⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Go With the Flow: Fast Diffusion for Gaussian Mixture Models
Authors:George Rapakoulias, Ali Reza Pedram, Panagiotis Tsiotras
Schr"{o}dinger Bridges (SB) are diffusion processes that steer, in finite time, a given initial distribution to another final one while minimizing a suitable cost functional. Although various methods for computing SBs have recently been proposed in the literature, most of these approaches require computationally expensive training schemes, even for solving low-dimensional problems. In this work, we propose an analytic parametrization of a set of feasible policies for steering the distribution of a dynamical system from one Gaussian Mixture Model (GMM) to another. Instead of relying on standard non-convex optimization techniques, the optimal policy within the set can be approximated as the solution of a low-dimensional linear program whose dimension scales linearly with the number of components in each mixture. Furthermore, our method generalizes naturally to more general classes of dynamical systems such as controllable Linear Time-Varying systems that cannot currently be solved using traditional neural SB approaches. We showcase the potential of this approach in low-to-moderate dimensional problems such as image-to-image translation in the latent space of an autoencoder, and various other examples. We also benchmark our approach on an Entropic Optimal Transport (EOT) problem and show that it outperforms state-of-the-art methods in cases where the boundary distributions are mixture models while requiring virtually no training.
薛定谔桥(Schrödinger Bridges,简称SB)是一种扩散过程,能够在有限时间内将给定的初始分布引导到另一个最终分布,同时最小化适当的成本函数。尽管最近在文献中提出了多种计算SB的方法,但大多数这些方法都需要计算昂贵的训练方案,即使对于解决低维问题也是如此。在这项工作中,我们提出了一组可行策略的解析参数化,以引导动力系统从一个高斯混合模型(Gaussian Mixture Model,简称GMM)分布到另一个GMM分布。我们并没有依赖标准的非凸优化技术,而是将集合中的最佳策略近似为低维线性程序的解,其维度与每个混合中的组件数成线性关系。此外,我们的方法自然地推广到更一般的动力系统类,如目前无法使用传统神经SB方法解决的可控线性时变系统。我们通过潜在空间自动编码器的图像到图像翻译以及其它各种示例来展示此方法的潜力。此外,我们在熵最优传输(EOT)问题上对我们的方法进行了基准测试,并显示它在边界分布为混合模型的情况下优于最新技术,并且几乎不需要进行训练。
论文及项目相关链接
Summary
本文提出了一种基于高斯混合模型(GMM)的Schrödinger桥(SB)的解析参数化方法,用于在有限时间内将一个初始分布导向另一个目标分布。通过线性规划近似最优策略,这种方法能在低维问题中快速求解,并自然推广到更一般的动力系统,如可控的线性时变系统。该方法在图像域转换等领域具有潜在应用价值,并在边界分布为混合模型的情况下,表现优于现有技术且几乎无需训练。
Key Takeaways
- 引入Schrödinger桥(SB)作为引导动态系统在有限时间内从一个初始分布转移到另一个目标分布的扩散过程。
- 提出一种基于高斯混合模型(GMM)的SB解析参数化方法。
- 利用低维线性规划近似求解最优策略,其维度与混合中的组件数量成线性关系。
- 方法自然推广到更一般的动力系统,如可控的线性时变系统。
- 在图像域转换等低至中等维度的应用中具有潜在价值。
- 在边界分布为混合模型的情况下,该方法表现优于现有技术。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的方法来解决Schrödinger桥问题(SB),特别是当边界分布是高斯混合模型(Gaussian Mixture Models, GMM)时。Schrödinger桥问题是一种扩散过程,它在有限时间内将一个给定的初始分布引导到另一个最终分布,同时最小化一个合适的成本函数。具体来说,论文试图解决的问题包括:
高维问题中的计算成本:尽管已有多种计算SB的方法,但这些方法大多需要计算成本高昂的训练方案,即使是在低维问题中也是如此。
对动态系统的推广:论文提出的方法不仅适用于简单的动态系统,还可以自然地推广到更一般的动态系统,例如可控的线性时变系统,这些系统在传统的基于神经网络的SB方法中目前还无法解决。
训练效率和准确性:论文展示的方法在训练速度和学习到的边界分布的准确性方面都优于现有的最先进方法,特别是在边界分布通过样本提供时。
实际应用:通过在低到中等维度的问题(例如在自动编码器的潜在空间中的图像到图像的翻译)和各种其他例子中展示这种方法的潜力,论文强调了其在从生成性AI到控制理论等多个领域的实际应用潜力。
总的来说,论文旨在提供一个快速、无需训练的方法来解决高斯混合模型边界分布的Schrödinger桥问题,并展示了该方法在多个领域的应用前景。
Q: 有哪些相关研究?
A: 论文中提到了多个与Schrödinger桥问题(SB)和最优传输(OT)问题相关的研究工作,以下是一些主要的相关研究:
Dynamic Iterative Proportional Fitting Method (IPF):
- Chen et al. (2016a), Pavon et al. (2021), De Bortoli et al. (2021) 提出了动态迭代比例拟合方法(IPF),这是一种早期解决SB问题的方法。
基于随机微分方程(SDEs)的方法:
- Chen et al. (2022), Liu et al. (2022b) 提出了利用前后向随机微分方程(SDEs)来局部解决最优性条件问题的方法,即Hamilton-Jacoby-Bellman (HJB) 和 Fokker-Plank-Kolmogorov (FPK) 偏微分方程(PDEs)。
Wasserstein Proximal recursion算法:
- Caluya & Halder (2021), Bunne et al. (2022) 提出了一种Wasserstein近端递归算法,通过解决一系列初始值问题来近似求解问题(3)。
基于参数化的方法:
- De Bortoli et al. (2021) 使用神经网络作为参数化函数逼近器来近似最优漂移函数。
- Pavon et al. (2021) 探索了使用基函数进行参数化的方法。
模拟自由方法:
- Chen et al. (2016b), Lipman et al. (2023), Liu et al. (2023) 提出了模拟自由方法,利用问题(3)的性质,例如将最优概率流分解为条件问题,有时甚至可以解析求解。
Gaussian Mixture Models (GMM):
- Korotin et al. (2024), Gushchin et al. (2024) 使用高斯混合模型来参数化Schrödinger势,提供了一种轻量级的SB求解器。
其他相关工作:
- Albergo & Vanden-Eijnden (2023) 开发了一种使用随机插值的正态化流构建方法。
- Balci & Bakolas (2023) 探索了使用条件高斯概率流构造SDEs的概念。
- Brigo (2002), Brigo et al. (2002) 在数学金融应用中讨论了构建SDEs作为高斯概率流的混合的概念。
这些研究为解决SB问题提供了不同的视角和方法,包括动态规划、随机控制、优化技术以及机器学习技术。论文提出的方法在这些现有工作的基础上,提供了一种新的解析参数化方法,特别适用于处理高斯混合模型边界分布的问题。
Q: 论文如何解决这个问题?
A: 论文提出了一种新的解析参数化方法来解决Schrödinger桥问题(SB),特别是当边界分布是高斯混合模型(GMM)时。具体解决方案如下:
混合策略构建:
- 论文提出了一种混合策略,该策略由条件策略组成,每个条件策略解决一个高斯桥子问题。具体来说,对于初始和最终的高斯混合模型中的每个组分对,都有一个条件策略将初始组分引导到最终组分。
- 这些条件策略被加权平均,形成整体策略,权重由转移概率决定。
解析参数化:
- 与依赖于标准非凸优化技术的现有方法不同,该方法通过解析参数化一组可行策略,允许在策略集合中近似最优策略。
- 这个最优策略可以通过解决一个低维线性规划问题来近似,其维度与每个混合模型中的组分数线性相关。
线性规划优化:
- 论文提出了一个线性规划问题,通过最小化一个上界来找到最优的权重λij,使得混合策略的成本最小化。
- 这个线性规划问题的解提供了原SB问题的可行解的上界,并且可以证明这个上界是紧的。
动态系统的推广:
- 该方法不仅适用于简单的动态系统,还可以自然地推广到更一般的动态系统,例如可控的线性时变(LTV)系统。
实验验证:
- 论文通过在低维玩具问题、中等维数的图像到图像翻译任务以及熵最优传输(EOT)基准测试中展示该方法的性能,证明了其在训练速度和学习到的边界分布的准确性方面优于现有方法。
无需训练的优势:
- 与需要大量计算资源来训练神经网络的现有方法不同,该方法通过解析方式近似最优策略,几乎不需要训练,这在计算效率上具有明显优势。
总结来说,论文通过构建混合策略、解析参数化和线性规划优化,提出了一种高效且准确的解决SB问题的新方法,特别是在处理高斯混合模型边界分布时。这种方法不仅计算效率高,而且可以推广到更广泛的动态系统,具有很好的应用前景。
Q: 论文做了哪些实验?
A: 论文中进行了多个实验来验证所提出方法的有效性,具体实验包括:
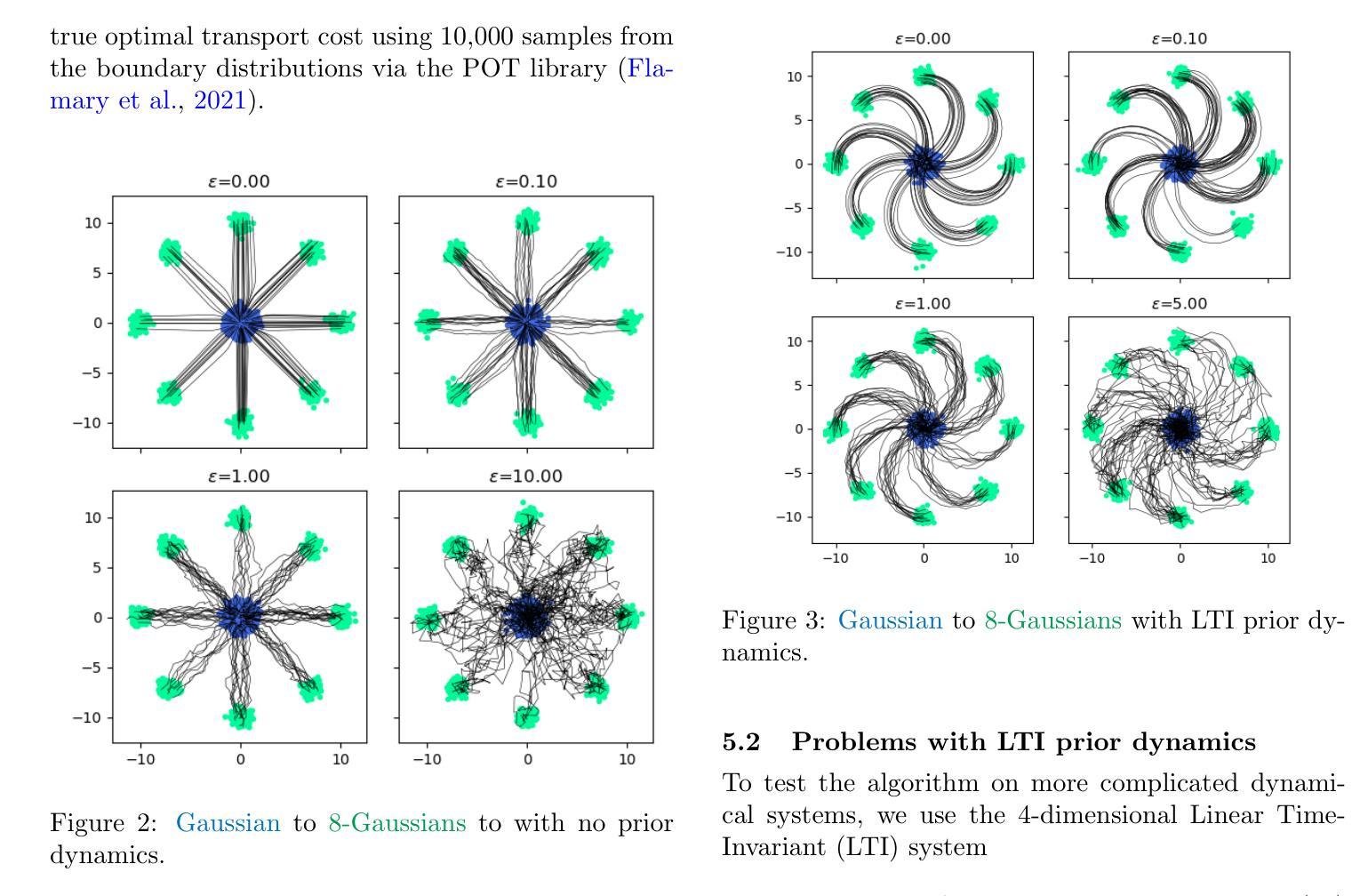
2D问题实验:
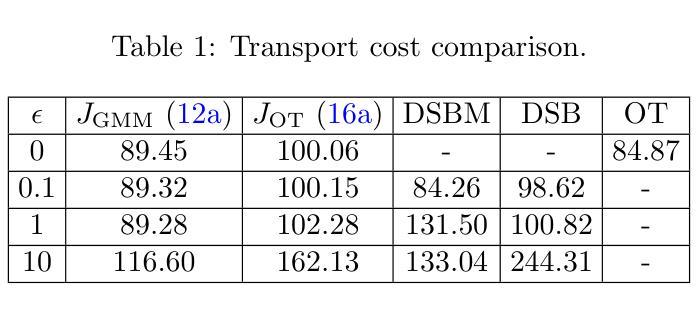
- 在二维玩具问题中测试算法,包括边界混合模型明确已知的情况。通过比较不同噪声水平下的传输成本,并与现有的最先进方法Diffusion Schrödinger Bridge (DSB) 和 Diffusion Schrödinger Bridge Matching (DSBM) 进行比较。
具有LTI先验动态的问题实验:
- 在更复杂的动态系统中测试算法,特别是4维线性时不变(LTI)系统。展示了该方法在处理具有不同信道的控制信号和随机扰动的系统的能力,这类系统在主流神经网络SB求解器中无法解决。
EOT基准测试:
- 在熵最优传输(EOT)基准测试中评估算法的性能。这些基准测试提供了边界测试分布,允许直接与所提出的方法进行比较。使用Bures-Wasserstein Unexplained Variance Percentage (cBW-UVP) 度量来评估方法的最优性。
图像到图像的翻译实验:
- 虽然混合模型不旨在捕捉高维分布如图像,但论文在自动编码器的潜在空间中使用算法执行从男性到女性和从成人到儿童的图像翻译任务。使用预训练的ALAE自动编码器,并在FFHQ数据集上进行实验。通过计算Fréchet inception distance (FID) 分数和ALAE-BW2分数来评估生成图像的质量,并与现有的最先进轻量级SB求解器进行比较。
这些实验覆盖了从低维到中等维数的问题,并展示了所提出方法在不同场景下的性能和适用性。通过这些实验,论文证明了其方法在训练速度和准确性方面优于现有方法,并且在实际应用中具有潜力。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的方法来解决高斯混合模型边界分布的Schrödinger桥问题,并在多个实验中展示了其潜力,但仍有一些方向可以进一步探索和研究:
算法的扩展性:
- 探索该方法在更高维度问题中的应用,例如在更大的图像数据集或更复杂的动态系统中。
算法的泛化能力:
- 研究该方法在处理非高斯分布或其他类型的混合模型时的表现和适用性。
算法的计算效率:
- 进一步优化算法的计算效率,尤其是在大规模问题中,以减少训练和推理时间。
算法的鲁棒性:
- 研究算法对于数据噪声、初始条件和模型参数变化的敏感性和鲁棒性。
与其他方法的结合:
- 探索将该方法与其他类型的SB求解器(如基于神经网络的方法)结合的可能性,以利用各自的优势解决更广泛的问题。
理论分析:
- 对算法的理论性能进行更深入的分析,包括收敛速度和误差界限。
实际应用中的测试:
- 在更多的实际应用中测试该方法,如在生物信息学、金融风险管理等领域,以验证其实际效果和适用性。
算法的实现和优化:
- 开发更高效的算法实现,可能包括并行计算和硬件加速。
算法的可解释性:
- 提高算法的可解释性,以便更好地理解其工作原理和决策过程。
算法的适应性:
- 研究算法对于动态变化环境的适应性,特别是在实时应用中。
这些方向不仅可以推动Schrödinger桥问题的研究进展,还可能为相关领域的研究和应用提供新的视角和工具。
Q: 总结一下论文的主要内容
A: 论文《Go With the Flow: Fast Diffusion for Gaussian Mixture Models》主要研究了如何快速解决具有高斯混合模型(GMM)边界分布的Schrödinger桥问题(SB)。以下是论文的主要内容总结:
问题背景:
- 论文首先介绍了Schrödinger桥问题,这是一种在有限时间内将一个给定的初始分布引导到另一个最终分布的扩散过程,同时最小化一个合适的成本函数。
现有方法的局限性:
- 论文指出现有的SB计算方法大多需要计算成本高昂的训练方案,即使是在低维问题中也是如此。
新方法提出:
- 论文提出了一种解析参数化方法,用于引导动态系统的分布从一个高斯混合模型(GMM)到另一个GMM。
- 该方法不依赖于标准的非凸优化技术,而是通过解决一个低维线性规划问题来近似最优策略。
方法的一般性:
- 论文展示该方法不仅适用于简单的动态系统,还可以自然地推广到更一般的动态系统,如可控的线性时变系统。
实验验证:
- 论文通过在低维玩具问题、图像到图像的翻译任务以及熵最优传输(EOT)基准测试中的实验,验证了所提方法的有效性。
- 实验结果表明,该方法在训练速度和学习到的边界分布的准确性方面优于现有的最先进方法。
主要贡献:
- 提出了一种无需训练的高效方法来解决SB问题,特别是当边界分布是GMM时。
- 该方法可以处理随机和确定性版本的SB问题,并自然地推广到具有一般线性时变结构的动态系统。
- 在多个实验中展示了该方法在训练速度和准确性方面的优势。
结论:
- 论文得出结论,所提出的方法为解决SB问题提供了一种新的、高效的解决方案,具有在多个领域应用的潜力,从生成性建模到控制理论。
总体而言,论文提出了一种创新的方法来解决SB问题,特别是在处理高斯混合模型边界分布时,展示了其在计算效率和准确性方面的优势,并证明了其在多个领域的应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Beyond Knowledge Silos: Task Fingerprinting for Democratization of Medical Imaging AI
Authors:Patrick Godau, Akriti Srivastava, Tim Adler, Lena Maier-Hein
The field of medical imaging AI is currently undergoing rapid transformations, with methodical research increasingly translated into clinical practice. Despite these successes, research suffers from knowledge silos, hindering collaboration and progress: Existing knowledge is scattered across publications and many details remain unpublished, while privacy regulations restrict data sharing. In the spirit of democratizing of AI, we propose a framework for secure knowledge transfer in the field of medical image analysis. The key to our approach is dataset “fingerprints”, structured representations of feature distributions, that enable quantification of task similarity. We tested our approach across 71 distinct tasks and 12 medical imaging modalities by transferring neural architectures, pretraining, augmentation policies, and multi-task learning. According to comprehensive analyses, our method outperforms traditional methods for identifying relevant knowledge and facilitates collaborative model training. Our framework fosters the democratization of AI in medical imaging and could become a valuable tool for promoting faster scientific advancement.
医学影像人工智能领域正在经历快速变革,方法论研究正逐步转化为临床实践。尽管已经取得了这些成果,但研究仍然面临着知识孤岛问题,阻碍了协作和进步:现有知识散见于各出版物中,许多细节尚未公布,同时隐私法规限制了数据共享。本着人工智能民主化的精神,我们提出了一个医学影像分析领域的安全知识转移框架。我们方法的关键是数据集“指纹”,即特征分布的结构化表示,它能够实现任务相似性的量化。我们通过迁移神经网络架构、预训练、增强策略和多任务学习,在71项不同任务和12种医学影像模态上测试了我们的方法。综合分析表明,我们的方法在识别相关知识和促进协同模型训练方面优于传统方法。我们的框架推动了医学影像人工智能的民主化,并可能成为推动科学快速发展的有价值工具。
论文及项目相关链接
Summary
医疗影像人工智能领域正经历快速变革,研究方法逐渐转化为临床实践。然而,知识孤岛问题阻碍了该领域的协作和进步,现有知识散见于出版物且许多细节尚未公开,隐私法规也限制了数据共享。为推进人工智能的民主化,我们提出一个医学图像分析领域的安全知识转移框架。该框架的关键在于数据集“指纹”,即特征分布的结构化表示,可量化任务相似性。通过在不同任务和医学成像模态下测试神经网络架构、预训练、增强策略和多任务学习,我们的方法表现优于传统方法,有助于识别相关知识和协作模型训练。该框架促进了医疗影像人工智能的民主化,可成为推动科学快速发展的宝贵工具。
Key Takeaways
- 医疗影像AI领域正经历快速变革,研究方法逐渐向临床实践转化。
- 知识孤岛问题阻碍了医疗影像AI领域的协作和进步。
- 现有知识散见于出版物,许多细节尚未公开。
- 隐私法规限制了医疗影像数据共享。
- 提出一个医学图像分析的安全知识转移框架,通过数据集“指纹”量化任务相似性。
- 该框架在多种任务和医学成像模态下测试表现优异,优于传统方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是医学影像人工智能(AI)领域中的知识孤岛问题。具体来说,论文指出了以下几个关键问题:
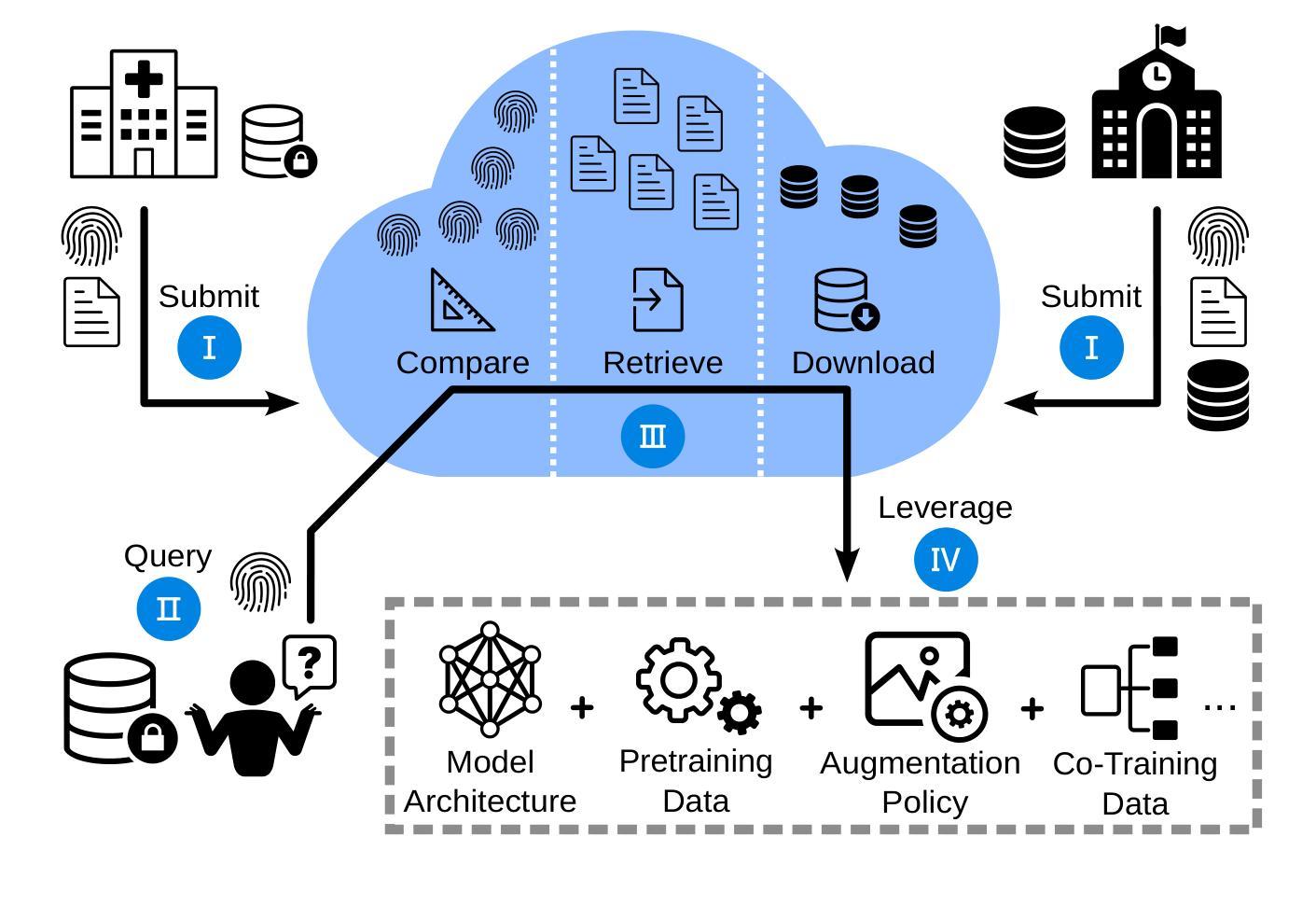
知识分散和隐私限制:在医学影像AI领域,由于隐私法规和数据共享限制,研究成果和知识常常分散在各种出版物中,许多细节未被公开,导致难以有效利用已有的研究成果。
数据孤岛:由于严格的隐私法规和高昂的标注成本,研究人员倾向于建立独立的私有数据集,导致知识被局限在个别研究者和实验室中,阻碍了科学进步和合作。
知识转移的挑战:选择合适的预训练模型、数据增强策略和神经网络架构对于新任务来说是一个耗时的过程,而且存在选择不恰当源任务导致的负面转移风险。
任务匹配的效率和隐私:在进行知识转移时,需要一种有效的方法来匹配源任务和目标任务,同时要考虑到数据隐私保护和计算复杂性。
为了解决这些问题,论文提出了一种名为“任务指纹”(task fingerprinting)的框架,旨在通过安全的知识转移促进AI在医学影像领域的民主化。该框架通过创建数据集的“指纹”——结构化的特征分布表示——来量化任务之间的相似性,从而实现知识的共享和转移,同时遵守隐私法规。
Q: 有哪些相关研究?
A: 论文中提到了多个与任务指纹和知识转移相关的研究工作,以下是一些主要的相关研究:
Transfer Learning: 论文提到了Transfer Learning的概念,可以追溯到1970年代,涉及从源任务到目标任务的知识转移。特别提到了预训练在大规模数据集上的模型,如ImageNet [2],作为加速模型收敛的常用实践。
Task Transferability Estimation (TTE): 论文讨论了TTE的研究,旨在量化任务之间知识转移的潜力。提到了一些关键的研究工作,例如:
- [9] Achille et al. 提出了学习任务的信息复杂性、它们的结构和它们之间的距离。
- [10] Ben-David et al. 分析了领域适应中的表示。
- [16] Molina-Moreno et al. 自动化选择用于生物医学成像的带注释预训练数据库。
- [17] Ramtoula et al. 提出了Visual DNA (VDNA),用于表示和比较图像。
Knowledge Transfer in Medical Imaging: 论文中提到了在医学影像领域内进行知识转移的研究,强调了将通用模型适应到特定下游任务的挑战:
- [6] Raghu et al. 讨论了医学影像中的迁移学习。
- [26] Godau et al. 提出了一种用于生物医学图像分析中的元学习的任务指纹方法。
Automated Machine Learning (AutoML): 论文提到了AutoML,旨在自动化机器学习算法的配置,包括数据预处理、特征工程和超参数优化。这与任务指纹的目标相似,即通过解决ML中的复杂步骤来实现AI的民主化。
Federated Learning: 论文讨论了Federated Learning作为一种保护数据隐私的协作学习方法,但也提到了它在同步、信任建立和准备方面的额外负担。
Foundation Models: 论文提到了最近出现的Foundation Models,这些模型通过大规模预训练可能弥合医学影像中不同模态之间的差距。
这些研究为任务指纹框架提供了理论基础和实践案例,展示了在医学影像AI领域中进行有效知识转移的潜力和挑战。论文通过与这些相关研究的比较,展示了其提出方法的优势和创新点。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为“任务指纹”(task fingerprinting)的框架来解决医学影像AI领域中的知识孤岛问题。具体来说,该框架通过以下几个步骤实现知识的安全转移和协作:
1. 任务指纹的创建
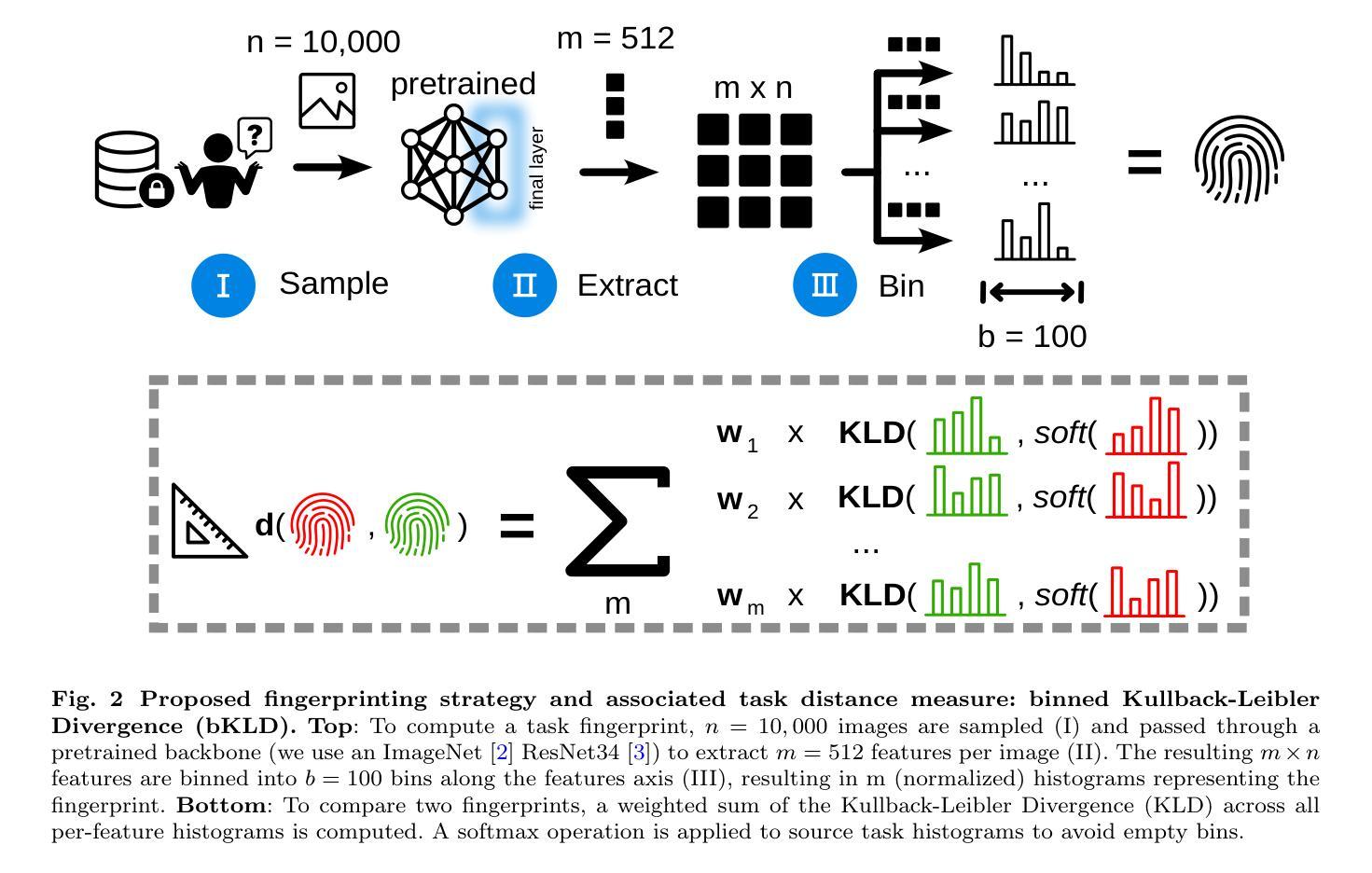
- 核心思想:任务指纹是从数据集中提取的、能够代表该任务特征的结构化表示。这些指纹能够在不泄露隐私的情况下捕捉任务的关键信息。
- 方法:通过将大量图像样本通过预训练的神经网络(如ResNet34)提取特征,然后将这些特征值分配到均匀的箱子(bins)中,形成特征分布直方图。这些直方图构成了任务的指纹。
2. 知识云(Knowledge Cloud)
- 概念:知识云是一个存储模型训练经验和底层数据封装表示(即任务指纹)的平台。贡献者可以提交训练元信息和选择性共享底层数据。
- 查询和利用:用户可以通过生成自己任务的指纹来查询知识云,检索与自己任务最相关的训练策略和数据。
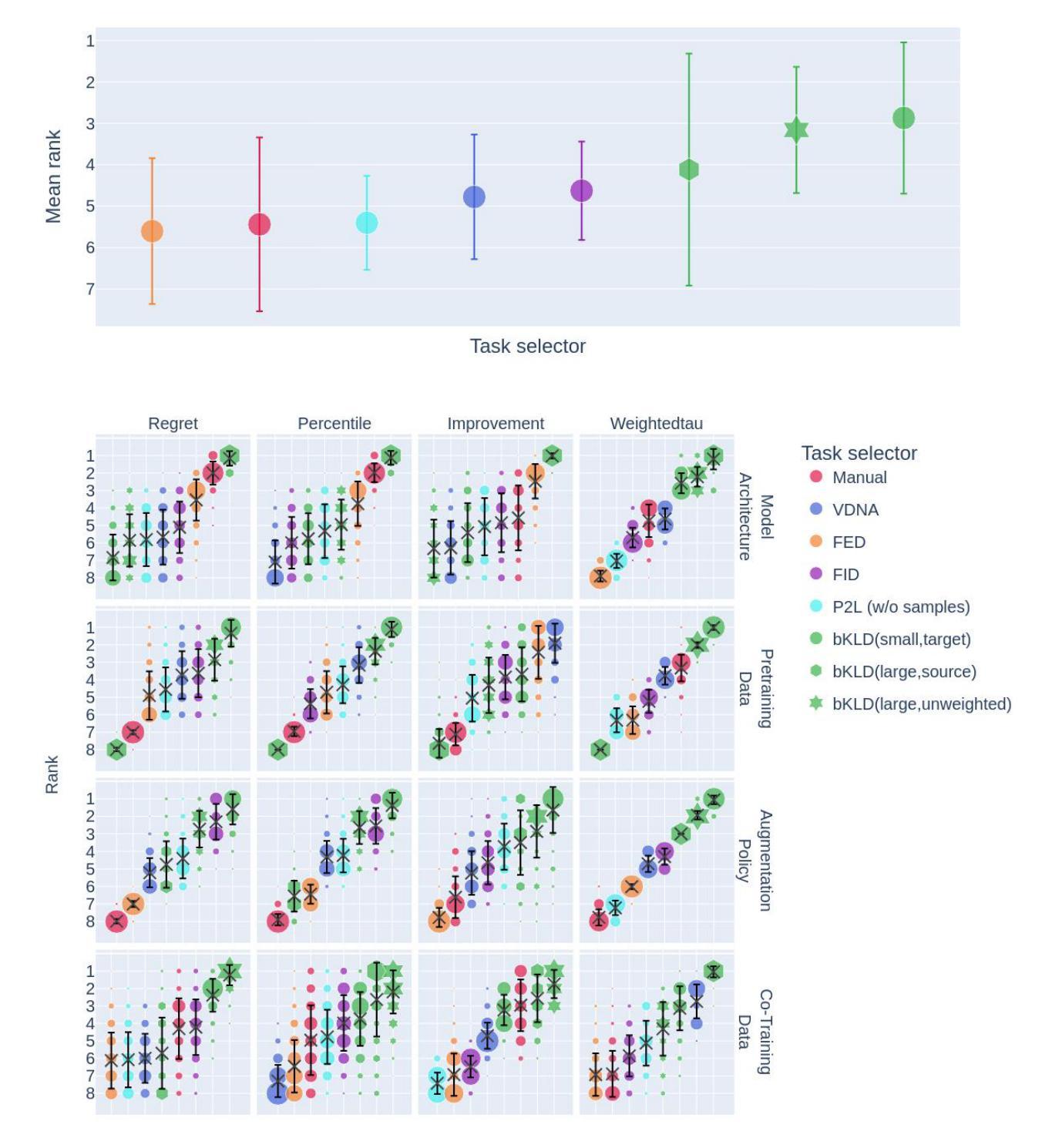
3. 任务距离度量(binned Kullback-Leibler Divergence, bKLD)
- 计算方法:提出了一种新的基于binning提取图像特征的任务距离度量方法,称为binned Kullback-Leibler Divergence(bKLD)。该方法通过计算两个任务指纹之间的Kullback-Leibler Divergence(KLD)的加权和来衡量任务之间的相似度。
- 优势:bKLD方法在计算效率和泛化能力方面表现出色,适用于不同的知识转移场景。
4. 知识转移场景
- 多样化应用:论文测试了四种不同的知识转移场景,包括模型架构转移、预训练数据、增强策略和共同训练数据,以验证任务指纹方法的有效性。
5. 实验验证
- 大规模实验:在71个不同的任务和12种医学影像模态上进行了实验,验证了该方法在异构任务集合上的有效性。
- 性能提升:通过与传统方法比较,证明了任务指纹方法在识别相关知识和促进协作模型训练方面的优势。
6. 开源和数据共享
- 代码和数据:论文提供了实验的代码、数据和中间结果,以促进社区的进一步研究和开发。
通过这种方法,论文旨在促进AI在医学影像领域的民主化,通过共享知识来加速科学进步,同时遵守数据隐私法规。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的任务指纹框架的有效性,具体实验包括:
1. 实验设置
- 任务池构建:作者收集了71个不同的、公开可用的数据集,覆盖了多种医学影像模态,以确保方法的广泛适用性。
- 任务分割:每个任务被分为训练集和测试集,比例为80:20,并确保类别分布均匀。
- 预处理:所有图像被处理为统一的分辨率(256×256像素),灰度图像被转换为RGB格式。
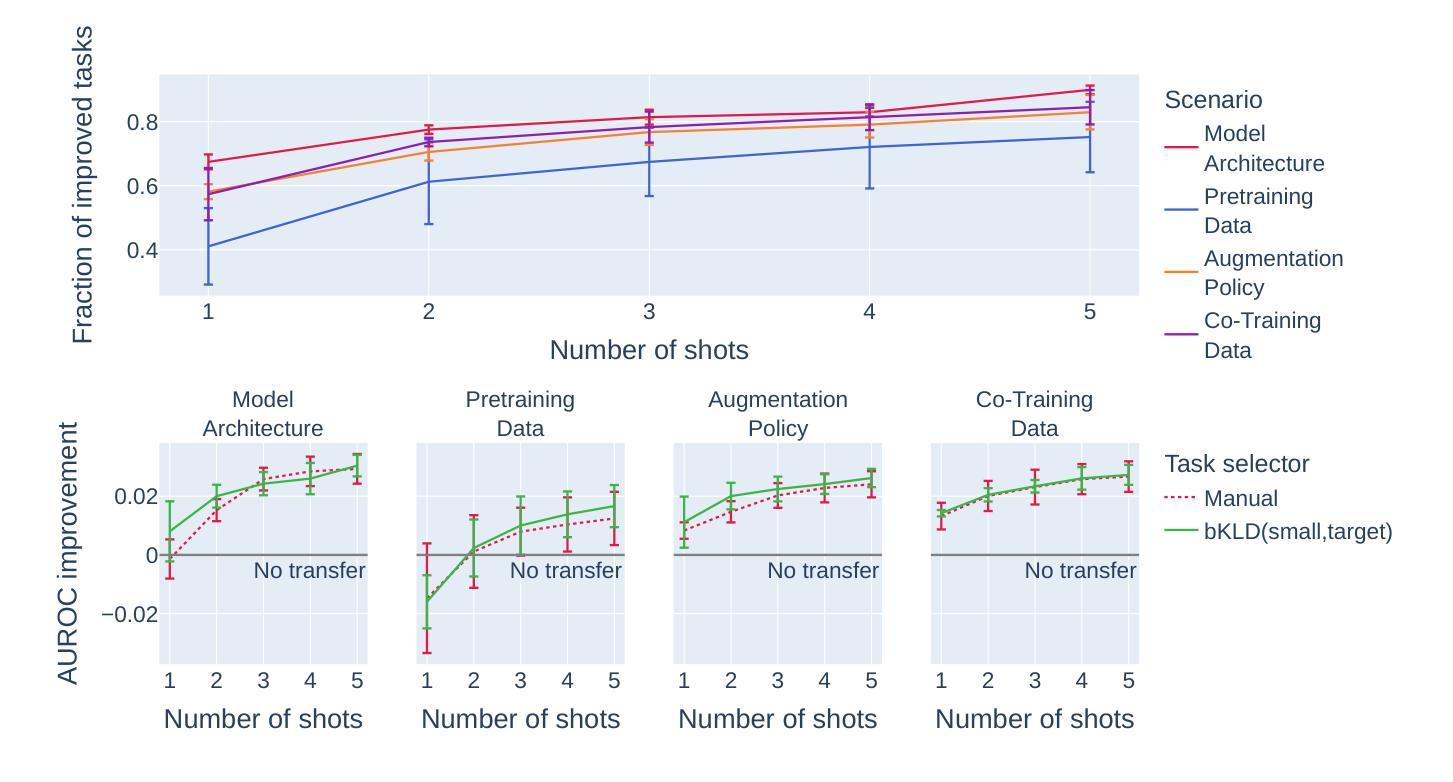
2. 知识转移场景设计
作者设计了四种知识转移场景,以覆盖不同的应用情况:
场景1:模型架构转移
- 使用源任务中表现最佳的神经网络架构来训练目标任务。
场景2:预训练数据
- 在源任务上预训练模型,然后在目标任务上进行微调。
场景3:增强策略
- 将源任务中自动学习到的数据增强策略应用到目标任务上。
场景4:共同训练数据
- 同时训练源任务和目标任务,共享神经网络的主干部分,但使用独立的分类头。
3. 单任务基线
- 作为对比,作者还训练了所有目标任务的“无转移”模型,以模拟在没有额外实验资源投入的情况下的模型性能。
4. 评估指标
- 使用平衡准确率(Balanced Accuracy, BA)和宏平均接收者操作特征曲线下面积(macro averaged Area Under the Receiver Operating Characteristic, AUROC)作为主要的性能评估指标。
5. 元指标
- 为了评估任务选择器的质量,作者使用了多种元指标,包括改进度量、百分位数、遗憾度量和增益度量。
6. 实验执行
- 作者训练了超过30,000个神经网络模型,仅用于评估部分,大约消耗了10,000 GPU小时的训练资源。
7. 与现有方法的比较
- 作者将提出的binned Kullback-Leibler Divergence(bKLD)任务距离度量与其他几种现有的任务相似性度量方法进行了比较,包括VisualDNA(VDNA)、Predict To Learn(P2L)、Fisher Embedding Distance(FED)和Fréchet Inception Distance(FID)。
8. 鲁棒性测试
- 作者还测试了不同任务大小对任务指纹方法的影响,以验证其在小样本情况下的鲁棒性。
这些实验全面地验证了任务指纹框架在不同知识转移场景下的有效性和鲁棒性,并与现有的方法进行了比较,展示了其在医学影像AI领域中的潜力。
Q: 有什么可以进一步探索的点?
A: 论文提出了任务指纹框架来促进医学影像AI领域的知识转移和合作,尽管取得了一定的成果,但仍有一些方面可以进一步探索和研究:
1. 多模态数据集成
- 论文中提到了将不同模态的数据集成到指纹中的潜力,这可以作为未来工作的一个方向,特别是在医学影像领域,多模态数据的融合对于提高诊断的准确性和鲁棒性具有重要意义。
2. 知识云的实施
- 实际部署一个知识云平台,以便于跨机构研究和知识共享。这需要解决技术、法律和伦理等方面的问题。
3. 扩展任务类型和数量
- 论文中的实验主要基于分类任务,未来可以探索其他类型的任务(如分割、检测等)以及更多的目标任务,以进一步验证框架的泛化能力。
4. 纠缠转移场景
- 论文中对每个转移场景进行了单独的实验,未来可以探索同时转移多个组件(例如,同时进行预训练和数据增强)的效果。
5. 自动化和智能化的任务指纹生成
- 研究如何自动化和智能化地生成和优化任务指纹,以减少手动调整和实验的需求。
6. 恶意数据的预防措施
- 在公开设置中,系统可能面临恶意行为者提交虚假数据的风险,需要开发有效的预防和检测机制。
7. 跨领域的知识转移
- 探索任务指纹框架在非医学影像领域的应用,例如自然语言处理或语音识别,验证其跨领域的有效性。
8. 环境影响和能源消耗
- 考虑到训练大量模型对环境的影响,研究如何通过知识转移减少模型训练的能源消耗和碳足迹。
9. 持续学习和知识增长
- 探索如何利用任务指纹框架实现持续学习和知识增长,自动地从新数据和任务中学习,提高AI系统的长期可扩展性。
10. 与其他AI技术的集成
- 研究如何将任务指纹框架与其他AI技术(如联邦学习、自动化机器学习AutoML)集成,以提高整体系统的效率和效果。
这些方向不仅可以推动任务指纹框架的发展,还可能对医学影像AI乃至整个人工智能领域产生深远的影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为“任务指纹”(task fingerprinting)的框架,旨在解决医学影像人工智能(AI)领域中的知识孤岛问题,并促进知识的安全转移和合作。以下是论文的主要内容总结:
1. 问题识别
- 医学影像AI领域存在知识分散和数据隐私问题,限制了数据共享和研究合作。
- 缺乏有效的方法来量化任务之间的相似性,阻碍了知识的转移和模型训练的最佳实践的复用。
2. 任务指纹框架
- 提出了任务指纹的概念,即结构化的特征分布表示,用于捕捉任务的关键信息并量化任务相似性。
- 通过比较任务指纹,可以识别出与新任务最相关的现有知识和数据,以促进模型训练。
3. 知识云
- 建立了一个名为知识云的平台,存储模型训练经验和数据的封装表示,允许用户提交和查询相关知识和数据。
4. binned Kullback-Leibler Divergence (bKLD)
- 开发了一种新的任务距离度量方法bKLD,通过计算任务指纹之间的Kullback-Leibler Divergence来衡量任务相似度。
- bKLD考虑了特征值的分布,允许灵活的权重调整,以适应不同的知识转移场景。
5. 实验验证
- 在71个不同任务和12种医学影像模态上进行了实验,测试了模型架构、预训练数据、增强策略和共同训练数据四种知识转移场景。
- 实验结果表明,任务指纹方法在识别相关知识和促进协作模型训练方面优于传统方法。
6. 开源和数据共享
- 提供了实验的代码、数据和中间结果,以促进社区的进一步研究和开发。
7. 未来研究方向
- 提出了未来可能的研究方向,包括多模态数据集成、知识云的实施、扩展任务类型和数量等。
总体而言,这篇论文提出了一个创新的框架,通过任务指纹和知识云促进医学影像AI领域的知识共享和合作,有望加速科学进步并提高模型训练的效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


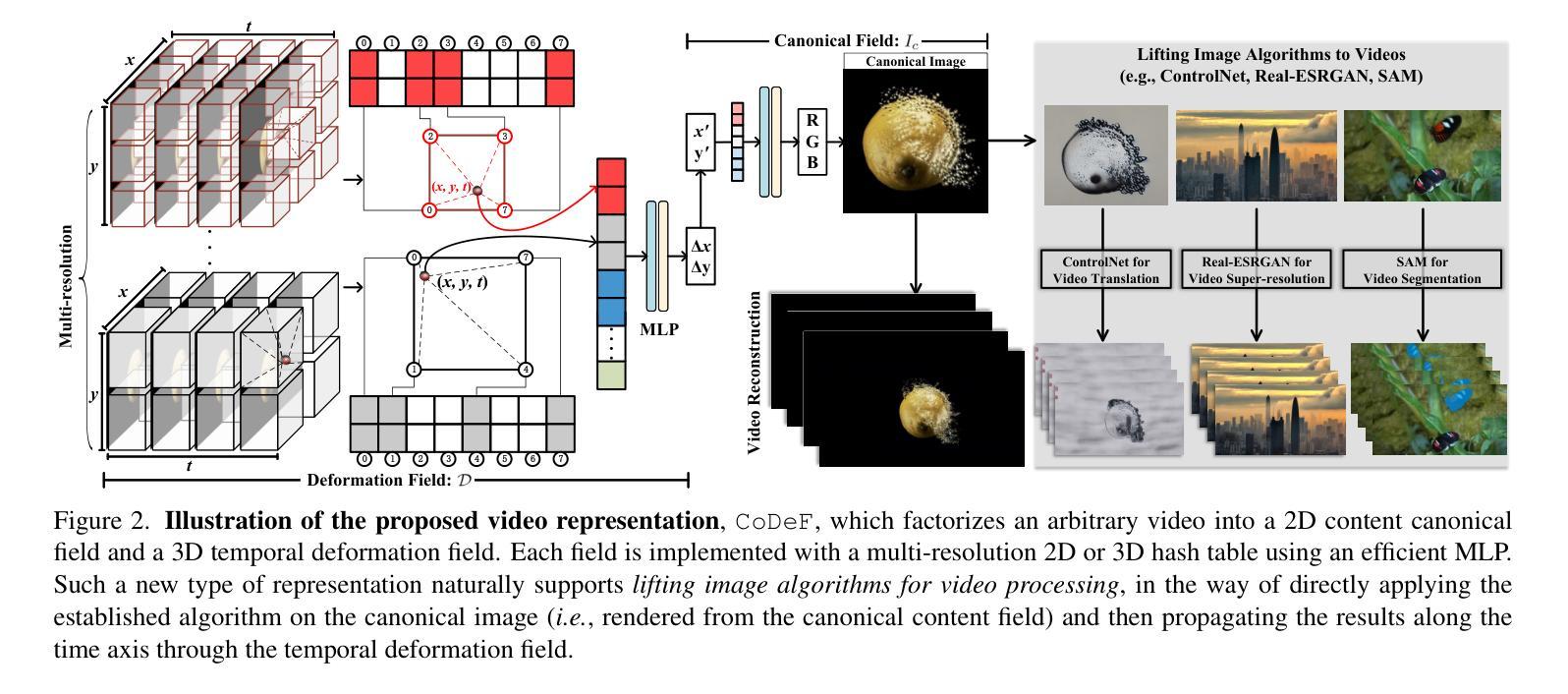
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Authors:Hao Ouyang, Qiuyu Wang, Yuxi Xiao, Qingyan Bai, Juntao Zhang, Kecheng Zheng, Xiaowei Zhou, Qifeng Chen, Yujun Shen
We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis. Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline. We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video. With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field. We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training. More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog. Project page can be found at https://qiuyu96.github.io/CoDeF/.
我们提出了一种新型视频表示方法——内容变形场(CoDeF)。它由一个标准内容场组成,该场聚集了视频中的所有静态内容,以及一个临时变形场,记录了从标准图像(即根据标准内容场呈现的图像)到时间轴上单个帧的变换。对于目标视频,这两个场通过精心设计的渲染管道进行联合优化以重建视频。我们在优化过程中明智地引入了一些正则化,鼓励标准内容场从视频继承语义(例如物体形状)。通过这种设计,CoDeF自然支持视频处理中的图像提升算法,也就是说,人们可以将图像算法应用于标准图像,并借助临时变形场轻松地将结果传播到整个视频。我们实验证明,CoDeF能够将图像到图像的翻译提升到视频到视频的翻译,并将关键点检测提升到关键点跟踪而无需任何训练。更重要的是,由于我们的提升策略只在一张图像上部署算法,我们在处理视频的跨帧一致性方面取得了优于现有视频到视频翻译方法的结果,甚至能够跟踪水和烟雾等非刚性物体。项目页面可在 https://qiuyu96.github.io/CoDeF/ 找到。
论文及项目相关链接
PDF Project Webpage: https://qiuyu96.github.io/CoDeF/, Code: https://github.com/qiuyu96/CoDeF
Summary
视频内容变形场(CoDeF)是一种新型视频表示方法,包含聚合静态内容的标准内容场和记录标准图像随时间变形的临时变形场。通过联合优化这两个字段,可以重建目标视频。CoDeF天然支持将图像算法应用于视频处理,并能将图像到图像的翻译提升到视频到视频的翻译,以及将关键点检测提升到关键点跟踪。得益于只在标准图像上部署算法的升降策略,CoDeF实现了卓越的跨帧一致性。
Key Takeaways
- CoDeF是一种新型视频表示方法,包括标准内容场和临时变形场。
- 通过联合优化这两个字段,可以重建目标视频。
- CoDeF支持将图像算法应用于视频处理。
- CoDeF可以将图像到图像的翻译提升到视频到视频的翻译,以及将关键点检测提升到关键点跟踪。
- CoDeF只在标准图像上部署算法,实现卓越的跨帧一致性。
- 与现有的视频到视频翻译方法相比,CoDeF具有更好的跨帧一致性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的视频表示方法,名为内容变形场(CoDeF),旨在解决视频处理中的两个主要问题:
高时间一致性(Temporal Consistency):在视频内容处理中,保持高时间一致性是一个挑战,因为神经网络的固有随机性使得视频帧之间的一致性难以保证。
与图像处理质量的差距:相比于图像处理领域取得的显著进展,视频处理的质量远远落后。这部分是由于视频数据集通常包含的质量较差的纹理,以及处理视频所需的更大计算资源。
论文的主要贡献是提出了一种新颖的视频表示方法,通过将视频分解为一个规范内容场(canonical content field)和一个时间变形场(temporal deformation field),可以直接将图像算法应用于视频处理,而无需对视频进行任何调整。这种方法不仅提高了处理视频的时间一致性,而且通过仅在一个图像上部署算法,实现了跨帧一致性的优越性,甚至能够跟踪非刚性对象,如水和烟雾等。
Q: 有哪些相关研究?
A: 论文中提到了多个与视频表示和视频处理相关的研究领域,以下是一些主要的相关研究工作:
隐式神经表示(Implicit Neural Representations):
- 使用基于坐标的多层感知器(MLPs)来准确表示图像、视频和3D/4D表示。
- 应用于新视角合成、图像超分辨率和3D/4D重建。
一致视频编辑(Consistent Video Editing):
- 包括基于传播的方法和基于分层表示的技术。
- 例如Text2Live,它通过修改优化的图集来实现时间一致的视频编辑。
通过生成模型进行视频处理(Video Processing via Generative Models):
- 扩散模型(Diffusion Models)在文本到图像生成方面取得了显著进展。
- 例如GLIDE、Dall-E 2、Stable Diffusion和Imagen等。
文本到视频生成(Text-to-Video Generation):
- 近年来成为研究热点,包括训练扩散模型或自回归变换器。
- 例如NUWA、CogVideo、Phenaki、Make-A-Video、Imagen Video和Gen-1等。
特定技术方法:
- 如ControlNet用于视频翻译、Real-ESRGAN用于视频超分辨率、SAM用于视频分割等。
视频表示的先前工作:
- 包括视频马赛克(Video Mosaics)和神经分层图像图集(Neural Layered Image Atlas)。
视频编辑和合成的其他方法:
- 包括基于传播的方法和基于分层表示的方法。
这些研究为本文提出的CoDeF方法提供了理论和技术背景,同时也展示了视频表示和处理领域的发展趋势。论文通过结合这些相关研究,提出了一种新的视频表示方法,以期解决现有方法在时间一致性和处理质量上的局限性。
Q: 论文如何解决这个问题?
A: 论文通过提出一种新的视频表示方法——内容变形场(CoDeF),来解决视频处理中的高时间一致性和与图像处理质量的差距问题。具体解决方案包括以下几个关键步骤:
视频表示的分解:将视频分解为两个主要组件——规范内容场(canonical content field)和时间变形场(temporal deformation field)。规范内容场聚合整个视频中的静态内容,而时间变形场记录从规范图像到每个单独帧的变换。
联合优化:通过精心设计的渲染管线,联合优化这两个场,以重建目标视频。
正则化引入:在优化过程中引入正则化,促使规范内容场继承视频的语义信息(例如,物体形状)。
提升图像算法:CoDeF设计上支持将图像算法应用于规范图像,并通过时间变形场轻松地将结果传播到整个视频。
多分辨率哈希编码:使用多分辨率哈希编码来表示时间变形,显著提高了重建复杂实体(如水和烟雾)的能力。
退火哈希训练:采用从粗糙到精细的退火哈希训练策略,以平衡规范图像的自然性和重建的忠实度。
流引导的一致性损失:使用流引导的一致性损失来增强变形场的平滑性,确保时间一致性和正确传播。
分组内容变形场:对于具有复杂多对象场景的视频,引入基于语义分割的多个内容变形场,以提高视频重建的准确性和鲁棒性。
应用到一致视频处理:利用优化后的内容变形场,将各种图像处理任务(如视频到视频翻译、关键点跟踪、对象分割等)提升到视频领域。
通过这些方法,CoDeF能够在不需要额外训练数据的情况下,直接将图像算法应用于视频处理,实现了优越的跨帧一致性,并能够处理非刚性对象,同时显著提高了视频处理的质量。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的CoDeF方法的有效性和多样性。以下是论文中提到的主要实验内容:
视频重建质量评估:通过与神经图像图集(Neural Image Atlas)进行比较,展示了CoDeF在处理非刚性运动时的优越性,如更精确地重建微妙的运动(例如眼睛的闪烁和面部纹理)。
视频到视频翻译:通过将图像翻译算法应用于规范图像,实现了视频到视频的翻译。与多个基线方法(如Text2Live、Tune-A-Video、FateZero)进行了定性比较,展示了CoDeF在保持高质量内容的同时确保了显著的时间一致性。
视频关键点跟踪:展示了通过估计每个单独帧的变形场,如何在规范空间内查询一个特定关键点的位置,并在所有帧中识别相应的点。
视频对象跟踪:使用规范图像上的分割算法,通过内容变形场将掩模传播到所有视频序列,展示了CoDeF在保持所有帧一致性方面的有效性。
视频超分辨率:通过直接将图像超分辨率算法应用于规范图像,执行视频超分辨率,生成了高质量的视频。
用户交互式视频编辑:展示了用户如何在规范图像上进行编辑,以执行自动编辑算法可能无法达到最佳结果的精确编辑。
消融研究:为了验证所提出模块的效果,进行了消融研究。例如,替换3D哈希编码为位置编码、去除退火哈希、不包含流损失等情况下的实验,展示了这些组件对视频重建质量的影响。
训练效率:论文还提到了CoDeF在训练效率上的优势,与先前的隐式分层表示方法相比,CoDeF的训练时间大大缩短。
这些实验不仅展示了CoDeF在不同视频处理任务中的应用潜力,还证明了其在提高时间一致性和处理质量方面的优势。论文中的实验结果和可视化进一步支持了CoDeF作为一种创新工具在视频处理领域的潜力。
Q: 有什么可以进一步探索的点?
A: 论文在最后一部分提出了几个未来工作可能探索的点,主要包括以下几个方面:
场景优化:当前的方法需要针对每个场景进行优化。论文提出,未来可以通过发展前馈隐式场技术来减少对特定场景优化的需求。
极端视角变化:在处理视角变化极大的场景时,当前方法可能面临挑战。论文建议,引入3D先验知识可能有助于提供额外的信息和约束,以改善这些场景的处理。
大型非刚性变形:处理大型非刚性变形仍然是一个问题。论文提出,使用多个规范图像可能是一个解决方案,因为它能更好地捕捉和表示复杂的变形。
提高效率和可扩展性:尽管CoDeF在训练效率上有所提升,但仍有进一步提高算法效率和可扩展性的空间,特别是在处理更长视频或更高分辨率视频时。
增强控制性和编辑能力:虽然CoDeF支持将图像算法应用于视频,但增强对视频内容的控制性和编辑能力,特别是在复杂场景下,也是一个值得探索的方向。
多模态数据融合:探索如何将视频表示方法与其他类型的数据(如音频、文本或3D模型)结合起来,以实现更丰富的多模态应用。
实时应用:将CoDeF应用于需要实时处理的场景,例如视频会议、增强现实或虚拟现实。
更广泛的应用场景:将CoDeF应用于更广泛的领域,如医学成像、安全监控、自动驾驶等,这些领域对视频处理有特定的需求和挑战。
用户交互和界面设计:改进用户交互方式,设计更直观的用户界面,使用户能够更容易地利用CoDeF进行视频编辑和创作。
模型泛化能力:提高模型对不同类型视频内容的泛化能力,包括不同的物体、动作和环境。
这些探索点表明,尽管CoDeF是一个有前景的方法,但仍有许多机会进一步改进和扩展其能力,以应对视频处理领域中的新挑战。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以概括为以下几个要点:
问题提出:论文指出了视频处理领域在保持高时间一致性和与图像处理质量方面存在的挑战。
CoDeF方法:提出了一种新的视频表示方法——内容变形场(CoDeF),它由规范内容场和时间变形场组成,用于解决视频处理中的挑战。
视频表示的分解:视频被分解为静态内容和随时间变化的变形,通过这种方式,可以直接将图像算法应用于视频处理。
优化与正则化:通过联合优化这两个场并引入正则化,保证了规范内容场能够继承视频的语义信息,同时保持时间变形场的平滑性。
多分辨率哈希编码:采用多分辨率哈希编码来增强时间变形场的表示能力,特别是在处理复杂动态场景时。
退火哈希训练:使用退火策略在训练过程中平衡规范图像的自然性和重建的忠实度。
实验验证:通过一系列实验,包括视频重建、视频到视频翻译、关键点跟踪、对象跟踪和超分辨率等任务,验证了CoDeF方法的有效性。
消融研究:通过消融实验展示了所提出模块的重要性,包括3D哈希编码、退火哈希和流引导的一致性损失。
未来工作:论文讨论了未来可能的研究方向,包括提高效率、处理极端视角变化、大型非刚性变形等问题。
结论:CoDeF方法在视频处理中展示了良好的性能,特别是在保持时间一致性和提高处理质量方面,为视频表示和处理提供了一个有前景的新方向。
整体而言,这篇论文提出了一种创新的视频表示框架,通过将图像算法应用于视频内容,有效地提高了视频处理的质量和一致性,同时为未来的研究提供了新的思路和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图