⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
All You Need in Knowledge Distillation Is a Tailored Coordinate System
Authors:Junjie Zhou, Ke Zhu, Jianxin Wu
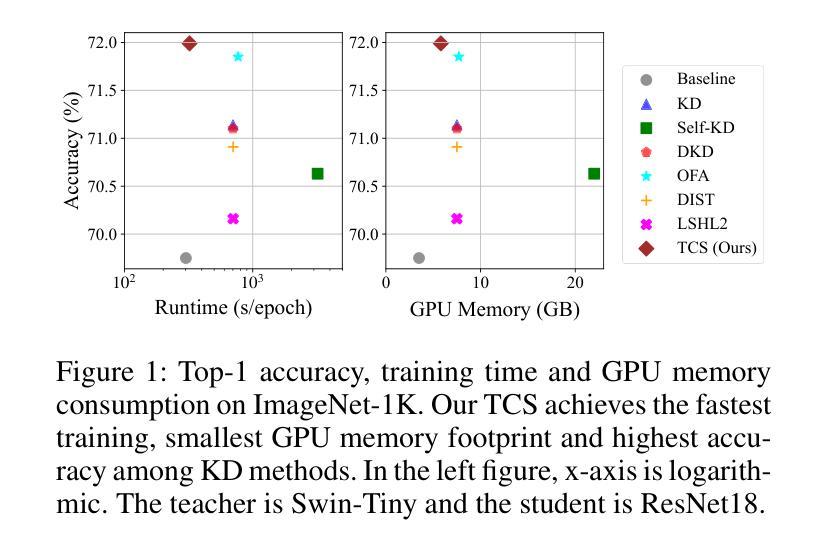
Knowledge Distillation (KD) is essential in transferring dark knowledge from a large teacher to a small student network, such that the student can be much more efficient than the teacher but with comparable accuracy. Existing KD methods, however, rely on a large teacher trained specifically for the target task, which is both very inflexible and inefficient. In this paper, we argue that a SSL-pretrained model can effectively act as the teacher and its dark knowledge can be captured by the coordinate system or linear subspace where the features lie in. We then need only one forward pass of the teacher, and then tailor the coordinate system (TCS) for the student network. Our TCS method is teacher-free and applies to diverse architectures, works well for KD and practical few-shot learning, and allows cross-architecture distillation with large capacity gap. Experiments show that TCS achieves significantly higher accuracy than state-of-the-art KD methods, while only requiring roughly half of their training time and GPU memory costs.
知识蒸馏(KD)对于将从大型教师网络转移到小型学生网络中的暗知识至关重要,这样学生可以比教师更有效率,但具有相当的准确性。然而,现有的KD方法依赖于专门为目标任务训练的大型教师,这既非常不灵活又效率低下。在本文中,我们认为SSL预训练模型可以有效地作为教师,其暗知识可以通过特征所在的坐标系或线性子空间来捕获。然后我们只需要教师的一次前向传递,然后为学生网络定制坐标系(TCS)。我们的TCS方法无需教师,适用于各种架构,对于KD和实用的少样本学习效果很好,并允许具有较大容量差距的跨架构蒸馏。实验表明,TCS方法的准确性显著高于最新的KD方法,同时仅需它们大约一半的训练时间和GPU内存成本。
论文及项目相关链接
Summary
本文提出了基于坐标系统(TCS)的知识蒸馏方法,利用自监督预训练模型作为教师模型,通过坐标系统或线性子空间捕获暗知识,实现教师模型的暗知识转移给学生模型。该方法无需特定教师模型,适用于不同架构,在知识蒸馏和实际应用中的少样本学习表现良好,可实现跨架构蒸馏,大幅降低训练时间和GPU内存成本。
Key Takeaways
- 知识蒸馏(KD)能将大型教师模型中的暗知识转移到小型学生模型中,使学生模型效率更高且准确性相当。
- 现有KD方法依赖于针对目标任务专门训练的大型教师模型,缺乏灵活性和效率。
- 自监督预训练模型可以作为有效的教师模型。
- 暗知识可以通过特征所在的坐标系统或线性子空间进行捕获。
- TCS方法无需特定教师模型,适用于各种架构,适用于KD和少样本学习。
- TCS方法允许跨架构蒸馏,具有大容量的差距。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决知识蒸馏(Knowledge Distillation, KD)中的几个关键问题:
依赖特定任务训练的教师模型:现有的知识蒸馏方法依赖于为特定任务训练的大型教师模型,这种方法成本高、繁琐且不灵活。
缺乏灵活性:KD方法主要利用logits作为训练信号,对于复杂任务(如目标检测)不够灵活,且当教师网络容量大而学生网络小的情况下也存在困难。
效率低下:基于特征的知识蒸馏方法虽然比基于logit的方法更灵活,但它们需要一个训练良好的教师模型和教师的前向传递,这几乎使时间和内存成本翻倍。
为了解决这些问题,论文提出了一种名为“定制坐标系统”(Tailored Coordinate System, TCS)的方法,旨在实现无需教师的、灵活且高效知识蒸馏。TCS方法从自监督学习(SSL)预训练模型中提取知识,适应特定任务和学生网络,同时减少训练时间和GPU内存成本。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
知识蒸馏(Knowledge Distillation, KD):
- 最初由Hinton等人提出,KD方法旨在将大型教师网络的知识转移到小型学生网络上。这包括直接的logits传递和特征或表示蒸馏方法。
自监督学习(Self-Supervised Learning, SSL):
- SSL预训练模型被期望用作KD中的教师模型,但相关研究较少,且准确性有限。
实际少样本学习(Practical Few-Shot Learning, pFSL):
- 与传统的少样本学习(Few-Shot Learning, FSL)不同,pFSL更适应现实世界场景,不依赖于预定义的基础集,而是选择SSL模型预训练在大规模数据集上。
特征模仿(Feature Mimicking):
- 由Wang, Ge, 和 Wu提出的方法,只模仿网络最后一层的特征,对TCS方法有启发作用。
PCA(主成分分析):
- 用于高效编码SSL预训练模型中特征所在的线性子空间,是TCS方法中的关键技术之一。
迭代特征选择(Iterative Feature Selection):
- 用于从PCA定义的坐标系中选择对目标任务有用的特征子集,是TCS方法的另一关键技术。
LSH特征模仿(LSH Feature Mimicking):
- 由Wang, Ge, 和 Wu提出的LSH损失函数,用于使相似特征在高维数据空间中被有效哈希到相同的“桶”中,减少计算成本。
这些研究构成了TCS方法的理论基础和技术支持,TCS方法综合了这些技术来实现无需教师的、灵活且高效知识蒸馏。
Q: 论文如何解决这个问题?
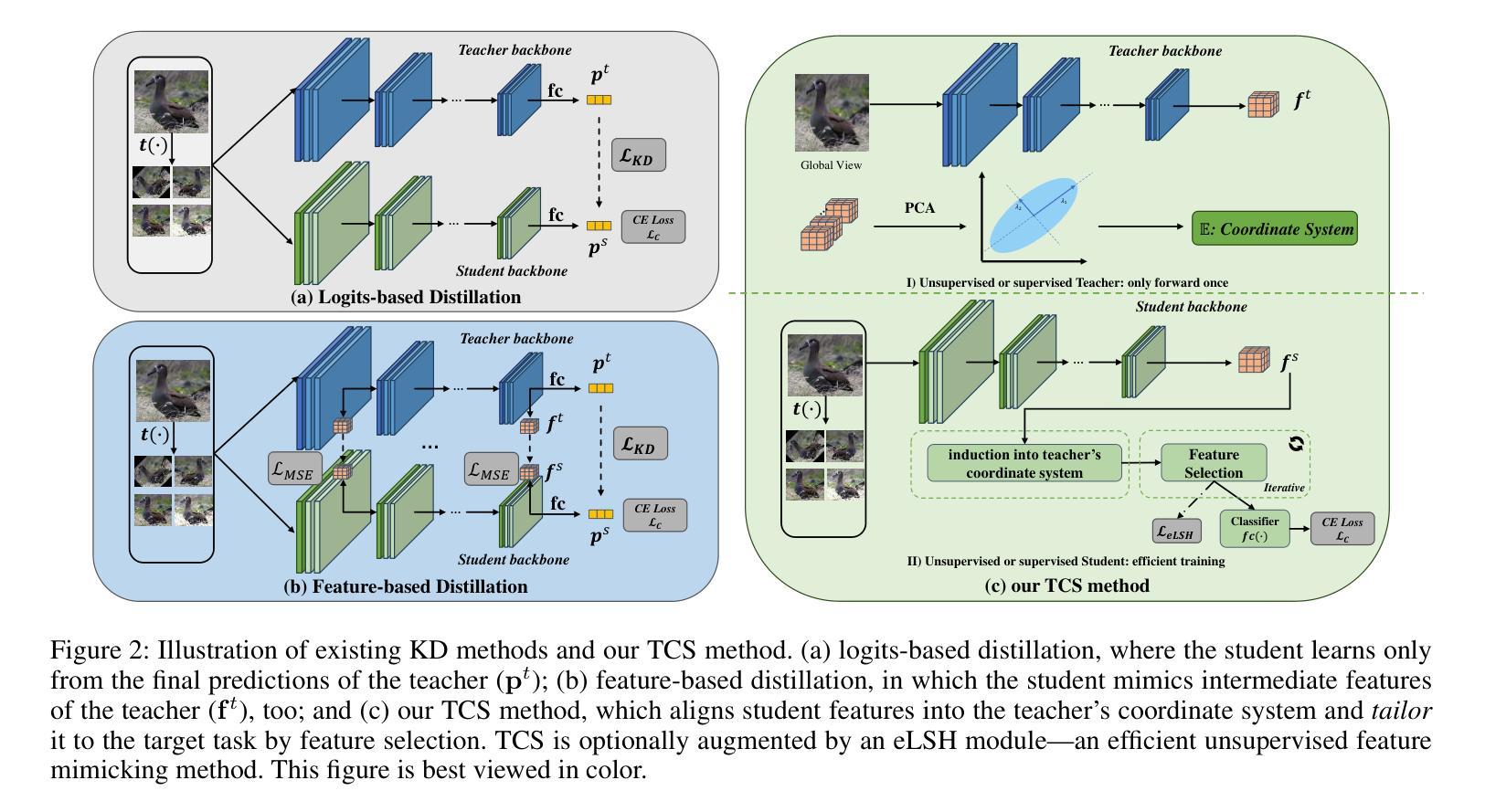
A: 论文通过提出一种名为“定制坐标系统”(Tailored Coordinate System, TCS)的方法来解决知识蒸馏中的问题。具体来说,TCS方法通过以下步骤实现解决方案:
提取教师特征:
- 利用目标任务的训练数据,通过单次前向传递提取教师模型的特征。
计算教师坐标系统:
- 使用主成分分析(PCA)从提取的特征中计算出教师的坐标系统。这个坐标系统或线性子空间编码了SSL预训练模型中的暗知识。
适应学生网络:
- 通过将学生网络的特征与教师的坐标系统对齐,将教师的暗知识传递给学生网络。
迭代特征选择:
- 引入一个可训练的掩码来选择对目标任务有用的PCA维度,形成定制的坐标系统(TCS)。
高效特征模仿(eLSH):
- 当教师模型是针对目标任务训练的,TCS方法使用eLSH损失来使学生特征模仿教师特征在PCA定义的坐标系统中的表现。
无需教师模型:
- TCS方法是无需教师的,意味着可以从SSL预训练模型中有效转移知识,而不需要为特定任务训练教师模型。
适应多样化架构:
- TCS方法适用于多种网络架构,包括CNNs、Transformers和MLPs,并且支持跨架构和大容量差距的知识蒸馏。
提高效率和准确性:
- 实验表明,TCS方法在保持高准确性的同时,相比于现有的KD方法,大约只需要一半的训练时间和GPU内存成本。
通过这些步骤,TCS方法解决了现有知识蒸馏方法中的灵活性和效率问题,并提供了一种新的、不依赖于特定任务训练教师模型的知识蒸馏策略。
Q: 论文做了哪些实验?
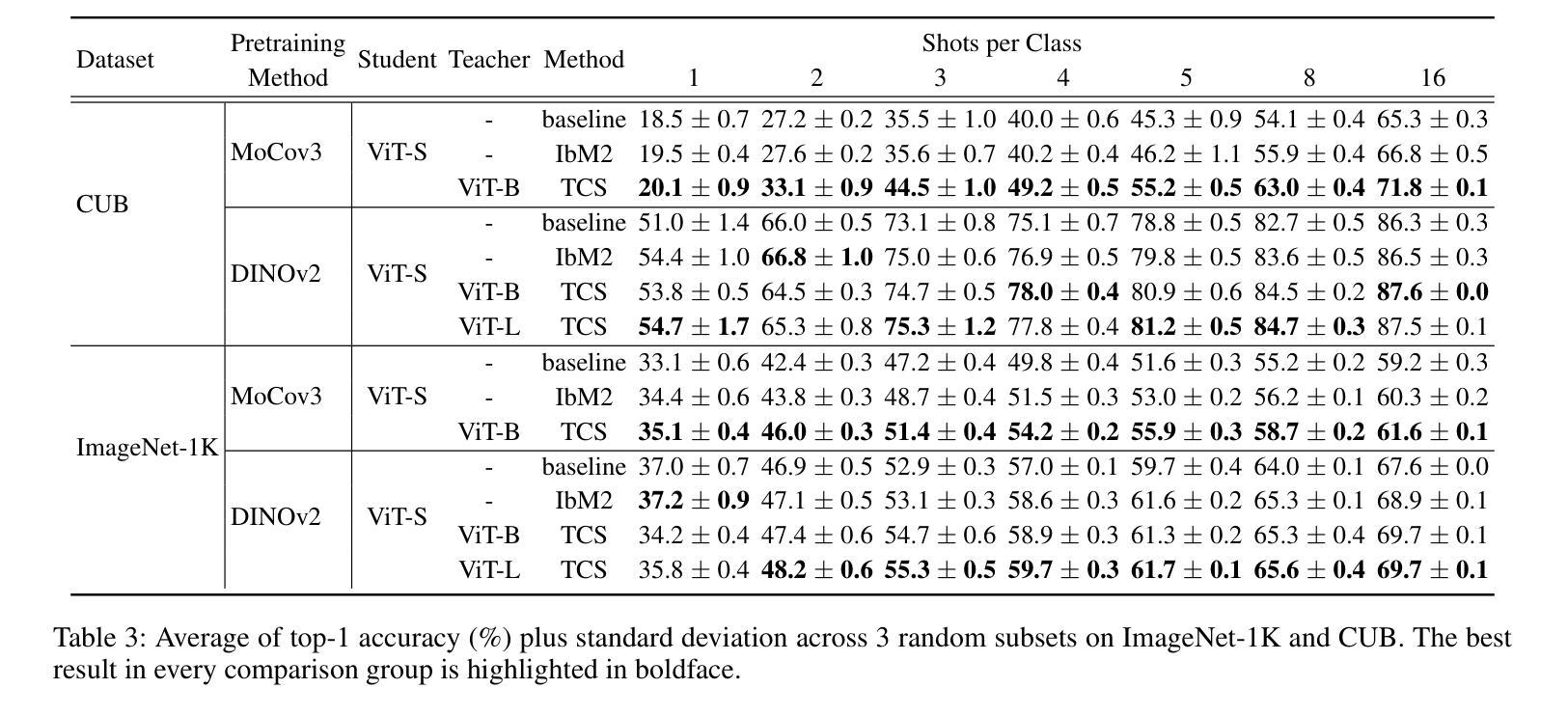
A: 论文中进行了以下实验来验证TCS方法的有效性:
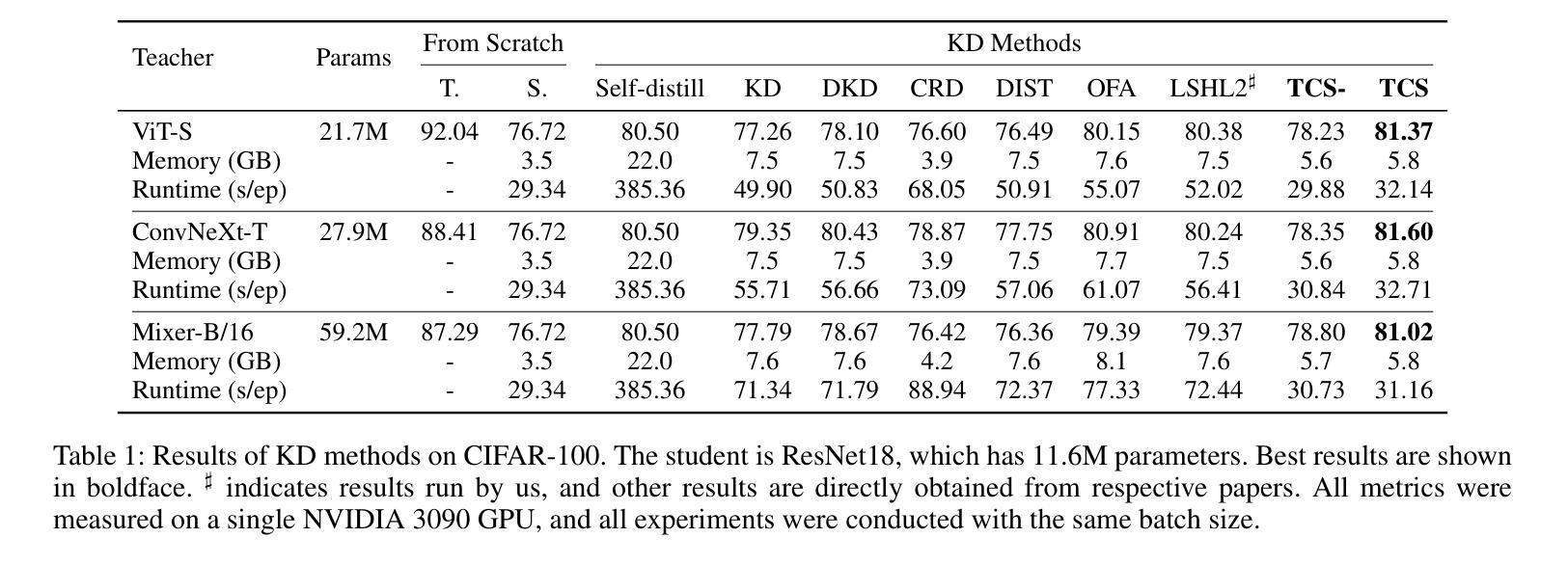
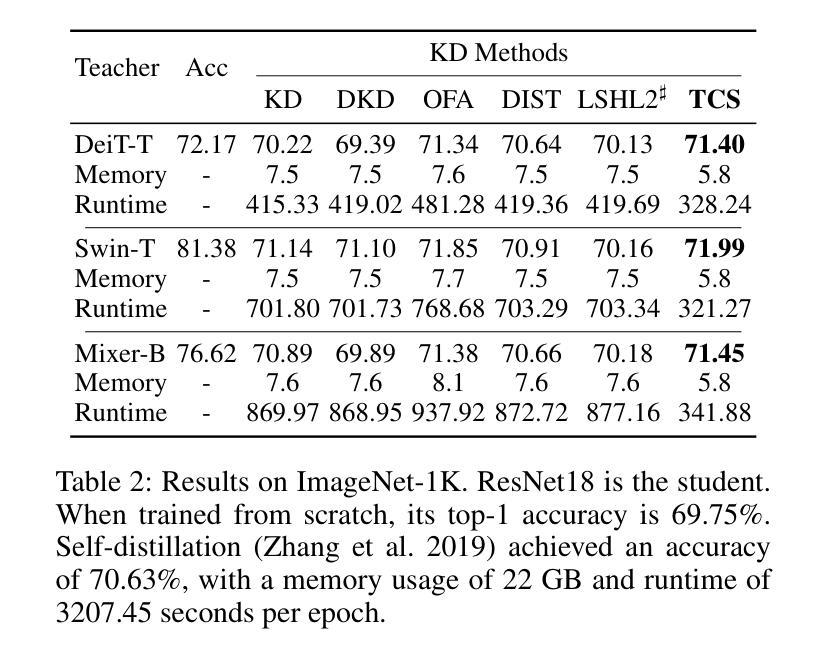
传统知识蒸馏(KD)实验:
- 在CIFAR-100和ImageNet-1K数据集上进行实验,比较了TCS方法与其他几种KD方法(如经典KD、DKD、CRD、DIST、OFA和LSHL2)的性能。
- 使用了不同的学生网络架构,包括ResNet、ViT、DeiT、Swin和MLP-Mixer。
- 评估了TCS方法在不同网络架构和容量差异下的适应性和效果。
实际少样本学习(pFSL)实验:
- 在ImageNet-1K和CUB-200-2011数据集上进行实验,遵循pFSL协议,随机采样训练集以形成k-shot学习的场景。
- 比较了TCS方法与IbM2方法的性能,使用了Vision Transformer(ViT)和ResNet50作为网络架构。
- 考虑了不同的自监督学习方法(如DINOv2和MoCov3)作为教师网络的预训练方法。
模型大小影响实验:
- 研究了教师和学生网络模型大小差异对TCS方法的影响,包括大容量差距对性能的影响。
坐标系统效果实验:
- 分析了不同数据来源对PCA坐标系统计算的影响,包括领域内数据和领域外数据。
- 比较了使用随机正交向量代替PCA坐标系统的效果。
这些实验全面评估了TCS方法在不同设置下的性能,包括与传统KD方法的比较、在少样本学习场景下的应用、模型大小差异的影响,以及坐标系统对知识蒸馏效果的贡献。通过这些实验,论文展示了TCS方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文提出了TCS(定制坐标系统)方法,并在知识蒸馏(KD)和实际少样本学习(pFSL)中验证了其有效性。以下是一些可以进一步探索的点:
扩展到其他任务:
- 将TCS方法应用于其他任务,如目标检测和分割模型,探索其在这些领域的有效性和可能的改进。
压缩和加速大型语言模型(LLMs):
- 由于TCS在自监督学习中表现良好,探索其在压缩和加速大型语言模型或大型多模态模型中的应用。
理论基础:
- 研究TCS方法的理论基础,特别是暗知识是如何通过坐标系统编码的,以及为何能够通过调整坐标系实现有效的知识传递。
优化迭代特征选择策略:
- 研究更高效或更精确的特征选择方法,以进一步优化TCS方法中的迭代特征选择模块。
跨领域适应性:
- 探索TCS方法在不同领域间的适应性,尤其是在领域差距较大时如何有效地传递知识。
与其他模型压缩技术的结合:
- 研究将TCS与其他模型压缩技术(如网络剪枝、量化)结合的可能性,以实现更高效的模型压缩策略。
提高泛化能力:
- 研究如何提高TCS方法的泛化能力,特别是在面对数据分布偏移时。
计算效率的进一步提升:
- 探索减少TCS方法中计算成本的方法,例如通过优化PCA计算或特征选择过程。
鲁棒性和可靠性研究:
- 对TCS方法在各种逆境条件下的鲁棒性和可靠性进行更深入的研究,包括对抗攻击、数据噪声等。
自动化和自适应调整超参数:
- 开发自动化机制来自适应调整TCS方法中的超参数,以提高方法的易用性和灵活性。
这些探索点可以帮助研究者更深入地理解TCS方法的原理,提高其性能,并扩展其在不同领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种新的知识蒸馏(KD)方法,名为“定制坐标系统”(Tailored Coordinate System, TCS),旨在解决现有KD方法中的一些主要问题,包括对特定任务训练的教师模型的依赖、缺乏灵活性和效率低下。以下是论文的主要内容总结:
问题陈述:
- 论文指出现有的KD方法依赖于为特定任务训练的大型教师模型,这种方法成本高、不灵活且效率低。
方法论:
- 提出了TCS方法,该方法从SSL预训练模型中提取知识,并将其适应于特定任务和学生网络。
- 使用PCA(主成分分析)来编码教师模型特征所在的线性子空间,并通过迭代特征选择方法定制坐标系统以适应目标任务。
实验验证:
- 在CIFAR-100和ImageNet-1K数据集上进行了实验,验证了TCS方法在不同网络架构和容量差异下的有效性。
- 在实际少样本学习(pFSL)场景中评估了TCS方法,并与现有方法进行了比较。
结果分析:
- TCS方法在保持高准确性的同时,相比于现有KD方法,大约只需要一半的训练时间和GPU内存成本。
- TCS方法对模型大小差异具有鲁棒性,并且能够从SSL预训练模型中有效提取和传递知识。
未来工作:
- 论文提出了未来可能的研究方向,包括将TCS方法扩展到其他任务、压缩大型语言模型、探索理论基础等。
总体而言,这篇论文提出了一种新颖的知识蒸馏方法,通过定制坐标系统有效地从SSL预训练模型中提取和传递知识,同时减少了训练成本,提高了灵活性和效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

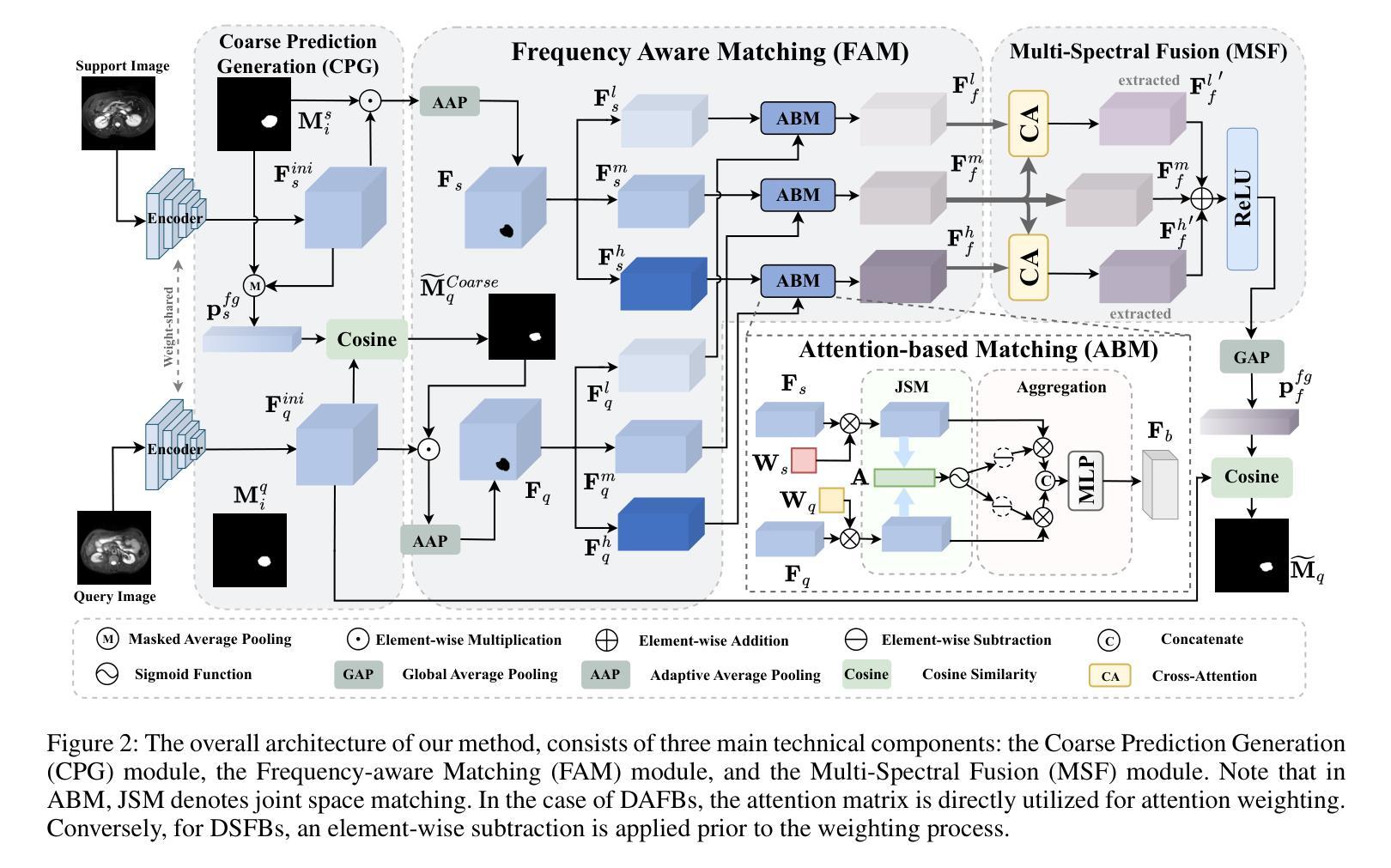
FAMNet: Frequency-aware Matching Network for Cross-domain Few-shot Medical Image Segmentation
Authors:Yuntian Bo, Yazhou Zhu, Lunbo Li, Haofeng Zhang
Existing few-shot medical image segmentation (FSMIS) models fail to address a practical issue in medical imaging: the domain shift caused by different imaging techniques, which limits the applicability to current FSMIS tasks. To overcome this limitation, we focus on the cross-domain few-shot medical image segmentation (CD-FSMIS) task, aiming to develop a generalized model capable of adapting to a broader range of medical image segmentation scenarios with limited labeled data from the novel target domain. Inspired by the characteristics of frequency domain similarity across different domains, we propose a Frequency-aware Matching Network (FAMNet), which includes two key components: a Frequency-aware Matching (FAM) module and a Multi-Spectral Fusion (MSF) module. The FAM module tackles two problems during the meta-learning phase: 1) intra-domain variance caused by the inherent support-query bias, due to the different appearances of organs and lesions, and 2) inter-domain variance caused by different medical imaging techniques. Additionally, we design an MSF module to integrate the different frequency features decoupled by the FAM module, and further mitigate the impact of inter-domain variance on the model’s segmentation performance. Combining these two modules, our FAMNet surpasses existing FSMIS models and Cross-domain Few-shot Semantic Segmentation models on three cross-domain datasets, achieving state-of-the-art performance in the CD-FSMIS task.
现有的小样本医学图像分割(FSMIS)模型无法解决医学成像中的一个实际问题:由不同成像技术引起的域偏移,这限制了其在当前FSMIS任务中的应用。为了克服这一局限性,我们专注于跨域小样本医学图像分割(CD-FSMIS)任务,旨在开发一种通用模型,能够在有限的新目标域的标记数据下,适应更广泛的医学图像分割场景。受不同领域频率域相似性特征的启发,我们提出了一种频率感知匹配网络(FAMNet),它包括两个关键组件:频率感知匹配(FAM)模块和多光谱融合(MSF)模块。FAM模块解决了元学习阶段的两个问题:1)由于器官和病变的不同外观造成的域内方差,这是固有的支持查询偏见的结果;以及2)由于不同的医学成像技术造成的跨域方差。此外,我们设计了一个MSF模块,以整合被FAM模块解耦的不同频率特征,并进一步减轻跨域方差对模型分割性能的影响。结合这两个模块,我们的FAMNet在三个跨域数据集上超越了现有的FSMIS模型和跨域小样本语义分割模型,在CD-FSMIS任务中达到了最新性能水平。
论文及项目相关链接
PDF Accepted by the 39th Annual AAAI Conference on Artificial Intelligence (AAAI-25)
Summary
本文提出解决跨域少样本医疗图像分割问题的新方法,针对现有模型难以适应不同医学影像技术带来的领域偏移问题。通过引入频率感知匹配网络(FAMNet),包括频率感知匹配模块和多光谱融合模块,提高了模型在跨域数据集上的分割性能,达到领先水平。
Key Takeaways
- 现有少样本医疗图像分割模型面临跨域问题,难以适应不同医学影像技术导致的领域偏移。
- 提出跨域少样本医疗图像分割(CD-FSMIS)任务,旨在开发能够适应更广泛医疗图像分割场景的通用模型。
- 频率感知匹配网络(FAMNet)包括频率感知匹配(FAM)模块和多光谱融合(MSF)模块两个关键组件。
- FAM模块解决元学习阶段的域内方差和域间方差问题。
- MSF模块用于整合由FAM模块分离的不同频率特征,进一步减轻域间方差对模型分割性能的影响。
- FAMNet在三个跨域数据集上超越现有FSMIS模型和跨域少样本语义分割模型,实现CD-FSMIS任务的最新性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是医学图像分割领域中的实际挑战:由于不同成像技术导致的领域偏移(domain shift),这限制了现有的少数样本医学图像分割(FSMIS)模型的适用性。具体来说,论文关注于跨领域少数样本医学图像分割(CD-FSMIS)任务,旨在开发一个能够适应更广泛的医学图像分割场景的泛化模型,即使在新的目标领域中只有有限的标记数据。
论文中提到的关键挑战包括:
领域内变化(Intra-domain variations):医学图像在个体器官之间表现出显著的变异性,例如大小、脂肪含量和病理变化,这使得找到相似的支持-查询对变得困难,导致支持-查询偏差和降低原型表示。
领域间变化(Inter-domain variations):即使在相同的器官或区域内,不同领域之间的空间域相似性表现出低相关性,而在频率域中,领域间变化主要在高低频带中表现明显,而中频带则相对相似。
为了克服这些限制,论文提出了一种新的频率感知匹配网络(FAMNet),包括两个关键组件:频率感知匹配(FAM)模块和多光谱融合(MSF)模块。FAM模块在元学习阶段解决领域内和领域间变化问题,而MSF模块设计用于整合由FAM模块解耦的不同频率特征,并进一步减轻领域间变化对模型分割性能的影响。通过结合这两个模块,FAMNet在三个跨领域数据集上超越了现有的FSMIS模型和跨领域少样本语义分割模型,实现了CD-FSMIS任务的最新性能。
Q: 有哪些相关研究?
A: 论文中提到了多个与跨领域少样本医学图像分割(CD-FSMIS)相关的研究领域和具体工作,可以分为以下几个部分:
1. 少样本医学图像分割(FSMIS)
交互网络(Interactive Networks):
- SENet(Guha Roy et al. 2019):在FSMIS任务中首次使用交互网络。
- MRrNet(Feng et al. 2021)、GCN-DE(Sun et al. 2022)、CRAPNet(Ding et al. 2023):通过注意力机制增强支持查询交互。
原型网络(Prototypical Networks):
- SSL-ALPNet(Ouyang et al. 2022):引入自监督框架,生成局部原型并使用基于超像素的伪标签进行训练。
- ADNet(Hansen et al. 2022)、CATNet(Lin et al. 2023)、GMRD(Cheng et al. 2024):通过不同的方法改进原型类的分布表示和支持查询交互。
2. 跨领域少样本语义分割(CD-FSS)
- 模型:
- PATNet(Lei et al. 2022)、PMNet(Chen et al. 2024)、DRAdapter(Su et al. 2024):这些模型尝试将领域特定特征映射到领域不可知特征,或通过样式扰动来适应目标领域风格。
3. 医学图像领域的泛化方法
- 领域随机化:
- 一些工作(Ouyang et al. 2021; Zhou et al. 2022; Xu et al. 2022; Su et al. 2023)主要关注领域随机化,而忽略了模型本身和少样本设置。
4. 其他相关工作
- 频率域和空间域的相似性度量:
- 使用结构相似性指数(SSIM)和归一化均方误差(NMSE)来量化CT和MRI在空间和频率域的相似性。
这些相关工作为论文提出的FAMNet提供了理论基础和技术对比,展示了在跨领域少样本医学图像分割任务中的研究进展和挑战。论文通过综合这些领域的技术和方法,提出了一个新的解决方案来提高模型在新目标领域的泛化能力和分割性能。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为FAMNet(Frequency-aware Matching Network)的模型,通过以下两个关键组件来解决跨领域少样本医学图像分割(CD-FSMIS)任务中的问题:
1. 频率感知匹配(FAM)模块
FAM模块的核心思想是在特定频率带内执行支持查询匹配,以消除支持查询偏差,并通过融合前景特征和突出协同部分来减少对显著领域差异的依赖。具体来说:
多频谱解耦:将前景特征从空间域转换到频率域,并使用带通滤波器将信号分解为高、中、低三个频带。
多频谱注意力匹配:对于不同的频带,应用不同的注意力加权机制,对于领域间变化较大的高频和低频带(DSFBs),采用抑制相似特征的策略;而对于领域间变化较小的中频带(DAFBs),则直接使用注意力权重。
2. 多光谱融合(MSF)模块
MSF模块旨在整合由FAM模块解耦的不同频率特征,并进一步减轻领域特定频率带的影响。具体来说:
交叉注意力机制:利用中频带信息从高频和低频特征中提取领域不变信息(DII),同时抑制领域特定信息(DVI)。
特征重组:将处理后的高频、中频和低频特征通过简单的加法整合,并通过ReLU激活函数输出最终的融合特征。
总体架构
特征提取:使用预训练的ResNet-50作为特征编码器提取支持和查询特征图。
粗略预测生成(CPG)模块:基于原型网络方法获得查询图像的粗略分割掩码。
频率感知匹配(FAM)模块:对支持和查询前景特征进行频率感知匹配。
多光谱融合(MSF)模块:基于交叉注意力机制融合不同频带的特征。
最终预测:通过计算前景原型与查询特征之间的余弦相似度来生成查询掩码的最终预测。
通过结合FAM和MSF模块,FAMNet不仅展示了强大的泛化能力,还有效地利用了样本空间中的领域不变交互信息,展现了优异的分割性能。论文通过在三个跨领域数据集上的实验验证了所提方法的有效性和优越性。
Q: 论文做了哪些实验?
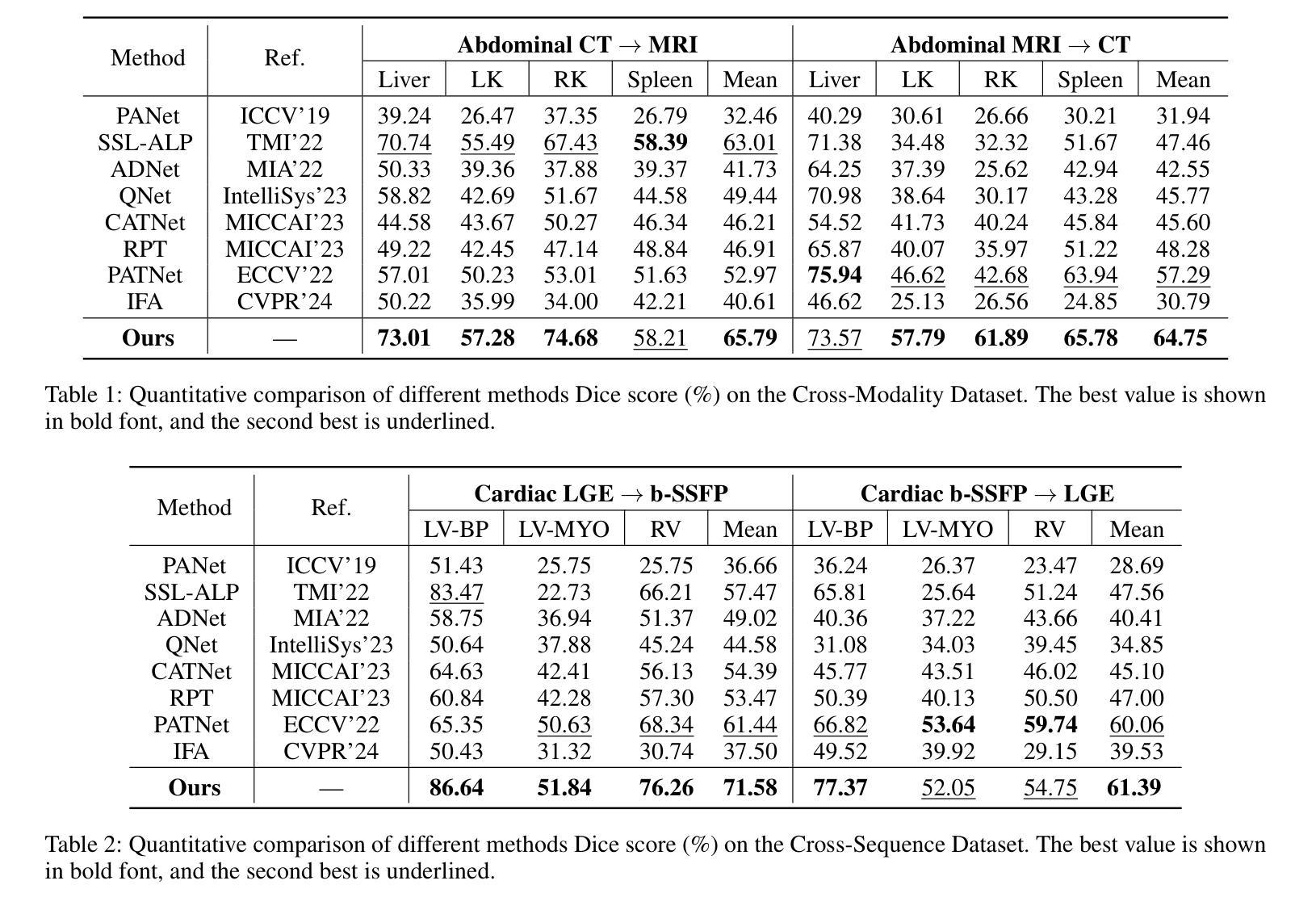
A: 论文中进行了一系列的实验来验证FAMNet模型的性能和有效性。具体实验包括:
数据集
- Cross-Modality 数据集:包含两个腹部数据集,Abd-MRI 和 Abd-CT,涵盖了左肾(LK)、右肾(RK)、肝脏和脾脏四个常见类别。
- Cross-Sequence 数据集:心脏数据集,包含LGE MRI扫描和b-SSFP MRI扫描,涵盖血池(LV-BP)、左心室心肌(LVMYO)和右心室心肌(RV)三个不同的标签。
- Cross-Institution 数据集:由伦敦大学学院医院(UCLH)和美国马里兰州贝塞斯达国家癌症研究所(NCI)提供的前列腺T2加权MRI扫描组成,涵盖膀胱、中央腺(CG)和直肠三个常见类别。
实施细节
- 使用3D supervoxel clustering方法生成伪掩码作为基于情节的元学习任务的监督。
- 在1-way 1-shot条件下进行实验。
- 使用SGD优化器,初始学习率0.001,动量0.9,每1K次迭代衰减因子0.95。
评估指标
- 使用Sorensen-Dice系数(DSC)作为评估模型的标准,衡量分割结果和真实标注之间的重叠程度。
定量和定性结果
- 与多种FSMIS模型(如PANet、SSL-ALPNet、ADNet等)和CD-FSS模型(如PATNet和IFA)进行比较。
- 在Cross-Modality数据集的CT → MRI和MRI → CT方向上,FAMNet均取得了显著的性能提升。
- 在Cross-Sequence数据集上,FAMNet在两个方向上均取得了最高的Dice分数,与次佳方法相比提高了10.14%和1.33%。
- 在Cross-Institution数据集上,FAMNet在UCLH → NCI和NCI → UCLH方向上分别比第二好的方法高1.80%和2.91%。
消融研究
- 分析了FAM模块和MSF模块对整体模型性能的贡献。
- 探讨了在DSFBs和DAFBs中应用不同注意力权重方法的影响。
- 研究了直接丢弃特定频率带对模型性能的影响。
- 分析了匹配仅限于特定频率带的影响。
- 讨论了不同频率带划分比例对模型性能的影响。
- 分析了通过自适应平均池化标准化前景像素数量N的影响。
可视化
- 展示了FAMNet在CT → MRI、LGE → b-SSFP和NCI → UCLH方向上的查询图像、真实标注、预测和不确定性图。
- 使用t-SNE可视化展示了FAMNet减少支持查询偏差的能力。
这些实验全面验证了FAMNet在跨领域少样本医学图像分割任务中的有效性和优越性能,并深入分析了模型的不同组件对性能的影响。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一个有效的FAMNet模型来解决跨领域少样本医学图像分割(CD-FSMIS)问题,但仍有一些方面可以进一步探索和改进:
1. 更多的领域和数据集
- 扩展数据集:在更多的跨领域数据集上验证模型的泛化能力,包括不同类型的医学图像(如超声、PET等)。
- 大规模数据集:探索在大规模跨领域数据集上的性能,以及如何处理类别不平衡问题。
2. 模型泛化能力的进一步提升
- 自适应领域判别:研究如何让模型自动学习哪些特征是领域特定的,哪些是领域不变的,以提高模型的泛化能力。
- 多任务学习:考虑将分割任务与其他相关任务(如分类、检测)结合起来,通过多任务学习提高模型的泛化能力。
3. 计算效率和实际应用
- 计算效率:优化模型结构和训练过程,减少计算资源消耗,使其更适合实际的临床应用。
- 实时性能:探索模型的实时性能,这对于手术导航等实时应用场景非常重要。
4. 模型解释性和可视化
- 特征可视化:进一步分析和可视化模型学习到的特征,以更好地理解模型的决策过程。
- 错误分析:对模型的失败案例进行详细分析,了解模型在哪些类型的图像或区域上表现不佳,并探索改进方法。
5. 模型鲁棒性
- 对抗性攻击和防御:研究模型对对抗性攻击的鲁棒性,并开发有效的防御策略。
- 数据增强和正则化:探索不同的数据增强技术和正则化方法,以提高模型对异常值和噪声的鲁棒性。
6. 跨模态融合
- 多模态融合策略:研究更先进的多模态融合策略,以充分利用不同模态的互补信息。
- 动态模态选择:开发动态模态选择机制,根据任务需求自动选择最相关的模态。
7. 临床验证和评估
- 临床合作:与临床医生合作,收集反馈,并根据临床需求调整和优化模型。
- 大规模临床试验:在大规模的临床试验中评估模型的性能和实用性。
这些方向不仅可以推动跨领域少样本医学图像分割技术的发展,还可能对其他领域的迁移学习和领域适应问题提供有价值的见解。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了跨领域少样本医学图像分割(CD-FSMIS)任务,并提出了一个名为FAMNet(Frequency-aware Matching Network)的模型来解决这一问题。以下是论文的主要内容总结:
问题背景
- 现有少样本医学图像分割(FSMIS)模型在面对不同成像技术导致的领域偏移时泛化能力有限,难以适应新的医学图像分割场景。
研究目标
- 提出一个能够适应新目标领域且只有少量标记数据的泛化模型,以提高在跨领域医学图像分割任务中的性能。
方法论
- FAMNet模型:包含两个关键组件,即频率感知匹配(FAM)模块和多光谱融合(MSF)模块。
- FAM模块:在元学习阶段处理领域内和领域间变化,通过在特定频率带内执行支持查询匹配来减少支持查询偏差,并整合频率域信息以降低对显著领域差异的依赖。
- MSF模块:整合由FAM模块解耦的不同频率特征,并进一步减轻领域特定频率带的影响。
实验
- 在三个跨领域数据集上进行了广泛的实验,包括Cross-Modality、Cross-Sequence和Cross-Institution数据集。
- 与多个现有的FSMIS和CD-FSS模型相比,FAMNet在CD-FSMIS任务上达到了最先进的性能。
- 通过消融研究和可视化分析验证了模型组件的有效性和模型对领域偏移的鲁棒性。
结论
- FAMNet通过其创新的频率感知匹配和多光谱融合策略,有效地解决了跨领域少样本医学图像分割中的挑战,展示了优异的泛化能力和分割性能。
总体而言,这篇论文针对医学图像分割领域中的实际问题提出了一种有效的解决方案,并通过一系列实验验证了其方法的有效性,为未来的研究和应用提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

First Train to Generate, then Generate to Train: UnitedSynT5 for Few-Shot NLI
Authors:Sourav Banerjee, Anush Mahajan, Ayushi Agarwal, Eishkaran Singh
Natural Language Inference (NLI) tasks require identifying the relationship between sentence pairs, typically classified as entailment, contradiction, or neutrality. While the current state-of-the-art (SOTA) model, Entailment Few-Shot Learning (EFL), achieves a 93.1% accuracy on the Stanford Natural Language Inference (SNLI) dataset, further advancements are constrained by the dataset’s limitations. To address this, we propose a novel approach leveraging synthetic data augmentation to enhance dataset diversity and complexity. We present UnitedSynT5, an advanced extension of EFL that leverages a T5-based generator to synthesize additional premise-hypothesis pairs, which are rigorously cleaned and integrated into the training data. These augmented examples are processed within the EFL framework, embedding labels directly into hypotheses for consistency. We train a GTR-T5-XL model on this expanded dataset, achieving a new benchmark of 94.7% accuracy on the SNLI dataset, 94.01% accuracy on the E-SNLI dataset, and 92.57% accuracy on the MultiNLI dataset, surpassing the previous SOTA models. This research demonstrates the potential of synthetic data augmentation in improving NLI models, offering a path forward for further advancements in natural language understanding tasks.
自然语言推理(NLI)任务需要识别句子对之间的关系,通常分为蕴涵、矛盾或中性。虽然当前最先进的模型——蕴涵小样本学习(EFL)在斯坦福自然语言推理(SNLI)数据集上达到了93.1%的准确率,但由于数据集的局限性,进一步的发展受到限制。针对这一问题,我们提出了一种利用合成数据增强来提高数据集多样性和复杂性的新方法。我们推出了UnitedSynT5,这是EFL的高级扩展,它利用基于T5的生成器合成额外的前提假设对,经过严格清洗和整合到训练数据中。这些增强的例子在EFL框架内进行处理,将标签直接嵌入假设中以保证一致性。我们在扩展后的数据集上训练了一个GTR-T5-XL模型,在SNLI数据集上达到了94.7%的新准确率,在E-SNLI数据集上达到了94.01%的准确率,在MultiNLI数据集上达到了92.57%的准确率,超越了之前的SOTA模型。该研究展示了合成数据增强在提高NLI模型潜力方面的潜力,为自然语言理解任务的进一步进步提供了方向。
论文及项目相关链接
PDF 14 pages
Summary
本文介绍了针对自然语言推理(NLI)任务的新方法,通过合成数据增强来提高数据集多样性和复杂性。提出一种基于T5生成器的合成方法,合成额外的前提假设对,并严格清洗整合到训练数据中。在扩展数据集上训练的GTR-T5-XL模型取得了新的里程碑,在SNLI、E-SNLI和MultiNLI数据集上的准确率分别达到了94.7%、94.01%和92.57%,超越了之前的最佳模型。研究证明了合成数据增强在改进NLI模型中的潜力,为未来自然语言理解任务的进步提供了方向。
Key Takeaways
- 自然语言推理(NLI)任务要求识别句子对之间的关系,分类为蕴含、矛盾或中立。
- 当前最佳模型Entailment Few-Shot Learning(EFL)在SNLI数据集上的准确率为93.1%。
- 提出一种新型方法,利用合成数据增强来提高数据集多样性和复杂性。
- 介绍了UnitedSynT5,一个先进的EFL扩展,使用T5生成器合成额外的前提假设对。
- 清洗并整合这些合成数据到训练数据中,然后在EFL框架内处理这些增强示例。
- 训练GTR-T5-XL模型在新数据集上取得显著成果,SNLI、E-SNLI和MultiNLI数据集上的准确率分别提高。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决自然语言推理(Natural Language Inference, NLI)任务中存在的挑战,特别是在数据集局限性和模型性能限制方面。具体来说,论文的目标是:
提升NLI任务的准确性:尽管现有的最先进模型(如Entailment Few-Shot Learning, EFL)在SNLI数据集上已经取得了93.1%的准确率,但进一步的提升受到数据集限制的阻碍。
增强数据集的多样性和复杂性:论文指出,现有的SNLI数据集包含570,000个人工标注的前提-假设对,但这仅捕捉了现实世界场景中一小部分的语言现象和推理模式。因此,需要通过合成数据增强来引入更大的语言多样性和复杂性。
克服现有模型的局限性:以往的模型,包括基于LSTM的方法和基于注意力机制的方法,都存在无法处理复杂语言现象、缺乏世界知识或推理链的问题。此外,预训练的变换器模型(如BERT及其变体)虽然有所改进,但在泛化到训练分布之外的模式上能力有限。
提出新的方法:为了解决这些挑战,论文提出了一个新颖的方法,即UnitedSynT5,它结合了合成数据增强和EFL框架。通过使用基于T5的生成器来创建额外的前提-假设对,这些数据经过严格的清洗和整合到训练数据中,以提高模型的泛化能力,并在NLI任务上取得了新的最先进性能。
总结来说,这篇论文旨在通过合成数据增强和先进的模型训练方法,提高NLI模型的准确性和泛化能力,从而在自然语言理解任务上取得进一步的进展。
Q: 有哪些相关研究?
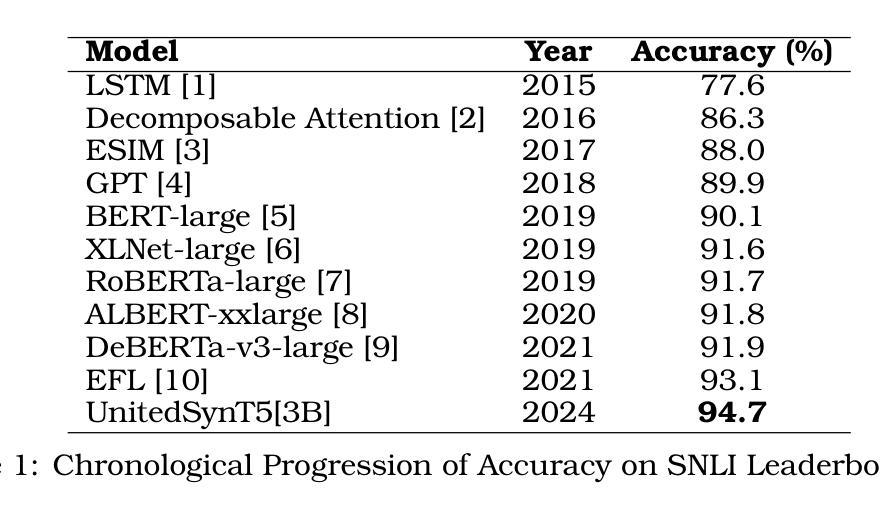
A: 论文中提到了多个与自然语言推理(NLI)相关的研究工作,以下是一些关键的相关研究:
LSTM [1] (2015): 最初的基于长短期记忆网络(LSTM)的模型,在SNLI数据集上取得了77.6%的准确率,为后续研究设定了基准。
Decomposable Attention [2] (2016): 引入了注意力机制,将准确率提高到86.3%。
ESIM [3] (2017): 增强型LSTM(ESIM)模型,将准确率进一步推高至88.0%。
GPT [4] (2018): 生成预训练(GPT)模型,实现了89.9%的准确率,展示了生成预训练的强大能力。
BERT-large [5] (2019): 基于双向变换器架构的BERT模型,在SNLI上达到了90.1%的准确率。
XLNet-large [6] (2019): 与BERT同年,XLNet模型通过广义自回归预训练达到了91.6%的准确率。
RoBERTa-large [7] (2019): 在BERT的基础上优化了训练过程,包括更长时间的训练和动态掩码,达到了91.7%的准确率。
ALBERT-xxlarge [8] (2020): 通过引入去耦注意力机制和增强掩码解码器架构,将性能略微提高至91.8%。
DeBERTa-v3-large [9] (2021): 进一步推动了界限至91.9%,强调了精确参数调整和架构创新在提高NLI性能中的重要性。
EFL [10] (2021): 引入了少量样本学习范式,通过将标签直接嵌入到假设中,将NLI重新构造为二元决策问题,实现了93.1%的准确率。
这些研究展示了NLI模型的逐步发展,每个新方法都针对其前身的具体局限性进行了改进。从依赖手工特征和浅层神经网络的早期模型,到引入注意力机制和先进的神经架构,再到基于大型语言模型和迁移学习技术的模型,这些研究构成了NLI领域的重要进展。论文提出的UnitedSynT5方法正是在这些研究的基础上,通过合成数据增强和EFL框架,进一步推动了NLI任务的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个新颖的方法,即UnitedSynT5,来解决自然语言推理(NLI)任务中存在的问题。这个方法结合了合成数据增强和Entailment Few-Shot Learning(EFL)框架,具体步骤如下:
合成数据生成:
- 使用基于T5的生成器来创建额外的前提-假设对,增强数据集的多样性和复杂性。
- 将初始训练数据集分割为生成集和少量样本集,利用少量样本集中的示例作为生成提示中的上下文参考,以提高假设生成的相关性和准确性。
数据清洗:
- 通过过滤机制移除不一致或冗余的数据,确保合成数据集的质量。
- 应用标签对齐和冗余消除标准,仅保留与人类标注数据一致且为新颖的示例。
EFL转换:
- 将合成数据转换为EFL框架,将标签信息直接嵌入到假设陈述中。
- 这种转换将三分类问题转化为二元决策问题,简化了分类任务。
训练GTR-T5-XL模型:
- 使用经过清洗和EFL转换的合成数据集来从头开始训练GTR-T5-XL模型。
- 配置模型输入维度、全连接层、激活函数和dropout率,以优化模型性能。
评估和性能测量:
- 在原始SNLI数据集上评估模型性能,与人类标注的标签进行比较。
- 通过反馈循环不断细化模型参数,提高模型对复杂和多样化前提-假设对的处理能力。
通过这些步骤,UnitedSynT5方法不仅提高了模型在SNLI数据集上的准确性,而且还在E-SNLI和MultiNLI数据集上取得了新的最先进性能,证明了合成数据增强在提升NLI模型性能方面的潜力。这种方法为自然语言理解任务的进一步发展提供了一条前进的道路。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
合成数据生成实验:
- 使用FLAN-T5 XL(3B)生成器基于原始SNLI数据集生成额外的前提-假设对。
- 通过随机选择少量样本集中的示例作为上下文参考,生成与任务一致的假设。
数据清洗实验:
- 对生成的合成数据进行系统性过滤,移除与GTR-T5-XL模型预测标签不一致或与现有训练数据重复的例子。
- 通过过滤过程,从初始的521,899个生成例子中移除了54,216个例子,保留了467,683个例子用于最终的训练数据集。
EFL转换实验:
- 将清洗后的合成数据转换为EFL框架,将标签信息直接嵌入到假设中,形成二元决策问题。
模型训练实验:
- 使用清洗和转换后的合成数据集训练GTR-T5-XL模型。
- 配置模型输入维度为768,包含三个全连接层,使用GeLU激活函数和0.1的dropout率。
性能评估实验:
- 在原始SNLI数据集上评估GTR-T5-XL模型的性能,与人类标注的标签进行比较。
- 通过反馈循环不断调整模型参数,以提高模型对复杂和多样化前提-假设对的处理能力。
跨数据集验证实验:
- 除了在SNLI数据集上测试外,还将相同的方法应用于E-SNLI和MultiNLI数据集,验证方法的普适性和效果。
- 在E-SNLI上达到了94.01%的准确率,在MultiNLI上达到了92.57%的准确率,均超越了之前的最佳模型。
这些实验的结果表明,通过合成数据增强和EFL框架相结合的方法,可以在多个NLI基准测试中实现新的最先进性能,证明了该方法在提高NLI模型泛化能力和准确性方面的有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可能的研究方向,以下是可以进一步探索的几个点:
不同训练/少量样本数据集划分比例的实验:
- 测试不同的训练/少量样本(train/few-shot)数据集划分比例,以及在提示中包含不同数量的少量样本(few-shot)例子,以找到优化模型性能相对于输入大小的配置。
合成数据增强在其他NLI方法中的应用:
- 探索合成数据增强技术在EFL框架之外的其他NLI方法中的有效性,以了解其在NLI模型开发中的广泛适用性。
模型的计算效率提升:
- 针对当前方法在计算效率方面的限制,研究如何减少输入提示中的令牌数量,以降低生成假设所需的计算资源,提高大规模应用的效率。
上下文一致性的改善:
- 针对小型模型(如T5-3B)在处理长提示时遇到的上下文一致性问题,研究如何改善模型处理复杂输入的能力。
模型泛化能力的提高:
- 进一步研究如何提高模型的泛化能力,使其能够更有效地处理未见过的数据。
模型性能与数据集大小的关系:
- 研究模型性能与数据集大小之间的关系,以及如何平衡数据集的规模和质量以优化模型训练。
更复杂的推理模式和语言现象的处理:
- 探索模型在处理更复杂的推理模式和语言现象(如否定、量化和世界知识)时的表现,并寻找改进的方法。
跨领域和跨语言的NLI任务:
- 将UnitedSynT5方法应用于跨领域和跨语言的NLI任务,检验其在不同领域和语言中的适用性和效果。
模型的可解释性和透明度:
- 提高模型决策过程的可解释性,以便更好地理解模型是如何学习和推理的。
模型的伦理和社会影响:
- 研究NLI模型在实际应用中的伦理和社会影响,确保技术的负责任使用。
这些探索点可以帮助研究者们更深入地理解NLI任务的挑战,推动NLI模型性能的进一步提升,并确保技术发展与社会价值相协调。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出自然语言推理(NLI)任务在确定两个句子之间的逻辑关系方面的重要性,以及现有最先进模型(SOTA)在SNLI数据集上的局限性。
现有模型的进展:
- 论文回顾了NLI模型的发展历程,包括早期的基于LSTM的模型,引入注意力机制的模型,以及基于大型语言模型(LLMs)和迁移学习技术的模型。
提出的方法:
- 论文提出了UnitedSynT5,这是一种结合了合成数据增强和EFL框架的新方法。通过使用基于T5的生成器来创建额外的前提-假设对,并将其整合到训练数据中,以提高数据集的多样性和复杂性。
实验设计:
- 论文详细描述了合成数据的生成过程、数据清洗、EFL转换以及使用增强数据集训练GTR-T5-XL模型的过程。
实验结果:
- 通过在SNLI、E-SNLI和MultiNLI数据集上的实验,论文展示了UnitedSynT5方法能够实现新的SOTA性能,证明了合成数据增强在提高NLI模型准确性和泛化能力方面的潜力。
讨论与未来工作:
- 论文讨论了当前方法的局限性,包括计算效率和模型性能,并提出了未来可能的研究方向,如探索不同的数据集划分比例、测试合成数据增强在其他NLI方法中的有效性等。
总结来说,这篇论文通过提出UnitedSynT5方法,展示了合成数据增强和EFL框架结合如何推动NLI任务的性能界限,同时也指出了未来研究的方向,以期进一步改进NLI模型的性能和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

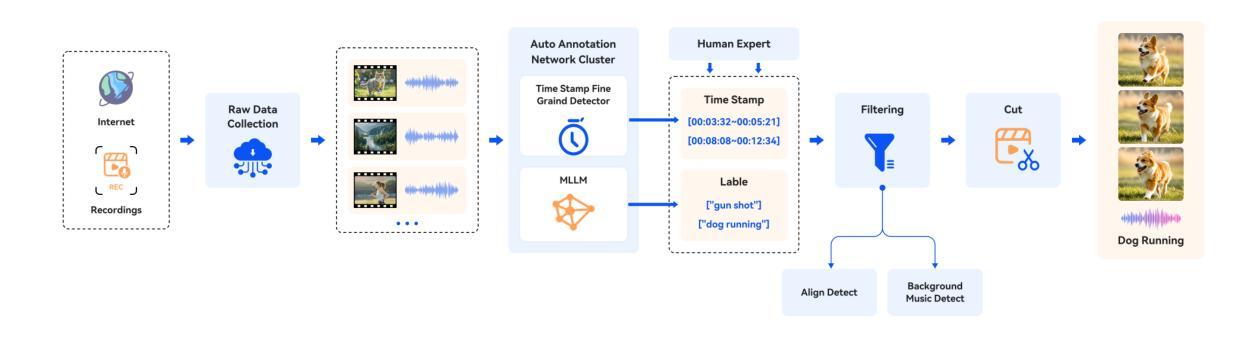
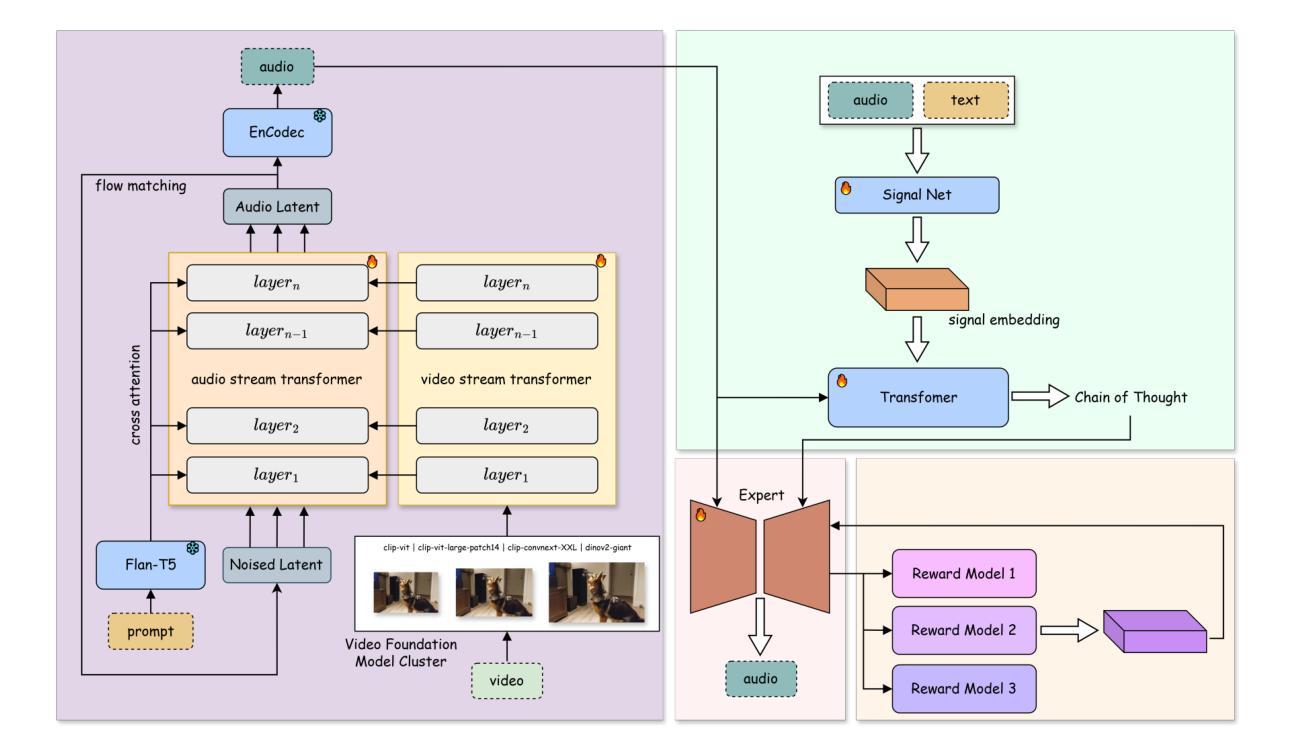
YingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls
Authors:Zihao Chen, Haomin Zhang, Xinhan Di, Haoyu Wang, Sizhe Shan, Junjie Zheng, Yunming Liang, Yihan Fan, Xinfa Zhu, Wenjie Tian, Yihua Wang, Chaofan Ding, Lei Xie
Generating sound effects for product-level videos, where only a small amount of labeled data is available for diverse scenes, requires the production of high-quality sounds in few-shot settings. To tackle the challenge of limited labeled data in real-world scenes, we introduce YingSound, a foundation model designed for video-guided sound generation that supports high-quality audio generation in few-shot settings. Specifically, YingSound consists of two major modules. The first module uses a conditional flow matching transformer to achieve effective semantic alignment in sound generation across audio and visual modalities. This module aims to build a learnable audio-visual aggregator (AVA) that integrates high-resolution visual features with corresponding audio features at multiple stages. The second module is developed with a proposed multi-modal visual-audio chain-of-thought (CoT) approach to generate finer sound effects in few-shot settings. Finally, an industry-standard video-to-audio (V2A) dataset that encompasses various real-world scenarios is presented. We show that YingSound effectively generates high-quality synchronized sounds across diverse conditional inputs through automated evaluations and human studies. Project Page: \url{https://giantailab.github.io/yingsound/}
在为产品级视频生成音效的过程中,仅在各种场景中获取少量标记数据,需要在少量样本的情况下生成高质量音效。为了应对现实场景中标记数据有限的问题,我们推出了YingSound,这是一款为视频引导的声音生成设计的基础模型,支持在少量样本的情况下生成高质量音频。具体来说,YingSound主要包括两个模块。第一个模块使用条件流匹配转换器,在音频和视觉模式之间实现有效的语义对齐音效生成。该模块旨在建立一个可学习的音频视觉聚合器(AVA),将高分辨率的视觉特征与多个阶段的相应音频特征进行集成。第二个模块采用提出的多模式视觉音频思维链(CoT)方法,以在少量样本的情况下生成更精细的音效。最后,我们展示了一个涵盖各种现实场景的行业标准视频到音频(V2A)数据集。通过自动化评估和人类研究,我们证明YingSound能够通过各种条件输入有效地生成高质量同步音效。项目页面:\url{https://giantailab.github.io/yingsound/}
论文及项目相关链接
PDF 16 pages, 4 figures
Summary
为产品级别视频生成声音效果,面临有限的标签数据挑战。我们引入YingSound模型,该模型专为视频引导的声音生成设计,支持在少量数据场景下生成高质量音频。YingSound包含两个主要模块,第一个模块使用条件流匹配转换器实现音频和视觉模态间声音生成的有效语义对齐。第二个模块采用提出的多模态视觉音频思维链方法,在少量数据场景下生成更精细的声音效果。此外,我们还展示了一个包含各种真实场景的行业标准视频到音频数据集,并通过自动化评估和人类研究证明YingSound能够有效生成高质量、跨不同条件输入的同步声音。
Key Takeaways
- YingSound模型专为视频引导的声音生成设计,适用于产品级别视频的声音效果生成。
- 该模型在有限的标签数据场景下仍能有效生成高质量音频。
- YingSound包含两个主要模块:第一个模块实现音频和视觉模态间声音生成的有效语义对齐;第二个模块在少量数据场景下生成更精细的声音效果。
- 提出了一种多模态视觉音频思维链方法,用于提高声音生成的精细度。
- YingSound模型在行业标准视频到音频数据集上进行了验证,表现优异。
- 通过自动化评估和人类研究证明YingSound模型生成的音频质量高且与视频同步。
- YingSound模型的应用前景广泛,可为电影、游戏、虚拟现实等多媒体产品提供高质量的声音效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为YingSound的系统,旨在解决以下问题:
视频引导的声音效果生成:在产品级视频中,尤其是在只有少量标记数据的多样化场景中,需要生成高质量的声效。YingSound旨在在少量样本设置下产生高质量的音频。
有限标记数据的挑战:在现实世界场景中,有限的标记数据是一个挑战。YingSound通过设计一个基础模型来应对这一问题,该模型支持视频引导的声音生成,并在少量样本设置下实现高质量音频生成。
音频和视觉模态间的语义对齐:通过使用条件流匹配变换器,YingSound建立了一个可学习的音频-视觉聚合器(AVA),在声音生成过程中实现音频和视觉模态间有效的语义对齐。
少量样本设置下的音频生成:提出了一种多模态视觉-音频链式思考(CoT)方法,以在少量样本设置下生成更精细的声音效果。
工业级视频到音频(V2A)数据集的创建:提供了一个涵盖各种真实世界场景的行业标准V2A数据集,以支持模型的训练和评估。
高质量同步声音的生成:通过自动化评估和人类研究,展示了YingSound在多样化条件输入下有效生成高质量同步声音的能力。
综上所述,YingSound通过结合多模态学习和少量样本学习技术,解决了在多样化和少量标记数据场景中生成高质量、同步声音效果的挑战。
Q: 有哪些相关研究?
A: 相关研究包括以下几个领域:
音频-视觉学习:
- 探索视听数据之间的语义联系,学习共享的视听关联。
- 研究视听声音定位和视听分割。
- 强调视听事件的时间对齐。
视频到音频(V2A)生成:
- 直接在大规模数据集上训练端到端模型。
- 在T2A模型的基础上构建,增强时间对齐和视频语义对齐。
- 采用扩散模型直接引导视觉特征生成Mel频谱图。
- 使用变换器架构自回归预测音频令牌。
特定的V2A模型和方法:
- Diff-Foley:采用对比音频-视觉预训练(CAVP)学习更对齐的特征,然后训练一个LDM。
- FoleyCrafter:利用预训练的文本到音频模型确保高质量音频生成。
- V2A-Mapper:引入模块以翻译视觉输入,实现高保真声音生成。
- Frieren:使用修正的流匹配合成高质量、时间对齐的音频。
以下是一些具体参考的文献:
- [49-56] 探索了音频和视觉数据之间的关系,包括语义连接、声音定位和时间对齐。
- [57-68] 描述了当前最先进的V2A模型,可以划分为直接在大规模数据集上训练的端到端模型和基于T2A模型的两阶段方法。
- [69-76] 提供了利用T2A模型能力的当前研究,通过时间或语义对齐实现高质量的V2A。
- [71] 和 [72] 利用预训练的文本到音频模型确保高质量音频生成,并采用时间和能量条件来指导声音效果生成。
- [73] 提出了关注感兴趣区域的掩码注意力模块(MAM)和在响度和时间上与视频对齐的声音合成的时间响度模块(TLM)。
这些相关研究构成了YingSound系统设计和发展的基础,并帮助解决视频引导的声音效果生成中的挑战。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为YingSound的系统,通过以下几个关键方法来解决视频引导的声音效果生成问题:
1. 学习音频-视觉聚合器(AVA)
YingSound设计了一个可学习的音频-视觉聚合器(AVA),这是一个动态模块,能够在流匹配变换器内部的多个阶段整合高分辨率的视觉特征与相应的音频特征,以实现音频和视觉模态间的有效语义对齐。
2. 多模态视觉-音频链式思考(CoT)方法
提出了一种多模态视觉-音频链式思考(CoT)方法,用于在少量样本设置下生成更精细的声音效果。这种方法通过专家模块进行多模态推理,以生成高质量、上下文适宜的音频。
3. 条件流匹配与变换器
YingSound基于流匹配和可扩展的扩散变换器(DiT)架构进行音频生成,该架构在图像和音频生成中已被证明是高质量和高效的。模型可以基于文本提示和视频条件进行训练。
4. 多阶段训练策略
YingSound采用了一种多阶段训练策略,从仅使用文本-音频(T2A)数据开始训练,然后加入视频条件模块,并在训练中保留文本和音频数据。最后,模型能够仅根据视频生成音频,以适应不同的训练阶段。
5. 行业标准视频到音频(V2A)数据集
开发了一个包含各种真实场景的行业标准视频到音频(V2A)数据集,包括电影、游戏和广告等,以支持模型的训练和评估。
6. 自动化评估和人类研究
通过自动化评估和人类研究,展示了YingSound在多样化条件输入下有效生成高质量同步声音的能力。
综合上述方法,YingSound能够有效地在少量样本设置下生成与视频同步的高质量音频,解决了在现实世界场景中有限标记数据的挑战,并推动了视频引导声音效果生成技术的发展。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
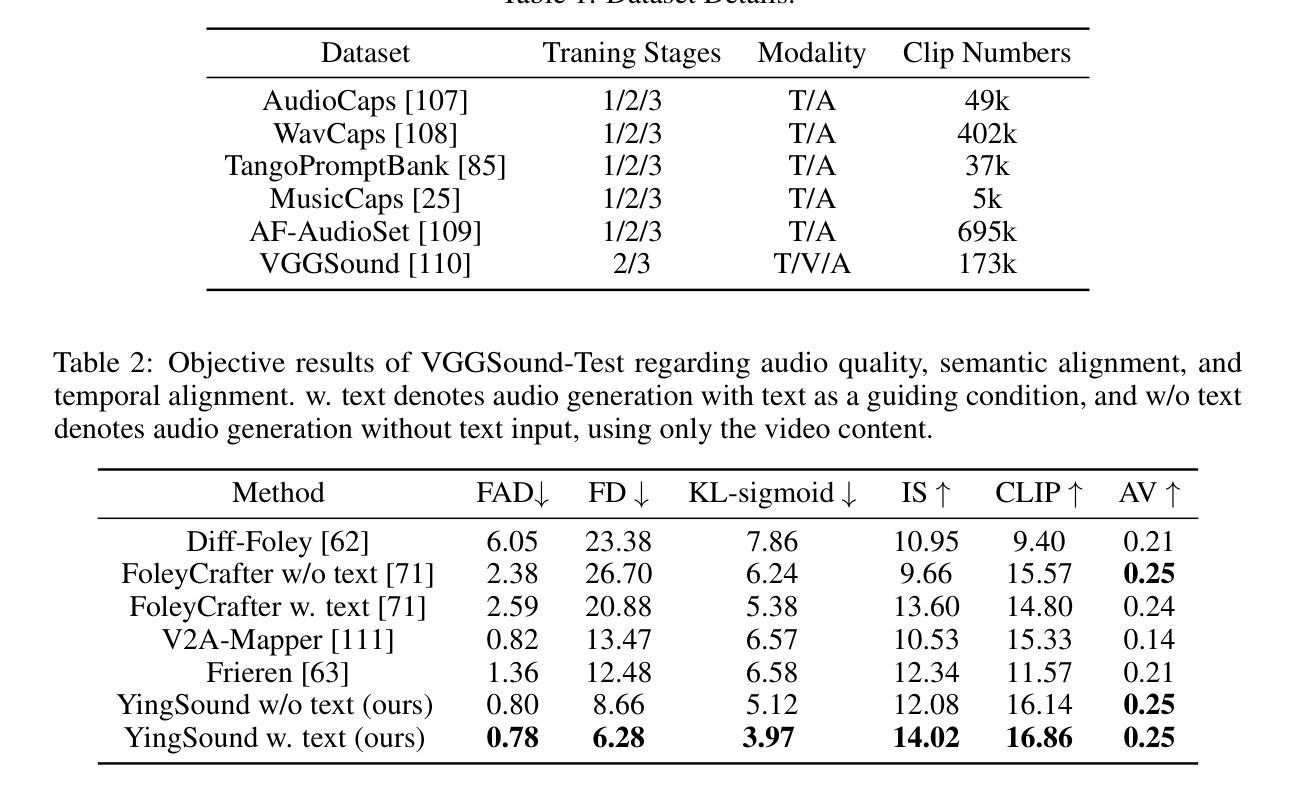
1. 实验设置
- 数据集:使用了约1.2M文本-音频对,涵盖了AudioCaps、WavCaps、TangoPromptBank、MusicCaps和AF-AudioSet等多个数据集,以及VGGSound作为视频相关输入。
- 实现细节:在不同的训练阶段使用了不同的数据集和训练步骤,详细说明了训练过程中的批处理大小、使用的GPU数量、优化器以及学习率等参数。
2. 视频到音频实验
- 音频保真度:通过Fréchet Audio Distance (FAD)、Fréchet Distance (FD) 和 KL-sigmoid 等指标评估生成音频的质量。
- 语义对齐:使用CLIP分数评估生成音频与视频之间的语义对齐程度。
- 时间对齐:使用AV分数评估输入音频和生成视频之间的时间对齐。
3. 定量比较
- VGGSound-Test数据集:包含15,446个YouTube视频,覆盖多种类型,用于评估模型在多个客观指标上的性能。
4. 与其他方法的比较
- 将YingSound与Diff-Foley、FoleyCrafter、V2A-Mapper和Frieren等最新方法进行了比较。
5. 应用案例
- 游戏角色动作的声音效果:展示了YingSound在为游戏角色动作生成声音效果方面的应用。
- 动画视频的声音效果:展示了YingSound在为动画视频添加动态和上下文相关音频方面的应用。
- 短视频的声音效果:展示了YingSound在为短视频创作者生成适应不同节奏的声音效果方面的应用。
这些实验不仅验证了YingSound模型在生成高质量、同步声音方面的能力,而且还展示了其在多种实际应用场景中的潜力和效果。通过这些实验,论文全面评估了YingSound的性能,并与现有技术进行了比较。
Q: 有什么可以进一步探索的点?
A: 论文提出了YingSound系统,虽然已经取得了一定的成果,但仍有一些可以进一步探索的点:
1. 模型泛化能力
进一步探索YingSound模型在不同类型的视频内容(如不同类型的电影、游戏和广告)上的泛化能力,特别是在更多样化和复杂场景中的应用。
2. 模型优化
研究不同的网络架构和训练策略,以提高YingSound模型的性能,尤其是在少量样本学习的情况下。
3. 多模态融合技术
深入研究和优化音频-视觉聚合器(AVA)的多模态融合技术,以更好地实现音频和视觉模态间的语义对齐。
4. 情感适应性音频生成
探索情感适应性音频生成,使音频效果能够根据视频内容的情感色彩进行适配。
5. 交互式应用
开发交互式应用,允许用户根据需要调整生成的声音效果,提高用户体验。
6. 实时性能
研究如何优化YingSound模型以实现实时音频生成,这对于游戏和虚拟现实等应用尤为重要。
7. 声音效果的多样性和自然性
进一步增强生成声音的多样性和自然性,使其更加贴近真实世界的声音效果。
8. 声音质量评估
开发更全面的声音质量评估体系,包括客观和主观评价指标,以更准确地衡量生成音频的质量。
9. 多语言和跨文化研究
探索YingSound在处理多语言和跨文化内容时的表现,以及如何优化模型以适应不同语言和文化背景下的声音效果生成。
10. 集成更先进的技术
考虑将最新的人工智能技术,如强化学习或元学习,集成到YingSound系统中,以提高其适应性和灵活性。
这些探索点可以帮助YingSound系统在视频引导的声音效果生成领域取得更多的技术突破,并扩展其在工业界和学术界的影响力。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:
- 论文针对的主要问题是在少量标记数据的多样化场景中为视频生成高质量的同步声音效果。
YingSound系统介绍:
- 论文介绍了一个名为YingSound的系统,这是一个基于视频引导的声音效果生成方法,能够在少量样本设置下产生高质量的音频。
系统组成:
- YingSound由两大部分构成:一个是基于条件流匹配变换器的模块,用于音频和视觉模态间语义对齐;另一个是多模态视觉-音频链式思考(CoT)模块,用于在少量样本设置下生成精细的声音效果。
数据集和训练策略:
- 论文提出了一个行业标准的V2A数据集,并描述了如何通过多阶段训练策略来训练YingSound模型,包括从文本到音频(T2A)数据的训练,逐渐过渡到视频到音频(V2A)数据的训练。
实验和评估:
- 论文通过一系列实验评估了YingSound模型的性能,包括音频保真度、语义对齐和时间对齐,并与现有技术进行了比较。
应用案例:
- 论文展示了YingSound在游戏角色动作、动画视频和短视频等场景中的应用案例,证明了其在实际应用中的有效性和潜力。
未来工作:
- 论文提出了未来可能的研究方向,包括模型泛化能力的提升、多模态融合技术的优化、情感适应性音频生成等。
总体而言,这篇论文提出了一个创新的视频引导的声音效果生成系统YingSound,通过结合多模态学习和少量样本学习技术,有效地解决了在多样化和少量标记数据场景中生成高质量、同步声音效果的挑战,并在多个应用场景中展示了其潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

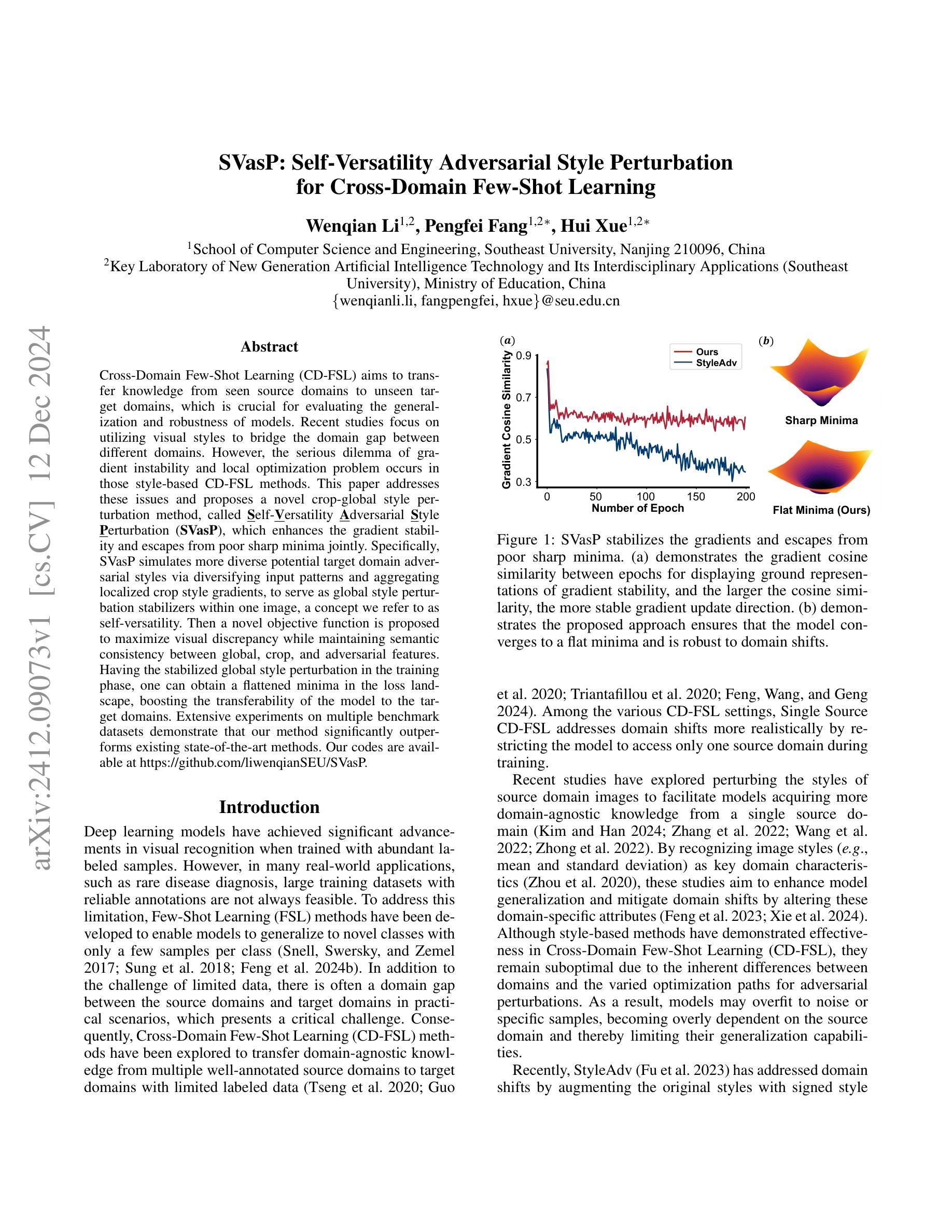
SVasP: Self-Versatility Adversarial Style Perturbation for Cross-Domain Few-Shot Learning
Authors:Wenqian Li, Pengfei Fang, Hui Xue
Cross-Domain Few-Shot Learning (CD-FSL) aims to transfer knowledge from seen source domains to unseen target domains, which is crucial for evaluating the generalization and robustness of models. Recent studies focus on utilizing visual styles to bridge the domain gap between different domains. However, the serious dilemma of gradient instability and local optimization problem occurs in those style-based CD-FSL methods. This paper addresses these issues and proposes a novel crop-global style perturbation method, called \underline{\textbf{S}}elf-\underline{\textbf{V}}ersatility \underline{\textbf{A}}dversarial \underline{\textbf{S}}tyle \underline{\textbf{P}}erturbation (\textbf{SVasP}), which enhances the gradient stability and escapes from poor sharp minima jointly. Specifically, SVasP simulates more diverse potential target domain adversarial styles via diversifying input patterns and aggregating localized crop style gradients, to serve as global style perturbation stabilizers within one image, a concept we refer to as self-versatility. Then a novel objective function is proposed to maximize visual discrepancy while maintaining semantic consistency between global, crop, and adversarial features. Having the stabilized global style perturbation in the training phase, one can obtain a flattened minima in the loss landscape, boosting the transferability of the model to the target domains. Extensive experiments on multiple benchmark datasets demonstrate that our method significantly outperforms existing state-of-the-art methods. Our codes are available at https://github.com/liwenqianSEU/SVasP.
跨域小样本学习(CD-FSL)旨在将从已见源域的知识转移到未见目标域,这对于评估模型的泛化和鲁棒性至关重要。最近的研究专注于利用视觉风格来弥合不同领域之间的领域差距。然而,基于风格的CD-FSL方法出现了严重的梯度不稳定和局部优化问题。本文针对这些问题,提出了一种新的全局风格扰动方法,称为自适应性对抗性风格扰动(SVasP),该方法增强了梯度稳定性并共同避免了不良的尖锐最小值。具体来说,SVasP通过多样化输入模式和聚合局部裁剪风格梯度来模拟更多样化的潜在目标域对抗风格,作为一张图像内的全局风格扰动稳定器,我们称之为自我适应性。然后提出了一种新的目标函数,以在保持全局、裁剪和对抗特征之间语义一致性的同时,最大化视觉差异。在训练阶段具有稳定的全局风格扰动,可以在损失景观中获得平坦的最小值,从而提高模型对目标域的迁移能力。在多个基准数据集上的大量实验表明,我们的方法显著优于现有的最先进的方法。我们的代码位于https://github.com/liwenqianSEU/SVasP。
论文及项目相关链接
Summary
本文介绍了跨域小样本学习(CD-FSL)中的知识迁移问题,重点讨论了如何从可见源域迁移到不可见目标域的问题。文章提出一种新型技术,名为Self-Versatility Adversarial Style Perturbation(SVasP),解决了现有风格基础CD-FSL方法中梯度不稳定和局部优化问题。SVasP技术通过在输入模式中模拟更多的潜在目标域对抗风格来提高梯度稳定性并摆脱糟糕的尖锐最小。它通过合并局部作物风格梯度在一张图像内构建全局风格扰动稳定器来实现自我兼容性。此外,提出了一种新的目标函数,旨在最大化全局、局部和对立特征之间的视觉差异同时保持语义一致性。在多个基准数据集上的实验表明,该方法显著优于现有技术。
Key Takeaways
- Cross-Domain Few-Shot Learning (CD-FSL) 旨在从可见源域迁移知识到不可见目标域,评估模型的泛化和鲁棒性。
- 当前研究主要通过利用视觉风格来缩小不同域之间的差距。
- 现有风格基础的CD-FSL方法面临梯度不稳定和局部优化问题。
- SVasP方法通过模拟更丰富的潜在目标域对抗风格提高梯度稳定性并解决局部优化问题。
- SVasP在一个图像内通过构建全局风格扰动稳定器实现自我兼容性。
- 提出了一种新的目标函数,旨在最大化视觉差异同时保持语义一致性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是跨域少样本学习(Cross-Domain Few-Shot Learning, CD-FSL)中的关键问题,即如何有效地将从一个或多个有标注的源域学到的知识迁移到未见过的目标域上。具体来说,论文关注以下几个问题:
域间差异(Domain Gap):在实际应用中,源域和目标域之间往往存在显著差异,这给模型的泛化能力带来了挑战。
模型鲁棒性(Model Robustness):现有基于风格迁移的方法在处理对抗性扰动时存在梯度不稳定和陷入局部最优的问题,这限制了模型对目标域的适应能力。
风格迁移的局限性(Limitations of Style-based Methods):尽管基于风格的方法在CD-FSL中显示出一定的效果,但由于领域间的固有差异和对抗性扰动的不同优化路径,这些方法仍然不是最优的。
为了解决这些问题,论文提出了一种名为自适应多样性对抗性风格扰动(Self-Versatility Adversarial Style Perturbation, SVasP)的新框架。该框架通过增强输入模式的多样性和聚合局部裁剪风格梯度来模拟更多潜在的目标域对抗性风格,从而增强模型梯度的稳定性,并从较差的尖锐最小值中逃逸出来,以提高模型对目标域的迁移能力。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要集中在以下几个领域:
跨域少样本学习(Cross-Domain Few-Shot Learning, CD-FSL):
- 该领域的研究旨在训练一个模型,使其能够从有标注的源域泛化到未标注的目标域。关键的基准包括BSCD-FSL、mini-CUB和Meta-Dataset等。
输入多样性增强(Input Diversity for Domain Shift):
- 许多方法通过增强输入多样性来解决域偏移问题。例如,在域泛化中,MiRe混合不同域的图像,CreTok结合令牌进行创造性生成。在目标检测中,DoubleAUG交换RGB通道,RECODE将视觉特征分解为主体、客体和空间特征。
基于梯度的优化(Gradient-based Optimization):
- 一系列基于梯度的优化方法被提出以增强模型的鲁棒性和泛化能力。例如,GradNorm和GAM探索梯度归一化技术,CGDM最小化源和目标样本之间的梯度差异,Fishr通过梯度协方差对齐域级损失景观,PCGrad解决多任务学习中的冲突梯度问题。
风格迁移(Style Transfer):
- 一些研究通过识别图像风格(例如均值和标准差)作为关键的域特征,并通过改变这些域特定属性来增强模型泛化和减轻域偏移。
对抗性训练(Adversarial Training):
- 一些研究通过对抗性训练来增强模型对输入扰动的鲁棒性,例如StyleAdv通过增加对抗性风格扰动来解决域偏移问题。
元学习(Meta-Learning):
- 元学习方法,如Prototypical Networks和Relation Networks,被用于Few-Shot Learning以实现对新类别的快速学习。
模型泛化和鲁棒性(Model Generalization and Robustness):
- 一些研究关注于如何提高模型的泛化能力,使其在面对不同的数据分布时保持稳定性和鲁棒性。
这些相关研究为解决跨域少样本学习问题提供了不同的视角和方法,而本文提出的SVasP框架则是在这些研究的基础上,进一步探索如何通过增强风格多样性和梯度稳定性来提高模型的跨域泛化能力。
Q: 论文如何解决这个问题?
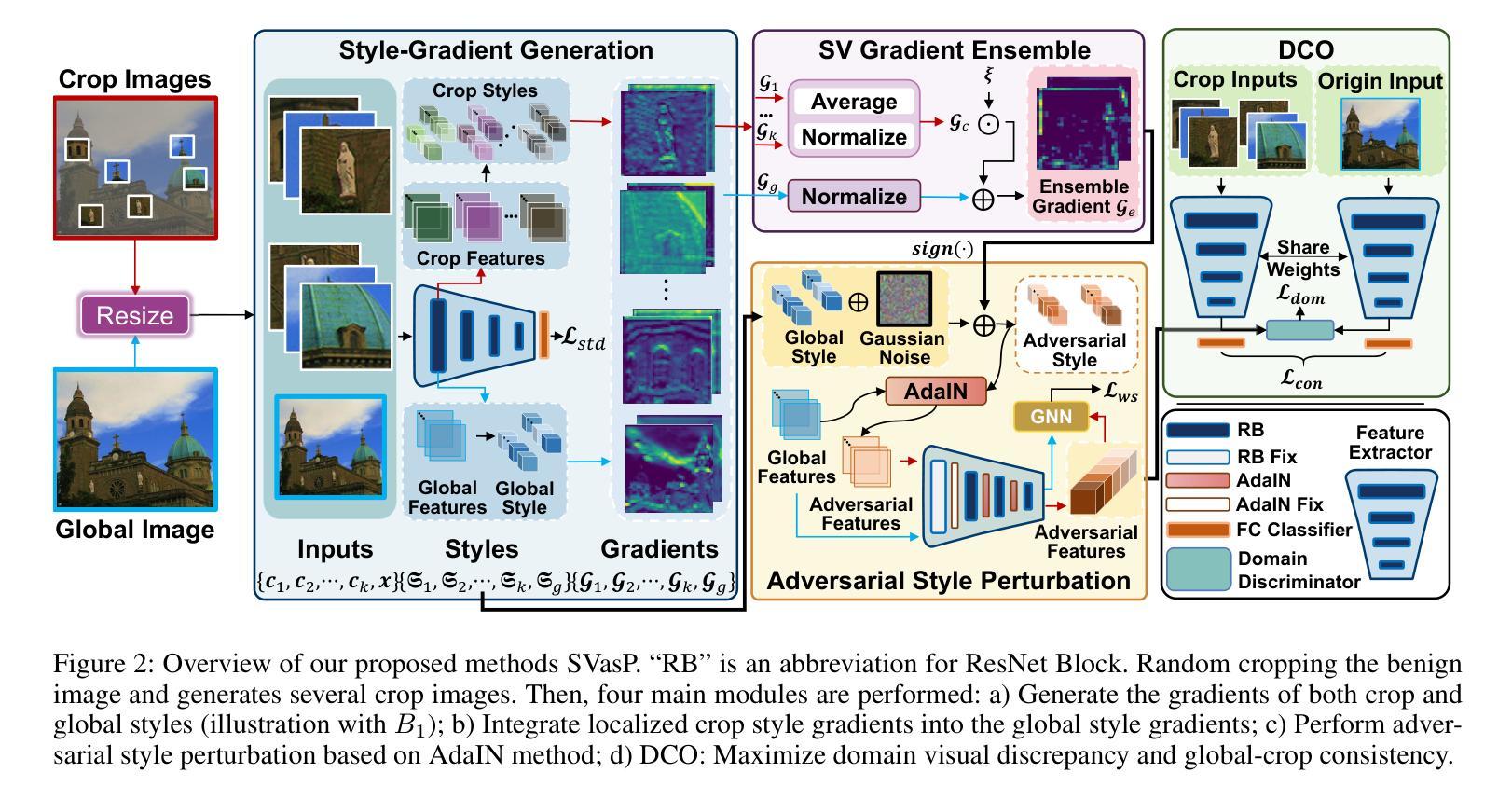
A: 论文通过提出一个名为Self-Versatility Adversarial Style Perturbation (SVasP)的新框架来解决跨域少样本学习中的问题。具体来说,SVasP框架通过以下几个关键步骤解决这个问题:
1. 自适应多样性对抗性风格扰动(Self-Versatility Adversarial Style Perturbation, SVasP)
- 风格扰动:SVasP通过模拟更多潜在的目标域对抗性风格来增强模型的泛化能力。这是通过多样化输入模式和聚合局部裁剪风格梯度来实现的,从而在单个图像内提供全局风格扰动稳定器,称为自适应多样性。
2. 风格梯度生成(Style-Gradient Generation)
- 全局与局部风格:SVasP模拟全局和局部(裁剪)特征的风格作为高斯分布,并计算这些风格的特征(均值和标准差)。
- 迭代方法:对于每个输入图像,SVasP随机裁剪多个局部图像,并在这些局部图像上迭代生成和整合风格梯度,然后将这些梯度应用于目标图像的全局风格。
3. 自适应多样性梯度集成(Self-Versatility Gradient Ensemble, SV)
- 梯度集成:SVasP通过集成局部裁剪风格梯度到全局风格梯度中,增强了模型梯度的稳定性。通过平均和归一化裁剪风格梯度,然后引入衰减因子来获得集成风格梯度。
4. 对抗性风格扰动(Adversarial Style Perturbation)
- 风格迁移:使用AdaIN方法执行风格迁移,以增强模型对未见风格的泛化能力。
- 随机初始化和对抗性风格:通过添加高斯噪声初始化全局风格,然后结合集成梯度生成对抗性风格。
5. 差异与一致性优化(Discrepancy & Consistency Optimization, DCO)
- 视觉差异最大化:最大化源域和目标域之间的视觉差异,同时保持语义一致性。
- 损失函数:设计了一个新的目标函数DCO,以最大化视觉差异和全局-局部语义一致性。
6. 实验验证
- 基准数据集:在多个基准数据集上进行广泛的实验,验证了所提出方法的有效性。
- 性能对比:与现有的最先进方法相比,SVasP在多个目标域上显著提高了模型的泛化能力。
通过这些方法,SVasP能够有效地稳定模型梯度,逃离不良的局部最小值,并提高模型对目标域的泛化能力。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列实验来验证所提出的Self-Versatility Adversarial Style Perturbation (SVasP)框架的有效性。以下是实验的具体内容:
数据集
- miniImageNet:用作源域数据集,包含64类。
- 目标域数据集:包括ChestX、ISIC、EuroSAT、CropDisease、CUB、Cars、Places和Plantae等八个数据集。
实验设置
- Single Source CD-FSL:在训练阶段仅使用源域数据集,目标域数据集在训练时不可用。
- 模型架构:使用了ResNet-10和ViT-small作为特征提取器,并结合GNN和ProtoNet作为N-way K-shot分类器。
- 训练策略:网络通过元训练(meta-training)进行优化,并在1000个episode上评估模型的平均分类准确率。
性能比较
- 与现有最先进方法的比较:与包括GNN、FWT、ATA、SET-RCL、StyleAdv、Fine-tune、BSR、NSAE和RDC等九种代表性的单源CD-FSL方法进行了比较。
- 准确率报告:在5-way 1-shot和5-way 5-shot任务中,报告了SVasP与这些方法在八个目标数据集上的平均准确率,并提供了95%的置信区间。
消融研究
- 不同组件的影响:通过移除SVasP的不同组件(如SV梯度集成模块、域差异损失Ldom、全局-局部一致性损失Lcon等),评估这些组件对模型性能的影响。
- 不同数量的裁剪(k值):研究了不同数量的裁剪图像对模型性能的影响。
- 不同的衰减因子ξ和λ:研究了这些超参数对模型性能的影响。
- κ1和κ2的选择方法:探讨了κ1和κ2不同取值对模型性能的影响。
- 不同尺度参数s:研究了裁剪图像的尺度参数对模型性能的影响。
可视化结果
- 损失景观可视化:通过可视化损失景观来验证SVasP模块的有效性,比较了有无SV梯度集成模块的模型。
- Grad-CAM可视化:使用Grad-CAM方法可视化了StyleAdv和SVasP模型在BSCD-FSL基准测试上的表现,以直观比较两种模型的注意力分布。
这些实验结果不仅验证了SVasP框架的有效性,还提供了对不同组件和参数设置影响的深入理解,从而证明了该方法在提高跨域少样本学习任务中的模型泛化能力方面的潜力。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的SVasP框架在跨域少样本学习方面取得了显著的成果,但仍有一些方向可以进一步探索和改进:
1. 更深层次的风格表示和扰动方法
- 探索更复杂或不同类型的风格表示方法,例如基于深度学习的风格迁移技术,可能会进一步提高模型对目标域风格的适应能力。
2. 多源域的支持
- 目前的研究集中在单源域的情况下,可以考虑多源域数据对模型泛化能力的影响,以及如何有效地整合来自多个源域的知识。
3. 不同网络架构的适应性
- 论文中使用了ResNet和ViT作为特征提取器,可以探索SVasP框架在其他类型的网络架构,如卷积网络、递归网络或Transformer网络中的性能和适应性。
4. 更广泛的数据集和任务
- 在更多种类的数据集和不同的任务(如语义分割、目标检测等)上验证SVasP框架的有效性,以测试其泛化能力和实用性。
5. 计算效率和实际应用
- 考虑模型的计算效率和实际部署问题,优化算法以减少计算资源消耗,使其更适合在资源受限的环境中使用。
6. 对抗性攻击和防御机制
- 研究SVasP框架在面对更复杂的对抗性攻击时的鲁棒性,并探索相应的防御机制。
7. 理论分析和解释性
- 对SVasP框架的理论分析,包括其在不同情况下的收敛性和泛化误差的界限,以及模型决策过程的可解释性。
8. 跨域学习中的领域适应性
- 研究如何动态调整领域适应策略,以便模型能够根据目标域的特性灵活调整其学习策略。
9. 长尾分布和类别不平衡问题
- 在目标域中可能存在类别不平衡问题,研究SVasP在处理长尾分布数据时的表现和相应的优化策略。
10. 实时跨域学习
- 考虑实时或在线学习场景,研究如何快速适应新的目标域,特别是在数据流不断变化的情况下。
这些方向不仅可以推动跨域少样本学习领域的研究进展,还可能为实际应用中的问题提供新的解决方案。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:论文针对的是跨域少样本学习(CD-FSL)问题,即如何在只有源域数据的情况下,使模型能够泛化到完全未见过的 target 域。
现有问题:作者指出现有的基于风格迁移的 CD-FSL 方法存在梯度不稳定和容易陷入局部最优的问题,这限制了模型的泛化能力。
方法论:论文提出了一个名为 Self-Versatility Adversarial Style Perturbation (SVasP) 的新框架,通过模拟更多的潜在目标域对抗性风格,增强模型梯度稳定性,并避免陷入不良的局部最小值。
核心思想:
- 自适应多样性:通过随机裁剪和调整输入图像,生成多样的局部风格梯度,并将其聚合为全局风格扰动。
- 对抗性风格扰动:利用 AdaIN 方法进行风格迁移,以增强模型对未见风格的泛化能力。
- 差异与一致性优化(DCO):设计了一个新的目标函数,旨在最大化源域和目标域之间的视觉差异,同时保持全局和局部特征之间的语义一致性。
实验验证:在多个基准数据集上进行广泛的实验,验证了 SVasP 框架的有效性,并与现有的最先进方法进行了比较,结果表明 SVasP 在多个目标域上显著提高了模型的泛化能力。
消融研究:通过一系列的消融实验,分析了不同组件和超参数对模型性能的影响,包括裁剪数量、衰减因子、κ1 和 κ2 的选择方法以及尺度参数等。
可视化结果:通过损失景观和 Grad-CAM 可视化结果,进一步展示了 SVasP 框架的有效性。
总结来说,这篇论文通过提出一个新颖的框架 SVasP,有效地解决了跨域少样本学习中的梯度不稳定和局部最优问题,并在多个数据集上验证了其优越的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Fully Open Source Moxin-7B Technical Report
Authors:Pu Zhao, Xuan Shen, Zhenglun Kong, Yixin Shen, Sung-En Chang, Timothy Rupprecht, Lei Lu, Enfu Nan, Changdi Yang, Yumei He, Xingchen Xu, Yu Huang, Wei Wang, Yue Chen, Yong He, Yanzhi Wang
Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be “open-source,” which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of “open science” through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.
近期,大型语言模型(LLM)经历了重大变革,其受欢迎程度和能力的迅速上升标志着这一变革。引领这一变革的是专有大型语言模型,如GPT-4和GPT-o1,它们由于出色的性能和多功能性,在人工智能领域引起了广泛关注。同时,开源大型语言模型,如LLaMA和Mistral,由于模型易于跨不同应用程序进行定制和部署,为LLM日益普及做出了巨大贡献。尽管开源大型语言模型为创新和研发提供了前所未有的机会,但大型语言模型的商业化引发了关于透明度、可重复性和安全的担忧。许多开源大型语言模型未能满足基本的透明度要求,隐瞒了关键组件,如训练代码和数据,有些则打着“开源”的旗号使用限制性许可,这可能阻碍大型语言模型的进一步创新。为了缓解这一问题,我们推出了Moxin 7B,这是一款完全遵循模型公开框架(MOF)的开源大型语言模型。MOF是一个评级分类系统,根据模型的完整性和开放性来评估人工智能模型,遵循公开科学、开源、开放数据和开放访问的原则。我们的模型通过全面发布预训练代码和配置、训练和微调数据集以及中间和最终检查点,达到了MOF分类体系中的最高级别“公开科学”。实验表明,与流行的大型语言模型相比,我们的模型在零样本评估中表现出卓越的性能,并在小样本评估中表现出竞争力。
论文及项目相关链接
Summary
大型语言模型(LLMs)正经历显著转变,其普及和能力均迅速增强。GPT-4和GPT-o1等专有LLMs引起了AI社区的广泛关注,同时LLaMA和Mistral等开源LLMs通过易于定制和部署的特点推动了LLMs的普及。然而,商业化的LLMs引发了对透明度、可重复性和安全的担忧。有些开源LLMs不满足基本的透明度要求,并隐藏关键组件如训练代码和数据。为解决这一问题,我们推出了遵循模型开放性框架(MOF)的Moxin 7B模型,该框架根据模型的完整性和开放性进行评级,并遵守公开科学、开放源代码、开放数据和开放访问的原则。Moxin 7B通过全面发布预训练代码和配置、训练和微调数据集以及中间和最终检查点,达到了MOF分类中的最高级别“公开科学”。实验表明,该模型在零样本评估中表现出卓越性能,与流行的7B模型相比具有优势,并在小样例评估中表现出竞争力。
Key Takeaways
- 大型语言模型(LLMs)正经历显著转变,其普及和能力迅速增强。
- 专有LLMs如GPT-4和GPT-o1受到广泛关注,同时开源LLMs如LLaMA和Mistral也有重要贡献。
- 商业化的LLMs引发透明度、可重复性和安全方面的担忧。
- 有些开源LLMs透明度不足,隐藏关键组件如训练代码和数据。
- 为解决上述问题,推出了Moxin 7B模型,遵循模型开放性框架(MOF)。
- Moxin 7B模型在零样本评估中表现出卓越性能,与主流模型相比具有优势。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是大型语言模型(LLMs)的开源性问题。尽管开源LLMs因其易于定制和部署而在AI社区中越来越受欢迎,但许多模型生产者限制了对其训练、微调和评估过程的可见性和访问,包括训练代码和数据等关键组件。有些甚至在使用限制性许可证的同时声称自己是“开源”的,这种做法为更广泛的AI研究社区研究、复制和创新先进LLMs创造了障碍,并且阻碍了企业充分利用开源模型进行创新性工业应用。因此,论文提出了一个完全开源的LLM——Moxin 7B,以应对这些挑战,并推动AI研究的民主化和开放创新。
Q: 有哪些相关研究?
A: 论文中提到了多个相关研究,以下是一些主要的相关研究和模型:
GPT-4 [1]:由OpenAI开发的一个大型语言模型,因其卓越的性能和多功能性而受到AI社区的广泛关注。
LLaMA [4]:一个开源的、可访问的、高能力的LLM,允许研究人员和实践者轻松获取、定制和部署LLM。
Falcon [5]:由NIST开发的一个后量子密码学项目,涉及大型语言模型。
Mistral [6]:一个7B参数的模型,展示了在各种评估基准上超过更大模型的性能。
Jamba [12], [13]:一个混合Transformer-MAMBA架构的语言模型,旨在优化性能。
XLNet [17]:使用SentencePiece作为其tokenizer的模型,展示了对不同于罗马语言的语言的处理能力。
Mixtral [23]:在模型中应用了Mixture of Experts (MoE)训练策略,取得了显著的成功。
Qwen [10], GLM-130B [64], Nemotron-4 [65]:这些研究尝试在预训练阶段加入指令性或高质量的数据,以增强模型在特定能力上的表现。
C4 dataset, The Pile [32]:早期的大规模数据集,用于支持大型语言模型的训练。
RefinedWeb [25], Dolma [43], FineWeb [44], RedPajama-v2 [45]:近年来引入的更大规模的数据集。
这些研究和模型展示了LLMs领域的发展,特别是在模型架构、tokenizer技术、训练策略和数据集构建方面的进步。论文中提出的Moxin 7B模型正是基于这些相关研究的基础上,进一步推动了LLMs的开源性和透明度。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决开源大型语言模型(LLMs)的透明度和可访问性问题:
引入Moxin 7B模型:提出了一个完全开源的LLM,Moxin 7B,该模型遵循Model Openness Framework(MOF)进行开发,MOF是一个评估AI模型基于其完整性和开放性的排名分类系统。
发布预训练代码和配置:Moxin 7B模型发布了其预训练代码和配置,使得研究人员能够复现模型的训练过程。
公开训练和微调数据集:提供了模型训练和微调使用的数据集,以确保模型的可复现性和透明度。
发布中间和最终检查点:提供了模型训练过程中的中间和最终检查点(checkpoints),进一步增强了模型的可访问性和透明度。
遵循开放科学原则:Moxin 7B模型实现了MOF的最高分类级别“开放科学”,通过全面发布预训练代码、配置、训练和微调数据集以及中间和最终检查点,遵循开放科学、开源、开放数据和开放获取的原则。
性能验证:通过实验表明,Moxin 7B模型在零样本(zero-shot)评估中相较于流行的7B模型展现出优越性能,在少样本(few-shot)评估中也具有竞争力。
建立新的研究标准:鼓励更多的工作建立可复现研究的新标准,促进一个更加包容和经济活跃的AI生态系统。
通过这些步骤,论文旨在推动LLMs研究的透明度和开放性,促进更广泛的研究社区参与和创新,并支持负责任的AI实践。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估Moxin 7B模型的性能:
零样本评估(Zero-Shot Evaluation):
- 对比了Moxin 7B模型与其他流行的7B模型在多个基准测试上的性能,包括AI2 Reasoning Challenge (ARC)、HellaSwag、MMLU、Winogrande和PIQA等任务。
- 展示了Moxin 7B-finetuned(经过微调的模型)相较于Moxin 7B-original(基础模型)在这些任务上的性能提升。
少样本评估(Few-Shot Evaluation):
- 同样对比了Moxin 7B模型与其他模型在Few-Shot设置下的性能,任务包括AI2 Reasoning Challenge、HellaSwag、MMLU和Winogrande等。
- 评估了Moxin 7B-original和Moxin 7B-finetuned在这些任务上的性能,并与其他SOTA(State-of-the-Art)基线进行比较。
对齐评估(Alignment Evaluation):
- 使用MTBench数据集评估了Moxin 7B-chat模型与其他聊天模型的对齐性能。
- MTBench是一个两轮对话数据集,包含80个问题,覆盖八个维度(推理、角色扮演、数学、编程、写作、人文、STEM和信息提取)。
这些实验旨在全面评估Moxin 7B模型在不同任务和设置下的性能,并与其他领先的语言模型进行公平比较。通过这些实验,论文证明了Moxin 7B模型在零样本和少样本评估中的优越性能,以及在对齐评估中的竞争力。
Q: 有什么可以进一步探索的点?
A: 论文提出了Moxin 7B这一完全开源的大型语言模型,并对其进行了评估。以下是一些可以进一步探索的点:
模型架构优化:
- 研究不同的模型架构对性能的影响,例如探索是否可以通过增加模型层数或改变注意力机制来进一步提升模型性能。
训练数据集的多样性和质量:
- 扩展和多样化训练数据集,以覆盖更多的领域和语言,提高模型的泛化能力。
- 进一步清洗和筛选数据集,以减少潜在的偏见和不当内容。
多模态能力:
- 探索将Moxin 7B扩展到多模态任务,例如结合视觉和语言信息进行图像描述或视频理解。
跨语言和跨文化能力:
- 研究模型在不同语言和文化背景下的表现,并针对特定语言或文化进行优化。
安全性和伦理考量:
- 进一步研究模型可能产生的伦理问题,例如生成有害内容或偏见,并开发相应的缓解策略。
长文本处理能力:
- 尽管Moxin 7B已经采用了一些技术来处理长文本,但进一步优化这些技术,以提高模型在处理更长文本时的效率和准确性。
模型压缩和优化:
- 研究模型压缩技术,以减少模型大小并提高推理速度,使其更适合在资源受限的环境中部署。
可解释性和透明度:
- 提高模型决策过程的可解释性,帮助用户理解模型的预测依据。
跨领域应用:
- 探索Moxin 7B在不同领域的应用潜力,如医疗、法律、教育等,并针对这些领域进行定制和优化。
模型微调和个性化:
- 研究如何通过微调来适应特定用户或任务的需求,并探索个性化模型的可能性。
这些探索点可以帮助研究社区更深入地理解Moxin 7B模型的潜力,并推动其在实际应用中的广泛使用。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概述如下:
背景与动机:
- 大型语言模型(LLMs)在AI社区中越来越受欢迎,但许多开源LLMs在透明度和可复现性方面存在问题,限制了进一步的创新和应用。
Moxin 7B模型介绍:
- 论文介绍了一个完全开源的LLM,Moxin 7B,它遵循Model Openness Framework(MOF)开发,实现了预训练代码、配置、训练和微调数据集以及中间和最终检查点的全面开放。
MOF框架:
- 论文提出了MOF框架,这是一个评估AI模型基于其完整性和开放性的排名分类系统,旨在促进透明度和可复现性。
模型架构:
- Moxin 7B模型扩展了Mistral模型架构,采用了分组查询注意力(GQA)和滑动窗口注意力(SWA)技术,以提高性能和效率。
训练数据:
- 论文详细描述了如何准备文本数据和编程语言相关的编码数据,以及如何通过数据去重和质量过滤来提高数据质量。
性能评估:
- 通过零样本评估和少样本评估,论文展示了Moxin 7B模型在多个基准测试上相较于其他流行7B模型的优越性能。
- 还包括了对齐评估,证明了Moxin 7B-chat模型在对话任务上的有效性。
结论:
- 论文强调了开源LLMs的重要性,并呼吁更多的工作来建立可复现研究的新标准,以促进一个更加包容和经济活跃的AI生态系统。
总的来说,这篇论文提出了一个完全开源的LLM,Moxin 7B,并通过一系列实验验证了其性能。论文强调了开源对于推动AI研究和应用的重要性,并鼓励社区采用开放和透明的实践。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Few-Shot Domain Adaptation for Named-Entity Recognition via Joint Constrained k-Means and Subspace Selection
Authors:Ayoub Hammal, Benno Uthayasooriyar, Caio Corro
Named-entity recognition (NER) is a task that typically requires large annotated datasets, which limits its applicability across domains with varying entity definitions. This paper addresses few-shot NER, aiming to transfer knowledge to new domains with minimal supervision. Unlike previous approaches that rely solely on limited annotated data, we propose a weakly supervised algorithm that combines small labeled datasets with large amounts of unlabeled data. Our method extends the k-means algorithm with label supervision, cluster size constraints and domain-specific discriminative subspace selection. This unified framework achieves state-of-the-art results in few-shot NER on several English datasets.
命名实体识别(NER)通常需要大量的标注数据集,这限制了其在具有不同实体定义的跨域中的应用。本文针对少样本NER,旨在以最小的监督将知识迁移到新的领域。不同于以前仅依赖有限标注数据的做法,我们提出了一种弱监督算法,该算法将少量有标签数据集与大量无标签数据相结合。我们的方法通过标签监督、聚类大小约束和领域特定的判别子空间选择来扩展k-means算法。这一统一框架在多个英文数据集的少样本NER上达到了最新水平的结果。
论文及项目相关链接
PDF COLING 2025
Summary
本文探讨了少样本命名实体识别(NER)问题,旨在将知识转移到新领域,只需少量监督。不同于之前仅依赖有限标注数据的做法,本文提出了一种弱监督算法,将小量有标签数据和大量无标签数据相结合。该方法扩展了k-means算法,增加了标签监督、集群大小约束和领域特定的判别子空间选择。该统一框架在多个英文数据集上的少样本NER实现了最新结果。
Key Takeaways
- 本文关注于少样本命名实体识别(NER),旨在解决跨领域实体定义差异带来的问题。
- 提出了一种弱监督算法,结合了少量有标签数据和大量无标签数据。
- 扩展了k-means算法,增加了标签监督、集群大小约束。
- 通过领域特定的判别子空间选择,提高了NER性能。
- 该方法在多个英文数据集上实现了最新的少样本NER结果。
- 这种方法的优势在于能够利用大量的无标签数据来增强模型的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是命名实体识别(Named-entity recognition, NER)中的少样本领域自适应(few-shot domain adaptation)问题。具体来说,论文的目标是在新领域中以最少的标注数据(即1-5个样本)来迁移NER模型的知识。这与传统的NER任务不同,后者通常需要大量的标注数据集,限制了其在不同领域中的适用性。论文提出了一种弱监督算法,该算法结合了少量标注数据集和大量未标注数据,以实现在新领域中的有效迁移。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的领域和具体工作:
少样本学习(Few-shot Learning):
- Vinyals et al. (2016) 提出了匹配网络(Matching Networks)用于少样本学习。
- Snell et al. (2017) 提出了原型网络(Prototypical Networks)用于少样本学习。
- Sung et al. (2018) 提出了关系网络(Relation Networks)用于少样本学习。
命名实体识别(NER)中的少样本学习:
- Fritzler et al. (2019) 将原型网络应用于NER任务。
- Yang and Katiyar (2020) 提出了一种基于最近邻分类的少样本NER方法。
- Das et al. (2022) 提出了CONTaiNER方法,该方法结合了对比学习和原型网络。
使用比率约束(Ratio Constraints)的研究:
- Ganchev et al. (2010) 提出了后验正则化(posterior regularization)的概念,这与使用比率约束在E-step中的思想相似。
- Ng (2000) 和 Bradley et al. (2000) 提出了约束k-means算法,这与本文中提出的比率约束类似。
子空间选择(Subspace Selection):
- Ding and Li (2007) 提出了判别性k-means(Discriminative k-means)方法,该方法联合了k-means和子空间选择。
- Ye et al. (2007a, 2007b) 也提出了与判别性k-means相关的工作。
度量学习(Metric Learning):
- 一些工作通过学习基于神经网络的度量距离来处理少样本学习问题,如Vinyals et al. (2016) 和 Snell et al. (2017)。
其他相关技术:
- Devlin et al. (2019) 提出了BERT模型,该模型在NER任务中被广泛使用。
- Ramshaw and Marcus (1995) 提出了BIO标注方案,这是NER任务中常用的一种标签编码方式。
这些工作为本研究提供了理论基础和技术背景,特别是在少样本学习、NER、度量学习和子空间选择等方面。论文中提出的新方法在这些领域的现有工作基础上进行了扩展和改进,以适应NER任务中的少样本领域自适应问题。
Q: 论文如何解决这个问题?
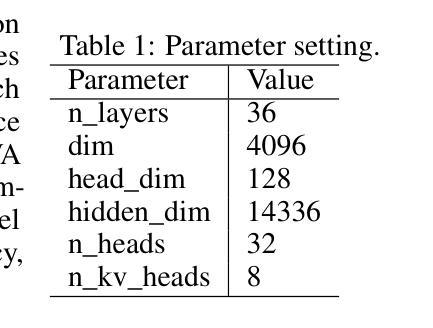
A: 论文通过提出一种弱监督学习算法来解决少样本领域自适应(few-shot domain adaptation)问题,具体方法如下:
结合有标签和无标签数据:
- 该方法利用少量的标注数据(称为支持集)和大量的未标注数据。未标注数据通常更容易获取,有助于提高模型的泛化能力。
扩展k-means算法:
- 论文将标准的k-means聚类算法扩展,使其能够处理有标签监督信息,并加入聚类大小约束和领域特定的判别性子空间选择。
引入比例约束:
- 论文在训练过程中引入了比例约束,特别是对于非实体(O标签)的比例约束,以充分利用未标注数据。
判别性聚类:
- 通过联合学习数据的子空间投影,使得聚类之间更加分离,这种方法也被称为判别性聚类。
确定性训练过程:
- 为了解决少样本学习中训练过程的不稳定性问题,论文设计了一种确定性的训练过程,确保每次训练的结果是一致的。
参数自由的优化方法:
- 论文提出的方法不需要调整学习参数,简化了模型训练过程。
实验验证:
- 论文在多个英文数据集上进行了实验,验证了提出方法的有效性,并与现有工作进行了比较,取得了最新的最佳结果。
具体来说,论文提出了以下几个关键技术点:
- 弱监督学习:通过k-means聚类算法结合少量标注数据和大量未标注数据进行学习。
- 比例约束算法:开发了新的算法来处理训练过程中的比例约束,包括硬聚类和软聚类两种情况。
- 子空间选择:将数据投影到一个子空间中,使得聚类更加分离,提高了模型的判别能力。
- 确定性训练:通过批量更新和确定性的初始化过程,避免了随机初始化带来的结果差异。
这些方法结合起来,使得论文提出的算法能够有效地在新领域中迁移NER模型的知识,即使在只有极少数标注样本的情况下。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估提出方法的有效性:
数据集:
- 使用了OntoNotes5作为通用数据集,以及CoNLL2003和WNUT17作为专门数据集。
预训练:
- 使用base-bert-cased模型进行预训练,并在源领域上进行3个epoch的训练。
少样本设置:
- 标签集扩展(Tag set extension):评估模型在新标签集上的性能,但不改变输入数据领域。使用OntoNotes5中的三个不同的标签集合,并遵循Yang和Katiyar (2020)的方法生成10个支持集。
- 领域转移(Domain transfer):评估模型在新的标签集和不同的输入数据源上的性能。使用OntoNotes5进行预训练,并在CoNLL2003和WNUT17上进行少样本性能评估,使用与Das et al. (2022)相同的支持集。
评估指标:
- 使用F1分数作为评估指标。
结果:
- 论文提供了在不同实验设置下的F1分数结果,包括1-shot和5-shot设置。
- 对比了提出方法与现有工作(如Proto、NNShot、StructShot、CONTaiNER等)的性能。
消融研究:
- 论文还进行了消融实验,以评估使用不同未标注数据集(如完整的训练和开发数据集、仅开发数据集、不使用未标注数据)对模型性能的影响。
- 另外,还评估了是否加入子空间选择步骤对模型性能的影响。
这些实验旨在全面评估提出方法在不同场景下的性能,并与现有技术进行比较。通过这些实验,论文展示了其方法在少样本领域自适应命名实体识别任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
对B标签和嵌套NER的处理:
- 论文提到,当前方法难以处理使用B标签区分连续实体以及嵌套NER中的内部实体。未来的研究可以探索如何改进算法以处理这些情况。
适应更广泛的实体类型:
- 尽管论文在几个数据集上取得了良好的结果,但可以探索算法对于更广泛的实体类型和领域适应性如何。
改进比例约束:
- 论文提出了基于比例约束的方法来利用未标注数据,未来的工作可以探索更复杂的约束或半监督信号,以进一步提高模型性能。
优化子空间选择:
- 子空间选择是提高聚类性能的关键步骤,研究不同的子空间选择方法或优化技术可能会进一步提升模型效果。
跨语言和跨文化领域的NER:
- 探索算法在跨语言和跨文化领域的适用性,尤其是在多语言和低资源语言环境中。
与其他少样本学习技术的结合:
- 考虑将论文中的方法与其他少样本学习技术(如元学习、迁移学习)结合,以进一步提高模型在新领域上的适应能力。
更深入的实验和分析:
- 对模型在不同条件下的性能进行更深入的实验和分析,包括不同大小和不同分布的支持集。
可解释性和鲁棒性分析:
- 对模型的决策过程进行可解释性分析,并探索提高模型鲁棒性的方法。
实时和动态环境下的应用:
- 探索模型在实时和动态环境下的应用,例如在线学习或流数据上的NER任务。
软件和硬件优化:
- 研究如何优化算法以提高计算效率,包括在硬件加速器上实现算法。
这些探索点可以帮助研究者更全面地理解和改进少样本领域自适应NER方法,并将其应用于更广泛的实际问题中。
Q: 总结一下论文的主要内容
A: 论文的主要内容包括以下几个方面:
问题定义:
- 论文针对的是命名实体识别(NER)任务中的少样本领域自适应问题,即如何在只有少量标注数据的新领域中有效迁移NER模型。
方法论:
- 提出了一种弱监督学习算法,该算法结合了小规模标注数据集和大规模未标注数据。
- 扩展了k-means算法,引入了标签监督、聚类大小约束和领域特定的判别性子空间选择。
比例约束:
- 引入了比例约束来利用未标注数据,特别是对于非实体(O标签)的比例约束,以提高模型性能。
判别性聚类:
- 通过联合学习数据的子空间投影,使得聚类之间更加分离,提高了模型的判别能力。
确定性训练过程:
- 为了解决少样本学习中训练过程的不稳定性问题,设计了一种确定性的训练过程,确保每次训练的结果是一致的。
实验验证:
- 在多个英文数据集上进行了实验,验证了提出方法的有效性,并与现有工作进行了比较,取得了最新的最佳结果。
主要贡献:
- 将少样本领域适应问题形式化为k-means聚类问题,使其能够利用额外的未标注数据。
- 提出了考虑比例约束的k-means的E步的新算法。
- 将聚类过程扩展为联合投影数据到一个聚类良好分离的子空间。
- 在不同的少样本设置下评估了方法,并取得了优于以往工作的结果。
代码开源:
- 论文提供了公开的代码,以便于其他研究者复现和进一步研究。
总的来说,论文提出了一种新的弱监督学习方法来处理NER任务中的少样本领域自适应问题,通过结合聚类算法和子空间选择,有效地利用了未标注数据,并在多个数据集上取得了优异的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

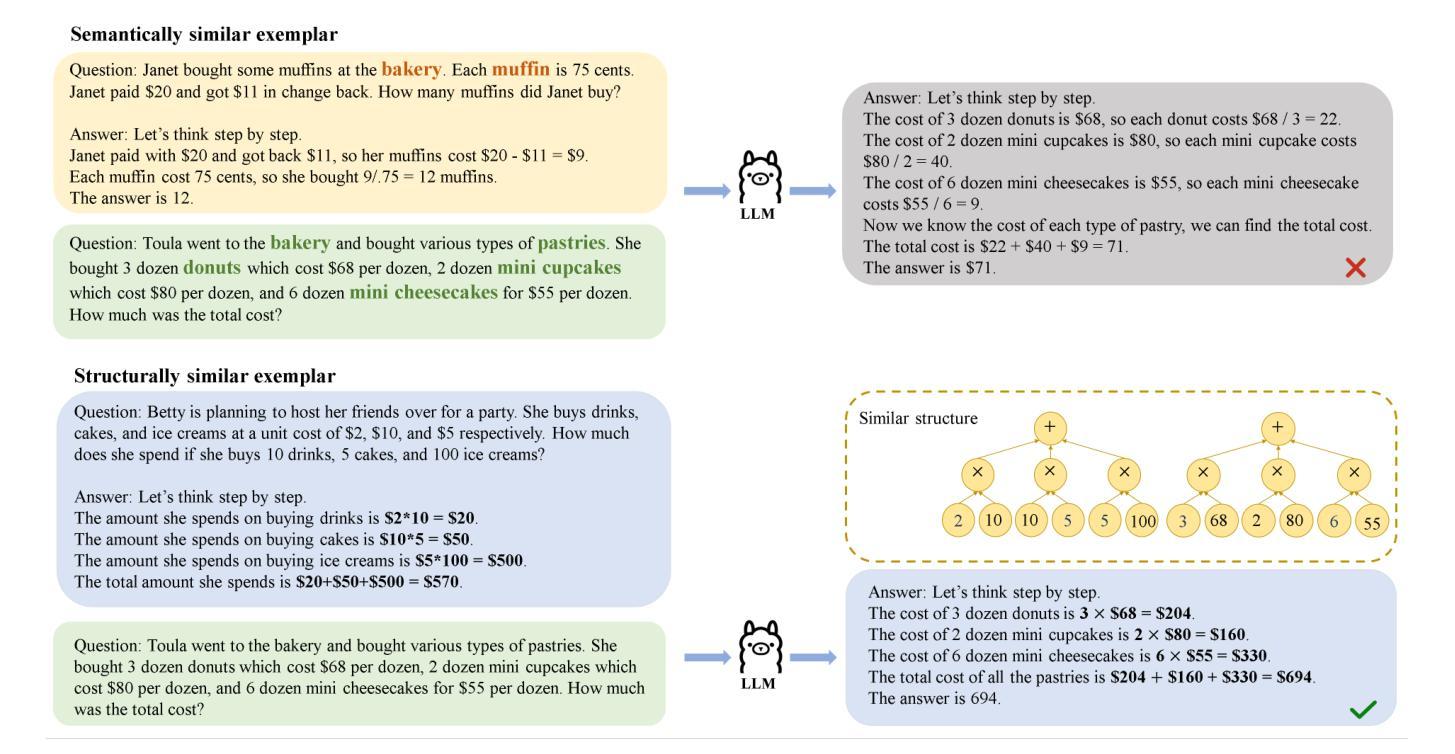
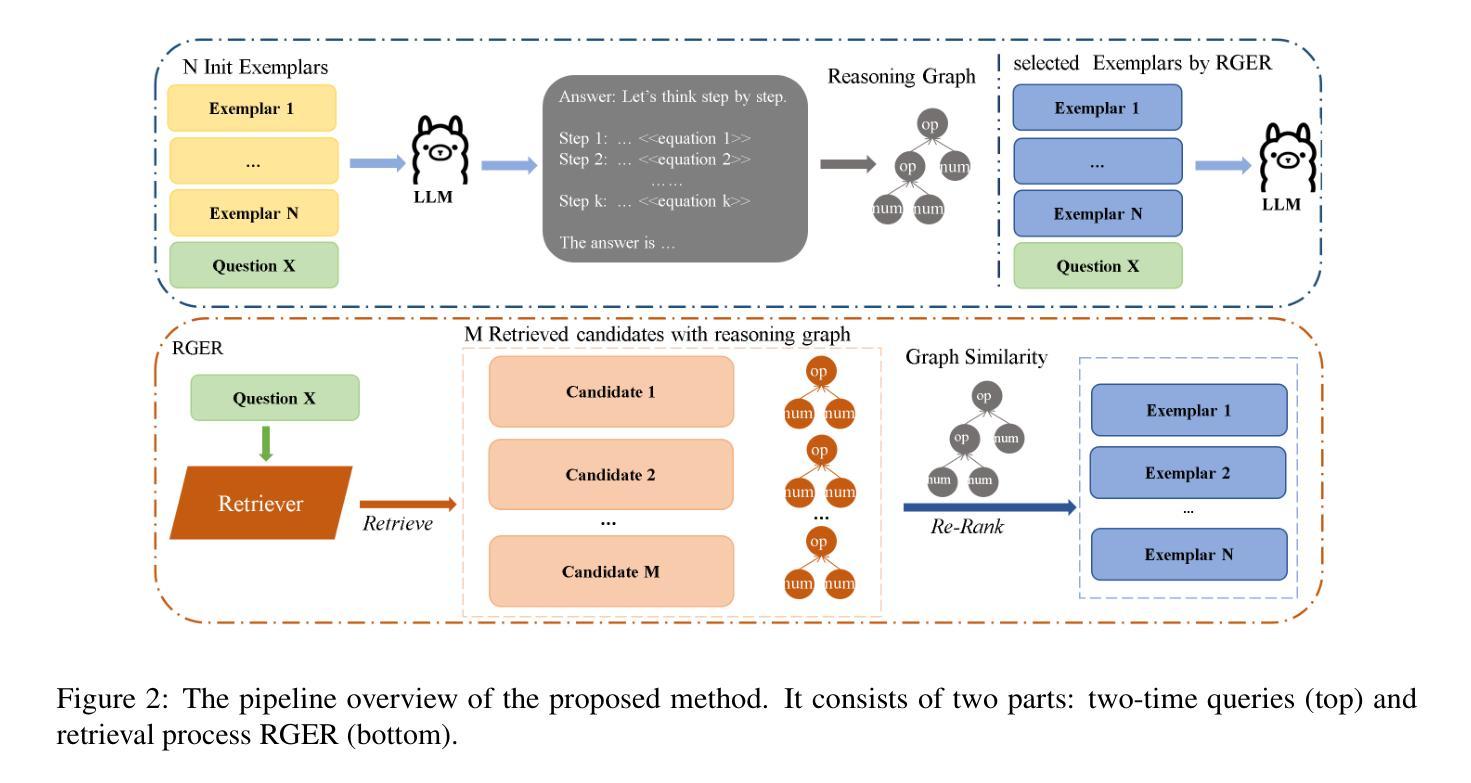
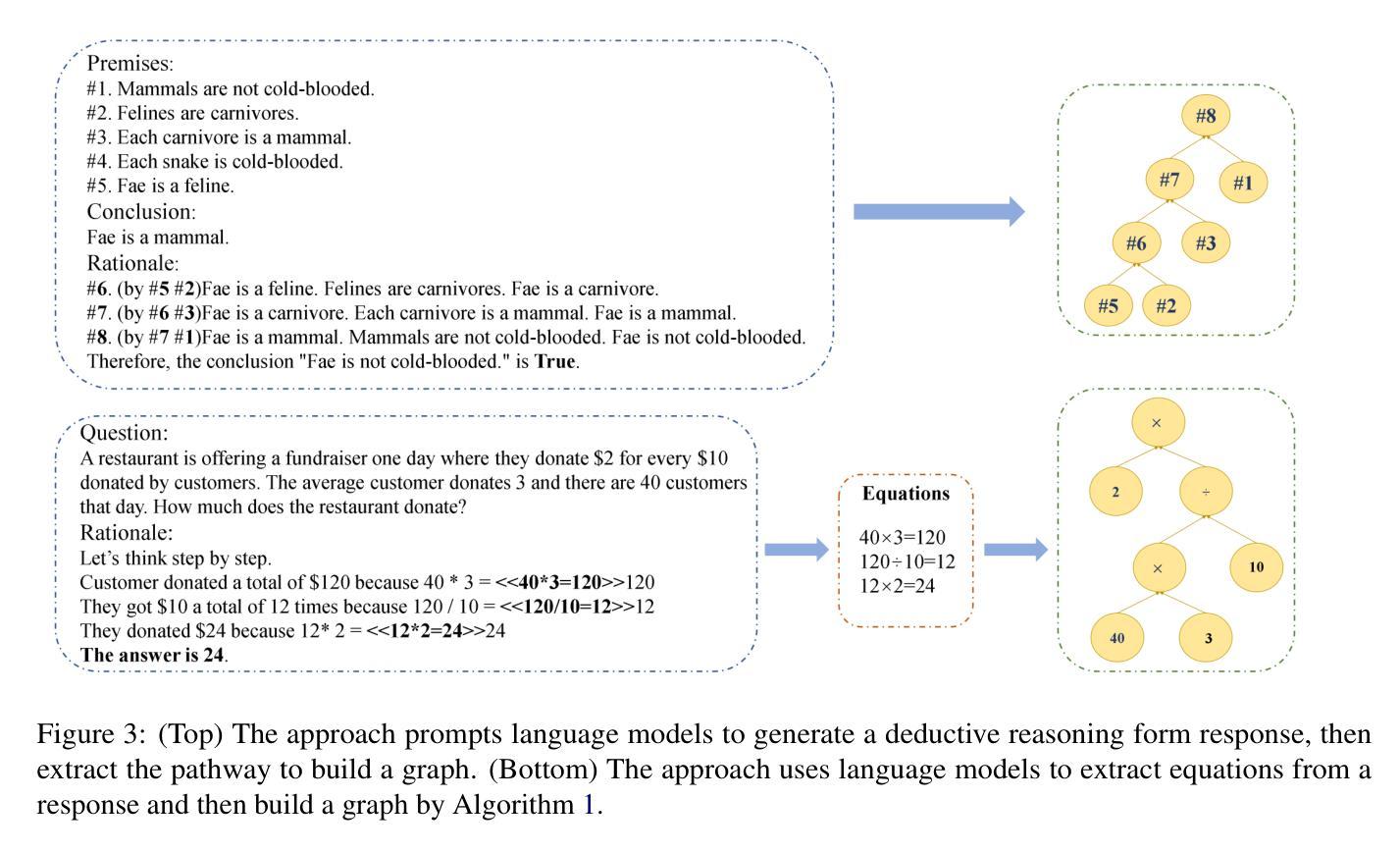
Reasoning Graph Enhanced Exemplars Retrieval for In-Context Learning
Authors:Yukang Lin, Bingchen Zhong, Shuoran Jiang, Joanna Siebert, Qingcai Chen
Large language models (LLMs) have exhibited remarkable few-shot learning capabilities and unified the paradigm of NLP tasks through the in-context learning (ICL) technique. Despite the success of ICL, the quality of the exemplar demonstrations can significantly influence the LLM’s performance. Existing exemplar selection methods mainly focus on the semantic similarity between queries and candidate exemplars. On the other hand, the logical connections between reasoning steps can be beneficial to depict the problem-solving process as well. In this paper, we proposes a novel method named Reasoning Graph-enhanced Exemplar Retrieval (RGER). RGER first quires LLM to generate an initial response, then expresses intermediate problem-solving steps to a graph structure. After that, it employs graph kernel to select exemplars with semantic and structural similarity. Extensive experiments demonstrate the structural relationship is helpful to the alignment of queries and candidate exemplars. The efficacy of RGER on math and logit reasoning tasks showcases its superiority over state-of-the-art retrieval-based approaches. Our code is released at https://github.com/Yukang-Lin/RGER.
大型语言模型(LLM)已经展现出令人印象深刻的少样本学习能力,并通过上下文学习(ICL)技术统一了自然语言处理任务的范式。尽管ICL取得了成功,但范例演示的质量会显著影响LLM的性能。现有的范例选择方法主要集中在查询和候选范例之间的语义相似性上。另一方面,推理步骤之间的逻辑联系也有利于描绘问题解决过程。在本文中,我们提出了一种名为Reasoning Graph-enhanced Exemplar Retrieval(RGER)的新方法。RGER首先请求LLM生成初步响应,然后将中间问题解决步骤表示为图形结构。之后,它采用图核方法选择具有语义和结构相似性的范例。大量实验表明,这种结构关系有助于查询和候选范例的对齐。RGER在数学和逻辑推理任务上的有效性展示了其在基于检索的最新技术上的优越性。我们的代码已发布在https://github.com/Yukang-Lin/RGER。
论文及项目相关链接
Summary
大型语言模型(LLM)在通过上下文学习(ICL)技术统一NLP任务方面表现出卓越的少量学习(few-shot learning)能力。现有范例选择方法主要关注查询与候选范例之间的语义相似性。本研究提出了一种新的方法——基于推理图的范例检索(RGER),该方法不仅考虑语义相似性,还利用推理图来捕捉问题解决的逻辑步骤。实验证明,结构关系有助于查询与候选范例的对齐,RGER在数学和逻辑推理任务上的效果优于当前先进的基于检索的方法。
Key Takeaways
- 大型语言模型展现出强大的少量学习能力,并通过上下文学习统一了NLP任务。
- 范例演示的质量对LLM性能有重要影响。
- 现有范例选择方法主要关注语义相似性。
- RGER方法通过结合推理图来捕捉问题解决的逻辑步骤。
- 结构关系有助于查询与候选范例的对齐。
- RGER在数学和逻辑推理任务上的表现优于现有方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为Reasoning Graph-enhanced Exemplar Retrieval (RGER)的新方法,旨在解决在上下文学习(In-Context Learning, ICL)中,如何有效地选择示例(exemplars)来提升大型语言模型(Large Language Models, LLMs)在复杂推理任务上的性能问题。在ICL中,通过给模型提供少量示例来使其能够在没有梯度更新的情况下完成未见任务。然而,选定的示例的质量会显著影响ICL的性能。现有的示例选择方法主要关注查询和候选示例之间的语义相似性,但往往忽略了推理步骤之间逻辑联系的重要性。RGER通过构建推理图来表示问题解决过程中的逻辑连接,并使用图核(graph kernel)方法来选择在语义和结构上与查询相似的示例,从而提高ICL在数学和逻辑推理任务上的性能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
In-Context Learning (ICL): 论文提到了ICL技术,它使得语言模型能够通过少量示例来执行未见任务,而无需梯度更新。相关研究包括Brown et al. (2020)和Dong et al. (2022)。
Exemplar Selection for ICL: 论文探讨了在ICL中如何选择有效的示例,包括使用检索式范例获取方法,如Liu et al. (2021), Li et al. (2023), Rubin et al. (2021), Ye et al. (2023), 和 Xiong et al. (2023)。
Graph Structure in Language Models: 论文中提到了图结构在语言模型中的应用,包括Cao (2023), Lu et al. (2024), Yao et al. (2023), Park et al. (2023), Luo et al. (2023), 和 Besta et al. (2024)。
Graph Kernel Methods: 论文中使用了图核方法来衡量图结构之间的相似性,相关研究包括Haussler et al. (1999), Borgwardt and Kriegel (2005), 和 Shervashidze et al. (2011)。
Reasoning and Problem Solving: 论文还涉及到了推理和问题解决的研究,如Cobbe et al. (2021), Ling et al. (2024), 和 Ling et al. (2017)。
这些研究为论文提出的RGER方法提供了理论基础和技术支持。论文通过结合这些相关领域的研究成果,提出了一种新的范例检索方法,以提高大型语言模型在复杂推理任务中的性能。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为Reasoning Graph-enhanced Exemplar Retrieval (RGER)的新方法来解决在上下文学习(In-Context Learning, ICL)中如何选择高质量的示例(exemplars)的问题。RGER方法通过以下几个步骤来解决这个问题:
生成初始响应:首先,利用大型语言模型(LLM)生成初始响应,以获取问题的中间推理步骤。
构建推理图:将问题解决步骤的逻辑关系抽象为图结构,使用有向图来表示推理路径,即中间步骤之间的拓扑关系。
检索候选示例:从经过微调的密集检索器中检索候选示例,然后使用图核方法重新对这些示例进行排序,以计算它们与查询在语义和结构上的相似度。
融合语义和结构相似度:结合语义相似度和结构相似度来选择最终的示例,这些示例将用于构建ICL的上下文。
图核方法:利用图核方法(如最短路径核和Weisfeiler-Lehman核)来评估问题生成的推理路径与候选示例之间的结构相似性。
实验验证:在数学和逻辑推理任务上进行了广泛的实验,结果表明RGER在提高ICL性能方面优于现有的基于检索的方法,并且展示了在不同任务和语言模型能力上的鲁棒性。
通过这种方式,RGER能够从结构和层次的角度过滤掉冗余信息,并在不同的复杂推理任务中实现优越的性能,展示了其在各种场景下的效能和鲁棒性。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来评估他们提出的Reasoning Graph Enhanced Exemplar Retrieval (RGER) 方法。以下是实验的主要部分:
数据集:实验使用了四个数学推理问题基准测试,包括GSM8K、AQUA、SVAMP和ASDIV,以及两个逻辑推理问题基准测试,即ProntoQA和FOLIO。
评估指标:主要使用准确率(Accuracy)作为评估所有任务性能的指标。对于分类任务AQUA,选择生成概率最高的选项作为答案。对于生成任务,采用贪婪解码以确保可重复性,然后使用附录B中显示的解析规则对生成的响应进行评估。
实现细节:在数学推理任务中,实验在三个大型语言模型(LLMs)上进行,包括两个开源模型Llama2-7B-chat和Vicuna-7B,以及一个商业模型GPT-3.5-turbo-0125。逻辑推理任务在LLAMA-3-8BInstruct模型上进行测试。与RGER方法比较的基线方法包括Manual-CoT、Complex-CoT、Auto-CoT、EPR、CEIL和DQ-LoRe。
主要结果:在数学推理任务中,RGER方法在Llama2-7B-chat和Vicuna-7B两个后端上的平均性能最高,分别比基线方法提高了6.7%和5.1%。在逻辑推理任务中,RGER在ProntoQA任务中优于所有手动设计的方法,并且在更复杂的FOLIO任务中也超过了其他基线。
封闭源模型的示例选择:作者考虑了一种设置,即使用较小的开源模型(Llama3-8B-Instruct)检索示例来提高大型商业模型(GPT-3.5Turbo-0125)的性能。实验结果显示,RGER方法在SVAMP和GSM8K数据集上的准确性超过了所有其他方法。
消融研究:作者对RGER方法的三个主要组成部分进行了详细分析:检索器、查询字段和重排指标。实验结果表明,RGER的每个组成部分都对其性能有积极影响。
响应质量的影响:作者还研究了初始响应质量与最终响应准确性之间的关系。实验结果表明,RGER在不同初始响应质量水平下都能保持较高的准确性,并且比DQ-LoRe方法更稳定。
案例研究:作者还提供了GSM8K数据集中单个数据点的检索结果案例研究,展示了不同检索方法的示例选择结果。
通过这些实验,作者证明了RGER方法在提高大型语言模型解决复杂推理任务的能力方面具有优越性和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 论文在最后一部分提出了一些可能的研究方向和进一步探索的点:
Prompting and Fine-tuning:虽然RGER为大型语言模型(LLMs)建立了一种示例选择策略,但作者指出,探索使用这种高质量的数据对LLMs进行微调(fine-tuning)的可能性是未来工作的一个方向。
Retriever Training:论文提到,尽管在相对任务上训练的检索器之间存在共性,但更准确的方法是使用与推理相同的LLM进行检索器训练和模型偏好训练。然而,由于对GPT-3.5-turbo生成概率的限制,作者遵循原则并使用开源模型进行实验。
结构化表示的改进:论文中提出的方法侧重于使用图结构来表示和选择示例。探索其他形式的结构化表示,如树结构或逻辑形式,可能有助于进一步改进模型性能。
跨领域和跨语言的泛化能力:虽然RGER在数学和逻辑推理任务上表现出色,但研究其在其他领域(如自然科学、社会科学等)和不同语言上的泛化能力也是一个有价值的方向。
更复杂的推理路径:论文中提出的方法在处理复杂推理任务时表现出色。然而,对于包含更长推理链或更复杂逻辑结构的任务,进一步研究和改进方法可能是必要的。
模型解释性和可视化:提高模型的可解释性,通过可视化技术展示模型是如何利用图结构信息来选择示例和进行推理的,可以帮助研究人员和用户更好地理解模型的行为。
鲁棒性和公平性:研究模型在面对错误信息、偏见或对抗性攻击时的鲁棒性,以及如何提高模型对不同人群和背景的公平性,是当前人工智能领域的热点问题。
实际应用场景:探索RGER方法在实际应用场景中的有效性,如教育、医疗咨询、法律分析等,可以推动该技术的实际应用和商业化。
这些探索点不仅可以推动ICL和LLMs的研究进展,还可能对人工智能的广泛应用产生重要影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Reasoning Graph-enhanced Exemplar Retrieval (RGER)的新方法,旨在改善大型语言模型(LLMs)在上下文学习(In-Context Learning, ICL)中的示例选择问题。以下是论文的主要内容概述:
问题背景:论文首先介绍了ICL技术,它允许LLMs通过少量示例来执行未见任务,无需梯度更新。然而,ICL的效果高度依赖于示例的选择,因此有效的示例选择是提高ICL性能的关键。
现有方法的局限性:现有的示例选择方法主要关注查询和候选示例之间的语义相似性,但这种方法可能会忽略问题的层次结构和推理路径,导致选择了错误的推理路径。
RGER方法:为了克服这些局限性,论文提出了RGER方法,它利用有向图来表示问题解决过程中的逻辑连接,并通过图核方法来选择在语义和结构上与查询相似的示例。
方法细节:
- 两阶段查询:首先,使用LLM生成初始响应,然后从响应中提取结构信息作为图。
- 检索器模型训练:使用对比学习训练一个编码器,以计算查询和示例之间的相似度。
- 推理图构建:自动从响应中提取计算步骤,并将其转换为图结构。
- 图核作为重排指标:使用图核方法来评估问题生成的推理路径与候选示例之间的结构相似性。
实验:在四个数学推理任务和两个逻辑推理任务上进行了广泛的实验。结果表明,RGER在提高ICL性能方面优于现有的基于检索的方法,并且在不同任务和语言模型上展现出鲁棒性。
贡献总结:
- 提出了一种新的基于推理图的示例选择方法。
- RGER在检索过程中考虑了语义关系、模型偏好和结构关系,提供了全面的查询示例考虑。
- 在复杂推理任务中展示了RGER的高效性和鲁棒性。
局限性和未来工作:论文讨论了RGER的局限性,包括对提示和微调的依赖,以及未来可能的研究方向,如使用RGER进行LLMs的微调。
伦理声明:论文提醒用户,尽管目的是提高模型性能,但LLMs可能偶尔生成有偏见或不可信的陈述,建议用户谨慎使用模型输出。
总的来说,这篇论文通过引入结构化推理图和图核方法,为提高LLMs在ICL中的示例选择和推理性能提供了一种新的视角和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


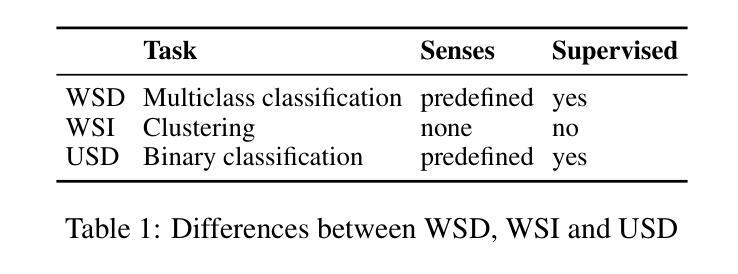
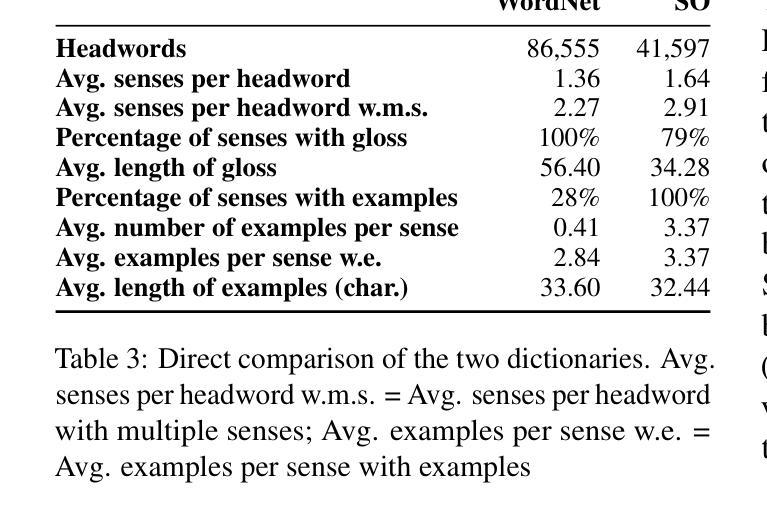
Detection of Non-recorded Word Senses in English and Swedish
Authors:Jonathan Lautenschlager, Emma Sköldberg, Simon Hengchen, Dominik Schlechtweg
This study addresses the task of Unknown Sense Detection in English and Swedish. The primary objective of this task is to determine whether the meaning of a particular word usage is documented in a dictionary or not. For this purpose, sense entries are compared with word usages from modern and historical corpora using a pre-trained Word-in-Context embedder that allows us to model this task in a few-shot scenario. Additionally, we use human annotations on the target corpora to adapt hyperparameters and evaluate our models using 5-fold cross-validation. Compared to a random sample from a corpus, our model is able to considerably increase the detected number of word usages with non-recorded senses.
本研究关注英文和瑞典语的未知词义检测任务。该任务的主要目标是确定某个单词的用法是否具有字典中的含义。为此,我们通过预训练的词在语境嵌入器(Word-in-Context embedder)将词义条目与现代和历史语料库中的词汇用法进行比较,这使我们能够在少量样本的情况下对此任务进行建模。此外,我们对目标语料库进行人工标注以适应超参数,并使用五倍交叉验证评估我们的模型。与语料库中的随机样本相比,我们的模型能够显著地增加检测到的不含记录的词义的词汇用法数量。
论文及项目相关链接
PDF 9 pages
Summary
本研究探讨了英语和瑞典语中未知词义检测的任务。主要目标是确定特定词汇用法是否在词典中有记载。为实现这一目标,该研究利用预训练的词在语境嵌入器,对比词义条目与现代和历史语料库中的词汇用法。此外,该研究还通过目标语料库的人类注释来调整超参数,并使用五折交叉验证来评估模型。与语料库的随机样本相比,该模型能够显著地增加检测到的未记录词义的词汇用法数量。
Key Takeaways
- 本研究关注未知词义检测任务,旨在确定特定词汇用法是否在词典中有记录。
- 研究采用预训练的词在语境嵌入器,对比词义条目与语料库中的词汇用法。
- 通过目标语料库的人类注释调整超参数,以提高模型的性能。
- 采用五折交叉验证评估模型。
- 模型能够显著地增加检测到的未记录词义的词汇用法数量。
- 该研究涉及英语和瑞典语两种语言的未知词义检测。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是未知词义检测(Unknown Sense Detection, USD),特别是在英语和瑞典语中。主要目标是确定特定词汇使用的意义是否在词典中有记录。这项任务涉及比较现代和历史语料库中的词汇使用与词典条目中的词义条目,以判断给定词汇使用的词义是否被词典中的任何词义覆盖。这项研究对于词典维护尤为重要,因为随着语言的发展,词典条目可能变得过时,而新词义或旧词义的丢失需要被识别和更新。论文中提出的方法利用预训练的Word-in-Context(WiC)模型来创建上下文化词嵌入,并尝试不同的方法来最大化从词典条目中利用的信息质量。此外,研究还使用人工注释来适应和评估模型性能。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
Word Sense Disambiguation (WSD): WSD是自然语言处理(NLP)中的经典任务,涉及在特定上下文中确定单词的意义。相关研究包括Burchardt等人(2009)的工作,他们使用大量手动注释数据来训练每个单词的分类器以消除歧义。
Word Sense Induction (WSI): WSI与WSD不同,它不假设有一个预定义的词义清单。它旨在通过聚类任务将单词使用按词义分组。相关研究包括Schütze(1998)和Erk(2006)的工作。
Unknown Sense Detection (USD): USD结合了WSD和WSI的方面,旨在发现那些在词典中没有记录的词义。Erk(2006)提出了一种USD的建模方法,通过测量目标使用和词典条目之间的向量表示的距离。
Contextualized Word Meaning Representations: 近年来,预训练的上下文化词嵌入模型(如BERT和SBERT)在NLP任务中取得了显著成效。这些模型能够捕捉单词在上下文中的语义信息,对于WSD和WSI任务尤为重要。
Lexical Semantic Change Detection: 与USD相关的任务还包括检测词汇语义变化,这涉及到比较不同时间点的语料库来识别词义的变化。相关研究包括Schlechtweg等人(2020)和Kurtyigit等人(2021)的工作。
Few-Shot Learning for WSD: 为了减少对大量手动注释数据的依赖,研究者们探索了在少量样本(few-shot)情况下进行WSD的方法。例如,Rachinskiy和Arefyev(2022)开发了一个模型,只训练一个分类器来处理所有单词的数据。
这些研究为本文提出的未知词义检测方法提供了理论基础和技术背景。论文中的方法试图通过使用预训练的WiC模型和人工注释来提高检测非记录词义的准确性和实用性。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决未知词义检测(USD)的问题:
数据准备:使用现代和历史语料库来收集单词使用实例,这些语料库包含了新旧词义的实例。同时,利用WordNet和Svensk ordbok(SO)这样的词典资源,为单词提供预定义的词义条目。
模型构建:开发了一系列模型,这些模型使用预训练的Word-in-Context(WiC)嵌入器(如XL-LEXEME)来生成目标单词使用和词典词义的上下文化嵌入。这些嵌入能够捕捉单词在特定上下文中的语义信息。
嵌入比较:通过计算目标使用嵌入与词典中所有词义嵌入的相似度,模型决定是否将单词使用归类为已知词义。如果相似度低于特定阈值,模型预测该单词使用表达了一个未知词义。
人工注释:为了适应和评估模型,进行了两阶段的人工注释。第一阶段是在随机样本上进行,以收集数据并为模型调整提供参考。第二阶段是对模型预测的单词使用进行评估,以确定模型预测的准确性。
模型评估与选择:通过k折交叉验证来选择最佳模型参数,优化F0.3分数(一种强调精确度的F分数变体),并建立基线模型以比较模型性能。
结果分析:分析模型在现代和历史数据上的表现,识别模型在处理不同类型数据时的行为差异,并指出模型在实际应用中的潜在改进方向。
局限性讨论:论文讨论了模型和实验过程中的局限性,如在第一阶段排除非主要同义词集、基线模型的独立运行、模型架构的弱点(如头词使用检测的不准确性)以及数据处理流程中的错误。
通过这些步骤,论文展示了一种自动化方法来检测词典中未记录的词义,这对于词典维护和更新具有实际意义。
Q: 论文做了哪些实验?
A: 论文进行了以下实验:
模型选择(Phase I: Model selection):
- 使用随机样本的人工注释数据进行模型选择。
- 采用k折交叉验证(10轮5折交叉验证)来评估模型性能,防止过拟合。
- 在交叉验证中,随机遮蔽(masking)一些已分配的词义作为模拟未知词义,以测试模型的预测能力。
- 根据F0.3分数(优化精确度的F分数变体)选择最佳模型参数。
模型预测(Phase II: Model prediction):
- 使用选定的模型对现代和历史语料库中的单词使用进行预测,以识别未记录的词义。
- 对预测结果进行人工注释,以评估模型预测的准确性。
- 分析模型在现代和历史数据上的表现,以及与随机基线和频率基线相比的性能。
人工分析(Manual Analysis):
- 对模型预测的真阳性(true positives)进行手动分析,以验证模型是否正确识别了未记录的词义。
- 识别模型在处理多词表达、专有名词和词形归一化等方面的问题。
注释结果比较(Annotation Results Comparison):
- 对比两个阶段的人工注释结果,分析模型在不同阶段的表现差异。
- 使用Krippendorff’s alpha计算注释者之间的一致性。
局限性讨论(Limitations):
- 讨论实验过程中的局限性,如注释条件的不一致性、基线模型的独立运行、模型架构的弱点等。
这些实验旨在全面评估模型在未知词义检测任务上的性能,并为未来的研究提供改进方向。通过这些实验,论文展示了模型在实际应用中的潜力,并为词典维护提供了一种自动化的方法。
Q: 有什么可以进一步探索的点?
A: 论文中提到了几个可以进一步探索的点:
改进头词使用检测:模型在检测头词使用方面存在问题,特别是在处理多词表达和专有名词时。未来的研究可以通过改进采样算法和匹配策略来提高检测的准确性。
使用集成方法:考虑使用集成学习方法或结合词义定义(gloss)和示例用法(example usages)的表示,例如通过平均向量来提高模型性能。
跨语言应用:虽然论文主要关注英语和瑞典语,但提出的模型和方法可以扩展到其他语言,探索跨语言的适用性和效果。
处理非主要同义词集:在第一阶段的注释中,非主要同义词集被排除在外。未来的实验应该确保预注释和后预测注释条件之间的一致性,以便进行无限制的比较。
优化数据处理流程:在数据处理流程中,存在一些错误,如去除使用中的重音符号。未来的工作应该修复这些问题,以确保模型使用干净、准确的数据进行预测。
词典资源的完整性:在处理瑞典语词典SO时,只考虑了主要词义,未考虑次要词义(如比喻用法)。未来的研究应该考虑这些次要词义,以减少对非记录词义的过度分类。
模型架构的改进:论文中提到模型架构存在一些弱点,未来的研究可以探索不同的模型架构,以提高对未知词义的检测能力。
实际应用中的支持:论文提出的方法可以用于词典维护。未来的工作可以探索如何将这些方法集成到词典编辑的实际流程中,以及如何与词典编纂者合作,以实现更有效的词典更新。
这些探索点为未来的研究提供了方向,旨在提高未知词义检测的准确性和实用性,以及更好地支持词典编纂和语言资源的维护。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括:
问题定义:研究聚焦于英语和瑞典语中的未知词义检测(USD),目的是确定特定单词使用的意义是否在词典中有所记录。
研究背景:介绍了与USD相关的任务,包括词义消歧(WSD)、词义归纳(WSI)和上下文化词义表示。讨论了这些任务在词典维护中的重要性。
方法论:提出了一种基于预训练的Word-in-Context(WiC)模型的方法,通过生成上下文化词嵌入来比较词典中的词义条目和现代及历史语料库中的单词使用。
实验设计:进行了两阶段的人工注释实验来评估模型。第一阶段是随机样本注释,用于模型调整;第二阶段是对模型预测结果的注释,用于评估模型性能。
模型选择与评估:通过k折交叉验证选择最佳模型参数,优化F0.3分数以强调精确度。比较了不同模型配置的性能,并建立了基线模型。
结果分析:分析了模型在现代和历史数据上的表现,发现模型能够显著提高检测到的非记录词义数量。同时,指出了模型在处理多词表达和专有名词时的问题。
局限性讨论:论文讨论了实验过程中的局限性,包括注释条件的不一致性、数据处理流程中的错误以及模型架构的弱点。
未来工作:提出了未来研究的方向,包括改进头词使用检测、使用集成方法、跨语言应用、处理非主要同义词集、优化数据处理流程和词典资源的完整性。
实际应用:论文展示了模型在词典维护中的潜在应用,提出了将自动化方法集成到词典编辑流程中的可能性。
总的来说,这篇论文提出了一种新的自动化方法来检测和更新词典中的未知词义,通过实验验证了其有效性,并为未来的研究和词典编纂实践提供了新的思路。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图