⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-13 更新
Vision Transformers for Efficient Indoor Pathloss Radio Map Prediction
Authors:Edvard Ghukasyan, Hrant Khachatrian, Rafayel Mkrtchyan, Theofanis P. Raptis
Vision Transformers (ViTs) have demonstrated remarkable success in achieving state-of-the-art performance across various image-based tasks and beyond. In this study, we employ a ViT-based neural network to address the problem of indoor pathloss radio map prediction. The network’s generalization ability is evaluated across diverse settings, including unseen buildings, frequencies, and antennas with varying radiation patterns. By leveraging extensive data augmentation techniques and pretrained DINOv2 weights, we achieve promising results, even under the most challenging scenarios.
视觉Transformer(ViT)在各种基于图像的任务以及其他领域取得了显著的成功,达到了最先进的性能。在这项研究中,我们采用基于ViT的神经网络来解决室内路径损耗无线电地图预测问题。该网络的泛化能力在多种环境下得到了评估,包括看不见的建筑物、频率和具有不同辐射模式的天线。通过利用广泛的数据增强技术和预训练的DINOv2权重,我们在最具挑战性的场景下也取得了有希望的成果。
论文及项目相关链接
PDF Work partly supported by the RA Science Committee grant No. 22rl-052 (DISTAL) and the EU under Italian National Recovery and Resilience Plan of NextGenerationEU on “Telecommunications of the Future” (PE00000001 - program “RESTART”)
Summary
本文利用Vision Transformer(ViT)神经网络解决室内路径损耗无线电地图预测问题,并在不同设置、建筑物、频率和天线辐射模式上进行了评估。通过利用数据增强技术和预训练的DINOv2权重,即使在最具挑战性的场景下也取得了有前景的结果。
Key Takeaways
- Vision Transformers (ViTs)已实现多种图像任务的最优性能,并被应用于室内路径损耗无线电地图预测。
- 研究采用ViT神经网络解决该问题。
- 网络的泛化能力在不同设置(包括未见过的建筑物、频率和天线)上得到了评估。
- 利用数据增强技术和预训练DINOv2权重来提高模型性能。
- 在最具挑战性的场景下,模型仍然表现优异。
- 此方法提供了一种有效的室内无线电环境预测手段,有助于优化室内无线通信网络。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是室内路径损耗(pathloss)无线电图(radio map)的准确预测。这是无线通信领域中的一个基本问题,它使得网络规划、资源分配和性能优化能够高效进行。由于室内环境具有复杂的几何结构、多样的材料和动态的障碍物,传统的经验性和解析性方法无法充分捕捉到复杂的路径损耗特征,因此,数据驱动的机器学习方法成为了一种强大的替代方案,它们可以直接从数据中学习复杂的模式。论文中提到的方法从卷积神经网络(CNN)转变为视觉变换器(Vision Transformers, ViTs),并将研究场景从室外转移到室内,以解决室内路径损耗无线电图预测的问题。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
室内无线电图构建:
- [1] Z. Xing 和 J. Chen, “Constructing indoor region-based radio map without location labels,” IEEE Transactions on Signal Processing, vol. 72, pp. 2512–2526, 2024.
室内无线电图估计:
- [2] R. Jaiswal, M. Elnourani, S. Deshmukh, 和 B. Beferull-Lozano, “Location-free indoor radio map estimation using transfer learning,” in 2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), 2023, pp. 1–7.
无线定位:
- [3] H. Khachatrian, R. Mkrtchyan, 和 T. P. Raptis, “Deep learning with synthetic data for wireless nlos positioning with a single base station,” Ad Hoc Networks, vol. 167, p. 103696, 2025.
- [4] R. Darbinyan, H. Khachatrian, R. Mkrtchyan, 和 T. P. Raptis, “Ml-based approaches for wireless nlos localization: Input representations and uncertainty estimation,” in 2023 IEEE Ninth International Conference on Big Data Computing Service and Applications (BigDataService), 2023, pp. 87–94.
环境图重建:
- [5] H. Khachatrian, R. Mkrtchyan, 和 T. P. Raptis, “Outdoor environment reconstruction with deep learning on radio propagation paths,” in 2024 International Wireless Communications and Mobile Computing (IWCMC), 2024, pp. 1498–1503.
数字孪生网络的工业数据和服务方面:
- [6] M. Becattini, D. Borsatti, A. Bujari, L. Carnevali, A. Garbugli, H. Khachatrian, T. P. Raptis, 和 D. Tarchi, “Empirical application insights on industrial data and service aspects of digital twin networks,” in 2024 IEEE International Mediterranean Conference on Communications and Networking (MeditCom), 2024, pp. 323–328.
稀疏无线电图的数据插补:
- [7] X. Li, H. Li, H. K.-H. Chan, H. Lu, 和 C. S. Jensen, “Data imputation for sparse radio maps in indoor positioning,” in 2023 IEEE 39th International Conference on Data Engineering (ICDE), 2023, pp. 2235–2248.
这些研究涵盖了室内无线电图的构建、估计、无线定位、环境图重建以及数字孪生网络的工业应用等方面,它们为室内路径损耗无线电图预测的研究提供了理论和技术基础。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决室内路径损耗无线电图预测的问题:
1. 数据描述和预处理
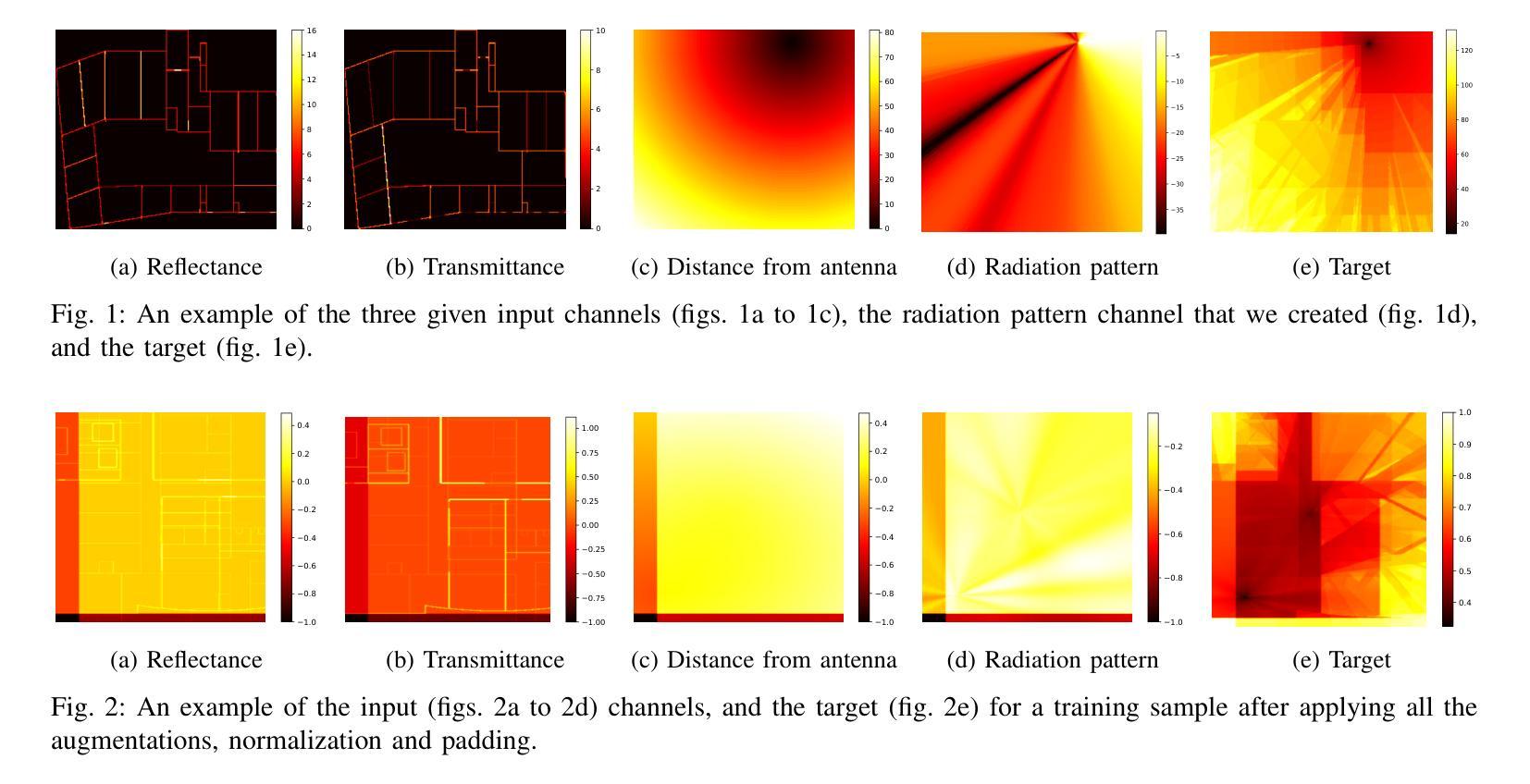
- 数据集构成:使用由射线追踪算法生成的路径损耗(PL)无线电图,包含25个室内几何结构、3个频段和5种天线辐射模式。
- 任务描述:设计三个任务,逐步增加模型泛化的挑战性,包括未见建筑、频率和天线辐射模式的泛化。
- 数据格式:建筑物和天线位置编码为三通道图像,每个像素对应0.25×0.25米的网格单元。
2. 模型设计和神经网络架构
- 数据预处理:包括数据准备、归一化和数据增强技术,以增强模型的泛化能力。
- 归一化:对反射率、透射率和距离的值进行归一化处理。
- 数据增强:应用MixUp、旋转和裁剪增强技术,以模拟现实世界中的多样化情况。
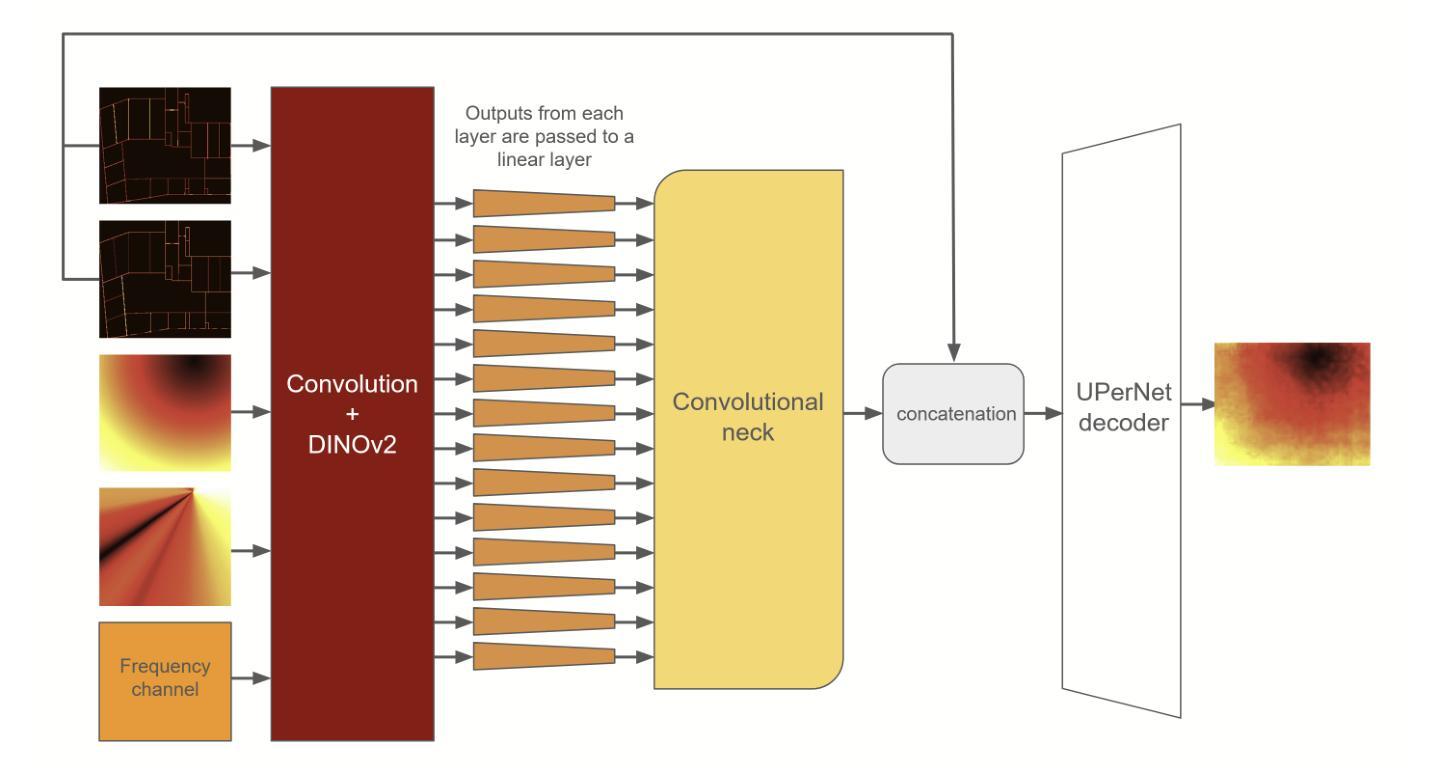
- 神经网络设计:采用基于DINOv2视觉变换器的神经网络,结合UPerNet卷积解码器和一个连接编码器和解码器的“颈部”网络。
- DINOv2视觉变换器:作为编码器,用于提取图像嵌入。
- UPerNet卷积解码器:用于从嵌入中重建输出。
- 颈部网络:连接ViT编码器和卷积解码器,增强房间边界信息。
3. 实验结果
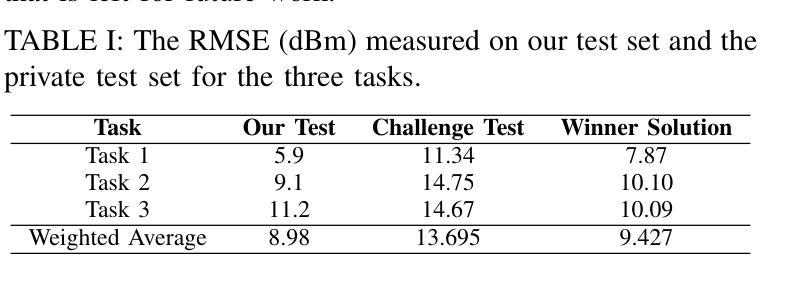
- 性能评估:在三个任务上评估模型性能,使用均方根误差(RMSE)作为衡量指标,并在ICASSP 2025室内路径损耗无线电图预测挑战赛的测试集上报告结果。
4. 分析和未来工作
- 性能分析:分析模型在不同测试集上的性能差异,指出建筑布局分布变化对性能的影响。
- 未来工作:提出需要进一步研究的方向,包括提高模型对建筑布局分布变化的鲁棒性,以及进一步的消融研究以确定输入表示或增强技术对模型鲁棒性的贡献。
通过这些步骤,论文展示了如何利用深度学习和视觉变换器来解决室内路径损耗无线电图预测的问题,并在挑战赛中取得了一定的成绩。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验:
数据预处理实验:
- 对输入数据进行标准化、归一化和数据增强,以提高模型的泛化能力。
- 应用了MixUp、旋转和裁剪等数据增强技术。
神经网络架构实验:
- 使用DINOv2视觉变换器作为编码器,UPerNet卷积解码器,以及连接编码器和解码器的“颈部”网络。
- 利用预训练的DINOv2权重进行训练,并调整嵌入大小以适应不同任务。
性能评估实验:
- 在三个不同的任务上评估模型性能,每个任务都设计来评估模型在不同条件下的泛化能力。
- 使用均方根误差(RMSE)作为性能指标。
测试集性能对比实验:
- 在自己创建的测试集和ICASSP 2025挑战赛提供的测试集上评估模型性能。
- 分析两个测试集之间的性能差异,主要归因于建筑布局的分布变化。
鲁棒性分析实验:
- 分析模型在不同任务之间性能的退化,特别是在不同频率和天线类型下的性能变化。
- 比较挑战赛测试集和自己的测试集上的性能退化,以评估模型对这些变化的鲁棒性。
这些实验旨在验证所提出方法的有效性,并评估模型在不同条件下的泛化能力和鲁棒性。通过这些实验,论文展示了其方法在室内路径损耗无线电图预测任务中的潜力,并指出了未来工作的方向。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
鲁棒性提升:
- 开发方法以增强深度学习模型对建筑布局分布变化的鲁棒性,这可能涉及改进的数据增强技术或更复杂的模型架构。
输入表示和增强技术的影响:
- 进行更多的消融研究以确定输入表示和增强技术对模型鲁棒性的具体贡献。
模型泛化能力的提高:
- 探索不同的神经网络架构和训练策略,以提高模型对未见建筑、频率和天线辐射模式的泛化能力。
更复杂的数据增强技术:
- 尝试更复杂的数据增强技术,如模拟不同的用户行为、动态障碍物和环境变化,以进一步提高模型的泛化能力。
多模态学习:
- 结合无线电信号传播数据和其他传感器数据(如Wi-Fi信号、蓝牙信号等),以提高路径损耗预测的准确性和鲁棒性。
模型解释性:
- 提高模型的可解释性,以便更好地理解模型是如何学习和预测路径损耗的,这可能有助于改进模型架构和训练过程。
跨场景泛化:
- 探索模型在不同场景(如从室内到室外环境)的泛化能力,并开发有效的迁移学习策略。
实时性能优化:
- 研究模型在实时应用中的性能,并优化模型以满足实时预测的需求。
模型压缩和加速:
- 研究模型压缩和加速技术,以使模型更适合部署在资源受限的设备上。
多任务学习:
- 探索多任务学习框架,同时预测路径损耗和其他相关的无线通信参数,以提高模型的效率和实用性。
这些探索点可以帮助研究者进一步提升模型的性能,扩展模型的应用范围,并更好地理解和改进深度学习在室内路径损耗预测中的应用。
Q: 总结一下论文的主要内容
A: 论文的主要内容总结如下:
研究背景与动机
- 论文针对室内环境中无线信号传播的路径损耗(pathloss)无线电图预测问题,这一问题对于无线通信网络的规划、资源分配和性能优化至关重要。
- 传统的经验性和解析性方法难以捕捉室内环境复杂的路径损耗特性,因此作者转向数据驱动的机器学习方法。
数据集描述
- 数据集包含25个室内几何结构、3个频段和5种天线辐射模式下的路径损耗(PL)无线电图,由射线追踪算法生成。
- 包含三个任务,从简单到复杂,逐步增加模型泛化的挑战性。
方法论
- 采用视觉变换器(ViT)基础的神经网络,特别是DINOv2模型,结合UPerNet卷积解码器。
- 通过数据预处理(包括归一化和数据增强)和利用预训练的DINOv2权重来训练模型。
实验结果
- 在自己创建的测试集和ICASSP 2025挑战赛提供的测试集上评估模型性能,使用均方根误差(RMSE)作为衡量指标。
- 结果显示模型在不同任务中具有较好的泛化能力和鲁棒性,尤其在频率和天线类型变化下的鲁棒性。
未来工作
- 提出了未来可能的研究方向,包括提高模型对建筑布局分布变化的鲁棒性,以及进一步的消融研究以确定输入表示或增强技术对模型鲁棒性的贡献。
总体而言,论文通过采用视觉变换器和一系列数据预处理技术,成功地将深度学习应用于室内路径损耗无线电图的预测问题,并在挑战赛中取得了较好的成绩。同时,论文也指出了未来研究的方向,以进一步提升模型的性能和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

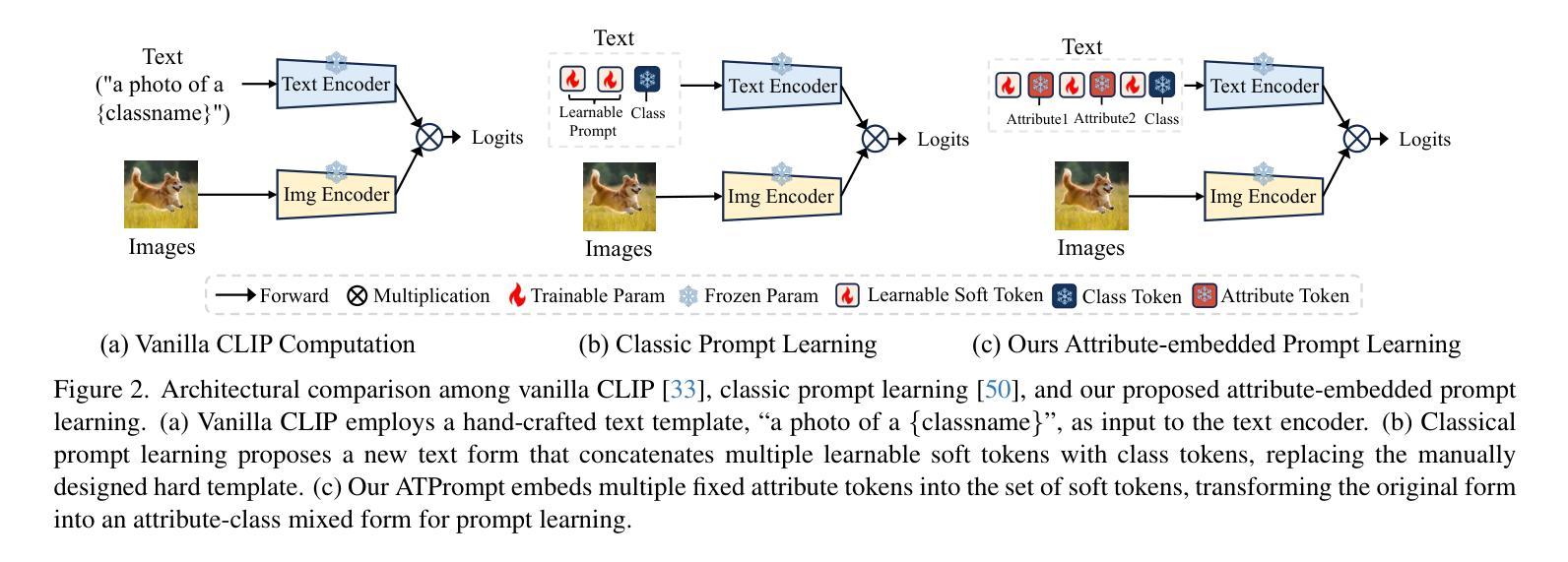
ATPrompt: Textual Prompt Learning with Embedded Attributes
Authors:Zheng Li, Yibing Song, Penghai Zhao, Ming-Ming Cheng, Xiang Li, Jian Yang
Textual-based prompt learning methods primarily employ multiple learnable soft prompts and hard class tokens in a cascading manner as text prompt inputs, aiming to align image and text (category) spaces for downstream tasks. However, current training is restricted to aligning images with predefined known categories and cannot be associated with unknown categories. In this work, we propose utilizing universal attributes as a bridge to enhance the alignment between images and unknown categories. Specifically, we introduce an Attribute-embedded Textual Prompt learning method for vision-language models, named ATPrompt. This approach expands the learning space of soft prompts from the original one-dimensional category level into the multi-dimensional attribute level by incorporating multiple universal attribute tokens into the learnable soft prompts. Through this modification, we transform the text prompt from a category-centric form to an attribute-category hybrid form. To finalize the attributes for downstream tasks, we propose a differentiable attribute search method that learns to identify representative and suitable attributes from a candidate pool summarized by a large language model. As an easy-to-use plug-in technique, ATPrompt can seamlessly replace the existing prompt format of textual-based methods, offering general improvements at a negligible computational cost. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
基于文本的提示学习方法主要采用多个可学习的软提示和硬类别令牌以级联方式作为文本提示输入,旨在对齐图像和文本(类别)空间以进行下游任务。然而,当前训练仅限于对齐图像与预定义的已知类别,无法与未知类别相关联。在本文中,我们提出利用通用属性作为桥梁,增强图像与未知类别之间的对齐。具体来说,我们为视觉语言模型引入了一种嵌入属性的文本提示学习方法,称为ATPrompt。该方法通过将多个通用属性令牌融入可学习的软提示中,将软提示的学习空间从原来的一维类别层面扩展到多维属性层面。通过这一改进,我们将文本提示从以类别为中心的形式转变为属性-类别混合形式。为了完成下游任务的属性,我们提出了一种可区分的属性搜索方法,该方法能够从大型语言模型总结出的候选池中学习识别有代表性和合适的属性。作为易于使用的插件技术,ATPrompt可以无缝替换基于文本的现有提示格式,在可忽略的计算成本下提供一般性的改进。在11个数据集上的大量实验证明了我们的方法的有效性。
论文及项目相关链接
PDF Technical Report. Project Page: https://zhengli97.github.io/ATPrompt/
Summary
文本提示学习方法主要通过使用可学习的软提示和硬类别标记来作为文本提示输入,旨在实现对下游任务中的图像和文本(类别)空间的对齐。然而,当前训练仅限于对齐图像与预定义的已知类别,无法与未知类别相关联。本研究提出利用通用属性作为桥梁,以增强图像与未知类别之间的对齐。具体来说,我们提出了一种名为ATPrompt的属性嵌入文本提示学习方法,该方法通过将多个通用属性标记融入可学习的软提示中,将软提示的学习空间从原始的一维类别层面扩展到多维属性层面。通过这种修改,我们将文本提示从以类别为中心的形式转变为属性-类别混合形式。为了确定下游任务的属性,我们提出了一种可区分的属性搜索方法,该方法可以从大型语言模型总结的候选池中学习识别有代表性的合适属性。作为易于使用的插件技术,ATPrompt可以无缝替换现有文本方法中的提示格式,以微小的计算成本提供一般的改进。在11个数据集上的广泛实验证明了我们的方法的有效性。
Key Takeaways
- 文本提示学习方法利用可学习的软提示和硬类别标记进行文本提示输入,旨在实现图像和文本(类别)空间对齐。
- 当前训练限制在于只能对齐图像与预定义的已知类别,无法处理未知类别。
- 研究提出利用通用属性增强图像与未知类别的对齐,通过属性嵌入文本提示学习方法(ATPrompt)实现。
- ATPrompt将软提示的学习空间扩展到多维属性层面,结合属性和类别信息形成文本提示。
- ATPrompt采用可区分属性搜索方法,从候选池中识别代表性属性。
- ATPrompt作为易用的插件技术,可无缝融入现有文本方法,以微小计算成本提供一般改进。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是现有文本提示学习方法在视觉-语言模型(VLMs)中的应用限制,特别是在对未知类别的图像和文本(类别)空间对齐方面的不足。具体来说,论文指出当前的方法主要依赖于预定义的已知类别来训练图像与文本的对齐,而无法有效地与未知类别建立准确的关联。为了解决这一问题,论文提出了一种新的属性嵌入的文本提示学习方法(ATPrompt),通过将通用属性作为桥梁来增强图像与未知类别之间的对齐。
主要问题可以总结为:
现有方法的局限性:当前的文本提示学习方法在训练时只能对齐已知类别的图像和文本,面对未知类别时无法建立准确的关联。
对未知类别的泛化能力:如何提升模型对未知类别的识别和泛化能力,特别是在零样本(zero-shot)场景下。
属性在对齐中的作用:探索如何利用属性信息来增强图像和文本之间的对齐,尤其是在类别信息不充分时。
自动化属性选择:如何从大型语言模型(LLMs)构建的候选池中自动选择适合特定任务的属性。
通过提出ATPrompt方法,论文旨在通过引入属性嵌入的文本提示来扩展软提示的学习空间,从一维的类别级别扩展到多维的属性级别,并通过自动化的属性搜索方法来选择适合的属性,从而提高模型对未知类别的识别能力,并在多个数据集上验证了该方法的有效性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个方面:
Prompt Learning for VLMs(视觉-语言模型的提示学习)
- CoOp [50]:提出了使用软文本标记和硬类别标记作为输入的概念。
- PromptSRC [16]:使用CLIP的原始特征来正则化学习软提示。
- PromptKD [24]:使用预训练的强教师模型来指导具有可学习提示的学生模型的学习。
Attributes for VLMs(视觉-语言模型的属性)
- VCD [28]:首次提出使用大型语言模型将类别名称分解为多个类内属性。
- ArGue [39]:将广泛描述分解为多个类内属性,并训练软提示与这些属性的编码特征对齐。
- AAPL [17]:引入一个元网络,基于编码的图像特征提取视觉属性特征,促进图像-文本对齐。
其他相关的视觉-语言模型和方法
- CLIP [33] 和 ALIGN [12]:展示了通过对比损失训练建立图像和文本(类别)空间对齐的模型。
- KgCoOp [45]:使用手工制作的硬提示在训练期间正则化可学习的软提示。
这些研究为本文提出的ATPrompt方法提供了理论基础和技术背景,特别是在提示学习、属性嵌入和视觉-语言模型的对齐方面。通过综合这些相关研究,本文旨在通过引入属性嵌入的文本提示学习来改进现有方法,增强模型对未知类别的对齐和识别能力。
Q: 论文如何解决这个问题?
A: 论文通过提出一种名为ATPrompt的属性嵌入文本提示学习方法来解决现有文本提示学习在对齐未知类别时的局限性。具体的解决方案包括以下几个关键步骤:
1. 属性嵌入文本提示(Attribute-embedded Textual Prompt)
- 扩展学习空间:ATPrompt通过在可学习的软提示中嵌入多个固定的通用属性标记,将软提示的学习空间从一维类别级别扩展到多维属性级别。这样,软提示不仅能学习特定于类别的表示,还能学习与属性相关的通用表示。
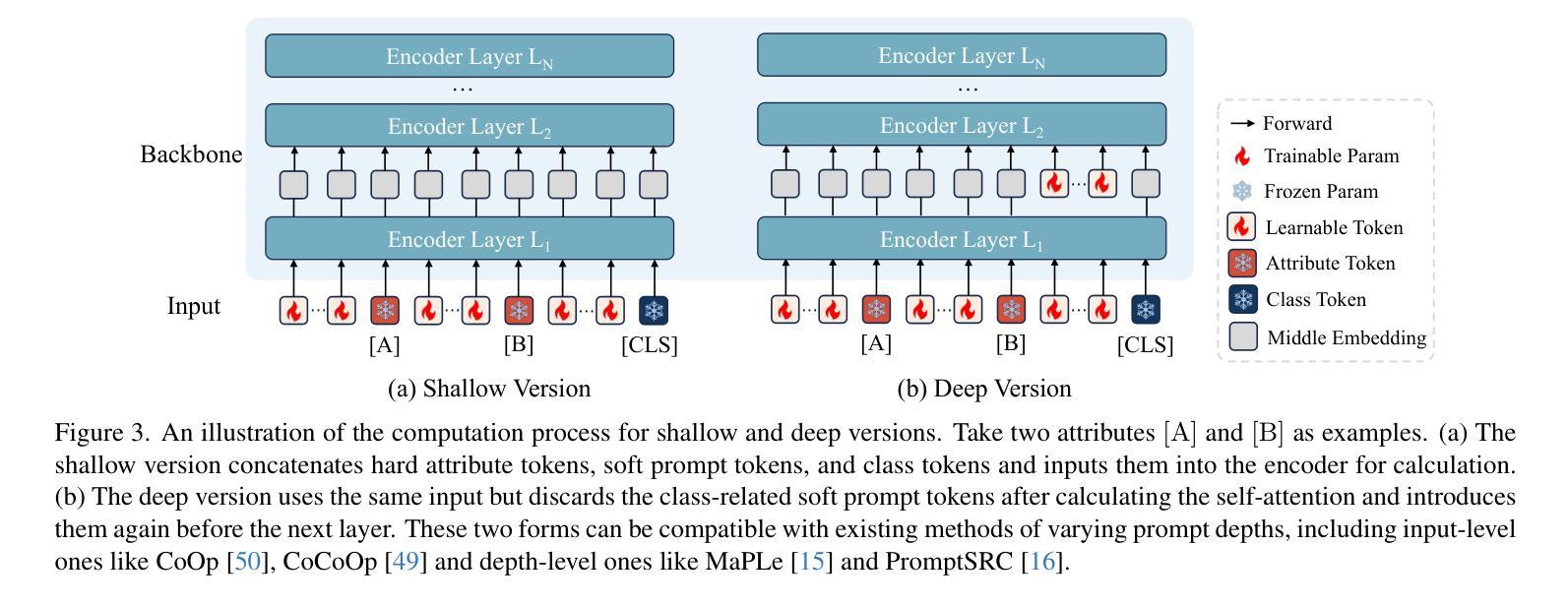
2. 不同版本的ATPrompt
- 浅层版本(Shallow Version):在文本编码器的输入层将硬属性标记、软提示标记和类别标记进行拼接。
- 深层版本(Deep Version):在深层网络中引入软提示,选择性地丢弃和重新引入与类别相关的软提示,而保留属性相关的软提示和硬提示。
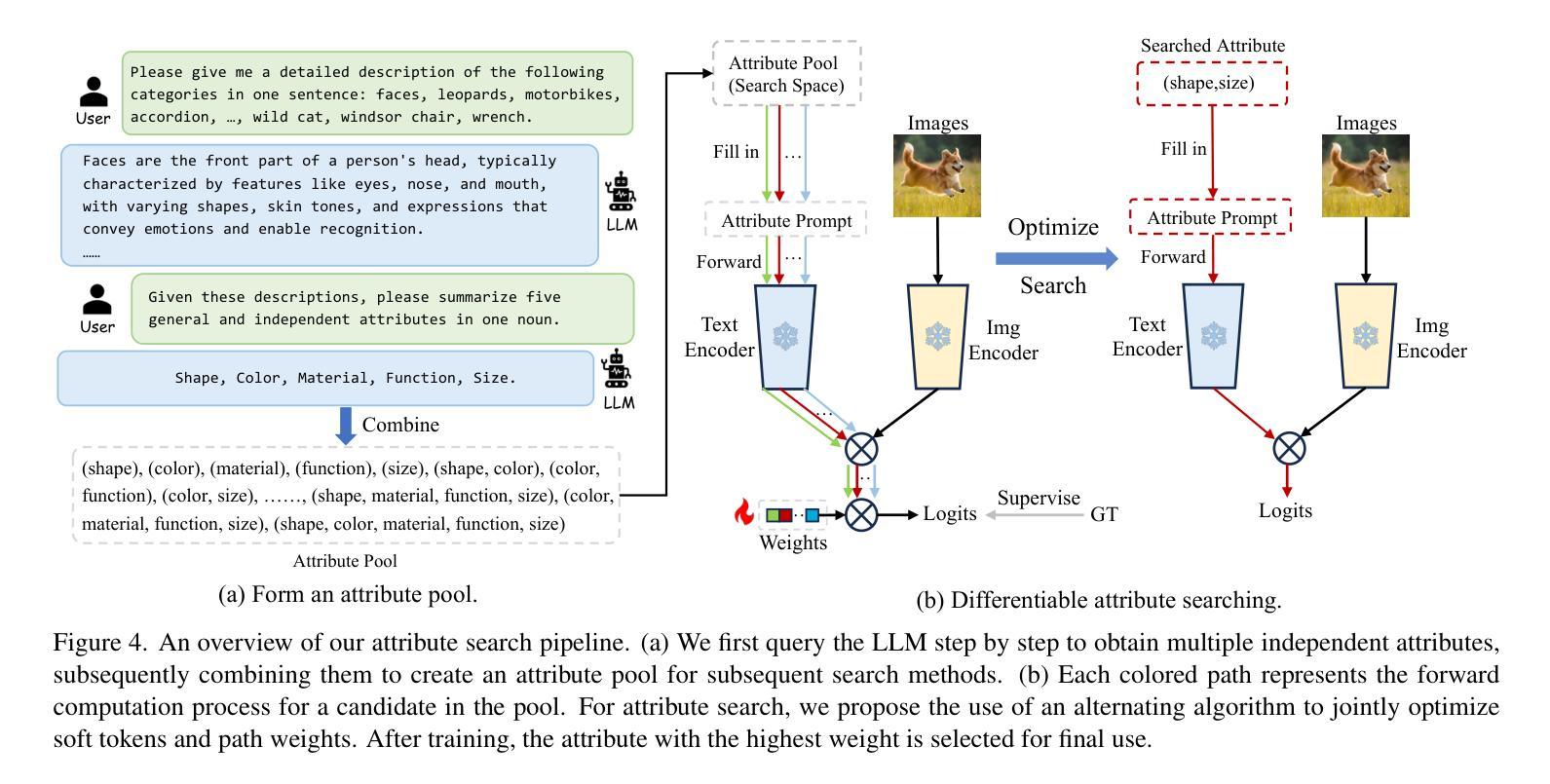
3. 可微分属性搜索方法(Differentiable Attribute Search Method)
- 属性池构建:利用大型语言模型(LLM)为当前下游任务的类别总结属性池。
- 自动化选择:提出一种可微分的属性搜索方法,从属性池中学习识别出最适合ATPrompt形式的代表性和合适属性。
4. 模型训练
- 最小化交叉熵损失:在标记数据集上训练模型,目标是最小化预测值和真实标签之间的交叉熵损失。
5. 实验验证
- 广泛的数据集实验:在11个数据集上进行实验,验证ATPrompt方法的有效性,展示其在不同基线方法上的平均性能提升。
通过这些解决方案,ATPrompt能够有效地将图像与未知类别进行对齐,提高了视觉-语言模型在下游任务中的性能,特别是在对未知类别的泛化能力方面。此外,作为一种即插即用的插件技术,ATPrompt能够无缝替换现有文本提示学习方法中的提示格式,以微不足道的计算成本获得普遍的性能提升。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验来验证ATPrompt方法的有效性:
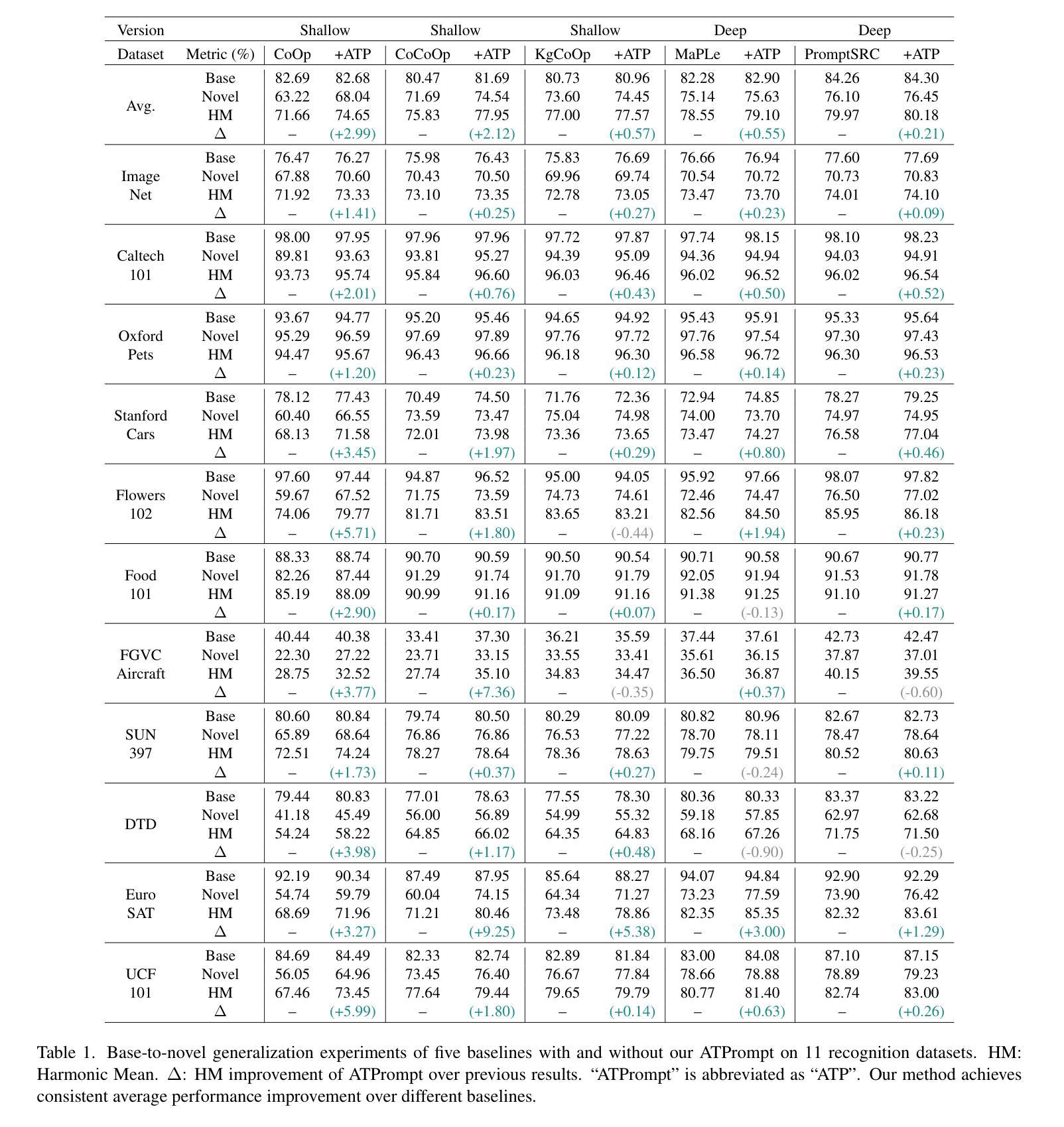
1. 基础到新类别的泛化实验(Base-to-Novel Generalization)
- 目的:测试模型在已知类别(基础类别)上训练后,对未知类别(新类别)的识别能力。
- 数据集:在11个识别数据集上进行实验,包括ImageNet-1K、Caltech-101、OxfordPets、StanfordCars、Flowers-102、Food-101、FGVCAircraft、SUN-397、DTD、EuroSAT和UCF-101。
- 方法:将数据集分为基类和新类,模型在基类训练集上训练,并在测试集上评估。
- 结果:ATPrompt在所有基线方法上都实现了一致的平均性能提升。
2. 跨数据集评估(Cross-dataset Evaluation)
- 目的:测试模型在一个源数据集(如ImageNet1K)上训练后,在不同分布的目标数据集上的泛化能力。
- 数据集:使用ImageNet-1K作为源数据集,并在11个不同的目标数据集上进行评估。
- 结果:ATPrompt在三个基线方法上都实现了一致的平均性能提升。
3. 进一步分析(Further Analysis)
- 软提示长度:研究不同长度的软提示对模型性能的影响。
- 类别标记位置:研究类别标记在文本提示中的不同位置对模型性能的影响。
- 深层版本的提示操作:比较在深层网络中对属性标记和类别标记的不同操作对模型性能的影响。
- 属性顺序:研究属性顺序的变化对模型性能的影响。
- 与其他属性的比较:比较使用不同来源的属性(如手动选择的类别不相关和常见属性)与通过ATPrompt方法自动搜索得到的属性的性能差异。
这些实验全面地评估了ATPrompt方法在不同场景下的性能,包括其对未知类别的泛化能力、跨数据集的泛化能力,以及不同配置和操作对模型性能的具体影响。通过这些实验,作者证明了ATPrompt方法的有效性和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和讨论部分,以下是一些可以进一步探索的点:
1. 优化属性搜索方法
- 探索不同的属性搜索策略:当前使用的可微分搜索方法虽然有效,但仍有优化空间。可以探索新的搜索算法或策略,以更高效地识别适合特定任务的属性。
2. 利用Chain-of-Thought (CoT) 方法
- 增强属性发现过程:利用CoT方法进一步探索多模态大型语言模型(MLLM)在属性发现过程中的潜力,以提高属性选择的准确性和效率。
3. 从显式到隐式属性的转变
- 隐式属性学习:研究如何从使用固定的显式属性转变为让模型自动学习隐式属性,使模型能够根据数据自动发现最有用的属性表示。
4. 多模态大型语言模型(MLLM)的应用
- 深入研究MLLM:探索如何更有效地利用MLLM来增强视觉-语言模型的性能,特别是在属性嵌入和对齐方面。
5. 扩展到其他任务和领域
- 跨任务和领域的泛化能力:将ATPrompt方法应用于其他视觉-语言任务,如视觉问答、图像描述等,并探索其在不同领域的泛化能力。
6. 提升计算效率
- 计算成本优化:研究如何减少ATPrompt方法的计算成本,使其更适合资源受限的环境或大规模应用。
7. 探索不同属性嵌入策略
- 属性嵌入的多样性:尝试不同的属性嵌入策略,例如学习属性嵌入权重或动态调整属性嵌入的方式。
8. 增强模型的解释性
- 模型解释性:研究如何增强模型的解释性,特别是在属性选择和嵌入过程中,以便更好地理解模型的决策过程。
9. 跨语言和文化的属性泛化
- 跨语言泛化:探索模型在处理不同语言和文化背景下的属性时的泛化能力,以及如何优化模型以适应全球化的应用场景。
这些探索点可以帮助研究者更深入地理解属性在视觉-语言模型中的作用,进一步优化ATPrompt方法,并扩展其在更广泛场景中的应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为ATPrompt的新型文本提示学习方法,旨在解决现有视觉-语言模型(VLMs)在对未知类别进行图像和文本对齐时的局限性。以下是论文的主要内容总结:
1. 问题陈述
- 现有基于文本的提示学习方法在训练时只能对齐已知类别,无法准确关联未知类别。
2. ATPrompt方法
- 属性嵌入:通过在软提示中嵌入通用属性标记,将学习空间从一维类别级别扩展到多维属性级别。
- 双版本设计:提出了浅层和深层两种版本的ATPrompt,以兼容不同深度的现有方法。
- 可微分属性搜索:利用大型语言模型(LLM)构建属性候选池,并使用可微分搜索方法自动选择最佳属性。
3. 实验验证
- 在11个数据集上进行了广泛的实验,包括基础到新类别的泛化和跨数据集评估。
- ATPrompt在多个基线方法上实现了一致的性能提升,证明了其有效性。
4. 进一步分析
- 研究了软提示长度、类别标记位置、深层版本的提示操作、属性顺序等因素对性能的影响。
- 与手动选择的不相关属性和常见属性进行了比较,证明了自动搜索属性的优越性。
5. 结论
- ATPrompt通过利用通用属性作为桥梁,增强了图像与未知类别之间的对齐,提高了VLMs对未知类别的识别能力。
6. 未来工作
- 探索更优化的属性搜索方法,利用多模态大型语言模型进一步提升属性发现过程。
- 从使用固定的显式属性转变为学习隐式属性,以自动发现适合的属性。
总体而言,这篇论文通过引入属性嵌入的文本提示学习,有效地扩展了VLMs的学习能力,使其能够更好地处理和对齐未知类别,为视觉-语言模型的提示学习领域提供了新的视角和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

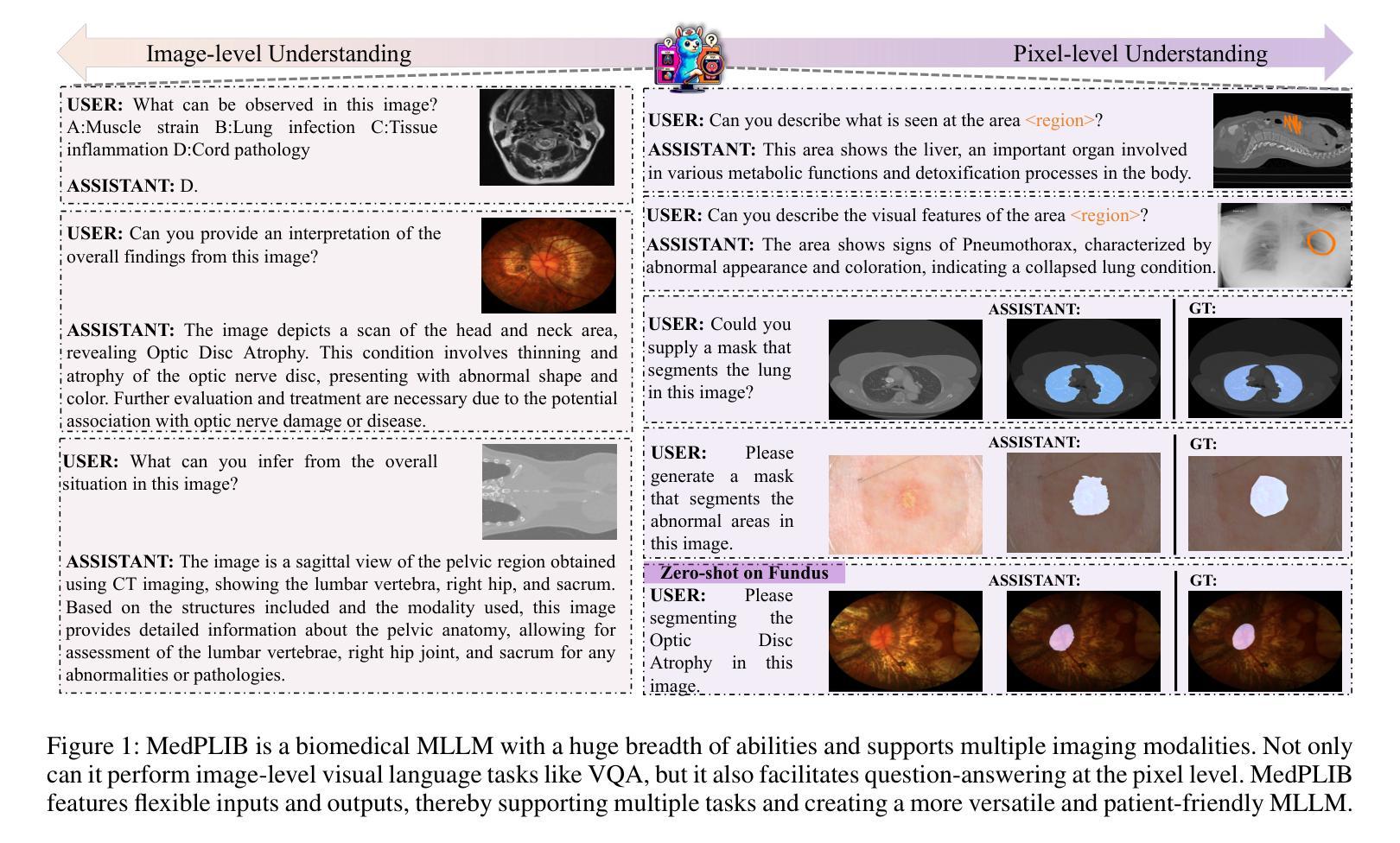
Towards a Multimodal Large Language Model with Pixel-Level Insight for Biomedicine
Authors:Xiaoshuang Huang, Lingdong Shen, Jia Liu, Fangxin Shang, Hongxiang Li, Haifeng Huang, Yehui Yang
In recent years, Multimodal Large Language Models (MLLM) have achieved notable advancements, demonstrating the feasibility of developing an intelligent biomedical assistant. However, current biomedical MLLMs predominantly focus on image-level understanding and restrict interactions to textual commands, thus limiting their capability boundaries and the flexibility of usage. In this paper, we introduce a novel end-to-end multimodal large language model for the biomedical domain, named MedPLIB, which possesses pixel-level understanding. Excitingly, it supports visual question answering (VQA), arbitrary pixel-level prompts (points, bounding boxes, and free-form shapes), and pixel-level grounding. We propose a novel Mixture-of-Experts (MoE) multi-stage training strategy, which divides MoE into separate training phases for a visual-language expert model and a pixel-grounding expert model, followed by fine-tuning using MoE. This strategy effectively coordinates multitask learning while maintaining the computational cost at inference equivalent to that of a single expert model. To advance the research of biomedical MLLMs, we introduce the Medical Complex Vision Question Answering Dataset (MeCoVQA), which comprises an array of 8 modalities for complex medical imaging question answering and image region understanding. Experimental results indicate that MedPLIB has achieved state-of-the-art outcomes across multiple medical visual language tasks. More importantly, in zero-shot evaluations for the pixel grounding task, MedPLIB leads the best small and large models by margins of 19.7 and 15.6 respectively on the mDice metric. The codes, data, and model checkpoints will be made publicly available at https://github.com/ShawnHuang497/MedPLIB.
近年来,多模态大型语言模型(MLLM)取得了显著的进步,证明了开发智能生物医学助理的可行性。然而,当前生物医学领域的MLLM主要侧重于图像级别的理解,并将交互限制为文本命令,从而限制了其能力边界和使用灵活性。在本文中,我们介绍了一种用于生物医学领域的新型端到端多模态大型语言模型,名为MedPLIB,它具有像素级别的理解能力。令人兴奋的是,它支持视觉问答(VQA)、任意像素级提示(点、边界框和自由形式形状)和像素级定位。我们提出了一种新型混合专家(MoE)多阶段训练策略,该策略将MoE分为视觉语言专家模型和像素定位专家模型的单独训练阶段,然后使用MoE进行微调。此策略有效地协调了多任务学习,同时保持推理阶段的计算成本相当于单个专家模型的成本。为了推动生物医学MLLM的研究,我们引入了医疗复杂视觉问答数据集(MeCoVQA),该数据集包含用于复杂医疗影像问答和图像区域理解的8种模式。实验结果表明,MedPLIB在多个医疗视觉语言任务中达到了最先进的成果。更重要的是,在像素定位任务的零样本评估中,MedPLIB在mDice指标上领先最佳小型和大型模型的边际分别为19.7和15.6。代码、数据和模型检查点将公开在https://github.com/ShawnHuang497/MedPLIB。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
本文介绍了一种针对生物医学领域的新型端到端多模态大型语言模型——MedPLIB,它具备像素级理解能力,支持视觉问答、任意像素级提示和像素级定位。提出一种新颖的分阶段训练策略——混合专家(MoE)多任务学习,实现了高效的计算成本下的多任务协调学习。同时,为推进生物医学多模态大型语言模型的研究,引入了复杂医疗视觉问答数据集MeCoVQA。实验结果显示,MedPLIB在多个医疗视觉语言任务上取得了最新成果,并在像素定位任务的零样本评估中领先其他小型和大型模型。
Key Takeaways
- MedPLIB是一个具备像素级理解能力的生物医学多模态大型语言模型。
- 支持视觉问答、任意像素级提示和像素级定位功能。
- 引入了一种新颖的分阶段训练策略——混合专家(MoE)多任务学习,实现高效的多任务协调学习。
- 公开了复杂医疗视觉问答数据集MeCoVQA,包含多种医学成像模态。
- MedPLIB在多个医疗视觉语言任务上取得最新成果。
- 在像素定位任务的零样本评估中,MedPLIB领先其他模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何开发一个具有像素级理解能力的多模态大型语言模型(MLLM),用于生物医学领域。具体来说,论文中提到了以下几个关键问题:
图像级理解的局限性:当前的生物医学MLLM主要关注图像级理解,并且将交互限制在文本命令上,这限制了它们的应用能力和灵活性。
像素级理解的需求:与自然世界中的图像级VQA不同,医疗领域需要更细粒度的像素级理解以确保准确性和答案的可解释性。
数据稀缺性:由于隐私法规和标注成本高昂,像素级和复杂VQA数据严重缺乏。
模型挑战:医学VQA通常需要结合空间理解(像素级理解)以确保信心和互操作性,将基于知识的问答和像素级分析集成在同一个MLLM中极其具有挑战性。
为了解决这些问题,论文提出了一个名为MedPLIB的新型端到端多模态大型语言模型,它具备像素级理解能力,并支持视觉问题回答(VQA)、任意像素级提示(点、边界框和自由形状区域)以及像素级定位。此外,论文还提出了一个新的多阶段专家混合(MoE)训练策略,并引入了一个名为MeCoVQA的数据集,以推动生物医学MLLM的研究进展。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
Biomedical Visual Question Answering (VQA):
- 早期的方法使用卷积神经网络(CNNs)和长短期记忆模型(LSTMs)来生成回答。
- 基于Transformer的方法,如BERT和BioBert,也在医学VQA中取得了令人印象深刻的性能。
Biomedical Image Segmentation:
- 几十年来,医学图像分割领域发展出了特定于单一成像模态的专家小型模型,例如U-Net、TransUnet和Swin-Unet。
- 最近的研究开始关注通用医学图像分割和文本引导的像素定位。
Mixture of Experts (MoE):
- MoE模型被提出以增加模型参数数量而不增加计算成本。
- 软路由(soft routers)和多模态及自然语言处理领域的研究,例如MoE-LLaVA和LLMBind。
Multimodal Large Language Models (MLLMs):
- 在自然领域,MLLMs在广泛的应用中取得了成功,例如GPT-4V和LLaVA。
- 生物医学领域也出现了一些专门的MLLMs,例如RadFM、LLaVA-Med和Med-PaLM M。
具体到论文中提到的一些模型和研究工作,包括但不限于:
- LLaVA (Liu et al. 2024): 一个在多模态领域取得广泛研究兴趣的模型。
- RadFM (Wu et al. 2023): 一个在医学VQA领域取得显著进展的模型。
- LLaVA-Med (Li et al. 2024): 一个专门针对生物医学领域的MLLM。
- LISA (Lai et al. 2024): 一个在通用领域具有影响力的MLLM,也用于像素级定位任务的比较。
这些研究为开发MedPLIB提供了理论基础和技术背景,同时也展示了在生物医学领域内MLLMs的发展潜力和面临的挑战。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法来解决提出的问题:
1. 模型架构 - MedPLIB
- 端到端MLLM:提出了一个名为MedPLIB的端到端多模态大型语言模型,它能够同时处理视觉问题回答(VQA)、像素级提示(包括点、边界框和自由形状区域)和像素级定位。
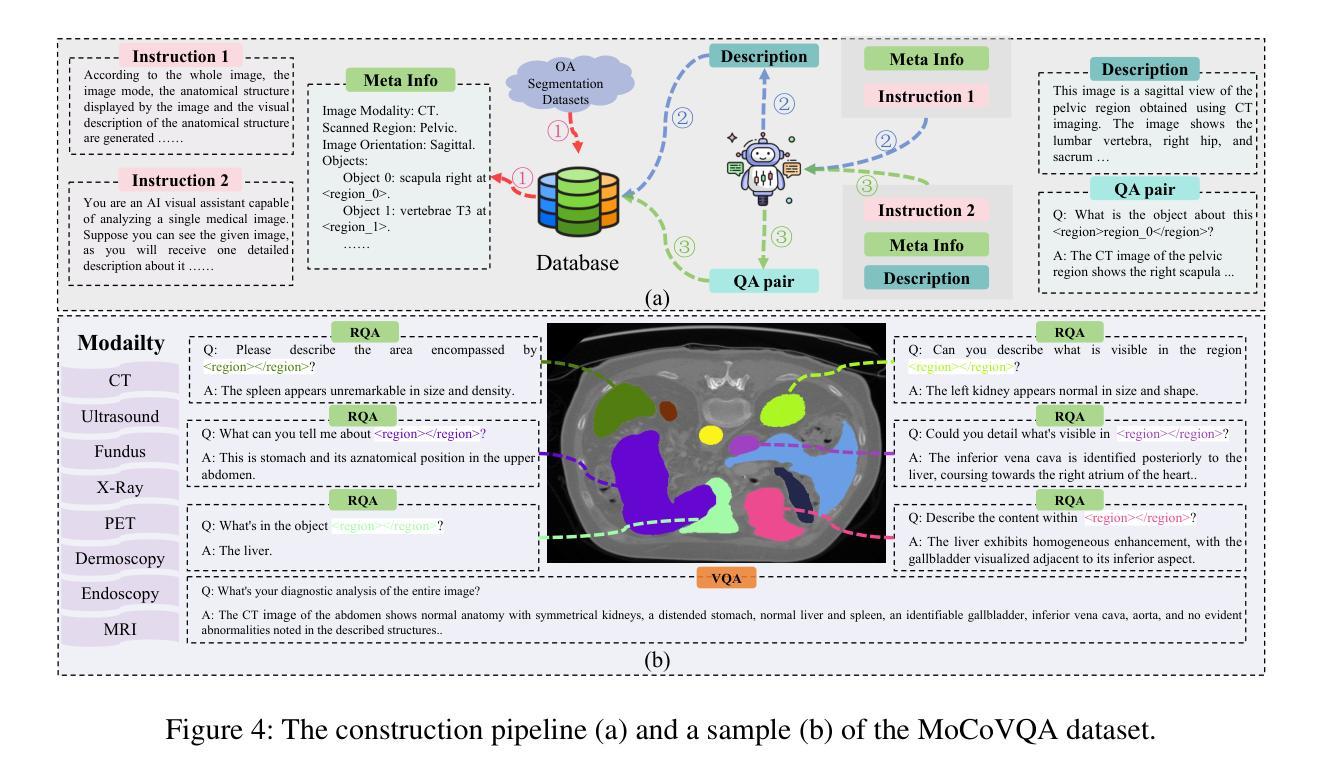
2. 数据集 - MeCoVQA
- 多模态数据集:为了解决数据稀缺问题,论文介绍了MeCoVQA数据集,它包含了8种模态的310k对问答数据,用于复杂的医学成像问答和图像区域理解。
3. 多阶段训练策略
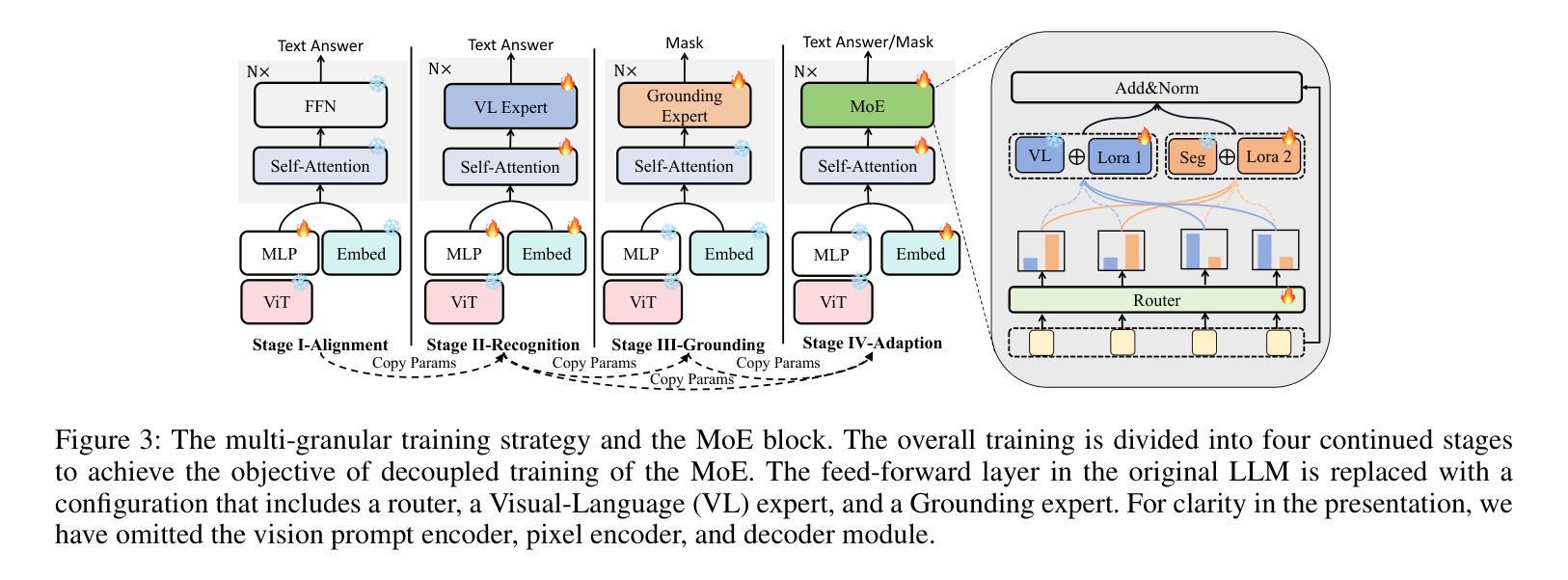
- **Mixture-of-Experts (MoE)**:提出了一种新颖的多阶段训练策略,将MoE分为不同的训练阶段,分别为视觉-语言专家模型和像素定位专家模型,然后通过MoE进行微调。这种策略有效地协调了多任务学习,并保持了与单一专家模型相当的计算成本。
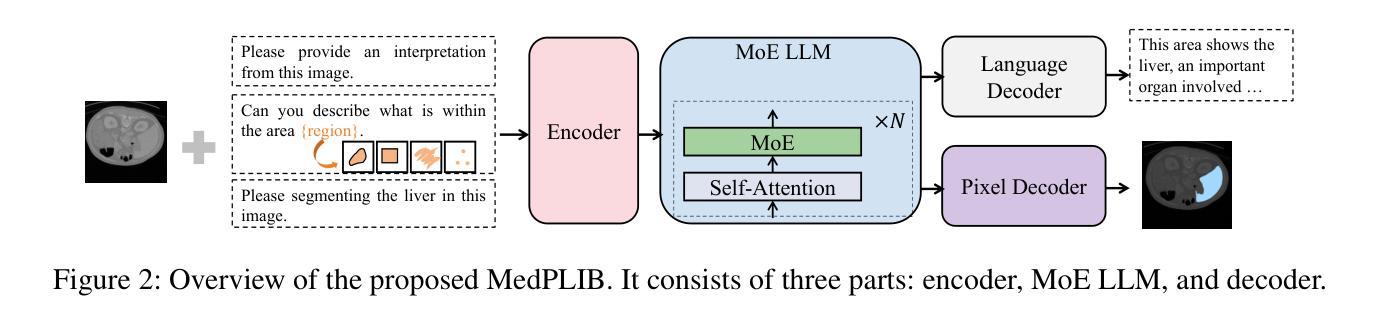
4. 架构细节
- 编码器、MoE LLM和解码器:MedPLIB由编码器、MoE LLM和解码器三部分组成,分别负责编码输入、处理多专家模型和解码输出。
5. 训练策略
- 四阶段训练:整个训练分为四个连续的阶段,包括对齐、识别、定位和适应,以实现MoE的解耦训练。
6. 开源贡献
- 代码和数据公开:论文承诺将数据、代码和模型检查点公开,以便研究社区使用和进一步研究。
通过这些方法,论文旨在推动生物医学MLLMs的研究进展,并提供一个能够处理更复杂任务和更灵活交互的智能生物医学助手。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估MedPLIB模型的性能,这些实验包括以下几个方面:
1. VQA基准测试性能评估
- OmniMedVQA基准:这是一个大型医学VQA基准,使用单选问题。论文在表1中展示了MedPLIB在七个不同模态上的性能,并与其它模型进行了比较。
2. 复杂VQA评估
- MeCoVQA-C:与OmniMedVQA相比,MeCoVQA-C具有更长的开放式问题。论文比较了MedPLIB与LISA模型的性能,并讨论了MedPLIB在处理长文本VQA任务时的平衡。
3. 区域级VQA评估
- MeCoVQA-R:区域级VQA要求像素级图像理解。论文展示了MedPLIB在区域级VQA任务上的性能,并与其它模型进行了比较。
4. 像素级定位评估
- MeCoVQA-G测试集:由于之前没有生物医学MLLM具备像素级定位能力,论文将MedPLIB与具有像素级定位能力的小模型和LISA模型进行了比较。
- 跨模态零样本测试:为了评估模型的泛化能力,论文在五个医学成像模态上进行了零样本评估。
5. 消融研究
- MoE的影响:研究了使用标准FFN和MoE对模型性能的影响。
- 多阶段训练的影响:探讨了不同训练阶段对模型性能的影响。
- Top-k的影响:研究了使用top1和top-2路由对模型性能的影响。
- 能力因子(CF)的影响:考察了能力因子对模型性能的影响。
6. 定性结果
- 论文还提供了MedPLIB在不同能力上的表现,包括各种模态的图像和文本信息处理的可视化结果。
这些实验全面评估了MedPLIB在不同医学视觉语言任务上的性能,并与现有技术进行了比较,同时也深入分析了模型的不同组件和训练策略对性能的影响。通过这些实验,论文证明了MedPLIB在多个医学视觉语言数据集上实现了最先进的结果,并展示了其在像素级定位任务上的零样本能力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
提高像素级定位的准确性:
- 尽管MedPLIB在像素级定位任务上取得了一定的进展,但在小目标的像素级定位上仍存在误差和幻觉问题。未来的研究可以专注于提高模型在这些方面的质量和可靠性。
扩展和多样化数据集:
- 尽管MeCoVQA数据集提供了多模态的问答对,但扩展数据集以包含更多的图像模态、更复杂的问答对,以及更多的像素级标注可以进一步提升模型的泛化能力和鲁棒性。
优化MoE训练策略:
- 论文提出了一种多阶段的MoE训练策略,进一步的研究可以探索不同的训练策略和路由算法,以更有效地平衡不同专家的负载和提高模型的整体效率。
跨模态学习:
- 考虑到不同医学成像模态之间的差异,研究如何利用跨模态学习来提高模型在一个模态上训练后在另一个模态上的性能。
模型解释性:
- 提高模型的可解释性,使医生和研究人员能够更好地理解模型的决策过程,特别是在像素级定位和复杂VQA任务中。
实时性能优化:
- 研究如何优化模型以满足实时或近实时的临床需求,这对于实际的医疗应用场景至关重要。
多任务学习:
- 探索模型在多任务学习框架下的表现,例如同时进行图像分割、疾病诊断和问答生成。
模型压缩和加速:
- 研究模型压缩技术以减少模型大小和加速推理时间,使其更适合在资源受限的环境中部署。
临床验证和集成:
- 与医疗专业人员合作,进行临床验证研究,以评估模型在实际临床工作流程中的有效性和实用性。
伦理和隐私问题:
- 考虑到生物医学数据的敏感性,进一步探索如何在保护患者隐私的同时利用这些数据进行研究。
这些探索点可以帮助推动多模态大型语言模型在生物医学领域的应用,并解决实际应用中遇到的关键挑战。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为MedPLIB的新型多模态大型语言模型(MLLM),专门针对生物医学领域,并具备像素级理解能力。以下是论文的主要内容总结:
问题识别:
- 论文指出,现有的生物医学MLLM主要关注图像级理解,限制了它们的应用范围和灵活性。同时,医学领域需要像素级理解以确保准确性和可解释性。
MedPLIB模型:
- 提出了MedPLIB,一个端到端的MLLM,支持视觉问题回答(VQA)、任意像素级提示(点、边界框和自由形状区域)以及像素级定位。
- 模型包括编码器、MoE LLM和解码器三个主要部分,采用多阶段训练策略,有效协调多任务学习,并保持计算成本。
MeCoVQA数据集:
- 为了解决像素级和复杂VQA数据的稀缺问题,论文引入了MeCoVQA数据集,包含8种模态的310k对问答数据,用于复杂的医学成像问答和图像区域理解。
实验结果:
- MedPLIB在多个医学视觉语言任务上取得了最先进的结果,特别是在零样本评估的像素定位任务中,相较于其他模型有显著的性能提升。
开源贡献:
- 论文承诺将代码、数据和模型检查点公开,以促进研究社区的进一步研究和应用。
挑战与未来工作:
- 论文讨论了MedPLIB在像素级定位小目标时的局限性,并指出未来的工作方向,包括提高结果的质量和可靠性。
总体而言,这篇论文提出了一个创新的MLLM框架,通过结合像素级理解和多模态输入输出,显著推进了生物医学领域的智能助理研究,并为未来的研究和应用奠定了基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

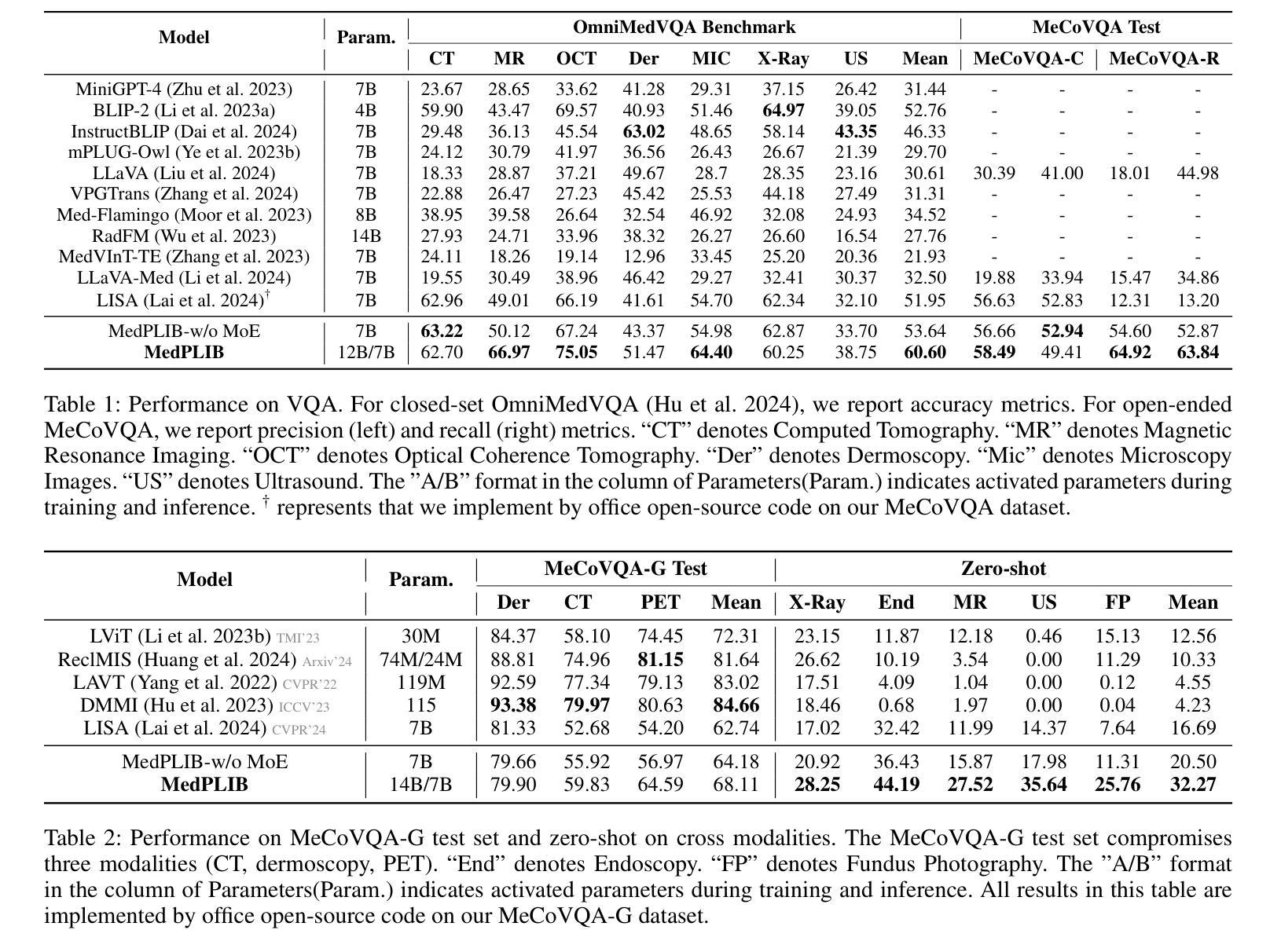
An Efficient Framework for Enhancing Discriminative Models via Diffusion Techniques
Authors:Chunxiao Li, Xiaoxiao Wang, Boming Miao, Chuanlong Xie, Zizhe Wang, Yao Zhu
Image classification serves as the cornerstone of computer vision, traditionally achieved through discriminative models based on deep neural networks. Recent advancements have introduced classification methods derived from generative models, which offer the advantage of zero-shot classification. However, these methods suffer from two main drawbacks: high computational overhead and inferior performance compared to discriminative models. Inspired by the coordinated cognitive processes of rapid-slow pathway interactions in the human brain during visual signal recognition, we propose the Diffusion-Based Discriminative Model Enhancement Framework (DBMEF). This framework seamlessly integrates discriminative and generative models in a training-free manner, leveraging discriminative models for initial predictions and endowing deep neural networks with rethinking capabilities via diffusion models. Consequently, DBMEF can effectively enhance the classification accuracy and generalization capability of discriminative models in a plug-and-play manner. We have conducted extensive experiments across 17 prevalent deep model architectures with different training methods, including both CNN-based models such as ResNet and Transformer-based models like ViT, to demonstrate the effectiveness of the proposed DBMEF. Specifically, the framework yields a 1.51% performance improvement for ResNet-50 on the ImageNet dataset and 3.02% on the ImageNet-A dataset. In conclusion, our research introduces a novel paradigm for image classification, demonstrating stable improvements across different datasets and neural networks.
图像分类是计算机视觉的基石,传统上是通过基于深度神经网络的判别模型来实现的。最近的进展引入了基于生成模型的分类方法,这些方法具有零样本分类的优点。然而,这些方法存在两个主要缺点:计算开销大以及相对于判别模型的性能较差。受人类大脑在识别视觉信号过程中快速-慢速路径交互的协同认知过程的启发,我们提出了基于扩散的判别模型增强框架(DBMEF)。该框架无缝集成了判别模型和生成模型,采用无训练的方式,利用判别模型进行初步预测,并通过扩散模型赋予深度神经网络反思能力。因此,DBMEF可以有效地提高判别模型的分类精度和泛化能力,即插即用。我们在使用不同训练方法的17种流行的深度模型架构上进行了广泛实验,包括基于CNN的模型(如ResNet)和基于Transformer的模型(如ViT),以证明所提出的DBMEF的有效性。具体来说,该框架在ImageNet数据集上为ResNet-50带来了1.51%的性能提升,在ImageNet-A数据集上带来了3.02%的提升。总之,我们的研究为图像分类引入了一种新的范式,并在不同的数据集和神经网络中实现了稳定的性能提升。
论文及项目相关链接
PDF Accepted by AAAI2025
摘要
本文介绍了基于扩散模型的判别模型增强框架(DBMEF),该框架结合了判别模型和生成模型的优点,实现了零样本分类。通过借鉴人类大脑在视觉信号识别过程中的快速-慢速路径交互的协同认知过程,DBMEF以无训练方式无缝集成了判别模型和生成模型。它利用判别模型进行初步预测,并通过扩散模型赋予深度神经网络反思能力。因此,DBMEF可以有效地提高判别模型的分类精度和泛化能力。实验表明,该框架在ResNet-50等CNN模型和ViT等Transformer模型上均表现出有效性,在ImageNet和ImageNet-A数据集上分别实现了1.51%和3.02%的性能提升。本文为图像分类引入了一种新的范式。
关键见解
- 介绍了基于扩散模型的判别模型增强框架(DBMEF),该框架结合了生成模型和判别模型的优点,可实现零样本分类。
- DBMEF通过借鉴人类大脑视觉信号识别的快速-慢速路径交互的协同认知过程,提高了判别模型的分类精度和泛化能力。
- DBMEF以无训练方式无缝集成了判别模型和生成模型,利用判别模型进行初步预测,并通过扩散模型赋予深度神经网络反思能力。
- 实验表明,DBMEF在多种深度模型架构和不同的训练方法中均表现出有效性,包括CNN和Transformer模型。
- 在ImageNet和ImageNet-A数据集上,DBMEF实现了显著的性能提升,证明了其在实际应用中的有效性。
- DBMEF框架提供了一种新的图像分类范式,为相关领域的研究提供了新的思路。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在图像分类任务中结合判别模型(discriminative models)和生成模型(generative models)的优势,以提高分类的准确性和泛化能力。具体来说,论文中提到了以下几个关键问题:
判别模型与生成模型的结合:传统的图像分类方法通常独立地使用判别模型或生成模型。判别模型直接对图像进行分类,而生成模型则通过学习数据的联合分布来实现分类。论文提出了一个框架,将这两种模型结合起来,以期达到更好的分类效果。
生成模型在分类中的高计算开销和性能不足:基于生成模型的分类方法,尽管提供了零样本分类(zero-shot classification)的优势,但它们存在两个主要缺点:高计算开销和相比判别模型的性能劣势。论文旨在通过提出的方法来克服这些问题。
模仿人脑处理视觉信号的过程:论文受到人脑在视觉信号识别过程中快速-慢速路径相互作用的协调认知过程的启发,提出了一个框架,通过模仿这一过程来增强判别模型的性能。
提高判别模型的分类准确性和泛化能力:论文提出的框架旨在通过无需训练的方式,以即插即用的形式增强判别模型的分类准确性和泛化能力。
处理分布偏移和低分辨率数据:论文还探讨了所提出框架在面对分布偏移和低分辨率数据时的有效性,以展示其在不同情况下的鲁棒性和适用性。
综上所述,论文的核心目标是提出一个有效的框架,通过结合判别模型和生成模型的优点,来提升图像分类任务的性能,并在不同的数据集和神经网络架构上展示其有效性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以概括为以下几个方面:
判别模型和生成模型在图像分类中的应用:
- 判别模型直接对图像分类,如VGG、ResNet、ViT等。
- 生成模型通过学习数据的联合分布来进行分类,例如基于能量的模型(EBM)和基于分数的模型(Score-Based Models)。
零样本分类(Zero-Shot Classification):
- 使用生成模型进行零样本分类的研究,如基于扩散模型(Diffusion Models)的方法。
扩散模型(Diffusion Models):
- 扩散模型在图像生成领域的应用,特别是在生成高质量图像方面超越了生成对抗网络(GANs)。
- 分类引导扩散(Classifier Guidance Diffusion)和无分类器引导扩散(Classifier-Free Guidance Diffusion)技术,这些技术通过在生成阶段调整图像的梯度来实现基于指定类别的条件生成。
基于分数的生成模型(Score-Based Generative Models):
- 使用基于分数的生成模型来估计条件概率(P(x|y)),并用于图像分类。
对抗性鲁棒性(Adversarial Robustness):
- 利用扩散模型评估传统判别分类器的对抗性鲁棒性。
结合判别模型和生成模型的方法:
- 先前的研究工作,如SBGC、RDC等,这些方法尝试将扩散模型整合到图像分类任务中。
改进扩散模型的分类性能:
- 将扩散模型应用于DiT-XL/2模型,并在ImageNet数据集上进行监督分类。
加速采样方法:
- 研究工作探索了加速扩散模型采样过程的方法,以减少分类单个图像所需的时间。
这些相关研究构成了论文提出的Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的理论基础和技术背景。论文通过结合这些领域的最新进展,提出了一个新的框架,旨在通过模仿人脑处理视觉信号的过程来增强判别模型的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的框架来解决上述问题。以下是该框架解决这些问题的关键步骤和方法:
1. 结合判别模型和生成模型
DBMEF框架通过以下步骤将判别模型和生成模型结合起来:
- 判别模型初步预测:使用判别模型对测试输入进行初步预测,类似于人脑中的快速通路。
- 生成模型重新评估:对于判别模型不确定的预测,使用扩散模型进行重新评估,模拟人脑中的慢速通路。
2. 模仿人脑处理视觉信号的过程
- 快速-慢速路径交互:框架受到人脑处理视觉信号时快速和慢速路径相互作用的启发,通过重复“猜测-验证-猜测-验证”的过程来识别对象。
3. 增强判别模型的性能
- 置信度保护器(Confidence Protector):通过一个置信度阈值来决定是否需要通过扩散模型进一步评估预测结果。
- 扩散模型分类器:将扩散模型的有条件去噪结果转化为后验概率的估计,以重新分类图像。
4. 处理分布偏移和低分辨率数据
- 适应不同数据集:框架在多个数据集上进行测试,包括ImageNet、ImageNet-A、CIFAR-10和CIFAR-100,以验证其对分布偏移和低分辨率数据的适应性。
5. 提升效率和准确性
- 减少计算开销:通过仅对判别模型不确定的预测进行扩散模型的重新评估,减少了整体计算开销。
- 提高分类准确性:通过结合判别模型的高效率和生成模型的精细化处理,DBMEF显著提高了分类的准确性。
6. 即插即用和无需训练
- 无需额外训练:DBMEF作为一个即插即用的框架,可以直接应用于现有的判别模型,无需额外的训练过程。
总结来说,DBMEF框架通过模仿人脑处理视觉信号的过程,结合了判别模型和生成模型的优势,以提高图像分类任务的准确性和泛化能力,同时减少了计算开销。通过在多个数据集和不同网络架构上的实验,论文证明了该框架的有效性和普适性。
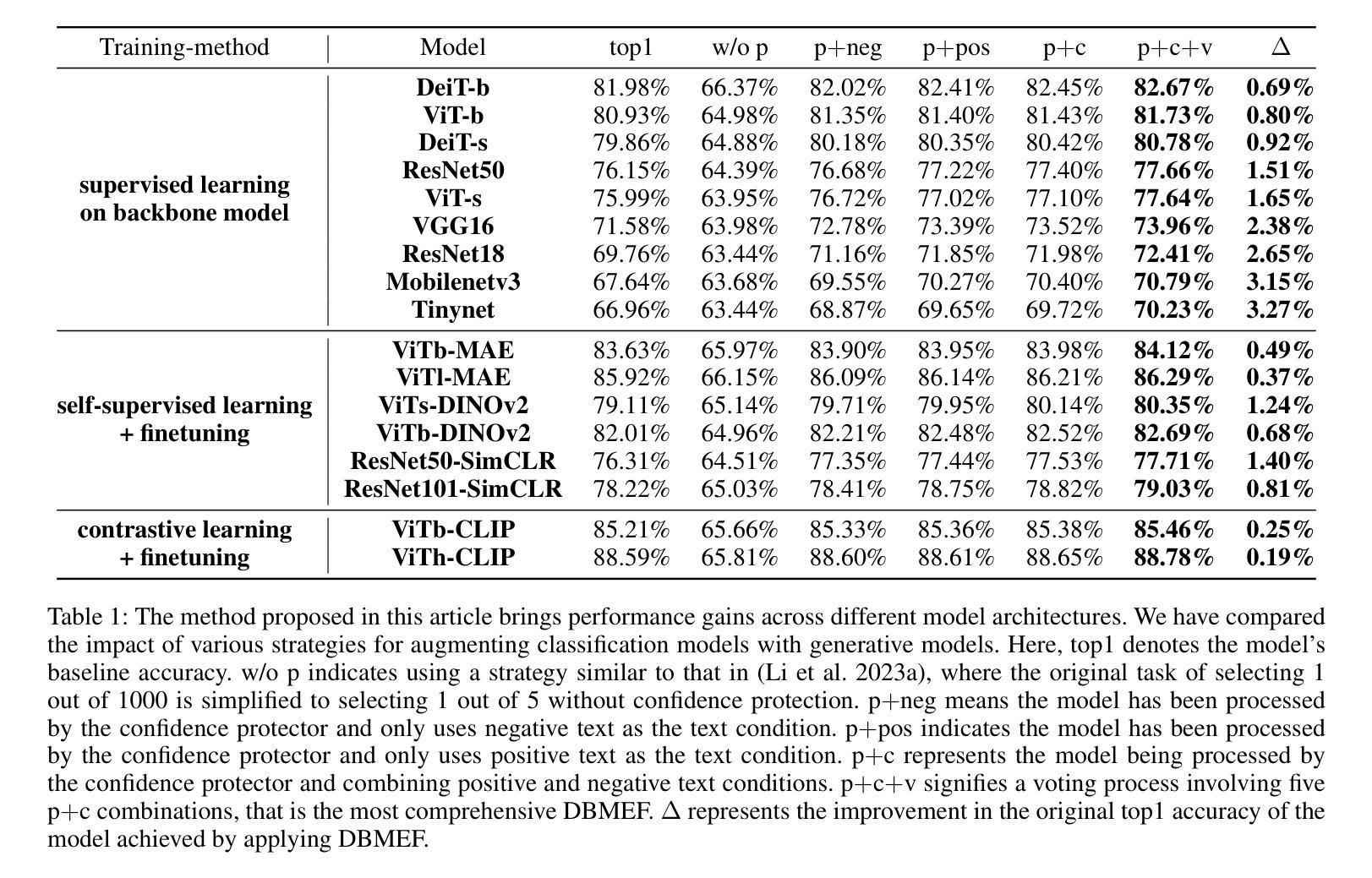
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的有效性。以下是实验的主要内容:
1. 不同模型架构的性能测试
- 基线模型:选择了17种基于不同训练方法、数据集和架构的判别模型,包括监督学习模型(如DeiT-Base、ViT-Base、ResNet50等)、自监督学习方法(如MAE、DINOv2等)以及对比学习模型(如CLIP)。
- 实验设置:使用Stable Diffusion V1-5作为扩散模型,设置保护阈值Prot、时间步长、负控制因子λ等参数,并在ImageNet2012-1k验证集上进行评估。
- 结果:DBMEF在这些模型上取得了0.19%到3.27%的准确率提升。
2. 分布偏移的性能测试
- 数据集:使用ImageNet-S、ImageNet-A、ImageNet-V2和ImageNet-E数据集来评估DBMEF在面对不同类型的分布偏移时的性能。
- 基线模型:使用ViT-Base、DeiT-Small、ResNet50和VGG16等预训练的深度判别模型。
- 结果:DBMEF在各种分布偏移数据集上均显示出稳定的性能提升,特别是在ImageNet-A上,ResNet50的准确率从0.00%提升到3.02%。
3. 低分辨率数据集的分类性能测试
- 数据集:选择CIFAR-10和CIFAR-100数据集,这些数据集包含的图像分辨率为32×32像素。
- 基线模型:使用ResNet18、ResNet34和ResNet50等模型,并在这些数据集上进行测试。
- 结果:即使在基线准确率已经很高的低分辨率图像上,应用DBMEF框架仍然能够进一步提升性能。
4. 超参数的影响测试
- 超参数:研究了保护阈值Prot、时间步长T、负控制因子λ以及扩散模型的选择对DBMEF性能的影响。
- 实验结果:分析了不同超参数设置对模型性能的具体影响,提供了关于如何选择这些参数以优化DBMEF性能的见解。
5. 置信度保护器和扩散模型的作用分析
- 置信度保护器:通过详细的可视化和分析,展示了置信度保护器对DBMEF性能的影响。
- 扩散模型:通过实验验证了扩散模型在DBMEF中的关键作用,与使用更多数据训练的判别模型相比,扩散模型提供了更好的性能提升。
这些实验全面地验证了DBMEF框架的有效性、普适性和鲁棒性,并深入分析了框架中各个组件的作用和影响。通过这些实验,论文展示了DBMEF在不同条件下都能显著提升图像分类任务的性能。
Q: 有什么可以进一步探索的点?
A: 论文提出的Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)为图像分类领域提供了一个新范式,以下是一些可以进一步探索的点:
1. 超参数优化
- 研究不同的超参数设置对DBMEF性能的影响,包括保护阈值(Prot)、时间步长(T)、负控制因子(λ)等,以找到最优的配置。
2. 扩散模型的改进
- 探索使用新一代的扩散模型,如更近期版本的Stable Diffusion或其他类型的扩散模型,以进一步提高DBMEF的性能。
- 研究如何定制扩散模型以更好地适应特定的判别模型和数据集。
3. 多模态数据集的应用
- 将DBMEF应用于多模态数据集,如结合图像和文本的数据集,探索其在多模态学习中的潜力。
4. 不同的网络架构
- 测试DBMEF在更多种类的深度学习架构上的效果,包括最新的卷积网络和Transformer变体。
5. 跨域泛化能力
- 研究DBMEF在面对更大分布偏移时的表现,例如跨域识别任务,以及如何改进框架以提高其跨域泛化能力。
6. 实时应用
- 探索DBMEF在实时应用中的可行性,例如在移动设备或嵌入式系统上的部署,并优化其以满足实时处理的需求。
7. 理论分析
- 深入研究DBMEF的理论基础,包括其统计性质和收敛性,以及如何从理论上解释其性能提升的原因。
8. 与其他生成模型的比较
- 将DBMEF与其他类型的生成模型(如GANs)进行比较,分析其在图像分类任务中的优缺点。
9. 鲁棒性和安全性测试
- 对DBMEF进行鲁棒性和安全性测试,特别是在对抗性攻击和数据隐私方面的表现。
10. 应用到其他视觉任务
- 将DBMEF框架扩展到其他计算机视觉任务,如目标检测、语义分割等,探索其在这些任务中的有效性和适用性。
这些探索点可以帮助研究者更深入地理解DBMEF的工作原理,优化其性能,并扩展其在计算机视觉领域的应用范围。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的新框架,旨在通过结合判别模型和生成模型的优势来增强图像分类任务的性能。以下是论文的主要内容总结:
1. 研究动机
- 传统的图像分类方法主要基于判别模型或生成模型,但存在各自的局限性。判别模型虽然分类速度快,但缺乏重新评估的能力;生成模型能进行细致的图像理解,但计算成本高且性能落后于判别模型。
2. DBMEF框架
- 框架概述:DBMEF框架通过模仿人脑处理视觉信号的快速和慢速路径交互过程,整合判别模型和生成模型,以提高分类的准确性和泛化能力。
- 关键组件:包括置信度保护器和扩散模型分类器,以及结合正负文本条件和投票机制的策略。
3. 方法论
- 判别模型初步预测:判别模型首先对测试输入进行预测,类似于人脑的快速通路。
- 生成模型重新评估:对于判别模型不确定的预测,通过扩散模型进行重新评估,模拟人脑的慢速通路。
- 置信度保护器:基于训练集正确分类样本的统计特性,决定是否需要通过扩散模型进一步评估。
- 扩散模型分类器:将扩散模型的有条件去噪结果转化为后验概率的估计,以重新分类图像。
4. 实验验证
- 在多个数据集(包括ImageNet、ImageNet-A、CIFAR-10和CIFAR-100)和多种深度模型架构上验证了DBMEF的有效性。
- 实现了在不同模型上0.19%到3.27%的准确率提升,并在分布偏移和低分辨率数据上显示出稳定的性能提升。
5. 超参数影响和组件作用分析
- 对保护阈值、时间步长、负控制因子等超参数进行了实验分析,探讨了它们对框架性能的影响。
- 分析了置信度保护器和扩散模型在DBMEF中的关键作用。
6. 结论
- DBMEF框架有效地提高了判别模型的分类准确性和泛化能力,同时减少了计算开销。
- 论文提出了一个新的图像分类范式,并鼓励未来研究进一步探索扩散模型在下游应用中的整合。
总体而言,论文通过提出DBMEF框架,展示了如何通过结合判别模型和生成模型的优势来提高图像分类任务的性能,并在多个数据集和模型上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

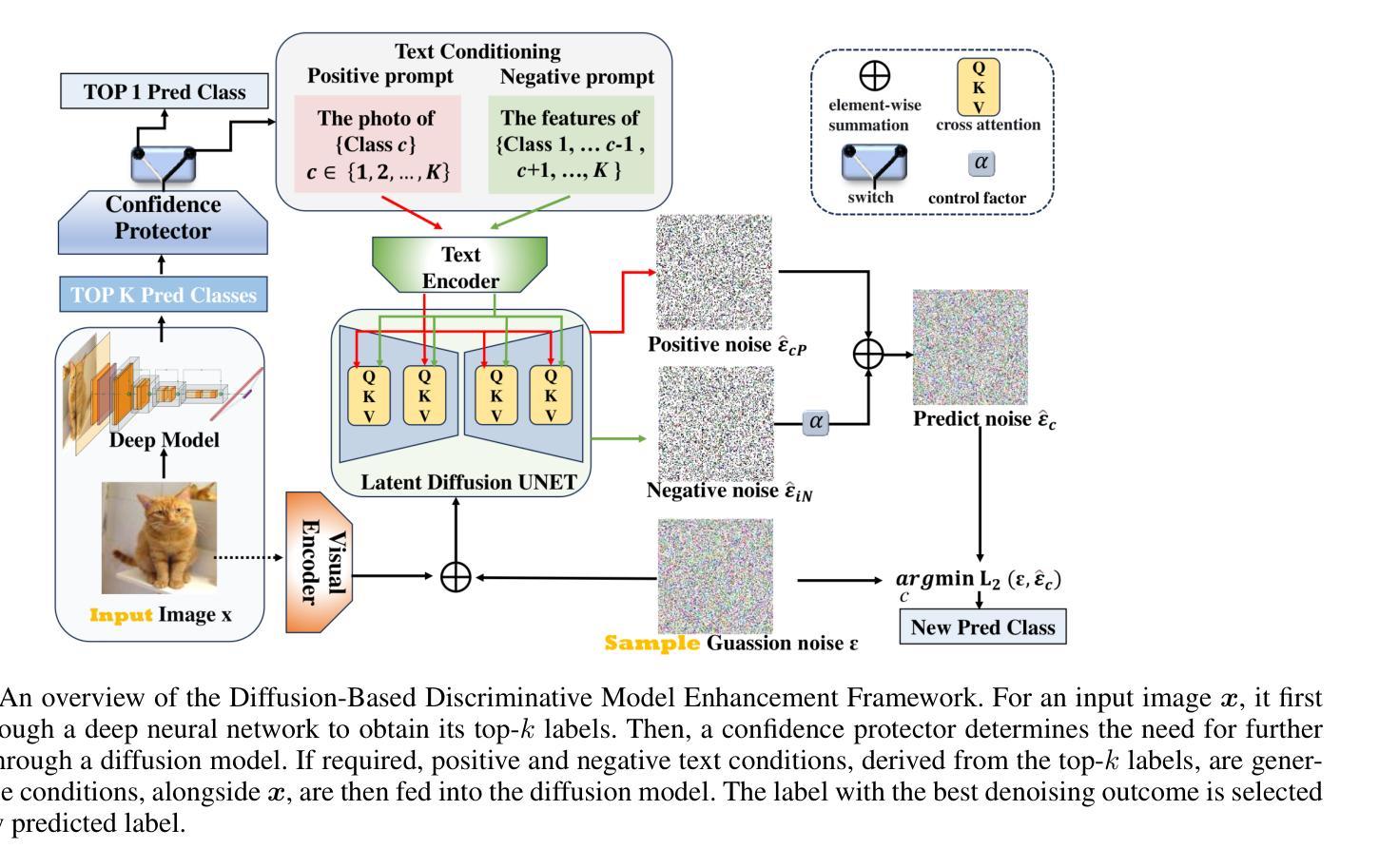
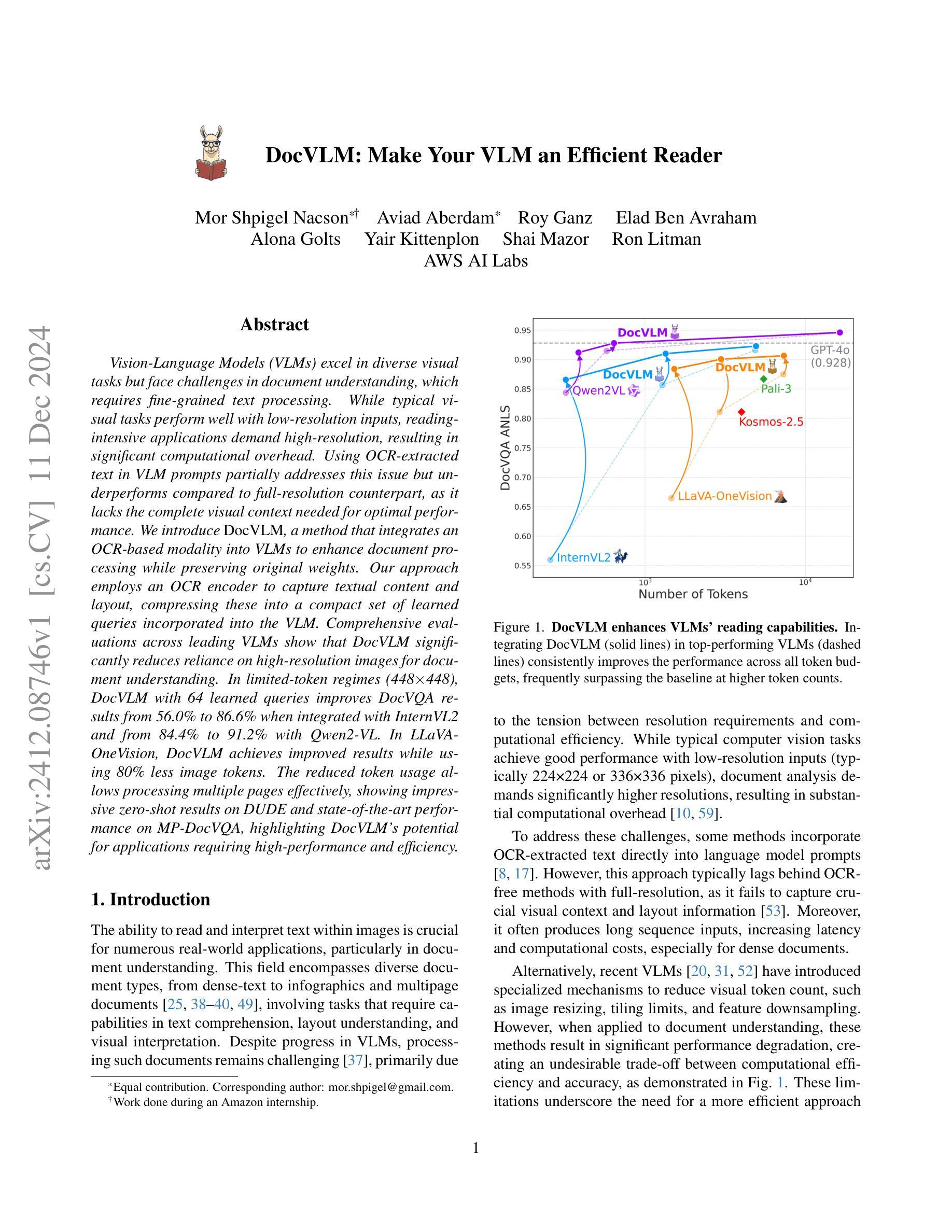
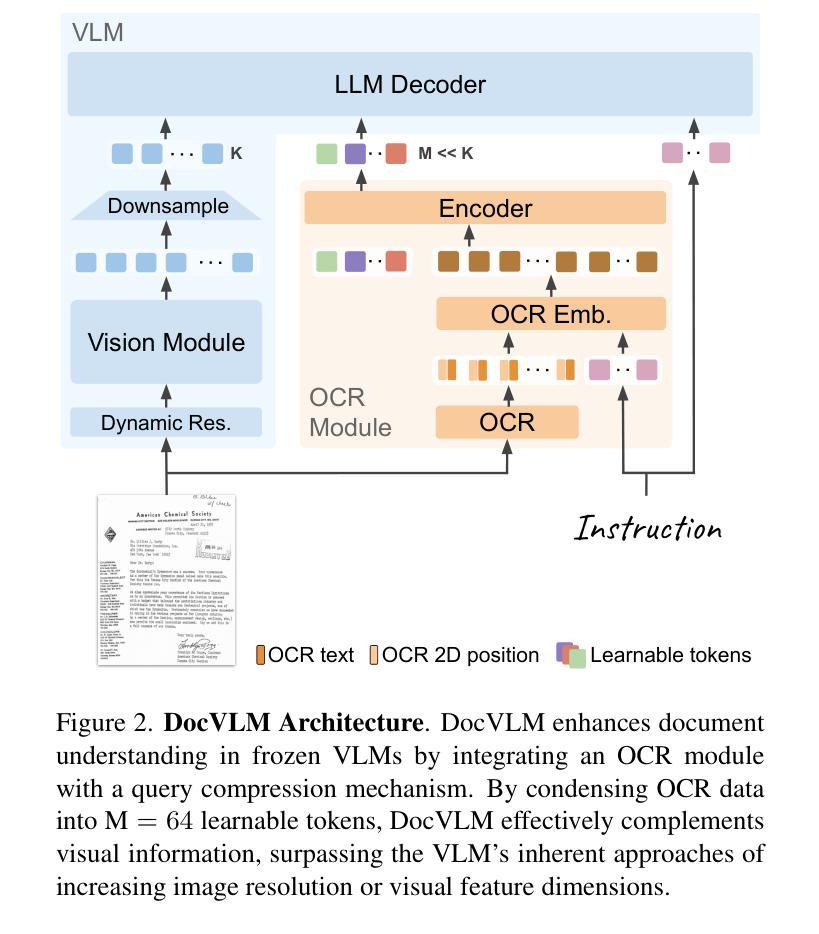
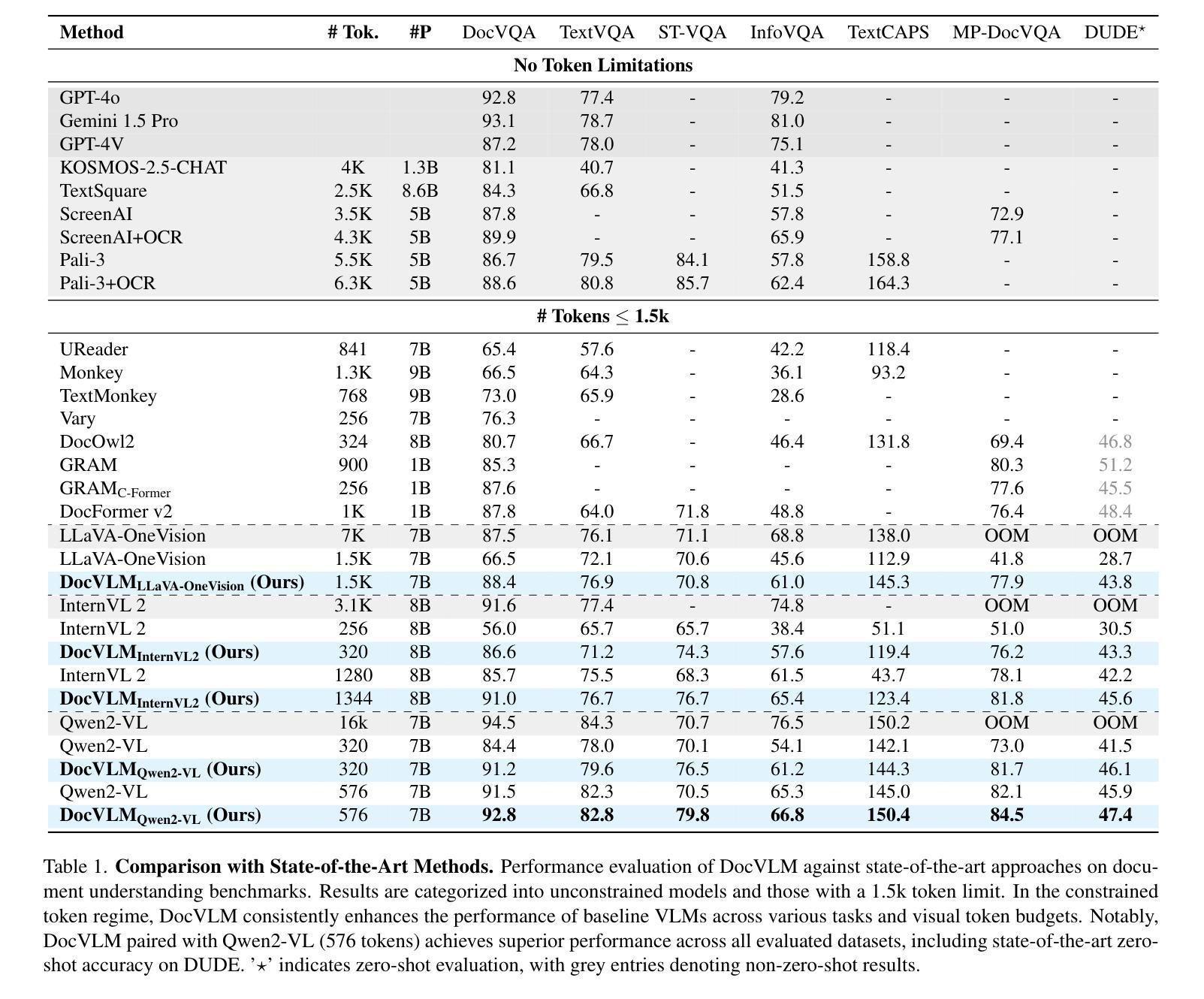
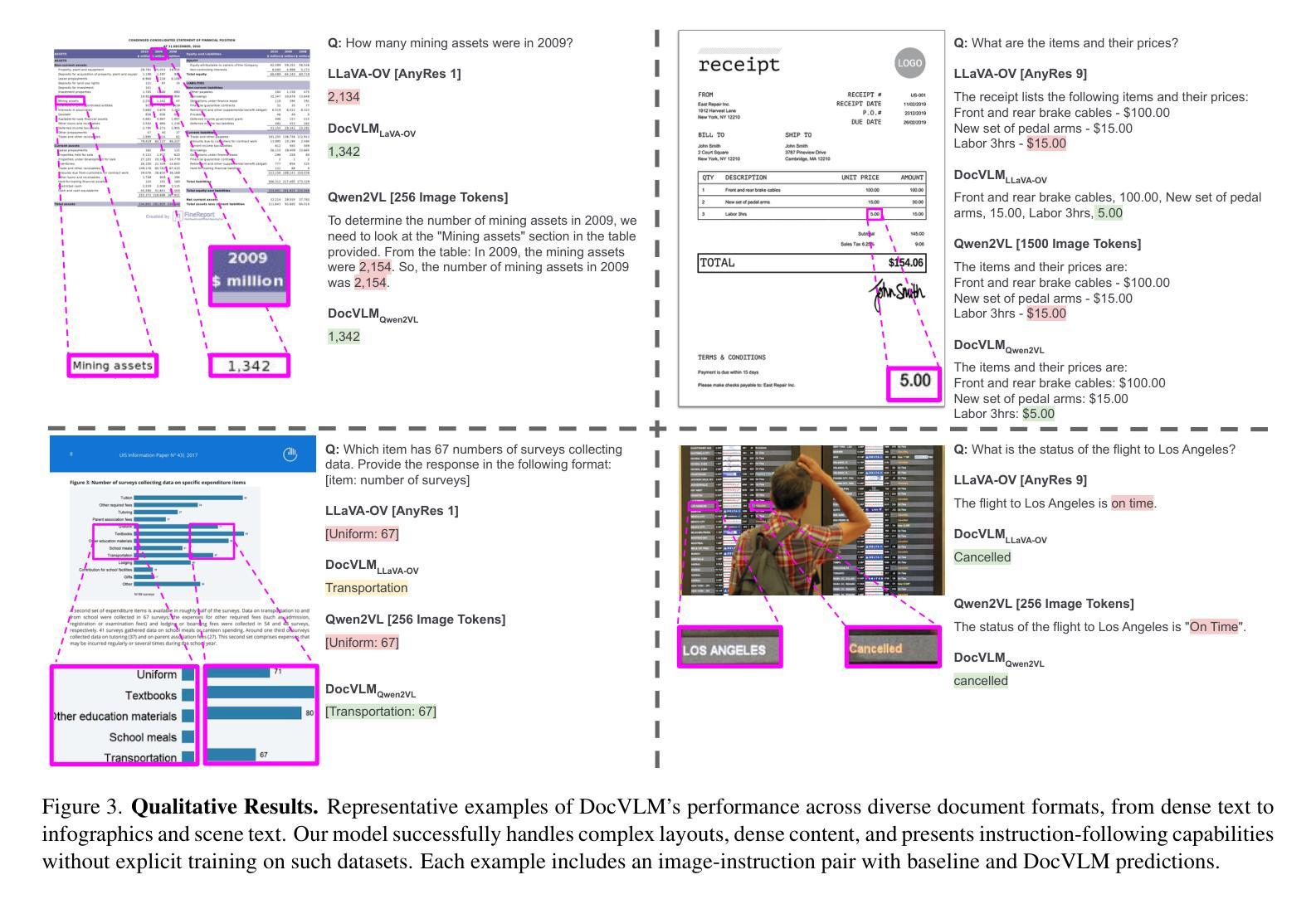
DocVLM: Make Your VLM an Efficient Reader
Authors:Mor Shpigel Nacson, Aviad Aberdam, Roy Ganz, Elad Ben Avraham, Alona Golts, Yair Kittenplon, Shai Mazor, Ron Litman
Vision-Language Models (VLMs) excel in diverse visual tasks but face challenges in document understanding, which requires fine-grained text processing. While typical visual tasks perform well with low-resolution inputs, reading-intensive applications demand high-resolution, resulting in significant computational overhead. Using OCR-extracted text in VLM prompts partially addresses this issue but underperforms compared to full-resolution counterpart, as it lacks the complete visual context needed for optimal performance. We introduce DocVLM, a method that integrates an OCR-based modality into VLMs to enhance document processing while preserving original weights. Our approach employs an OCR encoder to capture textual content and layout, compressing these into a compact set of learned queries incorporated into the VLM. Comprehensive evaluations across leading VLMs show that DocVLM significantly reduces reliance on high-resolution images for document understanding. In limited-token regimes (448$\times$448), DocVLM with 64 learned queries improves DocVQA results from 56.0% to 86.6% when integrated with InternVL2 and from 84.4% to 91.2% with Qwen2-VL. In LLaVA-OneVision, DocVLM achieves improved results while using 80% less image tokens. The reduced token usage allows processing multiple pages effectively, showing impressive zero-shot results on DUDE and state-of-the-art performance on MP-DocVQA, highlighting DocVLM’s potential for applications requiring high-performance and efficiency.
视觉语言模型(VLMs)在各种视觉任务中表现出色,但在文档理解方面面临挑战,这需要精细的文本处理。典型的视觉任务在低分辨率输入下表现良好,而阅读密集型应用则需要高分辨率,导致计算开销较大。在VLM提示中使用OCR提取的文本部分解决了这个问题,但与全分辨率的对应模型相比表现不佳,因为它缺乏获得最佳性能所需的完整视觉上下文。我们引入了DocVLM方法,它将基于OCR的模式集成到VLMs中,以增强文档处理功能同时保留原始权重。我们的方法使用OCR编码器来捕获文本内容和布局,将这些压缩成一组紧凑的学习查询并集成到VLM中。对领先的VLM的全面评估显示,DocVLM显著减少了对高分辨率图像进行文档理解的依赖。在有限的令牌体系(448x448)中,DocVLM与InternVL2集成后,DocVQA结果从56.0%提高到86.6%,与Qwen2-VL集成后从84.4%提高到91.2%。在LLaVA-OneVision中,DocVLM取得了更好的结果,同时使用的图像令牌减少了80%。减少的令牌使用量可以有效地处理多页,在DUDE上实现了令人印象深刻的零射击结果,并在MP-DocVQA上达到了最新水平性能。这突显了DocVLM在高性能和效率要求的应用中的潜力。
论文及项目相关链接
Summary
该文探讨了视觉语言模型(VLMs)在处理文档理解任务时的挑战。针对文档中的文本处理和视觉上下文需求,提出了一种新的方法DocVLM。该方法结合了OCR技术,通过OCR编码器捕捉文本内容和布局,将其压缩成一组学习查询并融入VLM中。实验表明,DocVLM能显著降低对高分辨率图像的依赖,提高文档理解的效果。在有限标记环境下,DocVLM能提高DocVQA的结果;而在LLaVA-OneVision中,DocVLM不仅提高了效果,还减少了图像标记的使用,显示出其在多页处理中的潜力。
Key Takeaways
- 视觉语言模型(VLMs)在处理文档理解任务时面临挑战,需要精细的文本处理和视觉上下文信息。
- DocVLM方法结合了OCR技术,通过OCR编码器捕捉文本内容和布局。
- DocVLM将文本信息和布局压缩成一组学习查询,并融入VLM中,以提高文档处理效果。
- DocVLM能显著降低对高分辨率图像的依赖,提高文档理解的效果。
- 在有限标记环境下,DocVLM能提高DocVQA的结果。
- DocVLM在LLaVA-OneVision中的使用不仅提高了效果,还显著减少了图像标记的使用,显示出其在处理多页文档中的潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是视觉语言模型(VLMs)在文档理解任务中面临的挑战,尤其是在处理需要细粒度文本处理的文档时。具体来说,论文中提到了以下几个关键问题:
分辨率与计算效率之间的矛盾:对于典型的计算机视觉任务,低分辨率输入(例如224×224或336×336像素)就能取得良好的性能。然而,文档分析需要更高的分辨率,导致计算开销显著增加。
OCR提取文本的使用限制:一些方法将OCR提取的文本直接整合到语言模型提示中,虽然这可以部分解决分辨率问题,但相比完全不使用OCR的方法,性能较差,因为它无法捕获重要的视觉上下文和布局信息。
长序列输入问题:上述方法还会产生长序列输入,这会增加延迟和计算成本,特别是在处理密集文档时。
视觉令牌数量减少导致的性能下降:尽管近期的VLMs引入了减少视觉令牌数量的机制(例如图像调整大小、平铺限制和特征下采样),但这些方法在文档理解任务中会导致显著的性能下降,造成了计算效率和准确性之间的不利权衡。
为了解决这些问题,论文提出了DocVLM,这是一个模型不可知的方法,通过有效利用OCR信息来增强VLMs的阅读能力。DocVLM通过OCR编码器捕获文本内容和布局,并将这些编码压缩成一组紧凑的学习查询,直接输入到VLM的语言模型部分,从而在保持原始权重的同时减少对高分辨率图像的依赖,并提高文档理解的效率和性能。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
OCR-free Document VLMs(不使用OCR的文档VLMs)
- 早期的VLMs使用相对较小的图像尺寸(例如,224×224和336×336),在自然图像任务上表现良好,但在文档理解方面表现不足。为了解决这个问题,近期的方法通过在高分辨率图像上操作来增强文档理解能力,并开发了各种策略来管理由此产生的计算负担。
- 直接处理方法,如Donut、PaLI-X和Qwen2-VL,尝试全分辨率处理但通常为了计算可行性而对图像进行调整大小。
- 基于平铺的方法,如UReader和InternVL2,通过独立处理图像平铺来提高效率。
- 其他方法,如LLaVA-1.5和LLaVA-OneVision,将整个图像作为平铺处理,但在将视觉特征输入到语言模型之前对它们进行下采样。
OCR-Enhanced Document Understanding(OCR增强的文档理解)
- 由于高效、开源的OCR模型和成本效益高的商业解决方案的广泛可用性,OCR方法在文档理解中得到了广泛应用。
- 一些最近的工作探索了将OCR系统与VLMs整合,通过将提取的文本直接输入到语言模型组件中。
- 一些方法进一步通过整合空间布局信息来增强这种整合。
Document Representation Compression(文档表示压缩)
- 为了解决处理文档时的效率挑战,开发了各种压缩技术。
- 对于OCR增强的方法,提出了使用Compression Transformer压缩多页文档中的OCR信号。
- 在OCR-free设置中,通用VLM方法如Q-former和Resampler压缩视觉特征,但在文本密集的图像中表现不佳。
- 特定于文档的方法如TokenPacker和DocCompressor实现了有效的视觉压缩,但在文档理解任务上的性能有所下降。
这些相关研究展示了在文档理解领域中,如何通过不同的方法来提高VLMs的性能,尤其是在处理高分辨率图像和文本信息时的计算效率和准确性之间的权衡。DocVLM方法正是在这些研究的基础上,提出了一种新的压缩机制,有效地将OCR数据整合到VLMs中,以提高文档理解的性能和效率。
Q: 论文如何解决这个问题?
A: 论文提出了DocVLM(Document Vision-Language Model),一个模型不可知的方法,通过有效利用OCR信息来增强VLMs的阅读能力。具体来说,解决方案包括以下几个关键步骤:
1. OCR编码器(OCR Encoder)
- 目的:捕获OCR提取的文本内容和布局信息。
- 实现:使用DocFormerV2的编码器组件,该组件是一个基于T5的编码器-解码器,专门为文档理解设计,整合了视觉、语言和空间特征。
- 优化:省略了DocFormerV2编码器的视觉分支,以避免与VLM的视觉能力冗余,并减少计算复杂性。
2. 查询压缩机制(Query Compression Mechanism)
- 目的:将OCR编码器的输出压缩成一组紧凑的学习查询(learned queries),以减少输入序列长度,同时保留关键文档信息。
- 实现:使用M个可学习的查询(通常M=64),这些查询与OCR嵌入和指令嵌入一起被OCR编码器处理。
- 输出:仅保留对应于学习查询的M个特征,这些压缩特征随后被投影以匹配VLM的隐藏维度,并与视觉令牌一起输入语言模型。
3. 训练策略(Training Strategy)
- 两阶段训练:
- 第一阶段(OCR-LLM Alignment):在此阶段,VLM不接收图像输入,仅依赖新引入的OCR模态。这有助于OCR组件与LLM输入空间对齐,并减少序列长度,提高训练效率。
- 第二阶段(Vision Alignment):在此阶段,引入视觉编码器提取的视觉信息,鼓励OCR组件补充视觉特征。这一阶段对于使用较少学习查询的情况特别有效,允许压缩的OCR信息更好地补充从视觉模态获得的信息。
4. 多页文档扩展(Multipage Document Extension)
- 目的:将DocVLM扩展到长上下文场景,如多页文档理解任务。
- 策略:
- 全局编码(Global Encoding):将整个文档的OCR信息压缩到64个学习查询中。
- 逐页编码(Page-wise Encoding):将每页的OCR信息分别压缩到64个学习查询中,然后将它们连接起来,结果为每页64个学习查询。
5. 实验验证(Experimental Validation)
- 模型集成:通过与三种领先的开源VLMs(LLaVA-OneVision、InternVL2和Qwen2-VL)集成来评估DocVLM的有效性。
- 性能比较:在多个文档理解基准上与现有方法进行比较,特别是在受限的令牌数量下的性能。
- 多页文档性能:在DUDE和MP-DocVQA等多页文档理解基准上展示DocVLM的零样本性能和最新性能。
通过上述方法,DocVLM有效地提高了VLMs在文档理解任务中的性能,同时显著降低了对高分辨率图像的依赖,减少了计算开销。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列实验来评估DocVLM的有效性。以下是实验的详细情况:
1. 实验设置(Experimental Setting)
- 模型集成:评估DocVLM通过与三种领先的开源VLMs集成的效果,包括LLaVA-OneVision、InternVL2和Qwen2-VL。这些模型采用不同的视觉令牌缩减策略,使得可以评估DocVLM在不同视觉处理方法中的有效性。
- 训练:采用两阶段训练策略。第一阶段专注于文本相关任务,第二阶段引入视觉信息以鼓励OCR组件补充视觉特征。
- 评估:集中在五个关键基准上进行评估,包括DocVQA、TextVQA、ST-VQA、InfoVQA和TextCaps。结果在测试集上报告,对于TextVQA和TextCaps由于测试服务器限制,在验证集上进行评估。使用ANLS作为所有数据集的评估指标,除了TextVQA使用VQAScore,TextCaps使用CIDEr。同时,还对多页文档理解基准DUDE和MP-DocVQA进行零样本评估。
2. 与最新方法的比较(State-of-the-art Comparisons)
- 与无令牌限制和有1.5k令牌限制的最新方法进行比较,展示DocVLM在令牌受限情况下对基线模型性能的提升。
3. 定性结果(Qualitative Results)
- 通过代表性例子展示DocVLM在不同文档格式上的性能,包括密集文本、信息图表和场景文本,展示DocVLM在复杂布局、密集内容处理和指令遵循能力方面的优势。
4. 扩展到多页文档(Scaling to Multipage Documents)
- 对不同DocVLM配置在多页文档理解任务上进行深入分析,特别是对Qwen2-VL基础模型在MP-DocVQA数据集上的性能进行测试,该数据集包含长达20页的文档。
5. 消融研究(Ablation Study)
- OCR编码策略的影响:比较三种OCR信息整合策略(原始VLM中的OCR单词插入、DocVLM未压缩OCR编码和DocVLM压缩OCR编码)在DocVQA测试集上的效果。
- 视觉和OCR令牌分配的平衡:研究不同配置(包括基线VLM、直接OCR单词插入、DocVLM未压缩OCR编码和DocVLM压缩学习查询)在不同视觉令牌分配下的性能。
- 压缩水平:分析不同压缩水平下DocVLM与Qwen2-VL集成的效果。
- 训练阶段:展示两阶段训练过程对DocVLM性能的影响。
这些实验全面评估了DocVLM在不同配置、不同视觉令牌限制和不同文档类型下的性能,证明了其在提高文档理解任务效率和准确性方面的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
1. 多模态融合技术
- 探索更先进的多模态融合技术,以更有效地结合文本和视觉信息,提高模型在复杂文档理解任务中的表现。
2. OCR准确性对模型性能的影响
- 研究OCR准确性对DocVLM性能的具体影响,并探索如何提高OCR预处理步骤的鲁棒性和准确性。
3. 模型泛化能力
- 在更多种类的文档和更长的上下文环境中测试DocVLM的泛化能力,例如不同类型的文档(如科学论文、法律文件等)。
4. 计算效率优化
- 进一步优化DocVLM的计算效率,特别是在处理高分辨率图像和长文档时,以适应资源受限的环境。
5. 模型可解释性
- 提高模型的可解释性,特别是在决策过程中如何权衡文本和视觉信息的影响。
6. 多语言和跨语言文档理解
- 探索DocVLM在多语言和跨语言文档理解任务中的应用,以及如何适应不同语言的文本和布局特点。
7. 实际应用中的部署和测试
- 在真实世界的应用场景中部署DocVLM,并收集反馈以评估其实用性和效果。
8. 模型训练和微调策略
- 研究不同的训练和微调策略,以进一步提高模型性能,并减少训练所需的计算资源。
9. 模型鲁棒性测试
- 对DocVLM进行鲁棒性测试,特别是在面对噪声、不清晰文本和不同质量的扫描文档时。
10. 与最新的VLMs和OCR技术的集成
- 将DocVLM与最新的视觉语言模型和OCR技术集成,以利用这些技术的改进。
11. 交互式文档理解
- 探索DocVLM在交互式文档理解任务中的应用,例如,当用户与文档进行交互并提出一系列问题时。
这些探索点可以帮助研究社区更深入地理解DocVLM的潜力和局限性,并推动文档理解技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题陈述
论文指出视觉语言模型(VLMs)在处理文档理解任务时面临的挑战,尤其是在需要细粒度文本处理的情况下。主要问题包括分辨率要求和计算效率之间的矛盾,以及现有方法在处理高分辨率图像时的性能下降。
2. DocVLM方法
为了解决这些问题,论文提出了DocVLM,这是一个模型不可知的方法,通过有效利用OCR信息来增强VLMs的阅读能力。DocVLM包括两个主要组件:一个OCR编码器和一个查询压缩机制。OCR编码器捕获文本内容和布局信息,查询压缩机制将这些信息压缩成一组紧凑的学习查询,直接输入到VLM的语言模型部分。
3. 实现细节
- OCR Encoder Architecture:使用DocFormerV2的编码器组件,处理用户指令和OCR数据。
- Query Compression Mechanism:通过M个可学习的查询(通常M=64)将OCR编码器的输出压缩成紧凑的特征表示。
- Vision Process:介绍了VLMs处理视觉信息的不同策略,包括图像调整大小、控制平铺数量和特征下采样。
4. 训练策略
论文采用了两阶段训练策略:第一阶段专注于OCR-LLM对齐,第二阶段引入视觉信息进行视觉对齐。
5. 多页文档扩展
论文还探讨了如何将DocVLM扩展到多页文档理解任务,并提出了全局编码和逐页编码两种策略。
6. 实验评估
通过与三种领先的VLMs(LLaVA-OneVision、InternVL2和Qwen2-VL)集成,论文在多个文档理解基准上评估了DocVLM的有效性。实验结果表明,DocVLM在低输入令牌情况下显著提高了性能,并且在多页文档理解任务上展示了强大的零样本性能和最新性能。
7. 消融研究
论文还进行了消融研究,探讨了OCR编码策略、视觉和OCR令牌分配平衡以及训练阶段对模型性能的影响。
总的来说,这篇论文提出了一个有效的方法来提高VLMs在文档理解任务中的性能和效率,同时减少了对高分辨率图像的依赖。通过整合OCR信息和压缩机制,DocVLM能够在保持原有VLM权重的同时,提高文档理解的准确性和计算效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Authors:Jaihyun Lew, Soohyuk Jang, Jaehoon Lee, Seungryong Yoo, Eunji Kim, Saehyung Lee, Jisoo Mok, Siwon Kim, Sungroh Yoon
Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Transformer最初是为自然语言处理(NLP)提出的突破性架构,在计算机视觉领域也取得了显著的成功。其成功的关键因素在于注意力机制,该机制能够建模标记之间的关系。虽然NLP中的标记化过程确保了单个标记不包含多个语义,但Vision Transformer(ViT)的标记化使用的是均匀划分的方形图像补丁生成的标记,这可能导致一个标记中任意混合视觉概念。在这项工作中,我们提出用超像素标记化替代ViT中的基于网格的标记化,超像素标记化使用超像素生成一个包含单个视觉概念的标记。然而,超像素的多样形状、大小和位置使得将超像素集成到ViT标记化中颇具挑战性。我们的标记化管道由预聚合提取和面向超像素的聚合组成,克服了超像素标记化中出现的挑战。大量实验表明,我们的方法与现有框架高度兼容,提高了ViT在各种下游任务上的准确性和稳健性。
论文及项目相关链接
Summary
本文探讨了Vision Transformer中的token化问题,提出了使用超级像素token化替代传统的网格化token化方式。由于超级像素的多样性和复杂性,将其集成到ViT的token化中颇具挑战。本文提出的tokenization流程包括预聚合提取和超级像素感知聚合,克服了超级像素token化的挑战,提高了ViT在各种下游任务上的准确性和鲁棒性。
Key Takeaways
- Vision Transformer在计算机视觉领域取得了显著成功,其成功的关键因素之一是注意力机制,该机制可以建模标记之间的关系。
- 传统ViT的token化是基于网格的,可能导致单个token中混合多个视觉概念。
- 本文提出了使用超级像素进行token化的新方法,旨在使每个token只包含一个视觉概念。
- 超级像素的多样性和复杂性使其难以集成到ViT的token化中。
- 本文提出的tokenization流程包括预聚合提取和超级像素感知聚合,以克服超级像素token化的挑战。
- 实验表明,该方法与现有框架兼容性强,能提高ViT在各种下游任务上的准确性和鲁棒性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在视觉Transformer(ViT)中实现更好的视觉令牌(token)化,以保持语义完整性。具体来说,论文指出在自然语言处理(NLP)中,Transformer架构的成功部分归因于注意力机制,该机制通过建模输入文本(表达为令牌)之间的关系来捕获上下文依赖性。而在计算机视觉领域,尽管ViT在多种视觉任务上取得了显著的成功,但其使用的基于均匀划分的正方形图像块的令牌化方法可能导致单个令牌中混合了多个视觉概念,这违背了令牌化的基本原则,即将输入转换为更小但结构更明确的子单元以供进一步处理。
为了解决这个问题,论文提出了一种基于超像素的令牌化方法,称为Superpixel Tokenization(SuiT),它利用超像素生成包含单一视觉概念的令牌,从而克服了基于网格的ViT令牌化中存在的问题。这种方法旨在通过使用超像素来改进ViT中的视觉令牌化过程,以获得更好的语义保留和更有效的特征表示。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是与Superpixel Tokenization for Vision Transformers(SuiT)相关的研究:
Superpixel-based Vision Models:
- 超像素作为计算机视觉中的一个基础概念,被用于多个任务,例如分割和目标检测。然而,这些工作没有展示超像素在广泛的视觉任务中的适用性。
- STViT [23] 通过超token注意力在所有层中应用类似超像素的聚类,但在token级别操作,导致粒度比超像素更粗。
- CoC [36] 在神经网络中借用了超像素的概念,但没有进一步探索超像素令牌化。
- SPFormer [37] 使用基于超像素的表示,但需要专门的注意力模块,难以以即插即用的方式与现有的ViT架构集成。
Tokenization Methods:
- Quadformer [44] 和 MSViT [16] 提出了自适应令牌化策略,根据图像内容动态调整令牌分辨率。
- SPiT [1] 和 sViT [28] 与SuiT的研究动机最相似,它们专注于令牌化模块,同时保持主干不变。SPiT从可解释AI(XAI)的角度分析了令牌化,但没有探索其在各种任务中的泛化能力。sViT旨在实现语义保留的令牌化,但仍然基于简单的边界框划分令牌,未能创建真正的语义保留令牌。
**Vision Transformers (ViTs)**:
- DeiT [50] 作为基线网络,SuiT与DeiT进行了比较,以展示SuiT在不同方面的优势,如分类准确度、计算成本和令牌数量。
Self-supervised Learning:
- DINO [9] 作为一种知名的自监督学习方法,被用来训练SuiT,以评估其在下游任务中的性能。
Zero-shot Salient Object Segmentation:
- TokenCut [56] 框架用于从注意力图中提取显著性掩码,SuiT在此框架下的性能被评估。
这些相关研究涵盖了超像素在视觉模型中的应用、不同的令牌化方法、ViTs的架构改进、自监督学习以及零样本分割任务。SuiT的研究在这些领域的基础上,探索了一种新的基于超像素的令牌化方法,旨在提高ViTs中的视觉令牌化质量,并在多个视觉任务中验证了其有效性。
Q: 论文如何解决这个问题?
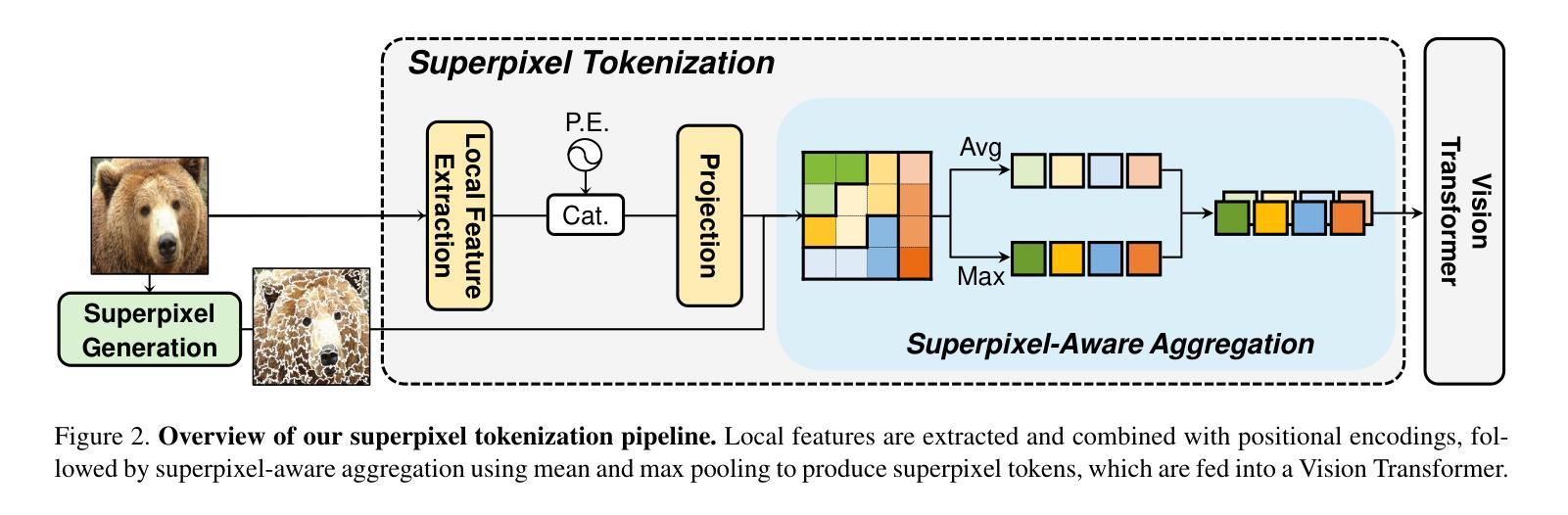
A: 论文通过提出一个新颖的基于超像素的令牌化流程来解决ViT中语义混合的问题,具体方法如下:
预聚合特征提取(Pre-aggregate Feature Extraction):
- 使用简单的卷积块从输入图像中提取局部特征。
- 结合正弦位置编码来处理超像素的复杂位置信息,采用可学习的频率以适应视觉任务。
- 将局部特征和位置特征结合,通过线性层投影得到预聚合特征。
超像素感知特征聚合(Superpixel-aware Feature Aggregation):
- 使用平均池化和最大池化操作来聚合每个超像素内的特征,以处理超像素大小和形状的不一致性。
- 平均池化捕获超像素中的共同特征,而最大池化识别最显著的特征。
- 将两种池化结果沿着通道维度拼接,形成每个超像素的D维令牌。
两阶段处理流程:
- 首先训练预聚合特征提取器,并在特征聚合之前应用它,以避免直接在输入图像上应用池化操作可能导致的信息严重丢失。
兼容性和灵活性:
- 提出的令牌化方法与现有的ViT框架兼容,并允许调整超像素令牌的数量,以适应不同的应用需求。
广泛的实验验证:
- 在包括ImageNet-1K分类、分割、迁移学习和自监督学习等多个下游任务上进行实验,验证了SuiT在准确性和鲁棒性方面相比基线方法的优越性。
分析和可视化:
- 通过额外的分析和可视化,展示了SuiT生成的图像令牌在保持语义信息方面比基于网格的令牌化方法更有效。
综上所述,论文提出的基于超像素的令牌化方法有效地解决了ViT中语义混合的问题,并通过一系列技术手段和广泛的实验验证了其有效性。
Q: 论文做了哪些实验?
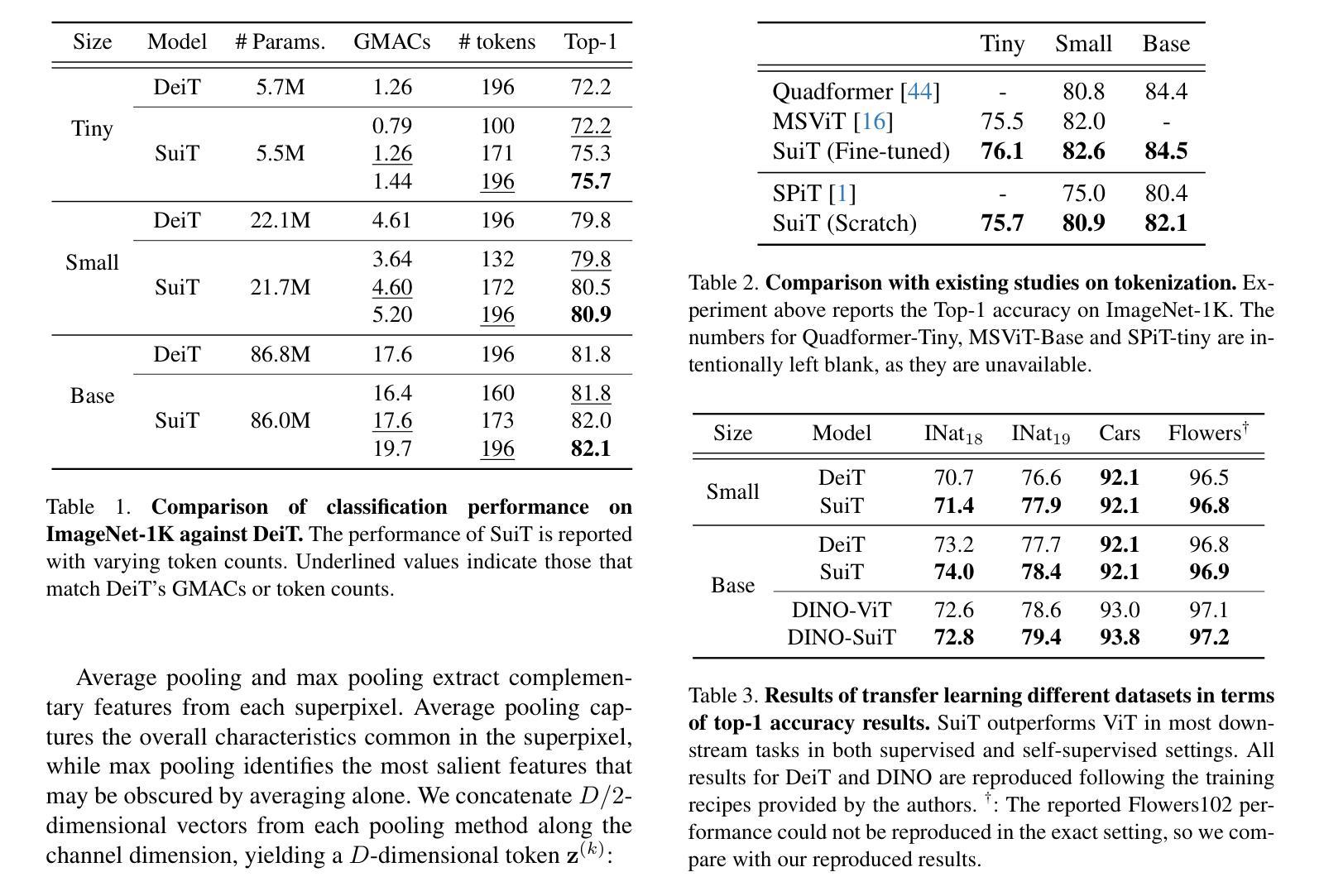
A: 论文中进行了一系列实验来验证所提出的Superpixel Tokenization(SuiT)方法的有效性。以下是实验的详细情况:
ImageNet-1K 分类:
- 作者在ImageNet-1K数据集上评估了SuiT,并与DeiT进行了比较。
- 实验包括从零开始训练(training from scratch)和从预训练权重微调(fine-tuning from pre-trained weights)两种设置。
- 对比了不同模型尺寸(Tiny, Small, Base)下的分类性能,包括准确度、计算成本(以GMACs衡量)和处理的令牌数量。
与现有令牌化方法的比较:
- 将SuiT与现有的一些令牌化方法(如Quadformer, MSViT, SPiT)在ImageNet-1K分类任务上进行了比较。
迁移学习(Transfer Learning):
- 评估了SuiT在迁移到不同下游任务时的泛化能力,包括iNaturalist、Flowers102和StanfordCars数据集。
- 比较了SuiT和DeiT在这些任务上的分类准确度。
自监督学习(Self-supervised Learning):
- 使用DINO自监督学习方法训练SuiT,并在下游任务中评估其性能。
- 比较了DINO-SuiT和DINO-ViT在多个数据集上的性能。
零样本显著对象分割(Zero-shot Salient Object Segmentation):
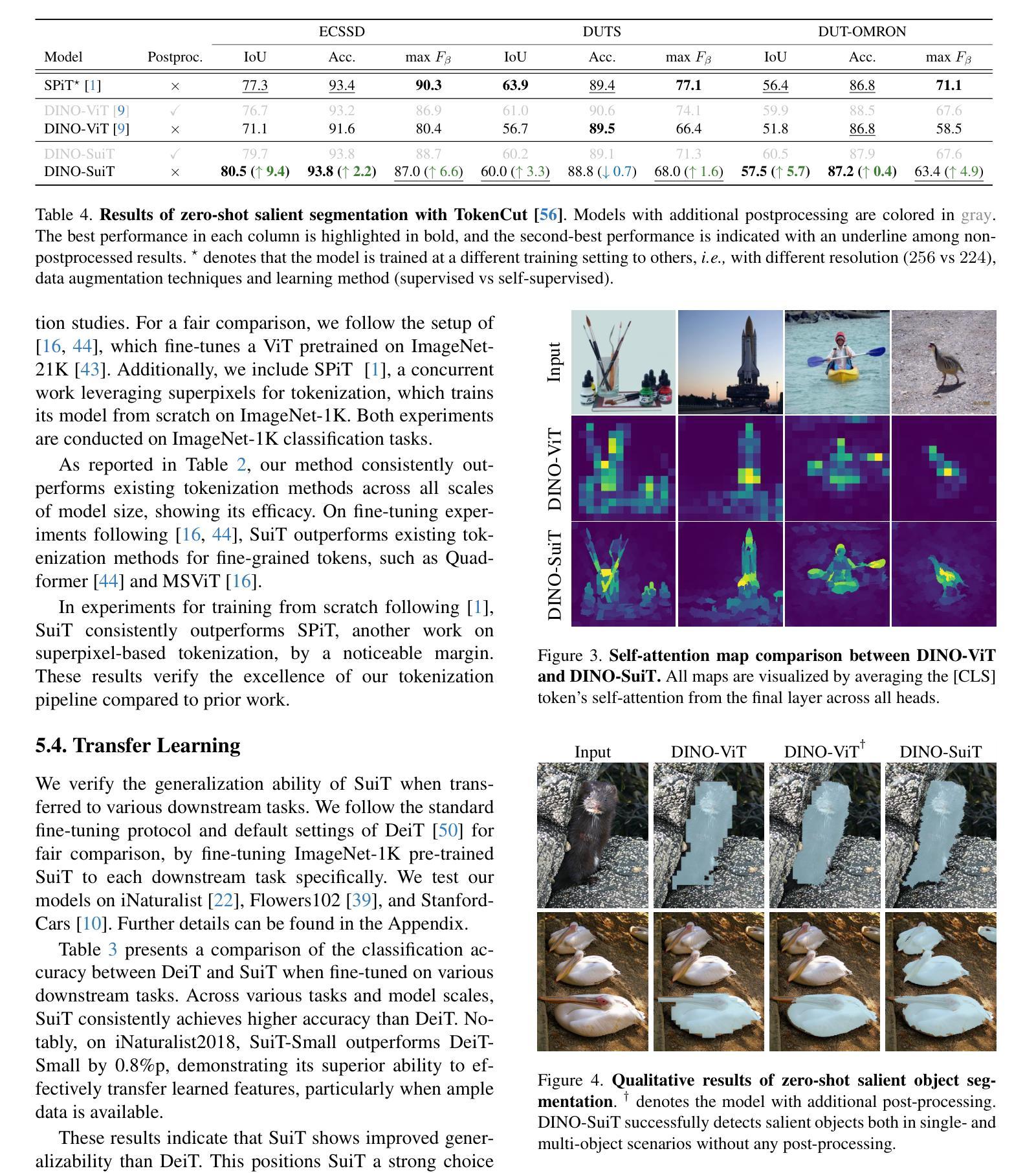
- 使用TokenCut框架,评估了SuiT在零样本显著对象分割任务上的性能。
- 比较了DINO-SuiT和DINO-ViT在ECSSD、DUTS和DUT-OMRON数据集上的性能,并展示了有无后处理情况下的结果。
分析:
- 语义完整性分析:通过K-means聚类分析了SuiT和DeiT的令牌嵌入空间,以验证SuiT在语义保留方面的优势。
- 类别可识别性分析:评估了SuiT和DeiT在不同层中类别特定编码的比例。
- 增强鲁棒性:在ImageNet-A和ImageNet-O数据集上评估了SuiT相对于DeiT在模型鲁棒性和域外泛化能力上的表现。
消融研究(Ablation Studies):
- 分析了预聚合特征提取中不同技术组件的影响,包括局部特征、位置编码和它们的组合方式。
- 评估了不同聚合方法对性能的影响,包括平均池化、最大池化和softmax池化。
这些实验全面地验证了SuiT在多个视觉任务中的有效性,并提供了对其机制和新出现属性的深入理解。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
超像素算法的改进:
- 研究不同的超像素生成算法对SuiT性能的影响,探索是否能找到更适合ViT的超像素算法。
超像素的动态调整:
- 探索根据图像内容动态调整超像素数量和大小的可能性,以适应不同分辨率和复杂度的图像。
注意力机制的改进:
- 研究是否可以对SuiT中的注意力机制进行改进,以更好地利用超像素的语义信息。
跨模态应用:
- 探索SuiT在多模态任务(如图像和文本的联合表示学习)中的应用,并分析其性能。
更广泛的下游任务:
- 将SuiT应用于更广泛的下游任务,如视频理解、3D对象识别等,以评估其泛化能力。
自监督学习框架的集成:
- 研究SuiT是否可以与其他自监督学习框架(如BYOL、SimCLR等)集成,并分析性能提升。
计算效率优化:
- 探索优化SuiT的方法,以减少计算资源消耗,使其更适合在资源受限的设备上部署。
解释性和可视化:
- 进一步研究SuiT的解释性,通过可视化技术揭示模型是如何学习和利用超像素信息的。
鲁棒性和泛化能力的增强:
- 研究如何通过数据增强、正则化等技术进一步提高SuiT的鲁棒性和泛化能力。
与现有ViT架构的比较:
- 与最新的ViT架构进行比较,分析SuiT在不同架构下的表现,并探索最佳实践。
损失函数和优化策略的改进:
- 研究不同的损失函数和优化策略对SuiT训练动态和最终性能的影响。
多尺度特征融合:
- 探索在SuiT中融合多尺度特征的方法,以捕获不同层次的语义信息。
这些探索点可以帮助研究者更深入地理解SuiT的工作机制,发现潜在的改进空间,并推动ViT在计算机视觉领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种新的基于超像素的令牌化方法(SuiT),用于改进视觉Transformer(ViT)中的视觉令牌化过程。以下是论文的主要内容总结:
问题陈述:
- 论文指出,传统的ViT使用均匀划分的正方形图像块作为令牌,这可能导致单个令牌中混合多个视觉概念,违背了令牌化的原则。
方法:
- 论文提出了SuiT,一种基于超像素的令牌化方法,利用超像素生成包含单一视觉概念的令牌,以保持语义完整性。
- SuiT包括两个主要技术组件:预聚合特征提取和超像素感知特征聚合。
- 预聚合特征提取通过卷积块提取局部特征,并结合正弦位置编码处理超像素的位置信息。
- 超像素感知特征聚合使用平均池化和最大池化操作聚合每个超像素内的特征,以处理超像素大小和形状的不一致性。
实验:
- 论文在多个下游任务上验证了SuiT的有效性,包括ImageNet-1K分类、迁移学习、自监督学习和零样本显著对象分割。
- SuiT在准确性和鲁棒性方面均优于基线方法,如DeiT。
分析:
- 通过K-means聚类分析和类别可识别性分析,论文展示了SuiT在保持语义信息方面的优势。
- 论文还分析了SuiT在增强模型鲁棒性和泛化能力方面的性能。
消融研究:
- 论文通过消融研究验证了预聚合特征提取和聚合方法中不同组件的重要性。
结论:
- 论文得出结论,SuiT通过利用超像素改进了ViT中的视觉令牌化过程,并在多个视觉任务中展示了其有效性。
- 论文希望其结果能激发对ViT中令牌设计的进一步探索,推动模型性能和可解释性的进步。
总的来说,这篇论文通过引入超像素概念来改进ViT的令牌化过程,提出了一种新的令牌化方法SuiT,并在多个视觉任务中验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图