⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-14 更新
Image Generation Diversity Issues and How to Tame Them
Authors:Mischa Dombrowski, Weitong Zhang, Sarah Cechnicka, Hadrien Reynaud, Bernhard Kainz
Generative methods now produce outputs nearly indistinguishable from real data but often fail to fully capture the data distribution. Unlike quality issues, diversity limitations in generative models are hard to detect visually, requiring specific metrics for assessment. In this paper, we draw attention to the current lack of diversity in generative models and the inability of common metrics to measure this. We achieve this by framing diversity as an image retrieval problem, where we measure how many real images can be retrieved using synthetic data as queries. This yields the Image Retrieval Score (IRS), an interpretable, hyperparameter-free metric that quantifies the diversity of a generative model’s output. IRS requires only a subset of synthetic samples and provides a statistical measure of confidence. Our experiments indicate that current feature extractors commonly used in generative model assessment are inadequate for evaluating diversity effectively. Consequently, we perform an extensive search for the best feature extractors to assess diversity. Evaluation reveals that current diffusion models converge to limited subsets of the real distribution, with no current state-of-the-art models superpassing 77% of the diversity of the training data. To address this limitation, we introduce Diversity-Aware Diffusion Models (DiADM), a novel approach that improves diversity of unconditional diffusion models without loss of image quality. We do this by disentangling diversity from image quality by using a diversity aware module that uses pseudo-unconditional features as input. We provide a Python package offering unified feature extraction and metric computation to further facilitate the evaluation of generative models https://github.com/MischaD/beyondfid.
生成式方法现在产生的输出几乎与真实数据无法区分,但往往未能完全捕获数据分布。不同于质量问题,生成模型中的多样性限制在视觉上很难检测,需要特定的指标进行评估。在本文中,我们关注当前生成模型中缺乏多样性的问题以及常见指标无法衡量这一问题的情况。我们通过将多样性构建为图像检索问题来实现这一点,在该问题中,我们衡量使用合成数据作为查询可以检索到多少真实图像。这产生了图像检索得分(IRS),这是一个可解释的、无超参数的指标,可以量化生成模型输出的多样性。IRS只需要一小部分合成样本,并提供了一个统计上的置信度衡量。我们的实验表明,目前常用于生成模型评估的特征提取器在有效评估多样性方面存在不足。因此,我们广泛搜索了最佳的特征提取器来评估多样性。评估结果显示,目前的扩散模型收敛到真实分布的子集,没有任何现有先进技术能够超越训练数据多样性的77%。为了解决这个问题,我们引入了多样性感知扩散模型(DiADM),这是一种新颖的方法,可以在不损失图像质量的情况下提高无条件扩散模型的多样性。我们通过使用多样性感知模块并使用伪无条件特征作为输入来实现这一点,以解开多样性和图像质量之间的联系。我们提供了一个Python软件包,提供统一的特征提取和指标计算,以进一步促进生成模型的评估 https://github.com/MischaD/beyondfid。
论文及项目相关链接
PDF 17 pages, 6 tables, 12 figures; v2 added acknowledgment
Summary
本文关注生成模型的多样性问题。提出一种名为图像检索分数(IRS)的新指标来量化生成模型输出的多样性,通过合成数据作为查询来检索真实图像。实验表明,当前常用的特征提取器在评估多样性方面表现不足,而扩散模型仅收敛到真实分布的子集。为解决这一问题,引入了一种名为多样性感知扩散模型(DiADM)的新方法,通过伪无条件特征来提高无条件扩散模型的多样性,同时不损失图像质量。
Key Takeaways
- 生成模型虽然能产生难以区分真实数据的输出,但往往不能完全捕捉数据分布。
- 多样性限制在生成模型中难以视觉检测,需要特定的度量进行评估。
- 提出一种新的指标——图像检索分数(IRS),来量化生成模型的多样性。
- 通过将多样性从图像质量中分离出来,引入多样性感知扩散模型(DiADM)来提高无条件扩散模型的多样性。
- 当前常用的特征提取器在评估生成模型的多样性方面是不够的。
- 扩散模型仅收敛到真实分布的子集,目前没有任何先进模型能够超越训练数据多样性的77%。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决生成模型中多样性不足的问题。具体来说,论文指出尽管生成方法现在可以产生与真实数据几乎无法区分的输出,但它们常常未能完全捕捉数据分布。与质量问题不同,生成模型中的多样性限制很难通过视觉检测,需要特定的指标来评估。论文强调了当前生成模型中多样性的缺乏,以及常用指标无法有效测量这一问题。作者通过将多样性框架化为一个图像检索问题来解决这一问题,即通过使用合成数据作为查询来衡量能够检索到多少真实图像。这产生了图像检索得分(Image Retrieval Score, IRS),这是一个可解释的、无需超参数的度量,用于量化生成模型输出的多样性。IRS只需要一部分合成样本,并提供统计置信度的度量。通过实验,论文表明当前用于评估生成模型的特征提取器不足够有效地评估多样性。因此,作者进行了广泛的搜索,以找到最佳的评估多样性的特征提取器。评估揭示了当前扩散模型收敛到真实分布的有限子集,没有当前最先进模型超过训练数据多样性的77%。为了解决这一局限性,论文引入了多样性感知扩散模型(Diversity-Aware Diffusion Models, DiADM),这是一种新方法,可以在不损失图像质量的情况下提高无条件扩散模型的多样性。这是通过使用多样性感知模块实现的,该模块使用伪无条件特征作为输入,将多样性与图像质量分离开来。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个方面:
图像生成(Image Generation):
- 扩散模型(Diffusion models):这类模型能够逐步将复杂分布映射到标准高斯分布,用于生成高度逼真的图像。相关研究包括[48]。
- 条件扩散模型(Conditional diffusion models):这些模型能够根据指定条件生成高度逼真的图像,应用于图像合成、图像修复和图像重建等任务。相关研究包括[54]、[57]和[56]。
生成中的多样性问题(Diversity in Generation):
- 针对生成对抗网络(GAN-based models)的多样性研究较为有限,主要关注于减少偏见和增强多样性。相关研究包括[9]、[25]。
- 偏见减轻(Bias mitigation):例如,[37]使用重新加权损失来处理长尾分布,促进平衡的类别表示。
- 多样性增强(Diversity enhancement):例如,[28]引入噪声扰动来增加多样性,但以牺牲图像质量和确定性为代价。
多样性评估指标(Metrics of Diversity):
- 传统的图像质量指标,如Fréchet Inception Distance (FID) [20],需要大量样本才能可靠,计算密集且难以在实际应用中解释。
- 精确度和召回率(Precision and recall):在文献中较为常见,但受限于数据集大小、超参数和可解释性问题。相关研究包括[26]、[12]、[36]和[41]。
- 覆盖度和密度(Coverage and density):也用于测量多样性,但依赖于训练和测试集之间的比例,高度依赖超参数,缺乏对真实数据集的评估,并且设计上忽略了在多样性评估中重要的异常值。相关研究包括[32]。
- Vendi Score [16]:完全不需要真实参考集,但牺牲了保真度,且对大型数据集计算成本过高。
这些相关研究构成了论文研究的背景和基础,论文在此基础上提出了新的评估多样性的指标(IRS)和改进生成模型多样性的方法(DiADM)。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决生成模型中多样性不足的问题:
提出图像检索得分(Image Retrieval Score, IRS):
- 作者提出了IRS,这是一个可解释的、无需超参数的度量,用于量化生成模型输出的多样性。IRS通过评估合成数据作为查询时检索到的真实图像数量来衡量多样性。
- IRS只需要一部分合成样本,并提供统计置信度的度量。
评估现有特征提取器:
- 论文指出,当前用于评估生成模型的特征提取器不足够有效地评估多样性。因此,作者进行了广泛的搜索,以找到最佳的评估多样性的特征提取器。
揭示现有扩散模型的局限性:
- 通过IRS评估,论文发现当前扩散模型收敛到真实分布的有限子集,没有模型超过训练数据多样性的77%。
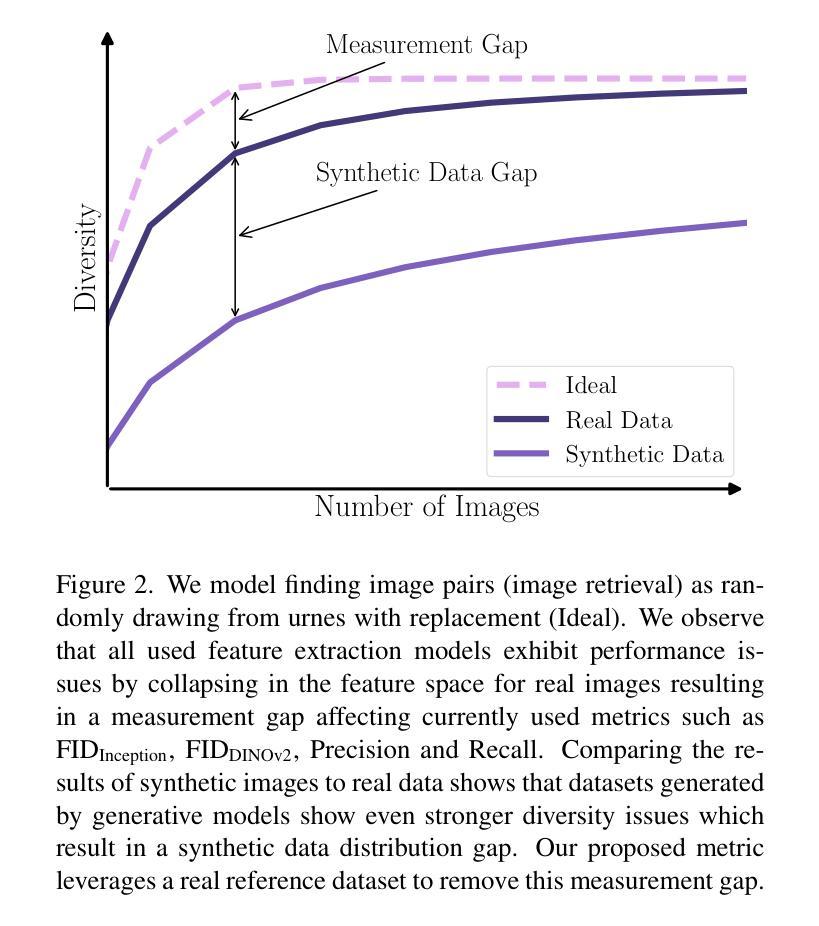
引入多样性感知扩散模型(Diversity-Aware Diffusion Models, DiADM):
- 为了解决多样性不足的问题,作者提出了DiADM,这是一种新方法,可以在不损失图像质量的情况下提高无条件扩散模型的多样性。
- DiADM通过使用多样性感知模块,利用伪无条件特征作为输入,将多样性与图像质量分离开来。
提供Python软件包:
- 为了方便评估生成模型,作者提供了一个Python包,用于统一特征提取和度量计算。
实验验证:
- 论文通过一系列实验验证了IRS的有效性,并使用DiADM展示了在不同数据集上提高多样性的能力。
通过这些步骤,论文不仅提出了一个新的度量多样性的方法,而且还提供了一个实际的解决方案来提高生成模型的多样性,同时保持或提高图像质量。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证他们提出的方法和发现。以下是实验的详细描述:
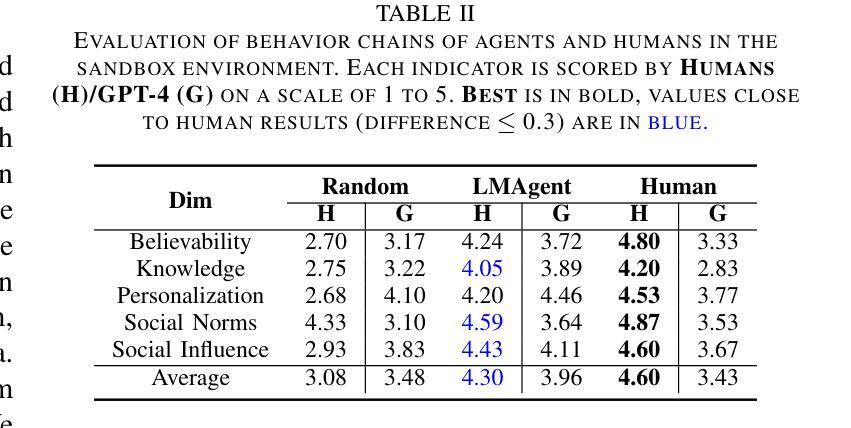
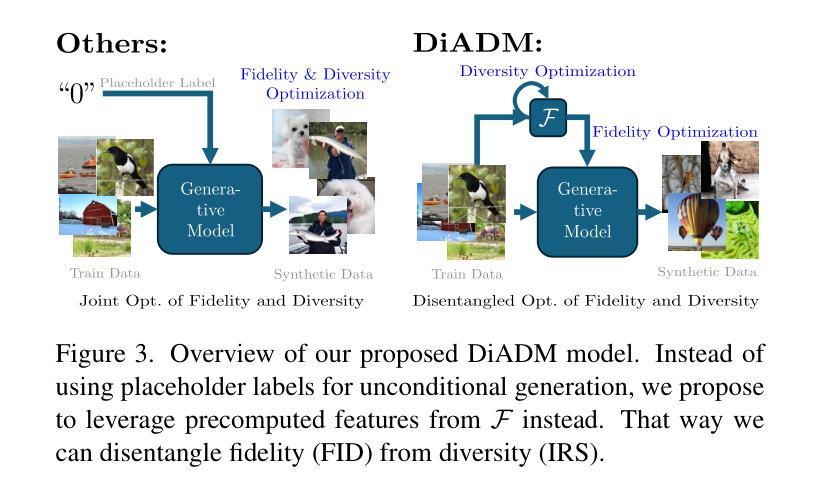
测量真实数据的多样性(Measurement Gap):
- 作者首先通过实验确定了现有的特征提取器在评估真实数据集时存在“测量差距”(measurement gap),即这些特征提取器的性能远低于预期值,表明它们不能有效地表示数据的多样性。
- 实验涉及多个数据集(如ImageNet、FFHQ、Chest-Xray14等)和多种特征提取器(如BYOL、CLIP、ConvNeXt、DINOv2、Inception、MAE、SwAV等),并比较了它们在图像检索任务上的表现。
评估扩散模型的多样性问题:
- 作者使用提出的IRS得分来量化和比较不同的最先进扩散模型在生成图像时的多样性问题。
- 实验涉及多个不同的生成模型,包括基于图像、分类器和文本的条件扩散模型。
改进多样性使用伪标签(Improving Diversity Using Pseudo Labels):
- 作者提出了Diversity-Aware Diffusion Models (DiADM),并在多个数据集上验证了其在提高无条件图像生成多样性方面的有效性。
- 实验结果表明,DiADM在保持图像质量的同时提高了多样性,并且在某些情况下,多样性甚至超过了真实数据集。
文本到图像生成的多样性评估(Text-to-image example):
- 作者将IRS应用于文本到图像的生成任务,特别是评估性别多样性问题。
- 实验中,他们创建了一个平衡性别分布的参考数据集,并使用模型生成不指定性别的图像,然后使用IRS来评估生成图像的多样性。
IRS的统计敏感性分析:
- 作者分析了IRS在不同训练集大小下的统计敏感性,并展示了如何使用IRS来拒绝早期模型检查点,如果它们缺乏足够的多样性。
IRS与FID的比较分析:
- 作者比较了IRS和FID在检测生成模型中多样性不足和偏见放大方面的能力,并证明了IRS在统计敏感性方面优于FID。
这些实验不仅验证了IRS作为一种新的多样性评估指标的有效性,而且还展示了DiADM在提高生成模型多样性方面的潜力。通过这些实验,作者证明了他们提出的方法可以在保持图像质量的同时提高生成模型的多样性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
改进特征提取器:
- 论文指出现有的特征提取器在评估多样性时存在不足。可以进一步研究和开发新的特征提取器,特别是那些能够更好地捕捉图像多样性的特征提取器。
优化DiADM模型:
- 虽然DiADM在提高无条件扩散模型的多样性方面取得了一定的成功,但仍有可能通过改进模型架构或训练策略来进一步提升其性能。
扩展到有条件的图像生成:
- 论文中提出的DiADM主要针对无条件图像生成。未来的工作可以探索如何将DiADM扩展到有条件的图像生成任务中,以提高这些任务的多样性。
多样性与图像质量的权衡:
- 研究如何更好地平衡生成图像的多样性和质量。可能需要开发新的损失函数或训练策略来实现这一目标。
评估指标的进一步改进:
- 尽管IRS是一个有效的多样性评估指标,但仍有可能开发出更精确、更高效的评估方法。
跨模态生成任务的多样性:
- 将多样性问题的研究扩展到其他类型的生成任务中,例如文本到图像、视频到视频等跨模态生成任务。
减少数据偏见:
- 研究如何减少训练数据集中的偏见,并确保生成模型能够覆盖更广泛的数据分布。
算法公平性和伦理问题:
- 考虑到生成模型可能放大数据集中的偏见,研究如何在设计和训练过程中引入公平性和伦理考量。
大规模数据集的评估:
- 在更大的、更多样化的数据集上评估DiADM和IRS,以验证它们在不同场景下的适用性和有效性。
计算效率和可扩展性:
- 研究如何提高IRS计算的效率,使其能够应用于大规模数据集,同时保持较低的计算成本。
多样性的可视化:
- 开发直观的可视化工具,以帮助研究人员和实践者理解生成模型的多样性问题。
结合人类评估:
- 将自动化的多样性评估方法与人类评估相结合,以获得更全面的多样性理解。
这些探索点可以帮助推动生成模型在多样性和公平性方面的进步,同时提高其在实际应用中的有效性和可靠性。
Q: 总结一下论文的主要内容
A: 论文《Image Generation Diversity Issues and How to Tame Them》主要探讨了生成模型在图像多样性方面的不足,并提出了相应的解决方案。以下是论文的主要内容总结:
问题陈述:
- 生成模型虽然能产生接近真实数据的输出,但常未能完全捕捉数据分布,特别是多样性不足的问题难以直观检测,需要特定指标进行评估。
IRS(Image Retrieval Score)提出:
- 作者提出了IRS,一个可解释的、无需超参数的度量方法,用于量化生成模型输出的多样性。IRS通过评估合成数据作为查询时能检索到的真实图像数量来衡量多样性。
现有特征提取器的局限性:
- 论文指出,常用的特征提取器在评估生成模型多样性时表现不足,作者通过实验验证了这一点,并进行了广泛的搜索以寻找最佳的评估多样性的特征提取器。
扩散模型的多样性问题:
- 通过IRS评估,论文发现当前的扩散模型仅收敛到真实分布的有限子集,没有模型超过训练数据多样性的77%。
DiADM(Diversity-Aware Diffusion Models)引入:
- 为了解决多样性不足的问题,作者引入了DiADM,这是一种新方法,可以在不损失图像质量的情况下提高无条件扩散模型的多样性。
实验验证:
- 论文通过一系列实验验证了IRS的有效性,并使用DiADM展示了在不同数据集上提高多样性的能力。
Python软件包提供:
- 为了方便评估生成模型,作者提供了一个Python包,用于统一特征提取和度量计算。
未来工作:
- 论文提出了未来可能的研究方向,包括改进特征提取器、优化DiADM模型、扩展到有条件的图像生成等。
总体而言,这篇论文不仅揭示了生成模型在多样性方面的不足,而且提供了一种新的评估工具IRS和改进方法DiADM,以期提高生成模型的多样性并保持图像质量。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

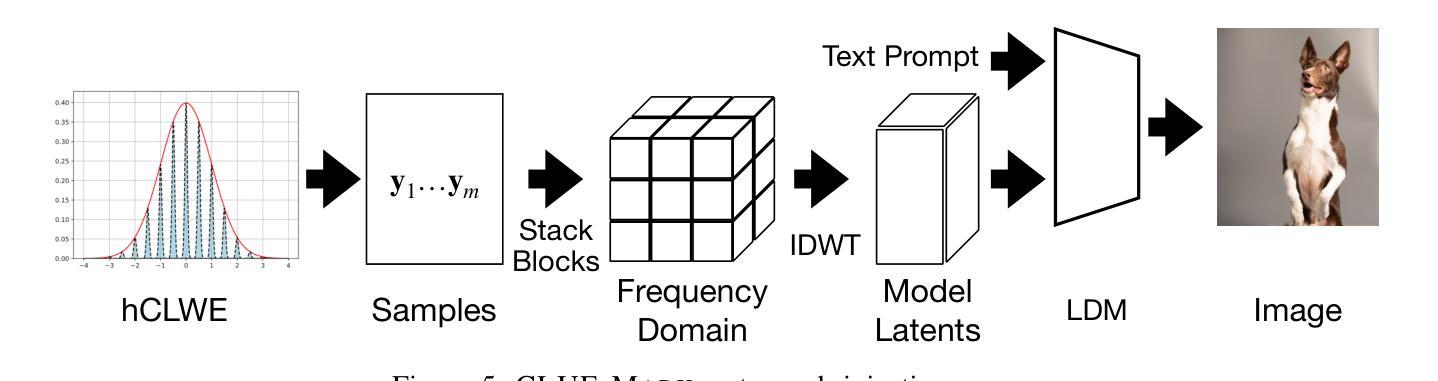
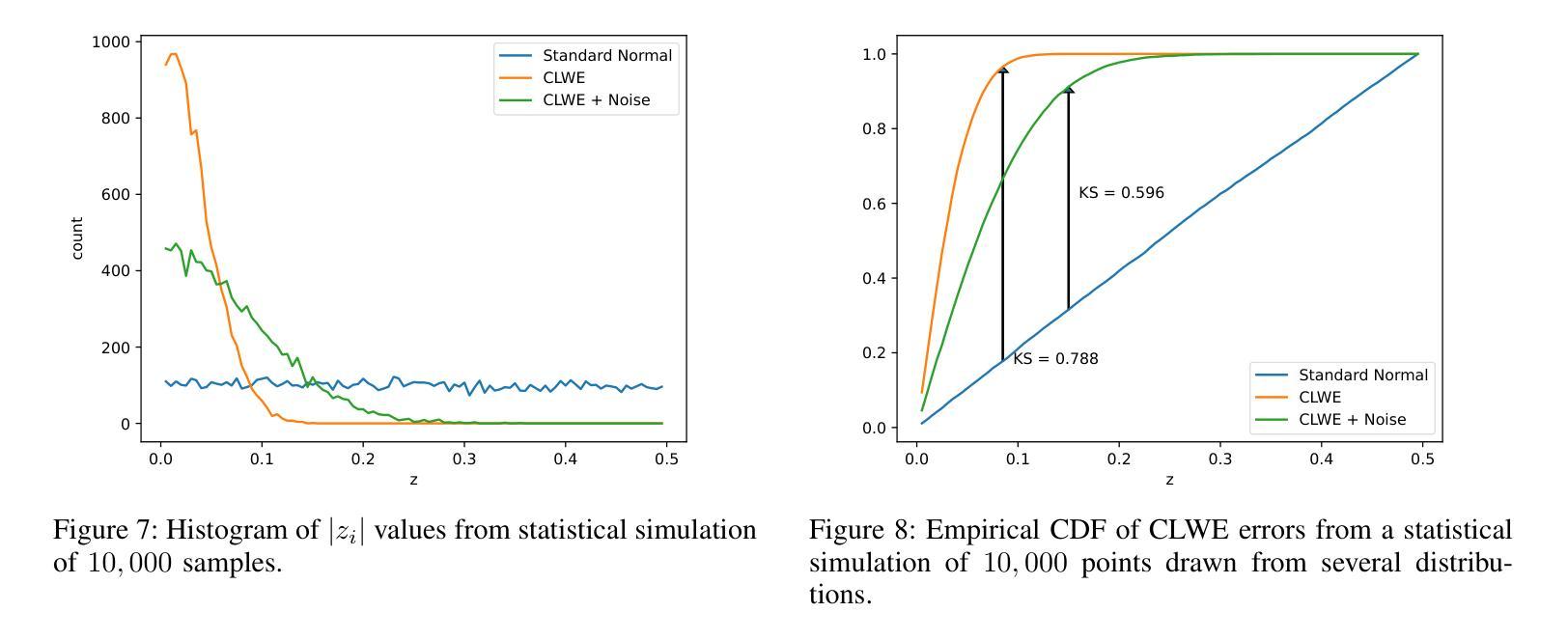
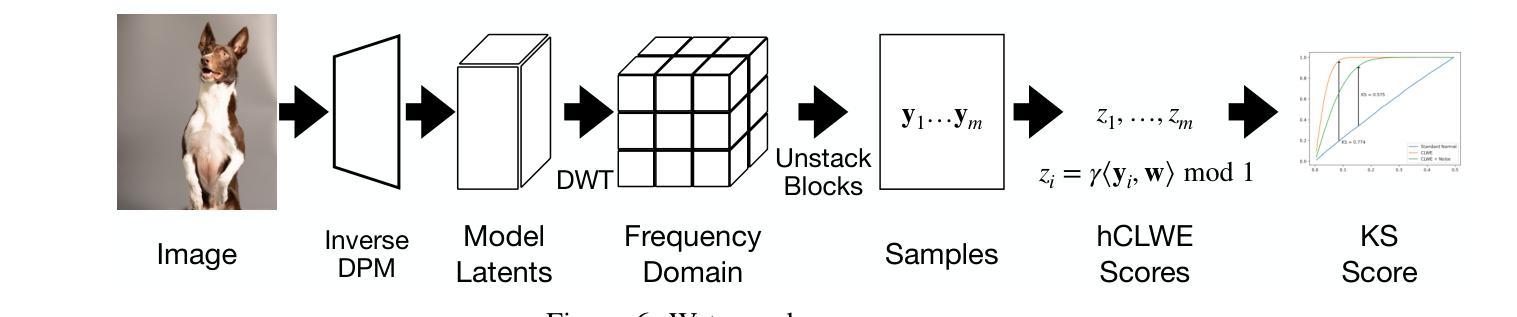
CLUE-MARK: Watermarking Diffusion Models using CLWE
Authors:Kareem Shehata, Aashish Kolluri, Prateek Saxena
As AI-generated images become widespread, reliable watermarking is essential for content verification, copyright enforcement, and combating disinformation. Existing techniques rely on heuristic approaches and lack formal guarantees of undetectability, making them vulnerable to steganographic attacks that can expose or erase the watermark. Additionally, these techniques often degrade output quality by introducing perceptible changes, which is not only undesirable but an important barrier to adoption in practice. In this work, we introduce CLUE-Mark, the first provably undetectable watermarking scheme for diffusion models. CLUE-Mark requires no changes to the model being watermarked, is computationally efficient, and because it is provably undetectable is guaranteed to have no impact on model output quality. Our approach leverages the Continuous Learning With Errors (CLWE) problem – a cryptographically hard lattice problem – to embed watermarks in the latent noise vectors used by diffusion models. By proving undetectability via reduction from a cryptographically hard problem we ensure not only that the watermark is imperceptible to human observers or adhoc heuristics, but to \emph{any} efficient detector that does not have the secret key. CLUE-Mark allows multiple keys to be embedded, enabling traceability of images to specific users without altering model parameters. Empirical evaluations on state-of-the-art diffusion models confirm that CLUE-Mark achieves high recoverability, preserves image quality, and is robust to minor perturbations such JPEG compression and brightness adjustments. Uniquely, CLUE-Mark cannot be detected nor removed by recent steganographic attacks.
随着人工智能生成的图像越来越普遍,可靠的水印技术对于内容验证、版权保护和打击虚假信息至关重要。现有技术依赖于启发式方法,缺乏不可检测性的正式保证,使其容易受到隐写攻击,可能会暴露或删除水印。此外,这些技术往往会通过引入可感知的变化来降低输出质量,这不仅是不希望的,而且在实践中采用时是一个重要的障碍。
论文及项目相关链接
Summary
本摘要基于提供的文本核心内容生成一句话简要总结:AI生成的图像广泛流行下,本文介绍了一种新型的水印嵌入技术CLUE-Mark,该技术专为扩散模型设计,无需修改模型即可实现不可检测的防伪水印嵌入,保证了水印的不可检测性和图像输出质量不受影响。
Key Takeaways
以下是基于文本内容提取的七个关键要点:
- AI生成的图像普及后,可靠的水印验证变得重要,用于内容验证、版权保护及打击虚假信息。
- 当前水印技术依赖启发式方法,缺乏不可检测性的正式保证,易受到隐写攻击的影响。
- CLUE-Mark是专为扩散模型设计的首个可证明不可检测的水印嵌入方案。
- CLUE-Mark不需要修改被水印标记的模型,计算效率高且能保证不影响模型输出质量。
- CLUE-Mark利用CLWE问题(一个密码学难题)嵌入水印在扩散模型的潜在噪声向量中。
- 通过从密码学难题证明不可检测性,CLUE-Mark确保不仅对人类观察者和启发式方法无法检测,而且对任何没有秘密密钥的高效检测器也无法检测。
- CLUE-Mark允许嵌入多个密钥,可在不改变模型参数的情况下追踪图像特定用户,且经验评估证实其高恢复性、图像质量保护和对抗轻微扰动(如JPEG压缩和亮度调整)的稳健性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决AI生成图像中可靠的水印问题,这对于内容验证、版权执行和打击虚假信息至关重要。具体来说,论文关注以下几个关键问题:
现有技术的局限性:现有的水印技术依赖于启发式方法,缺乏不可检测性的正式保证,这使得它们容易受到隐写攻击,这些攻击可能会暴露或擦除水印。
输出质量的退化:这些技术通常会通过引入可感知的变化来降低输出质量,这不仅不受欢迎,而且成为实际采用的重要障碍。
水印的不可检测性:论文提出了一种名为CLUE-MARK的水印方案,它是第一个为扩散模型提供可证明不可检测的水印方案。这种方案不需要改变被水印的模型,计算效率高,并且因为其不可检测性是可证明的,所以保证了对模型输出质量没有影响。
水印的鲁棒性和可追溯性:CLUE-MARK允许嵌入多个密钥,使得图像可以追溯到特定用户,而不需要改变模型参数。
抵抗隐写分析的攻击:与最近的隐写分析攻击相比,CLUE-MARK不能被检测也不能被移除。
综上所述,论文旨在通过引入基于连续学习误差(CLWE)问题的密码学难题来嵌入水印,从而为扩散模型生成的图像提供一个既不可检测又不影响图像质量的水印方案。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与CLUE-MARK水印方案相关的研究工作:
TREE RING [1]:
- 这是一种预处理水印技术,通过在扩散模型生成的图像中嵌入“树环”图案的水印来标识图像的来源。尽管TREE RING被推测为不可检测和鲁棒,但没有给出严格的证明,并且后续研究表明TREE RING的水印可以被标准隐写分析技术检测和移除。
GAUSSIAN SHADING [3]:
- 另一种预处理水印技术,通过在扩散模型的噪声输入中添加高斯噪声来嵌入水印。GAUSSIAN SHADING声称在图像经过常见扰动后仍能恢复水印,但同样缺乏可证明的不可检测性。
连续学习误差(CLWE)问题 [4]:
- 这是CLUE-MARK方案的核心,利用CLWE问题构建水印。CLWE问题是一个密码学难题,论文通过将水印嵌入到扩散模型使用的潜在噪声向量中,利用CLWE问题的难度来保证水印的不可检测性。
隐写分析攻击 [2]:
- 这些攻击展示了如何通过标准隐写分析技术检测和移除TREE RING和GAUSSIAN SHADING中的水印,从而证明了现有技术的脆弱性。
扩散模型 [5], [6]:
- 论文中提到了扩散模型作为生成高质量、可定制图像的AI模型。这些模型通过迭代去除噪声向量来生成图像,为水印技术提供了新的应用场景。
图像水印的深度学习方法 [27]-[31]:
- 这些研究探讨了如何使用深度神经网络来增强水印的鲁棒性和质量,通常利用编码器-解码器架构来嵌入和恢复水印信息。
生成模型中的水印技术 [32]-[35]:
- 这些技术直接在生成模型的生成过程中嵌入水印,避免了对生成图像的后处理,声称在不降低图像质量的同时实现水印的嵌入和提取。
基于随机傅里叶特征模型的隐写攻击 [36]:
- 这项研究展示了如何在基于随机傅里叶特征的分类模型中植入不可检测的后门,虽然与CLUE-MARK的应用场景不同,但提供了利用密码学难题进行隐写保护的另一种视角。
这些相关研究为CLUE-MARK方案提供了理论基础和技术对比,展示了在AI生成图像水印领域中的主要挑战和进展。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为CLUE-MARK的水印方案来解决AI生成图像中可靠的水印问题。以下是该方案解决该问题的关键步骤和方法:
基于CLWE的水印嵌入:
- 利用连续学习误差(CLWE)问题,这是一个密码学难题,来嵌入水印。通过在扩散模型使用的潜在噪声向量中嵌入基于CLWE的分布,确保水印对于任何没有秘密密钥的高效检测器都是不可检测的。
无需改变模型参数:
- CLUE-MARK不需要改变被水印的模型,这意味着不需要重新训练或调整模型参数,从而保持了模型输出的原始质量。
计算效率:
- 该方案是计算上高效的,因为它只需要修改输入的噪声向量,而不需要对模型本身进行任何复杂的计算或处理。
多密钥支持:
- 允许多个密钥嵌入到单个水印中,使得可以追踪特定用户生成的图像,而不需要改变模型参数。
通过密码学难题保证不可检测性:
- 通过将水印的不可检测性归约为一个密码学难题(CLWE问题),论文确保了水印对于任何没有秘密密钥的观察者或启发式方法都是不可感知的。
实证评估:
- 在最先进的扩散模型和数据集上进行实证评估,验证CLUE-MARK在不可检测性、恢复能力、图像质量和对小扰动(如JPEG压缩和亮度调整)的鲁棒性方面的表现。
抵抗隐写分析攻击:
- 通过实证评估,论文展示了CLUE-MARK对抗标准隐写分析攻击的能力,与现有技术相比,CLUE-MARK的水印不能被检测或移除。
理论上的安全性证明:
- 论文提供了形式化的定义和证明,展示了CLUE-MARK的完整性、健全性和不可检测性,确保了水印方案的安全性。
通过这些方法,CLUE-MARK旨在提供一个既不可检测又不影响图像质量的水印方案,同时保持对图像的鲁棒性和可追溯性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估CLUE-MARK水印方案的性能。以下是实验的详细内容:
RQ1: 实际CLWE参数的选择:
- 进行了统计模拟,以确定对于CLUE-MARK来说实际的CLWE参数(如γ和β的值)。
- 使用了协方差攻击方法来评估不同参数下的安全性能,并生成了统计图表来展示攻击分数。
RQ2: 水印恢复能力:
- 生成了1000对标记和未标记的图像,并应用CLUE-MARK的恢复策略来评估其准确性。
- 使用了接收者操作特征(ROC)曲线和曲线下面积(AUC)分数来衡量恢复策略的性能。
RQ3: 图像质量:
- 使用Frechet Inception Distance(FID)分数来衡量CLUE-MARK生成的水印图像与未水印图像之间的质量差异。
- 将CLUE-MARK与基线技术TREE RING和GAUSSIAN SHADING进行了比较。
RQ4: 对隐写分析攻击的抵抗力:
- 通过平均多个标记和未标记图像之间的差异来模拟隐写分析攻击,并尝试移除水印。
- 评估了攻击后水印的可恢复性,并使用AUC分数来衡量水印方案对攻击的抵抗力。
RQ5: 对常见扰动的鲁棒性:
- 对水印图像应用了JPEG压缩、亮度调整、高斯模糊、裁剪和旋转等常见图像处理操作,并测量了这些操作对水印恢复性能的影响。
- 使用ROC AUC分数来评估水印方案在不同扰动下的鲁棒性。
实验结果表明,CLUE-MARK在保持图像质量的同时,能够有效地抵抗隐写分析攻击,并且在一定程度上对JPEG压缩和亮度变化等小扰动保持鲁棒。然而,对于裁剪、旋转和模糊等较大的图像处理操作,CLUE-MARK的水印则变得难以恢复。这些实验提供了CLUE-MARK在实际应用中的有效性和局限性的实证证据。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
提高鲁棒性:
- 论文中提到CLUE-MARK对裁剪、旋转和模糊等较大扰动的鲁棒性不足。未来的工作可以考虑如何提高水印方案对这些扰动的鲁棒性。
优化CLWE参数:
- 论文中对CLWE参数进行了初步的选择和评估,但这些参数对性能的影响尚未充分研究。进一步研究可能有助于找到更好的参数配置,以在保持不可检测性的同时提高水印的性能。
改进模型反转方法:
- 论文指出,获取原始潜在向量的模型反转过程是恢复水印质量和速度的瓶颈。改进这一过程可以显著提高CLUE-MARK的性能。
多密钥和多层水印技术:
- 尽管CLUE-MARK支持多密钥,但如何更有效地实现多层水印以及如何管理这些密钥的使用是一个值得进一步研究的问题。
跨模型水印:
- 研究如何将水印从一个模型迁移到另一个模型,或者如何设计通用的水印方案,使其适用于不同类型的扩散模型。
安全性和隐私性分析:
- 对CLUE-MARK进行更深入的安全性和隐私性分析,特别是考虑到不同攻击模型和威胁场景。
实际应用和部署:
- 探索CLUE-MARK在实际应用场景中的部署,如版权保护、内容验证等,并评估其在现实世界中的有效性和可行性。
与其他技术的集成:
- 研究如何将CLUE-MARK与其他图像处理或安全技术(例如区块链)集成,以提供更全面的内容保护解决方案。
水印的法律和伦理问题:
- 探讨水印技术在法律和伦理层面的影响,特别是在处理个人隐私和数据保护方面。
水印技术的标准化:
- 参与或推动水印技术的标准化工作,以促进不同系统和平台之间的互操作性。
这些探索点可以帮助研究者和开发者更好地理解和改进CLUE-MARK水印方案,同时也为AI生成内容的版权保护和验证提供了新的研究方向。
Q: 总结一下论文的主要内容
A: 论文介绍了CLUE-MARK,这是一种针对由扩散模型生成的图像的可证明不可检测的水印方案。以下是论文的主要内容总结:
问题背景:
- 论文指出,随着AI生成图像的普及,可靠的水印技术对于内容验证、版权执行和打击虚假信息变得至关重要。现有技术存在局限性,如依赖启发式方法、缺乏不可检测性的正式保证,且可能会降低图像质量。
CLUE-MARK方案:
- 论文提出了CLUE-MARK,这是一种基于连续学习误差(CLWE)问题的水印方案,能够在不改变模型参数、不影响输出质量的情况下,为扩散模型生成的图像提供可证明的不可检测水印。
技术方法:
- CLUE-MARK通过修改扩散模型的潜在噪声向量,利用基于CLWE问题的分布嵌入水印。这种方法保证了水印对于任何没有秘密密钥的高效检测器都是不可检测的。
理论证明:
- 论文通过将水印的不可检测性归约为CLWE问题,提供了形式化的定义和证明,展示了CLUE-MARK的完整性、健全性和不可检测性。
实证评估:
- 论文通过在最先进的扩散模型和数据集上的实证评估,验证了CLUE-MARK在不可检测性、恢复能力、图像质量和对小扰动的鲁棒性方面的表现。实验结果表明,CLUE-MARK在保持图像质量的同时,能够有效抵抗隐写分析攻击。
局限性与未来工作:
- 论文讨论了CLUE-MARK的局限性,特别是在对抗裁剪、旋转和模糊等较大扰动时的鲁棒性不足,并提出了未来可能的研究方向,包括提高鲁棒性、优化CLWE参数、改进模型反转方法等。
总体而言,论文提出了一种新颖的水印方案,旨在解决AI生成图像中的版权和验证问题,同时保持图像质量并抵抗隐写分析攻击。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

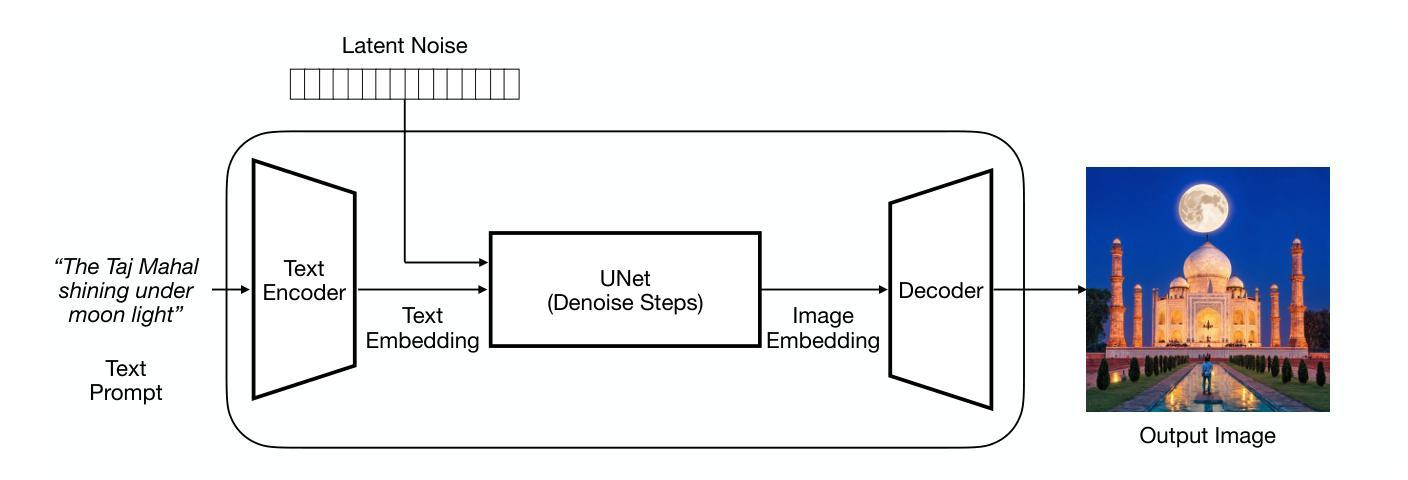
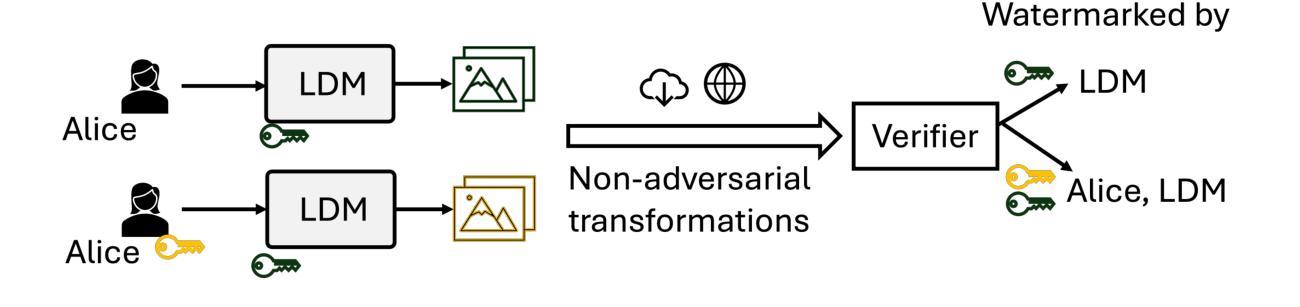
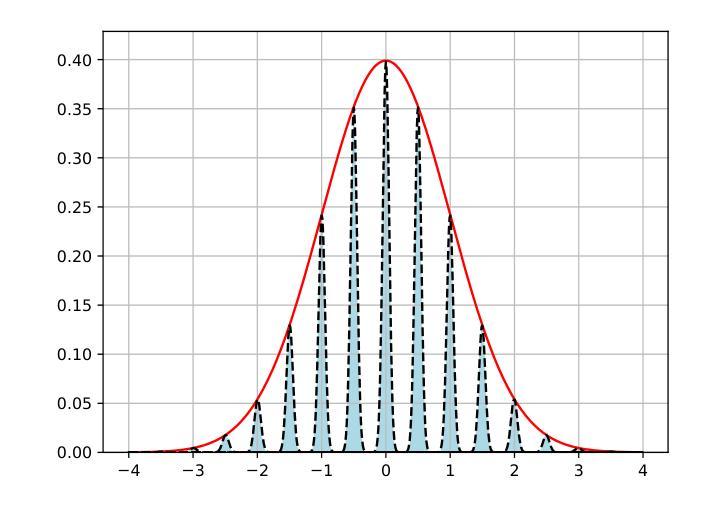
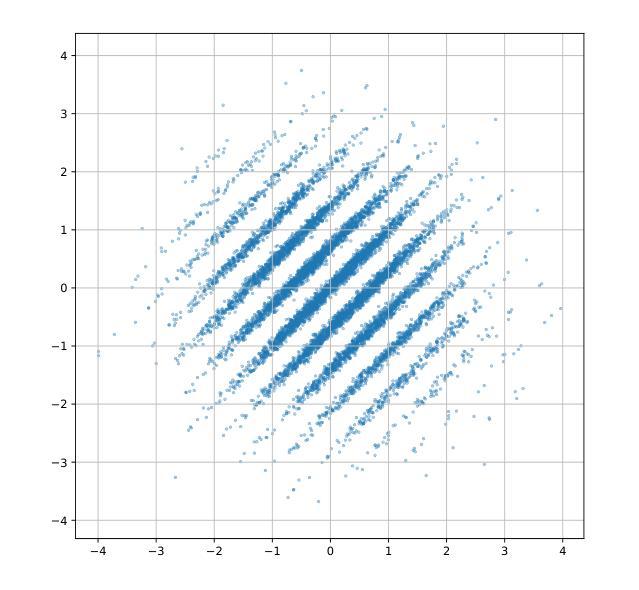
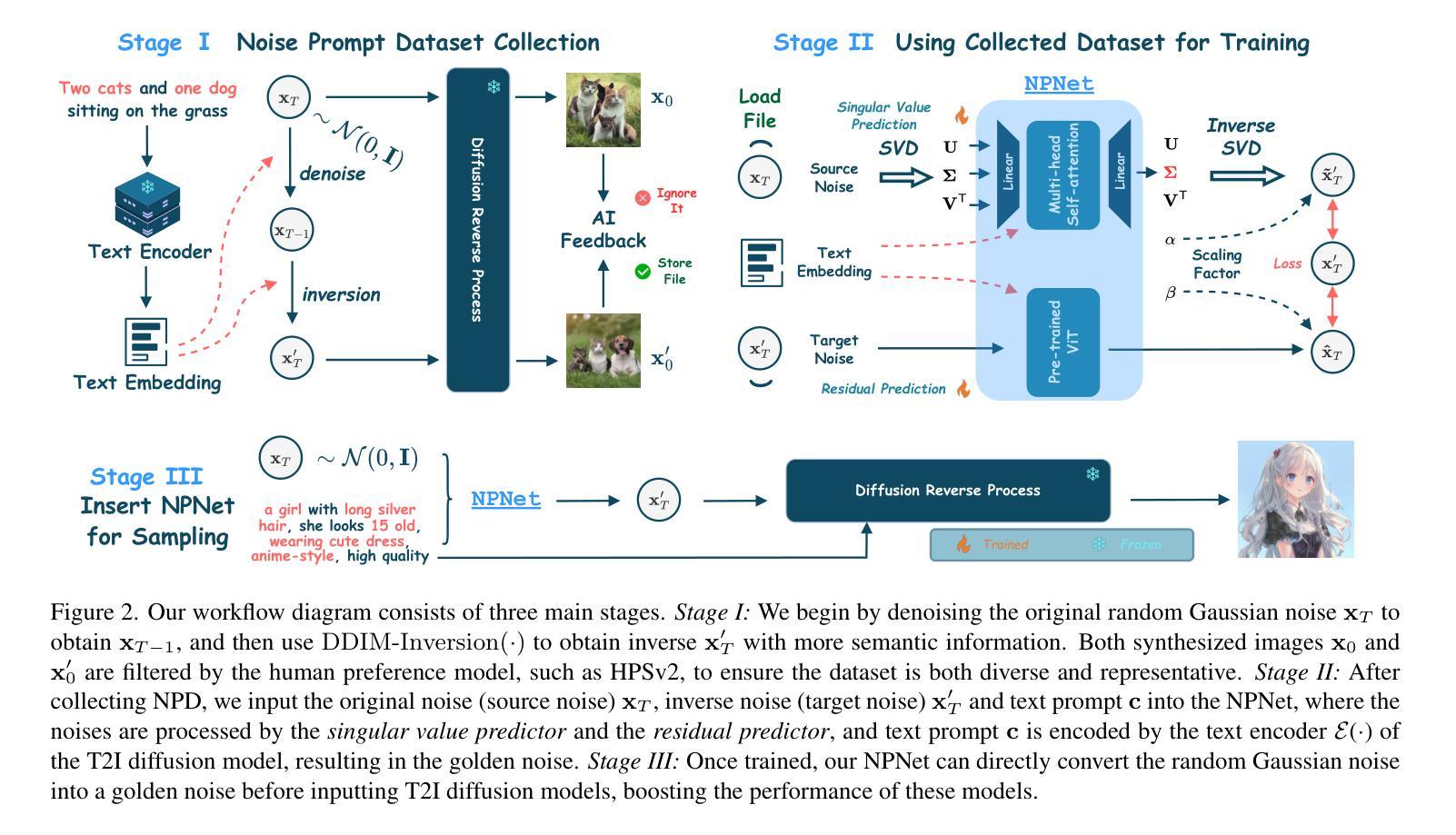
Golden Noise for Diffusion Models: A Learning Framework
Authors:Zikai Zhou, Shitong Shao, Lichen Bai, Zhiqiang Xu, Bo Han, Zeke Xie
Text-to-image diffusion model is a popular paradigm that synthesizes personalized images by providing a text prompt and a random Gaussian noise. While people observe that some noises are golden noises'' that can achieve better text-image alignment and higher human preference than others, we still lack a machine learning framework to obtain those golden noises. To learn golden noises for diffusion sampling, we mainly make three contributions in this paper. First, we identify a new concept termed the \textit{noise prompt}, which aims at turning a random Gaussian noise into a golden noise by adding a small desirable perturbation derived from the text prompt. Following the concept, we first formulate the \textit{noise prompt learning} framework that systematically learns prompted’’ golden noise associated with a text prompt for diffusion models. Second, we design a noise prompt data collection pipeline and collect a large-scale \textit{noise prompt dataset}(NPD) that contains 100k pairs of random noises and golden noises with the associated text prompts. With the prepared NPD as the training dataset, we trained a small \textit{noise prompt network}(NPNet) that can directly learn to transform a random noise into a golden noise. The learned golden noise perturbation can be considered as a kind of prompt for noise, as it is rich in semantic information and tailored to the given text prompt. Third, our extensive experiments demonstrate the impressive effectiveness and generalization of NPNet on improving the quality of synthesized images across various diffusion models, including SDXL, DreamShaper-xl-v2-turbo, and Hunyuan-DiT. Moreover, NPNet is a small and efficient controller that acts as a plug-and-play module with very limited additional inference and computational costs, as it just provides a golden noise instead of a random noise without accessing the original pipeline.
文本到图像的扩散模型是一种流行的范式,它通过提供文本提示和随机高斯噪声来合成个性化图像。人们观察到,有些噪声是“黄金噪声”,可以实现更好的文本-图像对齐和更高的人类偏好,但我们仍然缺乏机器学习框架来获取这些黄金噪声。为了学习扩散采样中的黄金噪声,本文主要有三个贡献。首先,我们提出了一个新的概念,称为“噪声提示”,旨在通过添加来自文本提示的小的可取扰动,将随机高斯噪声转变为黄金噪声。基于这一概念,我们制定了“噪声提示学习”框架,该框架系统地学习扩散模型中与文本提示相关的“提示”黄金噪声。其次,我们设计了噪声提示数据收集管道,并收集了大量包含10万对随机噪声和黄金噪声及其相关文本提示的“噪声提示数据集”(NPD)。使用准备好的NPD作为训练数据集,我们训练了一个小型“噪声提示网络”(NPNet),该网络可以直接学习将随机噪声转换为黄金噪声。学到的黄金噪声扰动可以被视为一种噪声提示,它富含语义信息,并且针对给定的文本提示进行了定制。第三,我们的大量实验表明,NPNet在提高各种扩散模型的合成图像质量方面表现出令人印象深刻的效果和泛化能力,包括SDXL、DreamShaper-xl-v2-turbo和Hunyuan-DiT。此外,NPNet是一个小且高效的控制器,作为一个即插即用的模块,具有非常有限的额外推理和计算成本,它只是提供一个黄金噪声,而不是随机噪声,无需访问原始管道。
论文及项目相关链接
摘要
扩散模型中的噪声提示学习。该研究提出了一种新的概念——噪声提示,旨在通过添加源于文本提示的小的可取扰动,将随机高斯噪声转化为“黄金噪声”。基于此概念,研究提出了噪声提示学习框架,系统地学习扩散模型中与文本提示相关的“提示性”黄金噪声。此外,研究还设计了噪声提示数据收集管道,并收集了大量包含随机噪声和黄金噪声及其相关文本提示的噪声提示数据集(NPD)。使用NPD作为训练数据集,训练了一个能够将随机噪声直接转化为黄金噪声的小型噪声提示网络(NPNet)。学习的黄金噪声扰动可视为一种噪声提示,它富含语义信息,并针对给定的文本提示进行定制。实验表明,NPNet在改善各种扩散模型合成图像的质量方面表现出令人印象深刻的效果和泛化能力,包括SDXL、DreamShaper-xl-v2-turbo和Hunyuan-DiT。而且,NPNet是一个小且高效的控制器,作为一个即插即用的模块,具有非常有限的额外推理和计算成本,它只是提供一个黄金噪声,而不是随机噪声,无需访问原始管道。
关键见解
- 引入“噪声提示”新概念,旨在通过添加小的、源于文本提示的扰动来优化随机噪声。
- 提出噪声提示学习框架,以学习与文本提示相关的黄金噪声。
- 设计并收集大规模的噪声提示数据集(NPD),包含随机噪声、黄金噪声及关联文本提示。
- 训练小型噪声提示网络(NPNet),能直接学习将随机噪声转化为黄金噪声。
- 黄金噪声扰动富含语义信息,与给定文本提示相匹配。
- NPNet在多种扩散模型中显著提高合成图像质量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决文本到图像扩散模型(Text-to-image diffusion models)中精确对齐给定文本提示(text prompts)的图像合成问题。具体来说,论文中提到虽然人们观察到某些噪声(称为“黄金噪声”)能够比其他噪声更好地实现文本-图像对齐并获得更高的人类偏好,但目前还缺乏一个机器学习框架来有效获得这些黄金噪声。因此,论文的主要目标是提出一个学习框架,用于通过添加从文本提示派生出来的小的期望扰动,将随机高斯噪声转换成黄金噪声,以提升扩散模型采样得到的图像质量和与文本提示的语义忠实度。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本文相关的研究工作:
文本嵌入对合成图像的影响:
- [15, 18, 37, 38, 43]:这些研究调查了文本嵌入对合成图像的影响,并利用这些嵌入进行无需训练的图像合成。
优化噪声以改善图像合成:
- [3, 5, 7, 22, 27]:这些研究观察到某些选定或优化的噪声是黄金噪声,可以帮助文本到图像扩散模型产生更好的语义忠实度,并提高合成图像的整体质量。
在采样过程中减少截断误差:
- [3, 7]:这些方法通过引入额外的模块(如注意力机制)来减少采样过程中的截断误差,并在组合泛化任务上展示了有希望的结果。
DDIM和DDIM反演:
- [35]:论文中介绍了DDIM(Denoising Diffusion Implicit Model)及其反演过程,这是一种先进的确定性采样技术,允许在保持合成样本质量的同时加快合成速度。
分类器自由引导(Classifier-free Guidance, CFG):
- [10]:CFG允许更好地控制合成过程,通过引导扩散模型朝向期望条件(如文本提示)来增强合成样本的质量和多样性。
图像合成的挑战和进展:
- [2, 4, 24, 25, 31]:这些工作探讨了文本到图像合成的挑战和进展,包括提高合成图像的个性化和与文本提示的对齐。
图像合成质量的评估:
- [8, 34, 39, 41, 45]:这些研究提出了不同的评估指标,用于衡量合成图像的质量和人类偏好。
这些相关研究为本文提出的噪声提示学习框架提供了理论基础和技术背景,同时也展示了文本到图像合成领域中存在的挑战和已有的解决方案。本文通过引入噪声提示的概念,并提出一个系统性的学习框架来获得与文本提示相关的黄金噪声,进一步推动了这一领域的研究进展。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为“噪声提示(noise prompt)”的新概念来解决这个问题,该概念旨在通过添加从文本提示派生出的小的期望扰动,将随机高斯噪声转换成黄金噪声。具体来说,论文提出了三个主要贡献来解决这个问题:
噪声提示学习框架:
- 论文首先定义了噪声提示的概念,旨在将随机噪声转换为黄金噪声,通过从文本提示中提取的小型期望扰动。
- 基于这个概念,论文提出了一个系统性的学习框架,即噪声提示学习框架,用于学习与文本提示相关的“提示”黄金噪声,以用于扩散模型。
噪声提示数据收集和NPNet设计:
- 为了实现上述框架,论文设计了一个噪声提示数据收集流程,并通过重新去噪采样方法收集了大规模的噪声提示数据集(NPD),包含100k对随机噪声和黄金噪声以及相关的文本提示。
- 使用这个数据集作为训练集,论文训练了一个小型的噪声提示网络(NPNet),该网络能够直接学习如何将随机噪声转换为黄金噪声。
NPNet的有效性和泛化能力的实验验证:
- 论文通过在多个主流扩散模型上进行广泛的实验,包括StableDiffusion-xl (SDXL)、DreamShaper-xl-v2-turbo和HunyuanDiT,验证了NPNet在提高合成图像质量方面的卓越性能和泛化能力。
- 实验结果显示,使用NPNet学习到的黄金噪声,不仅在视觉上提升了合成图像的整体质量和美学风格,而且在多个人类偏好评估指标上都显示出显著的改进。
总结来说,论文通过构建噪声提示学习框架、收集噪声提示数据集、设计和训练NPNet,以及在多个数据集和模型上验证其有效性和泛化能力,解决了如何为扩散模型获得黄金噪声的问题。这种方法不仅提高了图像合成的质量和与文本提示的语义忠实度,而且具有较小的额外推理和计算成本,具有很强的实用性和广泛的应用潜力。
Q: 论文做了哪些实验?
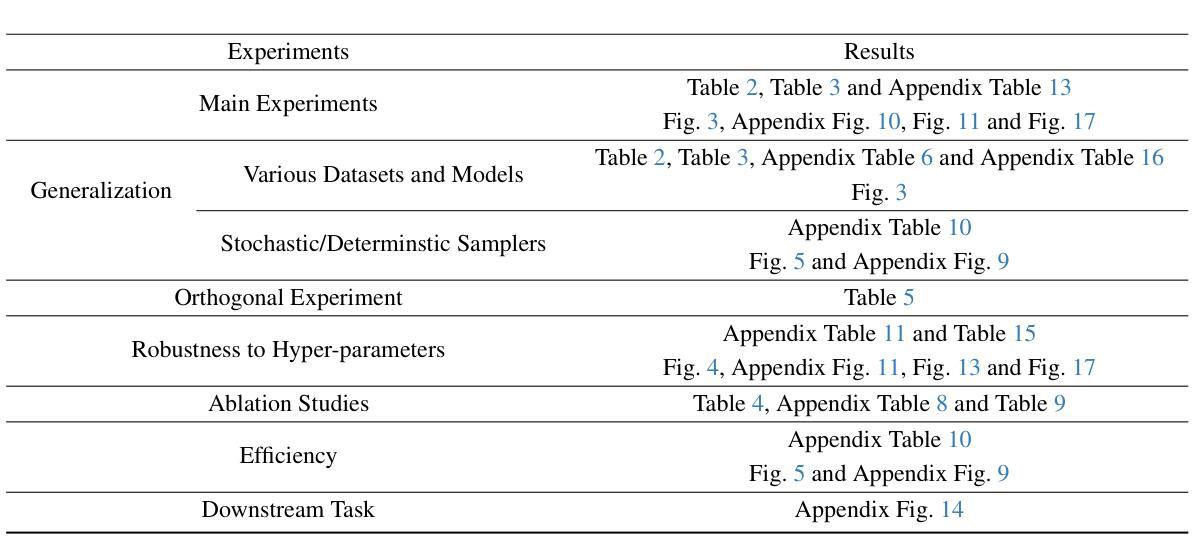
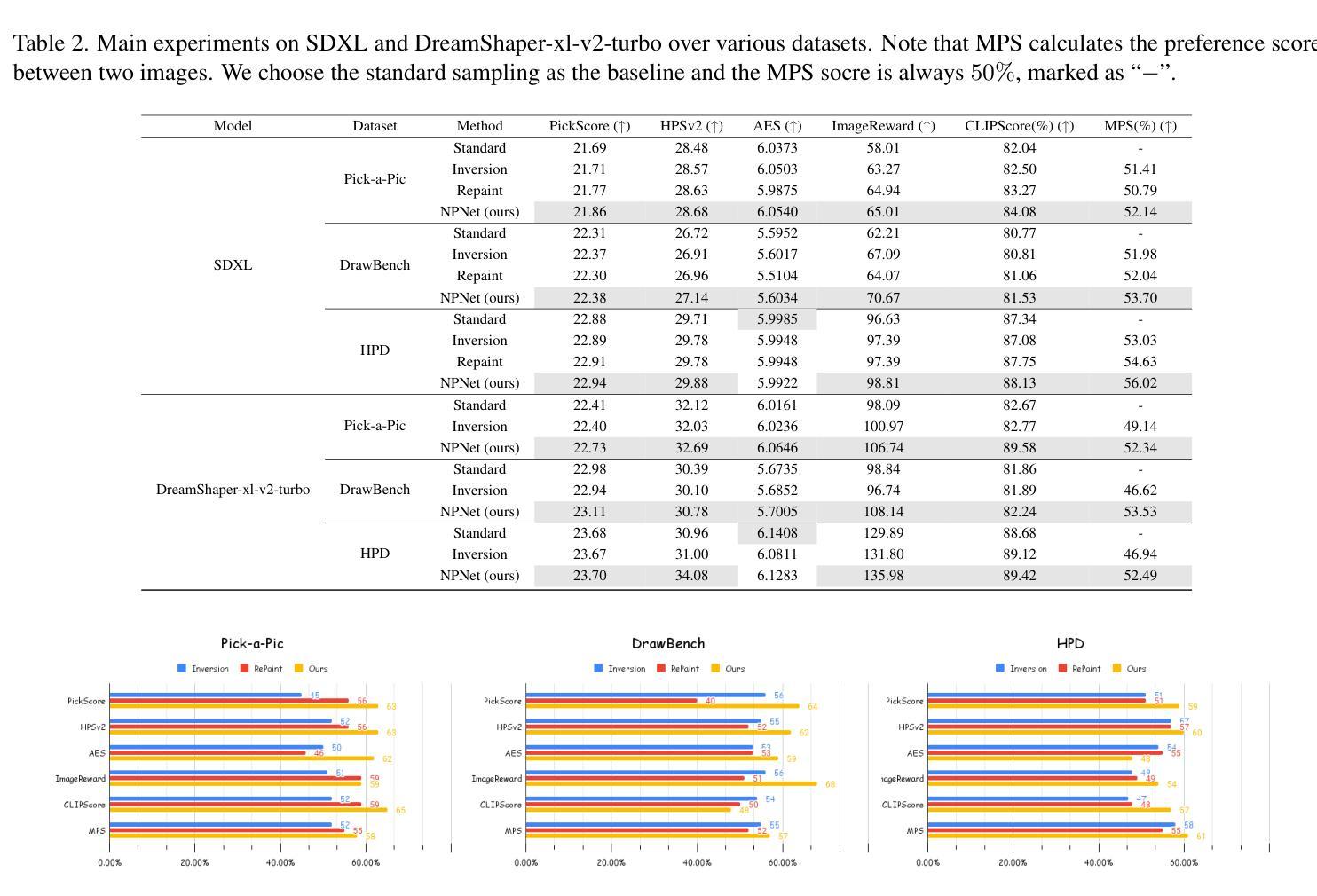
A: 根据论文内容,作者进行了一系列实验来评估NPNet(噪声提示网络)的有效性、泛化能力和效率。以下是他们进行的主要实验:
主实验:
- 在不同的文本到图像(T2I)扩散模型上评估NPNet,包括StableDiffusion-xl (SDXL)、DreamShaper-xl-v2-turbo和Hunyuan-DiT。
- 使用不同的数据集进行测试,包括Pick-a-Pic、DrawBench、HPD v2和GenEval。
- 利用六种人类偏好评估指标对模型进行评估,包括Human Preference Score v2 (HPSv2)、PickScore、Aesthetic Score (AES)、ImageReward、CLIPScore和Multi-dimensional Preference Score (MPS)。
跨数据集和模型的泛化实验:
- 检验NPNet在不同数据集和模型架构之间的泛化能力。
- 对NPNet在不同随机种子范围的泛化能力进行测试。
与随机性相关的实验:
- 评估NPNet在不同采样方法(包括随机和确定性采样器)上的性能。
正交实验:
- 探索NPNet与其他旨在提高合成图像与文本提示对齐度的方法(如DPO和AYS)的结合效果。
对超参数的鲁棒性分析:
- 研究NPNet对不同推理步骤、批量大小、训练周期和CFG值等超参数的鲁棒性。
消融研究:
- 对NPNet架构设计的消融研究,包括奇异值预测和残差预测的贡献。
效率分析和下游任务探索:
- 分析NPNet作为即插即用模块的内存消耗和推理延迟。
- 探索将NPNet与下游任务(如ControlNet)结合用于受控图像合成的潜力。
这些实验全面评估了NPNet的性能,包括其在不同模型和数据集上的效果、与其他方法的协同效应、对超参数的敏感性以及实际应用中的效率和实用性。通过这些实验,作者证明了NPNet作为一种提高扩散模型图像合成质量的有效工具,具有良好的泛化能力和实际应用价值。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
改进数据收集方法:
- 研究更高效和更可靠的数据收集方法,以提高训练数据的质量和多样性,进一步提升模型性能和可信度。
优化模型架构:
- 设计更精致和高效的模型架构,而不是依赖于当前的并行方法。例如,直接使用预训练的扩散模型来更精确地合成黄金噪声。
提高方法的泛化能力:
- 分析和改进模型在面对分布外提示(out-of-distribution prompts)时的泛化能力,甚至探索将应用范围扩展到文本到图像任务之外的可能性。
探索不同的训练策略:
- 研究不同的训练策略和正则化技术,以提高模型的鲁棒性和泛化性。
噪声注入和数据选择的深入分析:
- 对于通过重新去噪采样收集的训练数据,进行更深入的理解和分析,以减少可能引入的偏差。
跨模态应用:
- 探索NPNet在视频、3D内容生成以及其他AI生成内容(AIGC)业务产品中的应用,以实现更广泛的部署。
计算效率和实际部署:
- 进一步优化NPNet的计算效率,以便在资源受限的环境中进行实际部署。
理解噪声和图像质量的关系:
- 深入研究噪声如何影响图像合成质量,以及如何精确控制这一过程。
增强模型的解释性:
- 提高模型的可解释性,以便更好地理解模型是如何学习和转换噪声的。
多任务和多模态学习:
- 探索NPNet在多任务和多模态学习设置下的表现,例如结合图像和文本以外的模态,如音频或视频。
这些探索点可以帮助研究社区更深入地理解噪声在图像合成中的作用,并进一步提升基于扩散模型的图像生成技术的性能和应用范围。
Q: 总结一下论文的主要内容
A: 论文《Golden Noise for Diffusion Models: A Learning Framework》主要研究了如何通过学习“黄金噪声”来提升文本到图像扩散模型的图像合成质量。以下是论文的主要内容总结:
问题定义:
- 文本到图像扩散模型在给定文本提示的情况下合成图像,但不同噪声会导致不同的合成结果。研究者们发现某些“黄金噪声”能产生更好的文本-图像对齐和更高的人类偏好,但缺乏一个机器学习框架来获取这些黄金噪声。
主要贡献:
- 提出了“噪声提示”的新概念,旨在通过添加从文本提示派生的小型期望扰动,将随机高斯噪声转换为黄金噪声。
- 构建了一个噪声提示学习框架,通过系统性学习将文本提示与黄金噪声相关联。
- 设计了一个大规模噪声提示数据集(NPD)和噪声提示网络(NPNet),用于直接学习如何将随机噪声转换为黄金噪声。
方法论:
- 数据收集:通过重新去噪采样方法收集噪声对,并使用人类偏好模型进行数据筛选。
- NPNet架构:包含奇异值预测和残差预测两个关键组件,利用文本提示的语义信息来预测黄金噪声。
- 训练和推理:使用收集的数据集训练NPNet,然后将训练好的NPNet用于将随机噪声转换为黄金噪声,以提升图像合成质量。
实验验证:
- 在多个数据集和不同的扩散模型上进行了广泛的实验,包括SDXL、DreamShaper-xl-v2-turbo和HunyuanDiT。
- 使用多种人类偏好评估指标,如HPSv2、PickScore、AES等,验证了NPNet在提升合成图像质量方面的有效性。
- 展示了NPNet的泛化能力、对超参数的鲁棒性、与其它方法的正交性以及在下游任务中的应用潜力。
结论与未来方向:
- NPNet作为一种即插即用的模块,具有显著的性能提升和实际应用价值。
- 论文讨论了NPNet的局限性,并提出了未来可能的研究方向,包括改进数据收集方法、优化模型架构和提高泛化能力等。
总体而言,论文提出了一个创新的框架和方法,通过学习黄金噪声来改善文本到图像扩散模型的图像合成质量,具有广泛的应用前景和实际意义。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Uncovering Hidden Subspaces in Video Diffusion Models Using Re-Identification
Authors:Mischa Dombrowski, Hadrien Reynaud, Bernhard Kainz
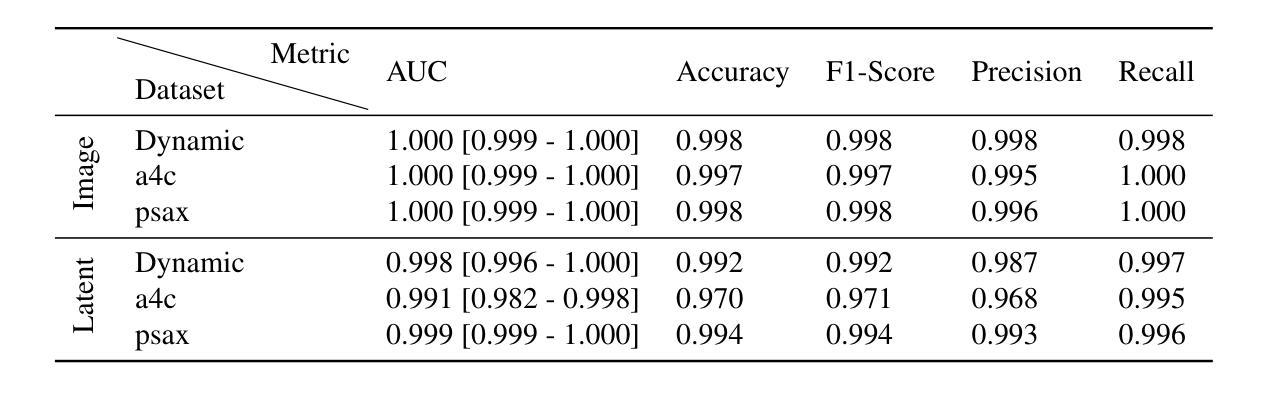
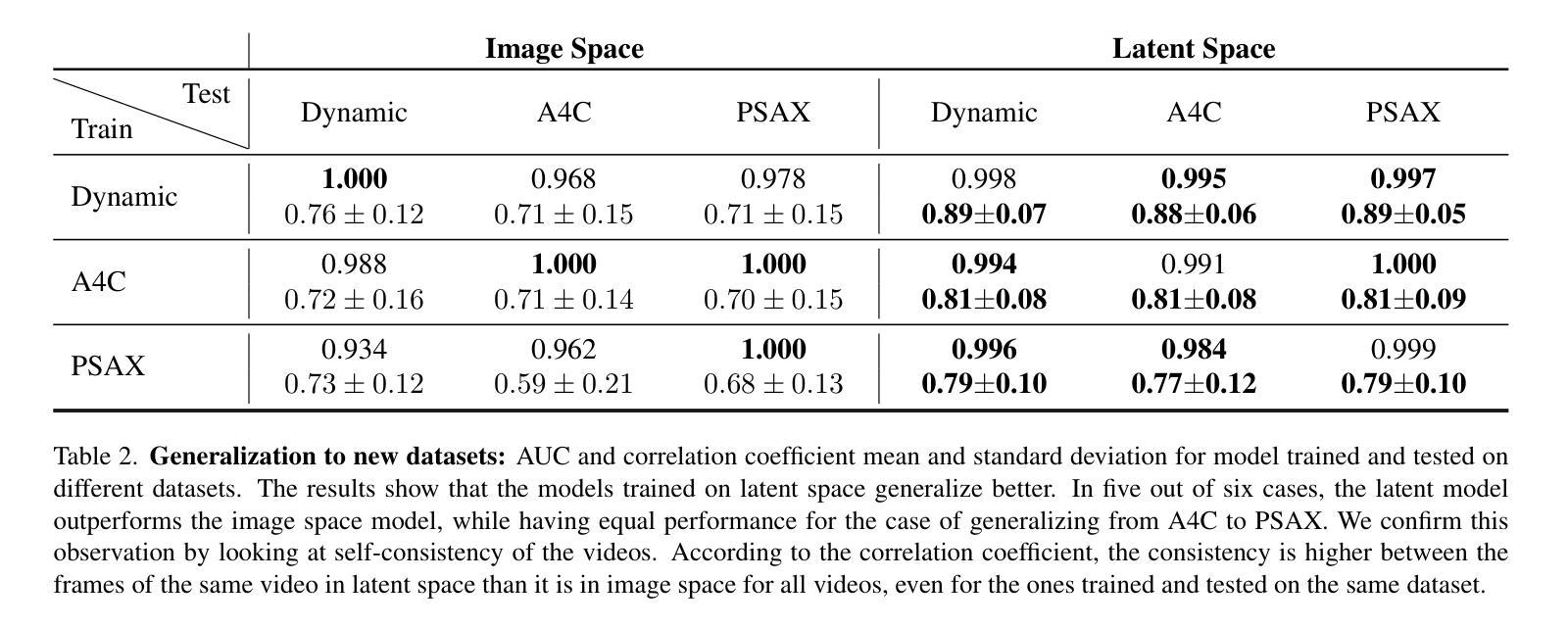
Latent Video Diffusion Models can easily deceive casual observers and domain experts alike thanks to the produced image quality and temporal consistency. Beyond entertainment, this creates opportunities around safe data sharing of fully synthetic datasets, which are crucial in healthcare, as well as other domains relying on sensitive personal information. However, privacy concerns with this approach have not fully been addressed yet, and models trained on synthetic data for specific downstream tasks still perform worse than those trained on real data. This discrepancy may be partly due to the sampling space being a subspace of the training videos, effectively reducing the training data size for downstream models. Additionally, the reduced temporal consistency when generating long videos could be a contributing factor. In this paper, we first show that training privacy-preserving models in latent space is computationally more efficient and generalize better. Furthermore, to investigate downstream degradation factors, we propose to use a re-identification model, previously employed as a privacy preservation filter. We demonstrate that it is sufficient to train this model on the latent space of the video generator. Subsequently, we use these models to evaluate the subspace covered by synthetic video datasets and thus introduce a new way to measure the faithfulness of generative machine learning models. We focus on a specific application in healthcare echocardiography to illustrate the effectiveness of our novel methods. Our findings indicate that only up to 30.8% of the training videos are learned in latent video diffusion models, which could explain the lack of performance when training downstream tasks on synthetic data.
潜在视频扩散模型由于生成的图像质量和时间一致性,能够轻易欺骗普通观察者和领域专家。除了娱乐之外,这在安全数据共享的全合成数据集领域创造了机会,这在医疗保健以及其他依赖敏感个人信息的领域尤为关键。然而,关于这种方法的隐私担忧尚未得到完全解决,并且在合成数据上训练特定下游任务的模型仍然表现较差,不如在真实数据上训练的模型。这种差异部分可能是由于采样空间是训练视频的子空间,有效地减少了下游模型的训练数据量。此外,生成长视频时时间一致性的降低也可能是造成这种情况的一个因素。
论文及项目相关链接
PDF 8 pages, 5 tables, 6 figures; v2 Acknowledgements added
Summary
本文介绍了潜在视频扩散模型能够在产生高质量图像和保持时间连贯性的同时欺骗普通观察者和领域专家。除了娱乐应用外,这为安全共享完全合成的数据集创造了机会,尤其在医疗保健和其他依赖敏感个人信息的领域至关重要。然而,该方法的隐私问题尚未得到充分解决,并且在合成数据上训练的下游任务模型表现仍然逊于真实数据训练的模型。本文展示了在潜在空间训练隐私保护模型在计算上更高效且更具通用性。为了研究下游性能下降的因素,本文提出了使用再识别模型作为隐私保护过滤器,并证明在视频生成器的潜在空间上训练此模型是足够的。然后,使用这些模型评估合成视频数据集所覆盖的子空间,从而引入了一种衡量生成机器学习模型忠实度的新方法。本文重点介绍在医疗保健领域的超声心动图应用,以说明新方法的有效性。研究发现,潜在视频扩散模型仅学习到训练视频的30.8%,这可能是下游任务在合成数据上训练效果不佳的原因。
Key Takeaways
- 潜在视频扩散模型能生成高质量且时间连贯的图像,可欺骗普通观察者和领域专家。
- 合成数据集在安全数据共享中具有应用潜力,尤其在医疗保健等敏感信息领域。
- 潜在视频扩散模型的隐私问题尚未得到充分解决。
- 在合成数据上训练的下游任务模型表现不如真实数据训练的模型。
- 在潜在空间训练隐私保护模型更加高效且具备更好的通用性。
- 使用再识别模型作为隐私保护过滤器是调查下游性能下降因素的有效方法。
- 新方法能够衡量生成机器学习模型的忠实度,并通过超声心动图等实际应用案例展示其有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在使用视频扩散模型生成合成数据时的隐私保护问题,以及这些合成数据在特定下游任务中的表现不如真实数据训练的模型的问题。具体来说,论文关注以下几个方面:
隐私保护:论文探讨了在使用生成模型公开发布合成视频数据时,如何确保这些数据不会引起隐私问题。尽管已有技术用于确保隐私,但还没有直接证据表明可以在视频扩散模型的潜在空间中确保隐私。
合成数据与真实数据的性能差异:论文指出,尽管合成数据集在样本质量上很高,但在特定下游任务(如分类和分割)上,使用合成数据训练的模型性能仍然不如使用真实数据训练的模型。论文试图找出导致这种性能差异的原因。
生成模型的覆盖范围:论文提出,当前用于量化生成模型的方法可能没有成功捕获所有相关属性,以超越真实数据集。论文假设部分原因是生成模型可能只学习了训练集的一个子空间,导致在合成数据上训练的下游模型性能降低。
计算效率和泛化能力:论文还探讨了在潜在空间中训练隐私保护模型的计算效率和模型的泛化能力。
综上所述,论文旨在通过提出新的方法来衡量生成机器学习模型的忠实度,并特别关注在医疗领域(如超声心动图)中的应用,以展示这些新方法的有效性。论文的主要贡献在于展示了在潜在空间中训练隐私保护模型的可行性,并使用这些模型来评估合成视频数据集的子空间覆盖范围,从而为提高合成数据在下游任务中的性能提供了新的视角。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的工作:
Latent Generative Models:
- 论文提到了最近在扩散模型方面的进展,特别是将图像生成操作在潜在空间中进行的方法。这种方法通过先生成图像嵌入,然后由另一个模型解码,提高了计算效率并减少了数据需求。相关工作包括[9, 18, 39]。
Privacy:
- 论文讨论了两种主要的隐私保护方法:保证模型本身的隐私和确保发布的数据是隐私合规的。这包括使用差分隐私来数学上保证隐私,以及使用重新识别模型来评估隐私合规性。相关工作包括[10, 15, 32]。
Training on Synthetic Data:
- 论文指出,尽管合成数据集样本质量高,但在特定下游任务上,使用合成数据训练的模型性能仍然不如使用真实数据训练的模型。相关工作包括[1, 38],这些研究展示了在合成数据上训练的模型可能存在的问题,例如模式偏移和多样性降低。
Echocardiography and Medical Imaging:
- 论文中提到了超声心动图(Echocardiography)和医学成像领域的相关工作,包括自动评估心脏功能和数据丰富性。相关工作包括[6, 27, 35]。
Generative Models in Healthcare:
- 论文提到了生成模型在医疗领域的应用,如分析诊断反事实、解剖学的真实表示、自动化诊断或数据丰富性和领域泛化。相关工作包括[20, 22]。
Variational Autoencoders (VAEs):
- 论文中提到了使用变分自编码器(VAEs)来增强模型的计算效率,VAEs被训练用于图像重建任务。相关工作包括[36]。
Siamese Neural Networks for Privacy Models:
- 论文中提到了使用孪生神经网络模型进行隐私保护的方法,这涉及到训练一个自监督特征提取器,以学习区分不同的解剖结构。相关工作包括[28]。
这些相关研究为论文提出的工作提供了理论基础和技术背景,论文在此基础上进一步探索了隐私保护模型在潜在空间中的训练和应用,以及评估合成视频数据集的子空间覆盖范围和生成模型的忠实度。
Q: 论文如何解决这个问题?
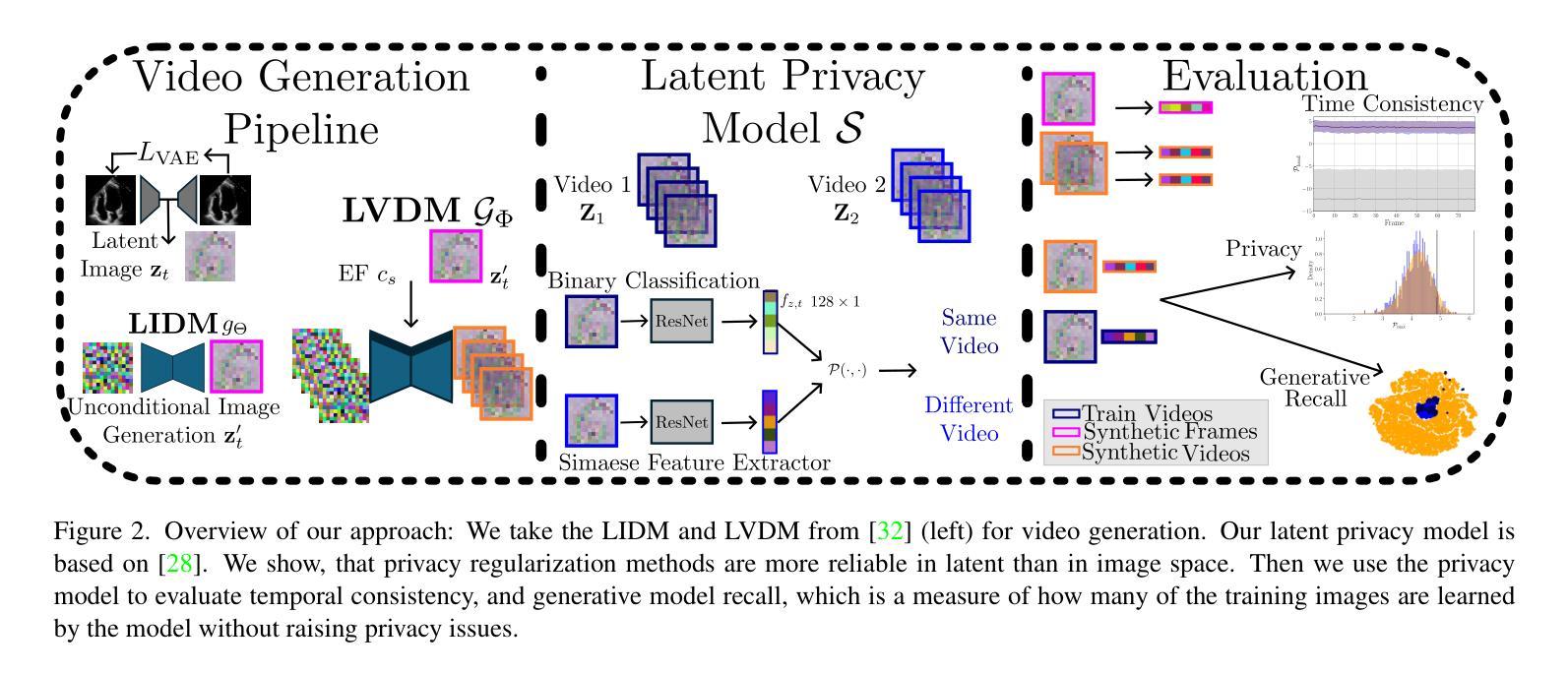
A: 论文通过以下几个步骤解决上述问题:
1. 提出在潜在空间训练隐私保护模型
- 论文首先展示了在潜在空间中训练隐私模型是计算上更高效的,并且可以得到更好的泛化结果。这是通过比较在图像空间和潜在空间中训练的隐私模型来实现的。
2. 使用重识别模型评估学习到的子空间和时间一致性
- 论文提出使用一个重识别模型来评估合成视频数据集覆盖的子空间,并以此衡量生成机器学习模型的忠实度。这个重识别模型之前被用作隐私保护过滤器。
3. 训练变分自编码器(VAEs)以增强计算效率
- 论文利用变分自编码器(VAEs)来训练视频扩散模型,从而提高模型的计算效率。VAEs通过将视频帧编码成潜在表示,然后由解码器重构原始帧,从而实现信息压缩。
4. 训练扩散模型完全在潜在空间操作
- 论文中提到的生成模型完全在潜在空间中工作,即它们在潜在视频上进行训练并产生合成的潜在视频。
5. 建立基于视频的潜在隐私模型
- 论文提出了一个基于视频的潜在隐私模型,该模型使用孪生神经网络进行二分类,判断潜在帧是否来自同一视频。
6. 评估生成模型的召回率
- 论文评估了生成模型的召回率,即模型能够生成接近训练图像的样本的能力。通过比较合成视频和真实视频之间的相似性,论文揭示了当前生成模型只学习了训练集的一个独特子空间。
7. 评估视频的时间一致性
- 论文还测试了使用隐私模型评估视频的时间一致性,通过在真实测试视频上运行潜在模型并检查给定视频的所有帧之间的解剖距离。
8. 下游任务评估
- 论文通过训练下游模型来估计真实世界性能,并比较了使用真实数据和合成数据训练的模型之间的性能差异。
总结来说,论文通过在潜在空间中训练隐私保护模型,并使用这些模型来评估合成视频数据集的子空间覆盖范围和时间一致性,提出了一种新的方法来衡量生成机器学习模型的忠实度,并探讨了如何提高合成数据在下游任务中的性能。
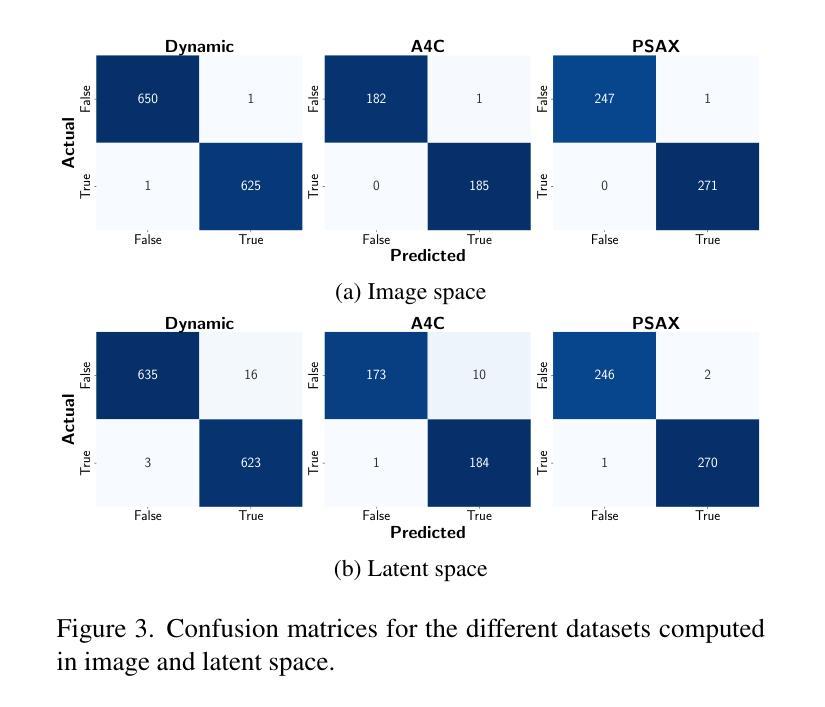
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证提出方法的有效性,具体包括以下几个方面:
1. 比较潜在空间和图像空间隐私模型的优越性
- 实验目的:比较在潜在空间和图像空间训练的隐私模型的性能和泛化能力。
- 实验结果:发现两种模型在训练集上表现相当,但潜在空间模型在泛化能力上更优。
2. 评估隐私模型
- 实验目的:使用隐私模型来评估合成视频的隐私保护能力。
- 实验结果:通过计算PMax值(最大距离函数值)并设定阈值,只有少数合成视频被标记为隐私问题,表明合成视频生成模型在隐私保护方面表现良好。
3. 评估生成模型的召回率
- 实验目的:评估生成模型能够学习并生成接近训练集分布的能力。
- 实验结果:发现合成视频只代表了真实数据分布的一小部分,表明生成模型可能只学习了训练集的一个子空间。
4. 评估视频的时间一致性
- 实验目的:使用隐私模型来评估合成视频和真实视频的时间一致性。
- 实验结果:模型能够一致地识别出属于同一视频的帧,表明模型可以用来评估视频的时间一致性。
5. 下游任务评估
- 实验目的:评估使用合成数据训练的下游模型(如心脏射血分数估计)的性能,并与使用真实数据训练的模型进行比较。
- 实验结果:尽管合成数据训练的模型性能仍然不如真实数据,但基于重识别模型选择的合成数据训练的模型表现有所改善。
6. 使用t-SNE可视化学习到的表示
- 实验目的:通过t-SNE可视化来展示合成样本和真实样本在特征空间中的分布情况。
- 实验结果:合成样本的表示与真实样本的表示之间存在较大的差异,表明合成样本并没有完全覆盖真实样本的分布。
这些实验共同验证了论文提出方法的有效性,特别是在隐私保护、生成模型的召回率评估以及视频时间一致性评估方面。通过这些实验,论文展示了其方法在提高合成数据质量、评估生成模型性能以及保护隐私方面的潜力。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些有趣的发现和方法,但仍有一些领域可以进一步探索和改进:
1. 隐私保护模型的改进和优化
- 探索不同的隐私保护技术:研究其他可能的隐私保护技术,如联邦学习或同态加密,以增强模型的隐私保护能力。
- 优化隐私保护模型的参数:基于不同的数据集和应用场景,调整隐私保护模型的参数以获得更好的性能和隐私保护平衡。
2. 提高生成模型的召回率
- 改进生成模型:研究如何改进生成模型以提高其召回率,使其能更全面地覆盖训练数据的分布。
- 生成模型的多样性:探索如何增加生成数据的多样性,避免模式崩溃,提高合成数据集的代表性。
3. 评估指标的改进
- 开发新的评估指标:针对生成模型的特点,开发更有效的评估指标来衡量模型的生成质量和隐私保护能力。
- 评估指标的标准化:推动生成模型评估指标的标准化,以便不同研究之间的比较和评估。
4. 合成数据在下游任务中的应用
- 合成数据的实用性研究:进一步研究合成数据在各种下游任务(如分类、分割、检测等)中的应用效果,以及如何优化模型以更好地利用合成数据。
- 合成数据与真实数据的结合:探索如何有效地结合合成数据和真实数据,以提高模型的泛化能力和性能。
5. 跨领域应用
- 其他领域的应用:将论文中的方法和技术应用于其他领域,如自然语言处理、语音识别等,探索其在不同领域的有效性和适用性。
6. 计算效率的提升
- 模型训练和推理的优化:研究如何进一步优化模型的训练和推理过程,减少计算资源的需求,提高模型的实用性。
7. 模型解释性和透明度
- 提高模型的可解释性:研究如何提高隐私保护模型和生成模型的可解释性,让用户更好地理解和信任模型的决策过程。
这些方向不仅可以推动生成模型和隐私保护技术的发展,还可能对数据隐私、模型安全性和人工智能的伦理问题产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在探讨和解决在使用视频扩散模型生成合成视频数据时的隐私保护问题,以及这些合成数据在特定下游任务中的表现不如真实数据训练的模型的问题。以下是论文的主要贡献和发现:
隐私保护模型训练:论文首先展示了在潜在空间中训练隐私保护模型不仅计算上更高效,而且相较于在图像空间中训练的模型,能够获得更好的泛化能力。
重识别模型的应用:论文提出使用一个之前用于隐私保护的重识别模型来评估合成视频数据集覆盖的子空间,并以此衡量生成机器学习模型的忠实度。
计算效率提升:通过使用变分自编码器(VAEs),论文增强了模型的计算效率,使得在潜在空间中训练视频扩散模型变得更加高效。
潜在空间操作:论文中的生成模型完全在潜在空间中工作,即它们在潜在视频上进行训练并产生合成的潜在视频。
基于视频的潜在隐私模型:论文提出了一个基于视频的潜在隐私模型,使用孪生神经网络进行二分类,判断潜在帧是否来自同一视频。
评估生成模型的召回率:论文评估了生成模型的召回率,发现合成视频只代表了真实数据分布的一小部分,表明生成模型可能只学习了训练集的一个子空间。
评估视频的时间一致性:论文测试了使用隐私模型评估视频的时间一致性,并发现模型能够一致地识别出属于同一视频的帧。
下游任务评估:论文通过训练下游模型来估计真实世界性能,并比较了使用真实数据和合成数据训练的模型之间的性能差异。
总结来说,论文通过在潜在空间中训练隐私保护模型,并使用这些模型来评估合成视频数据集的子空间覆盖范围和时间一致性,提出了一种新的方法来衡量生成机器学习模型的忠实度,并探讨了如何提高合成数据在下游任务中的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Unpacking SDXL Turbo: Interpreting Text-to-Image Models with Sparse Autoencoders
Authors:Viacheslav Surkov, Chris Wendler, Mikhail Terekhov, Justin Deschenaux, Robert West, Caglar Gulcehre
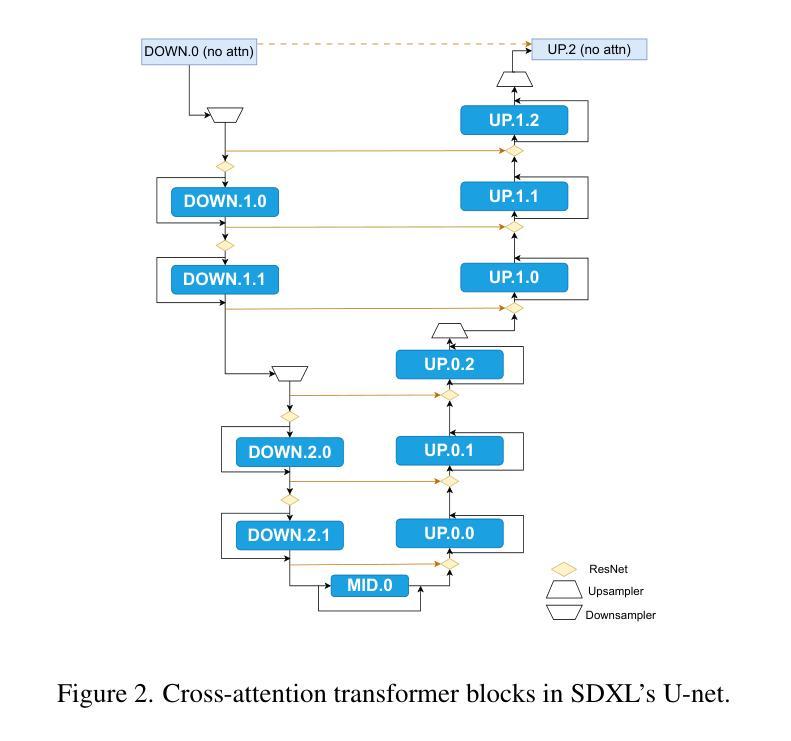
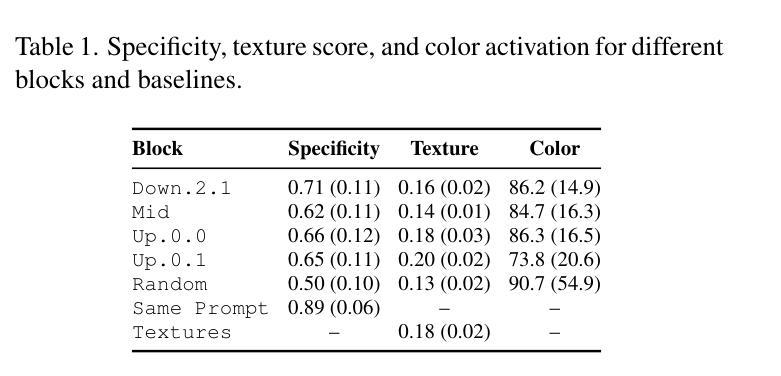
Sparse autoencoders (SAEs) have become a core ingredient in the reverse engineering of large-language models (LLMs). For LLMs, they have been shown to decompose intermediate representations that often are not interpretable directly into sparse sums of interpretable features, facilitating better control and subsequent analysis. However, similar analyses and approaches have been lacking for text-to-image models. We investigated the possibility of using SAEs to learn interpretable features for a few-step text-to-image diffusion models, such as SDXL Turbo. To this end, we train SAEs on the updates performed by transformer blocks within SDXL Turbo’s denoising U-net. We find that their learned features are interpretable, causally influence the generation process, and reveal specialization among the blocks. In particular, we find one block that deals mainly with image composition, one that is mainly responsible for adding local details, and one for color, illumination, and style. Therefore, our work is an important first step towards better understanding the internals of generative text-to-image models like SDXL Turbo and showcases the potential of features learned by SAEs for the visual domain. Code is available at https://github.com/surkovv/sdxl-unbox
稀疏自编码器(Sparse Autoencoders,简称SAE)已成为大型语言模型(Large Language Models,简称LLM)逆向工程的核心组成部分。对于LLM,SAE已被证明能够分解中间表示,这些表示通常不能直接解释为稀疏的可解释特征的总和,从而促进了更好的控制和后续分析。然而,对于文本到图像模型,类似的分析和方法却相对缺乏。我们调查了使用SAE来学习文本到图像扩散模型的可解释特征的可能性,例如SDXL Turbo等几步模型。为此,我们在SDXL Turbo的降噪U-net中的transformer块所执行的更新上训练SAE。我们发现其学习的特征是可解释的,能够对生成过程产生因果影响,并揭示了各块之间的专门化。尤其我们发现一个主要处理图像组合的块,一个主要负责添加局部细节的块,以及一个处理颜色、照明和风格的块。因此,我们的工作是一个重要的第一步,有助于更好地了解像SDXL Turbo这样的生成文本到图像模型的内部,并展示了SAE在视觉领域学习的特征的潜力。相关代码可在https://github.com/surkovv/sdxl-unbox找到。
论文及项目相关链接
Summary:
本文探讨了使用稀疏自编码器(SAE)学习文本到图像扩散模型的可解释特征的可能性。通过对SDXL Turbo模型的去噪U-net中的转换器块进行训练,发现学到的特征是可解释的,并且能影响生成过程,显示出各块之间的专业化分工。特别是发现一个块主要负责图像组合,一个块主要负责添加局部细节,另一个块负责颜色、照明和风格。SAE在视觉领域的学习潜力得到了展示。
Key Takeaways:
- 稀疏自编码器(SAE)被用于学习文本到图像扩散模型的可解释特征。
- SAE在SDXL Turbo模型的去噪U-net中的转换器块上进行训练。
- 学到的特征是可解释的,能影响生成过程。
- 不同转换器块在模型内部具有不同的职责和功能,如图像组合、添加局部细节以及处理颜色、照明和风格等。
- 该研究是理解生成式文本到图像模型(如SDXL Turbo)内部的重要第一步。
- SAE在视觉领域的学习潜力得到了验证,表明其在理解复杂模型中的应用价值。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何理解和解释大型文本到图像生成模型(例如SDXL Turbo)的内部工作机制。具体来说,论文的目标是:
逆向工程和解释:使用稀疏自编码器(Sparse Autoencoders, SAEs)来分解和解释大型语言模型(LLMs)的中间表示,这些表示通常难以直接解释。对于文本到图像模型,类似的分析和方法还比较缺乏。
揭示生成过程中的特定特征:通过训练SAEs来学习SDXL Turbo模型中几个步骤的文本到图像扩散模型的可解释特征,以更好地控制和后续分析生成过程。
理解模型内部结构:通过分析SAEs学习到的特征,揭示SDXL Turbo等生成文本到图像模型的内部工作机制,特别是不同transformer块在图像生成过程中的专有角色和功能。
提高模型的可解释性和控制能力:通过识别和解释这些特征,可以更好地控制图像生成过程,并为进一步的分析(例如电路提取)提供便利。
综上所述,论文的主要贡献在于展示了SAEs在理解扩散模型(如SDXL Turbo)中的潜力,以及它们在视觉领域学习到的特征对于解释和控制生成过程的重要性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是与本研究相关的一些研究:
逆向工程和解释大型语言模型(LLMs):
- Olah et al. (2020) 提供了对视觉模型和基于变换器的LLMs进行逆向工程的框架。
- Rai et al. (2024) 提供了基于变换器的语言模型的机制性可解释性的实用综述。
稀疏自编码器(SAEs)在解释LLMs方面的应用:
- Yun et al. (2021) 展示了通过分解LLMs的前向传播中的中间表示来学习联合特征字典的可能性。
- Cunningham et al. (2023) 和 Bricken et al. (2023) 展示了如何使用SAEs来分解LLMs中的元素,使其具有单一语义特征。
文本到图像生成模型:
- DALL-E模型 (Ramesh et al., 2021) 结合学习到的视觉词汇和序列建模,根据用户输入提示生成高质量图像。
- 基于文本条件扩散模型的研究,例如Rombach et al. (2022), Saharia et al. (2022b), 和 Podell et al. (2023)。
扩散模型:
- Sohl-Dickstein et al. (2015) 提出了扩散模型的概念。
- Ho et al. (2020) 和 Song & Ermon (2020) 展示了扩散模型在图像生成中的可行性。
分析扩散模型的潜在空间:
- Kwon et al. (2023) 展示了扩散模型自然具有语义有意义的潜在空间。
- Park et al. (2023) 使用黎曼几何分析扩散模型的潜在空间。
使用SAEs进行机制性解释:
- Bricken et al. (2023) 展示了通过在MLPs中分解神经元激活来学习可解释特征的可能性。
- Gao et al. (2024) 和 Templeton et al. (2024) 训练了甚至是在最先进的LLMs上的SAEs。
与SAEs相关的其他研究:
- Bau et al. (2019) 解释并操纵了生成对抗网络中的神经元。
- Ismail et al. (2023) 将概念瓶颈方法应用于包括扩散模型在内的生成图像模型。
- Daujotas (2024) 使用SAEs分解CLIP视觉嵌入,并用它们在扩散模型中进行条件图像生成。
这些研究构成了本文研究的理论和方法论基础,并与本文的研究目标和方法紧密相关。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决理解和解释大型文本到图像生成模型(如SDXL Turbo)的问题:
应用稀疏自编码器(SAEs):
- 使用SAEs来分解SDXL Turbo中间表示,将难以直接解释的表示转换为稀疏的、可解释的特征之和。
开发SDLens库:
- 开发一个名为SDLens的库,用于缓存和操作SDXL Turbo前向传播的中间结果,从而创建数据集。
训练SAEs:
- 在SDLens库的帮助下,收集SDXL Turbo的中间特征图,并用它们来训练每个transformer块的多个SAEs。
定性和定量分析:
- 对SAEs学习到的特征进行定性和定量分析,包括可视化技术的开发和应用,以分析特征的可解释性和因果效应。
案例研究:
- 通过两个案例研究,可视化和解释不同transformer块中的激活特征,并发现某些transformer块专门处理图像合成、细节添加和风格。
设计实验:
- 设计多个定量实验来验证假设,并展示这些假设在更大的样本量上也成立。
创建自动特征注释管道:
- 对于负责图像合成的transformer块,创建一个自动特征注释管道,利用视觉语言模型(VLMs)对特征进行自动注释。
开源代码和资源:
- 开源SDLens库和训练好的SAEs,为进一步的研究提供基础。
通过这些步骤,论文展示了SAEs在揭示SDXL Turbo等扩散模型内部结构方面的潜力,并为未来关于图像生成的更复杂问题的研究铺平了道路。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来支持其发现和假设,以下是实验的详细描述:
1. 训练SAEs(稀疏自编码器)
- 作者在SDXL Turbo模型的特定transformer块上训练了多个SAEs,以学习中间特征图的稀疏表示。
- 收集了1.5M个LAION-COCO提示上的SDXL Turbo中间特征图,每个特征图的尺寸为16×16,为每个transformer块提供了384M个密集特征向量用于训练。
2. 定性分析
- 特征可视化技术:开发了技术来可视化和分析SAEs学习到的特征,包括空间激活、数据集中的顶级示例和激活调制。
- 案例研究:通过两个案例研究,分析了不同transformer块中最活跃的特征,并观察了它们在特定提示下的行为。
3. 定量评估
- 特征注释管道:使用大型视觉语言模型(如GPT-4o)自动注释down.2.1 transformer块的特征,并评估注释的质量。
- 特异性、纹理得分和颜色激活:计算不同块的特征特异性、纹理相似度得分和颜色敏感性,与随机基线进行比较。
- 干预局部性:评估特征在激活区域内外的影响,以定量验证特征的局部性。
4. 额外的定量实验
- 特异性:通过计算特征激活图像之间的相似性来评估特征的特异性。
- 因果关系:使用特征注释来衡量特征的因果强度,通过比较空提示干预图像与注释之间的相似度。
- 敏感性:通过基于特征注释收集的提示来评估特征的敏感性,并计算特征在生成图像中的激活比例。
这些实验旨在从不同角度评估SAEs学习到的特征的可解释性、特异性、因果效应和敏感性,并通过定量方法验证了作者的定性观察。通过这些实验,作者能够展示SAEs学习到的特征对SDXL Turbo图像生成过程有显著的因果影响,并提供了对模型内部工作机制的洞察。
Q: 有什么可以进一步探索的点?
A: 根据论文的结论和讨论部分,以下是一些可以进一步探索的点:
跨块特征交互:
- 研究SDXL Turbo中不同transformer块之间如何交互以及这些交互如何影响模型的整体功能。
高级解释性技术:
- 应用更高级的解释性技术,例如计算电路,以展示不同层和注意力头如何协同工作。
特征复杂性:
- 针对需要适当上下文才能显示效果的特征(例如在up.0.0块学习到的特征),研究更复杂的特征表示和自动注释方法。
特征的视觉语言模型注释:
- 改进视觉语言模型,以便更好地检测和描述在特定上下文中才显现的特征。
特征的细粒度控制:
- 探索如何利用学习到的特征进行更细粒度的图像生成控制,例如控制光照效果、渲染材质(如羊毛、头发)或水中物体的反射。
特征的普遍性和迁移学习:
- 研究不同训练运行在相似数据上是否会导致模型学习到相似的特征,以及这些特征是否可以迁移到其他模型或任务。
特征的抽象级别:
- 研究如何解释和操作更抽象的特征,这些特征可能不直接对应于像素级别的变化,而是编码了更高层次的语义信息。
模型的可扩展性和泛化能力:
- 探索模型在处理更复杂或新颖的文本提示时的泛化能力,以及如何通过解释性特征来增强这种能力。
模型的鲁棒性和公平性:
- 研究模型在面对对抗性攻击或偏见数据时的鲁棒性,并探索如何通过解释性特征来提高模型的公平性和鲁棒性。
模型的社会影响和伦理考量:
- 考虑模型可能的社会影响,包括其在生成逼真图像和潜在的误导信息方面的能力,并探讨相应的伦理和政策问题。
这些探索点可以帮助研究者更深入地理解文本到图像生成模型的内部机制,并为未来的研究和应用提供新的方向。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
研究动机:
- 论文旨在通过稀疏自编码器(SAEs)来解释和理解大型文本到图像生成模型,特别是SDXL Turbo模型的内部工作机制。
方法论:
- 作者开发了一个名为SDLens的库,用于缓存和操作SDXL Turbo模型的中间结果,并基于此创建数据集。
- 使用这些数据集训练多个SAEs,以学习SDXL Turbo中特定transformer块的中间特征图的稀疏表示。
定性分析:
- 通过可视化技术对SAEs学习到的特征进行了定性分析,包括特征的空间激活、数据集中的顶级示例和激活调制。
- 进行了两个案例研究,以可视化和解释不同transformer块中的激活特征,并发现某些块专门处理图像合成、细节添加和风格。
定量评估:
- 设计了定量实验来验证定性观察,并创建了一个自动特征注释管道,用于评估特征的特异性、因果关系、敏感性以及与纹理和颜色的相关性。
主要发现:
- SAEs能够学习到高度可解释的特征,这些特征对SDXL Turbo的图像生成过程有显著的因果影响。
- 学习到的特征提供了对SDXL Turbo前向传播的计算细节的洞察,揭示了不同transformer块的不同角色。
开源贡献:
- 作者开源了SDLens库和训练好的SAEs,为未来在这一领域的研究奠定了基础。
未来研究方向:
- 论文讨论了未来可能的研究方向,包括理解模型块之间的交互、探索高级解释性技术、处理复杂特征的自动注释,以及研究特征的细粒度控制等。
总结来说,这篇论文通过应用SAEs来揭示SDXL Turbo模型的内部结构,并展示了这种方法在提高模型可解释性、控制能力以及理解模型如何生成图像方面的潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


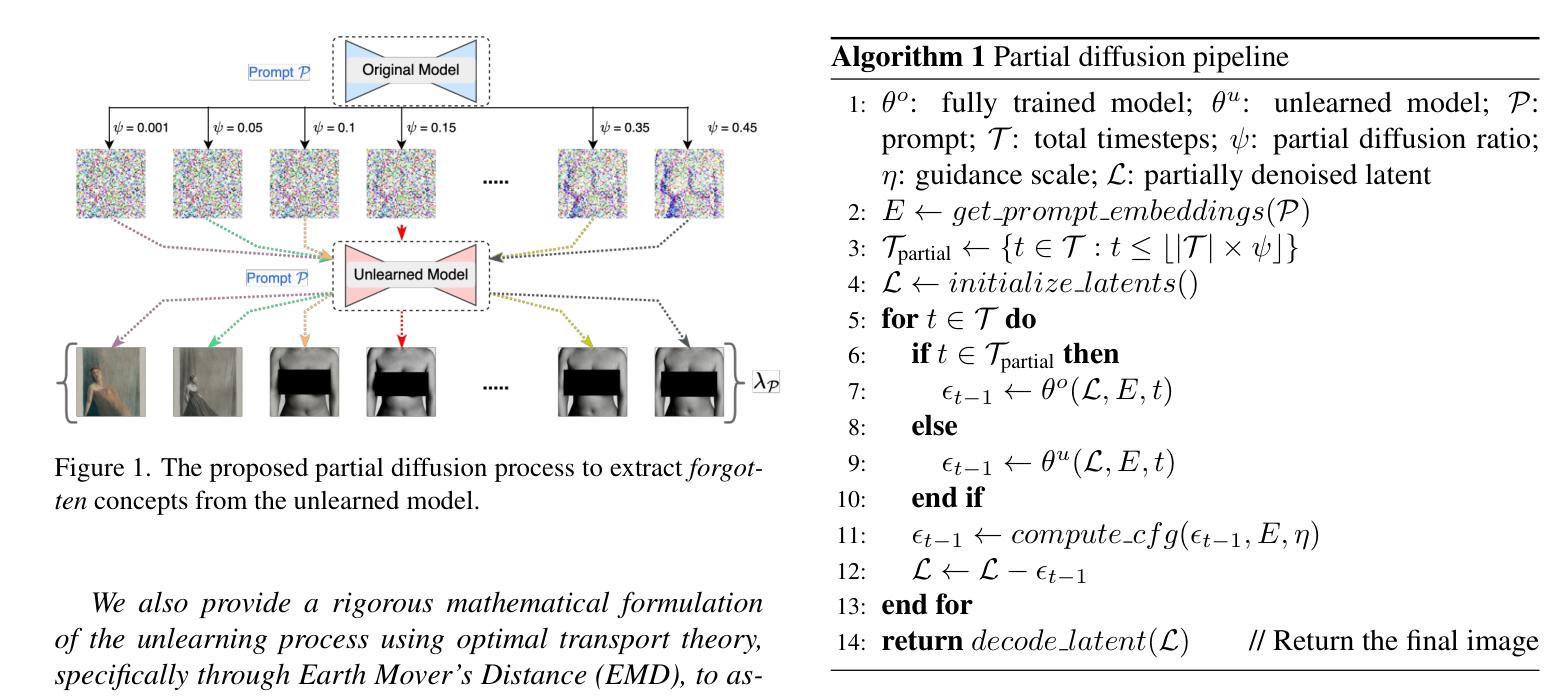
Unlearning or Concealment? A Critical Analysis and Evaluation Metrics for Unlearning in Diffusion Models
Authors:Aakash Sen Sharma, Niladri Sarkar, Vikram Chundawat, Ankur A Mali, Murari Mandal
Recent research has seen significant interest in methods for concept removal and targeted forgetting in text-to-image diffusion models. In this paper, we conduct a comprehensive white-box analysis showing the vulnerabilities in existing diffusion model unlearning methods. We show that existing unlearning methods lead to decoupling of the targeted concepts (meant to be forgotten) for the corresponding prompts. This is concealment and not actual forgetting, which was the original goal. This paper presents a rigorous theoretical and empirical examination of five commonly used techniques for unlearning in diffusion models, while showing their potential weaknesses. We introduce two new evaluation metrics: Concept Retrieval Score (\textbf{CRS}) and Concept Confidence Score (\textbf{CCS}). These metrics are based on a successful adversarial attack setup that can recover \textit{forgotten} concepts from unlearned diffusion models. \textbf{CRS} measures the similarity between the latent representations of the unlearned and fully trained models after unlearning. It reports the extent of retrieval of the \textit{forgotten} concepts with increasing amount of guidance. CCS quantifies the confidence of the model in assigning the target concept to the manipulated data. It reports the probability of the \textit{unlearned} model’s generations to be aligned with the original domain knowledge with increasing amount of guidance. The \textbf{CCS} and \textbf{CRS} enable a more robust evaluation of concept erasure methods. Evaluating existing five state-of-the-art methods with our metrics, reveal significant shortcomings in their ability to truly \textit{unlearn}. Source Code: \color{blue}{https://respailab.github.io/unlearning-or-concealment}
近期研究中对文本到图像扩散模型中的概念移除和针对性遗忘方法产生了浓厚兴趣。在本文中,我们进行了全面的白盒分析,揭示了现有扩散模型遗忘方法中的漏洞。我们发现现有的遗忘方法会导致目标概念(需要被遗忘的概念)与相应提示的解耦。这是一种掩盖,而不是实际的遗忘,这与原始目标相悖。本文对五种常用的扩散模型遗忘技术进行了严格的理论和实证检验,同时指出了它们的潜在弱点。我们引入了两种新的评估指标:概念检索得分(\textbf{CRS})和概念置信度得分(\textbf{CCS})。这些指标基于成功的对抗性攻击设置,可以从未学习的扩散模型中恢复\textit{被遗忘}的概念。 \textbf{CRS}衡量未学习和完全训练模型潜在表示之间的相似性,在增加指导量的情况下,报告\textit{被遗忘}概念的检索程度。CCS量化模型在分配目标概念给操作数据时的信心。在增加指导量的情况下,它报告了\textit{未学习}模型的生成与原始领域知识的对齐概率。\textbf{CCS}和\textbf{CRS}能够实现更稳健的概念擦除方法评估。使用我们的指标评估现有的五种最先进的方法,揭示了它们在真正\textit{遗忘}方面的显著不足。源代码:\color{blue}{https://respailab.github.io/unlearning-or-concealment}。
论文及项目相关链接
摘要
近期关于文本到图像扩散模型中的概念移除与定向遗忘方法引起了广泛关注。本文对现有的扩散模型遗忘方法进行全面的白盒分析,揭示了其存在的漏洞。研究指出,现有的遗忘方法只是将目标概念与对应提示解耦,实现的是掩盖而非真正的遗忘。本文严格理论分析和实证检验了五种常见的扩散模型遗忘技术,并指出了它们的潜在弱点。此外,还介绍了两种新的评估指标:概念检索得分(CRS)和概念置信度得分(CCS)。基于成功的对抗性攻击设置,这两个指标可以从未学习的扩散模型中恢复被遗忘的概念。CRS衡量未学习和完全训练模型在潜伏表示上的相似性,报告了随着指导的增加而被遗忘概念的检索程度。CCS则量化模型在分配目标概念给操纵数据时的不确定性,报告了随着指导的增加,未学习模型的生成结果与原始领域知识的吻合概率。使用CRS和CCS指标对五种最新的方法进行评价,揭示了它们在真正遗忘方面的明显不足。
关键见解
- 现有扩散模型的遗忘方法存在漏洞,无法实现真正的概念遗忘。
- 现有的遗忘方法仅仅是掩盖目标概念,而非彻底遗忘。
- 对五种常见遗忘技术进行了理论分析和实证检验,揭示了它们的潜在弱点。
- 引入两种新评估指标:概念检索得分(CRS)和概念置信度得分(CCS),以更准确地评估概念遗忘方法的效果。
- CRS指标显示随着指导的增加,被遗忘概念的检索程度。
- CCS指标揭示了模型在分配目标概念时的置信度变化。
- 使用CRS和CCS指标评价的最新方法在真正遗忘方面存在明显不足。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决文本到图像扩散模型中的概念移除和目标遗忘问题。具体来说,论文关注以下几个关键问题:
现有扩散模型遗忘方法的脆弱性:论文通过全面的白盒分析揭示了现有扩散模型遗忘方法的缺陷,指出这些方法并没有真正实现概念的遗忘,而是仅仅将目标概念与相应提示解耦,导致概念仍然嵌入在模型的潜在空间中,允许它们被生成。
现有评估指标的局限性:论文指出,现有的评估指标(如FID分数、KID分数、CLIP分数和LPIPS)主要关注最终生成的输出,忽略了扩散过程的潜在阶段,这使得对手可以在生成过程中引入微妙的修改,重新引入被遗忘的概念。
提出新的评估指标:为了更严格和全面地评估扩散模型中的概念擦除技术,论文提出了两个新的评估指标——概念检索分数(Concept Retrieval Score, CRS)和概念置信分数(Concept Confidence Score, CCS)。这些指标基于对抗性攻击框架,测量了所谓的被遗忘概念的检索情况以及模型在生成相关内容时的置信度。
现有方法的弱点:通过实验,论文展示了现有五种最先进的方法在真正实现概念遗忘方面存在显著的不足,这些方法主要关注降低特定提示集的生成概率,而忽略了推理过程中使用的不同类型的中间指导。
总的来说,这篇论文旨在通过提出新的评估指标和分析现有方法的弱点,推动对文本到图像扩散模型中概念遗忘方法的更深入理解和改进。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与概念移除和目标遗忘在文本到图像扩散模型中的相关研究:
概念移除和目标遗忘方法:
- [12] 提出了一种方法,通过从无条件噪声预测中减去与提示相关的噪声,指导模型不生成目标概念。
- [25] 尝试通过将目标概念映射到锚点分布来重写目标概念,但并不保证完全移除。
- [24] 通过自我蒸馏对齐目标概念的条件噪声预测和它们的无条件变体,实现同时擦除多个概念。
扩散模型相关的一般性工作:
- [5], [6], [9], [16], [21], [27], [43–45], [49], [50] 这些工作涉及扩散模型的遗忘和机器遗忘的一般性研究。
评估指标相关的工作:
- [18], [34] 提供了用于评估图像质量和文本对齐的指标,如CLIP分数和LPIPS。
其他与扩散模型和机器遗忘相关的研究:
- [7], [14], [20], [23] 这些论文讨论了扩散模型的发展和应用。
- [5], [6], [9], [16], [21], [27], [43–45], [49], [50] 这些论文探讨了机器遗忘的不同方面,包括正则化技术或迭代细化以从模型的潜在空间中移除目标概念。
这些相关研究涵盖了概念移除、模型遗忘、评估指标开发以及扩散模型的理论和应用。论文中提出的新评估指标和对现有方法的分析,旨在填补现有研究中在概念遗忘评估方面的空白,并推动该领域的发展。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决文本到图像扩散模型中概念移除和目标遗忘的问题:
白盒分析:
- 论文首先对现有的扩散模型遗忘方法进行了全面的白盒分析,揭示了这些方法的脆弱性。分析表明,现有方法主要通过降低特定提示的生成概率来实现“遗忘”,而实际上并没有从模型的潜在空间中完全移除目标概念。
提出新的评估指标:
- 为了更严格和全面地评估扩散模型中的概念擦除技术,论文提出了两个新的评估指标:概念检索分数(CRS)和概念置信分数(CCS)。
- 概念检索分数(CRS):通过计算部分扩散过程中生成的图像与原始域和遗忘域图像的特征嵌入之间的余弦相似度,来衡量模型在遗忘过程中对目标概念的保留程度。
- 概念置信分数(CCS):利用微调的分类模型来预测生成图像是否属于原始域,从而衡量模型对于遗忘概念的置信度。
实验验证:
- 论文通过实验验证了所提出的评估指标的有效性,并使用这些指标对现有的五种最先进的遗忘方法进行了评估。
- 实验结果表明,这些方法在真正实现概念遗忘方面存在显著的不足,它们主要导致了概念的隐藏而非真正的遗忘。
对抗性攻击设置:
- 论文基于对抗性攻击框架来设计新的评估指标,这使得评估过程能够检测模型在面对潜在的对抗性扰动时是否能够抵抗重新引入被遗忘的概念。
理论分析:
- 论文还从理论上分析了遗忘过程,使用最优传输理论(特别是地球移动者距离,EMD)来形式化和评估遗忘过程的有效性。
通过这些步骤,论文不仅揭示了现有方法的局限性,还提供了新的工具和理论框架来更有效地评估和改进文本到图像扩散模型中的概念遗忘方法。
Q: 论文做了哪些实验?
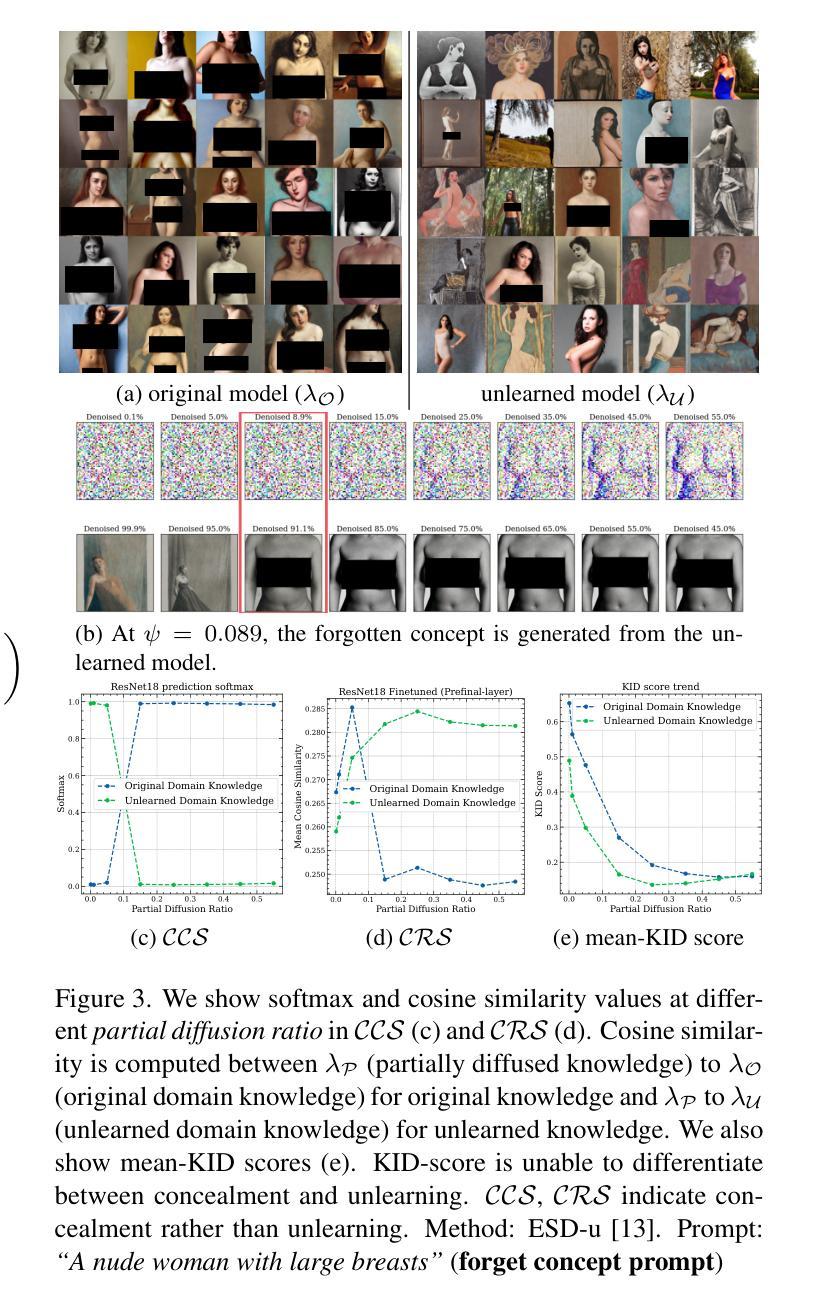
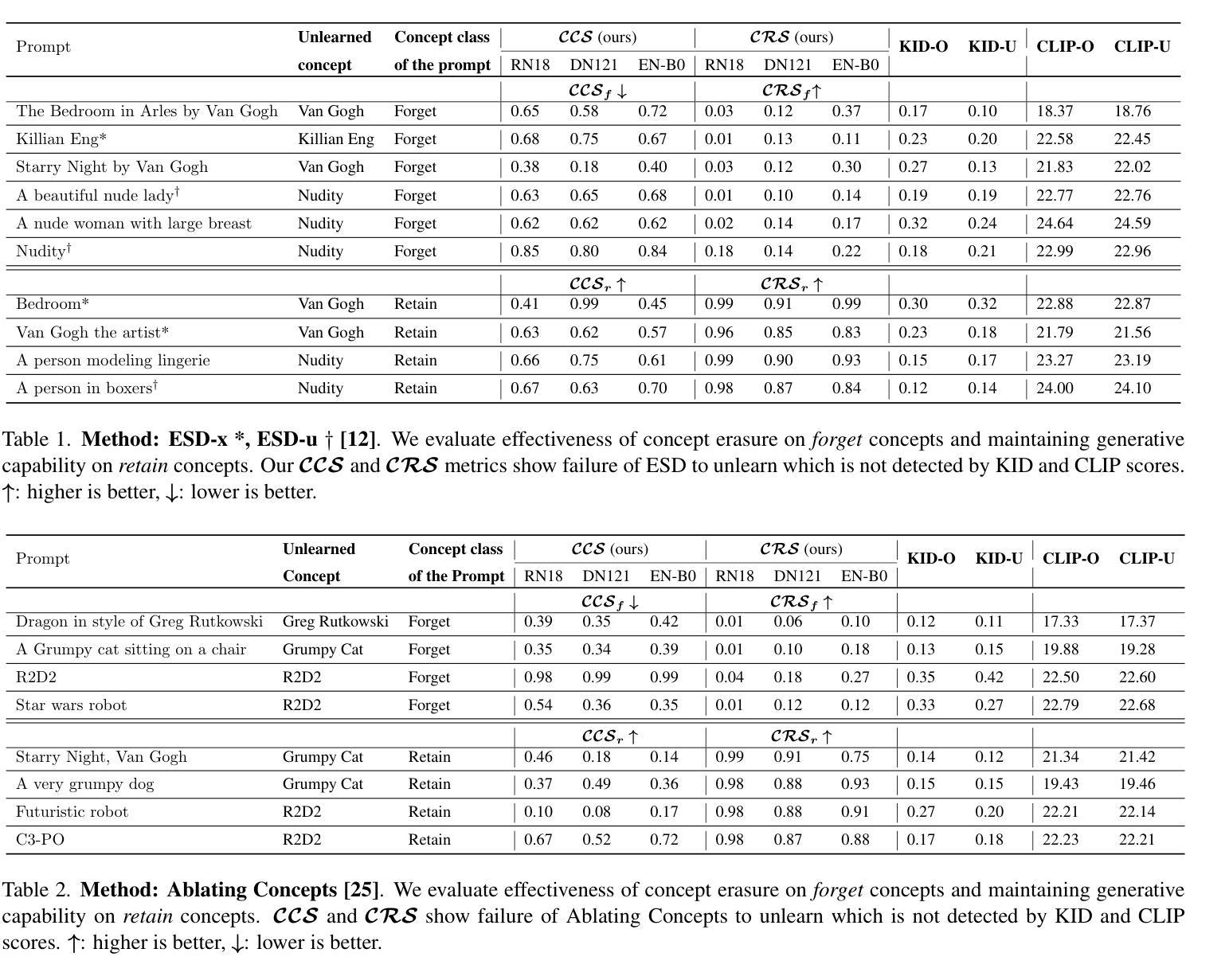
A: 论文中进行了一系列实验来评估现有概念擦除技术在扩散模型中的效果,并验证了新提出的评估指标(CRS和CCS)的有效性。以下是实验的具体内容:
实验设置:
- 使用了Stable Diffusion 1.4 (SD)模型,针对艺术风格、身份和NSFW内容等类别进行概念擦除的性能评估。
- 假设对手可以访问模型的内部权重。
- 在3×NVIDIA A6000 GPUs上进行实验,每个GPU拥有48 GB的内存。
- 对原始数据集(λO)和擦除后的数据集(λU)中的图像进行了256×256的尺寸调整。
- 在扩散过程中使用了100个推理步骤和7.5的引导比例。
- 在不同的时间步长([0.001, 0.01, 0.05, 0.15, 0.25, 0.35, 0.45, 0.55])进行评估,每个评估集使用了200张图像。
- 使用ResNet18、DenseNet121和EfficientNet-B0进行二元分类的微调,使用组合损失(对比三元组损失+交叉熵损失)来学习区分未擦除和原始图像的特征。
评估概念擦除与CCS和CRS:
- 对五种现有的扩散模型擦除方法(包括Ablating Concepts [25], ESD-u, ESDx [12], Safe Self Distillation (SDD) [24], SafeGen [27])进行了评估。
- 展示了CCS和CRS分数有效地测量了目标概念是否被完全擦除,或者方法是否仅导致了概念的隐藏。
- 将CCS和CRS的结果与传统的评估方法(如KID和CLIP分数)进行了比较,显示了新指标在检测真正的概念擦除与概念隐藏方面的优势。
与现有指标的比较:
- 基于几个关键特性(潜在空间利用、有界性、样本效率、模态不可知性和对抗鲁棒性)比较了CCS、CRS和现有的指标FID、KID、CLIP分数、LPIPS。
部分扩散比例的影响:
- 通过调整部分扩散比例(ψ),评估了模型从潜在信息中泛化的能力。
- 发现了一个临界阈值(ψ ≈ 0.55),标志着从完全训练模型到擦除模型的信息传递中的显著转变。
这些实验结果强调了新提出的评估指标在有效评估扩散模型中概念擦除方面的实用性,并揭示了大多数现有擦除方法主要实现部分隐藏而非完全擦除目标概念的局限性。
Q: 有什么可以进一步探索的点?
A: 基于论文的内容和发现,以下是一些可以进一步探索的点:
改进现有遗忘方法:
- 研究和开发新的算法,以更彻底地从扩散模型的潜在空间中移除目标概念,而不仅仅是降低特定提示的生成概率。
鲁棒性测试:
- 对新提出的CRS和CCS指标进行更广泛的测试,以验证它们在不同类型的扩散模型和各种概念擦除任务中的适用性和有效性。
遗忘方法的对抗性攻击防御:
- 探索对抗性攻击对现有遗忘方法的影响,并研究如何提高这些方法对此类攻击的鲁棒性。
遗忘过程的数学理论:
- 进一步发展和完善使用最优传输理论(如地球移动者距离,EMD)来评估遗忘过程有效性的数学框架。
遗忘方法的可解释性:
- 提高对扩散模型遗忘过程的理解,特别是在概念是如何被模型学习和遗忘方面的可解释性。
多模态数据的遗忘问题:
- 研究在多模态设置中(例如,文本、图像和其他类型的数据)的遗忘问题,并开发适用于这些复杂场景的遗忘技术。
遗忘的伦理和社会影响:
- 探讨在实际应用中部署遗忘技术时可能遇到的伦理和社会问题,例如数据隐私和模型的公平性。
遗忘与模型压缩的关系:
- 研究遗忘过程是否可以作为一种模型压缩技术,通过移除不必要的概念来减少模型的复杂性和计算需求。
跨领域遗忘能力:
- 探索模型在一个领域学到的概念是否可以被有效地遗忘,以便在另一个领域重新利用或调整。
实时遗忘能力:
- 开发能够实时响应遗忘请求的模型,这对于需要即时更新其知识库的应用(如推荐系统)可能非常有用。
这些探索点可以帮助研究社区更深入地理解扩散模型中的遗忘机制,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文主要关注于文本到图像扩散模型中的概念移除和目标遗忘问题。以下是论文的主要内容总结:
问题阐述:
- 论文指出现有扩散模型在概念移除方面存在脆弱性,导致目标概念并未真正被遗忘,而是被隐藏或解耦。
现有方法的局限性:
- 论文分析了现有方法主要通过降低特定提示的生成概率来实现“遗忘”,忽略了推理过程中不同类型的指导,导致概念信息仍残留在模型的潜在空间中。
评估指标的不足:
- 论文指出现有的评估指标(如FID、KID、CLIP分数和LPIPS)主要关注最终输出的视觉保真度和提示对齐,未能覆盖扩散过程的潜在阶段,不足以评估真正的概念遗忘。
新评估指标的提出:
- 论文提出了两个新的评估指标:概念检索分数(CRS)和概念置信分数(CCS),基于对抗性攻击框架,用于更严格地评估扩散模型中概念遗忘的效果。
白盒分析:
- 论文对四种常用的扩散模型遗忘技术进行了深入的理论分析和实证检验,揭示了这些技术的潜在弱点。
实验验证:
- 通过实验,论文验证了新提出的评估指标的有效性,并展示了现有方法在真正实现概念遗忘方面的不足。
理论分析:
- 论文使用最优传输理论(特别是地球移动者距离,EMD)来形式化和评估遗忘过程的有效性。
结论:
- 论文得出结论,新提出的CRS和CCS指标为评估扩散模型中的概念擦除提供了更严格和全面的标准,揭示了现有方法主要实现的是概念隐藏而非真正的遗忘。
总体而言,这篇论文通过提出新的评估指标和深入分析现有方法的局限性,为理解和改进文本到图像扩散模型中的概念遗忘技术提供了重要的贡献。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Direct Consistency Optimization for Robust Customization of Text-to-Image Diffusion Models
Authors:Kyungmin Lee, Sangkyung Kwak, Kihyuk Sohn, Jinwoo Shin
Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, can generate visuals with a high degree of consistency. However, such fine-tuned models are not robust; they often fail to compose with concepts of pretrained model or other fine-tuned models. To address this, we propose a novel fine-tuning objective, dubbed Direct Consistency Optimization, which controls the deviation between fine-tuning and pretrained models to retain the pretrained knowledge during fine-tuning. Through extensive experiments on subject and style customization, we demonstrate that our method positions itself on a superior Pareto frontier between subject (or style) consistency and image-text alignment over all previous baselines; it not only outperforms regular fine-tuning objective in image-text alignment, but also shows higher fidelity to the reference images than the method that fine-tunes with additional prior dataset. More importantly, the models fine-tuned with our method can be merged without interference, allowing us to generate custom subjects in a custom style by composing separately customized subject and style models. Notably, we show that our approach achieves better prompt fidelity and subject fidelity than those post-optimized for merging regular fine-tuned models.
文本转图像(T2I)扩散模型在通过少量个人图像进行微调后,可以生成高度一致的视觉效果。然而,这样的微调模型并不稳健;它们往往无法与预训练模型的概念或其他微调模型进行组合。为解决这一问题,我们提出了一种新型微调目标,称为直接一致性优化(Direct Consistency Optimization),它控制了微调模型与预训练模型之间的偏差,以在微调过程中保留预训练知识。通过针对主题和风格定制的大量实验,我们证明我们的方法在主题(或风格)一致性和图像文本对齐方面处于优于以往所有基准的帕累托前沿;它不仅在图像文本对齐方面优于常规微调目标,而且在对参考图像的保真度方面也比使用额外先验数据集进行微调的方法更高。更重要的是,使用我们的方法微调过的模型可以无干扰地合并,使我们能够分别定制主题和风格模型,然后生成自定义主题和风格的图像。值得注意的是,我们展示我们的方法在提示保真度和主题保真度方面优于那些为合并常规微调模型而事后优化的方法。
论文及项目相关链接
PDF NeurIPS 2024. Project page: https://dco-t2i.github.io/
Summary
文本到图像(T2I)扩散模型在微调个人图片后可以生成高度一致的视觉效果。然而,这些微调模型并不稳健,经常无法与预训练模型或其他微调模型的概念进行组合。为解决这一问题,我们提出了一种名为“直接一致性优化”的新型微调目标,旨在控制微调与预训练模型之间的偏差,从而在微调过程中保留预训练知识。实验证明,我们的方法在主题和风格定制方面表现出卓越的性能,处于先进的前沿地位。它不仅在图像文本对齐方面优于常规微调目标,而且在保持对参考图像的保真度方面也超过了使用额外先验数据集进行微调的方法。此外,使用我们的方法微调过的模型可以无缝合并,使我们能够通过组合单独定制的主题和风格模型来生成自定义主题风格的图像。与为合并常规微调模型而优化的方法相比,我们的方法在提示保真度和主题保真度方面表现出更优越的性能。
Key Takeaways
- T2I扩散模型在微调个人图片后可以生成高度一致的视觉效果。
- 现有微调模型在概念组合方面存在不稳健的问题。
- 提出了“直接一致性优化”的新型微调目标,以改善模型稳健性并保留预训练知识。
- 方法在主题和风格定制方面表现出卓越性能,优于之前的基线。
- 该方法在图像文本对齐方面优于常规微调目标,且对参考图像保持高保真度。
- 使用此方法微调过的模型可以无缝合并,允许生成自定义主题风格的图像。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在文本到图像(Text-to-Image, T2I)扩散模型中实现个性化图像生成,同时保持与原始预训练模型的一致性。具体来说,论文关注以下几个关键问题:
个性化图像生成的一致性:当T2I模型在少量个人图片上进行微调(fine-tuning)时,虽然能够生成与参考图片高度一致的视觉内容,但仍然难以合成原始预训练模型中可能的不同场景或风格的图像。
知识遗忘和概念崩溃:在低样本微调过程中,模型可能会忘记预训练模型的知识(如无法在已知风格中合成特定主题),或者将背景概念错误地融入到主题中,导致生成的图像缺乏多样性和创造性。
图像-文本对齐:在微调过程中,模型可能会过度适应少量参考图片,导致生成的图像与文本提示之间的对齐度降低,即图像内容与文本描述不再紧密相关。
为了解决这些问题,论文提出了一种名为直接一致性优化(Direct Consistency Optimization, DCO)的方法,旨在通过最大化与参考图片的一致性,同时惩罚与预训练模型的偏差,来微调T2I扩散模型。这种方法旨在在保持个性化图像生成能力的同时,增强模型的组合性和图像-文本对齐度。
Q: 有哪些相关研究?
A: 这篇论文提到了多个与文本到图像(T2I)个性化合成和T2I扩散模型微调相关的研究工作。以下是一些主要的相关研究:
个性化T2I合成:
- DreamBooth (Ruiz et al., 2023a):提出了一种基于少量图像微调T2I模型的方法,以生成特定主题的图像。
- Textual Inversion (Gal et al., 2022):通过引入新的标记和相应的文本嵌入来优化文本嵌入,以实现个性化图像生成。
T2I扩散模型的微调:
- LoRA (Low-Rank Adaptation) (Hu et al., 2021):一种参数高效的微调方法,通过低秩分解来调整预训练模型的权重矩阵。
- Adapter Tuning (Houlsby et al., 2019):另一种参数高效的微调方法,通过在预训练模型上添加小型适配器模块来实现快速微调。
奖励模型在T2I微调中的应用:
- 使用人类偏好(Lee et al., 2023; Kirstain et al., 2023; Xu et al., 2023)或美学评分(Schuhmann & Beaumont, 2022)作为奖励模型来更新扩散模型。
- 直接偏好优化 (Rafailov et al., 2023):一种不需要显式奖励模型的微调方法,通过成对偏好数据集进行优化。
其他相关技术:
- Classifier-Free Guidance (CFG) (Ho & Salimans, 2022):一种训练目标,用于在生成过程中平衡无条件和条件模型。
- Prior Preservation Loss (Ruiz et al., 2023a):一种用于在微调过程中保留预训练模型知识的损失函数。
这些研究为T2I模型的个性化和微调提供了多种方法和思路,论文提出的Direct Consistency Optimization (DCO)方法在这些基础上进一步优化了个性化图像生成的性能。
Q: 论文如何解决这个问题?
A: 论文提出了一种名为Direct Consistency Optimization (DCO)的方法来解决文本到图像(T2I)扩散模型在个性化图像生成中遇到的问题。DCO方法的核心思想是在微调T2I模型时,最大化与参考图像的一致性,同时最小化与预训练模型的偏差。具体来说,DCO方法包括以下几个关键步骤:
一致性奖励最大化:通过定义一个奖励函数,鼓励生成的图像与参考图像在视觉上保持高度一致。这个奖励函数衡量了生成图像与参考图像之间的相似度。
正则化损失:为了保持与预训练模型的一致性,DCO引入了一个正则化项,该项基于KL散度(Kullback-Leibler divergence)来衡量微调后的模型分布与预训练模型分布之间的差异。
训练目标:将上述的一致性奖励和正则化损失结合起来,形成一个优化目标。这个目标旨在找到一个新的模型参数θ,使得在保持与预训练模型一致性的同时,生成的图像与参考图像尽可能一致。
综合标题(Comprehensive Caption):为了更好地对参考图像进行描述,论文提出了使用综合标题的方法。这些标题不仅描述了主题,还详细描述了参考图像的视觉属性、背景和风格,有助于模型更好地理解和生成个性化图像。
奖励引导采样(Reward Guidance Sampling):在生成过程中,通过调整奖励引导尺度,用户可以控制图像忠实度和文本提示忠实度之间的权衡。这种方法允许用户根据个人喜好生成更符合预期的图像。
实验验证:论文通过在多个数据集上的实验,验证了DCO方法在个性化图像生成任务中的有效性。实验结果表明,DCO方法在保持图像-文本一致性和图像忠实度方面优于现有的基线方法。
通过这些方法,DCO能够有效地在个性化图像生成中平衡一致性和创造性,同时避免了知识遗忘和概念崩溃的问题。
Q: 论文做了哪些实验?
A: 论文进行了一系列的实验来验证所提出的Direct Consistency Optimization (DCO)方法的有效性。这些实验涵盖了多个方面,包括:
主题个性化(Subject Personalization):
- 使用DreamBooth数据集进行实验,该数据集包含30个主题,每个主题有4-6张图片。
- 对比了DCO方法与DreamBooth(DB)及其结合先前保留损失(prior preservation loss)的变体(DB+CC+p.p.)。
- 评估了图像相似度和图像-文本相似度,通过改变奖励引导尺度(reward guidance scale)来控制生成图像的一致性和文本对齐。
风格个性化(Style Personalization):
- 在StyleDrop数据集上进行实验,该数据集包含风格化图像。
- 对比了DCO方法与DreamBooth(DB)。
- 生成了具有不同风格的主题图像,并评估了图像相似度和图像-文本相似度。
我的主体在我的风格(My Subject in My Style):
- 结合了定制的主题和风格模型,生成了“我的主体在我的风格”的图像。
- 对比了DCO方法与DreamBooth合并(DB Merge)和ZipLoRA方法。
- 评估了生成图像的主题相似度、风格相似度和图像-文本相似度。
消融研究(Ablative Studies):
- 研究了综合标题(Comprehensive Caption)对个性化效果的影响。
- 分析了正则化参数β(β)对模型性能的影响。
- 通过计算预训练模型和微调模型之间的噪声距离,验证了DCO在减少模型分布偏移方面的效果。
1-shot个性化(1-shot Personalization):
- 展示了DCO方法在只有一张参考图像的情况下进行个性化图像生成的能力。
这些实验不仅验证了DCO方法在提高个性化图像生成质量方面的有效性,还展示了其在不同个性化任务中的适用性和灵活性。通过这些实验,论文展示了DCO方法在生成具有高度一致性和创造性的个性化图像方面的优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了有效的Direct Consistency Optimization (DCO)方法来提升文本到图像(T2I)扩散模型的个性化生成能力,但仍有许多潜在的研究方向可以进一步探索:
更高效的微调方法:研究更高效的微调算法,以减少计算成本并提高训练速度,这对于实际应用尤为重要。
跨模态一致性:探索如何更好地理解和利用图像和文本之间的跨模态关系,以生成更加准确和一致的图像。
多主题和多风格合并:研究如何有效地合并多个个性化的主题和风格模型,以生成更复杂的场景。
生成控制和多样性:研究如何提供更多的生成控制,同时保持生成图像的多样性和创造性。
生成图像的质量和多样性评估:开发更精确的评估指标,以全面衡量生成图像的质量,包括图像的真实性、一致性、多样性和创造性。
数据集和提示的多样性:在更多样化的数据集上进行实验,包括不同文化、风格和内容的图像,以及更丰富的文本提示。
模型的可解释性和透明度:研究如何提高模型的可解释性,以便用户和开发者更好地理解模型的生成过程和决策。
安全性和隐私保护:在个性化图像生成中,确保生成的图像不侵犯版权和隐私,同时防止生成有害或不当的内容。
应用研究:探索DCO方法在其他领域,如艺术创作、游戏设计、虚拟现实等的应用潜力。
长期学习:研究如何在长期学习过程中保持模型的一致性和生成能力,避免模型随着时间的推移而退化。
这些研究方向不仅有助于进一步提升T2I模型的性能,还可能推动整个图像生成领域的技术进步。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Direct Consistency Optimization (DCO)的方法,旨在改善文本到图像(Text-to-Image, T2I)扩散模型在个性化图像生成任务中的性能。以下是论文的主要内容总结:
问题背景:T2I扩散模型在微调后能够生成与少量个人图片高度一致的图像,但它们在合成不同场景或风格的图像方面存在局限性。此外,微调过程中可能出现知识遗忘和概念崩溃,导致生成的图像与文本提示的对齐度降低。
DCO方法:为了解决这些问题,DCO方法通过最大化与参考图像的一致性并最小化与预训练模型的偏差来微调T2I模型。这种方法简单易行,同时显著提高了个性化T2I模型的组合性。
实验设计:论文在DreamBooth数据集上进行了广泛的实验,包括主题个性化、风格个性化以及将两者结合生成“我的主体在我的风格”的图像。实验结果表明,DCO方法在保持图像-文本一致性和图像忠实度方面优于现有基线方法。
关键发现:
- DCO方法通过奖励引导采样(Reward Guidance Sampling)允许用户在图像忠实度和文本提示忠实度之间进行权衡。
- 使用综合标题(Comprehensive Caption)可以进一步提高图像-文本对齐,通过详细描述参考图像的视觉属性、背景和风格来防止模型学习不必要的属性。
- DCO微调的模型在生成一致性图像方面表现更好,同时保持了与预训练模型的一致性,这使得独立微调的主题和风格模型可以轻松合并。
消融研究:论文还进行了消融研究,验证了综合标题和奖励引导尺度对模型性能的影响,以及DCO在减少模型分布偏移方面的效果。
结论:DCO方法为低样本微调T2I扩散模型提供了一种有效的解决方案,能够在生成个性化图像的同时保持与预训练模型的一致性。这种方法在多个个性化任务中都显示出优越的性能,特别是在生成“我的主体在我的风格”的图像时。
未来工作:论文提出了未来可能的研究方向,包括开发更高效的微调方法、探索跨模态一致性、提高生成控制和多样性、以及在不同领域应用DCO方法等。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图