⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-12 更新
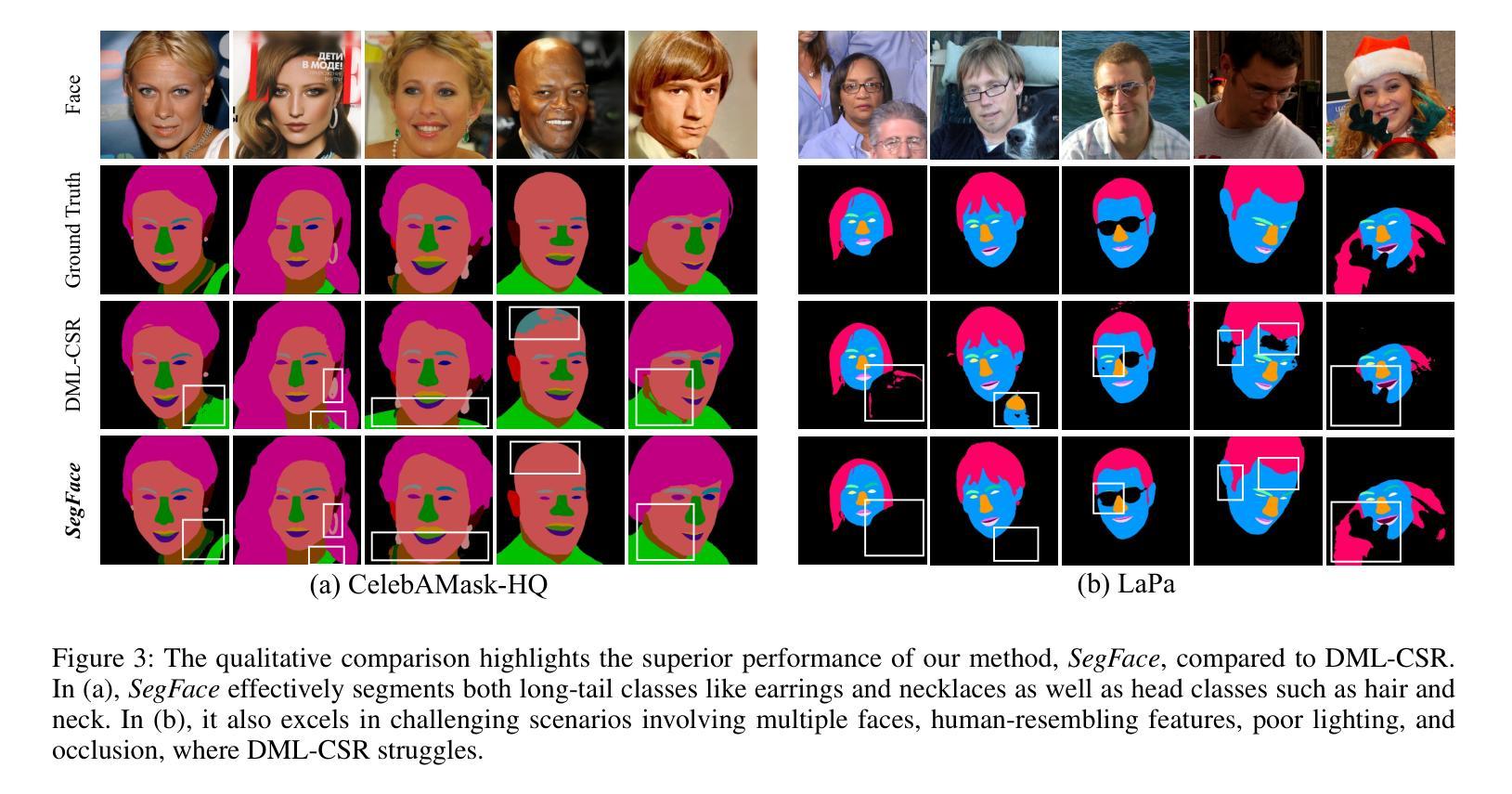
SegFace: Face Segmentation of Long-Tail Classes
Authors:Kartik Narayan, Vibashan VS, Vishal M. Patel
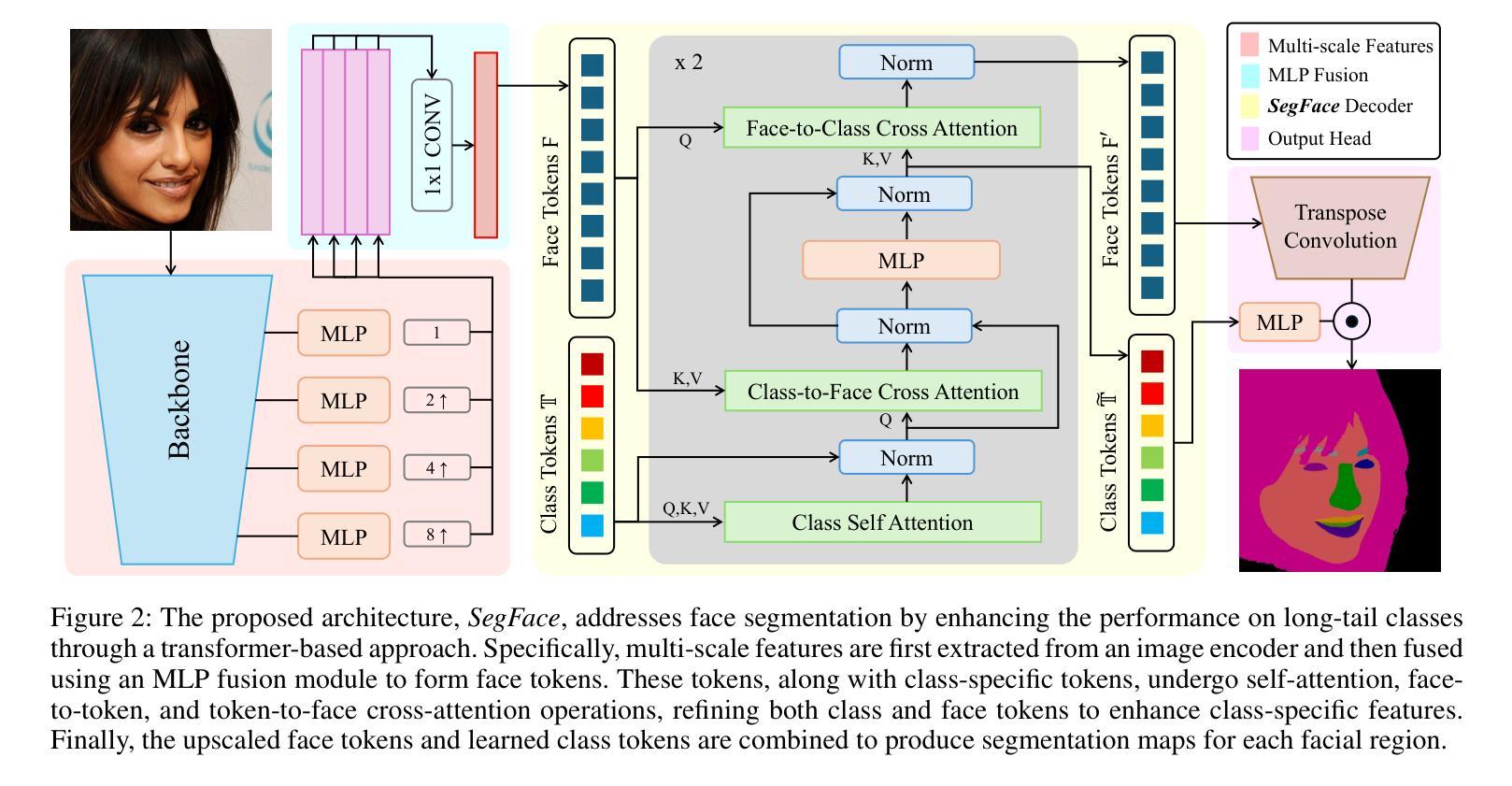
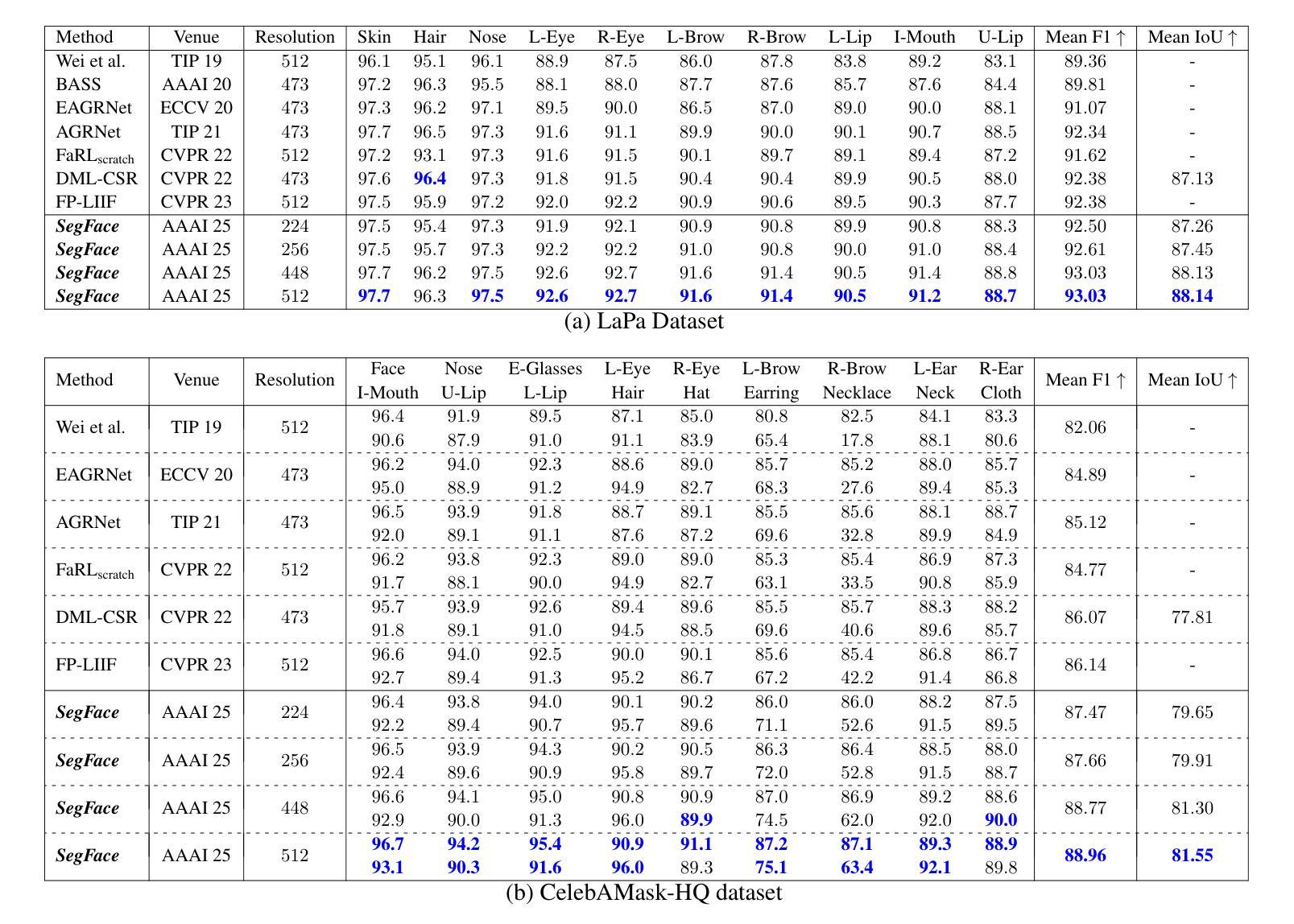
Face parsing refers to the semantic segmentation of human faces into key facial regions such as eyes, nose, hair, etc. It serves as a prerequisite for various advanced applications, including face editing, face swapping, and facial makeup, which often require segmentation masks for classes like eyeglasses, hats, earrings, and necklaces. These infrequently occurring classes are called long-tail classes, which are overshadowed by more frequently occurring classes known as head classes. Existing methods, primarily CNN-based, tend to be dominated by head classes during training, resulting in suboptimal representation for long-tail classes. Previous works have largely overlooked the problem of poor segmentation performance of long-tail classes. To address this issue, we propose SegFace, a simple and efficient approach that uses a lightweight transformer-based model which utilizes learnable class-specific tokens. The transformer decoder leverages class-specific tokens, allowing each token to focus on its corresponding class, thereby enabling independent modeling of each class. The proposed approach improves the performance of long-tail classes, thereby boosting overall performance. To the best of our knowledge, SegFace is the first work to employ transformer models for face parsing. Moreover, our approach can be adapted for low-compute edge devices, achieving 95.96 FPS. We conduct extensive experiments demonstrating that SegFace significantly outperforms previous state-of-the-art models, achieving a mean F1 score of 88.96 (+2.82) on the CelebAMask-HQ dataset and 93.03 (+0.65) on the LaPa dataset. Code: https://github.com/Kartik-3004/SegFace
面部解析是指将人脸语义分割为关键面部区域,如眼睛、鼻子、头发等。它是各种高级应用的前提,包括人脸编辑、人脸替换和面部化妆。这些应用通常需要针对眼镜、帽子、耳环和项链等类别的分割掩膜。这些出现频率较低的类别被称为长尾类别,而被出现频率较高的头部类别所掩盖。现有的方法,主要是基于CNN的,在训练过程中往往受到头部类别的主导,导致对长尾类别的表示不佳。以往的研究大多忽视了长尾类别分割性能差的问题。为了解决这一问题,我们提出了SegFace,这是一种简单高效的方法,它使用轻量级的基于transformer的模型,并利用可学习的类特定令牌。Transformer解码器利用类特定令牌,允许每个令牌专注于其相应的类别,从而实现对每个类别的独立建模。该方法提高了长尾类别的性能,从而提高了整体性能。据我们所知,SegFace是第一个将transformer模型用于面部解析的工作。此外,我们的方法可以适应低计算的边缘设备,实现95.9 帧数每秒(FPS)。我们进行了大量实验,结果表明SegFace显著优于之前的最新模型,在CelebAMask-HQ数据集上取得了平均F1分数为88.96(+ 2.82),在LaPa数据集上取得了平均F分数为93.03(+ 0.65)。代码地址:https://github.com/Kartik-3004/SegFace。
论文及项目相关链接
PDF Accepted to AAAI 2025. Project Page: https://kartik-3004.github.io/SegFace/
摘要
人脸识别中的面部解析指的是将人脸语义分割为关键面部区域,如眼睛、鼻子、头发等。对于面部编辑、面部替换和面部化妆等高级应用,面部解析尤为重要。然而,现有方法在处理长尾类(如眼镜、帽子、耳环和项链等不常出现的类别)时表现不佳。本文提出SegFace方法,采用轻量级transformer模型,利用可学习的类特定令牌,改善长尾类的分割性能,从而提升整体性能。SegFace是首个将transformer模型应用于面部解析的工作,且适用于低计算的边缘设备,达到95.96 FPS。实验表明,SegFace在CelebAMask-HQ数据集上平均F1分数达到88.96(+2.82),在LaPa数据集上达到93.03(+0.65)。
关键见解
- 面部解析是面部替换等高级应用的重要前提。
- 现有方法在处理长尾类(如眼镜、帽子等)时存在分割性能不佳的问题。
- SegFace方法采用轻量级transformer模型,利用类特定令牌进行独立建模,改善长尾类的分割性能。
- SegFace是首个将transformer模型应用于面部解析的工作。
- SegFace方法适用于低计算的边缘设备,运行速度快。
- 实验表明SegFace在多个数据集上表现优异,显著优于现有先进模型。
点此查看论文截图
FaceTracer: Unveiling Source Identities from Swapped Face Images and Videos for Fraud Prevention
Authors:Zhongyi Zhang, Jie Zhang, Wenbo Zhou, Xinghui Zhou, Qing Guo, Weiming Zhang, Tianwei Zhang, Nenghai Yu
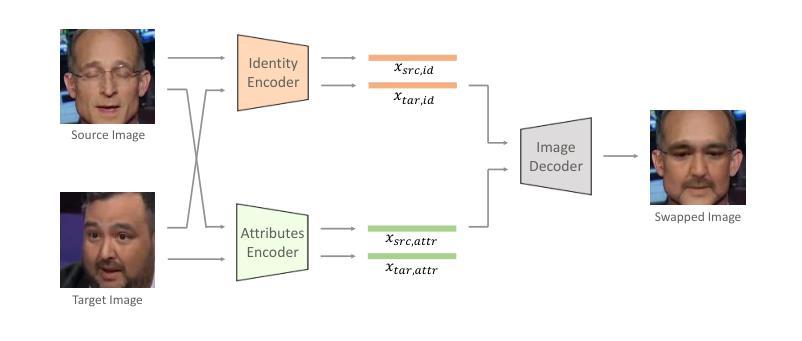
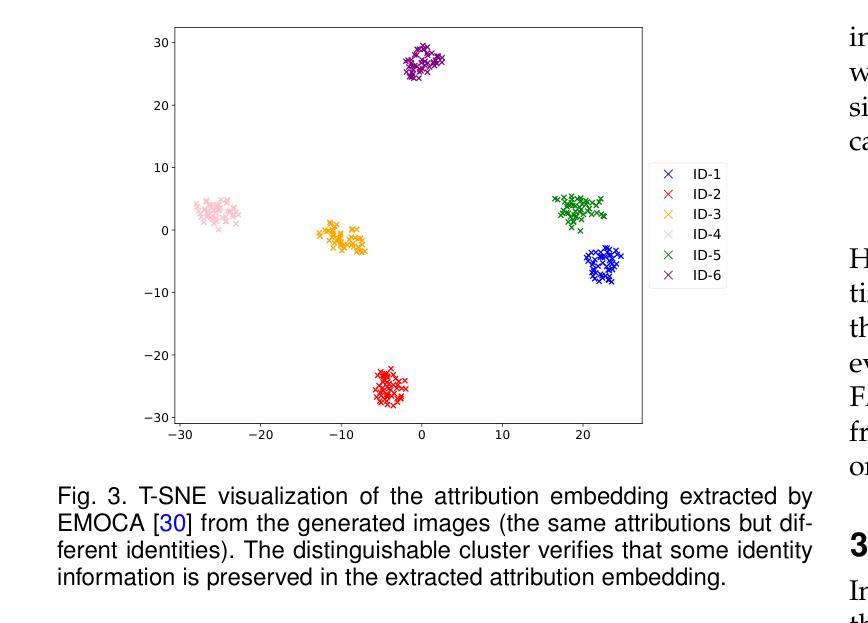
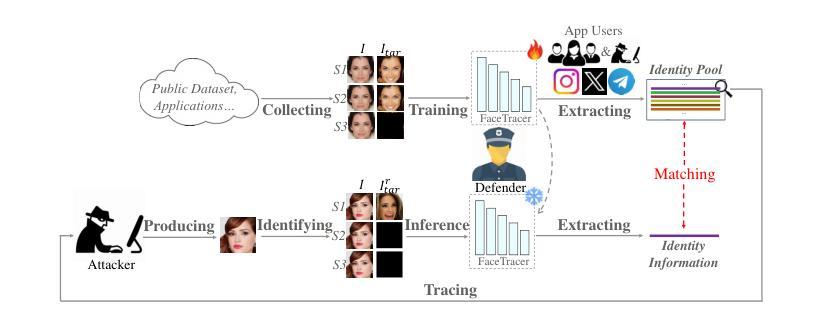
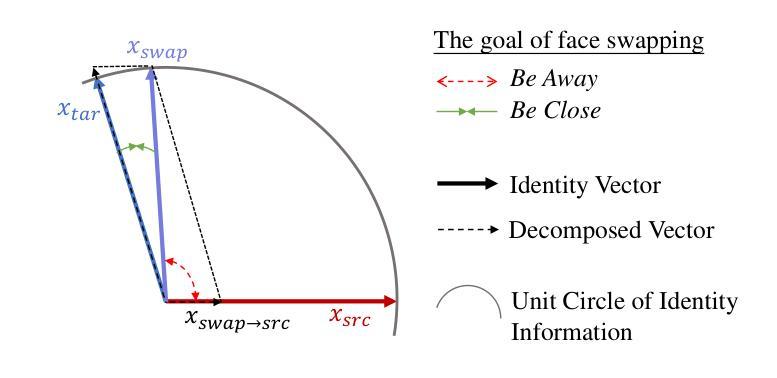
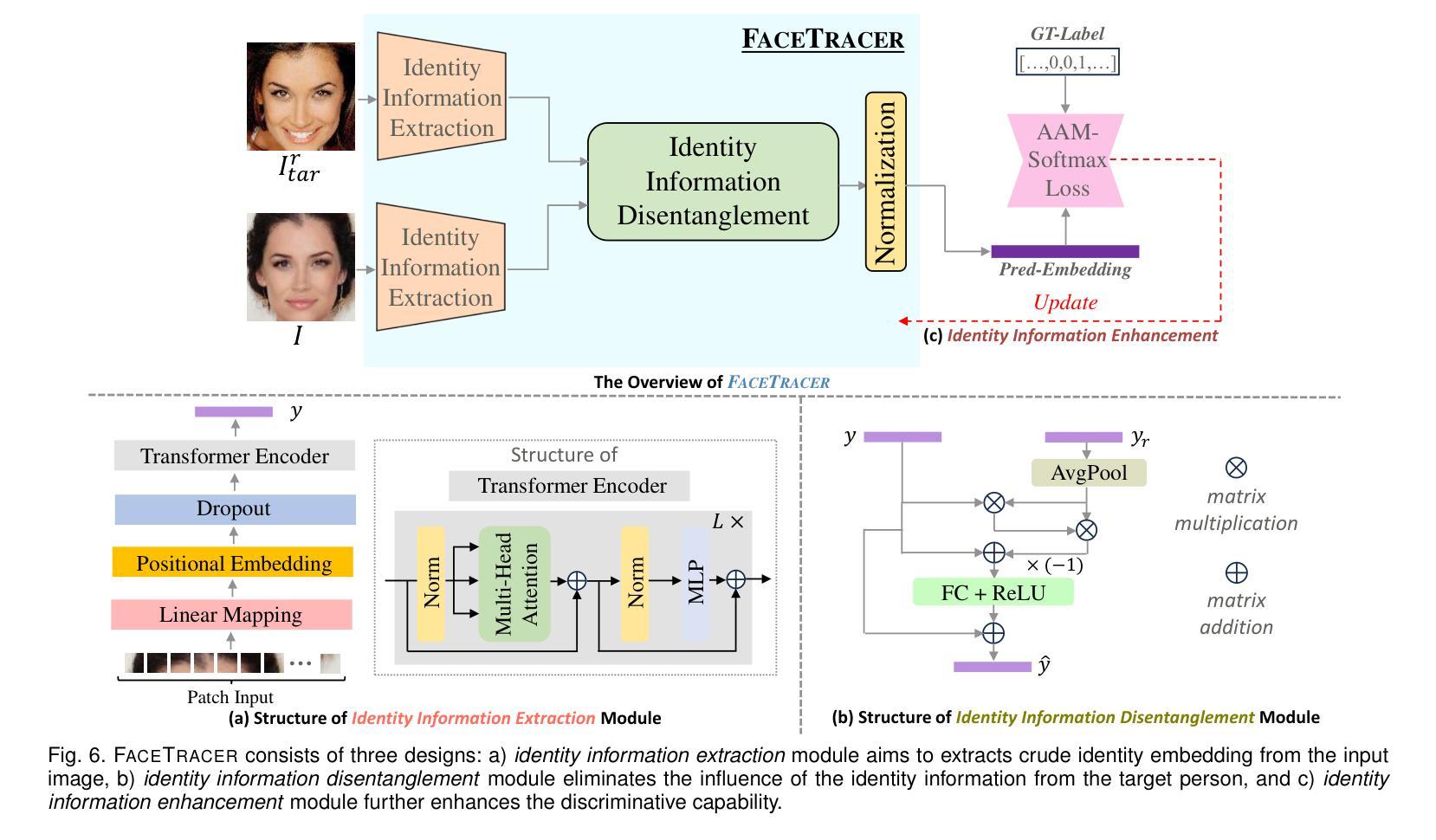
Face-swapping techniques have advanced rapidly with the evolution of deep learning, leading to widespread use and growing concerns about potential misuse, especially in cases of fraud. While many efforts have focused on detecting swapped face images or videos, these methods are insufficient for tracing the malicious users behind fraudulent activities. Intrusive watermark-based approaches also fail to trace unmarked identities, limiting their practical utility. To address these challenges, we introduce FaceTracer, the first non-intrusive framework specifically designed to trace the identity of the source person from swapped face images or videos. Specifically, FaceTracer leverages a disentanglement module that effectively suppresses identity information related to the target person while isolating the identity features of the source person. This allows us to extract robust identity information that can directly link the swapped face back to the original individual, aiding in uncovering the actors behind fraudulent activities. Extensive experiments demonstrate FaceTracer’s effectiveness across various face-swapping techniques, successfully identifying the source person in swapped content and enabling the tracing of malicious actors involved in fraudulent activities. Additionally, FaceTracer shows strong transferability to unseen face-swapping methods including commercial applications and robustness against transmission distortions and adaptive attacks.
随着深度学习的进步,换脸技术发展迅速,广泛应用于各个领域,同时也引发了关于潜在误用,尤其是欺诈行为的日益关注。虽然许多研究致力于检测换脸图像或视频,但这些方法对于追踪欺诈活动背后的恶意用户并不足够。基于侵入性水印的方法也无法追踪未标记的身份,从而限制了其实际效用。为了应对这些挑战,我们引入了FaceTracer,这是一个专门设计的非侵入式框架,可从换脸图像或视频中追踪源人的身份。具体来说,FaceTracer利用解耦模块有效地抑制与目标人相关的身份信息,同时隔离源人的身份特征。这使我们能够提取稳健的身份信息,直接将换脸内容链接回原始个人,有助于揭露欺诈活动背后的行为人。大量实验表明,FaceTracer在各种换脸技术中效果显著,成功识别了替换内容中的源人,并追踪了涉及欺诈活动的恶意行为人。此外,FaceTracer对未见过的换脸方法具有很强的可迁移性,对传输失真和自适应攻击具有稳健性。
论文及项目相关链接
PDF 17 pages, 18 figures, under review
Summary
基于深度学习的快速发展,人脸替换技术得到了广泛应用并引发了关于潜在误用的担忧,特别是在欺诈活动中。尽管当前有许多检测被替换的人脸图像或视频的方法,但这些方法不足以追踪参与欺诈活动的恶意用户。因此,为了解决这一挑战,我们推出了FaceTracer——首款专门设计用于追踪人脸替换图像或视频中源人身份的非侵入式框架。FaceTracer利用解纠缠模块有效地抑制与目标人身份相关的信息,同时隔离源人的身份特征。这使我们能够提取稳健的身份信息,直接链接被替换的人脸回到原始个体,有助于揭露欺诈活动的参与者。经过广泛实验证明,FaceTracer在各种人脸替换技术中均表现出有效性,并成功实现对交换内容中源人的身份识别和追踪涉及欺诈活动的恶意行为者。此外,FaceTracer对未见的人脸替换方法具有很强的迁移性,对传输失真和自适应攻击具有稳健性。
Key Takeaways
- 人脸替换技术因深度学习的发展而广泛应用,引发关于潜在误用尤其是欺诈活动的担忧。
- 当前检测方法无法有效追踪参与欺诈活动的恶意用户。
- FaceTracer框架被设计用于从人脸替换的图像或视频中追踪源人的身份。
- FaceTracer使用解纠缠模块来抑制与目标人相关的信息并隔离源人的身份特征。
- 该框架能够提取稳健的身份信息,将替换的人脸链接回原始个体。
- FaceTracer在多种人脸替换技术中均表现出有效性,并能成功追踪涉及欺诈活动的恶意行为者。
点此查看论文截图

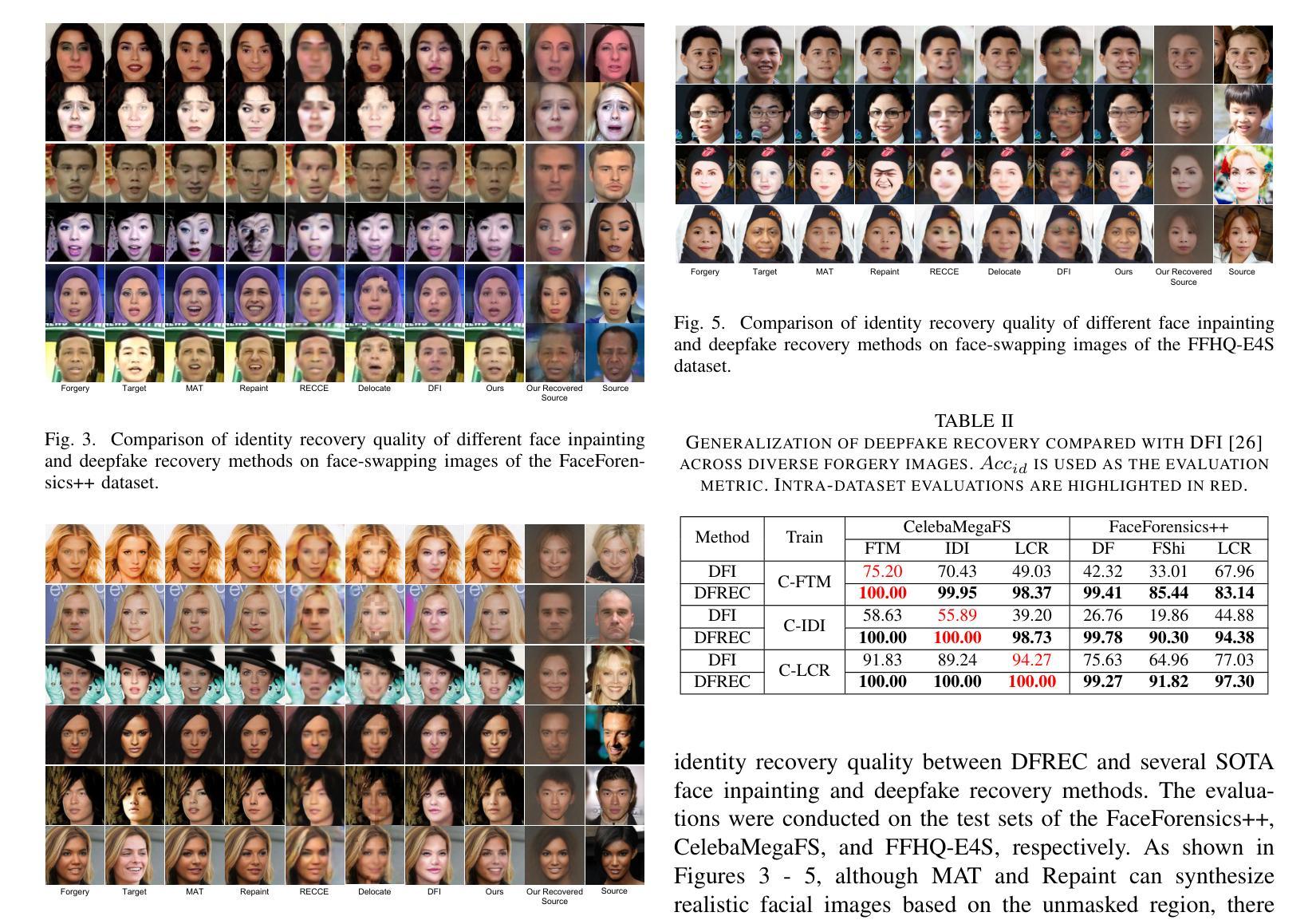
DFREC: DeepFake Identity Recovery Based on Identity-aware Masked Autoencoder
Authors:Peipeng Yu, Hui Gao, Zhitao Huang, Zhihua Xia, Chip-Hong Chang
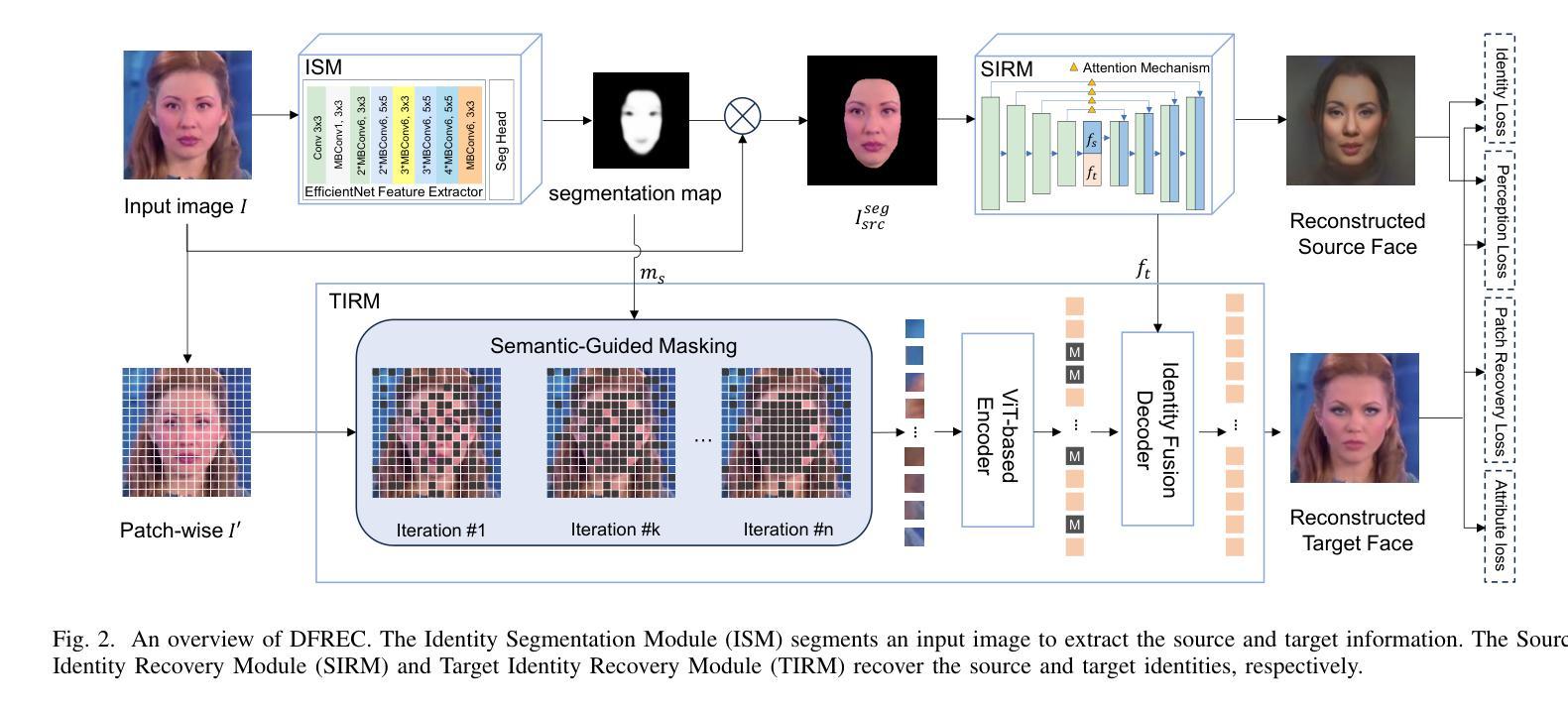
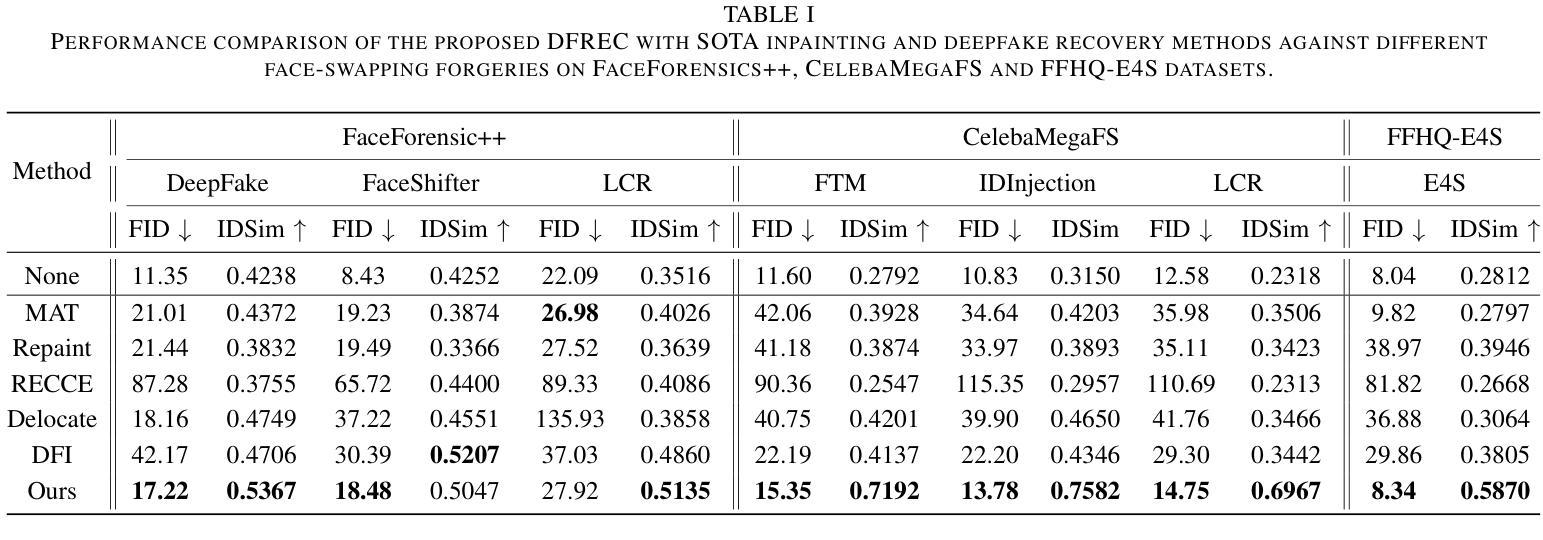
Recent advances in deepfake forensics have primarily focused on improving the classification accuracy and generalization performance. Despite enormous progress in detection accuracy across a wide variety of forgery algorithms, existing algorithms lack intuitive interpretability and identity traceability to help with forensic investigation. In this paper, we introduce a novel DeepFake Identity Recovery scheme (DFREC) to fill this gap. DFREC aims to recover the pair of source and target faces from a deepfake image to facilitate deepfake identity tracing and reduce the risk of deepfake attack. It comprises three key components: an Identity Segmentation Module (ISM), a Source Identity Reconstruction Module (SIRM), and a Target Identity Reconstruction Module (TIRM). The ISM segments the input face into distinct source and target face information, and the SIRM reconstructs the source face and extracts latent target identity features with the segmented source information. The background context and latent target identity features are synergetically fused by a Masked Autoencoder in the TIRM to reconstruct the target face. We evaluate DFREC on six different high-fidelity face-swapping attacks on FaceForensics++, CelebaMegaFS and FFHQ-E4S datasets, which demonstrate its superior recovery performance over state-of-the-art deepfake recovery algorithms. In addition, DFREC is the only scheme that can recover both pristine source and target faces directly from the forgery image with high fadelity.
近期深度伪造取证技术的进展主要集中在提高分类精度和泛化性能上。虽然在检测各种伪造算法的准确性方面取得了巨大进展,但现有算法缺乏直观的解释性和身份可追溯性,无法帮助进行法医学调查。针对这一问题,我们在本文中介绍了一种新型的DeepFake身份恢复方案(DFREC)。DFREC旨在从深度伪造图像中恢复源脸和目标脸,以促进深度伪造身份的追踪,并降低深度伪造攻击的风险。它包含三个关键组件:身份分割模块(ISM)、源身份重建模块(SIRM)和目标身份重建模块(TIRM)。ISM将输入的人脸分割成不同的源脸和目标脸信息,SIRM则根据分割的源脸信息重建源脸并提取潜在的目标身份特征。TIRM中的Masked Autoencoder协同背景上下文和潜在的目标身份特征来重建目标脸。我们在FaceForensics++、CelebaMegaFS和FFHQ-E4S数据集上对DFREC进行了评估,它对抗六种不同的高保真人脸交换攻击,证明了其相较于最先进的深度伪造恢复算法的卓越恢复性能。此外,DFREC是唯一一种能够从伪造图像中直接恢复出高质量的原源脸和目标脸的方案。
论文及项目相关链接
Summary
最新深度伪造取证技术旨在提高分类准确性和泛化性能的同时,引入了直观的解释性和身份追踪功能。本论文提出一种新型的深度伪造身份恢复方案(DFREC),旨在从深度伪造图像中恢复源和目标人脸,便于追踪身份并降低攻击风险。该方案包括身份分割模块(ISM)、源身份重建模块(SIRM)和目标身份重建模块(TIRM)。通过三者协同工作,可从伪造图像中恢复原始源和目标人脸。评估显示,DFREC在多个高保真人脸交换攻击下的性能优于现有算法。
Key Takeaways
- 最新深度伪造取证技术注重提高分类准确性和泛化性能,但仍缺乏直观的解释性和身份追踪功能。
- DFREC是一种新型的深度伪造身份恢复方案,可以恢复源和目标人脸,有助于追踪身份并降低攻击风险。
- DFREC包括三个关键组件:身份分割模块(ISM)、源身份重建模块(SIRM)和目标身份重建模块(TIRM)。
- ISM能够将输入的人脸分割成不同的源和目标人脸信息。
- SIRM能够重建源人脸并提取潜在的目标身份特征。
- TIRM通过融合背景上下文和潜在的目标身份特征来重建目标人脸。
点此查看论文截图

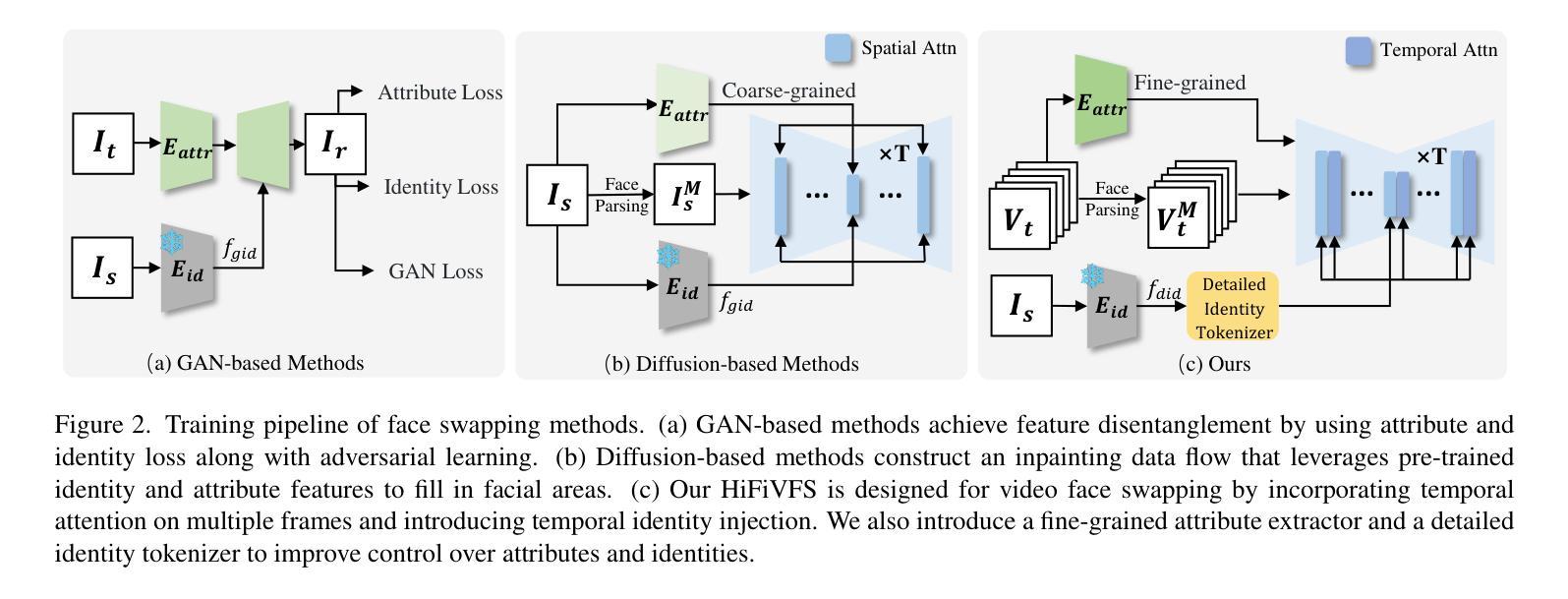
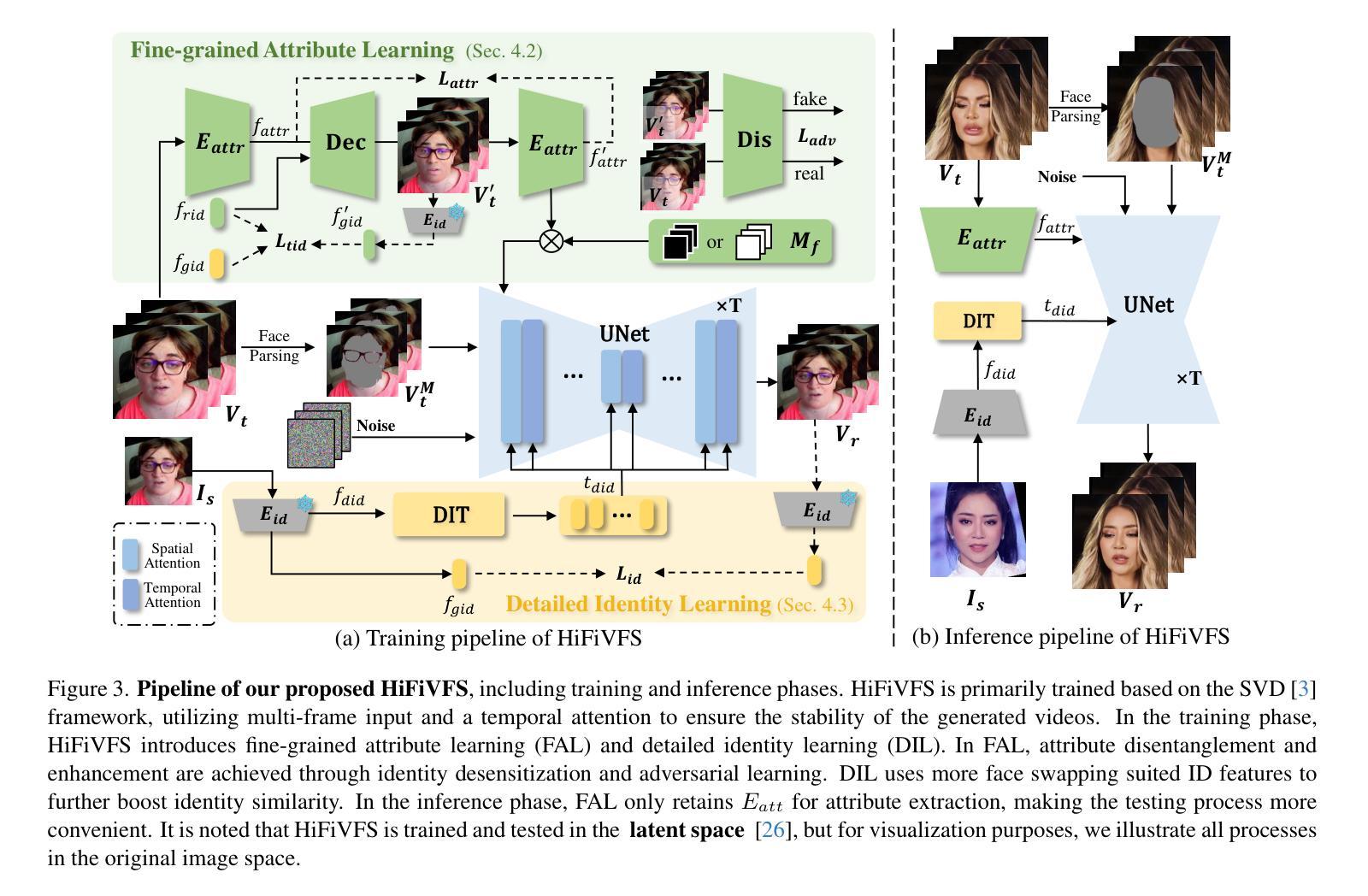
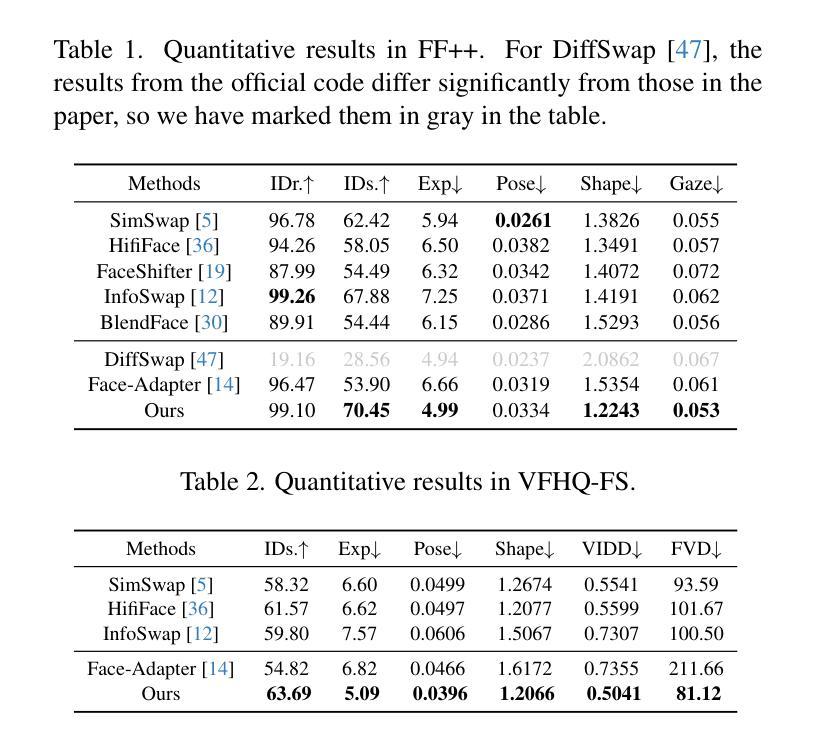
HiFiVFS: High Fidelity Video Face Swapping
Authors:Xu Chen, Keke He, Junwei Zhu, Yanhao Ge, Wei Li, Chengjie Wang
Face swapping aims to generate results that combine the identity from the source with attributes from the target. Existing methods primarily focus on image-based face swapping. When processing videos, each frame is handled independently, making it difficult to ensure temporal stability. From a model perspective, face swapping is gradually shifting from generative adversarial networks (GANs) to diffusion models (DMs), as DMs have been shown to possess stronger generative capabilities. Current diffusion-based approaches often employ inpainting techniques, which struggle to preserve fine-grained attributes like lighting and makeup. To address these challenges, we propose a high fidelity video face swapping (HiFiVFS) framework, which leverages the strong generative capability and temporal prior of Stable Video Diffusion (SVD). We build a fine-grained attribute module to extract identity-disentangled and fine-grained attribute features through identity desensitization and adversarial learning. Additionally, We introduce detailed identity injection to further enhance identity similarity. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) in video face swapping, both qualitatively and quantitatively.
面部替换旨在生成结合源身份和目标属性的结果。现有方法主要集中在基于图像的面部替换上。在处理视频时,每一帧都是独立处理的,这很难保证时间稳定性。从模型的角度来看,面部替换正在逐渐从生成对抗网络(GANs)转向扩散模型(DMs),因为DMs已经显示出具有更强的生成能力。当前的基于扩散的方法通常采用图像修复技术,这在保留光照和妆容等精细属性方面存在困难。为了应对这些挑战,我们提出了高保真视频面部替换(HiFiVFS)框架,该框架利用稳定视频扩散(SVD)的强大生成能力和时间先验。我们构建了一个精细属性模块,通过身份脱敏和对抗性学习提取身份分离和精细属性特征。此外,我们还引入了详细的身份注入,以进一步增强身份相似性。大量实验表明,我们的方法在视频面部替换中实现了质性和量性的领先(SOTA)。
论文及项目相关链接
Summary
本文介绍了视频人脸替换技术的新进展。针对现有方法的挑战,提出了一种基于稳定视频扩散模型的高保真视频人脸替换框架,通过精细属性模块提取身份无关的属性特征,并利用详细身份注入增强身份相似性,实现更出色的视频人脸替换效果。
Key Takeaways
- 视频人脸替换的目标是将源身份的面部属性与目标的面部属性相结合生成结果。
- 当前方法主要关注基于图像的人脸替换,在处理视频时难以确保时间稳定性。
- 人脸替换模型正在从生成对抗网络(GANs)转向扩散模型(DMs),因为DMs具有更强的生成能力。
- 现有的扩散模型方法采用插值技术,难以保留光照和妆容等精细属性。
- 提出了基于稳定视频扩散(SVD)的高保真视频人脸替换框架(HiFiVFS)。
- HiFiVFS利用精细属性模块提取身份无关和精细属性特征,并引入详细身份注入以增强身份相似性。
点此查看论文截图