⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
GoHD: Gaze-oriented and Highly Disentangled Portrait Animation with Rhythmic Poses and Realistic Expression
Authors:Ziqi Zhou, Weize Quan, Hailin Shi, Wei Li, Lili Wang, Dong-ming Yan
Audio-driven talking head generation necessitates seamless integration of audio and visual data amidst the challenges posed by diverse input portraits and intricate correlations between audio and facial motions. In response, we propose a robust framework GoHD designed to produce highly realistic, expressive, and controllable portrait videos from any reference identity with any motion. GoHD innovates with three key modules: Firstly, an animation module utilizing latent navigation is introduced to improve the generalization ability across unseen input styles. This module achieves high disentanglement of motion and identity, and it also incorporates gaze orientation to rectify unnatural eye movements that were previously overlooked. Secondly, a conformer-structured conditional diffusion model is designed to guarantee head poses that are aware of prosody. Thirdly, to estimate lip-synchronized and realistic expressions from the input audio within limited training data, a two-stage training strategy is devised to decouple frequent and frame-wise lip motion distillation from the generation of other more temporally dependent but less audio-related motions, e.g., blinks and frowns. Extensive experiments validate GoHD’s advanced generalization capabilities, demonstrating its effectiveness in generating realistic talking face results on arbitrary subjects.
音频驱动的谈话头部生成需要在面对由不同输入肖像和音频与面部动作之间的复杂关联所带来的挑战时,实现音频和视觉数据无缝集成。为此,我们提出了一个稳健的GoHD框架,旨在从任何参考身份和任何动作中产生高度逼真、富有表现力和可控的肖像视频。GoHD通过三个关键模块进行创新:首先,引入利用潜在导航的动画模块,以提高跨未见输入风格的泛化能力。该模块实现了动作和身份的高度分离,并纳入目光方向,以纠正以前被忽视的异常眼神动作。其次,设计了一个基于适配器结构的有条件扩散模型,以确保头部姿势能够感知韵律。第三,为了在有限的训练数据内从输入音频中估计出同步且逼真的表情,采用了一种两阶段训练策略,将频繁且帧级的嘴唇运动提炼与其他更时间上相关但较少与音频相关的动作生成解耦,例如眨眼和皱眉等。大量实验验证了GoHD先进的泛化能力,证明其在任意主体上生成逼真谈话面部结果的有效性。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
音频驱动的说话人头部生成需要应对音频与视觉数据融合的难题,以及不同输入肖像和音频与面部动作之间的复杂关联。为此,我们提出一个稳健的框架GoHD,能够以高度真实、富有表现力且可控的方式生成肖像视频,适用于任何参考身份和任何动作。GoHD创新性地引入三个关键模块:利用潜在导航的动画模块提高了跨未见输入风格的泛化能力;设计了一个符合头颈结构的条件扩散模型,确保头部姿势与语调相符;为了从输入音频中估计出同步且真实的表情,在有限的训练数据下,我们采用了分阶段训练策略,将频繁且帧级的唇运动与其他更时间相关但较少与音频相关的动作分离,如眨眼和皱眉等。实验结果证明了GoHD先进的泛化能力,其在任意主体的说话面部生成中展现出色的真实度。
Key Takeaways
- GoHD框架用于音频驱动的说话人头部生成,能生成高度真实、表现力丰富且可控的肖像视频。
- 引入潜在导航的动画模块,提高跨不同输入风格的泛化能力,并实现运动与身份的高解耦。
- 设计符合头颈结构的条件扩散模型,确保头部姿势与语调相匹配。
- 采用分阶段训练策略,以处理有限的训练数据,并分别处理唇运动与其他较少与音频相关的动作。
- GoHD能处理不同的输入肖像,生成逼真的谈话面部结果。
- 引入眼神方向矫正,改善之前被忽视的眼部不自然运动问题。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为GoHD(Gaze-oriented and Highly Disentangled)的框架,旨在解决音频驱动的头像生成中的关键挑战,包括:
多样化输入肖像的挑战:现有方法在处理不同外观、表情的输入肖像时,难以充分解耦身份和运动信息,导致泛化能力差和失真。
视线方向的自然性:在生成视频中,现有方法在视线方向的控制上存在限制,导致生成的视频看起来不自然。
音频与低频运动之间的复杂映射:例如头部姿势,需要模型同时具有韵律感知和结果多样性,但先前工作往往只强调其中一个方面。
音频同步唇部运动的学习:需要大量的训练样本对来实现跨模态适应,这对于普通研究者来说是不切实际的。
面部表情的复杂性:唇部运动需要精确的帧同步,而眼部运动(如眨眼和皱眉)更多依赖于时间动态,增加了整体表情生成过程的复杂性。
为了解决这些问题,GoHD框架通过三个关键模块来实现:一个利用潜在导航的动画模块来提高跨未见输入风格的泛化能力;一个设计用于保证韵律感知头部姿势的共形结构条件扩散模型;以及一个通过两阶段训练策略来估计音频同步和现实表情的表达估计器。这些模块共同作用,以生成更真实、富有表现力和可控制的头像视频。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是与GoHD框架相关的一些研究工作:
音频驱动的头像动画(Audio-driven Talking Face Animation):
- Chen et al. (2019) 提出了一种层次化的跨模态头像生成方法,使用显式的面部标记来增强音频-视觉控制。
- Zhou et al. (2019) 使用解耦的潜在表示来增强音频-视觉控制。
- PC-AVS (Zhou et al., 2021) 通过解耦的潜在姿势空间来解决头部姿势等自发运动的问题。
- StyleTalk (Ma et al., 2023a) 引入了风格可控的解码器。
- Yu et al. (2023) 将潜在空间分解为唇部和非唇部空间。
视频驱动的头像运动模仿(Video-driven Talking Face Motion Imitation):
- FOMM (Siarohin et al., 2019) 使用学习到的关键点及其仿射变换作为结构参考。
- 其他方法通过使用3D信息或深度信息,以及修改的运动估计来增强FOMM。
- LIA (Wang et al., 2022b) 引入了一个在潜在空间中导航的运动变形框架,避免了显式表示的错误。
其他相关工作:
- MakeItTalk (Zhou et al., 2020) 通过估计说话者特定的运动来限制表情传达。
- MODA (Liu et al., 2023) 通过使用更密集的标记来增强运动解耦。
- 一些工作探索了3DMMs,但出现了唇部运动不同步和姿势不真实的问题。
这些研究工作为GoHD框架的发展提供了理论基础和技术背景。GoHD框架通过引入新的方法来解决现有方法中存在的问题,如自然嘴形的保持、未见数据的严重形变扭曲和身份变化、音频同步唇部运动的生成难度等。通过这些相关研究,GoHD旨在实现对任何参考身份和任何运动的高度真实、富有表现力和可控制的头像视频生成。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为GoHD的框架,通过以下三个主要模块来解决音频驱动的头像生成中的问题:
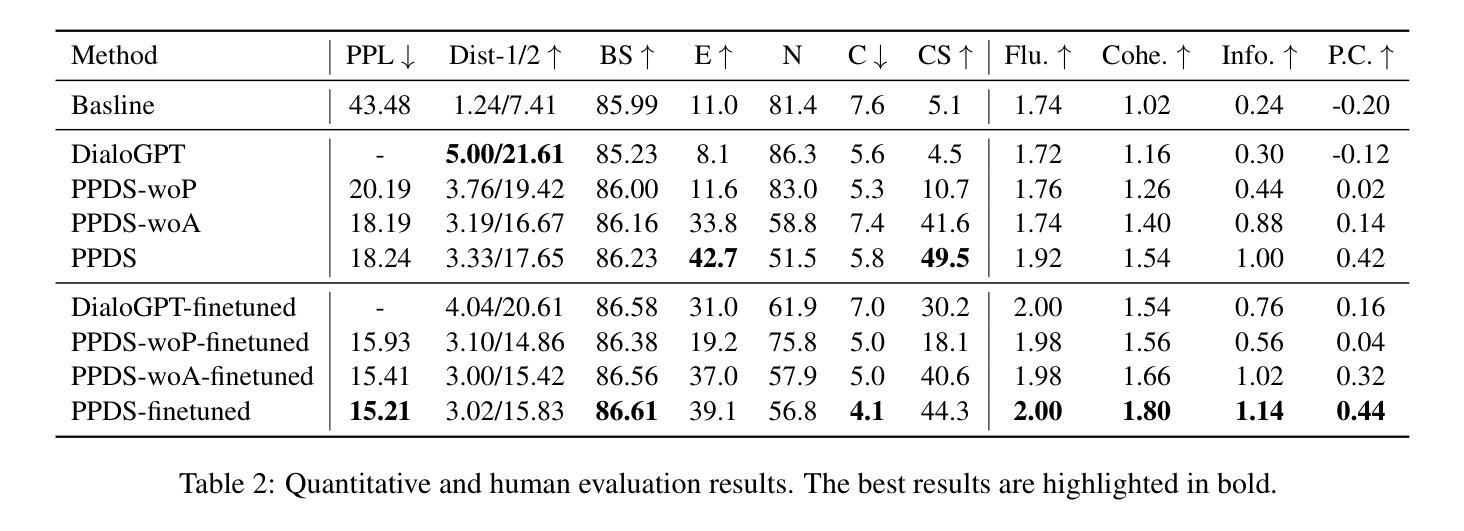
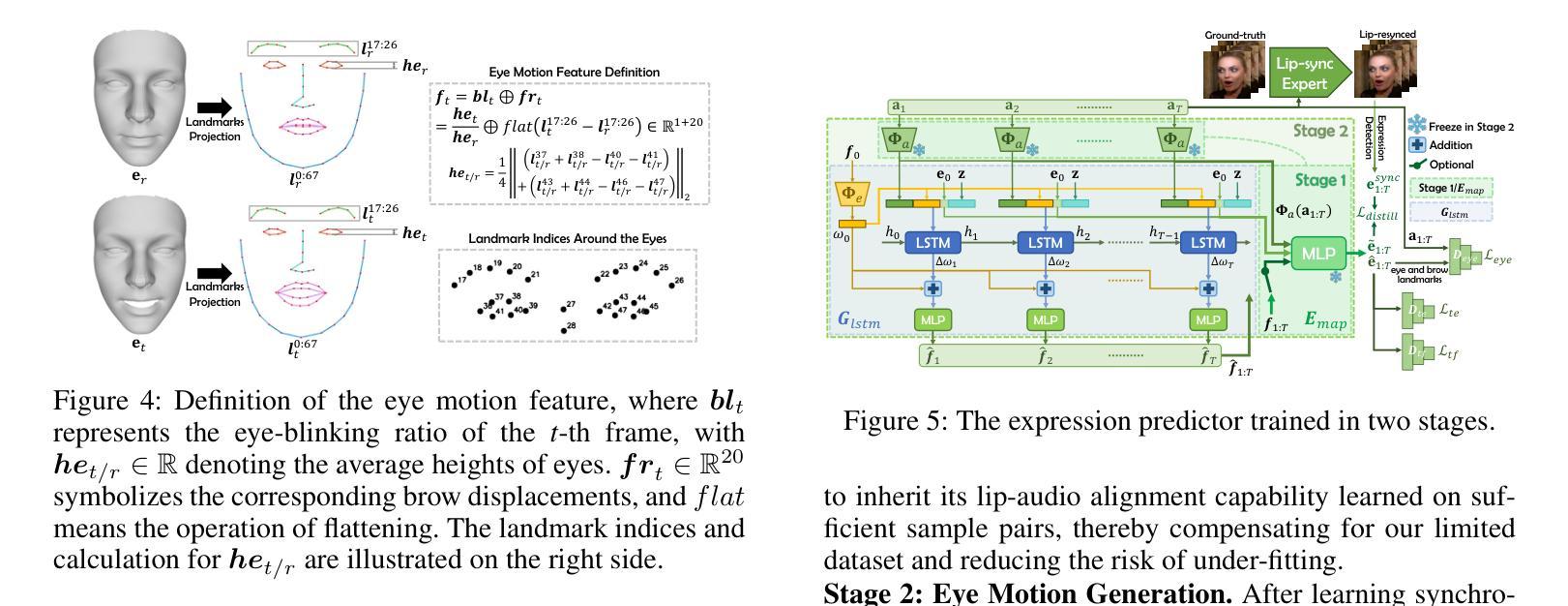
潜在导航的面部动画模块(Latent Navigable Face Animator):
- 利用潜在空间导航技术来解耦身份和运动,提高了对不同输入身份的泛化能力。
- 在此模块中,将输入的参考图像编码为潜在身份代码,与基于学习的运动代码库预测的运动向量结合,通过解码得到动画结果。
- 同时,考虑了视线方向作为条件,以修正潜在的不自然眼睛运动。
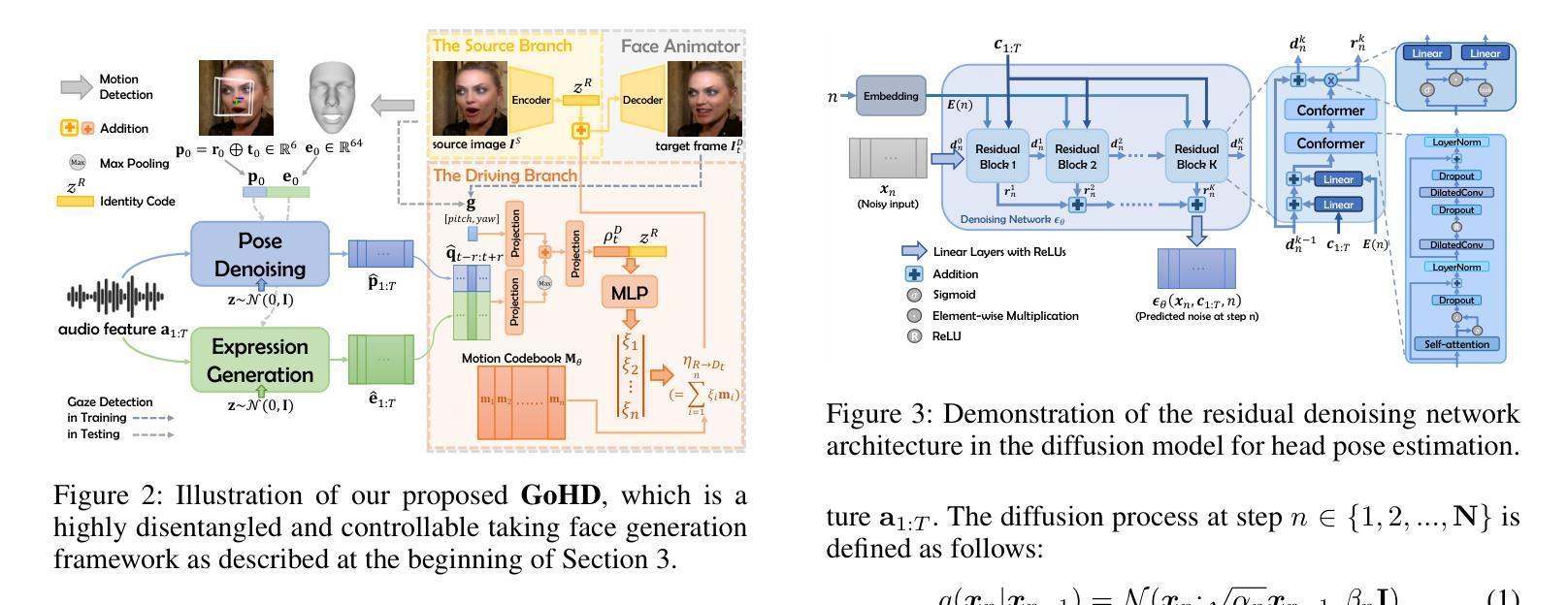
共形结构的条件扩散模型(Conformer-Structured Conditional Diffusion Model):
- 设计用于生成与音频节奏同步的头部姿势。
- 该模型使用扩张卷积和自注意力模块来捕捉音频提示,生成自然、有节奏的结果。
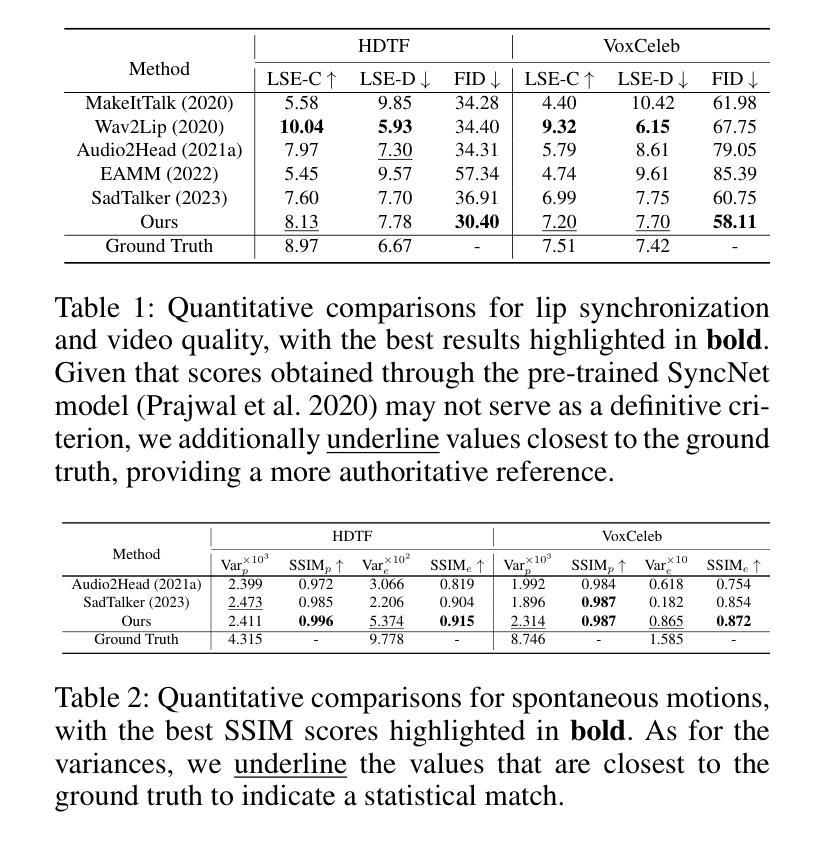
两阶段训练策略的表情估计器(Two-Stage Training Strategy for Expression Prediction):
- 首先,通过一个基于多层感知器(MLP)的网络从音频-视觉对中提取精确的帧同步唇部运动。
- 其次,使用长短期记忆网络(LSTM)生成依赖于时间动态的其他面部动作(例如眨眼和皱眉)。
具体来说,GoHD框架的工作流程如下:
步骤1:扩散式头部姿势生成(Diffused Head Poses):
- 使用条件扩散模型基于输入音频帧和原始参数合成一系列节奏性的头部姿势系数。
步骤2:音频到表情的预测(Audio-to-expression Prediction):
- 通过两阶段训练的预测器从给定的音频片段和原始表情参数中获得一系列表情系数。
步骤3:视线导向的面部动画(Gaze-oriented Face Animation):
- 结合预测的运动描述符和预定的视线方向,通过潜在空间导航实现健壮的面部运动转换,逐帧生成动画结果。
通过这种设计,GoHD能够有效地解决现有方法中存在的挑战,包括对不同输入身份的泛化能力差、视线方向的不自然、以及音频同步唇部运动的生成难度等问题,从而生成更真实、富有表现力和可控制的头像视频。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证GoHD框架的有效性,包括以下几个方面:
实验设置(Experimental Settings):
- 使用VoxCeleb数据集的一个子集作为训练集,HDTF数据集的部分用于生成运动描述符。
- 大部分测试在这两个数据集的未见过的视频上进行。
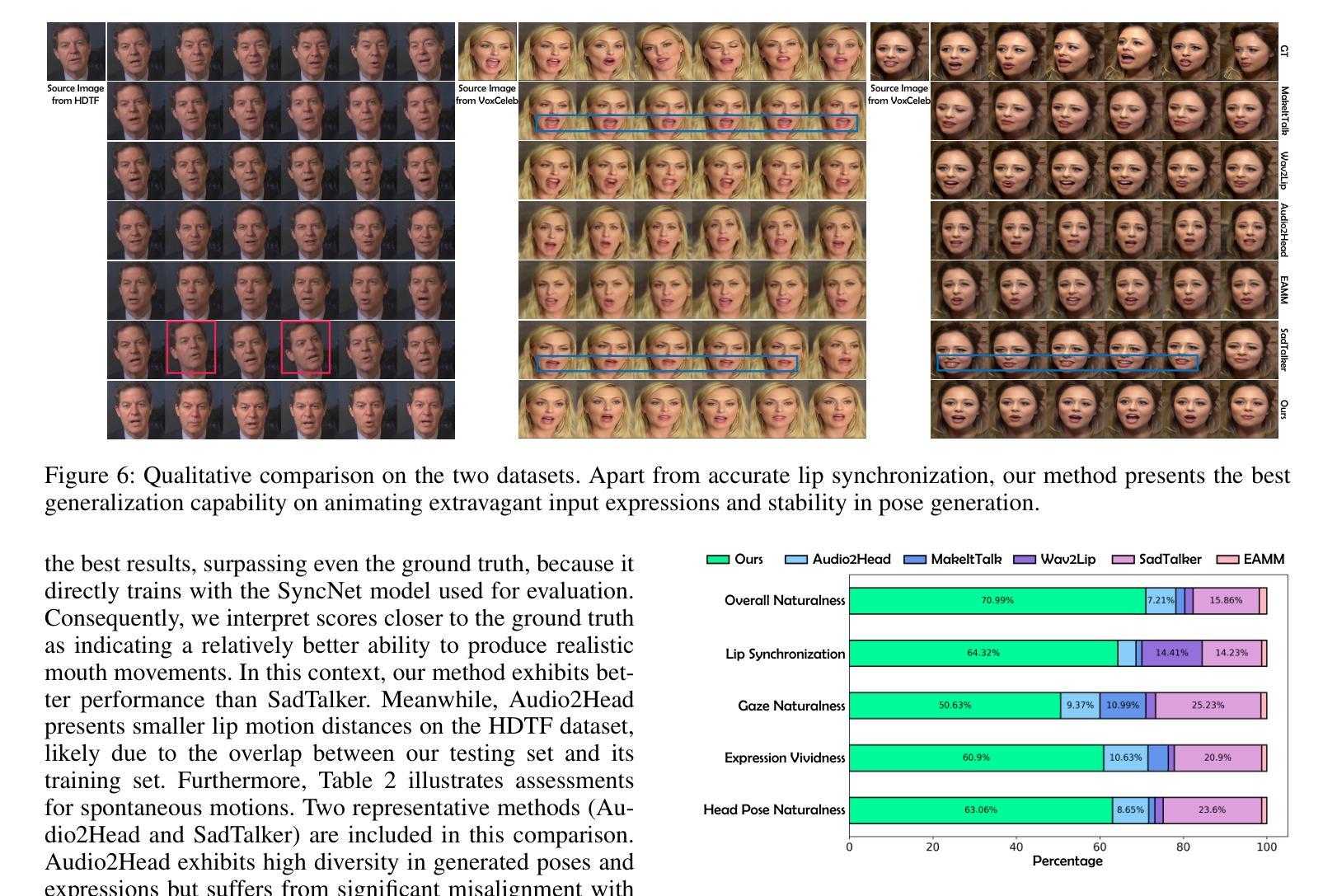
与最新方法的比较(Comparison with State-of-the-art Methods):
- 定量评估了唇同步和视频质量,与Wav2Lip、MakeItTalk、Audio2Head、EAMM和SadTalker等方法进行比较。
- 使用Frechet Inception Distance (FID)评估图像质量,使用预训练的SyncNet模型评估唇部运动的置信度(LSE-C)和距离(LSE-D)。
- 计算眼睛和眉毛地标序列的结构相似性(SSIMe)和方差(Vare)来评估眼部运动的自然性。
- 使用预训练的姿态检测模型评估生成视频中的姿态序列,并计算这些序列的结构相似性(SSIMp)和特征向量的平均方差(Varp)。
与最新方法的视觉比较(Qualitative Comparison):
- 在HDTF和VoxCeleb数据集上展示了不同方法的视觉效果比较。
用户研究(User Study):
- 邀请37名志愿者对不同方法在头部姿势自然性、表情生动性、视线自然性、唇同步和整体自然性等方面的性能进行评估。
验证实验(Validation Experiments):
- 运动插值(Motion Interpolation):展示了面部动画器在运动编辑中的鲁棒性。
- 视线控制(Gaze Orientation):验证了面部动画器在视线方向控制上的能力。
- 多模态驱动(Multi-modal Driving):展示了从源视频中提取中间运动描述符进行多模态驱动动画的效果。
消融研究(Ablation Study):
- 对两阶段表情预测策略的有效性进行验证。
这些实验全面评估了GoHD框架在生成逼真、可控制的头像视频方面的能力,并与现有技术进行了比较,证明了其在任意主题上生成逼真说话面部结果的先进性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和补充材料,以下是一些可以进一步探索的点:
提高运动描述符的精确度:
- 论文中提到输入运动描述符为显式表示,无法准确传达微妙的头部或面部运动。可以探索更精细的描述符,例如基于更高级的3D面部建模技术,以提高最终驱动结果的分辨率和细节。
改善时间连续性:
- 由于当前的框架是基于帧的驱动方法,可能在最终生成结果中出现轻微的抖动。可以研究如何引入时间连续性约束,以减少抖动并提高视频的真实性。
扩展到更广泛的数据集和应用场景:
- 尽管论文中使用了VoxCeleb和HDTF数据集,但测试可以扩展到更多样化的数据集,包括不同种族、年龄和表情的数据,以增强模型的泛化能力。
提高唇部和眼部运动的自然性:
- 尽管论文提出了两阶段训练策略来生成音频同步的面部表情,但在唇部和眼部运动的自然性方面仍有改进空间。可以进一步研究如何更准确地模拟这些复杂的面部运动。
多模态输入的融合:
- 论文提出了一种基于音频和视频驱动的动画方法,但可以考虑将更多的模态(如文本或情感状态)融入到动画生成过程中,以实现更丰富的交互和表达。
提高模型的鲁棒性和泛化能力:
- 探索不同的训练策略和正则化技术,以提高模型在面对不同输入风格和质量时的鲁棒性和泛化能力。
实时性能优化:
- 研究如何优化模型结构和计算过程,以实现实时或近实时的头像动画生成,这对于视频会议和虚拟主播等应用尤为重要。
伦理和安全问题:
- 考虑到深度伪造技术的潜在滥用风险,研究如何通过水印、检测算法等技术手段来确保生成内容的可追溯性和安全性。
用户交互和定制化:
- 开发用户友好的界面和工具,允许用户根据自己的需求定制和调整动画参数,以创造个性化的虚拟形象。
这些探索点不仅可以推动头像动画技术的发展,还有助于确保技术的安全和负责任使用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为GoHD(Gaze-oriented and Highly Disentangled)的框架,旨在生成高度逼真、富有表现力且可控制的头像视频。GoHD框架通过以下三个关键模块来解决音频驱动头像生成中的挑战:
潜在导航的面部动画模块:该模块利用潜在空间导航技术来解耦身份和运动信息,提高了对不同输入身份的泛化能力,并能修正不自然的眼睛运动。
共形结构的条件扩散模型:该模型用于生成与音频节奏同步的头部姿势,能够捕捉音频提示并生成自然、有节奏的结果。
两阶段训练策略的表情估计器:这一部分首先从音频-视觉对中提取精确的帧同步唇部运动,然后使用长短期记忆网络(LSTM)生成依赖于时间动态的其他面部动作,如眨眼和皱眉。
GoHD的工作流程包括:
- 利用条件扩散模型基于输入音频帧合成一系列节奏性的头部姿势系数。
- 通过两阶段训练的预测器从给定的音频片段和原始表情参数中获得一系列表情系数。
- 结合预测的运动描述符和预定的视线方向,通过潜在空间导航实现健壮的面部运动转换,逐帧生成动画结果。
论文通过一系列实验验证了GoHD框架的有效性,包括与最新技术的比较、视觉比较、用户研究、验证实验和消融研究。实验结果表明,GoHD能够在任意主题上生成逼真的说话面部结果。此外,论文还讨论了潜在的改进方向、限制和伦理考虑,强调了负责任地使用技术的重要性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
Authors:Chunyu Li, Chao Zhang, Weikai Xu, Jinghui Xie, Weiguo Feng, Bingyue Peng, Weiwei Xing
We present LatentSync, an end-to-end lip sync framework based on audio conditioned latent diffusion models without any intermediate motion representation, diverging from previous diffusion-based lip sync methods based on pixel space diffusion or two-stage generation. Our framework can leverage the powerful capabilities of Stable Diffusion to directly model complex audio-visual correlations. Additionally, we found that the diffusion-based lip sync methods exhibit inferior temporal consistency due to the inconsistency in the diffusion process across different frames. We propose Temporal REPresentation Alignment (TREPA) to enhance temporal consistency while preserving lip-sync accuracy. TREPA uses temporal representations extracted by large-scale self-supervised video models to align the generated frames with the ground truth frames. Furthermore, we observe the commonly encountered SyncNet convergence issue and conduct comprehensive empirical studies, identifying key factors affecting SyncNet convergence in terms of model architecture, training hyperparameters, and data preprocessing methods. We significantly improve the accuracy of SyncNet from 91% to 94% on the HDTF test set. Since we did not change the overall training framework of SyncNet, our experience can also be applied to other lip sync and audio-driven portrait animation methods that utilize SyncNet. Based on the above innovations, our method outperforms state-of-the-art lip sync methods across various metrics on the HDTF and VoxCeleb2 datasets.
我们提出了LatentSync,这是一个基于无中间运动表示的音频条件潜在扩散模型的端到端唇同步框架。它偏离了之前基于像素空间扩散或两阶段生成的扩散唇同步方法。我们的框架可以利用Stable Diffusion的强大能力直接对复杂的视听相关性进行建模。此外,我们发现基于扩散的唇同步方法由于不同帧之间的扩散过程不一致而表现出较差的时间一致性。我们提出时间表示对齐(TREPA)技术,以提高时间一致性,同时保持唇同步的准确性。TREPA使用大规模自监督视频模型提取的时间表示来对齐生成的帧与真实帧。此外,我们观察到常见的SyncNet收敛问题,并进行全面的实证研究,从模型架构、训练超参数和数据预处理方法等方面确定影响SyncNet收敛的关键因素。我们在HDTF测试集上将SyncNet的准确度从91%显著提高至94%。由于我们没有改变SyncNet的总体训练框架,因此我们的经验也可应用于其他采用SyncNet的唇同步和音频驱动的肖像动画方法。基于上述创新,我们的方法在HDTF和VoxCeleb2数据集上的各种指标上均优于最新的唇同步方法。
论文及项目相关链接
Summary:
我们提出一个名为LatentSync的端到端唇同步框架,该框架基于音频条件下的潜在扩散模型,无需任何中间运动表示。它与基于像素空间扩散或两阶段生成的先前扩散唇同步方法不同。我们的框架能够利用Stable Diffusion的强大功能直接建模复杂的音频视觉相关性。为解决扩散过程中不同帧间的不一致性导致的时空不一致性问题,我们提出时间表示对齐(TREPA)技术。此外,我们还观察到SyncNet收敛问题,并进行了综合实证研究,确定了影响SyncNet收敛的关键因素,如模型架构、训练超参数和数据预处理方法。基于上述创新,我们的方法在HDTF和VoxCeleb2数据集上的唇同步性能优于现有技术。
Key Takeaways:
- LatentSync是一个基于音频条件的潜在扩散模型的端到端唇同步框架,无需中间运动表示。
- LatentSync利用Stable Diffusion直接建模音频视觉相关性。
- 提出时间表示对齐(TREPA)技术,增强时空一致性,同时保持唇同步准确性。
- 观察到SyncNet收敛问题,并确定模型架构、训练超参数和数据预处理方法等因素对SyncNet收敛的影响。
- 通过改进,SyncNet在HDTF测试集上的准确率从91%提高到94%。
- 我们的经验可应用于其他唇同步和音频驱动肖像动画方法,这些方法也使用SyncNet。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为LatentSync的端到端唇形同步框架,旨在解决以下问题:
像素空间扩散的局限性:之前基于像素空间扩散的唇形同步方法存在采样速度慢和无法生成高分辨率视频的问题。
两阶段生成方法中的信息丢失:之前的方法采用两阶段生成过程,可能会在运动到图像的转换过程中丢失细微的表情信息,这些信息与语音的情感基调相关联。
时间一致性问题:基于扩散的唇形同步方法在多步生成过程中表现出较差的时间一致性,这可能是由于不同帧之间扩散过程的不一致性导致的。
SyncNet收敛问题:在唇形同步和音频驱动的人像动画方法中广泛使用的SyncNet存在收敛问题,导致训练损失停留在0.69不再下降。
为了解决这些问题,论文提出了以下主要贡献:
- 提出了一个基于音频条件潜在扩散模型的端到端唇形同步框架,无需任何中间运动表示。
- 通过综合实验研究,识别了影响SyncNet收敛的关键因素,并显著提高了SyncNet在HDTF测试集上的准确率。
- 提出了时间表示对齐(TREPA)方法来增强时间一致性,同时保持唇形同步的准确性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个类别:
1. Diffusion-based Lip Sync(基于扩散的唇形同步)
- [34] 和 **[2]**:都是基于像素空间音频条件扩散模型的端到端唇形同步方法。
- **[57]**:使用扩散模型完成音频到运动的转换,并使用VAE进行运动到图像的生成。
- **[64]**:使用transformers将音频转换为运动,并使用扩散模型进行运动到图像的生成。
- **[29]**:使用扩散自编码器将遮罩图像转换为语义潜在代码,并使用扩散模型基于语义潜在代码和音频生成图像。
2. Non-diffusion-based Lip Sync(非扩散基础的唇形同步)
- **Wav2Lip [36]**:经典的唇形同步方法,引入了使用预训练的SyncNet来监督生成器的训练。
- **[20]**:训练一个VQ-VAE来编码面部和头部姿态,然后在量化空间中训练唇形同步生成器以生成高分辨率图像。
- **StyleSync [18]**:遵循Wav2Lip的整体框架,主要创新是使用StyleGAN2作为生成器主干。
- **[8]**:将唇形同步分为三个组件:语义引导的重演网络、唇形同步网络和身份感知的细化与增强。
- **DINet [63]**:通过变形特征图来生成基于驱动音频的口型。
- **MuseTalk [61]**:使用Stable Diffusion的架构进行修复,但不执行扩散过程,并使用判别器进行对抗性学习,更像是基于GAN的框架。
这些相关工作为LatentSync框架的发展提供了理论基础和技术对比,使其能够在现有技术的基础上进行改进和创新。LatentSync通过结合这些相关研究的优势,提出了一种新的端到端唇形同步框架,旨在解决现有方法中的一些限制和问题。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了提出的问题:
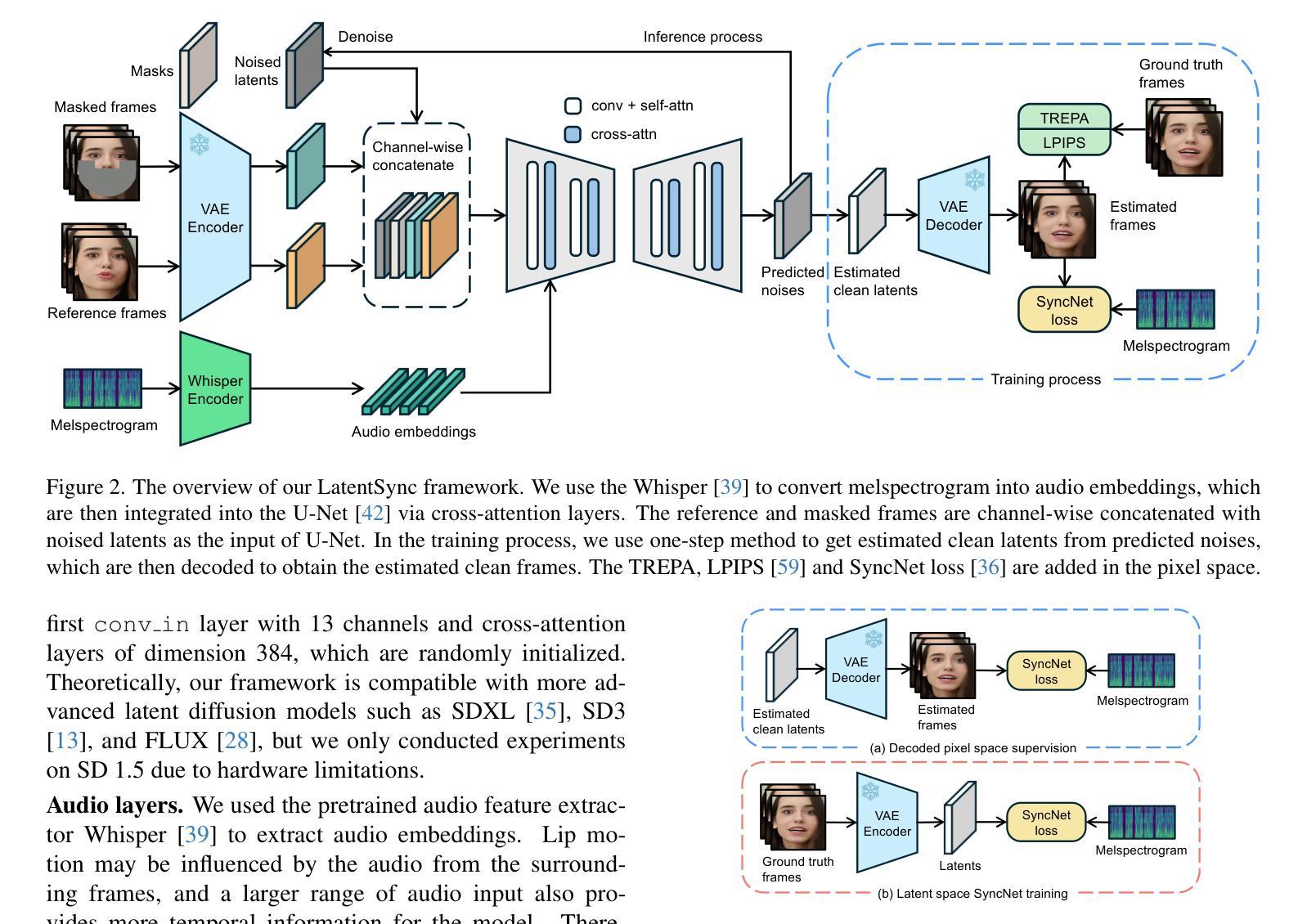
1. LatentSync框架
LatentSync是一个基于音频条件潜在扩散模型的端到端唇形同步框架,不需要任何中间的3D表示或2D地标。该框架利用Stable Diffusion的强大生成能力直接捕获复杂的音视频关联,从而生成动态和逼真的说话视频。
2. Temporal REPresentation Alignment (TREPA)
为了解决扩散模型中的时间一致性问题,论文提出了TREPA方法。TREPA通过使用大规模自监督视频模型VideoMAEv2提取的时间表示来对齐生成帧与真实帧之间的时间表示。这种方法类似于LPIPS,但关键区别在于它利用时间表示作为额外的损失,有效提高了时间一致性,同时保持了唇形同步的准确性。
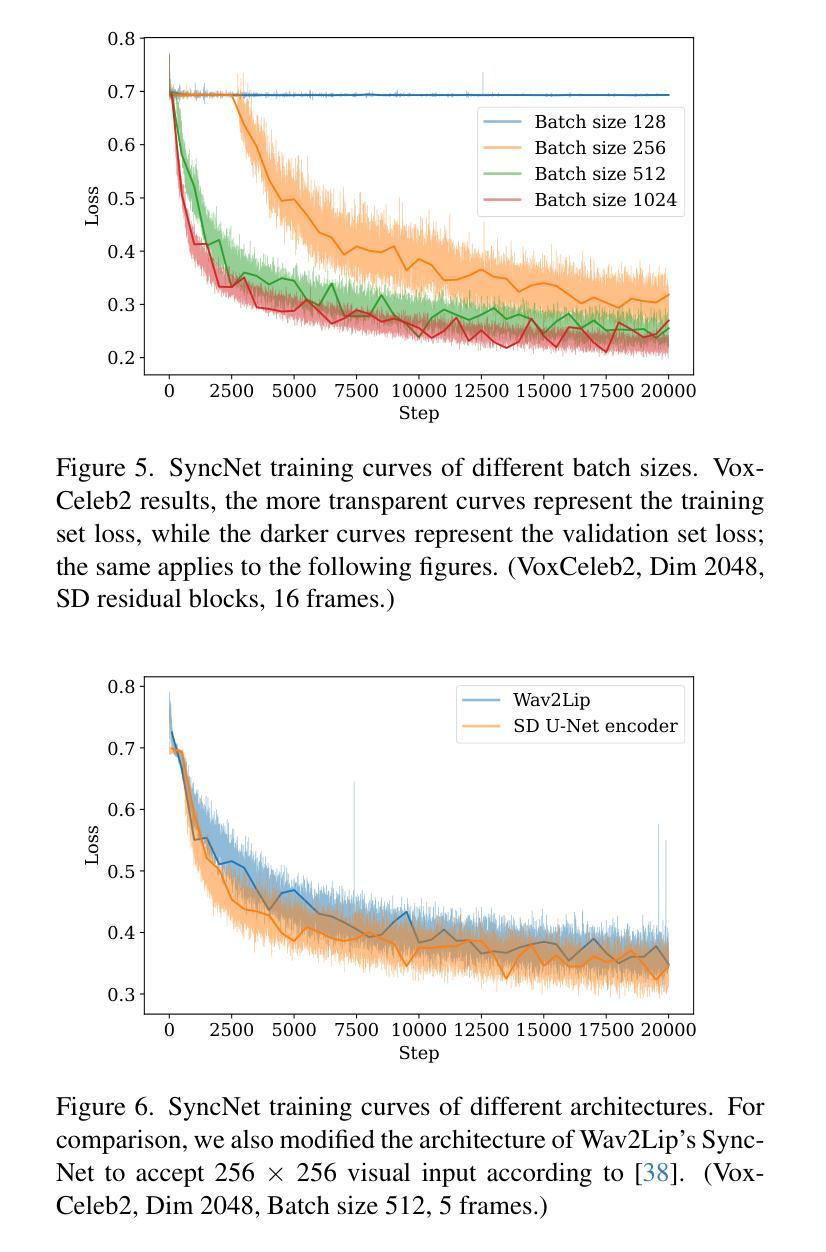
3. SyncNet的收敛问题研究
针对SyncNet的收敛问题,论文进行了广泛的实验研究,识别了影响SyncNet收敛的关键因素,包括模型架构、训练超参数和数据预处理方法。通过这些研究,论文显著提高了SyncNet在HDTF测试集上的准确率,从91%提高到94%。
4. 混合噪声模型
为了确保模型正确学习时间信息,输入噪声也需要具有时间一致性。论文采用了混合噪声模型,生成两个不同的噪声向量,一个是跨所有视频帧应用的公共噪声向量,另一个是帧特定的噪声向量。这种方法有助于模型更好地学习时间信息。
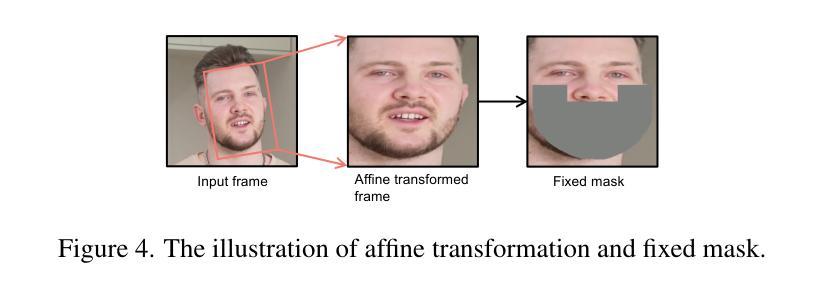
5. 仿射变换
在数据预处理阶段,使用仿射变换实现面部正面化,帮助模型在侧脸视图等具有挑战性的场景中有效学习面部特征,并使用固定掩码防止信息泄露。
总结
通过上述创新,LatentSync框架在HDTF和VoxCeleb2数据集上的各种指标上都优于现有的唇形同步方法。这些方法的结合不仅解决了像素空间扩散和两阶段生成方法中的问题,还提高了唇形同步的准确性和时间一致性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证LatentSync框架的性能和有效性:
1. 实验设置
- 数据集:使用VoxCeleb2和HDTF数据集的混合作为训练集,使用HDTF或VoxCeleb2的测试集进行评估。
- 实现细节:将视频转换为25 FPS,应用基于面部标志检测的仿射变换以获得256×256的面部视频。音频重新采样为16kHz,并使用20步DDIM采样进行推理。
- 评估指标:包括视觉质量(SSIM和FID)、唇形同步精度(SyncNet置信度分数Syncconf)和时间一致性(FVD)。
2. 比较实验
- 比较方法:选择了几种提供开源推理代码和检查点的最新技术方法进行比较,包括Wav2Lip、VideoReTalking、DINet和MuseTalk。
- 定量比较:在HDTF和VoxCeleb2数据集上使用上述评估指标进行定量比较。
- 定性比较:在跨生成设置中运行两个案例,展示LatentSync与最新技术唇形同步方法的定性比较。
3. 消融研究
- SyncNet的监督效果:研究了添加SyncNet监督对唇形同步精度和时间一致性的影响。
- 提高时间一致性的不同方法:比较了时间层和TREPA在提高时间一致性和唇形同步精度方面的效果。
- Wav2Lip与TREPA:展示了TREPA方法也可以改善Wav2Lip方法的时间一致性和唇形同步精度。
4. SyncNet收敛问题的实验研究
- 批量大小:分析了不同批量大小对SyncNet收敛的影响。
- 模型架构:尝试替换SyncNet的视觉和音频编码器,并分析了不同架构对收敛的影响。
- 自注意力:尝试移除自注意力块,并分析了这一改变对SyncNet收敛的影响。
- 输入帧数:分析了输入帧数对SyncNet收敛的影响。
- 数据预处理:分析了不同的数据预处理方法(包括音频-视觉偏移调整)对SyncNet收敛的影响。
这些实验全面评估了LatentSync框架的性能,并深入分析了影响唇形同步精度和时间一致性的关键因素,从而证明了该框架的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的LatentSync框架在唇形同步任务上取得了显著的性能提升,但仍有一些方向可以进一步探索和研究:
1. 模型泛化能力
- 跨数据集测试:在更多种类的数据集上测试LatentSync的泛化能力,特别是包含不同种族、年龄和表情的数据集。
- 野外数据测试:在更接近真实世界的野外数据上测试模型性能,包括不同光照、背景噪声和非标准录音条件下的数据。
2. 模型效率
- 计算复杂度:探索减少模型计算复杂度的方法,使其更适合在资源受限的设备上运行。
- 实时性能:优化模型以实现实时或近实时的唇形同步,这对于视频会议和在线教育等应用场景非常重要。
3. 模型解释性
- 特征可视化:研究模型内部特征图的变化,以更好地理解模型是如何学习和关联音频与视觉信息的。
- 注意力机制:利用注意力机制进一步解释模型在唇形同步过程中关注的重点区域。
4. 交互式应用
- 用户界面:开发用户友好的界面,允许用户自定义音频输入和目标视频,以及调整同步参数。
- 交互式编辑工具:提供工具允许用户对生成的唇形同步视频进行微调,以适应不同的应用需求。
5. 多模态融合
- 融合更多模态:探索将更多的模态信息(如情感分析、语音识别结果)融入模型,以增强唇形同步的自然性和准确性。
6. 模型鲁棒性
- 对抗性攻击:研究模型对对抗性攻击的鲁棒性,并开发防御机制以保护唇形同步结果不被恶意操纵。
- 异常处理:提高模型对异常输入(如模糊、遮挡)的处理能力,确保在各种条件下都能稳定生成高质量的唇形同步视频。
7. 跨语言和方言的适应性
- 多语言支持:扩展模型以支持不同语言和方言的唇形同步,这对于多语言应用尤为重要。
这些方向不仅可以推动唇形同步技术的发展,还能为相关领域的研究提供新的视角和方法。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题陈述
论文提出了一个名为LatentSync的唇形同步框架,旨在解决现有基于扩散模型的唇形同步方法存在的问题,包括像素空间扩散方法的低采样速度和分辨率限制,以及两阶段生成方法中的信息丢失问题。
2. LatentSync框架
LatentSync是一个端到端的唇形同步框架,基于音频条件的潜在扩散模型,不需要任何中间的运动表示。该框架利用Stable Diffusion模型直接捕获音视频之间的复杂关联,生成动态逼真的说话视频。
3. 时间表示对齐(TREPA)
为了提高时间一致性,论文提出了TREPA方法。TREPA使用大规模自监督视频模型提取的时间表示来对齐生成帧和真实帧,从而增强模型的时间一致性,同时保持唇形同步的准确性。
4. SyncNet收敛问题研究
论文对SyncNet的收敛问题进行了深入分析,并通过广泛的实验研究识别了影响SyncNet收敛的关键因素,包括模型架构、训练超参数和数据预处理方法。这些发现帮助将SyncNet的准确率从91%提高到94%。
5. 实验
论文通过一系列实验验证了LatentSync框架的有效性。这些实验包括与现有技术的比较、消融研究以及对SyncNet收敛问题的研究。实验结果表明,LatentSync在多个评估指标上优于现有的唇形同步方法。
6. 贡献总结
论文的主要贡献包括:
- 提出了一个无需中间运动表示的端到端唇形同步框架。
- 解决了SyncNet的收敛问题,并提高了其准确率。
- 提出了TREPA方法以改善时间一致性,同时保持唇形同步的准确性。
总的来说,这篇论文通过引入新的框架和方法,显著提高了唇形同步的准确性和时间一致性,为该领域的发展做出了重要贡献。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

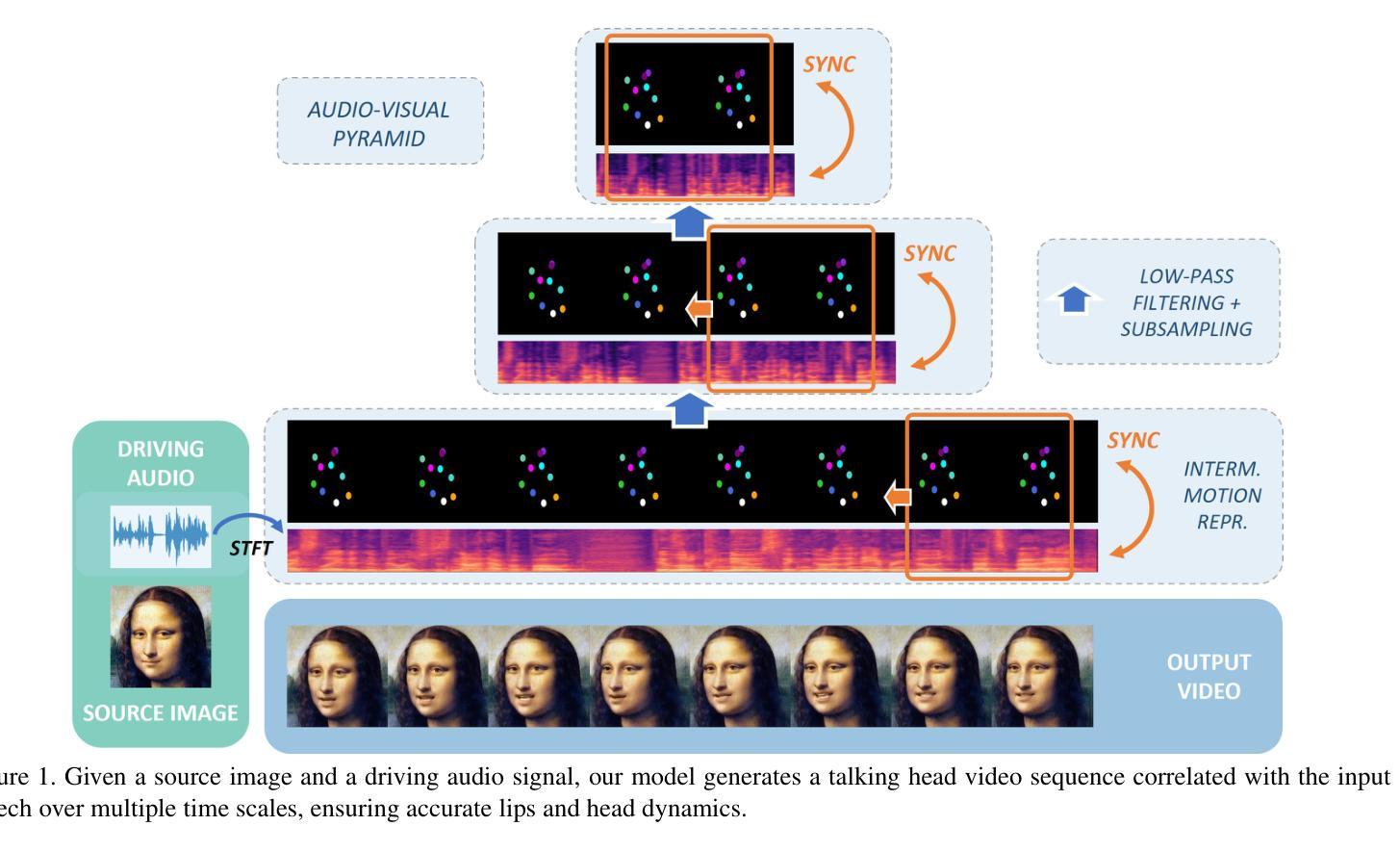
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Authors:Louis Airale, Dominique Vaufreydaz, Xavier Alameda-Pineda
Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress.However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected.In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips.In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales.Both the pyramid of audio-visual syncers and the generative models are trained in a low-dimensional space that fully preserves dynamics cues.The experiments show significant improvements over the state-of-the-art in head motion dynamics quality and especially in multi-scale audio-visual synchrony on a collection of benchmark datasets.
对静态面部图像进行深度生成模型动画并使用语音输入信号是一个热门的研究课题,并且最近取得了重要进展。然而,大量的努力都放在了唇部同步和渲染质量上,而自然头部动作的产生,以及头部动作与语音之间的视听相关性更是经常被忽视。在这项工作中,我们提出了一种多尺度视听同步损失和多尺度自回归GAN,以更好地处理语音和头部及唇部动态之间的短期和长期相关性。特别是,我们在多模态输入金字塔上训练了一组同步器模型,并使用这些模型作为多尺度生成网络的指导,以产生与音频对齐的运动展开,涉及多种时间尺度。无论是音频视觉同步器金字塔还是生成模型,都是在低维空间中训练的,这充分保留了动态线索。实验表明,与最新技术相比,在头部运动动态质量和多尺度视听同步方面都有显著提高,这一系列改进在一组基准数据集上得到了验证。
论文及项目相关链接
Summary
该研究利用深度生成模型和多尺度音频视觉同步损失以及多尺度自回归GAN技术,对静态面部图像进行动画处理,使其与语音输入信号同步。研究重点关注语音与头部和嘴唇动作的长期和短期相关性,训练了多尺度同步器模型作为多尺度生成网络的指导,显著提高了头部运动动态质量,特别是在基准数据集上的多尺度音频视觉同步性。
Key Takeaways
- 研究利用深度生成模型技术动画化静态面部图像,使其与语音输入信号同步。
- 头部运动和语音的短期和长期相关性是研究的重点。
- 提出了一种多尺度音频视觉同步损失方法,用于更好地处理语音与头部运动之间的相关性。
- 研究采用多尺度自回归GAN技术,训练了一系列同步器模型作为生成网络的指导。
- 在基准数据集上进行了实验,显著提高了头部运动动态质量。
- 实验结果在多尺度音频视觉同步方面表现出优越性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在生成逼真的说话头像(talking head generation)时,同步音频信号与头部和嘴唇动作,尤其是在保持自然头部运动和音频-视觉(audio-visual)相关性方面。具体来说,论文中提到了几个关键点:
音频-视觉同步性(Audio-Visual Synchrony):尽管已有研究在唇部同步和渲染质量方面取得了进展,但自然头部运动的生成以及头部运动与语音之间的音频-视觉相关性常常被忽视。
头部运动与语音的关联:已知语音和头部运动之间存在紧密联系,但这一关系在计算机视觉领域并未得到充分研究。
缺乏适当的损失函数:为了产生与输入音频信号充分相关的自然头部和唇部运动序列,缺乏一个能够同时处理短时和长时相关性的损失函数。
多尺度音频-视觉同步性(Multi-scale Audio-Visual Synchrony):为了捕捉不同时间尺度上的动作(如头部节奏),需要一个专门的损失函数来强制执行不同长度的音频-视觉片段之间的同步。
论文提出了一个多尺度音频-视觉同步损失函数和一个多尺度自回归生成对抗网络(Multi-Scale Autoregressive GAN),以更好地处理语音与头部和嘴唇动态之间的短时和长时相关性。通过在多模态输入金字塔上训练一系列同步模型,并在多尺度生成器网络中使用这些模型作为指导,来产生跨不同时间尺度的音频对齐运动。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
1. Talking Head Generation
- 身份依赖方法:需要针对特定身份进行微调,包括早期研究工作和基于NeRF框架的新近方法。
- 视觉质量高的方法:基于扩散模型的方法,这些方法通常以牺牲头部姿态控制为代价来提高视觉清晰度。
- 唇部同步准确性:主要关注唇部运动与输入语音信号之间的同步性,通常使用冻结的唇部同步模型来提高输出唇部与输入语音信号之间的同步性。
- 一次性方法:能够实时重演未见身份的单张源图像,并明确处理头部运动。
2. Video-Driven Face Reenactment
- 基于神经网络的面部动画:通过目标身份的驱动序列来引导源人脸的动画,以实现头部和唇部运动的监督。
- 低维表示:例如面部标志点或学习到的关键点,用于测量从给定目标图像到源图像的变形。
3. Multi-scale Data Processing
- 多尺度特征层次:在计算机视觉任务中,如目标检测或语义分割,已成为标准做法。
- 生成模型中的多尺度方法:可以在GANs的判别器网络中实现,以改善生成数据的多尺度忠实度,也可以在生成模型本身中实现。
4. 具体相关研究和方法
- Wav2Lip:使用预训练的唇部同步专家来学习音频-视觉同步,并在视觉配音任务中取得了最先进的性能。
- PC-AVS、EAMM:能够产生头部姿态的方法,尽管头部姿态的产生较为有限。
- MakeItTalk、Audio2Head、SadTalker:这些方法能够输出头部姿态,并且在处理头部运动方面取得了一定的成功。
这些相关研究为本文提出的多尺度音频-视觉同步损失和多尺度自回归生成对抗网络提供了背景和对比,展示了在生成与输入音频信号同步的头部和唇部运动方面的最新进展和挑战。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决了同步音频信号与头部和嘴唇动作的问题:
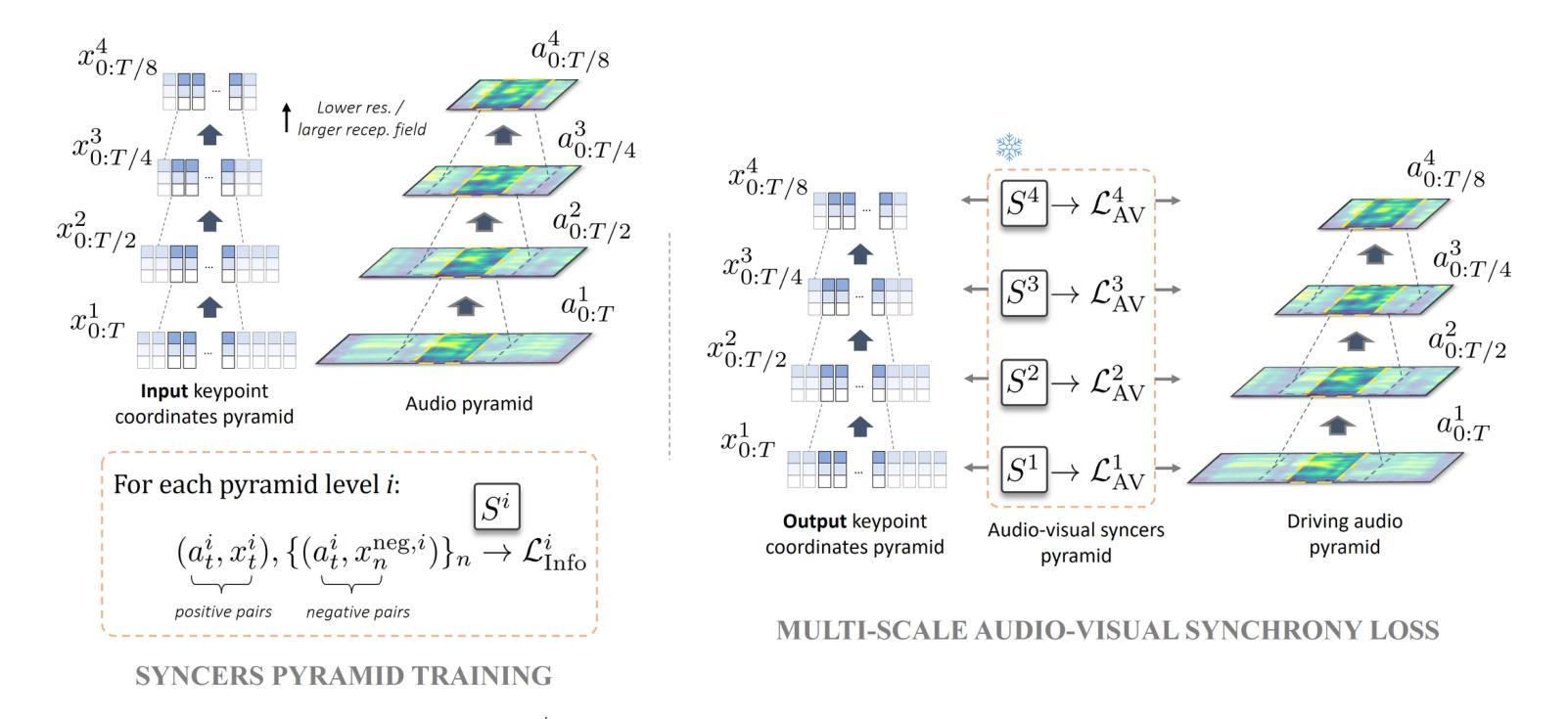
1. 多尺度音频-视觉同步损失(Multi-scale Audio-Visual Synchrony Loss)
- 金字塔同步器(Syncer Models):提出了一个金字塔结构的同步器模型,这些模型在多模态输入金字塔上进行训练,用以评估音频输入与整个面部动态(包括头部和嘴唇)在不同时间尺度上的相关性。
- 高斯金字塔:利用高斯金字塔对头部动态和音频进行多尺度表示,以捕捉从高频到低频的各种动态。
- 对比损失(Contrastive Losses):使用对比损失训练同步器网络,最大化同步音频-视觉片段与非同步片段之间的区分度。
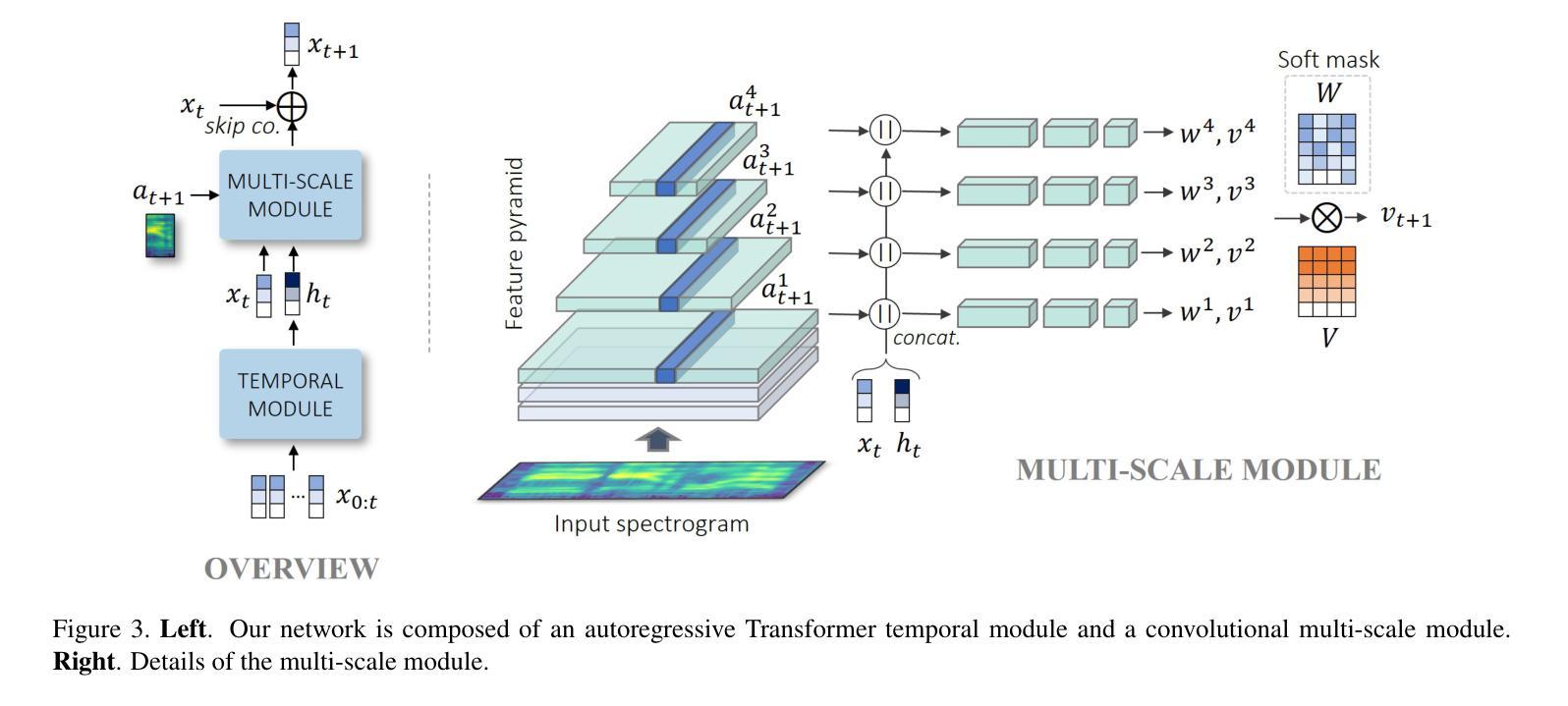
2. 多尺度自回归生成器(Multi-scale Autoregressive Generator)
- 残差自回归公式:生成器网络采用残差自回归结构,根据当前的关键点位置和下一时间步的音频输入来预测即时速度。
- 特征金字塔网络(FPN):多尺度模块基于特征金字塔网络实现,允许不同层次的损失项在网络的不同层级上发挥作用。
- 独立全连接分支:每个分支处理不同分辨率的输入,以产生不同频率的运动,并通过可学习的软空间掩码合并输出。
3. 整体架构和训练
- 判别器网络:使用两个判别器网络来提高生成关键点的静态和动态质量。
- 对抗性损失和重建损失:结合对抗性损失和重建损失,通过权重平衡这些损失项,以达到最佳的训练效果。
4. 实验验证
- 基准数据集:在多个基准数据集上进行实验,验证所提出方法在头部运动动态质量和多尺度音频-视觉同步性方面相对于现有技术的优势。
- 消融研究:通过消融研究来评估多尺度音频-视觉同步损失对模型性能的影响。
通过这些方法,论文成功地展示了一个能够处理短时和长时相关性、并生成与输入语音信号同步的自然头部和唇部运动的框架。此外,所提出的多尺度音频-视觉同步损失是一个独立的贡献,可以融合到不同的生成模型架构中,使其成为一个用于音频驱动的头部运动生成的多功能工具。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出方法(MS-Sync)的有效性,这些实验包括:
1. 实验协议(Experimental Protocol)
- 数据集:使用了VoxCeleb2数据集的两个不同预处理版本(VoxCeleb2 (I) 和 VoxCeleb2 (II)),HDTF数据集和LRS2数据集进行实验。
- 基准模型:与现有的多种一次性说话头像生成模型进行比较,包括Wav2Lip、IP_LAP、PC-AVS、EAMM、MakeItTalk、Audio2Head和SadTalker等。
- 训练细节:详细描述了模型的训练过程,包括使用的优化器、学习率和训练迭代次数等。
2. 图像域音频-视觉同步(Image-Domain AV Synchrony)
- 协议:使用标准指标(如SyncNet的绝对偏移|AV-Off|和置信度AV-Conf,以及正面化地标距离LMD)在VoxCeleb2 (I)和LRS2数据集上评估音频-视觉同步性。
- 结果:MS-Sync在多个指标上表现良好,特别是在SyncNet的置信度分数上显著优于其他方法。
3. 语音和刚性头部运动之间的多尺度相关性
- 协议:探索了语音和头部运动之间的相关性,使用在VoxCeleb2 (II)和HDTF数据集上训练的同步器网络来评估不同时间尺度上的音频-视觉同步性。
- 结果:MS-Sync在所有尺度上的表现均优于其他方法,表明该方法能够在多个时间尺度上成功地生成与音频输入时间对齐的头部运动。
4. 视觉质量(Visual Quality)
- 定量结果:使用Fréchet Inception Distance(FID)来衡量输出序列的视觉质量,并与其他方法进行比较。
- 定性比较:展示了MS-Sync在处理困难样本(如初始帧中嘴巴大张或眼睛闭合的情况)时的定性结果,并与其他方法进行了比较。
5. 消融研究(Ablation Study)
- 损失函数的权重:研究了对抗性损失和重建损失项对视觉质量和音频-视觉同步性的影响。
- 多尺度AV损失的影响:评估了使用多尺度AV损失与仅在最细尺度上强制同步的效果,证明了多尺度损失在长距离音频-视觉同步性方面的优势。
这些实验全面地评估了MS-Sync模型在音频-视觉同步性和视觉质量方面的表现,并与现有技术进行了比较,证明了所提出方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
1. 模型泛化能力
- 对不同身份和表情的泛化:研究模型对未见身份和不同表情的泛化能力,特别是在处理多样化数据集时的表现。
- 跨数据集泛化:测试模型在不同来源的数据集间的泛化能力,例如从电影、访谈到新闻播报等不同类型的视频。
2. 错误累积和序列长度
- 延长输出序列:探索模型在更长视频序列上的表现,以及如何减少连续自回归模型中的错误累积问题。
- 模型鲁棒性:研究模型对于输入噪声和不完美对齐的鲁棒性,并开发策略来提高模型的稳定性和鲁棒性。
3. 多模态融合和表示学习
- 更深层次的多模态融合:探索音频和视觉数据之间更深层次的融合方式,以提高同步精度和自然度。
- 无监督和自监督学习:研究无监督或自监督学习策略,以减少对大量标注数据的依赖。
4. 计算效率和实时应用
- 计算资源优化:优化模型结构和训练过程,以减少计算资源消耗,使其适用于实时应用或资源受限的环境。
- 移动端部署:研究模型压缩和加速技术,以便在移动设备或嵌入式系统上部署。
5. 交互式应用和用户控制
- 用户控制的面部动画:开发交互式应用,允许用户通过语音指令或其他输入控制面部动画的特定方面,如情感表达或头部姿态。
- 个性化和定制化:探索个性化模型训练技术,使用户能够定制和优化模型以适应自己的特定需求。
6. 伦理和隐私问题
- 数据隐私和安全性:研究数据隐私保护措施,确保用户数据的安全和合规性。
- 伦理使用指南:探讨深度伪造技术(deepfakes)的伦理问题,制定使用指南和政策,防止滥用。
7. 跨模态转换和生成
- 语音到面部动作的直接映射:研究从语音直接生成面部动作的模型,无需额外的音频特征提取。
- 多模态数据生成:探索生成与输入音频同步的面部表情和头部动作的同时,生成相应的语音或文本。
这些探索点可以帮助推动音频-视觉同步技术和应用的发展,同时解决实际应用中遇到的挑战。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
研究问题:论文针对的是在生成逼真的说话头像时,如何同步音频信号与头部和嘴唇动作,尤其是自然头部运动的生成以及头部运动与语音之间的音频-视觉相关性。
方法论:
- 提出了一个多尺度音频-视觉同步损失函数,通过训练一系列同步器模型(syncer models)在多模态输入金字塔上,以评估音频输入与整个面部动态(包括头部和嘴唇)在不同时间尺度上的相关性。
- 构建了一个多尺度自回归生成对抗网络(Multi-Scale Autoregressive GAN),称为MS-Sync,以处理短时和长时相关性,并生成跨不同时间尺度的音频对齐运动。
技术贡献:
- 首次训练音频-视觉同步器网络来测量头部运动与语音之间的相关性。
- 提出了一个多尺度音频-视觉同步损失,以生成与音频相关的多样化面部动态。
- 构建了一个有效的多尺度自回归GAN框架,通过广泛的实验展示了其在生成与语音同步的头部和嘴唇运动方面的优势。
实验验证:
- 在VoxCeleb2、HDTF和LRS2等多个基准数据集上进行了实验,验证了MS-Sync在头部运动动态质量和多尺度音频-视觉同步性方面相对于现有技术的优势。
- 进行了消融研究,证明了多尺度音频-视觉同步损失对模型性能的积极影响。
讨论与局限性:
- 论文讨论了MS-Sync框架的有效性,并指出了其局限性,如连续自回归模型中可能出现的错误累积问题,以及对互联网图片的敏感性。
- 论文还提出了可能的改进方向,包括通过传播视觉损失梯度来减轻这些问题。
结论:
- 论文得出结论,MS-Sync是第一个尝试在多个尺度上学习和建模音频-视觉相关性以生成说话头像的方法,实验结果非常鼓舞人心,并预见了这种方法在其他视听生成任务上的潜在应用。
总体而言,这篇论文提出了一个创新的多尺度方法来生成与输入语音同步的头部和唇部动作,为提高生成逼真说话头像的质量提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图