⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Coherent3D: Coherent 3D Portrait Video Reconstruction via Triplane Fusion
Authors:Shengze Wang, Xueting Li, Chao Liu, Matthew Chan, Michael Stengel, Henry Fuchs, Shalini De Mello, Koki Nagano
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user’s appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a 3D avatar built from a single reference image, but fail to faithfully preserve the user’s per-frame appearance (e.g., instantaneous facial expression and lighting). As a result, none of these two frameworks is an ideal solution for democratized 3D telepresence. In this work, we address this dilemma and propose a novel solution that maintains both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that takes the best of both worlds by fusing a canonical 3D prior from a reference view with dynamic appearance from per-frame input views, producing temporally stable 3D videos with faithful reconstruction of the user’s per-frame appearance. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction and temporal consistency on in-studio and in-the-wild datasets. https://research.nvidia.com/labs/amri/projects/coherent3d
最近单图像3D肖像重建的突破使电信系统能够通过单摄像头进行实时3D肖像视频流传输,实现了电信的民主化。然而,逐帧3D重建表现出时间上的不一致性并会忘记用户的外观。另一方面,自我再现方法可以通过单个参考图像构建的3D化身来呈现连贯的3D肖像,但无法忠实保留用户的逐帧外观(例如即时面部表情和照明)。因此,这两种框架都不适合用于民主化的3D电信的理想解决方案。在这项工作中,我们解决了这一困境,并提出了一种新型解决方案,该方案能够保持连贯的身份和动态的逐帧外观,以实现尽可能最佳的逼真效果。为此,我们提出了一种基于融合的新方法,该方法结合了参考视图的标准3D先验和逐帧输入视图的动态外观,生成了时间稳定的3D视频,忠实重建了用户的逐帧外观。我们的编码器方法仅使用由表情控制的3D GAN生成的人工数据训练,在工作室和野外数据集上均实现了最先进的3D重建和时间一致性。详情请参阅https://research.nvidia.com/labs/amri/projects/coherent3d。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2405.00794
Summary
单镜头实时三维肖像重建技术的最新突破使得电信系统能够实现实时三维肖像视频传输,推动了电信系统的民主化。然而,每帧的三维重建存在时间不一致性和用户外观记忆丢失的问题。另一方面,自重构方法能够通过单一参考图像驱动三维化身,生成连贯的三维肖像,但在保持每帧外观方面存在缺陷,如面部表情和照明等。为解决这一难题,本研究提出了一种融合方法,通过融合参考视角的规范三维先验与每帧输入视角的动态外观,生成具有时间稳定性的三维视频,真实还原用户的每帧外观。本研究采用合成数据训练的基于编码器的三维生成对抗网络模型达到了最优的三维重建和时间一致性。相关详细信息请访问研究项目页面查看:https://research.nvidia.com/labs/amri/projects/coherent3d。
Key Takeaways
- 单镜头实时三维肖像重建技术实现了电信系统的民主化。
- 当前技术存在每帧重建的时间不一致性和用户外观记忆丢失的问题。
- 自重构方法在生成连贯的三维肖像方面表现出潜力,但在保持每帧用户的真实外观方面存在不足。
- 本研究提出了一种融合方法,结合了规范三维先验和动态外观,生成具有时间稳定性的三维视频。
- 研究使用的模型是通过合成数据训练的基于编码器的三维生成对抗网络。
- 该模型在室内外数据集上均达到了先进的三维重建和时间一致性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在单目3D肖像视频重建中同时保持时间一致性和每帧图像的动态真实外观。具体来说,论文中提到了两个主要的挑战:
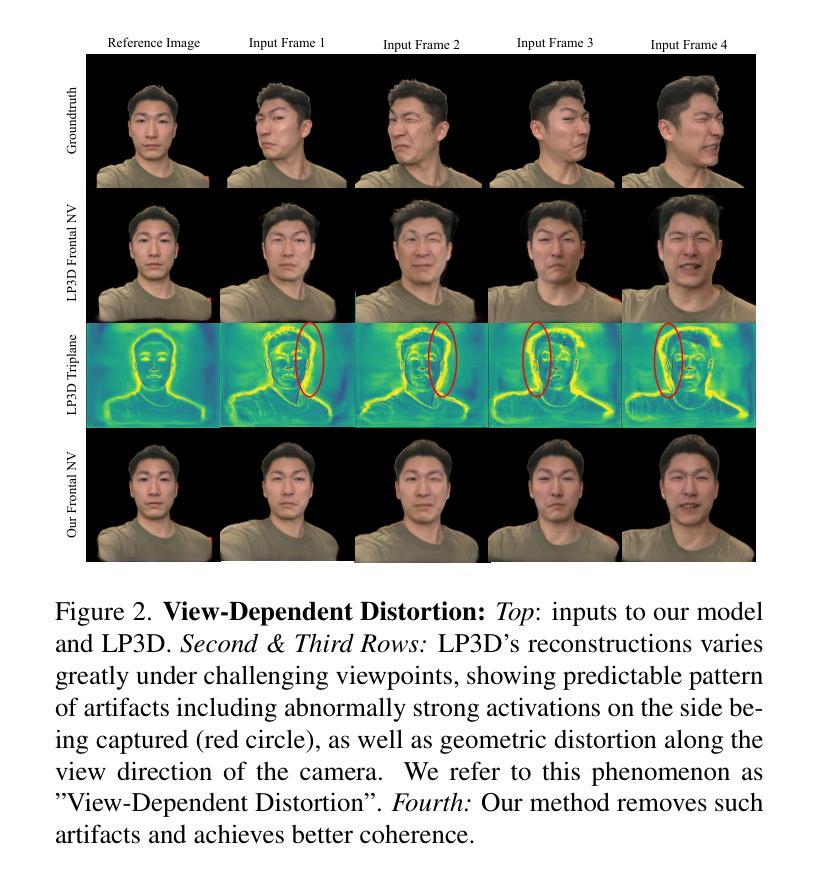
单帧3D重建的时间不一致性:传统的单帧3D重建方法(例如LP3D)能够较好地保留输入视频中的即时动态条件,如光照、表情和姿态,但它们在保持时间一致性方面存在根本性的局限性。这是因为单图像重建的固有不确定性,导致在渲染与输入视图大不相同的新视图时,系统必须猜测合理的内容,而这不能保证在多个时间帧中保持一致。
3D自重演方法无法准确保留用户的每帧外观:3D自重演方法(如GPAvatar)通过从一个或多个参考帧创建化身模型,并使用单独的驱动视频来驱动化身的面部表情和姿态,虽然可以获得时间一致的结果,但通常无法忠实地重建输入视频的动态条件,如光照、配饰或头发运动等。此外,这些重演方法在真实地重建用户的准确表情方面也存在困难,因为表情控制不够精确。
为了解决这些问题,论文提出了一种新的融合方法,结合了参考视图的规范3D先验和每帧输入视图的动态外观,生成了在时间上稳定的3D视频,并忠实地重建了用户的每帧外观。这种方法仅使用由表情条件3D GAN生成的合成数据进行训练,能够在工作室和野外数据集上实现最先进的3D重建和时间一致性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
2D肖像重演:
- 研究了如何将单一或几个参考肖像图像和驱动视频结合起来,通过转移驱动视频中的面部表情和姿态到面部肖像上。
- 相关文献:[9, 10, 16, 44, 51, 52, 58, 60–62, 64]。
3D感知肖像生成和重演:
- 利用可变形体积隐式辐射场(如NeRF)或高斯溅射与3D形态模型(3DMMs)结合,重建真实感和可动画化的体积头部化身。
- 相关文献:[1, 4, 13, 39, 43, 55, 65]。
3D GAN反演:
- 结合生成对抗网络(GANs)和神经体积渲染,实现从野外2D图像中无监督学习真实感3D头部。
- 相关文献:[5, 8, 15, 34, 42, 45, 53, 54, 56, 63, 66]。
单视图3D重建:
- 提出了基于编码器的解决方案,将单张面部图像提升到3D表示(如triplane)。
- 相关文献:[2, 50]。
3D肖像视频重建:
- 探索了如何从单目RGB视频中重建出具有时间一致性的3D肖像视频。
- 相关文献:[6, 26, 27, 31, 49, 57, 59]。
神经辐射场(NeRF):
- 用于场景表示和视图合成,通过神经网络学习场景的连续体积密度和颜色。
- 相关文献:[33]。
这些相关研究为本文提出的融合方法提供了理论基础和技术背景,涉及了从2D到3D的转换、3D感知的肖像生成、以及利用深度学习进行3D重建和动画化等领域。
Q: 论文如何解决这个问题?
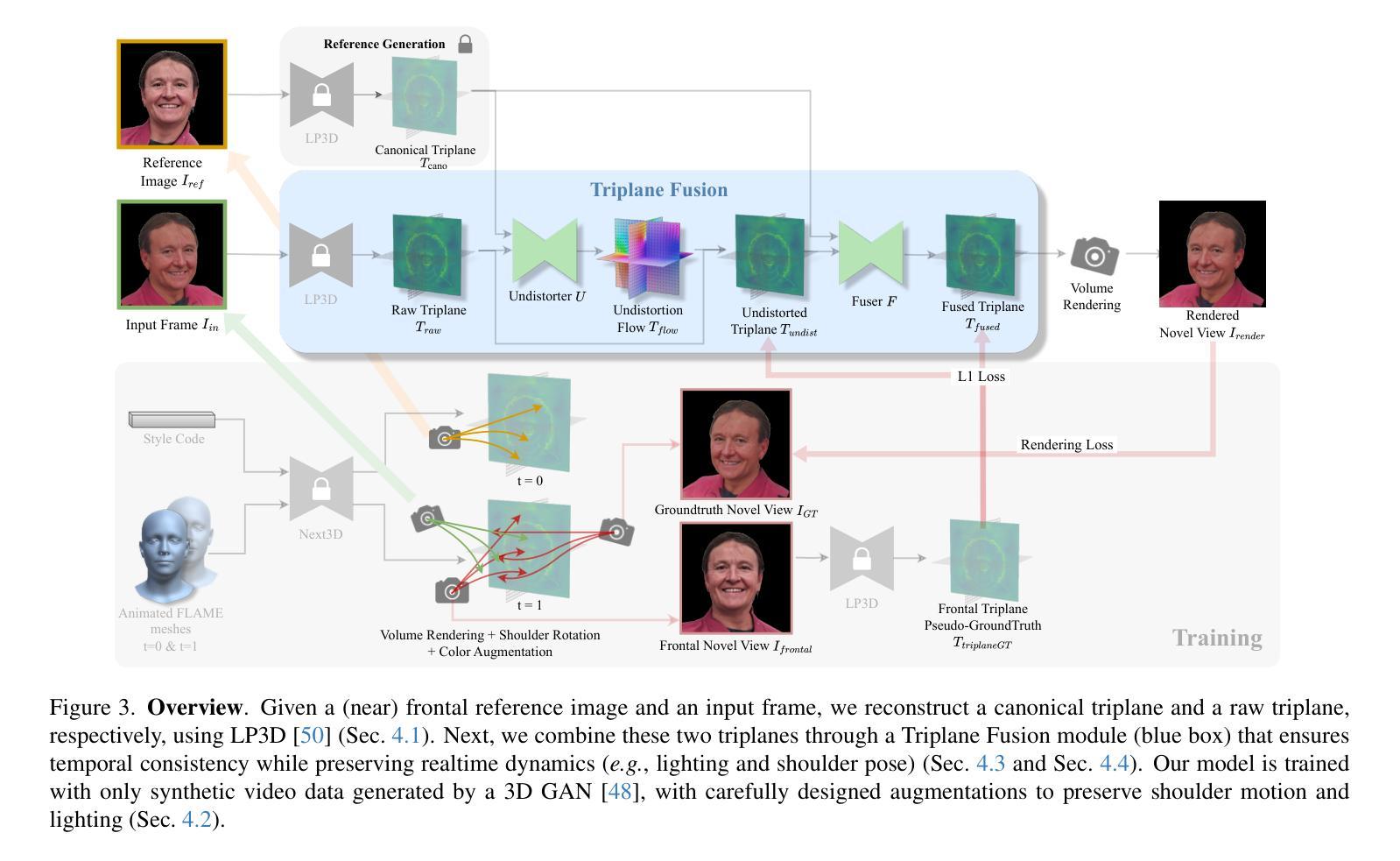
A: 论文通过提出一种新颖的融合方法解决了单目3D肖像视频重建中保持时间一致性和每帧图像动态真实外观的问题。下面是具体的解决方案步骤:
融合方法概述:
- 论文提出了一种融合基础的方法,结合了参考视图的规范3D先验和每帧输入视图的动态外观,生成了在时间上稳定的3D视频,并忠实地重建了用户的每帧外观。
使用额外的近正面参考图像:
- 利用额外的近正面参考图像(可以是从视频中捕获或提取的)编码成“规范triplane”,用于稳定3D视频生成。
转换每个输入视频帧:
- 将每个输入视频帧转换成原始triplane,使用预训练的LP3D编码器。
去除失真和保持身份:
- 通过“Triplane Undistorter”模块,去除由于输入帧视角引起的失真和身份扭曲,使用规范triplane作为参考。
- 利用SPyNet架构预测2D校正变形,然后根据估计的2D移动对原始triplane进行变形。
重建被遮挡区域:
- 通过“Triplane Fuser”模块,结合规范triplane和校正后的输入triplane,恢复输入帧中的被遮挡区域。
- 使用5层ConvNet基础的可见性估计器预测输入帧的可见性triplane,并结合可见性信息融合两个triplane。
训练损失:
- 定义了一个包含四个损失项的损失函数,提供了triplane空间指导和图像空间指导,以监督未失真、可见性预测和融合过程。
评估框架:
- 提出了一个新的多视图评估框架,使用多视图数据评估单视图3D肖像重建方法,以获得对方法重建质量和鲁棒性的洞察。
实验结果:
- 在工作室和野外数据集上评估了所提方法,并展示了其在时间一致性和重建精度方面达到了最先进的性能。
总结来说,论文通过结合规范3D先验的稳定性和准确性以及每帧观测的多样性,提出了一种新的融合方法,有效地解决了3D肖像视频重建中的时间一致性和动态真实外观保持问题。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来评估和验证他们提出的方法。以下是实验的详细情况:
量化评估:
- 数据集:使用NeRSemble数据集进行量化评估,这是一个高质量的多视角肖像视频数据集,使用16个校准的时间同步相机在控制的工作室环境中录制。
- 指标:使用ArcFace余弦距离来衡量身份准确性,使用NVIDIA Maxine AR SDK来衡量表达的准确性(通过比较渲染图像和基准图像的表情系数的L2距离)。
- 多视角评估:提出了新的多视角评估指标,包括整体合成质量和新视角合成(NVS)质量,以评估模型在不同输入-评估视点组合下的性能。
与现有方法的比较:
- 将提出的方法与三类最近的方法进行了比较:重建方法(如LP3D)、重演方法(如GPAvatar和Li等人的工作)、以及反演方法(如VIVE3D)。
- 使用提出的多视角评估协议评估每个模型,并在表1中展示了性能对比。
消融研究:
- 对模型的不同变体进行了消融研究,包括仅使用Triplane Undistorter、仅使用Triplane Fuser、以及结合两者的效果。
- 还探讨了使用光流代替Undistorter的效果,以及肩部增强对模型性能的影响。
定性评估:
- 由于篇幅限制,论文中提到了定性结果(如图像和视频结果)被放在了补充材料中。
- 在真实世界数据上进行了广泛的实验,展示了提出的方法在保持时间一致性和准确捕捉动态信息(如表情和光照变化)方面相较于LP3D和GPAvatar的优势。
这些实验旨在全面评估提出方法的有效性、准确性和鲁棒性,并与现有技术进行比较。通过量化和定性的结果,作者证明了他们的方法在3D肖像视频重建中实现了更好的时间一致性和动态真实外观的保持。
Q: 有什么可以进一步探索的点?
A: 论文在讨论部分提出了一些潜在的改进方向和未来工作,以下是一些可以进一步探索的点:
多参考图像融合:
- 目前的方法使用了单一参考图像,但结合多个具有不同表情和头部姿态的参考图像可能会进一步提升重建的质量。
网络结构优化:
- 调整和优化前馈网络结构,使其能够更好地整合多时间帧的信息,可能会改善时间一致性和动态信息的捕捉。
实时性能提升:
- 由于额外组件的加入,当前方法的运行时间性能低于实时。未来的工作可以探索如何优化模型结构和计算流程,以提高运行速度。
极端视角和表情的融合:
- 当融合极端侧视图和与参考视图截然不同的表情时,可能会因为triplane对齐的歧义而导致模糊的重建结果。研究如何更准确地处理这些情况是一个值得探索的问题。
更广泛的数据集和条件:
- 扩展研究到更广泛的数据集和条件,包括更多样的真实世界场景和光照条件,以增强模型的泛化能力。
更复杂的动态捕捉:
- 探索如何更准确地捕捉和重建更复杂的动态变化,如头发运动、服装动态等。
交互式应用和用户研究:
- 将重建技术应用于交互式应用,并进行用户研究,以评估用户体验和满意度。
模型压缩和移动端部署:
- 研究模型压缩和优化技术,使得3D重建模型可以在资源受限的移动端设备上运行。
结合硬件传感器数据:
- 考虑结合深度传感器或其他硬件传感器数据,以提供额外的几何和动态信息,增强重建的准确性。
多模态输入和输出:
- 探索结合语音、眼动等多模态输入,以及生成视频、全息图等多模态输出的可能性。
这些探索方向不仅可以推动3D重建技术的发展,还可能为虚拟现实、增强现实、远程协作等应用领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文针对单目3D肖像视频重建中的两个主要问题:单帧3D重建的时间不一致性和3D自重演方法无法准确保留用户的每帧外观。
研究目标:
- 提出一种新颖的融合方法,结合规范3D先验的稳定性和每帧输入视图的动态外观,以实现时间上稳定的3D视频和忠实的用户每帧外观重建。
方法论:
- 提出了一个基于融合的方法,使用额外的近正面参考图像编码成规范triplane,与每个输入视频帧转换成的原始triplane进行融合。
- 包括Triplane Undistorter模块去除视角依赖的失真和身份扭曲,以及Triplane Fuser模块恢复被遮挡区域并进一步稳定身份。
训练和损失函数:
- 使用由表情条件3D GAN生成的合成多视角视频数据集进行训练。
- 定义了一个包含四个损失项的损失函数,以监督未失真、可见性预测和融合过程。
评估框架:
- 提出了一个新的多视角评估框架,使用多视角数据评估单视图3D肖像重建方法,以获得对方法重建质量和鲁棒性的洞察。
实验结果:
- 在工作室和野外数据集上评估了所提方法,并展示了其在时间一致性和重建精度方面达到了最先进的性能。
- 与现有技术相比,论文提出的方法在保持时间一致性和动态真实外观方面表现更优。
讨论和未来工作:
- 论文讨论了方法的局限性,并提出了未来可能的改进方向,包括多参考图像融合、网络结构优化、实时性能提升等。
总结来说,这篇论文提出了一个创新的3D肖像视频重建方法,通过融合规范3D先验和动态外观信息,有效地解决了时间一致性和动态真实外观保持的问题,并在多个数据集上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
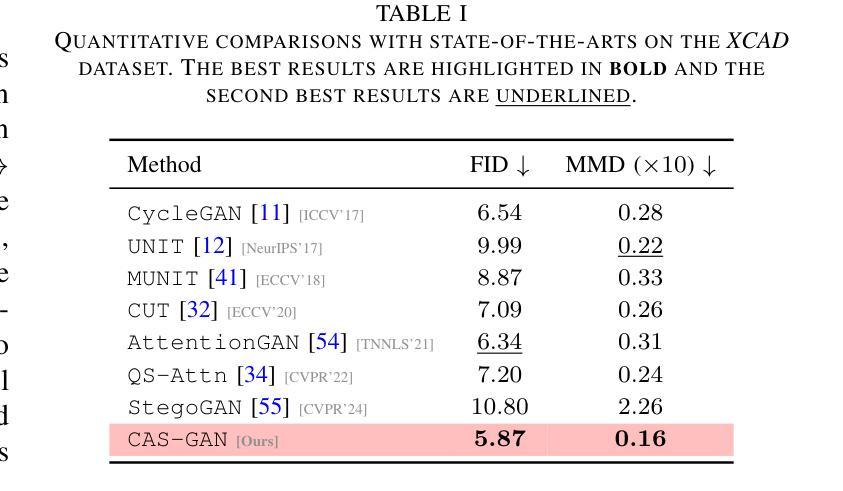
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight {\tt CAS-GAN}’s potential for clinical applications.
碘化造影剂在众多介入手术中广泛应用,但为患者带来较大的健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,可作为“虚拟造影剂”通过解耦表示学习和血管语义指导来合成X射线血管造影术,从而减少介入手术中碘化造影剂的使用。具体而言,我们的方法将X射线血管造影术分解成背景和血管成分,并利用医学先验知识。然后,一个专门的预测器学习这些成分之间的相互关系。此外,还引入了血管语义引导生成器和相应的损失函数,以提高生成图像的可视保真度。在XCAD数据集上的实验结果表明,我们的CAS-GAN达到了最先进的性能,FID为5.87,MMD为0.016。这些令人鼓舞的结果突出了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
Summary
本文介绍了一种新型的GAN框架——CAS-GAN,可作为“虚拟对比剂”来合成X光血管造影图像。通过解纠缠表示学习和血管语义引导,CAS-GAN减少了介入手术中碘对比剂的使用,降低了患者的健康风险。实验结果表明,CAS-GAN在XCAD数据集上的性能达到领先水平,具有潜在的临床应用价值。
Key Takeaways
- CAS-GAN作为一种新型的GAN框架,被用作“虚拟对比剂”,旨在合成X光血管造影图像。
- CAS-GAN通过解纠缠表示学习和血管语义引导,减少了对碘对比剂的依赖。
- 该方法将X光血管造影图像分解为背景和血管成分,利用医学先验知识。
- 引入了一个专门的预测器来学习这些成分之间的相互关系。
- 提出了一个血管语义引导的生成器和相应的损失函数,以提高生成图像的可视逼真度。
- 在XCAD数据集上的实验结果表明,CAS-GAN的性能达到了先进水平,具有潜在的临床应用价值。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
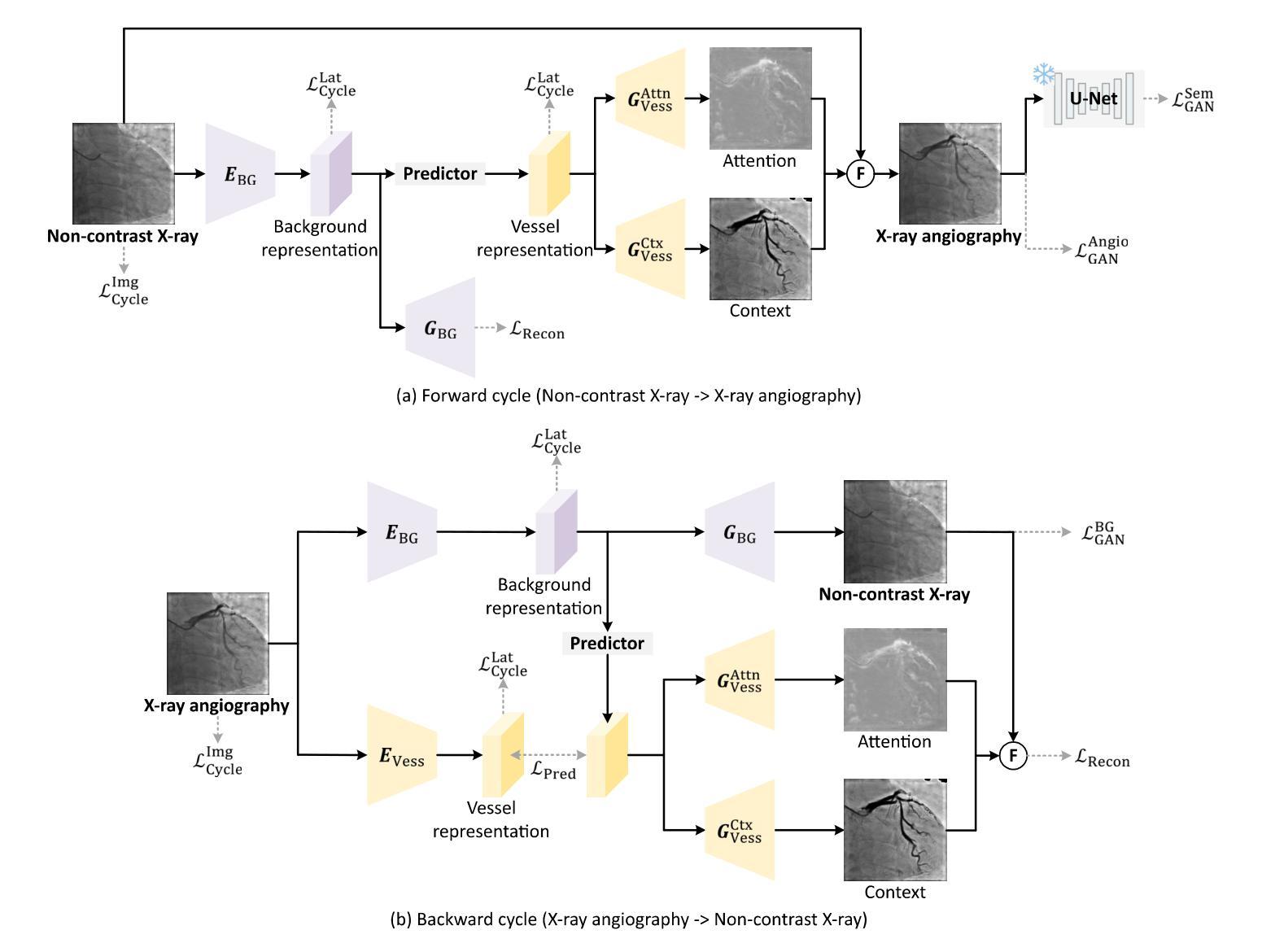
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
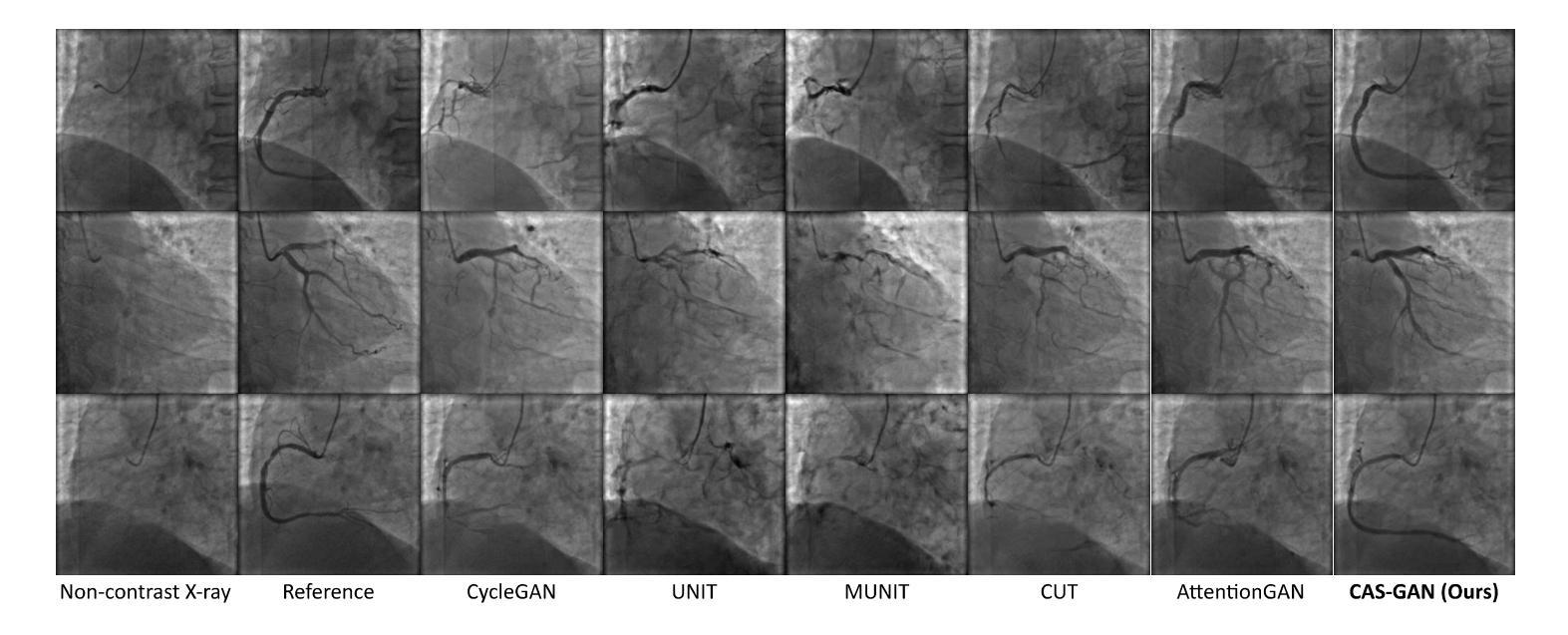
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
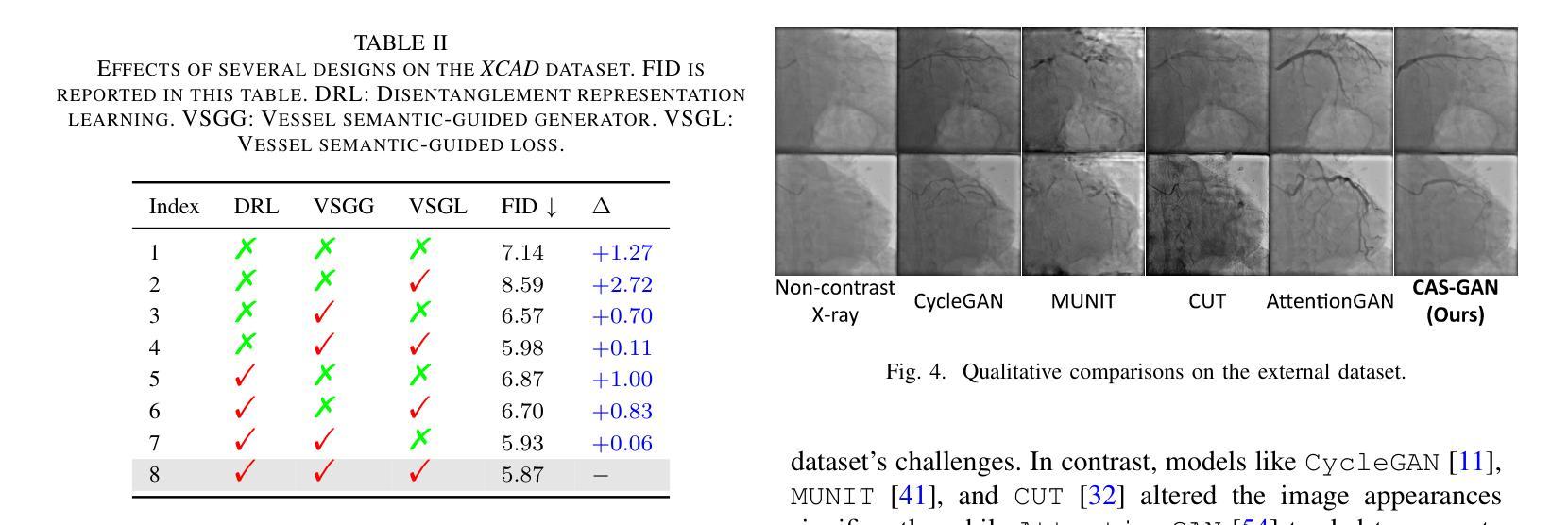
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

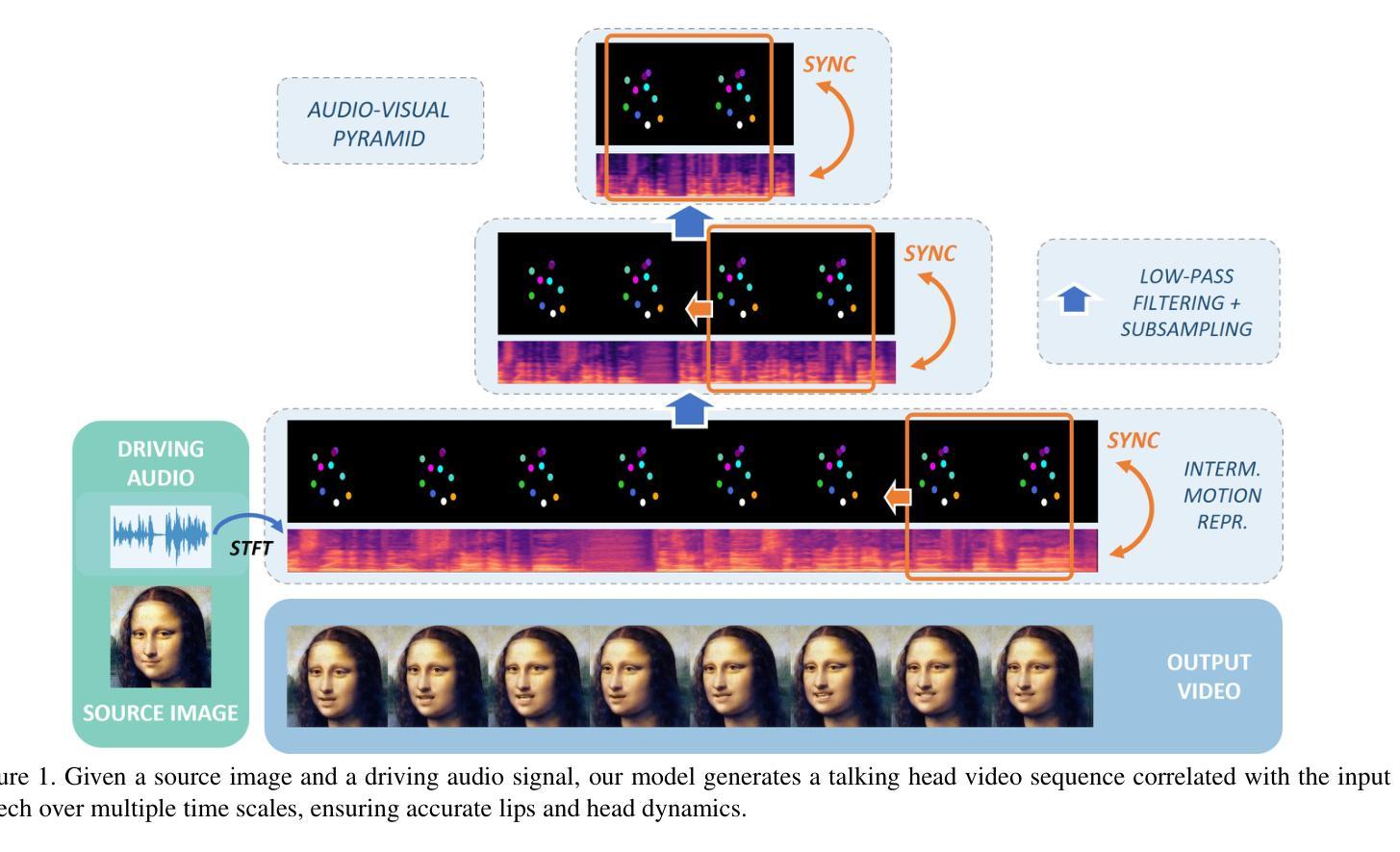
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Authors:Louis Airale, Dominique Vaufreydaz, Xavier Alameda-Pineda
Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress.However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected.In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips.In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales.Both the pyramid of audio-visual syncers and the generative models are trained in a low-dimensional space that fully preserves dynamics cues.The experiments show significant improvements over the state-of-the-art in head motion dynamics quality and especially in multi-scale audio-visual synchrony on a collection of benchmark datasets.
将静态面部图像使用深度生成模型结合语音输入信号进行动画化是一个热门的研究课题,并且最近取得了重要的进展。然而,大部分努力都放在了唇部同步和渲染质量上,而自然头部运动的生成,以及头部运动和语音之间的视听相关性更是经常被忽视。在这项工作中,我们提出了一种多尺度视听同步损失和多尺度自回归GAN,以更好地处理语音与头部和唇部动态之间的短期和长期相关性。特别地,我们在多模态输入金字塔上训练了一组同步器模型,并使用这些模型作为多尺度生成网络的指导,以产生与音频对齐的运动展开,涉及多种时间尺度。无论是音频-视觉同步器金字塔还是生成模型,都在一个充分保留动态线索的低维空间中进行训练。实验表明,与最新技术相比,在头部运动动态质量和多尺度视听同步方面都有显著提高,在一系列基准数据集上表现尤为突出。
论文及项目相关链接
Summary
该文研究了使用深度生成模型通过语音输入信号对静态面部图像进行动画化的技术。针对面部动画中的头部运动生成和音频视觉之间的关联问题,提出了一种多尺度音频视觉同步损失和多尺度自回归GAN。该方法能够更好处理语音与头部和唇部动态之间的短期和长期关联。通过训练一系列同步器模型对多模态输入金字塔进行处理,并在多尺度生成网络中使用这些模型作为指导,生成与音频对齐的运动展开,展示在不同时间尺度上的显著改进。
Key Takeaways
- 文章关注于使用深度生成模型进行静态面部图像的动画化研究。
- 现有研究多集中于唇部同步和渲染质量,而较少关注头部运动的自然生成以及音频视觉之间的关联。
- 提出了多尺度音频视觉同步损失,以更好地处理语音与头部和唇部动态之间的短期和长期关联。
- 采用了多尺度自回归GAN,能够在不同时间尺度上生成与音频对齐的运动展开。
- 训练了一系列同步器模型处理多模态输入金字塔,并在生成网络中使用这些模型作为指导。
- 方法在低维空间中训练音频视觉同步器和生成模型,能够充分保留动态线索。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在生成逼真的说话头像(talking head generation)时,同步音频信号与头部和嘴唇动作,尤其是在保持自然头部运动和音频-视觉(audio-visual)相关性方面。具体来说,论文中提到了几个关键点:
音频-视觉同步性(Audio-Visual Synchrony):尽管已有研究在唇部同步和渲染质量方面取得了进展,但自然头部运动的生成以及头部运动与语音之间的音频-视觉相关性常常被忽视。
头部运动与语音的关联:已知语音和头部运动之间存在紧密联系,但这一关系在计算机视觉领域并未得到充分研究。
缺乏适当的损失函数:为了产生与输入音频信号充分相关的自然头部和唇部运动序列,缺乏一个能够同时处理短时和长时相关性的损失函数。
多尺度音频-视觉同步性(Multi-scale Audio-Visual Synchrony):为了捕捉不同时间尺度上的动作(如头部节奏),需要一个专门的损失函数来强制执行不同长度的音频-视觉片段之间的同步。
论文提出了一个多尺度音频-视觉同步损失函数和一个多尺度自回归生成对抗网络(Multi-Scale Autoregressive GAN),以更好地处理语音与头部和嘴唇动态之间的短时和长时相关性。通过在多模态输入金字塔上训练一系列同步模型,并在多尺度生成器网络中使用这些模型作为指导,来产生跨不同时间尺度的音频对齐运动。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
1. Talking Head Generation
- 身份依赖方法:需要针对特定身份进行微调,包括早期研究工作和基于NeRF框架的新近方法。
- 视觉质量高的方法:基于扩散模型的方法,这些方法通常以牺牲头部姿态控制为代价来提高视觉清晰度。
- 唇部同步准确性:主要关注唇部运动与输入语音信号之间的同步性,通常使用冻结的唇部同步模型来提高输出唇部与输入语音信号之间的同步性。
- 一次性方法:能够实时重演未见身份的单张源图像,并明确处理头部运动。
2. Video-Driven Face Reenactment
- 基于神经网络的面部动画:通过目标身份的驱动序列来引导源人脸的动画,以实现头部和唇部运动的监督。
- 低维表示:例如面部标志点或学习到的关键点,用于测量从给定目标图像到源图像的变形。
3. Multi-scale Data Processing
- 多尺度特征层次:在计算机视觉任务中,如目标检测或语义分割,已成为标准做法。
- 生成模型中的多尺度方法:可以在GANs的判别器网络中实现,以改善生成数据的多尺度忠实度,也可以在生成模型本身中实现。
4. 具体相关研究和方法
- Wav2Lip:使用预训练的唇部同步专家来学习音频-视觉同步,并在视觉配音任务中取得了最先进的性能。
- PC-AVS、EAMM:能够产生头部姿态的方法,尽管头部姿态的产生较为有限。
- MakeItTalk、Audio2Head、SadTalker:这些方法能够输出头部姿态,并且在处理头部运动方面取得了一定的成功。
这些相关研究为本文提出的多尺度音频-视觉同步损失和多尺度自回归生成对抗网络提供了背景和对比,展示了在生成与输入音频信号同步的头部和唇部运动方面的最新进展和挑战。
Q: 论文如何解决这个问题?
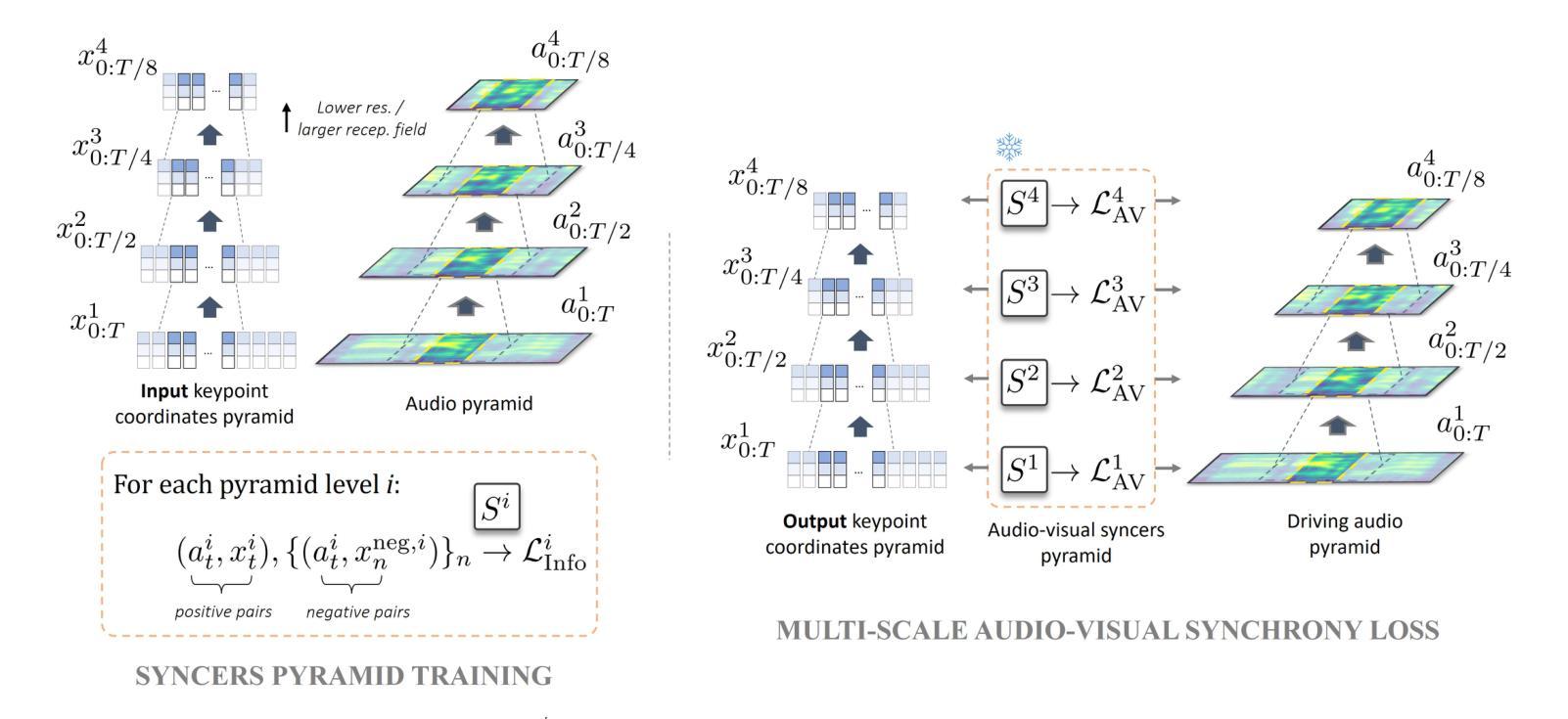
A: 论文通过以下几个关键步骤解决了同步音频信号与头部和嘴唇动作的问题:
1. 多尺度音频-视觉同步损失(Multi-scale Audio-Visual Synchrony Loss)
- 金字塔同步器(Syncer Models):提出了一个金字塔结构的同步器模型,这些模型在多模态输入金字塔上进行训练,用以评估音频输入与整个面部动态(包括头部和嘴唇)在不同时间尺度上的相关性。
- 高斯金字塔:利用高斯金字塔对头部动态和音频进行多尺度表示,以捕捉从高频到低频的各种动态。
- 对比损失(Contrastive Losses):使用对比损失训练同步器网络,最大化同步音频-视觉片段与非同步片段之间的区分度。
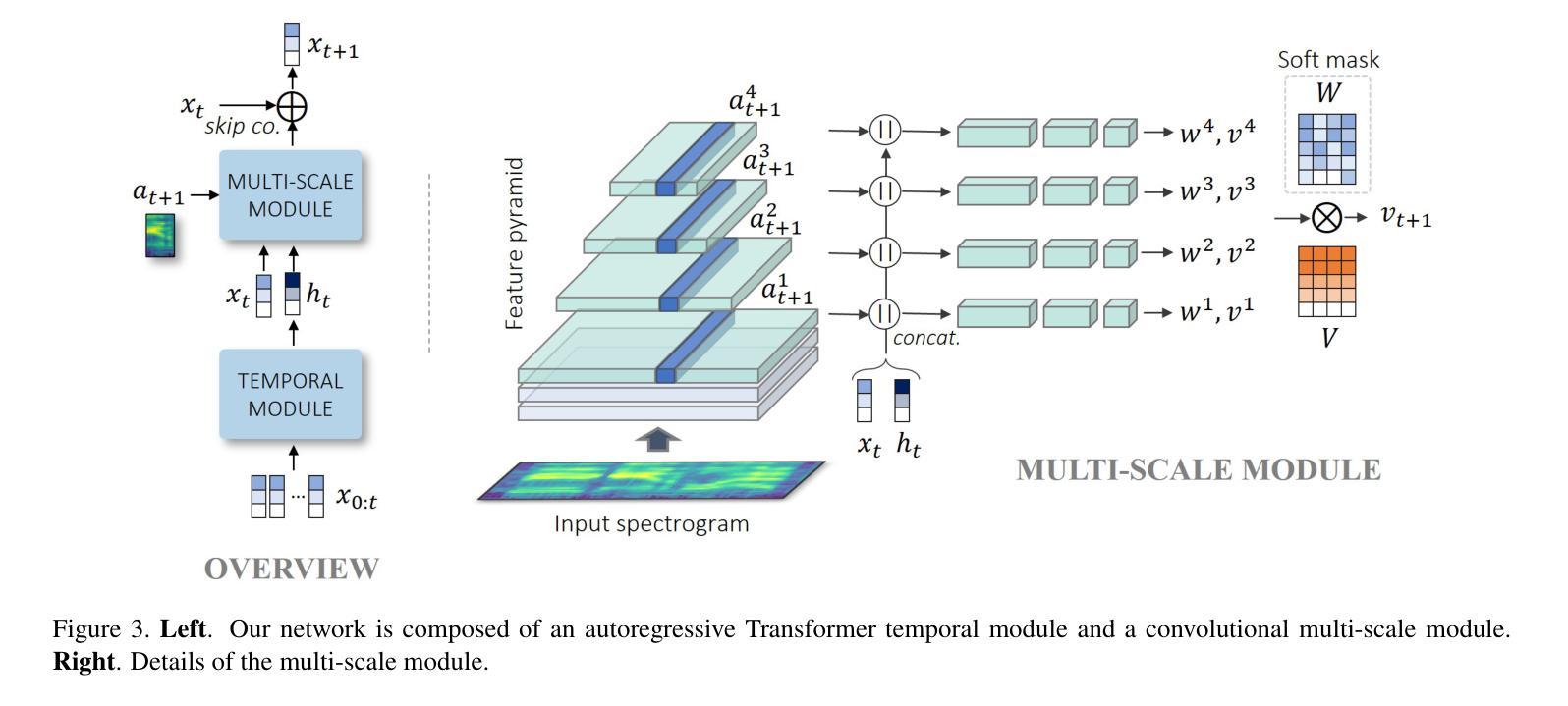
2. 多尺度自回归生成器(Multi-scale Autoregressive Generator)
- 残差自回归公式:生成器网络采用残差自回归结构,根据当前的关键点位置和下一时间步的音频输入来预测即时速度。
- 特征金字塔网络(FPN):多尺度模块基于特征金字塔网络实现,允许不同层次的损失项在网络的不同层级上发挥作用。
- 独立全连接分支:每个分支处理不同分辨率的输入,以产生不同频率的运动,并通过可学习的软空间掩码合并输出。
3. 整体架构和训练
- 判别器网络:使用两个判别器网络来提高生成关键点的静态和动态质量。
- 对抗性损失和重建损失:结合对抗性损失和重建损失,通过权重平衡这些损失项,以达到最佳的训练效果。
4. 实验验证
- 基准数据集:在多个基准数据集上进行实验,验证所提出方法在头部运动动态质量和多尺度音频-视觉同步性方面相对于现有技术的优势。
- 消融研究:通过消融研究来评估多尺度音频-视觉同步损失对模型性能的影响。
通过这些方法,论文成功地展示了一个能够处理短时和长时相关性、并生成与输入语音信号同步的自然头部和唇部运动的框架。此外,所提出的多尺度音频-视觉同步损失是一个独立的贡献,可以融合到不同的生成模型架构中,使其成为一个用于音频驱动的头部运动生成的多功能工具。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出方法(MS-Sync)的有效性,这些实验包括:
1. 实验协议(Experimental Protocol)
- 数据集:使用了VoxCeleb2数据集的两个不同预处理版本(VoxCeleb2 (I) 和 VoxCeleb2 (II)),HDTF数据集和LRS2数据集进行实验。
- 基准模型:与现有的多种一次性说话头像生成模型进行比较,包括Wav2Lip、IP_LAP、PC-AVS、EAMM、MakeItTalk、Audio2Head和SadTalker等。
- 训练细节:详细描述了模型的训练过程,包括使用的优化器、学习率和训练迭代次数等。
2. 图像域音频-视觉同步(Image-Domain AV Synchrony)
- 协议:使用标准指标(如SyncNet的绝对偏移|AV-Off|和置信度AV-Conf,以及正面化地标距离LMD)在VoxCeleb2 (I)和LRS2数据集上评估音频-视觉同步性。
- 结果:MS-Sync在多个指标上表现良好,特别是在SyncNet的置信度分数上显著优于其他方法。
3. 语音和刚性头部运动之间的多尺度相关性
- 协议:探索了语音和头部运动之间的相关性,使用在VoxCeleb2 (II)和HDTF数据集上训练的同步器网络来评估不同时间尺度上的音频-视觉同步性。
- 结果:MS-Sync在所有尺度上的表现均优于其他方法,表明该方法能够在多个时间尺度上成功地生成与音频输入时间对齐的头部运动。
4. 视觉质量(Visual Quality)
- 定量结果:使用Fréchet Inception Distance(FID)来衡量输出序列的视觉质量,并与其他方法进行比较。
- 定性比较:展示了MS-Sync在处理困难样本(如初始帧中嘴巴大张或眼睛闭合的情况)时的定性结果,并与其他方法进行了比较。
5. 消融研究(Ablation Study)
- 损失函数的权重:研究了对抗性损失和重建损失项对视觉质量和音频-视觉同步性的影响。
- 多尺度AV损失的影响:评估了使用多尺度AV损失与仅在最细尺度上强制同步的效果,证明了多尺度损失在长距离音频-视觉同步性方面的优势。
这些实验全面地评估了MS-Sync模型在音频-视觉同步性和视觉质量方面的表现,并与现有技术进行了比较,证明了所提出方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
1. 模型泛化能力
- 对不同身份和表情的泛化:研究模型对未见身份和不同表情的泛化能力,特别是在处理多样化数据集时的表现。
- 跨数据集泛化:测试模型在不同来源的数据集间的泛化能力,例如从电影、访谈到新闻播报等不同类型的视频。
2. 错误累积和序列长度
- 延长输出序列:探索模型在更长视频序列上的表现,以及如何减少连续自回归模型中的错误累积问题。
- 模型鲁棒性:研究模型对于输入噪声和不完美对齐的鲁棒性,并开发策略来提高模型的稳定性和鲁棒性。
3. 多模态融合和表示学习
- 更深层次的多模态融合:探索音频和视觉数据之间更深层次的融合方式,以提高同步精度和自然度。
- 无监督和自监督学习:研究无监督或自监督学习策略,以减少对大量标注数据的依赖。
4. 计算效率和实时应用
- 计算资源优化:优化模型结构和训练过程,以减少计算资源消耗,使其适用于实时应用或资源受限的环境。
- 移动端部署:研究模型压缩和加速技术,以便在移动设备或嵌入式系统上部署。
5. 交互式应用和用户控制
- 用户控制的面部动画:开发交互式应用,允许用户通过语音指令或其他输入控制面部动画的特定方面,如情感表达或头部姿态。
- 个性化和定制化:探索个性化模型训练技术,使用户能够定制和优化模型以适应自己的特定需求。
6. 伦理和隐私问题
- 数据隐私和安全性:研究数据隐私保护措施,确保用户数据的安全和合规性。
- 伦理使用指南:探讨深度伪造技术(deepfakes)的伦理问题,制定使用指南和政策,防止滥用。
7. 跨模态转换和生成
- 语音到面部动作的直接映射:研究从语音直接生成面部动作的模型,无需额外的音频特征提取。
- 多模态数据生成:探索生成与输入音频同步的面部表情和头部动作的同时,生成相应的语音或文本。
这些探索点可以帮助推动音频-视觉同步技术和应用的发展,同时解决实际应用中遇到的挑战。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
研究问题:论文针对的是在生成逼真的说话头像时,如何同步音频信号与头部和嘴唇动作,尤其是自然头部运动的生成以及头部运动与语音之间的音频-视觉相关性。
方法论:
- 提出了一个多尺度音频-视觉同步损失函数,通过训练一系列同步器模型(syncer models)在多模态输入金字塔上,以评估音频输入与整个面部动态(包括头部和嘴唇)在不同时间尺度上的相关性。
- 构建了一个多尺度自回归生成对抗网络(Multi-Scale Autoregressive GAN),称为MS-Sync,以处理短时和长时相关性,并生成跨不同时间尺度的音频对齐运动。
技术贡献:
- 首次训练音频-视觉同步器网络来测量头部运动与语音之间的相关性。
- 提出了一个多尺度音频-视觉同步损失,以生成与音频相关的多样化面部动态。
- 构建了一个有效的多尺度自回归GAN框架,通过广泛的实验展示了其在生成与语音同步的头部和嘴唇运动方面的优势。
实验验证:
- 在VoxCeleb2、HDTF和LRS2等多个基准数据集上进行了实验,验证了MS-Sync在头部运动动态质量和多尺度音频-视觉同步性方面相对于现有技术的优势。
- 进行了消融研究,证明了多尺度音频-视觉同步损失对模型性能的积极影响。
讨论与局限性:
- 论文讨论了MS-Sync框架的有效性,并指出了其局限性,如连续自回归模型中可能出现的错误累积问题,以及对互联网图片的敏感性。
- 论文还提出了可能的改进方向,包括通过传播视觉损失梯度来减轻这些问题。
结论:
- 论文得出结论,MS-Sync是第一个尝试在多个尺度上学习和建模音频-视觉相关性以生成说话头像的方法,实验结果非常鼓舞人心,并预见了这种方法在其他视听生成任务上的潜在应用。
总体而言,这篇论文提出了一个创新的多尺度方法来生成与输入语音同步的头部和唇部动作,为提高生成逼真说话头像的质量提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图