得了良好效果。
论文及项目相关链接
PDF Accepted by the EAAI Journal
Summary
基于Vision Transformer(ViT)的弱监督语义分割(WSSS)方法通过图像级标签生成可靠的伪标签,在识别完整对象区域方面表现出卓越的能力。然而,当前ViT方法存在局限性,如易受到异常补丁的主导,以及多阶段方法训练时间长、效率低。本文提出一种新型的基于ViT的WSSS方法——自适应补丁对比(APC),增强了补丁嵌入学习,提高了分割效果。APC通过自适应K池化层解决以前最大池化选择方法的局限性,并提出补丁对比学习(PCL)以增强补丁嵌入。此外,我们将现有的多阶段训练框架改进为端到端的单阶段训练,提高效率。实验结果表明,该方法在PASCAL VOC 2012和MS COCO 2014数据集上表现优异,训练时间短。
Key Takeaways
- WSSS利用图像级标签进行训练,生成像素级的伪标签。
- ViT在生成可靠伪标签方面表现出卓越的能力,特别是在识别完整对象区域方面。
- 当前ViT方法存在易受到异常补丁主导和多阶段训练时间长效率低的问题。
- 本文提出的APC方法通过自适应K池化层和补丁对比学习增强补丁嵌入学习,提高分割效果。
- APC改进了多阶段训练框架,提出端到端的单阶段训练方法,提高效率。
- 实验结果表明,APC方法在PASCAL VOC 2012和MS COCO 2014数据集上表现优异。
点此查看论文截图