⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
LoRACLR: Contrastive Adaptation for Customization of Diffusion Models
Authors:Enis Simsar, Thomas Hofmann, Federico Tombari, Pinar Yanardag
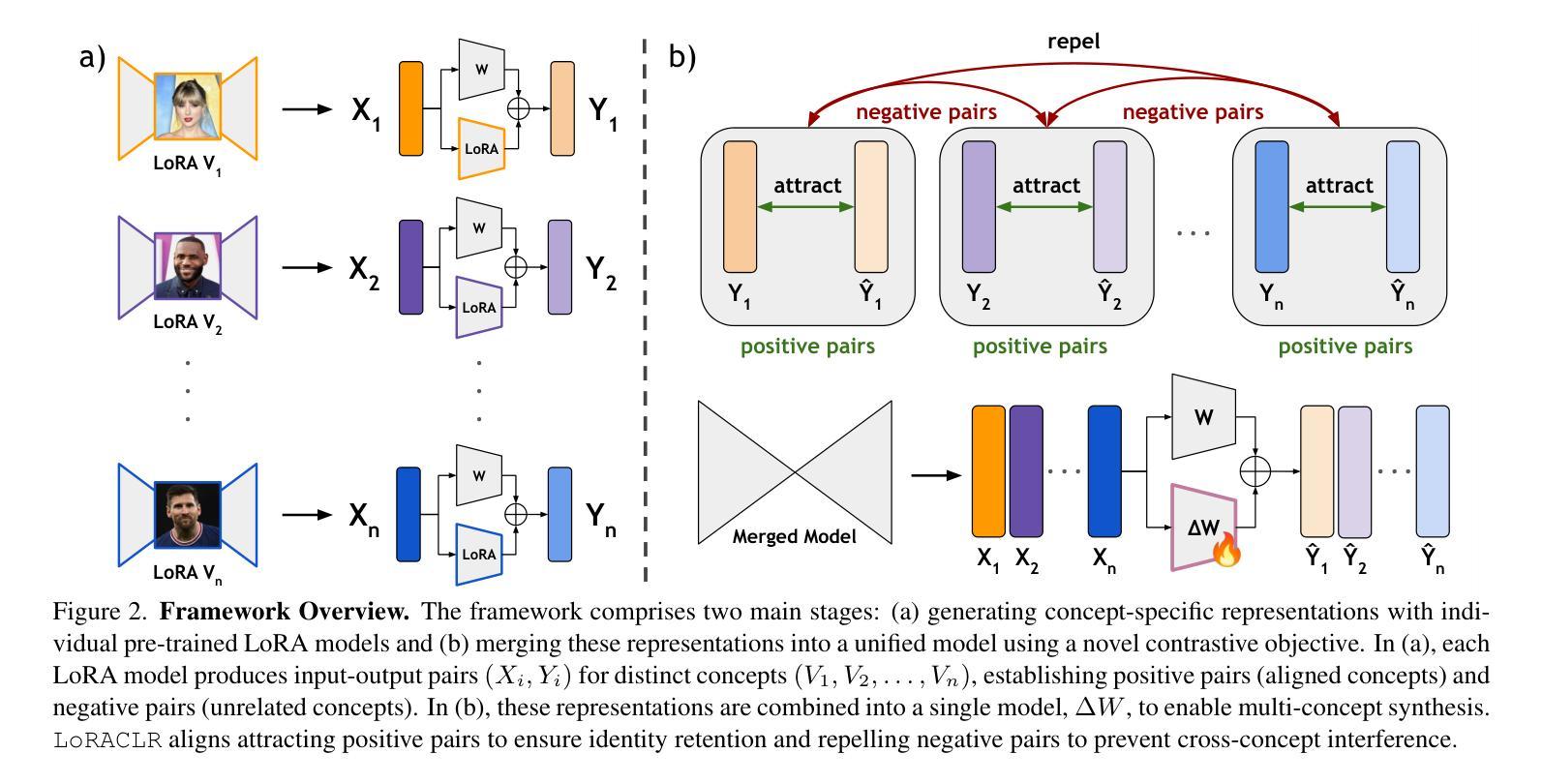
Recent advances in text-to-image customization have enabled high-fidelity, context-rich generation of personalized images, allowing specific concepts to appear in a variety of scenarios. However, current methods struggle with combining multiple personalized models, often leading to attribute entanglement or requiring separate training to preserve concept distinctiveness. We present LoRACLR, a novel approach for multi-concept image generation that merges multiple LoRA models, each fine-tuned for a distinct concept, into a single, unified model without additional individual fine-tuning. LoRACLR uses a contrastive objective to align and merge the weight spaces of these models, ensuring compatibility while minimizing interference. By enforcing distinct yet cohesive representations for each concept, LoRACLR enables efficient, scalable model composition for high-quality, multi-concept image synthesis. Our results highlight the effectiveness of LoRACLR in accurately merging multiple concepts, advancing the capabilities of personalized image generation.
最近文本到图像的定制技术取得了进展,能够实现高保真、语境丰富的个性化图像生成,让特定概念出现在多种场景中。然而,当前的方法在结合多个个性化模型时遇到了困难,往往会导致属性纠缠,或者需要单独训练以保持概念的独特性。我们提出了LoRACLR,这是一种多概念图像生成的新方法,它将多个针对特定概念进行微调LoRA模型合并为一个单一统一的模型,而无需进行额外的个体微调。LoRACLR使用对比目标来对齐和合并这些模型的权重空间,确保兼容性同时最小化干扰。通过对每个概念执行清晰而连贯的表示,LoRACLR能够实现高效、可扩展的模型组合,用于高质量的多概念图像合成。我们的结果突出了LoRACLR在准确合并多个概念方面的有效性,提高了个性化图像生成的能力。
论文及项目相关链接
PDF Project page: https://loraclr.github.io/
Summary
本文介绍了LoRACLR方法,这是一种将多个针对特定概念进行微调(fine-tuned)的LoRA模型合并为一个统一模型的技术。该方法使用对比目标(contrastive objective)来对齐和合并这些模型的权重空间,确保它们之间的兼容性并尽量减少干扰。通过这种技术,用户能够在合成高质量图像时有效地集成多个概念,从而提升个性化图像生成能力。
Key Takeaways
- LoRACLR实现了多个针对特定概念进行微调(fine-tuned)的LoRA模型的合并,提升了个性化图像生成能力。
- 对比目标(contrastive objective)用于对齐和合并模型的权重空间,确保概念之间的兼容性和最小化干扰。
- LoRACLR通过强制执行每个概念的独特且连贯的表示,实现了高效的可扩展模型组合。
- 该方法解决了当前方法结合多个个性化模型时的属性纠缠问题,无需单独训练即可保持概念独特性。
- LoRACLR能够准确地将多个概念合并在一起,进一步提高了个性化图像生成的效能和效率。
- 该技术对于推动文本到图像定制领域的最新进展具有重要意义。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为LoRACLR的新方法,旨在解决文本到图像生成领域中一个具体的挑战:如何将多个个性化的LoRA(Low-Rank Adaptation)模型合并成一个单一的、统一的模型,以便同时准确地生成多个概念(如不同的人物、对象或艺术风格)。具体来说,论文试图解决的问题包括:
多概念模型的合并难题:当前的多概念模型在保持各个概念质量方面存在挑战,它们可能需要对多个概念进行同时训练,或者需要每张图像的优化。
属性纠缠和概念区分度问题:在合并多个LoRA模型时,不同模型间可能会出现特征干扰,导致生成的图像中各个概念的区分度降低。
扩展性和效率问题:随着合并的LoRA模型数量增加,一些现有方法的性能会下降,或者需要依赖于分割模型的准确性,这些都限制了模型的广泛应用。
个性化图像生成的限制:现有的个性化图像生成技术在处理需要多个不同概念共存于单个输出图像的场景时,面临限制。
LoRACLR通过引入对比学习目标来对齐各个模型的权重空间,确保在联合组合中每个概念都能保持其独特性,同时兼容其他概念,从而解决了上述问题。这种方法不需要对原始LoRA模型进行重新训练或访问原始训练数据,提供了一种高效、可扩展的模型组合方式,用于高质量的多概念图像合成。
Q: 有哪些相关研究?
A: 论文中提到了多个与LoRACLR相关的研究工作,这些工作主要涉及文本条件图像合成、个性化图像生成和定制、以及合并多个概念的方法。以下是一些关键的相关研究:
文本条件图像合成:
- 使用GANs(生成对抗网络)和扩散模型进行文本到图像的合成,如Stable Diffusion、Imagen和DALL-E 2等。
- 早期的GAN方法侧重于基于类别或文本属性的图像生成。
个性化图像生成和定制:
- Textual Inversion (TI) 和 DreamBooth (DB) 是早期个性化图像生成的方法,它们通过学习一组有限的图像来嵌入用户特定的概念。
- P+ 方法通过结合更富有表现力的标记表示来增强主题对齐和生成中的保真度。
- Custom Diffusion 和 DB-LoRA 方法旨在通过只微调交叉注意力层或使用LoRA来提高定制的可扩展性和效率。
合并多个概念:
- Weighted summation 方法虽然简单,但会遭受特征干扰。
- Mix-of-Show 方法需要特殊的Embedding-Decomposed LoRAs (ED-LoRAs),这限制了与标准LoRA的兼容性。
- ZipLoRA 方法可以合并风格和内容LoRAs,但在需要多个内容LoRAs时会遇到困难。
- OMG 方法依赖于现成的分割来隔离主题,但其性能高度依赖于分割模型的准确性。
这些研究构成了LoRACLR方法的理论和实践基础,并为解决个性化图像合成中的多概念合并问题提供了不同的视角和方法。LoRACLR通过对比学习目标来对齐不同LoRA模型的权重空间,实现了在不牺牲各个概念独特性的情况下的高效合并。
Q: 论文如何解决这个问题?
A: 论文通过提出LoRACLR方法解决了合并多个个性化LoRA模型的问题,具体解决方案如下:
1. 对比学习目标(Contrastive Objective)
LoRACLR的核心是设计了一个对比损失目标,用来确保在统一模型中合并独立训练的LoRA模型时的兼容性。这个对比损失目标通过吸引相同LoRA模型生成的正样本对,同时排斥不同LoRA模型生成的负样本对,从而确保每个概念在合并模型中保持独特性。
2. 权重空间对齐
LoRACLR利用对比学习对齐各个模型的权重空间,确保每个概念在合并模型中都能保持高保真度,同时在联合构图中保持兼容性。
3. Delta-Based Merging(基于Delta的合并)
LoRACLR采用一个加性Delta(∆W)来合并LoRA模型,而不是直接修改基础权重。通过学习∆W来调整预训练的权重,既保留了每个模型的完整性,又确保了合并后的兼容性。
4. L2正则化
为了限制∆W的大小,确保其稀疏性和最小调整,LoRACLR应用了L2正则化项。
5. 优化目标
LoRACLR将对比合并损失(Lcontrastive)和基于Delta的损失(Ldelta)结合起来,形成总的优化目标(Ltotal),并通过梯度下降法更新∆W以最小化Ltotal。
6. 保留预训练模型
LoRACLR的一个关键优势是允许使用现有的LoRA模型,无需重新训练或访问原始训练数据,这使得模型组合变得可扩展,能够实现高质量的多概念图像生成。
7. 实验验证
论文通过广泛的实验验证了LoRACLR的有效性,包括与现有方法的比较、用户研究和消融研究,证明了LoRACLR在视觉质量和组合一致性方面相比其他方法的优越性。
总结来说,LoRACLR通过对比学习对齐不同LoRA模型的权重空间,并使用基于Delta的合并策略,实现了多概念图像的高效、高质量生成,同时保持了各个概念的独特性和兼容性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估LoRACLR方法的有效性,这些实验包括:
1. 实现细节
- 使用Stable Diffusion模型和ChilloutMix检查点进行实验,利用预训练的LoRA模型以减少计算开销。
- 在合并过程中使用1e-4的学习率,0.5的边际参数m,以及0.001的正则化系数λdelta。
- 所有实验在NVIDIA A100 GPU上进行,包括模型输出和处理。
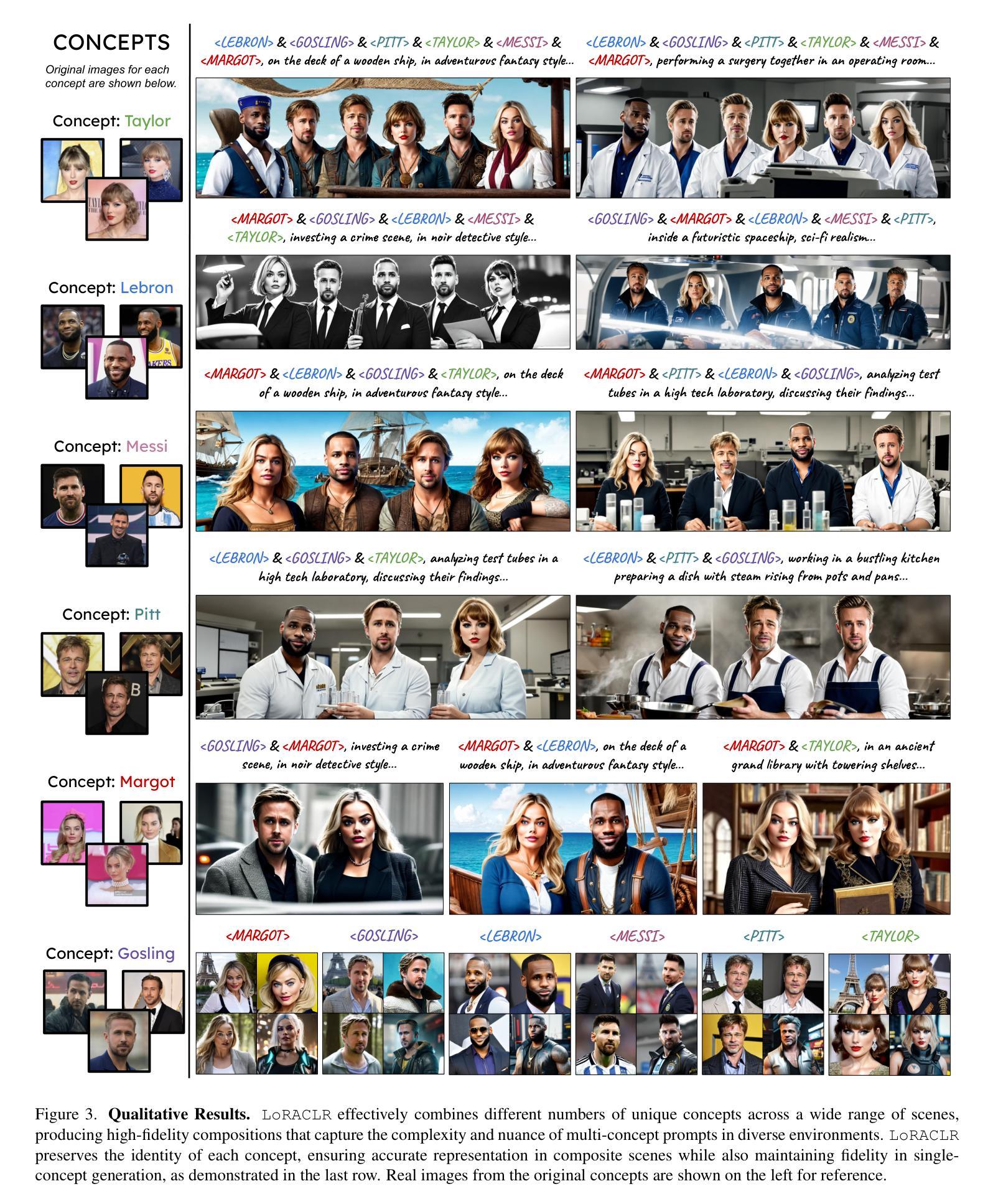
2. 定性结果
- 展示了LoRACLR在单一和多重主题下的能力,通过合并预训练的单概念LoRA和/或ED-LoRA模型,生成符合文本提示的合成图像。
- 通过视觉比较,展示了LoRACLR在不同场景下合并不同数量概念的能力,并与现有方法进行了比较。
3. 定量结果
- 使用与先前工作相同的实验设置和数据集,包括12个概念身份,每个身份由16个不同上下文中的目标概念图像表示。
- 使用三个关键指标评估方法:文本对齐、图像对齐和身份对齐。
- 展示了LoRACLR在合并前后的性能,并与其他方法进行了比较。
4. 用户研究
- 进行了一个涉及50名参与者的用户研究,让他们评估由LoRACLR和竞争方法生成的图像对的身份对齐。
- 参与者被要求根据参考图像评估合成图像在多大程度上捕捉了这些概念的身份。
5. 消融研究
- 探索了边际参数和λdelta参数对模型性能的影响,并确定了保持强大身份保持和复杂构图中视觉一致性的最优设置。
- 展示了模型即使在复杂的多概念构图中也能保持身份和视觉一致性。
6. 与OMG方法的比较
- 提供了与OMG方法的额外视觉比较,展示了LoRACLR在生成多概念场景时的优越性。
7. 更多定性比较
- 提供了额外的定性结果,以强调LoRACLR在生成涉及多个概念和复杂风格要求的场景时的鲁棒性。
这些实验全面评估了LoRACLR在不同方面的性能,包括其在保持身份、风格和上下文方面的准确性,以及与现有技术的比较。通过这些实验,论文证明了LoRACLR作为一种实用且可扩展的解决方案,用于生成模型中的组合定制。
Q: 有什么可以进一步探索的点?
A: 尽管LoRACLR在多概念图像生成方面取得了显著的成果,但仍有一些领域可以进一步探索和改进:
1. 模型泛化能力
探索LoRACLR在更广泛的主题和风格上的表现,包括更多样化和复杂的场景,以测试其泛化能力。
2. 计算效率优化
研究进一步减少LoRACLR合并过程计算需求的方法,使其更适合实时应用或资源受限的环境。
3. 交互式图像编辑
开发基于LoRACLR的交互式图像编辑工具,允许用户在生成图像后进一步微调和调整细节。
4. 多模态输入
研究将LoRACLR扩展到多模态输入,例如结合文本、图像甚至声音提示进行更丰富的图像生成。
5. 控制和解释性
提高LoRACLR生成过程中的控制能力,并增强模型的解释性,让用户更好地理解模型的决策过程。
6. 鲁棒性和安全性
增强LoRACLR对输入扰动和潜在恶意攻击的鲁棒性,并确保生成内容的安全性和合规性。
7. 社会和伦理考量
研究LoRACLR可能的社会影响,包括对版权、隐私和伦理问题的影响,并制定相应的指导原则。
8. 跨领域应用
探索LoRACLR在其他领域的应用,如虚拟现实、游戏开发、电影制作等,以评估其跨领域的实用性和有效性。
9. 模型压缩和加速
研究模型压缩技术,减少LoRACLR模型的大小,使其更适合在移动设备或边缘计算环境中部署。
10. 增强现实集成
考虑将LoRACLR集成到增强现实(AR)应用中,以实现实时的个性化图像生成和场景融合。
这些探索方向不仅可以推动LoRACLR技术的发展,还可能揭示新的研究问题和应用场景,进一步扩展个性化图像生成的边界。
Q: 总结一下论文的主要内容
A: 论文提出了LoRACLR,这是一种新颖的方法,用于多概念图像生成,能够将多个针对不同概念微调的LoRA(Low-Rank Adaptation)模型合并成一个统一的模型,以便同时准确地生成多个概念。以下是论文的主要内容总结:
1. 问题陈述
- 当前文本到图像的个性化生成方法难以合并多个个性化模型,导致属性纠缠或需要单独训练以保持概念的独特性。
2. LoRACLR方法
- LoRACLR使用对比学习目标来对齐和合并多个LoRA模型的权重空间,确保兼容性的同时最小化干扰。
- 通过强化每个概念的独特且连贯的表示,LoRACLR实现了高效、可扩展的模型组合,用于高质量的多概念图像合成。
3. 方法细节
- Low-Rank Adaptation Models:LoRA通过在冻结的基础层上添加低秩矩阵来微调大型模型,以最小的计算量适应新的风格或概念。
- LoRACLR框架:包括使用预训练的LoRA模型生成特定概念的输入输出对,并在合并这些表示时使用对比损失目标。
- Delta-Based Merging:使用可学习的∆W来调整预训练权重,而不是直接修改基础权重,保持每个模型的完整性。
4. 实验
- 实验使用Stable Diffusion模型,并与多个基线方法比较,包括DB-LoRA、P+、Custom Diffusion、Mix-of-Show和Orthogonal Adaptation。
- 通过定量和定性实验评估LoRACLR,包括文本对齐、图像对齐和身份对齐等指标。
- 用户研究和消融研究进一步验证了LoRACLR在身份保持和视觉一致性方面的优势。
5. 结果
- LoRACLR在合并多个概念时表现出色,能够准确捕捉每个身份并生成符合文本提示的合成图像。
- 与现有技术相比,LoRACLR在视觉质量和组合一致性方面取得了显著改进。
6. 社会影响和局限性
- 论文讨论了LoRACLR的潜在社会影响,包括误用风险,并强调了负责任地使用该技术的重要性。
7. 结论
- LoRACLR作为一种有效的多概念图像生成方法,与现有的LoRA模型兼容,并提供了一种高效灵活的解决方案,用于生成模型中的组合定制。
总体而言,LoRACLR通过其创新的对比学习目标和模型合并方法,为个性化和多概念图像生成领域提供了一个有力的工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Is Contrastive Distillation Enough for Learning Comprehensive 3D Representations?
Authors:Yifan Zhang, Junhui Hou
Cross-modal contrastive distillation has recently been explored for learning effective 3D representations. However, existing methods focus primarily on modality-shared features, neglecting the modality-specific features during the pre-training process, which leads to suboptimal representations. In this paper, we theoretically analyze the limitations of current contrastive methods for 3D representation learning and propose a new framework, namely CMCR, to address these shortcomings. Our approach improves upon traditional methods by better integrating both modality-shared and modality-specific features. Specifically, we introduce masked image modeling and occupancy estimation tasks to guide the network in learning more comprehensive modality-specific features. Furthermore, we propose a novel multi-modal unified codebook that learns an embedding space shared across different modalities. Besides, we introduce geometry-enhanced masked image modeling to further boost 3D representation learning. Extensive experiments demonstrate that our method mitigates the challenges faced by traditional approaches and consistently outperforms existing image-to-LiDAR contrastive distillation methods in downstream tasks. Code will be available at https://github.com/Eaphan/CMCR.
跨模态对比蒸馏最近被探索用于学习有效的3D表示。然而,现有方法主要集中在模态共享特征上,忽略了预训练过程中的模态特定特征,导致表示不佳。在本文中,我们理论分析了当前对比方法在3D表示学习上的局限性,并提出了一种新的框架,即CMCR,来解决这些不足。我们的方法通过更好地融合模态共享和模态特定特征来改进传统方法。具体来说,我们引入了掩膜图像建模和占用估计任务来指导网络学习更全面的模态特定特征。此外,我们提出了一种新的多模态统一编码簿,学习不同模态共享的嵌入空间。同时,我们引入了增强几何的掩膜图像建模,进一步促进3D表示学习。大量实验表明,我们的方法缓解了传统方法的挑战,并且在下游任务中始终优于现有的图像到激光雷达对比蒸馏方法。代码将在https://github.com/Eaphan/CMCR上提供。
论文及项目相关链接
PDF Under review
Summary
本文探讨了在跨模态对比蒸馏中模态特定特征的重要性,并为此提出了一种新的学习框架CMCR。该框架通过整合模态共享和模态特定特征,引入掩膜图像建模和占用估计任务,以及提出多模态统一编码本,以改进传统方法。实验证明,该方法在下游任务中表现优异。
Key Takeaways
- 现有对比蒸馏方法主要关注模态共享特征,忽略了模态特定特征,导致表示不佳。
- CMCR框架旨在解决现有方法的局限性,通过更好地整合模态共享和模态特定特征来学习更高效的3D表示。
- 引入掩膜图像建模和占用估计任务,以指导网络学习更全面的模态特定特征。
- 提出一种新型的多模态统一编码本,学习不同模态之间的共享嵌入空间。
- 引入几何增强的掩膜图像建模,进一步推动3D表示学习。
- 实验证明,CMCR方法能克服传统方法的挑战,并在下游任务中持续超越现有的图像到激光雷达对比蒸馏方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何通过自监督学习来有效地学习全面的3D表示。具体来说,论文指出现有的基于对比蒸馏的方法在进行3D表示学习时,主要关注于模态共享特征,而忽视了模态特定的特征,这导致了次优的表示。为了克服这一局限性,论文提出了一个新的框架CMCR(Cross-Modal Comprehensive Representation Learning),旨在通过整合模态共享和模态特定的特征来改善3D表示学习。
论文的主要贡献包括:
- 提供了对当前对比蒸馏方法在3D表示学习中局限性的理论分析。
- 在传统对比蒸馏方法的基础上,引入了一个新的框架,联合学习模态共享和模态特定特征。
- 提出了一个新颖的多模态统一码本,用于学习不同模态间的共享、模态不变的嵌入空间。
- 提出了几何增强的遮蔽图像建模,以增强3D表示学习。
通过广泛的实验,论文证明了所提出的方法能够减轻传统方法面临的挑战,并在下游任务中一致性地超越现有的图像到激光雷达对比蒸馏方法。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要涉及以下几个领域:
3D场景理解:
- 传统方法依赖于如原始点云、体素、范围视图和多视图融合等表示方法来捕获环境特征。
- 近期研究探索了减少对完全标注数据集依赖的方法,包括半监督、弱监督、自监督和主动学习策略。
3D表示学习:
- 自监督学习在3D点云上的最新进展与基于图像的方法并行发展,包括预测变换或重建点云部分的任务。
- 判别方法侧重于在不同层次的表示(点、段、区域)之间进行对比学习,以捕获几何和结构信息。
- 基于重建的方法,例如使用Chamfer距离或表面重建,旨在从掩蔽数据中恢复点云细节。
- 跨模态蒸馏方法利用同步的相机-激光雷达数据进行对比学习,从2D网络转移知识到3D网络。
向量量化和码本:
- 向量量化(VQ)技术最初引入于图像生成,将大量向量集合划分为由码本中的码向量表示的簇。
- VQ被集成到自动编码器框架中,如VQ-VAE,它通过将图像转换为离散代码序列并从这些代码中重建图像,从而实现更紧凑和稳定的潜在表示。
具体到论文中提及的一些相关研究工作,包括:
- **PPKT (Liu et al., 2021)**:利用像素到点的对比损失,无需图像或点云的标注数据。
- **SLidR (Sautier et al., 2022)**:引入超像素来分组来自视觉一致区域的像素和点,形成更结构化的对比任务。
- **Seal (Liu et al., 2024)**:利用视觉基础模型生成的语义丰富的超像素,并加入时间一致性正则化以增强点段上的稳定性。
- **CSC (Chen et al., 2024)**:研究跨场景语义一致性,以确保所有帧和场景间的语义一致性。
这些研究工作为本文提出的CMCR框架提供了理论基础和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了现有对比蒸馏方法在3D表示学习中忽视模态特定特征的问题:
理论分析:
- 论文首先对现有对比蒸馏方法进行了理论分析,指出这些方法主要关注于模态共享信息,而忽略了模态特定的、对任务有贡献的信息。基于此分析,论文提出了一种新的框架CMCR,以解决这些局限性。
双模态特征融合:
- 论文提出了一个新的框架,通过设计不同的头(heads)分别捕获模态共享特征和模态特定特征,使得网络能够同时学习这两种特征。
多模态统一码本(Multi-modal Unified Codebook):
- 引入了一个新的多模态统一码本,用于将2D和3D特征映射到一个共享的潜在空间。这个码本使得模型能够关注模态间的共同特征,同时通过使用不同的头保留每个模态的独特特征。
遮蔽图像建模和占据估计任务:
- 通过引入遮蔽图像建模(Masked Image Modeling)和占据估计(Occupancy Estimation)任务,驱动网络学习模态特定的信息。这些任务有助于网络学习到每个模态独特的、可能对下游任务有贡献的细节。
几何增强的遮蔽图像建模(Geometry Enhanced Masked Image Modeling):
- 利用3D特征协助重建遮蔽的图像区域,这个过程反过来又增强了对几何感知的3D表示的学习。
实验验证:
- 通过在多个下游任务上的广泛实验,包括3D语义分割、目标检测和全景分割,论文验证了所提方法的有效性,并与现有的自监督学习方法进行了比较,证明了其优越性。
总结来说,论文通过结合理论分析和实际的方法创新,提出了一个能够同时学习模态共享和模态特定特征的新框架,有效地提高了3D表示的全面性和下游任务的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的CMCR方法,并与现有的自监督学习方法进行比较。实验主要围绕以下三个下游任务进行:
3D语义分割:
- 使用MinkUNet作为3D语义分割任务的网络架构。
- 在nuScenes和SemanticKITTI数据集上进行评估,比较了不同比例的标注数据(1%, 5%, 10%, 25%, 和100%)下的模型性能。
- 进行了线性评估(Linear Probing),即仅训练分类头而冻结3D主干网络层,以评估自监督学习得到的表示的泛化能力。
3D目标检测:
- 使用VoxelNet和CenterPoint两种3D目标检测架构。
- 在nuScenes数据集上进行评估,使用了不同的标注数据比例(5%, 10%, 和20%)。
- 报告了平均精度均值(mAP)和nuScenes检测分数(NDS)作为性能指标。
3D全景分割:
- 使用PanopticPolarNet和Cylinder3D作为网络主干。
- 在nuScenes数据集上进行评估,使用了1%和5%的标注数据。
- 评估指标包括全景质量(PQ)、分割质量(SQ)和识别质量(RQ)。
此外,论文还进行了消融研究(Ablation Study),以评估模型中各个组件的影响,包括基本像素点对比学习、图像重建和占据估计任务、多模态统一码本以及几何增强的遮蔽图像建模等组件的效果。通过这些消融实验,论文展示了每个组件对模型性能的贡献,并证明了完整模型在预训练和微调任务中的优越性能。
最后,论文还探讨了不同码本大小对模型性能的影响,发现适中的码本大小(例如512)能够取得最佳的性能平衡。
这些实验结果表明,CMCR方法能够在多种3D感知任务中实现更好的性能,尤其是在标注数据有限的情况下,证明了所提出方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
任务特定的适应性:
- 探索CMCR框架在特定任务(如实例分割、动作识别等)中的适应性和优化策略,以提高这些任务的性能。
多模态融合策略:
- 研究和开发新的多模态融合技术,以更有效地整合来自不同传感器和模态的数据。
模型泛化能力:
- 进一步研究如何提高模型在面对不同环境条件(如不同天气、不同城市)下的泛化能力。
模型效率和实用性:
- 探索模型压缩和加速技术,以使CMCR框架更适合实际应用,特别是在资源受限的设备上。
增强学习与自监督学习的结合:
- 研究如何将增强学习策略融入自监督学习框架中,以进一步提高学习效率和性能。
更深层次的特征对齐:
- 研究更深层次的特征对齐技术,以更精确地捕捉不同模态之间的对应关系。
鲁棒性和错误分析:
- 对模型的鲁棒性进行更深入的分析,识别模型失败的案例,并探索解决方案。
跨域适应性:
- 研究模型在从合成数据到真实数据的迁移学习中的适应性,以及如何减少域间的分布差异。
大规模多模态数据集的构建:
- 构建更大规模、更多样化的多模态数据集,以支持更广泛的实验和应用。
模型解释性:
- 提高模型的可解释性,让研究人员和用户更好地理解模型的决策过程。
实时性能优化:
- 针对实时应用场景,优化模型以满足低延迟要求。
多任务学习框架:
- 将CMCR框架扩展到多任务学习设置中,同时处理多个相关的下游任务。
这些探索点可以帮助研究社区进一步推动3D表示学习和自监督学习领域的发展,提高模型的性能和实用性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出现有的基于对比蒸馏的方法在3D表示学习中主要关注模态共享特征,忽略了模态特定特征,导致学习到的表示不够全面。
理论分析:
- 论文对现有对比蒸馏方法的局限性进行了理论分析,提出了模态特定任务相关信息的概念,并指出仅最大化模态间共享信息是不够的。
方法论(CMCR框架):
- 提出了一个新的框架CMCR(Cross-Modal Comprehensive Representation Learning),通过整合模态共享和模态特定特征来改善3D表示学习。
- 引入了多模态统一码本,以学习跨不同模态的共享嵌入空间。
- 提出了几何增强的遮蔽图像建模和占据估计任务,以更好地学习模态特定的特征。
实验验证:
- 在多个下游任务(3D语义分割、目标检测和全景分割)上进行了广泛的实验,验证了CMCR方法的有效性。
- 实验结果表明,CMCR方法在各种任务和数据集上均优于现有的自监督学习方法。
主要贡献:
- 提供了现有对比蒸馏方法的理论分析。
- 提出了一个新的框架来联合学习模态共享和模态特定特征。
- 设计了多模态统一码本来防止模型将码本划分为模态特定的子空间。
- 通过实验验证了所提方法在多个下游任务中的有效性。
未来工作:
- 论文提出了一些未来可能的研究方向,包括任务特定的适应性改进、模型泛化能力的提升、以及多模态融合策略的进一步研究等。
总体而言,这篇论文通过理论分析和方法创新,提出了一个能够更全面学习3D表示的新框架CMCR,并在多个下游任务上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

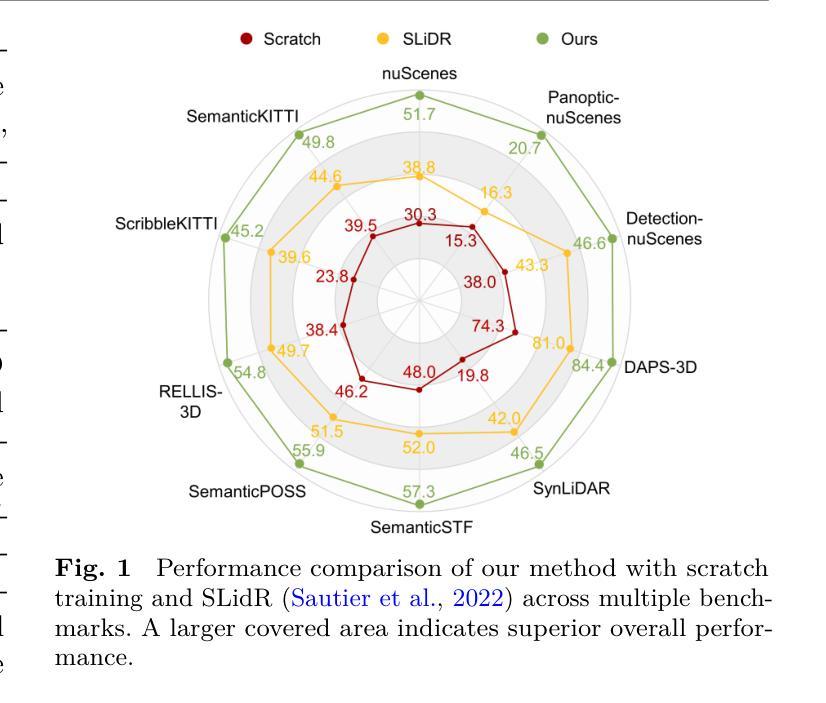
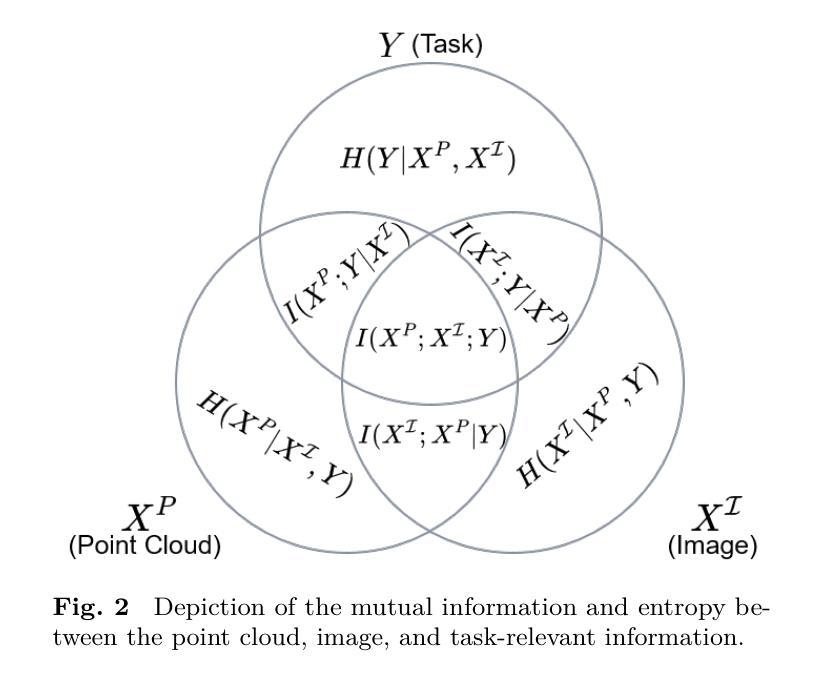
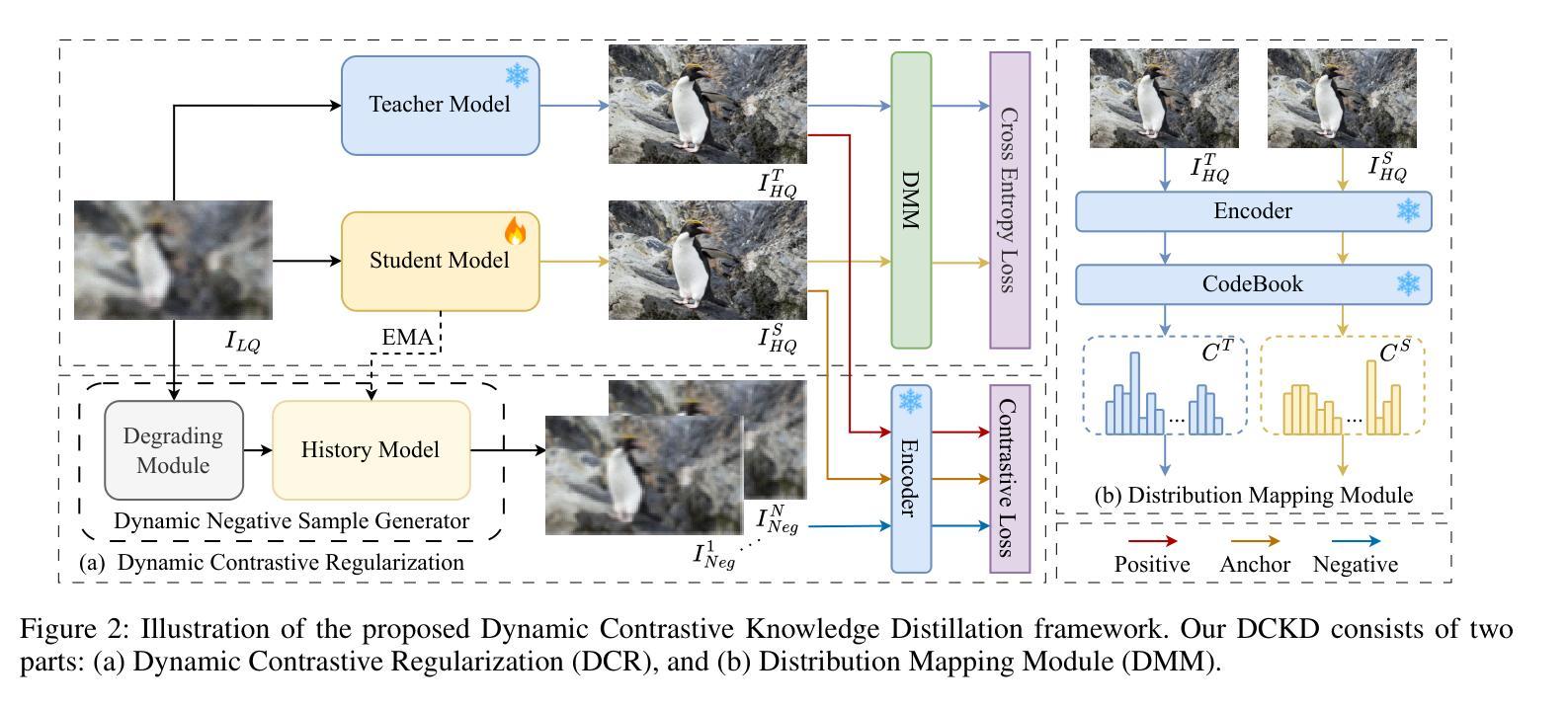
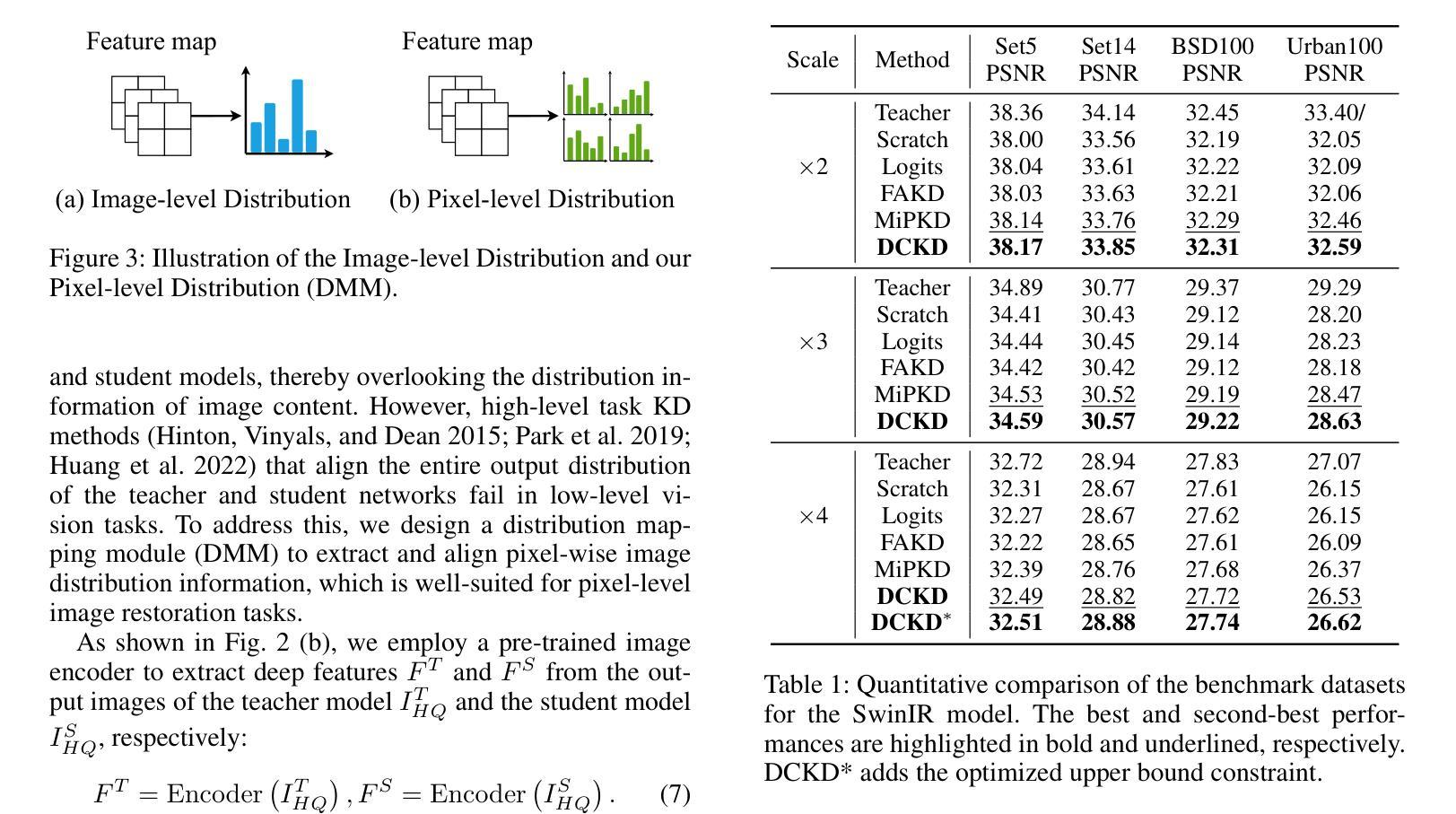
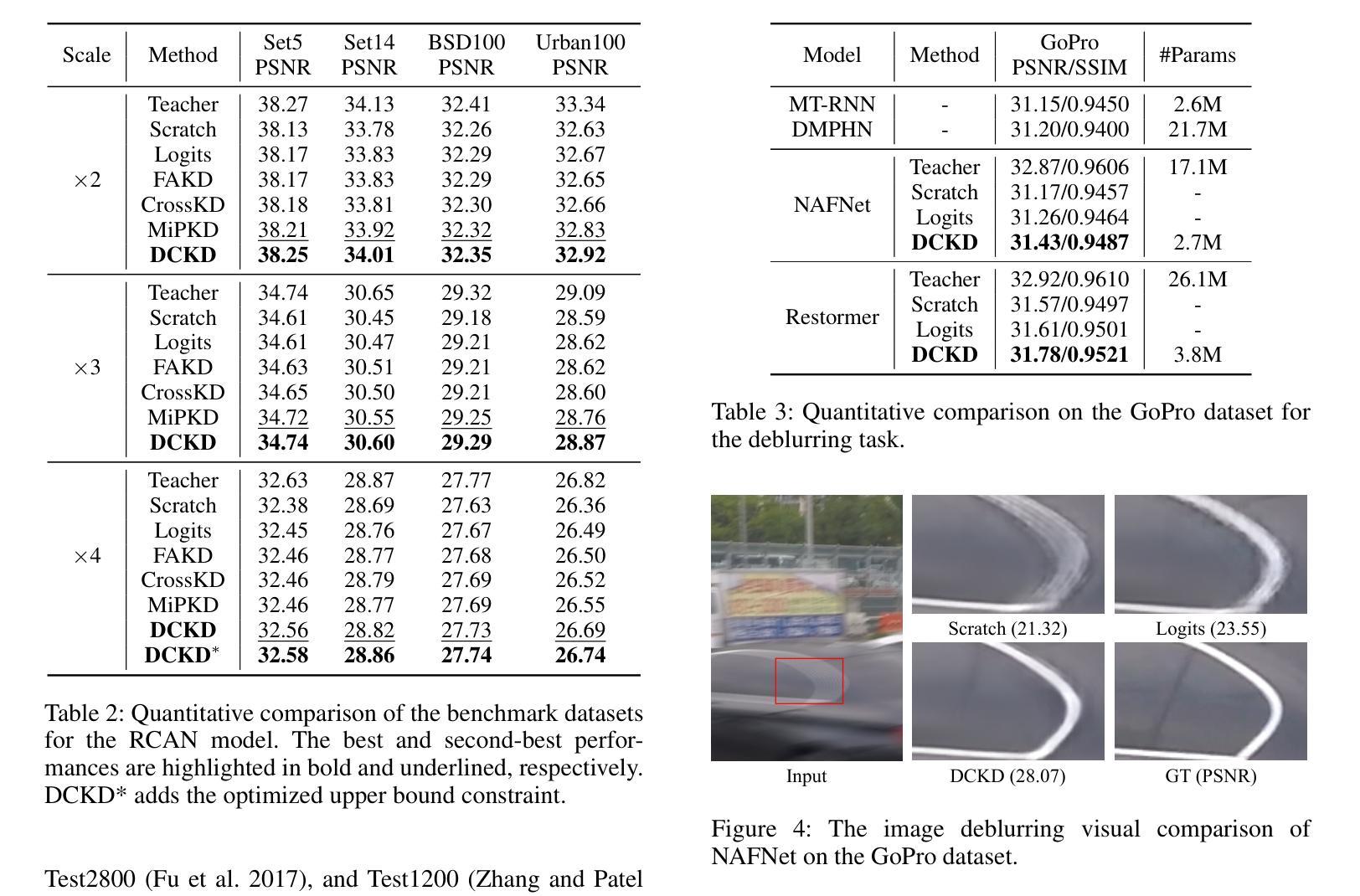
Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration
Authors:Yunshuai Zhou, Junbo Qiao, Jincheng Liao, Wei Li, Simiao Li, Jiao Xie, Yunhang Shen, Jie Hu, Shaohui Lin
Knowledge distillation (KD) is a valuable yet challenging approach that enhances a compact student network by learning from a high-performance but cumbersome teacher model. However, previous KD methods for image restoration overlook the state of the student during the distillation, adopting a fixed solution space that limits the capability of KD. Additionally, relying solely on L1-type loss struggles to leverage the distribution information of images. In this work, we propose a novel dynamic contrastive knowledge distillation (DCKD) framework for image restoration. Specifically, we introduce dynamic contrastive regularization to perceive the student’s learning state and dynamically adjust the distilled solution space using contrastive learning. Additionally, we also propose a distribution mapping module to extract and align the pixel-level category distribution of the teacher and student models. Note that the proposed DCKD is a structure-agnostic distillation framework, which can adapt to different backbones and can be combined with methods that optimize upper-bound constraints to further enhance model performance. Extensive experiments demonstrate that DCKD significantly outperforms the state-of-the-art KD methods across various image restoration tasks and backbones.
知识蒸馏(KD)是一种宝贵且具有挑战性的方法,通过从一个高性能但复杂的教师模型中学习来增强紧凑的学生网络。然而,用于图像恢复的先前KD方法忽略了学生在蒸馏过程中的状态,采用了固定的解空间,限制了KD的能力。此外,仅依赖L1类型的损失很难利用图像分布信息。在这项工作中,我们提出了用于图像恢复的新型动态对比知识蒸馏(DCKD)框架。具体来说,我们引入了动态对比正则化来感知学生的学习状态,并使用对比学习动态调整蒸馏解空间。此外,我们还提出了分布映射模块,以提取和对齐教师模型和学生模型的像素级类别分布。请注意,所提出的DCKD是一种结构无关的知识蒸馏框架,可以适应不同的主干,并且可以与优化上限约束的方法相结合,以进一步增强模型性能。大量实验表明,在各种图像恢复任务和不同主干上,DCKD显著优于最新KD方法。
论文及项目相关链接
Summary
本文提出了一种动态对比知识蒸馏(DCKD)框架,用于图像修复中的知识蒸馏。该框架引入动态对比正则化感知学生的学习状态,并使用对比学习动态调整蒸馏解空间。同时,提出了分布映射模块,以提取和对齐教师和学生的像素级类别分布。实验表明,相比当前先进的知识蒸馏方法,在多种图像修复任务和骨干网络下,DCKD有显著的优势。
Key Takeaways
- 知识蒸馏(KD)是一种增强紧凑学生网络性能的方法,通过从高性能但复杂的教师模型中学习来实现。
- 以往的KD方法在图像修复中忽视了学生的学习状态,采用固定的解空间限制了KD的能力。
- DCKD框架引入动态对比正则化,能感知学生的学习状态并动态调整蒸馏解空间。
- DCKD采用对比学习进行动态调整,有助于更有效地进行知识迁移。
- 分布映射模块的提出,用于提取和对齐教师与学生的像素级类别分布。
- DCKD框架是结构无关的,能适应不同的骨干网络,并能与其他优化上限约束的方法结合,进一步提高模型性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为动态对比知识蒸馏(Dynamic Contrastive Knowledge Distillation,简称DCKD)的新框架,旨在解决图像恢复任务中的知识蒸馏问题。具体来说,论文试图解决以下问题:
学生网络的学习状态被忽视:以往的知识蒸馏方法在图像恢复中忽略了学生网络在蒸馏过程中的状态,采用固定的解决方案空间,限制了知识蒸馏的能力。
依赖L1型损失的局限性:仅依赖L1型损失难以利用图像的分布信息,导致优化解决方案空间的难度增加,常常产生低质量的图像,伴有伪影、颜色失真和模糊。
提高模型性能和效率:现有的图像恢复模型虽然取得了一定的成功,但它们需要较高的资源,效率不高,这限制了它们在资源受限设备上的部署。
为了解决这些问题,论文提出了DCKD框架,通过动态对比正则化和分布映射模块来动态调整蒸馏的解决方案空间,并提取和对齐教师和学生模型之间的像素级类别分布。这一方法不仅适应于不同的网络结构,还可以与优化上限约束的方法结合,以进一步提升模型性能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
图像恢复(Image Restoration)
- 使用卷积神经网络(CNNs)和Transformer设计的各种模型,如SRCNN(Dong et al. 2015)和DnCNN(Zhang et al. 2017)。
- Transformer基方法,例如SwinIR(Liang et al. 2021)和Restormer(Zamir et al. 2022),利用自注意力机制捕获长距离依赖关系。
知识蒸馏(Knowledge Distillation, KD)
- 旨在将大型教师模型的知识转移到小型学生模型中,以减少部署成本并提高学生模型的性能。
- 在图像恢复领域的应用,如FAKD(He et al. 2020)、MiPKD(Li et al. 2024)和MTKD(Jiang et al. 2024)。
对比学习(Contrastive Learning)
- 结合对比学习和知识蒸馏来构建解决方案空间,例如Wang et al. 2021b和CSD(Wang et al. 2021c)。
模型压缩技术
- 包括量化(Du et al. 2021; Ayazoglu 2021; Hong et al. 2022)、剪枝(Fan et al. 2020; Wang et al. 2021a; Oh et al. 2022)、紧凑架构设计(Ahn, Kang, and Sohn 2018; Zhang et al. 2022; Chen et al. 2022a)和神经架构搜索(NAS)(Gou et al. 2020; Kim et al. 2021; He et al. 2022)。
特定任务的图像恢复方法
- 如超分辨率(Super-Resolution)、去模糊(Deblurring)和去雨(Deraining)等任务的特定研究。
自注意力机制和空间自适应特征金字塔注意力图
- 如SAFMN(Sun et al. 2023)和Restormer(Zamir et al. 2022)。
这些相关研究为DCKD框架的提出提供了理论基础和技术背景,同时也表明了图像恢复和模型压缩领域的研究进展和挑战。DCKD框架通过结合动态对比正则化和分布映射模块,旨在进一步提升图像恢复任务中知识蒸馏的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为动态对比知识蒸馏(Dynamic Contrastive Knowledge Distillation,DCKD)的新框架来解决上述问题。DCKD框架主要包括两个关键部分:动态对比正则化(Dynamic Contrastive Regularization,DCR)和分布映射模块(Distribution Mapping Module,DMM)。以下是这两个部分的具体解决方案:
动态对比正则化(DCR)
动态调整解决方案空间:DCR根据学生模型的学习状态动态调整解决方案空间。这是通过动态负样本生成器实现的,该生成器包括一个退化模块和一个历史模型。退化模块对输入图像应用随机退化操作,生成多个退化图像,然后历史模型基于学生模型的历史状态重建这些退化图像,产生作为解决方案空间下限的负样本。
动态对比损失:利用预训练的VQGAN作为特征编码器,计算学生模型输出、正样本(教师模型输出)和负样本之间的特征差异,构建动态对比损失。
指数移动平均(EMA):为了更好地捕捉学生模型的状态,引入EMA来更新历史模型的参数。
分布映射模块(DMM)
提取像素级类别分布信息:DMM旨在提取和对齐教师和学生模型输出之间的像素级类别分布信息。这通过使用预训练的图像编码器从教师和学生模型的输出图像中提取深度特征,然后使用VQGAN的码本将这些特征转换为类别分布来实现。
跨熵损失:通过交叉熵损失对齐教师和学生模型的类别分布,从而引入类别分布信息蒸馏。
总体损失函数
DCKD的总体损失函数包括重建损失、传统的知识蒸馏损失、动态对比损失和交叉熵损失,这些损失共同优化以提升学生模型的性能。
通过这种结构化的方法,DCKD能够动态地调整蒸馏过程中的约束,并引入像素级别的类别分布信息,从而显著提高学生模型在各种图像恢复任务中的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的动态对比知识蒸馏(DCKD)框架的有效性。实验覆盖了三个主要的图像恢复任务:图像超分辨率、图像去模糊和图像去雨。以下是具体的实验设置和结果:
实验设置
教师网络和学生网络:DCKD框架在多种基于Transformer的(如SwinIR)和基于CNN的(如RCAN)模型上进行了测试,以验证其在不同网络结构上的效果。
数据集和评估指标:对于图像超分辨率,使用了DIV2K数据集进行训练,并在Set5、Set14、BSD100和Urban100等基准数据集上进行评估。对于图像去模糊,使用了GoPro数据集进行训练和测试。对于图像去雨,使用了多个数据集的组合进行训练,并在Test100、Rain100H、Rain100L、Test2800和Test1200等数据集上进行评估。主要使用峰值信噪比(PSNR)和结构相似性(SSIM)作为评估指标。
实现细节:对于图像超分辨率任务,输入图像被随机裁剪成48×48的补丁,并进行水平和垂直翻转以及旋转的数据增强。所有模型都使用ADAM优化器进行训练,初始学习率设置为10^-4,并在每10^5次更新后衰减10倍。DCKD框架使用PyTorch实现,并在4个NVIDIA V100 GPU上进行训练。
实验结果
图像超分辨率:DCKD与多种代表性的知识蒸馏方法(包括从头开始训练、Logits、FAKD、CrossKD和MiPKD)进行了比较。结果表明,DCKD在所有尺度上的城市100数据集上均显著优于现有方法,性能提升超过0.1dB。
图像去模糊:在GoPro数据集上,DCKD在CNN基NAFNet和Transformer基Restormer上均显示出一致的有效性,与Logits知识蒸馏相比,性能提升了0.17dB。
图像去雨:在多个基准数据集上,DCKD的性能超过了其他蒸馏方法,例如在Rain100L数据集上,与Logits知识蒸馏相比,性能提升了0.55dB。
可视化比较
论文还提供了一些具有挑战性的视觉效果比较图,展示了DCKD在不同图像恢复任务上相比于其他知识蒸馏方法的优势,例如更好地捕捉结构纹理,更清晰地恢复图像细节等。
消融研究
此外,论文还进行了消融研究,探讨了DCKD框架中不同组件(如DCR和DMM)的效果,随机退化类型的影响,平衡权重的选择,负样本数量的影响,以及历史模型更新步长的影响。这些消融研究进一步验证了DCKD框架中各个组件的有效性和对性能的影响。
总体而言,这些实验和消融研究证明了DCKD框架在多种图像恢复任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的DCKD框架在图像恢复任务中取得了显著的性能提升,但仍有一些方向可以进一步探索和研究:
不同退化类型的适应性:
- 论文中主要关注了随机噪声退化,但实际应用中可能遇到更复杂的退化类型(如模糊、压缩伪影等)。研究DCKD框架对于不同类型和不同程度退化的适应性和鲁棒性是一个有价值的方向。
更深层次的分布对齐:
- 目前DCKD通过像素级类别分布进行分布对齐,未来可以探索更深层次的特征分布对齐,例如基于图像内容和语义信息的分布对齐。
跨任务的知识蒸馏:
- 探索DCKD框架在跨任务知识蒸馏中的潜力,例如将从一个任务(如超分辨率)学到的知识迁移到另一个任务(如去雨或去模糊)。
实时性能优化:
- 尽管DCKD在多个数据集上取得了良好的性能,但在实际应用中,尤其是在资源受限的设备上,实时性能是一个重要考量。研究如何进一步优化DCKD以满足实时处理的需求。
更广泛的模型和数据集验证:
- 在更多的模型架构和更广泛的数据集上验证DCKD框架的有效性,包括不同类型的CNN和Transformer模型,以及不同分辨率和质量的图像。
损失函数和优化策略的改进:
- 研究不同的损失函数和优化策略,以进一步提高学生模型的性能和泛化能力。
知识蒸馏的理论分析:
- 对DCKD框架的理论分析,包括蒸馏过程中的知识转移机制和动态调整解决方案空间的原理。
结合其他模型压缩技术:
- 将DCKD与其他模型压缩技术(如网络剪枝、量化)结合,以进一步减少模型的计算和存储需求。
可视化和解释性分析:
- 对DCKD框架中的关键组件(如DCR和DMM)进行可视化和解释性分析,以更好地理解知识蒸馏过程中发生了什么,以及如何改进。
实际应用中的部署和测试:
- 在实际应用场景中部署DCKD框架,并在真实世界数据上进行测试和优化,以验证其实用性和有效性。
这些方向不仅可以推动知识蒸馏技术的发展,还可能为图像恢复和其他计算机视觉任务带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为动态对比知识蒸馏(DCKD)的新框架,旨在提高图像恢复任务中知识蒸馏的效率和性能。以下是论文的主要内容总结:
问题陈述:
- 现有的知识蒸馏(KD)方法在图像恢复领域忽略了学生网络在学习过程中的状态,使用固定解决方案空间,限制了KD的能力。
- 仅依赖L1型损失无法充分利用图像分布信息,导致优化困难和图像质量下降。
DCKD框架:
- 提出了DCKD框架,包含动态对比正则化(DCR)和分布映射模块(DMM)两个主要部分。
- DCR通过动态调整解决方案空间来增强学生模型的约束。
- DMM首次在低级视觉任务中引入像素级类别信息蒸馏。
动态对比正则化(DCR):
- 利用动态负样本生成器和历史模型生成负样本,动态调整解决方案空间的下界。
- 采用预训练的VQGAN作为特征编码器,构建动态对比损失。
分布映射模块(DMM):
- 提取教师和学生模型输出的像素级类别分布信息,并通过交叉熵损失进行对齐。
实验验证:
- 在图像超分辨率、去模糊和去雨等任务上验证了DCKD框架的有效性。
- 与现有的KD方法相比,DCKD在多个基准数据集上取得了显著的性能提升。
消融研究:
- 通过消融实验验证了DCR和DMM模块的有效性,以及不同组件对性能的影响。
结论:
- DCKD通过动态调整解决方案空间和引入像素级类别信息,有效地提高了学生模型在图像恢复任务中的性能。
论文的主要贡献在于提出了一种新的知识蒸馏框架,能够在不同图像恢复任务中动态优化学生模型的学习过程,显著提升模型性能,同时保持模型的轻量化。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



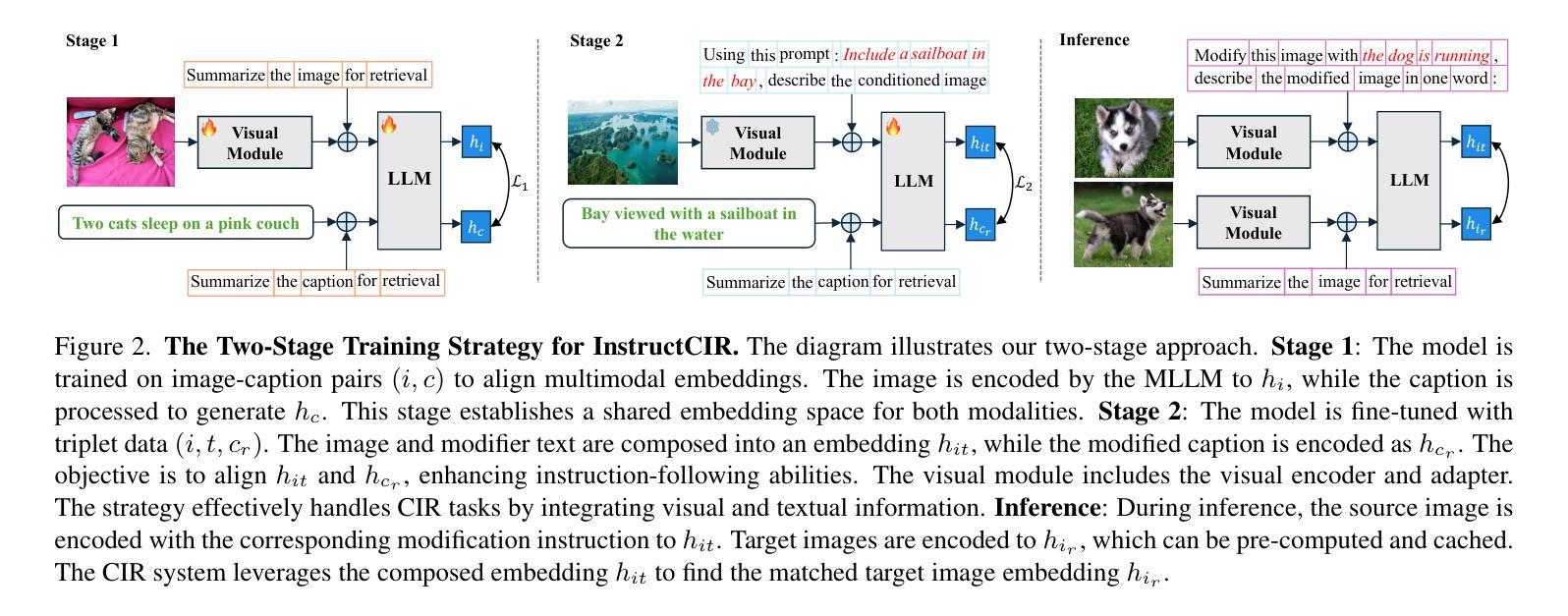
Compositional Image Retrieval via Instruction-Aware Contrastive Learning
Authors:Wenliang Zhong, Weizhi An, Feng Jiang, Hehuan Ma, Yuzhi Guo, Junzhou Huang
Composed Image Retrieval (CIR) involves retrieving a target image based on a composed query of an image paired with text that specifies modifications or changes to the visual reference. CIR is inherently an instruction-following task, as the model needs to interpret and apply modifications to the image. In practice, due to the scarcity of annotated data in downstream tasks, Zero-Shot CIR (ZS-CIR) is desirable. While existing ZS-CIR models based on CLIP have shown promising results, their capability in interpreting and following modification instructions remains limited. Some research attempts to address this by incorporating Large Language Models (LLMs). However, these approaches still face challenges in effectively integrating multimodal information and instruction understanding. To tackle above challenges, we propose a novel embedding method utilizing an instruction-tuned Multimodal LLM (MLLM) to generate composed representation, which significantly enhance the instruction following capability for a comprehensive integration between images and instructions. Nevertheless, directly applying MLLMs introduces a new challenge since MLLMs are primarily designed for text generation rather than embedding extraction as required in CIR. To address this, we introduce a two-stage training strategy to efficiently learn a joint multimodal embedding space and further refining the ability to follow modification instructions by tuning the model in a triplet dataset similar to the CIR format. Extensive experiments on four public datasets: FashionIQ, CIRR, GeneCIS, and CIRCO demonstrates the superior performance of our model, outperforming state-of-the-art baselines by a significant margin. Codes are available at the GitHub repository.
图像组合检索(CIR)是根据图像与文本(指定对视觉参考的修改或更改)组成的查询来检索目标图像的过程。CIR本质上是一个遵循指令的任务,因为模型需要解释并应用对图像的修改。在实践中,由于下游任务中标注数据的稀缺性,零样本图像组合检索(ZS-CIR)是理想的解决方案。虽然基于CLIP的现有ZS-CIR模型已经显示出有希望的结果,但它们在解释和遵循修改指令方面的能力仍然有限。一些研究试图通过融入大型语言模型(LLM)来解决这个问题。然而,这些方法在有效整合多模式信息和指令理解方面仍然面临挑战。为了应对上述挑战,我们提出了一种利用指令优化多模态LLM(MLLM)生成组合表示的新嵌入方法,这显著提高了遵循指令的能力,实现了图像和指令之间的全面集成。然而,直接应用MLLMs带来了新的问题,因为MLLMs主要设计用于文本生成,而不是如CIR所需的嵌入提取。为解决这一问题,我们引入了一种两阶段训练策略,以有效地学习联合多模式嵌入空间,并通过在类似于CIR格式的三元组数据集上调整模型,进一步改善遵循修改指令的能力。在四个公开数据集FashionIQ、CIRR、GeneCIS和CIRCO上的大量实验表明,我们的模型性能卓越,显著优于最新基线。代码可在GitHub仓库中找到。
论文及项目相关链接
PDF 9 pages, 8 figures
Summary
本文提出了利用指令优化的多模态大型语言模型(MLLM)生成组合表示的新型嵌入方法,以提高在图像检索中对指令的理解和执行能力。通过两阶段训练策略学习联合多模态嵌入空间,并在四个公共数据集上展示其超越现有技术的性能。
Key Takeaways
- Composed Image Retrieval (CIR)允许通过组合图像和文本查询来检索目标图像,文本指定对视觉参考的修改或变化。
- Zero-Shot CIR (ZS-CIR)因下游任务中标注数据的稀缺性而受欢迎。
- 现有基于CLIP的ZS-CIR模型在解释和应用修改指令方面的能力有限。
- 尝试结合大型语言模型(LLM)来解决这一问题,但仍面临有效整合多模态信息和指令理解上的挑战。
- 新型嵌入方法利用指令优化的多模态LLM(MLLM)生成组合表示,显著提高了指令执行能力,实现了图像和指令之间的全面整合。
- 直接应用MLLMs带来了新的挑战,因为MLLMs主要设计用于文本生成,而不是CIR所需的嵌入提取。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是组合图像检索(Composed Image Retrieval, CIR)中的问题,特别是在零样本(Zero-Shot)场景下。CIR任务涉及根据由图像和指定修改或变化的视觉参考文本组成的组合查询来检索目标图像。这项任务本质上是一个指令跟随任务,因为模型需要解释并应用对图像的修改。在实践中,由于下游任务中标注数据的稀缺,零样本CIR(ZSCIR)是可取的。尽管现有的基于CLIP的ZS-CIR模型显示出了有希望的结果,但它们在解释和遵循修改指令方面的能力仍然有限。一些研究尝试通过引入大型语言模型(LLMs)来解决这一挑战,但这些方法仍然面临着有效整合多模态信息和指令理解的挑战。
具体来说,论文中提出的问题包括:
指令跟随能力不足:现有的基于CLIP的ZS-CIR模型缺乏理解和遵循修改指令的能力,这限制了它们在CIR任务中的表现。
多模态信息整合挑战:尽管一些研究尝试通过引入LLMs来增强模型对指令的理解能力,但这些方法在有效整合多模态信息和指令理解方面仍面临挑战。
特定于任务的数据获取困难:CIR任务需要创建三元组数据(源图像、修改文本、目标图像),这增加了数据收集的复杂性和成本。
为了解决这些问题,论文提出了一种新的嵌入方法,该方法利用指令调整的多模态大型语言模型(MLLM)来生成组合表示,显著增强了指令跟随能力,并在图像和指令之间实现了全面的整合。此外,论文还提出了一个两阶段训练策略,以适应MLLMs在CIR任务中的使用,包括从文本生成转变为表示提取的对比学习,以及通过在类似CIR格式的三元组数据集上调整模型来进一步优化其遵循修改指令的能力。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以归纳为以下几个方向:
基于CLIP的ZS-CIR模型:
- Pic2Word [40] 和 SEARLE [3]:这些方法使用轻量级的投影模块将视觉嵌入映射到文本空间,增强了CLIP框架内视觉和文本模态之间的交互。
- LinCIR [17]:引入了一种仅使用语言的训练策略,利用文本中的关键词来表示图像。
LLMs在CIR中的应用:
- CIReVL [24]:利用ChatGPT结合图像标题和文本指令,实现无需训练的检索过程。
- VDG [21]:提出使用训练有素的多模态LLMs生成三元组数据,但LLM本身在检索过程中的作用有限。
- FROMAGe [25] 和 MCL [27]:采用图像描述和对比学习将LLMs与视觉编码器整合,但这些模型冻结了LLMs,仅将其作为静态编码器使用。
多模态大型语言模型(MLLMs):
- 这些模型展示了在多模态数据上强大的泛化、指令跟随和零样本能力,但在CIR任务中的应用尚未充分探索。
指令调整(Instruction Tuning):
- 这是一种在现代LLM训练中常用的策略,通过让模型接触各种提示来增强模型的泛化能力。
对比学习(Contrastive Learning):
- 对比学习用于学习视觉表示,通过使用正负样本对来训练模型区分不同图像。
零样本学习(Zero-Shot Learning):
- 零样本学习在CIR任务中尤为重要,因为它允许模型在没有特定任务标注数据的情况下进行训练和应用。
这些相关研究构成了论文提出的InstructCIR方法的理论和实践基础,同时也突显了现有方法的局限性,为InstructCIR的提出提供了动机。论文通过结合这些研究方向,提出了一个新的两阶段训练策略,旨在提高模型在CIR任务中的指令跟随能力和多模态信息整合能力。
Q: 论文如何解决这个问题?
A: 论文通过提出一个基于指令调整的多模态大型语言模型(MLLM)的方法来解决零样本组合图像检索(ZS-CIR)中的问题。具体来说,解决方案包括以下几个关键步骤:
1. 两阶段训练策略
第一阶段:对比学习
- 目标:创建一个联合的多模态嵌入空间,使MLLM从文本生成转变为有效的表示提取。
- 方法:使用纯图像-文本对进行对比学习,训练MLLM以产生适合检索的多模态嵌入。
第二阶段:指令对比调整
- 目标:增强MLLM对指令的敏感性,使其能够根据修改指令调整嵌入。
- 方法:在类似CIR任务的三元组数据集上微调模型,使图像-指令嵌入与目标标题嵌入对齐。
2. 构建指令感知数据集
- 方法:使用GPT-4o通过链式思考(Chain of Thought)方法从现有图像-标题对中生成三元组数据(源图像、修改指令、目标标题)。
- 目的:弥补图像-文本检索和组合图像检索之间的任务差异,为模型训练提供理想的资源。
3. 指令感知对比学习
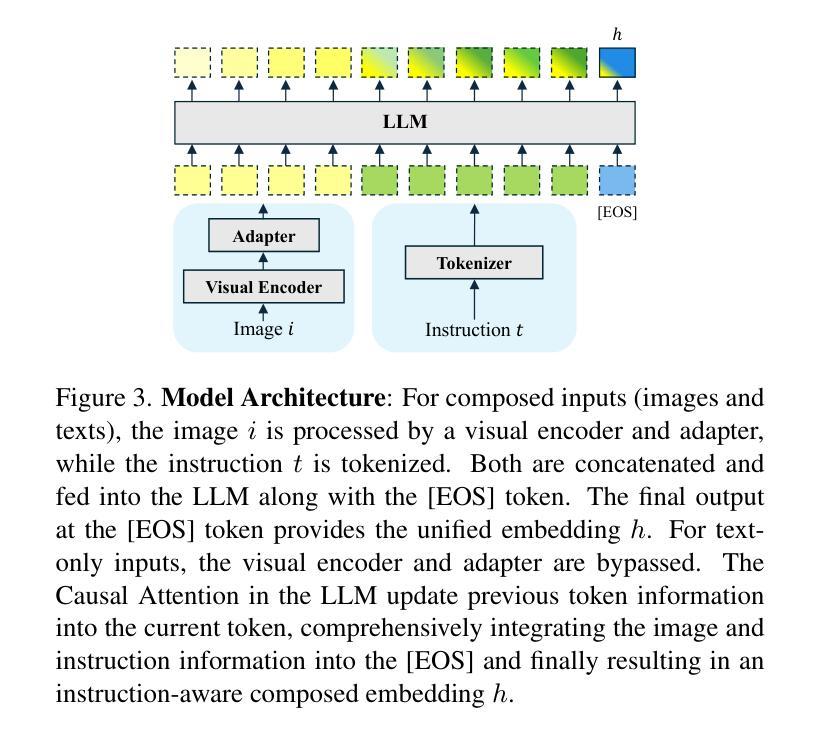
- 模型架构:使用视觉编码器和适配器处理图像,同时将指令文本化并输入MLLM以生成统一嵌入。
- 方法:在输入序列末尾添加特殊标记[EOS],并使用此标记的输出作为全局表示,以整合图像和指令信息。
4. 实验验证
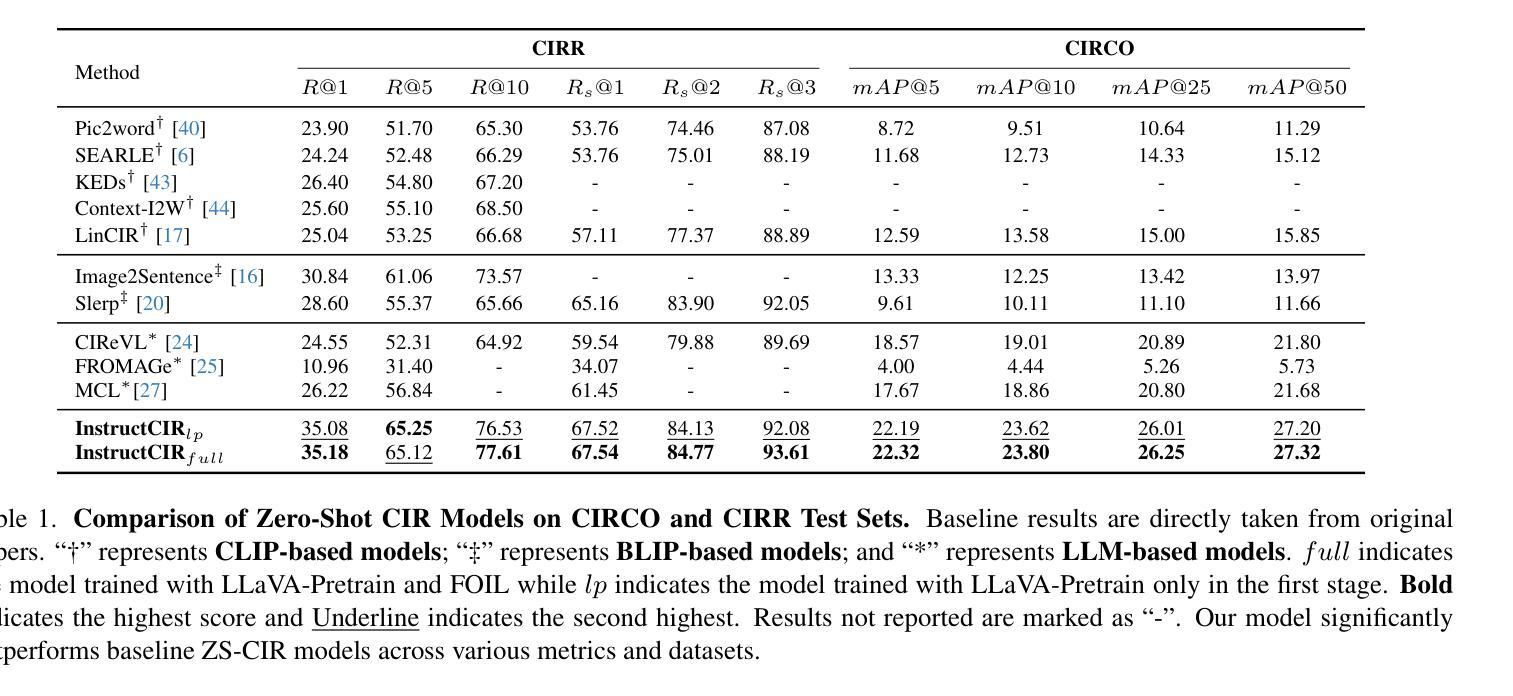
- 数据集:在四个公共数据集(FashionIQ、CIRR、GeneCIS、CIRCO)上进行广泛实验。
- 结果:与现有最先进基线相比,所提出的模型在性能上取得了显著提升。
通过这些方法,论文成功地提高了模型在零样本组合图像检索任务中的指令理解和跟随能力,并在多个数据集上验证了其有效性。这种方法充分利用了MLLMs在指令理解和多模态信息整合方面的优势,为解决ZS-CIR任务中的挑战提供了新的思路。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验来验证所提出的InstructCIR模型的性能,具体实验包括:
主实验:
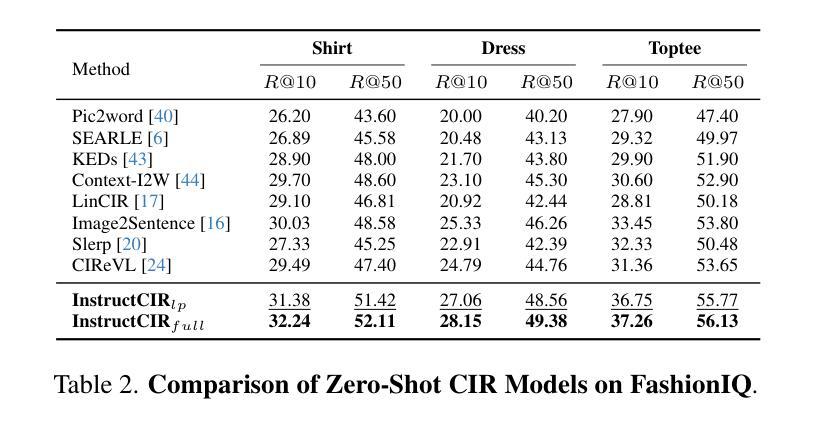
- 数据集:在四个公开的零样本CIR基准数据集上进行实验,分别是FashionIQ、CIRR、CIRCO和GeneCIS。
- 评估指标:对于FashionIQ、CIRR和GeneCIS,使用Recall@k (R@k)作为评估指标;对于CIRCO,使用mean Average Precision (mAP@k)来衡量。
- 结果:与现有的多个基线模型进行比较,包括基于CLIP的模型、基于BLIP的模型和基于LLM的模型,验证了InstructCIR在各个数据集上的性能优势。
消融研究:
- 不同训练阶段的贡献:分析了两阶段训练策略中每个阶段对模型性能的贡献,特别是第一阶段的对比学习和第二阶段的指令对比调整。
- 训练数据的影响:评估了不同规模的训练数据对模型性能的影响,包括使用全部原始配对数据与三元组数据的效果。
- 硬负样本和模板策略:探讨了在训练中使用硬负样本和随机选择模板的有效性。
- 适应复杂MLLM机制:分析了InstructCIR训练策略是否能够适应更复杂的MLLM机制,例如使用microsoft/Phi-3.5-vision-instruct作为基础模型。
注意力图分析:
- 定性分析:通过注意力图来分析InstructCIR如何关注图像中与指令相关的特定部分,展示了模型在训练前后对图像区域的关注差异。
这些实验全面地评估了InstructCIR模型的性能,并深入探讨了不同组件和训练策略对最终结果的影响。通过这些实验,论文证明了所提出方法的有效性和鲁棒性,并为未来的研究提供了有价值的见解。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
更大规模的MLLM模型:
- 探索使用更大规模的MLLM模型是否会进一步提升CIR任务的性能,并分析性能提升与模型规模之间的关系。
数据集的多样性和复杂性:
- 在更多样化和复杂性更高的数据集上测试InstructCIR模型,以评估其泛化能力和鲁棒性。
- 探索不同领域(如医疗、卫星图像等)的数据集,以验证模型在特定行业的适用性。
训练策略的优化:
- 研究不同的训练策略,如半监督学习或自监督学习,以减少对标注数据的依赖。
- 探索使用不同的优化算法或学习率调度策略,以提高模型训练的效率和效果。
模型解释性:
- 提高模型的可解释性,通过可视化技术(如注意力图)来更深入地理解模型是如何整合图像和文本信息的。
- 分析模型在处理特定类型指令时的行为,以识别模型的潜在偏差或局限性。
跨模态融合技术:
- 研究不同的图像和文本融合技术,以改善模型对多模态信息的整合能力。
- 探索使用其他类型的神经网络架构(如Transformer或Graph Network)来改进跨模态交互。
实时性能和资源效率:
- 针对移动或嵌入式设备优化模型,以实现实时CIR功能,同时保持较低的资源消耗。
- 研究模型压缩和加速技术,如知识蒸馏或量化,以提高模型的部署效率。
多语言和跨文化研究:
- 将模型扩展到多语言设置,以处理不同语言和文化背景下的图像和文本数据。
- 研究模型在跨文化CIR任务中的性能,以及如何调整模型以适应不同的文化差异。
长尾分布和类别不平衡:
- 研究模型在处理类别不平衡或长尾分布数据集时的表现,并开发策略来缓解这些问题。
结合其他模态信息:
- 考虑将其他类型的模态信息(如音频或视频)整合到CIR框架中,以实现更丰富的多模态交互。
这些探索点可以帮助研究者更全面地理解InstructCIR模型的潜力和局限性,并推动CIR技术的发展和应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为InstructCIR的零样本组合图像检索(ZS-CIR)模型,旨在解决现有ZS-CIR模型在理解和遵循修改指令方面的局限性。主要内容包括:
问题定义:
- 论文首先定义了组合图像检索(CIR)任务,即基于由图像和修改指令组成的查询来检索目标图像。
- 强调了CIR任务的指令跟随特性,并指出现有基于CLIP的模型在这方面的不足。
方法论:
- 提出了一种新的嵌入方法,利用指令调整的多模态大型语言模型(MLLM)生成能够整合图像和指令的组合表示。
- 引入了一个两阶段训练策略:
- 第一阶段:通过对比学习使用纯图像-文本对训练MLLM,使其从文本生成转变为表示提取。
- 第二阶段:在类似CIR任务的三元组数据集上微调MLLM,增强其遵循修改指令的能力。
数据集构建:
- 构建了一个指令感知的数据集,使用GPT-4o生成三元组数据(源图像、修改指令、目标标题),以支持模型训练。
模型架构:
- 描述了一个基于MLLM的模型架构,该架构可以处理图像、文本或两者的组合以生成统一的嵌入。
实验:
- 在四个公共数据集(FashionIQ、CIRR、GeneCIS、CIRCO)上进行了广泛的实验,验证了InstructCIR模型的优越性能。
- 与多个现有最先进基线模型进行了比较,InstructCIR在各项指标上均取得了显著的性能提升。
消融研究:
- 进行了消融研究来分析不同训练阶段、训练数据规模和硬负样本策略对模型性能的影响。
- 探讨了InstructCIR训练策略是否可适应更复杂的MLLM机制。
结论:
- 论文总结了InstructCIR模型的潜力,并强调了MLLM在CIR系统中的作用,为未来的研究提供了有价值的见解。
总体而言,这篇论文提出了一个创新的方法来提高CIR任务中模型对修改指令的理解和遵循能力,通过指令调整的MLLM和两阶段训练策略,显著提高了零样本场景下的图像检索性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight {\tt CAS-GAN}’s potential for clinical applications.
碘化造影剂在众多介入手术中广泛应用,但为患者带来较大的健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,作为“虚拟造影剂”通过解纠缠表示学习和血管语义指导来合成X射线血管造影术,从而减少介入手术中对碘化造影剂的依赖。具体来说,我们的方法将X射线血管造影术分解为背景和血管成分,利用医学先验知识。然后,一个专门的预测器学习这些成分之间的相互作用关系。此外,还引入了血管语义引导生成器和相应的损失函数,以提高生成图像的可视逼真度。在XCAD数据集上的实验结果表明,我们的CAS-GAN达到了最先进的性能,FID为5.87,MMD为0.016。这些令人鼓舞的结果突出了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
Summary
本论文提出了一种名为CAS-GAN的新型GAN框架,可作为“虚拟对比剂”来合成X射线血管造影图像。该技术通过解纠缠表示学习和血管语义指导,减少对含碘对比剂的需求。CAS-GAN能将X射线血管造影图像分解为背景和血管成分,并利用医学先验知识建立专门的预测模型。同时,引入血管语义引导的生成器和相应的损失函数,以提高生成图像的可视保真度。在XCAD数据集上的实验结果表明,CAS-GAN具有卓越的性能,达到了FID 5.87和MMD 0.016。这显示出CAS-GAN在临床应用中的潜力。
Key Takeaways
- CAS-GAN作为一种新型GAN框架,被用作“虚拟对比剂”,以合成X射线血管造影图像。
- 该技术通过解纠缠表示学习和血管语义指导,减少了对含碘对比剂的需求。
- CAS-GAN能将X射线血管造影图像分解为背景和血管成分,并利用医学先验知识建立预测模型。
- 引入了一种血管语义引导的生成器,以提高生成图像的可视保真度。
- CAS-GAN在XCAD数据集上的实验表现出卓越性能,达到了FID 5.87和MMD 0.016。
- CAS-GAN具有潜在的临床应用价值。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
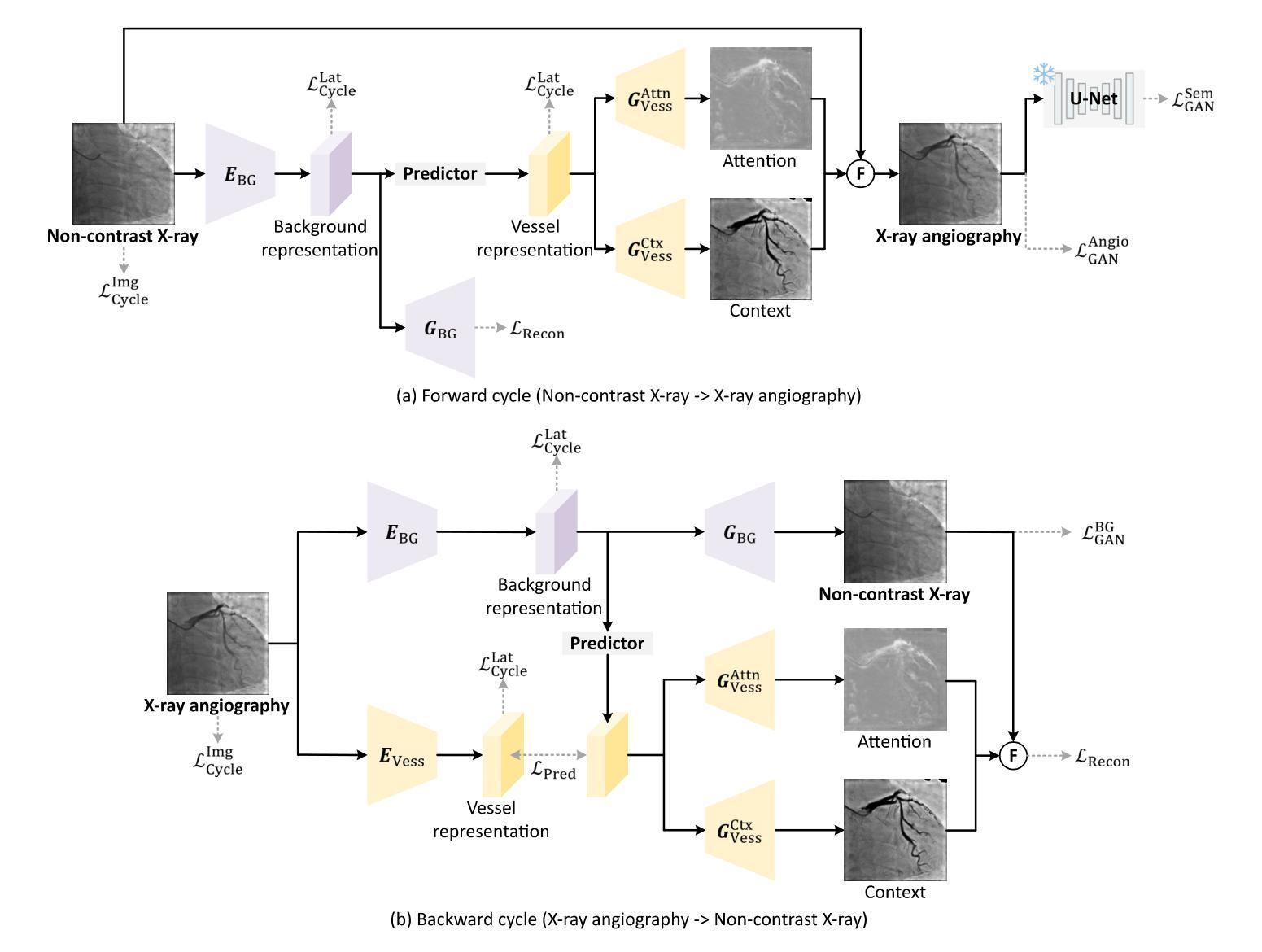
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
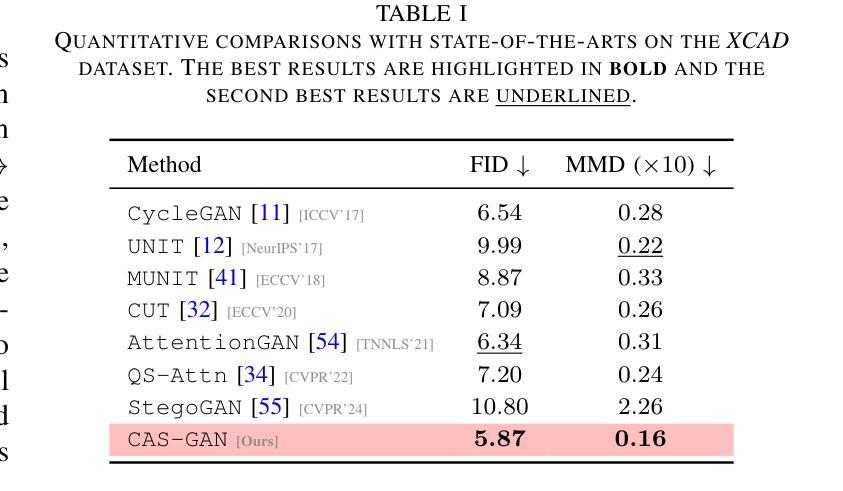
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
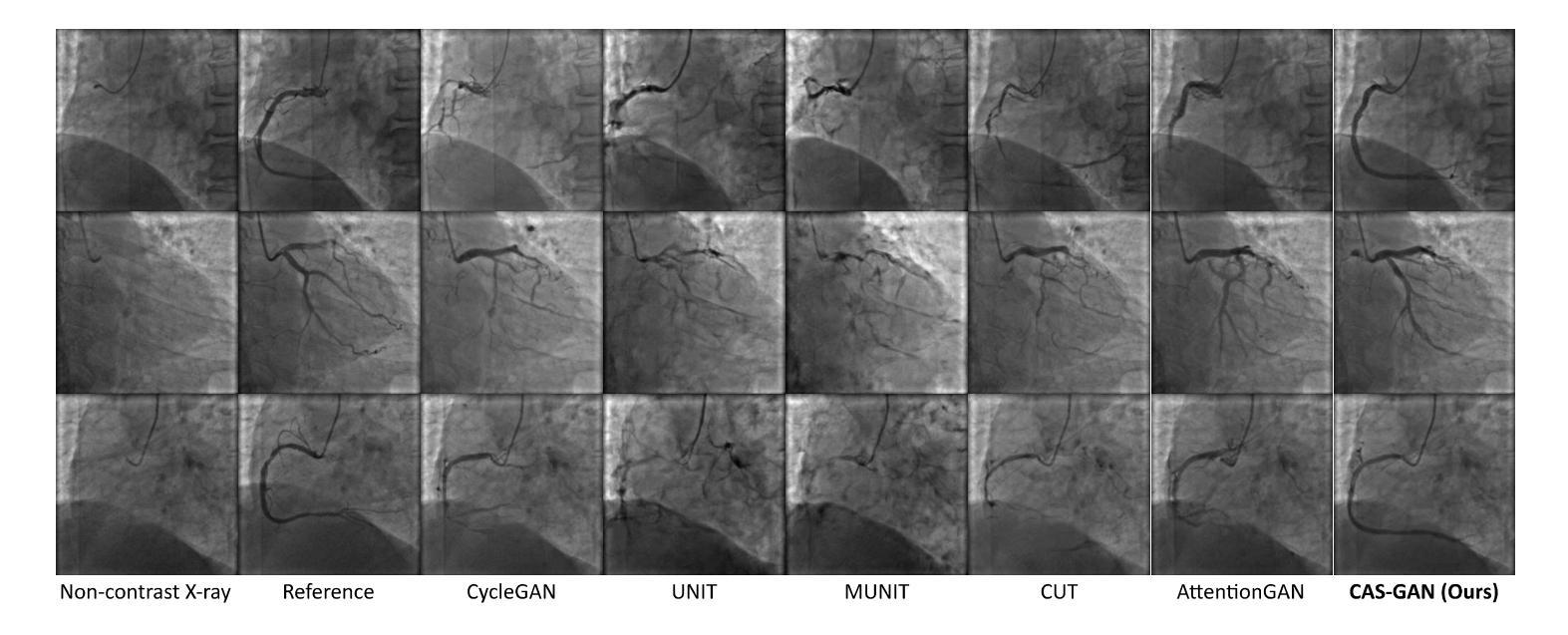
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
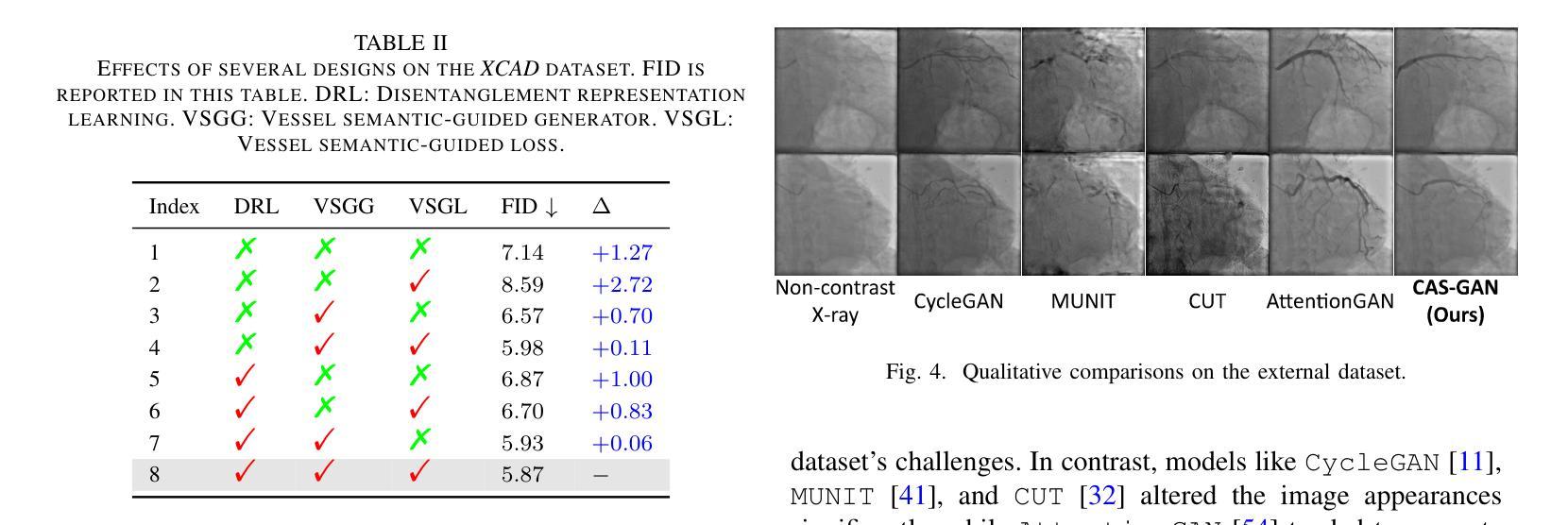
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图