⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Neptune: The Long Orbit to Benchmarking Long Video Understanding
Authors:Arsha Nagrani, Mingda Zhang, Ramin Mehran, Rachel Hornung, Nitesh Bharadwaj Gundavarapu, Nilpa Jha, Austin Myers, Xingyi Zhou, Boqing Gong, Cordelia Schmid, Mikhail Sirotenko, Yukun Zhu, Tobias Weyand
This paper describes a semi-automatic pipeline to generate challenging question-answer-decoy sets for understanding long videos. Many existing video datasets and models are focused on short clips (10s-30s). While some long video datasets do exist, they can often be solved by powerful image models applied per frame (and often to very few frames) in a video, and are usually manually annotated at high cost. In order to mitigate both these problems, we propose a scalable dataset creation pipeline which leverages large models (VLMs and LLMs), to automatically generate dense, time-aligned video captions, as well as tough question answer decoy sets for video segments (up to 15 minutes in length). Our dataset Neptune covers a broad range of long video reasoning abilities and consists of a subset that emphasizes multimodal reasoning. Since existing metrics for open-ended question answering are either rule-based or may rely on proprietary models, we provide a new open source model-based metric GEM to score open-ended responses on Neptune. Benchmark evaluations reveal that most current open-source long video models perform poorly on Neptune, particularly on questions testing temporal ordering, counting and state changes. Through Neptune, we aim to spur the development of more advanced models capable of understanding long videos. The dataset is available at https://github.com/google-deepmind/neptune
本文介绍了一种半自动流程,用于生成用于理解长视频的具有挑战性的问答干扰选项集。许多现有的视频数据集和模型都专注于短视频片段(10秒至30秒)。虽然也有一些长视频数据集存在,但它们通常可以通过应用于视频的每一帧(并且经常是很少的帧)的强大图像模型来解决,并且通常以高昂的成本进行手动标注。为了解决这两个问题,我们提出了一种可扩展的数据集创建流程,该流程利用大型模型(视觉语言模型和大型语言模型),自动生成密集、时间对齐的视频字幕,以及针对视频片段(长达15分钟)的难以回答的问题答案干扰选项集。我们的数据集Neptune涵盖了广泛的长期视频理解能力,其中包括强调多媒体理解的子集。由于现有的开放问答答题指标要么是规则基础的,要么可能依赖于专有模型,因此我们提供了一个新的开源模型指标GEM来对Neptune上的开放答案进行评分。基准评估表明,大多数当前的开源长视频模型在Neptune上的表现较差,特别是在测试时间顺序、计数和状态更改的问题方面。通过Neptune,我们的目标是促进更先进模型的发展,使其能够理解长视频。数据集可在https://github.com/google-deepmind/neptune找到。
论文及项目相关链接
Summary:本文提出了一种半自动创建问答数据集的管道方法,用于生成理解长视频的挑战性问题集。文章强调了对长视频理解的必要性和现有数据集的不足,通过提出利用大型模型和自动化生成视频描述的方式解决了手动标注的高成本问题。此外,还介绍了一种新的开放源代码模型度量标准GEM,用于评估长视频问题回答的质量。数据集Neptune旨在推动长视频理解模型的发展。
Key Takeaways:
- 提出了一种半自动创建问答数据集的管道方法,旨在解决手动标注的高成本问题。
- 强调了现有视频数据集在处理长视频方面的局限性,如持续时间短、过于依赖图像模型等。
- 利用大型模型和自动化生成时间对齐的视频描述以及针对长视频的问答数据。
- 新推出的数据集Neptune包含了强调多种模式推理的子集。
- 为长视频问答评估引入了新的开放源代码模型度量标准GEM。
- 基准评估显示大多数现有模型在Neptune上的表现不佳,特别是在测试时间顺序、计数和状态变化方面的能力方面有待提高。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何为长视频理解任务生成具有挑战性的问题-答案-诱饵集(QADs)。具体来说,论文中提到了以下几个关键问题:
长视频理解数据集的局限性:许多现有的视频数据集和模型都集中在短视频片段(10-30秒)上。虽然有一些长视频数据集存在,但它们通常可以通过强大的图像模型逐帧(甚至只处理视频中的少数几帧)应用来解决,并且这些数据集通常需要高昂的手动注释成本。
长视频理解的挑战:创建一个真正的长视频理解数据集需要大量的手动工作来选择、观看、理解和注释长视频,这些工作不仅成本高,而且难以保持一致性和多样性。
现有评估指标的不足:对于开放式问题回答,现有的评估指标要么基于规则,要么依赖于专有模型,这些指标可能无法准确衡量模型在长视频理解任务上的性能。
为了解决这些问题,论文提出了一个半自动的数据集创建流程,该流程利用大型视觉语言模型(VLMs)和大型语言模型(LLMs)自动生成密集的、时间对齐的视频字幕,并从中自动派生出针对视频片段(最长可达15分钟)的困难QADs。此外,论文还提供了一个新的开源模型基评估指标(GEM),用于在Neptune数据集上评估开放式回答。通过这种方式,论文旨在推动更先进的长视频理解模型的发展。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
视频问答(VideoQA):
- 早期的视频和语言模型,如Flamingo、BLIP2、Video-Llama、GIT2和PALI等,这些模型通常包含强大的视觉和语言编码器/解码器。
- Socratic风格的模型,结合了各种专门的冻结模型与精心提示的最新VLMs和LLMs,例如MoreVQA。
- 端到端的大型多模态模型,如Gemini和GPT-4,这些模型具有长上下文长度,能够处理包括视频、声音和文本在内的多模态数据。
视频QA基准测试:
- 推动评估时间相关问题、长视频以及多样化领域(如指导性和自我中心视频)的关键数据集。
- 总结现有的VideoQA基准测试,大多数数据集要么关注短视频(少于100秒),要么是可以仅用几帧解决的短视视频数据集。
开放式视频QA的评估指标:
- 早期QA数据集的评估指标,如BLEU、ROUGE和CIDEr等,这些指标主要测量n-gram重叠,并不完全捕捉任务的主观性。
- 其他指标包括SPICE(添加动作和对象关系),以及基于模型的指标,如BERT-Score、BERT-Score++、LEIC、NUBIA、TIGEr、CLIPScore和EMScore等。
- 特定于答案等价性的指标,如BEM,它在答案等价性数据集上微调BERT,显示出更好的QA评分。
长视频理解的数据集创建:
- EgoSchema,它通过提示LLMs生成,但覆盖的领域有限,依赖于现有注释,而Neptune覆盖更广泛的视频类型,其流程适用于任意视频。
- 其他通过提示LLMs生成的数据集,如ActivityNet-RTL、CinePile等。
这些相关研究为长视频理解领域的模型开发、数据集创建和评估指标提供了基础和对比。论文通过提出新的数据集Neptune和评估指标GEM,旨在进一步推动这一领域的研究进展。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决长视频理解的问题:
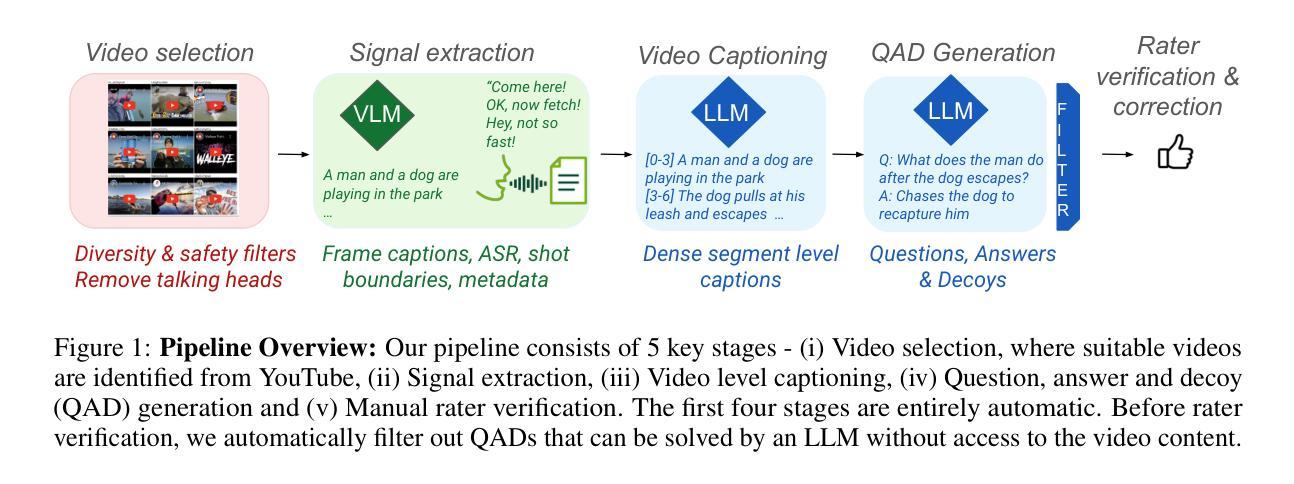
提出半自动数据集创建流程:
- 利用大型视觉语言模型(VLMs)和大型语言模型(LLMs)自动生成密集的、时间对齐的视频字幕。
- 从这些字幕中自动派生出针对视频片段的问题-答案-诱饵(QAD)集。
视频选择和信号提取:
- 从YT-Temporal-1Bn数据集中选择视频,并减少“谈话头”视频,以捕获更有趣的场景、对象和动作。
- 提取帧字幕、自动语音识别(ASR)、元数据和每个视频的镜头边界等信号。
自动视频字幕生成:
- 将提取的信号(帧字幕、ASR、标题和描述、镜头边界)自动组合,通过多阶段过程创建视频级字幕。
QAD生成:
- 通过定制的提示将视频字幕输入到LLMs中,自动生成问题、答案和诱饵。
- 采用两阶段方法:首先生成问题和答案,然后基于前一阶段的问题和答案生成六个诱饵。
基于LLM的盲过滤QAD:
- 使用LLM对答案候选进行排名,以去除可以通过常识或外部世界知识回答的问题。
手动评分者验证:
- 通过人工审核确保质量,评分者根据四个标准评估问题的质量,并标注所需模态。
- 评分者接受或修改答案,并从LLM生成的诱饵候选中选择最具挑战性的四个。
提供新的评估指标GEM:
- 为了评估开放式问题回答,论文提出了一个新的开源模型基评估指标GEM(Gemma Equivalence Metric)。
基准测试:
- 对现有的视频模型进行基准测试,揭示了开源视频模型和专有模型(如Gemini-1.5和GPT-4)之间的性能差距。
通过这些步骤,论文旨在创建一个能够评估长视频理解能力的可扩展数据集,并推动更先进的长视频理解模型的发展。此外,通过开源GEM评估指标,论文为学术界提供了一个可复用的、不受专有模型限制的评估工具。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验:
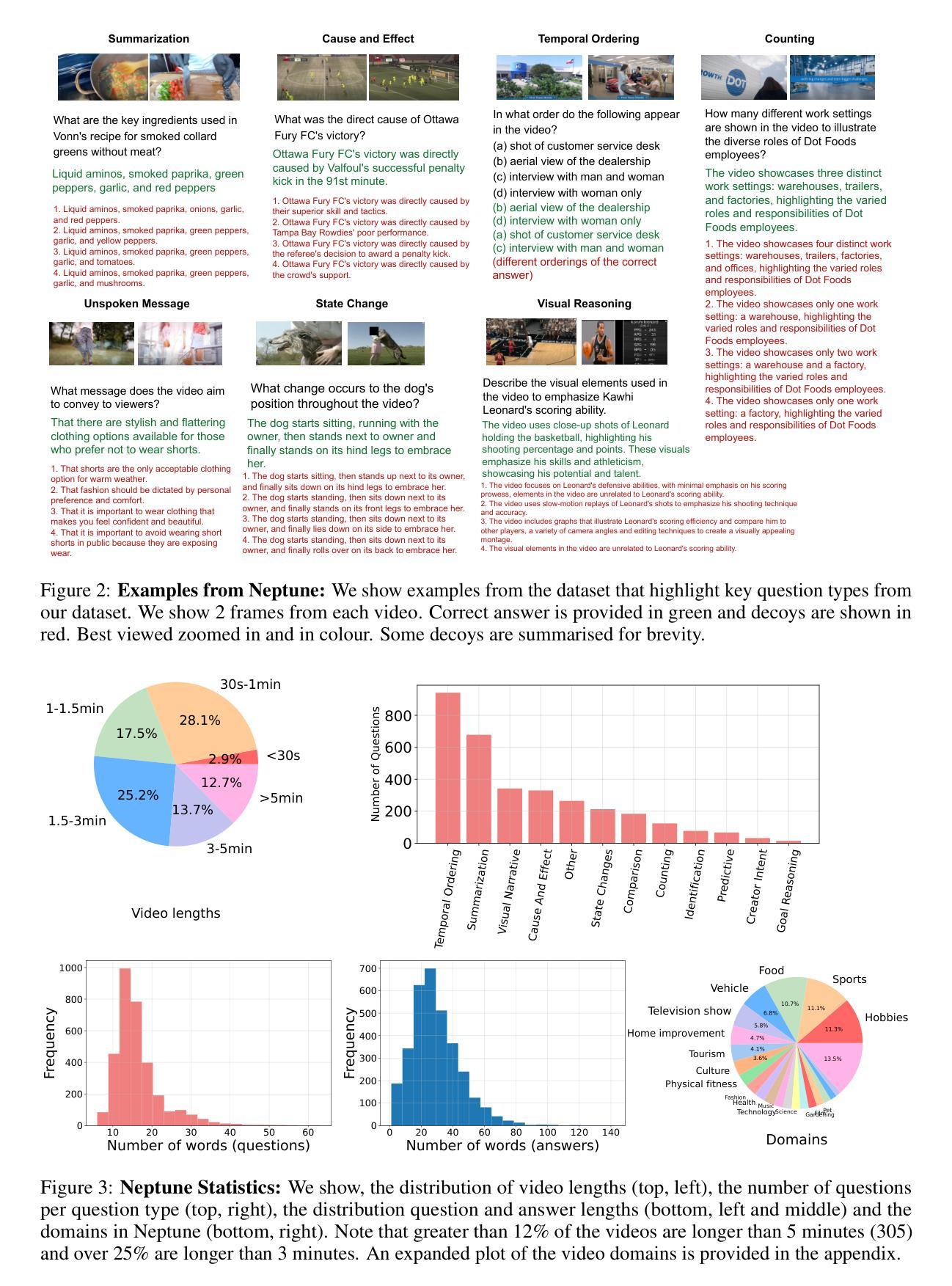
Neptune数据集的创建和评估:
- 作者首先介绍了他们创建的Neptune数据集,并提供了两种评估协议:多项选择评估和开放式评估。
GEM(Gemma Equivalence Metric)的创建和评估:
- 为了解决开放式问题回答的评估问题,作者手动构建了一个标记的开发集,并在这个集合上评估了多种基于规则和基于模型的指标。
- 他们比较了传统的指标(如CIDEr和ROUGE-L)和基于模型的指标(如BERT-Score和BEM)。
- 作者还微调了Gemma模型在BEM答案等价性数据集上,并提出了新的评估指标GEM。
基准测试:
- 作者对多种视频问答模型进行了基准测试,包括盲基线测试(只使用文本提示)、图像模型(如BLIP2)、短上下文MLLMs(如Video-LLaVA和VideoLLaMA2)、长上下文MLLMs(包括开源和闭源模型,如MA-LMM、MiniGPT4-Video、Gemini 1.5-pro和GPT-4o)。
- 他们评估了这些模型在Neptune数据集上的性能,并进行了模态消融研究,比较了仅使用ASR、仅使用视频帧和同时使用两者的性能。
Neptune-MMH子集的评估:
- 作者创建了Neptune-MMH子集,该子集包含视觉模态重要的问题,并评估了模型在这个更具挑战性的子集上的性能。
与人类提出的问题(HPQ)的比较:
- 为了测试自动数据管道的有效性和效率,作者让评分者完全手动地为数据集中的一个子集提出问题和答案(称为HPQ),并与自动生成的问题进行比较。
不同问题类型的性能分析:
- 作者分析了不同模型在Neptune数据集中不同问题类型(如时间排序、计数、状态变化等)上的性能,并指出了未来的研究方向。
这些实验旨在全面评估Neptune数据集的有效性,提出的GEM评估指标的性能,以及当前视频理解模型在长视频问答任务上的能力和局限性。通过这些实验,作者展示了Neptune作为一个评估长视频理解能力的基准测试的价值,并揭示了现有模型的不足。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
改进视频选择和信号提取:
- 研究更先进的视频选择算法,以从YouTube等平台中识别出更丰富、更具代表性的视频内容。
- 探索更多种类的视频信号提取技术,例如场景理解、物体检测和情绪分析,以增强视频字幕和QAD生成的上下文信息。
增强视频字幕生成:
- 研究如何结合更复杂的自然语言处理技术,以生成更准确和详细的视频字幕。
- 考虑引入额外的上下文信息,比如视频的元数据、用户评论和相关文本,以提高字幕生成的质量。
优化QAD生成算法:
- 探索不同的提示工程(prompt engineering)技术,以生成更多样化和更具挑战性的QADs。
- 研究如何利用强化学习或其他自动化方法来进一步减少人工审核的需求。
评估指标的改进:
- 继续优化GEM评估指标,使其能够更准确地衡量模型在开放式问题回答任务上的性能。
- 探索结合人类评估和自动评估的混合评估方法,以提高评估的可靠性和效率。
长视频理解模型的开发:
- 开发能够处理更长视频上下文和更复杂推理任务的新型视频语言模型。
- 研究如何将现有的长视频理解模型迁移到新的领域和数据集上,并评估其泛化能力。
减少模型偏见和提高数据集多样性:
- 分析Neptune数据集中潜在的偏见,并探索减少这些偏见的方法。
- 增强数据集的多样性,包括视频类型、语言和文化背景,以提高模型的包容性和适用性。
跨模态学习:
- 研究如何更有效地整合视觉、音频和文本信息,以提高模型的跨模态理解能力。
- 探索新的神经网络架构和学习算法,以增强模型对多模态数据的融合和推理能力。
实时视频理解和交互:
- 研究如何使视频理解模型适用于实时视频流,并支持实时交互和问答。
- 探索视频理解技术在实际应用中的潜力,如监控、教育和娱乐。
这些探索点可以帮助推动长视频理解领域的研究进展,并为开发更先进的视频问答系统提供新的思路和方法。
Q: 总结一下论文的主要内容
A: 本文介绍了一个名为Neptune的长视频理解基准测试,旨在通过一个半自动流程生成具有挑战性的问题-答案-诱饵集(QADs),以推动长视频理解技术的发展。以下是论文的主要内容总结:
问题陈述:
- 许多现有的视频数据集和模型专注于短视频片段,而长视频数据集要么依赖于图像模型,要么手动注释成本高。
Neptune数据集:
- 提出了一个可扩展的数据集创建流程,利用大型视觉语言模型(VLMs)和大型语言模型(LLMs)自动生成视频字幕和QADs。
- 数据集包含3,268个QAD注释,涵盖2,405个视频,视频长度从16秒到15分钟不等。
数据集创建流程:
- 包括视频选择、信号提取、视频字幕生成、QAD生成、基于LLM的盲过滤和手动评分者验证等阶段。
评估指标:
- 由于现有的开放式问题回答评估指标存在局限性,论文提出了一个新的开源模型基评估指标GEM(Gemma Equivalence Metric)。
实验与基准测试:
- 对多种视频问答模型进行了评估,包括盲基线、图像模型、短上下文MLLMs和长上下文MLLMs。
- 揭示了开源视频模型与专有模型(如Gemini-1.5和GPT-4)之间的性能差距。
主要贡献:
- 提出了一个可扩展的流程,用于为任何视频生成复杂的QAD注释,相比手动注释减少了一半的评分者时间。
- 发布了Neptune评估数据集,包括一个强调多模态推理的挑战性子集NEPTUNE-MMH。
- 提供了多项选择和开放式问题回答的评估协议,并提出了GEM这一新的开放式评估指标。
- 通过基准测试展示了当前开源长视频模型在Neptune上的性能,并指出了未来发展的方向。
未来工作:
- 论文指出了长视频理解领域的一些潜在研究方向,包括改进视频选择和信号提取、优化QAD生成算法、开发新的评估指标和提高模型的长视频理解能力。
总体而言,Neptune基准测试旨在通过提供新的数据集和评估指标,推动长视频理解技术的研究和模型开发。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图