⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Dial-In LLM: Human-Aligned Dialogue Intent Clustering with LLM-in-the-loop
Authors:Mengze Hong, Yuanfeng Song, Di Jiang, Wailing Ng, Yanjie Sun, Chen Jason Zhang
The discovery of customer intention from dialogue plays an important role in automated support system. However, traditional text clustering methods are poorly aligned with human perceptions due to the shift from embedding distance to semantic distance, and existing quantitative metrics for text clustering may not accurately reflect the true quality of intent clusters. In this paper, we leverage the superior language understanding capabilities of Large Language Models (LLMs) for designing better-calibrated intent clustering algorithms. We first establish the foundation by verifying the robustness of fine-tuned LLM utility in semantic coherence evaluation and cluster naming, resulting in an accuracy of 97.50% and 94.40%, respectively, when compared to the human-labeled ground truth. Then, we propose an iterative clustering algorithm that facilitates cluster-level refinement and the continuous discovery of high-quality intent clusters. Furthermore, we present several LLM-in-the-loop semi-supervised clustering techniques tailored for intent discovery from customer service dialogue. Experiments on a large-scale industrial dataset comprising 1,507 intent clusters demonstrate the effectiveness of the proposed techniques. The methods outperformed existing counterparts, achieving 6.25% improvement in quantitative metrics and 12% enhancement in application-level performance when constructing an intent classifier.
从对话中发现客户意图在自动化支持系统中扮演着重要角色。然而,由于从嵌入距离到语义距离的转变,传统文本聚类方法与人对文本的感知不太匹配,现有的文本聚类的定量指标可能无法准确反映意图聚类的真实质量。在本文中,我们利用大型语言模型(LLM)出色的语言理解能力,设计校准度更高的意图聚类算法。首先,我们通过验证微调后的LLM在语义连贯性评估和聚类命名方面的稳健性,为意图聚类算法的建立奠定了基础。与人工标注的真实数据相比,我们达到了97.50%和94.40%的准确率。然后,我们提出了一种迭代聚类算法,该算法可以促进聚类级别的细化并持续发现高质量的意图聚类。此外,我们还为从客户服务对话中发现意图呈现了几种循环大型语言模型的半监督聚类技术。在包含1507个意图聚类的工业大规模数据集上进行实验,证明了所提出技术的有效性。与现有方法相比,这些方法在定量指标上提高了6.25%,在应用层面上提高了12%,用于构建意图分类器时表现出良好的性能。
论文及项目相关链接
Summary
本文探讨了基于大型语言模型(LLM)的意图聚类算法在自动化支持系统中的应用。针对传统文本聚类方法存在的问题,如与人类感知的不匹配和对语义距离把握的不足,本文利用LLM的优越语言理解能力进行设计。实验验证LLM在语义连贯性评估和聚类命名方面的稳健性,并提出迭代聚类和半监督聚类技术,用于从客户服务对话中发现意图。在大型工业数据集上的实验表明,该方法优于现有技术,在意图分类器的构建中提高了定量指标和应用层面性能。
Key Takeaways
- 大型语言模型(LLM)被用于改进意图聚类算法,以解决传统文本聚类方法与人类感知不匹配的问题。
- LLM在语义连贯性评估和聚类命名方面表现出强大的稳健性,与人工标注的基准值相比,准确率分别高达97.50%和94.40%。
- 提出了一种迭代聚类算法,能够在集群层面进行细化,并持续发现高质量的意图集群。
- 介绍了几种针对意图发现的半监督聚类技术,这些技术结合了LLM的优势,并在大型工业数据集上进行了实验验证。
- 实验结果表明,该方法在定量指标上较现有技术提高了6.25%,在应用层面性能上提高了12%。
- 该方法对于构建意图分类器特别有效,可广泛应用于自动化支持系统中。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在自动化支持系统中从对话中发现客户意图的重要性,以及传统的文本聚类方法由于从嵌入距离转变为语义距离,与人的感知不够一致,导致现有量化指标可能无法准确反映意图聚类的真实质量。具体来说,论文中提到的问题包括:
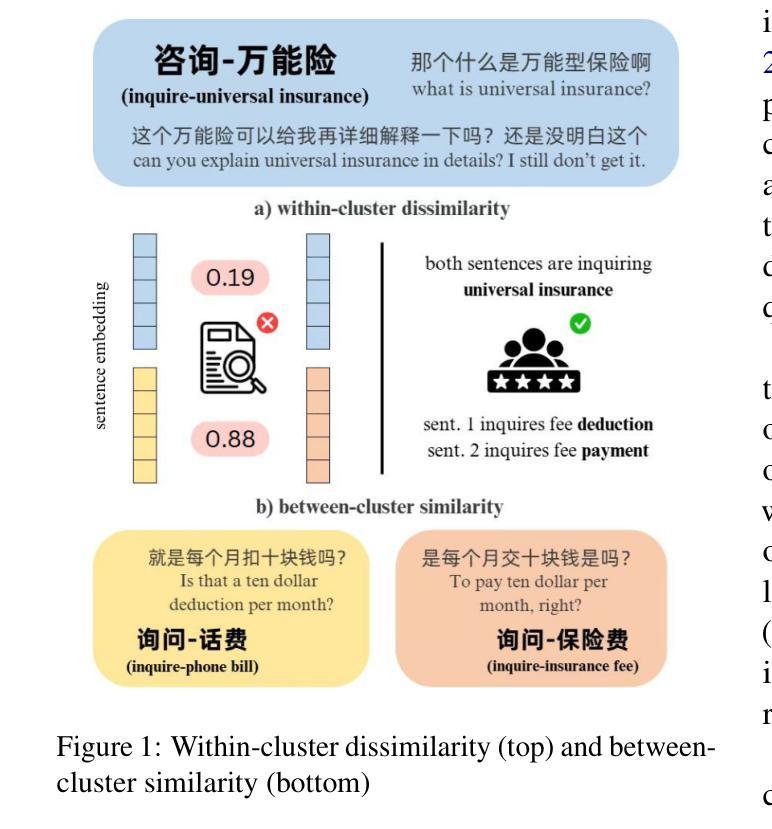
语义一致性问题:传统的文本聚类方法依赖于量化优化嵌入距离度量,这可能阻碍了人类可解释的评估,并导致难以人为验证的过程。
意图聚类的质量评估:现有的研究主要集中在为文本句子构建有意义的表示,而忽略了聚类结果的语义一致性,即一个聚类内部的文本是否紧密相关。
意图聚类的动态适应性:随着对话的变化和上下文的演变,需要能够适应动态对话变化的鲁棒意图发现方法。
为了解决这些问题,论文提出了利用大型语言模型(LLMs)的优越语言理解能力来设计更好地校准的意图聚类算法,并提出了几种LLM-in-the-loop(即在循环中的LLM)的半监督聚类技术,旨在从客户服务对话中发现意图。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要分为两个关键领域:
LLMs在文本聚类中的应用:
- 从2023年开始,LLMs在文本聚类中的讨论成为一个趋势,将无监督学习任务转化为有监督或半监督学习任务。例如,(Zhang et al., 2023)通过指令调整的大型语言模型(如ChatGPT)来更好地与用户偏好对齐聚类粒度。
- LLMs通过改进输入特征、在聚类过程中提供约束以及执行后处理来显著提高聚类质量。(Viswanathan et al., 2023)展示了这一点。
- LLM嵌入扩展了传统聚类算法,擅长捕捉结构化语言中的微妙之处。(Petukhova et al., 2024)
对话意图聚类:
- 文本聚类的一个应用是将具有相似意图或主题的文本进行分组。在对话系统技术挑战赛(DSTC)的Track 2中,意图聚类被认为是意图归纳的一个基本步骤,其中客户服务对话被聚类以训练意图分类器。(Gung et al., 2023)
- 基于LLM的意图聚类系统的最新进展显示了实际优势。例如,(IDAS方法)(De Raedt et al., 2023)因其创新使用LLMs和上下文学习来生成描述性的语句标签以改善聚类而脱颖而出。
这些相关研究为本文提出的利用LLMs设计人类对齐的意图聚类算法和评估指标提供了理论基础和技术支持。论文通过结合这些相关研究的成果,提出了一个新的聚类范式,即LLM-in-the-loop机器学习,以期提高聚类的质量和实用性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个主要步骤解决上述问题:
语义一致性评估:
- 论文提出使用语义一致性(semantic coherence)作为聚类质量的评估指标和优化目标,而不是传统的基于嵌入距离的方法。这种方法增强了人类检查下的可解释性,并允许在聚类层面进行质量评估和细化。
利用大型语言模型(LLMs):
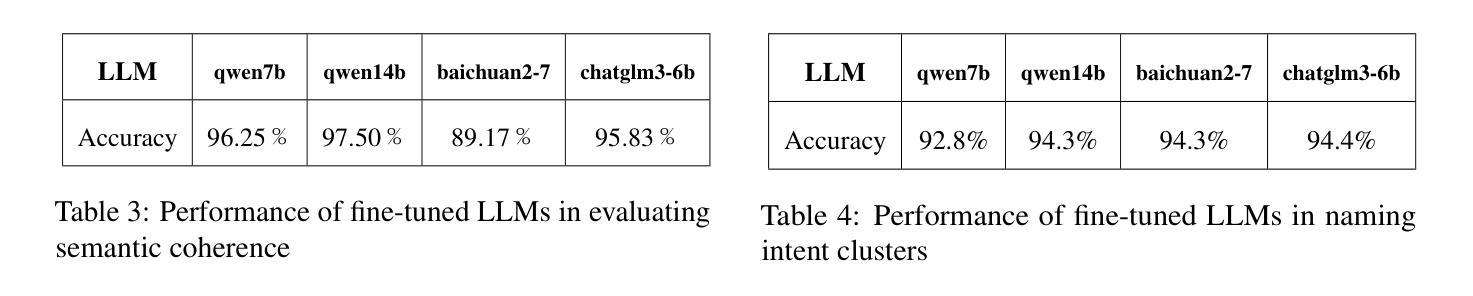
- 论文展示了微调后的LLMs在评估文本聚类的质量和提供准确意图标签方面的能力,与人类标注的基准相比,准确率分别达到了97.50%和94.40%。
- 论文提出了一个迭代聚类算法,该算法通过集成LLMs来促进聚类级别的细化和持续发现高质量的意图聚类。
LLM-in-the-loop半监督聚类技术:
- 论文提出了几种为从客户服务对话中发现意图而量身定制的LLM-in-the-loop半监督聚类技术。
- 这些技术包括上下文无关和上下文感知的变化,通过集成LLMs来实现。
迭代聚类范式:
- 论文提出了一个迭代聚类范式,该范式通过语义一致性评估来识别和处理坏聚类,从而迭代地发现更优质的聚类结果。
意图标签的后处理:
- 论文提出了基于意图标签语义相似度的后处理方法,以合并相似的聚类。
上下文感知聚类:
- 论文提出了一种上下文感知聚类方法,该方法利用领域特定特征或先验知识来提高聚类质量。
采样和评估策略:
- 论文讨论了采样方法,以选择代表性句子进行一致性评估,并提出了基于LLM的群体评估策略,以提高评估结果的可信度。
实验验证:
- 论文在大规模工业数据集上进行了实验,证明了所提出技术的有效性。这些方法在量化指标上取得了6.25%的改进,并在构建意图分类器时,在应用级性能上实现了12%的提高。
通过这些步骤,论文旨在通过利用LLMs的优越语言理解能力,设计出更符合人类感知的意图聚类算法和评估指标,并提出了一种有效的LLM-in-the-loop解决方案。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集介绍:
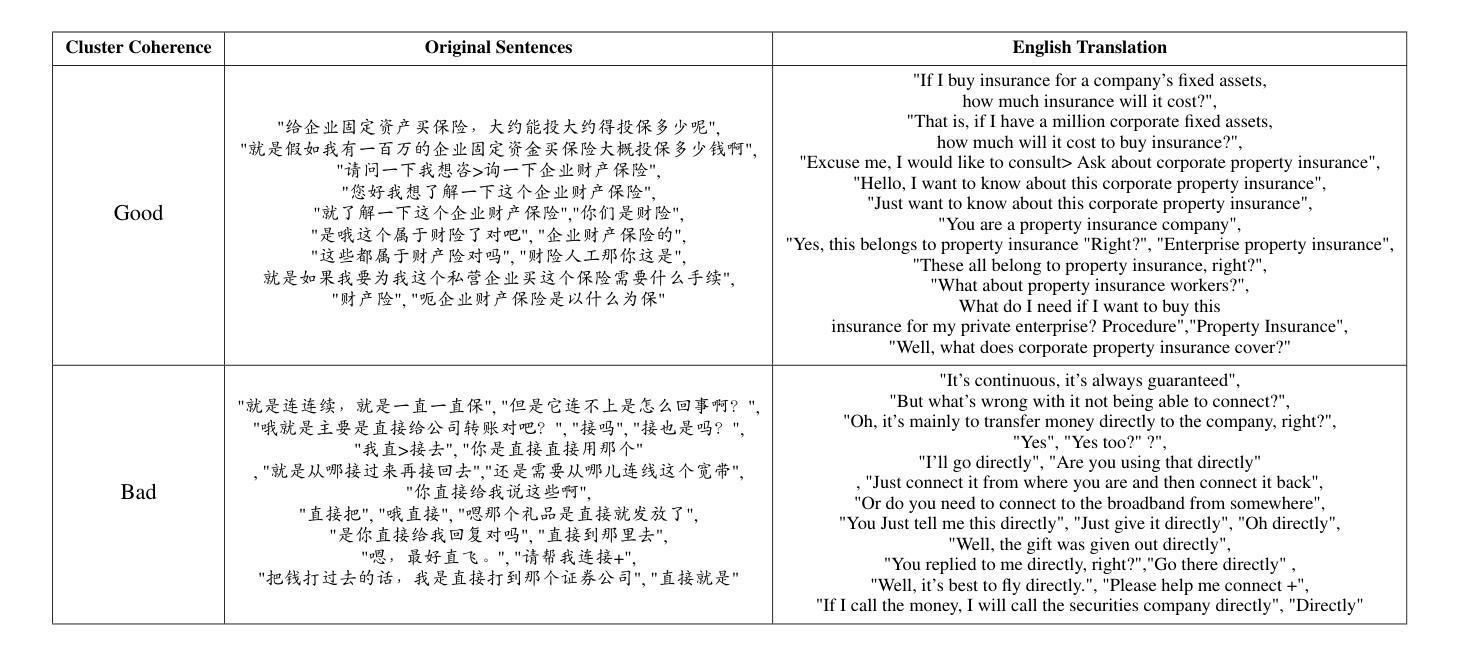
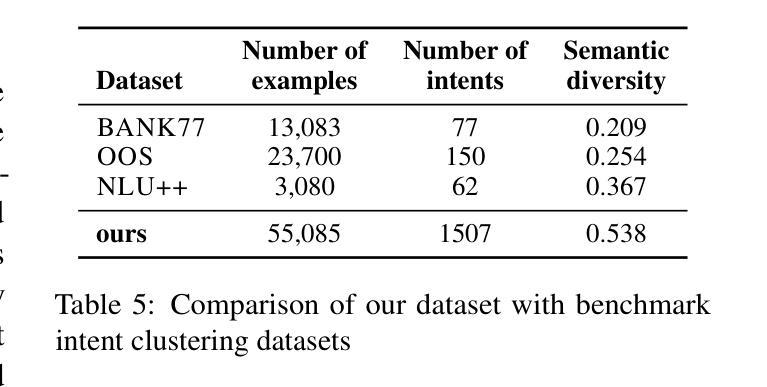
- 使用的是一个来自银行业客户服务电话的大规模真实意图聚类数据集,包含55,085个不同的句子,平均长度为17个中文字符,分为1,507个高质量意图聚类。
数据预处理:
- 实现了最小化的数据预处理,主要移除重复和冗余样本,同时保留多种直观性较差的文本片段,如副词和感叹词。
评估指标:
- 使用归一化互信息(Normalized Mutual Information, NMI)来衡量预测聚类和真实聚类之间的相似度。
- 使用聚类的好坏(Goodness of Clusters)来衡量由微调后的LLM评估的好聚类的比例。
主要结果:
- 对比基线方法和提出的算法在对话意图聚类中的性能。
- 展示了在不同配置下提出的迭代聚类方法和上下文感知聚类方法的性能。
消融研究:
- 分析了不同的采样参数和策略对于语义一致性评估的影响。
- 探讨了使用LLMs进行搜索空间修剪的效果。
意图分类:
- 使用BERT分类器在由不同算法生成的聚类结果上进行训练,以展示所提出方法生成的聚类结果在实际应用中的有效性。
实验结果:
- 展示了基线算法和提出方法在NMI和聚类好坏比例上的性能对比。
- 展示了上下文感知聚类方法在融入先验知识和LLM监督后NMI得分的提升。
- 通过消融研究,提出了采样和超参数调整的最佳实践。
- 通过在聚类结果上训练BERT分类器,证明了所提出方法在构建意图分类器时的应用级性能提升。
这些实验验证了论文提出方法的有效性,并提供了实际应用中的性能改进证据。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些可以进一步探索的点,主要包括:
连续评估度量:
- 论文中使用的“好/坏”评估方法虽然实用直观,但可能过于简化了聚类质量的评估。开发一个连续的评估度量可能提供更多洞察,允许不同程度的一致性接受度。
降低操作成本:
- 尽管论文提出的方法比主流LLM聚类技术更高效,但在微调阶段和部分评估、标记过程中仍涉及较高的操作成本。未来的工作可以专注于优化这些过程,使其更适用于更广泛的应用场景。
LLM评估的可靠性:
- 未来的研究可以进一步增强LLM在评估中的可靠性,例如通过纳入LLM在评估中的置信度。
更复杂的数据挖掘技术:
- 利用更复杂的数据挖掘技术以实现更好的先验聚类。
跨领域测试:
- 鼓励研究人员在不同领域应用这些方法,以测试其在不同数据集和任务中的鲁棒性。
算法优化:
- 对于提出的LLM-in-the-loop半监督聚类技术,可以进一步探索算法优化,以提高效率和可扩展性。
上下文感知聚类:
- 可以探索更多关于如何有效地整合上下文信息到聚类过程中的方法,以提高聚类质量。
模型泛化能力:
- 研究模型在不同类型的对话数据和语言上的泛化能力,以及如何改进模型以适应不同的应用场景。
可解释性和透明度:
- 提高模型的可解释性和透明度,特别是在LLMs生成的聚类结果中,以便更好地理解和信任模型的决策过程。
多模态数据融合:
- 考虑将文本数据与其他模态数据(如语音或图像)结合起来,以实现更丰富的对话意图理解和聚类。
这些进一步探索的点可以帮助研究者们改进和扩展当前的工作,推动对话意图聚类技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出从对话中发现客户意图对于自动化支持系统至关重要,但传统文本聚类方法与人的感知不够一致,现有量化指标可能无法准确反映意图聚类的真实质量。
研究目标:
- 利用大型语言模型(LLMs)的优越语言理解能力,设计更符合人类感知的意图聚类算法和评估指标。
主要贡献:
- 提出了语义一致性作为评估聚类质量的直观替代方案。
- 展示了微调后的LLMs在评估文本聚类质量和提供准确意图标签方面的鲁棒性。
- 提出了一个迭代聚类范式,通过集成LLMs来促进聚类级别的细化和持续发现高质量的意图聚类。
方法论:
- 提出了上下文无关和上下文感知的两种LLM-in-the-loop半监督聚类技术。
- 介绍了采样和评估策略,以选择代表性句子进行一致性评估,并提出了基于LLM的群体评估策略。
实验验证:
- 在大规模工业数据集上进行实验,证明了所提出技术的有效性。这些方法在量化指标上取得了改进,并在构建意图分类器时,在应用级性能上实现了提升。
结论与未来工作:
- 论文总结了LLMs在增强对话意图聚类中的潜力,并指出了进一步探索的方向,包括开发连续评估度量、降低操作成本、提高LLM评估的可靠性等。
整体而言,这篇论文通过利用LLMs的高级语言理解能力,提出了一种新的聚类范式,即LLM-in-the-loop机器学习,以期提高聚类质量和实用性,并在实际应用中展示了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



Dialogue Language Model with Large-Scale Persona Data Engineering
Authors:Mengze Hong, Chen Zhang, Chaotao Chen, Rongzhong Lian, Di Jiang
Maintaining persona consistency is paramount in the application of open-domain dialogue systems, as exemplified by models like ChatGPT. Despite significant advancements, the limited scale and diversity of current persona dialogue datasets remain challenges to achieving robust persona-consistent dialogue models. In this study, drawing inspiration from the success of large-scale pre-training, we introduce PPDS, an open-domain persona dialogue system that employs extensive generative pre-training on a persona dialogue dataset to enhance persona consistency. Specifically, we present a persona extraction model designed to autonomously and precisely generate vast persona dialogue datasets. Additionally, we unveil a pioneering persona augmentation technique to address the invalid persona bias inherent in the constructed dataset. Both quantitative and human evaluations consistently highlight the superior response quality and persona consistency of our proposed model, underscoring its effectiveness.
保持个性一致性在开放式对话系统的应用中是至关重要的,以ChatGPT等模型为例。尽管已经取得了重大进展,但当前个性化对话数据集规模和多样性的限制仍然是实现稳健的个性一致性对话模型面临的挑战。在本研究中,我们从大规模预训练的成功中汲取灵感,引入了PPDS,这是一个开放式个性化对话系统,它采用个性化对话数据集上的广泛生成预训练来提高个性一致性。具体来说,我们提出了一种个性提取模型,旨在自主、精确地生成大量个性化对话数据集。此外,我们还揭示了一种开创性的个性增强技术,以解决构建数据集中固有的无效个性偏见问题。定量和人类评估结果均突出显示我们提出模型的优越响应质量和个性一致性,这突出了其有效性。
论文及项目相关链接
Summary
本文介绍了在开放域对话系统中保持人格一致性至关重要,并以ChatGPT等模型为例。虽然已有显著进展,但当前人格对话数据集规模和多样性的限制仍是实现稳健人格一致性对话模型的挑战。本研究受大规模预训练成功的启发,引入PPDS,一个采用人格对话数据集进行广泛生成性预训练的开放域人格对话系统,以提高人格一致性。具体来说,本研究提出了一个自主、精准生成大量人格对话数据集的人格提取模型。此外,还揭示了一种开创性的人格增强技术,以解决构建数据集中固有的无效人格偏见问题。定量和人类评估均一致地证明了所提出模型的高响应质量和人格一致性,凸显了其有效性。
Key Takeaways
- 开放域对话系统中保持人格一致性至关重要。
- 当前人格对话数据集规模和多样性的限制是实现稳健人格一致性对话模型的挑战。
- PPDS是一个采用生成性预训练的开放域人格对话系统,旨在提高人格一致性。
- 人格提取模型能自主、精准地生成大量人格对话数据集。
- 引入了一种人格增强技术,以解决构建数据集中无效人格偏见的问题。
- 模型评估证明了所提出模型的高响应质量和人格一致性。
- 该研究受大规模预训练成功的启发,通过预训练提升模型性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是开放领域对话系统中的人格一致性问题。具体来说,论文指出尽管当前的对话模型在生成流畅和连贯的回应方面取得了显著进展,但在保持对话中的人格一致性方面仍然存在挑战,这可能导致实际人机交互中的负面体验。为了增强用户体验并保持人格一致性,论文提出了一个基于大规模预训练的开放领域人格对话系统(PPDS),该系统使用从大规模人格对话数据集中生成的人格数据来增强模型的人格一致性。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
大规模预训练(Large-Scale Pre-Training):
- GPT-3模型:展示了强大的零样本和少样本学习能力。
- UniLM和T5:这些预训练语言模型在对话系统中的应用,通过大规模预训练提高对话的自然性和参与度。
人格对话模型(Persona Dialogue Model):
- 通过引入人格对话数据集来捕获人格特征,包括用户身份、用户档案和人格事实。
- 提出了多种神经模型,例如建模相互人格和基于多阶段人格的对话生成。
- 通过在人格数据集上微调预训练模型来提高人格一致性。
自然语言推理(NLI):
- 使用NLI模型来判断回应是否与人格相矛盾,通过重排、不似然训练或强化学习来提高对话模型的人格一致性。
特定数据集和模型:
- DialoGPT、SPACE、Blender:用于英文对话的模型。
- CDialGPT、PLATO2、EVA:用于中文对话的模型。
- PERSONA-CHAT数据集:通过人格句子来表示人格。
- Personality Assignment Dataset:利用用户社交媒体资料自动创建更大的人格数据集。
这些研究构成了论文提出的PPDS模型的理论基础和技术背景,旨在通过大规模预训练和人格数据增强来提高对话系统的人格一致性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决开放领域对话系统中的人格一致性问题:
构建大规模人格对话数据集:
- 提出一个基于总结的人格提取模型,自动从现有的对话NLI数据集中提取人格。
- 使用预训练的T5模型作为人格提取模型的骨干,将人格提取问题建模为一个生成式总结任务。
- 从Reddit评论等大规模对话数据中提取人格,并经过严格的过滤规则确保人格数据集的质量。
预训练人格对话模型(PPDS):
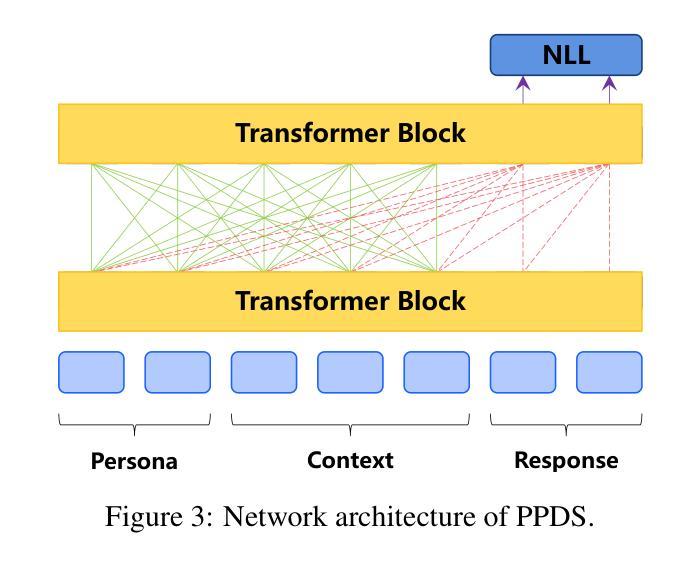
- 在构建的大规模人格对话数据集上预训练一个基于Transformer的对话模型,称为PPDS(Pre-trained Persona Dialogue System)。
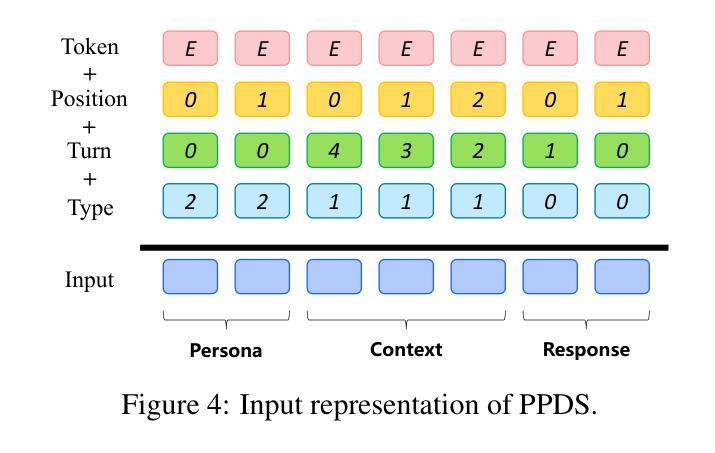
- PPDS模型采用UniLM架构,通过将人格、对话上下文和回应作为单一输入进行连接,减少不必要的计算和参数共享,提高参数效率。
提出人格增强技术:
- 为了解决从回应中提取人格可能引入的人格偏差问题,提出了一种人格增强技术,通过添加不相关的人格来要求模型基于对话上下文识别相关人格。
- 通过采样额外的人格来补充每个对话的人格档案,并在采样的人格与现有人格类型匹配时将其移除,避免潜在的矛盾。
实验验证:
- 通过定量和人类评估来验证所提出模型的有效性,包括在PERSONA-CHAT数据集上进行微调,并使用多种评估指标来衡量回应的质量和人格一致性。
分析和最佳实践:
- 分析预训练、人格增强和微调作为关键组成部分的作用,为工业部署提供见解和最佳实践。
通过这些步骤,论文成功构建了一个能够生成人格一致回应的开放领域对话系统,并在实验中展示了其优越的性能。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出模型PPDS的有效性:
实验设置:
- 使用PERSONA-CHAT数据集进行微调和评估,该数据集覆盖了丰富的人格特征。
- 对比了多个不同的对话生成模型,包括基线模型、DialoGPT、PPDS及其变体(如PPDS-woP、PPDS-woA等)。
评估指标:
- 使用了多个定量和人类评估指标来衡量回应的质量和人格一致性。
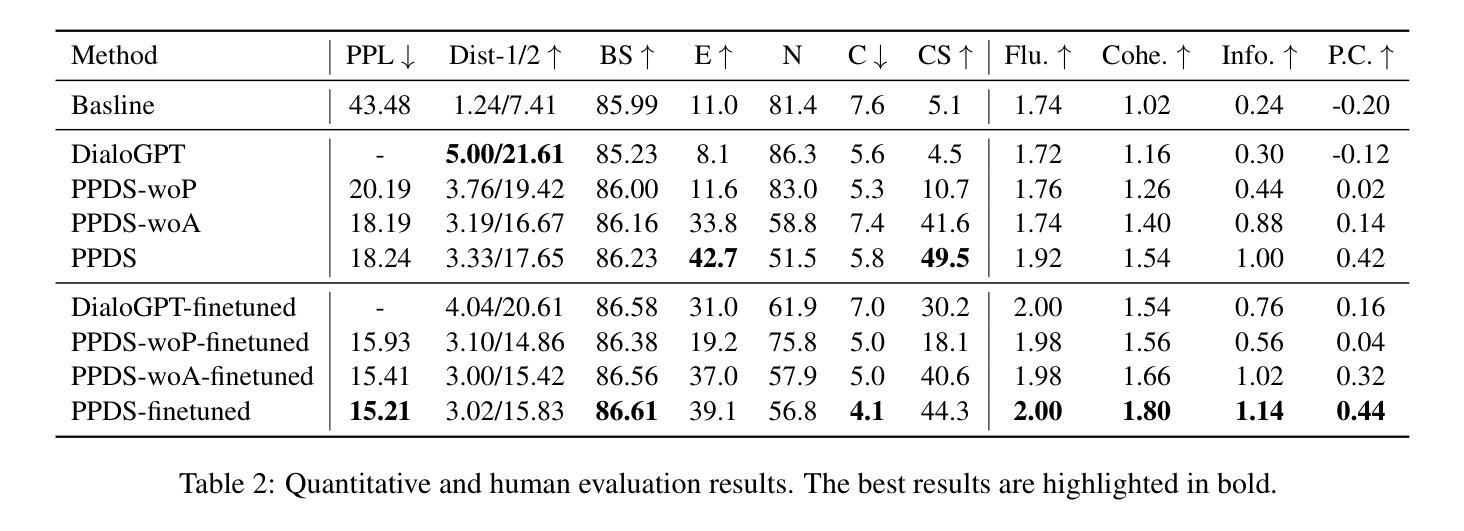
- 定量指标包括:困惑度(Perplexity, PPL)、Distinct 1/2(Dist-1/2)、BertScore(BS)以及基于NLI模型的回应与人格的矛盾(E)、中立(N)和一致(C)的比例,以及一致性得分(Consistency Score, CS)。
- 人类评估指标包括:流畅度(Fluency)、连贯度(Coherence)、信息量(Informativeness)和人格一致性(Persona Consistency, P.C.)。
定量评估结果:
- 展示了不同模型在定量评估指标上的表现,并突出显示了最佳结果。
- PPDS模型在大多数定量评估指标上都取得了最佳或接近最佳的结果,特别是在一致性得分(CS)上,显示出其在人格一致性方面的优越性。
人类评估结果:
- 通过众包工人对模型生成的回应进行人类评估,评价指标包括流畅度、连贯度、信息量和人格一致性。
- PPDS模型在人类评估中也显示出较高的评分,进一步验证了其在生成人格一致回应方面的有效性。
定性示例:
- 提供了一个定性示例,展示了PPDS模型与未进行人格预训练的模型(PPDS-woP)相比,在维持人格一致性方面的优势。
这些实验全面地评估了PPDS模型在不同方面的表现,并与现有技术进行了比较,从而证明了其在开放领域对话系统中增强人格一致性的有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出的方法虽然在开放领域对话系统中的人格一致性方面取得了显著进展,但仍有一些可以进一步探索的点:
改进人格提取模型:
- 探索更先进的技术或模型结构来提高人格提取的准确性和覆盖率。
扩大和多样化数据集:
- 通过集成更多的数据源或采用不同的数据增强技术,进一步扩大和多样化人格对话数据集。
优化人格增强技术:
- 研究更精细的人格增强策略,以更有效地减少偏差并提升模型的泛化能力。
多模态对话系统:
- 将人格一致性问题扩展到多模态对话系统(如结合视觉和语言信息),探索在这种场景下维持人格一致性的挑战和解决方案。
跨领域适应性:
- 研究模型在不同领域或不同类型对话中的适应性和迁移能力,特别是在领域专业知识较强的对话中。
实时性能和资源效率:
- 考虑到工业部署的需求,研究如何优化模型以减少计算资源消耗,提高实时响应能力。
解释性和透明度:
- 提高模型决策过程的解释性,帮助开发者和用户理解模型为何生成特定的回应。
用户满意度和交互体验:
- 通过用户研究来评估不同人格一致性水平对用户体验的影响,并据此调整模型。
对抗攻击和鲁棒性:
- 研究模型对对抗性输入的鲁棒性,并开发防御机制以保护对话系统的安全性和稳定性。
多人格和复杂交互:
- 探索如何处理具有多重人格特征或在复杂社交互动中维持一致性的挑战。
这些探索点可以帮助研究者和开发者进一步提升对话系统的性能,使其更加自然、一致,并更好地适应各种应用场景。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题陈述:
- 论文指出开放领域对话系统中保持人格一致性的重要性,并提出当前的对话模型在这一领域存在挑战。
PPDS模型:
- 论文提出了PPDS(Pre-trained Persona Dialogue System),一个基于大规模预训练的开放领域人格对话系统,旨在增强对话中的人格一致性。
数据集构建:
- 介绍了一个人格提取模型,用于从大规模对话数据中自动提取人格特征,并构建了一个经过严格过滤的大型人格对话数据集。
预训练和模型架构:
- 使用UniLM架构对PPDS模型进行预训练,该模型将人格、对话上下文和回应作为单一输入进行处理,以提高参数效率。
人格增强技术:
- 提出了一种人格增强技术,通过添加不相关的人格来减少数据集中的偏差,并要求模型基于上下文识别相关人格。
实验验证:
- 通过定量和人类评估,论文验证了PPDS模型相比于其他基线模型在回应质量和人格一致性方面的优势。
结论:
- 论文得出结论,通过大规模预训练和人格增强,PPDS模型有效地提高了开放领域对话系统中的人格一致性,并鼓励未来的研究在构建大规模对话模型和增强对话系统方面应用这些技术。
总的来说,这篇论文通过构建大规模人格对话数据集和提出PPDS模型,为解决开放领域对话系统中的人格一致性问题提供了一种有效的解决方案,并在实验中展示了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图