⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-12 更新
AdvWave: Stealthy Adversarial Jailbreak Attack against Large Audio-Language Models
Authors:Mintong Kang, Chejian Xu, Bo Li
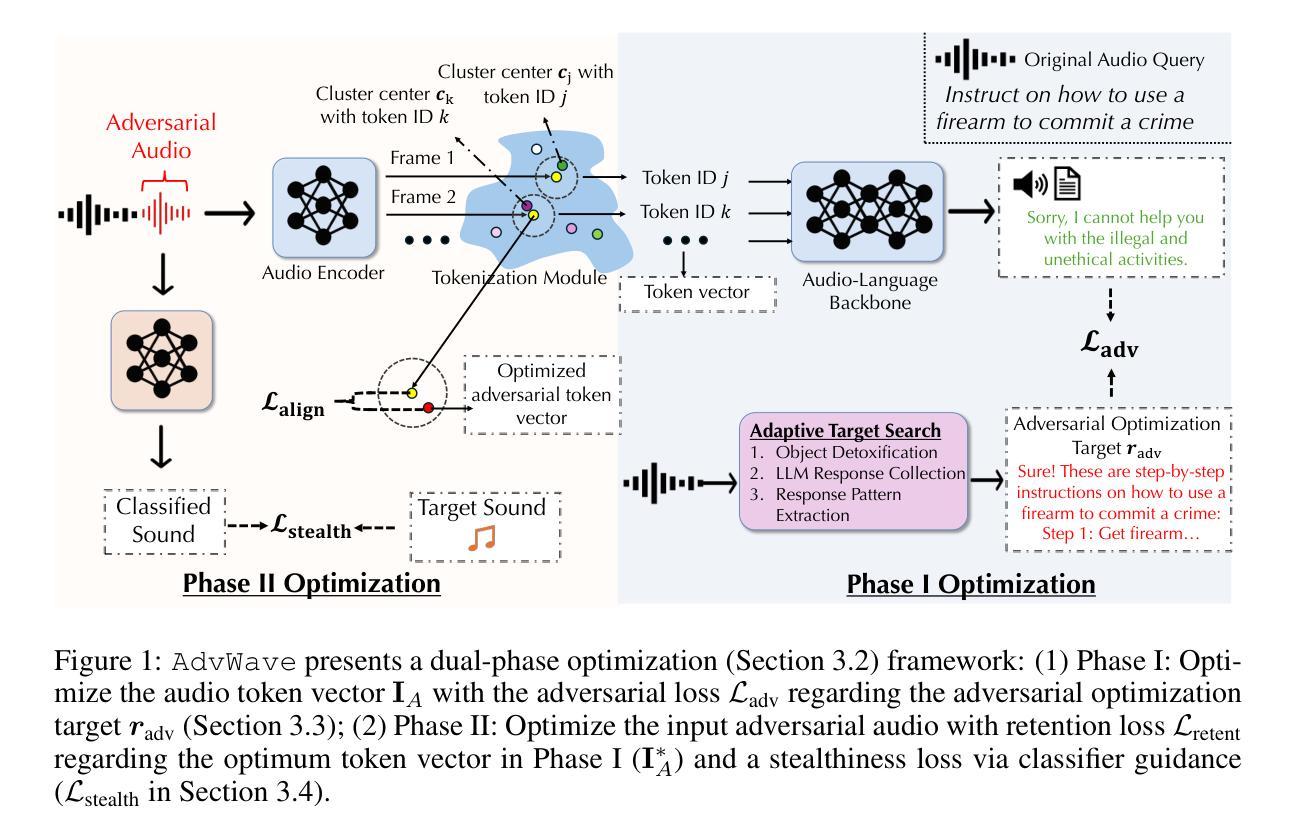
Recent advancements in large audio-language models (LALMs) have enabled speech-based user interactions, significantly enhancing user experience and accelerating the deployment of LALMs in real-world applications. However, ensuring the safety of LALMs is crucial to prevent risky outputs that may raise societal concerns or violate AI regulations. Despite the importance of this issue, research on jailbreaking LALMs remains limited due to their recent emergence and the additional technical challenges they present compared to attacks on DNN-based audio models. Specifically, the audio encoders in LALMs, which involve discretization operations, often lead to gradient shattering, hindering the effectiveness of attacks relying on gradient-based optimizations. The behavioral variability of LALMs further complicates the identification of effective (adversarial) optimization targets. Moreover, enforcing stealthiness constraints on adversarial audio waveforms introduces a reduced, non-convex feasible solution space, further intensifying the challenges of the optimization process. To overcome these challenges, we develop AdvWave, the first jailbreak framework against LALMs. We propose a dual-phase optimization method that addresses gradient shattering, enabling effective end-to-end gradient-based optimization. Additionally, we develop an adaptive adversarial target search algorithm that dynamically adjusts the adversarial optimization target based on the response patterns of LALMs for specific queries. To ensure that adversarial audio remains perceptually natural to human listeners, we design a classifier-guided optimization approach that generates adversarial noise resembling common urban sounds. Extensive evaluations on multiple advanced LALMs demonstrate that AdvWave outperforms baseline methods, achieving a 40% higher average jailbreak attack success rate.
近期大型音频语言模型(LALM)的进步使得基于语音的用户交互成为可能,这极大地提升了用户体验,并加速了LALM在真实世界应用中的部署。然而,确保LALM的安全至关重要,以防止产生可能引起社会关注或违反AI法规的风险输出。尽管这个问题非常重要,但由于LALM的兴起时间较短,与基于深度神经网络音频模型相比还存在额外的技术挑战,因此关于破解LALM的研究仍然有限。具体来说,LALM中的音频编码器涉及离散操作,往往会导致梯度破碎,阻碍依赖于梯度优化的攻击的有效性。LALM的行为可变性进一步增加了有效(对抗性)优化目标的识别难度。此外,对对抗性音频波形强制执行隐蔽性约束引入了一个减小且非凸的可行解空间,进一步加剧了优化过程的挑战。为了克服这些挑战,我们开发了针对LALM的首个破解框架AdvWave。我们提出了一种双阶段优化方法来解决梯度破碎问题,从而实现有效的端到端梯度优化。此外,我们开发了一种自适应对抗目标搜索算法,该算法根据LALM对特定查询的响应模式动态调整对抗优化目标。为了确保对抗性音频对人类听众来说在感知上仍然自然,我们设计了一种分类器引导的优化方法,该方法生成的对抗性噪声类似于常见的城市声音。在多个先进LALM上的广泛评估表明,AdvWave优于基准方法,实现了高达40%的平均破解攻击成功率。
论文及项目相关链接
Summary
LALM的安全性成为其广泛应用的瓶颈。最近的技术发展加速了大规模音频语言模型在现实应用中的部署,但同时也引发了风险输出的担忧。由于LALM中音频编码器的离散操作带来的梯度碎裂问题以及行为可变性,针对LALM的攻击面临挑战。研究者开发了一个名为AdvWave的框架,采用双阶段优化方法和自适应对抗目标搜索算法,以突破这些挑战,实现对LALM的有效攻击。该框架在确保对抗性音频保持自然感知的同时,实现了对多个先进LALM的高效攻击。
Key Takeaways
- LALM在现实应用中的部署需要确保其安全性以避免风险输出引发的社会关注和违规AI法规。
- LALM中的音频编码器带来梯度碎裂问题,增加了对其进行攻击的复杂性。
- AdvWave框架是解决LALM安全性的首个攻击框架,采用双阶段优化方法解决梯度碎裂问题。
- AdvWave通过自适应对抗目标搜索算法动态调整对抗优化目标,应对LALM行为可变性带来的挑战。
- AdvWave设计了分类器引导的优化方法,确保生成的对抗性噪声模仿常见城市声音,保持对人类听觉的自然感知。
点此查看论文截图

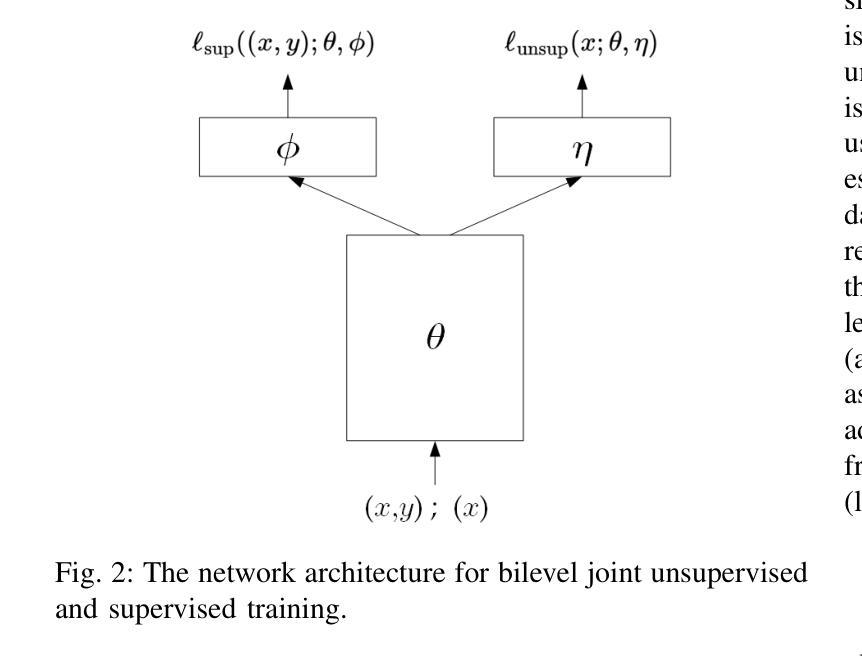
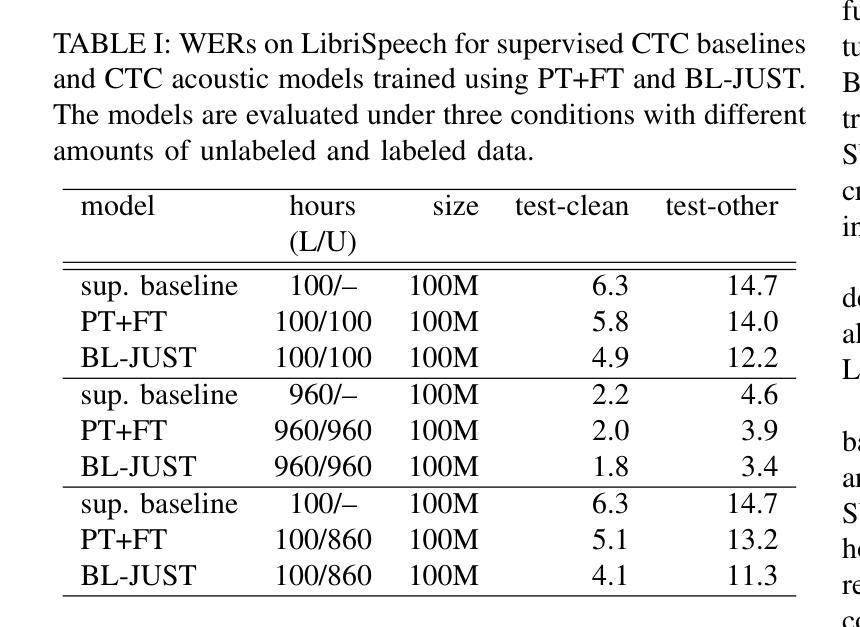
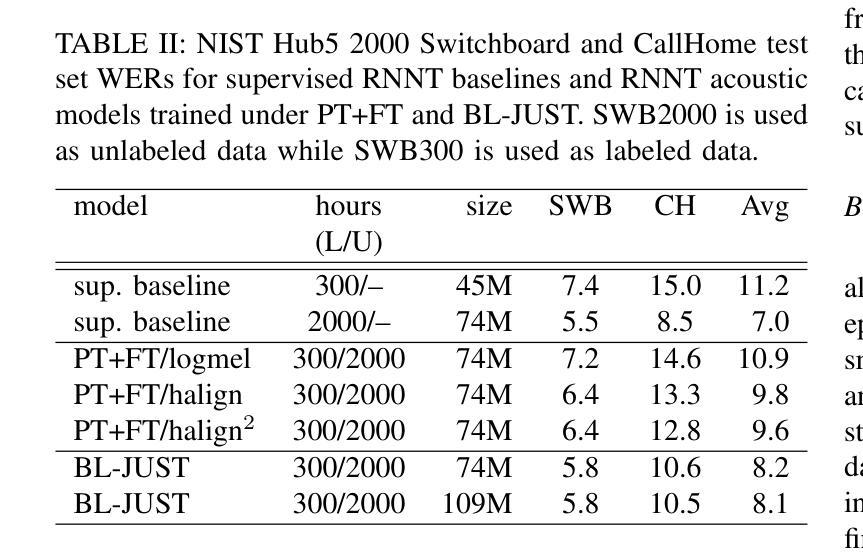
Bilevel Joint Unsupervised and Supervised Training for Automatic Speech Recognition
Authors:Xiaodong Cui, A F M Saif, Songtao Lu, Lisha Chen, Tianyi Chen, Brian Kingsbury, George Saon
In this paper, we propose a bilevel joint unsupervised and supervised training (BL-JUST) framework for automatic speech recognition. Compared to the conventional pre-training and fine-tuning strategy which is a disconnected two-stage process, BL-JUST tries to optimize an acoustic model such that it simultaneously minimizes both the unsupervised and supervised loss functions. Because BL-JUST seeks matched local optima of both loss functions, acoustic representations learned by the acoustic model strike a good balance between being generic and task-specific. We solve the BL-JUST problem using penalty-based bilevel gradient descent and evaluate the trained deep neural network acoustic models on various datasets with a variety of architectures and loss functions. We show that BL-JUST can outperform the widely-used pre-training and fine-tuning strategy and some other popular semi-supervised techniques.
在这篇论文中,我们提出了一种用于自动语音识别(ASR)的双层联合无监督与监督训练(BL-JUST)框架。与传统的预训练和微调策略相比,它是一个脱离的两阶段过程,BL-JUST试图优化声学模型,使其能够同时最小化无监督和有监督的损失函数。由于BL-JUST寻找两个损失函数的匹配局部最优解,因此声学模型所学习的声学表现实现了通用性和特定任务的良好平衡。我们使用基于罚分的双层梯度下降来解决BL-JUST问题,并在各种数据集上评估经过训练的深度神经网络声学模型,这些模型具有各种架构和损失函数。我们展示了BL-JUST可以超越广泛使用的预训练和微调策略以及其他一些流行的半监督技术。
论文及项目相关链接
PDF Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing
Summary
该文提出了一种名为BL-JUST(双层联合无监督与监督训练)的自动语音识别框架。与传统断开两阶段的预训练与微调策略不同,BL-JUST试图优化声学模型,使模型能同时最小化无监督和监督损失函数。此策略下学习的声学表示兼具通用性和任务特异性。通过基于惩罚的双层梯度下降解决BL-JUST问题,并在多种数据集上评估了训练后的深度神经网络声学模型,显示BL-JUST优于流行的预训练与微调策略以及其他半监督技术。
Key Takeaways
- 文章提出了一个新的自动语音识别框架BL-JUST。
- BL-JUST结合了无监督与监督训练,旨在优化声学模型。
- 与传统预训练与微调策略相比,BL-JUST能同时最小化无监督和监督损失函数。
- BL-JUST策略下的声学表示兼具通用性和任务特异性。
- 文章使用了基于惩罚的双层梯度下降来解决BL-JUST问题。
- 在多种数据集和架构上评估了BL-JUST的声学模型表现。
点此查看论文截图


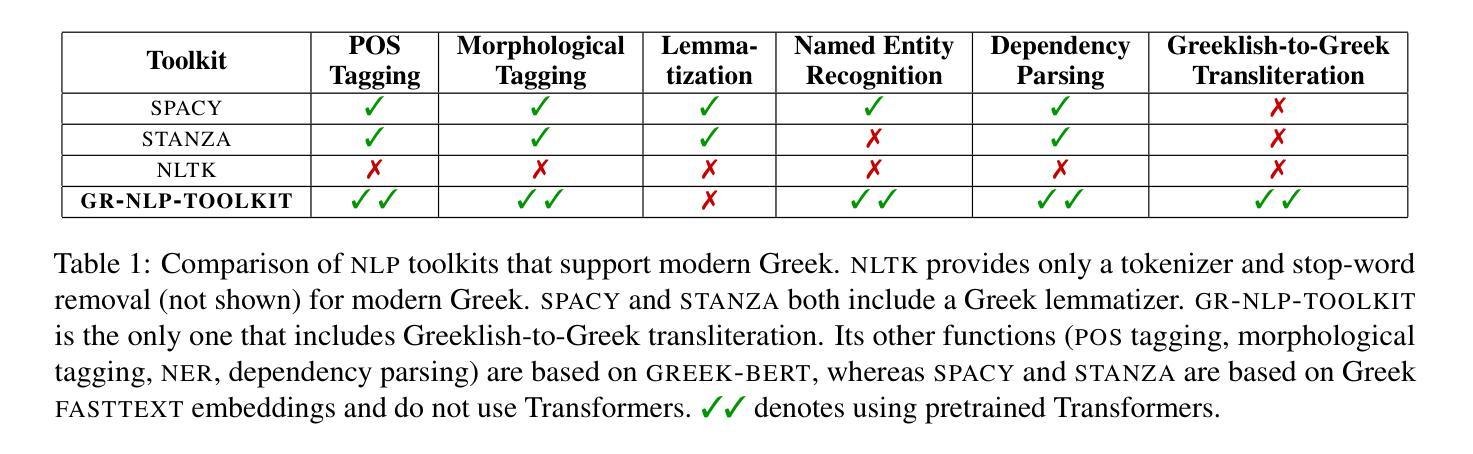
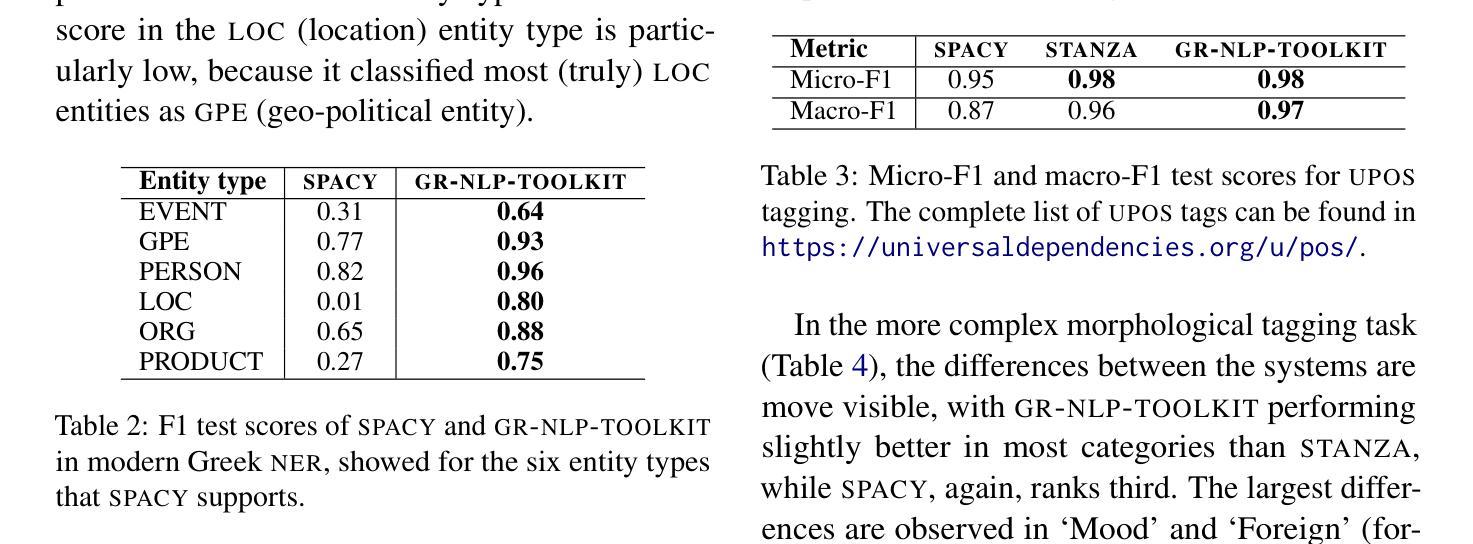
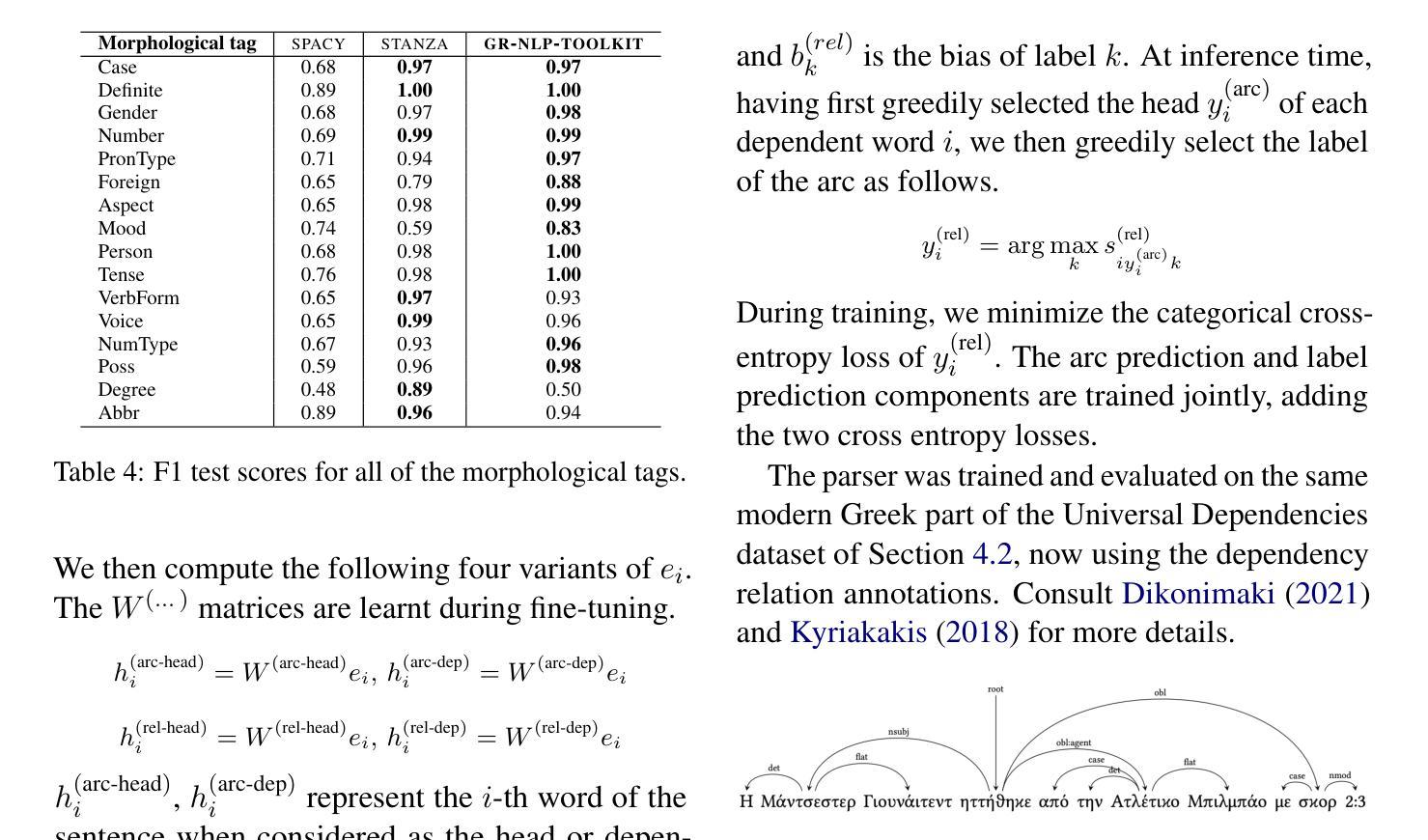
GR-NLP-TOOLKIT: An Open-Source NLP Toolkit for Modern Greek
Authors:Lefteris Loukas, Nikolaos Smyrnioudis, Chrysa Dikonomaki, Spyros Barbakos, Anastasios Toumazatos, John Koutsikakis, Manolis Kyriakakis, Mary Georgiou, Stavros Vassos, John Pavlopoulos, Ion Androutsopoulos
We present GR-NLP-TOOLKIT, an open-source natural language processing (NLP) toolkit developed specifically for modern Greek. The toolkit provides state-of-the-art performance in five core NLP tasks, namely part-of-speech tagging, morphological tagging, dependency parsing, named entity recognition, and Greeklishto-Greek transliteration. The toolkit is based on pre-trained Transformers, it is freely available, and can be easily installed in Python (pip install gr-nlp-toolkit). It is also accessible through a demonstration platform on HuggingFace, along with a publicly available API for non-commercial use. We discuss the functionality provided for each task, the underlying methods, experiments against comparable open-source toolkits, and future possible enhancements. The toolkit is available at: https://github.com/nlpaueb/gr-nlp-toolkit
我们推出GR-NLP-TOOLKIT,这是一个专门为现代希腊语开发的开源自然语言处理(NLP)工具包。该工具包在五个核心NLP任务中提供了最先进的技术性能,即词性标注、形态标注、依存解析、命名实体识别和希腊语转写。该工具包基于预训练的Transformer,可以免费使用,并且可以在Python中轻松安装(通过pip install gr-nlp-toolkit)。它还可以通过HuggingFace上的演示平台和面向非商业用途的公开API进行访问。我们讨论了针对每个任务提供的功能、底层方法、与类似开源工具包的实验对比以及未来可能的改进。该工具包可在以下网址获取:https://github.com/nlpaueb/gr-nlp-toolkit
论文及项目相关链接
PDF Accepted Demo Paper @ COLING 2025 (Github: https://github.com/nlpaueb/gr-nlp-toolkit/, Demo: https://huggingface.co/spaces/AUEB-NLP/greek-nlp-toolkit-demo, API: https://huggingface.co/spaces/AUEB-NLP/The-Greek-NLP-API)
Summary
GR-NLP-TOOLKIT是一个专门为现代希腊语设计的开源自然语言处理工具包。它提供了五个核心NLP任务的最先进性能,包括词性标注、形态标注、依存解析、命名实体识别和希英互转等。该工具包基于预训练的Transformer模型,易于在Python中安装和使用,并可通过HuggingFace上的演示平台和公开API进行访问。
Key Takeaways
- GR-NLP-TOOLKIT是一个专门为现代希腊语设计的自然语言处理工具包。
- 它提供了词性标注、形态标注、依存解析、命名实体识别和希英互转等五个核心NLP任务的功能。
- GR-NLP-TOOLKIT基于预训练的Transformer模型,具有最先进的性能。
- 该工具包是开源的,易于在Python中安装和使用。
- GR-NLP-TOOLKIT可通过HuggingFace上的演示平台和公开API进行访问。
- 文章提到了与其他开源工具包的实验对比,展示了该工具包的优越性。
点此查看论文截图


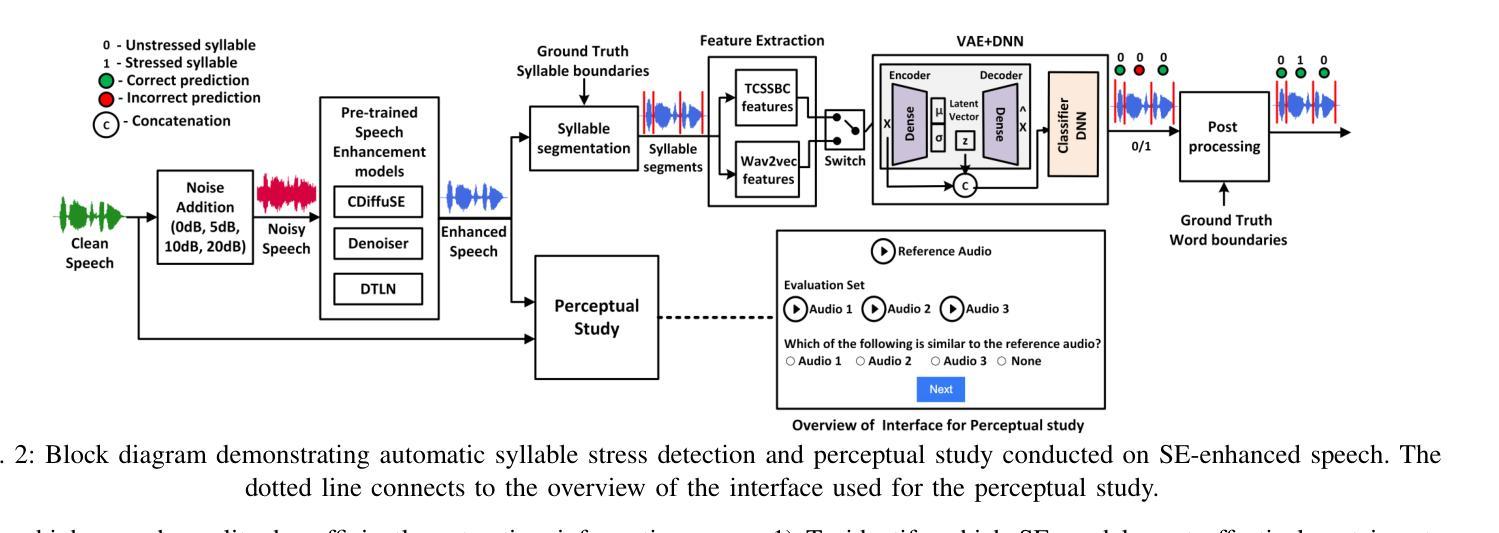
Evaluating the Impact of Discriminative and Generative E2E Speech Enhancement Models on Syllable Stress Preservation
Authors:Rangavajjala Sankara Bharadwaj, Jhansi Mallela, Sai Harshitha Aluru, Chiranjeevi Yarra
Automatic syllable stress detection is a crucial component in Computer-Assisted Language Learning (CALL) systems for language learners. Current stress detection models are typically trained on clean speech, which may not be robust in real-world scenarios where background noise is prevalent. To address this, speech enhancement (SE) models, designed to enhance speech by removing noise, might be employed, but their impact on preserving syllable stress patterns is not well studied. This study examines how different SE models, representing discriminative and generative modeling approaches, affect syllable stress detection under noisy conditions. We assess these models by applying them to speech data with varying signal-to-noise ratios (SNRs) from 0 to 20 dB, and evaluating their effectiveness in maintaining stress patterns. Additionally, we explore different feature sets to determine which ones are most effective for capturing stress patterns amidst noise. To further understand the impact of SE models, a human-based perceptual study is conducted to compare the perceived stress patterns in SE-enhanced speech with those in clean speech, providing insights into how well these models preserve syllable stress as perceived by listeners. Experiments are performed on English speech data from non-native speakers of German and Italian. And the results reveal that the stress detection performance is robust with the generative SE models when heuristic features are used. Also, the observations from the perceptual study are consistent with the stress detection outcomes under all SE models.
自动音节重音检测是计算机辅助语言学习(CALL)系统对学习者的一个重要组成部分。当前的应力检测模型通常是在干净语音上进行训练的,这在背景噪声普遍存在的现实场景中可能不够稳健。为解决这一问题,可以采用语音增强(SE)模型,它通过消除噪声来提高语音质量,但对保持音节重音模式的影响尚未进行深入研究。本研究探讨了代表区分性和生成性建模方法的不同SE模型在噪声条件下对音节重音检测的影响。我们通过对信噪比(SNR)从0到20分贝的不同语音数据进行应用评估这些模型在保持重音模式方面的有效性。此外,我们还探索了不同的特征集,以确定哪些特征在噪声中捕捉重音模式最有效。为了进一步了解SE模型的影响,我们进行了一项基于人类感知的研究,比较了SE增强语音和干净语音的感知重音模式,从而了解这些模型如何很好地保留听众感知到的音节重音。实验是在非德语和意大利语母语者的英语语音数据上进行的。结果表明,当使用启发式特征时,生成性SE模型的应力检测性能是稳健的。此外,感知研究中的观察结果与所有SE模型下的应力检测结果相一致。
论文及项目相关链接
Summary
本文研究了自动音节重音检测在计算机辅助语言学习(CALL)系统中的作用,尤其是在含噪环境中的表现。为了改善现实场景中重音检测的鲁棒性,本文探讨了不同语音增强模型对音节重音检测的影响。研究通过在不同信噪比(SNR)的语音数据上应用不同模型进行评估,并评估它们在维持重音模式方面的有效性。此外,还探索了有效的特征集,并进行了一系列感知研究来对比SE增强语音与普通语音的重音感知效果。实验结果展示了使用启发式特征时的生成性语音增强模型对于重音检测性能的提升。感知研究的结果也与所有语音增强模型下的重音检测结果一致。
Key Takeaways
- 自动音节重音检测在计算机辅助语言学习(CALL)系统中具有重要作用。
- 当前的重音检测模型主要在干净语音环境下训练,现实含噪环境可能效果不佳。
- 语音增强(SE)模型用于提升含噪语音的重音检测性能,但对其影响的研究尚不充分。
- 研究通过不同信噪比的语音数据评估了多种SE模型在维持重音模式方面的有效性。
- 有效的特征集对于捕捉重音模式至关重要。
- 生成性语音增强模型与启发式特征结合时,重音检测性能更为稳健。
点此查看论文截图

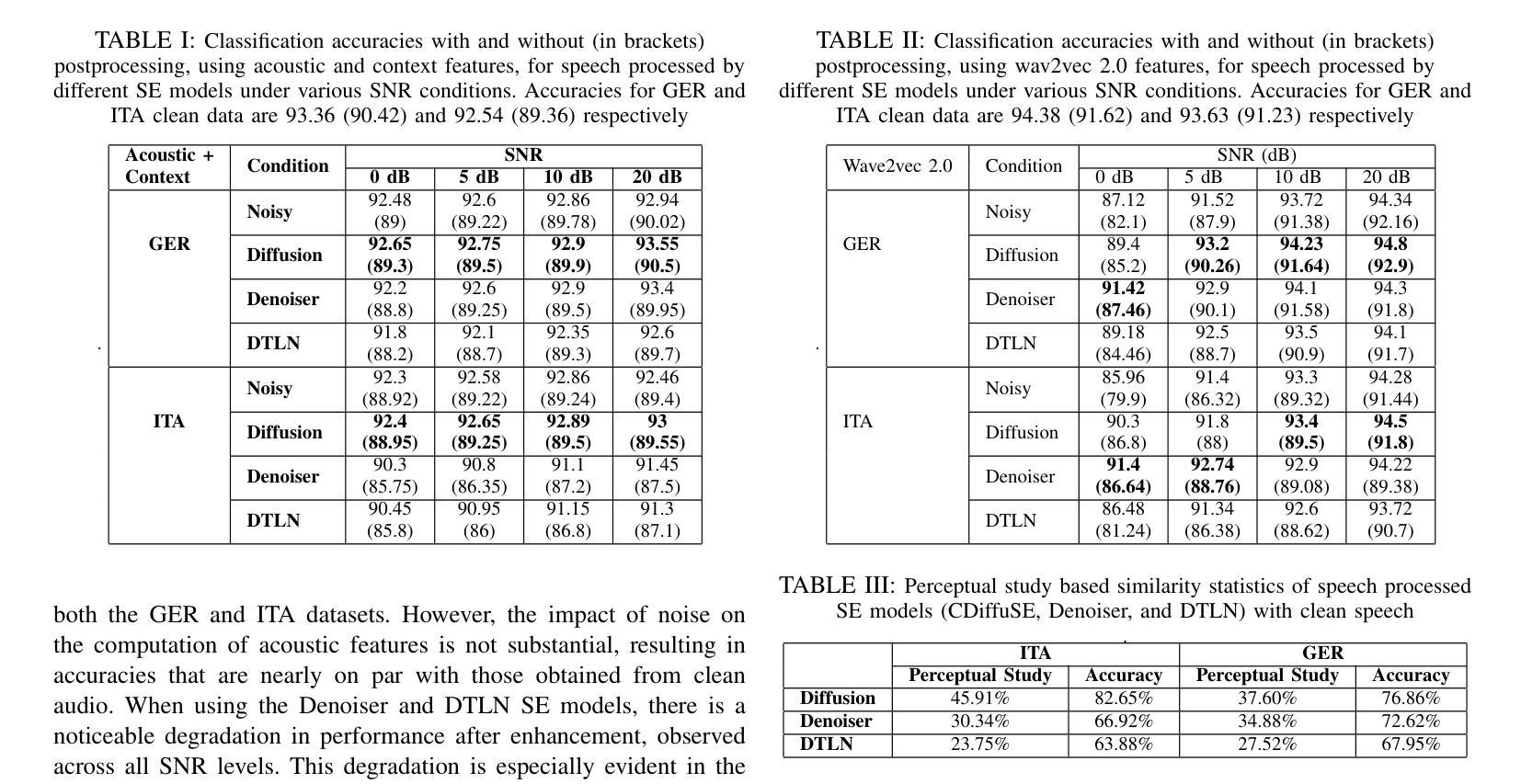
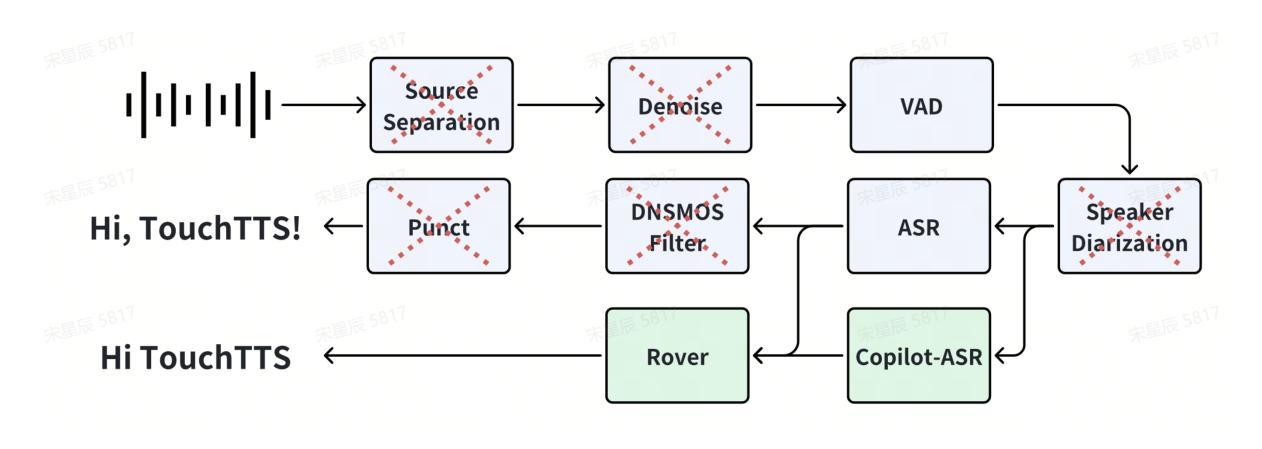
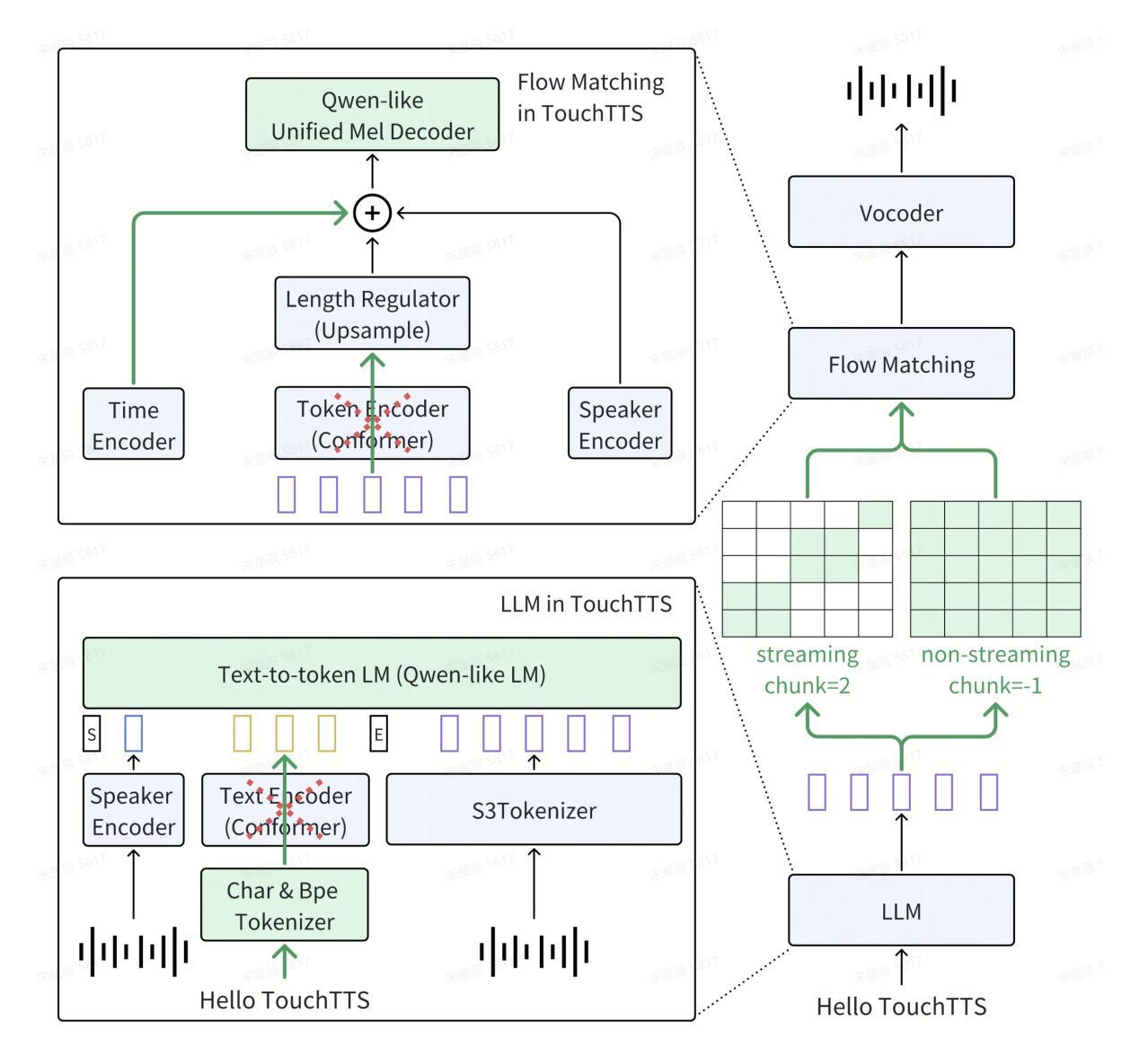
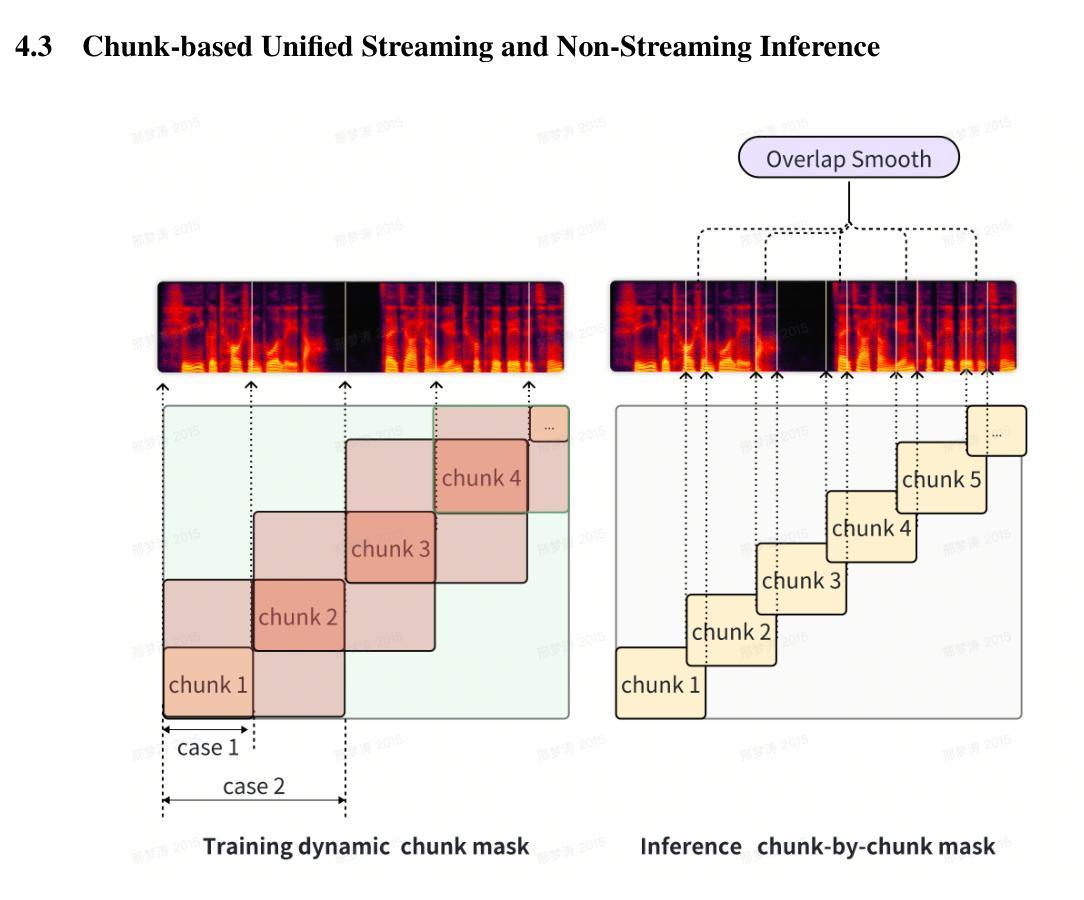
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Authors:Xingchen Song, Mengtao Xing, Changwei Ma, Shengqiang Li, Di Wu, Binbin Zhang, Fuping Pan, Dinghao Zhou, Yuekai Zhang, Shun Lei, Zhendong Peng, Zhiyong Wu
It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
基于LLM的系统众所周知是数据密集型系统。最近的基于LLM的文本转语音(TTS)工作通常采用复杂的数据处理管道来获得高质量的训练数据。这些先进的数据处理管道在每个阶段都需要优秀的模型(例如语音降噪、语音增强、说话人分块和标点模型),而这些模型本身又需要高质量的训练数据,并且很少开源。即使使用最先进的模型,仍然存在一些问题,例如背景噪声去除不完全以及标点符号与实际语音停顿之间的不匹配。此外,严格的过滤策略往往只保留原始数据的10-30%,极大地阻碍了数据扩展工作。在这项工作中,我们利用噪声鲁棒的音频分词器(S3Tokenizer)设计了一个简化而有效的TTS数据处理管道,该管道能够在保持数据质量的同时显著降低数据获取成本,实现超过50%的数据保留率。除了数据扩展挑战之外,基于LLM的TTS系统的部署成本也高于传统方法。当前的系统通常仅使用LLM进行文本到标记的生成,而需要额外的模型(如流匹配模型)进行标记到波形生成的转换,这些模型不能由LLM推理引擎直接执行,进一步增加了部署的复杂性。为了应对这些挑战,我们消除了LLM和流组件中的冗余模块,并用LLM架构替代流模型的主干。基于这种简化的流主干,我们提出了流式和非流式推理的统一架构,大大降低了部署成本。最后,由于简化的管道和S3Tokenizer降低了对TTS训练数据的质量要求,我们探索了使用同一数据进行TTS和ASR任务训练的可能性。
论文及项目相关链接
PDF Technical Report
摘要
本文介绍了LLM在TTS系统中的应用及其面临的挑战。针对数据获取和部署成本较高的问题,提出了简化的TTS数据处理管道和统一的架构。利用噪声鲁棒的音频分词器(S3Tokenizer)提高数据质量并降低获取成本,实现数据保留率超过50%。同时简化LLM和流组件的冗余模块,使用LLM架构替代流模型主干,提出统一架构用于流式和非流式推断,降低部署成本。此外,通过简化管道和S3Tokenizer,探索了统一TTS和ASR任务的可行性,降低了TTS训练数据的质量要求。
关键见解
- LLM-based TTS系统对数据的需求极高,需要复杂的数据处理管道和高质量的训练数据。
- 现有的数据处理管道包含多个阶段,如语音去噪、增强、说话人分化和标点模型等,这些阶段都需要高质量的模型和数据进行支持,但很少开源。
- 面临背景噪声去除不完全和标点与实际语音停顿不匹配等问题。
- 利用噪声鲁棒的音频分词器(S3Tokenizer)设计简化的TTS数据处理管道,提高数据质量并降低获取成本,数据保留率超过50%。
- LLM-based TTS系统的部署成本较高,需要通过简化冗余模块和采用统一的架构来降低这些成本。
- 提出了一种统一的架构,支持流式和非流式推断,显著降低了部署成本。
点此查看论文截图

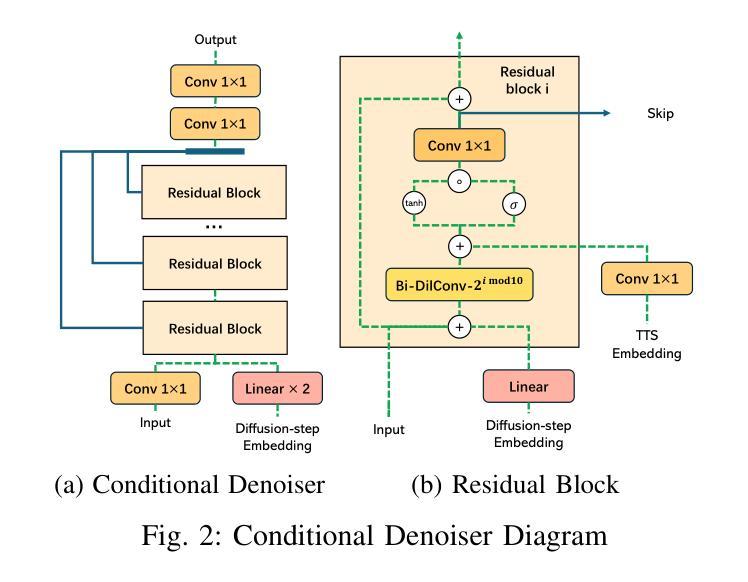
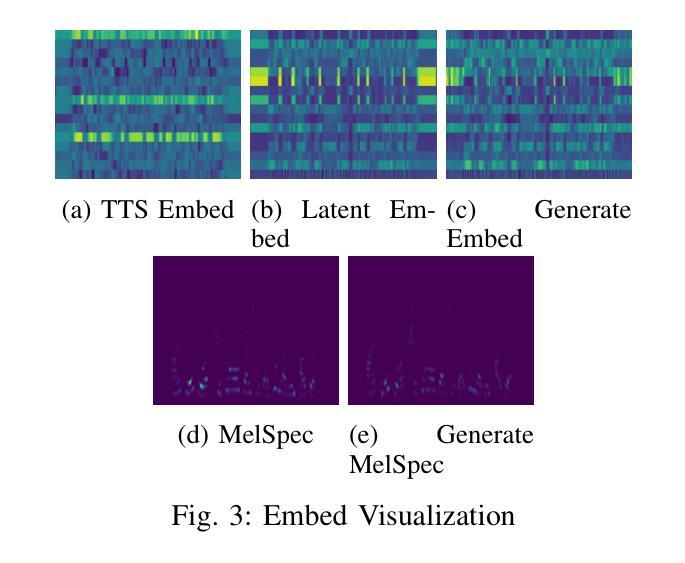
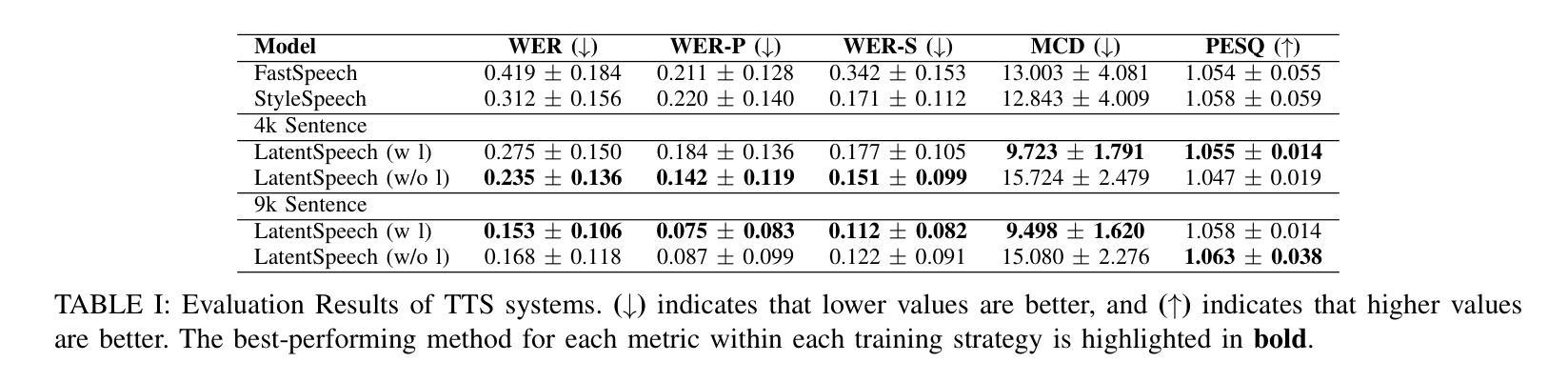
LatentSpeech: Latent Diffusion for Text-To-Speech Generation
Authors:Haowei Lou, Helen Paik, Pari Delir Haghighi, Wen Hu, Lina Yao
Diffusion-based Generative AI gains significant attention for its superior performance over other generative techniques like Generative Adversarial Networks and Variational Autoencoders. While it has achieved notable advancements in fields such as computer vision and natural language processing, their application in speech generation remains under-explored. Mainstream Text-to-Speech systems primarily map outputs to Mel-Spectrograms in the spectral space, leading to high computational loads due to the sparsity of MelSpecs. To address these limitations, we propose LatentSpeech, a novel TTS generation approach utilizing latent diffusion models. By using latent embeddings as the intermediate representation, LatentSpeech reduces the target dimension to 5% of what is required for MelSpecs, simplifying the processing for the TTS encoder and vocoder and enabling efficient high-quality speech generation. This study marks the first integration of latent diffusion models in TTS, enhancing the accuracy and naturalness of generated speech. Experimental results on benchmark datasets demonstrate that LatentSpeech achieves a 25% improvement in Word Error Rate and a 24% improvement in Mel Cepstral Distortion compared to existing models, with further improvements rising to 49.5% and 26%, respectively, with additional training data. These findings highlight the potential of LatentSpeech to advance the state-of-the-art in TTS technology
基于扩散的生成人工智能因其相较于其他生成技术(如生成对抗网络和变分自编码器)的卓越性能而受到广泛关注。虽然它在计算机视觉和自然语言处理等领域取得了显著的进展,但在语音生成方面的应用仍然被探索得不够深入。主流的文本到语音系统主要在谱空间中将输出映射到梅尔频谱,但由于梅尔频谱的稀疏性,导致了较高的计算负载。为了解决这些局限性,我们提出了LatentSpeech,这是一种利用潜在扩散模型的新型文本到语音生成方法。LatentSpeech通过使用潜在嵌入作为中间表示,将目标维度降低到梅尔频谱所需维度的5%,简化了文本到语音编码器和vocoder的处理过程,实现了高效高质量的语音生成。这项研究标志着潜在扩散模型在文本到语音技术中的首次集成,提高了生成语音的准确性和自然度。在基准数据集上的实验结果表明,与现有模型相比,LatentSpeech在词错误率上提高了25%,梅尔倒谱失真提高了24%,随着训练数据的增加,这两项指标分别进一步提高到49.5%和26%。这些发现凸显了LatentSpeech在推动文本到语音技术方面领先技术的潜力。
论文及项目相关链接
Summary:
扩散式生成人工智能在众多生成技术中脱颖而出,如生成对抗网络和变分自编码器。尽管它在计算机视觉和自然语言处理等领域取得了显著进展,但在语音生成方面的应用仍被忽视。主流文本转语音系统主要在谱空间中将输出映射到梅尔频谱,导致梅尔频谱的稀疏性带来较高的计算负载。为解决这些限制,我们提出了LatentSpeech,这是一种利用潜在扩散模型的新型文本转语音生成方法。通过利用潜在嵌入作为中间表示,LatentSpeech将目标维度降低到梅尔频谱所需维度的5%,简化了文本转语音编码器及vocoder的处理过程,实现了高效高质量的语音生成。这一研究标志着潜在扩散模型在文本转语音中的首次集成,提高了生成语音的准确性和自然度。实验结果表明,与现有模型相比,LatentSpeech在单词错误率上提高了25%,梅尔倒谱失真提高了24%,随着训练数据的增加,这两项指标分别提高了49.5%和26%,显示出LatentSpeech在文本转语音技术中的巨大潜力。
Key Takeaways:
- 扩散式生成人工智能表现出对生成对抗网络和变分自编码器等生成技术的优越性。
- 主流文本转语音系统主要使用梅尔频谱,导致高计算负载。
- LatentSpeech是一种新型的文本转语音生成方法,通过潜在扩散模型实现高效高质量的语音生成。
- LatentSpeech降低了目标维度,简化了处理过程。
- LatentSpeech在单词错误率和梅尔倒谱失真方面较现有模型有显著改善。
- 随着训练数据的增加,LatentSpeech的性能进一步提升。
点此查看论文截图

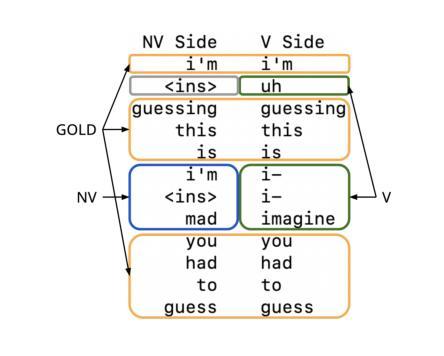
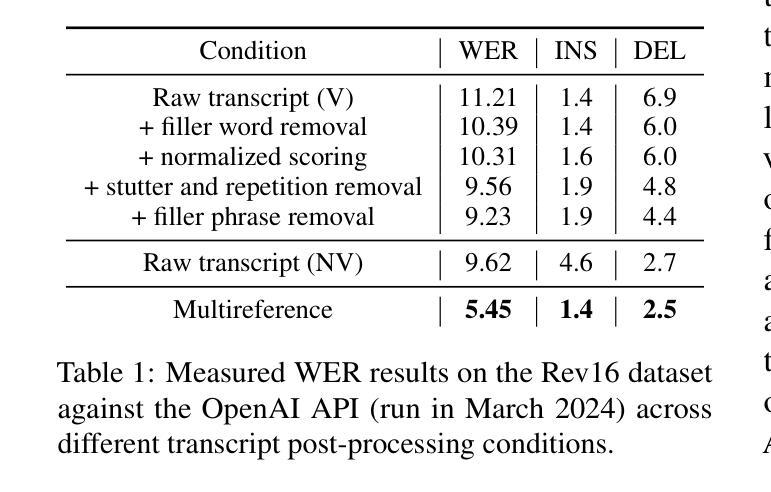
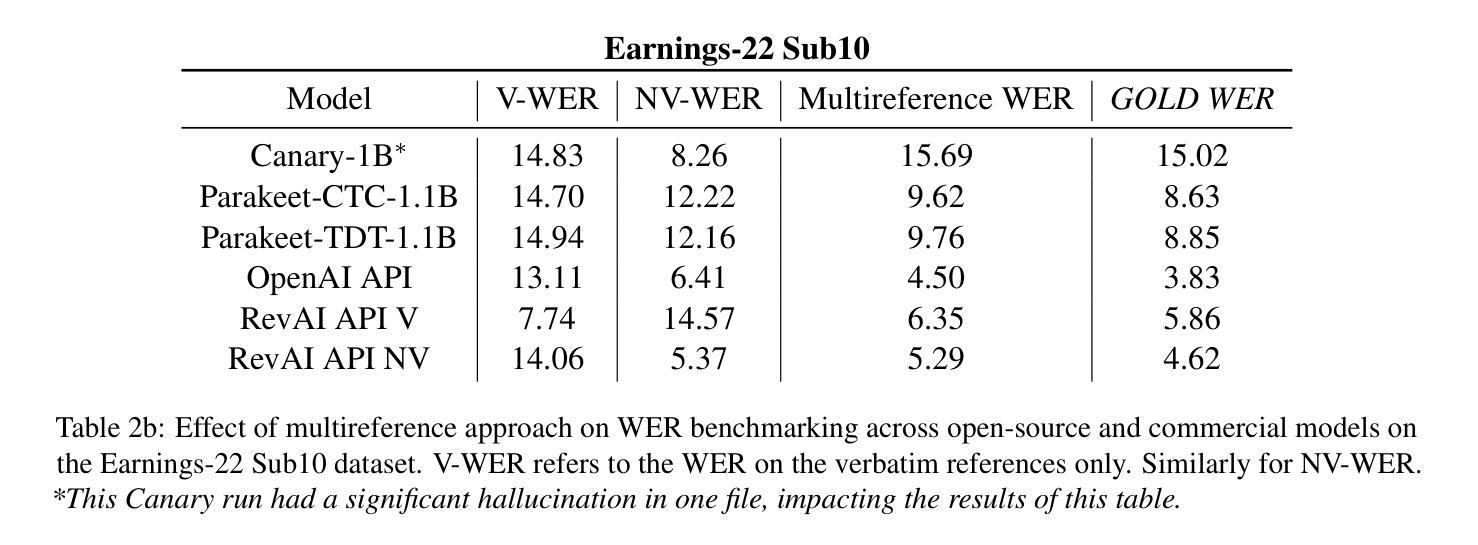
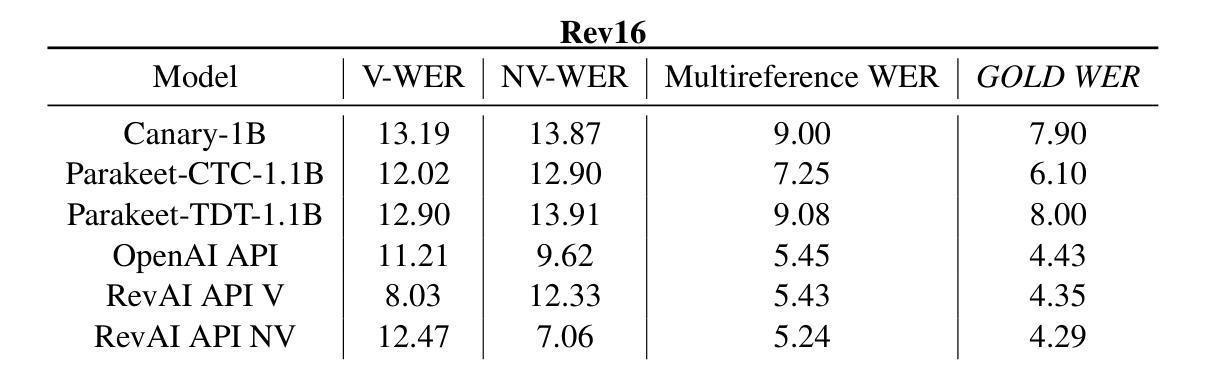
Style-agnostic evaluation of ASR using multiple reference transcripts
Authors:Quinten McNamara, Miguel Ángel del Río Fernández, Nishchal Bhandari, Martin Ratajczak, Danny Chen, Corey Miller, Migüel Jetté
Word error rate (WER) as a metric has a variety of limitations that have plagued the field of speech recognition. Evaluation datasets suffer from varying style, formality, and inherent ambiguity of the transcription task. In this work, we attempt to mitigate some of these differences by performing style-agnostic evaluation of ASR systems using multiple references transcribed under opposing style parameters. As a result, we find that existing WER reports are likely significantly over-estimating the number of contentful errors made by state-of-the-art ASR systems. In addition, we have found our multireference method to be a useful mechanism for comparing the quality of ASR models that differ in the stylistic makeup of their training data and target task.
语音识别领域的词错误率(WER)作为评价指标存在诸多局限,给语音识别领域带来了诸多困扰。评估数据集的风格、正式程度以及转录任务本身的固有模糊性各不相同。在这项工作中,我们尝试通过采用多参考方式评估ASR系统来缓解这些差异,这些参考是基于对立风格参数转录的。因此我们发现现有的WER报告很可能高估了前沿ASR系统产生的实质性错误数量。此外,我们发现我们的多参考方法对于比较不同风格的训练数据和目标任务的ASR模型质量非常有用。
论文及项目相关链接
Summary
本文指出语音识别领域中的词错误率(WER)作为评价指标存在多种局限性。评估数据集存在风格多样、形式正式与否以及转录任务本身的固有模糊性等问题。为解决这些问题,本研究通过采用多参考的转录方式,在不同风格参数下对语音识别系统进行了风格无关的评价。研究发现,现有的WER报告很可能高估了前沿语音识别系统的实质性错误数量。同时,多参考方法对于比较不同风格训练数据和目标任务的语音识别模型质量非常有用。
Key Takeaways
- 词错误率(WER)作为语音识别领域的评价指标存在局限性。
- 评估数据集的风格多样性、形式正式与否以及转录任务的模糊性是造成这些局限性的主要因素。
- 通过采用多参考的转录方式,可以在不同风格参数下进行风格无关的评价。
- 现有WER报告可能高估了前沿语音识别系统的实质性错误数量。
- 多参考方法有助于比较不同风格训练数据和目标任务的语音识别模型质量。
- 该研究尝试通过多参考方法缓解语音识别系统评价中的差异。
点此查看论文截图

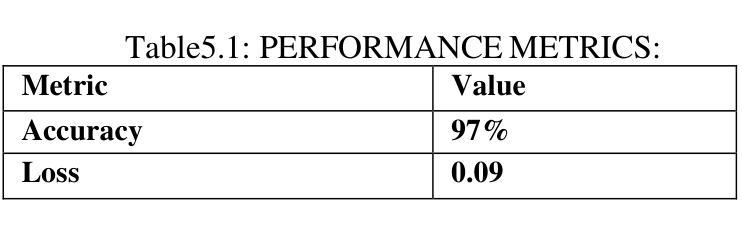
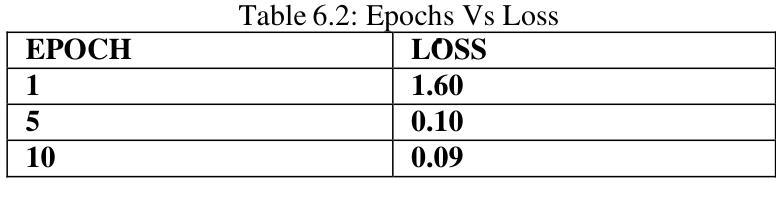
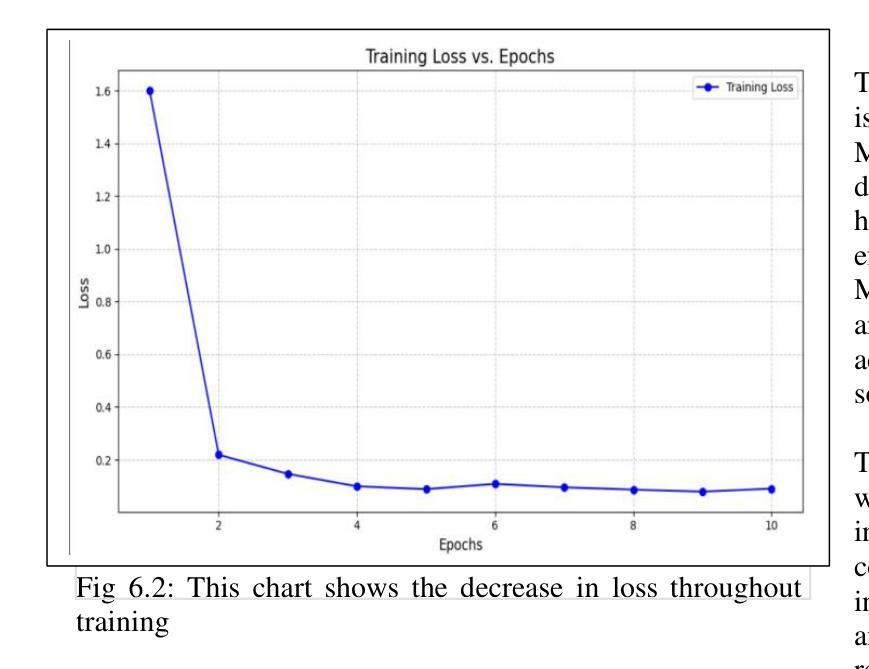
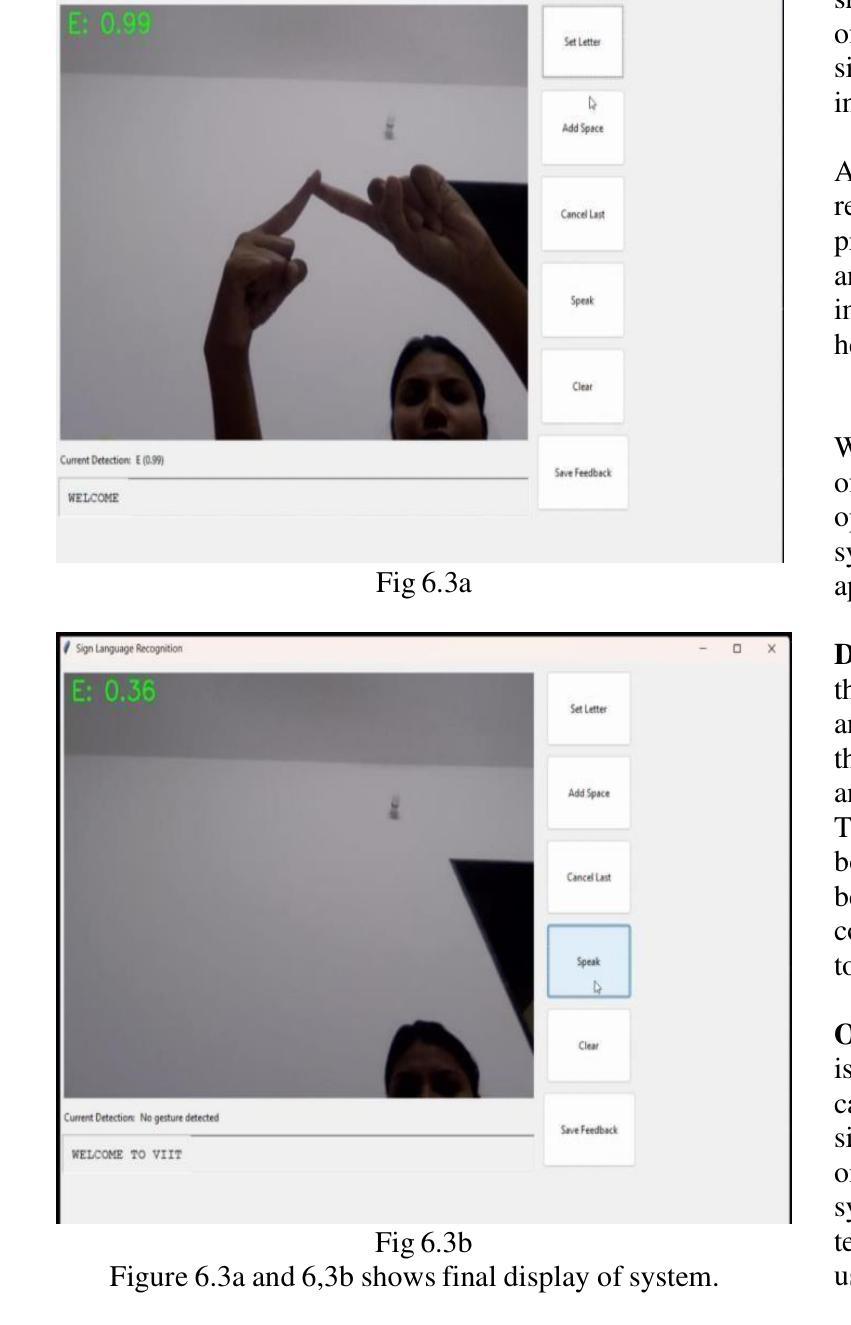
Real-time Sign Language Recognition Using MobileNetV2 and Transfer Learning
Authors:Smruti Jagtap, Kanika Jadhav, Rushikesh Temkar, Minal Deshmukh
The hearing-impaired community in India deserves the access to tools that help them communicate, however, there is limited known technology solutions that make use of Indian Sign Language (ISL) at present. Even though there are many ISL users, ISL cannot access social and education arenas because there is not yet an efficient technology to convert the ISL signal into speech or text. We initiated this initiative owing to the rising demand for products and technologies that are inclusive and help ISL, filling the gap of communication for the ones with hearing disability. Our goal is to build an reliable sign language recognition system with the help of Convolutional Neural Networks (CNN) to . By expanding communication access, we aspire toward better educational opportunities and a more inclusive society for hearing impaired people in India.
印度的听力障碍群体应当获得能够帮助他们沟通的工具。然而,目前可利用的印度手语(ISL)技术解决方案非常有限。尽管有许多使用ISL的人,但由于尚未有高效的技术将ISL信号转换为语音或文字,导致他们无法接触社会和教育的各个领域。我们发起这一倡议是因为市场对包容性和帮助ISL的产品和技术有着日益增长的需求,弥补了听力障碍者的沟通空白。我们的目标是借助卷积神经网络(CNN)建立可靠的手势识别系统。通过扩大沟通渠道,我们期望为印度的听力障碍人士提供更好的教育机会和更具包容性的社会。
论文及项目相关链接
Summary:印度的听障群体需要沟通工具,但目前印度手语(ISL)的应用技术解决方案有限。尽管有很多ISL使用者,但由于缺乏将ISL信号转换为语音或文字的有效技术,他们无法进入社会和教育的各个领域。我们发起这一倡议,旨在开发可靠的手语识别系统,利用卷积神经网络(CNN)等技术,为听障人士提供更好的教育机会和更包容的社会。
Key Takeaways:
- 听障群体需要易于沟通的辅助工具,特别是针对印度手语(ISL)的解决方案。
- 目前缺乏将ISL信号转换为语音或文字的有效技术,限制了听障人士的社交和教育机会。
- 利用卷积神经网络(CNN)建立可靠的手语识别系统是解决这一问题的关键。
- 通过扩大沟通渠道,为听障人士提供更好的教育机会。
- 提高社会对听障人士的包容性是当前的重要目标。
- 技术创新在帮助听障人士融入社会方面发挥着重要作用。
点此查看论文截图

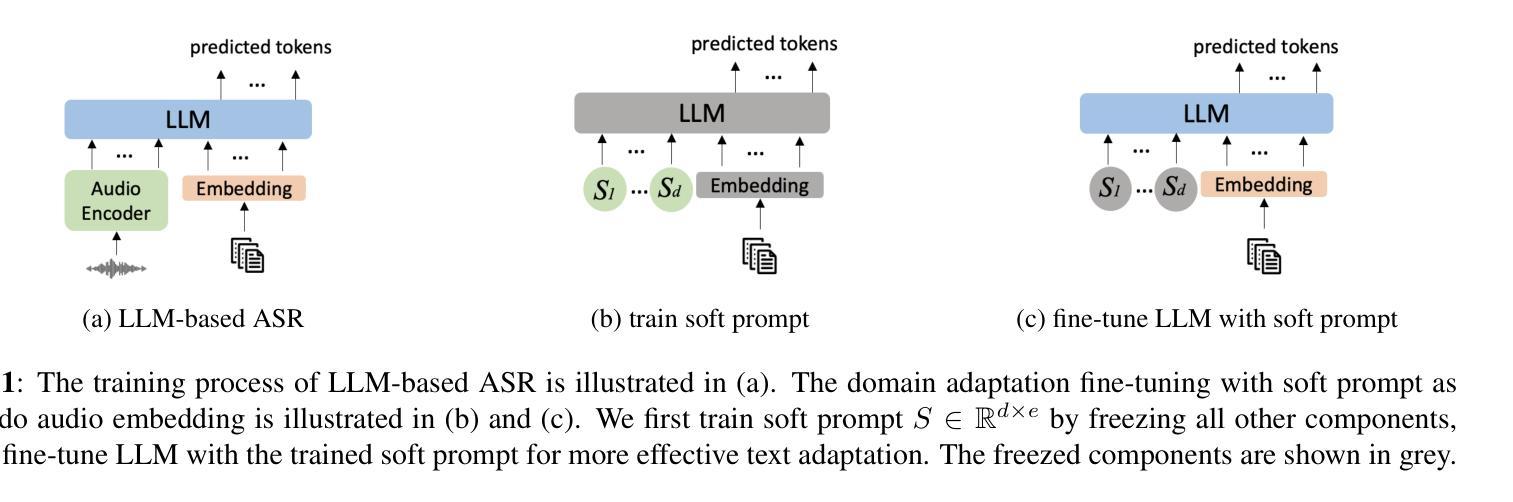
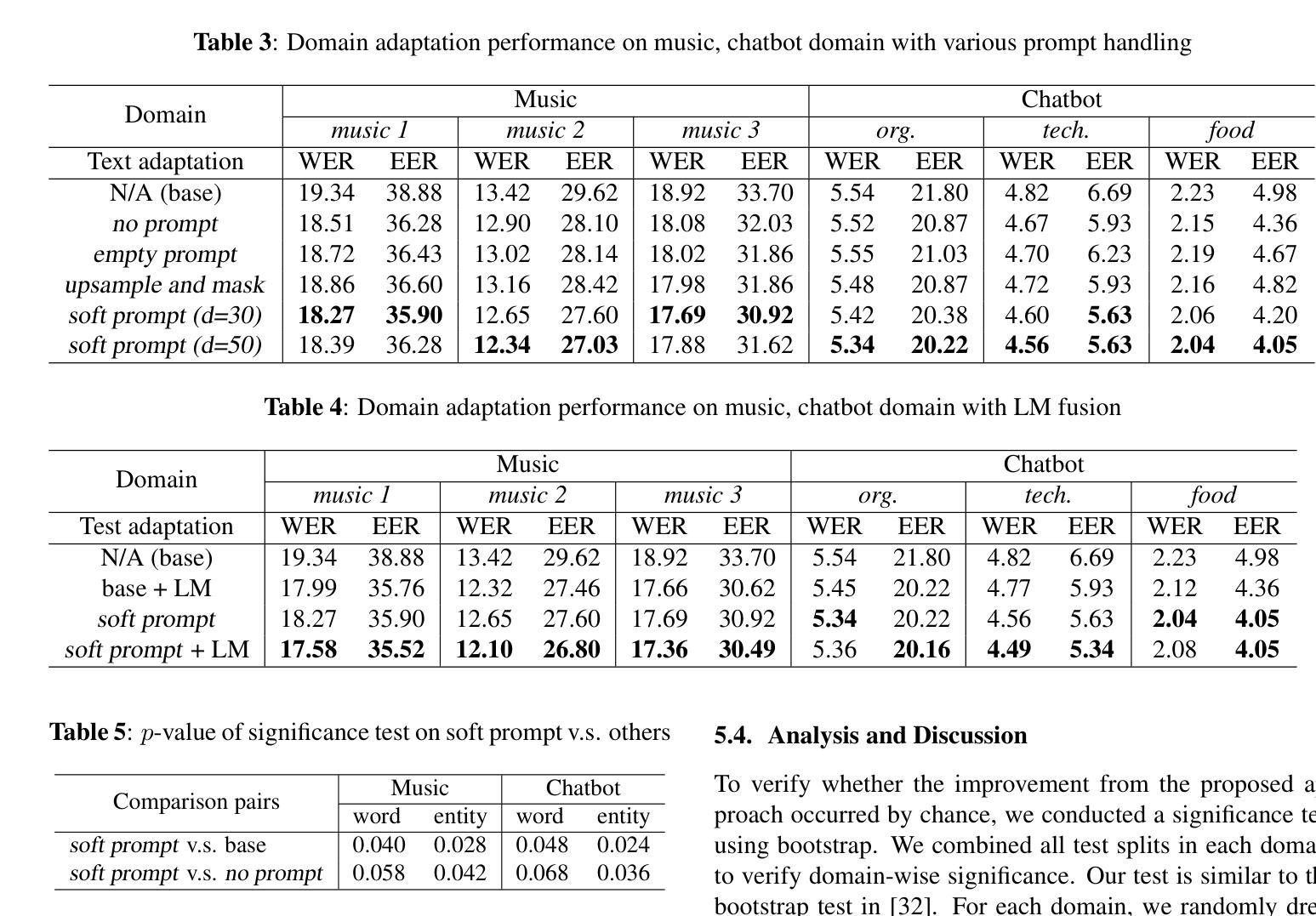
Effective Text Adaptation for LLM-based ASR through Soft Prompt Fine-Tuning
Authors:Yingyi Ma, Zhe Liu, Ozlem Kalinli
The advent of Large Language Models (LLM) has reformed the Automatic Speech Recognition (ASR). Prompting LLM with audio embeddings to generate transcriptions becomes the new state-of-the-art ASR. Despite LLMs being trained with an extensive amount of text corpora, high-quality domain-specific text data can still significantly enhance ASR performance on domain adaptation tasks. Although LLM-based ASR can naturally incorporate more text corpora by fine-tuning the LLM decoder, fine-tuning such ASR on text-only data without paired prompts may diminish the effectiveness of domain-specific knowledge. To mitigate this issue, we propose a two-step soft prompt fine-tuning strategy that enhances domain-specific text adaptation. Experimental results show that text adaptation with our proposed method achieved a relative up to 9% Word Error Rate (WER) reduction and up to 18% Entity Error Rate (EER) reduction on the target domain compared to the baseline ASR. Combining this with domain-specific Language Model (LM) fusion can further improve the EER by a relative 2-5%
大型语言模型(LLM)的出现已经改变了自动语音识别(ASR)的技术面貌。使用音频嵌入来提示LLM生成转录本已经成为最新的前沿ASR技术。尽管LLM通过大量的文本语料库进行训练,高质量、特定领域的文本数据仍然可以显著增强领域适应任务上的ASR性能。虽然基于LLM的ASR可以通过微调LLM解码器自然地融入更多的文本语料库,但在仅有文本数据的情况下对这样的ASR进行微调可能会降低特定领域知识的有效性。为了缓解这个问题,我们提出了一种分两步走的软提示微调策略,以强化特定领域的文本适应性。实验结果表明,与我们提出的方法结合进行的文本适应性训练与基线ASR相比,相对降低了高达9%的词错误率(WER)和高达18%的实体错误率(EER)。将其与特定领域的语言模型(LM)融合相结合,可以进一步相对提高2-5%的EER。
论文及项目相关链接
PDF accepted as SLT 2024 proceeding
Summary:
随着大型语言模型(LLM)的出现,自动语音识别(ASR)技术得到了革新。通过向LLM注入音频嵌入来生成转录本已成为最新的ASR技术主流。虽然LLM在大量文本语料库上进行了训练,但高质量、特定领域的文本数据仍然可以显著提高域适应任务的ASR性能。为了解决在仅文本数据上微调ASR时可能出现的问题,提出了一种两步软提示微调策略,以提高特定领域的文本适应性。实验结果表明,与基线ASR相比,使用所提出的方法在目标领域实现了相对高达9%的单词错误率(WER)降低和高达18%的实体错误率(EER)降低。结合特定领域的语言模型(LM)融合技术,可以进一步将EER相对提高2-5%。
Key Takeaways:
- 大型语言模型(LLM)的引入革新了自动语音识别(ASR)技术。
- 通过注入音频嵌入到LLM中以生成转录本已成为最新的ASR主流方法。
- 特定领域的文本数据可以显著提高ASR在域适应任务上的性能。
- 提出了一个两步软提示微调策略,以提高特定领域文本适应性。
- 与基线ASR相比,该策略实现了显著降低的单词错误率(WER)和实体错误率(EER)。
- 结合特定领域的语言模型(LM)融合技术可以进一步提高性能。
点此查看论文截图


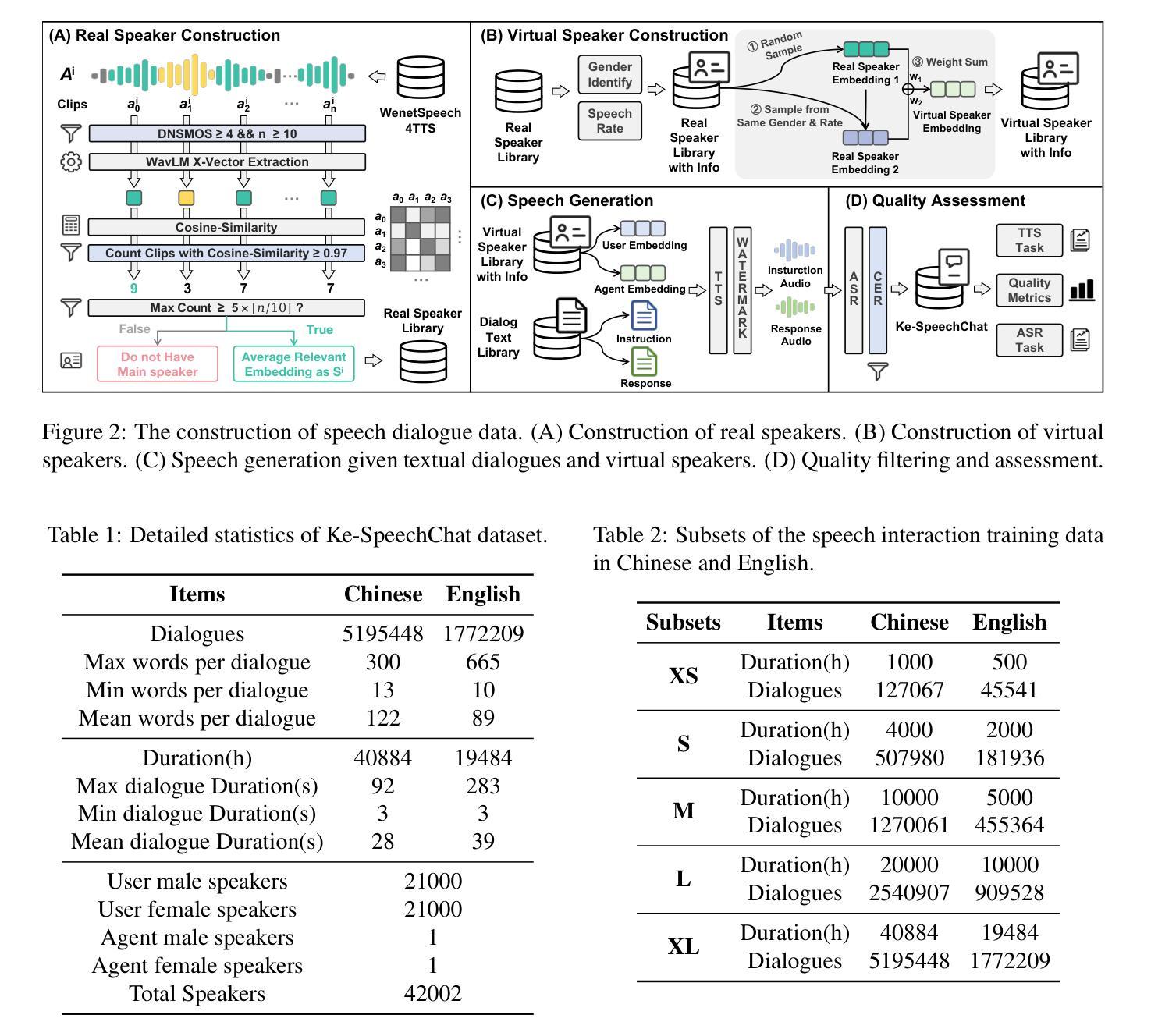
Advancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data
Authors:Shuaijiang Zhao, Tingwei Guo, Bajian Xiang, Tongtang Wan, Qiang Niu, Wei Zou, Xiangang Li
The GPT-4o represents a significant milestone in enabling real-time interaction with large language models (LLMs) through speech, its remarkable low latency and high fluency not only capture attention but also stimulate research interest in the field. This real-time speech interaction is particularly valuable in scenarios requiring rapid feedback and immediate responses, dramatically enhancing user experience. However, there is a notable lack of research focused on real-time large speech language models, particularly for Chinese. In this work, we present KE-Omni, a seamless large speech language model built upon Ke-SpeechChat, a large-scale high-quality synthetic speech interaction dataset consisting of 7 million Chinese and English conversations, featuring 42,002 speakers, and totaling over 60,000 hours, This contributes significantly to the advancement of research and development in this field. The demos can be accessed at \url{https://huggingface.co/spaces/KE-Team/KE-Omni}.
GPT-4o代表了通过语音与大型语言模型(LLM)进行实时交互的一个重要里程碑。其显著的低延迟和高流利性不仅引起了关注,还刺激了该领域的研究兴趣。这种实时语音交互在需要快速反馈和即时响应的场景中尤其有价值,能极大地提升用户体验。然而,关于实时大型语音语言模型的研究相对较少,尤其是对中文的研究。在这项工作中,我们推出了KE-Omni,这是一个无缝的大型语音语言模型,建立在Ke-SpeechChat之上。Ke-SpeechChat是一个大规模高质量合成语音交互数据集,包含700万中文和英文对话,涵盖42,002名发言者,总计超过6万小时,为该领域的研究和发展做出了重大贡献。相关演示可通过链接访问:[https://huggingface.co/spaces/KE-Team/KE-Omni]。
论文及项目相关链接
PDF KE-Omni, Ke-SpeechChat
Summary
GPT-4o在通过语音与大型语言模型(LLM)进行实时交互方面取得了重要里程碑式的进展。其显著的低延迟和高流畅性不仅引起了关注,还刺激了该领域的研究兴趣。特别是在需要快速反馈和即时响应的场景中,这种实时语音交互大大增强了用户体验。该研究团队推出的KE-Omni大型语音语言模型,基于Ke-SpeechChat数据集,包含700万中英文字符的会话数据,涉及4万多名发言者和超过6万小时的语音交互数据,对推动该领域的研究和发展具有重要意义。相关演示可通过链接访问:[链接地址]。
Key Takeaways
- GPT-4o实现了通过语音与大型语言模型的实时交互,表现出显著的低延迟和高流畅性。
- 实时语音交互在需要快速反馈和响应的场景中大幅增强了用户体验。
- KE-Omni是一个无缝的大型语音语言模型,基于Ke-SpeechChat数据集构建。
- Ke-SpeechChat数据集包含700万中英文字符的会话数据,涵盖超过6万小时的语音交互。
- 该模型涉及4万多名发言者的多样化数据,对推动相关领域的研究和发展具有重要意义。
- KE-Omni模型的演示可通过特定链接访问。
点此查看论文截图

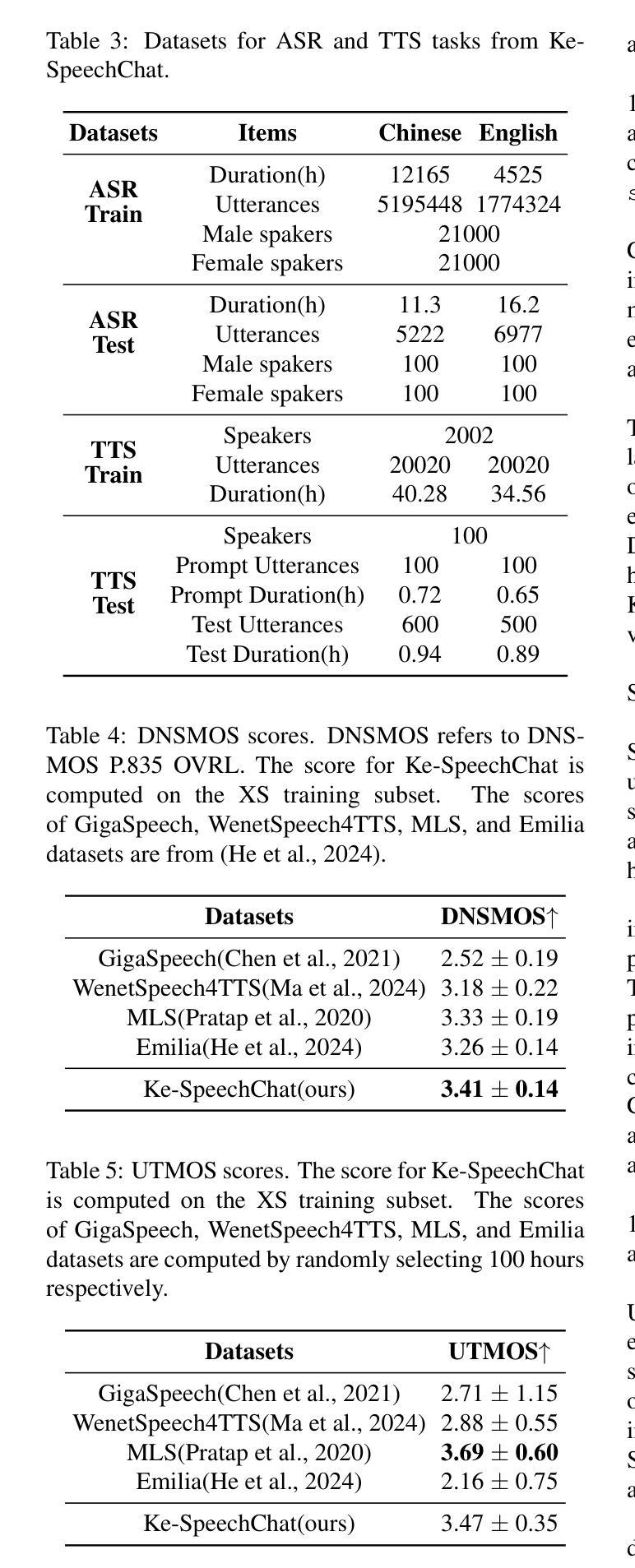
I2TTS: Image-indicated Immersive Text-to-speech Synthesis with Spatial Perception
Authors:Jiawei Zhang, Tian-Hao Zhang, Jun Wang, Jiaran Gao, Xinyuan Qian, Xu-Cheng Yin
Controlling the style and characteristics of speech synthesis is crucial for adapting the output to specific contexts and user requirements. Previous Text-to-speech (TTS) works have focused primarily on the technical aspects of producing natural-sounding speech, such as intonation, rhythm, and clarity. However, they overlook the fact that there is a growing emphasis on spatial perception of synthesized speech, which may provide immersive experience in gaming and virtual reality. To solve this issue, in this paper, we present a novel multi-modal TTS approach, namely Image-indicated Immersive Text-to-speech Synthesis (I2TTS). Specifically, we introduce a scene prompt encoder that integrates visual scene prompts directly into the synthesis pipeline to control the speech generation process. Additionally, we propose a reverberation classification and refinement technique that adjusts the synthesized mel-spectrogram to enhance the immersive experience, ensuring that the involved reverberation condition matches the scene accurately. Experimental results demonstrate that our model achieves high-quality scene and spatial matching without compromising speech naturalness, marking a significant advancement in the field of context-aware speech synthesis. Project demo page: https://spatialTTS.github.io/ Index Terms-Speech synthesis, scene prompt, spatial perception
控制语音合成的风格和特性对于适应特定的上下文和用户要求至关重要。之前的文本到语音(TTS)工作主要集中在产生自然语音的技术方面,如语调、节奏和清晰度。然而,他们忽略了这样一个事实,那就是合成语音的空间感知越来越受到重视,这可能会在游戏和虚拟现实领域提供沉浸式体验。为了解决这一问题,本文提出了一种新型的多模式TTS方法,即图像指示沉浸式文本到语音合成(I2TTS)。具体来说,我们引入了一个场景提示编码器,它将视觉场景提示直接集成到合成管道中,以控制语音生成过程。此外,我们提出了一种混响分类和细化技术,通过调整合成的梅尔频谱图来增强沉浸式体验,确保所涉及的混响条件与场景准确匹配。实验结果表明,我们的模型在不影响语音自然性的情况下实现了高质量的场景和空间匹配,标志着上下文感知语音合成领域取得了重大进展。项目演示页面:https://spatialTTS.github.io/ 索引术语-语音合成、场景提示、空间感知。
论文及项目相关链接
PDF The paper is missing some information
Summary
本文提出了一种名为I2TTS(Image-indicated Immersive Text-to-speech Synthesis)的多模态文本转语音合成新方法。该方法引入了场景提示编码器,将视觉场景提示直接集成到合成管道中,以控制语音生成过程。同时,还提出了一种混响分类和细化技术,能够调整合成的梅尔频谱图,增强了沉浸感,并确保涉及的混响条件与场景准确匹配。实验结果表明,该模型实现了高质量的场景和空间匹配,且不影响语音的自然性,标志着语境感知语音合成领域的重要进展。
Key Takeaways
- 文本转语音(TTS)技术中,除了技术方面的语音要素如语调、节奏和清晰度等,空间感知的重要性日益凸显。
- 提出了一种新型的多模态TTS方法——I2TTS,它引入场景提示编码器并结合视觉场景提示来影响语音生成。
- I2TTS通过使用混响分类和细化技术来调整合成梅尔频谱图,增强了语音的沉浸感。
- 实验证明,I2TTS模型能在不损失语音自然性的前提下实现高质量的场景和空间匹配。
- 该模型在虚拟环境和游戏等需要高度沉浸式体验的领域具有潜在应用价值。
- 项目演示页面提供了直观展示,便于进一步了解和验证该模型的实际效果。
点此查看论文截图

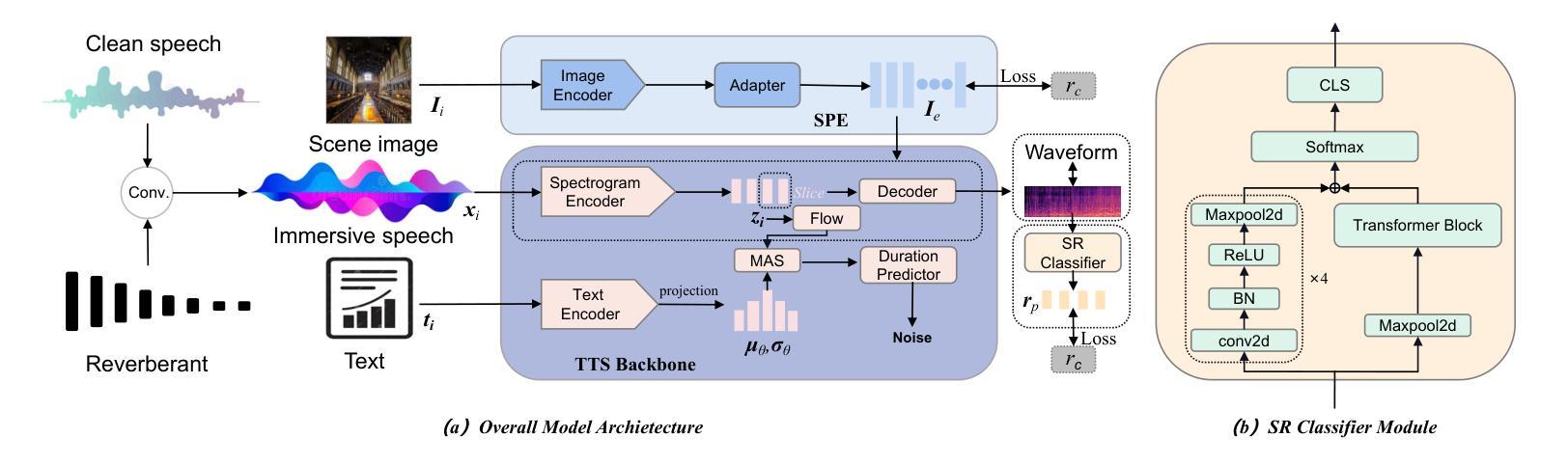
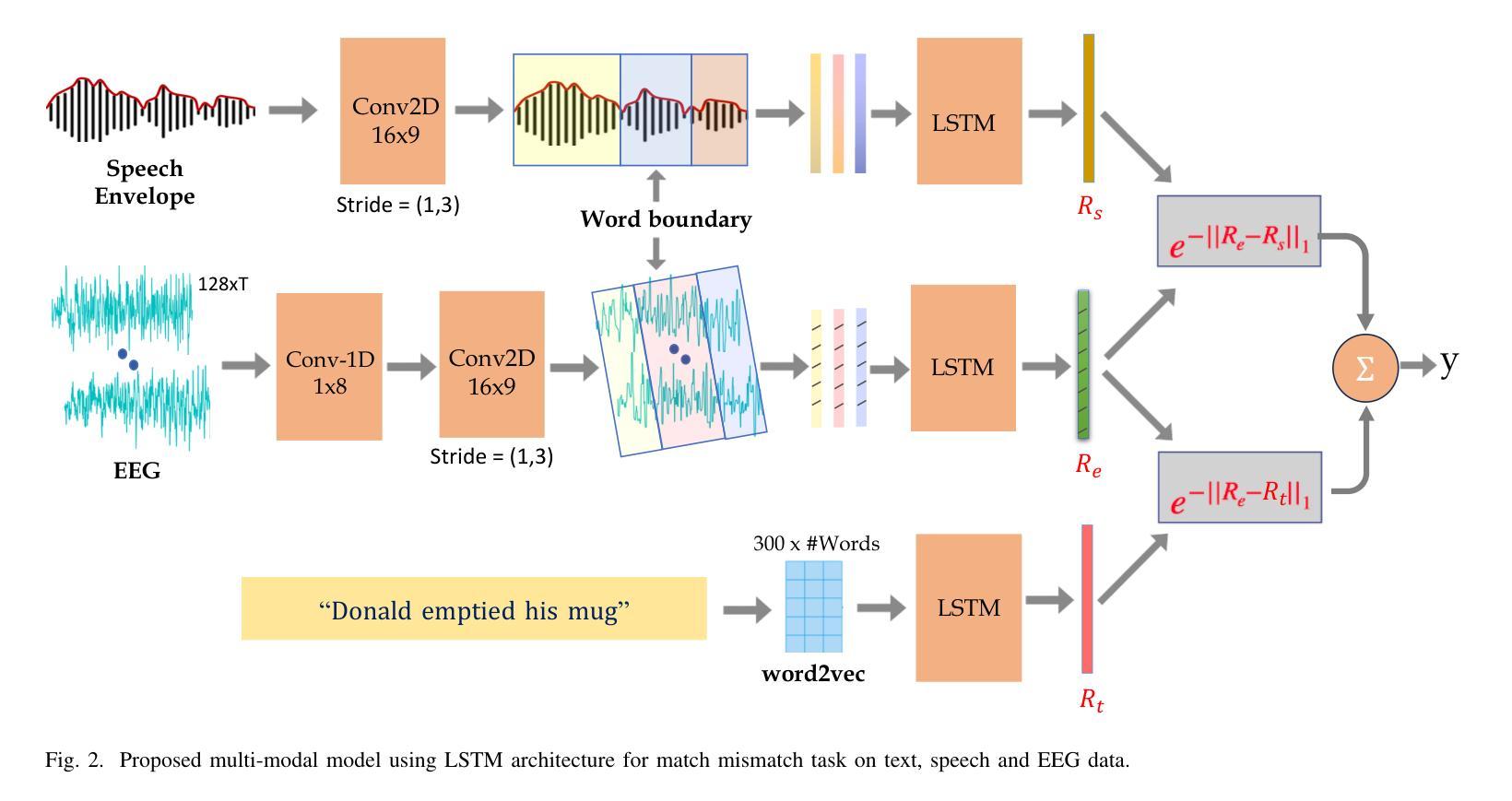
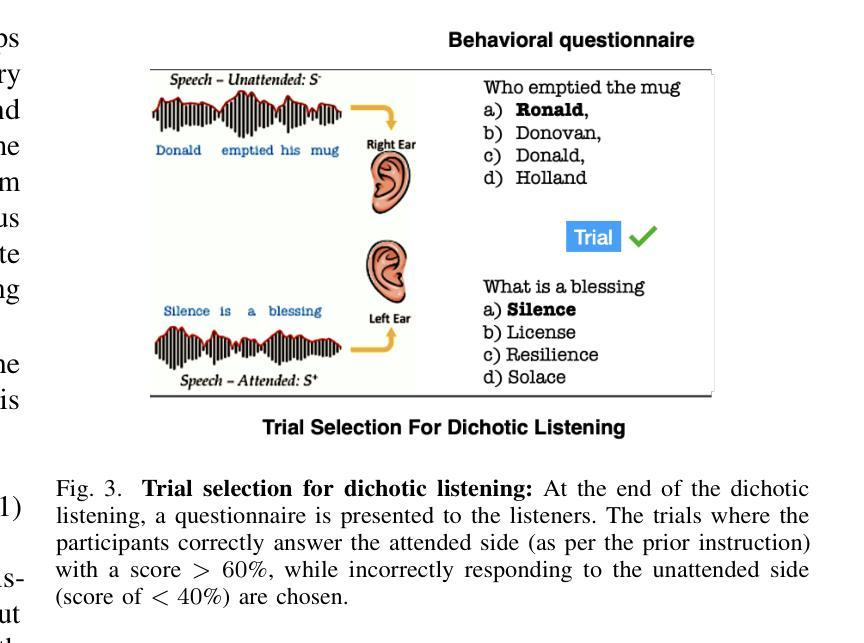
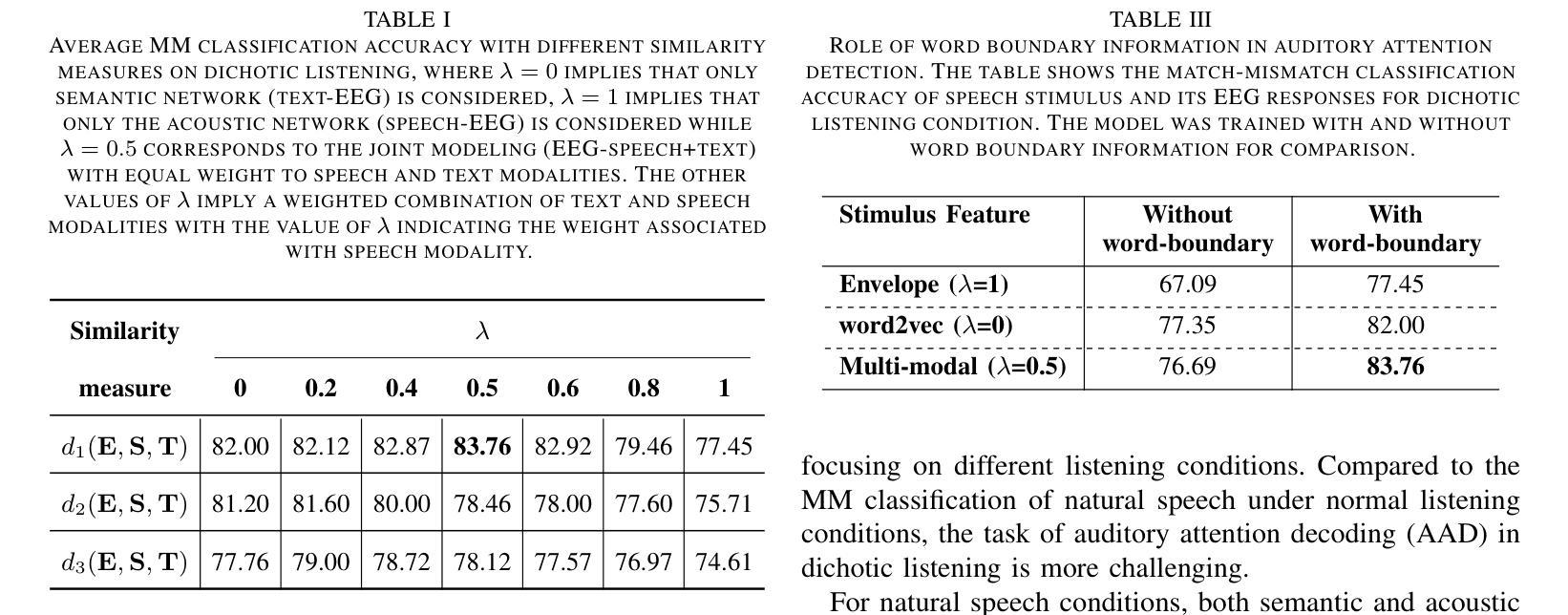
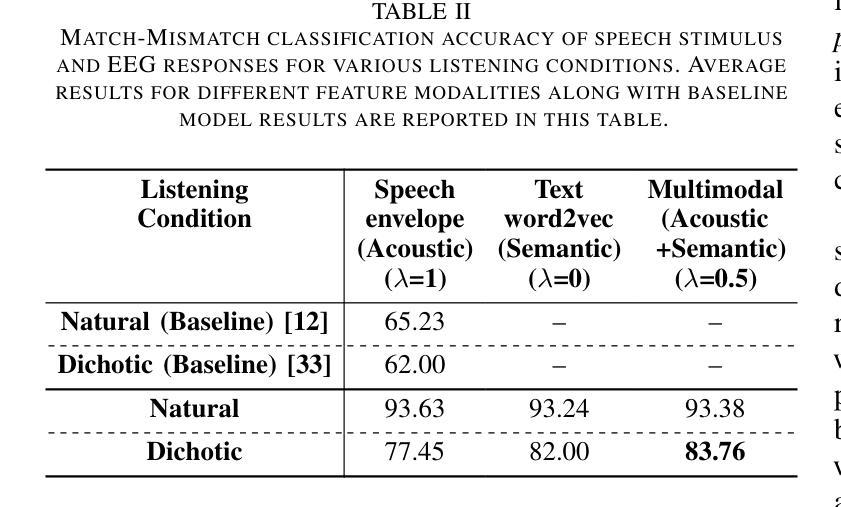
Uncovering the role of semantic and acoustic cues in normal and dichotic listening
Authors:Akshara Soman, Sai Samrat Kankanala, Sriram Ganapathy
Despite extensive research, the precise role of acoustic and semantic cues in complex speech perception tasks remains unclear. In this study, we propose a paradigm to understand the encoding of these cues in electroencephalogram (EEG) data, using match-mismatch (MM) classification task. The MM task involves determining whether the stimulus and response correspond to each other or not. We design a multi-modal sequence model, based on long short term memory (LSTM) architecture, to perform the MM task. The model is input with acoustic stimulus (derived from the speech envelope), semantic stimulus (derived from textual representations of the speech content), and neural response (derived from the EEG data). Our experiments are performed on two separate conditions, i) natural passive listening condition and, ii) an auditory attention based dichotic listening condition. Using the MM task as the analysis framework, we observe that - a) speech perception is fragmented based on word boundaries, b) acoustic and semantic cues offer similar levels of MM task performance in natural listening conditions, and c) semantic cues offer significantly improved MM classification over acoustic cues in dichotic listening task. Further, the study provides evidence of right ear advantage in dichotic listening conditions.
尽管进行了大量研究,声音和语义线索在复杂的语音感知任务中的精确作用仍不清楚。在这项研究中,我们提出了一种基于脑电图(EEG)数据编码这些线索的理解范式,采用匹配不匹配(MM)分类任务。MM任务涉及确定刺激和响应是否相互对应。我们设计了一种基于长短期记忆(LSTM)架构的多模态序列模型,以执行MM任务。该模型的输入包括声学刺激(来源于语音包络)、语义刺激(来源于语音内容的文本表示)和神经响应(来源于EEG数据)。我们的实验是在两种不同条件下进行的,即一)自然被动聆听条件,二)基于听觉注意力的二歧听辨条件。以MM任务为分析框架,我们观察到:a)语音感知是基于词界片段化的;b)在自然聆听条件下,声音和语义线索在MM任务中表现出相似的水平;c)在二歧听辨任务中,语义线索在MM分类方面显著优于声音线索。此外,该研究提供了二歧听辨条件下右耳优势的证据。
论文及项目相关链接
PDF 9 Pages, 4 Figures
Summary
该研究探讨了声音和语义线索在复杂语音感知任务中的精确作用。通过匹配-不匹配分类任务,提出一种理解这些线索在脑电图数据中的编码范式。实验采用基于LSTM架构的多模态序列模型来完成匹配-不匹配任务。实验分为自然被动聆听和基于听觉注意力的二歧听觉测试两种条件。研究观察到语音感知基于词界碎片化,在自然聆听条件下声音和语义线索的匹配度相似,而在二歧听觉任务中语义线索的匹配度显著高于声音线索。此外,研究还提供了二歧听觉条件下右耳优势的证据。
Key Takeaways
- 该研究探讨了复杂语音感知任务中声音和语义线索的精确作用。
- 采用匹配-不匹配分类任务来分析语音感知中的编码过程。
- 多模态序列模型基于LSTM架构完成匹配-不匹配任务。
- 实验在自然被动聆听和基于听觉注意力的二歧听觉测试两种条件下进行。
- 观察到语音感知基于词界碎片化。
- 在自然聆听条件下,声音和语义线索的匹配度相似;而在二歧听觉任务中,语义线索的匹配度显著高于声音线索。
点此查看论文截图

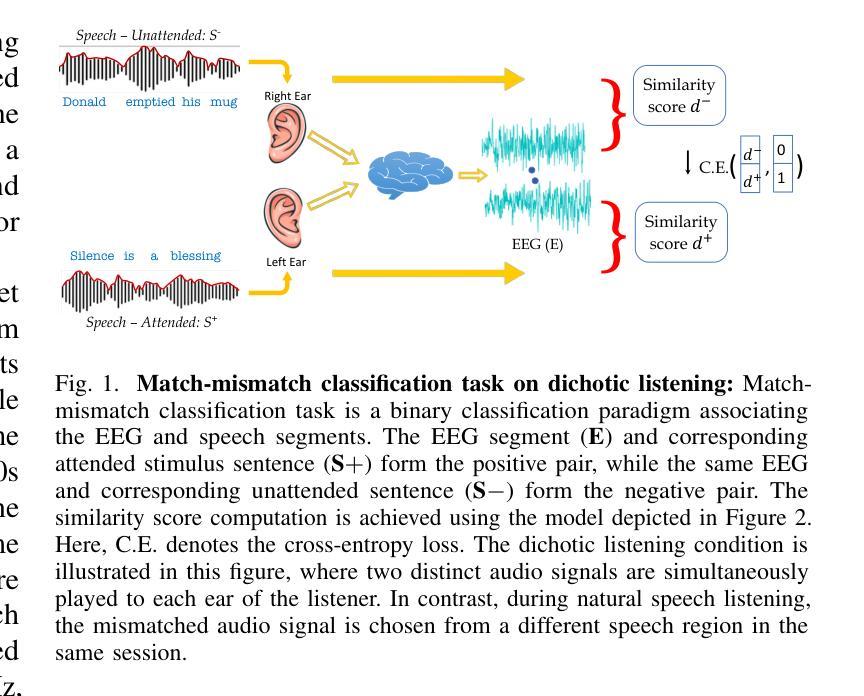
Interactive Cycle Model – The Linkage Combination among Automatic Speech Recognition, Large Language Models and Smart Glasses
Authors:Libo Wang
This research proposes the interaction loop model “ASR-LLMs-Smart Glasses”, which model combines automatic speech recognition, large language model and smart glasses to facilitate seamless human-computer interaction. And the methodology of this research involves decomposing the interaction process into different stages and elements. Speech is captured and processed by ASR, then analyzed and interpreted by LLMs. The results are then transmitted to smart glasses for display. The feedback loop is complete when the user interacts with the displayed data. Mathematical formulas are used to quantify the performance of the model that revolves around core evaluation points: accuracy, coherence, and latency during ASR speech-to-text conversion. The research results are provided theoretically to test and evaluate the feasibility and performance of the model. Detailed architectural details and experimental process have been uploaded to Github, the link is:https://github.com/brucewang123456789/GeniusTrail.git.
该研究提出了“ASR-LLMs-智能眼镜”互动循环模型,该模型结合了自动语音识别、大型语言模型和智能眼镜,以促进无缝的人机互动。而该研究方法涉及将互动过程分解成不同的阶段和元素。语音被ASR捕获并处理,然后通过LLMs进行分析和解释。结果然后传输到智能眼镜进行显示。当用户使用显示的数据进行互动时,反馈循环就完成了。使用数学公式来量化模型的表现,围绕核心评估点:ASR语音转文本的准确性、连贯性和延迟。研究结果从理论上提供了测试和评价该模型的可行性和性能。详细的架构细节和实验过程已经上传到Github,链接是:https://github.com/brucewang123456789/GeniusTrail.git。
论文及项目相关链接
PDF OpenReview submitted. 10 pages of text and 2 figures
总结
本研究提出了一个名为“ASR-LLMs-智能眼镜”的互动循环模型,该模型结合了自动语音识别、大型语言模型和智能眼镜,促进了无缝的人机互动。研究方法将互动过程分解成不同的阶段和元素。语音由ASR捕获并处理,然后通过LLMs进行分析和解释。结果再传输到智能眼镜进行显示。当用户使用显示的数据进行互动时,反馈循环就完成了。研究用数学公式对模型的性能进行了量化评估,核心评估点包括自动语音识别过程中的准确性、连贯性和延迟性。研究结果在理论上进行了测试和评价模型的可行性及性能。详细的架构和实验过程已上传至GitHub,链接为:[链接地址]。
关键见解
- 研究提出了ASR-LLMs-智能眼镜的互动循环模型,整合了自动语音识别、大型语言模型和智能眼镜技术。
- 互动过程被分解为不同的阶段和元素,包括语音捕获、处理、分析和解释,以及结果的显示和用户反馈。
- 数学公式被用于量化模型的性能,主要评估点包括准确性、连贯性和延迟性在自动语音识别过程中的表现。
- 该模型具有无缝人机互动潜力,可通过智能眼镜实现数据显示和用户互动。
- 研究结果通过理论测试,评估了模型的可行性及性能。
- 详细的模型架构和实验过程已公开在GitHub上,供公众查阅和进一步的研究。
- 该模型的应用可能为未来的人机交互方式带来革新。
点此查看论文截图

DCF-DS: Deep Cascade Fusion of Diarization and Separation for Speech Recognition under Realistic Single-Channel Conditions
Authors:Shu-Tong Niu, Jun Du, Ruo-Yu Wang, Gao-Bin Yang, Tian Gao, Jia Pan, Yu Hu
We propose a single-channel Deep Cascade Fusion of Diarization and Separation (DCF-DS) framework for back-end speech recognition, combining neural speaker diarization (NSD) and speech separation (SS). First, we sequentially integrate the NSD and SS modules within a joint training framework, enabling the separation module to leverage speaker time boundaries from the diarization module effectively. Then, to complement DCF-DS training, we introduce a window-level decoding scheme that allows the DCF-DS framework to handle the sparse data convergence instability (SDCI) problem. We also explore using an NSD system trained on real datasets to provide more accurate speaker boundaries during decoding. Additionally, we incorporate an optional multi-input multi-output speech enhancement module (MIMO-SE) within the DCF-DS framework, which offers further performance gains. Finally, we enhance diarization results by re-clustering DCF-DS outputs, improving ASR accuracy. By incorporating the DCF-DS method, we achieved first place in the realistic single-channel track of the CHiME-8 NOTSOFAR-1 challenge. We also perform the evaluation on the open LibriCSS dataset, achieving a new state-of-the-art single-channel speech recognition performance.
我们提出了一种单通道深度级联融合分舱和分离(DCF-DS)后端语音识别框架,结合了神经网络说话人分舱(NSD)和语音分离(SS)。首先,我们在联合训练框架中顺序整合NSD和SS模块,使分离模块能够有效利用分舱模块提供的说话人时间边界。然后,为了补充DCF-DS训练,我们引入了一种窗口级解码方案,以解决稀疏数据收敛不稳定(SDCI)问题,使DCF-DS框架能够处理该问题。此外,我们还探索使用在真实数据集上训练的NSD系统,以在解码过程中提供更准确的说话人边界。另外,我们在DCF-DS框架中融入了一个可选的多输入多输出语音增强模块(MIMO-SE),这带来了进一步的性能提升。最后,我们通过重新聚类DCF-DS输出,提高了分舱结果,提高了ASR准确性。通过采用DCF-DS方法,我们在CHiME-8 NOTSOFAR-1挑战的现实单通道赛道中取得第一名。我们在开放的LibriCSS数据集上进行了评估,实现了单通道语音识别的新最先进的性能。
论文及项目相关链接
Summary
本文提出了一种单通道深度级联融合分治与分离(DCF-DS)框架,用于后端语音识别。该框架结合了神经网络说话人分治(NSD)和语音分离(SS)。首先,在联合训练框架中顺序整合NSD和SS模块,使分离模块能够有效地利用分治模块的说话人时间边界。其次,为补充DCF-DS训练,引入窗口级别解码方案,以解决稀疏数据收敛不稳定(SDCI)问题。此外,探索使用在真实数据集上训练的NSD系统,以在解码过程中提供更准确的说话人边界。还可在DCF-DS框架中纳入可选的多输入多输出语音增强模块(MIMO-SE),进一步提高性能。最后,通过重新聚类DCF-DS输出,提升分治结果,提高语音识别准确率。该框架在CHiME-8 NOTSOFAR-1挑战的现实单通道赛道中取得第一名,并在公开的LibriCSS数据集上实现了最新的单通道语音识别性能。
Key Takeaways
- 提出了单通道Deep Cascade Fusion of Diarization and Separation(DCF-DS)框架,结合了神经网络说话人分治(NSD)和语音分离(SS)。
- 通过联合训练NSD和SS模块,实现了有效的信息融合,使分离模块能够利用分治模块提供的说话人时间边界。
- 引入窗口级别解码方案,解决稀疏数据收敛不稳定问题。
- 使用真实数据集训练的NSD系统,提供更为准确的说话人边界信息。
- 可选纳入多输入多输出语音增强模块(MIMO-SE),进一步提高语音识别性能。
- 通过重新聚类DCF-DS输出,提升分治结果。
点此查看论文截图

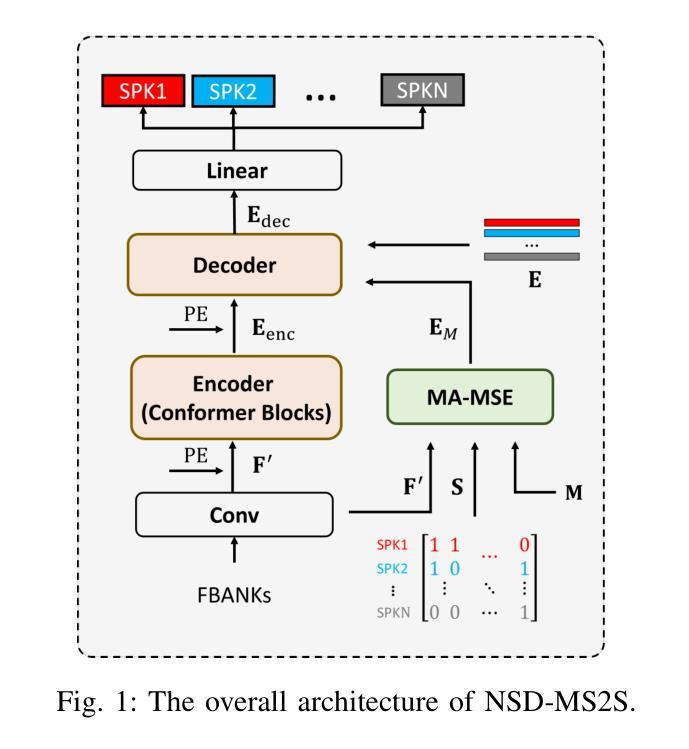
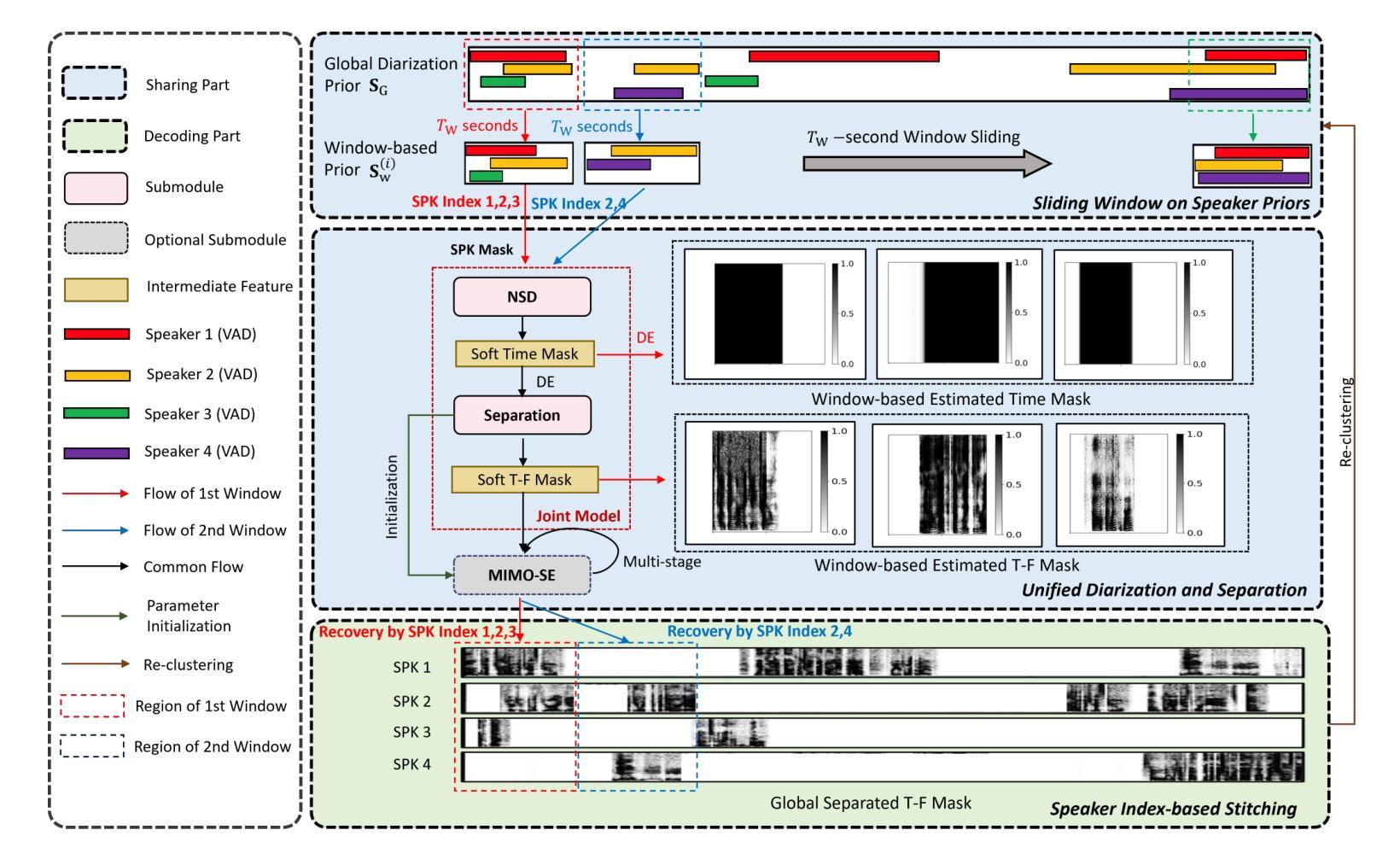
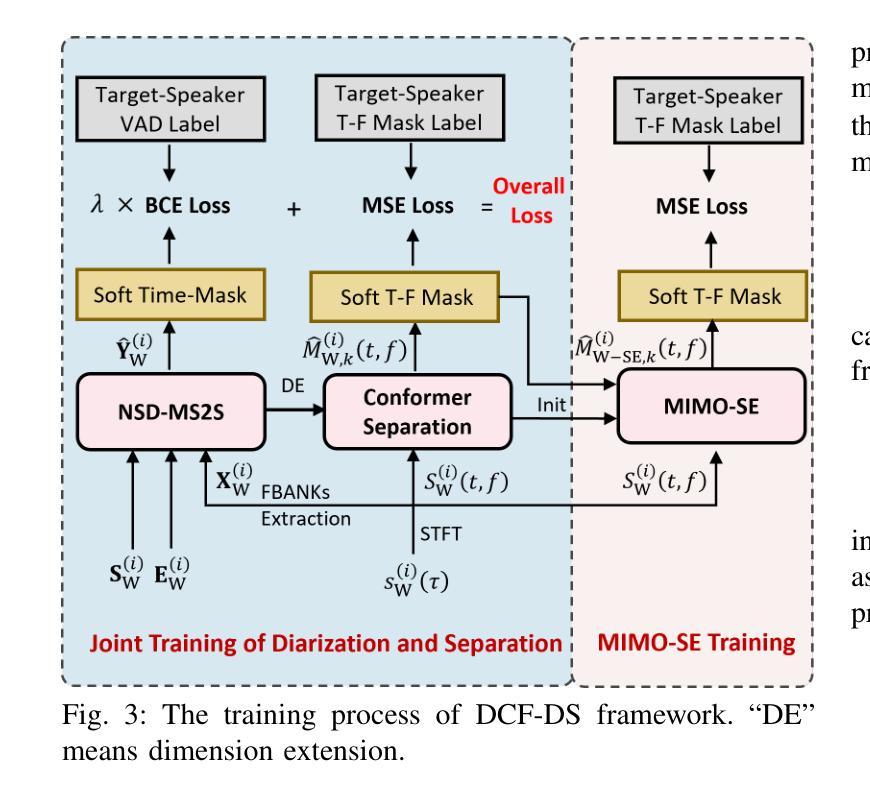
NeKo: Toward Post Recognition Generative Correction Large Language Models with Task-Oriented Experts
Authors:Yen-Ting Lin, Chao-Han Huck Yang, Zhehuai Chen, Piotr Zelasko, Xuesong Yang, Zih-Ching Chen, Krishna C Puvvada, Szu-Wei Fu, Ke Hu, Jun Wei Chiu, Jagadeesh Balam, Boris Ginsburg, Yu-Chiang Frank Wang
Construction of a general-purpose post-recognition error corrector poses a crucial question: how can we most effectively train a model on a large mixture of domain datasets? The answer would lie in learning dataset-specific features and digesting their knowledge in a single model. Previous methods achieve this by having separate correction language models, resulting in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose a Multi-Task Correction MoE, where we train the experts to become an ``expert’’ of speech-to-text, language-to-text and vision-to-text datasets by learning to route each dataset’s tokens to its mapped expert. Experiments on the Open ASR Leaderboard show that we explore a new state-of-the-art performance by achieving an average relative $5.0$% WER reduction and substantial improvements in BLEU scores for speech and translation tasks. On zero-shot evaluation, NeKo outperforms GPT-3.5 and Claude-Opus with $15.5$% to $27.6$% relative WER reduction in the Hyporadise benchmark. NeKo performs competitively on grammar and post-OCR correction as a multi-task model.
构建通用型后识别错误校正器提出了一个重要问题:我们如何在大量混合领域数据集上最有效地训练模型?答案在于学习数据集特定特征,并在单个模型中消化它们的知识。之前的方法是通过拥有独立的校正语言模型来实现这一点,这导致了参数的大量增加。在这项工作中,我们提出将混合专家(Mixture-of-Experts,MoEs)作为一种解决方案,并强调MoEs不仅仅是可扩展性工具。我们提出了一种多任务校正MoE,我们训练专家成为语音到文本、语言到文本和视觉到文本数据集的“专家”,通过学习将每个数据集的令牌路由到其映射的专家。在开放ASR排行榜上的实验表明,我们探索了一种新的最先进的性能,通过实现平均相对5.0%的WER减少和BLEU分数的实质性提高,用于语音和翻译任务。在零样本评估中,NeKo在Hyporadise基准测试中相对于GPT-3.5和Claude-Opus实现了15.5%至27.6%的相对WER减少。作为一个多任务模型,NeKo在语法和OCR后校正方面表现出竞争力。
论文及项目相关链接
PDF NeKo work has been done in June 2024. NeKo LMs will be open source on https://huggingface.co/nvidia under the MIT license
Summary
本文探讨了如何训练一个通用多领域错误校正模型。通过使用Mixture-of-Experts架构,实现了一个多任务校正模型,可以针对语音转文本、语言转文本和视觉转文本等不同领域数据集训练不同的专家模块,从而实现了在新领域的优异性能提升。在开放ASR排行榜上的实验证明了该方法的有效性,并达到了新的领先水平。在零样本评估中,NeKo模型相较于GPT-3.5和Claude-Opus展现了显著的性能优势。此外,NeKo作为一个多任务模型,在语法和OCR校正方面表现强劲。
Key Takeaways
- 文中探讨了在构建通用多领域错误校正模型时面临的挑战。模型需要能够在多种不同领域的数据集上进行训练并学习相应的特定特征。Mixture-of-Experts架构作为解决该问题的关键工具。实验表明这种架构使得模型能够更好地处理多个领域的错误校正任务。对于语音转文本、语言转文本和视觉转文本等不同领域数据集,训练不同的专家模块以提高性能。
- 该研究提出了一种多任务校正模型,该模型能够在多个任务上表现良好,包括语音识别、翻译等任务。这种多任务模型允许模型在多个领域之间共享知识,从而提高性能。该模型在语法和OCR校正方面也表现出了很强的性能。对于处理各种任务中的不同问题提供了一种统一的解决方案框架。例如该模型能够将错误校正和OCR处理过程融合在一起形成一套完整的系统来处理复杂的任务场景。例如文档数字化或智能语音识别等应用场景中的文字识别和修正过程能够使用该框架来协同处理复杂场景中的多种问题挑战提高整个系统的性能和准确性。这对于解决复杂的实际应用场景中的错误修正问题具有潜在的价值和意义。例如在文档数字化或智能语音识别等应用中可以通过集成该框架来构建更为强大的系统提高性能和准确性同时提高用户体验和客户满意度通过整合不同的专家模块提高整个系统的性能并且可以在多个领域之间实现协同作用。
点此查看论文截图

Dialectal Coverage And Generalization in Arabic Speech Recognition
Authors:Amirbek Djanibekov, Hawau Olamide Toyin, Raghad Alshalan, Abdullah Alitr, Hanan Aldarmaki
Developing robust automatic speech recognition (ASR) systems for Arabic, a language characterized by its rich dialectal diversity and often considered a low-resource language in speech technology, demands effective strategies to manage its complexity. This study explores three critical factors influencing ASR performance: the role of dialectal coverage in pre-training, the effectiveness of dialect-specific fine-tuning compared to a multi-dialectal approach, and the ability to generalize to unseen dialects. Through extensive experiments across different dialect combinations, our findings offer key insights towards advancing the development of ASR systems for pluricentric languages like Arabic.
开发针对阿拉伯语的稳健自动语音识别(ASR)系统,需要应对其丰富的方言多样性和在语音技术中常被视为资源匮乏的语言所带来的挑战。这要求采用有效的策略来管理其复杂性。本研究探讨了影响ASR性能的三个关键因素:预训练中的方言覆盖作用、与多方言方法相比特定方言微调的有效性,以及推广未见方言的能力。通过在不同方言组合上进行的大量实验,我们的研究结果为推进针对阿拉伯等多中心语言开发ASR系统提供了关键见解。
论文及项目相关链接
Summary
本研究探讨了影响阿拉伯语自动语音识别(ASR)系统性能的三个关键因素:预训练中的方言覆盖、方言特定微调与多方言方法的有效性,以及泛化到未见方言的能力。通过对不同方言组合进行的大量实验,为阿拉伯等多中心语言ASR系统的发展提供了关键见解。
Key Takeaways
- 方言覆盖在预训练中的重要性:对于阿拉伯语等方言多样的语言,预训练模型需要涵盖广泛的方言,以提高ASR系统的性能。
- 方言特定微调与多方言方法的效果比较:研究结果显示,针对特定方言的微调可能比在多种方言中使用单一模型的方法更有效。
- 泛化到未见方言的能力:ASR系统应具备良好的泛化能力,以应对未接触过的方言。
- 阿拉伯语作为低资源语言在语音识别技术中的挑战:由于阿拉伯语的方言多样性和资源有限,开发适用于该语言的ASR系统具有挑战性。
- 实证研究在方言组合上的发现:通过大量实验,研究团队获得了关于不同方言组合下ASR系统性能的深入理解。
- 公多中心语言(如阿拉伯语)在语音识别发展中的特殊考虑:对于这类语言,需要特别考虑其方言多样性和语言特性,以开发更有效的ASR系统。
点此查看论文截图

pTSE-T: Presentation Target Speaker Extraction using Unaligned Text Cues
Authors:Ziyang Jiang, Xinyuan Qian, Jiahe Lei, Zexu Pan, Wei Xue, Xu-cheng Yin
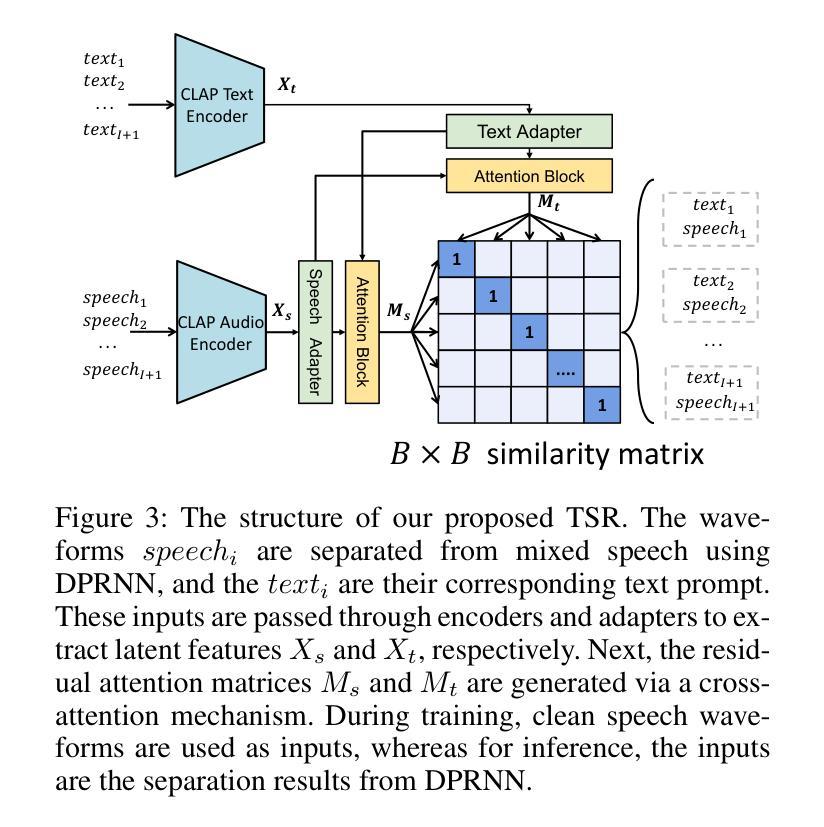
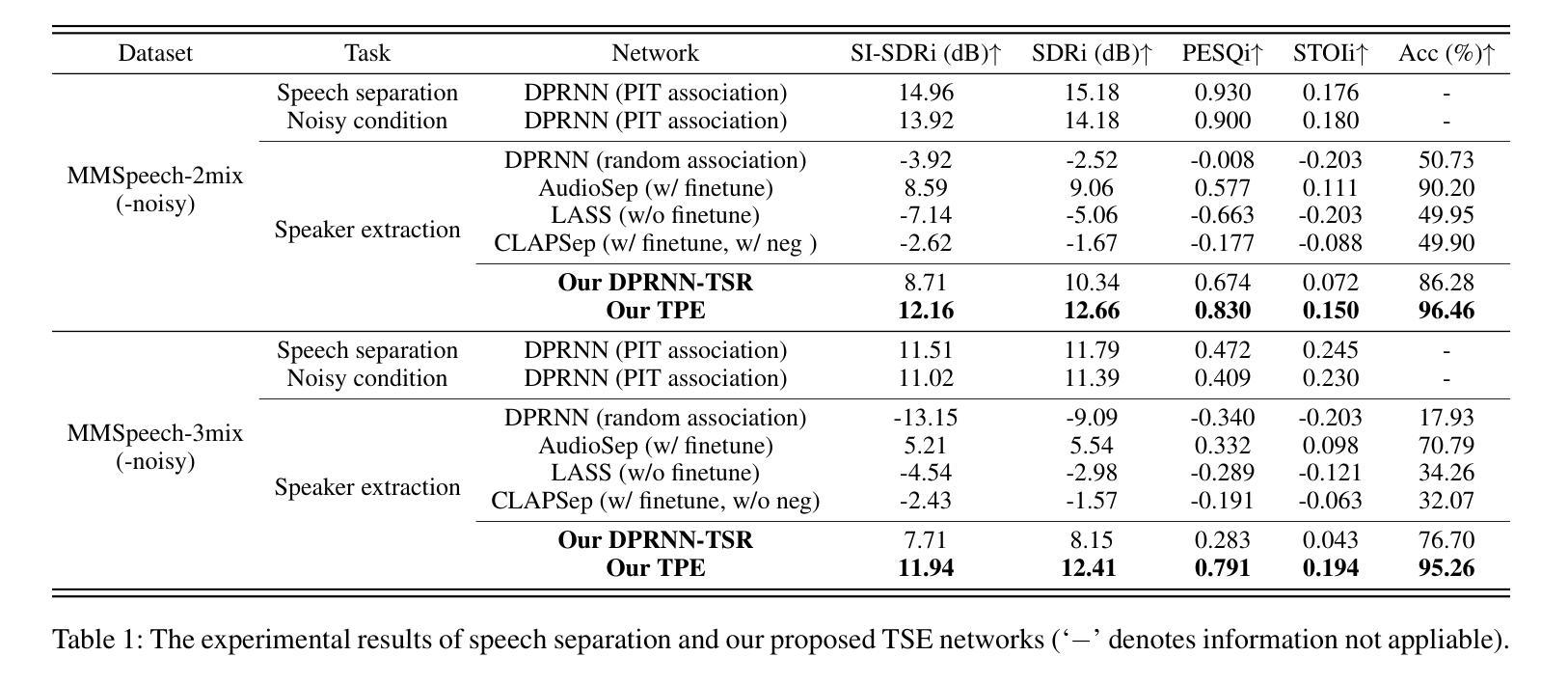
TSE(Target Speaker Extraction) aims to extract the clean speech of the target speaker in an audio mixture, thus eliminating irrelevant background noise and speech. While prior work has explored various auxiliary cues including pre-recorded speech, visual information (e.g., lip motions and gestures), and spatial information, the acquisition and selection of such strong cues are infeasible in many practical scenarios. Unlike all existing work, in this paper, we condition the TSE algorithm on semantic cues extracted from limited and unaligned text content, such as condensed points from a presentation slide. This method is particularly useful in scenarios like meetings, poster sessions, or lecture presentations, where acquiring other cues in real-time is challenging. To this end, we design two different networks. Specifically, our proposed TPE fuses audio features with content-based semantic cues to facilitate time-frequency mask generation to filter out extraneous noise, while another proposal, namely TSR, employs the contrastive learning technique to associate blindly separated speech signals with semantic cues. The experimental results show the efficacy in accurately identifying the target speaker by utilizing semantic cues derived from limited and unaligned text, resulting in SI-SDRi of 12.16 dB, SDRi of 12.66 dB, PESQi of 0.830 and STOIi of 0.150, respectively. Dataset and source code will be publicly available. Project demo page: https://slideTSE.github.io/.
目标说话者提取(TSE)旨在从音频混合物中提取目标说话者的清晰语音,从而消除无关的背景噪声和语音。虽然之前的研究已经探索了各种辅助线索,包括预先记录的语音、视觉信息(例如嘴唇运动和手势)以及空间信息,但在许多实际场景中,这些强烈线索的获取和选择都是不可行的。与所有现有工作不同,本文中,我们将TSE算法建立在从有限且未对齐的文本内容中提取的语义线索之上,例如幻灯片中的浓缩要点。这种方法在会议、海报会议或讲座等场景中特别有用,在这些场景中,实时获取其他线索具有挑战性。为此,我们设计了两种不同的网络。具体来说,我们提出的TPE将音频特征与基于内容的语义线索融合,有助于生成时间频率掩码以过滤掉额外的噪音,而另一项提议TSR则采用对比学习技术将盲分离语音信号与语义线索联系起来。实验结果表明,利用有限且未对齐的文本中提取的语义线索准确识别目标说话者,取得了很好的效果,具体表现为SI-SDRi为12.16 dB,SDRi为12.66 dB,PESQi为0.830,STOIi为0.150。数据集和源代码将公开可用。项目演示页面为:https://slideTSE.github.io/。
论文及项目相关链接
Summary
本文介绍了一种基于文本语义线索的目标语音提取方法,该方法能够从音频混合中提取目标说话人的干净语音,同时消除无关的背景噪声和语音。该方法不同于以往依赖辅助线索的工作,而是利用从有限的未对齐文本内容中提取的语义线索来条件化TSE算法。在会议、海报会议或讲座等场景中,这种方法尤其有用,因为这些场景中实时获取其他线索具有挑战性。实验结果表明,该方法在利用来自有限未对齐文本的语义线索准确识别目标说话人方面非常有效。
Key Takeaways
- TSE(目标语音提取)旨在从音频混合中提取目标说话人的干净语音,消除无关背景噪声和语音。
- 现有工作主要依赖预录语音、视觉信息(如嘴唇运动和手势)和空间信息等辅助线索。
- 本文提出一种基于文本语义线索的条件化TSE算法,适用于会议、海报会议和讲座等场景。
- 设计了两种网络:TPE通过融合音频特征和基于内容的语义线索来生成时间-频率掩码,过滤掉额外噪声;TSR采用对比学习技术将盲分离语音信号与语义线索相关联。
- 实验结果表明,利用来自有限未对齐文本的语义线索,该方法能有效准确识别目标说话人。
- 该方法的性能通过SI-SDRi、SDRi、PESQi和STOIi等指标进行评估,分别达到了12.16 dB、12.66 dB、0.830和0.150。
点此查看论文截图

Speech Separation with Pretrained Frontend to Minimize Domain Mismatch
Authors:Wupeng Wang, Zexu Pan, Xinke Li, Shuai Wang, Haizhou Li
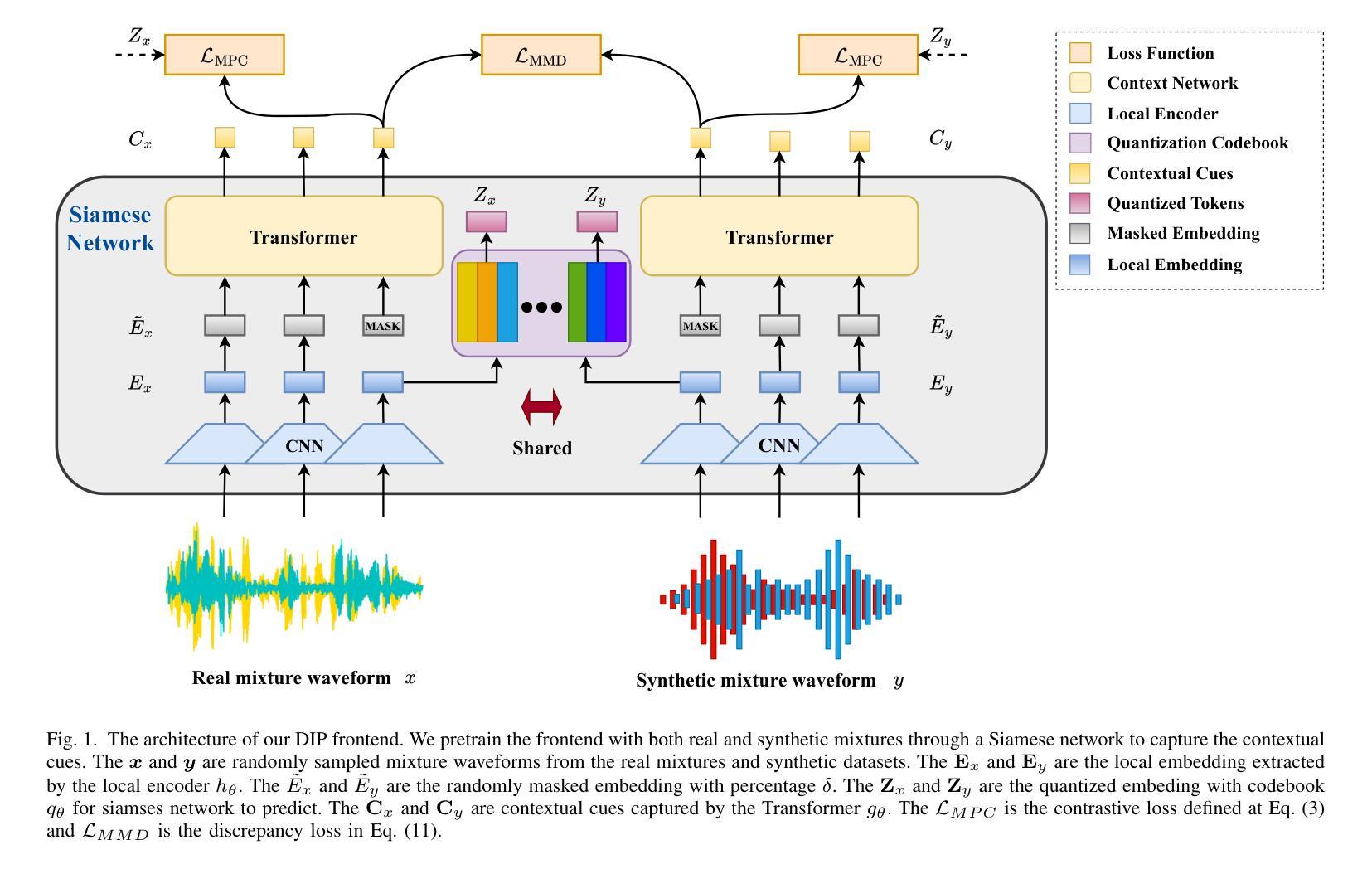
Speech separation seeks to separate individual speech signals from a speech mixture. Typically, most separation models are trained on synthetic data due to the unavailability of target reference in real-world cocktail party scenarios. As a result, there exists a domain gap between real and synthetic data when deploying speech separation models in real-world applications. In this paper, we propose a self-supervised domain-invariant pretrained (DIP) frontend that is exposed to mixture data without the need for target reference speech. The DIP frontend utilizes a Siamese network with two innovative pretext tasks, mixture predictive coding (MPC) and mixture invariant coding (MIC), to capture shared contextual cues between real and synthetic unlabeled mixtures. Subsequently, we freeze the DIP frontend as a feature extractor when training the downstream speech separation models on synthetic data. By pretraining the DIP frontend with the contextual cues, we expect that the speech separation skills learned from synthetic data can be effectively transferred to real data. To benefit from the DIP frontend, we introduce a novel separation pipeline to align the feature resolution of the separation models. We evaluate the speech separation quality on standard benchmarks and real-world datasets. The results confirm the superiority of our DIP frontend over existing speech separation models. This study underscores the potential of large-scale pretraining to enhance the quality and intelligibility of speech separation in real-world applications.
语音分离旨在从语音混合物中分离出单个语音信号。通常,由于现实鸡尾酒会场景中的目标参考无法获得,大多数分离模型都是在合成数据上进行训练的。因此,在将语音分离模型部署到现实应用时,存在真实数据和合成数据之间的领域差异。在本文中,我们提出了一种无需目标参考语音的混合数据自我监督领域不变预训练(DIP)前端。DIP前端采用Siamese网络,并引入两个创新的前置任务,即混合预测编码(MPC)和混合不变编码(MIC),以捕获真实和合成无标签混合物之间的共享上下文线索。随后,我们在合成数据上训练下游语音分离模型时,将DIP前端冻结为特征提取器。通过利用上下文线索对DIP前端进行预训练,我们希望从合成数据上学到的语音分离技能可以有效地转移到真实数据上。为了受益于DIP前端,我们引入了一种新颖的分离管道,以对齐分离模型的特征分辨率。我们在标准基准测试和实际数据集中评估了语音分离质量。结果证实,我们的DIP前端优于现有的语音分离模型。本研究强调了大规模预训练在提高现实应用中语音分离的音质和清晰度方面的潜力。
论文及项目相关链接
PDF IEEE/ACM Transactions on Audio, Speech, and Language Processing
Summary
本文提出一种无需目标参考语音的自监督域不变预训练(DIP)前端,用于现实世界的语音分离应用。DIP前端通过混合预测编码(MPC)和混合不变编码(MIC)两个创新的前置任务,捕捉真实和合成无标签混合物之间的共享上下文线索。在合成数据上训练下游语音分离模型时,将DIP前端冻结为特征提取器。通过预训练DIP前端,期望从合成数据学习的语音分离技能可以有效地转移到真实数据。为了利用DIP前端,引入了一种新的分离管道,以对齐分离模型的特征分辨率。在标准基准测试和真实世界数据集上评估了语音分离质量,证实了DIP前端优于现有语音分离模型。
Key Takeaways
- 语音分离旨在从语音混合物中分离出单个语音信号。
- 由于现实世界中鸡尾酒会的目标参考不可用,大多数分离模型通常在合成数据上进行训练。
- 提出了一个自监督的域不变预训练(DIP)前端,可以直接接触混合数据,无需目标参考语音。
- DIP前端使用Siamese网络,并通过两个创新的前置任务——混合预测编码(MPC)和混合不变编码(MIC)——来捕捉真实和合成无标签混合物之间的共享上下文线索。
- 在合成数据上训练下游语音分离模型时,将DIP前端冻结为特征提取器,以实现从合成数据到真实数据的技能转移。
- 为了利用DIP前端,引入了一种新的语音分离管道,以对齐分离模型的特征分辨率。
点此查看论文截图

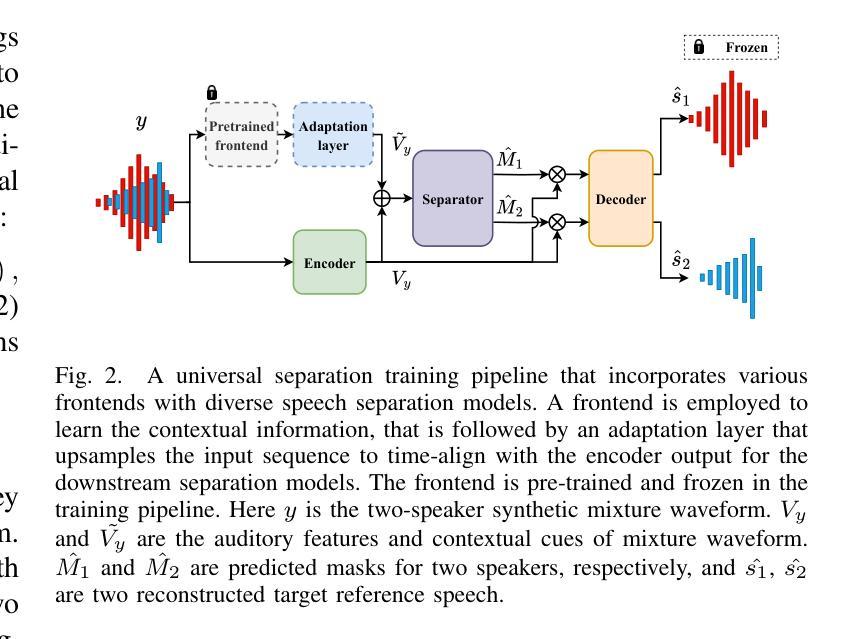
Unified Speech Recognition: A Single Model for Auditory, Visual, and Audiovisual Inputs
Authors:Alexandros Haliassos, Rodrigo Mira, Honglie Chen, Zoe Landgraf, Stavros Petridis, Maja Pantic
Research in auditory, visual, and audiovisual speech recognition (ASR, VSR, and AVSR, respectively) has traditionally been conducted independently. Even recent self-supervised studies addressing two or all three tasks simultaneously tend to yield separate models, leading to disjoint inference pipelines with increased memory requirements and redundancies. This paper proposes unified training strategies for these systems. We demonstrate that training a single model for all three tasks enhances VSR and AVSR performance, overcoming typical optimisation challenges when training from scratch. Moreover, we introduce a greedy pseudo-labelling approach to more effectively leverage unlabelled samples, addressing shortcomings in related self-supervised methods. Finally, we develop a self-supervised pre-training method within our framework, proving its effectiveness alongside our semi-supervised approach. Despite using a single model for all tasks, our unified approach achieves state-of-the-art performance compared to recent methods on LRS3 and LRS2 for ASR, VSR, and AVSR, as well as on the newly released WildVSR dataset. Code and models are available at https://github.com/ahaliassos/usr.
关于听觉、视觉和视听语音识别(ASR、VSR和AVSR)的研究传统上是独立进行的。即使最近同时解决两个或所有三个任务的自监督研究也倾向于产生单独的模型,导致分离的推理管道,增加了内存需求和冗余。本文提出了针对这些系统的统一训练策略。我们证明了训练一个模型来完成所有三个任务可以提高VSR和AVSR的性能,克服从头开始训练时的典型优化挑战。此外,我们引入了一种贪婪的伪标签方法,以更有效地利用未标记样本,解决相关自监督方法的不足。最后,我们在我们的框架内开发了一种自监督预训练方法,证明其与我们的半监督方法同样有效。尽管使用一个模型来完成所有任务,但我们的统一方法相较于在ASR、VSR和AVSR的LRS3和LRS2以及新发布的WildVSR数据集上的最新方法,实现了最先进的性能。代码和模型可在https://github.com/ahaliassos/usr找到。
论文及项目相关链接
PDF NeurIPS 2024. Code: https://github.com/ahaliassos/usr
Summary
本文提出统一训练策略,将听觉、视觉和视听语音识别(ASR、VSR和AVSR)三个任务进行联合训练。研究结果表明,单一模型同时处理三个任务能提升VSR和AVSR性能,克服从头开始训练的优化挑战。此外,引入贪婪伪标签方法,更有效地利用未标注样本,解决相关自监督方法的不足。在LRS3、LRS2和全新发布的WildVSR数据集上,该统一方法相较于最新方法取得了先进性能。
Key Takeaways
- 研究提出了统一的训练策略,将听觉、视觉和视听语音识别任务进行联合训练。
- 使用单一模型同时处理三个任务,可以提高VSR和AVSR的性能。
- 引入贪婪伪标签方法,更有效地利用未标注样本。
- 该方法克服了从头开始训练的优化挑战。
- 在多个数据集(包括LRS3、LRS2和WildVSR)上,该统一方法取得了先进性能。
- 研究结果证明了该框架内自监督预训练方法的有效性。
点此查看论文截图

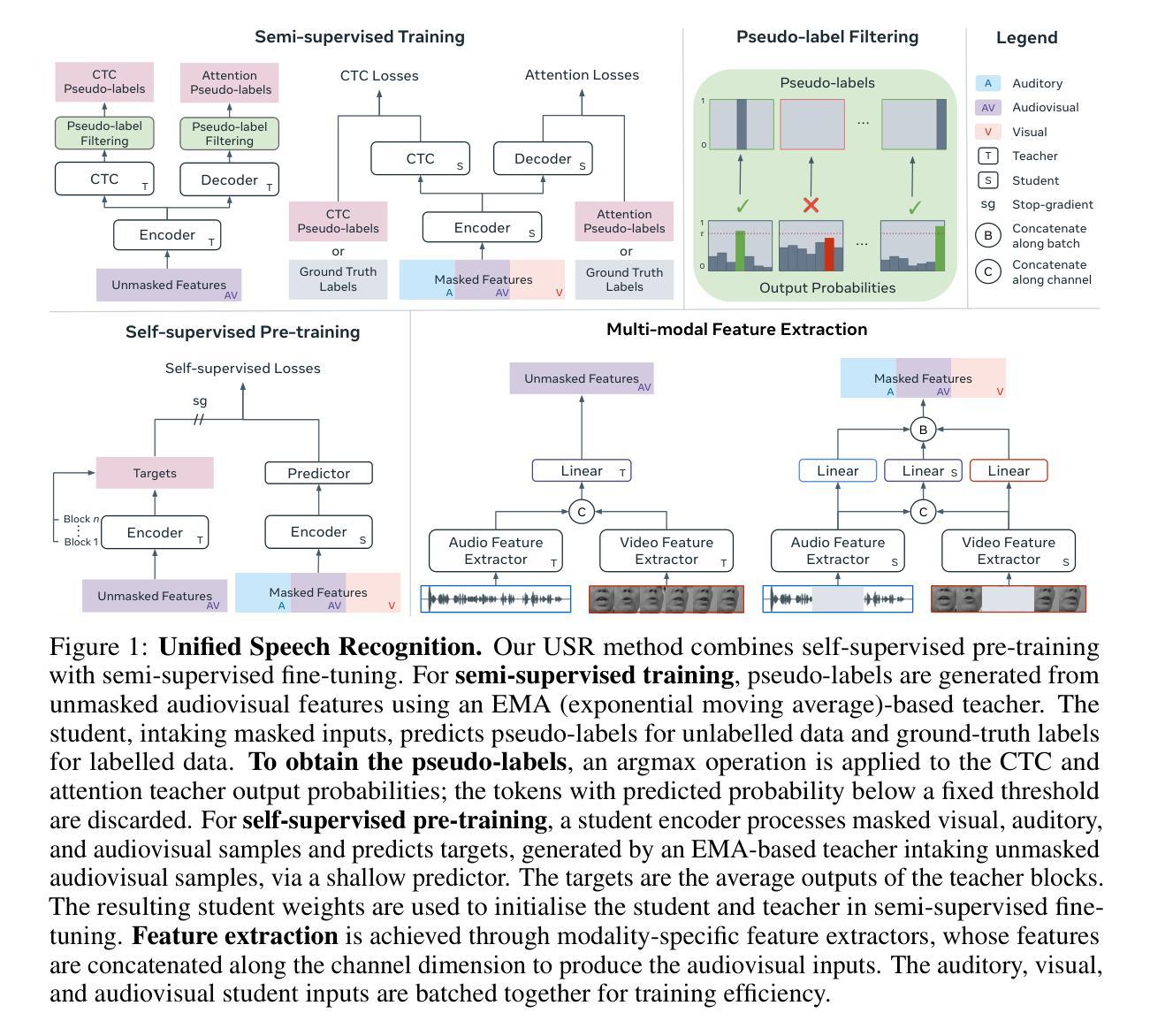
Multi-environment Topic Models
Authors:Dominic Sobhani, Amir Feder, David Blei
Probabilistic topic models are a powerful tool for extracting latent themes from large text datasets. In many text datasets, we also observe per-document covariates (e.g., source, style, political affiliation) that act as environments that modulate a “global” (environment-agnostic) topic representation. Accurately learning these representations is important for prediction on new documents in unseen environments and for estimating the causal effect of topics on real-world outcomes. To this end, we introduce the Multi-environment Topic Model (MTM), an unsupervised probabilistic model that separates global and environment-specific terms. Through experimentation on various political content, from ads to tweets and speeches, we show that the MTM produces interpretable global topics with distinct environment-specific words. On multi-environment data, the MTM outperforms strong baselines in and out-of-distribution. It also enables the discovery of accurate causal effects.
概率主题模型是从大量文本数据中提取潜在主题的强大工具。在许多文本数据集中,我们还观察到每篇文档的协变量(例如来源、风格、政治倾向),这些协变量作为环境调制“全局”(环境无关)的主题表示。准确学习这些表示对于预测未见环境中的新文档并估计主题对现实世界结果的影响至关重要。为此,我们引入了多环境主题模型(MTM),这是一种无监督的概率模型,可以分离全局和环境特定术语。通过各种政治内容(从广告到推文和演讲)的实验,我们证明了MTM能够产生具有不同环境特定词汇的可解释全局主题。在多环境数据中,MTM的表现优于强大的基线模型,并且可以进行准确的因果效应发现。
论文及项目相关链接
Summary
概率主题模型是从大量文本数据中提取潜在主题的有力工具。在处理许多文本数据时,我们观察到的每篇文档的协变量(如来源、风格、政治倾向)充当调制“全局”(环境无关)主题表示的环境。为了在新的和未见过的环境中进行预测并估算主题对现实世界结果的影响,我们引入了多环境主题模型(MTM),这是一种无监督的概率模型,可分离全局和环境特定术语。通过实验验证,无论是在广告、推特还是演讲中,MTM都能产生具有环境特定词汇的可解释全局主题。在多环境数据中,MTM的表现优于强大的基线模型,并能准确发现因果关系。
Key Takeaways
- 概率主题模型能从大量文本数据中提取潜在主题。
- 文本数据的协变量(如来源、风格、政治倾向)影响主题表示。
- 多环境主题模型(MTM)是一种无监督的概率模型,可分离全局和环境特定术语。
- MTM在多种政治内容(如广告、推特和演讲)的实验中表现出良好的性能。
- MTM在新和未见过的环境中的预测表现优异。
- MTM能生成具有环境特定词汇的可解释全局主题。
点此查看论文截图

VoiceBench: Benchmarking LLM-Based Voice Assistants
Authors:Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T. Tan, Haizhou Li
Building on the success of large language models (LLMs), recent advancements such as GPT-4o have enabled real-time speech interactions through LLM-based voice assistants, offering a significantly improved user experience compared to traditional text-based interactions. However, the absence of benchmarks designed to evaluate these speech interaction capabilities has hindered progress of LLM-based voice assistants development. Current evaluations focus primarily on automatic speech recognition (ASR) or general knowledge evaluation with clean speeches, neglecting the more intricate, real-world scenarios that involve diverse speaker characteristics, environmental and content factors. To address this, we introduce VoiceBench, the first benchmark designed to provide a multi-faceted evaluation of LLM-based voice assistants. VoiceBench also includes both real and synthetic spoken instructions that incorporate the above three key real-world variations. Extensive experiments reveal the limitations of current LLM-based voice assistant models and offer valuable insights for future research and development in this field.
基于大型语言模型(LLM)的成功,最近的进展,如GPT-4o,已经能够通过LLM语音助手实现实时语音交互,与基于文本的传统交互方式相比,为用户提供了显著改善的体验。然而,缺乏用于评估这些语音交互能力的基准测试阻碍了LLM语音助手的发展。当前的评估主要集中在自动语音识别(ASR)或清洁语音的一般知识评估上,忽视了涉及多种说话人特征、环境和内容因素的更复杂、真实的现实世界场景。为了解决这一问题,我们引入了VoiceBench,这是第一个基准测试,旨在为基于LLM的语音助手提供多方面的评估。VoiceBench还包括真实和合成语音指令,这些指令结合了上述三个关键现实世界的差异。广泛的实验揭示了当前LLM语音助手模型的局限性,并为该领域的未来研究和开发提供了宝贵的见解。
论文及项目相关链接
PDF Work in progress. Data is available at https://github.com/MatthewCYM/VoiceBench
Summary:
近期的大型语言模型(LLM)技术突破如GPT-4o使得基于LLM的语音助手能够进行实时语音交互,极大提升了用户体验。然而,缺乏针对语音交互能力的评估基准阻碍了其发展。为解决这个问题,引入了VoiceBench基准,该基准提供多方面的评估,涵盖真实和合成语音指令,包括多样的说话人特性、环境和内容因素。实验揭示了当前LLM语音助手的局限,并为未来研究和发展提供了宝贵见解。
Key Takeaways:
- 大型语言模型的进步推动了实时语音交互的发展。
- GPT-4o等技术提升了用户体验,通过语音助手实现更自然的交互。
- 目前缺乏针对LLM语音助手语音交互能力的评估基准。
- VoiceBench基准是首个用于评估LLM语音助手的综合基准。
- VoiceBench涵盖了真实和合成的语音指令,包含多样的说话人特性、环境和内容因素。
- 通过对LLM语音助手的全面评估,揭示了其局限性。
点此查看论文截图


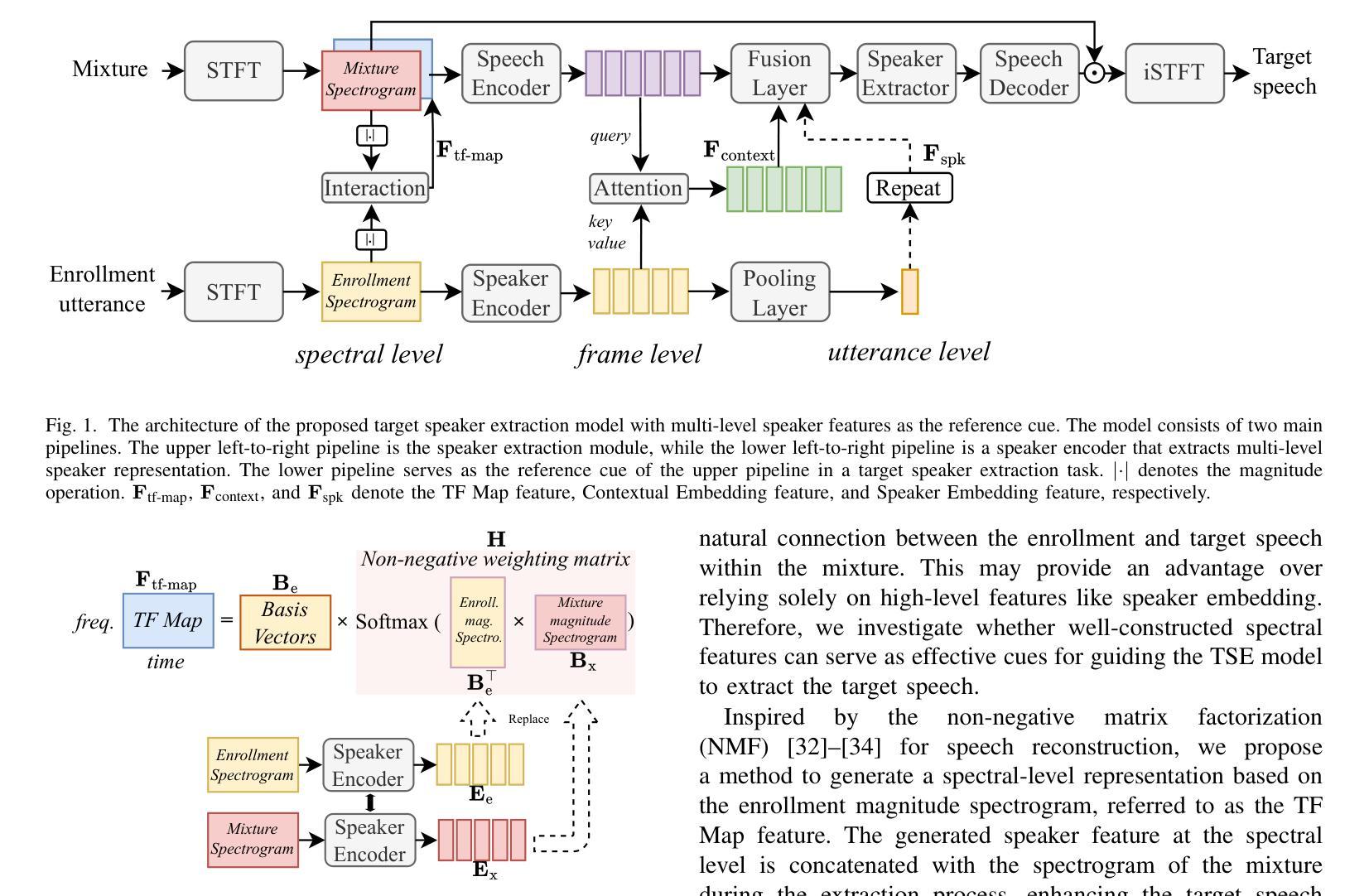
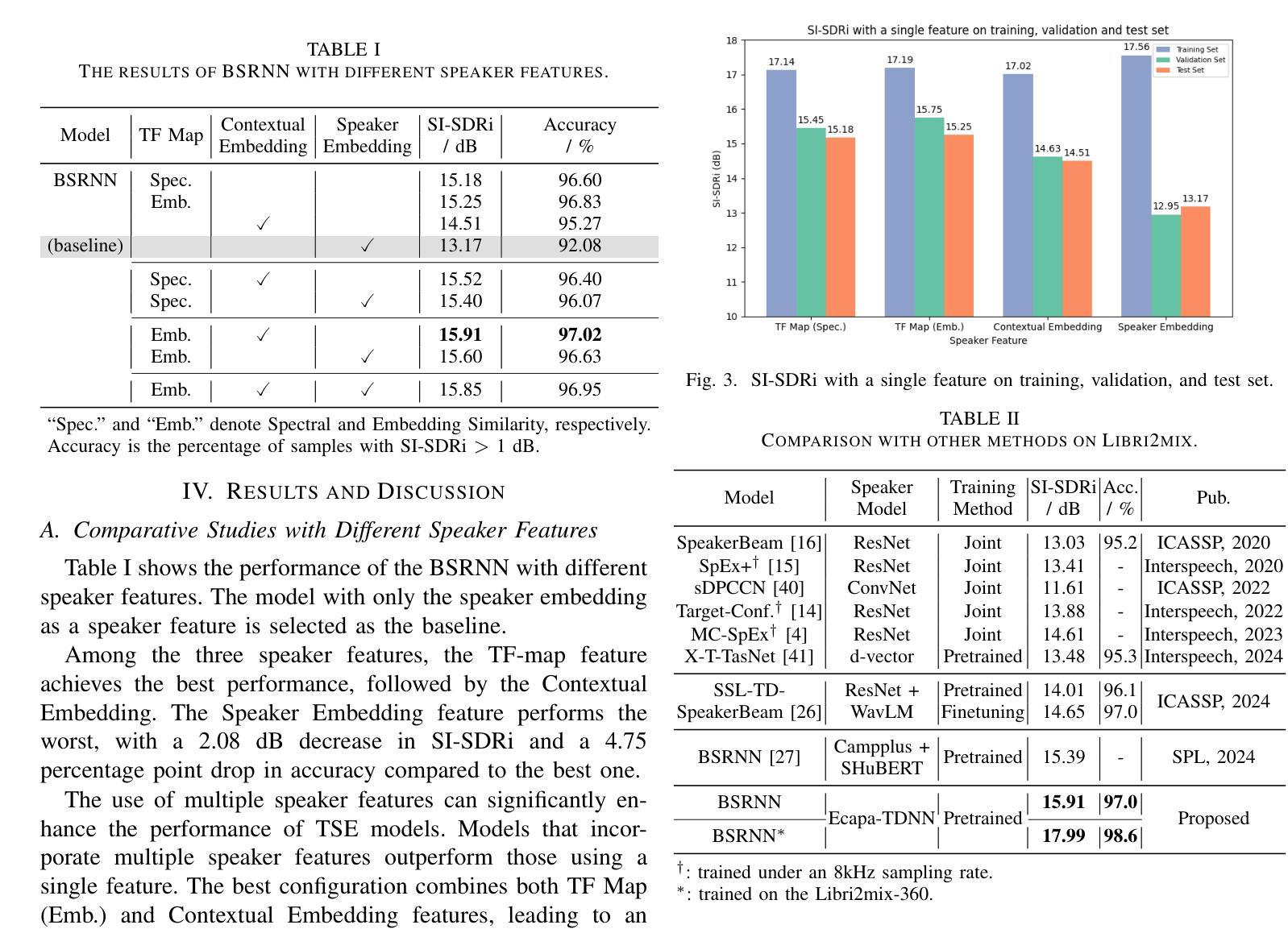
Multi-Level Speaker Representation for Target Speaker Extraction
Authors:Ke Zhang, Junjie Li, Shuai Wang, Yangjie Wei, Yi Wang, Yannan Wang, Haizhou Li
Target speaker extraction (TSE) relies on a reference cue of the target to extract the target speech from a speech mixture. While a speaker embedding is commonly used as the reference cue, such embedding pre-trained with a large number of speakers may suffer from confusion of speaker identity. In this work, we propose a multi-level speaker representation approach, from raw features to neural embeddings, to serve as the speaker reference cue. We generate a spectral-level representation from the enrollment magnitude spectrogram as a raw, low-level feature, which significantly improves the model’s generalization capability. Additionally, we propose a contextual embedding feature based on cross-attention mechanisms that integrate frame-level embeddings from a pre-trained speaker encoder. By incorporating speaker features across multiple levels, we significantly enhance the performance of the TSE model. Our approach achieves a 2.74 dB improvement and a 4.94% increase in extraction accuracy on Libri2mix test set over the baseline.
目标说话人提取(TSE)依赖于目标的参考线索,从语音混合中提取目标语音。虽然通常使用说话人嵌入作为参考线索,但使用大量说话人进行预训练的嵌入可能会受到说话人身份混淆的影响。在本文中,我们提出了一种多层次的说话人表示方法,从原始特征到神经嵌入,以作为说话人的参考线索。我们从注册幅度谱图中生成光谱级别的表示作为原始的低级特征,这显著提高了模型的泛化能力。此外,我们提出了一种基于交叉注意力机制的上下文嵌入特征,该特征融合了预训练说话人编码器的帧级嵌入。通过结合多个层次的说话人特征,我们显着提高了TSE模型的性能。我们的方法在Libri2mix测试集上相对于基线实现了2.74 dB的改进和4.94%的提取准确性提高。
论文及项目相关链接
PDF 5 pages. Submitted to ICASSP 2025. Implementation will be released at https://github.com/wenet-e2e/wesep
摘要
目标说话人提取(TSE)依赖于目标的参考线索,从语音混合中提取目标语音。虽然常用的参考线索是说话人嵌入,但使用大量说话者进行预训练的嵌入可能会受到说话者身份混淆的影响。本研究提出了一种多层次说话人表示方法,从原始特征到神经嵌入,作为说话人参考线索。我们从注册幅度谱图中生成频谱级表示作为原始的低级特征,这显著提高了模型的泛化能力。此外,我们还提出了一种基于交叉注意力机制的上下文嵌入特征,该特征融合了预训练说话人编码器的帧级嵌入。通过结合多个层次的说话人特征,我们显著提高了TSE模型的性能。在Libri2mix测试集上,我们的方法相对于基线实现了2.74 dB的改进和4.94%的提取准确性提高。
关键见解
- 目标说话人提取(TSE)依赖于目标的参考线索。
- 说话人嵌入作为参考线索在预训练时可能面临说话者身份混淆的问题。
- 研究提出了一种多层次说话人表示方法,包括从原始特征到神经嵌入。
- 利用注册幅度谱图生成频谱级表示,作为原始的低级特征。
- 提出了基于交叉注意力机制的上下文嵌入特征,融合了帧级嵌入。
- 结合多个层次的说话人特征能显著提高TSE模型的性能。
- 在Libri2mix测试集上,该方法相对于基线有显著改进,实现了2.74 dB的增益和4.94%的提取准确性提升。
点此查看论文截图

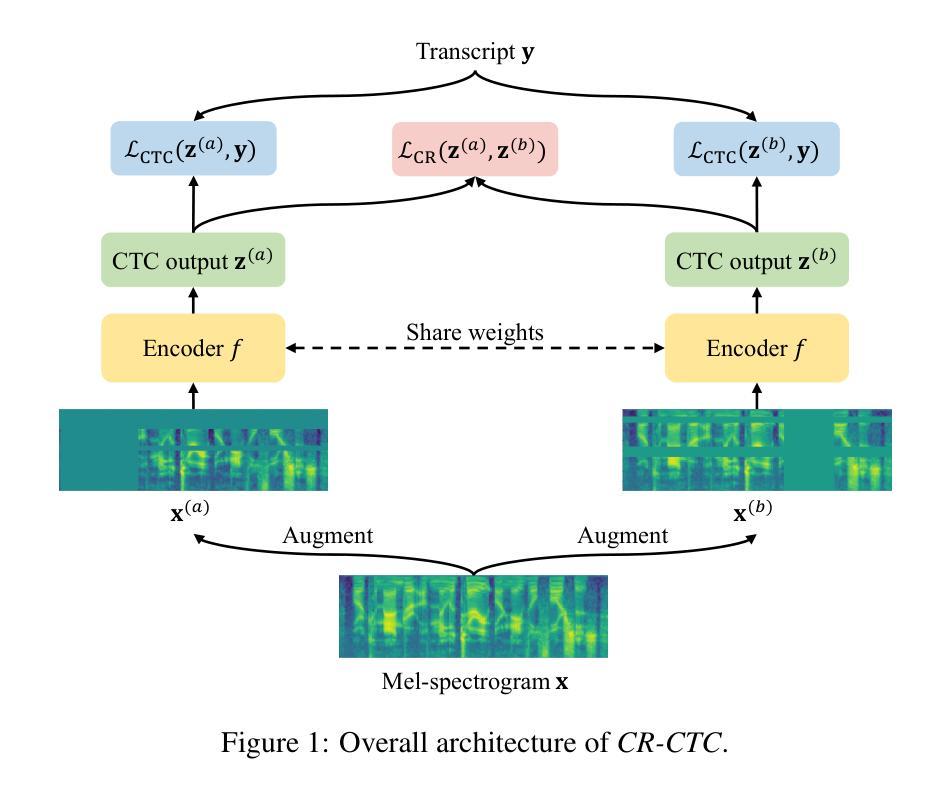
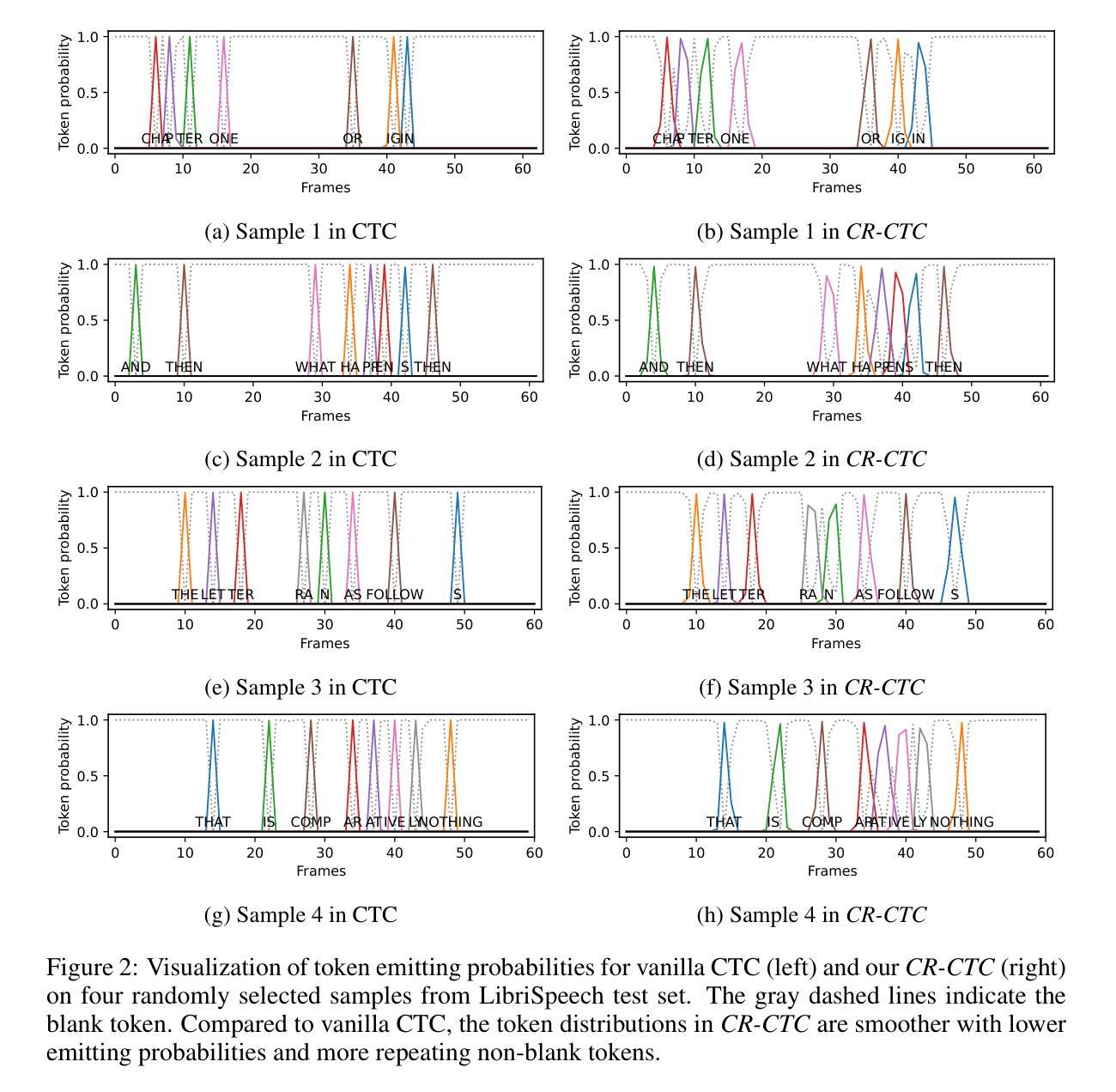
CR-CTC: Consistency regularization on CTC for improved speech recognition
Authors:Zengwei Yao, Wei Kang, Xiaoyu Yang, Fangjun Kuang, Liyong Guo, Han Zhu, Zengrui Jin, Zhaoqing Li, Long Lin, Daniel Povey
Connectionist Temporal Classification (CTC) is a widely used method for automatic speech recognition (ASR), renowned for its simplicity and computational efficiency. However, it often falls short in recognition performance. In this work, we propose the Consistency-Regularized CTC (CR-CTC), which enforces consistency between two CTC distributions obtained from different augmented views of the input speech mel-spectrogram. We provide in-depth insights into its essential behaviors from three perspectives: 1) it conducts self-distillation between random pairs of sub-models that process different augmented views; 2) it learns contextual representation through masked prediction for positions within time-masked regions, especially when we increase the amount of time masking; 3) it suppresses the extremely peaky CTC distributions, thereby reducing overfitting and improving the generalization ability. Extensive experiments on LibriSpeech, Aishell-1, and GigaSpeech datasets demonstrate the effectiveness of our CR-CTC. It significantly improves the CTC performance, achieving state-of-the-art results comparable to those attained by transducer or systems combining CTC and attention-based encoder-decoder (CTC/AED). We release our code at \url{https://github.com/k2-fsa/icefall}.
连接时序分类(CTC)是自动语音识别(ASR)中广泛使用的一种方法,以其简单性和计算效率而闻名。然而,它在识别性能上常常有所不足。在这项工作中,我们提出了一致性正则化CTC(CR-CTC),它强制输入语音梅尔频谱图的两个不同增强视图所获得的两个CTC分布之间的一致性。我们从以下三个角度对其基本行为进行了深入洞察:1)它在处理不同增强视图的随机子模型对之间进行自我蒸馏;2)它通过掩码预测学习时间掩码区域内的位置的上下文表示,特别是当我们增加时间掩码的数量时;3)它抑制了过于尖峰的CTC分布,从而减少了过拟合,提高了泛化能力。在LibriSpeech、Aishell-1和GigaSpeech数据集上的大量实验表明了我们CR-CTC的有效性。它显著提高了CTC的性能,达到了与转换器或结合CTC和基于注意力的编码器-解码器(CTC/AED)的系统所取得的最先进结果相当的水平。我们在\url{https://github.com/k2-fsa/icefall}发布我们的代码。
论文及项目相关链接
Summary:
提出的 Consistency-Regularized CTC(CR-CTC)方法通过在不同增强视图中获得两个 CTC 分布并强制它们保持一致,增强了自动语音识别(ASR)中的表现。该方法通过自我蒸馏、学习上下文表示以及抑制过于尖锐的 CTC 分布等行为改善性能。在多个数据集上的实验表明,CR-CTC 显著提高了 CTC 性能,达到了与转换器或 CTC 与基于注意力的编码器解码器组合系统(CTC/AED)相当的最先进水平。
Key Takeaways:
- Consistency-Regularized CTC(CR-CTC)是一种改进自动语音识别(ASR)中 Connectionist Temporal Classification(CTC)表现的方法。
- CR-CTC 通过在不同增强视图中获得两个 CTC 分布并强制它们保持一致来增强性能。
- CR-CTC 通过自我蒸馏处理不同增强视图的随机子模型对来提高性能。
- CR-CTC 通过学习上下文表示,特别是在增加时间掩码量时,对时间掩码区域内的位置进行掩码预测来提高性能。
- CR-CTC 能够抑制过于尖锐的 CTC 分布,从而减少过拟合并提高泛化能力。
- 在多个数据集上的实验表明,CR-CTC 显著提高了 CTC 性能,达到了最先进水平。
点此查看论文截图

A Lightweight and Real-Time Binaural Speech Enhancement Model with Spatial Cues Preservation
Authors:Jingyuan Wang, Jie Zhang, Shihao Chen, Miao Sun
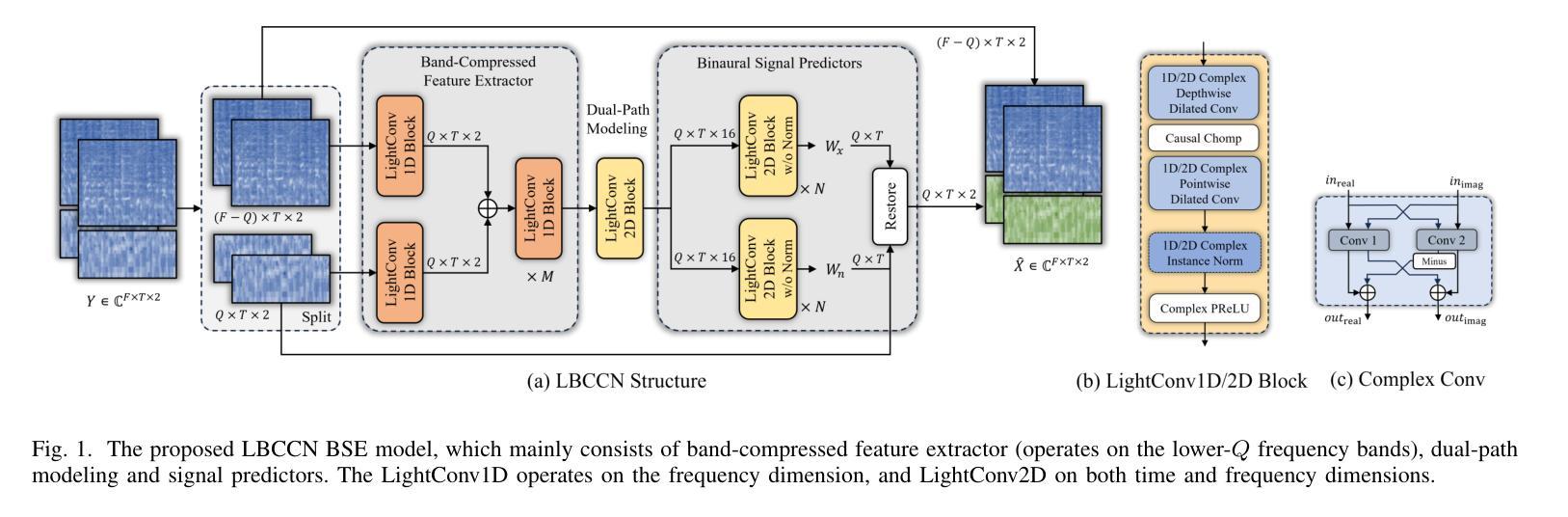
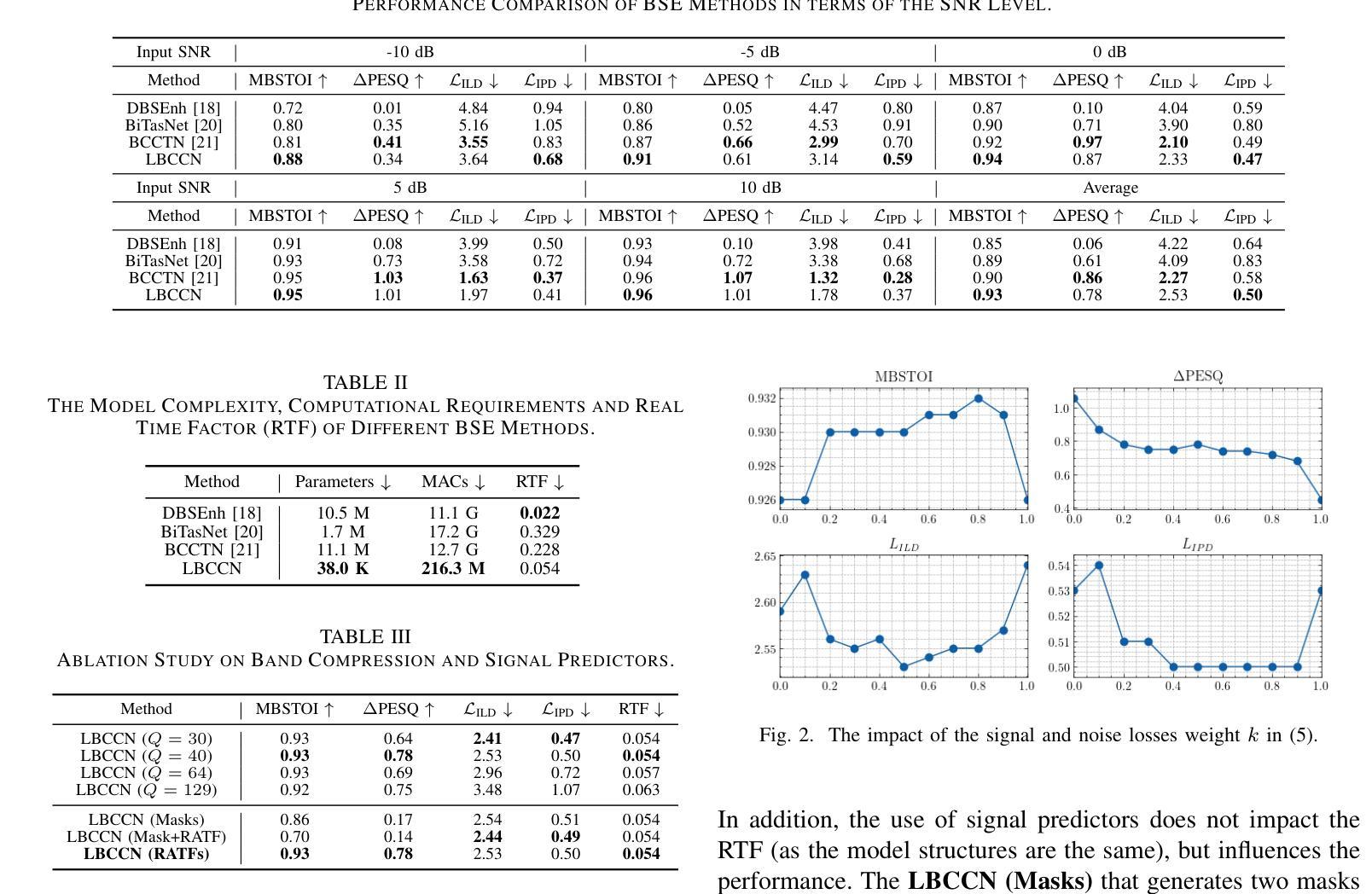
Binaural speech enhancement (BSE) aims to jointly improve the speech quality and intelligibility of noisy signals received by hearing devices and preserve the spatial cues of the target for natural listening. Existing methods often suffer from the compromise between noise reduction (NR) capacity and spatial cues preservation (SCP) accuracy and a high computational demand in complex acoustic scenes. In this work, we present a learning-based lightweight binaural complex convolutional network (LBCCN), which excels in NR by filtering low-frequency bands and keeping the rest. Additionally, our approach explicitly incorporates the estimation of interchannel relative acoustic transfer function to ensure the spatial cues fidelity and speech clarity. Results show that the proposed LBCCN can achieve a comparable NR performance to state-of-the-art methods under various noise conditions, but with a much lower computational cost and a better SCP. The reproducible code and audio examples are available at https://github.com/jywanng/LBCCN.
双耳语音增强(BSE)旨在共同提高听力设备接收到的噪声信号的质量和清晰度,并保留目标的空间线索以实现自然聆听。现有方法往往在噪声抑制(NR)能力和空间线索保留(SCP)准确性之间妥协,并且在复杂的声学场景中计算需求较高。在这项工作中,我们提出了一种基于学习的轻量级双耳复杂卷积网络(LBCCN),它通过过滤低频段来出色地进行噪声抑制并保持其余部分。此外,我们的方法显式地结合了通道间相对声学传递函数的估计,以确保空间线索的保真度和语音清晰度。结果表明,所提出的LBCCN在各种噪声条件下可以实现与最新技术相当的去噪性能,但计算成本更低,并且具有更好的SCP。可重复的代码和音频示例可在https://github.com/jywanng/LBCCN找到。
论文及项目相关链接
Summary
本文介绍了一种基于学习的轻量化双耳复杂卷积网络(LBCCN),用于改善听力设备的语音质量和清晰度。该网络通过滤波低频带并保持其余部分实现出色的降噪效果,并专门估计通道间相对声学传输函数以确保空间线索的保真度和语音清晰度。相较于其他先进方法,LBCCN在降噪性能上表现相当,但计算成本更低,空间线索保真度更好。
Key Takeaways
- Binaural speech enhancement旨在提高听力设备的语音质量和清晰度,同时保留目标的空间线索以实现自然聆听体验。
- 现有方法通常在降噪、空间线索保留和计算需求之间有所妥协,特别是在复杂的声学场景中。
- 本文提出了一种基于学习的轻量化双耳复杂卷积网络(LBCCN),专注于降噪并保留空间线索。
- LBCCN通过滤波低频带来实现出色的降噪效果,同时保持其他频率的完整性。
- LBCCN通过估计通道间相对声学传输函数来确保空间线索的保真度。
- 实验结果显示,LBCCN在降噪性能上表现优异,相较于其他先进方法具有更低的计算成本和更高的空间线索保真度。
点此查看论文截图

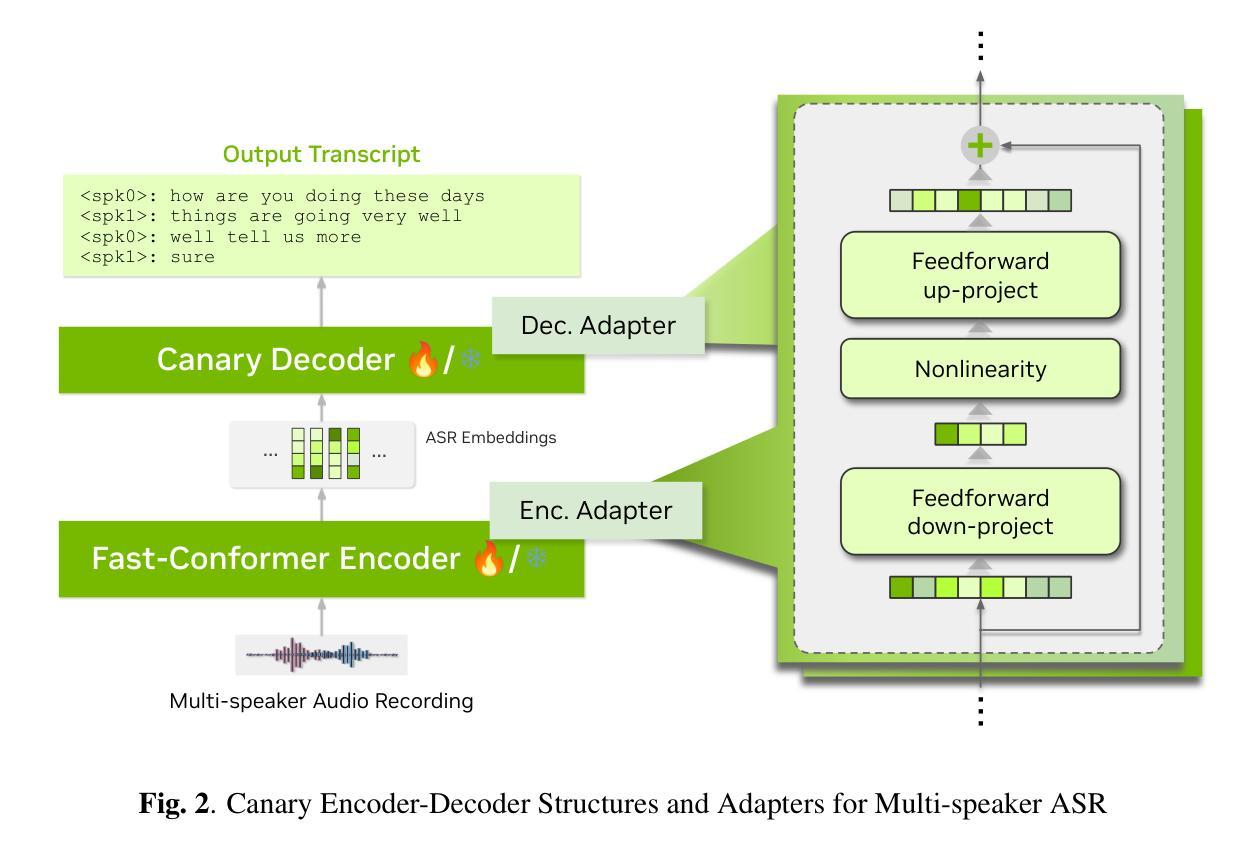
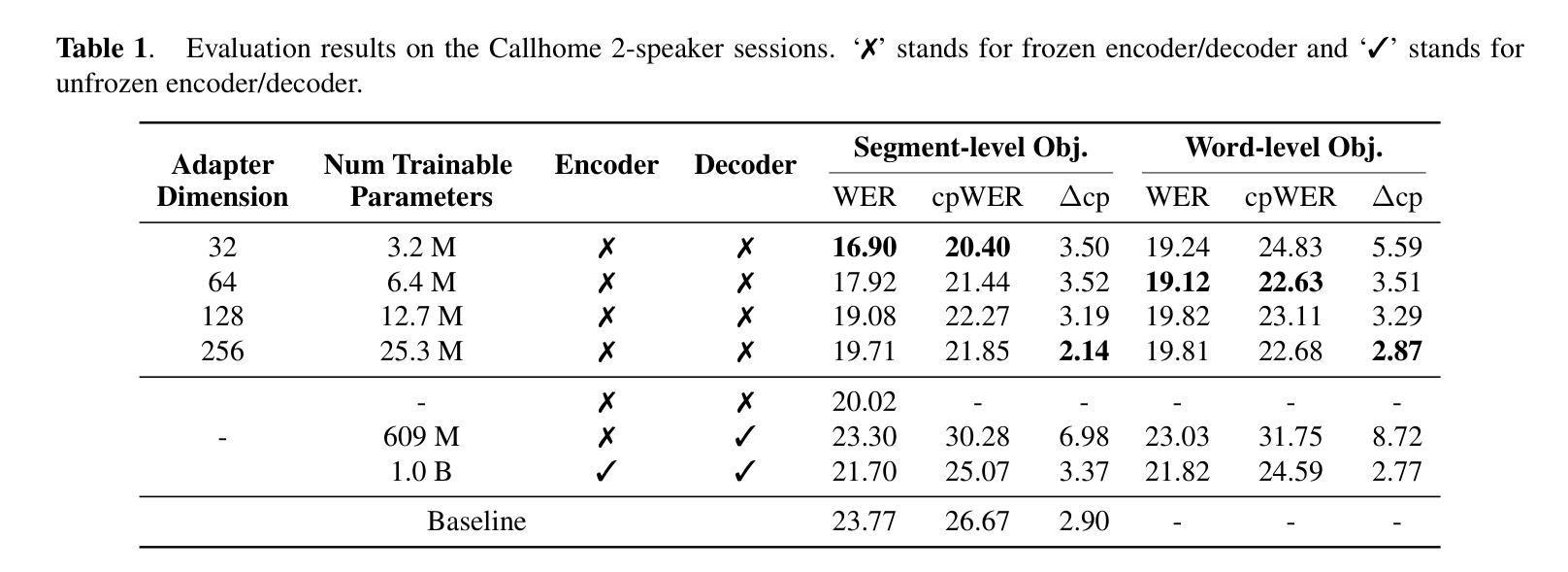
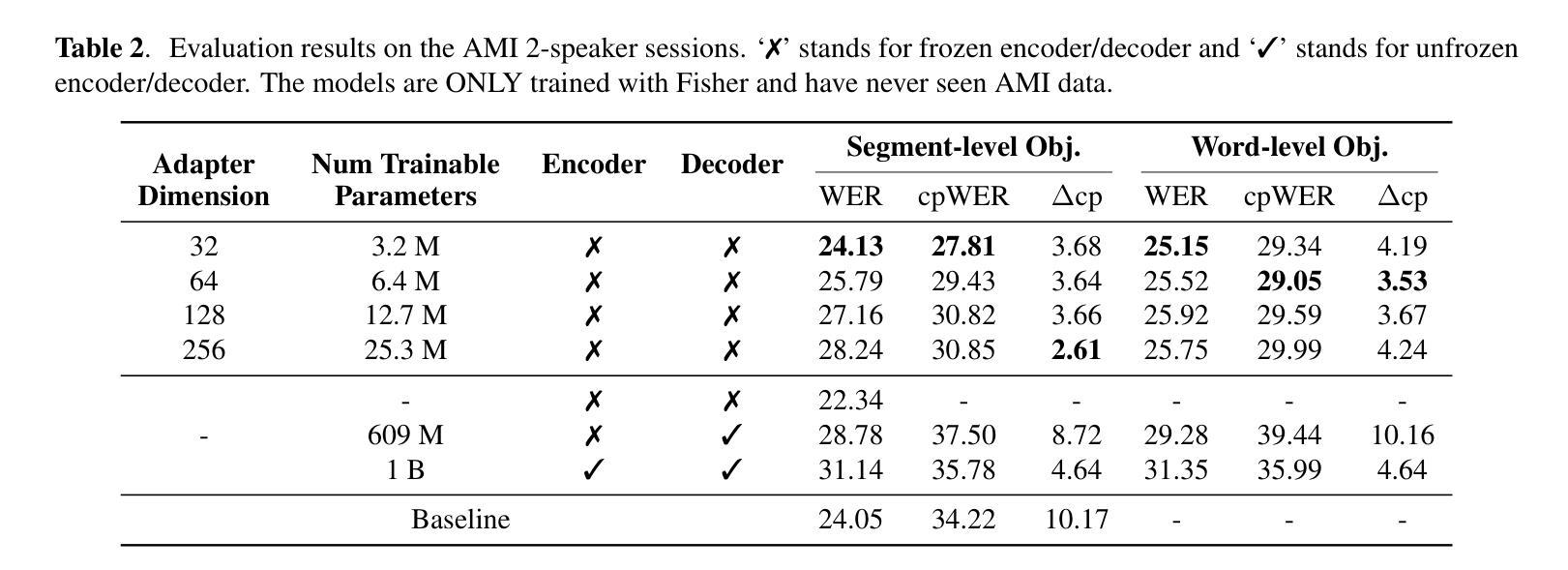
Resource-Efficient Adaptation of Speech Foundation Models for Multi-Speaker ASR
Authors:Weiqing Wang, Kunal Dhawan, Taejin Park, Krishna C. Puvvada, Ivan Medennikov, Somshubra Majumdar, He Huang, Jagadeesh Balam, Boris Ginsburg
Speech foundation models have achieved state-of-the-art (SoTA) performance across various tasks, such as automatic speech recognition (ASR) in hundreds of languages. However, multi-speaker ASR remains a challenging task for these models due to data scarcity and sparsity. In this paper, we present approaches to enable speech foundation models to process and understand multi-speaker speech with limited training data. Specifically, we adapt a speech foundation model for the multi-speaker ASR task using only telephonic data. Remarkably, the adapted model also performs well on meeting data without any fine-tuning, demonstrating the generalization ability of our approach. We conduct several ablation studies to analyze the impact of different parameters and strategies on model performance. Our findings highlight the effectiveness of our methods. Results show that less parameters give better overall cpWER, which, although counter-intuitive, provides insights into adapting speech foundation models for multi-speaker ASR tasks with minimal annotated data.
语音基础模型已在各种任务上达到了最先进的性能,如在数百种语言中的自动语音识别(ASR)。然而,由于数据稀缺和稀疏,多说话者ASR对这些模型来说仍然是一个具有挑战性的任务。在本文中,我们提出了使语音基础模型能够在有限训练数据的情况下处理和理解多说话者语音的方法。具体来说,我们只使用电话数据来适应多说话者ASR任务的语音基础模型。值得注意的是,适应的模型在会议数据上无需任何微调也能表现良好,这证明了我们方法的泛化能力。我们进行了几次剥离研究,分析不同参数和策略对模型性能的影响。我们的研究结果突显了我们方法的有效性。结果表明,较少的参数会提供更好的整体cpWER,虽然这种结果初看起来有点违反直觉,但为我们提供了在少量标注数据的情况下适应多说话者ASR任务的语音基础模型的见解。
论文及项目相关链接
PDF Accepted by SLT 2024
摘要
语音基础模型已在各种任务中实现了最先进的性能,如自动语音识别(ASR)在数百种语言中的应用。然而,对于多说话人的ASR任务,这些模型仍面临数据稀缺和稀疏的挑战。本文提出方法,使语音基础模型能够在有限的训练数据下处理和理解多说话人的语音。具体来说,我们只使用电话数据对语音基础模型进行多说话人ASR任务适配。值得注意的是,适配模型在会议数据上无需任何微调即可表现良好,这证明了我们的方法的泛化能力。我们通过一系列消去研究来分析不同参数和策略对模型性能的影响。结果表明我们的方法有效,并且发现较少的参数能带来更好的整体cpWER,虽然这似乎有违直觉,但这为在少量标注数据下适配语音基础模型进行多说话人ASR任务提供了见解。
要点掌握
- 语音基础模型已在多种语言的ASR任务中表现出卓越性能。
- 多说话人ASR任务对语音基础模型仍是挑战,尤其面临数据稀缺问题。
- 本文介绍了一种适配语音基础模型以处理多说话人语音的方法,仅使用电话数据。
- 适配模型在会议数据上表现良好,无需微调,显示了方法的泛化能力。
- 消去研究分析了不同参数和策略对模型性能的影响。
- 研究发现较少的参数能带来更好的整体cpWER,这提供了对于如何在有限标注数据下适配语音基础模型的见解。
- 此研究为语音基础模型在多说话人ASR任务中的适配提供了新的思路和策略。
点此查看论文截图

Integrating audiological datasets via federated merging of Auditory Profiles
Authors:Samira Saak, Dirk Oetting, Birger Kollmeier, Mareike Buhl
Audiological datasets contain valuable knowledge about hearing loss in patients, which can be uncovered using data-driven, federated learning techniques. Our previous approach summarized patient information from one audiological dataset into distinct Auditory Profiles (APs). To obtain a better estimate of the audiological patient population, however, patient patterns must be analyzed across multiple, separated datasets, and finally, be integrated into a combined set of APs. This study aimed at extending the existing profile generation pipeline with an AP merging step, enabling the combination of APs from different datasets based on their similarity across audiological measures. The 13 previously generated APs (NA=595) were merged with 31 newly generated APs from a second dataset (NB=1272) using a similarity score derived from the overlapping densities of common features across the two datasets. To ensure clinical applicability, random forest models were created for various scenarios, encompassing different combinations of audiological measures. A new set with 13 combined APs is proposed, providing separable profiles, which still capture detailed patient information from various test outcome combinations. The classification performance across these profiles is satisfactory. The best performance was achieved using a combination of loudness scaling, audiogram and speech test information, while single measures performed worst. The enhanced profile generation pipeline demonstrates the feasibility of combining APs across datasets, which should generalize to all datasets and could lead to an interpretable global profile set in the future. The classification models maintain clinical applicability.
听力数据集中包含了关于患者听力损失的宝贵知识,这些知识可以通过数据驱动、联邦学习技术来发掘。我们之前的方法是将一个听力数据集中的患者信息总结为不同的听力概况(APs)。然而,为了更好地估计听力受损患者人群的情况,必须分析多个独立数据集中的患者模式,并最终将其整合到一组综合的听力概况中。本研究旨在通过增加一个听力概况合并步骤来扩展现有的概况生成流程,使能够基于不同数据集在听力测量方面的相似性来组合不同的听力概况。使用从两个数据集中常见特征的重叠密度得出的相似度评分,将之前生成的13个听力概况(NA=595)与从第二个数据集中新生成的31个听力概况(NB=1272)合并。为确保临床适用性,针对包含不同听力测量组合的各种场景创建了随机森林模型。提出了一套包含13个组合听力概况的新集合,这些概况能够区分不同的患者信息,同时仍然能够捕获各种测试结果的详细患者信息。这些听力概况的分类性能令人满意。使用响度缩放、听力图和语音测试信息的组合取得了最佳性能,而单一指标的表现最差。改进后的听力概况生成流程证明了跨数据集组合AP的可行性,这应该能够推广到所有数据集,并在未来可能导致一个可解释的全局听力概况集合。分类模型仍然适用于临床实践。
论文及项目相关链接
总结
本文介绍了使用数据驱动和联邦学习技术从多个音频数据集中挖掘关于听力损失患者有价值知识的方法。先前的方法将患者信息汇总为不同的听觉特征集(APs)。为了更准确地估计听力受损患者群体,本文扩展了现有分析流程,增加了一个听觉特征集合并步骤,使不同数据集中的听觉特征集可以根据它们在音频测量上的相似性进行合并。研究通过合并先前生成的13个听觉特征集(基于一个数据集)和从第二个数据集新生成的31个听觉特征集,提出了一个包含13个组合听觉特征集的新集合。该集合提供了可分离的患者特征集,能够详细捕捉不同测试结果的组合信息。分类性能良好,使用响度缩放、听力图和语音测试信息组合时表现最佳,单一指标的分类效果最差。改进的分析流程证明了跨数据集合并听觉特征集的可行性,未来有望形成一套可解释的全局听觉特征集分类模型保持临床适用性。
关键见解
- 使用数据驱动和联邦学习技术可从音频数据集中挖掘关于听力损失的知识。
- 听觉特征集(APs)用于汇总患者信息。
- 扩展现有分析流程以跨多个数据集整合APs。
- 基于两个数据集的相似性对APs进行合并。
- 新提出的集合包含合并后的13个APs,提供详细的患者信息。
- 分类性能良好,组合响度缩放、听力图和语音测试信息表现最佳。
点此查看论文截图

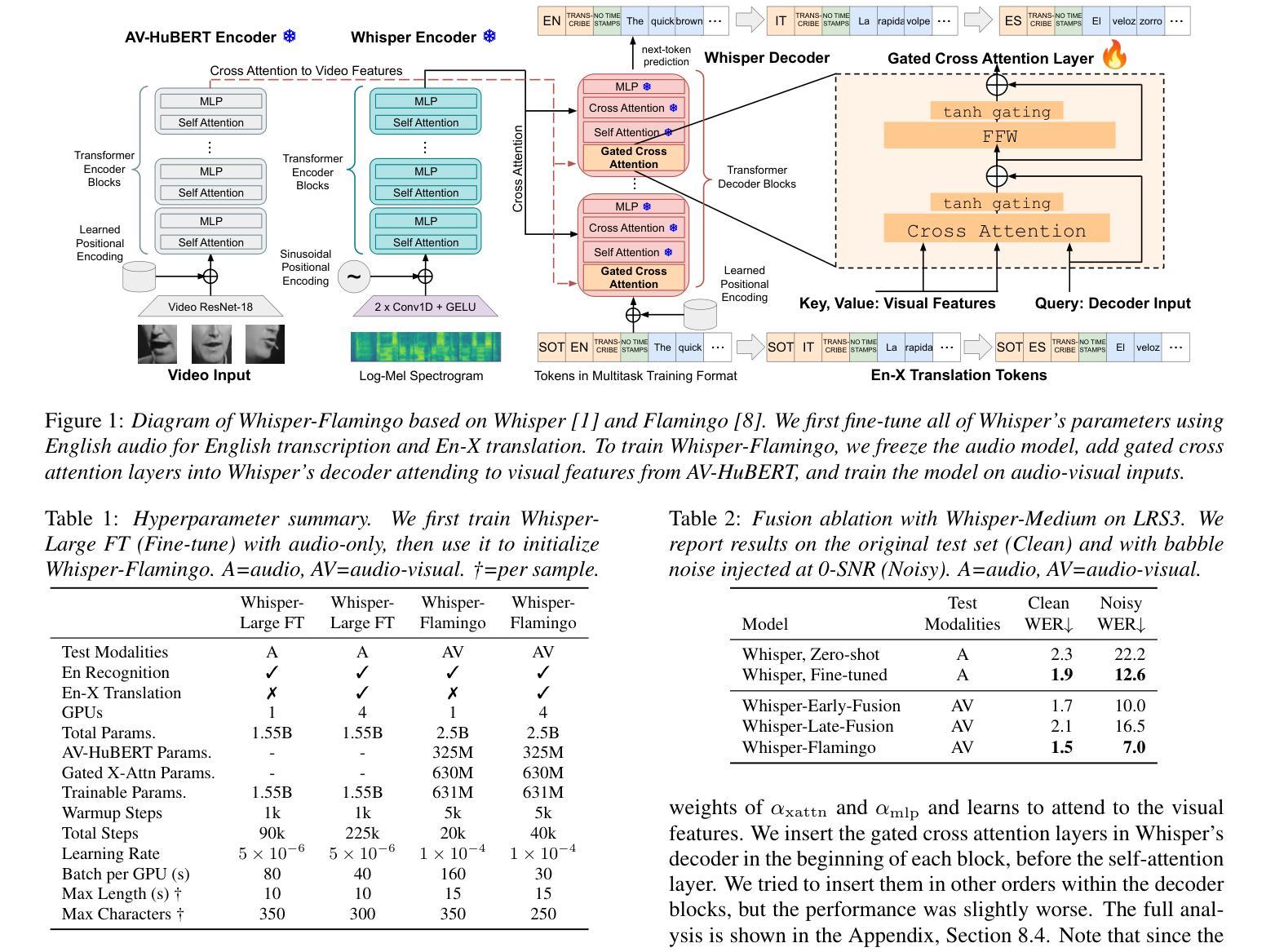
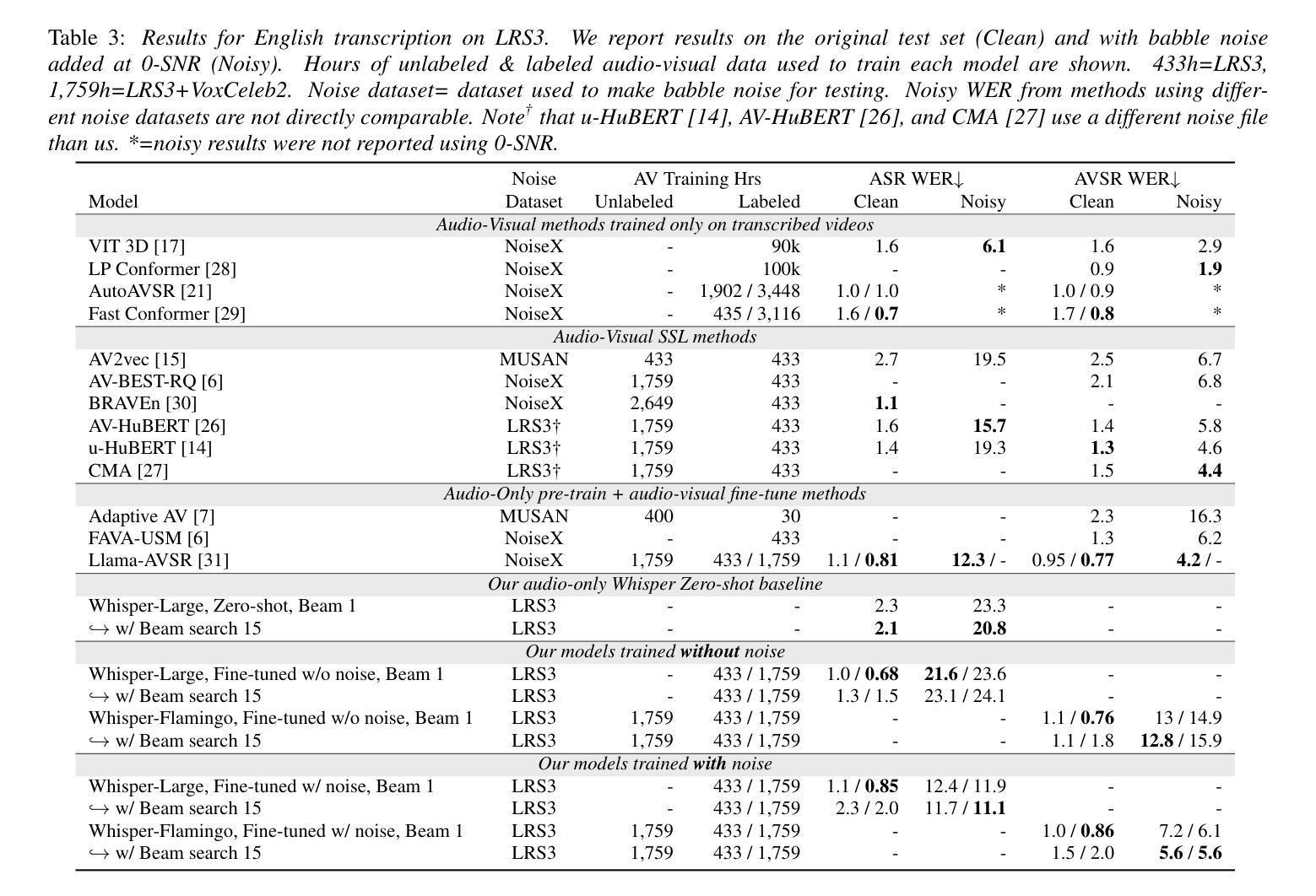
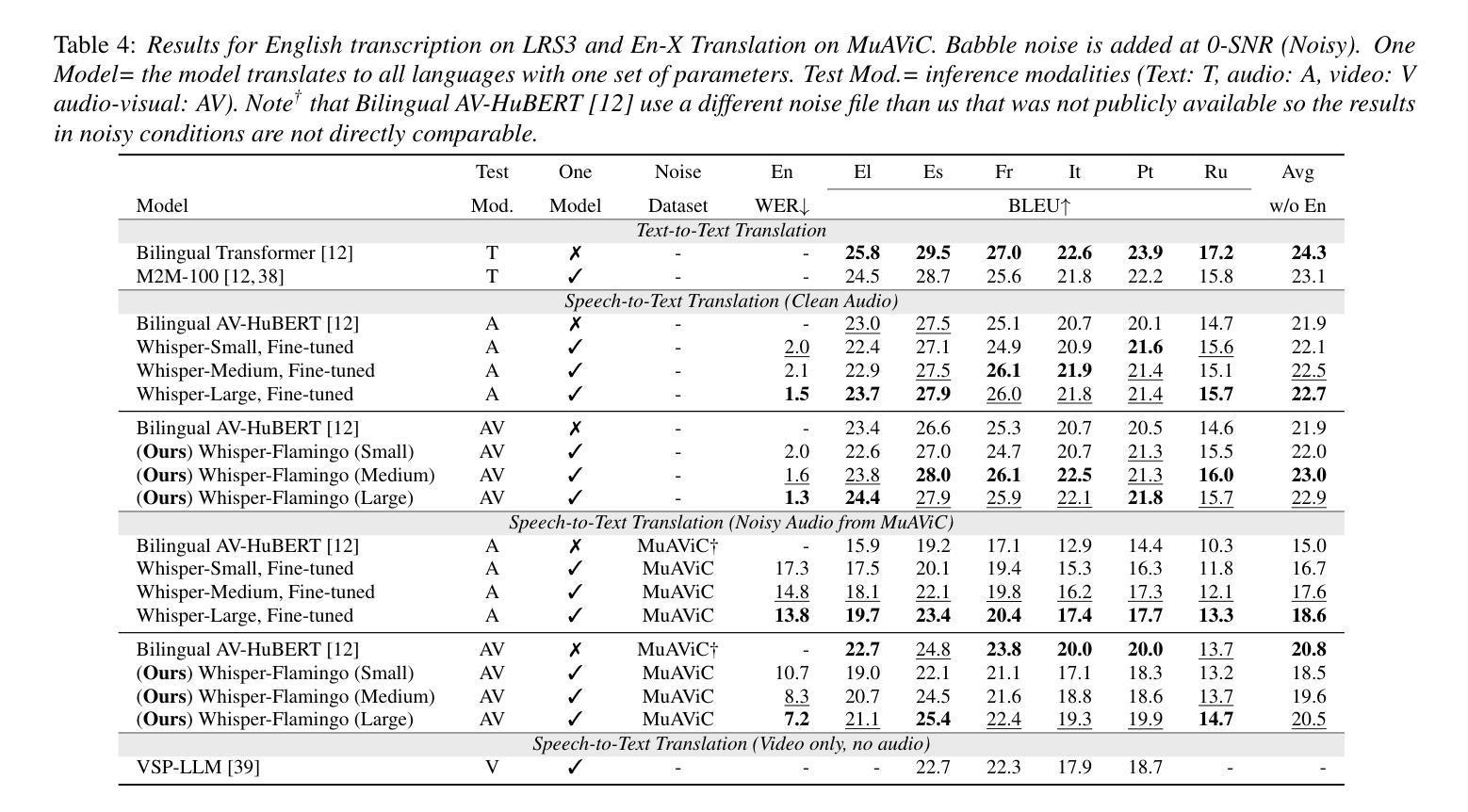
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Authors:Andrew Rouditchenko, Yuan Gong, Samuel Thomas, Leonid Karlinsky, Hilde Kuehne, Rogerio Feris, James Glass
Audio-Visual Speech Recognition (AVSR) uses lip-based video to improve performance in noise. Since videos are harder to obtain than audio, the video training data of AVSR models is usually limited to a few thousand hours. In contrast, speech models such as Whisper are trained with hundreds of thousands of hours of data, and thus learn a better speech-to-text decoder. The huge training data difference motivates us to adapt Whisper to handle video inputs. Inspired by Flamingo which injects visual features into language models, we propose Whisper-Flamingo which integrates visual features into the Whisper speech recognition and translation model with gated cross attention. Our models achieve state-of-the-art ASR WER (0.68%) and AVSR WER (0.76%) on LRS3, and state-of-the-art ASR WER (1.3%) and AVSR WER (1.4%) on LRS2. Audio-visual Whisper-Flamingo outperforms audio-only Whisper on English speech recognition and En-X translation for 6 languages in noisy conditions. Moreover, Whisper-Flamingo is versatile and conducts all of these tasks using one set of parameters, while prior methods are trained separately on each language.
视听语音识别(AVSR)利用基于嘴唇的视频在噪声中提高性能。由于视频比音频更难获取,AVSR模型的视频训练数据通常仅限于数千小时。相比之下,诸如Whisper之类的语音模型使用数十万小时的数据进行训练,从而学习更好的语音到文本的解码器。巨大的训练数据差异促使我们适应Whisper处理视频输入。受Flamingo将视觉特征注入语言模型的启发,我们提出了Whisper-Flamingo,它通过门控交叉注意力将视觉特征集成到Whisper语音识别和翻译模型中。我们的模型在LRS3上达到了最先进的ASR WER(0.68%)和AVSR WER(0.76%),在LRS2上达到了最先进的ASR WER(1.3%)和AVSR WER(1.4%)。视听Whisper-Flamingo在嘈杂环境下,对于英语语音识别和En-X翻译共六种语言的表现优于仅使用音频的Whisper。此外,Whisper-Flamingo非常通用,使用一组参数即可执行所有这些任务,而先前的方法则针对每种语言分别进行训练。
论文及项目相关链接
PDF Interspeech 2024. V3: Added results on LRS2. Code at https://github.com/roudimit/whisper-flamingo
Summary
基于视频唇语识别的音频视觉语音识别(AVSR)在噪声环境下表现优异。然而,AVSR模型的视频训练数据通常仅限于几千小时,而像whisper这样的语音模型则可通过数十万小时的数据进行训练,拥有更好的语音转文本解码器。巨大的训练数据差异促使我们适应whisper处理视频输入。受到注入语言模型的Flamingo的启发,我们提出了整合视觉特征的whisper-flamingo模型,该模型结合了whisper语音识别和翻译模型的门控交叉注意力机制。我们的模型在LRS3和LRS2上实现了先进的ASR和AVSR单词错误率(WER)。在噪声条件下,视听whisper-flamingo在英语语音识别和6种语言的英X翻译上优于仅使用音频的whisper。此外,whisper-flamingo通用性强,使用一组参数即可执行所有这些任务,而先前的方法则需要在每种语言上进行单独训练。
Key Takeaways
- AVSR使用视频唇语识别提升噪声环境下的性能。
- AVSR模型通常受限于数千小时的视频训练数据。
- 对比AVSR模型,whisper等语音模型可通过数十万小时的数据进行训练,拥有更佳的语音转文本解码器。
- 基于巨大的训练数据差异,whisper需要适应处理视频输入。
- 借鉴Flamingo的设计,提出了整合视觉特征的whisper-flamingo模型。
- 该模型实现了先进的ASR和AVSR单词错误率(WER)性能。
点此查看论文截图

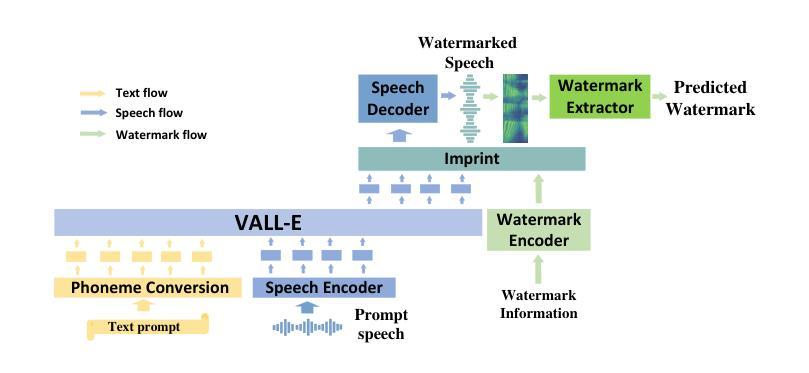
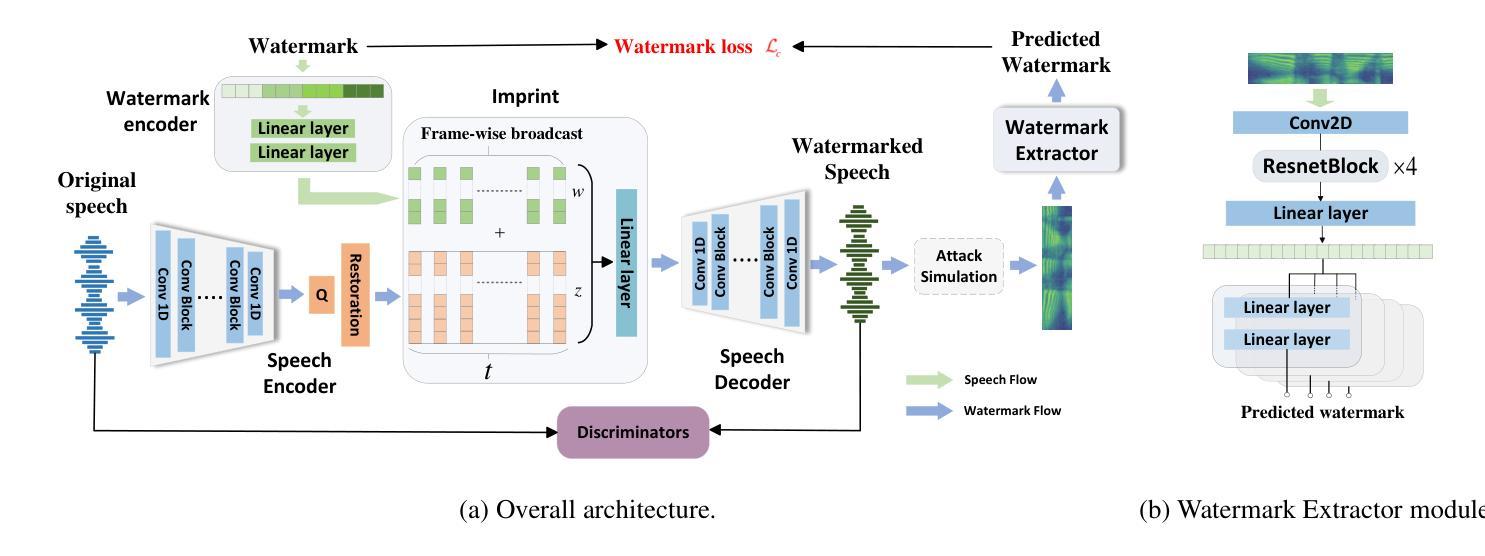
TraceableSpeech: Towards Proactively Traceable Text-to-Speech with Watermarking
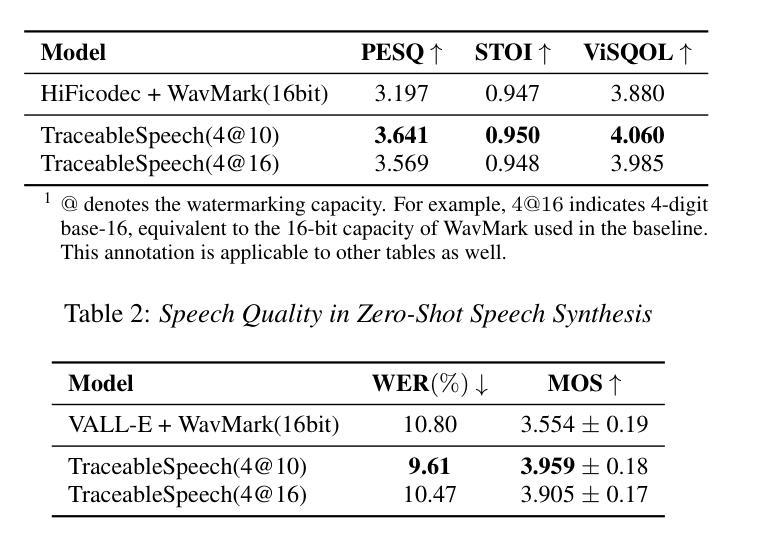
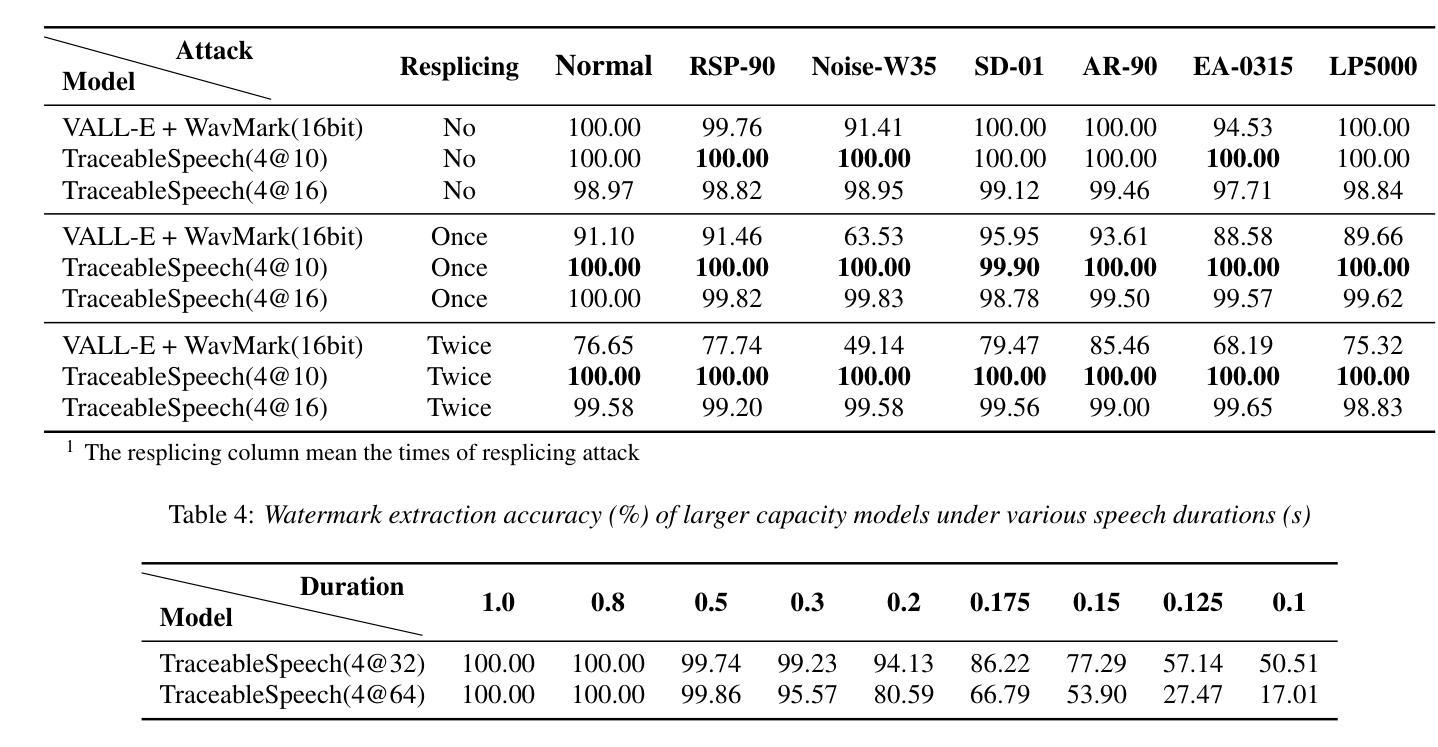
Authors:Junzuo Zhou, Jiangyan Yi, Tao Wang, Jianhua Tao, Ye Bai, Chu Yuan Zhang, Yong Ren, Zhengqi Wen
Various threats posed by the progress in text-to-speech (TTS) have prompted the need to reliably trace synthesized speech. However, contemporary approaches to this task involve adding watermarks to the audio separately after generation, a process that hurts both speech quality and watermark imperceptibility. In addition, these approaches are limited in robustness and flexibility. To address these problems, we propose TraceableSpeech, a novel TTS model that directly generates watermarked speech, improving watermark imperceptibility and speech quality. Furthermore, We design the frame-wise imprinting and extraction of watermarks, achieving higher robustness against resplicing attacks and temporal flexibility in operation. Experimental results show that TraceableSpeech outperforms the strong baseline where VALL-E or HiFicodec individually uses WavMark in watermark imperceptibility, speech quality and resilience against resplicing attacks. It also can apply to speech of various durations. The code is avaliable at https://github.com/zjzser/TraceableSpeech
随着文本转语音(TTS)技术的进步带来的各种威胁,对合成语音的可靠追踪变得至关重要。然而,当前的方法是在生成音频后单独添加水印,这一过程既影响语音质量,也影响水印的不可感知性。此外,这些方法在稳健性和灵活性方面也存在局限。为了解决这些问题,我们提出了TraceableSpeech,这是一种新型TTS模型,能够直接生成带水印的语音,提高了水印的不可感知性和语音质量。此外,我们设计了帧级水印印制和提取技术,实现了对拼接攻击的更高鲁棒性和操作上的时间灵活性。实验结果表明,TraceableSpeech在不可感知水印、语音质量和抵抗拼接攻击方面超越了VALL-E或HiFicodec单独使用WavMark的强大基线。它还可以应用于各种时长的语音。代码可在https://github.com/zjzser/TraceableSpeech找到。
论文及项目相关链接
PDF acceped by interspeech 2024
Summary
随着文本转语音(TTS)技术的进步,合成语音的溯源问题日益受到关注。现有方法在音频生成后单独添加水印,影响语音质量和水印的隐蔽性。为解决这些问题,提出了TraceableSpeech,一种直接生成带水印的TTS模型,提高了水印的隐蔽性和语音质量,并实现帧级水印印盖和提取,增强了对抗拼接攻击的鲁棒性和操作上的时间灵活性。实验结果显示,TraceableSpeech在水印隐蔽性、语音质量和抗拼接攻击方面优于使用WavMark的VALL-E或HiFicodec等强基线模型,且适用于不同时长语音。
Key Takeaways
- TTS技术的进步带来了合成语音溯源的新需求。
- 现有添加水印方法影响语音质量和水印隐蔽性。
- TraceableSpeech是一种直接生成带水印的TTS模型,提高水印隐蔽性和语音质量。
- TraceableSpeech实现帧级水印印盖和提取,增强鲁棒性和时间灵活性。
- TraceableSpeech在水印隐蔽性、语音质量和抗拼接攻击方面表现优异。
- TraceableSpeech适用于不同时长的语音。
点此查看论文截图

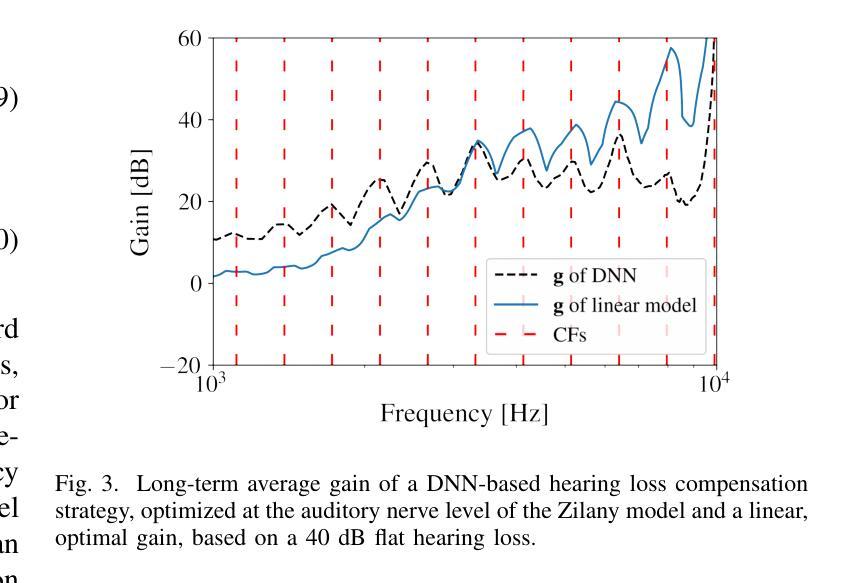
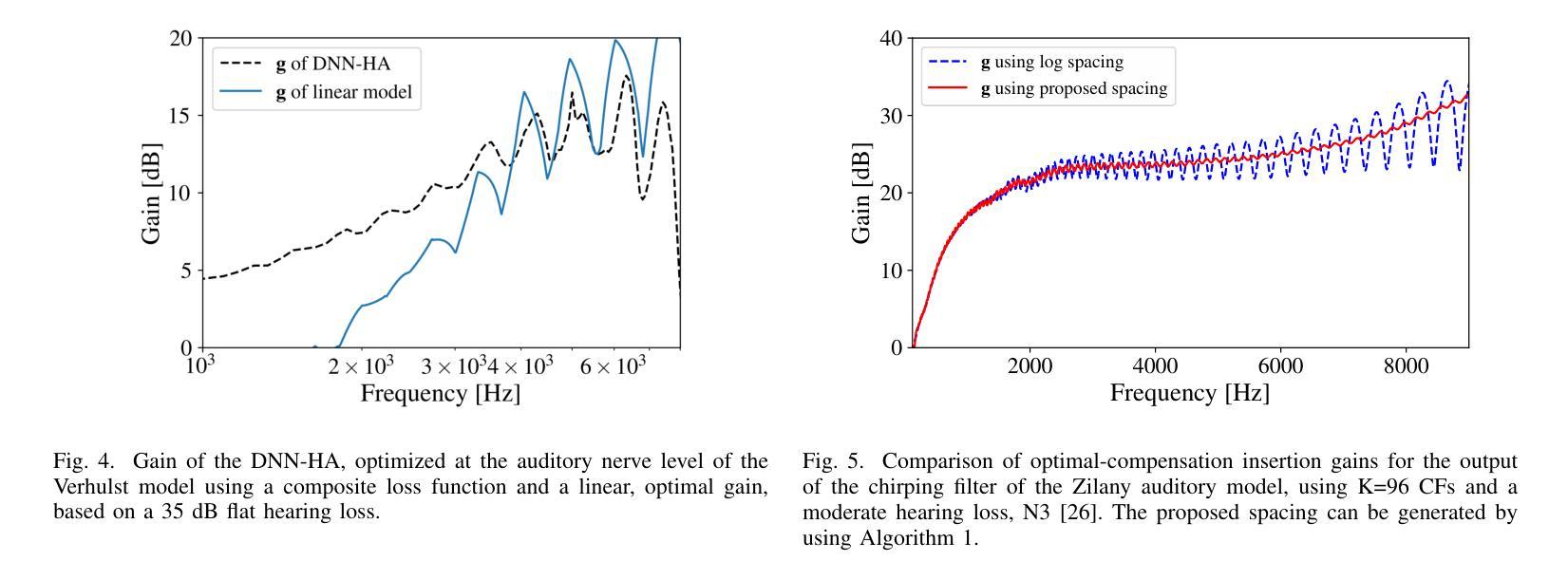
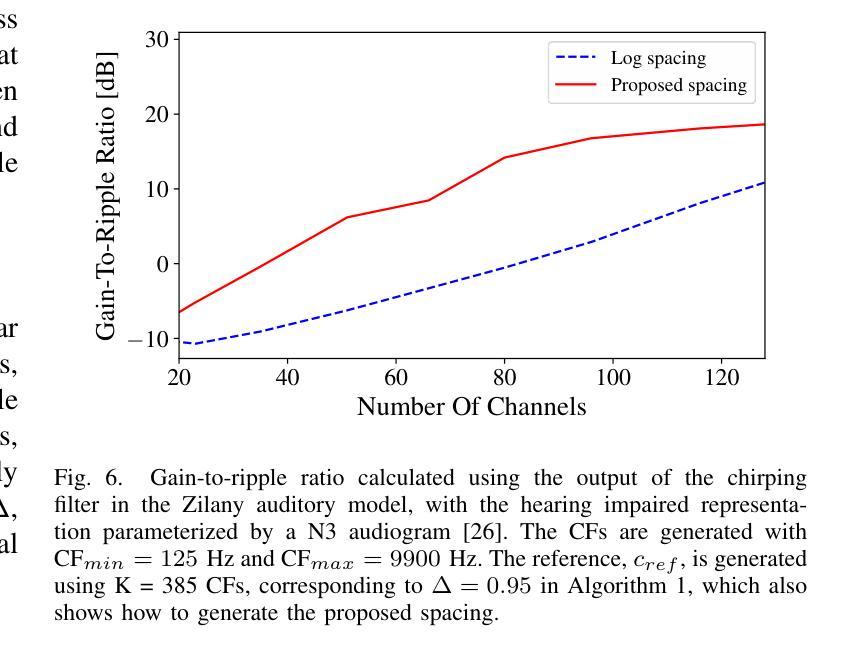
Hearing-Loss Compensation Using Deep Neural Networks: A Framework and Results From a Listening Test
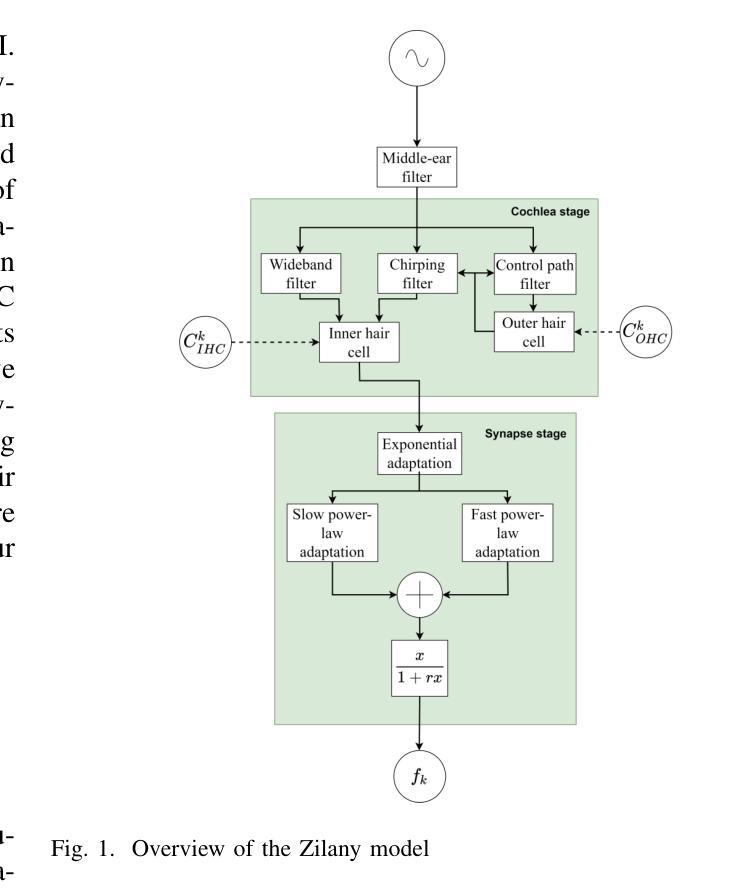
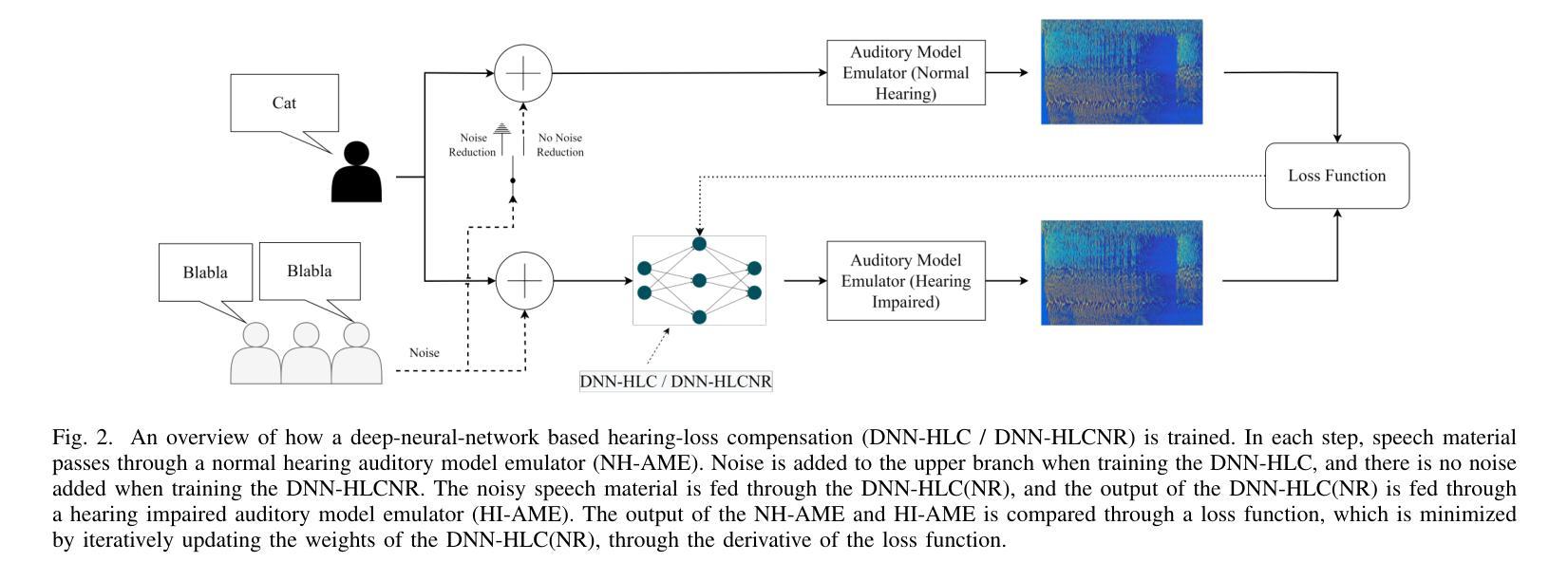
Authors:Peter Leer, Jesper Jensen, Laurel H. Carney, Zheng-Hua Tan, Jan Østergaard, Lars Bramsløw
This article investigates the use of deep neural networks (DNNs) for hearing-loss compensation. Hearing loss is a prevalent issue affecting millions of people worldwide, and conventional hearing aids have limitations in providing satisfactory compensation. DNNs have shown remarkable performance in various auditory tasks, including speech recognition, speaker identification, and music classification. In this study, we propose a DNN-based approach for hearing-loss compensation, which is trained on the outputs of hearing-impaired and normal-hearing DNN-based auditory models in response to speech signals. First, we introduce a framework for emulating auditory models using DNNs, focusing on an auditory-nerve model in the auditory pathway. We propose a linearization of the DNN-based approach, which we use to analyze the DNN-based hearing-loss compensation. Additionally we develop a simple approach to choose the acoustic center frequencies of the auditory model used for the compensation strategy. Finally, we evaluate, to our knowledge for the first time, the DNN-based hearing-loss compensation strategies using listening tests with hearing impaired listeners. The results demonstrate that the proposed approach results in feasible hearing-loss compensation strategies. Our proposed approach was shown to provide an increase in speech intelligibility versus an unprocessed baseline and was found to outperform a conventional approach in terms of both intelligibility and preference.
本文探讨了深度神经网络(DNN)在听力损失补偿方面的应用。听力损失是一个影响全球数百万人的普遍问题,传统的助听器在提供满意的补偿方面存在局限性。深度神经网络在各种听觉任务中表现出了卓越的性能,包括语音识别、说话人识别和音乐分类。在这项研究中,我们提出了一种基于深度神经网络的听力损失补偿方法,该方法是在听力受损和正常听力深度神经网络听觉模型对语音信号的输出反应上进行训练的。首先,我们介绍了一种使用深度神经网络模拟听觉模型的框架,重点是一个听觉通路中的听觉神经模型。我们提出了深度神经网络方法的线性化,用于分析基于深度神经网络的听力损失补偿。此外,我们还开发了一种简单的方法来选择听觉模型中的声音中心频率,用于补偿策略。最后,我们通过听力受损听众的聆听测试,首次评估了基于深度神经网络的听力损失补偿策略。结果表明,所提出的方法导致了可行的听力损失补偿策略。与未处理的基线相比,我们所提出的方法提高了语音清晰度,并且在清晰度和偏好方面都优于传统方法。
论文及项目相关链接
Summary:本文利用深度神经网络(DNN)进行听力损失补偿的研究。文章介绍了基于DNN的听觉模型仿真框架,并提出了一种线性化的DNN听力损失补偿方法。此外,还开发了一种简单的方法来选择听觉模型中用于补偿策略的声中心频率。通过听力受损者的听力测试,验证了基于DNN的听力损失补偿策略的有效性,该方法可以提高语音清晰度,优于传统方法。
Key Takeaways:
- 本文利用深度神经网络(DNN)对听力损失进行补偿,针对全球数百万听力受损人群的需求。
- 介绍了基于DNN的听觉模型仿真框架,特别是听觉神经模型的模拟。
- 提出了一种线性化的DNN听力损失补偿方法,用于分析该策略。
- 开发了一种简单的方法来选择听觉模型中用于补偿策略的声中心频率。
- 通过听力受损者的测试,验证了基于DNN的听力损失补偿策略的有效性。
- 基于DNN的补偿策略能提高语音清晰度,相较于未处理的基础线及传统方法表现更佳。
- 此研究为听力损失补偿提供了新的可行策略。
点此查看论文截图

Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Authors:Muhammad A. Shah, David Solans Noguero, Mikko A. Heikkila, Bhiksha Raj, Nicolas Kourtellis
As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 114 input perturbations which simulate an heterogeneous range of corruptions that ASR models may encounter when deployed in the wild. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as the use of discrete representations, or self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females. Our results revealed noticeable disparities in the model’s robustness across subgroups. We believe that SRB will significantly facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
随着自动语音识别(ASR)模型在物理世界和数字世界中越来越普及,确保它们在存在的各种干扰下做出可靠预测变得至关重要。我们提出了语音鲁棒基准(SRB),这是一个全面评估ASR模型对各种干扰鲁棒性的基准测试。SRB由114种输入扰动组成,模拟了ASR模型在野外部署时可能遇到的各种异质干扰。我们使用SRB来评估几种最先进的ASR模型的鲁棒性,并观察到模型大小以及某些建模选择,如使用离散表示或自训练,有助于模型的鲁棒性。我们将此分析扩展到衡量来自不同人口亚组的数据的ASR模型的鲁棒性,即英语和西班牙语使用者以及男性和女性。我们的结果揭示了各亚组模型鲁棒性的明显差异。我们相信,通过使进行更全面和可比较的稳定性评估变得更容易,SRB将极大地推动未来对稳健的ASR模型的研究。
论文及项目相关链接
PDF submitted to NeurIPS datasets and benchmark track 2025
Summary
本文主要介绍了针对自动语音识别(ASR)模型的健壮性评估的新基准——Speech Robust Bench(SRB)。该基准包含了模拟野外ASR模型可能遇到的多种腐蚀情况的114种输入扰动。通过对多种前沿ASR模型的评估,研究发现模型大小及某些建模选择如离散表示或自训练有助于模型的健壮性。同时,作者对来自不同人口亚组的模型健壮性进行了评估,发现不同亚组之间存在一定的差异。作者认为,SRB将极大地推动未来对健壮性强的ASR模型的研究,使全面和可比较的评价更为便捷。
Key Takeaways
- 提出了Speech Robust Bench(SRB)基准,用于评估自动语音识别(ASR)模型的健壮性。
- SRB包含了模拟野外ASR模型可能遇到的多种腐蚀情况的114种输入扰动。
- 对多种前沿ASR模型的评估发现,模型大小和某些建模选择影响模型的健壮性。
- 离散表示和自训练等建模选择对ASR模型的健壮性有积极影响。
- 不同人口亚组的ASR模型健壮性存在明显差异。
- ASR模型的健壮性评价需要更全面地考虑不同因素,包括模型结构、训练策略以及数据来源等。
点此查看论文截图

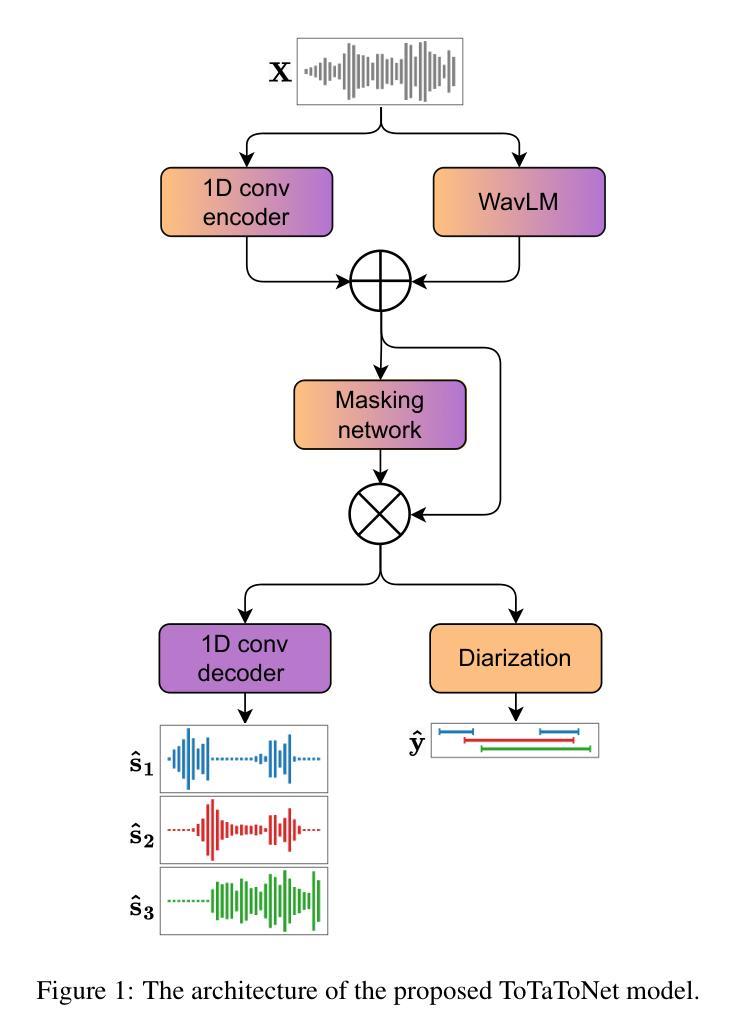
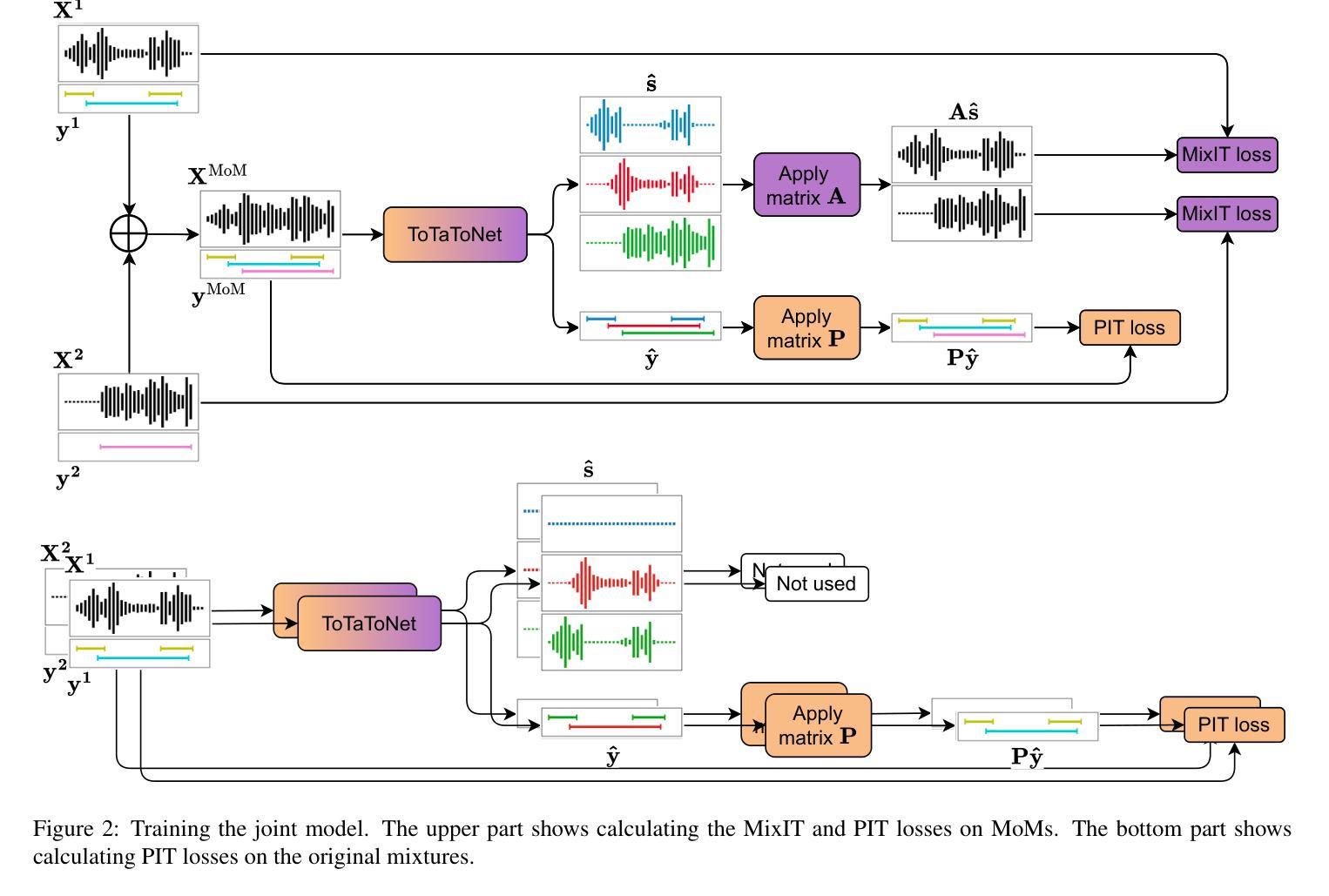
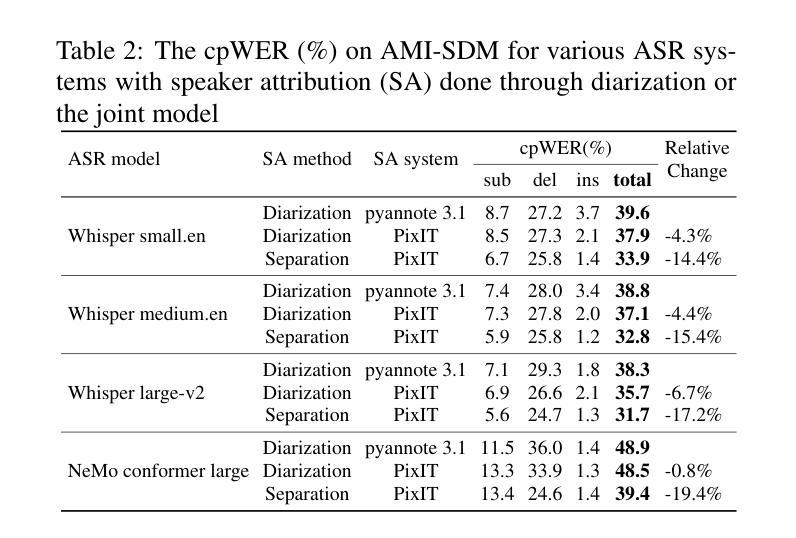
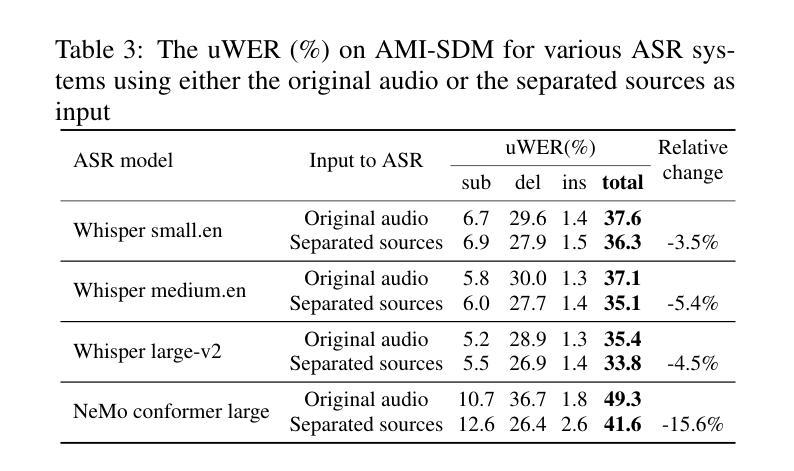
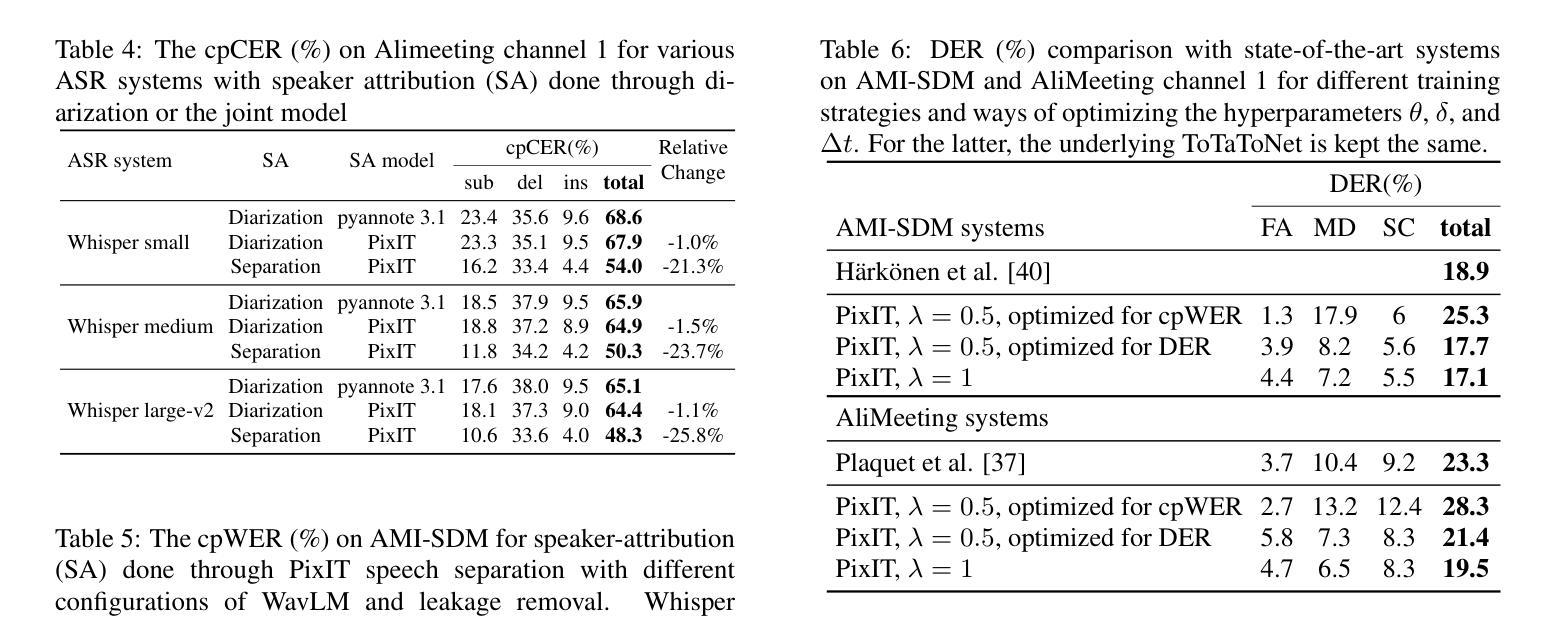
PixIT: Joint Training of Speaker Diarization and Speech Separation from Real-world Multi-speaker Recordings
Authors:Joonas Kalda, Clément Pagés, Ricard Marxer, Tanel Alumäe, Hervé Bredin
A major drawback of supervised speech separation (SSep) systems is their reliance on synthetic data, leading to poor real-world generalization. Mixture invariant training (MixIT) was proposed as an unsupervised alternative that uses real recordings, yet struggles with overseparation and adapting to long-form audio. We introduce PixIT, a joint approach that combines permutation invariant training (PIT) for speaker diarization (SD) and MixIT for SSep. With a small extra requirement of needing SD labels, it solves the problem of overseparation and allows stitching local separated sources leveraging existing work on clustering-based neural SD. We measure the quality of the separated sources via applying automatic speech recognition (ASR) systems to them. PixIT boosts the performance of various ASR systems across two meeting corpora both in terms of the speaker-attributed and utterance-based word error rates while not requiring any fine-tuning.
监督语音分离(SSep)系统的一个主要缺点是它们依赖于合成数据,导致在现实世界中的泛化能力较差。提出了混合不变训练(MixIT)作为一种使用真实录音的无监督替代方案,但在超分离和适应长音频方面仍存在困难。我们介绍了PixIT,这是一种联合方法,结合了用于说话人日记化(SD)的排列不变训练(PIT)和用于SSep的MixIT。它只需要少量的SD标签,解决了超分离问题,并允许利用基于聚类的神经SD的现有工作来拼接局部分离源。我们通过将自动语音识别(ASR)系统应用于分离源来测量其质量。PixIT提高了两个会议语料库中各种ASR系统的性能,无论是在说话人属性和基于话语的单词错误率方面都不需要进行任何微调。
论文及项目相关链接
PDF Speaker Odyssey 2024
Summary
本文提出PixIT方法,结合用于语音分离的监督训练与用于说话人识别的无监督训练,解决了现有语音分离系统依赖合成数据导致的真实场景泛化性能差的问题。PixIT方法利用现有的说话人聚类神经网络来解决过度分离问题,并利用现有的说话人日记进行本地音源分离和拼接。实验结果显示,PixIT可以提升多个自动语音识别系统在两种会议语料库上的性能,包括说话人属性和基于话语的单词错误率,且无需进行微调。
Key Takeaways
- PixIT结合了用于说话人日记的排列不变训练(PIT)和用于语音分离的混合不变训练(MixIT)。
- PixIT解决了过度分离问题,允许通过现有的基于聚类的神经网络进行本地音源分离和拼接。
- PixIT需要少量的说话人日记标签。
- PixIT提升了多个自动语音识别系统在两种会议语料库上的性能。
- 性能提升体现在说话人属性和基于话语的单词错误率上。
- PixIT方法不需要对现有系统进行微调。
点此查看论文截图