⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Authors:Zhisheng Zhong, Chengyao Wang, Yuqi Liu, Senqiao Yang, Longxiang Tang, Yuechen Zhang, Jingyao Li, Tianyuan Qu, Yanwei Li, Yukang Chen, Shaozuo Yu, Sitong Wu, Eric Lo, Shu Liu, Jiaya Jia
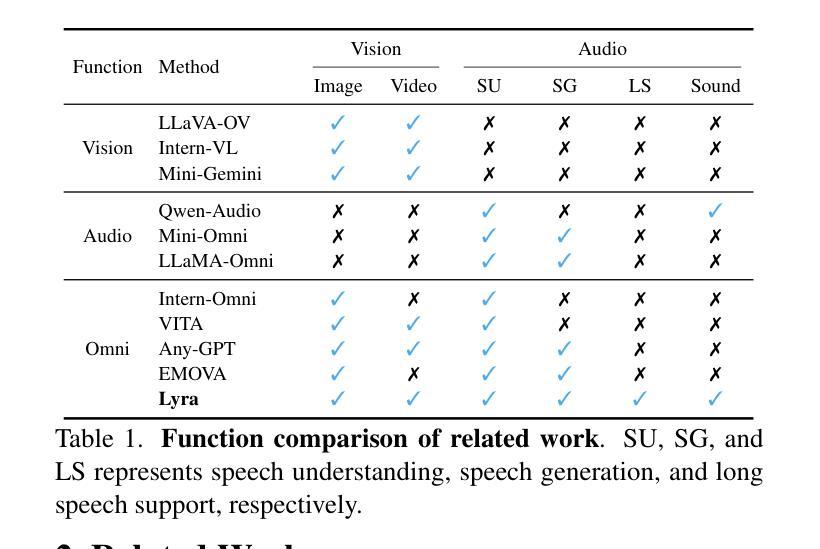
As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.
随着多模态大型语言模型(MLLMs)的发展,扩展单域功能之外的能力对于满足对更通用、更高效的AI的需求至关重要。然而,以前的通用模型在语音方面探索不足,忽视了其与多模态的集成。我们引入了Lyra,这是一个高效的多模态语言模型,增强了多模态能力,包括高级长语音理解、声音理解、跨模态效率和无缝语音交互。为了实现高效和语音为中心的能力,Lyra采用了三种策略:(1)利用现有的开源大型模型和提出的多模态LoRA来降低训练成本和数据要求;(2)使用潜在的多模态正则器和提取器来加强语音与其他模态之间的关系,从而提高模型性能;(3)构建一个高质量的大规模数据集,包含150万个多模态(语言、视觉、音频)数据样本和1.2万个长语音样本,使Lyra能够处理复杂的长语音输入,实现更稳健的全面认知。与其他通用方法相比,Lyra在各种视觉语言、视觉语音和语音语言基准测试上达到了最先进的性能,同时使用的计算资源更少,训练数据也更少。
论文及项目相关链接
PDF Tech report
Summary:随着多模态大型语言模型(MLLMs)的发展,为满足对更加通用和高效的AI的需求,扩展单一领域能力至关重要。然而,先前的全能模型在语音方面探索不足,忽视了其与多模态的集成。我们引入了Lyra,这是一种高效的多模态大型语言模型,能够增强包括高级长语音理解、声音理解、跨模态效率和无缝语音交互在内的多模态能力。为实现效率和语音为中心的功能,Lyra采用了三种策略:利用现有开源大型模型和提出的多模态LoRA减少训练成本和数据需求;使用潜在多模态正则器和提取器加强语音与其他模态之间的关系,从而提高模型性能;构建包含150万多个多模态(语言、视觉、音频)数据样本和1.2万个长语音样本的高质量数据集,使Lyra能够处理复杂的长语音输入并实现更稳健的全知认知。相较于其他全能方法,Lyra在各种视觉语言、视觉语音和语音语言基准测试上取得了最先进的性能表现,同时使用的计算资源更少且训练数据量更小。
Key Takeaways:
- Lyra是一种高效的多模态大型语言模型,旨在增强包括语音在内的多模态能力。
- Lyra通过三种策略实现效率和语音为中心的功能:利用现有模型和提出的多模态LoRA减少训练成本;使用潜在多模态正则器和提取器强化语音与其他模态的关系;构建高质量数据集以处理复杂的长语音输入。
- Lyra通过使用较少计算资源和训练数据,在多种基准测试中取得了最先进的性能表现。
- Lyra能处理高级长语音理解、声音理解、跨模态效率和无缝语音交互等任务。
- Lyra通过构建包含大量多模态数据样本的数据集实现更稳健的全知认知。
- 以前的全能模型在语音方面存在不足,而Lyra弥补了这一缺陷,实现了语音与多模态的集成。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为Lyra的多模态大型语言模型(MLLM),旨在解决以下几个关键问题:
多模态能力的扩展:随着大型语言模型(LLMs)的快速发展,需要将模型的能力从单一领域扩展到能够处理更多样化和复杂的多模态输入,例如视觉、语言、语音和声音等。
语音模态的整合不足:现有的多模态模型主要关注语音和文本之间的关系,而忽略了语音与其他模态(如视觉)之间的联系。这限制了模型在处理涉及语音的多模态任务时的性能。
数据集和上下文长度的挑战:为了训练强大的模型,需要大量的数据集,同时,随着对长文本、长视频等长上下文任务的需求增加,模型需要能够处理更长的上下文。
计算资源和环境问题:构建一个功能强大的模型可能需要大量的财务和计算资源,这不仅增加了成本,还引发了与高碳排放相关的环境问题。
为了解决这些问题,Lyra采用了以下策略:
- 利用现有的开源大型模型,并通过提出的多模态LoRA模块减少训练数据和成本,同时在特定模态中保持强大能力。
- 使用潜在的多模态正则化器和提取器来加强语音与其他模态之间的关系,从而提升模型性能。
- 构建一个包含1.5M多模态(语言、视觉、音频)数据样本和12K长语音样本的高质量、广泛的数据集,使Lyra能够处理复杂的长语音输入,并实现更强大的全模态认知。
总体而言,Lyra旨在通过上述方法实现更高效、多才多艺且强大的全模态认知能力。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究领域和具体工作包括:
多模态大型语言模型(MLLMs):
- GPTs [42]:展示了文本理解和生成的强大能力。
- LLaMA [12, 57] 和 Qwen [4, 67]:在文本理解和生成方面表现出色。
- 视觉语言模型(Vision Language Models)[28, 31–36, 60, 61, 68]:将LLMs扩展到视觉感知领域。
- 语音语言模型(Speech Language Models, SLMs)[49]:引入了实时语音理解和生成。
- 整合视觉、文本和音频的MLLMs [63],如AnyGPT [71]、VITA [16] 和 EMOVA [6]。
MLLMs的令牌减少技术:
- StreamingLLM [64] 和 FastGen [17]:通过选择性保留关键令牌来优化LLMs的内存使用。
- H2O [75]、ScissorHands [37] 和 Quest [53]:使用基于注意力的评分来优先考虑有价值的令牌。
- FastV [7]:减少视觉令牌以应对图像处理的高计算成本。
特定模态的模型:
- LLaVA-OV [28]、Intern-VL [9]、Mini-Gemini [31]:专注于视觉和语言模态。
- Qwen-Audio [10]、LLaMA-Omni [13]:专注于语音和语言模态。
长上下文处理:
- Long-document [5, 8] 和 long-video [15, 32, 62, 66, 73] 任务的基准测试。
环境问题和计算资源效率:
- 研究如何减少训练大型模型所需的数据量和计算资源,以减少碳排放。
特定数据集和模型架构:
- LLaMA3 [12]、Qwen2-VL [60]:作为Lyra的基础模型,展示了多模态能力。
- ChatTTS [1]:用于生成多样化的语音数据。
这些研究为Lyra提供了理论基础和技术背景,使其能够在多模态认知领域取得进展。Lyra通过整合这些研究的成果,并提出新的方法来提高效率和性能,从而在多模态理解和交互方面实现了新的突破。
Q: 论文如何解决这个问题?
A: 论文通过提出Lyra框架解决了上述问题,具体方法如下:
利用现有开源大型模型:
- 利用已有的强大的LLMs和VLMs(如LLaMA3和Qwen2-VL),通过提出的多模态LoRA模块,在特定模态中保持强大能力的同时,开发其在语音模态中的能力。
多模态LoRA(Low-Rank Adaptation):
- 使用多模态LoRA模块有效地保留开源大型模型在特定模态中的强大能力,同时用较少的训练数据发展其在语音模态中的能力。
潜在的多模态正则化器和提取器:
- 提出潜在的跨模态正则化器(latent cross-modality regularizer),加强语音和其他模态之间的关系,提升模型性能。
- 提出潜在的多模态提取器(latent multi-modality extractor),动态选择与文本查询相关的多模态令牌,丢弃冗余的多模态令牌,以提高效率。
构建高质量数据集:
- 构建包含1.5M多模态(语言、视觉、音频)数据样本的高质量数据集,以及12K长语音样本的数据集,使Lyra能够处理复杂的长语音输入,并实现更强大的全模态认知。
长语音能力的整合:
- 针对长语音处理的挑战,开发了第一个长语音SFT数据集,并采用类似于高分辨率图像分割方法的策略来处理长音频。
流式生成:
- 为了实现语音和文本的同时输出,引入了流式语音-文本生成组件,允许模型以流式方式输出文本和相应的音频。
通过这些方法,Lyra在多模态理解和推理任务中实现了更好的性能,同时减少了计算资源的使用,使其适合于对延迟敏感和需要处理长上下文的多模态应用。Lyra在各种视觉-语言、视觉-语音和语音-语言基准测试中取得了最新的性能,同时使用较少的计算资源和较少的训练数据。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估Lyra框架的性能和效率,具体实验包括:
实验设置:
- 实现了三个版本的Lyra模型:Lyra-Mini、Lyra-Base和Lyra-Pro,分别对应不同的模型大小。
- 使用了高质量的多模态数据集和长语音SFT数据集进行训练和优化。
主要结果:
- 在多个基准测试中与当前领先的VLMs(如Mini-Gemini、LLaVA-OV、Intern-VL2)和SLM(如Mini-Omni、SALMONN、Qwen2-Audio)以及Omni模型(如Intern-Omni、AnyGPT、VITA和EMOVA)进行了比较。
- 评估了Lyra在图像-语音、文本-语音和视频-语音任务中的性能。
定量结果:
- 提供了Lyra在各种视觉-语言、视觉-语音和语音-语言基准测试中的性能数据,展示了其在不同任务中的优越性。
定性结果:
- 展示了Lyra在实际世界设置中处理复杂多模态案例的能力,包括理解和推理任务。
组件分析:
- 潜在跨模态正则化器:评估了所提出的潜在跨模态正则化器对模型性能的影响。
- 潜在多模态提取器:分析了该模块在多模态任务中的效率和效果。
- 长语音能力整合:验证了模型处理长语音的能力,并与现有模型进行了比较。
- 多模态LoRA(MLoRA)管道:展示了MLoRA在保持原始视觉性能的同时增强新模态能力的有效性。
长语音“针堆”评估:
- 选择了五个超过3小时的音频文件,并在不同位置插入开放式音频问题和答案,测试Lyra模型的长语音处理能力。
基于VideoMME的实验:
- 从VideoMME基准测试中提取音频,并仅使用音频数据进行预测和评估。
这些实验全面评估了Lyra在多模态交互中的性能,特别是在语音模态的整合和处理方面,证明了Lyra在提高效率和性能方面的有效性。
Q: 有什么可以进一步探索的点?
A: 尽管Lyra在多模态大型语言模型(MLLMs)方面取得了显著进展,但仍有一些领域可以进一步探索和研究:
提高语音理解和生成的准确性:
- 尽管Lyra在语音模态上取得了进展,但提高语音理解和生成的准确性仍然是一个活跃的研究方向,特别是在嘈杂环境或不同口音和语言中。
增强模型的泛化能力:
- 探索如何使Lyra更好地泛化到未见过的数据和场景,包括跨领域和跨语言的应用。
环境声音和复杂场景的处理:
- 对于包含多种声音和复杂背景噪声的音频输入,研究如何提高模型的鲁棒性和准确性。
长上下文管理:
- 随着上下文长度的增加,研究如何有效地管理和利用长上下文信息,以提高模型的性能和效率。
计算和能源效率:
- 探索新的算法和技术,以进一步减少Lyra的计算需求和能源消耗,使其更加环保和实用。
多模态数据集的构建和增强:
- 构建更多样化和复杂的多模态数据集,以支持模型训练和评估,特别是在长语音和复杂场景下。
模型解释性和安全性:
- 提高模型的可解释性,确保其决策过程的透明度,并研究如何增强模型的安全性,防止潜在的滥用。
跨模态关联和交互:
- 深入研究不同模态之间的关联和交互,例如如何更好地整合视觉和语音信息,以实现更丰富的多模态理解和交互。
实时应用和系统集成:
- 研究如何将Lyra集成到实时应用中,例如智能助手和机器人,以及如何解决与此相关的技术挑战。
长语音和视频的深入分析:
- 对于长语音和视频内容,研究如何进行更深入的内容分析和理解,包括情感分析、事件检测和摘要生成。
这些研究方向不仅可以推动Lyra模型的发展,还可以为多模态人工智能的未来发展提供新的思路和解决方案。
Q: 总结一下论文的主要内容
A: 论文介绍了Lyra,这是一个高效且以语音为中心的多模态大型语言模型(MLLM)框架,旨在实现全方位的认知能力。以下是论文的主要内容总结:
问题陈述:
- 当前MLLMs主要限于两个模态,缺乏对语音模态的深入探索,特别是语音与其他模态(如视觉)之间的联系。
Lyra框架:
- 提出了Lyra,一个通过三种策略实现效率和语音中心能力的MLLM:
- 利用现有的开源大型模型,并通过多模态LoRA减少训练成本和数据需求。
- 使用潜在的多模态正则化器和提取器加强语音与其他模态之间的关系,提升模型性能。
- 构建包含1.5M多模态数据样本和12K长语音样本的高质量数据集,使Lyra能够处理复杂的长语音输入并实现更强大的全模态认知。
- 提出了Lyra,一个通过三种策略实现效率和语音中心能力的MLLM:
主要贡献:
- Lyra在多种视觉-语言、视觉-语音和语音-语言基准测试中实现了最新的性能,同时使用更少的计算资源和训练数据。
实验:
- 进行了一系列的实验来评估Lyra在多模态任务中的性能,包括定量和定性结果,以及组件分析。
方法细节:
- 详细描述了Lyra的四个主要组件:潜在跨模态正则化器、多模态LoRA、潜在多模态提取器和流式生成。
长语音处理:
- 为了处理长语音输入,开发了长语音SFT数据集,并采用了压缩技术来处理长语音。
结论:
- Lyra在整合复杂语音、视觉和语言模态方面取得了显著进展,为未来MLLMs的发展提供了新的方向。
总体而言,Lyra通过其创新的方法,在多模态AI领域中提供了一个高效且功能强大的解决方案,特别是在处理语音模态方面展现出了显著的优势。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

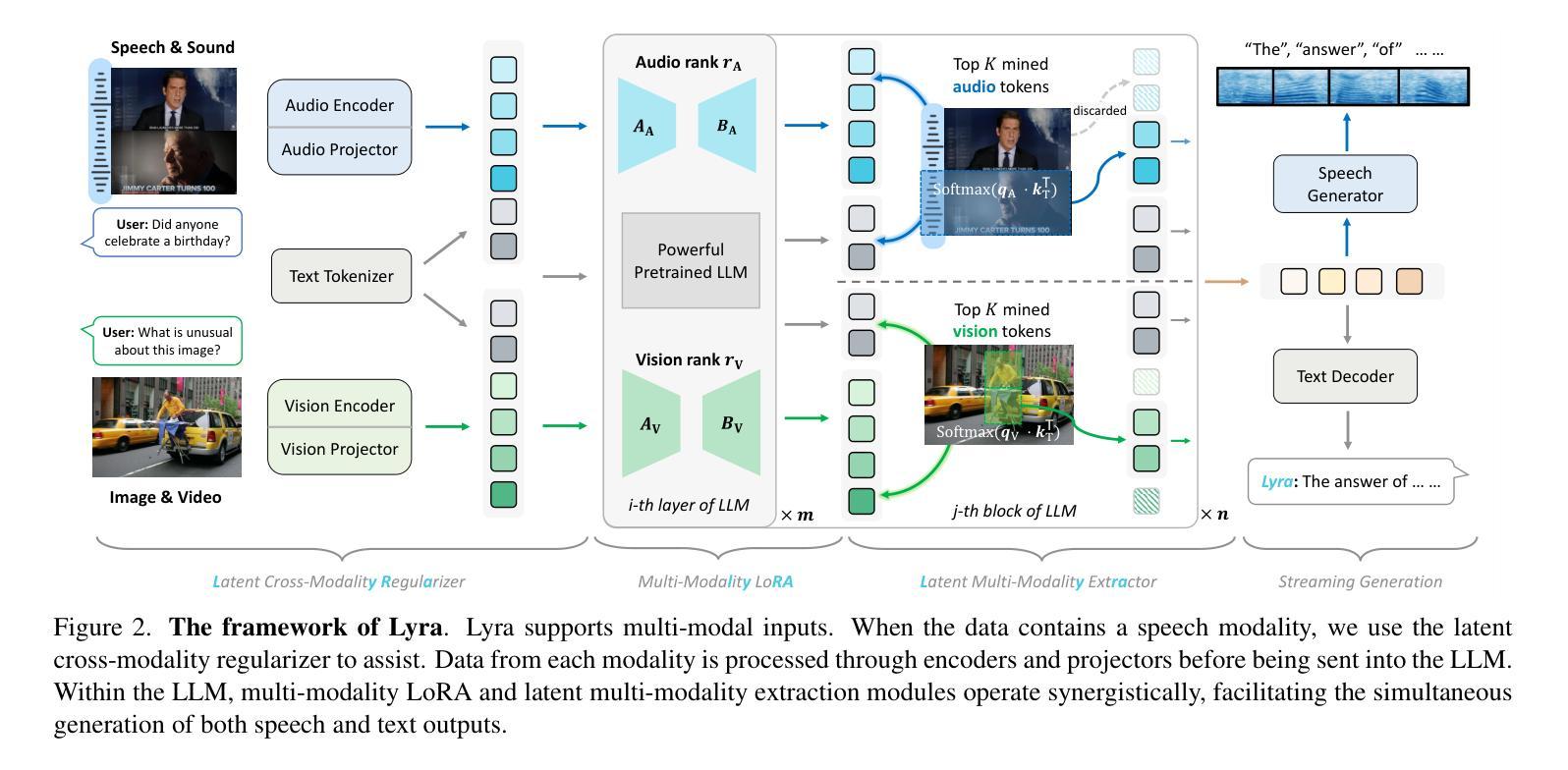

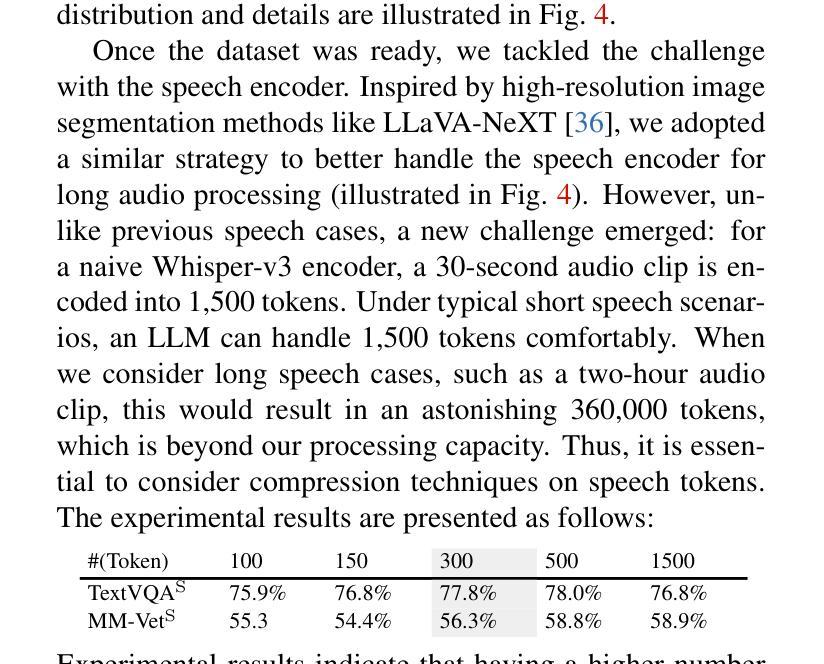
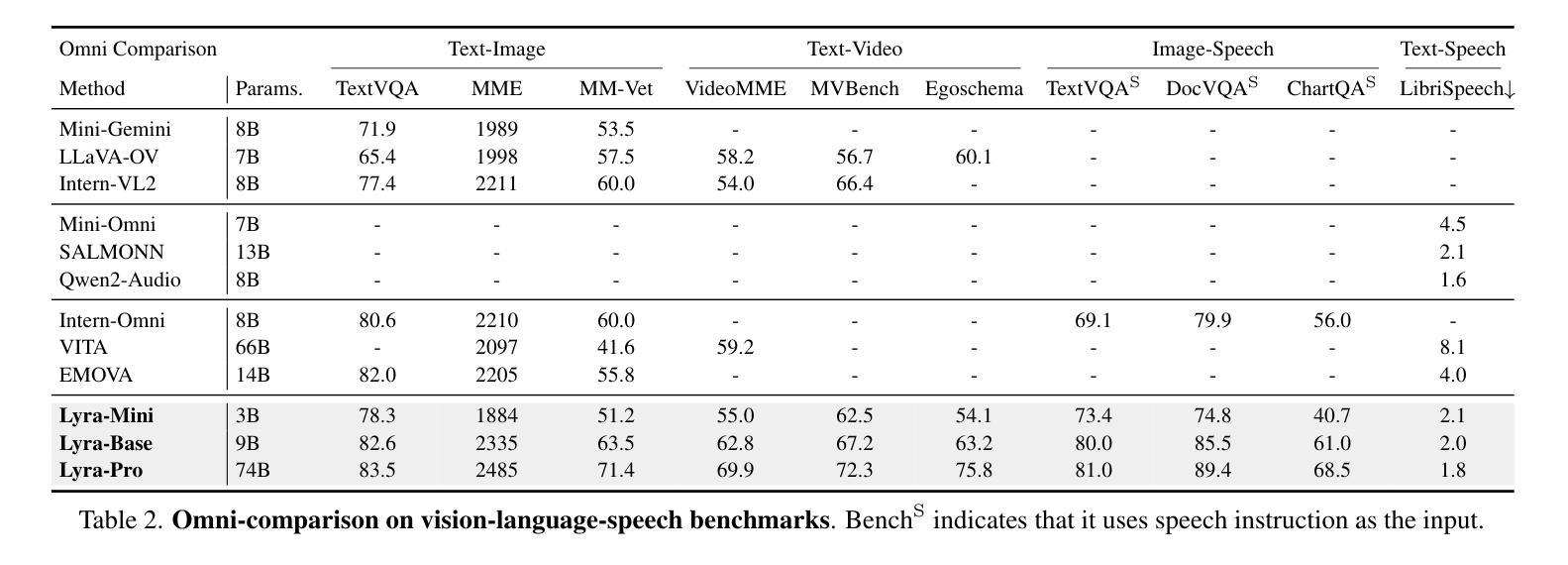
EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing
Authors:Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton van den Hengel, Jian Yang, Qingming Huang
Given a piece of text, a video clip, and a reference audio, the movie dubbing task aims to generate speech that aligns with the video while cloning the desired voice. The existing methods have two primary deficiencies: (1) They struggle to simultaneously hold audio-visual sync and achieve clear pronunciation; (2) They lack the capacity to express user-defined emotions. To address these problems, we propose EmoDubber, an emotion-controllable dubbing architecture that allows users to specify emotion type and emotional intensity while satisfying high-quality lip sync and pronunciation. Specifically, we first design Lip-related Prosody Aligning (LPA), which focuses on learning the inherent consistency between lip motion and prosody variation by duration level contrastive learning to incorporate reasonable alignment. Then, we design Pronunciation Enhancing (PE) strategy to fuse the video-level phoneme sequences by efficient conformer to improve speech intelligibility. Next, the speaker identity adapting module aims to decode acoustics prior and inject the speaker style embedding. After that, the proposed Flow-based User Emotion Controlling (FUEC) is used to synthesize waveform by flow matching prediction network conditioned on acoustics prior. In this process, the FUEC determines the gradient direction and guidance scale based on the user’s emotion instructions by the positive and negative guidance mechanism, which focuses on amplifying the desired emotion while suppressing others. Extensive experimental results on three benchmark datasets demonstrate favorable performance compared to several state-of-the-art methods.
给定一段文本、一个视频片段和参考音频,电影配音任务旨在生成与视频对齐的语音,同时克隆所需的语音。现有方法存在两个主要缺陷:(1)它们很难同时保持音视频同步和清晰的发音;(2)它们缺乏表达用户定义情绪的能力。为了解决这些问题,我们提出了EmoDubber,一种情感可控的配音架构,允许用户指定情绪类型和情绪强度,同时满足高质量的唇部同步和发音。具体来说,我们首先设计了一种唇相关韵律对齐(LPA)方法,通过时长级别对比学习来关注唇动和韵律变化之间的内在一致性,以实现合理对齐。然后,我们设计了发音增强(PE)策略,通过高效转换器融合视频级音素序列,以提高语音清晰度。接下来,语音人身份适配模块旨在解码声音先验并注入说话人风格嵌入。之后,所提出基于流的用户情绪控制(FUEC)方法被用于通过流匹配预测网络根据声音先验合成波形。在此过程中,FUEC通过正负指导机制根据用户的情绪指令确定梯度方向和指导规模,侧重于放大所需情绪的同时抑制其他情绪。在三个基准数据集上的广泛实验结果证明,与几种最新方法相比,该方法表现出优越的性能。
论文及项目相关链接
PDF Under review
Summary
基于给定的文本片段、视频剪辑和参考音频,电影配音任务旨在生成与视频对齐的语音,同时克隆所需的语音。现有方法存在两个主要缺陷:一是难以同时实现音视频同步和清晰的发音;二是无法表达用户定义的情绪。为此,我们提出了EmoDubber情感可控配音架构,允许用户指定情感类型和情感强度,同时满足高质量唇同步和发音。该架构通过设计一系列策略和技术模块解决上述问题。
Key Takeaways
- 电影配音任务旨在生成与视频对齐的语音,同时克隆所需的语音。
- 现有方法存在音视频同步和清晰发音的问题,无法表达用户定义的情绪。
- 提出了EmoDubber情感可控配音架构,可让用户指定情感类型和强度。
- EmoDubber架构包括多个技术模块,如唇相关语调对齐、发音增强、说话人身份适应模块和基于流动的用户情绪控制。
- 架构通过一系列策略和技术模块解决现有问题,实现高质量唇同步和发音。
- 架构采用流匹配预测网络合成波形,根据用户的情感指令确定梯度方向和指导规模。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为EmoDubber的电影配音架构,旨在解决现有电影配音方法中的两个主要缺陷:
音视频同步与清晰发音的挑战:现有的方法在生成与视频同步的语音时,往往难以同时保持音视频同步和清晰的发音。
缺乏情绪表达能力:现有的方法通常缺乏表达用户定义情绪的能力,这限制了它们在电影后期制作中的应用,尤其是在情感表达方面。
为了解决这些问题,EmoDubber架构允许用户指定所需的情绪类型和情绪强度,同时确保高质量的唇部同步和清晰的发音。具体来说,EmoDubber通过以下几个关键模块来实现这一目标:
- **Lip-related Prosody Aligning (LPA)**:通过时序级别的对比学习,学习唇动和韵律变化之间的固有一致性,以实现合理的对齐。
- **Pronunciation Enhancing (PE)**:通过扩展视频级别的音素序列并使用高效Conformer模型融合,以提高语音的可理解性。
- **Speaker Identity Adapting (SIA)**:通过注入说话人风格嵌入来生成声学先验信息。
- **Flow-based User Emotion Controlling (FUEC)**:基于流匹配预测网络,根据用户的情绪指令合成波形,同时通过正负引导机制(PNGM)灵活调整情绪强度。
通过这些模块,EmoDubber能够在保持音视频同步和清晰发音的同时,实现情绪的可控合成,从而满足电影制作或爱好者对配音质量的需求。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
Visual Voice Cloning (V2C):
- 该领域专注于生成与角色口型同步,并且具有参考音频中展示的嗓音风格的文本语音。一些工作专注于改善多说话人场景中的说话人身份识别,例如:
- V2CNet [3] 和 VDTTS [15] 使用预训练的 GE2E [47] 来获得独特且归一化的言语嵌入。
- StyleDubber [6] 应用多尺度学习将风格线索应用于 GE2E 提取的嵌入。
- Speak2Dub [50] 采用预训练策略在 TTS 语料库上提高表达性。
- 该领域专注于生成与角色口型同步,并且具有参考音频中展示的嗓音风格的文本语音。一些工作专注于改善多说话人场景中的说话人身份识别,例如:
Flow Matching 和 Classifier Guidance:
- Flow Matching 是一种无需模拟的方法,用于训练连续归一化流(CNFs)模型,这些模型可以模拟任意概率路径,并捕获由扩散过程表示的概率轨迹。它在图像生成和几何领域表现出色,例如:
- Stable Diffusion 3 [10], Lumina-T2X [11], 和 EQUIFM [44]。
- Classifier Guidance (CG) 被广泛用于控制特定属性,例如文本到图像和情感 TTS [13, 26, 45]。
- Flow Matching 是一种无需模拟的方法,用于训练连续归一化流(CNFs)模型,这些模型可以模拟任意概率路径,并捕获由扩散过程表示的概率轨迹。它在图像生成和几何领域表现出色,例如:
情感表达和控制:
- 一些研究 [18] 表明,配音中的情感强度可以影响听众的情感和对电影的心理感知。因此,电影的后期制作可以通过控制情感表达来弥补先前录音的不足。
音频-视觉同步评估:
- 使用 Lip Sync Error Distance (LSE-D) 和 Lip Sync Error Confidence (LSE-C) 等指标来量化生成语音与视频之间的同步性,这些指标基于预训练的 SyncNet [5]。
语音质量评估:
- 使用 Word Error Rate (WER) [36] 来衡量发音准确性,并使用 Speaker Encoder Cosine Similarity (SECS) 来评估生成配音与参考音频之间的音色一致性。
情感评估:
- 使用 Intensity Score 来衡量生成音频中的情感强度,这比之前使用平均分类概率的方法更精细。
这些相关研究为 EmoDubber 架构的开发提供了理论基础和技术背景,使其能够在保持音视频同步和清晰发音的同时,实现情绪的可控合成。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为EmoDubber的架构来解决电影配音中存在的问题,具体解决方案如下:
1. Lip-related Prosody Aligning (LPA)
- 目标:学习唇动和韵律变化之间的固有一致性,以实现正确的音视频对齐。
- 方法:通过时序级别的对比学习(Duration level contrastive learning),控制语音速度,使得模型能够推理正确的音视频对齐。
2. Pronunciation Enhancing (PE)
- 目标:提高语音的清晰度和可理解性。
- 方法:通过单调对齐搜索(Monotonic alignment search, MAS)扩展视频级别的音素序列,并与LPA的输出通过高效的Conformer模型进行融合。
3. Speaker Identity Adapting (SIA)
- 目标:生成声学先验信息,并注入说话人的风格。
- 方法:从PE模块的输出中吸收融合序列,并注入来自参考说话人的样式嵌入,以生成目标声学先验信息。
4. Flow-based User Emotion Controlling (FUEC)
- 目标:根据用户指定的情绪指令合成波形,同时渲染用户指定的情绪。
- 方法:使用基于流匹配的预测网络,并结合正负引导机制(Positive and Negative Guidance Mechanism, PNGM),动态调整流匹配向量场预测过程,以实现情绪强度的灵活控制。
技术细节
- 多尺度风格学习:通过多尺度学习来应用风格线索,增强说话人特征。
- 上下文视频场景的融合:通过结合前后视频场景来增强生成语音的韵律表达。
- 情感控制:通过情感专家分类器和流匹配预测网络,根据用户的情绪指令动态调整情绪强度。
实验结果
- 数据集:在三个基准数据集(Chem, GRID, V2C-Animation)上进行了广泛的实验。
- 性能:与几种最先进的方法相比,EmoDubber在音视频同步、发音清晰度和情感控制方面均展现出优越性能。
通过上述方法,EmoDubber能够在保持音视频同步和清晰发音的同时,实现情绪的可控合成,满足用户对电影配音质量和情感表达的需求。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证EmoDubber架构的性能和效果。以下是实验的详细内容:
1. 实施细节
- 视频帧采样率为25 FPS,所有音频重新采样为16kHz。
- 唇部区域调整为96×96,并在ResNet-18上进行预训练。
- STFT(短时傅里叶变换)的窗口长度、帧大小和跳跃长度分别为640、1024和160。
- 流预测网络在LibriSpeech上进行预训练。
- 使用PyTorch在GeForce RTX 4090 GPU上进行训练和推理。
2. 数据集
- Chem:一个流行的配音数据集,记录了化学老师在课堂上的讲话。
- GRID:一个多说话人的配音基准数据集。
- V2C-Animation:一个用于动画电影配音的多说话人数据集,包含身份和情感注释。
3. 评估指标
- 音视频同步评估:使用Lip Sync Error Distance (LSE-D) 和 Lip Sync Error Confidence (LSE-C)。
- 语音质量评估:使用Word Error Rate (WER)、Speaker Encoder Cosine Similarity (SECS)、Mel Cepstral Distortion Dynamic Time Warping (MCD) 和MCD-SL。
- 情感评估:使用Intensity Score来衡量生成音频中的情感强度。
- 主观评估:使用MOS-naturalness (MOS-N) 和 MOS-similarity (MOS-S) 来评估生成语音的自然度和目标语音的识别度。
4. 与现有技术的比较
- 与没有情感控制功能的SOTA(State-of-the-Art)配音模型进行比较,包括Fastspeech2、StyleSpeech、Face-TTS、V2C-Net、HPMDubbing、Speaker2Dub和StyleDubber等。
5. 消融研究
- 通过移除EmoDubber架构中的不同模块(LPA、PE、SIA)来评估每个模块对整体性能的贡献。
6. 情感控制评估
- 强度控制结果:展示了EmoDubber在Chem基准上通过调整正负引导尺度(α和β)来控制情感强度的能力。
- 情感零样本转换:在没有情感标签的Chem数据集上重新合成具有五种不同情感的语音,与现有的情感TTS基线模型GenerSpeech进行比较。
- 情感语音质量结果:在Chem测试集上测试了七种情感的语音质量,验证情感控制对音频-视觉同步、发音清晰度和说话人相似性的影响。
7. 定性结果
- 邀请志愿者在三个视频上表达预期的情感和强度,并使用EmoDubber生成的音频样本进行可视化比较。
这些实验全面评估了EmoDubber在音视频同步、语音质量、情感控制和用户自定义情感强度方面的表现,并与现有技术进行了比较,证明了其优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管EmoDubber在电影配音任务中取得了显著的性能,但仍有一些领域可以进一步探索和改进:
1. 模型泛化能力
- 多语言和方言支持:当前模型主要针对单一语言,探索多语言和方言的支持可以扩大模型的应用范围。
- 跨领域泛化:研究模型在不同类型的视频(如动画、纪录片、访谈等)和不同场景下的泛化能力。
2. 情感表达的精细度
- 更丰富的情感类别:目前EmoDubber主要处理几种基本情感,可以考虑引入更细致的情感类别,如“惊讶”、“轻蔑”等。
- 情感转换的平滑性:研究如何在不同情感之间平滑过渡,使配音听起来更自然。
3. 模型训练和优化
- 训练效率:探索更高效的训练策略,如迁移学习、半监督学习等,以减少训练时间和资源消耗。
- 模型压缩和加速:研究模型压缩技术,以便在资源受限的设备上部署EmoDubber。
4. 用户交互和控制
- 用户界面:开发直观的用户界面,让用户更容易地指定情感类型和强度,以及实时预览配音效果。
- 个性化定制:允许用户上传自己的语音样本,使模型能够学习并模仿用户的特定语音特征。
5. 音频和视频质量
- 更高分辨率的音频和视频:探索使用更高分辨率的音频和视频输入,以提高最终输出的质量。
- 噪声和复杂背景的处理:研究如何在嘈杂或复杂背景中保持高质量的唇音同步和清晰的发音。
6. 多模态融合
- 更多的视觉信息:除了唇动,还可以考虑融合面部表情、肢体语言等其他视觉信息,以增强情感表达。
- 音频-视觉不一致的处理:研究如何处理音频和视频不一致的情况,例如,当视频中的说话人快速移动或遮挡嘴唇时。
7. 伦理和隐私问题
- 数据隐私保护:确保在训练和使用过程中保护个人隐私,特别是在使用真实人物的视频时。
- 伦理使用指南:制定使用指南,防止EmoDubber被用于制造虚假信息或侵犯版权。
这些探索点不仅可以推动EmoDubber技术的发展,还有助于提高电影配音的自然度和表现力,同时也需要关注其在实际应用中的伦理和隐私问题。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为EmoDubber的情绪可控电影配音架构,旨在生成与视频同步的语音,同时复制所需的声音,并允许用户指定情绪类型和情绪强度。以下是论文的主要内容总结:
1. 问题定义
- 电影配音任务需要将文本转换成语音,与视频角色的口型同步,并表现出参考音频中的声音特征。
- 现有方法存在两个主要问题:音视频同步与清晰发音难以同时保证,以及缺乏表达用户定义情绪的能力。
2. EmoDubber架构
- **Lip-related Prosody Aligning (LPA)**:通过时序级别的对比学习,学习唇动和韵律变化之间的一致性,以实现音视频对齐。
- **Pronunciation Enhancing (PE)**:通过扩展视频级别的音素序列并使用高效Conformer模型融合,提高语音的可理解性。
- **Speaker Identity Adapting (SIA)**:生成声学先验信息,并注入说话人的风格。
- **Flow-based User Emotion Controlling (FUEC)**:基于流匹配预测网络,根据用户的情绪指令合成波形,并通过正负引导机制灵活调整情绪强度。
3. 实验
- 在三个基准数据集(Chem, GRID, V2C-Animation)上进行了广泛的实验。
- 使用了多种评估指标,包括音视频同步评估、语音质量评估、情感评估和主观评估。
- 实验结果表明,EmoDubber在保持音视频同步和清晰发音的同时,能够实现情绪的可控合成,并优于几种最先进的方法。
4. 贡献
- 提出了EmoDubber,一个可控情绪配音架构,允许用户指定所需情绪,同时满足高质量唇部同步和清晰发音。
- 设计了具有正负引导的FUEC,动态调整流匹配向量场预测过程,实现灵活的情绪强度控制。
- 通过时序级别的对比学习和音素增强策略,实现了高质量的唇部同步和清晰发音。
5. 未来工作
- 探索多语言和方言支持、情感表达的精细度、模型训练和优化、用户交互和控制、音频和视频质量、多模态融合以及伦理和隐私问题等方向。
EmoDubber的提出为电影配音领域带来了新的可能性,通过结合先进的语音合成技术和情感控制机制,提高了配音的自然度和表现力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

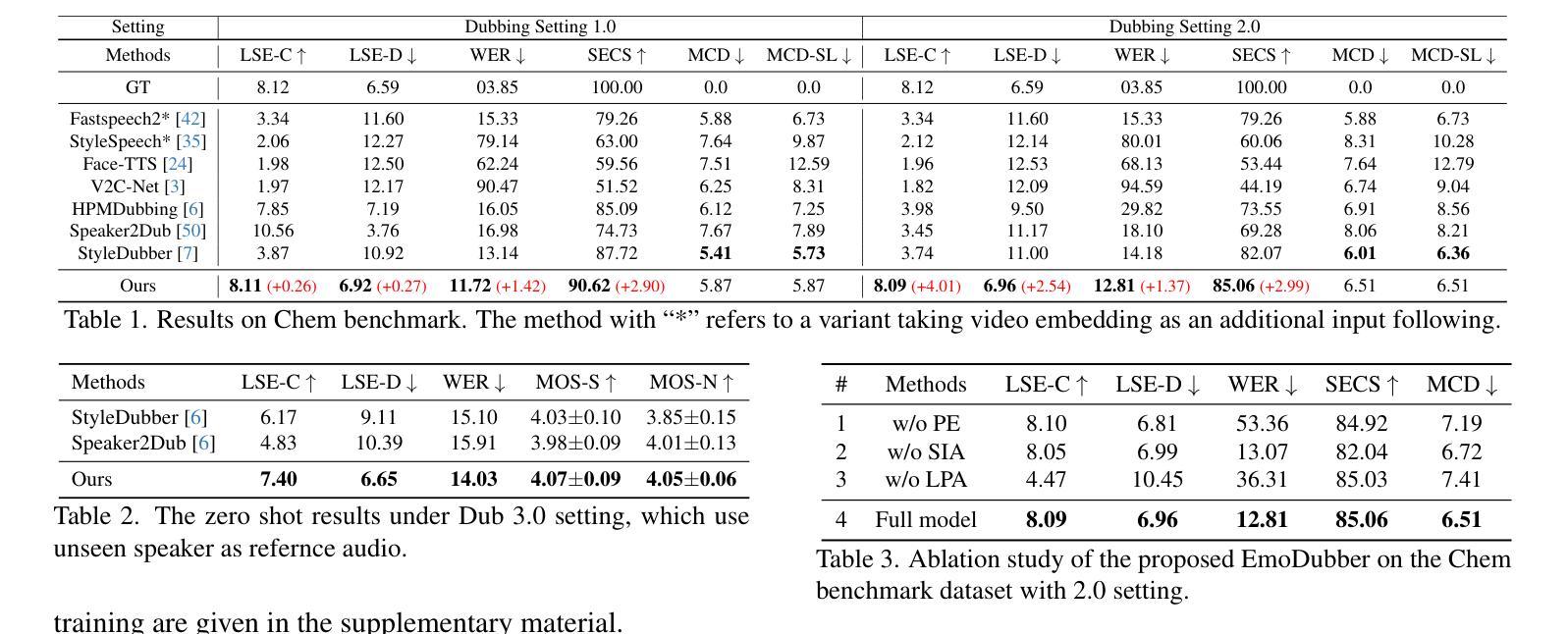
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Authors:Jianwei Cui, Yu Gu, Shihao Chen, Jie Zhang, Liping Chen, Lirong Dai
Singing Voice Synthesis (SVS) {aims} to generate singing voices {of high} fidelity and expressiveness. {Conventional SVS systems usually utilize} an acoustic model to transform a music score into acoustic features, {followed by a vocoder to reconstruct the} singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
歌唱声音合成(SVS)旨在生成具有高保真和表现力的歌唱声音。传统SVS系统通常使用声学模型将乐谱转换为声学特征,随后由声码器重建歌唱声音。最近有研究显示,在SVS和文本到语音(TTS)领域,端到端建模是有效的。因此,在这项工作中,我们提出了一种完全端到端的SVS方法,并采用了分段流式推理来解决实际使用中的延迟问题。需要注意的是,这是首次尝试使用VAE中的潜在表示来完全实现端到端流式音频合成。我们对使用潜在表示的流式SVS的性能进行了具体改进。实验结果表明,所提出的方法在流式SVS和TTS任务中实现了具有高度的表现力和音高准确度的合成音频。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
本文介绍了歌唱声音合成(SVS)的目标是通过端到端建模生成高保真和富有表现力的歌声。传统SVS系统通常使用声学模型将乐谱转换为声学特征,并使用vocoder重建歌声。最近,端到端建模在SVS和文本到语音(TTS)领域显示出有效性。本文提出了一种全端到端的SVS方法,并引入分段流式推理来解决实际使用中的延迟问题。这是首次尝试在VAE中使用潜在表示实现全端到流音频合成。
Key Takeaways
- 歌唱声音合成(SVS)旨在生成高保真和富有表现力的歌声。
- 传统SVS系统通常使用声学模型和vocoder来生成歌声。
- 端到端建模在SVS和文本到语音(TTS)领域被证明是有效的。
- 本文提出了一种全端到端的SVS方法,并引入流式推理来解决延迟问题。
- 这是首次在VAE中使用潜在表示实现全端到流音频合成。
- 通过对流式SVS的特定改进,提高了其性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
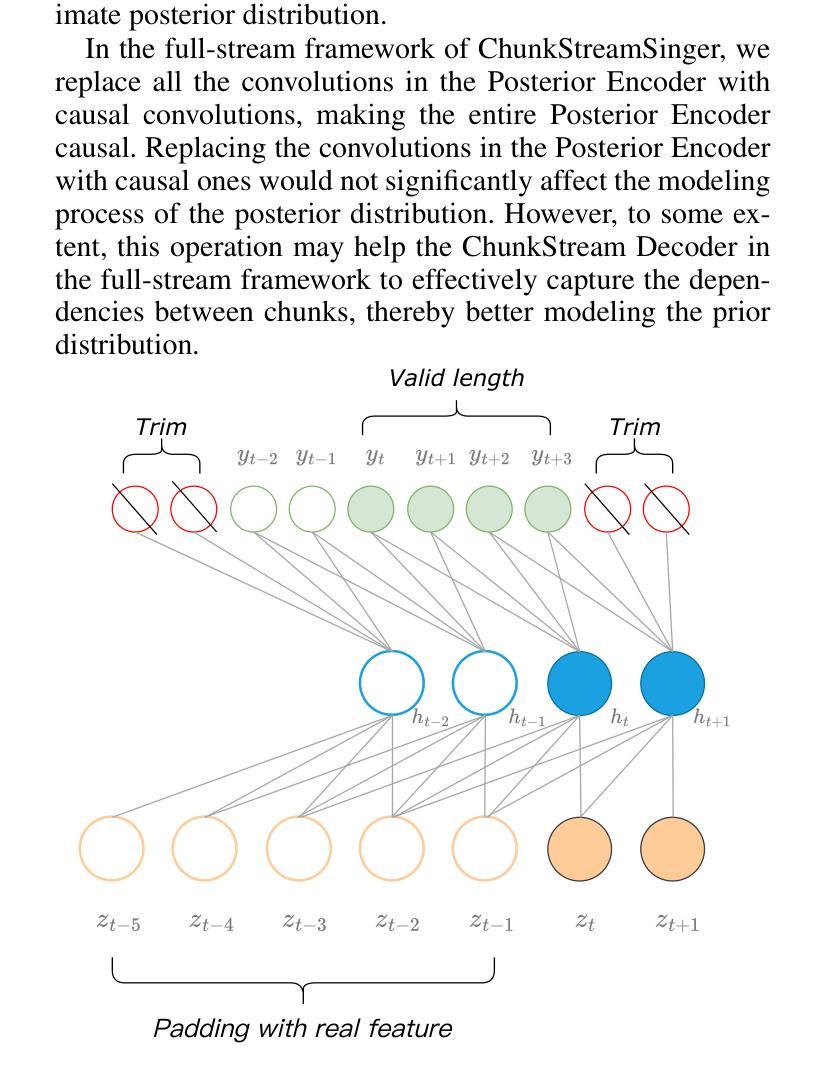
A: 这篇论文提出了一个基于条件变分自编码器(Conditional Variational Autoencoder, VAE)的端到端分块流式(chunkwise streaming)歌唱语音合成系统(ChunkStreamSinger, CSSinger),旨在解决以下问题:
实时性和计算资源限制:传统的歌唱语音合成(Singing Voice Synthesis, SVS)系统和文本到语音(Text to Speech, TTS)系统通常包含一个声学模型和一个声码器,这些系统在处理长序列时计算量大,实时性能不佳,尤其是在边缘设备和在线网络服务中部署时。
端到端流式音频合成:这是首次尝试完全实现使用VAE中的潜在表示进行端到端流式音频合成。流式合成对于减少延迟和提高实时性至关重要。
潜在表示用于声码器:使用VAE的潜在表示作为声码器的输入并不直观,尤其是对于歌唱语音,直接使用潜在表示进行音频生成会导致合成音频质量下降。
提高流式SVS性能:论文中提出了特定的改进措施,以增强使用潜在表示的流式SVS性能。
综上所述,论文的主要贡献在于提出了一种新的端到端流式歌唱语音合成方法,该方法不仅能够生成高表达性和音高准确性的合成音频,而且相较于传统的平行计算模型,能够显著降低延迟,提高实时性,更好地适应边缘设备和在线服务等实际应用场景。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个领域:
Singing Voice Synthesis (SVS): 论文提到了多个基于深度学习的SVS系统,例如XiaoiceSing、ByteSing、VISinger和VISinger2。这些系统利用深度神经网络生成基于乐谱的高质量歌唱语音。
Text-to-Speech (TTS): 论文中提到了TTS系统中使用的端到端建模方法,如VITS (Kim, Kong, and Son 2021) 和SiFiSinger (Cui et al. 2024),它们基于条件VAE框架进行声学建模和音频合成。
Conditional Variational Autoencoder (VAE): VAE作为一种深度生成模型,在语音合成领域有广泛应用,如VITS、VISinger和SiFiSinger等系统,它们利用VAE学习潜在空间表示,以提高合成音频的自然度和真实感。
Streaming and Autoregressive Modeling: 论文中提到了一些研究工作,它们关注于流式自回归建模,例如Tacotron2和WaveNet。这些模型分别用于声学建模和波形生成,但存在推理效率低下和生成速度慢的问题。
Neural Audio Synthesis: 论文中提到了HiFi-GAN,这是一个用于高保真语音合成的生成对抗网络,它在CSSinger系统中被用于流式音频合成。
Efficient Neural Audio Synthesis: 论文中提到了WaveRNN,这是一个用于实时应用的神经音频合成模型,它通过减小模型大小和权重稀疏化来加速生成过程。
这些相关研究为CSSinger系统的提出提供了理论基础和技术背景,CSSinger系统在这些研究的基础上,通过引入流式处理和潜在表示的改进,旨在实现更高效、更自然的歌唱语音合成。
Q: 论文如何解决这个问题?
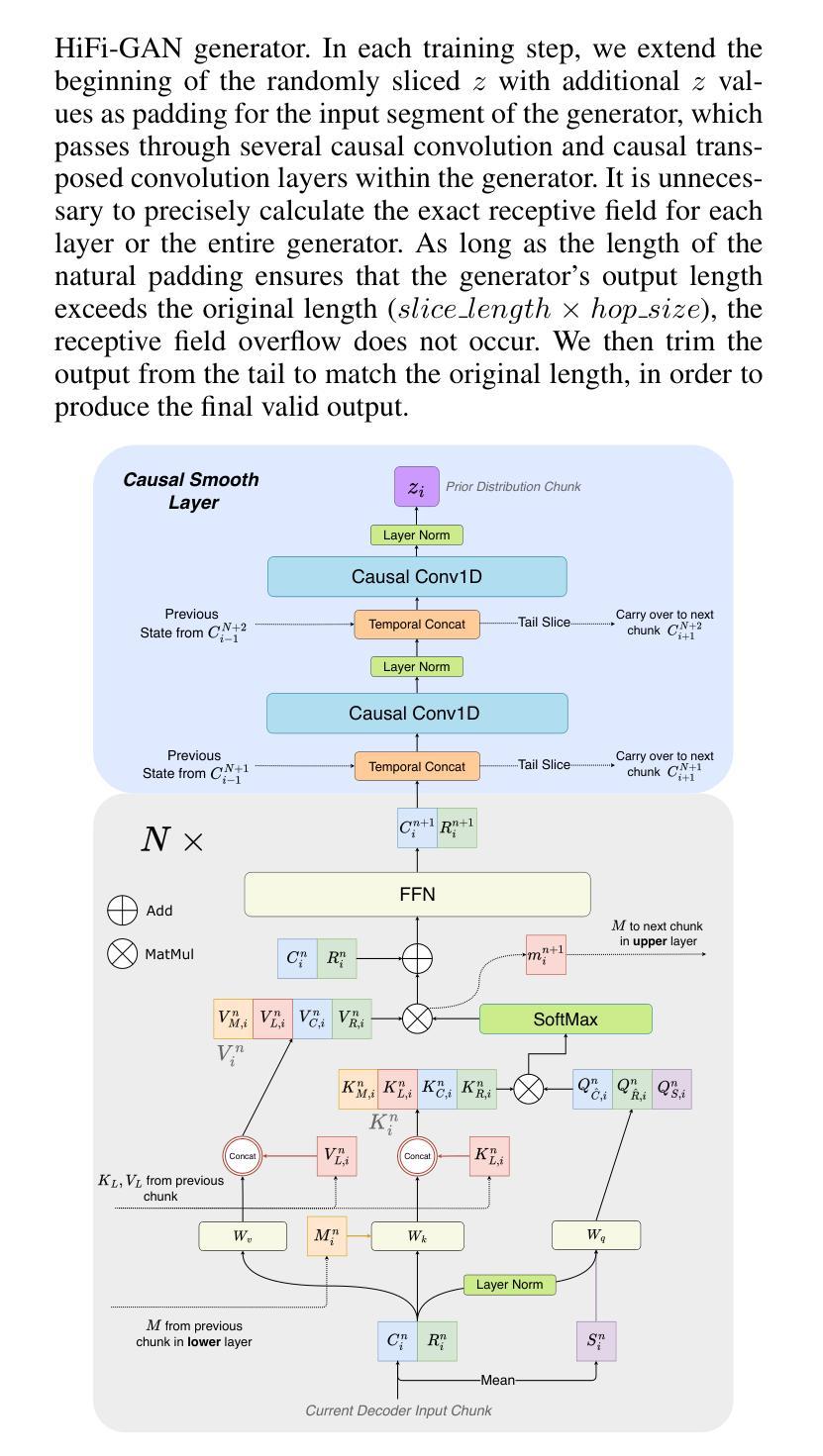
A: 论文通过提出一个名为ChunkStreamSinger(CSSinger)的系统来解决上述问题,具体解决方案包括以下几个关键点:
端到端条件VAE框架:
- 使用条件变分自编码器(VAE)来学习音乐评分(如歌词、音高、时长)的潜在表示,并直接生成合成音频。
- 该框架包括一个先验编码器(Prior Encoder)和一个后验编码器(Posterior Encoder),用于学习潜在空间的表示,并从这些表示中直接生成合成音频。
分块流式推理(Chunkwise Streaming Inference):
- 采用分块方式处理音频合成任务,降低实时处理的延迟,并减少计算资源消耗。
- 在声码器(vocoder)中使用因果转置卷积(causal transposed convolutions)来生成音频,避免了传统填充方法导致的音质下降问题。
自然填充(Natural Padding)策略:
- 为了避免在因果卷积中使用传统常数填充(如零填充或复制填充)导致的音质问题,论文提出了自然填充策略。
- 该策略通过在训练过程中动态地使用实际的潜在表示作为填充,而不是固定的常数值,以提高音频合成质量。
ChunkStream Decoder:
- 为了实现完全的流式推理,提出了ChunkStream Decoder,它将潜在表示的生成转换为基于块的流式处理。
- 该解码器借鉴了Emformer模型的机制,将完整的输入特征向量分解为多个固定长度的块,并在各个块之间提供上下文信息,确保注意力机制可以在每个块上并行计算。
因果平滑层(Causal Smooth Layer):
- 为了减少块之间的边界效应,引入了因果平滑层,该层由一维因果卷积和LayerNorm层组成。
- 这层保留了前一个块的相同层级的特征,并为下一个块提供特征,以增强合成音频的自然度和流畅性。
实验验证:
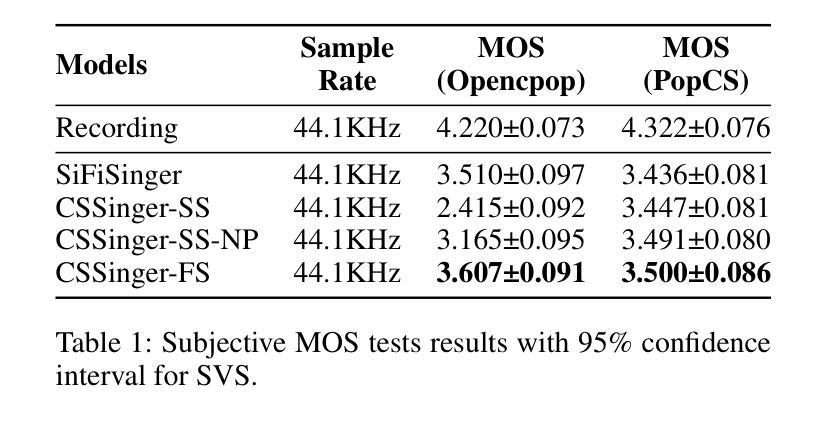
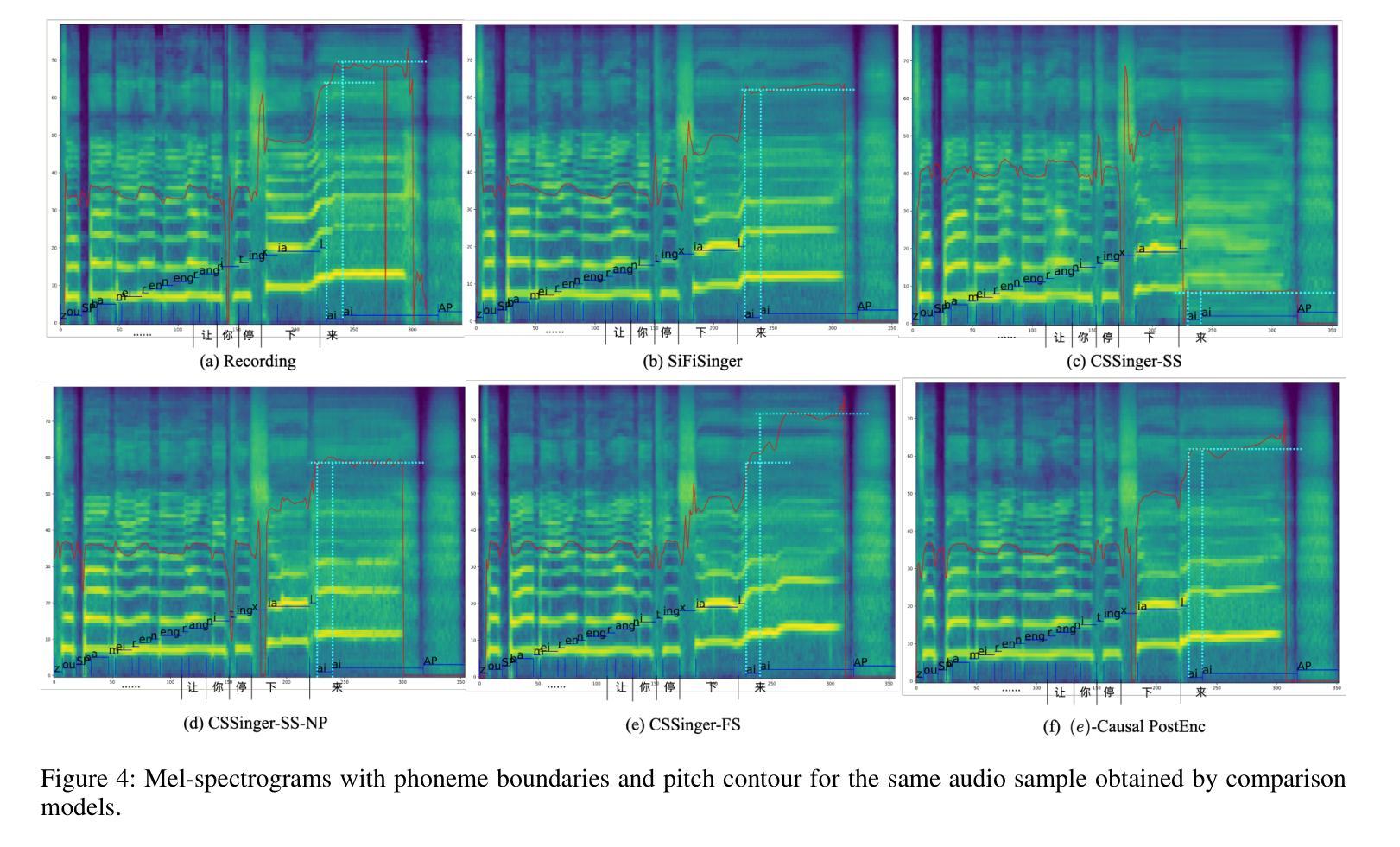
- 在多个中文歌唱语音数据集和一个TTS数据集上进行了实验,验证了所提出方法在主观和客观评价指标上相较于现有系统的优越性。
- 展示了CSSinger-FS在MOS评分和客观评价指标上的优势,并在不同硬件配置下评估了模型的延迟和实时性。
通过这些技术方案,论文成功地实现了一个低延迟、高效率的端到端流式歌唱语音合成系统,该系统不仅提高了合成音频的质量,还降低了实时应用中的延迟,使其更适合于边缘设备和在线服务等资源受限环境。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的ChunkStreamSinger(CSSinger)系统的性能,包括主观和客观的评估。以下是实验的详细内容:
数据集
- Opencpop2:一个公开的高质量中文歌唱语音数据集,包含100首普通话歌曲,由专业女歌手演唱,包含3,756个话语,总时长5.2小时。
- PopCS:另一个中文普通话歌唱语音数据集,包含117首歌曲,总时长约5.89小时,由专业女歌手演唱。
- Baker3:一个中文女性语音数据集,包含约12小时的标准普通话女性语音,包含10,000个句子,平均每个句子16个字符。
比较方法
- Recording:使用真实的歌唱语音音频作为基准。
- SiFiSinger:一个完全并行推理的基线系统。
- CSSinger-SS:CSSinger的半流式方法,只有HiFiGAN声码器以分块流式方式运行。
- CSSinger-SS-NP:CSSinger-SS加上自然填充(Natural Padding)的半流式结构。
- CSSingerFS(提出的模型):CSSinger的全流式框架,使用ChunkStream Decoder实现潜在表示z的流式推理。
实施细节
- 使用44.1KHz采样的音频处理Opencpop和PopCS数据集,而Baker数据集的音频采样率为48KHz,被重新采样到16KHz。
- 模型隐藏层大小设置为192,FFN隐藏层的通道数为768。
- Acoustic Model Decoder和ChunkStream Decoder都有4个注意力层。
- 使用diffsptk4提取80维melcepstrum(mcep)作为声学特征。
- 所有实验中HiFi-GAN生成器的训练随机切片大小设置为20,CSSinger模型的块大小也为20。
主要结果与分析
- 主观评估(MOS测试):在Opencpop和PopCS数据集上进行,随机选择20个样本,邀请20名母语人士进行主观评估。
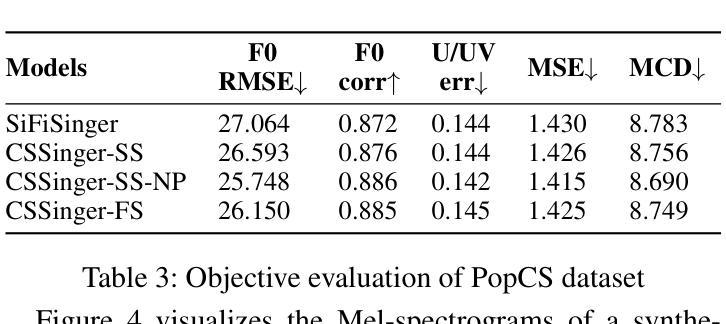
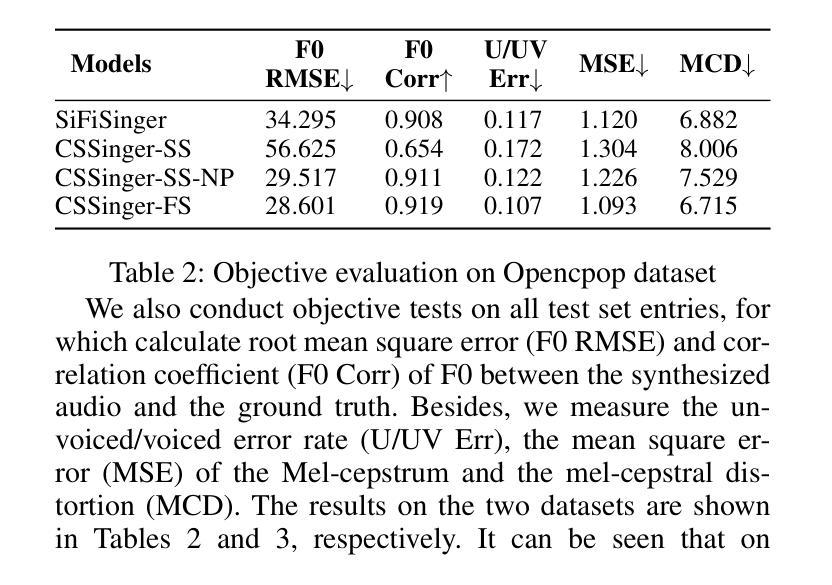
- 客观评估:计算合成音频与真实音频之间的基频均方根误差(F0 RMSE)、基频相关系数(F0 Corr)、无声/有声错误率(U/UV Err)、Mel-cepstrum均方误差(MSE)和Mel-cepstral失真(MCD)。
延迟评估
- 测量从输入特征到合成音频生成的延迟(秒)、从输入特征到音频处理完成的总处理时间(秒)和实时因子(RTF)作为系统效率的指标。
- 在GPU、CPU和单核单线程CPU限制(CPU-Limited)三种情况下测试延迟指标。
结论
- CSSinger-FS在多个客观和主观指标上表现出色,优于现有的并行和半流式系统。
- 在GPU和CPU硬件配置下,CSSinger-FS显示出较低的延迟和优越的实时推理效率,这对于高实时需求的应用和计算资源受限的场景非常重要。
这些实验全面评估了CSSinger系统的性能,证明了其在歌唱语音合成任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的ChunkStreamSinger(CSSinger)系统在歌唱语音合成方面取得了显著的性能提升,但仍有一些领域可以进一步探索和改进:
模型泛化能力:
- 在更多种类和风格的歌唱数据集上测试模型的泛化能力,包括不同语言、不同性别和不同演唱技巧的数据集。
更深入的客观评估:
- 开发更精细的客观评价指标,以更全面地评估合成音频的自然度、清晰度和音乐性等。
实时性能优化:
- 进一步优化模型以降低延迟和计算资源消耗,特别是在资源受限的设备上,如移动设备或嵌入式系统。
多风格和多歌手建模:
- 探索如何使模型能够处理多个歌手和不同演唱风格,提供更丰富的合成选项。
端到端训练的改进:
- 研究如何改进端到端训练过程,可能包括更好的损失函数、优化算法或正则化技术,以进一步提高合成质量。
声码器的改进:
- 研究新型声码器或改进现有声码器,以生成更高保真度和更自然的音频。
上下文感知建模:
- 提高模型对歌曲上下文的感知能力,例如,理解和模拟歌曲的情绪和节奏变化。
交互式应用:
- 探索CSSinger在交互式应用中的潜力,如卡拉OK系统或音乐教育软件,其中实时反馈和调整是必要的。
模型解释性:
- 提高模型的可解释性,帮助研究人员和开发者更好地理解模型的决策过程和潜在空间的结构。
多任务学习:
- 考虑将歌唱语音合成与其他任务(如音乐生成、节奏识别)结合起来,以创建更全面的音乐生成系统。
模型鲁棒性测试:
- 对模型进行鲁棒性测试,尤其是在面对不完整或噪声数据时的性能。
跨领域应用:
- 探索CSSinger在其他领域的应用,如语音编码、语音增强或语音转换。
这些探索方向不仅可以推动歌唱语音合成技术的发展,还可能为整个语音合成和音频处理领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个基于条件变分自编码器(Conditional Variational Autoencoder, VAE)的端到端分块流式(chunkwise streaming)歌唱语音合成系统ChunkStreamSinger(CSSinger)。以下是论文的主要内容总结:
问题陈述:
- 论文旨在解决传统歌唱语音合成(SVS)系统中存在的实时性和计算资源限制问题,特别是在边缘设备和在线网络服务中部署时的高延迟问题。
系统架构:
- CSSinger基于SiFiSinger构建,采用条件VAE框架,包含先验编码器和后验编码器,直接从音乐评分生成合成音频。
- 系统支持分块流式推理,以减少延迟并提高实时性。
关键技术:
- 自然填充(Natural Padding):解决VAE潜在表示用于声码器输入时的音质下降问题。
- ChunkStream Decoder:实现完全流式推理,将潜在表示的生成转换为基于块的流式处理。
- 因果平滑层(Causal Smooth Layer):减少块之间的边界效应,增强合成音频的自然度和流畅性。
实验验证:
- 在两个中文歌唱语音数据集和一个文本到语音(TTS)数据集上进行了实验,验证了CSSinger系统在主观和客观评价指标上相较于现有系统的优越性。
- 展示了CSSinger在不同硬件配置下(GPU和CPU)的低延迟和优越的实时推理效率。
结论:
- CSSinger-FS(全流式框架)在MOS评分和客观评价指标上优于现有的并行和半流式系统。
- 该系统不仅提高了合成音频的质量,还降低了实时应用中的延迟,使其更适合于边缘设备和在线服务等资源受限环境。
未来工作:
- 论文提出了一些可以进一步探索的方向,包括模型泛化能力的提升、实时性能的进一步优化、多风格和多歌手建模等。
总体而言,这篇论文提出了一个创新的端到端流式歌唱语音合成系统,通过引入先进的技术方案,有效地提高了合成音频的质量和实时性,为SVS领域的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

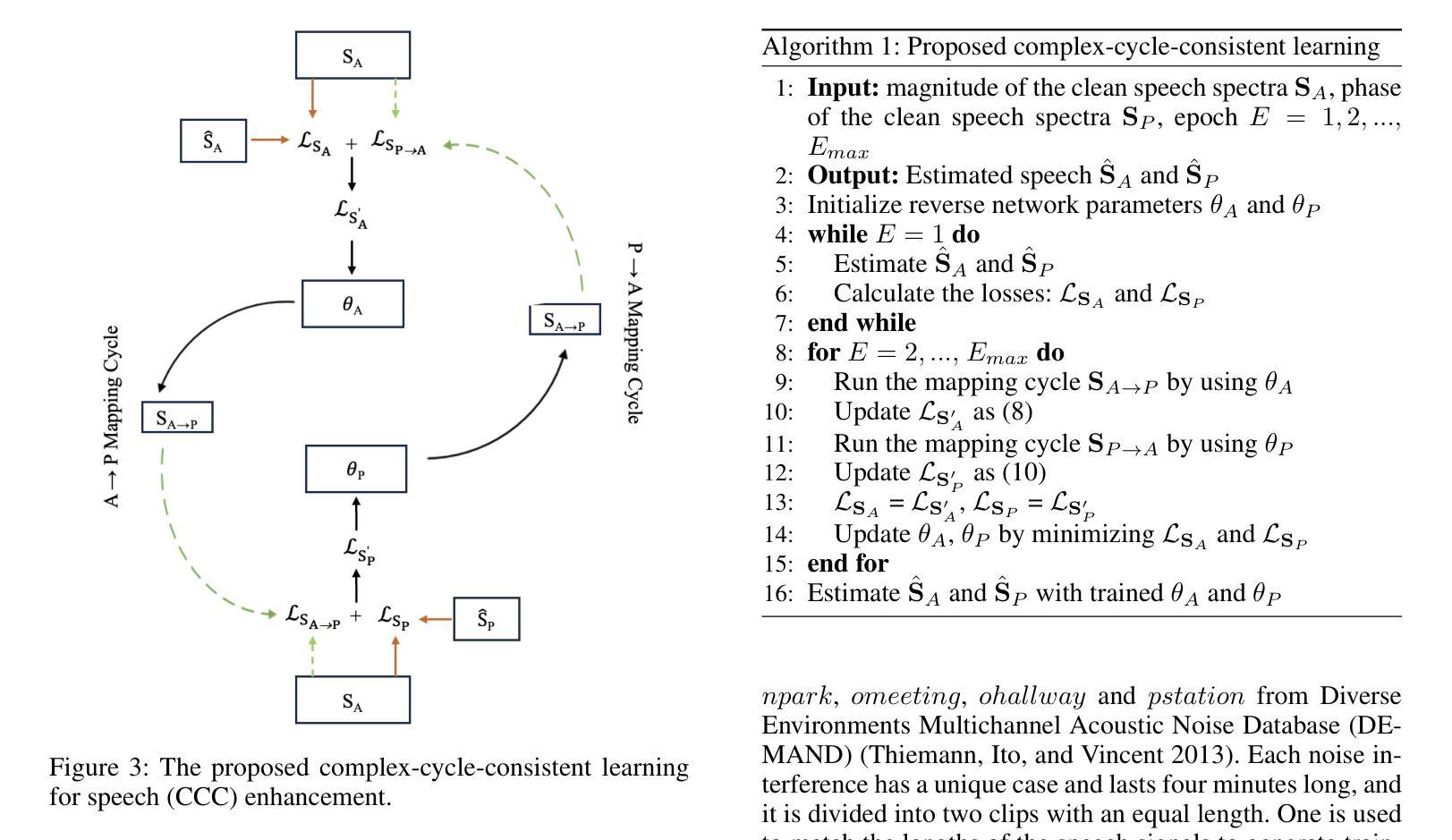
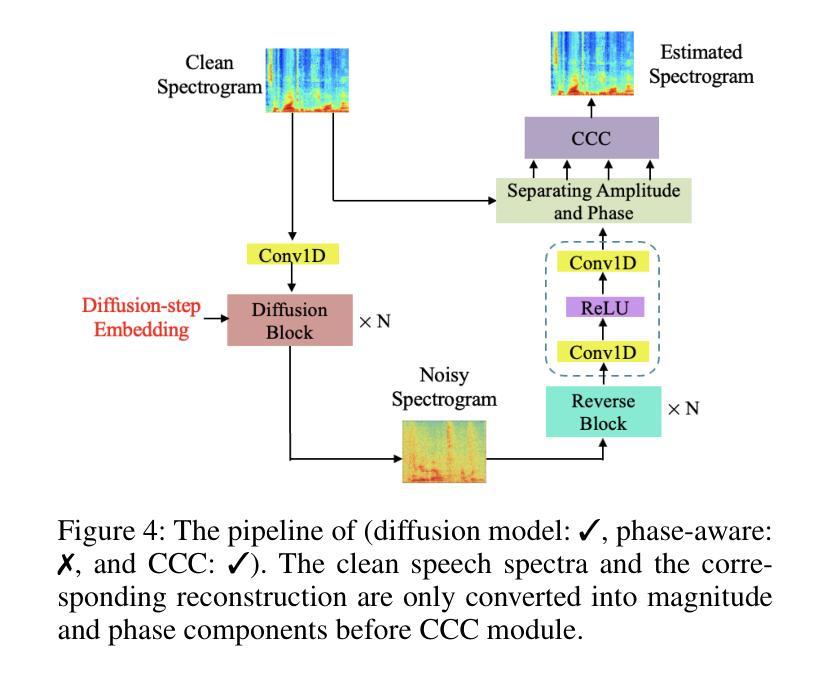
Complex-Cycle-Consistent Diffusion Model for Monaural Speech Enhancement
Authors:Yi Li, Yang Sun, Plamen Angelov
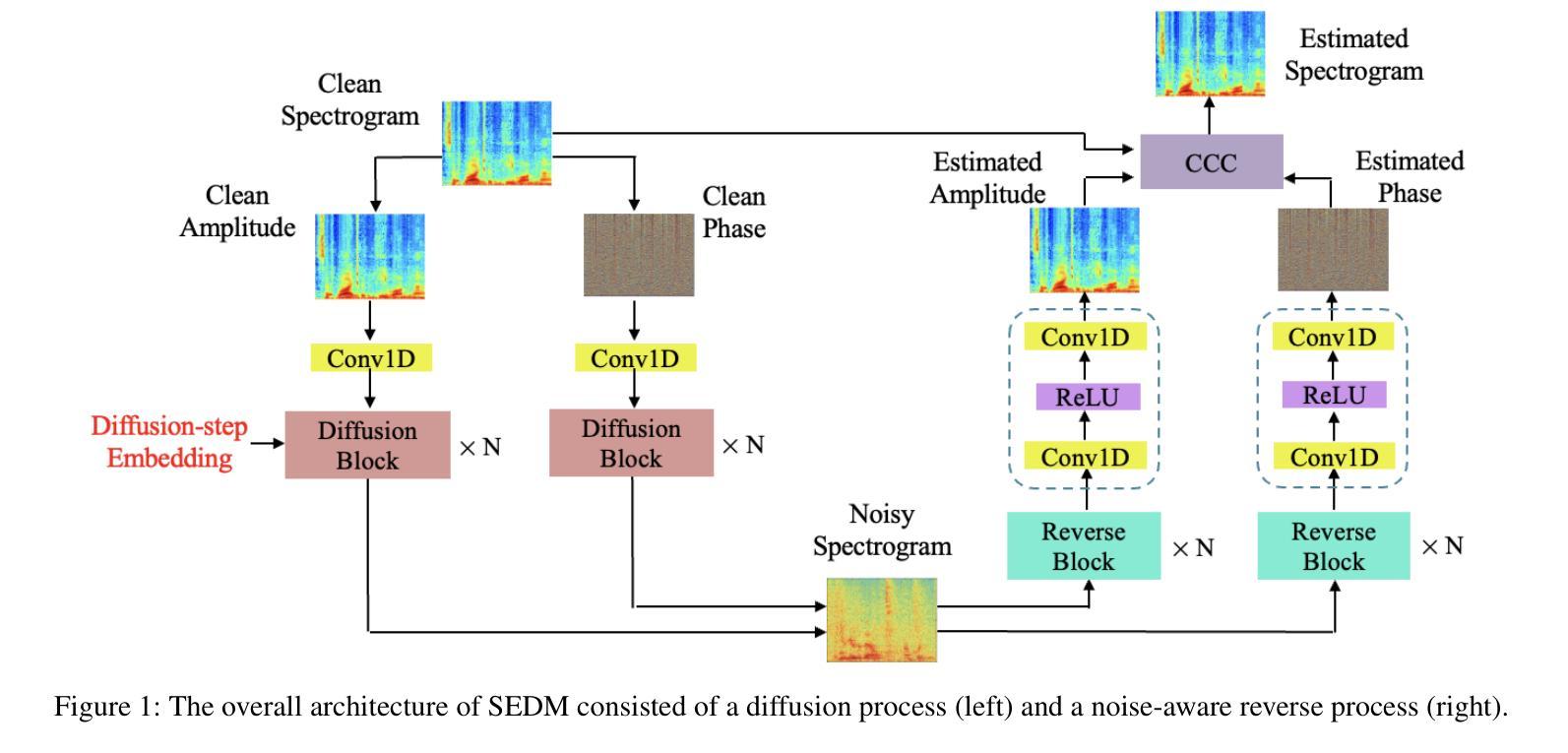
In this paper, we present a novel diffusion model-based monaural speech enhancement method. Our approach incorporates the separate estimation of speech spectra’s magnitude and phase in two diffusion networks. Throughout the diffusion process, noise clips from real-world noise interferences are added gradually to the clean speech spectra and a noise-aware reverse process is proposed to learn how to generate both clean speech spectra and noise spectra. Furthermore, to fully leverage the intrinsic relationship between magnitude and phase, we introduce a complex-cycle-consistent (CCC) mechanism that uses the estimated magnitude to map the phase, and vice versa. We implement this algorithm within a phase-aware speech enhancement diffusion model (SEDM). We conduct extensive experiments on public datasets to demonstrate the effectiveness of our method, highlighting the significant benefits of exploiting the intrinsic relationship between phase and magnitude information to enhance speech. The comparison to conventional diffusion models demonstrates the superiority of SEDM.
在本文中,我们提出了一种基于扩散模型的新型单通道语音增强方法。我们的方法在两个扩散网络中分别估计语音谱的幅度和相位。在扩散过程中,将来自现实世界噪声干扰的噪声片段逐渐添加到干净语音谱中,并提出了一个噪声感知的逆向过程来学习如何生成干净语音谱和噪声谱。此外,为了充分利用幅度和相位之间的内在关系,我们引入了一种复周期一致性(CCC)机制,该机制使用估计的幅度来映射相位,反之亦然。我们在一个相位感知语音增强扩散模型(SEDM)中实现此算法。我们在公共数据集上进行了大量实验,以证明我们的方法的有效性,并重点说明了利用相位和幅度信息之间内在关系来增强语音的重大优势。与常规扩散模型的对比表明了SEDM的优越性。
论文及项目相关链接
PDF AAAI 2025
Summary
该论文提出了一种基于扩散模型的新颖单通道语音增强方法。该方法在两个扩散网络中分别估计语音谱的幅度和相位,并在扩散过程中逐步添加现实世界噪声干扰的噪声片段。通过引入噪声感知逆向过程,学习如何生成干净语音谱和噪声谱。为了充分利用幅度和相位之间的内在关系,论文提出了一种复杂循环一致性(CCC)机制,使用估计的幅度来映射相位,反之亦然。该方法在公共数据集上进行了广泛的实验验证,证明了利用相位和幅度信息之间内在关系进行语音增强的显著优势,并与传统扩散模型相比展现了优越性。
Key Takeaways
- 论文提出了一种新的基于扩散模型的语音增强方法。
- 方法涉及在两个扩散网络中分别估计语音谱的幅度和相位。
- 通过逐步添加现实世界噪声片段,进行了噪声感知逆向过程学习。
- 引入了复杂循环一致性(CCC)机制,利用幅度和相位之间的内在关系。
- 方法在公共数据集上进行了广泛实验验证,表现出优越性。
- 论文强调了利用相位和幅度信息之间内在关系进行语音增强的重要性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种基于扩散模型的单声道语音增强方法,旨在解决现实世界声学环境中语音信号不可避免地受到背景噪声污染的问题。主要目标是从背景噪声中分离出目标语音信号,以改善语音质量和可理解性。具体来说,论文试图解决以下两个问题:
忽略幅度和相位之间的内在关系:传统基于深度学习的单声道语音增强方法通常在时频(T-F)域中工作,只估计幅度响应而保持相位响应不变。然而,幅度和相位是相互关联的,利用这种关系可以进一步提高语音增强性能。
使用高斯噪声而非实际噪声:扩散模型在语音增强中通常利用高斯噪声来学习基于最大熵和统计推断的去噪语音。但实际环境中的噪声远比高斯噪声复杂,使用实际噪声可能提升性能。
论文通过提出一种新的语音增强扩散模型(SEDM),该模型替换了前向过程中的高斯噪声为实际噪声,并引入了复杂循环一致(CCC)机制来利用幅度和相位之间的内在关系,以期提高语音增强的效果。
Q: 有哪些相关研究?
A: 论文中提到了以下与单声道语音增强和扩散模型相关的研究工作:
**Wang et al. (2014)**:提出了一种新的方法,通过提出复理想比例掩模(complex ideal ratio mask),允许同时增强幅度和相位谱,该方法在复域中操作。
**Williamson, Wang, and Wang (2016)**:基于复谱图的单声道语音增强中广泛采用了复谱图(即幅度和相位),因为它们通过利用语音信号的相位信息来提高性能。
**Shimauchlt et al. (2017)**:研究了幅度和相位之间的关系,并指出利用这种关系可以进一步改善语音增强性能。
**Sohl-Dickstein et al. (2015)**:最初提出了扩散模型,该模型展示了强大的生成能力,包括前向扩散过程和反向过程。
**Lu et al. (2021)**:首次将扩散模型应用于语音增强,引入了支持性反向过程的概念。
Hu et al. (2023) 和 **Lu et al. (2022)**:展示了扩散模型在语音增强领域的应用,并取得了优异的结果。
**Wu et al. (2023)**:在图像去噪领域,使用与环境设置相结合的实际噪声来更好地模拟噪声分布的复杂性,证明了使用实际噪声比高斯噪声可以提升性能。
这些相关工作为本文提出的基于扩散模型的单声道语音增强方法提供了理论基础和技术背景。论文通过结合这些相关研究,提出了一种新的方法来解决现有方法的局限性,并利用实际噪声和幅度-相位关系来提高语音增强的性能。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键贡献来解决单声道语音增强问题:
提出一种新的语音增强扩散模型(SEDM):
- 该模型替换了传统扩散模型中的高斯噪声,使用实际噪声来模拟噪声分布的复杂性。
- 通过在前向过程中随机选择不同噪声类型的噪声片段,更真实地模拟了现实世界中的噪声干扰。
引入噪声感知的反向过程:
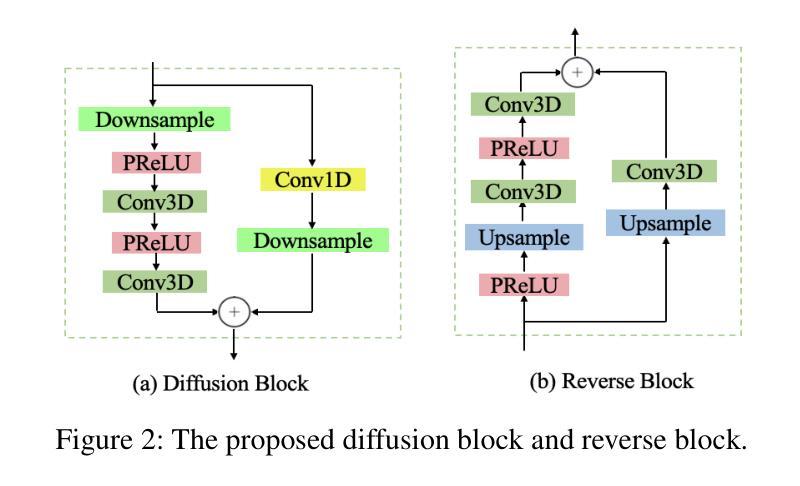
- 该过程从噪声语音谱图开始采样,旨在估计干净语音和噪声谱图,同时尽量减少引入额外噪声信号。
- 通过定义每个反向步骤的可训练参数,优化模型以生成之前的步骤,并恢复干净语音。
利用幅度和相位之间的内在关系:
- 通过引入复杂循环一致(CCC)机制,利用估计的幅度来映射相位,反之亦然,以提高估计精度。
- CCC模块包含两个长短期记忆(LSTM)网络,分别用于从相位到幅度和从幅度到相位的映射,并通过循环一致学习进一步优化模型参数。
实验验证:
- 在多个公共数据集上进行广泛的实验,验证所提方法的有效性,并与常规扩散模型进行比较,展示SEDM的优越性。
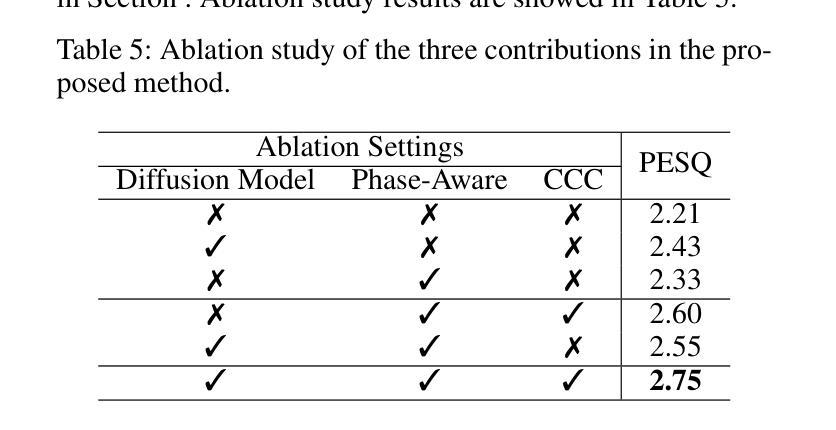
消融研究:
- 通过消融研究来验证每个贡献的有效性,包括扩散模型、相位感知和CCC机制,确认这些组件在提升语音增强性能方面的作用。
可视化和定性分析:
- 使用t-SNE可视化和定性分析来展示模型学习到的特征表示,并比较不同嵌入数量下的特征可分性。
鲁棒性测试:
- 评估SEDM模型在训练时使用实际噪声与高斯噪声的性能差异,并测试模型在面对训练中未见过的噪声类型时的鲁棒性。
通过这些方法,论文提出的SEDM模型能够有效地从噪声中分离出目标语音信号,并在多个标准数据集上取得了优于现有技术的性能。
Q: 论文做了哪些实验?
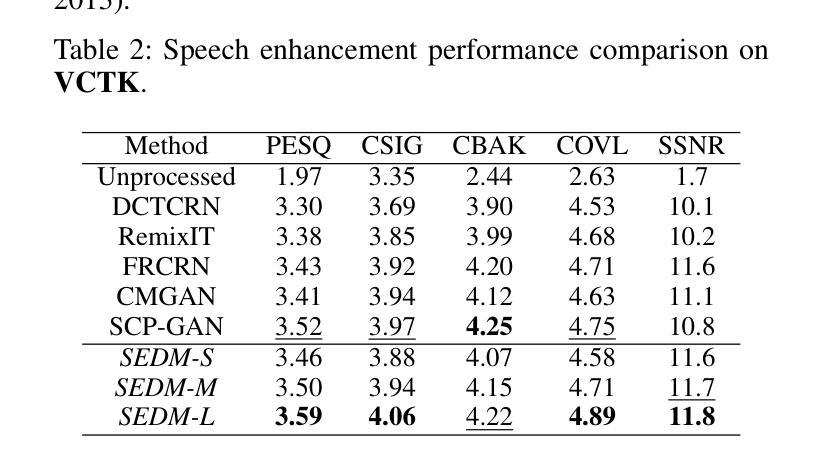
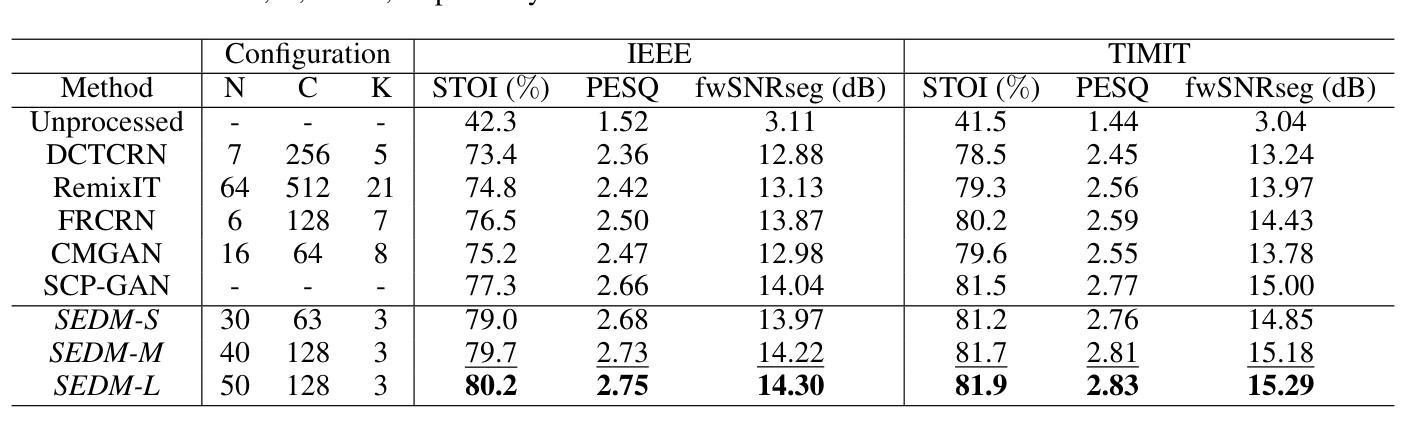
A: 论文中进行了一系列实验来验证所提出的基于扩散模型的单声道语音增强方法(SEDM)的有效性。以下是实验的详细内容:
数据集:
- 实验在几个公共语音数据集上进行,包括IEEE、TIMIT、VOICE BANK (VCTK) 和 Deep Noise Suppression (DNS) challenge。
模型配置:
- 设定了不同大小的SEDM模型(SEDM-S, SEDM-M, SEDM-L),在扩散块数和通道数方面有所不同。
- 使用了Adam优化器进行训练,设置了权重衰减、动量和批量大小等参数。
- 实验在Tesla V100 GPU上运行,所有语音话语被重新采样到16 kHz,并使用快速傅里叶变换(FFT)转换为语谱图。
性能评估指标:
- 使用短时客观可懂度(STOI)、语音质量感知评估(PESQ)和频率加权段信噪比(fwSNRseg)等指标评估增强语音的质量。
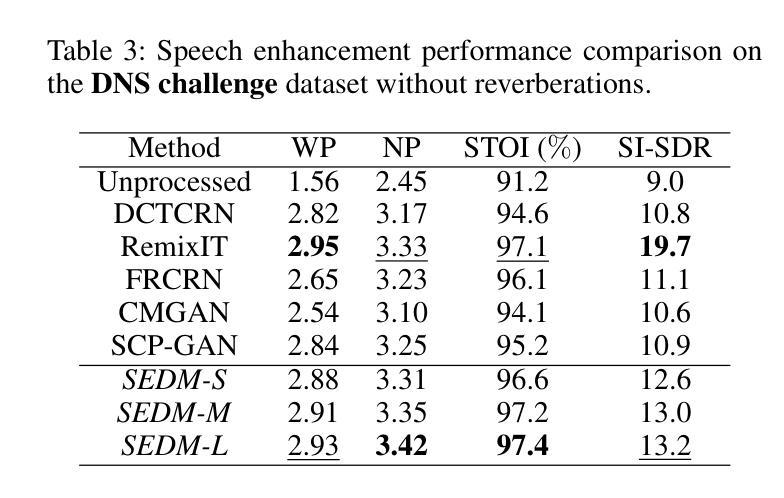
与现有技术的比较:
- 将SEDM与六种最先进的模型进行比较,包括DCTCRN、RemixIT、FRCRN、CMGAN和SCP-GAN。
- 在不同的信噪比(SNR)水平和十种噪声干扰下,评估了360个噪声语音信号的平均语音增强性能。
VCTK和DNS Challenge数据集上的评估:
- 在VCTK数据集上,随机生成了不同背景噪声和信噪比水平的噪声混合语音。
- 在DNS Challenge数据集上,使用了超过500小时的干净语音剪辑和超过180小时的噪声剪辑进行训练和测试。
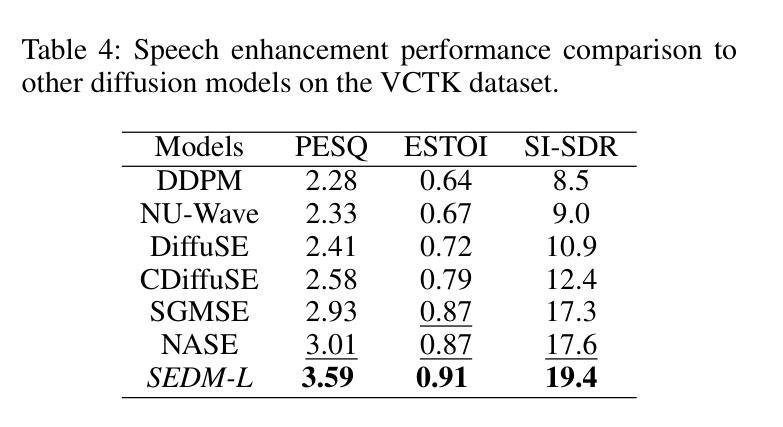
与其他扩散模型的比较:
- 将SEDM与包括DDPM、DiffuSE、NASE等在内的其他扩散模型进行比较。
消融研究:
- 对SEDM的各个组成部分(如扩散模型、相位感知和CCC机制)进行了消融研究,以验证每个部分对性能的贡献。
定性分析:
- 使用t-SNE可视化分析了不同嵌入数量下的特征表示的可分性。
鲁棒性测试:
- 比较了使用实际噪声和高斯噪声训练的SEDM模型,并在测试阶段评估了对看到和未看到噪声类型的鲁棒性。
这些实验全面评估了SEDM的性能,并与现有技术进行了比较,证明了SEDM在不同情况下的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的单声道语音增强方法,但仍有一些领域可以进一步探索和研究:
模型泛化能力:
- 研究模型对于未见过的噪声类型或在不同环境下录制的语音数据的泛化能力。
计算复杂度和实时性:
- 优化模型结构和算法以降低计算复杂度,使其适用于实时语音增强应用。
多声道语音增强:
- 将模型扩展到多声道或立体声语音增强任务,并探索如何利用额外的空间信息。
结合其他信号处理技术:
- 研究如何将传统的信号处理技术(例如滤波器、波束形成)与深度学习方法结合,以提高语音增强的性能。
更复杂的网络结构:
- 探索更复杂的网络结构或注意力机制,以更有效地捕捉语音和噪声之间的复杂关系。
噪声类型分类:
- 研究模型是否能够识别并分类不同的噪声类型,并据此调整其增强策略。
少样本学习:
- 研究在标注数据有限的情况下,如何利用少样本学习或无监督学习来训练有效的语音增强模型。
模型解释性:
- 提高模型的可解释性,以便更好地理解模型是如何学习和分离语音信号的。
跨领域应用:
- 探索模型在其他语言或口音的语音增强中的有效性,并研究跨领域应用的可能性。
与语音识别系统的集成:
- 研究如何将语音增强模型与自动语音识别(ASR)系统集成,以提高在噪声环境下的识别性能。
长期语音信号的处理:
- 研究模型处理长时间语音信号的能力,并探索如何有效地处理潜在的时变噪声特性。
优化损失函数:
- 研究和设计新的损失函数,以更好地利用幅度和相位信息,并提高语音增强质量。
这些方向不仅可以推动语音增强技术的发展,还可能对相关的音频处理和模式识别领域产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种基于扩散模型的单声道语音增强方法,旨在从背景噪声中分离出目标语音信号,以提高语音质量和可理解性。以下是论文的主要内容总结:
问题陈述:
- 论文指出现实环境中的语音信号常受到背景噪声的污染,导致语音质量和可理解性下降。单声道语音增强面临挑战,因为只能使用单个通道的信息。
现有方法的局限性:
- 传统方法通常在时频域中工作,只估计幅度响应而保持相位不变,忽略了幅度和相位之间的内在关系。
- 扩散模型通常使用高斯噪声,而实际环境中的噪声远比高斯噪声复杂。
方法论:
- 提出了一种新的语音增强扩散模型(SEDM),该模型用实际噪声替换了前向过程中的高斯噪声。
- 引入了噪声感知的反向过程,以学习生成干净语音和噪声谱图。
- 利用复杂循环一致(CCC)机制,通过估计的幅度映射相位,反之亦然,以提高估计精度。
实验验证:
- 在多个公共数据集上进行实验,包括IEEE、TIMIT、VCTK和DNS挑战。
- 使用STOI、PESQ和fwSNRseg等指标评估增强语音的质量。
- 与现有的六种最先进模型进行比较,展示了SEDM的有效性。
消融研究:
- 通过消融研究验证了扩散模型、相位感知和CCC机制对性能的贡献。
可视化和定性分析:
- 使用t-SNE可视化分析了不同嵌入数量下的特征表示的可分性。
- 提供了定性结果,展示了SEDM-L在增强性能上优于基线模型。
结论:
- SEDM方法在不同公共数据集上均优于现有的语音增强方法。
- 实验结果证实,实际噪声可以在一定程度上替代高斯噪声,提高语音增强的性能。
总体而言,这篇论文通过引入新的扩散模型和CCC机制,有效地利用了幅度和相位信息,提高了单声道语音增强的性能,并在多个标准数据集上验证了其优越性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Emotional Vietnamese Speech-Based Depression Diagnosis Using Dynamic Attention Mechanism
Authors:Quang-Anh N. D., Manh-Hung Ha, Thai Kim Dinh, Minh-Duc Pham, Ninh Nguyen Van
Major depressive disorder is a prevalent and serious mental health condition that negatively impacts your emotions, thoughts, actions, and overall perception of the world. It is complicated to determine whether a person is depressed due to the symptoms of depression not apparent. However, their voice can be one of the factor from which we can acknowledge signs of depression. People who are depressed express discomfort, sadness and they may speak slowly, trembly, and lose emotion in their voices. In this study, we proposed the Dynamic Convolutional Block Attention Module (Dynamic-CBAM) to utilized with in an Attention-GRU Network to classify the emotions by analyzing the audio signal of humans. Based on the results, we can diagnose which patients are depressed or prone to depression then so that treatment and prevention can be started as soon as possible. The research delves into the intricate computational steps involved in implementing a Attention-GRU deep learning architecture. Through experimentation, the model has achieved an impressive recognition with Unweighted Accuracy (UA) rate of 0.87 and 0.86 Weighted Accuracy (WA) rate and F1 rate of 0.87 in the VNEMOS dataset. Training code is released in https://github.com/fiyud/Emotional-Vietnamese-Speech-Based-Depression-Diagnosis-Using-Dynamic-Attention-Mechanism
重度抑郁症是一种常见且严重的心理健康疾病,会对你的情绪、思维、行为和整体世界观产生负面影响。由于抑郁症的症状并不明显,所以很难判断一个人是否抑郁。但是,他们的声音可以是我们察觉到抑郁迹象的一个因素。抑郁的人们会表现出不适、悲伤,他们说话可能缓慢、颤抖,声音中失去情感。在这项研究中,我们提出了动态卷积块注意力模块(Dynamic-CBAM),将其与注意力GRU网络结合,通过分析人类音频信号来分类情感。根据结果,我们可以诊断哪些患者患有抑郁症或容易患上抑郁症,以便尽早开始治疗和预防。该研究深入探讨了实现注意力GRU深度学习架构所涉及的复杂计算步骤。通过试验,该模型取得了令人印象深刻的识别效果,在VNEMOS数据集上实现了未加权准确率(UA)为0.87,加权准确率(WA)为0.86,F1分数为0.87。训练代码已发布在 https://github.com/fiyud/Emotional-Vietnamese-Speech-Based-Depression-Diagnosis-Using-Dynamic-Attention-Mechanism 上。
论文及项目相关链接
PDF 9 Page, 5 Figures
Summary
本文探讨了一种通过语音分析来诊断抑郁症的方法。研究提出了一种基于动态卷积块注意力模块(Dynamic-CBAM)的注意力GRU网络,通过分析人类音频信号来分类情感。通过实验研究,该模型在VNEMOS数据集上取得了显著的识别效果,未加权准确率(UA)达到0.87,加权准确率(WA)和F1分数也表现出色。
Key Takeaways
- 抑郁症是一种普遍而严重的精神健康疾病,可通过声音表达来识别其症状。
- 研究提出了Dynamic-CBAM与注意力GRU网络结合,用于通过音频信号分析情感分类。
- 该模型能够实现抑郁症的诊断,有助于尽早开始治疗和预防。
- 模型在VNEMOS数据集上取得了较高的未加权准确率(UA 0.87)。
- 模型还表现出良好的加权准确率(WA)和F1分数。
- 相关训练代码已发布在指定GitHub仓库中。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何通过分析越南语语音中的情感来识别抑郁倾向。具体来说,研究的主要目标是:
识别语音中的情感特征:通过分析语音信号的频率幅度来评估个体是否有抑郁倾向。研究者们想要识别说话者特定的情感特征,然后基于这些特征判断他们是否可能经历抑郁。
利用深度学习技术:通过使用深度学习技术,更全面和准确地评估和分析语音中的情感特征,包括语音的速度、音量、节奏和音调。
提高抑郁诊断的准确性和速度:通过完成这项研究,研究者们希望能够获得有用的信息来诊断抑郁,并能够更准确、更快速地检测出抑郁的迹象。
提出新的深度学习架构:研究中提出了一个新的基于注意力机制的深度学习架构(Dynamic-CBAM),用于从音频信号中分类情感。
改善抑郁症患者的治疗和预防:通过尽早识别出可能抑郁的患者,可以及时开始治疗和预防措施,从而减轻抑郁症对个人和社会的影响。
Q: 有哪些相关研究?
A: 论文中提到了以下与情感语音识别和抑郁症诊断相关的研究:
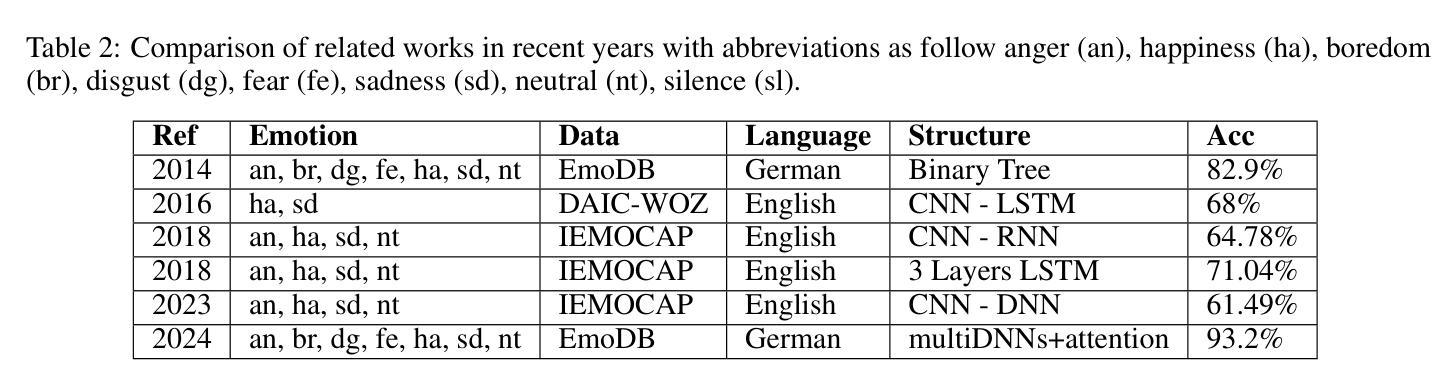
**E. Yüncü et al. (2014)**:使用支持向量机(SVM)分类器的二元决策树来识别EmoDB数据库中的七种情绪,达到了82.9%的最高准确率。
**Ha, Manh-Hung et al. (2024)**:利用基于非局部注意力机制和预训练模型的多个深度神经网络(DNNs),在情感识别上达到了93.2%的高准确率。
**XingChan Ma et al. (2016)**:使用卷积神经网络(CNN)和长短期记忆网络(LSTM)的神经网络结合,对DAIC-WOZ数据集的识别率达到了68%。
**Haytham et al. (2018)**:使用CNN-RNN结构在IEMOCAP数据库上进行情感识别,达到了64.78%的识别率。
**S. Tripathi et al. (2018)**:使用三层LSTM架构对IEMOCAP数据库进行情感区分,达到了71.04%的识别率。
**Toyoshima I et al. (2023)**:提出了一个基于多输入深度神经网络的语音情感识别模型,该模型通过CNN-DNN架构同时学习这两种音频特征(频谱图和gemaps),达到了61.49%的准确率。
这些研究展示了情感语音识别领域的进展,特别是在使用不同的深度学习架构和技术来提高识别准确率方面。论文中提出的模型在这些研究的基础上进一步探索了动态注意力机制和基于MFCC的特征提取,以提高对抑郁症的诊断能力。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决识别越南语语音中的情感以诊断抑郁倾向的问题:
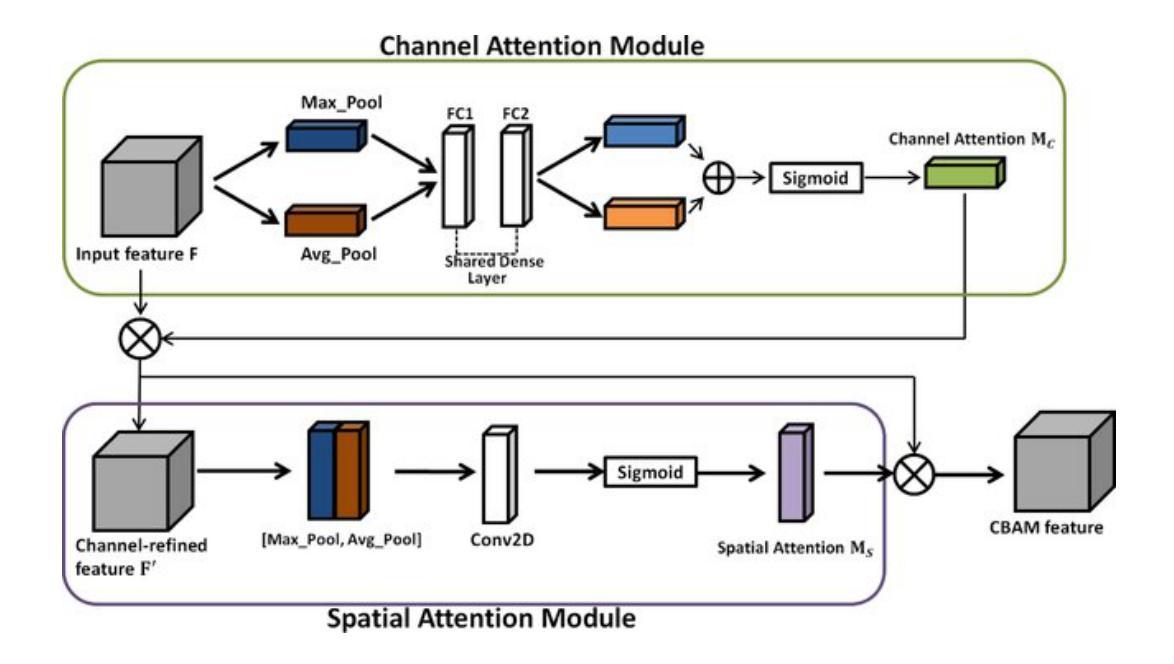
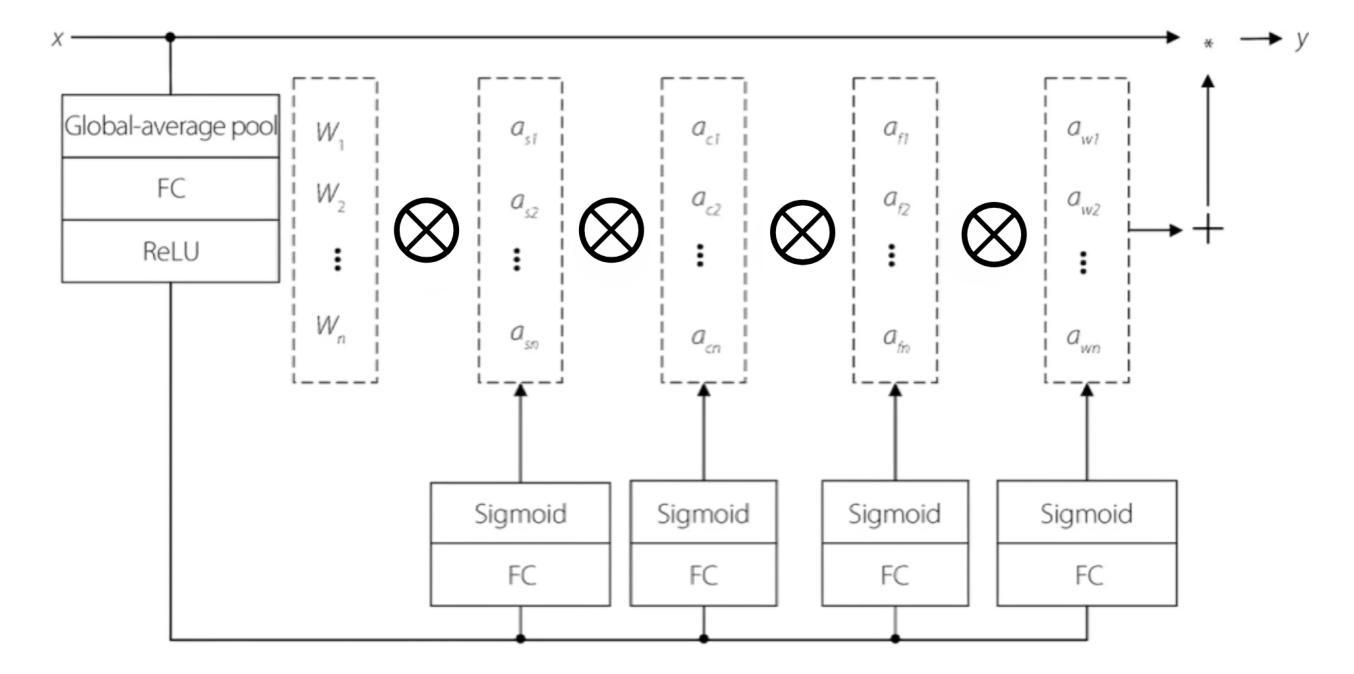
**提出Dynamic Convolutional Block Attention Module (Dynamic-CBAM)**:
- 修改了原有的Convolutional Block Attention Module (CBAM),引入了Omni-Dimensional Dynamic Convolution (ODConv)。
- CBAM是一个注意力机制,通过关注重要特征和抑制不必要的特征来增强标准卷积神经网络(CNNs)的特征。
- 通过通道注意力和空间注意力机制,动态调整卷积核,以适应不同的输入特征,捕捉更复杂的数据模式。
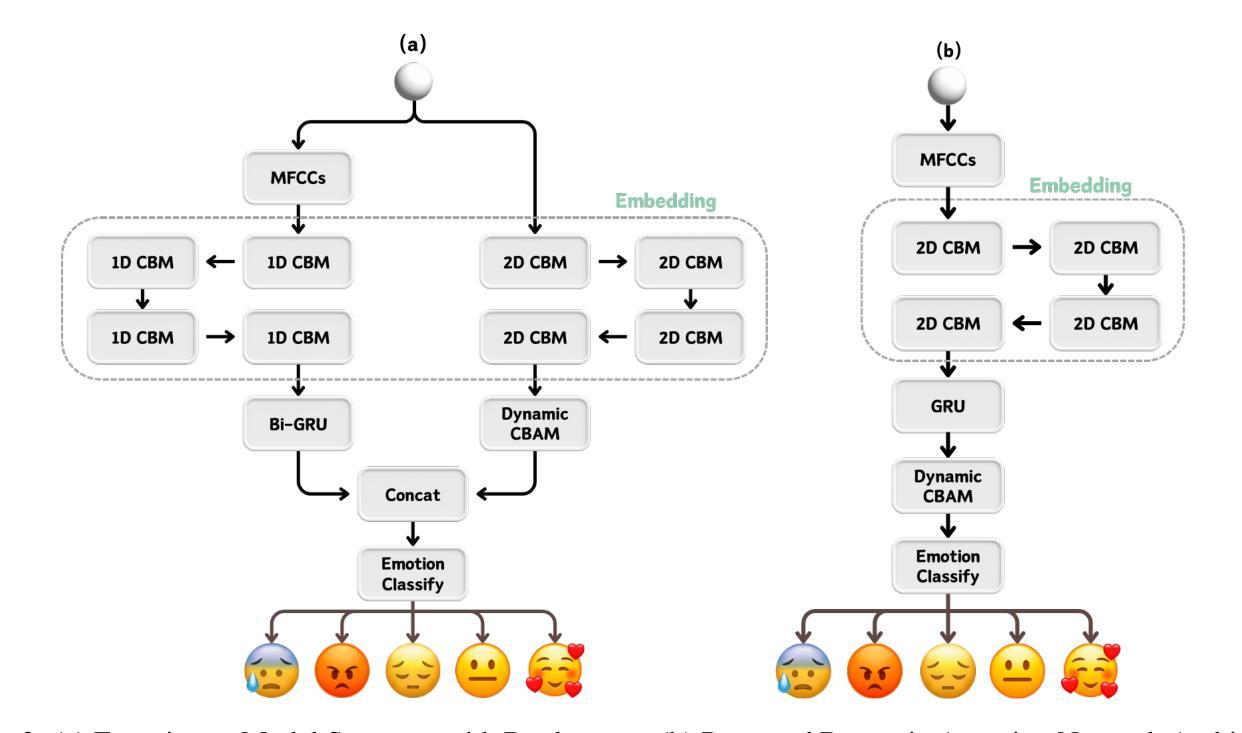
构建Dynamic-Attention Network:
- 提出了一个用于从音频数据中进行情感分类的架构,包括从原始波形和MFCCs(Mel-Frequency Cepstral Coefficients)的双流处理。
- 第一个流处理原始声波,通过嵌入层提取特征,然后输入到双向门控循环单元(Bi-GRU)层,捕捉音频序列中的长期依赖关系。
- 第二个流将原始音频转换为MFCCs,然后通过2D CBM层和提出的Dynamic-CBAM块处理,增强网络在通道和空间维度上的特征表示能力。
数据集构建和预处理:
- 使用越南语音情感数据集(VNEMOS),包含自然和表演数据,涵盖了五种基本人类情感:愤怒、快乐、悲伤、中性和恐惧。
- 对音频信号进行傅里叶变换和MFCC参数化,使用镜像填充技术处理不同长度的音频片段。
环境设置和损失函数:
- 使用K折分层交叉验证来确保训练和测试数据集中各类别的分布与原始数据集一致。
- 使用交叉熵损失函数进行模型训练。
评估指标:
- 使用精确度(Precision)、召回率(Recall)和F1分数作为评估标准,同时计算未加权准确率(UA)和加权准确率(WA)以提供模型性能的平衡视角。
实验和性能评估:
- 对比了不同模型配置的性能,验证了所提出模型的有效性。
- 提出的模型在VNEMOS数据集上取得了0.87的UA、0.86的WA和0.87的F1分数,显示了模型的高效性。
通过这些步骤,论文成功地展示了如何利用深度学习技术,特别是动态注意力机制,来分析语音信号中的情感特征,以识别抑郁倾向。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
模型结构测试:
- 论文测试了多种不同的网络结构,包括单流(One-stream)和双流(Dual-stream)模型,以及是否结合Bi-GRU层的处理方式。
- 比较了仅使用声波数据、仅使用MFCCs数据以及同时使用声波数据和MFCCs数据的效果。
数据集构建:
- 使用越南语音情感数据集(VNEMOS),该数据集包含了自然采集的数据和表演采集的数据,涵盖了五种基本人类情感:愤怒、快乐、悲伤、中性和恐惧。
预处理:
- 对音频信号进行重采样和MFCC参数化,以及使用镜像填充技术处理不同长度的音频片段。
环境设置:
- 使用5-Fold交叉验证来确保训练和测试数据集中各类别的分布与原始数据集一致。
损失函数和评估指标:
- 使用交叉熵损失函数进行模型训练。
- 使用精确度(Precision)、召回率(Recall)和F1分数作为评估标准,并计算未加权准确率(UA)和加权准确率(WA)。
性能评估:
- 对比了不同模型配置的性能,验证了所提出模型的有效性。
- 提出的模型在VNEMOS数据集上取得了0.87的UA、0.86的WA和0.87的F1分数。
混淆矩阵:
- 为了进一步可视化模型的有效性和鲁棒性,论文还提供了模型在VNEMOS数据集上的混淆矩阵。
这些实验结果表明,所提出的模型能够有效地从越南语语音中识别情感,进而用于抑郁倾向的诊断。通过这些实验,论文验证了模型结构、数据处理方法和评估指标的有效性,并展示了模型在实际数据集上的性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一个有效的抑郁倾向识别模型,并在VNEMOS数据集上取得了令人印象深刻的结果,但仍有一些可以进一步探索的点:
更大的数据集和多语言支持:
- 扩展数据集,包含更多的样本和更多样化的情感表达,以提高模型的泛化能力。
- 探索模型在其他语言和文化背景下的适用性和准确性。
改进的注意力机制:
- 研究其他类型的注意力机制,如自注意力(Self-Attention)或图注意力网络(Graph Attention Networks),以进一步提升模型性能。
模型鲁棒性测试:
- 在包含噪声和不同录音条件下的音频数据上测试模型的鲁棒性。
- 考虑实时语音数据流的情况,测试模型对实时数据的处理能力。
细粒度情感识别:
- 除了基本的五种情感分类外,探索模型对更细粒度情感(如焦虑、沮丧等)的识别能力。
多模态数据融合:
- 结合语音、文本和生理信号等多种模态的数据,以提高抑郁倾向识别的准确性。
模型解释性:
- 提高模型的可解释性,使医生和患者能够更好地理解模型的决策过程。
跨领域应用:
- 探索模型在其他领域的应用,如客户服务、健康监测和安全监控等。
模型压缩和优化:
- 研究模型压缩技术,以减少模型的计算资源需求,使其更适合在边缘设备上部署。
长期跟踪和干预效果评估:
- 利用模型进行长期跟踪,评估抑郁治疗效果和预防措施的有效性。
伦理和社会影响考量:
- 考虑模型部署过程中的伦理问题,如隐私保护、数据安全和潜在的偏见问题。
这些探索点可以帮助研究者们进一步提升模型的性能,扩展其应用范围,并确保技术的安全和负责任的使用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
研究背景与目的:
- 论文针对的是抑郁症的识别问题,抑郁症是一种普遍且严重的心理健康疾病,通过分析语音信号来识别抑郁倾向是一个潜在的解决方案。研究目标是利用深度学习技术,通过分析语音中的情感特征来诊断抑郁症。
方法论:
- 提出了一个新的深度学习架构,名为Dynamic Convolutional Block Attention Module(Dynamic-CBAM),用于增强情感识别的准确性。
- 构建了一个基于注意力-GRU网络的模型,用于分析人类的音频信号并分类情感。
- 使用了越南语音情感数据集(VNEMOS),包含自然和表演数据,涵盖了五种基本人类情感。
实验设置:
- 实验中使用了5-Fold交叉验证来评估模型性能,并采用了交叉熵损失函数。
- 评估指标包括精确度、召回率、F1分数、未加权准确率(UA)和加权准确率(WA)。
实验结果:
- 提出的模型在VNEMOS数据集上取得了0.87的UA、0.86的WA和0.87的F1分数,显示出良好的识别性能。
- 与以往的研究相比,提出的模型在情感识别上取得了更好的结果。
结论与未来工作:
- 论文得出结论,深度神经网络可以有效地从语音中识别情感,以识别抑郁倾向。
- 未来的工作将致力于提高模型的质量和准确性,并探索在没有语言障碍的情况下识别情感数据的可能性。
代码与数据集:
- 论文提供了训练代码的链接,以便其他研究者可以复现和进一步研究提出的模型。
整体而言,论文展示了一个基于深度学习的抑郁倾向识别方法,通过分析语音中的情感特征,实现了较高的识别准确率,并为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

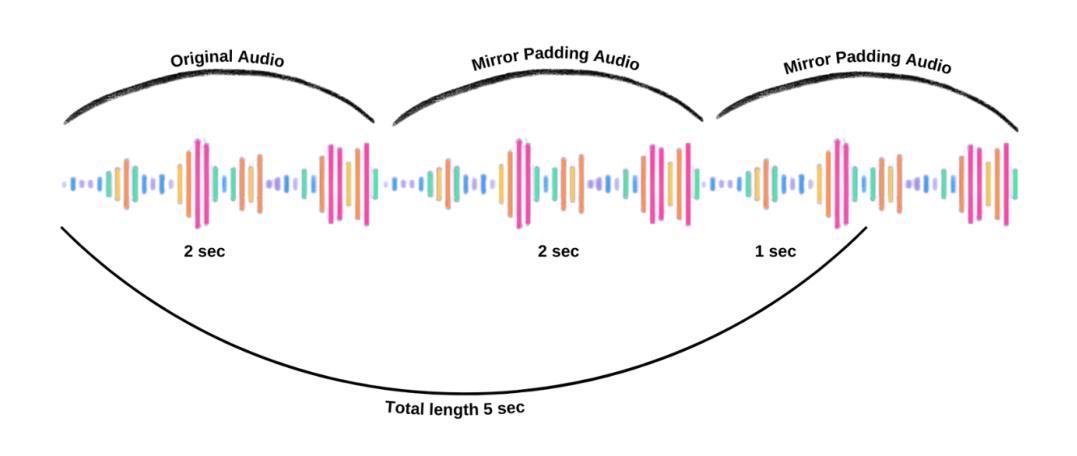
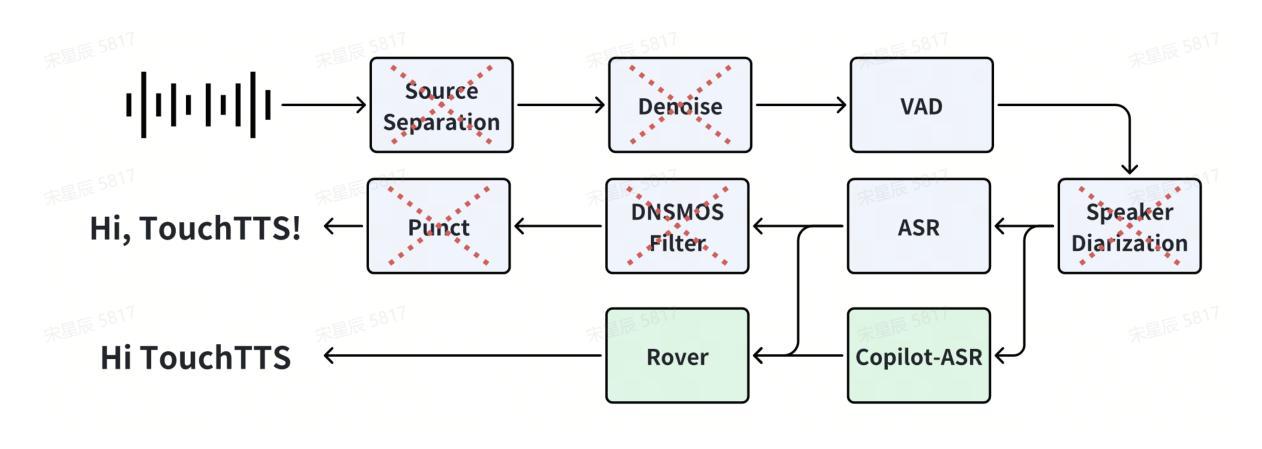
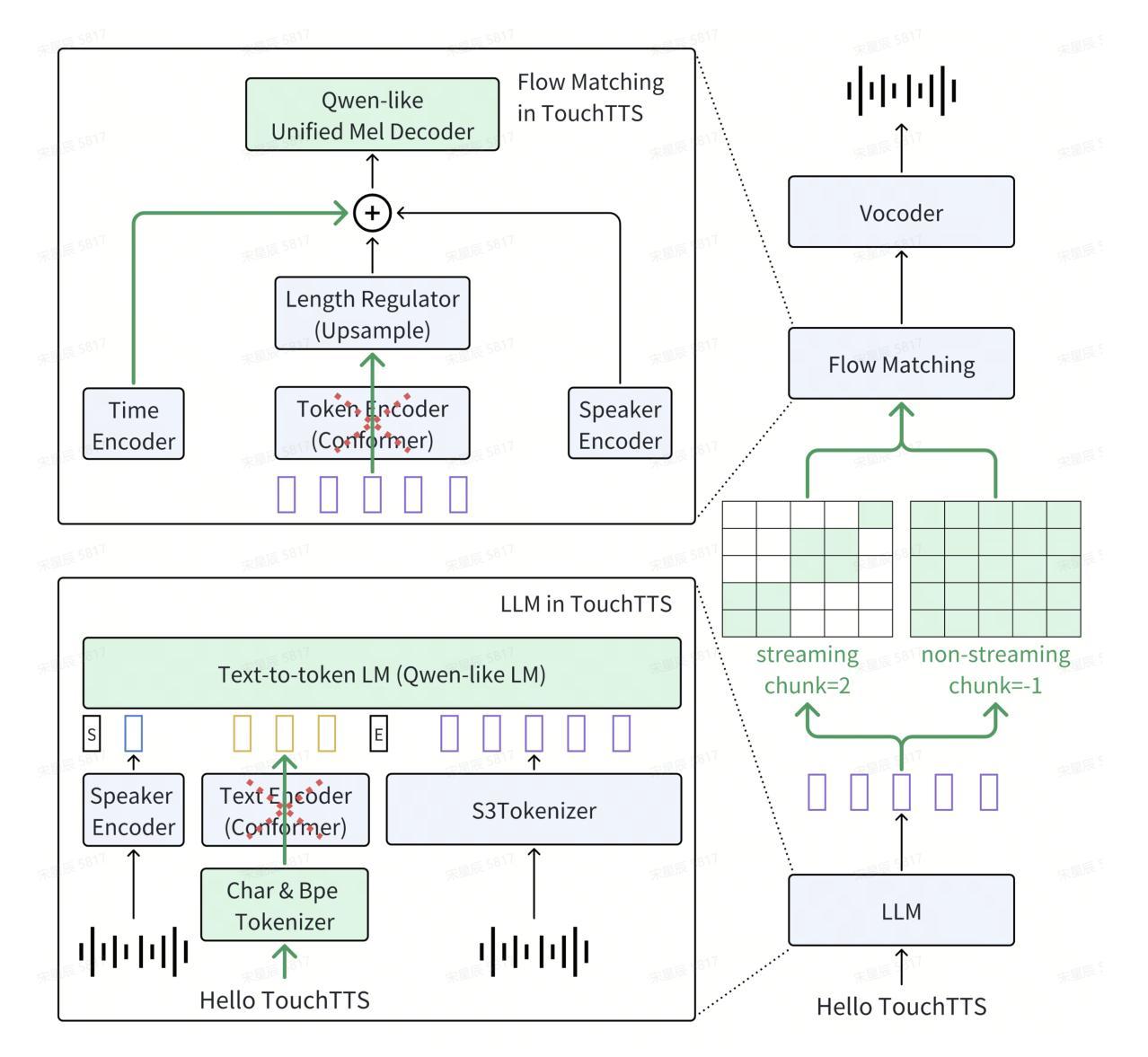
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Authors:Xingchen Song, Mengtao Xing, Changwei Ma, Shengqiang Li, Di Wu, Binbin Zhang, Fuping Pan, Dinghao Zhou, Yuekai Zhang, Shun Lei, Zhendong Peng, Zhiyong Wu
It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
基于大模型的文本语音转换系统对数据的需求极大。近期基于大模型的文本语音转换工作通常采用复杂的数据处理流程以获得高质量的训练数据。这些先进的数据处理流程需要每个阶段都有优秀的模型(例如语音降噪、语音增强、说话人分类和标点模型),而这些模型本身需要高质量的训练数据且很少开源。即使使用最先进的模型,仍存在一些问题,例如背景噪声去除不完全以及标点符号与实际语音停顿之间的不匹配。此外,严格的过滤策略通常仅保留原始数据的10-30%,极大地阻碍了数据扩展工作。在此工作中,我们利用噪声鲁棒的音频分词器(S3Tokenizer)设计了一个简化而有效的文本语音转换数据处理流程,该流程在保持数据质量的同时大幅降低了数据获取成本,实现了超过50%的数据保留率。除了数据扩展的挑战外,基于大模型的文本语音转换系统的部署成本也高于传统方法。当前系统通常仅使用大模型进行文本到标记的生成,而需要额外的模型(如流匹配模型)进行标记到波形生成,这些模型不能直接由大模型推理引擎执行,进一步增加了部署的复杂性。为了解决这些挑战,我们消除了大模型及流组件中的冗余模块,并用大模型架构替代流模型的主干。基于这一简化的流主干,我们提出了用于流式和非流式推理的统一架构,大幅降低了部署成本。最后,得益于简化的流程和S3Tokenizer对文本语音转换训练数据质量要求的降低,我们探索了使用统一数据进行文本语音转换和语音识别任务训练的可行性。
论文及项目相关链接
PDF Technical Report
摘要
本文介绍了LLM在TTS系统中的应用及其面临的挑战。针对数据获取和部署成本较高的问题,提出一种简化而有效的TTS数据处理管道,利用噪声鲁棒的音频分词器(S3Tokenizer)来提高数据质量并降低数据获取成本。此外,通过简化LLM和流组件中的冗余模块,提出一种统一的架构,用于流媒体和非流媒体推理,以降低部署成本。同时,简化管道和S3Tokenizer使得TTS训练数据的质量要求降低,从而有机会统一TTS和ASR的训练数据。
关键见解
- LLM-based TTS系统需要大量高质量的训练数据。
- 复杂的数据处理管道对模型性能提出了高要求,且存在数据损失问题。
- 利用噪声鲁棒的音频分词器(S3Tokenizer)设计简化的TTS数据处理管道,提高数据质量并降低数据获取成本。
- 提出一种统一的架构,简化LLM和流组件中的冗余模块,降低部署成本,并适用于流媒体和非流媒体推理。
- 简化后的管道和S3Tokenizer有助于统一TTS和ASR的训练数据,降低对TTS训练数据质量的要求。
- 尽管有先进的模型,但仍存在背景噪声去除不完全和标点与实际语音停顿不匹配的问题。
- 当前LLM-based TTS系统通常仅将LLM用于文本到代币的生成,需要额外的模型进行代币到波形生成,这增加了部署复杂性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题包括:
数据扩展和部署效率的挑战:大型语言模型(LLM)基础的文本到语音(TTS)系统在数据扩展和部署效率方面面临新的挑战。现有的TTS系统或大规模TTS数据集通常需要构建复杂的数据处理流程,将大量原始音频转换为高质量的TTS训练数据,但这些流程后只有10%到30%的数据可用于训练,导致数据扩展成为一个“烧钱游戏”。此外,即使经过精细的处理,也无法保证每个阶段不出现错误案例。
部署成本高:当前的LLM基础TTS系统通常需要将文本到令牌模型(例如流匹配模型)串联起来生成波形。这些串联的模型不仅不能直接由LLM推理引擎执行,增加了部署成本,同时也使得流式推理变得更加困难。
数据质量要求高:传统的TTS系统需要高质量的训练数据,而本文提出的解决方案旨在降低对TTS训练数据质量的要求,使得可以使用“脏数据”来克服数据扩展的挑战。
模型部署复杂性:由于LLM推理引擎无法重用特殊的U-Net结构,这增加了部署成本,并且使得流式推理更加困难。
为了解决这些问题,论文提出了一个简化的TTS数据处理流程,并基于此设计了一个面向部署的TTS架构,旨在降低数据获取成本,提高数据保留率,并简化部署过程。此外,论文还探索了使用相同的数据训练TTS和自动语音识别(ASR)任务的可行性。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的工作:
CosyVoice [1]:这是一个由LLM用于文本到令牌生成和条件流匹配模型用于令牌到语音合成的系统。本文扩展了CosyVoice,通过简化数据处理流程和模型架构,减少了数据获取和部署成本,并探索了统一流式和非流式推理的能力,以及使用相同数据训练TTS和ASR任务的可行性。
FishSpeech [7]:利用大型语言模型进行高级多语言文本到语音合成的研究。
FireRedTTS [8]:一个工业级生成性语音应用的基础文本到语音框架。
XimalayaTTS [9]:一个高质量的零拍摄语音生成模型。
WenetSpeech4TTS [10]:一个普通话TTS语料库,用于大型语音生成模型的基准测试。
Emilia [11]:一个广泛、多语言、多样化的语音数据集,用于大规模语音生成。
AutoPrep [12]:一个用于野外语音数据的自动预处理框架。
Matcha-TTS [2]:一个快速的TTS架构,具有条件流匹配。
Qwen2 [3]:一个用于因果语言模型的LLM架构,本文中用作LLM和流模型的骨干网络。
TensorRT-LLM [4] 和 vLLM [5]:用于LLM推理的库,本文旨在使模型能够直接在这些引擎上执行。
这些相关工作涵盖了TTS领域的多个方面,包括数据处理、模型架构、多语言支持、零拍摄生成以及推理优化。论文通过结合和扩展这些相关工作,提出了一个简化的TTS框架,旨在提高数据扩展性和部署效率。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键贡献来解决提出的问题:
简化数据处理流程
去除复杂模块:论文提出了一个高度简化的数据处理流程,去除了传统的语音处理中的噪声降低、语音增强、说话人分离和标点模块。
使用S3Tokenizer:利用S3Tokenizer的鲁棒性,该流程减少了对TTS训练数据质量的要求,提高了数据保留率,首次实现了超过50%的数据保留率。
Copilot-ASR交叉验证策略:通过使用两个不同的ASR模型进行二次转录,并基于两次转录结果的一致性来过滤数据,从而确保数据量和质量。
简化TTS架构
简化前端:对于中文使用字符单元,对于英文保持BPE分词,减少插入和删除错误。
Qwen骨干网络:用Qwen模型替换LLM和流模型中的文本编码器和令牌编码器,简化模型结构,并使其能够直接在TensorRT和vLLM等推理引擎上执行。
统一流式和非流式策略:通过控制输入的注意力掩码,实现了一个支持流式和非流式场景的统一流模型。
统一TTS和ASR任务
- 使用相同的数据训练:基于简化的数据处理流程和S3Tokenizer减少了TTS训练数据的质量要求,论文探索了使用相同的数据训练TTS和ASR任务的可行性。
实验验证
大规模数据集:论文在百万小时级别的数据上验证了简化数据处理流程的有效性。
模型比较:与现有TTS系统进行比较,展示了简化模型架构的性能。
流式推理分析:分析了不同流式配置下的性能,验证了动态块策略的有效性。
统一TTS和ASR模型评估:评估了使用连续特征和离散标记进行ASR任务的性能差异。
通过上述方法,论文旨在降低LLM基础TTS系统的数据获取成本,简化部署过程,并探索TTS和ASR任务的统一训练,以提高整体效率和效果。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出方法的有效性,具体实验包括:
前端比较实验:
- 对比了中文文本处理中使用字(character-based)单元和BPE(byte pair encoding)单元的效果。
- 通过控制变量,仅替换LLM的backbone为Qwen2ForCausalLM,并在1M小时数据上训练一个epoch来比较不同建模方法的效果。
模型比较实验:
- 使用TouchLLM-0.5B模型与其他TTS系统进行比较。
- 比较了仅使用说话人嵌入(NoPrompt)和使用提示文本及提示波形(ZeroShot)两种解码方法的效果。
流式推理结果分析:
- 对比了流式和非流式性能,特别是对于不同模型大小(TouchFlow-170M和TouchFlow-50M)的影响。
- 使用动态块策略训练的Qwen流模型,并在不同流式配置下进行比较。
推理基准测试:
- 对LLM(TouchLLM-0.5B)和流(TouchFlow-170M)模块进行了性能测试,测试了FP16和FP32精度下的处理速度。
- 分析了首块(First Chunk)生成的延迟。
统一TTS & ASR评估:
- 比较了独立的TTS模型和统一的TTS/ASR模型在TTS任务上的性能。
- 比较了在统一模型中,使用连续特征和离散标记进行ASR任务的性能差异。
这些实验覆盖了前端处理、模型性能、流式推理、推理效率和统一架构评估等多个方面,全面验证了论文提出方法的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 论文在最后部分提出了一些未来可能的研究方向,以下是一些可以进一步探索的点:
细粒度的风格控制:
- 情绪、呼吸、停顿等的精细控制尚未在模型中实现,未来可以通过对预训练模型进行微调来实现更细致的风格控制。
文本指令生成:
- 根据文本指令生成语音的能力,例如,根据指令“用悲伤的语气说这句话”,模型能够产生具有相应情感色彩的语音输出。
端到端语音交互:
- 类似于gpt-4o的研究,实现端到端的语音交互系统,这可能包括语音识别、理解和生成等能力。
数据预处理和增强:
- 探索更高效的数据预处理和增强技术,以进一步提高模型的鲁棒性和泛化能力。
模型压缩和优化:
- 研究模型压缩和优化技术,以减少模型的计算需求,使其更适合在资源受限的设备上部署。
多语言和跨语言能力:
- 扩展模型的多语言能力,特别是对于低资源语言,提高跨语言的语音合成和识别能力。
提高数据利用效率:
- 研究如何更有效地利用未标注数据,通过自监督学习等方法提高数据利用效率。
提高流式推理的效率和效果:
- 进一步优化流式推理策略,减少延迟,提高语音合成的自然度和流畅性。
统一TTS和ASR任务的深入研究:
- 更深入地研究如何有效地使用相同的数据训练TTS和ASR任务,并探索这种统一训练方法的优势和局限性。
可解释性和安全性:
- 提高模型的可解释性,确保生成语音的安全性和合规性,避免生成有害或不当的内容。
这些方向能够帮助研究者进一步提升TTS系统的性能,扩展其应用范围,并解决实际部署中遇到的问题。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为TouchTTS的简化文本到语音(TTS)框架,旨在解决LLM(大型语言模型)基础TTS系统在数据扩展和部署效率方面面临的挑战。以下是论文的主要内容总结:
1. 问题识别
- LLM基础系统需要大量训练数据,且现有系统采用复杂的数据处理流程,导致数据保留率低,增加数据获取成本。
- 部署成本高,现有系统使用LLM仅进行文本到令牌生成,需要额外模型进行令牌到波形生成,增加部署复杂性。
2. 简化数据处理流程
- 提出简化的数据处理流程,去除噪声降低、语音增强、说话人分离和标点模块。
- 使用S3Tokenizer提高对“脏数据”的鲁棒性,减少对高质量训练数据的需求。
- 采用Copilot-ASR交叉验证策略确保数据质量,实现超过50%的数据保留率。
3. 简化TTS架构
- 提出面向部署的架构,简化前端处理,使用字符单元处理中文,BPE处理英文。
- 使用Qwen作为LLM和流模型的骨干网络,去除冗余模块,简化模型结构。
- 实现统一的流式和非流式推理策略,通过控制注意力掩码实现。
4. 统一TTS和ASR任务
- 探索使用相同数据训练TTS和ASR任务的可行性,减少数据准备的复杂性。
5. 实验验证
- 在百万小时级别的数据上验证了简化数据处理流程的有效性。
- 与现有TTS系统比较,展示了简化模型架构的性能。
- 分析了不同流式配置下的性能,验证了动态块策略的有效性。
- 评估了使用连续特征和离散标记进行ASR任务的性能差异。
6. 未来工作
- 提出了未来可能的研究方向,包括细粒度的风格控制、文本指令生成、端到端语音交互等。
总体而言,论文提出了一个简化的TTS框架,通过简化数据处理流程和模型架构,降低了数据获取和部署成本,提高了数据扩展性和部署效率,并探索了TTS和ASR任务的统一训练,为未来TTS技术的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

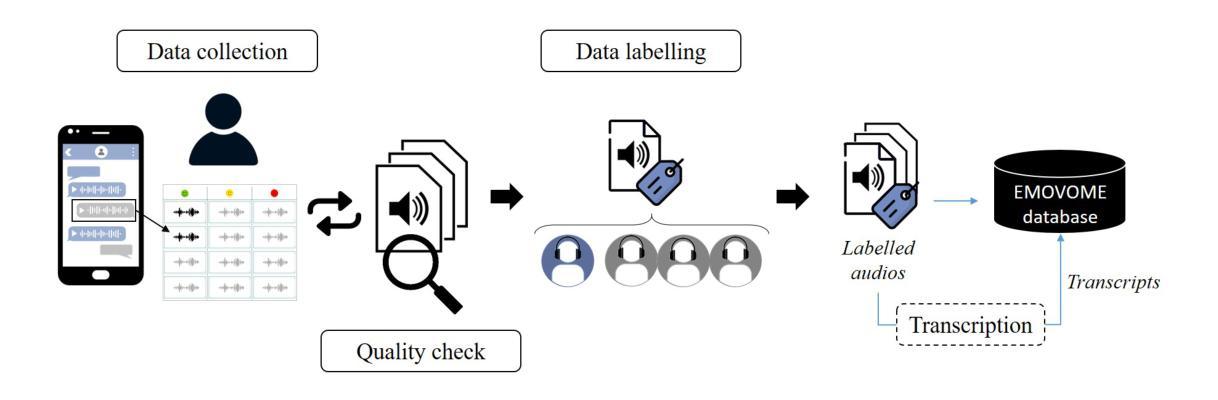
EMOVOME: A Dataset for Emotion Recognition in Spontaneous Real-Life Speech
Authors:Lucía Gómez-Zaragozá, Rocío del Amor, María José Castro-Bleda, Valery Naranjo, Mariano Alcañiz Raya, Javier Marín-Morales
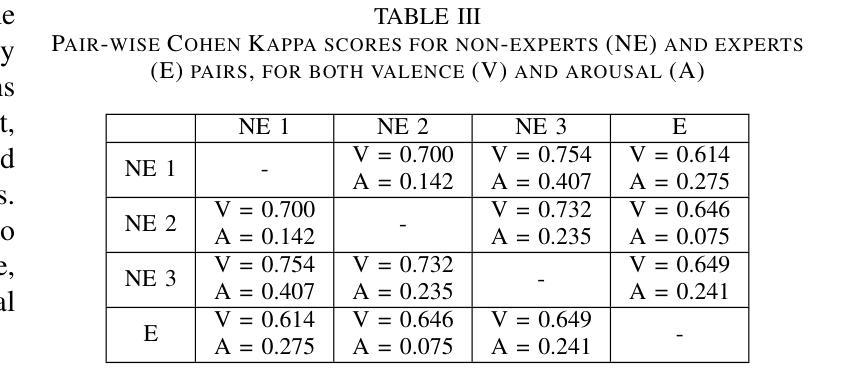
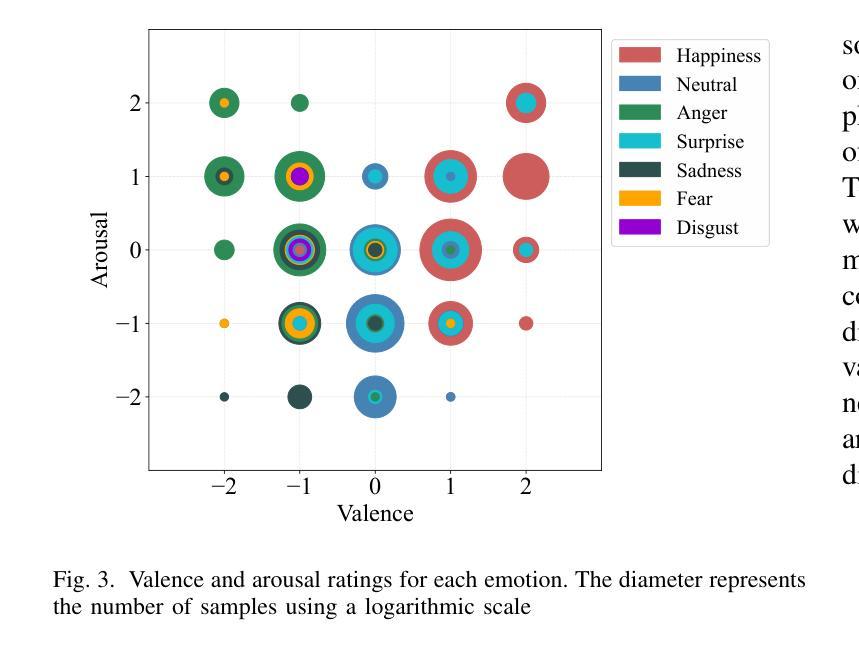
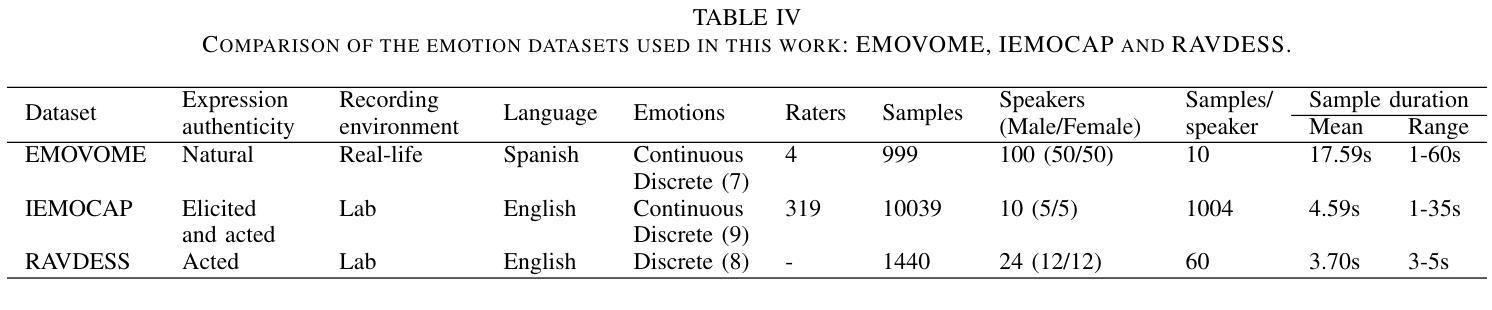
Spontaneous datasets for Speech Emotion Recognition (SER) are scarce and frequently derived from laboratory environments or staged scenarios, such as TV shows, limiting their application in real-world contexts. We developed and publicly released the Emotional Voice Messages (EMOVOME) dataset, including 999 voice messages from real conversations of 100 Spanish speakers on a messaging app, labeled in continuous and discrete emotions by expert and non-expert annotators. We evaluated speaker-independent SER models using acoustic features as baseline and transformer-based models. We compared the results with reference datasets including acted and elicited speech, and analyzed the influence of annotators and gender fairness. The pre-trained UniSpeech-SAT-Large model achieved the highest results, 61.64% and 55.57% Unweighted Accuracy (UA) for 3-class valence and arousal prediction respectively on EMOVOME, a 10% improvement over baseline models. For the emotion categories, 42.58% UA was obtained. EMOVOME performed lower than the acted RAVDESS dataset. The elicited IEMOCAP dataset also outperformed EMOVOME in predicting emotion categories, while similar results were obtained in valence and arousal. EMOVOME outcomes varied with annotator labels, showing better results and fairness when combining expert and non-expert annotations. This study highlights the gap between controlled and real-life scenarios, supporting further advancements in recognizing genuine emotions.
语音情感识别(SER)的自发数据集非常稀缺,通常来源于实验室环境或预设场景,如电视节目,这限制了它们在真实世界环境中的应用。我们开发并公开发布了情感语音消息(EMOVOME)数据集,其中包括来自即时通讯应用上100名西班牙语用户的真实对话中的999条语音消息,这些语音消息由专家和非专家注释者进行了连续和离散情绪的标注。我们使用了基于声学特征的说话人独立SER模型作为基线,并使用基于变压器模型进行了评估。我们将结果与包括表演和激发语音的参考数据集进行了比较,并分析了注释者和性别公平性的影响。在EMOVOME上,经过预训练的UniSpeech-SAT-Large模型取得了最高成绩,三价情绪预测和激发情绪预测的未加权准确率分别为61.64%和55.57%,比基线模型提高了10%。对于情绪类别,取得了42.58%的未加权准确率。EMOVOME的表现低于经过表演的RAVDESS数据集。在预测情绪类别方面,激发的IEMOCAP数据集也优于EMOVOME,而在价格和激发方面则得到了类似的结果。EMOVOME的结果与注释标签有关,当结合专家和非专家的注释时,结果更好且更公平。该研究突出了受控场景和真实场景之间的差距,有助于进一步推动对真实情感的识别发展。
论文及项目相关链接
PDF This article is a merged version of the description of the EMOVOME database in arXiv:2402.17496v1 and the speech emotion recognition models in arXiv:2403.02167v1. This work has been submitted to the IEEE for possible publication
摘要
本文介绍了自发语音情感识别数据集(SER)的稀缺性及其来源于实验室环境或舞台场景的局限性。为解决这一问题,研究者开发了公开的情绪语音消息(EMOVOME)数据集,包含来自即时通讯软件中真实对话的语音消息。该数据集由专家和非专家标注者进行连续和离散情绪的标注。研究采用基于说话人的独立SER模型进行评估,对比基准的声学特征模型和基于变压器的模型,与包含表现行为和激发情绪的参考数据集进行对比,并分析标注者和性别差异对结果的影响。使用预训练的UniSpeech-SAT-Large模型在EMOVOME上取得最高结果,情绪等级的三类预测获得加权精度(UA)为61.64%,激发情绪为55.57%,较基准模型提高了约一成。然而,在情感类别预测方面,EMOVOME的表现低于表现行为的RAVDESS数据集。激发情绪的IEMOCAP数据集在预测情感类别方面优于EMOVOME,而在情绪等级和激发情绪方面结果相似。EMOVOME的结果随标注者而异,结合专家和非专家标注的结果表现更佳且更公平。本研究揭示了受控场景与真实场景之间的差距,为识别真实情绪提供进一步支持。
关键见解
- 自发的语音情感识别数据集非常稀缺,通常源于实验室或舞台场景,限制了其在真实世界中的应用。
- 新开发的数据集EMOVOME包括真实的语音对话,涵盖不同情感的标注信息。
- 研究通过不同的SER模型评估EMOVOME性能,发现预训练的UniSpeech-SAT-Large模型在连续情感预测上表现最佳。
- EMOVOME的性能低于基于表现的参考数据集如RAVDESS,但在某些情感预测方面与基于激发情感的IEMOCAP数据集表现相似。
- EMOVOME的结果受标注者影响显著,结合专家和非专家标注的结果更为可靠和公平。
- 研究指出真实场景与受控场景之间的差异对情感识别的影响。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文主要研究和解决的问题是提高在真实世界场景中语音情感识别(Speech Emotion Recognition, SER)的准确性和适用性。具体来说,论文关注以下几个关键问题:
使用自然语音数据库进行SER建模:现有的情感语音数据库通常包含演员模拟的情感或在特定情境下诱发的情感,这限制了它们在现实世界场景中的应用。论文使用了名为Emotional Voice Messages (EMOVOME) 的数据库,这是一个包含100名西班牙语说话者在真实通信应用中自然、自发的语音消息的数据库。
创建独立于说话者的SER模型:研究者利用eGeMAPS特征、基于Transformer的模型及其组合来创建不依赖于特定说话者的SER模型。
评估不同情感模型的性能:论文比较了使用经典声学特征与最先进的语音嵌入(如预训练的UnispeechL模型)的SER模型的性能。
分析不同注释者标签和性别公平性对SER模型性能的影响:研究者探讨了专家和非专家注释者对情感标签的影响,以及模型在性别方面的公平性。
与现有数据库和模型的比较:论文将EMOVOME数据库的结果与现有的交互情感动态捕捉(IEMOCAP)数据库和Ryerson音频视觉情感语音和歌曲数据库(RAVDESS)进行了比较。
评估模型在真实生活情境中的有效性:通过这些比较,研究者旨在评估SER模型在真实生活情境中的有效性,并推动用于分析自发语音消息的应用程序的发展。
总的来说,这篇论文试图通过使用真实世界中的自然语音数据,结合先进的机器学习和深度学习技术,来提高SER的准确性和实用性。同时,它还关注了模型的公平性问题,确保模型不会因为性别等个体差异而产生偏见。
Q: 有哪些相关研究?
A: 论文中提到了与语音情感识别(SER)相关的多个研究领域和具体研究工作。以下是一些关键点和相关研究的概述:
情感数据库:研究者们通常依赖于情感数据库来训练和测试SER模型。这些数据库可以是基于行动的(acted)、诱发的(elicited)或自然的(natural)。论文中提到了EMOVOME、IEMOCAP和RAVDESS等数据库。
情感模型:情感可以通过连续的或离散的模型来表示。连续模型使用如价值(valence)和唤醒度(arousal)这样的维度来表示情感,而离散模型则基于基本情感类别。Ekman提出了著名的“六大”基本情感:恐惧、惊讶、快乐、悲伤、愤怒和厌恶。
特征提取和机器学习:传统的SER系统依赖于手工制作的特征,如声调和频谱特征。这些特征可以使用机器学习算法,如支持向量机(SVM)和K最近邻(KNN)进行情感识别。
深度学习和预训练模型:随着深度学习的发展,研究者开始直接使用原始信号来训练识别模型。论文中提到了使用卷积神经网络(CNN)和循环神经网络(RNN)的方法,以及使用自监督学习方法预训练的模型,如Wav2vec 2.0和HuBERT。
性别公平性:研究者关注模型在性别方面的公平性,即模型对于不同性别的个体或群体是否存在差异。
相关研究:论文中还提到了其他一些研究工作,它们探讨了使用西班牙语数据库的SER、预训练模型在情感识别任务中的应用、以及评估模型公平性的研究。
性能比较:论文中还总结了一些使用预训练模型和不同数据库进行情感分类的最新研究,包括使用wav2vec 2.0、HuBERT和UniSpeech-SAT等模型的研究。
情感识别的挑战:情感是主观的内部状态,这使得它们的理论概念化变得困难。此外,注释音频是一个具有挑战性的任务,因为不同的评价者可能对同一种情感有不同的感知。
这些研究为当前论文提供了背景和对比,帮助研究者评估他们的方法在现有技术中的位置。论文通过与这些相关工作的比较,展示了其在自然语音情感识别方面的贡献和潜在的应用价值。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提高语音情感识别(SER)在真实世界场景中准确性和适用性的问题:
创建EMOVOME数据库:研究者创建了一个名为EMOVOME的自然语音数据库,它包含了100名西班牙语说话者在真实通信应用中自然、自发的语音消息。这个数据库被用来训练和测试SER模型。
使用eGeMAPS特征和Transformer模型:研究者使用了eGeMAPS(扩展的日内瓦最小声学参数集)特征和基于Transformer的模型(如UnispeechL)来创建SER模型。这些模型能够捕捉语音信号的时间动态,并避免手工特征工程。
结合传统特征和预训练模型:研究者不仅单独使用eGeMAPS特征或预训练模型,还尝试将两者结合起来,以期望获得更好的性能。
比较不同方法的性能:研究者比较了使用传统声学特征和机器学习算法(作为基线方法)、仅使用预训练模型(Embeddings方法),以及结合使用eGeMAPS特征和预训练模型(Emb+eGeMAPS方法)的SER模型的性能。
评估注释者标签的影响:研究者分析了专家和非专家注释者对情感标签的不同标注方式对SER模型性能的影响。
性别公平性分析:研究者评估了模型在性别方面的公平性,即模型对于不同性别的说话者是否会产生不同的结果。
与现有数据库和模型的比较:研究者将EMOVOME数据库的结果与现有的IEMOCAP和RAVDESS数据库进行了比较,以评估其在真实生活情境中的有效性。
使用交叉验证和测试集评估:研究者使用交叉验证和独立的测试集来评估不同方法的性能,确保结果的可靠性和泛化能力。
通过这些步骤,论文展示了在自然语音情感识别任务中,使用先进的预训练模型和传统特征相结合的方法能够提高模型的性能,并且能够更好地处理真实世界中的语音数据。此外,论文还强调了评估模型公平性的重要性,并提出了未来研究方向,以进一步提高SER模型的准确性和适用性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估和比较不同的语音情感识别(SER)模型。以下是实验的主要步骤和内容:
数据集准备:研究者使用了三个数据库:EMOVOME、IEMOCAP和RAVDESS。这些数据库包含了不同类型(自然、诱发/行动)的语音样本,以及不同语言(主要是英语和西班牙语)的情感标注。
特征提取:对于基线方法,研究者使用了eGeMAPS特征集,并利用openSMILE工具包提取了88个声学特征。对于基于Transformer的模型,研究者使用了不同的预训练模型(如Wav2vec 2.0、HuBERT和UniSpeech-SAT)来提取语音嵌入。
模型训练:研究者训练了三种类型的模型:
- 基线模型:使用eGeMAPS特征和机器学习算法(SVM和KNN)。
- Embeddings模型:仅使用预训练模型提取的语音嵌入,后接一个线性层进行分类。
- Emb+eGeMAPS模型:将预训练模型提取的语音嵌入与eGeMAPS特征结合,然后通过一个线性层进行分类。
交叉验证:研究者使用交叉验证来评估模型性能,确保结果的稳健性。对于每个数据库,他们使用了不同的交叉验证方案,以保持说话者的独立性。
超参数调优:研究者对模型的超参数进行了调优,以找到最佳的性能。
测试集评估:使用独立的测试集来评估模型的泛化能力。
性能比较:研究者比较了不同模型在三个数据库上的性能,包括在价值(valence)、唤醒度(arousal)和情感类别预测上的表现。
注释者标签影响分析:研究者分析了专家和非专家注释者标签对EMOVOME数据库上SER模型性能的影响。
性别公平性评估:研究者计算了男性和女性说话者在测试集上的未加权准确率(UA)差异,以评估模型的性别公平性。
结果讨论:研究者讨论了实验结果,包括模型性能、不同注释者标签的影响、性别公平性以及与现有数据库和模型的比较。
这些实验的目的是全面评估在自然和非自然语音数据上SER模型的性能,并探索提高模型性能的不同方法。通过这些实验,研究者能够展示他们提出的方法在处理真实世界语音数据时的有效性,并为未来的研究方向提供了指导。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
改进EMOVOME数据库的标注:考虑引入更多标注者以减少个体偏见,并提高情感类别标注的一致性和准确性。
增加训练样本:探索使用其他西班牙语情感数据库(如EmoSpanishDB或MOUD)来扩展训练样本集,这可能有助于提高模型的泛化能力。
优化时间聚合方法:研究和测试不同的时间聚合技术,以更好地处理EMOVOME数据库中音频长度的变异性。
探索其他特征表示:除了eGeMAPS特征和Transformer模型提取的嵌入,还可以考虑其他声学特征或语音表示,如梅尔频率倒谱系数(MFCCs)或深度情感感知特征。
细粒度情感识别:尝试对更细粒度的情感类别进行分类,例如区分更多种类的复杂情感状态。
多模态情感识别:考虑将语音与其他模态(如文本、图像或视频)结合起来进行多模态情感识别。
实时情感识别系统:研究如何将SER模型应用于实时系统,例如用于心理健康监测或人机交互的系统。
跨语言和跨文化研究:探索SER模型在不同语言和文化背景下的适用性,以及如何调整模型以适应不同的语言和文化特征。
模型解释性:提高模型的可解释性,帮助理解模型是如何学习和识别不同情感的。
长期跟踪研究:进行长期跟踪研究,以评估SER模型在连续使用中的表现和稳定性。
公平性和偏见:深入研究模型在不同性别、年龄和文化背景的说话者上的公平性,以及如何减少潜在的偏见。
临床应用:探索SER模型在临床环境中的应用,例如在心理健康评估或疾病诊断中。
端到端学习:研究端到端学习的方法,其中模型直接从原始语音信号中学习情感特征,无需手动提取特征。
自监督学习:探索自监督学习方法在SER中的应用,以利用未标注的数据进行预训练。
模型鲁棒性:研究模型对不同录音条件(如背景噪声、麦克风质量)的鲁棒性,并开发提高鲁棒性的策略。
这些探索点可以帮助研究者进一步提高SER模型的性能,增强其在真实世界应用中的实用性,并推动情感识别技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题背景:论文指出现有的语音情感识别(SER)数据集通常包含模拟或诱发的情感,这限制了它们在现实世界场景中的应用。
EMOVOME数据库:研究者创建了一个名为EMOVOME的数据库,包含100名西班牙语说话者的自然、自发的语音消息,这些消息被专家和非专家标注了连续和离散的情感。
研究方法:论文提出了使用eGeMAPS特征、基于Transformer的模型及其组合来创建独立于说话者的SER模型。
性能比较:研究者将EMOVOME的结果与RAVDESS和IEMOCAP数据库的结果进行了比较,并分析了注释者和性别公平性的影响。
实验结果:预训练的UnispeechL模型及其与eGeMAPS的组合在3类价值和唤醒度预测中取得了最高结果,比基线模型提高了10%的未加权准确率(UA)。
情感类别预测:在情感类别预测中,EMOVOME的UA为42.58%,低于RAVDESS数据库。
注释者影响:论文发现,结合专家和非专家注释的情感标签可以提高模型的性能并改善公平性。
性别公平性:研究者评估了模型在性别方面的公平性,发现EMOVOME数据库中SER模型通常对男性说话者有更好的性能。
研究贡献:这项研究显著地推进了在真实生活情境中评估SER模型的工作,并为分析自发语音消息的应用程序的发展做出了贡献。
未来方向:论文提出了未来研究方向,包括改进EMOVOME的标注过程、探索更多的训练样本、优化时间聚合方法、提高模型的可解释性、评估模型的跨语言和跨文化适用性等。
总的来说,这篇论文通过创建一个新的自然语音情感数据库,并使用先进的声学特征和深度学习模型,对语音情感识别进行了深入的研究,为未来在更自然和复杂环境中的SER应用提供了有价值的见解和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

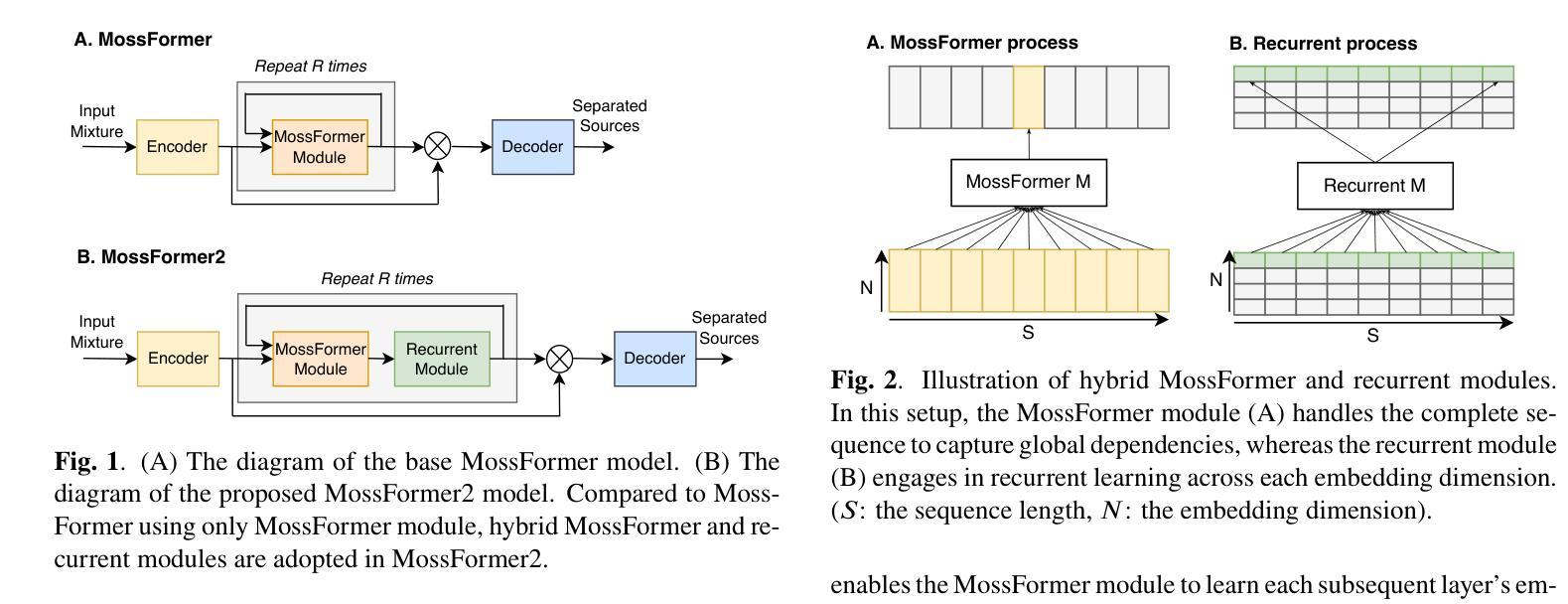
MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation
Authors:Shengkui Zhao, Yukun Ma, Chongjia Ni, Chong Zhang, Hao Wang, Trung Hieu Nguyen, Kun Zhou, Jiaqi Yip, Dianwen Ng, Bin Ma
Our previously proposed MossFormer has achieved promising performance in monaural speech separation. However, it predominantly adopts a self-attention-based MossFormer module, which tends to emphasize longer-range, coarser-scale dependencies, with a deficiency in effectively modelling finer-scale recurrent patterns. In this paper, we introduce a novel hybrid model that provides the capabilities to model both long-range, coarse-scale dependencies and fine-scale recurrent patterns by integrating a recurrent module into the MossFormer framework. Instead of applying the recurrent neural networks (RNNs) that use traditional recurrent connections, we present a recurrent module based on a feedforward sequential memory network (FSMN), which is considered “RNN-free” recurrent network due to the ability to capture recurrent patterns without using recurrent connections. Our recurrent module mainly comprises an enhanced dilated FSMN block by using gated convolutional units (GCU) and dense connections. In addition, a bottleneck layer and an output layer are also added for controlling information flow. The recurrent module relies on linear projections and convolutions for seamless, parallel processing of the entire sequence. The integrated MossFormer2 hybrid model demonstrates remarkable enhancements over MossFormer and surpasses other state-of-the-art methods in WSJ0-2/3mix, Libri2Mix, and WHAM!/WHAMR! benchmarks (https://github.com/modelscope/ClearerVoice-Studio).
我们之前提出的MossFormer在单声道语音分离方面取得了有前景的性能。然而,它主要采用了基于自注意力的MossFormer模块,这倾向于强调更长范围、更粗糙尺度的依赖关系,而在有效地建模更精细尺度的递归模式方面存在不足。在本文中,我们介绍了一种新型混合模型,它通过将在MossFormer框架中集成递归模块,提供了同时建模长距离、粗糙尺度依赖关系和精细尺度递归模式的能力。我们没有采用使用传统递归连接的循环神经网络(RNNs),而是提出了一种基于前馈序列记忆网络(FSMN)的递归模块。由于能够不使用递归连接捕捉递归模式,因此被认为是“无RNN”递归网络。我们的递归模块主要由基于门控卷积单元(GCU)和密集连接的增强扩展FSMN块组成。此外,还添加了瓶颈层和输出层以控制信息流。递归模块依赖于线性投影和卷积,以无缝、并行方式处理整个序列。集成的MossFormer2混合模型在MossFormer的基础上进行了显著的改进,并在WSJ0-2/iMix、Libri2Mix以及WHAM!/WHAMR!基准测试中超越了其他最新方法(https://github.com/modelscope/ClearerVoice-Studio)。
论文及项目相关链接
PDF 5 pages, 3 figures, accepted by ICASSP 2024
Summary
该文本介绍了MossFormer的优化模型——MossFormer2的研究。MossFormer已经取得显著的语音识别效果,但仍存在处理细粒度周期性模式的能力不足的问题。MossFormer2通过集成一种基于前馈序列记忆网络(FSMN)的递归模块,能够同时处理长距离粗粒度依赖和细粒度周期性模式。MossFormer2相较于MossFormer和其他先进方法有更出色的表现,在WSJ0-2/3mix、Libri2Mix和WHAM!/WHAMR!等多个基准测试中取得了显著的提升。
Key Takeaways
- MossFormer已在单声道语音分离领域表现出优异性能,但仍存在对细粒度周期性模式建模的缺陷。
- MossFormer2是MossFormer的优化模型,旨在解决上述问题。
- MossFormer2集成了基于FSMN的递归模块,可以模拟长期依赖关系和细粒度周期性模式。
- 该模型采用无RNN的递归网络设计,通过前馈方式捕捉周期性模式。
- MossFormer2包括增强型膨胀FSMN块,采用门控卷积单元和密集连接。
- 模型还包括用于控制信息流的瓶颈层和输出层。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是单声道语音分离问题,即从单一音频通道中估计出多个独立的语音源。具体来说,论文中提到了以下几个关键问题:
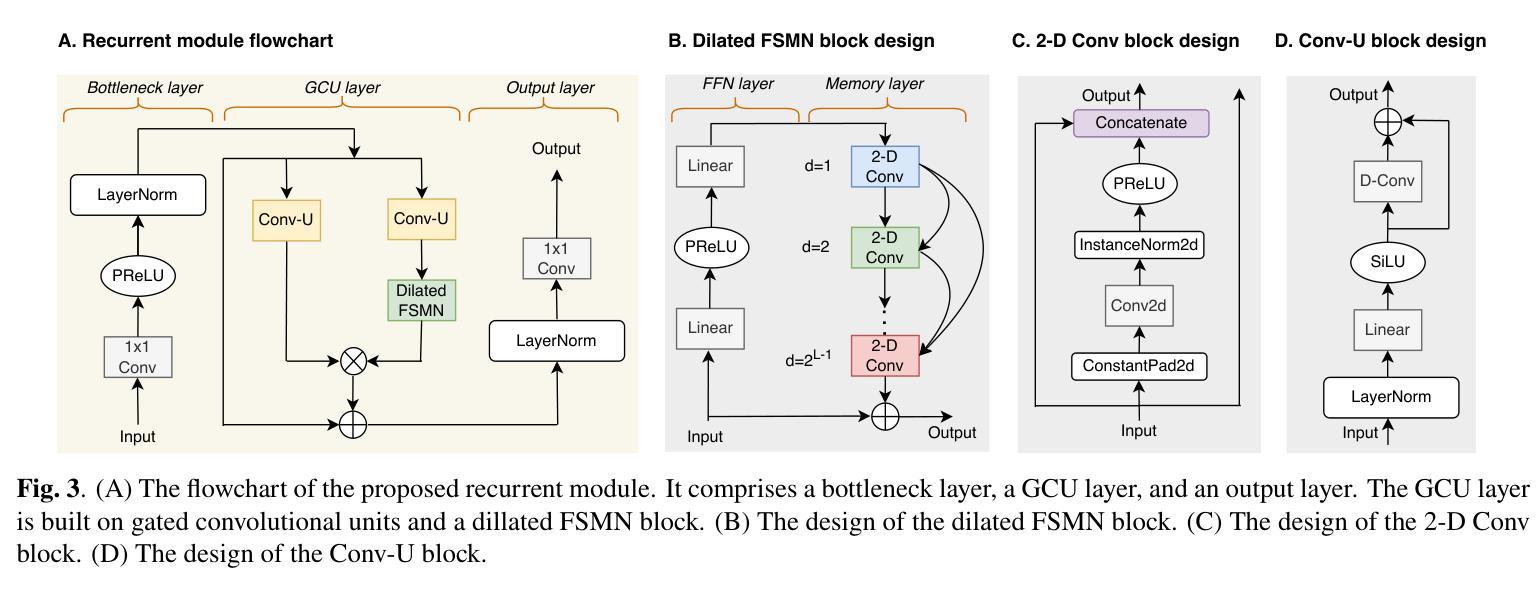
长程与细粒度依赖关系的建模:之前提出的MossFormer模型主要依赖于自注意力机制,这种机制更倾向于强调长程、粗粒度的依赖关系,而在有效建模细粒度的循环模式方面存在不足。
计算需求和推理速度:现有的模型架构严重依赖于双向LSTM网络,导致计算需求大,推理速度慢,限制了模型在更复杂场景下的可扩展性。
序列处理效率:在时间域方法中,使用较小的核尺寸可以提升分离性能,但这也导致了更长的序列,这在序列处理时带来了效率挑战。
全局信息的建模:尽管双路径方法尝试通过划分序列为更小的块并进行交替的内部处理和间处理步骤来解决效率问题,但这种方法引入了显著的处理开销,并且通过间处理对全局信息的建模效率不高。
为了解决这些问题,论文提出了一个混合模型MossFormer2,它结合了Transformer和基于前馈顺序记忆网络(FSMN)的无RNN循环模块,以同时建模长程粗粒度依赖和细粒度循环模式。
Q: 有哪些相关研究?
A: 论文中提到了多个与单声道语音分离相关的研究工作,以下是一些主要的相关研究:
TasNet [11]:引入了编码器-分离器-解码器框架的时间域方法,对后来的研究产生了重要影响。
Conv-TasNet [5]:通过使用一维卷积层改进了TasNet,实现了在语音分离性能上的显著提升。
Dual-Path RNN (DPRNN) [6] 和 Gated DPRNN [7]:这两个基于循环神经网络(RNN)的模型专注于通过双路径方法改进语音分离性能。
DPTNet [8] 和 SepFormer [10]:这两个基于Transformer的模型通过自注意力机制处理语音分离任务。
QDPN (Quasi-Dual-Path Network) [14]:这是一个准双路径网络,通过增加模型大小来提升性能。
SFSRNet [15]:专注于频域重建上下文中的超分辨率网络方面,需要复杂的多损失训练策略。
Separate and Diffuse [16]:利用预训练的扩散模型DiffWave来提升源分离性能。
Deepfsmn [17]:基于前馈顺序记忆网络(FSMN),用于大规模词汇连续语音识别。
这些研究工作为MossFormer2模型的提出提供了理论基础和技术背景。MossFormer2通过结合这些研究的优点,并引入无RNN的循环模块,旨在实现更好的语音分离性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个混合模型MossFormer2来解决单声道语音分离问题,具体方法如下:
1. 集成混合模型
MossFormer2模型结合了Transformer和基于前馈顺序记忆网络(FSMN)的无RNN循环模块,以同时建模长程粗粒度依赖和细粒度循环模式。
2. 增强的Dilated FSMN块
- Dilated FSMN:通过在FSMN中引入扩张机制(dilation),扩大了感受野,同时减少了内存资源的需求。
- 二维扩张卷积(2-D Conv):使用二维扩张卷积块来增强记忆层,通过不同的扩张因子来增加接收场,并促进不同分辨率下的上下文聚合。
3. Gated Convolutional Units (GCU)
- GCU层:在GCU层中,引入了门控机制,灵感来自于GLU(Gated Linear Unit)中的门控效果,以提高模型的性能。
- Conv-U块:使用一维深度卷积(D-Conv)层来辅助GCU层捕获局部模式。
4. 信息流控制
- 瓶颈层和输出层:通过添加瓶颈层和输出层来控制信息流,瓶颈层通过1x1卷积层减少嵌入维度,而输出层则恢复嵌入维度。
5. 平行处理
- 并行学习:在不同的嵌入维度上进行并行学习,利用自注意力和循环建模的结合优势,捕获广泛的依赖性和局部循环模式。
6. 实验验证
- 数据集:在多个语音分离基准数据集上评估MossFormer2的性能,包括WSJ0-2/3mix、Libri2Mix和WHAM!/WHAMR!。
- 训练设置:使用SpeechBrain工具包构建模型,并基于SI-SDR训练损失进行优化。
- 性能提升:通过实验结果证明了引入循环模块后,MossFormer2在SI-SDRi分数上的显著提升。
7. 消融研究
- 分析各组件的影响:通过消融研究分析了扩张FSMN、GCU层以及瓶颈层和输出层对模型性能的影响。
通过这些方法,MossFormer2能够在一个框架内同时捕获循环模式和全局依赖性,显著提高了单声道语音分离的性能,并在多个基准测试中超越了其他最先进的模型。
Q: 论文做了哪些实验?
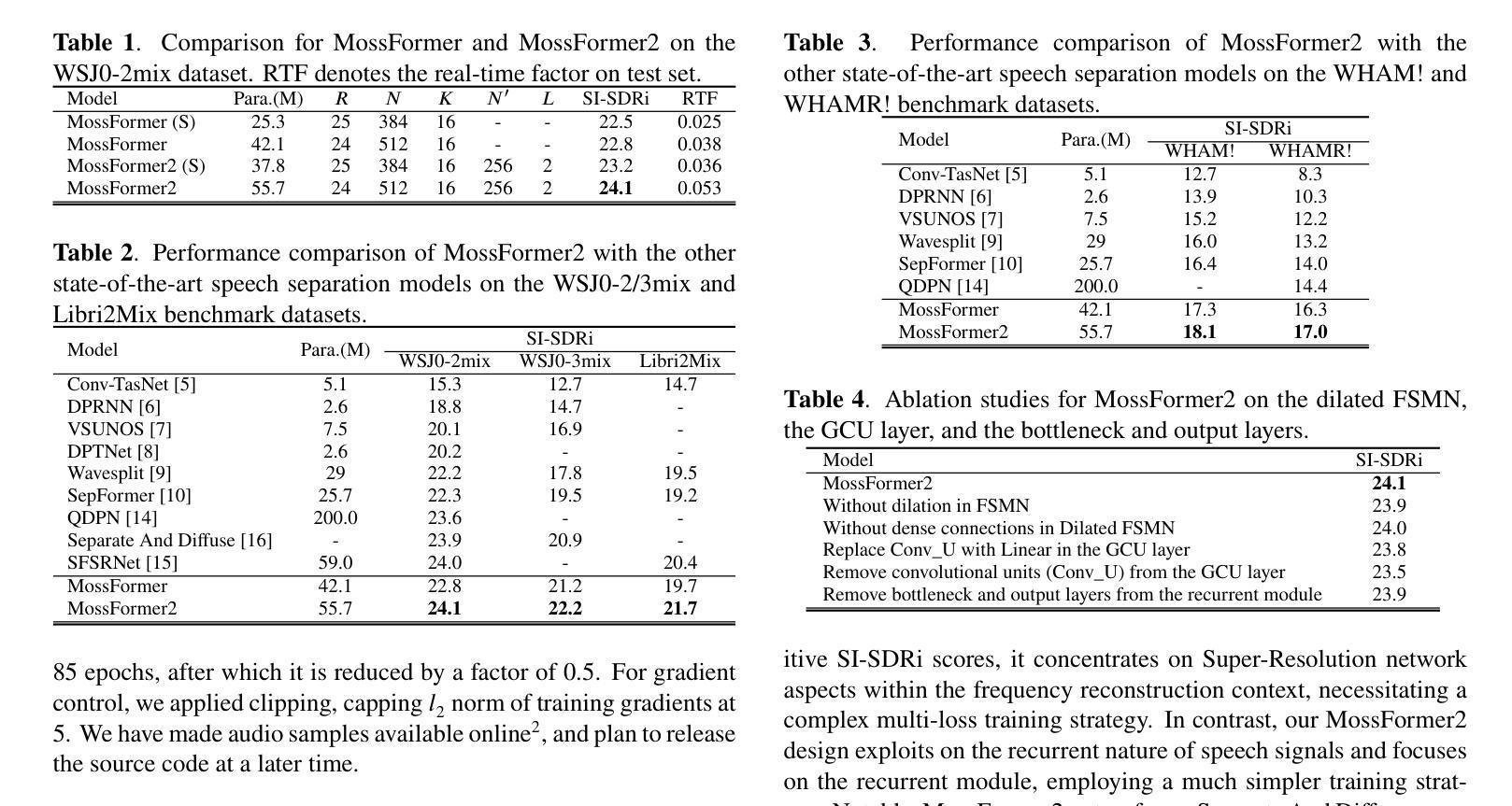
A: 论文中进行了以下实验来验证MossFormer2模型的性能:
1. 数据集评估
- WSJ0-2/3mix:包含2个和3个说话人干净的混合语音,从LDC WSJ-0语料库中随机抽取,包含30小时训练数据、10小时验证数据和5小时评估数据。
- Libri2Mix:包含2个说话人的干净混合语音,使用LibriSpeech ASR语料库中的语音,包含106小时训练数据以及各5.5小时的验证和评估数据。
- **WHAM!/WHAMR!**:WHAM!是WSJ0-2mix的噪声版本,而WHAMR!是WHAM!的混响版本。
2. 训练设置
- 使用SpeechBrain工具包构建模型,基于SI-SDR训练损失进行优化。
- 在单个NVIDIA V100 GPU上进行训练,使用Adam优化器,初始学习率设置为(1.5 \times 10^{-5}),批量大小为1。
- 训练过程中,学习率在前85个epoch保持不变,之后每次减少0.5倍。
- 应用梯度裁剪,将训练梯度的(L_2)范数限制在5以内。
3. 性能对比
- 与MossFormer模型进行比较,展示了引入循环模块后在SI-SDRi分数上的提升。
- 与其它最先进模型进行比较,包括Conv-TasNet、DPRNN、VSUNOS、DPTNet、Wavesplit、SepFormer、QDPN、Separate And Diffuse和SFSRNet等。
4. 消融研究
- 分析了扩张FSMN、GCU层以及瓶颈层和输出层对MossFormer2性能的影响。
5. 实时因子(RTF)测量
- 计算了MossFormer和MossFormer2的实时因子(RTF),以评估模型的时间效率。
这些实验结果表明,MossFormer2在多个语音分离基准数据集上均取得了优异的性能,并且通过消融研究验证了模型中各个组件的有效性。此外,实时因子的测量也显示了MossFormer2在保持高性能的同时具有较高的时间效率。
Q: 有什么可以进一步探索的点?
A: 尽管MossFormer2在单声道语音分离领域取得了显著的性能提升,但仍有一些方向可以进一步探索和研究:
1. 模型泛化能力
- 跨数据集泛化:研究MossFormer2在不同场景、不同噪声条件下的泛化能力,例如在真实世界录音数据上的表现。
- 多语言和方言的适应性:探索模型在处理不同语言和方言时的适应性和鲁棒性。
2. 模型压缩和优化
- 参数效率:研究如何进一步压缩MossFormer2模型,减少参数量,以便于在资源受限的设备上部署。
- 计算效率:探索更高效的算法或结构,以减少模型的计算复杂度和推理时间。
3. 损失函数和训练策略
- 新的损失函数:研究和设计新的损失函数,可能更好地捕捉语音信号的特性,从而进一步提升模型性能。
- 训练策略:探索不同的训练策略,如联邦学习或元学习,以提高模型的训练效率和泛化能力。
4. 模型解释性
- 特征可视化:通过可视化技术研究MossFormer2学习到的特征,以更好地理解模型的工作原理。
- 注意力机制分析:深入分析模型中的注意力权重,以揭示模型如何区分和处理不同的语音源。
5. 端到端系统集成
- 与识别系统的集成:将MossFormer2与自动语音识别系统集成,研究端到端的性能,并探索可能的优化策略。
- 实时系统开发:针对实时应用场景,开发和优化MossFormer2模型,以满足实时处理的需求。
6. 多模态学习
- 音频-视觉融合:探索结合音频和视觉信息来提升语音分离的性能,尤其是在多说话人和复杂环境中。
- 音频-文本融合:利用文本信息辅助语音分离,提高模型对说话内容的理解能力。
7. 无监督和半监督学习
- 无监督学习:研究无监督或自监督学习方法来训练MossFormer2,减少对大量标注数据的依赖。
- 半监督学习:探索半监督学习策略,利用少量标注数据和大量未标注数据来提升模型性能。
这些方向不仅可以推动单声道语音分离技术的发展,还可能对语音处理和模式识别领域的其他任务产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题背景与挑战
- 论文针对单声道语音分离问题,即从单一音频通道中分离出多个独立的语音源。
- 指出现有方法在处理长程依赖和细粒度循环模式时的局限性,以及计算需求大和推理速度慢的问题。
2. MossFormer2模型的提出
- 提出了MossFormer2,这是一个结合了Transformer和无RNN循环模块的混合模型,用于同时建模长程粗粒度依赖和细粒度循环模式。
- 引入基于前馈顺序记忆网络(FSMN)的循环模块,通过扩张机制、密集连接和门控机制增强循环模式的捕获能力。
3. 模型架构
- 详细描述了MossFormer2的架构,包括编码器、解码器、混合MossFormer和循环模块的设计。
- 介绍了RNN-free循环模块的具体实现,包括瓶颈层、GCU层和输出层。
4. 实验验证
- 在多个标准语音分离数据集上评估MossFormer2的性能,包括WSJ0-2/3mix、Libri2Mix和WHAM!/WHAMR!。
- 与MossFormer和其他最先进模型的性能比较,证明了MossFormer2在分离性能上的显著提升。
- 进行了消融研究,分析了模型中关键组件的影响。
5. 实时因子(RTF)测量
- 计算了MossFormer和MossFormer2的实时因子,展示了MossFormer2在保持高性能的同时具有较高的时间效率。
6. 结论
- MossFormer2通过结合Transformer和RNN-free循环模块,在单声道语音分离任务中取得了优异的性能。
- 论文强调了模型中各技术的影响,并展示了MossFormer2在多个基准测试中的优越性能。
总的来说,这篇论文提出了一个创新的混合模型MossFormer2,通过结合Transformer架构和无RNN循环模块,在单声道语音分离领域取得了突破性的性能提升,并在多个标准数据集上超越了现有的最先进方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图