⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Authors:Haonan Qiu, Shiwei Zhang, Yujie Wei, Ruihang Chu, Hangjie Yuan, Xiang Wang, Yingya Zhang, Ziwei Liu
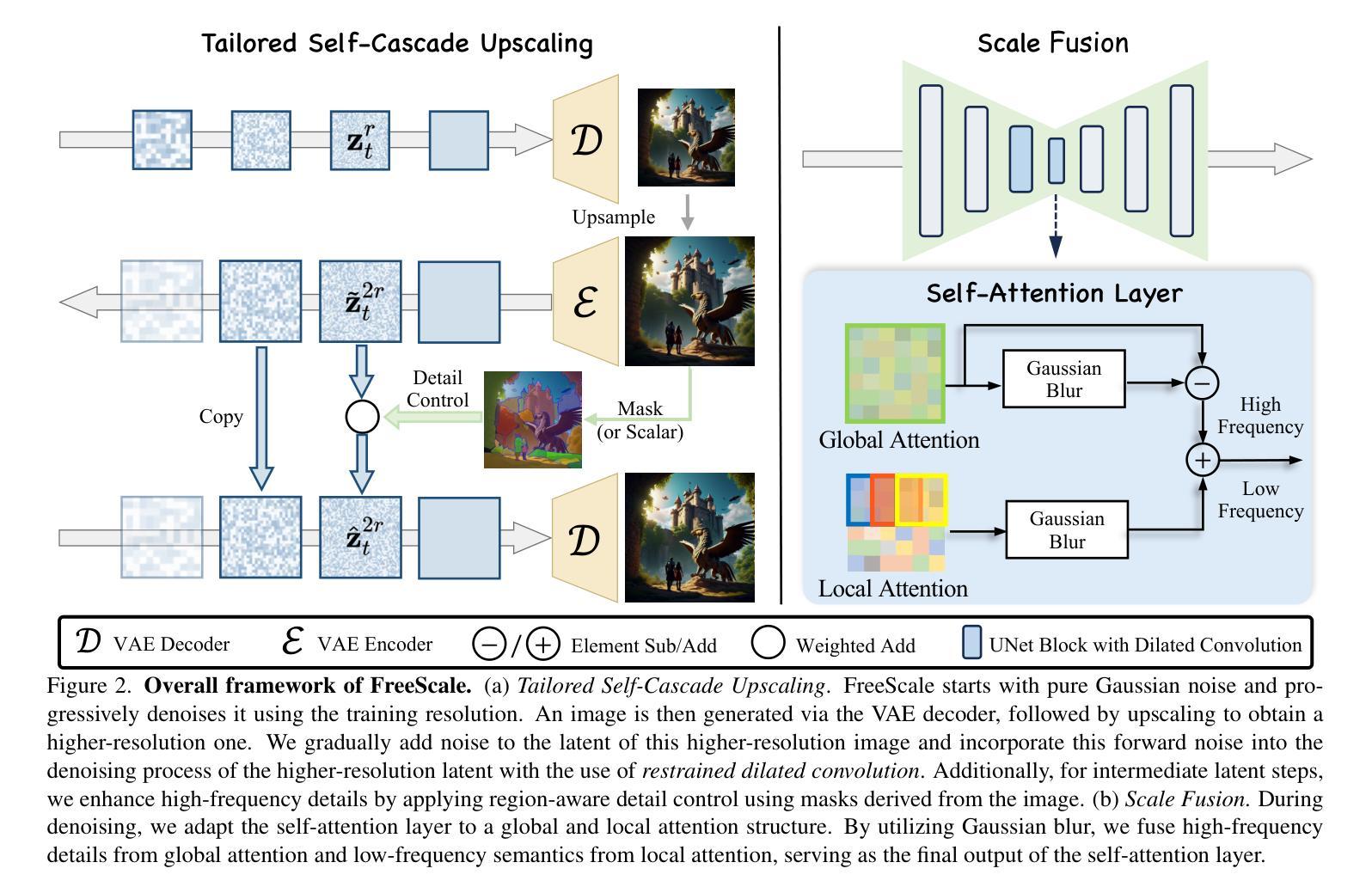
Visual diffusion models achieve remarkable progress, yet they are typically trained at limited resolutions due to the lack of high-resolution data and constrained computation resources, hampering their ability to generate high-fidelity images or videos at higher resolutions. Recent efforts have explored tuning-free strategies to exhibit the untapped potential higher-resolution visual generation of pre-trained models. However, these methods are still prone to producing low-quality visual content with repetitive patterns. The key obstacle lies in the inevitable increase in high-frequency information when the model generates visual content exceeding its training resolution, leading to undesirable repetitive patterns deriving from the accumulated errors. To tackle this challenge, we propose FreeScale, a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion. Specifically, FreeScale processes information from different receptive scales and then fuses it by extracting desired frequency components. Extensive experiments validate the superiority of our paradigm in extending the capabilities of higher-resolution visual generation for both image and video models. Notably, compared with the previous best-performing method, FreeScale unlocks the generation of 8k-resolution images for the first time.
视觉扩散模型取得了显著的进步,但由于缺乏高分辨率数据和有限的计算资源,它们通常只在有限的分辨率上进行训练,这限制了它们在更高分辨率下生成高保真图像或视频的能力。最近的研究已经探索了无微调策略来展示预训练模型尚未开发的潜在高分辨率视觉生成能力。然而,这些方法仍然容易产生具有重复模式的高质量视觉内容。主要障碍在于模型生成超过其训练分辨率的视觉内容时,高频信息不可避免的增多,导致来自累积误差的不理想的重复模式。为了应对这一挑战,我们提出了FreeScale,这是一种无需调整的无微调推断范式,通过尺度融合实现高分辨率视觉生成。具体来说,FreeScale处理来自不同感受尺度的信息,然后通过提取所需的频率成分将其融合。大量实验验证了我们的范式在图像和视频模型的高分辨率视觉生成能力方面的优越性。值得注意的是,与以前表现最好的方法相比,FreeScale首次实现了8k分辨率图像的生成。
论文及项目相关链接
PDF Project Page: http://haonanqiu.com/projects/FreeScale.html
Summary
视觉扩散模型取得显著进展,但受限于高分辨率数据的缺乏和计算资源的限制,通常只在低分辨率下进行训练,制约了其在更高分辨率下生成高保真图像或视频的能力。最近的研究尝试采用无需调整的策略来展示预训练模型在更高分辨率视觉生成方面的潜力,但这些方法仍容易产生带有重复模式的低质量视觉内容。关键障碍在于模型生成超过其训练分辨率的视觉内容时,高频信息的不可避免增加,导致源于累积误差的不理想重复模式。为解决这一挑战,我们提出FreeScale,一种无需调整的推理范式,通过尺度融合实现更高分辨率的视觉生成。它通过从不同接收尺度处理信息并融合,提取所需频率成分。大量实验验证了我们的方法在图像和视频模型的高分辨率视觉生成方面的优越性。特别是,与以前性能最佳的方法相比,FreeScale首次实现了8k分辨率图像的生成。
Key Takeaways
- 视觉扩散模型受限于高分辨率数据的缺乏和计算资源的限制,通常只在低分辨率环境下进行训练。
- 最近的策略尝试通过预训练模型进行更高分辨率的视觉生成,但易产生低质量和重复模式的视觉内容。
- 面临的关键挑战是模型在生成超过训练分辨率的视觉内容时,高频信息的增加导致出现重复模式。
- 提出了一种名为FreeScale的无需调整的推理范式,通过尺度融合来提高视觉生成的质量。
- FreeScale能够处理并融合不同尺度的信息,从而提取所需的频率成分。
- 实验证明FreeScale方法在图像和视频模型的高分辨率视觉生成方面具有优越性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是视觉扩散模型在生成更高分辨率图像和视频时面临的挑战。具体来说,这些挑战包括:
有限的训练数据和计算资源限制:由于缺乏高分辨率数据和受限的计算资源,当前的视觉扩散模型通常仅在有限的分辨率上进行训练,这限制了它们在更高分辨率下生成高保真图像或视频的能力。
重复模式和低质量视觉内容:尽管已有研究探索了无需微调(tuning-free)的策略来发挥预训练模型在更高分辨率视觉生成上的潜力,但这些方法仍然容易产生带有重复模式的低质量视觉内容。
高频信息增加导致的问题:当模型生成超出其训练分辨率的视觉内容时,不可避免地会增加高频信息,导致累积误差并产生不期望的重复模式。
为了应对这些挑战,论文提出了FreeScale,这是一个无需微调的推理范式,通过尺度融合(scale fusion)来实现更高分辨率的视觉生成。FreeScale通过处理不同感受野尺度的信息,然后通过提取所需的频率成分来融合它们,从而在保持结构整体合理性和对象局部质量的同时,扩展了图像和视频模型在更高分辨率视觉生成上的能力。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与FreeScale相关的研究工作:
扩散模型在视觉生成中的应用:
- DDPM [20] 和 Guided Diffusion [12]:展示了扩散过程能够产生出色的图像质量。
- LDM [39]:引入了潜在空间扩散,显著降低了计算负担和训练需求。
- SDXL [36]:基于LDM进一步推进了高分辨率图像合成。
- Pixart-alpha [11]:采用了基于变换器的架构,实现了高保真度和成本效益的图像生成。
- VDM [21] 和 LVDM [17]:在视频生成领域应用扩散模型,并提出了分层潜在视频扩散框架。
- Align-Your-Latents [6] 和 AnimateDiff [15]:引入时间变换器到现有的文本到图像(T2I)模型中,以实现文本到视频(T2V)的能力。
高分辨率视觉生成:
- 一类方法是使用高分辨率数据和大型模型进行训练/微调,如 [14, 22, 33, 38, 43, 51]。
- 另一类是无需额外数据需求的无需微调方法,如 [7, 13, 16, 18, 25, 27, 30, 31]。
- ScaleCrafter [18]:提出使用扩张卷积层来扩大卷积感受野,解决对象重复问题。
- MultiDiffusion [2] 和 DemoFusion [13]:通过融合局部和全局补丁来减少局部重复。
- FouriScale [23]:通过移除潜在的高频信号来消除重复,但可能导致颜色和纹理不自然。
其他相关技术:
- VideoComposer [46]:提供了可控的文本到视频(T2V)生成方法。
- VideoCrafter [9, 10] 和 SVD [5]:扩展了潜在视频扩散模型以处理大规模数据集。
- Lumiere [3]:提出了在空间时间U-Net中进行时间下采样以提高效率。
- CogVideoX [48] 和 Pyramid Flow [26]:展示了视频生成中的DiT结构的优越性能。
这些研究构成了FreeScale方法的理论和技术支持,FreeScale在此基础上进一步提出了无需微调的尺度融合策略,以实现更高分辨率的视觉生成。
Q: 论文如何解决这个问题?
A: 论文提出了FreeScale,一个无需微调的推理范式,通过以下方法解决高分辨率视觉生成中的问题:
1. 定制的自级联上采样(Tailored Self-Cascade Upscaling)
FreeScale使用自级联上采样框架逐步增加生成结果的分辨率,从低分辨率的合理视觉结构开始,然后保持这个结构生成更高分辨率的结果。具体来说,这个过程通过以下公式实现:
$$
\tilde{z}_r \sim \mathcal{N}\left(\sqrt{\bar{\alpha}_K \phi(z_r^0)}, \sqrt{1 - \bar{\alpha}_K} I\right)
$$
其中,$\tilde{z}$ 表示噪声中间潜在表示,$r$ 是分辨率级别,$\phi$ 是上采样操作。
2. 限制的扩张卷积(Restrained Dilated Convolution)
为了解决对象重复问题,FreeScale使用扩张卷积来增加卷积的感受野,但与之前工作不同的是,只在UNet的下块和中块中应用扩张卷积,并在最后几个时间步使用原始卷积。
3. 尺度融合(Scale Fusion)
尺度融合通过从不同感受野尺度处理信息并提取所需的频率成分来融合信息,平衡了局部和全局细节的增强。具体来说,尺度融合利用全局自注意力特征提取全局信息,并通过局部自注意力增强局部焦点。然后,通过以下公式融合高频细节和低频语义:
$$
h_{\text{fusion out}} = h_{\text{global out}} - G(h_{\text{global out}}) + G(h_{\text{local out}})
$$
其中,$G$ 是作为高斯模糊实现的低通滤波器,$h_{\text{global out}} - G(h_{\text{global out}})$ 作为 $h_{\text{fusion out}}$ 的高频部分,$G(h_{\text{local out}})$ 作为低频部分。
4. 灵活控制细节级别
FreeScale通过以下公式修改生成细节级别的控制:
$$
\hat{r}_t = c \times \tilde{z}_r^t + (1 - c) \times z_r^t
$$
其中,$c$ 是一个按比例缩放的余弦衰减因子,允许用户根据不同语义区域分配不同的值来控制细节级别。
通过这些方法,FreeScale能够有效地生成高分辨率图像和视频,同时避免了重复模式和质量退化的问题。实验结果表明,FreeScale在视觉质量上超越了现有方法,并且在推理时间上具有显著优势。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证FreeScale方法的有效性,包括以下几类实验:
1. 实验设置
- 模型和数据集:使用开源的文本到图像扩散模型SDXL和文本到视频扩散模型VideoCrafter2进行实验。
- 分辨率:图像生成在2048×2048和4096×4096分辨率下进行评估,视频生成在640分辨率下进行评估。
- GPU资源:所有实验都在单个A800 GPU上完成。
- 数据集:图像生成使用LAION5B数据集,视频生成使用WebVid-10M数据集。
- 评估指标:使用Frechet Image Distance (FID)、Kernel Image Distance (KID)、Frechet Video Distance (FVD)等指标评估生成质量。
2. 更高分辨率图像生成
- 对比方法:与SDXL直接推理(SDXL-DI)、ScaleCrafter、DemoFusion和FouriScale等方法进行比较。
- 定性比较:通过视觉比较展示FreeScale生成的图像在内容连贯性和局部细节上的优势。
- 定量比较:使用FID、KID、FIDc和KIDc等指标验证FreeScale在不同分辨率下的性能。
3. 更高分辨率视频生成
- 对比方法:与VideoCrafter2直接推理(VC2-DI)、ScaleCrafter和DemoFusion等方法进行比较。
- 定性比较:展示FreeScale在视频生成中保持高保真度的能力。
- 定量比较:使用FVD等指标评估视频生成质量。
4. 可控制细节级别的灵活性
- 演示:展示了如何通过调整不同区域的α值来控制生成结果中的细节级别。
5. 消融研究
- 组件效果:对FreeScale的三个主要组件(定制的自级联上采样、限制的扩张卷积和尺度融合)进行了消融研究,以展示每个组件对最终性能的贡献。
6. 用户研究
- 主观评估:通过用户研究评估生成图像的文本对齐、图像质量和视觉结构,并与基线方法进行比较。
这些实验全面地评估了FreeScale在不同方面的表现,包括图像和视频的高分辨率生成能力、细节控制的灵活性以及与其他方法的性能比较。通过这些实验,论文证明了FreeScale在无需微调的情况下有效提高了预训练扩散模型生成高分辨率结果的能力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和补充材料,以下是一些可以进一步探索的点:
1. 多GPU推理策略
- 内存限制问题:对于超过8k分辨率的图像生成,内存限制可能是一个问题。探索多GPU推理策略可能有助于缓解这一问题。
2. 推理加速技术
- 计算效率:尽管FreeScale的推理成本接近基础模型的直接推理,但对于超高分辨率生成,推理成本仍然很高。研究和应用推理加速技术可能有助于提高计算效率。
3. 模型的先验知识限制
- 上采样能力限制:FreeScale的上采样能力受限于模型学习的先验知识。探索如何突破这一限制,合理地添加更多细节,是一个重要的研究方向。
4. 模型泛化能力
- DiT-based LDMs:FreeScale目前仅支持UNet-based LDMs。探索如何将FreeScale适配到DiT-based LDMs,以利用这些模型在视觉生成上的优势。
5. 定制化解决方案
- 特定模型的适配:为DiT-based LDMs定制FreeScale的解决方案,以实现更好的性能和质量。
6. 质量损失问题
- 不同模型间的质量损失:使用DiT-based LDMs生成中间结果,再利用FreeScale生成更高分辨率结果时,可能会有轻微的质量损失。研究如何减少这种质量损失。
7. 知识蒸馏和压缩
- 模型压缩:探索知识蒸馏和模型压缩技术,以减少高分辨率生成时的内存和计算需求。
8. 跨模态融合
- 图像和文本的融合:FreeScale主要关注图像和视频生成,探索其在跨模态任务(如图像到图像翻译)中的应用潜力。
9. 实时应用
- 实时高分辨率生成:研究如何优化FreeScale以实现实时或近实时的高分辨率视觉内容生成。
10. 交互式应用
- 用户交互和编辑能力:探索FreeScale在交互式环境中的潜力,如允许用户在生成过程中进行编辑和调整。
这些探索点可以帮助进一步提升FreeScale的性能,扩展其应用范围,并解决当前的一些限制。
Q: 总结一下论文的主要内容
A: 论文提出了FreeScale,一个无需微调的推理范式,用于扩展预训练扩散模型在更高分辨率视觉生成上的能力。以下是论文的主要内容总结:
1. 问题背景
- 视觉扩散模型在生成高分辨率图像和视频方面受到训练数据和计算资源的限制。
- 现有方法在生成高分辨率内容时容易产生低质量的重复模式。
2. FreeScale方法
- 定制的自级联上采样:逐步增加生成结果的分辨率,从低分辨率的合理视觉结构开始,然后保持这个结构生成更高分辨率的结果。
- 限制的扩张卷积:使用扩张卷积增加卷积感受野,但只在UNet的下块和中块中应用,以避免局部重复问题。
- 尺度融合:通过处理不同感受野尺度的信息并提取所需的频率成分来融合信息,平衡局部和全局细节的增强。
- 灵活控制细节级别:允许用户根据不同语义区域分配不同的值来控制生成结果中的细节级别。
3. 实验验证
- 在图像和视频生成任务上,与现有方法相比,FreeScale在视觉质量上取得了显著优势,同时保持了较低的推理时间。
- 实现了8k分辨率图像的生成,突破了以往方法的限制。
4. 贡献总结
- 提出了FreeScale,一个无需微调的推理范式,使预训练的扩散模型能够生成更高分辨率的结果。
- 在文本到图像和文本到视频模型上验证了方法的有效性。
- 首次实现了8k分辨率图像的生成,与现有方法相比,在视觉质量上获得了显著提升。
5. 未来工作
- 探索多GPU推理策略以缓解内存限制。
- 应用推理加速技术以提高计算效率。
- 突破模型的先验知识限制,合理地添加更多细节。
- 适配DiT-based LDMs以利用这些模型的优势。
- 减少不同模型间生成结果的质量损失。
FreeScale通过其创新的方法,有效地解决了高分辨率视觉生成中的重复模式和质量退化问题,为未来在这一领域的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

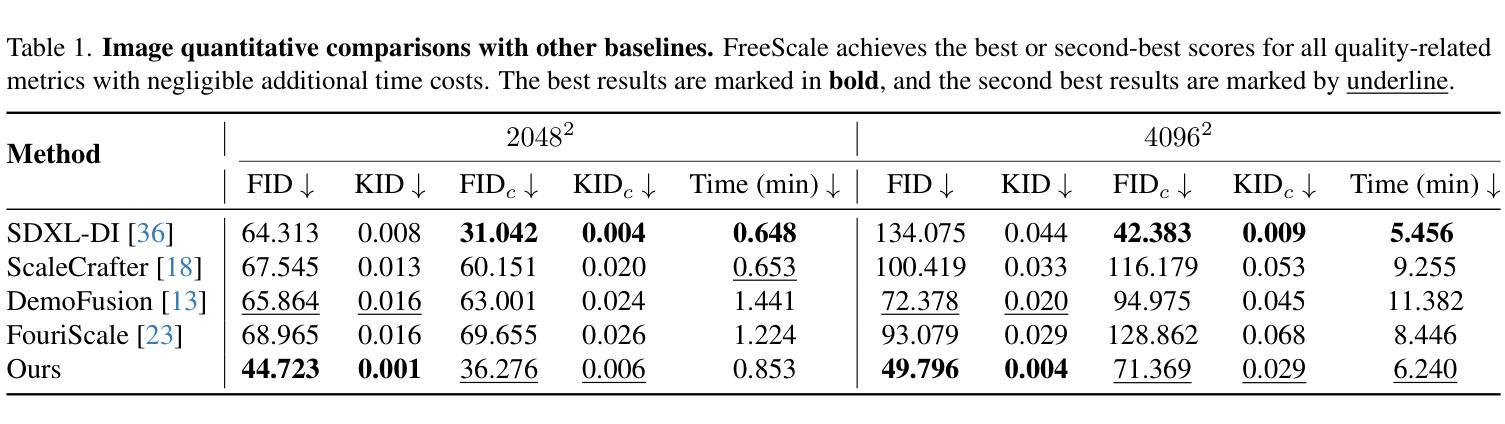

Illusion3D: 3D Multiview Illusion with 2D Diffusion Priors
Authors:Yue Feng, Vaibhav Sanjay, Spencer Lutz, Badour AlBahar, Songwei Ge, Jia-Bin Huang
Automatically generating multiview illusions is a compelling challenge, where a single piece of visual content offers distinct interpretations from different viewing perspectives. Traditional methods, such as shadow art and wire art, create interesting 3D illusions but are limited to simple visual outputs (i.e., figure-ground or line drawing), restricting their artistic expressiveness and practical versatility. Recent diffusion-based illusion generation methods can generate more intricate designs but are confined to 2D images. In this work, we present a simple yet effective approach for creating 3D multiview illusions based on user-provided text prompts or images. Our method leverages a pre-trained text-to-image diffusion model to optimize the textures and geometry of neural 3D representations through differentiable rendering. When viewed from multiple angles, this produces different interpretations. We develop several techniques to improve the quality of the generated 3D multiview illusions. We demonstrate the effectiveness of our approach through extensive experiments and showcase illusion generation with diverse 3D forms.
自动生成多视角错觉是一项引人入胜的挑战,其中,单一的视觉内容从不同的观看角度呈现出不同的解读。传统的方法,如影子艺术和线条艺术,可以创造出有趣的3D错觉,但它们仅限于简单的视觉输出(例如,图形背景或线条绘制),从而限制了其艺术表现力和实际应用的灵活性。最近的基于扩散的错觉生成方法可以生成更复杂的设计,但仅限于2D图像。在这项工作中,我们提出了一种简单而有效的方法,用于根据用户提供的文本提示或图像创建基于3D的多视角错觉。我们的方法利用预训练的文本到图像扩散模型,通过可微渲染优化神经3D表示的纹理和几何结构。从多个角度观看时,会产生不同的解读。我们开发了几种技术来提高所生成3D多视角错觉的质量。我们通过大量实验证明了我们的方法的有效性,并展示了具有多种3D形式的错觉生成。
论文及项目相关链接
PDF Project page: https://3d-multiview-illusion.github.io/
Summary
本文介绍了一种基于用户提供的文本提示或图像,创建3D多角度错觉的简单有效方法。该方法利用预训练的文本到图像扩散模型,通过可微分渲染优化神经3D表示的纹理和几何结构。从不同角度观看时,会产生不同的解读。
Key Takeaways
- 本文提出了一种创建3D多角度错觉的新方法,该方法结合了文本提示或图像。
- 该方法利用预训练的文本到图像扩散模型,优化神经3D表示的纹理和几何结构。
- 通过可微分渲染,能够实现多角度观看产生不同的视觉效果。
- 文章介绍了提高生成3D错觉质量的多项技术。
- 该方法突破了传统错觉生成方法的限制,能够生成更复杂的设计。
- 实验结果证明了该方法的有效性,并展示了在多种3D形式下的错觉生成。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何自动生成3D多视错觉(3D multiview illusions),即从不同的视角观察单一视觉内容时能够呈现出不同的解释或图像。具体来说,这项工作旨在扩展现有的多视错觉艺术形式(如基于阴影、线条或2D平面的错觉)到具有透视视角的3D表面。传统的方法,例如阴影艺术和线条艺术,虽然能够创造出有趣的3D错觉效果,但限于简单的视觉输出,这限制了它们的艺术表现力和实用性。而近期基于扩散模型的错觉生成方法虽然能够生成更复杂的设计,但这些方法仅限于2D图像。因此,该研究提出了一种基于用户提供的文本提示或图像来创建3D多视错觉的简单而有效的方法。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
2D错觉:
- 心理学家自1930年以来研究的关于人类对模糊和错觉图像的感知。
- 基于人类感知的算法开发,用于选择图像和创建定制的混合图像和马赛克图像。
- 将视觉错觉扩展到卷积神经网络(CNNs)。
- 使用各种模型(包括深度学习、GANs和扩散模型)实现场景中隐藏对象的伪装图像生成。
- 通过量化错觉图像中的歧义和使用生成分类器理解感知错觉。
3D错觉:
- 3D对象的感知可能涉及多种错觉形式,不同视角可能导致对同一对象的不同解释。
- 2D阴影和3D线条图的解释也是错觉的一部分。
- 反射艺术和反射圆柱艺术呈现有趣的视觉效果,但通常限于单一视角。
使用扩散模型的3D生成:
- 扩散模型在生成逼真的2D图像方面展现出了显著的能力,并且最近被广泛用于3D生成。
- 例如,DreamFusion、Magic3D和ProlificDreamer等方法利用文本到图像的扩散模型进行3D合成。
这些相关研究为本文提出的3D多视错觉生成方法提供了理论基础和技术背景。论文中提到的具体文献编号如下:
- [1] Michael Bach. Object perception: When our brain is impressed but we do not notice it. 2009.
- [2] Edwin G. Boring. A new ambiguous figure. American Journal of Psychology, 42:444, 1930.
- [3] Ryan Burgert, Xiang Li, Abe Leite, Kanchana Ranasinghe, and Michael Ryoo. Diffusion illusions: Hiding images in plain sight. In ACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024.
- [9] Daniel Geng, Inbum Park, and Andrew Owens. Visual anagrams: Generating multi-view optical illusions with diffusion models. ArXiv, abs/2311.17919, 2023.
- [19] Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In CVPR, 2023.
- [37] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In ICLR, 2022.
- [50] Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. In NeurIPS, 2023.
Q: 论文如何解决这个问题?
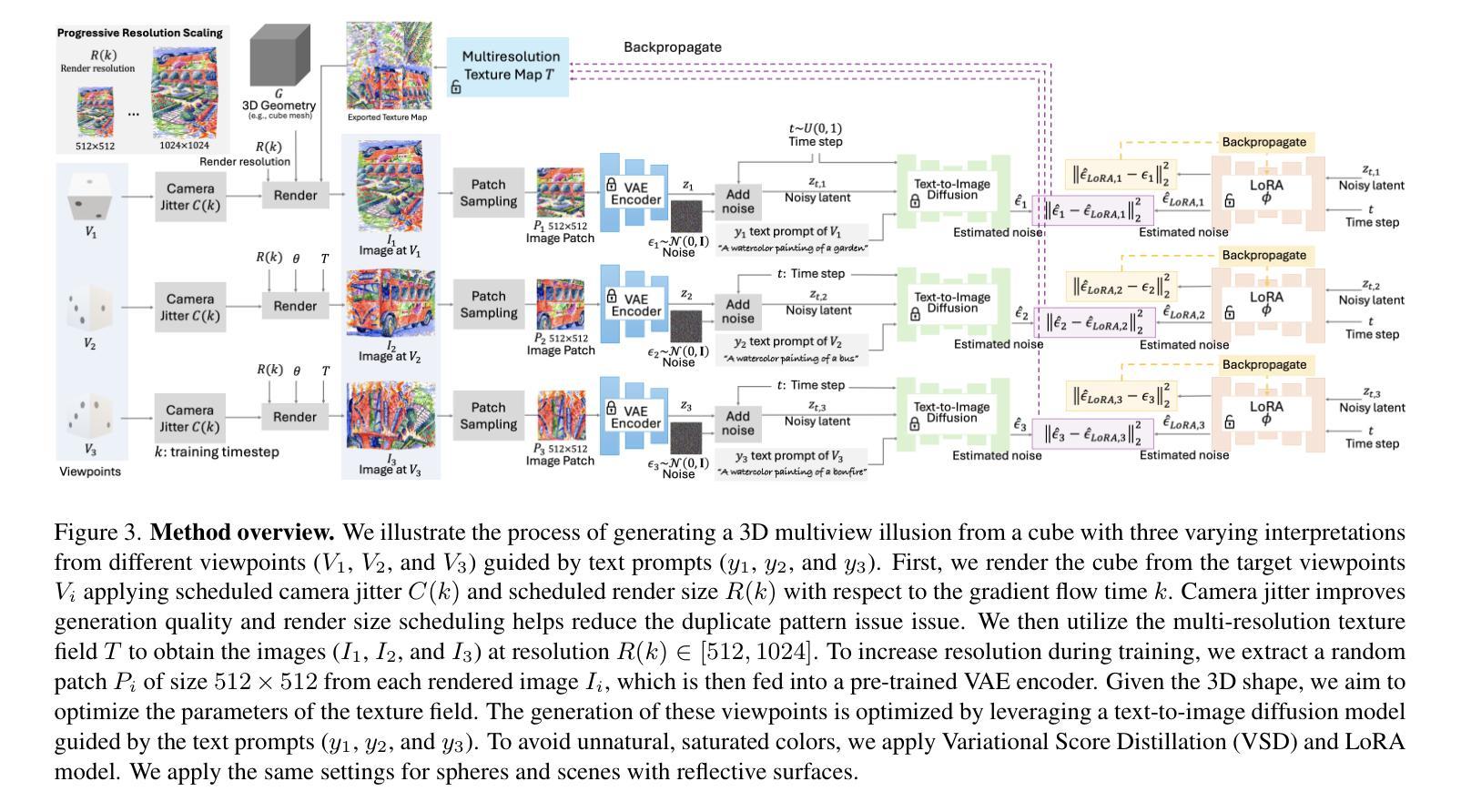
A: 论文通过以下几个关键步骤解决了自动生成3D多视错觉的问题:
预训练的扩散模型:
- 利用预训练的文本到图像扩散模型来优化神经3D表示的纹理和几何结构,通过可微分渲染技术生成从不同视角观察时呈现不同解释的3D错觉。
优化技术:
- 开发了几种技术来提高生成3D多视错觉的质量,包括:
- 分块去噪(Patch-wise denoising):允许基于VSD的方法在更高分辨率下有效优化。
- 计划性相机抖动(Scheduled camera jittering):在训练期间通过高斯噪声扰动渲染相机,以确保视角之间的平滑过渡。
- 渐进式渲染分辨率缩放(Progressive render resolution scaling):通过在优化过程中逐步增加渲染分辨率来提高生成错觉的质量,并减少重复图案问题。
- 开发了几种技术来提高生成3D多视错觉的质量,包括:
方法框架:
- 提出了一个简单的但有效的框架,通过文本提示和图像指导创建3D多视错觉。该方法优化3D神经表示,通过可微分渲染产生所需的视觉解释。
技术细节:
- 使用多分辨率哈希编码MLP从InstantNGP中嵌入纹理特征,并用神经网络参数化纹理场。
- 采用变分得分蒸馏(VSD)方法来更新纹理映射参数,并优化可训练的LoRA模块。
解决3D歧义问题:
- 针对3D歧义导致的局部最小值问题,提出了上述技术来改善优化过程,减少优化过程中的歧义和重复图案问题。
实验验证:
- 通过大量实验验证了所提方法的有效性,并展示了使用不同3D形式(包括立方体、球体、反射面和模糊3D形状)生成的错觉。
综上所述,论文通过结合预训练的扩散模型、优化技术、3D表示学习和渲染技术,提出了一种创新的方法来自动生成可以从多个视角提供不同视觉解释的3D多视错觉。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出方法的性能和有效性,具体包括:
与基线方法的比较:
- 论文定义了一个基线方法,并与其他几种基线方法(包括逆投影基线和潜在混合基线)进行了比较。这些基线方法使用Stable Diffusion独立生成图像并通过不同的方式优化立方体的纹理图。
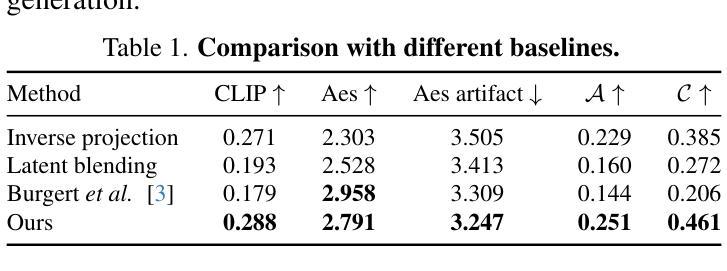
定量结果:
- 使用CLIP分数、审美分数、审美人工制品分数、对齐分数和隐藏分数等指标对不同方法进行了定量评估。这些指标用于衡量生成的错觉图像的质量。
定性结果:
- 展示了与基本基线方法的定性比较结果,证明了所提方法可以融合不同提示的内容并生成吸引人的结果。
反射表面和3D形状错觉的实验:
- 展示了在反射圆柱和曲面镜上生成的3D多视错觉,以及使用两个反射圆柱/镜子创建的错觉。
个性化图像错觉生成:
- 通过使用L2损失监督圆柱视图的生成,展示了如何使用实际的RGB图像生成个性化的错觉。
3D形状错觉:
- 训练了一个3D形状错觉模型,展示了通过观察旁边的反射圆柱来揭示不同内容的3D对象。
消融研究:
- 对不同的设计选择进行了消融研究,包括随机补丁去噪、有无分辨率缩放和有无相机抖动等,以评估这些组件和超参数对生成质量的影响。
失败案例分析:
- 展示了一些典型的失败案例,分析了随机补丁方法和所提方法的失败情况。
这些实验不仅验证了所提方法的有效性,还展示了该方法在实际应用中的潜力和限制。通过这些实验,论文证明了其方法在生成高质量3D多视错觉方面的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
更复杂的形状和结构:
- 研究可以探索将该方法应用于更复杂的3D形状和结构,例如非规则形状或更详细的3D模型,以提高艺术表现力和实用性。
优化效率和实时生成:
- 探索优化算法和计算框架,以减少生成3D多视错觉所需的时间和资源,实现更高效的实时生成。
增强现实感和真实感:
- 通过改进渲染技术和材质模拟,增强生成的3D错觉的真实感和视觉效果,使其更接近现实世界的物理特性。
交互式应用和用户体验:
- 开发交互式应用,允许用户实时调整视角和文本提示,以探索不同的3D错觉效果,增强用户体验。
更广泛的文本提示和风格:
- 扩展模型以处理更广泛的文本提示和艺术风格,提高模型的泛化能力和创造性。
解决高重叠和低扭曲形状的挑战:
- 针对高重叠和低扭曲形状难以生成高质量错觉的问题,研究新的技术解决方案。
负提示和内容隐藏:
- 探索使用负提示来改善特定视角内容的隐藏效果,增强错觉的艺术效果。
多模态输入和输出:
- 结合视觉、语音和触觉等多种感官输入和输出,创造更丰富的多模态3D多视错觉体验。
大规模数据集和训练:
- 构建和使用大规模的多视错觉数据集进行训练,以提高模型的鲁棒性和多样性。
跨领域应用:
- 探索3D多视错觉在游戏、电影、虚拟现实和教育等领域的应用,以实现更广泛的社会和经济价值。
这些探索点可以帮助推动3D多视错觉技术的发展,并将其应用于更广泛的领域和场景中。
Q: 总结一下论文的主要内容
A: 本文提出了一种创新的方法,名为Illusion3D,用于生成3D多视错觉,即从不同视角观察时能够呈现出不同视觉解释的3D表面。主要内容包括:
问题定义:
- 自动生成多视错觉是一个挑战,它允许单一视觉内容从不同视角提供不同的解释。传统方法如阴影艺术和线条艺术限于简单的视觉输出,而近期的扩散模型方法仅限于2D图像。
方法介绍:
- 该方法基于用户提供的文本提示或图像,利用预训练的文本到图像扩散模型,通过可微分渲染优化神经3D表示的纹理和几何结构,以产生不同视角下的多种解释。
技术贡献:
- 提出了分块去噪、计划性相机抖动和渐进式渲染分辨率缩放等技术,以提高生成3D多视错觉的质量。
- 这些技术解决了3D歧义导致的优化难题,如局部最小值问题和重复图案问题。
实验验证:
- 通过大量实验,包括与基线方法的比较、定量和定性结果分析、消融研究以及失败案例分析,验证了所提方法的有效性。
- 实验结果表明,该方法在生成具有不同3D形式(如立方体、球体和反射面)的高质量3D多视错觉方面具有优势。
潜在应用和未来研究方向:
- 论文讨论了该方法在艺术创作和实际应用中的潜力,并提出了未来可能的研究方向,包括探索更复杂的形状、优化效率、增强现实感、交互式应用等。
总体而言,Illusion3D通过结合预训练的扩散模型、3D表示学习和渲染技术,为自动生成3D多视错觉提供了一个有效的框架,并展示了在多个视角下创造动态视觉体验的能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


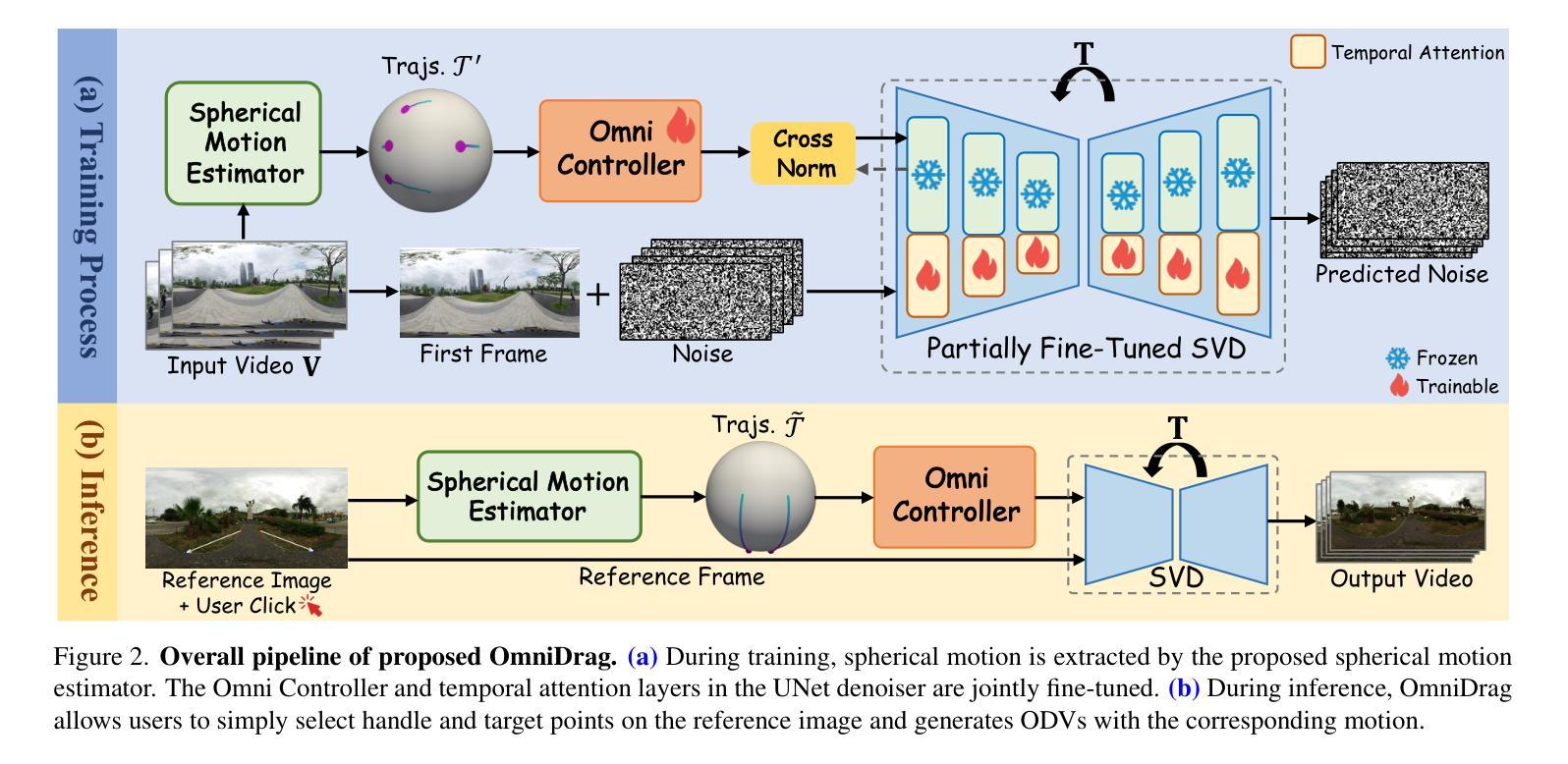
OmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation
Authors:Weiqi Li, Shijie Zhao, Chong Mou, Xuhan Sheng, Zhenyu Zhang, Qian Wang, Junlin Li, Li Zhang, Jian Zhang
As virtual reality gains popularity, the demand for controllable creation of immersive and dynamic omnidirectional videos (ODVs) is increasing. While previous text-to-ODV generation methods achieve impressive results, they struggle with content inaccuracies and inconsistencies due to reliance solely on textual inputs. Although recent motion control techniques provide fine-grained control for video generation, directly applying these methods to ODVs often results in spatial distortion and unsatisfactory performance, especially with complex spherical motions. To tackle these challenges, we propose OmniDrag, the first approach enabling both scene- and object-level motion control for accurate, high-quality omnidirectional image-to-video generation. Building on pretrained video diffusion models, we introduce an omnidirectional control module, which is jointly fine-tuned with temporal attention layers to effectively handle complex spherical motion. In addition, we develop a novel spherical motion estimator that accurately extracts motion-control signals and allows users to perform drag-style ODV generation by simply drawing handle and target points. We also present a new dataset, named Move360, addressing the scarcity of ODV data with large scene and object motions. Experiments demonstrate the significant superiority of OmniDrag in achieving holistic scene-level and fine-grained object-level control for ODV generation. The project page is available at https://lwq20020127.github.io/OmniDrag.
随着虚拟现实技术的普及,对可控创建沉浸式和动态全向视频(ODVs)的需求不断增加。虽然之前的文本到ODV生成方法取得了令人印象深刻的结果,但由于它们仅依赖于文本输入,因此在内容准确性和一致性方面存在挑战。虽然最近的运动控制技术为视频生成提供了精细的控制,但直接将这些方法应用于ODVs通常会导致空间失真和性能不佳,尤其是在复杂的球形运动中。为了应对这些挑战,我们提出了OmniDrag,这是一种新方法,能够实现对场景和对象级别的运动控制,以实现准确、高质量的全向图像到视频的生成。我们基于预训练的视频扩散模型,引入了一个全向控制模块,该模块与临时注意力层联合微调,以有效处理复杂的球形运动。此外,我们开发了一种新型球形运动估计器,能够准确提取运动控制信号,并允许用户通过简单地绘制把手和目标点来执行拖放式ODV生成。我们还展示了一个新的数据集Move360,以解决带有大场景和对象运动的大规模ODV数据稀缺问题。实验表明,OmniDrag在整体场景级别和精细的对象级别控制ODV生成方面表现出显著的优势。项目页面可在https://lwq20020127.github.io/OmniDrag访问。
论文及项目相关链接
Summary
随着虚拟现实技术的普及,全向视频(ODV)的需求不断增长。针对文本生成ODV方法的不足,如内容不准确和不一致,以及直接应用现有运动控制技术在ODV上会导致空间失真和性能不佳的问题,本文提出了一种全新的方法OmniDrag。该方法结合了预训练的视频扩散模型和全新设计的全向控制模块,能够处理复杂的球形运动,实现了场景和物体级别的运动控制,为准确、高质量的全向图像到视频的生成提供了解决方案。此外,还开发了一种新型球形运动估计器,并创建了一个新的数据集Move360。实验证明,OmniDrag在全景视频生成中实现了场景级别和精细物体级别的控制显著优于其他方法。
Key Takeaways
- 虚拟现实技术的普及促进了全向视频(ODV)需求的增长。
- 现有文本生成ODV方法存在内容不准确和不一致的问题。
- OmniDrag方法结合了预训练的视频扩散模型和全向控制模块,实现了场景和物体级别的运动控制。
- OmniDrag能够处理复杂的球形运动,为准确、高质量的全向图像到视频的生成提供了解决方案。
- 提出了一种新型球形运动估计器,提高了运动控制的准确性。
- 创建了新的数据集Move360,解决了ODV数据缺乏大规模场景和物体运动的问题。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为OmniDrag的方法,旨在解决以下问题:
虚拟现实中对沉浸式和动态全景视频(Omnidirectional Videos, ODVs)的可控创造需求增加:随着虚拟现实技术的发展,用户对能够生成高质量、沉浸式全景视频的需求日益增长。
现有方法的局限性:先前的方法,尤其是基于文本到全景视频(text-to-ODV)的生成方法,虽然取得了令人印象深刻的结果,但由于完全依赖于文本输入,常常导致内容不准确和不一致。
直接应用2D视频生成中的运动控制技术到ODVs中的挑战:这些方法在应用于全景视频生成时,常常导致空间失真和不满意的性能,特别是在处理复杂的球面运动时。
全景视频数据集样本运动幅度有限:现有的全景视频数据集包含的样本运动幅度有限,限制了深度可控全景视频生成模型在面对用户对更大运动范围要求时的有效性。
为了解决这些问题,OmniDrag作为第一个方法,能够基于强大的预训练视频扩散模型,实现对全景图像到视频生成的精确、高质量的运动控制。具体来说,OmniDrag引入了一个能够处理复杂球面运动的全方位控制器,并提出了一个新的球面运动估计器,允许用户通过简单地绘制手柄和目标点来进行拖拽风格的全景视频生成。此外,论文还介绍了一个新的数据集Move360,旨在解决全景视频数据缺乏大规模场景和对象运动的问题。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
1. 可控制的图像和视频生成
- 扩散模型:近期的发展中,扩散模型如Stable Diffusion、Imagen和DALL-E2等利用文本输入来指导生成过程。
- 额外控制模块:方法如ControlNet和T2I-Adapter将额外的控制模块整合到预训练的扩散模型中,以实现更精细的控制能力。
- 视频生成:早期方法依赖文本条件,如Video LDM、Imagen Video和AnimateDiff等。但最近的研究采用基于图像的条件进行更精确和有效的控制,例如Video ControlNet和ControlNeXt。
2. 全景图像和视频生成
- 基于生成对抗网络(GAN)的方法:广泛探索了基于GAN的方法来生成全景图像(ODIs)。
- 扩散模型:最近,扩散模型显著推进了ODI生成技术,例如PanoDiffusion、PanFusion和LayerPano3D等。
- 全景视频(ODV)生成:360DVD利用运动建模模块和360Adapter实现文本到ODV的生成,但完全依赖文本输入会导致生成帧的不准确和不一致。
3. 运动控制技术
- 基于轨迹的方法:如DragNUWA、MotionCtrl、DragAnything和Tora等,这些方法通过编码稀疏轨迹或相机运动到潜在空间来有效引导对象运动。
- 基于盒子的技术:如Peekaboo和Freetraj等,这些方法通过盒子来控制视频生成中的对象运动。
这些相关研究为OmniDrag提供了理论基础和技术背景,使其能够在全景视频生成领域实现精确的运动控制和高质量的视频生成。OmniDrag通过结合这些技术,提出了一种新的方法来处理全景视频中复杂的球面运动,并提供了用户友好的控制方式。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为OmniDrag的方法来解决上述问题,具体的解决方案包括以下几个关键点:
1. Omni Controller(全方位控制器)
- 动机:由于全景视频中的运动模式通常是球面的,这与2D视频中的简单运动模式不同,因此需要一个专门的控制器来处理这种复杂的球面运动。
- 方法:提出了一个轻量级的Omni Controller,它由多个ResNet块组成,用于提取控制信号,并将这些信号集成到主去噪分支中。
2. 联合微调技术(Joint Fine-tuning)
- 动机:为了有效地学习全景视频中的复杂球面运动模式,需要对控制器和时间注意力层进行联合微调。
- 方法:提出了联合微调Omni Controller和UNet去噪器中的时间注意力层的方法,以提高模型对球面运动模式的学习效果。
3. 球面运动估计器(Spherical Motion Estimator, SME)
- 动机:为了在训练和推理阶段提供精确的运动控制信号,需要一个能够准确捕捉球面运动的估计器。
- 方法:提出了一个新颖的SME,它使用等面积等纬度球面点初始化和基于球面距离的过滤器来跟踪和选择具有较大运动幅度的轨迹。在推理阶段,用户只需指定手柄和目标点,SME就可以通过球面插值自动估计整个轨迹。
4. Move360数据集
- 动机:为了训练OmniDrag模型,需要一个包含高质量运动内容的全景视频数据集。
- 方法:收集并构建了一个新的高质量全景视频数据集Move360,该数据集包含丰富的场景和对象运动,有助于提高OmniDrag的场景级控制能力。
5. 实验验证
- 动机:通过实验验证OmniDrag在生成平滑且视觉上吸引人的全景视频方面的效果和性能。
- 方法:与现有的一些最先进的视频生成方法进行了比较,包括DragNUWA、MotionCtrl和DragAnything,并在不同的控制条件下进行了评估。
通过这些解决方案,OmniDrag能够实现对全景图像到视频生成的精确、高质量的运动控制,同时提供了用户友好的交互方式,使得用户可以通过简单的点击和拖拽操作来控制视频内容。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证OmniDrag方法的有效性和性能。以下是实验的具体内容:
1. 实验设置
- 基础模型:选择Stable Video Diffusion (SVD)模型作为基础模型。
- 跟踪函数:使用CoTracker作为跟踪函数。
- 训练数据集:在Move360和WEB360数据集上训练OmniDrag。
- 优化器和迭代次数:使用Adam优化器进行40K次迭代训练。
- 分辨率和学习率:分辨率降低到640×320,学习率设置为(1 \times 10^{-5})。
- 评估指标:使用Fréchet Inception Distance (FID)、Fréchet Video Distance (FVD)和ObjMC等自动评估指标,以及进行人类评估来衡量结果的质量。
2. 与最新方法的比较
- 比较对象:与DragNUWA、MotionCtrl和DragAnything等最新视频生成方法进行比较。
- 控制条件:在场景级和对象级控制条件下进行实验。
- 参考图像:选择ODISR和SUN360数据集中的全景图像作为参考图像。
- 测试集:创建十二对输入作为测试集。
- 视觉比较和定量比较:展示视觉比较结果,并使用FID、FVD和ObjMC等指标进行定量比较。
3. 消融研究
- 联合微调时间注意力层:评估冻结整个主UNet去噪分支的变体。
- Move360数据集的影响:评估仅在WEB360数据集上训练的OmniDrag变体。
- 球面运动估计器(SME)的影响:评估替换HEALPix初始化、球面距离计算和球面插值的变体。
4. 定量和定性结果
- 定量结果:在表1中展示了OmniDrag与其他方法的定量比较结果。
- 视觉结果:在图5中展示了不同方法的视觉比较结果。
- 消融研究结果:在图6和图7中展示了消融研究的视觉结果,并在表2中提供了定量结果。
这些实验旨在全面评估OmniDrag在全景视频生成中的表现,特别是在场景级和对象级运动控制方面的能力。通过与现有技术的比较和消融研究,作者展示了OmniDrag在生成高质量、可控全景视频方面的优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管OmniDrag在全景视频生成方面取得了显著成果,但仍有一些领域可以进一步探索和改进:
1. 提高生成质量
- 基础模型的改进:尽管OmniDrag基于SVD模型,但在某些情况下生成质量仍有限制。研究更先进的视频生成模型可能进一步提升生成质量。
2. 相机和对象运动的解耦
- 运动解耦:将相机运动和对象运动分离是一个开放性问题。研究如何有效地区分和控制这两种运动,可能提高模型的灵活性和控制精度。
3. 交互方式的优化
- 用户交互:虽然OmniDrag提供了通过点击和拖拽来控制视频的简单交互方式,但可以进一步探索更自然和直观的交互方式,如语音控制或手势识别。
4. 数据集的扩展和多样化
- 数据集多样性:尽管Move360数据集提供了丰富的运动内容,但扩展数据集以包含更多样化的场景和运动对于提高模型的泛化能力至关重要。
5. 实时性能的提升
- 推理效率:OmniDrag在实际应用中可能需要实时生成视频,因此提高模型的推理效率是一个重要的研究方向。
6. 多模态输入的融合
- 多模态控制:除了基于图像和运动的控制,融合文本、音频等其他模态的输入可能提供更丰富的控制方式。
7. 模型的可解释性和稳定性
- 模型解释性:提高模型的可解释性,让研究者和用户更好地理解模型的决策过程。
- 模型稳定性:在各种输入条件下保持模型生成的稳定性和一致性。
8. 跨模态迁移学习
- 迁移学习:探索如何将OmniDrag模型迁移到其他相关任务,如视频预测、视频编辑等。
9. 长期运动趋势的学习
- 长期运动预测:研究模型如何捕捉和预测长时间跨度内的运动趋势。
这些方向不仅可以推动全景视频生成技术的发展,还可能对虚拟现实、增强现实以及其他多媒体应用产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为OmniDrag的新方法,用于实现对全景图像到视频生成(ODV)的运动控制。以下是论文的主要内容总结:
1. 问题背景
- 随着虚拟现实技术的发展,对沉浸式和动态全景视频(ODVs)的需求不断增加。
- 现有方法依赖文本输入,导致内容不准确和不一致。
- 直接应用2D视频生成技术到ODVs中会导致空间失真和性能不佳。
- 现有的ODV数据集样本运动幅度有限,限制了深度可控ODV生成模型的效果。
2. OmniDrag方法
- Omni Controller:提出了一个全方位控制器,接收轨迹作为输入,允许简单的拖拽式控制。
- 联合微调:提出了联合微调控制器和时间层在扩散去噪UNet中的方法,以有效学习复杂的球面运动模式。
- 球面运动估计器(SME):开发了一个球面运动估计器,用于在训练期间准确捕获控制信号,并在推理期间提供用户友好的交互。
- Move360数据集:收集了一个新的高质量ODV数据集,包含丰富的场景和对象运动,增强了OmniDrag的场景级控制能力。
3. 实验
- 与现有最先进的视频生成方法(如DragNUWA、MotionCtrl和DragAnything)进行了比较。
- 在场景级和对象级控制条件下进行了评估。
- 进行了消融研究,验证了OmniDrag各个组成部分的有效性。
4. 结果
- OmniDrag在生成平滑且视觉上吸引人的全景视频方面表现出色,并且在交互式运动控制方面优于其他方法。
- 实验结果表明,OmniDrag在视频质量和运动控制性能方面均优于现有技术。
5. 结论与局限性
- OmniDrag是一个新颖的基于扩散的方法,用于实现全景图像到视频的动态运动控制。
- 尽管取得了有希望的结果,但其生成质量仍受到基础SVD模型的限制。
- 解耦相机和对象级运动是一个未来的研究方向。
这篇论文通过引入新的技术和数据集,为全景视频的生成和控制提供了一个先进的解决方案,并展示了其在实际应用中的潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图




SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Authors:Dongting Hu, Jierun Chen, Xijie Huang, Huseyin Coskun, Arpit Sahni, Aarush Gupta, Anujraaj Goyal, Dishani Lahiri, Rajesh Singh, Yerlan Idelbayev, Junli Cao, Yanyu Li, Kwang-Ting Cheng, S. -H. Gary Chan, Mingming Gong, Sergey Tulyakov, Anil Kag, Yanwu Xu, Jian Ren
Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
现有的文本到图像(T2I)扩散模型面临几个局限性,包括模型体积大、运行速度慢以及在移动设备上的生成质量低。本文旨在通过开发一个极小且快速的T2I模型来解决所有这些挑战,该模型能够在移动平台上生成高分辨率和高质量的图像。我们提出了几种技术来实现这一目标。首先,我们系统地检查网络架构的设计选择,以减少模型参数和延迟,同时确保高质量的生成。其次,为了进一步提高生成质量,我们采用跨架构知识蒸馏的方法,从一个更大的模型中蒸馏知识,并使用多层次的方法从零开始引导我们的模型训练。第三,我们通过将对抗性指导与知识蒸馏相结合,实现了几步生成。我们的模型SnapGen首次在移动设备上实现了约1.4秒内生成1024x1024像素的图像。在ImageNet-1K上,我们的模型仅有3.72亿个参数,实现了256x256像素生成的FID为2.06。在T2I基准测试(即GenEval和DPG-Bench)中,我们的模型仅有3.79亿个参数,在显著更小的规模上超越了大规模模型(例如,比SDXL小7倍,比IF-XL小14倍)。
论文及项目相关链接
摘要
本文提出了一种针对文本到图像(T2I)扩散模型的优化方案,旨在解决现有模型面临的模型体积大、运行速度慢和在移动设备上生成质量低的问题。通过设计极小的快速T2I模型,实现了在移动平台上生成高分辨率高质量图像的目标。本文采用多种技术实现这一目标,包括系统研究网络架构的设计选择以减小模型参数和延迟,同时确保高质量生成;采用跨架构知识蒸馏技术,从大型模型中引导模型训练;以及结合对抗性指导和知识蒸馏实现几步生成。本文的模型SnapGen首次实现了在移动设备上以约1.4秒的时间生成1024x1024像素的图像。在ImageNet-1K上,仅有372M参数的模型实现了2.06的FID值(针对256x256像素生成)。在文本到图像基准测试(如GenEval和DPG-Bench)中,仅有379M参数的模型在尺寸显著减小的情况下(例如,比SDXL小7倍,比IF-XL小14倍)超越了大规模模型。
关键见解
- 文本到图像(T2I)扩散模型面临模型体积大、运行速度慢和在移动设备上生成质量低的问题。
- 提出了一种极小的快速T2I模型,能在移动平台上生成高分辨率高质量图像。
- 通过系统研究网络架构的设计选择,实现了模型参数和延迟的减少,同时保证了高质量生成。
- 采用跨架构知识蒸馏技术,利用多层次方法从大型模型中引导模型训练。
- 结合对抗性指导和知识蒸馏实现了模型的几步生成。
- 模型SnapGen在移动设备上实现了快速生成大分辨率图像。
- 模型在ImageNet-1K上表现出优异的性能,并在文本到图像基准测试中超越了大型模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决现有文本到图像(Text-to-Image, T2I)扩散模型在移动设备上部署时面临的几个主要问题,包括:
模型尺寸大:现有的T2I扩散模型通常具有庞大的模型尺寸,这使得它们难以被部署到资源受限的移动设备上。
运行速度慢:这些模型在移动设备上的运行速度较慢,无法满足用户对即时生成图像的需求。
图像生成质量低:在移动设备上部署的T2I模型往往无法生成高分辨率和高质量的图像。
为了解决这些问题,论文提出了一种极小且快速的T2I模型,能够在移动平台上生成高分辨率和高质量的图像。具体来说,论文提出了以下几种技术:
高效的网络架构:通过系统地检查网络架构设计选择,减少模型参数和延迟,同时确保生成质量。
改进的训练技术:引入了几项改进措施来从头开始训练一个紧凑的T2I模型,包括流匹配目标和多级知识蒸馏。
先进的步骤蒸馏:通过结合对抗训练和知识蒸馏,实现了几步生成,以减少去噪步骤,同时保持图像质量。
通过这些技术,论文中提出的模型SnapGen能够在移动设备上大约1.4秒内生成10242像素的高分辨率图像,并且在参数数量远少于现有大规模模型的情况下,在多个基准测试中取得了竞争性能。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的工作:
高分辨率文本到图像模型:
- SDXL [56]:采用级联方法和UNet主干生成高细节图像,产生保持锐度和清晰度的照片真实输出。
- 其他研究 [6, 7, 16, 21, 32, 39–41, 44, 48, 51, 71]:探索更先进的文本编码器、更好的图像细化或改进的数据集准备,以获得更好的文本-图像对齐或更高质量的生成。
高效的扩散模型:
- 一些工作探索了架构优化以去除大型模型中的冗余,展示了在设备上几秒钟内生成图像的能力 [11, 43, 69, 88]。
- SANA [76] 和 LinFusion [49]:通过整合线性注意力机制实现在笔记本GPU上1K分辨率的生成。
扩散模型中的知识蒸馏:
- 先前工作专注于将大型、高容量教师模型蒸馏到更紧凑、高效的学生模型中,保持架构结构 [35, 49]。
- 通过移除某些组件(如注意力或残差块)来降低模型复杂性,同时保持性能。
对抗性步骤蒸馏:
- UFOGen [79] 和 DMD2 [81]:使用对抗训练技术减少扩散步骤数,同时保持高图像质量。
其他相关技术:
- 流匹配 [47, 50]:作为目标函数,与大型模型如SD3 [19] 和 SD3.5 [3] 对齐,实现有效的知识和步骤蒸馏。
- 多级知识蒸馏与时间步长感知缩放:结合多个训练目标,考虑不同时间步长中的目标预测难度。
这些相关工作为本研究提供了理论基础和技术背景,使得研究者能够开发出更小、更快且能在移动设备上运行的高分辨率文本到图像模型。通过借鉴和改进这些技术,本研究的模型SnapGen在参数数量显著减少的同时,实现了与大型模型相媲美的图像生成质量。
Q: 论文如何解决这个问题?
A: 论文通过以下方法解决文本到图像扩散模型在移动设备上部署的问题:
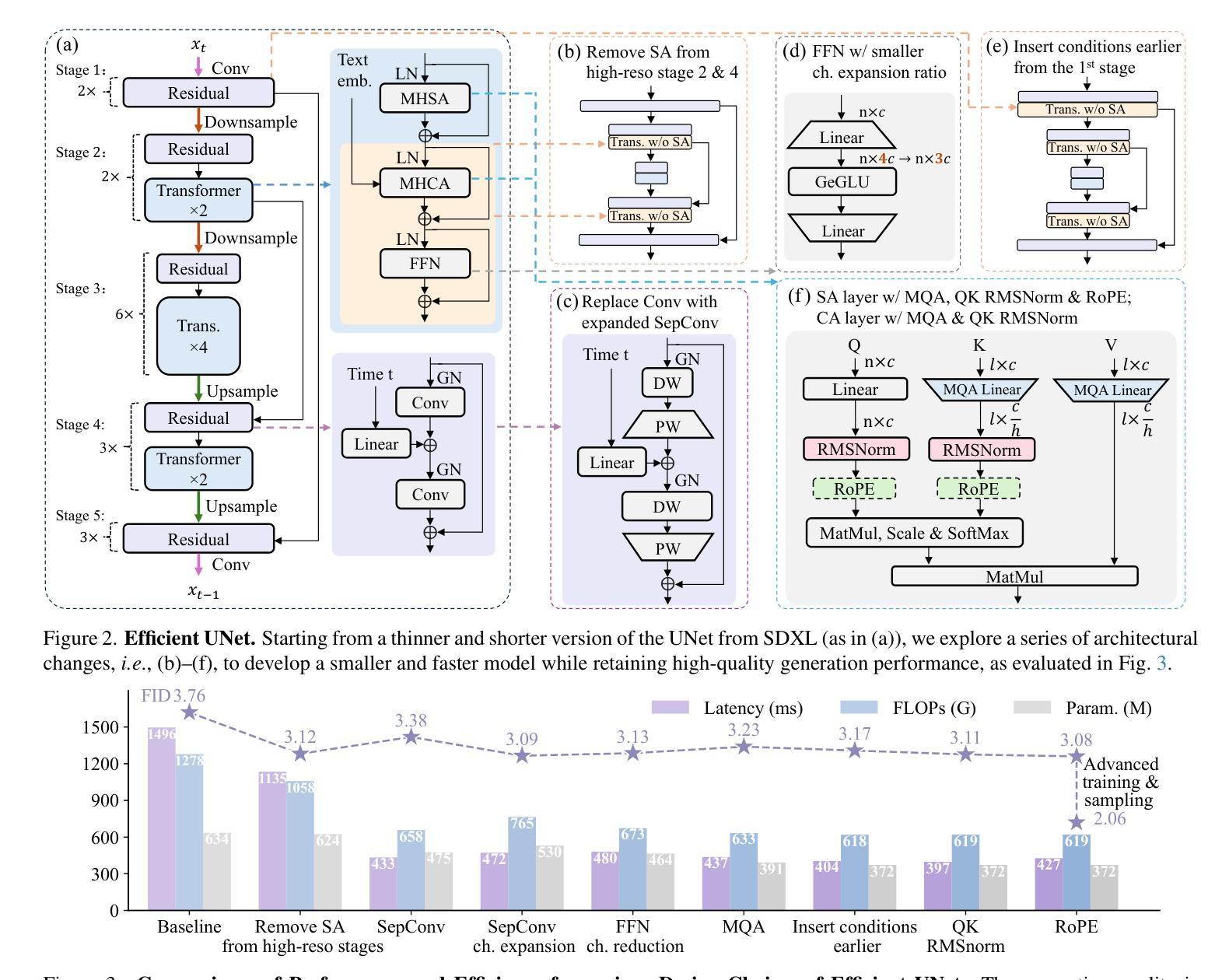
1. 高效网络架构
- 优化UNet和Autoencoder(AE):对网络架构进行深入分析,以获得资源使用和性能之间的最佳权衡。通过减少模型大小和计算复杂度,同时保持生成质量。
- 移除高分辨率阶段的自注意力(SA):由于自注意力层的二次计算复杂度,导致高分辨率输入时计算成本和内存消耗高,因此只在最低分辨率阶段保留SA层。
- 用可分离卷积(SepConv)替换普通卷积(Conv):减少参数和计算量,并通过扩展中间通道来平衡性能、延迟和模型参数。
- 精简前馈网络(FFN)层:降低FFN层的隐藏通道扩展比例,以减少模型参数和计算量。
- 用多查询注意力(MQA)替换多头自注意力(MHSA):减少参数和延迟,同时对性能影响最小。
- 将条件信息注入到第一阶段:确保从第一阶段开始就有条件引导,使模型更小、更快、更高效。
- 使用QK RMSNorm和RoPE位置嵌入:引入这些技术来增强模型,提高性能,同时引入的计算和参数开销可以忽略不计。
2. 改进的训练技术
- 流匹配目标:使用流匹配目标和Logit-Normal采样来增强训练稳定性。
- 多级知识蒸馏:结合输出蒸馏和特征蒸馏,使用来自大型模型的多级指导来从头开始训练我们的模型。
3. 先进的步骤蒸馏
- 对抗性步骤蒸馏:结合对抗训练和知识蒸馏,通过几步生成实现超快速的高质量生成。
4. 实验验证
- 量化基准测试:使用GenEval和DPG-Bench等基准测试评估模型性能。
- 人类评估:通过用户研究比较不同模型生成的图像在美学质量、文本-图像对齐和真实感方面的属性。
5. 移动设备部署
- 压缩解码器:开发新的压缩解码器架构,使其在移动设备上快速高效地进行高分辨率图像生成。
通过这些方法,论文成功地开发了一个参数数量仅为379M的模型SnapGen,该模型能够在移动设备上大约1.4秒内生成10242像素的高分辨率图像,并且在多个基准测试中超过了拥有数十亿参数的大型模型。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,以下是论文中进行的实验:
1. 效率和性能比较实验
- 对比不同网络架构设计选择(例如,去除自注意力层、替换卷积层、调整FFN层等)对模型效率(包括参数数量、延迟和FLOPs)和性能(FID得分)的影响。
2. 知识蒸馏实验
- 通过多级知识蒸馏来提升模型的图像生成质量,并比较有无知识蒸馏(KD)对模型在GenEval和DPG-Bench基准测试中的表现。
3. 量化基准测试
- 使用GenEval和DPG-Bench基准测试评估模型的文本到图像对齐能力。
- 报告模型在MS-COCO验证数据集上的CLIP得分以及在PixArt提示上的Image Reward得分,以衡量模型的审美质量。
4. 人类评估
- 通过用户研究比较不同模型生成的图像在图像-文本对齐、审美质量和真实感方面的属性。
5. 少步骤生成实验
- 比较模型在进行步骤蒸馏前后,在少步骤(4步和8步)生成情况下的性能,使用GenEval得分进行评估。
6. 模型细节和训练食谱
- 提供了模型的详细配置和训练策略,包括使用不同的文本编码器和多阶段训练方法。
7. 附加的定性比较和示例
- 展示了额外的定性可视化,比较了不同模型在1024×1024分辨率下的生成结果,并展示了由模型生成的额外图像示例。
8. 知识蒸馏组件的消融研究
- 对知识蒸馏的不同组件(包括不同蒸馏损失项和时间步长感知缩放操作)进行了消融研究,以展示它们对模型性能的提升。
这些实验旨在全面评估所提出的模型在效率、性能、图像质量和部署实用性等方面的表现,并与现有的一些最先进的模型进行比较。通过这些实验,论文证明了其模型在保持较小模型尺寸的同时,能够在移动设备上实现高质量的高分辨率图像生成。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种高效的文本到图像模型,并且取得了不错的效果,但仍有一些方向可以进一步探索和改进:
1. 模型泛化能力
- 跨领域测试:在不同的数据集和领域上测试模型的泛化能力,例如艺术风格、抽象概念等领域。
- 长尾分布处理:探索模型在处理类别不平衡数据时的表现和可能的改进方法。
2. 模型解释性
- 注意力可视化:分析模型内部的注意力机制,提供生成过程中的可视化解释。
- 特征重要性分析:研究不同特征对最终图像生成结果的影响,增强模型的可解释性。
3. 模型压缩和加速
- 知识蒸馏的改进:探索更高级的知识蒸馏技术,以进一步压缩模型大小并保持性能。
- 硬件加速:针对特定硬件平台(如特定型号的GPU或FPGA)优化模型,以实现更快的推理速度。
4. 多模态输入
- 多模态融合:研究如何将图像、文本和其他模态数据(如音频)融合,以生成更丰富的内容。
- 条件控制生成:允许用户通过多种条件(如风格、情感)控制生成过程,增强交互性和创造性。
5. 伦理和安全性
- 避免偏见和滥用:确保模型生成的内容不包含偏见,并且不能被用于制造虚假信息或滥用。
- 内容过滤机制:开发有效的内容过滤机制,防止生成不当或有害的图像。
6. 用户研究和体验
- 大规模用户测试:进行大规模的用户测试,收集反馈以改进模型的用户体验。
- 个性化定制:允许用户根据自己的偏好定制生成参数,提供更个性化的图像生成服务。
7. 模型鲁棒性
- 对抗性攻击防御:研究模型对对抗性攻击的鲁棒性,并开发防御机制。
- 数据增强和正则化:探索不同的数据增强和正则化技术,提高模型在面对异常输入时的稳定性和鲁棒性。
这些方向不仅可以推动文本到图像模型的技术发展,还可以扩展其应用范围,并确保技术的负责任使用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题阐述:
- 论文指出了现有的文本到图像(T2I)扩散模型在移动设备上部署时面临的挑战,包括模型尺寸大、运行速度慢和图像生成质量低。
研究目标:
- 旨在开发一个极小且快速的T2I模型,该模型能够在移动平台上生成高分辨率和高质量的图像。
方法论:
- 提出了几种技术来实现目标,包括:
- 高效的网络架构:通过系统地检查网络架构设计选择,减少模型参数和延迟,同时确保高生成质量。
- 改进的训练技术:使用流匹配作为目标,结合多级知识蒸馏,从头开始训练一个紧凑的T2I模型。
- 先进的步骤蒸馏:结合对抗训练和知识蒸馏,通过几步生成实现超快速的高质量生成。
- 提出了几种技术来实现目标,包括:
实验验证:
- 通过一系列实验,包括效率和性能比较、知识蒸馏效果、量化基准测试、人类评估和少步骤生成实验,验证了所提出模型的有效性。
- 模型在参数数量显著减少的同时,在多个基准测试中超过了拥有数十亿参数的大型模型。
主要贡献:
- 提出了一个参数数量仅为379M的模型SnapGen,该模型能够在移动设备上大约1.4秒内生成10242像素的高分辨率图像,并且在多个基准测试中取得了竞争性能。
未来工作:
- 论文也提出了一些可以进一步探索的方向,如模型泛化能力、模型解释性、模型压缩和加速、多模态输入、伦理和安全性以及用户研究和体验等。
总体而言,论文针对在移动设备上部署高分辨率文本到图像模型的挑战,提出了一种高效的解决方案,并通过对模型的系统优化和创新训练方法,实现了在保持较小模型尺寸的同时生成高质量图像的目标。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


EasyRef: Omni-Generalized Group Image Reference for Diffusion Models via Multimodal LLM
Authors:Zhuofan Zong, Dongzhi Jiang, Bingqi Ma, Guanglu Song, Hao Shao, Dazhong Shen, Yu Liu, Hongsheng Li
Significant achievements in personalization of diffusion models have been witnessed. Conventional tuning-free methods mostly encode multiple reference images by averaging their image embeddings as the injection condition, but such an image-independent operation cannot perform interaction among images to capture consistent visual elements within multiple references. Although the tuning-based Low-Rank Adaptation (LoRA) can effectively extract consistent elements within multiple images through the training process, it necessitates specific finetuning for each distinct image group. This paper introduces EasyRef, a novel plug-and-play adaptation method that enables diffusion models to be conditioned on multiple reference images and the text prompt. To effectively exploit consistent visual elements within multiple images, we leverage the multi-image comprehension and instruction-following capabilities of the multimodal large language model (MLLM), prompting it to capture consistent visual elements based on the instruction. Besides, injecting the MLLM’s representations into the diffusion process through adapters can easily generalize to unseen domains, mining the consistent visual elements within unseen data. To mitigate computational costs and enhance fine-grained detail preservation, we introduce an efficient reference aggregation strategy and a progressive training scheme. Finally, we introduce MRBench, a new multi-reference image generation benchmark. Experimental results demonstrate EasyRef surpasses both tuning-free methods like IP-Adapter and tuning-based methods like LoRA, achieving superior aesthetic quality and robust zero-shot generalization across diverse domains.
在扩散模型的个性化方面取得了显著的成就。传统的无需调整的方法大多通过将多个参考图像的平均图像嵌入作为注入条件来编码,但这样的图像无关操作无法在不同图像之间进行交互,从而无法捕获多个参考内的连续视觉元素。尽管基于调整的低秩适应(LoRA)可以有效地通过训练过程提取多个图像中的连续元素,但它需要针对每个不同的图像组进行特定的微调。本文介绍了一种新型的即插即用适应方法EasyRef,它使扩散模型能够基于多个参考图像和文本提示进行条件化。为了有效利用多个图像中的连续视觉元素,我们利用多模态大型语言模型(MLLM)的多图像理解和指令遵循能力,提示它基于指令捕获连续的视觉元素。此外,通过适配器将MLLM的表示注入扩散过程,可以轻松地推广到未见领域,挖掘未见数据中的连续视觉元素。为了降低计算成本并增强细节保留的精细度,我们引入了一种有效的参考聚合策略和一种渐进的训练方案。最后,我们引入了新的多参考图像生成基准MRBench。实验结果表明,EasyRef超越了无需调整的IP-Adapter方法和基于调整的LoRA方法,在美学质量和跨不同领域的零样本泛化方面都更具优势。
论文及项目相关链接
PDF Tech report
Summary
本文提出一种名为EasyRef的新型适应方法,使扩散模型能够根据多个参考图像和文本提示进行条件化。该方法利用多模态大型语言模型(MLLM)的多图像理解和指令遵循能力,有效捕捉多个图像中的一致视觉元素。通过注入MLLM的表示形式到扩散过程中,EasyRef能够轻松推广到未见领域,挖掘未见数据中的一致视觉元素。实验结果证明,EasyRef在美学质量和跨域零样本概括能力上超越了无调整方法和基于调整的方法。
Key Takeaways
- EasyRef是一种新型适应方法,用于使扩散模型能够根据多个参考图像和文本提示进行条件化。
- 该方法利用MLLM的多图像理解和指令遵循能力,有效捕捉多个图像中的一致视觉元素。
- 通过将MLLM的表示形式注入到扩散过程中,EasyRef能够轻松推广到未见领域。
- EasyRef采用高效的参考聚合策略和渐进式训练方案,以降低计算成本并增强精细细节保留。
- MRBench是一个新的多参考图像生成基准,用于评估类似EasyRef的方法。
- 实验结果表明,EasyRef在美学质量和跨域零样本概括能力上超越了现有方法。
- EasyRef具有广泛的应用前景,特别是在需要根据多个参考图像和文本提示生成图像的任务中。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为EasyRef的新方法,旨在解决以下问题:
多参考图像的一致性视觉元素捕捉问题:传统的无需调整的方法(tuning-free methods)主要通过平均多个参考图像的图像嵌入来编码,这种图像独立的操作无法在图像之间进行交互以捕获多个参考中的一致视觉元素。尽管基于调整的方法(tuning-based methods)如Low-Rank Adaptation (LoRA)可以通过训练过程提取多个图像中的一致元素,但它需要针对每个不同的图像组进行特定的微调。
个性化图像生成的控制性和精确性问题:为了提高扩散模型的控制性和精确性,研究者们探索了基于少量参考图像进行条件生成的个性化图像生成方法。这些方法主要分为无需调整的方法和基于调整的方法,但它们在处理多参考图像和文本提示时存在局限性。
计算成本和细粒度细节保持问题:为了减轻多图像输入的上下文长度对计算需求的影响,并解决MLLM(多模态大型语言模型)在捕获细粒度视觉细节方面的限制,论文提出了一种高效的参考聚合策略和渐进式训练方案。
多参考图像生成的评估问题:为了评估在多参考图像生成场景下的扩散模型,论文引入了一个名为MRBench的新评估基准。
总的来说,EasyRef旨在通过利用多模态大型语言模型(MLLM)的多图像理解和指令遵循能力,来有效地利用多个图像中的一致视觉元素,并将其注入到扩散过程中,以实现对多个参考图像和文本提示的条件化,同时保持对未见领域的强泛化能力。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要分为以下几个领域:
图像个性化(Image Personalization):
- 无需调整的方法(Tuning-free methods),例如IP-Adapter [48]、InstantStyle [41, 42]、IP-Adapter-Face [48] 和 InstantID [44],这些方法通过提取参考图像的视觉表示(如风格和特征)并将其注入扩散模型来增强图像提示能力。
- 基于调整的方法(Tuning-based methods),例如LoRA [14],通过使用有限的图像集对扩散模型进行微调。
多模态大型语言模型(Multimodal Large Language Models, MLLMs):
- 先驱工作如LLaVA [24] 和 BLIP-2 [17] 将视觉表示从预训练的CLIP视觉编码器投影到LLM以进行多模态理解。
- 混合视觉专家设计,例如SPHINX [21]、MoF [40] 和 MoVA [51],旨在增强MLLMs的视觉能力。
- 模型如LLaVANeXT [23] 和 Qwen2-VL [43] 寻求处理任意分辨率的图像。
扩散模型(Diffusion Models):
- 扩散模型因其在创建令人惊叹的图像方面的能力而受到关注,例如Denoising Diffusion Probabilistic Models (DDPMs) [13]。
图像生成和控制(Image Generation and Control):
- 研究者们探索了多种方法来改善扩散模型的精确性和可控性,包括风格和内容的控制,例如ControlNet++ [18] 和 Photomaker [19]。
评估指标(Evaluation Metrics):
- 用于评估图像生成模型性能的指标,例如CLIPScore [11] 用于图像描述的无参考评估。
这些相关研究构成了EasyRef方法的理论和实践基础,并为进一步的研究提供了对比和参考。论文通过与这些现有方法的比较,展示了EasyRef在多参考图像生成任务中的优越性和创新点。
Q: 论文如何解决这个问题?
A: 论文通过提出EasyRef方法解决了上述问题,具体解决方案如下:
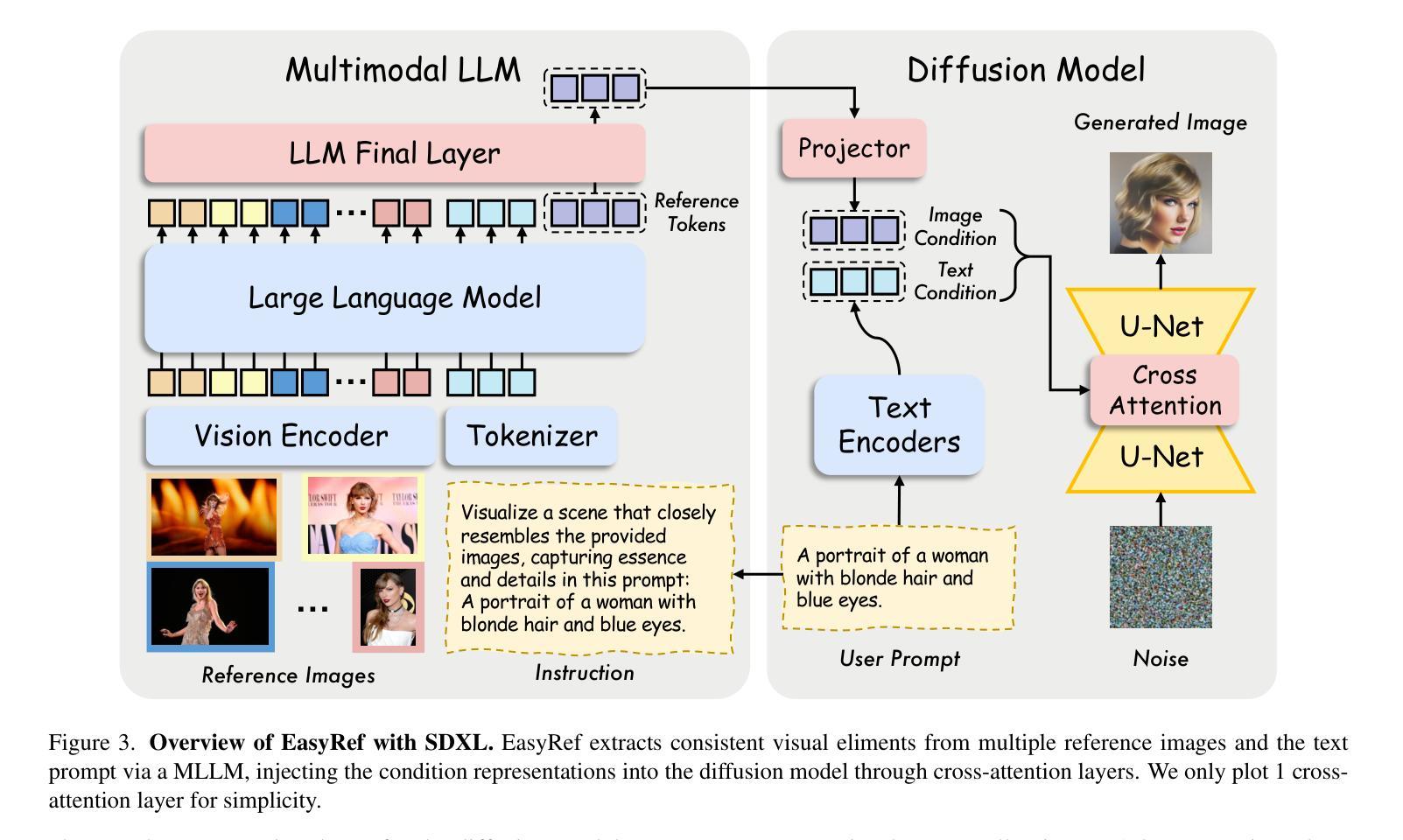
1. EasyRef方法概述
EasyRef是一种新型的即插即用适应方法,它使得扩散模型能够基于多个参考图像和文本提示进行条件生成。该方法利用多模态大型语言模型(MLLM)的多图像理解和指令遵循能力,来有效地从多个参考图像中提取一致的视觉元素,并将其注入到扩散过程中。
2. 关键组件
EasyRef主要包括以下四个关键组件:
- 预训练的扩散模型:用于条件图像生成。
- 预训练的MLLM:用于编码一组参考图像和文本提示。
- 条件投影器:将MLLM的表示映射到扩散模型的潜在空间。
- 可训练的适配器:将图像条件嵌入整合到扩散过程中。
3. 方法细节
- 参考表示编码:与传统方法不同,EasyRef不简单地平均所有参考图像的CLIP图像嵌入作为参考条件,而是利用MLLM的多图像理解和指令遵循能力,根据指令编码多参考输入和文本提示。
- 高效参考聚合:为了减轻多图像输入上下文长度对计算成本的影响,EasyRef将参考表示封装到N个可学习的参考标记(tokens)中,并在MLLM的最后层进行聚合和处理。
- 参考表示注入:将文本条件通过交叉注意力层注入到预训练的扩散模型中。
4. 渐进式训练方案
- 对齐预训练:在大规模数据集上优化MLLM的最后一层和参考标记,同时保持MLLM和扩散模型的初始能力。
- 单参考微调:在对齐预训练后,对MLLM进行单参考微调,增强其对细粒度视觉感知的能力。
- 多参考微调:使MLLM能够准确理解多个图像参考中的共同元素,并生成高质量、一致的图像。
5. 多参考生成基准(MRBench)
- 构建了一个包含多个参考图像的多参考图像生成基准,用于评估EasyRef的性能,并为未来的研究提供指导。
6. 实验结果
实验结果表明,EasyRef在多种领域中都取得了优越的审美质量和鲁棒的零样本泛化能力,超越了无需调整的方法(如IP-Adapter)和基于调整的方法(如LoRA)。
总结来说,EasyRef通过结合MLLM的多图像理解和指令遵循能力,以及适配器注入机制,有效地解决了多参考图像中的一致性视觉元素捕捉问题,同时保持了对未见领域的强泛化能力。此外,通过提出的高效参考聚合策略和渐进式训练方案,EasyRef在计算效率和细粒度细节保持方面也表现出色。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估EasyRef方法的性能,这些实验包括:
单参考图像场景下的定量比较(Single-image reference):
- 使用COCO 2017验证数据集(包含5000个图像-文本对)进行实验,比较EasyRef与其他方法(如IP-Adapter、LoRA等)在CLIP-T和DINO-I指标上的性能。
- 结果显示EasyRef在这些指标上一致性地超越了其他方法,展示了更好的对齐性能。
多参考图像生成(Multi-image references):
- 在MRBench数据集上比较EasyRef与IP-Adapter和LoRA的性能。
- 在零样本设置中,EasyRef在与参考图像和用户提示的对齐方面超越了IP-Adapter和LoRA。
人类评估(Human evaluation):
- 在MRBench上系统地评估EasyRef与IP-Adapter和LoRA在参考一致性和审美质量方面的表现。
- 结果显示EasyRef在图像-参考对齐和视觉美学方面优于其他模型。
与ControlNet的兼容性(Compatibility with ControlNet):
- 展示了EasyRef与流行的可控工具ControlNet的兼容性,与IP-Adapter相比,EasyRef在处理多个参考图像和额外结构控制时能生成更高质量、更一致的结果。
扩展参考图像数量的实验(Scaling the number of reference images):
- 评估EasyRef在不同数量的参考图像下的性能,分析了模型在训练约束内和超出训练约束时的表现。
多模态指令输入的消融研究(Multimodal instruction input):
- 研究了将指令包含在LLM输入中对生成性能的影响,发现包含指令可以提高生成性能。
参考标记设计的消融研究(Reference token design):
- 研究了不同数量的参考标记和插入位置对性能的影响,选择了64个标记并将其插入到最后一层以获得最佳性能。
参考表示聚合的消融研究(Reference representation aggregation):
- 比较了EasyRef的参考标记聚合方法与嵌入平均和嵌入连接的效果,发现使用MLLM的多图像理解能力可以提高模型性能。
渐进式训练方案的消融研究(Progressive training scheme):
- 通过系统地移除每个训练阶段,可视化了每个阶段对模型捕获细粒度视觉细节和保持身份一致性能力的影响。
这些实验全面评估了EasyRef在多参考图像生成任务中的性能,并与现有技术进行了比较,证明了EasyRef在审美质量和零样本泛化能力方面的优越性。
Q: 有什么可以进一步探索的点?
A: 尽管EasyRef在多参考图像生成领域取得了显著的成果,但仍有一些方向可以进一步探索和改进:
提高模型泛化能力:
- 探索新的训练策略或正则化技术,以增强模型对新领域和未见过的参考图像的泛化能力。
优化计算效率:
- 研究更高效的参考聚合策略,以降低模型在处理大量参考图像时的计算成本。
- 探索模型压缩和加速技术,以使EasyRef适用于资源受限的环境。
增强细粒度控制:
- 提高模型对图像中细粒度特征和复杂结构的控制能力,例如面部表情、纹理细节等。
- 结合用户研究反馈,优化模型以更好地满足特定用户需求。
改进评估基准:
- 扩展MRBench数据集,包含更多样化的参考图像和文本提示,以全面评估模型性能。
- 开发新的评估指标,更准确地衡量生成图像的质量和一致性。
多模态输入的深入研究:
- 研究如何更有效地结合文本、图像和其他模态信息,以提高生成图像的相关性和准确性。
- 探索不同类型指令对图像生成过程的影响。
跨领域应用:
- 将EasyRef应用于其他领域,如视频生成、3D建模或虚拟现实,以探索其在这些领域的潜力和局限性。
模型解释性:
- 提高模型的可解释性,帮助研究人员和用户理解模型的决策过程和潜在偏差。
- 研究如何通过可视化技术揭示MLLM在处理多参考图像时的内部机制。
鲁棒性和安全性:
- 增强模型对对抗性攻击和异常输入的鲁棒性。
- 确保生成图像的安全性和合规性,避免生成不当内容。
交互式应用:
- 开发基于EasyRef的交互式系统,允许用户实时提供反馈并调整生成过程。
- 结合自然语言处理技术,实现更自然和直观的用户交互。
这些方向不仅可以推动EasyRef技术的发展,还可能为多模态学习和扩散模型的研究提供新的视角和挑战。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了EasyRef,一个创新的即插即用适应方法,它使得扩散模型能够基于多个参考图像和文本提示进行条件生成。以下是论文的主要内容总结:
问题陈述:
- 现有方法在处理多参考图像时存在局限性,无法有效捕捉多个参考中的一致视觉元素。
- 需要一种新方法来提高扩散模型的个性化生成能力和控制精确性。
EasyRef方法:
- 提出了EasyRef,一个利用多模态大型语言模型(MLLM)的多图像理解和指令遵循能力的新型适应方法。
- EasyRef通过适配器将MLLM的表示注入到扩散过程中,以提取和利用多个参考图像中的一致视觉元素。
关键贡献:
- 提出了一种有效的参考聚合策略和渐进式训练方案,以减轻计算成本并增强MLLM的细粒度感知能力。
- 引入了MRBench,一个新的多参考图像生成基准,用于评估和指导未来的研究。
实验结果:
- EasyRef在多个领域中展现出优越的审美质量和鲁棒的零样本泛化能力,超越了无需调整的方法和基于调整的方法。
- 通过广泛的实验验证了EasyRef在多参考图像生成任务中的性能。
方法细节:
- EasyRef包括预训练的扩散模型、MLLM、条件投影器和可训练的适配器。
- 通过交叉注意力层将文本条件注入到扩散模型中。
- 采用渐进式训练策略,包括对齐预训练、单参考微调和多参考微调。
未来工作:
- 提出了一些潜在的研究方向,包括提高模型泛化能力、优化计算效率、增强细粒度控制等。
总体而言,EasyRef通过结合MLLM的多图像理解和指令遵循能力,以及适配器注入机制,有效地解决了多参考图像中的一致性视觉元素捕捉问题,同时保持了对未见领域的强泛化能力。这项工作为多参考图像生成领域提供了一种新的视角和解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


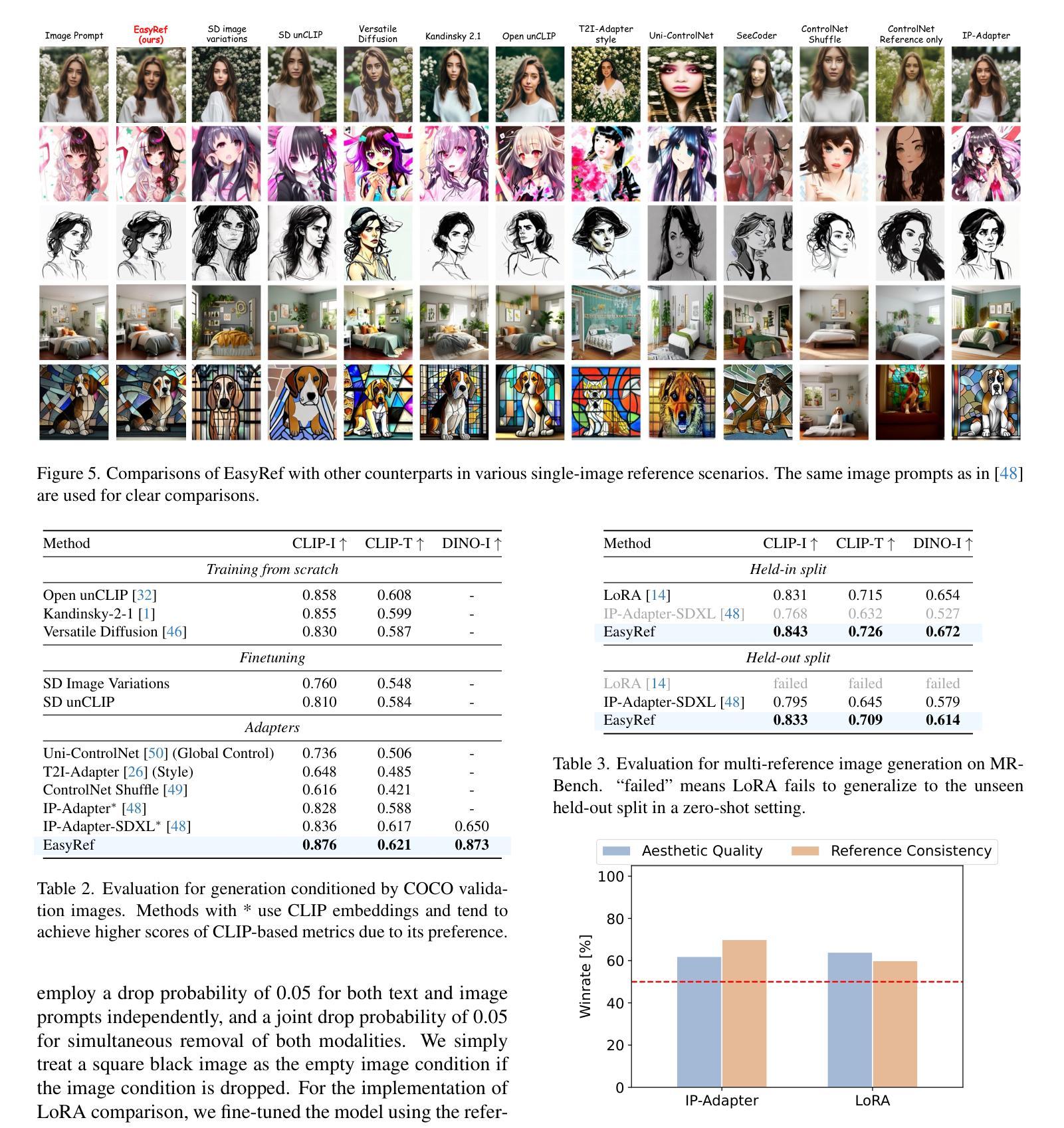
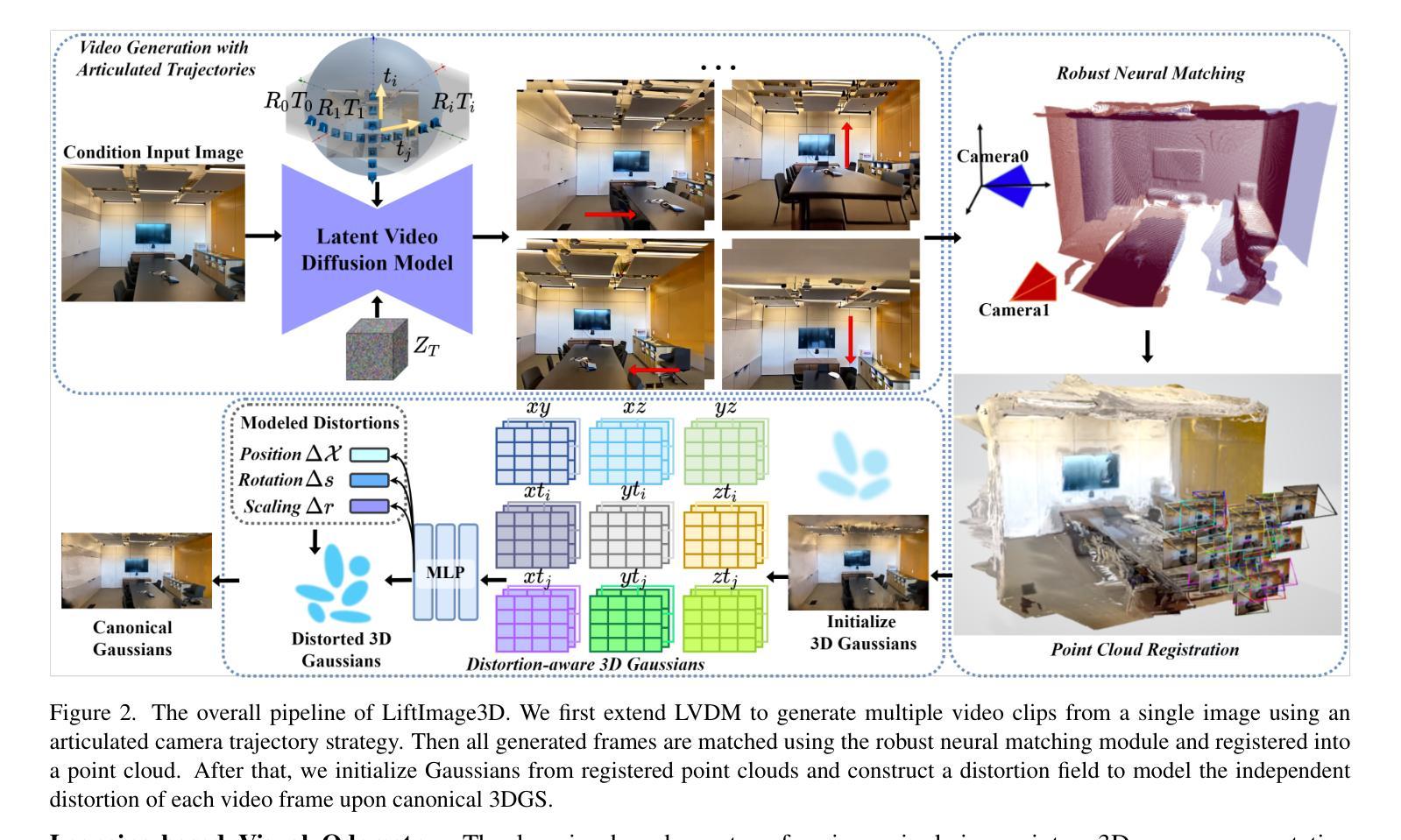
LiftImage3D: Lifting Any Single Image to 3D Gaussians with Video Generation Priors
Authors:Yabo Chen, Chen Yang, Jiemin Fang, Xiaopeng Zhang, Lingxi Xie, Wei Shen, Wenrui Dai, Hongkai Xiong, Qi Tian
Single-image 3D reconstruction remains a fundamental challenge in computer vision due to inherent geometric ambiguities and limited viewpoint information. Recent advances in Latent Video Diffusion Models (LVDMs) offer promising 3D priors learned from large-scale video data. However, leveraging these priors effectively faces three key challenges: (1) degradation in quality across large camera motions, (2) difficulties in achieving precise camera control, and (3) geometric distortions inherent to the diffusion process that damage 3D consistency. We address these challenges by proposing LiftImage3D, a framework that effectively releases LVDMs’ generative priors while ensuring 3D consistency. Specifically, we design an articulated trajectory strategy to generate video frames, which decomposes video sequences with large camera motions into ones with controllable small motions. Then we use robust neural matching models, i.e. MASt3R, to calibrate the camera poses of generated frames and produce corresponding point clouds. Finally, we propose a distortion-aware 3D Gaussian splatting representation, which can learn independent distortions between frames and output undistorted canonical Gaussians. Extensive experiments demonstrate that LiftImage3D achieves state-of-the-art performance on two challenging datasets, i.e. LLFF, DL3DV, and Tanks and Temples, and generalizes well to diverse in-the-wild images, from cartoon illustrations to complex real-world scenes.
单图像3D重建仍是计算机视觉领域的一个基本挑战,其挑战原因在于固有的几何模糊性和有限的视点信息。基于潜在视频扩散模型(LVDMs)的最新进展提供了从大规模视频数据中学习的有前途的3D先验知识。然而,有效利用这些先验知识面临三个关键挑战:(1)大相机运动导致的质量下降;(2)实现精确相机控制的困难;(3)扩散过程固有的几何失真损害3D一致性。我们通过提出LiftImage3D框架来解决这些挑战,该框架能够有效地释放LVDMs的生成先验知识,同时确保3D一致性。具体来说,我们设计了一种灵活的运动轨迹策略来生成视频帧,该策略将具有大相机运动的视频序列分解为具有可控小运动的序列。然后,我们使用鲁棒的神经匹配模型(即MASt3R)来校准生成帧的相机姿势并产生相应的点云。最后,我们提出了一种扭曲感知的3D高斯喷绘表示,它可以学习帧之间的独立扭曲并输出无扭曲的标准高斯。大量实验表明,LiftImage3D在两个具有挑战性的数据集LLFF、DL3DV以及Tanks and Temples上达到了最佳性能,并且在从卡通插图到复杂现实场景的多种野外图像上具有良好的泛化能力。
论文及项目相关链接
PDF Project page: https://liftimage3d.github.io/
Summary
基于大型视频数据的潜在视频扩散模型(LVDM)为三维重建提供了新的视角。然而,在应用这些模型时面临三大挑战:大相机运动导致的质量下降、难以精确控制相机以及扩散过程导致的几何失真。为解决这些问题,我们提出了LiftImage3D框架,该框架有效释放了LVDM的生成先验知识,同时保证了三维一致性。通过设计灵活的运动轨迹策略生成视频帧,并采用鲁棒性神经匹配模型校准相机姿态和生成点云,最终提出一种感知失真的三维高斯拼贴表示方法。实验表明,LiftImage3D在两个具有挑战性的数据集上取得了最佳性能,并很好地泛化到各种野外图像。
Key Takeaways
- 潜在视频扩散模型(LVDM)为三维重建提供新的视角。
- LVDM在应用时面临三大挑战:大相机运动导致质量下降、相机控制难度高和几何失真问题。
- LiftImage3D框架旨在解决这些挑战,通过释放LVDM的生成先验知识并保障三维一致性。
- 设计灵活的运动轨迹策略生成视频帧,分解大相机运动为可控的小运动。
- 采用鲁棒性神经匹配模型校准相机姿态和生成点云。
- 提出一种感知失真的三维高斯拼贴表示方法,学习帧间独立失真并输出无失真规范高斯。
- 实验表明,LiftImage3D在两个具有挑战性的数据集上表现最佳,并能很好地泛化到各种野外图像。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决单图像3D重建中的几个关键挑战,这些挑战包括:
大相机运动下的质量问题:现有方法在小相机运动下可以生成高质量的新视角图像,但当相机发生大幅度运动时,渲染质量会显著下降。这是因为在大视角变化中累积了生成误差,导致在远视图之间维持几何一致性变得困难。
精确相机控制的困难:尽管潜在视频扩散模型(LVDMs)擅长生成时间连贯的视频,但控制其生成以遵循期望的相机轨迹仍然是一个挑战。由于缺乏场景的底层3D信息,导致生成结果与输入相机条件不匹配。
扩散过程中的几何失真:扩散模型的固有噪声和去噪过程在帧生成过程中引入了微妙但持续的几何失真。这些失真虽然在视觉上不易察觉,但会在不同视图间累积,严重破坏3D重建质量,破坏帧之间的几何一致性。
为了应对这些挑战,论文提出了一个名为LiftImage3D的框架,该框架能够有效地利用LVDMs的生成先验,同时确保3D一致性。具体来说,论文设计了一个关节轨迹策略来生成视频帧,将具有大相机运动的视频序列分解为可控制的小运动。然后使用鲁棒的神经匹配模型(例如MASt3R)来校正生成帧的相机姿态,并产生相应的点云。最后,提出了一种失真感知的3D高斯溅射表示方法,该方法可以学习帧间的独立失真,并输出未失真的规范高斯。通过这些技术,LiftImage3D在多个具有挑战性的数据集上实现了最先进的性能,并且能够很好地泛化到多样化的野外图像,从卡通插图到复杂的真实世界场景。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
3D摄影:
- 利用多平面图像(MPI)技术从单张图像中合成新视角的场景。
- 基于深度的变形方法,用于引导变形视图中的修复。
2D生成模型基础上的单图像到3D:
- 研究者探索了仅使用单张图像生成3D模型和实现新视角合成的方法。
- 一些研究直接在3D数据上训练3D模型,但这些方法往往只在与训练集相似的场景上表现良好。
- 基于条件潜在扩散模型(LDM)的方法,通过大规模多视图图像学习构建几何先验。
基于LVDM(潜在视频扩散模型)的单图像到3D:
- 研究者认为视频扩散模型可以提供强大的多视图3D先验。
- 一些工作尝试在多视图数据集上微调LVDM,以增强生成新视图的能力。
以下是一些具体的相关工作和文献:
MPI(多平面图像)相关方法:
- [16, 29, 40] 基于MPI构建3D摄影的方法。
- [60, 61, 72, 93] MPI技术的发展和应用。
基于深度的变形和修复方法:
- [4, 77] 基于深度的变形方法。
- [6, 28, 46, 58, 70] 尝试使用文本到图像扩散方法生成视图外内容,并将其投影到扩展的多平面图像中。
单图像到3D模型生成:
- [5, 24, 30, 33, 57, 59, 73, 75, 88, 90] 使用单张图像生成3D模型和新视角合成的研究。
LVDM(潜在视频扩散模型)相关研究:
- [1, 37, 71] 探讨视频扩散模型在提供多视图3D先验方面的潜力。
- [15, 25, 42, 47, 64, 89] 在多视图数据集上微调LVDM以增强新视图合成能力的工作。
这些相关工作为LiftImage3D框架的发展提供了理论和技术基础,同时也突显了现有方法在处理大相机运动、精确相机控制和3D一致性失真方面的局限性。LiftImage3D通过结合关节轨迹策略、鲁棒的神经匹配和失真感知的3D高斯溅射表示等技术,旨在克服这些挑战,实现更高质量的单图像3D重建。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为LiftImage3D的框架来解决单图像3D重建中的挑战,具体解决方案包括以下几个关键组件:
1. 关节轨迹策略(Articulated Trajectory Strategy)
为了克服大相机运动导致的质量问题,论文设计了一种关节轨迹策略,将大的相机运动分解为小的、可控的步骤。这种方法通过将生成的帧用作后续视频生成的新起点,实现了在保持帧质量的同时扩大视图覆盖范围。
2. 鲁棒的神经匹配模型(Robust Neural Matching Models)
针对精确相机控制的挑战,论文采用了一种名为MASt3R的鲁棒神经匹配方法,直接从生成的帧中估计相机轨迹和粗略几何结构。这种方法绕过了输入条件和生成帧之间的不一致性,提高了相机控制的准确性。
3. 失真感知的3D高斯溅射表示(Distortion-aware 3D Gaussian Splatting)
为了处理扩散模型引入的3D不一致失真,论文提出了一种失真感知的3D高斯溅射(3DGS)表示方法。这种方法通过一个失真场来表示规范3DGS和失真的映射关系,能够学习帧间的独立失真,并输出未失真的规范高斯。
4. 深度先验注入(Depth Prior Injection)
为了产生更平滑和深度一致的结果,论文利用从神经匹配得到的粗糙但绝对的深度图来校准单目深度估计的精细深度图,确保深度图具有适当的比例和偏移。
5. 损失函数设计(Loss Function Design)
论文设计了一个损失函数,确保建模的失真不会偏离规范3DGS太远。这个损失函数结合了L1 RGB损失、LPIPS损失、基于网格的总变分损失以及L1深度损失,以优化失真场并确保3DGS的质量。
通过这些技术和策略的综合应用,LiftImage3D能够有效地利用潜在视频扩散模型(LVDMs)的生成先验,同时确保从单张图像到3D场景的重建过程中保持3D一致性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估LiftImage3D框架的性能,并与现有的最先进方法进行比较。以下是实验的具体内容:
1. 评估协议和数据集
- 数据集:实验使用了三个数据集:LLFF、DL3DV和Tanks and Temples。这些数据集包含了从室内到室外环境、单一对象到多个对象的多视角数据,适用于评估图像质量和3D一致性。
- 评估协议:遵循AdaMPI和SinMPI的评估协议,使用单个图像作为输入视图,并使用多个周围的视图作为真实图像进行定量评估。
2. 实施细节
- 相机运动方向:设置潜在相机姿态移动方向D为4,包括上、下、左和右。
- LVDM帧生成:LVDM每次产生16帧。
- MASt3R全局对齐:MASt3R需要400次迭代进行全局对齐。
- 3DGS训练:3DGS首先在常规设置下训练3k次迭代,然后使用失真场网络再训练14k次迭代。
3. 定量和定性比较
- 定量比较:在LLFF、DL3DV和Tanks and Temples数据集上,与先前的方法(如AdaMPI、SinMPI、LucidDreamer和ViewCrafter)进行了PSNR、SSIM和LPIPS等指标的定量比较,LiftImage3D在这些指标上显示出显著的改进。
- 定性比较:展示了LiftImage3D在非周围视图中的更强泛化能力,所有显示的图像都是从与输入图像差异较大的视点拍摄的。
4. 使用不同LVDMs的LiftImage3D
- 不同LVDMs:LiftImage3D可以利用不同的LVDMs(如MotionCtrl和ViewCrafter)来展示其在不同LVDM先验下的有效性。
- 结果:无论是使用MotionCtrl还是ViewCrafter作为LVDM的骨干网络,LiftImage3D都能显著提高性能。
5. 消融研究
- 失真感知3DGS:验证了失真感知3DGS设计的有效性。
- 二维时间戳:验证了二维时间戳设计的有效性。
- 深度先验注入:验证了深度先验注入模块的有效性,并通过可视化展示了如何利用神经匹配的粗糙深度图来校准单目深度估计的精细深度图。
这些实验全面评估了LiftImage3D在不同情况下的性能,并证明了其在单图像3D重建任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管LiftImage3D在单图像3D重建方面取得了显著进展,但仍有一些领域可以进一步探索和改进:
1. 提升相机控制精度
尽管LiftImage3D采用了MASt3R等鲁棒神经匹配模型来估计相机姿态,但在精确控制相机轨迹方面仍存在挑战。未来的工作可以探索更精细的相机控制策略,以进一步提高生成视频帧的质量和一致性。
2. 优化失真感知3DGS
失真感知3DGS是LiftImage3D中的关键技术之一,用于处理扩散模型引入的几何失真。未来的研究可以探索更高效的失真建模和补偿方法,以减少失真对3D重建质量的影响。
3. 深度先验的改进
虽然LiftImage3D利用了从神经匹配得到的粗糙深度图来校准单目深度估计,但深度估计的准确性仍有提升空间。研究更先进的深度估计方法,或者结合多模态数据(如立体视觉、激光雷达等)来提高深度信息的精度,可能是一个有价值的方向。
4. 泛化能力的增强
LiftImage3D在多种数据集上展示了良好的性能,但在处理更多样化和复杂场景时,其泛化能力仍需进一步提升。未来的工作可以探索如何使模型更好地适应不同的场景和条件,包括极端光照、遮挡和动态环境。
5. 实时性能的优化
LiftImage3D的处理流程可能在计算资源和时间上要求较高,限制了其在实时应用中的可行性。研究如何优化算法和计算流程,以实现更快的推理速度和更低的计算成本,对于实际应用至关重要。
6. 交互式应用的探索
将LiftImage3D应用于交互式环境,如虚拟现实(VR)和增强现实(AR),需要进一步研究。这包括提高场景的动态交互能力,以及在用户与环境互动时实时更新3D场景表示。
7. 多模态数据融合
考虑将LiftImage3D与其他类型的数据(如音频、触觉反馈)结合起来,以创建更丰富的多模态3D体验。这种融合可以提供更自然和沉浸式的用户体验。
8. 模型压缩和移动端部署
研究如何压缩LiftImage3D模型,以便在资源受限的设备(如智能手机和平板电脑)上部署。这对于将3D重建技术带到更广泛的用户群体具有重要意义。
通过在这些领域进行进一步的研究和开发,LiftImage3D及其衍生技术有望在未来实现更广泛的应用,并在单图像3D重建领域取得更大的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为LiftImage3D的框架,旨在利用视频生成先验将任何单张2D图像提升到3D高斯表示,以处理野外3D对象/场景。下面是论文的主要内容总结:
1. 问题背景与挑战:
- 单图像3D重建是计算机视觉中的一个基本挑战,由于几何歧义和有限的视点信息,任务十分困难。
- 近期的潜在视频扩散模型(LVDMs)提供了从大规模视频数据中学习到的有希望的3D先验。
2. 面临的三个关键挑战:
- 大相机运动下的退化:随着相机运动幅度的增加,渲染质量显著下降。
- 精确相机控制的困难:控制LVDMs生成遵循特定相机轨迹存在困难。
- 扩散过程中的几何失真:扩散模型的噪声和去噪过程引入的几何失真会破坏3D一致性。
3. LiftImage3D框架:
- 关节轨迹策略:将大的相机运动分解为小的、可控的步骤,以保证生成质量。
- 鲁棒神经匹配模型:使用MASt3R等模型校正生成帧的相机姿态,生成相应的点云。
- 失真感知3D高斯溅射(3DGS)表示:学习独立失真,输出未失真的规范高斯。
4. 贡献:
- 提出了一个系统化的框架,释放了LVDMs的3D能力,并以可控的方式提升单张图像至3D高斯。
- 通过关节轨迹策略、帧匹配策略、深度先验注入和有效的3DGS表示来解决从生成视频帧到3D重建的挑战。
- 在LLFF、DL3DV和Tanks and Temples数据集上进行了广泛的实验,证明了LiftImage3D在视觉质量和3D一致性方面相较于先前技术的状态-of-the-art性能。
5. 实验:
- 在多个数据集上进行了定量和定性比较,展示了LiftImage3D在不同情况下的有效性。
- 探讨了不同LVDMs在LiftImage3D框架下的性能,并进行了消融研究以验证各个组件的有效性。
6. 结论:
LiftImage3D作为一个创新的框架,通过一系列技术解决了使用LVDMs进行多视图帧生成时的挑战,并为未来利用视频生成先验促进3D重建的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Neural LightRig: Unlocking Accurate Object Normal and Material Estimation with Multi-Light Diffusion
Authors:Zexin He, Tengfei Wang, Xin Huang, Xingang Pan, Ziwei Liu
Recovering the geometry and materials of objects from a single image is challenging due to its under-constrained nature. In this paper, we present Neural LightRig, a novel framework that boosts intrinsic estimation by leveraging auxiliary multi-lighting conditions from 2D diffusion priors. Specifically, 1) we first leverage illumination priors from large-scale diffusion models to build our multi-light diffusion model on a synthetic relighting dataset with dedicated designs. This diffusion model generates multiple consistent images, each illuminated by point light sources in different directions. 2) By using these varied lighting images to reduce estimation uncertainty, we train a large G-buffer model with a U-Net backbone to accurately predict surface normals and materials. Extensive experiments validate that our approach significantly outperforms state-of-the-art methods, enabling accurate surface normal and PBR material estimation with vivid relighting effects. Code and dataset are available on our project page at https://projects.zxhezexin.com/neural-lightrig.
从单一图像中恢复物体的几何形状和材料是一项具有挑战性的任务,因为其本质上的约束不足。在本文中,我们提出了Neural LightRig,这是一个新型框架,它通过利用来自2D扩散先验的辅助多光照条件来提高内在估计。具体来说,1)我们首先利用大规模扩散模型的照明先验知识,在合成重光照数据集上建立我们的多光扩散模型,该数据集具有专门的设计。该扩散模型生成多个一致性的图像,每个图像都由不同方向的点光源照亮。2)通过使用这些不同的照明图像来减少估计的不确定性,我们训练了一个大型的G缓冲区模型,该模型以U-Net为主干,可以准确地预测表面法线和材料。大量实验验证,我们的方法显著优于最先进的方法,能够实现准确的表面法线和物理基础渲染材料估计,具有生动的重新照明效果。代码和数据集可在我们的项目页面https://projects.zxhezexin.com/neural-lightrig上找到。
论文及项目相关链接
PDF Project page: https://projects.zxhezexin.com/neural-lightrig
Summary
本文提出了Neural LightRig框架,通过利用辅助的二维扩散先验的多光照条件来提升内在估计。该框架利用大规模扩散模型产生的照明先验信息,在合成重光照数据集上建立多光扩散模型,生成由点光源从不同方向照射的多个一致图像。通过利用这些不同的光照图像来减少估计的不确定性,训练了一个大型G缓冲区模型,使用U-Net骨架来准确预测表面法线和材料。该方法显著优于现有技术,能够实现准确的表面法线和物理基础渲染材料估计,具有生动的重光照效果。
Key Takeaways
- Neural LightRig框架利用辅助的二维扩散先验的多光照条件来提升内在估计。
- 通过合成重光照数据集建立多光扩散模型,生成多个一致图像。
- 利用不同光照图像减少估计不确定性。
- 使用大型G缓冲区模型和U-Net骨架进行表面法线和材料的准确预测。
- 该方法显著优于现有技术。
- 实现准确的表面法线估计和物理基础渲染材料估计。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为Neural LightRig的新框架,旨在解决从单张图像中准确恢复物体的几何形状和基于物理的渲染(PBR)材料的问题。这是一个具有挑战性的任务,因为受到多种因素影响,如物体的几何形状、材料属性和环境光照之间的复杂相互作用,使得这个问题本质上是欠定的。具体来说,论文试图解决以下几个关键问题:
单图像的局限性:由于单张图像提供的信息有限,很难从中准确推断出物体的表面法线和材料属性。
光照条件的不确定性:不同的光照条件可能导致相同的图像外观,使得从单张图像中恢复物体的内在属性变得困难。
计算效率和准确性的平衡:优化基于渲染的方法虽然可以提供准确的结果,但通常计算成本高,并且严重依赖于可微渲染器的能力。
数据驱动方法的泛化能力:尽管数据驱动的方法在某些情况下表现出色,但由于从单张图像推断几何和材料的固有不确定性,它们的质量和泛化能力仍然是一个挑战。
为了解决这些问题,论文提出了利用多光源扩散模型来模拟不同方向光照下的图像,从而改善表面法线和材料估计的方法。通过这种方式,Neural LightRig框架能够生成在各种点光源下一致且高质量的重光照图像,显著减少了估计表面属性时的不确定性,并提高了预测的准确性。
Q: 有哪些相关研究?
A: 论文中提到了多个与Neural LightRig框架相关的研究领域和具体工作,可以概括如下:
扩散模型(Diffusion Models)
- 扩散模型在提供欠定任务的基本先验方面展现出了潜力。相关工作展示了图像扩散模型在新视角合成和高质量3D生成中的实用性。
- [38] High-resolution image synthesis with latent diffusion models.
- [43] Zero123++: a single image to consistent multi-view diffusion base model.
单目法线估计(Monocular Normal Estimation)
- 从单张图像估计表面法线是一个经典但欠定的问题。早期的工作依赖于光度线索或手工特征,而后来的工作采用深度学习来提高准确性。
- [15] Datadriven 3d primitives for single image understanding.
- [19] Automatic photo pop-up.
- [26] Discriminatively trained dense surface normal estimation.
材料估计(Material Estimation)
- 材料估计旨在从图像中恢复内在属性,这是一个欠定问题,因为多种材料和光照条件的组合可能导致相同的外观。
- [7] Nerd: Neural reflectance decomposition from image collections.
- [31] Shape and material capture at home.
逆渲染(Inverse Rendering)
- 逆渲染是一个关键问题,它促进了如电子游戏、增强现实和虚拟现实以及机器人技术等领域的广泛应用。
- [6] Shape, albedo, and illumination from a single image of an unknown object.
多视角图像生成和3D重建(Multi-View Image Generation and 3D Reconstruction)
- 这些工作利用扩散模型生成多视角图像,并训练重建模型进行3D重建。
- [21] LRM: Large reconstruction model for single image to 3d.
- [30] Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model.
光照和反射率分解(Lighting and Reflectance Decomposition)
- 这些方法优化神经表示,使用多视角图像来分解光照和材料属性。
- [45] Nerv: Neural reflectance and visibility fields for relighting and view synthesis.
这些相关工作为Neural LightRig框架提供了理论基础和技术背景,同时也展示了在单图像几何和材料估计方面的最新进展。通过结合这些相关技术,Neural LightRig旨在通过模拟多光源条件下的图像来提高表面法线和PBR材料的估计质量。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Neural LightRig的框架来解决从单张图像中准确恢复物体的几何形状和基于物理的渲染(PBR)材料的问题。该框架主要包含两个阶段:多光源扩散模型(Multi-Light Diffusion)和大型G缓冲区模型(Large G-Buffer Model)。以下是具体的解决方案:
1. 多光源扩散模型(Multi-Light Diffusion)
- 目的:利用大规模扩散模型中的光照先验来构建多光源扩散模型,生成由不同方向的点光源照明的多个一致图像。
- 生成多光源图像:通过这个模型,可以从输入图像I生成L个多光源图像,每个图像由不同方向的点光源照明。
- 混合条件策略:结合通道级联和参考注意力机制,将输入图像融合到扩散模型中,以生成高质量和逼真的多光源图像。
- 微调方案:采用两阶段训练策略,先冻结大部分参数,仅训练部分层以稳定早期训练,然后微调整个模型以适应多光源生成。
2. 大型G缓冲区模型(Large G-Buffer Model)
- 预测模型:使用U-Net架构来预测表面法线和PBR材料,因为U-Net在高分辨率预测中效率较高,并且适合学习空间关系。
- 训练目标:对G缓冲区属性应用损失函数,包括余弦相似性损失和均方误差(MSE)损失,以训练模型准确预测法线、反照率、粗糙度和金属度。
- 数据增强策略:为了弥合由扩散模型生成的多光源图像和真实渲染图像之间的域差距,设计了一系列数据增强策略,包括随机降级、随机强度调整、随机方向扰动和数据混合。
3. LightProp数据集
- 数据收集:构建一个合成数据集LightProp,包含80k个从Objaverse筛选的高质量对象,每个对象都有多光源图像和对应的G缓冲区图。
- 渲染设置:使用Blender的Cycles渲染引擎,为每个视点应用五种不同的照明条件,并生成多光源图像及其对应的G缓冲区图。
通过结合这些组件,Neural LightRig框架能够有效地从单张图像中估计出准确的表面法线和PBR材料,并在各种环境光照下渲染逼真的重光照图像。这种方法显著提高了表面法线估计、PBR材料估计和单图像重光照的质量和泛化能力。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估Neural LightRig框架的性能,这些实验包括定量评估和定性评估,具体如下:
1. 定量评估
表面法线估计:在LightProp数据集的1,000个未见过的对象的子集上计算度量指标,包括平均角度误差、中位数角度误差以及在不同角度阈值下的准确率(从3°到30°)。与DSINE、GeoWizard、Marigold和StableNormal等基线方法进行比较。
PBR材料估计和单图像重光照:计算反照率、粗糙度和金属度图的峰值信噪比(PSNR)和均方根误差(RMSE),并使用PSNR、SSIM和LPIPS评估重光照图像的质量。同时报告了每帧的平均时间,计算了从单个输入图像渲染120帧重光照图像的总时间,并除以帧数。
2. 定性评估
表面法线估计:在Objaverse子集和野外图像上展示与基线方法的定性比较结果,展示Neural LightRig在捕获复杂表面几何形状方面的优势。
PBR材料估计:比较Neural LightRig与基线方法在估计PBR材料方面的定性结果,展示Neural LightRig在区分金属和非金属材料方面的鲁棒性。
单图像重光照:展示Neural LightRig在不同环境光照下生成的逼真光照效果,并与DiLightNet和IC-Light等扩散模型进行比较。
3. 消融研究
多光源扩散的条件策略:探讨了不同的条件策略(如拼接、参考注意力和混合方法)对多光源扩散模型性能的影响。
多光源图像数量对性能的影响:评估了不同数量的多光源图像(0、3、6和9)对大型G缓冲区模型性能的影响。
增强策略的效果:检查了数据增强策略对提高G缓冲区预测模型的鲁棒性和泛化能力的影响。
这些实验全面评估了Neural LightRig在表面法线估计、PBR材料估计和单图像重光照方面的性能,并与现有方法进行了比较。通过定量和定性的结果,论文证明了Neural LightRig在这些任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管Neural LightRig框架在表面法线和PBR材料估计方面取得了显著的成果,但仍有一些可以进一步探索和改进的方向:
1. 复杂场景和多物体环境
当前的Neural LightRig框架主要针对单个物体的设计。将其扩展到更复杂的场景和多物体环境中是一个重要的研究方向。这可能需要处理物体间的遮挡、相互影响的光照以及更复杂的背景。
2. 提高模型分辨率
论文中提到的多光源扩散模型的分辨率限制了生成图像的细节水平。提高模型的分辨率可能有助于生成更高质量的多光源图像,从而提高最终表面属性预测的精度。
3. 优化计算效率
虽然Neural LightRig在性能上取得了突破,但扩散模型和大型G缓冲区模型的训练和推理可能仍然计算密集。进一步优化模型结构和训练过程,以减少计算资源的需求,是一个值得探索的方向。
4. 增强泛化能力
尽管Neural LightRig在合成数据集上表现出色,但在野外图像和多样化数据上可能面临泛化能力的挑战。增强模型对不同光照条件、材质和场景的泛化能力是一个重要的研究方向。
5. 集成到3D重建系统
将Neural LightRig与3D重建系统集成,以实现从单张或多张图像中恢复更完整的3D场景表示,这将是一个有价值的扩展。
6. 实时应用
探索Neural LightRig在实时应用中的潜力,例如增强现实(AR)和虚拟现实(VR),可能需要进一步的模型压缩和加速。
7. 更多的光照条件
当前的框架主要关注点光源照明。将其他类型的光源(如环境光、聚光灯等)纳入模型,以处理更丰富的光照环境。
8. 无监督或自监督学习
探索无监督或自监督学习策略,以减少对大量标注数据的依赖,这可能有助于模型在数据受限的情况下进行训练。
9. 错误分析和模型鲁棒性
进行更深入的错误分析,以识别模型在哪些类型的输入和条件下表现不佳,并针对性地改进模型的鲁棒性。
10. 用户交互和编辑能力
开发用户交互工具,允许用户对Neural LightRig生成的表面法线和材料进行编辑和调整,以满足特定的视觉效果需求。
这些方向不仅可以推动Neural LightRig框架的发展,还可能对计算机视觉和计算机图形学中的相关领域产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为Neural LightRig的框架,旨在从单张图像中准确估计物体的表面法线和基于物理的渲染(PBR)材料。以下是论文的主要内容总结:
1. 问题背景
- 从单张图像中恢复物体的几何形状和材料是一个具有挑战性的任务,因为这个问题本质上是欠定的。
- 该任务对于图形和计算机视觉领域至关重要,并且有许多应用,如视频游戏、增强现实和虚拟现实、机器人技术等。
2. Neural LightRig框架
- 多光源扩散模型:利用大规模扩散模型的光照先验,生成由不同方向的点光源照明的多个一致图像。
- 大型G缓冲区模型:使用U-Net架构,结合多光源图像来预测表面法线和PBR材料。
- LightProp数据集:构建了一个合成数据集,包含多光源图像和对应的G缓冲区图,用于训练和评估模型。
3. 方法细节
- 扩散模型:采用两阶段训练策略,先微调部分层以稳定早期训练,然后微调整个模型以适应多光源生成。
- 预测模型:使用U-Net架构进行高分辨率预测,并通过像素级端到端监督进行训练。
- 数据增强:设计了一系列数据增强策略,以弥合由扩散模型生成的多光源图像和真实渲染图像之间的域差距。
4. 实验
- 进行了定量和定性评估,验证了Neural LightRig在表面法线估计、PBR材料估计和单图像重光照方面的性能。
- 与现有方法相比,Neural LightRig在质量上和泛化能力上都有显著提升。
5. 贡献
- 提出了一种从单目图像中估计物体法线和PBR材料的新方法,通过模拟多光源条件来重新构造这个欠定问题。
- 构建了一个用于多光源图像生成和表面属性估计的合成数据集。
- 通过广泛的实验验证了该方法的有效性,并建立了新的最先进结果。
6. 未来工作
- 将Neural LightRig扩展到更复杂的场景和与3D重建系统的集成。
- 提高模型的分辨率和计算效率,增强模型的泛化能力。
这篇论文通过创新地结合扩散模型和大型G缓冲区模型,显著推进了从单张图像中恢复物体表面属性的研究。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

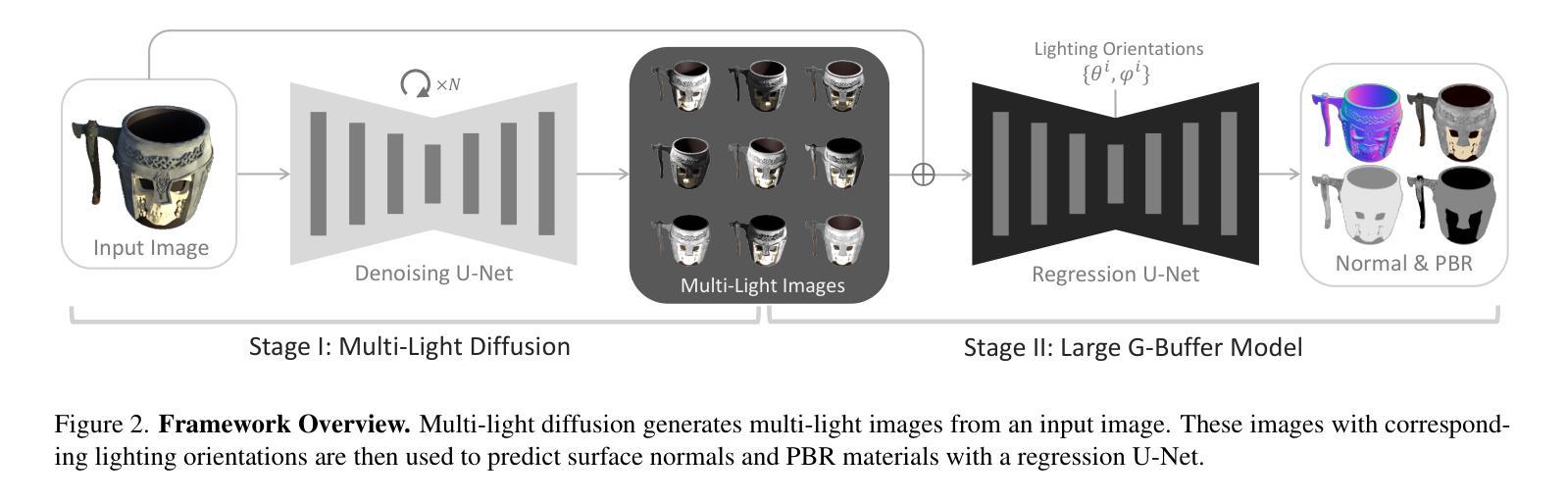
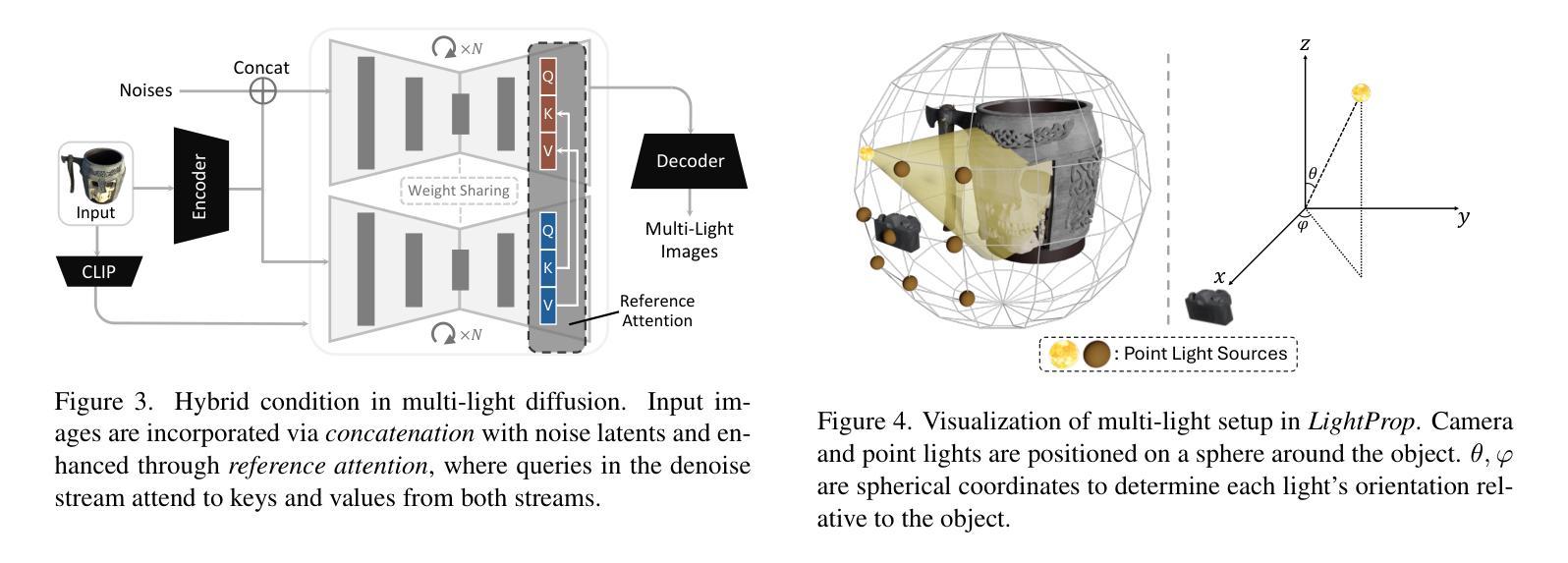
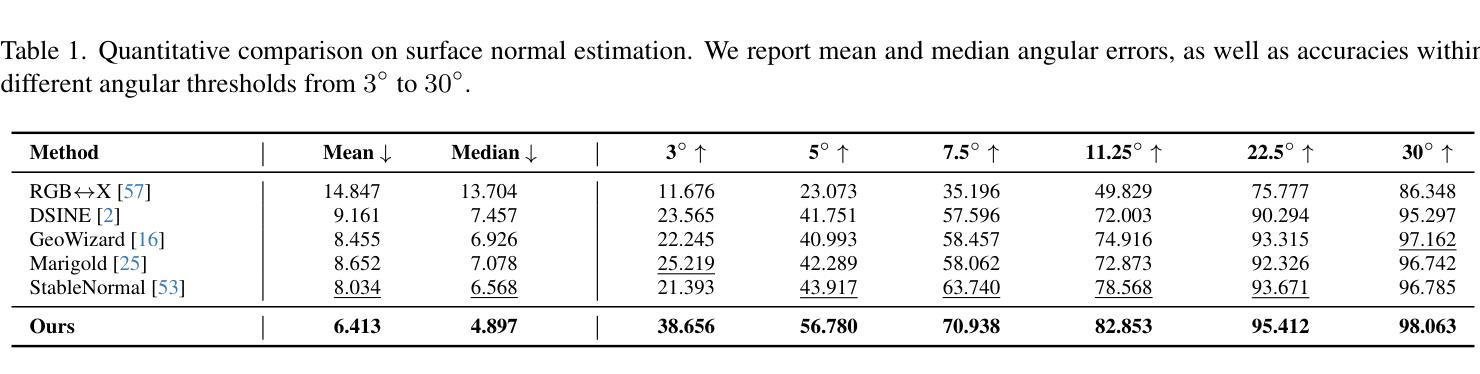
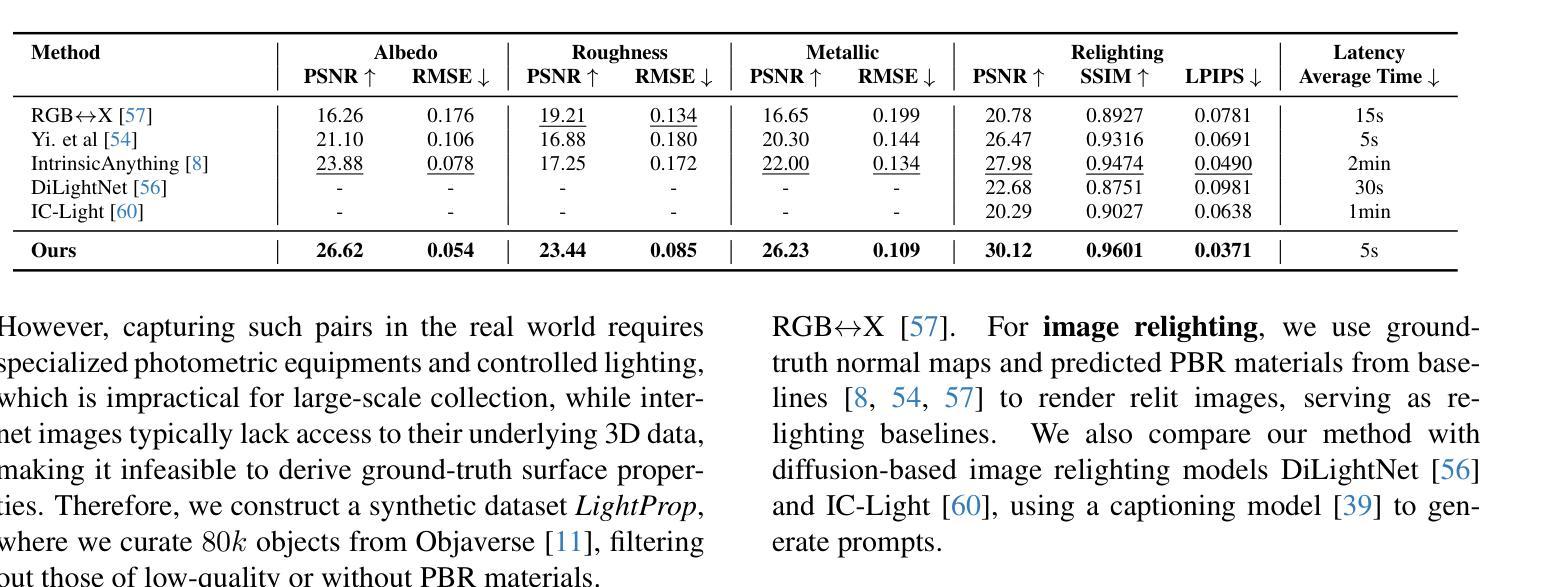

SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
Authors:Xueting Li, Ye Yuan, Shalini De Mello, Gilles Daviet, Jonathan Leaf, Miles Macklin, Jan Kautz, Umar Iqbal
We introduce SimAvatar, a framework designed to generate simulation-ready clothed 3D human avatars from a text prompt. Current text-driven human avatar generation methods either model hair, clothing, and the human body using a unified geometry or produce hair and garments that are not easily adaptable for simulation within existing simulation pipelines. The primary challenge lies in representing the hair and garment geometry in a way that allows leveraging established prior knowledge from foundational image diffusion models (e.g., Stable Diffusion) while being simulation-ready using either physics or neural simulators. To address this task, we propose a two-stage framework that combines the flexibility of 3D Gaussians with simulation-ready hair strands and garment meshes. Specifically, we first employ three text-conditioned 3D generative models to generate garment mesh, body shape and hair strands from the given text prompt. To leverage prior knowledge from foundational diffusion models, we attach 3D Gaussians to the body mesh, garment mesh, as well as hair strands and learn the avatar appearance through optimization. To drive the avatar given a pose sequence, we first apply physics simulators onto the garment meshes and hair strands. We then transfer the motion onto 3D Gaussians through carefully designed mechanisms for each body part. As a result, our synthesized avatars have vivid texture and realistic dynamic motion. To the best of our knowledge, our method is the first to produce highly realistic, fully simulation-ready 3D avatars, surpassing the capabilities of current approaches.
我们介绍了SimAvatar框架,该框架旨在从文本提示生成可用于模拟的穿衣3D人类头像。目前的文本驱动的人类头像生成方法要么使用统一几何对头发、服装和人体进行建模,要么生成在现有模拟管道中不易适应模拟的头发和服装。主要挑战在于以一种方式表示头发和服装几何,该方式允许利用来自基础图像扩散模型(例如Stable Diffusion)的现有先验知识,同时使用物理或神经模拟器进行模拟。为了解决此任务,我们提出了一种两阶段框架,该框架结合了3D高斯分布的灵活性与可用于模拟的头发束和服装网格。具体来说,我们首先采用三个文本条件化的3D生成模型,根据给定的文本提示生成服装网格、身体形状和头发束。为了利用基础扩散模型的先验知识,我们将3D高斯分布附加到身体网格、服装网格和头发束上,并通过优化学习头像外观。为了在给定的姿势序列驱动下驱动头像,我们首先对服装网格和头发束应用物理模拟器。然后,通过针对每个身体部位精心设计的机制,将运动转移到3D高斯分布上。因此,我们合成的头像具有生动的纹理和逼真的动态运动。据我们所知,我们的方法是第一个产生高度逼真、完全模拟就绪的3D头像的方法,超越了当前方法的能力。
论文及项目相关链接
PDF Project website: https://nvlabs.github.io/SimAvatar/
Summary
新一代文本驱动仿真化三维人物角色生成框架SimAvatar问世。通过结合文本提示与图像扩散模型,SimAvatar能生成逼真的仿真化三维人物角色,包括服装、发型等细节。采用两阶段方法,结合高斯分布模拟与物理仿真技术,实现角色纹理与动态运动的真实表现。目前该技术尚属领先。
Key Takeaways
- SimAvatar框架首次实现基于文本生成仿真化三维人物角色的技术。
- 利用文本提示与图像扩散模型生成服装、发型等细节。
- 采用两阶段方法结合高斯分布模拟与物理仿真技术,提高角色纹理和动态运动真实性。
- 角色动态表现利用物理仿真器驱动。运动效果可精准传输到不同身体部位的高斯分布模拟中。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为SimAvatar的框架,旨在解决如何从文本提示生成模拟就绪(simulation-ready)的、穿着服装的3D人体化身的问题。具体来说,论文试图解决以下几个挑战:
现有方法的局限性:当前基于文本驱动的人体化身生成方法要么使用统一的几何模型来建模头发、服装和人体,要么生成的头发和服装不容易适应现有的模拟流程。这些方法难以在保持模拟就绪性的同时利用基础图像扩散模型(例如Stable Diffusion)的先验知识。
头发和服装的几何表示:挑战在于如何表示头发和服装的几何形状,以便既能利用现有的扩散模型的先验知识,又能适应物理或神经网络模拟器进行模拟。
模拟准备性与细节表现:需要生成具有详细几何结构、真实纹理和动态服装及头发运动的3D化身,这些运动效果随姿势变化而变化,如头发流动和服装皱纹。
不同表示方式的整合:将当前模拟器使用的表示方式与文本驱动的化身生成流程所使用的表示方式相连接,前者通常需要干净、紧凑、平滑的网格或特定设计的发丝,后者则常采用隐式表示(如NeRF或SDF),这些虽然可以通过扩散模型的噪声信号进行优化,但难以转换为适合模拟的开放网格或发丝。
为了解决这些问题,SimAvatar框架采用了一个两阶段的方法,结合了3D高斯分布的灵活性和模拟就绪的头发丝和服装网格,使得生成的3D化身能够被现有的头发和服装模拟器轻松动画化,同时保持真实感和动态运动效果。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以归纳为以下几个领域:
文本到3D化身生成(Text to 3D Avatar Generation):
- ClipMatrix、AvatarClip、DreamAvatar、AvatarCraft、DreamHumans、DreamWaltz、AvatarVerse、HumanNorm、AvatarBooth等方法,这些方法通过文本或图像输入来生成和控制3D人体化身。
- TADA、GAvatar等方法,探索了不同的表示方式来建模化身,例如基于网格的方法和基于3D高斯的方法。
服装建模和模拟(Garment Modeling and Simulation):
- SMPL+D等方法,通过在SMPL人体网格上添加顶点位移来捕捉穿着服装的人体几何形状。
- BCNet、DeepCloth等方法,通过学习回归器直接预测服装类型和形状参数,或通过规范的UV表示来编码服装。
- 使用隐式无符号距离场(Unsigned Distance Fields, UDF)的方法,因其在建模任意拓扑和处理开放表面方面的灵活性而受到青睐。
头发建模和模拟(Hair Modeling and Simulation):
- 基于发丝表示的方法,因其与物理模拟器的兼容性和几何操作的便利性而受到青睐。
- 使用数据驱动先验的方法,基于扩散模型来估计合理的内部发丝,尽管在观测数据中这些发丝可能被遮挡。
- 使用3D高斯表示来有效模拟复杂头发纹理和不同发丝厚度的方法。
这些相关研究为SimAvatar框架的发展提供了理论基础和技术手段,特别是在3D人体建模、服装和头发的几何表示、物理模拟以及基于文本的生成模型等方面。SimAvatar框架通过结合这些领域的技术进展,提出了一种新的方法来生成具有独立层次的身体、服装和头发的模拟就绪3D化身。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SimAvatar的框架来解决从文本提示生成模拟就绪的3D人体化身的问题。该框架通过以下几个关键步骤来解决这个问题:
1. 两阶段框架
SimAvatar采用了一个两阶段框架,结合了3D高斯的灵活性和模拟就绪的头发丝以及服装网格。
2. 文本条件3D生成模型
- 服装网格生成:使用变分自编码器(VAE)学习服装几何分布,并训练一个条件潜在扩散模型从文本提示生成服装网格。
- 头发丝生成:利用基于扩散的文本到头发生成模型从文本提示创建头发丝。
- 身体形状生成:使用基于GPT的LLM模型预测头发丝和SMPL形状参数。
3. 3D高斯Splatting(3DGS)外观模型
- 在不同的人体部位(如头发、身体和服装)上附加3D高斯,并使用得分蒸馏采样(SDS)优化这些高斯属性,以学习真实的外观细节。
4. 动态模拟
- 服装模拟:使用神经网络模拟器(例如HOOD)根据目标身体姿势序列模拟服装网格。
- 头发模拟:使用头发模拟器根据目标身体网格序列和模拟的服装序列模拟头发丝。
5. 外观细节优化
- 使用SDS目标和预训练的文本到图像扩散模型来优化高斯的属性,从而精细化外观细节。
6. 特定部位的3D高斯定制
- 身体和服装网格:将3D高斯与身体和服装网格结合,并根据网格的运动来驱动这些高斯。
- 头发丝:为每根头发丝的每个线段分配一个3D高斯,并根据头发丝的运动来驱动这些高斯。
7. 着色模型
- 为了捕捉运动中的外观细节,如服装皱纹,将Phong着色模型纳入流程中。
8. 实验和评估
- 使用用户研究和定量评估(如VQAScore和CLIP分数)来验证SimAvatar在生成外观和动态运动方面相较于现有技术的优越性。
通过这些步骤,SimAvatar能够生成具有详细几何结构、真实纹理和动态服装及头发运动的3D化身,这些运动效果随姿势变化而变化,如头发流动和服装皱纹。这种方法不仅提高了生成化身的真实感,而且使得化身能够被现有的头发和服装模拟器轻松动画化。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估SimAvatar框架的性能:
1. 数据集
- 为了学习基于文本的服装扩散模型,作者使用了Garment Pattern Generator (GPG) 数据集和CLOTH3D 数据集,并利用GPT4v生成与服装网格配对的文本提示。
2. 定性评估
- 作者将SimAvatar生成的化身与几种最先进的文本驱动的3D化身生成方法(包括Fantasia3D、TADA和GAvatar)进行了视觉比较。
- 展示了在标准姿势下的合成化身以及动画化身,以展示SimAvatar在模拟动态效果(如服装皱纹和头发流动)方面的优势。
3. 用户研究
- 通过A/B用户研究定量评估SimAvatar。研究包括对22个提示的比较,生成静态360度视频和显示化身驱动的运动序列的视频。
- 用户被要求选择具有更好外观的方法和更注重运动的方法。研究收集了18名用户的540票,并在表格中展示了结果。
4. 定量评估
- 使用VQAScore和CLIP分数来定量比较SimAvatar与基线方法。
- VQAScore:评估生成资产与输入提示之间的对齐程度,特别适合涉及多个实体和关系的复杂提示。
- CLIP分数:虽然用于评估,但作者指出其在评估视觉质量和文本提示对齐方面的不可靠性。
5. 实施细节
- 描述了文本到服装扩散模型的训练细节和高斯化身学习的优化过程。
6. 层级训练策略
- 为了促进头发、身体和服装的解耦,作者采用了分别渲染每个层并使用不同提示进行优化的策略。
7. 消融研究
- 评估了不同模块的有效性,包括头发约束、提示工程和解耦训练策略,并展示了相应的定性结果。
8. 更多定性结果
- 提供了与基线方法的更多比较结果,并展示了SimAvatar方法的各个层(包括头发、面部、服装、身体和完整化身)的几何和纹理的额外结果。
这些实验全面评估了SimAvatar在生成现实感、可动画化3D服装化身方面的能力,并与现有技术进行了比较。通过这些实验,论文证明了SimAvatar在生成具有动态效果的高质量3D化身方面的有效性。
Q: 有什么可以进一步探索的点?
A: 论文在最后提出了几个可以进一步探索的点:
数据集多样性:当前的头发和服装生成模型是在特定的数据集上训练的,这可能因为训练数据的局限性而限制了生成的多样性。未来的工作可以探索方法,以生成超越现有数据集多样性的模拟就绪化身。
联合模拟:SimAvatar目前是顺序地模拟服装和头发,这在某些情况下(如穿着帽子的化身)可能会失败。实现头发和服装的联合模拟将使我们能够处理更复杂的服装。
配饰和鞋类:目前的SimAvatar框架中,配饰和鞋类仍然与身体或服装层纠缠在一起;未来的工作可以集中在生成完全分离的配饰和鞋类,以创建完全解耦的化身。
优化和计算效率:虽然SimAvatar能够生成高质量的3D化身,但是优化过程可能既耗时又计算密集。研究更高效的优化算法和计算策略可能是一个有价值的方向。
更复杂的纹理和外观细节:尽管SimAvatar在模拟动态服装和头发方面取得了进展,但在生成更复杂的纹理和外观细节方面仍有改进空间,例如模拟更逼真的织物纹理和更细致的光影效果。
交互性和实时应用:将SimAvatar应用于实时系统,如虚拟试衣或游戏,可能需要进一步的研究以确保实时性能和用户交互。
跨模态融合:探索将SimAvatar与其他模态的输入(如语音或视频)结合起来,以创建更丰富的交互体验。
更广泛的用户定制:提供更多的用户定制选项,允许用户调整化身的各种特征,包括面部特征、体型和风格。
评估和度量:开发和验证新的评估度量,以更准确地衡量3D化身生成系统的性能,特别是在动态模拟和真实感方面。
应用扩展:探索SimAvatar在其他领域的应用,如电影和游戏制作、虚拟助理、增强现实/虚拟现实和远程存在等。
这些方向都有助于推动3D人体化身生成技术的发展,并扩大其在不同领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为SimAvatar的框架,旨在从文本提示生成模拟就绪的3D人体化身,包括头发、服装和身体。以下是论文的主要内容总结:
问题定义:论文指出了现有文本驱动的3D人体化身生成方法的局限性,包括无法适应模拟流程的头发和服装表示,以及难以利用图像扩散模型的先验知识。
SimAvatar框架:提出了一个两阶段框架,首先使用文本条件的3D生成模型生成服装网格、身体形状和头发丝,然后通过优化附着在这些几何结构上的3D高斯来学习化身的外观。
服装和头发的模拟:利用物理模拟器和神经网络模拟器(如HOOD)来模拟服装和头发的运动,以实现动态效果,如流动的头发和服装皱纹。
3D高斯Splatting(3DGS):为了捕捉细节外观,框架在身体网格、服装网格和头发丝上附加3D高斯,并使用得分蒸馏采样(SDS)优化这些高斯的属性。
动态模拟:通过将运动从模拟的服装网格和头发丝转移到3D高斯,确保化身在不同姿势下的外观保持一致。
实验:通过定性和定量实验,包括用户研究和VQAScore评估,展示了SimAvatar在生成现实感和动态服装化身方面的优越性能。
未来工作:论文提出了几个未来研究方向,包括扩展数据集多样性、实现头发和服装的联合模拟、生成完全解耦的配饰和鞋类等。
总体而言,SimAvatar通过结合3D高斯的灵活性和模拟就绪的头发丝及服装网格,提出了一种新的方法来生成具有独立层次的身体、服装和头发的模拟就绪3D化身,这些化身在动画化时能够展现出逼真的动态效果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

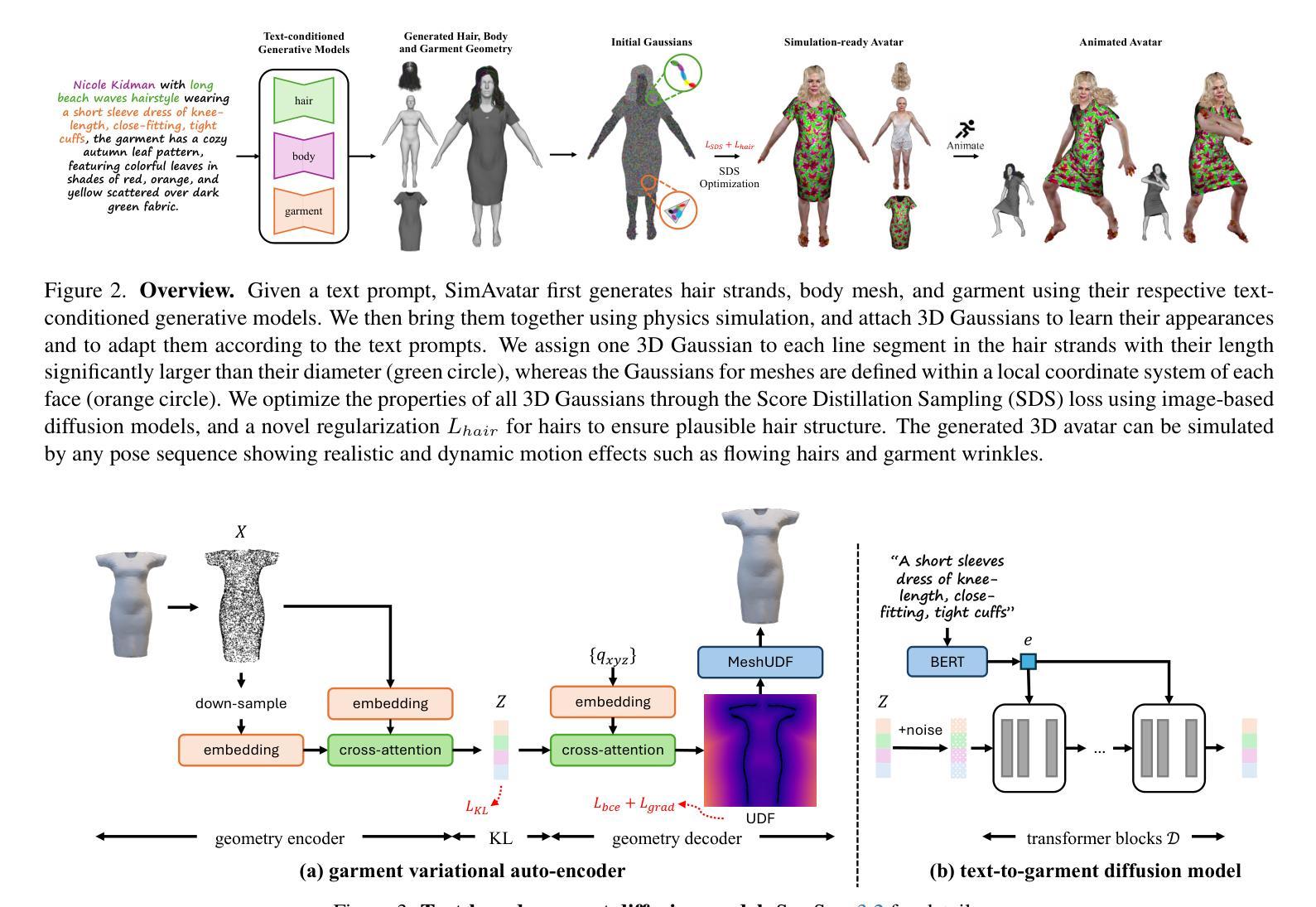
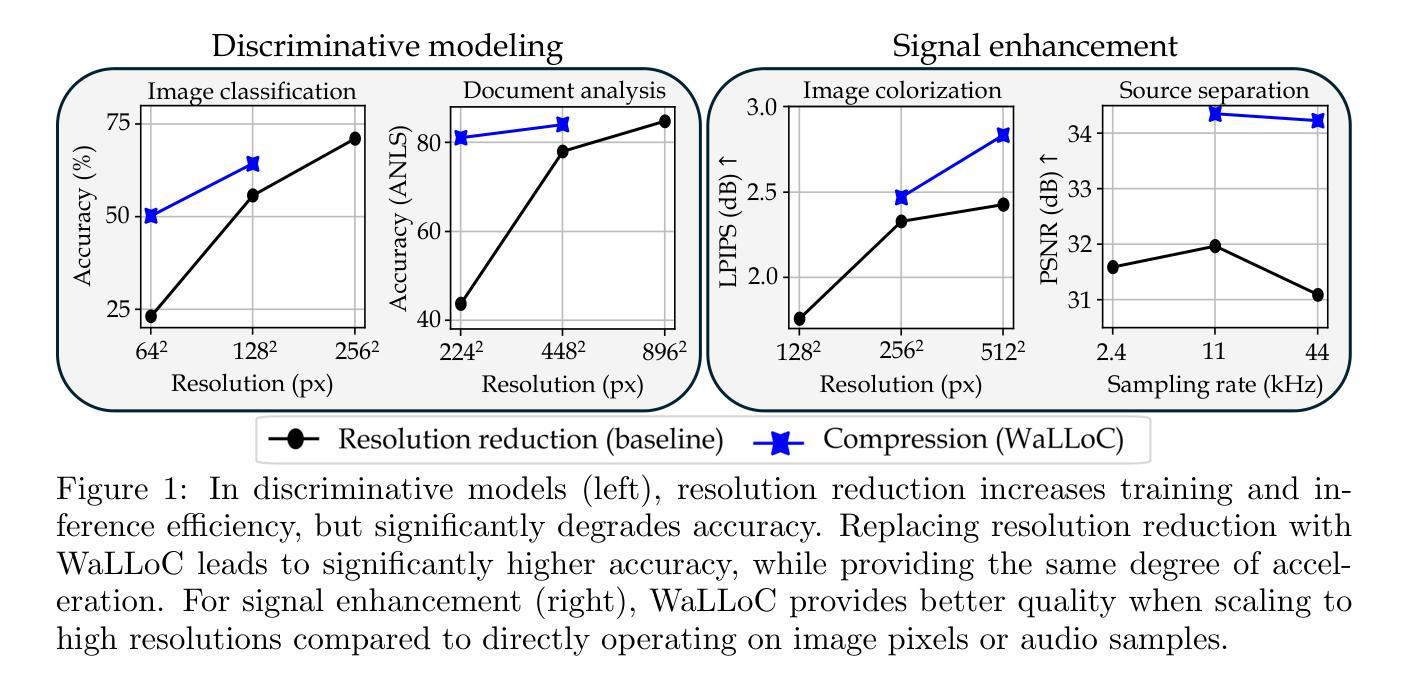
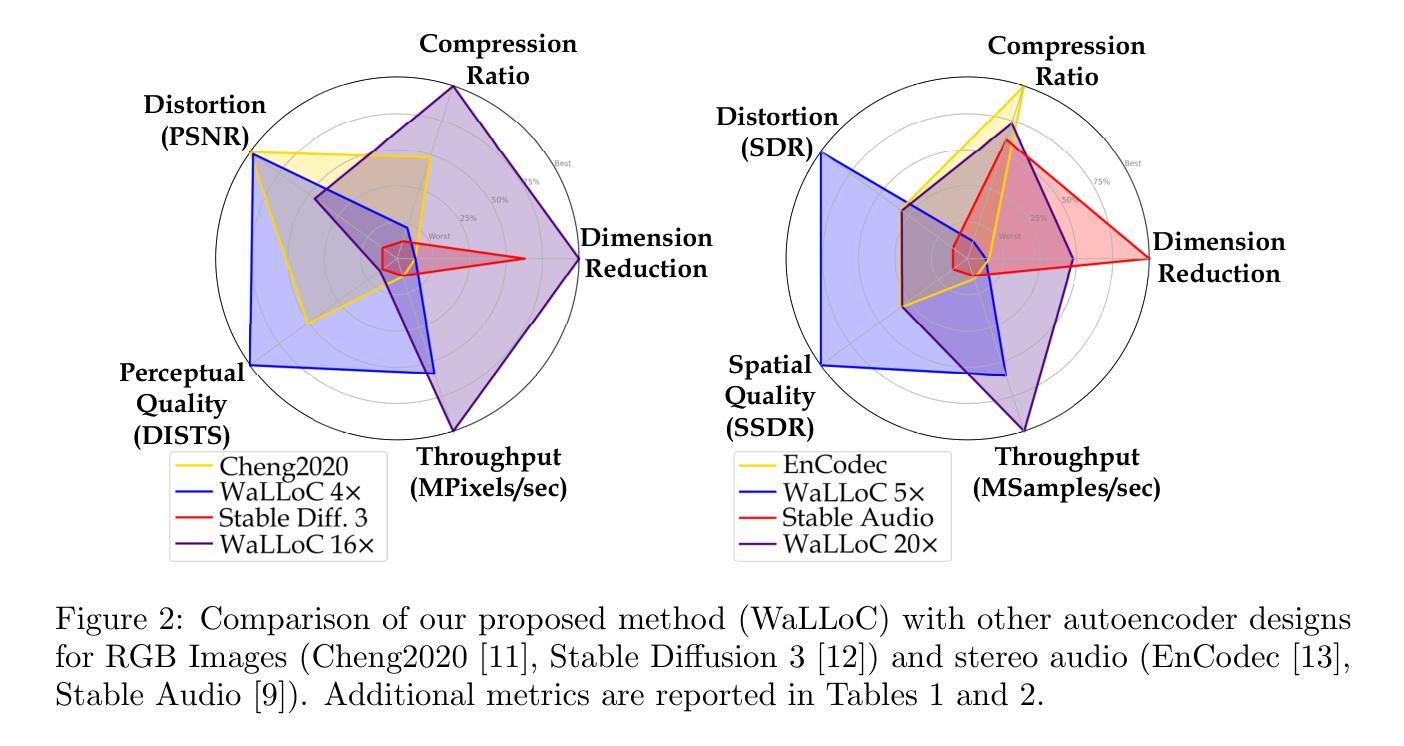
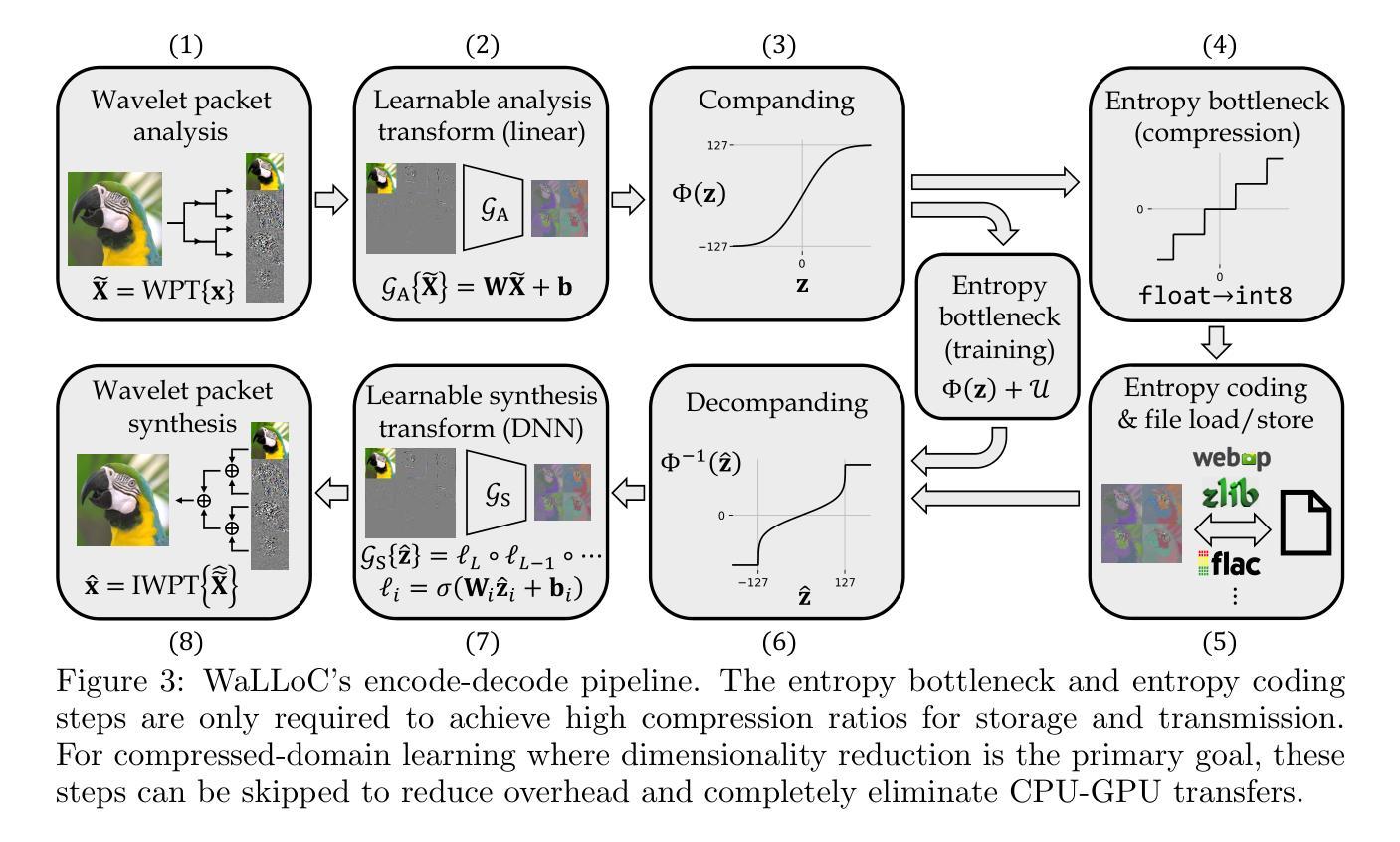
Learned Compression for Compressed Learning
Authors:Dan Jacobellis, Neeraja J. Yadwadkar
Modern sensors produce increasingly rich streams of high-resolution data. Due to resource constraints, machine learning systems discard the vast majority of this information via resolution reduction. Compressed-domain learning allows models to operate on compact latent representations, allowing higher effective resolution for the same budget. However, existing compression systems are not ideal for compressed learning. Linear transform coding and end-to-end learned compression systems reduce bitrate, but do not uniformly reduce dimensionality; thus, they do not meaningfully increase efficiency. Generative autoencoders reduce dimensionality, but their adversarial or perceptual objectives lead to significant information loss. To address these limitations, we introduce WaLLoC (Wavelet Learned Lossy Compression), a neural codec architecture that combines linear transform coding with nonlinear dimensionality-reducing autoencoders. WaLLoC sandwiches a shallow, asymmetric autoencoder and entropy bottleneck between an invertible wavelet packet transform. Across several key metrics, WaLLoC outperforms the autoencoders used in state-of-the-art latent diffusion models. WaLLoC does not require perceptual or adversarial losses to represent high-frequency detail, providing compatibility with modalities beyond RGB images and stereo audio. WaLLoC’s encoder consists almost entirely of linear operations, making it exceptionally efficient and suitable for mobile computing, remote sensing, and learning directly from compressed data. We demonstrate WaLLoC’s capability for compressed-domain learning across several tasks, including image classification, colorization, document understanding, and music source separation. Our code, experiments, and pre-trained audio and image codecs are available at https://ut-sysml.org/walloc
现代传感器产生越来越丰富的高分辨率数据流。由于资源限制,机器学习系统通过降低分辨率来丢弃绝大多数信息。压缩域学习允许模型在紧凑的潜在表示上运行,从而在相同的预算下实现更高的有效分辨率。然而,现有的压缩系统并不理想用于压缩学习。线性变换编码和端到端学习压缩系统降低了比特率,但并不统一地降低维度;因此,它们并没有有效地提高效率。生成自编码器降低了维度,但它们的对抗性或感知目标导致了信息的大量损失。为了解决这些局限性,我们引入了WaLLoC(Wavelet Learned Lossy Compression,小波学习有损压缩),这是一种神经网络编码架构,结合了线性变换编码和非线性降维自编码器。WaLLoC在可逆的小波包变换之间夹着一个浅的不对称自编码器和熵瓶颈。在多个关键指标上,WaLLoC的表现优于最先进潜伏扩散模型的自编码器。WaLLoC不需要感知或对抗性损失就能表示高频细节,为RGB图像和立体声音频以外的模式提供了兼容性。WaLLoC的编码器几乎完全由线性操作组成,使其非常高效,适用于移动计算、遥感以及直接从压缩数据中学习。我们在多个任务上展示了WaLLoC在压缩域学习的能力,包括图像分类、上色、文档理解和音乐源分离。我们的代码、实验以及预训练的音频和图像编码器可在https://ut-sysml.org/walloc上找到。
论文及项目相关链接
PDF Accepted as paper to 2025 IEEE Data Compression Conference
Summary:现代传感器产生大量丰富的高分辨率数据,但由于资源限制,机器学习系统通过降维来舍弃大部分信息。压缩域学习能让模型在压缩的潜在表示上运行,提高有效分辨率。然而,现有的压缩系统并不理想。线性变换编码和端到端学习压缩系统降低了比特率,但并不统一地降低维度,因此并未有效提高效率。为了解决这些问题,我们提出了WaLLoC(小波学习有损压缩),一种结合线性变换编码和非线性降维自动编码器的神经网络编码架构。WaLLoC在多个关键指标上优于现有扩散模型中使用的自动编码器。它不需要感知或对抗性损失就能表示高频细节,适用于非RGB图像和立体声频之外的模态。WaLLoC的编码器几乎完全由线性操作组成,使其非常高效,适用于移动计算、遥感以及直接从压缩数据中学习。我们在多个任务上展示了WaLLoC进行压缩域学习的能力。
Key Takeaways:
- 现代传感器产生大量高分辨率数据,但机器学习系统因资源限制常通过降维处理信息。
- 压缩域学习允许在紧凑的潜在表示上操作,提高有效分辨率。
- 现有压缩系统存在缺陷,无法统一降低维度以提高效率。
- WaLLoC结合线性变换编码和非线性降维自动编码器,以改进现有系统。
- WaLLoC在多个关键指标上超越现有自动编码器。
- WaLLoC无需感知或对抗性损失即可表示高频细节,适用于多种模态。
- WaLLoC的编码器高效且适用于多种场景,包括移动计算、遥感及从压缩数据中直接学习。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在资源受限的情况下,有效地利用高分辨率数据进行机器学习。具体来说,论文关注以下几个核心问题:
高分辨率数据的处理效率:现代传感器产生的高分辨率数据流非常丰富,但由于资源限制,大多数机器学习系统通过降低分辨率来丢弃这些信息,这导致了信息的大量损失。
压缩域学习(Compressed-domain learning):压缩域学习允许模型在紧凑的潜在表示上操作,从而在相同的预算下实现更高的有效分辨率。然而,现有的压缩系统并不理想,因为它们要么不均匀地降低维度,要么在保留细节方面存在问题。
现有压缩方法的局限性:包括线性变换编码方法、端到端学习压缩系统和生成自编码器在内的现有压缩方法,都不能很好地满足压缩域学习的需求。它们要么不能有效地降低维度,要么在编码效率上存在问题,要么在保留高频细节信息方面表现不佳。
为了解决这些问题,论文提出了一种名为WaLLoC(Wavelet Learned Lossy Compression)的神经编解码器架构,它结合了线性变换编码和非线性降维自编码器,旨在同时实现计算效率高的编码、高压缩比和均匀的维度降低,以支持压缩域学习。
Q: 有哪些相关研究?
A: 论文中提到了多个与压缩域学习(Compressed-domain learning)和神经网络压缩相关的研究工作。以下是一些主要的相关研究:
线性变换编码方法(Linear Transform Coding):
- 论文提到了传统的有损压缩标准,如JPEG和MP3,它们基于线性变换编码(LTC)。这些方法通过时间-频率变换集中信号能量,以达到高压缩比和最小的感知失真。
端到端学习压缩(End-to-end Learned Compression):
- 论文引用了Johannes Ballé的工作,他们提出了一种端到端优化的图像压缩方法,该方法通过非线性自编码器实现比传统LTC更高的压缩比。
- David Minnen和Nick Johnston的工作,他们推进了神经图像压缩的率失真计算前沿。
生成自编码器(Generative Autoencoders):
- 论文提到了Rombach等人的工作,他们使用潜在扩散模型进行高分辨率图像合成。
- 还有关于使用低分辨率生成模型与生成对抗自编码器(GADR-AE)配对的研究,这些模型在压缩域学习中取得了突破。
特定压缩算法和模型:
- 论文中还提到了Cheng等人的工作,他们提出了一种使用离散高斯混合似然和注意力模块的学习图像压缩方法。
- 论文还比较了WaLLoC与Stable Diffusion 3和EnCodec等其他自编码器设计。
压缩域学习的其他应用:
- 论文提到了EfficientNet模型,这是一个广泛使用的高效卷积神经网络模型,用于比较编码器的参数数量和计算复杂度。
- 还有关于使用WaLLoC进行图像分类、着色、文档理解和音乐源分离等任务的研究。
这些相关研究为WaLLoC的设计和评估提供了理论基础和技术对比,使得WaLLoC能够在压缩域学习中实现更高效的编码、更高的压缩比和更好的维度降低。
Q: 论文如何解决这个问题?
A: 论文通过提出WaLLoC(Wavelet Learned Lossy Compression)框架来解决压缩域学习中的问题。WaLLoC的设计旨在满足压缩域学习的三个关键要求:计算效率高的编码、高压缩比以及均匀的维度降低。以下是WaLLoC解决这些问题的具体方法:
计算效率高的编码:
- WaLLoC使用计算成本低廉且可逆的小波包变换(wavelet packet transform, WPT)来预先处理信号,以暴露信号冗余,从而减少自动编码(autoencoding)前的计算需求。
- WaLLoC的编码器主要由线性操作组成,几乎不需要参数,这使得编码过程非常高效,适合移动计算、远程传感和直接从压缩数据学习。
高压缩比:
- WaLLoC通过量化和熵编码实现高压缩比。为了使自动编码器的潜在表示对量化具有弹性,WaLLoC在训练期间引入了熵瓶颈(即添加噪声),以保证在推理时能够抵抗量化带来的失真。
- WaLLoC优化了噪声比例,以适应8位量化,并使用标准的无损编解码器(如PNG或WebP)进行熵编码,从而实现了比仅通过降低维度获得的压缩比高出12倍。
均匀的维度降低:
- WaLLoC的编码器将高维信号块投影到低维潜在表示中,实现了高达20倍的维度降低。
- WaLLoC的设计允许其作为分辨率降低的替代方案,同时在加速下游模型的同时提供更好的细节保留和下游准确性。
WaLLoC的实现:
- WaLLoC的编码器包括五个阶段:小波包变换(WPT)、学习分析变换、压缩处理、熵瓶颈和熵编码。
- 解码器则包括相反的操作:熵解码、解压缩处理、学习合成变换和逆WPT。
- WaLLoC在训练时采用均方重建误差最小化作为目标,并在不同的数据集上训练了多个编解码器。
压缩域学习的评估:
- 论文通过在多个机器学习任务(包括图像分类、着色、文档理解和音乐源分离)上评估WaLLoC,并与基于像素和基于样本的版本进行比较,展示了WaLLoC在压缩域学习中的有效性。
- WaLLoC在这些任务中表现出比简单分辨率降低更高的准确性,同时提供了相同的延迟和内存消耗改进。
通过这些方法,WaLLoC能够在保持高准确性的同时显著加速下游模型,实现了高达20倍的维度降低和最小的编码成本。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估WaLLoC(Wavelet Learned Lossy Compression)框架的性能和在压缩域学习中的有效性。以下是实验的具体内容:
压缩权衡分析:
- 比较WaLLoC与其他流行的传统和神经网络编解码器(包括WEBP、Cheng2020、Stable Diffusion 3和EnCodec)在五个关键指标上的表现:维度降低、压缩比、失真、感知质量和计算成本。
- 使用不同的平台(低功耗CPU、高功耗CPU和GPU)来测量这些编解码器的平均编码和解码吞吐量。
压缩学习和分辨率缩放:
- 在四个机器感知任务上评估WaLLoC:图像分类、图像着色、文档理解和音乐源分离。
- 对于图像分类和着色,训练了带有条件位置编码的ViT-Ti模型,并在ImageNet-1k数据集上进行测试。
- 对于音乐源分离,训练了一个CNN来分离MUSDB18-HQ中的音乐片段中的声乐轨道。
- 对于文档理解,使用了PaliGemma模型,并在DocVQA数据集上报告了平均归一化的Levenshtein相似度(ANLS)。
分辨率缩放策略:
- 对于图像分类,通过减少输入序列长度(4倍或16倍)来比较WaLLoC编码的输入与相同WaLLoC潜在表示上训练的模型的准确性。
- 对于文档理解,由于训练PaliGemma模型超出了工作范围,因此使用最高分辨率的PaliGemma变体在解码的WaLLoC表示上进行评估。
- 对于图像着色和音乐源分离,通过增加输入补丁大小来保持序列长度和所需计算大致恒定。
压缩域学习和分辨率缩放的结果:
- 展示了使用WaLLoC派生表示代替分辨率降低时性能的提高。在所有四个任务中,WaLLoC都提供了比简单分辨率降低更高的准确性,同时提供了相同的延迟和内存消耗改进。
这些实验全面评估了WaLLoC在压缩域学习中的性能,并与现有的压缩方法和直接在原始数据上操作的方法进行了比较。结果表明,WaLLoC在保持准确性的同时显著提高了计算效率和压缩比。
Q: 有什么可以进一步探索的点?
A: 论文在最后提出了一些未来工作的方向,指出了可以进一步探索的点:
扩展到高分辨率信号类型:
- WaLLoC可以扩展到其他高分辨率信号类型,例如高光谱图像或全切片显微镜图像。这些领域对现有压缩方法提出了额外的挑战,但由于信号冗余度更高,因此采用WaLLoC可能获得更大的潜在好处。
优化和改进编解码器架构:
- 进一步研究和优化WaLLoC的编解码器架构,以提高压缩效率和降低计算成本,特别是在资源受限的环境中。
探索不同的小波变换和滤波器:
- 研究不同的小波变换和滤波器,以找到在特定应用中提供最佳能量压缩和计算效率的组合。
增强模型的泛化能力:
- 探索如何提高WaLLoC模型在不同数据集和任务中的泛化能力,使其能够适应更广泛的应用场景。
提高压缩比和感知质量:
- 继续寻找提高压缩比和感知质量之间的平衡,特别是在不同的应用领域中。
实时压缩和去压缩的应用:
- 研究WaLLoC在需要实时压缩和去压缩的应用中的性能,例如视频会议、流媒体服务等。
跨模态学习:
- 探索WaLLoC在跨模态学习中的应用,例如结合图像和音频数据进行联合学习。
模型压缩和加速:
- 研究WaLLoC在模型压缩和加速方面的潜力,特别是在移动和边缘计算设备上。
对抗性攻击和模型鲁棒性:
- 研究WaLLoC模型对于对抗性攻击的鲁棒性,并探索提高模型鲁棒性的方法。
开源社区和工业界的合作:
- 与开源社区和工业界合作,进一步开发和优化WaLLoC框架,以及探索其在实际应用中的有效性。
这些方向为未来的研究提供了明确的道路,并有助于推动压缩域学习技术的发展和应用。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题背景:
- 现代传感器产生大量高分辨率数据,但机器学习系统因资源限制而丢弃大部分信息。
- 压缩域学习允许模型在压缩的潜在表示上操作,以提高效率和降低计算成本,但现有压缩方法并不理想。
WaLLoC框架:
- 提出了WaLLoC(Wavelet Learned Lossy Compression),一个结合线性变换编码和非线性自编码器的神经编解码器架构。
- WaLLoC旨在满足压缩域学习的三个关键要求:计算效率高的编码、高压缩比和均匀的维度降低。
主要贡献:
- 评估了现有压缩方法(线性变换编码、端到端学习压缩和生成自编码器)的局限性。
- 构建了适用于RGB图像和立体声音频的WaLLoC编解码器,并在多个关键指标上超越了现有的自编码器设计。
- 通过压缩域操作加速了多种机器学习模型,并在图像分类、着色、文档理解和音乐源分离等任务中展示了WaLLoC的有效性。
WaLLoC设计和实现:
- WaLLoC利用小波包变换(WPT)和熵瓶颈技术,实现了计算效率高的编码和高压缩比。
- WaLLoC的编码器主要由线性操作组成,适合移动计算和直接从压缩数据学习。
实验评估:
- 在多个任务上评估了WaLLoC,并与基于像素和基于样本的方法进行了比较。
- 结果表明,WaLLoC在保持准确性的同时显著提高了计算效率和压缩比。
未来工作:
- 探索将WaLLoC扩展到其他高分辨率信号类型,如高光谱图像或全切片显微镜图像。
- 进一步优化WaLLoC架构,提高压缩效率和降低计算成本。
总体而言,这篇论文提出了一个创新的压缩框架WaLLoC,旨在提高压缩域学习的效率和效果,并通过一系列实验验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Are Conditional Latent Diffusion Models Effective for Image Restoration?
Authors:Yunchen Yuan, Junyuan Xiao, Xinjie Li
Recent advancements in image restoration increasingly employ conditional latent diffusion models (CLDMs). While these models have demonstrated notable performance improvements in recent years, this work questions their suitability for IR tasks. CLDMs excel in capturing high-level semantic correlations, making them effective for tasks like text-to-image generation with spatial conditioning. However, in IR, where the goal is to enhance image perceptual quality, these models face difficulty of modeling the relationship between degraded images and ground truth images using a low-level representation. To support our claims, we compare state-of-the-art CLDMs with traditional image restoration models through extensive experiments. Results reveal that despite the scaling advantages of CLDMs, they suffer from high distortion and semantic deviation, especially in cases with minimal degradation, where traditional methods outperform them. Additionally, we perform empirical studies to examine the impact of various CLDM design elements on their restoration performance. We hope this finding inspires a reexamination of current CLDM-based IR solutions, opening up more opportunities in this field.
近期图像修复领域越来越广泛地应用了条件潜在扩散模型(CLDM)。虽然这些模型在近年来表现出了显著的性能提升,但本文对其在图像修复任务中的适用性提出了质疑。CLDM在捕捉高级语义关联方面表现出色,因此在空间条件下进行文本到图像生成等任务时非常有效。然而,在图像感知质量提升的图像修复任务中,这些模型在使用低级表示法建模退化图像和原始图像之间的关系时面临困难。为了支持我们的观点,我们通过大量实验将最先进的CLDM与传统图像修复模型进行了比较。结果表明,尽管CLDM具有规模优势,但在失真和语义偏差方面存在缺陷,尤其是在退化轻微的情况下,传统方法优于它们。此外,我们还通过实证研究检验了不同CLDM设计元素对修复性能的影响。我们希望这一发现能激发对当前基于CLDM的图像修复解决方案的重新审视,为该领域带来更多的机会。
论文及项目相关链接
PDF 16 pages, 12 figures, submitted to IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR 2025)
Summary
条件潜在扩散模型(CLDM)在图像修复任务上的适用性受到质疑。虽然CLDM在捕捉高级语义关联方面表现出色,适用于文本到图像生成等任务,但在图像修复中旨在提高图像感知质量的任务中,它们难以使用低级表示法来模拟退化图像和原始图像之间的关系。对比实验结果显示,尽管CLDM具有规模优势,但在轻微退化的场景中,传统方法表现更佳,存在较少的失真和语义偏差。此外,我们对CLDM的不同设计元素进行了实证研究,以评估其对修复性能的影响。
Key Takeaways
- 条件潜在扩散模型(CLDM)在图像修复任务上的适用性受到挑战。
- CLDM擅长捕捉高级语义关联,但在图像修复任务中面临建模退化图像和原始图像关系的困难。
- 对比实验显示,在轻微退化的场景中,传统方法表现优于CLDM。
- CLDM在高失真和语义偏差方面存在挑战。
- 通过对CLDM的不同设计元素进行实证研究,以评估其对图像修复性能的影响。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是评估条件潜在扩散模型(Conditional Latent Diffusion Models, CLDMs)在图像恢复(Image Restoration, IR)任务中的有效性。具体来说,论文提出了以下几个关键点:
CLDMs在图像恢复任务中的适用性质疑:尽管CLDMs在捕获高级语义相关性方面表现出色,适用于文本到图像的生成等任务,但在图像恢复任务中,这些模型面临着在低级表示中建模退化图像与真实图像之间关系的困难。
CLDMs与传统图像恢复模型的性能比较:通过广泛的实验比较,论文发现尽管CLDMs具有扩展优势,但在保持细节和实现良好失真度量方面表现不佳,尤其是在退化程度较低的情况下,传统方法的表现优于CLDMs。
CLDMs在图像恢复中的语义偏差问题:CLDMs在恢复过程中经常改变语义细节,导致与原始输入语义的偏差,这对于需要精确保真度的恢复任务来说尤其成问题。
CLDMs设计与图像恢复任务目标的不一致性:论文通过对CLDM架构的关键设计元素(如潜在空间表示、扩散过程中的噪声处理和多时间步采样)进行实证分析,发现这些元素对恢复质量的影响,并指出当前CLDM解决方案在架构上与图像恢复任务的目标不一致。
CLDMs在资源利用与模型性能之间的差距:尽管CLDMs在模型规模和训练数据量方面具有显著优势,但与传统模型相比,性能提升有限,并且引入了新的挑战,如失真和语义偏差。
综上所述,论文的核心问题是质疑CLDMs在图像恢复任务中的有效性,并通过对CLDMs与传统方法的比较分析,揭示了CLDMs在这一领域的局限性和潜在问题。
Q: 有哪些相关研究?
A: 论文中提到了多个与条件潜在扩散模型(CLDMs)和图像恢复(IR)相关的研究工作。以下是一些主要的相关研究:
图像恢复的传统方法:
- [2] J Amudha et al. 提供了数字图像恢复的综述。
- [4] Chaofeng Chen et al. 讨论了真实世界盲超分辨率通过特征匹配。
- [7] Rusul Sabah Jebur et al. 提供了深度学习中图像去噪的综述。
- [8] ChuMiao Li 提供了图像去模糊的综述。
- [9] Chongyi Li et al. 提供了深度学习在低光照图像和视频增强中的综述。
- [10] Haoying Li et al. 讨论了真实世界的深度局部运动去模糊。
扩散模型(DMs)和条件潜在扩散模型(CLDMs):
- [6] Jonathan Ho et al. 提出了去噪扩散概率模型。
- [11] Ming Li et al. 提出了Controlnet++,用于改善条件控制。
- [12] Xinqi Lin et al. 提出了DiffBIR,一种用于盲图像恢复的生成扩散先验方法。
- [16] Robin Rombach et al. 提出了高分辨率图像合成的潜在扩散模型。
- [26] Bin Xia et al. 提出了DiffIR,一种用于图像恢复的高效扩散模型。
- [27] Fanghua Yu et al. 讨论了模型扩展以实现野外照片真实感图像恢复。
图像恢复的深度学习方法:
- [17] Jingwen Su et al. 提供了图像恢复的深度学习方法的综述。
- [18] Xin Tao et al. 提出了用于深度图像去模糊的尺度递归网络。
- [19] Yang Tao et al. 提出了像素感知稳定扩散,用于真实图像超分辨率和个性化风格化。
- [20] Radu Timofte et al. 提供了NTIRE 2017单图像超分辨率挑战赛的方法和结果。
- [21] Fu-Jen Tsai et al. 提出了Stripformer,一种用于快速图像去模糊的条形变换器。
- [22] Jianyi Wang et al. 利用扩散先验进行真实世界图像超分辨率。
- [23] Xintao Wang et al. 提出了Real-ESRGAN,一种用纯合成数据训练真实世界盲超分辨率的方法。
- [24] Zhihao Wang et al. 提供了深度学习在图像超分辨率中的综述。
- [25] Jay Whang et al. 通过随机细化进行去模糊。
这些研究涵盖了图像恢复的传统方法、深度学习方法,以及扩散模型在图像生成和恢复中的应用。这些工作为理解CLDMs在图像恢复中的有效性提供了背景,并与本文的研究结果形成对比。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决对条件潜在扩散模型(CLDMs)在图像恢复任务中的有效性的质疑问题:
比较实验:
- 论文通过广泛的实验比较了当前最先进的基于CLDM的图像恢复模型与传统的深度学习方法。实验涉及多种任务,包括超分辨率和去模糊等经典图像恢复任务。
引入新的评估指标:
- 论文提出了一个新的评估指标“对齐(Alignment)”,用于衡量恢复图像与其退化输入之间的语义一致性。这对于评估现实世界中的盲图像恢复(BIR)任务尤为重要,因为这些任务缺乏对应的真实图像作为参考。
实证分析CLDM设计元素:
- 论文对CLDM的关键设计元素进行了实证分析,包括潜在空间表示、扩散过程中的噪声处理以及多时间步采样,以评估这些元素对恢复质量的影响。
资源利用与模型性能的对比:
- 论文分析了CLDM模型在资源利用(如模型规模和训练数据量)与实际性能之间的差距,揭示了CLDMs可能存在的性能限制。
提出未来研究方向:
- 论文指出了需要进一步探索的领域,包括更全面的模型和任务评估、深入探索影响因素、开发针对图像恢复的对齐度量方法,以及改进CLDM架构以更好地适应图像恢复任务。
结论和建议:
- 论文总结了CLDMs在图像恢复中的局限性,并建议未来的研究应该重新审视基于CLDM的图像恢复解决方案,开发更好的评估指标,并设计超越当前限制的创新模型。
通过这些步骤,论文不仅质疑了CLDMs在图像恢复任务中的有效性,而且提供了改进现有解决方案和推动该领域发展的见解和建议。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来比较条件潜在扩散模型(CLDMs)与传统图像恢复方法的性能,并分析了CLDMs在图像恢复任务中的有效性。具体的实验包括:
性能比较实验:
- 比较了最先进的CLDM模型与传统深度学习方法在多种图像恢复任务(包括超分辨率和去模糊)上的性能。
- 使用了不同的退化设置(如不同的下采样率和模糊核大小)来评估模型在不同退化水平下的表现。
信息保留率分析:
- 引入了信息保留率(information retention rate, γ)的概念来量化退化过程中的信息损失,并评估不同模型在不同退化水平上的表现。
语义偏差分析:
- 通过视觉和定量的方式分析了CLDM模型在恢复过程中引入的语义偏差问题。
- 提出了“对齐(Alignment)”作为一个新的评估指标,并使用DINOv2模型的嵌入差异来估计语义偏差。
资源利用与性能对比:
- 分析了CLDM模型在模型规模和训练数据量方面的优势与传统模型相比的性能提升,揭示了资源利用和模型性能之间的差距。
CLDM设计元素分析:
- 对CLDM的关键设计元素(如潜在空间表示、扩散过程中的噪声处理和多时间步采样)进行了实证分析,以评估这些元素对恢复质量的影响。
不同噪声水平的影响:
- 通过调整起始时间步来改变采样过程中的噪声水平,分析了不同噪声水平对图像恢复性能的影响。
多时间步采样的有效性:
- 通过改变采样步数来评估多时间步采样对图像恢复性能的影响。
一步预测能力测试:
- 测试了网络从纯高斯噪声开始预测的能力,并分析了多时间步采样过程中的性能变化。
这些实验提供了全面的性能评估,并揭示了CLDMs在图像恢复任务中的潜在问题和局限性。通过这些实验结果,论文挑战了CLDMs在图像恢复任务中的有效性,并为未来的研究方向提供了指导。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
更广泛的模型和任务评估:
- 对更多的模型和多样化的图像恢复任务设置进行广泛的测试,以获得更全面和可推广的结论。
- 开发标准化的基准测试协议,以评估模型在不同退化水平下的性能。
影响因素的深入探索:
- 研究不同的训练配置,例如在潜在空间、像素空间或基于特征的损失函数,动态噪声水平和时间步控制对性能的影响。
- 探讨恢复引导级别、无分类器引导和采样过程中噪声注入等因素的影响。
开发对齐度量指标:
- 鉴于缺乏成熟的度量指标,开发专门用于评估图像恢复中语义一致性的先进度量方法。
- 这些新指标将为图像恢复任务的评估提供新的方法。
优化CLDM架构:
- 调整CLDM架构以更好地适应图像恢复任务,解决高失真、对低退化样本的性能下降和语义偏差等挑战。
- 鉴于CLDM在数据可扩展性、模型大小和推理效率方面的优势,优化其架构可能会释放出超越当前限制的显著潜力。
改进评估框架:
- 结合对齐和感知评估,特别是对于现实世界的盲图像恢复(BIR)任务,开发更有效的评估框架。
探索新的训练策略:
- 研究新的训练策略,可能包括对抗性训练、多任务学习和自监督学习等,以提高CLDMs在图像恢复任务中的性能。
跨领域应用:
- 探索CLDMs在其他低级视觉任务中的应用,例如图像分割、目标检测等,并评估其有效性。
计算效率和实际部署:
- 研究如何提高CLDMs的计算效率,使其更适合实际部署和应用。
解释性和可视化分析:
- 提供更多关于CLDMs在图像恢复过程中的解释性和可视化分析,以更好地理解其行为和决策过程。
这些探索点不仅可以推动CLDMs在图像恢复领域的研究进展,还可能揭示新的研究方向和应用前景。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了条件潜在扩散模型(Conditional Latent Diffusion Models, CLDMs)在图像恢复任务中的有效性,并对其适用性提出了质疑。以下是论文的主要内容总结:
问题提出:
- 论文指出尽管CLDMs在捕获高级语义相关性方面表现出色,但其在图像恢复(IR)任务中的有效性尚未得到充分验证。IR任务要求精确建模低级表示,而CLDMs在这一领域面临挑战。
实验比较:
- 通过广泛实验比较了CLDMs与传统图像恢复模型,发现CLDMs在保持细节和失真度量方面表现不佳,尤其在退化程度较低的情况下。
语义偏差问题:
- 论文发现CLDMs在恢复过程中常引入语义偏差,提出了“对齐(Alignment)”作为新的评估指标,以衡量恢复图像与退化输入之间的语义一致性。
资源利用与性能对比:
- 分析了CLDMs在资源利用(模型规模和数据量)与实际性能之间的差距,指出CLDMs可能存在的性能限制。
CLDM设计元素分析:
- 对CLDM的关键设计元素(如潜在空间表示、噪声处理和多时间步采样)进行了实证分析,发现这些元素对恢复质量的影响有限。
结论与建议:
- 论文得出结论,CLDMs在图像恢复任务中存在显著局限性,并建议未来的研究应重新审视基于CLDM的图像恢复解决方案,并开发更好的评估指标和创新模型。
未来研究方向:
- 提出了进一步探索的领域,包括更全面的模型评估、深入探索影响因素、开发新的对齐度量指标,以及改进CLDM架构以更好地适应图像恢复任务。
总体而言,这篇论文挑战了CLDMs在图像恢复领域的应用,并提供了一系列的实验结果和分析来支持其观点,同时为未来的研究方向提供了指导。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

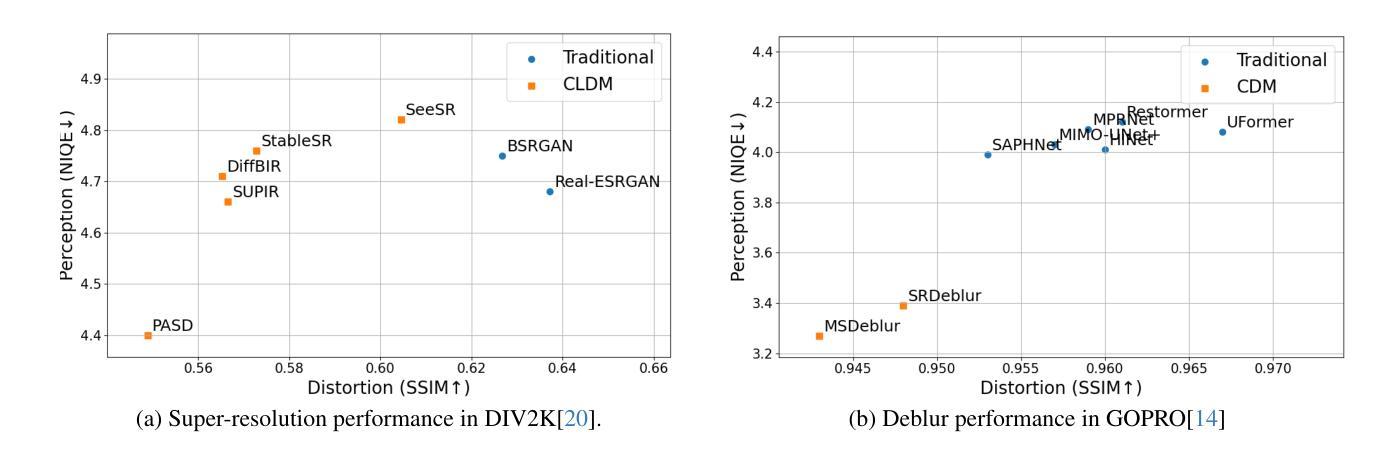

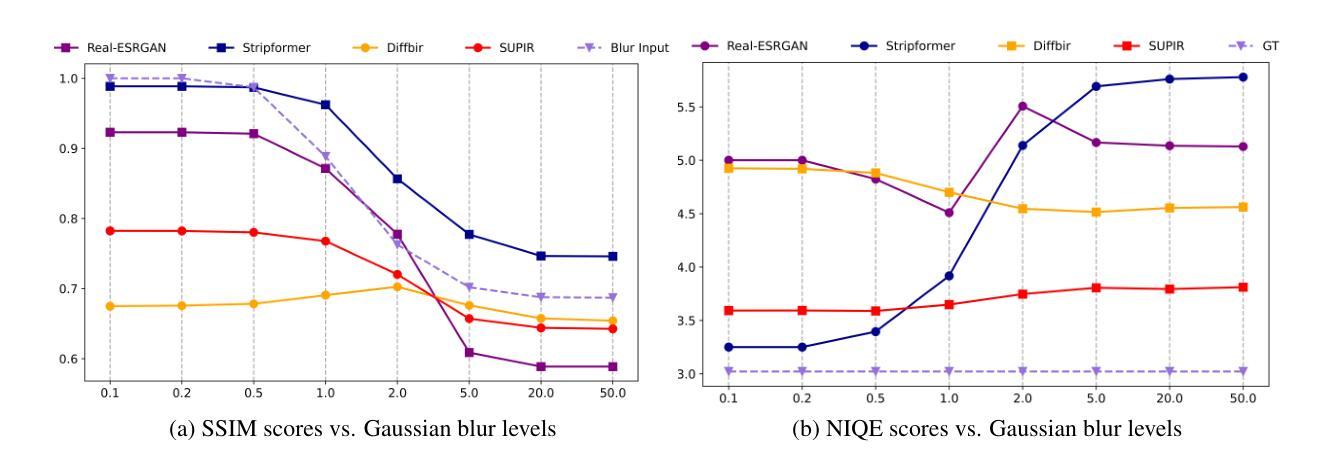
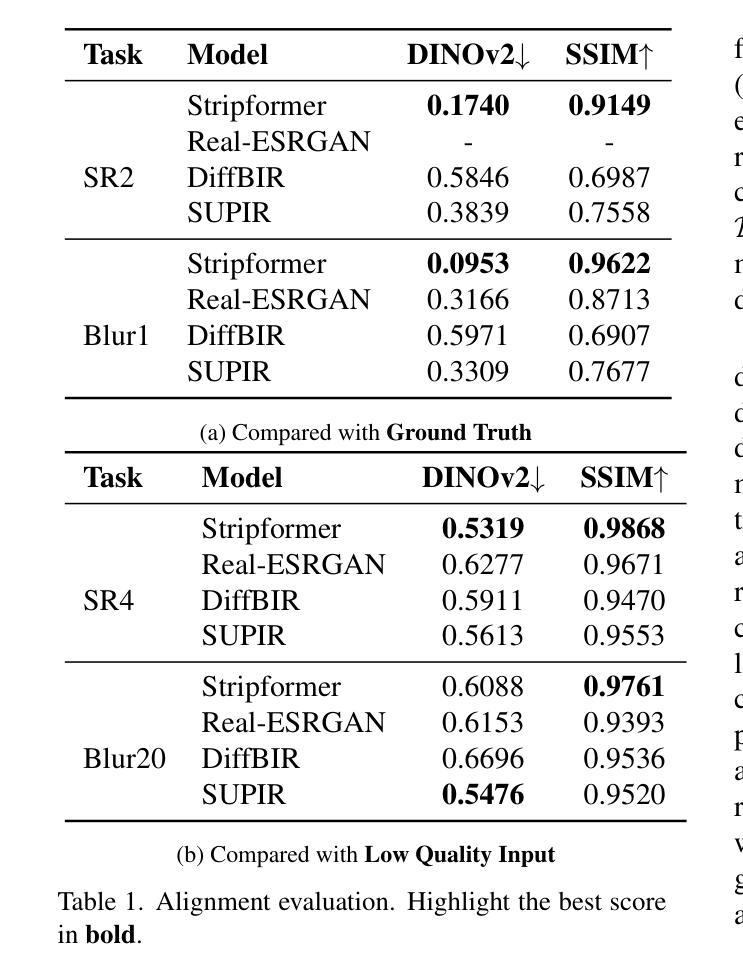
ExpRDiff: Short-exposure Guided Diffusion Model for Realistic Local Motion Deblurring
Authors:Zhongbao Yang, Jiangxin Dong, Jinhui Tang, Jinshan Pan
Removing blur caused by moving objects is challenging, as the moving objects are usually significantly blurry while the static background remains clear. Existing methods that rely on local blur detection often suffer from inaccuracies and cannot generate satisfactory results when focusing solely on blurred regions. To overcome these problems, we first design a context-based local blur detection module that incorporates additional contextual information to improve the identification of blurry regions. Considering that modern smartphones are equipped with cameras capable of providing short-exposure images, we develop a blur-aware guided image restoration method that utilizes sharp structural details from short-exposure images, facilitating accurate reconstruction of heavily blurred regions. Furthermore, to restore images realistically and visually-pleasant, we develop a short-exposure guided diffusion model that explores useful features from short-exposure images and blurred regions to better constrain the diffusion process. Finally, we formulate the above components into a simple yet effective network, named ExpRDiff. Experimental results show that ExpRDiff performs favorably against state-of-the-art methods.
去除运动物体造成的模糊是一项挑战,因为运动物体通常模糊严重,而静态背景保持清晰。现有方法大多依赖于局部模糊检测,但往往存在不准确的问题,并且当仅专注于模糊区域时,无法产生令人满意的结果。为了克服这些问题,我们首先设计了一个基于上下文的局部模糊检测模块,该模块结合了额外的上下文信息,提高了对模糊区域的识别能力。考虑到现代智能手机配备了能够拍摄短曝光图像的相机,我们开发了一种模糊感知引导图像恢复方法,该方法利用短曝光图像中的锐利结构细节,能够准确重建严重模糊的区域。此外,为了以逼真的方式恢复图像并使其视觉上令人愉悦,我们开发了一种短曝光引导扩散模型,该模型从短曝光图像和模糊区域中提取有用特征,以更好地约束扩散过程。最后,我们将上述组件整合成一个简单有效的网络,名为ExpRDiff。实验结果表明,ExpRDiff与最先进的方法相比表现良好。
论文及项目相关链接
PDF Project website: https://github.com/yzb1997/ExpRDiff
Summary
本文提出一种基于上下文信息的局部模糊检测模块,结合附加的上下文信息来提高模糊区域的识别准确性。同时,利用智能手机的短曝光图像功能,开发了一种模糊感知引导图像恢复方法,利用短曝光图像的清晰结构细节来准确重建模糊区域。此外,为了真实且视觉愉悦地恢复图像,还提出了一种短曝光引导扩散模型,从短曝光图像和模糊区域中提取有用特征来更好地约束扩散过程。整体方案被整合到一个简洁有效的网络ExpRDiff中,实验结果优于现有方法。
Key Takeaways
- 文中提出了一种基于上下文信息的局部模糊检测模块,以提高模糊区域的识别准确性。
- 利用智能手机的短曝光图像功能,提出了一种模糊感知引导图像恢复方法。
- 通过短曝光图像提供清晰结构细节,以准确重建模糊区域。
- 提出了一种短曝光引导扩散模型,结合模糊区域和短曝光图像的有用特征来约束扩散过程。
- 上述方案被整合到一个简洁有效的网络ExpRDiff中。
- ExpRDiff网络在去除移动物体造成的模糊方面表现出优越性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何去除由于移动物体引起的局部运动模糊。具体来说,挑战在于移动物体通常会变得非常模糊,而静态背景保持清晰。现有的依赖于局部模糊检测的方法往往因为准确性不足而无法生成令人满意的结果,尤其是在仅关注模糊区域时。为了克服这些问题,论文提出了一种新的方法,称为ExpRDiff,它通过以下几个关键步骤来改善局部去模糊和图像恢复的质量:
上下文基础的局部模糊检测模块:通过整合额外的上下文信息来改善对模糊区域的识别。
短曝光图像引导的图像恢复方法:利用短曝光图像中锐利的结构细节,帮助准确重建严重模糊的区域。
短曝光引导的扩散模型:探索短曝光图像和检测到的模糊区域中的特征,以更好地约束扩散过程,实现更逼真的图像恢复。
论文的目标是开发一个有效的方法,能够同时处理清晰背景和模糊物体,以获得更好的图像恢复效果。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个类别:
1. 基于手工先验的方法(Hand-crafted prior-based methods)
这些方法使用具有更清晰结构信息的参考图像作为有效先验来共同解决图像去模糊问题。例如:
- Chen et al. [2] 提出了利用两个不同模糊程度的图像进行联合去模糊的方法。
- Zhuo et al. [29] 和 Yuan et al. [24] 分别利用闪光灯图像和噪声图像作为参考图像来执行图像去模糊。
2. 基于深度学习的方法(Deep learning-based methods)
为了解决更复杂的图像去模糊情况并避免手动设计图像先验的局限性,研究者探索了基于深度学习的图像去模糊方法。例如:
- Zamir et al. [25] 提出了一个多阶段渐进式图像去模糊方法。
- Chen et al. [3] 提出了一个计算效率高的简单基线模型,该模型认为非线性激活函数是非必要的,并将其替换。
- Kong et al. [7] 和其他研究者探索了在高频域中计算注意力权重的转换器,以降低计算复杂度。
3. 基于扩散的图像恢复(Diffusion-based image restoration)
受到StableDiffusion-XL (SDXL) [16] 在图像生成领域的出色表现的启发,研究者发展了基于扩散的方法用于图像恢复。例如:
- Lin et al. [12] 和其他研究者利用退化网络从输入的退化图像生成清晰的图像或清晰的潜在表示,然后将其用于去噪模型和ControlNet [28] 来控制扩散过程并生成高质量的图像。
这些相关研究为本文提出的ExpRDiff方法提供了理论基础和技术背景。ExpRDiff通过结合短曝光图像和模糊区域的信息,旨在改善局部去模糊和实现更逼真的图像恢复效果。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为ExpRDiff的方法来解决局部运动模糊的问题,该方法包括以下几个关键组件:
1. 上下文基础的局部模糊检测模块(Context-based Local Blur Detection Module)
- 该模块通过整合额外的上下文信息来增强对模糊区域的识别能力。
- 将输入的模糊图像分割成多个非重叠的块,并使用一个简单的网络来估计每个块的置信度图,以区分模糊和清晰的区域。
2. 短曝光图像引导的图像恢复(Blurry-Aware Guided Image Restoration)
- 利用短曝光图像中的锐利结构细节,辅助重建严重模糊区域。
- 通过一个基于阈值的方法和优化问题求解,实现对模糊区域和清晰区域的区分处理,以改善图像恢复质量。
3. 短曝光引导的扩散模型(Short-Exposure Guided Diffusion Model)
- 为了恢复具有丰富细节的真实图像,该模型利用短曝光图像和模糊区域的特征来有效指导扩散过程。
- 通过一个特征融合模块(ExpBFusion),自适应地从短曝光图像和检测到的模糊区域提取有用特征,以指导扩散模型进行更好的图像恢复。
实现细节:
- ExpBFusion模块:使用softmax操作和点积注意力机制来融合来自短曝光图像和模糊区域的特征,以指导扩散模型中的多尺度特征。
- 训练和优化:使用AdamW优化器和特定的损失函数来训练网络,确保模型能够有效地从短曝光图像和模糊区域中提取特征,并利用这些特征来指导扩散过程。
贡献总结:
- 提出了一个基于上下文的局部模糊检测模块,以改善模糊区域的识别。
- 开发了一个短曝光图像引导的图像恢复方法,以去除局部模糊并区分处理模糊和清晰区域。
- 提出了一个短曝光引导的扩散模型,以探索短曝光图像和检测到的模糊区域中的有用特征,实现更逼真的图像恢复。
通过这些组件和技术,ExpRDiff能够在保持静态背景清晰的同时,有效去除移动物体的模糊,实现高质量的图像恢复。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估ExpRDiff方法的有效性,并与现有的最先进方法进行比较:
1. 实验设置(Experimental Settings)
- 训练数据集:使用ReLoBlur数据集作为训练数据集,并生成短曝光图像以用于训练。同时,作者捕获了一个真实的局部运动模糊数据集(LMBD),包含用于训练和评估的图像。
- 参数设置:使用PyTorch框架实现ExpRDiff,并在配备8个NVIDIA GeForce RTX 4090 GPU的机器上进行训练。使用AdamW优化器,并设置了相应的批次大小和学习率。
- 评估指标:主要使用NIQE、CLIPIQA+和MUSIQ-PAQ2PIQ作为评估指标,因为这些指标能够很好地衡量图像的视觉质量。
2. 与最先进方法的比较(Comparisons with the State of the Art)
- 比较了ExpRDiff与全局去模糊方法(如NAFNet、Restormer和MIMO-UNet)和局部去模糊方法(如LBAG和LMD-ViT)的性能。
- 对于需要短曝光图像作为引导的方法,作者还将这些方法的输入修改为模糊图像和短曝光图像的连接,以公平比较。
3. 在ReLoBlur合成数据集上的评估(Evaluations on the ReLoBlur Synthetic Dataset)
- 通过定量评估(如表1所示)和视觉比较(如图6所示),展示了ExpRDiff在合成数据集上的性能优势。
4. 在LMBD数据集上的评估(Evaluations on the LMBD Dataset)
- 同样通过定量评估(如表2所示)和视觉比较(如图7所示),展示了ExpRDiff在真实世界数据集上的性能优势。
5. 分析和讨论(Analysis and Discussion)
- 模糊感知引导图像恢复的影响:通过表3和图8展示了模糊感知引导图像恢复在去模糊中的效果。
- 短曝光引导扩散模型的影响:通过表4和图9展示了短曝光引导扩散模型在生成更清晰图像中的作用。
- 上下文基础局部模糊检测模块的影响:通过表5和图10展示了上下文基础局部模糊检测模块在识别模糊区域中的效果。
这些实验结果表明,ExpRDiff在去除局部运动模糊和恢复图像质量方面,相较于现有的最先进方法具有显著的性能优势。
Q: 有什么可以进一步探索的点?
A: 尽管ExpRDiff在局部运动去模糊方面取得了显著的性能,但仍有一些领域可以进一步探索和改进:
1. 算法的泛化能力
- 多场景和多条件下的测试:当前的研究可能在特定的数据集和条件下表现良好,但在不同的场景和不同的模糊条件下,算法的泛化能力需要进一步测试和验证。
- 实时性能:对于实际应用来说,算法的实时性能是一个重要的考量因素。未来的工作可以探索如何优化算法以满足实时处理的需求。
2. 算法的鲁棒性
- 对噪声和异常值的鲁棒性:在实际应用中,图像可能会包含各种噪声和异常值。研究算法对于这些干扰的鲁棒性是一个重要的研究方向。
- 对不同模糊核的适应性:局部运动模糊可能由不同的运动模式产生,算法对于不同模糊核的适应性也是一个值得探索的问题。
3. 算法的效率
- 计算复杂度的降低:尽管ExpRDiff已经是一个高效的算法,但在处理高分辨率图像时,计算复杂度仍然是一个挑战。研究如何进一步降低算法的计算复杂度,使其更适合资源受限的环境。
- 参数优化和网络结构简化:通过进一步的参数优化和网络结构简化,可以提高算法的效率和实用性。
4. 算法的可解释性
- 特征和决策的可视化:研究算法中关键特征和决策的可视化,可以帮助理解算法的工作原理,并指导未来的改进。
- 模型的解释性:提高模型的可解释性,使得用户能够理解模型的预测和决策过程。
5. 与其他技术的集成
- 与视频处理技术的集成:将图像去模糊技术扩展到视频领域,处理视频序列中的运动模糊问题。
- 与增强现实(AR)和虚拟现实(VR)技术的集成:在AR和VR应用中,实时去除模糊和提高图像质量是一个重要的研究方向。
6. 新的数据集和评估指标
- 新数据集的创建:创建包含更多样化模糊情况的数据集,以更全面地评估算法的性能。
- 新的评估指标:开发新的评估指标,更准确地衡量去模糊算法的性能,特别是在视觉质量和感知质量方面。
这些方向不仅可以推动局部运动去模糊技术的发展,还可以扩展其在更广泛领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为ExpRDiff的新方法,旨在解决移动物体引起的局部运动模糊问题,并改善图像的去模糊效果。以下是论文的主要内容总结:
问题陈述
- 移动物体在长曝光摄影中会产生显著的局部模糊,而静态背景保持清晰,这给图像去模糊带来了挑战。
方法论
- 上下文基础的局部模糊检测模块:通过整合上下文信息来改善模糊区域的识别。
- 短曝光图像引导的图像恢复:利用短曝光图像中的锐利细节辅助重建严重模糊区域。
- 短曝光引导的扩散模型:利用短曝光图像和模糊区域的特征来指导扩散过程,以实现更逼真的图像恢复。
实验
- 使用ReLoBlur和LMBD数据集进行训练和评估。
- 与现有的去模糊方法(包括全局和局部去模糊方法)进行比较。
- 通过定量和定性的结果展示ExpRDiff的有效性。
主要贡献
- 提出了一个基于上下文的局部模糊检测模块,以改善模糊区域的识别。
- 开发了一个短曝光图像引导的图像恢复方法,以去除局部模糊并区分处理模糊和清晰区域。
- 提出了一个短曝光引导的扩散模型,以探索短曝光图像和检测到的模糊区域中的有用特征,实现更逼真的图像恢复。
结论
- ExpRDiff在去除局部运动模糊和恢复图像质量方面,相较于现有的最先进方法具有显著的性能优势。
总体而言,这篇论文通过结合短曝光图像和模糊区域的信息,提出了一种新的去模糊框架,有效地改善了局部运动模糊图像的恢复质量。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

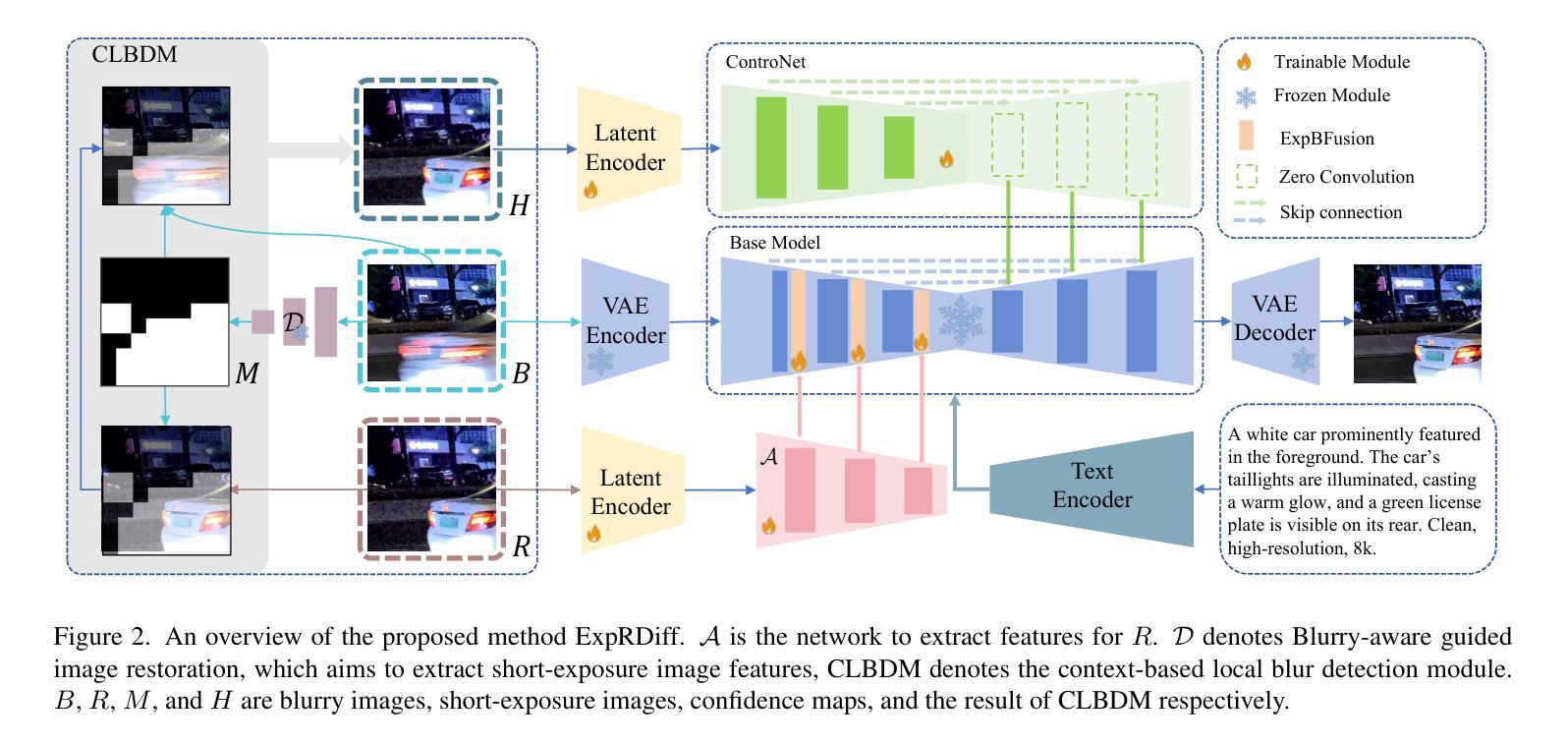
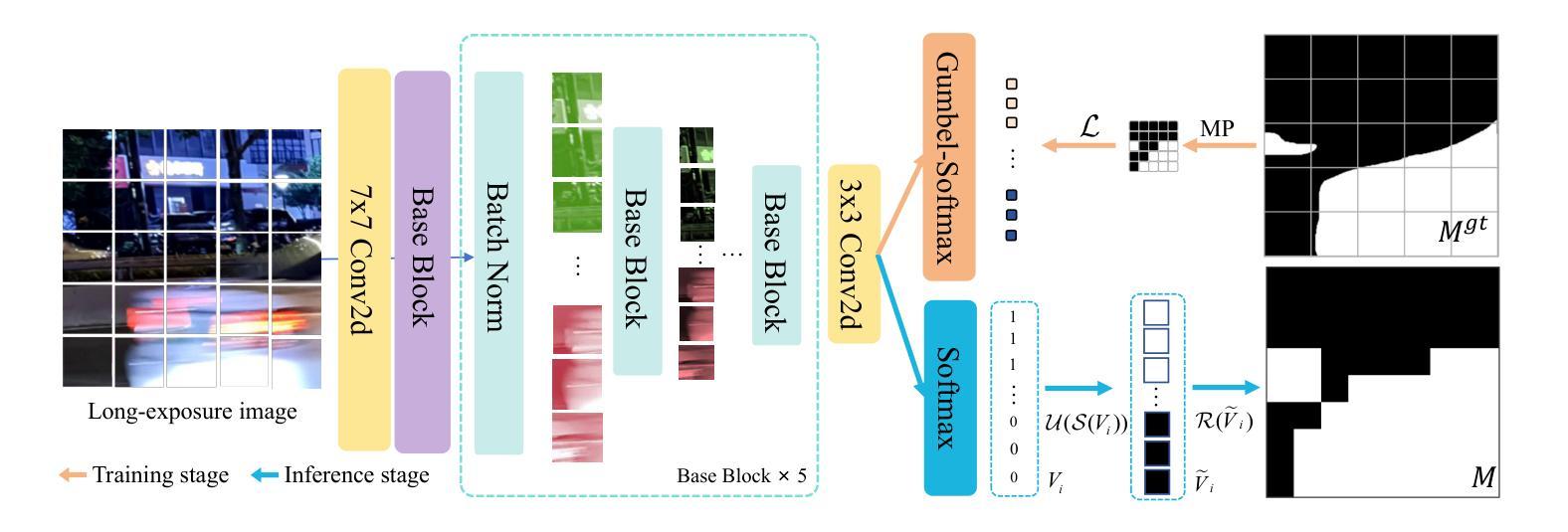
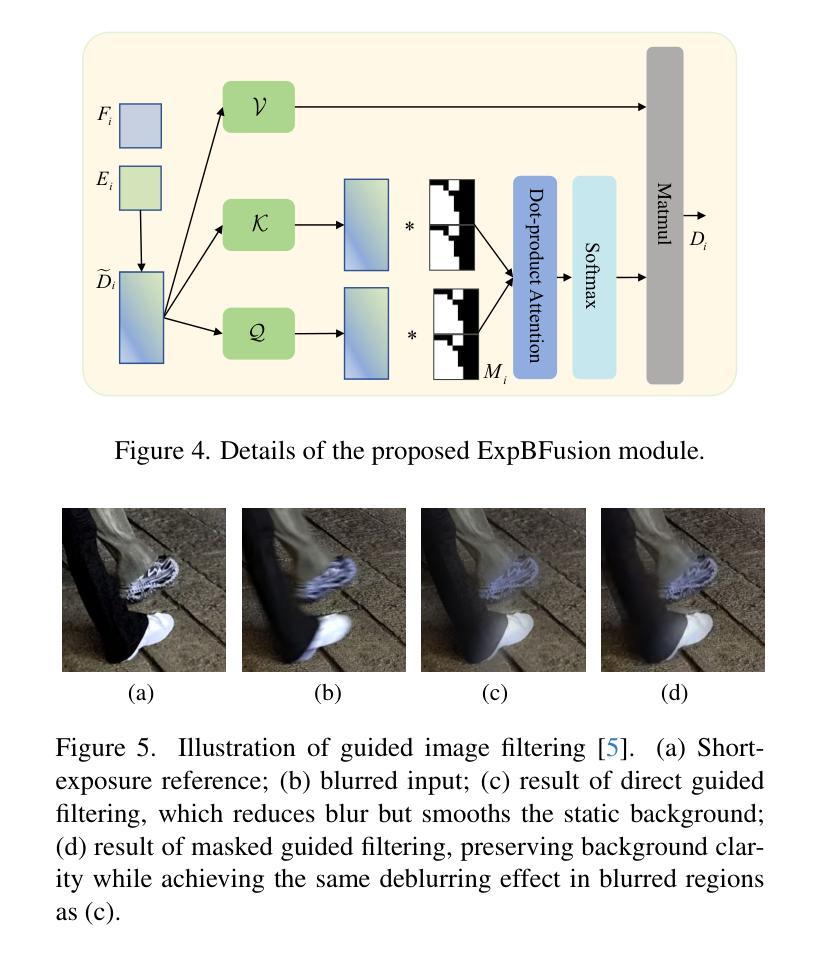

RAD: Region-Aware Diffusion Models for Image Inpainting
Authors:Sora Kim, Sungho Suh, Minsik Lee
Diffusion models have achieved remarkable success in image generation, with applications broadening across various domains. Inpainting is one such application that can benefit significantly from diffusion models. Existing methods either hijack the reverse process of a pretrained diffusion model or cast the problem into a larger framework, \ie, conditioned generation. However, these approaches often require nested loops in the generation process or additional components for conditioning. In this paper, we present region-aware diffusion models (RAD) for inpainting with a simple yet effective reformulation of the vanilla diffusion models. RAD utilizes a different noise schedule for each pixel, which allows local regions to be generated asynchronously while considering the global image context. A plain reverse process requires no additional components, enabling RAD to achieve inference time up to 100 times faster than the state-of-the-art approaches. Moreover, we employ low-rank adaptation (LoRA) to fine-tune RAD based on other pretrained diffusion models, reducing computational burdens in training as well. Experiments demonstrated that RAD provides state-of-the-art results both qualitatively and quantitatively, on the FFHQ, LSUN Bedroom, and ImageNet datasets.
扩散模型在图像生成方面取得了显著的成功,其应用正逐步扩展到各个领域。图像修复是其中之一,它可以从扩散模型中大大受益。现有方法要么接管预训练扩散模型的反向过程,要么将问题转化为更大的框架,即条件生成。然而,这些方法通常需要在生成过程中使用嵌套循环或添加条件组件。在本文中,我们提出了用于图像修复的区域感知扩散模型(RAD),这是对标准扩散模型的简单而有效的改造。RAD为每个像素使用不同的噪声调度,这允许局部区域在考虑全局图像上下文的同时进行异步生成。简单的反向过程不需要任何额外的组件,使RAD的推理时间达到最先进的方法的100倍。此外,我们采用了低秩适应(LoRA)技术对RAD进行微调,基于其他预训练的扩散模型,以减少训练中的计算负担。实验表明,无论是在FFHQ、LSUN卧室和ImageNet数据集上,RAD都提供了定性和定量上的最佳结果。
论文及项目相关链接
Summary
扩散模型在图像生成方面取得了显著的成功,并在多个领域得到了广泛的应用。本文提出了一种区域感知扩散模型(RAD)用于图像修复,通过对普通扩散模型的简单有效改革来实现。RAD利用每个像素的不同噪声调度,实现在考虑全局图像上下文的同时,局部区域进行异步生成。无需额外组件的纯粹逆向过程使得RAD的推理时间达到现有方法的100倍。此外,还采用低秩适配(LoRA)对RAD进行微调,基于其他预训练扩散模型,减轻训练的计算负担。实验表明,RAD在FFHQ、LSUN卧室和ImageNet数据集上,无论在定性还是定量方面均达到了最新水平。
Key Takeaways
- 扩散模型在多个领域取得了显著的成功,尤其是在图像生成方面。
- 论文介绍了一种区域感知扩散模型(RAD)用于图像修复的新应用。
- RAD通过对普通扩散模型的改革来实现,无需额外的组件。
- RAD使用不同的噪声调度为每个像素生成局部区域,同时考虑全局图像上下文。
- RAD的推理时间达到现有方法的最高速度之一。
- 使用低秩适配(LoRA)对RAD进行微调,可基于其他预训练扩散模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种名为Region-Aware Diffusion Models(RAD)的模型,旨在解决图像修复任务中的一个特定问题——图像修复(inpainting)。具体来说,论文试图解决以下问题:
现有方法的局限性:现有的图像修复方法通常需要在生成过程中使用嵌套循环或额外的组件来进行条件生成,这些方法往往计算复杂且推理时间长。
异步生成需求:传统的扩散模型在每个前向步骤中对所有像素应用相同的噪声,这限制了模型在局部区域内异步生成图像的能力。
提高推理速度:现有的基于扩散模型的方法在推理时速度较慢,论文旨在通过改进模型来显著提高推理速度。
减少训练负担:尽管重新设计生成过程可以避免额外的训练,但这种方法牺牲了推理速度。论文通过使用低秩适应(LoRA)技术在预训练的扩散模型上进行微调,以减少训练负担。
提高修复质量:论文提出的方法RAD旨在通过空间变化的噪声调度和空间噪声嵌入技术来提高图像修复的质量。
综上所述,论文的主要贡献在于提出了一种新的基于扩散模型的图像修复方法,该方法通过空间变化的噪声调度和有效的网络结构改进,实现了更快的推理速度和更高的修复质量,同时减少了训练的计算负担。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,相关研究主要集中在以下几个领域:
深度生成模型:包括生成对抗网络(GANs)[9]和扩散模型[12, 30],它们是无监督图像合成领域的突破性进展。
扩散模型(Diffusion Models):特别是去噪扩散概率模型(DDPM)[12, 30],它们通过学习逆转一个预定义的扩散过程来近似真实图像的分布。
图像修复(Image Inpainting):基于GANs[18, 33, 35, 42]和扩散模型[6, 20]的图像修复方法,这些方法尝试解决填补图像中缺失区域的问题。
条件生成技术:一些方法利用基于结构信息[19]或文本与掩码[37, 38, 44, 45]的条件生成技术来进行图像修复或编辑。
基于预训练扩散模型的图像编辑/修复:通过操纵现有扩散模型的生成过程来进行图像修复或编辑的方法[1, 2, 4–6, 10, 15, 20, 21, 34]。
性能改进研究:针对扩散模型的性能提升的研究[23, 25, 36],以及Dhariwal等人提出的首个超越GANs性能的扩散模型[8]。
低秩适应(LoRA):用于在预训练模型基础上进行微调的技术,以减少训练负担[13]。
其他图像编辑和合成方法:例如SmartBrush[37],它通过仅在图像修复区域添加噪声来进行对象修复,与RAD的方法相似,但增加了额外的模块来学习这种噪声。
这些相关研究构成了RAD方法的理论和实践基础,并为图像修复和编辑领域提供了多样化的技术路径。RAD方法通过结合这些相关技术,提出了一种新的图像修复框架,旨在提高推理速度并减少训练负担,同时保持或提高修复质量。
Q: 论文如何解决这个问题?
A: 论文通过提出Region-Aware Diffusion Models(RAD)解决了图像修复问题,具体解决方案如下:
1. 空间变化的噪声调度(Spatially Variant Noise Schedules)
RAD模型的核心在于为每个像素分配不同的噪声调度,允许局部区域异步生成,同时考虑全局图像上下文。这种方法自然地模拟了图像修复,通过仅在修复区域添加噪声并执行逆向过程。
2. Perlin噪声基础的噪声调度生成
为了有效地训练模型,论文提出了基于Perlin噪声生成伪真实噪声调度的方法。Perlin噪声因其平滑和自然主义模式而闻名,允许创建多样化和真实的掩码。
3. 空间噪声嵌入技术(Spatial Noise Embedding)
为了使去噪网络能够处理空间变化的噪声条件,论文引入了空间噪声嵌入技术。该技术通过将时间步骤( t )的嵌入替换为像素级噪声强度( \bar{b}_t ),直接将噪声条件告知网络,使其更容易学习空间变化的噪声。
4. 基于LoRA的训练
为了减少训练负担,论文采用了低秩适应(LoRA)技术对预训练的扩散模型进行微调,从而显著降低了计算需求。
5. 推理速度的提升
RAD模型通过简单的逆向过程实现快速推理,无需额外组件,使得推理速度比现有最先进方法快100倍。
6. 避免训练中的奇异性
论文还讨论了在训练过程中避免奇异性问题,确保模型训练的稳定性。
通过这些解决方案,RAD模型不仅提高了图像修复的速度和质量,还减少了训练所需的资源和时间,使得该方法在实际应用中更为可行。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证Region-Aware Diffusion Models(RAD)的性能:
1. 基准数据集验证
- FFHQ:包含70,000张高分辨率人脸图像的数据集,用于训练和评估高质量的图像生成模型。
- LSUN Bedroom:包含超过3百万张室内场景图像的大型数据集,用于学习复杂的房间布局。
- ImageNet:包含超过1.2百万张标记图像的大型图像数据集,覆盖了广泛的对象、动物、场景和复杂的视觉组合。
2. 实施细节
- 使用Adam优化器进行训练,学习率为(10^{-4}),总扩散步骤为2000,其中前1000步专用于第一阶段。
- 对于FFHQ和ImageNet,使用了16的批量大小;对于LSUN Bedroom,批量大小为8。
- 预定义了线性噪声时间表(\beta_t, \beta’_t \in (0.0001, 0.02))。
- 在修复过程中使用了100个采样步骤。
3. 验证设置
- 从所有数据集中留出1000张图像进行验证。
- 评估RAD在三种掩码配置下的性能:盒型(box)、极端(extreme)和宽泛(wide)。
4. 性能比较
- 使用Frechet Inception Distance(FID)和Learned Perceptual Image Patch Similarity(LPIPS)作为图像修复质量的度量。
- 与基于GAN和扩散模型的各种修复方法进行比较,包括LaMa、Score-SDE、DDRM、RePaint、MCG、DDNM和DeqIR。
5. 推理时间比较
- 在256×256图像上评估不同方法的推理时间,使用单个NVIDIA TITAN RTX GPU。
6. 多样性分析
- 展示了RAD在不同掩码配置下生成的多样化修复结果,突出了RAD产生各种合理和上下文一致的修复结果的能力。
7. 消融研究
- 比较了RAD与两种替代方法的性能:直接在预训练的ADM上执行RAD逆向步骤的方法,以及没有空间噪声嵌入的RAD。
- 验证了空间变化噪声训练和空间噪声嵌入对于RAD成功的重要性。
这些实验全面评估了RAD在图像修复任务中的性能,包括与现有技术的比较、推理时间的测量、结果多样性的展示以及关键组件有效性的验证。通过这些实验,论文展示了RAD在图像修复领域的优势和潜力。
Q: 有什么可以进一步探索的点?
A: 尽管RAD模型在图像修复任务中取得了显著的成果,但仍有一些可以进一步探索的点:
1. 扩展到其他图像编辑任务
RAD框架主要是为图像修复设计的,但其核心思想——空间变化的噪声调度——可以扩展到其他图像编辑任务,如:
- 文本到图像合成:将RAD与文本条件结合,实现根据文本描述生成特定内容的图像。
- 对象移植:在保持背景不变的情况下,将一个图像中的对象移植到另一个图像中。
- 风格转换:利用RAD模型实现不同风格之间的图像转换。
2. 提升模型泛化能力
研究如何使RAD模型更好地泛化到不同类型的图像和更复杂的修复场景,包括:
- 处理更复杂的掩码:当前模型依赖于Perlin噪声生成掩码,未来可以探索更多样化的掩码生成方法。
- 适应不同的图像内容:研究模型如何适应不同风格和复杂度的图像内容。
3. 进一步减少训练资源消耗
尽管RAD通过LoRA减少了训练负担,但仍有进一步优化的空间:
- 探索更高效的微调技术:寻找更高效的微调方法,以进一步减少在预训练模型基础上训练RAD所需的计算资源。
- 模型压缩:研究模型压缩技术,减少模型大小,同时保持性能。
4. 提高模型的鲁棒性
研究如何提高RAD模型对异常值和噪声的鲁棒性,特别是在实际应用中可能遇到的各种挑战:
- 对抗性攻击下的鲁棒性:研究模型在面对对抗性攻击时的表现,并提出改进措施。
- 不同质量的输入数据:研究模型如何处理低分辨率或压缩过的输入图像。
5. 理论分析
对RAD模型的理论基础进行更深入的分析,包括:
- 模型的数学性质:探索模型的数学性质,如稳定性和收敛性。
- 噪声调度的优化:研究如何优化噪声调度以提高模型性能。
6. 实际应用
探索RAD模型在实际应用中的潜力,例如:
- 医疗图像修复:将RAD应用于医疗图像中缺失区域的修复。
- 卫星图像处理:在卫星图像中修复云层遮挡的部分。
通过对这些方向的进一步探索,可以扩展RAD模型的应用范围,提高其性能,并为图像编辑和修复领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Region-Aware Diffusion Models(RAD)的新型图像修复模型,其核心贡献和内容可以总结如下:
1. 问题定义
RAD旨在解决图像修复任务中如何利用扩散模型高效、高质量地填充图像缺失区域的问题。相比于现有方法,RAD寻求减少推理时间并避免复杂的生成过程。
2. 核心方法
RAD通过为每个像素分配不同的噪声调度来实现区域内的异步生成,这一空间变化的噪声调度允许模型仅在特定区域内添加噪声并执行逆向过程,模拟图像修复。
3. 噪声调度生成
论文提出了基于Perlin噪声的方法来生成训练中使用的伪真实噪声掩码,以模拟真实世界的图像修复场景。
4. 空间噪声嵌入技术
RAD引入了一种空间噪声嵌入技术,通过将时间步骤嵌入替换为像素级的噪声强度嵌入,使网络能够更好地学习空间变化的噪声条件。
5. 基于LoRA的训练
为了减少训练负担,RAD采用了低秩适应(LoRA)技术在预训练的扩散模型基础上进行微调,显著降低了计算需求。
6. 实验验证
通过在FFHQ、LSUN Bedroom和ImageNet数据集上的实验,RAD在各种掩码配置下均显示出较现有最先进方法更快的推理速度和更高的修复质量。
7. 性能比较
RAD在FID和LPIPS等度量下均优于或媲美其他基线方法,同时推理速度快了约100倍。
8. 局限性和未来工作
尽管RAD在图像修复任务中取得了显著的性能提升,但其依赖于显式训练和基于掩码的噪声调度,未来工作可以探索将RAD应用于更广泛的图像编辑任务,并进一步优化模型性能和泛化能力。
总体而言,RAD通过其创新的空间变化噪声调度和有效的网络结构改进,在图像修复领域提供了一个快速且高质量的解决方案,并为扩散模型的应用和理论研究开辟了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

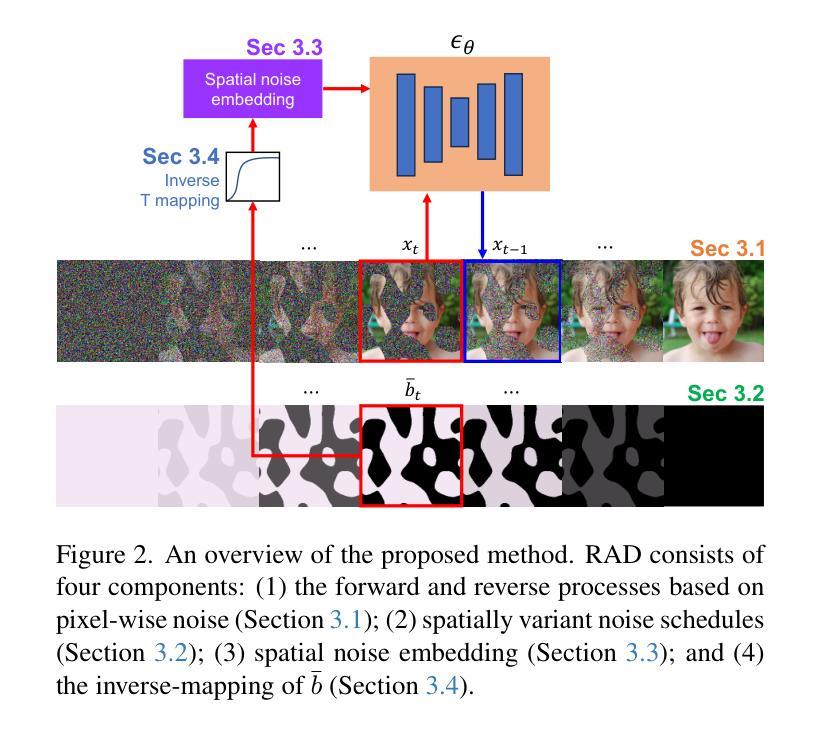

DECOR:Decomposition and Projection of Text Embeddings for Text-to-Image Customization
Authors:Geonhui Jang, Jin-Hwa Kim, Yong-Hyun Park, Junho Kim, Gayoung Lee, Yonghyun Jeong
Text-to-image (T2I) models can effectively capture the content or style of reference images to perform high-quality customization. A representative technique for this is fine-tuning using low-rank adaptations (LoRA), which enables efficient model customization with reference images. However, fine-tuning with a limited number of reference images often leads to overfitting, resulting in issues such as prompt misalignment or content leakage. These issues prevent the model from accurately following the input prompt or generating undesired objects during inference. To address this problem, we examine the text embeddings that guide the diffusion model during inference. This study decomposes the text embedding matrix and conducts a component analysis to understand the embedding space geometry and identify the cause of overfitting. Based on this, we propose DECOR, which projects text embeddings onto a vector space orthogonal to undesired token vectors, thereby reducing the influence of unwanted semantics in the text embeddings. Experimental results demonstrate that DECOR outperforms state-of-the-art customization models and achieves Pareto frontier performance across text and visual alignment evaluation metrics. Furthermore, it generates images more faithful to the input prompts, showcasing its effectiveness in addressing overfitting and enhancing text-to-image customization.
文本到图像(T2I)模型可以有效地捕捉参考图像的内容或风格,进行高质量定制。一种代表性的技术是使用低秩适应(LoRA)进行微调,这能够实现参考图像的有效的模型定制。然而,使用有限数量的参考图像进行微调常常会导致过拟合,从而引发诸如提示不对齐或内容泄漏等问题。这些问题使得模型无法准确遵循输入提示或在推理过程中生成不需要的对象。为了解决这个问题,我们研究了在推理过程中引导扩散模型的文本嵌入。本研究对文本嵌入矩阵进行分解并进行了组件分析,以了解嵌入空间几何并确定过拟合的原因。基于此,我们提出了DECOR,它将文本嵌入投影到与不需要的令牌向量正交的向量空间,从而减少了文本嵌入中不需要的语义的影响。实验结果表明,DECOR优于最新的定制模型,在文本和视觉对齐评价指标上实现了帕累托前沿性能。此外,它生成的图像对输入提示更加忠实,展示了其在解决过拟合问题和提高文本到图像定制效果方面的有效性。
论文及项目相关链接
Summary
文本到图像(T2I)模型可通过捕捉参考图像的内容或风格进行高质量定制。一种代表性的技术是使用低秩适配(LoRA)进行微调,这能够实现参考图像的模型定制。然而,使用有限数量的参考图像进行微调常常会导致过拟合,进而引发提示不对齐或内容泄露等问题。为解决这一问题,本研究分析了引导扩散模型进行推断的文本嵌入,分解文本嵌入矩阵并对其进行成分分析,以理解嵌入空间几何并确定过拟合的原因。基于此,我们提出了DECOR,它将文本嵌入投射到一个与不需要的令牌向量正交的向量空间,从而减少文本嵌入中不需要语义的影响。实验结果表明,DECOR在文本和视觉对齐评估指标上达到了帕累托前沿性能,并且生成的图像更加忠于输入提示,证明了它在解决过拟合问题和提高文本到图像定制方面的有效性。
Key Takeaways
- T2I模型能够通过捕捉参考图像的内容或风格实现高质量定制。
- 使用低秩适配(LoRA)技术可以进行模型微调,但使用有限参考图像会导致过拟合问题。
- 过拟合可能导致模型提示不对齐或内容泄露。
- 本研究通过分解文本嵌入矩阵并分析其成分,以理解嵌入空间几何和过拟合原因。
- 提出DECOR方法,通过将文本嵌入投射到与不需要的令牌向量正交的向量空间,减少不必要语义的影响。
- 实验结果显示DECOR在文本和视觉对齐评估指标上表现优异。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决文本到图像(Text-to-Image, T2I)模型在进行定制化任务时出现的两个主要问题:提示错位(prompt misalignment)和内容泄露(content leakage)。这些问题通常发生在使用少量参考图像进行微调时,导致模型无法准确遵循输入提示或在推理过程中生成不期望的对象。
具体来说,这些问题主要源于文本条件,即指导扩散模型采样过程中的文本嵌入。论文中提到,通过层次化分解文本嵌入矩阵,发现过拟合主要源于与参考图像纠缠在一起的词标记。为了解决这一挑战,论文提出了一个名为DECOR(DeCOmposition and pRojection)的新框架,该框架通过在文本嵌入空间中对文本嵌入进行基于投影的精细化处理,减少了不希望的语义对文本嵌入的影响。实验结果表明,DECOR在不增加额外训练的情况下,有效减少了这些影响,从而缓解了提示错位和内容泄露的问题,并在文本和视觉对齐评估指标上实现了帕累托前沿性能。
Q: 有哪些相关研究?
A: 根据论文内容,以下是与DECOR框架相关的一些研究工作:
文本到图像(T2I)模型的定制化:
- Textual Inversion [5] 和 DreamBooth [37]:这些方法通过学习用户提供的数据来创建定制化的表示。
- Custom Diffusion [18]:引入机制同时学习多个概念。
- SVDiff [8]:使用矩阵分解优化学习,以在紧凑的参数空间内进行优化。
- StyleDrop [42]、StyleAligned [10] 和 Visual Style Prompting [15]:这些方法在不需要额外训练的情况下,通过操纵自注意力来保持图像间的一致风格。
缓解定制化中的过拟合问题:
- FastComposer [47]:通过使用延迟主题条件来减轻过拟合。
- Mixture-of-Attention (MoA) [28]:平衡基础和个性化注意力以保留先前知识。
- Perfusion [45] 和 Infusion [50]:通过考虑预训练模型的分布来解决过拟合问题。
文本嵌入空间的分析和投影:
- Semantic projection [6] 和相关技术:利用文本嵌入在潜在空间中的正交性,将文本嵌入矩阵投影到特定语义轴上。
其他与文本嵌入和图像生成相关的技术:
- ControlNet [51]:允许扩散模型结合文本提示和视觉条件。
- Direct consistency optimization (DCO) [19]:一种新的扩散模型微调方法,灵感来自直接偏好优化(DPO)。
这些相关研究为DECOR框架提供了理论基础和技术背景,使其能够在文本到图像的定制化任务中有效地解决过拟合问题,并提高生成图像的质量和忠实度。论文中提到的这些方法和发现有助于理解如何通过改进文本嵌入和调整生成模型来提升定制化图像生成的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为DECOR(DeCOmposition and pRojection)的新框架来解决文本到图像(T2I)模型在定制化任务中的过拟合问题。DECOR框架的核心思想是通过分解和投影文本嵌入来减少不希望的语义对文本嵌入的影响。以下是具体的解决方案步骤:
1. 分析文本嵌入空间
- 利用奇异值分解(SVD)分析CLIP文本嵌入空间的结构,识别出主要、次要和残余成分。
- 发现主要成分主要捕获[PAD]标记的共同方向,而次要成分捕获词标记嵌入的信息。
2. 基于投影的语义分离
- 提出一种基于投影的技术,将文本嵌入从包含不期望元素的子空间中分离出来。
- 使用投影矩阵(P_{\tilde{X}})将文本嵌入(X)投影到不包含(\tilde{X})的子空间中,公式为(X’ = X - \alpha XP_{\tilde{X}}),其中(\alpha)是控制投影特征移除程度的超参数。
3. DECOR定制化框架
- 在LoRA(Low-Rank Adaptation)层的训练过程中遵循基线过程,但在推理过程中使用修改后的文本嵌入(X’)。
- 将经过投影处理的文本嵌入(X’)输入到LoRA层,以改善生成的图像质量。
4. 实验验证
- 通过个人化、风格化和内容-风格混合任务的实验,验证DECOR框架在减少提示错位和内容泄露方面的效果。
- 使用CLIP图像-文本相似度和DINO特征相似度等指标来定量评估生成图像的质量。
5. 优势和贡献
- DECOR框架无需额外训练即可减轻过拟合问题,提高了定制化任务的性能。
- 该研究首次详细分析了T2I定制化背景下的文本嵌入空间,并通过实验证明了DECOR框架的有效性。
总结来说,DECOR框架通过分析和调整文本嵌入空间,减少了不希望的语义对生成过程的影响,从而提高了T2I模型在定制化任务中的性能和生成图像的忠实度。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估DECOR框架在文本到图像(T2I)定制化任务中的有效性。这些实验包括个人化(personalization)、风格化(stylization)和内容-风格混合(content-style mixing)三个任务。以下是具体的实验设置和结果:
1. 个人化(Personalization)
- 数据集:使用DreamBooth数据集的一个子集,包含12个主题,每个主题使用4-5个参考图像训练LoRA层。
- 比较方法:与DreamBooth、Textual Inversion和Custom Diffusion等方法进行比较。
- 评估模板:使用设计好的艺术模板来评估额外描述在生成图像中的反映程度。
- 定性比较:DECOR在生成图像时更好地遵循了额外的风格描述,而其他方法如DreamBooth则倾向于复制参考图像。
- 定量比较:DECOR在文本对齐(CLIP图像-文本相似度)和视觉对齐(DINO特征相似度)方面展示了帕累托最优性,通过调整超参数α可以在这两个指标之间控制权衡。
2. 风格化(Stylization)
- 数据集:从StyleDrop数据集中选择,并添加额外的独特风格图像,共21个风格参考图像。
- 比较方法:与DreamBooth、StyleAligned、Visual Style Prompting、IP-Adapter和StyleDrop等方法进行比较。
- 定性比较:DECOR成功地将参考图像的风格转移到新对象上,同时忠实于给定的提示。相比之下,其他方法如DreamBooth存在内容泄露问题,StyleDrop未能准确捕获风格或文本保真度差。
- 定量比较:DECOR在文本对齐和视觉对齐方面展示了最优的权衡,通过调整α实现了这一点。
3. 内容-风格混合(Content-Style Mixing)
- 实验设置:基于合并内容LoRA(个人化LoRA层)和风格LoRA(风格化LoRA层)。
- 比较方法:与DreamBooth和ZipLoRA进行比较。
- 定性和定量比较:DECOR在没有失真的情况下表达了目标风格,而DreamBooth和ZipLoRA在合并内容和风格LoRA层时未能保留主题的身份或未能有效解决两个概念之间的冲突。
4. 消融研究和可视化
- α的调整:通过调整α,DECOR可以控制不希望的标记成分从嵌入中的移除程度,这有助于防止内容泄露和控制详细组件。
- 注意力图可视化:展示了在风格化过程中,DECOR如何通过正交投影减少不希望的标记嵌入的影响,从而改善了目标对象的特征计算。
这些实验全面评估了DECOR框架在不同定制化任务中的性能,并与现有的最先进方法进行了比较,证明了DECOR在提高文本到图像定制化任务性能方面的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和补充材料,以下是一些可以进一步探索的点:
1. 精确控制生成图像中的个别元素
虽然DECOR允许通过调整α来隐式控制生成图像中的细节视觉元素,但在提供显式控制方面存在局限性。未来的研究可以集中在如何实现对生成图像中个别元素的精确控制。
2. 结合其他微调方法
DECOR可以与其他微调方法(如ControlNet和DCO损失)结合使用,以增强定制化能力。未来的研究可以探索如何将DECOR与其他微调技术更好地整合,以提高图像生成的质量和多样性。
3. 扩展到其他类型的图像生成模型
DECOR框架主要针对基于LoRA的T2I模型。未来的研究可以探索将DECOR应用于其他类型的图像生成模型,如GANs或VQ-VAEs,以评估其适用性和有效性。
4. 提升文本嵌入的语义理解和操作
DECOR通过在文本嵌入空间中进行操作来改善图像生成。未来的工作可以进一步探索如何更深入地理解和操作文本嵌入的语义,以实现更精确的图像编辑和生成。
5. 结合人类偏好的评估模型
论文中提到了使用PickScore和Human Preference Score v2等模型来评估文本-图像对的兼容性。未来的研究可以进一步探索如何结合这些评估模型,以更好地捕捉人类对图像的主观偏好,并将其纳入图像生成流程。
6. 多模态学习和跨领域适应
考虑到DECOR在处理文本和图像的交互方面的能力,未来的研究可以探索如何利用多模态学习技术来提高模型在不同领域(如艺术风格迁移、多语言支持等)的适应性和性能。
7. 实时交互式图像生成
DECOR提供了一种无需额外训练即可调整图像生成轨迹的方法。这为开发实时交互式图像生成系统提供了可能性。未来的研究可以探索如何将DECOR应用于实时图像编辑和生成任务。
8. 可解释性和可视化
虽然DECOR通过调整文本嵌入来影响图像生成,但其内部工作机制和决策过程的可解释性仍然是一个开放的问题。未来的研究可以探索如何提高模型的可解释性,并通过可视化技术揭示模型的内部工作机制。
这些探索点不仅可以推动DECOR框架的发展,还可以为文本到图像的定制化生成领域带来新的视角和突破。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 文本到图像(T2I)模型在进行定制化任务时,如个人化、风格化和内容-风格混合,常因过拟合导致提示错位或内容泄露的问题。
研究动机:
- 分析了导致过拟合的原因,发现主要问题在于文本嵌入与参考图像之间的过度纠缠。
DECOR框架:
- 提出了DECOR(DeCOmposition and pRojection)框架,该框架通过分解文本嵌入矩阵并进行成分分析来理解嵌入空间的几何结构,并基于此提出基于投影的文本嵌入优化方法。
方法论:
- 使用奇异值分解(SVD)分析CLIP文本嵌入空间,并基于此提出一种将文本嵌入投影到与不想要的语义正交的向量空间的方法,以减少不希望的语义对文本嵌入的影响。
实验验证:
- 通过个人化、风格化和内容-风格混合任务的实验,验证了DECOR框架的有效性。实验结果显示DECOR在减少过拟合、提升文本和视觉对齐评估指标方面超越了现有的定制化模型。
主要贡献:
- 分析了T2I定制化任务中过拟合的原因,指出词标记是导致提示错位和内容泄露的主因。
- 提出了一种无需额外训练即可减轻过拟合影响的基于投影的文本嵌入精细化框架。
- 通过广泛的评估,展示了DECOR在解决过拟合问题和提升T2I定制化任务性能方面的有效性。
未来工作:
- 论文提出了未来可能的研究方向,包括结合DECOR与其他微调方法、扩展到其他类型的图像生成模型、提升文本嵌入的语义理解和操作等。
总结来说,这篇论文针对文本到图像模型在定制化任务中的过拟合问题,提出了一个新颖的基于文本嵌入分解和投影的解决方案,并通过一系列实验验证了其有效性,为文本到图像的定制化生成领域提供了新的思路和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图
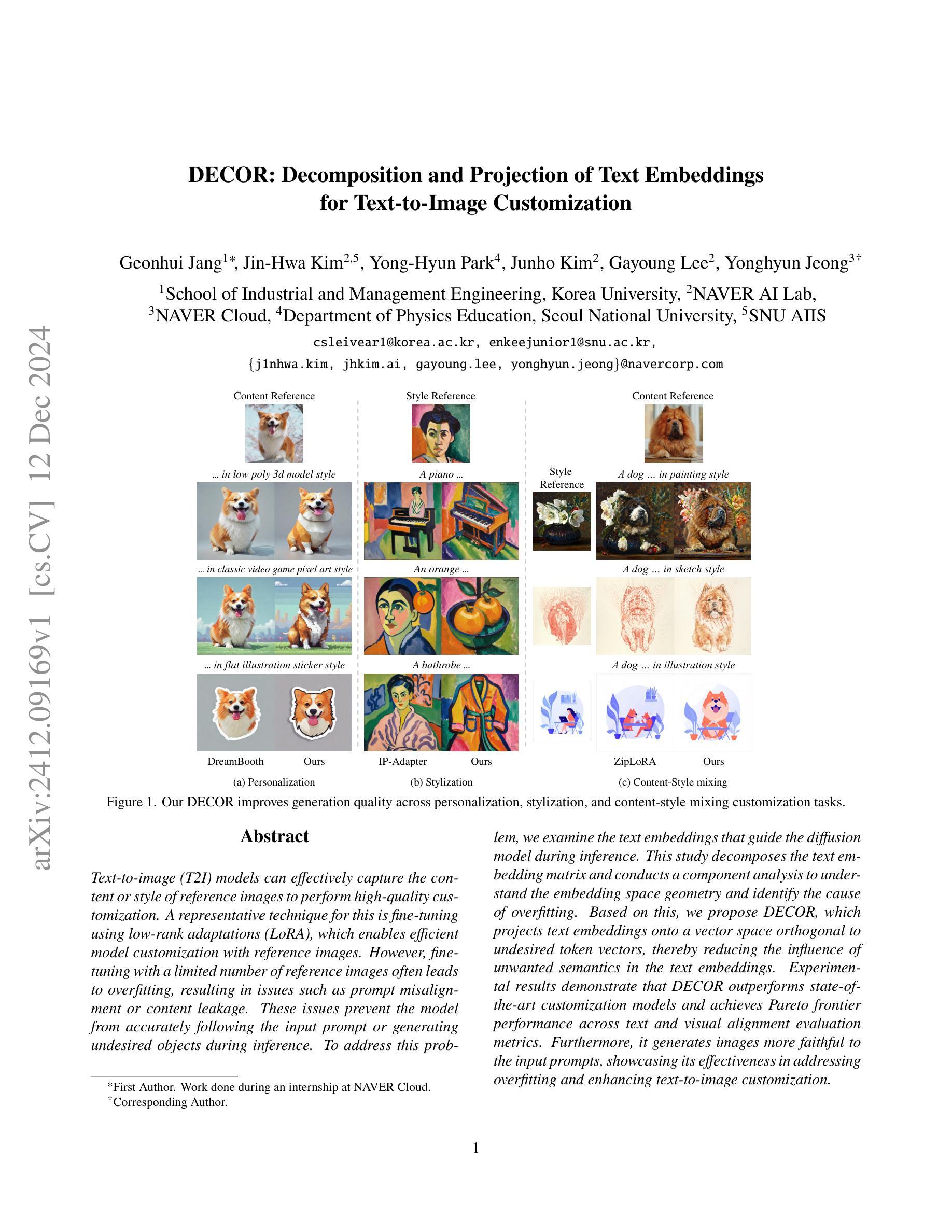
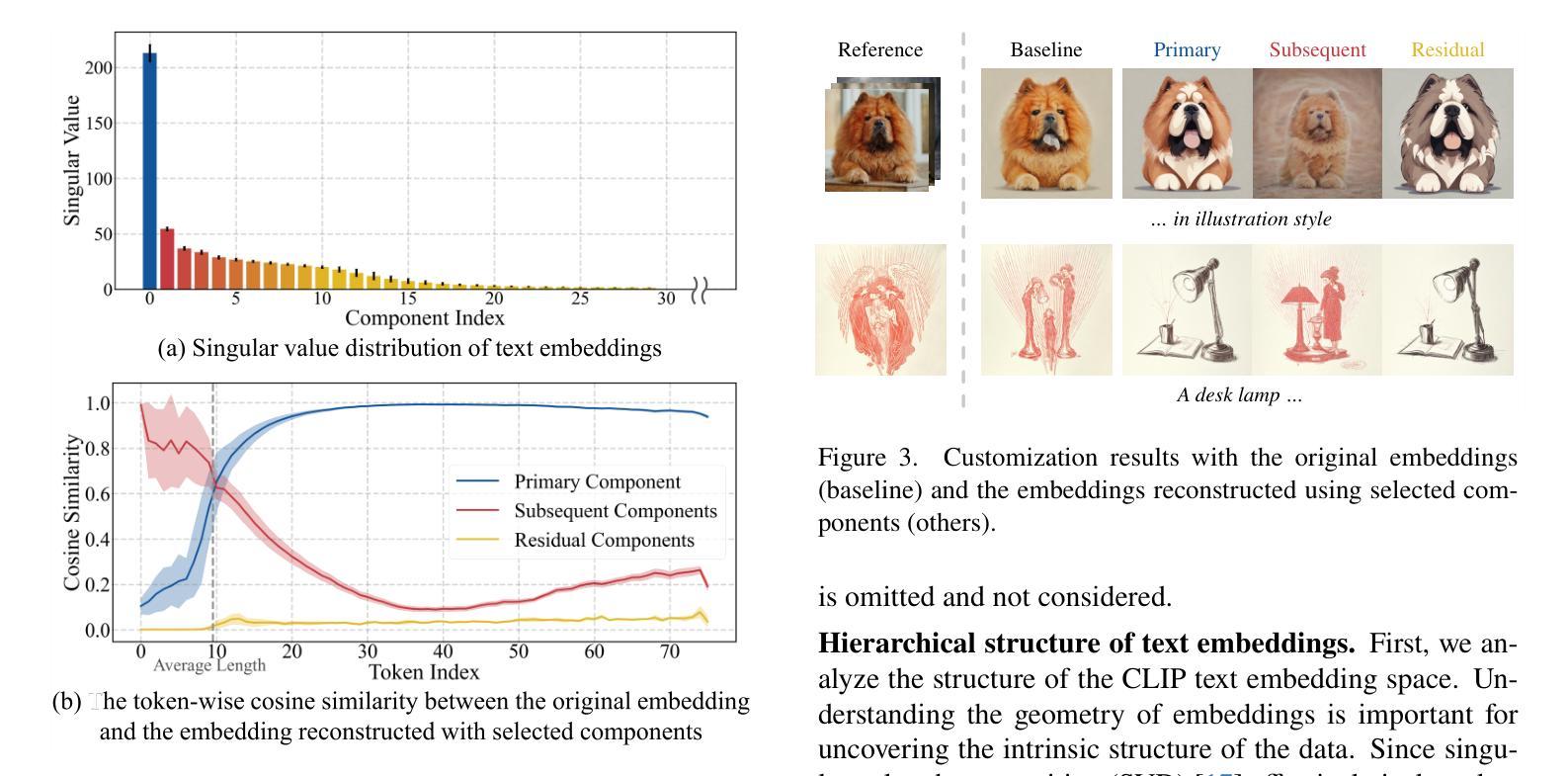
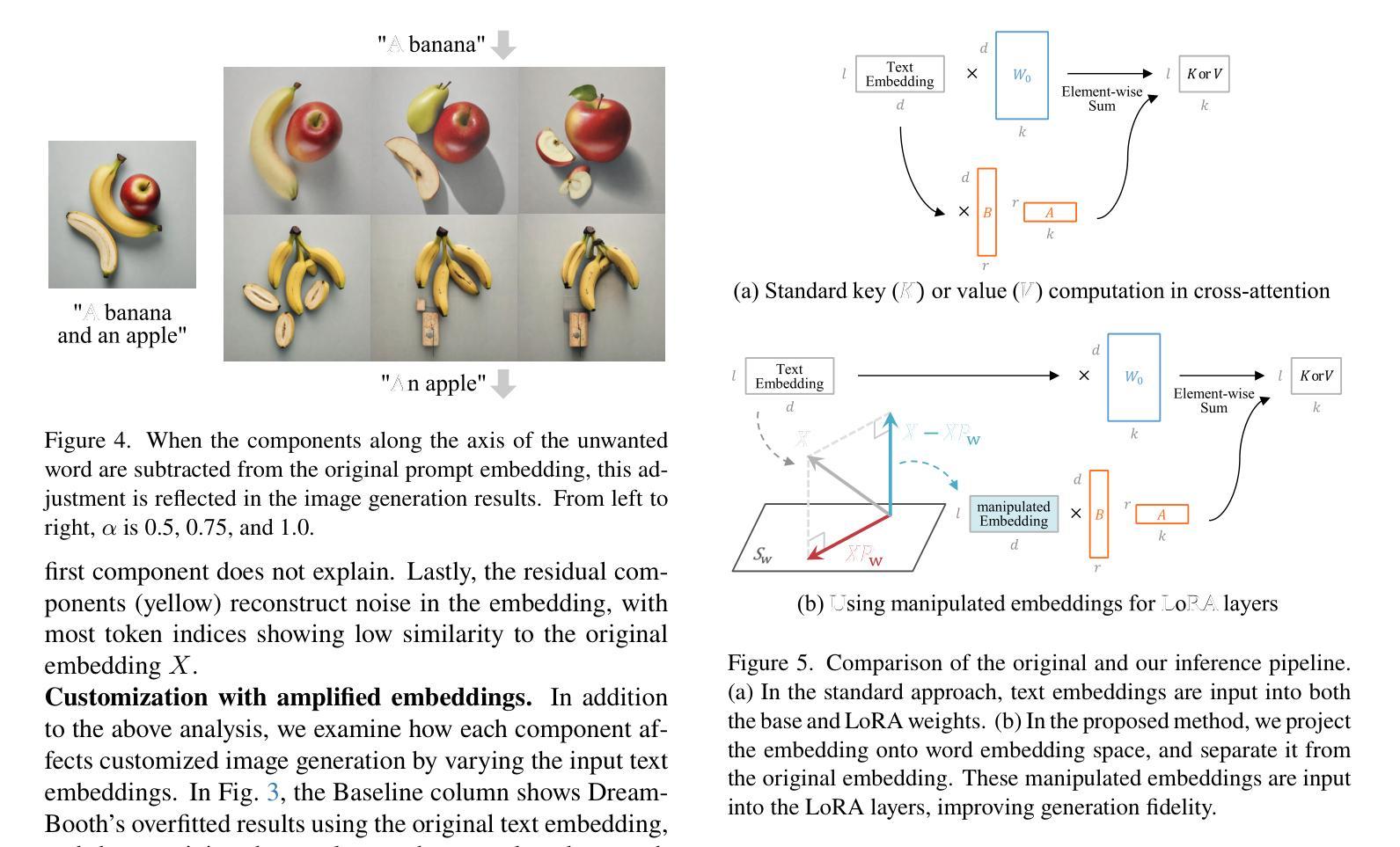
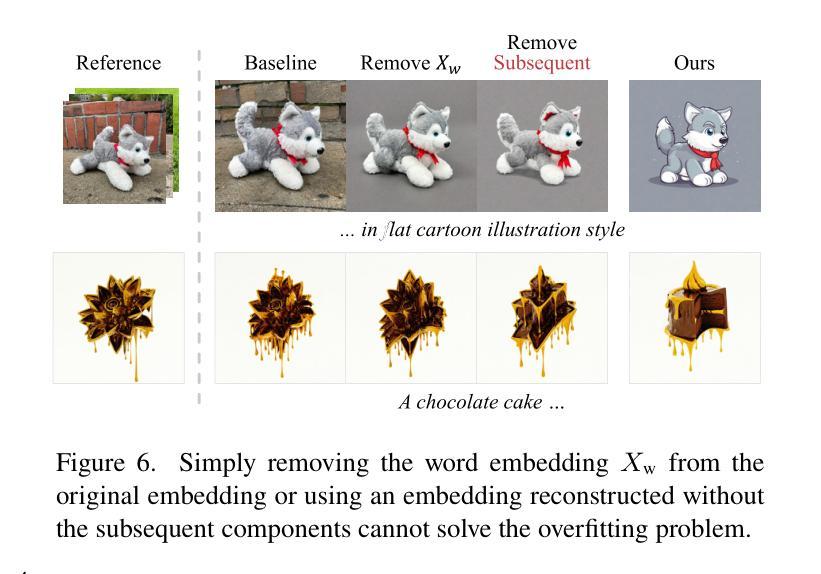

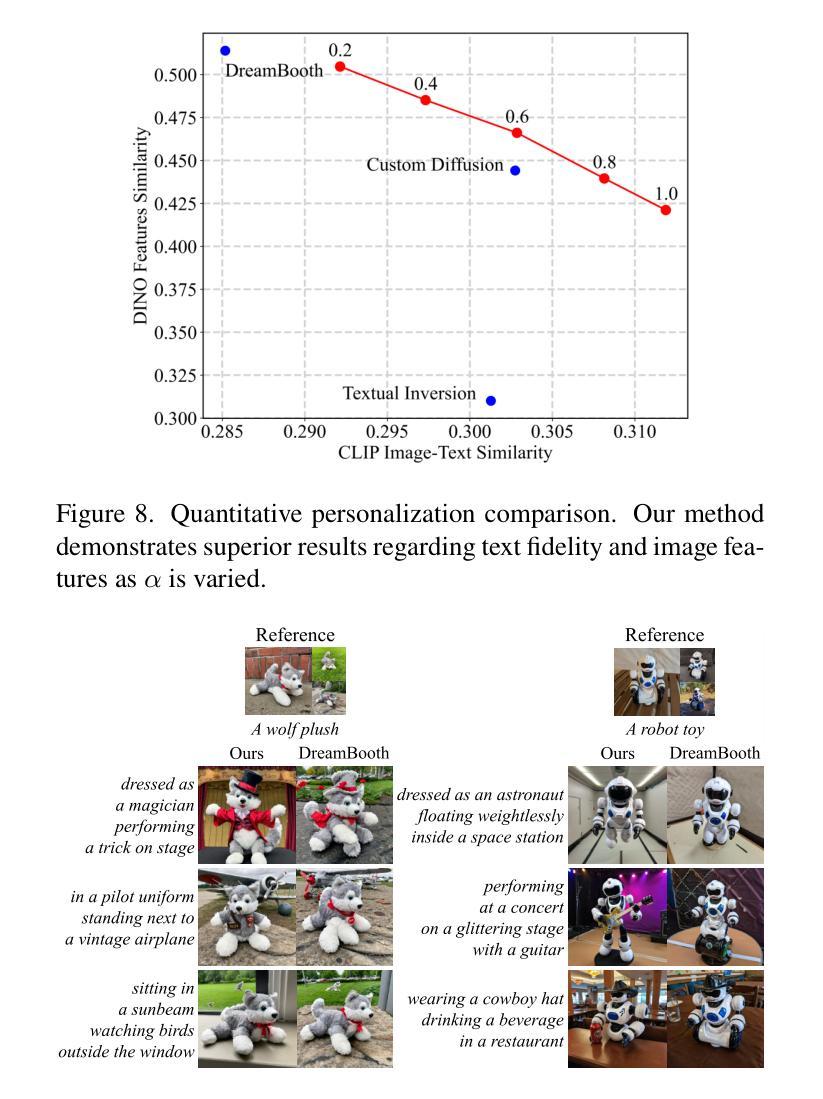
LVMark: Robust Watermark for latent video diffusion models
Authors:MinHyuk Jang, Youngdong Jang, JaeHyeok Lee, Kodai Kawamura, Feng Yang, Sangpil Kim
Rapid advancements in generative models have made it possible to create hyper-realistic videos. As their applicability increases, their unauthorized use has raised significant concerns, leading to the growing demand for techniques to protect the ownership of the generative model itself. While existing watermarking methods effectively embed watermarks into image-generative models, they fail to account for temporal information, resulting in poor performance when applied to video-generative models. To address this issue, we introduce a novel watermarking method called LVMark, which embeds watermarks into video diffusion models. A key component of LVMark is a selective weight modulation strategy that efficiently embeds watermark messages into the video diffusion model while preserving the quality of the generated videos. To accurately decode messages in the presence of malicious attacks, we design a watermark decoder that leverages spatio-temporal information in the 3D wavelet domain through a cross-attention module. To the best of our knowledge, our approach is the first to highlight the potential of video-generative model watermarking as a valuable tool for enhancing the effectiveness of ownership protection in video-generative models.
生成模型的快速发展使得创建超现实视频成为可能。随着其适用性的提高,未经授权的广泛使用引发了重大担忧,因此对保护生成模型本身所有权的技术的需求不断增长。虽然现有的水印方法能够有效地将水印嵌入图像生成模型中,但它们无法考虑时间信息,因此在应用于视频生成模型时表现不佳。为了解决这一问题,我们提出了一种新型水印方法——LVMark,它将水印嵌入视频扩散模型中。LVMark的关键组成部分是选择性权重调制策略,该策略能够高效地将水印信息嵌入视频扩散模型中,同时保持生成视频的质量。为了准确解码恶意攻击中的信息,我们设计了一个水印解码器,它利用三维小波域中的时空信息,通过交叉注意模块来实现。据我们所知,我们的方法是第一个强调视频生成模型水印在增强视频生成模型所有权保护方面的潜力。
论文及项目相关链接
Summary
该文本介绍了随着生成模型技术的快速发展,生成视频的真实性越来越高,其未经授权的滥用问题也日益严重。因此,对生成模型的所有权保护需求日益增长。现有水印方法虽能有效嵌入图像生成模型中,但无法处理视频生成模型中的时间信息。为解决这一问题,文本提出了一种新型水印方法——LVMark,该方法可将水印嵌入视频扩散模型中。LVMark的关键在于选择性权重调制策略,该策略能够在保证生成视频质量的同时,有效地将水印信息嵌入视频扩散模型。此外,为了准确解码恶意攻击下的水印信息,设计了一种利用三维小波域时空信息的水印解码器,通过跨注意力模块实现解码。据所知,该方法首次展示了视频生成模型水印在保护视频生成模型所有权方面的潜力。
Key Takeaways
- 生成模型技术快速发展,生成视频真实性提高,引发对未经授权使用的问题和对所有权保护的需求。
- 现有水印方法无法有效处理视频生成模型中的时间信息。
- 新型水印方法LVMark能将水印嵌入视频扩散模型。
- LVMark采用选择性权重调制策略,保证生成视频质量同时有效嵌入水印信息。
- 水印解码器利用三维小波域时空信息,通过跨注意力模块实现准确解码。
- LVMark方法对于保护视频生成模型的所有权具有潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在视频生成模型(特别是视频扩散模型)中嵌入水印,以保护模型所有权并防止未经授权的使用。随着生成模型技术的发展,创建超逼真视频成为可能,这带来了模型所有权侵权的问题。现有的水印方法主要针对图像生成模型,未能考虑视频特有的时间信息,导致在视频生成模型中的应用性能较差。因此,论文提出了一种新颖的水印方法LVMark,专门针对视频扩散模型,通过在视频扩散模型中嵌入水印来建立模型所有权。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
视频扩散模型(Video Diffusion Models):
- 论文提到了扩散模型作为一种强大的生成方法,通过逐步优化噪声数据来产生高质量的输出。特别提到了Latent Video Diffusion Models (LVDMs),它们在紧凑的潜在空间内优化时空特征,减少计算成本。
- 论文还提到了一些具体的模型,如OpenSora和Latte,它们使用DiT(Dense Transformer)模型长时序依赖关系;而Stable video diffusion和VideoCrafter则利用U-Net架构来捕捉空间和时间依赖性。
3D离散小波变换(3D Discrete Wavelet Transform, 3D DWT):
- 3D DWT用于分析视频的时间信息,通过在时间、高度和宽度上操作来分解视频的低频子带和高频子带。
- 论文指出,现有的视频处理方法利用3D DWT的这一特性来检测时间信息,而数字水印方法则应用3D DWT以增强水印的鲁棒性。
扩散模型水印(Diffusion Model Watermark):
- 数字水印技术在保护知识产权、确保内容真实性和所有权跟踪方面发挥着重要作用。最近,数字水印技术被应用于扩散模型,这些方法将水印嵌入到扩散模型生成的内容中,无需后处理步骤。
- 论文提到了一些主要关注图像生成模型的水印方法,这些方法在应用于视频扩散模型时表现不佳,从而凸显了对视频生成模型水印研究的需求。
这些相关研究为论文提出的LVMark方法提供了理论和技术背景,特别是在视频扩散模型、3D DWT和扩散模型水印方面的研究为LVMark的开发提供了直接的参考和对比。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为LVMark的新型水印方法来解决视频扩散模型中的所有权保护问题。以下是LVMark方法的关键组成部分和解决策略:
1. 重要性基于的权重调制(Importance-based Weight Modulation)
- LVMark通过选择性调制预训练潜在解码器(latent decoder)的权重参数来嵌入随机消息,从而使得在单次训练过程中能够嵌入多个随机消息,并保持视频质量。
- 为了最小化对视觉质量的影响,LVMark仅调制对视频质量影响最小的层的权重参数。通过预先测量每层的重要性,选择性地调制影响最小的50%层。
2. 畸变层(Distortion Layer)
- 为了提高对各种视频攻击的鲁棒性,LVMark在每次迭代中对生成的视频应用随机畸变,包括空间畸变(如裁剪和模糊)和压缩畸变(特别是H.264压缩)。
- 为了处理H.264压缩的非可微性问题,LVMark设计了一个H.264网络,通过训练来准确复制实际的H.264压缩,增强对H.264压缩的鲁棒性。
3. 鲁棒视频水印解码器(Robust Video Watermark Decoder)
- LVMark设计了一个水印解码器,通过融合RGB视频和3D小波变换的低频子带(LLL)来提取消息,利用这些空间-时间信息增强对视频压缩等攻击的鲁棒性。
- 水印解码器包括特征提取模块和特征融合模块,使用交叉注意力机制来有效融合RGB域和频率域的特征。
4. 训练目标(Training Objectives)
- LVMark设计了一个目标函数,平衡视觉质量和水印解码准确性之间的权衡。使用二元交叉熵损失来确保准确的水印解码,并采用WatsonVGG感知损失来增强生成视频的视觉质量。
- 引入加权块损失(weighted patch loss)来减少局部区域的伪影,通过计算视频块之间的平均绝对误差(MAE),并使用softmax函数生成损失分数图,然后将块MAE与分数图相乘,以在伪影可能出现的区域施加更多权重。
综上所述,LVMark通过上述方法在保持视频质量的同时嵌入水印,并通过鲁棒的水印解码器准确提取消息,从而解决了视频扩散模型中的所有权保护问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估LVMark方法的性能,这些实验主要围绕以下几个方面:
1. 数据集和实现细节
- 视频数据集:使用Panda-70M数据集,这是一个大规模的视频帧集合,以其多样性而闻名。从该数据集中随机下载了10K个视频,每个视频采样8帧,调整分辨率为256×256用于训练。
- 提示数据集:使用Vidprom数据集进行文本到视频生成的评估,使用GPT4生成提示。
- 模型架构:实验涉及两种类型的视频扩散模型:DiT和U-Net架构。对于DiT架构,使用了OpenSora模型;对于U-Net架构,使用了DynamiCrafter模型。
2. 评估指标
- 视频质量和比特准确性:使用峰值信噪比(PSNR)、结构相似性(SSIM)、LPIPS等指标来衡量视频质量,并对比原始视频和水印视频的差异。
- 容量:评估了32位和48位消息的嵌入能力。
- 鲁棒性:测试了包括裁剪、旋转、高斯模糊、JPEG压缩等图像失真,以及帧交换、帧平均、帧丢弃和H.264压缩等视频特定失真对水印的影响。
3. 实验结果
- 视频质量和比特准确性:LVMark在保持视频质量的同时,实现了最高的比特准确性。
- 视频质量和容量:分析了嵌入消息长度对视频质量和比特准确性的影响,LVMark在较长消息的情况下仍保持高比特准确性。
- 对视频畸变和模型畸变的鲁棒性:LVMark在各种攻击下均显示出良好的鲁棒性,特别是在H.264压缩下的表现优于其他方法。
4. 消融研究
- 权重调制率:探讨了调制率对视频质量和比特准确性的影响,发现50%的调制率是最佳平衡点。
- 3D DWT与2D DWT:比较了3D DWT和2D DWT在视频水印中的效果,3D DWT在时间一致性和视频质量方面表现更好。
- 低频子带的使用:分析了仅使用低频子带与结合RGB特征和低频子带的效果,后者在不牺牲PSNR的情况下显著提高了比特准确性。
- 加权块损失的影响:展示了加权块损失在减少局部伪影方面的有效性。
这些实验全面评估了LVMark方法在视频扩散模型水印中的表现,并证明了其在视频质量和鲁棒性方面的优越性。
Q: 有什么可以进一步探索的点?
A: 尽管LVMark在视频扩散模型的水印方面取得了显著的成果,但仍有一些领域可以进一步探索和研究:
1. 内存效率优化
- 论文提到训练扩散模型以嵌入水印需要大量的内存,达到约25GB。未来的工作可以探索更内存高效的水印方法,以降低计算资源的需求。
2. 提高鲁棒性
- 尽管LVMark在多种攻击下表现出了良好的鲁棒性,但在更复杂的攻击或未知攻击下的性能仍需进一步测试和优化。
3. 多模态水印技术
- 考虑将水印技术扩展到其他模态,如音频或文本,以实现多模态内容的保护。
4. 实时水印嵌入
- 研究如何将LVMark应用于实时视频生成系统中,以实现实时的水印嵌入和检测。
5. 跨模型水印
- 探索是否可以将一个模型中嵌入的水印有效地迁移到另一个模型中,以保护模型的跨平台使用。
6. 更大模型和数据集的测试
- 在更大的模型和更多样化的数据集上测试LVMark的性能,以评估其泛化能力。
7. 安全性和隐私性
- 研究水印技术可能涉及的隐私和安全问题,确保水印方法不会泄露敏感信息。
8. 用户自定义水印
- 开发允许用户自定义水印信息的方法,以适应不同的应用场景和用户需求。
9. 法律和伦理考量
- 研究水印技术在法律和伦理层面的影响,确保技术的应用符合相关法规和道德标准。
10. 与其他技术的集成
- 探索将水印技术与其他内容保护技术(如数字签名、区块链等)结合的可能性,以提供更全面的内容保护解决方案。
这些方向不仅可以推动视频水印技术的发展,还可能为数字内容保护领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
研究背景与动机:
- 快速发展的生成模型,尤其是视频生成模型,虽然提高了视频生成的质量,但也带来了模型所有权侵权的问题。
- 现有的图像水印方法不能直接应用于视频,因为它们没有考虑视频的时间信息,导致在视频生成模型中性能较差。
论文贡献:
- 提出了LVMark,一种新颖的视频扩散模型水印方法,据作者所知,这是首次针对视频生成模型提出的水印技术。
- 引入了基于重要性权重调制技术,可以在单次训练过程中嵌入多个消息,同时保持视频质量。
- 设计了一个鲁棒的水印解码器,利用3D小波变换(3D DWT)来捕获视频的时空信息,有效对抗视频特定攻击,如H.264压缩。
- 引入加权块损失,平衡视觉质量和消息解码准确性,减少局部区域的伪影。
方法细节:
- 重要性基于的权重调制:选择性调制潜在解码器的权重参数,以最小化对视频质量的影响。
- 畸变层:模拟真实世界中的视频攻击,增强模型对这些攻击的鲁棒性。
- 鲁棒视频水印解码器:结合RGB视频和3D DWT的低频子带,通过交叉注意力机制解码隐藏的消息。
- 训练目标:设计目标函数平衡视觉质量和水印解码准确性,包括二元交叉熵损失、WatsonVGG感知损失和加权块损失。
实验:
- 使用Panda-70M数据集进行训练,Vidprom数据集进行评估。
- 比较了LVMark和其他基线方法在视频质量和比特准确性、容量和鲁棒性方面的表现。
- 进行了消融研究,验证了各个组件的有效性,包括权重调制率、3D DWT和加权块损失。
结论与局限性:
- LVMark在视频扩散模型的水印方面表现出色,有效地嵌入水印并保持视频质量。
- 训练过程需要大量内存,未来工作可以探索更内存高效的水印方法。
论文通过LVMark方法,为视频生成模型的所有权保护提供了一种有效的技术解决方案,并展示了其在多种攻击下的鲁棒性,为数字内容保护领域提供了新的思路。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

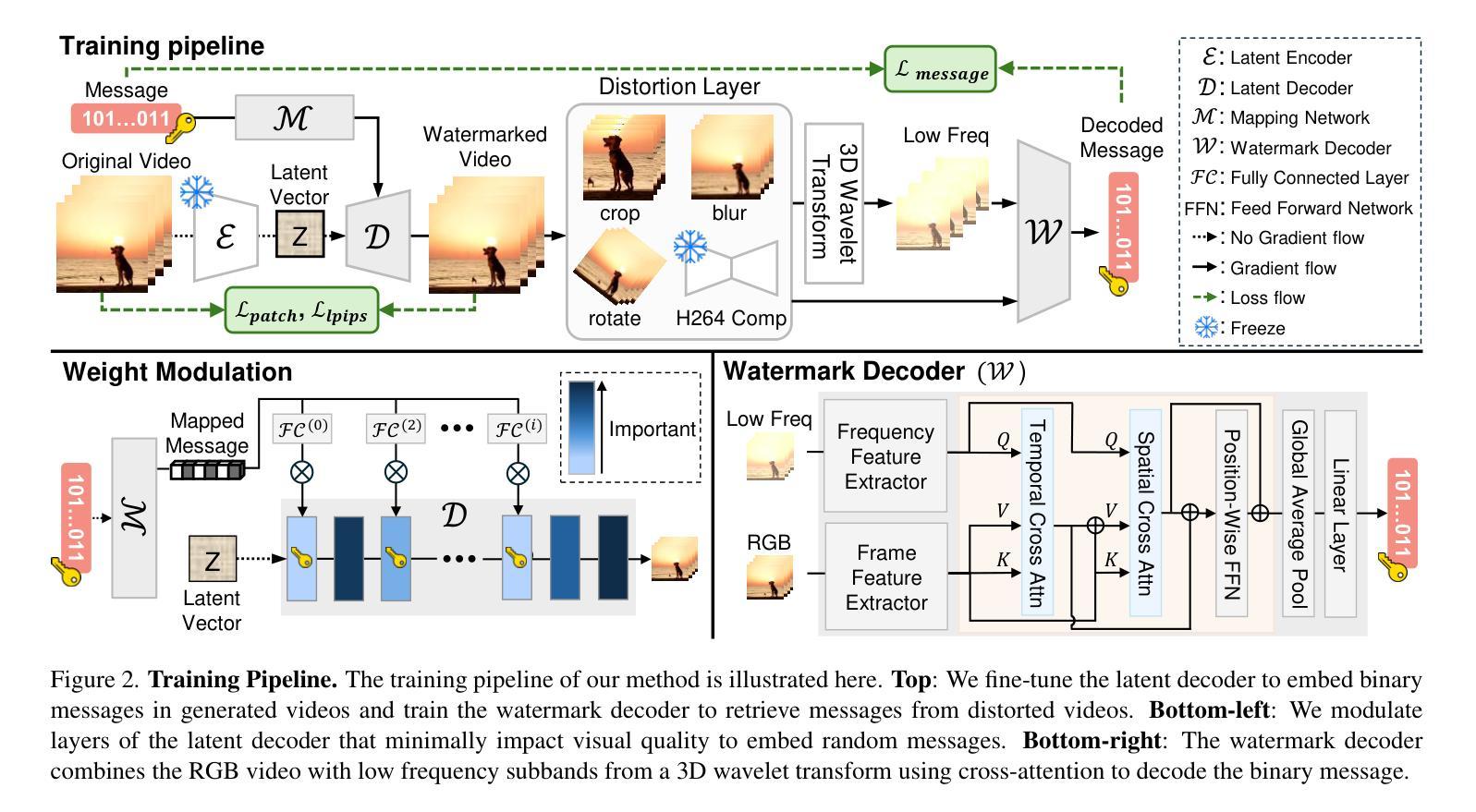
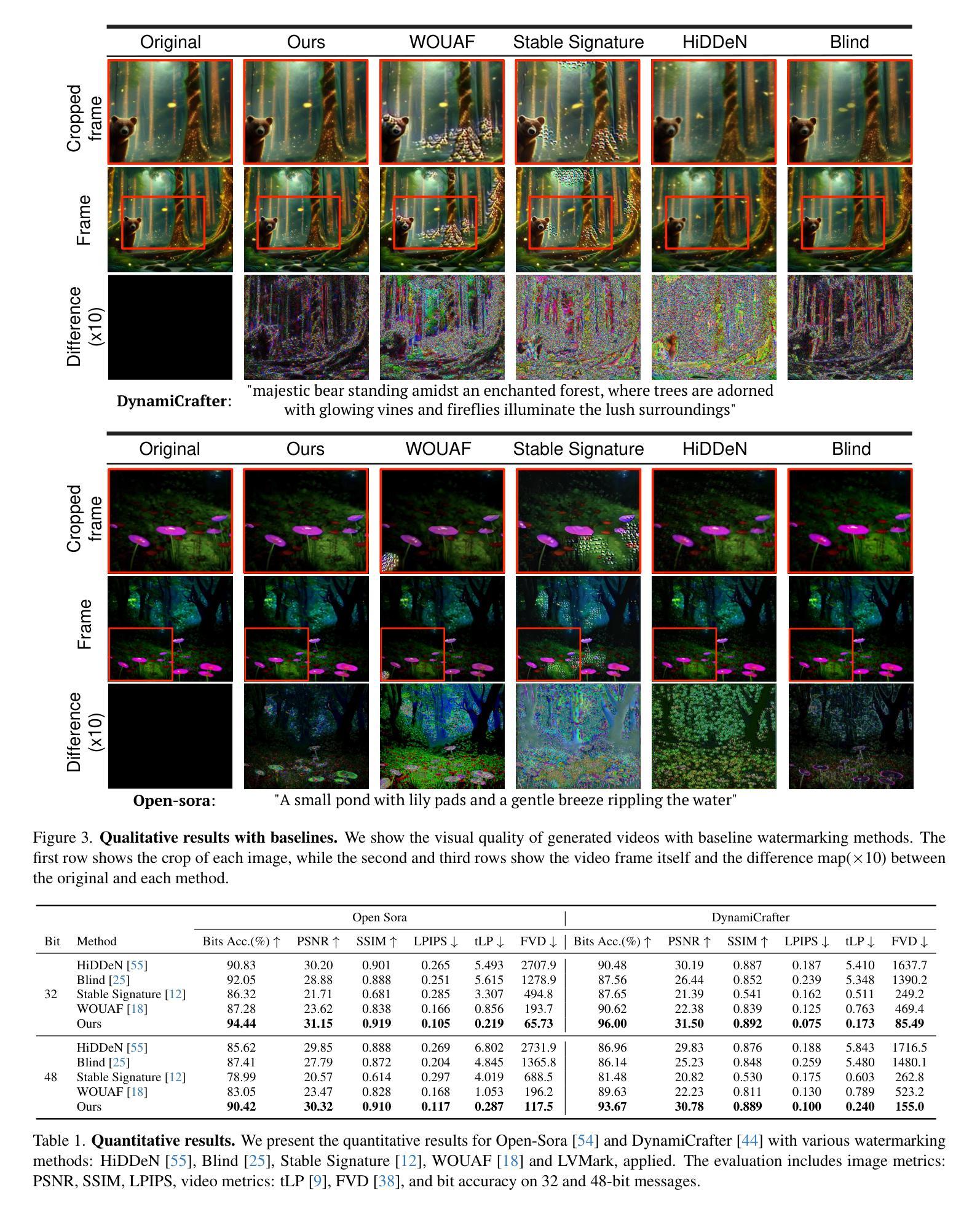
An Efficient Framework for Enhancing Discriminative Models via Diffusion Techniques
Authors:Chunxiao Li, Xiaoxiao Wang, Boming Miao, Chuanlong Xie, Zizhe Wang, Yao Zhu
Image classification serves as the cornerstone of computer vision, traditionally achieved through discriminative models based on deep neural networks. Recent advancements have introduced classification methods derived from generative models, which offer the advantage of zero-shot classification. However, these methods suffer from two main drawbacks: high computational overhead and inferior performance compared to discriminative models. Inspired by the coordinated cognitive processes of rapid-slow pathway interactions in the human brain during visual signal recognition, we propose the Diffusion-Based Discriminative Model Enhancement Framework (DBMEF). This framework seamlessly integrates discriminative and generative models in a training-free manner, leveraging discriminative models for initial predictions and endowing deep neural networks with rethinking capabilities via diffusion models. Consequently, DBMEF can effectively enhance the classification accuracy and generalization capability of discriminative models in a plug-and-play manner. We have conducted extensive experiments across 17 prevalent deep model architectures with different training methods, including both CNN-based models such as ResNet and Transformer-based models like ViT, to demonstrate the effectiveness of the proposed DBMEF. Specifically, the framework yields a 1.51% performance improvement for ResNet-50 on the ImageNet dataset and 3.02% on the ImageNet-A dataset. In conclusion, our research introduces a novel paradigm for image classification, demonstrating stable improvements across different datasets and neural networks.
图像分类作为计算机视觉的基石,传统上是通过基于深度神经网络的判别模型来实现的。最近的进展引入了基于生成模型的分类方法,它们具有零样本分类的优点。然而,这些方法存在两个主要缺点:计算开销大以及相较于判别模型的性能较差。受人类视觉信号识别过程中快速-慢速通路相互作用协同认知过程的启发,我们提出了基于扩散的判别模型增强框架(DBMEF)。该框架以无训练的方式无缝集成了判别模型和生成模型,利用判别模型进行初步预测,并通过扩散模型赋予深度神经网络反思能力。因此,DBMEF可以有效地提高判别模型的分类精度和泛化能力,即插即用。我们在使用不同训练方法的17种流行的深度模型架构上进行了广泛实验,包括基于CNN的模型(如ResNet)和基于Transformer的模型(如ViT),以证明所提出的DBMEF的有效性。具体来说,ResNet-50在ImageNet数据集上的性能提高了1.51%,在ImageNet-A数据集上提高了3.02%。总之,我们的研究为图像分类引入了一种新的范式,并在不同的数据集和神经网络中实现了稳定的性能提升。
论文及项目相关链接
PDF Accepted by AAAI2025
摘要
传统的图像分类是通过基于深度神经网络的判别模型来实现的。然而,近年来涌现出的由生成模型派生的分类方法虽然可以实现零样本分类,但存在计算开销大、性能较判别模型差的主要缺点。本文受人类大脑视觉信号识别过程中快速-慢速通路交互协同认知过程的启发,提出了基于扩散的判别模型增强框架(DBMEF)。该框架以无训练的方式无缝集成了判别模型和生成模型,利用判别模型进行初步预测,并通过扩散模型赋予深度神经网络反思能力。因此,DBMEF可以有效地提高判别模型的分类精度和泛化能力,以一种即插即用方式提升模型的性能。我们在包括CNN模型(如ResNet)和Transformer模型(如ViT)在内的17种流行的深度模型架构上进行了广泛的实验验证,证明了所提DBMEF的有效性。具体来说,在ImageNet数据集上,ResNet-50的性能提高了1.51%,在ImageNet-A数据集上提高了3.02%。总之,本研究为图像分类领域引入了一种新的范式,并证明了其在不同数据集和神经网络上的稳定改进。
关键见解
- 介绍了基于生成模型的图像分类方法,虽然可以实现零样本分类,但存在计算开销大、性能较判别模型差的问题。
- 提出了一种新型的图像分类框架——基于扩散的判别模型增强框架(DBMEF),该框架结合了判别模型和生成模型的优点。
- DBMEF通过利用判别模型进行初步预测,并借助扩散模型赋予深度神经网络反思能力,以提高分类精度和泛化能力。
- DBMEF在多种深度模型架构上进行了实验验证,包括CNN和Transformer模型。
- 在ImageNet和ImageNet-A数据集上的实验结果表明,DBMEF能够显著提高图像分类的性能。
- DBMEF为图像分类领域引入了一种新的研究范式,为未来的研究提供了新的方向。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在图像分类任务中结合判别模型(discriminative models)和生成模型(generative models)的优势,以提高分类的准确性和泛化能力。具体来说,论文中提到了以下几个关键问题:
判别模型与生成模型的结合:传统的图像分类方法通常独立地使用判别模型或生成模型。判别模型直接对图像进行分类,而生成模型则通过学习数据的联合分布来实现分类。论文提出了一个框架,将这两种模型结合起来,以期达到更好的分类效果。
生成模型在分类中的高计算开销和性能不足:基于生成模型的分类方法,尽管提供了零样本分类(zero-shot classification)的优势,但它们存在两个主要缺点:高计算开销和相比判别模型的性能劣势。论文旨在通过提出的方法来克服这些问题。
模仿人脑处理视觉信号的过程:论文受到人脑在视觉信号识别过程中快速-慢速路径相互作用的协调认知过程的启发,提出了一个框架,通过模仿这一过程来增强判别模型的性能。
提高判别模型的分类准确性和泛化能力:论文提出的框架旨在通过无需训练的方式,以即插即用的形式增强判别模型的分类准确性和泛化能力。
处理分布偏移和低分辨率数据:论文还探讨了所提出框架在面对分布偏移和低分辨率数据时的有效性,以展示其在不同情况下的鲁棒性和适用性。
综上所述,论文的核心目标是提出一个有效的框架,通过结合判别模型和生成模型的优点,来提升图像分类任务的性能,并在不同的数据集和神经网络架构上展示其有效性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以概括为以下几个方面:
判别模型和生成模型在图像分类中的应用:
- 判别模型直接对图像分类,如VGG、ResNet、ViT等。
- 生成模型通过学习数据的联合分布来进行分类,例如基于能量的模型(EBM)和基于分数的模型(Score-Based Models)。
零样本分类(Zero-Shot Classification):
- 使用生成模型进行零样本分类的研究,如基于扩散模型(Diffusion Models)的方法。
扩散模型(Diffusion Models):
- 扩散模型在图像生成领域的应用,特别是在生成高质量图像方面超越了生成对抗网络(GANs)。
- 分类引导扩散(Classifier Guidance Diffusion)和无分类器引导扩散(Classifier-Free Guidance Diffusion)技术,这些技术通过在生成阶段调整图像的梯度来实现基于指定类别的条件生成。
基于分数的生成模型(Score-Based Generative Models):
- 使用基于分数的生成模型来估计条件概率(P(x|y)),并用于图像分类。
对抗性鲁棒性(Adversarial Robustness):
- 利用扩散模型评估传统判别分类器的对抗性鲁棒性。
结合判别模型和生成模型的方法:
- 先前的研究工作,如SBGC、RDC等,这些方法尝试将扩散模型整合到图像分类任务中。
改进扩散模型的分类性能:
- 将扩散模型应用于DiT-XL/2模型,并在ImageNet数据集上进行监督分类。
加速采样方法:
- 研究工作探索了加速扩散模型采样过程的方法,以减少分类单个图像所需的时间。
这些相关研究构成了论文提出的Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的理论基础和技术背景。论文通过结合这些领域的最新进展,提出了一个新的框架,旨在通过模仿人脑处理视觉信号的过程来增强判别模型的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的框架来解决上述问题。以下是该框架解决这些问题的关键步骤和方法:
1. 结合判别模型和生成模型
DBMEF框架通过以下步骤将判别模型和生成模型结合起来:
- 判别模型初步预测:使用判别模型对测试输入进行初步预测,类似于人脑中的快速通路。
- 生成模型重新评估:对于判别模型不确定的预测,使用扩散模型进行重新评估,模拟人脑中的慢速通路。
2. 模仿人脑处理视觉信号的过程
- 快速-慢速路径交互:框架受到人脑处理视觉信号时快速和慢速路径相互作用的启发,通过重复“猜测-验证-猜测-验证”的过程来识别对象。
3. 增强判别模型的性能
- 置信度保护器(Confidence Protector):通过一个置信度阈值来决定是否需要通过扩散模型进一步评估预测结果。
- 扩散模型分类器:将扩散模型的有条件去噪结果转化为后验概率的估计,以重新分类图像。
4. 处理分布偏移和低分辨率数据
- 适应不同数据集:框架在多个数据集上进行测试,包括ImageNet、ImageNet-A、CIFAR-10和CIFAR-100,以验证其对分布偏移和低分辨率数据的适应性。
5. 提升效率和准确性
- 减少计算开销:通过仅对判别模型不确定的预测进行扩散模型的重新评估,减少了整体计算开销。
- 提高分类准确性:通过结合判别模型的高效率和生成模型的精细化处理,DBMEF显著提高了分类的准确性。
6. 即插即用和无需训练
- 无需额外训练:DBMEF作为一个即插即用的框架,可以直接应用于现有的判别模型,无需额外的训练过程。
总结来说,DBMEF框架通过模仿人脑处理视觉信号的过程,结合了判别模型和生成模型的优势,以提高图像分类任务的准确性和泛化能力,同时减少了计算开销。通过在多个数据集和不同网络架构上的实验,论文证明了该框架的有效性和普适性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的有效性。以下是实验的主要内容:
1. 不同模型架构的性能测试
- 基线模型:选择了17种基于不同训练方法、数据集和架构的判别模型,包括监督学习模型(如DeiT-Base、ViT-Base、ResNet50等)、自监督学习方法(如MAE、DINOv2等)以及对比学习模型(如CLIP)。
- 实验设置:使用Stable Diffusion V1-5作为扩散模型,设置保护阈值Prot、时间步长、负控制因子λ等参数,并在ImageNet2012-1k验证集上进行评估。
- 结果:DBMEF在这些模型上取得了0.19%到3.27%的准确率提升。
2. 分布偏移的性能测试
- 数据集:使用ImageNet-S、ImageNet-A、ImageNet-V2和ImageNet-E数据集来评估DBMEF在面对不同类型的分布偏移时的性能。
- 基线模型:使用ViT-Base、DeiT-Small、ResNet50和VGG16等预训练的深度判别模型。
- 结果:DBMEF在各种分布偏移数据集上均显示出稳定的性能提升,特别是在ImageNet-A上,ResNet50的准确率从0.00%提升到3.02%。
3. 低分辨率数据集的分类性能测试
- 数据集:选择CIFAR-10和CIFAR-100数据集,这些数据集包含的图像分辨率为32×32像素。
- 基线模型:使用ResNet18、ResNet34和ResNet50等模型,并在这些数据集上进行测试。
- 结果:即使在基线准确率已经很高的低分辨率图像上,应用DBMEF框架仍然能够进一步提升性能。
4. 超参数的影响测试
- 超参数:研究了保护阈值Prot、时间步长T、负控制因子λ以及扩散模型的选择对DBMEF性能的影响。
- 实验结果:分析了不同超参数设置对模型性能的具体影响,提供了关于如何选择这些参数以优化DBMEF性能的见解。
5. 置信度保护器和扩散模型的作用分析
- 置信度保护器:通过详细的可视化和分析,展示了置信度保护器对DBMEF性能的影响。
- 扩散模型:通过实验验证了扩散模型在DBMEF中的关键作用,与使用更多数据训练的判别模型相比,扩散模型提供了更好的性能提升。
这些实验全面地验证了DBMEF框架的有效性、普适性和鲁棒性,并深入分析了框架中各个组件的作用和影响。通过这些实验,论文展示了DBMEF在不同条件下都能显著提升图像分类任务的性能。
Q: 有什么可以进一步探索的点?
A: 论文提出的Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)为图像分类领域提供了一个新范式,以下是一些可以进一步探索的点:
1. 超参数优化
- 研究不同的超参数设置对DBMEF性能的影响,包括保护阈值(Prot)、时间步长(T)、负控制因子(λ)等,以找到最优的配置。
2. 扩散模型的改进
- 探索使用新一代的扩散模型,如更近期版本的Stable Diffusion或其他类型的扩散模型,以进一步提高DBMEF的性能。
- 研究如何定制扩散模型以更好地适应特定的判别模型和数据集。
3. 多模态数据集的应用
- 将DBMEF应用于多模态数据集,如结合图像和文本的数据集,探索其在多模态学习中的潜力。
4. 不同的网络架构
- 测试DBMEF在更多种类的深度学习架构上的效果,包括最新的卷积网络和Transformer变体。
5. 跨域泛化能力
- 研究DBMEF在面对更大分布偏移时的表现,例如跨域识别任务,以及如何改进框架以提高其跨域泛化能力。
6. 实时应用
- 探索DBMEF在实时应用中的可行性,例如在移动设备或嵌入式系统上的部署,并优化其以满足实时处理的需求。
7. 理论分析
- 深入研究DBMEF的理论基础,包括其统计性质和收敛性,以及如何从理论上解释其性能提升的原因。
8. 与其他生成模型的比较
- 将DBMEF与其他类型的生成模型(如GANs)进行比较,分析其在图像分类任务中的优缺点。
9. 鲁棒性和安全性测试
- 对DBMEF进行鲁棒性和安全性测试,特别是在对抗性攻击和数据隐私方面的表现。
10. 应用到其他视觉任务
- 将DBMEF框架扩展到其他计算机视觉任务,如目标检测、语义分割等,探索其在这些任务中的有效性和适用性。
这些探索点可以帮助研究者更深入地理解DBMEF的工作原理,优化其性能,并扩展其在计算机视觉领域的应用范围。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的新框架,旨在通过结合判别模型和生成模型的优势来增强图像分类任务的性能。以下是论文的主要内容总结:
1. 研究动机
- 传统的图像分类方法主要基于判别模型或生成模型,但存在各自的局限性。判别模型虽然分类速度快,但缺乏重新评估的能力;生成模型能进行细致的图像理解,但计算成本高且性能落后于判别模型。
2. DBMEF框架
- 框架概述:DBMEF框架通过模仿人脑处理视觉信号的快速和慢速路径交互过程,整合判别模型和生成模型,以提高分类的准确性和泛化能力。
- 关键组件:包括置信度保护器和扩散模型分类器,以及结合正负文本条件和投票机制的策略。
3. 方法论
- 判别模型初步预测:判别模型首先对测试输入进行预测,类似于人脑的快速通路。
- 生成模型重新评估:对于判别模型不确定的预测,通过扩散模型进行重新评估,模拟人脑的慢速通路。
- 置信度保护器:基于训练集正确分类样本的统计特性,决定是否需要通过扩散模型进一步评估。
- 扩散模型分类器:将扩散模型的有条件去噪结果转化为后验概率的估计,以重新分类图像。
4. 实验验证
- 在多个数据集(包括ImageNet、ImageNet-A、CIFAR-10和CIFAR-100)和多种深度模型架构上验证了DBMEF的有效性。
- 实现了在不同模型上0.19%到3.27%的准确率提升,并在分布偏移和低分辨率数据上显示出稳定的性能提升。
5. 超参数影响和组件作用分析
- 对保护阈值、时间步长、负控制因子等超参数进行了实验分析,探讨了它们对框架性能的影响。
- 分析了置信度保护器和扩散模型在DBMEF中的关键作用。
6. 结论
- DBMEF框架有效地提高了判别模型的分类准确性和泛化能力,同时减少了计算开销。
- 论文提出了一个新的图像分类范式,并鼓励未来研究进一步探索扩散模型在下游应用中的整合。
总体而言,论文通过提出DBMEF框架,展示了如何通过结合判别模型和生成模型的优势来提高图像分类任务的性能,并在多个数据集和模型上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

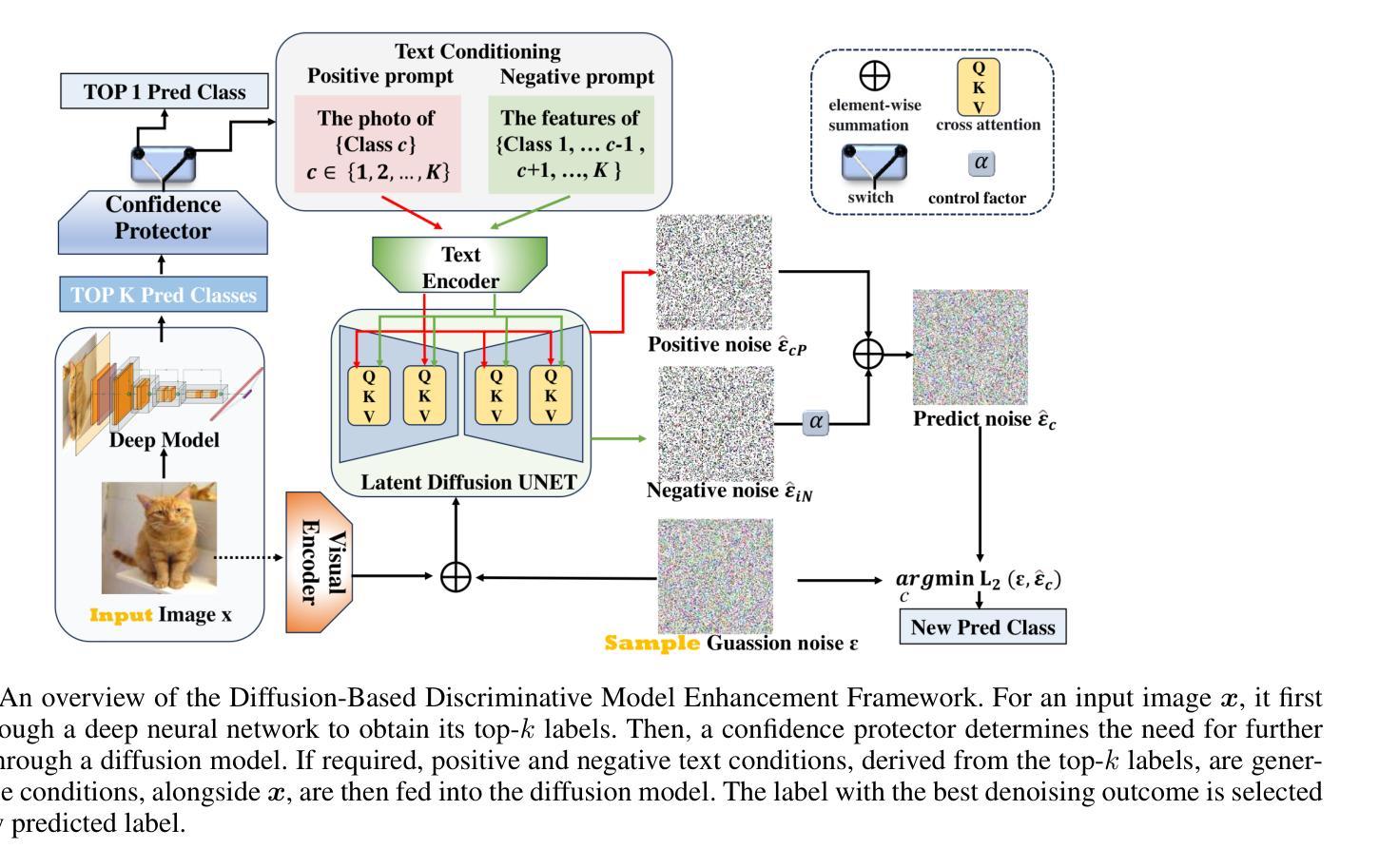
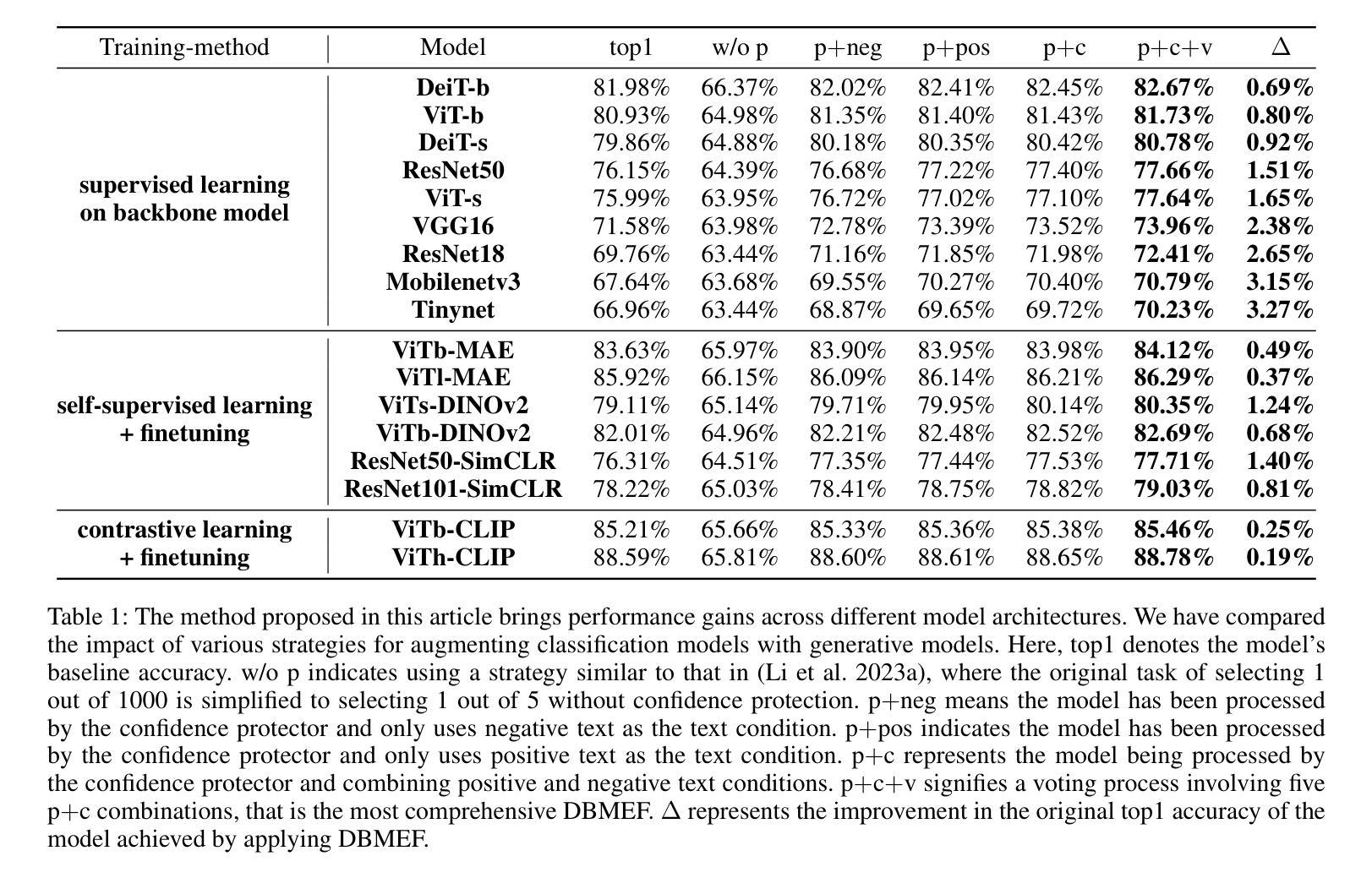
Arbitrary-steps Image Super-resolution via Diffusion Inversion
Authors:Zongsheng Yue, Kang Liao, Chen Change Loy
This study presents a new image super-resolution (SR) technique based on diffusion inversion, aiming at harnessing the rich image priors encapsulated in large pre-trained diffusion models to improve SR performance. We design a Partial noise Prediction strategy to construct an intermediate state of the diffusion model, which serves as the starting sampling point. Central to our approach is a deep noise predictor to estimate the optimal noise maps for the forward diffusion process. Once trained, this noise predictor can be used to initialize the sampling process partially along the diffusion trajectory, generating the desirable high-resolution result. Compared to existing approaches, our method offers a flexible and efficient sampling mechanism that supports an arbitrary number of sampling steps, ranging from one to five. Even with a single sampling step, our method demonstrates superior or comparable performance to recent state-of-the-art approaches. The code and model are publicly available at https://github.com/zsyOAOA/InvSR.
本研究提出了一种基于扩散反转的新型图像超分辨率(SR)技术,旨在利用预训练的大型扩散模型中封装的丰富图像先验知识来提高SR性能。我们设计了一种局部噪声预测策略,以构建扩散模型的中间状态,作为起始采样点。我们的方法的核心是一个深度噪声预测器,用于估计前向扩散过程的最佳噪声图。一旦训练完成,该噪声预测器可用于部分初始化扩散轨迹上的采样过程,生成理想的高分辨率结果。与现有方法相比,我们的方法提供了一种灵活高效的采样机制,支持从一到五任意的采样步骤数。即使只有一个采样步骤,我们的方法也表现出与最新先进技术方法相当或更优的性能。代码和模型可在https://github.com/zsyOAOA/InvSR上公开获取。
论文及项目相关链接
PDF 16 pages, 9 figures. Project: https://github.com/zsyOAOA/InvSR
Summary
本文介绍了一种基于扩散反转的新图像超分辨率(SR)技术,该技术利用大型预训练扩散模型中的丰富图像先验信息来提高SR性能。设计了一种部分噪声预测策略,构建扩散模型的中间状态,作为采样起始点。核心是一个深度噪声预测器,用于估计前向扩散过程的最佳噪声图。训练后的噪声预测器可用于沿扩散轨迹部分初始化采样过程,生成理想的高分辨率结果。与现有方法相比,该方法提供了灵活高效的采样机制,支持从一到五步的任意采样步骤数。即使使用单步采样,该方法也能达到或超过最近先进技术方法的性能。
Key Takeaways
- 基于扩散反转的新图像超分辨率技术利用预训练扩散模型的图像先验信息提高性能。
- 设计了部分噪声预测策略,构建了扩散模型的中间状态作为采样起始点。
- 引入深度噪声预测器,估计前向扩散过程的最佳噪声图。
- 训练后的噪声预测器可以初始化采样过程,生成高分辨率结果。
- 方法提供灵活高效的采样机制,支持任意数量的采样步骤。
- 与现有方法相比,该方法在单步采样时表现出卓越或相当的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的图像超分辨率(Super-Resolution, SR)技术,旨在解决从给定的低分辨率(Low-Resolution, LR)图像中恢复高分辨率(High-Resolution, HR)图像的问题。具体来说,这项工作试图解决以下几个关键问题:
利用扩散模型中的丰富图像先验:该研究旨在利用大型预训练扩散模型中包含的丰富图像先验来提升超分辨率性能。
优化扩散过程:通过设计一个部分噪声预测策略,构建扩散模型的中间状态作为起始采样点,进而优化从低分辨率到高分辨率图像的扩散过程。
高效的采样机制:提出了一个灵活且高效的采样机制,允许用户根据退化类型或具体需求自由调整采样步骤的数量。
改进扩散逆过程:通过训练一个深度噪声预测器来估计最优噪声图,从而在不修改扩散网络本身的情况下,最大化扩散先验的效用。
处理实际场景中的复杂性和未知性:针对实际场景中复杂且通常未知的退化模型,该研究试图通过扩散模型的强大生成能力来缓解超分辨率问题的不适定性(ill-posedness)。
提高采样效率和实用性:通过引入噪声预测模块,该方法在训练后能够实现高效的逆过程采样,避免了在推理过程中需要迭代优化的步骤,从而显著提高了扩散逆在超分辨率任务中的效率和实用性。
总的来说,这项工作的主要贡献在于提出了一种基于扩散逆的新颖超分辨率方法,该方法通过整合辅助噪声预测器来有效利用扩散先验,同时保持整个扩散网络固定,并且引入了一种灵活和高效的采样机制,允许进行任意数量的采样步骤。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个方面:
基于扩散模型的图像超分辨率(SR):
- 论文中提到了利用扩散先验进行SR的研究,包括通过优化或微调扩散模型的中间特征来与给定的低分辨率图像保持一致的方法,如DDRM、CCDF和DDNM等。
- 直接对预训练的大型文本到图像(T2I)模型进行微调以进行SR任务的方法,例如StableSR、DiffBIR、SeeSR、PASD、S3Diff等。
扩散逆(Diffusion Inversion):
- 扩散逆技术关注于确定最优的噪声图集,使得通过扩散模型处理后能够重建给定图像。DDIM通过将扩散模型泛化为一类非马尔可夫过程来建立确定性生成过程。
- 其他工作则专注于优化文本嵌入以更好地与所需的文本指导对齐,或者优化中间噪声图,以提升逆向质量。
生成对抗网络(GANs)逆:
- 论文提到了将GANs逆用于各种应用,包括图像超分辨率的研究。
图像退化和恢复:
- 论文中提到了与图像退化和恢复相关的研究,这些研究尝试通过解决优化问题或使用估计的退化模型来确保扩散模型的中间结果与给定的低分辨率图像保持一致。
图像编辑和图像质量评估:
- 论文中提到了一些与图像编辑和图像质量评估相关的研究,例如使用扩散模型进行图像编辑和使用各种图像质量评估指标来衡量超分辨率结果的性能。
深度学习和图像合成:
- 论文中提到了使用深度学习模型,特别是变换器(Transformers)进行高分辨率图像合成的研究。
这些相关研究构成了论文提出的基于扩散逆的图像超分辨率技术的理论基础和实践背景。论文通过结合这些相关领域的最新进展,提出了一种新的技术,旨在通过利用预训练扩散模型中的丰富图像先验来提高超分辨率任务的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一种基于扩散逆的图像超分辨率(SR)技术来解决这个问题,具体解决方案包括以下几个关键步骤:
部分噪声预测(Partial Noise Prediction, PnP)策略:
- 论文设计了一种PnP策略来构建扩散模型的中间状态,该状态作为采样过程的起始点。通过在低分辨率(LR)图像上添加噪声来模拟扩散模型的前向过程,其中噪声由噪声预测器预测,而不是随机采样。
深度噪声预测器:
- 论文引入了一个深度神经网络,称为噪声预测器,用于从给定的LR图像估计噪声图。这个噪声预测器在训练后可以用来部分初始化沿扩散轨迹的采样过程,生成期望的高分辨率(HR)结果。
灵活的采样机制:
- 与现有方法相比,论文提出的方法提供了一种灵活且高效的采样机制,支持从一到五个任意数量的采样步骤。这种灵活性使用户能够根据退化类型或特定需求自由调整采样步骤的数量。
优化和训练:
- 论文详细描述了如何通过训练噪声预测器来最小化估计的HR图像和真实HR图像之间的距离。训练过程中采用了L2损失、LPIPS损失和GAN损失,以优化噪声预测器的性能。
模型架构和训练细节:
- 论文提供了噪声预测器的架构细节,并详细说明了训练过程,包括数据集、优化算法、批次大小和学习率等。
实验验证:
- 论文通过在合成数据集和真实世界数据集上的实验来验证所提出方法的有效性,包括定量和定性的结果分析。
效率和实用性的改进:
- 论文提出的方法在保持性能的同时减少了采样步骤,提高了效率。此外,该方法的模型大小适中,使其适合实际应用。
通过这些步骤,论文成功地提出了一种新的基于扩散逆的图像超分辨率方法,该方法能够有效地利用预训练扩散模型中的图像先验,并提供了一种灵活的采样策略,以适应不同的退化条件和应用需求。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来评估提出方法的性能:
实验设置:
- 训练细节:作者描述了噪声预测器的训练过程,包括使用的数据集(LSDIR和FFHQ数据集的一个子集)、图像裁剪、低分辨率图像合成方法(RealESRGAN)、文本提示、优化算法(Adam)、批次大小、学习率、迭代次数以及损失函数中的超参数设置。
- 测试数据集:为了评估InvSR的性能,作者构建了一个名为ImageNet-Test的合成数据集,包含3,000张来自ImageNet验证集的图像。此外,还包括了两个真实世界数据集RealSR和RealSet80。
- 比较方法:作者将InvSR与九种最近的方法进行了比较,包括基于GAN的方法(BSRGAN和RealESRGAN)和基于扩散的方法(LDM、StableSR、DiffBIR、SeeSR、ResShift、SinSR和OSEDiff)。
- 评估指标:使用了包括PSNR、SSIM、LPIPS、NIQE、PI、CLIPIQA和MUSIQA在内的七个指标来全面评估不同方法的性能。
模型分析:
- 任意步数采样:分析了InvSR支持任意采样步数的灵活性,并与最近一些固定采样步数的高效扩散基SR方法进行了比较。
- 初始噪声预测:展示了初始采样步骤中预测的噪声图,并分析了其与图像内容的相关性。
与最新技术的比较:
- 合成数据集:在ImageNet-Test数据集上,使用七个定量指标对各种方法进行了全面评估,并提供了额外的定性比较。
- 真实世界数据集:在RealSR和RealSet80数据集上,主要关注非参考指标,并提供了详细的定量比较和视觉比较。
补充材料中的额外实验:
- 不同基础扩散模型的性能比较:比较了InvSR在两种不同的预训练扩散模型(SD-2.0和SD-Turbo)上的性能。
- 中间噪声预测的消融研究:探讨了在中间时间步使用额外噪声预测器的必要性。
- 损失函数的消融研究:分析了不同损失函数配置对模型性能的影响。
- 效率和限制讨论:讨论了InvSR的效率,并与其他方法进行了比较。
通过这些实验,论文全面评估了所提出InvSR方法的性能,并与现有的最先进技术进行了比较,证明了其在图像超分辨率任务中的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的基于扩散逆的图像超分辨率方法,但仍有一些领域可以进一步探索和改进:
模型泛化能力:
- 探索模型在不同类型的退化模型和更多样化的数据集上的泛化能力,包括不同场景、不同传感器捕获的图像等。
模型效率优化:
- 研究模型压缩和量化技术,以减少模型大小和加速推理过程,使其更适合实时应用。
噪声预测网络的改进:
- 研究更复杂的噪声预测网络架构,以提高噪声图预测的准确性,从而进一步提升超分辨率图像的质量。
多步采样策略的自动化调整:
- 开发自动化机制来确定最优的采样步数,根据输入图像的特定退化条件动态调整采样策略。
联合训练策略:
- 探索将噪声预测网络与扩散模型联合训练的可能性,以更有效地利用扩散先验。
损失函数的改进:
- 设计新的损失函数或优化现有损失函数的权重,以在保持图像细节和降低噪声之间取得更好的平衡。
跨模态学习:
- 考虑将跨模态学习整合到框架中,例如结合文本描述来指导图像超分辨率过程,以提高图像的视觉质量和感知真实性。
模型解释性:
- 提高模型的可解释性,理解模型在不同步骤中是如何学习和恢复高频细节的。
鲁棒性测试:
- 对模型进行更严格的鲁棒性测试,包括对抗性攻击和不同级别的噪声干扰,以评估其在极端条件下的性能。
实际应用测试:
- 在实际应用场景中测试模型的性能,如监控视频增强、医学成像和卫星图像处理等。
与最新技术的比较:
- 随着图像超分辨率领域的快速发展,定期与最新的技术进行比较,确保方法的先进性。
更深入的消融研究:
- 对模型的不同组件进行更深入的消融研究,以更精确地理解每个部分对最终性能的贡献。
这些探索方向不仅可以推动基于扩散逆的图像超分辨率技术的发展,还可能为整个图像恢复和计算机视觉领域带来新的见解和技术进步。
Q: 总结一下论文的主要内容
A: 论文提出了一种新的基于扩散逆的图像超分辨率(SR)技术,旨在利用大型预训练扩散模型中丰富的图像先验来提高SR性能。以下是论文的主要内容总结:
研究目标:
- 恢复高分辨率图像,解决实际场景中图像退化问题的复杂性和未知性。
方法论:
- 设计了部分噪声预测(Partial Noise Prediction, PnP)策略,构建扩散模型的中间状态作为采样起点。
- 引入深度噪声预测器来估计最优噪声图,用于初始化扩散模型的采样过程。
- 提出了一种灵活且高效的采样机制,支持从一到五个任意数量的采样步骤。
技术贡献:
- 提出了一种新颖的基于扩散逆的SR方法,通过集成辅助噪声预测器有效利用扩散先验,同时保持整个扩散网络固定。
- 引入了灵活的采样机制,允许用户根据退化类型或具体需求调整采样步骤。
实验验证:
- 在合成数据集和真实世界数据集上进行了广泛的实验,验证了所提方法的有效性。
- 与现有的最先进技术进行了比较,展示了在不同采样步骤下的性能。
主要贡献:
- 提出了一种新的基于扩散逆的SR方法,有效利用扩散先验,提高了SR性能。
- 引入了灵活的采样机制,允许任意采样步骤,提高了方法的适应性和实用性。
代码和模型:
- 提供了公开的代码和模型,以便研究社区进一步研究和应用。
总的来说,这项工作通过结合扩散模型的强生成能力和噪声预测技术,为图像超分辨率领域提供了一种新的视角和解决方案。通过灵活的采样机制,该方法能够适应不同的退化条件,实现高效且高质量的图像超分辨率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

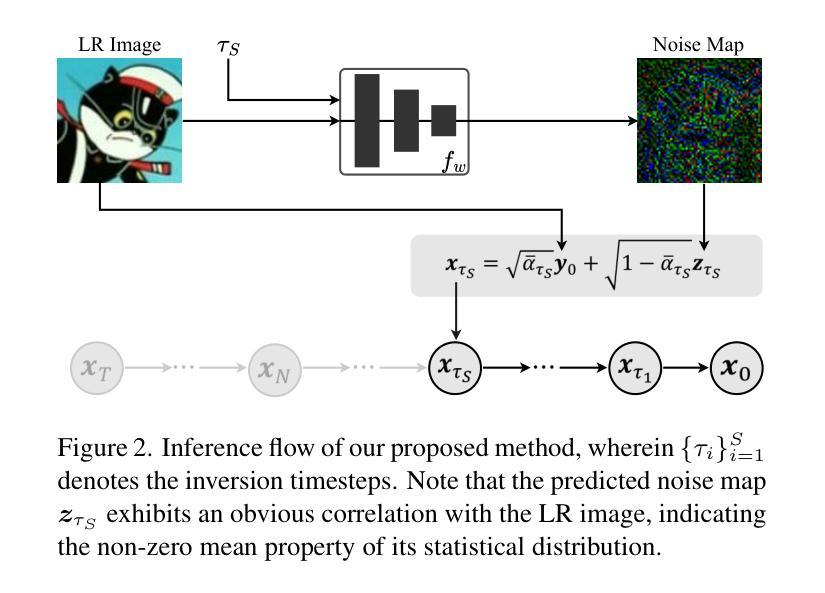
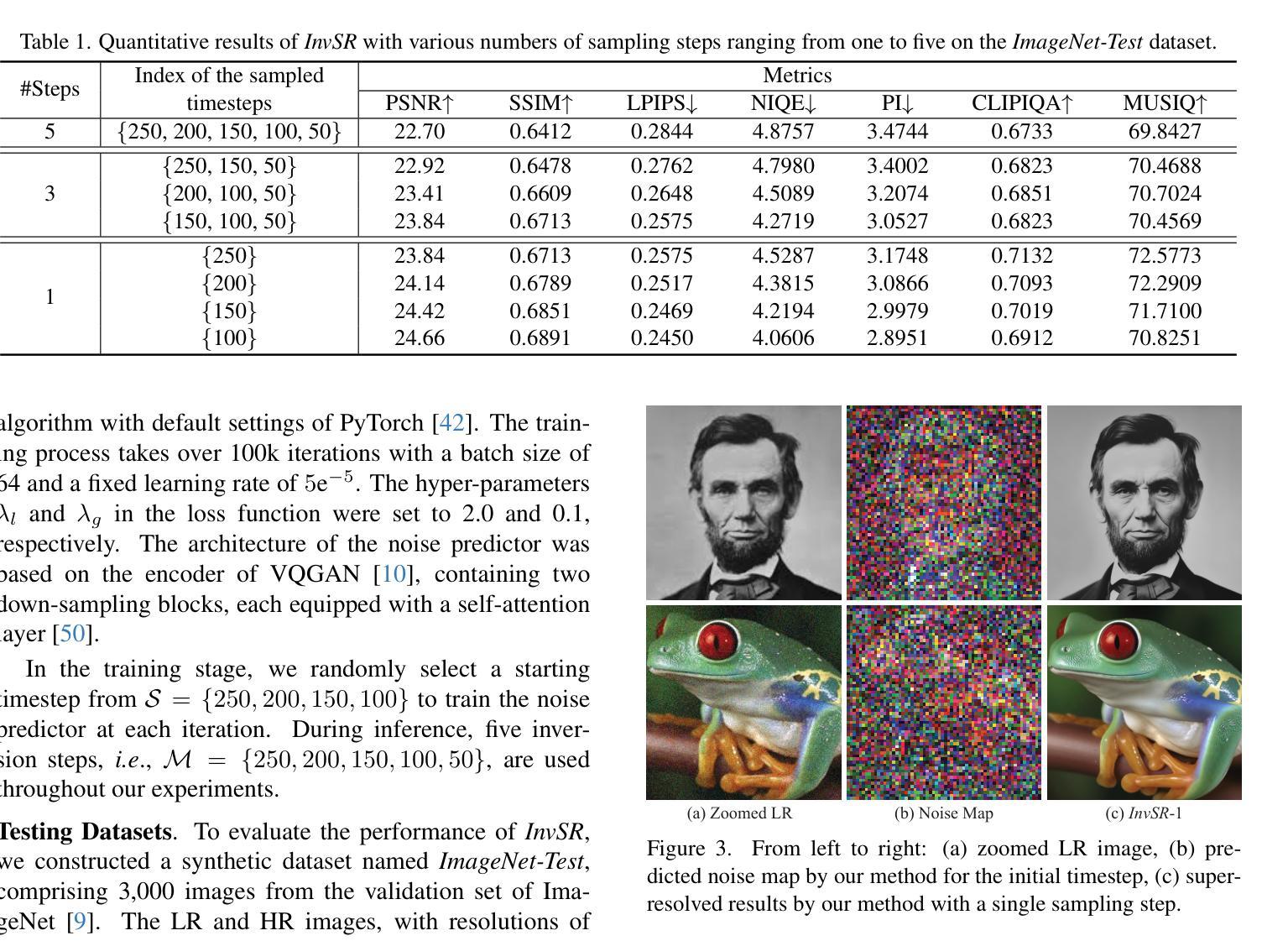
Interpreting Graphic Notation with MusicLDM: An AI Improvisation of Cornelius Cardew’s Treatise
Authors:Tornike Karchkhadze, Keren Shao, Shlomo Dubnov
This work presents a novel method for composing and improvising music inspired by Cornelius Cardew’s Treatise, using AI to bridge graphic notation and musical expression. By leveraging OpenAI’s ChatGPT to interpret the abstract visual elements of Treatise, we convert these graphical images into descriptive textual prompts. These prompts are then input into MusicLDM, a pre-trained latent diffusion model designed for music generation. We introduce a technique called “outpainting,” which overlaps sections of AI-generated music to create a seamless and cohesive composition. We demostrate a new perspective on performing and interpreting graphic scores, showing how AI can transform visual stimuli into sound and expand the creative possibilities in contemporary/experimental music composition. Musical pieces are available at https://bit.ly/TreatiseAI
本文介绍了一种受康拉迪斯·卡德伍 (Cornelius Cardew) 的《著作》启发而创作的新型音乐创作与即兴演奏方法,利用人工智能在图形符号与音乐表达之间搭建桥梁。我们借助OpenAI的ChatGPT解读《著作》中的抽象视觉元素,将这些图形图像转化为描述性的文本提示。这些提示然后输入到为音乐生成而预先训练的潜在扩散模型MusicLDM中。我们引入了一种名为“外画”的技术,通过重叠AI生成的音乐片段来创建无缝且连贯的乐曲。我们展示了执行和解读图形乐谱的新视角,展示了人工智能如何将视觉刺激转化为声音,并扩展了当代/实验性音乐创作的创意可能性。音乐作品可在https://bit.ly/TreatiseAI上找到。
论文及项目相关链接
Summary
本工作通过运用人工智能技术,以康奈尔纽斯·卡德夫的作品《Treatise》为灵感,提出了一种新颖的作曲与即兴音乐创作方法。研究团队利用OpenAI的ChatGPT解读《Treatise》中的抽象视觉元素,将这些图像转化为描述性的文本提示。这些提示被输入到预训练的潜在扩散模型MusicLDM中进行音乐生成。同时,团队介绍了一种名为“外绘画”的技术,该技术能将AI生成的音乐片段无缝衔接,形成连贯的作曲。该研究展示了执行和解读图形乐谱的新视角,展示了人工智能如何将视觉刺激转化为声音,并扩展了当代/实验音乐创作的创造性可能性。
Key Takeaways
- 运用了Cornelius Cardew的《Treatise》为灵感,提出了一种新颖的音乐创作方法。
- 利用OpenAI的ChatGPT转化图像为文本提示,作为音乐创作的输入。
- 采用了预训练的潜在扩散模型MusicLDM进行音乐生成。
- 介绍了一种名为“外绘画”的技术,能够实现AI生成音乐片段的无缝衔接。
- 展示了AI在将视觉刺激转化为声音方面的能力。
- 扩展了当代/实验音乐创作的创造性可能性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新颖的方法,旨在解决如何使用人工智能(AI)来解释和即兴创作受康纳留斯·卡迪尤(Cornelius Cardew)的《论述》(Treatise)启发的音乐作品的问题。《论述》是一部实验音乐和图形符号的里程碑作品,由抽象的形状、线条和符号组成,这些元素挑战了传统的音乐解释方式。论文中提出的方法使用AI技术将图形符号转换成音乐表达,具体来说,它通过以下几个步骤来解决这个问题:
图形符号的解释:利用OpenAI的ChatGPT来解释《论述》中的抽象视觉元素,并将这些图形图像转换成描述性的文本提示。
音乐生成:将上述文本提示输入到MusicLDM(一个预训练的潜在扩散模型,专为音乐生成设计),以生成相应的音乐序列。
平滑过渡技术:通过一种称为“outpainting”的技术,即重叠AI生成的音乐部分,来创建无缝且连贯的组合。
这项工作展示了AI如何在视觉艺术和音乐之间建立多模态关系,为非传统乐谱的表演、即兴创作和解释提供了新的视角,并推动了当代/实验音乐创作的边界。
Q: 有哪些相关研究?
A: 论文中提到了多个与AI音乐生成和图形符号解释相关的研究工作,具体如下:
原始音频域的生成模型:
- [1] A. van den Oord et al., “WaveNet: A Generative Model for Raw Audio,” 提出了WaveNet,这是一个用于原始音频数据生成的模型。
- [2] S. Mehri et al., “Samplernn: An unconditional end-to-end neural audio generation model,” 提出了一个无需条件的端到端神经音频生成模型。
- [3] C. Donahue et al., “Adversarial audio synthesis,” 介绍了一个对抗性音频合成方法。
- [4] P. Dhariwal et al., “Jukebox: A generative model for music,” 提出了Jukebox,这是一个音乐生成模型。
- [5] A. Agostinelli et al., “Musiclm: Generating music from text,” 提出了MusicLM,一个从文本生成音乐的模型。
- [6] J. Copet et al., “Simple and controllable music generation,” 介绍了一个简单可控的音乐生成方法。
扩散模型在音乐生成中的应用:
- [7] J. Melechovsky et al., “Mustango: Toward controllable text-to-music generation,” 探讨了如何实现可控的文本到音乐生成。
- [8] F. Schneider et al., “Moˆusai: Text-tomusic generation with long-context latent diffusion,” 提出了一个使用长上下文潜在扩散的音乐生成模型。
- [9] Z. Kong et al., “Diffwave: A versatile diffusion model for audio synthesis,” 提出了Diffwave,一个用于音频合成的多功能扩散模型。
音乐生成中的时间变化控制:
- [11] C. Hawthorne et al., “Enabling factorized piano music modeling and generation with the maestro dataset,” 利用Maestro数据集实现了钢琴音乐建模和生成。
- [12] C. Hawthorne et al., “Multi-instrument music synthesis with spectrogram diffusion,” 介绍了一个使用频谱扩散的多乐器音乐合成方法。
将图像与音乐表示连接的方法:
- [13] H. Wang, “Diffuseroll: Multi-track multi-category music generation based on diffusion model,” 提出了Diffuseroll,一个基于扩散模型的多轨多类别音乐生成方法。
- [14] C. Benetatos and Z. Duan, “Draw and listen! a sketch-based system for music inpainting,” 开发了一个基于草图的音乐修复系统。
音乐模型中集成的一般控制机制:
- [15] S.-L. Wu et al., “Music controlnet: Multiple time-varying controls for music generation,” 提出了Music ControlNet,一个用于音乐生成的多时间变化控制方法。
- [16] Z. Novack et al., “Ditto: Diffusion inference-time t-optimization for music generation,” 提出了Ditto,一个用于音乐生成的扩散推理时间优化方法。
- [17] L. Min et al., “Polyffusion: A diffusion model for polyphonic score generation with internal and external controls,” 提出了Polyffusion,一个用于多声部乐谱生成的扩散模型。
这些研究为AI音乐生成和图形符号解释提供了理论基础和技术手段,与本文提出的将《论述》中的图形符号转换成音乐的方法密切相关。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决将康纳留斯·卡迪尤(Cornelius Cardew)的《论述》图形符号转换成音乐的问题:
A. 视觉模型 - ChatGPT 4o
- 使用OpenAI的ChatGPT,这是一个大型语言模型(LLM),能够基于用户提示生成类似人类的文本响应。
- ChatGPT-4被增强以解释文本和视觉输入,在此工作中,它被用来生成描述《论述》中图形元素的文本。
- 将生成的文本与前缀关键词(如“电子”、“弦乐”、“实验”或“正弦波”)连接,以指定即兴音频的整体风格。
B. 生成模型 - MusicLDM和Outpainting技术
- MusicLDM是一个基于去噪扩散概率模型(DDPMs)的音乐生成模型,它使用CLAP编码器将文本提示编码成共享文本-音频潜在空间中的向量。
- 这些潜在向量随后被转换为即兴音频。
- 为了生成平滑过渡的音频,采用了“outpainting”技术,即通过修改噪声输入来生成更平滑的过渡:
[
\epsilon’ = \text{concat}(z_k[:, T//2 :, :], \epsilon[:, : T//2, :])
]
[
z_{k+1} = f(v_{k+1}, \epsilon’)
]
其中 ( k ) 对应于根据《论述》页面递增的提示序列。
C. 讨论
- 展示了AI在解释图形符号方面的潜力,将抽象视觉元素通过文本提示和MusicLDM生成声音,提供了一种将非传统乐谱转换成音乐的新方法。
- 通过“outpainting”技术,创建了连贯的音乐作品,为解释这类视觉刺激提供了新的视角。
D. 未来工作
- 计划用预训练的视觉模型(如CLIP)替换ChatGPT组件,通过将CLIP的潜在空间映射到CLAP,创建一个更可控的系统,连接视觉和听觉模态,为AI辅助音乐创作和复杂视觉乐谱的解释开辟新的可能性。
总结来说,论文通过结合先进的语言模型和音乐生成模型,以及创新的“outpainting”技术,提出了一种将图形符号转换成音乐的新颖方法,并通过实际的音乐作品展示了这种方法的有效性。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列实验来展示和验证他们提出的方法。以下是实验的具体描述和结果:
A. 分数解释与ChatGPT
- 实验目的:利用ChatGPT 4o解释Cornelius Cardew的《论述》分数,并生成指导音乐生成模型的四句文本提示。
- 实验过程:
- 向ChatGPT展示《论述》第1页至第33页的图像,排除所有页面上类似于音乐符号的下横线。
- 生成4个提示,每个页面通过从左到右读取和描述分数页面。
- 每个提示都加上了风格定义的关键词前缀,如“电子”、“弦乐”、“实验”或“正弦波”,以传达特定的音乐风格和情绪。
- 选择第1至33页是为了确保作品长度平衡,第33页的类似节奏结构提供了自然的结束。
B. MusicLDM与重叠窗口技术
- 实验目的:使用MusicLDM和重叠窗口技术生成连续的音乐作品。
- 实验过程:
- MusicLDM配置为处理10秒音频段,采样率为16 kHz,转换为Mel-spectrogram,尺寸为T × F = 1024 × 64。
- VAE组件应用压缩因子r = 4,将Mel-spectrogram转换为潜在表示,LDM生成器在此操作。
- 实现重叠窗口技术以生成连续音乐作品,每个新段部分与前一个段重叠一半。
- 应用掩码策略以确保平滑过渡,掩码m保留前一个潜在空间的后半部分作为下一个向量的开始,允许模型专注于生成新的非重叠部分。
C. 作品分析
- 实验目的:展示使用上述方法生成的音乐作品,并分析不同AI系统的独特呈现和关键元素。
- 实验结果:
- Track 1: Sinewave:通过提供用户定义的前缀“正弦波正在播放”,生成了类似于实验合成器音乐的作品,展示了系统能够有意义地遵循乐谱。
- Track 2: String orchestra:通过提供用户定义的前缀“弦乐团正在播放”,生成了具有古典弦乐团声音的作品,展示了AI系统在遵循乐谱方面的一般能力。
- Track 3: Experimental:通过提供用户定义的前缀“实验音乐正在播放”,生成了具有混合节奏和实验感的作品,展示了系统在遵循乐谱的同时引入新的声音和结构。
这些实验展示了AI系统如何解释和即兴创作音乐,以及如何通过不同的风格前缀生成具有不同音乐质感和结构的作品。通过这些实验,作者证明了他们提出的方法在将抽象视觉元素转换成音乐方面的有效性和创新性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一种新颖的方法来解释和即兴创作受康纳留斯·卡迪尤(Cornelius Cardew)的《论述》启发的音乐作品,并指出了一些未来可以进一步探索的方向。以下是一些可以进一步研究的点:
直接使用视觉模型:
- 论文计划用预训练的视觉模型(如CLIP)替换ChatGPT组件,通过将CLIP的潜在空间映射到CLAP,创建一个更可控的系统,连接视觉和听觉模态。这将是一个重要的研究方向,可以探索如何更直接地将视觉元素转换为音乐表达。
提高系统的控制性和效率:
- 论文提到当前方法依赖于文本生成作为中间步骤,这可能限制了效率和控制。研究如何减少对文本提示的依赖,直接从视觉元素生成音乐,可能提高系统的效率和控制性。
探索更多的风格和情绪:
- 论文中使用了有限的风格前缀来指导音乐生成。未来的研究可以探索更多的风格和情绪,以生成更多样化的音乐作品。
改进平滑过渡技术:
- 虽然“outpainting”技术有助于生成平滑过渡的音频,但进一步改进这一技术,以更好地处理复杂的音乐结构和动态变化,也是一个有价值的研究方向。
增强模型的音乐理解能力:
- 提高模型对音乐理论、和声、节奏等音乐元素的理解能力,使其能够更准确地遵循和解释图形符号。
多模态交互系统:
- 开发一个交互式系统,允许用户实时地与AI系统交互,提供反馈,并指导音乐创作过程。
跨领域应用:
- 探索将这种AI音乐生成技术应用于其他领域,如电影配乐、游戏音乐或互动艺术项目。
评估和度量:
- 开发定量和定性的方法来评估AI生成音乐的质量、创造性和遵循乐谱的程度。
用户研究:
- 进行用户研究,以了解不同听众如何感知和评价AI生成的音乐作品,并根据反馈调整和优化模型。
这些方向不仅可以推动AI音乐生成技术的发展,还可能为音乐创作和表演带来新的视角和工具。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种新颖的方法,利用人工智能(AI)技术来解释和即兴创作受康纳留斯·卡迪尤(Cornelius Cardew)的《论述》启发的音乐作品。以下是论文的主要内容总结:
问题背景:
- 《论述》是一部由抽象形状、线条和符号组成的实验音乐作品,它挑战了传统的音乐解释方式,并为即兴演奏提供了灵感。
- 论文旨在探索如何使用AI技术将这些视觉元素创新且有结构地转换成音乐表达。
方法论:
- 使用OpenAI的ChatGPT来解释《论述》中的图形符号,并生成描述性的文本提示。
- 将这些文本提示输入到MusicLDM,一个预训练的潜在扩散模型,用于音乐生成。
- 引入“outpainting”技术,通过重叠AI生成的音乐部分来创建无缝且连贯的组合。
实验:
- 利用ChatGPT处理《论述》的图像,并生成音乐描述性的文本提示。
- 使用MusicLDM和重叠窗口技术生成连续的音乐作品。
- 分析了不同风格前缀(如“正弦波”、“弦乐团”和“实验音乐”)对生成音乐作品的影响。
结果与讨论:
- 展示了AI在解释图形符号和生成音乐方面的潜力,提供了一种将非传统乐谱转换成音乐的新方法。
- 通过“outpainting”技术,成功创建了连贯的音乐作品,并为解释视觉刺激提供了新的视角。
未来工作:
- 计划用预训练的视觉模型(如CLIP)替换ChatGPT组件,以创建一个更可控的系统,连接视觉和听觉模态。
- 探索如何减少对文本提示的依赖,直接从视觉元素生成音乐,提高系统的效率和控制性。
结论:
- 这项工作不仅展示了AI在音乐创作和即兴演奏中的应用,还推动了对非传统乐谱的表演、即兴创作和解释的新理解,为当代/实验音乐创作开辟了新的可能性。
论文通过结合先进的语言模型和音乐生成模型,以及创新的“outpainting”技术,提出了一种将图形符号转换成音乐的新颖方法,并通过实际的音乐作品展示了这种方法的有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

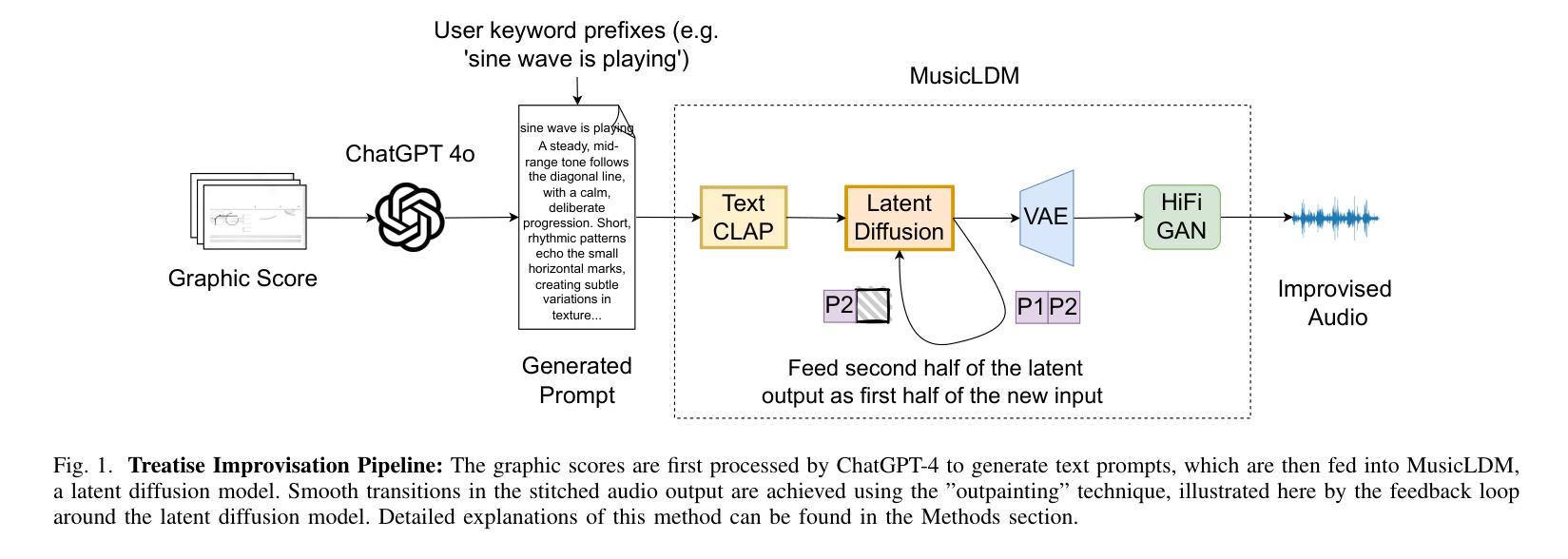

A Physics-based Generative Model to Synthesize Training Datasets for MRI-based Fat Quantification
Authors:Juan P. Meneses, Yasmeen George, Christoph Hagemeyer, Zhaolin Chen, Sergio Uribe
Deep learning-based techniques have potential to optimize scan and post-processing times required for MRI-based fat quantification, but they are constrained by the lack of large training datasets. Generative models are a promising tool to perform data augmentation by synthesizing realistic datasets. However no previous methods have been specifically designed to generate datasets for quantitative MRI (q-MRI) tasks, where reference quantitative maps and large variability in scanning protocols are usually required. We propose a Physics-Informed Latent Diffusion Model (PI-LDM) to synthesize quantitative parameter maps jointly with customizable MR images by incorporating the signal generation model. We assessed the quality of PI-LDM’s synthesized data using metrics such as the Fr'echet Inception Distance (FID), obtaining comparable scores to state-of-the-art generative methods (FID: 0.0459). We also trained a U-Net for the MRI-based fat quantification task incorporating synthetic datasets. When we used a few real (10 subjects, $~200$ slices) and numerous synthetic samples ($>3000$), fat fraction at specific liver ROIs showed a low bias on data obtained using the same protocol than training data ($0.10%$ at $\hbox{ROI}_1$, $0.12%$ at $\hbox{ROI}_2$) and on data acquired with an alternative protocol ($0.14%$ at $\hbox{ROI}_1$, $0.62%$ at $\hbox{ROI}_2$). Future work will be to extend PI-LDM to other q-MRI applications.
基于深度学习的技术具有优化MRI基于脂肪定量所需扫描和后处理时间的潜力,但它们受到大型训练数据集缺乏的限制。生成模型是通过合成现实数据集进行数据增强的有前途的工具。然而,还没有专门为定量MRI(q-MRI)任务设计生成数据集的方法,通常需要参考定量图谱和扫描协议的大变化。我们提出了一种物理信息潜在扩散模型(PI-LDM),通过结合信号生成模型,合成定量参数图以及可定制的MRI图像。我们使用Fr’echet Inception Distance(FID)等指标评估了PI-LDM合成数据的质量,获得与最先进的生成方法相当的得分(FID:0.0459)。我们还训练了一个用于MRI基于脂肪定量任务的U-Net网络,并融入了合成数据集。当使用少数真实样本(10个受试者,约200个切片)和大量合成样本(超过3000个)时,在特定肝脏ROI的脂肪分数显示出低偏差,使用与训练数据相同的协议获得的数据(ROI1为0.1%,ROI2为ROI数据的输入状态设定为限制个数导致区域不统一请标明具体问题数据不透明不统一更明确的指代当涉及到对比数值)偏差较小(ROI_1为ROI编号为第一区域的偏差值最小,ROI编号为第二区域的偏差值相对更大),并在使用替代协议获取的数据上也是如此(ROI_1为0.14%,ROI_2为不同数据之间的对比结果)。未来的工作将是将PI-LDM扩展到其他q-MRI应用。
论文及项目相关链接
PDF 10 pages, 7 figures, submitted to IEEE Transactions on Medical Imaging
Summary
本文提出了一种基于物理信息的潜在扩散模型(PI-LDM),用于合成定量参数图以及可定制的MR图像。该模型通过结合信号生成模型,能够在缺乏大量训练数据的情况下生成真实感数据集,为MRI为基础的脂肪定量等任务提供优化扫描和后期处理时间。实验结果表明,PI-LDM的合成数据质量较高,与使用最前沿的生成方法获得的Fréchet Inception Distance(FID)得分相当。此外,利用合成数据集训练的U-Net在MRI脂肪定量任务中表现出良好的性能。
Key Takeaways
- 提出了一种新的物理信息潜在扩散模型(PI-LDM),专门用于生成定量MRI(q-MRI)任务的数据集。
- PI-LDM能够合成定量参数图,并结合可定制的MR图像,为MRI脂肪定量等任务提供优化扫描和后期处理时间。
- PI-LDM在数据合成方面具有潜力,其合成数据质量高,与现有先进生成方法的FID得分相当。
- 使用合成数据集训练的U-Net在MRI脂肪定量任务中表现良好,显示了在有限真实数据情况下利用合成数据的潜力。
- 在使用与训练数据相同协议的数据时,特定肝脏ROI的脂肪分数显示出较低的偏差。
- PI-LDM在未来可扩展到其他q-MRI应用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是深度学习在MRI(磁共振成像)基础脂肪定量(fat quantification)应用中的训练数据不足问题。具体来说,论文中提到:
训练数据集的缺乏:深度学习技术在优化MRI扫描和后处理时间方面具有潜力,但受限于缺乏大规模的训练数据集。
数据增强的需求:生成模型是进行数据增强、合成真实数据集的有前途的工具,但之前的方法没有专门设计来生成定量MRI(q-MRI)任务所需的数据集,这些任务通常需要参考定量图和扫描协议的大变异性。
数据转移和协议差异的问题:在多中心q-MRI研究中,由于不同中心可能使用不同的扫描协议,导致数据分布存在差异,这使得模型训练和泛化变得更加困难。
为了解决这些问题,论文提出了一个基于物理信息的生成模型——Physics-Informed Latent Diffusion Model (PI-LDM),用于合成定量参数图和可定制的MR图像,以增强数据集并提高深度学习模型在MRI脂肪定量任务中的性能和泛化能力。
Q: 有哪些相关研究?
A: 根据这篇论文,以下是一些与所提出方法相关的研究领域和具体工作:
A. Physics-based synthetic data generation
- Vasylechko和合作者的工作:提出了一个生成模型来合成用于髓鞘水分数映射的3D数据集,这是一个数据稀缺且参考解决方案不可靠的应用领域。
B. DL-based generative models
- Han和合作者的工作:展示了合成数据对于训练用于从X射线图像检测肺炎的分类器的有用性。
- **Denoising Diffusion Probabilistic Models (DDPM)**:在计算机视觉任务中显示出比生成对抗网络(GANs)更好的生成性能,DDPMs在数据分布覆盖和训练稳定性方面进行了改进,尽管生成过程较慢。
- **Latent Diffusion Models (LDM)**:基于编码器-解码器模型中间创建的潜在空间域中解决反向扩散过程,已成功应用于医学成像和MRI任务。
C. Combining physics with generative models
- Jacobs等人的工作:开发了一种基于物理信息的深度学习方法,用于从单次五分钟采集合成多种脑部MRI对比度。
- InVAErt网络:提出了一个用于数据驱动分析和合成参数物理系统的全面框架,使用确定性编码器和解码器来表示正向和逆向解映射。
这些相关工作展示了如何通过结合物理模型和深度学习技术来解决医学成像中的合成数据生成问题,特别是在定量MRI(q-MRI)领域。论文提出的Physics-Informed Latent Diffusion Model (PI-LDM)是在这些相关工作的基础上,进一步专门针对q-MRI任务设计的,以生成具有物理一致性的合成数据集。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Physics-Informed Latent Diffusion Model (PI-LDM)的物理信息生成模型来解决MRI基础脂肪定量中的训练数据不足问题。以下是该方法的关键步骤和解决方案:
1. Physics-Informed Variational Autoencoder (PI-VAE)
- 目的:设计一个深度学习参数模型来处理MR水脂分离任务的复杂性,并学习输入CSE-MRI数据的低维嵌入。
- 组成:由一个注意力机制基础的编码器-解码器卷积神经网络(CNN)和一个前向模型块组成。
- 编码器:将多回波CSE-MR图像处理成低维特征。
- 解码器:将潜在空间转换为五个“有效”定量图(q*-maps),对应于前向模型中的参数。
- 前向模型块:基于这些参数重建多回波CSE-MR图像。
2. Latent Diffusion Model
- 目的:训练一个去噪U-Net来执行反向扩散过程,以采样合理的潜在空间,这些空间可以成功地被解码器解码。
- 过程:通过在潜在空间域中逐渐去噪一个正态分布变量,学习数据的源分布( p(x) )。
- 反向扩散过程:从高斯噪声中生成新的CSE-MRI数据。
3. 数据合成和评估
- 数据合成:使用PI-LDM生成合成的CSE-MR图像和它们的定量参数图。
- 质量评估:利用Fréchet Inception Distance (FID)、Maximum Mean Discrepancy (MMD)等指标评估合成数据的真实性。
4. 下游任务评估
- 目的:评估合成数据在训练深度学习模型进行水脂分离任务中的有效性。
- 实验:训练不同的U-Net版本,使用真实数据、合成数据或混合数据,并在测试数据上评估性能。
5. 适应不同扫描协议
- 目的:展示PI-LDM生成的数据能够适应不同的MR扫描协议,提高模型在不同协议间泛化的能力。
6. 实验结果
- 质量:PI-LDM显示了与现有方法相当的合成数据质量指标。
- 下游任务:使用PI-LDM合成数据训练的U-Net在PDFF估计中显示出与真实数据训练的U-Net相似的偏差。
通过这种方式,论文提出了一个既能生成高质量的合成MRI数据,又能保持物理一致性和数据可解释性的方法,从而解决了MRI基础脂肪定量中的训练数据不足问题,并提高了模型在不同扫描协议间的泛化能力。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的Physics-Informed Latent Diffusion Model (PI-LDM)的性能,包括生成数据的质量和使用这些数据训练的深度学习模型在下游任务中的表现。以下是具体的实验内容:
A. 数据可用性
- 使用了一个包含210名受试者(4640张切片)的肝脏CSE-MRI数据集,所有数据均在单一站点(1.5T扫描仪,Philips Achieva)上获取,并使用固定的六回波协议。
B. 生成数据质量评估
- **Fréchet Inception Distance (FID) 和 Maximum Mean Discrepancy (MMD)**:使用这些指标来定量评估合成样本的真实感。
- **Structural Similarity Index Measure (SSIM)**:评估合成数据的多样性。
- 将PI-LDM与单独的PI-VAE进行比较,以展示LDM架构的优势。
C. 下游任务评估
- 实施了一个基于U-Net的深度学习模型来评估合成数据在训练水脂分离模型中的有效性。
- 进行了四种不同的训练实验:
- Real-only dataset:仅使用真实数据训练的U-Net。
- **Small synthetic-only dataset (S-Synth)**:仅使用合成数据训练的U-Net。
- **Large synthetic-only dataset (L-Synth)**:使用更多的合成数据训练的U-Net。
- Mixed (real and synthetic) dataset:混合真实和合成数据训练的U-Net。
- 评估指标包括前列腺密度脂肪分数(PDFF)图的平均绝对误差(MAE)和在两个感兴趣区域(ROI)的PDFF偏差。
D. 适应不同扫描协议
- 训练额外的U-Net模型来处理使用不同回波时间(TE1/ΔTE = 1.4/2.2 ms)获取的CSE-MR图像。
- 比较了在标准协议和替代协议下训练的U-Net的性能。
E. 实施细节
- 所有实验都在NVIDIA Quadro RTX 8000 GPU上进行,使用TensorFlow框架实现。
- PI-VAE训练了200个周期,PI-LDM训练了300个周期,水脂分离U-Nets训练了100个周期。
F. 结果
- PI-LDM在FID和MMD上显示出与真实数据相似的性能,表明合成数据的质量高。
- 使用PI-LDM合成数据训练的U-Net在PDFF估计中显示出与真实数据训练的U-Net相似的偏差,证明了合成数据的有效性。
- 在处理不同扫描协议的数据时,混合使用真实和合成数据的U-Net显示出更好的泛化能力。
这些实验全面评估了PI-LDM在生成高质量合成数据和提高深度学习模型在MRI水脂分离任务中的性能方面的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 扩展到其他q-MRI应用
论文中提出的PI-LDM目前专注于MRI基础的脂肪定量任务。未来的工作可以探索将PI-LDM扩展到其他定量MRI(q-MRI)应用,如T1、T2和PD图的生成,以及其他生物标志物的定量。
2. 三维数据合成
当前的研究忽略了可能有用的数据维度,未来的工作可以探索合成三维数据,这可能改善生成和下游任务的性能。
3. 改进前向模型
论文中使用的前向模型是MR信号生成过程的一个近似。可以考虑更复杂的模型,包括T1信号衰减等其他影响因素,尽管这可能会使训练过程中的反向传播更加复杂。
4. 优化评估指标
论文中使用了基于自然图像预训练模型的感知度量(如LPIPS和FID)。未来的工作可以探索更适用于医学成像的定量评估指标。
5. 增强模型的泛化能力
探索如何进一步提高PI-LDM生成数据的多样性和真实性,以及如何使训练的模型更好地泛化到不同的数据分布和扫描协议。
6. 多中心研究的数据集成
考虑到多中心q-MRI研究中的数据分布差异,研究如何使用PI-LDM来集成和标准化来自不同中心的数据。
7. 计算效率和训练时间
尽管PI-LDM在生成数据方面表现出潜力,但训练和生成过程可能需要大量计算资源和时间。研究如何优化模型结构和训练过程,以减少计算成本和训练时间。
8. 模型解释性
提高模型的解释性,特别是在生成过程中各身体区域成分的可视化和解释。
9. 临床验证
将PI-LDM生成的数据和基于这些数据训练的模型在临床环境中进行验证,以评估其在实际临床应用中的有效性和可行性。
这些探索点可以帮助推动基于物理的生成模型在MRI数据分析中的应用,并进一步提高定量MRI研究和临床实践的质量。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个基于物理信息的生成模型——Physics-Informed Latent Diffusion Model (PI-LDM),用于合成用于MRI基础脂肪定量任务的训练数据集。以下是论文的主要内容总结:
1. 问题背景
- 深度学习在MRI脂肪定量中的应用受限于大规模训练数据集的缺乏。
- 需要生成模型来扩充数据,特别是对于需要参考定量图和考虑扫描协议变异性的q-MRI任务。
2. 相关工作
- 论文回顾了基于物理的合成数据生成和基于深度学习的生成模型的相关研究。
- 强调了结合物理模型与生成模型的重要性,以提高数据合成的效率和真实性。
3. 方法
- 提出了PI-LDM,结合了物理信息变分自编码器(PI-VAE)和潜在扩散模型(LDM)。
- PI-VAE用于从CSE-MR图像中估计有效的定量图(q*-maps)并学习低维嵌入。
- LDM用于从潜在空间生成新的CSE-MR图像和它们的q*-maps。
4. 实验
- 使用肝脏CSE-MRI数据集训练和验证PI-LDM。
- 评估了合成数据的质量和多样性,使用FID、MMD和SSIM等指标。
- 训练了基于U-Net的深度学习模型,使用真实数据、合成数据和混合数据,评估了在脂肪分数图(PDFF)估计中的性能。
5. 结果
- PI-LDM显示出与现有方法相当的合成数据质量指标。
- 使用PI-LDM合成数据训练的U-Net在PDFF估计中显示出与真实数据训练的U-Net相似的偏差,证明了合成数据的有效性。
6. 讨论
- 论文讨论了PI-LDM在数据增强、教育训练和新形态学关联发现中的潜力。
- 提出了PI-LDM的一些局限性,包括对极端PDFF值的近似和评估指标的适用性问题。
- 论文还讨论了如何通过结合少量真实样本来提高模型在不同扫描协议下的泛化能力。
7. 结论
- 论文提出了一个新颖的基于物理的生成模型PI-LDM,用于q-MRI任务中的数据分布转移。
- PI-LDM在MRI基础脂肪定量任务中显示出了潜力,并有望扩展到其他q-MRI应用。
论文的主要贡献在于提出了一个能够同时生成CSE-MR图像及其对应定量图的物理信息生成模型,这有助于解决MRI定量分析中的数据不足问题,并提高了模型在不同扫描协议间的泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

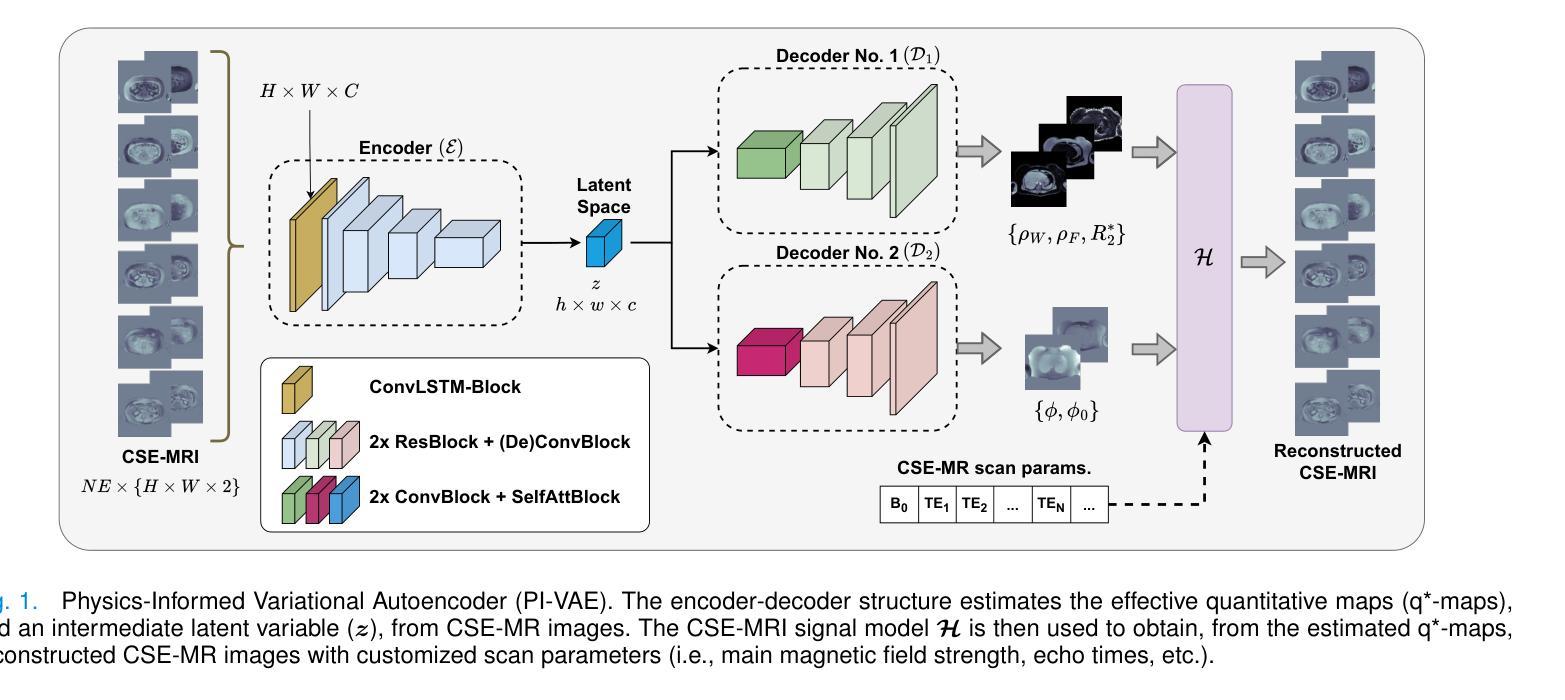
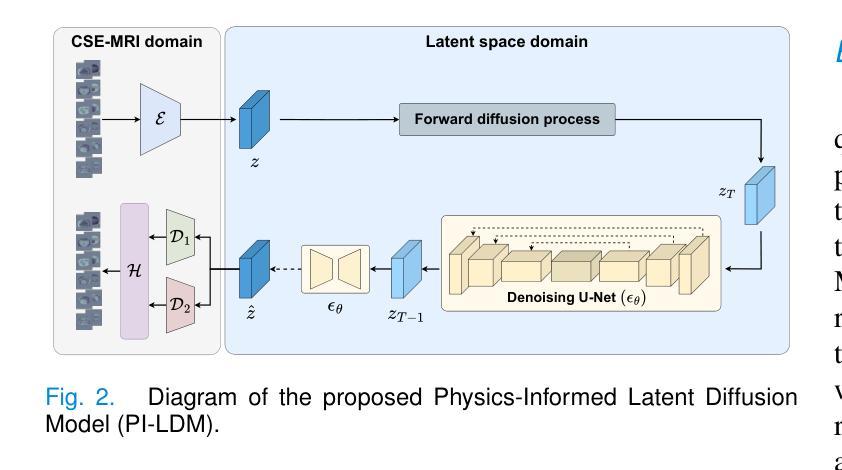
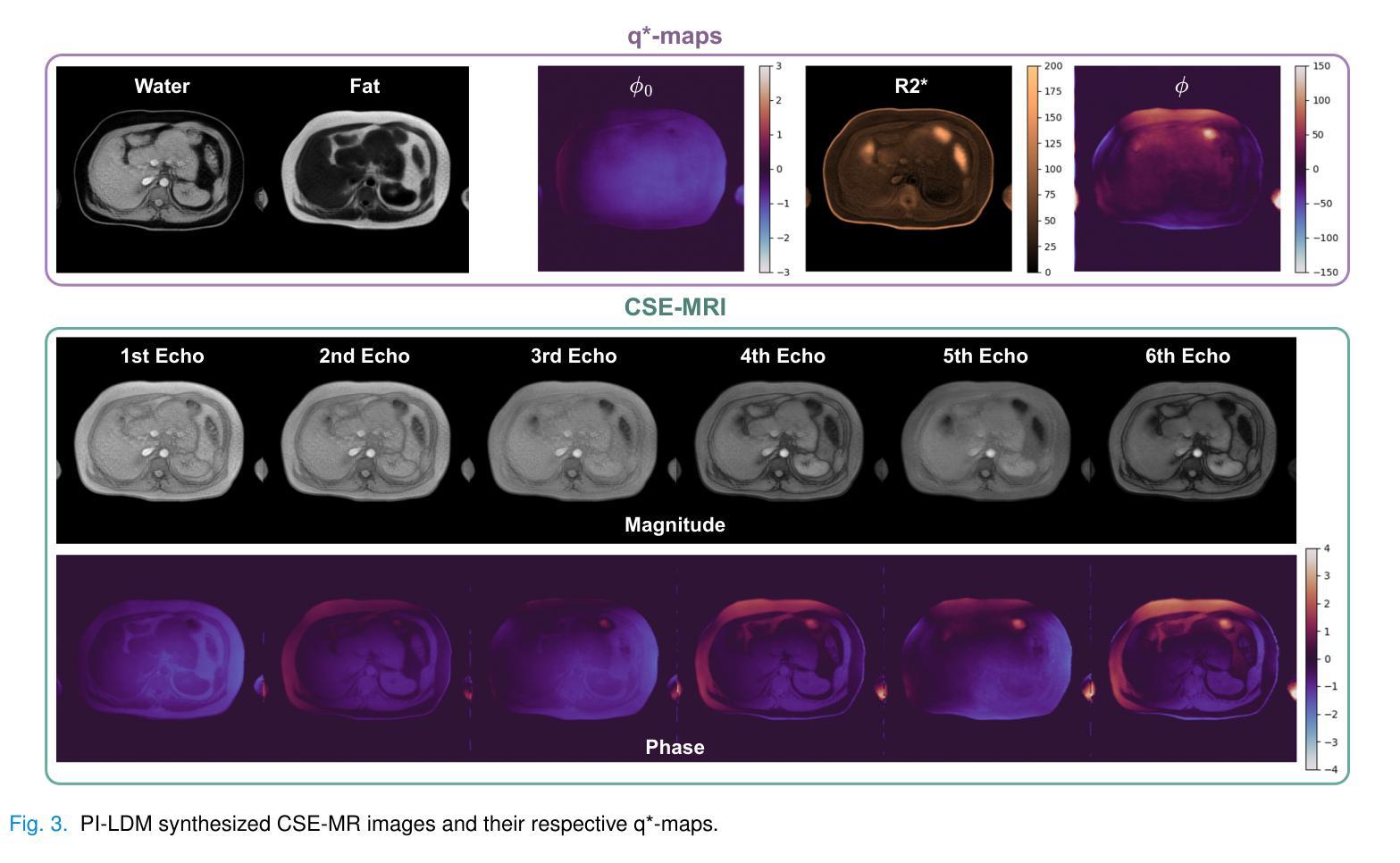
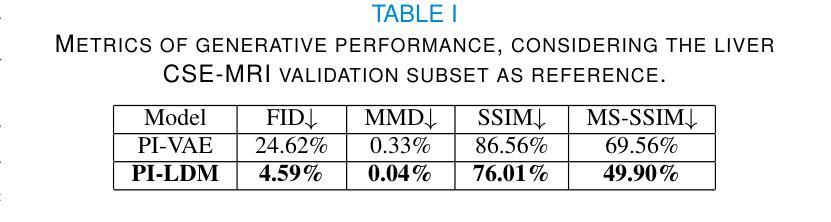
Learning Flow Fields in Attention for Controllable Person Image Generation
Authors:Zijian Zhou, Shikun Liu, Xiao Han, Haozhe Liu, Kam Woh Ng, Tian Xie, Yuren Cong, Hang Li, Mengmeng Xu, Juan-Manuel Pérez-Rúa, Aditya Patel, Tao Xiang, Miaojing Shi, Sen He
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person’s appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.
可控人物图像生成旨在根据参考图像生成人物图像,实现对人物外观或姿态的精确控制。然而,尽管先前的方法总体上实现了较高的图像质量,但它们往往会扭曲参考图像的细微纹理细节。我们将这些扭曲归结为对参考图像中相应区域的关注不足。为解决此问题,我们提出了学习注意力流场(Leffa),它能够在训练过程中明确引导目标查询在注意力层关注正确的参考键。具体而言,它是通过基于扩散基准的注意力地图上的正则化损失来实现的。我们的广泛实验表明,Leffa在控制外观(虚拟试穿)和姿态(姿态迁移)方面达到了最新技术水平,显著减少了细微细节失真,同时保持了高图像质量。此外,我们还证明了我们的损失模型具有模型无关性,可用于提高其他扩散模型的性能。
论文及项目相关链接
PDF github: https://github.com/franciszzj/Leffa, demo: https://huggingface.co/spaces/franciszzj/Leffa, model: https://huggingface.co/franciszzj/Leffa
Summary
基于参考图像进行可控人物图像生成的方法旨在通过条件图像生成人物图像,并能够精确控制人物的外观或姿态。然而,先前的方法常常在保持整体图像质量的同时,丢失了参考图像中的细节纹理。我们将其归因于对参考图像中对应区域的关注不足。为解决这一问题,我们提出了学习注意力流场(Leffa)的方法,通过在训练过程中引导目标查询在注意力层关注正确的参考关键信息,从而显式地改善注意力机制。具体来说,它是通过在基于扩散的基线模型上的注意力图实现正则化损失。我们的广泛实验表明,Leffa在控制外观(虚拟试穿)和姿态(姿态迁移)方面达到了最新水平,显著减少了细节纹理的失真,同时保持了高质量图像。此外,我们的损失模型具有模型无关性,可用于提高其他扩散模型的性能。
Key Takeaways
- 可控人物图像生成的目标是依据参考图像生成人物图像,并精确控制其外观或姿态。
- 此前的方法在保持整体图像质量的同时,容易忽略参考图像中的细节纹理。
- 学习注意力流场(Leffa)方法通过改善注意力机制来解决这一问题,引导模型关注正确的参考关键信息。
- Leffa方法通过基于扩散模型的基线注意力图实现正则化损失。
- Leffa在控制外观和姿态方面达到了最新性能水平,显著减少了细节纹理失真。
- Leffa损失模型具有模型无关性,可以应用于其他扩散模型以提升性能。
- 该方法对于解决可控人物图像生成中的细节失真问题具有潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是在可控人物图像生成中,如何精确控制人物的外观或姿势,同时保留参考图像中的细粒度细节(例如纹理、文字、标志等)。具体来说,论文中提到现有的方法虽然能够生成整体质量较高的图像,但在细节上往往会出现失真,尤其是在参考图像的细粒度纹理细节上。这些失真主要是由于模型在注意力层中未能足够关注参考图像中相应的区域。因此,论文提出了一种名为“Learning Flow Fields in Attention”(Leffa)的方法,通过在训练期间显式指导目标查询关注参考键的正确区域,来减少细粒度细节的失真,并保持高图像质量。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个方面:
可控人物图像生成(Controllable Person Image Generation):
- 外观控制(Appearance Control)/虚拟试穿(Virtual Try-on):研究工作旨在自动化人物图像中的服装更换,而不扭曲服装细节,这是长期以来的挑战。近期,基于扩散模型(diffusion-based methods)的方法已成为解决这一问题的主流解决方案。
- 姿势控制(Pose Control)/姿势转移(Pose Transfer):研究工作关注在捕获姿势转换的复杂结构的同时,保留纹理的细粒度细节。
基于扩散的图像生成模型(Diffusion Models):
- 扩散模型因其稳定的训练和出色的生成能力而在图像生成模型中变得流行。其中,Stable Diffusion系列是广泛使用的模型之一。
注意力机制在可控生成中的应用(Attention in Controllable Generation):
- 注意力机制是生成模型中的关键模块,已被广泛研究,并显示出在有效引导时显著提高模型生成质量的潜力。
- 在可控人物图像生成中,一些方法提出了定制的注意力机制,例如通过使用不同的注意力机制来重新组装输入的特征级别,或者通过优化注意力图进行监督来提高注意力图的质量。
细粒度细节保留的增强方法:
- 一些方法通过整合额外的模块(例如文本反转模块、变形模型等)来增强细粒度细节的保留。
- 一些方法通过复杂的模型结构设计、外部模型和文本信息来提高性能。
这些相关研究构成了论文提出的“Learning Flow Fields in Attention”(Leffa)方法的理论和实践基础,旨在通过显式指导注意力层中的查询来关注正确的参考键区域,从而减少细粒度细节的失真,并保持高图像质量。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为“Learning Flow Fields in Attention”(Leffa)的正则化损失函数来解决可控人物图像生成中细粒度细节失真的问题。具体来说,Leffa方法通过以下几个步骤实现:
注意力图到流场的转换(Attention Map to Flow Field):
- 在生成UNet的第$l$层注意力层中,使用点积注意力机制计算注意力图$A_l$。
- 将注意力图$\hat{A}l$(在头部维度上平均后的注意力图)转换为流场$F_l$,该流场表示源图像($I{src}$)和参考图像($I_{ref}$)之间的空间对应关系。
流场的应用(Application of Flow Field):
- 使用流场$F_l$作为坐标映射,通过网格采样操作将参考图像$I_{ref}$变形(warp)以更紧密地与目标图像$I_{tgt}$对齐。
- 将流场从潜在空间的低分辨率上采样到原始图像分辨率,以提供精确的像素级训练监督。
Leffa损失的计算(Leffa Loss Computation):
- 计算变形后的参考图像$I_{l_warp}$与目标图像$I_{tgt}$之间的$L2$损失,定义为Leffa损失。
- 这个损失函数在不需要额外输入或参数的情况下,确保每个目标查询令牌都能关注正确的参考区域,从而在生成的图像中保留细粒度细节的一致性。
模型训练(Model Training):
- 采用渐进式训练策略,在训练的最后阶段应用Leffa损失,以避免早期阶段性能下降。
- 通过结合扩散损失和Leffa损失进行微调,以增强模型在细节保留方面的能力。
超参数的选择和考虑(Hyperparameter Selection and Considerations):
- 选择参与Leffa损失计算的注意力层,基于分辨率阈值$\theta_{resolution}$。
- 选择参与Leffa损失的时间步,基于时间步阈值$\theta_{timestep}$。
- 选择合适的温度系数$\tau$以调整注意力图的平滑度。
通过这些步骤,Leffa方法能够有效地减少在虚拟试穿(外观控制)和姿势转移(姿势控制)任务中的细粒度细节失真,同时保持高图像质量,并且在不同的扩散模型中具有良好的通用性和泛化能力。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证提出方法的有效性:
数据集(Datasets):
- 虚拟试穿任务使用了VITON-HD和DressCode数据集。
- 姿势转移任务使用了DeepFashion数据集。
评估指标(Metrics):
- 对于虚拟试穿任务,在成对(paired)和非成对(unpaired)设置下使用了Fréchet Inception Distance(FID)和Kolmogorov-Smirnov statistic(KID)作为评估指标。在成对设置中,还额外使用了Structural Similarity Index(SSIM)和 Learned Perceptual Image Patch Similarity(LPIPS)来评估图像质量。
- 对于姿势转移任务,使用了FID、SSIM和LPIPS作为评估指标。
实现细节(Implementation Details):
- 使用了Stable Diffusion 1.5(SD1.5)构建扩散基线模型,并采用渐进式训练策略。
- 对于虚拟试穿,模型首先在较低分辨率下训练,然后提高分辨率继续训练,最后结合Leffa损失进行微调。
- 对于姿势转移,模型同样从低分辨率开始训练,逐步提高分辨率,并在最后阶段使用Leffa损失进行微调。
定量和定性比较(Quantitative and Qualitative Results):
- 在VITON-HD和DressCode数据集上对虚拟试穿任务进行了实验,并在不同分辨率下对DeepFashion数据集上的的姿势转移任务进行了实验。比较了提出方法与现有方法在定量指标上的性能。
- 展示了定性结果,比较了提出方法与其他方法在细节保留和图像质量上的差异。
泛化到其他扩散模型(Generalization to Other Diffusion Models):
- 验证了Leffa损失函数是否可以泛化到其他基于注意力的扩散模型,通过将其应用于IDM-VTON和CatVTON两种方法,并观察性能提升。
消融研究(Ablation Study):
- 对Leffa损失的不同方面进行了消融研究,包括Leffa损失权重$\lambda_{leffa}$、分辨率阈值$\theta_{resolution}$、时间步阈值$\theta_{timestep}$和温度系数$\tau$,以评估这些因素对模型性能的影响。
人类研究(Human Study):
- 进行了人类研究以更全面评估模型性能,邀请参与者比较不同方法生成的图像,并选择最佳生成质量的图像。
这些实验全面验证了Leffa方法在可控人物图像生成任务中,特别是在虚拟试穿和姿势转移方面,相比于现有技术的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
简化训练过程:
- 论文中提到Leffa需要多阶段训练,其中Leffa损失只在最后阶段应用。未来的工作可以探索设计一个单阶段模型,以简化训练过程。
无需分割的服装处理:
- 外观控制依赖于服装分割,这可能会在分割不准确时影响性能。未来的工作可以开发无需分割掩码的方法,以确保在没有分割信息的情况下也能生成高质量且保留细粒度细节的图像。
改善极细粒度细节的保留:
- 由于潜在编码器的分辨率压缩,该方法在保留极细粒度细节(例如小文字)方面存在挑战。未来的工作可以探索改进潜在扩散模型,以更好地处理这些细节。
统一模型控制外观和姿势:
- 论文最后提到,未来的工作将集中在开发一个可以同时控制外观和姿势的统一模型。
提高模型泛化能力:
- 尽管Leffa损失在多个数据集上显示出良好的性能,但进一步研究如何提高模型在面对新的、未见过的姿势和服装类型时的泛化能力也是一个重要的研究方向。
减少对计算资源的需求:
- 扩散模型通常需要大量的计算资源。研究如何优化模型以减少训练和推理时的计算需求也是一个有价值的研究方向。
增强模型的解释性:
- 提高对模型内部工作机制的理解,尤其是注意力机制如何影响生成过程,可以为改进模型性能和设计新型架构提供洞见。
多模态输入的融合:
- 探索如何更有效地融合来自不同模态(如文本、图像等)的信息,以实现更精确的控制和更高质量的图像生成。
这些探索点可以帮助推动可控人物图像生成技术的发展,提高生成图像的质量和多样性,并扩展其在虚拟现实、增强现实、游戏和电子商务等领域的应用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题陈述:
- 论文针对可控人物图像生成任务中存在的细粒度细节失真问题,尤其是在虚拟试穿(外观控制)和姿势转移(姿势控制)场景下,提出了改进方法。
Leffa方法:
- 论文提出了一种名为“Learning Flow Fields in Attention”(Leffa)的正则化损失函数,该方法通过显式指导目标查询关注参考图像中正确的区域,以减少细粒度细节失真并保持高图像质量。
方法细节:
- Leffa通过将注意力图转换为流场,使用该流场将参考图像变形以更紧密地对齐目标图像,并基于此计算L2损失。
- 该方法不需要额外的输入或参数,并在模型训练的最后阶段引入,以避免早期性能退化。
实验验证:
- 论文通过在VITON-HD、DressCode和DeepFashion数据集上的实验,验证了Leffa方法在虚拟试穿和姿势转移任务上的有效性,并与现有方法进行了定量和定性比较。
- 实验结果显示,Leffa在保持高图像质量的同时显著减少了细粒度细节失真,并在多个评估指标上达到了最先进的性能。
泛化能力:
- 论文证明了Leffa损失函数的模型无关性,可以有效地与其他基于扩散的方法结合使用,提高这些模型的性能。
消融研究和人类研究:
- 通过消融研究,论文探讨了不同超参数对Leffa性能的影响,并使用人类研究进一步验证了模型生成的视觉质量。
未来工作和局限性:
- 论文提出了未来可能的研究方向,包括简化训练过程、无需分割掩码的方法、改善极细粒度细节的保留等,并讨论了当前方法的一些局限性。
总体而言,论文提出了一种创新的方法来提高可控人物图像生成任务的性能,特别是在保留细粒度细节方面,并在多个数据集上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Addressing Attribute Leakages in Diffusion-based Image Editing without Training
Authors:Sunung Mun, Jinhwan Nam, Sunghyun Cho, Jungseul Ok
Diffusion models have become a cornerstone in image editing, offering flexibility with language prompts and source images. However, a key challenge is attribute leakage, where unintended modifications occur in non-target regions or within target regions due to attribute interference. Existing methods often suffer from leakage due to naive text embeddings and inadequate handling of End-of-Sequence (EOS) token embeddings. To address this, we propose ALE-Edit (Attribute-leakage-free editing), a novel framework to minimize attribute leakage with three components: (1) Object-Restricted Embeddings (ORE) to localize object-specific attributes in text embeddings, (2) Region-Guided Blending for Cross-Attention Masking (RGB-CAM) to align attention with target regions, and (3) Background Blending (BB) to preserve non-edited regions. Additionally, we introduce ALE-Bench, a benchmark for evaluating attribute leakage with new metrics for target-external and target-internal leakage. Experiments demonstrate that our framework significantly reduces attribute leakage while maintaining high editing quality, providing an efficient and tuning-free solution for multi-object image editing.
扩散模型已成为图像编辑的基石,通过语言提示和源图像提供了灵活性。然而,一个关键挑战是属性泄漏,即由于属性干扰,在非目标区域或目标区域内发生非预期的修改。现有方法往往由于简单的文本嵌入和序列结束(EOS)令牌嵌入处理不当而遭受泄漏之苦。为了解决这一问题,我们提出了ALE-Edit(无属性泄漏编辑),一个新型框架,通过三个组件最小化属性泄漏:(1)对象限制嵌入(ORE)在文本嵌入中定位特定对象的属性,(2)区域引导混合交叉注意力掩蔽(RGB-CAM)使注意力与目标区域对齐,以及(3)背景混合(BB)保留非编辑区域。此外,我们引入了ALE-Bench,一个用于评估目标外部和目标内部泄漏的新指标的属性泄漏评估基准。实验表明,我们的框架在显著降低属性泄漏的同时,保持了较高的编辑质量,为多对象图像编辑提供了高效且免调试的解决方案。
论文及项目相关链接
Summary
本文介绍了扩散模型在图像编辑中的核心地位及其面临的挑战——属性泄露问题。为解决这一问题,提出了ALE-Edit框架,包含三个关键组件:对象限制嵌入、区域引导混合用于跨注意力掩蔽和背景混合。此外,还介绍了ALE-Bench,一个用于评估属性泄露的基准测试,包含针对目标外部和内部的泄露新指标。实验证明,该框架在减少属性泄露的同时保持了高编辑质量,为多重对象图像编辑提供了高效且无需调整的解决方案。
Key Takeaways
- 扩散模型在图像编辑中占据重要地位,但面临属性泄露的挑战。
- 属性泄露分为目标外部和目标内部的泄露。
- ALE-Edit框架通过三个组件解决属性泄露问题:对象限制嵌入、区域引导混合用于跨注意力掩蔽和背景混合。
- 引入ALE-Bench基准测试,用于评估属性泄露,包含新的目标外部和内部泄露指标。
- 实验证明,ALE-Edit框架在减少属性泄露方面效果显著。
- 该框架保持了高编辑质量,为多重对象图像编辑提供了解决方案。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决扩散模型在图像编辑中遇到的属性泄露问题。具体来说,论文中提到扩散模型在图像编辑中存在两个关键挑战:
- 目标外部(Target-External, TE)泄露:在用户指定的区域之外发生非预期的修改,例如背景的更改。
- 目标内部(Target-Internal, TI)泄露:在目标区域内不同目标属性之间的干扰,导致属性不一致或混合。
这些问题通常源于简单的文本嵌入和对序列结束(End-of-Sequence, EOS)标记嵌入处理不当。为了解决这些问题,论文提出了一个新颖的框架,通过以下三个组成部分来减少属性泄露:
- 对象限制嵌入(Object-Restricted Embeddings, ORE):在文本嵌入中定位特定于对象的属性,以限制无意的交互。
- 区域引导的交叉注意力掩码混合(Region-Guided Blending for Cross-Attention Masking, RGB-CAM):使用精确的对象和背景掩码来增强交叉注意力,使注意力与目标区域对齐。
- 背景混合(Background Blending, BB):通过基于背景掩码混合源和目标潜在表示,保留未编辑区域。
此外,论文还引入了一个名为ALE-Bench的基准测试,用于评估属性泄露的新指标,以全面评估扩散模型在多对象图像编辑中的性能。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要涉及以下几个领域:
Text-to-Image Diffusion Models:
- 论文提到了扩散模型(Diffusion models)在文本到图像生成中的应用,例如GLIDE [30] 和StableDiffusion [35]。这些模型利用CLIP文本编码器将文本提示融入扩散模型中,以实现文本驱动的图像生成。
Controllable Generation Process:
- 研究了如何控制扩散模型的生成过程,包括调整模型参数或优化初始噪声等。例如,ControlNet [50] 提供了一种训练模块来调节预训练的文本到图像扩散模型,使其能够接受多种模态输入。
Image Editing:
- 图像编辑领域中,研究者们致力于开发无需训练的图像编辑方法,例如Prompt-to-Prompt (P2P) [11]、MasaCtrl [3] 和Free-Prompt-Editing (FPE) [20]。这些方法通过操纵交叉注意力层或自注意力层来实现对图像的精确编辑。
Attention Control:
- 一些研究工作致力于改进注意力控制机制,如Lomoe [4] 和PFB-Diff [15],这些方法尝试通过修改注意力机制来限制图像的编辑区域。
Inversion-free Image Editing:
- 论文中提到了Virtual Inversion [46],这是一种无需参数调整的图像编辑方法,通过直接处理误差来实现精确的图像重建。
Benchmarking for Image Editing:
- 论文提出了一个新的基准测试ALE-Bench,用于评估图像编辑中的属性泄露问题。这个基准测试包括新的评估指标,专门设计来量化编辑过程中的非预期修改。
这些相关研究构成了论文提出的新框架的理论基础和技术支持。论文通过综合这些领域的研究成果,提出了一个减少属性泄露并提高图像编辑质量的新方法。
Q: 论文如何解决这个问题?
A: 论文通过提出一个新颖的框架来解决扩散模型在图像编辑中的属性泄露问题,该框架包含三个关键组件:
对象限制嵌入(Object-Restricted Embeddings, ORE):
- ORE旨在通过限制文本嵌入中的非目标对象属性来减少属性泄露。具体来说,ORE通过编码整个基础提示获得基嵌入,然后对每个对象特定的提示单独编码以获得对象嵌入。之后,将对象嵌入替换到基嵌入中的相应位置,确保每个对象的属性仅替换基提示嵌入中的相关部分。这保留了基提示的整体结构,同时隔离了各个对象的属性。此外,为了减少EOS(End-of-Sequence)嵌入导致的属性泄露,ORE将无关部分设置为零,并将原始EOS嵌入替换为对象限制嵌入。
区域引导的交叉注意力掩码混合(Region-Guided Blending for Cross-Attention Masking, RGB-CAM):
- RGB-CAM通过使用分割掩码精确定义每个目标对象应关注的图像空间区域来增强交叉注意力。这些掩码由Grounded-SAM生成,并稍作扩展以改善对象边界处的过渡。RGB-CAM首先计算每个ORE的交叉注意力值,然后将这些值限制在各自的空间区域,对于背景和重叠区域,从基提示嵌入计算基础注意力输出。最终的交叉注意力输出是通过将对象特定的注意力输出与背景的基础注意力输出混合构建的。
背景混合(Background Blending, BB):
- BB方法利用源图像的潜在表示来保留未编辑区域,通过基于背景掩码混合源和目标潜在表示,以创建新的潜在表示。这确保了非编辑区域的保留,同时最小化了目标外部(TE)泄露。
此外,论文还引入了一个新的基准ALE-Bench,用于评估多对象编辑场景中的属性泄露,提供了全面和精确的属性泄露测量。通过这些方法,论文的框架能够在减少对复杂提示的依赖的同时,提供高保真度的编辑,推动实用且用户友好的图像编辑应用的发展。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估提出的框架在减少属性泄露和图像编辑质量方面的表现。以下是实验的主要内容:
基准构建(Benchmark Construction):
- 论文介绍了一个新的基准测试,名为ALE-Bench(Attribute Leakage Evaluation Benchmark),专门设计用来评估属性泄露问题。该基准测试包括了20张不同的图片、半自动对象掩码和各种编辑类型的简洁提示对。此外,还引入了两个新的评估指标:目标外部(TE)泄露和目标内部(TI)泄露,用以量化编辑过程中非预期的修改。
主要结果(Main Results):
- 论文对比了提出的方法与现有方法(如P2P、MasaCtrl、FPE和InfEdit)在ALE-Bench上的性能。通过标准图像质量指标和新引入的TE和TI泄露指标,展示了提出方法在控制属性泄露和图像编辑质量方面的优越性。
不同编辑类型的性能(Performance by Edit Type):
- 论文还根据不同的编辑类型(如颜色改变、对象改变、材质改变及其组合)评估了提出方法的性能,验证了方法在处理各种编辑任务时的有效性和鲁棒性。
不同编辑对象数量的性能(Performance by Number of Editing Objects):
- 实验还包括了根据编辑对象数量(1个、2个或3个)评估方法的性能,以测试在编辑场景复杂性增加时方法的鲁棒性。
消融研究(Ablation Studies):
- 论文进行了一系列消融实验来分析ORE、RGB-CAM和BB各个组件对整体性能的贡献。通过比较不同组件组合的性能,展示了这些组件如何协同工作以减少属性泄露并保持图像编辑质量。
在PIE-Bench上的评估(Evaluation on PIE-Bench):
- 除了ALE-Bench,论文还在现有的PIE-Bench上评估了提出的方法,以进一步验证方法的有效性。
这些实验全面评估了提出框架的性能,特别是在减少属性泄露和提高图像编辑质量方面,并通过与现有技术的比较以及不同场景下的性能分析,展示了其优越性和实用性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
扩展编辑任务的复杂性:
- 目前ALE-Bench主要关注基本和混合编辑任务(如颜色、对象、材质变化)。未来的工作可以探索更复杂的编辑任务,如风格迁移或添加/删除对象,这些任务中定义属性泄露可能更加模糊。
增强模型的泛化能力:
- 考虑到ALE-Bench数据集大小(20张图片)可能限制了对大型或多样化数据集训练的模型的评估。未来的工作可以扩大数据集规模,并纳入更多样化的编辑任务,以增强模型的泛化能力。
提高分割模型的准确性:
- 由于框架依赖于Grounded-SAM等分割模型来识别和编辑特定对象,提高这些分割模型的准确性和鲁棒性可以进一步提升编辑结果的质量。
优化和改进注意力控制机制:
- 论文中提到了通过调整自注意力控制计划来适应不同类型的编辑任务。未来的研究可以探索更精细的注意力控制策略,以实现更精确的编辑。
探索不同的文本嵌入方法:
- 论文提出了对象限制嵌入(ORE)来减少属性泄露。研究不同的文本嵌入技术,可能有助于进一步提高模型对文本提示的理解和应用。
模型的可解释性和控制性:
- 提高模型编辑决策的可解释性,使用户能够更好地理解和控制编辑过程,是一个有价值的研究方向。
跨模态编辑任务:
- 探索扩散模型在视频编辑或3D图像编辑中的应用,这些领域中的属性泄露问题可能有所不同,需要特别的解决方案。
模型的计算效率:
- 考虑实际应用中对计算资源的需求,优化模型以减少计算成本,使其更适合在资源受限的环境中使用。
用户研究和界面设计:
- 开发更直观的用户界面和交互方式,使用户更容易地进行图像编辑,同时收集用户反馈来改进模型性能。
模型的鲁棒性和安全性:
- 研究模型对于对抗性攻击和不当使用的鲁棒性,确保模型在现实世界应用中的安全性和可靠性。
这些探索点可以帮助推动扩散模型在图像编辑领域的进一步发展,提高编辑任务的精确度和模型的实用性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题阐述:
- 论文指出扩散模型在图像编辑中面临的主要挑战是属性泄露问题,包括目标外部(TE)泄露和目标内部(TI)泄露。
现有方法的局限性:
- 分析了现有方法在处理属性泄露时的不足,特别是在使用简单的文本嵌入和处理EOS(End-of-Sequence)标记嵌入时的问题。
提出的框架:
- 提出了一个包含三个关键组件的新框架来减少属性泄露:
- 对象限制嵌入(ORE):通过限制文本嵌入中的非目标对象属性来减少属性泄露。
- 区域引导的交叉注意力掩码混合(RGB-CAM):使用精确的对象和背景掩码来增强交叉注意力,使注意力与目标区域对齐。
- 背景混合(BB):通过混合源和目标潜在表示来保留未编辑区域。
- 提出了一个包含三个关键组件的新框架来减少属性泄露:
新的基准测试(ALE-Bench):
- 引入了一个新基准测试ALE-Bench,用于评估多对象编辑场景中的属性泄露,提供了全面和精确的属性泄露测量。
实验结果:
- 通过在ALE-Bench上的实验,展示了提出框架在减少属性泄露和保持高编辑质量方面的效果,与现有方法相比具有显著优势。
消融研究:
- 进行了消融实验来分析框架中各个组件对整体性能的贡献,证明了这些组件的协同作用对于减少属性泄露和保持图像编辑质量的重要性。
结论:
- 论文总结了提出方法在减少属性泄露和提供高保真度编辑方面的进步,并强调了其在实际应用中的潜力。
总的来说,这篇论文针对扩散模型在图像编辑中的属性泄露问题提出了一个新颖的解决方案,并通过实验验证了其有效性,为未来图像编辑技术的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图