⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Can Modern LLMs Act as Agent Cores in Radiology~Environments?
Authors:Qiaoyu Zheng, Chaoyi Wu, Pengcheng Qiu, Lisong Dai, Ya Zhang, Yanfeng Wang, Weidi Xie
Advancements in large language models (LLMs) have paved the way for LLM-based agent systems that offer enhanced accuracy and interpretability across various domains. Radiology, with its complex analytical requirements, is an ideal field for the application of these agents. This paper aims to investigate the pre-requisite question for building concrete radiology agents which is, `Can modern LLMs act as agent cores in radiology environments?’ To investigate it, we introduce RadABench with three-fold contributions: First, we present RadABench-Data, a comprehensive synthetic evaluation dataset for LLM-based agents, generated from an extensive taxonomy encompassing 6 anatomies, 5 imaging modalities, 10 tool categories, and 11 radiology tasks. Second, we propose RadABench-EvalPlat, a novel evaluation platform for agents featuring a prompt-driven workflow and the capability to simulate a wide range of radiology toolsets. Third, we assess the performance of 7 leading LLMs on our benchmark from 5 perspectives with multiple metrics. Our findings indicate that while current LLMs demonstrate strong capabilities in many areas, they are still not sufficiently advanced to serve as the central agent core in a fully operational radiology agent system. Additionally, we identify key factors influencing the performance of LLM-based agent cores, offering insights for clinicians on how to apply agent systems in real-world radiology practices effectively. All of our code and data are open-sourced in https://github.com/MAGIC-AI4Med/RadABench.
大型语言模型(LLM)的进步为基于LLM的代理系统铺平了道路,这些系统在各个领域提供了更高的准确性和可解释性。放射学由于其复杂的分析要求,是这些代理应用的理想领域。本文旨在探讨构建具体放射学代理的先决问题,即“现代LLM能否在放射学环境中作为代理核心?”为了调查这个问题,我们推出了RadABench,它有三方面的贡献:首先,我们展示了RadABench-Data,这是一套全面的合成评估数据集,用于基于LLM的代理,数据来自于广泛的分类,包括6个解剖学、5种成像模式、10个工具类别和11个放射学任务。其次,我们提出了RadABench-EvalPlat,这是一个新型代理评估平台,具有提示驱动的工作流程,能够模拟广泛的放射学工具集。第三,我们从5个角度对7款领先的LLM在我们的基准测试上的表现进行了评估,采用多个指标。我们的研究发现,虽然当前的LLM在许多领域表现出强大的能力,但它们仍然不足以作为完全运营的放射学代理系统的核心代理。此外,我们还确定了影响基于LLM的代理核心性能的关键因素,为临床医生提供了如何在现实世界的放射学实践中有效应用代理系统的见解。我们的所有代码和数据都在https://github.com/MAGIC-AI4Med/RadABench上开源。
论文及项目相关链接
PDF 22 pages,7 figures
Summary
本文探讨了现代大型语言模型(LLMs)在放射学环境中作为核心代理的潜力。为了评估LLMs在放射学领域的应用,介绍了RadABench平台,包括RadABench-Data数据集和RadABench-EvalPlat评估平台。通过对7种领先的LLMs进行评估,发现当前LLMs在许多领域表现出强大的能力,但仍不足以作为完全运作的放射学代理系统的核心。研究还识别了影响LLM代理核心性能的关键因素,为临床医生在实际放射学实践中有效应用代理系统提供了见解。
Key Takeaways
- 大型语言模型(LLMs)在放射学领域有广泛的应用潜力。
- RadABench平台包括RadABench-Data数据集和RadABench-EvalPlat评估平台,为LLMs在放射学领域的应用提供了资源和工具。
- 评估了7种领先的LLMs在放射学任务上的性能。
- 当前LLMs在许多领域表现出强大的能力,但仍需进一步提高才能作为完全运作的放射学代理系统的核心。
- 影响LLM代理核心性能的关键因素被识别,包括理解能力、交互能力、上下文感知能力等。
- 本文为临床医生在实际放射学实践中有效应用代理系统提供了见解。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了现代大型语言模型(LLMs)是否可以作为放射学环境中代理系统的核心。具体来说,论文试图解决的问题是:
“Can existing LLMs effectively interact with the radiological environment—understanding professional medical tool descriptions, accurately translating diverse clinical queries into actionable steps, and invoking tools to execute sub-tasks sequentially?”
即,现有的大型语言模型是否能够有效地与放射学环境互动,包括理解专业医疗工具的描述、准确地将不同的临床查询转化为可执行的步骤,以及顺序调用工具执行子任务。为了探索这个问题,作者引入了一个名为RadABench(放射学代理基准)的评估框架,旨在全面评估基于LLM的代理在放射学中的表现。这包括它们在分解复杂放射学成像任务和有效利用多样的医疗工具以生成准确和最优响应方面的能力。
Q: 有哪些相关研究?
A: 论文中提到了多个与大型语言模型(LLMs)在放射学环境中的应用相关的研究。以下是一些相关研究的概述:
放射学通用模型:
- 论文引用了一些研究,这些研究展示了放射学通用模型在处理单一框架内多种放射学分析方面的潜力。这些模型包括[4, 21, 22, 23, 24, 25, 26]。
LLM驱动的代理系统:
- 论文提到了一些LLM驱动的代理系统的研究,这些系统能够与外部工具互动,实现复杂、多步骤的任务,并在客户服务、业务自动化和创意内容生成等领域展现出显著的前景。相关研究包括[9, 10, 11, 12, 13, 14]。
LLM在临床设置中的应用:
- 论文讨论了LLMs在临床设置中,特别是在放射学中的集成仍然处于早期阶段的研究。相关研究包括[15, 16]。
放射学代理系统:
- 论文强调了放射学作为一个理想的领域,可以应用基于代理的系统,其中专门的工具(或模型)可以协作提供更健壮和精确的分析。相关研究包括[27]。
LLMs在医疗诊断中的应用:
- 论文引用了一些研究,这些研究强调了LLMs在临床设置中的潜力,包括支持决策制定、促进交互和调用工具的应用。相关研究包括[32, 33]。
LLMs在放射学特定任务中的挑战:
- 论文提到了一些研究,这些研究表明即使是最新的视觉-语言模型(VLMs)也难以进行可靠的医学图像分析。相关研究包括[34, 35]。
LLMs作为代理在医疗领域的应用:
- 论文引用了一些研究,这些研究限制了LLMs代理在医疗领域,特别是放射学中的适用性。相关研究包括[37]。
这些研究为论文提供了背景和动机,展示了LLMs在放射学中的应用前景以及面临的挑战,为进一步探索LLMs作为放射学代理核心的能力提供了理论基础和实证支持。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决“现代大型语言模型(LLMs)是否可以作为放射学环境中代理核心”的问题:
建立RadABench(放射学代理基准):
- 论文介绍了RadABench,这是一个用于评估基于LLM的放射学代理的综合资源。RadABench包括三个主要部分:数据集(RadABench-Data)、评估平台(RadABench-EvalPlat)和对多个领先LLMs的性能评估。
创建RadABench-Data(放射学代理评估数据集):
- 作者提出了一个专门设计的放射学数据集,包含2200个合成患者记录和24200个相关的问答(QA)对,涵盖了11种临床任务和10个高级工具类别,模拟了广泛的放射学场景。
开发RadABench-EvalPlat(放射学代理评估平台):
- 该平台模拟真实世界的临床环境,包含一个交互式提示系统,以促进迭代任务执行,并动态生成针对特定评估需求的放射学工具集。
评估领先的LLMs性能:
- 论文提供了一个系统的性能分析,评估了7个最先进的LLMs(包括封闭源模型和开源模型)在RadABench上的表现。评估从五个关键能力维度进行:链规划、最优工具编排、输入/输出(IO)组织、响应合成和不可解性解析。
设计评估指标:
- 为了全面评估LLMs作为代理核心的能力,论文设计了一系列评估指标,包括Levenshtein距离、假发现率、工具匹配准确率、最优工具得分、执行完成率、预失败成功百分比、目标命中率、里程碑命中率、BLEU、ROUGE、F1得分、RaTEScore、不可解性意识率和不可解性基础率。
开放源代码和数据:
- 为了促进研究的进一步发展,作者公开了所有的代码和数据,允许研究人员对新的模型进行基准测试,并推动该领域的发展。
通过这些步骤,论文不仅提出了一个问题,而且通过构建数据集、开发评估平台和执行系统性能评估来全面地探索和回答这个问题,为LLMs在放射学中的应用提供了深刻的见解和实际的评估结果。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估现代大型语言模型(LLMs)作为放射学环境中代理核心的性能。这些实验主要围绕以下几个方面:
数据集构建(RadABench-Data):
- 作者创建了一个包含2200个合成患者记录和24200个相关问答对的数据集,覆盖了11种临床任务和10个高级工具类别。
评估平台开发(RadABench-EvalPlat):
- 开发了一个自动化评估平台,模拟真实世界的临床环境,动态生成放射学工具集,并支持不同临床条件下的评估。
性能评估:
- 对7个最先进的LLMs进行了性能评估,包括封闭源模型(如GPT-4, GPT-4o, Gemini, Claude)和开源模型(如LLaMA, Mixtral, Qwen)。
关键能力评估:
- 从五个关键能力维度对LLMs进行了评估:
- 链规划(Chain Planning):比较预测和真实规划之间的差异。
- 最优工具编排(Optimal Tool Orchestration):评估适当工具选择的能力。
- 输入/输出组织(IO Organizing):确保正确的输入/输出格式化。
- 响应合成(Response Synthesis):评估生成响应的质量。
- 不可解性解析(Unsolvability Parsing):识别任务何时无法解决。
- 从五个关键能力维度对LLMs进行了评估:
量化分析:
- 对LLMs在不同条件下的表现进行了量化分析,包括:
- 响应令牌长度分析:评估模型的上下文窗口限制是否影响其作为代理核心的使用。
- 链规划能力分析:使用Levenshtein距离、假发现率和工具匹配准确率等指标。
- 最优工具选择能力分析:使用最优工具得分(OTS)等指标。
- 输入/输出组织能力分析:使用执行完成率(ECR)和预失败成功百分比(PFSP)等指标。
- 响应合成能力分析:使用目标命中率(THR)、里程碑命中率(MHR)和文本相似度指标(如BLEU、ROUGE和F1)。
- 不可解性解析能力分析:使用不可解性意识率(UAR)和不可解性基础率(UGR)等指标。
- 对LLMs在不同条件下的表现进行了量化分析,包括:
这些实验旨在全面评估LLMs在放射学任务中作为代理核心的能力,包括它们在任务分解、工具选择、执行、响应合成和处理不可解情况方面的表现。通过这些实验,论文揭示了现有LLMs在放射学应用中的潜力和局限性。
Q: 有什么可以进一步探索的点?
A: 论文在最后一部分提出了一些研究的局限性,并指出了未来有价值的研究方向。以下是一些可以进一步探索的点:
开发专门的医学领域LLMs:
- 尽管评估了七个最先进的通用LLMs,但这些模型并非专门针对医学领域设计的。开发专门针对医学领域,包括放射学的LLMs,可能会提高模型在专业任务中的表现。
使用视觉-语言模型(VLMs)作为代理核心:
- 将大型语言模型(LLMs)替换为视觉-语言模型(VLMs)可能显著提升系统能力。VLMs能够直接处理原始图像输入,提供更详细的分析,并精确响应图像相关查询。
工具的实际实施和错误传播研究:
- 目前的基准测试将工具输出视为理想化结果,并未考虑实际实施中可能出现的错误。未来的工作可以包括实现这些工具,使用它们的真实输出进行评估,并研究累积错误如何影响整体系统性能。
引入真实世界数据和手动评估:
- 尽管研究依靠合成数据和自动指标进行可扩展评估,但引入真实世界数据和手动评估将提供对代理系统性能更细致的理解。
优化LLMs的链规划和执行能力:
- 鉴于LLMs在复杂工具集条件下性能显著下降,未来的研究可以探索如何改进LLMs在链规划和执行任务中的能力,尤其是在面对不完整或不一致的工具集时。
提高LLMs的信息合成能力:
- LLMs在多轮次信息合成中性能下降,限制了其在迭代诊断过程和纵向患者监测中的潜力。研究可以集中在如何提升LLMs在处理多轮次信息时的性能。
减少“工具不完整幻觉”现象:
- LLMs在与外部工具交互时常常生成错误或不完整的输出,即“幻觉”。研究可以探索如何减少这种现象,以提高AI系统在临床决策中的可信度。
改进LLMs在严格IO格式组织方面的能力:
- LLMs常常未能精确遵循复杂的指令,尤其是在需要系统组织IO以链接不同工具的情况下。未来的研究可以集中在如何提升LLMs在组织任务和链接工具方面的性能。
基于性能的最优工具选择:
- 一个有效的代理系统需要能够基于客观的性能指标评估和选择最佳工具。研究可以集中在如何改进LLMs在这方面的能力。
开源与封闭源LLMs性能比较:
- 论文发现封闭源LLMs通常比开源替代品表现得更好。未来的研究可以进一步探索这种差异的原因,并寻求提高开源模型性能的方法。
这些方向提供了对如何改进LLMs以使其更适合临床放射学应用的深入见解,并可能推动未来在这一领域的研究和实践。
Q: 总结一下论文的主要内容
A: 这篇论文探讨了现代大型语言模型(LLMs)是否有潜力作为放射学环境中代理系统的核心。主要内容包括:
研究背景:
- 大型语言模型(LLMs)在多个领域展现了革命性的进展,尤其是在需要精确性、可解释性和可扩展性的放射学领域。
- 放射学需要解读详细的文本报告和复杂的医学影像数据,其复杂性超出了单一模型的能力,因此适合应用基于代理的系统。
研究问题:
- 论文提出了一个基本问题:现有的LLMs是否能有效与放射学环境互动,理解医学工具描述,准确转化临床查询,并顺序执行子任务。
RadABench的引入:
- 为了探索上述问题,作者介绍了RadABench(放射学代理基准),这是一个全面评估基于LLM的放射学代理的资源,包括数据集(RadABench-Data)和评估平台(RadABench-EvalPlat)。
数据集构建(RadABench-Data):
- 作者创建了一个包含2200个合成患者记录和24200个问答对的数据集,覆盖11种临床任务和10个工具类别,以模拟广泛的放射学场景。
评估平台开发(RadABench-EvalPlat):
- 开发了一个模拟真实临床环境的评估平台,能够动态生成放射学工具集,并支持不同临床条件下的评估。
性能评估:
- 对7个领先的LLMs进行了性能评估,从五个关键能力维度:链规划、最优工具编排、输入/输出组织、响应合成和不可解性解析。
实验结果:
- 研究发现,尽管当前LLMs在许多领域展现出强大的能力,但它们仍未足够先进,无法作为完全操作的放射学代理系统的核心。
研究影响和临床影响:
- 论文讨论了研究对学术界和放射学实践的影响,包括LLMs在放射学任务中的潜力和挑战。
限制和未来方向:
- 论文指出了研究的局限性,并提出了未来研究的方向,包括开发专门针对医学领域的LLMs、使用VLMs作为代理核心、工具的实际实施和错误传播研究等。
开源贡献:
- 作者公开了所有的代码和数据,以促进研究的进一步发展,并推动该领域的发展。
总结来说,这篇论文提供了一个全面的评估框架来测试现代LLMs在放射学环境中作为代理核心的能力,并揭示了它们在实际应用中面临的挑战和未来的改进方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Embeddings are all you need! Achieving High Performance Medical Image Classification through Training-Free Embedding Analysis
Authors:Raj Hansini Khoiwal, Alan B. McMillan
Developing artificial intelligence (AI) and machine learning (ML) models for medical imaging typically involves extensive training and testing on large datasets, consuming significant computational time, energy, and resources. There is a need for more efficient methods that can achieve comparable or superior diagnostic performance without the associated resource burden. We investigated the feasibility of replacing conventional training procedures with an embedding-based approach that leverages concise and semantically meaningful representations of medical images. Using pre-trained foundational models-specifically, convolutional neural networks (CNN) like ResNet and multimodal models like Contrastive Language-Image Pre-training (CLIP)-we generated image embeddings for multi-class classification tasks. Simple linear classifiers were then applied to these embeddings. The approach was evaluated across diverse medical imaging modalities, including retinal images, mammography, dermatoscopic images, and chest radiographs. Performance was compared to benchmark models trained and tested using traditional methods. The embedding-based models surpassed the benchmark area under the receiver operating characteristic curve (AUC-ROC) scores by up to 87 percentage in multi-class classification tasks across the various medical imaging modalities. Notably, CLIP embedding models achieved the highest AUC-ROC scores, demonstrating superior classification performance while significantly reducing computational demands. Our study indicates that leveraging embeddings from pre-trained foundational models can effectively replace conventional, resource-intensive training and testing procedures in medical image analysis. This embedding-based approach offers a more efficient alternative for image segmentation, classification, and prediction, potentially accelerating AI technology integration into clinical practice.
在医学成像领域开发人工智能(AI)和机器学习(ML)模型通常需要对大量数据集进行广泛的训练和测试,这需要消耗大量的计算时间、能源和资源。因此,需要更高效的方法,能够在不增加资源负担的情况下达到相当或更高的诊断性能。我们研究了用基于嵌入的方法取代传统训练程序的可行性,该方法利用医学图像的简洁、语义丰富的表示形式。我们使用预训练的基础模型(特别是ResNet等卷积神经网络(CNN)和Contrastive Language-Image Pre-training (CLIP)等多模态模型)生成用于多类分类任务的图像嵌入。然后,在这些嵌入上应用简单的线性分类器。该方法在多种医学成像模式(包括视网膜图像、乳腺X线摄影、皮肤镜图像和胸部X射线)上进行了评估。性能与使用传统方法训练和测试的基准模型进行了比较。在多种医学成像模式的多类分类任务中,基于嵌入的模型超出基准的受试者工作特征曲线下面积(AUC-ROC)得分高达87%。值得注意的是,CLIP嵌入模型获得了最高的AUC-ROC得分,展示了出色的分类性能,同时显著降低了计算需求。我们的研究表明,利用预训练基础模型的嵌入可以有效地替代医学图像分析中资源密集型的传统训练和测试程序。这种基于嵌入的方法为图像分割、分类和预测提供了更有效的替代方案,有望加快AI技术在临床实践中的整合。
论文及项目相关链接
PDF 15 pages, 7 figures, 3 tables
Summary
采用基于嵌入的方法,利用预训练的基础模型(如ResNet卷积神经网络和Contrastive Language-Image Pre-training (CLIP)多模态模型)生成医学图像嵌入,用于多类分类任务,并简化传统训练和测试流程。此方法在多种医学成像模态上表现优异,减少计算需求,为临床实践中AI技术的整合提供更有效率的替代方案。
Key Takeaways
- 医学图像分析中的AI和ML模型开发通常需要大量的数据集和计算资源。
- 研究人员尝试采用基于嵌入的方法替代传统训练程序。
- 使用预训练的基础模型(如CNN和CLIP)生成医学图像嵌入,用于多类分类任务。
- 基于嵌入的模型在多种医学成像模态上的性能超越了传统方法的基准模型。
- CLIP嵌入模型在多类分类任务中达到最高的AUC-ROC分数,表现出卓越的分类性能。
- 基于嵌入的方法显著减少了计算需求,为临床实践中AI技术的整合提供了更高效的替代方案。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是开发和部署医学影像中人工智能(AI)模型时面临的挑战,特别是在传统训练方法中需要大量数据集进行训练、测试,消耗显著的计算时间、能源和资源的问题。具体来说,论文探讨了以下几个关键问题:
传统训练方法的资源负担:传统的AI模型,尤其是深度学习算法,需要在大量标注的医学数据集上进行广泛的训练,以有效学习底层模式。这个过程计算密集、耗时且成本高昂,通常需要大量的计算资源和专业知识。
数据集的质量问题:依赖于大数据集可能会引入与数据质量相关的问题,例如数据偏差、不平衡或噪声。如果训练数据集存在这些问题,AI模型可能会无意中放大这些偏差,导致对训练集之外的数据泛化能力有限,性能下降。
寻找更高效的替代方法:鉴于上述挑战,论文强调了寻找能够使AI模型在没有传统训练方法的资源密集要求下有效工作的替代方法的需求。特别是,研究了利用图像嵌入作为分类器的可能性,这是一种通过机器学习模型(如深度神经网络)派生的图像的密集向量表示,能够捕获图像的语义信息。
提高诊断性能和效率:论文研究了是否可以用基于嵌入的方法替代传统的训练程序,并在不增加资源负担的情况下实现可比或更优的诊断性能。
综上所述,论文的核心目标是探索和验证一种基于图像嵌入的方法,以提高医学图像分类任务的效率和性能,同时减少计算资源的需求,从而加速AI技术在临床实践中的应用。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
深度学习在医学图像分析中的调查:
- Litjens G 等人的调查研究提供了深度学习在医学图像分析中的全面概述,包括自动图像分割、精确病变检测、准确疾病分类和生物标志物量化等方面的能力。[1]
高性能医学的人工智能:
- Topol EJ 讨论了人工智能与人类智能的融合,特别是在医学领域的高性能医学。[2]
医学视觉表示的对比学习:
- 有关医学视觉表示从配对图像和文本中通过对比学习的研究。[3]
医学图像分类的自监督学习:
- 系统性回顾和实施指南,讨论了自监督学习在医学图像分类中的应用。[4]
CLIP驱动的通用模型:
- Liu J 等人的研究利用CLIP(Contrastive Language-Image Pre-training)模型进行器官分割和肿瘤检测。[5]
无监督深度嵌入用于聚类分析:
- Xie J 等人的研究探讨了无监督深度嵌入在聚类分析中的应用。[6]
从自然语言监督中学习可转移的视觉模型:
- Radford A 等人介绍了CLIP模型,该模型通过自然语言监督学习视觉概念。[7]
深度残差学习用于图像识别:
- He K 等人的研究介绍了深度残差网络(ResNet)在图像识别中的应用。[8]
转移学习在医学图像分类中的应用:
- Kim HE 等人的文献综述探讨了转移学习在医学图像分类中的应用。[14]
深度学习对胸部放射图像诊断的影响:
- Rajpurkar P 等人的研究比较了CheXNeXt算法与执业放射科医生的诊断结果。[15]
医学图像分析的碳足迹:
- Selvan R 等人的研究讨论了选择和训练深度学习模型用于医学图像分析的碳足迹问题。[17]
MedNet:医学影像任务的预训练卷积神经网络模型:
- Alzubaidi L 等人的研究介绍了MedNet,这是一个用于医学影像任务的预训练卷积神经网络模型。[18]
这些研究为本文提出的基于嵌入的方法提供了理论基础和技术支持,同时也展示了医学图像分析领域中深度学习和预训练模型的应用进展。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决传统医学影像AI模型训练中遇到的资源负担问题:
使用预训练的基础模型:
- 论文使用了预训练的卷积神经网络(CNN),如ResNet,以及多模态模型如对比语言图像预训练(CLIP),来生成医学图像的嵌入表示。这些模型已经在大规模数据集上进行了预训练,能够提取图像中的高级视觉和语义特征。
生成图像嵌入:
- 利用上述预训练模型生成图像嵌入,这些嵌入是图像的密集向量表示,能够捕获图像的语义信息,并作为分类模型的主要输入。
应用简单的线性分类器:
- 在生成的嵌入上应用简单的线性分类器,如逻辑回归和支持向量机(SVM)。这些分类器因其计算效率和对高维数据的适用性而被选用。
跨不同医学影像模态评估性能:
- 论文在多种医学影像模态上评估了所提方法的性能,包括视网膜图像、乳房X线成像、皮肤镜图像和胸部放射图像。
与传统方法的性能比较:
- 将基于嵌入的模型与传统训练和测试方法得到的基准模型性能进行了比较。比较的指标包括准确度、敏感度、特异性和接收者操作特征曲线下面积(AUC)。
效率和性能的平衡:
- 论文发现基于嵌入的模型在多个数据集上达到了或超过了基准AUC值,特别是在皮肤病变和眼病分类数据集上显示出显著的性能提升。
环境影响的考虑:
- 考虑到AI的能源消耗和环境成本,论文提出的方法通过减少对高能耗GPU集群的依赖,提供了一种更高效的替代方案。
临床实践的潜在影响:
- 论文讨论了该方法在减少计算需求、提高模型泛化能力以及在资源有限的临床环境中快速部署AI工具的潜力。
综上所述,论文通过利用预训练模型的嵌入表示和简单的线性分类器,提供了一种在减少计算资源需求的同时,保持或提高诊断性能的医学图像分析方法。这种方法不仅提高了效率,还可能加速AI技术在临床实践中的应用。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估使用预训练模型生成的图像嵌入对于医学图像分类任务的有效性。以下是实验的关键方面:
研究设计:
- 实验是一个回顾性、横断面研究,涉及多个数据集,这些数据集代表了不同的成像模态和诊断挑战。
数据集:
- 实验使用了五个公开可用的、去标识化的医学影像数据集,包括CBIS-DDSM、CheXpert、HAM10000、PAD-UFES-20和ODIR。
数据预处理:
- 对每个数据集实施了特定的预处理步骤,以标准化图像并促进嵌入生成。
嵌入生成:
- 使用预训练的ResNet50和CLIP模型从医学影像中提取嵌入,这些嵌入捕获了图像的高级视觉和语义特征。
分类模型开发:
- 实现了包括逻辑回归和支持向量机(SVM)在内的线性分类器,用于分类任务。
性能评估指标:
- 使用准确度、精确度、召回率(敏感度)、F1分数和接收者操作特征曲线下面积(AUC)等指标来评估分类模型的性能。
结果比较:
- 将基于嵌入的分类器的性能与基准模型的性能进行了比较,这些基准模型是使用传统方法训练和测试的。
实验结果:
- 开发了总共20个基于嵌入的分类模型,并在五个医学影像数据集上进行了评估。这些模型结合了来自ResNet50或CLIP架构的嵌入以及逻辑回归(LR)或支持向量机(SVM)。
详细结果分析:
- 论文提供了每个数据集的详细性能指标,包括不同嵌入模型和线性分类器组合的准确度、精确度、召回率、F1分数和AUC值。
结果总结:
- 论文总结了基于嵌入的分类器在四个数据集中的表现超过了基准AUC值,特别是在皮肤病变和眼病分类数据集上显示出显著的改进。
这些实验结果表明,基于预训练模型和线性分类器的嵌入分类器可以作为传统从头开始训练的深度学习模型的有效和计算效率高的替代方案。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些可以进一步探索的点,以增强基于嵌入的分类器的性能,并扩展其在医学图像分析中的应用。以下是一些关键的探索方向:
复杂多标签任务的性能改进:
- 论文指出,在某些特定任务(如CBIS-DDSM和CheXpert数据集)中,基于嵌入的分类器的性能可能较低。未来的研究可以专注于改进这些复杂多标签任务的性能。
统计显著性测试:
- 为了进一步验证所提出方法的有效性,未来的研究可以包括统计显著性测试,以比较基于嵌入的分类器与传统方法之间的性能差异。
真实世界临床数据的验证:
- 论文提到,模型是在公开可用的数据集上评估的,这些数据集可能无法完全代表现实世界中的临床数据。未来的研究应该使用独立的临床数据集对模型进行外部验证,以评估其在不同临床环境和患者人群中的鲁棒性和可复现性。
更复杂的分类器:
- 论文中使用的是线性分类器,可能无法捕获医学影像数据中的复杂非线性关系。未来的研究可以探索将嵌入与更复杂的分类器(如深度神经网络)结合使用,以提高对非线性关系的建模能力。
领域特定的预训练:
- 尽管CLIP和ResNet50等预训练模型能够捕获广泛的视觉特征,但它们可能缺乏特定于医学影像的表示。未来的研究可以探索使用特定于医学影像的数据进行预训练,以进一步提升模型性能。
环境影响评估:
- 考虑到AI模型训练的环境成本,未来的研究可以进一步评估和优化基于嵌入的方法,以减少能源消耗和环境足迹。
模型的可解释性:
- 论文提到,线性分类器的简单性使得它们更易于解释。未来的研究可以进一步探索提高模型可解释性的方法,帮助临床医生理解和信任AI辅助诊断。
跨模态应用:
- 考虑到CLIP模型在整合视觉和语义信息方面的能力,未来的研究可以探索将基于嵌入的方法应用于跨模态医学影像分析任务,如结合图像和临床文本数据。
这些探索方向不仅可以推动基于嵌入的分类器在医学图像分析领域的发展,还可能对AI技术在临床实践中的应用产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出了在医学影像领域中使用人工智能(AI)和机器学习(ML)模型时面临的挑战,尤其是需要大量数据集进行训练、测试,消耗显著的计算资源和时间。
研究目标:
- 探索使用基于嵌入的方法替代传统的训练程序,以实现在医学图像分析中更高效的分类和预测。
方法论:
- 使用预训练的基础模型(如ResNet和CLIP)生成医学图像的嵌入表示,然后应用简单的线性分类器(如逻辑回归和支持向量机)进行分类任务。
- 进行了一项回顾性、横断面研究,涉及多个数据集,包括CBIS-DDSM、CheXpert、HAM10000、PAD-UFES-20和ODIR。
实验结果:
- 基于嵌入的模型在多个数据集上达到了或超过了传统方法的性能,尤其是在皮肤病变和眼病分类数据集上显示出显著的性能提升。
- CLIP嵌入模型在多个数据集上实现了最高的AUC-ROC分数,表明在分类性能上具有优越性,同时显著降低了计算需求。
讨论与结论:
- 基于嵌入的分类器可以作为传统深度学习模型的有效替代方案,特别是在资源受限的环境中。
- 提出了该方法的临床意义,包括减少计算需求、提高模型泛化能力以及促进AI技术在临床实践中的应用。
- 论文还讨论了研究的局限性,并提出了未来研究的方向,如改进性能、进行外部验证和探索更复杂的分类器。
补充材料:
- 提供了数据源、预处理步骤、模型开发方法和超参数优化等详细信息,以确保研究的可重复性。
总体而言,这篇论文展示了通过使用预训练模型的嵌入表示和简单的线性分类器,可以在减少计算资源需求的同时,保持或提高医学图像分类任务的性能,为AI技术在医学影像分析中的应用提供了一种新的高效方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

A comprehensive interpretable machine learning framework for Mild Cognitive Impairment and Alzheimer’s disease diagnosis
Authors:Maria Eleftheria Vlontzou, Maria Athanasiou, Kalliopi Dalakleidi, Ioanna Skampardoni, Christos Davatzikos, Konstantina Nikita
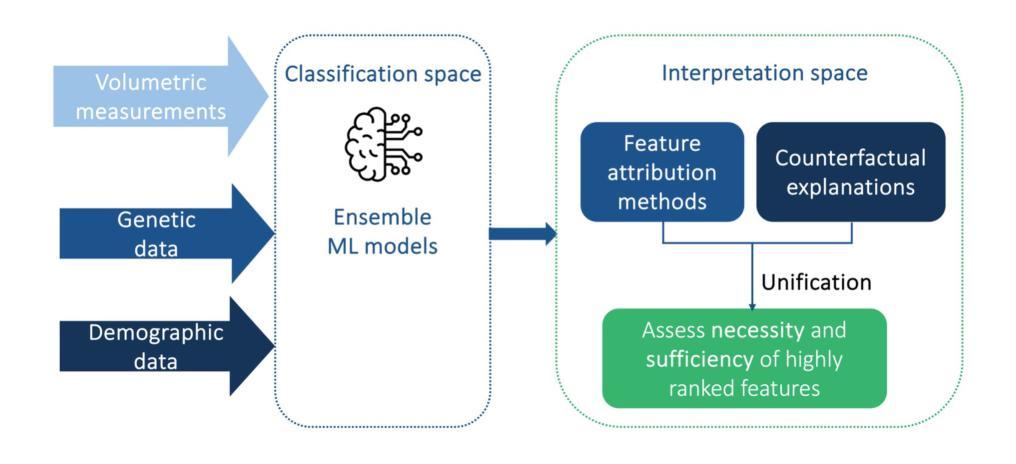
An interpretable machine learning (ML) framework is introduced to enhance the diagnosis of Mild Cognitive Impairment (MCI) and Alzheimer’s disease (AD) by ensuring robustness of the ML models’ interpretations. The dataset used comprises volumetric measurements from brain MRI and genetic data from healthy individuals and patients with MCI/AD, obtained through the Alzheimer’s Disease Neuroimaging Initiative. The existing class imbalance is addressed by an ensemble learning approach, while various attribution-based and counterfactual-based interpretability methods are leveraged towards producing diverse explanations related to the pathophysiology of MCI/AD. A unification method combining SHAP with counterfactual explanations assesses the interpretability techniques’ robustness. The best performing model yielded 87.5% balanced accuracy and 90.8% F1-score. The attribution-based interpretability methods highlighted significant volumetric and genetic features related to MCI/AD risk. The unification method provided useful insights regarding those features’ necessity and sufficiency, further showcasing their significance in MCI/AD diagnosis.
引入了一个可解释的机器学习(ML)框架,通过确保ML模型解释的稳健性来提高轻度认知障碍(MCI)和阿尔茨海默病(AD)的诊断。所使用的数据集包括来自阿尔茨海默症神经影像学倡议计划(ADNI)的脑MRI体积测量数据和来自健康个体以及MCI/AD患者的遗传数据。通过集成学习方法解决了现有的类别不平衡问题,同时利用各种基于归属度和基于反事实的解释方法,产生与MCI/AD病理生理学相关的多种解释。一种将SHAP与反事实解释相结合的方法评估了解释技术的稳健性。表现最佳的模型达到了87.5%的平衡准确率和90.8%的F1分数。基于归属度的解释方法突出了与MCI/AD风险相关的显著体积和遗传特征。统一方法提供了关于这些特征的必要性和充分性的有用见解,进一步展示了它们在MCI/AD诊断中的重要性。
论文及项目相关链接
PDF This preprint has not been peer-reviewed yet but has been submitted to a journal
Summary
引入可解释的机器学习框架,结合脑MRI体积测量和ADNI的遗传数据,用于增强轻度认知障碍和阿尔茨海默病的诊断。通过集成学习方法解决类别不平衡问题,并采用归因和基于反事实的解释方法提供与MCI/AD病理生理相关的多元解释。结合SHAP和反事实解释的统一方法评估了解释技术的稳健性。最佳模型实现了87.5%的平衡准确率和90.8%的F1分数。归因解释突出了与MCI/AD风险相关的关键体积和遗传特征,而统一方法则有助于了解这些特征的必要性和充分性,为诊断提供了更深入的了解。
Key Takeaways
- 引入可解释的机器学习框架以增强对轻度认知障碍和阿尔茨海默病的诊断。
- 数据集包含来自脑MRI的体积测量和来自ADNI的遗传数据。
- 采用集成学习方法解决现有类别不平衡问题。
- 使用归因和基于反事实的解释方法提供多元解释。
- 结合SHAP和反事实解释的统一方法评估模型解释的稳健性。
- 最佳模型的平衡准确率和F1分数分别为87.5%和90.8%。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个全面的可解释机器学习(ML)框架,旨在通过确保ML模型解释的稳健性来增强轻度认知障碍(MCI)和阿尔茨海默病(AD)的诊断。具体来说,论文试图解决以下几个问题:
数据异质性和类别不平衡问题:健康个体和MCI/AD患者的大脑MRI体积测量和遗传数据的异质性,以及类别不平衡可能引入的偏差,这些都可能削弱模型的泛化能力。
AI模型在临床决策中的透明度和可解释性需求:在临床决策中整合AI模型需要模型输出能够被理解和信任,以促进医疗从业者和患者之间的知情决策。
提高ML模型的预测准确性和解释性:研究通常关注模型的预测能力,而对其预测行为和结果的理解关注不足。此外,为了提高ML算法的预测准确性,模型复杂性增加,导致解释预测变得更加困难。
不同解释性方法的统一和稳健性评估:目前对于如何统一不同的解释性方法以及评估它们的稳健性的研究还相对有限。
论文的主要贡献在于提出了一个方法论框架,通过以下三个方面来解决上述挑战:
- 提出了一种基于集成学习的一对多(one versus one)分类方法,能够同时处理多类分类和不平衡数据问题。
- 结合了MRI的145个解剖脑区的体积测量和54个与AD相关的单核苷酸多态性(SNPs)来进行MCI和AD的诊断,并比较这些不同模态特征对分类的贡献。
- 采用了多种解释性方法,包括基于归因和基于反事实的方法,以提供模型预测的人类友好解释,并增加模型的可靠性。此外,论文还关注了通过实际因果关系方法统一不同的解释性技术,以评估应用解释性方法及其结果的稳健性。
Q: 有哪些相关研究?
A: 论文中提到了多个与轻度认知障碍(MCI)和阿尔茨海默病(AD)诊断相关的研究,以下是一些主要的相关研究:
Altaf et al. (2018): 使用SVM、集成、决策树和KNN等分类方法,结合MRI纹理特征和临床数据进行分类,准确率为79.8%。
Wang et al. (2018): 使用3D密集连接卷积网络(3D-DenseNets)对MRI图像进行分类,准确率达到97.52%。
Basheera et al. (2020): 结合MRI体积测量和临床数据,使用CNN进行分类,准确率为86.7%。
Lin et al. (2021): 结合MRI体积、PET强度、脑脊液生物标志物和APOE基因,使用LDA和ELM进行分类,准确率为66.7%,F1分数为64.9%。
ElSappagh et al. (2021): 结合MRI体积测量、PET、临床和遗传数据,使用RF、SVM和GB等方法进行分类,准确率为93.33%,F1分数为93.82%。
Xu et al. (2022): 使用SVM-SMOTE和RF方法结合临床数据进行分类,F1分数为87.7%。
Yi et al. (2023): 结合MRI体积测量、APOE基因和临床数据,使用XGBoost-SHAP(调整特征权重的XGBoost)进行分类,准确率为87.57%。
Amoroso et al. (2023): 结合MRI(脑连接网络度量)数据,使用RF、SVM、XGBoost、NB和LR等方法进行分类,F1分数为87.7%。
这些研究涵盖了不同的分类方法、输入特征、模型性能和可解释性技术。论文通过与这些研究的比较,展示了其提出的框架在MCI和AD诊断中的性能和可解释性方面的优势。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决提出的问题:
1. 提出可解释机器学习框架
论文提出了一个全面的可解释机器学习(ML)框架,该框架旨在增强对轻度认知障碍(MCI)和阿尔茨海默病(AD)的诊断,确保ML模型解释的稳健性。该框架包括以下几个关键组成部分:
- 集成学习方法:解决多类分类和数据不平衡问题。
- 多模态数据融合:结合MRI体积测量和遗传数据进行诊断。
- 多种解释性方法:提供模型预测的人类友好解释,并增加模型的可靠性。
- 解释性技术的统一:基于实际因果关系的方法,评估解释性方法的稳健性。
2. 数据集和特征选择
- 使用阿尔茨海默病神经影像倡议(ADNI)数据库中的健康个体和MCI/AD患者的大脑MRI体积测量和遗传数据。
- 包括145个解剖脑区的体积测量和54个与AD相关的单核苷酸多态性(SNPs)。
3. 集成学习方法
- 采用一对多(One versus One, OVO)分类方法和Bagging集成学习方法来处理多类分类和不平衡数据问题。
- 通过Bootstrap和聚合技术减少预测的方差,提高模型性能和鲁棒性。
4. 多种解释性方法
- 归因方法:使用SHAP(SHapley Additive exPlanations)方法提供全局解释,反映特征对模型输出的贡献。
- 局部解释:使用LIME(Local Interpretable Model-agnostic Explanations)方法提供个体预测的局部解释。
- 反事实解释:使用Permute Attack和DiCE(Diverse Counterfactual Explanations)方法提供反事实解释。
5. 解释性技术的统一
- 利用基于实际因果关系的方法,通过计算特征的必要性和充分性来评估不同解释性方法的稳健性。
- 计算特征的必要性(necessity)和充分性(sufficiency),以评估特征对模型预测的贡献程度。
6. 实验和评估
- 使用5x4折的嵌套交叉验证方案进行超参数调整和性能评估。
- 通过比较不同分类器的性能,选择最佳模型,并使用多种解释性方法对其进行解释和评估。
通过这些步骤,论文旨在提供一个可靠、透明和可信赖的决策支持工具,以改善AD的管理,并提供对MCI和AD诊断的深入理解。
Q: 论文做了哪些实验?
A: 根据论文内容,以下是进行的实验及其结果:
1. 分类器性能评估
- 训练和评估了基于不同算法的分类器,包括随机森林(RF)、逻辑回归(LR)、多层感知器(MLP)、支持向量机(SVM)、梯度提升(GB)和极端梯度提升(XGBoost)。
- 使用了一对所有(One versus All, OVA)和一对一对一(One versus One, OVO)分解方案,以及Bagging方法来解决多类和不平衡数据问题。
- 通过80:20的训练测试拆分(TTS)和Bagging方法后,基于5x4折嵌套交叉验证方案调整超参数,比较了加权F1分数和平衡准确度指标。
2. 个体解释性方法的应用
- 对两个表现最佳的分类器(SVM和RF)应用了多种解释性方法,包括Gini指数、SHAP、LIME局部解释、部分依赖图(PDPs)和反事实解释。
- 由于篇幅原因,主要展示了MCI与AD二元子问题的解释性结果,因为这两个类别最难区分。
3. 特征重要性排名
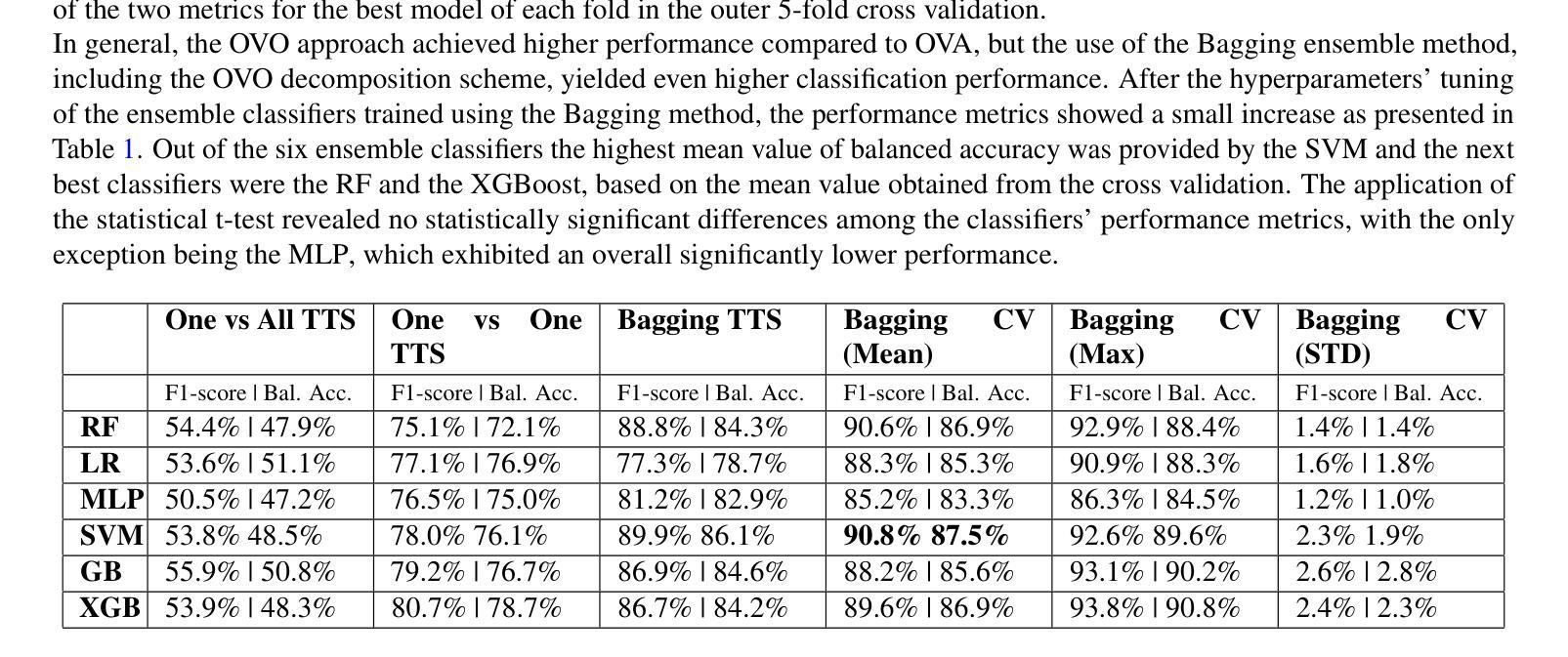
- 使用Gini指数和SHAP方法对特征进行排名,突出了文献中已知的重要感兴趣区域(ROIs)。
4. LIME局部解释
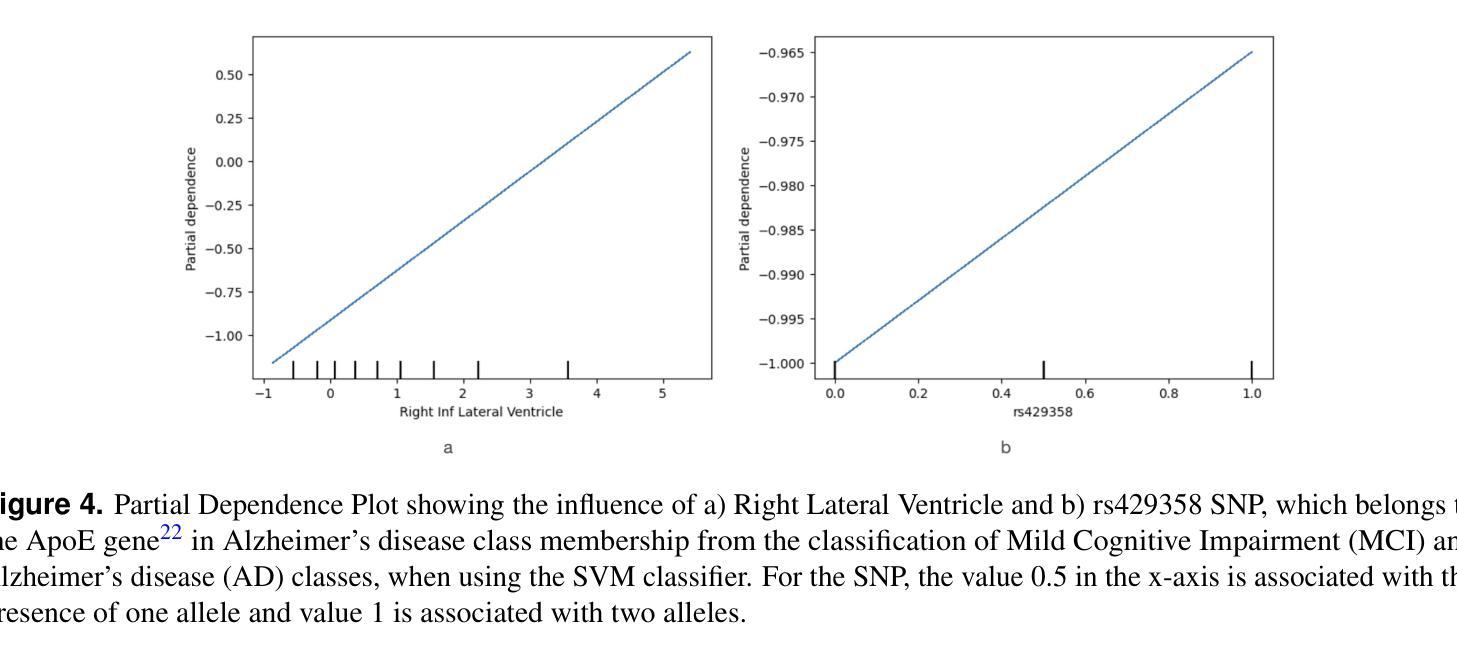
- 对指示性预测案例(包括真正例、真负例、假正例和假负例)获得了局部解释。
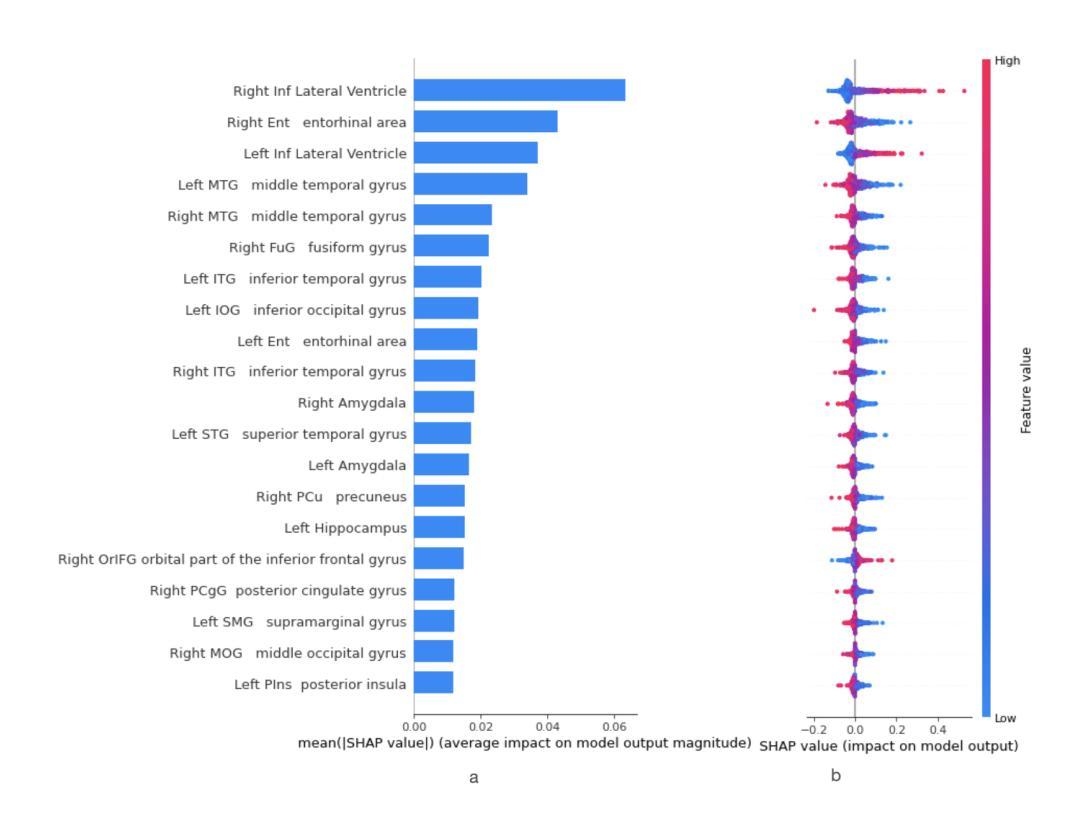
5. 部分依赖图(PDPs)
- 使用PDPs研究了SVM分类中选定特征对预测结果的影响,包括某些SNPs。
6. 统一特征归因和反事实解释
- 使用Permute Attack和Diverse Counterfactual Explanations(DiCE)方法,通过计算在生成的反事实例子中特征值被改变的频率来获得特征重要性排名。
- 计算了SHAP排名前10的特征的必要性和充分性,以评估它们的稳健性。
7. 实验结果
- SVM分类器在平衡准确度和F1分数上表现最佳,分别为87.5%和90.8%。
- 归因方法突出了与MCI/AD风险相关的重要的体积和遗传特征。
- 统一方法提供了关于这些特征在MCI/AD诊断中的必要性和充分性的有用见解。
这些实验结果提供了对模型预测的深入理解,并增强了模型解释的稳健性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 多类别解释性技术
论文中提到,当前框架及其解释性方法主要关注每一对类别的单独结果,而不是所有类别的整体情况。未来的工作可以探索多类别解释性技术,以提供对所有类别最终预测的可解释输出。
2. 深度学习算法
论文提到可以考虑使用额外的分类模型,如深度学习算法,以进一步提高框架的分类准确性。
3. 附加数据模态
论文建议可以包含额外的数据模态,例如认知评估,并评估它们对模型性能的贡献。
4. 解释性方法结果的统一技术
论文提到,进一步的技术探索可以集中在如何统一解释性方法的结果上,以突出AD病理生理学的其他重要方面。
5. 反事实生成方法的敏感性
论文中提到,统一框架对反事实生成方法较为敏感,这可能影响结果的一致性。未来的研究可以探索不同的反事实生成方法,以提高结果的稳定性和可靠性。
6. 模型的泛化能力
论文中提到了模型的泛化能力可能受到数据异质性的影响。未来的研究可以进一步探索如何提高模型的泛化能力,使其能够适应不同的数据集和临床环境。
7. 模型的临床应用
论文中提出的模型和解释性框架最终需要在临床环境中进行验证。未来的研究可以探索这些模型在实际临床决策支持系统中的集成和应用。
8. 模型解释的可视化工具
为了提高模型解释的可访问性和易理解性,可以开发更直观的可视化工具,帮助医疗专业人员和患者更好地理解模型的预测和解释。
9. 模型的公平性和伦理考量
随着机器学习模型在临床决策中的应用越来越广泛,其公平性和伦理问题也变得越来越重要。未来的研究可以探索如何确保模型的决策过程符合伦理标准,并且对所有患者群体都是公平的。
这些探索点可以帮助提高模型的准确性、可解释性、稳健性,并最终促进其在临床实践中的应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个全面的可解释机器学习(ML)框架,用于提高对轻度认知障碍(MCI)和阿尔茨海默病(AD)的诊断能力。以下是论文的主要内容总结:
1. 研究背景和挑战
- 阿尔茨海默病(AD)是最常见的痴呆形式,而轻度认知障碍(MCI)是发展为AD的一个风险因素。
- 临床决策支持系统(CDSS)越来越多地使用AI来加速MCI或AD的诊断和优化疾病管理。
- AI模型在处理来自不同来源的异构健康数据时面临挑战,包括数据类别不平衡和模型解释性的需求。
2. 提出的框架
- 论文提出了一个基于集成学习和多类别分类方案的ML框架,以解决多类分类和数据不平衡问题。
- 框架结合了MRI体积测量和遗传数据(SNPs)来进行MCI和AD的诊断。
- 使用多种解释性方法(包括归因和反事实方法)来提供模型预测的人类友好解释,并增加模型的可靠性。
- 通过基于实际因果关系的方法统一不同的解释性技术,以评估解释性方法的稳健性。
3. 实验和结果
- 训练和评估了多种基于不同算法的分类器,包括随机森林、逻辑回归、多层感知器、支持向量机、梯度提升和极端梯度提升。
- 使用了一对所有(OVA)和一对一对一(OVO)分解方案,以及Bagging方法来处理多类和不平衡数据问题。
- SVM分类器表现最佳,平衡准确度为87.5%,F1分数为90.8%。
- 归因方法突出了与MCI/AD风险相关的重要的体积和遗传特征。
- 统一方法提供了关于这些特征在MCI/AD诊断中的必要性和充分性的有用见解。
4. 讨论和未来工作
- 论文讨论了提出的框架与现有模型相比的性能,并指出了其可解释性方法的优势。
- 论文提出了未来可能的改进方向,包括探索多类别解释性技术、使用深度学习算法、包含额外的数据模态,以及进一步统一解释性方法的结果。
总体而言,这篇论文通过结合先进的机器学习技术和多种解释性方法,为MCI和AD的诊断提供了一个稳健和可解释的框架,旨在提高临床决策的质量和效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

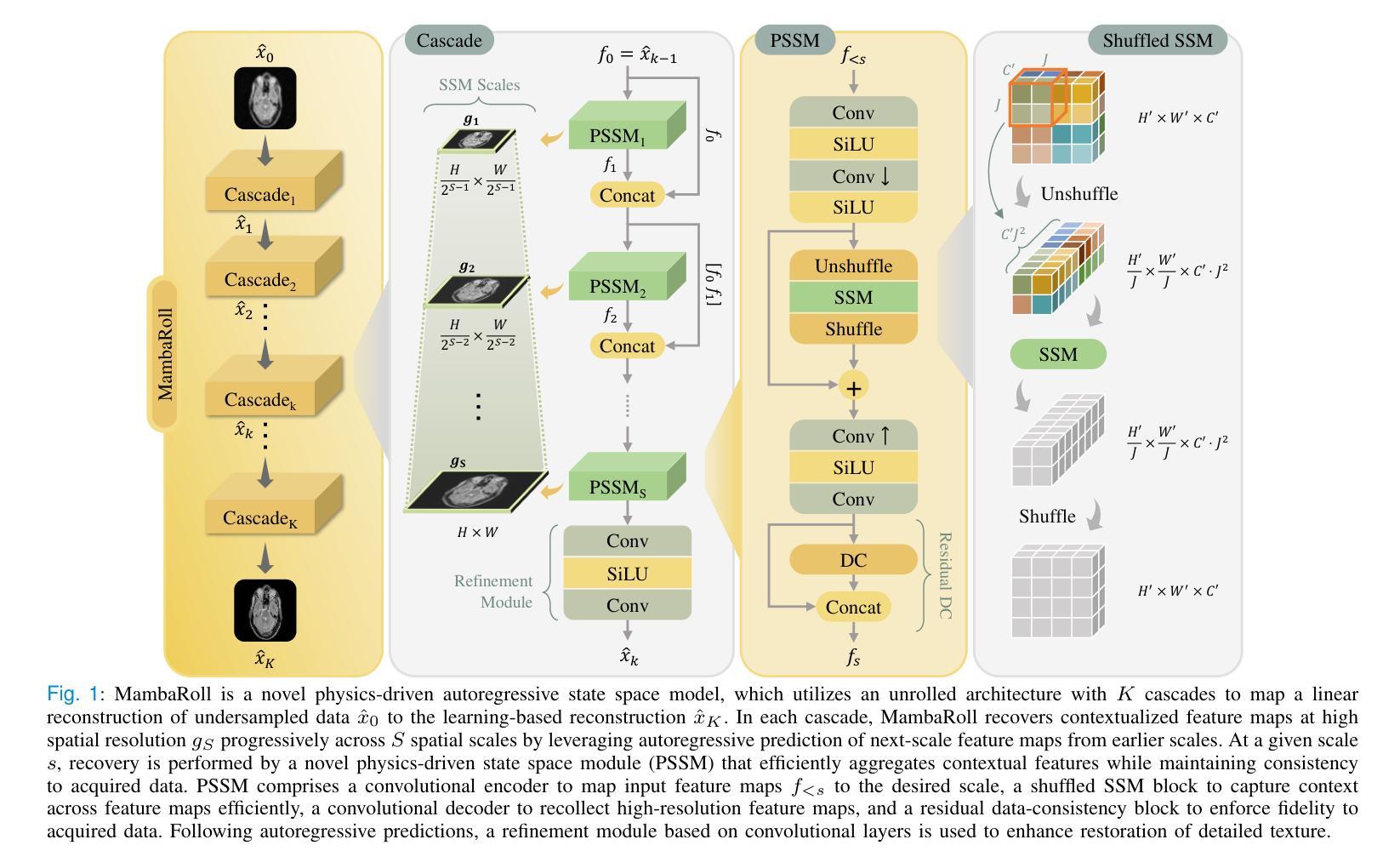
Physics-Driven Autoregressive State Space Models for Medical Image Reconstruction
Authors:Bilal Kabas, Fuat Arslan, Valiyeh A. Nezhad, Saban Ozturk, Emine U. Saritas, Tolga Çukur
Medical image reconstruction from undersampled acquisitions is an ill-posed problem that involves inversion of the imaging operator linking measurement and image domains. In recent years, physics-driven (PD) models have gained prominence in learning-based reconstruction given their enhanced balance between efficiency and performance. For reconstruction, PD models cascade data-consistency modules that enforce fidelity to acquired data based on the imaging operator, with network modules that process feature maps to alleviate image artifacts due to undersampling. Success in artifact suppression inevitably depends on the ability of the network modules to tease apart artifacts from underlying tissue structures, both of which can manifest contextual relations over broad spatial scales. Convolutional modules that excel at capturing local correlations are relatively insensitive to non-local context. While transformers promise elevated sensitivity to non-local context, practical implementations often suffer from a suboptimal trade-off between local and non-local sensitivity due to intrinsic model complexity. Here, we introduce a novel physics-driven autoregressive state space model (MambaRoll) for enhanced fidelity in medical image reconstruction. In each cascade of an unrolled architecture, MambaRoll employs an autoregressive framework based on physics-driven state space modules (PSSM), where PSSMs efficiently aggregate contextual features at a given spatial scale while maintaining fidelity to acquired data, and autoregressive prediction of next-scale feature maps from earlier spatial scales enhance capture of multi-scale contextual features. Demonstrations on accelerated MRI and sparse-view CT reconstructions indicate that MambaRoll outperforms state-of-the-art PD methods based on convolutional, transformer and conventional SSM modules.
从欠采样采集中进行医学图像重建是一个适定不良的问题,涉及到连接测量和图像域的成像算子的逆运算。近年来,由于其在效率和性能之间的平衡增强,物理驱动(PD)模型在基于学习的重建中备受瞩目。对于重建,PD模型级联数据一致性模块,该模块根据成像算子强制实施对获取数据的保真度,以及与处理特征图以减轻因欠采样导致的图像伪影的网络模块。伪影抑制的成功不可避免地取决于网络模块区分伪影和潜在组织结构的能力,这两者都可能在广泛的空间尺度上表现出上下文关系。卷积模块擅长捕捉局部相关性,对非局部上下文相对不敏感。虽然变压器承诺对非局部上下文有更高的敏感性,但由于其固有的模型复杂性,实际实现往往会在局部和非局部敏感性之间进行次优权衡。在这里,我们引入了一种新型物理驱动自回归状态空间模型(MambaRoll)来提高医学图像重建的保真度。在展开架构的每一层中,MambaRoll采用基于物理驱动状态空间模块的自回归框架(PSSM),其中PSSM可以有效地聚集给定空间尺度上的上下文特征,同时保持对获取数据的保真度,并且通过自回归预测下一尺度的特征图从较早的空间尺度增强了多尺度上下文特征的捕获。在加速MRI和稀疏视图CT重建中的演示表明,MambaRoll优于基于卷积、变压器和传统SSM模块的最先进PD方法。
论文及项目相关链接
PDF 10 pages, 4 figures
摘要
近期采用物理驱动(PD)模型在处理基于学习的重建图像问题上表现突出,其平衡了效率和性能。PD模型通过级联数据一致性模块和网络模块实现重建,前者根据成像算子强制实施对获取数据的保真度,后者处理特征映射以减轻欠采样引起的图像伪影。网络模块成功抑制伪影的能力取决于其对伪影和潜在组织结构的辨识能力,这两者可能在广泛的空间尺度上表现出上下文关系。虽然卷积模块擅长捕捉局部相关性,但对于非局部上下文则相对敏感不足。虽然变压器对非局部上下文的敏感性更高,但实际应用中往往因模型本身的复杂性而在局部和非局部敏感性之间做出次优权衡。这里,我们引入了一种新型物理驱动自回归状态空间模型(MambaRoll)来提高医学图像重建的保真度。在每个展开的架构级联中,MambaRoll采用基于物理驱动状态空间模块(PSSM)的自回归框架,PSSM在给定空间尺度上有效地聚合上下文特征,同时保持对获取数据的保真度,自回归预测下一尺度的特征映射则增强了多尺度上下文的捕获能力。在加速MRI和稀疏视图CT重建的演示中,MambaRoll表现出优于基于卷积、变压器和传统SSM模块的最新PD方法。
关键见解
- 医学图像重建是从欠采样采集中进行的一个不适定问题,涉及将测量和图像域相关联的成像算子的反转。
- 物理驱动(PD)模型在近年的学习重建中因其在效率和性能之间的平衡而受到重视。
- PD模型通过级联数据一致性模块和网络模块进行重建,前者根据成像算子保持对真实数据的保真度,后者旨在减少由于欠采样产生的图像伪影。
- 网络模块在辨识伪影与潜在组织结构方面的能力对于成功抑制伪影至关重要。
- 卷积模块擅长捕捉局部相关性,但在处理非局部上下文时存在局限性。
- 虽然变压器在非局部上下文敏感性上表现优越,但在实际应用中因模型复杂性而在局部与非局部敏感性之间做出权衡。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是从欠采样数据中进行医学图像重建的问题。具体来说,它关注于提高医学图像重建的质量,尤其是在加速MRI和稀疏视图CT重建的场景中,这些问题由于数据欠采样而导致的图像伪影和噪声而变得具有挑战性。论文中提到,传统的重建方法在处理这类问题时表现不佳,常常在重建图像中留下结构化的混叠伪影和噪声。因此,迫切需要能够提高从欠采样数据恢复的医学图像诊断质量的增强型重建方法。论文提出了一种新颖的基于物理的自回归状态空间模型(MambaRoll),用于提高医学图像重建的保真度。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个方面:
物理驱动(Physics-Driven, PD)模型:
- PD模型通过构建条件图像先验来将欠采样数据映射到全采样数据的真值图像。
- 这些模型采用展开的架构,交替网络模块和数据一致性模块来压制重建中的伪影,并确保对获得的数据保持忠实。
状态空间模型(State Space Models, SSM):
- SSM通过将像素扫描成一维序列,并执行递归建模来捕获序列元素之间的关系,从而在成像任务中显示出对长距离上下文关系的增强敏感性。
- 近期的一些研究采用了基于SSM的网络模块作为纯数据驱动架构的一部分来进行医学图像重建。
自回归模型:
- 自回归模型在计算机视觉任务中取得了成功,本研究中MambaRoll利用自回归方法在多个空间尺度上预测下一个尺度的特征图。
深度学习方法在医学图像重建中的应用:
- 包括使用卷积神经网络(CNN)、变压器(Transformer)和SSM等不同网络架构来提高医学图像重建的性能。
加速MRI和稀疏视图CT重建:
- 这些研究集中在如何通过减少采样数据来加速MRI扫描和CT扫描,同时使用深度学习技术来改善重建质量。
具体到论文中引用的一些研究工作,包括但不限于:
- [22] K. Hammernik et al., “Physics-driven deep learning for computational magnetic resonance imaging.”
- [42] L. Zhu et al., “Vision mamba: Efficient visual representation learning with bidirectional state space model.”
- [45] J. Huang et al., “Enhancing global sensitivity and uncertainty quantification in medical image reconstruction with monte carlo arbitrary-masked mamba.”
- [47] Y. Korkmaz and V. M. Patel, “MambaRecon: MRI Reconstruction with Structured State Space Models.”
这些相关研究为MambaRoll模型的开发提供了理论基础和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过提出一个新颖的物理驱动自回归状态空间模型(MambaRoll)来解决医学图像重建问题,具体方法如下:
1. 模型架构:
- MambaRoll基于一个展开的架构,该架构交替网络模块和数据一致性模块,以逐步恢复高分辨率的特征图。
- 每个级联(cascade)中,MambaRoll利用自回归框架基于物理驱动状态空间模块(PSSM),其中PSSM高效聚合给定空间尺度上的上下文特征,同时保持对采集数据的忠实度,自回归预测下一个尺度的特征图从早期空间尺度增强捕获多尺度上下文特征。
2. PSSM模块:
- PSSM模块是MambaRoll的核心,包含卷积编码器、shuffled SSM块、卷积解码器和残差数据一致性块。
- 卷积编码器将高分辨率特征图映射到目标尺度。
- Shuffled SSM块用于在特征图间高效捕获上下文。
- 卷积解码器用于重新收集高分辨率特征图。
- 残差数据一致性块用于确保重建数据与采集数据保持一致性。
3. 自回归预测:
- MambaRoll利用自回归预测在多个空间尺度上逐步聚合上下文表示,通过在每个尺度上解码高分辨率图像以促进对采集数据的忠实度。
4. 训练目标:
- MambaRoll的训练目标包括模型输出与参考图像之间的损失项,以及尺度特定解码图像与参考图像之间的损失项,通过这种方式训练模型以实现高质量的图像重建。
5. 性能评估:
- 论文通过在加速MRI和稀疏视图CT重建任务上的实验,表明MambaRoll在图像质量方面一致性地超越了现有的基于卷积、变压器和传统SSM模块的最先进方法。
总结来说,MambaRoll通过结合自回归预测和物理驱动的状态空间模型,在多个空间尺度上有效地聚合上下文特征,并保持对采集数据的忠实度,从而提高了医学图像重建的质量。
Q: 论文做了哪些实验?
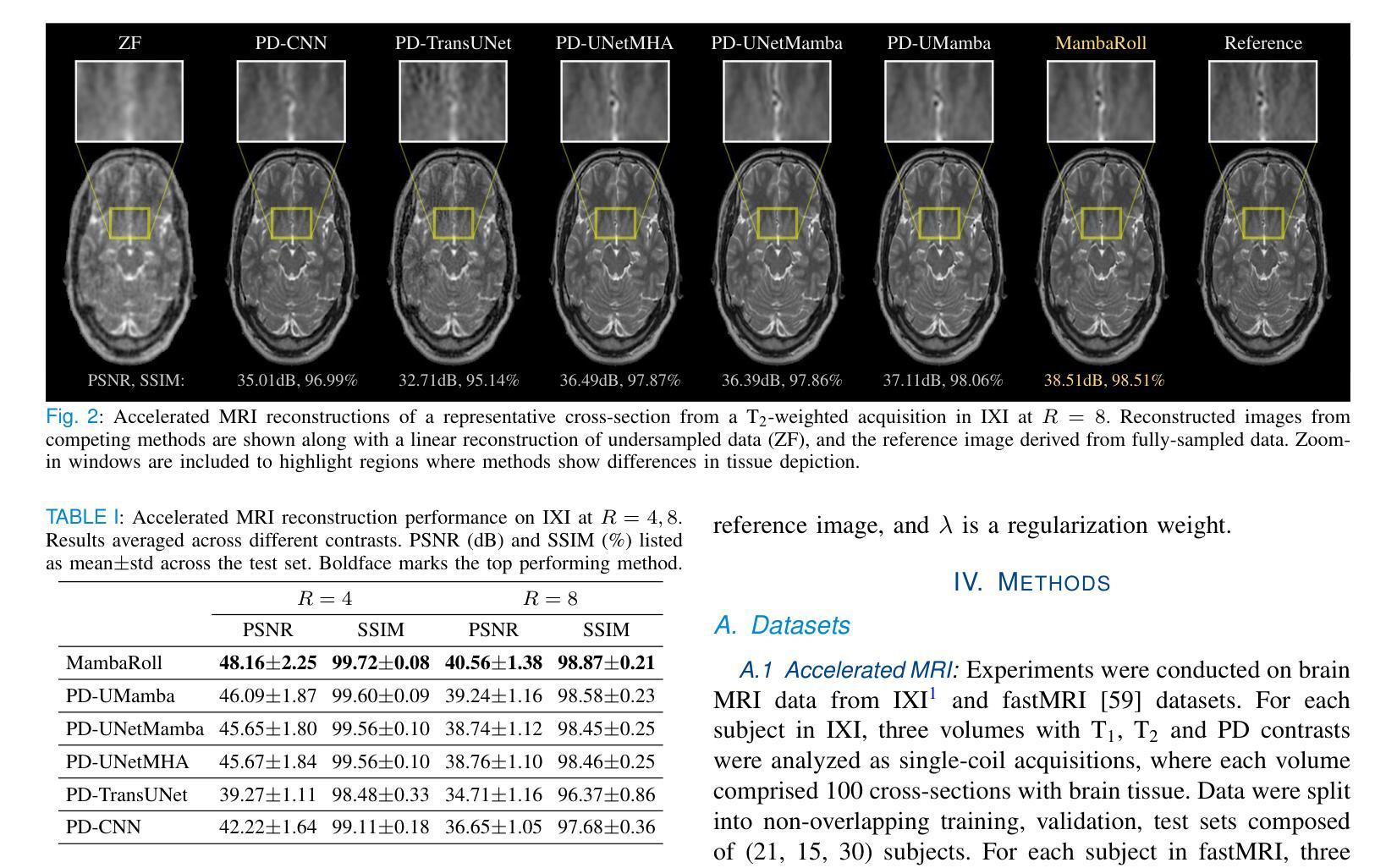
A: 论文中进行了以下实验来验证MambaRoll模型的性能:
A. 加速MRI重建
数据集:使用了IXI和fastMRI数据集中的大脑MRI数据。
- IXI数据集包含T1、T2和PD对比度的三个体积,每个体积由100个脑部横截面组成。
- fastMRI数据集包含T1、T2和FLAIR对比度的三个体积,每个体积由10个横截面组成。
采样策略:通过二维可变密度欠采样获得加速MRI扫描,欠采样率R = 4 - 8。
线性重建:通过零填充缺失的k空间样本,然后进行逆傅里叶变换获得欠采样数据的线性重建。
性能评估:使用峰值信噪比(PSNR)和结构相似性指数(SSIM)量化恢复图像与参考图像之间的性能差异。
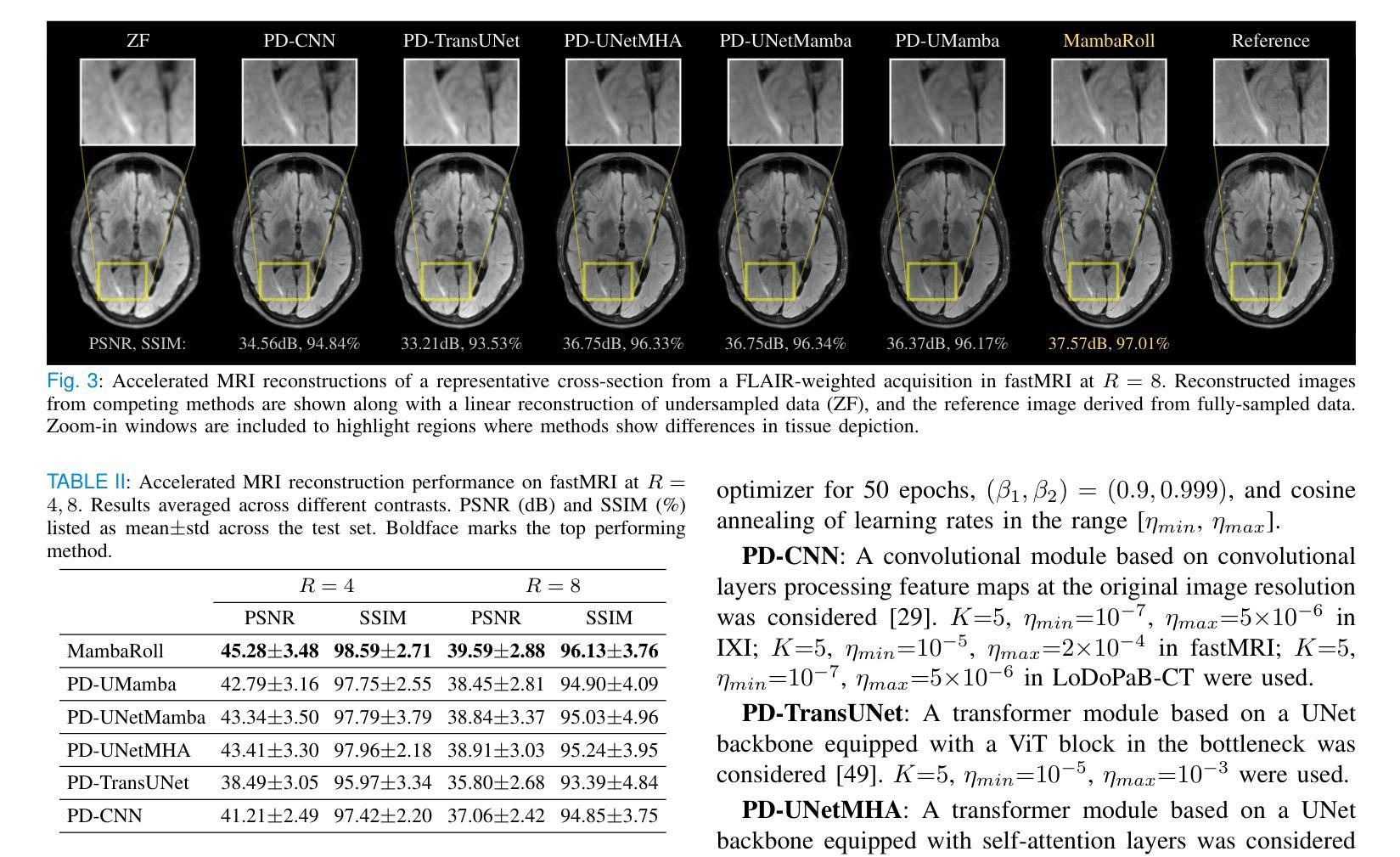
B. 稀疏视图CT重建
数据集:使用了LoDoPaB-CT数据集中的肺部CT数据。
- 每个受试者包含90个352×352大小的横截面。
采样策略:基于二维平行束几何的Radon变换获得稀疏视图CT扫描,并且sinogram在角度维度上以R = 4 - 6的速率欠采样。
线性重建:通过滤波反投影(FBP)获得欠采样数据的线性重建。
性能评估:同样使用PSNR和SSIM评估重建性能。
C. 消融研究
PSSM模块的重要性:通过训练一个移除PSSM模块但保留精炼模块的‘w/o PSSM’变体来评估PSSM模块的重要性。
自回归建模的重要性:通过训练一个在单一空间尺度上操作的‘w/o AR’变体来评估自回归建模的重要性。
数据一致性块的重要性:通过训练一个移除数据一致性块但保留残差连接的‘w/o DC’变体来评估数据一致性块的重要性。
SSM层与多头自注意力层的比较:通过训练一个用多头自注意力层替换SSM层的‘w MHSA’变体来评估SSM层在捕获医学图像上下文特征中的重要性。
这些实验结果表明,MambaRoll在加速MRI和稀疏视图CT重建任务中均显著优于现有的基于卷积、变压器和传统SSM模块的最先进方法,并且通过消融研究验证了MambaRoll各个组件的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文的讨论部分,以下是一些可以进一步探索的点:
自监督学习:
- 探索自监督学习方法,以在没有完整采样数据作为真值的情况下训练模型。
混合学习策略:
- 考虑结合自监督训练和监督微调的混合学习策略,以提高模型在包含未采样数据的数据集上的性能。
损失函数:
- 研究将自回归预测与生成性损失(如对抗性损失和扩散损失)结合的方法,以提高医学图像的现实感和对细节的敏感性。
多模态图像重建:
- 扩展MambaRoll以处理多模态图像,例如通过为不同模态分配单独的通道或使用跨模态交互的注意力模块。
架构改进:
- 探索结合注意力和SSM特征的混合设计,或在空间维度上添加自回归建模,以提高上下文敏感性。
多域架构:
- 考虑开发处理测量和图像域中数据的双域MambaRoll版本,以利用多域架构的优势。
测试时适应:
- 研究在难以构建训练集的情况下,如何通过测试时适应程序进行特定于主题的模型权重调整。
计算效率:
- 进一步优化MambaRoll的计算效率,使其更适合实时或近实时的医学图像重建应用。
跨领域验证:
- 在其他成像模态和任务上验证MambaRoll的性能,例如在超声或PET成像中的应用。
模型泛化能力:
- 研究MambaRoll在不同设备、不同成像协议和不同病理条件下的泛化能力。
这些探索点可以帮助进一步增强和验证MambaRoll模型的性能,并可能揭示新的应用领域和改进方向。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为MambaRoll的新型物理驱动自回归状态空间模型,用于提高医学图像重建的质量,特别是在加速MRI和稀疏视图CT重建方面。以下是论文的主要内容总结:
问题阐述:
- 医学图像重建是一个不适定问题,特别是从欠采样数据中重建图像时,传统方法常常导致伪影和噪声。
现有方法的局限性:
- 基于数据驱动的方法忽略了成像操作符,可能影响性能和泛化能力。
- 卷积模块对长距离上下文不敏感,而变换器模块则因复杂性限制了空间精度和训练效果。
MambaRoll模型:
- 一个基于展开架构的物理驱动模型,通过自回归框架在多个空间尺度上恢复高分辨率特征图。
- 核心是物理驱动状态空间模块(PSSM),集成了编码器、shuffled SSM块、解码器和残差数据一致性块,以有效聚合上下文特征并保持数据一致性。
实验验证:
- 在加速MRI和稀疏视图CT重建任务上,MambaRoll在图像质量上显著优于现有的基于卷积、变压器和传统SSM模块的方法。
贡献:
- 提出了首个物理驱动的自回归状态空间模型用于医学图像重建。
- 展示了在多个空间尺度上聚合上下文表示的能力,并在加速MRI和稀疏视图CT重建任务中验证了模型的有效性。
未来工作:
- 提出了一些可能的改进方向,包括自监督学习、混合学习策略、损失函数的改进、多模态图像重建、架构改进和多域架构等。
总体而言,论文通过引入MambaRoll模型,为医学图像重建领域提供了一个强大的新工具,能够更有效地处理欠采样数据并提高重建图像的质量。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

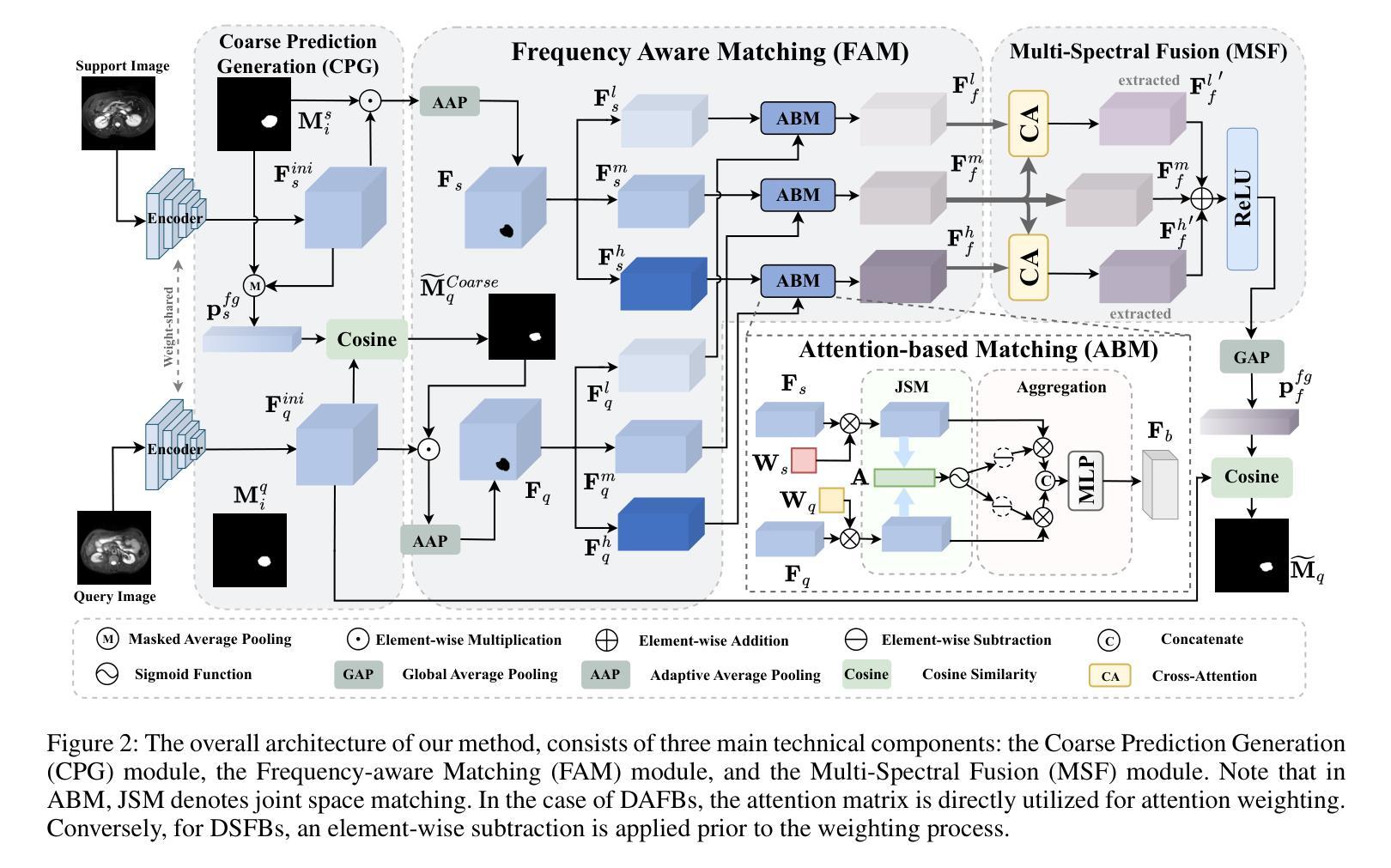
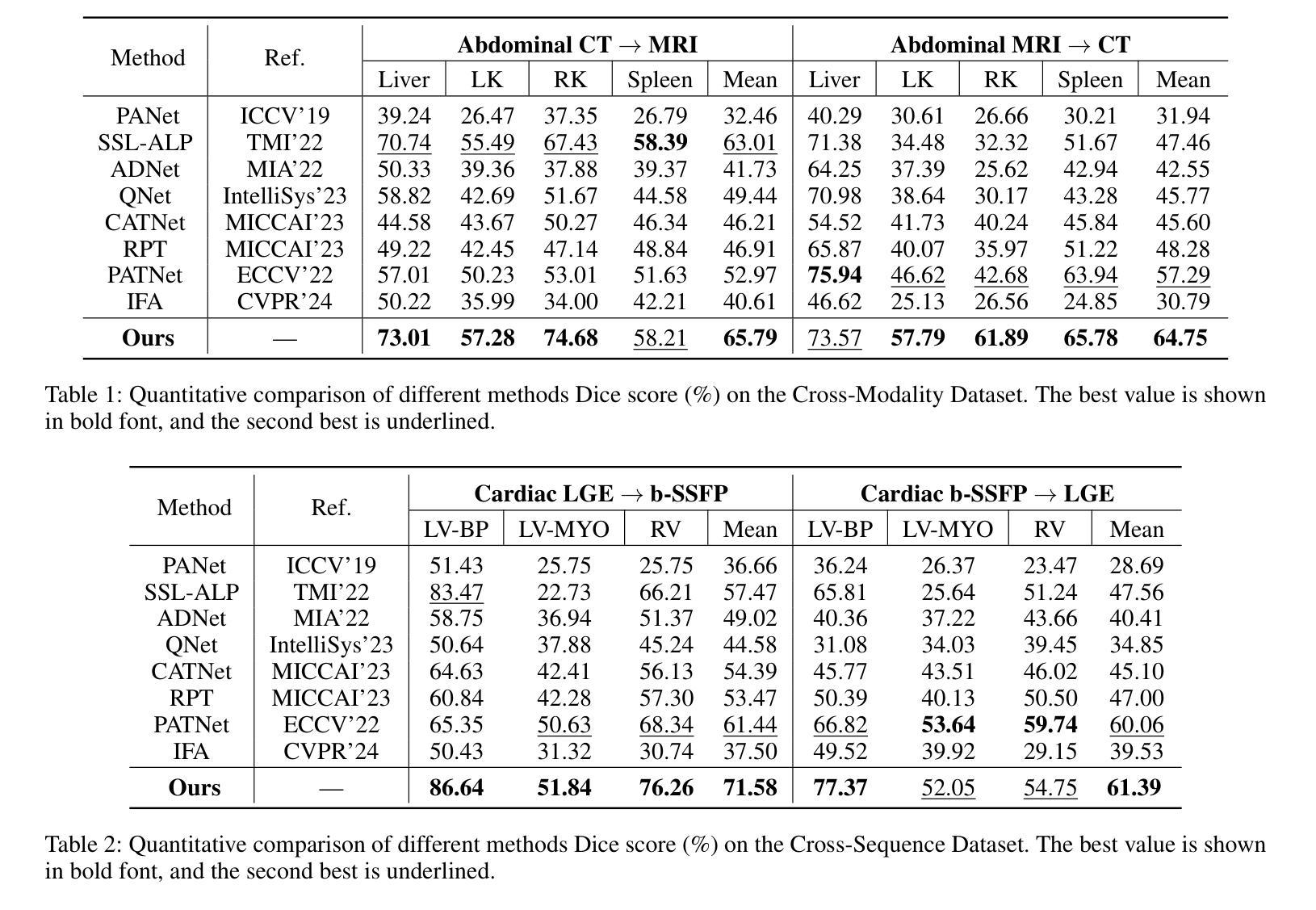
FAMNet: Frequency-aware Matching Network for Cross-domain Few-shot Medical Image Segmentation
Authors:Yuntian Bo, Yazhou Zhu, Lunbo Li, Haofeng Zhang
Existing few-shot medical image segmentation (FSMIS) models fail to address a practical issue in medical imaging: the domain shift caused by different imaging techniques, which limits the applicability to current FSMIS tasks. To overcome this limitation, we focus on the cross-domain few-shot medical image segmentation (CD-FSMIS) task, aiming to develop a generalized model capable of adapting to a broader range of medical image segmentation scenarios with limited labeled data from the novel target domain. Inspired by the characteristics of frequency domain similarity across different domains, we propose a Frequency-aware Matching Network (FAMNet), which includes two key components: a Frequency-aware Matching (FAM) module and a Multi-Spectral Fusion (MSF) module. The FAM module tackles two problems during the meta-learning phase: 1) intra-domain variance caused by the inherent support-query bias, due to the different appearances of organs and lesions, and 2) inter-domain variance caused by different medical imaging techniques. Additionally, we design an MSF module to integrate the different frequency features decoupled by the FAM module, and further mitigate the impact of inter-domain variance on the model’s segmentation performance. Combining these two modules, our FAMNet surpasses existing FSMIS models and Cross-domain Few-shot Semantic Segmentation models on three cross-domain datasets, achieving state-of-the-art performance in the CD-FSMIS task.
现有的一些医学图像分割模型的局限在于未能解决医学影像领域由不同成像技术造成的域偏移问题,这限制了它们在当前的医学图像分割任务中的应用。为了克服这一局限性,我们专注于跨域少样本医学图像分割(CD-FSMIS)任务,旨在开发一种通用的模型,能够适应更广泛的医学图像分割场景,并使用来自新型目标域的有限标记数据进行训练。受不同领域之间频率域相似性特征的启发,我们提出了一种频率感知匹配网络(FAMNet),它包括两个关键组件:频率感知匹配(FAM)模块和多光谱融合(MSF)模块。FAM模块解决了元学习阶段的两个问题:1)由于器官和病变的不同外观造成的固有支持查询偏差引起的域内方差;以及2)由于不同的医学影像技术引起的跨域方差。此外,我们设计了一个MSF模块来整合由FAM模块分离的不同的频率特征,并进一步减轻跨域方差对模型分割性能的影响。结合这两个模块,我们的FAMNet在三个跨域数据集上的表现超越了现有的FSMIS模型和跨域少样本语义分割模型,在CD-FSMIS任务中取得了最新最先进的性能。
论文及项目相关链接
PDF Accepted by the 39th Annual AAAI Conference on Artificial Intelligence (AAAI-25)
Summary
针对现有医学图像分割模型在面临不同成像技术导致的领域漂移问题时应用受限的问题,提出了跨领域少样本医学图像分割(CD-FSMIS)任务。研究团队受到不同领域频率域相似性特征的启发,设计了一种频率感知匹配网络(FAMNet),包括频率感知匹配(FAM)模块和多光谱融合(MSF)模块。该网络解决了元学习阶段的域内方差和域间方差问题,并在三个跨领域数据集上超越了现有的FSMIS模型和跨领域少样本语义分割模型,在CD-FSMIS任务中取得了最佳性能。
Key Takeaways
- 医学图像分割模型面临领域漂移问题,限制了其在不同成像技术下的适用性。
- 跨领域少样本医学图像分割(CD-FSMIS)任务旨在开发一个能够适应更广泛医学图像分割场景的通用模型。
- 研究团队受到不同领域频率域相似性特征的启发,设计了频率感知匹配网络(FAMNet)。
- FAMNet包括两个关键组件:频率感知匹配(FAM)模块和多光谱融合(MSF)模块。
- FAM模块解决了元学习阶段的域内方差和域间方差问题。
- MSF模块用于集成由FAM模块解耦的不同频率特征,进一步减轻域间方差对模型分割性能的影响。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是医学图像分割领域中的实际挑战:由于不同成像技术导致的领域偏移(domain shift),这限制了现有的少数样本医学图像分割(FSMIS)模型的适用性。具体来说,论文关注于跨领域少数样本医学图像分割(CD-FSMIS)任务,旨在开发一个能够适应更广泛的医学图像分割场景的泛化模型,即使在新的目标领域中只有有限的标记数据。
论文中提到的关键挑战包括:
领域内变化(Intra-domain variations):医学图像在个体器官之间表现出显著的变异性,例如大小、脂肪含量和病理变化,这使得找到相似的支持-查询对变得困难,导致支持-查询偏差和降低原型表示。
领域间变化(Inter-domain variations):即使在相同的器官或区域内,不同领域之间的空间域相似性表现出低相关性,而在频率域中,领域间变化主要在高低频带中表现明显,而中频带则相对相似。
为了克服这些限制,论文提出了一种新的频率感知匹配网络(FAMNet),包括两个关键组件:频率感知匹配(FAM)模块和多光谱融合(MSF)模块。FAM模块在元学习阶段解决领域内和领域间变化问题,而MSF模块设计用于整合由FAM模块解耦的不同频率特征,并进一步减轻领域间变化对模型分割性能的影响。通过结合这两个模块,FAMNet在三个跨领域数据集上超越了现有的FSMIS模型和跨领域少样本语义分割模型,实现了CD-FSMIS任务的最新性能。
Q: 有哪些相关研究?
A: 论文中提到了多个与跨领域少样本医学图像分割(CD-FSMIS)相关的研究领域和具体工作,可以分为以下几个部分:
1. 少样本医学图像分割(FSMIS)
交互网络(Interactive Networks):
- SENet(Guha Roy et al. 2019):在FSMIS任务中首次使用交互网络。
- MRrNet(Feng et al. 2021)、GCN-DE(Sun et al. 2022)、CRAPNet(Ding et al. 2023):通过注意力机制增强支持查询交互。
原型网络(Prototypical Networks):
- SSL-ALPNet(Ouyang et al. 2022):引入自监督框架,生成局部原型并使用基于超像素的伪标签进行训练。
- ADNet(Hansen et al. 2022)、CATNet(Lin et al. 2023)、GMRD(Cheng et al. 2024):通过不同的方法改进原型类的分布表示和支持查询交互。
2. 跨领域少样本语义分割(CD-FSS)
- 模型:
- PATNet(Lei et al. 2022)、PMNet(Chen et al. 2024)、DRAdapter(Su et al. 2024):这些模型尝试将领域特定特征映射到领域不可知特征,或通过样式扰动来适应目标领域风格。
3. 医学图像领域的泛化方法
- 领域随机化:
- 一些工作(Ouyang et al. 2021; Zhou et al. 2022; Xu et al. 2022; Su et al. 2023)主要关注领域随机化,而忽略了模型本身和少样本设置。
4. 其他相关工作
- 频率域和空间域的相似性度量:
- 使用结构相似性指数(SSIM)和归一化均方误差(NMSE)来量化CT和MRI在空间和频率域的相似性。
这些相关工作为论文提出的FAMNet提供了理论基础和技术对比,展示了在跨领域少样本医学图像分割任务中的研究进展和挑战。论文通过综合这些领域的技术和方法,提出了一个新的解决方案来提高模型在新目标领域的泛化能力和分割性能。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为FAMNet(Frequency-aware Matching Network)的模型,通过以下两个关键组件来解决跨领域少样本医学图像分割(CD-FSMIS)任务中的问题:
1. 频率感知匹配(FAM)模块
FAM模块的核心思想是在特定频率带内执行支持查询匹配,以消除支持查询偏差,并通过融合前景特征和突出协同部分来减少对显著领域差异的依赖。具体来说:
多频谱解耦:将前景特征从空间域转换到频率域,并使用带通滤波器将信号分解为高、中、低三个频带。
多频谱注意力匹配:对于不同的频带,应用不同的注意力加权机制,对于领域间变化较大的高频和低频带(DSFBs),采用抑制相似特征的策略;而对于领域间变化较小的中频带(DAFBs),则直接使用注意力权重。
2. 多光谱融合(MSF)模块
MSF模块旨在整合由FAM模块解耦的不同频率特征,并进一步减轻领域特定频率带的影响。具体来说:
交叉注意力机制:利用中频带信息从高频和低频特征中提取领域不变信息(DII),同时抑制领域特定信息(DVI)。
特征重组:将处理后的高频、中频和低频特征通过简单的加法整合,并通过ReLU激活函数输出最终的融合特征。
总体架构
特征提取:使用预训练的ResNet-50作为特征编码器提取支持和查询特征图。
粗略预测生成(CPG)模块:基于原型网络方法获得查询图像的粗略分割掩码。
频率感知匹配(FAM)模块:对支持和查询前景特征进行频率感知匹配。
多光谱融合(MSF)模块:基于交叉注意力机制融合不同频带的特征。
最终预测:通过计算前景原型与查询特征之间的余弦相似度来生成查询掩码的最终预测。
通过结合FAM和MSF模块,FAMNet不仅展示了强大的泛化能力,还有效地利用了样本空间中的领域不变交互信息,展现了优异的分割性能。论文通过在三个跨领域数据集上的实验验证了所提方法的有效性和优越性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来验证FAMNet模型的性能和有效性。具体实验包括:
数据集
- Cross-Modality 数据集:包含两个腹部数据集,Abd-MRI 和 Abd-CT,涵盖了左肾(LK)、右肾(RK)、肝脏和脾脏四个常见类别。
- Cross-Sequence 数据集:心脏数据集,包含LGE MRI扫描和b-SSFP MRI扫描,涵盖血池(LV-BP)、左心室心肌(LVMYO)和右心室心肌(RV)三个不同的标签。
- Cross-Institution 数据集:由伦敦大学学院医院(UCLH)和美国马里兰州贝塞斯达国家癌症研究所(NCI)提供的前列腺T2加权MRI扫描组成,涵盖膀胱、中央腺(CG)和直肠三个常见类别。
实施细节
- 使用3D supervoxel clustering方法生成伪掩码作为基于情节的元学习任务的监督。
- 在1-way 1-shot条件下进行实验。
- 使用SGD优化器,初始学习率0.001,动量0.9,每1K次迭代衰减因子0.95。
评估指标
- 使用Sorensen-Dice系数(DSC)作为评估模型的标准,衡量分割结果和真实标注之间的重叠程度。
定量和定性结果
- 与多种FSMIS模型(如PANet、SSL-ALPNet、ADNet等)和CD-FSS模型(如PATNet和IFA)进行比较。
- 在Cross-Modality数据集的CT → MRI和MRI → CT方向上,FAMNet均取得了显著的性能提升。
- 在Cross-Sequence数据集上,FAMNet在两个方向上均取得了最高的Dice分数,与次佳方法相比提高了10.14%和1.33%。
- 在Cross-Institution数据集上,FAMNet在UCLH → NCI和NCI → UCLH方向上分别比第二好的方法高1.80%和2.91%。
消融研究
- 分析了FAM模块和MSF模块对整体模型性能的贡献。
- 探讨了在DSFBs和DAFBs中应用不同注意力权重方法的影响。
- 研究了直接丢弃特定频率带对模型性能的影响。
- 分析了匹配仅限于特定频率带的影响。
- 讨论了不同频率带划分比例对模型性能的影响。
- 分析了通过自适应平均池化标准化前景像素数量N的影响。
可视化
- 展示了FAMNet在CT → MRI、LGE → b-SSFP和NCI → UCLH方向上的查询图像、真实标注、预测和不确定性图。
- 使用t-SNE可视化展示了FAMNet减少支持查询偏差的能力。
这些实验全面验证了FAMNet在跨领域少样本医学图像分割任务中的有效性和优越性能,并深入分析了模型的不同组件对性能的影响。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一个有效的FAMNet模型来解决跨领域少样本医学图像分割(CD-FSMIS)问题,但仍有一些方面可以进一步探索和改进:
1. 更多的领域和数据集
- 扩展数据集:在更多的跨领域数据集上验证模型的泛化能力,包括不同类型的医学图像(如超声、PET等)。
- 大规模数据集:探索在大规模跨领域数据集上的性能,以及如何处理类别不平衡问题。
2. 模型泛化能力的进一步提升
- 自适应领域判别:研究如何让模型自动学习哪些特征是领域特定的,哪些是领域不变的,以提高模型的泛化能力。
- 多任务学习:考虑将分割任务与其他相关任务(如分类、检测)结合起来,通过多任务学习提高模型的泛化能力。
3. 计算效率和实际应用
- 计算效率:优化模型结构和训练过程,减少计算资源消耗,使其更适合实际的临床应用。
- 实时性能:探索模型的实时性能,这对于手术导航等实时应用场景非常重要。
4. 模型解释性和可视化
- 特征可视化:进一步分析和可视化模型学习到的特征,以更好地理解模型的决策过程。
- 错误分析:对模型的失败案例进行详细分析,了解模型在哪些类型的图像或区域上表现不佳,并探索改进方法。
5. 模型鲁棒性
- 对抗性攻击和防御:研究模型对对抗性攻击的鲁棒性,并开发有效的防御策略。
- 数据增强和正则化:探索不同的数据增强技术和正则化方法,以提高模型对异常值和噪声的鲁棒性。
6. 跨模态融合
- 多模态融合策略:研究更先进的多模态融合策略,以充分利用不同模态的互补信息。
- 动态模态选择:开发动态模态选择机制,根据任务需求自动选择最相关的模态。
7. 临床验证和评估
- 临床合作:与临床医生合作,收集反馈,并根据临床需求调整和优化模型。
- 大规模临床试验:在大规模的临床试验中评估模型的性能和实用性。
这些方向不仅可以推动跨领域少样本医学图像分割技术的发展,还可能对其他领域的迁移学习和领域适应问题提供有价值的见解。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了跨领域少样本医学图像分割(CD-FSMIS)任务,并提出了一个名为FAMNet(Frequency-aware Matching Network)的模型来解决这一问题。以下是论文的主要内容总结:
问题背景
- 现有少样本医学图像分割(FSMIS)模型在面对不同成像技术导致的领域偏移时泛化能力有限,难以适应新的医学图像分割场景。
研究目标
- 提出一个能够适应新目标领域且只有少量标记数据的泛化模型,以提高在跨领域医学图像分割任务中的性能。
方法论
- FAMNet模型:包含两个关键组件,即频率感知匹配(FAM)模块和多光谱融合(MSF)模块。
- FAM模块:在元学习阶段处理领域内和领域间变化,通过在特定频率带内执行支持查询匹配来减少支持查询偏差,并整合频率域信息以降低对显著领域差异的依赖。
- MSF模块:整合由FAM模块解耦的不同频率特征,并进一步减轻领域特定频率带的影响。
实验
- 在三个跨领域数据集上进行了广泛的实验,包括Cross-Modality、Cross-Sequence和Cross-Institution数据集。
- 与多个现有的FSMIS和CD-FSS模型相比,FAMNet在CD-FSMIS任务上达到了最先进的性能。
- 通过消融研究和可视化分析验证了模型组件的有效性和模型对领域偏移的鲁棒性。
结论
- FAMNet通过其创新的频率感知匹配和多光谱融合策略,有效地解决了跨领域少样本医学图像分割中的挑战,展示了优异的泛化能力和分割性能。
总体而言,这篇论文针对医学图像分割领域中的实际问题提出了一种有效的解决方案,并通过一系列实验验证了其方法的有效性,为未来的研究和应用提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

On the effectiveness of Rotation-Equivariance in U-Net: A Benchmark for Image Segmentation
Authors:Robin Ghyselinck, Valentin Delchevalerie, Bruno Dumas, Benoît Frénay
Numerous studies have recently focused on incorporating different variations of equivariance in Convolutional Neural Networks (CNNs). In particular, rotation-equivariance has gathered significant attention due to its relevance in many applications related to medical imaging, microscopic imaging, satellite imaging, industrial tasks, etc. While prior research has primarily focused on enhancing classification tasks with rotation equivariant CNNs, their impact on more complex architectures, such as U-Net for image segmentation, remains scarcely explored. Indeed, previous work interested in integrating rotation-equivariance into U-Net architecture have focused on solving specific applications with a limited scope. In contrast, this paper aims to provide a more exhaustive evaluation of rotation equivariant U-Net for image segmentation across a broader range of tasks. We benchmark their effectiveness against standard U-Net architectures, assessing improvements in terms of performance and sustainability (i.e., computational cost). Our evaluation focuses on datasets whose orientation of objects of interest is arbitrary in the image (e.g., Kvasir-SEG), but also on more standard segmentation datasets (such as COCO-Stuff) as to explore the wider applicability of rotation equivariance beyond tasks undoubtedly concerned by rotation equivariance. The main contribution of this work is to provide insights into the trade-offs and advantages of integrating rotation equivariance for segmentation tasks.
最近,许多研究都集中在将不同形式的等价性(equivariance)引入卷积神经网络(CNN)中。特别是在医学影像、微观成像、卫星成像、工业任务等应用中,旋转等价性由于其重要性而备受关注。虽然先前的研究主要集中在利用旋转等价性CNN改进分类任务,但它们在更复杂的架构(如用于图像分割的U-Net)上的影响仍然鲜有研究。实际上,之前将旋转等价性集成到U-Net架构中的研究主要集中在解决具有有限范围的具体应用上。相比之下,本文旨在更全面地评估旋转等价性U-Net在更广泛的任务中进行图像分割的效果。我们将它们与标准U-Net架构进行基准测试,以评估其在性能和可持续性(即计算成本)方面的改进。我们的评估主要集中在对象方向在图像中是任意的数据集上(例如Kvasir-SEG),但也包括更标准的分割数据集(如COCO-Stuff),以探索旋转等价性在明确涉及旋转等价性的任务之外的更广泛应用。这项工作的主要贡献在于深入探讨了将旋转等价性集成到分割任务中的优缺点。
论文及项目相关链接
Summary
本文研究了旋转等变卷积神经网络(CNN)在图像分割任务中的表现,特别是在U-Net架构中的应用。文章对比了标准U-Net架构,评估了旋转等变U-Net在性能与计算成本方面的改善,并在多个数据集上进行广泛评估,探讨了其在更广泛应用领域的潜力。
Key Takeaways
- 旋转等变卷积神经网络(CNN)在图像分割任务中受到关注。
- 文章对比了标准U-Net架构与旋转等变U-Net的表现。
- 研究评估了旋转等变U-Net的性能和计算成本方面的改善。
- 文章在多个数据集上进行了广泛评估,包括针对目标方向任意性的数据集(如Kvasir-SEG)。
- 同时也对更标准的分割数据集(如COCO-Stuff)进行了评估,以探索旋转等变性的更广泛应用。
- 本文的主要贡献在于提供了在分割任务中集成旋转等变性的优缺点见解。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文主要探讨了在卷积神经网络(CNNs)中引入旋转等变性(rotation-equivariance)对于图像分割任务的有效性。具体来说,论文试图解决的问题包括:
旋转等变性在图像分割中的有效性评估:尽管旋转等变性在图像分类任务中已经得到了广泛的研究和应用,但其在更复杂的架构,如U-Net这类用于图像分割的网络中的影响尚未充分探索。论文旨在通过对旋转等变U-Net的性能进行基准测试,填补这一研究空白。
旋转等变U-Net与标准U-Net的性能对比:论文对比了旋转等变U-Net与传统U-Net在不同任务上的性能,包括模型准确性和计算成本(即可持续性)。这有助于理解在图像分割任务中引入旋转等变性的权衡和优势。
旋转等变性在不同数据集和任务中的适用性:论文不仅在明显需要旋转等变性的任务(如医学成像、显微镜成像等)上评估模型,还在更通用的任务(如COCO-Stuff)上进行测试,以探索旋转等变性在更广泛任务中的潜在优势。
旋转等变性对模型参数和计算资源的影响:论文评估了引入旋转等变性是否可以减少模型所需的参数数量和计算资源,从而提高模型的可持续性。
综上所述,论文的主要贡献在于提供了关于在不同应用场景下整合旋转等变性对分割任务的权衡和优势的见解,以及对旋转等变U-Net模型在多种分割任务中的有效性进行了综合评估。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个方面:
在CNN中引入等变性的研究:
- Weiler & Cesa (2019) 提出了一般E(2)-等变CNNs(E(2)-CNNs),该方法通过有限一组不可约表示来实现对连续群的等变性。
- Cohen & Welling (2016) 提出了群-CNN,通过在离散对称群中复制滤波器的不同版本来实现等变性。
- Worrall et al. (2017) 和 Delchevalerie et al. (2023) 探讨了等变CNN在图像分类任务中的应用。
旋转等变性在特定应用领域的研究:
- 在医学成像领域,Oreiller et al. (2022) 和 Elaldi et al. (2024) 研究了旋转等变性的应用。
- 在显微镜成像领域,Chidester et al. (2019b) 和 Graham et al. (2020) 探讨了旋转等变性的重要性。
- 在卫星成像领域,Marcos et al. (2018) 和 Li et al. (2020) 研究了旋转等变性的应用。
旋转等变性在U-Net架构中的研究:
- Chidester et al. (2019a) 是第一个在U-Net架构中考虑利用旋转等变性的研究,他们研究了在病理图像中分割细胞核的C4群卷积。
- Mitton & Murray-Smith (2021) 使用群-CNN进行森林砍伐分割任务。
- Oreiller et al. (2022) 引入了一种特定的局部旋转不变双谱U-Net,用于多器官细胞核分割任务。
这些研究为本文提供了理论基础和应用背景,同时也表明了旋转等变性在不同领域中的潜在价值和应用前景。本文通过在多个数据集上评估旋转等变U-Net模型,进一步扩展了这些研究,并探讨了旋转等变性在图像分割任务中的广泛适用性。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决旋转等变U-Net在图像分割任务中的有效性问题:
背景知识介绍:
- 论文首先介绍了图像分割任务和U-Net架构的背景知识。
- 接着讨论了在CNN中实现等变性的当前技术,特别是旋转等变性。
相关工作回顾:
- 论文回顾了先前研究,特别是那些专注于将旋转等变性应用于分类任务的研究,并指出了这些技术在分割任务中的研究不足。
数据集和模型选择:
- 选择了五个不同的数据集,包括二元分割和语义分割任务,覆盖了需要旋转等变性和标准应用的场景。
- 提出了两种主要类别的U-Net模型:传统的U-Net和等变U-Net,并为每个类别定义了不同大小的模型。
实验设计:
- 设计了实验来训练和评估不同配置的U-Net模型,包括优化器、损失函数和超参数的选择。
- 使用特定的评估指标来衡量模型性能,包括Dice Score、IoU、Precision、Recall和Accuracy等。
结果分析:
- 对比了标准U-Net和等变U-Net在不同数据集上的性能,包括模型准确性和计算成本。
- 分析了模型在不同数据量设置下的性能,以评估等变模型在数据受限情况下的有效性。
讨论:
- 根据实验结果,讨论了等变模型在不同任务和数据条件下的优势和局限性。
- 提供了关于何时使用等变U-Net模型的见解,并讨论了在计算资源方面潜在的可持续性改进。
结论和未来工作:
- 总结了研究发现,并讨论了等变U-Net在实际应用中的潜力和未来的研究方向。
通过这些步骤,论文提供了一个全面的评估,展示了旋转等变U-Net在多种图像分割任务中的有效性,并探讨了其在实际应用中的潜在价值。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验:
模型训练:
- 使用AdamW优化器对所有模型进行训练,针对不同数据集设定了特定的学习率和训练周期。
- 使用Dice Loss作为损失函数,因为它适合于处理分割任务中的不平衡数据。
- 对每个数据集应用了特定的数据增强技术,包括随机旋转、水平/垂直翻转和颜色归一化。
五折交叉验证:
- 对所有数据集实施五折交叉验证,以确保每个样本仅在测试集中出现一次,并提供结果的统计稳健性。
- 对于每个数据集,考虑了两种数据量设置:使用全部数据的“大数据设置”和仅使用每个训练折叠10%数据的“小数据设置”。
性能评估:
- 对于二元分割任务,使用了Dice Score、IoU、Precision、Recall和Accuracy等五个性能指标。
- 对于语义分割任务,使用了Mean IoU、Pixel Accuracy、Mean Accuracy和Frequency-weighted IoU等四个评估标准。
结果对比:
- 对比了标准U-Net和等变U-Net(包括C4、C8、D4对称群)在五个数据集上的性能。
- 分析了不同模型在大数据和小数据设置下的性能差异。
- 考察了模型性能与训练时间的关系,以评估模型的可持续性。
时间-性能分析:
- 对每个数据集,绘制了不同模型在小数据和大数据设置下,IoU分数随累计训练时间变化的图表。
- 分析了在固定训练周期内,不同模型配置(小模型和大模型)的性能表现。
这些实验旨在全面评估旋转等变U-Net在不同条件下的性能,并与标准U-Net进行比较,以确定在哪些情况下引入旋转等变性可以提高分割任务的性能和效率。
Q: 有什么可以进一步探索的点?
A: 根据论文的结论和讨论,以下是一些可以进一步探索的点:
设计新型网络结构:
- 设计能够同时提取等变和非等变特征的新型网络结构,以利用等变特征的互补信息,可能有助于提高复杂数据集上的性能。
优化旋转等变卷积:
- 研究和开发更高效的旋转等变卷积方法,以减少计算成本,提高训练速度。
探索不同的对称群:
- 除了C4、C8和D4之外,探索其他对称群可能带来的性能影响,以及它们如何适应不同的数据集和任务。
数据增强技术:
- 研究不同的数据增强技术,特别是那些可以增加模型对旋转变化鲁棒性的方法,以提高模型的泛化能力。
小样本学习:
- 在小样本学习环境下,进一步研究等变模型是否能够提供更好的性能,尤其是在医学成像等领域,这些领域常常面临样本不足的问题。
跨领域验证:
- 将等变U-Net模型应用于其他图像处理任务,例如目标检测或图像分类,验证其在这些任务中的有效性。
理论分析:
- 对旋转等变CNNs的理论基础进行更深入的研究,包括其对特征空间的影响和优化动态。
实际应用测试:
- 在真实世界的应用程序中测试等变U-Net模型,以评估其在实际环境中的表现和适用性。
参数和架构搜索:
- 使用自动化机器学习(AutoML)技术来搜索最佳的网络架构和超参数,以进一步提高等变U-Net的性能。
可解释性和可视化:
- 研究等变U-Net模型的决策过程,通过可视化技术揭示模型如何利用旋转等变特征进行分割。
这些探索方向不仅可以推动旋转等变CNNs的发展,还可能对整个深度学习领域产生积极影响,特别是在需要对图像方向变化具有鲁棒性的应用中。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了在不同图像分割任务中引入旋转等变性(rotation-equivariance)的有效性,并以U-Net架构为例进行了深入分析。以下是论文的主要内容总结:
研究背景与动机:
- 论文首先介绍了在卷积神经网络(CNNs)中引入等变性的重要性,特别是旋转等变性,它在医学成像、显微镜成像和卫星成像等领域的应用价值。
- 尽管旋转等变CNNs在分类任务中表现出优势,但其在更复杂的图像分割任务中的影响尚未充分研究。
相关工作回顾:
- 论文回顾了在CNNs中引入旋转等变性的相关研究,包括数据增强、群-CNN和一般E(2)-等变CNNs等方法。
- 指出了现有研究的局限性,尤其是在分割任务和复杂CNN架构中的应用。
数据集与模型:
- 选择了五个数据集,包括Kvasir-SEG、NucleiSeg、URDE、COCO-Stuff和iSAID,覆盖了二元分割和语义分割任务,以及需要旋转等变性和标准应用的场景。
- 提出了两种主要的U-Net模型:传统的U-Net和等变U-Net,并为每个类别定义了不同大小的模型。
实验设计:
- 设计了实验来训练和评估不同配置的U-Net模型,包括优化器、损失函数和超参数的选择。
- 使用了特定的评估指标来衡量模型性能,包括Dice Score、IoU、Precision、Recall和Accuracy等。
结果分析:
- 对比了标准U-Net和等变U-Net在不同数据集上的性能,包括模型准确性和计算成本。
- 分析了模型在不同数据量设置下的性能,以评估等变模型在数据受限情况下的有效性。
讨论:
- 根据实验结果,讨论了等变模型在不同任务和数据条件下的优势和局限性。
- 提供了关于何时使用等变U-Net模型的见解,并讨论了在计算资源方面潜在的可持续性改进。
结论与未来工作:
- 总结了研究发现,并讨论了等变U-Net在实际应用中的潜力和未来的研究方向。
论文通过一系列实验,提供了对旋转等变U-Net在多种图像分割任务中的有效性的综合评估,并探讨了其在实际应用中的潜在价值。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Probing the low-energy particle content of blazar jets through MeV observations
Authors:F. Tavecchio, L. Nava, A. Sciaccaluga, P. Coppi
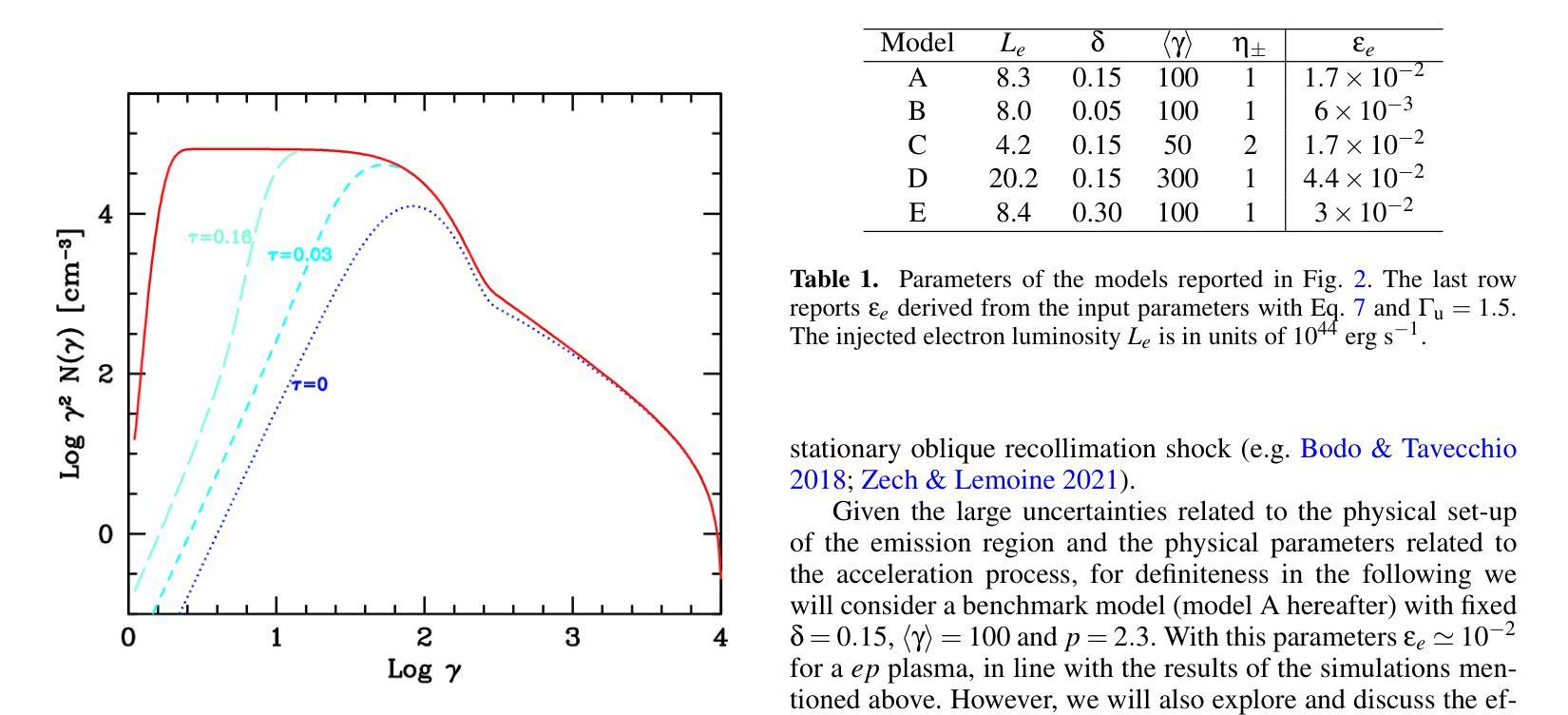
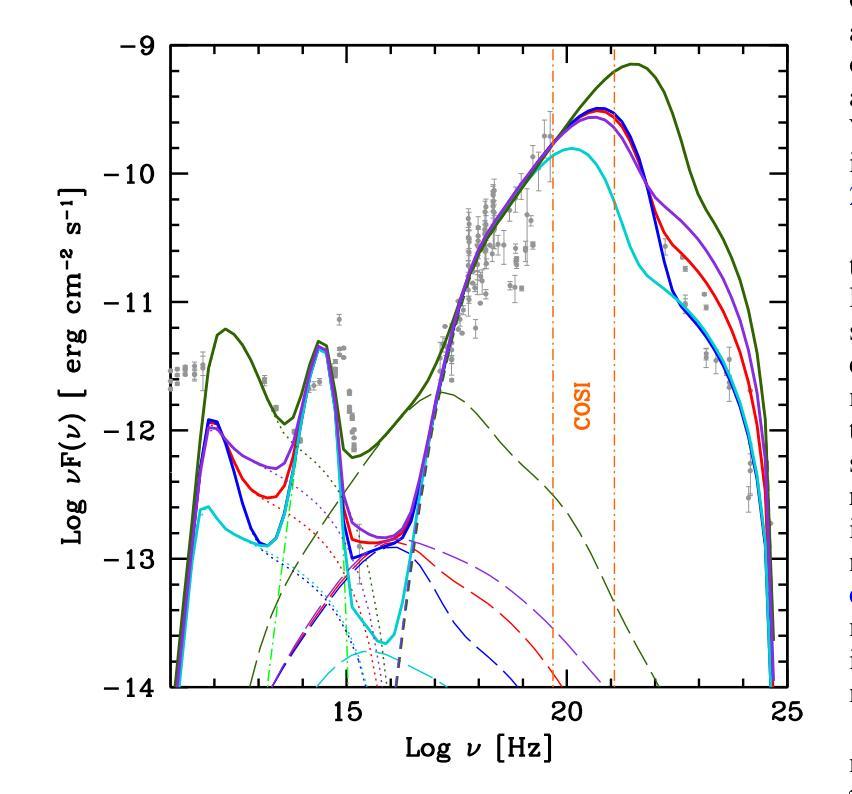
Many of the blazars observed by Fermi actually have the peak of their time-averaged gamma-ray emission outside the $\sim$ GeV Fermi energy range, at $\sim$ MeV energies. The detailed shape of the emission spectrum around the $\sim$ MeV peak places important constraints on acceleration and radiation mechanisms in the blazar jet and may not be the simple broken power law obtained by extrapolating from the observed X-ray and GeV gamma-ray spectra. In particular, state-of-the-art simulations of particle acceleration by shocks show that a significant fraction (possibly up to $\approx 90%$) of the available energy may go into bulk, quasi-thermal heating of the plasma crossing the shock rather than producing a non-thermal power law tail. Other gentler" but possibly more pervasive acceleration mechanisms such as shear acceleration at the jet boundary may result in a further build-up of the low-energy ($\gamma \lesssim 10^{2}$) electron/positron population in the jet. As already discussed for the case of gamma-ray bursts, the presence of a low-energy, Maxwellian-like bump’’ in the jet particle energy distribution can strongly affect the spectrum of the emitted radiation, e.g., producing an excess over the emission expected from a power-law extrapolation of a blazar’s GeV-TeV spectrum. We explore the potential detectability of the spectral component ascribable to a hot, quasi-thermal population of electrons in the high-energy emission of flat-spectrum radio quasars (FSRQ). We show that for typical FSRQ physical parameters, the expected spectral signature is located at $\sim$ MeV energies. For the brightest Fermi FSRQ sources, the presence of such a component will be constrained by the upcoming MeV Compton Spectrometer and Imager (COSI) satellite.
由费米观测到的许多耀斑实际上其时间平均的伽马射线发射峰值位于兆电子伏特(MeV)能量下,并不在费米的能量范围内(约千兆电子伏特)。发射光谱在兆电子伏特峰值周围的详细形状对耀斑喷射流的加速和辐射机制有着重要限制,可能并不是通过观测到的X射线和千兆电子伏特伽马射线光谱推断出的简单分段幂律。特别是,最新的冲击粒子加速模拟显示,相当一部分(可能高达约90%)可用能量可能用于冲击处穿过等离子体的集体准热加热,而不是产生非热幂律尾。其他较为温和的但可能更为普遍的加速机制,如喷射边界处的剪切加速,可能导致喷射中能量较低(γ≤约数百万电子伏)的电子/正电子种群进一步累积。如之前讨论过的伽马射线爆发的情况一样,喷射粒子能量分布中存在类似于麦克斯韦分布的“凸起”,会强烈影响发射的辐射光谱,例如产生超过通过耀斑的千兆电子伏特至太电子伏特光谱的幂律外推所预期的发射过剩。我们探讨了高温、准热电子群体所产生的高能谱分量在平谱射电类星(FSRQ)高能发射中的潜在可探测性。我们表明,对于典型的FSRQ物理参数,预期的光谱特征位于兆电子伏特能量下。对于最明亮的费米星载频率高于十电子伏的FSRQ源来说,该成分的存在将受到即将到来的MeV康普顿光谱仪和成像器(COSI)卫星的约束。
论文及项目相关链接
PDF 5 pages, 2 figures, submitted to A&A
摘要
由Fermi观测到的许多耀变体实际上在$\sim$MeV能量处其时间平均的伽马射线发射峰值位于$\sim$以外的费米能量范围之外。排放光谱在$\sim$MeV峰值周围的详细形状对耀变体射流中的加速和辐射机制施加了重要的限制,可能并不是通过从观测到的X射线和伽马射线光谱推断出的简单幂律所能得到的。尤其是,最先进的冲击粒子加速模拟表明,可用能量的很大一部分(可能高达$\approx 90%$)可能用于冲击穿过处的等离子体整体、准热加热,而不是产生非热幂律尾巴。其他更为普遍但较为温和的加速机制,如射流边界处的剪切加速,可能导致射流中低能(γ≲)电子/正电子群体的进一步聚集。对于已经讨论过的伽马射线爆发的情况,射流粒子能量分布中存在低能、类似麦克斯韦的“凸起”,会强烈影响发射的辐射光谱,例如产生超出从耀变体的伽马射线光谱推断出的幂律预期的过量辐射。我们探讨了可归因于射流中热、准热电子群体的光谱成分在高能发射中的潜在可探测性。我们表明,对于典型的耀变体物理参数,预期的谱特征位于$\sim$MeV能量处。对于最亮的费米耀变体源,这种成分的存在将由即将发射的MeV康普顿光谱仪和成像器(COSI)卫星进行约束。
关键见解
- 许多由Fermi观测到的耀变体其伽马射线发射峰值在MeV能量范围内,不在费米能量范围内。
- 发射光谱的详细形状对理解耀变体射流中的粒子加速和辐射机制非常重要。
- 先进的模拟表明,大部分能量可能用于等离子体在冲击区域的准热加热,而非仅产生非热幂律尾。
- 除了强烈的加速机制外,还存在更温和但可能更普遍的加速机制,如射流边界的剪切加速。
- 低能电子/正电子种群在射流中的积累可能影响发射的辐射光谱。
- 射流粒子能量分布中的Maxwellian-like“凸起”可以显著改变发射光谱,产生与预期不同的辐射。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了低能粒子在耀变体(blazar)喷流中的含量,并通过兆电子伏(MeV)观测来研究这些粒子的特性。具体来说,论文试图解决以下问题:
耀变体喷流中粒子加速和辐射机制的详细形状:论文指出,许多被费米望远镜(Fermi)观测到的耀变体在约MeV能量处达到它们的时间平均伽马射线发射峰值,而不是在费米望远镜约GeV能量范围内。这些MeV峰值附近的发射光谱的详细形状对于约束耀变体喷流中的加速和辐射机制非常重要。
粒子加速和能量耗散的机制:论文讨论了两种主要的竞争机制:扩散激波加速(DSA)和磁场重联(MR)。这两种机制在一定程度上是互补的,因为DSA只能在磁化程度较低(σ)的流动中有效工作,而MR自然需要高σ。
粒子加速过程的详细模拟:通过粒子模拟(PIC)模拟,研究了DSA和MR情况下的加速过程。DSA的一个确定预测是,在激波下游,粒子被加热并形成类似麦克斯韦分布,而只有一小部分粒子(约百分之几)反复穿过激波,经历DSA并形成包含≲10%激波耗散能量的幂律尾部。
耀变体喷流中低能电子/正电子群体的影响:论文还探讨了其他可能更普遍的加速机制,如在喷流边界的剪切加速,可能导致喷流中低能(γ ≲ 102)电子/正电子群体的进一步积累。
在FSRQ的高能发射中探测到的准热电子群体的光谱成分:论文探索了在平坦谱射电类星体(FSRQ)的高能发射中,归因于热、准热电子群体的光谱成分的潜在可探测性,并展示了对于典型的FSRQ物理参数,预期的光谱特征位于约MeV能量。
综上所述,论文的主要目标是探索FSRQ中电子热隆起在发射中的潜在特征,并讨论了通过未来的MeV康普顿光谱仪和成像仪(COSI)卫星对这些特征进行观测的前景。
Q: 有哪些相关研究?
A: 论文中提到了多个与耀变体喷流和粒子加速相关的研究,以下是一些关键的参考文献和它们的贡献:
Blandford et al. (2019): 讨论了外星系相对论性喷流背后的物理过程,包括喷流动力学、组成和磁场的作用。
Sironi et al. (2015a, 2015b): 探讨了磁场重联(MR)和扩散激波加速(DSA)作为粒子加速的两种主要机制,并讨论了它们在不同磁化程度下的适用性。
Tchekhovskoy et al. (2011): 研究了涉及磁场和黑洞旋转的喷流发射机制,这些机制倾向于支持磁场重联。
Sikora et al. (2005), Celotti & Ghisellini (2008), Tavecchio & Ghisellini (2016): 提出了与发射区域相关的小磁化模型,可能支持扩散激波加速。
Liodakis et al. (2022): 通过IXPE卫星的偏振频道结果,指出激波可能是加速的主要因素。
Bolis et al. (2024): 提出了另一种解释,包括Poynting主导的喷流。
Sironi & Spitkovsky (2011, 2014), Werner et al. (2018), Petropoulou et al. (2019), Werner & Uzdensky (2024): 通过粒子模拟(PIC)模拟详细研究了DSA和MR情况下的加速过程。
Giannios & Spitkovsky (2009): 讨论了DSA预测的显著热隆起对光谱特征的影响。
Eichler & Waxman (2005), Warren et al. (2018), Gao et al. (2024): 探讨了伽马射线暴(GRB)中热成分的可能性。
Spitkovsky (2008): 描述了DSA情况下粒子被加热并形成类似麦克斯韦分布的预测。
Summerlin & Baring (2012): 通过蒙特卡洛方法模拟了DSA,也得出了类似的分布。
Ghisellini & Tavecchio (2009): 讨论了FSRQs的高能发射,这些发射可能通过逆康普顿散射(IC)机制产生。
这些研究为理解耀变体喷流中的物理过程提供了理论基础和观测数据,特别是在粒子加速和辐射机制方面。论文中还引用了其他一些文献来支持其模型和分析,涵盖了从喷流的动力学到粒子加速的细节,以及这些过程对观测到的光谱的影响。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决研究问题:
理论模型构建:
- 论文采用了一个标准的单区域模型(one-zone model)来模拟喷流中的能量耗散区域,其中考虑了相对论性电子通过同步辐射和逆康普顿散射(IC)机制的发射。
- 引入了一个混合的初始电子能量分布(EED),包括热分布和非热幂律尾部,基于Giannios & Spitkovsky (2009)的工作。
参数设定:
- 论文设定了一系列基准参数,这些参数基于先前对FSRQs的模型研究,包括喷流的物理尺寸、磁场强度、洛伦兹因子和观测角度等。
- 对于注入的电子能量分布,论文设定了参数如能量分数δ、平均洛伦兹因子⟨γ⟩、电子的注入光度Le、幂律尾部的斜率p和截止能量γc。
数值计算:
- 使用数值方法解决连续性方程,计算在光穿越时间后电子能量分布(EED)的变化。
- 计算了电子的辐射冷却率,包括同步辐射和IC辐射,并忽略了绝热冷却和粒子从源的逃逸。
光谱能量分布(SED)分析:
- 根据计算得到的EED,计算了FSRQs的光谱能量分布(SED),包括同步辐射、同步自康普顿(SSC)和外部康普顿(EC)的贡献。
- 分析了不同参数设置下(如不同的δ和⟨γ⟩)的SED特征,特别是MeV波段的特征,因为这是探测准热电子群体的关键波段。
观测数据对比:
- 论文讨论了如何利用未来的MeV康普顿光谱仪和成像仪(COSI)卫星的数据来测试模型预测。
- 通过比较模型预测的SED与实际观测数据,评估了模型的有效性,并探讨了不同参数设置对观测结果的影响。
讨论和展望:
- 论文讨论了结果的物理意义,包括不同喷流组成和加速过程对观测到的光谱的影响。
- 提出了未来观测的潜在应用,例如通过COSI卫星观测最亮的FSRQs的MeV通量变化,以追踪EED的变化。
通过这些步骤,论文旨在揭示FSRQs喷流中低能粒子群体的特性,并通过MeV观测来探测这些群体的潜在影响。这种方法提供了一种结合理论模型和观测数据来研究高能天体物理现象的新途径。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,本文并没有进行传统意义上的实验操作,而是通过以下方式进行研究:
理论建模与数值模拟:作者构建了一个理论模型来模拟耀变体喷流中的粒子加速和辐射过程。这个模型基于一个单区域方法,考虑了相对论性电子通过同步辐射和逆康普顿散射(IC)机制的发射。
参数化研究:作者设定了一系列基准参数,这些参数基于先前对平坦谱射电类星体(FSRQ)的研究。他们通过改变这些参数(例如能量分数δ、平均洛伦兹因子⟨γ⟩、电子的注入光度Le、幂律尾部的斜率p和截止能量γc)来研究它们对模型预测的影响。
数值计算:作者使用数值方法(特别是Chang & Cooper 1970提出的隐式方法)来解决连续性方程,计算在光穿越时间后电子能量分布(EED)的变化。
光谱能量分布(SED)计算:基于计算得到的EED,作者计算了FSRQs的光谱能量分布(SED),包括同步辐射、同步自康普顿(SSC)和外部康普顿(EC)的贡献。
结果分析与讨论:作者分析了不同参数设置下的SED特征,特别是MeV波段的特征,并讨论了这些结果对理解耀变体喷流中粒子加速和辐射机制的意义。
观测数据对比:作者讨论了如何利用未来的MeV康普顿光谱仪和成像仪(COSI)卫星的数据来测试模型预测,并与实际观测数据进行对比。
总的来说,本文的研究方法侧重于理论建模和数值模拟,而不是实验室或现场的实验操作。通过这种方法,作者旨在探索FSRQs喷流中低能粒子群体的特性,并预测它们在MeV波段的潜在观测特征。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些有前景的研究方向和可以进一步探索的点:
COSI卫星的观测计划:
- 论文计划进行专门的模拟,以评估使用COSI卫星进行观测的可行性。这包括对最亮的FSRQs在MeV波段的通量变化进行追踪,以研究EED的变化。
粒子加速过程的详细模拟:
- 论文提到了扩散激波加速(DSA)和磁场重联(MR)作为粒子加速的两种主要机制。可以进一步通过粒子模拟(PIC)模拟来研究这些过程的细节,特别是在不同的磁化程度和流动条件下。
不同类型耀变体的喷流特性:
- 论文主要关注了最强大的FSRQs。对于其他类型的耀变体,如低功率的FSRQs和不同类型的BL Lac对象,研究它们的喷流特性和辐射机制也是有价值的。
喷流组成的影响:
- 论文讨论了喷流组成(如电子-正电子对的丰富程度)对观测光谱的影响。可以进一步研究不同的喷流组成对粒子加速和辐射过程的影响。
喷流的时变特性:
- 论文提到了喷流的物理参数(如δ和⟨γ⟩)可能随时间变化,这会影响热隆起的位置和相对水平。可以进一步研究这些时变特性,以及它们如何影响观测到的光谱。
KN效应对高能部分逆康普顿分量的影响:
- 对于高功率的FSRQs,KN(Klein-Nishina)效应可能会影响逆康普顿分量的高能部分,使得识别光谱结构变得更加困难。可以进一步研究KN效应对不同类型耀变体光谱的影响。
不同磁化程度下的粒子加速:
- 论文提到了在不同的磁化程度下,DSA和MR对非热电子能量分数的影响。可以进一步研究这些条件下的粒子加速效率和光谱特征。
喷流动力学和能量耗散的多波段观测:
- 通过结合从射电到γ射线的多波段观测,可以更全面地研究喷流动力学和能量耗散过程。这包括研究不同波段的辐射特征和它们之间的关联。
这些研究方向可以帮助我们更深入地理解耀变体喷流中的物理过程,并为未来的观测提供理论基础和预测。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究背景:
- 论文聚焦于通过MeV观测来探测低能粒子在耀变体(blazar)喷流中的含量。许多耀变体的峰值伽马射线发射位于MeV能量范围,这与费米望远镜观测到的GeV能量范围不同。
理论模型:
- 作者采用了一个单区域模型来模拟喷流中的能量耗散区域,假设该区域被一个混乱的磁场充满,并且相对论性电子通过同步辐射和逆康普顿散射机制发射。
- 论文考虑了电子的初始能量分布是混合的,包括一个热分布和一个非热幂律尾部。
参数化与数值计算:
- 作者设定了一系列基准参数,包括喷流的物理尺寸、磁场强度、洛伦兹因子和观测角度等。
- 使用数值方法解决连续性方程,计算了在光穿越时间后电子能量分布的变化。
光谱能量分布(SED)分析:
- 基于计算得到的电子能量分布,作者计算了FSRQs的SED,包括同步辐射、同步自康普顿(SSC)和外部康普顿(EC)的贡献。
- 分析了不同参数设置下的SED特征,特别是MeV波段的特征。
观测数据对比与预测:
- 论文讨论了如何利用未来的MeV康普顿光谱仪和成像仪(COSI)卫星的数据来测试模型预测,并与实际观测数据进行对比。
- 论文指出,通过比较模型预测的SED与实际观测数据,可以评估模型的有效性,并探讨了不同参数设置对观测结果的影响。
结果与讨论:
- 论文得出结论,FSRQs喷流中的热成分峰值预期在0.1-10 MeV范围内,与观测到的最强大的FSRQ相符。
- 论文还讨论了喷流组成、粒子加速过程和KN效应对观测光谱的影响,并提出了未来观测的潜在应用。
进一步探索的方向:
- 论文提出了一些可以进一步探索的研究方向,包括COSI卫星的观测计划、粒子加速过程的详细模拟、不同类型耀变体的喷流特性、喷流的时变特性等。
总的来说,这篇论文通过理论建模和数值模拟,研究了FSRQs喷流中低能粒子群体的特性,并通过MeV观测来探测这些群体的潜在影响,为理解耀变体喷流中的物理过程提供了新的视角。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Radiology Report Generation via Multi-objective Preference Optimization
Authors:Ting Xiao, Lei Shi, Peng Liu, Zhe Wang, Chenjia Bai
Automatic Radiology Report Generation (RRG) is an important topic for alleviating the substantial workload of radiologists. Existing RRG approaches rely on supervised regression based on different architectures or additional knowledge injection,while the generated report may not align optimally with radiologists’ preferences. Especially, since the preferences of radiologists are inherently heterogeneous and multidimensional, e.g., some may prioritize report fluency, while others emphasize clinical accuracy. To address this problem,we propose a new RRG method via Multi-objective Preference Optimization (MPO) to align the pre-trained RRG model with multiple human preferences, which can be formulated by multi-dimensional reward functions and optimized by multi-objective reinforcement learning (RL). Specifically, we use a preference vector to represent the weight of preferences and use it as a condition for the RRG model. Then, a linearly weighed reward is obtained via a dot product between the preference vector and multi-dimensional reward.Next,the RRG model is optimized to align with the preference vector by optimizing such a reward via RL. In the training stage,we randomly sample diverse preference vectors from the preference space and align the model by optimizing the weighted multi-objective rewards, which leads to an optimal policy on the entire preference space. When inference,our model can generate reports aligned with specific preferences without further fine-tuning. Extensive experiments on two public datasets show the proposed method can generate reports that cater to different preferences in a single model and achieve state-of-the-art performance.
自动放射学报告生成(RRG)是缓解放射科医生巨大工作量的一个重要课题。现有的RRG方法依赖于基于不同架构的监督回归或额外知识注入,而生成的报告可能无法最佳地与放射科医生的偏好对齐。尤其地,由于放射科医生的偏好本质上是异质和多维的,例如,有些人可能优先注重报告流畅性,而另一些人则强调临床准确性。为了解决这个问题,我们提出了一种新的RRG方法,即基于多目标偏好优化(MPO)的方法,使预训练的RRG模型与多种人类偏好对齐。这可以通过多维奖励函数来表述,并使用多目标强化学习(RL)进行优化。具体来说,我们使用偏好向量来表示偏好的权重,并将其作为RRG模型的条件。然后,通过偏好向量与多维奖励之间的点积获得线性加权奖励。接下来,通过RL优化此类奖励,使RRG模型与偏好向量对齐。在训练阶段,我们从偏好空间中随机抽取不同的偏好向量,通过优化加权的多目标奖励来使模型对齐,从而在整个偏好空间上达到最优策略。在推理时,我们的模型可以在无需进一步微调的情况下,生成符合特定偏好的报告。在两个公共数据集上的大量实验表明,所提方法能够在单个模型中生成满足不同偏好的报告,并达到最先进的性能。
论文及项目相关链接
PDF 11 pages,3 figures
Summary
针对放射科医生报告生成(RRG)中现有方法可能无法完全符合放射科医生偏好多样性的问题,本文提出了一种新的多目标偏好优化(MPO)方法。该方法使用强化学习优化预训练的RRG模型,使其与多维度的放射科医生偏好对齐。实验结果显示,该方法能够在单一模型中生成满足不同偏好的报告,达到业界最佳性能。
Key Takeaways
- 放射科医生报告生成(RRG)是重要的研究议题,旨在缓解放射科医生的工作量。
- 当前RRG方法主要通过监督回归与不同架构或额外知识注入来实现,但生成的报告可能无法最佳地与放射科医生的偏好对齐。
- 放射科医生的偏好是多样且多维度的,例如报告的流畅性与临床准确性等。
- 本文提出了多目标偏好优化(MPO)方法来解决这一问题,使用强化学习优化预训练的RRG模型,使其适应多种医生偏好。
- 通过偏好向量来表示医生的偏好权重,并在训练阶段随机采样不同的偏好向量来优化模型。
- 实验证明,该方法能够在单一模型中生成满足不同偏好的报告,并在公开数据集上达到业界最佳性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是放射科医生在自动放射报告生成(Radiology Report Generation, RRG)中面临的偏好多样性和多维性问题。具体来说,论文中提到现有的RRG方法主要依赖于不同架构的监督回归或额外知识注入,但这些生成的报告可能无法最佳地符合放射科医生的偏好。由于放射科医生的偏好本质上是异质的和多维的,例如,一些医生可能优先考虑报告的流畅性,而其他医生可能更强调临床准确性。因此,RRG模型必须能够迎合不同放射科医生的多样化偏好,这是一个挑战,并且之前的研究中尚未探索。为了解决这个问题,论文提出了一种新的RRG方法,通过多目标偏好优化(Multi-objective Preference Optimization, MPO)来调整预训练的RRG模型以符合多种人类偏好。
Q: 有哪些相关研究?
A: 相关研究主要可以分为两大类:提高模型架构和注入额外知识。
提高模型架构:
- 早期的RRG研究基于CNN-RNN或CNN-LSTM架构。
- 最近的工作集中在基于CNN-Transformer架构的网络上进行改进。例如,CMN和MAN引入了跨模态记忆网络,XPRONET提出了跨模态原型驱动网络,METrans引入了多个可学习的“专家”标记。
- 为了捕捉放射图像的微妙差异,开发了多种注意力机制来增强报告生成中的特征鲁棒性,例如共同注意力机制、Ali-Transformer模型和跨模态对比注意力模型等。
注入额外知识:
- 这类工作探索注入额外知识,如疾病标签、检索报告和知识图,以协助报告生成。例如,PPKED结合异常发现、知识图和检索报告来模仿放射科医生的工作模式,KiUT通过注入知识蒸馏器整合视觉和上下文知识以及外部临床洞察来增强结果。
通过强化学习进行RRG:
- 将强化学习(RL)整合到RRG任务中,通过精心设计奖励的适当监督来增强报告生成能力。这些奖励通常基于自然语言生成(NLG)指标或语义相关性指标计算。
这些相关研究构成了自动放射报告生成领域的研究进展,并且本文提出的多目标偏好优化(MPO)方法在这些现有研究的基础上,尝试解决放射科医生偏好的多样性和多维性问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一种新的自动放射报告生成(RRG)方法,即多目标偏好优化(Multi-objective Preference Optimization, MPO),来解决放射科医生偏好的多样性和多维性问题。具体解决方案包括以下几个关键步骤:
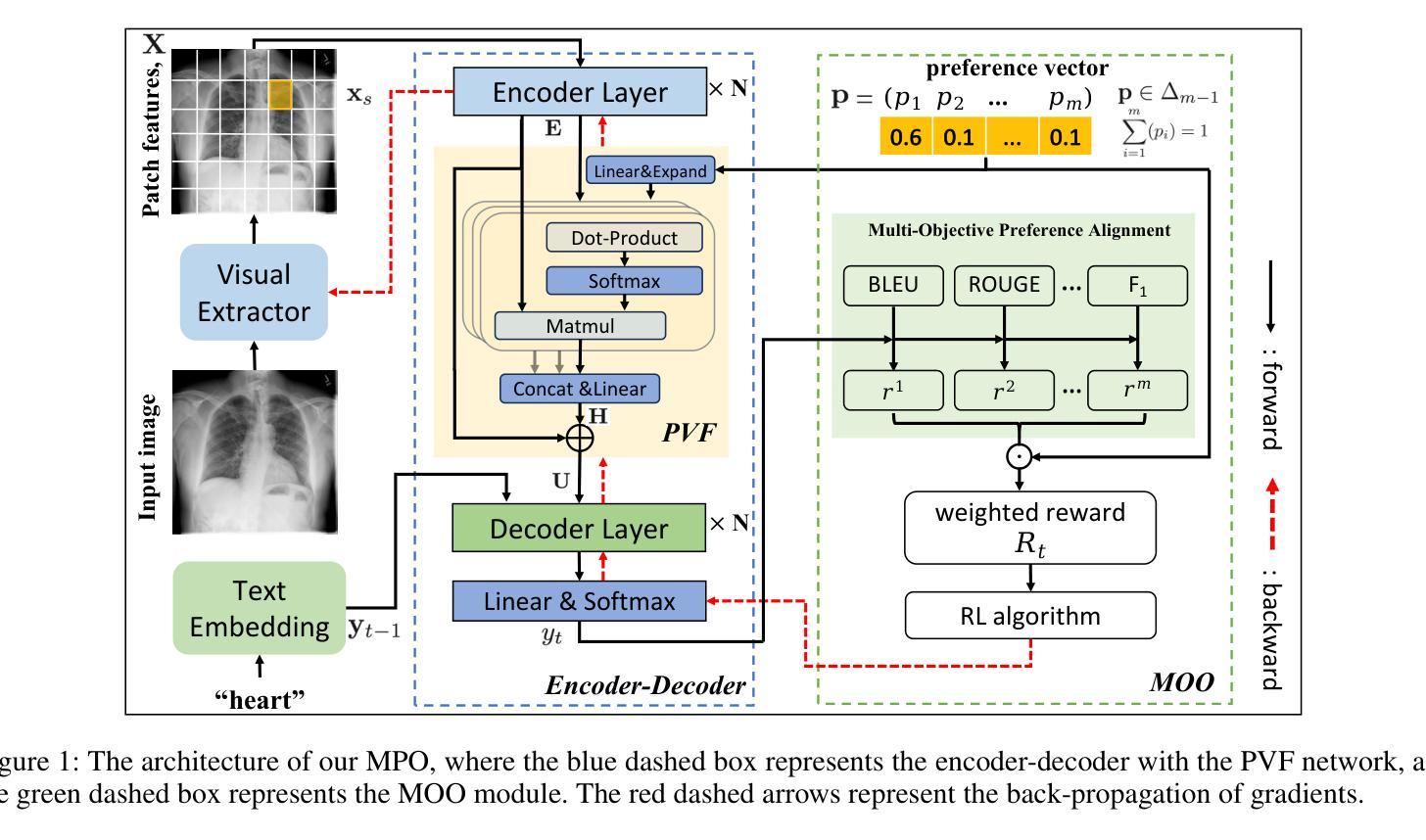
多目标偏好优化(MPO):
- 利用多维奖励函数和多目标强化学习(RL)来优化预训练的RRG模型,使其符合多种人类偏好。
偏好向量融合(Preference Vector Fusion, PVF)网络:
- 在标准的Transformer模型的编码器和解码器之间引入PVF网络,使用多头注意力机制和残差连接将偏好向量与编码的图像特征融合,实现条件生成。
多目标优化(MOO)模块:
- 使用偏好向量表示偏好的权重,并通过点积将多维奖励与偏好向量线性加权结合。
- 然后,使用RL优化加权后的多目标奖励函数,促使RRG模型与偏好向量对齐。
训练阶段:
- 在训练阶段,从偏好空间中随机采样多样化的偏好向量,并通过优化加权的多目标奖励函数来对齐模型,从而在整体偏好空间上获得最优策略。
推理阶段:
- 在推理阶段,给定一个偏好向量,模型可以生成符合特定偏好的报告,无需进一步微调。
实验验证:
- 通过在两个公共数据集上的广泛实验,验证所提方法可以在单一模型内迎合不同偏好,并实现最先进的性能。
通过这些步骤,论文提出的MPO方法能够使RRG模型适应不同放射科医生的偏好,同时保持生成报告的高质量,解决了放射科医生偏好的异质性和多维性问题。
Q: 论文做了哪些实验?
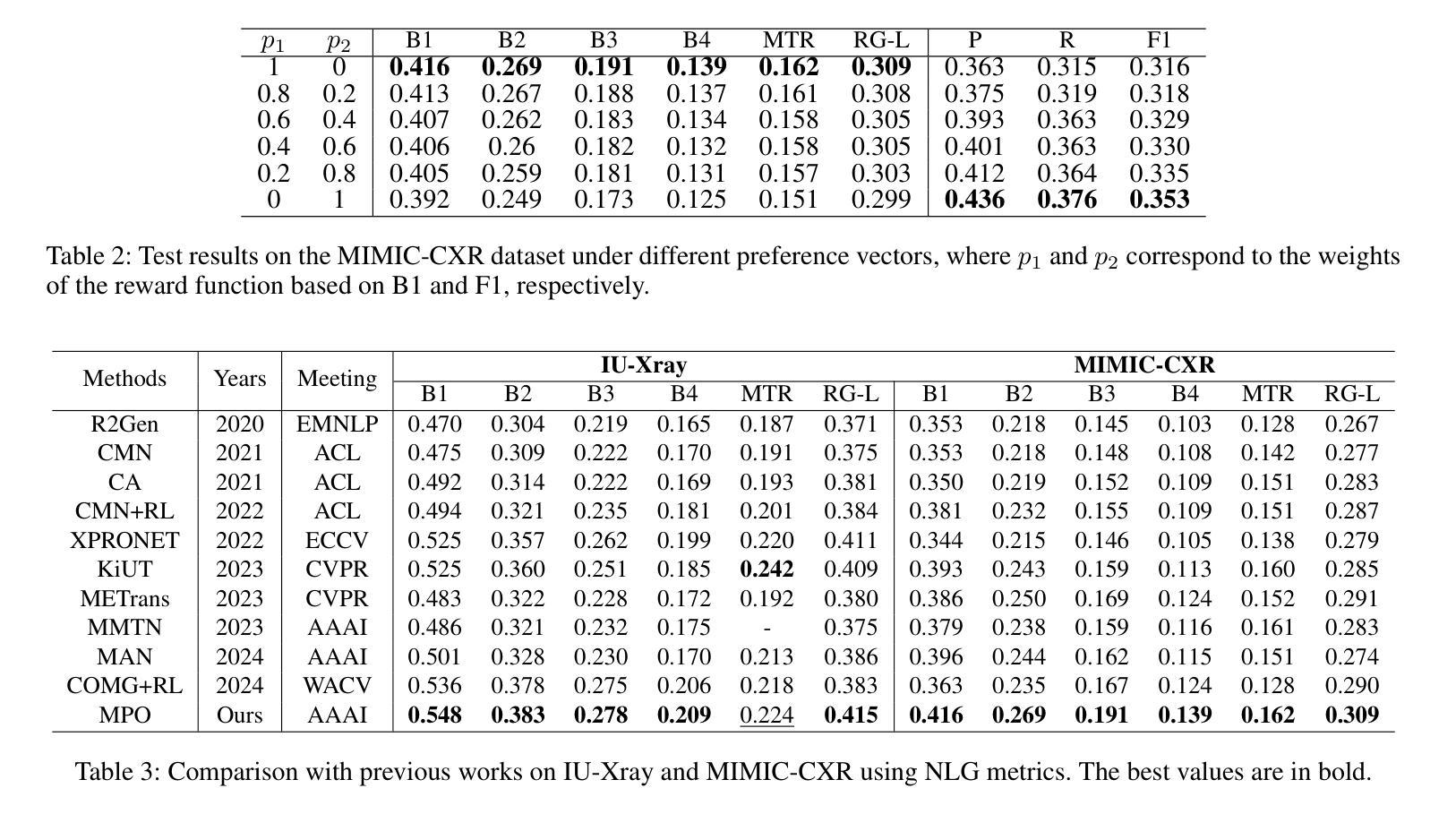
A: 论文中进行了以下实验来验证所提出的多目标偏好优化(MPO)方法的有效性:
数据集:
- IU-Xray:包含7,470张胸部X光图像和3,955份报告。
- MIMIC-CXR:包含337,110张胸部X光图像和227,835份相应的报告。
评估指标:
- 自然语言生成(NLG)指标:包括BLEU{1-4}、METOR和ROUGE-L,用于评估生成文本报告的质量。
- 临床效果(CE)指标:使用CheXbert标注14种医学报告中的观察结果,计算Precision(P)、Recall(R)和F1分数。
实现细节:
- 使用PyTorch实现,训练在NVIDIA 4090 GPU上进行。
- 使用预训练在ImageNet上的ResNet101作为视觉提取器,以及随机初始化的Transformer作为编码器-解码器模型。
- 使用Adam优化器进行训练,并包含宽度为3的beam search。
- 对于IU-Xray,最大报告长度设置为60个单词;对于MIMIC-CXR,最大长度设置为100个单词。
偏好指导的有效性:
- 在二维和三维偏好向量空间中测试模型,展示不同偏好向量配置下的测试结果,验证模型行为可以通过控制偏好向量来定制。
定性结果:
- 对MIMIC-CXR数据集进行定性分析,比较不同偏好配置下生成的报告与参考报告(GT)之间的差异。
与先前工作的比较:
- 将MPO方法与过去五年内的一系列最先进(SOTA)方法进行比较,包括R2Gen、CMN、CA、CMN+RL等,使用NLG和CE指标。
消融研究:
- 对MPO方法中的每个组件进行消融研究,包括基础模型(Base)、结合MOO模块的模型(Base+MOO)和完整模型(Base+MOO+PVF)。
融合方法:
- 探索不同的融合方法来融合偏好向量,包括连接(Concat)、加法(Add)和点乘(Mul)方法,并与PVF网络进行比较。
超参数分析:
- 对PVF网络中的超参数α进行分析,以确定其对模型性能的影响。
计算复杂性和效率分析:
- 对比不同方法在IU-Xray和MIMIC-CXR数据集上的参数数量、FLOPs、GPU内存使用情况以及训练/推理时间。
这些实验全面地评估了MPO方法在自动放射报告生成任务中的性能,并与现有技术进行了比较,证明了其在迎合不同放射科医生偏好的同时,能够生成更高质量的报告。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
新的评价指标作为奖励函数:
- 论文提到在未来的工作中,将探索设计新的评价指标作为偏好对齐的奖励函数。这可能包括更精细的临床准确性指标或考虑医生反馈的个性化指标。
偏好学习的自动化:
- 研究如何自动学习和调整偏好向量,以更好地适应不同放射科医生的偏好,而无需手动配置。
多模态学习:
- 进一步探索如何结合图像、文本和其他医疗数据(如患者历史数据)来生成更准确的报告。
模型的可解释性和透明度:
- 提高模型的可解释性,让医生能够理解模型生成报告的依据,增加其信任度和接受度。
跨领域适应性:
- 研究模型在不同类型的放射图像(如CT、MRI)和不同身体部位(如头部、腹部)的适应性和泛化能力。
实时性能优化:
- 探索如何优化模型以满足实时或近实时的临床需求,特别是在大规模应用中。
模型鲁棒性测试:
- 对模型进行压力测试和鲁棒性评估,确保在面对异常、模糊或不完整数据时仍能生成准确报告。
多语言和跨文化适应性:
- 研究模型在不同语言和文化背景下的适用性,为全球医疗环境提供支持。
集成更多临床知识:
- 通过集成更丰富的医学知识(如解剖学、病理学知识)来提升报告的深度和准确性。
模型压缩和优化:
- 研究如何压缩和优化模型,以便于在资源受限的医疗环境中部署。
用户研究和临床试验:
- 进行用户研究和临床试验,收集医生和患者的反馈,以改进模型的实际应用效果。
这些探索点可以帮助推动自动放射报告生成技术的发展,提高其在实际医疗场景中的应用价值。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 自动化放射报告生成(RRG)旨在减轻放射科医生的工作负担,但现有方法可能无法很好地符合放射科医生的个性化偏好,这些偏好是异质和多维的。
研究目标:
- 提出一种新的RRG方法,通过多目标偏好优化(MPO)来调整预训练的RRG模型,使其能够符合多个人类的偏好。
方法论:
- 提出了包含两个新模块的MPO方法:偏好向量融合(PVF)网络和多目标优化(MOO)模块。
- PVF网络使用多头注意力机制和残差连接将偏好向量与编码的图像特征融合,实现条件生成。
- MOO模块通过偏好向量加权多维奖励,并使用强化学习(RL)优化加权奖励函数,以对齐模型与偏好。
训练和推理:
- 在训练阶段,从偏好空间中随机采样多样化的偏好向量,并通过优化加权的多目标奖励函数来对齐模型。
- 在推理阶段,模型可以根据给定的偏好向量生成符合特定偏好的报告,无需进一步微调。
实验验证:
- 在两个公共数据集IU-Xray和MIMIC-CXR上进行了广泛的实验,验证了所提方法可以在单一模型内迎合不同偏好,并实现最先进的性能。
主要贡献:
- 提出了一种新的RRG方法,首次将人类偏好与RRG模型对齐作为一个多目标优化强化学习问题。
- 提出了PVF模块,使用注意力机制和残差连接融合编码图像特征与偏好向量。
- 证明了所提方法能够在不同偏好下生成报告,无需进一步微调,并且在两个公共数据集上实现了最佳性能。
未来工作:
- 探索设计新的评价指标作为偏好对齐的奖励函数。
综上所述,论文通过提出一种新的多目标偏好优化方法,有效地解决了放射科医生在自动放射报告生成中的个性化偏好问题,并在实验中验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



Beyond Knowledge Silos: Task Fingerprinting for Democratization of Medical Imaging AI
Authors:Patrick Godau, Akriti Srivastava, Tim Adler, Lena Maier-Hein
The field of medical imaging AI is currently undergoing rapid transformations, with methodical research increasingly translated into clinical practice. Despite these successes, research suffers from knowledge silos, hindering collaboration and progress: Existing knowledge is scattered across publications and many details remain unpublished, while privacy regulations restrict data sharing. In the spirit of democratizing of AI, we propose a framework for secure knowledge transfer in the field of medical image analysis. The key to our approach is dataset “fingerprints”, structured representations of feature distributions, that enable quantification of task similarity. We tested our approach across 71 distinct tasks and 12 medical imaging modalities by transferring neural architectures, pretraining, augmentation policies, and multi-task learning. According to comprehensive analyses, our method outperforms traditional methods for identifying relevant knowledge and facilitates collaborative model training. Our framework fosters the democratization of AI in medical imaging and could become a valuable tool for promoting faster scientific advancement.
医学影像人工智能领域目前正在经历快速变革,方法论研究正越来越多地转化为临床实践。尽管取得了这些成功,但由于知识孤岛的存在阻碍了协作和进步,研究工作仍面临挑战:现有知识散见于出版物中,许多细节尚未公布,隐私法规限制了数据共享。本着人工智能民主化的精神,我们提出了医学影像分析领域的安全知识转移框架。我们的方法的关键在于数据集“指纹”,即特征分布的结构化表示,这使我们能够量化任务相似性。我们通过迁移神经网络架构、预训练、增强策略和多任务学习,在71个不同任务和12种医学影像模式上测试了我们的方法。综合分析表明,我们的方法优于传统方法,能更有效地识别相关知识,促进模型协作训练。我们的框架推动了医学影像人工智能的民主化,并可能成为促进科学快速进步的有价值的工具。
论文及项目相关链接
Summary
医学成像人工智能领域正在经历快速变革,虽然方法论研究越来越多地应用于临床实践,但知识孤岛问题阻碍了协作和进步。为此,我们提出了一个安全的医学图像分析知识转移框架。关键方法是使用数据集“指纹”,即特征分布的结构化表示,以量化任务相似性。我们在不同的任务和医学成像模态上测试了这种方法,并取得了卓越的分析效果,为相关的知识识别提供了更高效的方法,促进了模型协同训练。该框架有助于推动医学成像领域的AI民主化,成为促进科学快速进步的重要工具。
Key Takeaways
- 医学成像AI领域正在迅速发展,并越来越多地应用于临床实践。
- 当前研究面临知识孤岛问题,限制了协作和进步。
- 提出了一种新的安全知识转移框架,用于医学图像分析领域。
- 关键方法包括使用数据集“指纹”即特征分布的结构化表示来量化任务相似性。
- 在不同的任务和医学成像模态上进行了测试,验证了该方法的有效性。
- 该方法超越了传统方法,在识别相关知识和促进模型协同训练方面表现出优势。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是医学影像人工智能(AI)领域中的知识孤岛问题。具体来说,论文指出了以下几个关键问题:
知识分散和隐私限制:在医学影像AI领域,由于隐私法规和数据共享限制,研究成果和知识常常分散在各种出版物中,许多细节未被公开,导致难以有效利用已有的研究成果。
数据孤岛:由于严格的隐私法规和高昂的标注成本,研究人员倾向于建立独立的私有数据集,导致知识被局限在个别研究者和实验室中,阻碍了科学进步和合作。
知识转移的挑战:选择合适的预训练模型、数据增强策略和神经网络架构对于新任务来说是一个耗时的过程,而且存在选择不恰当源任务导致的负面转移风险。
任务匹配的效率和隐私:在进行知识转移时,需要一种有效的方法来匹配源任务和目标任务,同时要考虑到数据隐私保护和计算复杂性。
为了解决这些问题,论文提出了一种名为“任务指纹”(task fingerprinting)的框架,旨在通过安全的知识转移促进AI在医学影像领域的民主化。该框架通过创建数据集的“指纹”——结构化的特征分布表示——来量化任务之间的相似性,从而实现知识的共享和转移,同时遵守隐私法规。
Q: 有哪些相关研究?
A: 论文中提到了多个与任务指纹和知识转移相关的研究工作,以下是一些主要的相关研究:
Transfer Learning: 论文提到了Transfer Learning的概念,可以追溯到1970年代,涉及从源任务到目标任务的知识转移。特别提到了预训练在大规模数据集上的模型,如ImageNet [2],作为加速模型收敛的常用实践。
Task Transferability Estimation (TTE): 论文讨论了TTE的研究,旨在量化任务之间知识转移的潜力。提到了一些关键的研究工作,例如:
- [9] Achille et al. 提出了学习任务的信息复杂性、它们的结构和它们之间的距离。
- [10] Ben-David et al. 分析了领域适应中的表示。
- [16] Molina-Moreno et al. 自动化选择用于生物医学成像的带注释预训练数据库。
- [17] Ramtoula et al. 提出了Visual DNA (VDNA),用于表示和比较图像。
Knowledge Transfer in Medical Imaging: 论文中提到了在医学影像领域内进行知识转移的研究,强调了将通用模型适应到特定下游任务的挑战:
- [6] Raghu et al. 讨论了医学影像中的迁移学习。
- [26] Godau et al. 提出了一种用于生物医学图像分析中的元学习的任务指纹方法。
Automated Machine Learning (AutoML): 论文提到了AutoML,旨在自动化机器学习算法的配置,包括数据预处理、特征工程和超参数优化。这与任务指纹的目标相似,即通过解决ML中的复杂步骤来实现AI的民主化。
Federated Learning: 论文讨论了Federated Learning作为一种保护数据隐私的协作学习方法,但也提到了它在同步、信任建立和准备方面的额外负担。
Foundation Models: 论文提到了最近出现的Foundation Models,这些模型通过大规模预训练可能弥合医学影像中不同模态之间的差距。
这些研究为任务指纹框架提供了理论基础和实践案例,展示了在医学影像AI领域中进行有效知识转移的潜力和挑战。论文通过与这些相关研究的比较,展示了其提出方法的优势和创新点。
Q: 论文如何解决这个问题?
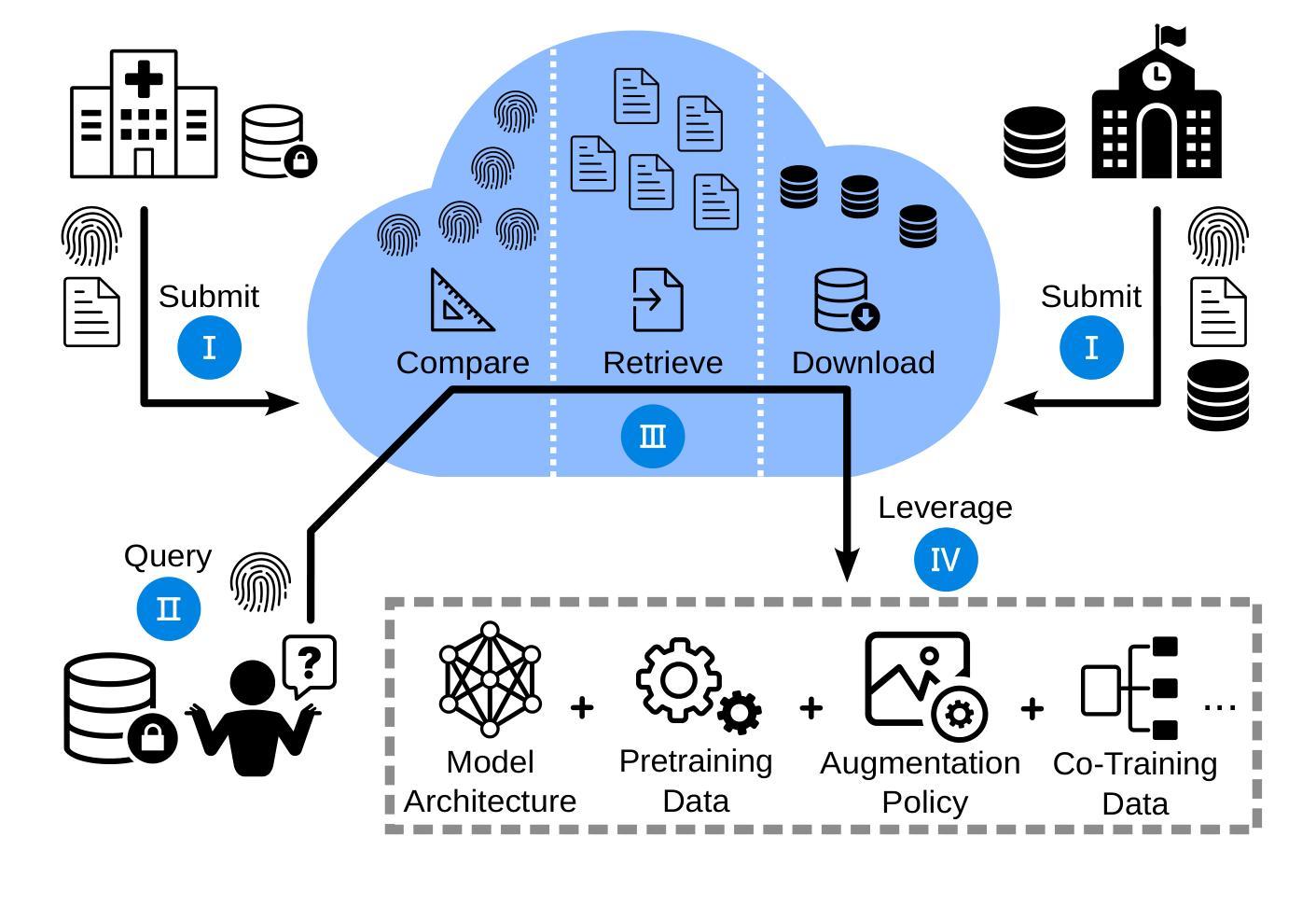
A: 论文提出了一个名为“任务指纹”(task fingerprinting)的框架来解决医学影像AI领域中的知识孤岛问题。具体来说,该框架通过以下几个步骤实现知识的安全转移和协作:
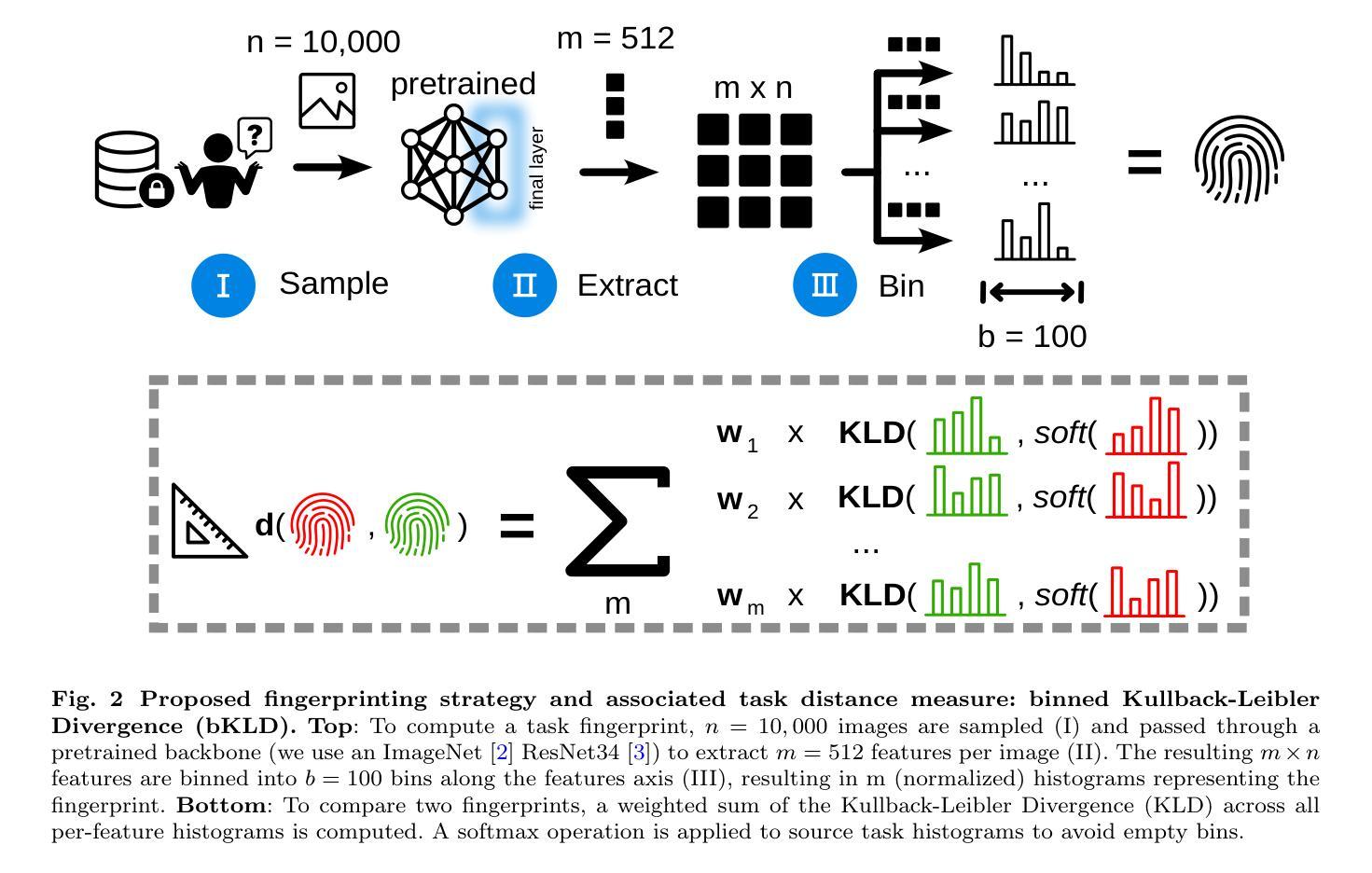
1. 任务指纹的创建
- 核心思想:任务指纹是从数据集中提取的、能够代表该任务特征的结构化表示。这些指纹能够在不泄露隐私的情况下捕捉任务的关键信息。
- 方法:通过将大量图像样本通过预训练的神经网络(如ResNet34)提取特征,然后将这些特征值分配到均匀的箱子(bins)中,形成特征分布直方图。这些直方图构成了任务的指纹。
2. 知识云(Knowledge Cloud)
- 概念:知识云是一个存储模型训练经验和底层数据封装表示(即任务指纹)的平台。贡献者可以提交训练元信息和选择性共享底层数据。
- 查询和利用:用户可以通过生成自己任务的指纹来查询知识云,检索与自己任务最相关的训练策略和数据。
3. 任务距离度量(binned Kullback-Leibler Divergence, bKLD)
- 计算方法:提出了一种新的基于binning提取图像特征的任务距离度量方法,称为binned Kullback-Leibler Divergence(bKLD)。该方法通过计算两个任务指纹之间的Kullback-Leibler Divergence(KLD)的加权和来衡量任务之间的相似度。
- 优势:bKLD方法在计算效率和泛化能力方面表现出色,适用于不同的知识转移场景。
4. 知识转移场景
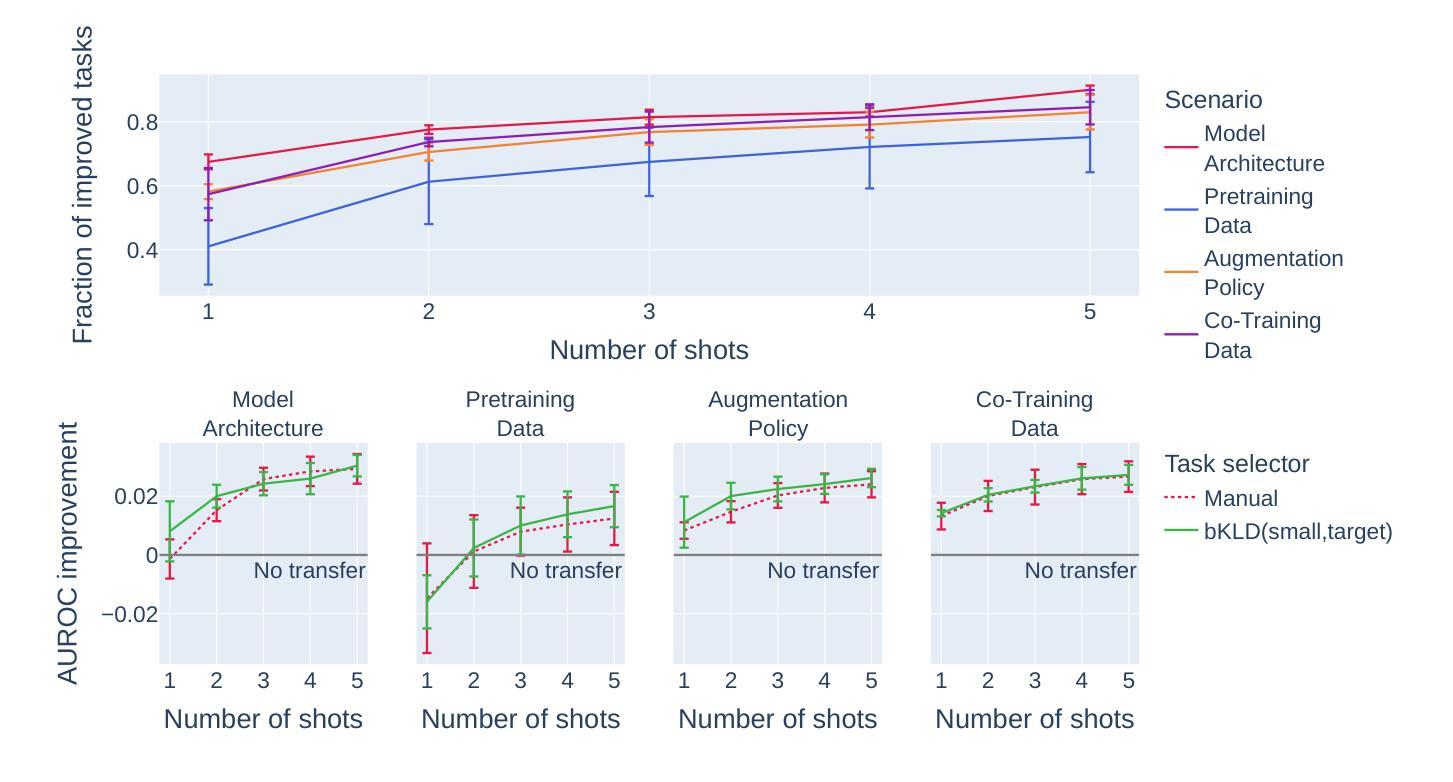
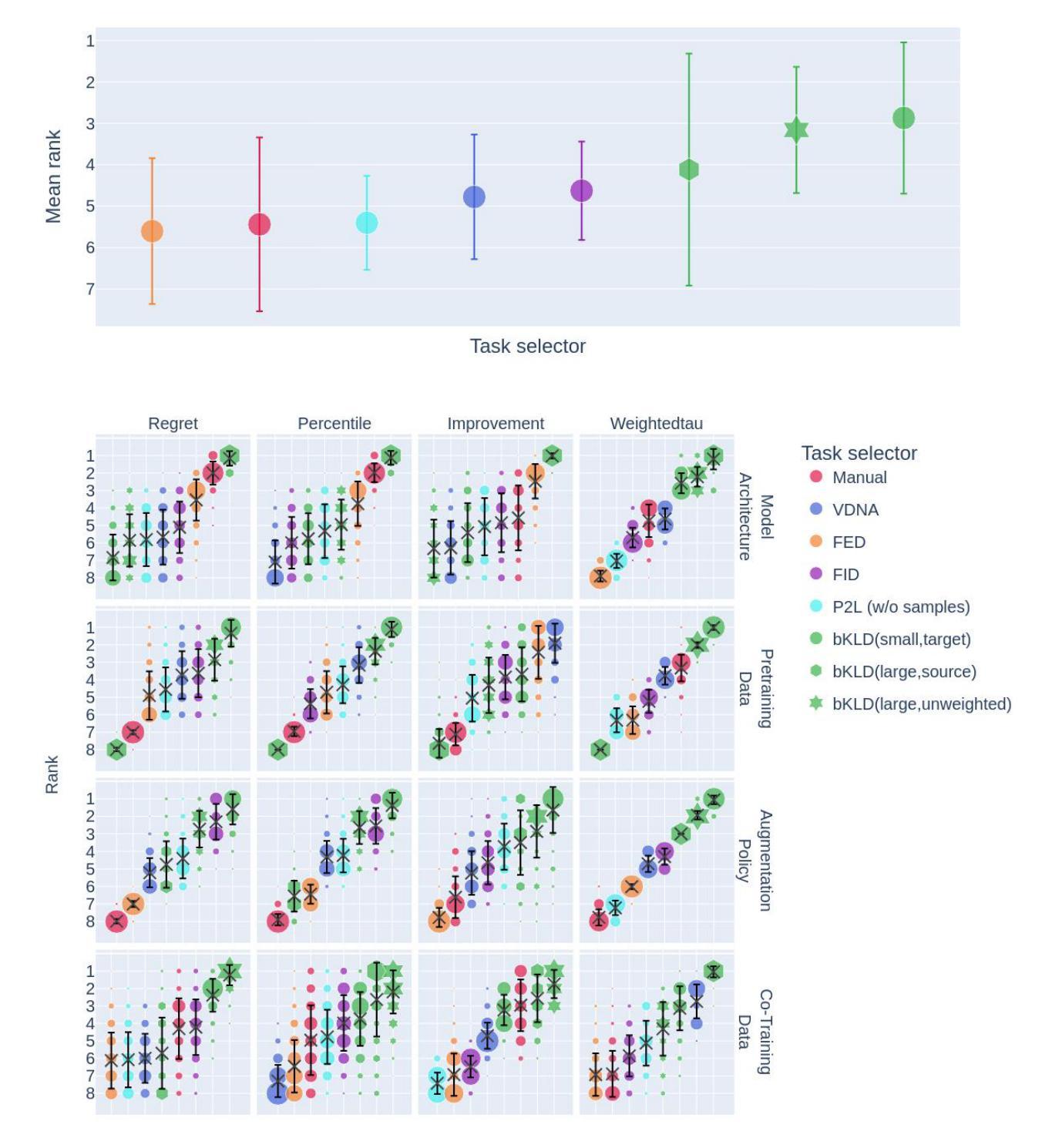
- 多样化应用:论文测试了四种不同的知识转移场景,包括模型架构转移、预训练数据、增强策略和共同训练数据,以验证任务指纹方法的有效性。
5. 实验验证
- 大规模实验:在71个不同的任务和12种医学影像模态上进行了实验,验证了该方法在异构任务集合上的有效性。
- 性能提升:通过与传统方法比较,证明了任务指纹方法在识别相关知识和促进协作模型训练方面的优势。
6. 开源和数据共享
- 代码和数据:论文提供了实验的代码、数据和中间结果,以促进社区的进一步研究和开发。
通过这种方法,论文旨在促进AI在医学影像领域的民主化,通过共享知识来加速科学进步,同时遵守数据隐私法规。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的任务指纹框架的有效性,具体实验包括:
1. 实验设置
- 任务池构建:作者收集了71个不同的、公开可用的数据集,覆盖了多种医学影像模态,以确保方法的广泛适用性。
- 任务分割:每个任务被分为训练集和测试集,比例为80:20,并确保类别分布均匀。
- 预处理:所有图像被处理为统一的分辨率(256×256像素),灰度图像被转换为RGB格式。
2. 知识转移场景设计
作者设计了四种知识转移场景,以覆盖不同的应用情况:
场景1:模型架构转移
- 使用源任务中表现最佳的神经网络架构来训练目标任务。
场景2:预训练数据
- 在源任务上预训练模型,然后在目标任务上进行微调。
场景3:增强策略
- 将源任务中自动学习到的数据增强策略应用到目标任务上。
场景4:共同训练数据
- 同时训练源任务和目标任务,共享神经网络的主干部分,但使用独立的分类头。
3. 单任务基线
- 作为对比,作者还训练了所有目标任务的“无转移”模型,以模拟在没有额外实验资源投入的情况下的模型性能。
4. 评估指标
- 使用平衡准确率(Balanced Accuracy, BA)和宏平均接收者操作特征曲线下面积(macro averaged Area Under the Receiver Operating Characteristic, AUROC)作为主要的性能评估指标。
5. 元指标
- 为了评估任务选择器的质量,作者使用了多种元指标,包括改进度量、百分位数、遗憾度量和增益度量。
6. 实验执行
- 作者训练了超过30,000个神经网络模型,仅用于评估部分,大约消耗了10,000 GPU小时的训练资源。
7. 与现有方法的比较
- 作者将提出的binned Kullback-Leibler Divergence(bKLD)任务距离度量与其他几种现有的任务相似性度量方法进行了比较,包括VisualDNA(VDNA)、Predict To Learn(P2L)、Fisher Embedding Distance(FED)和Fréchet Inception Distance(FID)。
8. 鲁棒性测试
- 作者还测试了不同任务大小对任务指纹方法的影响,以验证其在小样本情况下的鲁棒性。
这些实验全面地验证了任务指纹框架在不同知识转移场景下的有效性和鲁棒性,并与现有的方法进行了比较,展示了其在医学影像AI领域中的潜力。
Q: 有什么可以进一步探索的点?
A: 论文提出了任务指纹框架来促进医学影像AI领域的知识转移和合作,尽管取得了一定的成果,但仍有一些方面可以进一步探索和研究:
1. 多模态数据集成
- 论文中提到了将不同模态的数据集成到指纹中的潜力,这可以作为未来工作的一个方向,特别是在医学影像领域,多模态数据的融合对于提高诊断的准确性和鲁棒性具有重要意义。
2. 知识云的实施
- 实际部署一个知识云平台,以便于跨机构研究和知识共享。这需要解决技术、法律和伦理等方面的问题。
3. 扩展任务类型和数量
- 论文中的实验主要基于分类任务,未来可以探索其他类型的任务(如分割、检测等)以及更多的目标任务,以进一步验证框架的泛化能力。
4. 纠缠转移场景
- 论文中对每个转移场景进行了单独的实验,未来可以探索同时转移多个组件(例如,同时进行预训练和数据增强)的效果。
5. 自动化和智能化的任务指纹生成
- 研究如何自动化和智能化地生成和优化任务指纹,以减少手动调整和实验的需求。
6. 恶意数据的预防措施
- 在公开设置中,系统可能面临恶意行为者提交虚假数据的风险,需要开发有效的预防和检测机制。
7. 跨领域的知识转移
- 探索任务指纹框架在非医学影像领域的应用,例如自然语言处理或语音识别,验证其跨领域的有效性。
8. 环境影响和能源消耗
- 考虑到训练大量模型对环境的影响,研究如何通过知识转移减少模型训练的能源消耗和碳足迹。
9. 持续学习和知识增长
- 探索如何利用任务指纹框架实现持续学习和知识增长,自动地从新数据和任务中学习,提高AI系统的长期可扩展性。
10. 与其他AI技术的集成
- 研究如何将任务指纹框架与其他AI技术(如联邦学习、自动化机器学习AutoML)集成,以提高整体系统的效率和效果。
这些方向不仅可以推动任务指纹框架的发展,还可能对医学影像AI乃至整个人工智能领域产生深远的影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为“任务指纹”(task fingerprinting)的框架,旨在解决医学影像人工智能(AI)领域中的知识孤岛问题,并促进知识的安全转移和合作。以下是论文的主要内容总结:
1. 问题识别
- 医学影像AI领域存在知识分散和数据隐私问题,限制了数据共享和研究合作。
- 缺乏有效的方法来量化任务之间的相似性,阻碍了知识的转移和模型训练的最佳实践的复用。
2. 任务指纹框架
- 提出了任务指纹的概念,即结构化的特征分布表示,用于捕捉任务的关键信息并量化任务相似性。
- 通过比较任务指纹,可以识别出与新任务最相关的现有知识和数据,以促进模型训练。
3. 知识云
- 建立了一个名为知识云的平台,存储模型训练经验和数据的封装表示,允许用户提交和查询相关知识和数据。
4. binned Kullback-Leibler Divergence (bKLD)
- 开发了一种新的任务距离度量方法bKLD,通过计算任务指纹之间的Kullback-Leibler Divergence来衡量任务相似度。
- bKLD考虑了特征值的分布,允许灵活的权重调整,以适应不同的知识转移场景。
5. 实验验证
- 在71个不同任务和12种医学影像模态上进行了实验,测试了模型架构、预训练数据、增强策略和共同训练数据四种知识转移场景。
- 实验结果表明,任务指纹方法在识别相关知识和促进协作模型训练方面优于传统方法。
6. 开源和数据共享
- 提供了实验的代码、数据和中间结果,以促进社区的进一步研究和开发。
7. 未来研究方向
- 提出了未来可能的研究方向,包括多模态数据集成、知识云的实施、扩展任务类型和数量等。
总体而言,这篇论文提出了一个创新的框架,通过任务指纹和知识云促进医学影像AI领域的知识共享和合作,有望加速科学进步并提高模型训练的效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Ultrafast dynamic Coulomb screening of X-ray core excitons in photoexcited semiconductors
Authors:Thomas C. Rossi, Lu Qiao, Conner P. Dykstra, Ronaldo Rodrigues Pela, Richard Gnewkow, Rachel F. Wallick, John H. Burke, Erin Nicholas, Anne-Marie March, Gilles Doumy, D. Bruce Buchholz, Christiane Deparis, Jesus Zuñiga-Pérez, Michael Weise, Klaus Ellmer, Mattis Fondell, Claudia Draxl, Renske M. van der Veen
Ultrafast X-ray spectroscopy has been revolutionized in recent years due to the advent of fourth-generation X-ray facilities. In solid-state materials, core excitons determine the energy and line shape of absorption features in core-level spectroscopies such as X-ray absorption spectroscopy. The screening of core excitons is an inherent many-body process that can reveal insight into charge-transfer excitations and electronic correlations. Under non-equilibrium conditions such as after photoexcitation, however, core-exciton screening is still not fully understood. Here we demonstrate the dynamic Coulomb screening of core excitons induced by photoexcited carriers by employing X-ray transient absorption (XTA) spectroscopy with picosecond time resolution. Our interpretation is supported by state-of-the-art ab initio theory, combining constrained and real-time time-dependent density functional theory with many-body perturbation theory. Using ZnO as an archetypal wide band-gap semiconductor, we show that the Coulomb screening by photoexcited carriers at the Zn K-edge leads to a decrease in the core-exciton binding energy, which depends nonlinearly on both the excitation density and the distribution of photoexcited carriers in reciprocal space. The effect of Coulomb screening dominates over Pauli blocking in the XTA spectra. We show that dynamic core-exciton screening is also observed at other X-ray absorption edges and theoretically predict the effect of core-exciton screening on the femtosecond time scale for the case of ZnO, a major step towards hard X-ray excitonics. The results have implications for the interpretation of ultrafast X-ray spectra in general and their use in tracking charge carrier dynamics in complex materials on atomic length scales.
近年来,由于第四代X射线设施的出现,超快X射线光谱技术发生了革命性的变革。在固态材料中,核心激子决定了核心能级光谱(如X射线吸收光谱)中的能量和谱线形状。核心激子的筛选是一种固有的多体过程,可以揭示电荷转移激发和电子关联性的洞察。然而,在非平衡态条件下,例如光激发后,核心激子筛选尚未完全理解。在这里,我们采用具有皮秒时间分辨率的X射线瞬态吸收(XTA)光谱技术,展示了由光激发载流子引起的核心激子的动态库仑筛选。我们的解释得到了最先进的从头计算理论的支持,该理论结合了约束和实时时间依赖密度泛函理论与多体扰动理论。我们以ZnO作为典型的宽禁带半导体为例,表明光激发载流子在Zn K边附近的库仑筛选导致核心激子结合能降低,这种降低非线性地取决于激发密度和光激发载流子在倒空间中的分布。库仑筛选效应在XTA光谱中占据主导地位,超过了泡利阻塞效应。我们证明了在其它X射线吸收边也观察到动态核心激子筛选,并对ZnO的情况进行了飞秒时间尺度上的核心激子筛选效应的理论预测,这是朝着硬X射线激子学迈出的重要一步。该研究结果对于解释超快X射线光谱的一般应用及其在原子尺度上跟踪复杂材料中的电荷载流子动力学具有重要意义。
论文及项目相关链接
PDF 43 pages, 37 figures
摘要
新一代第四代X射线设施的出现彻底改变了超快X射线光谱学。在固态材料中,核心激子的能量和光谱吸收特征线型由核心能级光谱(如X射线吸收光谱)决定。核心激子的屏蔽作用是一种固有的多体过程,能够揭示电荷转移激发和电子关联性的见解。然而,在光激发后的非平衡条件下,核心激子屏蔽作用尚未完全理解。本文通过采用具有皮秒时间分辨率的X射线瞬态吸收光谱法(XTA),展示了光激发载流子诱导的核心激子动态库仑屏蔽作用。我们的解释得到了最先进的从头计算理论的支持,该理论结合了约束和实时时间依赖密度泛函理论与多体扰动理论的计算。以ZnO作为典型的宽禁带半导体为例,我们表明光激发载流子在Zn K边缘的库仑屏蔽作用导致核心激子结合能降低,这种降低与激发密度和光激发载流子在倒数空间中的分布呈非线性关系。库仑屏蔽作用在XTA光谱中占据主导地位,超过了泡利阻塞效应。我们证明了动态核心激子屏蔽作用也出现在其他X射线吸收边缘,并对ZnO的情况预测了飞秒时间尺度上的核心激子屏蔽作用的影响,这是朝着硬X射线激子学的重要一步。该研究结果对于解释超快X射线光谱的通用性及其在复杂材料中原子的电荷载流子动力学的追踪应用具有重要影响。
关键见解
- 第四代X射线设施的发展彻底改变了超快X射线光谱学的研究。
- 核心激子在固态材料的X射线光谱中起到关键作用,其屏蔽作用是一个多体过程。
- 通过X射线瞬态吸收光谱法,观察到光激发载流子对核心激子的动态库仑屏蔽作用。
- 库仑屏蔽效应在XTA光谱中比泡利阻塞效应更为显著。
- 动态核心激子屏蔽作用在其他X射线吸收边缘也被观察到。
- 以ZnO为例,预测了核心激子屏蔽作用在飞秒时间尺度上的影响。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在光激发半导体中,X射线核心激发态(core excitons)的超快动态库仑屏蔽效应。具体来说,论文试图解决以下几个关键问题:
核心激发态的屏蔽机制:在非平衡条件下,例如光激发后,核心激发态的库仑屏蔽尚未被完全理解。论文通过实验和理论计算,揭示了光激发载流子对核心激发态屏蔽的影响。
超快X射线光谱学的应用:论文利用超快X射线光谱学(Ultrafast X-ray spectroscopy)来研究固体材料中的载流子动力学,特别是核心激发态的能量和线形变化。
多体效应对X射线吸收光谱的影响:论文探讨了在光激发条件下,多体效应(如库仑屏蔽和泡利阻塞)如何影响X射线吸收光谱(XAS)。
时间分辨光谱与理论模型的结合:通过结合实验和第一性原理理论计算,论文旨在提供对光激发半导体中核心激发态变化的深入理解,并预测这些效应在飞秒时间尺度上的行为。
硬X射线激子学的发展:论文的结果对硬X射线激子学领域具有重要意义,有助于开发新一代基于X射线的光电子器件。
总的来说,这篇论文试图通过实验和理论的结合,深入理解光激发半导体中核心激发态的动力学行为,并探索这些动力学过程对材料电子结构的影响。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究领域和具体文献:
超快X射线光谱学:这项技术在固体材料中用于探测载流子动力学和局部结构变化。相关文献包括[16] C. Rein 等人的工作,他们使用X射线光谱学研究了电荷密度动力学。
光激发半导体中的电子动力学:研究了载流子-载流子和载流子-声子相互作用,以及库仑屏蔽效应对半导体电子性质的影响。相关文献包括[1] R. Huber 等人的研究。
X射线吸收光谱(XAS):用于探测材料的电子和晶格结构,特别是在核心水平和未占据态密度之间的电子跃迁。相关文献包括[6] C. S. Schnohr 和 M. C. Ridgway 编辑的《X-Ray Absorption Spectroscopy of Semiconductors》。
多体微扰理论(MBPT)和贝特-萨佩特方程(BSE):用于精确描述电子激发态,包括电子-空穴相互作用。相关文献包括[24] G. Onida, L. Reining 和 A. Rubio 的综述文章。
光激发引起的集体扰动:研究了光激发引起的集体扰动在飞秒时间尺度上的动力学,这对于超快光电子学具有重要意义。相关文献包括[5] D. Zimin 等人的研究。
硬X射线激子学:探索了硬X射线范围内的激子动力学和操控,相关文献包括[83] A. Moulet 等人的工作。
时间分辨光发射光谱学:用于研究核心激发态的再规范化,如[68] M. Dendzik 等人的研究。
密度泛函理论(DFT)和时间依赖的密度泛函理论(TDDFT):用于计算材料的XAS光谱,相关文献包括[22] C. A. Ullrich 的书籍和[23] C. Pemmaraju 的综述文章。
ZnO材料的性质:ZnO作为一种重要的半导体材料,其光电性质被广泛研究,相关文献包括[38] K. S. Leschkies 等人的工作。
这些文献涵盖了从理论模型到实验技术,再到特定材料性质的广泛研究领域,为本论文的研究提供了理论和实验基础。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决光激发半导体中核心激发态的超快动态库仑屏蔽问题:
实验部分
超快X射线吸收光谱(XTA)测量:
- 使用皮秒和飞秒时间分辨的X射线吸收光谱(XAS)和X射线瞬态吸收(XTA)光谱技术来探测ZnO半导体材料中的核心激发态。
- 在Zn K边和L3边进行实验,以研究不同核心水平上的激发态动力学。
样品合成与表征:
- 通过脉冲激光沉积(PLD)和分子束外延(MBE)等方法合成ZnO薄膜样品,并使用X射线衍射(XRD)和光谱椭偏仪对其结构和光学性质进行表征。
温度依赖的XAS光谱测量:
- 测量不同温度下的XAS光谱,以分离热效应和非热效应对XTA光谱的贡献。
理论部分
第一性原理计算:
- 结合约束密度泛函理论(cDFT)和实时时间依赖的密度泛函理论(RT-TDDFT)以及贝特-萨佩特方程(BSE)来计算XAS光谱。
- 这些方法允许研究光激发载流子对核心激发态的多体相互作用的影响。
非平衡态的BSE计算:
- 将BSE扩展到非平衡态,考虑由泵浦脉冲产生的受限制的电子和空穴的占据情况。
- 分离多体相互作用为泡利阻塞和库仑屏蔽两部分,以研究它们对XTA光谱的贡献。
分析和解释实验数据:
- 将实验测量的XTA光谱与理论计算结果进行比较,以揭示光激发载流子如何影响核心激发态的动力学和能量变化。
结果与讨论
库仑屏蔽与泡利阻塞的影响:
- 发现库仑屏蔽是XTA光谱中的主导效应,而泡利阻塞的贡献相对较小。
- 库仑屏蔽导致核心激发态束缚能的降低,这取决于激发密度和光激发载流子在倒空间的分布。
飞秒时间尺度的动态库仑屏蔽:
- 预测在飞秒时间尺度上,ZnO中的核心激发态库仑屏蔽对XTA光谱的影响,为硬X射线激子学的发展提供了重要步骤。
建立新的实验和理论工具:
- 通过实验和理论的结合,建立了一种新的方法来追踪复杂材料中载流子动力学,为超快X射线光谱学的应用提供了新的视角。
综上所述,论文通过实验和理论的紧密结合,系统地研究了光激发半导体中核心激发态的超快动态库仑屏蔽效应,并揭示了其对材料电子结构的影响。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,实验部分包括以下几个方面:
1. X射线吸收光谱(XAS)和X射线瞬态吸收(XTA)光谱测量
- Zn K边实验:在Advanced Photon Source (APS)的7ID-D束线上进行,使用p极化的X射线,测量了ZnO薄膜在Zn K边的XAS和XTA光谱。
- Zn L3边实验:在BESSY II的UE52-SGM束线上进行,测量了ZnO薄膜在Zn L3边的XAS和XTA光谱。
2. 样品合成与表征
- ZnO薄膜合成:通过脉冲激光沉积(PLD)和分子束外延(MBE)或射频溅射方法生长ZnO薄膜。
- X射线衍射(XRD):用于检查ZnO薄膜的晶体取向。
- 光谱椭偏仪:用于确定ZnO薄膜的厚度和光学常数。
3. 温度依赖的XAS光谱测量
- 测量了不同温度(从室温到190°C)下ZnO薄膜的XAS光谱,以研究温度对XAS光谱的影响。
4. 激光激发实验
- 使用Nd:YVO4激光器(在Zn K边实验中)和Yb掺杂的混合光纤/晶体激光系统(在Zn L3边实验中)进行激光激发。
- 激光激发后,通过测量XAS和XTA光谱来研究光激发载流子对ZnO薄膜电子结构的影响。
5. 数据处理
- 对XAS和XTA光谱数据进行背景减除、边缘跳跃归一化和后边缘平坦化处理。
- 分离XTA光谱中的热和非热贡献,以研究光激发引起的电子结构变化。
这些实验综合了X射线光谱学、样品制备技术、温度控制实验和激光激发技术,旨在深入理解光激发半导体中核心激发态的动力学行为。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
不同材料体系的核心激发态动力学:
- 研究其他半导体材料或不同带隙材料中的核心激发态动力学,以了解这些现象是否具有普遍性。
飞秒时间尺度的动力学:
- 使用飞秒X射线源进一步探索光激发后立即发生的超快动力学过程,包括激发态的弛豫和能量转移。
多体效应的深入研究:
- 对泡利阻塞和库仑屏蔽等多体效应进行更深入的理论分析,以更好地理解它们在不同条件下的行为。
界面和异质结构中的动力学:
- 研究在半导体异质结构或界面处的核心激发态动力学,这些区域通常具有复杂的电子和结构特性。
光激发载流子的调控:
- 探索通过外部条件(如电场、应力或化学掺杂)调控光激发载流子的分布和动力学,以实现对核心激发态的精确控制。
硬X射线激子学的应用:
- 基于论文中发现的硬X射线核心激发态的调控机制,开发新型光电子器件,如超快光开关或高灵敏度探测器。
理论模型的改进和验证:
- 开发和测试更精确的理论模型,以更好地描述多体效应和非平衡态下的电子动力学。
实验技术的改进:
- 提高时间分辨X射线光谱学的时空分辨率,以便在更短的时间尺度和更小的空间尺度上观察电子动力学。
与超快光学光谱学的结合:
- 结合超快光学光谱学技术,如超快拉曼散射或超快荧光光谱学,以提供关于电子动力学和结构变化的互补信息。
材料的功能性研究:
- 研究核心激发态动力学对材料光电性能的影响,如载流子迁移率、光催化活性等,以指导新型功能材料的设计。
这些探索点可以帮助科学家更全面地理解光激发半导体中的复杂电子动力学,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了光激发半导体中X射线核心激发态的超快动态库仑屏蔽效应。以下是论文的主要内容总结:
研究背景与目的
- 超快X射线光谱学技术的发展使得研究固体材料中核心激发态的动力学成为可能。
- 核心激发态的库仑屏蔽是一个多体过程,与电荷转移激发和电子关联有关。
- 在非平衡条件下,如光激发后,核心激发态的库仑屏蔽尚未被充分理解。
实验方法
- 使用皮秒时间分辨的X射线瞬态吸收(XTA)光谱来研究ZnO半导体中的核心激发态。
- 结合温度依赖的X射线吸收光谱(XAS)来分离热和非热贡献。
- 在Zn K边和L3边进行实验,以研究不同核心水平上的激发态动力学。
理论方法
- 结合约束密度泛函理论(cDFT)和实时时间依赖的密度泛函理论(RT-TDDFT)以及贝特-萨佩特方程(BSE)来计算XAS光谱。
- 扩展BSE到非平衡态,考虑由泵浦脉冲产生的受限制的电子和空穴的占据情况。
- 分离多体相互作用为泡利阻塞和库仑屏蔽两部分,以研究它们对XTA光谱的贡献。
主要发现
- 光激发载流子对核心激发态的库仑屏蔽导致核心激发态束缚能的降低,这种效应与激发密度和光激发载流子在倒空间的分布有关。
- 库仑屏蔽效应在XTA光谱中占主导地位,而泡利阻塞的贡献相对较小。
- 动态核心激发态屏蔽也在其他X射线吸收边观察到,并且预测了在飞秒时间尺度上的核心激发态屏蔽效应。
意义与应用
- 这些结果对于解释超快X射线光谱以及它们在追踪复杂材料中载流子动力学方面的应用具有重要意义。
- 为硬X射线激子学的发展提供了重要的理论基础和实验数据。
总的来说,这篇论文通过实验和理论的结合,深入研究了光激发半导体中核心激发态的超快动态库仑屏蔽效应,并揭示了其对材料电子结构的影响,为相关领域的研究和应用提供了新的视角和工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

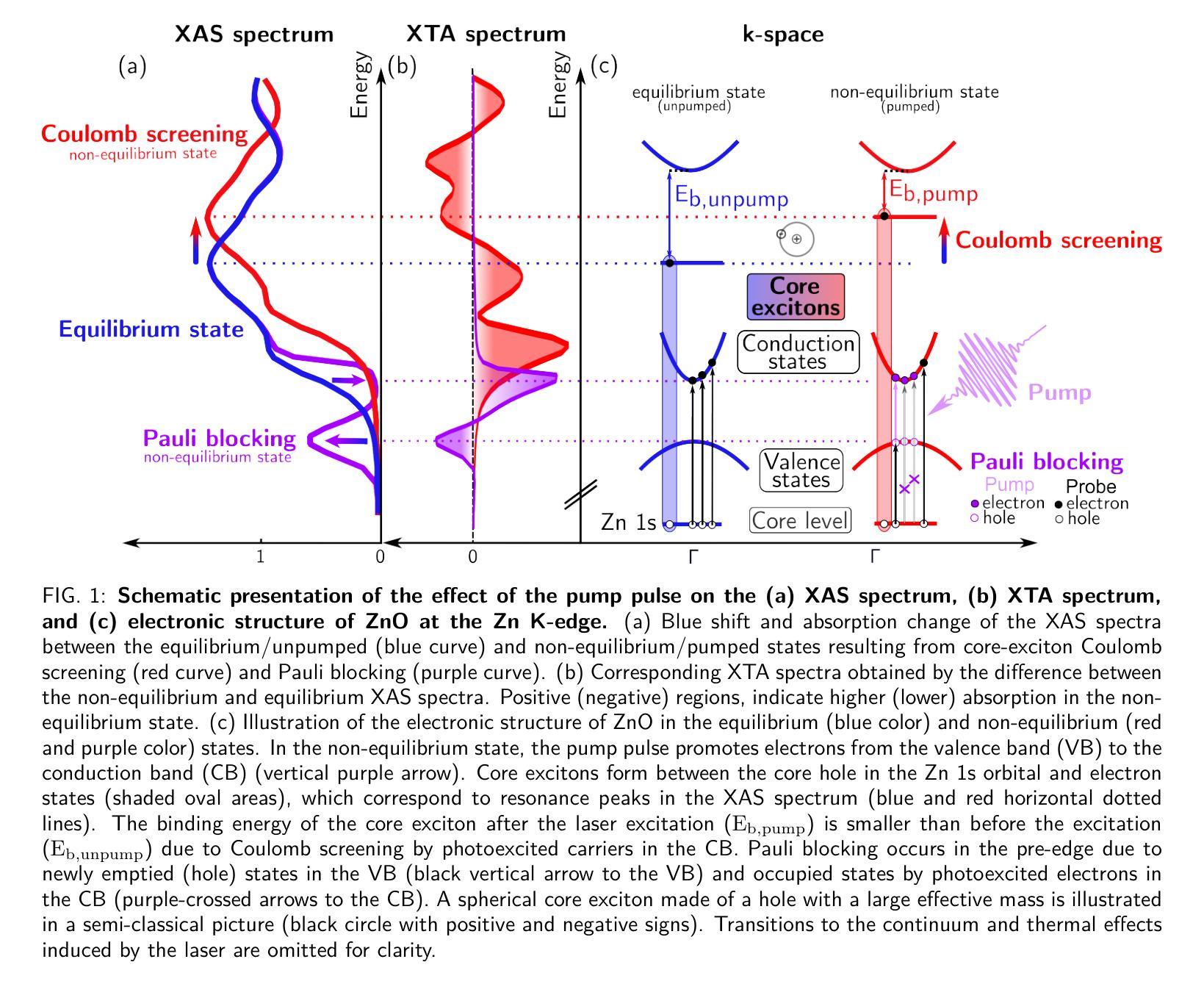
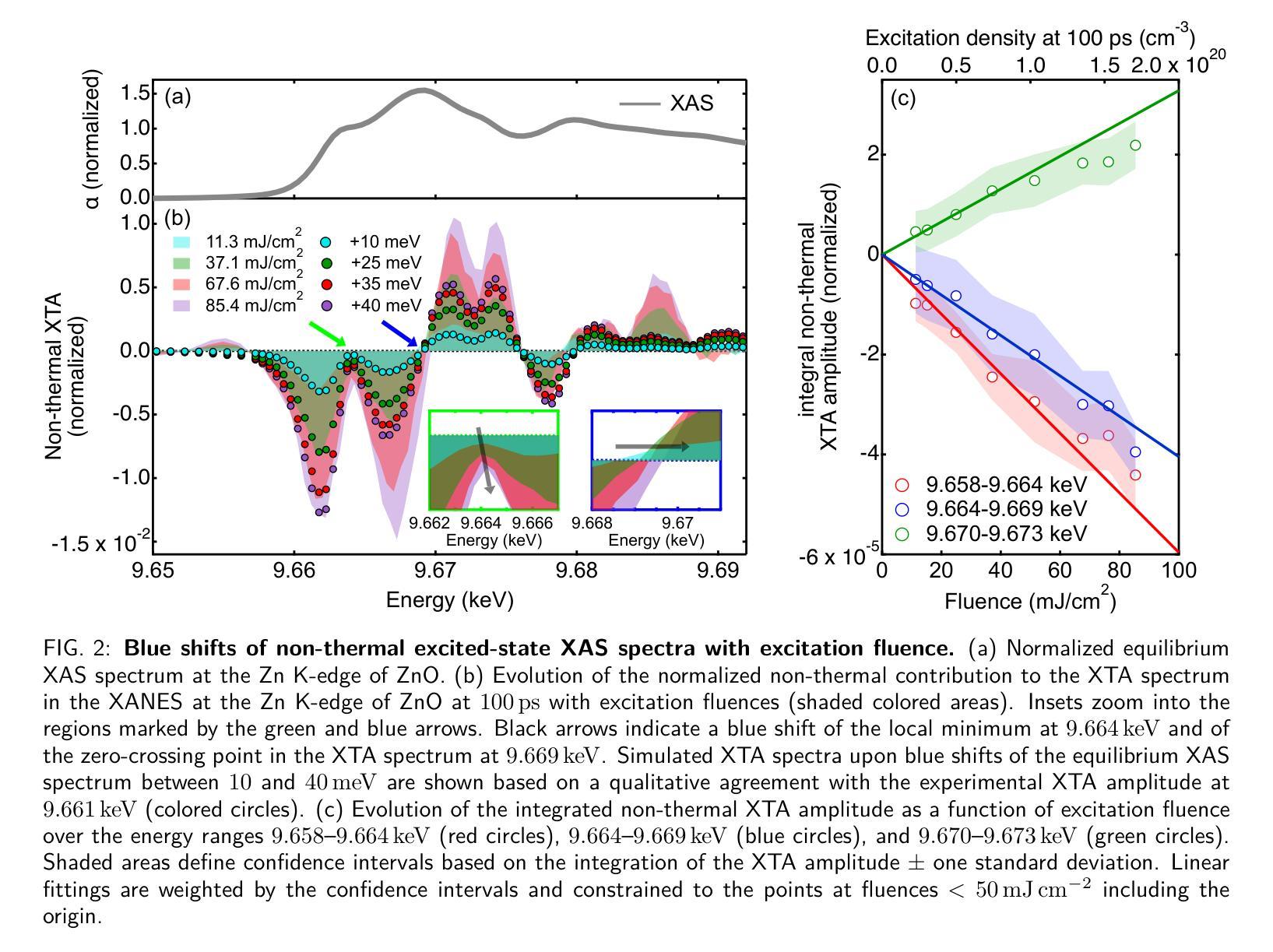
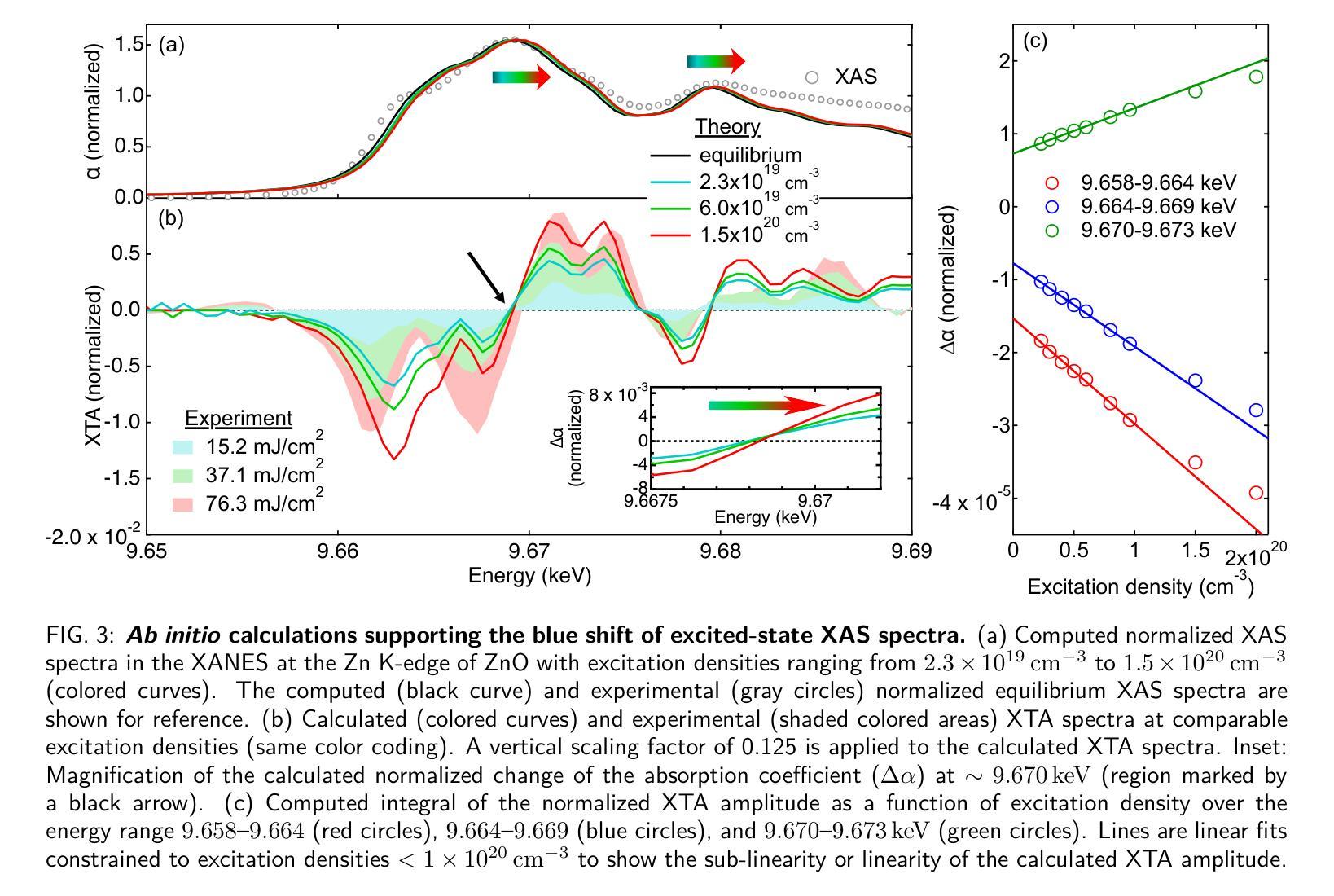
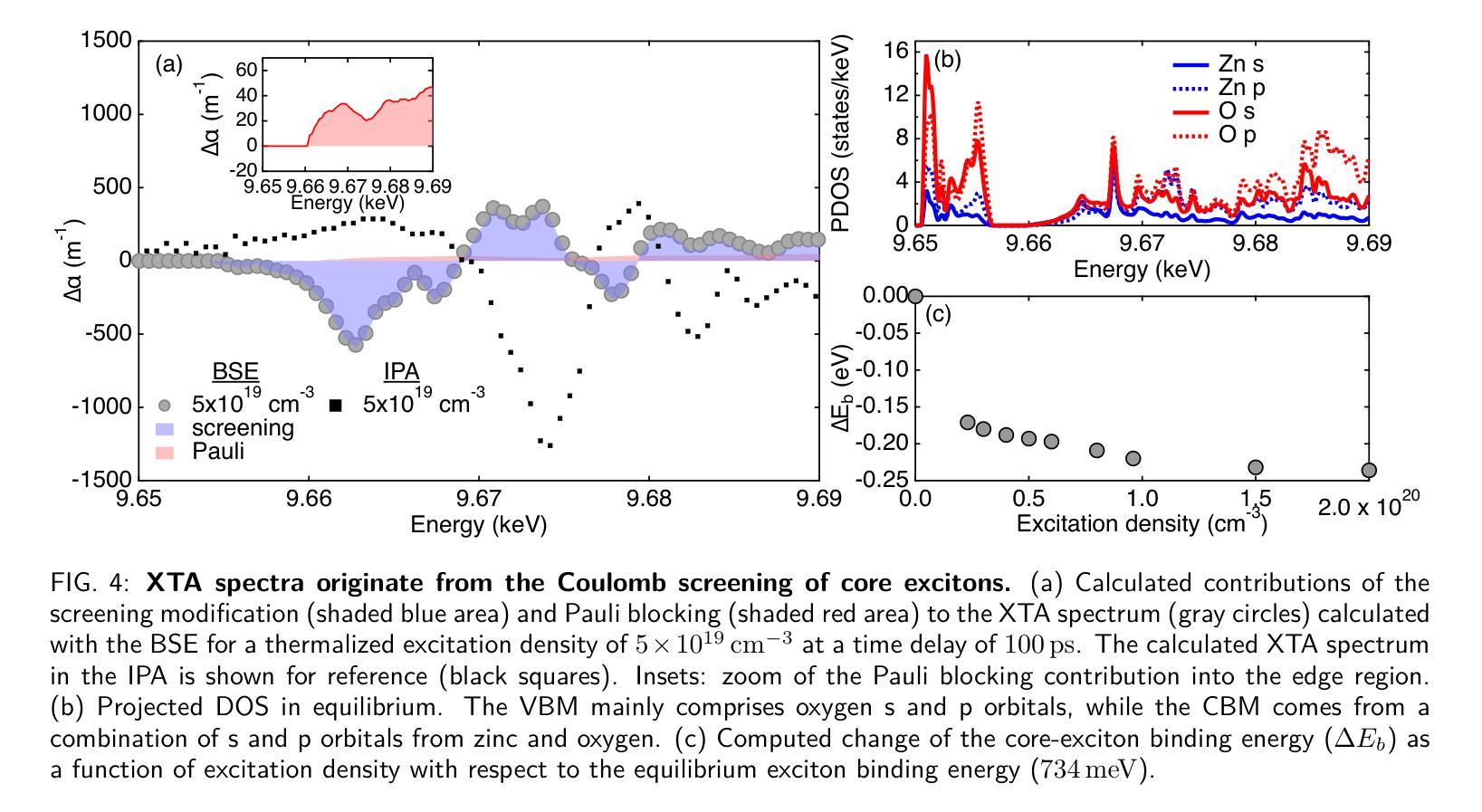
CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight {\tt CAS-GAN}’s potential for clinical applications.
碘化造影剂在众多的介入手术中得到了广泛应用,但为患者带来了巨大的健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,可作为“虚拟造影剂”通过解耦表示学习和血管语义指导来合成X射线血管造影术,从而减少介入手术中对比碘造影剂的使用依赖。具体来说,我们的方法会将X射线血管造影分解成背景和血管两部分成分,借助医学先验知识来实现这一点。一个专业的预测器学习这两个组成部分之间的关联映射关系。此外,引入了血管语义导向生成器和相应的损失函数,以提高生成图像的可视保真度。在XCAD数据集上的实验结果表明,我们的CAS-GAN表现达到了最先进的技术水平,实现了FID分数为5.87和MMD分数为0.016的效果。这些积极的结果表明了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
Summary
该文介绍了一种名为CAS-GAN的新型GAN框架,作为“虚拟对比剂”在介入手术中合成X光血管造影术。通过解耦表示学习和血管语义指导,减少了对比碘造影剂的使用风险。实验结果表明,CAS-GAN在XCAD数据集上达到了领先水平,具有潜在的临床应用价值。
Key Takeaways
- CAS-GAN框架被提出作为“虚拟对比剂”,用于合成X光血管造影术。
- 该框架通过解耦表示学习将X光血管造影术分解为背景与血管成分。
- 医学先验知识被用于指导学习过程,提高生成的图像质量。
- 引入了一个血管语义引导的生成器和相应的损失函数。
- 在XCAD数据集上的实验结果表明CAS-GAN达到了领先水平。
- CAS-GAN的FID和MMD指标分别为5.87和0.016,显示出良好的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图