⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Feat2GS: Probing Visual Foundation Models with Gaussian Splatting
Authors:Yue Chen, Xingyu Chen, Anpei Chen, Gerard Pons-Moll, Yuliang Xiu
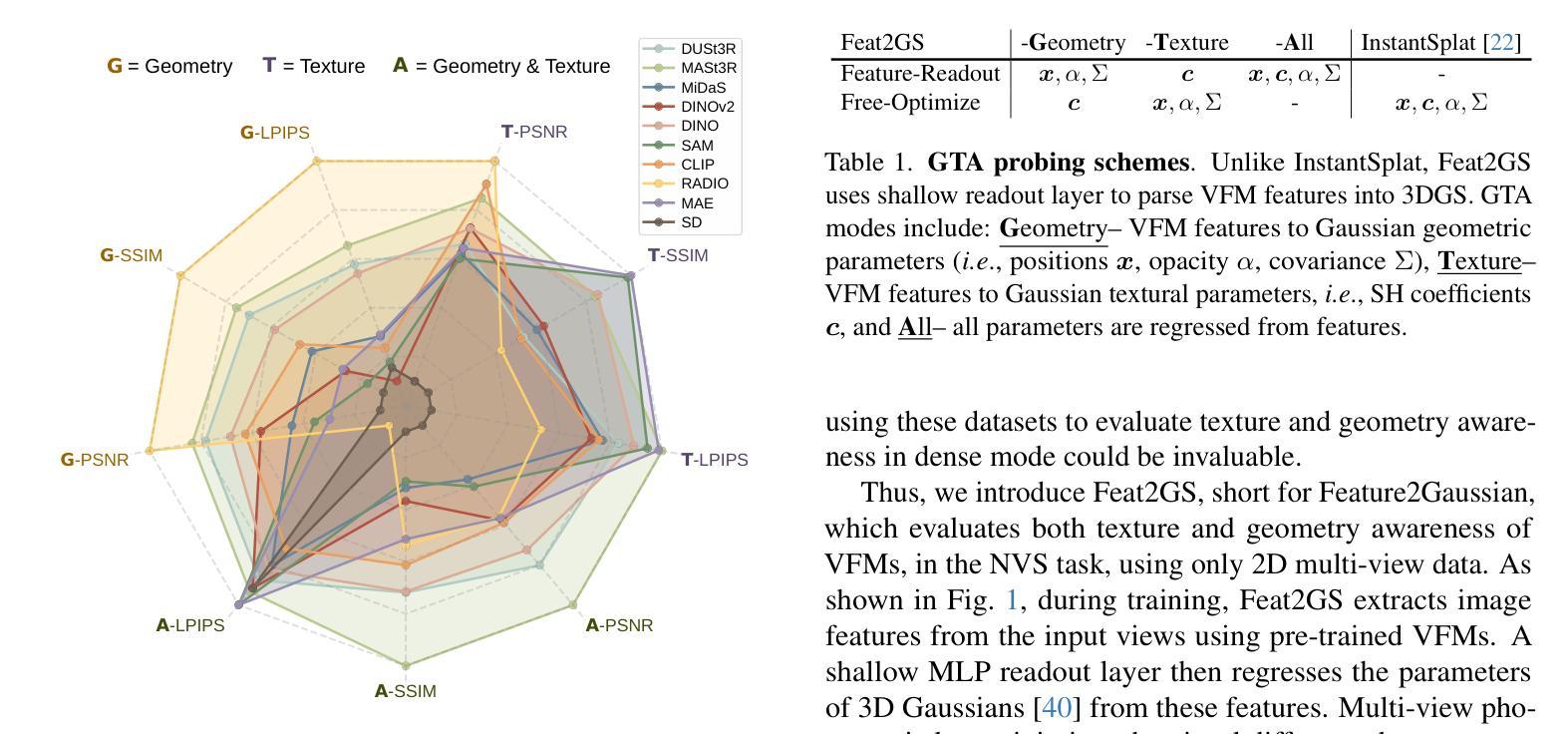
Given that visual foundation models (VFMs) are trained on extensive datasets but often limited to 2D images, a natural question arises: how well do they understand the 3D world? With the differences in architecture and training protocols (i.e., objectives, proxy tasks), a unified framework to fairly and comprehensively probe their 3D awareness is urgently needed. Existing works on 3D probing suggest single-view 2.5D estimation (e.g., depth and normal) or two-view sparse 2D correspondence (e.g., matching and tracking). Unfortunately, these tasks ignore texture awareness, and require 3D data as ground-truth, which limits the scale and diversity of their evaluation set. To address these issues, we introduce Feat2GS, which readout 3D Gaussians attributes from VFM features extracted from unposed images. This allows us to probe 3D awareness for geometry and texture via novel view synthesis, without requiring 3D data. Additionally, the disentanglement of 3DGS parameters - geometry ($\boldsymbol{x}, \alpha, \Sigma$) and texture ($\boldsymbol{c}$) - enables separate analysis of texture and geometry awareness. Under Feat2GS, we conduct extensive experiments to probe the 3D awareness of several VFMs, and investigate the ingredients that lead to a 3D aware VFM. Building on these findings, we develop several variants that achieve state-of-the-art across diverse datasets. This makes Feat2GS useful for probing VFMs, and as a simple-yet-effective baseline for novel-view synthesis. Code and data will be made available at https://fanegg.github.io/Feat2GS/.
考虑到视觉基础模型(VFMs)是在大规模数据集上进行训练,但通常仅限于2D图像,一个自然的问题出现了:他们对3D世界的理解程度如何?由于架构和训练协议(即目标、代理任务)存在差异,迫切需要一个统一框架来公平全面地探测他们的3D意识。现有的关于3D探测的工作建议进行单视图2.5D估计(例如深度和正常)或两视图稀疏2D对应(例如匹配和跟踪)。然而,这些任务忽略了纹理意识,并且需要3D数据作为真实值,这限制了其评估集规模和多样性。为了解决这些问题,我们引入了Feat2GS,它能够从无姿态图像中提取的VFM特征中读出3D高斯属性。这使我们能够通过无需要求真实值来探索几何和纹理的新视图合成能力。另外,通过对三维几何表面特征(几何信息(x、α、Σ))与表面纹理颜色(纹理信息)的解耦处理,实现对纹理和几何意识的独立分析。在Feat2GS下,我们对多个VFM进行了大量实验来探测其三维意识,并探讨了导致三维感知VFM的成分。基于这些发现,我们开发了几种变体在多种数据集上达到了最先进的性能。这使得Feat2GS对于探测VFM非常有用,并作为一个简单有效的基线用于新颖视图合成。代码和数据将在https://fanegg.github.io/Feat2GS/上提供。
论文及项目相关链接
PDF Project Page: https://fanegg.github.io/Feat2GS/
Summary
该文探讨了视觉基础模型(VFMs)对三维世界理解的问题,提出一种名为Feat2GS的新方法,通过从非姿态图像中提取的VFM特征读出三维高斯属性,以评估其对几何和纹理的感知能力。该方法无需依赖三维数据,可通过新视角合成技术来检测模型的感知能力。同时,对三维高斯参数进行解耦分析,实现了对纹理和几何感知的单独分析。经过广泛实验验证,Feat2GS能高效评估多个VFM的三维感知能力,且基于此开发的模型在多个数据集上达到最佳状态。该框架可为新视角合成提供简单有效的基线方法。详情参见代码和数据链接:https://fanegg.github.io/Feat2GS/。总结如下:提出Feat2GS框架解决评估问题,借助解耦的三维高斯参数有效分析模型对纹理和几何感知能力,为VFMs的评估和新型视角合成提供实用工具。
Key Takeaways
以下是该文的关键要点:
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何评估视觉基础模型(Visual Foundation Models,简称VFMs)对3D世界的理解和表达能力。尽管VFMs在大量数据集上进行了训练并且通常仅限于2D图像,但它们对3D世界的理解程度仍然是一个开放的问题。具体来说,论文探讨了以下几个关键问题:
VFMs的3D意识:VFMs是否能够理解3D世界中的几何和纹理信息?它们的3D表达能力如何?
统一评估框架的需求:由于VFMs的架构和训练协议(例如目标、代理任务)存在差异,需要一个统一的框架来公平且全面地评估它们的3D意识。
纹理意识的缺失:现有的3D探测工作通常忽略了纹理意识,并且需要3D数据作为真值,这限制了评估集的规模和多样性。
无需3D数据的3D意识评估:如何不依赖于3D数据,通过2D图像来评估VFMs的3D意识?
为了解决这些问题,论文提出了Feat2GS(Feature to Gaussian Splatting)框架,它能够从未经摆拍的图像中提取VFMs的特征,并将其读出为3D高斯(3DGS)属性,从而通过新视角合成(Novel View Synthesis, NVS)任务来探测VFMs的3D意识,而不需要3D数据。此外,Feat2GS还能够将3DGS参数分为几何和纹理两部分,分别分析VFMs的纹理和几何意识。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与Feat2GS研究相关的工作:
3D Awareness of VFMs:
- 测量VFMs的3D意识,包括多视图对象一致性、空间视觉问题回答、视觉视角取向和机器人学习等方面的研究。
- 细粒度的3D探测工作,使用2.5D代理任务(例如几何线索估计和视图标记估计)和两视图稀疏点匹配及跟踪来评估VFMs的3D意识。
NVS from Casual Images:
- 针对稀疏和随意捕获的图像进行新视角合成(NVS)的研究,包括各种正则化技术和视觉先验,例如深度、预训练的视觉特征、扩散先验和前馈建模等。
- 一些方法尝试在NVS优化过程中优化相机姿态,使用技术如粗到精编码、局部到全局配准、几何约束、对抗性目标、密集对应和外部先验等。
3D Feature Fields:
- 3D神经场(例如NeRF和3DGS)通过聚合多个视图的2D特征到3D规范框架中来建模特征。
- 使用不同的VFMs(如DINO、CLIP、Stable Diffusion、SAM和LSeg)作为特征提取器,为3D特征场提供不同的能力。
Specific VFMs and Methods:
- DINO:自监督学习框架,用于提取区分性特征。
- CLIP:将语言与图像连接起来,用于基于文本的查询和编辑。
- SAM:学习“对象”概念,用于分组、分割和3D场景理解。
- DUSt3R:用于从大规模数据集中训练模型,实现任意图像集合的“无约束立体3D重建”。
- InstantSplat:优化3DGS从稀疏捕获中使用DUSt3R估计的相机。
这些相关工作涵盖了3D意识评估的不同方面,包括使用2D和3D数据的VFMs训练、特征提取、3D场景理解和新视角合成。Feat2GS通过提供一个统一的框架来评估VFMs的3D意识,并通过NVS任务来实现这一点,而不需要3D数据,这在上述工作中是一个创新点。
Q: 论文如何解决这个问题?
A: 论文通过提出Feat2GS(Feature to Gaussian Splatting)框架来解决评估视觉基础模型(VFMs)对3D世界理解的问题。以下是解决这个问题的关键步骤和方法:
3D Gaussians Readout(3DGS读出):
- Feat2GS从VFMs提取的特征中读出3D高斯(3DGS)属性,这些属性包括几何参数(位置x、不透明度α、协方差Σ)和纹理参数(球谐系数c)。
- 通过一个轻量级的多层感知机(MLP)读出层,使用光度损失来训练,将像素级特征转换为3D高斯。
Novel View Synthesis(NVS)作为代理任务:
- 利用新视角合成(NVS)作为评估3D意识的代理任务,不需要3D数据。
- 通过比较不同数据集上的NVS质量,评估VFMs的几何和纹理意识。
参数解耦和独立分析:
- 将3DGS参数分为几何和纹理两组,允许独立分析VFMs的纹理和几何意识。
- 每个组可以在“Feature-Readout”和“Free-Optimize”模式之间切换,以使用VFM特征作为输入或自由优化。
多模式探测(GTA模式):
- 提出了三种探测模式(Geometry-Texture-All,简称GTA),包括仅读出几何参数、仅读出纹理参数和读出所有参数。
- 这些模式允许评估VFMs在不同方面的3D意识,并确定它们在哪些方面表现出色或不足。
实验和分析:
- 对多个主流VFMs进行了广泛的实验,分析了它们在不同数据集上的表现。
- 揭示了VFMs的常见缺点,并探讨了如何改进它们。
基于发现的NVS基线设计:
- 根据实验结果,设计了几种Feat2GS变体,在多个数据集上实现了新视角合成(NVS)的最新性能。
通过这种方法,Feat2GS提供了一个统一的框架,用于在不需要3D标签的情况下,评估预训练VFMs的3D意识(包括纹理和几何意识),并为NVS任务提供了一个简单但有效的基线。此外,Feat2GS的代码和数据将在其项目网站上公开,以促进进一步的研究和开发。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和分析视觉基础模型(VFMs)的3D意识,以及Feat2GS框架的性能。以下是实验的关键部分:
实验设置:
- 特征(Features):实验关注了10种VFMs,包括不同数据类型(2D vs. 3D)和监督策略(例如自监督 vs. 监督学习)。
- 数据集(Datasets):使用了七个多视图数据集,这些数据集具有不同的场景类型、复杂性和视图范围。
- 评估指标(Metrics):使用标准指标PSNR、SSIM和LPIPS评估新视角合成(NVS)的质量。
动机验证:
- NVS与3D指标的相关性:验证了通过NVS质量与3D指标(例如点云的准确性、完整性和距离)之间的强相关性,支持使用NVS作为3D评估的代理。
- 数据多样性对全面探测的重要性:展示了在不同数据集上评估结果的差异,强调了数据多样性的重要性。
发现:
- 整体性能:使用三种探测模式(Geometry、Texture和All)评估VFMs,并分析了它们在不同数据集上的表现。
- 纹理不友好的训练策略:分析了VFMs在纹理模式下的表现差的原因,指出了当前VFMs缺乏纹理意识的问题。
- 纹理意识从掩蔽图像重建中受益:发现具有掩蔽图像重建预训练的VFMs在纹理意识方面表现更好。
- 几何意识从3D数据中受益:指出3D数据对于学习跨视图一致的几何意识至关重要。
- 模型集成的帮助:展示了通过简单地连接不同VFMs的特征,可以获得与模型蒸馏相似的结果。
应用:
- 特征选择:基于上述发现,设计了三种Feat2GS变体,并与当前最先进的InstantSplat进行了比较。
- 特征集成:探索了通过连接不同VFMs的特征来提高NVS性能的可能性。
- 特征微调:研究了在热启动阶段对特征进行微调是否有益,并与未微调的特征进行了比较。
这些实验不仅验证了Feat2GS框架的有效性,还提供了对VFMs 3D意识的深入理解,并为改进VFMs和NVS任务提供了有价值的见解。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
改进相机姿态和点云初始化:
- 研究如何减少Feat2GS对初始化相机姿态和点云估计的依赖,可能通过利用VFM特征直接初始化姿态和点云。
处理长期、野外数据集:
- 扩展Feat2GS以处理长时间跨度和野外环境中捕获的数据集,这可能需要结合不同的渲染梯度和优化策略。
动态场景的评估:
- 由于Feat2GS目前仅限于静态场景,探索如何将其扩展到动态场景的评估,例如通过4D高斯Splatting技术。
VFM特征集成和蒸馏:
- 进一步研究如何通过简单的特征连接或更复杂的模型蒸馏技术来提高VFMs的性能。
纹理意识的改进:
- 探索新的训练策略或损失函数,以增强VFMs的纹理意识,特别是在大规模2D数据上训练时。
跨数据集和跨领域的泛化能力:
- 研究VFMs在不同数据集和领域中的泛化能力,以及如何通过多任务学习或领域适应来提高这种泛化能力。
更细粒度的3D意识评估:
- 开发更细粒度的方法来评估VFMs的3D意识,可能包括对深度、法线、形状和纹理等不同几何和外观线索的单独评估。
与现有技术的集成:
- 将Feat2GS与现有的3D视觉技术(如NeRF、MVS)集成,以创建更强大的3D理解和重建系统。
优化和计算效率:
- 研究如何优化Feat2GS的计算过程,提高其效率和可扩展性,使其能够处理更大规模的数据集和更高分辨率的图像。
多模态数据融合:
- 探索将Feat2GS应用于多模态数据(如图像、点云、深度图)的融合,以实现更全面的3D场景理解。
这些探索点可以帮助推动VFMs和3D视觉领域的研究进展,提高模型的3D意识和实际应用效果。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为Feat2GS(Feature to Gaussian Splatting)的框架,旨在评估视觉基础模型(VFMs)对3D世界的理解和表达能力,特别是它们的几何和纹理意识。以下是论文的主要内容总结:
问题阐述:
- 论文指出,尽管VFMs在大量数据集上训练并展现出强大的2D推理能力,但它们对3D世界的理解程度尚不清楚。
Feat2GS框架:
- Feat2GS通过从VFMs提取的特征中读出3D高斯(3DGS)属性,来评估VFMs的3D意识,包括几何和纹理。
- 该框架不需要3D数据,而是通过新视角合成(NVS)任务在2D多视图数据上评估VFMs。
关键贡献:
- 提供了一个统一的框架来评估预训练VFMs的3D意识,无需3D标签。
- 通过广泛的实验,评估了多种主流VFMs,并分析了它们在不同数据集上的表现。
- 设计了几种Feat2GS变体,这些变体在多个数据集上实现了新视角合成(NVS)的最新性能。
实验和分析:
- 论文对10种VFMs进行了实验,使用七个多视图数据集,覆盖了从简单场景到日常捕获的广泛场景。
- 通过三种探测模式(Geometry、Texture和All)评估VFMs,并分析了它们的性能。
- 发现VFMs在几何意识方面表现良好,但在纹理意识方面存在不足。
应用:
- 基于实验结果,设计了三种Feat2GS变体,与当前最先进的InstantSplat进行了比较,并在NVS任务中取得了更好的性能。
局限性和未来工作:
- Feat2GS依赖于相机姿态和点云的初始化,可能需要改进以减少对这些初始化的依赖。
- 框架目前限于静态场景,未来可能需要扩展到动态视频的评估。
- 论文提出了一些可能的改进方向,包括改进相机姿态估计、处理长期野外数据集和动态场景评估。
总体而言,Feat2GS为理解和改进VFMs的3D意识提供了一个有力的工具,并为NVS任务提供了一个简单而有效的基线。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

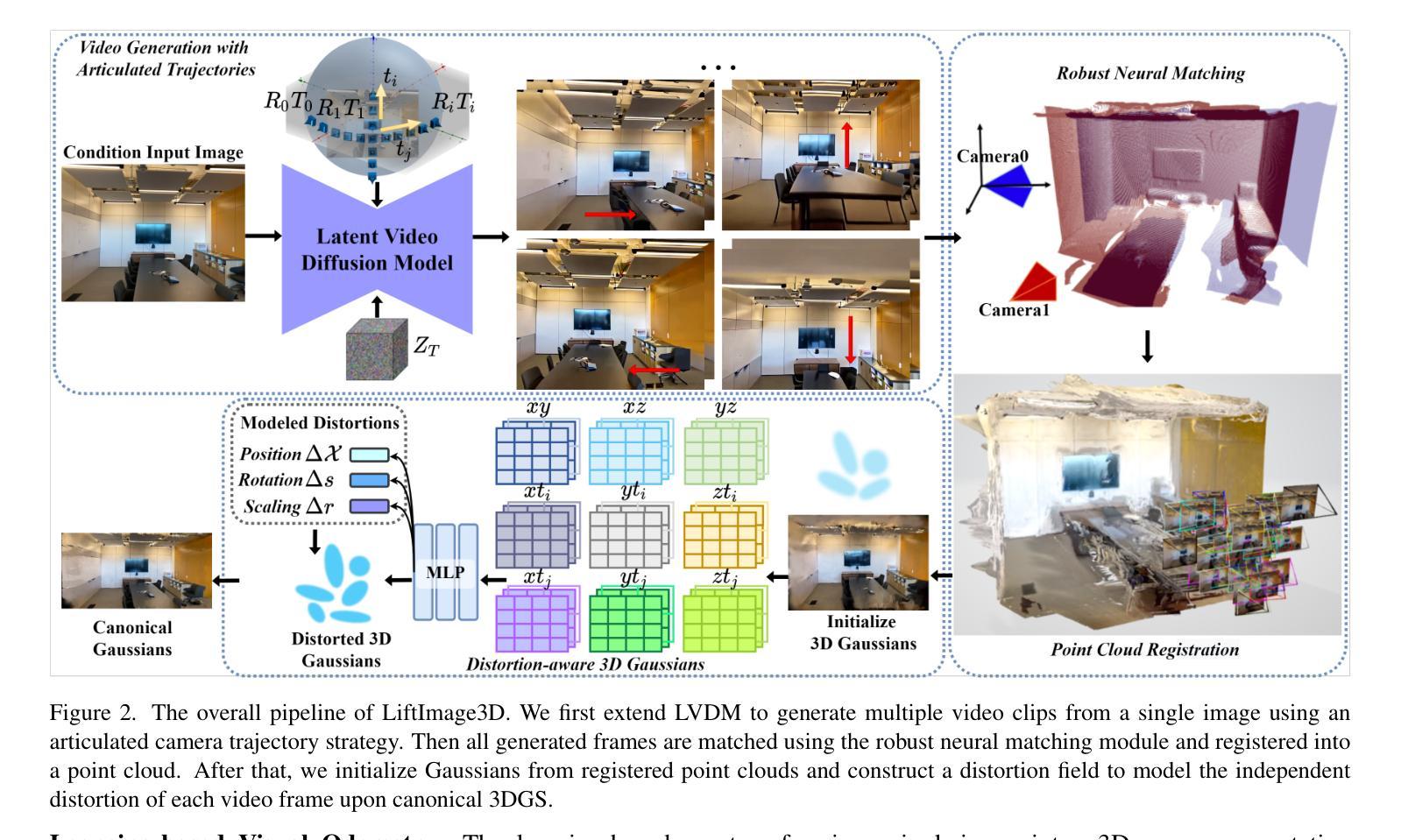
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Authors:Yabo Chen, Chen Yang, Jiemin Fang, Xiaopeng Zhang, Lingxi Xie, Wei Shen, Wenrui Dai, Hongkai Xiong, Qi Tian
Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs’ generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.
单图像3D重建仍然是计算机视觉领域的一个基本挑战,这是由于固有的几何不确定性和有限的视点信息造成的。最近,潜在视频扩散模型(LVDMs)的进展提供了从大规模视频数据中学习的有前途的3D先验知识。然而,有效利用这些先验知识面临三个主要挑战:(1)在大相机运动过程中的质量下降;(2)实现精确相机控制的困难;(3)扩散过程固有的几何失真损害3D一致性。我们通过提出LiftImage3D框架来解决这些挑战,该框架可以有效地释放LVDMs的生成先验知识,同时确保3D一致性。具体来说,我们设计了一种关节轨迹策略来生成视频帧,该策略将具有大相机运动的视频序列分解为具有可控小运动的序列。然后,我们使用鲁棒的神经匹配模型(即MASt3R)来校准生成帧的相机姿态,并产生相应的点云。最后,我们提出了一种扭曲感知的3D高斯平铺表示,它可以学习帧之间的独立扭曲,并输出无扭曲的标准高斯。大量实验表明,LiftImage3D在两个具有挑战性的数据集LLFF、DL3DV以及Tanks and Temples上达到了最先进的性能,并能很好地推广到各种野外图像,从卡通插图到复杂的真实场景。
论文及项目相关链接
PDF Project page: https://liftimage3d.github.io/
Summary
该文探讨了单图像3D重建领域面临的挑战,包括由于固有几何歧义性和有限的视角信息所带来的问题。文章介绍了潜在视频扩散模型(LVDMs)在3D重建中的潜力以及所面临的三大挑战。为解决这些问题,提出了一种名为LiftImage3D的框架,该框架能够释放LVDMs的生成先验信息,同时确保3D一致性。通过设计灵活的轨迹策略生成视频帧,使用鲁棒性神经匹配模型校准生成的帧的相机姿态并生成相应的点云。最后,提出了一种感知失真的3D高斯喷溅表示方法,该方法可以学习帧之间的独立失真并输出无失真的规范高斯。实验表明,LiftImage3D在两个具有挑战性的数据集上取得了最佳性能,并能很好地推广到各种野外图像,包括卡通插图和复杂的真实场景。
Key Takeaways
- 单图像3D重建是计算机视觉领域的一个基本挑战,面临着固有的几何歧义性和有限的视角信息的问题。
- 潜在视频扩散模型(LVDMs)在3D重建中展现出巨大的潜力,但存在质量下降、精确相机控制困难以及几何失真等挑战。
- LiftImage3D框架被提出来解决这些挑战,能够释放LVDMs的生成先验信息,同时确保3D一致性。
- LiftImage3D通过设计灵活的轨迹策略生成视频帧,将大相机运动的视频序列分解为可控的小运动序列。
- 使用鲁棒性神经匹配模型(如MASt3R)来校准生成的帧的相机姿态并产生对应的点云。
- 提出了一种感知失真的3D高斯喷溅表示方法,能够学习帧间的独立失真并输出无失真规范高斯。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决单图像3D重建中的几个关键挑战,这些挑战包括:
大相机运动下的质量问题:现有方法在小相机运动下可以生成高质量的新视角图像,但当相机发生大幅度运动时,渲染质量会显著下降。这是因为在大视角变化中累积了生成误差,导致在远视图之间维持几何一致性变得困难。
精确相机控制的困难:尽管潜在视频扩散模型(LVDMs)擅长生成时间连贯的视频,但控制其生成以遵循期望的相机轨迹仍然是一个挑战。由于缺乏场景的底层3D信息,导致生成结果与输入相机条件不匹配。
扩散过程中的几何失真:扩散模型的固有噪声和去噪过程在帧生成过程中引入了微妙但持续的几何失真。这些失真虽然在视觉上不易察觉,但会在不同视图间累积,严重破坏3D重建质量,破坏帧之间的几何一致性。
为了应对这些挑战,论文提出了一个名为LiftImage3D的框架,该框架能够有效地利用LVDMs的生成先验,同时确保3D一致性。具体来说,论文设计了一个关节轨迹策略来生成视频帧,将具有大相机运动的视频序列分解为可控制的小运动。然后使用鲁棒的神经匹配模型(例如MASt3R)来校正生成帧的相机姿态,并产生相应的点云。最后,提出了一种失真感知的3D高斯溅射表示方法,该方法可以学习帧间的独立失真,并输出未失真的规范高斯。通过这些技术,LiftImage3D在多个具有挑战性的数据集上实现了最先进的性能,并且能够很好地泛化到多样化的野外图像,从卡通插图到复杂的真实世界场景。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
3D摄影:
- 利用多平面图像(MPI)技术从单张图像中合成新视角的场景。
- 基于深度的变形方法,用于引导变形视图中的修复。
2D生成模型基础上的单图像到3D:
- 研究者探索了仅使用单张图像生成3D模型和实现新视角合成的方法。
- 一些研究直接在3D数据上训练3D模型,但这些方法往往只在与训练集相似的场景上表现良好。
- 基于条件潜在扩散模型(LDM)的方法,通过大规模多视图图像学习构建几何先验。
基于LVDM(潜在视频扩散模型)的单图像到3D:
- 研究者认为视频扩散模型可以提供强大的多视图3D先验。
- 一些工作尝试在多视图数据集上微调LVDM,以增强生成新视图的能力。
以下是一些具体的相关工作和文献:
MPI(多平面图像)相关方法:
- [16, 29, 40] 基于MPI构建3D摄影的方法。
- [60, 61, 72, 93] MPI技术的发展和应用。
基于深度的变形和修复方法:
- [4, 77] 基于深度的变形方法。
- [6, 28, 46, 58, 70] 尝试使用文本到图像扩散方法生成视图外内容,并将其投影到扩展的多平面图像中。
单图像到3D模型生成:
- [5, 24, 30, 33, 57, 59, 73, 75, 88, 90] 使用单张图像生成3D模型和新视角合成的研究。
LVDM(潜在视频扩散模型)相关研究:
- [1, 37, 71] 探讨视频扩散模型在提供多视图3D先验方面的潜力。
- [15, 25, 42, 47, 64, 89] 在多视图数据集上微调LVDM以增强新视图合成能力的工作。
这些相关工作为LiftImage3D框架的发展提供了理论和技术基础,同时也突显了现有方法在处理大相机运动、精确相机控制和3D一致性失真方面的局限性。LiftImage3D通过结合关节轨迹策略、鲁棒的神经匹配和失真感知的3D高斯溅射表示等技术,旨在克服这些挑战,实现更高质量的单图像3D重建。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为LiftImage3D的框架来解决单图像3D重建中的挑战,具体解决方案包括以下几个关键组件:
1. 关节轨迹策略(Articulated Trajectory Strategy)
为了克服大相机运动导致的质量问题,论文设计了一种关节轨迹策略,将大的相机运动分解为小的、可控的步骤。这种方法通过将生成的帧用作后续视频生成的新起点,实现了在保持帧质量的同时扩大视图覆盖范围。
2. 鲁棒的神经匹配模型(Robust Neural Matching Models)
针对精确相机控制的挑战,论文采用了一种名为MASt3R的鲁棒神经匹配方法,直接从生成的帧中估计相机轨迹和粗略几何结构。这种方法绕过了输入条件和生成帧之间的不一致性,提高了相机控制的准确性。
3. 失真感知的3D高斯溅射表示(Distortion-aware 3D Gaussian Splatting)
为了处理扩散模型引入的3D不一致失真,论文提出了一种失真感知的3D高斯溅射(3DGS)表示方法。这种方法通过一个失真场来表示规范3DGS和失真的映射关系,能够学习帧间的独立失真,并输出未失真的规范高斯。
4. 深度先验注入(Depth Prior Injection)
为了产生更平滑和深度一致的结果,论文利用从神经匹配得到的粗糙但绝对的深度图来校准单目深度估计的精细深度图,确保深度图具有适当的比例和偏移。
5. 损失函数设计(Loss Function Design)
论文设计了一个损失函数,确保建模的失真不会偏离规范3DGS太远。这个损失函数结合了L1 RGB损失、LPIPS损失、基于网格的总变分损失以及L1深度损失,以优化失真场并确保3DGS的质量。
通过这些技术和策略的综合应用,LiftImage3D能够有效地利用潜在视频扩散模型(LVDMs)的生成先验,同时确保从单张图像到3D场景的重建过程中保持3D一致性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估LiftImage3D框架的性能,并与现有的最先进方法进行比较。以下是实验的具体内容:
1. 评估协议和数据集
- 数据集:实验使用了三个数据集:LLFF、DL3DV和Tanks and Temples。这些数据集包含了从室内到室外环境、单一对象到多个对象的多视角数据,适用于评估图像质量和3D一致性。
- 评估协议:遵循AdaMPI和SinMPI的评估协议,使用单个图像作为输入视图,并使用多个周围的视图作为真实图像进行定量评估。
2. 实施细节
- 相机运动方向:设置潜在相机姿态移动方向D为4,包括上、下、左和右。
- LVDM帧生成:LVDM每次产生16帧。
- MASt3R全局对齐:MASt3R需要400次迭代进行全局对齐。
- 3DGS训练:3DGS首先在常规设置下训练3k次迭代,然后使用失真场网络再训练14k次迭代。
3. 定量和定性比较
- 定量比较:在LLFF、DL3DV和Tanks and Temples数据集上,与先前的方法(如AdaMPI、SinMPI、LucidDreamer和ViewCrafter)进行了PSNR、SSIM和LPIPS等指标的定量比较,LiftImage3D在这些指标上显示出显著的改进。
- 定性比较:展示了LiftImage3D在非周围视图中的更强泛化能力,所有显示的图像都是从与输入图像差异较大的视点拍摄的。
4. 使用不同LVDMs的LiftImage3D
- 不同LVDMs:LiftImage3D可以利用不同的LVDMs(如MotionCtrl和ViewCrafter)来展示其在不同LVDM先验下的有效性。
- 结果:无论是使用MotionCtrl还是ViewCrafter作为LVDM的骨干网络,LiftImage3D都能显著提高性能。
5. 消融研究
- 失真感知3DGS:验证了失真感知3DGS设计的有效性。
- 二维时间戳:验证了二维时间戳设计的有效性。
- 深度先验注入:验证了深度先验注入模块的有效性,并通过可视化展示了如何利用神经匹配的粗糙深度图来校准单目深度估计的精细深度图。
这些实验全面评估了LiftImage3D在不同情况下的性能,并证明了其在单图像3D重建任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管LiftImage3D在单图像3D重建方面取得了显著进展,但仍有一些领域可以进一步探索和改进:
1. 提升相机控制精度
尽管LiftImage3D采用了MASt3R等鲁棒神经匹配模型来估计相机姿态,但在精确控制相机轨迹方面仍存在挑战。未来的工作可以探索更精细的相机控制策略,以进一步提高生成视频帧的质量和一致性。
2. 优化失真感知3DGS
失真感知3DGS是LiftImage3D中的关键技术之一,用于处理扩散模型引入的几何失真。未来的研究可以探索更高效的失真建模和补偿方法,以减少失真对3D重建质量的影响。
3. 深度先验的改进
虽然LiftImage3D利用了从神经匹配得到的粗糙深度图来校准单目深度估计,但深度估计的准确性仍有提升空间。研究更先进的深度估计方法,或者结合多模态数据(如立体视觉、激光雷达等)来提高深度信息的精度,可能是一个有价值的方向。
4. 泛化能力的增强
LiftImage3D在多种数据集上展示了良好的性能,但在处理更多样化和复杂场景时,其泛化能力仍需进一步提升。未来的工作可以探索如何使模型更好地适应不同的场景和条件,包括极端光照、遮挡和动态环境。
5. 实时性能的优化
LiftImage3D的处理流程可能在计算资源和时间上要求较高,限制了其在实时应用中的可行性。研究如何优化算法和计算流程,以实现更快的推理速度和更低的计算成本,对于实际应用至关重要。
6. 交互式应用的探索
将LiftImage3D应用于交互式环境,如虚拟现实(VR)和增强现实(AR),需要进一步研究。这包括提高场景的动态交互能力,以及在用户与环境互动时实时更新3D场景表示。
7. 多模态数据融合
考虑将LiftImage3D与其他类型的数据(如音频、触觉反馈)结合起来,以创建更丰富的多模态3D体验。这种融合可以提供更自然和沉浸式的用户体验。
8. 模型压缩和移动端部署
研究如何压缩LiftImage3D模型,以便在资源受限的设备(如智能手机和平板电脑)上部署。这对于将3D重建技术带到更广泛的用户群体具有重要意义。
通过在这些领域进行进一步的研究和开发,LiftImage3D及其衍生技术有望在未来实现更广泛的应用,并在单图像3D重建领域取得更大的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为LiftImage3D的框架,旨在利用视频生成先验将任何单张2D图像提升到3D高斯表示,以处理野外3D对象/场景。下面是论文的主要内容总结:
1. 问题背景与挑战:
- 单图像3D重建是计算机视觉中的一个基本挑战,由于几何歧义和有限的视点信息,任务十分困难。
- 近期的潜在视频扩散模型(LVDMs)提供了从大规模视频数据中学习到的有希望的3D先验。
2. 面临的三个关键挑战:
- 大相机运动下的退化:随着相机运动幅度的增加,渲染质量显著下降。
- 精确相机控制的困难:控制LVDMs生成遵循特定相机轨迹存在困难。
- 扩散过程中的几何失真:扩散模型的噪声和去噪过程引入的几何失真会破坏3D一致性。
3. LiftImage3D框架:
- 关节轨迹策略:将大的相机运动分解为小的、可控的步骤,以保证生成质量。
- 鲁棒神经匹配模型:使用MASt3R等模型校正生成帧的相机姿态,生成相应的点云。
- 失真感知3D高斯溅射(3DGS)表示:学习独立失真,输出未失真的规范高斯。
4. 贡献:
- 提出了一个系统化的框架,释放了LVDMs的3D能力,并以可控的方式提升单张图像至3D高斯。
- 通过关节轨迹策略、帧匹配策略、深度先验注入和有效的3DGS表示来解决从生成视频帧到3D重建的挑战。
- 在LLFF、DL3DV和Tanks and Temples数据集上进行了广泛的实验,证明了LiftImage3D在视觉质量和3D一致性方面相较于先前技术的状态-of-the-art性能。
5. 实验:
- 在多个数据集上进行了定量和定性比较,展示了LiftImage3D在不同情况下的有效性。
- 探讨了不同LVDMs在LiftImage3D框架下的性能,并进行了消融研究以验证各个组件的有效性。
6. 结论:
LiftImage3D作为一个创新的框架,通过一系列技术解决了使用LVDMs进行多视图帧生成时的挑战,并为未来利用视频生成先验促进3D重建的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

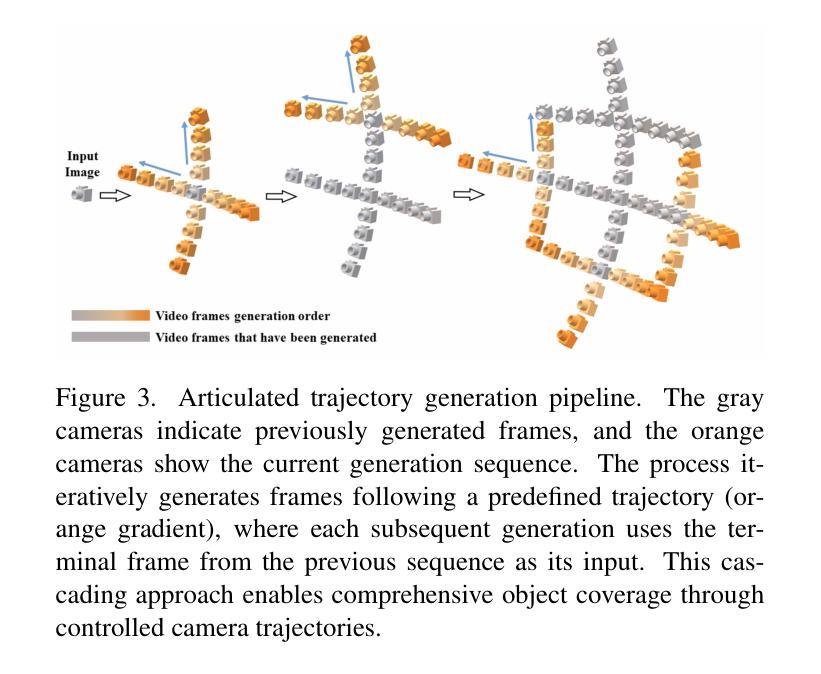
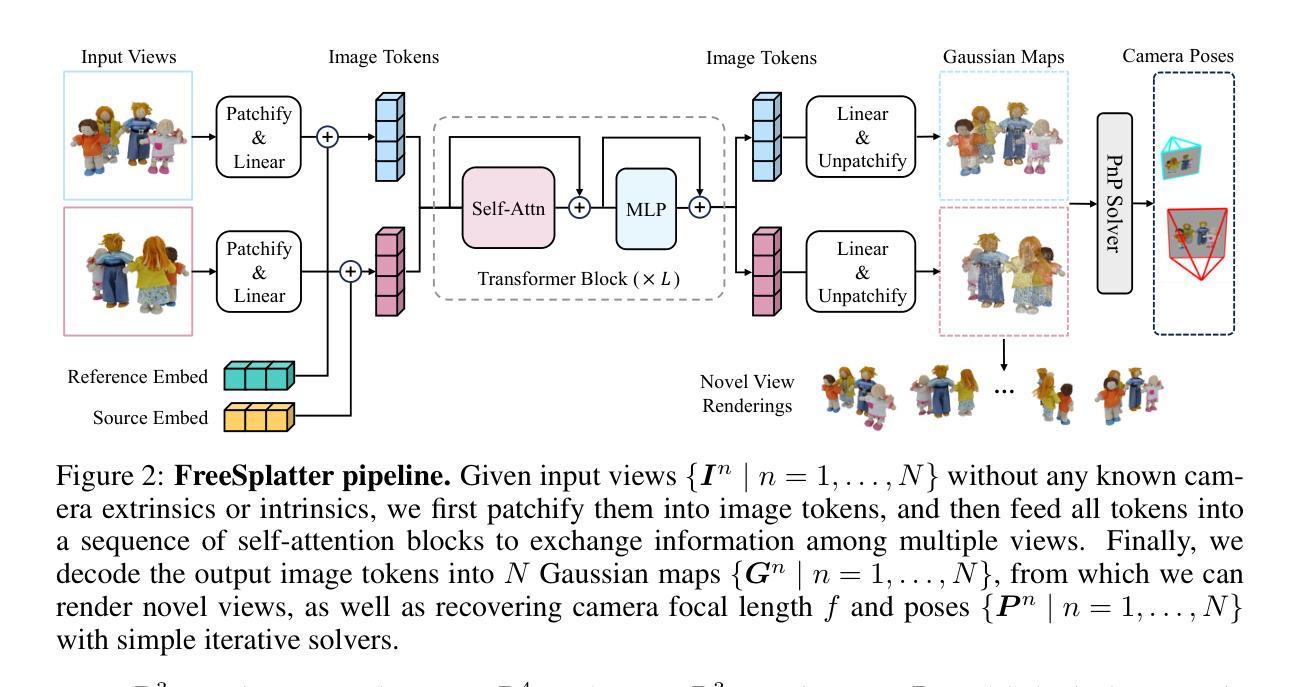
FreeSplatter: Pose-free Gaussian Splatting for Sparse-view 3D Reconstruction
Authors:Jiale Xu, Shenghua Gao, Ying Shan
Existing sparse-view reconstruction models heavily rely on accurate known camera poses. However, deriving camera extrinsics and intrinsics from sparse-view images presents significant challenges. In this work, we present FreeSplatter, a highly scalable, feed-forward reconstruction framework capable of generating high-quality 3D Gaussians from uncalibrated sparse-view images and recovering their camera parameters in mere seconds. FreeSplatter is built upon a streamlined transformer architecture, comprising sequential self-attention blocks that facilitate information exchange among multi-view image tokens and decode them into pixel-wise 3D Gaussian primitives. The predicted Gaussian primitives are situated in a unified reference frame, allowing for high-fidelity 3D modeling and instant camera parameter estimation using off-the-shelf solvers. To cater to both object-centric and scene-level reconstruction, we train two model variants of FreeSplatter on extensive datasets. In both scenarios, FreeSplatter outperforms state-of-the-art baselines in terms of reconstruction quality and pose estimation accuracy. Furthermore, we showcase FreeSplatter’s potential in enhancing the productivity of downstream applications, such as text/image-to-3D content creation.
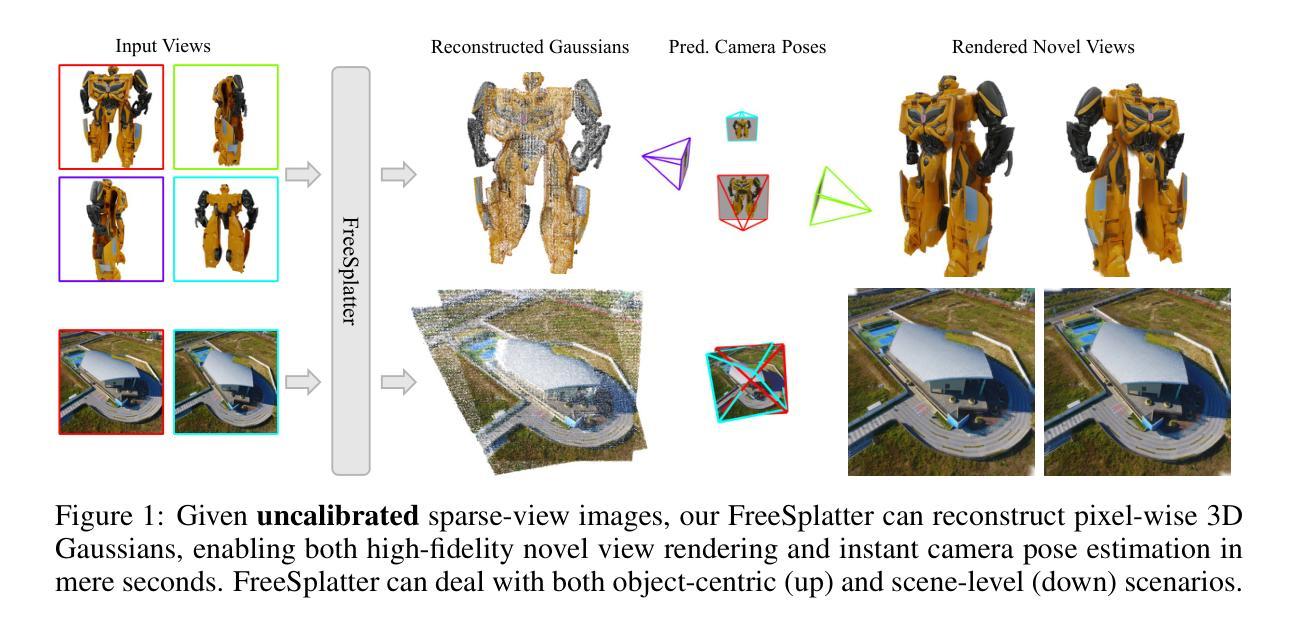
现有的稀疏视图重建模型严重依赖于准确的已知相机姿态。然而,从稀疏视图图像中得出相机的外部和内部参数存在很大的挑战。在这项工作中,我们提出了FreeSplatter,一个高度可扩展的、前馈的重建框架,能够从未校准的稀疏视图图像生成高质量的三维高斯,并在数秒内恢复其相机参数。FreeSplatter建立在简化的transformer架构上,包含顺序的自注意力块,这些块促进了多视图图像标记之间的信息交换,并将其解码为像素级的三维高斯基本体。预测的Gaussian基本体位于统一的参考框架内,允许使用现成的求解器进行高保真三维建模和即时相机参数估计。为了适应以对象为中心和场景级别的重建,我们在大量数据集上训练了FreeSplatter的两个变体模型。在两种情况下,FreeSplatter在重建质量和姿态估计准确性方面都超过了最先进的基线。此外,我们还展示了FreeSplatter在提高下游应用程序(如文本/图像到三维内容的创建)的生产力方面的潜力。
论文及项目相关链接
PDF Project page: https://bluestyle97.github.io/projects/freesplatter/
Summary
本文介绍了一种名为FreeSplatter的高度可扩展的、前馈式的重建框架,能够从未校准的稀疏视角图像生成高质量的三维高斯图,并在数秒内恢复相机参数。该框架基于简化的转换器架构,通过顺序自注意力块促进多视角图像标记之间的信息交流,并将其解码为像素级三维高斯基本体。预测的Gaussian基本体位于统一的参考框架内,可实现高保真三维建模和即时相机参数估计。FreeSplatter有两种模型变体,分别适用于对象级和场景级重建,并在重建质量和姿态估计准确性方面优于现有技术基线。此外,展示了FreeSplatter在文本/图像到三维内容创建等下游应用中的潜力。
Key Takeaways
- FreeSplatter是一个强大的重建框架,能够从稀疏视角图像生成高质量的三维高斯图。
- 框架具备高度可扩展性和快速性,能在数秒内恢复相机参数。
- FreeSplatter基于转换器架构,通过自注意力块处理多视角图像信息。
- 预测的三维高斯基本体位于统一参考框架内,便于高保真建模和参数估计。
- FreeSplatter有两种模型变体,分别适用于对象级和场景级的重建任务。
- 在重建质量和姿态估计方面,FreeSplatter优于现有技术基线。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为FreeSplatter的框架,旨在解决稀疏视图3D重建中准确相机姿态估计的挑战。现有的稀疏视图重建模型严重依赖于准确的已知相机姿态,但在稀疏视图图像中推导出相机的外参和内参存在显著挑战。FreeSplatter框架能够从未经校准的稀疏视图图像中生成高质量的3D高斯(Gaussian)并恢复相机参数,且仅需几秒钟即可完成。具体来说,该工作主要解决以下问题:
稀疏视图重建难题:在稀疏视图场景中,传统的相机校准技术(如结构从运动SfM)由于图像重叠不足而往往失败,导致重建质量下降。
无需已知相机姿态:现有的一些通用重建模型虽然以向前反馈的方式处理稀疏视图重建,但主要假设可以访问准确的相机姿态和内参,或者在预处理步骤中获得,从而绕过了实际应用场景中推导相机参数的困难。
重建质量和效率:FreeSplatter基于一个可扩展的单流(single-stream)变换器(transformer)架构,能够将多视图图像标记映射到像素对齐的高斯图中,无需输入相机姿态、内参或后对齐步骤。
多视图信息融合:FreeSplatter通过顺序自注意力(self-attention)块促进多视图图像标记之间的信息交换,并将它们解码成像素级3D高斯原语。
即时相机参数估计:预测的高斯原语位于统一的参考框架中,允许使用现成的求解器进行高保真度3D建模和快速相机参数估计。
综上所述,FreeSplatter框架通过直接从多视图图像预测“高斯图”来实现高质量的3D建模和快速相机姿态估计,从而解决了在没有准确相机姿态信息的情况下进行稀疏视图3D重建的问题。
Q: 有哪些相关研究?
A: 根据论文内容,FreeSplatter框架在研究中涉及的相关研究领域和具体工作主要包括:
神经场景表示和可微分渲染:
- Neural Radiance Fields (NeRF) (Mildenhall et al., 2021):一种用于多视图重建的神经场景表示方法。
- Gaussian Splatting (GS) (Kerbl et al., 2023):一种基于高斯的3D场景表示方法,用于实现高效的视图合成。
稀疏视图重建:
- Generalizable reconstruction models (Hong et al., 2024b; Xu et al., 2024a; Charatan et al., 2024):尝试以向前反馈的方式处理稀疏视图重建的模型,这些模型主要假设可以访问准确的相机姿态和内参。
无需相机姿态的重建模型:
- PF-LRM (Wang et al., 2024a) 和 LEAP (Jiang et al., 2024b):这两个工作共享类似的框架,使用变换器将多视图图像标记映射到NeRF表示中。
- DUSt3R (Wang et al., 2024b):提出了一种联合3D重建和姿态估计的新范式,通过将SfM和多视图立体匹配(MVS)建模为端到端的点回归任务。
大型重建模型(LRMs):
- 利用大规模3D数据集训练的模型,用于开放类别图像到3D重建。这些模型使用可扩展的前馈变换器架构将稀疏视图图像标记映射到3D triplane NeRF,并使用多视图渲染损失进行监督。
3D高斯Splats(3DGS):
- 与NeRF的MLP基础隐式表示相比,3DGS用点云明确表示场景,平衡了高保真度和实时渲染速度。
其他相关工作:
- InstantSplat (Fan et al., 2024) 和 Splatt3R (Smart et al., 2024):这些工作利用DUSt3R/MASt3R的无姿态重建能力进行稀疏视图重建。
这些研究构成了FreeSplatter框架的研究背景和理论基础,展示了在3D重建和相机姿态估计领域中,如何利用深度学习和可微分渲染技术来处理稀疏视图下的重建问题。FreeSplatter通过结合这些技术,提出了一种无需已知相机姿态的高质量3D重建框架。
Q: 论文如何解决这个问题?
A: 论文通过提出FreeSplatter框架解决了稀疏视图3D重建中准确相机姿态估计的问题,具体解决方案如下:
基于变换器的架构:
FreeSplatter构建在一个流线型的变换器架构之上,该架构由顺序自注意力块组成,这些块促进了多视图图像标记之间的信息交换,并将它们解码成像素级3D高斯原语。无需已知相机姿态:
FreeSplatter不依赖于输入图像的相机姿态和内参,可以直接从多视图图像中预测每个像素对应的高斯图,从而避免了在稀疏视图场景中推导相机参数的困难。高斯图的预测:
通过变换器架构,FreeSplatter预测出多视图图像中每个像素对应的3D高斯原语,并将其放置在统一的参考框架中,这允许进行高保真度的3D建模和快速的相机参数估计。联合优化:
FreeSplatter通过端到端训练实现了高斯位置和属性的同时优化,这与依赖于固定架构和单独训练高斯头的方法相比,可以更有效地利用渲染监督信号。像素对齐损失:
为了确保预测的高斯与对应的像素对齐,FreeSplatter引入了像素对齐损失,这不仅提高了渲染质量,而且对相机参数估计至关重要。分阶段训练策略:
由于在没有已知相机姿态和内参的情况下预测正确的高斯位置非常困难,FreeSplatter采用了分阶段训练策略,先通过位置损失对模型进行预训练,以学习预测大致正确的高斯位置,再通过像素对齐损失进行更细致的几何监督。模型变体:
FreeSplatter训练了两种模型变体(FreeSplatter-O和FreeSplatter-S)分别处理以对象为中心和场景级别的重建场景,这两种变体共享相同的模型架构,但针对不同任务进行了必要的调整。即时相机参数估计:
利用预测的高斯位置,FreeSplatter可以使用现成的求解器(如PnP-RANSAC)在几秒钟内估计相机的外参和内参。
通过上述方法,FreeSplatter能够在无需准确相机姿态信息的情况下,从稀疏视图图像中生成高质量的3D模型,并准确估计相机参数,从而解决了稀疏视图3D重建中的一个关键问题。
Q: 论文做了哪些实验?
A: 论文中进行了多个实验来验证FreeSplatter框架的性能和效果,具体实验包括:
稀疏视图重建:
- 对比了FreeSplatter与现有的稀疏视图重建方法,包括LGM、InstantMesh和Splatt3R等,使用标准指标(如PSNR、SSIM和LPIPS)评估重建质量。
- 在对象中心和场景级别的数据集上进行了评估,包括OmniObject3D、Google Scanned Objects、ScanNet++和CO3Dv2等。
相机姿态估计:
- 评估了FreeSplatter在相机姿态估计方面的能力,与MASt3R、FORGE和PoseDiffusion等方法进行了对比。
- 使用了不同的旋转和翻译指标来评估姿态估计的准确性,包括相对旋转误差(RRE)、相对旋转精度(RRA)和翻译误差(TE)。
消融研究:
- 探究了输入视图数量对重建质量的影响。
- 研究了像素对齐损失对模型性能的影响,通过对比有无像素对齐损失的模型在重建质量上的差异。
跨数据集泛化能力:
- 验证了FreeSplatter-O在未见过的数据集(如ABO和OmniObject3D)上的泛化能力。
- 评估了FreeSplatter-S在RealEstate10K数据集上的零样本(zero-shot)视图合成能力,并与其他方法进行了对比。
3D内容创建应用:
- 展示了FreeSplatter在3D内容创建中的潜在应用,如将文本/图像转换为3D模型。
- 结合多视图扩散模型(如Zero123++和MVDream)生成多视图图像,并使用FreeSplatter进行重建和新视图渲染。
这些实验全面评估了FreeSplatter在不同方面的性能,包括重建质量、姿态估计准确性、泛化能力和实际应用潜力。通过这些实验,论文证明了FreeSplatter在稀疏视图3D重建领域的优势和有效性。
Q: 有什么可以进一步探索的点?
A: 尽管FreeSplatter在稀疏视图3D重建领域取得了显著的成果,但仍有一些可以进一步探索的点:
统一模型架构:
- 论文中提到FreeSplatter需要两个不同的模型变体来处理对象中心和场景级别的重建任务。未来的工作可以探索开发一个统一的模型架构,同时处理这两种任务。
无需深度数据的训练:
- FreeSplatter的预训练阶段依赖于深度数据。研究如何在没有深度标签的数据集上进行训练,例如RealEstate10K和MVImgNet,将是一个有价值的方向。
扩展数据集和训练策略:
- 扩展模型训练所使用的数据集范围,以包含更多种类的场景和对象,可能有助于提升模型的泛化能力和性能。
优化模型效率和可扩展性:
- 进一步优化FreeSplatter的计算效率和内存使用,使其能够处理更高分辨率的图像和更复杂的场景。
增强模型的鲁棒性:
- 提高模型对于输入噪声、遮挡和不完整视图的鲁棒性,以适应现实世界中的各种挑战。
多模态输入融合:
- 探索将FreeSplatter与其他模态的输入(如深度图、点云数据)结合,以提高重建的精度和完整性。
实时3D重建应用:
- 研究如何将FreeSplatter应用于实时3D重建任务,例如增强现实(AR)和虚拟现实(VR)应用。
自监督学习:
- 探索自监督学习策略,减少对标注数据的依赖,提高模型在各种数据集上的适用性。
跨模态3D重建:
- 研究如何将FreeSplatter应用于跨模态3D重建任务,例如从2D图像到3D模型的转换,或者从文本描述生成3D内容。
模型解释性和可视化:
- 提高模型内部工作机制的透明度,通过可视化技术帮助研究人员和用户更好地理解模型的决策过程。
这些方向不仅可以推动3D重建技术的发展,还可能为计算机视觉和机器学习领域带来新的见解和突破。
Q: 总结一下论文的主要内容
A: 论文提出了FreeSplatter,这是一个用于稀疏视图3D重建的框架,它能够从未经校准的稀疏视图图像中生成高质量的3D高斯并恢复相机参数。以下是论文的主要内容总结:
问题陈述:
- 现有稀疏视图重建模型依赖于准确的相机姿态,但在实际应用中,从稀疏视图图像中获取精确的相机外参和内参存在挑战。
FreeSplatter框架:
- 提出了FreeSplatter,一个可扩展的前馈重建框架,利用变换器架构从多视图图像中预测3D高斯原语,并在统一参考框架中恢复相机参数。
方法细节:
- FreeSplatter基于3D高斯Splatting(3DGS)表示场景,通过有效的光栅化器实现快速渲染。
- 使用自注意力机制促进多视图信息融合,并预测像素级3D高斯原语。
- 引入像素对齐损失以确保高斯分布在相机射线上,提高渲染质量和相机参数估计的准确性。
模型变体:
- 训练了两个FreeSplatter变体(FreeSplatter-O和FreeSplatter-S)分别针对对象中心和场景级别的重建任务。
实验结果:
- 在多个数据集上评估了FreeSplatter的性能,包括OmniObject3D、Google Scanned Objects、ScanNet++和CO3Dv2。
- 实验结果显示FreeSplatter在重建质量和姿态估计准确性方面优于现有技术。
应用潜力:
- 展示了FreeSplatter在提高下游应用(如文本/图像到3D内容创建)生产力方面的潜力。
局限性和未来工作:
- 论文讨论了FreeSplatter的局限性,包括对深度数据的依赖和需要不同模型变体处理不同任务。
- 提出了未来的研究方向,包括开发统一模型架构和减少对深度标签的依赖。
总的来说,FreeSplatter通过其创新的变换器架构和3D高斯Splatting表示,为无需精确相机姿态的稀疏视图3D重建提供了一个高效且高质量的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


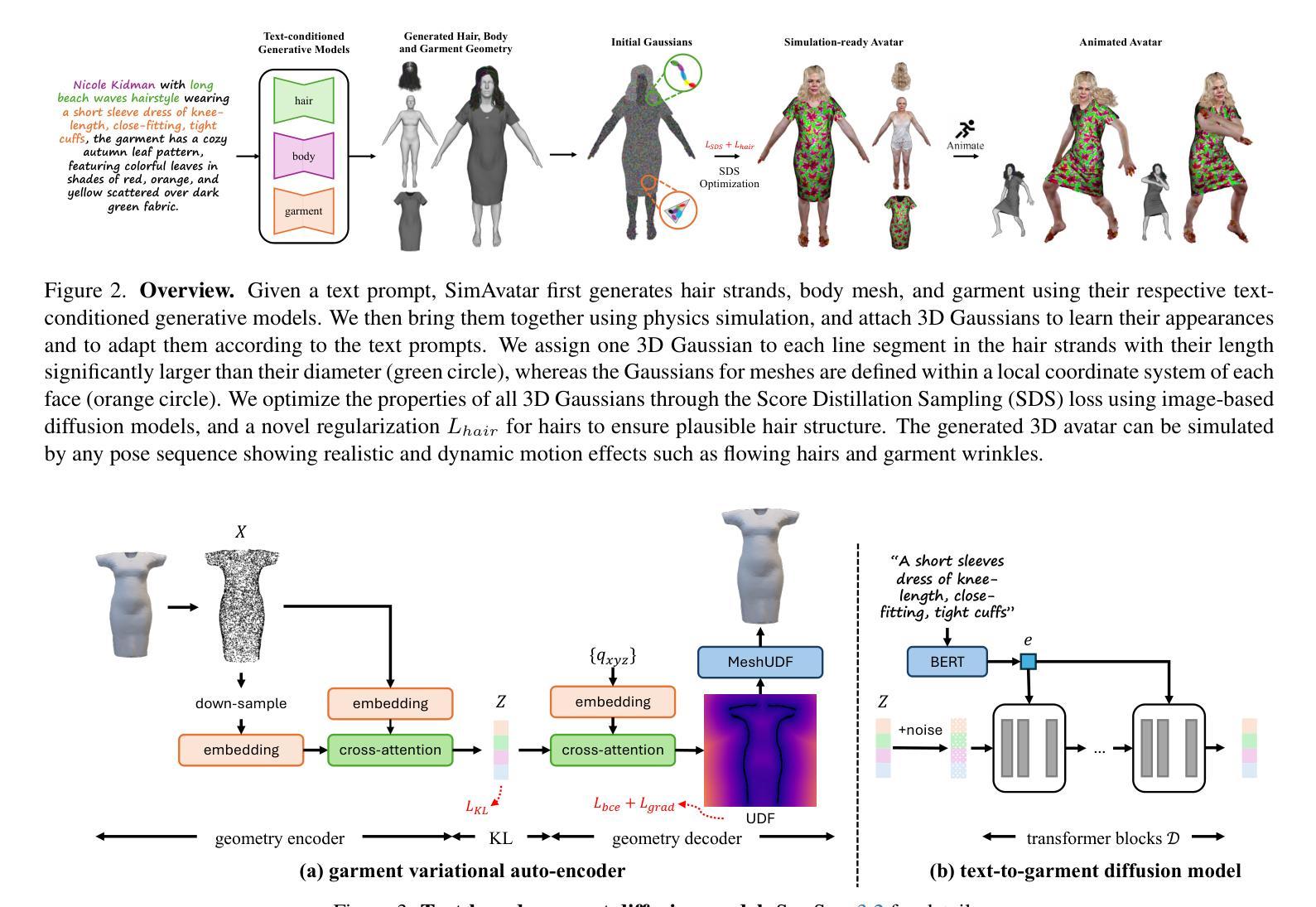
SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
Authors:Xueting Li, Ye Yuan, Shalini De Mello, Gilles Daviet, Jonathan Leaf, Miles Macklin, Jan Kautz, Umar Iqbal
We introduce SimAvatar, a framework designed to generate simulation-ready clothed 3D human avatars from a text prompt. Current text-driven human avatar generation methods either model hair, clothing, and the human body using a unified geometry or produce hair and garments that are not easily adaptable for simulation within existing simulation pipelines. The primary challenge lies in representing the hair and garment geometry in a way that allows leveraging established prior knowledge from foundational image diffusion models (e.g., Stable Diffusion) while being simulation-ready using either physics or neural simulators. To address this task, we propose a two-stage framework that combines the flexibility of 3D Gaussians with simulation-ready hair strands and garment meshes. Specifically, we first employ three text-conditioned 3D generative models to generate garment mesh, body shape and hair strands from the given text prompt. To leverage prior knowledge from foundational diffusion models, we attach 3D Gaussians to the body mesh, garment mesh, as well as hair strands and learn the avatar appearance through optimization. To drive the avatar given a pose sequence, we first apply physics simulators onto the garment meshes and hair strands. We then transfer the motion onto 3D Gaussians through carefully designed mechanisms for each body part. As a result, our synthesized avatars have vivid texture and realistic dynamic motion. To the best of our knowledge, our method is the first to produce highly realistic, fully simulation-ready 3D avatars, surpassing the capabilities of current approaches.
我们介绍了SimAvatar框架,该框架旨在从文本提示生成可用于模拟的穿衣3D人类角色。现有的文本驱动的人类角色生成方法要么使用统一几何对头发、服装和人体进行建模,要么产生不容易在现有模拟管道中进行模拟的头发和服装。主要挑战在于以一种能够利用基础图像扩散模型(例如Stable Diffusion)的先验知识的方式表示头发和服装的几何形状,同时使用物理或神经网络模拟器进行模拟。为了解决这个问题,我们提出了一个两阶段的框架,该框架结合了3D高斯分布的灵活性与可用于模拟的头发束和服装网格。具体来说,我们首先使用三个文本条件化的3D生成模型来根据给定的文本提示生成服装网格、身体形状和头发束。为了利用基础扩散模型的先验知识,我们将3D高斯分布附加到身体网格、服装网格和头发束上,并通过优化来学习角色外观。为了在给定的姿势序列驱动下驱动角色,我们首先将物理模拟器应用于服装网格和头发束。然后,我们通过为每个身体部分精心设计的机制将运动转移到3D高斯分布上。因此,我们合成的角色具有生动的纹理和逼真的动态运动。据我们所知,我们的方法是第一个生成高度逼真、完全模拟就绪的3D角色的方法,超越了当前方法的能力。
论文及项目相关链接
PDF Project website: https://nvlabs.github.io/SimAvatar/
Summary
新一代SimAvatar框架可从文本提示生成模拟就绪的穿衣3D人类角色。它通过结合文本驱动的角色生成方法与仿真技术,解决了传统方法难以模拟角色服装和头发的问题。SimAvatar采用两阶段框架,利用图像扩散模型的先验知识生成服装网格、身体形态和头发线条,并通过优化学习角色外观。此外,它利用物理模拟器驱动角色的动作,并将运动转移到角色每个身体部分的3D高斯模型上,从而实现逼真的动态效果。此为目前领先技术,可生成高度逼真的模拟就绪角色。
Key Takeaways
- SimAvatar是一个从文本提示生成模拟就绪的穿衣3D人类角色的框架。
- 它解决了传统方法在模拟角色服装和头发方面的难题。
- SimAvatar结合文本驱动的角色生成方法与仿真技术。
- 采用两阶段框架生成服装网格、身体形态和头发线条。
- 利用图像扩散模型的先验知识进行优化学习角色外观。
- 利用物理模拟器驱动角色动作,实现逼真动态效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为SimAvatar的框架,旨在解决如何从文本提示生成模拟就绪(simulation-ready)的、穿着服装的3D人体化身的问题。具体来说,论文试图解决以下几个挑战:
现有方法的局限性:当前基于文本驱动的人体化身生成方法要么使用统一的几何模型来建模头发、服装和人体,要么生成的头发和服装不容易适应现有的模拟流程。这些方法难以在保持模拟就绪性的同时利用基础图像扩散模型(例如Stable Diffusion)的先验知识。
头发和服装的几何表示:挑战在于如何表示头发和服装的几何形状,以便既能利用现有的扩散模型的先验知识,又能适应物理或神经网络模拟器进行模拟。
模拟准备性与细节表现:需要生成具有详细几何结构、真实纹理和动态服装及头发运动的3D化身,这些运动效果随姿势变化而变化,如头发流动和服装皱纹。
不同表示方式的整合:将当前模拟器使用的表示方式与文本驱动的化身生成流程所使用的表示方式相连接,前者通常需要干净、紧凑、平滑的网格或特定设计的发丝,后者则常采用隐式表示(如NeRF或SDF),这些虽然可以通过扩散模型的噪声信号进行优化,但难以转换为适合模拟的开放网格或发丝。
为了解决这些问题,SimAvatar框架采用了一个两阶段的方法,结合了3D高斯分布的灵活性和模拟就绪的头发丝和服装网格,使得生成的3D化身能够被现有的头发和服装模拟器轻松动画化,同时保持真实感和动态运动效果。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以归纳为以下几个领域:
文本到3D化身生成(Text to 3D Avatar Generation):
- ClipMatrix、AvatarClip、DreamAvatar、AvatarCraft、DreamHumans、DreamWaltz、AvatarVerse、HumanNorm、AvatarBooth等方法,这些方法通过文本或图像输入来生成和控制3D人体化身。
- TADA、GAvatar等方法,探索了不同的表示方式来建模化身,例如基于网格的方法和基于3D高斯的方法。
服装建模和模拟(Garment Modeling and Simulation):
- SMPL+D等方法,通过在SMPL人体网格上添加顶点位移来捕捉穿着服装的人体几何形状。
- BCNet、DeepCloth等方法,通过学习回归器直接预测服装类型和形状参数,或通过规范的UV表示来编码服装。
- 使用隐式无符号距离场(Unsigned Distance Fields, UDF)的方法,因其在建模任意拓扑和处理开放表面方面的灵活性而受到青睐。
头发建模和模拟(Hair Modeling and Simulation):
- 基于发丝表示的方法,因其与物理模拟器的兼容性和几何操作的便利性而受到青睐。
- 使用数据驱动先验的方法,基于扩散模型来估计合理的内部发丝,尽管在观测数据中这些发丝可能被遮挡。
- 使用3D高斯表示来有效模拟复杂头发纹理和不同发丝厚度的方法。
这些相关研究为SimAvatar框架的发展提供了理论基础和技术手段,特别是在3D人体建模、服装和头发的几何表示、物理模拟以及基于文本的生成模型等方面。SimAvatar框架通过结合这些领域的技术进展,提出了一种新的方法来生成具有独立层次的身体、服装和头发的模拟就绪3D化身。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SimAvatar的框架来解决从文本提示生成模拟就绪的3D人体化身的问题。该框架通过以下几个关键步骤来解决这个问题:
1. 两阶段框架
SimAvatar采用了一个两阶段框架,结合了3D高斯的灵活性和模拟就绪的头发丝以及服装网格。
2. 文本条件3D生成模型
- 服装网格生成:使用变分自编码器(VAE)学习服装几何分布,并训练一个条件潜在扩散模型从文本提示生成服装网格。
- 头发丝生成:利用基于扩散的文本到头发生成模型从文本提示创建头发丝。
- 身体形状生成:使用基于GPT的LLM模型预测头发丝和SMPL形状参数。
3. 3D高斯Splatting(3DGS)外观模型
- 在不同的人体部位(如头发、身体和服装)上附加3D高斯,并使用得分蒸馏采样(SDS)优化这些高斯属性,以学习真实的外观细节。
4. 动态模拟
- 服装模拟:使用神经网络模拟器(例如HOOD)根据目标身体姿势序列模拟服装网格。
- 头发模拟:使用头发模拟器根据目标身体网格序列和模拟的服装序列模拟头发丝。
5. 外观细节优化
- 使用SDS目标和预训练的文本到图像扩散模型来优化高斯的属性,从而精细化外观细节。
6. 特定部位的3D高斯定制
- 身体和服装网格:将3D高斯与身体和服装网格结合,并根据网格的运动来驱动这些高斯。
- 头发丝:为每根头发丝的每个线段分配一个3D高斯,并根据头发丝的运动来驱动这些高斯。
7. 着色模型
- 为了捕捉运动中的外观细节,如服装皱纹,将Phong着色模型纳入流程中。
8. 实验和评估
- 使用用户研究和定量评估(如VQAScore和CLIP分数)来验证SimAvatar在生成外观和动态运动方面相较于现有技术的优越性。
通过这些步骤,SimAvatar能够生成具有详细几何结构、真实纹理和动态服装及头发运动的3D化身,这些运动效果随姿势变化而变化,如头发流动和服装皱纹。这种方法不仅提高了生成化身的真实感,而且使得化身能够被现有的头发和服装模拟器轻松动画化。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估SimAvatar框架的性能:
1. 数据集
- 为了学习基于文本的服装扩散模型,作者使用了Garment Pattern Generator (GPG) 数据集和CLOTH3D 数据集,并利用GPT4v生成与服装网格配对的文本提示。
2. 定性评估
- 作者将SimAvatar生成的化身与几种最先进的文本驱动的3D化身生成方法(包括Fantasia3D、TADA和GAvatar)进行了视觉比较。
- 展示了在标准姿势下的合成化身以及动画化身,以展示SimAvatar在模拟动态效果(如服装皱纹和头发流动)方面的优势。
3. 用户研究
- 通过A/B用户研究定量评估SimAvatar。研究包括对22个提示的比较,生成静态360度视频和显示化身驱动的运动序列的视频。
- 用户被要求选择具有更好外观的方法和更注重运动的方法。研究收集了18名用户的540票,并在表格中展示了结果。
4. 定量评估
- 使用VQAScore和CLIP分数来定量比较SimAvatar与基线方法。
- VQAScore:评估生成资产与输入提示之间的对齐程度,特别适合涉及多个实体和关系的复杂提示。
- CLIP分数:虽然用于评估,但作者指出其在评估视觉质量和文本提示对齐方面的不可靠性。
5. 实施细节
- 描述了文本到服装扩散模型的训练细节和高斯化身学习的优化过程。
6. 层级训练策略
- 为了促进头发、身体和服装的解耦,作者采用了分别渲染每个层并使用不同提示进行优化的策略。
7. 消融研究
- 评估了不同模块的有效性,包括头发约束、提示工程和解耦训练策略,并展示了相应的定性结果。
8. 更多定性结果
- 提供了与基线方法的更多比较结果,并展示了SimAvatar方法的各个层(包括头发、面部、服装、身体和完整化身)的几何和纹理的额外结果。
这些实验全面评估了SimAvatar在生成现实感、可动画化3D服装化身方面的能力,并与现有技术进行了比较。通过这些实验,论文证明了SimAvatar在生成具有动态效果的高质量3D化身方面的有效性。
Q: 有什么可以进一步探索的点?
A: 论文在最后提出了几个可以进一步探索的点:
数据集多样性:当前的头发和服装生成模型是在特定的数据集上训练的,这可能因为训练数据的局限性而限制了生成的多样性。未来的工作可以探索方法,以生成超越现有数据集多样性的模拟就绪化身。
联合模拟:SimAvatar目前是顺序地模拟服装和头发,这在某些情况下(如穿着帽子的化身)可能会失败。实现头发和服装的联合模拟将使我们能够处理更复杂的服装。
配饰和鞋类:目前的SimAvatar框架中,配饰和鞋类仍然与身体或服装层纠缠在一起;未来的工作可以集中在生成完全分离的配饰和鞋类,以创建完全解耦的化身。
优化和计算效率:虽然SimAvatar能够生成高质量的3D化身,但是优化过程可能既耗时又计算密集。研究更高效的优化算法和计算策略可能是一个有价值的方向。
更复杂的纹理和外观细节:尽管SimAvatar在模拟动态服装和头发方面取得了进展,但在生成更复杂的纹理和外观细节方面仍有改进空间,例如模拟更逼真的织物纹理和更细致的光影效果。
交互性和实时应用:将SimAvatar应用于实时系统,如虚拟试衣或游戏,可能需要进一步的研究以确保实时性能和用户交互。
跨模态融合:探索将SimAvatar与其他模态的输入(如语音或视频)结合起来,以创建更丰富的交互体验。
更广泛的用户定制:提供更多的用户定制选项,允许用户调整化身的各种特征,包括面部特征、体型和风格。
评估和度量:开发和验证新的评估度量,以更准确地衡量3D化身生成系统的性能,特别是在动态模拟和真实感方面。
应用扩展:探索SimAvatar在其他领域的应用,如电影和游戏制作、虚拟助理、增强现实/虚拟现实和远程存在等。
这些方向都有助于推动3D人体化身生成技术的发展,并扩大其在不同领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为SimAvatar的框架,旨在从文本提示生成模拟就绪的3D人体化身,包括头发、服装和身体。以下是论文的主要内容总结:
问题定义:论文指出了现有文本驱动的3D人体化身生成方法的局限性,包括无法适应模拟流程的头发和服装表示,以及难以利用图像扩散模型的先验知识。
SimAvatar框架:提出了一个两阶段框架,首先使用文本条件的3D生成模型生成服装网格、身体形状和头发丝,然后通过优化附着在这些几何结构上的3D高斯来学习化身的外观。
服装和头发的模拟:利用物理模拟器和神经网络模拟器(如HOOD)来模拟服装和头发的运动,以实现动态效果,如流动的头发和服装皱纹。
3D高斯Splatting(3DGS):为了捕捉细节外观,框架在身体网格、服装网格和头发丝上附加3D高斯,并使用得分蒸馏采样(SDS)优化这些高斯的属性。
动态模拟:通过将运动从模拟的服装网格和头发丝转移到3D高斯,确保化身在不同姿势下的外观保持一致。
实验:通过定性和定量实验,包括用户研究和VQAScore评估,展示了SimAvatar在生成现实感和动态服装化身方面的优越性能。
未来工作:论文提出了几个未来研究方向,包括扩展数据集多样性、实现头发和服装的联合模拟、生成完全解耦的配饰和鞋类等。
总体而言,SimAvatar通过结合3D高斯的灵活性和模拟就绪的头发丝及服装网格,提出了一种新的方法来生成具有独立层次的身体、服装和头发的模拟就绪3D化身,这些化身在动画化时能够展现出逼真的动态效果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

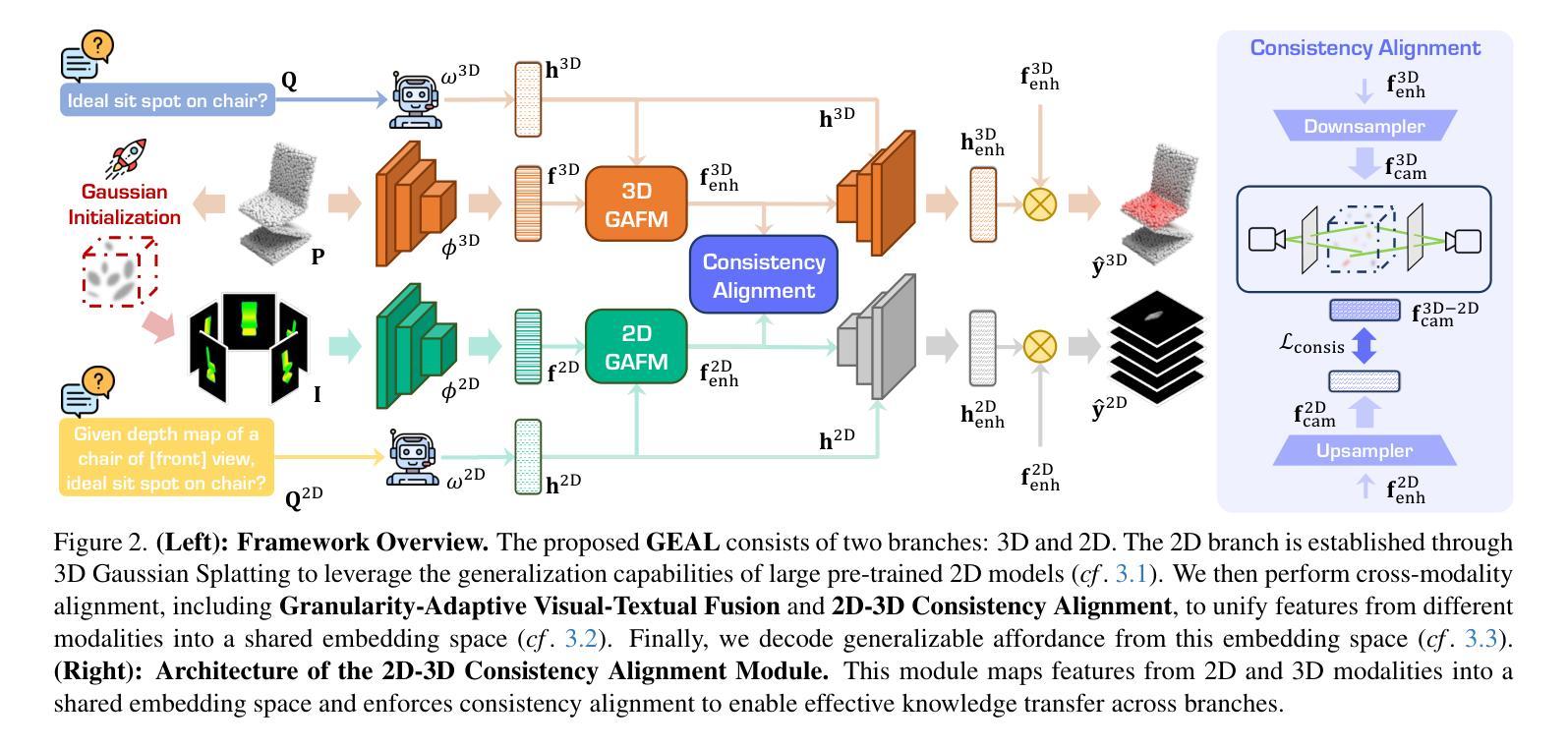
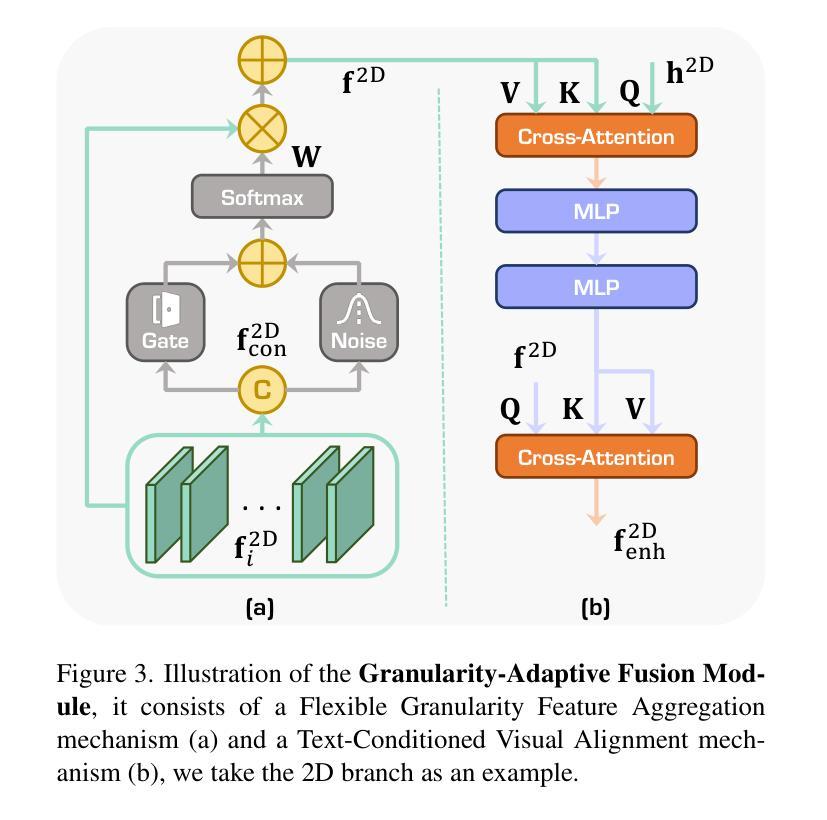
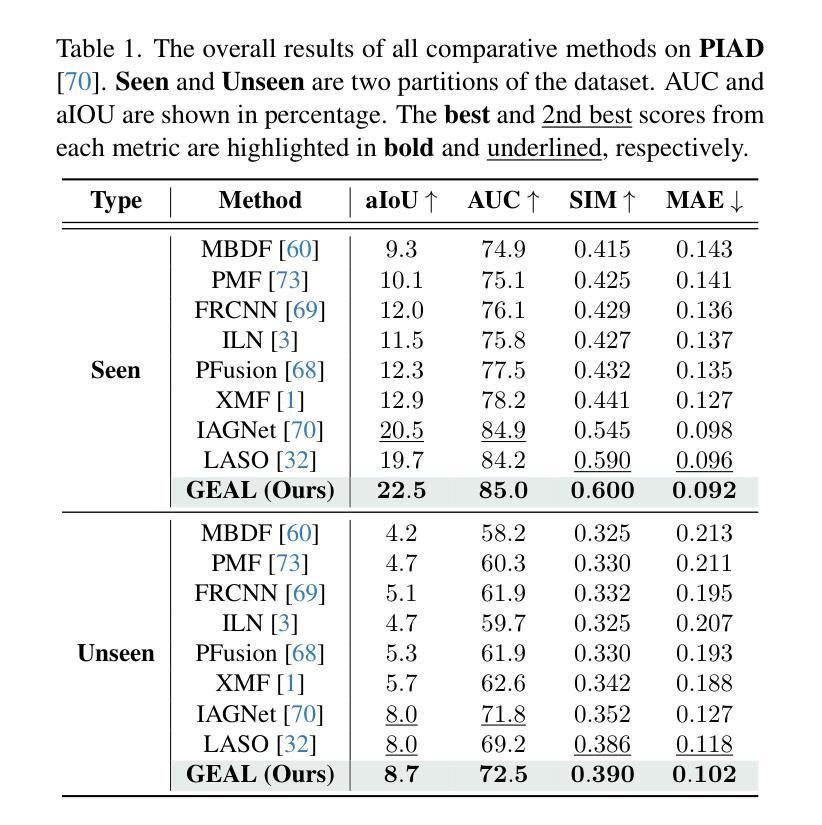
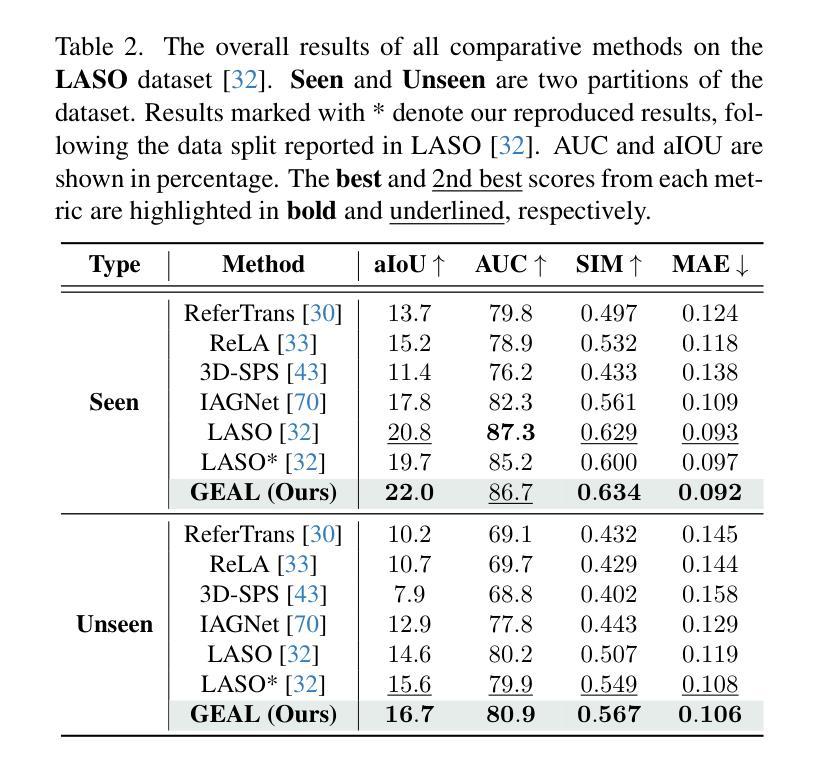
GEAL: Generalizable 3D Affordance Learning with Cross-Modal Consistency
Authors:Dongyue Lu, Lingdong Kong, Tianxin Huang, Gim Hee Lee
Identifying affordance regions on 3D objects from semantic cues is essential for robotics and human-machine interaction. However, existing 3D affordance learning methods struggle with generalization and robustness due to limited annotated data and a reliance on 3D backbones focused on geometric encoding, which often lack resilience to real-world noise and data corruption. We propose GEAL, a novel framework designed to enhance the generalization and robustness of 3D affordance learning by leveraging large-scale pre-trained 2D models. We employ a dual-branch architecture with Gaussian splatting to establish consistent mappings between 3D point clouds and 2D representations, enabling realistic 2D renderings from sparse point clouds. A granularity-adaptive fusion module and a 2D-3D consistency alignment module further strengthen cross-modal alignment and knowledge transfer, allowing the 3D branch to benefit from the rich semantics and generalization capacity of 2D models. To holistically assess the robustness, we introduce two new corruption-based benchmarks: PIAD-C and LASO-C. Extensive experiments on public datasets and our benchmarks show that GEAL consistently outperforms existing methods across seen and novel object categories, as well as corrupted data, demonstrating robust and adaptable affordance prediction under diverse conditions. Code and corruption datasets have been made publicly available.
从语义线索识别3D物体上的适宜性区域对于机器人技术和人机交互至关重要。然而,现有的3D适宜性学习方法在泛化和鲁棒性方面遇到了挑战,这主要是由于标注数据有限,且依赖于专注于几何编码的3D主干网,后者通常对现实世界中的噪声和数据损坏缺乏韧性。我们提出了GEAL,这是一个利用大规模预训练2D模型增强3D适宜性学习泛化和鲁棒性的新型框架。我们采用具有高斯平铺的双分支架构来建立3D点云和2D表示之间的一致映射,从而实现从稀疏点云的逼真2D渲染。粒度自适应融合模块和2D-3D一致性对齐模块进一步加强了跨模态对齐和知识迁移,使3D分支能够从2D模型的丰富语义和泛化能力中受益。为了全面评估鲁棒性,我们引入了两个新的基于腐败的基准测试:PIAD-C和LASO-C。在公共数据集和我们的基准测试上的大量实验表明,GEAL在已知和新型对象类别以及损坏数据方面始终优于现有方法,在多种条件下显示出稳健和可适应的适宜性预测。代码和腐败数据集已公开可用。
论文及项目相关链接
PDF 22 pages, 8 figures, 12 tables; Project Page at https://dylanorange.github.io/projects/geal
摘要
基于语义线索识别三维物体上的可用性区域对于机器人和人机交互至关重要。然而,现有的三维可用性学习方法受限于标注数据有限和对以几何编码为重点的三维主干的依赖,缺乏在现实世界噪声和数据损坏下的稳健性。我们提出GEAL框架,旨在利用大规模预训练的二维模型增强三维可用性学习的泛化和稳健性。我们采用具有高斯拼接的双分支架构建立三维点云与二维表示之间的持续映射关系,使稀疏点云实现逼真的二维渲染成为可能。粒度自适应融合模块和二维-三维一致性对齐模块进一步加强跨模态对齐和知识迁移,使三维分支受益于二维模型的丰富语义和泛化能力。为了全面评估稳健性,我们引入了两个新的基于腐败的基准测试:PIAD-C和LASO-C。在公共数据集和我们自己的基准测试上的大量实验表明,GEAL在已知和未知对象类别以及损坏数据上均表现优于现有方法,展示在不同条件下对可用性预测的稳健性和适应性。代码和腐败数据集已公开提供。
关键见解
- 识别三维物体上的可用性区域对机器人和人机交互至关重要。
- 现有三维可用性学习方法受限于标注数据有限和对几何编码的依赖,缺乏泛化和稳健性。
- 提出GEAL框架,利用大规模预训练的二维模型增强三维可用性学习的泛化和稳健性。
- 采用双分支架构和高斯拼接技术实现三维点云与二维表示的持续映射。
- 粒度自适应融合模块和二维-三维一致性对齐模块加强跨模态对齐和知识迁移。
- 在公共数据集和基准测试上进行了大量实验,证明GEAL优于现有方法。
- 引入两个新的基于腐败的基准测试来全面评估模型的稳健性,代码和腐败数据集已公开。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为GEAL(Generalizable 3D Affordance Learning)的框架,旨在解决3D affordance learning(3D可操作性学习)中的两个主要问题:泛化能力和鲁棒性。具体来说,论文指出现有的3D affordance学习方法面临以下挑战:
泛化能力不足:由于标注数据有限,3D affordance模型通常比2D模型表现出更差的泛化能力。这些模型通常依赖于仅关注位置和几何编码的3D骨干网络,限制了它们捕获全局语义内容的能力。
鲁棒性差:3D模型在现实世界环境中对传感器不准确、场景复杂或处理伪影产生的噪声和数据损坏非常敏感,这进一步阻碍了当前3D affordance学习方法的鲁棒性和适应性。
为了克服这些限制,GEAL框架通过以下方式增强3D affordance学习的泛化和鲁棒性:
- 利用大规模预训练的2D模型来提升泛化能力。
- 采用双分支架构和高斯绘制(Gaussian splatting)技术在3D点云和2D表示之间建立一致的映射。
- 引入粒度自适应融合模块和2D-3D一致性对齐模块,加强跨模态对齐和知识转移。
此外,论文还引入了两个新的基于损坏数据的基准测试PIAD-C和LASO-C,以全面评估3D affordance学习在现实世界条件下的鲁棒性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
2D Affordance Learning(2D 可操作性学习)
- 早期方法主要识别图像和视频中的交互区域,但这些方法通常缺乏精确定位可操作性相关对象部分的能力。
- 后来的研究通过使用2D数据改善了可操作性定位。
- 最近,大规模预训练模型通过将视觉特征与可操作性相关的文本描述对齐,减少了对手动标签的依赖,并提高了新上下文中的可操作性预测能力。
3D Affordance Learning(3D 可操作性学习)
- 将可操作性检测扩展到3D空间面临准确空间和深度信息需求的挑战。
- 一些研究使用2D数据检测3D可操作性区域,但通常难以精确定位3D交互点。
- 随着大规模3D对象数据集的可用性,研究工作开始直接在3D结构上映射可操作性,以捕获复杂的空间关系。
- 最近的方法利用2D视觉和语言模型进行开放词汇可操作性检测,增强了泛化能力,无需固定标签集。
Robustness for 3D Affordance Learning(3D 可操作性学习的鲁棒性)
- 现实世界中的3D可操作性学习不可避免地面临由场景复杂性、传感器不准确和处理错误引起的点云损坏的挑战。
- 现有研究旨在改进和基准测试3D感知中噪声和腐败的鲁棒性,但可操作性学习特别需要在变化和降级的数据条件下精确识别交互区域。
论文中还提到了一些具体的工作和方法,例如:
- LASO [32]:一种基于文本条件的可操作性分割方法,侧重于文本和3D对象之间的跨模态对齐。
- IAGNet [70]:通过将知识从2D示范图像转移到点云来实现3D可操作性定位的方法。
- 3D-SPS [43]:一个3D视觉定位方法,通过选择语言关键点进行可操作性分割。
- ReLA [33] 和 ReferTrans [30]:这些方法用于图像基础的指代表达分割,通过适应图像区域特征到分组点特征来进行点云分割。
这些相关研究为3D affordance learning提供了理论基础和方法论,同时也突显了该领域面临的挑战和未来的发展方向。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为GEAL(Generalizable 3D Affordance Learning)的框架来解决3D affordance learning中的泛化和鲁棒性问题。具体解决方案如下:
1. 双分支架构与高斯绘制(Gaussian Splatting)
- 3D-2D映射:使用3D Gaussian Splatting(3DGS)技术将3D点云映射到2D表示,从而利用大规模预训练的2D模型的优势。3DGS通过将3D场景表示为高斯原语,实现从任意视点的快速、可微分、逼真渲染。
- 建立2D分支:通过3DGS从稀疏的3D数据直接生成逼真的2D渲染图像,保留关键的语义和深度信息,为下游的可操作性学习任务提供支持。
2. 跨模态一致性对齐
- 粒度自适应融合模块(Granularity-Adaptive Fusion Module, GAFM):动态整合不同粒度的视觉和文本特征,以适应各种规模和粒度的可操作性查询。
- 2D-3D一致性对齐模块(2D-3D Consistency Alignment Module, CAM):确保2D和3D特征在共享嵌入空间中的一致性对齐,通过最小化对齐的2D和3D特征之间的差异来强化跨模态的知识传递。
3. 解码可操作性
- Transformer解码器:利用文本特征关注增强的视觉特征,聚焦模型对特定对象部分的准确预测。
4. 训练策略
- 二阶段训练方法:首先训练2D分支,然后冻结2D分支的所有层(除了CAM),训练3D分支以适应3D特定的特征。
5. 鲁棒性基准测试
- 建立两个新的基于损坏数据的基准测试PIAD-C和LASO-C:通过引入现实世界的损坏类型(如缩放、裁剪等),评估3D affordance模型的鲁棒性。
6. 实验验证
- 在公共数据集和新提出的基准测试上进行广泛的实验,验证GEAL方法在主流和损坏的3D affordance学习基准测试中的性能,证明了其在多样化条件下的泛化能力和鲁棒性。
通过上述方法,GEAL框架有效地利用了预训练的2D模型的丰富语义信息和泛化能力,提高了3D affordance学习的泛化性和鲁棒性,并在多样化条件下实现了鲁棒的可操作性预测。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证GEAL框架的性能和鲁棒性。具体实验包括:
1. 实验设置
- 实现细节:模型使用PyTorch实现,并采用Adam优化器进行训练。
- 数据集:实验主要在LASO和PIAD数据集上进行,这两个数据集提供了成对的可操作性和点云数据。
- 评估指标:使用了AUC、aIoU、SIM和MAE四个指标来全面评估模型性能。
2. 与最新方法的比较
- 在Seen类别和Unseen类别设置下,将GEAL与现有的最先进方法(如LASO和IAGNet)进行比较。在PIAD和LASO数据集上评估模型性能,特别是在未见类别上评估模型对新对象的泛化能力。
3. 鲁棒性测试
- 在提出的PIAD-C和LASO-C基准测试上评估GEAL的鲁棒性,这些基准测试包含了不同类型的损坏数据。
- 比较GEAL与LASO在各种损坏类型和严重级别下的性能,以评估模型在现实世界条件下的鲁棒性。
4. 消融研究
- 对GEAL框架中的不同组件(如2D分支、3D分支、一致性对齐模块和粒度自适应融合模块)进行消融研究,以评估每个组件对整体性能的贡献。
- 对高斯绘制(Gaussian Splatting)的不同配置进行调优,包括渲染分辨率、视图数量和视图依赖提示的使用,以确定最佳配置。
5. 定量和定性结果
- 提供了额外的定量结果,包括在PIAD和LASO数据集上的类别-wise和损坏-wise评估指标。
- 提供了额外的定性结果,通过可视化示例展示GEAL和LASO在PIAD和PIAD-C数据集上的表现。
这些实验全面评估了GEAL框架在标准和损坏条件下的性能,证明了其在多样化条件下的泛化能力和鲁棒性。通过这些实验,作者展示了GEAL在3D affordance learning任务中的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的GEAL框架在3D affordance learning领域取得了显著的进展,但仍有一些方向可以进一步探索和研究:
1. 内部可操作性的泛化
论文提到GEAL框架在处理与对象内部属性相关的可操作性(例如“contain”)时存在局限性。未来的研究可以探索如何通过改进点云处理技术或整合更多类型的数据(如CT扫描数据)来提高对内部结构和属性的理解。
2. 跨模态融合技术
虽然GEAL利用了2D和3D数据的融合,但跨模态融合技术本身是一个活跃的研究领域。研究者可以探索新的融合策略,如基于注意力机制或其他先进的特征融合技术,以进一步提升模型性能。
3. 模型泛化能力的进一步提升
尽管GEAL通过整合预训练的2D模型提高了泛化能力,但仍有空间进一步提升模型对新场景和新对象的适应能力。这可能涉及到更复杂的元学习策略或持续学习框架。
4. 计算效率优化
高性能模型往往需要大量的计算资源。研究如何优化模型结构和训练过程,以减少资源消耗,特别是在资源受限的环境中,这将是一个重要的研究方向。
5. 多模态输入的融合
GEAL主要处理了2D图像和3D点云的融合。未来研究可以考虑整合更多的模态,例如视频、深度图像或触觉反馈,以实现更全面的交互理解和更复杂的任务。
6. 鲁棒性的进一步提升
尽管GEAL在鲁棒性方面已经取得了进展,但在极端条件下的性能仍需进一步提高。研究如何使模型对极端噪声和损坏更加鲁棒,例如通过引入对抗训练或异常检测机制。
7. 伦理和社会影响
随着技术的发展,需要进一步探讨其伦理和社会影响,确保技术的负责任使用,并制定相应的指导原则和法规。
8. 实际应用测试
将GEAL框架应用于实际的机器人系统或增强现实/虚拟现实环境中,测试其在现实世界任务中的表现,并根据实际反馈进一步调整和优化模型。
这些方向不仅可以推动3D affordance learning技术的发展,还可能对相关领域如计算机视觉、机器人学和人机交互产生深远影响。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为GEAL(Generalizable 3D Affordance Learning)的框架,旨在提高3D affordance learning的泛化能力和鲁棒性。以下是论文的主要内容总结:
1. 问题陈述
- 3D affordance learning对于机器人和人机交互领域至关重要,但现有方法由于标注数据有限和对几何编码的依赖,泛化和鲁棒性较差。
2. GEAL框架
- 双分支架构:利用大规模预训练的2D模型,通过3D Gaussian splatting(3DGS)技术在3D点云和2D表示之间建立一致的映射。
- 跨模态对齐:包括粒度自适应融合模块(GAFM)和2D-3D一致性对齐模块(CAM),以加强跨模态对齐和知识转移。
- 解码过程:通过transformer解码器结合文本特征和视觉特征,预测可操作性分数。
3. 鲁棒性基准测试
- 引入两个新的基于损坏数据的基准测试PIAD-C和LASO-C,以全面评估3D affordance学习在现实世界条件下的鲁棒性。
4. 实验验证
- 在公共数据集和新提出的基准测试上进行广泛的实验,证明GEAL在主流和损坏的3D affordance学习基准测试中的性能,验证了其泛化能力和鲁棒性。
5. 主要贡献
- 提出了GEAL,一个新颖的方法,通过3DGS开发3D点云的2D可操作性预测分支,利用预训练的2D基础模型的鲁棒泛化和语义理解。
- 提出了粒度自适应融合和2D-3D一致性对齐,以整合和传播跨双分支架构的知识,增强3D分支的泛化能力。
- 建立了两个基于损坏的基准测试PIAD-C和LASO-C,为社区提供了鲁棒性分析的标准。
- 通过在多样化条件下的实验验证了GEAL方法的强大性能,证明了其泛化能力和鲁棒性。
总的来说,GEAL通过结合2D和3D数据的优势,有效地提高了3D affordance learning的泛化和鲁棒性,并在多样化条件下实现了鲁棒的可操作性预测。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Advancing Extended Reality with 3D Gaussian Splatting: Innovations and Prospects
Authors:Shi Qiu, Binzhu Xie, Qixuan Liu, Pheng-Ann Heng
3D Gaussian Splatting (3DGS) has attracted significant attention for its potential to revolutionize 3D representation, rendering, and interaction. Despite the rapid growth of 3DGS research, its direct application to Extended Reality (XR) remains underexplored. Although many studies recognize the potential of 3DGS for XR, few have explicitly focused on or demonstrated its effectiveness within XR environments. In this paper, we aim to synthesize innovations in 3DGS that show specific potential for advancing XR research and development. We conduct a comprehensive review of publicly available 3DGS papers, with a focus on those referencing XR-related concepts. Additionally, we perform an in-depth analysis of innovations explicitly relevant to XR and propose a taxonomy to highlight their significance. Building on these insights, we propose several prospective XR research areas where 3DGS can make promising contributions, yet remain rarely touched. By investigating the intersection of 3DGS and XR, this paper provides a roadmap to push the boundaries of XR using cutting-edge 3DGS techniques.
3D高斯拼接(3DGS)因其改变3D表示、渲染和交互的潜力而备受关注。尽管3DGS研究发展迅速,但其对扩展现实(XR)的直接应用仍然被探索不足。尽管许多研究认识到3DGS对XR的潜力,但很少有研究明确关注或证明其在XR环境中的有效性。在本文中,我们旨在综合3DGS的创新,展示其对推进XR研究和开发的特定潜力。我们对公开可用的3DGS论文进行了全面的综述,重点介绍了那些参考XR相关概念的文章。此外,我们对与XR明确相关的创新进行了深入分析,并提出了一个分类来突出它们的重要性。基于这些见解,我们提出了几个有前景的XR研究领域,在这些领域中,3DGS可以做出有希望的贡献,但仍然很少触及。本文通过研究3DGS和XR的交集,为使用最前沿的3DGS技术推动XR的边界提供了路线图。
论文及项目相关链接
PDF IEEE AIxVR 2025
Summary
3DGS技术对于扩展现实(XR)的潜力尚待充分发掘。虽然许多研究认识到其在XR领域的潜力,但对其在XR环境中的具体应用和效果的研究仍然有限。本文旨在整合关于对XR有推进潜力的3DGS创新研究,并对现有的公开文献进行全面回顾,重点关注涉及XR相关概念的文献。通过对明确与XR相关的创新的深入分析,本文提出了一套分类方案来突显其重要性。在此基础上,本文展望了基于先进3DGS技术的XR研究领域中的未来潜在贡献方向。
Key Takeaways
- 3DGS在三维表示、渲染和交互方面的潜力已获得广泛关注,但其应用于扩展现实(XR)领域的直接应用尚未得到深入研究。
- 尽管众多研究承认3DGS对XR的潜力,但明确关注或展示其在XR环境中效果的文献仍较少。
- 本文全面回顾了关于涉及XR相关概念的公开可用的3DGS文献。
- 通过深入分析明确与XR相关的创新,提出了一个分类方案来突显其重要性。
- 本文指出了基于先进的3DGS技术对推进XR研究具有显著潜力的几个方向,但这些方向尚鲜有人研究。
- 本文强调了深入研究和发展先进3DGS技术对于推动XR领域的发展具有重要意义。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了3D Gaussian Splatting(3DGS)技术在Extended Reality(XR)领域的应用潜力,并试图解决3DGS直接应用于XR环境中研究不足的问题。具体来说,论文试图解决以下几个问题:
3DGS与XR的结合:尽管许多研究认识到3DGS在XR中的潜在相关性,但很少有研究具体利用3DGS技术在XR环境中进行应用和评估。论文旨在填补这一空白,通过综合3DGS的创新技术,探索其在XR领域的应用前景。
XR体验的提升:论文旨在通过3DGS技术推动XR研究和开发,以实现更沉浸式、互动性和智能化的XR体验。
3D表示和渲染技术的改进:论文强调了在3D表示、渲染和交互技术方面取得的进步对于实现真正沉浸式XR体验的重要性,并探讨了3DGS在这些领域的潜力。
实时性能和系统整合的挑战:针对现有基于Neural Radiance Fields(NeRF)的方法在实时性能和有效整合到XR系统中面临的挑战,论文提出了3DGS作为一种有效的3D表示方法,以实现实时渲染和操纵,从而改善性能。
未来研究方向的指引:论文通过分析3DGS文献和与XR相关的创新技术,提出了几个有前景的XR研究领域,这些领域3DGS可以做出贡献但目前尚未被充分探索。
综上所述,论文的主要目标是探索3DGS与XR的交集,提供一条利用尖端3DGS技术推动XR边界的路线图。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要分为以下几个方面:
3DGS针对XR的研究工作
- VR-GS:Jiang等人提出了基于3DGS的物理感知系统,用于在VR中平滑创建、编辑和交互体验。
- DualGS:Jiang等人通过引入Dual Gaussian Splatting(DualGS),减少了体积视频在XR环境中的存储和渲染需求。
- RGCA:Saito等人利用3D Gaussians实现高保真、实时渲染虚拟化身,以增强XR中的现实感。
3DGS技术综述
- 3DGS技术综述:2024年有几篇综述文章全面探索了3DGS技术的最新进展,包括其基础理论、优化方法、应用和未来研究方向。
- 特定应用综述:一些综述专注于3DGS在特定下游应用的发展,如3D人类建模、同时定位与地图构建(SLAM)技术以及3D重建和新视角合成技术。
3DGS在XR中的创新应用
- 3D内容创建:3DGS在人类化身建模、场景重建和从文本到3D生成方面的应用。
- 渲染与可视化:3DGS在实时渲染、低延迟流媒体和高保真渲染方面的应用。
- 交互与操作:3DGS在交互式场景编辑和虚拟对象控制方面的应用。
- 系统优化与效率:3DGS在数据压缩和硬件加速方面的应用。
- 专门应用:3DGS在SLAM和医疗XR中的应用。
这些相关研究展示了3DGS技术在XR领域的多样化应用和潜在影响。论文通过综合这些研究,提出了3DGS与XR技术结合的未来研究方向,并为进一步探索3DGS在XR中的应用提供了路线图。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决3DGS在XR领域应用不足的问题:
1. 综合分析3DGS文献
- 作者对272篇公开可用的3DGS相关论文进行了全面的回顾,这些论文涵盖了顶级AI会议如CVPR、ECCV、SIGGRAPH和NeurIPS等近期发表的作品。
- 通过筛选与XR相关的内容,评估了这些论文与XR领域的相关性。
2. 构建创新分类体系
- 作者基于收集的文献和关键创新点,识别出五个与XR应用显著对齐的关键领域,并形成了一个分类体系(Taxonomy)。
- 这个分类体系覆盖了3D内容创建、渲染与可视化、交互与操作、系统优化与效率以及专门应用等多个方面。
3. 提出未来研究方向
- 论文提出了几个未来研究领域,这些领域3DGS可以做出贡献但目前尚未被充分探索,例如网格建模、动态场景表示、开放世界场景理解、手部追踪、Passthrough功能和沉浸式可视化等。
4. 提供路线图
- 通过上述分析,论文提供了一个路线图,旨在推动3DGS技术在XR中的应用,以实现更沉浸式、互动性和智能化的XR体验。
5. 激发和指导未来的研究工作
- 论文旨在激发和指导未来的研究工作,通过利用3DGS推动XR的边界,为XR领域带来更多创新和改进。
通过这些步骤,论文不仅识别了3DGS在XR中的潜在应用,还为未来的研究提供了明确的方向和框架,从而有助于推动3DGS技术在XR领域的发展和应用。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,论文中并没有明确提到具体的实验部分。论文的重点在于对3D Gaussian Splatting(3DGS)技术在Extended Reality(XR)领域的应用潜力进行综合分析和前瞻性研究。主要工作包括:
文献回顾:对272篇公开发表的3DGS相关论文进行了系统性回顾,筛选出与XR相关的内容进行分析。
创新点分析:基于收集的文献,分析了与XR相关的3DGS创新点,并提出了一个分类体系来突出这些创新的重要性。
未来研究方向提议:基于对现有3DGS技术的分析,提出了几个未来可能的研究方向,这些方向3DGS可以对XR领域做出贡献。
技术路线图提供:通过分析3DGS与XR的交集,提供了一个技术路线图,以推动3DGS技术在XR中的应用。
因此,论文更像是一篇综述性质的研究,它侧重于理论分析、技术趋势的识别和未来研究方向的提议,而不是具体的实验验证。论文的贡献在于为3DGS和XR的交叉领域提供了一个清晰的框架和研究路线,旨在指导未来的实证研究和技术开发。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
网格建模(Mesh Modeling)
- 研究如何使用3DGS表示复杂的几何形状和表面细节,以创建更逼真和互动的虚拟环境。
动态场景表示(Dynamic Scene Representation)
- 开发3DGS技术以实现实时动态内容捕获、处理和渲染,特别是针对4D体积视频的应用。
- 优化3DGS以提高其在大规模虚拟空间中的可扩展性。
开放世界场景理解(Open-world Scene Understanding)
- 利用3DGS进行开放词汇的3D分割,以提高AR/MR应用的场景理解能力。
- 结合最新的视觉基础模型(如SAM)来增强场景理解。
手部追踪(Hand Tracking)
- 利用3DGS进行实时捕获和渲染手部动作和手势的细节,以提高XR交互的精确度。
- 估计手部姿态,识别复杂手势和手指动作。
Passthrough功能(Passthrough Capabilities)
- 增强XR设备将物理和虚拟世界融合的能力,提高安全性和沉浸感。
- 探索如何准确实时重建用户周围环境,并保持不同光照条件下的高视觉保真度。
沉浸式可视化(Immersive Visualization)
- 将复杂数据集表示为具有丰富属性的高效3D高斯,使用户能够在XR应用中更直观地探索和交互数据。
- 将3DGS应用于科学研究、医学教育和统计分析等领域的复杂高维数据处理和理解。
性能优化和资源管理
- 研究如何进一步优化3DGS技术以减少延迟,提高渲染效率,并降低对计算资源的需求。
- 探索新的算法和技术,以实现在资源受限的设备上进行高质量的3DGS渲染。
跨模态融合和交互
- 研究如何将3DGS与其他模态(如触觉反馈、声音)结合,以创建更丰富的多模态XR体验。
应用特定优化
- 针对特定应用(如医疗模拟、教育、娱乐)优化3DGS技术,以满足这些领域特定的需求和挑战。
这些探索点不仅涵盖了技术的深化和优化,也包括了新应用领域的拓展,有助于推动3DGS技术在XR领域的发展和应用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
研究背景与动机
- 3D Gaussian Splatting (3DGS) 是一种新兴技术,对3D表示、渲染和交互具有潜在的革新能力。
- 尽管3DGS在3D领域迅速发展,但其在Extended Reality (XR) 环境中的应用尚未充分探索。
研究目标
- 综合3DGS的创新技术,明确其在XR领域的应用潜力。
- 提供一个路线图,推动3DGS技术在XR中的应用,以实现更沉浸式、互动性和智能化的XR体验。
方法论
- 对272篇公开发表的3DGS相关论文进行全面回顾,筛选出与XR相关的内容。
- 提出分类体系,明确3DGS在XR中的五个关键创新领域:3D内容创建、渲染与可视化、交互与操作、系统优化与效率、专门应用。
创新点分析
- 识别并分析了与XR应用显著对齐的3DGS关键创新点。
- 基于这些创新点,提出了未来XR研究的方向,包括网格建模、动态场景表示、开放世界场景理解、手部追踪、Passthrough功能和沉浸式可视化等。
结论与未来工作
- 论文强调了3DGS技术在XR领域应用的重要性,并期望通过这项研究激发和指导未来的研究工作。
- 作者计划在未来提供更全面的调查,覆盖3DGS的全部进展及其对XR的影响。
总体而言,这篇论文为3DGS与XR的交叉领域提供了一个清晰的框架和研究路线,旨在指导未来的实证研究和技术开发。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

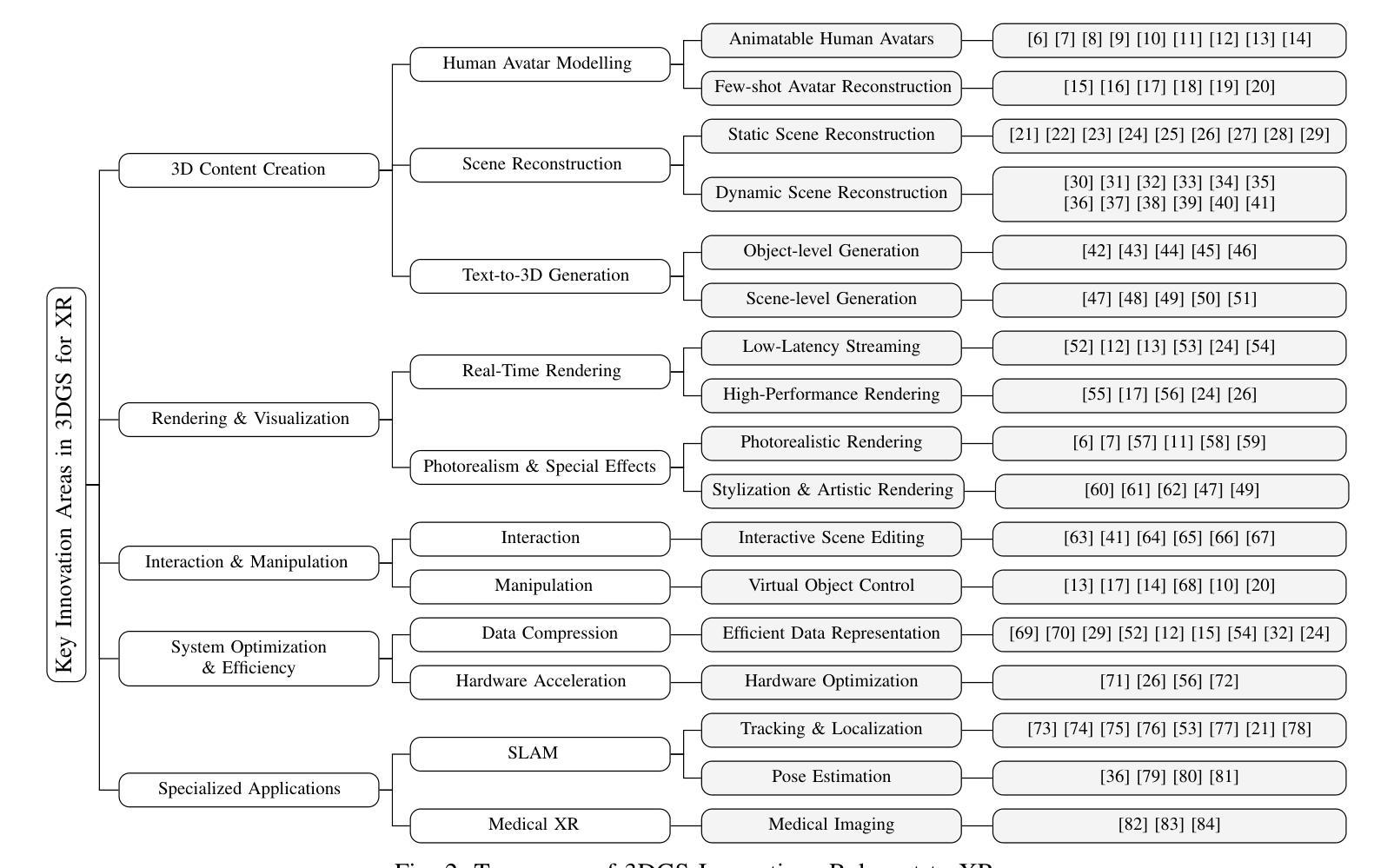
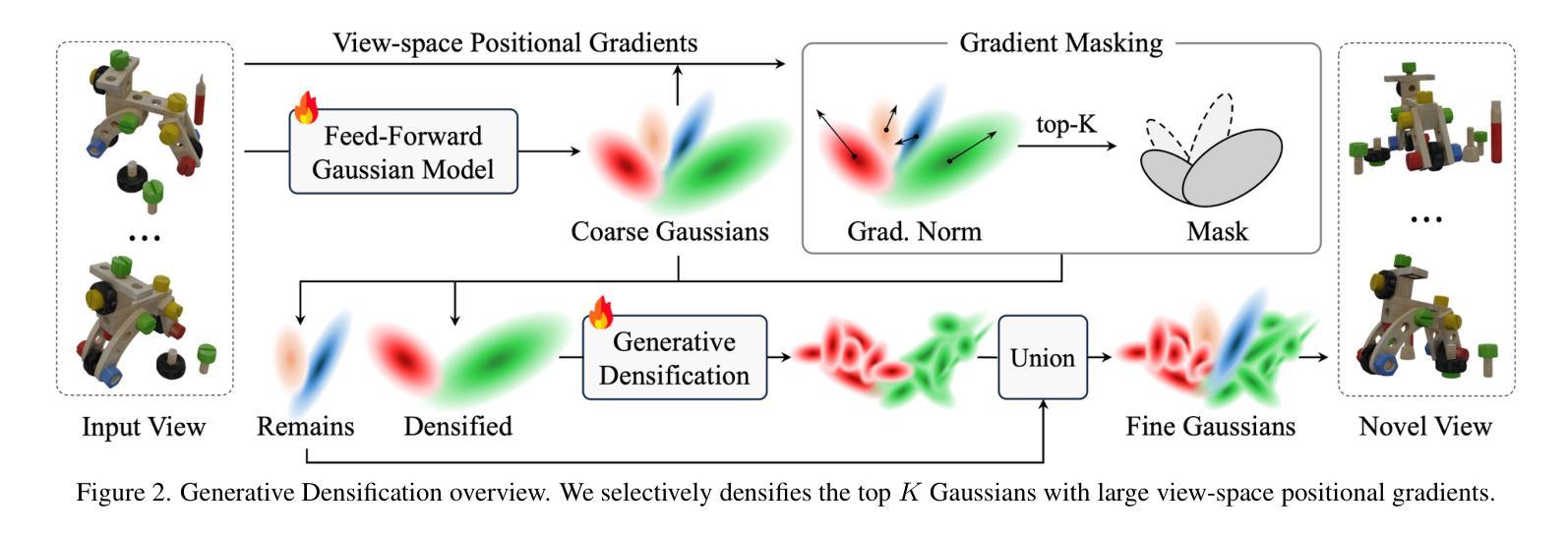
Generative Densification: Learning to Densify Gaussians for High-Fidelity Generalizable 3D Reconstruction
Authors:Seungtae Nam, Xiangyu Sun, Gyeongjin Kang, Younggeun Lee, Seungjun Oh, Eunbyung Park
Generalized feed-forward Gaussian models have achieved significant progress in sparse-view 3D reconstruction by leveraging prior knowledge from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be adapted to the feed-forward models, it may not be ideally suited for generalized scenarios. In this paper, we propose Generative Densification, an efficient and generalizable method to densify Gaussians generated by feed-forward models. Unlike the 3D-GS densification strategy, which iteratively splits and clones raw Gaussian parameters, our method up-samples feature representations from the feed-forward models and generates their corresponding fine Gaussians in a single forward pass, leveraging the embedded prior knowledge for enhanced generalization. Experimental results on both object-level and scene-level reconstruction tasks demonstrate that our method outperforms state-of-the-art approaches with comparable or smaller model sizes, achieving notable improvements in representing fine details.
广义前馈高斯模型通过利用大型多视角数据集中的先验知识,在稀疏视角3D重建方面取得了显著进展。然而,由于高斯数量的限制,这些模型往往难以表示高频细节。虽然场景3D高斯拼贴(3D-GS)优化中使用的密集化策略可以适应前馈模型,但可能不适用于通用场景。在本文中,我们提出了生成式密集化(Generative Densification),这是一种有效且通用的方法来密集化前馈模型生成的高斯。与3D-GS密集化策略不同,我们的方法不需要迭代地分裂和克隆原始高斯参数,而是对前馈模型的特性表示进行上采样,并在单次前向传递中生成其对应的精细高斯,利用嵌入的先验知识来提高泛化能力。在对象级和场景级的重建任务上的实验结果表明,我们的方法在具有相当或更小模型大小的最先进方法中表现更好,在表示细节方面取得了显著的改进。
论文及项目相关链接
PDF Project page: https://stnamjef.github.io/GenerativeDensification/
Summary
本文提出了基于广义前馈高斯模型的生成型稠化方法,用于稀疏视角的3D重建。该方法通过利用大型多视角数据集的前置知识,实现了显著进展。针对前馈模型生成的高斯稀疏表示,采用稠化策略提高高频细节的表达能力。不同于传统的3D-GS稠化策略,该方法通过一次前向传递,对特征表示进行上采样并生成对应的精细高斯,从而增强模型的泛化能力。实验结果表明,该方法在物体级别和场景级别的重建任务上均优于最新技术,且在模型大小相当的情况下,对精细细节的表达能力有显著改善。
Key Takeaways
- 广义前馈高斯模型利用大型多视角数据集的前置知识,在稀疏视角的3D重建中取得显著进展。
- 高斯模型的稠化策略有助于提高高频细节的表达能力。
- 传统的3D-GS稠化策略可能不适用于所有场景,需要一种更高效且可泛化的方法。
- 提出了生成型稠化方法,通过一次前向传递上采样特征表示并生成对应的精细高斯。
- 该方法利用嵌入的前置知识增强模型的泛化能力。
- 实验结果表明,该方法在物体级别和场景级别的重建任务上均优于最新技术。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在稀疏视图3D重建中有效地表示高频细节。具体来说,论文中提到的现有基于前馈高斯模型(feed-forward Gaussian models)在从有限数量的图像中重建3D场景或对象时,常常难以捕捉到高频细节,这是因为它们使用的高斯(Gaussian)数量有限,并且缺乏专门针对这些方法的密集化(densification)策略。为了提高模型在高频细节表示上的性能,论文提出了一种名为“Generative Densification”(生成式密集化)的新方法,旨在通过智能地增加高斯的数量来提高重建质量,同时保持模型的泛化能力。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是与本研究相关的一些关键相关研究:
3D Gaussian Splatting (3D-GS):
- 这是一种用于高质量3D场景重建和实时新视角合成的技术,通过一组可学习的高斯原语表示3D场景,并利用快速可微分的光栅化流水线。[13]
Generalized Feed-forward Gaussian Models:
- 这些模型通过从大型多视图数据集(例如Objaverse和RE10K)中学习到的3D先验知识,从单个或少数图像中生成3D高斯原语以重建3D场景或对象。[3, 5, 7, 29, 30, 37, 41, 42, 45]
Pixel-aligned Gaussian Representations:
- 每个高斯假设在每个像素的射线上,并且通过深度来确定其与射线原点的距离。这种深度要么是直接从像素级图像特征中回归出来的,要么是通过高斯存在于射线上某深度的概率来确定的。[3, 29]
Adaptive Density Control of Gaussians:
- 自适应密集化策略在填补空白区域和捕捉细节方面起着关键作用。它涉及计算不同视图之间高斯位置的视空间位置梯度的范数,只选择梯度大的高斯进行密集化。[13]
MCMC-GS:
- 提出了一种使用随机梯度Langevin Dynamics更新来优化高斯的方法,提高了对初始化的鲁棒性。[14]
AbsGS:
- 引入了同向视空间梯度作为密集化的标准,以解决大高斯的问题。[38]
Feed-forward NeRF Models:
- 包括MVSNeRF和MuRF,这些模型用于比较对象级和场景级重建任务的性能。[4, 34]
Pixel-aligned Gaussian Models:
- 包括pixelSplat, DepthSplat和MVSplat等模型,这些模型用于比较场景级重建任务的性能。[3, 35, 7]
这些相关研究构成了本论文研究的理论和实践基础,论文中提出的“Generative Densification”方法在这些现有工作的基础上,旨在通过更有效的高斯密集化策略来提高3D重建的质量,并在多个数据集上验证了其有效性。
Q: 论文如何解决这个问题?
A: 论文通过提出一种名为“Generative Densification”(GD)的新方法来解决上述问题。GD是一种高效且可泛化的方法,用于密集化由前馈模型生成的高斯(Gaussians)。以下是GD方法的关键步骤和特点:
基于梯度的高斯选择:
- 使用视空间位置梯度来识别需要额外高斯的细节区域。选择梯度最大的前K个高斯进行密集化。
特征表示上采样和高斯生成:
- GD不是直接在原始高斯参数上进行操作,而是上采样前馈模型的特征表示,并在单次前向传递中生成对应的精细高斯,利用嵌入的先验知识来增强泛化能力。
高效的点级变换器(Point-level Transformer):
- 利用空间填充曲线排序高斯,将它们重新排列成不重叠的组,并在组内应用注意力机制,从而在3D空间中直接进行高效操作。
可学习的掩码(Learnable Masking):
- 为了优化密集化过程,GD预测每个密集化层的置信度掩码,以过滤出不需要进一步密集化的高斯。
全局自适应归一化(Global Adaptive Normalization):
- 引入全局自适应归一化,以补充局部特征,通过平均选定的高斯特征并使用这些特征来缩放归一化特征。
集成到现有模型:
- 作者将GD集成到了两个现有的前馈高斯模型中:LaRa用于对象级重建,MVSplat用于场景级重建,并通过大规模数据集Gobjaverse和RE10K上的实验验证了GD的有效性。
量化和定性分析:
- 论文提供了量化结果,展示了GD方法在对象级和场景级重建任务中的性能提升,并进行了定性分析,突出了GD在捕捉细节和复杂结构方面的优势。
通过以上步骤,GD方法有效地提高了3D重建的细节捕捉能力,并在多个数据集上展示了其优越的性能和泛化能力。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验来验证他们提出的方法“Generative Densification”(GD)的性能:
实验设置:
- 实现细节:描述了训练GD模块与LaRa和MVSplat主干网络的详细设置,包括训练周期、批量大小以及训练硬件配置。
- 数据集:使用了包括Gobjaverse、Google Scanned Objects、Co3D、RE10K、ACID和DTU等多个数据集进行训练和评估。
- 基线对比:与多个现有方法进行比较,包括LaRa、LGM、GS-LRM、MVSNeRF、MuRF、pixelNeRF、GPNR、pixelSplat、DepthSplat和MVSplat等。
对象级重建:
- 定量比较:在Gobjaverse数据集上,使用峰值信噪比(PSNR)、结构相似性(SSIM)和感知损失(LPIPS)等指标,与基线模型进行定量比较。
- 定性比较:通过可视化渲染图像,展示GD模型在细节捕捉上相较于基线LaRa模型的改进。
场景级重建:
- 定量比较:在RE10K数据集上,同样使用PSNR、SSIM和LPIPS等指标,与包括MVSplat在内的多个基线模型进行定量比较。
- 定性比较:通过可视化渲染图像,展示GD模型在重建复杂室内和室外场景时的优势,特别是在细节重建和去除伪影方面。
跨数据集评估:
- 对象级模型:在Google Scanned Objects和Co3D数据集上评估GD模型的跨数据集泛化能力。
- 场景级模型:在ACID和DTU数据集上评估GD模型的跨数据集泛化能力。
粗高斯与细高斯的比较:
- 提供了一个直观的例子来比较粗高斯和细高斯在位置、不透明度和尺度上的属性,并分析了它们在重建细节时的差异。
消融研究:
- 探讨了不同数量的输入高斯和可学习掩码对模型性能的影响,通过对比不同配置下的定量结果来验证这些组件的重要性。
这些实验全面评估了GD方法在不同场景下的性能,并与多个现有技术进行了比较,以展示其在3D重建任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Generative Densification (GD) 方法在3D重建任务中取得了显著的性能提升,但仍有一些方向可以进一步探索和改进:
算法效率优化:
- 探索更高效的数据结构和算法来处理高斯的密集化过程,减少内存和计算需求,使其能够处理更大规模的3D数据。
自适应密集化策略:
- 研究更精细的自适应密集化策略,以便更智能地选择需要密集化的区域,可能通过结合多种视觉和几何特征来实现。
多模态输入:
- 将GD方法扩展到多模态输入,例如结合图像、深度图、点云等多种数据源,以提高重建的精度和鲁棒性。
更广泛的数据集测试:
- 在更多种类的3D数据集上测试GD方法,包括具有挑战性的动态场景、复杂光照和遮挡情况的数据集。
实时重建应用:
- 针对实时3D重建应用优化GD方法,例如增强现实(AR)和虚拟现实(VR),这可能需要进一步降低算法的延迟和资源消耗。
网络架构改进:
- 研究不同的神经网络架构,以更有效地学习从输入图像到高斯表示的映射,可能包括深度学习中的新发展,如注意力机制和图卷积网络。
细节捕捉能力:
- 尽管GD在高频细节捕捉方面取得了进展,但仍可以进一步研究如何更好地重建细小结构,例如通过改进上采样策略或引入新的损失函数。
跨模态泛化能力:
- 探索GD方法在跨模态泛化方面的潜力,例如从照片到手绘草图的3D重建,或者从模拟数据到真实世界的迁移学习。
模型解释性:
- 提高模型的可解释性,例如通过可视化网络中间层的特征,以更好地理解模型是如何学习和重建3D场景的。
鲁棒性测试:
- 对模型进行更多的鲁棒性测试,包括对抗性攻击、异常值处理和噪声干扰,以评估模型在现实世界应用中的稳定性。
这些方向不仅可以推动GD方法的发展,还可能为3D重建和计算机视觉领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为“Generative Densification”(GD)的新方法,旨在提高基于前馈模型的3D重建质量,特别是在高频细节表示方面。以下是论文的主要内容总结:
问题陈述:
- 现有的前馈高斯模型在稀疏视图3D重建中难以捕捉高频细节,主要是因为高斯数量有限且缺乏有效的密集化策略。
方法介绍:
- GD方法通过选择性地密集化前馈模型生成的高斯来提高细节捕捉能力,这一过程在单次前向传递中完成,利用了从大型多视图数据集中学习到的先验知识以增强泛化能力。
关键技术:
- 基于梯度的高斯选择:选择具有大视空间位置梯度的高斯进行密集化。
- 特征上采样和高斯生成:在前馈模型的特征表示上进行上采样,并生成相应的精细高斯。
- 点级变换器:使用空间填充曲线排序高斯,并通过分组注意力机制实现高效操作。
- 可学习的掩码:预测置信度掩码以过滤不需要进一步密集化的高斯。
- 全局自适应归一化:引入全局特征以补充局部上下文。
实验验证:
- 在对象级和场景级重建任务上,与现有技术相比,GD方法在多个数据集上均显示出优越的性能,特别是在高频细节的重建上。
量化和定性结果:
- 通过定量指标(如PSNR、SSIM和LPIPS)和定性分析(如图像对比和高斯属性分析),验证了GD方法的有效性。
跨数据集评估:
- GD方法在不同数据集上显示出良好的泛化能力,证明了其在多种场景下的适用性。
消融研究:
- 通过消融研究验证了梯度掩码和可学习掩码等组件的重要性。
结论:
- GD方法为生成用于高保真度、可泛化3D重建的精细高斯开辟了新的研究方向,并在对象级和场景级重建任务中建立了新的基准。
总体而言,这篇论文通过提出一种新的高斯密集化策略,有效地提高了3D重建的细节捕捉能力,并在多个数据集上验证了其有效性和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

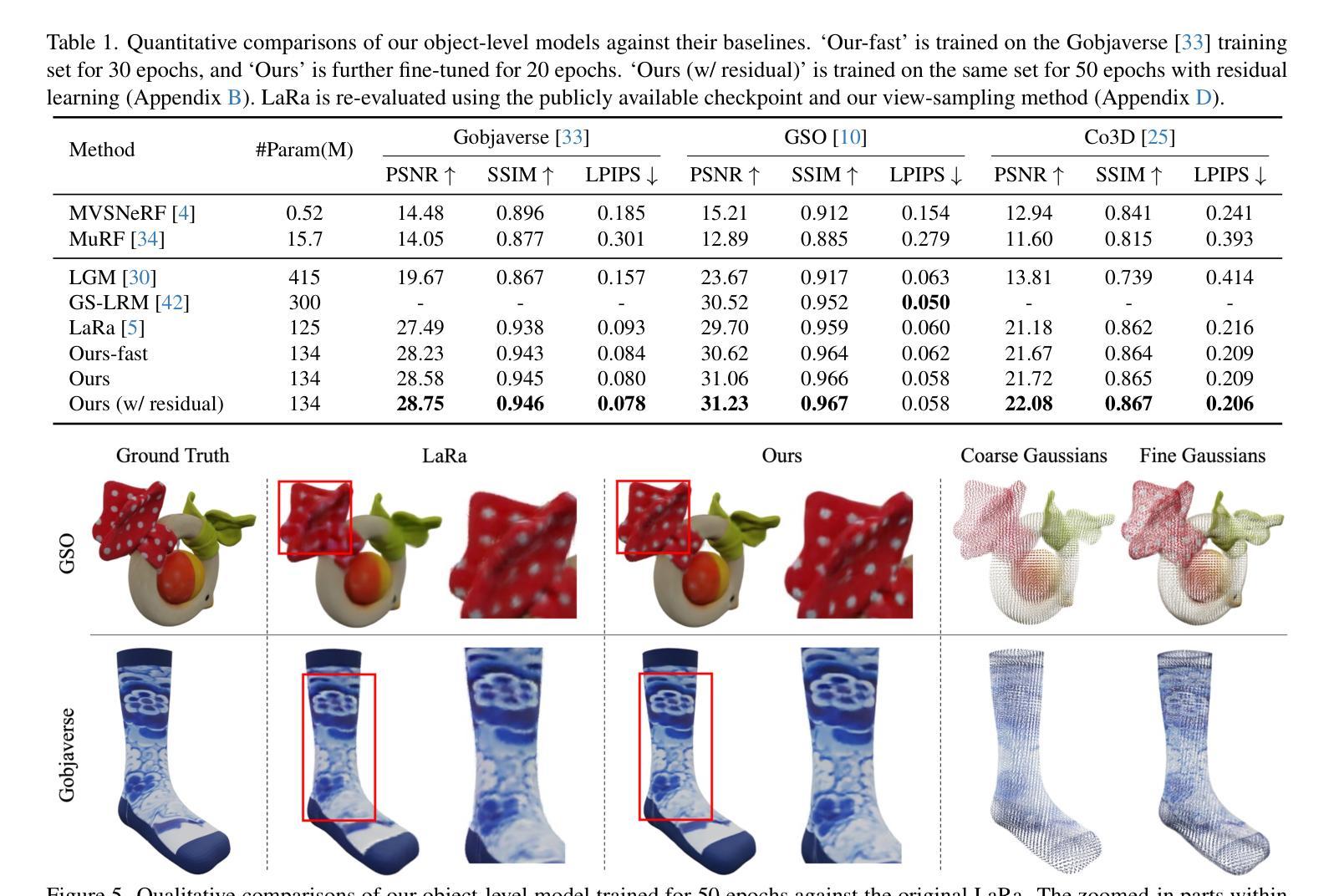
Efficient Semantic Splatting for Remote Sensing Multi-view Segmentation
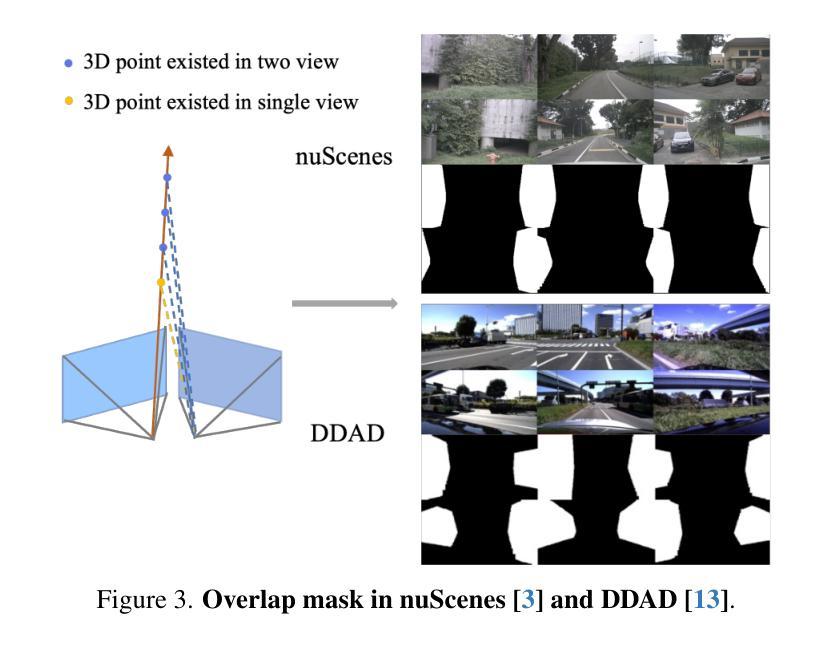
Authors:Zipeng Qi, Hao Chen, Haotian Zhang, Zhengxia Zou, Zhenwei Shi
In this paper, we propose a novel semantic splatting approach based on Gaussian Splatting to achieve efficient and low-latency. Our method projects the RGB attributes and semantic features of point clouds onto the image plane, simultaneously rendering RGB images and semantic segmentation results. Leveraging the explicit structure of point clouds and a one-time rendering strategy, our approach significantly enhances efficiency during optimization and rendering. Additionally, we employ SAM2 to generate pseudo-labels for boundary regions, which often lack sufficient supervision, and introduce two-level aggregation losses at the 2D feature map and 3D spatial levels to improve the view-consistent and spatial continuity.
本文提出了一种基于高斯映射的新型语义平铺方法,以实现高效和低延迟。我们的方法将点云的RGB属性和语义特征投影到图像平面上,同时呈现RGB图像和语义分割结果。通过利用点云的明确结构和一次性渲染策略,我们的方法在优化和渲染过程中大大提高了效率。此外,我们还使用SAM2为缺乏足够监督的边界区域生成伪标签,并在二维特征图和三维空间级别引入两级聚合损失,以提高视图一致性和空间连续性。
论文及项目相关链接
摘要
本文提出了一种基于高斯融合的新型语义融合方法,以实现高效和低延迟。该方法将点云的RGB属性和语义特征投影到图像平面上,同时呈现RGB图像和语义分割结果。通过利用点云的明确结构和一次性渲染策略,我们的方法极大地提高了优化和渲染过程中的效率。此外,我们采用SAM2为边界区域生成伪标签,这些区域通常缺乏足够的监督信息,并在二维特征图和三维空间级别引入两级聚合损失,以提高视图一致性和空间连续性。
要点总结
- 提出了一种基于高斯融合的新型语义融合方法。
- 通过将点云属性投影到图像平面,实现了RGB图像和语义分割结果的同步渲染。
- 利用点云的明确结构和一次性渲染策略,提高了优化和渲染的效率。
- 采用SAM2生成边界区域的伪标签,解决了缺乏足够监督的问题。
- 在二维特征图和三维空间级别引入两级聚合损失,提高视图一致性和空间连续性。
- 该方法注重效率和低延迟,为实时处理和快速反应应用提供了可能性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是遥感多视图图像分割中的立体场景感知问题。具体来说,这项任务涉及处理从不同视角捕获的RGB图像,并为每个视图生成一致的语义分割结果,即使在稀疏标签监督条件下也是如此。传统的基于训练的方法(如CNNs和Transformers)由于处理一般空间信息的能力有限,通常难以保持视图一致性。论文中提出的方法旨在通过优化映射空间坐标和采样点的语义特征之间的关系,重新构思图像感知任务为像素渲染任务,并利用点之间的空间关系来确保结果中的视图一致性和空间连续性。此外,论文还旨在解决现有方法在优化和渲染过程中高延迟的问题,并提出了一种基于高斯绘制的语义绘制方法,以实现高效且低延迟的处理。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
A. 基于训练的分割方法(Training-based Segmentation)
- CNN-based models:这类模型主要关注于保留详细信息和提取准确且丰富的抽象特征。许多模型基于编码器-解码器框架,例如U-Net,它通过级联卷积核提取图像特征,并通过对称的解码器重建特征图和上采样分辨率。此外,一些方法引入了空洞卷积来扩大感受野而不牺牲分辨率,并采用多尺度信息融合和特征金字塔策略来捕获更丰富的抽象特征。
- Transformer-based models:最初在自然语言处理(NLP)领域引入的Transformer架构,现在已广泛应用于图像处理领域,如分类、目标检测和分割任务。这类架构将图像块视为tokens,并通过级联层处理,其中注意力机制有效处理长距离依赖关系和探索tokens之间的关系。
B. 基于优化的分割方法(Optimization-based Segmentation)
- NeRF-like approaches:这类方法利用隐式神经网络(如NeRF)处理从多个视角捕获的单个场景。这些方法通过从相机到每个像素的射线上采样空间点来划分3D空间,并为每个采样点分配颜色和密度属性。
- Gaussian Splatting:从RGB渲染扩展到分割任务的方法,主要关注于室内场景,并依赖全视图监督以实现实例识别。
C. Segment Anything (SAM)
- SAM:这是一个基础视觉模型,旨在根据输入的视觉提示(如点或边界框)生成准确的图像分割。SAM由图像编码器、提示编码器和掩码解码器三个关键模块组成,能够生成代表可能包含目标对象的区域的掩码。
D. 坐标系统转换(Coordinate System Conversion)
- 论文还介绍了不同坐标系统之间的转换,包括像素坐标系统、图像坐标系统、相机坐标系统和世界坐标系统之间的转换关系。
这些相关研究为论文提出的新方法提供了理论基础和技术背景,使其能够在有限的标注图像条件下实现多视图分割,并提高分割的视图一致性和空间连续性。
Q: 论文如何解决这个问题?
A: 论文提出了一种高效的语义绘制方法,基于高斯绘制(Gaussian Splatting)技术来解决遥感多视图图像分割问题。具体解决方案包括以下几个关键步骤:
1. 语义绘制方法
- 扩展高斯绘制:首先将高斯绘制技术扩展到遥感图像语义分割领域,为每个采样点引入语义头和转换层,从绘制的特征图中生成分割结果。
- 连续语义特征:将离散的语义类别值转换为高维连续语义特征,分配给每个点,使其可微分,从而优化模型。
2. 利用SAM2生成伪标签
- 边界区域的挑战:针对边界区域常常缺乏足够的监督信息的问题,使用SAM2(一种基础模型)生成这些区域的伪标签,提高这些区域的分割精度。
3. 设计聚合损失
- 2D特征图和3D空间点级别的聚合损失:为了增强模型在2D特征图和3D空间点级别上的空间一致性,设计了两级聚合损失,改善了空间连续性和分割性能。
4. 优化过程
- 自监督优化:通过自监督机制优化颜色相关参数和语义相关参数,使用L1和LD-SSIM损失函数优化颜色渲染结果,使用交叉熵损失优化语义渲染结果。
- 参数细节:提供了方法的参数细节,包括优化过程的步数、点云中的最大点数、语义特征通道数等。
5. 实验验证
- 数据集和指标:使用合成数据和真实数据集进行实验,采用mIoU作为性能评估指标。
- 比较方法:与基于训练的分割方法和基于优化的分割方法进行比较,展示了提出方法在准确性和效率方面的优势。
6. 进一步工作
- 改进3D结构表示:探索更适合稀疏空间特性的3D结构表示,例如使用线性函数代替高斯函数。
- 整合隐式神经函数:计划将隐式神经函数与绘制技术整合,以估计点云中每个点的语义神经函数,进一步提高空间一致性。
综上所述,论文通过结合高斯绘制技术、SAM2生成的伪标签和聚合损失,提出了一种既高效又准确的多视图图像分割方法,特别适用于稀疏标签的遥感场景。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来验证所提出方法的有效性:
数据集和指标
- 数据集:使用的是包含六个由CARLA平台生成的合成子数据集和三个从Google Maps收集的真实子数据集的遥感多视图分割数据集。每个场景包含大约100张从不同角度拍摄的图像,其中只有2%到6%的图像在训练集中有对应的标注。
- 评估指标:使用平均交并比(mean Intersection over Union, mIoU)作为评估和比较不同方法性能的指标。
比较方法
- 与多种基于训练的分割方法进行比较,包括CNN-based的SegNet、Unet、DANet和DeepLabv3,以及基于Transformer的SETR。
- 与多种基于优化的分割方法进行比较,包括Sem-NeRF、Color-NeRF和IRT。
整体比较结果
- 定量分析:通过mIoU评估不同方法的性能,并比较了不同方法的处理时间。
- 定性分析:展示了从四个合成子数据集和两个真实子数据集中选取的六个测试视图的输入RGB图像及其对应的语义分割结果。
视图一致性比较
- 比较了Unet、IRT和提出方法在不同视图间的分割一致性。
消融研究
- 验证了SAM2生成的伪标签、2D聚合损失(L2D_a)和3D聚合损失(L3D_a)的必要性。
参数研究
- 研究了两种类型的视图(带有真实标签和带有伪标签)的比例以及L2D_a和L3D_a的权重对方法性能的影响。
这些实验全面评估了所提出方法在不同条件下的性能,并与现有技术进行了比较,从而证明了该方法在多视图遥感图像分割任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文在最后一部分提出了一些可以进一步探索的方向,具体包括:
更适当的3D结构表示:探索更适合稀疏空间特性的3D结构表示方法,例如使用线性函数代替高斯函数。这可能有助于提高模型在处理稀疏数据时的效率和准确性。
整合隐式神经函数与绘制技术:计划将隐式神经函数与高斯绘制技术整合,以估计点云中每个点的语义神经函数,这可能进一步提升空间一致性,并改善模型在处理复杂场景时的性能。
优化算法和参数调整:进一步研究和优化算法,包括参数调整和损失函数的设计,以提高模型的泛化能力和适应性。
多模态数据融合:考虑将其他类型的数据(如深度信息、红外图像等)与RGB图像结合,以提供更丰富的场景信息,并提高分割的准确性。
实时性能优化:研究如何优化模型以实现实时或近实时的分割性能,这对于许多实际应用(如自动驾驶、机器人导航等)至关重要。
更广泛的数据集测试:在更多样和更具挑战性的数据集上测试模型,以评估其鲁棒性和泛化能力。
模型压缩和加速:研究模型压缩和加速技术,以使模型更适合在资源受限的设备上部署。
无监督或自监督学习:探索无监督或自监督学习策略,以减少对大量标注数据的依赖。
跨域适应性:研究模型在不同领域(如从仿真环境到真实世界场景)的适应性和迁移学习能力。
这些方向都旨在进一步提升模型的性能,扩展其应用范围,并推动遥感图像分割技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:论文针对遥感多视图图像分割问题,旨在实现对目标场景的立体感知,即使在稀疏标签监督条件下也能产生每个视图一致的语义分割结果。
方法论:提出了一种基于高斯绘制的语义绘制方法,通过将RGB属性和语义特征投影到图像平面同时渲染RGB图像和语义分割结果,以提高优化和渲染的效率。
技术创新:
- 引入了SAM2生成边界区域的伪标签,以解决有限标签条件下边界区域的分割挑战。
- 设计了两级聚合损失,增强了2D特征图和3D空间点级别上的空间一致性,改善了分割性能。
实验验证:
- 使用合成数据和真实数据集进行广泛实验,验证了所提方法的有效性。
- 与基于训练的方法和基于优化的方法进行比较,展示了所提方法在准确性和效率方面的优势。
结果分析:
- 从定量和定性角度分析了实验结果,证明了所提方法在多视图分割任务中的优越性。
- 进行了视图一致性比较和消融研究,验证了各个组件的有效性。
未来工作:提出了进一步探索的方向,包括改进3D结构表示、整合隐式神经函数与高斯绘制技术等。
结论:论文得出结论,所提出的基于高斯绘制的语义绘制方法在稀疏标签条件下,能够实现高效且准确的多视图图像分割,为实际应用提供了一个坚实的基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


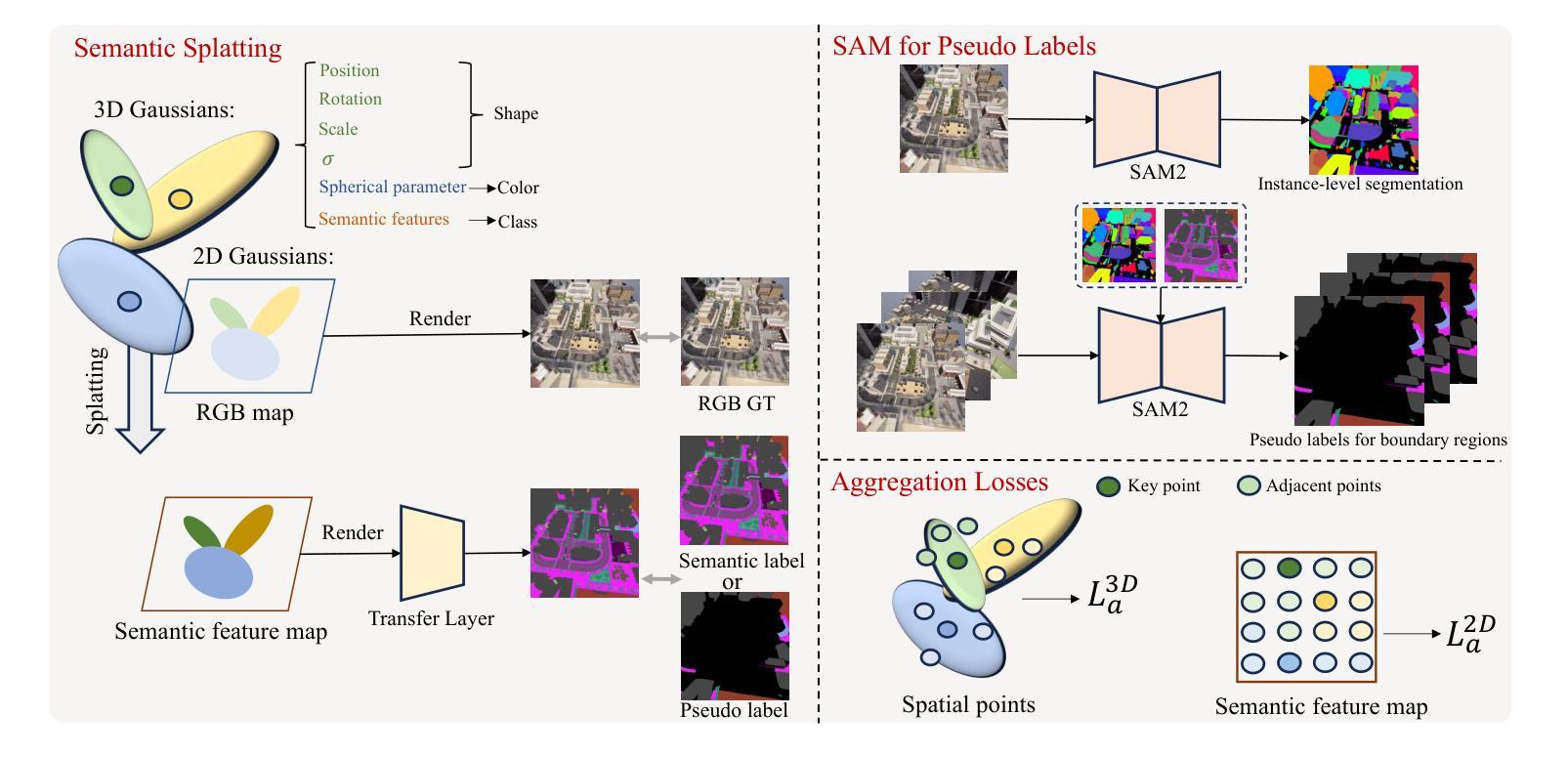
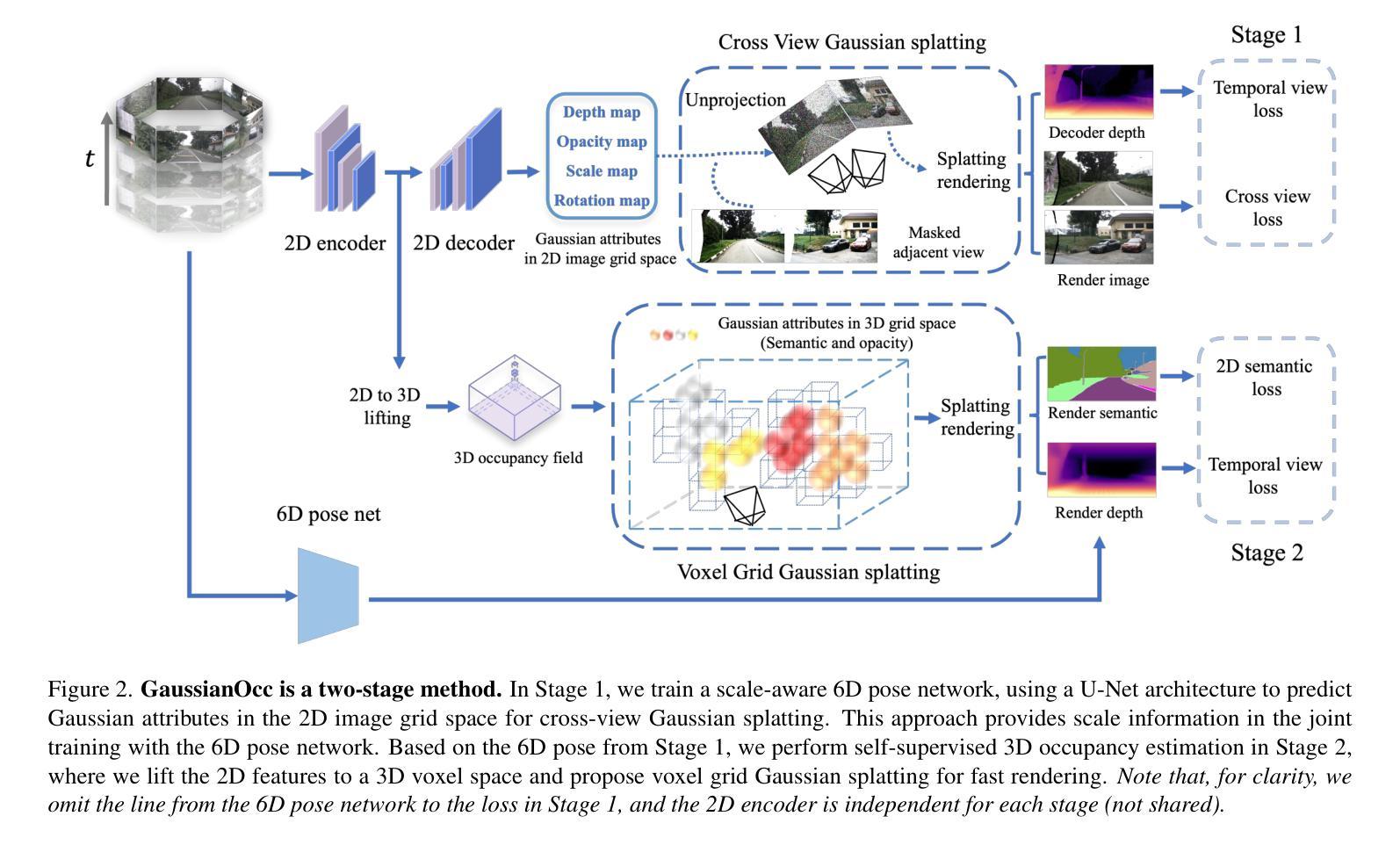
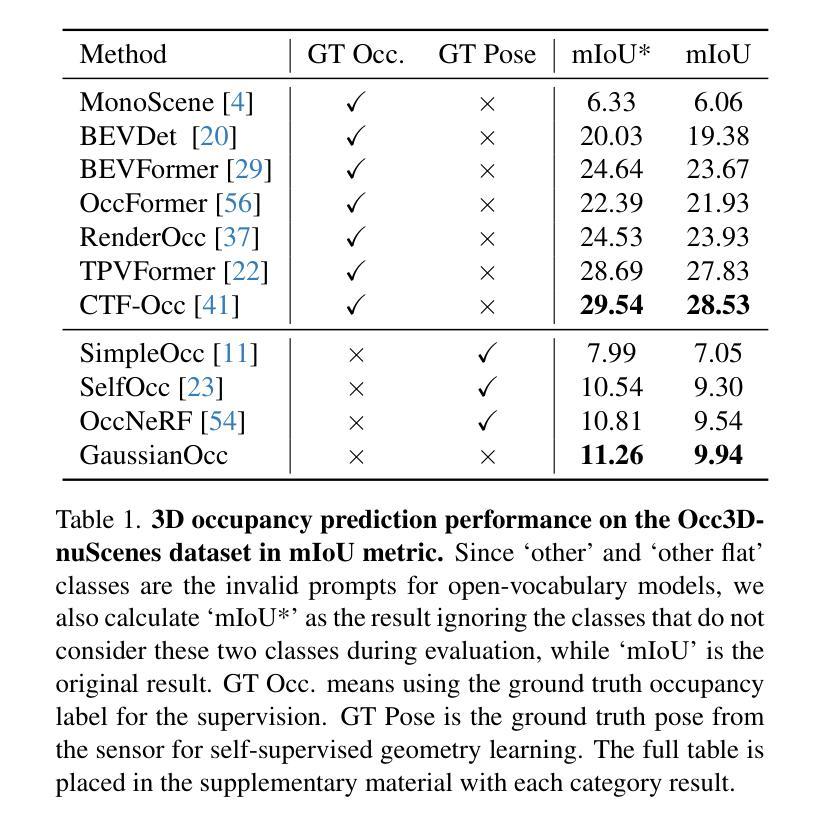
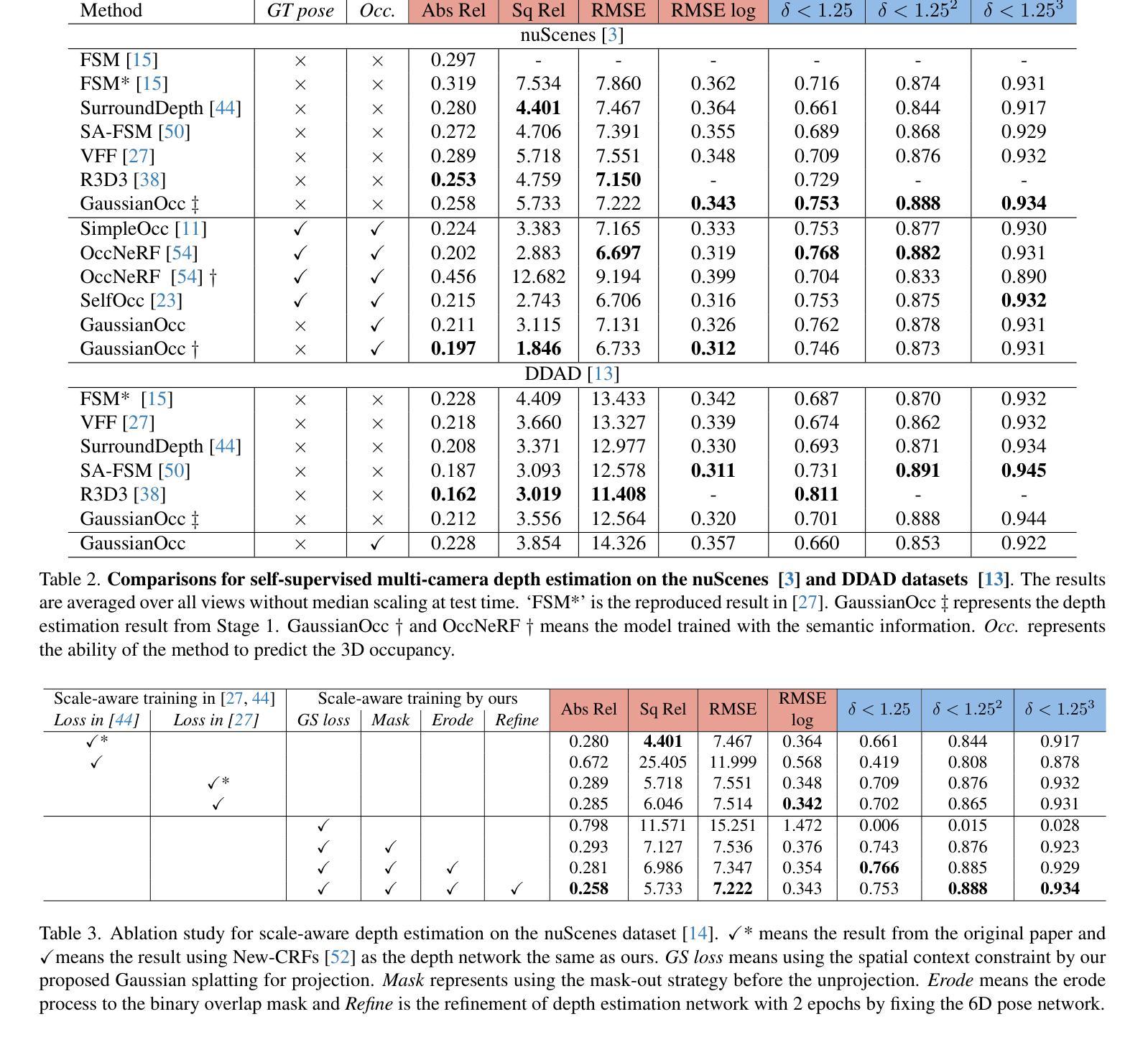
GaussianOcc: Fully Self-supervised and Efficient 3D Occupancy Estimation with Gaussian Splatting
Authors:Wanshui Gan, Fang Liu, Hongbin Xu, Ningkai Mo, Naoto Yokoya
We introduce GaussianOcc, a systematic method that investigates the two usages of Gaussian splatting for fully self-supervised and efficient 3D occupancy estimation in surround views. First, traditional methods for self-supervised 3D occupancy estimation still require ground truth 6D poses from sensors during training. To address this limitation, we propose Gaussian Splatting for Projection (GSP) module to provide accurate scale information for fully self-supervised training from adjacent view projection. Additionally, existing methods rely on volume rendering for final 3D voxel representation learning using 2D signals (depth maps, semantic maps), which is both time-consuming and less effective. We propose Gaussian Splatting from Voxel space (GSV) to leverage the fast rendering properties of Gaussian splatting. As a result, the proposed GaussianOcc method enables fully self-supervised (no ground truth pose) 3D occupancy estimation in competitive performance with low computational cost (2.7 times faster in training and 5 times faster in rendering). The relevant code is available in https://github.com/GANWANSHUI/GaussianOcc.git.
我们介绍了GaussianOcc,这是一种系统方法,探讨了高斯贴图技术在全自我监督的高效三维占用率估计中的两种应用。首先,现有的自我监督三维占用率估计的传统方法仍然需要在训练期间使用传感器的真实地面六维姿态。为了解决这一局限性,我们提出了用于投影的高斯贴图(GSP)模块,以提供准确的尺度信息,通过相邻视图投影进行全自我监督训练。此外,现有方法依赖于体积渲染进行最终的三维体素表示学习,使用二维信号(深度图、语义图),这既耗时又效率低下。我们提出了基于体素空间的高斯贴图(GSV),利用高斯贴图的快速渲染特性。因此,所提出的高斯占据方法能够在不需要真实地面姿态的情况下实现全自我监督的三维占用率估计,在具有竞争力的性能同时拥有较低的计算成本(训练速度提高了2.7倍,渲染速度提高了5倍)。相关代码可在https://github.com/GANWANSHUI/GaussianOcc.git中找到。
论文及项目相关链接
PDF Project page: https://ganwanshui.github.io/GaussianOcc/
Summary
高斯Occ方法利用高斯喷涂技术,实现了无需地面真实姿态的全自监督三维占用估计。为解决传统方法的限制,提出高斯喷涂投影(GSP)模块,提供准确的尺度信息用于从相邻视图投影进行完全自监督训练。同时,利用高斯喷涂的快速渲染特性,提出了从体素空间的高斯喷涂(GSV),以提高学习效率。该方法在无需地面真实姿态的情况下实现了高性能的三维占用估计,计算成本低,训练速度快2.7倍,渲染速度快5倍。
Key Takeaways
- 高斯Occ方法利用高斯喷涂技术实现全自监督三维占用估计。
- 提出高斯喷涂投影(GSP)模块,提供准确的尺度信息用于自监督训练。
- 现有方法依赖体积渲染进行体素表示学习,效率低下。
- 高斯Occ方法通过利用高斯喷涂的快速渲染特性,提高了学习效率。
- 该方法实现了无需地面真实姿态的高性能三维占用估计。
- 高斯Occ方法计算成本低,训练速度快,渲染速度更快。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为GaussianOcc的系统方法,旨在解决3D占据估计中的两个主要问题:
完全自监督训练的需求:传统的自监督3D占据估计方法在训练期间仍然需要传感器提供的地面真实6D姿态(ground truth 6D poses)。GaussianOcc通过提出Gaussian Splatting for Projection (GSP)模块,提供了一种从相邻视图投影中获取精确尺度信息的方法,从而实现了完全自监督训练,不再需要地面真实6D姿态。
体积渲染的效率问题:现有方法依赖于体积渲染技术,使用2D信号(如深度图、语义图)来学习最终的3D体素表示,这一过程既耗时又不够高效。GaussianOcc提出了直接从体素空间进行Gaussian Splatting的方法(Gaussian Splatting from Voxel space, GSV),利用Gaussian Splatting的快速渲染特性,提高了渲染效率。
总的来说,GaussianOcc的目标是在保持竞争性能的同时,实现完全自监督的3D占据估计,并显著降低计算成本,使得训练速度提高2.7倍,渲染速度提高5倍。
Q: 有哪些相关研究?
A: 论文中提到了以下几类相关研究:
Surround view depth estimation:
- 涉及环视设置中的深度估计问题,提供了一个以自我为中心的360度感知解决方案。
- 引用了FSM [16]、SurroundDepth [44]、VFF [28] 和 R3D3 [38] 等研究,这些工作通过不同的方法学习深度尺度,例如利用立体约束、从运动结构(Structure-from-Motion, SFM)中提取稀疏点云等。
Surround view 3D occupancy estimation:
- 环视3D占据估计近年来受到关注,基于NuScenes数据集提出了多个基准。
- 提到了SimpleOcc [12]、RenderOcc [37]、OccNeRF [54] 和 SelfOcc [24] 等方法,这些研究利用体积渲染技术进行3D监督学习,使用2D监督信号(例如语义图和深度图)。
3D Gaussian splatting:
- 3D高斯绘制已成为使用良好姿势图像建模3D和4D场景的流行方法。
- 论文中提到了GaussianFormer [25] 和 GaussianBeV [6] 两项与GaussianOcc密切相关的工作,它们关注3D占据估计和BEV预测。
这些相关研究为GaussianOcc提供了理论基础和技术背景,同时也突显了现有方法的局限性,GaussianOcc正是为了解决这些局限性而提出的。通过探索高斯绘制的新用途,GaussianOcc旨在实现完全自监督和高效的3D占据估计。
Q: 论文如何解决这个问题?
A: 论文通过提出GaussianOcc方法来解决3D占据估计中的问题,具体解决方案包括以下几个关键点:
1. Gaussian Splatting for Projection (GSP) 模块
- 目的:提供完全自监督训练所需的尺度信息,消除对地面真实6D姿态的依赖。
- 实现:利用相邻视图投影进行跨视图绘制,通过联合训练6D姿态网络,构建跨视图损失,提供尺度信息。
2. Gaussian Splatting from Voxel space (GSV) 方法
- 目的:提高渲染效率,减少体积渲染所需的密集采样操作。
- 实现:直接在3D体素空间进行高斯绘制,每个体素网格的顶点被视为一个3D高斯,优化这些高斯的属性(例如语义特征和不透明度)。
3. 两阶段训练过程
- 第一阶段:联合训练深度估计网络和6D姿态网络,使用GSP模块进行尺度感知训练。
- 第二阶段:在不优化6D姿态网络的情况下,训练3D占据网络,利用GSV进行快速渲染。
4. 损失函数设计
- 总损失函数:结合了时间视图光度损失、跨视图光度损失、2D语义损失和整个体素空间的正则化损失。
- 平衡参数:通过参数β平衡不同损失项的重要性。
5. 实验验证
- 数据集:使用nuScenes和DDAD数据集进行3D占据估计和深度估计的实验。
- 性能指标:使用mIoU(mean Intersection over Union)和RayIoU等指标评估3D占据估计的性能,并对比了不同方法的渲染效率。
通过上述解决方案,GaussianOcc能够在无需地面真实6D姿态和占据标签的情况下,实现高效的3D占据估计,同时显著提高了训练和渲染的速度。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证GaussianOcc方法的有效性:
1. 3D 占据估计性能评估
- 数据集:nuScenes 和 DDAD 数据集。
- 指标:使用 mean Intersection over Union (mIoU) 和 RayIoU 指标来评估3D占据估计的性能。
- 结果:GaussianOcc在与其他自监督方法相比时,展现出了最佳的性能,无需依赖于地面真实占据标签和6D姿态进行训练。
2. 深度估计性能评估
- 数据集:nuScenes 和 DDAD 数据集。
- 指标:使用误差指标(Abs Rel, Sq Rel, RMSE, RMSE log)和阈值准确度指标(δ < 1.25, δ < 1.252, δ < 1.253)来评估深度图的性能。
- 结果:GaussianOcc在单目深度估计的第一阶段实现了顶尖的性能,并在渲染深度的第二阶段也取得了有竞争力的结果。
3. 消融研究
- 尺度感知训练:比较了使用Gaussian Splatting进行尺度感知训练的方法与现有使用SFM损失进行训练的方法。
- 6D姿态和训练策略:比较了使用地面真实姿态和学习到的姿态对深度估计性能的影响,并评估了两阶段训练方法与使用地面真实姿态训练的模型的性能。
- 体积渲染与绘制渲染:比较了体积渲染(VR)和绘制渲染(SR)在体素空间中的性能。
- 渲染效率分析:分析了体积渲染和绘制渲染在不同分辨率下的渲染效率和训练时间。
4. 定性结果展示
- 可视化:提供了nuScenes 和 DDAD 数据集的渲染深度图和3D占据预测的可视化结果。
- 视频:提供了附加视频以展示序列的可视化结果。
这些实验全面评估了GaussianOcc在3D占据估计和深度估计任务中的性能,并与现有方法进行了比较,验证了其在自监督学习、渲染效率和泛化能力方面的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 改进2D语义图的准确性
- 论文中提到,错误预测的一些情况可能与2D语义图的不准确性有关。因此,改进2D语义图的质量,可能有助于提高3D占据估计的准确性。
2. 处理自我遮挡问题
- 在DDAD数据集中,由于自我遮挡导致的误投影问题,特别是在汽车后部摄像头的某些情况下。研究如何更好地处理自我遮挡,以提高3D占据估计的鲁棒性。
3. 扩展到3D占据流的渲染
- 论文提到计划探索将绘制渲染用于3D占据流的未来工作。这是一个值得进一步研究的方向,特别是在动态场景下的3D占据预测。
4. 探索不同的网络架构和训练策略
- 尽管GaussianOcc在当前的网络架构下表现良好,但探索不同的网络架构和训练策略可能会进一步提高性能。
5. 跨数据集的泛化能力
- 在论文中,GaussianOcc在nuScenes和DDAD数据集上进行了测试。进一步探索该方法在其他数据集上的泛化能力,特别是在不同的环境和条件下。
6. 实时性能优化
- 尽管GaussianOcc已经比传统体积渲染快很多,但在实时应用中进一步优化计算效率和降低延迟也是一个重要的研究方向。
7. 多模态数据融合
- 考虑到自动驾驶中多模态数据(如雷达、激光雷达)的重要性,研究如何将这些数据与视觉数据结合,以提高3D占据估计的准确性和鲁棒性。
8. 可解释性和安全性
- 在自动驾驶领域,模型的可解释性和安全性至关重要。研究如何提高GaussianOcc的可解释性,并确保其在安全性方面的可靠性。
这些探索点可以帮助研究者们进一步提升3D占据估计技术的性能和应用范围,特别是在自动驾驶和其他机器人视觉应用中。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了GaussianOcc,这是一个全新的完全自监督且高效的3D占据估计方法,主要贡献和内容可以总结如下:
1. 问题背景
- 针对自动驾驶领域中环视3D占据估计的需求,提出了一种无需地面真实6D姿态和占据标签的自监督学习方法。
2. 主要贡献
- 提出了Gaussian Splatting for Projection (GSP)模块,用于从相邻视图投影中获取尺度信息,实现完全自监督训练。
- 提出了Gaussian Splatting from Voxel space (GSV)方法,直接在体素空间进行高斯绘制,以提高渲染效率。
- 实现了在无需地面真实姿态和标签的情况下,进行有效的3D占据估计,同时显著降低了计算成本。
3. 方法细节
- Gaussian Splatting:利用高斯分布对3D场景进行建模,每个点表示为一个高斯分布,具有位置、颜色、旋转、尺度和不透明度等属性。
- 跨视图高斯绘制:通过相邻视图间的高斯绘制提供尺度信息,消除了对地面真实6D姿态的依赖。
- 体素网格高斯绘制:在3D体素网格中,每个顶点视为一个3D高斯,直接优化这些高斯的属性以加速渲染过程。
4. 实验验证
- 在nuScenes和DDAD数据集上进行了3D占据估计和深度估计的实验,验证了GaussianOcc在性能和效率上的优势。
- 通过消融研究和不同设置下的比较,展示了所提方法的有效性和效率。
5. 结论
- GaussianOcc作为一种完全自监督且高效的3D占据估计方法,通过精心设计的跨视图绘制渲染和体素网格高斯绘制,能够准确学习深度和6D姿态,降低计算成本,具有较强的泛化能力。
6. 未来工作
- 提出了一些潜在的改进方向,包括处理自我遮挡问题、探索3D占据流的渲染、优化实时性能等。
总体而言,这篇论文提出了一个创新的3D占据估计框架,通过自监督学习和高效的渲染技术,为自动驾驶领域的感知任务提供了一种新的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


FastLGS: Speeding up Language Embedded Gaussians with Feature Grid Mapping
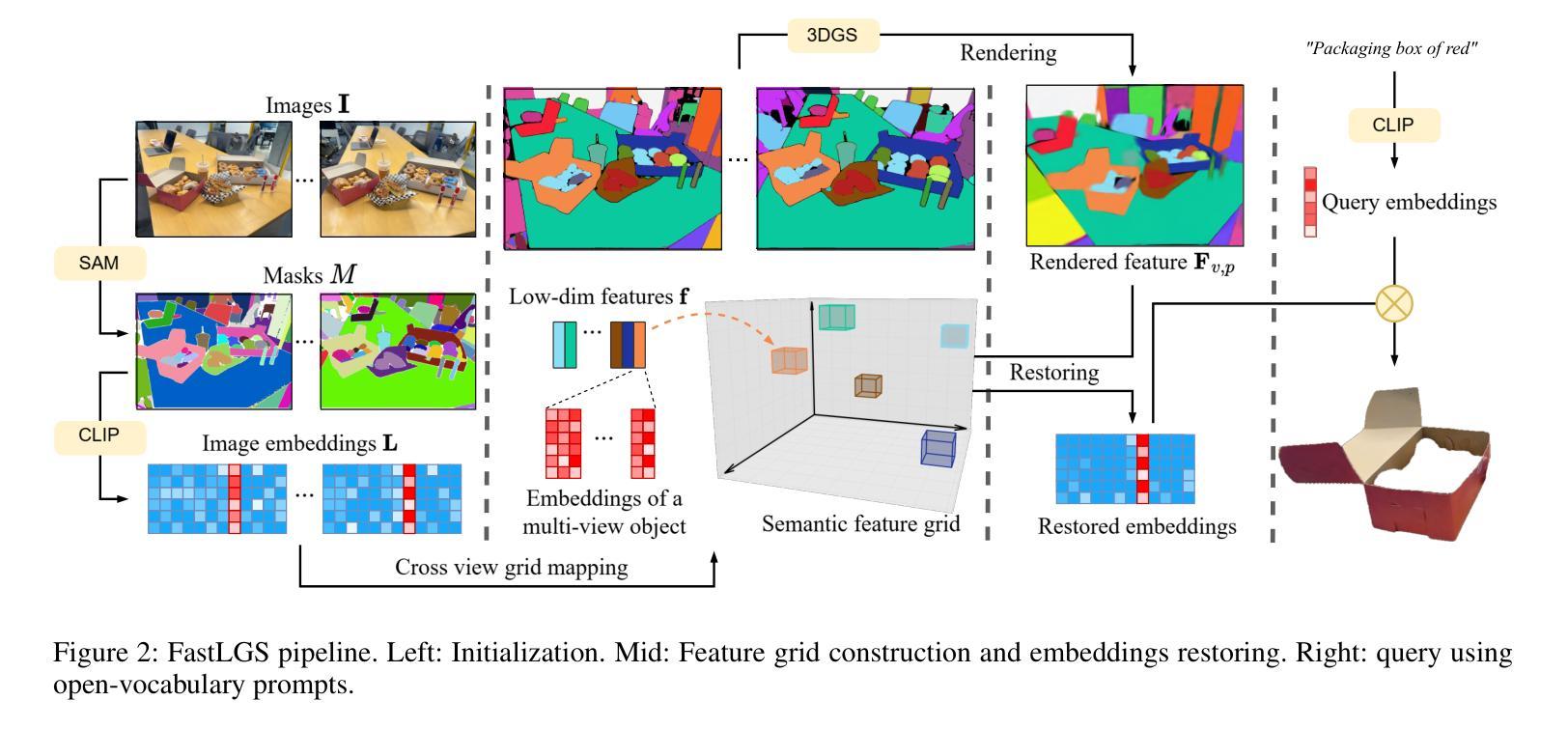
Authors:Yuzhou Ji, He Zhu, Junshu Tang, Wuyi Liu, Zhizhong Zhang, Xin Tan, Yuan Xie
The semantically interactive radiance field has always been an appealing task for its potential to facilitate user-friendly and automated real-world 3D scene understanding applications. However, it is a challenging task to achieve high quality, efficiency and zero-shot ability at the same time with semantics in radiance fields. In this work, we present FastLGS, an approach that supports real-time open-vocabulary query within 3D Gaussian Splatting (3DGS) under high resolution. We propose the semantic feature grid to save multi-view CLIP features which are extracted based on Segment Anything Model (SAM) masks, and map the grids to low dimensional features for semantic field training through 3DGS. Once trained, we can restore pixel-aligned CLIP embeddings through feature grids from rendered features for open-vocabulary queries. Comparisons with other state-of-the-art methods prove that FastLGS can achieve the first place performance concerning both speed and accuracy, where FastLGS is 98x faster than LERF and 4x faster than LangSplat. Meanwhile, experiments show that FastLGS is adaptive and compatible with many downstream tasks, such as 3D segmentation and 3D object inpainting, which can be easily applied to other 3D manipulation systems.
语义交互辐射场因其实现用户友好和自动化现实世界三维场景理解应用的潜力而一直是一个吸引人的任务。然而,在辐射场中实现语义的同时实现高质量、高效率以及零样本能力是一项具有挑战性的任务。在这项工作中,我们提出了FastLGS方法,该方法支持在高分辨率下实时进行三维高斯混合模型(3DGS)内的开放词汇查询。我们提出了语义特征网格来保存基于任何物体分割模型(SAM)掩膜提取的多视图CLIP特征,并通过三维高斯混合模型将网格映射到低维特征进行语义场训练。一旦训练完成,我们可以通过从渲染特征中提取的特征网格恢复像素对齐的CLIP嵌入,以支持开放词汇查询。与其他最先进方法的比较证明,FastLGS在速度和准确性方面均达到领先水平,FastLGS的速度比LERF快98倍,比LangSplat快4倍。同时,实验表明FastLGS具有良好的适应性和兼容性,适用于许多下游任务,如三维分割和三维物体填充,可以轻松应用于其他三维操作系统。
论文及项目相关链接
PDF This paper is accepted to AAAI 2025
Summary
本论文提出了FastLGS方法,通过在3D高斯映射(3DGS)下构建语义特征网格,实现实时开放词汇查询。该方法基于多视图CLIP特征,利用Segment Anything Model(SAM)掩膜提取特征,并将网格映射到低维特征进行语义场训练。训练后,可通过特征网格恢复像素对齐的CLIP嵌入,用于开放词汇查询。与其他先进方法相比,FastLGS在速度和准确性方面均表现优异,且适应于多种下游任务,如3D分割和3D对象补全。
Key Takeaways
- FastLGS是一种在3D高斯映射(3DGS)下实现实时开放词汇查询的方法。
- 通过构建语义特征网格,实现多视图CLIP特征的提取和利用。
- 利用Segment Anything Model(SAM)掩膜进行特征提取。
- 将网格映射到低维特征进行语义场训练。
- 训练后可通过特征网格恢复像素对齐的CLIP嵌入。
- FastLGS在速度和准确性方面表现优异,相较于其他方法有明显优势。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在保持高效率和零样本能力的同时,实现具有语义交互性的辐射场(radiance fields)的高质量3D场景理解。具体来说,论文中提到的挑战包括:
同时实现准确性、效率和开放词汇级别的语义基础:现有的方法通常只关注于区分对象的准确性,这些方法通常只分配标签或低级特征给点,而这些特征不足以支持自然的模态交互。
引入零样本语义和友好交互:使用预训练的文本-图像模型和高级特征可能是一个解决方案,但这些方法面临着平衡开放词汇能力和定位准确性的困境。
对象中心与CLIP嵌入的结合:直接构建一个高级CLIP领域不仅耗时,而且由于不同视角的同一对象可能提供接近但不同的CLIP特征,导致跨视图不一致。
查询策略:如果像LERF那样通过计算每个像素的CLIP相关性来进行查询,这种方法在计算上是不切实际的。
为了解决上述挑战,论文提出了FastLGS方法,它通过特征网格映射策略在3D高斯绘制(3DGS)中加速构建准确的3D开放词汇语义领域,以实现实时开放词汇查询和3D场景理解。
Q: 有哪些相关研究?
A: 论文中提到了多个与FastLGS相关的研究工作,这些工作主要涉及3D场景理解、语义分割、神经辐射场(NeRF)及其变种3D高斯绘制(3DGS),以及将语义信息整合到3D建模中的技术。以下是一些关键的相关研究:
NeRF和3DGS:
- NeRF (Mildenhall et al., 2021):首次引入神经辐射场来表示和渲染3D场景。
- 3D Gaussian Splatting (3DGS) (Kerbl et al., 2023):优化了点云的高斯核渲染,适用于实时应用。
2D和3D分割:
- SEgmentation TRansformer (SETR) (Zheng et al., 2021):在2D图像分割中采用Transformer架构。
- **SAM (Kirillov et al., 2023)**:使用各种提示进行分割的模型。
- Cylinder3D (Zhou et al., 2020):用于驾驶场景中LiDAR语义分割的模型。
语义3D场景:
- Semantic-NeRF (Zhi et al., 2021):将语义层引入NeRF,为丰富的场景理解铺平了道路。
- LERF (Kerr et al., 2023):支持像素对齐的CLIP嵌入查询,支持长尾开放词汇查询。
- LEGaussians (Shi et al., 2024):提出了专门的嵌入程序以实现更平滑的查询。
其他相关技术:
- DINO (Caron et al., 2021):一种自监督视觉Transformer,用于提取特征。
- Panoptic Lifting (Siddiqui et al., 2023):将2D特征提升到3D辐射场中,提供语义分割。
这些研究为FastLGS提供了理论基础和技术背景,特别是在3D场景理解和语义交互方面。FastLGS通过结合这些技术,旨在实现更快速、更准确的3D语义场构建和查询。
Q: 论文如何解决这个问题?
A: 论文通过提出FastLGS方法解决了在3D场景理解中同时实现高效率、高精度和零样本能力的挑战。以下是FastLGS方法的关键解决方案:
1. 特征网格映射策略(Semantic Feature Grid)
- 多视图CLIP特征存储:FastLGS首先提取基于SAM(Segment Anything Model)掩码的多视图CLIP特征,并将这些特征存储在一个特征网格中。
- 低维特征映射:将高维CLIP特征映射到低维空间,以便于在3DGS中进行语义场训练。这一步骤解决了直接在高维空间训练可能导致的内存需求过高和渲染效率低下的问题。
2. 跨视图网格映射(Cross View Grid Mapping)
- 关键点对应和特征相似性比较:为了在不同视图间实现对象特征的一致性,FastLGS采用了关键点对应和特征相似性比较的策略。这包括使用SIFT和KNN算法进行关键点匹配,以及基于CLIP特征和颜色分布的相似性计算。
3. 高斯训练(Training Features for Gaussians)
- 低维特征与高斯的结合:在3DGS框架下,FastLGS训练每个高斯的低维特征,以构建特征场。这种方法使得在推理阶段能够渲染像素对齐的特征,并在特征网格内恢复语义信息,以响应开放词汇查询。
4. 推理和查询(Querying Features)
- 像素对齐特征的渲染和恢复:在推理阶段,FastLGS能够根据渲染的像素对齐特征和特征网格恢复出准确的CLIP嵌入,从而生成开放词汇查询的结果。
- 相关性评分和目标掩码:通过计算图像嵌入和文本提示嵌入之间的余弦相似度,FastLGS能够为每个查询计算相关性评分,并确定目标网格,进而生成目标掩码。
5. 实验和下游任务的适应性
- 速度和准确性的比较:FastLGS在速度和准确性方面均优于现有方法,如LERF、LangSplat和LEGaussians。
- 下游任务的适应性:FastLGS不仅速度快,而且能够适应多种下游任务,如3D分割和3D对象修复,这表明其在3D操作系统中具有广泛的应用潜力。
总结来说,FastLGS通过特征网格映射策略和跨视图一致性处理,有效地在3D高斯绘制框架下实现了快速且准确的3D开放词汇语义场构建和查询,解决了现有方法在效率和准确性之间的权衡问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证FastLGS方法的性能和效果。以下是实验的主要内容:
1. 定量实验
- 数据集:在SPIn-NeRF、LERF和3D-OVS数据集上进行训练和评估。
- 与其他最先进方法的比较:
- SPIn-NeRF数据集:评估了IoU和像素准确度,并展示了每个查询的时间消耗。
- LERF数据集:报告了3D对象定位任务的定位精度。
- 3D-OVS数据集:与2D和3D的开放词汇分割方法进行了比较。
2. 下游任务测试
- 语言驱动的3D分割:将FastLGS与SAGA(Segment Any 3D Gaussians)集成,实现基于自然语言的3D分割。
- 语言驱动的对象修复:生成跨视图的目标掩码,并使用这些掩码作为多视图分割掩码,进行3D对象修复。
3. 消融研究
- 查询特征的消融:验证了语义特征网格(SFG)对于查询性能的必要性。
- 跨视图匹配的消融:评估了关键点对应(KP)和颜色分布特征(CD)对于建立跨视图网格映射准确性的影响。
4. 实验结果
- 速度和准确性:FastLGS在速度和准确性方面均优于现有方法,如LERF、LangSplat和LEGaussians。
- 下游任务的适应性:FastLGS不仅速度快,而且能够适应多种下游任务,如3D分割和3D对象修复,这表明其在3D操作系统中具有广泛的应用潜力。
5. 实验参数
- 使用了与LERF相同的OpenClip ViTB/16模型和与LangSplat相同的SAM ViT-H模型。
- 在3DGS中训练特征和场景30,000次迭代。
- 设置了激活阈值τac、对应阈值τ和θ分别为5.0、4和0.95。
- 权重α设置为0.3。
- f被归一化到(0, 255)^3。
所有实验结果均在单个TITAN RTX GPU上运行得出。这些实验全面地评估了FastLGS的性能,并证明了其在实时3D场景理解和交互中的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管FastLGS在构建准确的3D开放词汇语义场方面取得了显著进展,但仍有一些领域可以进一步探索和改进:
多粒度特征网格构建:论文中提到,FastLGS目前遵循以对象为中心的范式,这在查询对象的部分时可能会遇到挑战,例如“自行车把手”或“椅子腿”。通过构建多粒度的特征网格,可能可以更好地处理这些复杂的查询。
跨视图一致性的改进:尽管FastLGS通过跨视图网格映射策略提高了对象一致性,但在不同视角下保持掩码提取和查询结果的一致性仍然是一个挑战,需要进一步的研究。
更广泛的下游任务适应性:虽然FastLGS已经展示了与3D分割和对象修复等任务的兼容性,但探索其在其他3D操作任务(如3D场景编辑、物体放置和场景生成)中的应用也是一个有价值的研究方向。
优化和加速:虽然FastLGS在查询速度上已经取得了显著的改进,但进一步优化算法以减少训练和推理时间,特别是在更大规模的数据集和更高分辨率的场景中,也是一个重要的研究方向。
提高语义交互的质量:尽管FastLGS能够生成与自然语言查询相对应的高质量掩码,但在处理模糊或不明确的语言指令时,如何提高系统的鲁棒性和准确性仍是一个挑战。
零样本学习能力的提升:零样本学习是FastLGS的一个关键特性,研究如何进一步提升模型在没有看到过的类别上的性能,特别是在复杂和多样化的现实世界场景中,也是一个重要的研究方向。
多模态输入的支持:目前FastLGS主要依赖于视觉和语言输入,探索如何整合其他模态的信息,如声音或触觉反馈,以实现更丰富的交互和理解也是一个有趣的研究方向。
模型泛化能力的测试:在更多样化和更具挑战性的数据集上测试FastLGS的性能,以评估其泛化能力,并根据发现的问题进行模型改进。
这些方向不仅可以推动FastLGS技术的发展,还可能对3D场景理解和交互领域的研究产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
问题定义:
- 论文旨在解决在3D场景理解中同时实现高质量、高效率和零样本能力的挑战,特别是在语义交互方面。
FastLGS方法:
- 提出了FastLGS(Fast Language Embedded Gaussians with Feature Grid Mapping),一种加速构建3D开放词汇语义场的方法,基于3D高斯绘制(3DGS)。
- 通过特征网格映射策略,将多视图CLIP特征映射到低维空间,以提高效率和准确性。
关键技术:
- 语义特征网格:存储多视图语言特征,并将其映射到低维特征空间。
- 跨视图网格映射:通过关键点对应和特征相似性比较,实现对象特征在不同视图间的一致性。
- 高斯训练:训练映射后的低维特征,构建特征场,以支持快速渲染和查询。
实验验证:
- 在SPIn-NeRF、LERF和3D-OVS数据集上进行定量实验,与现有最先进方法比较,证明了FastLGS在速度和准确性上的优势。
- 展示了FastLGS在下游任务(如3D分割和对象修复)中的应用潜力。
消融研究:
- 通过消融实验验证了特征网格和跨视图匹配策略的有效性。
结论与未来工作:
- FastLGS通过特征网格映射和多视图CLIP嵌入恢复,实现了快速、准确的3D语义场构建和查询。
- 提出了未来可能的研究方向,包括多粒度特征网格构建和跨视图一致性改进。
总体而言,这篇论文提出了一种新的方法来加速3D场景理解中的语义交互,通过创新的特征网格映射策略和跨视图一致性处理,在效率和准确性上都取得了显著的改进,并展示了其在多个下游任务中的应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



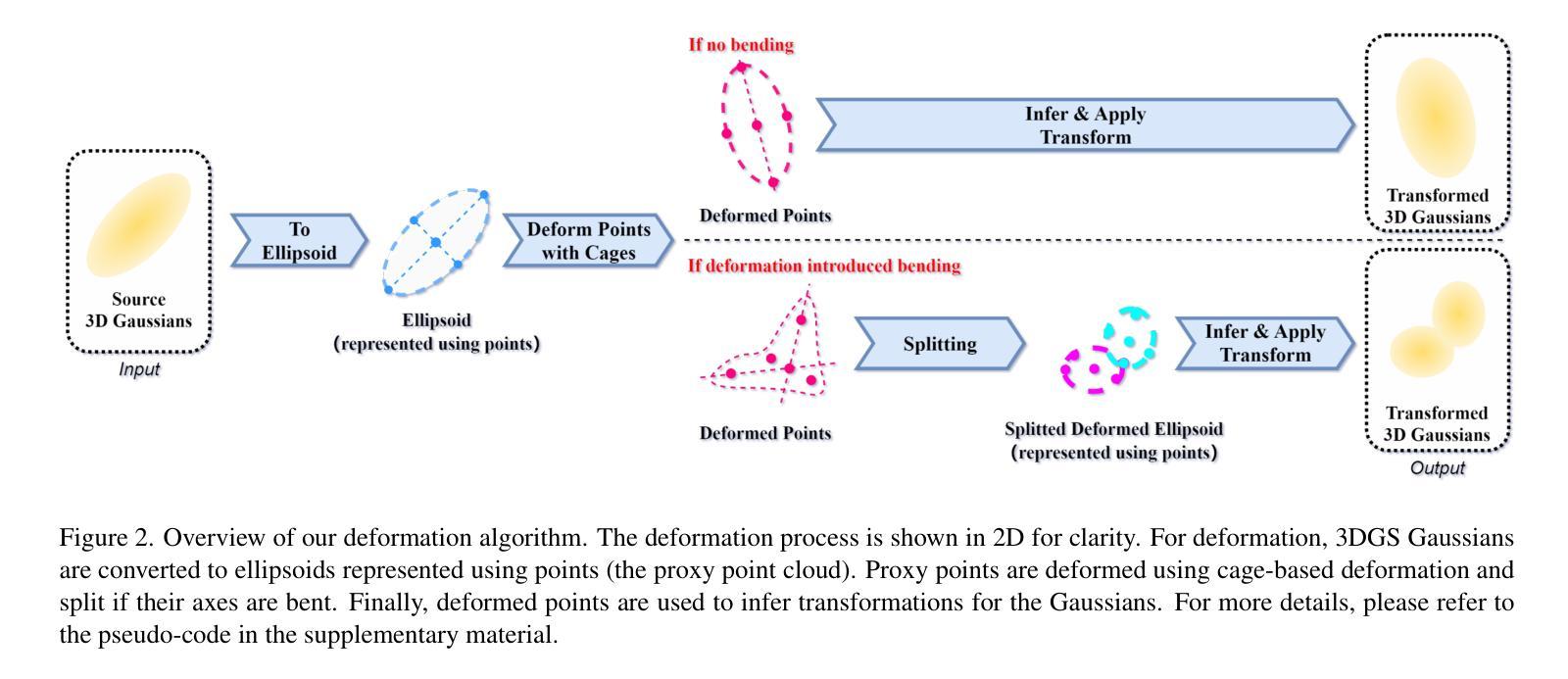
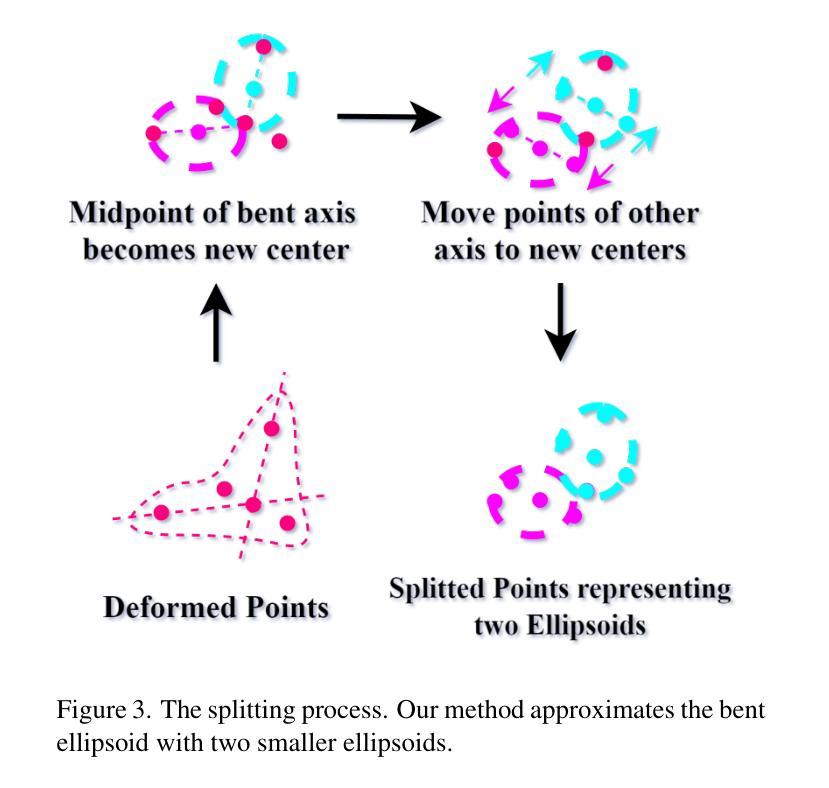
GSDeformer: Direct, Real-time and Extensible Cage-based Deformation for 3D Gaussian Splatting
Authors:Jiajun Huang, Shuolin Xu, Hongchuan Yu, Jian Jun Zhang, Hammadi Nait Charif
We present GSDeformer, a method that achieves cage-based deformation on 3D Gaussian Splatting (3DGS). Our method bridges cage-based deformation and 3DGS using a proxy point cloud representation. The point cloud is created from 3DGS, and deformations on the point cloud translate to transformations on the 3D Gaussians that comprise 3DGS. To handle potential bending from deformation, we employ a splitting process to approximate it. Our method does not extend or modify the core architecture of 3DGS; thus, it can work with any existing trained vanilla 3DGS as well as its variants. We also automated cage construction from 3DGS for convenience. Experiments show that GSDeformer produces superior deformation results than current methods, is robust under extreme deformations, does not require retraining for editing, runs in real-time(60FPS), and can extend to other 3DGS variants.
我们提出了GSDeformer方法,该方法实现了基于笼子的变形在三维高斯拼贴(3DGS)上的应用。我们的方法通过代理点云表示将基于笼子的变形和3DGS联系起来。点云是通过三维高斯拼贴创建的,点云上的变形会转化为三维高斯上的变换,这些高斯构成三维高斯拼贴。为了处理变形可能产生的弯曲,我们采用分裂过程进行近似处理。我们的方法不会扩展或修改三维高斯拼贴的核心架构,因此它可以与现有的任何普通三维高斯拼贴及其变体一起使用。我们还为了便利自动从三维高斯拼贴构建笼子。实验表明,GSDeformer产生的变形结果优于当前方法,在极端变形下表现稳健,无需针对编辑进行再训练,实时运行(每秒运行帧数达到60帧),并可扩展到其他三维高斯拼贴变体。
论文及项目相关链接
PDF Project Page: https://jhuangbu.github.io/gsdeformer, Video: https://www.youtube.com/watch?v=-ecrj48-MqM
Summary
GSDeformer方法实现了基于笼子的变形在三维高斯展布(3DGS)上的应用。该方法通过代理点云表示将笼状变形与3DGS相结合。点云由3DGS生成,对点云的变形会转化为对构成3DGS的三维高斯值的变换。为了处理潜在的变形弯曲,采用分裂过程进行近似处理。该方法不扩展或修改3DGS的核心架构,因此可与任何现有的训练好的普通3DGS及其变体一起使用。实验表明,GSDeformer产生的变形结果优于当前方法,极端变形下表现稳健,无需重新训练即可进行编辑,可实时运行(每秒60帧),并且可以扩展到其他3DGS变体。
Key Takeaways
- GSDeformer实现了基于笼子的变形在三维高斯展布(3DGS)上的运用。
- 通过代理点云表示将笼状变形与3DGS结合。
- 点云由3DGS生成,变形可转化为对三维高斯值的变换。
- 采用分裂过程处理潜在的变形弯曲。
- GSDeformer不修改3DGS的核心架构,可与其他变体兼容。
- 实验显示GSDeformer结果优于当前方法,表现稳健,可实时运行。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种名为GSDeformer的新方法,旨在解决3D Gaussian Splatting(3DGS)表示的自由形态变形问题。具体来说,它试图解决以下几个关键问题:
现有方法的局限性:现有的3DGS变形方法,如基于体积渲染的方法(例如DeformingNeRF和NeRFShop),并不适用于3DGS,因为3DGS使用的是光栅化渲染,而不是体积渲染。
对3DGS架构的修改:一些能够实现3DGS变形的工作(如GaMeS、Gaussian Frosting或SC-GS)需要对3DGS表示进行非平凡的扩展或需要额外的数据,这使得编辑现有的训练好的3DGS或将其与其他3DGS相关工作集成变得困难。
用户对场景的自由操作需求:为了使3DGS表示能够用于实际的下游应用,如动画、虚拟现实或增强现实,用户需要能够出于隐私或艺术目的轻松自由地操纵捕获的场景。
集成与兼容性:现有的变形方法往往需要对3DGS的底层架构进行修改,这限制了它们与其他方法的集成能力。
为了克服这些挑战,论文提出了GSDeformer,这是一种无需对3DGS架构进行任何修改即可实现自由变形的方法。它通过将3DGS转换为代理点云表示,然后使用基于笼子的变形(Cage-based Deformation, CBD)来推断应用于3D高斯的变换,从而实现了这一点。此外,论文还提出了一种自动笼子构建算法,以最小化手动工作量。这种方法不仅易于使用,而且与现有方法相比,在质量上具有可比性,同时更直接、更易于与其他3DGS的并行发展集成。
Q: 有哪些相关研究?
A: 论文中提到了多个与3D Gaussian Splatting (3DGS) 场景编辑和变形相关的研究工作。以下是一些主要的相关研究:
Neural Radiance Fields (NeRF) 和其变形方法,如:
- DeformingNeRF [Xu and Harada 2022]: 在Neural Radiance Fields上实现变形的方法。
- NeRFShop [Jambon et al. 2023]: 允许对NeRF进行交互式编辑的方法。
3DGS的变形和编辑方法,包括:
- SuGaR [Guédon and Lepetit 2023]: 提出了一种从3DGS生成网格的方法,并引入了一系列训练正则化以提高从3DGS提取的网格的质量。
- GaussianFrosting [Guédon and Lepetit 2024]: 在SuGaR的基础上提出了一种更灵活的将分布绑定到网格上的方法。
- GaMeS [Waczyńska et al. 2024]: 基于提供的初始网格构建其表示,并基于此进行进一步训练。
- SC-GS [Huang et al. 2023]: 提出了通过从视频中学习控制点的运动来变形高斯分布的方法。
基于控制点的变形方法,例如SC-GS,它通过学习视频中的运动来转移控制点的权重。
基于物理模拟的3DGS操作方法,如:
- PhysGaussian [Xie et al. 2023]: 结合了3DGS和Material Point Method动力学,创建了在触摸或推动下的合理物体变形。
- Gaussian Splashing [Feng et al. 2024]: 结合了3DGS和基于位置的动力学(PBD)进行模拟。
- Spring-Gaus [Zhong et al. 2024]: 将弹簧-质量模型结合到动态3DGS的架构中,并从视频中学习物理属性。
其他编辑3DGS场景的方法,包括文本提示驱动的高级编辑方法,如:
- GaussianEditor [Chen et al. 2023]
- VcEdit [Wang et al. 2024]
- GaussCtrl [Wu et al. 2024]
这些研究工作为3DGS的编辑和变形提供了不同的方法和技术,但它们通常需要对3DGS架构进行修改、需要额外的数据或有其他限制。相比之下,GSDeformer提出了一种无需修改3DGS架构即可实现自由变形的方法,这使得它能够更容易地集成到现有的3DGS表示中,并与其他方法协同工作。
Q: 论文如何解决这个问题?
A: 论文通过提出GSDeformer方法解决了3D Gaussian Splatting (3DGS) 的自由形态变形问题。具体解决步骤如下:
代理点云表示:将3DGS转换成一种新颖的代理点云表示形式。这种表示允许对3D高斯分布进行变形,从而推断出应用于3DGS的变换。
基于笼子的变形(Cage-based Deformation, CBD):扩展了传统的网格变形方法,将其应用于3DGS。通过变形一个粗略的网格(称为“笼子”),可以根据笼子的变形来推断内部精细网格或点的变形。
自动笼子构建算法:提出了一种自动化算法来构建用于变形3DGS的笼子,以减少手动工作量。
不修改3DGS的底层架构:GSDeformer不修改3DGS的底层架构,这意味着任何现有的、训练有素的3DGS模型都可以通过GSDeformer轻松编辑。
直接变形方法:通过直接对3DGS的变换进行操作,GSDeformer能够对任何训练好的标准3DGS模型进行变形,无需广泛的重新训练或转换。
实验验证:通过在合成和真实世界场景上进行测试,展示了GSDeformer的编辑能力。结果表明,自动构建的笼子生成了易于使用的代理网格,而变形算法则实现了与现有方法相当或更优的3DGS变形和操纵质量。
比较分析:与其他需要3DGS架构修改的方法相比,GSDeformer展示了在易用性和结果质量方面的竞争力,同时具有更简单、要求更少的优势。
通过这些方法,GSDeformer实现了对3DGS的高质量、直观且易于集成的自由形态变形,克服了现有技术的局限性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来展示GSDeformer方法的能力和验证其效果。以下是实验的主要内容:
场景编辑:作者在合成数据集(Synthetic NeRF)和真实世界数据集(MipNeRF360)上展示了算法的变形能力。通过自动构建的笼子,然后手动变形这些笼子,展示了对场景中对象的高质量变形、简单变换和放大。
变形算法评估:为了评估变形质量,作者在合成NeRF和合成NSVF数据集上进行了进一步实验。使用DeformingNeRF、SuGaR和GaMeS的源和目标笼子作为标准化比较,展示了GSDeformer与这些方法在变形质量上的可比性。
笼子构建算法:作者展示了自动笼子构建算法在合成NeRF数据集上的应用效果,并将其生成的笼子与GaMeS和SuGaR生成的代理网格进行了比较,证明了GSDeformer生成的笼子更简单、更易于操作。
变形算法比较:通过与DeformingNeRF、SuGaR和GaMeS等方法的比较,展示了GSDeformer在保持3DGS架构不变、无需视频数据训练的情况下,能够实现与这些方法相当的变形质量。
消融研究:为了证明GSDeformer方法中代理点云和仿射变换技巧的必要性,作者将其与仅使用基于笼子的变形来变换高斯均值的简单基线方法进行了比较。实验结果表明,简单基线方法会导致显著的变形伪影,而GSDeformer通过推断完整的仿射变换并将其应用于高斯分布,能够处理旋转并避免这些问题。
渲染视图比较:提供了原始场景和变形场景的渲染视图,并在底部右下角提供了放大的视图,以展示GSDeformer与DeformingNeRF、SuGaR和GaMeS等方法相比,在不修改3DGS架构的情况下,能够产生相当质量的结果。
这些实验验证了GSDeformer在3DGS场景表示的自由变形方面的有效性和优越性,展示了其在不同场景和条件下的适用性和稳定性。
Q: 有什么可以进一步探索的点?
A: 尽管GSDeformer在3DGS的自由形态变形方面取得了显著成果,但仍有一些潜在的研究方向和改进点可以进一步探索:
实时变形性能:论文中提到当前方法还无法实现实时变形。研究如何优化算法以实现更快的变形处理速度,使其适用于需要实时反馈的应用场景,如虚拟现实或增强现实。
颜色参数变换:论文中未详细讨论颜色参数(如球谐函数)的变换。研究如何扩展GSDeformer以支持颜色和材质的变形,以实现更丰富的视觉效果。
用户界面和交互:开发更直观的用户界面和交互方式,使用户能够更容易地操作笼子和控制变形过程,提高非专业用户的易用性。
自动化和智能化:研究如何通过机器学习技术自动化变形过程,例如,通过分析用户的编辑意图或场景内容自动生成笼子或推荐变形。
多模态数据融合:探索将3DGS与其他类型的数据(如视频、音频或文本描述)结合的方法,以实现更丰富的场景表示和编辑能力。
物理和行为模拟:将物理模拟和行为动画集成到GSDeformer中,以实现更逼真和动态的场景变形和交互。
大规模场景和数据集:研究如何在大规模场景和大型数据集上应用GSDeformer,以及如何处理和优化大规模数据的效率和存储问题。
多用户协作和编辑:开发支持多用户同时编辑和协作的系统,以便于团队工作和协作创作。
跨平台和设备兼容性:研究如何使GSDeformer兼容不同的平台和设备,包括移动设备、桌面计算机和专业图形工作站。
开源和社区贡献:考虑将GSDeformer开源,鼓励社区贡献和协作,以促进技术的快速发展和广泛应用。
这些探索点可以帮助推动GSDeformer及相关技术的发展,拓宽其应用范围,并为未来的研究和开发提供新的方向。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了GSDeformer,一种用于3D Gaussian Splatting(3DGS)的直接基于笼子的变形方法。以下是论文的主要内容总结:
问题背景:3DGS是一种高质量的场景表示技术,但现有的方法不支持对3DGS进行自由形态的变形,这限制了它在动画、虚拟现实和增强现实等下游应用的实用性。
GSDeformer方法:提出了一种新的方法,允许在不改变3DGS底层架构的情况下,对3DGS进行自由形态的变形。该方法通过将3DGS转换为代理点云表示,然后使用基于笼子的变形(Cage-based Deformation, CBD)来实现。
自动笼子构建算法:提出了一种自动化算法来构建用于变形3DGS的笼子,减少了手动工作量,并使得变形过程更加直观和易于操作。
实验结果:通过在合成和真实世界场景上的实验,展示了GSDeformer在各种变形任务中的高质量结果,包括扭曲、移动、扩展和提升等操作。
比较分析:与现有方法(如DeformingNeRF、SuGaR、GaMeS等)进行了比较,证明了GSDeformer在易用性、质量和集成性方面的优势。
技术细节:详细介绍了GSDeformer的算法流程,包括代理点云的创建、基于笼子的变形、仿射变换的推断以及变形的施加。
消融研究:通过消融实验,展示了代理点云和仿射变换在避免变形伪影中的重要性。
未来工作:讨论了未来可能的研究方向,包括实现实时变形、扩展颜色参数变换、改进用户界面和交互、自动化和智能化变形等。
总的来说,这篇论文提出了一种创新的方法,使得3DGS表示的场景可以被高效、直观地编辑和变形,为3D场景表示和编辑领域带来了有价值的贡献。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图