⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
Authors:Xueting Li, Ye Yuan, Shalini De Mello, Gilles Daviet, Jonathan Leaf, Miles Macklin, Jan Kautz, Umar Iqbal
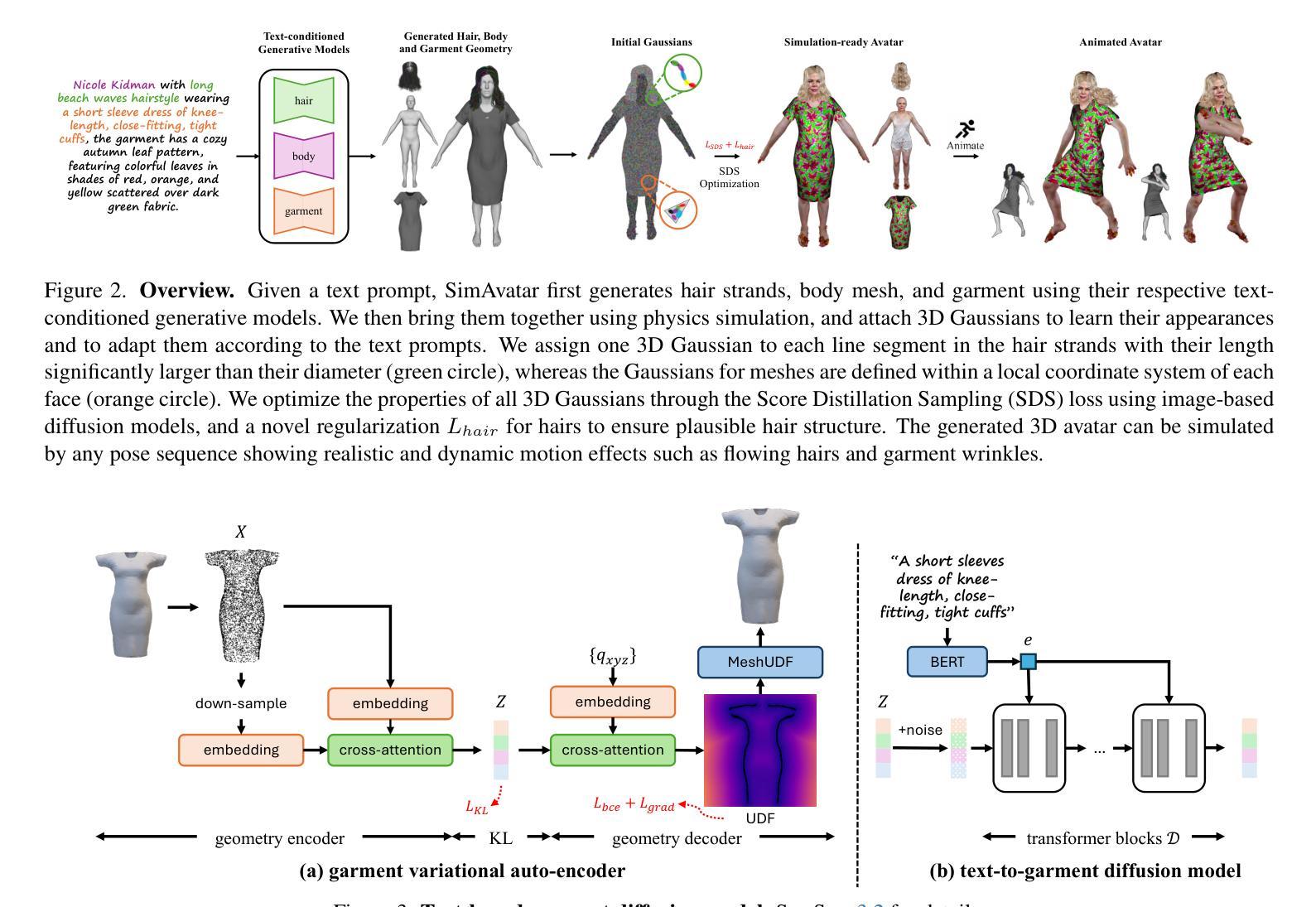
We introduce SimAvatar, a framework designed to generate simulation-ready clothed 3D human avatars from a text prompt. Current text-driven human avatar generation methods either model hair, clothing, and the human body using a unified geometry or produce hair and garments that are not easily adaptable for simulation within existing simulation pipelines. The primary challenge lies in representing the hair and garment geometry in a way that allows leveraging established prior knowledge from foundational image diffusion models (e.g., Stable Diffusion) while being simulation-ready using either physics or neural simulators. To address this task, we propose a two-stage framework that combines the flexibility of 3D Gaussians with simulation-ready hair strands and garment meshes. Specifically, we first employ three text-conditioned 3D generative models to generate garment mesh, body shape and hair strands from the given text prompt. To leverage prior knowledge from foundational diffusion models, we attach 3D Gaussians to the body mesh, garment mesh, as well as hair strands and learn the avatar appearance through optimization. To drive the avatar given a pose sequence, we first apply physics simulators onto the garment meshes and hair strands. We then transfer the motion onto 3D Gaussians through carefully designed mechanisms for each body part. As a result, our synthesized avatars have vivid texture and realistic dynamic motion. To the best of our knowledge, our method is the first to produce highly realistic, fully simulation-ready 3D avatars, surpassing the capabilities of current approaches.
我们介绍了SimAvatar框架,该框架旨在从文本提示生成可用于模拟的穿衣3D人类化身。当前的文本驱动人类化身生成方法要么使用统一几何对头发、服装和人体进行建模,要么生成不易在现有模拟管道中进行模拟的头发和服装。主要挑战在于以允许利用基础图像扩散模型(例如Stable Diffusion)的先验知识的方式表示头发和服装几何形状,同时使用物理或神经网络模拟器进行模拟。为了解决这个问题,我们提出了一个两阶段框架,它将3D高斯分布的灵活性与可用于模拟的头发束和服装网格相结合。具体来说,我们首先采用三个文本条件驱动的3D生成模型,根据给定的文本提示生成服装网格、身体形状和头发束。为了利用基础扩散模型的先验知识,我们将3D高斯分布附加到身体网格、服装网格和头发束上,并通过优化学习化身外观。为了在给定的姿势序列驱动下驱动化身,我们首先将物理模拟器应用于服装网格和头发束。然后,我们通过为每个身体部分精心设计的机制将运动转移到3D高斯分布上。因此,我们合成的化身具有生动的纹理和逼真的动态运动。据我们所知,我们的方法是第一个能够生成高度逼真、完全模拟就绪的3D化身的方法,超越了当前方法的能力。
论文及项目相关链接
PDF Project website: https://nvlabs.github.io/SimAvatar/
Summary
SimAvatar框架能够根据文本提示生成可用于模拟的穿衣3D人类角色。它通过两个阶段实现,首先使用文本驱动的三维生成模型生成服装网格、身体形态和头发丝缕,然后利用物理或神经网络模拟器进行模拟。该方法利用基础扩散模型的先验知识,通过优化学习角色外观,并将动态运动转移到每个身体部分的3D高斯分布上,从而生成具有逼真动态和纹理的合成角色。这是首个能够生成高度逼真且完全可用于模拟的3D角色的方法。
Key Takeaways
- SimAvatar是一个能够从文本提示生成模拟就绪的穿衣3D人类角色的框架。
- 它采用两个阶段的方法,首先生成服装网格、身体形态和头发丝缕,然后进行模拟。
- 该方法结合了3D高斯分布的灵活性和模拟就绪的头发丝缕和服装网格。
- 它利用基础扩散模型的先验知识,并通过优化学习角色外观。
- SimAvatar能够生成具有逼真动态和纹理的合成角色。
- 该方法是首个能够生成高度逼真且完全可用于模拟的3D角色的方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为SimAvatar的框架,旨在解决如何从文本提示生成模拟就绪(simulation-ready)的、穿着服装的3D人体化身的问题。具体来说,论文试图解决以下几个挑战:
现有方法的局限性:当前基于文本驱动的人体化身生成方法要么使用统一的几何模型来建模头发、服装和人体,要么生成的头发和服装不容易适应现有的模拟流程。这些方法难以在保持模拟就绪性的同时利用基础图像扩散模型(例如Stable Diffusion)的先验知识。
头发和服装的几何表示:挑战在于如何表示头发和服装的几何形状,以便既能利用现有的扩散模型的先验知识,又能适应物理或神经网络模拟器进行模拟。
模拟准备性与细节表现:需要生成具有详细几何结构、真实纹理和动态服装及头发运动的3D化身,这些运动效果随姿势变化而变化,如头发流动和服装皱纹。
不同表示方式的整合:将当前模拟器使用的表示方式与文本驱动的化身生成流程所使用的表示方式相连接,前者通常需要干净、紧凑、平滑的网格或特定设计的发丝,后者则常采用隐式表示(如NeRF或SDF),这些虽然可以通过扩散模型的噪声信号进行优化,但难以转换为适合模拟的开放网格或发丝。
为了解决这些问题,SimAvatar框架采用了一个两阶段的方法,结合了3D高斯分布的灵活性和模拟就绪的头发丝和服装网格,使得生成的3D化身能够被现有的头发和服装模拟器轻松动画化,同时保持真实感和动态运动效果。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以归纳为以下几个领域:
文本到3D化身生成(Text to 3D Avatar Generation):
- ClipMatrix、AvatarClip、DreamAvatar、AvatarCraft、DreamHumans、DreamWaltz、AvatarVerse、HumanNorm、AvatarBooth等方法,这些方法通过文本或图像输入来生成和控制3D人体化身。
- TADA、GAvatar等方法,探索了不同的表示方式来建模化身,例如基于网格的方法和基于3D高斯的方法。
服装建模和模拟(Garment Modeling and Simulation):
- SMPL+D等方法,通过在SMPL人体网格上添加顶点位移来捕捉穿着服装的人体几何形状。
- BCNet、DeepCloth等方法,通过学习回归器直接预测服装类型和形状参数,或通过规范的UV表示来编码服装。
- 使用隐式无符号距离场(Unsigned Distance Fields, UDF)的方法,因其在建模任意拓扑和处理开放表面方面的灵活性而受到青睐。
头发建模和模拟(Hair Modeling and Simulation):
- 基于发丝表示的方法,因其与物理模拟器的兼容性和几何操作的便利性而受到青睐。
- 使用数据驱动先验的方法,基于扩散模型来估计合理的内部发丝,尽管在观测数据中这些发丝可能被遮挡。
- 使用3D高斯表示来有效模拟复杂头发纹理和不同发丝厚度的方法。
这些相关研究为SimAvatar框架的发展提供了理论基础和技术手段,特别是在3D人体建模、服装和头发的几何表示、物理模拟以及基于文本的生成模型等方面。SimAvatar框架通过结合这些领域的技术进展,提出了一种新的方法来生成具有独立层次的身体、服装和头发的模拟就绪3D化身。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SimAvatar的框架来解决从文本提示生成模拟就绪的3D人体化身的问题。该框架通过以下几个关键步骤来解决这个问题:
1. 两阶段框架
SimAvatar采用了一个两阶段框架,结合了3D高斯的灵活性和模拟就绪的头发丝以及服装网格。
2. 文本条件3D生成模型
- 服装网格生成:使用变分自编码器(VAE)学习服装几何分布,并训练一个条件潜在扩散模型从文本提示生成服装网格。
- 头发丝生成:利用基于扩散的文本到头发生成模型从文本提示创建头发丝。
- 身体形状生成:使用基于GPT的LLM模型预测头发丝和SMPL形状参数。
3. 3D高斯Splatting(3DGS)外观模型
- 在不同的人体部位(如头发、身体和服装)上附加3D高斯,并使用得分蒸馏采样(SDS)优化这些高斯属性,以学习真实的外观细节。
4. 动态模拟
- 服装模拟:使用神经网络模拟器(例如HOOD)根据目标身体姿势序列模拟服装网格。
- 头发模拟:使用头发模拟器根据目标身体网格序列和模拟的服装序列模拟头发丝。
5. 外观细节优化
- 使用SDS目标和预训练的文本到图像扩散模型来优化高斯的属性,从而精细化外观细节。
6. 特定部位的3D高斯定制
- 身体和服装网格:将3D高斯与身体和服装网格结合,并根据网格的运动来驱动这些高斯。
- 头发丝:为每根头发丝的每个线段分配一个3D高斯,并根据头发丝的运动来驱动这些高斯。
7. 着色模型
- 为了捕捉运动中的外观细节,如服装皱纹,将Phong着色模型纳入流程中。
8. 实验和评估
- 使用用户研究和定量评估(如VQAScore和CLIP分数)来验证SimAvatar在生成外观和动态运动方面相较于现有技术的优越性。
通过这些步骤,SimAvatar能够生成具有详细几何结构、真实纹理和动态服装及头发运动的3D化身,这些运动效果随姿势变化而变化,如头发流动和服装皱纹。这种方法不仅提高了生成化身的真实感,而且使得化身能够被现有的头发和服装模拟器轻松动画化。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估SimAvatar框架的性能:
1. 数据集
- 为了学习基于文本的服装扩散模型,作者使用了Garment Pattern Generator (GPG) 数据集和CLOTH3D 数据集,并利用GPT4v生成与服装网格配对的文本提示。
2. 定性评估
- 作者将SimAvatar生成的化身与几种最先进的文本驱动的3D化身生成方法(包括Fantasia3D、TADA和GAvatar)进行了视觉比较。
- 展示了在标准姿势下的合成化身以及动画化身,以展示SimAvatar在模拟动态效果(如服装皱纹和头发流动)方面的优势。
3. 用户研究
- 通过A/B用户研究定量评估SimAvatar。研究包括对22个提示的比较,生成静态360度视频和显示化身驱动的运动序列的视频。
- 用户被要求选择具有更好外观的方法和更注重运动的方法。研究收集了18名用户的540票,并在表格中展示了结果。
4. 定量评估
- 使用VQAScore和CLIP分数来定量比较SimAvatar与基线方法。
- VQAScore:评估生成资产与输入提示之间的对齐程度,特别适合涉及多个实体和关系的复杂提示。
- CLIP分数:虽然用于评估,但作者指出其在评估视觉质量和文本提示对齐方面的不可靠性。
5. 实施细节
- 描述了文本到服装扩散模型的训练细节和高斯化身学习的优化过程。
6. 层级训练策略
- 为了促进头发、身体和服装的解耦,作者采用了分别渲染每个层并使用不同提示进行优化的策略。
7. 消融研究
- 评估了不同模块的有效性,包括头发约束、提示工程和解耦训练策略,并展示了相应的定性结果。
8. 更多定性结果
- 提供了与基线方法的更多比较结果,并展示了SimAvatar方法的各个层(包括头发、面部、服装、身体和完整化身)的几何和纹理的额外结果。
这些实验全面评估了SimAvatar在生成现实感、可动画化3D服装化身方面的能力,并与现有技术进行了比较。通过这些实验,论文证明了SimAvatar在生成具有动态效果的高质量3D化身方面的有效性。
Q: 有什么可以进一步探索的点?
A: 论文在最后提出了几个可以进一步探索的点:
数据集多样性:当前的头发和服装生成模型是在特定的数据集上训练的,这可能因为训练数据的局限性而限制了生成的多样性。未来的工作可以探索方法,以生成超越现有数据集多样性的模拟就绪化身。
联合模拟:SimAvatar目前是顺序地模拟服装和头发,这在某些情况下(如穿着帽子的化身)可能会失败。实现头发和服装的联合模拟将使我们能够处理更复杂的服装。
配饰和鞋类:目前的SimAvatar框架中,配饰和鞋类仍然与身体或服装层纠缠在一起;未来的工作可以集中在生成完全分离的配饰和鞋类,以创建完全解耦的化身。
优化和计算效率:虽然SimAvatar能够生成高质量的3D化身,但是优化过程可能既耗时又计算密集。研究更高效的优化算法和计算策略可能是一个有价值的方向。
更复杂的纹理和外观细节:尽管SimAvatar在模拟动态服装和头发方面取得了进展,但在生成更复杂的纹理和外观细节方面仍有改进空间,例如模拟更逼真的织物纹理和更细致的光影效果。
交互性和实时应用:将SimAvatar应用于实时系统,如虚拟试衣或游戏,可能需要进一步的研究以确保实时性能和用户交互。
跨模态融合:探索将SimAvatar与其他模态的输入(如语音或视频)结合起来,以创建更丰富的交互体验。
更广泛的用户定制:提供更多的用户定制选项,允许用户调整化身的各种特征,包括面部特征、体型和风格。
评估和度量:开发和验证新的评估度量,以更准确地衡量3D化身生成系统的性能,特别是在动态模拟和真实感方面。
应用扩展:探索SimAvatar在其他领域的应用,如电影和游戏制作、虚拟助理、增强现实/虚拟现实和远程存在等。
这些方向都有助于推动3D人体化身生成技术的发展,并扩大其在不同领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为SimAvatar的框架,旨在从文本提示生成模拟就绪的3D人体化身,包括头发、服装和身体。以下是论文的主要内容总结:
问题定义:论文指出了现有文本驱动的3D人体化身生成方法的局限性,包括无法适应模拟流程的头发和服装表示,以及难以利用图像扩散模型的先验知识。
SimAvatar框架:提出了一个两阶段框架,首先使用文本条件的3D生成模型生成服装网格、身体形状和头发丝,然后通过优化附着在这些几何结构上的3D高斯来学习化身的外观。
服装和头发的模拟:利用物理模拟器和神经网络模拟器(如HOOD)来模拟服装和头发的运动,以实现动态效果,如流动的头发和服装皱纹。
3D高斯Splatting(3DGS):为了捕捉细节外观,框架在身体网格、服装网格和头发丝上附加3D高斯,并使用得分蒸馏采样(SDS)优化这些高斯的属性。
动态模拟:通过将运动从模拟的服装网格和头发丝转移到3D高斯,确保化身在不同姿势下的外观保持一致。
实验:通过定性和定量实验,包括用户研究和VQAScore评估,展示了SimAvatar在生成现实感和动态服装化身方面的优越性能。
未来工作:论文提出了几个未来研究方向,包括扩展数据集多样性、实现头发和服装的联合模拟、生成完全解耦的配饰和鞋类等。
总体而言,SimAvatar通过结合3D高斯的灵活性和模拟就绪的头发丝及服装网格,提出了一种新的方法来生成具有独立层次的身体、服装和头发的模拟就绪3D化身,这些化身在动画化时能够展现出逼真的动态效果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图