⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
FD2-Net: Frequency-Driven Feature Decomposition Network for Infrared-Visible Object Detection
Authors:Ke Li, Di Wang, Zhangyuan Hu, Shaofeng Li, Weiping Ni, Lin Zhao, Quan Wang
Infrared-visible object detection (IVOD) seeks to harness the complementary information in infrared and visible images, thereby enhancing the performance of detectors in complex environments. However, existing methods often neglect the frequency characteristics of complementary information, such as the abundant high-frequency details in visible images and the valuable low-frequency thermal information in infrared images, thus constraining detection performance. To solve this problem, we introduce a novel Frequency-Driven Feature Decomposition Network for IVOD, called FD2-Net, which effectively captures the unique frequency representations of complementary information across multimodal visual spaces. Specifically, we propose a feature decomposition encoder, wherein the high-frequency unit (HFU) utilizes discrete cosine transform to capture representative high-frequency features, while the low-frequency unit (LFU) employs dynamic receptive fields to model the multi-scale context of diverse objects. Next, we adopt a parameter-free complementary strengths strategy to enhance multimodal features through seamless inter-frequency recoupling. Furthermore, we innovatively design a multimodal reconstruction mechanism that recovers image details lost during feature extraction, further leveraging the complementary information from infrared and visible images to enhance overall representational capacity. Extensive experiments demonstrate that FD2-Net outperforms state-of-the-art (SOTA) models across various IVOD benchmarks, i.e. LLVIP (96.2% mAP), FLIR (82.9% mAP), and M3FD (83.5% mAP).
红外可见目标检测(IVOD)旨在利用红外图像和可见图像中的互补信息,从而提高复杂环境中的检测器性能。然而,现有方法往往忽略了互补信息的频率特性,例如可见图像中丰富的高频细节和红外图像中宝贵的低频热信息,从而限制了检测性能。为了解决这个问题,我们提出了一种用于IVOD的新型频率驱动特征分解网络,称为FD2-Net,该网络可以有效地捕获跨多模态视觉空间的互补信息的独特频率表示。具体来说,我们提出了一种特征分解编码器,其中高频单元(HFU)利用离散余弦变换来捕获具有代表性的高频特征,而低频单元(LFU)则采用动态感受野来对不同对象的多尺度上下文进行建模。接下来,我们采用无参数的互补强度策略来增强多模态特征,通过无缝的跨频率重新耦合来实现。此外,我们还创新地设计了一种多模态重建机制,以恢复在特征提取过程中丢失的图像细节,进一步利用红外和可见图像的互补信息来提高整体表示能力。大量实验表明,FD2-Net在多种IVOD基准测试中均优于最新模型,例如在LLVIP上达到96.2%的mAP,在FLIR上达到82.9%的mAP以及在M3FD上达到83.5%的mAP。
论文及项目相关链接
PDF This work is accepted by AAAI 2025
Summary:红外可见目标检测(IVOD)旨在利用红外和可见图像中的互补信息,提高复杂环境中的检测性能。然而,现有方法常常忽视互补信息的频率特性,如可见图像中的丰富高频细节和红外图像中的宝贵低频热信息。为解决此问题,我们提出一种新型的频率驱动特征分解网络FD2-Net,能有效捕捉跨多模态视觉空间的互补信息的独特频率表示。通过特征分解编码器、参数化互补强度策略和多模态重建机制等手段,FD2-Net在多个IVOD基准测试中表现出超越现有模型的性能,如LLVIP(96.2% mAP)、FLIR(82.9% mAP)和M3FD(83.5% mAP)。
Key Takeaways:
- IVOD旨在结合红外和可见图像中的互补信息,提高检测性能。
- 现有方法忽视了互补信息的频率特性,如高频细节和低频热信息。
- 提出一种新型频率驱动特征分解网络FD2-Net。
- FD2-Net通过特征分解编码器捕捉多模态视觉空间的独特频率表示。
- 采用参数化互补强度策略增强多模态特征。
- 设计多模态重建机制,恢复图像细节,提高表示能力。
- FD2-Net在多个IVOD基准测试中表现优越。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是红外-可见光目标检测(Infrared-Visible Object Detection, IVOD)中的问题。具体来说,论文旨在通过利用红外和可见光图像中的互补信息来增强复杂环境下探测器的性能。现有方法往往忽视了互补信息的频率特性,例如可见图像中丰富的高频细节和红外图像中有价值的低频热信息,这限制了检测性能。因此,论文提出了一种新的频率驱动的特征分解网络(FD2-Net),有效地捕获跨多模态视觉空间的互补信息的独特频率表示,以改善目标检测的性能。
Q: 有哪些相关研究?
A: 相关研究主要集中在以下几个方面:
通用目标检测(General Object Detection):
- 两阶段检测器(Two-stage detectors),如Faster R-CNN,包含区域提议网络(Region Proposal Network, RPN)、感兴趣区域(Region of Interest, RoI)池化和检测头。
- 一阶段检测器(One-stage detectors),如YOLO系列,直接从密集采样的网格预测边界框和类别,实现更快的推理速度。
红外-可见光目标检测(Infrared-Visible Object Detection, IVOD):
- TINet:通过强调红外和可见光图像之间的差异来增强互补信息的提取。
- AR-CNN:提出区域特征对齐模块以增强检测性能,针对可见光和红外图像在空间维度的错位。
- DMAF:设计了一种基于照明条件的特征对齐模块,选择特征并适应性地对齐跨模态特征。
- APWNet:引入图像融合损失以增强YOLOv5的性能。
- SuperYOLO:添加图像超分辨率分支以加强特征提取能力。
- LRAF-Net:通过融合可见光和红外特征的长程依赖性来提高检测性能。
- DFANet:引入对抗性特征提取和发散模块以提取具有独特信息的差异化红外和可见光特征。
特征提取和融合技术:
- 探索改进的融合技术,以有效地捕获红外-可见光图像的互补特征。
这些相关研究为本文提出的FD2-Net提供了理论基础和技术背景,特别是在多模态特征提取、融合以及目标检测方面。FD2-Net通过频率驱动的特征分解和多模态重建机制,有效地利用了红外和可见光图像中的互补信息,以提高目标检测的性能。
Q: 论文如何解决这个问题?
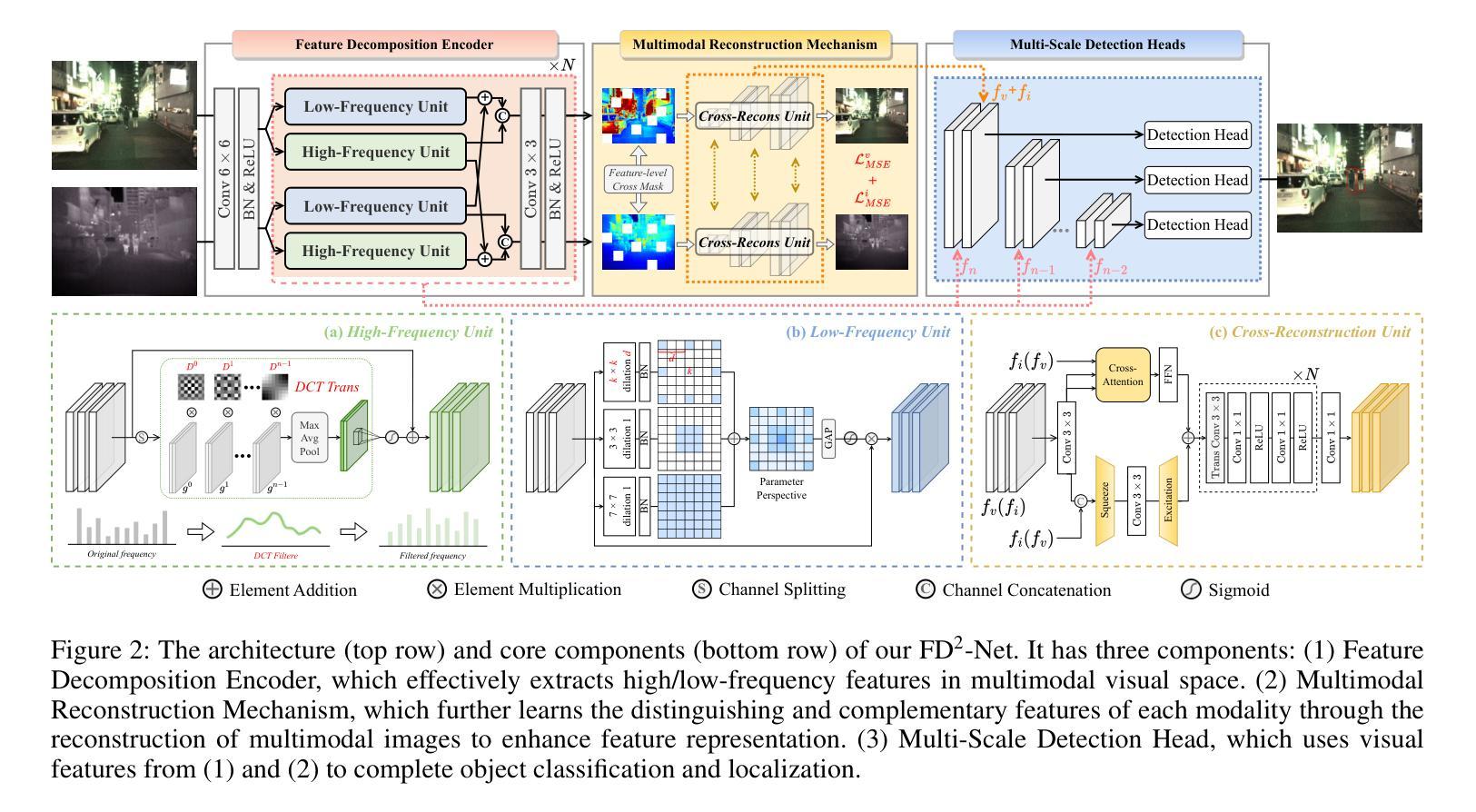
A: 论文通过提出一种名为FD2-Net(Frequency-Driven Feature Decomposition Network)的新型网络架构来解决红外-可见光目标检测(IVOD)中的问题。具体解决方案包括以下几个关键组件:
特征分解编码器(Feature Decomposition Encoder):
- 高频单元(High-Frequency Unit, HFU):利用离散余弦变换(Discrete Cosine Transform, DCT)捕获代表性的高频特征,如边缘和纹理。
- 低频单元(Low-Frequency Unit, LFU):采用动态接收场(dynamic receptive fields)来模拟不同物体的多尺度上下文信息,捕获低频结构和环境关系。
- 互补强度策略(Complementary Strengths Strategy, CSS):通过无缝的频率间重耦合来增强多模态特征。
多模态重建机制(Multimodal Reconstruction Mechanism):
- 特征级交叉掩码(Feature-level Cross Mask):通过不对称掩码策略,迫使网络从互补模态中获取有用信息。
- 交叉重建单元(Cross-Reconstruction Unit, CRU):通过细粒度局部和粗粒度全局交互学习互补特征,恢复多模态图像。
多尺度检测头(Multi-Scale Detection Heads):
- 构建特征金字塔网络(Feature Pyramid Network, FPN),利用编码器在不同阶段提取的多尺度特征。
- 在FPN的最高分辨率层,整合重建的多模态特征以进一步增强检测。
- 配置不同尺度的三个检测头以准确检测物体。
通过这些组件,FD2-Net能够有效地从红外和可见光图像中提取互补特征,并利用这些特征来增强目标检测的性能。具体来说,FD2-Net通过频率分解来保留更多的代表性低频和高频信息,并通过多模态重建机制进一步利用互补信息来恢复结构和纹理细节,从而提高检测的准确性和鲁棒性。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验来验证FD2-Net模型的有效性,实验包括以下几个方面:
数据集:
- LLVIP数据集:一个大规模的行人检测数据集,专门收集于低光照条件下,主要展示极暗场景。
- FLIR数据集:一个具有挑战性的多光谱目标检测基准,包含日间和夜间场景。
- M3FD数据集:包含RGB和热图像的4200对图像,涉及六个类别的对象。
方法比较:
- 将FD2Net与多种基线和SOTA(State-of-the-Art)方法进行比较,包括SDNet、TarDAL、DensFuse、U2Fusion、CDDFuse、SegMiF、DDFM、MetaF、LRRNet、CSSA和TFDet等。
主要结果:
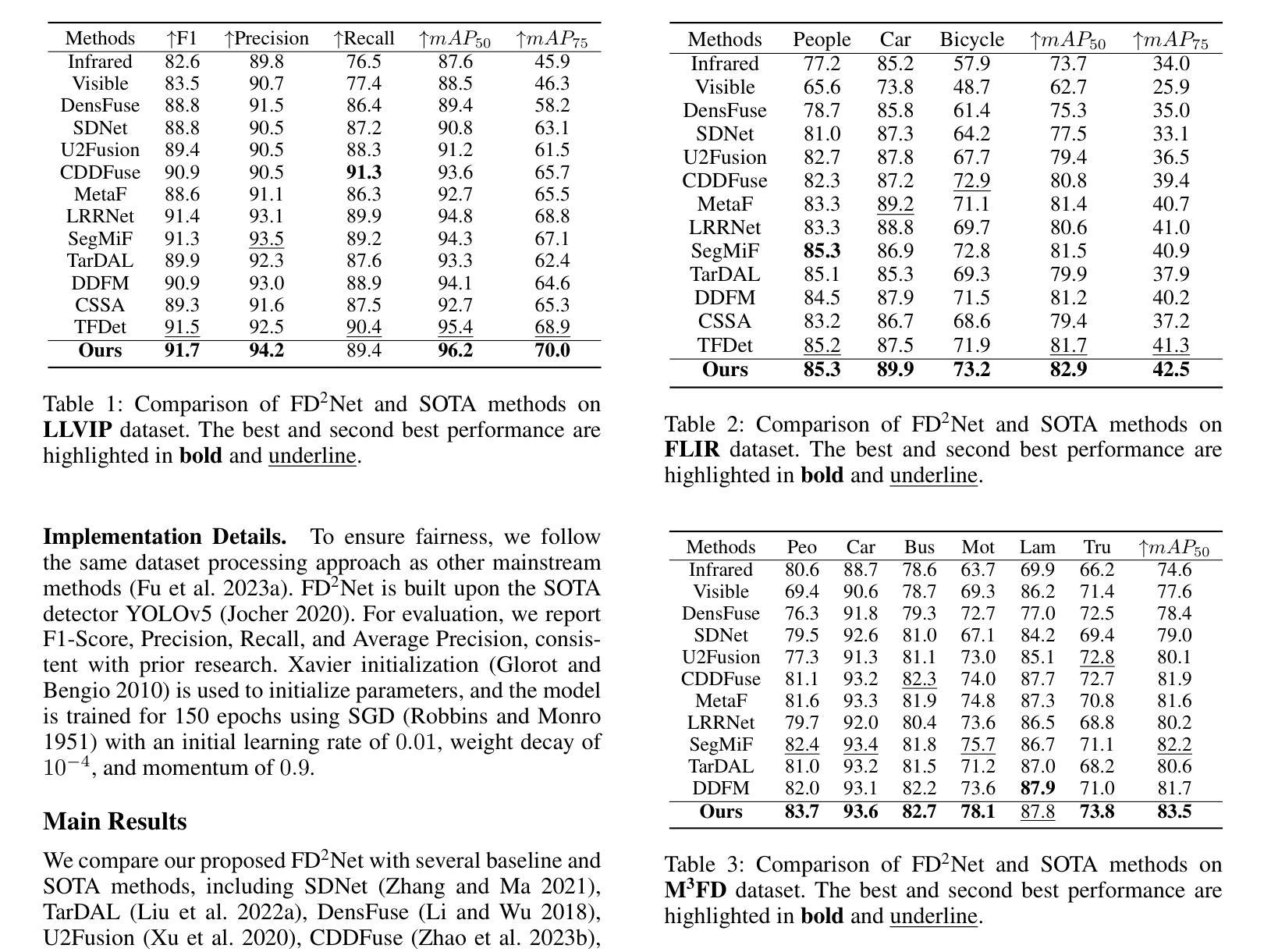
- 在LLVIP数据集上,FD2Net在mAP50指标上达到了96.2%的准确率,超越了其他SOTA方法。
- 在FLIR数据集上,FD2Net在mAP50和mAP75指标上分别达到了82.9%和41.9%,建立了新的SOTA基准。
- 在M3FD数据集上,FD2Net在mAP50指标上达到了83.5%的准确率,并在“人”和“摩托车”类别中取得了超过先前最佳方法的检测精度。
视觉比较:
- 展示了FD2Net与其他10种SOTA方法的检测结果的视觉比较,突出显示了FD2Net在各种挑战性场景中的优越性能。
消融研究:
- 对FD2Net的不同组件进行了消融研究,以评估各个组件对模型性能的影响,包括高频单元(HFU)、低频单元(LFU)和交叉重建单元(CRU)。
特征图可视化:
- 对原始YOLOv5和FD2Net的特征图进行了可视化比较,以展示FD2Net在特征表示能力上的优势。
这些实验结果表明,FD2Net能够有效地从红外和可见光图像中提取互补特征,并利用这些特征来增强目标检测的性能,达到了竞争性红外-可见光目标检测基准中的SOTA性能。
Q: 有什么可以进一步探索的点?
A: 尽管FD2-Net在红外-可见光目标检测(IVOD)领域取得了显著的性能提升,但仍有一些方向可以进一步探索和改进:
更深层次的特征融合策略:
- 探索更复杂的特征融合方法,例如基于注意力机制的融合策略,以更有效地结合来自不同模态的特征。
多模态数据增强技术:
- 研究新的数据增强技术,以提高模型对不同环境条件和目标姿态变化的鲁棒性。
模型压缩和加速:
- 考虑模型的计算效率和实际部署需求,研究模型压缩和加速技术,以适应资源受限的设备。
小目标和遮挡目标检测:
- 针对小目标和遮挡目标检测的挑战,研究专门的检测头和损失函数,以提高模型在这些情况下的性能。
跨模态一致性学习:
- 研究如何更好地学习跨模态一致性,以减少不同传感器之间特征表示的差异。
多任务学习框架:
- 将目标检测任务与其他视觉任务(如分割、识别)结合在一个统一的多任务学习框架中,以提高模型的整体性能。
更广泛的数据集和应用场景:
- 在更广泛的数据集和应用场景中评估模型性能,包括不同天气条件、不同时间段和不同类型的目标。
模型的可解释性和泛化能力:
- 提高模型的可解释性,分析和理解模型做出决策的原因,以及提高模型对未见数据的泛化能力。
对抗性攻击和防御机制:
- 研究对抗性攻击对模型性能的影响,并开发有效的防御机制来提高模型的安全性。
实时性能优化:
- 针对实时应用场景,进一步优化模型的推理速度,以满足实时或近实时处理的需求。
这些方向不仅可以推动IVOD技术的发展,还可能对计算机视觉领域的其他任务产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题陈述:
论文针对的是红外-可见光目标检测(IVOD)问题,旨在通过结合红外和可见光图像中的互补信息来提高复杂环境下的目标检测性能。现有方法的局限性:
现有方法往往忽视了互补信息的频率特性,例如可见光图像中的高频细节和红外图像中的低频热信息,这限制了检测性能。FD2-Net网络架构:
论文提出了一种新的频率驱动的特征分解网络(FD2-Net),该网络能够有效捕获跨多模态视觉空间的互补信息的独特频率表示。关键组件:
- 特征分解编码器:包含高频单元(HFU)和低频单元(LFU),分别捕获高频和低频特征。
- 互补强度策略:通过频率间重耦合增强多模态特征。
- 多模态重建机制:通过特征级交叉掩码和交叉重建单元(CRU)进一步增强特征表示。
- 多尺度检测头:基于特征金字塔网络(FPN)构建,用于对象分类和定位。
实验验证:
论文通过在LLVIP、FLIR和M3FD三个IVOD基准数据集上的实验,验证了FD2-Net的有效性。FD2-Net在这些数据集上均取得了SOTA性能。消融研究:
论文还进行了消融研究,以评估不同组件对模型性能的影响,进一步证明了所提方法的有效性。结论:
FD2-Net通过有效地建模高频和低频特征,并利用多模态重建机制更有效地利用多模态图像中的互补信息,实现了在竞争性红外-可见光目标检测基准中的SOTA性能。
论文的贡献在于提出了一种新的IVOD范式,通过频率分解和多模态重建机制,有效地提取和利用了红外和可见光图像中的互补特征,从而提高了目标检测的准确性和鲁棒性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

UADet: A Remarkably Simple Yet Effective Uncertainty-Aware Open-Set Object Detection Framework
Authors:Silin Cheng, Yuanpei Liu, Kai Han
We tackle the challenging problem of Open-Set Object Detection (OSOD), which aims to detect both known and unknown objects in unlabelled images. The main difficulty arises from the absence of supervision for these unknown classes, making it challenging to distinguish them from the background. Existing OSOD detectors either fail to properly exploit or inadequately leverage the abundant unlabeled unknown objects in training data, restricting their performance. To address these limitations, we propose UADet, an Uncertainty-Aware Open-Set Object Detector that considers appearance and geometric uncertainty. By integrating these uncertainty measures, UADet effectively reduces the number of unannotated instances incorrectly utilized or omitted by previous methods. Extensive experiments on OSOD benchmarks demonstrate that UADet substantially outperforms previous state-of-the-art (SOTA) methods in detecting both known and unknown objects, achieving a 1.8x improvement in unknown recall while maintaining high performance on known classes. When extended to Open World Object Detection (OWOD), our method shows significant advantages over the current SOTA method, with average improvements of 13.8% and 6.9% in unknown recall on M-OWODB and S-OWODB benchmarks, respectively. Extensive results validate the effectiveness of our uncertainty-aware approach across different open-set scenarios.
我们解决了开放集物体检测(OSOD)这一具有挑战性的问题,其目标是在未标记的图像中检测已知和未知物体。主要困难在于这些未知类别缺乏监督,使得将它们与背景区分开来具有挑战性。现有的OSOD检测器要么未能充分利用,要么不足以利用训练数据中的大量未标记的未知物体,从而限制了它们的性能。为了解决这些局限性,我们提出了UADet,一种不确定性感知的开放集物体检测器,它考虑了外观和几何不确定性。通过整合这些不确定性度量,UADet有效地减少了先前方法错误使用或遗漏未注释实例的数量。在OSOD基准测试上的广泛实验表明,UADet在检测已知和未知物体方面大大优于先前最先进的(SOTA)方法,在未知召回率方面实现了1.8倍的改进,同时保持对已知类的高性能。将其扩展到开放世界物体检测(OWOD)时,我们的方法在M-OWODB和S-OWODB基准测试上均显示出对当前SOTA方法的显著优势,未知召回率平均提高了13.8%和6.9%。大量结果验证了我们在不同开放集场景中的不确定性感知方法的有效性。
论文及项目相关链接
PDF Under review
Summary:
针对开放集物体检测(OSOD)问题,提出一种不确定性感知的开放集物体检测器UADet,能检测未知物体并考虑外观和几何不确定性。通过整合这些不确定性度量,UADet有效减少了之前方法误用或遗漏未标注实例的数量。在OSOD基准测试中,UADet在检测已知和未知物体方面大幅超越了现有先进技术,未知召回率提高了1.8倍,同时保持了对已知类的高性能。扩展到开放世界物体检测(OWOD)时,我们的方法在M-OWODB和S-OWODB基准测试上未知召回率平均提高了13.8%和6.9%。
Key Takeaways:
- 该文本主要介绍了开放集物体检测(OSOD)问题及其挑战。
- 现有OSOD检测器无法充分利用训练数据中的未标记未知物体。
- 提出了一种新的不确定性感知的开放集物体检测器UADet,结合外观和几何不确定性。
- UADet在OSOD基准测试中显著优于现有技术,未知召回率提高1.8倍,同时保持对已知类的高性能。
- UADet在开放世界物体检测(OWOD)中也表现出显著优势,特别是在M-OWODB和S-OWODB基准测试上。
- UADet通过考虑不确定性,有效减少了误用或遗漏未标注实例的数量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是开放集目标检测(Open-Set Object Detection, OSOD)这一挑战性问题。开放集目标检测的目标是在未标记的图像中同时检测已知类别和未知类别的物体。这个问题的主要难点在于未知类别的物体在训练数据中没有标注,因此很难将它们与背景区分开来。现有的开放集目标检测方法要么未能充分利用,要么不恰当地利用了训练数据中的大量未标记未知物体,限制了它们的表现。为了解决这些限制,论文提出了一个名为UADet的不确定性感知开放集目标检测框架,该框架考虑了外观和几何不确定性,通过整合这些不确定性度量,有效地减少了以前方法中错误使用或遗漏的未标注实例的数量。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
开放集识别和检测(Open-Set Recognition and Detection):
- 最初的开放集识别(OSR)问题被定义为一个约束最小化问题,并在后续工作中扩展到多类分类器。
- 深度学习基础上的开放集识别方法,如OpenMax,利用特征空间分析和集成风险估计进行未知检测。
- 其他方法包括原型学习、基于自编码器的重建和生成建模等策略。
开放世界目标检测(Open-world Object Detection, OWOD):
- OWOD任务扩展了OSOD任务到动态场景,模型需要在新知识不断加入的同时识别已知和未知物体。
- 研究工作主要分为两类:一类仅依赖标注实例学习通用特征以泛化到未知类别;另一类通过伪标签策略积极利用未标记实例。
基于不同检测架构的方法:
- 一些方法基于Faster R-CNN和DETR等检测架构,通过不同的策略处理未标记实例。
不确定性量化:
- 近年来的OSOD研究关注于不确定性量化,包括Dropout采样和高斯混合建模等技术。
相关技术:
- 包括特征金字塔网络(FPN)用于特征提取,以及多种优化技术和损失函数用于模型训练。
这些相关研究构成了开放集目标检测领域的研究基础,并为本文提出的UADet框架提供了理论和技术支持。论文中还引用了多个具体的文献来支持上述相关研究领域的内容。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为UADet(Uncertainty-Aware Open-Set Object Detector)的框架来解决开放集目标检测问题。UADet主要通过以下几个关键步骤来解决这个问题:
1. 考虑外观和几何不确定性
UADet在利用训练图像中的未知对象时引入了不确定性感知,这包括外观不确定性(即对象位于前景的可能性)和几何不确定性(即与已知对象的重叠量)。通过整合这些因素,UADet能够更有效地减少以前方法中错误使用或遗漏的未标注实例的数量。
2. 外观不确定性建模
- 利用RPN(Region Proposal Network)的objectness分数作为外观不确定性的指标,假设负样本包含未知前景对象的概率与objectness分数成正比。
3. 几何不确定性建模
- 使用proposal与已知对象的真实边界框(GT box)之间的交并比(IoU)作为几何不确定性的度量,将几何不确定性与外观不确定性结合起来,以减少对已知类别预测的干扰。
4. 标签分配策略
- 对于每个负样本proposal,UADet提出了一种基于不确定性的软标签分配策略,该策略结合了外观和几何不确定性,以更准确地标注未知对象。
5. 整体优化
- UADet通过多任务损失进行训练,包括RPN损失、边界框回归损失和基于不确定性感知的分类损失。
6. 扩展到开放世界目标检测(OWOD)
- UADet的方法可以很容易地扩展到OWOD任务,通过结合示例重放(exemplar replay)策略进行微调,以减轻对先前学习类别的灾难性遗忘。
7. 实验验证
- 论文通过在公共基准测试上的广泛实验验证了UADet的有效性,包括在OSOD和OWOD任务上都取得了新的最佳性能。
综上所述,UADet通过考虑不确定性并将其整合到目标检测框架中,有效地提高了对未知类别的检测能力,同时保持了对已知类别的高性能。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验来验证UADet框架的有效性。以下是实验的主要部分:
1. 实验设置
- 数据集:UADet在由PASCAL VOC0712和MS COCO数据集构建的OSOD基准上进行评估,包括VOC-COCO-{T1, T2}设置,以及M-OWODB和S-OWODB这两个开放世界目标检测(OWOD)基准。
2. 主要结果
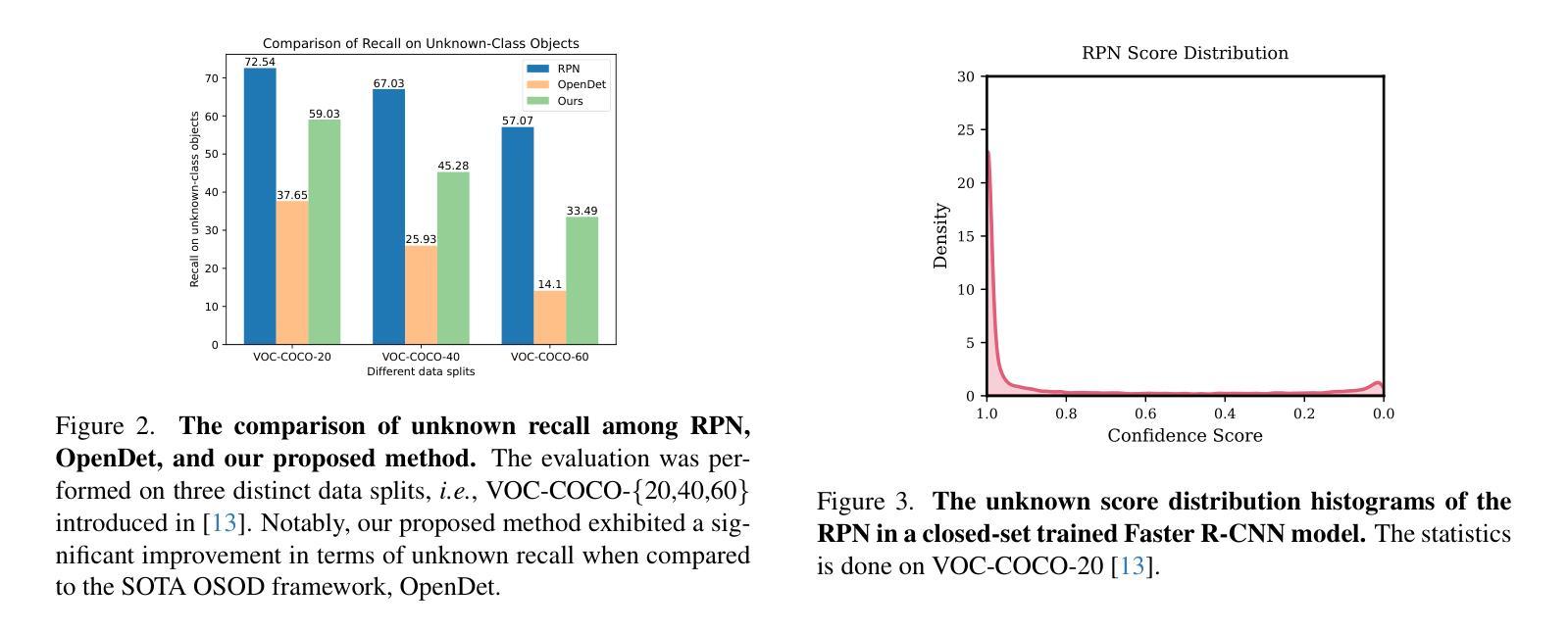
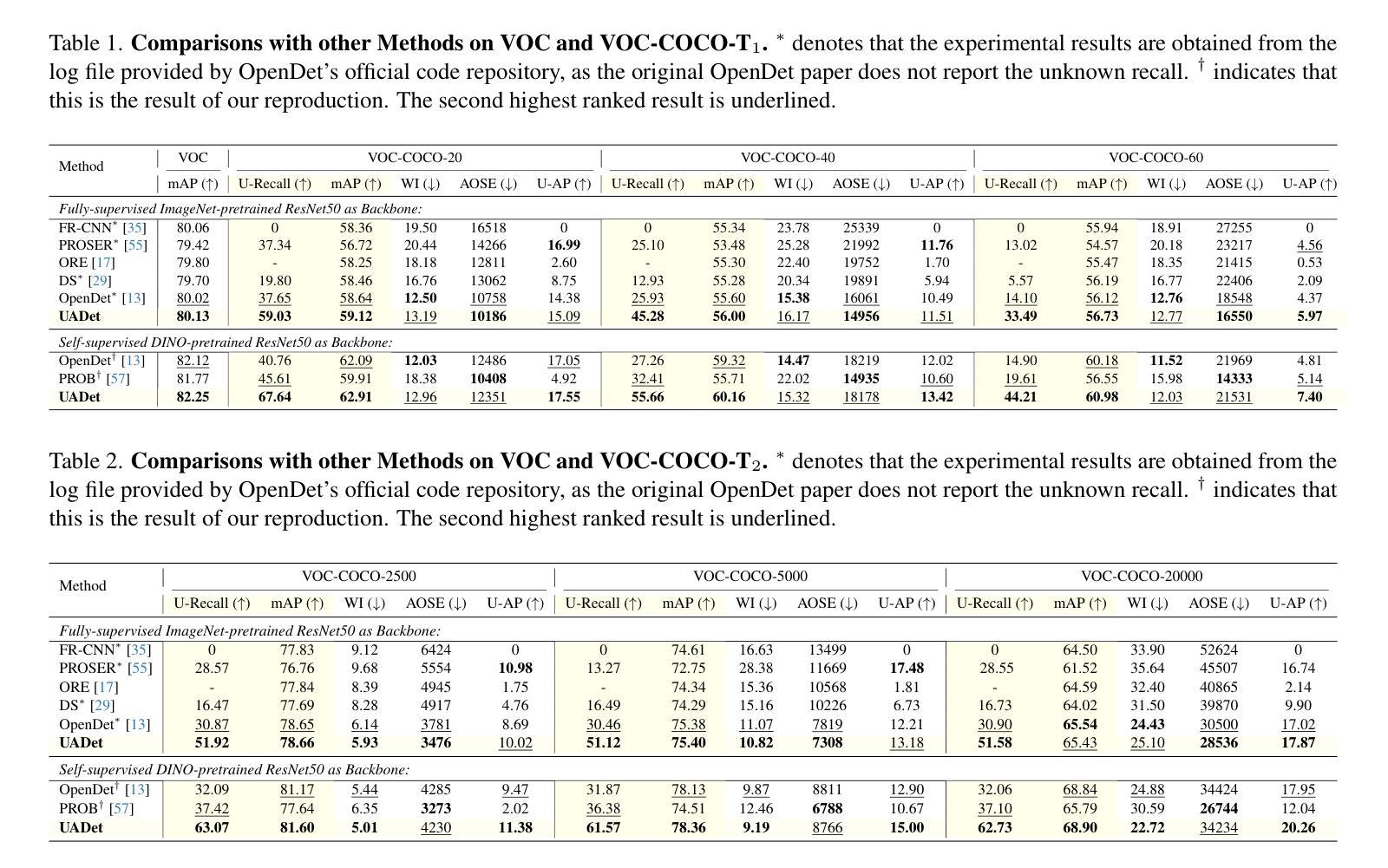
VOC-COCO-{T1, T2}基准:UADet与现有的最先进的OSOD方法进行了比较,显示出在未知类别召回率(U-Recall)方面的显著提升,同时保持了已知类别的平均精度(mAP)。
M-OWODB和S-OWODB基准:UADet在OWOD任务上的性能也得到了评估,与现有的OWOD方法相比,在未知类别召回率上有显著提高,同时保持了对已知类别的竞争力或更好的mAP分数。
3. 消融研究
不同不确定性度量的有效性:研究了仅使用几何不确定性、外观不确定性以及两者结合的效果。
不同类型的负样本:评估了仅使用几何不确定性、外观不确定性以及两者结合对模型性能的影响。
定性比较:提供了UADet与OpenDet和top-k硬伪标签方法的定性比较,展示了UADet在检测重叠未知对象、更准确定位未知对象和对背景噪声的鲁棒性方面的优势。
4. 扩展实验
基于Transformer的架构:在Swin Transformer作为骨干网络的情况下,评估了UADet的性能,证明了其泛化能力。
VOC-COCO-10000数据集:在更大的数据集上进一步评估了UADet的性能,以展示其在更大规模未知实例上的有效性和鲁棒性。
5. 附加消融研究
不同组合的外观和几何不确定性:实验了外观不确定性和几何不确定性的不同组合,以模拟负样本属于“未知”类别的概率。
与top-k硬标签策略的比较:通过为负样本分配top-k硬标签和UADet提出的不确定性感知软标签,比较了两种方法的性能。
这些实验全面地验证了UADet框架在不同开放集场景下的有效性,并与现有的最先进方法进行了比较,证明了其在未知对象检测能力上的优越性。
Q: 有什么可以进一步探索的点?
A: 尽管UADet在开放集目标检测领域取得了显著的性能提升,但仍有一些方向可以进一步探索和研究:
1. 不确定性度量的改进和优化
- 探索更多种类的不确定性度量方法,例如基于模型自信度的不确定性、数据不确定性等。
- 研究如何更有效地结合多种不确定性度量,以提高未知对象检测的准确性和鲁棒性。
2. 模型泛化能力的增强
- 在更多种类的骨干网络和检测架构上验证UADet的泛化能力,例如在YOLO、Transformer等架构上的应用。
- 研究如何通过数据增强、正则化技术等手段进一步提升模型的泛化能力。
3. 实际应用场景的测试
- 将UADet应用于更多样化的实际应用场景,如自动驾驶、视频监控等,验证其在现实世界条件下的表现。
- 研究如何针对特定应用场景优化UADet,以满足特定需求。
4. 计算效率和实时性
- 研究如何优化UADet的计算效率,减少模型的推理时间,使其适用于需要实时反馈的应用场景。
- 探索模型压缩、量化等技术在UADet中的应用,以进一步降低模型的计算成本。
5. 多模态数据的融合
- 考虑将视觉数据与其他模态数据(如雷达、激光雷达)结合起来,以提高开放集目标检测的性能。
- 研究如何有效地融合多模态数据,解决数据不一致性、同步等问题。
6. 半监督和无监督学习
- 探索在半监督或无监督设置下训练UADet的可能性,减少对大量标注数据的依赖。
- 研究如何利用少量标注数据和大量未标注数据来提高模型性能。
7. 长尾分布问题
- 研究UADet在处理类别不平衡问题时的表现,特别是在长尾分布的情况下。
- 探索如何通过重采样、重权重等技术改善模型在长尾分布下的性能。
这些方向不仅可以推动开放集目标检测技术的发展,还可能对计算机视觉和人工智能的其他领域产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为UADet的开放集目标检测框架,旨在提高对未知类别物体的检测能力。以下是论文的主要内容总结:
问题背景
- 开放集目标检测(OSOD)旨在检测包括已知和未知类别的物体,挑战在于未知类别缺乏标注信息。
主要贡献
- 识别问题:发现现有OSOD方法在未知类别召回上存在不足,并指出了现有方法未能充分利用或错误处理未标注实例的问题。
- 提出UADet:一个简单而有效的不确定性感知框架,通过考虑外观和几何不确定性来更好地利用训练数据中的未标注未知对象。
- 实验验证:在多个基准测试上进行了广泛的实验,证明了UADet在OSOD和OWOD任务上均取得了新的最佳性能。
方法论
- 不确定性建模:UADet利用外观不确定性(基于RPN的objectness分数)和几何不确定性(基于proposal与GT的IoU)来为负样本(未知类别)分配软标签。
- 训练优化:通过多任务损失进行训练,包括RPN损失、回归损失和分类损失。
- 扩展到OWOD:UADet可以扩展到开放世界目标检测任务,通过示例重放策略进行增量学习。
实验结果
- 在VOC-COCO基准上,UADet在未知类别召回上取得了显著提升,同时保持了已知类别的高mAP。
- 在OWOD基准上,UADet在未知类别召回上取得了更大的提升,同时保持了已知类别的竞争力。
结论
UADet通过简单而有效的不确定性感知策略,在开放集目标检测领域取得了突破性的性能,证明了其在不同开放集场景下的有效性和鲁棒性。
这篇论文为开放集目标检测领域提供了一个新思路,通过不确定性感知来提高对未知类别的检测能力,为未来的研究和应用奠定了基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


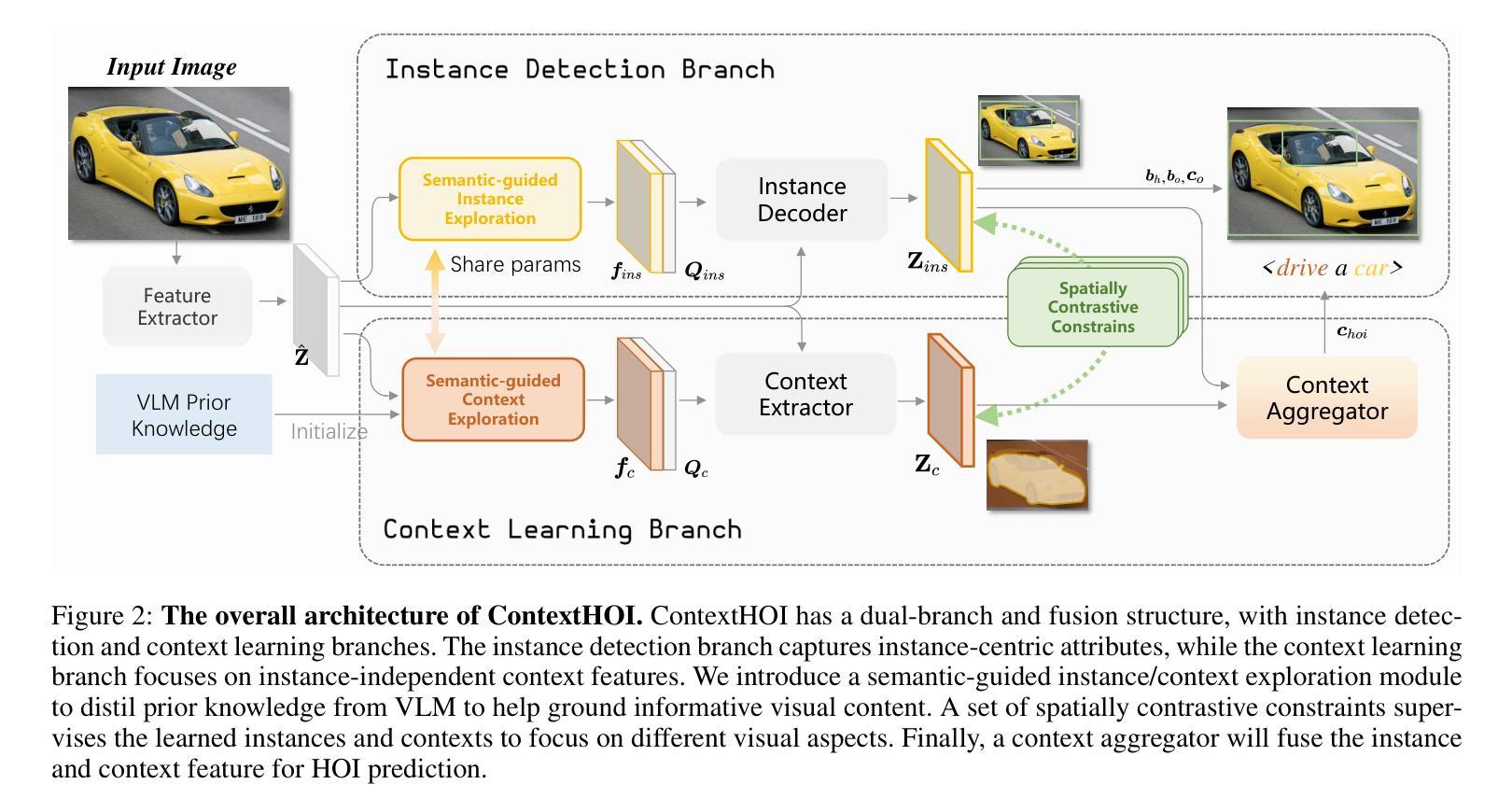
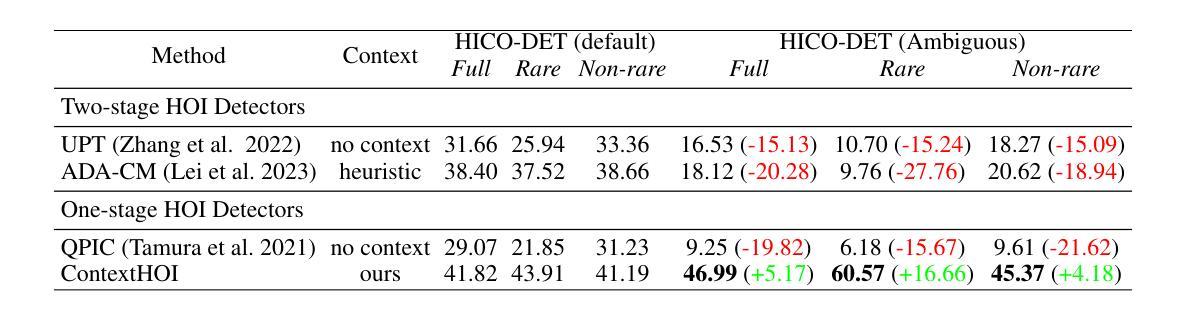
ContextHOI: Spatial Context Learning for Human-Object Interaction Detection
Authors:Mingda Jia, Liming Zhao, Ge Li, Yun Zheng
Spatial contexts, such as the backgrounds and surroundings, are considered critical in Human-Object Interaction (HOI) recognition, especially when the instance-centric foreground is blurred or occluded. Recent advancements in HOI detectors are usually built upon detection transformer pipelines. While such an object-detection-oriented paradigm shows promise in localizing objects, its exploration of spatial context is often insufficient for accurately recognizing human actions. To enhance the capabilities of object detectors for HOI detection, we present a dual-branch framework named ContextHOI, which efficiently captures both object detection features and spatial contexts. In the context branch, we train the model to extract informative spatial context without requiring additional hand-craft background labels. Furthermore, we introduce context-aware spatial and semantic supervision to the context branch to filter out irrelevant noise and capture informative contexts. ContextHOI achieves state-of-the-art performance on the HICO-DET and v-coco benchmarks. For further validation, we construct a novel benchmark, HICO-ambiguous, which is a subset of HICO-DET that contains images with occluded or impaired instance cues. Extensive experiments across all benchmarks, complemented by visualizations, underscore the enhancements provided by ContextHOI, especially in recognizing interactions involving occluded or blurred instances.
空间上下文,例如背景和周围环境,被认为是人类与物体交互(HOI)识别中的关键因素,特别是在以实例为中心的前景模糊或被遮挡的情况下。HOI检测器的最新进展通常建立在检测转换器管道之上。虽然这种面向对象检测的范式在定位对象方面显示出前景,但在探索空间上下文方面往往不足以准确识别人类行为。为了增强物体检测器在HOI检测方面的能力,我们提出了一种名为ContextHOI的双分支框架,它能够有效地捕获物体检测特征和空间上下文。在上下文分支中,我们训练模型以提取具有信息量的空间上下文,而无需额外的手工背景标签。此外,我们在上下文分支引入了上下文感知的空间和语义监督,以过滤掉无关的噪声并捕获具有信息量的上下文。ContextHOI在HICO-DET和v-coco基准测试中实现了最先进的性能。为了进一步的验证,我们构建了一个新的基准测试集HICO-ambiguous,它是HICO-DET的一个子集,包含被遮挡或受损的实例线索的图像。在所有基准测试集上的广泛实验以及可视化结果都强调了ContextHOI所提供的增强功能,特别是在识别涉及被遮挡或模糊实例的交互方面。
论文及项目相关链接
PDF in proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI-25)
Summary:
本文强调空间上下文在人机交互(HOI)识别中的重要性,特别是在实例中心前景模糊或被遮挡的情况下。文章提出了一个名为ContextHOI的双分支框架,用于增强对象检测器在HOI检测方面的能力。该框架可以高效捕获对象检测特征和空间上下文,并通过上下文分支的训练,提取具有信息量的空间上下文,而无需额外的手工背景标签。此外,还引入了上下文感知的空间和语义监督,以过滤掉无关的噪声并捕获具有信息量的上下文。ContextHOI在HICO-DET和v-coco等基准测试上取得了最先进的性能。为进行进一步验证,还构建了一个名为HICO-ambiguous的新基准测试集,其中包含带有遮挡或受损实例线索的图像。大量实验和可视化结果都突出了ContextHOI的增强效果,特别是在识别涉及被遮挡或模糊实例的交互方面。
Key Takeaways:
- 空间上下文在人机交互(HOI)识别中至关重要,尤其是在实例中心前景模糊或被遮挡时。
- ContextHOI是一个双分支框架,旨在增强对象检测器在HOI检测方面的能力。
- ContextHOI可以高效捕获对象检测特征和空间上下文。
- 上下文分支的训练能够提取具有信息量的空间上下文,无需额外的手工背景标签。
- 引入了上下文感知的空间和语义监督,以提高模型的性能。
- ContextHOI在多个基准测试上取得了最先进的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为ContextHOI的框架,旨在解决在人-物交互(Human-Object Interaction, HOI)检测中准确识别交互动作时面临的挑战,尤其是在前景实例模糊或被遮挡的情况下。具体来说,论文试图解决的问题包括:
现有HOI检测器的局限性:现有的HOI检测器通常基于检测变换器(detector transformers)流水线构建,这些检测器在定位对象方面表现出色,但在探索空间上下文以准确识别人类行为方面往往不足。
对空间上下文的不足探索:尽管基于变换器的对象检测器在模型能力上给人印象深刻,但它们在固有的最小上下文建模和HOI检测所必需的广泛上下文要求之间存在错位。
对模糊或被遮挡实例的鲁棒性不足:现有的HOI检测器在识别有限前景视觉线索的HOI场景时面临困难,例如当主体模糊或被遮挡时。
为了解决这些问题,论文提出了ContextHOI,这是一个双分支框架,有效地捕获对象检测特征和空间上下文。该框架通过在上下文分支中训练模型提取信息性的空间上下文,而无需额外的手工艺背景标签,并且引入了上下文感知的空间和语义监督来过滤不相关的噪声并捕获信息性上下文。通过这些方法,ContextHOI在HICO-DET和v-coco基准测试中实现了最先进的性能,并在包含被遮挡或模糊实例线索的HICO-DET(ambiguous)新基准测试中展现了显著的鲁棒性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个方面:
基于变换器的HOI检测器:
- 一阶段HOI检测器,如Tamura等人(2021)和Ning等人(2023)提出的基于共享、并行或顺序变换器的方法。
- 两阶段HOI检测器,如Zhang等人(2022)和Lei等人(2023)提出的使用预训练对象检测器作为背景来捕获实例位置和前景属性的方法。
空间上下文学习在HOI中的作用:
- 在对象检测、场景图生成和群体识别等任务中,空间上下文起着至关重要的作用。
- 在HOI检测中,一些工作通过定制的空间模块来捕获上下文,例如Gao等人(2020)和Wang等人(2019)提出的基于密集图的方法,以及后来关注实例中心上下文的方法。
语义引导的学习方法:
- 一些研究利用可学习的文本嵌入来表示伪背景类别,如Yuan等人(2022, 2023)。
- 其他研究学习全局概念记忆以探索背景信息,如Lei等人(2023)和Wang等人(2024)。
基于图的方法:
- Gao等人(2020)和Zhang等人(2021)使用图结构来捕获全局上下文信息。
基于实例中心的方法:
- Gao等人(2018)和Wang等人(2019)专注于实例中心的上下文。
遮挡部分外推(OPE):
- Wang等人(2024)通过遮挡部分外推增强实例特征。
基于Transformer的对象检测器:
- 许多现代HOI检测器基于DETR(Detection Transformer)构建,如Carion等人(2020)的工作。
这些相关研究提供了ContextHOI框架设计的理论基础和技术支持,同时也突显了现有方法在空间上下文建模和鲁棒性方面的不足,为ContextHOI的提出提供了研究动机。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为ContextHOI的双分支框架来解决HOI检测中空间上下文不足的问题,具体解决方案包括以下几个关键组件:
双分支架构:
- 实例检测分支:利用预训练的视觉编码器提取图像特征,并使用实例解码器生成实例中心特征。
- 上下文学习分支:设计上下文提取器独立于实例提取上下文特征,增强对场景的全局理解,并减少对对象检测失败的依赖。
空间对比约束(Spatially Contrastive Constraints):
- 提出了三个级别的空间对比约束(特征级、区域级和实例级),目的是让实例解码器和上下文提取器关注不同的视觉区域。
- 引入动态距离权重到实例级约束中,以保持学习到的上下文的合适空间形状。
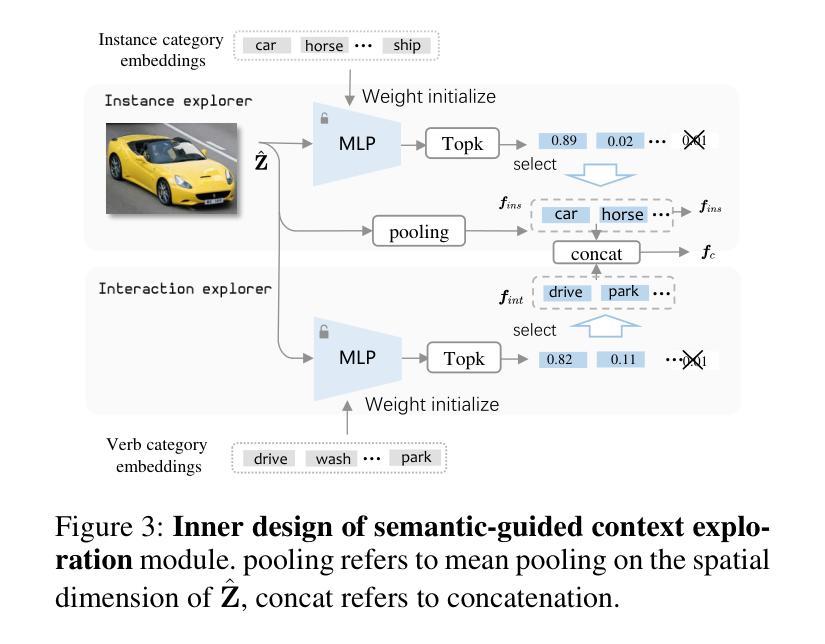
语义引导的上下文探索(Semantic-guided Context Exploration):
- 构建可学习的实例和交互探索器,并使用VLM(视觉-语言模型)的文本嵌入初始化它们的权重,以从VLM中提取先验知识。
- 通过计算视觉特征和语言表示之间的相似度来优化调整探索器,选择与类别最相关的特征图作为上下文引导。
上下文聚合器(Context Aggregator):
- 学习聚合查询来融合互补的实例检测特征和上下文特征,使用多分支变换器解码器实现特征融合。
端到端训练方法:
- ContextHOI以集合预测的方式进行端到端训练,结合传统的HOI损失和空间对比约束损失进行优化。
新基准测试(HICO-DET Ambiguous):
- 构建了一个新的基准测试,用于评估模型在处理前景视觉内容不清晰时的鲁棒性。
通过这些方法,ContextHOI能够有效地从对象检测器中提取实例特征,并结合学习到的上下文信息来增强HOI预测的鲁棒性,特别是在前景实例模糊或被遮挡的情况下。此外,该框架在HICO-DET和v-coco基准测试中取得了竞争性能,并在新的HICO-DET(ambiguous)基准测试中展现了显著的鲁棒性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证ContextHOI框架的性能和鲁棒性。具体的实验包括:
基准测试:
- HICO-DET 和 v-coco:在这两个广泛使用的HOI检测基准上进行实验,验证ContextHOI在常规设置下的性能。
新基准测试:
- **HICO-DET (ambiguous)**:构建了一个专门的基准测试,用于评估模型在处理前景视觉属性不清晰时的鲁棒性。这个基准测试包括了从HICO-DET测试集中选取的包含看不见的主体、被遮挡的主体、模糊的主体和难以区分的实例的图像。
性能比较:
- 将ContextHOI与现有的最先进方法(state-of-the-art methods)在HICO-DET(默认设置)和HICO-DET(ambiguous)上进行比较,以展示ContextHOI在处理不清晰实例时的鲁棒性。
模块消融实验:
- 对提出的空间对比约束和语义引导上下文探索进行消融实验,以验证这些组件对性能的贡献。
- 评估了不同组件(如特征级约束、区域级约束和实例级约束)对模型性能的影响。
不同VLMs作为知识教师的效果:
- 比较了不使用先验知识、使用EVA-01和CLIP ViT-L/14作为先验知识教师时ContextHOI的性能。
上下文聚合器的实现:
- 评估了不同机制(如简单的门控加法和共享交叉注意力)在整合实例和上下文特征时的效果。
模型效率:
- 在HICO-DET测试图像上评估ContextHOI的计算成本(GFLOPs)和帧率(FPS),并与HOICLIP进行比较。
可视化分析:
- 通过可视化分析展示了ContextHOI学习到的空间上下文特征,以及在处理具有不清晰或被遮挡实例的图像时的交互预测能力。
这些实验全面评估了ContextHOI在不同设置下的性能,并验证了其在处理具有挑战性的HOI检测任务时的有效性和鲁棒性。通过这些实验,论文展示了ContextHOI在提升HOI检测准确性和鲁棒性方面的潜力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来可能的研究方向,可以进一步探索的点包括:
更细粒度的上下文学习:
- 探索更细粒度的上下文学习方法,以更好地减少背景噪声,提高对复杂场景的鲁棒性。
上下文的显式建模:
- 研究如何显式地建模和利用上下文信息,以提高HOI检测的性能。
上下文的动态性和时序性:
- 考虑上下文信息的动态变化和时序性,特别是在视频序列或长时间交互中。
跨模态融合:
- 进一步探索如何有效地融合视觉和语言模态的信息,以提高上下文感知的HOI检测。
无监督和自监督学习:
- 研究无监督或自监督学习策略,以减少对大量标注数据的依赖,并提高模型的泛化能力。
更复杂的场景和交互:
- 在更复杂的场景和更多样化的交互类型上测试和改进模型,以提高模型的适用性和灵活性。
实时性能优化:
- 针对实时应用场景,优化模型的计算效率和推理速度。
长尾分布问题:
- 针对HOI检测中的长尾分布问题,研究如何提高对罕见交互类型的检测性能。
模型的可解释性:
- 提高模型的可解释性,以便更好地理解模型是如何利用上下文信息进行预测的。
多模态输入:
- 探索模型对多模态输入(如视觉、语音、文本)的处理能力,以实现更全面的交互理解。
这些方向不仅可以推动HOI检测技术的发展,还可能对计算机视觉和人工智能的其他领域产生积极影响。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为ContextHOI的框架,旨在通过有效地结合对象检测特征和空间上下文信息来提高人-物交互(HOI)检测的性能,尤其是在前景实例模糊或被遮挡的情况下。以下是论文的主要内容总结:
问题陈述:
- 论文指出,现有的HOI检测器在处理前景视觉线索有限的场景时存在困难,尤其是在主体模糊或被遮挡的情况下。
ContextHOI框架:
- 提出了一个双分支框架,包括实例检测分支和上下文学习分支,以增强对象检测器对HOI检测的能力。
- 实例检测分支负责捕获实例中心属性,而上下文学习分支专注于捕获空间上下文特征。
空间对比约束:
- 引入了一套空间对比约束,包括特征级、区域级和实例级约束,以促使实例解码器和上下文提取器关注不同的视觉区域。
语义引导的上下文探索:
- 利用预训练的视觉-语言模型(VLM)来初始化探索器的权重,并提取类别相关的相似性,以提供语义引导的上下文探索。
上下文聚合器:
- 设计了上下文聚合器来融合实例和上下文特征,以便于交互预测。
实验验证:
- 在HICO-DET和v-coco基准测试中验证了ContextHOI的性能,并构建了一个新的基准测试HICO-DET(ambiguous),用于评估模型在处理不清晰前景视觉内容时的鲁棒性。
- 通过广泛的实验和可视化分析,证明了ContextHOI在识别被遮挡或模糊实例的交互方面的优势。
贡献:
- 论文的贡献在于重新审视和探索空间上下文在HOI检测中的重要性,并提出了一种系统学习空间上下文以增强HOI检测的方法。
- ContextHOI在HICO-DET和v-coco基准测试中取得了竞争性能,并在HICO-DET(ambiguous)基准测试中取得了显著的鲁棒性。
未来工作:
- 论文提出了未来可能的研究方向,包括探索更细粒度的上下文学习方法和提高模型的可解释性等。
总体而言,ContextHOI通过创新的空间上下文学习方法,有效地提高了HOI检测的准确性和鲁棒性,尤其是在复杂和不确定的视觉环境中。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



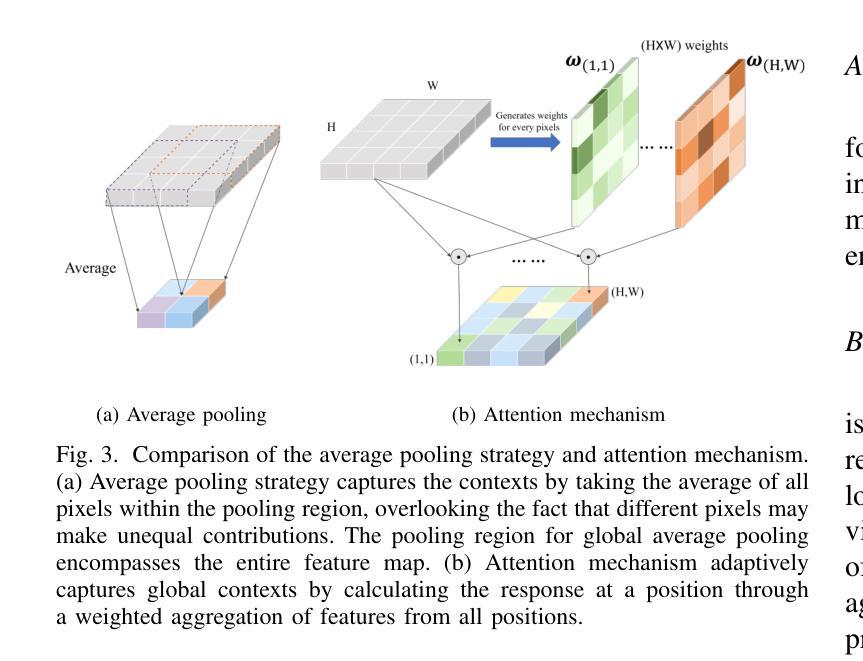
A Deep Semantic Segmentation Network with Semantic and Contextual Refinements
Authors:Zhiyan Wang, Deyin Liu, Lin Yuanbo Wu, Song Wang, Xin Guo, Lin Qi
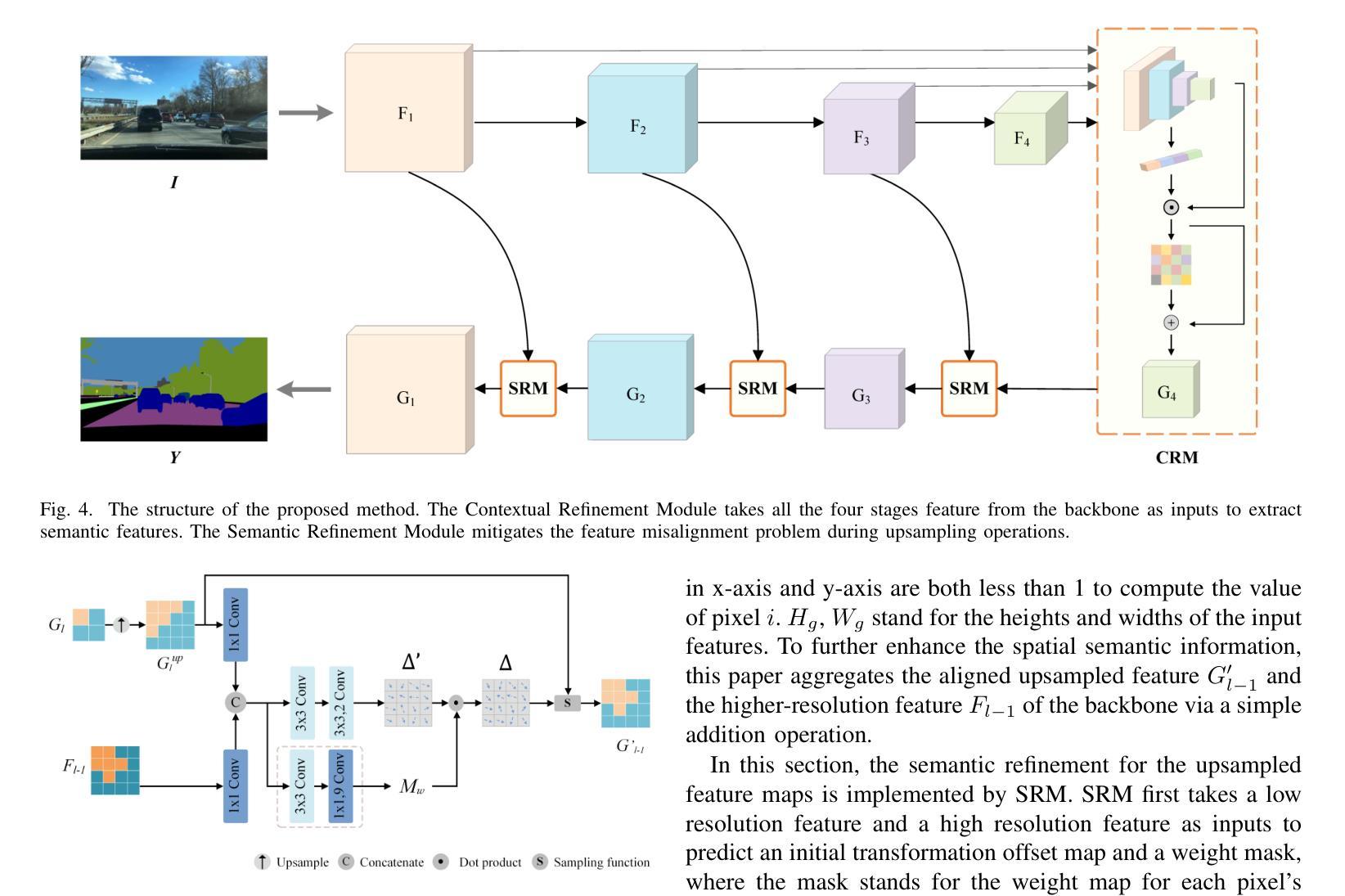
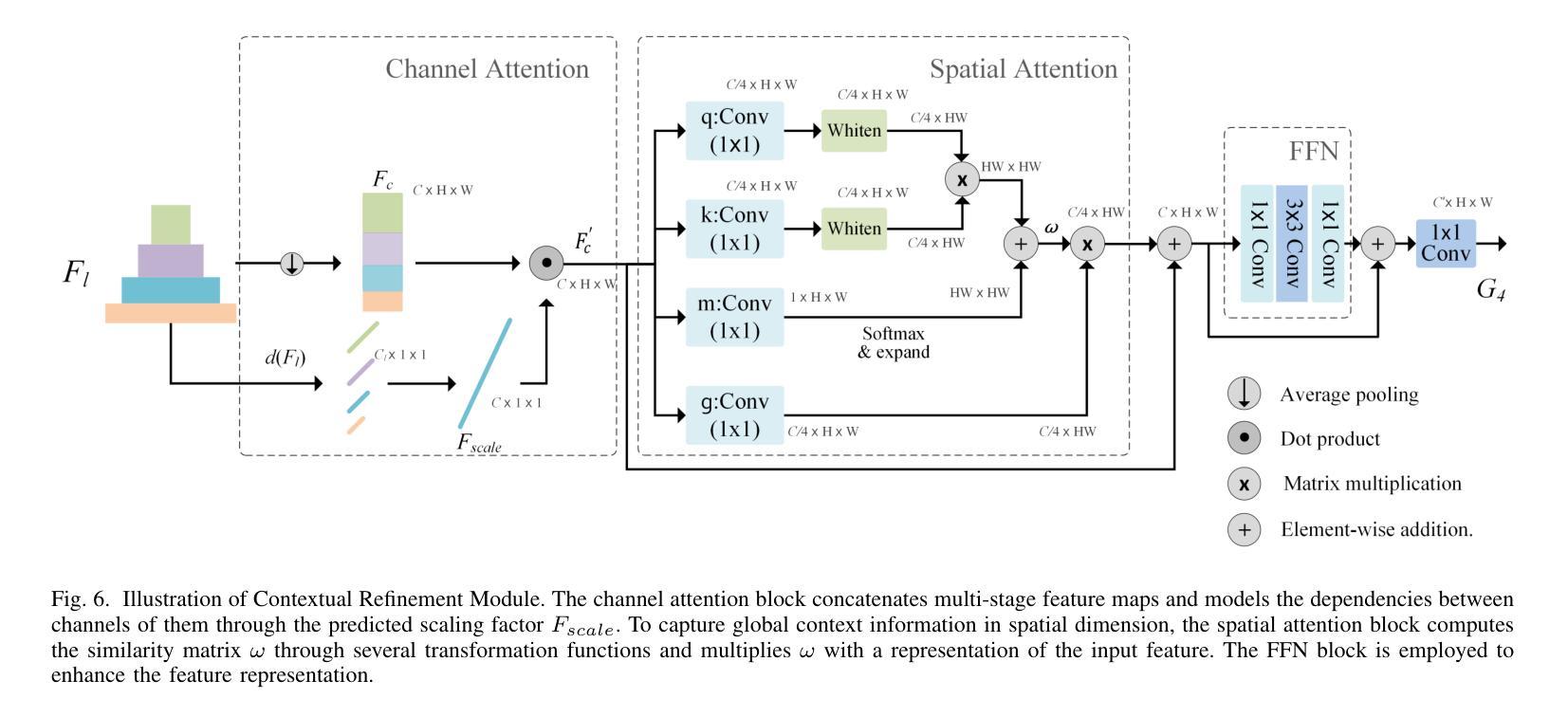
Semantic segmentation is a fundamental task in multimedia processing, which can be used for analyzing, understanding, editing contents of images and videos, among others. To accelerate the analysis of multimedia data, existing segmentation researches tend to extract semantic information by progressively reducing the spatial resolutions of feature maps. However, this approach introduces a misalignment problem when restoring the resolution of high-level feature maps. In this paper, we design a Semantic Refinement Module (SRM) to address this issue within the segmentation network. Specifically, SRM is designed to learn a transformation offset for each pixel in the upsampled feature maps, guided by high-resolution feature maps and neighboring offsets. By applying these offsets to the upsampled feature maps, SRM enhances the semantic representation of the segmentation network, particularly for pixels around object boundaries. Furthermore, a Contextual Refinement Module (CRM) is presented to capture global context information across both spatial and channel dimensions. To balance dimensions between channel and space, we aggregate the semantic maps from all four stages of the backbone to enrich channel context information. The efficacy of these proposed modules is validated on three widely used datasets-Cityscapes, Bdd100K, and ADE20K-demonstrating superior performance compared to state-of-the-art methods. Additionally, this paper extends these modules to a lightweight segmentation network, achieving an mIoU of 82.5% on the Cityscapes validation set with only 137.9 GFLOPs.
语义分割是多媒体处理中的一项基本任务,可用于分析、理解图像和视频内容等。为了加快多媒体数据的分析,现有的分割研究倾向于通过逐步减少特征图的空间分辨率来提取语义信息。然而,这种方法在恢复高级特征图的分辨率时引入了对齐问题。针对这一问题,本文设计了一个语义细化模块(SRM)来解决分割网络中的这个问题。具体来说,SRM旨在学习上采样特征图中每个像素的转换偏移量,该偏移量由高分辨率特征图和相邻偏移量引导。将这些偏移量应用于上采样特征图,SRM增强了分割网络的语义表示,特别是对于目标边界附近的像素。此外,还提出了一种上下文细化模块(CRM)来捕获空间和通道维度上的全局上下文信息。为了平衡通道和空间维度之间的平衡,我们从主干网络的四个阶段聚合语义图,以丰富通道上下文信息。这些所提模块的有效性在Cityscapes、Bdd100K和ADE20K三个广泛使用的数据集上得到了验证,与最先进的方法相比,表现出优越的性能。此外,本文将这些模块扩展到了一个轻量级的分割网络,在Cityscapes验证集上实现了82.5%的mIoU,同时仅使用了137.9 GFLOPs。
论文及项目相关链接
PDF Accept by tmm
Summary
该文关注语义分割中的分辨率恢复问题,提出了Semantic Refinement Module(SRM)和Contextual Refinement Module(CRM)来解决这一问题。SRM通过学习每个像素的转换偏移,提高上采样特征图的语义表示,特别是在物体边界附近的像素。CRM用于捕获跨空间和通道维度的全局上下文信息。通过结合这四个阶段的语义图来丰富通道上下文信息,并在三个广泛使用的数据集上验证了所提模块的有效性。此外,该文还将这些模块扩展到轻量级分割网络,在Cityscapes验证集上实现了82.5%的mIoU,且计算量仅为137.9 GFLOPs。
Key Takeaways
- 语义分割是多媒体处理中的基础任务,可用于分析和理解图像和视频内容。
- 现有分割研究倾向于通过逐步降低特征图的空间分辨率来提取语义信息,但这种方法会引发分辨率恢复时的错位问题。
- SRM(Semantic Refinement Module)被设计来解决这个问题,通过为每个像素学习转换偏移,提高上采样特征图的语义表示。
- CRM(Contextual Refinement Module)用于捕获全局上下文信息,结合空间和通道维度。
- 通过结合四个阶段的语义图来丰富通道上下文信息,提高分割网络的性能。
- 在三个广泛使用的数据集上验证了所提模块的有效性,显示出了比最新方法更优越的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是语义分割任务中的关键问题,包括:
特征图分辨率降低导致的错位问题:在现有的语义分割研究中,为了提取语义信息,特征图的空间分辨率会逐渐降低,这导致在恢复高级别特征图分辨率时引入了错位问题,尤其是在目标边界附近的像素语义标签分配上。
全局上下文信息的捕获不足:尽管降低特征图的空间分辨率可以扩大感受野,但其范围仍然受限,导致无法充分利用图像中不同区域的像素对语义标记的贡献。
为了解决这些问题,论文提出了两个主要模块:
语义细化模块(Semantic Refinement Module, SRM):用于学习上采样特征图中每个像素的变换偏移量,通过高分辨率特征图和邻近像素的偏移量来指导,增强了分割网络对目标边界附近像素的语义表示。
上下文细化模块(Contextual Refinement Module, CRM):用于捕获全局上下文信息,通过注意力机制在空间和通道两个维度上探索像素之间的依赖关系,以自适应的方式捕获全局上下文信息。
这些模块的提出旨在提高语义分割的准确性,尤其是在目标边界附近像素的语义标签分配上,并增强模型对全局上下文信息的捕获能力。
Q: 有哪些相关研究?
A: 相关研究主要分为两大类:语义特征增强和上下文建模。以下是一些具体的相关研究工作:
语义特征增强
多尺度特征融合:
- Unet[28] 和 FPN[29] 通过横向连接将低级特征与空间细节融合到解码阶段,增强了网络对语义特征的表示能力。
- SegNet[30] 使用在最大池化阶段确定的池化索引来恢复更多空间细节。
- GUM[15] 使用高分辨率特征图作为指导,上采样低分辨率特征图,减少上采样特征图的空间偏移。
学习对齐策略:
- IFA[31] 允许学习准确表示连续信息场的特征,并在相邻特征图之间实现精确的特征对齐。
- SFNet[19] 通过学习不同分辨率网络层之间的“语义流”来对齐上采样特征图。
- AlignSeg[18] 学习高低分辨率特征图的变换偏移量,减少对象内部的过多细节。
上下文建模
扩大感受野:
- Atrous convolution[33] 通过增加核大小来扩大感受野,同时保持有限的计算成本。
- PAC[34] 提出了视角自适应卷积的概念,用于捕获不同大小和配置的感受野。
多尺度空间池化:
- ParseNet[20] 引入全局平均池化机制来获取全局上下文。
- Pyramid Pooling Module (PPM)[21] 设计用于通过融合不同金字塔尺度的上下文信息来利用全局上下文信息。
- Deep Aggregation Pyramid Pooling Module (DAPPM)[22] 通过更多的尺度和深度特征聚合来增强PPM[21]。
注意力机制:
- PSANet[24] 设计了一个逐点空间注意力模块,动态建模长距离上下文信息。
- Wang et al.[35] 提出了非局部块模块,通过所有像素的加权平均捕获全局依赖性。
- SENet[25] 使用轻量级门控机制来建模通道维度上的上下文依赖关系。
这些研究工作为本文提出的语义细化模块(SRM)和上下文细化模块(CRM)提供了理论基础和技术参考。通过结合这些相关技术,本文旨在进一步改进语义分割的性能,尤其是在目标边界附近的像素语义标签分配和全局上下文信息捕获方面。
Q: 论文如何解决这个问题?
A: 论文通过提出两个创新模块来解决上述问题:语义细化模块(Semantic Refinement Module, SRM)和上下文细化模块(Contextual Refinement Module, CRM)。
语义细化模块(SRM)
SRM旨在解决上采样特征图中的错位问题,具体步骤如下:
初始变换偏移学习:
- SRM利用高分辨率特征图来指导学习上采样特征图中每个像素的粗略变换偏移量。
邻居偏移的影响评估:
- 进一步通过学习一个像素级掩码来考虑局部区域内邻居偏移对每个像素的影响,并据此优化粗略偏移量。
最终变换偏移计算:
- 通过结合初始变换偏移和邻居偏移的影响,计算最终的变换偏移量。
特征图对齐:
- 使用不同的iable image sampling function根据最终偏移量对上采样的特征图进行对齐处理,以增强语义表示。
特征图聚合:
- 将对齐后的特征图与更高分辨率的特征图进行聚合,以进一步增强空间语义信息。
上下文细化模块(CRM)
CRM旨在捕获全局上下文信息,具体步骤如下:
通道注意力块:
- 设计用于从多阶段特征图中提取依赖关系,通过预测的缩放因子重新校准这些特征图。
空间注意力块:
- 基于Disentangled Non-Local (DNL)模型,自适应地为不同位置的像素分配权重,捕获基于贡献的全局上下文信息。
前馈网络(FFN)块:
- 用于增强CRM的特征表示能力。
特征图聚合:
- 将来自四个不同阶段的语义图聚合在一起,以增加通道数,增强通道上下文信息。
通过这两个模块,论文在不同分割网络中实现了改进,实验结果表明这些模块可以一致性地提高语义分割性能,并在Cityscapes、Bdd100K和ADE20K三个数据集上取得了新的最好结果。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的语义细化模块(SRM)和上下文细化模块(CRM)的有效性,并与现有的一些先进方法进行了比较。以下是实验的具体内容:
数据集
- Cityscapes:包含5000张高分辨率图像,用于城市街景的语义分割。
- Bdd100K:包含7000张图像,用于更多样化的驾驶场景的语义分割。
- ADE20K:包含150个类别的场景解析,包含20210张图像。
实施细节
- 使用PyTorch框架实现网络。
- 采用数据增强,包括随机水平翻转、随机缩放和随机裁剪。
- 使用Adam优化器和多项式学习率策略。
- 对于Cityscapes,批量大小为16,对于Bdd100K和ADE20K,批量大小为32。
- 所有数据集训练周期设置为600。
消融实验
- 对比了仅使用基线模型、加入SRM、加入CRM以及同时加入SRM和CRM的效果,使用mIoU(平均交并比)评估性能。
与其他对齐模块的比较
- 将SRM与其他几种对齐模块(如Bilinear、AlignFA、FAM)进行比较,评估在三个数据集上的性能。
与其他上下文建模模块的比较
- 将CRM与其他几种上下文建模模块(如PPM、DAPPM、CCAM、DAM)进行比较,同样在三个数据集上评估性能。
与最新先进方法的比较
- 在Cityscapes数据集上,将提出的方法与一系列最新的先进方法(包括基于CNN的方法和基于Vision Transformer的方法)进行比较。
轻量级模型比较
- 展示了提出的方法在轻量级模型设置下的性能,与多个轻量级网络进行比较。
每个类别的结果
- 在Cityscapes验证集上,展示了提出方法与基线方法在每个类别上的IoU性能。
可视化结果
- 展示了Cityscapes验证集上的定性结果,比较了基线和提出方法的分割效果。
Bdd100K和ADE20K数据集的实验
- 在Bdd100K和ADE20K验证集上进一步验证了提出方法的有效性,并与一些先进方法进行比较。
这些实验全面评估了提出方法的有效性,并显示了其在不同设置和数据集上的性能优势。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了有效的语义分割网络,但仍有一些方面可以进一步探索和研究:
1. 模块泛化能力的测试
- 不同数据集和场景:在更多种类的数据集上测试SRM和CRM的泛化能力,例如医学图像、卫星图像等。
- 不同分辨率的输入:测试网络对不同分辨率输入图像的适应性和鲁棒性。
2. 模块性能的优化
- 计算复杂度:探索减少SRM和CRM计算复杂度的方法,使其更适合实时或者资源受限的应用场景。
- 参数效率:研究是否可以通过改进网络结构或训练策略减少模型参数,同时保持性能。
3. 模块集成与协同
- 与其他网络结构的集成:尝试将SRM和CRM集成到其他类型的网络结构中,例如Transformer或者卷积网络的新变种。
- 多任务学习:探索SRM和CRM在多任务学习框架下的表现,例如同时进行语义分割和实例分割。
4. 损失函数和优化策略
- 损失函数的改进:研究新的损失函数或者损失权重调整策略,以进一步提高分割精度。
- 优化算法:尝试不同的优化算法,比如AdamW、RMSprop等,来加速训练过程或提高模型性能。
5. 注意力机制的深入研究
- 自注意力机制:研究自注意力机制在语义分割中的应用,以及如何与SRM和CRM结合。
- 动态注意力分配:探索动态调整注意力权重的方法,以适应不同的分割任务。
6. 模型解释性
- 特征可视化:通过可视化技术研究SRM和CRM学习到的特征,增加模型的可解释性。
- 错误分析:进行错误分析,了解模型在哪些类型的图像或对象上表现不佳,并针对性地改进。
7. 跨模态和多模态学习
- 跨模态分割:探索模型在处理不同模态数据(例如,RGB-D图像)时的表现和适应性。
- 多模态融合:研究如何有效地融合来自不同传感器或模态的数据以提高分割性能。
这些探索方向不仅可以推动语义分割技术的发展,还可能为计算机视觉的其他领域带来新的洞见和方法。
Q: 总结一下论文的主要内容
A: 本文主要研究了语义分割领域中的两个关键问题:特征图分辨率降低导致的错位问题和全局上下文信息捕获不足。为解决这些问题,作者提出了两个创新模块:语义细化模块(SRM)和上下文细化模块(CRM),并将其集成到不同的语义分割网络中。以下是论文的主要内容总结:
1. 问题陈述
- 语义分割是多媒体处理中的基础任务,用于分析和理解图像和视频内容。
- 传统方法通过降低特征图的空间分辨率提取语义信息,但这种方法引入了解码过程中特征图恢复分辨率时的错位问题。
- 受限的感受野范围使得模型难以利用图像中其他区域的像素对语义标记的贡献。
2. 方法论
- 语义细化模块(SRM):设计用于学习上采样特征图中每个像素的变换偏移量,通过高分辨率特征图和邻居偏移量来指导,增强了分割网络对目标边界附近像素的语义表示。
- 上下文细化模块(CRM):通过注意力机制捕获全局上下文信息,同时考虑空间和通道两个维度的像素依赖关系,以自适应的方式捕获全局上下文信息。
3. 实验验证
- 在Cityscapes、Bdd100K和ADE20K三个广泛使用的公开数据集上验证了所提方法的有效性。
- 与现有先进方法相比,所提方法在性能上取得了显著提升,并在轻量级模型上也展现出良好的性能。
4. 贡献
- 提出了SRM模块,通过考虑局部邻居偏移的影响,提高了目标边界附近像素的语义标签分配精度。
- 提出了CRM模块,通过探索像素在空间和通道两个维度上的依赖关系,捕获全局上下文信息。
- 将SRM和CRM模块扩展到不同的分割网络中,证明了这些模块的有效性和普适性。
5. 结论
- 所提出的语义和上下文细化模块能够有效提升语义分割的性能,尤其在目标边界附近的像素语义标签分配和全局上下文信息捕获方面。
- 这些模块的加入使得模型在多个数据集上达到了新的最好结果,展示了模型的优越性能和应用潜力。
总体而言,本文通过引入SRM和CRM两个模块,有效地解决了语义分割中的错位问题和全局上下文信息捕获不足的问题,提高了语义分割的准确性和效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Efficient Semantic Splatting for Remote Sensing Multi-view Segmentation
Authors:Zipeng Qi, Hao Chen, Haotian Zhang, Zhengxia Zou, Zhenwei Shi
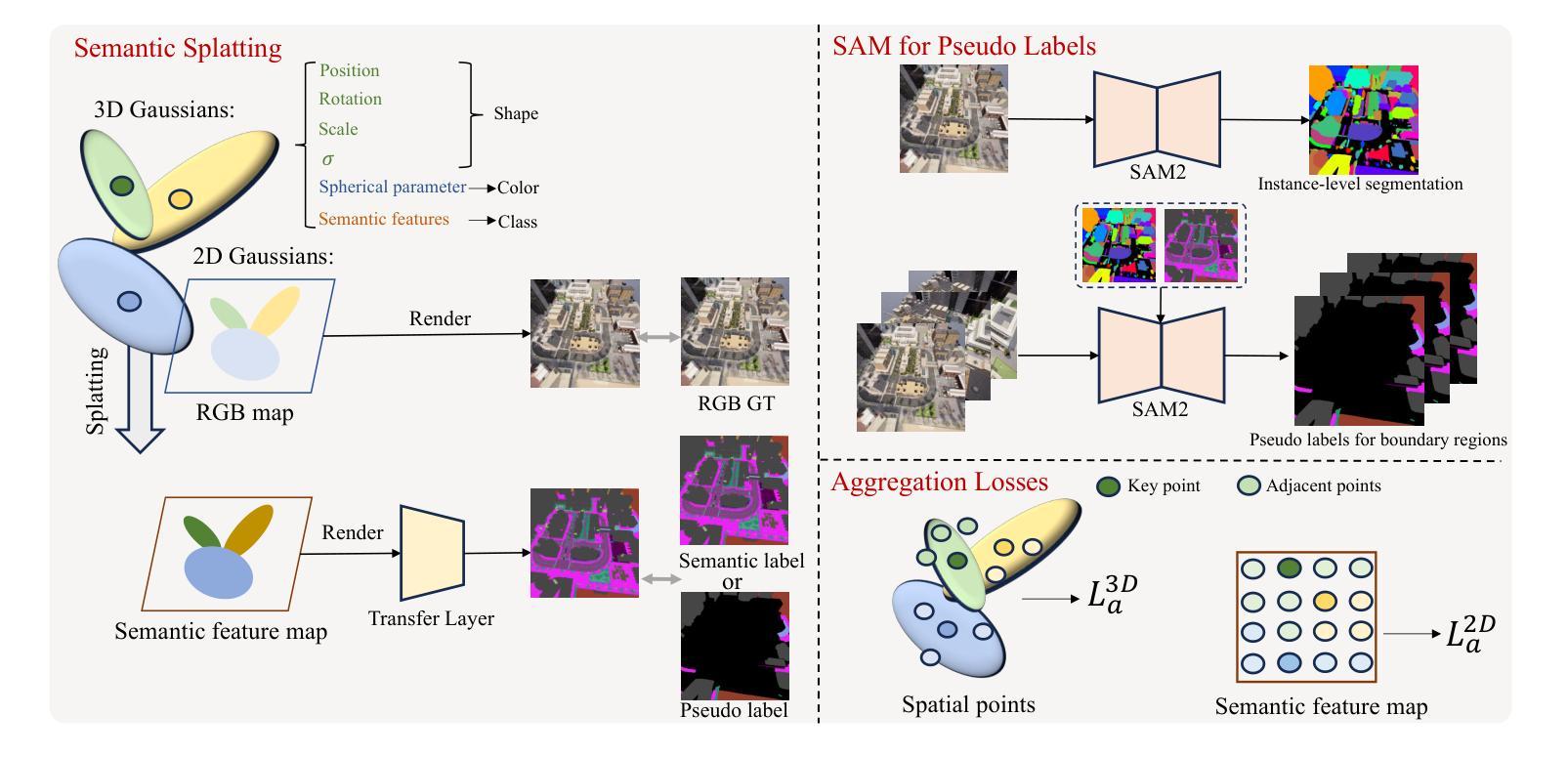
In this paper, we propose a novel semantic splatting approach based on Gaussian Splatting to achieve efficient and low-latency. Our method projects the RGB attributes and semantic features of point clouds onto the image plane, simultaneously rendering RGB images and semantic segmentation results. Leveraging the explicit structure of point clouds and a one-time rendering strategy, our approach significantly enhances efficiency during optimization and rendering. Additionally, we employ SAM2 to generate pseudo-labels for boundary regions, which often lack sufficient supervision, and introduce two-level aggregation losses at the 2D feature map and 3D spatial levels to improve the view-consistent and spatial continuity.
在这篇论文中,我们提出了一种基于高斯拼贴的新型语义拼贴方法,以实现高效和低延迟。我们的方法将点云的RGB属性和语义特征投射到图像平面上,同时呈现RGB图像和语义分割结果。我们充分利用点云的明确结构和一次性渲染策略,大大提高了优化和渲染过程中的效率。此外,我们还使用SAM2为边界区域生成伪标签,这些区域通常缺乏足够的监督,并在二维特征图和三维空间级别引入两级聚合损失,以提高视图一致性和空间连续性。
论文及项目相关链接
Summary
本文提出了一种基于高斯融合的新型语义融合方法,实现了高效和低延迟的点云语义分割。该方法将点云的RGB属性和语义特征投影到图像平面上,同时生成RGB图像和语义分割结果。利用点云的明确结构和一次性渲染策略,该方法在优化和渲染过程中显著提高效率。此外,通过SAM2为边界区域生成伪标签,并引入二维特征图和三维空间的两级聚合损失,提高了视图一致性和空间连续性。
Key Takeaways
- 该论文提出了一种基于高斯融合的新型语义融合方法,旨在实现高效和低延迟的点云语义分割。
- 该方法融合了点云的RGB属性和语义特征,并将它们投影到图像平面上,以便同时生成RGB图像和语义分割结果。
- 利用点云的明确结构,该方法在优化和渲染过程中展现出显著的优势。
- 为了解决边界区域缺乏足够监督的问题,论文采用SAM2生成伪标签。
- 论文引入了二维特征图和三维空间的两级聚合损失,以提高模型在视图一致性和空间连续性方面的性能。
- 该方法在实现点云语义分割的同时,还注重了一次性渲染策略,进一步提升了效率。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是遥感多视图图像分割中的立体场景感知问题。具体来说,这项任务涉及处理从不同视角捕获的RGB图像,并为每个视图生成一致的语义分割结果,即使在稀疏标签监督条件下也是如此。传统的基于训练的方法(如CNNs和Transformers)由于处理一般空间信息的能力有限,通常难以保持视图一致性。论文中提出的方法旨在通过优化映射空间坐标和采样点的语义特征之间的关系,重新构思图像感知任务为像素渲染任务,并利用点之间的空间关系来确保结果中的视图一致性和空间连续性。此外,论文还旨在解决现有方法在优化和渲染过程中高延迟的问题,并提出了一种基于高斯绘制的语义绘制方法,以实现高效且低延迟的处理。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
A. 基于训练的分割方法(Training-based Segmentation)
- CNN-based models:这类模型主要关注于保留详细信息和提取准确且丰富的抽象特征。许多模型基于编码器-解码器框架,例如U-Net,它通过级联卷积核提取图像特征,并通过对称的解码器重建特征图和上采样分辨率。此外,一些方法引入了空洞卷积来扩大感受野而不牺牲分辨率,并采用多尺度信息融合和特征金字塔策略来捕获更丰富的抽象特征。
- Transformer-based models:最初在自然语言处理(NLP)领域引入的Transformer架构,现在已广泛应用于图像处理领域,如分类、目标检测和分割任务。这类架构将图像块视为tokens,并通过级联层处理,其中注意力机制有效处理长距离依赖关系和探索tokens之间的关系。
B. 基于优化的分割方法(Optimization-based Segmentation)
- NeRF-like approaches:这类方法利用隐式神经网络(如NeRF)处理从多个视角捕获的单个场景。这些方法通过从相机到每个像素的射线上采样空间点来划分3D空间,并为每个采样点分配颜色和密度属性。
- Gaussian Splatting:从RGB渲染扩展到分割任务的方法,主要关注于室内场景,并依赖全视图监督以实现实例识别。
C. Segment Anything (SAM)
- SAM:这是一个基础视觉模型,旨在根据输入的视觉提示(如点或边界框)生成准确的图像分割。SAM由图像编码器、提示编码器和掩码解码器三个关键模块组成,能够生成代表可能包含目标对象的区域的掩码。
D. 坐标系统转换(Coordinate System Conversion)
- 论文还介绍了不同坐标系统之间的转换,包括像素坐标系统、图像坐标系统、相机坐标系统和世界坐标系统之间的转换关系。
这些相关研究为论文提出的新方法提供了理论基础和技术背景,使其能够在有限的标注图像条件下实现多视图分割,并提高分割的视图一致性和空间连续性。
Q: 论文如何解决这个问题?
A: 论文提出了一种高效的语义绘制方法,基于高斯绘制(Gaussian Splatting)技术来解决遥感多视图图像分割问题。具体解决方案包括以下几个关键步骤:
1. 语义绘制方法
- 扩展高斯绘制:首先将高斯绘制技术扩展到遥感图像语义分割领域,为每个采样点引入语义头和转换层,从绘制的特征图中生成分割结果。
- 连续语义特征:将离散的语义类别值转换为高维连续语义特征,分配给每个点,使其可微分,从而优化模型。
2. 利用SAM2生成伪标签
- 边界区域的挑战:针对边界区域常常缺乏足够的监督信息的问题,使用SAM2(一种基础模型)生成这些区域的伪标签,提高这些区域的分割精度。
3. 设计聚合损失
- 2D特征图和3D空间点级别的聚合损失:为了增强模型在2D特征图和3D空间点级别上的空间一致性,设计了两级聚合损失,改善了空间连续性和分割性能。
4. 优化过程
- 自监督优化:通过自监督机制优化颜色相关参数和语义相关参数,使用L1和LD-SSIM损失函数优化颜色渲染结果,使用交叉熵损失优化语义渲染结果。
- 参数细节:提供了方法的参数细节,包括优化过程的步数、点云中的最大点数、语义特征通道数等。
5. 实验验证
- 数据集和指标:使用合成数据和真实数据集进行实验,采用mIoU作为性能评估指标。
- 比较方法:与基于训练的分割方法和基于优化的分割方法进行比较,展示了提出方法在准确性和效率方面的优势。
6. 进一步工作
- 改进3D结构表示:探索更适合稀疏空间特性的3D结构表示,例如使用线性函数代替高斯函数。
- 整合隐式神经函数:计划将隐式神经函数与绘制技术整合,以估计点云中每个点的语义神经函数,进一步提高空间一致性。
综上所述,论文通过结合高斯绘制技术、SAM2生成的伪标签和聚合损失,提出了一种既高效又准确的多视图图像分割方法,特别适用于稀疏标签的遥感场景。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来验证所提出方法的有效性:
数据集和指标
- 数据集:使用的是包含六个由CARLA平台生成的合成子数据集和三个从Google Maps收集的真实子数据集的遥感多视图分割数据集。每个场景包含大约100张从不同角度拍摄的图像,其中只有2%到6%的图像在训练集中有对应的标注。
- 评估指标:使用平均交并比(mean Intersection over Union, mIoU)作为评估和比较不同方法性能的指标。
比较方法
- 与多种基于训练的分割方法进行比较,包括CNN-based的SegNet、Unet、DANet和DeepLabv3,以及基于Transformer的SETR。
- 与多种基于优化的分割方法进行比较,包括Sem-NeRF、Color-NeRF和IRT。
整体比较结果
- 定量分析:通过mIoU评估不同方法的性能,并比较了不同方法的处理时间。
- 定性分析:展示了从四个合成子数据集和两个真实子数据集中选取的六个测试视图的输入RGB图像及其对应的语义分割结果。
视图一致性比较
- 比较了Unet、IRT和提出方法在不同视图间的分割一致性。
消融研究
- 验证了SAM2生成的伪标签、2D聚合损失(L2D_a)和3D聚合损失(L3D_a)的必要性。
参数研究
- 研究了两种类型的视图(带有真实标签和带有伪标签)的比例以及L2D_a和L3D_a的权重对方法性能的影响。
这些实验全面评估了所提出方法在不同条件下的性能,并与现有技术进行了比较,从而证明了该方法在多视图遥感图像分割任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文在最后一部分提出了一些可以进一步探索的方向,具体包括:
更适当的3D结构表示:探索更适合稀疏空间特性的3D结构表示方法,例如使用线性函数代替高斯函数。这可能有助于提高模型在处理稀疏数据时的效率和准确性。
整合隐式神经函数与绘制技术:计划将隐式神经函数与高斯绘制技术整合,以估计点云中每个点的语义神经函数,这可能进一步提升空间一致性,并改善模型在处理复杂场景时的性能。
优化算法和参数调整:进一步研究和优化算法,包括参数调整和损失函数的设计,以提高模型的泛化能力和适应性。
多模态数据融合:考虑将其他类型的数据(如深度信息、红外图像等)与RGB图像结合,以提供更丰富的场景信息,并提高分割的准确性。
实时性能优化:研究如何优化模型以实现实时或近实时的分割性能,这对于许多实际应用(如自动驾驶、机器人导航等)至关重要。
更广泛的数据集测试:在更多样和更具挑战性的数据集上测试模型,以评估其鲁棒性和泛化能力。
模型压缩和加速:研究模型压缩和加速技术,以使模型更适合在资源受限的设备上部署。
无监督或自监督学习:探索无监督或自监督学习策略,以减少对大量标注数据的依赖。
跨域适应性:研究模型在不同领域(如从仿真环境到真实世界场景)的适应性和迁移学习能力。
这些方向都旨在进一步提升模型的性能,扩展其应用范围,并推动遥感图像分割技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:论文针对遥感多视图图像分割问题,旨在实现对目标场景的立体感知,即使在稀疏标签监督条件下也能产生每个视图一致的语义分割结果。
方法论:提出了一种基于高斯绘制的语义绘制方法,通过将RGB属性和语义特征投影到图像平面同时渲染RGB图像和语义分割结果,以提高优化和渲染的效率。
技术创新:
- 引入了SAM2生成边界区域的伪标签,以解决有限标签条件下边界区域的分割挑战。
- 设计了两级聚合损失,增强了2D特征图和3D空间点级别上的空间一致性,改善了分割性能。
实验验证:
- 使用合成数据和真实数据集进行广泛实验,验证了所提方法的有效性。
- 与基于训练的方法和基于优化的方法进行比较,展示了所提方法在准确性和效率方面的优势。
结果分析:
- 从定量和定性角度分析了实验结果,证明了所提方法在多视图分割任务中的优越性。
- 进行了视图一致性比较和消融研究,验证了各个组件的有效性。
未来工作:提出了进一步探索的方向,包括改进3D结构表示、整合隐式神经函数与高斯绘制技术等。
结论:论文得出结论,所提出的基于高斯绘制的语义绘制方法在稀疏标签条件下,能够实现高效且准确的多视图图像分割,为实际应用提供了一个坚实的基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


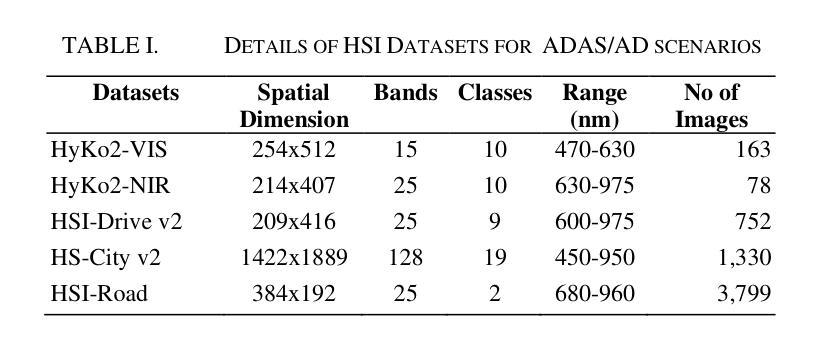
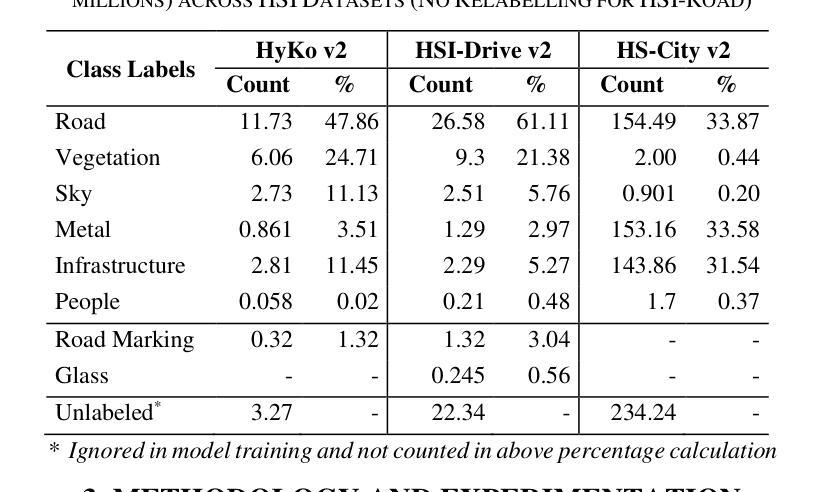
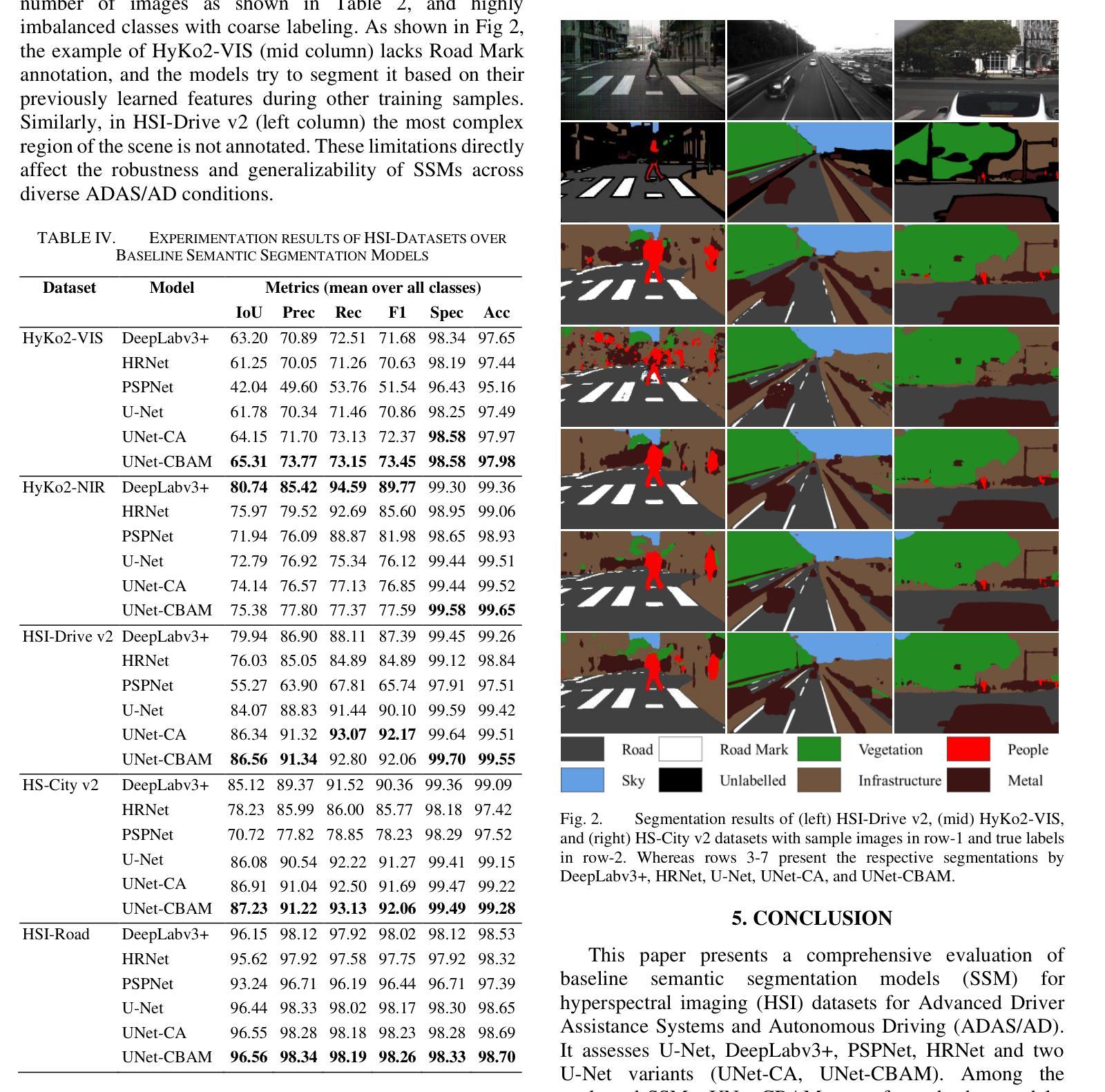
Hyperspectral Imaging-Based Perception in Autonomous Driving Scenarios: Benchmarking Baseline Semantic Segmentation Models
Authors:Imad Ali Shah, Jiarong Li, Martin Glavin, Edward Jones, Enda Ward, Brian Deegan
Hyperspectral Imaging (HSI) is known for its advantages over traditional RGB imaging in remote sensing, agriculture, and medicine. Recently, it has gained attention for enhancing Advanced Driving Assistance Systems (ADAS) perception. Several HSI datasets such as HyKo, HSI-Drive, HSI-Road, and Hyperspectral City have been made available. However, a comprehensive evaluation of semantic segmentation models (SSM) using these datasets is lacking. To address this gap, we evaluated the available annotated HSI datasets on four deep learning-based baseline SSMs: DeepLab v3+, HRNet, PSPNet, and U-Net, along with its two variants: Coordinate Attention (UNet-CA) and Convolutional Block-Attention Module (UNet-CBAM). The original model architectures were adapted to handle the varying spatial and spectral dimensions of the datasets. These baseline SSMs were trained using a class-weighted loss function for individual HSI datasets and evaluated using mean-based metrics such as intersection over union (IoU), recall, precision, F1 score, specificity, and accuracy. Our results indicate that UNet-CBAM, which extracts channel-wise features, outperforms other SSMs and shows potential to leverage spectral information for enhanced semantic segmentation. This study establishes a baseline SSM benchmark on available annotated datasets for future evaluation of HSI-based ADAS perception. However, limitations of current HSI datasets, such as limited dataset size, high class imbalance, and lack of fine-grained annotations, remain significant constraints for developing robust SSMs for ADAS applications.
高光谱成像(HSI)在遥感、农业和医学领域相对于传统RGB成像的优势已被广泛认知。最近,它在增强高级驾驶辅助系统(ADAS)感知方面引起了关注。已经推出了几个HSI数据集,如HyKo、HSI-Drive、HSI-Road和Hyperspectral City。然而,使用这些数据集对语义分割模型(SSM)的综合评估仍然缺乏。为了填补这一空白,我们评估了四个基于深度学习的基线SSM在可用注释的HSI数据集上的表现:DeepLab v3+、HRNet、PSPNet和U-Net,以及它的两个变体:坐标注意力(UNet-CA)和卷积块注意力模块(UNet-CBAM)。原始模型架构被调整以适应数据集的不同的空间和光谱维度。这些基线SSM使用针对各个HSI数据集的类加权损失函数进行训练,并使用基于均值的度量方法进行评估,如交集比联合(IoU)、召回率、精确度、F1分数、特异性和准确性。我们的结果表明,提取通道特征的UNet-CBAM表现优于其他SSM,并显示出利用光谱信息进行增强语义分割的潜力。这项研究在可用注释数据集上建立了基线SSM基准,用于未来评估基于HSI的ADAS感知。然而,当前HSI数据集的局限性,如数据集大小有限、类不平衡和缺乏精细注释,仍为开发用于ADAS应用的稳健SSM带来重大制约。
论文及项目相关链接
PDF Accepted and Presented at IEEE WHISPERS 2024
Summary:
本文研究了超光谱成像(HSI)在高级驾驶辅助系统(ADAS)感知中的应用。通过对多个HSI数据集的评价,本文对比了四种基于深度学习的语义分割模型(SSM)。研究发现,结合了注意力机制的UNet模型在处理带有标注的HSI数据集时表现最佳,特别是在利用光谱信息方面展现出潜力。然而,现有的HSI数据集仍存在局限性,如数据量有限、类别不平衡和缺乏精细标注等,限制了SSM在ADAS应用中的稳健发展。
Key Takeaways:
- 超光谱成像(HSI)在高级驾驶辅助系统(ADAS)感知领域受到关注。
- 多个HSI数据集如HyKo、HSI-Drive等已被开发并应用。
- 四种基于深度学习的语义分割模型(SSM)被评估用于处理HSI数据集。
- UNet结合注意力机制(UNet-CBAM)在处理HSI数据集时表现最好,可有效利用光谱信息。
- 目前存在的HSI数据集在大小、类别平衡和精细标注方面存在局限性。
- 这些局限性限制了SSM在ADAS应用中的稳健发展。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在自动驾驶场景中,如何利用高光谱成像(Hyperspectral Imaging, HSI)技术来增强高级驾驶辅助系统(Advanced Driver Assistance Systems, ADAS)的感知能力。具体来说,论文旨在通过以下几个方面来解决这个问题:
HSI数据集的评估:目前缺乏对用于ADAS场景的高光谱成像数据集(如HyKo、HSI-Drive、HSI-Road和Hyperspectral City)的全面评估。这些数据集对于开发和评估能够处理HSI数据的语义分割模型(Semantic Segmentation Models, SSM)至关重要。
基准SSM模型的建立:论文提出了一个基于现有标注的HSI数据集的基准SSM,以便于比较不同模型的性能,并为未来的HSI在ADAS/AD应用中的研究提供基础。
模型架构的适应性调整:由于HSI数据集在空间和光谱维度上的差异性,需要对原始模型架构进行调整,以适应不同数据集的输入尺寸和光谱分辨率。
模型性能的评估:使用多种性能指标(如交并比IoU、召回率、精确度、F1分数、特异性和准确度)来评估不同SSM模型在HSI数据集上的表现。
HSI数据集的局限性:论文还指出了当前HSI数据集的局限性,如数据集规模有限、类别不平衡和缺乏细粒度的标注,这些限制对开发鲁棒的SSM构成了挑战。
总的来说,论文的目标是通过评估和调整不同的深度学习基线模型,建立一个HSI数据集的基准SSM,以促进HSI技术在ADAS和自动驾驶领域的应用和发展。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个领域:
深度学习技术在HSI分割中的应用:尽管深度学习技术在遥感等领域已被广泛用于HSI分割,但在ADAS/AD(自动驾驶辅助系统/自动驾驶)领域的应用还相对有限。论文提到了CNN(卷积神经网络)在提取HSI的光谱-空间特征方面表现出色,同时RNNs(递归神经网络)、GANs(生成对抗网络)、DBNs(深度置信网络)、GCNs(图卷积网络)和基于Transformer的ViT(Vision Transformer)也在HSI领域显示出潜力,但在ADAS/AD中的HSI应用尚未被充分探索。
RGB和多模态成像在ADAS/AD感知中的研究:大多数与ADAS/AD感知相关的研究集中在RGB成像和多模态成像上。论文提到了几个基准数据集,如KITTI和Cityscapes用于RGB数据,nuScenes、Waymo Open Dataset、KAIST多光谱和FLIR ADAS热成像数据集被广泛认为是多模态分割的标准。
HSI数据集的研究:虽然HSI数据集的数量有限,但最近开始受到关注。论文中提到了几个完全标注的HSI数据集,包括HyKo v1-v2、HSI-Drive v1-v2、HS-City v1-v2和HSI-Road,这些数据集为HSI在ADAS/AD应用中的研究提供了基础,但其数据集大小和多样性仍然不足以支持鲁棒的ADAS/AD应用。
HSI在ADAS/AD中的标准化基线SSMs的研究:目前,HSI在ADAS/AD中缺乏标准化的基线SSMs,研究人员主要由于HSI数据的高维度而评估自己的数据集。这种缺乏标准化基准影响了HSI在ADAS/AD中的潜力理解的比较分析。
论文通过建立跨可用数据集的基线SSM基准,旨在填补这一空白,并为未来的HSI在ADAS/AD应用中的研究提供基础。这项工作不仅促进了模型性能的比较分析,还为HSI在ADAS/AD中的进一步研究提供了基础。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决HSI在自动驾驶场景中的应用问题:
数据集评估:
- 对现有的四个标注过的HSI数据集(HyKo v2, HSI-Drive v2, HS-City v2, 和 HSI-Road)进行了评估。
- 重新定义了这些数据集中的通用类别标签,以便于模型训练和比较。
模型选择与适应性调整:
- 选择了四种基线SSM模型(U-Net, DeepLab v3+, PSPNet, HRNet)以及两种U-Net变体(UNet-CA, UNet-CBAM)。
- 根据HSI数据集的不同空间和光谱维度调整了这些模型的架构,包括输入输出层和内部层的调整。
实验设置:
- 使用了最优的超参数设置,包括批量大小、学习率、优化器、调度器和损失函数。
- 采用了混合精度训练,没有使用正则化或早停策略。
性能评估:
- 使用了多种评价指标,包括交并比(IoU)、精确度(Prec)、召回率(Rec)、F1分数、特异性(Spec)和准确度(Acc)。
- 对所有类别的平均值进行了评估,以提供模型性能的全面分析。
结果分析:
- 发现UNet-CBAM模型在所有评估的数据集上均表现最佳,特别是在HSI-Road数据集上达到了非常高的准确度。
- 强调了注意力机制(特别是CBAM中的通道级特征提取)在特征提取中的重要性。
讨论与未来工作:
- 论文讨论了HSI数据集的局限性,如数据集规模有限、类别不平衡和缺乏细粒度的标注。
- 提出了未来研究的方向,包括开发更大、更多样化且具有细粒度标注的数据集,以促进更鲁棒和泛化性强的SSM的发展。
通过这些步骤,论文不仅建立了HSI数据集的基线SSM基准,而且为HSI在ADAS/AD领域的进一步研究提供了基础和方向。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集预处理:
- 对四个公开可用的HSI数据集(HyKo v2, HSI-Drive v2, HS-City v2, 和 HSI-Road)进行了预处理,包括重新定义类别标签以实现跨数据集的一致性,并调整HS-City v2数据集的空间维度以加速模型训练。
模型选择与调整:
- 选择了四种基线SSM模型(U-Net, DeepLab v3+, PSPNet, HRNet)和两种U-Net变体(UNet-CA, UNet-CBAM)。
- 对这些模型的架构进行了调整,以适应不同HSI数据集的空间和光谱维度。
模型训练:
- 使用了类权重交叉熵损失函数对模型进行训练,以解决类别不平衡问题。
- 应用了ReduceOnPlateau学习率调度器,并在达到最小阈值时将学习率重启至90%,以改善在高光谱优化任务中的收敛性。
性能评估:
- 使用了多个评价指标,包括交并比(IoU)、精确度(Prec)、召回率(Rec)、F1分数、特异性(Spec)和准确度(Acc),对模型性能进行了全面评估。
- 对所有类别的平均值进行了评估,以提供模型性能的全面分析。
结果分析:
- 对比了不同模型在各个数据集上的性能,特别是UNet-CBAM模型在多个数据集上均表现最佳。
- 分析了注意力机制,特别是CBAM中的通道级特征提取对于HSI数据集语义分割的重要性。
可视化结果:
- 展示了不同模型在HSI-Drive v2、HyKo2-VIS和HS-City v2数据集上的分割结果,包括样本图像和真实标签,以及各个模型的分割效果。
这些实验结果不仅为HSI在ADAS/AD领域的应用提供了标准化的基线SSM基准,而且揭示了注意力机制在HSI数据集语义分割中的潜力,同时也指出了现有HSI数据集的局限性,并为未来的研究方向提供了指导。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
更大的数据集和数据增强:
- 开发更大、更多样化的HSI数据集,以提高模型的泛化能力。
- 探索数据增强技术,以解决现有数据集中的类别不平衡和样本不足问题。
细粒度标注:
- 提供更细粒度的标注,以提高模型对复杂场景的理解能力。
- 探索自动标注技术,以减少人工标注的工作量和成本。
模型架构的改进:
- 研究和开发新的或改进的深度学习架构,以更好地处理HSI数据的高维度和复杂性。
- 探索轻量级模型,以便于在资源受限的嵌入式系统中部署。
注意力机制的应用:
- 进一步研究和优化注意力机制,特别是通道级特征提取,以充分利用HSI数据的光谱信息。
- 探索不同类型的注意力机制,如空间注意力、通道注意力和混合注意力,以提高模型性能。
跨模态融合:
- 研究如何将HSI数据与传统的RGB数据、LiDAR数据等其他模态数据融合,以提高自动驾驶系统的整体感知能力。
- 探索多模态融合策略,如早期融合、中期融合和晚期融合,以确定最佳的融合方法。
实时性能优化:
- 优化模型以满足实时应用的需求,如减少计算延迟和提高处理速度。
- 研究如何在保持高准确度的同时减少模型的复杂度和计算资源需求。
鲁棒性和泛化能力的提高:
- 研究如何提高模型在不同环境条件(如不同的光照、天气和季节)下的鲁棒性。
- 探索模型在未见过的新的驾驶场景中的泛化能力。
新的损失函数和优化策略:
- 开发新的损失函数,以更好地处理HSI数据的特性和应用需求。
- 探索新的优化策略,以提高模型的训练效率和收敛速度。
可解释性和安全性分析:
- 提高模型的可解释性,以便更好地理解模型的决策过程。
- 研究模型的安全性和可靠性,以确保在自动驾驶系统中的安全性。
这些探索点可以帮助研究者们进一步提高HSI在ADAS和自动驾驶领域的应用效果,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 本文主要内容包括以下几个方面:
研究背景与动机:
- 论文介绍了高光谱成像(HSI)技术在自动驾驶辅助系统(ADAS)中的优势,包括其在遥感、农业和医学等领域的应用,并指出HSI技术在动态和实时应用中的潜力。
现有HSI数据集的评估:
- 论文评估了四个现有的HSI数据集(HyKo、HSI-Drive、HSI-Road和Hyperspectral City),指出了这些数据集在规模、多样性和标注方面的局限性。
基线模型的建立与评估:
- 论文选择了四种深度学习基线模型(DeepLab v3+、HRNet、PSPNet、U-Net)及其两个变体(UNet-CA和UNet-CBAM),并调整了它们的架构以适应不同HSI数据集的空间和光谱维度。
- 使用类权重损失函数训练模型,并采用多个性能指标(IoU、精确度、召回率、F1分数、特异性和准确度)进行评估。
实验结果与分析:
- 论文展示了不同模型在各个HSI数据集上的性能,并发现UNet-CBAM模型在多数情况下表现最佳,尤其是在HSI-Road数据集上。
- 分析了注意力机制,特别是CBAM中的通道级特征提取对于HSI数据集语义分割的重要性。
HSI数据集的局限性与未来工作:
- 论文讨论了HSI数据集的局限性,包括数据集规模有限、类别不平衡和缺乏细粒度的标注,并提出了未来研究的方向,如开发更大、更多样化且具有细粒度标注的数据集。
结论:
- 论文总结了UNet-CBAM模型在HSI数据集上的优势,并强调了开发更鲁棒和泛化性强的SSMs的重要性,以促进HSI技术在ADAS和自动驾驶领域的应用。
整体而言,论文提供了一个HSI数据集的基线SSM基准,并为HSI在ADAS/AD领域的进一步研究提供了基础和方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


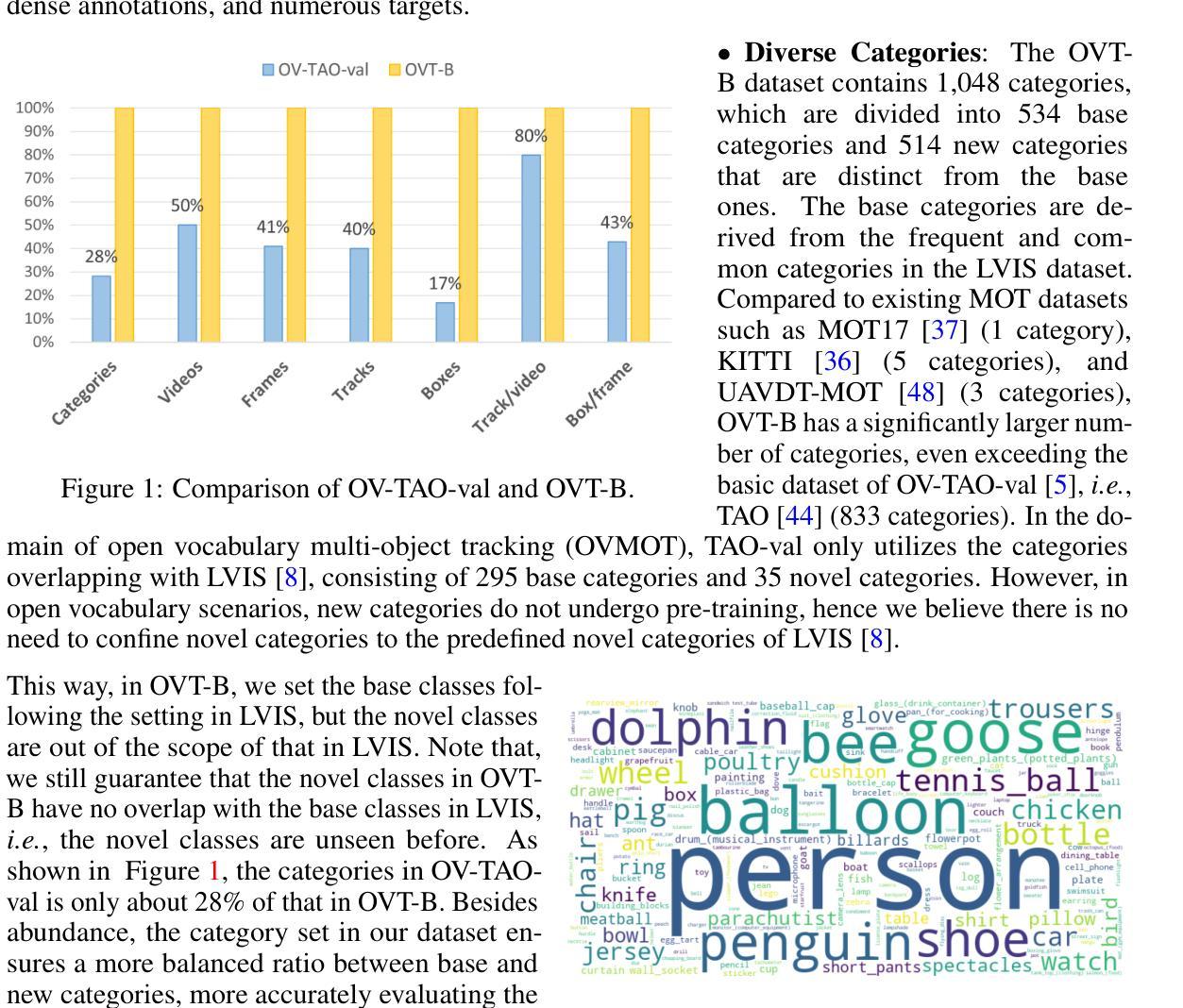
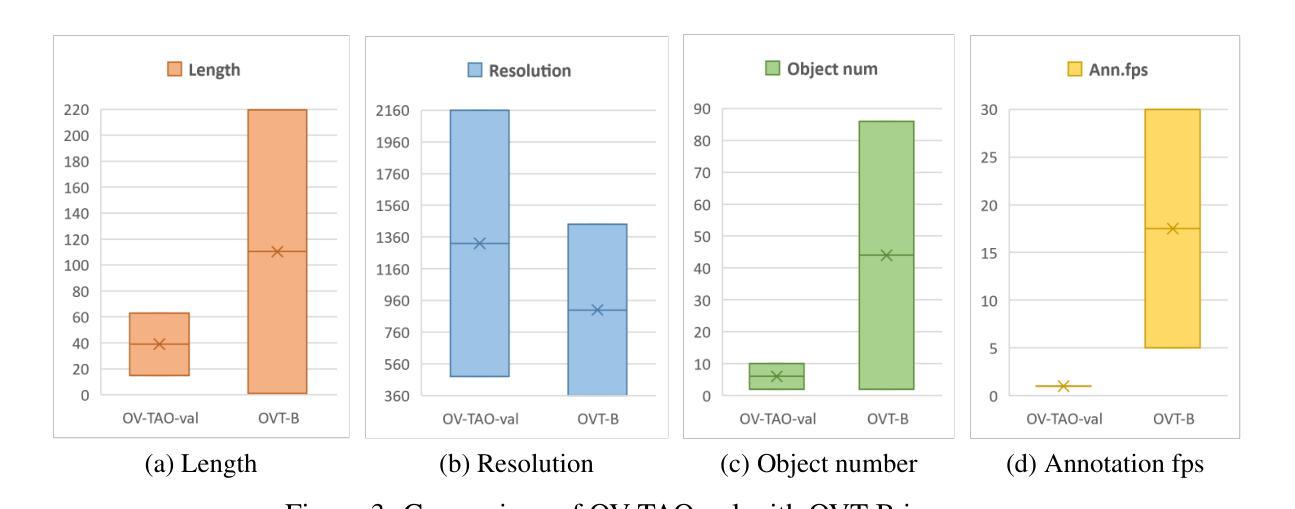
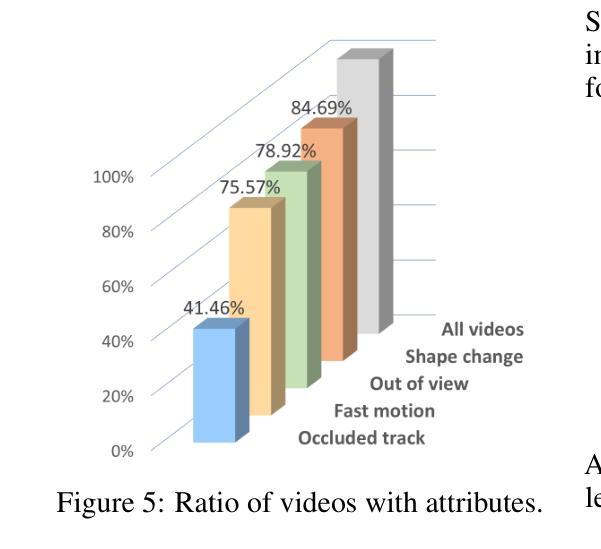
OVT-B: A New Large-Scale Benchmark for Open-Vocabulary Multi-Object Tracking
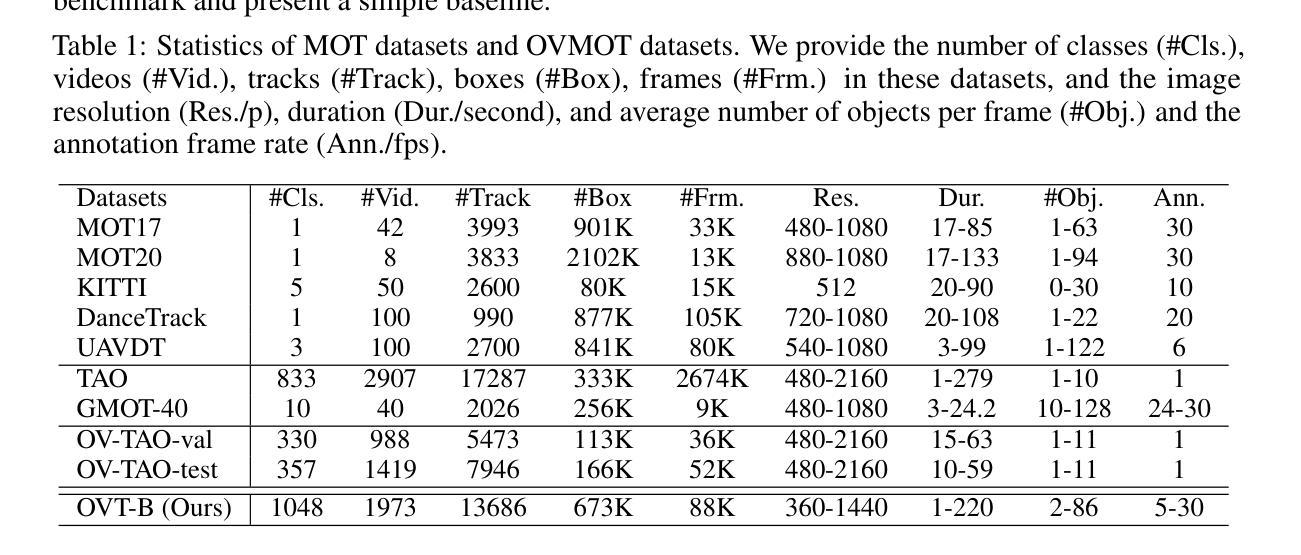
Authors:Haiji Liang, Ruize Han
Open-vocabulary object perception has become an important topic in artificial intelligence, which aims to identify objects with novel classes that have not been seen during training. Under this setting, open-vocabulary object detection (OVD) in a single image has been studied in many literature. However, open-vocabulary object tracking (OVT) from a video has been studied less, and one reason is the shortage of benchmarks. In this work, we have built a new large-scale benchmark for open-vocabulary multi-object tracking namely OVT-B. OVT-B contains 1,048 categories of objects and 1,973 videos with 637,608 bounding box annotations, which is much larger than the sole open-vocabulary tracking dataset, i.e., OVTAO-val dataset (200+ categories, 900+ videos). The proposed OVT-B can be used as a new benchmark to pave the way for OVT research. We also develop a simple yet effective baseline method for OVT. It integrates the motion features for object tracking, which is an important feature for MOT but is ignored in previous OVT methods. Experimental results have verified the usefulness of the proposed benchmark and the effectiveness of our method. We have released the benchmark to the public at https://github.com/Coo1Sea/OVT-B-Dataset.
开放词汇对象感知在人工智能中成为一个重要话题,旨在识别训练期间未见的新类别的对象。在这种背景下,单张图像中的开放词汇对象检测(OVD)已在许多文献中进行了研究。然而,视频的开放词汇对象跟踪(OVT)的研究较少,其中一个原因是缺乏基准测试集。在这项工作中,我们为开放词汇多对象跟踪建立了一个新的大规模基准测试集,名为OVT-B。OVT-B包含1048个类别的对象和1973个视频,带有637608个边界框标注,这远大于唯一的开放词汇跟踪数据集,即OVTAO-val数据集(200多个类别,900多个视频)。所提出的OVT-B可以作为新的基准测试集,为OVT研究铺平道路。我们还开发了一种简单有效的OVT基线方法。它集成了用于对象跟踪的运动特征,这是MOT中一个重要特征,但在以前的OVT方法中却被忽略了。实验结果验证了所提出基准测试集的有效性和我们方法的有效性。我们已在https://github.com/Coo1Sea/OVT-B-Dataset 向公众发布该基准测试集。
论文及项目相关链接
PDF 15 pages, 6 figures, accepted at NeurIPS 2024 Dataset and Benchmark Track
Summary
本文介绍了一个针对开放词汇多目标跟踪的新大规模基准数据集OVT-B的建立和基线方法的开发。OVT-B包含超过一千种物体类别,并且提供标注好的视频信息。该研究提出了一种新的基准测试方法,整合了运动特征进行目标跟踪,并验证了其有效性。数据集已公开于GitHub上。
Key Takeaways
- 开放词汇目标感知已成为人工智能领域的重要课题,旨在识别训练期间未见的新类别对象。在此背景下,本文研究了单幅图像中的开放词汇目标检测(OVD)。但对于视频中的开放词汇目标跟踪(OVT)的研究较少。其中一个原因是缺乏基准数据集。
- 本文建立了一个新的大规模基准数据集OVT-B,包含一千多种物体类别和大量标注视频信息。这使得OVT研究有了新的基准测试方法。这是迄今为止最大的开放词汇跟踪数据集之一。
- OVT-B可以作为开放词汇多目标跟踪研究的新基准数据集,推动该领域的发展。
- 开发了一种简单有效的基线方法用于OVT,该方法整合了运动特征进行目标跟踪。这在MOT中是一个重要的特征,但在之前的OVT方法中常被忽略。
- 实验结果验证了所提出基准数据集的有效性以及所开发方法的实用性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是开放词汇多目标跟踪(Open-Vocabulary Multi-Object Tracking,简称OVMOT)的研究缺乏综合性的基准数据集。具体来说,论文中提到以下几个关键点:
开放词汇目标跟踪的挑战:在开放词汇目标检测(Open-Vocabulary Object Detection,简称OVD)领域,已有研究能够直接检测训练过程中未见过的类别对象。然而,将开放词汇的概念扩展到视频流中的多目标跟踪任务(OVT)的研究相对较少,部分原因是缺乏足够的基准数据集来评估这些方法的性能。
现有数据集的局限性:目前最大的挑战是缺乏一个包含大量视频和类别的综合性基准数据集来准确评估新的OVMOT方法的性能。现有的OV-TAO-val数据集在类别数量和视频数量上都不足以满足开放词汇研究的需求。
构建新的基准数据集OVT-B:为了推动OVMOT研究的发展,作者构建了一个名为OVT-B(Open-Vocabulary Tracking Benchmark)的大规模基准数据集。该数据集包含1,048个类别的对象和1,973个视频,总共有637,608个边界框注释,远超现有的OV-TAO-val数据集。
**开发新的基线方法OVTrack+**:除了构建数据集,作者还开发了一个简单的基线方法OVTrack+,该方法结合了外观和运动信息来提高跟踪性能,解决了以往方法中忽视运动特征的问题。
综上所述,这篇论文的主要贡献在于提出了一个大规模的开放词汇多目标跟踪基准数据集OVT-B,并开发了一个结合运动特征的基线跟踪方法OVTrack+,旨在为OVMOT研究提供新的平台和方法。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
多目标跟踪(MOT):
- 传统的MOT任务主要关注特定类别(如行人和车辆)的跟踪,例如SORT [1]、DeepSORT [2] 等方法。
开放词汇目标检测(OVD):
- OVD旨在检测训练过程中未见过的新类别对象。相关研究包括OVRCNN [25]、CLIP [26]、VilD [3]、OV-DETR [28] 等。
开放词汇多目标跟踪(OVMOT):
- OVTrack [5] 是第一个尝试将开放词汇与多目标跟踪结合的研究,开发了一个简单的基线方法。
- VOVTrack [47] 提出了一种自监督的训练方式,使用原始视频而不是图像对来训练网络。
通用多目标跟踪(GMOT):
- GMOT40 [43] 和 TAO [44] 数据集扩展了跟踪任务到更广泛的类别,促进了能够跟踪更多类别的模型的发展。
开放世界/开放词汇跟踪(Open-World/OVMOT):
- Open World Tracking [45] 使用 OWTA 作为评估指标来跟踪未知类别。
- SimOWT [46] 使用自训练范式在开放世界跟踪中取得了最先进的性能。
基于Transformer的MOT方法:
- 一些研究将Transformer架构引入到MOT任务中,例如MOTR [21] 和 TrackFormer [22]。
其他相关数据集和方法:
- 论文中还提到了多个用于多目标跟踪、视频实例分割和视频目标检测的数据集,如AnimalTrack [49]、GMOT-40 [43]、LV-VIS [50]、OVIS [51]、UVO [52]、YouTube-VIS [53] 和 ImageNet-VID [54]。
- 论文中还提到了一些用于评估和比较不同跟踪方法性能的指标,如TETA [6]。
这些相关研究为开放词汇多目标跟踪领域的研究提供了理论基础和技术手段,同时也突显了构建新的基准数据集和开发新方法的必要性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个主要步骤来解决开放词汇多目标跟踪(OVMOT)面临的挑战:
构建新的基准数据集OVT-B:
- 作者创建了一个大规模的开放词汇多目标跟踪数据集OVT-B,包含1,048个类别和1,973个视频,总共637,608个边界框注释。
- 数据集来源于多个现有数据集,通过统一格式和处理不同数据集的特定问题(如不同的标注格式、类别定义和遮挡表示方式)来构建统一的注释。
**开发新的基线方法OVTrack+**:
- 论文提出了一个简单的基线方法OVTrack+,该方法整合了外观和运动信息来提高跟踪性能。
- OVTrack+使用Kalman滤波器来预测目标的运动位置,并结合目标的外观嵌入来计算最终的关联距离,使用匈牙利算法进行最优匹配。
实验验证:
- 作者在OVT-B数据集上进行了广泛的实验,验证了所提出的数据集和方法的有效性。
- 实验结果表明,OVTrack+在TETA、LocA和AssA指标上相比之前的OVTrack方法有更高的性能,尽管在ClsA上略有下降。
分析和讨论:
- 论文讨论了OVMOT与传统MOT的区别,并从实践中提供了一些经验和教训,以应对OVMOT的新挑战。
- 论文还对OVMOT的未来研究方向提出了一些看法,包括如何改进模型的分类能力、如何处理不同子任务之间的性能平衡,以及可能需要的新评估指标。
通过这些步骤,论文不仅提供了一个新的大规模基准数据集来促进OVMOT的研究,还开发了一个有效的基线方法来展示如何结合运动和外观信息来提高跟踪性能,并对未来的研究方向提供了指导。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来验证提出的OVT-B基准数据集和OVTrack+基线方法的有效性:
与现有方法的比较:
- 作者将OVTrack+与几种现有的多目标跟踪方法进行了比较,包括ByteTrack、OC-SORT、StrongSORT和OVTrack。这些方法代表了不同的跟踪范式,包括基于运动的方法、基于外观的方法以及混合方法。
在OV-TAO-val和OVT-B数据集上的评估:
- 作者在OV-TAO-val和新提出的OVT-B数据集上评估了这些方法的性能。这包括比较不同方法在整体跟踪精度(TETA)、定位精度(LocA)、关联精度(AssA)和分类精度(ClsA)上的表现。
深入分析:
- 作者深入分析了OVT-B数据集相比于OV-TAO-val数据集在跟踪任务上的挑战和特点。这包括分析数据集中目标的数量、分辨率、遮挡情况、目标大小和形状等属性。
- 作者还探讨了OVT-B数据集在评估模型性能时的优势,如更高的标注帧率和更丰富的跟踪场景。
讨论新的挑战和经验:
- 作者讨论了OVMOT与传统MOT的区别,并分享了在实践中学到的一些经验和教训。这包括对分类置信度的不可靠性、类别信息作为关联线索的不切实际性等问题的讨论。
- 作者还对未来的研究方向提出了一些看法,包括如何改进模型的分类能力、如何处理不同子任务之间的性能平衡,以及可能需要的新评估指标。
通过这些实验和分析,作者验证了OVT-B数据集的挑战性和多样性,以及OVTrack+方法在整合运动和外观信息方面的优势。这些实验结果为OVMOT领域的未来研究提供了有价值的见解和方向。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和讨论部分,以下是一些可以进一步探索的点:
改进分类能力:
- 论文指出,目前的方法在新类别对象的分类上表现不佳。因此,研究如何提高开放词汇跟踪方法中新类别对象的分类能力是一个值得探索的方向。
子任务间的性能平衡:
- 论文提到,不同的子任务(定位、分类、跟踪)之间可能需要相互补充以达到更好的整体性能。探索如何平衡和优化这些子任务的性能是一个有价值的研究方向。
评估指标:
- 论文中提到,现有的评估指标TETA直接计算定位、分类和跟踪精度的平均值,但没有考虑不同子任务的难度差异。因此,开发新的评估指标以更合理地评估跟踪方法的性能是一个潜在的研究方向。
跟踪-by-检测方法:
- 论文认为,在开放词汇设置中,跟踪-by-检测方法可能是未来的主流框架。因此,研究如何改进这类方法,特别是在检测阶段就具有开放类别识别能力,是一个重要的研究方向。
联合嵌入方法:
- 尽管论文认为跟踪-by-检测方法可能是未来的主流,但也提到了联合嵌入跟踪和检测特征的方法。探索有效的联合嵌入方法,特别是能够处理多任务互补的方法,是另一个值得研究的方向。
数据集的扩展和增强:
- 虽然OVT-B数据集比现有的数据集大得多,但扩展数据集以包含更多的类别和场景,或增强数据集的多样性和复杂性,可以进一步推动该领域的发展。
算法的鲁棒性和泛化能力:
- 开放词汇跟踪方法在面对类别多样性和样本分布不均时的鲁棒性和泛化能力是一个重要的研究点。研究如何提高算法在复杂和未知环境中的性能是必要的。
实时性能:
- 跟踪算法的实时性能对于许多应用场景至关重要。研究如何提高开放词汇跟踪方法的计算效率和实时性是一个实际且重要的研究方向。
多模态融合:
- 考虑到视觉和语言模型在开放词汇检测中的成功,进一步探索多模态融合策略,以提高跟踪任务中对象的识别和关联能力,也是一个有前景的研究方向。
这些探索点可以帮助推动开放词汇多目标跟踪技术的发展,提高其在实际应用中的有效性和可靠性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题阐述:
- 论文提出了开放词汇多目标跟踪(OVMOT)面临的一个重要挑战,即缺乏用于评估和推进该领域研究的大规模基准数据集。
OVT-B数据集构建:
- 作者构建了一个新的大规模基准数据集OVT-B,包含1,048个类别和1,973个视频,总共637,608个边界框注释,远超现有的OV-TAO-val数据集。
- 数据集来源于多个现有数据集,作者通过统一格式和处理不同数据集的特定问题来构建统一的注释。
OVTrack+基线方法:
- 论文提出了一个简单的基线方法OVTrack+,该方法整合了外观和运动信息来提高跟踪性能。
- OVTrack+使用Kalman滤波器来预测目标的运动位置,并结合目标的外观嵌入来计算最终的关联距离,使用匈牙利算法进行最优匹配。
实验验证:
- 作者在OV-TAO-val和新提出的OVT-B数据集上评估了OVTrack+方法,并与其他几种现有的多目标跟踪方法进行了比较。
- 实验结果表明,OVTrack+在TETA、LocA和AssA指标上相比之前的OVTrack方法有更高的性能。
分析和讨论:
- 论文讨论了OVMOT与传统MOT的区别,并从实践中提供了一些经验和教训,以应对OVMOT的新挑战。
- 论文还对OVMOT的未来研究方向提出了一些看法,包括如何改进模型的分类能力、如何处理不同子任务之间的性能平衡,以及可能需要的新评估指标。
总的来说,这篇论文通过构建一个新的大规模基准数据集OVT-B和开发一个新的基线方法OVTrack+,为开放词汇多目标跟踪领域的研究提供了新的平台和方法,并通过实验验证了其有效性,同时也为未来的研究方向提供了指导。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

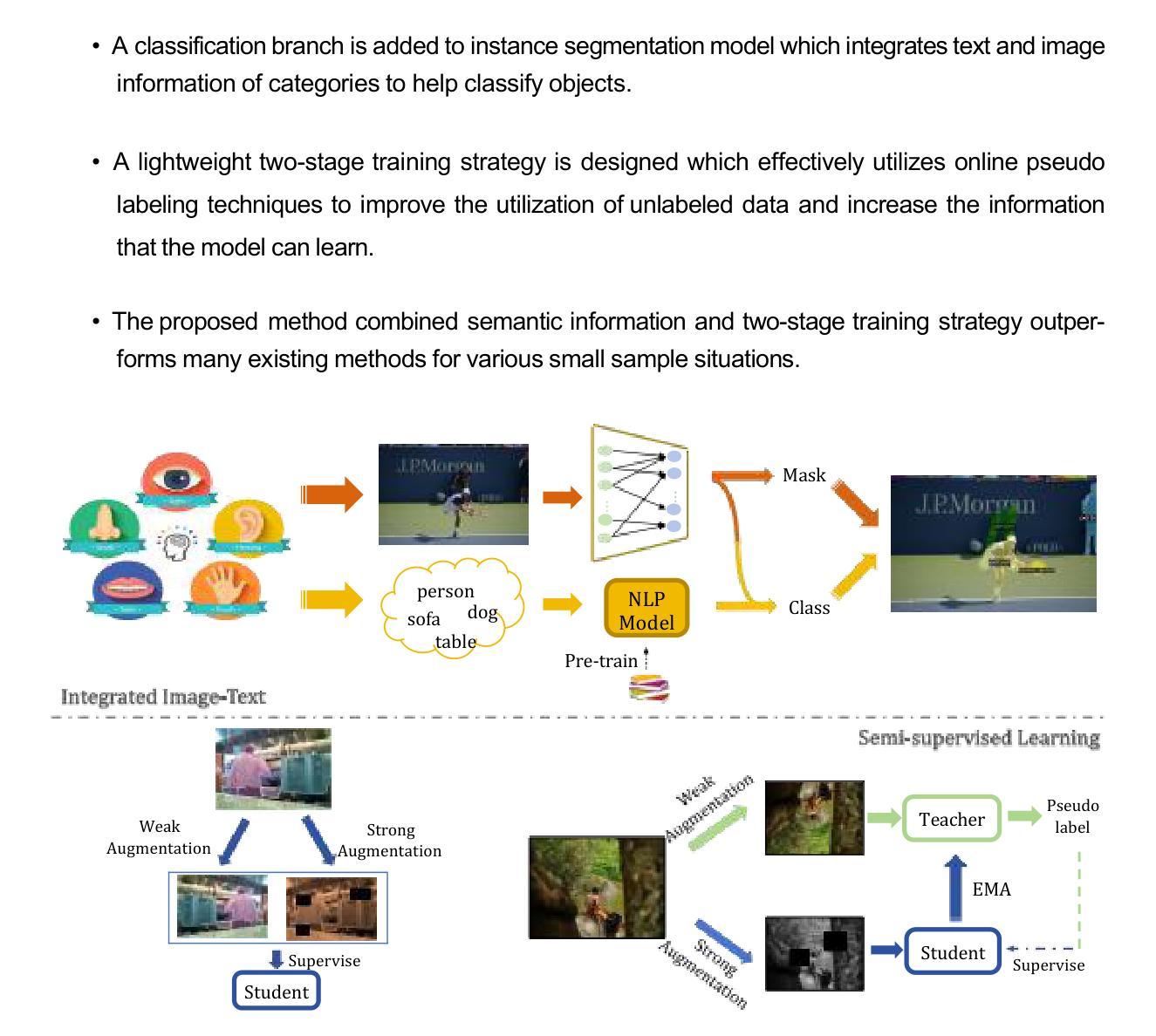
Integrated Image-Text Based on Semi-supervised Learning for Small Sample Instance Segmentation
Authors:Ruting Chi, Zhiyi Huang, Yuexing Han
Small sample instance segmentation is a very challenging task, and many existing methods follow the training strategy of meta-learning which pre-train models on support set and fine-tune on query set. The pre-training phase, which is highly task related, requires a significant amount of additional training time and the selection of datasets with close proximity to ensure effectiveness. The article proposes a novel small sample instance segmentation solution from the perspective of maximizing the utilization of existing information without increasing annotation burden and training costs. The proposed method designs two modules to address the problems encountered in small sample instance segmentation. First, it helps the model fully utilize unlabeled data by learning to generate pseudo labels, increasing the number of available samples. Second, by integrating the features of text and image, more accurate classification results can be obtained. These two modules are suitable for box-free and box-dependent frameworks. In the way, the proposed method not only improves the performance of small sample instance segmentation, but also greatly reduce reliance on pre-training. We have conducted experiments in three datasets from different scenes: on land, underwater and under microscope. As evidenced by our experiments, integrated image-text corrects the confidence of classification, and pseudo labels help the model obtain preciser masks. All the results demonstrate the effectiveness and superiority of our method.
小样例实例分割是一项极具挑战性的任务,许多现有方法采用元学习的训练策略,即在支持集上预训练模型,并在查询集上进行微调。与任务高度相关的预训练阶段需要大量的额外训练时间和选择接近的数据集以确保有效性。文章提出了一种新的小样例实例分割解决方案,从最大化利用现有信息出发,且不增加标注负担和训练成本。所提出的方法设计了两个模块来解决小样例实例分割中遇到的问题。首先,它通过学习生成伪标签,帮助模型充分利用未标记的数据,增加了可用样本的数量。其次,通过整合文本和图像的特征,可以获得更准确的分类结果。这两个模块适用于无框和依赖于框的框架。通过这种方式,所提出的方法不仅提高了小样例实例分割的性能,而且极大地减少了对预训练的依赖。我们在三个不同场景的数据库进行了实验:陆地、水下和显微镜下的数据。实验证明,整合图像-文本校正了分类的置信度,伪标签帮助模型获得了更精确的掩膜。所有结果都证明了我们方法的有效性和优越性。
论文及项目相关链接
Summary
本文提出一种小样例实例分割解决方案,旨在最大化利用现有信息,同时不增加标注负担和训练成本。该方法设计两个模块,通过生成伪标签和利用文本与图像特征融合,解决小样例实例分割中的问题,提高分类准确性并减少对预训练的依赖。实验证明该方法在陆地、水下和显微镜等不同场景下的数据集上表现优越。
Key Takeaways
- 小样例实例分割是一项具有挑战性的任务,现有方法多采用元学习训练策略,需大量额外训练时间和选择接近的数据集以确保效果。
- 本文提出一种新型小样例实例分割方法,旨在最大化利用现有信息,同时不增加标注负担和训练成本。
- 方法设计两个模块:通过生成伪标签充分利用无标签数据,增加可用样本数量;通过融合文本和图像特征,提高分类准确性。
- 该方法适用于无边界框和有边界框的框架。
- 实验证明该方法在多个不同场景下的数据集上表现优越,集成图像文本修正分类置信度,伪标签帮助模型获得更精确的掩膜。
- 该方法不仅提高了小样例实例分割的性能,而且大大降低了对预训练的依赖。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是小样本实例分割(small sample instance segmentation)的问题。小样本实例分割是一个非常具有挑战性的任务,尤其是在数据稀缺的情况下。现有的许多方法依赖于元学习(meta-learning)的训练策略,即在支持集(support set)上预训练模型,并在查询集(query set)上进行微调。这种预训练阶段与特定任务高度相关,需要大量的额外训练时间,并且需要选择与支持集接近的数据集以确保有效性。
论文提出了一种新的方法,从最大化利用现有信息的角度出发,无需增加标注负担和训练成本,来解决小样本实例分割中遇到的问题。具体来说,该方法设计了两个模块来解决小样本实例分割中的问题:
- 生成伪标签(Pseudo Labels)模块:通过学习生成伪标签,帮助模型充分利用未标记数据,增加可用样本数量。
- 图像-文本融合(Integrated Image-Text)模块:通过整合文本和图像特征,可以获得更准确的分类结果。
这两个模块适用于无框(box-free)和依赖框(box-dependent)框架,从而不仅提高了小样本实例分割的性能,还大大降低了对预训练的依赖。论文通过在不同场景下的三个数据集(陆地、水下和显微镜下)进行实验,证明了所提方法的有效性和优越性。
Q: 有哪些相关研究?
A: 论文中提到了多个与小样本学习、半监督学习、小样本实例分割以及视觉任务中的语义模块相关的研究工作。以下是一些主要的相关研究:
小样本学习(Small Sample Learning)
- 数据增强方法:例如Mixup[9],Supermix[10],Stylemix[11],TokenMixup[12]等,这些方法通过不同的数据增强技术来增加样本数量。
- 模型优化方法:如原型网络(Prototypical networks)[14]和匹配网络(matching networks)[15],这些基于度量学习的方法通过限制样本对之间的距离来学习特征。
- 迁移学习方法:例如MAML[16],这类方法首先在大规模数据上进行预训练,然后在目标领域进行微调。
半监督学习(Semi-supervised Learning)
- 一致性正则化方法:例如Π-model[17],Temporal Ensembling[17],Mean Teacher[18],Virtual Adversarial Training (VAT)[19]等,这些方法通过在未标记数据上添加噪声来最小化模型预测结果的差异,以提高模型的泛化能力。
- 伪标签方法:例如Meta pseudo labels[22],这类方法使用教师模型为未标记数据生成伪标签,并与标记数据一起训练学生模型。
小样本实例分割(Small Sample Instance Segmentation)
- 基于元学习的方法:如FGN[7],RefT[26],FAPIS[27]等,这些方法通过引入不同的指导机制来增强模型在小样本数据上的性能。
- 其他小样本实例分割方法:例如iFS-RCNN[39],PAIS[40]等,这些方法在小样本实例分割任务上进行了探索和应用。
视觉任务中的语义模块(Semantic Modules in Visual Tasks)
- **CLIP[28]**:通过添加图像的文本描述来改善图像识别任务,可以扩展到语义分割和目标检测任务。
- **GroupViT[29]**:利用图像-文本对来监督模型训练,无需掩码即可执行简单的分割任务。
- **TriNet[30]**:将特征空间映射到语义空间,实现小样本数据增强。
这些研究为小样本实例分割问题提供了不同的视角和解决方案,而本文提出的SemInst方法则是在这些现有研究的基础上,通过结合图像-文本信息和半监督学习策略来提高小样本实例分割的性能。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SemInst(Semi-supervised Instanse Segmentator with Semantic Classes)的新方法来解决小样本实例分割问题。SemInst通过以下两个主要模块来提高性能并减少对预训练的依赖:
1. 语义分支(Semantic Branch)
- 目的:增强模型对类别的分类能力,通过整合文本和图像信息来帮助分类对象。
- 实现:使用预训练在大规模文本上的SciBert模型来提取类别的词嵌入(word embeddings),然后将这些语义特征与图像特征相结合,以此来提升分类的准确性。
- 融合:通过一个投影层调整词嵌入的维度,使其与图像特征维度一致,然后通过乘法融合图像特征和语义特征,最后通过一个多层感知机(MLP)得到分类结果。
2. 两阶段训练策略(Two-stage Training)
- 目的:充分利用未标记数据的信息,通过伪标签技术提高模型的泛化能力。
- 实现:分为监督训练阶段和半监督训练阶段。
- 监督训练阶段:仅使用标记数据训练教师模型(Teacher)。
- 半监督训练阶段:学生模型(Student)用监督训练阶段得到的模型权重初始化,教师模型生成伪标签,学生模型通过标记数据和带有伪标签的未标记数据进行训练。
- 更新策略:教师模型的参数通过指数移动平均(EMA)方式更新,这有助于保持监督训练的参数,并吸收未标记数据的影响,使得教师模型提供的伪标签更加可靠。
通过结合这两个策略,SemInst不仅提高了小样本实例分割的性能,还减少了对大规模数据集预训练的依赖。实验结果表明,SemInst在不同场景的三个数据集上均取得了优越的性能,证明了该方法的有效性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估所提出的SemInst方法在小样本实例分割任务上的有效性。以下是实验的详细情况:
实验设置
- 基础模型:使用了两种基础模型,即基于框的方法Mask R-CNN和无框方法FastInst。
- 数据集:实验在三个不同的数据集上进行,包括海洋垃圾数据集TrashCan、COCO2017和2205DSS(在显微镜下收集的双相不锈钢类别数据)。
- 训练策略:模型在标记数据上进行监督训练,然后在标记数据和未标记数据上进行半监督训练。
数据集描述
- TrashCan:包含22个类别,训练集有6065张图像,验证集有1147张图像。
- COCO2017:包含80个类别,训练集有118278张图像,验证集有5000张图像,测试集有40640张图像。
- 2205DSS:包含42张标记的显微镜图像和45张未标记图像。
实验结果
- 性能比较:SemInst方法与多个现有方法进行了比较,包括Mask R-CNN、FastInst、iFS-RCNN、Noisy Boundary和PAIS。
- 评估指标:使用VOC挑战的标准指标评估模型性能,包括平均精度(AP)、AP50和AP75。
比较结果
- TrashCan数据集:SemInst在不同比例的样本中均取得了第一或第二的最佳性能。
- COCO数据集:SemInst在所有比较模型中表现最佳。
- 2205DSS数据集:基于Mask R-CNN的SemInst模型表现优于基于FastInst的模型。
消融研究
- 语义分支和两阶段训练的有效性:通过在TrashCan、COCO2017和2205DSS数据集上进行消融实验,证明了这两个模块对提高模型性能的重要性。
- 不同阈值对分类分数的影响:研究了在半监督训练中不同阈值对模型性能的影响,发现适当的阈值可以提高模型性能。
- 标记与未标记图像比例的影响:研究了在半监督训练阶段,标记数据与未标记数据的不同比例对模型性能的影响,发现设置相等数量的标记和未标记数据可以获得更好的性能。
这些实验结果表明,SemInst方法能够有效地提高小样本实例分割的性能,并且通过消融研究进一步验证了所提出模块的有效性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的SemInst方法在小样本实例分割任务上取得了一定的成效,但仍有一些可以进一步探索和改进的点:
1. 语义分支的改进和优化
- 多模态融合技术:探索更先进的图像和文本融合技术,例如使用更复杂的注意力机制或者图神经网络来融合图像和文本特征。
- 领域适应性:研究如何使语义分支更好地适应不同的领域或任务,尤其是在跨领域的情况下。
2. 半监督学习策略的增强
- 动态阈值调整:根据模型在训练过程中的表现动态调整伪标签生成的阈值,以提高伪标签的质量。
- 一致性正则化技术:结合其他一致性正则化技术,如Mean Teacher或VAT,来进一步提高模型的鲁棒性和泛化能力。
3. 模型训练和优化
- 损失函数的改进:设计新的损失函数或者对现有损失函数进行改进,以更好地处理小样本问题。
- 训练动态调整:研究如何动态调整训练过程中的学习率和其他超参数,以提高模型的训练效率和性能。
4. 数据增强和生成技术
- 更复杂的数据增强:探索更复杂的数据增强技术,如生成对抗网络(GANs)生成的数据,以增加样本多样性。
- 领域特定的数据增强:针对特定领域(如医学图像)设计更有效的数据增强策略。
5. 模型泛化能力的测试
- 跨领域测试:在不同的领域和数据集上测试SemInst模型的泛化能力,以评估其在更广泛场景下的应用潜力。
- 长尾分布问题:研究如何在长尾分布的数据集中提高模型的性能,特别是在少数类上的性能。
6. 实际应用和案例研究
- 特定领域的应用:将SemInst模型应用于具体的实际问题,如医疗诊断、工业检测等,以验证其在实际应用中的有效性。
- 案例研究:通过具体的案例研究,深入分析模型在处理复杂实例分割任务时的表现和限制。
这些探索点不仅可以推动小样本实例分割技术的发展,还可能为其他相关的计算机视觉任务提供新的见解和方法。
Q: 总结一下论文的主要内容
A: 本文提出了一种名为SemInst的半监督实例分割模型,旨在解决小样本情况下的实例分割问题。SemInst通过最大化现有信息的利用,避免了增加额外的标注负担和训练成本。以下是论文的主要内容总结:
1. 问题背景
- 实例分割任务要求在图像中定位目标对象,并预测其掩码和类别。
- 小样本实例分割是一个挑战性任务,许多现有方法依赖于大规模数据集和元学习策略,这些策略需要大量的预训练时间和数据集选择工作。
2. SemInst方法
- 语义分支(Semantic Branch):通过整合图像和文本特征增强分类能力,使用SciBert提取类别的词嵌入,并与图像特征结合。
- 两阶段训练策略:包括监督学习和半监督学习,利用在线伪标签技术提高未标记数据的利用效率。
3. 实验
- 在三个不同场景的数据集(陆地、水下和显微镜下)上进行了实验验证。
- 与现有方法(如Mask R-CNN、FastInst等)相比,SemInst在多个指标上取得了优越的性能。
- 消融实验进一步证明了语义分支和两阶段训练策略的有效性。
4. 主要贡献
- 提出了一种新的小样本实例分割解决方案,减少了对大规模数据集和预训练的依赖。
- 设计了语义分支和两阶段训练策略,提高了模型性能,并在多个数据集上验证了有效性。
5. 结论
- SemInst通过整合图像-文本信息和半监督训练,有效地提高了小样本实例分割的性能。
- 该方法为如何在数据稀缺情况下充分提取信息提供了参考和启示。
论文通过提出一种创新的方法来解决小样本实例分割问题,并在多个数据集上验证了其有效性,为未来的研究提供了新的方向和思路。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Impact of imperfect annotations on CNN training and performance for instance segmentation and classification in digital pathology
Authors:Laura Gálvez Jiménez, Christine Decaestecker
Segmentation and classification of large numbers of instances, such as cell nuclei, are crucial tasks in digital pathology for accurate diagnosis. However, the availability of high-quality datasets for deep learning methods is often limited due to the complexity of the annotation process. In this work, we investigate the impact of noisy annotations on the training and performance of a state-of-the-art CNN model for the combined task of detecting, segmenting and classifying nuclei in histopathology images. In this context, we investigate the conditions for determining an appropriate number of training epochs to prevent overfitting to annotation noise during training. Our results indicate that the utilisation of a small, correctly annotated validation set is instrumental in avoiding overfitting and maintaining model performance to a large extent. Additionally, our findings underscore the beneficial role of pre-training.
在数字病理学中进行大量实例(如细胞核)的分割和分类是准确诊断的关键任务。然而,由于标注过程的复杂性,深度学习方法可用的高质量数据集往往有限。在这项工作中,我们研究了噪声标注对训练和最先进CNN模型在病理图像中检测、分割和分类细胞核任务的训练和性能的影响。在此背景下,我们调查了确定适当训练周期数的条件,以防止在训练过程中对标注噪声过度拟合。我们的结果表明,使用一个小而正确的验证集对于避免过度拟合并保持模型性能在很大程度上发挥了重要作用。此外,我们的研究还强调了预训练的有益作用。
论文及项目相关链接
Summary
在数字病理学中,对大量实例如细胞核进行分割和分类是准确诊断的关键任务。然而,由于标注过程的复杂性,高质量数据集用于深度学习方法的可用性受到限制。本研究调查了标注噪声对训练及最先进CNN模型在病理图像中检测、分割和分类细胞核任务性能的影响。我们探究了确定适当训练周期数的条件以防止对标注噪声的过拟合现象。结果指示正确标注的小规模验证集在避免过拟合以及维持模型性能方面发挥重要作用。此外,我们的研究还强调了预训练的有益作用。
Key Takeaways
- 在数字病理学中,细胞核等对象的检测和分类对准确诊断至关重要。
- 由于标注过程的复杂性,高质量数据集在深学习方法中的可用性受限。
- 标注噪声对训练和模型性能有显著影响。
- 利用正确标注的小规模验证集能有效避免模型对标注噪声的过拟合。
- 预训练在提升模型性能方面具有积极作用。
- 研究表明,确定适当的训练周期数是防止过拟合的关键。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在数字病理学中,不完美的标注对于卷积神经网络(CNN)在进行实例分割和分类任务时的训练和性能的影响。具体来说,论文试图解决以下几个问题:
不完美标注的影响:研究了带有噪声的标注对于最先进的CNN模型在检测、分割和分类组织病理学图像中的细胞核的任务的影响。
训练周期的确定:探讨了在存在标注噪声的情况下,如何确定适当的训练周期以防止对噪声的过拟合。
模型性能的维持:分析了使用少量正确标注的验证集对于避免过拟合和在很大程度上维持模型性能的重要性。
预训练的作用:论文还强调了预训练在提高模型对不完美标注的鲁棒性方面的有益作用。
总的来说,这项工作旨在填补当前研究中关于处理医学图像中多实例分割和分类任务中不完美标注的挑战的空白,并提出了一些方法来减轻这些不完美标注对模型性能的负面影响。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,相关研究主要集中在以下几个方面:
不完美或错误标注的影响:
- 研究了医学图像分割中的标注噪声,包括观察者间变异性、标注者错误以及计算机生成标签的错误。
- 探索了不完美标注对组织病理学图像分割的影响,例如通过模拟遗漏和不精确的标注对腺管分割性能的影响。
- 研究了不精确或有偏差的边界框对性能的影响,以及在合成数据集中错误包含对象对性能的影响。
避免在训练过程中对标注噪声过拟合的方法:
- 早期停止深度网络训练的需求,特别是在医学领域之外的图像分类任务中。
- 识别和清除(或清洗)错误标注的方法,例如在脑损伤分割中的标签清洗,以及在食管内窥镜数据集中执行数据修剪。
- 半监督方法的使用,这些方法在能够识别足够数量的正确标注以进行监督阶段的情况下可能是合适的。
多实例分割和分类的更复杂任务:
- 研究了在数字病理学中结合检测、分割和分类实例(如细胞核或腺管)的任务。
- 探索了这些任务中标注噪声的不同表现形式,包括影响图像背景(如遗漏标注)和前景(如实例类别错误)的错误。
与不完美标注相关的研究:
- 论文中还提到了一些研究,这些研究集中在图像分类任务中学习有噪声的标签,强调了拥有一个干净的验证集对于确定停止点的重要性。
这些相关研究涵盖了从基础的标注噪声影响分析,到开发避免过拟合标注噪声的高级方法,再到特定于数字病理学的多实例分割和分类任务的研究。论文通过引用这些相关工作,建立了研究的背景,并在此基础上进一步探讨了在存在不完美标注的情况下如何提高CNN模型的性能和鲁棒性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决不完美标注对CNN训练和性能影响的问题:
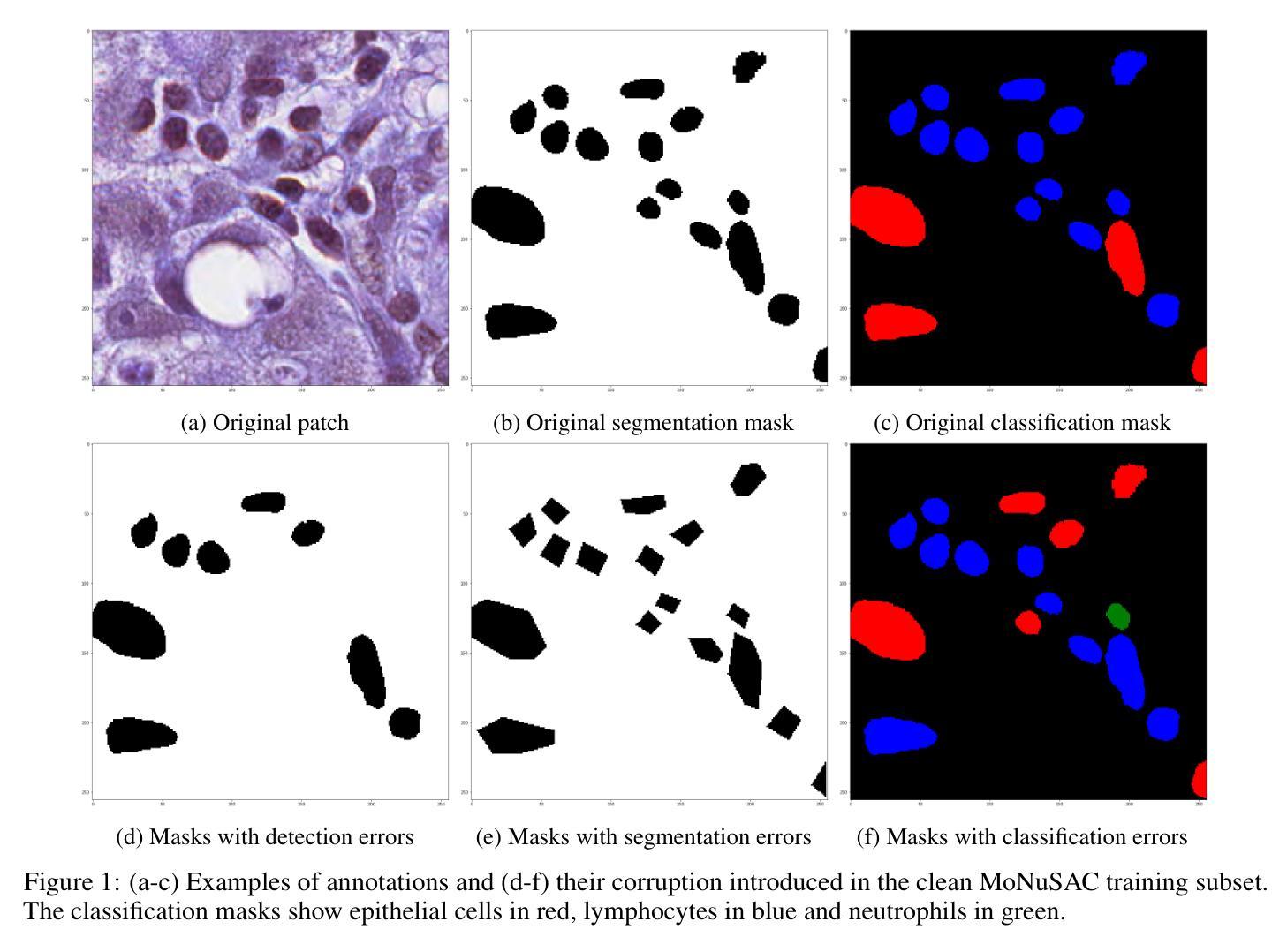
引入噪声标注:
- 通过在干净的训练集中有意引入不同类型的标注错误(包括检测误差、分割误差和分类误差),模拟现实世界中的不完美标注情况。
模型选择:
- 使用了专为细胞核分割和分类任务设计的最先进的Hover-Net模型,该模型已经在相关领域展现出了对不完美训练集标注的鲁棒性。
预训练和微调:
- 模型首先在与目标任务相似的干净数据集上进行预训练,然后在目标任务的数据集上进行微调。这种两阶段训练方法有助于提高模型对标注噪声的鲁棒性。
训练终止策略:
- 通过在干净的验证集上监控模型的损失,来确定合适的训练周期,避免对标注噪声的过拟合。使用早停策略(early stopping)来防止模型在训练过程中对噪声数据过度拟合。
性能评估:
- 使用特定的性能指标分别评估检测、分割和分类任务。这有助于准确理解不同类型的标注噪声对模型性能的具体影响。
实验验证:
- 进行了一系列实验,包括改变噪声水平和类型,以及使用不同的数据集,来验证所提出方法的有效性。实验结果表明,使用少量正确标注的验证集和预训练可以显著提高模型对标注噪声的鲁棒性,并且能够在很大程度上维持模型性能。
讨论和未来工作:
- 论文最后讨论了研究的局限性,并提出了未来可能的研究方向,如改进早停策略,探索更好的特征提取方法,以及比较不同模型架构对标注噪声的鲁棒性。
通过这些步骤,论文不仅分析了不完美标注对CNN模型性能的影响,还提出了有效的策略来减轻这些影响,从而提高了模型在实际应用中的鲁棒性和可靠性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估不同类型的标注噪声(检测噪声、分割噪声和分类噪声)对基于Hover-Net模型的多实例分割和分类任务的影响。以下是实验的主要步骤和内容:
数据集准备:
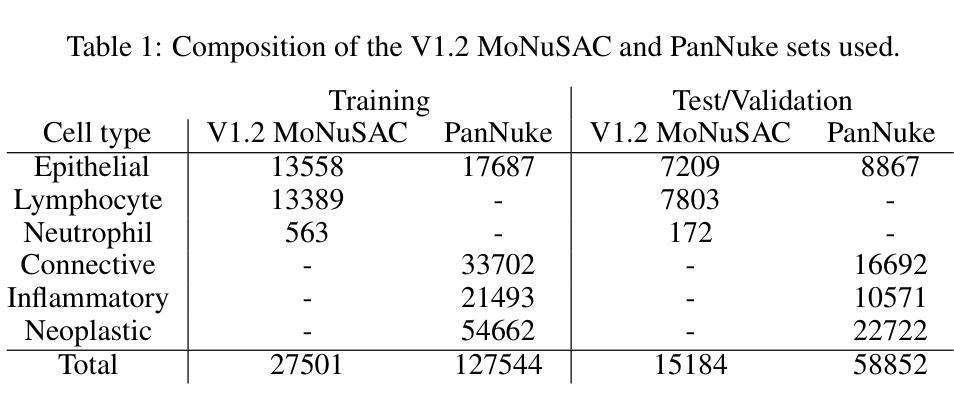
- 使用了两个公开的数据集:MoNuSAC和PanNuke。这些数据集包含了多种类型的细胞核的图像,并且已经被标注了分割和分类信息。
引入标注噪声:
- 在干净的训练集中引入了三种类型的噪声:检测误差、分割误差和分类误差。这些噪声以不同的比例被引入,以模拟不同程度的标注不完美。
模型训练:
- 使用了Hover-Net模型进行训练。模型首先在预训练阶段使用一个干净的数据集(如PanNuke)进行预训练,然后在目标数据集(如MoNuSAC)上进行微调。
训练终止策略:
- 实现了一种基于验证集损失的早停策略,以确定最佳的训练周期并避免对标注噪声的过拟合。
性能评估:
- 使用特定的性能指标来评估检测、分割和分类任务。这些指标包括精确度、召回率、F1分数、IoU(交并比)和Hausdorff距离等。
实验设计:
- 实验包括了不同噪声水平的单独影响和组合影响的分析。例如,首先分析检测噪声的影响,然后是分割噪声,接着是分类噪声,最后是这些噪声类型的组合。
结果分析:
- 对比了在有无早停策略的情况下,模型在测试集上的性能。结果表明,使用早停策略可以有效减轻标注噪声对模型性能的负面影响。
对比实验:
- 对比了使用不同预训练数据(如PanNuke和ImageNet)对模型性能的影响。结果表明,使用与目标任务相似的干净数据集进行预训练可以提高模型的鲁棒性,并减少所需的训练周期。
扩展实验:
- 将类似的实验扩展到PanNuke数据集,以验证早停策略在不同数据集上的有效性。
这些实验全面地评估了标注噪声对模型性能的影响,并验证了早停策略和预训练在提高模型鲁棒性方面的有效性。通过这些实验,论文为处理数字病理图像中的不完美标注提供了有价值的见解和方法。
Q: 有什么可以进一步探索的点?
A: 根据论文的讨论和结论部分,以下是一些可以进一步探索的点:
改进早停策略:
- 目前的早停策略主要基于验证集上的损失函数,未来的研究可以探索更多基于不同性能指标的早停策略,例如针对检测和分类任务的类平衡指标。
对称与非对称噪声的比较:
- 论文中主要考虑了对称噪声,未来的研究可以探讨非对称噪声对模型性能的影响,并比较对称与非对称噪声的影响差异。
类平衡的最优训练周期确定:
- 研究如何通过类平衡的方式确定模型的最优训练周期,特别是在检测和分类任务中,以更有效地处理类别不平衡问题。
增强模型的鲁棒性:
- 进一步研究如何通过改进模型架构或训练策略来提高模型对于标注噪声的鲁棒性,例如使用自监督学习方法或变换器(transformer)架构。
半监督和自监督方法的应用:
- 探索半监督和自监督学习方法在处理标注噪声中的应用,并与当前的CNN方法进行比较。
更复杂的标注噪声模拟:
- 模拟更加复杂和多样的标注噪声,以更真实地反映现实世界中的标注误差,并评估模型在这些情况下的性能。
跨数据集的泛化能力:
- 研究模型在不同数据集间的泛化能力,特别是在不同组织样本和标注噪声水平下的泛化性能。
计算资源和效率的优化:
- 考虑到变换器等模型在训练时对计算资源的高需求,研究如何优化这些模型以减少训练时间和资源消耗。
更广泛的数据集验证:
- 在更多、更广泛的数据集上验证所提方法的有效性,包括不同类型和来源的组织病理学图像。
实际临床应用的评估:
- 将模型部署到实际的临床环境中,评估其在真实世界数据上的性能和鲁棒性,并收集临床医生的反馈用于进一步改进模型。
这些探索点可以帮助研究者更深入地理解标注噪声对模型性能的影响,并开发出更加强大和鲁棒的模型来处理现实世界中的不完美数据。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了在数字病理学中,不完美标注对卷积神经网络(CNN)进行实例分割和分类任务时的训练和性能的影响。以下是论文的主要内容概述:
问题背景:在数字病理学中,由于标注过程的复杂性和时间消耗,高质量的数据集往往有限。这导致在深度学习方法中存在大量实例(如细胞核)的分割和分类任务时,标注噪声是一个普遍存在的问题。
研究目标:本研究旨在调查噪声标注对于最先进的CNN模型在组织病理学图像中进行核检测、分割和分类任务的性能和训练的影响,并确定防止在训练过程中对标注噪声过拟合的适当条件。
方法论:
- 使用了两个数据集:MoNuSAC和PanNuke,并在这些数据集上引入了不同类型的标注噪声。
- 选用了Hover-Net模型,这是一个为细胞核分割和分类任务设计的CNN架构。
- 实施了一种预训练和微调的训练策略,并引入了基于干净验证集的早停策略,以避免过拟合。
实验设计和结果:
- 进行了多种实验,包括引入不同水平和类型的标注噪声,并评估了模型在原始测试集上的性能。
- 结果表明,使用少量正确标注的验证集和预训练可以显著提高模型对标注噪声的鲁棒性,并在很大程度上维持模型性能。
主要贡献:
- 分析了不完美标注对训练过程的影响,并强调了确定适当训练周期以防止过拟合标注噪声的重要性。
- 展示了通过基于模型评估使用干净验证集的早停策略可以显著恢复性能。
- 强调了预训练在提高模型鲁棒性方面的好处。
讨论和未来工作:
- 论文讨论了研究的局限性,并提出了未来可能的研究方向,包括改进早停策略、探索更好的特征提取方法,以及比较不同模型架构对标注噪声的鲁棒性。
总体而言,这篇论文提供了对于在存在不完美标注的情况下如何提高CNN模型在数字病理学中的鲁棒性和性能的深入见解,并提出了一些有效的策略来减轻这些影响。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图